|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
|
|
Tuning is a very challenging business. In which it is much easier to do harm then good. Especially if your understanding of the problem in hand is limited, or, worse, if you are barking to the wrong tree.
Another fact which make tuning even more challenging is that there is no free lunch and the more optimized system is, the more specialized for a particular application it became. As the result any changes in application can disproportionally negatively affect performance. In other words highly tuned to particular application server is a brittle server and such level of tuning can backfire when you update or replace the application, as assumption you made no longer hold true. As Donald Knuth used to say "premature optimization is the root of all evil" (Computer Programming as an Art, 1974 Turing Award Lecture, CACM 17 (12), pp. 667–673) and he definitely knows what he is talking about ;-).
We can categorized the effects of performance tuning (aka optimization) in two categories:
The most typical mistake in optimization is losing the initial configuration. In case tuning is limited to Linux box even the simplest baseline such are making a tar of /etc directory before making changes can save your from a lot of troubles and embarrassment, when after the set of changes that lead to nothing good you suddenly discover that you do not know what the initial parameters were. If you are working strictly in command like history might help a little bit, but otherwise this is a SNAFU. Getting into this situation also might mean lack of preparation and/or lack of situational awareness. You need to take several steps to prevent this blunder from occurring.
When you examine TCP/IP performance, a number of factors influence the result and typically it's often not clear how those factors interact. So general rule is to change one parameter at a time, measure performance, compare with baseline and only then continue. The key here is measurement of result. If there is improvement the change has right to live, if not you probably should instantly discard it. It is prudent to minimize changes. Excessive changes can backfire and they are more sensitive to any even small change of environment.
The optimal TCP/IP parameters depends on the speed, as well as latency of your network. Often defining layer is the application. You should investigate which factor is the most important in to your situation. Optimizing wrong layer for a wrong reason is the most common mistake in TCP optimization.
|
Optimizing wrong layer for a wrong reason is the most common mistake in TCP optimization |
See TCP/IP Network Troubleshooting and Network Troubleshooting Tools for more general discussion
|
|
Several more specific issues are covered at
Notes:
Execute command
/sbin/sysctl -a | egrep "kernel.shmall|kernel.shmmax|kernel.shmmn|kernel.sem"
and compare the values with the values in the table below
Don't trust recommendations below blindly. Verify that they produce improvements. Refer to the
operating system documentation for more information about tuning kernel parameters.
echo 1024 65000 > /proc/sys/net/ipv4/ip_local_port_rangeThis simply allows more local ports to be available. Generally not a issue, but for example in a web server benchmarking scenario you often need more ports available. A common example is clients running `ab` or `http_load` or similar software.
echo 262143 > /proc/sys/net/core/rmem_max echo 262143 > /proc/sys/net/core/rmem_defaultThis will increase the amount of memory available for socket input queues. The "wmem_*" values do the same for output queues.
|
Parameter |
Minimum Value |
Recommended value |
File |
| semmsl
semmns semopm semmni |
250
32000 100 128 |
Set only if those that are set by OS or other applications are lower | /proc/sys/kernel/sem |
| shmall | 2097152 | shmmax/page_size usually page_size=4 |
/proc/sys/kernel/shmall |
| shmmax | Minimum of the following values:
· Half the size of the memory · 4GB - 1 byte Note: The minimum value required for shmmax is 0.5 GB. However, Oracle recommends that you set the value of shmmax to 2.0 GB for optimum performance of the system. |
Mostly important for databases like Oracle. Half of RAM or if swap file is less then half of RAM the size of swap file | /proc/sys/kernel/shmmax |
| shmmni | 4096 | /proc/sys/kernel/shmmni | |
| file-max | 512 * PROCESSES | /proc/sys/fs/file-max | |
| ip_local_port_range | Minimum:1024
Maximum: 65000 |
/proc/sys/net/ipv4/ip_local_port_range | |
| rmem_default | 4194304 | /proc/sys/net/core/rmem_default | |
| rmem_max | 4194304 | /proc/sys/net/core/rmem_max | |
| wmem_default | 262144 | /proc/sys/net/core/wmem_default | |
| wmem_max | 262144 | /proc/sys/net/core/wmem_max | |
| tcp_wmem | 262144 | /proc/sys/net/ipv4/tcp_wmem | |
| tcp_rmem | 4194304 | /proc/sys/net/ipv4/tcp_rmem |
To display the current value specified for these kernel parameters, and to change them if necessary, use the following steps:
· Enter the commands shown in the following table to display the current values of the kernel parameters, make a note of these values and identify any values that you must change:
|
Parameter |
Command |
| semmsl, semmns, semopm, and semmni | # /sbin/sysctl -a | grep sem
This command displays the value of the semaphore parameters in the order listed. |
| shmall, shmmax, and shmmni | # /sbin/sysctl -a | grep shm
This command displays the details of the shared memory segment sizes. |
| file-max | # /sbin/sysctl -a | grep file-max
This command displays the maximum number of file handles. |
| ip_local_port_range | # /sbin/sysctl -a | grep ip_local_port_range
This command displays a range of port numbers. |
| rmem_default | # /sbin/sysctl -a | grep rmem_default |
| rmem_max | # /sbin/sysctl -a | grep rmem_max |
| wmem_default | # /sbin/sysctl -a | grep wmem_default |
| wmem_max | # /sbin/sysctl -a | grep wmem_max |
| tcp_wmem | # /sbin/sysctl -a | grep tcp_wmem |
| tcp_rmem | # /sbin/sysctl -a | grep tcp_rmem |
If the value of any kernel parameter is less then the minimum value, then complete the following procedure:
Using any text editor, create or edit the /etc/sysctl.conf file, and add or edit lines similar to the following:
Note:
Include lines only for the kernel parameter values that you want to change. For the semaphore parameters (kernel.sem), you must specify all four values. However, if any of the current values are larger than the minimum value, then specify the larger value.
fs.file-max = 512 * PROCESSES
kernel.shmall = 2097152
kernel.shmmax = 2147483648
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
or
kernel.sem = 250 256000 100 1024
net.ipv4.ip_local_port_range = 1024 65000
net.core.rmem_default = 4194304
net.core.rmem_max = 4194304
net.core.wmem_default = 262144
net.core.wmem_max = 262144
net.ipv4.tcp_wmem = 262144 262144 262144
net.ipv4.tcp_rmem = 4194304 4194304 4194304
Note:
The minimum value required for shmmax is 0.5 GB. However, Oracle recommends that you set the value of shmmax to 2.0 GB for optimum performance of the system.
By specifying the values in the /etc/sysctl.conf file, they persist when you restart the system. However, on SUSE Linux Enterprise Server systems, enter the following command to ensure that the system reads the /etc/sysctl.conf file when it restarts:
# /sbin/chkconfig boot.sysctl on
Enter the following command to change the current values of the kernel parameters:
# /sbin/sysctl -p
Review the output from this command to verify that the values are correct. If the values are incorrect, edit the /etc/sysctl.conf file, then enter this command again.
Enter the command /sbin/sysctl -a to confirm that the values are set correctly.
On SUSE systems only, enter the following command to cause the system to read the /etc/sysctl.conf file when it restarts:
# /sbin/chkconfig boot.sysctl on
On SUSE systems only, you must enter the GID of the oinstall group as the value for the parameter /proc/sys/vm/hugetlb_shm_group. Doing this grants members of oinstall a group permission to create shared memory segments.
For example, where the oinstall group GID is 501:
# echo 501 > /proc/sys/vm/hugetlb_shm_group
After running this command, use vi to add the following text to /etc/sysctl.conf, and enable the boot.sysctl script to run on system restart:
vm.hugetlb_shm_group=501
Note:
Only one group can be defined as the vm.hugetlb_shm_group.
After updating the values of kernel parameters in the /etc/sysctl.conf file, either restart the computer, or run the command sysctl -p to make the changes in the /etc/sysctl.conf file available in the active kernel memory.
As mentioned in TCP performance tuning - how to tune linux (acc.umu.se) another important thing to try is to increase tcp windows sizing parameters:
The short summary:
The default Linux tcp window sizing parameters before 2.6.17 sucks.
The short fix [wirespeed for gigE within 5 ms RTT and fastE within 50 ms RTT]:
in /etc/sysctl.conf
net/core/rmem_max = 8738000
net/core/wmem_max = 6553600net/ipv4/tcp_rmem = 8192 873800 8738000
net/ipv4/tcp_wmem = 4096 655360 6553600It might also be a good idea to increase vm/min_free_kbytes, especially if you have e1000 with NAPI or similar. A sensible value is 16M or 64M: vm/min_free_kbytes = 65536
If you run an ancient kernel, increase the txqueuelen to at least 1000: ifconfig ethN txqueuelen 1000
If you are seeing "TCP: drop open request" for real load (not a DDoS), you need to increase tcp_max_syn_backlog (8192 worked much better than 1024 on heavy webserver load).
The background:
TCP performance is limited by latency and window size (and overhead, which reduces the effective window size) by window_size/RTT (this is how much data that can be "in transit" over the link at any given moment).
To get the actual transfer speeds possible you have to divide the resulting window by the latency (in seconds):
The overhead is: window/2^tcp_adv_win_scale (tcp_adv_win_scale default is 2)
So for linux default parameters for the recieve window (tcp_rmem): 87380 - (87380 / 2^2) = 65536.
Given a transatlantic link (150 ms RTT), the maximum performance ends up at: 65536/0.150 = 436906 bytes/s or about 400 kbyte/s, which is really slow today.
With the increased default size:
(873800 - 873800/2^2)/0.150 = 4369000 bytes/s, or about 4Mbytes/s, which is resonable for a modern network. And note that this is the default, if the sender is configured with a larger window size it will happily scale up to 10 times this (8738000*0.75/0.150 = ~40Mbytes/s), pretty good for a modern network.
2.6.17 and later have reasonably good defaults values, and actually tune the window size up to the max allowed, if the other side supports it. So since then most of this guide is not needed. For good long-haul throughput the maximum value might need to be increased though.
For the txqueuelen, this is mostly relevant for gigE, but should not hurt anything else. Old kernels have shipped with a default txqueuelen of 100, which is definitely too low and hurts performance.
net/core/[rw]mem_max is in bytes, and the largest possible window size. net/ipv4/tcp_[rw]mem is in bytes and is "min default max" for the tcp windows, this is negotiated between both sender and receiver. "r" is for when this machine is on the recieving end, "w" when the connection is initiated from this machine.
There are more tuning parameters, for the Linux kernel they are documented in Documentation/networking/ip-sysctl.txt, but in our experience only the parameters above need tuning to get good tcp performance..
So, what's the downside?
None pretty much. It uses a bit more kernel memory, but this is well regulated by a tuning parameter (net/ipv4/tcp_mem) that has good defaults (percentage of physical ram). Note that you shouldn't touch that unless you really know what you are doing. If you change it and set it too high, you might end up with no memory left for processes and stuff.
If you go up above the middle value of net/ipv4/tcp_mem, you enter tcp_memory_pressure, which means that new tcp windows won't grow until you have gotten back under the pressure value. Allowing bigger windows means that it takes fewer connections for someone evil to make the rest of the tcp streams to go slow.
What you remove is an artificial limit to tcp performance, without that limit you are bounded by the available end-to-end bandwidth and loss. So you might end up saturating your uplink more effectively, but tcp is good at handling this.
The txqueuelen increase will eat about 1.5 megabytes of memory at most given an MSS of 1500 bytes (normal ethernet).
