|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| Checking the loaded functions | Encoding and decoding strings |
Manipulating files and pathnames |
Arguments | |||
| Interacting with the user | Manipulating strings | Parsing command line options | Printing messages to the console | Using external programs | Catching signals | Manipulating variables |
| Sysadmin Horror Stories | Unix shells history | Tips | Humor | Etc |
|
|
Functions in shell are really scripts which run in the current context of the current shell instance (no secondary shell is forked to run the function; it's run within the current shell.)
|
|
Functions provide a lot more flexibility that aliases. Here are two simplest functions possible: "do nothing" function and "Hello world" function:
function quit {
exit
}
function hello {
print "Hello world !"
}
hello
quit
Declaring a function is just a matter of writing function my_func { my_code }. Functions can be declared in arbitrary order. But they need to be declared before they are invoked in the script.
Calling a function is just like calling another program, you just write its name and (optionally) arguments separated by spaces.
NOTE: you can't enclose arguments in round parenthesis -- this would be a syntactic error. You can't use comma after arguments like you are inclined after using C or Perl.
The best way to create a set of useful shell functions in a separate file. Then you can source the file with the dot (.) command or in your startup scripts. You can also just enter the function at the command line.
To create a function from the command line, you would do something like this:
$ psgrep() {
> ps -ef | grep $1
> }
This is a pretty simple function, and could be implemented as an alias as well. Let's try to solve the problem of displayed files over 1K. awk can be used to find any matching files that are larger than 100K bytes:
largesize() {
ls -la | awk ' { if ( $5 gt 100000 ) print $1 } '
}
As in almost any programming language, you can use functions to group pieces of code in a more logical way or practice the divine art of recursion.
Bash shell's function feature is pretty primitive and just an slightly enhanced version of a similar facility in the System V Bourne shell. You can create collection of functions that help you in your work and store them in you .profile file.
Functions are faster then subshell invocation: when you invoke a function, it is already in memory. Modern computers have large RAM, so there is no need to worry about the amount of space a typical function takes up.
The other advantage of functions is that they can and should be used for organizing shell scripts into modular "chunks" of related functions that are easier to develop and maintain. To define a function, you can use the following form (there is also second C-style form of function definition that we will not discuss hee):
function function_name {
shell commands
}
You can also delete a function definition with the command unset -f function_name.
Like list of aliases is produced by typing command alias, you can find out what functions are defined in your login session by typing functions. The shell will print not just the names but the definitions of all functions, in alphabetical order by function name. Since this may result in long output, you might want to pipe the output through more or redirect it to a file and view it with the view command.
Note: functions is actually an alias for typeset -f;
There are two important differences between functions and scripts. First, functions do not run in separate processes, as scripts are when you invoke them by name; the "semantics" of running a function are more like those of your .profile when you log in or any script when invoked with the "dot" command. Second, if a function has the same name as a script or executable program, the function takes precedence.
|
if a function has the same name as a script or executable program, the function takes precedence. |
This is a good time to show the order of precedence for the various sources of commands. When you type a command to the shell, it looks in the following places until it finds a match:
Note: that means that you can overwrite built-ins with functions
If you need to know the exact source of a command, you can use the whence built-in command .If you type whence -v command_name, you also get information about how particular command is implemented, for example:
$ whence -v cd cd is a shell builtin $ whence -v function function is a keyword $ whence -v man man is /usr/bin/man $ whence -v ll ll is an alias for ls -l
The statement return N, which causes the surrounding script or function to exit with exit status N. N is actually optional; it defaults to 0.
In the scripts that finish without a return statement (i.e., every one we have seen so far) the return value is equal to the return value (sucess of failue) of the last executed statement.
Exist is similar to return: the statement exit N exits the entire script, no matter how deeply you are nested in functions.
For example is we need a function to implement enhanced cd we can write something like:
function cd {
"cd" $*
rs=$?
print $OLDPWD -> $PWD
return $rs
}
Here is fist save the exit status of cd in the variable rs and then return it as the return value of the function.
# Capture value returned by last command
ret=$?
return $ret
return [n], exit
[n] return, the function returns when it reaches
the end, and the value is the exit status of the last command it ran.
Example:
die()
{
# Print an error message and exit with given status
# call as: die status "message" ["message" ...]
exitstat=$1; shift
for i in "$@"; do
print -R "$i"
done
exit $exitstat
}
[ -w $filename ] || \ die 1 "$file not writeable" "check permissions"
Example:
logme()
{
# Print or not depending on global "$verbosity"
# Change the verbosity with a single variable.
# Arg. 1 is the level for this message.
level=$1; shift
if [[ $level -le $verbosity ]]; then
print -R $*
fi
}
verbosity=2
logme 1 This message will appear
logme 3 This only appears if verbosity is 3 or higher
Two common errors with declaring and using functions are
The following example illustrates the first type of error:
lsl { ls -l ; }
Here, the parentheses are missing after lsl. This is an invalid function definition and will result in an error message similar to the following:
sh: syntax error: '}' unexpected
The following command illustrates the second type of error:
$ lsl()
Here, the function lsl is executed along with the parentheses, (). This will not work because the shell interprets it as a redefinition of the function with the name lsl. Usually such an invocation results in a prompt similar to the following:
>
This is a prompt produced by the shell when it expects you to provide more input. The input it expects is the body of the function lsl.
NOTES:
For example:
name_error()
{
echo " $@ contains errors, it must contain only letters"
}
Here is an example of a function that takes arbitrary number of parameters and prints some information about them:
function invocation_inform {
print "The first argument is:" $1
print "List of argumnets is:" $@
print "Number of arguments is:" $#
}
The command shift performs shifts of argument to the left by given number of positions, extra argumnat shifted to left of index 1 are discarded
1=$2 2=$3 ...
for every argument, regardless of how many there are. If you supply a numeric argument to shift , it will shift the arguments that many times over; for example, shift 3 has this effect:
1=$4 2=$5 ...
This leads immediately to some code that handles a single option (call it -o ) and arbitrarily many arguments:
if [[ $1 = -o ]]; then # process the -o option shift fi # normal processing of arguments...
After the if construct, $1 , $2 , etc., are set to the correct arguments.
Messages to stdout may be captured by command substitution (`myfunction`,
which provides another way for a function to return information to the calling script. Beware of side-effects
(and reducing reusability) in functions which perform I/O.
Calling a function is just like calling another program, you just write its name and (optionally) arguments separated by spaces
NOTE: you can't enclose arguments in round parenthesis -- this would be a syntactic error. You can't use comma after arguments like you are inclined after using C or Perl.
arg1_echo test all_arg_echo test 1 test 2
the set command displays all the loaded functions available to the shell.
$ set
USER=dave
findit=()
{
if [ $# -lt 1 ]; then
echo "usage :findit file";
return 1;
fi;
find / -name $1 -print
}
...
You can use unset command to remove functions:
unset function_name
Traditionally .bash_profile file contained aliases, but now they are often separates and group into a separate file, for example .aliases. So for functions it might be also be beneficial to use a separate file called, for example, .functions.
Let's consider a very artificial (bad) example of creating a function that will call find for each argument so that we can find several different files with one command (useless exersize) The function will now look like this:
$ pg .functions
#!/bin/sh
findit()
{
# findit if [ $# -lt 1 ]; then echo "usage :findit file" return 1 fi for member do find / -name $member -print done
}
Now source the file again:
. ./.functions
Using the set command to see that it is indeed loaded, you will notice that the shell has correctly interpreted the for loop to take in all parameters.
$ set
findit=()
{
if [ $# -lt 1 ]; then
echo "usage :`basename $0` file";
return 1;
fi;
for loop in "$@";
do
find / -name $loop -print;
done
}
...
Now to execute the changed Supplying a couple of files to find:
$ findit LPSO.doc passwd /usr/local/accounts/LPSO.doc /etc/passwd ...
By default all variables, except for the special variables associated with function arguments, have global scope. In ksh, bash, and zsh, variables with local scope can be declared using the typeset command. The typeset command is discussed later in this chapter. This command is not supported in the Bourne shell, so it is not possible to have programmer-defined local variables in scripts that rely strictly on the Bourne shell.
Local variables are defined using typeset command (in bash you usually use declare instead):
typeset var1[=val1] ... varN[=valN]
Here, var1 ... varN are variable names and val1 ... valN are values to assign to the variables. The values are optional as the following example illustrates:
typeset fruit1 fruit2=banana
If you need to know the exact source of a command, there is an option to the whence built-in command.. whence by itself will print the pathname of a command if the command is a script or executable program, but it will only parrot the command's name back if it is anything else. But if you type whence -v commandname , you get more complete information, such as:
$ whence -v cd cd is a shell builtin $ whence -v function function is a keyword $ whence -v man man is /usr/bin/man $ whence -v ll ll is an alias for ls -l
We will refer mainly to scripts throughout the remainder of this book, but unless we note otherwise, you should assume that whatever we say applies equally to functions.
shell assignment statment has the form of varname=value, e.g.:
$ greeting="hello world!" $ print "$greeting"
Some environment variables are predefined by the shell when you log in. There are several built-in variables that are vital to shell programming like HOME, HOSTNAME, PWD, OLD_PWD, etc
There is also a special class on built-in variables called positional parameters. These hold the command-line arguments to scripts when they are invoked. Positional parameters have names 1, 2, 3, etc., meaning that their values are denoted by $1, $2, $3, etc. There is also a positional parameter 0, whose value is the name of the script (i.e., the command typed in to invoke it).
Two special variables contain all of the positional parameters (except positional parameter 0):
* and @. The difference between them is subtle but important, and it's apparent
only when they are used within double quotes:
"$*" is a single string that consists of all of the positional
parameters, separated by the first character in the environment variable IFS (internal field
separator), which is a space, TAB, and NEWLINE by default. "$@" is equal to "$1"
"$2"... "$N", where
N is the number of positional parameters. That is, it's equal to N separate double-quoted
strings, which are separated by spaces. We'll explore the ramifications of this difference in a little
while.The variable $# holds the number of positional parameters (as a character string). All of these variables are "read-only," meaning that you can't assign new values to them within scripts.
For example, assume that you create a file testme that contains the following simple shell script:
print "testme: $@" print "$0: Arg 1 is '$1' and Arg 2 is $2" print "$# arguments"
Then if you type bash 3.2, you will see the following output:
testme: bash 3.2 testme: Arg 1 is 'bash' and Arg 2 is '3.2' 2 arguments
In this case, $3, $4, etc., are all unset, which means that the shell will substitute the empty (or null) string for them (Unless the option nounset is turned on).
Shell functions use positional parameters and special variables like * and #
in exactly the same way as shell scripts do. If you wanted to define testme as a function,
you could put the following in your .profile or environment file:
function testme {
print "testme: $*"
print "$0: $1 and $2"
print "$# arguments"
}
You will get the same result if you type testme bash 3.2
Typically, several shell functions are defined within a single shell script. Therefore each function will need to handle its own arguments, which in turn means that each function needs to keep track of positional parameters separately. Sure enough, each function has its own copies of these variables (even though functions don't run in their own subshells, as scripts do); we say that such variables are local to the function.
However, other variables defined within functions are not local (they are global), meaning that their values are known throughout the entire shell script. For example, assume that you have a shell script called ascript that contains this:
Note: typeset can be used for making variables local to functions.
Let's take a closer look at "$@" and "$*". These variables are
two of the shell's greatest idiosyncracies, so we'll discuss some of the most common sources of confusion.
*" are separated by the first character of IFS
instead of spaces to give you some output flexibility. As a simple example, let's say you want to
print a list of positional parameters separated by commas. This script would do it:OLD_IFS=IFSIFS=, print $*IFS=$OLD_IFS
Generally you should restore IFS to old value as soon as you finish use a new value
Before we show the many things you can do with shell variables, we have to make a confession: the syntax of $varname for taking the value of a variable is not quite accurate. Actually, it's the simple form of the more general syntax, which is ${varname}.
Why two syntaxes? For one thing, the more general syntax is necessary if your code refers to more than nine positional parameters: you must use ${10} for the tenth instead of $10.
Also useful is the next character is not a delimiter:
PS1="${LOGNAME}_ "
we would get the desired $yourname_. It is safe to omit the curly brackets ({}) if the variable name is followed by a character that isn't a letter, digit, or underscore.
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
Jul 08, 2020 | www.tldp.org
Appendix E. Exit Codes With Special Meanings Table E-1. Reserved Exit Codes
Exit Code Number Meaning Example Comments 1 Catchall for general errors let "var1 = 1/0" Miscellaneous errors, such as "divide by zero" and other impermissible operations 2 Misuse of shell builtins (according to Bash documentation) empty_function() {} Missing keyword or command, or permission problem (and diff return code on a failed binary file comparison ). 126 Command invoked cannot execute /dev/null Permission problem or command is not an executable 127 "command not found" illegal_command Possible problem with $PATH or a typo 128 Invalid argument to exit exit 3.14159 exit takes only integer args in the range 0 - 255 (see first footnote) 128+n Fatal error signal "n" kill -9 $PPID of script $? returns 137 (128 + 9) 130 Script terminated by Control-C Ctl-C Control-C is fatal error signal 2 , (130 = 128 + 2, see above) 255* Exit status out of range exit -1 exit takes only integer args in the range 0 - 255 According to the above table, exit codes 1 - 2, 126 - 165, and 255 [1] have special meanings, and should therefore be avoided for user-specified exit parameters. Ending a script with exit 127 would certainly cause confusion when troubleshooting (is the error code a "command not found" or a user-defined one?). However, many scripts use an exit 1 as a general bailout-upon-error. Since exit code 1 signifies so many possible errors, it is not particularly useful in debugging.
There has been an attempt to systematize exit status numbers (see /usr/include/sysexits.h ), but this is intended for C and C++ programmers. A similar standard for scripting might be appropriate. The author of this document proposes restricting user-defined exit codes to the range 64 - 113 (in addition to 0 , for success), to conform with the C/C++ standard. This would allot 50 valid codes, and make troubleshooting scripts more straightforward. [2] All user-defined exit codes in the accompanying examples to this document conform to this standard, except where overriding circumstances exist, as in Example 9-2 .
Notes
Issuing a $? from the command-line after a shell script exits gives results consistent with the table above only from the Bash or sh prompt. Running the C-shell or tcsh may give different values in some cases.
[1] Out of range exit values can result in unexpected exit codes. An exit value greater than 255 returns an exit code modulo 256 . For example, exit 3809 gives an exit code of 225 (3809 % 256 = 225). [2] An update of /usr/include/sysexits.h allocates previously unused exit codes from 64 - 78 . It may be anticipated that the range of unallotted exit codes will be further restricted in the future. The author of this document will not do fixups on the scripting examples to conform to the changing standard. This should not cause any problems, since there is no overlap or conflict in usage of exit codes between compiled C/C++ binaries and shell scripts.
Jul 08, 2020 | zwischenzugs.com
Not everyone knows that every time you run a shell command in bash, an 'exit code' is returned to bash.
Generally, if a command 'succeeds' you get an error code of
0. If it doesn't succeed, you get a non-zero code.
1is a 'general error', and others can give you more information (e.g. which signal killed it, for example). 255 is upper limit and is "internal error"grep joeuser /etc/passwd # in case of success returns 0, otherwise 1or
grep not_there /dev/null echo $?
$?is a special bash variable that's set to the exit code of each command after it runs.Grep uses exit codes to indicate whether it matched or not. I have to look up every time which way round it goes: does finding a match or not return
0?
Sep 11, 2009 | www.linuxjournal.com
Bash functions, unlike functions in most programming languages do not allow you to return a value to the caller. When a bash function ends its return value is its status: zero for success, non-zero for failure. To return values, you can set a global variable with the result, or use command substitution, or you can pass in the name of a variable to use as the result variable. The examples below describe these different mechanisms.
Although bash has a return statement, the only thing you can specify with it is the function's status, which is a numeric value like the value specified in an exit statement. The status value is stored in the $? variable. If a function does not contain a return statement, its status is set based on the status of the last statement executed in the function. To actually return arbitrary values to the caller you must use other mechanisms.
The simplest way to return a value from a bash function is to just set a global variable to the result. Since all variables in bash are global by default this is easy:
function myfunc() { myresult='some value' } myfunc echo $myresultThe code above sets the global variable myresult to the function result. Reasonably simple, but as we all know, using global variables, particularly in large programs, can lead to difficult to find bugs.
A better approach is to use local variables in your functions. The problem then becomes how do you get the result to the caller. One mechanism is to use command substitution:
function myfunc() { local myresult='some value' echo "$myresult" } result=$(myfunc) # or result=`myfunc` echo $resultHere the result is output to the stdout and the caller uses command substitution to capture the value in a variable. The variable can then be used as needed.
The other way to return a value is to write your function so that it accepts a variable name as part of its command line and then set that variable to the result of the function:
function myfunc() { local __resultvar=$1 local myresult='some value' eval $__resultvar="'$myresult'" } myfunc result echo $resultSince we have the name of the variable to set stored in a variable, we can't set the variable directly, we have to use eval to actually do the setting. The eval statement basically tells bash to interpret the line twice, the first interpretation above results in the string result='some value' which is then interpreted once more and ends up setting the caller's variable.
When you store the name of the variable passed on the command line, make sure you store it in a local variable with a name that won't be (unlikely to be) used by the caller (which is why I used __resultvar rather than just resultvar ). If you don't, and the caller happens to choose the same name for their result variable as you use for storing the name, the result variable will not get set. For example, the following does not work:
function myfunc() { local result=$1 local myresult='some value' eval $result="'$myresult'" } myfunc result echo $resultThe reason it doesn't work is because when eval does the second interpretation and evaluates result='some value' , result is now a local variable in the function, and so it gets set rather than setting the caller's result variable.
For more flexibility, you may want to write your functions so that they combine both result variables and command substitution:
function myfunc() { local __resultvar=$1 local myresult='some value' if [[ "$__resultvar" ]]; then eval $__resultvar="'$myresult'" else echo "$myresult" fi } myfunc result echo $result result2=$(myfunc) echo $result2Here, if no variable name is passed to the function, the value is output to the standard output.
Mitch Frazier is an embedded systems programmer at Emerson Electric Co. Mitch has been a contributor to and a friend of Linux Journal since the early 2000s.
David Krmpotic • 6 years ago • edited ,lxw David Krmpotic • 6 years ago ,This is the best way: http://stackoverflow.com/a/... return by reference:
function pass_back_a_string() {
eval "$1='foo bar rab oof'"
}return_var=''
pass_back_a_string return_var
echo $return_varphil • 6 years ago ,I agree. After reading this passage, the same idea with yours occurred to me.
lxw • 6 years ago ,Since this page is a top hit on google:
The only real issue I see with returning via echo is that forking the process means no longer allowing it access to set 'global' variables. They are still global in the sense that you can retrieve them and set them within the new forked process, but as soon as that process is done, you will not see any of those changes.
e.g.
#!/bin/bashmyGlobal="very global"
call1() {
myGlobal="not so global"
echo "${myGlobal}"
}tmp=$(call1) # keep in mind '$()' starts a new process
echo "${tmp}" # prints "not so global"
echo "${myGlobal}" # prints "very global"code_monk • 6 years ago • edited ,Hello everyone,
In the 3rd method, I don't think the local variable __resultvar is necessary to use. Any problems with the following code?
function myfunc()
{
local myresult='some value'
eval "$1"="'$myresult'"
}myfunc result
echo $resultEmil Vikström code_monk • 5 years ago ,i would caution against returning integers with "return $int". My code was working fine until it came across a -2 (negative two), and treated it as if it were 254, which tells me that bash functions return 8-bit unsigned ints that are not protected from overflow
A function behaves as any other Bash command, and indeed POSIX processes. That is, they can write to stdout, read from stdin and have a return code. The return code is, as you have already noticed, a value between 0 and 255. By convention 0 means success while any other return code means failure.
This is also why Bash "if" statements treat 0 as success and non+zero as failure (most other programming languages do the opposite).
Jun 12, 2020 | opensource.com
Source is like a Python import or a Java include. Learn it to expand your Bash prowess. Seth Kenlon (Red Hat) Feed 25 up 2 comments Image by : Opensource.com x Subscribe nowWhen you log into a Linux shell, you inherit a specific working environment. An environment , in the context of a shell, means that there are certain variables already set for you, which ensures your commands work as intended. For instance, the PATH environment variable defines where your shell looks for commands. Without it, nearly everything you try to do in Bash would fail with a command not found error. Your environment, while mostly invisible to you as you go about your everyday tasks, is vitally important.
There are many ways to affect your shell environment. You can make modifications in configuration files, such as
Add to your environment with source~/.bashrcand~/.profile, you can run services at startup, and you can create your own custom commands or script your own Bash functions .Bash (along with some other shells) has a built-in command called
source. And here's where it can get confusing:sourceperforms the same function as the command.(yes, that's but a single dot), and it's not the samesourceas theTclcommand (which may come up on your screen if you typeman source). The built-insourcecommand isn't in yourPATHat all, in fact. It's a command that comes included as a part of Bash, and to get further information about it, you can typehelp source.The
More on Bash.command is POSIX -compliant. Thesourcecommand is not defined by POSIX but is interchangeable with the.command.According to Bash
- Bash cheat sheet
- An introduction to programming with Bash
- A sysadmin's guide to Bash scripting
- Latest Bash articles
help, thesourcecommand executes a file in your current shell. The clause "in your current shell" is significant, because it means it doesn't launch a sub-shell; therefore, whatever you execute withsourcehappens within and affects your current environment.Before exploring how
#!/usr/bin/env bashsourcecan affect your environment, trysourceon a test file to ensure that it executes code as expected. First, create a simple Bash script and save it as a file calledhello.sh:
echo "hello world"Using
$ source hello.shsource, you can run this script even without setting the executable bit:
hello worldYou can also use the built-in
$ . hello.sh.command for the same results:
hello worldThe
Set variables and import functionssourceand.commands successfully execute the contents of the test file.You can use
sourceto "import" a file into your shell environment, just as you might use theincludekeyword in C or C++ to reference a library or theimportkeyword in Python to bring in a module. This is one of the most common uses forsource, and it's a common default inclusion in.bashrcfiles tosourcea file called.bash_aliasesso that any custom aliases you define get imported into your environment when you log in.Here's an example of importing a Bash function. First, create a function in a file called
function myip () {myfunctions. This prints your public IP address and your local IP address:
curl http: // icanhazip.comip addr | grep inet $IP | \
cut -d "/" -f 1 | \
grep -v 127 \.0 | \
grep -v \:\: 1 | \
awk '{$1=$1};1'
}Import the function into your shell:
$ source myfunctionsTest your new function:
$ myip
93.184.216.34
inet 192.168.0.23
inet6 fbd4:e85f:49c: 2121 :ce12:ef79:0e77:59d1
inet 10.8.42.38 Search for sourceWhen you use
sourcein Bash, it searches your current directory for the file you reference. This doesn't happen in all shells, so check your documentation if you're not using Bash.If Bash can't find the file to execute, it searches your
PATHinstead. Again, this isn't the default for all shells, so check your documentation if you're not using Bash.These are both nice convenience features in Bash. This behavior is surprisingly powerful because it allows you to store common functions in a centralized location on your drive and then treat your environment like an integrated development environment (IDE). You don't have to worry about where your functions are stored, because you know they're in your local equivalent of
/usr/include, so no matter where you are when you source them, Bash finds them.For instance, you could create a directory called
~/.local/includeas a storage area for common functions and then put this block of code into your.bashrcfile:for i in $HOME / .local / include /* ; do source $i
doneThis "imports" any file containing custom functions in
~/.local/includeinto your shell environment.Bash is the only shell that searches both the current directory and your
Using source for open sourcePATHwhen you use either thesourceor the.command.Using
sourceor.to execute files can be a convenient way to affect your environment while keeping your alterations modular. The next time you're thinking of copying and pasting big blocks of code into your.bashrcfile, consider placing related functions or groups of aliases into dedicated files, and then usesourceto ingest them.Get started with Bash scripting for sysadmins Learn the commands and features that make Bash one of the most powerful shells available.
Seth Kenlon (Red Hat) Introduction to automation with Bash scripts In the first article in this four-part series, learn how to create a simple shell script and why they are the best way to automate tasks.
David Both (Correspondent) Bash cheat sheet: Key combos and special syntax Download our new cheat sheet for Bash commands and shortcuts you need to talk to your computer.
Jul 25, 2017 | wiki.bash-hackers.org
Intro The day will come when you want to give arguments to your scripts. These arguments are known as positional parameters . Some relevant special parameters are described below:
Parameter(s) Description $0the first positional parameter, equivalent to argv[0]in C, see the first argument$FUNCNAMEthe function name ( attention : inside a function, $0is still the$0of the shell, not the function name)$1 $9the argument list elements from 1 to 9 ${10} ${N}the argument list elements beyond 9 (note the parameter expansion syntax!) $*all positional parameters except $0, see mass usage$@all positional parameters except $0, see mass usage$#the number of arguments, not counting $0These positional parameters reflect exactly what was given to the script when it was called.
Option-switch parsing (e.g.
