Excessive automation can be a problem. It increase the number of layers between fundamental process and sysadmin. and thus it
makes troubleshooting much harder.
Moreover often it does not not produce tangible benefits in comparison with simpler tools while increasing the level of
complexity of environment.
@William Gruff #40
The real world usage of AI, to date, is primarily replacing the rank and file of human
experience.
Where before you would have individuals who have attained expertise in an area, and who would
be paid to exercise it, now AI can learn from the extant work and repeat it.
The problem, though, is that AI is eminently vulnerable to attack. In particular - if the
area involves change, which most do, then the AI must be periodically retrained to take into
account the differences. Being fundamentally stupid, AI literally cannot integrate new data
on top of old but must start from scratch.
I don't have the link, but I did see an excellent example: a cat vs. AI.
While a cat can't play chess, the cat can walk, can recognize objects visually, can
communicate even without a vocal cord, can interact with its environment and even learn new
behaviors.
In this example, you can see one of the fundamental differences between functional organisms
and AI: AI can be trained to perform extremely well, but it requires very narrow focus.
IBM spend years and literally tens of thousands of engineering hours to create the AI that
could beat Jeapordy champions - but that particular creation is still largely useless for
anything else. IBM is desperately attempting to monetize that investment through its Think
Build Grow program - think AWS for AI. I saw a demo - it was particularly interesting because
this AI program ingests some 3 million English language web articles; IBM showed its contents
via a very cool looking wrap around display room in its Think Build Grow promotion
campaign.
What was really amusing was a couple of things:
1) the fact that the data was already corrupt: this demo was about 2 months ago - and there
were spikes of "data" coming from Ecuador and the tip of South America. Ecuador doesn't speak
English. I don't even know if there are any English web or print publications there. But I'd
bet large sums of money that the (English) Twitter campaign being run on behalf of the coup
was responsible for this spike.
2) Among the top 30 topics was Donald Trump. Given the type of audience you would expect
for this subject, it was enormously embarrassing that Trump coverage was assessed as net
positive - so much so that the IBM representative dived into the data to ascertain why the AI
had a net positive rating (the program also does sentiment analysis). It turns out that a
couple of articles which were clearly extremely peripheral to Trump, but which did mention
his name, were the cause. The net positive rating was from this handful of articles even
though the relationship was very weak and there were far fewer net "positive" vs. negative
articles shown in the first couple passes of source articles (again, IBM's sentiment analysis
- not a human's).
I have other examples: SF is home to a host of self-driving testing initiatives. Uber had
a lot about 4 blocks from where I live, for months, where they based their self driving cars
out of (since moved). The self-driving delivery robots (sidewalk) - I've seen them tested
here as well.
Some examples of how they fail: I was riding a bus, which was stopped at an intersection
behind a Drive test vehicle at a red light(Drive is nVidia's self driving). This intersection
is somewhat unusual: there are 5 entrances/exits to this intersection, so the traffic light
sequence and the driving action is definitely atypical.
The light turns green, the Drive car wants to turn immediately left (as opposed to 2nd
left, as opposed to straight or right). It accelerates into the intersection and starts
turning; literally halfway into the intersection, it slams on its brakes. The bus, which was
accelerating behind it in order to go straight, is forced to also slam on its brakes. There
was no incoming car - because of the complex left turn setup, the street the Drive car and
bus were on, is the only one that is allowed to traverse when that light is green (initially.
After a 30 second? pause, the opposite "straight" street is allowed to drive).
Why did the Drive car slam on its brakes in the middle of the intersection? No way to know
for sure, but I would bet money that the sensors saw the cars waiting at the 2nd left street
and thought it was going the wrong way. Note this is just a few months ago.
There are many other examples of AI being fundamentally brittle: Google's first version of
human recognition via machine vision classified black people as gorillas:
Google Photos fail
A project at MIT inserted code into AI machine vision programs to show what these were
actually seeing when recognizing objects; it turns out that what the AIs were recognizing
were radically different from reality. For example, while the algo could recognize a
dumbbell, it turns out that the reference image that the algo used was a dumbbell plus an
arm. Because all of the training photos for a dumbbell included an arm...
This fundamental lack of basic concepts, a coherent worldview or any other type of rooting
in reality is why AI is also pathetically easy to fool. This research showed that the top of
the line machine vision for self driving could be tricked into recognizing stop signs as
speed limit signs Confusing self driving
cars
To be clear, fundamentally it doesn't matter for most applications if the AI is "close
enough". If a company can replace 90% of its expensive, older workers or first world, English
speaking workers with an AI - even if the AI is working only 75% of the time, it is still a
huge win. For example: I was told by a person selling chatbots to Sprint that 90% of Sprint's
customer inquiries were one of 10 questions...
And lastly: are robots/AI taking jobs? Certainly it is true anecdotally, but the overall
economic statistics aren't showing this. In particular, if AI was really taking jobs - then
we should be seeing productivity numbers increase more than in the past. But this isn't
happening:
Productivity for the past 30 years
Note in the graph that productivity was increasing much more up until 2010 - when it leveled
off.
Dean Baker has written about this extensively - it is absolutely clear that it is outsourced
of manufacturing jobs which is why US incomes have been stagnant for decades.
Being a "progressive trendy techy" is an identity and a lifestyle. They have a dress code.
A unique lexicon. Similar mannerisms and methods of speaking. An approved system of beliefs
regarding politics and society.
For all intents and purposes the "tech industry" is a giant freakish cult.
Mastering the Command Line: Use timedatectl to Control System Time and Date in Linux
By Himanshu Arora
– Posted on Nov 11, 2014 Nov 9, 2014 in Linux
The timedatectl command in Linux allows you to query and change the system
clock and its settings. It comes as part of systemd, a replacement for the sysvinit daemon used
in the GNU/Linux and Unix systems.
In this article, we will discuss this command and the features it provides using relevant
examples.
Timedatectl examples
Note – All examples described in this article are tested on GNU bash, version
4.3.11(1).
Display system date/time information
Simply run the command without any command line options or flags, and it gives you
information on the system's current date and time, as well as time-related settings. For
example, here is the output when I executed the command on my system:
$ timedatectl
Local time: Sat 2014-11-08 05:46:40 IST
Universal time: Sat 2014-11-08 00:16:40 UTC
Timezone: Asia/Kolkata (IST, +0530)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a
So you can see that the output contains information on LTC, UTC, and time zone, as well as
settings related to NTP, RTC and DST for the localhost.
Update the system date or time
using the set-time option
To set the system clock to a specified date or time, use the set-time option
followed by a string containing the new date/time information. For example, to change the
system time to 6:40 am, I used the following command:
$ sudo timedatectl set-time "2014-11-08 06:40:00"
and here is the output:
$ timedatectl
Local time: Sat 2014-11-08 06:40:02 IST
Universal time: Sat 2014-11-08 01:10:02 UTC
Timezone: Asia/Kolkata (IST, +0530)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
Observe that the Local time field now shows the updated time. Similarly, you can update the
system date, too.
Update the system time zone using the set-timezone option
To set the system time zone to the specified value, you can use the
set-timezone option followed by the time zone value. To help you with the task,
the timedatectl command also provides another useful option.
list-timezones provides you with a list of available time zones to choose
from.
For example, here is the scrollable list of time zones the timedatectl command
produced on my system:
To change the system's current time zone from Asia/Kolkata to Asia/Kathmandu, here is the
command I used:
$ timedatectl set-timezone Asia/Kathmandu
and to verify the change, here is the output of the timedatectl command:
$ timedatectl
Local time: Sat 2014-11-08 07:11:23 NPT
Universal time: Sat 2014-11-08 01:26:23 UTC
Timezone: Asia/Kathmandu (NPT, +0545)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
You can see that the time zone was changed to the new value.
Configure RTC
You can also use the timedatectl command to configure RTC (real-time clock).
For those who are unaware, RTC is a battery-powered computer clock that keeps track of the time
even when the system is turned off. The timedatectl command offers a
set-local-rtc option which can be used to maintain the RTC in either local time or
universal time.
This option requires a boolean argument. If 0 is supplied, the system is configured to
maintain the RTC in universal time:
$ timedatectl set-local-rtc 0
but in case 1 is supplied, it will maintain the RTC in local time instead.
$ timedatectl set-local-rtc 1
A word of caution : Maintaining the RTC in the local time zone is not fully supported and
will create various problems with time zone changes and daylight saving adjustments. If at all
possible, use RTC in UTC.
Another point worth noting is that if set-local-rtc is invoked and the
--adjust-system-clock option is passed, the system clock is synchronized from the
RTC again, taking the new setting into account. Otherwise the RTC is synchronized from the
system clock.
Configure NTP-based network time synchronization
NTP, or Network Time Protocol, is a networking protocol for clock synchronization between
computer systems over packet-switched, variable-latency data networks. It is intended to
synchronize all participating computers to within a few milliseconds of
UTC.
The timedatectl command provides a set-ntp option that controls
whether NTP based network time synchronization is enabled. This option expects a boolean
argument. To enable NTP-based time synchronization, run the following command:
$ timedatectl set-ntp true
To disable, run:
$ timedatectl set-ntp false
Conclusion
As evident from the examples described above, the timedatectl command is a
handy tool for system administrators who can use it to to adjust various system clocks and RTC
configurations as well as poll remote servers for time information. To learn more about the
command, head over to its man page .
Time is an important aspect in Linux systems especially in critical services such as cron
jobs. Having the correct time on the server ensures that the server operates in a healthy
environment that consists of distributed systems and maintains accuracy in the workplace.
In this tutorial, we will focus on how to set time/date/time zone and to synchronize the
server clock with your Ubuntu Linux machine.
Check Current Time
You can verify the current time and date using the date and the
timedatectl commands. These linux commands
can be executed straight from the terminal as a regular user or as a superuser. The commands
are handy usefulness of the two commands is seen when you want to correct a wrong time from the
command line.
Using the date command
Log in as a root user and use the command as follows
$ date
Output
You can also use the same command to check a date 2 days ago
$ date --date="2 days ago"
Output
Using
timedatectl command
Checking on the status of the time on your system as well as the present time settings, use
the command timedatectl as shown
# timedatectl
or
# timedatectl status
Changing
Time
We use the timedatectl to change system time using the format HH:MM: SS. HH
stands for the hour in 24-hour format, MM stands for minutes and SS for seconds.
Setting the time to 09:08:07 use the command as follows (using the timedatectl)
# timedatectl set-time 09:08:07
using date command
Changing time means all the system processes are running on the same clock putting the
desktop and server at the same time. From the command line, use date command as follows
To change the locale to either AM or PM use the %p in the following format.
# date +%T%p -s "6:10:30AM"
# date +%T%p -s "12:10:30PM"
Change Date
Generally, you want your system date and time is set automatically. If for some reason you
have to change it manually using date command, we can use this command :
# date --set="20140125 09:17:00"
It will set your current date and time of your system into 'January 25, 2014' and '09:17:00
AM'. Please note, that you must have root privilege to do this.
You can use timedatectl to set the time and the date respectively. The accepted format is
YYYY-MM-DD, YYYY represents the year, MM the month in two digits and DD for the day in two
digits. Changing the date to 15 January 2019, you should use the following command
# timedatectl set-time 20190115
Create custom date format
To create custom date format, use a plus sign (+)
$ date +"Day : %d Month : %m Year : %Y"
Day: 05 Month: 12 Year: 2013
$ date +%D
12/05/13
%D format follows Year/Month/Day format .
You can also put the day name if you want. Here are some examples :
$ date +"%a %b %d %y"
Fri 06 Dec 2013
$ date +"%A %B %d %Y"
Friday December 06 2013
$ date +"%A %B %d %Y %T"
Friday December 06 2013 00:30:37
$ date +"%A %B-%d-%Y %c"
Friday December-06-2013 12:30:37 AM WIB
List/Change time zone
Changing the time zone is crucial when you want to ensure that everything synchronizes with
the Network Time Protocol. The first thing to do is to list all the region's time zones using
the list-time zones option or grep to make the command easy to understand
# timedatectl list-timezones
The above command will present a scrollable format.
Recommended timezone for servers is UTC as it doesn't have daylight savings. If you know,
the specific time zones set it using the name using the following command
# timedatectl set-timezone America/Los_Angeles
To display timezone execute
# timedatectl | grep "Time"
Set
the Local-rtc
The Real-time clock (RTC) which is also referred to as the hardware clock is independent of
the operating system and continues to run even when the server is shut down.
Use the following command
# timedatectl set-local-rtc 0
In addition, the following command for the local time
# timedatectl set-local-rtc 1
Check/Change CMOS Time
The computer CMOS battery will automatically synchronize time with system clock as long as
the CMOS is working correctly.
Use the hwclock command to check the CMOS date as follows
# hwclock
To synchronize the CMOS date with system date use the following format
# hwclock –systohc
To have the correct time for your Linux environment is critical because many operations
depend on it. Such operations include logging events and corn jobs as well. we hope you found
this article useful.
I have a program running under screen. In fact, when I detach from the session and check netstat, I can see the program is still
running (which is what I want):
udp 0 0 127.0.0.1:1720 0.0.0.0:* 3759/ruby
Now I want to reattach to the session running that process. So I start up a new terminal, and type screen -r
$ screen -r
There are several suitable screens on:
5169.pts-2.teamviggy (05/31/2013 09:30:28 PM) (Detached)
4872.pts-2.teamviggy (05/31/2013 09:25:30 PM) (Detached)
4572.pts-2.teamviggy (05/31/2013 09:07:17 PM) (Detached)
4073.pts-2.teamviggy (05/31/2013 08:50:54 PM) (Detached)
3600.pts-2.teamviggy (05/31/2013 08:40:14 PM) (Detached)
Type "screen [-d] -r [pid.]tty.host" to resume one of them.
But how do I know which one is the session running that process I created?
Now one of the documents I came across said:
"When you're using a window, type C-a A to give it a name. This name will be used in the window listing, and will help you
remember what you're doing in each window when you start using a lot of windows."
The thing is when I am in a new screen session, I try to press control+a A and nothing happens.
Paul ,
There are two levels of "listings" involved here. First, you have the "window listing" within an individual session, which is
what ctrl-A A is for, and second there is a "session listing" which is what you have pasted in your question and what can also
be viewed with screen -ls .
You can customize the session names with the -S parameter, otherwise it uses your hostname (teamviggy), for example:
$ screen
(ctrl-A d to detach)
$ screen -S myprogramrunningunderscreen
(ctrl-A d to detach)
$ screen -ls
There are screens on:
4964.myprogramrunningunderscreen (05/31/2013 09:42:29 PM) (Detached)
4874.pts-1.creeper (05/31/2013 09:39:12 PM) (Detached)
2 Sockets in /var/run/screen/S-paul.
As a bonus, you can use an unambiguous abbreviation of the name you pass to -S later to reconnect:
screen -r myprog
(I am reconnected to the myprogramrunningunderscreen session)
njcwotx ,
I had a case where screen -r failed to reattach. Adding the -d flag so it looked like this
screen -d -r
worked for me. It detached the previous screen and allowed me to reattach. See the Man Page for more information.
Dr K ,
An easy way is to simply reconnect to an arbitrary screen with
screen -r
Then once you are running screen, you can get a list of all active screens by hitting Ctrl-A " (i.e. control-A
followed by a double quote). Then you can just select the active screens one at a time and see what they are running. Naming the
screens will, of course, make it easier to identify the right one.
Just my two cents
Lefty G Balogh ,
I tend to use the following combo where I need to work on several machines in several clusters:
screen -S clusterX
This creates the new screen session where I can build up the environment.
screen -dRR clusterX
This is what I use subsequently to reattach to that screen session. The nifty bits are that if the session is attached elsewhere,
it detaches that other display. Moreover, if there is no session for some quirky reason, like someone rebooted my server without
me knowing, it creates one. Finally. if multiple sessions exist, it uses the first one.
Also here's few useful explanations from man screen on cryptic parameters
-d -r Reattach a session and if necessary detach it first.
-d -R Reattach a session and if necessary detach or even create it
first.
-d -RR Reattach a session and if necessary detach or create it. Use
the first session if more than one session is available.
-D -r Reattach a session. If necessary detach and logout remotely
first.
there is more with -D so be sure to check man screen
tilnam , 2018-03-14 17:12:06
The output of screen -list is formatted like pid.tty.host . The pids can be used to get the first child
process with pstree :
System administration isn't easy nor is it for the thin-skinned.
Notable quotes:
"... System administration covers just about every aspect of hardware and software management for both physical and virtual systems. ..."
"... An SA's day is very full. In fact, you never really finish, but you have to pick a point in time to abandon your activities. Being an SA is a 24x7x365 job, which does take its toll on you physically and mentally. You'll hear a lot about burnout in this field. We, at Enable Sysadmin, have written several articles on the topic. ..."
"... You are the person who gets blamed when things go wrong and when things go right, it's "just part of your job." It's a tough place to be. ..."
"... Dealing with people is hard. Learn to breathe, smile, and comply if you want to survive and maintain your sanity. ..."
A Linux system administrator wears many hats and the smaller your environment, the more hats
you will wear. Linux administration covers backups, file restores, disaster recovery, new
system builds, hardware maintenance, automation, user maintenance, filesystem housekeeping,
application installation and configuration, system security management, and storage management.
System administration covers just about every aspect of hardware and software management for
both physical and virtual systems.
Oddly enough, you also need a broad knowledge base of network configuration, virtualization,
interoperability, and yes, even Windows operating systems. A Linux system administrator needs
to have some technical knowledge of network security, firewalls, databases, and all aspects of
a working network. The reason is that, while you're primarily a Linux SA, you're also part of a
larger support team that often must work together to solve complex problems.
Security, in some form or another, is often at the root of issues confronting a support
team. A user might not have proper access or too much access. A daemon might not have the
correct permissions to write to a log directory. A firewall exception hasn't been saved into
the running configuration of a network appliance. There are hundreds of fail points in a
network and your job is to help locate and resolve failures.
Linux system administration also requires that you stay on top of best practices, learn new
software, maintain patches, read and comply with security notifications, and apply hardware
updates. An SA's day is very full. In fact, you never really finish, but you have to pick a
point in time to abandon your activities. Being an SA is a 24x7x365 job, which does take its
toll on you physically and mentally. You'll hear a lot about burnout in this field. We, at
Enable Sysadmin, have written several articles on the topic.
The hardest part of the job
Doing the technical stuff is relatively easy. It's dealing with people that makes the job
really hard. That sounds terrible but it's true. On one side, you deal with your management,
which is not always easy. You are the person who gets blamed when things go wrong and when
things go right, it's "just part of your job." It's a tough place to be.
Coworkers don't seem to make life better for the SA. They should, but they often don't.
You'll deal with lazy, unmotivated coworkers so often that you'll feel that you're carrying all
the weight of the job yourself. Not all coworkers are bad. Some are helpful, diligent,
proactive types and I've never had the pleasure of working with too many of them. It's hard to
do your work and then take on the dubious responsibility of making sure everyone else does
theirs as well.
And then there are users. Oh the bane of every SA's life, the end user. An SA friend of mine
once said, "You know, this would be a great job if I just didn't have to interface with users."
Agreed. But then again, with no users, there's probably also not a job. Dealing with computers
is easy. Dealing with people is hard. Learn to breathe, smile, and comply if you want to
survive and maintain your sanity.
# dig 2daygeek.com SOA +noall +answer
or
# dig -t SOA 2daygeek.com +noall +answer
2daygeek.com. 3599 IN SOA jean.ns.cloudflare.com. dns.cloudflare.com. 2032249144 10000 2400 604800 3600
9) How to Lookup a Domain Reverse DNS "PTR" Record on Linux Using the dig Command
Enter the domain's IP address with the host command to find the domain's reverse DNS (PTR)
record.
10) How to Find All Possible Records for a Domain on Linux Using the dig Command
Input the domain name followed by the dig command to find all possible records for a domain
(A, NS, PTR, MX, SPF, TXT).
# dig 2daygeek.com ANY +noall +answer
; <<>> DiG 9.8.2rc1-RedHat-9.8.2-0.23.rc1.el6_5.1 <<>> 2daygeek.com ANY +noall +answer
;; global options: +cmd
2daygeek.com. 12922 IN TXT "v=spf1 ip4:182.71.233.70 +a +mx +ip4:49.50.66.31 ?all"
2daygeek.com. 12693 IN MX 0 2daygeek.com.
2daygeek.com. 12670 IN A 182.71.233.70
2daygeek.com. 84670 IN NS ns2.2daygeek.in.
2daygeek.com. 84670 IN NS ns1.2daygeek.in.
11) How to Lookup a Particular Name Server for a Domain Name
Also, you can look up a specific name server for a domain name using the dig command.
# dig jean.ns.cloudflare.com 2daygeek.com
; <<>> DiG 9.14.7 <<>> jean.ns.cloudflare.com 2daygeek.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 10718
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;jean.ns.cloudflare.com. IN A
;; ANSWER SECTION:
jean.ns.cloudflare.com. 21599 IN A 173.245.58.121
;; Query time: 23 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Tue Nov 12 11:22:50 IST 2019
;; MSG SIZE rcvd: 67
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 45300
;; flags: qr rd ra; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 512
;; QUESTION SECTION:
;2daygeek.com. IN A
;; ANSWER SECTION:
2daygeek.com. 299 IN A 104.27.156.177
2daygeek.com. 299 IN A 104.27.157.177
;; Query time: 23 msec
;; SERVER: 192.168.1.1#53(192.168.1.1)
;; WHEN: Tue Nov 12 11:22:50 IST 2019
;; MSG SIZE rcvd: 73
12) How To Query Multiple Domains DNS Information Using the dig Command
You can query DNS information for multiple domains at once using the dig command.
# dig 2daygeek.com NS +noall +answer linuxtechnews.com TXT +noall +answer magesh.co.in SOA +noall +answer
2daygeek.com. 21578 IN NS jean.ns.cloudflare.com.
2daygeek.com. 21578 IN NS vin.ns.cloudflare.com.
linuxtechnews.com. 299 IN TXT "ca3-e9556bfcccf1456aa9008dbad23367e6"
linuxtechnews.com. 299 IN TXT "google-site-verification=a34OylEd_vQ7A_hIYWQ4wJ2jGrMgT0pRdu_CcvgSp4w"
magesh.co.in. 3599 IN SOA jean.ns.cloudflare.com. dns.cloudflare.com. 2032053532 10000 2400 604800 3600
13) How To Query DNS Information for Multiple Domains Using the dig Command from a text
File
To do so, first create a file and add it to the list of domains you want to check for DNS
records.
In my case, I've created a file named dig-demo.txt and added some domains to
it.
# vi dig-demo.txt
2daygeek.com
linuxtechnews.com
magesh.co.in
Once you have done the above operation, run the dig command to view DNS information.
# dig -f /home/daygeek/shell-script/dig-test.txt NS +noall +answer
2daygeek.com. 21599 IN NS jean.ns.cloudflare.com.
2daygeek.com. 21599 IN NS vin.ns.cloudflare.com.
linuxtechnews.com. 21599 IN NS jean.ns.cloudflare.com.
linuxtechnews.com. 21599 IN NS vin.ns.cloudflare.com.
magesh.co.in. 21599 IN NS jean.ns.cloudflare.com.
magesh.co.in. 21599 IN NS vin.ns.cloudflare.com.
14) How to use the .digrc File
You can control the behavior of the dig command by adding the ".digrc" file to the user's
home directory.
If you want to perform dig command with only answer section. Create the .digrc
file in the user's home directory and save the default options +noall and
+answer .
# vi ~/.digrc
+noall +answer
Once you done the above step. Simple run the dig command and see a magic.
# dig 2daygeek.com NS
2daygeek.com. 21478 IN NS jean.ns.cloudflare.com.
2daygeek.com. 21478 IN NS vin.ns.cloudflare.com.
I had to use file recovery software when I accidentally formatted my backup. It worked, but
I now have 37,000 text files with numbers where names used to be.
If I name each file with the first 20-30 characters, I can sort the text-wheat from the
bit-chaff.
I have the vague idea of using whatever the equivalent of
head
is on Windows, but that's as far as I got. I'm not so hot on bash scripting either.
9 comments
54% Upvoted
This thread is archived
New comments cannot be posted and votes cannot be cast
Sort by
level 1
Answer: not really. The environment and script's working, but whenever
there's a forward slash or non-escaping character in the text, it chokes when it tries to set up a new
directory, and it deletes the file suffix. :-/ Good thing I used a copy of the data.
Need something to strip out the characters and spaces, and add the file
suffix, before it tries to rename.
sed
? Also needs
file
to identify it as true text. I can do the suffix at least:
for i in *; do mv $i "$(head -c 30 "$i").txt"; done
I recommend you use 'head -1', which will make the first line of the file
the filename and you won't have to worry about newlines. Then you can change the spaces to underscores with:
There's the
file
program on
*nix that'll tell you, in a verbose manner, the type of the file you give it as an argument, irregardless of
its file extension. Example:
$ file test.mp3
test.mp3: , 48 kHz, JntStereo
$ file mbr.bin
mbr.bin: data
$ file CalendarExport.ics
CalendarExport.ics: HTML document, UTF-8 Unicode text, with very long lines, with CRLF, LF line terminators
$ file jmk.doc
jmk.doc: Composite Document File V2 Document, Little Endian, Os: Windows, Version 6.0, Code page: 1250, Title: xx, Author: xx, Template: Normal, Last Saved By: xx, Revision Number: 4, Name of Creating Application: Microsoft Office Word, Total Editing Time: 2d+03:32:00, Last Printed: Fri Feb 22 11:29:00 2008, Create Time/Date: Fri Jan 4 12:57:00 2013, Last Saved Time/Date: Sun Jan 6 16:30:00 2013, Number of Pages: 6, Number of Words: 1711, Number of Characters: 11808, Security: 0
Thank you, but the software I used to recover (R-Undelete) sorted them
already. I found another program, RenameMaestro, that renames according to metadata in zip, rar, pdf, doc and
other files, but text files are too basic.
Not command line, but you could probably do this pretty easily in python,
using "glob" to get filenames, and os read and move/rename functions to get the text and change filenames.
level 1
So far, you're not getting many windows command line ideas
:(. I don't have any either, but here's an idea:
Use one of the live Linux distributions (Porteus is pretty
cool, but there're a slew of others). In that Linux environment, you can mount your Windows
hard drive, and use Linux tools, maybe something like
/u/tatumc
suggested.
r/commandline
Mirroring a running system into a ramdiskGreg Marsden
In this blog post, Oracle Linux kernel developer William Roche presents a method to
mirror a running system into a ramdisk.
A RAM mirrored System ?
There are cases where a system can boot correctly but after some time, can lose its system
disk access - for example an iSCSI system disk configuration that has network issues, or any
other disk driver problem. Once the system disk is no longer accessible, we rapidly face a hang
situation followed by I/O failures, without the possibility of local investigation on this
machine. I/O errors can be reported on the console:
XFS (dm-0): Log I/O Error Detected....
Or losing access to basic commands like:
# ls
-bash: /bin/ls: Input/output error
The approach presented here allows a small system disk space to be mirrored in memory to
avoid the above I/O failures situation, which provides the ability to investigate the reasons
for the disk loss. The system disk loss will be noticed as an I/O hang, at which point there
will be a transition to use only the ram-disk.
To enable this, the Oracle Linux developer Philip "Bryce" Copeland created the following
method (more details will follow):
Create a "small enough" system disk image using LVM (a minimized Oracle Linux
installation does that)
After the system is started, create a ramdisk and use it as a mirror for the system
volume
when/if the (primary) system disk access is lost, the ramdisk continues to provide all
necessary system functions.
Disk and memory sizes:
As we are going to mirror the entire system installation to the memory, this system
installation image has to fit in a fraction of the memory - giving enough memory room to hold
the mirror image and necessary running space.
Of course this is a trade-off between the memory available to the server and the minimal
disk size needed to run the system. For example a 12GB disk space can be used for a minimal
system installation on a 16GB memory machine.
A standard Oracle Linux installation uses XFS as root fs, which (currently) can't be shrunk.
In order to generate a usable "small enough" system, it is recommended to proceed to the OS
installation on a correctly sized disk space. Of course, a correctly sized installation
location can be created using partitions of large physical disk. Then, the needed application
filesystems can be mounted from their current installation disk(s). Some system adjustments may
also be required (services added, configuration changes, etc...).
This configuration phase should not be underestimated as it can be difficult to separate the
system from the needed applications, and keeping both on the same space could be too large for
a RAM disk mirroring.
The idea is not to keep an entire system load active when losing disks access, but to be
able to have enough system to avoid system commands access failure and analyze the
situation.
We are also going to avoid the use of swap. When the system disk access is lost, we don't
want to require it for swap data. Also, we don't want to use more memory space to hold a swap
space mirror. The memory is better used directly by the system itself.
The system installation can have a swap space (for example a 1.2GB space on our 12GB disk
example) but we are neither going to mirror it nor use it.
Our 12GB disk example could be used with: 1GB /boot space, 11GB LVM Space (1.2GB swap
volume, 9.8 GB root volume).
Ramdisk
memory footprint:
The ramdisk size has to be a little larger (8M) than the root volume size that we are going
to mirror, making room for metadata. But we can deal with 2 types of ramdisk:
A classical Block Ram Disk (brd) device
A memory compressed Ram Block Device (zram)
We can expect roughly 30% to 50% memory space gain from zram compared to brd, but zram must
use 4k I/O blocks only. This means that the filesystem used for root has to only deal with a
multiple of 4k I/Os.
Basic commands:
Here is a simple list of commands to manually create and use a ramdisk and mirror the root
filesystem space. We create a temporary configuration that needs to be undone or the subsequent
reboot will not work. But we also provide below a way of automating at startup and
shutdown.
Note the root volume size (considered to be ol/root in this example):
# lvconvert -y -m 0 ol/root /dev/ram0Logical volume ol/rootsuccessfully converted.# vgreduce ol /dev/ram0Removed"/dev/ram0"from volume group"ol"# mount /boot# mount /boot/efi# swapon
-a
What about in-memory compression ?
