|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
By Dr. Nikolai Bezroukov
Version 0.7 (Oct 09, 2020)
|
|
There's no benefits to rewriting a ton of code from one similar language to another. This is especially stupid, if we are talking about sysadmin utilities. Perl 5 is here to stay and will not go anywhere. Perl is much closer to shell, knowledge of which is a must for any sysadmin then Python. Any sysadmin worth its title knows Bash and AWK, even if he does not know Perl; and that means that he/she can at least superficially understand Perl code.
But popularity of Python and its dominance in research creates pressure for Perl programmers to learn Python. also sometimes the test of maintaining Perl code gets into the hand of Python programmers who iether do not know or hate Perl. In such cases it make sense to try to migrate some of utilities that can benefit from Python features (to example tuples) to Python, so that they can be maintained in Python. For Perl programmer who want to lean some Python this is probably the fastest way to learn Python. People who wrote complex Perl scripts can eventually adapt to Python idiosyncrasies, although not without huge effort and pain in the process. For experienced Perl programmer many things in Python look wrong and many unnecessary convoluted and. worse, completely detached from Unix culture. That latter is true as Python created came from Europe and was influenced (albeit indirectly) to "Pascal family" tradition, the set of language developed by famous language designer Nicklaus Wirth and which is completely distinct from C-language tradition which dominated in the USA. Although formally ABC which was a direct Python prototype was influenced by SETL originally developed by (Jack) Jacob T. Schwartz at the New York University (NYU) Courant Institute of Mathematical Sciences in the late 1960s. Also developers previously used some idiosyncratic "teaching" OS.
BTW Nicklaus Wirth he popularized the adage now named Wirth's law, which states that software is getting slower more rapidly than hardware becomes faster. In his 1995 paper A Plea for Lean Software he attributes it to Martin Reiser , who in the preface to his book on the Oberon System wrote:
"The hope is that the progress in hardware will cure all software ills. However, a critical observer may observe that software manages to outgrow hardware in size and sluggishness."[3] Other observers had noted this for some time before; indeed, the trend was becoming obvious as early as 1987.[4].
I think Wirth would strongly disapprove Python 3.8 :-)
At the very beginning any Perl programmer feels about Python like experienced floor dancer put on skates and pushed on a skating ring.
|
At the very beginning any Perl programmer feels about Python like experienced floor dancer put on skates and pushed on a skating ring |
Here the sweet dream of semi-automatic translation comes into play. The author is trying to implement this idea with his pythonizer tool.
Some progress was achieved during a year of development. See Two-pass "fuzzy" transformer from Perl to "semi-Python" Currently pythonizer is version 0.5, but despite being essentially in alpha stage it proved to be pretty useful for such tasks. At least for me.
But of course transliteration is never enough. Rewriting even medium complexity Perl script in Python, usually requires some level of redesign, as languages have different ways to express things and there is no direct mapping between several functions and special variables from Perl to Python. Arrays in Perl behave differently (Python has fixed sized arrays, while Perl has "automatically expandable" arrays, so the assignment of index out of range expands the array in Perl and generates an exception in Python (which can be used to expand the array to necessary size). But that means that a typical loop that create array in Perl is not directly translatable in Python.
Also set of text processing function is Python is richer and better thought out, so in many cases instead of regular expressions you can use them.
Many simple Perl regex (for example used for stripping leading or trailing blanks) can be rewritten with functions in Python. But the problem is that the set of modifiers in Python is more limited. Due to this translation of some functions from Perl to Python requires jumping through hoops. One classic example is the translation of the statement $line=~tr/:,;/ /s
Also even if a similar function exists in Python there is no guarantee that it behaves the same way as corresponding Perl function. For example, while $^O gives you operating system in Perl as "linux" on linux and "cygwin" on CygWin, Python os.name gives you "posix" in both cases. The same is true for other flavors of Unix, for example, for Solaris. It also returns posix in Python.
Python 2.7 probably will stay with us much longer then Python designer anticipated. And there are several reasons for this and first of all change of string representation from ASCII to Unicode in Python 3.
Python idiosyncratic for loop that uses range in Python 2.x allocates all elements on the range at once and only then iterates over them. To compensate for this design blunder (outside usage for intro courses) Perl 2.7 has xrange function. But the function xrange() has been removed in python 3.5
One of the headaches of translating Perl assignments within conditional statements was absence of corresponding Python feature. And this is explainable as Python was first designed as the language for novices, kind of new Basic. And such construct is error prone and benefits mainly seasoned programmers.
Python 3.8 implements the walrus operator ( C-style assignment expression), which looks like this:
name := expression
Slightly artificial but simple example (most commonly walrus is used when you search sub-string in the string and want to preserve the starting position of this search)
my_list = [1,2,3,4,5]
if len(my_list) > 3:
print(f"The list is too long with {len(my_list)}
elements")
In this case the walrus operator eliminates the need to call the len() function twice.
my_list = [1,2,3,4,5]
if (n := len(my_list)) > 3:
print(f"The list is too long with {n} elements")
The walrus also can be used with for and while loops. It simplifies translating Perl while loop that otherwise generally need to be translated by duplicating the code in while clause before and at the end of the loop (the only viable method of translation Perl while loop with the assignment if the target is Python 2,7) .
Without walrus operator:
line = file.read() while line: process(line) line = file.read()
With walrus operator the loop resembles the typical Perl loop while( $line=<> ) much more:
while line := file.read(): process(line)
F-stings used in example above introduced in Python 3.6 more or less corresponds to Perl double quoted constants (new is well forgotten old). They simplify the translation of Perl double quotes literals, which otherwise need to be decompiled into series of concatenations. Problem remains abut they are much less:
print(f"Hello, {name}. You are {age}.")
In Python 2.7 print is a statement while in 3.x it is a function with additional capabilities due to availability of keyword arguments. Keyword argument end="" is used to avoid printing a newline at the end of function call.
Only simple scripts that use non OO subset of Perl5 can be semi-automatically translated. Luckily, they constitute significant share of useful Perl scripts, especially small (less then 1K lines). By semi-automatically I means that you can automatically find close correspondence for approximately 80-90% of statements, and do the rest of conversion manually. In other words as the first step you can generate "Pythonized" Perl and then try to correct/transform remaining differences and problems by hand. This approach works well for the majority of monolithic simple ( non OO) scripts.
For non OO subset of Perl 5 there are also greater similarities with Python: a very similar precedence model for operators, access to a very similar set of basic data types – the familiar scalar, array, and hash are all available to us, albeit under different names. Regex are different, but basics of Perl regex are similar to Python re.match and re.matchall. Many simple Perl regex operation, such as trimming leading or tail blanks are better implemented in Python using built-in functions.
As soon as you encounter the script with Perl5 pointers or OO, the situation became close to hopeless and complete rewrite might be a better option then semi-automated translation. Which probably involves algorithm redesign, so this task can be classified as "software renovation"
The test below shows the current capabilities version pythonizer the source code of which was recently uploaded to GitHub It was run using the source of pre_pythonizer.pl -- the script which was already posted on GitHub (see see pre_pythonizer.pl ):
Full protocol is available: Full protocol of translation of pre_pythonizer.pl by the current version of pythonizer. Here is a relevant fragment:
PYTHONIZER: Fuzzy translator of Python to Perl. Version 0.50 (last modified 200831_0011) Running at 20/08/31 09:11
Logs are at /tmp/Pythonizer/pythonizer.200831_0911.log. Type -h for help.
================================================================================
Results of transcription are written to the file pre_pythonizer.py
==========================================================================================
... ... ...
54 | 0 | |#$debug=3; # starting from Debug=3 only the first chunk processed
55 | 0 | |STOP_STRING='' # In debug mode gives you an ability to switch trace on any type of error message for example S (via hook in logme).
#PL: $STOP_STRING='';
56 | 0 | |use_git_repo='' #PL: $use_git_repo='';
57 | 0 | |
58 | 0 | |# You can switch on tracing from particular line of source ( -1 to disable)
59 | 0 | |breakpoint=-1 #PL: $breakpoint=-1;
60 | 0 | |SCRIPT_NAME=__file__[__file__.rfind('/')+1:] #PL: $SCRIPT_NAME=substr($0,rindex($0,'/')+1);
61 | 0 | |if (dotpos:=SCRIPT_NAME.find('.'))>-1: #PL: if( ($dotpos=index($SCRIPT_NAME,'.'))>-1 ) {
62 | 1 | | SCRIPT_NAME=SCRIPT_NAME[0:dotpos] #PL: $SCRIPT_NAME=substr($SCRIPT_NAME,0,$dotpos);
64 | 0 | |
65 | 0 | |OS=os.name # $^O is built-in Perl variable that contains OS name
#PL: $OS=$^O;
66 | 0 | |if OS=='cygwin': #PL: if($OS eq 'cygwin' ){
67 | 1 | | HOME='/cygdrive/f/_Scripts' # $HOME/Archive is used for backups
#PL: $HOME="/cygdrive/f/_Scripts";
68 | 0 | |elif OS=='linux': #PL: elsif($OS eq 'linux' ){
69 | 1 | | HOME=os.environ['HOME'] # $HOME/Archive is used for backups
#PL: $HOME=$ENV{'HOME'};
71 | 0 | |LOG_DIR=f"/tmp/{SCRIPT_NAME}" #PL: $LOG_DIR="/tmp/$SCRIPT_NAME";
72 | 0 | |FormattedMain=('sub main\n','{\n') #PL: @FormattedMain=("sub main\n","{\n");
73 | 0 | |FormattedSource=FormattedSub.copy #PL: @FormattedSource=@FormattedSub=@FormattedData=();
74 | 0 | |mainlineno=len(FormattedMain) # we need to reserve one line for sub main
#PL: $mainlineno=scalar( @FormattedMain);
75 | 0 | |sourcelineno=sublineno=datalineno=0 #PL: $sourcelineno=$sublineno=$datalineno=0;
76 | 0 | |
77 | 0 | |tab=4 #PL: $tab=4;
78 | 0 | |nest_corrections=0 #PL: $nest_corrections=0;
79 | 0 | |keyword={'if': 1,'while': 1,'unless': 1,'until': 1,'for': 1,'foreach': 1,'given': 1,'when': 1,'default': 1}
#PL: %keyword=('if'=>1,'while'=>1,'unless'=>1, 'until'=>1,'for'=>1,'foreach'=>1,'give
Cont: n'=>1,'when'=>1,'default'=>1);
80 | 0 | |
81 | 0 | |logme(['D',1,2]) # E and S to console, everything to the log.
#PL: logme('D',1,2);
82 | 0 | |banner([LOG_DIR,SCRIPT_NAME,'PREPYTHONIZER: Phase 1 of pythonizer',30]) # Opens SYSLOG and print STDERRs banner; parameter 4 is log retention period
#PL: banner($LOG_DIR,$SCRIPT_NAME,'PREPYTHONIZER: Phase 1 of pythonizer',30);
83 | 0 | |get_params() # At this point debug flag can be reset
#PL: get_params();
84 | 0 | |if debug>0: #PL: if( $debug>0 ){
85 | 1 | | logme(['D',2,2]) # Max verbosity
#PL: logme('D',2,2);
86 | 1 | | print(f"ATTENTION!!! {SCRIPT_NAME} is working in debugging mode {debug} with autocommit of source to {HOME}/Archive\n",file=sys.stderr,end="")
#PL: print STDERR "ATTENTION!!! $SCRIPT_NAME is working in debugging mode $debug with
Cont: autocommit of source to $HOME/Archive\n";
87 | 1 | | autocommit([f"{HOME}/Archive",use_git_repo]) # commit source archive directory (which can be controlled by GIT)
#PL: autocommit("$HOME/Archive",$use_git_repo);
89 | 0 | |print(f"Log is written to {LOG_DIR}, The original file will be saved as {fname}.original unless this file already exists ")
#PL: say "Log is written to $LOG_DIR, The original file will be saved as $fname.origi
Cont: nal unless this file already exists ";
90 | 0 | |print('=' * 80,'\n',file=sys.stderr) #PL: say STDERR "=" x 80,"\n";
91 | 0 | |
92 | 0 | |#
93 | 0 | |# Main loop initialization variables
94 | 0 | |#
95 | 0 | |new_nest=cur_nest=0 #PL: $new_nest=$cur_nest=0;
96 | 0 | |#$top=0; $stack[$top]='';
97 | 0 | |lineno=noformat=SubsNo=0 #PL: $lineno=$noformat=$SubsNo=0;
98 | 0 | |here_delim='\n' # impossible combination
#PL: $here_delim="\n";
99 | 0 | |InfoTags='' #PL: $InfoTags='';
100 | 0 | |SourceText=sys.stdin.readlines().copy #PL: @SourceText=<STDIN>;
101 | 0 | |
102 | 0 | |#
103 | 0 | |# Slurp the initial comment block and use statements
104 | 0 | |#
105 | 0 | |ChannelNo=lineno=0 #PL: $ChannelNo=$lineno=0;
106 | 0 | |while 1: #PL: while(1){
107 | 1 | | if lineno==breakpoint: #PL: if( $lineno == $breakpoint ){
109 | 2 | | pdb.set_trace() #PL: }
110 | 1 | | line=line.rstrip("\n") #PL: chomp($line=$SourceText[$lineno]);
111 | 1 | | if re.match(r'^\s*$',line): #PL: if( $line=~/^\s*$/ ){
112 | 2 | | process_line(['\n',-1000]) #PL: process_line("\n",-1000);
113 | 2 | | lineno+=1 #PL: $lineno++;
114 | 2 | | continue #PL: next;
116 | 1 | | intact_line=line #PL: $intact_line=$line;
117 | 1 | | if intact_line[0:1]=='#': #PL: if( substr($intact_line,0,1) eq '#' ){
118 | 2 | | process_line([line,-1000]) #PL: process_line($line,-1000);
119 | 2 | | lineno+=1 #PL: $lineno++;
120 | 2 | | continue #PL: next;
122 | 1 | | line=normalize_line(line) #PL: $line=normalize_line($line);
123 | 1 | | line=line.rstrip("\n") #PL: chomp($line);
124 | 1 | | (line)=line.split(' '),1 #PL: ($line)=split(' ',$line,1);
125 | 1 | | if re.match(r'^use\s+',line): #PL: if($line=~/^use\s+/){
126 | 2 | | process_line([line,-1000]) #PL: process_line($line,-1000);
127 | 1 | | else: #PL: else{
128 | 2 | | break #PL: last;
130 | 1 | | lineno+=1 #PL: $lineno++;
131 | 0 | |#while
While only a small fragment is shown, the program was able to translate (or more correctly transliterate) all the code.
also the current version does not attempt to match types and convert numeric values into string, when necessary. For example, instead of:
InfoTags="=" + cur_nestthere should be:
InfoTags="=" + str(cur_nest)
For full protocol see Full protocol of translation of pre_pythonizer.pl by version 0.07 of pythonizer
For some additional information see Two-pass "fuzzy" transformer from Perl to "semi-Python"
The idea that that you can define your own types with a set operation on them sounds great, but the devil is in detail. As soon as you start using somebody else modules you are thrown into the necessity of learning of underling type system used in the package. And this is not a trivial exercise as the package designer typically has much higher level of understanding of language than you. And uses it in more complex way, including the use and abuse of type system.
For a Perl programmer the benefits of more strict type system are not obvious, but the pain of using it is quite evident from the very beginning.
We will illustrate subtle difficulties arising in more strict type system on example of two very simple Perl functions: functions defined and exists .
The function defined is used in Perl for determining if element of the array with the particular index exists. But in Python the attempt to access the array element with subscript above max element allocated generates exception so you need to check first if the index is within the bounds, and only then check for the existence of the particular element.
For scalar variables in Perl defined function determines if the variable was assigned any value, or not. If not it returns special value undef, similar to Python None (see discussion at Stack Overflow ). But Python variables don't have an initial, empty state. Python variables are bound (only) when they're defined. You can't create a Python variable without giving it a value. So Python fragment
>>> if a == None:
... print ("OK")
...
Un-expectantly print nothing and does not produce any error message.
NOTE: in Perl attempt to assign an element above current upper bound simply extends the array to this new bound, no questions asked.
If element does not exists and you use the value in expression Perl convents undef in two usable default values depending on context (string operation, or numeric):
All this needs to be manually programmed in Python.
Function exists in Perl is applicable to hashes and checks if element of the hash with the particular key exists.
And in different contexts Python programmer use different expressions of the same:
if d is a dictionary, d.get(k) will return d[k] if it exists, but None if d has no key k.
NOTE: Perl exists returns 1, if the element exists and 0 if it is not (not undef) if the value of the hash element with the given key is undef. So in Perl the element of hash can exist, but has not been defined.
Language designers usually have pretty strange and different tastes as for the rules of visibility of variables and lifespan of variables. Here lies one of the main problem with conversion of Perl script into Python.
Generally the part of a program where a variable is accessible is called the scope of the variable, and the duration for which the variable exists its lifetime.
Classic rules were established by PL/1 in late 60th and they include three parameters
Visibility of variables is a tricky concept. It is somewhat similar to Unix hierarchical filesystem structure and the concept of permissions on files.
It can be regulated only by special types of blocks (subroutines in Python), or all blocks including loops and if statement blocks like in Perl. Not that it matter much but that complicates exact translation as there is no way to exactly translate such typical usage of my variable in Perl in such simple construct as:
for( my $i; $i<@text_array; $i++){
...
}
Here $i in undefined outside the loop body, which does not have a proper Python analog as in Python local variables visibility is subroutines block.
Python uses "birth on the first assignment" concept: variables comes into being when it is initialized. If variable first initialized within a subroutine, it gets a local scope, else a global scope. So the scope (local or global) is determined implicitly, based on the point in which the variable is initialized:
foo = 12 bar = 19
The variable also can be explicitly declared as global so that subroutines within a program can see and change it. But the trick is that this variable should already exist in main namespace. If it does not exists Python interpreter complains that this is a name error. In other words you need to initialize global variables first before you can use global declaration in subroutines.
Variable is local if outer subroutines can's see and change it. But Python introduced "sunglass" visibility for global variables: global variables in Python declared in outer scope of a given subroutine are restricted to "read-only mode" -- the "inner" subroutines can see them and fetch their value (read them), but can't change them without additional declaration "global". This visibility mode does not have direct analogs in Perl so Perl global variables need to be made visible in subroutines by explicitly declaring them as global.
Bu that's only beginning of the troubles. Even worse is that fact that Python does not allow to initialize the global variable at declaration. So Perl initialization of such variables need to be does separately and in some case (state variables) moved to other context or you need to jump though the hoops and introduce special variable that record number of invocations of the subroutine.
In Perl, which originated from shell and AWK, any global variable can be declared and changed in any subroutine without limitations, unless they are masked by declaration of local (my) variable with the same name. By default all declaration of variables in Perl are global unless pragma strict is used. In version 5.10 with the introduction of state variables it becomes more tricky.
In Perl local variables can be static (called state): they are created and initialized on loading the program or module and retain value from one subroutine invocation to another.
It does not matter whether they were declared in a subroutine or not: subroutine defines only scope for them, not the lifespan. Unfortunately there are no such variables in Python and you need to emulate them with global variables.
NOTE: To emulate Perl behaviour of state variables with Python global variables you need to avoid conflicts with "regular" global variables used in main or other subs; to achieve that you can prefix the name of the variable with the name of the sub. So that
sub mysub { state $limit=132; ... ... ... }translated to something like
def mysub: global mysub_limitmysub_limit=132def mysub2 global message_levelmessage_level=3
As you can see the translation involved two steps:
def mysub():
global mysub_state_init_done
global a,b,c
if mysub_state_init_done==0:
[a,b,c]=[0,1,3]
mysub_state_init_done==1
mysub_state_init_done=0
mysub()
print(a,b,c)
In Python you can't initialize global variables along with declaration.
# python3.8 globals.py
File "globals.py", line 4
global s = "initialization_in_global_statement_is_prohibited"
^
SyntaxError: invalid syntax
While Perl scripts with program script behave better, many old scripts do not use this pragma. Such "ancient" scripts tend to overuse global variables (partially because initially in Perl those were the only variable available)
In Perl global variable can be declared any subroutine and even if their use is limited to subroutines they are still global. Actually this is the default scope and visibility of variables in Perl, which stems from shell. if Unix filesystem terms all files in Perl have by default mode 777. That's why later Perl tried to restrict this with pragma strict.
In Python you can see variables that are declared in outer scope -- that is, get their values -- but you can't set their values without using a nonlocal or global statement.
A variable which is defined inside a function is local to that function. It is accessible from the point at which it is defined until the end of the function, and exists for as long as the function is executing.
The parameter names in the function definition behave like local variables, but they contain the values that we pass into the function when we call it.
In Perl, the my declares a lexical variable. A variable can be initialized with =. This variable can either be declared first and later initialized or declared and initialized at once.
my $foo; # declare $foo = 12; # initialize my $bar = 19; # both at once
Also, as you may have noticed, variables in Perl usually start with sigils -- symbols indicating the type of their container. Variables starting with a $ hold scalars. Variables starting with an @ hold arrays, and variables starting with a % hold a hash (dict). Sigilless variables, declared with a \ but used without them, are bound to the value they are assigned to and are thus immutable.
Please note that, from now on, we are going to use sigilless variables in most examples just to illustrate the similarity with Python. That is technically correct, but in general we are going to use sigilless variables in places where their immutability (or independence of type, when they are used in signatures) is needed or needs to be highlighted.
s = 10
L = [1, 2, 3]
d = { a : 12, b : 99 }
print s
print l[2]
print d['a']
# 10, 2, 12
Perl
my $s = 10;
my @l = 1, 2, 3;
my %d = (a => 12, b => 99);
my \x = 99;
say $s;
say @l[1];
say $d{'a'}
say x;
# 10, 2, 12, 99
Blocks
In Python, indentation is used to indicate a block so { and } in Perl translated into indent in Python. Blocks in Perl and Python
determine visibility. But only Per allow arbitrary blocks. In Python you are out of luck and need some conditional
prefix
[127] # cat blocks.py
:
print( "block nestin 1")
:
print(block nesting 2")
print("block nesting zero")
Instead you need something like
[127] # cat blocks.py
if True :
print( "block nestin 1")
if True :
print(block nesting 2")
print("block nesting zero")
So you need to invent prefixes:
if True :
print( "block nesting 1")
if True :
print("block nesting 2")
print("block nesting zero")
This Fortran-style
solution has its pluses and minuses. In a way you can view ":" as an equivalent of opening bracket in Perl, which makes the
situation half less bizarre.
Python
if 1 == 2:
print "Wait, what?"
else:
print "1 is not 2."
Perl
if( 1 == 2 ){
say "Wait, what?"
} else {
say "1 is not 2."
}
If you strongly allergic to absence of closing bracket you can imitate it with comment of ';'. Parentheses are optional in both languages for expressions in conditionals, as shown above. Perl has yet another function of blocks -- it allow loop control statements such as last and next in any block. This capability
need to be emulated in Python.
Scope of variables
In Python, functions and classes create a new scope, but no other block constructor (e.g. loops, conditionals) creates a scope. In
Python 2, list comprehensions do not create a new scope, but in Python 3, they do.
In Perl any block create a new scope and local variable are limited ot this particular scope: my variables belong to the scope defined by curvy brackets in which
they are enclosed. Otherwise in Perl the variable is
simply global
Python
if True:
x = 10
print x
# x is now 10
Perl
if True {
my $x = 10
}
say $x
# error, $x is not declared in this scope
my $x;
if True {
$x = 10
}
say $x
# ok, $x is 10
Python
x = 10
for x in 1, 2, 3:
pass
print x
# x is 3
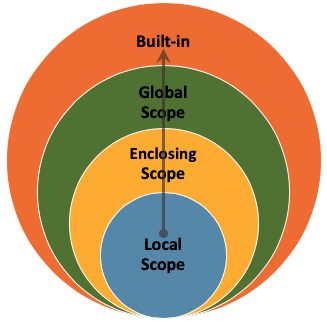
LEGB (Local -> Enclosing -> Global -> Built-in) rule
Whenever a variable is defined outside of any function, it becomes a global variable, and its scope is anywhere within the program.
Which means it can be read by any function but written only by functions which declare it as global.
The following quote was
borrowed from Python Scope & the LEGB Rule- Resolving Names in Your
Code – Real Python with some clarifications
LEGB (Local -> Enclosing -> Global -> Built-in) is the logic followed by a Python interpreter when it is executing your program.
Let's say you're calling print(x) within inner(),
which is a function nested in outer().
Then Python will first look if "x" was defined locally within inner().
If not, the variable defined in outer() will
be used. This is the enclosing function. If it also wasn't defined there, the Python interpreter will go up another level - to
the global scope. Above that, you will only find the built-in scope, which contains special variables reserved for Python itself.

So far, so good!
Here is another useful discussion, this time in Stack Overflow (
Python variable visibility)
range_dur = 0
xrange_dur = 0
def do_range():
nonlocal range_dur
start = time.time()
for i in range(2,10):
print i
range_dur += time.time() - start
def do_xrange():
nonlocal xrange_dur
start = time.time()
for i in xrange(2,10):
print i
xrange_dur += time.time() - start
do_range()
do_xrange()
print range_dur
print xrange_dur
if __name__ == '__main__':
main()
Prefix and postfix operators "++" and '--"
When people coming from C/C++, Java or Perl write x[++i] or if ++i > len(line): it will compile in Python.
But the meaning is different and incorrect. In Python ++ is not a special operator. It is two unary operators "+", which does not change
the value of the variable. Opps !
Only starting from Python 3.8 you can use walrus operator to imitate prefix "++" and "--" operators is subscripts like x[i:=i+1]
The situation with postfix ++ and -- operators is even more bizarre. They just do not exists and need to be emulated, which
is not easy. See
Behaviour of increment and decrement operators in Python - Stack Overflow One pretty tricky hack is
def PostIncr(name, local={}):
#Equivalent to name++
if name in local:
local[name]+=1
return local[name]-1
globals()[name]+=1
return globals()[name]-1
def PostDecrement(name, local={}):
#Equivalent to name--
if name in local:
local[name]-=1
return local[name]+1
globals()[name]-=1
return globals()[name]+1
In this case you are probably better off modifying algorithms to prefix notation or use iterable objects.
Lists in Perl vs Lists in Python
Dimension of lists in Perl are flexible. Which means that an assignment of the element above current size (above max
index) leads to automatic extension of
the list to the necessary size.
In Python the size of the list is fixed at creation and is, essentially, a part of its type. So it can be expanded only via append
operation, never via assignment. That leads to Pascal style allocation of two dimensional lists in Python, which suggests that iether
many Python programmers do not understand the language or the language has way too many gotchas:
myList=[[0] * n] * m # Pascal style allocation of two dimensional list(list of lists) -- Incorrect solution
And here troubles start (How
to initialize a two-dimensional array in Python- - Stack Overflow: )
You can do just this:
[[element] * numcols] * numrows
For example:
>>> [['a'] *3] * 2
[['a', 'a', 'a'], ['a', 'a', 'a']]
But this has a undesired side effect:
>>> b = [['a']*3]*3
>>> b
[['a', 'a', 'a'], ['a', 'a', 'a'], ['a', 'a', 'a']]
>>> b[1][1]
'a'
>>> b[1][1] = 'b'
>>> b
[['a', 'b', 'a'], ['a', 'b', 'a'], ['a', 'b', 'a']]
...In my experience, this "undesirable" effect is often a source of some very bad logical errors. ...Because of the undersired
side effect, you cannot really treat it as a matrix.
Here is another description of this gotcha
How to initialize a
two-dimensional array in Python -- Stack Overflow
Don't use [[v]*n]*n, it is a trap!
>>> a = [[0]*3]*3
>>> a
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> a[0][0]=1
>>> a
[[1, 0, 0], [1, 0, 0], [1, 0, 0]]
but
t = [ [0]*3 for i in range(3)]
works great.
Assignment of complex structures, such as lists and hashes in Perl is "copy" assignment in terms of Python. It
creates a copy of the structure not just an alias to the pointer to this structure. This affects translation of assignment of
lists and hashes.
Generally the statement @a_list=@b_list in Perl requires copy method to be used in Python.
Assignments: copy of value vs copy of pointer
Assignment in Perl is almost always copy of value assignments, even for aggregate data types such as list, arrays and
hashes. They create a new variable as copy the content of the variable on the right side into it.
In Python assignments are copy assignment only for simple types (integer, strings, etc) and this is a trap for Perl programmers.
So the assignment for list should be written as application of the method copy to the list on the right side, not as a simple
assignment.
In other words, Perl
@x=@y
corresponds to Python
x=y.copy
NOTE: In Python the assignment x=y essentially copy the reference y to reference x and does not create new copy
of any aggregate varible. Some Python tutorials try to explain this using concept of labels, but this is bunk -- Python
operates with references to object just like Perl can.
Another problem is that widespread usage of strict pragma in Perl led to the annoying proliferation of usage of function
defined, to check if the variable is initialized. But the meaning of defined function is different then the
meaning of the variable having the value None on Python. In Python the usage of variable that was not assigned a value of
the right side of the assignment statement is a compile time error, if complier can detect this, and runtime error otherwise.
Due to this check var != None is not applicable to variable which are not yet defined (which in
Python means assigned a value).
As in Python the valuable that is first assigned value within function is local to this function assignment of
the value value None can be used for imitation of Perl my variables, which are not assigned the initial
(default) value at declaration.
Comparison of variable and type casting
Type casting means to convert variable data of one type to another type, In Perl type casting is done automatically during
comparisons, in Python you need explicitly use functions int(), float(), or str().
Perl enforces conversion of variables in comparison depending of the type of comparison (numeric or spring) for which like Unix
shell it uses two set of comparison operations: regular for numeric comparison and abbreviations like eq, gt,
lt for string comparison. The latter feature is a frequent source of errors in Perl, especially if a programmer uses
another language along with Perl, for example C or Javascript. So, for example, Perl if statement:
if ( $a > $b ) {
$max=$a;
}else{
$max=$b;
}
implicitly involves forced conversion to float of both operands, if they are strings. But in reality most Perl
programmers do not change type of their variables after the first assignment and thus in most cases the use of if float(a)>float(b):
would be is redundant. Few exception can be corrected by hand.
The real problem is the treatment of input values, when they are converted to numeric values. In Perl the string 123abc
will convert to 123 in numerical assignment. Python int and float function will not do that.
Another problem is that numeric type in Perl is by default represented by float even if this is a counter in the for loop.
Here Python offer usage of int. So if the initial value of the index is fractional you need explicit conversion to
int via floor function. But such cases are rare.
Function mapping
Python has around 100 built-in functions, while Python with its plethora of built-in functions and methods has much more. So some analogs to Perl
function almost always can be found but the devil is in details, as type
systems of both languages are radically different and conversion functions play much more prominent role in Python then in Perl. Two
examples when we have problems do exists for hashes vs dictionaries (for example the close analog in conditional statement is not a
function but in keyword; another is dict.has_key() function)
See Perl to Python functions map
Some Perl functions badly map to Python. One such function is tr. In Python translation of one character set to another
was made into two stage operation: first you need to create a map of characters using maketrans function, and only
then you can use translate function, using this map.
Another difficulty is that only modifier 'd' in Perl tr function is directly translatable. And its translation differs
between Python 2.7 and Python 3.x and even between Python 3.0-3.5 and Python 3.6-3.8.
All other modifiers (which means c, r and s) present difficulties:
- c Complement the SEARCHLIST. (need to be emulated Complement search list also need to be translated
manually. via deletion from full set of characters, the characters present in the string.
- d Delete found but unreplaced characters (can be translated).
- r Return the modified string and leave the original
string untouched. This is a tricky case which depends on context. In Perl normally tr is operation that modifies the
source string. With Python 'r' behaviour is default. So in most cases no translation is needed. This option is used very
rarely in Perl in any case and most Perl programmers do not suspect that it exists
- ($HOST = $host) =~ tr/a-z/A-Z/;
- $HOST = $host =~ tr/a-z/A-Z/r; # same thing
- @stripped = map tr/a-zA-Z/ /csr, @original; # /r with map
- s Squash duplicate replaced characters.If order to replicate squash modifier (s) you need to write you own tr
function which iterates over the string as there is no direct mapping.
Some idioms like
tr [\200-\377] [\000-\177]; # delete 8th bit
generally are translatable.
But in Python there is no way to know how many replacements in the string were made by the translate function so idioms like
if ($line=~tr/a/a/) {...}
Need to be translated into a custom written function.
Regular expressions
the standard way of using regex in Python is recompiling them via re.compile function. This is the only way to pass
regex modifiers to the regex.
Here’s a table of the available flags for re-complie , followed by a more detailed explanation of each one.
|
Flag |
Meaning |
|---|---|
|
|
Makes several escapes like |
|
|
Make |
|
|
Do case-insensitive matches. Corresponds to Perl i |
|
|
Do a locale-aware match. |
|
|
Multi-line matching, affecting |
|
|
Enable verbose REs, which can be organized more cleanly and understandably. |
in Perl modifier are as following
mTreat the string being matched
against as multiple lines. That is, change "^" and "$" from
matching the start of the string's first line and the end of its last line to matching the start and end of each line within the
string.
sTreat the string as single line.
That is, change "." to
match any character whatsoever, even a newline, which normally it would not match.
Used together, as /ms ,
they let the "." match
any character whatsoever, while still allowing "^" and "$" to
match, respectively, just after and just before newlines within the string.
i
Do case-insensitive pattern matching. For example, "A" will match "a" under /i .
x and xxExtend your pattern's legibility by permitting whitespace and comments. Details in /x and /xx
p
Preserve the string matched such that ${^PREMATCH} , ${^MATCH} ,
and ${^POSTMATCH} are
available for use after matching.
In Perl 5.20 and higher this is ignored. Due to a new
copy-on-write mechanism, ${^PREMATCH} , ${^MATCH} ,
and ${^POSTMATCH} will
be available after the match regardless of the modifier.
a , d , l ,
and uThese modifiers, all new in 5.14, affect which character-set rules (Unicode, etc.) are used, as described below in Character set modifiers.
n
Prevent the grouping metacharacters () from
capturing. This modifier, new in 5.22, will stop $1 , $2 , etc...
from being filled in.
There are a number of flags that can be found at the end of regular expression constructs that are not generic
regular expression flags, but apply to the operation being performed, like matching or substitution (m// or s/// respectively).
Flags described further in Using regular expressions in Perl in perlretut are:
Substitution-specific modifiers described in s/PATTERN/REPLACEMENT/msixpodualngcer in perlop are:
Bothe language deviate from classic C-language control structures but is a different ways. In booth language a better language and a set of control structure is hidden and strives to get our but can not.
Python introduced a new syntax for the for loop by using function range instead of specifying the condition for exit and increment like in classic C-loop. In most cases this is OK, although this is less flexible control structure than classic for loop.
Perl brazenly renamed C loop control statements (next instead of continue and last instead of break) under the false pretext of being more "English language like" -- the latter is fake justification that is often used to justify numerous Perl warts). Nothing can be further from English language then a programming language.
It also tried to innovate and introduced a new one -- continue block, which proved to be only marginally useful and is not used much to matter.
Python has just for loop and while loop. While loop is pretty much traditional:
my $j = 1;
while $j < 3 {
say $j;
$j += 1
}
Python for loop is idiosyncratic and deviates from C-language tradition:for i in range(1,3):
print i
j = 1
# 1, 2, 1, 2
Perl has traditional C-style for loops and while loops, which are well understood but suffers from a classic C-wart -- using round bracket to delimit conditionals. For loop in Perl allows multiple counters, the feature which proved to be a flop and never used.
(Perl also has until loop: repeat...until repeat...while which need to be emulated in Python, but they are rarely use, so this is not a problem.
Python implements C-style addition control operators within the loop: last leaves a loop in Perl, and is analogous to break in Python. continue in Python corresponds to the next in Perl.
Python
for i in range(10):
if i == 3:
continue
if i == 5:
break
print i
Using if as a statement modifier (as above) is acceptable in Perl, even outside of a list comprehension.
The yield statement within a for loop in Python, which produces a generator, is not available in Perl 5.
Python
def count():
for i in 1, 2, 3:
yield i
Both language has postfix conditionals, only postfix loop for some very strange reason called list comprehensions (may be because they are not that comprehensible).
Absence of postfix conditions is not a big deal, as prefix conditions are more clear, so instead of
return if( $i < $limit );
you can write
if i>limit: return
Python wants to be idiosyncratic here too. But, at least, such a construct is present (BTW it is not needed for novices at all ;-):
$imax=($a>$b) ? $a : $b;
imax=a if (a<b) else b
SyntaxError: invalid syntax >>> a=1 if True File "", line 1 a=1 if True ^ SyntaxError: invalid syntax >>> a=1 if True else 0
Declaring a function (subroutine) with def in Python is accomplished with sub in Perl.
def add(a, b):
return a + b
In Perl all arguments are converted into the array with the name @_ and are referenced by index. This is approach is similar to bash and it automatically provides variable number of parameters as well as the ability to check that number of parameters actually passed and set defaults fro missing without any additional language constructs.
The return in Perl is optional; if it is absent that the value of the last expression is used as the return value:
sub add {
$_[0]+$_[1]; # equivalent to return $_[0]+$_[1]; This idiosyncrasy is rarely used.
}
Python 2 functions can be called with positional arguments or keyword arguments. These are determined by the caller. In Python 3, some arguments may be "keyword only".
def speak(word, times):
for i in range(times):
print word
speak('hi', 2)
speak(word='hi', times=2)
sub speak
{
my ($work, $times)=@_;
say $word for ^$times
}
speak('hi', 2);
In Python 3, the input keyword is used to prompt the user. This keyword can be provided with an optional argument which is written to standard output without a trailing newline:
user_input = input("Say hi → ")
print(user_input)
looping over files given on the command line or stdin
The useful Perl idiom of:
while (<>) {
... # code for each line
}
loops over each line of every file named on the commandline when executing the script; or, if no files are named, it will loop over
every line of the standard input file descriptor. The Python fileinput module does a similar task:
import fileinput
for line in fileinput.input():
... # code to process each line
The fileinput module also allows in place editing or editing with the creation of a backup of the files.In Python 3 versions, open can act as iterator, so you would just write:
for line in open(filename):
... # code to process each line
If you want to read from standard in, then use it as the filename:
import sys
for line in open(sys.stdin):
... # code to process each line
If you want to loop over several filenames given on the command line, then you need to write an outer loop over the command line. (You
might also choose to use the fileinput module as noted above).
Perl does this implistly
import sys
for fname in sys.argv[1:]
for line in open(fname):
... # code to process each line
Tom Limoncelli in his post Python for Perl Programmers observed
There are certain Perl idioms that every Perl programmer uses: "while (<>) { foo; }" and "foo ~= s/old/new/g" both come to mind.When I was learning Python I was pretty peeved that certain Python books don't get to that kind of thing until much later chapters. One didn't cover that kind of thing until the end! As [a long-time Perl user]( https://everythingsysadmin.com/2011/03/overheard-at-the-office-perl-e.html ) this annoyed and confused me.
While they might have been trying to send a message that Python has better ways to do those things, I think the real problem was that the audience for a general Python book is a lot bigger than the audience for a book for Perl people learning Python. Imagine how confusing it would be to a person learning their first programming language if their book started out comparing one language you didn't know to a different language you didn't know!
So here are the idioms I wish were in Chapter 1. I'll be updating this document as I think of new ones, but I'm trying to keep this to be a short list.
Processing every line in a file
Perl:
while (<>) { print $_; }Python:
for line in file('filename.txt'): print lineTo emulate the Perl <> technique that reads every file on the command line or stdin if there is none:
import fileinput for line in fileinput.input(): print lineIf you must access stdin directly, that is in the "sys" module:
import sys for line in sys.stdin: print lineHowever, most Python programmers tend to just read the entire file into one huge string and process it that way. I feel funny doing that. Having used machines with very limited amounts of RAM, I tend to try to keep my file processing to a single line at a time. However, that method is going the way of the dodo.
contents = file('filename.txt').read() all_input = sys.stdin.read()If you want the file to be one string per line, with the newline removed just change read() to readlines()
list_of_strings = file('filename.txt').readlines() all_input_as_list = sys.stdin.readlines()Regular expressions
Python has a very powerful RE system, you just have to enable it with "import re". Any place you can use a regular expression you can also use a compiled regular expression. Python people tend to always compile their regular expressions; I guess they aren't used to writing throw-away scripts like in Perl:
import re RE_DATE = re.compile(r'\d\d\d\d-\d{1,2}-\d{1,2}') for line in sys.stdin: mo = re.search(RE_DATE, line) if mo: print mo.group(0)There is re.search() and re.match(). re.match() only matches if the string starts with the regular expression. It is like putting a "^" at the front of your regex. re.search() is like putting a ".*" at the front of your regex. Since match comes before search alphabetically, most Perl users find "match" in the documentation, try to use it, and get confused that r'foo' does not match 'i foo you'. My advice? Pretend match doesn't exist (just kidding).
The big change you'll have to get used to is that the result of a match is an object, and you pull various bits of information from the object. If nothing is found, you don't get an object, you get None, which makes it easy to test for in a if/then. An object is always True, None is always false. Now that code above makes more sense, right?
Yes, you can put parenthesis around parts of the regular expression to extract out data. That's where the match object that gets returned is pretty cool:
import re for line in sys.stdin: mo = re.search(r'(\d\d\d\d)-(\d{1,2})-(\d{1,2})', line) if mo: print mo.group(0)The first thing you'll notice is that the "mo =" and the "if" are on separate lines. There is no "if x = re.search() then" idiom in Python like there is in Perl. It is annoying at first, but eventually I got used to it and now I appreciate that I can't accidentally assign a variable that I meant to compare.
Let's look at that match object that we assigned to the variable "mo" earlier:
- mo.group(0) -- The part of the string that matched the regex.
- mo.group(1) -- The first ()'ed part
- mo.group(2) -- The second ()'ed part
- mo.group(1,3) -- The first and third matched parts (as a tuple)
- mo.groups() -- A tuple containing all the matched parts.
The perl s// substitutions are easily done with re.sub() but if you don't require a regular expression "replace" is much faster:
>>> re.sub(r'\d\d+', r'', '1 22 333 4444 55555') '1 ' >>> re.sub(r'\d+', r'', '9876 and 1234') ' and ' >>> re.sub(r'remove', r'', 'can you remove from') 'can you from' >>> 'can you remove from'.replace('remove', '') 'can you from'You can even do multiple parenthesis substitutions as you would expect:
>>> re.sub(r'(\d+) and (\d+)', r'yours=\1 mine=\2', '9876 and 1234') 'yours=9876 mine=1234'After you get used to that, read the ""pydoc re" page":http://docs.python.org/library/re.html for more information.
String manipulations
I found it odd that Python folks don't use regular expressions as much as Perl people. At first I though this was due to the fact that Python makes it more cumbersome ('cause I didn't like to have to do 'import re').
It turns out that Python string handling can be more powerful. For example the common Perl idiom "s/foo/bar" (as long as "foo" is not a regex) is as simple as:
credit = 'i made this' print credit.replace('made', 'created')or
print 'i made this'.replace('made', 'created')It is kind of fun that strings are objects that have methods. It looks funny at first.
Notice that replace returns a string. It doesn't modify the string. In fact, strings can not be modified, only created. Python cleans up for automatically, and it can't do that very easily if things change out from under it. This is very Lisp-like. This is odd at first but you get used to it. Wait... by "odd" I mean "totally fucking annoying". However, I assure you that eventually you'll see the benefits of string de-duplication and (I'm told) speed.
It does mean, however, that accumulating data in a string is painfully slow:
s = 'this is the first part\n' s += 'i added this.\n' s += 'and this.\n' s += 'and then this.\n'The above code is bad. Each assignment copies all the previous data just to make a new string. The more you accumulate, the more copying is needed. The Pythonic way is to accumulate a list of the strings and join them later.
s = [] s.append('this is the first part\n') s.append('i added this.\n') s.append('and this.\n') s.append('and then this.\n') print ''.join(s)It seems slower, but it is actually faster. The strings stay in their place. Each addition to "s" is just adding a pointer to where the strings are in memory. You've essentially built up a linked list of pointers, which are much more light-weight and faster to manage than copying those strings around. At the end, you join the strings. Python makes one run through all the strings, copying them to a buffer, a pointer to which is sent to the "print" routine. This is about the same amount of work as Perl, which internally was copying the strings into a buffer along the way. Perl did copy-bytes, copy-bytes, copy-bytes, copy-bytes, pass pointer to print. Python did append-pointer 4 times then a highly optimized copy-bytes, copy-bytes, copy-bytes, copy-bytes, pass pointer to print.
joining and splitting.