-hfor displaying help) is not performed at this point.See also the dictionary entry for "parameter" . The first argument The very first argument you can access is referenced as
$0. It is usually set to the script's name exactly as called, and it's set on shell initialization:Testscript - it just echos
$0:#!/bin/bash echo "$0"You see,$0is always set to the name the script is called with ($is the prompt ):> ./testscript ./testscript> /usr/bin/testscript /usr/bin/testscriptHowever, this isn't true for login shells:
> echo "$0" -bashIn other terms,
$0is not a positional parameter, it's a special parameter independent from the positional parameter list. It can be set to anything. In the ideal case it's the pathname of the script, but since this gets set on invocation, the invoking program can easily influence it (theloginprogram does that for login shells, by prefixing a dash, for example).Inside a function,
$0still behaves as described above. To get the function name, use$FUNCNAME. Shifting The builtin commandshiftis used to change the positional parameter values:
$1will be discarded$2will become$1$3will become$2- in general:
$Nwill become$N-1The command can take a number as argument: Number of positions to shift. e.g.
shift 4shifts$5to$1. Using them Enough theory, you want to access your script-arguments. Well, here we go. One by one One way is to access specific parameters:#!/bin/bash echo "Total number of arguments: $#" echo "Argument 1: $1" echo "Argument 2: $2" echo "Argument 3: $3" echo "Argument 4: $4" echo "Argument 5: $5"While useful in another situation, this way is lacks flexibility. The maximum number of arguments is a fixedvalue - which is a bad idea if you write a script that takes many filenames as arguments.
⇒ forget that one Loops There are several ways to loop through the positional parameters.
You can code a C-style for-loop using
$#as the end value. On every iteration, theshift-command is used to shift the argument list:numargs=$# for ((i=1 ; i <= numargs ; i++)) do echo "$1" shift doneNot very stylish, but usable. The
numargsvariable is used to store the initial value of$#because the shift command will change it as the script runs.
Another way to iterate one argument at a time is the
forloop without a given wordlist. The loop uses the positional parameters as a wordlist:for arg do echo "$arg" doneAdvantage: The positional parameters will be preserved
The next method is similar to the first example (the
forloop), but it doesn't test for reaching$#. It shifts and checks if$1still expands to something, using the test command :while [ "$1" ] do echo "$1" shift doneLooks nice, but has the disadvantage of stopping when
$1is empty (null-string). Let's modify it to run as long as$1is defined (but may be null), using parameter expansion for an alternate value :while [ "${1+defined}" ]; do echo "$1" shift doneGetopts There is a small tutorial dedicated to ''getopts'' ( under construction ). Mass usage All Positional Parameters Sometimes it's necessary to just "relay" or "pass" given arguments to another program. It's very inefficient to do that in one of these loops, as you will destroy integrity, most likely (spaces!).
The shell developers created
$*and$@for this purpose.As overview:
Syntax Effective result $*$1 $2 $3 ${N}$@$1 $2 $3 ${N}"$*""$1c$2c$3c c${N}""$@""$1" "$2" "$3" "${N}"Without being quoted (double quotes), both have the same effect: All positional parameters from
$1to the last one used are expanded without any special handling.When the
$*special parameter is double quoted, it expands to the equivalent of:"$1c$2c$3c$4c ..$N", where 'c' is the first character ofIFS.But when the
$@special parameter is used inside double quotes, it expands to the equivanent of
"$1" "$2" "$3" "$4" .. "$N"which reflects all positional parameters as they were set initially and passed to the script or function. If you want to re-use your positional parameters to call another program (for example in a wrapper-script), then this is the choice for you, use double quoted
"$@".Well, let's just say: You almost always want a quoted
"$@"! Range Of Positional Parameters Another way to mass expand the positional parameters is similar to what is possible for a range of characters using substring expansion on normal parameters and the mass expansion range of arrays .
${@:START:COUNT}
${*:START:COUNT}
"${@:START:COUNT}"
"${*:START:COUNT}"The rules for using
@or*and quoting are the same as above. This will expandCOUNTnumber of positional parameters beginning atSTART.COUNTcan be omitted (${@:START}), in which case, all positional parameters beginning atSTARTare expanded.If
STARTis negative, the positional parameters are numbered in reverse starting with the last one.
COUNTmay not be negative, i.e. the element count may not be decremented.Example: START at the last positional parameter:
echo "${@: -1}"Attention : As of Bash 4, a
STARTof0includes the special parameter$0, i.e. the shell name or whatever $0 is set to, when the positional parameters are in use. ASTARTof1begins at$1. In Bash 3 and older, both0and1began at$1. Setting Positional Parameters Setting positional parameters with command line arguments, is not the only way to set them. The builtin command, set may be used to "artificially" change the positional parameters from inside the script or function:set "This is" my new "set of" positional parameters # RESULTS IN # $1: This is # $2: my # $3: new # $4: set of # $5: positional # $6: parametersIt's wise to signal "end of options" when setting positional parameters this way. If not, the dashes might be interpreted as an option switch by
setitself:# both ways work, but behave differently. See the article about the set command! set -- ... set - ...Alternately this will also preserve any verbose (-v) or tracing (-x) flags, which may otherwise be reset by
setset -$- ...
continue Production examples Using a while loop To make your program accept options as standard command syntax:
COMMAND [options] <params># Like 'cat -A file.txt'See simple option parsing code below. It's not that flexible. It doesn't auto-interpret combined options (-fu USER) but it works and is a good rudimentary way to parse your arguments.
#!/bin/sh # Keeping options in alphabetical order makes it easy to add more. while : do case "$1" in -f | --file) file="$2" # You may want to check validity of $2 shift 2 ;; -h | --help) display_help # Call your function # no shifting needed here, we're done. exit 0 ;; -u | --user) username="$2" # You may want to check validity of $2 shift 2 ;; -v | --verbose) # It's better to assign a string, than a number like "verbose=1" # because if you're debugging the script with "bash -x" code like this: # # if [ "$verbose" ] ... # # You will see: # # if [ "verbose" ] ... # # Instead of cryptic # # if [ "1" ] ... # verbose="verbose" shift ;; --) # End of all options shift break; -*) echo "Error: Unknown option: $1" >&2 exit 1 ;; *) # No more options break ;; esac done # End of fileFilter unwanted options with a wrapper script This simple wrapper enables filtering unwanted options (here:
-aand–allforls) out of the command line. It reads the positional parameters and builds a filtered array consisting of them, then callslswith the new option set. It also respects the–as "end of options" forlsand doesn't change anything after it:#!/bin/bash # simple ls(1) wrapper that doesn't allow the -a option options=() # the buffer array for the parameters eoo=0 # end of options reached while [[ $1 ]] do if ! ((eoo)); then case "$1" in -a) shift ;; --all) shift ;; -[^-]*a*|-a?*) options+=("${1//a}") shift ;; --) eoo=1 options+=("$1") shift ;; *) options+=("$1") shift ;; esac else options+=("$1") # Another (worse) way of doing the same thing: # options=("${options[@]}" "$1") shift fi done /bin/ls "${options[@]}"Using getopts There is a small tutorial dedicated to ''getopts'' ( under construction ). See also
Discussion 2010/04/14 14:20
- Internal: Small getopts tutorial
- Internal: The while-loop
- Internal: The C-style for-loop
- Internal: Arrays (for equivalent syntax for mass-expansion)
- Internal: Substring expansion on a parameter (for equivalent syntax for mass-expansion)
- Dictionary, internal: Parameter
The shell-developers invented $* and $@ for this purpose.Without being quoted (double-quoted), both have the same effect: All positional parameters from $1 to the last used one >are expanded, separated by the first character of IFS (represented by "c" here, but usually a space):
$1c$2c$3c$4c........$NWithout double quotes, $* and $@ are expanding the positional parameters separated by only space, not by IFS.
#!/bin/bash export IFS='-' echo -e $* echo -e $@$./test "This is" 2 3 This is 2 3 This is 2 3(Edited: Inserted code tags)
2010/04/14 17:12 Thank you very much for this finding. I know how$*works, thus I can't understand why I described it that wrong. I guess it was in some late night session.Thanks again.
2011/02/18 16:11 #!/bin/bashOLDIFS="$IFS" IFS='-' #export IFS='-'
#echo -e $* #echo -e $@ #should be echo -e "$*" echo -e "$@" IFS="$OLDIFS"
2011/02/18 16:14 #should be echo -e "$*" Dave Carlton , 2010/05/18 15:23 I would suggext using a different prompt as the $ is confusing to newbies. Otherwise, an excellent treatise on use of positional parameters. 2010/05/24 10:48 Thanks for the suggestion, I use "> " here now, and I'll change it in whatever text I edit in future (whole wiki). Let's see if "> " is okay. 2012/04/20 10:32 Here's yet another non-getopts way.http://bsdpants.blogspot.de/2007/02/option-ize-your-shell-scripts.html
2012/07/16 14:48 Hi there!What if I use "$@" in subsequent function calls, but arguments are strings?
I mean, having:
#!/bin/bash echo "$@" echo n: $#If you use it
mypc$ script arg1 arg2 "asd asd" arg4 arg1 arg2 asd asd arg4 n: 4But having
#!/bin/bash myfunc() { echo "$@" echo n: $# } ech "$@" echo n: $# myfunc "$@"you get:
mypc$ myscrpt arg1 arg2 "asd asd" arg4 arg1 arg2 asd asd arg4 4 arg1 arg2 asd asd arg4 5As you can see, there is no way to make know the function that a parameter is a string and not a space separated list of arguments.
Any idea of how to solve it? I've test calling functions and doing expansion in almost all ways with no results.
2012/08/12 09:11 I don't know why it fails for you. It should work if you use"$@", of course.See the exmaple I used your second script with:
$ ./args1 a b c "d e" f a b c d e f n: 5 a b c d e f n: 52015/06/10 10:00 Thanks a lot for this tutorial. Especially the first example is very helpful.
Mar 30, 2018 | sookocheff.com
Parsing bash script options with getopts Posted on January 4, 2015 | 5 minutes | Kevin Sookocheff A common task in shell scripting is to parse command line arguments to your script. Bash provides the
getoptsbuilt-in function to do just that. This tutorial explains how to use thegetoptsbuilt-in function to parse arguments and options to a bash script.The
getoptsfunction takes three parameters. The first is a specification of which options are valid, listed as a sequence of letters. For example, the string'ht'signifies that the options-hand-tare valid.The second argument to
getoptsis a variable that will be populated with the option or argument to be processed next. In the following loop,optwill hold the value of the current option that has been parsed bygetopts.while getopts ":ht" opt; do case ${opt} in h ) # process option a ;; t ) # process option t ;; \? ) echo "Usage: cmd [-h] [-t]" ;; esac doneThis example shows a few additional features of
getopts. First, if an invalid option is provided, the option variable is assigned the value?. You can catch this case and provide an appropriate usage message to the user. Second, this behaviour is only true when you prepend the list of valid options with:to disable the default error handling of invalid options. It is recommended to always disable the default error handling in your scripts.The third argument to
Shifting processed optionsgetoptsis the list of arguments and options to be processed. When not provided, this defaults to the arguments and options provided to the application ($@). You can provide this third argument to usegetoptsto parse any list of arguments and options you provide.The variable
OPTINDholds the number of options parsed by the last call togetopts. It is common practice to call theshiftcommand at the end of your processing loop to remove options that have already been handled from$@.shift $((OPTIND -1))Parsing options with argumentsOptions that themselves have arguments are signified with a
:. The argument to an option is placed in the variableOPTARG. In the following example, the optionttakes an argument. When the argument is provided, we copy its value to the variabletarget. If no argument is providedgetoptswill setoptto:. We can recognize this error condition by catching the:case and printing an appropriate error message.while getopts ":t:" opt; do case ${opt} in t ) target=$OPTARG ;; \? ) echo "Invalid option: $OPTARG" 1>&2 ;; : ) echo "Invalid option: $OPTARG requires an argument" 1>&2 ;; esac done shift $((OPTIND -1))An extended example – parsing nested arguments and optionsLet's walk through an extended example of processing a command that takes options, has a sub-command, and whose sub-command takes an additional option that has an argument. This is a mouthful so let's break it down using an example. Let's say we are writing our own version of the
pipcommand . In this version you can callpipwith the-hoption to display a help message.> pip -h Usage: pip -h Display this help message. pip install Install a Python package.We can use
getoptsto parse the-hoption with the followingwhileloop. In it we catch invalid options with\?andshiftall arguments that have been processed withshift $((OPTIND -1)).while getopts ":h" opt; do case ${opt} in h ) echo "Usage:" echo " pip -h Display this help message." echo " pip install Install a Python package." exit 0 ;; \? ) echo "Invalid Option: -$OPTARG" 1>&2 exit 1 ;; esac done shift $((OPTIND -1))Now let's add the sub-command
installto our script.installtakes as an argument the Python package to install.> pip install urllib3
installalso takes an option,-t.-ttakes as an argument the location to install the package to relative to the current directory.> pip install urllib3 -t ./src/libTo process this line we must find the sub-command to execute. This value is the first argument to our script.
subcommand=$1 shift # Remove `pip` from the argument listNow we can process the sub-command
install. In our example, the option-tis actually an option that follows the package argument so we begin by removinginstallfrom the argument list and processing the remainder of the line.case "$subcommand" in install) package=$1 shift # Remove `install` from the argument list ;; esacAfter shifting the argument list we can process the remaining arguments as if they are of the form
package -t src/lib. The-toption takes an argument itself. This argument will be stored in the variableOPTARGand we save it to the variabletargetfor further work.case "$subcommand" in install) package=$1 shift # Remove `install` from the argument list while getopts ":t:" opt; do case ${opt} in t ) target=$OPTARG ;; \? ) echo "Invalid Option: -$OPTARG" 1>&2 exit 1 ;; : ) echo "Invalid Option: -$OPTARG requires an argument" 1>&2 exit 1 ;; esac done shift $((OPTIND -1)) ;; esacPutting this all together, we end up with the following script that parses arguments to our version of
pipand its sub-commandinstall.package="" # Default to empty package target="" # Default to empty target # Parse options to the `pip` command while getopts ":h" opt; do case ${opt} in h ) echo "Usage:" echo " pip -h Display this help message." echo " pip install <package> Install <package>." exit 0 ;; \? ) echo "Invalid Option: -$OPTARG" 1>&2 exit 1 ;; esac done shift $((OPTIND -1)) subcommand=$1; shift # Remove 'pip' from the argument list case "$subcommand" in # Parse options to the install sub command install) package=$1; shift # Remove 'install' from the argument list # Process package options while getopts ":t:" opt; do case ${opt} in t ) target=$OPTARG ;; \? ) echo "Invalid Option: -$OPTARG" 1>&2 exit 1 ;; : ) echo "Invalid Option: -$OPTARG requires an argument" 1>&2 exit 1 ;; esac done shift $((OPTIND -1)) ;; esacAfter processing the above sequence of commands, the variable
bash getoptspackagewill hold the package to install and the variabletargetwill hold the target to install the package to. You can use this as a template for processing any set of arguments and options to your scripts.
Jul 10, 2017 | stackoverflow.com
Livven, Jul 10, 2017 at 8:11
Update: It's been more than 5 years since I started this answer. Thank you for LOTS of great edits/comments/suggestions. In order save maintenance time, I've modified the code block to be 100% copy-paste ready. Please do not post comments like "What if you changed X to Y ". Instead, copy-paste the code block, see the output, make the change, rerun the script, and comment "I changed X to Y and " I don't have time to test your ideas and tell you if they work.
Method #1: Using bash without getopt[s]Two common ways to pass key-value-pair arguments are:
Bash Space-Separated (e.g.,--option argument) (without getopt[s])Usage
demo-space-separated.sh -e conf -s /etc -l /usr/lib /etc/hostscat >/tmp/demo-space-separated.sh <<'EOF' #!/bin/bash POSITIONAL=() while [[ $# -gt 0 ]] do key="$1" case $key in -e|--extension) EXTENSION="$2" shift # past argument shift # past value ;; -s|--searchpath) SEARCHPATH="$2" shift # past argument shift # past value ;; -l|--lib) LIBPATH="$2" shift # past argument shift # past value ;; --default) DEFAULT=YES shift # past argument ;; *) # unknown option POSITIONAL+=("$1") # save it in an array for later shift # past argument ;; esac done set -- "${POSITIONAL[@]}" # restore positional parameters echo "FILE EXTENSION = ${EXTENSION}" echo "SEARCH PATH = ${SEARCHPATH}" echo "LIBRARY PATH = ${LIBPATH}" echo "DEFAULT = ${DEFAULT}" echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l) if [[ -n $1 ]]; then echo "Last line of file specified as non-opt/last argument:" tail -1 "$1" fi EOF chmod +x /tmp/demo-space-separated.sh /tmp/demo-space-separated.sh -e conf -s /etc -l /usr/lib /etc/hostsoutput from copy-pasting the block above:
FILE EXTENSION = conf SEARCH PATH = /etc LIBRARY PATH = /usr/lib DEFAULT = Number files in SEARCH PATH with EXTENSION: 14 Last line of file specified as non-opt/last argument: #93.184.216.34 example.comBash Equals-Separated (e.g.,--option=argument) (without getopt[s])Usage
demo-equals-separated.sh -e=conf -s=/etc -l=/usr/lib /etc/hostscat >/tmp/demo-equals-separated.sh <<'EOF' #!/bin/bash for i in "$@" do case $i in -e=*|--extension=*) EXTENSION="${i#*=}" shift # past argument=value ;; -s=*|--searchpath=*) SEARCHPATH="${i#*=}" shift # past argument=value ;; -l=*|--lib=*) LIBPATH="${i#*=}" shift # past argument=value ;; --default) DEFAULT=YES shift # past argument with no value ;; *) # unknown option ;; esac done echo "FILE EXTENSION = ${EXTENSION}" echo "SEARCH PATH = ${SEARCHPATH}" echo "LIBRARY PATH = ${LIBPATH}" echo "DEFAULT = ${DEFAULT}" echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l) if [[ -n $1 ]]; then echo "Last line of file specified as non-opt/last argument:" tail -1 $1 fi EOF chmod +x /tmp/demo-equals-separated.sh /tmp/demo-equals-separated.sh -e=conf -s=/etc -l=/usr/lib /etc/hostsoutput from copy-pasting the block above:
FILE EXTENSION = conf SEARCH PATH = /etc LIBRARY PATH = /usr/lib DEFAULT = Number files in SEARCH PATH with EXTENSION: 14 Last line of file specified as non-opt/last argument: #93.184.216.34 example.comTo better understand
Method #2: Using bash with getopt[s]${i#*=}search for "Substring Removal" in this guide . It is functionally equivalent to`sed 's/[^=]*=//' <<< "$i"`which calls a needless subprocess or`echo "$i" | sed 's/[^=]*=//'`which calls two needless subprocesses.from: http://mywiki.wooledge.org/BashFAQ/035#getopts
getopt(1) limitations (older, relatively-recent
getoptversions):
- can't handle arguments that are empty strings
- can't handle arguments with embedded whitespace
More recent
getoptversions don't have these limitations.Additionally, the POSIX shell (and others) offer
getoptswhich doesn't have these limitations. I've included a simplisticgetoptsexample.Usage
demo-getopts.sh -vf /etc/hosts foo barcat >/tmp/demo-getopts.sh <<'EOF' #!/bin/sh # A POSIX variable OPTIND=1 # Reset in case getopts has been used previously in the shell. # Initialize our own variables: output_file="" verbose=0 while getopts "h?vf:" opt; do case "$opt" in h|\?) show_help exit 0 ;; v) verbose=1 ;; f) output_file=$OPTARG ;; esac done shift $((OPTIND-1)) [ "${1:-}" = "--" ] && shift echo "verbose=$verbose, output_file='$output_file', Leftovers: $@" EOF chmod +x /tmp/demo-getopts.sh /tmp/demo-getopts.sh -vf /etc/hosts foo baroutput from copy-pasting the block above:
verbose=1, output_file='/etc/hosts', Leftovers: foo barThe advantages of
getoptsare:
- It's more portable, and will work in other shells like
dash.- It can handle multiple single options like
-vf filenamein the typical Unix way, automatically.The disadvantage of
getoptsis that it can only handle short options (-h, not--help) without additional code.There is a getopts tutorial which explains what all of the syntax and variables mean. In bash, there is also
help getopts, which might be informative.johncip ,Jul 23, 2018 at 15:15
No answer mentions enhanced getopt . And the top-voted answer is misleading: It either ignores-vfdstyle short options (requested by the OP) or options after positional arguments (also requested by the OP); and it ignores parsing-errors. Instead:
- Use enhanced
getoptfrom util-linux or formerly GNU glibc . 1- It works with
getopt_long()the C function of GNU glibc.- Has all useful distinguishing features (the others don't have them):
- handles spaces, quoting characters and even binary in arguments 2 (non-enhanced
getoptcan't do this)- it can handle options at the end:
script.sh -o outFile file1 file2 -v(getoptsdoesn't do this)- allows
=-style long options:script.sh --outfile=fileOut --infile fileIn(allowing both is lengthy if self parsing)- allows combined short options, e.g.
-vfd(real work if self parsing)- allows touching option-arguments, e.g.
-oOutfileor-vfdoOutfile- Is so old already 3 that no GNU system is missing this (e.g. any Linux has it).
- You can test for its existence with:
getopt --test→ return value 4.- Other
getoptor shell-builtingetoptsare of limited use.The following calls
myscript -vfd ./foo/bar/someFile -o /fizz/someOtherFile myscript -v -f -d -o/fizz/someOtherFile -- ./foo/bar/someFile myscript --verbose --force --debug ./foo/bar/someFile -o/fizz/someOtherFile myscript --output=/fizz/someOtherFile ./foo/bar/someFile -vfd myscript ./foo/bar/someFile -df -v --output /fizz/someOtherFileall return
verbose: y, force: y, debug: y, in: ./foo/bar/someFile, out: /fizz/someOtherFilewith the following
myscript#!/bin/bash # saner programming env: these switches turn some bugs into errors set -o errexit -o pipefail -o noclobber -o nounset # -allow a command to fail with !'s side effect on errexit # -use return value from ${PIPESTATUS[0]}, because ! hosed $? ! getopt --test > /dev/null if [[ ${PIPESTATUS[0]} -ne 4 ]]; then echo 'I'm sorry, `getopt --test` failed in this environment.' exit 1 fi OPTIONS=dfo:v LONGOPTS=debug,force,output:,verbose # -regarding ! and PIPESTATUS see above # -temporarily store output to be able to check for errors # -activate quoting/enhanced mode (e.g. by writing out "--options") # -pass arguments only via -- "$@" to separate them correctly ! PARSED=$(getopt --options=$OPTIONS --longoptions=$LONGOPTS --name "$0" -- "$@") if [[ ${PIPESTATUS[0]} -ne 0 ]]; then # e.g. return value is 1 # then getopt has complained about wrong arguments to stdout exit 2 fi # read getopt's output this way to handle the quoting right: eval set -- "$PARSED" d=n f=n v=n outFile=- # now enjoy the options in order and nicely split until we see -- while true; do case "$1" in -d|--debug) d=y shift ;; -f|--force) f=y shift ;; -v|--verbose) v=y shift ;; -o|--output) outFile="$2" shift 2 ;; --) shift break ;; *) echo "Programming error" exit 3 ;; esac done # handle non-option arguments if [[ $# -ne 1 ]]; then echo "$0: A single input file is required." exit 4 fi echo "verbose: $v, force: $f, debug: $d, in: $1, out: $outFile"
1 enhanced getopt is available on most "bash-systems", including Cygwin; on OS X try brew install gnu-getopt or
sudo port install getopt
2 the POSIXexec()conventions have no reliable way to pass binary NULL in command line arguments; those bytes prematurely end the argument
3 first version released in 1997 or before (I only tracked it back to 1997)Tobias Kienzler ,Mar 19, 2016 at 15:23
from : digitalpeer.com with minor modificationsUsage
myscript.sh -p=my_prefix -s=dirname -l=libname#!/bin/bash for i in "$@" do case $i in -p=*|--prefix=*) PREFIX="${i#*=}" ;; -s=*|--searchpath=*) SEARCHPATH="${i#*=}" ;; -l=*|--lib=*) DIR="${i#*=}" ;; --default) DEFAULT=YES ;; *) # unknown option ;; esac done echo PREFIX = ${PREFIX} echo SEARCH PATH = ${SEARCHPATH} echo DIRS = ${DIR} echo DEFAULT = ${DEFAULT}To better understand
${i#*=}search for "Substring Removal" in this guide . It is functionally equivalent to`sed 's/[^=]*=//' <<< "$i"`which calls a needless subprocess or`echo "$i" | sed 's/[^=]*=//'`which calls two needless subprocesses.Robert Siemer ,Jun 1, 2018 at 1:57
getopt()/getopts()is a good option. Stolen from here :The simple use of "getopt" is shown in this mini-script:
#!/bin/bash echo "Before getopt" for i do echo $i done args=`getopt abc:d $*` set -- $args echo "After getopt" for i do echo "-->$i" doneWhat we have said is that any of -a, -b, -c or -d will be allowed, but that -c is followed by an argument (the "c:" says that).