As indicated above, zRAM devices can compress data in-memory, but 2 main problems need to be
fixed:
LVM does take into account zRAM devices by default
zRAM only works with 4K I/Os
Make lvm work with zram:
The lvm configuration file has to be changed to take into account the "zram" type of
devices. Including the following "types" entry to the /etc/lvm/lvm.conf file in its "devices"
section:
We can notice here that the sector size (sectsz) used on this root fs is a standard 512
bytes. This fs type cannot be mirrored with a zRAM device, and needs to be recreated with 4k
sector sizes.
Transforming the root file system to 4k sector size:
This is simply a backup (to a zram disk) and restore procedure after recreating the root FS.
To do so, the system has to be booted from another system image. Booting from an installation
DVD image can be a good possibility.
Boot from an OL installation DVD [Choose "Troubleshooting", "Rescue a Oracle Linux
system", "3) Skip to shell"]
A service Unit file can also be created: /etc/systemd/system/raid1-ramdisk.service
[https://github.com/oracle/linux-blog-sample-code/blob/ramdisk-system-image/raid1-ramdisk.service]
[Unit]Description=Enable RAMdisk RAID 1 on LVMAfter=local-fs.targetBefore=shutdown.target reboot.target halt.target[Service]ExecStart=/usr/sbin/start-raid1-ramdiskExecStop=/usr/sbin/stop-raid1-ramdiskType=oneshotRemainAfterExit=yesTimeoutSec=0[Install]WantedBy=multi-user.target
Conclusion:
When the system disk access problem manifests itself, the ramdisk mirror branch will provide
the possibility to investigate the situation. This procedure goal is not to keep the system
running on this memory mirror configuration, but help investigate a bad situation.
When the problem is identified and fixed, I really recommend to come back to a standard
configuration -- enjoying the entire memory of the system, a standard system disk, a possible
swap space etc.
Hoping the method described here can help. I also want to thank for their reviews Philip
"Bryce" Copeland who also created the first prototype of the above scripts, and Mark Kanda who
also helped testing many aspects of this work.
chkservice, a terminal user interface (TUI) for managing systemd units, has been updated recently with window resize and search
support.
chkservice is a simplistic
systemd unit manager that uses ncurses for its terminal interface.
Using it you can enable or disable, and start or stop a systemd unit. It also shows the units status (enabled, disabled, static or
masked).
You can navigate the chkservice user interface using keyboard shortcuts:
Up or l to move cursor up
Down or j to move cursor down
PgUp or b to move page up
PgDown or f to move page down
To enable or disable a unit press Space , and to start or stop a unity press s . You can access the help
screen which shows all available keys by pressing ? .
The command line tool had its first release in August 2017, with no new releases until a few days ago when version 0.2 was released,
quickly followed by 0.3.
With the latest 0.3 release, chkservice adds a search feature that allows easily searching through all systemd units.
To
search, type / followed by your search query, and press Enter . To search for the next item matching your
search query you'll have to type / again, followed by Enter or Ctrl + m (without entering
any search text).
Another addition to the latest chkservice is window resize support. In the 0.1 version, the tool would close when the user tried
to resize the terminal window. That's no longer the case now, chkservice allowing the resize of the terminal window it runs in.
And finally, the last addition to the latest chkservice 0.3 is G-g navigation support . Press G
( Shift + g ) to navigate to the bottom, and g to navigate to the top.
Download and install chkservice
The initial (0.1) chkservice version can be found
in the official repositories of a few Linux distributions, including Debian and Ubuntu (and Debian or Ubuntu based Linux distribution
-- e.g. Linux Mint, Pop!_OS, Elementary OS and so on).
There are some third-party repositories available as well, including a Fedora Copr, Ubuntu / Linux Mint PPA, and Arch Linux AUR,
but at the time I'm writing this, only the AUR package
was updated to the latest chkservice version 0.3.
You may also install chkservice from source. Use the instructions provided in the tool's
readme to either create a DEB package or install
it directly.
No new interesting ideas for such an important topic whatsoever. One of the main problems here is documenting actions of
each administrator in such a way that the set of actions was visible to everybody in a convenient and transparent matter. With
multiple terminal opened Unix history is not the file from which you can deduct each sysadmin actions as parts of the
history from additional terminals are missing. , not smooch access. Actually Solaris has some ideas implemented in Solaris 10, but they never made it to Linux
In our team we have three seasoned Linux sysadmins having to administer a few dozen Debian
servers. Previously we have all worked as root using SSH public key authentication. But we had a discussion on what is the best practice
for that scenario and couldn't agree on anything.
Everybody's SSH public key is put into ~root/.ssh/authorized_keys2
Advantage: easy to use, SSH agent forwarding works easily, little overhead
Disadvantage: missing auditing (you never know which "root" made a change), accidents are more likely
Using personalized accounts and sudo
That way we would login with personalized accounts using SSH public keys and use sudo to do single tasks with root
permissions. In addition we could give ourselves the "adm" group that allows us to view log files.
Advantage: good auditing, sudo prevents us from doing idiotic things too easily
Disadvantage: SSH agent forwarding breaks, it's a hassle because barely anything can be done as non-root
Using multiple UID 0 users
This is a very unique proposal from one of the sysadmins. He suggest to create three users in /etc/passwd all having UID 0 but
different login names. He claims that this is not actually forbidden and allow everyone to be UID 0 but still being able to audit.
Advantage: SSH agent forwarding works, auditing might work (untested), no sudo hassle
Disadvantage: feels pretty dirty - couldn't find it documented anywhere as an allowed way
Comments:
About your "couldn't find it documented anywhere as an allowed way" statement: Have a look to the -o flag in
the useradd manual page. This flag is there to allow multiple users sharing the same uid. –
jlliagre May 21 '12 at 11:38
Can you explain what you mean by "SSH agent forwarding breaks" in the second option? We use this at my work and ssh agent
forwarding works just fine. – Patrick May 21 '12 at 12:01
Another consequence of sudo method: You can no longer SCP/FTP as root. Any file transfers will first need to be moved into
the person's home directory and then copied over in the terminal. This is an advantage and a disadvantage depending on perspective.
– user606723 May 21 '12 at 14:43
The second option is the best one IMHO. Personal accounts, sudo access. Disable root access via SSH completely. We have a few hundred
servers and half a dozen system admins, this is how we do it.
How does agent forwarding break exactly?
Also, if it's such a hassle using sudo in front of every task you can invoke a sudo shell with sudo -s
or switch to a root shell with sudo su -
10 Rather than disable root access by SSH completely, I recommend making root access by SSH require keys, creating one key
with a very strong keyphrase and keeping it locked away for emergency use only. If you have permanent console access this is less
useful, but if you don't, it can be very handy. – EightBitTony
May 21 '12 at 13:02
17 I recommend disabling root login over SSH for security purposes. If you really need to be logged in as root, log in as
a non-root user and su. – taz May 21 '12 at 14:29
+1.. I'd go further than saying "The second option is the best". I'd it's the only reasonable option. Options one and three
vastly decrease the security of the system from both outside attacks and mistakes. Besides, #2 is how the system was designed
to be primarily used. – Ben Lee May 23 '12 at 18:28
2 Please, elaborate on sudo -s . Am I correct to understand that sudo -i is no difference to using
su - or basically logging in as root apart from additional log entry compared to plain root login? If that's true,
how and why is it better than plain root login? – PF4Public
Jun 3 '16 at 20:32
add a comment
| 9 With regard to the 3rd suggested strategy, other than perusal of the useradd -o -u userXXX options as recommended
by @jlliagre, I am not familiar with running multiple users as the same uid. (hence if you do go ahead with that, I would be interested
if you could update the post with any issues (or sucesses) that arise...)
I guess my first observation regarding the first option "Everybody's SSH public key is put into ~root/.ssh/authorized_keys2",
is that unless you absolutely are never going to work on any other systems;
then at least some of the time, you are going to have to work with user accounts and sudo
The second observation would be, that if you work on systems that aspire to HIPAA, PCI-DSS compliance, or stuff like CAPP and
EAL, then you are going to have to work around the issues of sudo because;
It an industry standard to provide non-root individual user accounts, that can be audited, disabled, expired, etc, typically
using some centralized user database.
So; Using personalized accounts and sudo
It is unfortunate that as a sysadmin, almost everything you will need to do on a remote machine is going to require some elevated
permissions, however it is annoying that most of the SSH based tools and utilities are busted while you are in sudo
Hence I can pass on some tricks that I use to work-around the annoyances of sudo that you mention. The first problem
is that if root login is blocked using PermitRootLogin=no or that you do not have the root using ssh key, then it makes
SCP files something of a PITA.
Problem 1 : You want to scp files from the remote side, but they require root access, however you cannot login to the remote box
as root directly.
Boring Solution : copy the files to home directory, chown, and scp down.
ssh userXXX@remotesystem , sudo su - etc, cp /etc/somefiles to /home/userXXX/somefiles
, chown -R userXXX /home/userXXX/somefiles , use scp to retrieve files from remote.
Less Boring Solution : sftp supports the -s sftp_server flag, hence you can do something like the following (if you
have configured password-less sudo in /etc/sudoers );
(you can also use this hack-around with sshfs, but I am not sure its recommended... ;-)
If you don't have password-less sudo rights, or for some configured reason that method above is broken, I can suggest one more
less boring file transfer method, to access remote root files.
Port Forward Ninja Method :
Login to the remote host, but specify that the remote port 3022 (can be anything free, and non-reserved for admins, ie >1024)
is to be forwarded back to port 22 on the local side.
[localuser@localmachine ~]$ ssh userXXX@remotehost -R 3022:localhost:22
Last login: Mon May 21 05:46:07 2012 from 123.123.123.123
------------------------------------------------------------------------
This is a private system; blah blah blah
------------------------------------------------------------------------
Get root in the normal fashion...
-bash-3.2$ sudo su -
[root@remotehost ~]#
Now you can scp the files in the other direction avoiding the boring boring step of making a intermediate copy of the files;
Problem 2: SSH agent forwarding : If you load the root profile, e.g. by specifying a login shell, the necessary environment variables
for SSH agent forwarding such as SSH_AUTH_SOCK are reset, hence SSH agent forwarding is "broken" under sudo su
- .
Half baked answer :
Anything that properly loads a root shell, is going to rightfully reset the environment, however there is a slight work-around
your can use when you need BOTH root permission AND the ability to use the SSH Agent, AT THE SAME TIME
This achieves a kind of chimera profile, that should really not be used, because it is a nasty hack , but is useful when you need
to SCP files from the remote host as root, to some other remote host.
Anyway, you can enable that your user can preserve their ENV variables, by setting the following in sudoers;
Defaults:userXXX !env_reset
this allows you to create nasty hybrid login environments like so;
login as normal;
[localuser@localmachine ~]$ ssh userXXX@remotehost
Last login: Mon May 21 12:33:12 2012 from 123.123.123.123
------------------------------------------------------------------------
This is a private system; blah blah blah
------------------------------------------------------------------------
-bash-3.2$ env | grep SSH_AUTH
SSH_AUTH_SOCK=/tmp/ssh-qwO715/agent.1971
create a bash shell, that runs /root/.profile and /root/.bashrc . but preserves SSH_AUTH_SOCK
-bash-3.2$ sudo -E bash -l
So this shell has root permissions, and root $PATH (but a borked home directory...)
bash-3.2# id
uid=0(root) gid=0(root) groups=0(root),1(bin),2(daemon),3(sys),4(adm),6(disk),10(wheel) context=user_u:system_r:unconfined_t
bash-3.2# echo $PATH
/usr/kerberos/sbin:/usr/local/sbin:/usr/sbin:/sbin:/home/xtrabm/xtrabackup-manager:/usr/kerberos/bin:/opt/admin/bin:/usr/local/bin:/bin:/usr/bin:/opt/mx/bin
But you can use that invocation to do things that require remote sudo root, but also the SSH agent access like so;
add a comment
| 2 The 3rd option looks ideal - but have you actually tried it out to see what's happenning? While you might see the
additional usernames in the authentication step, any reverse lookup is going to return the same value.
Allowing root direct ssh access is a bad idea, even if your machines are not connected to the internet / use strong passwords.
Usually I use 'su' rather than sudo for root access.
4 Adding multiple users with the same UID adds problems. When applications go to look up the username for a UID number, they
can look up the wrong username. Applications which run under root can think they're running as the wrong user, and lots of weird
errors will start popping up (I tried it once). – Patrick
May 21 '12 at 11:59
8 The third option is just a bloody bad idea . You're essentially breaking the 1:1 relation between UIDs and usernames,
and literally everything in unix expects that relation to hold. Just because there's no explicit rule not to do it doesn't
mean it's a good idea. – Shadur May 21 '12 at 14:28
Sorry, but the third option is a horrible idea. Having multiple UID 0 people logging in is just asking for problems to be
multiplied. Option number 2 is the only sane one. – Doug May
21 '12 at 20:01
The third option doesn't deserve that many downvotes. There is no command in Unix I'm aware of that is confused by this trick,
people might be but commands should not care. It is just a different login name but as soon as you are logged in, the first name
found matching the uid in the password database is used so just make sure the real username (here root) appears first there. –
jlliagre May 21 '12 at 21:38
@Patrick Have you seen this in practice? As much as I tested, then applications pick root user if root
user is the first one in /etc/passwd with UID 0. I tend to agree with jlliagre. The only downside that I see,
is that each user is a root user and sometimes it might be confusing to understand who did what. –
Martin Sep 4 '16 at 18:31
on one ill-fated day.I can see to be bad enough if you have more than a handful admins.
(2) Is probably more engineered - and you can become full-fledged root through sudo su -. Accidents are still possible though.
(3) I would not touch with a barge pole. I used it on Suns, in order to have a non-barebone-sh root account (if I remember correctly)
but it was never robust - plus I doubt it would be very auditable.
Means that you're allowing SSH access as root . If this machine is in any way public facing, this is just a terrible
idea; back when I ran SSH on port 22, my VPS got multiple attempts hourly to authenticate as root. I had a basic IDS set up to
log and ban IPs that made multiple failed attempts, but they kept coming. Thankfully, I'd disabled SSH access as the root user
as soon as I had my own account and sudo configured. Additionally, you have virtually no audit trail doing this.
Provides root access as and when it is needed. Yes, you barely have any privileges as a standard user, but this is pretty
much exactly what you want; if an account does get compromised, you want it to be limited in its abilities. You want any super
user access to require a password re-entry. Additionally, sudo access can be controlled through user groups, and restricted to
particular commands if you like, giving you more control over who has access to what. Additionally, commands run as sudo can be
logged, so it provides a much better audit trail if things go wrong. Oh, and don't just run "sudo su -" as soon as you log in.
That's terrible, terrible practice.
Your sysadmin's idea is bad. And he should feel bad. No, *nix machines probably won't stop you from doing this, but both your
file system, and virtually every application out there expects each user to have a unique UID. If you start going down this road,
I can guarantee that you'll run into problems. Maybe not immediately, but eventually. For example, despite displaying nice friendly
names, files and directories use UID numbers to designate their owners; if you run into a program that has a problem with duplicate
UIDs down the line, you can't just change a UID in your passwd file later on without having to do some serious manual file system
cleanup.
sudo is the way forward. It may cause additional hassle with running commands as root, but it provides you with a
more secure box, both in terms of access and auditing.
Definitely option 2, but use groups to give each user as much control as possible without needing to use sudo. sudo in front of every
command loses half the benefit because you are always in the danger zone. If you make the relevant directories writable by the sysadmins
without sudo you return sudo to the exception which makes everyone feel safer.
In the old days, sudo did not exist. As a consequence, having multiple UID 0 users was the only available alternative. But it's
still not that good, notably with logging based on the UID to obtain the username. Nowadays, sudo is the only appropriate solution.
Forget anything else.
It is documented permissible by fact. BSD unices have had their toor account for a long time, and bashroot
users tend to be accepted practice on systems where csh is standard (accepted malpractice ;)
add a comment
| 0 Perhaps I'm weird, but method (3) is what popped into my mind first as well. Pros: you'd have every users name in logs and
would know who did what as root. Cons: they'd each be root all the time, so mistakes can be catastrophic.
I'd like to question why you need all admins to have root access. All 3 methods you propose have one distinct disadvantage: once
an admin runs a sudo bash -l or sudo su - or such, you lose your ability to track who does what and after
that, a mistake can be catastrophic. Moreover, in case of possible misbehaviour, this even might end up a lot worse.
Instead you might want to consider going another way:
Create your admin users as regular users
Decide who needs to do what job (apache management / postfix management etc)
Add users to related groups (such as add "martin" to "postfix" and "mail", "amavis" if you use it, etc.)
give only relative sudo powers: (visudo -> let martin use /etc/init.d/postfix , /usr/bin/postsuper etc.)
This way, martin would be able to safely handle postfix, and in case of mistake or misbehaviour, you'd only lose your postfix
system, not entire server.
Same logic can be applied to any other subsystem, such as apache, mysql, etc.
Of course, this is purely theoretical at this point, and might be hard to set up. It does look like a better way to go tho. At
least to me. If anyone tries this, please let me know how it went.
I should add handling SSH connections is pretty basic in this context. Whatever method you use, do not permit root logins
over SSH, let the individual users ssh with their own credentials, and handle sudo/nosudo/etc from there. –
Tuncay Göncüoğlu Nov 30 '12 at 17:53
No time for
commands? Scheduling tasks with cron means programs can run but you don't have to stay up
late.9 comments Image by :
Internet Archive Book Images. Modified by Opensource.com. CC BY-SA 4.0 x Subscribe now
Instead, I use two service utilities that allow me to run commands, programs, and tasks at
predetermined times. The cron
and at services enable sysadmins to schedule tasks to run at a specific time in the future. The
at service specifies a one-time task that runs at a certain time. The cron service can schedule
tasks on a repetitive basis, such as daily, weekly, or monthly.
In this article, I'll introduce the cron service and how to use it.
Common (and
uncommon) cron uses
I use the cron service to schedule obvious things, such as regular backups that occur daily
at 2 a.m. I also use it for less obvious things.
The system times (i.e., the operating system time) on my many computers are set using the
Network Time Protocol (NTP). While NTP sets the system time, it does not set the hardware
time, which can drift. I use cron to set the hardware time based on the system time.
I also have a Bash program I run early every morning that creates a new "message of the
day" (MOTD) on each computer. It contains information, such as disk usage, that should be
current in order to be useful.
Many system processes and services, like Logwatch , logrotate , and Rootkit Hunter , use the cron service to schedule
tasks and run programs every day.
The crond daemon is the background service that enables cron functionality.
The cron service checks for files in the /var/spool/cron and /etc/cron.d directories and the
/etc/anacrontab file. The contents of these files define cron jobs that are to be run at
various intervals. The individual user cron files are located in /var/spool/cron , and system
services and applications generally add cron job files in the /etc/cron.d directory. The
/etc/anacrontab is a special case that will be covered later in this article.
Using
crontab
The cron utility runs based on commands specified in a cron table ( crontab ). Each user,
including root, can have a cron file. These files don't exist by default, but can be created in
the /var/spool/cron directory using the crontab -e command that's also used to edit a cron file
(see the script below). I strongly recommend that you not use a standard editor (such as
Vi, Vim, Emacs, Nano, or any of the many other editors that are available). Using the crontab
command not only allows you to edit the command, it also restarts the crond daemon when you
save and exit the editor. The crontab command uses Vi as its underlying editor, because Vi is
always present (on even the most basic of installations).
New cron files are empty, so commands must be added from scratch. I added the job definition
example below to my own cron files, just as a quick reference, so I know what the various parts
of a command mean. Feel free to copy it for your own use.
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
# backup using the rsbu program to the internal 4TB HDD and then 4TB external
01 01 * * * / usr / local / bin / rsbu -vbd1 ; / usr / local / bin / rsbu -vbd2
# Set the hardware clock to keep it in sync with the more accurate system clock
03 05 * * * / sbin / hwclock --systohc
# Perform monthly updates on the first of the month
# 25 04 1 * * /usr/bin/dnf -y update
The crontab command is used to view or edit the cron files.
The first three lines in the code above set up a default environment. The environment must
be set to whatever is necessary for a given user because cron does not provide an environment
of any kind. The SHELL variable specifies the shell to use when commands are executed. This
example specifies the Bash shell. The MAILTO variable sets the email address where cron job
results will be sent. These emails can provide the status of the cron job (backups, updates,
etc.) and consist of the output you would see if you ran the program manually from the command
line. The third line sets up the PATH for the environment. Even though the path is set here, I
always prepend the fully qualified path to each executable.
There are several comment lines in the example above that detail the syntax required to
define a cron job. I'll break those commands down, then add a few more to show you some more
advanced capabilities of crontab files.
This line in my /etc/crontab runs a script that performs backups for my
systems.
This line runs my self-written Bash shell script, rsbu , that backs up all my systems. This
job kicks off at 1:01 a.m. (01 01) every day. The asterisks (*) in positions three, four, and
five of the time specification are like file globs, or wildcards, for other time divisions;
they specify "every day of the month," "every month," and "every day of the week." This line
runs my backups twice; one backs up to an internal dedicated backup hard drive, and the other
backs up to an external USB drive that I can take to the safe deposit box.
The following line sets the hardware clock on the computer using the system clock as the
source of an accurate time. This line is set to run at 5:03 a.m. (03 05) every day.
03 05 * * * /sbin/hwclock --systohc
This line sets the hardware clock using the system time as the source.
I was using the third and final cron job (commented out) to perform a dnf or yum update at
04:25 a.m. on the first day of each month, but I commented it out so it no longer runs.
# 25 04 1 * * /usr/bin/dnf -y update
This line used to perform a monthly update, but I've commented it
out.
Other scheduling tricks
Now let's do some things that are a little more interesting than these basics. Suppose you
want to run a particular job every Thursday at 3 p.m.:
00 15 * * Thu /usr/local/bin/mycronjob.sh
This line runs mycronjob.sh every Thursday at 3 p.m.
Or, maybe you need to run quarterly reports after the end of each quarter. The cron service
has no option for "The last day of the month," so instead you can use the first day of the
following month, as shown below. (This assumes that the data needed for the reports will be
ready when the job is set to run.)
02 03 1 1,4,7,10 * /usr/local/bin/reports.sh
This cron job runs quarterly reports on the first day of the month after a quarter
ends.
The following shows a job that runs one minute past every hour between 9:01 a.m. and 5:01
p.m.
01 09-17 * * * /usr/local/bin/hourlyreminder.sh
Sometimes you want to run jobs at regular times during normal business hours.
I have encountered situations where I need to run a job every two, three, or four hours.
That can be accomplished by dividing the hours by the desired interval, such as */3 for every
three hours, or 6-18/3 to run every three hours between 6 a.m. and 6 p.m. Other intervals can
be divided similarly; for example, the expression */15 in the minutes position means "run the
job every 15 minutes."
*/5 08-18/2 * * * /usr/local/bin/mycronjob.sh
This cron job runs every five minutes during every hour between 8 a.m. and 5:58
p.m.
One thing to note: The division expressions must result in a remainder of zero for the job
to run. That's why, in this example, the job is set to run every five minutes (08:05, 08:10,
08:15, etc.) during even-numbered hours from 8 a.m. to 6 p.m., but not during any odd-numbered
hours. For example, the job will not run at all from 9 p.m. to 9:59 a.m.
I am sure you can come up with many other possibilities based on these
examples.
Regular users with cron access could make mistakes that, for example, might cause system
resources (such as memory and CPU time) to be swamped. To prevent possible misuse, the sysadmin
can limit user access by creating a /etc/cron.allow file that contains a list of all users with
permission to create cron jobs. The root user cannot be prevented from using cron.
By preventing non-root users from creating their own cron jobs, it may be necessary for root
to add their cron jobs to the root crontab. "But wait!" you say. "Doesn't that run those jobs
as root?" Not necessarily. In the first example in this article, the username field shown in
the comments can be used to specify the user ID a job is to have when it runs. This prevents
the specified non-root user's jobs from running as root. The following example shows a job
definition that runs a job as the user "student":
04 07 * * * student /usr/local/bin/mycronjob.sh
If no user is specified, the job is run as the user that owns the crontab file, root in this
case.
cron.d
The directory /etc/cron.d is where some applications, such as SpamAssassin and sysstat , install cron files. Because there is no
spamassassin or sysstat user, these programs need a place to locate cron files, so they are
placed in /etc/cron.d .
The /etc/cron.d/sysstat file below contains cron jobs that relate to system activity
reporting (SAR). These cron files have the same format as a user cron file.
# Run system
activity accounting tool every 10 minutes
*/ 10 * * * * root / usr / lib64 / sa / sa1 1 1
# Generate a daily summary of process accounting at 23:53
53 23 * * * root / usr / lib64 / sa / sa2 -A
The sysstat package installs the /etc/cron.d/sysstat cron file to run programs for
SAR.
The sysstat cron file has two lines that perform tasks. The first line runs the sa1 program
every 10 minutes to collect data stored in special binary files in the /var/log/sa directory.
Then, every night at 23:53, the sa2 program runs to create a daily summary.
Scheduling
tips
Some of the times I set in the crontab files seem rather random -- and to some extent they
are. Trying to schedule cron jobs can be challenging, especially as the number of jobs
increases. I usually have only a few tasks to schedule on each of my computers, which is
simpler than in some of the production and lab environments where I have worked.
One system I administered had around a dozen cron jobs that ran every night and an
additional three or four that ran on weekends or the first of the month. That was a challenge,
because if too many jobs ran at the same time -- especially the backups and compiles -- the
system would run out of RAM and nearly fill the swap file, which resulted in system thrashing
while performance tanked, so nothing got done. We added more memory and improved how we
scheduled tasks. We also removed a task that was very poorly written and used large amounts of
memory.
The crond service assumes that the host computer runs all the time. That means that if the
computer is turned off during a period when cron jobs were scheduled to run, they will not run
until the next time they are scheduled. This might cause problems if they are critical cron
jobs. Fortunately, there is another option for running jobs at regular intervals: anacron
.
anacron
The anacron program
performs the same function as crond, but it adds the ability to run jobs that were skipped,
such as if the computer was off or otherwise unable to run the job for one or more cycles. This
is very useful for laptops and other computers that are turned off or put into sleep mode.
As soon as the computer is turned on and booted, anacron checks to see whether configured
jobs missed their last scheduled run. If they have, those jobs run immediately, but only once
(no matter how many cycles have been missed). For example, if a weekly job was not run for
three weeks because the system was shut down while you were on vacation, it would be run soon
after you turn the computer on, but only once, not three times.
The anacron program provides some easy options for running regularly scheduled tasks. Just
install your scripts in the /etc/cron.[hourly|daily|weekly|monthly] directories, depending how
frequently they need to be run.
How does this work? The sequence is simpler than it first appears.
The crond service runs the cron job specified in /etc/cron.d/0hourly .
# Run the hourly jobs
SHELL = / bin / bash
PATH = / sbin: / bin: / usr / sbin: / usr / bin
MAILTO =root
01 * * * * root run-parts / etc / cron.hourly
The contents of /etc/cron.d/0hourly cause the shell scripts located in /etc/cron.hourly
to run.
The cron job specified in /etc/cron.d/0hourly runs the run-parts program once per
hour.
The run-parts program runs all the scripts located in the /etc/cron.hourly
directory.
The /etc/cron.hourly directory contains the 0anacron script, which runs the anacron
program using the /etdc/anacrontab configuration file shown here.
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL = / bin / sh
PATH = / sbin: / bin: / usr / sbin: / usr / bin
MAILTO =root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY = 45
# the jobs will be started during the following hours only
START_HOURS_RANGE = 3 - 22
The contents of /etc/anacrontab file runs the executable files in the
cron.[daily|weekly|monthly] directories at the appropriate times.
The anacron program runs the programs located in /etc/cron.daily once per day; it runs
the jobs located in /etc/cron.weekly once per week, and the jobs in cron.monthly once per
month. Note the specified delay times in each line that help prevent these jobs from
overlapping themselves and other cron jobs.
Instead of placing complete Bash programs in the cron.X directories, I install them in the
/usr/local/bin directory, which allows me to run them easily from the command line. Then I add
a symlink in the appropriate cron directory, such as /etc/cron.daily .
The anacron program is not designed to run programs at specific times. Rather, it is
intended to run programs at intervals that begin at the specified times, such as 3 a.m. (see
the START_HOURS_RANGE line in the script just above) of each day, on Sunday (to begin the
week), and on the first day of the month. If any one or more cycles are missed, anacron will
run the missed jobs once, as soon as possible.
More on setting limits
I use most of these methods for scheduling tasks to run on my computers. All those tasks are
ones that need to run with root privileges. It's rare in my experience that regular users
really need a cron job. One case was a developer user who needed a cron job to kick off a daily
compile in a development lab.
It is important to restrict access to cron functions by non-root users. However, there are
circumstances when a user needs to set a task to run at pre-specified times, and cron can allow
them to do that. Many users do not understand how to properly configure these tasks using cron
and they make mistakes. Those mistakes may be harmless, but, more often than not, they can
cause problems. By setting functional policies that cause users to interact with the sysadmin,
individual cron jobs are much less likely to interfere with other users and other system
functions.
It is possible to set limits on the total resources that can be allocated to individual
users or groups, but that is an article for another time.
For more information, the man pages for cron , crontab , anacron , anacrontab , and run-parts
all have excellent information and descriptions of how the cron system works.
Cron is definitely a good tool. But if you need to do more advanced scheduling then Apache
Airflow is great for this.
Airflow has a number of advantages over Cron. The most important are: Dependencies (let
tasks run after other tasks), nice web based overview, automatic failure recovery and a
centralized scheduler. The disadvantages are that you will need to setup the scheduler and
some other centralized components on one server and a worker on each machine you want to run
stuff on.
You definitely want to use Cron for some stuff. But if you find that Cron is too limited
for your use case I would recommend looking into Airflow.
