- x < filename: This opens a file in read mode and assigns the descriptor named a, whose value falls between 3 and 9. We can choose any name by the means of which we can easily access the file content through the stdin.
- 1 > filename: This redirects the standard output to filename. If it does not exist, it gets created; if it exists, the pre-existing data is overwritten.
- 1 >> filename: This redirects the standard output to filename. If it does not exist, it is created; otherwise, the contents get appended to the pre-existing data.
- 2 > filename: This redirects the standard error to filename. If it does not exist, it gets created; if it exists, the pre-existing data is overwritten.
- 2 >> filename: This redirects the standard error to filename. If it does not exist, it is created; otherwise, the contents get appended to the pre-existing data.
- &> filename: This redirects both the stdout and the stderr to filename. This redirects the standard error to filename. If it does not exist, it gets created; if it exists, the pre-existing data is overwritten.
- 2>&1: This redirects the stderr to the stdout. If you use this with a program, its error messages will be redirected to the stdout, that is, usually, the monitor.
- y>&x: This redirects the file descriptor for y to x so that the output from the file pointed by descriptor y will be redirected to the file pointed by descriptor x.
- >&x: This redirects the file descriptor 1 that is associated with the stdout to the file pointed by the descriptor x, so whatever hits the standard output will be written in the file pointed by x.
- x<> filename: This opens a file in read/write mode and assigns the descriptor x to it. If the file does not exist, it is created, and if the descriptor is omitted, it defaults to 0, the stdin.
- x<&-: This closes the file opened in read mode and associated with the descriptor x.
- 0<&- or <&-: This closes the file opened in read mode and associated with the descriptor 0, the stdin , which is then closed.
- x>&-: This closes the file opened in write mode and associated with the descriptor x.
- 1>&- or >&-: This closes the file opened in write mode and associated with the descriptor 1, the stdout, which is then closed.
Pipes as cascading redirection
Instead of files, the results of a command can be redirected as input to another command. This process is called piping and uses the vertical bar (or pipe) operator |.
who | wc -l # count the number or users
Any number of commands can be strung together with vertical bar symbols. A group of such commands is called a pipeline.
If one command ends prematurely in a series of pipe commands, for example, because you interrupted a command with a Ctrl-C, Bash displays the message "Broken Pipe" on the screen.
Bash and the process tree [Bash Hackers Wiki]
Pipes are a very powerful tool. You can connect the output of one process to the input of another process. We won't delve into pipign at this point, we just want to see how it looks in the process tree. Again, we execute some commands, this time, we'll run
lsandgrep:$ ls | grep myfileIt results in a tree like this:
+-- ls xterm ----- bash --| +-- grepNote once again,
lscan't influence thegrepenvironment.grepcan't influence thelsenvironmet, and neithergrepnorlscan influence thebashenvironment.How is that related to shell programming?!?
Well, imagine some Bash code that reads data from a pipe. For example, the internal command
read, which reads data from stdin and puts it into a variable. We run it in a loop here to count input lines:counter=0 cat /etc/passwd | while read; do ((counter++)); done echo "Lines: $counter"What? It's 0? Yes! The number of lines might not be 0, but the variable
$counterstill is 0. Why? Remember the diagram from above? Rewriting it a bit, we have:+-- cat /etc/passwd xterm ----- bash --| +-- bash (while read; do ((counter++)); done)See the relationship? The forked Bash process will count the lines like a charm. It will also set the variable
counteras directed. But if everything ends, this extra process will be terminated - your "counter" variable is gone You see a 0 because in the main shell it was 0, and wasn't changed by the child process!So, how do we count the lines? Easy: Avoid the subshell. The details don't matter, the important thing is the shell that sets the counter must be the "main shell". For example:
counter=0 while read; do ((counter++)); done </etc/passwd echo "Lines: $counter"It's nearly self-explanitory. The
whileloop runs in the current shell, the counter is incremented in the current shell, everything vital happens in the current shell, also thereadcommand sets the variableREPLY(the default if nothing is given), though we don't use it here.Bash creates subshells or subprocesses on various actions it performs:
As shown above, Bash will create subprocesses everytime it executes commands. That's nothing new.
But if your command is a subprocess that sets variables you want to use in your main script, that won't work.
For exactly this purpose, there's the
sourcecommand (also: the dot.command). Source doesn't execute the script, it imports the other script's code into the current shell:source ./myvariables.sh # equivalent to: . ./myvariables.shExplicit subshell
If you group commands by enclosing them in parentheses, these commands are run inside a subshell:
(echo PASSWD follows; cat /etc/passwd; echo GROUP follows; cat /etc/group) >output.txtCommand substitution
With command substitution you re-use the output of another command asr command line, for example to set a variable. The other command is run in a subshell:
number_of_users=$(cat /etc/passwd | wc -l)Note that, in this example, a second subshell was created by using a pipe in the command substitution:+-- cat /etc/passwd xterm ----- bash ----- bash (cmd. subst.) --| +-- wc -l< not suspect exist.
Arithmetic Expressions
The ((...)) Command
The ((...)) command is equivalent to the let command, except that all characters between the (( and )) are treated as quoted arithmetic expressions. This is more convenient to use than let, because many of the arithmetic operators have special meaning to the Korn shell. The following commands are equivalent:
$ let "X=X + 1"
and
$ ((X=X + 1))
Before the Korn shell let and ((...)) commands, the only way to perform arithmetic was with expr. For example, to do the same increment X operation using expr:
$ X=`expr $X + 1`
In tests on a few systems, the let command performed the same operation 35-60 times faster! That is quite a difference.
Processing Arguments
You can easily write scripts that process arguments, because a set of special shell variables holds the values of arguments specified when your script is invoked.
For example, here's a simple one-line script that prints the value of its second argument:
echo My second argument has the value $2.
Suppose you store this script in the file second, change its access mode to permit execution, and invoke it as follows:
./second a b c
The script will print the output:
My second argument has the value b.
$0 The command name. $1, $2, ... , $9 The
individual arguments of the command. $* The entire list of arguments, treated as
a single word. $@ The entire list of arguments, treated as a series of words.$?
The exit status of the previous command. The value 0 denotes successful completion. $$
he process id of the current process.
Notice that the shell provides variables for accessing only nine arguments. Nevertheless, you
can access more than nine arguments. The key to doing so is the shift command,
which discards the value of the first argument and shifts the remaining values down one position.
Thus, after executing the shift command, the shell variable $9 contains
the value of the tenth argument. To access the eleventh and subsequent arguments, you simply execute
the shift command the appropriate number of times.
Exit Codes
The shell variable $? holds the numeric exit status of the most recently completed
command. By convention, an exit status of zero denotes successful completion; other values denote
error conditions of various sorts.
You can set the error code in a script by issuing the exit command, which terminates the script and posts the specified exit status. The format of the command is:
exit status
where status is a non-negative integer that specifies
the exit status.
Conditional Logic
A shell script can employ conditional logic, which lets the script take different action based on the values of arguments, shell variables, or other conditions. The test command lets you specify a condition, which can be either true or false. Conditional commands (including the if, case, while, and until commands) use the test command to evaluate conditions.
The test command
The test command evaluates its arguments and sets the exit status to 0, which indicates that the specified condition was true, or a non-zero value, which indicates that the specified condition was false. Some commonly used argument forms used with the test command:
-dfileThe specified file exists and is a directory.-efileThe specified file exists.-rfileThe specified file exists and is readable.-sfileThe specified file exists and has non-zero size.-wfileThe specified file exists and is writable.-xfileThe specified file exists and is executable.-LfileThe specified file exists and is a symbolic link.f1-ntf2Filef1is newer than filef2.f1-otf2Filef1is older than filef2.-ns1Strings1has nonzero length.-zs1Strings1has zero length.s1=s2Strings1is the same as strings2.s1!=s2Strings1is not the same as strings2.n1-eqn2Integern1is equal to integern2.n1-gen2Integern1is greater than or equal to integern2.n1-gtn2Integern1is greater than integern2.n1-len2Integern1is less than integern2.n1-ltn2Integern1is less than or equal to integern2.n1-nen2Integern1is not equal to integern2.!Thenotoperator, which reverses the value of the following condition.-aTheandoperator, which joins two conditions. Both conditions must be true for the overall result to be true.-oTheoroperator, which joins two conditions. If either condition is true, the overall result is true.-
\( ... \)You can group expressions within the test command by enclosing them within\(and\).
To see the test command in action, consider the following script:
test -d $1 echo $?
This script tests whether its first argument specifies a directory and displays the resulting exit status, a zero or a non-zero value that reflects the result of the test.
Suppose the script were stored in the file tester, which permitted read access. Executing the script might yield results similar to the following:
$ ./tester / 0 $ ./tester /missing 1
These results indicate that the / directory exists and that the /missing directory does not exist.
The if command
The test command is not of much use by itself, but combined with commands such as the if command, it is useful indeed. The if command has the following form:
if command then commands else commands fi
Usually the command that immediately follows the word if is a test command. However, this need not be so. The if command merely executes the specified command and tests its exit status. If the exit status is 0, the first set of commands is executed; otherwise the second set of commands is executed. An abbreviated form of the if command does nothing if the specified condition is false:
if command then commands fi
When you type an if command, it occupies several lines; nevertheless it's considered a single command. To underscore this, the shell provides a special prompt (called the secondary prompt) after you enter each line. Often, scripts are entered by using a text editor; when you enter a script using a text editor you don't see the secondary prompt, or any other shell prompt for that matter.
As an example, suppose you want to delete a file file1
if it's older than another file file2. The following command
would accomplish the desired result:
if test file1 -ot file2 then rm file1 fi
You could incorporate this command in a script that accepts arguments specifying the filenames:
if test $1 -ot $2 then rm $1 echo Deleted the old file. fi
If you name the script riddance and invoke it as follows:
riddance thursday wednesday
the script will delete the file thursday if that file is older than the file wednesday.
The case command
The case command provides a more sophisticated form of conditional processing:
case value in pattern1) commands;; pattern2) commands ;; ... esac
The case command attempts to match the specified value against a series of patterns. The commands associated with the first matching pattern, if any, are executed. Patterns are built using characters and metacharacters, such as those used to specify command arguments. As an example, here's a case command that interprets the value of the first argument of its script:
case $1 in -r) echo Force deletion without confirmation ;; -i) echo Confirm before deleting ;; *) echo Unknown argument ;; esac
The command echoes a different line of text, depending on the value of the script's first argument. As done here, it's good practice to include a final pattern that matches any value.
The while command
The while command lets you execute a series of commands iteratively (that is, repeatedly) so long as a condition tests true:
while command do commands done
Here's a script that uses a while command to print its arguments on successive lines:
echo $1 while shift 2> /dev/null do echo $1 done
The commands that comprise the do part of a while (or another loop command) can include if commands, case commands, and even other while commands. However, scripts rapidly become difficult to understand when this occurs often. You should include conditional commands within other conditional commands only with due consideration for the clarity of the result. Include a comment command (#) to clarify difficult constructs.
The until command
The until command lets you execute a series of commands iteratively (that is, repeatedly) so long as a condition tests false:
until command do commands done
Here's a script that uses an until command to print its arguments on successive lines, until it encounters an argument that has the value red:
until test $1 = red do echo $1 shift done
For example, if the script were named stopandgo and stored in the current working directory, the command:
./stopandgo green yellow red blue
would print the lines:
green yellow
The for command
The for command iterates over the elements of a specified list:
for variable in list do commands done
Within the commands, you can reference the current element of the list by means of the shell
variable $ variable, where
variable is the name specified following the for.
The list typically takes the form of a series of arguments, which can incorporate metacharacters.
For example, the following for command:
for i in 2 4 6 8 do echo $i done
prints the numbers 2, 4, 6, and 8 on successive lines.
A special form of the for command iterates over the arguments of a script:
for variable do commands done
For example, the following script prints its arguments on successive lines:
for i do echo $i done
The break and continue commands
The break and continue commands are simple commands that take no arguments. When the shell encounters a break command, it immediately exits the body of the enclosing loop ( while, until, or for) command. When the shell encounters a continue command, it immediately discontinues the current iteration of the loop. If the loop condition permits, other iterations may occur; otherwise the loop is exited.
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
NEWS CONTENTS
- 20210612 : The use of PS4= LINENO in debugging bash scripts ( Jun 10, 2021 , www.redhat.com )
- 20210608 : Basic scripting on Unix and Linux by Sandra Henry-Stocker ( Mar 10, 2021 , www.networkworld.com )
- 20210401 : How to use range and sequence expression in bash by Dan Nanni ( Mar 29, 2021 , www.xmodulo.com )
- 20210330 : How to catch and handle errors in bash ( Mar 30, 2021 , www.xmodulo.com )
- 20210324 : How to read data from text files by Roberto Nozaki ( Mar 24, 2021 , www.redhat.com )
- 20210314 : while loops in Bash ( Mar 14, 2021 , www.redhat.com )
- 20201122 : Read a file line by line ( Jul 07, 2020 , www.redhat.com )
- 20200704* Learn Bash Debugging Techniques the Hard Way by Ian Miell ( Jul 04, 2020 , zwischenzugs.com ) [Recommended]
- 20200702 : Associative arrays in Bash by Seth Kenlon ( Apr 02, 2020 , opensource.com )
- 20200305 : Debug your shell scripts with bashdb by Ben Martin ( Nov 24, 2008 , www.linux.com )
- 20191128 : Beginner shell scripting: Is there a shell script to rename a text file from its first line? ( Sep 30, 2010 , www.reddit.com )
- 20190907 : How to Debug Bash Scripts by Mike Ward ( Sep 05, 2019 , linuxconfig.org )
- 20190906 : Using Case Insensitive Matches with Bash Case Statements by Steven Vona ( Jun 30, 2019 , www.putorius.net )
- 20190902 : Switch statement for bash script ( Sep 02, 2019 , www.linuxquestions.org )
- 20190828 : Echo Command in Linux with Examples ( Aug 28, 2019 , linoxide.com )
- 20190827 : Bash Variables - Bash Reference Manual ( Aug 27, 2019 , bash.cyberciti.biz )
- 20190827 : linux - How to show line number when executing bash script ( Aug 27, 2019 , stackoverflow.com )
- 20181017 : How to use arrays in bash script - LinuxConfig.org ( Oct 17, 2018 , linuxconfig.org )
- 20180601 : Introduction to Bash arrays by Robert Aboukhalil ( Jun 01, 2018 , opensource.com )
- 20180426 : Bash Range How to iterate over sequences generated on the shell Linux Hint by Fahmida Yesmin ( Apr 26, 2018 , linuxhint.com )
- 20171209 : linux - What does the line '!-bin-sh -e' do ( Dec 09, 2017 , stackoverflow.com )
- 20171025 : How to modify scripts behavior on signals using bash traps - LinuxConfig.org ( Oct 25, 2017 , linuxconfig.org )
- 20170901 : linux - Looping through the content of a file in Bash - Stack Overflow ( Sep 01, 2017 , stackoverflow.com )
- 20170726 : I feel stupid declare not found in bash scripting ( www.linuxquestions.org )
- 20170726 : Associative array declaration gotcha ( Jul 26, 2017 , unix.stackexchange.com )
- 20170725* Beginner Mistakes ( Jul 25, 2017 , wiki.bash-hackers.org ) [Recommended]
- 20170725 : Arrays in bash 4.x ( Jul 25, 2017 , wiki.bash-hackers.org )
Old News ;-)
[Jun 12, 2021] The use of PS4= LINENO in debugging bash scripts
Jun 10, 2021 | www.redhat.com
Exit status
In Bash scripting,
$?prints the exit status. If it returns zero, it means there is no error. If it is non-zero, then you can conclude the earlier task has some issue.A basic example is as follows:
$ cat myscript.sh #!/bin/bash mkdir learning echo $?If you run the above script once, it will print
0because the directory does not exist, therefore the script will create it. Naturally, you will get a non-zero value if you run the script a second time, as seen below:$ sh myscript.sh mkdir: cannot create directory 'learning': File exists 1In the cloudBest practices
- Understanding cloud computing
- Free course: Red Hat OpenStack Technical Overview
- Free e-book: Hybrid Cloud Strategy for Dummies
It is always recommended to enable the debug mode by adding the
-eoption to your shell script as below:$ cat test3.sh !/bin/bash set -x echo "hello World" mkdiir testing ./test3.sh + echo 'hello World' hello World + mkdiir testing ./test3.sh: line 4: mkdiir: command not foundYou can write a debug function as below, which helps to call it anytime, using the example below:
$ cat debug.sh #!/bin/bash _DEBUG="on" function DEBUG() { [ "$_DEBUG" == "on" ] && $@ } DEBUG echo 'Testing Debudding' DEBUG set -x a=2 b=3 c=$(( $a + $b )) DEBUG set +x echo "$a + $b = $c"Which prints:
$ ./debug.sh Testing Debudding + a=2 + b=3 + c=5 + DEBUG set +x + '[' on == on ']' + set +x 2 + 3 = 5Standard error redirectionYou can redirect all the system errors to a custom file using standard errors, which can be denoted by the number 2 . Execute it in normal Bash commands, as demonstrated below:
$ mkdir users 2> errors.txt $ cat errors.txt mkdir: cannot create directory "˜users': File existsMost of the time, it is difficult to find the exact line number in scripts. To print the line number with the error, use the PS4 option (supported with Bash 4.1 or later). Example below:
$ cat test3.sh #!/bin/bash PS4='LINENO:' set -x echo "hello World" mkdiir testingYou can easily see the line number while reading the errors:
$ /test3.sh 5: echo 'hello World' hello World 6: mkdiir testing ./test3.sh: line 6: mkdiir: command not found
[Jun 08, 2021] Basic scripting on Unix and Linux by Sandra Henry-Stocker
Mar 10, 2021 | www.networkworld.com
... ... ...
Different ways to loopThere are a number of ways to loop within a script. Use for when you want to loop a preset number of times. For example:
#!/bin/bash for day in Sun Mon Tue Wed Thu Fri Sat do echo $day doneor
#!/bin/bash for letter in {a..z} do echo $letter doneUse while when you want to loop as long as some condition exists or doesn't exist.
#!/bin/bash n=1 while [ $n -le 4 ] do echo $n ((n++)) doneUsing case statementsCase statements allow your scripts to react differently depending on what values are being examined. In the script below, we use different commands to extract the contents of the file provided as an argument by identifying the file type.