This killed me until I got used to it. The join string is not a parameter to join but is a method of the string type.
Perl:
new = join('|', str1, str2, str3)Python:
new = '|'.join([str1, str2, str3])Python's join is a function of the delimiter string. It hurt my brain until I got used to it.
Oh, the join() function only takes one argument. What? It's joining a list of things... why does it take only one argument? Well, that one argument is a list. (see example above). I guess that makes the syntax more uniform.
Splitting strings is much more like Perl...
Kind of. The parameter is what you split on, or leave it blank for "awk-like splitting" (which heathens call "perl-like splitting" but they are forgetting their history).
Perl:
my @values = split('|', $data);Python:
values = data.split('|');You can split a string literal too. In this example we don't give split() any parameters so that it does "awk-like splitting".
print 'one two three four'.split() ['one', 'two', 'three', 'four']If you have a multi-line string that you want to break into its individual lines, bigstring.splitlines() will do that for you.
Getting help
pydoc fooexcept it doesn't work half the time because you need to know the module something is in . I prefer the "quick search" box on http://docs.python.org or "just use Google".
I have not read ""Python for Unix and Linux System Administration":http://www.amazon.com/dp/0596515820/safocus-20" but the table of contents looks excellent. I have read most of Python Cookbook (the first edition, there is a 2nd edition out too) and learned a lot. Both are from O'Reilly and can be read on Safari Books Online.
That's it!
That's it! Those few idioms make up most of the Perl code I usually wrote. Learning Python would have been so much easier if someone had showed me the Python equivalents early on.
One last thing... As a sysadmin there are a few modules that I've found useful:
- subprocess -- Replaces the need to figure out Popen(), system() and a ton of other error-prone system calls.
- logging -- very nice way to log debug info
- os -- OS-independent ways to do things like copy files, look at ENV variables, etc.
- sys -- argv, stdio, etc.
- gflags -- My fav. flag/getopt replacement http://code.google.com/p/python-gflags/
- pexpect -- Like Expect.PM http://pexpect.sourceforge.net/
- paramiko -- Python access to ssh/scp/sftp. http://www.lag.net/paramiko/
See also
- PerlPhrasebook - http://wiki.python.org/moin/PerlPhrasebook is kind of ok, but hasn't been updated in a while.
Variables such as $_ (the result of operation, such as reading a line from a file) and $. (line number) gives a lot of troubles. Python implements neither. So they need to be emulated.
With mapping Perl functions to Python we also run into multiple problems. For example, while string function index exists in Python as method in string class, its behaviour is different from behaviour of Perl index function. It raises exception is substring is not found. You need to use a different string class methods find (and rfind) to imitate Perl behavior in which if substring is not found the function simply returns -1 making it compatible with Perl index behaviour.
Python 2.7 does not allow assignments in conditional expressions (for a good reason, as they can be a source of of subtle bugs) so in this case you iether need to translate the script into Python 3.8 or factored out of conditional expressions and convert them into statements the precede comparison:
61 | 0 | |dotpos=SCRIPT_NAME.find( '.') #Perl: if( ($dotpos=index($SCRIPT_NAME,'.'))>-1 ) {
61 | 0 | |if dotpos>-1:
62 | 1 | | SCRIPT_NAME=SCRIPT_NAME[0:dotpos] #Perl: $SCRIPT_NAME=substr($SCRIPT_NAME,0,$dotpos);
64 | 0 | |
Perl left hand substr function does not have direct Python analogs and needs to be emulated iether via concatenation or via join function.
Even larger problems exists with translation of double quoted and HERE strings. The closest analog are Python 3 f-strings. The latter is a literal string, prefixed with ‘f’, which contains expressions inside curvy braces. Each expression is replaced with their values. Like any Perl double quoted string, an f-string is really an expression evaluated at run time, not a constant value. (Python f-string tutorial - formatting strings in Python with f-string):
print(f'{name} is {age} years old')Python f-strings are available since Python 3.6. The string has the
fprefix and uses{}to evaluate variables.$ python formatting_st...
We can work with dictionaries in f-strings.
dicts.py#!/usr/bin/env python3 user = {'name': 'John Doe', 'occupation': 'gardener'} print(f"{user['name']} is a {user['occupation']}")...Python 3.8 introduced the self-documenting expression with the
debug.py=character.#!/usr/bin/env python3 import math x = 0.8 print(f'{math.cos(x) = }') print(f'{math.sin(x) = }')
The self-documenting expression are re-invention of PL/1 put data statement. They makes code more concise, readable, and less prone to error when printing variables with their names (and that is useful not only in debugging by in many "production" cases such as printing options, etc. )
To take advantage of this new feature, type your f-string as follows:
f'{expr=}'where
expris the variable that you want to expose. In this way, you get to generate a string that will show both your expression and its output.
And this is only the beginning of troubles with conversion from Perl to Python. Generally the more rich subset of Perl is used, the lessee are chances that semiautomatic translation is useful.
Several emulators of Perl features exist. for example fileinput.py that comes with the standard Python distribution allows to iterate between all files supplied as the argument (implicit cat for the files), while glob.py allow to return list of files for given regular expression.
So Perl behaviour when by default default arguments re viewed as files that are concatenated can be emulated this way
In addition, tempfile.py help to create temp files.
NOTE: BTW Python 3 (and to a lesser extent Python 2.5+) supports coroutines, so in many cases of sysadmins related scripts a large Perl script might be broken into several "passes" to make them simpler and make debugging more transparent. That's a distinct advantage which allows to create more manageable easier understandable programs.
While having there own set of warts, Python avoids three major Perl pitfalls and that also complicates translation:
Coercing type of operands by the operand, when any operator can convert the variable into a new type
(often with disastrous results as in case converting text string to a number). In reality most Perl programmers imitate "strong
typing" -- the type of a variable never changes during execution of the script. That helps a lot. But you need somehow to
figure this out for semi-automatic translations. Which means it requires preliminary pass (which is desirable from several other
standpoints)
Assignment of arrays and hashes ion Perl is copy method in Python.
There are many subtle differences is treating each of "composite" data types as as lists and
hashes/dictionaries between Perl and Python. For example the size of the list is one of "fixed" properties of the list in
Python (list can be extended only via append operator) but it is implicit operation in Perl. Which means that such simple
statement as $a[$i]=5
should be translated differently depending on whether $i is within the bound of the list or in upside them.
Perl operations with pointers generally are untranslatable directly into Python.
While we discuss the conversion of Perl to Python as something already decided, often it is better not to move to Python. Much depends on the skillset available on the floor. Outside simple scripts a direct conversion of reasonably complex medium size script (over 1K lines) is a very complex task even for high level professional who devoted much of his/her professional career to studying programming languages
A useful discussion can be found at Conversion of Perl to Python page and for details) and often requires restructuring of the code. If you need a small change in existing Perl code, usually correcting it directly is a better deal. Maybe adding use strict, and running the script via perltidy. You might benefit from buying some books like Perl Cookbook, or talking to your co-workers.
If you plan to re-write existing, working Perl code because you're worried about Perl being not-quite-as-purely OO as Python, then there is no help. You need to pay the price. That's actually a good punishment for their folly ;-). OO fundamentalists is the worst type of co-workers you can have in any case and the decision to occupy them with some semi-useless task is a good management decision.
The same is true for those who are worried about Perl obsolesce. Please note that many people who predicted the demise of Fortran are already gone, but Fortran is here to stay. This also can be a "programming fashion addicts" with the beta addicts mentality: "Ooh! I found this cool new OO language and want to share its coolness with everyone by converting old scripts to it!" Of course, programming is driven by fashion, much like woman clothing, but an excessive zeal in following fashion can cost you...
Learning Python typically requires forgetting Perl: few programmers are able to write fluently in both languages as are they sufficiently similar and at the same time require different code practices. Also the volume and the complexity of each language is so big that you just can't have enough memory cells for both. Of course, we ned to admin that games with Perl 6 (when people who decided to go this way knew in advance that they have neither resources, not talent to do a proper job) undermines Perl, and pushed many people to Python.
Perl is more close to Unix culture while Python looks like a completely foreign entity with its own idiosyncratic vision. Also the cost of running Python in many case is excessive and that's why it is now squeezes by Go language.
From the point of view of history of evolution of programming language, Python represents a descendant of Nicklaus Wirth family of languages (Pascal, Modula, Modula 2). Or more correctly it is a direct descendant of ABC ( white space for indentation, syntax of if statements with semicolon as the delimiter (bad idea if you ask me) as in if expression: syntax, etc) with some Perl ideas incorporated in the process (Perl 4 existed during the first several year of Python development and greatly influenced Python development)
Most system administrators who know Perl are quite satisfied with it. In Unix sysadmin domain Perl is slightly higher language then Python in a sense that you can write the same utility with less lines of code. Those sysadmin usually started their small projects in Python in order to better understand the needs and problem that users which use Python as their primary (and often the only) programming language face. This page is written for them. I assume high to medium level of proficiency in Perl on this page.
Actually studying Python allow better understand strong points of Perl. After using Python such thing that people generally do not value much like double quoted strings or integration of regular expression engine into the language now look in completely different light.
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
Sep 29, 2020 | drjohnstechtalk.com
Pythonizer
If you fit a certain profile: been in IT for > 20 years, managed to crate a few utility scripts in Perl, ut never wrapped your head around the newer and flashier Python, this blog post is for you.
Conversely, if you have grown up with Python and find yourself stuck maintaining some obscure legacy Perl code, this post is also for you.
A friend of mine has written a conceptually cool program that converts Perl programs into Python which he calls a Pythonizer .
I'm sure it won't do well with special Perl packages and such. In fact it is an alpha release I think. But perhaps for those scripts which use the basic built-in Perl functions and operations, it will do the job.
When I get a chance to try it myself I will give some more feedback here. I have a perfect example in mind, i.e., a self-contained little Perl script which ought to work if anything will.
Conclusion
Old Perl programs have been given new life by Pythonizer, which can convert Perl programs into Python.
References and related
h ttps://github.com/softpano/pythonizer
Perl is not a dead language after all. Work continues on Perl 7, which will be known as v5.32. Should be ready next year: https://www.perl.com/article/announcing-perl-7/?ref=alian.info
Jan 01, 2014 | stackoverflow.com
Ask Question Asked 6 years, 3 months ago Active 7 months ago Viewed 77k times
Juicy ,
I am using:
grepOut = subprocess.check_output("grep " + search + " tmp", shell=True)To run a terminal command, I know that I can use a try/except to catch the error but how can I get the value of the error code?
I found this on the official documentation:
exception subprocess.CalledProcessError Exception raised when a process run by check_call() or check_output() returns a non-zero exit status. returncode Exit status of the child process.But there are no examples given and Google was of no help.
jfs ,
"Google was of no help" : the first link (almost there it showse.output), the second link is the exact match (it showse.returncode) the search term:CalledProcessError. – jfs May 2 '14 at 15:06DanGar , 2014-05-02 05:07:05
You can get the error code and results from the exception that is raised.
This can be done through the fields
returncodeandoutput.For example:
import subprocess try: grepOut = subprocess.check_output("grep " + "test" + " tmp", shell=True) except subprocess.CalledProcessError as grepexc: print "error code", grepexc.returncode, grepexc.outputDanGar ,
Thank you exactly what I wanted. But now I am wondering, is there a way to get a return code without a try/except? IE just get the return code of the check_output, whether it is 0 or 1 or other is not important to me and I don't actually need to save the output. – Juicy May 2 '14 at 5:12jfs , 2014-05-02 16:09:20
is there a way to get a return code without a try/except?
check_outputraises an exception if it receives non-zero exit status because it frequently means that a command failed.grepmay return non-zero exit status even if there is no error -- you could use.communicate()in this case:from subprocess import Popen, PIPE pattern, filename = 'test', 'tmp' p = Popen(['grep', pattern, filename], stdin=PIPE, stdout=PIPE, stderr=PIPE, bufsize=-1) output, error = p.communicate() if p.returncode == 0: print('%r is found in %s: %r' % (pattern, filename, output)) elif p.returncode == 1: print('%r is NOT found in %s: %r' % (pattern, filename, output)) else: assert p.returncode > 1 print('error occurred: %r' % (error,))You don't need to call an external command to filter lines, you could do it in pure Python:
with open('tmp') as file: for line in file: if 'test' in line: print line,If you don't need the output; you could use
subprocess.call():import os from subprocess import call try: from subprocess import DEVNULL # Python 3 except ImportError: # Python 2 DEVNULL = open(os.devnull, 'r+b', 0) returncode = call(['grep', 'test', 'tmp'], stdin=DEVNULL, stdout=DEVNULL, stderr=DEVNULL)mkobit , 2017-09-15 14:52:56
Python 3.5 introduced the
subprocess.run()method. The signature looks like:subprocess.run( args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False )The returned result is a
subprocess.CompletedProcess. In 3.5, you can access theargs,returncode,stdout, andstderrfrom the executed process.Example:
>>> result = subprocess.run(['ls', '/tmp'], stdout=subprocess.DEVNULL) >>> result.returncode 0 >>> result = subprocess.run(['ls', '/nonexistent'], stderr=subprocess.DEVNULL) >>> result.returncode 2Dean Kayton ,
I reckon this is the most up-to-date approach. The syntax is much more simple and intuitive and was probably added for just that reason. – Dean Kayton Jul 22 '19 at 11:46Noam Manos ,
In Python 2 - use commands module:
import command rc, out = commands.getstatusoutput("ls missing-file") if rc != 0: print "Error occurred: %s" % outIn Python 3 - use subprocess module:
import subprocess rc, out = subprocess.getstatusoutput("ls missing-file") if rc != 0: print ("Error occurred:", out)Error occurred: ls: cannot access missing-file: No such file or directory
Jan 01, 2014 | stackoverflow.com
subprocess.check_output return code Ask Question Asked 6 years, 3 months ago Active 7 months ago Viewed 77k times
Juicy ,
I am using:
grepOut = subprocess.check_output("grep " + search + " tmp", shell=True)To run a terminal command, I know that I can use a try/except to catch the error but how can I get the value of the error code?
I found this on the official documentation:
exception subprocess.CalledProcessError Exception raised when a process run by check_call() or check_output() returns a non-zero exit status. returncode Exit status of the child process.But there are no examples given and Google was of no help.
jfs ,
"Google was of no help" : the first link (almost there it showse.output), the second link is the exact match (it showse.returncode) the search term:CalledProcessError. – jfs May 2 '14 at 15:06DanGar , 2014-05-02 05:07:05
You can get the error code and results from the exception that is raised.
This can be done through the fields
returncodeandoutput.For example:
import subprocess try: grepOut = subprocess.check_output("grep " + "test" + " tmp", shell=True) except subprocess.CalledProcessError as grepexc: print "error code", grepexc.returncode, grepexc.outputDanGar ,
Thank you exactly what I wanted. But now I am wondering, is there a way to get a return code without a try/except? IE just get the return code of the check_output, whether it is 0 or 1 or other is not important to me and I don't actually need to save the output. – Juicy May 2 '14 at 5:12jfs , 2014-05-02 16:09:20
is there a way to get a return code without a try/except?
check_outputraises an exception if it receives non-zero exit status because it frequently means that a command failed.grepmay return non-zero exit status even if there is no error -- you could use.communicate()in this case:from subprocess import Popen, PIPE pattern, filename = 'test', 'tmp' p = Popen(['grep', pattern, filename], stdin=PIPE, stdout=PIPE, stderr=PIPE, bufsize=-1) output, error = p.communicate() if p.returncode == 0: print('%r is found in %s: %r' % (pattern, filename, output)) elif p.returncode == 1: print('%r is NOT found in %s: %r' % (pattern, filename, output)) else: assert p.returncode > 1 print('error occurred: %r' % (error,))You don't need to call an external command to filter lines, you could do it in pure Python:
with open('tmp') as file: for line in file: if 'test' in line: print line,If you don't need the output; you could use
subprocess.call():import os from subprocess import call try: from subprocess import DEVNULL # Python 3 except ImportError: # Python 2 DEVNULL = open(os.devnull, 'r+b', 0) returncode = call(['grep', 'test', 'tmp'], stdin=DEVNULL, stdout=DEVNULL, stderr=DEVNULL)> ,
add a commentmkobit , 2017-09-15 14:52:56
Python 3.5 introduced the
subprocess.run()method. The signature looks like:subprocess.run( args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False )The returned result is a
subprocess.CompletedProcess. In 3.5, you can access theargs,returncode,stdout, andstderrfrom the executed process.Example:
>>> result = subprocess.run(['ls', '/tmp'], stdout=subprocess.DEVNULL) >>> result.returncode 0 >>> result = subprocess.run(['ls', '/nonexistent'], stderr=subprocess.DEVNULL) >>> result.returncode 2Dean Kayton ,
I reckon this is the most up-to-date approach. The syntax is much more simple and intuitive and was probably added for just that reason. – Dean Kayton Jul 22 '19 at 11:46simfinite , 2019-07-01 14:36:06
To get both output and return code (without try/except) simply use subprocess.getstatusoutput (Python 3 required)
electrovir ,
please read stackoverflow.com/help/how-to-answer on how to write a good answer. – DjSh Jul 1 '19 at 14:45> ,
In Python 2 - use commands module:
import command rc, out = commands.getstatusoutput("ls missing-file") if rc != 0: print "Error occurred: %s" % outIn Python 3 - use subprocess module:
import subprocess rc, out = subprocess.getstatusoutput("ls missing-file") if rc != 0: print ("Error occurred:", out)Error occurred: ls: cannot access missing-file: No such file or directory
Aug 19, 2020 | stackoverflow.com
n This question already has answers here : subprocess.check_output return code (5 answers) Closed 5 years ago .
While developing python wrapper library for Android Debug Bridge (ADB), I'm using subprocess to execute adb commands in shell. Here is the simplified example:
import subprocess ... def exec_adb_command(adb_command): return = subprocess.call(adb_command)If command executed propery exec_adb_command returns 0 which is OK.
But some adb commands return not only "0" or "1" but also generate some output which I want to catch also. adb devices for example:
D:\git\adb-lib\test>adb devices List of devices attached 07eeb4bb deviceI've already tried subprocess.check_output() for that purpose, and it does return output but not the return code ("0" or "1").
Ideally I would want to get a tuple where t[0] is return code and t[1] is actual output.
Am I missing something in subprocess module which already allows to get such kind of results?
Thanks! python subprocess adb share improve this question follow asked Jun 19 '15 at 12:10 Viktor Malyi 1,761 2 2 gold badges 18 18 silver badges 34 34 bronze badges
> ,
add a comment 1 Answer Active Oldest VotesPadraic Cunningham ,
Popen and communicate will allow you to get the output and the return code.
from subprocess import Popen,PIPE,STDOUT out = Popen(["adb", "devices"],stderr=STDOUT,stdout=PIPE) t = out.communicate()[0],out.returncode print(t) ('List of devices attached \n\n', 0)check_output may also be suitable, a non-zero exit status will raise a CalledProcessError:
from subprocess import check_output, CalledProcessError try: out = check_output(["adb", "devices"]) t = 0, out except CalledProcessError as e: t = e.returncode, e.messageYou also need to redirect stderr to store the error output:
from subprocess import check_output, CalledProcessError from tempfile import TemporaryFile def get_out(*args): with TemporaryFile() as t: try: out = check_output(args, stderr=t) return 0, out except CalledProcessError as e: t.seek(0) return e.returncode, t.read()Just pass your commands:
In [5]: get_out("adb","devices") Out[5]: (0, 'List of devices attached \n\n') In [6]: get_out("adb","devices","foo") Out[6]: (1, 'Usage: adb devices [-l]\n')Noam Manos ,
Thank you for the broad answer! – Viktor Malyi Jun 19 '15 at 12:48
Aug 18, 2020 | axialcorps.wordpress.com
Don't Slurp: How to Read Files in Python Posted on September 27, 2013 by mssaxm
A few weeks ago, a well-intentioned Python programmer asked a straight-forward question to a LinkedIn group for professional Python programmers:
What's the best way to read file in Python?
Invariably a few programmers jumped in and told our well-intentioned programmer to just read the whole thing into memory:
f = open('/path/to/file', 'r+') contents = f.read()Just to mix things up, someone followed-up to demonstrate the exact same technique using 'with' (a great improvement as it ensures the file is properly closed in all cases):
with open('/path/to/file', 'r+') as f: contents = f.read() # do more stuffEither implementation boils down to the use of a technique we call " slurping ", and it's by far the most common way you'll encounter files being read in the wild. It also happens to nearly always be the wrong way to read a file for 2 reasons:
A Better Way: Filter
- It's quite memory inefficient
- It's slower than processing data as it is read, because it defers any processing done on read data until after all data has been read into memory, rather than processing as data is read.
A UNIX filter is a program that reads from stdin and writes to stdout . Filters are usually written in such a way that you can either read from stdin, or read from 1 or more files passed on the command line. There are many examples of filters: grep, sed, awk, cut, cat, wc and sh, just to name a few of the most commonly used ones.
One thing nearly all filters have in common is that they are stream processors, meaning that they work on chunks of data as they flow through the program. Because stdin is a line-buffered file by default, the most efficient chunk of data to work on ends up being the line, and so nearly all stream-processors operate on streams one line at a time. Python has some syntactic sugar that makes stream-processing line-by-line even more straight-forward than it usually would be:
# a simple filter that prepends line numbers import sys lineno = 0 # this reads in one line at a time from stdin for line in sys.stdin: lineno += 1 print '{:>6} {}'.format(lineno, line[:-1])Our stream-processor is now more memory efficient than our slurp approach for all files with more than 1 line, and we are emitting incremental data to stdout (where another program might start immediately consuming it) rather than waiting until we've consumed the whole file to start processing it. To see just how much faster this is, let's look at the speed of each program over 10 million lines:
$ # slurp version $ jot 10000000 | time python lineno-slurp > /dev/null 16.42 real 10.63 user 0.46 sys $ # stream version $ jot 10000000 | time python lineno-stream > /dev/null 11.52 real 11.48 user 0.02 sysAnd of course it's also more memory efficient. So the moral of the story is that Python makes it simple and elegant to write stream-processors on line-buffered data-streams. We can easily apply the pattern above to an arbitrary number of files as well:
# a simple filter that prepends line numbers # import sys EDIT: unused, pointed out in comments here and on HN for fname in ( 'file.txt', 'file2.txt, ): with open(fname, 'r+') as f: lineno = 0 # this reads in one line at a time from stdin for line in f: lineno += 1 print '{:>6} {}'.format(lineno, line[:-1])
Jan 01, 2009 | stackoverflow.com
Ask Question Asked 10 years, 9 months ago Active 9 months ago Viewed 18k times
Mike Caron , 2009-10-27 16:08:07
Is there a one-liner to read all the lines of a file in Python, rather than the standard:
f = open('x.txt') cts = f.read() f.close()Seems like this is done so often that there's got to be a one-liner. Any ideas?
tripleee ,
Funny, I needed this again and I googled for it. Never thought my own question would come up :) – Mike Caron May 10 '11 at 15:23Alex Martelli , 2009-10-27 16:10:00
This will slurp the content into a single string in Python 2.6 1 and above:
with open('x.txt') as x: f = x.read()And this will create a list of lines:
with open('x.txt') as x: f = x.readlines()These approaches guarantee immediate closure of the input file right after the reading.
Footnote:
- This approach can also be used in Python 2.5 using
from __future__ import with_statement.
An older approach that does not guarantee immediate closure is to use this to create a single string:
f = open('x.txt').read()And this to create a list of lines:
f = open('x.txt').readlines()In practice it will be immediately closed in some versions of CPython, but closed "only when the garbage collector gets around to it" in Jython, IronPython, and probably some future version of CPython.
Mark Lakata ,
That's what I would have guessed, but didn't know when the opened file would be closed. Thanks! – Mike Caron Oct 27 '09 at 16:11Lutz Prechelt , 2013-09-24 09:25:29
If you are on Python3, make sure you properly respect your file's input encoding, e.g.:
import codecs with codecs.open(filename, 'r', encoding="utf8") as file: cts = file.read()Find the list of codec names in the Python3 codec list . (The mechanism is also advisable for Python2 whenever you expect any non-ASCII input)
Eponymous ,
Some people may consider the encoding issue to be off-topic. Also, my code is not minimal: using the builtinopenas inopen(filename, 'r', encoding='utf8')would save the import statement and make the answer a better fit with the question. – Lutz Prechelt Dec 10 '15 at 9:44> ,
Starting in Python 3.5 , you can use the
pathlibmodule for a more modern interface. Being Python 3, it makes a distinction between reading text and reading bytes:from pathlib import Path text_string = Path('x.txt').read_text() # type: str byte_string = Path('x.txt').read_bytes() # type: bytes
Jan 01, 2008 | stackoverflow.com
Ask Question Asked 11 years, 11 months ago Active 3 months ago Viewed 3.5m times
> ,
How do you call an external command (as if I'd typed it at the Unix shell or Windows command prompt) from within a Python script?freshWoWer , 2008-09-18 01:35:30
edited Nov 27 '19 at 21:26 Chris 80.2k 21 21 gold badges 175 175 silver badges 162 162 bronze badges asked Sep 18 '08 at 1:35 freshWoWer 51.3k 10 10 gold badges 31 31 silver badges 33 33 bronze badges> ,
add a comment 61 Answers Active Oldest Votes 1 2 3 Next> ,
Look at the subprocess module in the standard library:import subprocess subprocess.run(["ls", "-l"])The advantage of
subprocessvs.systemis that it is more flexible (you can get thestdout,stderr, the "real" status code, better error handling, etc...).The official documentation recommends the
subprocessmodule over the alternativeos.system():The
subprocessmodule provides more powerful facilities for spawning new processes and retrieving their results; using that module is preferable to using this function [os.system()].The Replacing Older Functions with the subprocess Module section in the
subprocessdocumentation may have some helpful recipes.For versions of Python before 3.5, use
call:import subprocess subprocess.call(["ls", "-l"])David Cournapeau , 2008-09-18 01:39:35
edited Aug 31 '19 at 3:17 Corey Goldberg 50.5k 23 23 gold badges 114 114 silver badges 133 133 bronze badges answered Sep 18 '08 at 1:39 David Cournapeau 67.7k 7 7 gold badges 58 58 silver badges 67 67 bronze badgesDaniel F ,
Is there a way to use variable substitution? IE I tried to doecho $PATHby usingcall(["echo", "$PATH"]), but it just echoed the literal string$PATHinstead of doing any substitution. I know I could get the PATH environment variable, but I'm wondering if there is an easy way to have the command behave exactly as if I had executed it in bash. – Kevin Wheeler Sep 1 '15 at 23:17Eli Courtwright ,
Here's a summary of the ways to call external programs and the advantages and disadvantages of each:
os.system("some_command with args")passes the command and arguments to your system's shell. This is nice because you can actually run multiple commands at once in this manner and set up pipes and input/output redirection. For example:os.system("some_command < input_file | another_command > output_file")However, while this is convenient, you have to manually handle the escaping of shell characters such as spaces, etc. On the other hand, this also lets you run commands which are simply shell commands and not actually external programs. See the documentation .
stream = os.popen("some_command with args")will do the same thing asos.systemexcept that it gives you a file-like object that you can use to access standard input/output for that process. There are 3 other variants of popen that all handle the i/o slightly differently. If you pass everything as a string, then your command is passed to the shell; if you pass them as a list then you don't need to worry about escaping anything. See the documentation .- The
Popenclass of thesubprocessmodule. This is intended as a replacement foros.popenbut has the downside of being slightly more complicated by virtue of being so comprehensive. For example, you'd say:print subprocess.Popen("echo Hello World", shell=True, stdout=subprocess.PIPE).stdout.read()instead of:
print os.popen("echo Hello World").read()but it is nice to have all of the options there in one unified class instead of 4 different popen functions. See the documentation .
- The
callfunction from thesubprocessmodule. This is basically just like thePopenclass and takes all of the same arguments, but it simply waits until the command completes and gives you the return code. For example:return_code = subprocess.call("echo Hello World", shell=True)See the documentation .
- If you're on Python 3.5 or later, you can use the new
subprocess.runfunction, which is a lot like the above but even more flexible and returns aCompletedProcessobject when the command finishes executing.- The os module also has all of the fork/exec/spawn functions that you'd have in a C program, but I don't recommend using them directly.
The
subprocessmodule should probably be what you use.Finally please be aware that for all methods where you pass the final command to be executed by the shell as a string and you are responsible for escaping it. There are serious security implications if any part of the string that you pass can not be fully trusted. For example, if a user is entering some/any part of the string. If you are unsure, only use these methods with constants. To give you a hint of the implications consider this code:
print subprocess.Popen("echo %s " % user_input, stdout=PIPE).stdout.read()and imagine that the user enters something "my mama didnt love me && rm -rf /" which could erase the whole filesystem.
tripleee ,
Nice answer/explanation. How is this answer justifying Python's motto as described in this article ? fastcompany.com/3026446/ "Stylistically, Perl and Python have different philosophies. Perl's best known mottos is " There's More Than One Way to Do It". Python is designed to have one obvious way to do it" Seem like it should be the other way! In Perl I know only two ways to execute a command - using back-tick oropen. – Jean May 26 '15 at 21:16> ,
> ,
show 1 more comment> ,
Typical implementation:import subprocess p = subprocess.Popen('ls', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) for line in p.stdout.readlines(): print line, retval = p.wait()You are free to do what you want with the
stdoutdata in the pipe. In fact, you can simply omit those parameters (stdout=andstderr=) and it'll behave likeos.system().EmmEff ,
edited Oct 4 '19 at 2:33 Trenton McKinney 13.5k 13 13 gold badges 27 27 silver badges 43 43 bronze badges answered Sep 18 '08 at 18:20 EmmEff 6,517 2 2 gold badges 14 14 silver badges 18 18 bronze badgestripleee ,
.readlines()reads all lines at once i.e., it blocks until the subprocess exits (closes its end of the pipe). To read in real time (if there is no buffering issues) you could:for line in iter(p.stdout.readline, ''): print line,– jfs Nov 16 '12 at 14:12newtover , 2010-02-12 10:15:34
Some hints on detaching the child process from the calling one (starting the child process in background).Suppose you want to start a long task from a CGI script. That is, the child process should live longer than the CGI script execution process.
The classical example from the subprocess module documentation is:
import subprocess import sys # Some code here pid = subprocess.Popen([sys.executable, "longtask.py"]) # Call subprocess # Some more code hereThe idea here is that you do not want to wait in the line 'call subprocess' until the longtask.py is finished. But it is not clear what happens after the line 'some more code here' from the example.
My target platform was FreeBSD, but the development was on Windows, so I faced the problem on Windows first.
On Windows (Windows XP), the parent process will not finish until the longtask.py has finished its work. It is not what you want in a CGI script. The problem is not specific to Python; in the PHP community the problems are the same.
The solution is to pass DETACHED_PROCESS Process Creation Flag to the underlying CreateProcess function in Windows API. If you happen to have installed pywin32, you can import the flag from the win32process module, otherwise you should define it yourself:
DETACHED_PROCESS = 0x00000008 pid = subprocess.Popen([sys.executable, "longtask.py"], creationflags=DETACHED_PROCESS).pid/* UPD 2015.10.27 @eryksun in a comment below notes, that the semantically correct flag is CREATE_NEW_CONSOLE (0x00000010) */
On FreeBSD we have another problem: when the parent process is finished, it finishes the child processes as well. And that is not what you want in a CGI script either. Some experiments showed that the problem seemed to be in sharing sys.stdout. And the working solution was the following:
pid = subprocess.Popen([sys.executable, "longtask.py"], stdout=subprocess.PIPE, stderr=subprocess.PIPE, stdin=subprocess.PIPE)I have not checked the code on other platforms and do not know the reasons of the behaviour on FreeBSD. If anyone knows, please share your ideas. Googling on starting background processes in Python does not shed any light yet.
maranas ,
i noticed a possible "quirk" with developing py2exe apps in pydev+eclipse. i was able to tell that the main script was not detached because eclipse's output window was not terminating; even if the script executes to completion it is still waiting for returns. but, when i tried compiling to a py2exe executable, the expected behavior occurs (runs the processes as detached, then quits). i am not sure, but the executable name is not in the process list anymore. this works for all approaches (os.system("start *"), os.spawnl with os.P_DETACH, subprocs, etc.) – maranas Apr 9 '10 at 8:09> ,
Charlie Parker ,
you might also need CREATE_NEW_PROCESS_GROUP flag. See Popen waiting for child process even when the immediate child has terminated – jfs Nov 16 '12 at 14:16nimish , 2008-09-18 01:37:24
import os os.system("your command")Note that this is dangerous, since the command isn't cleaned. I leave it up to you to google for the relevant documentation on the 'os' and 'sys' modules. There are a bunch of functions (exec* and spawn*) that will do similar things.
tripleee ,
No idea what I meant nearly a decade ago (check the date!), but if I had to guess, it would be that there's no validation done. – nimish Jun 6 '18 at 16:01> ,
Nikolay Shindarov ,
Note the timestamp on this guy: the "correct" answer has 40x the votes and is answer #1. – nimish Dec 3 '18 at 18:41sirwart , 2008-09-18 01:42:30
I'd recommend using the subprocess module instead of os.system because it does shell escaping for you and is therefore much safer.subprocess.call(['ping', 'localhost'])Lie Ryan ,
If you want to create a list out of a command with parameters , a list which can be used withsubprocesswhenshell=False, then useshlex.splitfor an easy way to do this docs.python.org/2/library/shlex.html#shlex.split (it's the recommended way according to the docs docs.python.org/2/library/subprocess.html#popen-constructor ) – Daniel F Sep 20 '18 at 18:07> ,
> ,
add a comment> ,
import os cmd = 'ls -al' os.system(cmd)If you want to return the results of the command, you can use
os.popen. However, this is deprecated since version 2.6 in favor of the subprocess module , which other answers have covered well.Alexandra Franks ,
edited Jan 26 '16 at 16:53 Patrick M 8,966 8 8 gold badges 54 54 silver badges 93 93 bronze badges answered Sep 18 '08 at 1:37 Alexandra Franks 2,726 1 1 gold badge 16 16 silver badges 22 22 bronze badgesStefan Gruenwald ,
popen is deprecated in favor of subprocess . – Fox Wilson Aug 8 '14 at 0:22> ,
There are lots of different libraries which allow you to call external commands with Python. For each library I've given a description and shown an example of calling an external command. The command I used as the example isls -l(list all files). If you want to find out more about any of the libraries I've listed and linked the documentation for each of them.Sources:
- subprocess: https://docs.python.org/3.5/library/subprocess.html
- shlex: https://docs.python.org/3/library/shlex.html
- os: https://docs.python.org/3.5/library/os.html
- sh: https://amoffat.github.io/sh/
- plumbum: https://plumbum.readthedocs.io/en/latest/
- pexpect: https://pexpect.readthedocs.io/en/stable/
- fabric: http://www.fabfile.org/
- envoy: https://github.com/kennethreitz/envoy
- commands: https://docs.python.org/2/library/commands.html
These are all the libraries:
Hopefully this will help you make a decision on which library to use :)
subprocess
Subprocess allows you to call external commands and connect them to their input/output/error pipes (stdin, stdout, and stderr). Subprocess is the default choice for running commands, but sometimes other modules are better.
subprocess.run(["ls", "-l"]) # Run command subprocess.run(["ls", "-l"], stdout=subprocess.PIPE) # This will run the command and return any output subprocess.run(shlex.split("ls -l")) # You can also use the shlex library to split the commandos
os is used for "operating system dependent functionality". It can also be used to call external commands with
os.systemandos.popen(Note: There is also a subprocess.popen). os will always run the shell and is a simple alternative for people who don't need to, or don't know how to usesubprocess.run.os.system("ls -l") # run command os.popen("ls -l").read() # This will run the command and return any outputsh
sh is a subprocess interface which lets you call programs as if they were functions. This is useful if you want to run a command multiple times.
sh.ls("-l") # Run command normally ls_cmd = sh.Command("ls") # Save command as a variable ls_cmd() # Run command as if it were a functionplumbum
plumbum is a library for "script-like" Python programs. You can call programs like functions as in
sh. Plumbum is useful if you want to run a pipeline without the shell.ls_cmd = plumbum.local("ls -l") # get command ls_cmd() # run commandpexpect
pexpect lets you spawn child applications, control them and find patterns in their output. This is a better alternative to subprocess for commands that expect a tty on Unix.
pexpect.run("ls -l") # Run command as normal child = pexpect.spawn('scp foo [email protected]:.') # Spawns child application child.expect('Password:') # When this is the output child.sendline('mypassword')fabric
fabric is a Python 2.5 and 2.7 library. It allows you to execute local and remote shell commands. Fabric is simple alternative for running commands in a secure shell (SSH)
fabric.operations.local('ls -l') # Run command as normal fabric.operations.local('ls -l', capture = True) # Run command and receive outputenvoy
envoy is known as "subprocess for humans". It is used as a convenience wrapper around the
subprocessmodule.r = envoy.run("ls -l") # Run command r.std_out # get outputcommands
commandscontains wrapper functions foros.popen, but it has been removed from Python 3 sincesubprocessis a better alternative.The edit was based on J.F. Sebastian's comment.
Tom Fuller ,
edited May 28 '17 at 23:14 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Oct 29 '16 at 14:02 Tom Fuller 4,280 6 6 gold badges 29 29 silver badges 38 38 bronze badges> ,
add a comment> ,
I always usefabricfor this things like:from fabric.operations import local result = local('ls', capture=True) print "Content:/n%s" % (result, )But this seem to be a good tool:
sh(Python subprocess interface) .Look at an example:
from sh import vgdisplay print vgdisplay() print vgdisplay('-v') print vgdisplay(v=True)Jorge E. Cardona ,
edited Nov 29 '19 at 21:47 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Mar 13 '12 at 0:12 Jorge E. Cardona 81.8k 3 3 gold badges 29 29 silver badges 39 39 bronze badges> ,
add a comment> ,
Check the "pexpect" Python library, too.It allows for interactive controlling of external programs/commands, even ssh, ftp, telnet, etc. You can just type something like:
child = pexpect.spawn('ftp 192.168.0.24') child.expect('(?i)name .*: ') child.sendline('anonymous') child.expect('(?i)password')athanassis , 2010-10-07 07:09:04
edited May 28 '17 at 23:02 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Oct 7 '10 at 7:09 athanassis 909 6 6 silver badges 4 4 bronze badges> ,
add a comment> ,
With the standard libraryUse the subprocess module (Python 3):
import subprocess subprocess.run(['ls', '-l'])It is the recommended standard way. However, more complicated tasks (pipes, output, input, etc.) can be tedious to construct and write.
Note on Python version: If you are still using Python 2, subprocess.call works in a similar way.
ProTip: shlex.split can help you to parse the command for
run,call, and othersubprocessfunctions in case you don't want (or you can't!) provide them in form of lists:import shlex import subprocess subprocess.run(shlex.split('ls -l'))With external dependenciesIf you do not mind external dependencies, use plumbum :
from plumbum.cmd import ifconfig print(ifconfig['wlan0']())It is the best
subprocesswrapper. It's cross-platform, i.e. it works on both Windows and Unix-like systems. Install bypip install plumbum.Another popular library is sh :
from sh import ifconfig print(ifconfig('wlan0'))However,
shdropped Windows support, so it's not as awesome as it used to be. Install bypip install sh.6 revs, 2 users 79%
, 2019-11-29 21:54:25edited Nov 29 '19 at 21:54 community wiki
6 revs, 2 users 79%
Honza Javorek> ,
add a comment> ,
If you need the output from the command you are calling, then you can use subprocess.check_output (Python 2.7+).>>> subprocess.check_output(["ls", "-l", "/dev/null"]) 'crw-rw-rw- 1 root root 1, 3 Oct 18 2007 /dev/null\n'Also note the shell parameter.
If shell is
True, the specified command will be executed through the shell. This can be useful if you are using Python primarily for the enhanced control flow it offers over most system shells and still want convenient access to other shell features such as shell pipes, filename wildcards, environment variable expansion, and expansion of ~ to a user's home directory. However, note that Python itself offers implementations of many shell-like features (in particular,glob,fnmatch,os.walk(),os.path.expandvars(),os.path.expanduser(), andshutil).Facundo Casco , 2011-04-28 20:29:29
edited Jun 3 '18 at 20:18 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Apr 28 '11 at 20:29 Facundo Casco 8,229 5 5 gold badges 38 38 silver badges 61 61 bronze badgesBruno Bronosky ,
Note thatcheck_outputrequires a list rather than a string. If you don't rely on quoted spaces to make your call valid, the simplest, most readable way to do this issubprocess.check_output("ls -l /dev/null".split()). – Bruno Bronosky Jan 30 '18 at 18:18> ,
This is how I run my commands. This code has everything you need pretty muchfrom subprocess import Popen, PIPE cmd = "ls -l ~/" p = Popen(cmd , shell=True, stdout=PIPE, stderr=PIPE) out, err = p.communicate() print "Return code: ", p.returncode print out.rstrip(), err.rstrip()Usman Khan , 2012-10-28 05:14:01
edited Oct 28 '12 at 5:44 answered Oct 28 '12 at 5:14 Usman Khan 621 5 5 silver badges 3 3 bronze badgesAdam Matan ,
I think it's acceptable for hard-coded commands, if it increases readability. – Adam Matan Apr 2 '14 at 13:07> ,
Update:
subprocess.runis the recommended approach as of Python 3.5 if your code does not need to maintain compatibility with earlier Python versions. It's more consistent and offers similar ease-of-use as Envoy. (Piping isn't as straightforward though. See this question for how .)Here's some examples from the documentation .
Run a process:
>>> subprocess.run(["ls", "-l"]) # Doesn't capture output CompletedProcess(args=['ls', '-l'], returncode=0)Raise on failed run:
>>> subprocess.run("exit 1", shell=True, check=True) Traceback (most recent call last): ... subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1Capture output:
>>> subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE) CompletedProcess(args=['ls', '-l', '/dev/null'], returncode=0, stdout=b'crw-rw-rw- 1 root root 1, 3 Jan 23 16:23 /dev/null\n')Original answer:I recommend trying Envoy . It's a wrapper for subprocess, which in turn aims to replace the older modules and functions. Envoy is subprocess for humans.
Example usage from the README :
>>> r = envoy.run('git config', data='data to pipe in', timeout=2) >>> r.status_code 129 >>> r.std_out 'usage: git config [options]' >>> r.std_err ''Pipe stuff around too:
>>> r = envoy.run('uptime | pbcopy') >>> r.command 'pbcopy' >>> r.status_code 0 >>> r.history [<Response 'uptime'>]Joe , 2012-11-15 17:13:22
edited Nov 29 '19 at 21:52 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Nov 15 '12 at 17:13 Joe 14.1k 9 9 gold badges 52 52 silver badges 69 69 bronze badges> ,
add a comment> ,
Use subprocess ....or for a very simple command:
import os os.system('cat testfile')Ben Hoffstein , 2008-09-18 01:43:30
edited Nov 29 '19 at 21:39 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Sep 18 '08 at 1:43 Ben Hoffstein 96.2k 8 8 gold badges 97 97 silver badges 117 117 bronze badges> ,
add a comment> ,
Calling an external command in PythonSimple, use
subprocess.run, which returns aCompletedProcessobject:>>> import subprocess >>> completed_process = subprocess.run('python --version') Python 3.6.1 :: Anaconda 4.4.0 (64-bit) >>> completed_process CompletedProcess(args='python --version', returncode=0)Why?As of Python 3.5, the documentation recommends subprocess.run :
The recommended approach to invoking subprocesses is to use the run() function for all use cases it can handle. For more advanced use cases, the underlying Popen interface can be used directly.