Hi David,
you have a well done article. Much appreciated. I make use of the @reboot crontab entry. With
crontab and root. I run the following.
@reboot /bin/dofstrim.sh
I wanted to run fstrim for my SSD drive once and only once per week.
dofstrim.sh is a script that runs the "fstrim" program once per week, irrespective of the
number of times the system is rebooted. I happen to have several Linux systems sharing one
computer, and each system has a root crontab with that entry. Since I may hop from Linux to
Linux in the day or several times per week, my dofstrim.sh only runs fstrim once per week,
irrespective which Linux system I boot. I make use of a common partition to all Linux
systems, a partition mounted as "/scratch" and the wonderful Linux command line "date"
program.
The dofstrim.sh listing follows below.
#!/bin/bash
# run fstrim either once/week or once/day not once for every reboot
#
# Use the date function to extract today's day number or week number
# the day number range is 1..366, weekno is 1 to 53
#WEEKLY=0 #once per day
WEEKLY=1 #once per week
lockdir='/scratch/lock/'
if [[ WEEKLY -eq 1 ]]; then
dayno="$lockdir/dofstrim.weekno"
today=$(date +%V)
else
dayno=$lockdir/dofstrim.dayno
today=$(date +%j)
fi
prevval="000"
if [ -f "$dayno" ]
then
prevval=$(cat ${dayno} )
if [ x$prevval = x ];then
prevval="000"
fi
else
mkdir -p $lockdir
fi
if [ ${prevval} -ne ${today} ]
then
/sbin/fstrim -a
echo $today > $dayno
fi
I had thought to use anacron, but then fstrim would be run frequently as each linux's
anacron would have a similar entry.
The "date" program produces a day number or a week number, depending upon the +%V or +%j
Running a report on the last day of the month is easy if you use the date program. Use the
date function from Linux as shown
*/9 15 28-31 * * [ `date -d +'1 day' +\%d` -eq 1 ] && echo "Tomorrow is the first
of month Today(now) is `date`" >> /root/message
Once per day from the 28th to the 31st, the date function is executed.
If the result of date +1day is the first of the month, today must be the last day of the
month.
Tired of typing the same long commands over
and over? Do you feel inefficient working on the command line? Bash aliases can make a world of
difference.
28 comments
A Bash alias is a method of supplementing or overriding Bash commands with new ones. Bash
aliases make it easy for users to customize their experience in a POSIX terminal.
They are often defined in $HOME/.bashrc or $HOME/bash_aliases (which must be loaded by
$HOME/.bashrc ).
Most distributions add at least some popular aliases in the default .bashrc file of any new
user account. These are simple ones to demonstrate the syntax of a Bash alias:
alias ls =
'ls -F'
alias ll = 'ls -lh'
Not all distributions ship with pre-populated aliases, though. If you add aliases manually,
then you must load them into your current Bash session:
$ source ~/.bashrc
Otherwise, you can close your terminal and re-open it so that it reloads its configuration
file.
With those aliases defined in your Bash initialization script, you can then type ll and get
the results of ls -l , and when you type ls you get, instead of the output of plain old
ls .
Those aliases are great to have, but they just scratch the surface of what's possible. Here
are the top 10 Bash aliases that, once you try them, you won't be able to live
without.
Set up first
Before beginning, create a file called ~/.bash_aliases :
$ touch ~/.bash_aliases
Then, make sure that this code appears in your ~/.bashrc file:
if [ -e $HOME /
.bash_aliases ] ; then
source $HOME / .bash_aliases
fi
If you want to try any of the aliases in this article for yourself, enter them into your
.bash_aliases file, and then load them into your Bash session with the source ~/.bashrc
command.
Sort by file size
If you started your computing life with GUI file managers like Nautilus in GNOME, the Finder
in MacOS, or Explorer in Windows, then you're probably used to sorting a list of files by their
size. You can do that in a terminal as well, but it's not exactly succinct.
Add this alias to your configuration on a GNU system:
alias lt = 'ls --human-readable
--size -1 -S --classify'
This alias replaces lt with an ls command that displays the size of each item, and then
sorts it by size, in a single column, with a notation to indicate the kind of file. Load your
new alias, and then try it out:
In fact, even on Linux, that command is useful, because using ls lists directories and
symlinks as being 0 in size, which may not be the information you actually want. It's your
choice.
Thanks to Brad Alexander for this alias idea.
View only mounted drives
The mount command used to be so simple. With just one command, you could get a list of all
the mounted filesystems on your computer, and it was frequently used for an overview of what
drives were attached to a workstation. It used to be impressive to see more than three or four
entries because most computers don't have many more USB ports than that, so the results were
manageable.
Computers are a little more complicated now, and between LVM, physical drives, network
storage, and virtual filesystems, the results of mount can be difficult to parse:
sysfs on
/sys type sysfs (rw,nosuid,nodev,noexec,relatime,seclabel)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs
(rw,nosuid,seclabel,size=8131024k,nr_inodes=2032756,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
[...]
/dev/nvme0n1p2 on /boot type ext4 (rw,relatime,seclabel)
/dev/nvme0n1p1 on /boot/efi type vfat
(rw,relatime,fmask=0077,dmask=0077,codepage=437,iocharset=ascii,shortname=winnt,errors=remount-ro)
[...]
gvfsd-fuse on /run/user/100977/gvfs type fuse.gvfsd-fuse
(rw,nosuid,nodev,relatime,user_id=100977,group_id=100977)
/dev/sda1 on /run/media/seth/pocket type ext4
(rw,nosuid,nodev,relatime,seclabel,uhelper=udisks2)
/dev/sdc1 on /run/media/seth/trip type ext4
(rw,nosuid,nodev,relatime,seclabel,uhelper=udisks2)
binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)
This alias uses awk to parse the output of mount by column, reducing the output to what you
probably looking for (what hard drives, and not file systems, are mounted):
On MacOS, the mount command doesn't provide terribly verbose output, so an alias may be
overkill. However, if you prefer a succinct report, try this:
alias mnt = 'mount | grep -E
^/dev | column -t'
The results:
$ mnt
/dev/disk1s1 on / (apfs, local, journaled)
/dev/disk1s4 on /private/var/vm (apfs, local, noexec, journaled, noatime, nobrowse) Find a
command in your grep history
Sometimes you figure out how to do something in the terminal, and promise yourself that
you'll never forget what you've just learned. Then an hour goes by, and you've completely
forgotten what you did.
Searching through your Bash history is something everyone has to do from time to time. If
you know exactly what you're searching for, you can use Ctrl+R to do a reverse search through
your history, but sometimes you can't remember the exact command you want to find.
Here's an alias to make that task a little easier:
It happens every Monday: You get to work, you sit down at your computer, you open a
terminal, and you find you've forgotten what you were doing last Friday. What you need is an
alias to list the most recently modified files.
You can use the ls command to create an alias to help you find where you left off:
alias
left = 'ls -t -1'
The output is simple, although you can extend it with the -- long option if you prefer. The
alias, as listed, displays this:
$ left
demo.jpeg
demo.xcf
design-proposal.md
rejects.txt
brainstorm.txt
query-letter.xml Count files
If you need to know how many files you have in a directory, the solution is one of the most
classic examples of UNIX command construction: You list files with the ls command, control its
output to be only one column with the -1 option, and then pipe that output to the wc (word
count) command to count how many lines of single files there are.
It's a brilliant demonstration of how the UNIX philosophy allows users to build their own
solutions using small system components. This command combination is also a lot to type if you
happen to do it several times a day, and it doesn't exactly work for a directory of directories
without using the -R option, which introduces new lines to the output and renders the exercise
useless.
Instead, this alias makes the process easy:
alias count = 'find . -type f | wc -l'
This one counts files, ignoring directories, but not the contents of directories. If
you have a project folder containing two directories, each of which contains two files, the
alias returns four, because there are four files in the entire project.
$ ls
foo bar
$ count
4 Create a Python virtual environment
Do you code in Python?
Do you code in Python a lot?
If you do, then you know that creating a Python virtual environment requires, at the very
least, 53 keystrokes.
That's 49 too many, but that's easily circumvented with two new aliases called ve and va
:
alias ve = 'python3 -m venv ./venv'
alias va = 'source ./venv/bin/activate'
Running ve creates a new directory, called venv , containing the usual virtual environment
filesystem for Python3. The va alias activates the environment in your current shell:
$ cd
my-project
$ ve
$ va
(venv) $ Add a copy progress bar
Everybody pokes fun at progress bars because they're infamously inaccurate. And yet, deep
down, we all seem to want them. The UNIX cp command has no progress bar, but it does have a -v
option for verbosity, meaning that it echoes the name of each file being copied to your
terminal. That's a pretty good hack, but it doesn't work so well when you're copying one big
file and want some indication of how much of the file has yet to be transferred.
The pv command provides a progress bar during copy, but it's not common as a default
application. On the other hand, the rsync command is included in the default installation of
nearly every POSIX system available, and it's widely recognized as one of the smartest ways to
copy files both remotely and locally.
Better yet, it has a built-in progress bar.
alias cpv = 'rsync -ah --info=progress2'
Using this alias is the same as using the cp command:
An interesting side effect of using this command is that rsync copies both files and
directories without the -r flag that cp would otherwise require.
Protect yourself from
file removal accidents
You shouldn't use the rm command. The rm manual even says so:
Warning : If you use 'rm' to remove a file, it is usually possible to recover the
contents of that file. If you want more assurance that the contents are truly unrecoverable,
consider using 'shred'.
If you want to remove a file, you should move the file to your Trash, just as you do when
using a desktop.
POSIX makes this easy, because the Trash is an accessible, actual location in your
filesystem. That location may change, depending on your platform: On a FreeDesktop , the Trash is located at
~/.local/share/Trash , while on MacOS it's ~/.Trash , but either way, it's just a directory
into which you place files that you want out of sight until you're ready to erase them
forever.
This simple alias provides a way to toss files into the Trash bin from your
terminal:
alias tcn = 'mv --force -t ~/.local/share/Trash '
This alias uses a little-known mv flag that enables you to provide the file you want to move
as the final argument, ignoring the usual requirement for that file to be listed first. Now you
can use your new command to move files and folders to your system Trash:
$ ls
foo bar
$ tcn foo
$ ls
bar
Now the file is "gone," but only until you realize in a cold sweat that you still need it.
At that point, you can rescue the file from your system Trash; be sure to tip the Bash and mv
developers on the way out.
Note: If you need a more robust Trash command with better FreeDesktop compliance, see
Trashy .
Simplify your Git
workflow
Everyone has a unique workflow, but there are usually repetitive tasks no matter what. If
you work with Git on a regular basis, then there's probably some sequence you find yourself
repeating pretty frequently. Maybe you find yourself going back to the master branch and
pulling the latest changes over and over again during the day, or maybe you find yourself
creating tags and then pushing them to the remote, or maybe it's something else entirely.
No matter what Git incantation you've grown tired of typing, you may be able to alleviate
some pain with a Bash alias. Largely thanks to its ability to pass arguments to hooks, Git has
a rich set of introspective commands that save you from having to perform uncanny feats in
Bash.
For instance, while you might struggle to locate, in Bash, a project's top-level directory
(which, as far as Bash is concerned, is an entirely arbitrary designation, since the absolute
top level to a computer is the root directory), Git knows its top level with a simple query. If
you study up on Git hooks, you'll find yourself able to find out all kinds of information that
Bash knows nothing about, but you can leverage that information with a Bash alias.
Here's an alias to find the top level of a Git project, no matter where in that project you
are currently working, and then to change directory to it, change to the master branch, and
perform a Git pull:
This kind of alias is by no means a universally useful alias, but it demonstrates how a
relatively simple alias can eliminate a lot of laborious navigation, commands, and waiting for
prompts.
A simpler, and probably more universal, alias returns you to the Git project's top level.
This alias is useful because when you're working on a project, that project more or less
becomes your "temporary home" directory. It should be as simple to go "home" as it is to go to
your actual home, and here's an alias to do it:
alias cg = 'cd `git rev-parse
--show-toplevel`'
Now the command cg takes you to the top of your Git project, no matter how deep into its
directory structure you have descended.
Change directories and view the contents at the
same time
It was once (allegedly) proposed by a leading scientist that we could solve many of the
planet's energy problems by harnessing the energy expended by geeks typing cd followed by ls
.
It's a common pattern, because generally when you change directories, you have the impulse or
the need to see what's around.
But "walking" your computer's directory tree doesn't have to be a start-and-stop
process.
This one's cheating, because it's not an alias at all, but it's a great excuse to explore
Bash functions. While aliases are great for quick substitutions, Bash allows you to add local
functions in your .bashrc file (or a separate functions file that you load into .bashrc , just
as you do your aliases file).
To keep things modular, create a new file called ~/.bash_functions and then have your
.bashrc load it:
if [ -e $HOME / .bash_functions ] ; then
source $HOME / .bash_functions
fi
In the functions file, add this code:
function cl () {
DIR = "$*" ;
# if no DIR given, go home
if [ $# -lt 1 ] ; then
DIR = $HOME ;
fi ;
builtin cd " ${DIR} " && \
# use your preferred ls command
ls -F --color =auto
}
Load the function into your Bash session and then try it out:
Functions are much more flexible than aliases, but with that flexibility comes the
responsibility for you to ensure that your code makes sense and does what you expect. Aliases
are meant to be simple, so keep them easy, but useful. For serious modifications to how Bash
behaves, use functions or custom shell scripts saved to a location in your PATH .
For the record, there are some clever hacks to implement the cd and ls sequence as an
alias, so if you're patient enough, then the sky is the limit even using humble
aliases.
Start aliasing and functioning
Customizing your environment is what makes Linux fun, and increasing your efficiency is what
makes Linux life-changing. Get started with simple aliases, graduate to functions, and post
your must-have aliases in the comments!
My backup tool of choice (rdiff-backup) handles these sorts of comparisons pretty well, so
I tend to be confident in my backup files. That said, there's always the edge case, and this
kind of function is a great solution for those. Thanks!
A few of my "cannot-live-withouts" are regex based:
Decomment removes full-line comments and blank lines. For example, when looking at a
"stock" /etc/httpd/whatever.conf file that has a gazillion lines in it,
alias decomment='egrep -v "^[[:space:]]*((#|;|//).*)?$" '
will show you that only four lines in the file actually DO anything, and the gazillion
minus four are comments. I use this ALL the time with config files, Python (and other
languages) code, and god knows where else.
Then there's unprintables and expletives which are both very similar:
alias unprintable='grep --color="auto" -P -n "[\x00-\x1E]"'
alias expletives='grep --color="auto" -P -n "[^\x00-\x7E]" '
The first shows which lines (with line numbers) in a file contain control characters, and
the second shows which lines in a file contain anything "above" a RUBOUT, er, excuse me, I
mean above ASCII 127. (I feel old.) ;-) Handy when, for example, someone gives you a program
that they edited or created with LibreOffice, and oops... half of the quoted strings have
"real" curly opening and closing quote marks instead of ASCII 0x22 "straight" quote mark
delimiters... But there's actually a few curlies you want to keep, so a "nuke 'em all in one
swell foop" approach won't work.
Thanks for this post! I have created a Github repo- https://github.com/bhuvana-guna/awesome-bash-shortcuts
with a motive to create an extended list of aliases/functions for various programs. As I am a
newbie to terminal and linux, please do contribute to it with these and other super awesome
utilities and help others easily access them.
Did you know that Perl is a great programming language for system administrators? Perl is
platform-independent so you can do things on different operating systems without rewriting your
scripts. Scripting in Perl is quick and easy, and its portability makes your scripts amazingly
useful. Here are a few examples, just to get your creative juices flowing! Renaming a bunch
of files
Suppose you need to rename a whole bunch of files in a directory. In this case, we've got a
directory full of .xml files, and we want to rename them all to .html
. Easy-peasy!
Then just cd to the directory where you need to make the change, and run the script. You
could put this in a cron job, if you needed to run it regularly, and it is easily enhanced to
accept parameters.
Speaking of accepting parameters, let's take a look at a script that does just
that.
Suppose you need to regularly create Linux user accounts on your system, and the format of
the username is first initial/last name, as is common in many businesses. (This is, of course,
a good idea, until you get John Smith and Jane Smith working at the same company -- or want
John to have two accounts, as he works part-time in two different departments. But humor me,
okay?) Each user account needs to be in a group based on their department, and home directories
are of the format /home/<department>/<username> . Let's take a look at a
script to do that:
# If the user calls the script with no parameters,
# give them help!
if ( not @ ARGV ) {
usage () ;
}
# Gather our options; if they specify any undefined option,
# they'll get sent some help!
my %opts ;
GetOptions ( \%opts ,
'fname=s' ,
'lname=s' ,
'dept=s' ,
'run' ,
) or usage () ;
# Let's validate our inputs. All three parameters are
# required, and must be alphabetic.
# You could be clever, and do this with a foreach loop,
# but let's keep it simple for now.
if ( not $opts { fname } or $opts { fname } !~ /^[a-zA-Z]+$/ ) {
usage ( "First name must be alphabetic" ) ;
}
if ( not $opts { lname } or $opts { lname } !~ /^[a-zA-Z]+$/ ) {
usage ( "Last name must be alphabetic" ) ;
}
if ( not $opts { dept } or $opts { dept } !~ /^[a-zA-Z]+$/ ) {
usage ( "Department must be alphabetic" ) ;
}
print "$cmd \n "
;
if ( $opts { run }) { system $cmd ;
} else { print "You need to
add the --run flag to actually execute \n " ;
}
sub usage {
my ( $msg ) = @_ ;
if ( $msg ) { print "$msg \n\n "
;
} print "Usage: $0
--fname FirstName --lname LastName --dept Department --run \n " ; exit ;
}
As with the previous script, there are opportunities for enhancement, but something like
this might be all that you need for this task.
One more, just for fun!
Change copyright text in every Perl source file in a directory
tree
Now we're going to try a mass edit. Suppose you've got a directory full of code, and each
file has a copyright statement somewhere in it. (Rich Bowen wrote a great article, Copyright
statements proliferate inside open source code a couple of years ago that discusses the
wisdom of copyright statements in open source code. It is a good read, and I recommend it
highly. But again, humor me.) You want to change that text in each and every file in the
directory tree. File::Find and File::Slurp are your
friends!
#!/usr/bin/perl
use strict ;
use warnings ;
use File :: Find qw
( find ) ;
use File :: Slurp qw (
read_file write_file ) ;
# If the user gives a directory name, use that. Otherwise,
# use the current directory.
my $dir = $ARGV [ 0 ] || '.' ;
# File::Find::find is kind of dark-arts magic.
# You give it a reference to some code,
# and a directory to hunt in, and it will
# execute that code on every file in the
# directory, and all subdirectories. In this
# case, \&change_file is the reference
# to our code, a subroutine. You could, if
# what you wanted to do was really short,
# include it in a { } block instead. But doing
# it this way is nice and readable.
find ( \&change_file , $dir ) ;
sub change_file {
my $name = $_ ;
# If the file is a directory, symlink, or other
# non-regular file, don't do anything
if ( not - f $name ) { return ;
}
# If it's not Perl, don't do anything.
# Gobble up the file, complete with carriage
# returns and everything.
# Be wary of this if you have very large files
# on a system with limited memory!
my $data = read_file ( $name ) ;
# Use a regex to make the change. If the string appears
# more than once, this will change it everywhere!
Because of Perl's portability, you could use this script on a Windows system as well as a
Linux system -- it Just Works because of the underlying Perl interpreter code. In our
create-an-account code above, that one is not portable, but is Linux-specific because it uses
Linux commands such as adduser .
In my experience, I've found it useful to have a Git repository of these things somewhere
that I can clone on each new system I'm working with. Over time, you'll think of changes to
make to the code to enhance the capabilities, or you'll add new scripts, and Git can help you
make sure that all your tools and tricks are available on all your systems.
I hope these little scripts have given you some ideas how you can use Perl to make your
system administration life a little easier. In addition to these longer scripts, take a look at
a fantastic list of Perl one-liners, and links to other
Perl magic assembled by Mischa Peterson.
Chronyd is a better choice for most networks than ntpd for keeping computers synchronized
with the Network Time Protocol.
"Does anybody really know what time it is? Does anybody really care?"
– Chicago ,
1969
Perhaps that rock group didn't care what time it was, but our computers do need to know the
exact time. Timekeeping is very important to computer networks. In banking, stock markets, and
other financial businesses, transactions must be maintained in the proper order, and exact time
sequences are critical for that. For sysadmins and DevOps professionals, it's easier to follow
the trail of email through a series of servers or to determine the exact sequence of events
using log files on geographically dispersed hosts when exact times are kept on the computers in
question.
I used to work at an organization that received over 20 million emails per day and had four
servers just to accept and do a basic filter on the incoming flood of email. From there, emails
were sent to one of four other servers to perform more complex anti-spam assessments, then they
were delivered to one of several additional servers where the emails were placed in the correct
inboxes. At each layer, the emails would be sent to one of the next-level servers, selected
only by the randomness of round-robin DNS. Sometimes we had to trace a new message through the
system until we could determine where it "got lost," according to the pointy-haired bosses. We
had to do this with frightening regularity.
Most of that email turned out to be spam. Some people actually complained that their [joke,
cat pic, recipe, inspirational saying, or other-strange-email]-of-the-day was missing and asked
us to find it. We did reject those opportunities.
Our email and other transactional searches were aided by log entries with timestamps that --
today -- can resolve down to the nanosecond in even the slowest of modern Linux computers. In
very high-volume transaction environments, even a few microseconds of difference in the system
clocks can mean sorting thousands of transactions to find the correct one(s).
The NTP
server hierarchy
Computers worldwide use the Network Time Protocol (NTP) to
synchronize their times with internet standard reference clocks via a hierarchy of NTP servers.
The primary servers are at stratum 1, and they are connected directly to various national time
services at stratum 0 via satellite, radio, or even modems over phone lines. The time service
at stratum 0 may be an atomic clock, a radio receiver tuned to the signals broadcast by an
atomic clock, or a GPS receiver using the highly accurate clock signals broadcast by GPS
satellites.
To prevent time requests from time servers lower in the hierarchy (i.e., with a higher
stratum number) from overwhelming the primary reference servers, there are several thousand
public NTP stratum 2 servers that are open and available for anyone to use. Many organizations
with large numbers of hosts that need an NTP server will set up their own time servers so that
only one local host accesses the stratum 2 time servers, then they configure the remaining
network hosts to use the local time server which, in my case, is a stratum 3 server.
NTP
choices
The original NTP daemon, ntpd , has been joined by a newer one, chronyd . Both keep the
local host's time synchronized with the time server. Both services are available, and I have
seen nothing to indicate that this will change anytime soon.
Chrony has features that make it the better choice for most environments for the following
reasons:
Chrony can synchronize to the time server much faster than NTP. This is good for laptops
or desktops that don't run constantly.
It can compensate for fluctuating clock frequencies, such as when a host hibernates or
enters sleep mode, or when the clock speed varies due to frequency stepping that slows clock
speeds when loads are low.
It handles intermittent network connections and bandwidth saturation.
It adjusts for network delays and latency.
After the initial time sync, Chrony never steps the clock. This ensures stable and
consistent time intervals for system services and applications.
Chrony can work even without a network connection. In this case, the local host or server
can be updated manually.
The NTP and Chrony RPM packages are available from standard Fedora repositories. You can
install both and switch between them, but modern Fedora, CentOS, and RHEL releases have moved
from NTP to Chrony as their default time-keeping implementation. I have found that Chrony works
well, provides a better interface for the sysadmin, presents much more information, and
increases control.
Just to make it clear, NTP is a protocol that is implemented with either NTP or Chrony. If
you'd like to know more, read this comparison between NTP and Chrony as
implementations of the NTP protocol.
This article explains how to configure Chrony clients and servers on a Fedora host, but the
configuration for CentOS and RHEL current releases works the same.
Chrony structure
The Chrony daemon, chronyd , runs in the background and monitors the time and status of the
time server specified in the chrony.conf file. If the local time needs to be adjusted, chronyd
does it smoothly without the programmatic trauma that would occur if the clock were instantly
reset to a new time.
Chrony's chronyc tool allows someone to monitor the current status of Chrony and make
changes if necessary. The chronyc utility can be used as a command that accepts subcommands, or
it can be used as an interactive text-mode program. This article will explain both
uses.
Client configuration
The NTP client configuration is simple and requires little or no intervention. The NTP
server can be defined during the Linux installation or provided by the DHCP server at boot
time. The default /etc/chrony.conf file (shown below in its entirety) requires no intervention
to work properly as a client. For Fedora, Chrony uses the Fedora NTP pool, and CentOS and RHEL
have their own NTP server pools. Like many Red Hat-based distributions, the configuration file
is well commented.
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
pool 2.fedora.pool.ntp.org iburst
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/drift
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable kernel synchronization of the real-time clock (RTC).
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust
# the system clock.
#minsources 2
# Allow NTP client access from local network.
#allow 192.168.0.0/16
# Serve time even if not synchronized to a time source.
#local stratum 10
# Specify file containing keys for NTP authentication.
keyfile /etc/chrony.keys
# Get TAI-UTC offset and leap seconds from the system tz database.
leapsectz right/UTC
# Specify directory for log files.
logdir /var/log/chrony
# Select which information is logged.
#log measurements statistics tracking
Let's look at the current status of NTP on a virtual machine I use for testing. The chronyc
command, when used with the tracking subcommand, provides statistics that report how far off
the local system is from the reference server.
[root@studentvm1 ~]# chronyc tracking
Reference ID : 23ABED4D (ec2-35-171-237-77.compute-1.amazonaws.com)
Stratum : 3
Ref time (UTC) : Fri Nov 16 16:21:30 2018
System time : 0.000645622 seconds slow of NTP time
Last offset : -0.000308577 seconds
RMS offset : 0.000786140 seconds
Frequency : 0.147 ppm slow
Residual freq : -0.073 ppm
Skew : 0.062 ppm
Root delay : 0.041452706 seconds
Root dispersion : 0.022665167 seconds
Update interval : 1044.2 seconds
Leap status : Normal
[root@studentvm1 ~]#
The Reference ID in the first line of the result is the server the host is synchronized to
-- in this case, a stratum 3 reference server that was last contacted by the host at 16:21:30
2018. The other lines are described in the chronyc(1) man page .
The sources subcommand is also useful because it provides information about the time source
configured in chrony.conf .
The first source in the list is the time server I set up for my personal network. The others
were provided by the pool. Even though my NTP server doesn't appear in the Chrony configuration
file above, my DHCP server provides its IP address for the NTP server. The "S" column -- Source
State -- indicates with an asterisk ( * ) the server our host is synced to. This is consistent
with the data from the tracking subcommand.
The -v option provides a nice description of the fields in this output.
[root@studentvm1
~]# chronyc sources -v
210 Number of sources = 5
If I wanted my server to be the preferred reference time source for this host, I would add
the line below to the /etc/chrony.conf file.
server 192.168.0.51 iburst prefer
I usually place this line just above the first pool server statement near the top of the
file. There is no special reason for this, except I like to keep the server statements
together. It would work just as well at the bottom of the file, and I have done that on several
hosts. This configuration file is not sequence-sensitive.
The prefer option marks this as the preferred reference source. As such, this host will
always be synchronized with this reference source (as long as it is available). We can also use
the fully qualified hostname for a remote reference server or the hostname only (without the
domain name) for a local reference time source as long as the search statement is set in the
/etc/resolv.conf file. I prefer the IP address to ensure that the time source is accessible
even if DNS is not working. In most environments, the server name is probably the better
option, because NTP will continue to work even if the server's IP address changes.
If you don't have a specific reference source you want to synchronize to, it is fine to use
the defaults.
Configuring an NTP server with Chrony
The nice thing about the Chrony configuration file is that this single file configures the
host as both a client and a server. To add a server function to our host -- it will always be a
client, obtaining its time from a reference server -- we just need to make a couple of changes
to the Chrony configuration, then configure the host's firewall to accept NTP requests.
Open the /etc/chrony.conf file in your favorite text editor and uncomment the local stratum
10 line. This enables the Chrony NTP server to continue to act as if it were connected to a
remote reference server if the internet connection fails; this enables the host to continue to
be an NTP server to other hosts on the local network.
Let's restart chronyd and track how the service is working for a few minutes. Before we
enable our host as an NTP server, we want to test a bit.
The results should look like this. The watch command runs the chronyc tracking command every
two seconds so we can watch changes occur over time.
Every 2.0s: chronyc tracking
studentvm1: Fri Nov 16 20:59:31 2018
Reference ID : C0A80033 (192.168.0.51)
Stratum : 4
Ref time (UTC) : Sat Nov 17 01:58:51 2018
System time : 0.001598277 seconds fast of NTP time
Last offset : +0.001791533 seconds
RMS offset : 0.001791533 seconds
Frequency : 0.546 ppm slow
Residual freq : -0.175 ppm
Skew : 0.168 ppm
Root delay : 0.094823152 seconds
Root dispersion : 0.021242738 seconds
Update interval : 65.0 seconds
Leap status : Normal
Notice that my NTP server, the studentvm1 host, synchronizes to the host at 192.168.0.51,
which is my internal network NTP server, at stratum 4. Synchronizing directly to the Fedora
pool machines would result in synchronization at stratum 3. Notice also that the amount of
error decreases over time. Eventually, it should stabilize with a tiny variation around a
fairly small range of error. The size of the error depends upon the stratum and other network
factors. After a few minutes, use Ctrl+C to break out of the watch loop.
To turn our host into an NTP server, we need to allow it to listen on the local network.
Uncomment the following line to allow hosts on the local network to access our NTP server.
#
Allow NTP client access from local network.
allow 192.168.0.0/16
Note that the server can listen for requests on any local network it's attached to. The IP
address in the "allow" line is just intended for illustrative purposes. Be sure to change the
IP network and subnet mask in that line to match your local network's.
Restart chronyd .
[root@studentvm1 ~]# systemctl restart chronyd
To allow other hosts on your network to access this server, configure the firewall to allow
inbound UDP packets on port 123. Check your firewall's documentation to find out how to do
that.