If we call this "g" and try it out:
bash-2.05a$ ./g -abc foo Before getopt -abc foo After getopt -->-a -->-b -->-c -->foo -->--We start with two arguments, and "getopt" breaks apart the options and puts each in its own argument. It also added "--".
hfossli ,Jan 31 at 20:05
More succinct wayscript.sh
#!/bin/bash while [[ "$#" -gt 0 ]]; do case $1 in -d|--deploy) deploy="$2"; shift;; -u|--uglify) uglify=1;; *) echo "Unknown parameter passed: $1"; exit 1;; esac; shift; done echo "Should deploy? $deploy" echo "Should uglify? $uglify"Usage:
./script.sh -d dev -u # OR: ./script.sh --deploy dev --uglifybronson ,Apr 27 at 23:22
At the risk of adding another example to ignore, here's my scheme.
- handles
-n argand--name=arg- allows arguments at the end
- shows sane errors if anything is misspelled
- compatible, doesn't use bashisms
- readable, doesn't require maintaining state in a loop
Hope it's useful to someone.
while [ "$#" -gt 0 ]; do case "$1" in -n) name="$2"; shift 2;; -p) pidfile="$2"; shift 2;; -l) logfile="$2"; shift 2;; --name=*) name="${1#*=}"; shift 1;; --pidfile=*) pidfile="${1#*=}"; shift 1;; --logfile=*) logfile="${1#*=}"; shift 1;; --name|--pidfile|--logfile) echo "$1 requires an argument" >&2; exit 1;; -*) echo "unknown option: $1" >&2; exit 1;; *) handle_argument "$1"; shift 1;; esac doneRobert Siemer ,Jun 6, 2016 at 19:28
I'm about 4 years late to this question, but want to give back. I used the earlier answers as a starting point to tidy up my old adhoc param parsing. I then refactored out the following template code. It handles both long and short params, using = or space separated arguments, as well as multiple short params grouped together. Finally it re-inserts any non-param arguments back into the $1,$2.. variables. I hope it's useful.#!/usr/bin/env bash # NOTICE: Uncomment if your script depends on bashisms. #if [ -z "$BASH_VERSION" ]; then bash $0 $@ ; exit $? ; fi echo "Before" for i ; do echo - $i ; done # Code template for parsing command line parameters using only portable shell # code, while handling both long and short params, handling '-f file' and # '-f=file' style param data and also capturing non-parameters to be inserted # back into the shell positional parameters. while [ -n "$1" ]; do # Copy so we can modify it (can't modify $1) OPT="$1" # Detect argument termination if [ x"$OPT" = x"--" ]; then shift for OPT ; do REMAINS="$REMAINS \"$OPT\"" done break fi # Parse current opt while [ x"$OPT" != x"-" ] ; do case "$OPT" in # Handle --flag=value opts like this -c=* | --config=* ) CONFIGFILE="${OPT#*=}" shift ;; # and --flag value opts like this -c* | --config ) CONFIGFILE="$2" shift ;; -f* | --force ) FORCE=true ;; -r* | --retry ) RETRY=true ;; # Anything unknown is recorded for later * ) REMAINS="$REMAINS \"$OPT\"" break ;; esac # Check for multiple short options # NOTICE: be sure to update this pattern to match valid options NEXTOPT="${OPT#-[cfr]}" # try removing single short opt if [ x"$OPT" != x"$NEXTOPT" ] ; then OPT="-$NEXTOPT" # multiple short opts, keep going else break # long form, exit inner loop fi done # Done with that param. move to next shift done # Set the non-parameters back into the positional parameters ($1 $2 ..) eval set -- $REMAINS echo -e "After: \n configfile='$CONFIGFILE' \n force='$FORCE' \n retry='$RETRY' \n remains='$REMAINS'" for i ; do echo - $i ; done> ,
I have found the matter to write portable parsing in scripts so frustrating that I have written Argbash - a FOSS code generator that can generate the arguments-parsing code for your script plus it has some nice features:
May 10, 2013 | stackoverflow.com
An example of how to use getopts in bash Ask Question Asked 6 years, 3 months ago Active 10 months ago Viewed 419k times 288 132
chepner ,May 10, 2013 at 13:42
I want to callmyscriptfile in this way:$ ./myscript -s 45 -p any_stringor
$ ./myscript -h >>> should display help $ ./myscript >>> should display helpMy requirements are:
getopthere to get the input arguments- check that
-sexists, if not return error- check that the value after the
-sis 45 or 90- check that the
-pexists and there is an input string after- if the user enters
./myscript -hor just./myscriptthen display helpI tried so far this code:
#!/bin/bash while getopts "h:s:" arg; do case $arg in h) echo "usage" ;; s) strength=$OPTARG echo $strength ;; esac doneBut with that code I get errors. How to do it with Bash and
getopt?,
#!/bin/bash usage() { echo "Usage: $0 [-s <45|90>] [-p <string>]" 1>&2; exit 1; } while getopts ":s:p:" o; do case "${o}" in s) s=${OPTARG} ((s == 45 || s == 90)) || usage ;; p) p=${OPTARG} ;; *) usage ;; esac done shift $((OPTIND-1)) if [ -z "${s}" ] || [ -z "${p}" ]; then usage fi echo "s = ${s}" echo "p = ${p}"Example runs:
$ ./myscript.sh Usage: ./myscript.sh [-s <45|90>] [-p <string>] $ ./myscript.sh -h Usage: ./myscript.sh [-s <45|90>] [-p <string>] $ ./myscript.sh -s "" -p "" Usage: ./myscript.sh [-s <45|90>] [-p <string>] $ ./myscript.sh -s 10 -p foo Usage: ./myscript.sh [-s <45|90>] [-p <string>] $ ./myscript.sh -s 45 -p foo s = 45 p = foo $ ./myscript.sh -s 90 -p bar s = 90 p = bar
Aug 07, 2016 | shapeshed.com
Tutorial on using exit codes from Linux or UNIX commands. Examples of how to get the exit code of a command, how to set the exit code and how to suppress exit codes.Estimated reading time: 3 minutes
Table of contentsWhat is an exit code in the UNIX or Linux shell?
An exit code, or sometimes known as a return code, is the code returned to a parent process by an executable. On POSIX systems the standard exit code is
0for success and any number from1to255for anything else.Exit codes can be interpreted by machine scripts to adapt in the event of successes of failures. If exit codes are not set the exit code will be the exit code of the last run command.
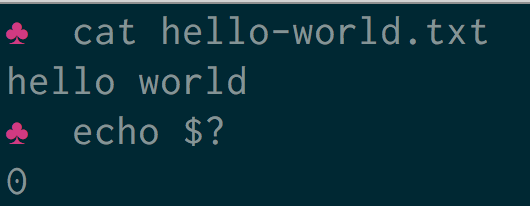
How to get the exit code of a commandTo get the exit code of a command type
echo $?at the command prompt. In the following example a file is printed to the terminal using the cat command.cat file.txt hello world echo $? 0The command was successful. The file exists and there are no errors in reading the file or writing it to the terminal. The exit code is therefore
0.In the following example the file does not exist.
cat doesnotexist.txt cat: doesnotexist.txt: No such file or directory echo $? 1The exit code is
How to use exit codes in scripts1as the operation was not successful.To use exit codes in scripts an
ifstatement can be used to see if an operation was successful.#!/bin/bash cat file.txt if [ $? -eq 0 ] then echo "The script ran ok" exit 0 else echo "The script failed" >&2 exit 1 fiIf the command was unsuccessful the exit code will be
How to set an exit code0and 'The script ran ok' will be printed to the terminal.To set an exit code in a script use
exit 0where0is the number you want to return. In the following example a shell script exits with a1. This file is saved asexit.sh.#!/bin/bash exit 1Executing this script shows that the exit code is correctly set.
bash exit.sh echo $? 1What exit code should I use?The Linux Documentation Project has a list of reserved codes that also offers advice on what code to use for specific scenarios. These are the standard error codes in Linux or UNIX.
How to suppress exit statuses
1- Catchall for general errors2- Misuse of shell builtins (according to Bash documentation)126- Command invoked cannot execute127- "command not found"128- Invalid argument to exit128+n- Fatal error signal "n"130- Script terminated by Control-C255\*- Exit status out of rangeSometimes there may be a requirement to suppress an exit status. It may be that a command is being run within another script and that anything other than a
0status is undesirable.In the following example a file is printed to the terminal using cat . This file does not exist so will cause an exit status of
1.To suppress the error message any output to standard error is sent to
/dev/nullusing2>/dev/null.If the cat command fails an
ORoperation can be used to provide a fallback -cat file.txt || exit 0. In this case an exit code of0is returned even if there is an error.Combining both the suppression of error output and the
ORoperation the following script returns a status code of0with no output even though the file does not exist.#!/bin/bash cat 'doesnotexist.txt' 2>/dev/null || exit 0Further reading
Aug 26, 2019 | www.shellscript.sh
Exit codes are a number between 0 and 255, which is returned by any Unix command when it returns control to its parent process.
Other numbers can be used, but these are treated modulo 256, soexit -10is equivalent toexit 246, andexit 257is equivalent toexit 1.These can be used within a shell script to change the flow of execution depending on the success or failure of commands executed. This was briefly introduced in Variables - Part II . Here we shall look in more detail in the available interpretations of exit codes.
Success is traditionally represented with
exit 0; failure is normally indicated with a non-zero exit-code. This value can indicate different reasons for failure.
For example, GNUgrepreturns0on success,1if no matches were found, and2for other errors (syntax errors, non-existent input files, etc).We shall look at three different methods for checking error status, and discuss the pros and cons of each approach.
Firstly, the simple approach:
#!/bin/sh # First attempt at checking return codes USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1` if [ "$?" -ne "0" ]; then echo "Sorry, cannot find user ${1} in /etc/passwd" exit 1 fi NAME=`grep "^${1}:" /etc/passwd|cut -d":" -f5` HOMEDIR=`grep "^${1}:" /etc/passwd|cut -d":" -f6` echo "USERNAME: $USERNAME" echo "NAME: $NAME" echo "HOMEDIR: $HOMEDIR"
This script works fine if you supply a valid username in/etc/passwd. However, if you enter an invalid code, it does not do what you might at first expect - it keeps running, and just shows:USERNAME: NAME: HOMEDIR:Why is this? As mentioned, the$?variable is set to the return code of the last executed command . In this case, that iscut.cuthad no problems which it feels like reporting - as far as I can tell from testing it, and reading the documentation,cutreturns zero whatever happens! It was fed an empty string, and did its job - returned the first field of its input, which just happened to be the empty string.So what do we do? If we have an error here,
grepwill report it, notcut. Therefore, we have to testgrep's return code, notcut's.
#!/bin/sh # Second attempt at checking return codes grep "^${1}:" /etc/passwd > /dev/null 2>&1 if [ "$?" -ne "0" ]; then echo "Sorry, cannot find user ${1} in /etc/passwd" exit 1 fi USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1` NAME=`grep "^${1}:" /etc/passwd|cut -d":" -f5` HOMEDIR=`grep "^${1}:" /etc/passwd|cut -d":" -f6` echo "USERNAME: $USERNAME" echo "NAME: $NAME" echo "HOMEDIR: $HOMEDIR"
This fixes the problem for us, though at the expense of slightly longer code.
That is the basic way which textbooks might show you, but it is far from being all there is to know about error-checking in shell scripts. This method may not be the most suitable to your particular command-sequence, or may be unmaintainable. Below, we shall investigate two alternative approaches.As a second approach, we can tidy this somewhat by putting the test into a separate function, instead of littering the code with lots of 4-line tests:
#!/bin/sh # A Tidier approach check_errs() { # Function. Parameter 1 is the return code # Para. 2 is text to display on failure. if [ "${1}" -ne "0" ]; then echo "ERROR # ${1} : ${2}" # as a bonus, make our script exit with the right error code. exit ${1} fi } ### main script starts here ### grep "^${1}:" /etc/passwd > /dev/null 2>&1 check_errs $? "User ${1} not found in /etc/passwd" USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1` check_errs $? "Cut returned an error" echo "USERNAME: $USERNAME" check_errs $? "echo returned an error - very strange!"
This allows us to test for errors 3 times, with customised error messages, without having to write 3 individual tests. By writing the test routine once. we can call it as many times as we wish, creating a more intelligent script, at very little expense to the programmer. Perl programmers will recognise this as being similar to thediecommand in Perl.As a third approach, we shall look at a simpler and cruder method. I tend to use this for building Linux kernels - simple automations which, if they go well, should just get on with it, but when things go wrong, tend to require the operator to do something intelligent (ie, that which a script cannot do!):
#!/bin/sh cd /usr/src/linux && \ make dep && make bzImage && make modules && make modules_install && \ cp arch/i386/boot/bzImage /boot/my-new-kernel && cp System.map /boot && \ echo "Your new kernel awaits, m'lord."This script runs through the various tasks involved in building a Linux kernel (which can take quite a while), and uses the&&operator to check for success. To do this withifwould involve:
#!/bin/sh cd /usr/src/linux if [ "$?" -eq "0" ]; then make dep if [ "$?" -eq "0" ]; then make bzImage if [ "$?" -eq "0" ]; then make modules if [ "$?" -eq "0" ]; then make modules_install if [ "$?" -eq "0" ]; then cp arch/i386/boot/bzImage /boot/my-new-kernel if [ "$?" -eq "0" ]; then cp System.map /boot/ if [ "$?" -eq "0" ]; then echo "Your new kernel awaits, m'lord." fi fi fi fi fi fi fi fi
... which I, personally, find pretty difficult to follow.
The&&and||operators are the shell's equivalent of AND and OR tests. These can be thrown together as above, or:
#!/bin/sh cp /foo /bar && echo Success || echo FailedThis code will either echo
Successor
Faileddepending on whether or not the
cpcommand was successful. Look carefully at this; the construct iscommand && command-to-execute-on-success || command-to-execute-on-failureOnly one command can be in each part. This method is handy for simple success / fail scenarios, but if you want to check on the status of the
echocommands themselves, it is easy to quickly become confused about which&&and||applies to which command. It is also very difficult to maintain. Therefore this construct is only recommended for simple sequencing of commands.In earlier versions, I had suggested that you can use a subshell to execute multiple commands depending on whether the
cpcommand succeeded or failed:cp /foo /bar && ( echo Success ; echo Success part II; ) || ( echo Failed ; echo Failed part II )But in fact, Marcel found that this does not work properly. The syntax for a subshell is:
( command1 ; command2; command3 )The return code of the subshell is the return code of the final command (
command3in this example). That return code will affect the overall command. So the output of this script:cp /foo /bar && ( echo Success ; echo Success part II; /bin/false ) || ( echo Failed ; echo Failed part II )Is that it runs the Success part (because
cpsucceeded, and then - because/bin/falsereturns failure, it also executes the Failure part:Success Success part II Failed Failed part IISo if you need to execute multiple commands as a result of the status of some other condition, it is better (and much clearer) to use the standard
if,then,elsesyntax.
Jun 18, 2019 | linuxconfig.org
Before proceeding further, let me give you one tip. In the example above the shell tried to expand a non-existing variable, producing a blank result. This can be very dangerous, especially when working with path names, therefore, when writing scripts, it's always recommended to use the
nounsetoption which causes the shell to exit with error whenever a non existing variable is referenced:$ set -o nounset $ echo "You are reading this article on $site_!" bash: site_: unbound variableWorking with indirectionThe use of the
${!parameter}syntax, adds a level of indirection to our parameter expansion. What does it mean? The parameter which the shell will try to expand is notparameter; instead it will try to use the the value ofparameteras the name of the variable to be expanded. Let's explain this with an example. We all know theHOMEvariable expands in the path of the user home directory in the system, right?$ echo "${HOME}" /home/egdocVery well, if now we assign the string "HOME", to another variable, and use this type of expansion, we obtain:
$ variable_to_inspect="HOME" $ echo "${!variable_to_inspect}" /home/egdocAs you can see in the example above, instead of obtaining "HOME" as a result, as it would have happened if we performed a simple expansion, the shell used the value of
Case modification expansionvariable_to_inspectas the name of the variable to expand, that's why we talk about a level of indirection.This parameter expansion syntax let us change the case of the alphabetic characters inside the string resulting from the expansion of the parameter. Say we have a variable called
name; to capitalize the text returned by the expansion of the variable we would use the${parameter^}syntax:$ name="egidio" $ echo "${name^}" EgidioWhat if we want to uppercase the entire string, instead of capitalize it? Easy! we use the
${parameter^^}syntax:$ echo "${name^^}" EGIDIOSimilarly, to lowercase the first character of a string, we use the
${parameter,}expansion syntax:$ name="EGIDIO" $ echo "${name,}" eGIDIOTo lowercase the entire string, instead, we use the
${parameter,,}syntax:$ name="EGIDIO" $ echo "${name,,}" egidioIn all cases a
patternto match a single character can also be provided. When the pattern is provided the operation is applied only to the parts of the original string that matches it:$ name="EGIDIO" $ echo "${name,,[DIO]}" EGidio
In the example above we enclose the characters in square brackets: this causes anyone of them to be matched as a pattern.
When using the expansions we explained in this paragraph and the
parameteris an array subscripted by@or*, the operation is applied to all the elements contained in it:$ my_array=(one two three) $ echo "${my_array[@]^^}" ONE TWO THREEWhen the index of a specific element in the array is referenced, instead, the operation is applied only to it:
$ my_array=(one two three) $ echo "${my_array[2]^^}" THREESubstring removalThe next syntax we will examine allows us to remove a
patternfrom the beginning or from the end of string resulting from the expansion of a parameter.Remove matching pattern from the beginning of the stringThe next syntax we will examine,
${parameter#pattern}, allows us to remove apatternfrom the beginning of the string resulting from theparameterexpansion:$ name="Egidio" $ echo "${name#Egi}" dioA similar result can be obtained by using the
"${parameter##pattern}"syntax, but with one important difference: contrary to the one we used in the example above, which removes the shortest matching pattern from the beginning of the string, it removes the longest one. The difference is clearly visible when using the*character in thepattern:$ name="Egidio Docile" $ echo "${name#*i}" dio DocileIn the example above we used
*as part of the pattern that should be removed from the string resulting by the expansion of thenamevariable. Thiswildcardmatches any character, so the pattern itself translates in "'i' character and everything before it". As we already said, when we use the${parameter#pattern}syntax, the shortest matching pattern is removed, in this case it is "Egi". Let's see what happens when we use the"${parameter##pattern}"syntax instead:$ name="Egidio Docile" $ echo "${name##*i}" leThis time the longest matching pattern is removed ("Egidio Doci"): the longest possible match includes the third 'i' and everything before it. The result of the expansion is just "le".
Remove matching pattern from the end of the stringThe syntax we saw above remove the shortest or longest matching pattern from the beginning of the string. If we want the pattern to be removed from the end of the string, instead, we must use the
${parameter%pattern}or${parameter%%pattern}expansions, to remove, respectively, the shortest and longest match from the end of the string:$ name="Egidio Docile" $ echo "${name%i*}" Egidio DocIn this example the pattern we provided roughly translates in "'i' character and everything after it starting from the end of the string". The shortest match is "ile", so what is returned is "Egidio Doc". If we try the same example but we use the syntax which removes the longest match we obtain:
$ name="Egidio Docile" $ echo "${name%%i*}" EgIn this case the once the longest match is removed, what is returned is "Eg".
In all the expansions we saw above, if
parameteris an array and it is subscripted with*or@, the removal of the matching pattern is applied to all its elements:$ my_array=(one two three) $ echo "${my_array[@]#*o}" ne three
Search and replace patternWe used the previous syntax to remove a matching pattern from the beginning or from the end of the string resulting from the expansion of a parameter. What if we want to replace
patternwith something else? We can use the${parameter/pattern/string}or${parameter//pattern/string}syntax. The former replaces only the first occurrence of the pattern, the latter all the occurrences:$ phrase="yellow is the sun and yellow is the lemon" $ echo "${phrase/yellow/red}" red is the sun and yellow is the lemonThe
parameter(phrase) is expanded, and the longest match of thepattern(yellow) is matched against it. The match is then replaced by the providedstring(red). As you can observe only the first occurrence is replaced, so the lemon remains yellow! If we want to change all the occurrences of the pattern, we must prefix it with the/character:$ phrase="yellow is the sun and yellow is the lemon" $ echo "${phrase//yellow/red}" red is the sun and red is the lemonThis time all the occurrences of "yellow" has been replaced by "red". As you can see the pattern is matched wherever it is found in the string resulting from the expansion of
parameter. If we want to specify that it must be matched only at the beginning or at the end of the string, we must prefix it respectively with the#or%character.Just like in the previous cases, if
parameteris an array subscripted by either*or@, the substitution happens in each one of its elements:$ my_array=(one two three) $ echo "${my_array[@]/o/u}" une twu threeSubstring expansionThe
${parameter:offset}and${parameter:offset:length}expansions let us expand only a part of the parameter, returning a substring starting at the specifiedoffsetandlengthcharacters long. If the length is not specified the expansion proceeds until the end of the original string. This type of expansion is calledsubstring expansion:$ name="Egidio Docile" $ echo "${name:3}" dio DocileIn the example above we provided just the
offset, without specifying thelength, therefore the result of the expansion was the substring obtained by starting at the character specified by the offset (3).If we specify a length, the substring will start at
offsetand will belengthcharacters long:$ echo "${name:3:3}" dioIf the
offsetis negative, it is calculated from the end of the string. In this case an additional space must be added after:otherwise the shell will consider it as another type of expansion identified by:-which is used to provide a default value if the parameter to be expanded doesn't exist (we talked about it in the article about managing the expansion of empty or unset bash variables ):$ echo "${name: -6}" DocileIf the provided
lengthis negative, instead of being interpreted as the total number of characters the resulting string should be long, it is considered as an offset to be calculated from the end of the string. The result of the expansion will therefore be a substring starting atoffsetand ending atlengthcharacters from the end of the original string:$ echo "${name:7:-3}" DocWhen using this expansion and
parameteris an indexed array subscribed by*or@, theoffsetis relative to the indexes of the array elements. For example:$ my_array=(one two three) $ echo "${my_array[@]:0:2}" one two $ echo "${my_array[@]: -2}" two three
Jul 04, 2018 | stackoverflow.com
Lawrence Johnston ,Oct 10, 2008 at 16:57
Say, I have a script that gets called with this line:./myscript -vfd ./foo/bar/someFile -o /fizz/someOtherFileor this one:
./myscript -v -f -d -o /fizz/someOtherFile ./foo/bar/someFileWhat's the accepted way of parsing this such that in each case (or some combination of the two)
$v,$f, and$dwill all be set totrueand$outFilewill be equal to/fizz/someOtherFile?Inanc Gumus ,Apr 15, 2016 at 19:11
See my very easy and no-dependency answer here: stackoverflow.com/a/33826763/115363 – Inanc Gumus Apr 15 '16 at 19:11dezza ,Aug 2, 2016 at 2:13
For zsh-users there's a great builtin called zparseopts which can do:zparseopts -D -E -M -- d=debug -debug=dAnd have both-dand--debugin the$debugarrayecho $+debug[1]will return 0 or 1 if one of those are used. Ref: zsh.org/mla/users/2011/msg00350.html – dezza Aug 2 '16 at 2:13Bruno Bronosky ,Jan 7, 2013 at 20:01
Preferred Method: Using straight bash without getopt[s]I originally answered the question as the OP asked. This Q/A is getting a lot of attention, so I should also offer the non-magic way to do this. I'm going to expand upon guneysus's answer to fix the nasty sed and include Tobias Kienzler's suggestion .
Two of the most common ways to pass key value pair arguments are:
Straight Bash Space SeparatedUsage
./myscript.sh -e conf -s /etc -l /usr/lib /etc/hosts#!/bin/bash POSITIONAL=() while [[ $# -gt 0 ]] do key="$1" case $key in -e|--extension) EXTENSION="$2" shift # past argument shift # past value ;; -s|--searchpath) SEARCHPATH="$2" shift # past argument shift # past value ;; -l|--lib) LIBPATH="$2" shift # past argument shift # past value ;; --default) DEFAULT=YES shift # past argument ;; *) # unknown option POSITIONAL+=("$1") # save it in an array for later shift # past argument ;; esac done set -- "${POSITIONAL[@]}" # restore positional parameters echo FILE EXTENSION = "${EXTENSION}" echo SEARCH PATH = "${SEARCHPATH}" echo LIBRARY PATH = "${LIBPATH}" echo DEFAULT = "${DEFAULT}" echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l) if [[ -n $1 ]]; then echo "Last line of file specified as non-opt/last argument:" tail -1 "$1" fiStraight Bash Equals SeparatedUsage
./myscript.sh -e=conf -s=/etc -l=/usr/lib /etc/hosts#!/bin/bash for i in "$@" do case $i in -e=*|--extension=*) EXTENSION="${i#*=}" shift # past argument=value ;; -s=*|--searchpath=*) SEARCHPATH="${i#*=}" shift # past argument=value ;; -l=*|--lib=*) LIBPATH="${i#*=}" shift # past argument=value ;; --default) DEFAULT=YES shift # past argument with no value ;; *) # unknown option ;; esac done echo "FILE EXTENSION = ${EXTENSION}" echo "SEARCH PATH = ${SEARCHPATH}" echo "LIBRARY PATH = ${LIBPATH}" echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l) if [[ -n $1 ]]; then echo "Last line of file specified as non-opt/last argument:" tail -1 $1 fiTo better understand
Using getopt[s]${i#*=}search for "Substring Removal" in this guide . It is functionally equivalent to`sed 's/[^=]*=//' <<< "$i"`which calls a needless subprocess or`echo "$i" | sed 's/[^=]*=//'`which calls two needless subprocesses.from: http://mywiki.wooledge.org/BashFAQ/035#getopts
Never use getopt(1).
getoptcannot handle empty arguments strings, or arguments with embedded whitespace. Please forget that it ever existed.The POSIX shell (and others) offer
getoptswhich is safe to use instead. Here is a simplisticgetoptsexample:#!/bin/sh # A POSIX variable OPTIND=1 # Reset in case getopts has been used previously in the shell. # Initialize our own variables: output_file="" verbose=0 while getopts "h?vf:" opt; do case "$opt" in h|\?) show_help exit 0 ;; v) verbose=1 ;; f) output_file=$OPTARG ;; esac done shift $((OPTIND-1)) [ "${1:-}" = "--" ] && shift echo "verbose=$verbose, output_file='$output_file', Leftovers: $@" # End of fileThe advantages of
getoptsare:
- It's portable, and will work in e.g. dash.