#!/bin/bash if [ $# -eq 0 ]; then echo -n "filename> " read filename else filename=$1 fi if [ ! -f "$filename" ]; then echo "No such file: $filename" exit fi case $filename in *.tar) tar xf $filename;; *.tar.bz2) tar xjf $filename;; *.tbz) tar xjf $filename;; *.tbz2) tar xjf $filename;; *.tgz) tar xzf $filename;; *.tar.gz) tar xzf $filename;; *.gz) gunzip $filename;; *.bz2) bunzip2 $filename;; *.zip) unzip $filename;; *.Z) uncompress $filename;; *.rar) rar x $filename ;; *) echo "No extract option for $filename" esacNote that this script also prompts for a file name if none was provided and then checks to make sure that the file specified actually exists. Only after that does it bother with the extraction.
Reacting to errorsYou can detect and react to errors within scripts and, in doing so, avoid other errors. The trick is to check the exit codes after commands are run. If an exit code has a value other than zero, an error occurred. In this script, we look to see if Apache is running, but send the output from the check to /dev/null . We then check to see if the exit code isn't equal to zero as this would indicate that the ps command did not get a response. If the exit code is not zero, the script informs the user that Apache isn't running.
#!/bin/bash ps -ef | grep apache2 > /dev/null if [ $? != 0 ]; then echo Apache is not running exit fi
[Apr 01, 2021] How to use range and sequence expression in bash by Dan Nanni
Mar 29, 2021 | www.xmodulo.com
When you are writing a bash script, there are situations where you need to generate a sequence of numbers or strings . One common use of such sequence data is for loop iteration. When you iterate over a range of numbers, the range may be defined in many different ways (e.g., [0, 1, 2,..., 99, 100], [50, 55, 60,..., 75, 80], [10, 9, 8,..., 1, 0], etc). Loop iteration may not be just over a range of numbers. You may need to iterate over a sequence of strings with particular patterns (e.g., incrementing filenames; img001.jpg, img002.jpg, img003.jpg). For this type of loop control, you need to be able to generate a sequence of numbers and/or strings flexibly.
While you can use a dedicated tool like
Brace Expansionseqto generate a range of numbers, it is really not necessary to add such external dependency in your bash script when bash itself provides a powerful built-in range function called brace expansion . In this tutorial, let's find out how to generate a sequence of data in bash using brace expansion and what are useful brace expansion examples .Bash's built-in range function is realized by so-called brace expansion . In a nutshell, brace expansion allows you to generate a sequence of strings based on supplied string and numeric input data. The syntax of brace expansion is the following.
{<string1>,<string2>,...,<stringN>} {<start-number>..<end-number>} {<start-number>..<end-number>..<increment>} <prefix-string>{......} {......}<suffix-string> <prefix-string>{......}<suffix-string>All these sequence expressions are iterable, meaning you can use them for while/for loops . In the rest of the tutorial, let's go over each of these expressions to clarify their use cases.
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=5674857721&adk=3047986842&adf=3341013331&pi=t.ma~as.5674857721&w=1200&fwrn=4&lmt=1617109287&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Frange-sequence-expression-bash.html&flash=0&wgl=1&dt=1617311559984&bpp=49&bdt=419&idt=296&shv=r20210331&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280&correlator=486211930057&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617311560&ga_hid=1542200251&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=1350&biw=1519&bih=762&scr_x=0&scr_y=0&eid=42530672%2C44740079%2C44739537%2C44739387&oid=3&pvsid=2774697899597512&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C762&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&ifi=2&uci=a!2&btvi=1&fsb=1&xpc=Ug4rFEoUn3&p=https%3A//www.xmodulo.com&dtd=306
Use Case #1: List a Sequence of StringsThe first use case of brace expansion is a simple string list, which is a comma-separated list of string literals within the braces. Here we are not generating a sequence of data, but simply list a pre-defined sequence of string data.
{<string1>,<string2>,...,<stringN>}You can use this brace expansion to iterate over the string list as follows.
for fruit in {apple,orange,lemon}; do echo $fruit doneapple orange lemonThis expression is also useful to invoke a particular command multiple times with different parameters.
For example, you can create multiple subdirectories in one shot with:
$ mkdir -p /home/xmodulo/users/{dan,john,alex,michael,emma}To create multiple empty files:
$ touch /tmp/{1,2,3,4}.logUse Case #2: Define a Range of Numbershttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=1795540232&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617109287&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Frange-sequence-expression-bash.html&flash=0&wgl=1&dt=1617311560086&bpp=3&bdt=522&idt=212&shv=r20210331&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200&correlator=486211930057&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617311560&ga_hid=1542200251&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=2661&biw=1519&bih=762&scr_x=0&scr_y=0&eid=42530672%2C44740079%2C44739537%2C44739387&oid=3&pvsid=2774697899597512&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C762&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&ifi=3&uci=a!3&btvi=2&fsb=1&xpc=4Qr9I1IICq&p=https%3A//www.xmodulo.com&dtd=230
The most common use case of brace expansion is to define a range of numbers for loop iteration. For that, you can use the following expressions, where you specify the start/end of the range, as well as an optional increment value.
{<start-number>..<end-number>} {<start-number>..<end-number>..<increment>}To define a sequence of integers between 10 and 20:
echo {10..20} 10 11 12 13 14 15 16 17 18 19 20You can easily integrate this brace expansion in a loop:
for num in {10..20}; do echo $num doneTo generate a sequence of numbers with an increment of 2 between 0 and 20:
echo {0..20..2} 0 2 4 6 8 10 12 14 16 18 20You can generate a sequence of decrementing numbers as well:
echo {20..10} 20 19 18 17 16 15 14 13 12 11 10echo {20..10..-2} 20 18 16 14 12 10You can also pad the numbers with leading zeros, in case you need to use the same number of digits. For example:
echo {00..20..2} 00 02 04 06 08 10 12 14 16 18 20Use Case #3: Generate a Sequence of Charactershttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=2275625677&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617109287&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Frange-sequence-expression-bash.html&flash=0&wgl=1&adsid=ChEI8N6VgwYQhfmhjs6mgZfVARIqAB-w9KHKYtk-pO1suXBsxL8W2AonVwnPmH2XuFwrRPO8MEEAXQpMrZaL&dt=1617311560089&bpp=13&bdt=524&idt=234&shv=r20210331&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200%2C1200x200%2C0x0%2C1519x762&nras=2&correlator=486211930057&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617311560&ga_hid=1542200251&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=4285&biw=1519&bih=762&scr_x=0&scr_y=1242&eid=42530672%2C44740079%2C44739537%2C44739387&oid=3&psts=AGkb-H_lFqstnD2HWv6DycAKvGu9yoyyH3Im0lIwlWU9l6Uc-8KMKIFblasNhvUgGzV4BHfOo--XblJj_VswXA%2CAGkb-H9o5YtqjrXVMh6mfBSJzTIgoTV2500RL7u85T0dFqY9L2FCM8n5K3kCkE5gmmIGpZe6AF47pvNGmYctKA%2CAGkb-H-ww6bPiVlNqpc1PRrGrEXcujNuzAiKCh9dMztOCLvaTDy5GzZj2TpeUNENhbxuLuuOYYD5RgOfQA&pvsid=2774697899597512&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C762&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&jar=2021-04-01-17&ifi=4&uci=a!4&btvi=3&fsb=1&xpc=QImaZvyQly&p=https%3A//www.xmodulo.com&dtd=27097
Brace expansion can be used to generate not just a sequence of numbers, but also a sequence of characters.
{<start-character>..<end-character>}To generate a sequence of alphabet characters between 'd' and 'p':
echo {d..p} d e f g h i j k l m n o pYou can generate a sequence of upper-case alphabets as well.
for char1 in {A..B}; do for char2 in {A..B}; do echo "${char1}${char2}" done doneAA AB BA BBUse Case #4: Generate a Sequence of Strings with Prefix/SuffixIt's possible to add a prefix and/or a suffix to a given brace expression as follows.
<prefix-string>{......} {......}<suffix-string> <prefix-string>{......}<suffix-string>Using this feature, you can easily generate a list of sequentially numbered filenames:
# create incrementing filenames for filename in img_{00..5}.jpg; do echo $filename doneimg_00.jpg img_01.jpg img_02.jpg img_03.jpg img_04.jpg img_05.jpgUse Case #5: Combine Multiple Brace Expansionshttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=1069835252&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617109287&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Frange-sequence-expression-bash.html&flash=0&wgl=1&adsid=ChEI8N6VgwYQhfmhjs6mgZfVARIqAB-w9KHKYtk-pO1suXBsxL8W2AonVwnPmH2XuFwrRPO8MEEAXQpMrZaL&dt=1617311560132&bpp=3&bdt=568&idt=193&shv=r20210331&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200%2C1200x200%2C0x0%2C1519x762%2C1200x200&nras=2&correlator=486211930057&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617311560&ga_hid=1542200251&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=6156&biw=1519&bih=762&scr_x=0&scr_y=3151&eid=42530672%2C44740079%2C44739537%2C44739387&oid=3&psts=AGkb-H_lFqstnD2HWv6DycAKvGu9yoyyH3Im0lIwlWU9l6Uc-8KMKIFblasNhvUgGzV4BHfOo--XblJj_VswXA%2CAGkb-H9o5YtqjrXVMh6mfBSJzTIgoTV2500RL7u85T0dFqY9L2FCM8n5K3kCkE5gmmIGpZe6AF47pvNGmYctKA%2CAGkb-H-ww6bPiVlNqpc1PRrGrEXcujNuzAiKCh9dMztOCLvaTDy5GzZj2TpeUNENhbxuLuuOYYD5RgOfQA%2CAGkb-H_oWO6sMjx-sSACXECD6aXL8a7NcIP5miVIHjPj27ExAouRoqV1vRbD0UeQxrrlNTPAZbGg7YubopvUSA&pvsid=2774697899597512&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C762&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&jar=2021-04-01-17&ifi=5&uci=a!5&btvi=4&fsb=1&xpc=twNmeHYXl4&p=https%3A//www.xmodulo.com&dtd=41555
Finally, it's possible to combine multiple brace expansions, in which case the combined expressions will generate all possible combinations of sequence data produced by each expression.
For example, we have the following script that prints all possible combinations of two-character alphabet strings using double-loop iteration.
for char1 in {A..Z}; do for char2 in {A..Z}; do echo "${char1}${char2}" done doneBy combining two brace expansions, the following single loop can produce the same output as above.
for str in {A..Z}{A..Z}; do echo $str doneConclusionIn this tutorial, I described a bash's built-in mechanism called brace expansion, which allows you to easily generate a sequence of arbitrary strings in a single command line. Brace expansion is useful not just for a bash script, but also in your command line environment (e.g., when you need to run the same command multiple times with different arguments). If you know any useful brace expansion tips and use cases, feel free to share it in the comment.
If you find this tutorial helpful, I recommend you check out the series ofbashshell scripting tutorials provided by Xmodulo.
[Mar 30, 2021] How to catch and handle errors in bash
Mar 30, 2021 | www.xmodulo.com
How to catch and handle errors in bash
Last updated on March 28, 2021 by Dan Nanni
https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=280&slotname=6357311593&adk=3477157422&adf=3251077269&pi=t.ma~as.6357311593&w=1200&fwrn=4&fwrnh=100&lmt=1617039750&rafmt=1&psa=1&format=1200x280&url=https%3A%2F%2Fwww.xmodulo.com%2Fcatch-handle-errors-bash.html&flash=0&fwr=0&fwrattr=true&rpe=1&resp_fmts=3&wgl=1&dt=1617150500578&bpp=19&bdt=670&idt=289&shv=r20210322&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&correlator=2807789420329&frm=20&pv=2&ga_vid=288434327.1614570002&ga_sid=1617150501&ga_hid=294975347&ga_fc=0&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=31&ady=254&biw=1519&bih=714&scr_x=0&scr_y=0&eid=42530672%2C44740079%2C44739387&oid=3&pvsid=3816417963868055&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C714&vis=1&rsz=%7C%7CeE%7C&abl=CS&pfx=0&fu=8320&bc=31&ifi=1&uci=a!1&fsb=1&xpc=FeLkc0yKaB&p=https%3A//www.xmodulo.com&dtd=346
In an ideal world, things always work as expected, but you know that's hardly the case. The same goes in the world of bash scripting. Writing a robust, bug-free bash script is always challenging even for a seasoned system administrator. Even if you write a perfect bash script, the script may still go awry due to external factors such as invalid input or network problems. While you cannot prevent all errors in your bash script, at least you should try to handle possible error conditions in a more predictable and controlled fashion.
That is easier said than done, especially since error handling in bash is notoriously difficult. The bash shell does not have any fancy exception swallowing mechanism like try/catch constructs. Some bash errors may be silently ignored but may have consequences down the line. The bash shell does not even have a proper debugger.
In this tutorial, I'll introduce basic tips to catch and handle errors in bash . Although the presented error handling techniques are not as fancy as those available in other programming languages, hopefully by adopting the practice, you may be able to handle potential bash errors more gracefully.
Bash Error Handling Tip #1: Check the Exit Statushttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=5674857721&adk=3047986842&adf=3341013331&pi=t.ma~as.5674857721&w=1200&fwrn=4&lmt=1617039750&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Fcatch-handle-errors-bash.html&flash=0&wgl=1&dt=1617150500597&bpp=37&bdt=688&idt=355&shv=r20210322&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280&correlator=2807789420329&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617150501&ga_hid=294975347&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=1003&biw=1519&bih=714&scr_x=0&scr_y=0&eid=42530672%2C44740079%2C44739387&oid=3&pvsid=3816417963868055&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C714&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&ifi=2&uci=a!2&btvi=1&fsb=1&xpc=R4Jgtckaf2&p=https%3A//www.xmodulo.com&dtd=373
As the first line of defense, it is always recommended to check the exit status of a command, as a non-zero exit status typically indicates some type of error. For example:
if ! some_command; then echo "some_command returned an error" fiAnother (more compact) way to trigger error handling based on an exit status is to use an OR list:
<command1> || <command2>With this OR statement, <command2> is executed if and only if <command1> returns a non-zero exit status. So you can replace <command2> with your own error handling routine. For example:
error_exit() { echo "Error: $1" exit 1 } run-some-bad-command || error_exit "Some error occurred"Bash provides a built-in variable called
$?, which tells you the exit status of the last executed command. Note that when a bash function is called,$?reads the exit status of the last command called inside the function. Since some non-zero exit codes have special meanings , you can handle them selectively. For example:# run some command status=$? if [ $status -eq 1 ]; then echo "General error" elif [ $status -eq 2 ]; then echo "Misuse of shell builtins" elif [ $status -eq 126 ]; then echo "Command invoked cannot execute" elif [ $status -eq 128 ]; then echo "Invalid argument" fiBash Error Handling Tip #2: Exit on Errors in Bashhttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=1795540232&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617039750&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Fcatch-handle-errors-bash.html&flash=0&wgl=1&dt=1617150500635&bpp=53&bdt=726&idt=346&shv=r20210322&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200&correlator=2807789420329&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617150501&ga_hid=294975347&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=2621&biw=1519&bih=714&scr_x=0&scr_y=0&eid=42530672%2C44740079%2C44739387&oid=3&pvsid=3816417963868055&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C714&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&ifi=3&uci=a!3&btvi=2&fsb=1&xpc=xlM0hGwtiw&p=https%3A//www.xmodulo.com&dtd=367
When you encounter an error in a bash script, by default, it throws an error message to
stderr, but continues its execution in the rest of the script. In fact you see the same behavior in a terminal window; even if you type a wrong command by accident, it will not kill your terminal. You will just see the "command not found" error, but you terminal/bash session will still remain.This default shell behavior may not be desirable for some bash script. For example, if your script contains a critical code block where no error is allowed, you want your script to exit immediately upon encountering any error inside that code block. To activate this "exit-on-error" behavior in bash, you can use the
setcommand as follows.set -e # # some critical code block where no error is allowed # set +eOnce called with
-eoption, thesetcommand causes the bash shell to exit immediately if any subsequent command exits with a non-zero status (caused by an error condition). The+eoption turns the shell back to the default mode.set -eis equivalent toset -o errexit. Likewise,set +eis a shorthand command forset +o errexit.However, one special error condition not captured by
set -eis when an error occurs somewhere inside a pipeline of commands. This is because a pipeline returns a non-zero status only if the last command in the pipeline fails. Any error produced by previous command(s) in the pipeline is not visible outside the pipeline, and so does not kill a bash script. For example:set -e true | false | true echo "This will be printed" # "false" inside the pipeline not detectedIf you want any failure in pipelines to also exit a bash script, you need to add
-o pipefailoption. For example:set -o pipefail -e true | false | true # "false" inside the pipeline detected correctly echo "This will not be printed"Therefore, to protect a critical code block against any type of command errors or pipeline errors, use the following pair of
setcommands.set -o pipefail -e # # some critical code block where no error or pipeline error is allowed # set +o pipefail +eBash Error Handling Tip #3: Try and Catch Statements in Bashhttps://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=2275625677&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617039750&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Fcatch-handle-errors-bash.html&flash=0&wgl=1&adsid=ChAI8JiLgwYQkvKD_-vdud51EioAsc7QJfPbVjxhaA0k3D4cZGdWuanTHT1OnZFf-sYZ_FlsHeNm-m93y6g&dt=1617150500736&bpp=3&bdt=827&idt=284&shv=r20210322&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200%2C1200x200%2C0x0%2C1519x714&nras=2&correlator=2807789420329&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617150501&ga_hid=294975347&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=4322&biw=1519&bih=714&scr_x=0&scr_y=1473&eid=42530672%2C44740079%2C44739387&oid=3&psts=AGkb-H9kB9XBPoFQr4Nvbpzi-IDFo1H7_NaIL8M18sGGWSqpMo6EvnCzj-Qorx0rQkLTtpYfrxcistXQ3NLI%2CAGkb-H9NblhEl8n-XjoXLiznZ70w5Gvz_2AR1xlm3w9htg9Uoc9EqNnh-BnrA3HlHfn539NkqfOg0pb4UgvAzA%2CAGkb-H_8XpQQ502aEe7wRqWV9odZAPWfUTDNYIPLyzG6DAnUhxH_sAn3FM_H-EjHMVFKcfuXC1svgR-pJ4tNKQ&pvsid=3816417963868055&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C714&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&jar=2021-03-30-23&ifi=4&uci=a!4&btvi=3&fsb=1&xpc=v8JM1LJbyF&p=https%3A//www.xmodulo.com&dtd=7982
Although the