Testing
Your host is now an NTP server. You can test it with another host or a VM that has access to
the network on which the NTP server is listening. Configure the client to use the new NTP
server as the preferred server in the /etc/chrony.conf file, then monitor that client using the
chronyc tools we used above.
Chronyc as an interactive tool
As I mentioned earlier, chronyc can be used as an interactive command tool. Simply run the
command without a subcommand and you get a chronyc command prompt.
[root@studentvm1 ~]#
chronyc
chrony version 3.4
Copyright (C) 1997-2003, 2007, 2009-2018 Richard P. Curnow and others
chrony comes with ABSOLUTELY NO WARRANTY. This is free software, and
you are welcome to redistribute it under certain conditions. See the
GNU General Public License version 2 for details.
chronyc>
You can enter just the subcommands at this prompt. Try using the tracking , ntpdata , and
sources commands. The chronyc command line allows command recall and editing for chronyc
subcommands. You can use the help subcommand to get a list of possible commands and their
syntax.
Conclusion
Chrony is a powerful tool for synchronizing the times of client hosts, whether they are all
on the local network or scattered around the globe. It's easy to configure because, despite the
large number of options available, only a few configurations are required for most
circumstances.
After my client computers have synchronized with the NTP server, I like to set the system
hardware clock from the system (OS) time by using the following command:
/sbin/hwclock --systohc
This command can be added as a cron job or a script in cron.daily to keep the hardware clock
synced with the system time.
Chrony and NTP (the service) both use the same configuration, and the files' contents are
interchangeable. The man pages for chronyd , chronyc , and chrony.conf contain an amazing amount of
information that can help you get started or learn about esoteric configuration options.
Do you run your own NTP server? Let us know in the comments and be sure to tell us which
implementation you are using, NTP or Chrony.
Logreduce machine learning
model is trained using previous successful job runs to extract anomalies from failed runs'
logs.
This principle can also be applied to other use cases, for example, extracting anomalies
from Journald or other
systemwide regular log files.
Using machine learning to reduce noise
A typical log file contains many nominal events ("baselines") along with a few exceptions
that are relevant to the developer. Baselines may contain random elements such as timestamps or
unique identifiers that are difficult to detect and remove. To remove the baseline events, we
can use a k -nearest neighbors
pattern recognition algorithm ( k -NN).
Log events must be converted to numeric values for k -NN regression. Using the
generic feature extraction tool
HashingVectorizer enables the process to be applied to any type of log. It hashes each word
and encodes each event in a sparse matrix. To further reduce the search space, tokenization
removes known random words, such as dates or IP addresses.
The Logreduce Python software transparently implements this process. Logreduce's initial
goal was to assist with Zuul CI job failure
analyses using the build database, and it is now integrated into the Software Factory development forge's job logs
process.
At its simplest, Logreduce compares files or directories and removes lines that are similar.
Logreduce builds a model for each source file and outputs any of the target's lines whose
distances are above a defined threshold by using the following syntax: distance |
filename:line-number: line-content .
$ logreduce diff / var / log / audit / audit.log.1 /
var / log / audit / audit.log
INFO logreduce.Classifier - Training took 21.982s at 0.364MB / s ( 1.314kl / s ) ( 8.000 MB -
28.884 kilo-lines )
0.244 | audit.log: 19963 : type =USER_AUTH acct = "root" exe = "/usr/bin/su" hostname
=managesf.sftests.com
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB / s ( 1.094kl / s ) ( 5.607 MB -
20.015 kilo-lines )
99.99 % reduction ( from 20015 lines to 1
A more advanced Logreduce use can train a model offline to be reused. Many variants of the
baselines can be used to fit the k -NN search tree.
$ logreduce dir-train audit.clf /
var / log / audit / audit.log. *
INFO logreduce.Classifier - Training took 80.883s at 0.396MB / s ( 1.397kl / s ) ( 32.001 MB -
112.977 kilo-lines )
DEBUG logreduce.Classifier - audit.clf: written
$ logreduce dir-run audit.clf / var / log / audit / audit.log
Logreduce also implements interfaces to discover baselines for Journald time ranges
(days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that
group anomalies found in multiple files in a simple interface.
The key to using k -NN regression for anomaly detection is to have a database of
known good baselines, which the model uses to detect lines that deviate too far. This method
relies on the baselines containing all nominal events, as anything that isn't found in the
baseline will be reported as anomalous.
CI jobs are great targets for k -NN regression because the job outputs are often
deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul
job roles that can be used as part of a failed job post task in order to issue a concise report
(instead of the full job's logs). This principle can be applied to other cases, as long as
baselines can be constructed in advance. For example, a nominal system's SoS report can be used to find issues in a
defective deployment.
The next version of Logreduce introduces a server mode to offload log processing to an
external service where reports can be further analyzed. It also supports importing existing
reports and requests to analyze a Zuul build. The services run analyses asynchronously and
feature a web interface to adjust scores and remove false positives.
Reviewed reports can be archived as a standalone dataset with the target log files and the
scores for anomalous lines recorded in a flat JSON file.
Project roadmap
Logreduce is already being used effectively, but there are many opportunities for improving
the tool. Plans for the future include:
Curating many annotated anomalies found in log files and producing a public domain
dataset to enable further research. Anomaly detection in log files is a challenging topic,
and having a common dataset to test new models would help identify new solutions.
Reusing the annotated anomalies with the model to refine the distances reported. For
example, when users mark lines as false positives by setting their distance to zero, the
model could reduce the score of those lines in future reports.
Fingerprinting archived anomalies to detect when a new report contains an already known
anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user
that the job hit a known issue. When the issue is fixed, the service could automatically
restart the job.
Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins
builds, Travis CI, and more.
If you are interested in getting involved in this project, please contact us on the
#log-classify Freenode IRC channel. Feedback is always appreciated!
No longer a simple log-processing pipeline, Logstash has evolved into a powerful and
versatile data processing tool. Here are basics to get you started. 19 Oct 2017 Feed 298
up Image by : Opensource.com x Subscribe now
Get the highlights in your inbox every week.
https://opensource.com/eloqua-embedded-email-capture-block.html?offer_id=70160000000QzXNAA0
Logstash , an open
source tool released by Elastic , is
designed to ingest and transform data. It was originally built to be a log-processing pipeline
to ingest logging data into ElasticSearch . Several versions later, it
can do much more.
At its core, Logstash is a form of Extract-Transform-Load (ETL) pipeline. Unstructured log
data is extracted , filters transform it, and the results are loaded into some form of data
store.
Logstash can take a line of text like this syslog example:
Sep 11 14:13:38 vorthys
sshd[16998]: Received disconnect from 192.0.2.11 port 53730:11: disconnected by user
and transform it into a much richer datastructure:
Depending on what you are using for your backing store, you can find events like this by
using indexed fields rather than grepping terabytes of text. If you're generating tens to
hundreds of gigabytes of logs a day, that matters.
Internal architecture
Logstash has a three-stage pipeline implemented in JRuby:
The input stage plugins extract data. This can be from logfiles, a TCP or UDP listener, one
of several protocol-specific plugins such as syslog or IRC, or even queuing systems such as
Redis, AQMP, or Kafka. This stage tags incoming events with metadata surrounding where the
events came from.
The filter stage plugins transform and enrich the data. This is the stage that produces the
sshd_action and sshd_tuple fields in the example above. This is where
you'll find most of Logstash's value.
The output stage plugins load the processed events into something else, such as
ElasticSearch or another document-database, or a queuing system such as Redis, AQMP, or Kafka.
It can also be configured to communicate with an API. It is also possible to hook up something
like PagerDuty to your Logstash
outputs.
Have a cron job that checks if your backups completed successfully? It can issue an alarm in
the logging stream. This is picked up by an input, and a filter config set up to catch those
events marks it up, allowing a conditional output to know this event is for it. This is how you
can add alarms to scripts that would otherwise need to create their own notification layers, or
that operate on systems that aren't allowed to communicate with the outside
world.
Threads
In general, each input runs in its own thread. The filter and output stages are more
complicated. In Logstash 1.5 through 2.1, the filter stage had a configurable number of
threads, with the output stage occupying a single thread. That changed in Logstash 2.2, when
the filter-stage threads were built to handle the output stage. With one fewer internal queue
to keep track of, throughput improved with Logstash 2.2.
If you're running an older version, it's worth upgrading to at least 2.2. When we moved from
1.5 to 2.2, we saw a 20-25% increase in overall throughput. Logstash also spent less time in
wait states, so we used more of the CPU (47% vs 75%).
Configuring the pipeline
Logstash can take a single file or a directory for its configuration. If a directory is
given, it reads the files in lexical order. This is important, as ordering is significant for
filter plugins (we'll discuss that in more detail later).
Here is a bare Logstash config file:
input { }
filter { }
output { }
Each of these will contain zero or more plugin configurations, and there can be multiple
blocks.
Input config
An input section can look like this:
input {
syslog {
port => 514
type => "syslog_server"
}
}
This tells Logstash to open the syslog
{ } plugin on port 514 and will set the document type for each event coming in
through that plugin to be syslog_server . This plugin follows RFC 3164 only, not
the newer RFC 5424.
Here is a slightly more complex input block:
# Pull in syslog data
input {
file {
path => [
"/var/log/syslog" ,
"/var/log/auth.log"
]
type => "syslog"
}
}
# Pull in application - log data. They emit data in JSON form.
input {
file {
path => [
"/var/log/app/worker_info.log" ,
"/var/log/app/broker_info.log" ,
"/var/log/app/supervisor.log"
]
exclude => "*.gz"
type => "applog"
codec => "json"
}
}
This one uses two different input { } blocks to call different invocations of
the file {
} plugin : One tracks system-level logs, the other tracks application-level logs. By
using two different input { } blocks, a Java thread is spawned for each one. For a
multi-core system, different cores keep track of the configured files; if one thread blocks,
the other will continue to function.
Both of these file { } blocks could be put into the same input { }
block; they would simply run in the same thread -- Logstash doesn't really care.
Filter
config
The filter section is where you transform your data into something that's newer and easier
to work with. Filters can get quite complex. Here are a few examples of filters that accomplish
different goals:
filter {
if [ program ] == "metrics_fetcher" {
mutate {
add_tag => [ 'metrics' ]
}
}
}
In this example, if the program field, populated by the syslog
plugin in the example input at the top, reads metrics_fetcher , then it tags the
event metrics . This tag could be used in a later filter plugin to further enrich
the data.
filter {
if "metrics" in [ tags ] {
kv {
source => "message"
target => "metrics"
}
}
}
This one runs only if metrics is in the list of tags. It then uses the
kv { } plugin to populate a new set of fields based on the
key=value pairs in the message field. These new keys are placed as
sub-fields of the metrics field, allowing the text pages_per_second=42
faults=0 to become metrics.pages_per_second = 42 and metrics.faults =
0 on the event.
Why wouldn't you just put this in the same conditional that set the tag value?
Because there are multiple ways an event could get the metrics tag -- this way,
the kv filter will handle them all.
Because the filters are ordered, being sure that the filter plugin that defines the
metrics tag is run before the conditional that checks for it is important. Here
are guidelines to ensure your filter sections are optimally ordered:
Your early filters should apply as much metadata as possible.
Using the metadata, perform detailed parsing of events.
In your late filters, regularize your data to reduce problems downstream.
Ensure field data types get cast to a unified value. priority could be
boolean, integer, or string.
Some systems, including ElasticSearch, will quietly convert types for you.
Sending strings into a boolean field won't give you the results you want.
Other systems will reject a value outright if it isn't in the right data
type.
The
mutate { } plugin is helpful here, as it has methods to coerce fields
into specific data types.
Here are useful plugins to extract fields from long strings:
date : Many
logging systems emit a timestamp. This plugin parses that timestamp and sets the timestamp of
the event to be that embedded time. By default, the timestamp of the event is when it was
ingested , which could be seconds, hours, or even days later.
kv : As
previously demonstrated, it can turn strings like backup_state=failed
progress=0.24 into fields you can perform operations on.
csv : When
given a list of columns to expect, it can create fields on the event based on comma-separated
values.
json : If a
field is formatted in JSON, this will turn it into fields. Very powerful!
xml : Like
the JSON plugin, this will turn a field containing XML data into new fields.
grok :
This is your regex engine. If you need to translate strings like The accounting
backup failed into something that will pass if [backup_status] ==
'failed' , this will do it.
Elastic would like you to send it all into ElasticSearch, but anything that can accept a
JSON document, or the datastructure it represents, can be an output. Keep in mind that events
can be sent to multiple outputs. Consider this example of metrics:
output {
# Send to the local ElasticSearch port , and rotate the index daily.
elasticsearch {
hosts => [
"localhost" ,
"logelastic.prod.internal"
]
template_name => "logstash"
index => "logstash-{+YYYY.MM.dd}"
}
if "metrics" in [ tags ] {
influxdb {
host => "influx.prod.internal"
db => "logstash"
measurement => "appstats"
# This next bit only works because it is already a hash.
data_points => "%{metrics}"
send_as_tags => [ 'environment' , 'application' ]
}
}
}
Remember the metrics example above? This is how we can output it. The events
tagged metrics will get sent to ElasticSearch in their full event form. In
addition, the subfields under the metrics field on that event will be sent to
influxdb
, in the logstash database, under the appstats measurement. Along
with the measurements, the values of the environment and application
fields will be submitted as indexed tags.
There are a great many outputs. Here are some grouped by type:
API enpoints : Jira, PagerDuty, Rackspace, Redmine, Zabbix
Alexey thanks for great video, I have a question, how did you integrate the fzf and bat.
When I am in my zsh using tmux then when I type fzf and search for a file I am not able to
select multiple files using TAB I can do this inside VIM but not in the tmux iTerm terminal
also I am not able to see the preview I have already installed bat using brew on my mac book
pro. also when I type cd ** it doesn't work
Thanks for the video. When searching in vim dotfiles are hidden. How can we configure so
that dotfiles are shown but .git and .git subfolders are ignored?
Having a hard time remembering a command? Normally you might resort to a man page, but some
man pages have a hard time getting to the point. It's the reason Chris Allen Lane came up with
the idea (and more importantly, the code) for a cheat command .
The cheat command displays cheatsheets for common tasks in your terminal. It's a man page
without the preamble. It cuts to the chase and tells you exactly how to do whatever it is
you're trying to do. And if it lacks a common example that you think ought to be included, you
can submit an update.
$ cheat tar
# To extract an uncompressed archive:
tar -xvf '/path/to/foo.tar'
# To extract a .gz archive:
tar -xzvf '/path/to/foo.tgz'
[ ... ]
You can also treat cheat as a local cheatsheet system, which is great for all the in-house
commands you and your team have invented over the years. You can easily add a local cheatsheet
to your own home directory, and cheat will find and display it just as if it were a popular
system command.
Let's first cover what alerts are not . Alerts should not be sent if the human
responder can't do anything about the problem. This includes alerts that are sent to multiple
individuals with only a few who can respond, or situations where every anomaly in the system
triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a
specific medium until the system escalates to a medium that isn't already saturated.
For example, if an operator receives hundreds of emails a day from the alerting system, that
operator will soon ignore all emails from the alerting system. The operator will respond to a
real incident only when he or she is experiencing the problem, emailed by a customer, or called
by the boss. In this case, alerts have lost their meaning and usefulness.
Alerts are not a constant stream of information or a status update. They are meant to convey
a problem from which the system can't automatically recover, and they are sent only to the
individual most likely to be able to recover the system. Everything that falls outside this
definition isn't an alert and will only damage your employees and company culture.
Everyone has a different set of alert types, so I won't discuss things like priority levels
(P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I'll
describe the generic categories emergent in complex systems' incident response.
You might have noticed I mentioned an "Informational" alert type right after I wrote that
alerts shouldn't be informational. Well, not everyone agrees, but I don't consider something an
alert if it isn't sent to anyone. It is a data point that many systems refer to as an alert. It
represents some event that should be known but not responded to. It is generally part of the
visualization system of the alerting tool and not an event that triggers actual notifications.
Mike Julian covers this and other aspects of alerting in his book Practical Monitoring . It's a must read for work in
this area.
Non-informational alerts consist of types that can be responded to or require action. I
group these into two categories: internal outage and external outage. (Most companies have more
than two levels for prioritizing their response efforts.) Degraded system performance is
considered an outage in this model, as the impact to each user is usually unknown.
Internal outages are a lower priority than external outages, but they still need to be
responded to quickly. They often include internal systems that company employees use or
components of applications that are visible only to company employees.
External outages consist of any system outage that would immediately impact a customer.
These don't include a system outage that prevents releasing updates to the system. They do
include customer-facing application failures, database outages, and networking partitions that
hurt availability or consistency if either can impact a user. They also include outages of
tools that may not have a direct impact on users, as the application continues to run but this
transparent dependency impacts performance. This is common when the system uses some external
service or data source that isn't necessary for full functionality but may cause delays as the
application performs retries or handles errors from this external
dependency.
Visualizations
There are many visualization types, and I won't cover them all here. It's a fascinating area
of research. On the data analytics side of my career, learning and applying that knowledge is a
constant challenge. We need to provide simple representations of complex system outputs for the
widest dissemination of information. Google Charts and Tableau have a
wide selection of visualization types. We'll cover the most common visualizations and some
innovative solutions for quickly understanding systems.
Line chart
The line chart is probably the most common visualization. It does a pretty good job of
producing an understanding of a system over time. A line chart in a metrics system would have a
line for each unique metric or some aggregation of metrics. This can get confusing when there
are a lot of metrics in the same dashboard (as shown below), but most systems can select
specific metrics to view rather than having all of them visible. Also, anomalous behavior is
easy to spot if it's significant enough to escape the noise of normal operations. Below we can
see purple, yellow, and light blue lines that might indicate anomalous
behavior.
Another feature of a line chart is that you can often stack them to show relationships. For
example, you might want to look at requests on each server individually, but also in aggregate.
This allows you to understand the overall system as well as each instance in the same
graph.
Another common visualization is the heatmap. It is useful when looking at histograms. This
type of visualization is similar to a bar chart but can show gradients within the bars
representing the different percentiles of the overall metric. For example, suppose you're
looking at request latencies and you want to quickly understand the overall trend as well as
the distribution of all requests. A heatmap is great for this, and it can use color to
disambiguate the quantity of each section with a quick glance.
The heatmap below shows the higher concentration around the centerline of the graph with an
easy-to-understand visualization of the distribution vertically for each time bucket. We might
want to review a couple of points in time where the distribution gets wide while the others are
fairly tight like at 14:00. This distribution might be a negative performance
indicator.
The last common visualization I'll cover here is the gauge, which helps users understand a
single metric quickly. Gauges can represent a single metric, like your speedometer represents
your driving speed or your gas gauge represents the amount of gas in your car. Similar to the
gas gauge, most monitoring gauges clearly indicate what is good and what isn't. Often (as is
shown below), good is represented by green, getting worse by orange, and "everything is
breaking" by red. The middle row below shows traditional gauges.
This image shows more than just traditional gauges. The other gauges are single stat
representations that are similar to the function of the classic gauge. They all use the same
color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is
probably the best example of a gauge that allows you to glance at a dashboard and know that
everything is healthy (or not). This type of visualization is usually what I put on a top-level
dashboard. It offers a full, high-level understanding of system health in seconds.
Flame
graphs
A less common visualization is the flame graph, introduced by Netflix's Brendan Gregg in 2011. It's not
ideal for dashboarding or quickly observing high-level system concerns; it's normally seen when
trying to understand a specific application problem. This visualization focuses on CPU and
memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis
shows stack depth. Each rectangle is a stack frame and includes the function being called. The
wider the rectangle, the more it appears in the stack. This method is invaluable when trying to
diagnose system performance at the application level and I urge everyone to give it a
try.
There are several commercial options for alerting, but since this is Opensource.com, I'll
cover only systems that are being used at scale by real companies that you can use at no cost.
Hopefully, you'll be able to contribute new and innovative features to make these systems even
better.
Alerting toolsBosun
If you've ever done anything with computers and gotten stuck, the help you received was
probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around
a crowdsourced question-and-answer model. Stack Overflow is very popular with developers, and Super User is popular with operations. However,
there are now hundreds of sites ranging from parenting to sci-fi and philosophy to
bicycles.
Stack Exchange open-sourced its alert management system, Bosun , around the same time Prometheus and its AlertManager system were released.
There were many similarities in the two systems, and that's a really good thing. Like
Prometheus, Bosun is written in Golang. Bosun's scope is more extensive than Prometheus' as it
can interact with systems beyond metrics aggregation. It can also ingest data from log and
event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
Bosun's architecture consists of a single server binary, a backend like OpenTSDB, Redis, and
scollector agents . The scollector
agents automatically detect services on a host and report metrics for those processes and other
system resources. This data is sent to a metrics backend. The Bosun server binary then queries
the backends to determine if any alerts need to be fired. Bosun can also be used by tools like
Grafana to query the underlying backends
through one common interface. Redis is used to store state and metadata for Bosun.
A really neat feature of Bosun is that it lets you test your alerts against historical data.
This was something I missed in Prometheus several years ago, when I had data for an issue I
wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to
create and insert dummy data. This system alleviates that very time-consuming process.
Bosun also has the usual features like showing simple graphs and creating alerts. It has a
powerful expression language for writing alerting rules. However, it only has email and HTTP
notification configurations, which means connecting to Slack and other tools requires a bit
more customization ( which its
documentation covers ). Similar to Prometheus, Bosun can use templates for these
notifications, which means they can look as awesome as you want them to. You can use all your
HTML and CSS skills to create the baddest email alert anyone has ever seen.
Cabot
Cabot was created by a company called
Arachnys . You may not know who
Arachnys is or what it does, but you have probably felt its impact: It built the leading
cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a
previous company, I was involved in similar functions around "know your customer" laws. Most
companies would consider it a very bad thing to be linked to a terrorist group, for example,
funneling money through their systems. These solutions also help defend against less-atrocious
offenders like fraudsters who could also pose a risk to the institution.
So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it
was a Christmas project built because its developers couldn't wrap their heads around
Nagios . And really, who can blame them?
Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the
project. (Another interesting factoid: The name comes from the creator's dog.)
The Cabot architecture is similar to Bosun in that it doesn't collect any data. Instead, it
accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull
(rather than a push) model for alerting. It reaches out into each system's API and retrieves
the information it needs to make a decision based on a specific check. Cabot stores the
alerting data in a Postgres database and also has a cache using Redis.
Cabot natively supports Graphite ,
but it also supports Jenkins , which is rare
in this area. Arachnys uses Jenkins
like a centralized cron, but I like this idea of treating build failures like outages.
Obviously, a build failure isn't as critical as a production outage, but it could still alert
the team and escalate if the failure isn't resolved. Who actually checks Jenkins every time an
email comes in about a build failure? Yeah, me too!
Another interesting feature is that Cabot can integrate with Google Calendar for on-call
rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation.
This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn't
support anything more complex than primary and backup personnel, but there is certainly room
for additional features. The docs say if you want something more advanced, you should look at a
commercial option.
StatsAgg
StatsAgg ? How
did that make the list? Well, it's not every day you come across a publishing company that has
created an alerting platform. I think that deserves recognition. Of course, Pearson isn't just a publishing company anymore; it has
several web presences and a joint venture with O'Reilly Media . However, I still think of it as the company
that published my schoolbooks and tests.
StatsAgg isn't just an alerting platform; it's also a metrics aggregation platform. And it's
kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as
inputs, but it can also forward those metrics to their respective platforms. This is an
interesting concept, but potentially risky as loads increase on a central service. However, if
the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend
storage platform has an outage.
StatsAgg is written in Java and consists only of the main server and UI, which keeps
complexity to a minimum. It can send alerts based on regular expression matching and is focused
on alerting by service rather than host or instance. Its goal is to fill a void in the open
source observability stack, and I think it does that quite well.
Visualization toolsGrafana
Almost everyone knows about Grafana , and
many have used it. I have used it for years whenever I need a simple dashboard. The tool I used
before was deprecated, and I was fairly distraught about that until Grafana made it okay.
Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around
Christmastime, and released in January 2014. It has come a long way in just a few years. It
started life as a Kibana dashboarding system, and Torkel forked it into what became
Grafana.
Grafana's sole focus is presenting monitoring data in a more usable and pleasing way. It can
natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There's
an Enterprise version that uses plugins for more data sources, but there's no reason those
other data source plugins couldn't be created as open source, as the Grafana plugin ecosystem
already offers many other data sources.
What does Grafana do for me? It provides a central location for understanding my system. It
is web-based, so anyone can access the information, although it can be restricted using
different authentication methods. Grafana can provide knowledge at a glance using many
different types of visualizations. However, it has started integrating alerting and other
features that aren't traditionally combined with visualizations.
Now you can set alerts visually. That means you can look at a graph, maybe even one showing
where an alert should have triggered due to some degradation of the system, click on the graph
where you want the alert to trigger, and then tell Grafana where to send the alert. That's a
pretty powerful addition that won't necessarily replace an alerting platform, but it can
certainly help augment it by providing a different perspective on alerting criteria.
Grafana has also introduced more collaboration features. Users have been able to share
dashboards for a long time, meaning you don't have to create your own dashboard for your
Kubernetes
cluster because there are several already available -- with some maintained by Kubernetes
developers and others by Grafana developers.
The most significant addition around collaboration is annotations. Annotations allow a user
to add context to part of a graph. Other users can then use this context to understand the
system better. This is an invaluable tool when a team is in the middle of an incident and
communication and common understanding are critical. Having all the information right where
you're already looking makes it much more likely that knowledge will be shared across the team
quickly. It's also a nice feature to use during blameless postmortems when the team is trying
to understand how the failure occurred and learn more about their system.
Vizceral
Netflix created Vizceral
to understand its traffic patterns better when performing a traffic failover. Unlike Grafana,
which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses
this tool internally and says it is no longer actively maintained, but it still updates the
tool periodically. I highlight it here primarily to point out an interesting visualization
mechanism and how it can help solve a problem. It's worth running it in a demo environment just
to better grasp the concepts and witness what's possible with these systems.
Find and
fix outlier events that create issues before they trigger severe production problems. Black
swans are a metaphor for outlier events that are severe in impact (like the 2008 financial
crash). In production systems, these are the incidents that trigger problems that you didn't
know you had, cause major visible impact, and can't be fixed quickly and easily by a rollback
or some other standard response from your on-call playbook. They are the events you tell new
engineers about years after the fact.
Black swans, by definition, can't be predicted, but sometimes there are patterns we can find
and use to create defenses against categories of related problems.
For example, a large proportion of failures are a direct result of changes (code,
environment, or configuration). Each bug triggered in this way is distinctive and
unpredictable, but the common practice of canarying all changes is somewhat effective against
this class of problems, and automated rollbacks have become a standard mitigation.
As our profession continues to mature, other kinds of problems are becoming well-understood
classes of hazards with generalized prevention strategies.
Black swans observed in the
wild
All technology organizations have production problems, but not all of them share their
analyses. The organizations that publicly discuss incidents are doing us all a service. The
following incidents describe one class of a problem and are by no means isolated instances. We
all have black swans lurking in our systems; it's just some of us don't know it
yet.
Running headlong into any sort of limit can produce very severe incidents. A canonical
example of this was Instapaper's
outage in February 2017 . I challenge any engineer who has carried a pager to read the
outage report without a chill running up their spine. Instapaper's production database was on a
filesystem that, unknown to the team running the service, had a 2TB limit. With no warning, it
stopped accepting writes. Full recovery took days and required migrating its database.
One way to get advance knowledge of system limits is to test periodically. Good load testing
(on a production replica) ought to involve write transactions and should involve growing each
datastore beyond its current production size. It's easy to forget to test things that aren't
your main datastores (such as Zookeeper). If you hit limits during testing, you have time to
fix the problems. Given that resolution of limits-related issues can involve major changes
(like splitting a datastore), time is invaluable.
When it comes to cloud services, if your service generates unusual loads or uses less widely
used products or features (such as older or newer ones), you may be more at risk of hitting
limits. It's worth load testing these, too. But warn your cloud provider first.
Finally, where limits are known, add monitoring (with associated documentation) so you will
know when your systems are approaching those ceilings. Don't rely on people still being around
to remember.
Spreading slowness
"The world is much more correlated than we give credit to. And so we see more of what
Nassim Taleb calls 'black swan events' -- rare events happen more often than they should
because the world is more correlated." -- Richard
Thaler
HostedGraphite's postmortem on how an
AWS outage took down its load balancers (which are not hosted on AWS) is a good example of
just how much correlation exists in distributed computing systems. In this case, the
load-balancer connection pools were saturated by slow connections from customers that were
hosted in AWS. The same kinds of saturation can happen with application threads, locks, and
database connections -- any kind of resource monopolized by slow operations.
HostedGraphite's incident is an example of externally imposed slowness, but often slowness
can result from saturation somewhere in your own system creating a cascade and causing other
parts of your system to slow down. An incident at Spotify
demonstrates such spread -- the streaming service's frontends became unhealthy due to
saturation in a different microservice. Enforcing deadlines for all requests, as well as
limiting the length of request queues, can prevent such spread. Your service will serve at
least some traffic, and recovery will be easier because fewer parts of your system will be
broken.
Retries should be limited with exponential backoff and some jitter. An outage at Square, in
which its Redis datastore
became overloaded due to a piece of code that retried failed transactions up to 500 times
with no backoff, demonstrates the potential severity of excessive retries. The Circuit
Breaker design pattern can be helpful here, too.
Often, failure scenarios arise when a system is under unusually heavy load. This can arise
organically from users, but often it arises from systems. A surge of cron jobs that starts at
midnight is a venerable example. Mobile clients can also be a source of coordinated demand if
they are programmed to fetch updates at the same time (of course, it is much better to jitter
such requests).