- It can handle things like
-vf filenamein the expected Unix way, automatically.The disadvantage of
getoptsis that it can only handle short options (-h, not--help) without trickery.There is a getopts tutorial which explains what all of the syntax and variables mean. In bash, there is also
help getopts, which might be informative.Livven ,Jun 6, 2013 at 21:19
Is this really true? According to Wikipedia there's a newer GNU enhanced version ofgetoptwhich includes all the functionality ofgetoptsand then some.man getopton Ubuntu 13.04 outputsgetopt - parse command options (enhanced)as the name, so I presume this enhanced version is standard now. – Livven Jun 6 '13 at 21:19szablica ,Jul 17, 2013 at 15:23
That something is a certain way on your system is a very weak premise to base asumptions of "being standard" on. – szablica Jul 17 '13 at 15:23Stephane Chazelas ,Aug 20, 2014 at 19:55
@Livven, thatgetoptis not a GNU utility, it's part ofutil-linux. – Stephane Chazelas Aug 20 '14 at 19:55Nicolas Mongrain-Lacombe ,Jun 19, 2016 at 21:22
If you use-gt 0, remove yourshiftafter theesac, augment all theshiftby 1 and add this case:*) break;;you can handle non optionnal arguments. Ex: pastebin.com/6DJ57HTc – Nicolas Mongrain-Lacombe Jun 19 '16 at 21:22kolydart ,Jul 10, 2017 at 8:11
You do not echo–default. In the first example, I notice that if–defaultis the last argument, it is not processed (considered as non-opt), unlesswhile [[ $# -gt 1 ]]is set aswhile [[ $# -gt 0 ]]– kolydart Jul 10 '17 at 8:11Robert Siemer ,Apr 20, 2015 at 17:47
No answer mentions enhanced getopt . And the top-voted answer is misleading: It ignores-vfdstyle short options (requested by the OP), options after positional arguments (also requested by the OP) and it ignores parsing-errors. Instead:
- Use enhanced
getoptfrom util-linux or formerly GNU glibc . 1- It works with
getopt_long()the C function of GNU glibc.- Has all useful distinguishing features (the others don't have them):
- handles spaces, quoting characters and even binary in arguments 2
- it can handle options at the end:
script.sh -o outFile file1 file2 -v- allows
=-style long options:script.sh --outfile=fileOut --infile fileIn- Is so old already 3 that no GNU system is missing this (e.g. any Linux has it).
- You can test for its existence with:
getopt --test→ return value 4.- Other
getoptor shell-builtingetoptsare of limited use.The following calls
myscript -vfd ./foo/bar/someFile -o /fizz/someOtherFile myscript -v -f -d -o/fizz/someOtherFile -- ./foo/bar/someFile myscript --verbose --force --debug ./foo/bar/someFile -o/fizz/someOtherFile myscript --output=/fizz/someOtherFile ./foo/bar/someFile -vfd myscript ./foo/bar/someFile -df -v --output /fizz/someOtherFileall return
verbose: y, force: y, debug: y, in: ./foo/bar/someFile, out: /fizz/someOtherFilewith the following
myscript#!/bin/bash getopt --test > /dev/null if [[ $? -ne 4 ]]; then echo "I'm sorry, `getopt --test` failed in this environment." exit 1 fi OPTIONS=dfo:v LONGOPTIONS=debug,force,output:,verbose # -temporarily store output to be able to check for errors # -e.g. use "--options" parameter by name to activate quoting/enhanced mode # -pass arguments only via -- "$@" to separate them correctly PARSED=$(getopt --options=$OPTIONS --longoptions=$LONGOPTIONS --name "$0" -- "$@") if [[ $? -ne 0 ]]; then # e.g. $? == 1 # then getopt has complained about wrong arguments to stdout exit 2 fi # read getopt's output this way to handle the quoting right: eval set -- "$PARSED" # now enjoy the options in order and nicely split until we see -- while true; do case "$1" in -d|--debug) d=y shift ;; -f|--force) f=y shift ;; -v|--verbose) v=y shift ;; -o|--output) outFile="$2" shift 2 ;; --) shift break ;; *) echo "Programming error" exit 3 ;; esac done # handle non-option arguments if [[ $# -ne 1 ]]; then echo "$0: A single input file is required." exit 4 fi echo "verbose: $v, force: $f, debug: $d, in: $1, out: $outFile"
1 enhanced getopt is available on most "bash-systems", including Cygwin; on OS X try brew install gnu-getopt
2 the POSIXexec()conventions have no reliable way to pass binary NULL in command line arguments; those bytes prematurely end the argument
3 first version released in 1997 or before (I only tracked it back to 1997)johncip ,Jan 12, 2017 at 2:00
Thanks for this. Just confirmed from the feature table at en.wikipedia.org/wiki/Getopts , if you need support for long options, and you're not on Solaris,getoptis the way to go. – johncip Jan 12 '17 at 2:00Kaushal Modi ,Apr 27, 2017 at 14:02
I believe that the only caveat withgetoptis that it cannot be used conveniently in wrapper scripts where one might have few options specific to the wrapper script, and then pass the non-wrapper-script options to the wrapped executable, intact. Let's say I have agrepwrapper calledmygrepand I have an option--foospecific tomygrep, then I cannot domygrep --foo -A 2, and have the-A 2passed automatically togrep; I need to domygrep --foo -- -A 2. Here is my implementation on top of your solution. – Kaushal Modi Apr 27 '17 at 14:02bobpaul ,Mar 20 at 16:45
Alex, I agree and there's really no way around that since we need to know the actual return value ofgetopt --test. I'm a big fan of "Unofficial Bash Strict mode", (which includesset -e), and I just put the check for getopt ABOVEset -euo pipefailandIFS=$'\n\t'in my script. – bobpaul Mar 20 at 16:45Robert Siemer ,Mar 21 at 9:10
@bobpaul Oh, there is a way around that. And I'll edit my answer soon to reflect my collections regarding this issue (set -e)... – Robert Siemer Mar 21 at 9:10Robert Siemer ,Mar 21 at 9:16
@bobpaul Your statement about util-linux is wrong and misleading as well: the package is marked "essential" on Ubuntu/Debian. As such, it is always installed. – Which distros are you talking about (where you say it needs to be installed on purpose)? – Robert Siemer Mar 21 at 9:16guneysus ,Nov 13, 2012 at 10:31
from :digitalpeer.comwith minor modificationsUsage
myscript.sh -p=my_prefix -s=dirname -l=libname#!/bin/bash for i in "$@" do case $i in -p=*|--prefix=*) PREFIX="${i#*=}" ;; -s=*|--searchpath=*) SEARCHPATH="${i#*=}" ;; -l=*|--lib=*) DIR="${i#*=}" ;; --default) DEFAULT=YES ;; *) # unknown option ;; esac done echo PREFIX = ${PREFIX} echo SEARCH PATH = ${SEARCHPATH} echo DIRS = ${DIR} echo DEFAULT = ${DEFAULT}To better understand
${i#*=}search for "Substring Removal" in this guide . It is functionally equivalent to`sed 's/[^=]*=//' <<< "$i"`which calls a needless subprocess or`echo "$i" | sed 's/[^=]*=//'`which calls two needless subprocesses.Tobias Kienzler ,Nov 12, 2013 at 12:48
Neat! Though this won't work for space-separated arguments à lamount -t tempfs .... One can probably fix this via something likewhile [ $# -ge 1 ]; do param=$1; shift; case $param in; -p) prefix=$1; shift;;etc – Tobias Kienzler Nov 12 '13 at 12:48Robert Siemer ,Mar 19, 2016 at 15:23
This can't handle-vfdstyle combined short options. – Robert Siemer Mar 19 '16 at 15:23bekur ,Dec 19, 2017 at 23:27
link is broken! – bekur Dec 19 '17 at 23:27Matt J ,Oct 10, 2008 at 17:03
getopt()/getopts()is a good option. Stolen from here :The simple use of "getopt" is shown in this mini-script:
#!/bin/bash echo "Before getopt" for i do echo $i done args=`getopt abc:d $*` set -- $args echo "After getopt" for i do echo "-->$i" doneWhat we have said is that any of -a, -b, -c or -d will be allowed, but that -c is followed by an argument (the "c:" says that).
If we call this "g" and try it out:
bash-2.05a$ ./g -abc foo Before getopt -abc foo After getopt -->-a -->-b -->-c -->foo -->--We start with two arguments, and "getopt" breaks apart the options and puts each in its own argument. It also added "--".
Robert Siemer ,Apr 16, 2016 at 14:37
Using$*is broken usage ofgetopt. (It hoses arguments with spaces.) See my answer for proper usage. – Robert Siemer Apr 16 '16 at 14:37SDsolar ,Aug 10, 2017 at 14:07
Why would you want to make it more complicated? – SDsolar Aug 10 '17 at 14:07thebunnyrules ,Jun 1 at 1:57
@Matt J, the first part of the script (for i) would be able to handle arguments with spaces in them if you use "$i" instead of $i. The getopts does not seem to be able to handle arguments with spaces. What would be the advantage of using getopt over the for i loop? – thebunnyrules Jun 1 at 1:57bronson ,Jul 15, 2015 at 23:43
At the risk of adding another example to ignore, here's my scheme.
- handles
-n argand--name=arg- allows arguments at the end
- shows sane errors if anything is misspelled
- compatible, doesn't use bashisms
- readable, doesn't require maintaining state in a loop
Hope it's useful to someone.
while [ "$#" -gt 0 ]; do case "$1" in -n) name="$2"; shift 2;; -p) pidfile="$2"; shift 2;; -l) logfile="$2"; shift 2;; --name=*) name="${1#*=}"; shift 1;; --pidfile=*) pidfile="${1#*=}"; shift 1;; --logfile=*) logfile="${1#*=}"; shift 1;; --name|--pidfile|--logfile) echo "$1 requires an argument" >&2; exit 1;; -*) echo "unknown option: $1" >&2; exit 1;; *) handle_argument "$1"; shift 1;; esac donerhombidodecahedron ,Sep 11, 2015 at 8:40
What is the "handle_argument" function? – rhombidodecahedron Sep 11 '15 at 8:40bronson ,Oct 8, 2015 at 20:41
Sorry for the delay. In my script, the handle_argument function receives all the non-option arguments. You can replace that line with whatever you'd like, maybe*) die "unrecognized argument: $1"or collect the args into a variable*) args+="$1"; shift 1;;. – bronson Oct 8 '15 at 20:41Guilherme Garnier ,Apr 13 at 16:10
Amazing! I've tested a couple of answers, but this is the only one that worked for all cases, including many positional parameters (both before and after flags) – Guilherme Garnier Apr 13 at 16:10Shane Day ,Jul 1, 2014 at 1:20
I'm about 4 years late to this question, but want to give back. I used the earlier answers as a starting point to tidy up my old adhoc param parsing. I then refactored out the following template code. It handles both long and short params, using = or space separated arguments, as well as multiple short params grouped together. Finally it re-inserts any non-param arguments back into the $1,$2.. variables. I hope it's useful.#!/usr/bin/env bash # NOTICE: Uncomment if your script depends on bashisms. #if [ -z "$BASH_VERSION" ]; then bash $0 $@ ; exit $? ; fi echo "Before" for i ; do echo - $i ; done # Code template for parsing command line parameters using only portable shell # code, while handling both long and short params, handling '-f file' and # '-f=file' style param data and also capturing non-parameters to be inserted # back into the shell positional parameters. while [ -n "$1" ]; do # Copy so we can modify it (can't modify $1) OPT="$1" # Detect argument termination if [ x"$OPT" = x"--" ]; then shift for OPT ; do REMAINS="$REMAINS \"$OPT\"" done break fi # Parse current opt while [ x"$OPT" != x"-" ] ; do case "$OPT" in # Handle --flag=value opts like this -c=* | --config=* ) CONFIGFILE="${OPT#*=}" shift ;; # and --flag value opts like this -c* | --config ) CONFIGFILE="$2" shift ;; -f* | --force ) FORCE=true ;; -r* | --retry ) RETRY=true ;; # Anything unknown is recorded for later * ) REMAINS="$REMAINS \"$OPT\"" break ;; esac # Check for multiple short options # NOTICE: be sure to update this pattern to match valid options NEXTOPT="${OPT#-[cfr]}" # try removing single short opt if [ x"$OPT" != x"$NEXTOPT" ] ; then OPT="-$NEXTOPT" # multiple short opts, keep going else break # long form, exit inner loop fi done # Done with that param. move to next shift done # Set the non-parameters back into the positional parameters ($1 $2 ..) eval set -- $REMAINS echo -e "After: \n configfile='$CONFIGFILE' \n force='$FORCE' \n retry='$RETRY' \n remains='$REMAINS'" for i ; do echo - $i ; doneRobert Siemer ,Dec 6, 2015 at 13:47
This code can't handle options with arguments like this:-c1. And the use of=to separate short options from their arguments is unusual... – Robert Siemer Dec 6 '15 at 13:47sfnd ,Jun 6, 2016 at 19:28
I ran into two problems with this useful chunk of code: 1) the "shift" in the case of "-c=foo" ends up eating the next parameter; and 2) 'c' should not be included in the "[cfr]" pattern for combinable short options. – sfnd Jun 6 '16 at 19:28Inanc Gumus ,Nov 20, 2015 at 12:28
More succinct wayscript.sh
#!/bin/bash while [[ "$#" > 0 ]]; do case $1 in -d|--deploy) deploy="$2"; shift;; -u|--uglify) uglify=1;; *) echo "Unknown parameter passed: $1"; exit 1;; esac; shift; done echo "Should deploy? $deploy" echo "Should uglify? $uglify"Usage:
./script.sh -d dev -u # OR: ./script.sh --deploy dev --uglifyhfossli ,Apr 7 at 20:58
This is what I am doing. Have towhile [[ "$#" > 1 ]]if I want to support ending the line with a boolean flag./script.sh --debug dev --uglify fast --verbose. Example: gist.github.com/hfossli/4368aa5a577742c3c9f9266ed214aa58 – hfossli Apr 7 at 20:58hfossli ,Apr 7 at 21:09
I sent an edit request. I just tested this and it works perfectly. – hfossli Apr 7 at 21:09hfossli ,Apr 7 at 21:10
Wow! Simple and clean! This is how I'm using this: gist.github.com/hfossli/4368aa5a577742c3c9f9266ed214aa58 – hfossli Apr 7 at 21:10Ponyboy47 ,Sep 8, 2016 at 18:59
My answer is largely based on the answer by Bruno Bronosky , but I sort of mashed his two pure bash implementations into one that I use pretty frequently.# As long as there is at least one more argument, keep looping while [[ $# -gt 0 ]]; do key="$1" case "$key" in # This is a flag type option. Will catch either -f or --foo -f|--foo) FOO=1 ;; # Also a flag type option. Will catch either -b or --bar -b|--bar) BAR=1 ;; # This is an arg value type option. Will catch -o value or --output-file value -o|--output-file) shift # past the key and to the value OUTPUTFILE="$1" ;; # This is an arg=value type option. Will catch -o=value or --output-file=value -o=*|--output-file=*) # No need to shift here since the value is part of the same string OUTPUTFILE="${key#*=}" ;; *) # Do whatever you want with extra options echo "Unknown option '$key'" ;; esac # Shift after checking all the cases to get the next option shift doneThis allows you to have both space separated options/values, as well as equal defined values.
So you could run your script using:
./myscript --foo -b -o /fizz/file.txtas well as:
./myscript -f --bar -o=/fizz/file.txtand both should have the same end result.
PROS:
- Allows for both -arg=value and -arg value
- Works with any arg name that you can use in bash
- Meaning -a or -arg or --arg or -a-r-g or whatever
- Pure bash. No need to learn/use getopt or getopts
CONS:
- Can't combine args
- Meaning no -abc. You must do -a -b -c
These are the only pros/cons I can think of off the top of my head
bubla ,Jul 10, 2016 at 22:40
I have found the matter to write portable parsing in scripts so frustrating that I have written Argbash - a FOSS code generator that can generate the arguments-parsing code for your script plus it has some nice features:RichVel ,Aug 18, 2016 at 5:34
Thanks for writing argbash, I just used it and found it works well. I mostly went for argbash because it's a code generator supporting the older bash 3.x found on OS X 10.11 El Capitan. The only downside is that the code-generator approach means quite a lot of code in your main script, compared to calling a module. – RichVel Aug 18 '16 at 5:34bubla ,Aug 23, 2016 at 20:40
You can actually use Argbash in a way that it produces tailor-made parsing library just for you that you can have included in your script or you can have it in a separate file and just source it. I have added an example to demonstrate that and I have made it more explicit in the documentation, too. – bubla Aug 23 '16 at 20:40RichVel ,Aug 24, 2016 at 5:47
Good to know. That example is interesting but still not really clear - maybe you can change name of the generated script to 'parse_lib.sh' or similar and show where the main script calls it (like in the wrapping script section which is more complex use case). – RichVel Aug 24 '16 at 5:47bubla ,Dec 2, 2016 at 20:12
The issues were addressed in recent version of argbash: Documentation has been improved, a quickstart argbash-init script has been introduced and you can even use argbash online at argbash.io/generate – bubla Dec 2 '16 at 20:12Alek ,Mar 1, 2012 at 15:15
I think this one is simple enough to use:#!/bin/bash # readopt='getopts $opts opt;rc=$?;[ $rc$opt == 0? ]&&exit 1;[ $rc == 0 ]||{ shift $[OPTIND-1];false; }' opts=vfdo: # Enumerating options while eval $readopt do echo OPT:$opt ${OPTARG+OPTARG:$OPTARG} done # Enumerating arguments for arg do echo ARG:$arg doneInvocation example:
./myscript -v -do /fizz/someOtherFile -f ./foo/bar/someFile OPT:v OPT:d OPT:o OPTARG:/fizz/someOtherFile OPT:f ARG:./foo/bar/someFileerm3nda ,May 20, 2015 at 22:50
I read all and this one is my preferred one. I don't like to use-a=1as argc style. I prefer to put first the main option -options and later the special ones with single spacing-o option. Im looking for the simplest-vs-better way to read argvs. – erm3nda May 20 '15 at 22:50erm3nda ,May 20, 2015 at 23:25
It's working really well but if you pass an argument to a non a: option all the following options would be taken as arguments. You can check this line./myscript -v -d fail -o /fizz/someOtherFile -f ./foo/bar/someFilewith your own script. -d option is not set as d: – erm3nda May 20 '15 at 23:25unsynchronized ,Jun 9, 2014 at 13:46
Expanding on the excellent answer by @guneysus, here is a tweak that lets user use whichever syntax they prefer, egcommand -x=myfilename.ext --another_switchvs
command -x myfilename.ext --another_switchThat is to say the equals can be replaced with whitespace.
This "fuzzy interpretation" might not be to your liking, but if you are making scripts that are interchangeable with other utilities (as is the case with mine, which must work with ffmpeg), the flexibility is useful.
STD_IN=0 prefix="" key="" value="" for keyValue in "$@" do case "${prefix}${keyValue}" in -i=*|--input_filename=*) key="-i"; value="${keyValue#*=}";; -ss=*|--seek_from=*) key="-ss"; value="${keyValue#*=}";; -t=*|--play_seconds=*) key="-t"; value="${keyValue#*=}";; -|--stdin) key="-"; value=1;; *) value=$keyValue;; esac case $key in -i) MOVIE=$(resolveMovie "${value}"); prefix=""; key="";; -ss) SEEK_FROM="${value}"; prefix=""; key="";; -t) PLAY_SECONDS="${value}"; prefix=""; key="";; -) STD_IN=${value}; prefix=""; key="";; *) prefix="${keyValue}=";; esac donevangorra ,Feb 12, 2015 at 21:50
getopts works great if #1 you have it installed and #2 you intend to run it on the same platform. OSX and Linux (for example) behave differently in this respect.Here is a (non getopts) solution that supports equals, non-equals, and boolean flags. For example you could run your script in this way:
./script --arg1=value1 --arg2 value2 --shouldClean # parse the arguments. COUNTER=0 ARGS=("$@") while [ $COUNTER -lt $# ] do arg=${ARGS[$COUNTER]} let COUNTER=COUNTER+1 nextArg=${ARGS[$COUNTER]} if [[ $skipNext -eq 1 ]]; then echo "Skipping" skipNext=0 continue fi argKey="" argVal="" if [[ "$arg" =~ ^\- ]]; then # if the format is: -key=value if [[ "$arg" =~ \= ]]; then argVal=$(echo "$arg" | cut -d'=' -f2) argKey=$(echo "$arg" | cut -d'=' -f1) skipNext=0 # if the format is: -key value elif [[ ! "$nextArg" =~ ^\- ]]; then argKey="$arg" argVal="$nextArg" skipNext=1 # if the format is: -key (a boolean flag) elif [[ "$nextArg" =~ ^\- ]] || [[ -z "$nextArg" ]]; then argKey="$arg" argVal="" skipNext=0 fi # if the format has not flag, just a value. else argKey="" argVal="$arg" skipNext=0 fi case "$argKey" in --source-scmurl) SOURCE_URL="$argVal" ;; --dest-scmurl) DEST_URL="$argVal" ;; --version-num) VERSION_NUM="$argVal" ;; -c|--clean) CLEAN_BEFORE_START="1" ;; -h|--help|-help|--h) showUsage exit ;; esac doneakostadinov ,Jul 19, 2013 at 7:50
This is how I do in a function to avoid breaking getopts run at the same time somewhere higher in stack:function waitForWeb () { local OPTIND=1 OPTARG OPTION local host=localhost port=8080 proto=http while getopts "h:p:r:" OPTION; do case "$OPTION" in h) host="$OPTARG" ;; p) port="$OPTARG" ;; r) proto="$OPTARG" ;; esac done ... }Renato Silva ,Jul 4, 2016 at 16:47
EasyOptions does not require any parsing:## Options: ## --verbose, -v Verbose mode ## --output=FILE Output filename source easyoptions || exit if test -n "${verbose}"; then echo "output file is ${output}" echo "${arguments[@]}" fiOleksii Chekulaiev ,Jul 1, 2016 at 20:56
I give you The Functionparse_paramsthat will parse params:
- Without polluting global scope.