Here's an example of the simplest possible usage - and it does exactly as asked:
>>> import subprocess >>> completed_process = subprocess.run('python --version') Python 3.6.1 :: Anaconda 4.4.0 (64-bit) >>> completed_process CompletedProcess(args='python --version', returncode=0)
runwaits for the command to successfully finish, then returns aCompletedProcessobject. It may instead raiseTimeoutExpired(if you give it atimeout=argument) orCalledProcessError(if it fails and you passcheck=True).As you might infer from the above example, stdout and stderr both get piped to your own stdout and stderr by default.
We can inspect the returned object and see the command that was given and the returncode:
>>> completed_process.args 'python --version' >>> completed_process.returncode 0Capturing outputIf you want to capture the output, you can pass
subprocess.PIPEto the appropriatestderrorstdout:>>> cp = subprocess.run('python --version', stderr=subprocess.PIPE, stdout=subprocess.PIPE) >>> cp.stderr b'Python 3.6.1 :: Anaconda 4.4.0 (64-bit)\r\n' >>> cp.stdout b''(I find it interesting and slightly counterintuitive that the version info gets put to stderr instead of stdout.)
Pass a command listOne might easily move from manually providing a command string (like the question suggests) to providing a string built programmatically. Don't build strings programmatically. This is a potential security issue. It's better to assume you don't trust the input.
>>> import textwrap >>> args = ['python', textwrap.__file__] >>> cp = subprocess.run(args, stdout=subprocess.PIPE) >>> cp.stdout b'Hello there.\r\n This is indented.\r\n'Note, only
Full Signatureargsshould be passed positionally.Here's the actual signature in the source and as shown by
help(run):def run(*popenargs, input=None, timeout=None, check=False, **kwargs):The
popenargsandkwargsare given to thePopenconstructor.inputcan be a string of bytes (or unicode, if specify encoding oruniversal_newlines=True) that will be piped to the subprocess's stdin.The documentation describes
timeout=andcheck=Truebetter than I could:The timeout argument is passed to Popen.communicate(). If the timeout expires, the child process will be killed and waited for. The TimeoutExpired exception will be re-raised after the child process has terminated.
If check is true, and the process exits with a non-zero exit code, a CalledProcessError exception will be raised. Attributes of that exception hold the arguments, the exit code, and stdout and stderr if they were captured.
and this example for
check=Trueis better than one I could come up with:Expanded Signature>>> subprocess.run("exit 1", shell=True, check=True) Traceback (most recent call last): ... subprocess.CalledProcessError: Command 'exit 1' returned non-zero exit status 1Here's an expanded signature, as given in the documentation:
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, cwd=None, timeout=None, check=False, encoding=None, errors=None)Note that this indicates that only the args list should be passed positionally. So pass the remaining arguments as keyword arguments.
PopenWhen use
Popeninstead? I would struggle to find use-case based on the arguments alone. Direct usage ofPopenwould, however, give you access to its methods, includingpoll, 'send_signal', 'terminate', and 'wait'.Here's the
Popensignature as given in the source . I think this is the most precise encapsulation of the information (as opposed tohelp(Popen)):def __init__(self, args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=_PLATFORM_DEFAULT_CLOSE_FDS, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=(), *, encoding=None, errors=None):But more informative is the
Popendocumentation :subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=(), *, encoding=None, errors=None)Execute a child program in a new process. On POSIX, the class uses os.execvp()-like behavior to execute the child program. On Windows, the class uses the Windows CreateProcess() function. The arguments to Popen are as follows.
Understanding the remaining documentation on
Popenwill be left as an exercise for the reader.Aaron Hall , 2017-10-18 16:37:52
answered Oct 18 '17 at 16:37 Aaron Hall ♦ 254k 68 68 gold badges 349 349 silver badges 300 300 bronze badgestripleee ,
A simple example of two-way communication between a primary process and a subprocess can be found here: stackoverflow.com/a/52841475/1349673 – James Hirschorn Oct 16 '18 at 18:05> ,
os.systemis OK, but kind of dated. It's also not very secure. Instead, trysubprocess.subprocessdoes not call sh directly and is therefore more secure thanos.system.Get more information here .
Martin W , 2008-09-18 01:53:27
edited Dec 10 '16 at 13:25 Dimitris Fasarakis Hilliard 106k 24 24 gold badges 206 206 silver badges 210 210 bronze badges answered Sep 18 '08 at 1:53 Martin W 1,269 7 7 silver badges 12 12 bronze badgestripleee ,
While I agree with the overall recommendation,subprocessdoes not remove all of the security problems, and has some pesky issues of its own. – tripleee Dec 3 '18 at 5:36> ,
There is also Plumbum>>> from plumbum import local >>> ls = local["ls"] >>> ls LocalCommand(<LocalPath /bin/ls>) >>> ls() u'build.py\ndist\ndocs\nLICENSE\nplumbum\nREADME.rst\nsetup.py\ntests\ntodo.txt\n' >>> notepad = local["c:\\windows\\notepad.exe"] >>> notepad() # Notepad window pops up u'' # Notepad window is closed by user, command returnsstuckintheshuck ,
answered Oct 10 '14 at 17:41 stuckintheshuck 2,123 2 2 gold badges 22 22 silver badges 31 31 bronze badges> ,
add a comment> ,
It can be this simple:import os cmd = "your command" os.system(cmd)Samadi Salahedine , 2018-04-30 13:47:17
edited Jun 8 '18 at 12:06 answered Apr 30 '18 at 13:47 Samadi Salahedine 478 4 4 silver badges 12 12 bronze badgestripleee ,
This fails to point out the drawbacks, which are explained in much more detail in PEP-324 . The documentation foros.systemexplicitly recommends avoiding it in favor ofsubprocess. – tripleee Dec 3 '18 at 5:02> ,
Use:import os cmd = 'ls -al' os.system(cmd)os - This module provides a portable way of using operating system-dependent functionality.
For the more
osfunctions, here is the documentation.Priyankara ,
edited May 28 '17 at 23:05 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jun 29 '15 at 11:34 Priyankara 710 11 11 silver badges 20 20 bronze badgesCorey Goldberg ,
it's also deprecated. use subprocess – Corey Goldberg Dec 9 '15 at 18:13> ,
I quite like shell_command for its simplicity. It's built on top of the subprocess module.Here's an example from the documentation:
>>> from shell_command import shell_call >>> shell_call("ls *.py") setup.py shell_command.py test_shell_command.py 0 >>> shell_call("ls -l *.py") -rw-r--r-- 1 ncoghlan ncoghlan 391 2011-12-11 12:07 setup.py -rw-r--r-- 1 ncoghlan ncoghlan 7855 2011-12-11 16:16 shell_command.py -rwxr-xr-x 1 ncoghlan ncoghlan 8463 2011-12-11 16:17 test_shell_command.py 0mdwhatcott ,
edited Nov 29 '19 at 21:49 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Aug 13 '12 at 18:36 mdwhatcott 4,547 2 2 gold badges 29 29 silver badges 45 45 bronze badges> ,
add a comment> ,
There is another difference here which is not mentioned previously.
subprocess.Popenexecutes the <command> as a subprocess. In my case, I need to execute file <a> which needs to communicate with another program, <b>.I tried subprocess, and execution was successful. However <b> could not communicate with <a>. Everything is normal when I run both from the terminal.
One more: (NOTE: kwrite behaves different from other applications. If you try the below with Firefox, the results will not be the same.)
If you try
os.system("kwrite"), program flow freezes until the user closes kwrite. To overcome that I tried insteados.system(konsole -e kwrite). This time program continued to flow, but kwrite became the subprocess of the console.Anyone runs the kwrite not being a subprocess (i.e. in the system monitor it must appear at the leftmost edge of the tree).
Atinc Delican ,
edited Jun 3 '18 at 20:14 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jan 8 '10 at 21:11 Atinc Delican 265 2 2 silver badges 2 2 bronze badgesPeter Mortensen ,
What do you mean by "Anyone runs the kwrite not being a subprocess" ? – Peter Mortensen Jun 3 '18 at 20:14> ,
os.systemdoes not allow you to store results, so if you want to store results in some list or something, asubprocess.callworks.Saurabh Bangad ,
edited Nov 29 '19 at 21:48 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jun 11 '12 at 22:28 Saurabh Bangad 357 2 2 silver badges 2 2 bronze badges> ,
add a comment> ,
subprocess.check_callis convenient if you don't want to test return values. It throws an exception on any error.cdunn2001 , 2011-01-18 19:21:44
answered Jan 18 '11 at 19:21 cdunn2001 14.9k 7 7 gold badges 49 49 silver badges 42 42 bronze badges> ,
add a comment> ,
I tend to use subprocess together with shlex (to handle escaping of quoted strings):>>> import subprocess, shlex >>> command = 'ls -l "/your/path/with spaces/"' >>> call_params = shlex.split(command) >>> print call_params ["ls", "-l", "/your/path/with spaces/"] >>> subprocess.call(call_params)Emil Stenström , 2014-04-30 14:37:04
answered Apr 30 '14 at 14:37 Emil Stenström 8,952 8 8 gold badges 43 43 silver badges 68 68 bronze badges> ,
add a comment> ,
Shameless plug, I wrote a library for this :P https://github.com/houqp/shell.pyIt's basically a wrapper for popen and shlex for now. It also supports piping commands so you can chain commands easier in Python. So you can do things like:
ex('echo hello shell.py') | "awk '{print $2}'"houqp , 2014-05-01 20:49:01
answered May 1 '14 at 20:49 houqp 571 7 7 silver badges 11 11 bronze badges> ,
add a comment> ,
You can use Popen, and then you can check the procedure's status:from subprocess import Popen proc = Popen(['ls', '-l']) if proc.poll() is None: proc.kill()Check out subprocess.Popen .
admire ,
edited May 28 '17 at 23:01 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jul 16 '12 at 15:16 admire 320 2 2 silver badges 6 6 bronze badges> ,
add a comment> ,
In Windows you can just import thesubprocessmodule and run external commands by callingsubprocess.Popen(),subprocess.Popen().communicate()andsubprocess.Popen().wait()as below:# Python script to run a command line import subprocess def execute(cmd): """ Purpose : To execute a command and return exit status Argument : cmd - command to execute Return : exit_code """ process = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) (result, error) = process.communicate() rc = process.wait() if rc != 0: print "Error: failed to execute command:", cmd print error return result # def command = "tasklist | grep python" print "This process detail: \n", execute(command)Output:
This process detail: python.exe 604 RDP-Tcp#0 4 5,660 KSwadhikar C ,
edited May 28 '17 at 23:08 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jun 17 '16 at 9:14 Swadhikar C 1,578 1 1 gold badge 15 15 silver badges 27 27 bronze badges> ,
add a comment> ,
To fetch the network id from the OpenStack Neutron :#!/usr/bin/python import os netid = "nova net-list | awk '/ External / { print $2 }'" temp = os.popen(netid).read() /* Here temp also contains new line (\n) */ networkId = temp.rstrip() print(networkId)Output of nova net-list
+--------------------------------------+------------+------+ | ID | Label | CIDR | +--------------------------------------+------------+------+ | 431c9014-5b5d-4b51-a357-66020ffbb123 | test1 | None | | 27a74fcd-37c0-4789-9414-9531b7e3f126 | External | None | | 5a2712e9-70dc-4b0e-9281-17e02f4684c9 | management | None | | 7aa697f5-0e60-4c15-b4cc-9cb659698512 | Internal | None | +--------------------------------------+------------+------+Output of print(networkId)
27a74fcd-37c0-4789-9414-9531b7e3f126IRSHAD ,
edited Nov 29 '19 at 22:05 Peter Mortensen 26.3k 21 21 gold badges 91 91 silver badges 121 121 bronze badges answered Jul 20 '16 at 9:50 IRSHAD 1,995 22 22 silver badges 34 34 bronze badgestripleee ,
You should not recommendos.popen()in 2016. The Awk script could easily be replaced with native Python code. – tripleee Dec 3 '18 at 5:49Yuval Atzmon ,
Under Linux, in case you would like to call an external command that will execute independently (will keep running after the python script terminates), you can use a simple queue as task spooler or the at commandAn example with task spooler:
import os os.system('ts <your-command>')Notes about task spooler (
ts):
- You could set the number of concurrent processes to be run ("slots") with:
ts -S <number-of-slots>- Installing
tsdoesn't requires admin privileges. You can download and compile it from source with a simplemake, add it to your path and you're done.tripleee ,
tsis not standard on any distro I know of, though the pointer toatis mildly useful. You should probably also mentionbatch. As elsewhere, theos.system()recommendation should probably at least mention thatsubprocessis its recommended replacement. – tripleee Dec 3 '18 at 5:43
Aug 15, 2020 | perlmonks.com
on Aug 14, 2020 at 05:06 UTC ( # 11120738 = perlquestion : print w/replies , xml ) Need Help?? aartist has asked for the wisdom of the Perl Monks concerning the following question: What is Perl equivalent of this python code ?
with open("welcome.txt") as file:There is a context manager magic to handle failure in python. How to achieve similar thing in Perl ?
pryrt on Aug 14, 2020 at 05:42 UTC
Re: Opening a file in Perluse warnings; use strict; use autodie; # this is the "magic to handle failure" of open ... { open my $fh, '<', 'welcome.txt'; ... } # auto closes file handle when $fh goes out of context ... [download]
jcb on Aug 14, 2020 at 09:29 UTC
Re^2: Opening a file in Perl
by jcb on Aug 14, 2020 at 09:29 UTCThe major difference here is that, where Python uses explicit magic, Perl uses garbage collection. Perl's reference counting garbage collector is extremely efficient, even though it leaks memory with reference cycles. As a result, not only is open my $fh, ... more efficient, with no extra runtime magic to support a filehandle upon entering the block, it is also possible to pass $fh as a return value or store it in some structure such that it will outlast the scope in which it was opened. Garbage collection means that lexical and dynamic scopes are independent.
The with open(...) as fh: construct in Python is shorthand for a try/finally block that ensures fh is closed when execution leaves the block. Perl is far more flexible here: files are closed explicitly with close or implicitly when their handles are garbage-collected. (This is why bareword filehandles must be explicitly closed: package variables remain in-scope until the interpreter exits.)
Again, in Perl filehandles remain open (unless explicitly closed) as long as references to them exist, while the Python with open(...) as fh: construct limits both the lexical and dynamic extent of the filehandle.
stevieb on Aug 14, 2020 at 06:36 UTC
Re: Opening a file in PerlPython:
with open("welcome.txt") as file: ... # do stuff [download]Perl:
{ # can be any block; sub, named or just empty open my $fh, 'welcome.txt' or die "couldn't open file!: $!"; ... # do stuff } # file is auto-closed here [download]"There is a context manager magic to handle failure in python."Python isn't as 'scope context sensitive' as Perl is in some regards. In Python, the "with" context is no more than a block encapsulated within braces in Perl. Essentially, in Python, the "with" signifies what is called a 'block' or 'scope' in Perl. It simply means everything indented underneath of this "with" will be automatically garbage collected/files closed when the block (ie. context) exits (in basic usage).
- Comment on Opening a file in Perl
- Send private /msg to aartist
Replies are listed 'Best First'.
Jan 01, 2012 | stackoverflow.com
Ask Question Asked 8 years, 6 months ago Active 4 days ago Viewed 190k times
depling ,
A = os.path.join(os.path.dirname(__file__), '..') B = os.path.dirname(os.path.realpath(__file__)) C = os.path.abspath(os.path.dirname(__file__))I usually just hardwire these with the actual path. But there is a reason for these statements that determine path at runtime, and I would really like to understant the os.path module so I can start using it.
> ,
add a comment 5 Answers Active Oldest Votespaxdiablo , 2012-02-14 03:55:19
When a module is loaded from a file in Python,
__file__is set to its path. You can then use that with other functions to find the directory that the file is located in.Taking your examples one at a time:
A = os.path.join(os.path.dirname(__file__), '..') # A is the parent directory of the directory where program resides. B = os.path.dirname(os.path.realpath(__file__)) # B is the canonicalised (?) directory where the program resides. C = os.path.abspath(os.path.dirname(__file__)) # C is the absolute path of the directory where the program resides.You can see the various values returned from these here:
import os print(__file__) print(os.path.join(os.path.dirname(__file__), '..')) print(os.path.dirname(os.path.realpath(__file__))) print(os.path.abspath(os.path.dirname(__file__)))and make sure you run it from different locations (such as
./text.py,~/python/text.pyand so forth) to see what difference that makes.YOUNG ,
Good answer, but see other an important detail from other answers:__file__is NOT defined in all cases, e.g. statically linked C modules. We can't count on__file__always being available. – Chris Johnson Feb 18 '14 at 15:46Derek Litz , 2012-02-14 04:16:32
I just want to address some confusion first.
__file__is not a wildcard it is an attribute. Double underscore attributes and methods are considered to be "special" by convention and serve a special purpose.http://docs.python.org/reference/datamodel.html shows many of the special methods and attributes, if not all of them.
In this case
__file__is an attribute of a module (a module object). In Python a.pyfile is a module. Soimport amodulewill have an attribute of__file__which means different things under difference circumstances.Taken from the docs:
__file__is the pathname of the file from which the module was loaded, if it was loaded from a file. The__file__attribute is not present for C modules that are statically linked into the interpreter; for extension modules loaded dynamically from a shared library, it is the pathname of the shared library file.In your case the module is accessing it's own
__file__attribute in the global namespace.To see this in action try:
# file: test.py print globals() print __file__And run:
python test.py {'__builtins__': <module '__builtin__' (built-in)>, '__name__': '__main__', '__file__': 'test_print__file__.py', '__doc__': None, '__package__': None} test_print__file__.py> ,
add a comment> ,
Per the documentation :
__file__is the pathname of the file from which the module was loaded, if it was loaded from a file. The__file__attribute is not present for C modules that are statically linked into the interpreter; for extension modules loaded dynamically from a shared library, it is the pathname of the shared library file.and also :
__file__is to be the "path" to the file unless the module is built-in (and thus listed insys.builtin_module_names) in which case the attribute is not set.
Jan 01, 2017 | stackoverflow.com
Asked 10 years, 1 month ago Active 23 days ago Viewed 99k times
Joey ,
How can I get the file name and line number in python script.
Exactly the file information we get from an exception traceback. In this case without raising an exception.
> ,
add a comment 9 Answers Active Oldest VotesJoey ,
Thanks to mcandre, the answer is:
#python3 from inspect import currentframe, getframeinfo frameinfo = getframeinfo(currentframe()) print(frameinfo.filename, frameinfo.lineno)MCG ,
Does using this method have any performance impact (like minor increase in run time or more CPU needed ) ? – gsinha Dec 14 '14 at 5:41aaren ,
Whether you use
currentframe().f_backdepends on whether you are using a function or not.Calling inspect directly:
from inspect import currentframe, getframeinfo cf = currentframe() filename = getframeinfo(cf).filename print "This is line 5, python says line ", cf.f_lineno print "The filename is ", filenameCalling a function that does it for you:
from inspect import currentframe def get_linenumber(): cf = currentframe() return cf.f_back.f_lineno print "This is line 7, python says line ", get_linenumber()MikeyE ,
Plus one, for providing a solution in a callable function. Very nice! – MikeyE Oct 28 '17 at 2:43Streamsoup , 2017-08-21 12:05:28
Handy if used in a common file - prints file name, line number and function of the caller:
import inspect def getLineInfo(): print(inspect.stack()[1][1],":",inspect.stack()[1][2],":", inspect.stack()[1][3])> ,
add a commentarilou ,
Filename :
__file__ # or sys.argv[0]Line :
inspect.currentframe().f_lineno(not
inspect.currentframe().f_back.f_linenoas mentioned above)bgoodr ,
NameError: global name '__file__' is not definedon my Python interpreter:Python 2.7.6 (default, Sep 26 2014, 15:59:23). See stackoverflow.com/questions/9271464/ – bgoodr May 5 '17 at 17:41Mohammad Shahid Siddiqui ,
Better to use sys also-
print dir(sys._getframe()) print dir(sys._getframe().f_lineno) print sys._getframe().f_linenoThe output is:
['__class__', '__delattr__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'f_back', 'f_builtins', 'f_code', 'f_exc_traceback', 'f_exc_type', 'f_exc_value', 'f_globals', 'f_lasti', 'f_lineno', 'f_locals', 'f_restricted', 'f_trace'] ['__abs__', '__add__', '__and__', '__class__', '__cmp__', '__coerce__', '__delattr__', '__div__', '__divmod__', '__doc__', '__float__', '__floordiv__', '__format__', '__getattribute__', '__getnewargs__', '__hash__', '__hex__', '__index__', '__init__', '__int__', '__invert__', '__long__', '__lshift__', '__mod__', '__mul__', '__neg__', '__new__', '__nonzero__', '__oct__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdiv__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'imag', 'numerator', 'real'] 14> ,
add a commentDanilo ,
Just to contribute,
there is a
linecachemodule in python, here is two links that can help.linecache module documentation
linecache source codeIn a sense, you can "dump" a whole file into its cache , and read it with linecache.cache data from class.
import linecache as allLines ## have in mind that fileName in linecache behaves as any other open statement, you will need a path to a file if file is not in the same directory as script linesList = allLines.updatechache( fileName ,None) for i,x in enumerate(lineslist): print(i,x) #prints the line number and content #or for more info print(line.cache) #or you need a specific line specLine = allLines.getline(fileName,numbOfLine) #returns a textual line from that number of lineFor additional info, for error handling, you can simply use
from sys import exc_info try: raise YourError # or some other error except Exception: print(exc_info() )> ,
add a commentHaroon Rashedu , 2014-06-18 01:09:09
import inspect file_name = __FILE__ current_line_no = inspect.stack()[0][2] current_function_name = inspect.stack()[0][3] #Try printing inspect.stack() you can see current stack and pick whatever you wantbgoodr ,
Similar to__file__: See stackoverflow.com/questions/3056048/ – bgoodr May 5 '17 at 17:45Thickycat , 2019-12-03 15:55:40
In Python 3 you can use a variation on:
def Deb(msg = None): print(f"Debug {sys._getframe().f_back.f_lineno}: {msg if msg is not None else ''}")In code, you can then use:
Deb("Some useful information") Deb()To produce:
123: Some useful information 124:Where the 123 and 124 are the lines that the calls are made from.
> ,
add a comment> ,
Here's what works for me to get the line number in Python 3.7.3 in VSCode 1.39.2 (
dmsgis my mnemonic for debug message):import inspect def dmsg(text_s): print (str(inspect.currentframe().f_back.f_lineno) + '| ' + text_s)To call showing a variable
name_sand its value:name_s = put_code_here dmsg('name_s: ' + name_s)Output looks like this:
37| name_s: value_of_variable_at_line_37
Jan 01, 2011 | stackoverflow.com
How to determine file, function and line number? Ask Question Asked 9 years ago Active 1 year, 11 months ago Viewed 32k times
pengdu ,
In C++, I can print debug output like this:
printf( "FILE: %s, FUNC: %s, LINE: %d, LOG: %s\n", __FILE__, __FUNCTION__, __LINE__, logmessage );How can I do something similar in Python?
Matt Joiner ,
You always print error log like that? That's remarkable, since there is noTugrul Ates ,
There is a module named
inspectwhich provides these information.Example usage:
import inspect def PrintFrame(): callerframerecord = inspect.stack()[1] # 0 represents this line # 1 represents line at caller frame = callerframerecord[0] info = inspect.getframeinfo(frame) print(info.filename) # __FILE__ -> Test.py print(info.function) # __FUNCTION__ -> Main print(info.lineno) # __LINE__ -> 13 def Main(): PrintFrame() # for this line Main()However, please remember that there is an easier way to obtain the name of the currently executing file:
print(__file__)Preet Sangha , 2011-07-25 01:35:08
For example
import inspect frame = inspect.currentframe() # __FILE__ fileName = frame.f_code.co_filename # __LINE__ fileNo = frame.f_linenoThere's more here http://docs.python.org/library/inspect.html
ahuigo ,
And a simple way to get fileNo:fileNo = frame.f_lineno– ahuigo Oct 4 '16 at 3:51Matthew , 2014-07-29 22:37:03
Building on geowar's answer:
class __LINE__(object): import sys def __repr__(self): try: raise Exception except: return str(sys.exc_info()[2].tb_frame.f_back.f_lineno) __LINE__ = __LINE__()If you normally want to use
__LINE__in e.g.str()orrepr()is taken), the above will allow you to omit the()s.(Obvious extension to add a
__call__left as an exercise to the reader.)Christoph Böddeker , 2017-05-29 17:49:39
I was also interested in a __LINE__ command in python. My starting point was https://stackoverflow.com/a/6811020 and I extended it with a metaclass object. With this modification it has the same behavior like in C++.
import inspect class Meta(type): def __repr__(self): # Inspiration: https://stackoverflow.com/a/6811020 callerframerecord = inspect.stack()[1] # 0 represents this line # 1 represents line at caller frame = callerframerecord[0] info = inspect.getframeinfo(frame) # print(info.filename) # __FILE__ -> Test.py # print(info.function) # __FUNCTION__ -> Main # print(info.lineno) # __LINE__ -> 13 return str(info.lineno) class __LINE__(metaclass=Meta): pass print(__LINE__) # print for example 18> ,
add a commentMohammad Shahid Siddiqui ,
You can refer my answer: https://stackoverflow.com/a/45973480/1591700
import sys print sys._getframe().f_linenoYou can also make lambda function
> ,
add a commentHugh Perkins , 2018-07-14 21:50:41
wow, 7 year old question :)
Anyway, taking Tugrul's answer, and writing it as a
debugtype method, it can look something like:def debug(message): import sys import inspect callerframerecord = inspect.stack()[1] frame = callerframerecord[0] info = inspect.getframeinfo(frame) print(info.filename, 'func=%s' % info.function, 'line=%s:' % info.lineno, message) def somefunc(): debug('inside some func') debug('this') debug('is a') debug('test message') somefunc()Output:
/tmp/test2.py func=<module> line=12: this /tmp/test2.py func=<module> line=13: is a /tmp/test2.py func=<module> line=14: test message /tmp/test2.py func=somefunc line=10: inside some func> ,
add a comment> ,
import inspect . . . def __LINE__(): try: raise Exception except: return sys.exc_info()[2].tb_frame.f_back.f_lineno def __FILE__(): return inspect.currentframe().f_code.co_filename . . . print "file: '%s', line: %d" % (__FILE__(), __LINE__())
Aug 11, 2020 | realpython.com
Your Guide to the Python print() Function
by Bartosz Zaczyński Aug 12, 2019 8 Comments basics python
Tweet Share EmailTable of Contents
- Printing in a Nutshell
- Understanding Python print()
- Printing With Style
- Mocking Python print() in Unit Tests
- print() Debugging
- Thread-Safe Printing
- Python Print Counterparts
- Conclusion

Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: The Python print() Function: Go Beyond the Basics
If you're like most Python users, including me, then you probably started your Python journey by learning about
print(). It helped you write your very ownhello worldone-liner. You can use it to display formatted messages onto the screen and perhaps find some bugs. But if you think that's all there is to know about Python'sprint()function, then you're missing out on a lot!Keep reading to take full advantage of this seemingly boring and unappreciated little function. This tutorial will get you up to speed with using Python
print()effectively. However, prepare for a deep dive as you go through the sections. You may be surprised how muchprint()has to offer!By the end of this tutorial, you'll know how to:
- Avoid common mistakes with Python's
print()- Deal with newlines, character encodings, and buffering
- Write text to files
- Mock
print()in unit tests- Build advanced user interfaces in the terminal
If you're a complete beginner, then you'll benefit most from reading the first part of this tutorial, which illustrates the essentials of printing in Python. Otherwise, feel free to skip that part and jump around as you see fit.
Note:
print()was a major addition to Python 3, in which it replaced the oldThere were a number of good reasons for that, as you'll see shortly. Although this tutorial focuses on Python 3, it does show the old way of printing in Python for reference.
Free Bonus: Click here to get our free Python Cheat Sheet that shows you the basics of Python 3, like working with data types, dictionaries, lists, and Python functions.
Remove ads Printing in a NutshellLet's jump in by looking at a few real-life examples of printing in Python. By the end of this section, you'll know every possible way of calling
Callingprint(). Or, in programmer lingo, you'd say you'll be familiar with the function signature .print()The simplest example of using Python
>>>print()requires just a few keystrokes:>>> print()You don't pass any arguments, but you still need to put empty parentheses at the end, which tell Python to actually execute the function rather than just refer to it by name.
This will produce an invisible newline character, which in turn will cause a blank line to appear on your screen. You can call
print()multiple times like this to add vertical space. It's just as if you were hitting Enter on your keyboard in a word processor.Newline Character Show/Hide
As you just saw, calling
print()without arguments results in a blank line , which is a line comprised solely of the newline character. Don't confuse this with an empty line , which doesn't contain any characters at all, not even the newline!You can use Python's string literals to visualize these two:
'\n' # Blank line '' # Empty lineThe first one is one character long, whereas the second one has no content.
Note: To remove the newline character from a string in Python, use its
>>>.rstrip()method, like this:>>> 'A line of text.\n'.rstrip() 'A line of text.'This strips any trailing whitespace from the right edge of the string of characters.
In a more common scenario, you'd want to communicate some message to the end user. There are a few ways to achieve this.
First, you may pass a string literal directly to
>>>print():>>> print('Please wait while the program is loading...')This will print the message verbatim onto the screen.
String Literals Show/Hide
Secondly, you could extract that message into its own variable with a meaningful name to enhance readability and promote code reuse:
>>>>>> message = 'Please wait while the program is loading...' >>> print(message)Lastly, you could pass an expression, like string concatenation , to be evaluated before printing the result:
>>>>>> import os >>> print('Hello, ' + os.getlogin() + '! How are you?') Hello, jdoe! How are you?In fact, there are a dozen ways to format messages in Python. I highly encourage you to take a look at f-strings , introduced in Python 3.6, because they offer the most concise syntax of them all:
>>>>>> import os >>> print(f'Hello, {os.getlogin()}! How are you?')Moreover, f-strings will prevent you from making a common mistake, which is forgetting to type cast concatenated operands. Python is a strongly typed language, which means it won't allow you to do this:
>>>>>> 'My age is ' + 42 Traceback (most recent call last): File "<input>", line 1, in <module> 'My age is ' + 42 TypeError: can only concatenate str (not "int") to strThat's wrong because adding numbers to strings doesn't make sense. You need to explicitly convert the number to string first, in order to join them together:
>>>>>> 'My age is ' + str(42) 'My age is 42'Unless you handle such errors yourself, the Python interpreter will let you know about a problem by showing a traceback .
Note:
str()is a global built-in function that converts an object into its string representation.You can call it directly on any object, for example, a number:
>>>>>> str(3.14) '3.14'Built-in data types have a predefined string representation out of the box, but later in this article, you'll find out how to provide one for your custom classes.
As with any function, it doesn't matter whether you pass a literal, a variable, or an expression. Unlike many other functions, however,
print()will accept anything regardless of its type.So far, you only looked at the string, but how about other data types? Let's try literals of different built-in types and see what comes out:
>>>>>> print(42) # <class 'int'> 42 >>> print(3.14) # <class 'float'> 3.14 >>> print(1 + 2j) # <class 'complex'> (1+2j) >>> print(True) # <class 'bool'> True >>> print([1, 2, 3]) # <class 'list'> [1, 2, 3] >>> print((1, 2, 3)) # <class 'tuple'> (1, 2, 3) >>> print({'red', 'green', 'blue'}) # <class 'set'> {'red', 'green', 'blue'} >>> print({'name': 'Alice', 'age': 42}) # <class 'dict'> {'name': 'Alice', 'age': 42} >>> print('hello') # <class 'str'> helloWatch out for the
>>>Noneconstant, though. Despite being used to indicate an absence of a value, it will show up as'None'rather than an empty string:>>> print(None) NoneHow does
print()know how to work with all these different types? Well, the short answer is that it doesn't. It implicitly callsstr()behind the scenes to type cast any object into a string. Afterward, it treats strings in a uniform way.Later in this tutorial, you'll learn how to use this mechanism for printing custom data types such as your classes.
Okay, you're now able to call
print()with a single argument or without any arguments. You know how to print fixed or formatted messages onto the screen. The next subsection will expand on message formatting a little bit.Syntax in Python 2 Show/Hide
https://dd2e52e7059e45793acb595de4e9337c.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html Remove ads Separating Multiple Arguments
You saw
print()called without any arguments to produce a blank line and then called with a single argument to display either a fixed or a formatted message.However, it turns out that this function can accept any number of positional arguments , including zero, one, or more arguments. That's very handy in a common case of message formatting, where you'd want to join a few elements together.
Positional Arguments Show/Hide
Let's have a look at this example:
>>>>>> import os >>> print('My name is', os.getlogin(), 'and I am', 42) My name is jdoe and I am 42
print()concatenated all four arguments passed to it, and it inserted a single space between them so that you didn't end up with a squashed message like'My name isjdoeand I am42'.Notice that it also took care of proper type casting by implicitly calling
>>>str()on each argument before joining them together. If you recall from the previous subsection, a naïve concatenation may easily result in an error due to incompatible types:>>> print('My age is: ' + 42) Traceback (most recent call last): File "<input>", line 1, in <module> print('My age is: ' + 42) TypeError: can only concatenate str (not "int") to strApart from accepting a variable number of positional arguments,
print()defines four named or keyword arguments , which are optional since they all have default values. You can view their brief documentation by callinghelp(print)from the interactive interpreter.Let's focus on
sepjust for now. It stands for separator and is assigned a single space (' ') by default. It determines the value to join elements with.It has to be either a string or
>>>None, but the latter has the same effect as the default space:>>> print('hello', 'world', sep=None) hello world >>> print('hello', 'world', sep=' ') hello world >>> print('hello', 'world') hello worldIf you wanted to suppress the separator completely, you'd have to pass an empty string (
>>>'') instead:>>> print('hello', 'world', sep='') helloworldYou may want
>>>print()to join its arguments as separate lines. In that case, simply pass the escaped newline character described earlier:>>> print('hello', 'world', sep='\n') hello worldA more useful example of the
>>>sepparameter would be printing something like file paths:>>> print('home', 'user', 'documents', sep='/') home/user/documentsRemember that the separator comes between the elements, not around them, so you need to account for that in one way or another:
>>>>>> print('/home', 'user', 'documents', sep='/') /home/user/documents >>> print('', 'home', 'user', 'documents', sep='/') /home/user/documentsSpecifically, you can insert a slash character (
/) into the first positional argument, or use an empty string as the first argument to enforce the leading slash.Note: Be careful about joining elements of a list or tuple.
Doing it manually will result in a well-known
>>>TypeErrorif at least one of the elements isn't a string:>>> print(' '.join(['jdoe is', 42, 'years old'])) Traceback (most recent call last): File "<input>", line 1, in <module> print(','.join(['jdoe is', 42, 'years old'])) TypeError: sequence item 1: expected str instance, int foundIt's safer to just unpack the sequence with the star operator (
>>>*) and letprint()handle type casting:>>> print(*['jdoe is', 42, 'years old']) jdoe is 42 years oldUnpacking is effectively the same as calling
print()with individual elements of the list.One more interesting example could be exporting data to a comma-separated values (CSV) format:
>>>>>> print(1, 'Python Tricks', 'Dan Bader', sep=',') 1,Python Tricks,Dan BaderThis wouldn't handle edge cases such as escaping commas correctly, but for simple use cases, it should do. The line above would show up in your terminal window. In order to save it to a file, you'd have to redirect the output. Later in this section, you'll see how to use
print()to write text to files straight from Python.Finally, the
>>>sepparameter isn't constrained to a single character only. You can join elements with strings of any length:>>> print('node', 'child', 'child', sep=' -> ') node -> child -> childIn the upcoming subsections, you'll explore the remaining keyword arguments of the
print()function.Syntax in Python 2 Show/Hide
https://dd2e52e7059e45793acb595de4e9337c.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html Remove ads Preventing Line Breaks
Sometimes you don't want to end your message with a trailing newline so that subsequent calls to
print()will continue on the same line. Classic examples include updating the progress of a long-running operation or prompting the user for input. In the latter case, you want the user to type in the answer on the same line:Are you sure you want to do this? [y/n] yMany programming languages expose functions similar to
print()through their standard libraries, but they let you decide whether to add a newline or not. For example, in Java and C#, you have two distinct functions, while other languages require you to explicitly append\nat the end of a string literal.Here are a few examples of syntax in such languages:
Language Example Perl print "hello world\n"C printf("hello world\n");C++ std::cout << "hello world" << std::endl;In contrast, Python's
print()function always adds\nwithout asking, because that's what you want in most cases. To disable it, you can take advantage of yet another keyword argument,end, which dictates what to end the line with.In terms of semantics, the
endparameter is almost identical to thesepone that you saw earlier:
- It must be a string or
None.- It can be arbitrarily long.
- It has a default value of
'\n'.- If equal to
None, it'll have the same effect as the default value.- If equal to an empty string (
''), it'll suppress the newline.Now you understand what's happening under the hood when you're calling
print()without arguments. Since you don't provide any positional arguments to the function, there's nothing to be joined, and so the default separator isn't used at all. However, the default value ofendstill applies, and a blank line shows up.Note: You may be wondering why the
endparameter has a fixed default value rather than whatever makes sense on your operating system.Well, you don't have to worry about newline representation across different operating systems when printing, because
print()will handle the conversion automatically. Just remember to always use the\nescape sequence in string literals.This is currently the most portable way of printing a newline character in Python:
>>>>>> print('line1\nline2\nline3') line1 line2 line3If you were to try to forcefully print a Windows-specific newline character on a Linux machine, for example, you'd end up with broken output:
>>>>>> print('line1\r\nline2\r\nline3') line3On the flip side, when you open a file for reading with
open(), you don't need to care about newline representation either. The function will translate any system-specific newline it encounters into a universal'\n'. At the same time, you have control over how the newlines should be treated both on input and output if you really need that.To disable the newline, you must specify an empty string through the
endkeyword argument:print('Checking file integrity...', end='') # (...) print('ok')Even though these are two separate
print()calls, which can execute a long time apart, you'll eventually see only one line. First, it'll look like this:Checking file integrity...However, after the second call to
print(), the same line will appear on the screen as:Checking file integrity...okAs with
sep, you can useendto join individual pieces into a big blob of text with a custom separator. Instead of joining multiple arguments, however, it'll append text from each function call to the same line:print('The first sentence', end='. ') print('The second sentence', end='. ') print('The last sentence.')These three instructions will output a single line of text:
The first sentence. The second sentence. The last sentence.You can mix the two keyword arguments:
print('Mercury', 'Venus', 'Earth', sep=', ', end=', ') print('Mars', 'Jupiter', 'Saturn', sep=', ', end=', ') print('Uranus', 'Neptune', 'Pluto', sep=', ')Not only do you get a single line of text, but all items are separated with a comma:
Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune, PlutoThere's nothing to stop you from using the newline character with some extra padding around it:
print('Printing in a Nutshell', end='\n * ') print('Calling Print', end='\n * ') print('Separating Multiple Arguments', end='\n * ') print('Preventing Line Breaks')It would print out the following piece of text:
Printing in a Nutshell * Calling Print * Separating Multiple Arguments * Preventing Line BreaksAs you can see, the
endkeyword argument will accept arbitrary strings.Note: Looping over lines in a text file preserves their own newline characters, which combined with the
>>>print()function's default behavior will result in a redundant newline character:>>> with open('file.txt') as file_object: ... for line in file_object: ... print(line) ... Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodoThere are two newlines after each line of text. You want to strip one of the them, as shown earlier in this article, before printing the line:
print(line.rstrip())Alternatively, you can keep the newline in the content but suppress the one appended by
>>>print()automatically. You'd use theendkeyword argument to do that:>>> with open('file.txt') as file_object: ... for line in file_object: ... print(line, end='') ... Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodoBy ending a line with an empty string, you effectively disable one of the newlines.
You're getting more acquainted with printing in Python, but there's still a lot of useful information ahead. In the upcoming subsection, you'll learn how to intercept and redirect the
print()function's output.Syntax in Python 2 Show/Hide
Remove ads Printing to a FileBelieve it or not,
print()doesn't know how to turn messages into text on your screen, and frankly it doesn't need to. That's a job for lower-level layers of code, which understand bytes and know how to push them around.
print()is an abstraction over these layers, providing a convenient interface that merely delegates the actual printing to a stream or file-like object . A stream can be any file on your disk, a network socket, or perhaps an in-memory buffer.In addition to this, there are three standard streams provided by the operating system:
stdin: standard inputstdout: standard outputstderr: standard errorStandard Streams Show/Hide
In Python, you can access all standard streams through the built-in
>>>sysmodule:>>> import sys >>> sys.stdin <_io.TextIOWrapper name='<stdin>' mode='r' encoding='UTF-8'> >>> sys.stdin.fileno() 0 >>> sys.stdout <_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'> >>> sys.stdout.fileno() 1 >>> sys.stderr <_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'> >>> sys.stderr.fileno() 2As you can see, these predefined values resemble file-like objects with
modeandencodingattributes as well as.read()and.write()methods among many others.By default,
print()is bound tosys.stdoutthrough itsfileargument, but you can change that. Use that keyword argument to indicate a file that was open in write or append mode, so that messages go straight to it:with open('file.txt', mode='w') as file_object: print('hello world', file=file_object)This will make your code immune to stream redirection at the operating system level, which might or might not be desired.
For more information on working with files in Python , you can check out Reading and Writing Files in Python (Guide) .
Note: Don't try using
print()for writing binary data as it's only well suited for text.Just call the binary file's
.write()directly:with open('file.dat', 'wb') as file_object: file_object.write(bytes(4)) file_object.write(b'\xff')If you wanted to write raw bytes on the standard output, then this will fail too because
>>>sys.stdoutis a character stream:>>> import sys >>> sys.stdout.write(bytes(4)) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: write() argument must be str, not bytesYou must dig deeper to get a handle of the underlying byte stream instead:
>>>>>> import sys >>> num_bytes_written = sys.stdout.buffer.write(b'\x41\x0a') AThis prints an uppercase letter
Aand a newline character, which correspond to decimal values of 65 and 10 in ASCII. However, they're encoded using hexadecimal notation in the bytes literal.Note that
print()has no control over character encoding . It's the stream's responsibility to encode received Unicode strings into bytes correctly. In most cases, you won't set the encoding yourself, because the default UTF-8 is what you want. If you really need to, perhaps for legacy systems, you can use theencodingargument ofopen():with open('file.txt', mode='w', encoding='iso-8859-1') as file_object: print('über naïve café', file=file_object)Instead of a real file existing somewhere in your file system, you can provide a fake one, which would reside in your computer's memory. You'll use this technique later for mocking
>>>print()in unit tests:>>> import io >>> fake_file = io.StringIO() >>> print('hello world', file=fake_file) >>> fake_file.getvalue() 'hello world\n'If you got to this point, then you're left with only one keyword argument in
print(), which you'll see in the next subsection. It's probably the least used of them all. Nevertheless, there are times when it's absolutely necessary.Syntax in Python 2 Show/Hide
Remove ads Bufferingprint()CallsIn the previous subsection, you learned that
print()delegates printing to a file-like object such assys.stdout. Some streams, however, buffer certain I/O operations to enhance performance, which can get in the way. Let's take a look at an example.Imagine you were writing a countdown timer, which should append the remaining time to the same line every second:
3...2...1...Go!Your first attempt may look something like this:
import time num_seconds = 3 for countdown in reversed(range(num_seconds + 1)): if countdown > 0: print(countdown, end='...') time.sleep(1) else: print('Go!')As long as the
countdownvariable is greater than zero, the code keeps appending text without a trailing newline and then goes to sleep for one second. Finally, when the countdown is finished, it printsGo!and terminates the line.Unexpectedly, instead of counting down every second, the program idles wastefully for three seconds, and then suddenly prints the entire line at once:
That's because the operating system buffers subsequent writes to the standard output in this case. You need to know that there are three kinds of streams with respect to buffering:
- Unbuffered
- Line-buffered
- Block-buffered
Unbuffered is self-explanatory, that is, no buffering is taking place, and all writes have immediate effect. A line-buffered stream waits before firing any I/O calls until a line break appears somewhere in the buffer, whereas a block-buffered one simply allows the buffer to fill up to a certain size regardless of its content. Standard output is both line-buffered and block-buffered , depending on which event comes first.