Events occurring at pre-configured times aren't the only source of thundering herds. Slack
experienced multiple
outages over a short time due to large numbers of clients being disconnected and
immediately reconnecting, causing large spikes of load. CircleCI saw a severe outage when a GitLab outage
ended, leading to a surge of builds queued in its database, which became saturated and very
slow.
Almost any service can be the target of a thundering herd. Planning for such eventualities
-- and testing that your plan works as intended -- is therefore a must. Client backoff and
load shedding are
often core to such approaches.
If your systems must constantly ingest data that can't be dropped, it's key to have a
scalable way to buffer this data in a queue for later processing.
Automation systems are
complex systems
"Complex systems are intrinsically hazardous systems." -- Richard Cook,
MD
If your systems must constantly ingest data that can't be dropped, it's key to have a
scalable way to buffer this data in a queue for later processing. The trend for the past
several years has been strongly towards more automation of software operations. Automation of
anything that can reduce your system's capacity (e.g., erasing disks, decommissioning devices,
taking down serving jobs) needs to be done with care. Accidents (due to bugs or incorrect
invocations) with this kind of automation can take down your system very efficiently,
potentially in ways that are hard to recover from.
Christina Schulman and Etienne Perot of Google describe some examples in their talk
Help Protect Your
Data Centers with Safety Constraints . One incident sent Google's entire in-house content
delivery network (CDN) to disk-erase.
Schulman and Perot suggest using a central service to manage constraints, which limits the
pace at which destructive automation can operate, and being aware of system conditions (for
example, avoiding destructive operations if the service has recently had an alert).
Automation systems can also cause havoc when they interact with operators (or with other
automated systems). Reddit
experienced a major outage when its automation restarted a system that operators had stopped
for maintenance. Once you have multiple automation systems, their potential interactions become
extremely complex and impossible to predict.
It will help to deal with the inevitable surprises if all this automation writes logs to an
easily searchable, central place. Automation systems should always have a mechanism to allow
them to be quickly turned off (fully or only for a subset of operations or
targets).
Defense against the dark swans
These are not the only black swans that might be waiting to strike your systems. There are
many other kinds of severe problem that can be avoided using techniques such as canarying, load
testing, chaos engineering, disaster testing, and fuzz testing -- and of course designing for
redundancy and resiliency. Even with all that, at some point your system will fail.
To ensure your organization can respond effectively, make sure your key technical staff and
your leadership have a way to coordinate during an outage. For example, one unpleasant issue
you might have to deal with is a complete outage of your network. It's important to have a
fail-safe communications channel completely independent of your own infrastructure and its
dependencies. For instance, if you run on AWS, using a service that also runs on AWS as your
fail-safe communication method is not a good idea. A phone bridge or an IRC server that runs
somewhere separate from your main systems is good. Make sure everyone knows what the
communications platform is and practices using it.
Another principle is to ensure that your monitoring and your operational tools rely on your
production systems as little as possible. Separate your control and your data planes so you can
make changes even when systems are not healthy. Don't use a single message queue for both data
processing and config changes or monitoring, for example -- use separate instances. In
SparkPost: The Day
the DNS Died , Jeremy Blosser presents an example where critical tools relied on the
production DNS setup, which failed.
The psychology of battling the black swan
To ensure your organization can respond effectively, make sure your key technical staff and
your leadership have a way to coordinate during an outage. Dealing with major incidents in
production can be stressful. It really helps to have a structured incident-management process
in place for these situations. Many technology organizations ( including Google )
successfully use a version of FEMA's Incident Command System. There should be a clear way for
any on-call individual to call for assistance in the event of a major problem they can't
resolve alone.
For long-running incidents, it's important to make sure people don't work for unreasonable
lengths of time and get breaks to eat and sleep (uninterrupted by a pager). It's easy for
exhausted engineers to make a mistake or overlook something that might resolve the incident
faster.
Learn more
There are many other things that could be said about black (or formerly black) swans and
strategies for dealing with them. If you'd like to learn more, I highly recommend these two
books dealing with resilience and stability in production: Susan Fowler's Production-Ready
Microservices and Michael T. Nygard's Release It! .
You knew this would come first. Data recovery is a time-intensive process and rarely
produces 100% correct results. If you don't have a backup plan in place, start one now.
Better yet, implement two. First, provide users with local backups with a tool like
rsnapshot . This utility creates snapshots
of each user's data in a ~/.snapshots directory, making it trivial for them to
recover their own data quickly.
Second, while these local backups are convenient, also set up a remote backup plan for your
organization. Tools like AMANDA or
BackupPC are solid choices
for this task. You can run them as a daemon so that backups happen automatically.
Backup planning and preparation pay for themselves in both time, and peace of mind. There's
nothing like not needing emergency response procedures in the first place.
Ban rm
On modern operating systems, there is a Trash or Bin folder where users drag the files they
don't want out of sight without deleting them just yet. Traditionally, the Linux terminal has
no such holding area, so many terminal power users have the bad habit of permanently deleting
data they believe they no longer need. Since there is no "undelete" command, this habit can be
quite problematic should a power user (or administrator) accidentally delete a directory full
of important data.
Many users say they favor the absolute deletion of files, claiming that they prefer their
computers to do exactly what they tell them to do. Few of those users, though, forego their
rm command for the more complete shred , which really
removes their data. In other words, most terminal users invoke the rm command
because it removes data, but take comfort in knowing that file recovery tools exist as a
hacker's un- rm . Still, using those tools take up their administrator's precious
time. Don't let your users -- or yourself -- fall prey to this breach of logic.
If you really want to remove data, then rm is not sufficient. Use the
shred -u command instead, which overwrites, and then thoroughly deletes the
specified data
However, if you don't want to actually remove data, don't use rm . This command
is not feature-complete, in that it has no undo feature, but has the capacity to be undone.
Instead, use trashy or
trash-cli to "delete"
files into a trash bin while using your terminal, like so:
$ trash ~/example.txt
$ trash --list
example.txt
One advantage of these commands is that the trash bin they use is the same your desktop's
trash bin. With them, you can recover your trashed files by opening either your desktop Trash
folder, or through the terminal.
If you've already developed a bad rm habit and find the trash
command difficult to remember, create an alias for yourself:
$ echo "alias rm='trash'"
Even better, create this alias for everyone. Your time as a system administrator is too
valuable to spend hours struggling with file recovery tools just because someone mis-typed an
rm command.
Respond efficiently
Unfortunately, it can't be helped. At some point, you'll have to recover lost files, or
worse. Let's take a look at emergency response best practices to make the job easier. Before
you even start, understanding what caused the data to be lost in the first place can save you a
lot of time:
If someone was careless with their trash bin habits or messed up dangerous remove or
shred commands, then you need to recover a deleted file.
If someone accidentally overwrote a partition table, then the files aren't really lost.
The drive layout is.
In the case of a dying hard drive, recovering data is secondary to the race against
decay to recover
the bits themselves (you can worry about carving those bits into intelligible files
later).
No matter how the problem began, start your rescue mission with a few best practices:
Stop using the drive that contains the lost data, no matter what the reason. The more you
do on this drive, the more you risk overwriting the data you're trying to rescue. Halt and
power down the victim computer, and then either reboot using a thumb drive, or extract the
damaged hard drive and attach it to your rescue machine.
Do not use the victim hard drive as the recovery location. Place rescued data on a spare
volume that you're sure is working. Don't copy it back to the victim drive until it's been
confirmed that the data has been sufficiently recovered.
If you think the drive is dying, your first priority after powering it down is to obtain
a duplicate image, using a tool like ddrescue or Clonezilla .
Once you have a sense of what went wrong, It's time to choose the right tool to fix the
problem. Two such tools are Scalpel and TestDisk , both of which operate just as well on
a disk image as on a physical drive.
Practice (or, go break stuff)
At some point in your career, you'll have to recover data. The smart practices discussed
above can minimize how often this happens, but there's no avoiding this problem. Don't wait
until disaster strikes to get familiar with data recovery tools. After you set up your local
and remote backups, implement command-line trash bins, and limit the rm command,
it's time to practice your data recovery techniques.
Download and practice using Scalpel, TestDisk, or whatever other tools you feel might be
useful. Be sure to practice data recovery safely, though. Find an old computer, install Linux
onto it, and then generate, destroy, and recover. If nothing else, doing so teaches you to
respect data structures, filesystems, and a good backup plan. And when the time comes and you
have to put those skills to real use, you'll appreciate knowing what to do.
Wiping out of /etc directory is one thing that sysadmin accidentally do. This is often happen
if the other directory is name etc, for example /Backup/etc. In such cases you automatically put
a slash in front of etc because it is ingrained in your mind. And you put the slash in front of
etc subconsciously, not realizing what you are doing. And then faces consequences. If you do not
use saferm, the result are pretty devastating. In most cases the sever does not die, but new
logins are impossible. SSH session survives. That's why it is important to backup /etc/at the
first login to the server. On modern severs it takes a couple of seconds.
If subdirectories are intact then you still can copy the content from another server. But content of sysconfig subdirectory in
linux is unique to the server and you need a backup to restore it.
Notable quotes:
"... As root. I thought I was deleting some stale cache files for one of our programs. Instead, I wiped out all files in the /etc directory by mistake. Ouch. ..."
"... I put together a simple strategy: Don't reboot the server. Use an identical system as a template, and re-create the ..."
rm
command in the wrong directory. As root. I thought I was deleting some stale cache files for
one of our programs. Instead, I wiped out all files in the /etc directory by
mistake. Ouch.
My clue that I'd done something wrong was an error message that rm couldn't
delete certain subdirectories. But the cache directory should contain only files! I immediately
stopped the rm command and looked at what I'd done. And then I panicked. All at
once, a million thoughts ran through my head. Did I just destroy an important server? What was
going to happen to the system? Would I get fired?
Fortunately, I'd run rm * and not rm -rf * so I'd deleted only
files. The subdirectories were still there. But that didn't make me feel any better.
Immediately, I went to my supervisor and told her what I'd done. She saw that I felt really
dumb about my mistake, but I owned it. Despite the urgency, she took a few minutes to do some
coaching with me. "You're not the first person to do this," she said. "What would someone else
do in your situation?" That helped me calm down and focus. I started to think less about the
stupid thing I had just done, and more about what I was going to do next.
I put together a simple strategy: Don't reboot the server. Use an identical system as a
template, and re-create the /etc directory.
Once I had my plan of action, the rest was easy. It was just a matter of running the right
commands to copy the /etc files from another server and edit the configuration so
it matched the system. Thanks to my practice of documenting everything, I used my existing
documentation to make any final adjustments. I avoided having to completely restore the server,
which would have meant a huge disruption.
To be sure, I learned from that mistake. For the rest of my years as a systems
administrator, I always confirmed what directory I was in before running any command.
I also learned the value of building a "mistake strategy." When things go wrong, it's
natural to panic and think about all the bad things that might happen next. That's human
nature. But creating a "mistake strategy" helps me stop worrying about what just went wrong and
focus on making things better. I may still think about it, but knowing my next steps allows me
to "get over it."
This is mostly the list. You need to do your own research. Some improtant backup applications
are not mentioned. It is unclear from it what are methods used in each, and why each of them is
preferable to tar. The stress in the list is on portability (Linux plus Mc and windows, not just
Linux)
Recently, we published a poll that asked readers to
vote on their favorite open source backup solution. We offered six solutions recommended by our
moderator community --
Cronopete, Deja Dup, Rclone, Rdiff-backup, Restic, and Rsync -- and invited readers to share
other options in the comments. And you came through, offering 13 other solutions (so far) that
we either hadn't considered or hadn't even heard of.
By far the most popular suggestion was BorgBackup . It is a deduplicating backup solution that
features compression and encryption. It is supported on Linux, MacOS, and BSD and has a BSD
License.
Second was UrBackup , which does
full and incremental image and file backups; you can save whole partitions or single
directories. It has clients for Windows, Linux, and MacOS and has a GNU Affero Public
License.
Third was LuckyBackup ;
according to its website, "it is simple to use, fast (transfers over only changes made and not
all data), safe (keeps your data safe by checking all declared directories before proceeding in
any data manipulation), reliable, and fully customizable." It carries a GNU Public License.
Casync is
content-addressable synchronization -- it's designed for backup and synchronizing and stores
and retrieves multiple related versions of large file systems. It is licensed with the GNU
Lesser Public License.
Syncthing synchronizes files between
two computers. It is licensed with the Mozilla Public License and, according to its website, is
secure and private. It works on MacOS, Windows, Linux, FreeBSD, Solaris, and OpenBSD.
Duplicati is a free backup solution
that works on Windows, MacOS, and Linux and a variety of standard protocols, such as FTP, SSH,
and WebDAV, and cloud services. It features strong encryption and is licensed with the GPL.
Dirvish is a disk-based virtual image
backup system licensed under OSL-3.0. It also requires Rsync, Perl5, and SSH to be
installed.
Bacula 's website says it "is a set of
computer programs that permits the system administrator to manage backup, recovery, and
verification of computer data across a network of computers of different kinds." It is
supported on Linux, FreeBSD, Windows, MacOS, OpenBSD, and Solaris and the bulk of its source
code is licensed under AGPLv3.
BackupPC "is a
high-performance, enterprise-grade system for backing up Linux, Windows, and MacOS PCs and
laptops to a server's disk," according to its website. It is licensed under the GPLv3.
Amanda is a backup system written in C
and Perl that allows a system administrator to back up an entire network of client machines to
a single server using tape, disk, or cloud-based systems. It was developed and copyrighted in
1991 at the University of Maryland and has a BSD-style license.
Back in Time is a
simple backup utility designed for Linux. It provides a command line client and a GUI, both
written in Python. To do a backup, just specify where to store snapshots, what folders to back
up, and the frequency of the backups. BackInTime is licensed with GPLv2.
Timeshift is a backup
utility for Linux that is similar to System Restore for Windows and Time Capsule for MacOS.
According to its GitHub repository, "Timeshift protects your system by taking incremental
snapshots of the file system at regular intervals. These snapshots can be restored at a later
date to undo all changes to the system."
Kup is a backup solution that
was created to help users back up their files to a USB drive, but it can also be used to
perform network backups. According to its GitHub repository, "When you plug in your external
hard drive, Kup will automatically start copying your latest changes."
The sudo command comes with a huge set of defaults. Still, there are situations when you
want to override some of these. This is when you use the Defaults statement in the
configuration. Usually, these defaults are enforced on every user, but you can narrow the
setting down to a subset of users based on host, username, and so on. Here is an example that
my generation of sysadmins loves to hear about: insults. These are just some funny messages for
when someone mistypes a password:
czanik @ linux-mewy:~ > sudo ls
[ sudo ] password for root:
Hold it up to the light --- not a brain in sight !
[ sudo ] password for root:
My pet ferret can type better than you !
[ sudo ] password for root:
sudo: 3 incorrect password attempts
czanik @ linux-mewy:~ >
Because not everyone is a fan of sysadmin humor, these insults are disabled by default. The
following example shows how to enable this setting only for your seasoned sysadmins, who are
members of the wheel group:
Defaults !insults
Defaults:%wheel insults
I do not have enough fingers to count how many people thanked me for bringing these messages
back.
Digest verification
There are, of course, more serious features in sudo as well. One of them is digest
verification. You can include the digest of applications in your configuration:
peter ALL = sha244:11925141bb22866afdf257ce7790bd6275feda80b3b241c108b79c88 /usr/bin/passwd
In this case, sudo checks and compares the digest of the application to the one stored in
the configuration before running the application. If they do not match, sudo refuses to run the
application. While it is difficult to maintain this information in your configuration -- there
are no automated tools for this purpose -- these digests can provide you with an additional
layer of protection.
Session recording
Session recording is also a lesser-known feature of sudo . After my demo, many people leave
my talk with plans to implement it on their infrastructure. Why? Because with session
recording, you see not just the command name, but also everything that happened in the
terminal. You can see what your admins are doing even if they have shell access and logs only
show that bash is started.
There is one limitation, currently. Records are stored locally, so with enough permissions,
users can delete their traces. Stay tuned for upcoming features. New features
There is a new version of sudo right around the corner. Version 1.9 will include many
interesting new features. Here are the most important planned features:
A recording service to collect session recordings centrally, which offers many advantages
compared to local storage:
It is more convenient to search in one place.
Recordings are available even if the sender machine is down.
Recordings cannot be deleted by someone who wants to delete their tracks.
The audit plugin does not add new features to sudoers , but instead provides an API for
plugins to easily access any kind of sudo logs. This plugin enables creating custom logs from
sudo events using plugins.
The approval plugin enables session approvals without using third-party plugins.
And my personal favorite: Python support for plugins, which enables you to easily extend
sudo using Python code instead of coding natively in C.
Conclusion
I hope this article proved to you that sudo is a lot more than just a simple prefix. There
are tons of possibilities to fine-tune permissions on your system. You cannot just fine-tune
permissions, but also improve security by checking digests. Session recordings enable you to
check what is happening on your systems. You can also extend the functionality of sudo using
plugins, either using something already available or writing your own. Finally, given the list
of upcoming features you can see that even if sudo is decades old, it is a living project that
is constantly evolving.
If you want to learn more about sudo , here are a few resources:
Your Linux terminal probably supports Unicode, so why not take advantage of that and add
a seasonal touch to your prompt? 11 Dec 2018 Jason Baker (Red Hat) Feed 84
up 3 comments Image credits : Jason Baker x Subscribe now
Hello once again for another installment of the Linux command-line toys advent calendar. If
this is your first visit to the series, you might be asking yourself what a command-line toy
even is? Really, we're keeping it pretty open-ended: It's anything that's a fun diversion at
the terminal, and we're giving bonus points for anything holiday-themed.
Maybe you've seen some of these before, maybe you haven't. Either way, we hope you have
fun.
Today's toy is super-simple: It's your Bash prompt. Your Bash prompt? Yep! We've got a few
more weeks of the holiday season left to stare at it, and even more weeks of winter here in the
northern hemisphere, so why not have some fun with it.
Your Bash prompt currently might be a simple dollar sign ( $ ), or more likely, it's
something a little longer. If you're not sure what makes up your Bash prompt right now, you can
find it in an environment variable called $PS1. To see it, type:
echo $PS1
For me, this returns:
[\u@\h \W]\$
The \u , \h , and \W are special characters for username, hostname, and working directory.
There are others you can use as well; for help building out your Bash prompt, you can use
EzPrompt , an online generator of PS1
configurations that includes lots of options including date and time, Git status, and more.
You may have other variables that make up your Bash prompt set as well; $PS2 for me contains
the closing brace of my command prompt. See this article for more information.
To change your prompt, simply set the environment variable in your terminal like this:
$
PS1 = '\u is cold: '
jehb is cold:
To set it permanently, add the same code to your /etc/bashrc using your favorite text
editor.
So what does this have to do with winterization? Well, chances are on a modern machine, your
terminal support Unicode, so you're not limited to the standard ASCII character set. You can
use any emoji that's a part of the Unicode specification, including a snowflake ❄, a
snowman ☃, or a pair of skis 🎿. You've got plenty of wintery options to choose
from.
🎄 Christmas Tree
🧥 Coat
🦌 Deer
🧤 Gloves
🤶 Mrs. Claus
🎅 Santa Claus
🧣 Scarf
🎿 Skis
🏂 Snowboarder
❄ Snowflake
☃ Snowman
⛄ Snowman Without Snow
🎁 Wrapped Gift
Pick your favorite, and enjoy some winter cheer. Fun fact: modern filesystems also support
Unicode characters in their filenames, meaning you can technically name your next program
"❄❄❄❄❄.py" . That said, please don't.
Do you have a favorite command-line toy that you think I ought to include? The calendar for
this series is mostly filled out but I've got a few spots left. Let me know in the comments
below, and I'll check it out. If there's space, I'll try to include it. If not, but I get some
good submissions, I'll do a round-up of honorable mentions at the end.
**PS1** - The value of this parameter is expanded and used as the primary prompt string. The default value is \u@\h \W\\$ .
**PS2** - The value of this parameter is expanded as with PS1 and used as the secondary prompt string. The default is ]
**PS3** - The value of this parameter is used as the prompt for the select command
**PS4** - The value of this parameter is expanded as with PS1 and the value is printed before each command bash displays during an execution trace. The first character of PS4 is replicated multiple times, as necessary, to indicate multiple levels of indirection. The default is +
PS1
is a primary prompt variable which holds
\u@\h \W\\$
special bash
characters. This is the default structure of the bash prompt and is displayed every time a user logs in
using a terminal. These default values are set in the
/etc/bashrc
file.
The special characters in the default prompt are as follows:
This solution is part of Red Hat's fast-track publication program, providing a huge library of solutions
that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the
instant it becomes available, these articles may be presented in a raw and unedited form.
2 Comments
Log in to comment
MW
Community Member
48
points
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
On RHEL 7 instead of the solution suggested above create a /etc/profile.d/custom.sh which
contains
Hello Red Hat community! I also found this useful:
Raw
Special prompt variable characters:
\d The date, in "Weekday Month Date" format (e.g., "Tue May 26").
\h The hostname, up to the first . (e.g. deckard)
\H The hostname. (e.g. deckard.SS64.com)
\j The number of jobs currently managed by the shell.
\l The basename of the shell's terminal device name.
\s The name of the shell, the basename of $0 (the portion following
the final slash).
\t The time, in 24-hour HH:MM:SS format.
\T The time, in 12-hour HH:MM:SS format.
\@ The time, in 12-hour am/pm format.
\u The username of the current user.
\v The version of Bash (e.g., 2.00)
\V The release of Bash, version + patchlevel (e.g., 2.00.0)
\w The current working directory.
\W The basename of $PWD.
\! The history number of this command.
\# The command number of this command.
\$ If you are not root, inserts a "$"; if you are root, you get a "#" (root uid = 0)
\nnn The character whose ASCII code is the octal value nnn.
\n A newline.
\r A carriage return.
\e An escape character (typically a color code).
\a A bell character.
\\ A backslash.
\[ Begin a sequence of non-printing characters. (like color escape sequences). This
allows bash to calculate word wrapping correctly.
\] End a sequence of non-printing characters.
Using single quotes instead of double quotes when exporting your PS variables is recommended, it makes the prompt a tiny bit faster to evaluate plus you can then do an echo $PS1 to see the current prompt settings.
To explain the above, I'm builidng my bash prompt by executing a function stored in a
string, which was a decision made as the result of
this question . Let's pretend like it works fine, because it does, except when unicode
characters get involved
I am trying to find the proper way to escape a unicode character, because right now it
messes with the bash line length. An easy way to test if it's broken is to type a long
command, execute it, press CTRL-R and type to find it, and then pressing CTRL-A CTRL-E to
jump to the beginning / end of the line. If the text gets garbled then it's not working.
I have tried several things to properly escape the unicode character in the function
string, but nothing seems to be working.
Which is the main reason I made the prompt a function string. That escape sequence does
NOT mess with the line length, it's just the unicode character.
The \[...\] sequence says to ignore this part of the string completely, which is
useful when your prompt contains a zero-length sequence, such as a control sequence which
changes the text color or the title bar, say. But in this case, you are printing a character,
so the length of it is not zero. Perhaps you could work around this by, say, using a no-op
escape sequence to fool Bash into calculating the correct line length, but it sounds like
that way lies madness.
The correct solution would be for the line length calculations in Bash to correctly grok
UTF-8 (or whichever Unicode encoding it is that you are using). Uhm, have you tried without
the \[...\] sequence?
Edit: The following implements the solution I propose in the comments below. The cursor
position is saved, then two spaces are printed, outside of \[...\] , then the
cursor position is restored, and the Unicode character is printed on top of the two spaces.
This assumes a fixed font width, with double width for the Unicode character.
PS1='\['"`tput sc`"'\] \['"`tput rc`"'༇ \] \$ '
At least in the OSX Terminal, Bash 3.2.17(1)-release, this passes cursory [sic]
testing.
In the interest of transparency and legibility, I have ignored the requirement to have the
prompt's functionality inside a function, and the color coding; this just changes the prompt
to the character, space, dollar prompt, space. Adapt to suit your somewhat more complex
needs.
The trick as pointed out in @tripleee's link is the use of the commands tput
sc and tput rc which save and then restore the cursor position. The code
is effectively saving the cursor position, printing two spaces for width, restoring the
cursor position to before the spaces, then printing the special character so that the width
of the line is from the two spaces, not the character.
> ,
(Not the answer to your problem, but some pointers and general experience related to your
issue.)
I see the behaviour you describe about cmd-line editing (Ctrl-R, ... Cntrl-A Ctrl-E ...)
all the time, even without unicode chars.
At one work-site, I spent the time to figure out the diff between the terminals
interpretation of the TERM setting VS the TERM definition used by the OS (well, stty I
suppose).
NOW, when I have this problem, I escape out of my current attempt to edit the line, bring
the line up again, and then immediately go to the 'vi' mode, which opens the vi editor.
(press just the 'v' char, right?). All the ease of use of a full-fledged session of vi; why
go with less ;-)?
Looking again at your problem description, when you say
That is just a string definition, right? and I'm assuming your simplifying the problem
definition by assuming this is the output of your my_function . It seems very
likely in the steps of creating the function definition, calling the function AND using the
values returned are a lot of opportunities for shell-quoting to not work the way you want it
to.
If you edit your question to include the my_function definition, and its
complete use (reducing your function to just what is causing the problem), it may be easier
for others to help with this too. Finally, do you use set -vx regularly? It can
help show how/wnen/what of variable expansions, you may find something there.
Failing all of those, look at Orielly termcap & terminfo
. You may need to look at the man page for your local systems stty and related
cmds AND you may do well to look for user groups specific to you Linux system (I'm assuming
you use a Linux variant).
In Figure 1, two complete physical hard drives and one partition from a third hard drive
have been combined into a single volume group. Two logical volumes have been created from the
space in the volume group, and a filesystem, such as an EXT3 or EXT4 filesystem has been
created on each of the two logical volumes.
Figure 1: LVM allows combining partitions and entire hard drives into Volume
Groups.
Adding disk space to a host is fairly straightforward but, in my experience, is done
relatively infrequently. The basic steps needed are listed below. You can either create an
entirely new volume group or you can add the new space to an existing volume group and either
expand an existing logical volume or create a new one.
Adding a new logical volume
There are times when it is necessary to add a new logical volume to a host. For example,
after noticing that the directory containing virtual disks for my VirtualBox virtual machines
was filling up the /home filesystem, I decided to create a new logical volume in which to store
the virtual machine data, including the virtual disks. This would free up a great deal of space
in my /home filesystem and also allow me to manage the disk space for the VMs
independently.
The basic steps for adding a new logical volume are as follows.
If necessary, install a new hard drive.
Optional: Create a partition on the hard drive.
Create a physical volume (PV) of the complete hard drive or a partition on the hard
drive.
Assign the new physical volume to an existing volume group (VG) or create a new volume
group.
Create a new logical volumes (LV) from the space in the volume group.
Create a filesystem on the new logical volume.
Add appropriate entries to /etc/fstab for mounting the filesystem.
Mount the filesystem.
Now for the details. The following sequence is taken from an example I used as a lab project
when teaching about Linux filesystems.
Example
This example shows how to use the CLI to extend an existing volume group to add more space
to it, create a new logical volume in that space, and create a filesystem on the logical
volume. This procedure can be performed on a running, mounted filesystem.
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted
filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
Install
hard drive
If there is not enough space in the volume group on the existing hard drive(s) in the system
to add the desired amount of space it may be necessary to add a new hard drive and create the
space to add to the Logical Volume. First, install the physical hard drive, and then perform
the following steps.
Create Physical Volume from hard drive
It is first necessary to create a new Physical Volume (PV). Use the command below, which
assumes that the new hard drive is assigned as /dev/hdd.
pvcreate /dev/hdd
It is not necessary to create a partition of any kind on the new hard drive. This creation
of the Physical Volume which will be recognized by the Logical Volume Manager can be performed
on a newly installed raw disk or on a Linux partition of type 83. If you are going to use the
entire hard drive, creating a partition first does not offer any particular advantages and uses
disk space for metadata that could otherwise be used as part of the PV.
Extend the
existing Volume Group
In this example we will extend an existing volume group rather than creating a new one; you
can choose to do it either way. After the Physical Volume has been created, extend the existing
Volume Group (VG) to include the space on the new PV. In this example the existing Volume Group
is named MyVG01.
vgextend /dev/MyVG01 /dev/hdd
Create the Logical Volume
First create the Logical Volume (LV) from existing free space within the Volume Group. The
command below creates a LV with a size of 50GB. The Volume Group name is MyVG01 and the Logical
Volume Name is Stuff.
lvcreate -L +50G --name Stuff MyVG01
Create the filesystem
Creating the Logical Volume does not create the filesystem. That task must be performed
separately. The command below creates an EXT4 filesystem that fits the newly created Logical
Volume.
mkfs -t ext4 /dev/MyVG01/Stuff
Add a filesystem label
Adding a filesystem label makes it easy to identify the filesystem later in case of a crash
or other disk related problems.
e2label /dev/MyVG01/Stuff Stuff
Mount the filesystem
At this point you can create a mount point, add an appropriate entry to the /etc/fstab file,
and mount the filesystem.
You should also check to verify the volume has been created correctly. You can use the
df , lvs, and vgs commands to do this.
Resizing a logical volume in
an LVM filesystem
The need to resize a filesystem has been around since the beginning of the first versions of
Unix and has not gone away with Linux. It has gotten easier, however, with Logical Volume
Management.
If necessary, install a new hard drive.
Optional: Create a partition on the hard drive.
Create a physical volume (PV) of the complete hard drive or a partition on the hard
drive.
Assign the new physical volume to an existing volume group (VG) or create a new volume
group.
Create one or more logical volumes (LV) from the space in the volume group, or expand an
existing logical volume with some or all of the new space in the volume group.
If you created a new logical volume, create a filesystem on it. If adding space to an
existing logical volume, use the resize2fs command to enlarge the filesystem to fill the
space in the logical volume.
Add appropriate entries to /etc/fstab for mounting the filesystem.
Mount the filesystem.