setcommand allows you to terminate a bash script upon any error that you deem critical, this mechanism is often not sufficient in more complex bash scripts where different types of errors could happen.To be able to detect and handle different types of errors/exceptions more flexibly, you will need try/catch statements, which however are missing in bash. At least we can mimic the behaviors of try/catch as shown in this
trycatch.shscript:function try() { [[ $- = *e* ]]; SAVED_OPT_E=$? set +e } function throw() { exit $1 } function catch() { export exception_code=$? (( $SAVED_OPT_E )) && set +e return $exception_code }Here we define several custom bash functions to mimic the semantic of try and catch statements. The
throw()function is supposed to raise a custom (non-zero) exception. We needset +e, so that the non-zero returned bythrow()will not terminate a bash script. Insidecatch(), we store the value of exception raised bythrow()in a bash variableexception_code, so that we can handle the exception in a user-defined fashion.Perhaps an example bash script will make it clear how
trycatch.shworks. See the example below that utilizestrycatch.sh.# Include trybatch.sh as a library source ./trycatch.sh # Define custom exception types export ERR_BAD=100 export ERR_WORSE=101 export ERR_CRITICAL=102 try ( echo "Start of the try block" # When a command returns a non-zero, a custom exception is raised. run-command || throw $ERR_BAD run-command2 || throw $ERR_WORSE run-command3 || throw $ERR_CRITICAL # This statement is not reached if there is any exception raised # inside the try block. echo "End of the try block" ) catch || { case $exception_code in $ERR_BAD) echo "This error is bad" ;; $ERR_WORSE) echo "This error is worse" ;; $ERR_CRITICAL) echo "This error is critical" ;; *) echo "Unknown error: $exit_code" throw $exit_code # re-throw an unhandled exception ;; esac }In this example script, we define three types of custom exceptions. We can choose to raise any of these exceptions depending on a given error condition. The OR list
<command> || throw <exception>allows us to invokethrow()function with a chosen <exception> value as a parameter, if <command> returns a non-zero exit status. If <command> is completed successfully,throw()function will be ignored. Once an exception is raised, the raised exception can be handled accordingly inside the subsequent catch block. As you can see, this provides a more flexible way of handling different types of error conditions.https://googleads.g.doubleclick.net/pagead/ads?client=ca-pub-7245163904660683&output=html&h=200&slotname=1246960885&adk=2798017750&adf=1069835252&pi=t.ma~as.1246960885&w=1200&fwrn=4&lmt=1617039750&rafmt=11&psa=1&format=1200x200&url=https%3A%2F%2Fwww.xmodulo.com%2Fcatch-handle-errors-bash.html&flash=0&wgl=1&adsid=ChAI8JiLgwYQkvKD_-vdud51EioAsc7QJfPbVjxhaA0k3D4cZGdWuanTHT1OnZFf-sYZ_FlsHeNm-m93y6g&dt=1617150500740&bpp=33&bdt=832&idt=288&shv=r20210322&cbv=r20190131&ptt=9&saldr=aa&abxe=1&cookie=ID%3Dc3dfa6581a6e36dd-22096420bac60000%3AT%3D1614570003%3ART%3D1614570003%3AS%3DALNI_MZbq_6NmD0W6EwR1pZiXu91X_Gmaw&prev_fmts=1200x280%2C1200x200%2C1200x200%2C0x0%2C1519x714%2C1200x200&nras=2&correlator=2807789420329&frm=20&pv=1&ga_vid=288434327.1614570002&ga_sid=1617150501&ga_hid=294975347&ga_fc=0&rplot=4&u_tz=-240&u_his=1&u_java=0&u_h=864&u_w=1536&u_ah=864&u_aw=1536&u_cd=24&u_nplug=3&u_nmime=4&adx=160&ady=6943&biw=1519&bih=714&scr_x=0&scr_y=4095&eid=42530672%2C44740079%2C44739387&oid=3&psts=AGkb-H9kB9XBPoFQr4Nvbpzi-IDFo1H7_NaIL8M18sGGWSqpMo6EvnCzj-Qorx0rQkLTtpYfrxcistXQ3NLI%2CAGkb-H9NblhEl8n-XjoXLiznZ70w5Gvz_2AR1xlm3w9htg9Uoc9EqNnh-BnrA3HlHfn539NkqfOg0pb4UgvAzA%2CAGkb-H_8XpQQ502aEe7wRqWV9odZAPWfUTDNYIPLyzG6DAnUhxH_sAn3FM_H-EjHMVFKcfuXC1svgR-pJ4tNKQ%2CAGkb-H_LZaKgZXHhi-mp793u920dtCBuBuOdBYfg8GxP5Yl69G1LrubEm-DNODFvz9VDpFX0r4wQgNJ9B_IZKQ&pvsid=3816417963868055&pem=502&ref=https%3A%2F%2Fwww.linuxtoday.com%2F&rx=0&eae=0&fc=896&brdim=1536%2C0%2C1536%2C0%2C1536%2C0%2C1536%2C864%2C1536%2C714&vis=1&rsz=%7C%7CeEbr%7C&abl=CS&pfx=0&fu=8320&bc=31&jar=2021-03-30-23&ifi=5&uci=a!5&btvi=4&fsb=1&xpc=cNiz7hdTMs&p=https%3A//www.xmodulo.com&dtd=13575
Granted, this is not a full-blown try/catch constructs. One limitation of this approach is that the
Conclusiontryblock is executed in a sub-shell . As you may know, any variables defined in a sub-shell are not visible to its parent shell. Also, you cannot modify the variables that are defined in the parent shell inside thetryblock, as the parent shell and the sub-shell have separate scopes for variables.In this bash tutorial, I presented basic error handling tips that may come in handy when you want to write a more robust bash script. As expected these tips are not as sophisticated as the error handling constructs available in other programming language. If the bash script you are writing requires more advanced error handling than this, perhaps bash is not the right language for your task. You probably want to turn to other languages such as Python.
Let me conclude the tutorial by mentioning one essential tool that every shell script writer should be familiar with. ShellCheck is a static analysis tool for shell scripts. It can detect and point out syntax errors, bad coding practice and possible semantic issues in a shell script with much clarity. Definitely check it out if you haven't tried it.
If you find this tutorial helpful, I recommend you check out the series ofbashshell scripting tutorials provided by Xmodulo.
[Mar 24, 2021] How to read data from text files by Roberto Nozaki
Mar 24, 2021 | www.redhat.com
The following is the script I use to test the servers:
1 #!/bin/bash 2 3 input_file=hosts.csv 4 output_file=hosts_tested.csv 5 6 echo "ServerName,IP,PING,DNS,SSH" > "$output_file" 7 8 tail -n +2 "$input_file" | while IFS=, read -r host ip _ 9 do 10 if ping -c 3 "$ip" > /dev/null; then 11 ping_status="OK" 12 else 13 ping_status="FAIL" 14 fi 15 16 if nslookup "$host" > /dev/null; then 17 dns_status="OK" 18 else 19 dns_status="FAIL" 20 fi 21 22 if nc -z -w3 "$ip" 22 > /dev/null; then 23 ssh_status="OK" 24 else 25 ssh_status="FAIL" 26 fi 27 28 echo "Host = $host IP = $ip" PING_STATUS = $ping_status DNS_STATUS = $dns_status SSH_STATUS = $ssh_status 29 echo "$host,$ip,$ping_status,$dns_status,$ssh_status" >> $output_file 30 done
[Mar 14, 2021] while loops in Bash
Mar 14, 2021 | www.redhat.com
while true do df -k | grep home sleep 1 doneIn this case, you're running the loop with a true condition, which means it will run forever or until you hit CTRL-C. Therefore, you need to keep an eye on it (otherwise, it will remain using the system's resources).
Note : If you use a loop like this, you need to include a command like
2. Waiting for a condition to become truesleepto give the system some time to breathe between executions. Running anything non-stop could become a performance issue, especially if the commands inside the loop involve I/O operations.There are variations of this scenario. For example, you know that at some point, the process will create a directory, and you are just waiting for that moment to perform other validations.
You can have a
whileloop to keep checking for that directory's existence and only write a message while the directory does not exist.https://asciinema.org/a/BQN8CDagw6k8bSbGJPYi5kqpg/embed?
If you want to do something more elaborate, you could create a script and show a more clear indication that the loop condition became true:
#!/bin/bash while [ ! -d directory_expected ] do echo "`date` - Still waiting" sleep 1 done echo "DIRECTORY IS THERE!!!"More about automation3. Using a while loop to manipulate a file
- An introduction to Ansible
- 3 ways to try Ansible Tower free
- Free Ansible e-books
- Getting started with network automation
Another useful application of a
whileloop is to combine it with thereadcommand to have access to columns (or fields) quickly from a text file and perform some actions on them.In the following example, you are simply picking the columns from a text file with a predictable format and printing the values that you want to use to populate an
/etc/hostsfile.https://asciinema.org/a/2b1u28XqoC7j7Muhd5zXqHkYP/embed?
Here the assumption is that the file has columns delimited by spaces or tabs and that there are no spaces in the content of the columns. That could shift the content of the fields and not give you what you needed.
Notice that you're just doing a simple operation to extract and manipulate information and not concerned about the command's reusability. I would classify this as one of those "quick and dirty tricks."
Of course, if this was something that you would repeatedly do, you should run it from a script, use proper names for the variables, and all those good practices (including transforming the filename in an argument and defining where to send the output, but today, the topic is
whileloops).#!/bin/bash cat servers.txt | grep -v CPU | while read servername cpu ram ip do echo $ip $servername done
[Nov 22, 2020] Read a file line by line
Jul 07, 2020 | www.redhat.com
Assume I have a file with a lot of IP addresses and want to operate on those IP addresses. For example, I want to run
digto retrieve reverse-DNS information for the IP addresses listed in the file. I also want to skip IP addresses that start with a comment (# or hashtag).I'll use fileA as an example. Its contents are:
10.10.12.13 some ip in dc1 10.10.12.14 another ip in dc2 #10.10.12.15 not used IP 10.10.12.16 another IPI could copy and paste each IP address, and then run
digmanually:$> dig +short -x 10.10.12.13Or I could do this:
$> while read -r ip _; do [[ $ip == \#* ]] && continue; dig +short -x "$ip"; done < ipfileWhat if I want to swap the columns in fileA? For example, I want to put IP addresses in the right-most column so that fileA looks like this:
some ip in dc1 10.10.12.13 another ip in dc2 10.10.12.14 not used IP #10.10.12.15 another IP 10.10.12.16I run:
$> while read -r ip rest; do printf '%s %s\n' "$rest" "$ip"; done < fileA
[Jul 04, 2020] Learn Bash Debugging Techniques the Hard Way by Ian Miell
Highly recommended!
Notable quotes:
"... NOTE: If you are on a Mac, then you might only get second-level granularity on the date! ..."
Jul 04, 2020 | zwischenzugs.com
... ... ... Managing Variables
Variables are a core part of most serious bash scripts (and even one-liners!), so managing them is another important way to reduce the possibility of your script breaking.
Change your script to add the 'set' line immediately after the first line and see what happens:
#!/bin/bash set -o nounset A="some value" echo "${A}" echo "${B}"...I always set
Tracing Variablesnounseton my scripts as a habit. It can catch many problems before they become serious.If you are working with a particularly complex script, then you can get to the point where you are unsure what happened to a variable.
Try running this script and see what happens:
#!/bin/bash set -o nounset declare A="some value" function a { echo "${BASH_SOURCE}>A A=${A} LINENO:${1}" } trap "a $LINENO" DEBUG B=value echo "${A}" A="another value" echo "${A}" echo "${B}"There's a problem with this code. The output is slightly wrong. Can you work out what is going on? If so, try and fix it.
You may need to refer to the bash man page, and make sure you understand quoting in bash properly.
It's quite a tricky one to fix 'properly', so if you can't fix it, or work out what's wrong with it, then ask me directly and I will help.
Profiling Bash ScriptsReturning to the
xtrace(orset -xflag), we can exploit its use of aPSvariable to implement the profiling of a script:#!/bin/bash set -o nounset set -o xtrace declare A="some value" PS4='$(date "+%s%N => ")' B= echo "${A}" A="another value" echo "${A}" echo "${B}" ls pwd curl -q bbc.co.ukFrom this you should be able to tell what
PS4does. Have a play with it, and read up and experiment with the otherPSvariables to get familiar with what they do.NOTE: If you are on a Mac, then you might only get second-level granularity on the date!
Linting with ShellcheckFinally, here is a very useful tip for understanding bash more deeply and improving any bash scripts you come across.
Shellcheck is a website and a package available on most platforms that gives you advice to help fix and improve your shell scripts. Very often, its advice has prompted me to research more deeply and understand bash better.
Here is some example output from a script I found on my laptop:
$ shellcheck shrinkpdf.sh In shrinkpdf.sh line 44: -dColorImageResolution=$3 \ ^-- SC2086: Double quote to prevent globbing and word splitting. In shrinkpdf.sh line 46: -dGrayImageResolution=$3 \ ^-- SC2086: Double quote to prevent globbing and word splitting. In shrinkpdf.sh line 48: -dMonoImageResolution=$3 \ ^-- SC2086: Double quote to prevent globbing and word splitting. In shrinkpdf.sh line 57: if [ ! -f "$1" -o ! -f "$2" ]; then ^-- SC2166: Prefer [ p ] || [ q ] as [ p -o q ] is not well defined. In shrinkpdf.sh line 60: ISIZE="$(echo $(wc -c "$1") | cut -f1 -d\ )" ^-- SC2046: Quote this to prevent word splitting. ^-- SC2005: Useless echo? Instead of 'echo $(cmd)', just use 'cmd'. In shrinkpdf.sh line 61: OSIZE="$(echo $(wc -c "$2") | cut -f1 -d\ )" ^-- SC2046: Quote this to prevent word splitting. ^-- SC2005: Useless echo? Instead of 'echo $(cmd)', just use 'cmd'.The most common reminders are regarding potential quoting issues, but you can see other useful tips in the above output, such as preferred arguments to the
Exercisetestconstruct, and advice on "useless"echos.1) Find a large bash script on a social coding site such as GitHub, and run
shellcheckover it. Contribute back any improvements you find.
[Jul 02, 2020] Associative arrays in Bash by Seth Kenlon
Apr 02, 2020 | opensource.com
Originally from: Get started with Bash scripting for sysadmins - Opensource.com
Most shells offer the ability to create, manipulate, and query indexed arrays. In plain English, an indexed array is a list of things prefixed with a number. This list of things, along with their assigned number, is conveniently wrapped up in a single variable, which makes it easy to "carry" it around in your code.
Bash, however, includes the ability to create associative arrays and treats these arrays the same as any other array. An associative array lets you create lists of key and value pairs, instead of just numbered values.
The nice thing about associative arrays is that keys can be arbitrary:
$ declare -A userdata
$ userdata [ name ] =seth
$ userdata [ pass ] =8eab07eb620533b083f241ec4e6b9724
$ userdata [ login ] = ` date --utc + % s `Query any key:
$ echo " ${userdata[name]} "
seth
$ echo " ${userdata[login]} "
1583362192Most of the usual array operations you'd expect from an array are available.
Resources
- How to program with Bash: Syntax and tools
- How to program with Bash: Logical operators and shell expansions
- How to program with Bash: Loops
[Mar 05, 2020] Debug your shell scripts with bashdb by Ben Martin
Nov 24, 2008 | www.linux.com
Author: Ben Martin
The Bash Debugger Project (bashdb) lets you set breakpoints, inspect variables, perform a backtrace, and step through a bash script line by line. In other words, it provides the features you expect in a C/C++ debugger to anyone programming a bash script.To see if your standard bash executable has bashdb support, execute the command shown below; if you are not taken to a bashdb prompt then you'll have to install bashdb yourself.
$ bash --debugger -c "set|grep -i dbg" ... bashdbThe Ubuntu Intrepid repository contains a package for bashdb, but there is no special bashdb package in the openSUSE 11 or Fedora 9 repositories. I built from source using version 4.0-0.1 of bashdb on a 64-bit Fedora 9 machine, using the normal
./configure; make; sudo make installcommands.You can start the Bash Debugger using the
bash --debugger foo.shsyntax or thebashdb foo.shcommand. The former method is recommended except in cases where I/O redirection might cause issues, and it's what I used. You can also use bashdb through ddd or from an Emacs buffer.The syntax for many of the commands in bashdb mimics that of gdb, the GNU debugger. You can
stepinto functions, usenextto execute the next line without stepping into any functions, generate a backtrace withbt, exit bashdb withquitor Ctrl-D, and examine a variable withprint $foo. Aside from the prefixing of the variable with$at the end of the last sentence, there are some other minor differences that you'll notice. For instance, pressing Enter on a blank line in bashdb executes the previous step or next command instead of whatever the previous command was.The print command forces you to prefix shell variables with the dollar sign (
$foo). A slightly shorter way of inspecting variables and functions is to use thex foocommand, which usesdeclareto print variables and functions.Both bashdb and your script run inside the same bash shell. Because bash lacks some namespace properties, bashdb will include some functions and symbols into the global namespace which your script can get at. bashdb prefixes its symbols with
_Dbg_, so you should avoid that prefix in your scripts to avoid potential clashes. bashdb also uses some environment variables; it uses theDBG_prefix for its own, and relies on some standard bash ones that begin withBASH_.To illustrate the use of bashdb, I'll work on the small bash script below, which expects a numeric argument
#!/bin/bash version="0.01"; fibonacci() { n=${1:?If you want the nth fibonacci number, you must supply n as the first parameter.} if [ $n -le 1 ]; then echo $n else l=`fibonacci $((n-1))` r=`fibonacci $((n-2))` echo $((l + r)) fi } for i in `seq 1 10` do result=$(fibonacci $i) echo "i=$i result=$result" donenand calculates the nth Fibonacci number .The below session shows bashdb in action, stepping over and then into the fibonacci function and inspecting variables. I've made my input text bold for ease of reading. An initial backtrace (
$ bash --debugger ./fibonacci.sh ... (/home/ben/testing/bashdb/fibonacci.sh:3): 3: version="0.01"; bashdb bt ->0 in file `./fibonacci.sh' at line 3 ##1 main() called from file `./fibonacci.sh' at line 0 bashdb next (/home/ben/testing/bashdb/fibonacci.sh:16): 16: for i in `seq 1 10` bashdb list 16:==>for i in `seq 1 10` 17: do 18: result=$(fibonacci $i) 19: echo "i=$i result=$result" 20: done bashdb next (/home/ben/testing/bashdb/fibonacci.sh:18): 18: result=$(fibonacci $i) bashdb (/home/ben/testing/bashdb/fibonacci.sh:19): 19: echo "i=$i result=$result" bashdb x i result declare -- i="1" declare -- result="" bashdb print $i $result 1 bashdb break fibonacci Breakpoint 1 set in file /home/ben/testing/bashdb/fibonacci.sh, line 5. bashdb continue Breakpoint 1 hit (1 times). (/home/ben/testing/bashdb/fibonacci.sh:5): 5: fibonacci() { bashdb next (/home/ben/testing/bashdb/fibonacci.sh:6): 6: n=${1:?If you want the nth fibonacci number, you must supply n as the first parameter.} bashdb next (/home/ben/testing/bashdb/fibonacci.sh:7): 7: if [ $n -le 1 ]; then bashdb x n declare -- n="2" bashdb quitbt) shows that the script begins at line 3, which is where the version variable is written. Thenextandlistcommands then progress to the next line of the script a few times and show the context of the current execution line. After one of thenextcommands I press Enter to executenextagain. I invoke theexaminecommand through the single letter shortcutx. Notice that the variables are printed out usingdeclareas opposed to their display on the next line usingfibonaccifunction andcontinuethe execution of the shell script. Thefibonaccifunction is called and I move to thenextline a few times and inspect a variable.Notice that the number in the bashdb prompt toward the end of the above example is enclosed in parentheses. Each set of parentheses indicates that you have entered a subshell. In this example this is due to being inside a shell function.