Buffering helps to reduce the number of expensive I/O calls. Think about sending messages over a high-latency network, for example. When you connect to a remote server to execute commands over the SSH protocol, each of your keystrokes may actually produce an individual data packet, which is orders of magnitude bigger than its payload. What an overhead! It would make sense to wait until at least a few characters are typed and then send them together. That's where buffering steps in.
On the other hand, buffering can sometimes have undesired effects as you just saw with the countdown example. To fix it, you can simply tell
print()to forcefully flush the stream without waiting for a newline character in the buffer using itsflushflag:print(countdown, end='...', flush=True)That's all. Your countdown should work as expected now, but don't take my word for it. Go ahead and test it to see the difference.
Congratulations! At this point, you've seen examples of calling
print()that cover all of its parameters. You know their purpose and when to use them. Understanding the signature is only the beginning, however. In the upcoming sections, you'll see why.Syntax in Python 2 Show/Hide Printing Custom Data Types
Up until now, you only dealt with built-in data types such as strings and numbers, but you'll often want to print your own abstract data types. Let's have a look at different ways of defining them.
For simple objects without any logic, whose purpose is to carry data, you'll typically take advantage of
>>>namedtuple, which is available in the standard library. Named tuples have a neat textual representation out of the box:>>> from collections import namedtuple >>> Person = namedtuple('Person', 'name age') >>> jdoe = Person('John Doe', 42) >>> print(jdoe) Person(name='John Doe', age=42)That's great as long as holding data is enough, but in order to add behaviors to the
Persontype, you'll eventually need to define a class. Take a look at this example:class Person: def __init__(self, name, age): self.name, self.age = name, ageIf you now create an instance of the
>>>Personclass and try to print it, you'll get this bizarre output, which is quite different from the equivalentnamedtuple:>>> jdoe = Person('John Doe', 42) >>> print(jdoe) <__main__.Person object at 0x7fcac3fed1d0>It's the default representation of objects, which comprises their address in memory, the corresponding class name and a module in which they were defined. You'll fix that in a bit, but just for the record, as a quick workaround you could combine
namedtupleand a custom class through inheritance :from collections import namedtuple class Person(namedtuple('Person', 'name age')): passYour
Personclass has just become a specialized kind ofnamedtuplewith two attributes, which you can customize.Note: In Python 3, the
passstatement can be replaced with the ellipsis (...) literal to indicate a placeholder:def delta(a, b, c): ...This prevents the interpreter from raising
IndentationErrordue to missing indented block of code.That's better than a plain
namedtuple, because not only do you get printing right for free, but you can also add custom methods and properties to the class. However, it solves one problem while introducing another. Remember that tuples, including named tuples, are immutable in Python, so they can't change their values once created.It's true that designing immutable data types is desirable, but in many cases, you'll want them to allow for change, so you're back with regular classes again.
Note: Following other languages and frameworks, Python 3.7 introduced data classes , which you can think of as mutable tuples. This way, you get the best of both worlds:
>>>>>> from dataclasses import dataclass >>> @dataclass ... class Person: ... name: str ... age: int ... ... def celebrate_birthday(self): ... self.age += 1 ... >>> jdoe = Person('John Doe', 42) >>> jdoe.celebrate_birthday() >>> print(jdoe) Person(name='John Doe', age=43)The syntax for variable annotations , which is required to specify class fields with their corresponding types, was defined in Python 3.6.
From earlier subsections, you already know that
>>>print()implicitly calls the built-instr()function to convert its positional arguments into strings. Indeed, callingstr()manually against an instance of the regularPersonclass yields the same result as printing it:>>> jdoe = Person('John Doe', 42) >>> str(jdoe) '<__main__.Person object at 0x7fcac3fed1d0>'
str(), in turn, looks for one of two magic methods within the class body, which you typically implement. If it doesn't find one, then it falls back to the ugly default representation. Those magic methods are, in order of search:
def __str__(self)def __repr__(self)The first one is recommended to return a short, human-readable text, which includes information from the most relevant attributes. After all, you don't want to expose sensitive data, such as user passwords, when printing objects.
However, the other one should provide complete information about an object, to allow for restoring its state from a string. Ideally, it should return valid Python code, so that you can pass it directly to
>>>eval():>>> repr(jdoe) "Person(name='John Doe', age=42)" >>> type(eval(repr(jdoe))) <class '__main__.Person'>Notice the use of another built-in function,
repr(), which always tries to call.__repr__()in an object, but falls back to the default representation if it doesn't find that method.Note: Even though
print()itself usesstr()for type casting, some compound data types delegate that call torepr()on their members. This happens to lists and tuples, for example.Consider this class with both magic methods, which return alternative string representations of the same object:
class User: def __init__(self, login, password): self.login = login self.password = password def __str__(self): return self.login def __repr__(self): return f"User('{self.login}', '{self.password}')"If you print a single object of the
>>>Userclass, then you won't see the password, becauseprint(user)will callstr(user), which eventually will invokeuser.__str__():>>> user = User('jdoe', 's3cret') >>> print(user) jdoeHowever, if you put the same
>>>uservariable inside a list by wrapping it in square brackets, then the password will become clearly visible:>>> print([user]) [User('jdoe', 's3cret')]That's because sequences, such as lists and tuples, implement their
.__str__()method so that all of their elements are first converted withrepr().Python gives you a lot of freedom when it comes to defining your own data types if none of the built-in ones meet your needs. Some of them, such as named tuples and data classes, offer string representations that look good without requiring any work on your part. Still, for the most flexibility, you'll have to define a class and override its magic methods described above.
Syntax in Python 2 Show/Hide
Remove ads Understanding Pythonprint()You know how to use
Print Is a Function in Python 3print()quite well at this point, but knowing what it is will allow you to use it even more effectively and consciously. After reading this section, you'll understand how printing in Python has improved over the years.You've seen that
>>>print()is a function in Python 3. More specifically, it's a built-in function, which means that you don't need to import it from anywhere:>>> print <built-in function print>It's always available in the global namespace so that you can call it directly, but you can also access it through a module from the standard library:
>>>>>> import builtins >>> builtins.print <built-in function print>This way, you can avoid name collisions with custom functions. Let's say you wanted to redefine
>>>print()so that it doesn't append a trailing newline. At the same time, you wanted to rename the original function to something likeprintln():>>> import builtins >>> println = builtins.print >>> def print(*args, **kwargs): ... builtins.print(*args, **kwargs, end='') ... >>> println('hello') hello >>> print('hello\n') helloNow you have two separate printing functions just like in the Java programming language. You'll define custom
print()functions in the mocking section later as well. Also, note that you wouldn't be able to overwriteprint()in the first place if it wasn't a function.On the other hand,
>>>print()isn't a function in the mathematical sense, because it doesn't return any meaningful value other than the implicitNone:>>> value = print('hello world') hello world >>> print(value) NoneSuch functions are, in fact, procedures or subroutines that you call to achieve some kind of side-effect, which ultimately is a change of a global state. In the case of
print(), that side-effect is showing a message on the standard output or writing to a file.Because
print()is a function, it has a well-defined signature with known attributes. You can quickly find its documentation using the editor of your choice, without having to remember some weird syntax for performing a certain task.Besides, functions are easier to extend . Adding a new feature to a function is as easy as adding another keyword argument, whereas changing the language to support that new feature is much more cumbersome. Think of stream redirection or buffer flushing, for example.
Another benefit of
print()being a function is composability . Functions are so-called first-class objects or first-class citizens in Python, which is a fancy way of saying they're values just like strings or numbers. This way, you can assign a function to a variable, pass it to another function, or even return one from another.print()isn't different in this regard. For instance, you can take advantage of it for dependency injection:def download(url, log=print): log(f'Downloading {url}') # ... def custom_print(*args): pass # Do not print anything download('/js/app.js', log=custom_print)Here, the
logparameter lets you inject a callback function, which defaults toprint()but can be any callable. In this example, printing is completely disabled by substitutingprint()with a dummy function that does nothing.Note: A dependency is any piece of code required by another bit of code.
Dependency injection is a technique used in code design to make it more testable, reusable, and open for extension. You can achieve it by referring to dependencies indirectly through abstract interfaces and by providing them in a push rather than pull fashion.
There's a funny explanation of dependency injection circulating on the Internet:
Dependency injection for five-year-olds
When you go and get things out of the refrigerator for yourself, you can cause problems. You might leave the door open, you might get something Mommy or Daddy doesn't want you to have. You might even be looking for something we don't even have or which has expired.
What you should be doing is stating a need, "I need something to drink with lunch," and then we will make sure you have something when you sit down to eat.
-- John Munsch, 28 October 2009. ( Source )
Composition allows you to combine a few functions into a new one of the same kind. Let's see this in action by specifying a custom
>>>error()function that prints to the standard error stream and prefixes all messages with a given log level:>>> from functools import partial >>> import sys >>> redirect = lambda function, stream: partial(function, file=stream) >>> prefix = lambda function, prefix: partial(function, prefix) >>> error = prefix(redirect(print, sys.stderr), '[ERROR]') >>> error('Something went wrong') [ERROR] Something went wrongThis custom function uses partial functions to achieve the desired effect. It's an advanced concept borrowed from the functional programming paradigm, so you don't need to go too deep into that topic for now. However, if you're interested in this topic, I recommend taking a look at the
functoolsmodule.Unlike statements, functions are values. That means you can mix them with expressions , in particular, lambda expressions . Instead of defining a full-blown function to replace
>>>print()with, you can make an anonymous lambda expression that calls it:>>> download('/js/app.js', lambda msg: print('[INFO]', msg)) [INFO] Downloading /js/app.jsHowever, because a lambda expression is defined in place, there's no way of referring to it elsewhere in the code.
Note: In Python, you can't put statements, such as assignments, conditional statements, loops, and so on, in an anonymous lambda function . It has to be a single expression!
Another kind of expression is a ternary conditional expression:
>>>>>> user = 'jdoe' >>> print('Hi!') if user is None else print(f'Hi, {user}.') Hi, jdoe.Python has both conditional statements and conditional expressions . The latter is evaluated to a single value that can be assigned to a variable or passed to a function. In the example above, you're interested in the side-effect rather than the value, which evaluates to
None, so you simply ignore it.As you can see, functions allow for an elegant and extensible solution, which is consistent with the rest of the language. In the next subsection, you'll discover how not having
Remove adsprint()as a function caused a lot of headaches.A statement is an instruction that may evoke a side-effect when executed but never evaluates to a value. In other words, you wouldn't be able to print a statement or assign it to a variable like this:
result = print 'hello world'That's a syntax error in Python 2.
Here are a few more examples of statements in Python:
- assignment:
=- conditional:
if- loop:
while- assertion :
assertNote: Python 3.8 brings a controversial walrus operator (
:=), which is an assignment expression . With it, you can evaluate an expression and assign the result to a variable at the same time, even within another expression!Take a look at this example, which calls an expensive function once and then reuses the result for further computation:
# Python 3.8+ values = [y := f(x), y**2, y**3]This is useful for simplifying the code without losing its efficiency. Typically, performant code tends to be more verbose:
y = f(x) values = [y, y**2, y**3]The controversy behind this new piece of syntax caused a lot of argument. An abundance of negative comments and heated debates eventually led Guido van Rossum to step down from the Benevolent Dictator For Life or BDFL position.
Statements are usually comprised of reserved keywords such as
if,for, orFurthermore, you can't print from anonymous functions, because statements aren't accepted in lambda expressions:
>>>>>> lambda: print 'hello world' File "<stdin>", line 1 lambda: print 'hello world' ^ SyntaxError: invalid syntaxThe syntax of the
>>>>>> print 'Please wait...' Please wait... >>> print('Please wait...') Please wait...At other times they change how the message is printed:
>>>>>> print 'My name is', 'John' My name is John >>> print('My name is', 'John') ('My name is', 'John')String concatenation can raise a
>>>TypeErrordue to incompatible types, which you have to handle manually, for example:>>> values = ['jdoe', 'is', 42, 'years old'] >>> print ' '.join(map(str, values)) jdoe is 42 years oldCompare this with similar code in Python 3, which leverages sequence unpacking:
>>>>>> values = ['jdoe', 'is', 42, 'years old'] >>> print(*values) # Python 3 jdoe is 42 years oldThere aren't any keyword arguments for common tasks such as flushing the buffer or stream redirection. You need to remember the quirky syntax instead. Even the built-in
>>>help()function isn't that helpful with regards to the>>> help(print) File "<stdin>", line 1 help(print) ^ SyntaxError: invalid syntaxTrailing newline removal doesn't work quite right, because it adds an unwanted space. You can't compose multiple
The list of problems goes on and on. If you're curious, you can jump back to the previous section and look for more detailed explanations of the syntax in Python 2.
However, you can mitigate some of those problems with a much simpler approach. It turns out the
print()function was backported to ease the migration to Python 3. You can import it from a special__future__module, which exposes a selection of language features released in later Python versions.Note: You may import future functions as well as baked-in language constructs such as the
withstatement.To find out exactly what features are available to you, inspect the module:
>>>>>> import __future__ >>> __future__.all_feature_names ['nested_scopes', 'generators', 'division', 'absolute_import', 'with_statement', 'print_function', 'unicode_literals']You could also call
dir(__future__), but that would show a lot of uninteresting internal details of the module.To enable the
print()function in Python 2, you need to add this import statement at the beginning of your source code:from __future__ import print_functionFrom now on the
print()function at your disposal. Note that it isn't the same function like the one in Python 3, because it's missing theflushkeyword argument, but the rest of the arguments are the same.Other than that, it doesn't spare you from managing character encodings properly.
Here's an example of calling the
>>>print()function in Python 2:>>> from __future__ import print_function >>> import sys >>> print('I am a function in Python', sys.version_info.major) I am a function in Python 2You now have an idea of how printing in Python evolved and, most importantly, understand why these backward-incompatible changes were necessary. Knowing this will surely help you become a better Python programmer.
Remove ads Printing With StyleIf you thought that printing was only about lighting pixels up on the screen, then technically you'd be right. However, there are ways to make it look cool. In this section, you'll find out how to format complex data structures, add colors and other decorations, build interfaces, use animation, and even play sounds with text!
Pretty-Printing Nested Data StructuresComputer languages allow you to represent data as well as executable code in a structured way. Unlike Python, however, most languages give you a lot of freedom in using whitespace and formatting. This can be useful, for example in compression, but it sometimes leads to less readable code.
Pretty-printing is about making a piece of data or code look more appealing to the human eye so that it can be understood more easily. This is done by indenting certain lines, inserting newlines, reordering elements, and so forth.
Python comes with the
pprintmodule in its standard library, which will help you in pretty-printing large data structures that don't fit on a single line. Because it prints in a more human-friendly way, many popular REPL tools, including JupyterLab and IPython , use it by default in place of the regularprint()function.Note: To toggle pretty printing in IPython, issue the following command:
>>>In [1]: %pprint Pretty printing has been turned OFF In [2]: %pprint Pretty printing has been turned ONThis is an example of Magic in IPython. There are a lot of built-in commands that start with a percent sign (
%), but you can find more on PyPI , or even create your own.If you don't care about not having access to the original
>>>print()function, then you can replace it withpprint()in your code using import renaming:>>> from pprint import pprint as print >>> print <function pprint at 0x7f7a775a3510>Personally, I like to have both functions at my fingertips, so I'd rather use something like
ppas a short alias:from pprint import pprint as ppAt first glance, there's hardly any difference between the two functions, and in some cases there's virtually none:
>>>>>> print(42) 42 >>> pp(42) 42 >>> print('hello') hello >>> pp('hello') 'hello' # Did you spot the difference?That's because
>>>pprint()callsrepr()instead of the usualstr()for type casting, so that you may evaluate its output as Python code if you want to. The differences become apparent as you start feeding it more complex data structures:>>> data = {'powers': [x**10 for x in range(10)]} >>> pp(data) {'powers': [0, 1, 1024, 59049, 1048576, 9765625, 60466176, 282475249, 1073741824, 3486784401]}The function applies reasonable formatting to improve readability, but you can customize it even further with a couple of parameters. For example, you may limit a deeply nested hierarchy by showing an ellipsis below a given level:
>>>>>> cities = {'USA': {'Texas': {'Dallas': ['Irving']}}} >>> pp(cities, depth=3) {'USA': {'Texas': {'Dallas': [...]}}}The ordinary
>>>print()also uses ellipses but for displaying recursive data structures, which form a cycle, to avoid stack overflow error:>>> items = [1, 2, 3] >>> items.append(items) >>> print(items) [1, 2, 3, [...]]However,
>>>pprint()is more explicit about it by including the unique identity of a self-referencing object:>>> pp(items) [1, 2, 3, <Recursion on list with id=140635757287688>] >>> id(items) 140635757287688The last element in the list is the same object as the entire list.
Note: Recursive or very large data sets can be dealt with using the
>>>reprlibmodule as well:>>> import reprlib >>> reprlib.repr([x**10 for x in range(10)]) '[0, 1, 1024, 59049, 1048576, 9765625, ...]'This module supports most of the built-in types and is used by the Python debugger.
pprint()automatically sorts dictionary keys for you before printing, which allows for consistent comparison. When you're comparing strings, you often don't care about a particular order of serialized attributes. Anyways, it's always best to compare actual dictionaries before serialization.Dictionaries often represent JSON data , which is widely used on the Internet. To correctly serialize a dictionary into a valid JSON-formatted string, you can take advantage of the
>>>jsonmodule. It too has pretty-printing capabilities:>>> import json >>> data = {'username': 'jdoe', 'password': 's3cret'} >>> ugly = json.dumps(data) >>> pretty = json.dumps(data, indent=4, sort_keys=True) >>> print(ugly) {"username": "jdoe", "password": "s3cret"} >>> print(pretty) { "password": "s3cret", "username": "jdoe" }Notice, however, that you need to handle printing yourself, because it's not something you'd typically want to do. Similarly, the
pprintmodule has an additionalpformat()function that returns a string, in case you had to do something other than printing it.Surprisingly, the signature of
Remove ads Adding Colors With ANSI Escape Sequencespprint()is nothing like theprint()function's one. You can't even pass more than one positional argument, which shows how much it focuses on printing data structures.As personal computers got more sophisticated, they had better graphics and could display more colors. However, different vendors had their own idea about the API design for controlling it. That changed a few decades ago when people at the American National Standards Institute decided to unify it by defining ANSI escape codes .
Most of today's terminal emulators support this standard to some degree. Until recently, the Windows operating system was a notable exception. Therefore, if you want the best portability, use the
coloramalibrary in Python. It translates ANSI codes to their appropriate counterparts in Windows while keeping them intact in other operating systems.To check if your terminal understands a subset of the ANSI escape sequences, for example, related to colors, you can try using the following command:
$ tput colorsMy default terminal on Linux says it can display 256 distinct colors, while xterm gives me only 8. The command would return a negative number if colors were unsupported.
ANSI escape sequences are like a markup language for the terminal. In HTML you work with tags, such as
<b>or<i>, to change how elements look in the document. These tags are mixed with your content, but they're not visible themselves. Similarly, escape codes won't show up in the terminal as long as it recognizes them. Otherwise, they'll appear in the literal form as if you were viewing the source of a website.As its name implies, a sequence must begin with the non-printable Esc character, whose ASCII value is 27, sometimes denoted as
>>>0x1bin hexadecimal or033in octal. You may use Python number literals to quickly verify it's indeed the same number:>>> 27 == 0x1b == 0o33 TrueAdditionally, you can obtain it with the
\eescape sequence in the shell:$ echo -e "\e"The most common ANSI escape sequences take the following form:
Element Description Example Esc non-printable escape character \033[opening square bracket [numeric code one or more numbers separated with ;0character code uppercase or lowercase letter mThe numeric code can be one or more numbers separated with a semicolon, while the character code is just one letter. Their specific meaning is defined by the ANSI standard. For example, to reset all formatting, you would type one of the following commands, which use the code zero and the letter
m:$ echo -e "\e[0m" $ echo -e "\x1b[0m" $ echo -e "\033[0m"At the other end of the spectrum, you have compound code values. To set foreground and background with RGB channels, given that your terminal supports 24-bit depth, you could provide multiple numbers:
$ echo -e "\e[38;2;0;0;0m\e[48;2;255;255;255mBlack on white\e[0m"It's not just text color that you can set with the ANSI escape codes. You can, for example, clear and scroll the terminal window, change its background, move the cursor around, make the text blink or decorate it with an underline.
In Python, you'd probably write a helper function to allow for wrapping arbitrary codes into a sequence:
>>>>>> def esc(code): ... return f'\033[{code}m' ... >>> print(esc('31;1;4') + 'really' + esc(0) + ' important')This would make the word
reallyappear in red, bold, and underlined font:
However, there are higher-level abstractions over ANSI escape codes, such as the mentioned
Remove ads Building Console User Interfacescoloramalibrary, as well as tools for building user interfaces in the console.While playing with ANSI escape codes is undeniably a ton of fun, in the real world you'd rather have more abstract building blocks to put together a user interface. There are a few libraries that provide such a high level of control over the terminal, but
cursesseems to be the most popular choice.Note: To use the
curseslibrary in Windows, you need to install a third-party package:C:\> pip install windows-cursesThat's because
cursesisn't available in the standard library of the Python distribution for Windows.Primarily, it allows you to think in terms of independent graphical widgets instead of a blob of text. Besides, you get a lot of freedom in expressing your inner artist, because it's really like painting a blank canvas. The library hides the complexities of having to deal with different terminals. Other than that, it has great support for keyboard events, which might be useful for writing video games.
How about making a retro snake game? Let's create a Python snake simulator:
First, you need to import the
cursesmodule. Since it modifies the state of a running terminal, it's important to handle errors and gracefully restore the previous state. You can do this manually, but the library comes with a convenient wrapper for your main function:import curses def main(screen): pass if __name__ == '__main__': curses.wrapper(main)Note, the function must accept a reference to the screen object, also known as
stdscr, that you'll use later for additional setup.If you run this program now, you won't see any effects, because it terminates immediately. However, you can add a small delay to have a sneak peek:
import time, curses def main(screen): time.sleep(1) if __name__ == '__main__': curses.wrapper(main)This time the screen went completely blank for a second, but the cursor was still blinking. To hide it, just call one of the configuration functions defined in the module:
import time, curses def main(screen): curses.curs_set(0) # Hide the cursor time.sleep(1) if __name__ == '__main__': curses.wrapper(main)Let's define the snake as a list of points in screen coordinates:
snake = [(0, i) for i in reversed(range(20))]The head of the snake is always the first element in the list, whereas the tail is the last one. The initial shape of the snake is horizontal, starting from the top-left corner of the screen and facing to the right. While its y-coordinate stays at zero, its x-coordinate decreases from head to tail.
To draw the snake, you'll start with the head and then follow with the remaining segments. Each segment carries
(y, x)coordinates, so you can unpack them:# Draw the snake screen.addstr(*snake[0], '@') for segment in snake[1:]: screen.addstr(*segment, '*')Again, if you run this code now, it won't display anything, because you must explicitly refresh the screen afterward:
import time, curses def main(screen): curses.curs_set(0) # Hide the cursor snake = [(0, i) for i in reversed(range(20))] # Draw the snake screen.addstr(*snake[0], '@') for segment in snake[1:]: screen.addstr(*segment, '*') screen.refresh() time.sleep(1) if __name__ == '__main__': curses.wrapper(main)You want to move the snake in one of four directions, which can be defined as vectors. Eventually, the direction will change in response to an arrow keystroke, so you may hook it up to the library's key codes:
directions = { curses.KEY_UP: (-1, 0), curses.KEY_DOWN: (1, 0), curses.KEY_LEFT: (0, -1), curses.KEY_RIGHT: (0, 1), } direction = directions[curses.KEY_RIGHT]How does a snake move? It turns out that only its head really moves to a new location, while all other segments shift towards it. In each step, almost all segments remain the same, except for the head and the tail. Assuming the snake isn't growing, you can remove the tail and insert a new head at the beginning of the list:
# Move the snake snake.pop() snake.insert(0, tuple(map(sum, zip(snake[0], direction))))To get the new coordinates of the head, you need to add the direction vector to it. However, adding tuples in Python results in a bigger tuple instead of the algebraic sum of the corresponding vector components. One way to fix this is by using the built-in
zip(),sum(), andmap()functions.The direction will change on a keystroke, so you need to call
.getch()to obtain the pressed key code. However, if the pressed key doesn't correspond to the arrow keys defined earlier as dictionary keys, the direction won't change:# Change direction on arrow keystroke direction = directions.get(screen.getch(), direction)By default, however,
.getch()is a blocking call that would prevent the snake from moving unless there was a keystroke. Therefore, you need to make the call non-blocking by adding yet another configuration:def main(screen): curses.curs_set(0) # Hide the cursor screen.nodelay(True) # Don't block I/O callsYou're almost done, but there's just one last thing left. If you now loop this code, the snake will appear to be growing instead of moving. That's because you have to erase the screen explicitly before each iteration.
Finally, this is all you need to play the snake game in Python:
import time, curses def main(screen): curses.curs_set(0) # Hide the cursor screen.nodelay(True) # Don't block I/O calls directions = { curses.KEY_UP: (-1, 0), curses.KEY_DOWN: (1, 0), curses.KEY_LEFT: (0, -1), curses.KEY_RIGHT: (0, 1), } direction = directions[curses.KEY_RIGHT] snake = [(0, i) for i in reversed(range(20))] while True: screen.erase() # Draw the snake screen.addstr(*snake[0], '@') for segment in snake[1:]: screen.addstr(*segment, '*') # Move the snake snake.pop() snake.insert(0, tuple(map(sum, zip(snake[0], direction)))) # Change direction on arrow keystroke direction = directions.get(screen.getch(), direction) screen.refresh() time.sleep(0.1) if __name__ == '__main__': curses.wrapper(main)This is merely scratching the surface of the possibilities that the
Living It Up With Cool Animationscursesmodule opens up. You may use it for game development like this or more business-oriented applications.Not only can animations make the user interface more appealing to the eye, but they also improve the overall user experience. When you provide early feedback to the user, for example, they'll know if your program's still working or if it's time to kill it.
To animate text in the terminal, you have to be able to freely move the cursor around. You can do this with one of the tools mentioned previously, that is ANSI escape codes or the
curseslibrary. However, I'd like to show you an even simpler way.If the animation can be constrained to a single line of text, then you might be interested in two special escape character sequences:
- Carriage return:
\r- Backspace:
\bThe first one moves the cursor to the beginning of the line, whereas the second one moves it only one character to the left. They both work in a non-destructive way without overwriting text that's already been written.
Let's take a look at a few examples.
You'll often want to display some kind of a spinning wheel to indicate a work in progress without knowing exactly how much time's left to finish:
Many command line tools use this trick while downloading data over the network. You can make a really simple stop motion animation from a sequence of characters that will cycle in a round-robin fashion:
from itertools import cycle from time import sleep for frame in cycle(r'-\|/-\|/'): print('\r', frame, sep='', end='', flush=True) sleep(0.2)The loop gets the next character to print, then moves the cursor to the beginning of the line, and overwrites whatever there was before without adding a newline. You don't want extra space between positional arguments, so separator argument must be blank. Also, notice the use of Python's raw strings due to backslash characters present in the literal.
When you know the remaining time or task completion percentage, then you're able to show an animated progress bar:
First, you need to calculate how many hashtags to display and how many blank spaces to insert. Next, you erase the line and build the bar from scratch:
from time import sleep def progress(percent=0, width=30): left = width * percent // 100 right = width - left print('\r[', '#' * left, ' ' * right, ']', f' {percent:.0f}%', sep='', end='', flush=True) for i in range(101): progress(i) sleep(0.1)As before, each request for update repaints the entire line.
Note: There's a feature-rich
progressbar2library, along with a few other similar tools, that can show progress in a much more comprehensive way. Making Sounds Withprint()If you're old enough to remember computers with a PC speaker, then you must also remember their distinctive beep sound, often used to indicate hardware problems. They could barely make any more noises than that, yet video games seemed so much better with it.
Today you can still take advantage of this small loudspeaker, but chances are your laptop didn't come with one. In such a case, you can enable terminal bell emulation in your shell, so that a system warning sound is played instead.
Go ahead and type this command to see if your terminal can play a sound:
$ echo -e "\a"This would normally print text, but the
-eflag enables the interpretation of backslash escapes. As you can see, there's a dedicated escape sequence\a, which stands for "alert", that outputs a special bell character . Some terminals make a sound whenever they see it.Similarly, you can print this character in Python. Perhaps in a loop to form some kind of melody. While it's only a single note, you can still vary the length of pauses between consecutive instances. That seems like a perfect toy for Morse code playback!
The rules are the following:
- Letters are encoded with a sequence of dot (·) and dash (–) symbols.
- A dot is one unit of time.
- A dash is three units of time.
- Individual symbols in a letter are spaced one unit of time apart.
- Symbols of two adjacent letters are spaced three units of time apart.
- Symbols of two adjacent words are spaced seven units of time apart.
According to those rules, you could be "printing" an SOS signal indefinitely in the following way:
while True: dot() symbol_space() dot() symbol_space() dot() letter_space() dash() symbol_space() dash() symbol_space() dash() letter_space() dot() symbol_space() dot() symbol_space() dot() word_space()In Python, you can implement it in merely ten lines of code:
from time import sleep speed = 0.1 def signal(duration, symbol): sleep(duration) print(symbol, end='', flush=True) dot = lambda: signal(speed, '·\a') dash = lambda: signal(3*speed, '−\a') symbol_space = lambda: signal(speed, '') letter_space = lambda: signal(3*speed, '') word_space = lambda: signal(7*speed, ' ')Maybe you could even take it one step further and make a command line tool for translating text into Morse code? Either way, I hope you're having fun with this!
Mocking Pythonprint()in Unit TestsNowadays, it's expected that you ship code that meets high quality standards. If you aspire to become a professional, you must learn how to test your code.
Software testing is especially important in dynamically typed languages, such as Python, which don't have a compiler to warn you about obvious mistakes. Defects can make their way to the production environment and remain dormant for a long time, until that one day when a branch of code finally gets executed.
Sure, you have linters , type checkers , and other tools for static code analysis to assist you. But they won't tell you whether your program does what it's supposed to do on the business level.
So, should you be testing
print()? No. After all, it's a built-in function that must have already gone through a comprehensive suite of tests. What you want to test, though, is whether your code is callingprint()at the right time with the expected parameters. That's known as a behavior .You can test behaviors by mocking real objects or functions. In this case, you want to mock
print()to record and verify its invocations.Note: You might have heard the terms: dummy , fake , stub , spy , or mock used interchangeably. Some people make a distinction between them, while others don't.
Martin Fowler explains their differences in a short glossary and collectively calls them test doubles .
Mocking in Python can be done twofold. First, you can take the traditional path of statically-typed languages by employing dependency injection. This may sometimes require you to change the code under test, which isn't always possible if the code is defined in an external library:
def download(url, log=print): log(f'Downloading {url}') # ...This is the same example I used in an earlier section to talk about function composition. It basically allows for substituting
>>>print()with a custom function of the same interface. To check if it prints the right message, you have to intercept it by injecting a mocked function:>>> def mock_print(message): ... mock_print.last_message = message ... >>> download('resource', mock_print) >>> assert 'Downloading resource' == mock_print.last_messageCalling this mock makes it save the last message in an attribute, which you can inspect later, for example in an
assertstatement.In a slightly alternative solution, instead of replacing the entire
>>>print()function with a custom wrapper, you could redirect the standard output to an in-memory file-like stream of characters:>>> def download(url, stream=None): ... print(f'Downloading {url}', file=stream) ... # ... ... >>> import io >>> memory_buffer = io.StringIO() >>> download('app.js', memory_buffer) >>> download('style.css', memory_buffer) >>> memory_buffer.getvalue() 'Downloading app.js\nDownloading style.css\n'This time the function explicitly calls
print(), but it exposes itsfileparameter to the outside world.However, a more Pythonic way of mocking objects takes advantage of the built-in
mockmodule, which uses a technique called monkey patching . This derogatory name stems from it being a "dirty hack" that you can easily shoot yourself in the foot with. It's less elegant than dependency injection but definitely quick and convenient.Note: The
mockmodule got absorbed by the standard library in Python 3, but before that, it was a third-party package. You had to install it separately:$ pip2 install mockOther than that, you referred to it as
mock, whereas in Python 3 it's part of the unit testing module, so you must import fromunittest.mock.What monkey patching does is alter implementation dynamically at runtime. Such a change is visible globally, so it may have unwanted consequences. In practice, however, patching only affects the code for the duration of test execution.
To mock
print()in a test case, you'll typically use the@patchdecorator and specify a target for patching by referring to it with a fully qualified name, that is including the module name:from unittest.mock import patch @patch('builtins.print') def test_print(mock_print): print('not a real print') mock_print.assert_called_with('not a real print')This will automatically create the mock for you and inject it to the test function. However, you need to declare that your test function accepts a mock now. The underlying mock object has lots of useful methods and attributes for verifying behavior.
Did you notice anything peculiar about that code snippet?
Despite injecting a mock to the function, you're not calling it directly, although you could. That injected mock is only used to make assertions afterward and maybe to prepare the context before running the test.
In real life, mocking helps to isolate the code under test by removing dependencies such as a database connection. You rarely call mocks in a test, because that doesn't make much sense. Rather, it's other pieces of code that call your mock indirectly without knowing it.
Here's what that means:
from unittest.mock import patch def greet(name): print(f'Hello, {name}!') @patch('builtins.print') def test_greet(mock_print): greet('John') mock_print.assert_called_with('Hello, John!')The code under test is a function that prints a greeting. Even though it's a fairly simple function, you can't test it easily because it doesn't return a value. It has a side-effect.
To eliminate that side-effect, you need to mock the dependency out. Patching lets you avoid making changes to the original function, which can remain agnostic about
print(). It thinks it's callingprint(), but in reality, it's calling a mock you're in total control of.There are many reasons for testing software. One of them is looking for bugs. When you write tests, you often want to get rid of the
print()function, for example, by mocking it away. Paradoxically, however, that same function can help you find bugs during a related process of debugging you'll read about in the next section.Syntax in Python 2 Show/Hide
print()DebuggingIn this section, you'll take a look at the available tools for debugging in Python, starting from a humble
print()function, through theloggingmodule, to a fully fledged debugger. After reading it, you'll be able to make an educated decision about which of them is the most suitable in a given situation.Note: Debugging is the process of looking for the root causes of bugs or defects in software after they've been discovered, as well as taking steps to fix them.
The term bug has an amusing story about the origin of its name. Tracing
Also known as print debugging or caveman debugging , it's the most basic form of debugging. While a little bit old-fashioned, it's still powerful and has its uses.
The idea is to follow the path of program execution until it stops abruptly, or gives incorrect results, to identify the exact instruction with a problem. You do that by inserting print statements with words that stand out in carefully chosen places.
Take a look at this example, which manifests a rounding error:
>>>>>> def average(numbers): ... print('debug1:', numbers) ... if len(numbers) > 0: ... print('debug2:', sum(numbers)) ... return sum(numbers) / len(numbers) ... >>> 0.1 == average(3*[0.1]) debug1: [0.1, 0.1, 0.1] debug2: 0.30000000000000004 FalseAs you can see, the function doesn't return the expected value of
0.1, but now you know it's because the sum is a little off. Tracing the state of variables at different steps of the algorithm can give you a hint where the issue is.Rounding Error Show/Hide
This method is simple and intuitive and will work in pretty much every programming language out there. Not to mention, it's a great exercise in the learning process.
On the other hand, once you master more advanced techniques, it's hard to go back, because they allow you to find bugs much quicker. Tracing is a laborious manual process, which can let even more errors slip through. The build and deploy cycle takes time. Afterward, you need to remember to meticulously remove all the
print()calls you made without accidentally touching the genuine ones.Besides, it requires you to make changes in the code, which isn't always possible. Maybe you're debugging an application running in a remote web server or want to diagnose a problem in a post-mortem fashion. Sometimes you simply don't have access to the standard output.
That's precisely where logging shines.
LoggingLet's pretend for a minute that you're running an e-commerce website. One day, an angry customer makes a phone call complaining about a failed transaction and saying he lost his money. He claims to have tried purchasing a few items, but in the end, there was some cryptic error that prevented him from finishing that order. Yet, when he checked his bank account, the money was gone.
You apologize sincerely and make a refund, but also don't want this to happen again in the future. How do you debug that? If only you had some trace of what happened, ideally in the form of a chronological list of events with their context.
Whenever you find yourself doing print debugging, consider turning it into permanent log messages. This may help in situations like this, when you need to analyze a problem after it happened, in an environment that you don't have access to.
There are sophisticated tools for log aggregation and searching, but at the most basic level, you can think of logs as text files. Each line conveys detailed information about an event in your system. Usually, it won't contain personally identifying information, though, in some cases, it may be mandated by law.
Here's a breakdown of a typical log record:
[2019-06-14 15:18:34,517][DEBUG][root][MainThread] Customer(id=123) logged outAs you can see, it has a structured form. Apart from a descriptive message, there are a few customizable fields, which provide the context of an event. Here, you have the exact date and time, the log level, the logger name, and the thread name.
Log levels allow you to filter messages quickly to reduce noise. If you're looking for an error, you don't want to see all the warnings or debug messages, for example. It's trivial to disable or enable messages at certain log levels through the configuration, without even touching the code.
With logging, you can keep your debug messages separate from the standard output. All the log messages go to the standard error stream by default, which can conveniently show up in different colors. However, you can redirect log messages to separate files, even for individual modules!
Quite commonly, misconfigured logging can lead to running out of space on the server's disk. To prevent that, you may set up log rotation , which will keep the log files for a specified duration, such as one week, or once they hit a certain size. Nevertheless, it's always a good practice to archive older logs. Some regulations enforce that customer data be kept for as long as five years!
Compared to other programming languages, logging in Python is simpler, because the
loggingmodule is bundled with the standard library. You just import and configure it in as little as two lines of code:import logging logging.basicConfig(level=logging.DEBUG)You can call functions defined at the module level, which are hooked to the root logger , but more the common practice is to obtain a dedicated logger for each of your source files:
logging.debug('hello') # Module-level function logger = logging.getLogger(__name__) logger.debug('hello') # Logger's methodThe advantage of using custom loggers is more fine-grain control. They're usually named after the module they were defined in through the
__name__variable.Note: There's a somewhat related
warningsmodule in Python, which can also log messages to the standard error stream. However, it has a narrower spectrum of applications, mostly in library code, whereas client applications should use theloggingmodule.That said, you can make them work together by calling
logging.captureWarnings(True).One last reason to switch from the
Debuggingprint()function to logging is thread safety. In the upcoming section, you'll see that the former doesn't play well with multiple threads of execution.The truth is that neither tracing nor logging can be considered real debugging. To do actual debugging, you need a debugger tool, which allows you to do the following:
- Step through the code interactively.
- Set breakpoints, including conditional breakpoints.
- Introspect variables in memory.
- Evaluate custom expressions at runtime.
A crude debugger that runs in the terminal, unsurprisingly named
pdbfor "The Python Debugger," is distributed as part of the standard library. This makes it always available, so it may be your only choice for performing remote debugging. Perhaps that's a good reason to get familiar with it.However, it doesn't come with a graphical interface, so using
pdbmay be a bit tricky. If you can't edit the code, you have to run it as a module and pass your script's location:$ python -m pdb my_script.pyOtherwise, you can set up a breakpoint directly in the code, which will pause the execution of your script and drop you into the debugger. The old way of doing this required two steps:
>>>>>> import pdb >>> pdb.set_trace() --Return-- > <stdin>(1)<module>()->None (Pdb)This shows up an interactive prompt, which might look intimidating at first. However, you can still type native Python at this point to examine or modify the state of local variables. Apart from that, there's really only a handful of debugger-specific commands that you want to use for stepping through the code.
Note: It's customary to put the two instructions for spinning up a debugger on a single line. This requires the use of a semicolon, which is rarely found in Python programs:
import pdb; pdb.set_trace()While certainly not Pythonic, it stands out as a reminder to remove it after you're done with debugging.
Since Python 3.7, you can also call the built-in
breakpoint()function, which does the same thing, but in a more compact way and with some additional bells and whistles :def average(numbers): if len(numbers) > 0: breakpoint() # Python 3.7+ return sum(numbers) / len(numbers)You're probably going to use a visual debugger integrated with a code editor for the most part. PyCharm has an excellent debugger, which boasts high performance, but you'll find plenty of alternative IDEs with debuggers, both paid and free of charge.
Debugging isn't the proverbial silver bullet. Sometimes logging or tracing will be a better solution. For example, defects that are hard to reproduce, such as race conditions , often result from temporal coupling. When you stop at a breakpoint, that little pause in program execution may mask the problem. It's kind of like the Heisenberg principle : you can't measure and observe a bug at the same time.
These methods aren't mutually exclusive. They complement each other.
Thread-Safe PrintingI briefly touched upon the thread safety issue before, recommending
loggingover theprint()function. If you're still reading this, then you must be comfortable with the concept of threads .Thread safety means that a piece of code can be safely shared between multiple threads of execution. The simplest strategy for ensuring thread-safety is by sharing immutable objects only. If threads can't modify an object's state, then there's no risk of breaking its consistency.
Another method takes advantage of local memory , which makes each thread receive its own copy of the same object. That way, other threads can't see the changes made to it in the current thread.
But that doesn't solve the problem, does it? You often want your threads to cooperate by being able to mutate a shared resource. The most common way of synchronizing concurrent access to such a resource is by locking it. This gives exclusive write access to one or sometimes a few threads at a time.
However, locking is expensive and reduces concurrent throughput, so other means for controlling access have been invented, such as atomic variables or the compare-and-swap algorithm.
Printing isn't thread-safe in Python. The
print()function holds a reference to the standard output, which is a shared global variable. In theory, because there's no locking, a context switch could happen during a call tosys.stdout.write(), intertwining bits of text from multipleprint()calls.Note: A context switch means that one thread halts its execution, either voluntarily or not, so that another one can take over. This might happen at any moment, even in the middle of a function call.
In practice, however, that doesn't happen. No matter how hard you try, writing to the standard output seems to be atomic. The only problem that you may sometimes observe is with messed up line breaks:
[Thread-3 A][Thread-2 A][Thread-1 A] [Thread-3 B][Thread-1 B] [Thread-1 C][Thread-3 C] [Thread-2 B] [Thread-2 C]To simulate this, you can increase the likelihood of a context switch by making the underlying
.write()method go to sleep for a random amount of time. How? By mocking it, which you already know about from an earlier section:import sys from time import sleep from random import random from threading import current_thread, Thread from unittest.mock import patch write = sys.stdout.write def slow_write(text): sleep(random()) write(text) def task(): thread_name = current_thread().name for letter in 'ABC': print(f'[{thread_name} {letter}]') with patch('sys.stdout') as mock_stdout: mock_stdout.write = slow_write for _ in range(3): Thread(target=task).start()First, you need to store the original
.write()method in a variable, which you'll delegate to later. Then you provide your fake implementation, which will take up to one second to execute. Each thread will make a fewprint()calls with its name and a letter: A, B, and C.If you read the mocking section before, then you may already have an idea of why printing misbehaves like that. Nonetheless, to make it crystal clear, you can capture values fed into your
slow_write()function. You'll notice that you get a slightly different sequence each time:[ '[Thread-3 A]', '[Thread-2 A]', '[Thread-1 A]', '\n', '\n', '[Thread-3 B]', (...) ]Even though
sys.stdout.write()itself is an atomic operation, a single call to theprint()function can yield more than one write. For example, line breaks are written separately from the rest of the text, and context switching takes place between those writes.Note: The atomic nature of the standard output in Python is a byproduct of the Global Interpreter Lock , which applies locking around bytecode instructions. Be aware, however, that many interpreter flavors don't have the GIL, where multi-threaded printing requires explicit locking.