Regarding min_free_kbytes, faster networking means kernel buffers get full faster and you need more headroom to be able to allocate them. You need to have enough to last until the vm manages to free up more memory, and at high transfer speeds you have high buffer filling speeds too. This will eat memory though, memory that will not be available for normal processes or file cache.
If you see stuff like "swapper: page allocation failure. order:0, mode:0x20" you definately need to increase min_free_kbytes for the vm.
BDP is a calculation of how much data your network supports in transit between two points (client & server, two peers, etc.). It’s based on your connection’s latency and available bandwidth. but BDP can also indicate the ideal advertised TCP window size. To find your BDP, multiply the bandwidth by the round trip time (latency), then divide the product by 8.
A higher latency means a higher BDP and warrants a higher default receive window size.
See also NFS performance tuning
The basic tuning steps include:
Try using NFSv3 if you are currently using NFSv2. There can be very significant performance increases with this change.
Increasing the read write block size. This is done with the rsize and wsize mount options. They need to the mount options used by the NFS clients. Values of 4096 and 8192 reportedly increase performance. But see the notes in the HOWTO about experimenting and measuring the performance implications. The limits on these are 8192 for NFSv2 and 32768 for NFSv3
Another approach is to increase the number of nfsd threads running. This is normally controlled by the nfsd init script. On Red Hat Linux machines, the value "RPCNFSDCOUNT" in the nfs init script controls this value. The best way to determine if you need this is to experiment. The HOWTO mentions a way to determine thread usage.
Another good tool for getting some handle on NFS server performance is `nfsstat`. This util reads the info in /proc/net/rpc/nfs[d] and displays it in a somewhat readable format. Some info intended for tuning Solaris, but useful for it's description of the nfsstat format
See also the tcp tuning info
Make sure you starting a ton of initial daemons if you want good benchmark scores.
Something like:
#######
MinSpareServers 20
MaxSpareServers 80
StartServers 32
# this can be higher if apache is recompiled
MaxClients 256
MaxRequestsPerChild 10000
Note: Starting a massive amount of httpd processes is really a benchmark hack. In most real world
cases, setting a high number for max servers, and a sane spare server setting will be more than adequate.
It's just the instant on load that benchmarks typically generate that the StartServers helps with.
The MaxRequestPerChild should be bumped up if you are sure that your httpd processes do not leak memory. Setting this value to 0 will cause the processes to never reach a limit.
One of the best resources on tuning these values, especially for app servers, is the mod_perl performance tuning documentation.
Bumping the number of available httpd processes
Apache sets a maximum number of possible processes at compile time. It is set to 256 by default, but in this kind of scenario, can often be exceeded.
To change this, you will need to chage the hardcoded limit in the apache source code, and recompile it. An example of the change is below:
--- apache_1.3.6/src/include/httpd.h.prezab Fri Aug 6 20:11:14 1999 +++ apache_1.3.6/src/include/httpd.h Fri Aug 6 20:12:50 1999 @@ -306,7 +306,7 @@ * the overhead. */ #ifndef HARD_SERVER_LIMIT -#define HARD_SERVER_LIMIT 256 +#define HARD_SERVER_LIMIT 4000 #endif /*
To make useage of this many apache's however, you will also need to boost the number of processes support, at least for 2.2 kernels. See the section on kernel process limits for info on increasing this.
In cases where each connection takes a long time to complete, this is only compounded. Connections can be slow to complete because of large amounts of cpu or i/o usage in dynamic apps, large files being transferred, or just talking to clients on slow links.
There are several strategies to mitigate this. The basic idea being to free up heavyweight apache processes from having to handle slow to complete connections.
Static Content Servers
If the servers are serving lots of static files (images, videos, pdf's, etc), a common approach is to serve these files off a dedicated server. This could be a very light apache setup, or any many cases, something like thttpd, boa, khttpd, or TUX. In some cases it is possible to run the static server on the same server, addressed via a different hostname.For purely static content, some of the other smaller more lightweight web servers can offer very good performance. They arent nearly as powerful or as flexible as apache, but for very specific performance crucial tasks, they can be a big win.
Boa: http://www.boa.org/If you need even more ExtremeWebServerPerformance, you probabaly want to take a look at TUX, written by Ingo Molnar. This is the current world record holder for SpecWeb99. It probabaly owns the right to be called the worlds fastest web server.
Proxy Usage For servers that are serving dynamic content, or ssl content, a better approach is to employ a reverse-proxy. Typically, this would done with either apache's mod_proxy, or Squid. There can be several advantages from this type of configuration, including content caching, load balancing, and the prospect of moving slow connections to lighter weight servers.The easiest approache is probabaly to use mod_proxy and the "ProxyPass" directive to pass content to another server. mod_proxy supports a degree of caching that can offer a significant performance boost. But another advantage is that since the proxy server and the web server are likely to have a very fast interconnect, the web server can quickly serve up large content, freeing up a apache process, why the proxy slowly feeds out the content to clients. This can be further enhanced by increasing the amount of socket buffer memory thats for the kernel. See the section on tcp tuning for info on this.
ListenBacklog
One of the most frustrating thing for a user of a website, is to get "connection refused" error messages. With apache, the common cause of this is for the number of concurent connections to exceed the number of available httpd processes that are available to handle connections.The apache ListenBacklog paramater lets you specify what backlog paramater is set to listen(). By default on linux, this can be as high as 128.
Increasing this allows a limited number of httpd's to handle a burst of attempted connections.
There are some experimental patches from SGI that accelerate apache. More info at:
http://oss.sgi.com/projects/apache/I havent really had a chance to test the SGI patches yet, but I've been told they are pretty effective.
The first one is to rebuild it with mmap support. In cases where you are serving up a large amount of small files, this seems to be particularly useful. You just need to add a "--with-mmap" to the configure line.
You also want to make sure the following options are enabled in the /etc/smb.conf file:
read raw = no read prediction = true level2 oplocks = true
One of the better resources for tuning samba is the "Using Samba" book from O'Reilly. The Chapter on performance tuning is available online.
I use the values:
cachesize 10000 dbcachesize 100000 sizelimit 10000 loglevel 0 dbcacheNoWsync index cn,uid index uidnumber index gid index gidnumber index mail
If you add the following parameters to /etc/openldap/slapd.conf before entering the info into the database, they will all get indexed and performance will increase.
See Sendmail performance tuning
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
09.30.2008You've just had your first cup of coffee and have received that dreaded phone call. The system is slow. What are you going to do? This article will discuss performance bottlenecks and optimization in Red Hat Enterprise Linux (RHEL5).
Before getting into any monitoring or tuning specifics, you should always use some kind of tuning methodology. This is one which I've used successfully through the years:
1. Baseline – The first thing you must do is establish a baseline, which is a snapshot of how the system appears when it's performing well. This baseline should not only compile data, but also document your system's configuration (RAM, CPU and I/O). This is necessary because you need to know what a well-performing system looks like prior to fixing it.
2. Stress testing and monitoring – This is the part where you monitor and stress your systems at peak workloads. It's the monitoring which is key here – as you cannot effectively tune anything without some historic trending data.
3. Bottleneck identification – This is where you come up with the diagnosis for what is ailing your system. The primary objective of section 2 is to determine the bottleneck. I like to use several monitoring tools here. This allows me to cross-reference my data for accuracy.
4. Tune – Only after you've identified the bottleneck can you tune it.
5. Repeat – Once you've tuned it, you can start the cycle again – but this time start from step 2 (monitoring) – as you already have your baseline.
It's important to note that you should only make one change at a time. Otherwise, you'll never know exactly what impacted any changes which might have occurred. It is only by repeating your tests and consistently monitoring your systems that you can determine if your tuning is making an impact.
RHEL monitoring toolsBefore we can begin to improve the performance of our system, we need to use the monitoring tools available to us to baseline. Here are some monitoring tools you should consider using:
OprofileThis tool (made available in RHEL5) utilizes the processor to retrieve kernel system information about system executables. It allows one to collect samples of performance data every time a counter detects an interrupt. I like the tool also because it carries little overhead – which is very important because you don't want monitoring tools to be causing system bottlenecks. One important limitation is that the tool is very much geared towards finding problems with CPU limited processes. It does not identify processes which are sleeping or waiting on I/O.
The steps used to start up Oprofile include setting up the profiler, starting it and then dumping the data.
First we'll set up the profile. This option assumes that one wants to monitor the kernel.
# opcontrol --setup -vmlinux=/usr/lib/debug/lib/modules/'uname -r'/vmlinuxThen we can start it up.
# opcontrol --startFinally, we'll dump the data.
# opcontrol --stop/--shutdown/--dumpThis tool (introduced in RHEL5) collects data by analyzing the running kernel. It really helps one come up with a correct diagnosis of a performance problem and is tailor-made for developers. SystemTap eliminates the need for the developer to go through the recompile and reinstallation process to collect data.
FryskThis is another tool which was introduced by Red Hat in RHEL5. What does it do for you? It allows both developers and system administrators to monitor running processes and threads. Frysk differs from Oprofile in that it uses 100% reliable information (similar to SystemTap) - not just a sampling of data. It also runs in user mode and does not require kernel modules or elevated privileges. Allowing one to stop or start running threads or processes is also a very useful feature.
Some more general Linux tools include top and vmstat. While these are considered more basic, often I find them much more useful than more complex tools. Certainly they are easier to use and can help provide information in a much quicker fashion.Top provides a quick snapshot of what is going on in your system – in a friendly character-based display.
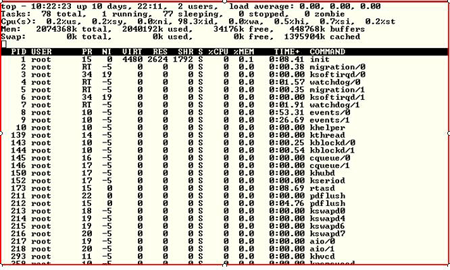
It also provides information on CPU, Memory and Swap Space.
Let's look at vmstat – one of the oldest but more important Unix/Linux tools ever created. Vmstat allows one to get a valuable snapshot of process, memory, sway I/O and overall CPU utilization.Now let's define some of the fields:
Memory
swpd – The amount of virtual memory
free – The amount of free memory
buff – Amount of memory used for buffers
cache – Amount of memory used as page cacheProcess
r – number of run-able processes
b – number or processes sleeping. Make sure this number does not exceed the amount of run-able processes, because when this condition occurs it usually signifies that there are performance problems.Swap
CPU
si – the amount of memory swapped in from disk
so – the amount of memory swapped out.
This is another important field you should be monitoring – if you are swapping out data, you will likely be having performance problems with virtual memory.
us – The % of time spent in user-level code.
It is preferable for you to have processes which spend more time in user code rather than system code. Time spent in system level code usually means that the process is tied up in the kernel rather than processing real data.
sy – the time spent in system level code
id – the amount of time the CPU is idle wa – The amount of time the system is spending waiting for I/O.If your system is waiting on I/O – everything tends to come to a halt. I start to get worried when this is > 10.
There is also:
Free – This tool provides memory information, giving you data around the total amount of free and used physical and swap memory.
Now that we've analyzed our systems – lets look at what we can do to optimize and tune our systems.
CPU Overhead – Shutting Running Processes
Linux starts up all sorts of processes which are usually not required. This includes processes such as autofs, cups, xfs, nfslock and sendmail. As a general rule, shut down anything that isn't explicitly required. How do you do this? The best method is to use the chkconfig command.Here's how we can shut these processes down.