In the below example I use a watchpoint to see if and where the
(/home/ben/testing/bashdb/fibonacci.sh:3): 3: version="0.01"; bashdb<0> next (/home/ben/testing/bashdb/fibonacci.sh:16): 16: for i in `seq 1 10` bashdb<1> watch result 0: ($result)==0 arith: 0 bashdb<2> c Watchpoint 0: $result changed: old value: '' new value: '1' (/home/ben/testing/bashdb/fibonacci.sh:19): 19: echo "i=$i result=$result" bashdb<3> c i=1 result=1 i=2 result=1 Watchpoint 0: $result changed: old value: '1' new value: '2' (/home/ben/testing/bashdb/fibonacci.sh:19): 19: echo "i=$i result=$result"resultvariable changes. Notice the initialnextcommand. I found that if I didn't issue that next then my watch would fail to work. As you can see, after I issuecto continue execution, execution is stopped whenever the result variable is about to change, and the new and old value are displayed.To get around the strange initial
$ bash --debugger ./fibonacci.sh (/home/ben/testing/bashdb/fibonacci.sh:3): 3: version="0.01"; bashdb<0> watche result > 4 0: (result > 4)==0 arith: 1 bashdb<1> continue i=1 result=1 i=2 result=1 i=3 result=2 i=4 result=3 Watchpoint 0: result > 4 changed: old value: '0' new value: '1' (/home/ben/testing/bashdb/fibonacci.sh:19): 19: echo "i=$i result=$result"nextrequirement I used thewatchecommand in the below session, which lets you stop whenever an expression becomes true. In this case I'm not overly interested in the first few Fibonacci numbers so I set a watch to have execution stop when the result is greater than 4. You can also use awatchecommand without a condition; for example,watche resultwould stop execution whenever the result variable changed.When a shell script goes wrong, many folks use the time-tested method of incrementally adding in
echoorprintfstatements to look for invalid values or code paths that are never reached. With bashdb, you can save yourself time by just adding a few watches on variables or setting a few breakpoints.
[Nov 28, 2019] Beginner shell scripting: Is there a shell script to rename a text file from its first line?
Sep 30, 2010 | www.reddit.com
1 r/commandline • Posted by u/acksed 6 years ago
I had to use file recovery software when I accidentally formatted my backup. It worked, but I now have 37,000 text files with numbers where names used to be.
If I name each file with the first 20-30 characters, I can sort the text-wheat from the bit-chaff.
I have the vague idea of using whatever the equivalent of head is on Windows, but that's as far as I got. I'm not so hot on bash scripting either. 9 comments 54% Upvoted This thread is archived New comments cannot be posted and votes cannot be cast Sort by level 1
tatumc 6 points · 6 years ago
acksed 2 points · 6 years agoTo rename each file with the first line of the file, you can do:
for i in *; do mv $i "$(head -1 "$i")"; doneYou can use cp instead of mv or make a backup of the dir first to be sure you don't accidentally nuke anything. level 2
· edited 6 years agotatumc 1 point · 6 years agoThis is almost exactly what I wanted. Thanks! A quick tweak:
for i in *; do mv $i "$(head -c 30 "$i")"; doneNow, I know CygWin is a thing, wonder if it'll work for me. level 3
acksed 1 point · 6 years agoJust keep in mind that 'head -c' will include newlines which will garble the new file names. level 3
· edited 6 years agotatumc 1 point · 6 years agoAnswer: not really. The environment and script's working, but whenever there's a forward slash or non-escaping character in the text, it chokes when it tries to set up a new directory, and it deletes the file suffix. :-/ Good thing I used a copy of the data.
Need something to strip out the characters and spaces, and add the file suffix, before it tries to rename.
sed? Also needsfileto identify it as true text. I can do the suffix at least:for i in *; do mv $i "$(head -c 30 "$i").txt"; donelevel 4yeayoushookme 1 point · 6 years agoI recommend you use 'head -1', which will make the first line of the file the filename and you won't have to worry about newlines. Then you can change the spaces to underscores with:
for i in *; do mv -v "$i" `echo $i | tr ' ' '_' `level 1· edited 6 years agoacksed 1 point · 6 years agoThere's the
fileprogram on *nix that'll tell you, in a verbose manner, the type of the file you give it as an argument, irregardless of its file extension. Example:$ file test.mp3 test.mp3: , 48 kHz, JntStereo $ file mbr.bin mbr.bin: data $ file CalendarExport.ics CalendarExport.ics: HTML document, UTF-8 Unicode text, with very long lines, with CRLF, LF line terminators $ file jmk.doc jmk.doc: Composite Document File V2 Document, Little Endian, Os: Windows, Version 6.0, Code page: 1250, Title: xx, Author: xx, Template: Normal, Last Saved By: xx, Revision Number: 4, Name of Creating Application: Microsoft Office Word, Total Editing Time: 2d+03:32:00, Last Printed: Fri Feb 22 11:29:00 2008, Create Time/Date: Fri Jan 4 12:57:00 2013, Last Saved Time/Date: Sun Jan 6 16:30:00 2013, Number of Pages: 6, Number of Words: 1711, Number of Characters: 11808, Security: 0level 2· edited 6 years agoRonaldoNazario 1 point · 6 years agoThank you, but the software I used to recover (R-Undelete) sorted them already. I found another program, RenameMaestro, that renames according to metadata in zip, rar, pdf, doc and other files, but text files are too basic.
Edit: You were right, I did need it. level 1
pfp-disciple 1 point · 6 years agoNot command line, but you could probably do this pretty easily in python, using "glob" to get filenames, and os read and move/rename functions to get the text and change filenames. level 1
So far, you're not getting many windows command line ideas :(. I don't have any either, but here's an idea:
Use one of the live Linux distributions (Porteus is pretty cool, but there're a slew of others). In that Linux environment, you can mount your Windows hard drive, and use Linux tools, maybe something like /u/tatumc suggested. r/commandline
[Sep 07, 2019] How to Debug Bash Scripts by Mike Ward
Sep 05, 2019 | linuxconfig.org
05 September 2019
... ... ... How to use other Bash optionsThe Bash options for debugging are turned off by default, but once they are turned on by using the set command, they stay on until explicitly turned off. If you are not sure which options are enabled, you can examine the
$-variable to see the current state of all the variables.$ echo $- himBHs $ set -xv && echo $- himvxBHsThere is another useful switch we can use to help us find variables referenced without having any value set. This is the
-uswitch, and just like-xand-vit can also be used on the command line, as we see in the following example:<img src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at command line" width=1200 height=254 /> Setting
uoption at the command lineWe mistakenly assigned a value of 7 to the variable called "level" then tried to echo a variable named "score" that simply resulted in printing nothing at all to the screen. Absolutely no debug information was given. Setting our
-uswitch allows us to see a specific error message, "score: unbound variable" that indicates exactly what went wrong.We can use those options in short Bash scripts to give us debug information to identify problems that do not otherwise trigger feedback from the Bash interpreter. Let's walk through a couple of examples.
#!/bin/bash read -p "Path to be added: " $path if [ "$path" = "/home/mike/bin" ]; then echo $path >> $PATH echo "new path: $PATH" else echo "did not modify PATH" fi<img src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath script" width=1200 height=417 /> Using
xoption when running your Bash scriptIn the example above we run the addpath script normally and it simply does not modify our
PATH. It does not give us any indication of why or clues to mistakes made. Running it again using the-xoption clearly shows us that the left side of our comparison is an empty string.$pathis an empty string because we accidentally put a dollar sign in front of "path" in our read statement. Sometimes we look right at a mistake like this and it doesn't look wrong until we get a clue and think, "Why is$pathevaluated to an empty string?"Looking this next example, we also get no indication of an error from the interpreter. We only get one value printed per line instead of two. This is not an error that will halt execution of the script, so we're left to simply wonder without being given any clues. Using the
-uswitch,we immediately get a notification that our variablejis not bound to a value. So these are real time savers when we make mistakes that do not result in actual errors from the Bash interpreter's point of view.#!/bin/bash for i in 1 2 3 do echo $i $j done<img src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh script" width=1200 height=291 /> Using
uoption running your script from the command lineNow surely you are thinking that sounds fine, but we seldom need help debugging mistakes made in one-liners at the command line or in short scripts like these. We typically struggle with debugging when we deal with longer and more complicated scripts, and we rarely need to set these options and leave them set while we run multiple scripts. Setting
-xvoptions and then running a more complex script will often add confusion by doubling or tripling the amount of output generated.Fortunately we can use these options in a more precise way by placing them inside our scripts. Instead of explicitly invoking a Bash shell with an option from the command line, we can set an option by adding it to the shebang line instead.
#!/bin/bash -xThis will set the
-xoption for the entire file or until it is unset during the script execution, allowing you to simply run the script by typing the filename instead of passing it to Bash as a parameter. A long script or one that has a lot of output will still become unwieldy using this technique however, so let's look at a more specific way to use options.
For a more targeted approach, surround only the suspicious blocks of code with the options you want. This approach is great for scripts that generate menus or detailed output, and it is accomplished by using the set keyword with plus or minus once again.
#!/bin/bash read -p "Path to be added: " $path set -xv if [ "$path" = "/home/mike/bin" ]; then echo $path >> $PATH echo "new path: $PATH" else echo "did not modify PATH" fi set +xv<img src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath script" width=1200 height=469 /> Wrapping options around a block of code in your script
We surrounded only the blocks of code we suspect in order to reduce the output, making our task easier in the process. Notice we turn on our options only for the code block containing our if-then-else statement, then turn off the option(s) at the end of the suspect block. We can turn these options on and off multiple times in a single script if we can't narrow down the suspicious areas, or if we want to evaluate the state of variables at various points as we progress through the script. There is no need to turn off an option If we want it to continue for the remainder of the script execution.
For completeness sake we should mention also that there are debuggers written by third parties that will allow us to step through the code execution line by line. You might want to investigate these tools, but most people find that that they are not actually needed.
As seasoned programmers will suggest, if your code is too complex to isolate suspicious blocks with these options then the real problem is that the code should be refactored. Overly complex code means bugs can be difficult to detect and maintenance can be time consuming and costly.
One final thing to mention regarding Bash debugging options is that a file globbing option also exists and is set with
-f. Setting this option will turn off globbing (expansion of wildcards to generate file names) while it is enabled. This-foption can be a switch used at the command line with bash, after the shebang in a file or, as in this example to surround a block of code.#!/bin/bash echo "ignore fileglobbing option turned off" ls * echo "ignore file globbing option set" set -f ls * set +f<img src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option" width=1200 height=314 /> Using
foption to turn off file globbing How to use trap to help debugThere are more involved techniques worth considering if your scripts are complicated, including using an assert function as mentioned earlier. One such method to keep in mind is the use of trap. Shell scripts allow us to trap signals and do something at that point.
A simple but useful example you can use in your Bash scripts is to trap on
EXIT.#!/bin/bash trap 'echo score is $score, status is $status' EXIT if [ -z ]; then status="default" else status= fi score=0 if [ ${USER} = 'superman' ]; then score=99 elif [ $# -gt 1 ]; then score= fi<img src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap EXIT" width=1200 height=469 /> Using trap
EXITto help debug your script
As you can see just dumping the current values of variables to the screen can be useful to show where your logic is failing. The
EXITsignal obviously does not need an explicitexitstatement to be generated; in this case theechostatement is executed when the end of the script is reached.Another useful trap to use with Bash scripts is
DEBUG. This happens after every statement, so it can be used as a brute force way to show the values of variables at each step in the script execution.#!/bin/bash trap 'echo "line ${LINENO}: score is $score"' DEBUG score=0 if [ "${USER}" = "mike" ]; then let "score += 1" fi let "score += 1" if [ "" = "7" ]; then score=7 fi exit 0<img src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap DEBUG" width=1200 height=469 /> Using trap
DEBUGto help debug your script ConclusionWhen you notice your Bash script not behaving as expected and the reason is not clear to you for whatever reason, consider what information would be useful to help you identify the cause then use the most comfortable tools available to help you pinpoint the issue. The xtrace option
-xis easy to use and probably the most useful of the options presented here, so consider trying it out next time you're faced with a script that's not doing what you thought it would
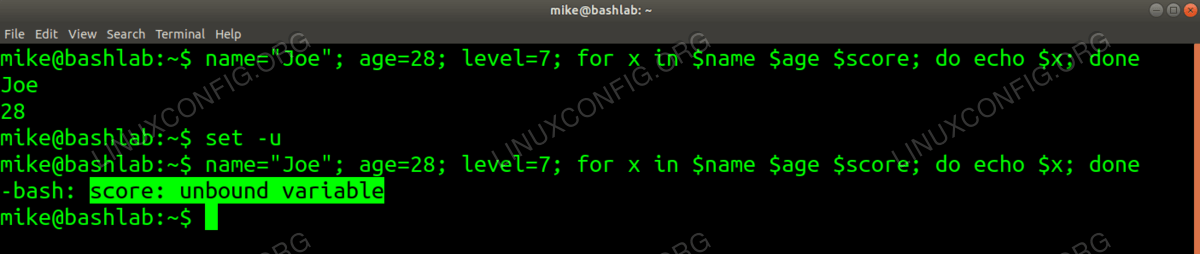 <img
src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at
command line" width=1200 height=254 /> Setting
<img
src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at
command line" width=1200 height=254 /> Setting 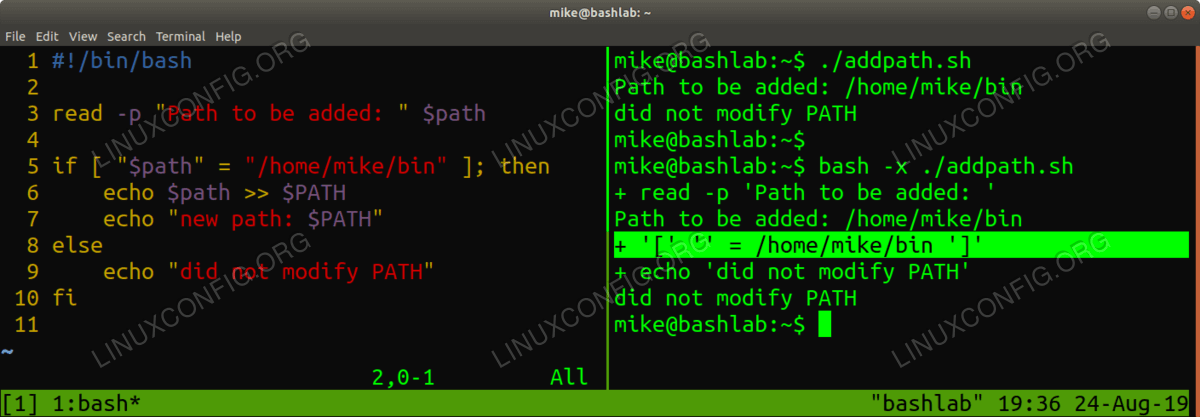 <img
src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=417 /> Using
<img
src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=417 /> Using  <img
src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh
script" width=1200 height=291 /> Using
<img
src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh
script" width=1200 height=291 /> Using 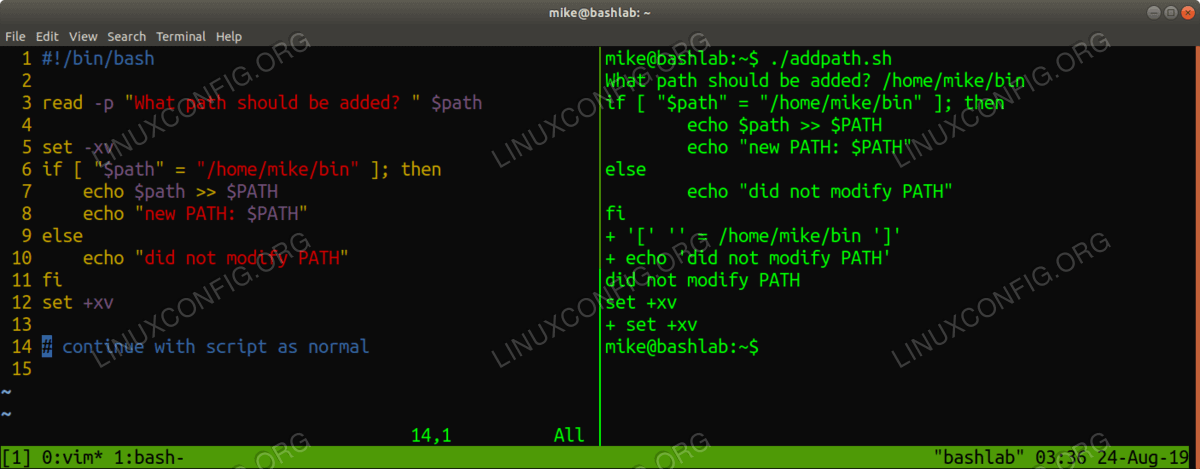 <img
src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=469 /> Wrapping options around a block of code in your script
<img
src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=469 /> Wrapping options around a block of code in your script
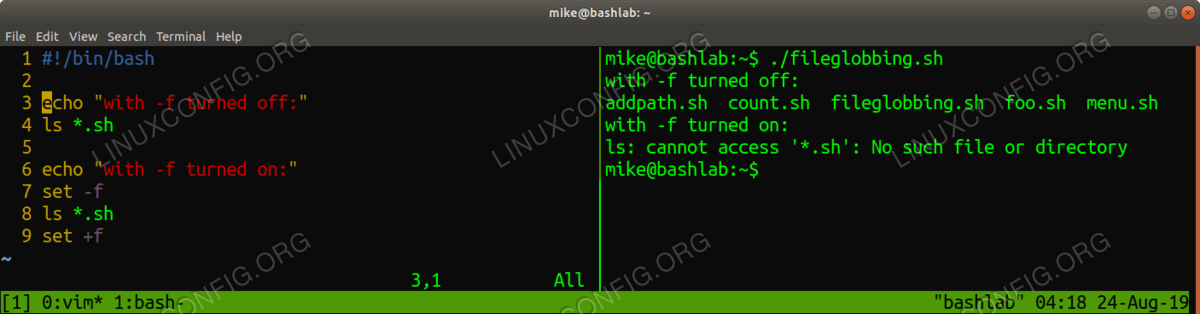 <img
src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option"
width=1200 height=314 /> Using
<img
src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option"
width=1200 height=314 /> Using  <img
src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap
EXIT" width=1200 height=469 /> Using trap
<img
src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap
EXIT" width=1200 height=469 /> Using trap 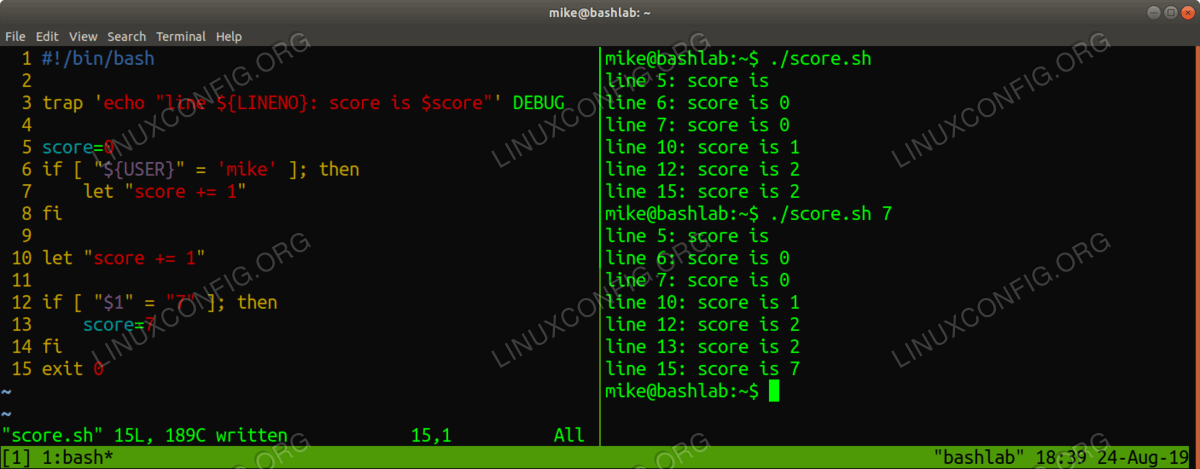 <img
src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap
DEBUG" width=1200 height=469 /> Using trap
<img
src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap
DEBUG" width=1200 height=469 /> Using trap [Sep 06, 2019] Using Case Insensitive Matches with Bash Case Statements by Steven Vona
Jun 30, 2019 | www.putorius.net
If you want to match the pattern regardless of it's case (Capital letters or lowercase letters) you can set the nocasematch shell option with the shopt builtin. You can do this as the first line of your script. Since the script will run in a subshell it won't effect your normal environment.