Example
This example describes how to resize an existing Logical Volume in an LVM environment using
the CLI. It adds about 50GB of space to the /Stuff filesystem. This procedure can be used on a
mounted, live filesystem only with the Linux 2.6 Kernel (and higher) and EXT3 and EXT4
filesystems. I do not recommend that you do so on any critical system, but it can be done and I
have done so many times; even on the root (/) filesystem. Use your judgment.
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted
filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
Install the
hard drive
If there is not enough space on the existing hard drive(s) in the system to add the desired
amount of space it may be necessary to add a new hard drive and create the space to add to the
Logical Volume. First, install the physical hard drive and then perform the following
steps.
Create a Physical Volume from the hard drive
It is first necessary to create a new Physical Volume (PV). Use the command below, which
assumes that the new hard drive is assigned as /dev/hdd.
pvcreate /dev/hdd
It is not necessary to create a partition of any kind on the new hard drive. This creation
of the Physical Volume which will be recognized by the Logical Volume Manager can be performed
on a newly installed raw disk or on a Linux partition of type 83. If you are going to use the
entire hard drive, creating a partition first does not offer any particular advantages and uses
disk space for metadata that could otherwise be used as part of the PV.
Add PV to
existing Volume Group
For this example, we will use the new PV to extend an existing Volume Group. After the
Physical Volume has been created, extend the existing Volume Group (VG) to include the space on
the new PV. In this example, the existing Volume Group is named MyVG01.
vgextend /dev/MyVG01 /dev/hdd
Extend the Logical Volume
Extend the Logical Volume (LV) from existing free space within the Volume Group. The command
below expands the LV by 50GB. The Volume Group name is MyVG01 and the Logical Volume Name is
Stuff.
lvextend -L +50G /dev/MyVG01/Stuff
Expand the filesystem
Extending the Logical Volume will also expand the filesystem if you use the -r option. If
you do not use the -r option, that task must be performed separately. The command below resizes
the filesystem to fit the newly resized Logical Volume.
resize2fs /dev/MyVG01/Stuff
You should check to verify the resizing has been performed correctly. You can use the
df , lvs, and vgs commands to do this.
Tips
Over the years I have learned a few things that can make logical volume management even
easier than it already is. Hopefully these tips can prove of some value to you.
Use the Extended file systems unless you have a clear reason to use another filesystem.
Not all filesystems support resizing but EXT2, 3, and 4 do. The EXT filesystems are also very
fast and efficient. In any event, they can be tuned by a knowledgeable sysadmin to meet the
needs of most environments if the defaults tuning parameters do not.
Use meaningful volume and volume group names.
Use EXT filesystem labels.
I know that, like me, many sysadmins have resisted the change to Logical Volume Management.
I hope that this article will encourage you to at least try LVM. I am really glad that I did;
my disk management tasks are much easier since I made the switch. TopicsBusiness Linux How-tos and tutorials
SysadminAbout the author David Both - David Both is an Open Source Software and
GNU/Linux advocate, trainer, writer, and speaker who lives in Raleigh North Carolina. He is a
strong proponent of and evangelist for the "Linux Philosophy." David has been in the IT
industry for nearly 50 years. He has taught RHCE classes for Red Hat and has worked at MCI
Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open
Source Software for over 20 years. David prefers to purchase the components and build
his...
NixCraft
Use the site's internal search function. With more than a decade of regular updates, there's
gold to be found here -- useful scripts and handy hints that can solve your problem straight
away. This is often the second place I look after Google.
Webmin
This gives you a nice web interface to remotely edit your configuration files. It cuts down on
a lot of time spent having to juggle directory paths and sudo nano , which is
handy when you're handling several customers.
Windows Subsystem for
Linux
The reality of the modern workplace is that most employees are on Windows, while the grown-up
gear in the server room is on Linux. So sometimes you find yourself trying to do admin tasks
from (gasp) a Windows desktop.
What do you do? Install a virtual machine? It's actually much faster and far less work to
configure if you install the Windows Subsystem for Linux compatibility layer, now available at
no cost on Windows 10.
This gives you a Bash terminal in a window where you can run Bash scripts and Linux binaries
on the local machine, have full access to both Windows and Linux filesystems, and mount network
drives. It's available in Ubuntu, OpenSUSE, SLES, Debian, and Kali flavors.
mRemoteNG
This is an excellent SSH and remote desktop client for when you have 100+ servers to
manage.
Setting up a network so you don't have to do it again
A poorly planned network is the sworn enemy of the admin who hates working overtime.
IP
Addressing Schemes that Scale
The diabolical thing about running out of IP addresses is that, when it happens, the network's
grown large enough that a new addressing scheme is an expensive, time-consuming pain in the
proverbial.
Ain't nobody got time for that!
At some point, IPv6 will finally arrive to save the day. Until then, these
one-size-fits-most IP addressing schemes should keep you going, no matter how many
network-connected wearables, tablets, smart locks, lights, security cameras, VoIP headsets, and
espresso machines the world throws at us.
Linux Chmod Permissions Cheat
Sheet
A short but sweet cheat sheet of Bash commands to set permissions across the network. This is
so when Bill from Customer Service falls for that ransomware scam, you're recovering just his
files and not the entire company's.
VLSM Subnet Calculator
Just put in the number of networks you want to create from an address space and the number of
hosts you want per network, and it calculates what the subnet mask should be for
everything.
Single-purpose Linux distributions
Need a Linux box that does just one thing? It helps if someone else has already sweated the
small stuff on an operating system you can install and have ready immediately.
Each of these has, at one point, made my work day so much easier.
Porteus Kiosk
This is for when you want a computer totally locked down to just a web browser. With a little
tweaking, you can even lock the browser down to just one website. This is great for public
access machines. It works with touchscreens or with a keyboard and mouse.
Parted Magic
This is an operating system you can boot from a USB drive to partition hard drives, recover
data, and run benchmarking tools.
IPFire
Hahahaha, I still can't believe someone called a router/firewall/proxy combo "I pee fire."
That's my second favorite thing about this Linux distribution. My favorite is that it's a
seriously solid software suite. It's so easy to set up and configure, and there is a heap of
plugins available to extend it.
What about your top tools and cheat sheets?
So, how about you? What tools, resources, and cheat sheets have you found to make the
workday easier? I'd love to know. Please share in the comments.
The output from the sar command can be detailed, or you can choose to limit the data
displayed. For example, enter the sar command with no options, which displays only
aggregate CPU performance data. The sar command uses the current day by default, starting at
midnight, so you should only see the CPU data for today.
On the other hand, using the sar -A command shows all of the data that has been
collected for today. Enter the sar -A | less command now and page through the
output to view the many types of data collected by SAR, including disk and network usage, CPU
context switches (how many times per second the CPU switched from one program to another), page
swaps, memory and swap space usage, and much more. Use the man page for the sar command to
interpret the results and to get an idea of the many options available. Many of those options
allow you to view specific data, such as network and disk performance.
I typically use the sar -A command because many of the types of data available
are interrelated, and sometimes I find something that gives me a clue to a performance problem
in a section of the output that I might not have looked at otherwise. The -A
option displays all of the collected data types.
Look at the entire output of the sar -A | less command to get a feel for the
type and amount of data displayed. Be sure to look at the CPU usage data as well as the
processes started per second (proc/s) and context switches per second (cswch/s). If the number
of context switches increases rapidly, that can indicate that running processes are being
swapped off the CPU very frequently.
You can limit the total amount of data to the total CPU activity with the sar
-u command. Try that and notice that you only get the composite CPU data, not the data
for the individual CPUs. Also try the -r option for memory, and -S
for swap space. Combining these options so the following command will display CPU, memory, and
swap space is also possible:
sar -urS
Using the -p option displays block device names for hard drives instead of the
much more cryptic device identifiers, and -d displays only the block devices --
the hard drives. Issue the following command to view all of the block device data in a readable
format using the names as they are found in the /dev directory:
sar -dp | less
If you want only data between certain times, you can use -s and -e
to define the start and end times, respectively. The following command displays all CPU data,
both individual and aggregate for the time period between 7:50 AM and 8:11 AM today:
sar -P ALL -s 07:50:00 -e 08:11:00
Note that all times must be in 24-hour format. If you have multiple CPUs, each CPU is
detailed individually, and the average for all CPUs is also given.
The next command uses the -n option to display network statistics for all
interfaces:
sar -n ALL | less
Data for previous days
Data collected for previous days can also be examined by specifying the desired log file.
Assume that today's date is September 3 and you want to see the data for yesterday, the
following command displays all collected data for September 2. The last two digits of each file
are the day of the month on which the data was collected:
sar -A -f /var/log/sa/sa02 | less
You can use the command below, where DD is the day of the month for
yesterday:
sar -A -f /var/log/sa/saDD | less
Realtime data
You can also use SAR to display (nearly) realtime data. The following command displays
memory usage in 5- second intervals for 10 iterations:
sar -r 5 10
This is an interesting option for sar as it can provide a series of data points for a
defined period of time that can be examined in detail and compared. The /proc filesystem All of
this data for SAR and the system monitoring tools covered in my previous article must come from
somewhere. Fortunately, all of that kernel data is easily available in the /proc filesystem. In
fact, because the kernel performance data stored there is all in ASCII text format, it can be
displayed using simple commands like cat so that the individual programs do not
have to load their own kernel modules to collect it. This saves system resources and makes the
data more accurate. SAR and the system monitoring tools I have discussed in my previous article
all collect their data from the /proc filesystem.
Note that /proc is a virtual filesystem and only exists in RAM while Linux is running. It is
not stored on the hard drive.
Even though I won't get into detail, the /proc filesystem also contains the live kernel
tuning parameters and variables. Thus you can change the kernel tuning by simply changing the
appropriate kernel tuning variable in /proc; no reboot is required.
Change to the /proc directory and list the files there.You will see, in addition to the data
files, a large quantity of numbered directories. Each of these directories represents a process
where the directory name is the Process ID (PID). You can delve into those directories to
locate information about individual processes that might be of interest.
To view this data, simply cat some of the following files:
cmdline -- displays the kernel command line, including all parameters passed
to it.
cpuinfo -- displays information about the CPU(s) including flags, model name
stepping, and cache size.
meminfo -- displays very detailed information about memory, including data
such as active and inactive memory, and total virtual memory allocated and that used, that is
not always displayed by other tools.
iomem and ioports -- lists the memory ranges and ports defined
for various I/O devices.
You will see that, although the data is available in these files, much of it is not
annotated in any way. That means you will have work to do to identify and extract the desired
data. However, the monitoring tools already discussed already do that for the data they are
designed to display.
There is so much more data in the /proc filesystem that the best way to learn more about it
is to refer to the proc(5) man page, which contains detailed information about the various
files found there.
Next time I will pull all this together and discuss how I have used these tools to solve
problems.
David Both -David Both is an Open Source Software and GNU/Linux
advocate, trainer, writer, and speaker who lives in Raleigh North Carolina. He is a strong
proponent of and evangelist for the "Linux Philosophy." David has been in the IT industry for
nearly 50 years. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco,
and the State of North Carolina. He has been working with Linux and Open Source Software for
over 20 years.
filesystem-level snapshot replication to move data from one machine to another, fast
. For enormous blobs like virtual machine images, we're talking
several orders of magnitude faster than rsync .
If that isn't cool enough already, you don't even necessarily need to restore from
backup if you lost the production hardware; you can just boot up the VM directly on the local
hotspare hardware, or the remote disaster recovery hardware, as appropriate. So even in case
of catastrophic hardware failure , you're still looking at that 59m RPO, <1m RTO.
https://www.youtube.com/embed/5hEixXutaPo
Backups -- and recoveries -- don't get much easier than this.
This makes it not only possible, but easy to replicate multiple-terabyte VM images
hourly over a local network, and daily over a VPN. We're not talking enterprise 100mbps
symmetrical fiber, either. Most of my clients have 5mbps or less available for upload, which
doesn't keep them from automated, nightly over-the-air backups, usually to a machine sitting
quietly in an owner's house.
Preventing your own Humpty Level Events
Sanoid is open source software, and so are all its dependencies. You can run Sanoid and
Syncoid themselves on pretty much anything with ZFS. I developed it and use it on Linux myself,
but people are using it (and I support it) on OpenIndiana, FreeBSD, and FreeNAS too.
You can find the GPLv3 licensed code on the
website (which actually just redirects to Sanoid's GitHub project page), and there's also a
Chef Cookbook and an
Arch AUR repo
available from third parties.
Let's first cover what alerts are not . Alerts should not be sent if the human
responder can't do anything about the problem. This includes alerts that are sent to multiple
individuals with only a few who can respond, or situations where every anomaly in the system
triggers an alert. This leads to alert fatigue and receivers ignoring all alerts within a
specific medium until the system escalates to a medium that isn't already saturated.
For example, if an operator receives hundreds of emails a day from the alerting system, that
operator will soon ignore all emails from the alerting system. The operator will respond to a
real incident only when he or she is experiencing the problem, emailed by a customer, or called
by the boss. In this case, alerts have lost their meaning and usefulness.
Alerts are not a constant stream of information or a status update. They are meant to convey
a problem from which the system can't automatically recover, and they are sent only to the
individual most likely to be able to recover the system. Everything that falls outside this
definition isn't an alert and will only damage your employees and company culture.
Everyone has a different set of alert types, so I won't discuss things like priority levels
(P1-P5) or models that use words like "Informational," "Warning," and "Critical." Instead, I'll
describe the generic categories emergent in complex systems' incident response.
You might have noticed I mentioned an "Informational" alert type right after I wrote that
alerts shouldn't be informational. Well, not everyone agrees, but I don't consider something an
alert if it isn't sent to anyone. It is a data point that many systems refer to as an alert. It
represents some event that should be known but not responded to. It is generally part of the
visualization system of the alerting tool and not an event that triggers actual notifications.
Mike Julian covers this and other aspects of alerting in his book Practical Monitoring . It's a must read for work in
this area.
Non-informational alerts consist of types that can be responded to or require action. I
group these into two categories: internal outage and external outage. (Most companies have more
than two levels for prioritizing their response efforts.) Degraded system performance is
considered an outage in this model, as the impact to each user is usually unknown.
Internal outages are a lower priority than external outages, but they still need to be
responded to quickly. They often include internal systems that company employees use or
components of applications that are visible only to company employees.
External outages consist of any system outage that would immediately impact a customer.
These don't include a system outage that prevents releasing updates to the system. They do
include customer-facing application failures, database outages, and networking partitions that
hurt availability or consistency if either can impact a user. They also include outages of
tools that may not have a direct impact on users, as the application continues to run but this
transparent dependency impacts performance. This is common when the system uses some external
service or data source that isn't necessary for full functionality but may cause delays as the
application performs retries or handles errors from this external
dependency.
Visualizations
There are many visualization types, and I won't cover them all here. It's a fascinating area
of research. On the data analytics side of my career, learning and applying that knowledge is a
constant challenge. We need to provide simple representations of complex system outputs for the
widest dissemination of information. Google Charts and Tableau have a
wide selection of visualization types. We'll cover the most common visualizations and some
innovative solutions for quickly understanding systems.
Line chart
The line chart is probably the most common visualization. It does a pretty good job of
producing an understanding of a system over time. A line chart in a metrics system would have a
line for each unique metric or some aggregation of metrics. This can get confusing when there
are a lot of metrics in the same dashboard (as shown below), but most systems can select
specific metrics to view rather than having all of them visible. Also, anomalous behavior is
easy to spot if it's significant enough to escape the noise of normal operations. Below we can
see purple, yellow, and light blue lines that might indicate anomalous
behavior.
Another feature of a line chart is that you can often stack them to show relationships. For
example, you might want to look at requests on each server individually, but also in aggregate.
This allows you to understand the overall system as well as each instance in the same
graph.
Another common visualization is the heatmap. It is useful when looking at histograms. This
type of visualization is similar to a bar chart but can show gradients within the bars
representing the different percentiles of the overall metric. For example, suppose you're
looking at request latencies and you want to quickly understand the overall trend as well as
the distribution of all requests. A heatmap is great for this, and it can use color to
disambiguate the quantity of each section with a quick glance.
The heatmap below shows the higher concentration around the centerline of the graph with an
easy-to-understand visualization of the distribution vertically for each time bucket. We might
want to review a couple of points in time where the distribution gets wide while the others are
fairly tight like at 14:00. This distribution might be a negative performance
indicator.
The last common visualization I'll cover here is the gauge, which helps users understand a
single metric quickly. Gauges can represent a single metric, like your speedometer represents
your driving speed or your gas gauge represents the amount of gas in your car. Similar to the
gas gauge, most monitoring gauges clearly indicate what is good and what isn't. Often (as is
shown below), good is represented by green, getting worse by orange, and "everything is
breaking" by red. The middle row below shows traditional gauges.
This image shows more than just traditional gauges. The other gauges are single stat
representations that are similar to the function of the classic gauge. They all use the same
color scheme to quickly indicate system health with just a glance. Arguably, the bottom row is
probably the best example of a gauge that allows you to glance at a dashboard and know that
everything is healthy (or not). This type of visualization is usually what I put on a top-level
dashboard. It offers a full, high-level understanding of system health in seconds.
Flame
graphs
A less common visualization is the flame graph, introduced by Netflix's Brendan Gregg in 2011. It's not
ideal for dashboarding or quickly observing high-level system concerns; it's normally seen when
trying to understand a specific application problem. This visualization focuses on CPU and
memory and the associated frames. The X-axis lists the frames alphabetically, and the Y-axis
shows stack depth. Each rectangle is a stack frame and includes the function being called. The
wider the rectangle, the more it appears in the stack. This method is invaluable when trying to
diagnose system performance at the application level and I urge everyone to give it a
try.
There are several commercial options for alerting, but since this is Opensource.com, I'll
cover only systems that are being used at scale by real companies that you can use at no cost.
Hopefully, you'll be able to contribute new and innovative features to make these systems even
better.
Alerting toolsBosun
If you've ever done anything with computers and gotten stuck, the help you received was
probably thanks to a Stack Exchange system. Stack Exchange runs many different websites around
a crowdsourced question-and-answer model. Stack Overflow is very popular with developers, and Super User is popular with operations. However,
there are now hundreds of sites ranging from parenting to sci-fi and philosophy to
bicycles.
Stack Exchange open-sourced its alert management system, Bosun , around the same time Prometheus and its AlertManager system were released.
There were many similarities in the two systems, and that's a really good thing. Like
Prometheus, Bosun is written in Golang. Bosun's scope is more extensive than Prometheus' as it
can interact with systems beyond metrics aggregation. It can also ingest data from log and
event aggregation systems. It supports Graphite, InfluxDB, OpenTSDB, and Elasticsearch.
Bosun's architecture consists of a single server binary, a backend like OpenTSDB, Redis, and
scollector agents . The scollector
agents automatically detect services on a host and report metrics for those processes and other
system resources. This data is sent to a metrics backend. The Bosun server binary then queries
the backends to determine if any alerts need to be fired. Bosun can also be used by tools like
Grafana to query the underlying backends
through one common interface. Redis is used to store state and metadata for Bosun.
A really neat feature of Bosun is that it lets you test your alerts against historical data.
This was something I missed in Prometheus several years ago, when I had data for an issue I
wanted alerts on but no easy way to test it. To make sure my alerts were working, I had to
create and insert dummy data. This system alleviates that very time-consuming process.
Bosun also has the usual features like showing simple graphs and creating alerts. It has a
powerful expression language for writing alerting rules. However, it only has email and HTTP
notification configurations, which means connecting to Slack and other tools requires a bit
more customization ( which its
documentation covers ). Similar to Prometheus, Bosun can use templates for these
notifications, which means they can look as awesome as you want them to. You can use all your
HTML and CSS skills to create the baddest email alert anyone has ever seen.
Cabot
Cabot was created by a company called
Arachnys . You may not know who
Arachnys is or what it does, but you have probably felt its impact: It built the leading
cloud-based solution for fighting financial crimes. That sounds pretty cool, right? At a
previous company, I was involved in similar functions around "know your customer" laws. Most
companies would consider it a very bad thing to be linked to a terrorist group, for example,
funneling money through their systems. These solutions also help defend against less-atrocious
offenders like fraudsters who could also pose a risk to the institution.
So why did Arachnys create Cabot? Well, it is kind of a Christmas present to everyone, as it
was a Christmas project built because its developers couldn't wrap their heads around
Nagios . And really, who can blame them?
Cabot was written with Django and Bootstrap, so it should be easy for most to contribute to the
project. (Another interesting factoid: The name comes from the creator's dog.)
The Cabot architecture is similar to Bosun in that it doesn't collect any data. Instead, it
accesses data through the APIs of the tools it is alerting for. Therefore, Cabot uses a pull
(rather than a push) model for alerting. It reaches out into each system's API and retrieves
the information it needs to make a decision based on a specific check. Cabot stores the
alerting data in a Postgres database and also has a cache using Redis.
Cabot natively supports Graphite ,
but it also supports Jenkins , which is rare
in this area. Arachnys uses Jenkins
like a centralized cron, but I like this idea of treating build failures like outages.
Obviously, a build failure isn't as critical as a production outage, but it could still alert
the team and escalate if the failure isn't resolved. Who actually checks Jenkins every time an
email comes in about a build failure? Yeah, me too!
Another interesting feature is that Cabot can integrate with Google Calendar for on-call
rotations. Cabot calls this feature Rota, which is a British term for a roster or rotation.
This makes a lot of sense, and I wish other systems would take this idea further. Cabot doesn't
support anything more complex than primary and backup personnel, but there is certainly room
for additional features. The docs say if you want something more advanced, you should look at a
commercial option.
StatsAgg
StatsAgg ? How
did that make the list? Well, it's not every day you come across a publishing company that has
created an alerting platform. I think that deserves recognition. Of course, Pearson isn't just a publishing company anymore; it has
several web presences and a joint venture with O'Reilly Media . However, I still think of it as the company
that published my schoolbooks and tests.
StatsAgg isn't just an alerting platform; it's also a metrics aggregation platform. And it's
kind of like a proxy for other systems. It supports Graphite, StatsD, InfluxDB, and OpenTSDB as
inputs, but it can also forward those metrics to their respective platforms. This is an
interesting concept, but potentially risky as loads increase on a central service. However, if
the StatsAgg infrastructure is robust enough, it can still produce alerts even when a backend
storage platform has an outage.
StatsAgg is written in Java and consists only of the main server and UI, which keeps
complexity to a minimum. It can send alerts based on regular expression matching and is focused
on alerting by service rather than host or instance. Its goal is to fill a void in the open
source observability stack, and I think it does that quite well.
Visualization toolsGrafana
Almost everyone knows about Grafana , and
many have used it. I have used it for years whenever I need a simple dashboard. The tool I used
before was deprecated, and I was fairly distraught about that until Grafana made it okay.
Grafana was gifted to us by Torkel Ödegaard. Like Cabot, Grafana was also created around
Christmastime, and released in January 2014. It has come a long way in just a few years. It
started life as a Kibana dashboarding system, and Torkel forked it into what became
Grafana.
Grafana's sole focus is presenting monitoring data in a more usable and pleasing way. It can
natively gather data from Graphite, Elasticsearch, OpenTSDB, Prometheus, and InfluxDB. There's
an Enterprise version that uses plugins for more data sources, but there's no reason those
other data source plugins couldn't be created as open source, as the Grafana plugin ecosystem
already offers many other data sources.
What does Grafana do for me? It provides a central location for understanding my system. It
is web-based, so anyone can access the information, although it can be restricted using
different authentication methods. Grafana can provide knowledge at a glance using many
different types of visualizations. However, it has started integrating alerting and other
features that aren't traditionally combined with visualizations.
Now you can set alerts visually. That means you can look at a graph, maybe even one showing
where an alert should have triggered due to some degradation of the system, click on the graph
where you want the alert to trigger, and then tell Grafana where to send the alert. That's a
pretty powerful addition that won't necessarily replace an alerting platform, but it can
certainly help augment it by providing a different perspective on alerting criteria.
Grafana has also introduced more collaboration features. Users have been able to share
dashboards for a long time, meaning you don't have to create your own dashboard for your
Kubernetes
cluster because there are several already available -- with some maintained by Kubernetes
developers and others by Grafana developers.
The most significant addition around collaboration is annotations. Annotations allow a user
to add context to part of a graph. Other users can then use this context to understand the
system better. This is an invaluable tool when a team is in the middle of an incident and
communication and common understanding are critical. Having all the information right where
you're already looking makes it much more likely that knowledge will be shared across the team
quickly. It's also a nice feature to use during blameless postmortems when the team is trying
to understand how the failure occurred and learn more about their system.
Vizceral
Netflix created Vizceral
to understand its traffic patterns better when performing a traffic failover. Unlike Grafana,
which is a more general tool, Vizceral serves a very specific use case. Netflix no longer uses
this tool internally and says it is no longer actively maintained, but it still updates the
tool periodically. I highlight it here primarily to point out an interesting visualization
mechanism and how it can help solve a problem. It's worth running it in a demo environment just
to better grasp the concepts and witness what's possible with these systems.
What breaks our systems: A taxonomy of black swansFind and fix outlier events
that create issues before they trigger severe production problems. 25 Oct 2018 Laura Nolan Feed 147
up 2 comments Image credits : Eumelincen . CC0 x
Subscribe now
Black swans, by definition, can't be predicted, but sometimes there are patterns we can find
and use to create defenses against categories of related problems.
For example, a large proportion of failures are a direct result of changes (code,
environment, or configuration). Each bug triggered in this way is distinctive and
unpredictable, but the common practice of canarying all changes is somewhat effective against
this class of problems, and automated rollbacks have become a standard mitigation.
As our profession continues to mature, other kinds of problems are becoming well-understood
classes of hazards with generalized prevention strategies.
Black swans observed in the
wild
All technology organizations have production problems, but not all of them share their
analyses. The organizations that publicly discuss incidents are doing us all a service. The
following incidents describe one class of a problem and are by no means isolated instances. We
all have black swans lurking in our systems; it's just some of us don't know it
yet.
Running headlong into any sort of limit can produce very severe incidents. A canonical
example of this was Instapaper's
outage in February 2017 . I challenge any engineer who has carried a pager to read the
outage report without a chill running up their spine. Instapaper's production database was on a
filesystem that, unknown to the team running the service, had a 2TB limit. With no warning, it
stopped accepting writes. Full recovery took days and required migrating its database.
One way to get advance knowledge of system limits is to test periodically. Good load testing
(on a production replica) ought to involve write transactions and should involve growing each
datastore beyond its current production size. It's easy to forget to test things that aren't
your main datastores (such as Zookeeper). If you hit limits during testing, you have time to
fix the problems. Given that resolution of limits-related issues can involve major changes
(like splitting a datastore), time is invaluable.
When it comes to cloud services, if your service generates unusual loads or uses less widely
used products or features (such as older or newer ones), you may be more at risk of hitting
limits. It's worth load testing these, too. But warn your cloud provider first.
Finally, where limits are known, add monitoring (with associated documentation) so you will
know when your systems are approaching those ceilings. Don't rely on people still being around
to remember.
Spreading slowness
"The world is much more correlated than we give credit to. And so we see more of what
Nassim Taleb calls 'black swan events' -- rare events happen more often than they should
because the world is more correlated." -- Richard
Thaler
HostedGraphite's postmortem on how an
AWS outage took down its load balancers (which are not hosted on AWS) is a good example of
just how much correlation exists in distributed computing systems. In this case, the
load-balancer connection pools were saturated by slow connections from customers that were
hosted in AWS. The same kinds of saturation can happen with application threads, locks, and
database connections -- any kind of resource monopolized by slow operations.
HostedGraphite's incident is an example of externally imposed slowness, but often slowness
can result from saturation somewhere in your own system creating a cascade and causing other
parts of your system to slow down. An incident at Spotify
demonstrates such spread -- the streaming service's frontends became unhealthy due to
saturation in a different microservice. Enforcing deadlines for all requests, as well as
limiting the length of request queues, can prevent such spread. Your service will serve at
least some traffic, and recovery will be easier because fewer parts of your system will be
broken.
Retries should be limited with exponential backoff and some jitter. An outage at Square, in
which its Redis datastore
became overloaded due to a piece of code that retried failed transactions up to 500 times
with no backoff, demonstrates the potential severity of excessive retries. The Circuit
Breaker design pattern can be helpful here, too.
Often, failure scenarios arise when a system is under unusually heavy load. This can arise
organically from users, but often it arises from systems. A surge of cron jobs that starts at
midnight is a venerable example. Mobile clients can also be a source of coordinated demand if
they are programmed to fetch updates at the same time (of course, it is much better to jitter
such requests).
Events occurring at pre-configured times aren't the only source of thundering herds. Slack
experienced multiple
outages over a short time due to large numbers of clients being disconnected and
immediately reconnecting, causing large spikes of load. CircleCI saw a severe outage when a GitLab outage
ended, leading to a surge of builds queued in its database, which became saturated and very
slow.
Almost any service can be the target of a thundering herd. Planning for such eventualities
-- and testing that your plan works as intended -- is therefore a must. Client backoff and
load shedding are
often core to such approaches.
If your systems must constantly ingest data that can't be dropped, it's key to have a
scalable way to buffer this data in a queue for later processing.
Automation systems are
complex systems
"Complex systems are intrinsically hazardous systems." -- Richard Cook,
MD
If your systems must constantly ingest data that can't be dropped, it's key to have a
scalable way to buffer this data in a queue for later processing. The trend for the past
several years has been strongly towards more automation of software operations. Automation of
anything that can reduce your system's capacity (e.g., erasing disks, decommissioning devices,
taking down serving jobs) needs to be done with care. Accidents (due to bugs or incorrect
invocations) with this kind of automation can take down your system very efficiently,
potentially in ways that are hard to recover from.
Christina Schulman and Etienne Perot of Google describe some examples in their talk
Help Protect Your
Data Centers with Safety Constraints . One incident sent Google's entire in-house content
delivery network (CDN) to disk-erase.