You can make the newline character become an integral part of the message by handling it manually:
print(f'[{thread_name} {letter}]\n', end='')This will fix the output:
[Thread-2 A] [Thread-1 A] [Thread-3 A] [Thread-1 B] [Thread-3 B] [Thread-2 B] [Thread-1 C] [Thread-2 C] [Thread-3 C]Notice, however, that the
print()function still keeps making a separate call for the empty suffix, which translates to uselesssys.stdout.write('')instruction:[ '[Thread-2 A]\n', '[Thread-1 A]\n', '[Thread-3 A]\n', '', '', '', '[Thread-1 B]\n', (...) ]A truly thread-safe version of the
print()function could look like this:import threading lock = threading.Lock() def thread_safe_print(*args, **kwargs): with lock: print(*args, **kwargs)You can put that function in a module and import it elsewhere:
from thread_safe_print import thread_safe_print def task(): thread_name = current_thread().name for letter in 'ABC': thread_safe_print(f'[{thread_name} {letter}]')Now, despite making two writes per each
print()request, only one thread is allowed to interact with the stream, while the rest must wait:[ # Lock acquired by Thread-3 '[Thread-3 A]', '\n', # Lock released by Thread-3 # Lock acquired by Thread-1 '[Thread-1 B]', '\n', # Lock released by Thread-1 (...) ]I added comments to indicate how the lock is limiting access to the shared resource.
Note: Even in single-threaded code, you might get caught up in a similar situation. Specifically, when you're printing to the standard output and the standard error streams at the same time. Unless you redirect one or both of them to separate files, they'll both share a single terminal window.
Conversely, the
>>>loggingmodule is thread-safe by design, which is reflected by its ability to display thread names in the formatted message:>>> import logging >>> logging.basicConfig(format='%(threadName)s %(message)s') >>> logging.error('hello') MainThread helloIt's another reason why you might not want to use the
Python Print Counterpartsprint()function all the time.By now, you know a lot of what there is to know about
Built-Inprint()! The subject, however, wouldn't be complete without talking about its counterparts a little bit. Whileprint()is about the output, there are functions and libraries for the input.Python comes with a built-in function for accepting input from the user, predictably called
>>>input(). It accepts data from the standard input stream, which is usually the keyboard:>>> name = input('Enter your name: ') Enter your name: jdoe >>> print(name) jdoeThe function always returns a string, so you might need to parse it accordingly:
try: age = int(input('How old are you? ')) except ValueError: passThe prompt parameter is completely optional, so nothing will show if you skip it, but the function will still work:
>>>>>> x = input() hello world >>> print(x) hello worldNevertheless, throwing in a descriptive call to action makes the user experience so much better.
Note: To read from the standard input in Python 2, you have to call
raw_input()instead, which is yet another built-in. Unfortunately, there's also a misleadingly namedinput()function, which does a slightly different thing.In fact, it also takes the input from the standard stream, but then it tries to evaluate it as if it was Python code. Because that's a potential security vulnerability , this function was completely removed from Python 3, while
raw_input()got renamed toinput().Here's a quick comparison of the available functions and what they do:
Python 2 Python 3 raw_input()input()input()eval(input())As you can tell, it's still possible to simulate the old behavior in Python 3.
Asking the user for a password with
>>>input()is a bad idea because it'll show up in plaintext as they're typing it. In this case, you should be using thegetpass()function instead, which masks typed characters. This function is defined in a module under the same name, which is also available in the standard library:>>> from getpass import getpass >>> password = getpass() Password: >>> print(password) s3cretThe
>>>getpassmodule has another function for getting the user's name from an environment variable:>>> from getpass import getuser >>> getuser() 'jdoe'Python's built-in functions for handling the standard input are quite limited. At the same time, there are plenty of third-party packages, which offer much more sophisticated tools.
Third-PartyThere are external Python packages out there that allow for building complex graphical interfaces specifically to collect data from the user. Some of their features include:
- Advanced formatting and styling
- Automated parsing, validation, and sanitization of user data
- A declarative style of defining layouts
- Interactive autocompletion
- Mouse support
- Predefined widgets such as checklists or menus
- Searchable history of typed commands
- Syntax highlighting
Demonstrating such tools is outside of the scope of this article, but you may want to try them out. I personally got to know about some of those through the Python Bytes Podcast . Here they are:
Nonetheless, it's worth mentioning a command line tool called
rlwrapthat adds powerful line editing capabilities to your Python scripts for free. You don't have to do anything for it to work!Let's assume you wrote a command-line interface that understands three instructions, including one for adding numbers:
print('Type "help", "exit", "add a [b [c ...]]"') while True: command, *arguments = input('~ ').split(' ') if len(command) > 0: if command.lower() == 'exit': break elif command.lower() == 'help': print('This is help.') elif command.lower() == 'add': print(sum(map(int, arguments))) else: print('Unknown command')At first glance, it seems like a typical prompt when you run it:
$ python calculator.py Type "help", "exit", "add a [b [c ...]]" ~ add 1 2 3 4 10 ~ aad 2 3 Unknown command ~ exit $But as soon as you make a mistake and want to fix it, you'll see that none of the function keys work as expected. Hitting the Left arrow, for example, results in this instead of moving the cursor back:
$ python calculator.py Type "help", "exit", "add a [b [c ...]]" ~ aad^[[DNow, you can wrap the same script with the
rlwrapcommand. Not only will you get the arrow keys working, but you'll also be able to search through the persistent history of your custom commands, use autocompletion, and edit the line with shortcuts:$ rlwrap python calculator.py Type "help", "exit", "add a [b [c ...]]" (reverse-i-search)`a': add 1 2 3 4Isn't that great?
ConclusionYou're now armed with a body of knowledge about the
print()function in Python, as well as many surrounding topics. You have a deep understanding of what it is and how it works, involving all of its key elements. Numerous examples gave you insight into its evolution from Python 2.Apart from that, you learned how to:
- Avoid common mistakes with
print()in Python- Deal with newlines, character encodings and buffering
- Write text to files
- Mock the
print()function in unit tests- Build advanced user interfaces in the terminal
Now that you know all this, you can make interactive programs that communicate with users or produce data in popular file formats. You're able to quickly diagnose problems in your code and protect yourself from them. Last but not least, you know how to implement the classic snake game.
If you're still thirsty for more information, have questions, or simply would like to share your thoughts, then feel free to reach out in the comments section below.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: The Python print() Function: Go Beyond the Basics
🐍 Python Tricks 💌
Get a short & sweet Python Trick delivered to your inbox every couple of days. No spam ever. Unsubscribe any time. Curated by the Real Python team.
Send Me Python Tricks "
About Bartosz Zaczyński

Bartosz is a bootcamp instructor, author, and polyglot programmer in love with Python. He helps his students get into software engineering by sharing over a decade of commercial experience in the IT industry.
" More about Bartosz
Each tutorial at Real Python is created by a team of developers so that it meets our high quality standards. The team members who worked on this tutorial are:

Aldren

Joanna

Mike
Master Real-World Python Skills
With Unlimited Access to Real Python
Join us and get access to hundreds of tutorials, hands-on video courses, and a community of expert Pythonistas:
What Do You Think?
Tweet Share EmailReal Python Comment Policy: The most useful comments are those written with the goal of learning from or helping out other readers -- after reading the whole article and all the earlier comments. Complaints and insults generally won't make the cut here.
What's your #1 takeaway or favorite thing you learned? How are you going to put your newfound skills to use? Leave a comment below and let us know.
Dec 02, 2019 | linuxize.com
•When writing Python scripts, you may want to perform a certain action only if a file or directory exists or not. For example, you may want to read or write data to a configuration file or to create the file only if it already doesn't exist.
In Python, there are many different ways to check whether a file exists and determine the type of the file.
This tutorial shows three different techniques about how to check for a file's existence.
Check if File ExistsThe simplest way to check whether a file exists is to try to open the file. This approach doesn't require importing any module and works with both Python 2 and 3. Use this method if you want to open the file and perform some action.
The following snippet is using a simple try-except block. We are trying to open the file
filename.txt, and if the file doesn't exist, anIOErrorexception is raised and "File not accessible" message is printed:https://9f52ccb5806fd37a4e75782fd0787d35.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html
try: f = open("filename.txt") # Do something with the file except IOError: print("File not accessible") finally: f.close()CopyIf you are using Python 3, you can also use
FileNotFoundErrorinstead ofIOErrorexception.withkeyword, which makes sure the file is properly closed after the file operations are completed, even if an exception is raised during the operation. It also makes your code shorter because you do not need to close the file using theclosefunction.The following code is equivalent to the previous example:
try: with open('/etc/hosts') as f: print(f.readlines()) # Do something with the file except IOError: print("File not accessible")CopyIn the examples above, we were using the try-except block and opening the file to avoid the race condition. Race conditions happen when you have more than one process accessing the same file.
For example, when you check the existence of a file another process may create, delete, or block the file in the timeframe between the check and the file opening. This may cause your code to break.
Check if File Exists using the os.path ModuleThe
os.pathmodule provides some useful functions for working with pathnames. The module is available for both Python 2 and 3.In the context of this tutorial, the most important functions are:
os.path.exists(path)- Returns true if thepathis a file, directory, or a valid symlink.os.path.isfile(path)- Returns true if thepathis a regular file or a symlink to a file.os.path.isdir(path)- Returns true if thepathis a directory or a symlink to a directory.The following
ifstatement checks whether the filefilename.txtexist:import os.path if os.path.isfile('filename.txt'): print ("File exist") else: print ("File not exist")CopyUse this method when you need to check whether the file exists or not before performing an action on the file. For example copying or deleting a file .
If you want to open and modify the file prefer to use the previous method.
Check if File Exists using the pathlib ModuleThe
pathlibmodule is available in Python 3.4 and above. This module provides an object-oriented interface for working with filesystem paths for different operating systems.https://9f52ccb5806fd37a4e75782fd0787d35.safeframe.googlesyndication.com/safeframe/1-0-37/html/container.html
filename.txtexist:from pathlib import Path if Path('filename.txt').is_file(): print ("File exist") else: print ("File not exist")Copy
is_filereturns true if thepathis a regular file or a symlink to a file. To check for a directory existence use theis_dirmethod.The main difference between
pathlibandos.pathis thatpathliballows you to work with the paths asPathobjects with relevant methods and attributes instead of normalstrobjects.If you want to use this module in Python 2 you can install it with pip :
pip install pathlib2ConclusionIn this guide, we have shown you how to check if a file or directory exists using Python.
Aug 10, 2020 | www.journaldev.com
here are three ways to read data from stdin in Python.
- sys.stdin
- input() built-in function
- fileinput.input() function
Table of Contents [ hide ]
1. Using sys.stdin to read from standard input
- 1 1. Using sys.stdin to read from standard input
- 2 2. Using input() function to read stdin data
- 3 3. Reading Standard Input using fileinput module
Python sys module stdin is used by the interpreter for standard input. Internally, it calls the input() function. The input string is appended with a newline character (\n) in the end. So, you can use the rstrip() function to remove it.
Here is a simple program to read user messages from the standard input and process it. The program will terminate when the user enters "Exit" message.
import sys for line in sys.stdin: if 'Exit' == line.rstrip(): break print(f'Processing Message from sys.stdin *****{line}*****') print("Done")Output:
Hi Processing Message from sys.stdin *****Hi ***** Hello Processing Message from sys.stdin *****Hello ***** Exit Done2. Using input() function to read stdin dataWe can also use Python input() function to read the standard input data. We can also prompt a message to the user.
Here is a simple example to read and process the standard input message in the infinite loop, unless the user enters the Exit message.
while True: data = input("Please enter the message:\n") if 'Exit' == data: break print(f'Processing Message from input() *****{data}*****') print("Done")
Jan 01, 2011 | stackoverflow.com
Ask Question Asked 9 years, 4 months ago Active 1 month ago Viewed 170k times
https://tpc.googlesyndication.com/safeframe/1-0-37/html/container.html Report this ad
Charles Holbrow ,
I want to read a .csv file in python.
- I don't know if the file exists.
- My current solution is below. It feels sloppy to me because the two separate exception tests are awkwardly juxtaposed.
Is there a prettier way to do it?
import csv fName = "aFile.csv" try: with open(fName, 'rb') as f: reader = csv.reader(f) for row in reader: pass #do stuff here except IOError: print "Could not read file:", fNamepink spikyhairman ,
If a non-existing file is not an error case but a likely circumstance then checking for and handling its absence/non-readability explicitly before (and additionally to) thetrymight be worth it. This can be done withos.path.exists(file)andos.access(file, os.R_OK)respectively. Such check can never be free from a race condition though but vanishing files are seldom a normal circumstance ;) – stefanct Apr 8 '17 at 14:50jscs , 2011-04-11 20:55:54
I guess I misunderstood what was being asked. Re-re-reading, it looks like Tim's answer is what you want. Let me just add this, however: if you want to catch an exception from
open, thenopenhas to be wrapped in atry. If the call toopenis in the header of awith, then thewithhas to be in atryto catch the exception. There's no way around that.So the answer is either: "Tim's way" or "No, you're doing it correctly.".
Previous unhelpful answer to which all the comments refer:
import os if os.path.exists(fName): with open(fName, 'rb') as f: try: # do stuff except : # whatever reader errors you care about # handle errorGabe ,
Just because a file exists doesn't mean that you can read it! – Gabe Apr 11 '11 at 20:59Tim Pietzcker , 2011-04-11 21:01:58
How about this:
try: f = open(fname, 'rb') except OSError: print "Could not open/read file:", fname sys.exit() with f: reader = csv.reader(f) for row in reader: pass #do stuff hereTim Pietzcker ,
The only problem with this is that the file is opened outside of thewithblock. So if an exception occurs between thetryblock containing the call toopenand thewithstatement, the file doesn't get closed. In this case, where things are very simple, it's not an obvious issue, but it could still pose a danger when refactoring or otherwise modifying the code. That being said, I don't think there's a better way to do this (other than the original version). – intuited Apr 11 '11 at 21:12edW , 2016-02-25 20:38:35
Here is a read/write example. The with statements insure the close() statement will be called by the file object regardless of whether an exception is thrown. http://effbot.org/zone/python-with-statement.htm
import sys fIn = 'symbolsIn.csv' fOut = 'symbolsOut.csv' try: with open(fIn, 'r') as f: file_content = f.read() print "read file " + fIn if not file_content: print "no data in file " + fIn file_content = "name,phone,address\n" with open(fOut, 'w') as dest: dest.write(file_content) print "wrote file " + fOut except IOError as e: print "I/O error({0}): {1}".format(e.errno, e.strerror) except: #handle other exceptions such as attribute errors print "Unexpected error:", sys.exc_info()[0] print "done"> ,
add a comment> ,
fname = 'filenotfound.txt' try: f = open(fname, 'rb') except FileNotFoundError: print("file {} does not exist".format(fname)) file filenotfound.txt does not existexception FileNotFoundError Raised when a file or directory is requested but doesn't exist. Corresponds to errno ENOENT.
https://docs.python.org/3/library/exceptions.html
This exception does not exist in Python 2.
os.path. islink ( path )Aug 10, 2020 | linuxize.com
The
os.pathmodule provides some useful functions for working with pathnames. The module is available for both Python 2 and 3.In the context of this tutorial, the most important functions are:
os.path.exists(path)- Returns true if thepathis a file, directory, or a valid symlink.os.path.isfile(path)- Returns true if thepathis a regular file or a symlink to a file.os.path.isdir(path)- Returns true if thepathis a directory or a symlink to a directory.The following
ifstatement checks whether the filefilename.txtexist:
Aug 10, 2020 | docs.python.org
open( file , mode='r' , buffering=-1 , encoding=None , errors=None , newline=None , closefd=True , opener=None )Open file and return a corresponding file object . If the file cannot be opened, an
OSErroris raised. See Reading and Writing Files for more examples of how to use this function.file is a path-like object giving the pathname (absolute or relative to the current working directory) of the file to be opened or an integer file descriptor of the file to be wrapped. (If a file descriptor is given, it is closed when the returned I/O object is closed, unless closefd is set to
False.)mode is an optional string that specifies the mode in which the file is opened. It defaults to
'r'which means open for reading in text mode. Other common values are'w'for writing (truncating the file if it already exists),'x'for exclusive creation and'a'for appending (which on some Unix systems, means that all writes append to the end of the file regardless of the current seek position). In text mode, if encoding is not specified the encoding used is platform dependent:locale.getpreferredencoding(False)is called to get the current locale encoding. (For reading and writing raw bytes use binary mode and leave encoding unspecified.) The available modes are:
Character
Meaning
'r'open for reading (default)
'w'open for writing, truncating the file first
'x'open for exclusive creation, failing if the file already exists
'a'open for writing, appending to the end of the file if it exists
'b'binary mode
't'text mode (default)
'+'open for updating (reading and writing)
The default mode is
'r'(open for reading text, synonym of'rt'). Modes'w+'and'w+b'open and truncate the file. Modes'r+'and'r+b'open the file with no truncation.As mentioned in the Overview , Python distinguishes between binary and text I/O. Files opened in binary mode (including
'b'in the mode argument) return contents asbytesobjects without any decoding. In text mode (the default, or when't'is included in the mode argument), the contents of the file are returned asstr, the bytes having been first decoded using a platform-dependent encoding or using the specified encoding if given.There is an additional mode character permitted,
'U', which no longer has any effect, and is considered deprecated. It previously enabled universal newlines in text mode, which became the default behaviour in Python 3.0. Refer to the documentation of the newline parameter for further details.Note
Python doesn't depend on the underlying operating system's notion of text files; all the processing is done by Python itself, and is therefore platform-independent.
buffering is an optional integer used to set the buffering policy. Pass 0 to switch buffering off (only allowed in binary mode), 1 to select line buffering (only usable in text mode), and an integer > 1 to indicate the size in bytes of a fixed-size chunk buffer. When no buffering argument is given, the default buffering policy works as follows:
Binary files are buffered in fixed-size chunks; the size of the buffer is chosen using a heuristic trying to determine the underlying device's "block size" and falling back on
io.DEFAULT_BUFFER_SIZE. On many systems, the buffer will typically be 4096 or 8192 bytes long."Interactive" text files (files for which
isatty()returnsTrue) use line buffering. Other text files use the policy described above for binary files.encoding is the name of the encoding used to decode or encode the file. This should only be used in text mode. The default encoding is platform dependent (whatever
locale.getpreferredencoding()returns), but any text encoding supported by Python can be used. See thecodecsmodule for the list of supported encodings.errors is an optional string that specifies how encoding and decoding errors are to be handled -- this cannot be used in binary mode. A variety of standard error handlers are available (listed under Error Handlers ), though any error handling name that has been registered with
codecs.register_error()is also valid. The standard names include:
'strict'to raise aValueErrorexception if there is an encoding error. The default value ofNonehas the same effect.
'ignore'ignores errors. Note that ignoring encoding errors can lead to data loss.
'replace'causes a replacement marker (such as'?') to be inserted where there is malformed data.
'surrogateescape'will represent any incorrect bytes as code points in the Unicode Private Use Area ranging from U+DC80 to U+DCFF. These private code points will then be turned back into the same bytes when thesurrogateescapeerror handler is used when writing data. This is useful for processing files in an unknown encoding.
'xmlcharrefreplace'is only supported when writing to a file. Characters not supported by the encoding are replaced with the appropriate XML character reference&#nnn;.
'backslashreplace'replaces malformed data by Python's backslashed escape sequences.
'namereplace'(also only supported when writing) replaces unsupported characters with\N{...}escape sequences.newline controls how universal newlines mode works (it only applies to text mode). It can be
None,'','\n','\r', and'\r\n'. It works as follows:
When reading input from the stream, if newline is
None, universal newlines mode is enabled. Lines in the input can end in'\n','\r', or'\r\n', and these are translated into'\n'before being returned to the caller. If it is'', universal newlines mode is enabled, but line endings are returned to the caller untranslated. If it has any of the other legal values, input lines are only terminated by the given string, and the line ending is returned to the caller untranslated.When writing output to the stream, if newline is
None, any'\n'characters written are translated to the system default line separator,os.linesep. If newline is''or'\n', no translation takes place. If newline is any of the other legal values, any'\n'characters written are translated to the given string.If closefd is
Falseand a file descriptor rather than a filename was given, the underlying file descriptor will be kept open when the file is closed. If a filename is given closefd must beTrue(the default) otherwise an error will be raised.A custom opener can be used by passing a callable as opener . The underlying file descriptor for the file object is then obtained by calling opener with ( file , flags ). opener must return an open file descriptor (passing
os.openas opener results in functionality similar to passingNone).The newly created file is non-inheritable .
The following example uses the dir_fd parameter of the
>>>os.open()function to open a file relative to a given directory:>>> import os >>> dir_fd = os.open('somedir', os.O_RDONLY) >>> def opener(path, flags): ... return os.open(path, flags, dir_fd=dir_fd) ... >>> with open('spamspam.txt', 'w', opener=opener) as f: ... print('This will be written to somedir/spamspam.txt', file=f) ... >>> os.close(dir_fd) # don't leak a file descriptorThe type of file object returned by the
open()function depends on the mode. Whenopen()is used to open a file in a text mode ('w','r','wt','rt', etc.), it returns a subclass ofio.TextIOBase(specificallyio.TextIOWrapper). When used to open a file in a binary mode with buffering, the returned class is a subclass ofio.BufferedIOBase. The exact class varies: in read binary mode, it returns anio.BufferedReader; in write binary and append binary modes, it returns anio.BufferedWriter, and in read/write mode, it returns anio.BufferedRandom. When buffering is disabled, the raw stream, a subclass ofio.RawIOBase,io.FileIO, is returned.See also the file handling modules, such as,
fileinput,io(whereopen()is declared),os,os.path,tempfile, andshutil.Raises an auditing event
openwith argumentsfile,mode,flags.The
modeandflagsarguments may have been modified or inferred from the original call.Changed in version 3.3:
The opener parameter was added.
The
'x'mode was added.
FileExistsErroris now raised if the file opened in exclusive creation mode ('x') already exists.Changed in version 3.4:builtin_functions__python_
The file is now non-inheritable.
Deprecated since version 3.4, will be removed in version 3.9: The
'U'mode.Changed in version 3.5:
If the system call is interrupted and the signal handler does not raise an exception, the function now retries the system call instead of raising an
InterruptedErrorexception (see PEP 475 for the rationale).The
'namereplace'error handler was added.Changed in version 3.6:
Support added to accept objects implementing
os.PathLike.On Windows, opening a console buffer may return a subclass of
io.RawIOBaseother thanio.FileIO.
Jan 01, 2012 | stackoverflow.com
Ask Question Asked 8 years, 5 months ago Active 1 year, 5 months ago Viewed 570k times
> ,
I'm looking at how to do file input and output in Python. I've written the following code to read a list of names (one per line) from a file into another file while checking a name against the names in the file and appending text to the occurrences in the file. The code works. Could it be done better?I'd wanted to use the
with open(...statement for both input and output files but can't see how they could be in the same block meaning I'd need to store the names in a temporary location.def filter(txt, oldfile, newfile): '''\ Read a list of names from a file line by line into an output file. If a line begins with a particular name, insert a string of text after the name before appending the line to the output file. ''' outfile = open(newfile, 'w') with open(oldfile, 'r', encoding='utf-8') as infile: for line in infile: if line.startswith(txt): line = line[0:len(txt)] + ' - Truly a great person!\n' outfile.write(line) outfile.close() return # Do I gain anything by including this? # input the name you want to check against text = input('Please enter the name of a great person: ') letsgo = filter(text,'Spanish', 'Spanish2')Disnami ,
edited Jan 24 '17 at 14:57 marcospereira 11.1k 3 3 gold badges 40 40 silver badges 49 49 bronze badges asked Feb 14 '12 at 19:26 Disnami 2,263 2 2 gold badges 12 12 silver badges 15 15 bronze badgesTom ,
"meaning I'd need to store the names in a temporary location"? Can you explain what you mean by this? – S.Lott Feb 14 '12 at 19:58> ,
Python allows putting multipleopen()statements in a singlewith. You comma-separate them. Your code would then be:def filter(txt, oldfile, newfile): '''\ Read a list of names from a file line by line into an output file. If a line begins with a particular name, insert a string of text after the name before appending the line to the output file. ''' with open(newfile, 'w') as outfile, open(oldfile, 'r', encoding='utf-8') as infile: for line in infile: if line.startswith(txt): line = line[0:len(txt)] + ' - Truly a great person!\n' outfile.write(line) # input the name you want to check against text = input('Please enter the name of a great person: ') letsgo = filter(text,'Spanish', 'Spanish2')And no, you don't gain anything by putting an explicit
returnat the end of your function. You can usereturnto exit early, but you had it at the end, and the function will exit without it. (Of course with functions that return a value, you use thereturnto specify the value to return.)Using multiple
open()items withwithwas not supported in Python 2.5 when thewithstatement was introduced, or in Python 2.6, but it is supported in Python 2.7 and Python 3.1 or newer.If you are writing code that must run in Python 2.5, 2.6 or 3.0, nest the
withstatements as the other answers suggested or usecontextlib.nested.steveha , 2012-02-14 19:33:29
edited Oct 28 '13 at 21:40 answered Feb 14 '12 at 19:33 steveha 63.8k 16 16 gold badges 80 80 silver badges 109 109 bronze badges> ,
add a comment> ,
Use nested blocks like this,with open(newfile, 'w') as outfile: with open(oldfile, 'r', encoding='utf-8') as infile: # your logic goes right here
Nov 21, 2019 | stackoverflow.com
Ask Question Asked 8 years, 7 months ago Active 3 months ago Viewed 762k times 1239 170
Steve Howard ,Jul 31, 2013 at 14:05
There are several ways to write to stderr:# Note: this first one does not work in Python 3 print >> sys.stderr, "spam" sys.stderr.write("spam\n") os.write(2, b"spam\n") from __future__ import print_function print("spam", file=sys.stderr)That seems to contradict zen of Python #13 † , so what's the difference here and are there any advantages or disadvantages to one way or the other? Which way should be used?
† There should be one -- and preferably only one -- obvious way to do it.
Dan H ,May 16, 2017 at 22:51
I found this to be the only one short + flexible + portable + readable:from __future__ import print_function import sys def eprint(*args, **kwargs): print(*args, file=sys.stderr, **kwargs)The function
eprintcan be used in the same way as the standard>>> print("Test") Test >>> eprint("Test") Test >>> eprint("foo", "bar", "baz", sep="---") foo---bar---bazDheeraj V.S. ,Jan 13, 2013 at 3:18
import sys sys.stderr.write()Is my choice, just more readable and saying exactly what you intend to do and portable across versions.
Edit: being 'pythonic' is a third thought to me over readability and performance... with these two things in mind, with python 80% of your code will be pythonic. list comprehension being the 'big thing' that isn't used as often (readability).
Michael Scheper ,Aug 26 at 17:01
print >> sys.stderris gone in Python3. http://docs.python.org/3.0/whatsnew/3.0.html says:Old: print >>sys.stderr, "fatal error" New: print("fatal error", file=sys.stderr)For many of us, it feels somewhat unnatural to relegate the destination to the end of the command. The alternative
sys.stderr.write("fatal error\n")looks more object oriented, and elegantly goes from the generic to the specific. But note that
writeis not a 1:1 replacement forluketparkinson ,Apr 23, 2013 at 10:04
For Python 2 my choice is:print >> sys.stderr, 'spam'Because you can simply print lists/dicts etc. without convert it to string.print >> sys.stderr, {'spam': 'spam'}instead of:sys.stderr.write(str({'spam': 'spam'}))Mnebuerquo ,Jul 11 at 9:44
Nobody's mentionedloggingyet, but logging was created specifically to communicate error messages. By default it is set up to write to stderr. This script:# foo.py import logging logging.basicConfig(format='%(message)s') logging.warning('I print to stderr by default') logging.info('For this you must change the level and add a handler.') print('hello world')has the following result when run on the command line:
$ python3 foo.py > bar.txt I print to stderr by default(and bar.txt contains the 'hello world')
(Note,
logging.warnhas been deprecated , uselogging.warninginstead)porgarmingduod ,Apr 15, 2016 at 1:37
I would say that your first approach:print >> sys.stderr, 'spam'is the "One . . . obvious way to do it" The others don't satisfy rule #1 ("Beautiful is better than ugly.")
Rebs ,Dec 30, 2013 at 2:26
I did the following using Python 3:from sys import stderr def print_err(*args, **kwargs): print(*args, file=stderr, **kwargs)So now I'm able to add keyword arguments, for example, to avoid carriage return:
print_err("Error: end of the file reached. The word ", end='') print_err(word, "was not found")AMS ,Nov 5, 2015 at 14:15
This will mimic the standard print function but output on stderrdef print_err(*args): sys.stderr.write(' '.join(map(str,args)) + '\n')Agi Hammerthief ,Dec 31, 2015 at 22:58
EDIT In hind-sight, I think the potential confusion with changing sys.stderr and not seeing the behaviour updated makes this answer not as good as just using a simple function as others have pointed out.Using partial only saves you 1 line of code. The potential confusion is not worth saving 1 line of code.
original
To make it even easier, here's a version that uses 'partial', which is a big help in wrapping functions.
from __future__ import print_function import sys from functools import partial error = partial(print, file=sys.stderr)You then use it like so
error('An error occured!')You can check that it's printing to stderr and not stdout by doing the following (over-riding code from http://coreygoldberg.blogspot.com.au/2009/05/python-redirect-or-turn-off-stdout-and.html ):
# over-ride stderr to prove that this function works. class NullDevice(): def write(self, s): pass sys.stderr = NullDevice() # we must import print error AFTER we've removed the null device because # it has been assigned and will not be re-evaluated. # assume error function is in print_error.py from print_error import error # no message should be printed error("You won't see this error!")The downside to this is partial assigns the value of sys.stderr to the wrapped function at the time of creation. Which means, if you redirect stderr later it won't affect this function. If you plan to redirect stderr, then use the **kwargs method mentioned by aaguirre on this page.
Florian Castellane ,Jan 8 at 6:57
In Python 3, one can just use print():print(*objects, sep=' ', end='\n', file=sys.stdout, flush=False)almost out of the box:
import sys print("Hello, world!", file=sys.stderr)or:
from sys import stderr print("Hello, world!", file=stderr)This is straightforward and does not need to include anything besides
sys.stderr.phoenix ,Mar 2, 2016 at 23:57
The same applies to stdout:print 'spam' sys.stdout.write('spam\n')As stated in the other answers, print offers a pretty interface that is often more convenient (e.g. for printing debug information), while write is faster and can also be more convenient when you have to format the output exactly in certain way. I would consider maintainability as well:
- You may later decide to switch between stdout/stderr and a regular file.
- print() syntax has changed in Python 3, so if you need to support both versions, write() might be better.
user1928764 ,Feb 10, 2016 at 2:29
I am working in python 3.4.3. I am cutting out a little typing that shows how I got here:[18:19 jsilverman@JSILVERMAN-LT7 pexpect]$ python3 >>> import sys >>> print("testing", file=sys.stderr) testing >>> [18:19 jsilverman@JSILVERMAN-LT7 pexpect]$Did it work? Try redirecting stderr to a file and see what happens:
[18:22 jsilverman@JSILVERMAN-LT7 pexpect]$ python3 2> /tmp/test.txt >>> import sys >>> print("testing", file=sys.stderr) >>> [18:22 jsilverman@JSILVERMAN-LT7 pexpect]$ [18:22 jsilverman@JSILVERMAN-LT7 pexpect]$ cat /tmp/test.txt Python 3.4.3 (default, May 5 2015, 17:58:45) [GCC 4.9.2] on cygwin Type "help", "copyright", "credits" or "license" for more information. testing [18:22 jsilverman@JSILVERMAN-LT7 pexpect]$Well, aside from the fact that the little introduction that python gives you has been slurped into stderr (where else would it go?), it works.
hamish ,Oct 8, 2017 at 16:18
If you do a simple test:import time import sys def run1(runs): x = 0 cur = time.time() while x < runs: x += 1 print >> sys.stderr, 'X' elapsed = (time.time()-cur) return elapsed def run2(runs): x = 0 cur = time.time() while x < runs: x += 1 sys.stderr.write('X\n') sys.stderr.flush() elapsed = (time.time()-cur) return elapsed def compare(runs): sum1, sum2 = 0, 0 x = 0 while x < runs: x += 1 sum1 += run1(runs) sum2 += run2(runs) return sum1, sum2 if __name__ == '__main__': s1, s2 = compare(1000) print "Using (print >> sys.stderr, 'X'): %s" %(s1) print "Using (sys.stderr.write('X'),sys.stderr.flush()):%s" %(s2) print "Ratio: %f" %(float(s1) / float(s2))You will find that sys.stderr.write() is consistently 1.81 times faster!
Vinay Kumar ,Jan 30, 2018 at 13:17
Answer to the question is : There are different way to print stderr in python but that depends on 1.) which python version we are using 2.) what exact output we want.
The differnce between print and stderr's write function: stderr : stderr (standard error) is pipe that is built into every UNIX/Linux system, when your program crashes and prints out debugging information (like a traceback in Python), it goes to the stderr pipe.
print : print is a wrapper that formats the inputs (the input is the space between argument and the newline at the end) and it then calls the write function of a given object, the given object by default is sys.stdout, but we can pass a file i.e we can print the input in a file also.
Python2: If we are using python2 then
>>> import sys >>> print "hi" hi >>> print("hi") hi >>> print >> sys.stderr.write("hi") hiPython2 trailing comma has in Python3 become a parameter, so if we use trailing commas to avoid the newline after a print, this will in Python3 look like print('Text to print', end=' ') which is a syntax error under Python2.
http://python3porting.com/noconv.html
If we check same above sceario in python3:
>>> import sys >>> print("hi") hiUnder Python 2.6 there is a future import to make print into a function. So to avoid any syntax errors and other differences we should start any file where we use print() with from future import print_function. The future import only works under Python 2.6 and later, so for Python 2.5 and earlier you have two options. You can either convert the more complex print to something simpler, or you can use a separate print function that works under both Python2 and Python3.
>>> from __future__ import print_function >>> >>> def printex(*args, **kwargs): ... print(*args, file=sys.stderr, **kwargs) ... >>> printex("hii") hii >>>Case: Point to be noted that sys.stderr.write() or sys.stdout.write() ( stdout (standard output) is a pipe that is built into every UNIX/Linux system) is not a replacement for print, but yes we can use it as a alternative in some case. Print is a wrapper which wraps the input with space and newline at the end and uses the write function to write. This is the reason sys.stderr.write() is faster.
Note: we can also trace and debugg using Logging
#test.py import logging logging.info('This is the existing protocol.') FORMAT = "%(asctime)-15s %(clientip)s %(user)-8s %(message)s" logging.basicConfig(format=FORMAT) d = {'clientip': '192.168.0.1', 'user': 'fbloggs'} logging.warning("Protocol problem: %s", "connection reset", extra=d)https://docs.python.org/2/library/logging.html#logger-objects
Nov 22, 2012 | stackoverflow.com
Vartec's answer doesn't read all lines, so I made a version that did:
def run_command(command): p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) return iter(p.stdout.readline, b'')Usage is the same as the accepted answer:
command = 'mysqladmin create test -uroot -pmysqladmin12'.split() for line in run_command(command): print(line)share python - Running shell command and capturing the output - Stack Overflow Share a link to this answer Copy link | improve this answer edited May 23 '17 at 11:33 Community ♦ 1 1 1 silver badge answered Oct 30 '12 at 9:24 Max Ekman Max Ekman 769 5 5 silver badges 5 5 bronze badges
- 6 you could use
return iter(p.stdout.readline, b'')instead of the while loop – jfs Nov 22 '12 at 15:44- 1 That is a pretty cool use of iter, didn't know that! I updated the code. – Max Ekman Nov 28 '12 at 21:53
- I'm pretty sure stdout keeps all output, it's a stream object with a buffer. I use a very similar technique to deplete all remaining output after a Popen have completed, and in my case, using poll() and readline during the execution to capture output live also. – Max Ekman Nov 28 '12 at 21:55
- I've removed my misleading comment. I can confirm,
p.stdout.readline()may return the non-empty previously-buffered output even if the child process have exited already (p.poll()is notNone). – jfs Sep 18 '14 at 3:12- This code doesn't work. See here stackoverflow.com/questions/24340877/ – thang May 3 '15 at 6:00
Nov 13, 2019 | unix.stackexchange.com
Execute shell commands in Python Ask Question Asked 4 years ago Active 2 months ago Viewed 557k times 67 32
fooot ,Nov 8, 2017 at 21:39
I'm currently studying penetration testing and Python programming. I just want to know how I would go about executing a Linux command in Python. The commands I want to execute are:echo 1 > /proc/sys/net/ipv4/ip_forward iptables -t nat -A PREROUTING -p tcp --destination-port 80 -j REDIRECT --to-port 8080If I just use
binarysubstrate ,Feb 28 at 19:58
You can useos.system(), like this:import os os.system('ls')Or in your case:
os.system('echo 1 > /proc/sys/net/ipv4/ip_forward') os.system('iptables -t nat -A PREROUTING -p tcp --destination-port 80 -j REDIRECT --to-port 8080')Better yet, you can use subprocess's call, it is safer, more powerful and likely faster:
from subprocess import call call('echo "I like potatos"', shell=True)Or, without invoking shell:
call(['echo', 'I like potatos'])If you want to capture the output, one way of doing it is like this:
import subprocess cmd = ['echo', 'I like potatos'] proc = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE) o, e = proc.communicate() print('Output: ' + o.decode('ascii')) print('Error: ' + e.decode('ascii')) print('code: ' + str(proc.returncode))I highly recommend setting a
timeoutincommunicate, and also to capture the exceptions you can get when calling it. This is a very error-prone code, so you should expect errors to happen and handle them accordingly.jordanm ,Oct 23, 2015 at 15:43
The first command simply writes to a file. You wouldn't execute that as a shell command becausepythoncan read and write to files without the help of a shell:with open('/proc/sys/net/ipv4/ip_forward', 'w') as f: f.write("1")The
iptablescommand is something you may want to execute externally. The best way to do this is to use the subprocess module .import subprocess subprocess.check_call(['iptables', '-t', 'nat', '-A', 'PREROUTING', '-p', 'tcp', '--destination-port', '80', '-j', 'REDIRECT', '--to-port', '8080'])Note that this method also does not use a shell, which is unnecessary overhead.
Tom Hunt ,Oct 23, 2015 at 15:41
The quickest way:import os os.system("your command here")This isn't the most flexible approach; if you need any more control over your process than "run it once, to completion, and block until it exits", then you should use the
subprocessmodule instead.jordanm ,Apr 5, 2018 at 9:23
As a general rule, you'd better use python bindings whenever possible (better Exception catching, among other advantages.)For the
echocommand, it's obviously better to use python to write in the file as suggested in @jordanm's answer.For the
iptablescommand, maybepython-iptables( PyPi page , GitHub page with description and doc ) would provide what you need (I didn't check your specific command).This would make you depend on an external lib, so you have to weight the benefits. Using subprocess works, but if you want to use the output, you'll have to parse it yourself, and deal with output changes in future
iptablesversions.,
A python version of your shell. Be careful, I haven't tested it.from subprocess import run def bash(command): run(command.split()) >>> bash('find / -name null') /dev/null /sys/fs/selinux/null /sys/devices/virtual/mem/null /sys/class/mem/null /usr/lib/kbd/consoletrans/null
Nov 11, 2019 | www.python-course.eu
Python and the Shell Shell
Shell is a term, which is often used and often misunderstood. Like the shell of an egg, either hen or Python snake, or a mussel, the shell in computer science is generally seen as a piece of software that provides an interface for a user to some other software or the operating system. So the shell can be an interface between the operating system and the services of the kernel of this operating system. But a web browser or a program functioning as an email client can be seen as shell as well.
Understanding this, it's obvious that a shell can be either
But in most cases the term shell is used as a synonym for a command line interface (CLI). The best known and most often used shells under Linux and Unix are the Bourne-Shell, C-Shell or Bash shell. The Bourne shell (sh) was modelled after the Multics shell, and is the first Unix shell.
- a command-line interface (CLI)
or- a graphical user interface (GUI)
Most operating system shells can be used in both interactive and batch mode. System programming System programming (also known as systems programming) stands for the activity of programming system components or system software. System programming provides software or services to the computer hardware, while application programming produces software which provides tools or services for the user."System focused programming" as it is made possible with the aid of the sys and the os module, serves as an abstraction layer between the application, i.e. the Python script or program, and the operating system, e.g. Linux or Microsoft Windows. By means of the abstraction layer it is possible to implement platform independent applications in Python, even if they access operating specific functionalities.
Therefore Python is well suited for system programming, or even platform independent system programming. The general advantages of Python are valid in system focused programming as well:
The os Module The os module is the most important module for interacting with the operating system. The os module allows platform independent programming by providing abstract methods. Nevertheless it is also possible by using the system() and the exec*() function families to include system independent program parts. (Remark: The exec*()-Functions are introduced in detail in our chapter " Forks and Forking in Python ")
- simple and clear
- Well structured
- highly flexible
The os module provides various methods, e.g. the access to the file system. Executing Shell scripts with os.system() It's not possible in Python to read a character without having to type the return key as well. On the other hand this is very easy on the Bash shell. The Bash command "read -n 1waits for a key (any key) to be typed. If you import os, it's easy to write a script providing getch() by using os.system() and the Bash shell. getch() waits just for one character to be typed without a return:import os def getch(): os.system("bash -c \"read -n 1\"") getch()The script above works only under Linux. Under Windows you will have to import the module msvcrt. Pricipially we only have to import getch() from this module.
So this is the Windows solution of the problem:from msvcrt import getchThe following script implements a platform independent solution to the problem:import os, platform if platform.system() == "Windows": import msvcrt def getch(): if platform.system() == "Linux": os.system("bash -c \"read -n 1\"") else: msvcrt.getch() print("Type a key!") getch() print("Okay")The previous script harbours a problem. You can't use the getch() function, if you are interested in the key which has been typed, because os.system() doesn't return the result of the called shell commands.
We show in the following script, how we can execute shell scripts and return the output of these scripts into python by using os.popen():>>> import os >>> dir = os.popen("ls").readlines() >>> print dir ['curses.py\n', 'curses.pyc\n', 'errors.txt\n', 'getch.py\n', 'getch.pyc\n', 'more.py\n', 'numbers.txt\n', 'output.txt\n', 'redirecting_output.py\n', 'redirecting_stderr2.py\n', 'redirecting_stderr.py\n', 'streams.py\n', 'test.txt\n'] >>>The output of the shell script can be read line by line, as can be seen in the following example:import os command = " " while (command != "exit"): command = raw_input("Command: ") handle = os.popen(command) line = " " while line: line = handle.read() print line handle.close() print "Ciao that's it!"subprocess Module The subprocess module is available since Python 2.4.
It's possible to create spawn processes with the module subprocess, connect to their input, output, and error pipes, and obtain their return codes.
The module subprocess was created to replace various other modules:Working with the subprocess Module Instead of using the system method of the os-Module
- os.system
- os.spawn*
- os.popen*
- popen2.*
- commands.*
os.system('touch xyz')we can use the Popen() command of the subprocess Module. By using Popen() we are capable to get the output of the script:>>> x = subprocess.Popen(['touch', 'xyz']) >>> print x >>> x.poll() 0 >>> x.returncode 0The shell commandcp -r xyz abccan be send to the shell from Python by using the Popen() method of the subprocess-Module in the following way:p = subprocess.Popen(['cp','-r', "xyz", "abc"])There is no need to escape the Shell metacharacters like $, > usw..
If you want to emulate the behaviour of os.system, the optional parameter shell has to be set to true, i.e.shell=Trueand we have to use a string instead of a list:p=subprocess.Popen("cp -r xyz abc", shell=True)
As we have said above, it is also possible to catch the output from the shell command or shell script into Python. To do this, we have to set the optional parameter stdout of Popen() to subprocess.PIPE:>>> process = subprocess.Popen(['ls','-l'], stdout=subprocess.PIPE) >>> print process.stdout.read() total 132 -rw-r--r-- 1 bernd bernd 0 2010-10-06 10:03 abc -rw-r--r-- 1 bernd bernd 0 2010-10-06 10:04 abcd -rw-r--r-- 1 bernd bernd 660 2010-09-30 21:34 curses.pyIf a shell command or shell script has been started with Popen(), the Python script doesn't wait until the shell command or shell script is finished. To wait until it is finished, you have to use the wait() method:
>>> process = subprocess.Popen(['ls','-l'], stdout=subprocess.PIPE) >>> process.wait() 0Functions to manipulate paths, files and directories
Function Description getcwd() returns a string with the path of the current working directory chdir(path) Change the current working directory to path.