[root ((Content component not found.)) _29_140_234 ~]# chkconfig --del xfsYou can also use the GUI - /usr/bin/system-config-services to shut down daemon process.
Tuning the kernel
To tune your kernel for optimal performance, start with:sysctl – This is the command we use for changing kernel parameters. The parameters themselves are found in /proc/sys/kernel
Let's change some of the parameters. We'll start with the msgmax parameter. This parameter specifies the maximum allowable size of a single message in an IPC message queue. Let's view how it currently looks.
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 65536
[root ((Content component not found.)) _29_139_52 ~]#There are three ways to make these kinds of kernel changes. One way is to change this using the echo command.
[root ((Content component not found.)) _29_139_52 ~]# echo 131072 >/proc/sys/kernel/msgmax
[root ((Content component not found.)) _29_139_52 ~]# sysctl kernel.msgmax
kernel.msgmax = 131072
[root ((Content component not found.)) _29_139_52 ~]#Another parameter that is changed quite frequently is SHMMAX, which is used to define the maximum size (in bytes) for a shared memory segment. In Oracle this should be set large enough for the largest SGA size. Let's look at the default parameter:
# sysctl kernel.shmmax
kernel.shmmax = 268435456This is in bytes – which translates to 256 MG. Let's change this to 512 MG, using the -w flag.
[root ((Content component not found.)) _29_139_52 ~]# sysctl -w kernel.shmmax=5368709132
kernel.shmmax = 5368709132
[root ((Content component not found.)) _29_139_52 ~]#The final method for making changes is to use a text editor such as vi – directly editing the /etc/sysctl.conf file to manually make our changes.
To allow the parameter to take affect dynamically without a reboot, issue the sysctl command with the -p parameter.
Obviously, there is more to performance tuning and optimization than we can discuss in the context of this small article – entire books have been written on Linux performance tuning. For those of you first getting your hands dirty with tuning, I suggest you tread lightly and spend time working on development, test and/or sandbox environments prior to deploying any changes into production. Ensure that you monitor the effects of any changes that you make immediately; it's imperative to know the effect of your change. Be prepared for the possibility that fixing your bottleneck has created another one. This is actually not a bad thing in itself, as long as your overall performance has improved and you understand fully what is happening.
Performance monitoring and tuning is a dynamic process which does not stop after you have fixed a problem. All you've done is established a new baseline. Don't rest on your laurels, and understand that performance monitoring must be a routine part of your role as a systems administrator.About the author: Ken Milberg is a systems consultant with two decades of experience working with Unix and Linux systems. He is a SearchEnterpriseLinux.com Ask the Experts advisor and columnist.
Feb 03, 2006
Tip 3. Adjust TCP windows for the Bandwidth Delay Product
TCP depends on several factors for performance. Two of the most important are the link bandwidth (the rate at which packets can be transmitted on the network) and the round-trip time, or RTT (the delay between a segment being sent and its acknowledgment from the peer). These two values determine what is called the Bandwidth Delay Product (BDP).
Given the link bandwidth rate and the RTT, you can calculate the BDP, but what does this do for you? It turns out that the BDP gives you an easy way to calculate the theoretical optimal TCP socket buffer sizes (which hold both the queued data awaiting transmission and queued data awaiting receipt by the application). If the buffer is too small, the TCP window cannot fully open, and this limits performance. If it's too large, precious memory resources can be wasted. If you set the buffer just right, you can fully utilize the available bandwidth. Let's look at an example:
BDP = link_bandwidth * RTTIf your application communicates over a 100Mbps local area network with a 50 ms RTT, the BDP is:
100MBps * 0.050 sec / 8 = 0.625MB = 625KBNote: I divide by 8 to convert from bits to bytes communicated.
So, set your TCP window to the BDP, or 625KB. But the default window for TCP on Linux 2.6 is 110KB, which limits your bandwidth for the connection to 2.2MBps, as I've calculated here:
throughput = window_size / RTT 110KB / 0.050 = 2.2MBpsIf instead you use the window size calculated above, you get a whopping 12.5MBps, as shown here:
625KB / 0.050 = 12.5MBpsThat's quite a difference and will provide greater throughput for your socket. So you now know how to calculate the optimal socket buffer size for your socket. But how do you make this change?
... ... ...
Table 1 is a list of several tunable parameters that can help you increase the performance of the Linux TCP/IP stack.
Table 1. Kernel tunable parameters for TCP/IP stack performance Tunable parameter Default value Option description /proc/sys/net/core/rmem_default"110592" Defines the default receive window size; for a large BDP, the size should be larger. /proc/sys/net/core/rmem_max"110592" Defines the maximum receive window size; for a large BDP, the size should be larger. /proc/sys/net/core/wmem_default"110592" Defines the default send window size; for a large BDP, the size should be larger. /proc/sys/net/core/wmem_max"110592" Defines the maximum send window size; for a large BDP, the size should be larger. /proc/sys/net/ipv4/tcp_window_scaling"1" Enables window scaling as defined by RFC 1323; must be enabled to support windows larger than 64KB. /proc/sys/net/ipv4/tcp_sack"1" Enables selective acknowledgment, which improves performance by selectively acknowledging packets received out of order (causing the sender to retransmit only the missing segments); should be enabled (for wide area network communication), but it can increase CPU utilization. /proc/sys/net/ipv4/tcp_fack"1" Enables Forward Acknowledgment, which operates with Selective Acknowledgment (SACK) to reduce congestion; should be enabled. /proc/sys/net/ipv4/tcp_timestamps"1" Enables calculation of RTT in a more accurate way (see RFC 1323) than the retransmission timeout; should be enabled for performance. /proc/sys/net/ipv4/tcp_mem"24576 32768 49152" Determines how the TCP stack should behave for memory usage; each count is in memory pages (typically 4KB). The first value is the low threshold for memory usage. The second value is the threshold for a memory pressure mode to begin to apply pressure to buffer usage. The third value is the maximum threshold. At this level, packets can be dropped to reduce memory usage. Increase the count for large BDP (but remember, it's memory pages, not bytes). /proc/sys/net/ipv4/tcp_wmem"4096 16384 131072" Defines per-socket memory usage for auto-tuning. The first value is the minimum number of bytes allocated for the socket's send buffer. The second value is the default (overridden by wmem_default) to which the buffer can grow under non-heavy system loads. The third value is the maximum send buffer space (overridden bywmem_max)./proc/sys/net/ipv4/tcp_rmem"4096 87380 174760" Same as tcp_wmemexcept that it refers to receive buffers for auto-tuning./proc/sys/net/ipv4/tcp_low_latency"0" Allows the TCP/IP stack to give deference to low latency over higher throughput; should be disabled. /proc/sys/net/ipv4/tcp_westwood"0" Enables a sender-side congestion control algorithm that maintains estimates of throughput and tries to optimize the overall utilization of bandwidth; should be enabled for WAN communication. This option is also useful for wireless interfaces, as packet loss may not be caused by congestion. /proc/sys/net/ipv4/tcp_bic"1" Enables Binary Increase Congestion for fast long-distance networks; permits better utilization of links operating at gigabit speeds; should be enabled for WAN communication. As with any tuning effort, the best approach is experimental in nature. Your application behavior, processor speed, and availability of memory all affect how these parameters will alter performance. In some cases, what you think should be beneficial can be detrimental (and vice versa). So, try an option and then check the result. In other words, trust but verify.
Bonus tip: A word about persistent configuration. Note that if you reboot a GNU/Linux system, any tunable kernel parameters that you changed revert to their default. To make yours the default parameter, use the file
/etc/sysctl.confto configure the parameters at boot-time for your configuration.
11/17/2005 | O'Reilly Media
Computing the TCP Buffer Size
Assuming there is no network congestion or packet loss, network throughput is directly related to TCP buffer size and the network latency. Network latency is the amount of time for a packet to traverse the network. To calculate maximum throughput:
Throughput = buffer size / latencyTypical network latency from Sunnyvale to Reston is about 40ms, and Windows XP has a default TCP buffer size of 17,520 bytes. Therefore, Bob's maximum possible throughput is:
17520 Bytes / .04 seconds = .44 MBytes/sec = 3.5 Mbits/secondThe default TCP buffer size for Mac OS X is 64K, so with Mac OS X he would have done a bit better, but still nowhere near the 100Mbps that should be possible.
65936 Bytes / .04 seconds = 1.6 MBytes/sec = 13 Mbits/second(Network people always use bits per second, but the rest of the computing world thinks in terms of bytes, not bits. This often leads to confusion.)
Most networking experts agree that the optimal TCP buffer size for a given network link is double the value for delay times bandwidth:
buffer size = 2 * delay * bandwidthThe
pingprogram will give you the round trip time (RTT) for the network link, which is twice the delay, so the formula simplifies to:buffer size = RTT * bandwidthFor Bob's network,
pingreturned a RTT of 80ms. This means that his TCP buffer size should be:.08 seconds * 100 Mbps / 8 = 1 MByteBob knew the speed of his company's VPN, but often you will not know the capacity of the network path. Determining this can be difficult. These days, most wide area backbone links are at least 1Gbps (in the United States, Europe, and Japan anyway), so the bottleneck links are likely to be the local networks at each endpoint. In my experience, most office computers connect to 100Mbps Ethernet networks, so when in doubt, 100Mbps (12MBps) is a good value to use.
Tuning the buffer size will have no effect on networks that are 10Mbps or less; for example, with the hosts connected to a DSL link, cable modem, ISDN, or T1 line. There is a program called pathrate that does a good job of estimating network bandwidth. However, this program works on Linux only, and requires the ability to log in to both computers to start the program.
Setting the TCP Buffer Size
There are two TCP settings to consider: the default TCP buffer size and the maximum TCP buffer size. A user-level program can modify the default buffer size, but the maximum buffer size requires administrator privileges. Note that most of today's Unix-based OSes by default have a maximum TCP buffer size of only 256K. Windows does not have a maximum buffer size by default, but the administrator may set one. It is necessary to change both the send and receive TCP buffers. Changing only the send buffer will have no effect, as TCP negotiates the buffer size to be the smaller of the two. This means that it is not necessary to set both the send and receive buffer to the optimal value. A common technique is to set the buffer in the server quite large (for example, 1,024K) and then let the client determine and set the correct "optimal" value for that network path. To set the TCP buffer, use the setSendBufferSize and setReceiveBufferSize methods in Java, or the
setsockoptcall in C. Here is an example of how to set TCP buffer sizes within your application using Java:java.net.Socket skt; int sndsize; int sockbufsize; /* set send buffer */ skt.setSendBufferSize(sndsize); /* check to make sure you received what you asked for */ sockbufsize = skt.getSendBufferSize(); /* set receive buffer */ skt.setReceiveBufferSize(sndsize); /* check to make sure you received what you asked for */ sockbufsize = skt.getReceiveBufferSize();It is always a good idea to call
getSendBufferSize(orgetReceiveBufferSize) after setting the buffer size. This will ensure that the OS supports buffers of that size. Thesetsockoptcall will not return an error if you use a value larger than the maximum buffer size, but will just use the maximum size instead of the value you specify. Linux mysteriously doubles whatever value you pass in for the buffer size, so when you do agetSendBufferSize/getReceiveBufferSizeyou will see double what you asked for. Don't worry, as this is "normal" for Linux.