- Effortlessly returns to you ready to use variables so that you could build further logic on them
- Amount of dashes before params does not matter (
--allequals-allequalsall=all)The script below is a copy-paste working demonstration. See
show_usefunction to understand how to useparse_params.Limitations:
- Does not support space delimited params (
-d 1)- Param names will lose dashes so
--any-paramand-anyparamare equivalenteval $(parse_params "$@")must be used inside bash function (it will not work in the global scope)
#!/bin/bash # Universal Bash parameter parsing # Parse equal sign separated params into named local variables # Standalone named parameter value will equal its param name (--force creates variable $force=="force") # Parses multi-valued named params into an array (--path=path1 --path=path2 creates ${path[*]} array) # Parses un-named params into ${ARGV[*]} array # Additionally puts all named params into ${ARGN[*]} array # Additionally puts all standalone "option" params into ${ARGO[*]} array # @author Oleksii Chekulaiev # @version v1.3 (May-14-2018) parse_params () { local existing_named local ARGV=() # un-named params local ARGN=() # named params local ARGO=() # options (--params) echo "local ARGV=(); local ARGN=(); local ARGO=();" while [[ "$1" != "" ]]; do # Escape asterisk to prevent bash asterisk expansion _escaped=${1/\*/\'\"*\"\'} # If equals delimited named parameter if [[ "$1" =~ ^..*=..* ]]; then # Add to named parameters array echo "ARGN+=('$_escaped');" # key is part before first = local _key=$(echo "$1" | cut -d = -f 1) # val is everything after key and = (protect from param==value error) local _val="${1/$_key=}" # remove dashes from key name _key=${_key//\-} # search for existing parameter name if (echo "$existing_named" | grep "\b$_key\b" >/dev/null); then # if name already exists then it's a multi-value named parameter # re-declare it as an array if needed if ! (declare -p _key 2> /dev/null | grep -q 'declare \-a'); then echo "$_key=(\"\$$_key\");" fi # append new value echo "$_key+=('$_val');" else # single-value named parameter echo "local $_key=\"$_val\";" existing_named=" $_key" fi # If standalone named parameter elif [[ "$1" =~ ^\-. ]]; then # Add to options array echo "ARGO+=('$_escaped');" # remove dashes local _key=${1//\-} echo "local $_key=\"$_key\";" # non-named parameter else # Escape asterisk to prevent bash asterisk expansion _escaped=${1/\*/\'\"*\"\'} echo "ARGV+=('$_escaped');" fi shift done } #--------------------------- DEMO OF THE USAGE ------------------------------- show_use () { eval $(parse_params "$@") # -- echo "${ARGV[0]}" # print first unnamed param echo "${ARGV[1]}" # print second unnamed param echo "${ARGN[0]}" # print first named param echo "${ARG0[0]}" # print first option param (--force) echo "$anyparam" # print --anyparam value echo "$k" # print k=5 value echo "${multivalue[0]}" # print first value of multi-value echo "${multivalue[1]}" # print second value of multi-value [[ "$force" == "force" ]] && echo "\$force is set so let the force be with you" } show_use "param 1" --anyparam="my value" param2 k=5 --force --multi-value=test1 --multi-value=test2Oleksii Chekulaiev ,Sep 28, 2016 at 12:55
To use the demo to parse params that come into your bash script you just doshow_use "$@"– Oleksii Chekulaiev Sep 28 '16 at 12:55Oleksii Chekulaiev ,Sep 28, 2016 at 12:58
Basically I found out that github.com/renatosilva/easyoptions does the same in the same way but is a bit more massive than this function. – Oleksii Chekulaiev Sep 28 '16 at 12:58galmok ,Jun 24, 2015 at 10:54
I'd like to offer my version of option parsing, that allows for the following:-s p1 --stage p1 -w somefolder --workfolder somefolder -sw p1 somefolder -e=helloAlso allows for this (could be unwanted):
-s--workfolder p1 somefolder -se=hello p1 -swe=hello p1 somefolderYou have to decide before use if = is to be used on an option or not. This is to keep the code clean(ish).
while [[ $# > 0 ]] do key="$1" while [[ ${key+x} ]] do case $key in -s*|--stage) STAGE="$2" shift # option has parameter ;; -w*|--workfolder) workfolder="$2" shift # option has parameter ;; -e=*) EXAMPLE="${key#*=}" break # option has been fully handled ;; *) # unknown option echo Unknown option: $key #1>&2 exit 10 # either this: my preferred way to handle unknown options break # or this: do this to signal the option has been handled (if exit isn't used) ;; esac # prepare for next option in this key, if any [[ "$key" = -? || "$key" == --* ]] && unset key || key="${key/#-?/-}" done shift # option(s) fully processed, proceed to next input argument doneLuca Davanzo ,Nov 14, 2016 at 17:56
what's the meaning for "+x" on ${key+x} ? – Luca Davanzo Nov 14 '16 at 17:56galmok ,Nov 15, 2016 at 9:10
It is a test to see if 'key' is present or not. Further down I unset key and this breaks the inner while loop. – galmok Nov 15 '16 at 9:10Mark Fox ,Apr 27, 2015 at 2:42
Mixing positional and flag-based arguments --param=arg (equals delimited)Freely mixing flags between positional arguments:
./script.sh dumbo 127.0.0.1 --environment=production -q -d ./script.sh dumbo --environment=production 127.0.0.1 --quiet -dcan be accomplished with a fairly concise approach:
# process flags pointer=1 while [[ $pointer -le $# ]]; do param=${!pointer} if [[ $param != "-"* ]]; then ((pointer++)) # not a parameter flag so advance pointer else case $param in # paramter-flags with arguments -e=*|--environment=*) environment="${param#*=}";; --another=*) another="${param#*=}";; # binary flags -q|--quiet) quiet=true;; -d) debug=true;; esac # splice out pointer frame from positional list [[ $pointer -gt 1 ]] \ && set -- ${@:1:((pointer - 1))} ${@:((pointer + 1)):$#} \ || set -- ${@:((pointer + 1)):$#}; fi done # positional remain node_name=$1 ip_address=$2--param arg (space delimited)It's usualy clearer to not mix
--flag=valueand--flag valuestyles../script.sh dumbo 127.0.0.1 --environment production -q -dThis is a little dicey to read, but is still valid
./script.sh dumbo --environment production 127.0.0.1 --quiet -dSource
# process flags pointer=1 while [[ $pointer -le $# ]]; do if [[ ${!pointer} != "-"* ]]; then ((pointer++)) # not a parameter flag so advance pointer else param=${!pointer} ((pointer_plus = pointer + 1)) slice_len=1 case $param in # paramter-flags with arguments -e|--environment) environment=${!pointer_plus}; ((slice_len++));; --another) another=${!pointer_plus}; ((slice_len++));; # binary flags -q|--quiet) quiet=true;; -d) debug=true;; esac # splice out pointer frame from positional list [[ $pointer -gt 1 ]] \ && set -- ${@:1:((pointer - 1))} ${@:((pointer + $slice_len)):$#} \ || set -- ${@:((pointer + $slice_len)):$#}; fi done # positional remain node_name=$1 ip_address=$2schily ,Oct 19, 2015 at 13:59
Note thatgetopt(1)was a short living mistake from AT&T.getopt was created in 1984 but already buried in 1986 because it was not really usable.
A proof for the fact that
getoptis very outdated is that thegetopt(1)man page still mentions"$*"instead of"$@", that was added to the Bourne Shell in 1986 together with thegetopts(1)shell builtin in order to deal with arguments with spaces inside.BTW: if you are interested in parsing long options in shell scripts, it may be of interest to know that the
getopt(3)implementation from libc (Solaris) andksh93both added a uniform long option implementation that supports long options as aliases for short options. This causesksh93and theBourne Shellto implement a uniform interface for long options viagetopts.An example for long options taken from the Bourne Shell man page:
getopts "f:(file)(input-file)o:(output-file)" OPTX "$@"shows how long option aliases may be used in both Bourne Shell and ksh93.
See the man page of a recent Bourne Shell:
http://schillix.sourceforge.net/man/man1/bosh.1.html
and the man page for getopt(3) from OpenSolaris:
http://schillix.sourceforge.net/man/man3c/getopt.3c.html
and last, the getopt(1) man page to verify the outdated $*:
Volodymyr M. Lisivka ,Jul 9, 2013 at 16:51
Use module "arguments" from bash-modulesExample:
#!/bin/bash . import.sh log arguments NAME="world" parse_arguments "-n|--name)NAME;S" -- "$@" || { error "Cannot parse command line." exit 1 } info "Hello, $NAME!"Mike Q ,Jun 14, 2014 at 18:01
This also might be useful to know, you can set a value and if someone provides input, override the default with that value..myscript.sh -f ./serverlist.txt or just ./myscript.sh (and it takes defaults)
#!/bin/bash # --- set the value, if there is inputs, override the defaults. HOME_FOLDER="${HOME}/owned_id_checker" SERVER_FILE_LIST="${HOME_FOLDER}/server_list.txt" while [[ $# > 1 ]] do key="$1" shift case $key in -i|--inputlist) SERVER_FILE_LIST="$1" shift ;; esac done echo "SERVER LIST = ${SERVER_FILE_LIST}"phk ,Oct 17, 2015 at 21:17
Another solution without getopt[s], POSIX, old Unix styleSimilar to the solution Bruno Bronosky posted this here is one without the usage of
getopt(s).Main differentiating feature of my solution is that it allows to have options concatenated together just like
Code with example optionstar -xzf foo.tar.gzis equal totar -x -z -f foo.tar.gz. And just like intar,psetc. the leading hyphen is optional for a block of short options (but this can be changed easily). Long options are supported as well (but when a block starts with one then two leading hyphens are required).#!/bin/sh echo echo "POSIX-compliant getopt(s)-free old-style-supporting option parser from phk@[se.unix]" echo print_usage() { echo "Usage: $0 {a|b|c} [ARG...] Options: --aaa-0-args -a Option without arguments. --bbb-1-args ARG -b ARG Option with one argument. --ccc-2-args ARG1 ARG2 -c ARG1 ARG2 Option with two arguments. " >&2 } if [ $# -le 0 ]; then print_usage exit 1 fi opt= while :; do if [ $# -le 0 ]; then # no parameters remaining -> end option parsing break elif [ ! "$opt" ]; then # we are at the beginning of a fresh block # remove optional leading hyphen and strip trailing whitespaces opt=$(echo "$1" | sed 's/^-\?\([a-zA-Z0-9\?-]*\)/\1/') fi # get the first character -> check whether long option first_chr=$(echo "$opt" | awk '{print substr($1, 1, 1)}') [ "$first_chr" = - ] && long_option=T || long_option=F # note to write the options here with a leading hyphen less # also do not forget to end short options with a star case $opt in -) # end of options shift break ;; a*|-aaa-0-args) echo "Option AAA activated!" ;; b*|-bbb-1-args) if [ "$2" ]; then echo "Option BBB with argument '$2' activated!" shift else echo "BBB parameters incomplete!" >&2 print_usage exit 1 fi ;; c*|-ccc-2-args) if [ "$2" ] && [ "$3" ]; then echo "Option CCC with arguments '$2' and '$3' activated!" shift 2 else echo "CCC parameters incomplete!" >&2 print_usage exit 1 fi ;; h*|\?*|-help) print_usage exit 0 ;; *) if [ "$long_option" = T ]; then opt=$(echo "$opt" | awk '{print substr($1, 2)}') else opt=$first_chr fi printf 'Error: Unknown option: "%s"\n' "$opt" >&2 print_usage exit 1 ;; esac if [ "$long_option" = T ]; then # if we had a long option then we are going to get a new block next shift opt= else # if we had a short option then just move to the next character opt=$(echo "$opt" | awk '{print substr($1, 2)}') # if block is now empty then shift to the next one [ "$opt" ] || shift fi done echo "Doing something..." exit 0For the example usage please see the examples further below.
Position of options with argumentsFor what its worth there the options with arguments don't be the last (only long options need to be). So while e.g. in
Multiple options with argumentstar(at least in some implementations) thefoptions needs to be last because the file name follows (tar xzf bar.tar.gzworks buttar xfz bar.tar.gzdoes not) this is not the case here (see the later examples).As another bonus the option parameters are consumed in the order of the options by the parameters with required options. Just look at the output of my script here with the command line
abc X Y Z(or-abc X Y Z):Option AAA activated! Option BBB with argument 'X' activated! Option CCC with arguments 'Y' and 'Z' activated!Long options concatenated as wellAlso you can also have long options in option block given that they occur last in the block. So the following command lines are all equivalent (including the order in which the options and its arguments are being processed):
-cba Z Y Xcba Z Y X-cb-aaa-0-args Z Y X-c-bbb-1-args Z Y X -a--ccc-2-args Z Y -ba Xc Z Y b X a-c Z Y -b X -a--ccc-2-args Z Y --bbb-1-args X --aaa-0-argsAll of these lead to:
Option CCC with arguments 'Z' and 'Y' activated! Option BBB with argument 'X' activated! Option AAA activated! Doing something...Not in this solution Optional argumentsOptions with optional arguments should be possible with a bit of work, e.g. by looking forward whether there is a block without a hyphen; the user would then need to put a hyphen in front of every block following a block with a parameter having an optional parameter. Maybe this is too complicated to communicate to the user so better just require a leading hyphen altogether in this case.
Things get even more complicated with multiple possible parameters. I would advise against making the options trying to be smart by determining whether the an argument might be for it or not (e.g. with an option just takes a number as an optional argument) because this might break in the future.
I personally favor additional options instead of optional arguments.
Option arguments introduced with an equal signJust like with optional arguments I am not a fan of this (BTW, is there a thread for discussing the pros/cons of different parameter styles?) but if you want this you could probably implement it yourself just like done at http://mywiki.wooledge.org/BashFAQ/035#Manual_loop with a
Other notes--long-with-arg=?*case statement and then stripping the equal sign (this is BTW the site that says that making parameter concatenation is possible with some effort but "left [it] as an exercise for the reader" which made me take them at their word but I started from scratch).POSIX-compliant, works even on ancient Busybox setups I had to deal with (with e.g.
cut,headandgetoptsmissing).Noah ,Aug 29, 2016 at 3:44
Solution that preserves unhandled arguments. Demos Included.Here is my solution. It is VERY flexible and unlike others, shouldn't require external packages and handles leftover arguments cleanly.
Usage is:
./myscript -flag flagvariable -otherflag flagvar2All you have to do is edit the validflags line. It prepends a hyphen and searches all arguments. It then defines the next argument as the flag name e.g.
./myscript -flag flagvariable -otherflag flagvar2 echo $flag $otherflag flagvariable flagvar2The main code (short version, verbose with examples further down, also a version with erroring out):
#!/usr/bin/env bash #shebang.io validflags="rate time number" count=1 for arg in $@ do match=0 argval=$1 for flag in $validflags do sflag="-"$flag if [ "$argval" == "$sflag" ] then declare $flag=$2 match=1 fi done if [ "$match" == "1" ] then shift 2 else leftovers=$(echo $leftovers $argval) shift fi count=$(($count+1)) done #Cleanup then restore the leftovers shift $# set -- $leftoversThe verbose version with built in echo demos:
#!/usr/bin/env bash #shebang.io rate=30 time=30 number=30 echo "all args $@" validflags="rate time number" count=1 for arg in $@ do match=0 argval=$1 # argval=$(echo $@ | cut -d ' ' -f$count) for flag in $validflags do sflag="-"$flag if [ "$argval" == "$sflag" ] then declare $flag=$2 match=1 fi done if [ "$match" == "1" ] then shift 2 else leftovers=$(echo $leftovers $argval) shift fi count=$(($count+1)) done #Cleanup then restore the leftovers echo "pre final clear args: $@" shift $# echo "post final clear args: $@" set -- $leftovers echo "all post set args: $@" echo arg1: $1 arg2: $2 echo leftovers: $leftovers echo rate $rate time $time number $numberFinal one, this one errors out if an invalid -argument is passed through.
#!/usr/bin/env bash #shebang.io rate=30 time=30 number=30 validflags="rate time number" count=1 for arg in $@ do argval=$1 match=0 if [ "${argval:0:1}" == "-" ] then for flag in $validflags do sflag="-"$flag if [ "$argval" == "$sflag" ] then declare $flag=$2 match=1 fi done if [ "$match" == "0" ] then echo "Bad argument: $argval" exit 1 fi shift 2 else leftovers=$(echo $leftovers $argval) shift fi count=$(($count+1)) done #Cleanup then restore the leftovers shift $# set -- $leftovers echo rate $rate time $time number $number echo leftovers: $leftoversPros: What it does, it handles very well. It preserves unused arguments which a lot of the other solutions here don't. It also allows for variables to be called without being defined by hand in the script. It also allows prepopulation of variables if no corresponding argument is given. (See verbose example).
Cons: Can't parse a single complex arg string e.g. -xcvf would process as a single argument. You could somewhat easily write additional code into mine that adds this functionality though.
Daniel Bigham ,Aug 8, 2016 at 12:42
The top answer to this question seemed a bit buggy when I tried it -- here's my solution which I've found to be more robust:boolean_arg="" arg_with_value="" while [[ $# -gt 0 ]] do key="$1" case $key in -b|--boolean-arg) boolean_arg=true shift ;; -a|--arg-with-value) arg_with_value="$2" shift shift ;; -*) echo "Unknown option: $1" exit 1 ;; *) arg_num=$(( $arg_num + 1 )) case $arg_num in 1) first_normal_arg="$1" shift ;; 2) second_normal_arg="$1" shift ;; *) bad_args=TRUE esac ;; esac done # Handy to have this here when adding arguments to # see if they're working. Just edit the '0' to be '1'. if [[ 0 == 1 ]]; then echo "first_normal_arg: $first_normal_arg" echo "second_normal_arg: $second_normal_arg" echo "boolean_arg: $boolean_arg" echo "arg_with_value: $arg_with_value" exit 0 fi if [[ $bad_args == TRUE || $arg_num < 2 ]]; then echo "Usage: $(basename "$0") <first-normal-arg> <second-normal-arg> [--boolean-arg] [--arg-with-value VALUE]" exit 1 fiphyatt ,Sep 7, 2016 at 18:25
This example shows how to usegetoptandevalandHEREDOCandshiftto handle short and long parameters with and without a required value that follows. Also the switch/case statement is concise and easy to follow.#!/usr/bin/env bash # usage function function usage() { cat << HEREDOC Usage: $progname [--num NUM] [--time TIME_STR] [--verbose] [--dry-run] optional arguments: -h, --help show this help message and exit -n, --num NUM pass in a number -t, --time TIME_STR pass in a time string -v, --verbose increase the verbosity of the bash script --dry-run do a dry run, don't change any files HEREDOC } # initialize variables progname=$(basename $0) verbose=0 dryrun=0 num_str= time_str= # use getopt and store the output into $OPTS # note the use of -o for the short options, --long for the long name options # and a : for any option that takes a parameter OPTS=$(getopt -o "hn:t:v" --long "help,num:,time:,verbose,dry-run" -n "$progname" -- "$@") if [ $? != 0 ] ; then echo "Error in command line arguments." >&2 ; usage; exit 1 ; fi eval set -- "$OPTS" while true; do # uncomment the next line to see how shift is working # echo "\$1:\"$1\" \$2:\"$2\"" case "$1" in -h | --help ) usage; exit; ;; -n | --num ) num_str="$2"; shift 2 ;; -t | --time ) time_str="$2"; shift 2 ;; --dry-run ) dryrun=1; shift ;; -v | --verbose ) verbose=$((verbose + 1)); shift ;; -- ) shift; break ;; * ) break ;; esac done if (( $verbose > 0 )); then # print out all the parameters we read in cat <<-EOM num=$num_str time=$time_str verbose=$verbose dryrun=$dryrun EOM fi # The rest of your script belowThe most significant lines of the script above are these:
OPTS=$(getopt -o "hn:t:v" --long "help,num:,time:,verbose,dry-run" -n "$progname" -- "$@") if [ $? != 0 ] ; then echo "Error in command line arguments." >&2 ; exit 1 ; fi eval set -- "$OPTS" while true; do case "$1" in -h | --help ) usage; exit; ;; -n | --num ) num_str="$2"; shift 2 ;; -t | --time ) time_str="$2"; shift 2 ;; --dry-run ) dryrun=1; shift ;; -v | --verbose ) verbose=$((verbose + 1)); shift ;; -- ) shift; break ;; * ) break ;; esac doneShort, to the point, readable, and handles just about everything (IMHO).
Hope that helps someone.
Emeric Verschuur ,Feb 20, 2017 at 21:30
I have write a bash helper to write a nice bash toolproject home: https://gitlab.mbedsys.org/mbedsys/bashopts
example:
#!/bin/bash -ei # load the library . bashopts.sh # Enable backtrace dusplay on error trap 'bashopts_exit_handle' ERR # Initialize the library bashopts_setup -n "$0" -d "This is myapp tool description displayed on help message" -s "$HOME/.config/myapprc" # Declare the options bashopts_declare -n first_name -l first -o f -d "First name" -t string -i -s -r bashopts_declare -n last_name -l last -o l -d "Last name" -t string -i -s -r bashopts_declare -n display_name -l display-name -t string -d "Display name" -e "\$first_name \$last_name" bashopts_declare -n age -l number -d "Age" -t number bashopts_declare -n email_list -t string -m add -l email -d "Email adress" # Parse arguments bashopts_parse_args "$@" # Process argument bashopts_process_argswill give help:
NAME: ./example.sh - This is myapp tool description displayed on help message USAGE: [options and commands] [-- [extra args]] OPTIONS: -h,--help Display this help -n,--non-interactive true Non interactive mode - [$bashopts_non_interactive] (type:boolean, default:false) -f,--first "John" First name - [$first_name] (type:string, default:"") -l,--last "Smith" Last name - [$last_name] (type:string, default:"") --display-name "John Smith" Display name - [$display_name] (type:string, default:"$first_name $last_name") --number 0 Age - [$age] (type:number, default:0) --email Email adress - [$email_list] (type:string, default:"")enjoy :)
Josh Wulf ,Jun 24, 2017 at 18:07
I get this on Mac OS X: ``` lib/bashopts.sh: line 138: declare: -A: invalid option declare: usage: declare [-afFirtx] [-p] [name[=value] ...] Error in lib/bashopts.sh:138. 'declare -x -A bashopts_optprop_name' exited with status 2 Call tree: 1: lib/controller.sh:4 source(...) Exiting with status 1 ``` – Josh Wulf Jun 24 '17 at 18:07Josh Wulf ,Jun 24, 2017 at 18:17
You need Bash version 4 to use this. On Mac, the default version is 3. You can use home brew to install bash 4. – Josh Wulf Jun 24 '17 at 18:17a_z ,Mar 15, 2017 at 13:24
Here is my approach - using regexp.
- no getopts
- it handles block of short parameters
-qwerty- it handles short parameters
-q -w -e- it handles long options
--qwerty- you can pass attribute to short or long option (if you are using block of short options, attribute is attached to the last option)
- you can use spaces or
=to provide attributes, but attribute matches until encountering hyphen+space "delimiter", so in--q=qwe tyqwe tyis one attribute- it handles mix of all above so
-o a -op attr ibute --option=att ribu te --op-tion attribute --option att-ributeis validscript:
#!/usr/bin/env sh help_menu() { echo "Usage: ${0##*/} [-h][-l FILENAME][-d] Options: -h, --help display this help and exit -l, --logfile=FILENAME filename -d, --debug enable debug " } parse_options() { case $opt in h|help) help_menu exit ;; l|logfile) logfile=${attr} ;; d|debug) debug=true ;; *) echo "Unknown option: ${opt}\nRun ${0##*/} -h for help.">&2 exit 1 esac } options=$@ until [ "$options" = "" ]; do if [[ $options =~ (^ *(--([a-zA-Z0-9-]+)|-([a-zA-Z0-9-]+))(( |=)(([\_\.\?\/\\a-zA-Z0-9]?[ -]?[\_\.\?a-zA-Z0-9]+)+))?(.*)|(.+)) ]]; then if [[ ${BASH_REMATCH[3]} ]]; then # for --option[=][attribute] or --option[=][attribute] opt=${BASH_REMATCH[3]} attr=${BASH_REMATCH[7]} options=${BASH_REMATCH[9]} elif [[ ${BASH_REMATCH[4]} ]]; then # for block options -qwert[=][attribute] or single short option -a[=][attribute] pile=${BASH_REMATCH[4]} while (( ${#pile} > 1 )); do opt=${pile:0:1} attr="" pile=${pile/${pile:0:1}/} parse_options done opt=$pile attr=${BASH_REMATCH[7]} options=${BASH_REMATCH[9]} else # leftovers that don't match opt=${BASH_REMATCH[10]} options="" fi parse_options fi donemauron85 ,Jun 21, 2017 at 6:03
Like this one. Maybe just add -e param to echo with new line. – mauron85 Jun 21 '17 at 6:03John ,Oct 10, 2017 at 22:49
Assume we create a shell script namedtest_args.shas follow#!/bin/sh until [ $# -eq 0 ] do name=${1:1}; shift; if [[ -z "$1" || $1 == -* ]] ; then eval "export $name=true"; else eval "export $name=$1"; shift; fi done echo "year=$year month=$month day=$day flag=$flag"After we run the following command:
sh test_args.sh -year 2017 -flag -month 12 -day 22The output would be:
year=2017 month=12 day=22 flag=trueWill Barnwell ,Oct 10, 2017 at 23:57
This takes the same approach as Noah's answer , but has less safety checks / safeguards. This allows us to write arbitrary arguments into the script's environment and I'm pretty sure your use of eval here may allow command injection. – Will Barnwell Oct 10 '17 at 23:57Masadow ,Oct 6, 2015 at 8:53
Here is my improved solution of Bruno Bronosky's answer using variable arrays.it lets you mix parameters position and give you a parameter array preserving the order without the options
#!/bin/bash echo $@ PARAMS=() SOFT=0 SKIP=() for i in "$@" do case $i in -n=*|--skip=*) SKIP+=("${i#*=}") ;; -s|--soft) SOFT=1 ;; *) # unknown option PARAMS+=("$i") ;; esac done echo "SKIP = ${SKIP[@]}" echo "SOFT = $SOFT" echo "Parameters:" echo ${PARAMS[@]}Will output for example:
$ ./test.sh parameter -s somefile --skip=.c --skip=.obj parameter -s somefile --skip=.c --skip=.obj SKIP = .c .obj SOFT = 1 Parameters: parameter somefileJason S ,Dec 3, 2017 at 1:01
You use shift on the known arguments and not on the unknown ones so your remaining$@will be all but the first two arguments (in the order they are passed in), which could lead to some mistakes if you try to use$@later. You don't need the shift for the = parameters, since you're not handling spaces and you're getting the value with the substring removal#*=– Jason S Dec 3 '17 at 1:01Masadow ,Dec 5, 2017 at 9:17
You're right, in fact, since I build a PARAMS variable, I don't need to use shift at all – Masadow Dec 5 '17 at 9:17
Nov 01, 2017 | sanctum.geek.nz
A more flexible method for defining custom commands for an interactive shell (or within a script) is to use a shell function. We could declare our
llfunction in a Bash startup file as a function instead of an alias like so:# Shortcut to call ls(1) with the -l flag ll() { command ls -l "$@" }Note the use of the
commandbuiltin here to specify that thellfunction should invoke the program namedls, and not any function namedls. This is particularly important when writing a function wrapper around a command, to stop an infinite loop where the function calls itself indefinitely:# Always add -q to invocations of gdb(1) gdb() { command gdb -q "$@" }In both examples, note also the use of the
"$@"expansion, to add to the final command line any arguments given to the function. We wrap it in double quotes to stop spaces and other shell metacharacters in the arguments causing problems. This means that thellcommand will work correctly if you were to pass it further options and/or one or more directories as arguments:$ ll -a $ ll ~/.configShell functions declared in this way are specified by POSIX for Bourne-style shells, so they should work in your shell of choice, including Bash,
dash, Korn shell, and Zsh. They can also be used within scripts, allowing you to abstract away multiple instances of similar commands to improve the clarity of your script, in much the same way the basics of functions work in general-purpose programming languages.Functions are a good and portable way to approach adding features to your interactive shell; written carefully, they even allow you to port features you might like from other shells into your shell of choice. I'm fond of taking commands I like from Korn shell or Zsh and implementing them in Bash or POSIX shell functions, such as Zsh's
varedor its two-argumentcdfeatures.If you end up writing a lot of shell functions, you should consider putting them into separate configuration subfiles to keep your shell's primary startup file from becoming unmanageably large.