Example under Windows:
>>> os.chdir("c:\Windows") >>> os.getcwd() 'c:\\Windows'An similiar example under Linux:>>> import os >>> os.getcwd() '/home/homer' >>> os.chdir("/home/lisa") >>> os.getcwd() '/home/lisa' >>>getcwdu() like getcwd() but unicode as output listdir(path) A list with the content of the directory defined by "path", i.e. subdirectories and file names. >>> os.listdir("/home/homer") ['.gnome2', '.pulse', '.gconf', '.gconfd', '.beagle', '.gnome2_private', '.gksu.lock', 'Public', '.ICEauthority', '.bash_history', '.compiz', '.gvfs', '.update-notifier', '.cache', 'Desktop', 'Videos', '.profile', '.config', '.esd_auth', '.viminfo', '.sudo_as_admin_successful', 'mbox', '.xsession-errors', '.bashrc', 'Music', '.dbus', '.local', '.gstreamer-0.10', 'Documents', '.gtk-bookmarks', 'Downloads', 'Pictures', '.pulse-cookie', '.nautilus', 'examples.desktop', 'Templates', '.bash_logout'] >>>mkdir(path[, mode=0755]) Create a directory named path with numeric mode "mode", if it doesn't already exist. The default mode is 0777 (octal). On some systems, mode is ignored. If it is used, the current umask value is first masked out. If the directory already exists, OSError is raised. Parent directories will not be created, if they don't exist. makedirs(name[, mode=511]) Recursive directory creation function. Like mkdir(), but makes all intermediate-level directories needed to contain the leaf directory. Raises an error exception if the leaf directory already exists or cannot be created. rename(old, new) The file or directory "old" is renamed to "new" If "new" is a directory, an error will be raised. On Unix and Linux, if "new" exists and is a file, it will be replaced silently if the user has permission to do so. renames(old, new) Works like rename(), except that it creates recursively any intermediate directories needed to make the "new" pathname. rmdir(path) remove (delete) the directory "path". rmdir() works only, if the direcotry "path" is empty, otherwise an error is raised. To remove whole directory trees, shutil.rmdtree() can be used.
Further function and methods working on files and directories can be found in the module shutil. Amongst other possibilities it provides the possibility to copy files and directories with shutil.copyfile(src,dst).Previous Chapter: Introduction into the sys module
Next Chapter: Forks and Forking in Python
Nov 11, 2019 | www.journaldev.com
In this tutorial we will learn about Python System Command. Previously we learned about Python Random Number .
Table of Contents [ hide ]
Python System CommandWhile making a program in python, you may need to exeucte some shell commands for your program. For example, if you use
PycharmIDE, you may notice that there is option to share your project on github. And you probably know that file transferring is done by git , which is operated using command line. So, Pycharm executes some shell commands in background to do it.However, In this tutorial we will learn some basics about executing shell commands from your python code.
Python os.system() functionWe can execute system command by using os.system() function. According to the official document, it has been said that
This is implemented by calling the Standard C function system(), and has the same limitations.
However, if command generates any output, it is sent to the interpreter standard output stream. Using this command is not recommended. In the following code we will try to know the version of git using the system command
import os cmd = "git --version" returned_value = os.system(cmd) # returns the exit code in unix print('returned value:', returned_value)git --version.The following output found in ubuntu 16.04 where git is installed already.
git version 2 .14.2 returned value : 0Notice that we are not printing the git version command output to console, it's being printed because console is the standard output stream here.
Python subprocess.call() FunctionIn the previous section, we saw that
os.system()function works fine. But it's not recommended way to execute shell commands. We will use Python subprocess module to execute system commands.We can run shell commands by using
import subprocess cmd = "git --version" returned_value = subprocess.call(cmd, shell=True) # returns the exit code in unix print('returned value:', returned_value)subprocess.call()function. See the following code which is equivalent to the previous code.And the output will be same also.
Python subprocess.check_output() function

So far, we executed the system commands with the help of python. But we could not manipulate the output produced by those commands. Using
import subprocess cmd = "date" # returns output as byte string returned_output = subprocess.check_output(cmd) # using decode() function to convert byte string to string print('Current date is:', returned_output.decode( "utf-8" ))subprocess.check_output()function we can store the output in a variable.It will produce output like the following
Current date is : Thu Oct 5 16 :31:41 IST 2017So, in the above sections we have discussed about basic ideas about executing python system command. But there is no limit in learning. If you wish, you can learn more about Python System command using subprocess module from official documentation .
Nov 11, 2019 | stackoverflow.com
Environment variables are accessed through os.environimport os print(os.environ['HOME'])Or you can see a list of all the environment variables using:
os.environAs sometimes you might need to see a complete list!
# using get will return `None` if a key is not present rather than raise a `KeyError` print(os.environ.get('KEY_THAT_MIGHT_EXIST')) # os.getenv is equivalent, and can also give a default value instead of `None` print(os.getenv('KEY_THAT_MIGHT_EXIST', default_value))Python default installation on Windows is
C:\Python. If you want to find out while running python you can do:import sys print(sys.prefix),
import sys print sys.argv[0]This will print
foo.pyforpython foo.py,dir/foo.pyforpython dir/foo.py, etc. It's the first argument topython. (Note that after py2exe it would befoo.exe.)
Nov 11, 2019 | stackoverflow.com
> ,May 29, 2012 at 21:57
Possible Duplicate:
Python: What OS am I running on?As the title says, how can I find the current operating system in python?
Shital Shah ,Sep 23 at 23:34
I usually usesys.platform( docs ) to get the platform.sys.platformwill distinguish between linux, other unixes, and OS X, whileos.nameis "posix" for all of them.For much more detailed information, use the platform module . This has cross-platform functions that will give you information on the machine architecture, OS and OS version, version of Python, etc. Also it has os-specific functions to get things like the particular linux distribution.
xssChauhan ,Sep 9 at 7:34
If you want user readable data but still detailed, you can use platform.platform()>>> import platform >>> platform.platform() 'Linux-3.3.0-8.fc16.x86_64-x86_64-with-fedora-16-Verne'
platformalso has some other useful methods:>>> platform.system() 'Windows' >>> platform.release() 'XP' >>> platform.version() '5.1.2600'Here's a few different possible calls you can make to identify where you are
import platform import sys def linux_distribution(): try: return platform.linux_distribution() except: return "N/A" print("""Python version: %s dist: %s linux_distribution: %s system: %s machine: %s platform: %s uname: %s version: %s mac_ver: %s """ % ( sys.version.split('\n'), str(platform.dist()), linux_distribution(), platform.system(), platform.machine(), platform.platform(), platform.uname(), platform.version(), platform.mac_ver(),))The outputs of this script ran on a few different systems (Linux, Windows, Solaris, MacOS) and architectures (x86, x64, Itanium, power pc, sparc) is available here: https://github.com/hpcugent/easybuild/wiki/OS_flavor_name_version
Steg ,Mar 31, 2015 at 15:13
import os print os.nameThis gives you the essential information you will usually need. To distinguish between, say, different editions of Windows, you will have to use a platform-specific method.
UnkwnTech ,Sep 21, 2008 at 6:17
https://docs.python.org/library/os.htmlTo complement Greg's post, if you're on a posix system, which includes MacOS, Linux, Unix, etc. you can use os.uname() to get a better feel for what kind of system it is.
> ,
Something along the lines:import os if (os.name == "posix"): print os.system("uname -a") # insert other possible OSes here # ... else: print "unknown OS"
Nov 11, 2019 | stackoverflow.com
Ask Question Asked 6 years, 8 months ago Active 6 years, 8 months ago Viewed 2k times 0
dylanoo ,Feb 18, 2013 at 17:09
I have one problem regarding using python to process the trace file (it contains billion lines of data).What I want to do is, the program will find one specific line in the file (say it is line# x), and it needs to find another symbol from this (line# x) in the file. Once it finds the line, starts from (line# x) again to search another one.
What I did now, is as following, but the problem is it always needs to reopen the file and read from the beginning to find the match ones (line # > x, and contain the symbol I want). For one big trace file, it takes too long to processing.
1.
for line in file.readlines() i++ #update the line number if i > x: if (line.find()):or:
for i, line in enumerate(open(file)): if i > x: if ....Anyone can give me one hint on better ideas?
Thanks
dylanoo ,Feb 18, 2013 at 20:24
If the file is otherwise stable, usefileobj.tell()to remember your position in the file, then next time usefileobj.seek(pos)to return to that same position in the file.This only works if you do not use the fileobject as an iterator (no
for line in fileobject)ornext(fileobject)) as that uses a read-ahead buffer that will obscure the exact position.Instead, use:
for line in iter(fileobj.readline, ''):to still use
fileobjin an iteration context.Martijn Pieters ♦ ,Feb 18, 2013 at 17:30
I suggest you use random access, and record where your line started. Something like:index = [] fh = open(gash.txt) for line in fh: if target in line: index.append(fh.tell() - len(line))Then, when you want to recall the contents, use
fh.seek(index[n]).A couple of "gotchas":
- Notice that the index position will not be the same as the line number. If you need the line number then maybe use a dictionary, with the line number as the key.
- On Windows, you will have to adjust the file position by -1. This is because the "\r" is stripped out and does not appear in the
len(line).
Oct 22, 2019 | stackoverflow.com
Ask Question Asked 9 years, 8 months ago Active 11 months ago Viewed 22k times 53 47
Hamish Grubijan ,Feb 17, 2010 at 17:56
I am an experienced Perl developer with some degree of experience and/or familiarity with other languages (working experience with C/C++, school experience with Java and Scheme, and passing familiarity with many others).I might need to get some web work done in Python (most immediately, related to Google App Engine). As such, I'd like to ask SO overmind for good references on how to best learn Python for someone who's coming from Perl background (e.g. the emphasis would be on differences between the two and how to translate perl idiomatics into Python idiomatics, as opposed to generic Python references). Something also centered on Web development is even better. I'll take anything - articles, tutorials, books, sample apps?
Thanks!
FMc ,Dec 19, 2014 at 17:50
I've recently had to make a similar transition for work reasons, and it's been pretty painful. For better or worse, Python has a very different philosophy and way of working than Perl, and getting used to that can be frustrating. The things I've found most useful have been
- Spend a few hours going through all the basics. I found the official tutorial quite good, if a little dry.
- A good reference book to look up basic stuff ("how do I get the length of a string again?"). The ones I've found most useful are the Python Pocket Reference and Python Essential Reference .
- Take a look at this handy Perl<->Python phrasebook (common tasks, side by side, in both languages).
- A reference for the Python approach to "common tasks". I use the Python Cookbook .
- An ipython terminal open at all times to test syntax, introspect object methods etc.
- Get pip and easy-install (to install Python modules easily).
- Learn about unit tests fast. This is because without
use strictyou will feel crippled, and you will make many elementary mistakes which will appear as runtime errors. I recommend nose rather than the unittest framework that comes with the core install. unittest is very verbose if you're used to Test::More .- Check out Python questions on Stack Overflow. In particular, Python - Things one MUST avoid and Python 2.x gotcha's and landmines are well worth a read.
Personally, I found Dive Into Python annoying and patronising, but it's freely available online, so you can form your own judgment on that.
Philip Durbin ,Feb 18, 2010 at 18:12
If you happen to be a fan of The Perl Cookbook , you might be interested in checking out PLEAC, the Programming Language Examples Alike Cookbook , specifically the section that shows the Perl Cookbook code translated into Python .larley ,Feb 18, 2010 at 6:16
Being a hardcore Perl programmer, all I can say is DO NOT BUY O'Reilly's "Learning Python". It is nowhere NEAR as good as "Learning Perl", and there's no equivalent I know of to Larry Wall's "Programming Perl", which is simply unbeatable.I've had the most success taking past Perl programs and translating them into Python, trying to make use of as many new techniques as possible.
Mike Graham ,Feb 17, 2010 at 18:02
Check out the official tutorial , which is actually pretty good. If you are interested in web development you should be ready at that point to jump right in to the documentation of the web framework you will be working with; Python has many to choose from, with zope, cherrypy, pylons, and werkzeug all having good reputations.I would not try to search for things specifically meant to help you transition from Perl, which are not to be of as high of quality as references that can be useful for more people.
ghostdog74 ,Feb 18, 2010 at 1:17
This is the site you should really go to. There's a section called Getting Started which you should take a look. There are also recommendations on books. On top of that, you might also be interested in this on "idioms"sateesh ,Feb 17, 2010 at 18:08
If what you are looking at is succinct, concise reference to python then the book Python Essential Reference might be helpful.Robert P ,May 31, 2013 at 22:39
I wouldn't try to compare Perl and Python too much in order to learn Python, especially since you have working knowledge of other languages. If you are unfamiliar with OOP/Functional programming aspects and just looking to work procedurally like in Perl, start learning the Python language constructs / syntax and then do a couple examples. if you are making a switch to OO or functional style paradigms, I would read up on OO fundamentals first, then start on Python syntax and examples...so you have a sort of mental blueprint of how things can be constructed before you start working with the actual materials. this is just my humble opinion however..
Feb 01, 2014 | stackoverflow.com
Ask Question Asked 5 years, 8 months ago Active 5 years, 8 months ago Viewed 303 times -3
Jim Garrison ,Feb 1, 2014 at 22:24
I am trying to translate a Perl function into a Python function, but I am having trouble figuring out what some of the Perl to Python function equivalents.Perl function:
sub reverse_hex { my $HEXDATE = shift; my @bytearry=(); my $byte_cnt = 0; my $max_byte_cnt = 8; my $byte_offset = 0; while($byte_cnt < $max_byte_cnt) { my $tmp_str = substr($HEXDATE,$byte_offset,2); push(@bytearry,$tmp_str); $byte_cnt++; $byte_offset+=2; } return join('',reverse(@bytearry)); }I am not sure what "push", "shift", and "substr" are doing here that would be the same in Python.
Any help will be much appreciated.
Kenosis ,Feb 1, 2014 at 22:17
The Perl subroutine seems rather complicated for what it does, viz., taking chunks of two chars at a time (the first 16 chars) from the sent string and then reverses it. Another Perl option is:sub reverse_hex { return join '', reverse unpack 'A2' x 8, $_[0]; }First,
unpackhere takes two characters at a time (eight times) and produces a list. That list isreversed andjoined to produce the final string.Here's a Python subroutine to accomplish this:
def reverse_hex(HEXDATE): hexVals = [HEXDATE[i:i + 2] for i in xrange(0, 16, 2)] reversedHexVals = hexVals[::-1] return ''.join(reversedHexVals)The list comprehension produces eight elements of two characters each.
[::-1]reverses the list's elements and the result isjoined and returned.Hope this helps!
MikeMayer67 ,Feb 2, 2014 at 2:10
I realize that you are asking about the perl to python translation, but if you have any control over the perl, I would like to point out that this function is a lot more complicated than it needs to be.The entire thing could be replaced with:
sub reverse_hex { my $hexdate = shift; my @bytes = $hexdate =~ /../g; # break $hexdate into array of character pairs return join '', reverse(@bytes); }Not only is this shorter, it is much easier to get your head around. Of course, if you have no control over the perl, you are stuck with what you were dealt.
Jan 05, 2018 | cmdlinetips.com
Often one might need to read the entire content of a text file (or flat file) at once in python. In this post, we showed an example of reading the whole file and reading a text file line by line. Here is another way to import the entire content of a text file.
1 2 3 4 5 6 7 8 # Open a file: filefile=open('my_text_file',mode='r')# read all lines at onceall_of_it=file.read()# close the filefile.close()
Oct 13, 2019 | stackoverflow.com
what is the system function in python Ask Question Asked 9 years, 3 months ago Active 9 years, 3 months ago Viewed 6k times 1
Eva Feldman ,Jul 6, 2010 at 15:55
I want to play with system command in python . for example we have this function in perl : system("ls -la"); and its run ls -la what is the system function in python ? Thanks in Advance .Felix Kling ,Jul 6, 2010 at 15:58
It isos.system:import os os.system('ls -la')But this won't give you any output. So
subprocess.check_outputis probably more what you want:>>> import subprocess >>> subprocess.check_output(["ls", "-l", "/dev/null"]) 'crw-rw-rw- 1 root root 1, 3 Oct 18 2007 /dev/null\n'KLee1 ,Jul 6, 2010 at 16:00
import os os.system("")From here
> ,
In theosmodule there isos.system().But if you want to do more advanced things with subprocesses the
subprocessmodule provides a higher level interface with more possibilities that is usually preferable.
csestack.org
How to open the File in Python?You can use the same code as I have mentioned for creating a file. You can use the same code as I have mentioned for creating a file.open("myFile.txt", "r") as fObjHow to Read File in Python?First, open the file in reading mode "r" and then read the content from the file. First, open the file in reading mode "r" and then read the content from the file.All the file contents will be saved in a single string object. You can also use "with" statement with an open file. All the file contents will be saved in a single string object. You can also use "with" statement with an open file. You can also use "with" statement with an open file. You can also use "with" statement with an open file.
1 2 3 open("myFile.txt") as fObjdata=fObj.read()(data)
withopen("myFile.txt") as fObj:data=fObj.read()(data)There are multiple benefits of using "with" statement. We will see the benefits in the later part of this tutorial. Now a day it has become standard practice opening file "with" There are multiple benefits of using "with" statement. We will see the benefits in the later part of this tutorial. Now a day it has become standard practice opening file "with" Now a day it has become standard practice opening file "with" Now a day it has become standard practice opening file "with"
How to Read Line-by-Line File into List?Rather than reading complete file text in a single string object, what if you want to read the file line-by-line? Rather than reading complete file text in a single string object, what if you want to read the file line-by-line?
withopen("myFile.txt") as fObj:liData=fObj.readlines()(liData)Each line in the file will be saved as one element in the list. So the size of the list will be the same as the number of lines in the file. Reading file in the list is very important when you want to manipulate the text in each line of the file. After reading file content in the list, you just need to loop over each element in the list and perform your desired operation. Python provides Each line in the file will be saved as one element in the list. So the size of the list will be the same as the number of lines in the file. Reading file in the list is very important when you want to manipulate the text in each line of the file. After reading file content in the list, you just need to loop over each element in the list and perform your desired operation. Python provides Reading file in the list is very important when you want to manipulate the text in each line of the file. After reading file content in the list, you just need to loop over each element in the list and perform your desired operation. Python provides Reading file in the list is very important when you want to manipulate the text in each line of the file. After reading file content in the list, you just need to loop over each element in the list and perform your desired operation. Python provides Python provides Python provides multiple list operations which makes your work associated with the file operation even easier.
How to Write a File in Python?Two operations. First, open the file and then write the text content in it. File object has write() method associated with it to write the text in the file. Two operations. First, open the file and then write the text content in it. File object has write() method associated with it to write the text in the file. File object has write() method associated with it to write the text in the file. File object has write() method associated with it to write the text in the file.
withopen("myFile.txt",'a+') as fOut:fOut.write("my data to add."+'\n')Here, Here,
- We are opening the file in "a+" mode so that, it will append the new content at the end of the file.
- The "\n" character is used to add the next in a new line.
... ... ..
Sep 30, 2019 | stackoverflow.com
Zygimantas ,Aug 9, 2011 at 13:05
How to delete a file or folder in Python?Lu55 ,Jul 10, 2018 at 13:52
os.remove()removes a file.
os.rmdir()removes an empty directory.
shutil.rmtree()deletes a directory and all its contents.
Pathobjects from the Python 3.4+pathlibmodule also expose these instance methods:
pathlib.Path.unlink()removes a file or symbolic link.pathlib.Path.rmdir()removes an empty directory.Éric Araujo ,May 22 at 21:37
Python syntax to delete a fileimport os os.remove("/tmp/<file_name>.txt")Or
import os os.unlink("/tmp/<file_name>.txt")Best practice
- First, check whether the file or folder exists or not then only delete that file. This can be achieved in two ways :
a.os.path.isfile("/path/to/file")
b. Useexception handling.
EXAMPLE for
os.path.isfile#!/usr/bin/python import os myfile="/tmp/foo.txt" ## If file exists, delete it ## if os.path.isfile(myfile): os.remove(myfile) else: ## Show an error ## print("Error: %s file not found" % myfile)Exception Handling#!/usr/bin/python import os ## Get input ## myfile= raw_input("Enter file name to delete: ") ## Try to delete the file ## try: os.remove(myfile) except OSError as e: ## if failed, report it back to the user ## print ("Error: %s - %s." % (e.filename, e.strerror))RESPECTIVE OUTPUTEnter file name to delete : demo.txt Error: demo.txt - No such file or directory. Enter file name to delete : rrr.txt Error: rrr.txt - Operation not permitted. Enter file name to delete : foo.txtPython syntax to delete a foldershutil.rmtree()Example for
shutil.rmtree()#!/usr/bin/python import os import sys import shutil # Get directory name mydir= raw_input("Enter directory name: ") ## Try to remove tree; if failed show an error using try...except on screen try: shutil.rmtree(mydir) except OSError as e: print ("Error: %s - %s." % (e.filename, e.strerror))Paebbels ,Apr 25, 2016 at 19:38
Useshutil.rmtree(path[, ignore_errors[, onerror]])(See complete documentation on shutil ) and/or
os.removeand
os.rmdir(Complete documentation on os .)
Kaz ,Sep 8, 2018 at 22:37
Create a function for you guys.def remove(path): """ param <path> could either be relative or absolute. """ if os.path.isfile(path): os.remove(path) # remove the file elif os.path.isdir(path): shutil.rmtree(path) # remove dir and all contains else: raise ValueError("file {} is not a file or dir.".format(path))
Sep 30, 2019 | www.programiz.com
Python File I/O In this article, you'll learn about Python file operations. More specifically, opening a file, reading from it, writing into it, closing it and various file methods you should be aware of. What is a file?
File is a named location on disk to store related information. It is used to permanently store data in a non-volatile memory (e.g. hard disk).
Since, random access memory (RAM) is volatile which loses its data when computer is turned off, we use files for future use of the data.
When we want to read from or write to a file we need to open it first. When we are done, it needs to be closed, so that resources that are tied with the file are freed.
Hence, in Python, a file operation takes place in the following order.
- Open a file
- Read or write (perform operation)
- Close the file
How to open a file?Python has a built-in function
open()to open a file. This function returns a file object, also called a handle, as it is used to read or modify the file accordingly.
>>> f = open ( "test.txt" ) # open file in current directory>>> f = open ( "C:/Python33/README.txt" ) # specifying full pathWe can specify the mode while opening a file. In mode, we specify whether we want to read
'r', write'w'or append'a'to the file. We also specify if we want to open the file in text mode or binary mode.The default is reading in text mode. In this mode, we get strings when reading from the file.
On the other hand, binary mode returns bytes and this is the mode to be used when dealing with non-text files like image or exe files.
Python File Modes Mode Description 'r' Open a file for reading. (default) 'w' Open a file for writing. Creates a new file if it does not exist or truncates the file if it exists. 'x' Open a file for exclusive creation. If the file already exists, the operation fails. 'a' Open for appending at the end of the file without truncating it. Creates a new file if it does not exist. 't' Open in text mode. (default) 'b' Open in binary mode. '+' Open a file for updating (reading and writing)
f = open ( "test.txt" ) # equivalent to 'r' or 'rt'f = open ( "test.txt" , 'w' ) # write in text modef = open ( "img.bmp" , 'r+b' ) # read and write in binary modeUnlike other languages, the character
'a'does not imply the number 97 until it is encoded usingASCII(or other equivalent encodings).Moreover, the default encoding is platform dependent. In windows, it is
'cp1252'but'utf-8'in Linux.So, we must not also rely on the default encoding or else our code will behave differently in different platforms.
Hence, when working with files in text mode, it is highly recommended to specify the encoding type.
f = open ( "test.txt" , mode = 'r' , encoding = 'utf-8' )
How to close a file Using Python?When we are done with operations to the file, we need to properly close the file.
Closing a file will free up the resources that were tied with the file and is done using Python
close()method.Python has a garbage collector to clean up unreferenced objects but, we must not rely on it to close the file.
f = open ( "test.txt" , encoding = 'utf-8' )# perform file operationsf . close ()This method is not entirely safe. If an exception occurs when we are performing some operation with the file, the code exits without closing the file.
A safer way is to use a try...finally block.
try :f = open ( "test.txt" , encoding = 'utf-8' )# perform file operationsfinally :f . close ()This way, we are guaranteed that the file is properly closed even if an exception is raised, causing program flow to stop.
The best way to do this is using the
withstatement. This ensures that the file is closed when the block insidewithis exited.We don't need to explicitly call the
close()method. It is done internally.
with open ( "test.txt" , encoding = 'utf-8' ) as f :# perform file operations
How to write to File Using Python?In order to write into a file in Python, we need to open it in write
'w', append'a'or exclusive creation'x'mode.We need to be careful with the
'w'mode as it will overwrite into the file if it already exists. All previous data are erased.Writing a string or sequence of bytes (for binary files) is done using
write()method. This method returns the number of characters written to the file.
with open ( "test.txt" , 'w' , encoding = 'utf-8' ) as f :f . write ( "my first file\n" )f . write ( "This file\n\n" )f . write ( "contains three lines\n" )This program will create a new file named
'test.txt'if it does not exist. If it does exist, it is overwritten.We must include the newline characters ourselves to distinguish different lines.
How to read files in Python?To read a file in Python, we must open the file in reading mode.
There are various methods available for this purpose. We can use the
read(size)method to read in size number of data. If size parameter is not specified, it reads and returns up to the end of the file.
>>> f = open ( "test.txt" , 'r' , encoding = 'utf-8' )>>> f . read ( 4 ) # read the first 4 data'This'>>> f . read ( 4 ) # read the next 4 data' is '>>> f . read () # read in the rest till end of file'my first file\nThis file\ncontains three lines\n'>>> f . read () # further reading returns empty sting''We can see that, the
read()method returns newline as'\n'. Once the end of file is reached, we get empty string on further reading.We can change our current file cursor (position) using the
seek()method. Similarly, thetell()method returns our current position (in number of bytes).
>>> f . tell () # get the current file position56>>> f . seek ( 0 ) # bring file cursor to initial position0>>> print ( f . read ()) # read the entire fileThis is my first fileThis filecontains three linesWe can read a file line-by-line using a for loop . This is both efficient and fast.
>>> for line in f :... print ( line , end = '' )...This is my first fileThis filecontains three linesThe lines in file itself has a newline character
'\n'.Moreover, the
print()end parameter to avoid two newlines when printing.Alternately, we can use
readline()method to read individual lines of a file. This method reads a file till the newline, including the newline character.
>>> f . readline ()'This is my first file\n'>>> f . readline ()'This file\n'>>> f . readline ()'contains three lines\n'>>> f . readline ()''Lastly, the
readlines()method returns a list of remaining lines of the entire file. All these reading method return empty values when end of file (EOF) is reached.
>>> f . readlines ()[ 'This is my first file\n' , 'This file\n' , 'contains three lines\n' ]
Python File MethodsThere are various methods available with the file object. Some of them have been used in above examples.
Here is the complete list of methods in text mode with a brief description.
Python File Methods Method Description close() Close an open file. It has no effect if the file is already closed. detach() Separate the underlying binary buffer from the TextIOBaseand return it.fileno() Return an integer number (file descriptor) of the file. flush() Flush the write buffer of the file stream. isatty() Return Trueif the file stream is interactive.read( n ) Read atmost n characters form the file. Reads till end of file if it is negative or None.readable() Returns Trueif the file stream can be read from.readline( n =-1) Read and return one line from the file. Reads in at most n bytes if specified. readlines( n =-1) Read and return a list of lines from the file. Reads in at most n bytes/characters if specified. seek( offset , from = SEEK_SET)Change the file position to offset bytes, in reference to from (start, current, end). seekable() Returns Trueif the file stream supports random access.tell() Returns the current file location. truncate( size = None)Resize the file stream to size bytes. If size is not specified, resize to current location. writable() Returns Trueif the file stream can be written to.write( s ) Write string s to the file and return the number of characters written. writelines( lines ) Write a list of lines to the file.
wiki.python.org
ContentsIntroduction This phrasebook contains a collection of idioms, various ways of accomplishing common tasks, tricks and useful things to know, in Perl and Python side-by-side. I hope this will be useful for people switching from Perl to Python, and for people deciding which to choose. The first part of the phrasebook is based on Tom Christiansen's Perl Data Structures Cookbook .
- Introduction
- The obvious
- The not so obvious
- Simple types
- Importing
- Common tasks
- Some general comparisons
- Lists of lists
- Lists of lists: preliminaries
- requires/imports
- Declaration of a list of lists
- Generation of a list of lists
- Filling a list of lists with function calls
- Filling a list of lists with function calls, using temporaries
- Adding to an existing row in a list of lists
- Accessing elements of a list of lists
- Printing a list of lists
- Hashes/dictionaries of lists
- Lists of hashes/dictionaries
- Interface to the Tk GUI toolkit
I have only been working on this for a short time, so many of the translations could probably be improved, and the format could be greatly cleaned up. I will get the data-structures cookbook translated first and then go back to clean up the code. Also, since I have been using Python for far less time than Perl, there are certainly idioms I don't know or that I will misuse. Please feel free to fix and update. -- Other references: PLEAC . -- Thanks to David Ascher, Guido van Rossum, Tom Christiansen, Larry Wall and Eric Daniel for helpful comments. -- TODO:
QUESTIONS:
- break up into multiple smaller pages
- use modern Python idioms
- use modern Perl idioms
- add more points of comparison
- Use sorted() where appropriate once 2.4 has been out a while.
- Get rid of map() where possible.
- Simple types (strings, lists, dictionaries, etc.)
- Common tasks (reading from a file, exception handling, splitting strings, regular expression manipulation, etc.)
- Sections 4 and 5 of the Perl Data Structures Cookbook.
- Vertical whitespace needs fixing.
The obvious Python don't need no steenking semicolons.
- Should function and data structure names for python code be in python_style (and more appropriate/informative)?
The not so obvious There are many Integrated Development Environments, (IDEs), for Python that are usually recommended to new users and used by seasoned Python programmers alike. The Idle IDE is a TK based GUI providing language-aware editing, debugging and command line shell for Python that is part of the Python distribution.
Many of the python examples shown can be experimented with in the Idle IDE.
Simple types Strings
Creating a string$s = 'a string';s = 'a string'The $ in Perl indicates a scalar variable, which may hold a string, a number, or a reference. There's no such thing as a string variable in Python, where variables may only hold references.
- You can program in a Pythonesque subset of Perl by restricting yourself to scalar variables and references. The main difference is that Perl doesn't do implicit dereferencing like Python does.
Quoting$s1 = "some string"; $s2 = "a string with\ncontrol characters\n"; $s3 = 'a "quoted" string'; $s4 = "a 'quoted' string"; $s5 = qq/a string with '" both kinds of quotes/; $s6 = "another string with '\" both kinds of quotes"; $s7 = 'a stri\ng that au\tomatically escapes backslashes'; foreach my $i ($s1, $s2, $s3, $s4, $s5, $s6, $s7) { print "$i\n"; }s1 = "some string" s2 = "a string with\ncontrol characters\n" s3 = 'a "quoted" string' s4 = "a 'quoted' string" s5 = '''a string with '" both kinds of quotes''' s6 = "another string with '\" both kinds of quotes" s7 = r"a stri\ng that au\tomatically escapes backslashes" for i in (s1, s2, s3, s4, s5, s6, s7): print iIn both languages, strings can be single-quoted or double-quoted. In Python, there is no difference between the two except that in single- quoted strings double-quotes need not be escaped by doubling them, and vice versa.In Perl, double-quoted strings have control characters and variables interpolated inside them (see below) and single-quoted strings do not.
Both languages provide other quoting mechanisms; Python uses triple quotes (single or double, makes no difference) for multi-line strings; Python has the r prefix ( r"some string" or r'some string' or r"""some string""" or r'''some string''' ) to indicate strings in which backslash is automatically escaped -- highly useful for regular expressions.
Perl has very elaborate (and very useful) quoting mechanisms; see the operators q , qq , qw , qx , etc. in the PerlManual . Quoting is definitely one of the areas where Perl excels. Note that in Perl you can always replace foreach with for , which is shorter; but explicitly writing foreach is clearer, so you don't confuse it with the other kind of for .
Interpolation$name = "Fred"; $header1 = "Dear $name,"; $title = "Dr."; $header2 = "Dear $title $name,"; print "$header1\n$header2\n";name = "Fred" header1 = "Dear %s," % name title = "Dr." header2 = "Dear %(title)s %(name)s," % vars() print header1 print header2Perl's interpolation is much more convenient, though slightly less powerful than Python's % operator. Remember that in Perl variables are interpolated within double-quoted strings, but not single-quoted strings. Perl has a function sprintf that uses the % conversion á la C; so the above lines could have been written:$name = "Fred"; $header1 = sprintf "Dear %s,", $name; $title = "Dr."; $header2 = sprintf "Dear %s %s,", $name, $title;Python's % (format) operator is generally the way to go when you have more than minimal string formatting to do (you can use + for concatenation, and [:] for slicing). It has three forms. In the first, there is a single % specifier in the string; the specifiers are roughly those of C's sprintf. The right-hand side of the format operator specifies the value to be used at that point:x = 1.0/3.0 s = 'the value of x is roughly %.4f' % xIf you have several specifiers, you give the values in a list on the right hand side:x = 1.0/3.0 y = 1.0/4.0 s = 'the value of x,y is roughly %.4f,%.4f' % (x, y)Finally, you can give a name and a format specifier:x = 1.0/3.0 y = 1.0/4.0 s = 'the value of x,y is roughly %(x).4f,%(y).4f' % vars()The name in parentheses is used as a key into the dictionary you provide on the right-hand side; its value is formatted according to the specifier following the parentheses. Some useful dictionaries are locals() (the local symbol table), globals() (the global symbol table), and vars() (equivalent to locals() except when an argument is given, in which case it returns arg.__dict__ ). PEP215 proposed a $"$var" substitution mode as an alternative to "%(var)s" % locals() , but was rejected in favor of the explicit Template class proposed in PEP292 , which required no syntax changes.Modifying a string$s1 = "new string"; # change to new string $s2 = "new\nstring\with\nnew\nlines"; # change to new string $s2 =~ s/\n/[newline]/g; # substitute newlines with the text "[newline]" $s2 = substr $s2, 0, 3,''; # extract the first 3 chars: "new" print "$s1\n$s2\n";s1 = "new string" # change to new string # substitute newlines with the text "[newline]" s2 = s2.replace("\n", "[newline]") s2 = s2[:3] print s1 print s2In Perl, strings are mutable; the third assignment modifies s2 . In Python, strings are immutable, so you have to do this operation a little differently, by slicing the string into the appropriate pieces. A Python string is just an array of characters, so all of the array operations are applicable to strings. In particular, if a is an array, a[x:y] is the slice of a from index x up to, but not including, index y . If x is omitted, the slice starts at the beginning of the array; if y is omitted, the slice ends at the last element. If either index is negative, the length of the array is added to it. So a[-4:] is the last four characters of a. In Perl, slicing is performed by giving the array a list of indices to be included in the slice. This list can be any arbitrary list and by using the range operator ... , you can get Python like slicing. If any of the indices in the list is out of bounds an undef is inserted there.@array = ('zero', 'one', 'two', 'three', 'four') # slicing with range operator to generate slice index list @slice = @array[0..2] # returns ('zero', 'one', 'two') # Using arbitary index lists @slice = @array[0,3,2] # returns ('zero', 'three', 'two') @slice = @array[0,9,1] # returns ('zero', undef, 'one')Note: Perl range operator uses a closed interval. To get the range to the end of the array, the last index must be used as@a=(1,2,3,4,5); $#a; # last index, 4, because the firs index is 0 as in Python. @a[ 2..$#a ] # as Python's a[2:]Importing In Perl a module is simply a package with a package name. ( see: perldoc -f package ). The symbols exported by the module depends on the module itself. The module may export symbols - mostly functions - by default, on request or none of them. In the latter case the module usually a class or has special access, like File::Spec.In Perl the module interfaces may vary - see the doc of the particular module.
use Module; # imports module. It exports module symbols by default, those appears in the package namespace. use Module qw(symbol1 symbol2 symbol3); # preferred or use Module "symbol1";from module import symbol1, symbol2, symbol3 # Allows mysymbol.func() from module import symbol1 as mysymbol # Unless the module is specifically designed for this kind of import, don't use it from module import * module.func()Common tasks Reading a file as a list of linesmy $filename = "cooktest1.1-1"; open my $f, $filename or die "can't open $filename: $!\n"; @lines = <$f>;filename = "cooktest1.1-1" f = open(filename) # Python has exceptions with somewhat-easy to # understand error messages. If the file could # not be opened, it would say "No such file or # directory: %filename" which is as # understandable as "can't open $filename:" lines = f.readlines()In Perl, variables are always preceded by a symbol that indicates their type. A $ indicates a simple type (number, string or reference), an @ indicates an array, a % indicates a hash (dictionary).In Python, objects must be initialized before they are used, and the initialization determines the type. For example, a = [] creates an empty array a , d = {} creates an empty dictionary. looping over files given on the command line or stdin
The useful Perl idiom of:
while (<>) { ... # code for each line }loops over each line of every file named on the commandline when executing the script; or, if no files are named, it will loop over every line of the standard input file descriptor. The Python fileinput module does a similar task:import fileinput for line in fileinput.input(): ... # code to process each lineThe fileinput module also allows inplace editing or editing with the creation of a backup of the files, and a different list of files can be given instead of taking the command line arguments. In more recent python versions, files can act as iterators, so you would just write:for line in open(filename): ... # code to process each lineIf you want to read from standard in, then use it as the filename:import sys for line in open(sys.stdin): ... # code to process each lineIf you want to loop over several filenames given on the command line, then you could write an outer loop over the command line. (You might also choose to use the fileinput module as noted above).import sys for fname in sys.argv[1:] for line in open(fname): ... # code to process each lineSome general comparisons This section is under construction; for the moment I am just putting random notes here. I will organize them later.While most of the concerns are subjective here this one is obviously wrong. Perl has standard modules - eg. File::Spec -, and in general the module portability does not second to Python's. On the other hand, the CPAN - central module library - is a central module repository with elaborate interfaces.
- Perl's regular expressions are much more accessible than those of Python being embedded in Perl syntax in contrast to Pythons import of its re module.
- Perl's quoting mechanisms are more powerful than those of Python.
- I find Python's syntax much cleaner than Perl's
- I find Perl's syntax too flexible, leading to silent errors. The -w flag and use strict helps quite a bit, but still not as much as Python.
- I like Python's small core with a large number of standard libraries. Perl has a much larger core, and though many libraries are available, since they are not standard, it is often best to avoid them for portability.
Lists of lists The Perl code in this section is taken, with permission, almost directly from Tom Christiansen's Perl Data Structures Cookbook , part 1, release 0.1, with a few typos fixed.
- Python's object model is very uniform, allowing you, for example, to define types that can be used wherever a standard file object can be used.
- Python allows you to define operators for user-defined types. The operator overloading facility in Perl is provided as an add-on --- the overload module.
Lists of lists: preliminaries
sub printSep { print "=" x 60, "\n" } sub printLoL { my ($s, $lol) = @_; print "$s\n"; foreach my $l (@$lol) { print "@{$l}\n"; } printSep(); } # which is longhand for: sub printLoL { print "$_[0]\n"; print "@$_\n" foreach @{$_[1]}; printSep(); } # or even: sub printLoL { print "$_[0]\n", map("@$_\n" , @{$_[1]}), "=" x 60, "\n"; } # return numeric (or other) converted to string sub somefunc { "". shift }def printSep(): print '=' * 60 def printLoL(s, lol): out = [s] + [" ".join(str(elem)) for elem in lol] print "\n".join(out) printSep() def somefunc(i): return str(i) # string representation of iprintLoL pretty-prints a list of lists. printSep prints a line of equal signs as a separator. somefunc is a function that is used in various places below.Lost in the translationIn converting Perl examples so directly to Python, whilst initially useful, the casual browser should be aware that the task of printLoL is usually accomplished by justprint lolAs Python can print default string representations of all objects. An import of the pprint at the beginning of a module would then allowpprint(lol)to substitute for all cases of printLol in a more 'pythonic' way. ( pprint gives even more formatting options when printing data structures). requires/importsimport sysPerl's use is roughly equivalent to Python's import . Perl has much more built in, so nothing here requires importing.For many simple operations, Perl will use a regular expression where Pythonic code won't. Should you really need to use regular expressions, import the re module.
- "Some people, when confronted with a problem, think 'I know, I'll use regular expressions.' Now they have two problems." - Jamie Zawinski
Declaration of a list of lists
@LoL = ( [ "fred", "barney" ], [ "george", "jane", "elroy" ], [ "homer", "marge", "bart" ], ); @LoLsave = @LoL; # for later printLoL 'Families:', \@LoL;LoL = [["fred", "barney"], ["george", "jane", "elroy"], ["homer", "marge", "bart"]] LoLsave = LoL[:] # See comment below printLoL('Families:', LoL)In Python, you are always dealing with references to objects. If you just assign one variable to another, e.g.,a = [1, 2, 3] b = ayou have just made b refer to the same array as a . Changing the values in b will affect a . Sometimes what you want is to make a copy of a list, so you can manipulate it without changing the original. In this case, you want to make a new list whose elements are copies of the elements of the original list. This is done with a full array slice --- the start of the range defaults to the beginning of the list and the end defaults to the end of the list, soa = [1, 2, 3] b = a[:]makes a separate copy of a. Note that this is not necessarily the same thing as a deep copy, since references in the original array will be shared with references in the new array:a = [ [1, 2, 3], [4, 5, 6] ] b = a[:] b[0][0] = 999 print a[0][0] # prints 999You can make a deep copy using the copy module:import copy a = [[1, 2, 3], [4, 5, 6]] b = copy.deepcopy(a) b[0][0] = 999 print a[0][0] # prints 1Generation of a list of listsReading from a file line by lineopen my $f, "cookbook.data1" or die $!; my @LoL; while (<$f>) { push @LoL, [ split ]; } printLoL "read from a file: ", \@LoL;LoL = [] for line in open('cookbook.data1'): LoL.append(line[:-1].split()) printLoL('read from a file: ', LoL)Unless you expect to be reading huge files, or want feedback as you read the file, it is easier to slurp the file in in one go. In Perl, reading from a file-handle, e.g., <STDIN> , has a context-dependent effect. If the handle is read from in a scalar context, like $a = <STDIN>; , one line is read. If it is read in a list context, like @a = <STDIN>; the whole file is read, and the call evaluates to a list of the lines in the file.Reading from a file in one goopen my $f, "cookbook.data1" or die $!; @LoL = map [split], <$f>; printLoL "slurped from a file: ", \@LoL;LoL = [line[:-1].split() for line in open('cookbook.data1')] printLoL("slurped from a file: ", LoL)Thanks to Adam Krolnik for help with the Perl syntax here. Filling a list of lists with function callsforeach my $i ( 0 .. 9 ) { $LoL[$i] = [ somefunc $i ]; } printLoL("filled with somefunc:", \@LoL);LoL = [0] * 10 # populate the array -- see comment below for i in range(10): LoL[i] = somefunc(i) # assuming that somefunc(i) returns the list that we want printLoL('filled with somefunc:', LoL)Or:LoL = [] for i in range(10): LoL.append( somefunc(i) ) printLoL('filled with somefunc:', LoL)Alternatively, you can use a list comprehension:LoL = [somefunc(i) for i in range(10)] printLoL('filled with somefunc:', LoL)In python:Filling a list of lists with function calls, using temporaries
- You have to populate the matrix -- this doesn't happen automatically in Python.