Slaptijack
If you have been following our TCP Performance Tuning series, you'll know that we want to enable RFC 1323 Window Scaling and increase the TCP window size to 1 MB. To do this, we'll add the following lines to
/etc/sysctl.confand issuesudo sysctl -pto apply the changes immediately.
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.core.rmem_default = 1048576
net.core.wmem_default = 1048576
net.ipv4.tcp_rmem = 4096 1048576 16777216
net.ipv4.tcp_wmem = 4096 1048576 16777216
net.ipv4.tcp_congestion_control = bic
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1As before, we're setting the maximum buffer size large and the default window size to 1 MB. RFC 1323 is enabled via
net.ipv4.tcp_window_scalingandnet.ipv4.tcp_timestamps. These options are probably on by default, but it never hurts to force them via/etc/sysctl.conf. Finally, we are choosing BIC as our TCP Congestion Control Algorithm. Again, that value is most likely the default on your system (especially any kernel version after 2.6.12).
Mar 18 , 2013 | NASA
- Article ID: 138
- Posted: 26 Jul, 2010 by Dunbar J.
- Updated: 18 Mar, 2013 by Massaro K.
This document describes additional TCP settings that can be tuned on high-performance Linux systems. This is intended for 10-Gigabit hosts, but can also be applied to 1-Gigabit hosts. The following steps should be taken in addition to the steps outlined in TCP Performance Tuning for WAN transfers.
Configure the following /etc/sysctl.conf settings for faster TCP
- Set maximum TCP window sizes to 12 megabytes:
net.core.rmem_max = 11960320 net.core.wmem_max = 11960320- Set minimum, default, and maximum TCP buffer limits:
net.ipv4.tcp_rmem = 4096 524288 11960320 net.ipv4.tcp_wmem = 4096 524288 11960320- Set maximum network input buffer queue length:
net.core.netdev_max_backlog = 30000- Disable caching of TCP congestion state (Linux Kernel version 2.6 only). Fixes a bug in some Linux stacks:
net.ipv4.tcp_no_metrics_save = 1- Use the BIC TCP congestion control algorithm instead of the TCP Reno algorithm (Linux Kernel versions 2.6.8 to 2.6.18):
net.ipv4.tcp_congestion_control = bic- Use the CUBIC TCP congestion control algorithm instead of the TCP Reno algorithm (Linux Kernel versions 2.6.18 and newer):
net.ipv4.tcp_congestion_control = cubic- Set the following to 1 (should default to 1 on most systems):
net.ipv4.tcp_window_scaling =1 net.ipv4.tcp_timestamps = 1 net.ipv4.tcp_sack = 1A reboot will be needed for changes to /etc/sysctl.conf to take effect, or you can attempt to reload sysctl settings (as root) with sysctl -p.
For additional information visit the Energy Science Network website.
If you have a 10-Gb system or if you follow these steps and are still getting less than your expected throughput, please contact NAS Control Room staff at [email protected], and we will work with you on tuning your system to optimize file transfers.
Oct 29, 2010 | Linux Administration
To make persistent changes to the kernel settings described bellow, add the entries to the /etc/sysctl.conf file and then run "sysctl -p" to apply.Like all operating systems, the default maximum Linux TCP buffer sizes are way too small. I suggest changing them to the following settings:
To increase TCP max buffer size setable using setsockopt():
To increase Linux autotuning TCP buffer limits min, default, and max number of bytes to use set max to 16MB for 1GE, and 32M or 54M for 10GE:
1 2
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432You should also verify that the following are all set to the default value of 1:
1 2
net.ipv4.tcp_rmem = 4096 87380 33554432
net.ipv4.tcp_wmem = 4096 65536 33554432Note: you should leave tcp_mem alone. The defaults are fine.
1 2
3sysctl net.ipv4.tcp_window_scaling
sysctl net.ipv4.tcp_timestampssysctl net.ipv4.tcp_sack
Another thing you can do to help increase TCP throughput with 1GB NICs is to increase the size of the interface queue. For paths with more than 50 ms RTT, a value of 5000-10000 is recommended. To increase txqueuelen, do the following:
You can achieve increases in bandwidth of up to 10x by doing this on some long, fast paths. This is only a good idea for Gigabit Ethernet connected hosts, and may have other side effects such as uneven sharing between multiple streams.
1 [root@server1 ~]ifconfigeth0 txqueuelen 5000
Other kernel settings that help with the overall server performance when it comes to network traffic are the following:
TCP_FIN_TIMEOUT - This setting determines the time that must elapse before TCP/IP can release a closed connection and reuse its resources. During this TIME_WAIT state, reopening the connection to the client costs less than establishing a new connection. By reducing the value of this entry, TCP/IP can release closed connections faster, making more resources available for new connections. Addjust this in the presense of many connections sitting in the TIME_WAIT state:
TCP_KEEPALIVE_INTERVAL - This determines the wait time between isAlive interval probes. To set:
1 [root@server:~]# echo 30 > /proc/sys/net/ipv4/tcp_fin_timeout
TCP_KEEPALIVE_PROBES - This determines the number of probes before timing out. To set:
1 [root@server:~]# echo 30 > /proc/sys/net/ipv4/tcp_keepalive_intvl
TCP_TW_RECYCLE - This enables fast recycling of TIME_WAIT sockets. The default value is 0 (disabled). Should be used with caution with loadbalancers.
1 [root@server:~]# echo 5 > /proc/sys/net/ipv4/tcp_keepalive_probes
TCP_TW_REUSE - This allows reusing sockets in TIME_WAIT state for new connections when it is safe from protocol viewpoint. Default value is 0 (disabled). It is generally a safer alternative to tcp_tw_recycle
1 [root@server:~]# echo 1 > /proc/sys/net/ipv4/tcp_tw_recycle
Note: The tcp_tw_reuse setting is particularly useful in environments where numerous short connections are open and left in TIME_WAIT state, such as web servers and loadbalancers. Reusing the sockets can be very effective in reducing server load.
1 [root@server:~]# echo 1 > /proc/sys/net/ipv4/tcp_tw_reuseStarting in Linux 2.6.7 (and back-ported to 2.4.27), linux includes alternative congestion control algorithms beside the traditional 'reno' algorithm. These are designed to recover quickly from packet loss on high-speed WANs.
There are a couple additional sysctl settings for kernels 2.6 and newer:
Not to cache ssthresh from previous connection:To increase this for 10G NICS:
1 net.ipv4.tcp_no_metrics_save = 1Starting with version 2.6.13, Linux supports pluggable congestion control algorithms . The congestion control algorithm used is set using the sysctl variable net.ipv4.tcp_congestion_control, which is set to bic/cubic or reno by default, depending on which version of the 2.6 kernel you are using.
1 net.core.netdev_max_backlog = 30000To get a list of congestion control algorithms that are available in your kernel (if you are running 2.6.20 or higher), run:
The choice of congestion control options is selected when you build the kernel. The following are some of the options are available in the 2.6.23 kernel:
1 [root@server1 ~]# sysctl net.ipv4.tcp_available_congestion_control* reno: Traditional TCP used by almost all other OSes. (default)
* cubic: CUBIC-TCP (NOTE: There is a cubic bug in the Linux 2.6.18 kernel used by Redhat Enterprise Linux 5.3 and Scientific Linux 5.3. Use 2.6.18.2 or higher!)* bic: BIC-TCP
* htcp: Hamilton TCP* vegas: TCP Vegas
* westwood: optimized for lossy networks
If cubic and/or htcp are not listed when you do 'sysctl net.ipv4.tcp_available_congestion_control', try the following, as most distributions include them as loadable kernel modules:
For long fast paths, I highly recommend using cubic or htcp. Cubic is the default for a number of Linux distributions, but if is not the default on your system, you can do the following:
1 2
[root@server1 ~]# /sbin/modprobe tcp_htcp
[root@server1 ~]# /sbin/modprobe tcp_cubicOn systems supporting RPMS, You can also try using the ktune RPM, which sets many of these as well.
1 [root@server1 ~]# sysctl -w net.ipv4.tcp_congestion_control=cubic
If you have a load server that has many connections in TIME_WAIT state decrease the TIME_WAIT interval that determines the time that must elapse before TCP/IP can release a closed connection and reuse its resources. This interval between closure and release is known as the TIME_WAIT state or twice the maximum segment lifetime (2MSL) state. During this time, reopening the connection to the client and server cost less than establishing a new connection. By reducing the value of this entry, TCP/IP can release closed connections faster, providing more resources for new connections. Adjust this parameter if the running application requires rapid release, the creation of new connections, and a low throughput due to many connections sitting in the TIME_WAIT state:
If you are often dealing with SYN floods the following tunning can be helpful:
1 [root@host1 ~]# echo 5 > /proc/sys/net/ipv4/tcp_fin_timeout
The parameter on line 1 is the maximum number of remembered connection requests, which still have not received an acknowledgment from connecting clients.
1 2
3[root@host1 ~]# sysctl -w net.ipv4.tcp_max_syn_backlog="16384"
[root@host1 ~]# sysctl -w net.ipv4.tcp_synack_retries="1"[root@host1 ~]# sysctl -w net.ipv4.tcp_max_orphans="400000"
The parameter on line 2 determines the number of SYN+ACK packets sent before the kernel gives up on the connection. To open the other side of the connection, the kernel sends a SYN with a piggybacked ACK on it, to acknowledge the earlier received SYN. This is part 2 of the three-way handshake.
And lastly on line 3 is the maximum number of TCP sockets not attached to any user file handle, held by system. If this number is exceeded orphaned connections are reset immediately and warning is printed. This limit exists only to prevent simple DoS attacks, you _must_ not rely on this or lower the limit artificially, but rather increase it (probably, after increasing installed memory), if network conditions require more than default value, and tune network services to linger and kill such states more aggressively.More information on tuning parameters and defaults for Linux 2.6 are available in the file ip-sysctl.txt, which is part of the 2.6 source distribution.
Warning on Large MTUs: If you have configured your Linux host to use 9K MTUs, but the connection is using 1500 byte packets, then you actually need 9/1.5 = 6 times more buffer space in order to fill the pipe. In fact some device drivers only allocate memory in power of two sizes, so you may even need 16/1.5 = 11 times more buffer space!
And finally a warning for both 2.4 and 2.6: for very large BDP paths where the TCP window is > 20 MB, you are likely to hit the Linux SACK implementation problem. If Linux has too many packets in flight when it gets a SACK event, it takes too long to located the SACKed packet, and you get a TCP timeout and CWND goes back to 1 packet. Restricting the TCP buffer size to about 12 MB seems to avoid this problem, but clearly limits your total throughput. Another solution is to disable SACK.
Starting with Linux 2.4, Linux implemented a sender-side autotuning mechanism, so that setting the optimal buffer size on the sender is not needed. This assumes you have set large buffers on the receive side, as the sending buffer will not grow beyond the size of the receive buffer.
However, Linux 2.4 has some other strange behavior that one needs to be aware of. For example: The value for ssthresh for a given path is cached in the routing table. This means that if a connection has has a retransmission and reduces its window, then all connections to that host for the next 10 minutes will use a reduced window size, and not even try to increase its window. The only way to disable this behavior is to do the following before all new connections (you must be root):
Lastly I would like to point out how important it is to have a sufficient number of available file descriptors, since pretty much everything on Linux is a file.
1 [root@server1 ~]# sysctl -w net.ipv4.route.flush=1To check your current max and availability run the following:
The first value (197600) is the number of allocated file handles.