#!/bin/bash shopt -s nocasematch read -p "Name a Star Trek character: " CHAR case $CHAR in "Seven of Nine" | Neelix | Chokotay | Tuvok | Janeway ) echo "$CHAR was in Star Trek Voyager" ;;& Archer | Phlox | Tpol | Tucker ) echo "$CHAR was in Star Trek Enterprise" ;;& Odo | Sisko | Dax | Worf | Quark ) echo "$CHAR was in Star Trek Deep Space Nine" ;;& Worf | Data | Riker | Picard ) echo "$CHAR was in Star Trek The Next Generation" && echo "/etc/redhat-release" ;; *) echo "$CHAR is not in this script." ;; esac
[Sep 02, 2019] Switch statement for bash script
Sep 02, 2019 | www.linuxquestions.org
Switch statement for bash script
<a rel='nofollow' target='_blank' href='//rev.linuxquestions.org/www/delivery/ck.php?n=a054b75'><img border='0' alt='' src='//rev.linuxquestions.org/www/delivery/avw.php?zoneid=10&n=a054b75' /></a>
[ Log in to get rid of this advertisement] Hello, i am currently trying out the switch statement using bash script.CODE:
showmenu () {
echo "1. Number1"
echo "2. Number2"
echo "3. Number3"
echo "4. All"
echo "5. Quit"
}while true
do
showmenu
read choice
echo "Enter a choice:"
case "$choice" in
"1")
echo "Number One"
;;
"2")
echo "Number Two"
;;
"3")
echo "Number Three"
;;
"4")
echo "Number One, Two, Three"
;;
"5")
echo "Program Exited"
exit 0
;;
*)
echo "Please enter number ONLY ranging from 1-5!"
;;
esac
doneOUTPUT:
1. Number1
2. Number2
3. Number3
4. All
5. Quit
Enter a choice:So, when the code is run, a menu with option 1-5 will be shown, then the user will be asked to enter a choice and finally an output is shown. But it is possible if the user want to enter multiple choices. For example, user enter choice "1" and "3", so the output will be "Number One" and "Number Three". Any idea?
Just something to get you started. Code:
#! /bin/bash showmenu () { typeset ii typeset -i jj=1 typeset -i kk typeset -i valid=0 # valid=1 if input is good while (( ! valid )) do for ii in "${options[@]}" do echo "$jj) $ii" let jj++ done read -e -p 'Select a list of actions : ' -a answer jj=0 valid=1 for kk in "${answer[@]}" do if (( kk < 1 || kk > "${#options[@]}" )) then echo "Error Item $jj is out of bounds" 1>&2 valid=0 break fi let jj++ done done } typeset -r c1=Number1 typeset -r c2=Number2 typeset -r c3=Number3 typeset -r c4=All typeset -r c5=Quit typeset -ra options=($c1 $c2 $c3 $c4 $c5) typeset -a answer typeset -i kk while true do showmenu for kk in "${answer[@]}" do case $kk in 1) echo 'Number One' ;; 2) echo 'Number Two' ;; 3) echo 'Number Three' ;; 4) echo 'Number One, Two, Three' ;; 5) echo 'Program Exit' exit 0 ;; esac done done
stevenworr View Public Profile View LQ Blog View Review Entries View HCL Entries Find More Posts by stevenworr
11-16-2009, 10:10 PM
# 4 wjs1990 Member
Registered: Nov 2009 Posts: 30
Original Poster
Rep:Ok will try it out first. Thanks.
Last edited by wjs1990; 11-16-2009 at 10:13 PM .
wjs1990 View Public Profile View LQ Blog View Review Entries View HCL Entries Find More Posts by wjs1990
# 5 evo2 LQ Guru
Registered: Jan 2009 Location: Japan Distribution: Mostly Debian and CentOS Posts: 5,945
Rep:

This can be done just by wrapping your case block in a for loop and changing one line. Code:
#!/bin/bash showmenu () { echo "1. Number1" echo "2. Number2" echo "3. Number3" echo "4. All" echo "5. Quit" } while true ; do showmenu read choices for choice in $choices ; do case "$choice" in 1) echo "Number One" ;; 2) echo "Number Two" ;; 3) echo "Number Three" ;; 4) echo "Numbers One, two, three" ;; 5) echo "Exit" exit 0 ;; *) echo "Please enter number ONLY ranging from 1-5!" ;; esac done doneYou can now enter any number of numbers seperated by white space.Cheers,
EVo2.
[Aug 28, 2019] Echo Command in Linux with Examples
Notable quotes:
"... The -e parameter is used for the interpretation of backslashes ..."
"... The -n option is used for omitting trailing newline. ..."
Aug 28, 2019 | linoxide.com
The -e parameter is used for the interpretation of backslashes
... ... ...
To create a new line after each word in a string use the -e operator with the \n option as shown$ echo -e "Linux \nis \nan \nopensource \noperating \nsystem"... ... ...
Omit echoing trailing newlineThe -n option is used for omitting trailing newline. This is shown in the example below
$ echo -n "Linux is an opensource operating system"Sample Output
Linux is an opensource operating systemjames@buster:/$
[Aug 27, 2019] Bash Variables - Bash Reference Manual
Aug 27, 2019 | bash.cyberciti.biz
BASH_LINENOAn array variable whose members are the line numbers in source files corresponding to each member of FUNCNAME .
${BASH_LINENO[$i]}is the line number in the source file where${FUNCNAME[$i]}was called. The corresponding source file name is${BASH_SOURCE[$i]}. UseLINENOto obtain the current line number.
[Aug 27, 2019] linux - How to show line number when executing bash script
Aug 27, 2019 | stackoverflow.com
How to show line number when executing bash script Ask Question Asked 6 years, 1 month ago Active 1 year, 4 months ago Viewed 47k times 68 31
dspjm ,Jul 23, 2013 at 7:31
I have a test script which has a lot of commands and will generate lots of output, I useset -xorset -vandset -e, so the script would stop when error occurs. However, it's still rather difficult for me to locate which line did the execution stop in order to locate the problem. Is there a method which can output the line number of the script before each line is executed? Or output the line number before the command exhibition generated byset -x? Or any method which can deal with my script line location problem would be a great help. Thanks.Suvarna Pattayil ,Jul 28, 2017 at 17:25
You mention that you're already using-x. The variablePS4denotes the value is the prompt printed before the command line is echoed when the-xoption is set and defaults to:followed by space.You can change
PS4to emit theLINENO(The line number in the script or shell function currently executing).For example, if your script reads:
$ cat script foo=10 echo ${foo} echo $((2 + 2))Executing it thus would print line numbers:
$ PS4='Line ${LINENO}: ' bash -x script Line 1: foo=10 Line 2: echo 10 10 Line 3: echo 4 4http://wiki.bash-hackers.org/scripting/debuggingtips gives the ultimate
PS4that would output everything you will possibly need for tracing:export PS4='+(${BASH_SOURCE}:${LINENO}): ${FUNCNAME[0]:+${FUNCNAME[0]}(): }'Deqing ,Jul 23, 2013 at 8:16
In Bash,$LINENOcontains the line number where the script currently executing.If you need to know the line number where the function was called, try
$BASH_LINENO. Note that this variable is an array.For example:
#!/bin/bash function log() { echo "LINENO: ${LINENO}" echo "BASH_LINENO: ${BASH_LINENO[*]}" } function foo() { log "$@" } foo "$@"See here for details of Bash variables.
Eliran Malka ,Apr 25, 2017 at 10:14
Simple (but powerful) solution: Placeechoaround the code you think that causes the problem and move theecholine by line until the messages does not appear anymore on screen - because the script has stop because of an error before.Even more powerful solution: Install
bashdbthe bash debugger and debug the script line by linekklepper ,Apr 2, 2018 at 22:44
Workaround for shells without LINENOIn a fairly sophisticated script I wouldn't like to see all line numbers; rather I would like to be in control of the output.
Define a function
echo_line_no () { grep -n "$1" $0 | sed "s/echo_line_no//" # grep the line(s) containing input $1 with line numbers # replace the function name with nothing } # echo_line_noUse it with quotes like
echo_line_no "this is a simple comment with a line number"Output is
16 "this is a simple comment with a line number"if the number of this line in the source file is 16.
This basically answers the question How to show line number when executing bash script for users of ash or other shells without
LINENO.Anything more to add?
Sure. Why do you need this? How do you work with this? What can you do with this? Is this simple approach really sufficient or useful? Why do you want to tinker with this at all?
Want to know more? Read reflections on debugging
[Oct 17, 2018] How to use arrays in bash script - LinuxConfig.org
Oct 17, 2018 | linuxconfig.org
Create indexed arrays on the fly We can create indexed arrays with a more concise syntax, by simply assign them some values:
$ my_array=(foo bar)In this case we assigned multiple items at once to the array, but we can also insert one value at a time, specifying its index:$ my_array[0]=fooArray operations Once an array is created, we can perform some useful operations on it, like displaying its keys and values or modifying it by appending or removing elements: Print the values of an array To display all the values of an array we can use the following shell expansion syntax:${my_array[@]}Or even:${my_array[*]}Both syntax let us access all the values of the array and produce the same results, unless the expansion it's quoted. In this case a difference arises: in the first case, when using@, the expansion will result in a word for each element of the array. This becomes immediately clear when performing afor loop. As an example, imagine we have an array with two elements, "foo" and "bar":$ my_array=(foo bar)Performing aforloop on it will produce the following result:$ for i in "${my_array[@]}"; do echo "$i"; done foo barWhen using*, and the variable is quoted, instead, a single "result" will be produced, containing all the elements of the array:$ for i in "${my_array[*]}"; do echo "$i"; done foo bar
Print the keys of an array It's even possible to retrieve and print the keys used in an indexed or associative array, instead of their respective values. The syntax is almost identical, but relies on the use of the!operator:$ my_array=(foo bar baz) $ for index in "${!my_array[@]}"; do echo "$index"; done 0 1 2The same is valid for associative arrays:$ declare -A my_array $ my_array=([foo]=bar [baz]=foobar) $ for key in "${!my_array[@]}"; do echo "$key"; done baz fooAs you can see, being the latter an associative array, we can't count on the fact that retrieved values are returned in the same order in which they were declared. Getting the size of an array We can retrieve the size of an array (the number of elements contained in it), by using a specific shell expansion:$ my_array=(foo bar baz) $ echo "the array contains ${#my_array[@]} elements" the array contains 3 elementsWe have created an array which contains three elements, "foo", "bar" and "baz", then by using the syntax above, which differs from the one we saw before to retrieve the array values only for the#character before the array name, we retrieved the number of the elements in the array instead of its content. Adding elements to an array As we saw, we can add elements to an indexed or associative array by specifying respectively their index or associative key. In the case of indexed arrays, we can also simply add an element, by appending to the end of the array, using the+=operator:$ my_array=(foo bar) $ my_array+=(baz)If we now print the content of the array we see that the element has been added successfully:$ echo "${my_array[@]}" foo bar bazMultiple elements can be added at a time:$ my_array=(foo bar) $ my_array+=(baz foobar) $ echo "${my_array[@]}" foo bar baz foobarTo add elements to an associative array, we are bound to specify also their associated keys:$ declare -A my_array # Add single element $ my_array[foo]="bar" # Add multiple elements at a time $ my_array+=([baz]=foobar [foobarbaz]=baz)
Deleting an element from the array To delete an element from the array we need to know it's index or its key in the case of an associative array, and use theunsetcommand. Let's see an example:$ my_array=(foo bar baz) $ unset my_array[1] $ echo ${my_array[@]} foo bazWe have created a simple array containing three elements, "foo", "bar" and "baz", then we deleted "bar" from it runningunsetand referencing the index of "bar" in the array: in this case we know it was1, since bash arrays start at 0. If we check the indexes of the array, we can now see that1is missing:$ echo ${!my_array[@]} 0 2The same thing it's valid for associative arrays:$ declare -A my_array $ my_array+=([foo]=bar [baz]=foobar) $ unset my_array[foo] $ echo ${my_array[@]} foobarIn the example above, the value referenced by the "foo" key has been deleted, leaving only "foobar" in the array.Deleting an entire array, it's even simpler: we just pass the array name as an argument to the
unsetcommand without specifying any index or key:$ unset my_array $ echo ${!my_array[@]}After executingunsetagainst the entire array, when trying to print its content an empty result is returned: the array doesn't exist anymore. Conclusions In this tutorial we saw the difference between indexed and associative arrays in bash, how to initialize them and how to perform fundamental operations, like displaying their keys and values and appending or removing items. Finally we saw how to unset them completely. Bash syntax can sometimes be pretty weird, but using arrays in scripts can be really useful. When a script starts to become more complex than expected, my advice is, however, to switch to a more capable scripting language such as python.
[Jun 01, 2018] Introduction to Bash arrays by Robert Aboukhalil
Jun 01, 2018 | opensource.com
... ... ...
Looping through arrays
Although in the examples above we used integer indices in our arrays, let's consider two occasions when that won't be the case: First, if we wanted the
Looping through array elements$i-th element of the array, where$iis a variable containing the index of interest, we can retrieve that element using:echo ${allThreads[$i]}. Second, to output all the elements of an array, we replace the numeric index with the@symbol (you can think of@as standing forall):echo ${allThreads[@]}.With that in mind, let's loop through
for t in ${allThreads[@]} ; do$allThreadsand launch the pipeline for each value of--threads:
. / pipeline --threads $t
doneLooping through array indices
Next, let's consider a slightly different approach. Rather than looping over array elements , we can loop over array indices :
for i in ${!allThreads[@]} ; do
. / pipeline --threads ${allThreads[$i]}
doneLet's break that down: As we saw above,
${allThreads[@]}represents all the elements in our array. Adding an exclamation mark to make it${!allThreads[@]}will return the list of all array indices (in our case 0 to 7). In other words, theforloop is looping through all indices$iand reading the$i-th element from$allThreadsto set the value of the--threadsparameter.This is much harsher on the eyes, so you may be wondering why I bother introducing it in the first place. That's because there are times where you need to know both the index and the value within a loop, e.g., if you want to ignore the first element of an array, using indices saves you from creating an additional variable that you then increment inside the loop.
Populating arraysSo far, we've been able to launch the pipeline for each
Some useful syntax--threadsof interest. Now, let's assume the output to our pipeline is the runtime in seconds. We would like to capture that output at each iteration and save it in another array so we can do various manipulations with it at the end.But before diving into the code, we need to introduce some more syntax. First, we need to be able to retrieve the output of a Bash command. To do so, use the following syntax:
output=$( ./my_script.sh ), which will store the output of our commands into the variable$output.The second bit of syntax we need is how to append the value we just retrieved to an array. The syntax to do that will look familiar:
myArray+=( "newElement1" "newElement2" )The parameter sweepPutting everything together, here is our script for launching our parameter sweep:
allThreads = ( 1 2 4 8 16 32 64 128 )
allRuntimes = ()
for t in ${allThreads[@]} ; do
runtime =$ ( . / pipeline --threads $t )
allRuntimes+= ( $runtime )
doneAnd voilà!
What else you got?In this article, we covered the scenario of using arrays for parameter sweeps. But I promise there are more reasons to use Bash arrays -- here are two more examples.