- It doesn't matter what type the initial elements of the matrix are, as long as they exist.
foreach my $i (0..9) { @tmp = somefunc $i; $LoL[$i] = [ @tmp ]; } printLoL ("filled with somefunc via temps:", \@LoL);for i in range(10): tmp = somefunc(i) LoL[i] = tmp printLoL('filled with somefunc via temps:', LoL)@LoL = map [ somefunc $_ ], 0..9; printLoL 'filled with map', \@LoL;LoL = map(lambda x: somefunc(x), range(10)) printLoL('filled with map', LoL)Both Perl and Python allow you to map an operation over a list, or to loop through the list and apply the operation yourself. I don't believe it is advisable to choose one of these techniques to the exclusion of the other --- there are times when looping is more understandable, and times when mapping is. If conceptually the idea you want to express is "do this to each element of the list", I would recommend mapping because it expresses this precisely. If you want more precise control of the flow during this process, particularly for debugging, use loops. Tom Christiansen suggests that it is often better to make it clear that a function is being defined, by writing:@LoL = map {[ somefunc($_) ]} 0..9;rather than@LoL = map [ somefunc($_) ], 0..9;or@LoL = map ([ somefunc($_)], 0..9);Adding to an existing row in a list of lists@LoL = @LoLsave; # start afresh push @{$LoL[0]}, "wilma", "betty"; printLoL ('after appending to first element:', \@LoL);LoL = LoLsave[:] # start afresh LoL[0] += ["wilma", "betty"] printLoL('after appending to first element:', LoL)In python, the + operator is defined to mean concatenation for sequences. The + operator returns a new list object. Alternative to the above code that modify the original list object is to append each element of the list to LoL[0] :LoL[0].append("wilma") LoL[0].append("betty")Or to extend:LoL[0].extend(["wilma", "betty"])Accessing elements of a list of listsOne element$LoL[0][0] = "Fred"; print ("first element is now $LoL[0][0]\n"); printSep();LoL[0][0] = "Fred" print 'first element is now', LoL[0][0] printSep()Another element# upcase the first letter of each word # s/(\w)/\u$1/ is almost equivalent to Python .capitalize() [.capitalize() also lowercases the remaining letters] $LoL[1][1] =~ s{\b(\w)}{\u$1}g; print ("element 1, 1 is now $LoL[1][1]\n"); printSep();LoL[1][1] = LoL[1][1].title() print 'element 1, 1 is now', LoL[1][1] printSep()Perl's regexp matching and substitution is enormously powerful; see especially the new syntax for comments and whitespace inside regular expressions. Python replaced its original regular expression module some years ago with one that closely matches the capabilities of Perls, including being able to do advanced RE tasks such as calling a function to provide the data for an RE substitution, and the optional inclusion of whitespace and comments in REs.In Python, string methods are often used where Perl would use a regex. Among these string methods are title() and capitalize() . In the context of names, title() will be used as it correctly changes "smith-jones" to "Smith-Jones" whereas capitalize() would produce "Smith-jones".
str2 = str1.capitalize() in Python is equivalent to $str2 = ucfirst(lc($str1)) in Perl.
Python's str2 = str1.title() is equivalent to Perl's:
$str2 = $str1; $str2 =~ s{\b(\w)(\w*)\b}{\u$1\L$2\E}g;This is because regular expression search and replace operations modify the string in place (Perl strings are mutable). Printing a list of listsPrint a list of lists using referencesforeach my $aref ( @LoL ) { print "\t [ @$aref ],\n"; } printSep();for a in LoL: print "\t [ %s ]," % a printSep()[Need a pointer to the % operator]Print a list of lists using indicesforeach my $i ( 0 .. $#LoL ) { print "\t [ @{$LoL[$i]} ],\n"; } printSep();for i in range(len(LoL)): print "\t [ %s ]," % LoL[i] printSep()The highest valid index of an array A :But note: The highest valid upper bound to a python range is len(A) as in
- Perl: $#A .
- Python: len(A) - 1 .
A[0:len(A)]Size of an array A :Note: Perl does not really have a length operator like Python. scalar() simply provides a scalar context, and in a scalar context an array returns its size. (Perl is context-sensitive and things behave differently based on their context.) Generate range of numbers:
- Perl: scalar(@A)
- Python: len(A)
Note: Perl uses a closed interval, while Python uses a closed-open interval. You will notice that this pattern is quite consistently applied in both languages. [Link to details of the range function]
- Perl: (0..9)
- Python: range(0, 10) or simply range(10) (assumes 0 as initial)
Print a list of lists element by elementforeach my $i ( 0 .. $#LoL ) { foreach my $j ( 0 .. $#{$LoL[$i]} ) { print "elt $i $j is $LoL[$i][$j]\n"; } } printSep();for i, mylist in enumerate(LoL): for j, elem in enumerate(mylist): print 'elt %d %d is %s' % (i, j, elem) printSep()Print a list of lists using mapsub printLine { print "@{shift()}\n" } map printLine($_), @LoL; printSep();# This is legal but Do Not Do This def printLine(l): print " ".join(l) map(printLine, LoL) printSep()Print a list of lists using map and anonymous functionsprint map "@$_\n", @LoL; printSep();# This is legal but Do Not Do This map(lambda x: sys.stdout.write(" ".join(x)), LoL) printSep()The lack of true lambda expressions in Python is not really a problem, since all it means is that you have to provide a name for the function. Since you can define a function within another function, this does not lead to namespace clutter.In Perl, a function can be defined inside another function, but it is defined in the namespace of the current package. If you need Python-like scoping of functions, you can create an anonymous subroutine and assign it to a lexically scoped variable:
# A Python function with its own private function def lolprint(LoL): # Private function def lprint(alist): print " ".join(str(alist)) map(lprint, LoL) # Achieving the same in Perl sub lolprint { # Private function # (function reference stored in a lexically scoped variable) my $lprint = sub { my $list = shift; print "@$list"; }; map $lprint->($_), @_; } # In Perl, if you did this, the function is no longer private. sub lolprint { # This is not a private function sub lprint { my $list = shift; print "@$list"; }; map lprint($_), @_; }Hashes/dictionaries of lists The Perl code in this section is taken, with permission, almost directly from Tom Christiansen's Perl Data Structures Cookbook , part 2, release 0.1, with a few typos fixed.Associative arrays are containers that hold pairs of elements. The first element of a pair is the key , the second is the value . In Python, the key may be of any type which is hashable (mutable data structures, like lists, sets, dictionaries, are no hashable). In Perl, the keys of a hash are converted into strings, which means if you try to use a reference as a key, it will get converted to some string representation, and you will not be able to use it as a reference anymore. Associative arrays are sometimes called maps, dictionaries (Python, Smalltalk), or hashes (Perl). Preliminaries
sub printSep { print "=" x 60, "\n" } sub printHoL { my ($s, $hol) = @_; print "$s\n"; foreach my $k (sort keys (%$hol)) { my ($v) = $hol->{$k}; print "$k: @$v\n"; } printSep(); } sub get_family { my ($group) = @_; $group =~ s/s$//; $group = "\u$group"; return ("Mr-$group", "Mrs-$group", "$group-Jr"); }def printSep(): print '=' * 60 def printHoL(s, hol): print s for key, value in sorted(hol.items()): print key, ':', " ".join(value) printSep() def get_family(group): group = group.title() return ["Mr-" + group, "Mrs-" + group, group + "-Jr"]printHoL pretty-prints a hash/dictionary of lists. printSep prints a line of equal signs as a separator. get_family makes a list of names from a "group name", e.g., flintstones becomes [ "Mr-Flintstone", "Mrs-Flintstone", "Flintstone-Jr" ] This is for generating lists to fill a hash/dictionary. hol.items()` converts a dictionary to a list of (key, value) pairs, eg: [('flintstones', ['fred', 'barney']), ('jetsons', ['george', 'jane', 'elroy']), ('simpsons', ['homer', 'marge', 'bart'])] This list is then sorted (sorting is in-place in python) and then the pairs in the list are unpacked and used. If you didn't care for the results to be sorted (which is often true), you would simply do this:sub printHoL { my ($s, $hol) = @_; print "$s\n"; while (my ($k, $v) = each (%$hol)) { print "$k: @$v\n") } printSep(); }def printHoL(s, hol): print s for key, value in hol.items(): print key, ':', " ".join(value) printSep()Declaration of a hash of lists%HoL = ( flintstones => [ "fred", "barney" ], jetsons => [ "george", "jane", "elroy" ], simpsons => [ "homer", "marge", "bart" ], ); printHoL 'names', \%HoL;HoL = { 'flintstones' : ['fred', 'barney'], 'jetsons' : ['george', 'jane', 'elroy'], 'simpsons': ['homer', 'marge', 'bart'], } printHoL('names', HoL)In python, the print statement has very good default semantics --- most of the time, it does exactly what you want, putting a space between the arguments, and a newline at the end. If you want more control over the formatting, use the % operator [link to % operator]: rather thanprint k, ':', " ".join(v)you could useprint "%s: %s" % (k, " ".join(v))to avoid the space before the colon. Note that both Perl and python let you have a comma after the last element of a list. This is especially useful for automatically generated lists, where you don't want to have to worry about a special case at the end. Larry Wall says:
- The Perl code can be written in a more Pythonesque way, and means pretty much the identical thing. Perl always uses scalar variables for references. Note the brackets rather than the parens to get an anonymous hash constructor.
$HoL = { flintstones => [ "fred", "barney" ], jetsons => [ "george", "jane", "elroy" ], simpsons => [ "homer", "marge", "bart" ], }; printHoL (\'names\', $HoL);Note that since $HoL is already a ref, the \\ is no longer necessary. Initializing hashes of listsInitializing hashes of lists from a fileThe file is assumed to consist of a sequence of lines of the form:flintstones: fred barney wilma dinomy %HoL; open my $f, "cookTest.2" or die $!; while ( <$f> ) { next unless s/^(.*?):\s*//; $HoL{$1} = [ split ]; } printHoL 'read from file cookTest.2', \%HoL;HoL = {} for line in open('cookTest.2'): try: surname, people = line.split(":", 1) except ValueError: # can't split on ":" so no ":" in the line continue HoL[surname] = people.split() printHoL('read from file cookTest.2', HoL)Note that the Perl hash doesn't need to be initialized.Reading into a hash of lists from a file with temporaries# flintstones: fred barney wilma dino open my $f, "cookTest.3" or die $!; my %HoL; while ( defined(my $line = <$f>) ) { next unless $line =~ /:/; ($who, $rest) = split /:\s*/, $line, 2; @fields = split ' ', $rest; $HoL{$who} = [ @fields ]; } printHoL 'read from cookTest.3', \%HoL;HoL = {} for line in open('cookTest.3'): try: n = line.index(":") except ValueError: # ":" not found continue who, rest = line[:n], line[n+1:] # n+1 skips the colon fields = rest.split() HoL[who] = fields printHoL ('read from cookTest.3', HoL)Initializing a hash of lists from function callsFor each key of the hash, we call a function that creates a list, and associate the key with this list.my %HoL; foreach my $group (qw/simpsons jetsons flintstones/) { $HoL{$group} = [get_family $group]; } printHoL 'filled by get_family', \%HoL;HoL = {} for group in ("simpsons", "jetsons", "flintstones"): HoL[group] = get_family(group) printHoL ('filled by get_family', HoL)The python section could [but should NOT] have been written:HoL={} def set(group, hol=HoL): hol[group] = get_family(group) map(set, ("simpsons", "jetsons", "flintstones" )) printHoL ('filled by get_family', HoL)The Perl section could have been written:my %Hol; map {$HoL{$_} = [ get_family $_ ]} qw/simpsons jetsons flintstones/;The Perl section could also have been written like this (each of the control statements, if , unless , while , until , foreach , etc., can be written as a "modifier" at the end of a statement):my %HoL; $HoL{$_} = [get_family $_] foreach (qw/simpsons jetsons flintstones/);Initializing a hash of lists from function calls with temporariesFor each key of the hash, we call a function that creates a list, and associate the key with this list. The list is assigned to a local variable (where it could be modified, for example).my %HoL; foreach my $group (qw/simpsons jetsons flintstones/) { my @members = get_family $group; $HoL{$group} = [@members]; } printHoL 'by get_family with temps', \%HoL;HoL = {} for group in ("simpsons", "jetsons", "flintstones"): members = get_family(group) HoL[group] = members printHoL ('by get_family with temps', HoL)Append to a list in a hash of lists We want to add two strings to the list of strings indexed by the name flintstones .push @{ $HoL{flintstones} }, "wilma", "betty"; print "@{$HoL{flintstones}}\n"); printSep();HoL['flintstones'].extend(['wilma', 'betty']) print " ".join(HoL['flintstones']) printSep()Note: There is a big difference between the above two examples, which create a new list, leaving the original list object unchanged; and the following two examples, which modify the original list.HoL['flintstones'] += ['wilma', 'betty'] print " ".join(HoL['flintstones']) printSep()$HoL{'flintstones'} = [ @{ $HoL{'flintstones'} }, "wilma", "betty" ]; print "@{$HoL{flintstones}}\n"); printSep();Access elements of a hash of listsAccess a single elementAssign to the first element of the list indexed by flintstones .$HoL{flintstones}[0] = "Fred"; print $HoL{flintstones}[0], "\n"; printSep();HoL['flintstones'][0] = "Fred" print HoL['flintstones'][0] printSep()Tom Christiansen explains when you don't need quotes around strings in Perl:If blah were a function then you would have to use $something{blah()} to overwrite the stringificiation. Barewords are autoquoted in braces and as the LHS operand of =&rt; as well.
- It's whenever you have a bareword (identifier token) in braces. Thus ${blah} and $something{blah} don't need quotes.
Change a single elementThis upcases the first letter in the second element of the array indexed by simpsons . # another element$HoL{simpsons}[1] =~ s/(\w)/\u$1/; printHoL 'after modifying an element', \%HoL;HoL['simpsons'][1] = HoL['simpsons'][1].title() printHoL ('after modifying an element', HoL)Print a hash of lists Various different ways of printing it out.Simple printPrinted sorted by family name, in the format:family1: member1-1 member1-2... family2: member2-1 member2-2... ...foreach my $family ( sort keys %HoL ) { print "$family: @{ $HoL{$family} }\n"; } printSep();families = sorted(HoL.items()); for surname, members in families: print '%s: %s' % (surname, " ".join(members)) printSep()Print with indicesfor my $family ( sort keys %HoL ) { print "family: "; for my $i ( 0 .. $#{ $HoL{$family}} ) { print " $i = $HoL{$family}[$i]"; } print "\n"; } printSep();for surname in sorted(HoL.keys()): print 'surname: ', for i, member in enumerate(HoL[surname]): print '%d = %s' % (i, member), print printSep()Print sorted by number of memberspush (@{$HoL{simpsons}}, 'Lisa'); for my $family ( sort { @{$HoL{$b}} <=> @{$HoL{$a}} } keys %HoL ) { print "$family: @{ $HoL{$family} }\n" }HoL['simpsons'] += ['Lisa'] def keyNumberMembers(x): return len(x[1]) families = HoL.items() families.sort(key=keyNumberMembers) for surname, members in families: print "%s:" % surname, " ".join(members)You can use a lambda expression in python here, too, though I don't find it very readable:HoL['simpsons'] += ['Lisa'] families = HoL.items() families.sort(key=lambda x: len(x[1])) for surname, members in k: print "%s:" % surname, " ".join(members))Print sorted by number of members, and by name within each listforeach my $family ( sort { @{$HoL{$b}} <=> @{$HoL{$a}} } keys %HoL ) { print "$family: @{[ sort @{ $HoL{$family}} ]}\n"; }families = HoL.items() families.sort(key=lambda x: len(x[1])) for surname, members in families: members.sort() print "%s: %s" % (family, ", ".join(members))Do it more like the Perl version:for surname, members in sorted(HoL.items(), key=lambda x: len(x[1])): print "%s: %s" % (family, ", ".join(sorted(members)))Lists of hashes/dictionaries The Perl code in this section is taken, with permission, almost directly from Tom Christiansen's Perl Data Structures Cookbook , part 3, release 0.1, with a few typos fixed. Lists of hashes: preliminariessub printSep { print "=" x 60, "\n" } sub printLoH { my ($s, $loh) = @_; print "$s\n"; foreach my $h (@$loh) { print "[\n"; foreach my $k (sort keys %$h) { print " $k => $h->{$k}\n"; } print "]\n"; } printSep(); }import sys def printSep(): print '=' * 60 def printLoH(s,loh): print s for h in loh: print "[" items = h.items() items.sort() for key, val in items: print ' %s => %s' % (key, val) print "]" printSep()The only reason I sort the keys here is to make sure that python and Perl print the elements of the dictionary in the same order. Note that sorting in Perl generates a new list, while in python sorting is done in-place. This means that you can avoid making a copy while sorting in python. The disadvantage is a clumsier syntax for the common case where you do want a copy. Larry Wall says that in Perl, you almost always do want the copy; I am not sure whether this is true in Python. If you wanted to do the copy, you would just do this (in Python 2.4+):import sys def printSep(): print '=' * 60 def printLoH(s,loh): print s for h in loh: print "[" for key, val in sorted(h.items()): print ' %s => %s' % (key, val) print "]" printSep()Declaration of a list of hashes@LoH = ( { Lead => "fred", Friend => "barney", }, { Lead => "george", Wife => "jane", Son => "elroy", }, { Lead => "homer", Wife => "marge", Son => "bart", } ); printLoH ('initial value', \@LoH);LoH = [ { "Lead" : "fred", "Friend" : "barney" }, { "Lead" : "george", "Wife" : "jane", "Son" : "elroy" }, { "Lead" : "homer", "Wife" : "marge", "Son" : "bart" } ] printLoH ('initial value', LoH)Generation of a list of hashesReading a list of hashes from a fileThe format of the file is expected to be:LEAD=fred FRIEND=barney LEAD=homer WIFE=marge ...my @LoH; open my $f, "cooktest.4" or die $!; while ( <$f> ) { my $rec = {}; for my $field ( split ) { ($key, $value) = split /=/, $field; $rec->{$key} = $value; } push @LoH, $rec; } printLoH 'after reading from file cooktest.4', LoH;LoH = [] for line in open("cooktest.4") rec = {} for field in line.split(): key, value = field.split('=', 1) rec[key] = value LoH.append (rec) printLoH ('after reading from file cooktest.4', LoH)Reading a list of hashes from a file without temporariesmy @LoH; open my $f, "cooktest.4" or die $!; while ( <$f> ) { push @LoH, { split /[\s=]+/ }; } printLoH ('direct read from file', \@LoH);# This builds a list of (key, value) pairs, and then creates the # dictionary from those. A temporary pairs is used for readability LoH = [] for line in open("cooktest.4") pairs = [field.split("=", 1) for field in line.split()] LoH.append(dict(pairs)) printLoH ('direct read from file', LoH)If you really want no temporaries at all, you could (but shouldn't) use the one line list comprehension (line breaks for legibility):LoH = [dict([field.split("=", 1) for field in line.split()]) for line in open("cooktest.4")] printLoH ('direct read from file', LoH)Generation of a list of hashes from function callsPreliminaries
For convenience, these functions and variables are global. getnextpairset returns the elements of the array _getnextpairsetdata. I don't know why Tom chose to make this return a list in Perl, rather than a reference to a hash. Perhaps to keep the order. You can still initialize a hash with the result. In python, returning a dictionary is definitely the way to go.$_getnextpairsetcounter = 0; @_getnextpairsetdata = ( ["lead", "fred", "daughter", "pebbles"], ["lead", "kirk", "first_officer", "spock", "doc", "mccoy"]); sub getnextpairset{ if ($_getnextpairsetcounter > $#_getnextpairsetdata) { return (); } return @{$_getnextpairsetdata[$_getnextpairsetcounter++]}; } sub parsepairs{ my $line = shift; chomp $line; return split (/[= ]/, $line); }_getnextpairsetcounter = 0 _getnextpairsetdata =\ [ {"lead" : "fred", "daughter" : "pebbles"}, {"lead" : "kirk", "first_officer" : "spock", "doc" : "mccoy"} ] def getnextpairset(): global _getnextpairsetcounter if _getnextpairsetcounter == len(_getnextpairsetdata) : return '' result = _getnextpairsetdata[_getnextpairsetcounter] _getnextpairsetcounter += 1 return result def parsepairs(line): line = line[:-1] # chop last character off dict = {} pairs = regsub.split (line, "[= ]") for i in range(0, len(pairs), 2): dict[pairs[i]] = pairs[i+1] return dictThis would be much more elegant as a class, both in python and Perl. [add a pointer to classes when we get there]Generation
Call a function returning a list (in Perl) or a dictionary (in python). In Perl, the list is of the form ("lead","fred","daughter","pebbles") ; in python, the dictionary is of the form {"lead" : "fred", "daughter" : "pebbles"} .# calling a function that returns a key,value list, like my @LoH; while ( my %fields = getnextpairset() ) { push @LoH, { %fields }; } printLoH ('filled with getnextpairset', \@LoH);LoH = [] while True: fields = getnextpairset() if not fields: break LoH.append (fields) printLoH ('filled with getnextpairset', LoH)Generation without temporaries
Sep 14, 2019 | wiki.python.org
my @LoH; open my $f, "cooktest.4" or die $!; while (<$f>) { push @LoH, { parsepairs($_) }; } printLoH 'generated from function calls with no temps', \@LoH;LoH = [parsepairs(line) for line in open("cooktest.4")] printLoH ('generated from function calls with no temps', LoH)Adding a key/value pair to an element$LoH[0]{PET} = "dino"; $LoH[2]{PET} = "santa's little helper"; printLoH ('after addition of key/value pairs', \@LoH);LoH[0]["PET"] = "dino" LoH[2]["PET"] = "santa's little helper" printLoH ('after addition of key/value pairs', LoH)Accessing elements of a list of hashes$LoH[0]{LEAD} = "fred"; print $LoH[0]{LEAD}, "\n"; s/(\w)/\u$1/, print "$_\n" for $LoH[1]{LEAD}; printSep();LoH[0]["LEAD"] = "fred" print (LoH[0]["LEAD"]) LoH[1]["LEAD"] = LoH[1]["LEAD"].title() print (LoH[1]["LEAD"]) printSep()Printing a list of hashesSimple printfor my $href ( @LoH ) { print "{ "; for my $role ( sort keys %$href ) { print "$role=$href->{$role} "; } print "}\n"; }for href in LoH: print "{", items = href.items(); items.sort() for role, val in items: print "%s=%s" %(role, val), print "}"Note the comma after the print in the python segment -- this means "don't add a newline".
Print with indicesfor my $i ( 0 .. $#LoH ) { print "$i is { "; for my $role ( sort keys %{ $LoH[$i] } ) { print "$role=$LoH[$i]{$role} "; } print "}\n"; }for i, elem in enumerate(LoH): print i, "is {", items = elem.items(); items.sort() for role, val in items: print "%s=%s" % (role, val), print "}"Note the comma after the print in the python segment -- this means "don't add a newline". It does, however, add a space.
Print whole thing one at a timefor my $i ( 0 .. $#LoH ) { for my $role ( sort keys %{ $LoH[$i] } ) { print "elt $i $role is $LoH[$i]{$role}\n"; } }for i, elem in enumerate(LoH): items = elem.items(); items.sort() for role, val in items: print "elt", i, role, "is", valInterface to the Tk GUI toolkitThe Perl versions of this code have not been tested, as we don't currently have a working version of Perl and Tk.
[Links to tkinter doc]
PreliminariesAll the following code snippets will need these declarations first:
use Tk;from Tkinter import * import sysHello world label$top = MainWindow->new; $hello = $top->Button( '-text' => 'Hello, world', '-command' => sub {print STDOUT "Hello, world\n";exit 0;} ); $hello->pack; MainLoop;top = Tk() def buttonFunction () : print 'Hello, world' sys.exit (-1) hello = Button(top, {'text' : 'Hello, world', 'command' : buttonFunction}) hello.pack() top.mainloop()clear
PerlPhrasebook (last edited 2012-04-26 23:22:09 by 137 )
Unable to edit the page? See the FrontPage for instructions.
Sep 12, 2019 | everythingsysadmin.com
Tom Limoncelli's EverythingSysadmin Blog
Python for Perl Programmers There are certain Perl idioms that every Perl programmer uses: "while (<>) { foo; }" and "foo ~= s/old/new/g" both come to mind.When I was learning Python I was pretty peeved that certain Python books don't get to that kind of thing until much later chapters. One didn't cover that kind of thing until the end! As [a long-time Perl user](https://everythingsysadmin.com/2011/03/overheard-at-the-office-perl-e.html) this annoyed and confused me.
While they might have been trying to send a message that Python has better ways to do those things, I think the real problem was that the audience for a general Python book is a lot bigger than the audience for a book for Perl people learning Python. Imagine how confusing it would be to a person learning their first programming language if their book started out comparing one language you didn't know to a different language you didn't know!
So here are the idioms I wish were in Chapter 1. I'll be updating this document as I think of new ones, but I'm trying to keep this to be a short list.
Processing every line in a filePerl:
while (<>) { print $_; }Python:
for line in file('filename.txt'): print lineTo emulate the Perl <> technique that reads every file on the command line or stdin if there is none:
import fileinput for line in fileinput.input(): print lineIf you must access stdin directly, that is in the "sys" module:
import sys for line in sys.stdin: print lineHowever, most Python programmers tend to just read the entire file into one huge string and process it that way. I feel funny doing that. Having used machines with very limited amounts of RAM, I tend to try to keep my file processing to a single line at a time. However, that method is going the way of the dodo.
contents = file('filename.txt').read() all_input = sys.stdin.read()If you want the file to be one string per line, with the newline removed just change read() to readlines()
list_of_strings = file('filename.txt').readlines() all_input_as_list = sys.stdin.readlines()Regular expressionsPython has a very powerful RE system, you just have to enable it with "import re". Any place you can use a regular expression you can also use a compiled regular expresion. Python people tend to always compile their regular expressions; I guess they aren't used to writing throw-away scripts like in Perl:
import re RE_DATE = re.compile(r'\d\d\d\d-\d{1,2}-\d{1,2}') for line in sys.stdin: mo = re.search(RE_DATE, line) if mo: print mo.group(0)There is re.search() and re.match(). re.match() only matches if the string starts with the regular expression. It is like putting a "^" at the front of your regex. re.search() is like putting a ".*" at the front of your regex. Since match comes before search alphabetically, most Perl users find "match" in the documentation, try to use it, and get confused that r'foo' does not match 'i foo you'. My advice? Pretend match doesn't exist (just kidding).
The big change you'll have to get used to is that the result of a match is an object, and you pull various bits of information from the object. If nothing is found, you don't get an object, you get None, which makes it easy to test for in a if/then. An object is always True, None is always false. Now that code above makes more sense, right?
Yes, you can put parenthesis around parts of the regular expression to extract out data. That's where the match object that gets returned is pretty cool:
import re for line in sys.stdin: mo = re.search(r'(\d\d\d\d)-(\d{1,2})-(\d{1,2})', line) if mo: print mo.group(0)The first thing you'll notice is that the "mo =" and the "if" are on separate lines. There is no "if x = re.search() then" idiom in Python like there is in Perl. It is annoying at first, but eventually I got used to it and now I appreciate that I can't accidentally assign a variable that I meant to compare.
Let's look at that match object that we assigned to the variable "mo" earlier:
- mo.group(0) -- The part of the string that matched the regex.
- mo.group(1) -- The first ()'ed part
- mo.group(2) -- The second ()'ed part
- mo.group(1,3) -- The first and third matched parts (as a tuple)
- mo.groups() -- A tuple containing all the matched parts.
The perl s// substitutions are easily done with re.sub() but if you don't require a regular expression "replace" is much faster:
>>> re.sub(r'\d\d+', r'', '1 22 333 4444 55555') '1 ' >>> re.sub(r'\d+', r'', '9876 and 1234') ' and ' >>> re.sub(r'remove', r'', 'can you remove from') 'can you from' >>> 'can you remove from'.replace('remove', '') 'can you from'You can even do multiple parenthesis substitutions as you would expect:
>>> re.sub(r'(\d+) and (\d+)', r'yours=\1 mine=\2', '9876 and 1234') 'yours=9876 mine=1234'After you get used to that, read the ""pydoc re" page":http://docs.python.org/library/re.html for more information.
String manipulationsI found it odd that Python folks don't use regular expressions as much as Perl people. At first I though this was due to the fact that Python makes it more cumbersome ('cause I didn't like to have to do 'import re'). It turns out that Python string handling can be more powerful. For example the common Perl idiom "s/foo/bar" (as long as "foo" is not a regex) is as simple as:
credit = 'i made this' print credit.replace('made', 'created')or
print 'i made this'.replace('made', 'created')
It is kind of fun that strings are objects that have methods. It looks funny at first.
Notice that replace returns a string. It doesn't modify the string. In fact, strings can not be modified, only created. Python cleans up for automatically, and it can't do that very easily if things change out from under it. This is very Lisp-like. This is odd at first but you get used to it. Wait... by "odd" I mean "totally fucking annoying". However, I assure you that eventually you'll see the benefits of string de-duplication and (I'm told) speed.
It does mean, however, that accumulating data in a string is painfully slow:
s = 'this is the first part\n' s += 'i added this.\n' s += 'and this.\n' s += 'and then this.\n'The above code is bad. Each assignment copies all the previous data just to make a new string. The more you accumulate, the more copying is needed. The Pythonic way is to accumulate a list of the strings and join them later.
s = [] s.append('this is the first part\n') s.append('i added this.\n') s.append('and this.\n') s.append('and then this.\n') print ''.join(s)It seems slower, but it is actually faster. The strings stay in their place. Each addition to "s" is just adding a pointer to where the strings are in memory. You've essentially built up a linked list of pointers, which are much more light-weight and faster to manage than copying those strings around. At the end, you join the strings. Python makes one run through all the strings, copying them to a buffer, a pointer to which is sent to the "print" routine. This is about the same amount of work as Perl, which internally was copying the strings into a buffer along the way. Perl did copy-bytes, copy-bytes, copy-bytes, copy-bytes, pass pointer to print. Python did append-pointer 4 times then a highly optimized copy-bytes, copy-bytes, copy-bytes, copy-bytes, pass pointer to print.
joining and splitting.This killed me until I got used to it. The join string is not a parameter to join but is a method of the string type.
Perl:
new = join('|', str1, str2, str3)Python:
new = '|'.join([str1, str2, str3])Python's join is a function of the delimiter string. It hurt my brain until I got used to it.
Oh, the join() function only takes one argument. What? It's joining a list of things... why does it take only one argument? Well, that one argument is a list. (see example above). I guess that makes the syntax more uniform.
Splitting strings is much more like Perl... kind of. The parameter is what you split on, or leave it blank for "awk-like splitting" (which heathens call "perl-like splitting" but they are forgetting their history).
Perl:
my @values = split('|', $data);Python:
values = data.split('|'); You can split a string literal too. In this example we don't give split() any parameters so that it does "awk-like splitting".print 'one two three four'.split() ['one', 'two', 'three', 'four']If you have a multi-line string that you want to break into its individual lines, bigstring.splitlines() will do that for you.
Getting helppydoc fooexcept it doesn't work half the time because you need to know the module something is in . I prefer the "quick search" box on http://docs.python.org or "just use Google".
I have not read ""Python for Unix and Linux System Administration":http://www.amazon.com/dp/0596515820/safocus-20" but the table of contents looks excellent. I have read most of Python Cookbook (the first edition, there is a 2nd edition out too) and learned a lot. Both are from O'R eilly and can be read on Safari Books Online .
That's it!That's it! Those few idioms make up most of the Perl code I usually wrote. Learning Python would have been so much easier if someone had showed me the Python equivalents early on.
One last thing... As a sysadmin there are a few modules that I've found useful:
14 Comments
- subprocess -- Replaces the need to figure out Popen(), system() and a ton of other error-prone system calls.
- logging -- very nice way to log debug info
- os -- OS-independent ways to do things like copy files, look at ENV variables, etc.
- sys -- argv, stdio, etc.
- gflags -- My fav. flag/getopt replacement http://code.google.com/p/python-gflags/
- pexpect -- Like Expect.PM http://pexpect.sourceforge.net/
- paramiko -- Python access to ssh/scp/sftp. http://www.lag.net/paramiko/
- PerlPhrasebook - http://wiki.python.org/moin/PerlPhrasebook is kind of ok, but hasn't been updated in a while.
swheatley | March 31, 2011 9:26 AM Once you get comfortable with Python basics, I highly recommend checking out David Beazley's "Generator Tricks for System Programmers" . This is a great compromise between the classic one-line-at-a-time processing you mention in your post, but allows you to treat the source as if all the lines were read into memory already. John | March 31, 2011 4:17 PM Would be nice if you also included an example of doing regex-based search/replace when there's ()'s involved.
Paddy3118 | April 1, 2011 3:00 AM You missed the following page that does more of the same for Python 2.X:http://wiki.python.org/moin/PerlPhrasebook
- Paddy.
Chaos | April 2, 2011 10:14 PM Do you know of any good references for pexpect? I use it a lot, but i wouldn't say i've gotten used to it (i'm not really an expect expert either), and i get bitten a lot.Tom Limoncelli replied to comment from martin | April 6, 2011 10:36 AM Perl will only recopy the string if it needs to because the buffer allocated to it has run out of space. It will allocate a new (larger) buffer, copy the string there, and do the operation in that new buffer. If you keep appending small strings to a string, it may have to recopy the string every time, or every other time, or less depending on how much extra space it allocates. However, you can modify the string in-place without causing it to need to recopy if the change doesn't affect the length of the string. In other words, you can "poke" a replacement character at position 3 to change '123456' to '123x56'.
Python, however, can not change a string. Ever. They are allocated with the exact amount of space required, no extra, and even then they are immutable. You can't take a string and change the 3rd char in. Methods like replace() return a new string with the result; the old string is still there. Something like "x += 'foo'" creates a new string and destroys the old one invisibly.
Gustavo Chaves | April 17, 2011 7:19 PM Perl regexes are implicitly compiled unless they are the result of scalar interpolation. That's why you only ocasionally see things like qr/RE/ or /RE/o in scripts. In Python you have to be explicit all the time I guess.
Jack | April 4, 2012 11:37 AM argparse >> gflags uwe | April 4, 2012 2:06 PM On the split part, in python it would be:
values = data.split('|')Alex Aminoff | December 6, 2013 4:45 PM I'm really having a hard time understanding how to easily and quickly interpolate variables into strings, especially for repetitive stuff like debug messages.
In perl, I surely spend half my day typing
print "at this point in the program, here is foo:$foo bar:$bar" if $debug
In python, there are several ways to do this but it appears that they either require more typing, especially closing the quote on my string and using +, or referring to each substituted string in two places, like
print " foo:%s bar:%s" % str(foo),str(bar)
which is terrible because if I want to add another variable baz, I have to modify two places in the line.
I need this to be really easy because my generate and test cycle frequently includes such print statements.
Do python programmers just do the entire generate and test cycle in some different way? Bob DuCharme | January 20, 2015 5:22 PM Thanks for writing this. You wrote "Imagine how confusing it would be to a person learning their first programming language if their book started out comparing one language you didn't know to a different language you didn't know!" I've been learning about Scala lately, and I know the basics of Java, but most tutorials assume that you know Java really well, which is annoying. Best of Blog
- Assessing Progress with "DevOps Look-for's"
- So your management fails at IT, huh?
- 4 unix commands I abuse every day
- a list of dumb things to check
- April showers bring May Flowers... but May brings...
- The right answer
- Tips for Technical Resumes
Navigation
Recent Entries
- Home
- Ordering Information
- Articles by the authors
- Time Management Wiki
- TPOSANA Wiki
- Contact Us
- Privacy Policy
Search
- Demo Data as Code
- Next nycdevops meetup: Kubernetes Informers (Wed, June 19)
- April NYC DevOps Meetup: Building a tamper-evident CI/CD system
- DevOpsDays-NYC nearly sold out! Register soon!
- Ericsson/O2 outage root cause announced
- Understanding your competition is a culture
- Taryn's SQL upgrade blog post
- Google Authenticator tips
- SREs with Windows experience? (NYC-area)
- I'll be at All-Day-DevOps: Free registration!
Search blog entries:
ArchivesRSS Feed Syndicate this site (XML) Credits
- August 2019
- June 2019
- April 2019
- January 2019
- December 2018
- November 2018
- October 2018
- September 2018
- August 2018
- June 2018
- May 2018
- April 2018
- More Archives
- Powered by:
Movable Type 6.3.8- Bandwidth by:
DataBasement.org- Site design by:
Mihai Bocsaru- Movable Type development by:
PRO IT Service- Movable Type
upgrade by:
MovableTypeUpgrade.com
This weblog is licensed under a Creative Commons License .
https://banners.itunes.apple.com/banner.html?partnerId=&aId=&bt=catalog&t=catalog_white&id=568428364&c=us&l=en-US&w=180&h=150&store=apps



Mar 17, 2019 | stackoverflow.com
John Kugelman ,Jul 1, 2009 at 3:29
I found this Perl script while migrating my SQLite database to mysqlI was wondering (since I don't know Perl) how could one rewrite this in Python?
Bonus points for the shortest (code) answer :)
edit : sorry I meant shortest code, not strictly shortest answer
#! /usr/bin/perl while ($line = <>){ if (($line !~ /BEGIN TRANSACTION/) && ($line !~ /COMMIT/) && ($line !~ /sqlite_sequence/) && ($line !~ /CREATE UNIQUE INDEX/)){ if ($line =~ /CREATE TABLE \"([a-z_]*)\"(.*)/){ $name = $1; $sub = $2; $sub =~ s/\"//g; #" $line = "DROP TABLE IF EXISTS $name;\nCREATE TABLE IF NOT EXISTS $name$sub\n"; } elsif ($line =~ /INSERT INTO \"([a-z_]*)\"(.*)/){ $line = "INSERT INTO $1$2\n"; $line =~ s/\"/\\\"/g; #" $line =~ s/\"/\'/g; #" }else{ $line =~ s/\'\'/\\\'/g; #' } $line =~ s/([^\\'])\'t\'(.)/$1THIS_IS_TRUE$2/g; #' $line =~ s/THIS_IS_TRUE/1/g; $line =~ s/([^\\'])\'f\'(.)/$1THIS_IS_FALSE$2/g; #' $line =~ s/THIS_IS_FALSE/0/g; $line =~ s/AUTOINCREMENT/AUTO_INCREMENT/g; print $line; } }Some additional code was necessary to successfully migrate the sqlite database (handles one line Create table statements, foreign keys, fixes a bug in the original program that converted empty fields
''to\'.I posted the code on the migrating my SQLite database to mysql Question
Jiaaro ,Jul 2, 2009 at 10:15
Here's a pretty literal translation with just the minimum of obvious style changes (putting all code into a function, using string rather than re operations where possible).import re, fileinput def main(): for line in fileinput.input(): process = False for nope in ('BEGIN TRANSACTION','COMMIT', 'sqlite_sequence','CREATE UNIQUE INDEX'): if nope in line: break else: process = True if not process: continue m = re.search('CREATE TABLE "([a-z_]*)"(.*)', line) if m: name, sub = m.groups() line = '''DROP TABLE IF EXISTS %(name)s; CREATE TABLE IF NOT EXISTS %(name)s%(sub)s ''' line = line % dict(name=name, sub=sub) else: m = re.search('INSERT INTO "([a-z_]*)"(.*)', line) if m: line = 'INSERT INTO %s%s\n' % m.groups() line = line.replace('"', r'\"') line = line.replace('"', "'") line = re.sub(r"([^'])'t'(.)", r"\1THIS_IS_TRUE\2", line) line = line.replace('THIS_IS_TRUE', '1') line = re.sub(r"([^'])'f'(.)", r"\1THIS_IS_FALSE\2", line) line = line.replace('THIS_IS_FALSE', '0') line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT') print line, main()dr jimbob ,May 20, 2018 at 0:54
Alex Martelli's solution above works good, but needs some fixes and additions:In the lines using regular expression substitution, the insertion of the matched groups must be double-escaped OR the replacement string must be prefixed with r to mark is as regular expression:
line = re.sub(r"([^'])'t'(.)", "\\1THIS_IS_TRUE\\2", line)or
line = re.sub(r"([^'])'f'(.)", r"\1THIS_IS_FALSE\2", line)Also, this line should be added before print:
line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT')Last, the column names in create statements should be backticks in MySQL. Add this in line 15:
sub = sub.replace('"','`')Here's the complete script with modifications:
import re, fileinput def main(): for line in fileinput.input(): process = False for nope in ('BEGIN TRANSACTION','COMMIT', 'sqlite_sequence','CREATE UNIQUE INDEX'): if nope in line: break else: process = True if not process: continue m = re.search('CREATE TABLE "([a-z_]*)"(.*)', line) if m: name, sub = m.groups() sub = sub.replace('"','`') line = '''DROP TABLE IF EXISTS %(name)s; CREATE TABLE IF NOT EXISTS %(name)s%(sub)s ''' line = line % dict(name=name, sub=sub) else: m = re.search('INSERT INTO "([a-z_]*)"(.*)', line) if m: line = 'INSERT INTO %s%s\n' % m.groups() line = line.replace('"', r'\"') line = line.replace('"', "'") line = re.sub(r"([^'])'t'(.)", "\\1THIS_IS_TRUE\\2", line) line = line.replace('THIS_IS_TRUE', '1') line = re.sub(r"([^'])'f'(.)", "\\1THIS_IS_FALSE\\2", line) line = line.replace('THIS_IS_FALSE', '0') line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT') if re.search('^CREATE INDEX', line): line = line.replace('"','`') print line, main()Brad Gilbert ,Jul 1, 2009 at 18:43
Here is a slightly better version of the original.#! /usr/bin/perl use strict; use warnings; use 5.010; # for s/\K//; while( <> ){ next if m' BEGIN TRANSACTION | COMMIT | sqlite_sequence | CREATE UNIQUE INDEX 'x; if( my($name,$sub) = m'CREATE TABLE \"([a-z_]*)\"(.*)' ){ # remove " $sub =~ s/\"//g; #" $_ = "DROP TABLE IF EXISTS $name;\nCREATE TABLE IF NOT EXISTS $name$sub\n"; }elsif( /INSERT INTO \"([a-z_]*)\"(.*)/ ){ $_ = "INSERT INTO $1$2\n"; # " => \" s/\"/\\\"/g; #" # " => ' s/\"/\'/g; #" }else{ # '' => \' s/\'\'/\\\'/g; #' } # 't' => 1 s/[^\\']\K\'t\'/1/g; #' # 'f' => 0 s/[^\\']\K\'f\'/0/g; #' s/AUTOINCREMENT/AUTO_INCREMENT/g; print; }Mickey Mouse ,Jun 14, 2011 at 15:48
all of scripts on this page can't deal with simple sqlite3:PRAGMA foreign_keys=OFF; BEGIN TRANSACTION; CREATE TABLE Filename ( FilenameId INTEGER, Name TEXT DEFAULT '', PRIMARY KEY(FilenameId) ); INSERT INTO "Filename" VALUES(1,''); INSERT INTO "Filename" VALUES(2,'bigfile1'); INSERT INTO "Filename" VALUES(3,'%gconf-tree.xml');None were able to reformat "table_name" into proper mysql's `table_name` . Some messed up empty string value.
Sinan Ünür ,Jul 1, 2009 at 3:24
I am not sure what is so hard to understand about this that it requires a snide remark as in your comment above. Note that<>is called the diamond operator.s///is the substitution operator and//is the match operatorm//.Ken_g6 ,Jul 1, 2009 at 3:22
Based on http://docs.python.org/dev/howto/regex.html ...
- Replace
$line =~ /.*/withre.search(r".*", line).$line !~ /.*/is just!($line =~ /.*/).- Replace
$line =~ s/.*/x/gwithline=re.sub(r".*", "x", line).- Replace
$1through$9insidere.subwith\1through\9respectively.- Outside a sub, save the return value, i.e.
m=re.search(), and replace$1with the return value ofm.group(1).- For
"INSERT INTO $1$2\n"specifically, you can do"INSERT INTO %s%s\n" % (m.group(1), m.group(2)).hpavc ,Jul 1, 2009 at 12:33
Real issue is do you know actually how to migrate the database? What is presented is merely a search and replace loop.> ,
Shortest? The tilde signifies a regex in perl. "import re" and go from there. The only key differences are that you'll be using \1 and \2 instead of $1 and $2 when you assign values, and you'll be using %s for when you're replacing regexp matches inside strings.
Mar 16, 2019 | stackoverflow.com
Translating Perl to Python Ask Question 21
John Kugelman ,Jul 1, 2009 at 3:29
I found this Perl script while migrating my SQLite database to mysqlI was wondering (since I don't know Perl) how could one rewrite this in Python?