1 2
[root@host1 ~]# sysctl fs.file-nr
fs.file-nr = 197600 0 3624009
The second value (0) is the number of unused but allocated file handles. And the third value (3624009) is the system-wide maximum number of file handles. It can be increased by tuning the following kernel parameter:To see how many file descriptors are being used by a process you can use one of the following:
1 [root@host1 ~]# echo 10000000 > /proc/sys/fs/file-maxThe 28290 number is the process id.
1 2
[root@host1 ~]# lsof -a -p 28290
[root@host1 ~]# ls -l /proc/28290/fd | wc -l
Open files
Since we deal with a lot of file handles (each TCP socket requires a file handle), we need to keep our open file limit high. The current value can be seen using
ulimit -a(look for open files). We set this value to999999and hope that we never need a million or more files open. In practice we never do.We set this limit by putting a file into
/etc/security/limits.d/that contains the following two lines:* soft nofile 999999 * hard nofile 999999(side node: it took me 10 minutes trying to convince Markdown that those asterisks were to be printed as asterisks)
If you don't do this, you'll run out of open file handles and could see one or more parts of your stack die.
Ephemeral Ports
The second thing to do is to increase the number of Ephemeral Ports available to your application. By default this is all ports from
32768to61000. We change this to all ports from18000to65535. Ports below 18000 are reserved for current and future use of the application itself. This may change in the future, but is sufficient for what we need right now, largely because of what we do next.TIME_WAIT state
TCP connections go through various states during their lifetime. There's the handshake that goes through multiple states, then the
ESTABLISHEDstate, and then a whole bunch of states for either end to terminate the connection, and finally aTIME_WAITstate that lasts a really long time. If you're interested in all the states, read through the netstat man page, but right now the only one we care about is theTIME_WAITstate, and we care about it mainly because it's so long.By default, a connection is supposed to stay in the
TIME_WAITstate for twice the msl. Its purpose is to make sure any lost packets that arrive after a connection is closed do not confuse the TCP subsystem (the full details of this are beyond the scope of this article, but ask me if you'd like details). The defaultmslis 60 seconds, which puts the defaultTIME_WAIT timeoutvalue at 2 minutes. Which means you'll run out of available ports if you receive more than about 400 requests a second, or if we look back to how nginx does proxies, this actually translates to 200 requests per second. Not good for scaling.We fixed this by setting the timeout value to 1 second.
I'll let that sink in a bit. Essentially we reduced the timeout value by 99.16%. This is a huge reduction, and not to be taken lightly. Any documentation you read will recommend against it, but here's why we did it.
Again, remember the point of the
TIME_WAITstate is to avoid confusing the transport layer. The transport layer will get confused if it receives an out of order packet on a currently established socket, and send a reset packet in response. The key here is the term established socket. A socket is a tuple of 4 terms. The source and destination IPs and ports. Now for our purposes, our server IP is constant, so that leaves 3 variables.Our port numbers are recycled, and we have 47535 of them. That leaves the other end of the connection.
In order for a collision to take place, we'd have to get a new connection from an existing client, AND that client would have to use the same port number that it used for the earlier connection, AND our server would have to assign the same port number to this connection as it did before. Given that we use persistent HTTP connections between clients and nginx, the probability of this happening is so low that we can ignore it. 1 second is a long enough
TIME_WAITtimeout.The two TCP tuning parameters were set using
sysctlby putting a file into/etc/sysctl.d/with the following:net.ipv4.ip_local_port_range = 18000 65535 net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait = 1Connection Tracking
The next parameter we looked at was Connection Tracking. This is a side effect of using
iptables. Sinceiptablesneeds to allow two-way communication between established HTTP and ssh connections, it needs to keep track of which connections are established, and it puts these into a connection tracking table. This table grows. And grows. And grows.You can see the current size of this table using
sysctl net.netfilter.nf_conntrack_countand its limit usingsysctl net.nf_conntrack_max. If count crosses max, your linux system will stop accepting new TCP connections and you'll never know about this. The only indication that this has happened is a single line hidden somewhere in/var/log/syslogsaying that you're out of connection tracking entries. One line, once, when it first happens.A better indication is if count is always very close to max. You might think, "Hey, we've set max exactly right.", but you'd be wrong.
What you need to do (or at least that's what you first think) is to increase max.
Keep in mind though, that the larger this value, the more RAM the kernel will use to keep track of these entries. RAM that could be used by your application.
We started down this path, increasing
net.nf_conntrack_max, but soon we were just pushing it up every day. Connections that were getting in there were never getting out.nf_conntrack_tcp_timeout_established
It turns out that there's another timeout value you need to be concerned with. The established connection timeout. Technically this should only apply to connections that are in the
ESTABLISHEDstate, and a connection should get out of this state when aFINpacket goes through in either direction. This doesn't appear to happen and I'm not entirely sure why.So how long do connections stay in this table then? The default value for
nf_conntrack_tcp_timeout_establishedis 432000 seconds. I'll wait for you to do the long division…Fun times.
I changed the timeout value to 10 minutes (600 seconds) and in a few days time I noticed
conntrack_countgo down steadily until it sat at a very manageable level of a few thousand.We did this by adding another line to the sysctl file:
net.netfilter.nf_conntrack_tcp_timeout_established=600Speed bump
At this point we were in a pretty good state. Our beacon collectors ran for months (not counting scheduled reboots) without a problem, until a couple of days ago, when one of them just stopped responding to any kind of network requests. No ping responses, no
ACKpackets to aSYN, nothing. All established ssh and HTTP connections terminated and the box was doing nothing. I still had console access, and couldn't tell what was wrong. The system was using less than 1% CPU and less than 10% of RAM. All processes that were supposed to be running were running, but nothing was coming in or going out.I looked through
syslog, and found one obscure message repeated several times.IPv4: dst cache overflowWell, there were other messages, but this was the one that mattered.
I did a bit of searching online, and found something about an rt_cache leak in 2.6.18. We're on 3.5.2, so it shouldn't have been a problem, but I investigated anyway.
The details of the post above related to 2.6, and 3.5 was different, with no
ip_dst_cacheentry in/proc/slabinfoso I started searching for its equivalent on 3.5 when I came across Vincent Bernat's post on the IPv4 route cache. This is an excellent resource to understand the route cache on linux, and that's where I found out about thelnstatcommand. This is something that needs to be added to any monitoring and stats gathering scripts that you run. Further reading suggests that the dst cache gc routines are complicated, and a bug anywhere could result in a leak, one which could take several weeks to become apparent.From what I can tell, there doesn't appear to be an
rt_cacheleak. The number of cache entries increases and decreases with traffic, but I'll keep monitoring it to see if that changes over time.Other things to tune
There are a few other things you might want to tune, but they're becoming less of an issue as base system configs evolve.
TCP Window Sizes
This is related to TCP Slow Start, and I'd love to go into the details, but our friends Sajal and Aaron over at CDN Planet have already done an awesome job explaining how to tune TCP initcwnd for optimum performance.
This is not an issue for us because the 3.5 kernel's default window size is already set to 10.
Window size after idle
Related to the above is the
sysctlsettingnet.ipv4.tcp_slow_start_after_idle. This tells the system whether it should start at the default window size only for new TCP connections or also for existing TCP connections that have been idle for too long (on 3.5, too long is 1 second, but seenet.sctp.rto_initialfor its current value on your system). If you're using persistent HTTP connections, you're likely to end up in this state, so setnet.ipv4.tcp_slow_start_after_idle=0(just put it into the sysctl config file mentioned above).Endgame
After changing all these settings, a single quad core vm (though using only one core) with 1Gig of RAM has been able to handle all the load that's been thrown at it. We never run out of open file handles, never run out of ports, never run out of connection tracking entries and never run out of RAM.
We have several weeks before another one of our beacon collectors runs into the dst cache issue, and I'll be ready with the numbers when that happens.
Thanks for reading, and let us know how these settings work out for you if you try them out. If you'd like to measure the real user impact of your changes, have a look at our Real User Measurement tool at LogNormal.
Update 2012-09-28: There are some great comments on hacker news with much more information.
Adapted from UNIX network performance analysis by Martin Brown, published at developerWorks Sep 08, 2009
The performance of your network can have a significant impact on the general performance and reliability of the rest of your environment. If different applications and services are waiting for data over the network, or your clients are having trouble connecting or receiving the information, then you need to address these issues.
Performance issues can also affect the reliability of your applications and environment, and can both be triggered by network faults, and in some cases they can even be the reason for a network fault. To understand and diagnose network issues, you first need to unde the nature of the issue; usually the problem will be related either to a latency or a bandwidth issue.
In general, network performance issues are often tied to the underlying hardware; you cannot exceed the physical limits of the network environment.
This article looks at the following steps involved in identifying performance issues:
- Getting a baseline performance level
- Determining where the problem lies
- Getting statistics
- Identifying the bottleneck
Understanding network metrics
To understand and diagnose performance issues, you first need to determine your baseline performance level. Let's first introduce two of the key concepts used in determining baseline performance: network latency and network bandwidth.
Network latency
The network latency is the time between sending a request to a destination and the destination actually receiving the sent packet. As a metric for network performance, increased latency is a good indicator of a busy network, as it either indicates that the number of packets being transmitted exceeds the capacity, or that the senders of data are having to wait before either transmission or re-transmission.
Network latency can also be introduced when the complexity of the network and the number of hosts or gateways that a packet has to travel through increases. The length of cable between points can also have an effect on the latency. For long distances, traditional copper cable will always be slower than using a fibre optic connection.
Network latency is also different from application latency. Network latency deals exclusively with the transmission of packets over the network, while application latency refers to the delay between the application receiving a request and its ability to respond.
Network bandwidth
Bandwidth is a measure of the number of packets that can be transmitted over a network during a specific period of time. The bandwidth affects how much data can be transmitted, and will either limit the transmission of data to one host to the practical maximum supported by the network connection, or will limit the aggregate transmission rate when dealing with multiple simultaneous connections.
The network bandwidth should, in theory, never change, unless you change the networking interface and hardware. The major variable within network bandwidth is in the number of hosts using the network at any given time.
For example, a 1GB Ethernet interface can talk 1GB to one other network host, 100MB to ten simultaneous hosts, or 10MB to 100 hosts. In reality, of course, the sustained bandwidth is not often required. There will be many hundreds of smaller requests from a number of different hosts over a period of time, and so the available bandwidth of a server can appear much greater than the sum of the client bandwidth.
Getting network statistics
Before you can identify whether there is a problem within your network, you first need to have a baseline performance on which to base your assumptions. To do this you must check the various parameters -- latency, performance and any tests relevant to your network application environment -- to determine the performance and then monitor and compare this over time.
When performing the baseline networking tests, you should do them under controlled conditions. Ideally, you should perform them under both isolated (meaning with no other network traffic) and with typical network traffic to give you the two baselines:
- For the isolated monitoring, you should check the performance between the server and one or more clients when there is no other traffic on the network. This means either shutting down other services, or, ideally, putting the server and client into an isolated network environment completely separate (but identical to) your standard network environment
- For the standard monitoring, you should have the clients and servers attached to your standard network, and have the normal background traffic working, but all application-specific traffic (such as e-mail, file serving, Web serving) disabled, except on the server that you are testing.
For the actual testing process, there are a number of standard tools and tests that you can perform to determine your baseline values.