Log alertingIn this scenario, your app is divided into modules, each with its own log file. We can write a cron job script to email the right person when there are signs of trouble in certain modules:
# List of logs and who should be notified of issues
logPaths = ( "api.log" "auth.log" "jenkins.log" "data.log" )
logEmails = ( "jay@email" "emma@email" "jon@email" "sophia@email" )# Look for signs of trouble in each log
for i in ${!logPaths[@]} ;
do
log = ${logPaths[$i]}
stakeholder = ${logEmails[$i]}
numErrors =$ ( tail -n 100 " $log " | grep "ERROR" | wc -l )# Warn stakeholders if recently saw > 5 errors
API queries
if [[ " $numErrors " -gt 5 ]] ;
then
emailRecipient = " $stakeholder "
emailSubject = "WARNING: ${log} showing unusual levels of errors"
emailBody = " ${numErrors} errors found in log ${log} "
echo " $emailBody " | mailx -s " $emailSubject " " $emailRecipient "
fi
doneSay you want to generate some analytics about which users comment the most on your Medium posts. Since we don't have direct database access, SQL is out of the question, but we can use APIs!
To avoid getting into a long discussion about API authentication and tokens, we'll instead use JSONPlaceholder , a public-facing API testing service, as our endpoint. Once we query each post and retrieve the emails of everyone who commented, we can append those emails to our results array:
endpoint = "https://jsonplaceholder.typicode.com/comments"
allEmails = ()# Query first 10 posts
for postId in { 1 .. 10 } ;
do
# Make API call to fetch emails of this posts's commenters
response =$ ( curl " ${endpoint} ?postId= ${postId} " )# Use jq to parse the JSON response into an array
allEmails+= ( $ ( jq '.[].email' <<< " $response " ) )
doneNote here that I'm using the
jqtool to parse JSON from the command line. The syntax ofjqis beyond the scope of this article, but I highly recommend you look into it.As you might imagine, there are countless other scenarios in which using Bash arrays can help, and I hope the examples outlined in this article have given you some food for thought. If you have other examples to share from your own work, please leave a comment below.
But wait, there's more!Since we covered quite a bit of array syntax in this article, here's a summary of what we covered, along with some more advanced tricks we did not cover:
One last thought
Syntax Result arr=()Create an empty array arr=(1 2 3)Initialize array ${arr[2]}Retrieve third element ${arr[@]}Retrieve all elements ${!arr[@]}Retrieve array indices ${#arr[@]}Calculate array size arr[0]=3Overwrite 1st element arr+=(4)Append value(s) str=$(ls)Save lsoutput as a stringarr=( $(ls) )Save lsoutput as an array of files${arr[@]:s:n}Retrieve elements at indices ntos+nAs we've discovered, Bash arrays sure have strange syntax, but I hope this article convinced you that they are extremely powerful. Once you get the hang of the syntax, you'll find yourself using Bash arrays quite often.
... ... ...
Robert Aboukhalil is a Bioinformatics Software Engineer. In his work, he develops cloud applications for the analysis and interactive visualization of genomics data. Robert holds a Ph.D. in Bioinformatics from Cold Spring Harbor Laboratory and a B.Eng. in Computer Engineering from McGill.
[Apr 26, 2018] Bash Range How to iterate over sequences generated on the shell Linux Hint by Fahmida Yesmin
Notable quotes:
"... When only upper limit is used then the number will start from 1 and increment by one in each step. ..."
Apr 26, 2018 | linuxhint.com
Bash Range: How to iterate over sequences generated on the shell 2 days ago You can iterate the sequence of numbers in bash by two ways. One is by using seq command and another is by specifying range in for loop. In seq command, the sequence starts from one, the number increments by one in each step and print each number in each line up to the upper limit by default. If the number starts from upper limit then it decrements by one in each step. Normally, all numbers are interpreted as floating point but if the sequence starts from integer then the list of decimal integers will print. If seq command can execute successfully then it returns 0, otherwise it returns any non-zero number. You can also iterate the sequence of numbers using for loop with range. Both seq command and for loop with range are shown in this tutorial by using examples.
The options of seq command:
You can use seq command by using the following options.
Examples of seq command:
- -w This option is used to pad the numbers with leading zeros to print all numbers with equal width.
- -f format This option is used to print number with particular format. Floating number can be formatted by using %f, %g and %e as conversion characters. %g is used as default.
- -s string This option is used to separate the numbers with string. The default value is newline ('\n').
You can apply seq command by three ways. You can use only upper limit or upper and lower limit or upper and lower limit with increment or decrement value of each step . Different uses of the seq command with options are shown in the following examples.
Example-1: seq command without optionWhen only upper limit is used then the number will start from 1 and increment by one in each step. The following command will print the number from 1 to 4.
$ seq 4When the two values are used with seq command then first value will be used as starting number and second value will be used as ending number. The following command will print the number from 7 to 15.
$ seq 7 15When you will use three values with seq command then the second value will be used as increment or decrement value for each step. For the following command, the starting number is 10, ending number is 1 and each step will be counted by decrementing 2.
$ seq 10 -2 1Example-2: seq with –w optionThe following command will print the output by adding leading zero for the number from 1 to 9.
$ seq -w 0110Example-3: seq with –s optionThe following command uses "-" as separator for each sequence number. The sequence of numbers will print by adding "-" as separator.
$ seq -s - 8Example-4: seq with -f option
The following command will print 10 date values starting from 1. Here, "%g" option is used to add sequence number with other string value.
$ seq -f "%g/04/2018" 10The following command is used to generate the sequence of floating point number using "%f" . Here, the number will start from 3 and increment by 0.8 in each step and the last number will be less than or equal to 6.
$ seq -f "%f" 3 0.8 6Example-5: Write the sequence in a file
If you want to save the sequence of number into a file without printing in the console then you can use the following commands. The first command will print the numbers to a file named " seq.txt ". The number will generate from 5 to 20 and increment by 10 in each step. The second command is used to view the content of " seq.txt" file.
seq 5 10 20 | cat > seq.txt cat seq.txtExample-6: Using seq in for loop
Suppose, you want to create files named fn1 to fn10 using for loop with seq. Create a file named "sq1.bash" and add the following code. For loop will iterate for 10 times using seq command and create 10 files in the sequence fn1, fn2,fn3 ..fn10.
#!/bin/bash
for i in ` seq 10 ` ; do touch fn. $i doneRun the following commands to execute the code of the bash file and check the files are created or not.
bash sq1.bash lsExamples of for loop with range: Example-7: For loop with range
The alternative of seq command is range. You can use range in for loop to generate sequence of numbers like seq. Write the following code in a bash file named " sq2.bash ". The loop will iterate for 5 times and print the square root of each number in each step.
#!/bin/bash
for n in { 1 .. 5 } ; do (( result =n * n ))
echo $n square = $result
doneRun the command to execute the script of the file.
bash sq2.bashExample-8: For loop with range and increment value
By default, the number is increment by one in each step in range like seq. You can also change the increment value in range. Write the following code in a bash file named " sq3.bash ". The for loop in the script will iterate for 5 times, each step is incremented by 2 and print all odd numbers between 1 to 10.
#!/bin/bash
echo "all odd numbers from 1 to 10 are"
for i in { 1 .. 10 .. 2 }; do echo $i ; doneRun the command to execute the script of the file.
bash sq3.bashIf you want to work with the sequence of numbers then you can use any of the options that are shown in this tutorial. After completing this tutorial, you will be able to use seq command and for loop with range more efficiently in your bash script.
[Dec 09, 2017] linux - What does the line '!-bin-sh -e' do
Dec 09, 2017 | stackoverflow.com
,
That line defines what program will execute the given script. Forshnormally that line should start with the # character as so:#!/bin/sh -eThe -e flag's long name is
errexit, causing the script to immediately exit on the first error.
[Oct 25, 2017] How to modify scripts behavior on signals using bash traps - LinuxConfig.org
Oct 25, 2017 | linuxconfig.org
Trap syntax is very simple and easy to understand: first we must call the trap builtin, followed by the action(s) to be executed, then we must specify the signal(s) we want to react to:
trap [-lp] [[arg] sigspec]Let's see what the possibletrapoptions are for.When used with the
-lflag, the trap command will just display a list of signals associated with their numbers. It's the same output you can obtain running thekill -lcommand:$ trap -l 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP 6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1 11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM 16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP 21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ 26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR 31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3 38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8 43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13 48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12 53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7 58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2 63) SIGRTMAX-1 64) SIGRTMAXIt's really important to specify that it's possible to react only to signals which allows the script to respond: theSIGKILLandSIGSTOPsignals cannot be caught, blocked or ignored.Apart from signals, traps can also react to some
pseudo-signalsuch as EXIT, ERR or DEBUG, but we will see them in detail later. For now just remember that a signal can be specified either by its number or by its name, even without theSIGprefix.About the
-poption now. This option has sense only when a command is not provided (otherwise it will produce an error). When trap is used with it, a list of the previously set traps will be displayed. If the signal name or number is specified, only the trap set for that specific signal will be displayed, otherwise no distinctions will be made, and all the traps will be displayed:$ trap 'echo "SIGINT caught!"' SIGINTWe set a trap to catch the SIGINT signal: it will just display the "SIGINT caught" message onscreen when given signal will be received by the shell. If we now use trap with the -p option, it will display the trap we just defined:$ trap -p trap -- 'echo "SIGINT caught!"' SIGINTBy the way, the trap is now "active", so if we send a SIGINT signal, either using the kill command, or with the CTRL-c shortcut, the associated command in the trap will be executed (^C is just printed because of the key combination):^CSIGINT caught!Trap in action We now will write a simple script to show trap in action, here it is:#!/usr/bin/env bash # # A simple script to demonstrate how trap works # set -e set -u set -o pipefail trap 'echo "signal caught, cleaning..."; rm -i linux_tarball.tar.xz' SIGINT SIGTERM echo "Downloading tarball..." wget -O linux_tarball.tar.xz https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.13.5.tar.xz &> /dev/nullThe above script just tries to download the latest linux kernel tarball into the directory from what it is launched usingwget. During the task, if the SIGINT or SIGTERM signals are received (notice how you can specify more than one signal on the same line), the partially downloaded file will be deleted.In this case the command are actually two: the first is the
echowhich prints the message onscreen, and the second is the actualrmcommand (we provided the -i option to it, so it will ask user confirmation before removing), and they are separated by a semicolon. Instead of specifying commands this way, you can also call functions: this would give you more re-usability. Notice that if you don't provide any command the signal(s) will just be ignored!This is the output of the script above when it receives a SIGINT signal:
$ ./fetchlinux.sh Downloading tarball... ^Csignal caught, cleaning... rm: remove regular file 'linux_tarball.tar.xz'?A very important thing to remember is that when a script is terminated by a signal, like above, its exist status will be the result of128 + the signal number. As you can see, the script above, being terminated by a SIGINT, has an exit status of130:$ echo $? 130Lastly, you can disable a trap just by callingtrapfollowed by the-sign, followed by the signal(s) name or number:trap - SIGINT SIGTERMThe signals will take back the value they had upon the entrance to shell. Pseudo-signals As already mentioned above, trap can be set not only for signals which allows the script to respond but also to what we can call "pseudo-signals". They are not technically signals, but correspond to certain situations that can be specified: EXIT WhenEXITis specified in a trap, the command of the trap will be execute on exit from the shell. ERR This will cause the argument of the trap to be executed when a command returns a non-zero exit status, with some exceptions (the same of the shell errexit option): the command must not be part of awhileoruntilloop; it must not be part of anifconstruct, nor part of a&&or||list, and its value must not be inverted by using the!operator. DEBUG This will cause the argument of the trap to be executed before every simple command,for,caseorselectcommands, and before the first command in shell functions RETURN The argument of the trap is executed after a function or a script sourced by usingsourceor the.command.
[Sep 01, 2017] linux - Looping through the content of a file in Bash - Stack Overflow
Notable quotes:
"... done <<< "$(...)" ..."
Sep 01, 2017 | stackoverflow.com
down vote favorite 234Peter Mortensen , asked Oct 5 '09 at 17:52
How do I iterate through each line of a text file with Bash ?With this script
echo "Start!" for p in (peptides.txt) do echo "${p}" doneI get this output on the screen:
Start! ./runPep.sh: line 3: syntax error near unexpected token `(' ./runPep.sh: line 3: `for p in (peptides.txt)'(Later I want to do something more complicated with $p than just output to the screen.)
The environment variable SHELL is (from env):
SHELL=/bin/bash
/bin/bash --versionoutput:GNU bash, version 3.1.17(1)-release (x86_64-suse-linux-gnu) Copyright (C) 2005 Free Software Foundation, Inc.
cat /proc/versionoutput:Linux version 2.6.18.2-34-default (geeko@buildhost) (gcc version 4.1.2 20061115 (prerelease) (SUSE Linux)) #1 SMP Mon Nov 27 11:46:27 UTC 2006The file peptides.txt contains:
RKEKNVQ IPKKLLQK QYFHQLEKMNVK IPKKLLQK GDLSTALEVAIDCYEK QYFHQLEKMNVKIPENIYR RKEKNVQ VLAKHGKLQDAIN ILGFMK LEDVALQILLBruno De Fraine , answered Oct 5 '09 at 18:00
One way to do it is:while read p; do echo $p done <peptides.txt
Exceptionally, if the loop body may read from standard input , you can open the file using a different file descriptor:
while read -u 10 p; do ... done 10<peptides.txtHere, 10 is just an arbitrary number (different from 0, 1, 2).
Warren Young , answered Oct 5 '09 at 17:54
cat peptides.txt | while read line do # do something with $line here doneStan Graves , answered Oct 5 '09 at 18:18
Option 1a: While loop: Single line at a time: Input redirection#!/bin/bash filename='peptides.txt' echo Start while read p; do echo $p done < $filenameOption 1b: While loop: Single line at a time:
Open the file, read from a file descriptor (in this case file descriptor #4).#!/bin/bash filename='peptides.txt' exec 4<$filename echo Start while read -u4 p ; do echo $p doneOption 2: For loop: Read file into single variable and parse.
This syntax will parse "lines" based on any white space between the tokens. This still works because the given input file lines are single work tokens. If there were more than one token per line, then this method would not work as well. Also, reading the full file into a single variable is not a good strategy for large files.#!/bin/bash filename='peptides.txt' filelines=`cat $filename` echo Start for line in $filelines ; do echo $line donemightypile , answered Oct 4 '13 at 13:30
This is no better than other answers, but is one more way to get the job done in a file without spaces (see comments). I find that I often need one-liners to dig through lists in text files without the extra step of using separate script files.for word in $(cat peptides.txt); do echo $word; doneThis format allows me to put it all in one command-line. Change the "echo $word" portion to whatever you want and you can issue multiple commands separated by semicolons. The following example uses the file's contents as arguments into two other scripts you may have written.
for word in $(cat peptides.txt); do cmd_a.sh $word; cmd_b.py $word; doneOr if you intend to use this like a stream editor (learn sed) you can dump the output to another file as follows.
for word in $(cat peptides.txt); do cmd_a.sh $word; cmd_b.py $word; done > outfile.txtI've used these as written above because I have used text files where I've created them with one word per line. (See comments) If you have spaces that you don't want splitting your words/lines, it gets a little uglier, but the same command still works as follows:
OLDIFS=$IFS; IFS=$'\n'; for line in $(cat peptides.txt); do cmd_a.sh $line; cmd_b.py $line; done > outfile.txt; IFS=$OLDIFSThis just tells the shell to split on newlines only, not spaces, then returns the environment back to what it was previously. At this point, you may want to consider putting it all into a shell script rather than squeezing it all into a single line, though.
Best of luck!
Jahid , answered Jun 9 '15 at 15:09
Use a while loop, like this:while IFS= read -r line; do echo "$line" done <fileNotes:
- If you don't set the
IFSproperly, you will lose indentation.- You should almost always use the -r option with read.
- Don't read lines with
forcodeforester , answered Jan 14 at 3:30
A few more things not covered by other answers: Reading from a delimited file# ':' is the delimiter here, and there are three fields on each line in the file # IFS set below is restricted to the context of `read`, it doesn't affect any other code while IFS=: read -r field1 field2 field3; do # process the fields # if the line has less than three fields, the missing fields will be set to an empty string # if the line has more than three fields, `field3` will get all the values, including the third field plus the delimiter(s) done < input.txtReading from more than one file at a timewhile read -u 3 -r line1 && read -u 4 -r line2; do # process the lines # note that the loop will end when we reach EOF on either of the files, because of the `&&` done 3< input1.txt 4< input2.txtReading a whole file into an array (Bash version 4+)readarray -t my_array < my_fileor
mapfile -t my_array < my_fileAnd then
for line in "${my_array[@]}"; do # process the lines doneAnjul Sharma , answered Mar 8 '16 at 16:10
If you don't want your read to be broken by newline character, use -#!/bin/bash while IFS='' read -r line || [[ -n "$line" ]]; do echo "$line" done < "$1"Then run the script with file name as parameter.
Sine , answered Nov 14 '13 at 14:23
#!/bin/bash # # Change the file name from "test" to desired input file # (The comments in bash are prefixed with #'s) for x in $(cat test.txt) do echo $x donedawg , answered Feb 3 '16 at 19:15
Suppose you have this file:$ cat /tmp/test.txt Line 1 Line 2 has leading space Line 3 followed by blank line Line 5 (follows a blank line) and has trailing space Line 6 has no ending CRThere are four elements that will alter the meaning of the file output read by many Bash solutions:
- The blank line 4;
- Leading or trailing spaces on two lines;
- Maintaining the meaning of individual lines (i.e., each line is a record);
- The line 6 not terminated with a CR.
If you want the text file line by line including blank lines and terminating lines without CR, you must use a while loop and you must have an alternate test for the final line.
Here are the methods that may change the file (in comparison to what
catreturns):1) Lose the last line and leading and trailing spaces:
$ while read -r p; do printf "%s\n" "'$p'"; done </tmp/test.txt 'Line 1' 'Line 2 has leading space' 'Line 3 followed by blank line' '' 'Line 5 (follows a blank line) and has trailing space'(If you do
while IFS= read -r p; do printf "%s\n" "'$p'"; done </tmp/test.txtinstead, you preserve the leading and trailing spaces but still lose the last line if it is not terminated with CR)2) Using process substitution with
catwill reads the entire file in one gulp and loses the meaning of individual lines:$ for p in "$(cat /tmp/test.txt)"; do printf "%s\n" "'$p'"; done 'Line 1 Line 2 has leading space Line 3 followed by blank line Line 5 (follows a blank line) and has trailing space Line 6 has no ending CR'(If you remove the
"from$(cat /tmp/test.txt)you read the file word by word rather than one gulp. Also probably not what is intended...)