Schulman and Perot suggest using a central service to manage constraints, which limits the
pace at which destructive automation can operate, and being aware of system conditions (for
example, avoiding destructive operations if the service has recently had an alert).
Automation systems can also cause havoc when they interact with operators (or with other
automated systems). Reddit
experienced a major outage when its automation restarted a system that operators had stopped
for maintenance. Once you have multiple automation systems, their potential interactions become
extremely complex and impossible to predict.
It will help to deal with the inevitable surprises if all this automation writes logs to an
easily searchable, central place. Automation systems should always have a mechanism to allow
them to be quickly turned off (fully or only for a subset of operations or
targets).
Defense against the dark swans
These are not the only black swans that might be waiting to strike your systems. There are
many other kinds of severe problem that can be avoided using techniques such as canarying, load
testing, chaos engineering, disaster testing, and fuzz testing -- and of course designing for
redundancy and resiliency. Even with all that, at some point your system will fail.
To ensure your organization can respond effectively, make sure your key technical staff and
your leadership have a way to coordinate during an outage. For example, one unpleasant issue
you might have to deal with is a complete outage of your network. It's important to have a
fail-safe communications channel completely independent of your own infrastructure and its
dependencies. For instance, if you run on AWS, using a service that also runs on AWS as your
fail-safe communication method is not a good idea. A phone bridge or an IRC server that runs
somewhere separate from your main systems is good. Make sure everyone knows what the
communications platform is and practices using it.
Another principle is to ensure that your monitoring and your operational tools rely on your
production systems as little as possible. Separate your control and your data planes so you can
make changes even when systems are not healthy. Don't use a single message queue for both data
processing and config changes or monitoring, for example -- use separate instances. In
SparkPost: The Day
the DNS Died , Jeremy Blosser presents an example where critical tools relied on the
production DNS setup, which failed.
The psychology of battling the black swan
To ensure your organization can respond effectively, make sure your key technical staff and
your leadership have a way to coordinate during an outage. Dealing with major incidents in
production can be stressful. It really helps to have a structured incident-management process
in place for these situations. Many technology organizations ( including Google )
successfully use a version of FEMA's Incident Command System. There should be a clear way for
any on-call individual to call for assistance in the event of a major problem they can't
resolve alone.
For long-running incidents, it's important to make sure people don't work for unreasonable
lengths of time and get breaks to eat and sleep (uninterrupted by a pager). It's easy for
exhausted engineers to make a mistake or overlook something that might resolve the incident
faster.
Learn more
There are many other things that could be said about black (or formerly black) swans and
strategies for dealing with them. If you'd like to learn more, I highly recommend these two
books dealing with resilience and stability in production: Susan Fowler's Production-Ready
Microservices and Michael T. Nygard's Release It! .
You knew this would come first. Data recovery is a time-intensive process and rarely
produces 100% correct results. If you don't have a backup plan in place, start one now.
Better yet, implement two. First, provide users with local backups with a tool like
rsnapshot . This utility creates snapshots
of each user's data in a ~/.snapshots directory, making it trivial for them to
recover their own data quickly.
Second, while these local backups are convenient, also set up a remote backup plan for your
organization. Tools like AMANDA or
BackupPC are solid choices
for this task. You can run them as a daemon so that backups happen automatically.
Backup planning and preparation pay for themselves in both time, and peace of mind. There's
nothing like not needing emergency response procedures in the first place.
Ban rm
On modern operating systems, there is a Trash or Bin folder where users drag the files they
don't want out of sight without deleting them just yet. Traditionally, the Linux terminal has
no such holding area, so many terminal power users have the bad habit of permanently deleting
data they believe they no longer need. Since there is no "undelete" command, this habit can be
quite problematic should a power user (or administrator) accidentally delete a directory full
of important data.
Many users say they favor the absolute deletion of files, claiming that they prefer their
computers to do exactly what they tell them to do. Few of those users, though, forego their
rm command for the more complete shred , which really
removes their data. In other words, most terminal users invoke the rm command
because it removes data, but take comfort in knowing that file recovery tools exist as a
hacker's un- rm . Still, using those tools take up their administrator's precious
time. Don't let your users -- or yourself -- fall prey to this breach of logic.
If you really want to remove data, then rm is not sufficient. Use the
shred -u command instead, which overwrites, and then thoroughly deletes the
specified data
However, if you don't want to actually remove data, don't use rm . This command
is not feature-complete, in that it has no undo feature, but has the capacity to be undone.
Instead, use trashy or
trash-cli to "delete"
files into a trash bin while using your terminal, like so:
$ trash ~/example.txt
$ trash --list
example.txt
One advantage of these commands is that the trash bin they use is the same your desktop's
trash bin. With them, you can recover your trashed files by opening either your desktop Trash
folder, or through the terminal.
If you've already developed a bad rm habit and find the trash
command difficult to remember, create an alias for yourself:
$ echo "alias rm='trash'"
Even better, create this alias for everyone. Your time as a system administrator is too
valuable to spend hours struggling with file recovery tools just because someone mis-typed an
rm command.
Respond efficiently
Unfortunately, it can't be helped. At some point, you'll have to recover lost files, or
worse. Let's take a look at emergency response best practices to make the job easier. Before
you even start, understanding what caused the data to be lost in the first place can save you a
lot of time:
If someone was careless with their trash bin habits or messed up dangerous remove or
shred commands, then you need to recover a deleted file.
If someone accidentally overwrote a partition table, then the files aren't really lost.
The drive layout is.
In the case of a dying hard drive, recovering data is secondary to the race against
decay to recover
the bits themselves (you can worry about carving those bits into intelligible files
later).
No matter how the problem began, start your rescue mission with a few best practices:
Stop using the drive that contains the lost data, no matter what the reason. The more you
do on this drive, the more you risk overwriting the data you're trying to rescue. Halt and
power down the victim computer, and then either reboot using a thumb drive, or extract the
damaged hard drive and attach it to your rescue machine.
Do not use the victim hard drive as the recovery location. Place rescued data on a spare
volume that you're sure is working. Don't copy it back to the victim drive until it's been
confirmed that the data has been sufficiently recovered.
If you think the drive is dying, your first priority after powering it down is to obtain
a duplicate image, using a tool like ddrescue or Clonezilla .
Once you have a sense of what went wrong, It's time to choose the right tool to fix the
problem. Two such tools are Scalpel and TestDisk , both of which operate just as well on
a disk image as on a physical drive.
Practice (or, go break stuff)
At some point in your career, you'll have to recover data. The smart practices discussed
above can minimize how often this happens, but there's no avoiding this problem. Don't wait
until disaster strikes to get familiar with data recovery tools. After you set up your local
and remote backups, implement command-line trash bins, and limit the rm command,
it's time to practice your data recovery techniques.
Download and practice using Scalpel, TestDisk, or whatever other tools you feel might be
useful. Be sure to practice data recovery safely, though. Find an old computer, install Linux
onto it, and then generate, destroy, and recover. If nothing else, doing so teaches you to
respect data structures, filesystems, and a good backup plan. And when the time comes and you
have to put those skills to real use, you'll appreciate knowing what to do.
Get the details on what's inside your computer from the command line. 16 Sep 2019
Howard Fosdick Feed 44
up 5 comments Image by : Opensource.com x Subscribe now
The easiest way is to do that is with one of the standard Linux GUI programs:
i-nex collects
hardware information and displays it in a manner similar to the popular CPU-Z under Windows.
HardInfo
displays hardware specifics and even includes a set of eight popular benchmark programs you
can run to gauge your system's performance.
KInfoCenter and
Lshw also
display hardware details and are available in many software repositories.
Alternatively, you could open up the box and read the labels on the disks, memory, and other
devices. Or you could enter the boot-time panels -- the so-called UEFI or BIOS panels. Just hit
the proper program
function key during the boot process to access them. These two methods give you hardware
details but omit software information.
Or, you could issue a Linux line command. Wait a minute that sounds difficult. Why would you
do this?
Sometimes it's easy to find a specific bit of information through a well-targeted line
command. Perhaps you don't have a GUI program available or don't want to install one.
Probably the main reason to use line commands is for writing scripts. Whether you employ the
Linux shell or another programming language, scripting typically requires coding line
commands.
Many line commands for detecting hardware must be issued under root authority. So either
switch to the root user ID, or issue the command under your regular user ID preceded by sudo
:
sudo <the_line_command>
and respond to the prompt for the root password.
This article introduces many of the most useful line commands for system discovery. The
quick reference chart at the end summarizes them.
Hardware overview
There are several line commands that will give you a comprehensive overview of your
computer's hardware.
The inxi command lists details about your system, CPU, graphics, audio, networking, drives,
partitions, sensors, and more. Forum participants often ask for its output when they're trying
to help others solve problems. It's a standard diagnostic for problem-solving:
inxi -Fxz
The -F flag means you'll get full output, x adds details, and z masks out personally
identifying information like MAC and IP addresses.
The hwinfo and lshw commands display much of the same information in different formats:
hwinfo --short
or
lshw -short
The long forms of these two commands spew out exhaustive -- but hard to read -- output:
hwinfo
or
lshw
CPU details
You can learn everything about your CPU through line commands. View CPU details by issuing
either the lscpu command or its close relative lshw :
lscpu
or
lshw -C cpu
In both cases, the last few lines of output list all the CPU's capabilities. Here you can
find out whether your processor supports specific features.
With all these commands, you can reduce verbiage and narrow any answer down to a single
detail by parsing the command output with the grep command. For example, to view only the CPU
make and model:
The -i flag on the grep command simply ensures your search ignores whether the output it
searches is upper or lower case.
Memory
Linux line commands enable you to gather all possible details about your computer's memory.
You can even determine whether you can add extra memory to the computer without opening up the
box.
To list each memory stick and its capacity, issue the dmidecode command:
dmidecode -t memory | grep -i size
For more specifics on system memory, including type, size, speed, and voltage of each RAM
stick, try:
lshw -short -C memory
One thing you'll surely want to know is is the maximum memory you can install on your
computer:
dmidecode -t memory | grep -i max
Now find out whether there are any open slots to insert additional memory sticks. You can do
this without opening your computer by issuing this command:
lshw -short -C memory | grep -i empty
A null response means all the memory slots are already in use.
Determining how much video memory you have requires a pair of commands. First, list all
devices with the lspci command and limit the output displayed to the video device you're
interested in:
lspci | grep -i vga
The output line that identifies the video controller will typically look something like
this:
Now reissue the lspci command, referencing the video device number as the selected
device:
lspci -v -s 00:02.0
The output line identified as prefetchable is the amount of video RAM on your
system:
...
Memory at f0100000 ( 32 -bit, non-prefetchable ) [ size =512K ]
I / O ports at 1230 [ size = 8 ]
Memory at e0000000 ( 32 -bit, prefetchable ) [ size =256M ]
Memory at f0000000 ( 32 -bit, non-prefetchable ) [ size =1M ]
...
Finally, to show current memory use in megabytes, issue:
free -m
This tells how much memory is free, how much is in use, the size of the swap area, and
whether it's being used. For example, the output might look like this:
total used free
shared buff / cache available
Mem: 11891 1326 8877 212 1687 10077
Swap: 1999 0 1999
The top command gives you more detail on memory use. It shows current overall memory and CPU
use and also breaks it down by process ID, user ID, and the commands being run. It displays
full-screen text output:
top
Disks, filesystems, and devices
You can easily determine whatever you wish to know about disks, partitions, filesystems, and
other devices.
To display a single line describing each disk device:
lshw -short -C disk
Get details on any specific SATA disk, such as its model and serial numbers, supported
modes, sector count, and more with:
hdparm -i /dev/sda
Of course, you should replace sda with sdb or another device mnemonic if necessary.
To list all disks with all their defined partitions, along with the size of each, issue:
lsblk
For more detail, including the number of sectors, size, filesystem ID and type, and
partition starting and ending sectors:
fdisk -l
To start up Linux, you need to identify mountable partitions to the GRUB bootloader. You can find this
information with the blkid command. It lists each partition's unique identifier (UUID) and its
filesystem type (e.g., ext3 or ext4):
blkid
To list the mounted filesystems, their mount points, and the space used and available for
each (in megabytes):
df -m
Finally, you can list details for all USB and PCI buses and devices with these commands:
lsusb
or
lspci
Network
Linux offers tons of networking line commands. Here are just a few.
To see hardware details about your network card, issue:
lshw -C network
Traditionally, the command to show network interfaces was ifconfig :
ifconfig -a
But many people now use:
ip link show
or
netstat -i
In reading the output, it helps to know common network abbreviations:
Abbreviation
Meaning
lo
Loopback interface
eth0 or enp*
Ethernet interface
wlan0
Wireless interface
ppp0
Point-to-Point Protocol interface (used by a dial-up modem, PPTP VPN
connection, or USB modem)
vboxnet0 or vmnet*
Virtual machine interface
The asterisks in this table are wildcard characters, serving as a placeholder for whatever
series of characters appear from system to system.
To show your default gateway and routing tables, issue either of these commands:
ip route | column -t
or
netstat -r
Software
Let's conclude with two commands that display low-level software details. For example, what
if you want to know whether you have the latest firmware installed? This command shows the UEFI
or BIOS date and version:
dmidecode -t bios
What is the kernel version, and is it 64-bit? And what is the network hostname? To find out,
issue:
uname -a
Quick reference chart
This chart summarizes all the commands covered in this article:
Building from scratch an agentless inventory system for Linux servers is a very
time-consuming task. To have precise information about your server's inventory, Ansible comes to be very handy, especially if you
are restricted to install an agent on the servers. However, there are some pieces of
information that the Ansible's inventory mechanism cannot retrieve from the default inventory.
In this case, a Playbook needs to be created to retrieve those pieces of information. Examples
are VMware tool and other application versions which you might want to include in your
inventory system. Since Ansible makes it easy to create JSON files, this can be easily
manipulated for other interesting tasks, say an HTML static page. I would recommend Ansible-CMDB which is very handy
for such conversion. The Ansible-CMDB allows you to create a pure HTML file based on the JSON
file that was generated by Ansible. Ansible-CMDB is another amazing tool created by Ferry Boender .
Let's have a look how the agentless servers inventory with Ansible and Ansible-CMDB works.
It's important to understand the prerequisites needed before installing Ansible. There are
other articles which I published on Ansible:
1. In this article, you will get an overview of what Ansible inventory
is capable of. Start by gathering the information that you will need for your inventory system.
The goal is to make a plan first.
2. As explained in the article Getting started with Ansible
deployment , you have to define a group and record the name of your servers(which can be
resolved through the host file or DNS server) or IP's. Let's assume that the name of the group
is " test ".
3. Launch the following command to see a JSON output which will describe the inventory of
the machine. As you may notice that Ansible had fetched all the data.
Ansible -m setup test
4. You can also append the output to a specific directory for future use with Ansible-cmdb.
I would advise creating a specific directory (I created /home/Ansible-Workdesk ) to prevent
confusion where the file is appended.
Ansible-m setup --tree out/ test
5. At this point, you will have several files created in a tree format, i.e; specific file
with the name of the server containing JSON information about the servers inventory.
Getting Hands-on with Ansible-cmdb
6. Now, you will have to install Ansible-cmdb which is pretty fast and easy. Do make sure
that you follow all the requirements before installation:
git clone https://github.com/fboender/ansible-cmdb
cd ansible-cmdb && make install
7. To convert the JSON files into HTML, use the following command:
ansible-cmdb -t html_fancy_split out/
8. You should notice a directory called "cmdb" which contain some HTML files. Open the
index.html and view your server inventory system.
Tweaking the default template
9. As mentioned previously, there is some information which is not available by default on
the index.html template. You can tweak the
/usr/local/lib/ansible-cmdb/ansiblecmdb/data/tpl/html_fancy_defs.html page and add more
content, for example, ' uptime ' of the servers. To make the " Uptime " column visible, add the
following line in the " Column definitions " section:
13 open source backup solutionsReaders suggest more than a dozen of their
favorite solutions for protecting data. 07 Mar 2019 Don Watkins (Community Moderator) Feed 124
up 6 comments Image by : Opensource.com x Subscribe now
Get the highlights in your inbox every week.
https://opensource.com/eloqua-embedded-email-capture-block.html?offer_id=70160000000QzXNAA0
poll
that asked readers to vote on their favorite open source backup solution. We offered six
solutions recommended by our moderator community -- Cronopete, Deja Dup,
Rclone, Rdiff-backup, Restic, and Rsync -- and invited readers to share other options in the
comments. And you came through, offering 13 other solutions (so far) that we either hadn't
considered or hadn't even heard of.
By far the most popular suggestion was BorgBackup . It is a deduplicating backup solution that
features compression and encryption. It is supported on Linux, MacOS, and BSD and has a BSD
License.
Second was UrBackup , which does
full and incremental image and file backups; you can save whole partitions or single
directories. It has clients for Windows, Linux, and MacOS and has a GNU Affero Public
License.
Third was LuckyBackup ;
according to its website, "it is simple to use, fast (transfers over only changes made and not
all data), safe (keeps your data safe by checking all declared directories before proceeding in
any data manipulation), reliable, and fully customizable." It carries a GNU Public License.
Casync is
content-addressable synchronization -- it's designed for backup and synchronizing and stores
and retrieves multiple related versions of large file systems. It is licensed with the GNU
Lesser Public License.
Syncthing synchronizes files between
two computers. It is licensed with the Mozilla Public License and, according to its website, is
secure and private. It works on MacOS, Windows, Linux, FreeBSD, Solaris, and OpenBSD.
Duplicati is a free backup solution
that works on Windows, MacOS, and Linux and a variety of standard protocols, such as FTP, SSH,
and WebDAV, and cloud services. It features strong encryption and is licensed with the GPL.
Dirvish is a disk-based virtual image
backup system licensed under OSL-3.0. It also requires Rsync, Perl5, and SSH to be
installed.
Bacula 's website says it "is a set of
computer programs that permits the system administrator to manage backup, recovery, and
verification of computer data across a network of computers of different kinds." It is
supported on Linux, FreeBSD, Windows, MacOS, OpenBSD, and Solaris and the bulk of its source
code is licensed under AGPLv3.
BackupPC "is a
high-performance, enterprise-grade system for backing up Linux, Windows, and MacOS PCs and
laptops to a server's disk," according to its website. It is licensed under the GPLv3.
Amanda is a backup system written in C
and Perl that allows a system administrator to back up an entire network of client machines to
a single server using tape, disk, or cloud-based systems. It was developed and copyrighted in
1991 at the University of Maryland and has a BSD-style license.
Back in Time is a
simple backup utility designed for Linux. It provides a command line client and a GUI, both
written in Python. To do a backup, just specify where to store snapshots, what folders to back
up, and the frequency of the backups. BackInTime is licensed with GPLv2.
Timeshift is a backup
utility for Linux that is similar to System Restore for Windows and Time Capsule for MacOS.
According to its GitHub repository, "Timeshift protects your system by taking incremental
snapshots of the file system at regular intervals. These snapshots can be restored at a later
date to undo all changes to the system."
Kup is a backup solution that
was created to help users back up their files to a USB drive, but it can also be used to
perform network backups. According to its GitHub repository, "When you plug in your external
hard drive, Kup will automatically start copying your latest changes."
A common pitfall sysadmins run into when setting up monitoring systems is to alert on too
many things. These days, it's simple to monitor just about any aspect of a server's health, so
it's tempting to overload your monitoring system with all kinds of system checks. One of the
main ongoing maintenance tasks for any monitoring system is setting appropriate alert
thresholds to reduce false positives. This means the more checks you have in place, the higher
the maintenance burden. As a result, I have a few different rules I apply to my monitoring
checks when determining thresholds for notifications.
Critical alerts must be something I want to be woken up about at 3am.
A common cause of sysadmin burnout is being woken up with alerts for systems that don't
matter. If you don't have a 24x7 international development team, you probably don't care if the
build server has a problem at 3am, or even if you do, you probably are going to wait until the
morning to fix it. By restricting critical alerts to just those systems that must be online
24x7, you help reduce false positives and make sure that real problems are addressed
quickly.
Critical alerts must be actionable.
Some organizations send alerts when just about anything happens on a system. If I'm being
woken up at 3am, I want to have a specific action plan associated with that alert so I can fix
it. Again, too many false positives will burn out a sysadmin that's on call, and nothing is
more frustrating than getting woken up with an alert that you can't do anything about. Every
critical alert should have an obvious action plan the sysadmin can follow to fix it.
Warning alerts tell me about problems that will be critical if I don't fix them.
There are many problems on a system that I may want to know about and may want to
investigate, but they aren't worth getting out of bed at 3am. Warning alerts don't trigger a
pager, but they still send me a quieter notification. For instance, if load, used disk space or
RAM grows to a certain point where the system is still healthy but if left unchecked may not
be, I get a warning alert so I can investigate when I get a chance. On the other hand, if I got
only a warning alert, but the system was no longer responding, that's an indication I may need
to change my alert thresholds.
Repeat warning alerts periodically.
I think of warning alerts like this thing nagging at you to look at it and fix it during the
work day. If you send warning alerts too frequently, they just spam your inbox and are ignored,
so I've found that spacing them out to alert every hour or so is enough to remind me of the
problem but not so frequent that I ignore it completely.
Everything else is monitored, but doesn't send an alert.
There are many things in my monitoring system that help provide overall context when I'm
investigating a problem, but by themselves, they aren't actionable and aren't anything I want
to get alerts about. In other cases, I want to collect metrics from my systems to build
trending graphs later. I disable alerts altogether on those kinds of checks. They still show up
in my monitoring system and provide a good audit trail when I'm investigating a problem, but
they don't page me with useless notifications.
Kyle's rule.
One final note about alert thresholds: I've developed a practice in my years as a sysadmin
that I've found is important enough as a way to reduce burnout that I take it with me to every
team I'm on. My rule is this:
If sysadmins were kept up during the night because of false alarms, they can clear their
projects for the next day and spend time tuning alert thresholds so it doesn't happen
again.
There is nothing worse than being kept up all night because of false positive alerts and
knowing that the next night will be the same and that there's nothing you can do about it. If
that kind of thing continues, it inevitably will lead either to burnout or to sysadmins
silencing their pagers. Setting aside time for sysadmins to fix false alarms helps, because
they get a chance to improve their night's sleep the next night. As a team lead or manager,
sometimes this has meant that I've taken on a sysadmin's tickets for them during the day so
they can fix alerts.
Paging
Sending an alert often is referred to as paging or being paged, because in the past,
sysadmins, like doctors, carried pagers on them. Their monitoring systems were set to send a
basic numerical alert to the pager when there was a problem, so that sysadmins could be alerted
even when they weren't at a computer or when they were asleep. Although we still refer to it as
paging, and some older-school teams still pass around an actual pager, these days,
notifications more often are handled by alerts to mobile phones.
The first question you need to answer when you set up alerting is what method you will use
for notifications. When you are deciding how to set up pager notifications, look for a few
specific qualities.
Something that will alert you wherever you are geographically.
A number of cool office projects on the web exist where a broken software build triggers a
big red flashing light in the office. That kind of notification is fine for office-hour alerts
for non-critical systems, but it isn't appropriate as a pager notification even during the day,
because a sysadmin who is in a meeting room or at lunch would not be notified. These days, this
generally means some kind of notification needs to be sent to your phone.
An alert should stand out from other notifications.
False alarms can be a big problem with paging systems, as sysadmins naturally will start
ignoring alerts. Likewise, if you use the same ringtone for alerts that you use for any other
email, your brain will start to tune alerts out. If you use email for alerts, use filtering
rules so that on-call alerts generate a completely different and louder ringtone from regular
emails and vibrate the phone as well, so you can be notified even if you silence your phone or
are in a loud room. In the past, when BlackBerries were popular, you could set rules such that
certain emails generated a "Level One" alert that was different from regular email
notifications.
The BlackBerry days are gone now, and currently, many organizations (in particular startups)
use Google Apps for their corporate email. The Gmail Android application lets you set
per-folder (called labels) notification rules so you can create a filter that moves all on-call
alerts to a particular folder and then set that folder so that it generates a unique alert,
vibrates and does so for every new email to that folder. If you don't have that option, most
email software that supports multiple accounts will let you set different notifications for
each account so you may need to resort to a separate email account just for alerts.
Something that will wake you up all hours of the night.
Some sysadmins are deep sleepers, and whatever notification system you choose needs to be
something that will wake them up in the middle of the night. After all, servers always seem to
misbehave at around 3am. Pick a ringtone that is loud, possibly obnoxious if necessary, and
also make sure to enable phone vibrations. Also configure your alert system to re-send
notifications if an alert isn't acknowledged within a couple minutes. Sometimes the first alert
isn't enough to wake people up completely, but it might move them from deep sleep to a lighter
sleep so the follow-up alert will wake them up.
While ChatOps (using chat as a method of getting notifications and performing administration
tasks) might be okay for general non-critical daytime notifications, they are not appropriate
for pager alerts. Even if you have an application on your phone set to notify you about unread
messages in chat, many chat applications default to a "quiet time" in the middle of the night.
If you disable that, you risk being paged in the middle of the night just because someone sent
you a message. Also, many third-party ChatOps systems aren't necessarily known for their
mission-critical reliability and have had outages that have spanned many hours. You don't want
your critical alerts to rely on an unreliable system.
Something that is fast and reliable.
Your notification system needs to be reliable and able to alert you quickly at all times. To
me, this means alerting is done in-house, but many organizations opt for third parties to
receive and escalate their notifications. Every additional layer you can add to your alerting
is another layer of latency and another place where a notification may be dropped. Just make
sure whatever method you choose is reliable and that you have some way of discovering when your
monitoring system itself is offline.
In the next section, I cover how to set up escalations -- meaning, how you alert other
members of the team if the person on call isn't responding. Part of setting up escalations is
picking a secondary, backup method of notification that relies on a different infrastructure
from your primary one. So if you use your corporate Exchange server for primary notifications,
you might select a personal Gmail account as a secondary. If you have a Google Apps account as
your primary notification, you may pick SMS as your secondary alert.
Email servers have outages like anything else, and the goal here is to make sure that even
if your primary method of notifications has an outage, you have some alternate way of finding
out about it. I've had a number of occasions where my SMS secondary alert came in before my
primary just due to latency with email syncing to my phone.
Create some means of alerting the whole team.
In addition to having individual alerting rules that will page someone who is on call, it's
useful to have some way of paging an entire team in the event of an "all hands on deck" crisis.
This may be a particular email alias or a particular key word in an email subject. However you
set it up, it's important that everyone knows that this is a "pull in case of fire"
notification and shouldn't be abused with non-critical messages.
Alert Escalations
Once you have alerts set up, the next step is to configure alert escalations. Even the
best-designed notification system alerting the most well intentioned sysadmin will fail from
time to time either because a sysadmin's phone crashed, had no cell signal, or for whatever
reason, the sysadmin didn't notice the alert. When that happens, you want to make sure that
others on the team (and the on-call person's second notification) is alerted so someone can
address the alert.
Alert escalations are one of those areas that some monitoring systems do better than others.
Although the configuration can be challenging compared to other systems, I've found Nagios to
provide a rich set of escalation schedules. Other organizations may opt to use a third-party
notification system specifically because their chosen monitoring solution doesn't have the
ability to define strong escalation paths. A simple escalation system might look like the
following:
Initial alert goes to the on-call sysadmin and repeats every five minutes.
If the on-call sysadmin doesn't acknowledge or fix the alert within 15 minutes, it
escalates to the secondary alert and also to the rest of the team.
These alerts repeat every five minutes until they are acknowledged or fixed.
The idea here is to give the on-call sysadmin time to address the alert so you aren't waking
everyone up at 3am, yet also provide the rest of the team with a way to find out about the
alert if the first sysadmin can't fix it in time or is unavailable. Depending on your
particular SLAs, you may want to shorten or lengthen these time periods between escalations or
make them more sophisticated with the addition of an on-call backup who is alerted before the
full team. In general, organize your escalations so they strike the right balance between
giving the on-call person a chance to respond before paging the entire team, yet not letting
too much time pass in the event of an outage in case the person on call can't respond.
If you are part of a larger international team, you even may be able to set up escalations
that follow the sun. In that case, you would select on-call administrators for each geographic
region and set up the alerts so that they were aware of the different time periods and time of
day in those regions, and then alert the appropriate on-call sysadmin first. Then you can have
escalations page the rest of the team, regardless of geography, in the event that an alert
isn't solved.
On-Call Rotation
During World War One, the horrors of being in the trenches at the front lines were such that
they caused a new range of psychological problems (labeled shell shock) that, given time,
affected even the most hardened soldiers. The steady barrage of explosions, gun fire, sleep
deprivation and fear day in and out took its toll, and eventually both sides in the war
realized the importance of rotating troops away from the front line to recuperate.
It's not fair to compare being on call with the horrors of war, but that said, it also takes
a kind of psychological toll that if left unchecked, it will burn out your team. The
responsibility of being on call is a burden even if you aren't alerted during a particular
period. It usually means you must carry your laptop with you at all times, and in some
organizations, it may affect whether you can go to the movies or on vacation. In some badly run
organizations, being on call means a nightmare of alerts where you can expect to have a ruined
weekend of firefighting every time. Because being on call can be stressful, in particular if
you get a lot of nighttime alerts, it's important to rotate out sysadmins on call so they get a
break.
The length of time for being on call will vary depending on the size of your team and how
much of a burden being on call is. Generally speaking, a one- to four-week rotation is common,
with two-week rotations often hitting the sweet spot. With a large enough team, a two-week
rotation is short enough that any individual member of the team doesn't shoulder too much of
the burden. But, even if you have only a three-person team, it means a sysadmin gets a full
month without worrying about being on call.
Holiday on call.
Holidays place a particular challenge on your on-call rotation, because it ends up being
unfair for whichever sysadmin it lands on. In particular, being on call in late December can
disrupt all kinds of family time. If you have a professional, trustworthy team with good
teamwork, what I've found works well is to share the on-call burden across the team during
specific known holiday days, such as Thanksgiving, Christmas Eve, Christmas and New Year's Eve.