Measuring latency
The ping sends an echo packet to the device, and expects the device to echo the packet contents back. During the process, ping can monitor the time it takes to send and receive the response, which can be an effective method of measuring the response time of the echo process. In the simplest form, you can send an echo request to a host and find out the response time:
$ ping example PING example.example.pri (192.168.0.2): 56 data bytes 64 bytes from 192.168.0.2: icmp_seq=0 ttl=64 time=0.169 ms 64 bytes from 192.168.0.2: icmp_seq=1 ttl=64 time=0.167 ms ^C --- example.example.pri ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max/stddev = 0.167/0.168/0.169/0.001 msYou need to use Control-C to stop the ping process. On Solaris and AIX®, you need to use the
-soption to send more than one echo packet and get the timing information. For getting baseline figures, you can use the-coption (on Linux®) to specify the count. On Solaris/AIX, you must specify the packet size (the default is 56 bytes), and the number of packets to send so that you do not have to manually terminate the process. You can then use this to extract the timing information automatically:$ ping -s example 56 10 PING example: 56 data bytes 64 bytes from example.example.pri (192.168.0.2): icmp_seq=0. time=0.143 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=1. time=0.163 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=2. time=0.146 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=3. time=0.134 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=4. time=0.151 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=5. time=0.107 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=6. time=0.142 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=7. time=0.136 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=8. time=0.143 ms 64 bytes from example.example.pri (192.168.0.2): icmp_seq=9. time=0.103 ms ----example PING Statistics---- 10 packets transmitted, 10 packets received, 0% packet loss round-trip (ms) min/avg/max/stddev = 0.103/0.137/0.163/0.019The example above was made during a quiet period on the network. If the host being checked (or the network itself) was busy during the testing period, the ping times could be increased significantly. However, ping alone is not necessarily an indicator of a problem, but it can occasionally give you a quick idea if there is something that needs to be identified.
It is possible to switch off support for ping, and so you should ensure that you can reach the host before using it as a verification that a host is available.
Ideally, you should track the ping times between specific hosts over a period of time, and even continually, so that you can track the average response times and then identify where to start looking.
Using sprayd
The sprayd daemon and the associated spray tool send a large stream of packets to a specified host and determine how many of those packets get a response. As a method for measuring the performance of a network, it should not be relied on as a performance metric because it uses a connectionless transport mechanism. By definition, packets sent using connectionless transport are not guaranteed to reach their destination, and so dropped packets are allowed in the communication anyway.
That said, using spray can tell you whether there is a lot of traffic on the network, because if the connectionless transport (UDP) is dropping packets, then it probably means the network (or the host) is too busy to carry the packets.
Spray is available on Solaris and AIX, and some other UNIX platforms. You may need to enable the spray daemon (usually through inetd) to use it. Once the sprayd daemon has been started, you can run spray specifying the hostname
$ spray tiger sending 1162 packets of length 86 to tiger ... 101 packets (8.692%) dropped by tiger 70 packets/sec, 6078 bytes/secAs already mentioned, the speed should not be relied upon, but the dropped packet counts can be a useful metric.
Using simple network transfer tests
The best method for determining the bandwidth performance of your network is to check the actual speed when transferring data to or from the machine. There are lots of different tools that you can use to perform the tests across a number of different applications and protocols, but usually the simplest method is the most effective one.
For example, to determine the network bandwidth when transferring a file over the network using NFS, you can time a simple file transfer test. To create a simple test, create a large file using mkfile (for example, 2GB:
$ mkfile 2g 2gbfile), and then time how long it takes to transfer the file over a network to another machine:.$ time cp /nfs/mysql-live/transient/2gbfile . real 3m45.648s user 0m0.010s sys 0m9.840sYou should run the tests multiple times and then take the average of the transfer process to get an idea of the standard performance.You can automate the copy and timing process by using a Perl script:
#!/usr/bin/perl use Benchmark; use File::Copy; use Data::Dumper; my $file = shift or die "Need a file to copy from\n"; my $srcdir = shift or die "Need a source directory to copy from\n"; my $count = shift || 10; my $t = timeit($count,sub {copy(sprintf("%s/%s",$srcdir,$file),$file)}); printf("Time is %.2fs\n",($t->[0]/$count));To execute, supply the name of the source file and the source directory, and an optional count of the number of copies to make. You can then execute the script and get a time:.
$ ./timexfer.pl 2gbfile /nfs/mysql-live/transient 20 Time is 28.45sYou can use this both to create a baseline figure and during normal operations to check the transfer performance.
Diagnosing a problem
Typically, you will identify a network problem only when a network-related application fails for some reason. However, it is important to identify that the problem is network related and not a problem elsewhere.
First, you should try to reach the machine using ping. If the machine does not respond to a ping request, and other network communication does not work, then your first option should be to check the physical cables and make sure everything is still connected.
If you can still connect to the machine, but the ping time is increased, then you need to determine where the problem lies. An increase in ping times can in rare cases be related to the load on the machine, but more often than not indicates an issue with the network.
Once you get a long ping time from one machine, you should run ping from another machine on the network, ideally on a different network switch, to find out if the problem is related to the specific machine or the network.
If the ping times are higher than you expect, then you should start to get some basic statistics about the network interface you are using to see if the problem is related to the network interface, or a specific protocol.
Under Linux, you can get some basic network statistic information by using the ifconfig tool:
$ ifconfig eth1 eth1 Link encap:Ethernet HWaddr 00:1a:ee:01:01:c0 inet addr:192.168.0.2 Bcast:192.168.3.255 Mask:255.255.252.0 inet6 addr: fe80::21a:eeff:fe01:1c0/64 Scope:Link UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1 RX packets:7916836 errors:0 dropped:78489 overruns:0 frame:0 TX packets:6285476 errors:0 dropped:0 overruns:0 carrier:0 collisions:0 txqueuelen:1000 RX bytes:11675092739 (10.8 GiB) TX bytes:581702020 (554.7 MiB) Interrupt:16 Base address:0x2000The important rows are those beginning RX and TX, which show information about the packets sent and received. The packets value is a simple count of the packets transferred. The errors, dropped, and overruns figures show how many of the packets indicated some kind of fault. A high number of dropped packets in comparison to the packets sent probably indicate that the network is busy.
You can also get extended statistic information on all platforms by using the netstat tool. Under Linux, the tool provides more specific base protocol statistics, such as the packet transmissions for TCP-IP and UDP packet types. Again, the information contains some basic statistics.
$ netstat -s Ip: 8437387 total packets received 1 with invalid addresses 0 forwarded 0 incoming packets discarded 8437383 incoming packets delivered 6820934 requests sent out 6 reassemblies required 3 packets reassembled ok ... ... ...Under Solaris and other UNIX variants, the information provided by netstat differs depending upon the platform. For example, under Solaris, you get detailed statistics for each protocol, and separate information for IPv4 and IPv6 connections (see Listing 9). The output in the listing has been truncated.
$ netstat -s RAWIP rawipInDatagrams = 440 rawipInErrors = 0 rawipInCksumErrs = 0 rawipOutDatagrams = 91 rawipOutErrors = 0 UDP udpInDatagrams = 15756 udpInErrors = 0 udpOutDatagrams = 16515 udpOutErrors = 0 TCP tcpRtoAlgorithm = 4 tcpRtoMin = 400 tcpRtoMax = 60000 tcpMaxConn = -1 ... ... ... ...In all cases, you are looking for a high level of error packets, retransmissions, or dropped packet transmission, all of which indicate that the network is busy. If the error rate is excessively high compared to the packets transmitted or received, then it may indicate a fault with the network hardware.
When checking problems related to NFS connections, and indeed most other network applications, you should first ensure that the issue is not related to a problem on the machine, such as high load (which will obviously affect the speed at which requests can be processed). A simple check using uptime and ps to identify the processes will tell you how busy the machine is.
You can also check the NFS statistics that are generated by the NFS service. The nfsstat command generates detailed stats for both the server and client side of the NFS service. For example, the statistics in Listing 10 show the detailed NFS v3 statistics for the server side of the NFS service, selected by using the
-scommand-line option and-vto specify the NFS version.$ nfsstat -s -v3 Server rpc: Connection oriented: calls badcalls nullrecv badlen xdrcall dupchecks dupreqs 36118 0 0 0 0 410 0 Connectionless: calls badcalls nullrecv badlen xdrcall dupchecks dupreqs 75 0 0 0 0 0 0 Server NFSv3: calls badcalls 35847 0 Version 3: (35942 calls) null getattr setattr lookup access readlink 15 0% 190 0% 83 0% 3555 9% 21222 59% 0 0% read write create mkdir symlink mknod 9895 27% 300 0% 7 0% 0 0% 0 0% 0 0% remove rmdir rename link readdir readdirplus 0 0% 0 0% 0 0% 0 0% 37 0% 20 0% fsstat fsinfo pathconf commit 521 1% 2 0% 1 0% 94 0% Server nfs_acl: Version 3: (0 calls) null getacl setacl getxattrdir 0 0% 0 0% 0 0% 0 0%A high number of badcalls values indicate that bad requests are being sent to the server, which may indicate that a client is not functioning correctly and submitting bad requests, either due to a software problem or faulty hardware.
If you can ping the machine, but the network performance is still a problem, then you need to determine where in your network the performance problem is located. In a larger network where you have different segments of your network separated by routers, you can use the traceroute tool determine whether there is a specific point in the route between the two machines where there is a problem.
Related to the ping tool, the traceroute tool will normally provide you with the ping times for each router that the network packets travel through to reach their destination. In a larger network this can help you isolate where the problem is. This can also be used to identify potential problems when sending packets over the Internet, where different routers are used at different points to transmit packets between different Internet Service Providers (ISP).
For example, the trace shown in Listing 11 is between two offices in the UK that use two different ISPs. In this case, the destination machine cannot be reached due to a fault.
$ traceroute gendarme.example.com traceroute to gendarme.example.com (82.70.138.102), 30 hops max, 40 byte packets 1 voyager.example.pri (192.168.1.1) 14.998 ms 95.530 ms 4.922 ms 2 dsl.vispa.net.uk (83.217.160.18) 32.251 ms 95.674 ms 30.742 ms 3 rt-gw1.tcm.vispa.net.uk (62.24.228.1) 49.178 ms 47.718 ms 123.261 ms 4 195.50.119.249 (195.50.119.249) 47.036 ms 50.440 ms 143.123 ms 5 ae-11-11.car1.Manchesteruk1.Level3.net (4.69.133.97) 92.398 ms 137.382 ms 52.780 ms 6 PACKET-EXCH.car1.Manchester1.Level3.net (195.16.169.90) 45.791 ms 140.165 ms 35.312 ms 7 spinoza-ae2-0.hq.zen.net.uk (62.3.80.54) 33.034 ms 39.442 ms 33.253 ms 8 galileo-fe-3-1-172.hq.zen.net.uk (62.3.80.174) 34.341 ms 33.684 ms 33.703 ms 9 * * * 10 * * * 11 * * * 12 * * *In a smaller network you are unlikely to have routers separating the networks, and so traceroute will not be of any help. Both ping and traceroute rely on being able to reach a host to determine the problem.
You are now armed with some knowledge and techniques to deal with UNIX network performance.
Identifying UNIX network performance issues is hard to determine from a single machine when the problem is usually widespread across the network. It is usually possible, though, to use ping and/or traceroute to narrow down the machine by looking at the performance from different points within your network. Once you have some starting points, you can use the other network tools to get more detailed information about the protocol or application that is causing the problem. This article looked at the basic methods to get baseline information and then the different tools that can be used to zero in on the issue.