The most robust and simplest way to read a file line-by-line and preserve all spacing is:
$ while IFS= read -r line || [[ -n $line ]]; do printf "'%s'\n" "$line"; done </tmp/test.txt 'Line 1' ' Line 2 has leading space' 'Line 3 followed by blank line' '' 'Line 5 (follows a blank line) and has trailing space ' 'Line 6 has no ending CR'If you want to strip leading and trading spaces, remove the
IFS=part:$ while read -r line || [[ -n $line ]]; do printf "'%s'\n" "$line"; done </tmp/test.txt 'Line 1' 'Line 2 has leading space' 'Line 3 followed by blank line' '' 'Line 5 (follows a blank line) and has trailing space' 'Line 6 has no ending CR'(A text file without a terminating
\n, while fairly common, is considered broken under POSIX. If you can count on the trailing\nyou do not need|| [[ -n $line ]]in thewhileloop.)More at the BASH FAQ
,
Here is my real life example how to loop lines of another program output, check for substrings, drop double quotes from variable, use that variable outside of the loop. I guess quite many is asking these questions sooner or later.##Parse FPS from first video stream, drop quotes from fps variable ## streams.stream.0.codec_type="video" ## streams.stream.0.r_frame_rate="24000/1001" ## streams.stream.0.avg_frame_rate="24000/1001" FPS=unknown while read -r line; do if [[ $FPS == "unknown" ]] && [[ $line == *".codec_type=\"video\""* ]]; then echo ParseFPS $line FPS=parse fi if [[ $FPS == "parse" ]] && [[ $line == *".r_frame_rate="* ]]; then echo ParseFPS $line FPS=${line##*=} FPS="${FPS%\"}" FPS="${FPS#\"}" fi done <<< "$(ffprobe -v quiet -print_format flat -show_format -show_streams -i "$input")" if [ "$FPS" == "unknown" ] || [ "$FPS" == "parse" ]; then echo ParseFPS Unknown frame rate fi echo Found $FPSDeclare variable outside of the loop, set value and use it outside of loop requires done <<< "$(...)" syntax. Application need to be run within a context of current console. Quotes around the command keeps newlines of output stream.
Loop match for substrings then reads name=value pair, splits right-side part of last = character, drops first quote, drops last quote, we have a clean value to be used elsewhere.
[Jul 26, 2017] I feel stupid declare not found in bash scripting
A single space can make a huge difference in bash :-)
www.linuxquestions.org
Mohtek
I feel stupid: declare not found in bash scripting? I was anxious to get my feet wet, and I'm only up to my toes before I'm stuck...this seems very very easy but I'm not sure what I've done wrong. Below is the script and its output. What the heck am I missing?
______________________________________________________
#!/bin/bash
declare -a PROD[0]="computers" PROD[1]="HomeAutomation"
printf "${ PROD[*]}"
_______________________________________________________products.sh: 6: declare: not found
products.sh: 8: Syntax error: Bad substitutionI ran what you posted (but at the command line, not in a script, though that should make no significant difference), and got this:
Code:
-bash: ${ PROD[*]}: bad substitution
In other words, I couldn't reproduce your first problem, the "declare: not found" error. Try the declare command by itself, on the command line.
And I got rid of the "bad substitution" problem when I removed the space which is between the ${ and the PROD on the printf line.
Hope this helps.
blackhole54
The previous poster identified your second problem.
As far as your first problem goes ... I am not a bash guru although I have written a number of bash scripts. So far I have found no need for declare statements. I suspect that you might not need it either. But if you do want to use it, the following does work:
Code:
#!/bin/bashdeclare -a PROD
PROD[0]="computers"
PROD[1]="HomeAutomation"
printf "${PROD[*]}\n"EDIT: My original post was based on an older version of bash. When I tried the declare statement you posted I got an error message, but one that was different from yours. I just tried it on a newer version of bash, and your declare statement worked fine. So it might depend on the version of bash you are running. What I posted above runs fine on both versions.
[Jul 26, 2017] Associative array declaration gotcha
Jul 26, 2017 | unix.stackexchange.com
Ron Burk :
Obviously cut out of a much more complex script that was more meaningful:
bash array readonly#!/bin/bash function InitializeConfig(){ declare -r -g -A SHCFG_INIT=( [a]=b ) declare -r -g -A SHCFG_INIT=( [c]=d ) echo "This statement never gets executed" } set -o xtrace InitializeConfig echo "Back from function"The output looks like this:ronburk@ubuntu:~/ubucfg$ bash bug.sh + InitializeConfig + SHCFG_INIT=([a]=b) + declare -r -g -A SHCFG_INIT + SHCFG_INIT=([c]=d) + echo 'Back from function' Back from functionBash seems to silently execute a function return upon the second declare statement. Starting to think this really is a new bug, but happy to learn otherwise.Other details:
Machine: x86_64 OS: linux-gnu Compiler: gcc Compilation CFLAGS: -DPROGRAM='bash' -DCONF_HOSTTYPE='x86_64' -DCONF_OSTYPE='linux-gnu' -DCONF_MACHTYPE='x86_64-pc-linux-gn$ uname output: Linux ubuntu 3.16.0-38-generic #52~14.04.1-Ubuntu SMP Fri May 8 09:43:57 UTC 2015 x86_64 x86_64 x86_64 GNU/Lin$ Machine Type: x86_64-pc-linux-gnu Bash Version: 4.3 Patch Level: 11 Release Status: release
share improve this question edited Jun 14 '15 at 17:43 asked Jun 14 '15 at 7:05 118
add a comment |
Weird. Doesn't happen in bash 4.2.53(1). – choroba Jun 14 '15 at 7:22
I can reproduce this problem with bash version 4.3.11 (Ubuntu 14.04.1 LTS). It works fine with bash 4.2.8 (Ubuntu 11.04). – Cyrus Jun 14 '15 at 7:34
Maybe related: unix.stackexchange.com/q/56815/116972 I can get expected result with declare -r -g -A 'SHCFG_INIT=( [a]=b )'. – yaegashi Jun 14 '15 at 23:22By gum, you're right! Then I get readonly warning on second declare, which is reasonable, and the function completes. The xtrace output is also interesting; implies
declarewithout single quotes is really treated as two steps. Ready to become superstitious about always single-quoting the argument todeclare. Hard to see how popping the function stack can be anything but a bug, though. – Ron Burk Jun 14 '15 at 23:58I found this thread in [email protected] related to
test -von an assoc array. In short, bash implicitly didtest -v SHCFG_INIT[0]in your script. I'm not sure this behavior got introduced in 4.3.You might want to use
declare -pto workaround this...if declare p SHCFG_INIT >/dev/null >& ; then echo "looks like SHCFG_INIT not defined" fi ====
Well, rats. I think your answer is correct, but also reveals I'm really asking two separate questions when I thought they were probably the same issue. Since the title better reflects what turns out to be the "other" question, I'll leave this up for a while and see if anybody knows what's up with the mysterious implicit function return... Thanks! – Ron Burk Jun 14 '15 at 17:01
Edited question to focus on the remaining issue. Thanks again for the answer on the "-v" issue with associative arrays. – Ron Burk Jun 14 '15 at 17:55
Accepting this answer. Complete answer is here plus your comments above plus (IMHO) there's a bug in this version of bash (can't see how there can be any excuse for popping the function stack without warning). Thanks for your excellent research on this! – Ron Burk Jun 21 '15 at 19:31
[Jul 25, 2017] Beginner Mistakes
Highly recommended!
Jul 25, 2017 | wiki.bash-hackers.org
Script execution Your perfect Bash script executes with syntax errors If you write Bash scripts with Bash specific syntax and features, run them with Bash , and run them with Bash in native mode .
Wrong
- no shebang
- the interpreter used depends on the OS implementation and current shell
- can be run by calling bash with the script name as an argument, e.g.
bash myscript#!/bin/shshebang
- depends on what
/bin/shactually is, for a Bash it means compatiblity mode, not native modeSee also:
Your script named "test" doesn't execute Give it another name. The executabletestalready exists.In Bash it's a builtin. With other shells, it might be an executable file. Either way, it's bad name choice!
Workaround: You can call it using the pathname:
/home/user/bin/testGlobbing Brace expansion is not globbing The following command line is not related to globbing (filename expansion):
# YOU EXPECT # -i1.vob -i2.vob -i3.vob .... echo -i{*.vob,} # YOU GET # -i*.vob -iWhy? The brace expansion is simple text substitution. All possible text formed by the prefix, the postfix and the braces themselves are generated. In the example, these are only two:-i*.voband-i. The filename expansion happens after that, so there is a chance that-i*.vobis expanded to a filename - if you have files like-ihello.vob. But it definitely doesn't do what you expected.Please see:
Test-command
if [ $foo ]if [-d $dir]Please see:
Variables Setting variables The Dollar-Sign There is no$(dollar-sign) when you reference the name of a variable! Bash is not PHP!# THIS IS WRONG! $myvar="Hello world!"A variable name preceeded with a dollar-sign always means that the variable gets expanded . In the example above, it might expand to nothing (because it wasn't set), effectively resulting in
="Hello world!"which definitely is wrong !When you need the name of a variable, you write only the name , for example
- (as shown above) to set variables:
picture=/usr/share/images/foo.png- to name variables to be used by the
readbuiltin command:read picture- to name variables to be unset:
unset pictureWhen you need the content of a variable, you prefix its name with a dollar-sign , like
Whitespace Putting spaces on either or both sides of the equal-sign (
- echo "The used picture is: $picture"
=) when assigning a value to a variable will fail.# INCORRECT 1 example = Hello # INCORRECT 2 example= Hello # INCORRECT 3 example =HelloThe only valid form is no spaces between the variable name and assigned value
# CORRECT 1 example=Hello # CORRECT 2 example=" Hello"Expanding (using) variables A typical beginner's trap is quoting.
As noted above, when you want to expand a variable i.e. "get the content", the variable name needs to be prefixed with a dollar-sign. But, since Bash knows various ways to quote and does word-splitting, the result isn't always the same.
Let's define an example variable containing text with spaces:
example="Hello world"
Used form result number of words $exampleHello world2 "$example"Hello world1 \$example$example1 '$example'$example1 If you use parameter expansion, you must use the name (
PATH) of the referenced variables/parameters. i.e. not ($PATH):# WRONG! echo "The first character of PATH is ${$PATH:0:1}" # CORRECT echo "The first character of PATH is ${PATH:0:1}"Note that if you are using variables in arithmetic expressions , then the bare name is allowed:
((a=$a+7)) # Add 7 to a ((a = a + 7)) # Add 7 to a. Identical to the previous command. ((a += 7)) # Add 7 to a. Identical to the previous command. a=$((a+7)) # POSIX-compatible version of previous code.Please see:
Exporting Exporting a variable means to give newly created (child-)processes a copy of that variable. not copy a variable created in a child process to the parent process. The following example does not work, since the variablehellois set in a child process (the process you execute to start that script./script.sh):$ cat script.sh export hello=world $ ./script.sh $ echo $hello $Exporting is one-way. The direction is parent process to child process, not the reverse. The above example will work, when you don't execute the script, but include ("source") it:
$ source ./script.sh $ echo $hello world $In this case, the export command is of no use.Please see:
Exit codes Reacting to exit codes If you just want to react to an exit code, regardless of its specific value, you don't need to use$?in a test command like this:grep ^root: etc passwd >/ dev null >& if $? -neq then echo "root was not found - check the pub at the corner" fiThis can be simplified to:
if grep ^root: etc passwd >/ dev null >& then echo "root was not found - check the pub at the corner" fiOr, simpler yet:
grep ^root: etc passwd >/ dev null >& || echo "root was not found - check the pub at the corner"If you need the specific value of
$?, there's no other choice. But if you need only a "true/false" exit indication, there's no need for$?.See also:
Output vs. Return Value It's important to remember the different ways to run a child command, and whether you want the output, the return value, or neither.When you want to run a command (or a pipeline) and save (or print) the output , whether as a string or an array, you use Bash's
$(command)syntax:$(ls -l /tmp) newvariable=$(printf "foo")When you want to use the return value of a command, just use the command, or add ( ) to run a command or pipeline in a subshell:
if grep someuser /etc/passwd ; then # do something fi if ( w | grep someuser | grep sqlplus ) ; then # someuser is logged in and running sqlplus fiMake sure you're using the form you intended:
# WRONG! if $(grep ERROR /var/log/messages) ; then # send alerts fi
[Jul 25, 2017] Arrays in bash 4.x
Jul 25, 2017 | wiki.bash-hackers.org
Purpose An array is a parameter that holds mappings from keys to values. Arrays are used to store a collection of parameters into a parameter. Arrays (in any programming language) are a useful and common composite data structure, and one of the most important scripting features in Bash and other shells.
Here is an abstract representation of an array named
NAMES. The indexes go from 0 to 3.NAMES 0: Peter 1: Anna 2: Greg 3: JanInstead of using 4 separate variables, multiple related variables are grouped grouped together into elements of the array, accessible by their key . If you want the second name, ask for index 1 of the array
NAMES. Indexing Bash supports two different types of ksh-like one-dimensional arrays. Multidimensional arrays are not implemented .Syntax Referencing To accommodate referring to array variables and their individual elements, Bash extends the parameter naming scheme with a subscript suffix. Any valid ordinary scalar parameter name is also a valid array name:
- Indexed arrays use positive integer numbers as keys. Indexed arrays are always sparse , meaning indexes are not necessarily contiguous. All syntax used for both assigning and dereferencing indexed arrays is an arithmetic evaluation context (see Referencing ). As in C and many other languages, the numerical array indexes start at 0 (zero). Indexed arrays are the most common, useful, and portable type. Indexed arrays were first introduced to Bourne-like shells by ksh88. Similar, partially compatible syntax was inherited by many derivatives including Bash. Indexed arrays always carry the
-aattribute.- Associative arrays (sometimes known as a "hash" or "dict") use arbitrary nonempty strings as keys. In other words, associative arrays allow you to look up a value from a table based upon its corresponding string label. Associative arrays are always unordered , they merely associate key-value pairs. If you retrieve multiple values from the array at once, you can't count on them coming out in the same order you put them in. Associative arrays always carry the
-Aattribute, and unlike indexed arrays, Bash requires that they always be declared explicitly (as indexed arrays are the default, see declaration ). Associative arrays were first introduced in ksh93, and similar mechanisms were later adopted by Zsh and Bash version 4. These three are currently the only POSIX-compatible shells with any associative array support.[[:alpha:]_][[:alnum:]_]*. The parameter name may be followed by an optional subscript enclosed in square brackets to refer to a member of the array.The overall syntax is
arrname[subscript]- where for indexed arrays,subscriptis any valid arithmetic expression, and for associative arrays, any nonempty string. Subscripts are first processed for parameter and arithmetic expansions, and command and process substitutions. When used within parameter expansions or as an argument to the unset builtin, the special subscripts*and@are also accepted which act upon arrays analogously to the way the@and*special parameters act upon the positional parameters. In parsing the subscript, bash ignores any text that follows the closing bracket up to the end of the parameter name.With few exceptions, names of this form may be used anywhere ordinary parameter names are valid, such as within arithmetic expressions , parameter expansions , and as arguments to builtins that accept parameter names. An array is a Bash parameter that has been given the
-a(for indexed) or-A(for associative) attributes . However, any regular (non-special or positional) parameter may be validly referenced using a subscript, because in most contexts, referring to the zeroth element of an array is synonymous with referring to the array name without a subscript.# "x" is an ordinary non-array parameter. $ x=hi; printf '%s ' "$x" "${x[0]}"; echo "${_[0]}" hi hi hiThe only exceptions to this rule are in a few cases where the array variable's name refers to the array as a whole. This is the case for the
unsetbuiltin (see destruction ) and when declaring an array without assigning any values (see declaration ). Declaration The following explicitly give variables array attributes, making them arrays:Storing values Storing values in arrays is quite as simple as storing values in normal variables.
Syntax Description ARRAY=()Declares an indexed array ARRAYand initializes it to be empty. This can also be used to empty an existing array.ARRAY[0]=Generally sets the first element of an indexed array. If no array ARRAYexisted before, it is created.declare -a ARRAYDeclares an indexed array ARRAY. An existing array is not initialized.declare -A ARRAYDeclares an associative array ARRAY. This is the one and only way to create associative arrays.
Syntax Description ARRAY[N]=VALUESets the element Nof the indexed arrayARRAYtoVALUE.Ncan be any valid arithmetic expressionARRAY[STRING]=VALUESets the element indexed by STRINGof the associative arrayARRAY.ARRAY=VALUEAs above. If no index is given, as a default the zeroth element is set to VALUE. Careful, this is even true of associative arrays - there is no error if no key is specified, and the value is assigned to string index "0".ARRAY=(E1 E2 )Compound array assignment - sets the whole array ARRAYto the given list of elements indexed sequentially starting at zero. The array is unset before assignment unless the += operator is used. When the list is empty (ARRAY=()), the array will be set to an empty array. This method obviously does not use explicit indexes. An associative array can not be set like that! Clearing an associative array usingARRAY=()works.ARRAY=([X]=E1 [Y]=E2 )Compound assignment for indexed arrays with index-value pairs declared individually (here for example XandY). X and Y are arithmetic expressions. This syntax can be combined with the above - elements declared without an explicitly specified index are assigned sequentially starting at either the last element with an explicit index, or zero.ARRAY=([S1]=E1 [S2]=E2 )Individual mass-setting for associative arrays . The named indexes (here: S1andS2) are strings.ARRAY+=(E1 E2 )Append to ARRAY. As of now, arrays can't be exported. Getting values article about parameter expansion and check the notes about arrays.
Syntax Description ${ARRAY[N]}Expands to the value of the index Nin the indexed arrayARRAY. IfNis a negative number, it's treated as the offset from the maximum assigned index (can't be used for assignment) - 1${ARRAY[S]}Expands to the value of the index Sin the associative arrayARRAY."${ARRAY[@]}"
${ARRAY[@]}
"${ARRAY[*]}"
${ARRAY[*]}Similar to mass-expanding positional parameters , this expands to all elements. If unquoted, both subscripts *and@expand to the same result, if quoted,@expands to all elements individually quoted,*expands to all elements quoted as a whole."${ARRAY[@]:N:M}"
${ARRAY[@]:N:M}
"${ARRAY[*]:N:M}"
${ARRAY[*]:N:M}Similar to what this syntax does for the characters of a single string when doing substring expansion , this expands to Melements starting with elementN. This way you can mass-expand individual indexes. The rules for quoting and the subscripts*and@are the same as above for the other mass-expansions.For clarification: When you use the subscripts
@or*for mass-expanding, then the behaviour is exactly what it is for$@and$*when mass-expanding the positional parameters . You should read this article to understand what's going on. MetadataDestruction The unset builtin command is used to destroy (unset) arrays or individual elements of arrays.