Examples from the authorYou can take a look at some of the shell functions I have defined here that are useful to me in general shell usage; a lot of these amount to implementing convenience features that I wish my shell had, especially for quick directory navigation, or adding options to commands:
Other examples Variables in shell functionsYou can manipulate variables within shell functions, too:
# Print the filename of a path, stripping off its leading path and # extension fn() { name=$1 name=${name##*/} name=${name%.*} printf '%s\n' "$name" }This works fine, but the catch is that after the function is done, the value for
namewill still be defined in the shell, and will overwrite whatever was in there previously:$ printf '%s\n' "$name" foobar $ fn /home/you/Task_List.doc Task_List $ printf '%s\n' "$name" Task_ListThis may be desirable if you actually want the function to change some aspect of your current shell session, such as managing variables or changing the working directory. If you don't want that, you will probably want to find some means of avoiding name collisions in your variables.
If your function is only for use with a shell that provides the
local(Bash) ortypeset(Ksh) features, you can declare the variable as local to the function to remove its global scope, to prevent this happening:# Bash-like fn() { local name name=$1 name=${name##*/} name=${name%.*} printf '%s\n' "$name" } # Ksh-like # Note different syntax for first line function fn { typeset name name=$1 name=${name##*/} name=${name%.*} printf '%s\n' "$name" }If you're using a shell that lacks these features, or you want to aim for POSIX compatibility, things are a little trickier, since local function variables aren't specified by the standard. One option is to use a subshell , so that the variables are only defined for the duration of the function:
# POSIX; note we're using plain parentheses rather than curly brackets, for # a subshell fn() ( name=$1 name=${name##*/} name=${name%.*} printf '%s\n' "$name" ) # POSIX; alternative approach using command substitution: fn() { printf '%s\n' "$( name=$1 name=${name##*/} name=${name%.*} printf %s "$name" )" }This subshell method also allows you to change directory with
cdwithin a function without changing the working directory of the user's interactive shell, or to change shell options withsetor Bash options withshoptonly temporarily for the purposes of the function.Another method to deal with variables is to manipulate the positional parameters directly (
$1,$2) withset, since they are local to the function call too:# POSIX; using positional parameters fn() { set -- "${1##*/}" set -- "${1%.*}" printf '%s\n' "$1" }These methods work well, and can sometimes even be combined, but they're awkward to write, and harder to read than the modern shell versions. If you only need your functions to work with your modern shell, I recommend just using
Keeping functions for laterlocalortypeset. The Bash Guide on Greg's Wiki has a very thorough breakdown of functions in Bash, if you want to read about this and other aspects of functions in more detail.As you get comfortable with defining and using functions during an interactive session, you might define them in ad-hoc ways on the command line for calling in a loop or some other similar circumstance, just to solve a task in that moment.
As an example, I recently made an ad-hoc function called
monitto run a set of commands for its hostname argument that together established different types of monitoring system checks, using an existing script callednmfs:$ monit() { nmfs "$1" Ping Y ; nmfs "$1" HTTP Y ; nmfs "$1" SNMP Y ; } $ for host in webhost{1..10} ; do > monit "$host" > doneAfter that task was done, I realized I was likely to use the
monitcommand interactively again, so I decided to keep it. Shell functions only last as long as the current shell, so if you want to make them permanent, you need to store their definitions somewhere in your startup files. If you're using Bash, and you're content to just add things to the end of your~/.bashrcfile, you could just do something like this:$ declare -f monit >> ~/.bashrcThat would append the existing definition of
monitin parseable form to your~/.bashrcfile, and themonitfunction would then be loaded and available to you for future interactive sessions. Later on, I ended up convertingmonitinto a shell script, as its use wasn't limited to just an interactive shell.If you want a more robust approach to keeping functions like this for Bash permanently, I wrote a tool called Bashkeep , which allows you to quickly store functions and variables defined in your current shell into separate and appropriately-named files, including viewing and managing the list of names conveniently:
$ keep monit $ keep monit $ ls ~/.bashkeep.d monit.bash $ keep -d monit
Oct 28, 2013 | sanctum.geek.nz
In Bash scripting (and shell scripting in general), we often want to check the exit value of a command to decide an action to take after it completes, likely for the purpose of error handling. For example, to determine whether a particular regular expression
regexwas present somewhere in a fileoptions, we might applygrep(1)with its POSIX-qoption to suppress output and just use the exit value:grep -q regex optionsAn approach sometimes taken is then to test the exit value with the
$?parameter, usingifto check if it's non-zero, which is not very elegant and a bit hard to read:# Bad practice grep -q regex options if (($? > 0)); then printf '%s\n' 'myscript: Pattern not found!' >&2 exit 1 fiBecause the
ifconstruct by design tests the exit value of commands , it's better to test the command directly , making the expansion of$?unnecessary:# Better if grep -q regex options; then # Do nothing : else printf '%s\n' 'myscript: Pattern not found!\n' >&2 exit 1 fiWe can precede the command to be tested with
!to negate the test as well, to prevent us having to useelseas well:# Best if ! grep -q regex options; then printf '%s\n' 'myscript: Pattern not found!' >&2 exit 1 fiAn alternative syntax is to use
&&and||to performifandelsetests with grouped commands between braces, but these tend to be harder to read:# Alternative grep -q regex options || { printf '%s\n' 'myscript: Pattern not found!' >&2 exit 1 }With this syntax, the two commands in the block are only executed if the
grep(1)call exits with a non-zero status. We can apply&&instead to execute commands if it does exit with zero.That syntax can be convenient for quickly short-circuiting failures in scripts, for example due to nonexistent commands, particularly if the command being tested already outputs its own error message. This therefore cuts the script off if the given command fails, likely due to
ffmpeg(1)being unavailable on the system:hash ffmpeg || exit 1Note that the braces for a grouped command are not needed here, as there's only one command to be run in case of failure, the
exitcall.Calls to
cdare another good use case here, as running a script in the wrong directory if a call tocdfails could have really nasty effects:cd wherever || exit 1In general, you'll probably only want to test
$?when you have specific non-zero error conditions to catch. For example, if we were using the--max-deleteoption forrsync(1), we could check a call's return value to see whetherrsync(1)hit the threshold for deleted file count and write a message to a logfile appropriately:rsync --archive --delete --max-delete=5 source destination if (($? == 25)); then printf '%s\n' 'Deletion limit was reached' >"$logfile" fiIt may be tempting to use the
errexitfeature in the hopes of stopping a script as soon as it encounters any error, but there are some problems with its usage that make it a bit error-prone. It's generally more straightforward to simply write your own error handling using the methods above.For a really thorough breakdown of dealing with conditionals in Bash, take a look at the relevant chapter of the Bash Guide .
Jul 25, 2017 | wiki.bash-hackers.org
Intro The day will come when you want to give arguments to your scripts. These arguments are known as positional parameters . Some relevant special parameters are described below:
Parameter(s) Description $0the first positional parameter, equivalent to argv[0]in C, see the first argument$FUNCNAMEthe function name ( attention : inside a function, $0is still the$0of the shell, not the function name)$1 $9the argument list elements from 1 to 9 ${10} ${N}the argument list elements beyond 9 (note the parameter expansion syntax!) $*all positional parameters except $0, see mass usage$@all positional parameters except $0, see mass usage$#the number of arguments, not counting $0These positional parameters reflect exactly what was given to the script when it was called.
Option-switch parsing (e.g.
-hfor displaying help) is not performed at this point.See also the dictionary entry for "parameter" . The first argument The very first argument you can access is referenced as
$0. It is usually set to the script's name exactly as called, and it's set on shell initialization:Testscript - it just echos
$0:#!/bin/bash echo "$0"You see,$0is always set to the name the script is called with ($is the prompt ):> ./testscript ./testscript> /usr/bin/testscript /usr/bin/testscriptHowever, this isn't true for login shells:
> echo "$0" -bashIn other terms,
$0is not a positional parameter, it's a special parameter independent from the positional parameter list. It can be set to anything. In the ideal case it's the pathname of the script, but since this gets set on invocation, the invoking program can easily influence it (theloginprogram does that for login shells, by prefixing a dash, for example).Inside a function,
$0still behaves as described above. To get the function name, use$FUNCNAME. Shifting The builtin commandshiftis used to change the positional parameter values:
$1will be discarded$2will become$1$3will become$2- in general:
$Nwill become$N-1The command can take a number as argument: Number of positions to shift. e.g.
shift 4shifts$5to$1. Using them Enough theory, you want to access your script-arguments. Well, here we go. One by one One way is to access specific parameters:#!/bin/bash echo "Total number of arguments: $#" echo "Argument 1: $1" echo "Argument 2: $2" echo "Argument 3: $3" echo "Argument 4: $4" echo "Argument 5: $5"While useful in another situation, this way is lacks flexibility. The maximum number of arguments is a fixedvalue - which is a bad idea if you write a script that takes many filenames as arguments.
⇒ forget that one Loops There are several ways to loop through the positional parameters.
You can code a C-style for-loop using
$#as the end value. On every iteration, theshift-command is used to shift the argument list:numargs=$# for ((i=1 ; i <= numargs ; i++)) do echo "$1" shift doneNot very stylish, but usable. The
numargsvariable is used to store the initial value of$#because the shift command will change it as the script runs.
Another way to iterate one argument at a time is the
forloop without a given wordlist. The loop uses the positional parameters as a wordlist:for arg do echo "$arg" doneAdvantage: The positional parameters will be preserved
The next method is similar to the first example (the
forloop), but it doesn't test for reaching$#. It shifts and checks if$1still expands to something, using the test command :while [ "$1" ] do echo "$1" shift doneLooks nice, but has the disadvantage of stopping when
$1is empty (null-string). Let's modify it to run as long as$1is defined (but may be null), using parameter expansion for an alternate value :while [ "${1+defined}" ]; do echo "$1" shift doneGetopts There is a small tutorial dedicated to ''getopts'' ( under construction ). Mass usage All Positional Parameters Sometimes it's necessary to just "relay" or "pass" given arguments to another program. It's very inefficient to do that in one of these loops, as you will destroy integrity, most likely (spaces!).
The shell developers created
$*and$@for this purpose.As overview:
Syntax Effective result $*$1 $2 $3 ${N}$@$1 $2 $3 ${N}"$*""$1c$2c$3c c${N}""$@""$1" "$2" "$3" "${N}"Without being quoted (double quotes), both have the same effect: All positional parameters from
$1to the last one used are expanded without any special handling.When the
$*special parameter is double quoted, it expands to the equivalent of:"$1c$2c$3c$4c ..$N", where 'c' is the first character ofIFS.But when the
$@special parameter is used inside double quotes, it expands to the equivanent of
"$1" "$2" "$3" "$4" .. "$N"which reflects all positional parameters as they were set initially and passed to the script or function. If you want to re-use your positional parameters to call another program (for example in a wrapper-script), then this is the choice for you, use double quoted
"$@".Well, let's just say: You almost always want a quoted
"$@"! Range Of Positional Parameters Another way to mass expand the positional parameters is similar to what is possible for a range of characters using substring expansion on normal parameters and the mass expansion range of arrays .
${@:START:COUNT}
${*:START:COUNT}
"${@:START:COUNT}"
"${*:START:COUNT}"The rules for using
@or*and quoting are the same as above. This will expandCOUNTnumber of positional parameters beginning atSTART.COUNTcan be omitted (${@:START}), in which case, all positional parameters beginning atSTARTare expanded.If
STARTis negative, the positional parameters are numbered in reverse starting with the last one.
COUNTmay not be negative, i.e. the element count may not be decremented.Example: START at the last positional parameter:
echo "${@: -1}"Attention : As of Bash 4, a
STARTof0includes the special parameter$0, i.e. the shell name or whatever $0 is set to, when the positional parameters are in use. ASTARTof1begins at$1. In Bash 3 and older, both0and1began at$1. Setting Positional Parameters Setting positional parameters with command line arguments, is not the only way to set them. The builtin command, set may be used to "artificially" change the positional parameters from inside the script or function:set "This is" my new "set of" positional parameters # RESULTS IN # $1: This is # $2: my # $3: new # $4: set of # $5: positional # $6: parametersIt's wise to signal "end of options" when setting positional parameters this way. If not, the dashes might be interpreted as an option switch by
setitself:# both ways work, but behave differently. See the article about the set command! set -- ... set - ...Alternately this will also preserve any verbose (-v) or tracing (-x) flags, which may otherwise be reset by
setset -$- ...Production examples Using a while loop To make your program accept options as standard command syntax:
COMMAND [options] <params># Like 'cat -A file.txt'See simple option parsing code below. It's not that flexible. It doesn't auto-interpret combined options (-fu USER) but it works and is a good rudimentary way to parse your arguments.
#!/bin/sh # Keeping options in alphabetical order makes it easy to add more. while : do case "$1" in -f | --file) file="$2" # You may want to check validity of $2 shift 2 ;; -h | --help) display_help # Call your function # no shifting needed here, we're done. exit 0 ;; -u | --user) username="$2" # You may want to check validity of $2 shift 2 ;; -v | --verbose) # It's better to assign a string, than a number like "verbose=1" # because if you're debugging the script with "bash -x" code like this: # # if [ "$verbose" ] ... # # You will see: # # if [ "verbose" ] ... # # Instead of cryptic # # if [ "1" ] ... # verbose="verbose" shift ;; --) # End of all options shift break; -*) echo "Error: Unknown option: $1" >&2 exit 1 ;; *) # No more options break ;; esac done # End of fileFilter unwanted options with a wrapper script This simple wrapper enables filtering unwanted options (here:
-aand–allforls) out of the command line. It reads the positional parameters and builds a filtered array consisting of them, then callslswith the new option set. It also respects the–as "end of options" forlsand doesn't change anything after it:#!/bin/bash # simple ls(1) wrapper that doesn't allow the -a option options=() # the buffer array for the parameters eoo=0 # end of options reached while [[ $1 ]] do if ! ((eoo)); then case "$1" in -a) shift ;; --all) shift ;; -[^-]*a*|-a?*) options+=("${1//a}") shift ;; --) eoo=1 options+=("$1") shift ;; *) options+=("$1") shift ;; esac else options+=("$1") # Another (worse) way of doing the same thing: # options=("${options[@]}" "$1") shift fi done /bin/ls "${options[@]}"Using getopts There is a small tutorial dedicated to ''getopts'' ( under construction ). See also
Discussion 2010/04/14 14:20
- Internal: Small getopts tutorial
- Internal: The while-loop
- Internal: The C-style for-loop
- Internal: Arrays (for equivalent syntax for mass-expansion)
- Internal: Substring expansion on a parameter (for equivalent syntax for mass-expansion)
- Dictionary, internal: Parameter
The shell-developers invented $* and $@ for this purpose.Without being quoted (double-quoted), both have the same effect: All positional parameters from $1 to the last used one >are expanded, separated by the first character of IFS (represented by "c" here, but usually a space):
$1c$2c$3c$4c........$NWithout double quotes, $* and $@ are expanding the positional parameters separated by only space, not by IFS.
#!/bin/bash export IFS='-' echo -e $* echo -e $@$./test "This is" 2 3 This is 2 3 This is 2 32011/02/18 16:11 #!/bin/bashOLDIFS="$IFS" IFS='-' #export IFS='-'
#echo -e $* #echo -e $@ #should be echo -e "$*" echo -e "$@" IFS="$OLDIFS"
2011/02/18 16:14 #should be echo -e "$*"2012/04/20 10:32 Here's yet another non-getopts way.
http://bsdpants.blogspot.de/2007/02/option-ize-your-shell-scripts.html
2012/07/16 14:48 Hi there!What if I use "$@" in subsequent function calls, but arguments are strings?
I mean, having:
#!/bin/bash echo "$@" echo n: $#If you use it
mypc$ script arg1 arg2 "asd asd" arg4 arg1 arg2 asd asd arg4 n: 4But having
#!/bin/bash myfunc() { echo "$@" echo n: $# } echo "$@" echo n: $# myfunc "$@"you get:
mypc$ myscrpt arg1 arg2 "asd asd" arg4 arg1 arg2 asd asd arg4 4 arg1 arg2 asd asd arg4 5As you can see, there is no way to make know the function that a parameter is a string and not a space separated list of arguments.
Any idea of how to solve it? I've test calling functions and doing expansion in almost all ways with no results.
2012/08/12 09:11 I don't know why it fails for you. It should work if you use
"$@", of course.See the example I used your second script with:
$ ./args1 a b c "d e" f a b c d e f n: 5 a b c d e f n: 5
# Append to .bashrc or call it from there.
# Save some typing at the command line :)
# longlist a directory, by page # lo [directoryname] lo () { if [ -d "$1" ] ; then ls -al "$1" | less else ls -al $(pwd) | less fi }# Same as above but recursivelro () { if [ -d "$1" ] ; then ls -alR "$1" | less else ls -alR $(pwd) | less fi } export -f lo lro
BigAdmin
Here is a simple way to create a script that will behave both as an executable script and as a ksh function. Being an executable script means the script can be run from any shell. Being a ksh function means the script can be optimized to run faster if launched from a ksh shell. This is an attempt to get the best of both worlds.
Procedure
Start by writing a ksh function. A ksh function is just like a ksh script except the script code is enclosed within a
function name { script }construct.Take the following example:
# Example script function fun { print "pid=$$ cmd=$0 args=$*" opts="$-" }Save the text in a file. You'll notice nothing happens if you try to execute the code as a script:
ksh ./exampleIn order to use a function, the file must first be sourced. Sourcing the file will create the function definition in the current shell. After the function has been sourced, it can then be executed when you call it by name:
.. ./example funTo make the function execute as a script, the function must be called within the file. Add the bold text to the example function.
# Example script function fun { print "pid=$$ cmd=$0 args=$*" opts="$-" } fun $*Now you have a file that executes like a ksh script and sources like a ksh function. One caveat is that the file now executes while it is being sourced.
There are advantages and disadvantages to how the code is executed. If the file was executed as a script, the system spawns a child ksh process, loads the function definition, and then executes the function. If the file was sourced, no child process is created, the function definition is loaded into the current shell process, and the function is then executed.
Sourcing the file will make it run faster because no extra processes are created, however, loading a function occupies environment memory space. Functions can also manipulate environment variables whereas a script only gets a copy to work with. In programming terms, a function can use call by reference parameters via shell variables. A shell script is always call by value via arguments.
Advanced Information
When working with functions, it's advantageous to use ksh autoloading. Autoloading eliminates the need to source a file before executing the function. This is accomplished by saving the file with the same name as the function. In the above example, save the example as the file name "
fun". Then set theFPATHenvironment variable to the directory where the filefunis. Now, all that needs to be done is type "fun" on the command line to execute the function.Notice the double output the first time
funis called. This is because the first time the function is called, the file must be sourced, and in sourcing the file, the function gets called. What we need is to only call the function when the file is executed as a script, but skip calling the function if the file is sourced. To accomplish this, notice the output of the script when executing it as opposed to sourcing it. When the file is sourced,arg0is always-ksh. Also, note the difference inoptswhen the script is sourced. Test the output ofarg0to determine if the function should be called or not. Also, make the file a self-executing script. After all, no one likes having to type "ksh" before running every ksh script.[[ "${0##*/}" == "fun" ]] && fun $* Now the file is a self-executing script as well as a self-sourcing function (when used with ksh autoloading). What becomes more interesting is that since the file can be an autoload function as well as a stand-alone script, it could be placed in a single directory and have both
PATHandFPATHpoint to it.# ${HOME}/.profile FPATH=${HOME}/bin PATH=${FPATH}:${PATH}In this setup,
funwill always be called as a function unless it's explicitly called as${HOME}/bin/fun.Considerations
Even though the file can be executed as a function or a script, there are minor differences in behavior between the two. When the file is sourced as a function, all local environment variables will be visible to the script. If the file is executed as a script, only exported environment variables will be visible. Also, when sourced, a function can modify all environment variables. When the file is executed, all visible environment variables are only copies. We may want to make special allowances depending on how the file is called. Take the following example.
#!/bin/ksh # Add arg2 to the contents of arg1 function addTo { eval $1=$(($1 + $2)) } if [[ "${0##*/}" == "addTo" ]]; then addTo $* eval print \$$1 fiThe script is called by naming an environment variable and a quantity to add to that variable. When sourced, the script will directly modify the environment variable with the new value. However, when executed as a script, the environment variable cannot be modified, so the result must be output instead. Here is a sample run of both situations.
# called as a function var=5 addTo var 3 print $var # called as a script var=5 export var var=$(./addTo var 3) print $varNote the extra steps needed when executing this example as a script. The
varmust be exported prior to running the script or else it won't be visible. Also, because a script can't manipulate the current environment, you must capture the new result.Extra
function-alityIt's possible to package several functions into a single file. This is nice for distribution as you only need to maintain a single file. In order to maintain autoloading functionality, all that needs to be done is create a link for each function named in the file.
#!/bin/ksh function addTo { eval $1=$(($1 + $2)) } function multiplyBy { eval $1=$(($1 * $2)) } if [[ "${0##*/}" == "addTo" ]] \ || [[ "${0##*/}" == "multiplyBy" ]]; then ${0##*/} $* eval print \$$1 fi if [[ ! -f "${0%/*}/addTo" ]] \ || [[ ! -f "${0%/*}/multiplyBy" ]]; then ln "${0}" "${0%/*}/addTo" ln "${0}" "${0%/*}/multiplyBy" chmod u+rx "${0}" fiNotice the extra code at the bottom. This text could be saved in a file named
myDist. The first time the file is sourced or executed, the appropriate links and file permissions will be put in place, thus creating a single distribution for multiple functions. Couple that with making the file a script executable and you end up with a single distribution of multiple scripts. It's like a shar file, but nothing actually gets unpacked.The only downside to this distribution tactic is that BigAdmin will only credit you for each file submission, not based on the actual number of executable programs...
Time to Run
Try some of the sample code in this document. Get comfortable with the usage of each snippet to understand the differences and limitations. In general, it's safest to always distribute a script, but it's nice to have a function when speed is a consideration. Do some timing tests.
export var=8 time ./addTo var 5 time addTo var 5If this code were part of an inner-loop calculation of a larger script, that speed difference could be significant.
This document aims to provide the best of both worlds. You can have a script and retain function speed for when it's needed. I hope you have enjoyed this document and its content. Thanks to Sun and BigAdmin for the hosting and support to make contributions like this possible.
Google matched content |
This package is an attempt to make GNU
basha viable solution for medium sized scripts. A problem with bash is that it doesn't provide encapsulation of any sort, beside the feature of providing functions. This problem is partly solved by writing subscripts and invoking them in the main script, but this is not always the best solution.A set of modules implementing common operations and a script template are provided by this package and the author has used them with success in implementing non-small scripts.