Nov 29, 2010 | Network World
A Linux system can be tweaked to a degree Windows users may envy (or fear) especially for networking. Tweaking a Linux box for networking is a bit more mundane than other platforms: there are specific driver settings one can work with but its best flexibility comes from a mix of OS-level modifications and adherence to different RFCs.
ifconfig (interface) txqueuelen #
Software buffers for network adapters on Linux start off at a conservative 1000 packets. Network researchers and scientists have mucked around with this, and figured out that we should be using 10,000 for anything decent on a LAN; more if you're running GB or 10GE stuff. Slow interfaces, such as modems and WAN links, can default to 0-100, but don't be afraid to bump it up towards 1000 and see if your performance improves. Bumping up this setting does use memory, so be careful if you're using an embedded router or something (I've used 10,000 on 16MB RAM OpenWRT units, no prob).
You can edit /etc/rc.local, add an "up" command to /etc/networking/interfaces, or whatever your distribution suggests and it's best to put a command like this at startup.
/etc/sysctl.conf
This file governs default behavior for many network and file operation settings on Linux and other *nix-based systems. If you deploy Ubuntu or Fedora systems, you'll notice they will add their own tweaks (usually security or file-oriented) to the file: don't delete those, unless you read up on them, or see any that are contradicted by the suggested additions here...
net.ipv4.tcp_rfc1337=1
net.ipv4.tcp_window_scaling=1
net.ipv4.tcp_workaround_signed_windows=1
net.ipv4.tcp_sack=1
net.ipv4.tcp_fack=1
net.ipv4.tcp_low_latency=1
net.ipv4.ip_no_pmtu_disc=0
net.ipv4.tcp_mtu_probing=1
net.ipv4.tcp_frto=2
net.ipv4.tcp_frto_response=2
net.ipv4.tcp_congestion_control=illinois1. RFC 1337, TIME-WAIT Assassination Hazards in TCP, a fix written in 1992 for some theoretically-possible failure modes for TCP connections. To this day this RFC still has people confused if it negatively impacts performance or not or is supported by any decent router. Murphy's Law is that the only router that it would even have trouble with, is most likely your own.
2. TCP window scaling tries to avoid getting the network adapter saturated with incoming packets.
3. TCP SACK and FACK refer to options found in RFC 2018 and are also documented back to Linux Kernel 2.6.17 with an experimental "TCP-Peach" set of functions. These are meant to get you your data without excessive losses.
4. The latency setting is 1 if you prefer more packets vs bandwidth, or 0 if you prefer bandwidth. More packets are ideal for things like Remote Desktop and VOIP: less for bulk downloading.
5. I found RFC 2923, which is a good review of PMTU. IPv6 uses PMTU by default to avoid segmenting packets at the router level, but its optional for IPv4. PMTU is meant to inform routers of the best packet sizes to use between links, but its a common admin practice to block ICMP ports that allow pinging, thus breaking this mechanism. Linux tries to use it, and so do I: if you have problems, you have a problem router, and can change the "no" setting to 1. "MTU probing" is also a part of this: 1 means try, and 0 means don't.
6. FRTO is a mechanism in newer Linux kernels to optimize for wireless hosts: use it if you have them; delete the setting, or set to 0, if you don't.
For further study, there's a great IBM article regarding network optimizations: it was my source for some of these settings, as well as following numerous articles on tweaking Linux networking over the years (SpeedGuide has one from 2003).
TCP Congestion Controls
Windows Vista and newer gained Compound TCP as an alternative to standard TCP Reno. Linux Kernel 2.6 has had numerous mechanisms available to it for some time: 2.6.19 defaulted to CUBIC which was supposed to work well over "long links." My two personal favorites: TCP Westwood + and TCP Illinois. But you can dig in, look at different research papers online, and see what works best for your environment.
1. Make sure your kernel has the correct module: in my example, I use TCP Illinois, which has been compiled with any standard Ubuntu kernel since 2008, and is found as tcp_illinois.
2. Add said kernel module to /etc/modules
3. Change /etc/sysctl.conf to use the non "tcp_" part of your selection.
There you have it -- some of my favorite Linux tweaks for networking. I'm interested in hearing how these worked for you. If you have some of your own, please post a comment and share them with other readers.
How To: Network / TCP / UDP Tuning This is a very basic step by step description of how to improve the performance networking (TCP & UDP) on Linux 2.4+ for high-bandwidth applications. These settings are especially important for GigE links. Jump to Quick Step or All The Steps.
Assumptions
This howto assumes that the machine being tuned is involved in supporting high-bandwidth applications. Making these modifications on a machine that supports multiple users and/or multiple connections is not recommended - it may cause the machine to deny connections because of a lack of memory allocation.
The Steps
- Make sure that you have root privleges.
- Type: sysctl -a | grep mem
This will display your current buffer settings. Save These! You may want to roll-back these changes
- Type: sysctl -w net.core.rmem_max=8388608
This sets the max OS receive buffer size for all types of connections.
- Type: sysctl -w net.core.wmem_max=8388608
This sets the max OS send buffer size for all types of connections.
- Type: sysctl -w net.core.rmem_default=65536
This sets the default OS receive buffer size for all types of connections.
- Type: sysctl -w net.core.wmem_default=65536
This sets the default OS send buffer size for all types of connections.- Type: sysctl -w net.ipv4.tcp_mem='8388608 8388608 8388608'
TCP Autotuning setting. "The tcp_mem variable defines how the TCP stack should behave when it comes to memory usage. ... The first value specified in the tcp_mem variable tells the kernel the low threshold. Below this point, the TCP stack do not bother at all about putting any pressure on the memory usage by different TCP sockets. ... The second value tells the kernel at which point to start pressuring memory usage down. ... The final value tells the kernel how many memory pages it may use maximally. If this value is reached, TCP streams and packets start getting dropped until we reach a lower memory usage again. This value includes all TCP sockets currently in use."- Type: sysctl -w net.ipv4.tcp_rmem='4096 87380 8388608'
TCP Autotuning setting. "The first value tells the kernel the minimum receive buffer for each TCP connection, and this buffer is always allocated to a TCP socket, even under high pressure on the system. ... The second value specified tells the kernel the default receive buffer allocated for each TCP socket. This value overrides the /proc/sys/net/core/rmem_default value used by other protocols. ... The third and last value specified in this variable specifies the maximum receive buffer that can be allocated for a TCP socket."- Type: sysctl -w net.ipv4.tcp_wmem='4096 65536 8388608'
TCP Autotuning setting. "This variable takes 3 different values which holds information on how much TCP sendbuffer memory space each TCP socket has to use. Every TCP socket has this much buffer space to use before the buffer is filled up. Each of the three values are used under different conditions. ... The first value in this variable tells the minimum TCP send buffer space available for a single TCP socket. ... The second value in the variable tells us the default buffer space allowed for a single TCP socket to use. ... The third value tells the kernel the maximum TCP send buffer space."- Type:sysctl -w net.ipv4.route.flush=1
This will enusre that immediatly subsequent connections use these values.
Quick Step
Cut and paste the following into a linux shell with root privleges:sysctl -w net.core.rmem_max=8388608
sysctl -w net.core.wmem_max=8388608
sysctl -w net.core.rmem_default=65536
sysctl -w net.core.wmem_default=65536
sysctl -w net.ipv4.tcp_rmem='4096 87380 8388608'
sysctl -w net.ipv4.tcp_wmem='4096 65536 8388608'
sysctl -w net.ipv4.tcp_mem='8388608 8388608 8388608'
sysctl -w net.ipv4.route.flush=1
References
All of this information comes directly from these very reliable sources:
- Pittsburgh Super Computing Center TCP Tuning Guide
- Summary of Buffer Sizes for Various Os's
- Ipsysctl tutorial 1.0.3
Feedback
Please send me some feedback on how this worked for you. I'd be happy to help you figure it out on yours. I've used these or similar settings for a number of high-bandwidth applications with great results.
There are a lot of differences between Linux version 2.4 and 2.6, so first we'll cover the tuning issues that are the same in both 2.4 and 2.6. To change TCP settings in, you add the entries below to the file /etc/sysctl.conf, and then run "sysctl -p".
Like all operating systems, the default maximum Linux TCP buffer sizes are way too small. I suggest changing them to the following settings:
# increase TCP max buffer size setable using setsockopt() net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 # increase Linux autotuning TCP buffer limits # min, default, and max number of bytes to use # set max to at least 4MB, or higher if you use very high BDP paths = 4096 87380 16777216 net.ipv4.tcp_wmem = 4096 65536 16777216You should also verify that the following are all set to the default value of 1
sysctl net.ipv4.tcp_window_scaling sysctl net.ipv4.tcp_timestamps sysctl net.ipv4.tcp_sackNote: you should leave tcp_mem alone. The defaults are fine.
Another thing you can try that may help increase TCP throughput is to increase the size of the interface queue. To do this, do the following:
ifconfig eth0 txqueuelen 1000I've seen increases in bandwidth of up to 8x by doing this on some long, fast paths. This is only a good idea for Gigabit Ethernet connected hosts, and may have other side effects such as uneven sharing between multiple streams.
Also, I've been told that for some network paths, using the Linux 'tc' (traffic control) system to pace traffic out of the host can help improve total throughput.
Linux 2.6Starting in Linux 2.6.7 (and back-ported to 2.4.27), linux includes alternative congestion control algorithms beside the traditional 'reno' algorithm. These are designed to recover quickly from packet loss on high-speed WANs.
Linux 2.6 also includes and both send and receiver-side automatic buffer tuning (up to the maximum sizes specified above). There is also a setting to fix the ssthresh caching weirdness described above.
There are a couple additional sysctl settings for 2.6:
# don't cache ssthresh from previous connection net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 # recommended to increase this for 1000 BT or higher net.core.netdev_max_backlog = 2500 # for 10 GigE, use this # net.core.netdev_max_backlog = 30000Starting with version 2.6.13, Linux supports pluggable congestion control algorithms . The congestion control algorithm used is set using the sysctl variable net.ipv4.tcp_congestion_control, which is set to cubic or reno by default, depending on which version of the 2.6 kernel you are using.
To get a list of congestion control algorithms that are available in your kernel, run:
sysctl net.ipv4.tcp_available_congestion_controlThe choice of congestion control options is selected when you build the kernel. The following are some of the options are available in the 2.6.23 kernel:
- reno: Traditional TCP used by almost all other OSes. (default)
- cubic: CUBIC-TCP (NOTE: There is a cubic bug in the Linux 2.6.18 kernel. Use 2.6.19 or higher!)
- bic: BIC-TCP
- htcp: Hamilton TCP
- vegas: TCP Vegas
- westwood: optimized for lossy networks
For very long fast paths, I suggest trying cubic or htcp if reno is not is not performing as desired. To set this, do the following:
sysctl -w net.ipv4.tcp_congestion_control=htcpMore information on each of these algorithms and some results can be found here .
More information on tuning parameters and defaults for Linux 2.6 are available in the file ip-sysctl.txt, which is part of the 2.6 source distribution.
Warning on Large MTUs: If you have configured your Linux host to use 9K MTUs, but the connection is using 1500 byte packets, then you actually need 9/1.5 = 6 times more buffer space in order to fill the pipe. In fact some device drivers only allocate memory in power of two sizes, so you may even need 16/1.5 = 11 times more buffer space!