Bonus points for the shortest (code) answer :)
edit : sorry I meant shortest code, not strictly shortest answer
#! /usr/bin/perl while ($line = <>){ if (($line !~ /BEGIN TRANSACTION/) && ($line !~ /COMMIT/) && ($line !~ /sqlite_sequence/) && ($line !~ /CREATE UNIQUE INDEX/)){ if ($line =~ /CREATE TABLE \"([a-z_]*)\"(.*)/){ $name = $1; $sub = $2; $sub =~ s/\"//g; #" $line = "DROP TABLE IF EXISTS $name;\nCREATE TABLE IF NOT EXISTS $name$sub\n"; } elsif ($line =~ /INSERT INTO \"([a-z_]*)\"(.*)/){ $line = "INSERT INTO $1$2\n"; $line =~ s/\"/\\\"/g; #" $line =~ s/\"/\'/g; #" }else{ $line =~ s/\'\'/\\\'/g; #' } $line =~ s/([^\\'])\'t\'(.)/$1THIS_IS_TRUE$2/g; #' $line =~ s/THIS_IS_TRUE/1/g; $line =~ s/([^\\'])\'f\'(.)/$1THIS_IS_FALSE$2/g; #' $line =~ s/THIS_IS_FALSE/0/g; $line =~ s/AUTOINCREMENT/AUTO_INCREMENT/g; print $line; } }Some additional code was necessary to successfully migrate the sqlite database (handles one line Create table statements, foreign keys, fixes a bug in the original program that converted empty fields
''to\'.I posted the code on the migrating my SQLite database to mysql Question
Jiaaro ,Jul 2, 2009 at 10:15
Here's a pretty literal translation with just the minimum of obvious style changes (putting all code into a function, using string rather than re operations where possible).import re, fileinput def main(): for line in fileinput.input(): process = False for nope in ('BEGIN TRANSACTION','COMMIT', 'sqlite_sequence','CREATE UNIQUE INDEX'): if nope in line: break else: process = True if not process: continue m = re.search('CREATE TABLE "([a-z_]*)"(.*)', line) if m: name, sub = m.groups() line = '''DROP TABLE IF EXISTS %(name)s; CREATE TABLE IF NOT EXISTS %(name)s%(sub)s ''' line = line % dict(name=name, sub=sub) else: m = re.search('INSERT INTO "([a-z_]*)"(.*)', line) if m: line = 'INSERT INTO %s%s\n' % m.groups() line = line.replace('"', r'\"') line = line.replace('"', "'") line = re.sub(r"([^'])'t'(.)", r"\1THIS_IS_TRUE\2", line) line = line.replace('THIS_IS_TRUE', '1') line = re.sub(r"([^'])'f'(.)", r"\1THIS_IS_FALSE\2", line) line = line.replace('THIS_IS_FALSE', '0') line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT') print line, main()dr jimbob ,May 20, 2018 at 0:54
Alex Martelli's solution above works good, but needs some fixes and additions:In the lines using regular expression substitution, the insertion of the matched groups must be double-escaped OR the replacement string must be prefixed with r to mark is as regular expression:
line = re.sub(r"([^'])'t'(.)", "\\1THIS_IS_TRUE\\2", line)or
line = re.sub(r"([^'])'f'(.)", r"\1THIS_IS_FALSE\2", line)Also, this line should be added before print:
line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT')Last, the column names in create statements should be backticks in MySQL. Add this in line 15:
sub = sub.replace('"','`')Here's the complete script with modifications:
import re, fileinput def main(): for line in fileinput.input(): process = False for nope in ('BEGIN TRANSACTION','COMMIT', 'sqlite_sequence','CREATE UNIQUE INDEX'): if nope in line: break else: process = True if not process: continue m = re.search('CREATE TABLE "([a-z_]*)"(.*)', line) if m: name, sub = m.groups() sub = sub.replace('"','`') line = '''DROP TABLE IF EXISTS %(name)s; CREATE TABLE IF NOT EXISTS %(name)s%(sub)s ''' line = line % dict(name=name, sub=sub) else: m = re.search('INSERT INTO "([a-z_]*)"(.*)', line) if m: line = 'INSERT INTO %s%s\n' % m.groups() line = line.replace('"', r'\"') line = line.replace('"', "'") line = re.sub(r"([^'])'t'(.)", "\\1THIS_IS_TRUE\\2", line) line = line.replace('THIS_IS_TRUE', '1') line = re.sub(r"([^'])'f'(.)", "\\1THIS_IS_FALSE\\2", line) line = line.replace('THIS_IS_FALSE', '0') line = line.replace('AUTOINCREMENT', 'AUTO_INCREMENT') if re.search('^CREATE INDEX', line): line = line.replace('"','`') print line, main()Brad Gilbert ,Jul 1, 2009 at 18:43
Here is a slightly better version of the original.#! /usr/bin/perl use strict; use warnings; use 5.010; # for s/\K//; while( <> ){ next if m' BEGIN TRANSACTION | COMMIT | sqlite_sequence | CREATE UNIQUE INDEX 'x; if( my($name,$sub) = m'CREATE TABLE \"([a-z_]*)\"(.*)' ){ # remove " $sub =~ s/\"//g; #" $_ = "DROP TABLE IF EXISTS $name;\nCREATE TABLE IF NOT EXISTS $name$sub\n"; }elsif( /INSERT INTO \"([a-z_]*)\"(.*)/ ){ $_ = "INSERT INTO $1$2\n"; # " => \" s/\"/\\\"/g; #" # " => ' s/\"/\'/g; #" }else{ # '' => \' s/\'\'/\\\'/g; #' } # 't' => 1 s/[^\\']\K\'t\'/1/g; #' # 'f' => 0 s/[^\\']\K\'f\'/0/g; #' s/AUTOINCREMENT/AUTO_INCREMENT/g; print; }Mickey Mouse ,Jun 14, 2011 at 15:48
all of scripts on this page can't deal with simple sqlite3:PRAGMA foreign_keys=OFF; BEGIN TRANSACTION; CREATE TABLE Filename ( FilenameId INTEGER, Name TEXT DEFAULT '', PRIMARY KEY(FilenameId) ); INSERT INTO "Filename" VALUES(1,''); INSERT INTO "Filename" VALUES(2,'bigfile1'); INSERT INTO "Filename" VALUES(3,'%gconf-tree.xml');None were able to reformat "table_name" into proper mysql's `table_name` . Some messed up empty string value.
Sinan Ünür ,Jul 1, 2009 at 3:24
I am not sure what is so hard to understand about this that it requires a snide remark as in your comment above. Note that<>is called the diamond operator.s///is the substitution operator and//is the match operatorm//.Ken_g6 ,Jul 1, 2009 at 3:22
Based on http://docs.python.org/dev/howto/regex.html ...
- Replace
$line =~ /.*/withre.search(r".*", line).$line !~ /.*/is just!($line =~ /.*/).- Replace
$line =~ s/.*/x/gwithline=re.sub(r".*", "x", line).- Replace
$1through$9insidere.subwith\1through\9respectively.- Outside a sub, save the return value, i.e.
m=re.search(), and replace$1with the return value ofm.group(1).- For
"INSERT INTO $1$2\n"specifically, you can do"INSERT INTO %s%s\n" % (m.group(1), m.group(2)).hpavc ,Jul 1, 2009 at 12:33
Real issue is do you know actually how to migrate the database? What is presented is merely a search and replace loop.> ,
Shortest? The tilde signifies a regex in perl. "import re" and go from there. The only key differences are that you'll be using \1 and \2 instead of $1 and $2 when you assign values, and you'll be using %s for when you're replacing regexp matches inside strings.
Mar 16, 2019 | stackoverflow.com
Regex translation from Perl to Python Ask Question 1
royskatt ,Jan 30, 2014 at 14:45
I would like to rewrite a small Perl programm to Python. I am processing text files with it as follows:Input:
00000001;Root;; 00000002; Documents;; 00000003; oracle-advanced_plsql.zip;file; 00000004; Public;; 00000005; backup;; 00000006; 20110323-JM-F.7z.001;file; 00000007; 20110426-JM-F.7z.001;file; 00000008; 20110603-JM-F.7z.001;file; 00000009; 20110701-JM-F-via-summer_school;; 00000010; 20110701-JM-F-yyy.7z.001;file;Desired output:
00000001;;Root;; 00000002; ;Documents;; 00000003; ;oracle-advanced_plsql.zip;file; 00000004; ;Public;; 00000005; ;backup;; 00000006; ;20110323-JM-F.7z.001;file; 00000007; ;20110426-JM-F.7z.001;file; 00000008; ;20110603-JM-F.7z.001;file; 00000009; ;20110701-JM-F-via-summer_school;; 00000010; ;20110701-JM-F-yyy.7z.001;file;Here is the working Perl code:
#filename: perl_regex.pl #/usr/bin/perl -w while(<>) { s/^(.*?;.*?)(\w)/$1;$2/; print $_; }It call it from the command line:
perl_regex.pl input.txtExplanation of the Perl-style regex:
s/ # start search-and-replace regexp ^ # start at the beginning of this line ( # save the matched characters until ')' in $1 .*?; # go forward until finding the first semicolon .*? # go forward until finding... (to be continued below) ) ( # save the matched characters until ')' in $2 \w # ... the next alphanumeric character. ) / # continue with the replace part $1;$2 # write all characters found above, but insert a ; before $2 / # finish the search-and-replace regexp.Could anyone tell me, how to get the same result in Python? Especially for the $1 and $2 variables I couldn't find something alike.
royskatt ,Jan 31, 2014 at 6:18
Python regular expression is very similar to Perl's, except:
- In Python there's no regular expression literal. It should be expressed using string. I used
r'raw string literal'in the following code.- Backreferences are expressed as
\1,\2, .. or\g<1>,\g<2>, ..- ...
Use
re.subto replace.import re import sys for line in sys.stdin: # Explicitly iterate standard input line by line # `line` contains trailing newline! line = re.sub(r'^(.*?;.*?)(\w)', r'\1;\2', line) #print(line) # This print trailing newline sys.stdout.write(line) # Print the replaced string back.royskatt ,Jan 31, 2014 at 16:36
The replace instruction for s/pattern/replace/ in python regexes is the re.sub(pattern, replace, string) function, or re.compile(pattern).sub(replace, string). In your case, you will do it so:_re_pattern = re.compile(r"^(.*?;.*?)(\w)") result = _re_pattern.sub(r"\1;\2", line)Note that
$1becomes\1. As for perl, you need to iterate over your lines the way you want to do it (open, inputfile, splitlines, ...).
Dec 03, 2017 | stackoverflow.com
Syed Mustafa Zinoor ,Mar 4, 2015 at 15:51
The index() in Perl returns the location of a text between a start point and an endpoint. Is there something similar in Python. If not how can this be implemented.Example : in Perl, I would write an index function to return the index of a string as follows
start = index(input_text,text_to_search,starting_point_of_search)+off_set_lengthWhat should be the equivalent in Python?
Kasramvd ,Mar 4, 2015 at 15:54
In python you can usestr.find()to find the index of a sub-string inside a string :>>> s '123string 1abcabcstring 2123string 3abc123stringnabc' >>> s.find('3a') 35string.find(s, sub[, start[, end]]) Return the lowest index in s where the substring sub is found such that sub is wholly contained in s[start:end]. Return -1 on failure. Defaults for start and end and interpretation of negative values is the same as for slices.
Nov 02, 2001 | perlmonks.com
abs(x) Perl equivalent: abs(x)apply(function, args [, keywords ]) Perl equivalent: noneReturns the absolute value of a number (plain or long integer or floating point number). If you supply a complex number then only the magnitude is returned.
For example:
>>> print abs( -- 2.4) 2.4 >>> print abs(4+2j) 4.472135955Applies the arguments args to function, which must be a function, method or other callable object. The args must be supplied as a sequence, lists are converted to tuples before being applied. The function is called using args as individual arguments, for example:
apply(add,(1,3,4))is equivalent to:
add(1,3,4)You need to use the apply function in situations where you are building up a list of arguments in a list or tuple and want to supply the list as individual arguments. This is especially useful in situations where you want to supply a varying list of arguments to a function.
The optional keywords argument should be a dictionary whose keys are strings, these will be used as keyword arguments to be supplied to the end of the argument list.
Notes for Perl programmers
The apply() function gets round the absence in Python of a way of dynamically calling a method or function. It also solves problems where you need to supply a list of arguments to a function that you are building dynamically. In Perl, arguments are progressively taken off an argument stack ( @_ ), whereas Python uses fixed argument names. The apply() is frequently used where we need to supply a variable list of arguments to the function that we've probably built up in an array or tuple.
You can also use it to call a function or method based on a string by using the return value from a call to eval(). The eval() function returns a valid Python expression, which can include a valid method or code object. For example, here's a function called run() which runs the method cmd on the imapcon object, which is actually an instance of the imaplib class for communicating with IMAP servers:
def run(cmd, args): typ, dat = apply(eval('imapcon.%s' % cmd), args) return datThe imaplib module provides methods for all of the standard IMAP commands. So, to obtain the number of messages you send the select function, which means calling the select() method on an imaplib instance. By using the function above we can execute the select() method using:
run('select',())This in effect calls:
imapcon.select()We can get the contents of a specific message using:
data = run('fetch', (message,'(FLAGS RFC822.HEADER)'))[0]In Perl, we'd do the same thing by using a symbolic reference, or by using the symbol table to determine the code reference we need to use. For example, a typical trick is to dynamically call a function based on a string supplied by the user, often within a web application:
my $func = sprintf("%s_%s",$action,$subaction); *code = \&{$func}; &code($user,$group,$session);buffer(object [, offset [, size ] ]) Perl equivalent: nonecallable(object) Perl equivalent: UNIVERSAL::can(METHOD) or exists() when supplied a function referenceCreates a new buffer on the object providing it supports the buffer call interface (such objects include strings, arrays, and buffers). The new buffer references the object using a slice starting from offset and extending to the end of the object or to the length size. If no arguments are given then the buffer covers the entire sequence.
Buffer objects are used to create a more friendly interface to certain object types. For example, the string object type is made available through a buffer object which allows you to access the information within the string on a byte by byte basis.
Notes for Perl programmers
The buffer() is similar in principle to the tie system for tying complex data structures to a simplified structure. However, whereas the tie system is flexible enough to provide you with different methods for accessing scalar, array or hash data sources, the buffer() function is only suitable for sequence objects.
chr(i) Perl equivalent: chr()Returns true if object is callable, false if not. Callable objects include functions, methods and code objects, and also classes (which return a new instance when called) and class instances which have the call method defined.
Notes for Perl programmers
The callable() function is slightly different to the closest suggestion given above. The callable() function only returns true if the method is defined within the given instance or class, it doesn't return a reference to the method itself. Also, callable() is designed to test any object or class that could be callable. This makes it appear to be as flexible as both UNIVERSAL::can() and defined(), when in truth all Python entities are objects or classes.
cmp(x, y) Perl equivalent: The <=> and cmp operatorsReturns a single character string matching the ASCII code i. For example:
>>> print chr(72)+chr(101)+chr(108)+chr(108)+chr(111) HelloThe chr() function is the opposite of ord() which converts characters back to ASCII integer codes. The argument should be in the range 0 to 255, a ValueError exception will be raised if the argument is outside that limit.
coerce(x, y)Compares the two objects and and returns an integer according to the outcome. The return value is negative if x < y, zero if x == y and positive if x > y. Note that this specifically compares the values rather than any reference relationship, such that:
>>> a = 99 >>> b = int('99') >>> cmp(a,b) 0Notes for Perl programmers
The cmp() function in Python is similar to the cmp operator in Perl, in that it compares the values of the objects you supply as arguments, but unlike Perl's cmp it works on all objects. You should be using cmp() within a sort() method to guarantee the correct sorting order.
Perl equivalent: none
Return a tuple consisting of the two numeric arguments converted to a common type, using the same rules as used by arithmetic operations. For example:
>>> a = 1 >>> b = 1.2 >>> coerce(a,b) (1.0, 1.2) >>> a = 1+2j >>> b = 4.3e10 >>> coerce(a,b) ((1+2j), (43000000000+0j))Notes for Perl programmers
Perl automatically translates between strings, integers and floating point numbers during any numerical expression. Although Python does not perform the automatic conversion of strings to numerical values (see the float() and int() functions later in this chapter), numbers are converted between integer, floating point, and complex types. The coerce() function exists to avoid constructs like:
$fpvalue = $intvalue/1.0;compile(string, filename, kind) Perl equivalent: anonymous subroutinecomplex(real [, imag ]) Perl equivalent: noneCompile string into a code object, which can later be executed by the exec statement to evaluate using eval(). The filename should be the name of the file from which the code was read, or a suitable identifier if generated internally. The kind argument specifies what kind of code is contained in string. See Table 8.1 for more information of the possible values.
Table 8.1. The kinds of code compiled by compile()
Kind value Code compiled exec Sequence of statements eval Single expression single Single interactive statement For example:
>>> a = compile('print "Hello World"','<string>','single') >>> exec(a) Hello World >>> eval(a) Hello WorldNotes for Perl programmers
This is similar, but not identical to the process for creating anonymous functions within Perl, which internally create CV (Code Value) objects. However, compile() more closely matches the result of a parsed but unexecuted Perl eval() function call. Instead of returning a value, compile() returns the pre-compiled code ready to be executed.
delattr(object, name) Perl equivalent: the delete() function on hash/array based objectsReturns a complex number with the real component real and the imaginary component imag, if supplied.
dir( [object ]) Perl equivalent: noneDeletes the attribute name from the object object, providing the object allows you to. Identical to the statement:
del object.nameHowever, it allows you to define object and name pragmatically, rather than explicitly in the code.
eval(expression [, globals [, locals ] ]) Perl equivalent: eval()When supplied without an argument lists the names within the current local symbol table. For example:
>>> import smtplib, sys, os >>> dir() ['__builtins__', '__doc__', '__name__', 'os', 'smtplib', 'sys']When supplied with an argument, returns a list of attributes for that object. This can be useful for determining the objects and methods defined within a module:
>>> import sys >>> dir(sys) ['__doc__', '__name__', '__stderr__', '__stdin__', '__stdout__', 'argv', 'builtin_module_names', 'byteorder', 'copyright', 'exc_info', 'exc_type', 'exec_prefix', 'executable', 'exit', 'getdefaultencoding', 'getrecursionlimit', 'getrefcount', 'hexversion', 'maxint', 'modules', 'path', 'platform', 'prefix', 'ps1', 'ps2', 'setcheckinterval', 'setprofile', 'setrecursionlimit', 'settrace', 'stderr', 'stdin', 'stdout', 'version', 'version_info']The information is built up from the __ dict __, __ methods __, and __ members __ attributes of the given object and may not be complete -- for example, methods and attributes inherited from other classes will not normally be included.
Notes for Perl programmers
Although there is no direct equivalent, the dir() function provides similar information to using keys() on a hash-based object, i.e.:
@attributes = keys %{ $objref};although it doesn't list any methods, or using keys() on a package's symbol table:
@entities = keys %main::;divmod(a, b) Perl equivalent: noneReturns a tuple containing the quotient and remainder of divided by b. For example:
>>> divmod(7,4) (1, 3)For integers the value returned is the same as a / b and a % b. If the values supplied are floating point numbers the result is (q, a % b), where q is usually math.floor(a / b) but may be 1 less than that. In any case q * b + a % b is very close to a, if a % b is non-zero it has the same sign as b, and 0 <= abs(a % b) < abs(b).
execfile(file [, globals [, locals ] ]) Perl equivalent: do, or require, or eval()Evaluates the string expression, parsing and evaluating it as a standard Python expression. When called without any additional arguments the expression has access to the same global and local objects in which it is called. Alternatively, you can supply the global and local symbol tables as dictio-naries (see the globals() and locals() functions elsewhere in this chapter).
The return value is the value of the evaluated expression. For example:
>>> a = 99 >>> eval('divmod(a,7)') (14,1)Any syntax errors are raised as exceptions.
You can also use eval() to execute code objects, such as those created by the compile() function, but only when the code object has been compiled using the "eval" mode.
To execute arbitrary Python code incorporating statements as well as expressions, use the exec statement or use execfile() to dynamically execute a file.
Notes for Perl programmers
Although eval() appears to be identical to the Perl eval() function there are some differences:
Python's eval() function is designed to evaluate an expression and return a value.
Python's eval() can return an object, including a function or normal object type, rather than just a value or reference.
Python's eval() is not designed to execute an arbitrary piece of any Python code (although it will) but just a simple expression, use the exec statement instead.
filter(function, list) Perl equivalent: grep() or map()Identical to the exec statement, except that it executes statements from a file instead from a string. The globals and locals arguments should be dictionaries containing the symbol tables that will be available to the file during execution. If locals, is omitted then all references use the globals namespace. If both are omitted, then the file has access to the current symbol tables as at the time of execution.
Notes for Perl programmers
The execfile() function most closely matches Perl's eval() function in that it will execute a file of code as if the code was executed within the realms of the current interpreter instance, with access to the same functions and variables. However, if you supply your own globals or locals dictionaries then it can function as an alternative to Perl's Safe module for executing code within a fixed environment.
float(x) Perl equivalent: noneFilters the items in list according to whether function returns true, returning the new list. For example:
a = [1,2,3,4,5,6,7,8,9] b = filter(lambda x: x > 6, a) print bIf function is None, then the identity function is used and all the elements in list which are false are removed instead.
Notes for Perl programmers
The filter() function is a general purpose equivalent of the Perl grep() function. If you are looking for an alternative to Perl's grep() function consider using the example below:
def grep(pattern,list): import re retlist = [] regex = re.compile(pattern) for element in list: if (regex.search(element)): retlist.append(element) return retlistgetattr(object, name [, default ]) Perl equivalent: noneConverts x, which can be a string or number, to a floating point number.
globals() Perl equivalent: noneReturns the value of the attribute name of the object object. Syntactically the statement
getattr(x,'myvalue')is identical to
x.myvalueIf name does not exist then the function returns default if supplied, or raises AttributeError otherwise.
Notes for Perl programmers
Because Perl's object system is based on the core scalar, array, and hash data types we can access an objects attribute pragmatically simply by supplying the variable name when accessing the array or hash element, for example:
$attribute = $object[$var]; $attribute = $object{$var};However, we can't do this in Python -- you must use getattr(). The above lines are equivalent to:
attribute = getattr(object, var)hasattr(object, name) Perl equivalent: exists() or defined() to determine data, or UNIVERSAL::can(METHOD) to check for a particular methodReturns a dictionary representing the current global symbol table. This is always the dictionary of the current module -- if called within a function or method then it returns the symbol table for the module where the function or method is defined, not the function from where it is called.
Notes for Perl programmers
The globals() function is normally used in conjunction with the exec statement and the eval() and execfile() functions, among others. The closest equivalent in Perl is to access the symbol tables directly:
@globals = keys %main::;hash(object) Perl equivalent: noneReturns true if the object has an attribute matching the string name. Returns zero otherwise.
Notes for Perl programmers
This is the Python equivalent of the Perl exists() method, but it also follows the inheritance tree, functionality only available in Perl through the universal can() method.
hex(x) Perl equivalent: printf("%x",$scalarReturns the integer hash value for an object. The hash value is the same for any two objects that compare equally. Not applicable to mutable objects.
id(object) Perl equivalent: noneConverts an integer number to a hexadecimal string that is a valid Python expression.
Notes for Perl programmers
This is the opposite of the Perl hex() function which converts a hexadecimal or octal string to it's integer equivalent. The Python hex() function is equivalent to:
printf("%x",$value);input( [prompt ]) Perl equivalent: read() or sysread()Returns an integer (or long integer) -- the identity -- which is guaranteed to be unique and constant during the lifetime of the object.
int(x [, radix ]) Perl equivalent: int(), hex(), oct()Equivalent to eval(raw_input(prompt)). See raw_input() in this chapter for more information.
Notes for Perl programmers
This is the equivalent of the Term::Readline::readline() function/ method.
intern(string) Perl equivalent: noneConverts the number or string x to a plain integer. The radix argument if supplied is used as the base to use for the conversion and should be an integer in the range 2 to 36.
isinstance(object, class) Perl equivalent: UNIVERSAL::isa()Adds string to the table of "interned" strings, returning the interned version. Interned strings are available through a pointer, rather than raw string, allowing lookups of dictionary keys to be made using pointer rather than string comparisons. This provides a small performance gain over the normal string comparison methods.
Names used within the Python namespace tables and the dictionaries used to hold module, class or instance attributes are normally interned to aid the speed of execution of the script.
Interned strings are not garbage collected, so be aware that using interned strings on large dictionary key sets will increase the memory requirement significantly, even after the dictionary keys have gone out of scope.
issubclass(class1, class2) Perl equivalent: UNIVERSAL::isa()Returns true if object is an instance of class. Determination will follow the normal inheritance rules and subclasses. You can also use the function to identify if object is of a particular type by using the type class definitions in the types module. If class is not a class or type object then a TypeError exception is raised.
len(s) Perl equivalent: length(), scalar @array, scalar keys %hashReturn true if class1 is a subclass of class2. A class is always considered as a subclass of itself. A TypeError exception is raised if either argument is not a class object.
Returns the length of a sequence (string, tuple, or list) or dictionary object.
Notes for Perl programmers
The Python len() function works for all sequence-based objects, so we can rewrite the following Perl code:
$length = length($string); $length = scalar @array;in Python as:
length = len(string) length = len(array)list(sequence) Perl equivalent: The qw// or () operators, or split('',$string)locals() Perl equivalent: noneReturns a list whose items and order are the same as those in sequence. For example:
>>> list('abc') ['a', 'b', 'c'] >>> list([1,2,3]) [1, 2, 3]Notes for Perl programmers
Because Python strings are sequences of individual characters, Python can convert a single sequence of characters into a list (or tuple) of individual characters.
long(x) Perl equivalent: int()Returns a dictionary representing the current local symbol table.
map(function, list, ) Perl equivalent: map()Converts a string or number to a long integer. Conversion of a floating point number follows the same rules as int().
max(s [, args ]) Perl equivalent: noneApplies function to each item of list and returns the new list. For example:
>>> a = [1,2,3,4] >>> map(lambda x: pow(x,2), a) [1,4,9,16]If additional lists are supplied then they are supplied to function in parallel. Lists are padded with None until all lists are of the same length.
If function is None then the identity function is assumed, causing map() to return list with all false arguments removed. If the function is None and multiple list arguments are supplied then a list of tuples of each argument of the list is returned, for example:
>>> map(None, [1,2,3,4], [4,5,6,7]) [(1, 4), (2, 5), (3, 6), (4, 7)]The result is identical to that produced by the zip() function.
Notes for Perl programmers
The operation of the Python map() is identical to the Perl map() except for the treatment of multiple lists. In Perl, the following statement would apply function to each item in the remaining arguments to the function, just as if the arguments had been concatenated into a new list:
@chars = map(chr,(@list, $scalar, @array));Trying the same in Python would result in chr() being passed as three arguments instead of one. Instead, concatenate the strings:
chars = map(lambda x: chr(x), list+scalar+array)Also be aware that unless the function is predefined, you will have to use lambda to create an anonymous function. This is because Python doesn't have an equivalent to the $_ 'scratchpad' variable.
min(s [, args ]) Perl equivalent: noneWhen supplied with a single argument, returns the maximum value in the sequence s. When supplied a list of arguments, returns the largest argument from those supplied. See min() for more details.
open(filename [, mode [, bufsize ] ])When supplied with a single argument, returns the minimum value in the sequence s. When supplied a list of arguments, returns the smallest value from all the arguments. Note that sequences in a multi-argument call are not traversed -- each argument is compared as a whole, such that:
min([1,2,3],[4,5,6])returns:
[1, 2, 3]And not the often expected 1.
oct(x) Perl equivalent: printf("%o",$scalar)Converts an integer number to an octal string. The result is a valid Python expression. For example:
>>> oct(2001) '03721'Note that the returned value is always unsigned, such that oct(-1) will yield "037777777777" on a 32 bit machine.
Note for Perl programmers
This is not the same as the Perl oct() function -- this returns an octal number, it does not convert an octal string back to an integer.
ord(c) Perl equivalent: ord()Perl equivalent: open() or sysopen()
Opens the file identified by filename, using the mode mode and buffering type bufsize. Returns a file object (see Chapters 3 and 6 for more information).
The mode is the same as that used by the system fopen() function -- see Table 8.2 for a list of valid modes. If mode is omitted then it defaults to r.
Table 8.2. File modes for the open() function
Mode Meaning r Reading w Writing a Appending (file position automatically seeks to the end during the open) r+ Open for updating (reading and writing) w+ Truncates (empties) the file and then opens it for reading and writing a+ Opens the file for reading and writing, automatically changes current file position to the end of the file b When appended to any option opens the file in binary rather than text mode (Windows, DOS and some other OS unaffected)
The optional bufsize argument determines the size of the buffer to use while reading from the file. The different values supported are listed in Table 8.3 . If omitted, the system default is used.
For example, to open a file for reading in binary mode using a 256 character buffer:
myfile = open('myfile.txt','rb', 256);Table 8.3. Buffer sizes supported by the open() function
Bufsize value Description 0 Disable buffering 1 Line buffered >1 Use a buffer that is approximately bufsize characters in length <0 Use the system default (line buffered for tty devices and fully buffered for any other file Notes for Perl programmers
See Table 8.4 for the Python equivalents of the Perl file opening formats.
Table 8.4. Python and Perl file opening formats
Perl format Python mode "" or "<file" r ">file" w ">>file" a "+<file" r+ "+>file" w+ "+>>file" a+
The "b" option when opening a file is the equivalent of using binmode:
open(DATA, $file); binmode DATAThe buffer option is far more extensive than Perl's. The Perl fragment:
open(DATA, 'myfile.txt'); autoflush DATA 1;is equivalent to:
myfile=open('myfile.txt','r',0);pow(x, y [, z ]) Perl equivalent: x**yReturns the ASCII or Unicode numeric code of the string of one character c. This is the inverse of chr() and unichr().
range( [start, ] stop [, step ]) Perl equivalent: noneReturns the value of raised to the power of y. If is supplied then calculate raised to the power modulo z, calculated more efficiently than using:
pow(x,y) % zThe supplied arguments should be numeric types, and the types supplied determine the return type. If the calculated value cannot be represented by the supplied argument types then an exception is raised. For example, the following will fail:
pow(2,-1)But:
pow(2.0,-1)is valid.
Note for Perl programmers
To protect yourself from accidentally supplying the wrong number type to pow(), you might want to consider using the float() function:
pow(float(mynumber),-1)raw_input([prompt ]) Perl equivalent: read() or sysread() on STDIN or Term::Readline::readline()Returns a list of numbers starting from start and ending before stop using step as the interval. All numbers should be supplied and are returned as plain integers. If step is omitted then the step value defaults to one. If start is omitted then the sequence starts at zero. Note that the two arguments form of the call assumes that start and stop are supplied -- if you want to specify a step you must supply all three arguments.
For positive values of step:
>>> range(10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> range(5,10) [5, 6, 7, 8, 9] >>> range(5,25,5) [5, 10, 15, 20]Note that the final number is stop -- step, the range goes up to, but not including, the stop value.
If you supply a negative value to step then the range counts down, rather than up, and stop must be lower than start otherwise the returned list will be empty. For example:
>>> range(10,0,-1) [10, 9, 8, 7, 6, 5, 4, 3, 2, 1] >>> range (25,0,-5) [25, 20, 15, 10, 5] >>> range(0,10,-1) []Notes for Perl programmers
The Python range() function gets round the limitation of the Perl .. range operator allowing you to create your own range with a suitable step in both ascending and descending order. Be aware however that the Python range() and xrange() functions return a list up to but not including the final value, unlike the Perl range operator.
reduce(function, sequence [, initializer ]) Perl equivalent: noneAccepts raw input from sys.stdin, returning a string. Input is terminated by a newline, and this is stripped before the string is returned to the caller. If prompt is supplied, then it is output to sys.stdout without a trailing newline and used as the prompt for input. For example:
>>> name = raw_input('Name? ') Name? MartinIf the readline module has been loaded then features such as line editing and history are supported during input.
Note for Perl programmers
Note that Python automatically strips the newline or carriage return character for you, you do not need to manually remove the line termination.
reload(module) Perl equivalent: no direct equivalent, but you can use eval()Applies the function (supporting two arguments) cumulatively to each element of sequence, reducing the entire statement to a single value. For example, to emulate the (factorial) mathematical operator:
reduce(lambda x,y: x*y, [1,2,3,4,5])the effect is to perform the calculation:
((((1*2)*3)*4)*5)which equals 120.
If initializer is supplied then it's used as the first element in the sequence:
>>> reduce(lambda x,y: x*y, [1,2,3,4,5],10) 1200repr(object) Perl equivalent: Data::DumperReloads an already imported module. The reload includes the normal parsing and initializing processes employed when the module was imported originally. This allows you to reload a Python module without needing to exit the interpreter.
There are a number of caveats for using reload():
If the module is syntactically correct, but fails during initialization, then the import process does not bind its name correctly in the symbol table. You will need to use import to load the module before it can be reloaded.
The reloaded module does not delete entries in the symbol table for the old version of the module first. For identically named objects and functions this is not a problem, but if you rename an entity its value will remain in the symbol table after a reload.
Reloading of extension modules (which rely on built-in or dynamically loaded libraries for support) is supported, but is probably pointless and may actually fail.
If a module imports objects from another module using the from import form then reload does not redefine the objects imported. You can get round this by using the import form.
Reloading modules that provide classes will not affect any existing instances of that class -- the existing instances will continue to use the old method definitions. Only new instances of the class will use the new forms. This also holds true for derived classes.
round(x[, n ]) Perl equivalent: sprintf()Returns a string representation of object. This is identical to using backquotes on an object or attribute. The string returned would yield an object with the same value as that when passed to eval().
Notes for Perl programmers
Both the `` operator and the repr() function generate a printable form of any object and also simultaneously create a textual representation that can be evaluated. This can be useful in situations such as configuration files where you want to output a textual version of a particular object or variable that can be re-evaluated.
setattr(object, name, value) Perl equivalent: noneReturns the floating point value rounded to n digits after the decimal point. Rounds to nearest whole number if is not specified. For example:
>>> round(0.4) 0.0 >>> round(0.5) 1.0 >>> round(-0.5) -1.0 >>> round(3.14159264,2) 3.14 >>> round(1985,-2) 2000.0As you can see, a negative number rounds to that many places before the decimal point. Also note that rounding is handled strictly on the point described by n, that is:
>>> round(1945,-1) 1950.0 >>> round(1945,-2) 1900.0In the second example the "4" in 1945 is rounded to the next nearest, resulting in 1900, rather than rounding the "5" to make 1950 and then rounding 1950 up to 2000.
slice( [start, ] stop [, step ]) Perl equivalent: noneSets the attribute name of object to value. The opposite of the getattr() function which merely gets the information. The statement:
setattr(myobj, 'myattr', 'new value')is equivalent to:
myobj.myattr = 'new value'but can be used in situations where the attribute is known pragmatically by name, rather than explicitly as an attribute.
Note for Perl programmers
The setattr() function gets round the limitation of soft references and hash- or array-based objects used in Perl. In Perl you would be able to use:
$object{'myattr'} = $value;Python does not support soft or symbolic references, the statement:
object.'myattr' = valueis invalid.
str(object) Perl equivalent: none, although Data::Dumper will show information for some objectsReturns a slice object representing the set of indices specified by range(start, stop, step). If one argument is supplied then it's used as stop, two arguments imply start and stop. The default value for any unsupplied argument is None. Slice objects have three attributes ( start, stop, step ) which merely return the corresponding argument supplied to the slice() function during the object's creation.
tuple(sequence) Perl equivalent: noneReturns a string representation of object. This is similar to the repr() function except that the return value is designed to be a printable string, rather than a string that is compatible with the eval function.
type(object) Perl equivalent: the ref() function returns the base object type or its classReturns a tuple whose items are the same and in the same order as the items in sequence. Examples:
>>> tuple('abc') ('a', 'b', 'c') >>> tuple([1,2,3]) (1, 2, 3)Returns the type of object. The return value is a type object, as described by the types module. For example:
>>> import types >>> if type(string) == types.StringType: print "This is a string"Notes for Perl programmers
The return value from type can be printed, for example:
>>> a = 1 >>> print type(a) <type 'int'>in the same way as the output from the Perl ref() function. However, it's more practical to compare the value to one of those in the types module if you are looking for a specific type. The full list of types supported by the types module is listed below:
BufferType BuiltinFunctionType BuiltinMethodType ClassType CodeType ComplexType DictType DictionaryType EllipsisType FileType FloatType FrameType FunctionType InstanceType IntType LambdaType ListType LongType MethodType ModuleType NoneType SliceType StringType TracebackType TupleType TypeType UnboundMethodType UnicodeType XRangeType
unichr(i) Perl equivalent: the Perl chr() function natively decodes Unicode characters
unicode(string [, encoding [, errors ] ]) Perl equivalent: none, Perl automatically decodes Unicode strings nativelyReturns a Unicode string of one character whose code is the integer -- this is the Unicode equivalent of the chr() function described earlier in this chapter. Note that to convert a Unicode character back into its integer form you use ord(), there is no uniord() function. A ValueError exception is raised if the integer supplied is outside the range 0. to 65535.
Notes for Perl programmers
Note that you must use the unichr() function if want to encode a Unicode character, the Python chr() function does not understand Unicode characters. However, the Python ord() function does decode them.
vars( [object ]) Perl equivalent: similar to accessing the symbol table directly using %main::Decodes the Unicode string using the codec encoding. The default behavior (when encoding is not supplied) is to decode UTF-8 in strict mode, errors raising ValueError. See the codecs module for a list of suitable codecs.
zip(seq1, ) Perl equivalent: noneReturns a dictionary corresponding to the current local symbol table. When supplied with a module, class, or class instance, returns a dictionary corresponding to that object's symbol table. Does not modify the returned dictionary as the effects are undefined. xrange( [start, ] stop [, step ])
Perl equivalent: none
Works in the same way as the range() function, except that it returns an xrange object. An xrange object is an opaque object type which returns the same information as the list requested, without having to store each individual element in the list. This is particularly useful in situations where you are creating very large lists, the memory saved by using xrange() over range() can be considerable.
Notes for Perl programmers
The xrange() function gets around the similar problem in Perl of creating very large lists which are used for iteration in a loop. For example, in Perl it's a bad idea to do:
foreach $count (1..100000)Instead we'd do:
for($count = 1;$count<=100000;$count++)In Python the temptation is to use:
foreach count in range(1,100000):However, it's more efficient to use:
foreach count in xrange(1,100000):Takes a series of sequences and returns them as a list of tuples, where each tuple contains the th element of each of the supplied sequences. For example:
>>> a = [1,2,3,4] >>> b = [5,6,7,8] >>> zip(a,b) [(1, 5), (2, 6), (3, 7), (4, 8)]
Nov 09, 2017 | stackoverflow.com
I think you should rewrite your code. The quality of the results of a parsing effort depends on your Perl coding style. I think the quote below sums up the theoretical side very well. From Wikipedia: Perl in Wikipedia
Perl has a Turing-complete grammar because parsing can be affected by run-time code executed during the compile phase.[25] Therefore, Perl cannot be parsed by a straight Lex/Yacc lexer/parser combination. Instead, the interpreter implements its own lexer, which coordinates with a modified GNU bison parser to resolve ambiguities in the language.
It is often said that "Only perl can parse Perl," meaning that only the Perl interpreter (perl) can parse the Perl language (Perl), but even this is not, in general, true. Because the Perl interpreter can simulate a Turing machine during its compile phase, it would need to decide the Halting Problem in order to complete parsing in every case. It's a long-standing result that the Halting Problem is undecidable, and therefore not even Perl can always parse Perl. Perl makes the unusual choice of giving the user access to its full programming power in its own compile phase. The cost in terms of theoretical purity is high, but practical inconvenience seems to be rare.
Other programs that undertake to parse Perl, such as source-code analyzers and auto-indenters, have to contend not only with ambiguous syntactic constructs but also with the undecidability of Perl parsing in the general case. Adam Kennedy's PPI project focused on parsing Perl code as a document (retaining its integrity as a document), instead of parsing Perl as executable code (which not even Perl itself can always do). It was Kennedy who first conjectured that, "parsing Perl suffers from the 'Halting Problem'."[26], and this was later proved.[27]
Starting in 5.10, you can compile perl with the experimental Misc Attribute Decoration enabled and set the PERL_XMLDUMP environment variable to a filename to get an XML dump of the parse tree (including comments - very helpful for language translators). Though as the doc says, this is a work in progress.
Looking at the PLEAC stuff, what we have here is a case of a rote translation of a technique from one language causing another to look bad. For example, its rare in Perl to work character-by-character. Why? For one, its a pain in the ass. A fair cop. For another, you can usually do it faster and easier with a regex. One can reverse the OP's statement and say "in Perl, regexes are so easy that most of the time other string manipulation is not needed". Anyhow, the OP's sentiment is correct. You do things differently in Perl than in Python so a rote translator would produce nasty code. – Schwern Apr 8 '10 at 11:47
down vote Converting would require writing a Perl parser, semantic checker, and Python code generator.Not practical. Perl parsers are hard enough for the Perl teams to get right. You'd be better off translating Perl to Python from the Perl AST (opcodes) using the Perl Opcode or related modules.
http://perldoc.perl.org/Opcode.html
Some notations do not map from Perl to Python without some work. Perl's closures are different, for example. So is its regex support.
In short, either convert it by hand, or use some integration modules to call Python from Perl or vice-versa
My conclusionPython is an excellent language for my intended use. It is a good language for many of the applications that one would use Lisp as a rapid prototyping environment for. The three main drawbacks are (1) execution time is slow, (2) there is very little compile-time error analysis, even less than Lisp, and (3) Python isn't called "Java", which is a requirement in its own right for some of my audience. I need to determine if JPython is close enough for them.
Python can be seen as either a practical (better libraries) version of Scheme, or as a cleaned-up (no $@&%) version of Perl.
While Perl's philosophy is TIMTOWTDI (there's more than one way to do it), Python tries to provide a minimal subset that people will tend to use in the same way. One of Python's controversial features, using indentation level rather than begin/end or {/}, was driven by this philosophy: since there are no braces, there are no style wars over where to put the braces. Interestingly, Lisp has exactly the same philosophy on this point: everyone uses emacs to indent their code.
If you deleted the parens on control structure special forms, Lisp and Python programs would look quite similar.
Python has the philosophy of making sensible compromises that make the easy things very easy, and don't preclude too many hard things. In my opinion it does a very good job. The easy things are easy, the harder things are progressively harder, and you tend not to notice the inconsistencies. Lisp has the philosophy of making fewer compromises: of providing a very powerful and totally consistent core.
This can make Lisp harder to learn because you operate at a higher level of abstraction right from the start and because you need to understand what you're doing, rather than just relying on what feels or looks nice.
But it also means that in Lisp it is easier to add levels of abstraction and complexity; Lisp makes the very hard things not too hard.
Python is a really clean and elegant interpreted OO language. I don't think many folks will argue that Perl is the same.
Well, Python was OO from the ground up and Perl was not, and it shows. But as far as elegance is concerned, it is rather in the eye of the beholder.
The fact that there are many compact ways to solve the same problem was a goal of Perl, and it is hard to imagine a language which achieves this to a higher degree. In that sense, you have to grant that Perl does what it sets out to do brilliantly.
I think of Perl as a radical language and Python as a rather conservative: it takes conventional notions of what is needed in a language to efficiently support a programming project and pares away everything that is unnecessary baggage. Perl, at least my take on it, rejects at the outset that there is any one way to support a programming project and encourages the programmer to adopt whatever stance works to solve the problem.
The interesting thing is that for me the common juxtaposition of Perl and Python makes more sense than you'd think at the outset. I've tried my hand at each for projects, and I don't find I'm particularly more productive in one than the other. Perhaps Perl has a slight edge because I've been using it longer, and most of the projects I've tried are typical of the classic Perl problem space of Practical Extraction and Reporting.
I don't really find one language to be more maintainable than the other; perhaps Python restricts certain bad habits that Perl permits, but in reality efficient and sensible problem decomposition and program organization are rather more important. Perhaps the flavor of bad programming varies somewhat between the languages -- bad Perl is dense and indigestible, bad Python is bland and undifferentiated.
Google matched content |
Video tutorials
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: May, 30, 2021