The philosophy of MBFL is to do the work as much as possible without external commands. For example: string manipulation is done using the special variable substitution provided by
bash, and no use is done of utilities likesed,grepanded.The library is better used if our script is developed on the template provided in the package (
examples/template.sh). This is because with MBFL some choices have been made to reduce the application dependent part of the script to the smallest dimension; if we follow another schema, MBFL modules may be indequate. This is especially true for the options parsing module.The best way to use the library is to include at runtime the library file
libmbfl.shi; this is possible by installing MBFL on the system and using this code in the scripts:mbfl_INTERACTIVE='no' source "${MBFL_LIBRARY:=`mbfl-config`}"after the service variables have been declared (Service Variables for details). This code will read the full pathname of the library from the environment variable
MBFL_LIBRARY; if this variable is not set: the scriptmbfl-configis invoked with no arguments to acquire the pathname of the library.mbfl-configis installed in thebindirectory with the library.Another solution is to include the library directly in the script; this is easy if we preprocess our scripts with GNU
m4:m4_changequote([[, ]]) m4_include(libmbfl.sh)is all we need to do. We can preprocess the script with:
$ m4 --prefix-builtins --include=/path/to/library \ script.sh.m4 >script.sheasy to do in a
Makefile; we can take the MBFL'sMakefileas example of this method.It is also interesting to process the script with the following rule:
M4 = ... M4FLAGS = --prefix-builtins --include=/path/to/library %.sh: %.sh.m4 $(M4) $(M4FLAGS) $(<) | \ grep --invert-match -e '^#' -e '^$$' | \ sed -e "s/^ \\+//" >$(@)this will remove all the comments and blank lines, decreasing the size of the script significantly if one makes use of verbose comments; note that this will wipe out the
#!/bin/bashfirst line also.Usually we want the script to begin with
#!/bin/bashfollowed by a comment describing the license terms.
Encoding and decoding strings
The purpose of this module is to let an external process invoke a bash script with
damncommand line arguments: strings including blanks or strange characters that may trigger
quoting rules.
This problem can arise when using scripting languages with some sort of eval command.
The solution is to encode the argument string in hexadecimal or octal format strings, so that all
the damn characters are converted to "good" ones. The the bash script can convert them
back.
| mbfl_decode_hex string | Function |
| Decodes a hex string and outputs it on stdout. |
| mbfl_decode_oct string | Function |
| Decodes a oct string and outputs it on stdout. |
Example:
mbfl_decode_hex 414243 -> ABC
| mbfl_file_extension pathname | Function |
Extracts the extension from a file name. Searches the last dot (.) character
in the argument string and echoes to stdout the range of characters from the dot to the end, not
including the dot. If a slash (/) character is found first, echoes to stdout the
empty string. |
| mbfl_file_dirname pathname | Function |
| Extracts the directory part from a fully qualified file name. Searches the last slash character
in the input string and echoes to stdout the range of characters from the first to the slash,
not including the slash.
If no slash is found: echoes a single dot (the current directory). If the input string begins with |
| mbfl_file_rootname pathname | Function |
| Extracts the root portion of a file name. Searches the last dot character in the argument
string and echoes to stdout the range of characters from the beginning to the dot, not including
the dot.
If a slash character is found first, or no dot is found, or the dot is the first character, echoes to stdout the empty string. |
| mbfl_file_tail pathnbame | Function |
| Extracts the file portion from a fully qualified file name. Searches the last slash character in the input string and echoes to stdout the range of characters from the slash to the end, not including the slash. If no slash is found: echoes the whole string. |
| mbfl_file_split pathname | Function |
Separates a file name into its components. One or more contiguous occurrences of the slash
character are used as separator. The components are stored in an array named SPLITPATH,
that may be declared local in the scope of the caller; the base index is zero. The
number of elements in the array is stored in a variable named SPLITCOUNT. Returns
true. |
| mbfl_file_normalise pathname ?prefix? | Function |
Normalises a file name: removes all the occurrences of . and ...
If pathname is relative (according to If prefix is present and non empty, and pathname is relative (according
to Echoes to stdout the normalised file name; returns true. |
| mbfl_file_is_absolute pathname | Function |
Returns true if the first character in pathname is a slash (/); else
returns false. |
| mbfl_file_is_absolute_dirname pathname | Function |
Returns true if pathname is a directory according to mbfl_file_is_directory
and an absolute pathname according to mbfl_file_is_absolute. |
| mbfl_file_is_absolute_filename pathname | Function |
Returns true if pathname is a file according to mbfl_file_is_file
and an absolute pathname according to mbfl_file_is_absolute. |
| mbfl_file_find_tmpdir ?PATHNAME? | Function |
Finds a value for a temporary directory. If PATHNAME is not null and is a directory
and is writable it is accepted; else the value /tmp/$USER, where USER
is the environment variable, is tried; finally the value /tmp is tried. When a value
is accepted it's echoed to stdout. Returns true if a value is found, false otherwise. |
| mbfl_file_enable_listing | Function |
Declares to the program module the commands required to retrieve informations about files
and directories (Program Declaring). The programs are:
ls. |
| mbfl_file_get_owner pathname | Function |
| Prints the owner of the file. |
| mbfl_file_get_group pathname | Function |
| Prints the group of the file. |
| mbfl_file_get_size pathname | Function |
| Prints the size of the file. |
| mbfl_file_normalise_link pathname | Function |
Makes use of the readlink to normalise the pathname of a symbolic link (remember
that a symbolic link references a file, never a directory). Echoes to stdout the normalised pathname.
The command line of readlink -fn $pathname |
| mbfl_file_enable_make_directory | Function |
Declares to the program module the commands required to create directories (Program
Declaring). The programs are: mkdir. |
| mbfl_file_make_directory pathname ?permissions? | Function |
| Creates a directory named pathname; all the unexistent parents are created, too. If permissions is present: it is the specification of directory permissions in octal mode. |
| mbfl_file_enable_copy | Function |
Declares to the program module the commands required to copy files and directories (Program
Declaring). The programs are: cp. |
| mbfl_file_copy source target ?...? | Function |
| Copies the source, a file, to target, a file pathname. Additional arguments
are handed to the command unchanged.
If source does not exist, or if it is not a file, an error is generated and the return value is 1. No test is done upon target. |
| mbfl_file_copy_recursively source target ?...? | Function |
Copies the source, a directory, to target, a directory pathname. Additional
arguments are handed to the command unchanged. This function is like mbfl_file_copy,
but it adds --recursive to the command line of cp.
If source does not exist, or if it is not a file, an error is generated and the return value is 1. No test is done upon target. |
Files removal is forced: the --force option to rm is always used. It is
responsibility of the caller to validate the operation before invoking these functions.
Some functions test the existence of the pathname before attempting to remove it: this is done only if test execution is disabled; if test execution is enabled the command line is echoed to stderr to make it easier to debug scripts.
| mbfl_file_enable_remove | Function |
Declares to the program module the commands required to remove files and directories (Program
Declaring). The programs are: rm and rmdir. |
| mbfl_file_remove pathname | Function |
| Removes pathname, no matter if it is a file or directory. If it is a directory: descends the sublevels removing all of them. If an error occurs returns 1. |
| mbfl_file_remove_file pathname | Function |
| Removes the file selected by pathname. If the file does not exist or it is not a file or an error occurs: returns 1. |
| mbfl_file_remove_directory pathname | Function |
| Removes the directory selected by pathname. If the directory does not exist or an error occurs: returns 1. |
Remember that when we execute a script with the --test option: the external commands
are not executed: a command line is echoed to stdout. It is recommended to use this mode to fine tune
the command line options required by tar.
| mbfl_file_enable_tar | Function |
Declares to the program module the tar command (Program
Declaring). |
| mbfl_tar_exec ?...? | Function |
Executes tar with whatever arguments are used. Returns the return code of
tar. |
| mbfl_tar_create_to_stdout directory ?...? | Function |
Creates an archive and sends it to stdout. The root of the archive is the directory.
Files are selected with the . pattern. tar flags may be appended to
the invocation to this function. In case of error returns 1. |
| mbfl_tar_extract_from_stdin directory ?...? | Function |
Reads an archive from stdin and extracts it under directory. tar flags
may be appended to the invocation to this function. In case of error returns 1. |
| mbfl_tar_extract_from_file directory archive ?...? | Function |
Reads an archive from a file and extracts it under directory. tar
flags may be appended to the invocation to this function. In case of error returns 1. |
| mbfl_tar_create_to_file directory archive ?...? | Function |
Creates an archive named archive holding the contents of directory.
Before creating the archive, the process changes the current directory to directory
and selects the files with the pattern .. tar flags may be appended
to the invocation to this function. In case of error returns 1. |
| mbfl_tar_archive_directory_to_file directory archive ?...? | Function |
Like mbfl_tar_create_to_file but archives all the contents of directory,
including the directory itself (not its parents). |
| mbfl_tar_list archive ?...? | Function |
Prints to stdout the list of files in archive. tar flags may be appended
to the invocation to this function. In case of error returns 1. |
| mbfl_file_is_file filename | Function |
| Returns true if filename is not the empty string and is a file. |
| mbfl_file_is_readable filename | Function |
| Returns true if filename is not the empty string, is a file and is readable. |
| mbfl_file_is_writable filename | Function |
| Returns true if filename is not the empty string, is a file and is writable. |
| mbfl_file_is_directory directory | Function |
| Returns true if directory is not the empty string and is a directory. |
| mbfl_file_directory_is_readable directory | Function |
| Returns true if directory is not the empty string, is a directory and is readable. |
| mbfl_file_directory_is_writable directory | Function |
| Returns true if directory is not the empty string, is a directory and is writable. |
| mbfl_file_is_symlink pathname | Function |
| Returns true if pathname is not the empty string and is a symbolic link. |
| mbfl_cd dirname ?...? | Function |
Changes directory to dirname. Optional flags to cd may be appended.
|
The getopt module defines a set of procedures to be used to process command line arguments with the following format:
-a a with no value; -a123 a with value 123; --bianco bianco with no value; --color=bianco color with value bianco. Requires the message module (Message for details).
The module contains, at the root level, a block of code like the following:
ARGC=0
declare -a ARGV ARGV1
for ((ARGC1=0; $# > 0; ++ARGC1)); do
ARGV1[$ARGC1]="$1"
shift
done
this block is executed when the script is evaluated. Its purpose is to store command line arguments
in the global array ARGV1 and the number of command line arguments in the global variable
ARGC1.
The global array ARGV and the global variable ARGC are predefined and should
be used by the mbfl_getopts functions to store non-option command line arguments.
Example:
$ script --gulp wo --gasp=123 wa
if the script makes use of the library, the strings wo and wa will go into
ARGV and ARGC will be set to 2. The option arguments are processed and some
action is performed to register them.
We can access the non-option arguments with the following code:
for ((i=0; $i < $ARGC; ++i)); do
# do something with ${ARGV[$i]}
done
To use this module we have to declare a set of script options; we declare a new script option with
the function mbfl_declare_option. Options declaration should be done at the beginning of
the script, before doing anything; for example: right after the MBFL library code.
In the main block of the script: options are parsed by invoking mbfl_getopts_parse:
this function will update a global variable and invoke a script function for each option on the command
line.
Example of option declaration:
mbfl_declare_option ALPHA no a alpha noarg "enable alpha option"
this code declares an option with no argument and properties:
script_option_ALPHA, which will be set to no by default
and to yes if the option is used; -a; --alpha; enable alpha option, to be shown in the usage output. If the option is used: the function script_option_update_alpha is invoked (if it exists)
with no arguments, after the variable script_option_ALPHA has been set to yes.
Valid option usages are:
$ script.sh -a $ script.sh --alpha
Another example:
mbfl_declare_option BETA 123 b beta witharg "select beta value"
this code declares an option with argument and properties:
script_option_BETA, which will be set to 123 by default
and to the value selected on the command line if the option is used; -b; --beta; select beta value, to be shown in the usage output. If the option is used: the function script_option_update_beta is invoked (if it exists)
with no arguments, after the variable script_option_BETA has been set to the selected value.
Valid option usages are:
$ script.sh -b456 $ script.sh --beta=456
A set of predefined options is recognised by the library and not handed to the user defined functions.
--encoded-args If this option is used: the values are decoded by mbfl_getopts_parse before storing
them in the ARGV array and before being stored in the option's specific global variables.
-v --verbose mbfl_option_verbose returns true (Message,
for details). --silent mbfl_option_verbose returns false. --verbose-program --verbose option is added to the command line of external programs that
support it. The fuction mbfl_option_verbose_program returns true or false depending
on the state of this option. --show-program --debug --test --null mbfl_option_NULL is set to yes. -f --force mbfl_option_INTERACTIVE is set to
no. -i --interactive mbfl_option_INTERACTIVE is set to
yes. --validate-programs --version mbfl_message_VERSION,
then exits with code zero. The variable makes use of the service variables (Service
Variables, for details). --version-only script_VERSION,
then exits with code zero. --license
mbfl_message_LICENSE_*, then exits with code zero. The variable makes use of the service variables
(Service Variables, for details). -h --help --usage script_USAGE;
a newline; the string options:; a newline; an automatically generated string describing
the options declared with mbfl_declare_option; a string describing the MBFL
default options. Then exits with code zero. The following options may be used to set, unset and query the state of the predefined options.
| mbfl_option_encoded_args | Function |
| mbfl_set_option_encoded_args | Function |
| mbfl_unset_option_encoded_args | Function |
| Query/sets/unsets the encoded arguments option. |
| mbfl_option_encoded_args | Function |
| mbfl_set_option_encoded_args | Function |
| mbfl_unset_option_encoded_args | Function |
| Query/sets/unsets the verbose messages option. |
| mbfl_option_verbose_program | Function |
| mbfl_set_option_verbose_program | Function |
| mbfl_unset_option_verbose_program | Function |
| Query/sets/unsets verbose execution for external programs.
This option, of course, is supported only for programs that are known by MBFL
(like |
| mbfl_option_show_program | Function |
| mbfl_set_option_show_program | Function |
| mbfl_unset_option_show_program | Function |
| Prints the command line of executed external program. This does not disable program execution, it just prints the command line before executing it. |
| mbfl_option_test | Function |
| mbfl_set_option_test | Function |
| mbfl_unset_option_test | Function |
| Query/sets/unsets the test execution option. |
| mbfl_option_debug | Function |
| mbfl_set_option_debug | Function |
| mbfl_unset_option_debug | Function |
| Query/sets/unsets the debug messages option. |
| mbfl_option_null | Function |
| mbfl_set_option_null | Function |
| mbfl_unset_option_null | Function |
| Query/sets/unsets the null list separator option. |
| mbfl_option_interactive | Function |
| mbfl_set_option_interactive | Function |
| mbfl_unset_option_interactive | Function |
| Query/sets/unsets the interactive excution option. |
| mbfl_declare_option keyword default brief long hasarg description | Function |
Declares a new option. Arguments description follows.
|
| mbfl_getopts_parse | Function |
Parses a set of command line options. The options are handed to user defined functions. The
global array ARGV1 and the global variable ARGC1 are supposed to hold
the command line arguments and the number of command line arguments. Non-option arguments are
left in the global array ARGV, the global variable ARGC holds the number
of elements in ARGV. |
| mbfl_getopts_islong string varname | Function |
| Verifies if a string is a long option without argument. string is the string to
validate, varname is the optional name of a variable that's set to the option name,
without the leading dashes.
Returns with code zero if the string is a long option without argument, else returns with code one. An option must be of the form |
| mbfl_getopts_islong_with string optname varname | Function |
Verifies if a string is a long option with argument. Arguments:
Returns with code zero if the string is a long option with argument, else returns with code one. An option must be of the form If the argument is not an option with value, the variable names are ignored. |
| mbfl_getopts_isbrief string varname | Function |
| Verifies if a string is a brief option without argument. Arguments: string is the
string to validate, varname optional name of a variable that's set to the option name,
without the leading dash.
Returns with code zero if the argument is a brief option without argument, else returns with code one. A brief option must be of the form |
| mbfl_getopts_isbrief_with string optname valname | Function |
Verifies if a string is a brief option without argument. Arguments:
Returns with code zero if the argument is a brief option without argument, else returns with code one. A brief option must be of the form |
| mbfl_wrong_num_args required present | Function |
| Validates the number of arguments. required is the required number of arguments, present is the given number of arguments on the command line. If the number of arguments is different from the required one: prints an error message and returns with code one; else returns with code zero. |
| mbfl_argv_from_stdin | Function |
If the ARGC global variable is set to zero: fills the global variable ARGV
with lines from stdin. If the global variable mbfl_option_NULL is set to yes:
lines are read using the null character as terminator, else they are read using the standard newline
as terminator.
This function may block waiting for input. |
| mbfl_argv_all_files | Function |
Checks that all the arguments in ARGV are file names of existent file. Returns
with code zero if no errors, else prints an error message and returns with code 1. |
Some feature and behaviour of the library is configured by the return value of the following set of functions. All of these functions are defined by the Getopts module, but they can be redefined by the script.
| mbfl_option_encoded_args | Function |
Returns true if the option --encoded-args was used on the command line. |
| mbfl_option_verbose | Function |
Returns true if the option --verbose was used on the command line after all the
occurrences of --silent. Returns false if the option --silent was used
on the command line after all the occurrences of --verbose. |
| mbfl_option_test | Function |
Returns true if the option --test was used on the command line. |
| mbfl_option_debug | Function |
Returns true if the option --debug was used on the command line. |
| mbfl_option_null | Function |
Returns true if the option --null was used on the command line. |
| mbfl_option_interactive | Function |
Returns true if the option --interactive was used on the command line after all
the occurrences of --force. Returns false if the option --force was
used on the command line after all the occurrences of --interactive. |
This module allows one to print messages on an output channel. Various forms of message are supported.
All the function names are prefixed with mbfl_message_. All the messages will have the
forms:
<progname>: <message> <progname>: [error|warning]: <message>
The following global variables are declared:
mbfl_message_PROGNAME mbfl_message_VERBOSE yes if verbose messages should be displayed, else no;
| mbfl_message_set_program PROGNAME | Function |
| Sets the script official name to put at the beginning of messages. |
| mbfl_message_set_channel channel | Function |
| Selects the channel to be used to output messages. |
| mbfl_message_string string | Function |
Outputs a message to the selected channel. Echoes a string composed of: the content of the
mbfl_message_PROGNAME global variable; a colon; a space; the provided message.
A newline character is NOT appended to the message. Escape characters are allowed in the message. |
| mbfl_message_verbose string | Function |
Outputs a message to the selected channel, but only if the evaluation of the function/alias
mbfl_option_verbose returns true.
Echoes a string composed of: the content of the A newline character is NOT appended to the message. Escape characters are allowed in the message. |
| mbfl_message_verbose_end string | Function |
Outputs a message to the selected channel, but only if the evaluation of the function/alias
mbfl_option_verbose returns true.
Echoes the string. A newline character is NOT appended to the message. Escape characters are allowed in the message. |
| mbfl_message_debug string | Function |
Outputs a message to the selected channel, but only if the evaluation of the function/alias
mbfl_option_debug returns true.
Echoes a string composed of: the content of the A newline character is NOT appended to the message. Escape characters are allowed in the message. |
| mbfl_message_warning string | Function |
Outputs a warning message to the selected channel. Echoes a string composed of: the content
of the mbfl_message_PROGNAME global variable; a colon; a space; the string
warning; a colon; a space; the provided message.
A newline character IS appended to the message. Escape characters are allowed in the message. |
| mbfl_message_error string | Function |
Outputs a error message to the selected channel. Echoes a string composed of: the content
of the mbfl_message_PROGNAME global variable; a colon; a space; the string
error; a colon; a space; the provided message.
A newline character IS appended to the message. Escape characters are allowed in the message. |
This module declares a set of global variables all prefixed with mbfl_program_. We have
to look at the module's code to see which one are declared.
MBFL allows a script to execute a "dry run", that is: do not perform any operation on the system, just print messages describing what will happen if the script is executed with the selected options. This implies, in the MBFL model, that no external program is executed.
When this feature is turned on: mbfl_program_exec does not execute the program, instead
it prints the command line on standard error and returns true.
| mbfl_set_option_test | Function |
Enables the script test option. After this a script should not do anything on the system,
just print messages describing the operations. This function is invoked when the predefined option
--test is used on the command line. |
| mbfl_unset_option_test | Function |
| Disables the script test option. After this a script should perform normal operations. |
| mbfl_option_test | Function |
| Returns true if test execution is enabled, else returns false. |
The simpler way to test the availability of a program is to look for it just before it is used. The following function should be used at the beginning of a function that makes use of external programs.
| mbfl_program_check program ?program ...? | Function |
| Checks the availability of programs. All the pathnames on the command line are checked: if one is not executable an error message is printed on stderr. Returns false if a program can't be found, true otherwise. |
| mbfl_program_find program | Function |
A wrapper for: type -ap program that looks for a program in the current search path: prints the full pathname of the program found, or prints an empty string if nothing is found. |
| mbfl_program_exec arg ... | Function |
| Evaluates a command line.
If the function If the function |
To make a script model simpler, we assume that the unavailability of a program at the time of its execution is a fatal error. So if we need to execute a program and the executable is not there, the script must be aborted on the spot.
Functions are available to test the availability of a program, so we can try to locate an alternative or terminate the process under the script control. On a system where executables may vanish from one moment to another, no matter how we test a program existence, there's always the possibility that the program is not "there" when we invoke it.
If we just use mbfl_program_exec to invoke an external program, the function will try
and fail if the executable is unavailable: the return code will be false.
The vanishing of a program is a rare event: if it's there when we look for it, probably it will be there also a few moments later when we invoke it. For this reason, MBFL proposes a set of functions with which we can declare the intention of a script to use a set of programs; a command line option is predefined to let the user test the availability of all the declared programs before invoking the script.
| mbfl_declare_program program | Function |
| Registers program as the name of a program required by the script. The return value is always zero. |
| mbfl_program_validate_declared | Function |
| Validates the existence of all the declared programs. The return value is zero if all the
programs are found, one otherwise.
This function is invoked by It is a good idea to invoke this function at the beginning of a script, just before starting
to do stuff, example: mbfl_program_validate_declared || mbfl_exit_program_not_found If verbose messages are enabled: a brief summary is echoed to stderr; from the command line
the option |
| mbfl_program_found program | Function |
Prints the pathname of the previously declared program. Returns zero if the program
was found, otherwise prints an error message and exits the script by invoking mbfl_exit_program_not_found.
This function should be used to retrieve the pathname of the program to be used as first argument
to |
| mbfl_exit_program_not_found | Function |
| Terminates the script with exit code 20. This function may be redefined by a script to make use of a different exit code; it may even be redefined to execute arbitrary code and then exit. |
MBFL provides an interface to the trap builtin that allows the execution
of more than one function when a signal is received; this may sound useless, but that is it.
| mbfl_signal_map_signame_to_signum sigspec | Function |
| Converts sigspec to the corresponding signal number, then prints the number. |
| mbfl_signal_attach sigspec handler | Function |
| Append handler to the list of functions that are executed whenever sigspec is received. |
| mbfl_signal_invoke_handlers signum | Function |
| Invokes all the handlers registered for signum. This function is not meant to be used during normal scripts execution, but it may be useful to debug a script. |
| mbfl_string_is_quoted_char string position | Function |
Returns true if the character at position in string is quoted; else
returns false. A character is considered quoted if it is preceeded by an odd number of backslashes
(\). position is a zero-based index. |
| mbfl_string_is_equal_unquoted_char string position char | Function |
Returns true if the character at position in string is equal to
char and is not quoted (according to mbfl_string_is_quoted_char); else returns
false. position is a zero-based index. |
| mbfl_string_quote string | Function |
Prints string with quoted characters. All the occurrences of the backslash character,
\, are substituted with a quoted backslash, \\. Returns true. |
| mbfl_string_index string index | Function |
| Selects a character from a string. Echoes to stdout the selected character. If the index is out of range: the empty string is echoed to stdout. |
| mbfl_string_first string char ?begin? | Function |
| Searches characters in a string. Arguments: string, the target string; char,
the character to look for; begin, optional, the index of the character in the target
string from which the search begins (defaults to zero).
Prints an integer representing the index of the first occurrence of char in string. If the character is not found: nothing is sent to stdout. |
| mbfl_string_last string char ?begin? | Function |
| Searches characters in a string starting from the end. Arguments: string, the target
string; char, the character to look for; begin, optional, the index of the
character in the target string from which the search begins (defaults to zero).
Prints an integer representing the index of the last occurrence of char in string. If the character is not found: nothing is sent to stdout. |
| mbfl_string_range string begin end | Function |
Extracts a range of characters from a string. Arguments: string, the source string;
begin, the index of the first character in the range; end, optional, the
index of the character next to the last in the range, this character is not extracted. end
defaults to the last character in the string; if equal to end: the end of the range
is the end of the string. Echoes to stdout the selected range of characters. |
| mbfl_string_equal_substring string position pattern | Function |
| Returns true if the substring starting at position in string is equal to pattern; else returns false. If position plus the length of pattern is greater than the length of string: the return value is false, always. |
| mbfl_string_chars string | Function |
Splits a string into characters. Fills an array named SPLITFIELD with the characters
from the string; the number of elements in the array is stored in a variable named SPLITCOUNT.
Both SPLITFIELD and SPLITCOUNT may be declared local in
the scope of the caller.