And finally a warning for both 2.4 and 2.6: for very large BDP paths where the TCP window is > 20 MB, you are likely to hit the Linux SACK implementation problem. If Linux has too many packets in flight when it gets a SACK event, it takes too long to located the SACKed packet, and you get a TCP timeout and CWND goes back to 1 packet. Restricting the TCP buffer size to about 12 MB seems to avoid this problem, but clearly limits your total throughput. Another solution is to disable SACK.
TCP Receive Window (RWIN)
In computer networking, RWIN (TCP Receive Window) is the maximum amount of data that a computer will accept before acknowledging the sender. In practical terms, that means when you download say a 20 MB file, the remote server does not just send you the 20 MB continuously after you request it. When your computer sends the request for the file, your computer tells the remote server what your RWIN value is; the remote server then starts streaming data at you until it reaches your RWIN value, and then the server waits until your computer acknowledges that you received that data OK. Once your computer sends the acknowledgement, then the server continues to send more data in chunks of your RWIN value, each time waiting for your acknowledgment before proceeding to send more.
Now the crux of the problem here is with what is called latency, or the amount of time that it takes to send and receive packets from the remote server. Note that latency will depend not only on how fast the connection is between you and the remote server, but it also includes all additional delays, such as the time that it takes for the server to process your request and respond. You can easily find out the latency between you and the remote server with the ping command. When you use ping, the time that ping reports is the round-trip time (RTT), or latency, between you and the remote server.
When I ping google.com, I typically get a latency of 100 msec. Now if there were no concept of RWIN, and thus my computer had to acknowledge every single packet sent between me and google, then transfer speed between me and them would be simply the (packet size)/RTT. Thus for a maximum sized packet (my MTU as we learned above), my transfer speed would be:
1492 bytes/.1 sec = 14,920 B/sec or 14.57 KiB/sec
That is pathetically slow considering that my connection is 3 Mb/sec, which is the same as 366 KiB/sec; so I would be using only about 4% of my available bandwidth. Therefore, we use the concept of RWIN so that a remote server can stream data to me without having to acknowledge every single packet and slow everything down to a crawl.
Note that the TCP receive window (RWIN) is independent of the MTU setting. RWIN is determined by the BDP (Bandwidth Delay Product) for your internet connection, and BDP can be calculated as:
BDP = max bandwidth of your internet connection (Bytes/second) * RTT (seconds)
Therefore RWIN does not depend on the TCP packet size, and TCP packet size is of course limited by the MTU (Maximum Transmission Unit).
Before we change RWIN, use the following command to get the kernel variables related to RWIN:
sysctl -a 2> /dev/null | grep -iE "_mem |_rmem|_wmem"
Note the space after the _mem is deliberate, don't remove it or add other spaces elsewhere between the quotes.
You should get the following three variables:
net.ipv4.tcp_rmem = 4096 87380 2584576
net.ipv4.tcp_wmem = 4096 16384 2584576
net.ipv4.tcp_mem = 258576 258576 258576The variable numbers are in bytes, and they represent the minimum, default, and maximum values for each of those variables.
net.ipv4.tcp_rmem = Receive window memory vector
net.ipv4.tcp_wmem = Send window memory vector
net.ipv4.tcp_mem = TCP stack memory vectorNote that there is no exact equivalent variable in Linux that corresponds to RWIN, the closest is the net.ipv4.tcp_rmem variable. The variables above control the actual memory usage (not just the TCP window size) and include memory used by the socket data structures as well as memory wasted by short packets in large buffers. The maximum values have to be larger than the BDP (Bandwidth Delay Product) of the path by some suitable overhead.
To try and optimize RWIN, first use ping to send the maximum size packet your connection allows (MTU) to some distant server. Since my MTU is 1492, the ping command payload would be 1492-28=1464. Thus:
ping -s 1464 -c5 google.com
PING google.com (64.233.167.99) 1464(1492) bytes of data.
64 bytes from py-in-f99.google.com (64.233.167.99): icmp_seq=1 ttl=237 (truncated)
64 bytes from py-in-f99.google.com (64.233.167.99): icmp_seq=2 ttl=237 (truncated)
64 bytes from py-in-f99.google.com (64.233.167.99): icmp_seq=3 ttl=237 (truncated)
64 bytes from py-in-f99.google.com (64.233.167.99): icmp_seq=4 ttl=237 (truncated)
64 bytes from py-in-f99.google.com (64.233.167.99): icmp_seq=5 ttl=237 (truncated)--- google.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 101.411/102.699/105.723/1.637 msNote though that you should run the above test several times at different times during the day, and also try pinging other destinations. You'll see RTT might vary quite a bit.
But for the above example, the RTT average is about 103 msec. Now since the maximum speed of my internet connection is 3 Mbits/sec, then the BDP is:
Code:(3,000,000 bits/sec) * (.103 sec) * (1 byte/8 bits) = 38,625 bytes
Thus I should set the default value in net.ipv4.tcp_rmem to about 39,000. For my internet connection, I've seen RTT as bad as 500 msec, which would lead to a BDP of 187,000 bytes.
Therefore, I could set the max value in net.ipv4.tcp_rmem to about 187,000. The values in net.ipv4.tcp_wmem should be the same as net.ipv4.tcp_rmem since both sending and receiving use the same internet connection. And since net.ipv4.tcp_mem is the maximum total memory buffer for TCP transactions, it is usually set to the the max value used in net.ipv4.tcp_rmem and net.ipv4.tcp_wmem.
And lastly, there are two more kernel TCP variables related to RWIN that you should set:
sysctl -a 2> /dev/null | grep -iE "rcvbuf|save"
which returns:
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1Note enabling net.ipv4.tcp_no_metrics_save (setting it to 1) means have Linux optimize the TCP receive window dynamically between the values in net.ipv4.tcp_rmem and net.ipv4.tcp_wmem. And enabling net.ipv4.tcp_moderate_rcvbuf removes an odd behavior in the 2.6 kernels, whereby the kernel stores the slow start threshold for a client between TCP sessions. This can cause undesired results, as a single period of congestion can affect many subsequent connections.
Before you change any of the above variables, try going to http://www.speedtest.net or a similar website and check the speed of your connection. Then temporarily change the variables by using the following command with your own computed values:
sudo sysctl -w net.ipv4.tcp_rmem="4096 39000 187000" net.ipv4.tcp_wmem="4096 39000 187000" net.ipv4.tcp_mem="187000 187000 187000" net.ipv4.tcp_no_metrics_save=1 net.ipv4.tcp_moderate_rcvbuf=1
Then retest your connection and see if your speed improved at all.
Once you tweak the values to your liking, you can make them permanent by adding them to /etc/sysctl.conf as follows:
net.ipv4.tcp_rmem=4096 39000 187000
net.ipv4.tcp_wmem=4096 39000 187000
net.ipv4.tcp_mem=187000 187000 187000
net.ipv4.tcp_no_metrics_save=1
net.ipv4.tcp_moderate_rcvbuf=1And then do the following command to make the changes permanent:
sudo sysctl -p
Ubuntu Forums
PoshMay 24th, 2007, 02:14 PM
I don't believe this will work as intended on machines with Edgy and beyond. From what I understand if you have tcp_moderate_rcvbuf = 1 (which is default) then the receive window is adjusted automatically. Now setting the max values could help but I'm not sure what setting the defalts do when you have tcp_moderate_rcvbuf enabled. Also I believe you will probably want to use net.ipv4.tcp_no_metrics_save = 1 instead of using the route.flush=1.Here is a website with some tuning tips (http://dsd.lbl.gov/TCP-tuning/linux.html)
OldGafSeptember 5th, 2006, 02:55 PM
Add the following to /etc/sysctl.conf (substituting your window size in place of 524288, if necessary):# Tweaks for faster broadband...
net.core.rmem_default = 524288
net.core.rmem_max = 524288
net.core.wmem_default = 524288
net.core.wmem_max = 524288
net.ipv4.tcp_wmem = 4096 87380 524288
net.ipv4.tcp_rmem = 4096 87380 524288
net.ipv4.tcp_mem = 524288 524288 524288
net.ipv4.tcp_rfc1337 = 1
net.ipv4.ip_no_pmtu_disc = 0
net.ipv4.tcp_sack = 1
net.ipv4.tcp_fack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_ecn = 0
net.ipv4.route.flush = 1Then to have the settings take effect immediately, run:
sysctl -p
See the whole story here. (http://www.santa-li.com/linuxonbb.html)
Made a HUGE diff for me \\:D/
Thank you guys. This topic solved my high response times for my router. Here is the config I use:
#net.core.rmem_default = 4194304
# default values seems to work fine with my system
net.core.rmem_max = 4194304
#net.core.wmem_default = 4194304
# default values seems to work fine with my system
net.core.wmem_max = 4194304
net.ipv4.tcp_wmem = 4096 87380 4194304
net.ipv4.tcp_rmem = 4096 87380 4194304
#net.ipv4.tcp_mem = 256960 256960 4194304
# this should be uncommented only if it's not working well
net.ipv4.tcp_rfc1337 = 1
net.ipv4.ip_no_pmtu_disc = 0
net.ipv4.tcp_sack = 1
net.ipv4.tcp_fack = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_ecn = 0
net.ipv4.route.flush = 1# don't cache ssthresh from previous connection
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
# recommended to increase this for 1000 BT or higher
net.core.netdev_max_backlog = 2500
net.ipv4.tcp_congestion_control=cubicThis settings work very well on an 2 mbit connection
June 05, 2007 | IBM Redbooks
Over the past few years, Linux has made its way into the data centers of many corporations all over the globe. The Linux operating system has become accepted by both the scientific and enterprise user population. Today, Linux is by far the most versatile operating system. You can find Linux on embedded devices such as firewalls and cell phones and mainframes. Naturally, performance of the Linux operating system has become a hot topic for both scientific and enterprise users. However, calculating a global weather forecast and hosting a database impose different requirements on the operating system. Linux has to accommodate all possible usage scenarios with the most optimal performance. The consequence of this challenge is that most Linux distributions contain general tuning parameters to accommodate all users.
IBM® has embraced Linux, and it is recognized as an operating system suitable for enterprise-level applications running on IBM systems. Most enterprise applications are now available on Linux, including file and print servers, database servers, Web servers, and collaboration and mail servers.
With use of Linux in an enterprise-class server comes the need to monitor performance and, when necessary, tune the server to remove bottlenecks that affect users. This IBM Redpaper describes the methods you can use to tune Linux, tools that you can use to monitor and analyze server performance, and key tuning parameters for specific server applications. The purpose of this redpaper is to understand, analyze, and tune the Linux operating system to yield superior performance for any type of application you plan to run on these systems.
The tuning parameters, benchmark results, and monitoring tools used in our test environment were executed on Red Hat and Novell SUSE Linux kernel 2.6 systems running on IBM System x servers and IBM System z servers. However, the information in this redpaper should be helpful for all Linux hardware platforms.
Linux TCP-IP Tuning (slides only) Stephen Hemminger. Sr. Staff Engineer, Linux Kongress 2004
Tuning for Linux platforms - Oracle GlassFish Server 3.1 Performance Tuning Guide
http://linuxperf.nl.linux.org/
http://www.citi.umich.edu/projects/citi-netscape/
http://home.att.net/~jageorge/performance.html
http://www.psc.edu/networking/perf_tune.html#Linux
Need to stress out an ftp server, or measure how many users it can support? dkftpbench can do it.Want to write your own highly efficient networking software, but annoyed by having to support very different code for Linux, FreeBSD, and Solaris? libPoller can help.
dklimits
This is part of the dkftpbench package.
fd-limit
thread-limit
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: February 10, 2021