Syntax Description ${#ARRAY[N]}Expands to the length of an individual array member at index N( stringlength${#ARRAY[STRING]}Expands to the length of an individual associative array member at index STRING( stringlength )${#ARRAY[@]}
${#ARRAY[*]}Expands to the number of elements in ARRAY${!ARRAY[@]}
${!ARRAY[*]}Expands to the indexes in ARRAYsince BASH 3.0
Syntax Description unset -v ARRAY
unset -v ARRAY[@]
unset -v ARRAY[*]Destroys a complete array unset -v ARRAY[N]Destroys the array element at index Nunset -v ARRAY[STRING]Destroys the array element of the associative array at index STRINGIt is best to explicitly specify -v when unsetting variables with unset.
pathname expansion to occur due to the presence of glob characters.Example: You are in a directory with a file named
x1, and you want to destroy an array elementx[1], withunset x[1]then pathname expansion will expand to the filenamex1and break your processing!Even worse, if
nullglobis set, your array/index will disappear.To avoid this, always quote the array name and index:
unset -v 'x[1]'This applies generally to all commands which take variable names as arguments. Single quotes preferred.
Usage Numerical Index Numerical indexed arrays are easy to understand and easy to use. The Purpose and Indexing chapters above more or less explain all the needed background theory.
Now, some examples and comments for you.
Let's say we have an array
sentencewhich is initialized as follows:sentence=(Be liberal in what you accept, and conservative in what you send)Since no special code is there to prevent word splitting (no quotes), every word there will be assigned to an individual array element. When you count the words you see, you should get 12. Now let's see if Bash has the same opinion:
$ echo ${#sentence[@]} 12Yes, 12. Fine. You can take this number to walk through the array. Just subtract 1 from the number of elements, and start your walk at 0 (zero)
((n_elements=${#sentence[@]}, max_index=n_elements - 1)) for ((i = 0; i <= max_index; i++)); do echo "Element $i: '${sentence[i]}'" doneYou always have to remember that, it seems newbies have problems sometimes. Please understand that numerical array indexing begins at 0 (zero)
The method above, walking through an array by just knowing its number of elements, only works for arrays where all elements are set, of course. If one element in the middle is removed, then the calculation is nonsense, because the number of elements doesn't correspond to the highest used index anymore (we call them " sparse arrays "). Associative (Bash 4) Associative arrays (or hash tables ) are not much more complicated than numerical indexed arrays. The numerical index value (in Bash a number starting at zero) just is replaced with an arbitrary string:
# declare -A, introduced with Bash 4 to declare an associative array declare -A sentence sentence[Begin]='Be liberal in what' sentence[Middle]='you accept, and conservative' sentence[End]='in what you send' sentence['Very end']=...Beware: don't rely on the fact that the elements are ordered in memory like they were declared, it could look like this:
# output from 'set' command sentence=([End]="in what you send" [Middle]="you accept, and conservative " [Begin]="Be liberal in what " ["Very end"]="...")This effectively means, you can get the data back with"${sentence[@]}", of course (just like with numerical indexing), but you can't rely on a specific order. If you want to store ordered data, or re-order data, go with numerical indexes. For associative arrays, you usually query known index values:for element in Begin Middle End "Very end"; do printf "%s" "${sentence[$element]}" done printf "\n"A nice code example: Checking for duplicate files using an associative array indexed with the SHA sum of the files:
# Thanks to Tramp in #bash for the idea and the code unset flist; declare -A flist; while read -r sum fname; do if [[ ${flist[$sum]} ]]; then printf 'rm -- "%s" # Same as >%s<\n' "$fname" "${flist[$sum]}" else flist[$sum]="$fname" fi done < <(find . -type f -exec sha256sum {} +) >rmdupsInteger arrays Any type attributes applied to an array apply to all elements of the array. If the integer attribute is set for either indexed or associative arrays, then values are considered as arithmetic for both compound and ordinary assignment, and the += operator is modified in the same way as for ordinary integer variables.
~ $ ( declare -ia 'a=(2+4 [2]=2+2 [a[2]]="a[2]")' 'a+=(42 [a[4]]+=3)'; declare -p a ) declare -ai a='([0]="6" [2]="4" [4]="7" [5]="42")'
a[0]is assigned to the result of2+4.a[1]gets the result of2+2. The last index in the first assignment is the result ofa[2], which has already been assigned as4, and its value is also givena[2].This shows that even though any existing arrays named
ain the current scope have already been unset by using=instead of+=to the compound assignment, arithmetic variables within keys can self-reference any elements already assigned within the same compound-assignment. With integer arrays this also applies to expressions to the right of the=. (See evaluation order , the right side of an arithmetic assignment is typically evaluated first in Bash.)The second compound assignment argument to declare uses
+=, so it appends after the last element of the existing array rather than deleting it and creating a new array, soa[5]gets42.Lastly, the element whose index is the value of
a[4](4), gets3added to its existing value, makinga[4]==7. Note that having the integer attribute set this time causes += to add, rather than append a string, as it would for a non-integer array.The single quotes force the assignments to be evaluated in the environment of
declare. This is important because attributes are only applied to the assignment after assignment arguments are processed. Without them the+=compound assignment would have been invalid, and strings would have been inserted into the integer array without evaluating the arithmetic. A special-case of this is shown in the next section.eval, but there are differences.)'Todo:' Discuss this in detail.Indirection Arrays can be expanded indirectly using the indirect parameter expansion syntax. Parameters whose values are of the form:
name[index],name[@], orname[*]when expanded indirectly produce the expected results. This is mainly useful for passing arrays (especially multiple arrays) by name to a function.This example is an "isSubset"-like predicate which returns true if all key-value pairs of the array given as the first argument to isSubset correspond to a key-value of the array given as the second argument. It demonstrates both indirect array expansion and indirect key-passing without eval using the aforementioned special compound assignment expansion.
isSubset() { local -a 'xkeys=("${!'"$1"'[@]}")' 'ykeys=("${!'"$2"'[@]}")' set -- "${@/%/[key]}" (( ${#xkeys[@]} <= ${#ykeys[@]} )) || return 1 local key for key in "${xkeys[@]}"; do [[ ${!2+_} && ${!1} == ${!2} ]] || return 1 done } main() { # "a" is a subset of "b" local -a 'a=({0..5})' 'b=({0..10})' isSubset a b echo $? # true # "a" contains a key not in "b" local -a 'a=([5]=5 {6..11})' 'b=({0..10})' isSubset a b echo $? # false # "a" contains an element whose value != the corresponding member of "b" local -a 'a=([5]=5 6 8 9 10)' 'b=({0..10})' isSubset a b echo $? # false } mainThis script is one way of implementing a crude multidimensional associative array by storing array definitions in an array and referencing them through indirection. The script takes two keys and dynamically calls a function whose name is resolved from the array.
callFuncs() { # Set up indirect references as positional parameters to minimize local name collisions. set -- "${@:1:3}" ${2+'a["$1"]' "$1"'["$2"]'} # The only way to test for set but null parameters is unfortunately to test each individually. local x for x; do [[ $x ]] || return 0 done local -A a=( [foo]='([r]=f [s]=g [t]=h)' [bar]='([u]=i [v]=j [w]=k)' [baz]='([x]=l [y]=m [z]=n)' ) ${4+${a["$1"]+"${1}=${!3}"}} # For example, if "$1" is "bar" then define a new array: bar=([u]=i [v]=j [w]=k) ${4+${a["$1"]+"${!4-:}"}} # Now just lookup the new array. for inputs: "bar" "v", the function named "j" will be called, which prints "j" to stdout. } main() { # Define functions named {f..n} which just print their own names. local fun='() { echo "$FUNCNAME"; }' x for x in {f..n}; do eval "${x}${fun}" done callFuncs "$@" } main "$@"Bugs and Portability Considerations
Bugs
- Arrays are not specified by POSIX. One-dimensional indexed arrays are supported using similar syntax and semantics by most Korn-like shells.
- Associative arrays are supported via
typeset -Ain Bash 4, Zsh, and Ksh93.- In Ksh93, arrays whose types are not given explicitly are not necessarily indexed. Arrays defined using compound assignments which specify subscripts are associative by default. In Bash, associative arrays can only be created by explicitly declaring them as associative, otherwise they are always indexed. In addition, ksh93 has several other compound structures whose types can be determined by the compound assignment syntax used to create them.
- In Ksh93, using the
=compound assignment operator unsets the array, including any attributes that have been set on the array prior to assignment. In order to preserve attributes, you must use the+=operator. However, declaring an associative array, then attempting ana=( )style compound assignment without specifying indexes is an error. I can't explain this inconsistency.$ ksh -c 'function f { typeset -a a; a=([0]=foo [1]=bar); typeset -p a; }; f' # Attribute is lost, and since subscripts are given, we default to associative. typeset -A a=([0]=foo [1]=bar) $ ksh -c 'function f { typeset -a a; a+=([0]=foo [1]=bar); typeset -p a; }; f' # Now using += gives us the expected results. typeset -a a=(foo bar) $ ksh -c 'function f { typeset -A a; a=(foo bar); typeset -p a; }; f' # On top of that, the reverse does NOT unset the attribute. No idea why. ksh: f: line 1: cannot append index array to associative array a- Only Bash and mksh support compound assignment with mixed explicit subscripts and automatically incrementing subscripts. In ksh93, in order to specify individual subscripts within a compound assignment, all subscripts must be given (or none). Zsh doesn't support specifying individual subscripts at all.
- Appending to a compound assignment is a fairly portable way to append elements after the last index of an array. In Bash, this also sets append mode for all individual assignments within the compound assignment, such that if a lower subscript is specified, subsequent elements will be appended to previous values. In ksh93, it causes subscripts to be ignored, forcing appending everything after the last element. (Appending has different meaning due to support for multi-dimensional arrays and nested compound datastructures.)
$ ksh -c 'function f { typeset -a a; a+=(foo bar baz); a+=([3]=blah [0]=bork [1]=blarg [2]=zooj); typeset -p a; }; f' # ksh93 forces appending to the array, disregarding subscripts typeset -a a=(foo bar baz '[3]=blah' '[0]=bork' '[1]=blarg' '[2]=zooj') $ bash -c 'function f { typeset -a a; a+=(foo bar baz); a+=(blah [0]=bork blarg zooj); typeset -p a; }; f' # Bash applies += to every individual subscript. declare -a a='([0]="foobork" [1]="barblarg" [2]="bazzooj" [3]="blah")' $ mksh -c 'function f { typeset -a a; a+=(foo bar baz); a+=(blah [0]=bork blarg zooj); typeset -p a; }; f' # Mksh does like Bash, but clobbers previous values rather than appending. set -A a typeset a[0]=bork typeset a[1]=blarg typeset a[2]=zooj typeset a[3]=blah- In Bash and Zsh, the alternate value assignment parameter expansion (
${arr[idx]:=foo}) evaluates the subscript twice, first to determine whether to expand the alternate, and second to determine the index to assign the alternate to. See evaluation order .$ : ${_[$(echo $RANDOM >&2)1]:=$(echo hi >&2)} 13574 hi 14485- In Zsh, arrays are indexed starting at 1 in its default mode. Emulation modes are required in order to get any kind of portability.
- Zsh and mksh do not support compound assignment arguments to
typeset.- Ksh88 didn't support modern compound array assignment syntax. The original (and most portable) way to assign multiple elements is to use the
set -A name arg1 arg2syntax. This is supported by almost all shells that support ksh-like arrays except for Bash. Additionally, these shells usually support an optional-sargument tosetwhich performs lexicographic sorting on either array elements or the positional parameters. Bash has no built-in sorting ability other than the usual comparison operators.$ ksh -c 'set -A arr -- foo bar bork baz; typeset -p arr' # Classic array assignment syntax typeset -a arr=(foo bar bork baz) $ ksh -c 'set -sA arr -- foo bar bork baz; typeset -p arr' # Native sorting! typeset -a arr=(bar baz bork foo) $ mksh -c 'set -sA arr -- foo "[3]=bar" "[2]=baz" "[7]=bork"; typeset -p arr' # Probably a bug. I think the maintainer is aware of it. set -A arr typeset arr[2]=baz typeset arr[3]=bar typeset arr[7]=bork typeset arr[8]=foo- Evaluation order for assignments involving arrays varies significantly depending on context. Notably, the order of evaluating the subscript or the value first can change in almost every shell for both expansions and arithmetic variables. See evaluation order for details.
- Bash 4.1.* and below cannot use negative subscripts to address array indexes relative to the highest-numbered index. You must use the subscript expansion, i.e.
"${arr[@]:(-n):1}", to expand the nth-last element (or the next-highest indexed afternifarr[n]is unset). In Bash 4.2, you may expand (but not assign to) a negative index. In Bash 4.3, ksh93, and zsh, you may both assign and expand negative offsets.- ksh93 also has an additional slice notation:
"${arr[n..m]}"wherenandmare arithmetic expressions. These are needed for use with multi-dimensional arrays.- Assigning or referencing negative indexes in mksh causes wrap-around. The max index appears to be
UINT_MAX, which would be addressed byarr[-1].- So far, Bash's
-v vartest doesn't support individual array subscripts. You may supply an array name to test whether an array is defined, but can't check an element. ksh93's-vsupports both. Other shells lack a-vtest.Evaluation order Here are some of the nasty details of array assignment evaluation order. You can use this testcase code to generate these results.
- Fixed in 4.3 Bash 4.2.* and earlier considers each chunk of a compound assignment, including the subscript for globbing. The subscript part is considered quoted, but any unquoted glob characters on the right-hand side of the
[ ]=will be clumped with the subscript and counted as a glob. Therefore, you must quote anything on the right of the=sign. This is fixed in 4.3, so that each subscript assignment statement is expanded following the same rules as an ordinary assignment. This also works correctly in ksh93.$ touch '[1]=a'; bash -c 'a=([1]=*); echo "${a[@]}"' [1]=amksh has a similar but even worse problem in that the entire subscript is considered a glob.$ touch 1=a; mksh -c 'a=([123]=*); print -r -- "${a[@]}"' 1=a- Fixed in 4.3 In addition to the above globbing issue, assignments preceding "declare" have an additional effect on brace and pathname expansion.
$ set -x; foo=bar declare arr=( {1..10} ) + foo=bar + declare 'a=(1)' 'a=(2)' 'a=(3)' 'a=(4)' 'a=(5)' $ touch xy=foo $ declare x[y]=* + declare 'x[y]=*' $ foo=bar declare x[y]=* + foo=bar + declare xy=fooEach word (the entire assignment) is subject to globbing and brace expansion. This appears to trigger the same strange expansion mode aslet,eval, other declaration commands, and maybe more.- Fixed in 4.3 Indirection combined with another modifier expands arrays to a single word.
$ a=({a..c}) b=a[@]; printf '<%s> ' "${!b}"; echo; printf '<%s> ' "${!b/%/foo}"; echo <a> <b> <c> <a b cfoo>- Fixed in 4.3 Process substitutions are evaluated within array indexes. Zsh and ksh don't do this in any arithmetic context.
# print "moo" dev=fd=1 _[1<(echo moo >&2)]= # Fork bomb ${dev[${dev='dev[1>(${dev[dev]})]'}]}Each testcase prints evaluation order for indexed array assignment contexts. Each context is tested for expansions (represented by digits) and arithmetic (letters), ordered from left to right within the expression. The output corresponds to the way evaluation is re-ordered for each shell: a[ $1 a ]=${b[ $2 b ]:=${c[ $3 c ]}} No attributes a[ $1 a ]=${b[ $2 b ]:=c[ $3 c ]} typeset -ia a a[ $1 a ]=${b[ $2 b ]:=c[ $3 c ]} typeset -ia b a[ $1 a ]=${b[ $2 b ]:=c[ $3 c ]} typeset -ia a b (( a[ $1 a ] = b[ $2 b ] ${c[ $3 c ]} )) No attributes (( a[ $1 a ] = ${b[ $2 b ]:=c[ $3 c ]} )) typeset -ia b a+=( [ $1 a ]=${b[ $2 b ]:=${c[ $3 c ]}} [ $4 d ]=$(( $5 e )) ) typeset -a a a+=( [ $1 a ]=${b[ $2 b ]:=c[ $3 c ]} [ $4 d ]=${5}e ) typeset -ia a bash: 4.2.42(1)-release 2 b 3 c 2 b 1 a 2 b 3 2 b 1 a c 2 b 3 2 b c 1 a 2 b 3 2 b c 1 a c 1 2 3 c b a 1 2 b 3 2 b c c a 1 2 b 3 c 2 b 4 5 e a d 1 2 b 3 2 b 4 5 a c d e ksh93: Version AJM 93v- 2013-02-22 1 2 b b a 1 2 b b a 1 2 b b a 1 2 b b a 1 2 3 c b a 1 2 b b a 1 2 b b a 4 5 e d 1 2 b b a 4 5 d e mksh: @(#)MIRBSD KSH R44 2013/02/24 2 b 3 c 1 a 2 b 3 1 a c 2 b 3 c 1 a 2 b 3 c 1 a 1 2 3 c a b 1 2 b 3 c a 1 2 b 3 c 4 5 e a d 1 2 b 3 4 5 a c d e zsh: 5.0.2 2 b 3 c 2 b 1 a 2 b 3 2 b 1 a c 2 b 1 a 2 b 1 a 1 2 3 c b a 1 2 b a 1 2 b 3 c 2 b 4 5 e 1 2 b 3 2 b 4 5See also
- Parameter expansion (contains sections for arrays)
- The classic for-loop (contains some examples to iterate over arrays)
- The declare builtin command
- BashFAQ 005 - How can I use array variables? - A very detailed discussion on arrays with many examples.
- BashSheet - Arrays - Bashsheet quick-reference on Greycat's wiki.
Recommended Links
Google matched content |
Softpanorama Recommended
Top articles
[Jul 04, 2020] Learn Bash Debugging Techniques the Hard Way by Ian Miell Published on Jul 04, 2020 | zwischenzugs.com
[Jul 25, 2017] Beginner Mistakes Published on Jul 25, 2017 | wiki.bash-hackers.org
Sites
Top articles
Sites
...
Etc
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: June, 08, 2021