The difference between this function and using: |
Example of usage for mbfl_string_chars:
string="abcde\nfghilm"
mbfl_string_chars "${string}"
# Now:
# "${#string}" = $SPLITCOUNT
# a = "${SPLITFIELD[0]}"
# b = "${SPLITFIELD[1]}"
# c = "${SPLITFIELD[2]}"
# d = "${SPLITFIELD[3]}"
# e = "${SPLITFIELD[4]}"
# \n = "${SPLITFIELD[5]}"
# f = "${SPLITFIELD[6]}"
# g = "${SPLITFIELD[7]}"
# h = "${SPLITFIELD[8]}"
# i = "${SPLITFIELD[9]}"
# l = "${SPLITFIELD[10]}"
# m = "${SPLITFIELD[11]}"
| mbfl_string_split string separator | Function |
Splits string into fields using seprator. Fills an array named
SPLITFIELD with the characters from the string; the number of elements in the array is
stored in a variable named SPLITCOUNT. Both SPLITFIELD and SPLITCOUNT
may be declared local in the scope of the caller. |
| mbfl_string_toupper string | Function |
| Outputs string with all the occurrencies of lower case ASCII characters (no accents) turned into upper case. |
| mbfl_string_tolower string | Function |
| Outputs string with all the occurrencies of upper case ASCII characters (no accents) turned into lower case. |
| mbfl-string-is-alpha-char char | Function |
Returns true if char is in one of the ranges: a-z, A-Z.
|
| mbfl-string-is-digit-char char | Function |
Returns true if char is in one of the ranges: 0-9. |
| mbfl-string-is-alnum-char char | Function |
Returns true if mbfl-string-is-alpha-char || mbfl-string-is-digit-char
returns true when acting on char. |
| mbfl-string-is-noblank-char char | Function |
Returns true if char is in none of the characters: , \n, \r,
\f, \t. char is meant to be the unquoted version of the non-blank
characters: the one obtained with: $'char' |
| mbfl-string-is-name-char char | Function |
Returns true if mbfl-string-is-alnum-char returns true when acting upon
char or char is an underscore, _. |
| mbfl-string-is-alpha string | Function |
| mbfl-string-is-digit string | Function |
| mbfl-string-is-alnum string | Function |
| mbfl-string-is-noblank string | Function |
| mbfl-string-is-name string | Function |
Return true if the associated char function returns true for each character in string.
As an additional constraint: mbfl-string-is-name returns false if mbfl-string-is-digit
returns true when acting upon the first character of string. |
| mbfl_string_replace string pattern ?subst? | Function |
| Replaces all the occurrences of pattern in string with subst; prints the result. If not used, subst defaults to the empty string. |
| mbfl_sprintf varname format ... | Function |
Makes use of printf to format the string format with the additional
arguments, then stores the result in varname: if this name is local in the scope of
the caller, this has the effect of filling the variable in that scope. |
| mbfl_string_skip string varname char | Function |
| Skips all the characters in a string equal to char. varname is the name of a variable in the scope of the caller: its value is the offset of the first character to test in string. The offset is incremented until a char different from char is found, then the value of varname is update to the position of the different char. If the initial value of the offset corresponds to a char equal to char, the variable is left untouched. Returns true. |
| mbfl_dialog_yes_or_no string ?progname? | Function |
Prints the question string on the standard output and waits for the user to type
yes or no in the standard input. Returns true if the user has typed
yes, false if the user has typed no.
The optional parameter progname is used as prefix for the prompt; if not given: defaults to the value of script_PROGNAME (Service Variables for details). |
| mbfl_dialog_ask_password prompt | Function |
| Prints prompts followed by a colon and a space, then reads a password from the terminal. Prints the password. |
| mbfl_variable_find_in_array element | Function |
Searches the array mbfl_FIELDS for a value equal to element. If it
is found: prints the index and returns true; else prints nothing and returns false.
|
| mbfl_variable_element_is_in_array element | Function |
A wrapper for mbfl_variable_find_in_array that does not print anything. |
| mbfl_variable_colon_variable_to_array varname | Function |
Reads varname's value, a colon separated list of string, and stores each string
in the array mbfl_FIELDS, starting with a base index of zero. |
mbfl_variable_array_to_colon_variable varname |
Function |
Stores each value in the array mbfl_FIELDS in varname as a colon separated
list of strings. |
| mbfl_variable_colon_variable_drop_duplicate varname | Function |
| Reads varname's value, a colon separated list of string, and removes duplicates. |
MBFL declares a function to drive the execution of the script; its purpose is to make use of the other modules to reduce the size of scripts depending on MBFL. All the code blocks in the script, with the exception of global variables declaration, should be enclosed in functions.
| mbfl_main | Function |
Must be the last line of code in the script. Does the following.
|
| mbfl_invoke_script_function funcname | Function |
If funcname is the name of an existing function: it is invoked with no arguments;
the return value is the one of the function. The existence test is performed with: type -t FUNCNAME = function |
| mbfl_main_set_main funcname | Function |
Selects the main function storing funcname into mbfl_main_SCRIPT_FUNCTION.
|
MBFL comes with a little library of functions that may be used to build test suites;
its aim is at building tests for bash functions/commands/scripts.
The ideas at the base of this library are taken from the tcltest package distributed
with the TCL core 1; this package had contributions
from the following people/entities: Sun Microsystems, Inc.; Scriptics Corporation; Ajuba Solutions;
Don Porter, NIST; probably many many others.
The library tries to do as much as possible using functions and aliases, not variables; this is an attempt to let the user redefine functions to his taste.
A useful way to organise a test suite is to split it into a set of files: one for each module to be tested.
The file mbfltest.sh must be sourced at the beginning of each test file.
The function dotest should be invoked at the end of each module in the test suite; each
module should define functions starting with the same prefix. A module should be stored in a file, and
should look like the following:
# mymodule.test --
source mbfltest.sh
source module.sh
function module-featureA-1.1 () { ... }
function module-featureA-1.2 () { ... }
function module-featureA-2.1 () { ... }
function module-featureB-1.1 () { ... }
function module-featureB-1.2 () { ... }
dotest module-
### end of file
the file should be executed with:
$ bash mymodule.test
To test just "feature A":
$ TESTMATCH=module-featureA bash mymodule.test
Remember that the source builtin will look for files in the directories selected by
the PATH environment variables, so we may want to do:
$ PATH="path/to/modules:${PATH}" \
TESTMATCH=module-featureA bash mymodule.test
It is better to put such stuff in a Makefile, with GNU make:
top_srcdir = ...
builddir = ...
BASHPROG = bash
MODULES = moduleA moduleB
testdir = $(top_srcdir)/tests
test_FILES = $(foreach f, $(MODULES), $(testdir)/$(f).test)
test_TARGETS = test-modules
test_ENV = PATH=$(builddir):$(testdir):$(PATH) TESTMATCH=$(TESTMATCH)
test_CMD = $(test_ENV) $(BASHPROG)
.PHONY: test-modules
test-modules:
ifneq ($(strip $(test_FILES)),)
@$(foreach f, $(test_FILES), $(test_CMD) $(f);)
endif
| dotest-set-verbose | Function |
| dotest-unset-verbose | Function |
| Set or unset verbose execution. If verbose mode is on: some commands output messages on stderr describing what is going on. Examples: files and directories creation/removal. |
| dotest-option-verbose | Function |
| Returns true if verbose mode is on, false otherwise. |
| dotest-set-test | Function |
| dotest-unset-test | Function |
Set or unset test execution. If test mode is on: external commands (like rm and
mkdir) are not executed, the command line is sent to stderr. Test mode is meant to
be used to debug the test library functions. |
| dotest-option-test | Function |
| Returns true if test mode is on, false otherwise. |
| dotest-set-report-start | Function |
| dotest-unset-report-start | Function |
| Set or unset printing a message upon starting a function. |
| dotest-option-report-start | Function |
| Returns true if start function reporting is on; otherwise returns false. |
| dotest-set-report-success | Function |
| dotest-unset-report-success | Function |
| Set or unset printing a message when a function execution succeeds. Failed tests always cause a message to be printed. |
| dotest-option-report-success | Function |
| Returns true if success function reporting is on; otherwise returns false. |
| dotest pattern | Funciton |
Run all the functions matching pattern. Usually pattern is the first
part of the name of the functions to be executed; the function names are selected with the following
code: compgen -A function "$pattern" There's no constraint on function names, but they must be one-word names. Before running a test function: the current process working directory is saved, and it is restored after the execution is terminated. The return value of the test functions is used as result of the test: true, the test succeeded;
false, the test failed. Remembering that the return value of a function is the return value of
its last executed command, the functions |
Messages are printed before and after the execution of each function, according to the mode selected
with: dotest-set-report-success, dotest-set-report-start, ...
(Testing Config for details).
The following environment variables may configure the behaviour of dotest.
TESTMATCH TESTSTART yes: it is equivalent to invoking dotest-set-report-start; if
no: it is equivalent to invoking dotest-unset-report-start. TESTSUCCESS yes: it is equivalent to invoking dotest-set-report-success; if
no: it is equivalent to invoking dotest-unset-report-success.
| dotest-equal expected got | Function |
| Compares the two parameters and returns true if they are equal; returns false otherwise. In the latter case prints a message showing the expected value and the wrong one. Must be used as last command in a function, so that its return value is equal to that of the function. |
Example:
function my-func () {
echo $(($1 + $2))
}
function mytest-1.1 () {
dotest-result 5 `my-func 2 3`
}
dotest mytest-
another example:
function my-func () {
echo $(($1 + $2))
}
function mytest-1.1 () {
dotest-result 5 `my-func 2 3` && \
dotest-result 5 `my-func 1 4` && \
dotest-result 5 `my-func 3 2` && \
}
dotest mytest-
| dotest-output ?string? | Function |
Reads all the available lines from stdin accumulating them into a local variable, separated
by \n; then compares the input with string, or the empty string if
string is not present, and returns true if they are equal, false otherwise. |
Example of test for a function that echoes its three parameters:
function my-lib-function () {
echo $1 $2 $3
}
function mytest-1.1 () {
my-lib-function a b c | dotest-output a b c
}
dotest mytest
Example of test for a function that is supposed to print nothing:
function my-lib-function () {
test "$1" != "$2" && echo error
}
function mytest-1.1 () {
my-lib-function a a | dotest-output
}
dotest mytest
Here is a small script that asks for a first name then a second name:
$ pg func2 #!/bin/sh # func2 echo -n "What is your first name :" read F_NAME echo -n "What is your surname :" read S_NAME
We first assign the $1 variable to a more meaningful name. Awk is then used to test
if the whole record passed contains only characters. The output of this command, which is 1 for non-letters
and null for OK, is held in the variable _LETTERS_ONLY.
A test on the variable is then carried out. If it holds any value then it's an error, but if it holds no value then it's OK. A return code is then executed based on this test. Using the return code enables the script to look cleaner when the test is done on the function on the calling part of the script.
To test the outcome of the function we can use this format of the if statement if we wanted:
if char_name $F_NAME; then echo "OK" else echo "ERRORS" fi
If there is an error we can create another function to echo the error out to the screen:
name_error()
# name_error
# display an error message
{
echo " $@ contains errors, it must contain only letters"
}
The function name_error will be used to echo out all errors disregarding any invalid entries. Using the special variable $@ allows all arguments to be echoed. In this case it's the value of either F_NAME or S_NAME. Here's what the finished script now looks like, using the functions:
$ pg func2
!/bin/sh
char_name()
# char_name
# to call: char_name string
# check if $1 does indeed contain only characters a-z,A-Z
{
# assign the argurment across to new variable
_LETTERS_ONLY=$1
_LETTERS_ONLY=`echo $1|awk '{if($0~/[^a-zA-Z]/) print "1"}'`
if [ "$_LETTERS_ONLY" != "" ]
then
# oops errors
return 1
else
# contains only chars
return 0
fi
}
name_error()
# display an error message
{
echo " $@ contains errors, it must contain only letters"
}
while :
do
echo -n "What is your first name :"
read F_NAME
if char_name $F_NAME
then
# all ok breakout
break
else
name_error $F_NAME
fi
done
while :
do
echo -n "What is your surname :"
read S_NAME
if char_name $S_NAME
then
# all ok breakout
break
else
name_error $S_NAME
fi
done
Here's what the output looks like when the script is run:
$ func2 What is your first name :Davi2d Davi2d contains errors, it must contain only letters What is your first name :David What is your surname :Tansley1 Tansley1 contains errors, it must contain only letters What is your surname :Tansley
When navigating menus, one of the most frustrating tasks is having to keep hitting the return key after every selection, or when a 'press any key to continue' prompt appears. A command that can help us with not having to hit return to send a key sequence is the dd command.
The dd command is used mostly for conversions and interrogating problems with data on tapes or normal tape archiving tasks, but it can also be used to create fixed length files. Here a 1-megabyte file is created with the filename myfile.
dd if=/dev/zero of=myfile count=512 bs=2048
Here's the function:
read_a_char()
# read_a_char
{
# save the settings
SAVEDSTTY=`stty -g`
# set terminal raw please
stty cbreak
# read and output only one character
dd if=/dev/tty bs=1 count=1 2> /dev/null
# restore terminal and restore stty
stty -cbreak
stty $SAVEDSTTY
}
To call the function and return the character typed in, use command substitution. Here's an example.
echo -n "Hit Any Key To Continue" character=`read_a_char` echo " In case you are wondering you pressed $character"
Testing for the presence of directories is a fairly common task when copying files around. This function will test the filename passed to the function to see if it is a directory. Because we are using the return command with a succeed or failure value, the if statement becomes the most obvious choice in testing the result.
Here's the function.
isdir()
{
# is_it_a_directory
if [ $# -lt 1 ]; then
echo "isdir needs an argument"
return 1
fi
# is it a directory ?
_DIRECTORY_NAME=$1
if [ ! -d $_DIRECTORY_NAME ]; then
# no it is not
return 1
else
# yes it is
return 0
fi
}
When you are on a big system, and you want to contact one of the users who is logged in, don't you just hate it when you have forgotten the person's full name? Many a time I have seen users locking up a process, but their user ID means nothing to me, so I have to grep the passwd file to get their full name. Then I can get on with the nice part where I can ring them up to give the user a telling off.
Here's a function that can save you from grep ing the /etc/passwd file to see the user's full name.
On my system the user's full name is kept in field 5 of the passwd file; yours might be different, so you will have to change the field number to suit your passwd file.
The function is passed a user ID or many IDs, and the function just grep s the passwd file.
Here's the function:
whois()
# whois
# to call: whois userid
{
# check we have the right params
if [ $# -lt 1 ]; then
echo "whois : need user id's please"
return 1
fi
for loop
do
_USER_NAME=`grep $loop /etc/passwd | awk -F: '{print $4}'`
if [ "$_USER_NAME" = "" ]; then
echo "whois: Sorry cannot find $loop"
else
echo "$loop is $_USER_NAME"
fi
done
}
When you are in vi you can number your lines which is great for debugging, but if you want to print out some files with line numbers then you have to use the command nl. Here is a function that does what nl does best – numbering the lines in a file. The original file is not overwritten.
number_file()
# number_file
# to call: number_file filename
{
_FILENAME=$1
# check we have the right params
if [ $# -ne 1 ]; then
echo "number_file: I need a filename to number"
return 1
fi
loop=1
while read LINE
do
echo "$loop: $LINE"
loop=`expr $loop + 1`
done < $_FILENAME
}
You may need to convert text from lower to upper case sometimes, for example to create directories in a filesystem with upper case only, or to input data into a field you are validating that requires the text to be in upper case.
Here is a function that will do it for you. No points for guessing it's tr.
str_to_upper ()
# str_to_upper
# to call: str_to_upper $1
{
_STR=$1
# check we have the right params
if [ $# -ne 1 ]; then
echo "number_file: I need a string to convert please"
return 1
fi
echo $@ |tr '[a-z]' '[A-Z]'
}
The variable UPPER holds the newly returned upper case string. Notice the use again of using the special parameter $@ to pass all arguments. The str_to_upper can be called in two ways. You can either supply the string in a script like this:
UPPER=`str_to_upper "documents.live"` echo $upper
or supply an argument to the function instead of a string, like this:
UPPER=`str_to_upper $1` echo $UPPER
Both of these examples use substitution to get the returned function results.
The function str_to_upper does a case conversion, but sometimes you only need to know if a string is upper case before continuing with some processing, perhaps to write a field of text to a file. The is_upper function does just that. Using an if statement in the script will determine if the string passed is indeed upper case.
Here is the function.
is_upper()
# is_upper
# to call: is_upper $1
{
# check we have the right params
if [ $# -ne 1 ]; then
echo "is_upper: I need a string to test OK"
return 1
fi
# use awk to check we have only upper case
_IS_UPPER=`echo $1|awk '{if($0~/[^A-Z]/) print "1"}'`
if [ "$_IS_UPPER" != "" ]
then
# no, they are not all upper case
return 1
else
# yes all upper case
return 0
fi
}
To test if a string is indeed lower case, just replace the existing awk statement with this
one inside the function is_upper and call it is_lower.
_IS_LOWER=`echo $1|awk '{if($0~/[^a-z]/) print "1"}'`
Now I've done it. Because I have shown you the str_to_upper, I'd better show you its sister function str_to_lower. No guesses here please on how this one works.
str_to_lower ()
# str_to_lower
# to call: str_to_lower $1
{
# check we have the right params
if [ $# -ne 1 ]; then
echo "str_to_lower: I need a string to convert please"
return 1
fi
echo $@ |tr '[A-Z]' '[a-z]'
}
The variable LOWER holds the newly returned lower case string. Notice the use again of using the special parameter $@ to pass all arguments. The str_to_lower can be called in two ways. You can either supply the string in a script like this:
LOWER=`str_to_lower "documents.live"` echo $LOWER
Validating input into a field is a common task in scripts. Validating can mean many things, whether it's numeric, character only, formats, or the length of the field.
Suppose you had a script where the user enters data into a name field via an interactive screen. You will want to check that the field contains only a certain number of characters, say 20 for a person's name. It's easy for the user to input up to 50 characters into a field. This is what this next function will check. You pass the function two parameters, the actual string and the maximum length the string should be.
Here's the function:
check_length()
# check_length
# to call: check_length string max_length_of_string
{
_STR=$1
_MAX=$2
# check we have the right params
if [ $# -ne 2 ]; then
echo "check_length: I need a string and max length the string should be"
return 1
fi
# check the length of the string
_LENGTH=`echo $_STR |awk '{print length($0)}'`
if [ "$_LENGTH" -gt "$_MAX" ]; then
# length of string is too big
return 1
else
# string is ok in length
return 0
fi
}
You could call the function check_length like this:
$ pg test_name
# !/bin/sh
# test_name
while :
do
echo -n "Enter your FIRST name :"
read NAME
if check_length $NAME 10
then
break
# do nothing fall through condition all is ok
else
echo "The name field is too long 10 characters max"
fi
done
Using the above piece of code this is how the output could look.
$ val_max Enter your FIRST name :Pertererrrrrrrrrrrrrrr The name field is too long 10 characters max Enter your FIRST name :Peter
You could use the wc command to get the length of the string, but beware: there is a glitch when using wc in taking input from the keyboard. If you hit the space bar a few times after typing in a name, wc will almost always retain some of the spaces as part of the string, thus giving a false length size. Awk truncates end of string spaces by default when reading in via the keyboard.
Here's an example of the wc glitch (or maybe it's a feature):
echo -n "name :" read NAME echo $NAME | wc -c
chop
The chop function chops off characters from the beginning of a string. The function chop is passed a string; you specify how many characters to chop off the string starting from the first character. Suppose you had the string MYDOCUMENT.DOC and you wanted the MYDOCUMENT part chopped, so that the function returned only .DOC. You would pass the following to the chop function:
MYDOCUMENT.DOC 10
Here's the function chop:
# check we have the right params
if [ $# -ne 2 ]; then
echo "check_length: I need a string and how many characters to chop"
return 1
fi
# check the length of the string first
# we can't chop more than what's in the string !!
_LENGTH=`echo $_STR |awk '{print length($0)}'`
if [ "$_LENGTH" -lt "$_CHOP" ]; then
echo "Sorry you have asked to chop more characters than there are in
the string"
return 1
fi
echo $_STR |awk '{print substr($1,'$_CHOP')}'
}
The returned string newly chopped is held in the variable CHOPPED. To call the function
chop, you could use:
or you could call this way:
When generating reports or creating screen displays, it is sometimes convenient to the programmer to have a quick way of displaying the full month. This function, called months, will accept the month number or month abbreviation and then return the full month.
For example, passing 3 or 03 will return March. Here's the function.
months()
{
# months
_MONTH=$1
# check we have the right params
if [ $# -ne 1 ]; then
echo "months: I need a number 1 to 12 "
return 1
fi
case $_MONTH in
1|01|Jan)_FULL="January" ;;
2|02|Feb)_FULL="February" ;;
3|03|Mar)_FULL="March";;
4|04|Apr)_FULL="April";;
5|05|May)_FULL="May";;
6|06|Jun)_FULL="June";;
7|07|Jul)_FULL="July";;
8|08|Aug)_FULL="August";;
9|10|Sep|Sept)_FULL="September";;
10|Oct)_FULL="October";;
11|Nov)_FULL="November";;
12|Dec)_FULL="December";;
*) echo "months: Unknown month"
return 1
;;
esac
echo $_FULL
}
To call the function months you can use either of the following methods.
months 04
The above method will display the month April; or from a script:
MY_MONTH=`months 06` echo "Generating the Report for Month End $MY_MONTH" ...
which would output the month June.
To use a function in a script, create the function, and make sure it is above the code that calls it. Here's a script that uses a couple of functions. We have seen the script before; it tests to see if a directory exists.
### END OF FUNCTIONS
echo -n "enter destination directory :"
read DIREC
if is_it_a_directory $DIREC
then :
else
error_msg "$DIREC does not exist...creating it now"
mkdir $DIREC > /dev/null 2>&1
if [ $? != 0 ]
then
error_msg "Could not create directory:: check it out!"
exit 1
else :
fi
fi # not a directory
echo "extracting files..."
In the above script two functions are declared at the top of the script and called from the main part of the script. All functions should go at the top of the script before any of the main scripting blocks begin. Notice the error message statement; the function error_msg is used, and all arguments passed to the function error_msg are just echoed out with a couple of bleeps.
We have already seen how to call functions from the command line; these types of functions are generally used for system reporting utilities.
Let's use the above function again, but this time put it in a function file. We will call it functions.sh, the sh meaning shell scripts.
#---------------------------------------------
error_msg()
{
echo -e "\007"
echo $@
echo -e "\007"
return 0
}
Now let's create the script that will use functions in the file functions.sh. We can then use these functions. Notice the functions file is sourced with the command format:
. /<path to file>
# now we can use the function(s)
echo -n "enter destination directory :"
read DIREC
if is_it_a_directory $DIREC
then :
else
error_msg "$DIREC does not exist...creating it now"
mkdir $DIREC > /dev/null 2>&1
if [ $? != 0 ]
then
error_msg "Could not create directory:: check it out!"
exit 1
else :
fi
fi # not a directory
echo "extracting files..."
When we run the above script we get the same output as if we had the function inside our script:
$ direc_check enter destination directory :AUDIT AUDIT does not exist...creating it now extracting files...
To source a file, it does not only have to contain functions – it can contain global variables that make up a configuration file.
Suppose you had a couple of backup scripts that archived different parts of a system. It would be a good idea to share one common configuration file. All you need to do is to create your variables inside a file then when one of the backup scripts kicks off it can load these variables in to see if the user wants to change any of the defaults before the archive actually begins. It may be the case that you want the archive to go to a different media.
Of course this approach can be used by any scripts that share a common configuration to carry out a process. Here's an example. The following configuration contains default environments that are shared by a few backup scripts I use.
Here's the file.
$ pg backfunc #!/bin/sh # name: backfunc # config file that holds the defaults for the archive systems _CODE="comet" _FULLBACKUP="yes" _LOGFILE="/logs/backup/" _DEVICE="/dev/rmt/0n" _INFORM="yes" _PRINT_STATS="yes"
The descriptions are clear. The first field _CODE holds a code word. To be able to view this and thus change the values the user must first enter a code that matches up with the value of _CODE, which is "comet".
Here's the script that prompts for a password then displays the default configuration:
$ pg readfunc
#!/bin/sh
# readfunc
if [ -r backfunc ]; then
# source the file
. /backfunc
else
echo "$`basename $0` cannot locate backfunc file"
fi
echo -n "Enter the code name :"
# does the code entered match the code from backfunc file ???
if [ "${CODE}" != "${_CODE}" ]; then
echo "Wrong code...exiting..will use defaults"
exit 1
fi
echo " The environment config file reports"
echo "Full Backup Required : $_FULLBACKUP"
echo "The Logfile Is : $_LOGFILE"
echo "The Device To Backup To is : $_DEVICE"
echo "You Are To Be Informed by Mail : $_INFORM"
echo "A Statistic Report To Be Printed: $_PRINT_STATS"
When the script is run, you are prompted for the code. If the code matches, you can view the defaults. A fully working script would then let the user change the defaults.
$ readback Enter the code name :comet The environment config file reports Full Backup Required : yes The Logfile Is : /logs/backup/ The Device To Backup To is : /dev/rmt/0n You Are To Be Informed by Mail : yes A Statistic Report To Be Printed: yes
When you have got a set of functions you like, put them in a functions file, then other scripts can use the functions as well.
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: September 10, 2019