In this model, alerts go out to every member of the team, and everyone responds to the alert
and to each other based on their availability. After all, not everyone eats Thanksgiving dinner
at the same time, so if one person is sitting down to eat, but another person has two more
hours before dinner, when the alert goes out, the first person can reply "at dinner", but the
next person can reply "on it", and that way, the burden is shared.
If you are new to on-call alerting, I hope you have found this list of practices useful. You
will find a lot of these practices in place in many larger organizations with seasoned
sysadmins, because over time, everyone runs into the same kinds of problems with monitoring and
alerting. Most of these policies should apply whether you are in a large organization or a
small one, and even if you are the only DevOps engineer on staff, all that means is that you
have an advantage at creating an alerting policy that will avoid some common pitfalls and
overall burnout.
This is the fourth in a series of articles on systems administrator fundamentals. These
days, DevOps has made even the job title "systems administrator" seems a bit archaic like the
"systems analyst" title it replaced. These DevOps positions are rather different from sysadmin
jobs in the past with a much larger emphasis on software development far beyond basic shell
scripting and as a result often are filled with people with software development backgrounds
without much prior sysadmin experience.
In the past, a sysadmin would enter the role at a junior level and be mentored by a senior
sysadmin on the team, but in many cases these days, companies go quite a while with cloud
outsourcing before their first DevOps hire. As a result, the DevOps engineer might be thrust
into the role at a junior level with no mentor around apart from search engines and Stack
Overflow posts.
In the first article in this series, I
explained how to approach alerting and on-call rotations as a sysadmin. In the second article
, I discussed how to automate yourself out of a job. In the third , I covered why and how
you should use tickets. In this article, I describe the overall sysadmin career path and what I
consider the attributes that might make you a "senior sysadmin" instead of a "sysadmin" or
"junior sysadmin", along with some tips on how to level up.
Keep in mind that titles are pretty fluid and loose things, and that they mean different
things to different people. Also, it will take different people different amounts of time to
"level up" depending on their innate sysadmin skills, their work ethic and the opportunities
they get to gain more experience. That said, be suspicious of anyone who leveled up to a senior
level in any field in only a year or two -- it takes time in a career to make the kinds of
mistakes and learn the kinds of lessons you need to learn before you can move up to the next
level.
Kyle Rankin is a Tech Editor and columnist at Linux Journal and the Chief Security
Officer at Purism. He is the author of Linux Hardening in Hostile Networks , DevOps
Troubleshooting , The Official Ubuntu Server Book , Knoppix Hacks ,
Knoppix Pocket Reference , Linux Multimedia Hacks and Ubuntu Hacks , and
also a contributor to a number of other O'Reilly books. Rankin speaks frequently on security
and open-source software including at BsidesLV, O'Reilly Security Conference, OSCON, SCALE,
CactusCon, Linux World Expo and Penguicon. You can follow him at @kylerankin.
FollowDigital Marketing Executive at LASCO Financial Services
Though mistakes are not intentional and are inevitable, that doesn't mean we should take a
carefree approach to getting things done. There are some mistakes we make in the workplace,
which could be easily avoided if we paid a little more attention to what we were doing. Agree?
We've all made them and possibly mulled over a few silly mistakes we have made in the past.
But, I am here to tell you that mistakes doesn't make you 'bad' person, it's more of a great
learning experience - of what you can do better and how you can get it right the next time. And
having made a few silly mistakes in my work life, I guarantee that if you adopt a few of these
approaches that I have been applying in my work life, I am pretty sure you too will make you
fewer mistakes at work.
1. Give your full attention to what you are doing
...dedicate uninterrupted times to accomplish that [important] task. Do whatever it takes,
to get it done with your full attention, so if it means eliminating distractions, taking breaks
in between and working with a to-do list, do it. But trying to send emails, editing that blog
post and doing whatever else, may lead to you making a few unwanted mistakes.
Tip:
Eliminate distractions.2. Ask Questions
Often, we make mistakes because we didn't ask that one question. Either we were too proud to
or we thought we had it 'covered.' Unsure about the next step to take or how to undertake a
task? Do your homework and ask someone who is more knowledgeable than you are, ask someone who
can guide you accordingly. Worried about what others will think? Who cares? Asking questions
only make you smarter, not dumb. And so what if others think you are dumb. Their opinion
doesn't matter anyway, asking questions helps you to make fewer mistakes and as my mom would
say, 'Put on the mask and ask' . Each task usually comes with a challenge and requires
you learn something new, so use the resources available to you, like the more experienced
colleagues to get all the information you need that will enable you to make fewer
mistakes.
Tip: Do your homework. Ask for help.3. Use checklists
Checklists can be used to help you structure what needs to be done before you publish that
article or submit that project. They are quite useful especially when you have a million things
to do. Since I am responsible for getting multiple tasks done, I often use checklists/to-do
lists to help keep me get structured and to ensure I don't leave anything undone. In general,
lists are great and using one to detail things to do, or steps required to move to the next
stage will help to minimize errors, especially when you have a number of things on your plate.
And did I mention,
Richard Branson is also big on lists . That's how he gets a lot
of things done.
4. Review, review, review
Carefully review your work. I must admit, I get a little paranoid, about delivering
error-free work. Like, seriously, I don't like making them and often beat up myself if I send
an email with some silly grammatical errors. And that's why reviewing your work before you
click send, is a must-do. Often, we submit our work with errors because we are working against
a tight deadline and didn't give yourself enough time to review what was done. The last thing
you really need is your boss in neck for the document that was due last week, which you just
completed without much time to review it. So, if you have spent endless hours working on a
project, is proud your work and ready to show it to the team - take a break and come back to
review it. Taking a break and then getting back to review what was done will allow you to find
those mistakes before others can. And yes, the checklist is quite useful in the review process
- so use it.
Tip: Get a second eye.5. Get a second eye
Even when you have done careful review, chances are there will still be mistakes. It
happens. So getting a second eye, especially one from a more experienced person can find that
one error you overlooked. Sometimes we overlook the details, because we are in a hurry or not
100% focused on the task at hand, getting that other set of eyes to check for errors or an
important point, that you missed, is always useful.
Tip: Get a second eye from someone
more experienced or knowledgeable.6. Allow enough time
In making mistakes at work, I realise I am more prone to making mistakes when I am working
against a
tight deadline . Failure to allow enough time for a project or for review can lead to
missed requirements and incompleteness, which results in failure to meet desired expectations.
That's why it is essential to be smart in estimating the time needed to accomplish a task,
which should include time for review. Ideally, you want to give yourself enough time, to do
research, complete a document/project, review what was done and ask for a second eye , so
setting realistic schedules is most important in making fewer mistakes.
Tip: Limit
working against tight deadlines.7. Learn from others mistakes
No matter how much you know or think you know, it always important to learn from the
mistakes of others. What silly mistakes did a co-worker make that caused a big stir in the
office? Make note of it and intentionally try not to make the same mistakes too. Some of the
greatest lessons are those we learn from others. So pay attention to past mistakes made, what
they did right, what they didn't nail and how they got out of the rut.
Tip: Pay close
attention to the mistakes others make.
No matter how much you know or think you know, it is always important to learn from the
mistakes of others. Remember, mistakes are meant to teach you not break you . So if you make
mistakes, it only shows us that sometimes we need to take a different approach to getting
things done.
Mistakes are meant to teach you not break you
No one wants to make mistakes; I sure don't. But that does not mean we should be afraid of
them. I have made quite a few mistakes in my work life, which has only proven that I need to be
more attentive and that I need to ask for help more than I usually do. So, take the necessary
steps to make fewer mistakes but at the same time, don't beat up yourself over the ones you
make.
A great resource on mistakes in the workplace, Mistakes I Made at Work . A great
resource on focusing on less and increasing productivity, One
Thing .
For more musings, career lessons and tips that you can apply to your personal and
professional life visit my personal blog, www.careyleedixon.com . I enjoy working on being the
version of myself, helping others to grow in their personal and professional lives while doing
what matters. For questions or to book me for writing/speaking engagements on career and
personal development, email me at [email protected]
Here's another issue I see all too often. After a few hours (or a couple of days) working
with Linux, new users will give up for one reason or another. I understand giving up when they
realize something simply doesn't work (such as when they MUST use a proprietary application or
file format). But seeing Linux not work under average demands is rare these days. If you see
new Linux users getting frustrated, try to give them a little extra guidance. Sometimes getting
over that initial hump is the biggest challenge they will face.
In
my 22-year-old career as an IT specialist, I encountered two major issues where -- due to my
mistakes -- important production databases were blown apart. Here are my stories. Freshman
mistake
The first time was in the late 1990s when I started working at a service provider for my
local municipality's social benefit agency. I got an assignment as a newbie system
administrator to remove retired databases from the server where databases for different
departments were consolidated.
Due to a type error on a top-level directory, I removed two live database files instead of
the one retired database. What was worse was that due to the complexity of the database
consolidation during the restore, other databases were hit, too. Repairing all databases took
approximately 22 hours.
What helped
A good backup that was tested each night by recovering an empty file at the end of the tar
archive catalog, after the backup was made. Future-looking statement
It's important to learn from our mistakes. What I learned is this:
Write down the steps you will perform and have them checked by a senior sysadmin. It was
the first time I did not ask for a review by one of the seniors. My bad.
Be nice to colleagues from other teams. It was a DBA that saved me.
Do not copy such a complex setup of sharing databases over shared file systems.
Before doing a life cycle management migration, go for a separation of the filesystems
per database to avoid the complexity and reduce the chances of human error.
Change your approach: Later in my career, I always tried to avoid lift and shift
migrations.
Senior sysadmin mistake
In a period where partly offshoring IT activities was common practice in order to reduce
costs, I had to take over a database filesystem extension on a Red Hat 5 cluster. Given that I
set up this system a couple of years before, I had not checked the current situation.
I assumed the offshore team was familiar with the need to attach all shared LUNs to both
nodes of the two-node cluster. My bad, never assume. As an Australian tourist once mentioned
when a friend and I were on a vacation in Ireland after my Latin grammar school graduation: "Do
not make an ars out of you me." Or, another phrase: "Assuming is the mother of all
mistakes."
Well, I fell for my own trap. I went for the filesystem extension on the active node, and
without checking the passive node's ( node2 ) status, tested a failover. Because
we had agreed to run the database on node2 until the next update window, I had put
myself in trouble.
As the databases started to fail, we brought the database cluster down. No issues yet, but
all hell broke loose when I ran a filesystem check on an LVM-based system with missing physical
volumes.
Looking back
I would say you're stupid to myself. Running pvs , lvs , or
vgs would have alerted me that LVM detected issues. Also, comparing multipath
configuration files would have revealed probable issues.
So, next time, I would first, check to see if LVM contains issues before going for the last
resort: A filesystem check and trying to fix the millions of errors. Most of the time you will
destroy files, anyway.
What saved my day
What saved my day back then was:
My good relations with colleagues over all teams, where a short talk with a great storage
admin created the correct zoning to the required LUNs, and I got great help from a DBA who
had deep knowledge of the clustered databases.
A good database backup.
Great management and a great service manager. They kept the annoyed customer away from
us.
Not making make promises I could not keep, like: "I will fix it in three hours." Instead,
statements such as the one below help keep the customer satisfied: "At the current rate of
fixing the filesystem, I cannot guarantee a fix within so many hours. As we just passed the
10% mark, I suggest we stop this approach and discuss another way to solve the issue."
Future-looking statement
I definitely learned some things. For example, always check the environment you're about to
work on before any change. Never assume that you know how an environment looks -- change is a
constant in IT.
Also, share what you learned from your mistakes. Train offshore colleagues instead of
blaming them. Also, inform them about the impact the issue had on the customer's business. A
continent's major transport hub cannot be put on hold due to a sysadmin's mistake.
A shutdown of the transport hub might have been needed if we failed to solve the issue and
the backup site in a data centre of another service provider would have been hurt too. Part of
the hub is a harbour and we could have blown up a part of the harbour next to a village
of about 10,000 people if both a cotton ship and an oil tanker would have gotten lost on the
harbour master's map and collided.
General lessons learned
I learned some important lessons overall from these and other mistakes:
Be humble enough to admit your mistakes.
Be arrogant enough to state that you are one of the few people that can help fix the
issues you caused.
Show leadership of the solvers' team, or at least make sure that all of the team's roles
will be fulfilled -- including the customer relations manager.
Take back the role of problem-solver after the team is created, if that is what was
requested.
"Be part of the solution, do not become part of the problem," as a colleague says.
I cannot stress this enough: Learn from your mistakes to avoid them in the future, rather
than learning how to make them on a weekly basis. Jan Gerrit Kootstra Solution Designer
(for Telco network services). Red Hat Accelerator. More about me
I had only one backup copy of my QT project and I just wanted to get a directory called
functions. I end up deleting entire backup (note -c switch instead of -x): cd /mnt/bacupusbharddisk
tar -zcvf project.tar.gz functions
I had no backup. Similarly I end up running rsync command and deleted all new files by
overwriting files from backup set (now I have switched to rsnapshot ) rsync -av -delete /dest /src
Again, I had no backup.
... ... ...
All men make mistakes, but only wise men learn from their mistakes --
Winston Churchill .
From all those mistakes I have learn that:
You must keep a good set of backups. Test your backups regularly too.
The clear choice for preserving all data of UNIX file systems is dump, which is only tool
that guaranties recovery under all conditions. (see Torture-testing Backup and
Archive Programs paper).
Never use rsync with single backup directory. Create a snapshots using rsync or
rsnapshots .
Use CVS/git to store configuration files.
Wait and read command line twice before hitting the dam [Enter] key.
Use your well tested perl / shell scripts and open source configuration management
software such as puppet, Ansible, Cfengine or Chef to configure all servers. This also
applies to day today jobs such as creating the users and more.
Mistakes are the inevitable, so have you made any mistakes that have caused some sort of
downtime? Please add them into the comments section below.
"... If you lose a drive in a volume group, you can force the volume group online with the missing physical volume, but you will be unable to open the LV's that were contained on the dead PV, whether they be in whole or in part. ..."
"... So, if you had for instance 10 LV's, 3 total on the first drive, #4 partially on first drive and second drive, then 5-7 on drive #2 wholly, then 8-10 on drive 3, you would be potentially able to force the VG online and recover LV's 1,2,3,8,9,10.. #4,5,6,7 would be completely lost. ..."
"... LVM doesn't really have the concept of a partition it uses PVs (Physical Volumes), which can be a partition. These PVs are broken up into extents and then these are mapped to the LVs (Logical Volumes). When you create the LVs you can specify if the data is striped or mirrored but the default is linear allocation. So it would use the extents in the first PV then the 2nd then the 3rd. ..."
"... As Peter has said the blocks appear as 0's if a PV goes missing. So you can potentially do data recovery on files that are on the other PVs. But I wouldn't rely on it. You normally see LVM used in conjunction with RAIDs for this reason. ..."
"... it's effectively as if a huge chunk of your disk suddenly turned to badblocks. You can patch things back together with a new, empty drive to which you give the same UUID, and then run an fsck on any filesystems on logical volumes that went across the bad drive to hope you can salvage something. ..."
1) How does the system determine what partition to use first?
2) Can I find what disk a file or folder is physically on?
3) If I lose a drive in the LVM, do I lose all data, or just data physically on that disk?
storage lvm
share
HopelessN00b 49k 25 25 gold badges
121 121 silver badges 194 194 bronze badges asked Dec 2 '10 at 2:28 Luke has no
name Luke has no name 989 10 10 silver badges 13 13 bronze badges
The system fills from the first disk in the volume group to the last, unless you
configure striping with extents.
I don't think this is possible, but where I'd start to look is in the lvs/vgs commands
man pages.
If you lose a drive in a volume group, you can force the volume group online with the
missing physical volume, but you will be unable to open the LV's that were contained on the
dead PV, whether they be in whole or in part.
So, if you had for instance 10 LV's, 3 total on
the first drive, #4 partially on first drive and second drive, then 5-7 on drive #2 wholly,
then 8-10 on drive 3, you would be potentially able to force the VG online and recover LV's
1,2,3,8,9,10.. #4,5,6,7 would be completely lost.
Peter Grace Peter Grace 2,676 2 2 gold
badges 22 22 silver badges 38 38 bronze badges
1) How does the system determine what partition to use first?
LVM doesn't really have the concept of a partition it uses PVs (Physical Volumes), which can
be a partition. These PVs are broken up into extents and then these are mapped to the LVs
(Logical Volumes). When you create the LVs you can specify if the data is striped or mirrored
but the default is linear allocation. So it would use the extents in the first PV then the 2nd
then the 3rd.
2) Can I find what disk a file or folder is physically on?
You can determine what PVs a LV has allocation extents on. But I don't know of a way to get
that information for an individual file.
3) If I lose a drive in the LVM, do I lose all data, or just data physically on that
disk?
As Peter has said the blocks appear as 0's if a PV goes missing. So you can potentially do
data recovery on files that are on the other PVs. But I wouldn't rely on it. You normally see
LVM used in conjunction with RAIDs for this reason.
So here's a derivative of my question: I have 3x1 TB drives and I want to use 3TB of that
space. What's the best way to configure the drives so I am not splitting my data over
folders/mountpoints? or is there a way at all, other than what I've implied above? –
Luke has no
name Dec 2 '10 at 5:12
If you want to use 3TB and aren't willing to split data over folders/mount points I don't
see any other way. There may be some virtual filesystem solution to this problem like unionfs
although I'm not sure if it would solve your particular problem. But LVM is certainly the
most straight forward and simple solution as such it's the one I'd go with. –
3dinfluence Dec 2
'10 at 14:51
add a comment | 2 I don't know the answer to #2, so I'll leave that
to someone else. I suspect "no", but I'm willing to be happily surprised.
1 is: you tell it, when you combine the physical volumes into a volume group.
3 is: it's effectively as if a huge chunk of your disk suddenly turned to badblocks. You can
patch things back together with a new, empty drive to which you give the same UUID, and then
run an fsck on any filesystems on logical volumes that went across the bad drive to hope you can
salvage something.
And to the overall, unasked question: yeah, you probably don't really want to do that.
"... RAID5 can survive a single drive failure. However, once you replace that drive, it has to be initialized. Depending on the controller and other things, this can take anywhere from 5-18 hours. During this time, all drives will be in constant use to re-create the failed drive. It is during this time that people worry that the rebuild would cause another drive near death to die, causing a complete array failure. ..."
"... If during a rebuild one of the remaining disks experiences BER, your rebuild stops and you may have headaches recovering from such a situation, depending on controller design and user interaction. ..."
"... RAID5 + a GOOD backup is something to consider, though. ..."
"... Raid-5 is obsolete if you use large drives , such as 2TB or 3TB disks. You should instead use raid-6 ..."
"... RAID 6 offers more redundancy than RAID 5 (which is absolutely essential, RAID 5 is a walking disaster) at the cost of multiple parity writes per data write. This means the performance will be typically worse (although it's not theoretically much worse, since the parity operations are in parallel). ..."
RAID5 can survive a single drive failure. However, once you replace that drive, it has to be initialized. Depending on the
controller and other things, this can take anywhere from 5-18 hours. During this time, all drives will be in constant use to re-create
the failed drive. It is during this time that people worry that the rebuild would cause another drive near death to die, causing
a complete array failure.
This isn't the only danger. The problem with 2TB disks, especially if they are not 4K sector disks, is that they have relative
high BER rate for their capacity, so the likelihood of BER actually occurring and translating into an unreadable sector is something
to worry about.
If during a rebuild one of the remaining disks experiences BER, your rebuild stops and you may have headaches recovering from
such a situation, depending on controller design and user interaction.
So i would say with modern high-BER drives you should say:
RAID5: 0 complete disk failures, BER covered
RAID6: 1 complete disk failure, BER covered
So essentially you'll lose one parity disk alone for the BER issue. Not everyone will agree with my analysis, but considering
RAID5 with today's high-capacity drives 'safe' is open for debate.
RAID5 + a GOOD backup is something to consider, though.
So you're saying BER is the error count that 'escapes' the ECC correction? I do not believe that is correct, but i'm open
to good arguments or links.
As i understand, the BER is what prompt bad sectors, where the number of errors exceed that of the ECC error correcting
ability; and you will have an unrecoverable sector (Current Pending Sector in SMART output).
The short story first: Your consumer level 1TB SATA drive has a 44% chance that it can be completely read without any error.
If you run a RAID setup, this is really bad news because it may prevent rebuilding an array in the case of disk failure,
making your RAID not so Redundant. Click to expand...
Not sure on the numbers the article comes up with, though.
BER simply means that while reading your data from the disk drive you will get an average of one non-recoverable error in
so many bits read, as specified by the manufacturer. Click to expand...
Rebuilding the data on a replacement drive with most RAID algorithms requires that all the other data on the other drives
be pristine and error free. If there is a single error in a single sector, then the data for the corresponding sector on
the replacement drive cannot be reconstructed, and therefore the RAID rebuild fails and data is lost. The frequency of this
disastrous occurrence is derived from the BER. Simple calculations will show that the chance of data loss due to BER is
much greater than all other reasons combined. Click to expand...
These links do suggest that BER works to produce un-recoverable sectors, and not 'escape' them as 'undetected' bad sectors,
if i understood you correctly.
That's guy's a bit of a scaremonger to be honest. He may have a point with consumer drives, but the article is sensationalised
to a certain degree. However, there are still a few outfits that won't go past 500GB/drive in an array (even with enterprise
drives), simply to reduce the failure window during a rebuild. Click to expand...
Why is he a scaremonger? He is correct. Have you read his article? In fact, he has copied his argument from Adam Leventhal(?)
that was one of the ZFS developers I believe.
Adam's argument goes likes this:
Disks are getting larger all the time, in fact, the storage increases exponentially. At the same time, the bandwidth is increasing
not that fast - we are still at 100MB/sek even after decades. So, bandwidth has increased maybe 20x after decades. While storage
has increased from 10MB to 3TB = 300.000 times.
The trend is clear. In the future when we have 10TB drives, they will not be much faster than today. This means, to repair
an raid with 3TB disks today, will take several days, maybe even one week. With 10TB drives, it will take several weeks, maybe
a month.
Repairing a raid stresses the other disks much, which means they can break too. Experienced sysadmins reports that this
happens quite often during a repair. Maybe because those disks come from the same batch, they have the same weakness. Some
sysadmins therefore mix disks from different vendors and batches.
Hence, I would not want to run a raid with 3TB disks and only use raid-5. During those days, if only another disk crashes
you have lost all your data.
Hence, that article is correct, and he is not a scaremonger. Raid-5 is obsolete if you use large drives, such as 2TB or
3TB disks. You should instead use raid-6 (two disks can fail). That is the conclusion of the article: use raid-6 with large
disks, forget raid-5. This is true, and not scaremongery.
In fact, ZFS has therefore something called raidz3 - which means that three disks can fail without problems. To the OT:
no raid-5 is not safe. Neither is raid-6, because neither of them can not always repair nor detect corrupted data. There are
cases when they dont even notice that you got corrupted bits. See my other thread for more information about this. That is
the reason people are switching to ZFS - which always CAN detect and repair those corrupted bits. I suggest, sell your hardware
raid card, and use ZFS which requires no hardware. ZFS just uses JBOD.
The trend is clear. In the future when we have 10TB drives, they will not be much faster than today. This means, to repair
an raid with 3TB disks today, will take several days, maybe even one week. With 10TB drives, it will take several weeks,
maybe a month. Click to expand...
While I agree with the general claim that the larger HDDs (1.5, 2, 3TBs) are best used in RAID 6, your claim about rebuild
times is way off.
I think it is not unreasonable to assume that the 10TB drives will be able to read and write at 200 MB/s or more. We already
have 2TB drives with 150MB/s sequential speeds, so 200 MB/s is actually a conservative estimate.
10e12/200e6 = 50000 secs = 13.9 hours. Even if there is 100% overhead (half the throughput), that is less than 28 hours
to do the rebuild. It is a long time, but it is no where near a month! Try to back your claims in reality.
And you have again made the false claim that "ZFS - which always CAN detect and repair those corrupted bits". ZFS can usually
detect corrupted bits, and can usually correct them if you have duplication or parity, but nothing can always detect and repair.
ZFS is safer than many alternatives, but nothing is perfectly safe. Corruption can and has happened with ZFS, and it will happen
again.
Hence, that article is correct, and he is not a scaremonger. Raid-5 is obsolete if you use large drives , such as 2TB or
3TB disks. You should instead use raid-6 ( two disks can fail). That is the conclusion of the article: use raid-6 with large
disks, forget raid-5 . This is true, and not scaremongery.
RAID 6 offers more redundancy than RAID 5 (which is absolutely essential, RAID 5 is a walking disaster) at
the cost of multiple parity writes per data write. This means the performance will be typically worse (although it's not theoretically
much worse, since the parity operations are in parallel).
Blame the Policies, Not the Robots
By Jared Bernstein and Dean Baker - Washington Post
The claim that automation is responsible for massive job losses has been made in almost
every one of the Democratic debates. In the last debate, technology entrepreneur Andrew Yang
told of automation closing stores on Main Street and of self-driving trucks that would
shortly displace "3.5 million truckers or the 7 million Americans who work in truck stops,
motels, and diners" that serve them. Rep. Tulsi Gabbard (Hawaii) suggested that the
"automation revolution" was at "the heart of the fear that is well-founded."
When Sen. Elizabeth Warren (Mass.) argued that trade was a bigger culprit than automation,
the fact-checker at the Associated Press claimed she was "off" and that "economists mostly
blame those job losses on automation and robots, not trade deals."
In fact, such claims about the impact of automation are seriously at odds with the
standard data that we economists rely on in our work. And because the data so clearly
contradict the narrative, the automation view misrepresents our actual current challenges and
distracts from effective solutions.
Output-per-hour, or productivity, is one of those key data points. If a firm applies a
technology that increases its output without adding additional workers, its productivity goes
up, making it a critical diagnostic in this space.
Contrary to the claim that automation has led to massive job displacement, data from the
Bureau of Labor Statistics (BLS) show that productivity is growing at a historically slow
pace. Since 2005, it has been increasing at just over a 1 percent annual rate. That compares
with a rate of almost 3 percent annually in the decade from 1995 to 2005.
This productivity slowdown has occurred across advanced economies. If the robots are
hiding from the people compiling the productivity data at BLS, they are also managing to hide
from the statistical agencies in other countries.
Furthermore, the idea that jobs are disappearing is directly contradicted by the fact that
we have the lowest unemployment rate in 50 years. The recovery that began in June 2009 is the
longest on record. To be clear, many of those jobs are of poor quality, and there are people
and places that have been left behind, often where factories have closed. But this, as Warren
correctly claimed, was more about trade than technology.
Consider, for example, the "China shock" of the 2000s, when sharply rising imports from
countries with much lower-paid labor than ours drove up the U.S. trade deficit by 2.4
percentage points of GDP (almost $520 billion in today's economy). From 2000 to 2007 (before
the Great Recession), the country lost 3.4 million manufacturing jobs, or 20 percent of the
total.
Addressing that loss, Susan Houseman, an economist who has done exhaustive, evidence-based
analysis debunking the automation explanation, argues that "intuitively and quite simply,
there doesn't seem to have been a technology shock that could have caused a 20 to 30 percent
decline in manufacturing employment in the space of a decade." What really happened in those
years was that policymakers sat by while millions of U.S. factory workers and their
communities were exposed to global competition with no plan for transition or adjustment to
the shock, decimating parts of Ohio, Michigan and Pennsylvania. That was the fault of the
policymakers, not the robots.
Before the China shock, from 1970 to 2000, the number (not the share) of manufacturing
jobs held remarkably steady at around 17 million. Conversely, since 2010 and post-China
shock, the trade deficit has stabilized and manufacturing has been adding jobs at a modest
pace. (Most recently, the trade war has significantly dented the sector and worsened the
trade deficit.) Over these periods, productivity, automation and robotics all grew apace.
In other words, automation isn't the problem. We need to look elsewhere to craft a
progressive jobs agenda that focuses on the real needs of working people.
First and foremost, the low unemployment rate -- which wouldn't prevail if the automation
story were true -- is giving workers at the middle and the bottom a bit more of the
bargaining power they require to achieve real wage gains. The median weekly wage has risen at
an annual average rate, after adjusting for inflation, of 1.5 percent over the past four
years. For workers at the bottom end of the wage ladder (the 10th percentile), it has risen
2.8 percent annually, boosted also by minimum wage increases in many states and cities.
To be clear, these are not outsize wage gains, and they certainly are not sufficient to
reverse four decades of wage stagnation and rising inequality. But they are evidence that
current technologies are not preventing us from running hotter-for-longer labor markets with
the capacity to generate more broadly shared prosperity.
National minimum wage hikes will further boost incomes at the bottom. Stronger labor
unions will help ensure that workers get a fairer share of productivity gains. Still, many
toiling in low-wage jobs, even with recent gains, will still be hard-pressed to afford child
care, health care, college tuition and adequate housing without significant government
subsidies.
Contrary to those hawking the automation story, faster productivity growth -- by boosting
growth and pretax national income -- would make it easier to meet these challenges. The
problem isn't and never was automation. Working with better technology to produce more
efficiently, not to mention more sustainably, is something we should obviously welcome.
The thing to fear isn't productivity growth. It's false narratives and bad economic
policy.
An inode is a data structure in UNIX operating systems that contains important information
pertaining to files within a file system. When a file system is created in UNIX, a set amount
of inodes is created, as well. Usually, about 1 percent of the total file system disk space is
allocated to the inode table.
How do we find a file's inode ?
ls -i Command: display inode
ls -i Command: display inode
$ls -i /etc/bashrc
131094 /etc/bashrc
131094 is the inode of /etc/bashrc.
find / -inum XXXXXX -print to find the full path for each file pointing to inode XXXXXX.
Though you can use the example to do rm action, but simply I discourage to do so, for
security concern in find command, also in other file system, same inode refers a very different
file.
filesystem repair
If you get a bad luck on your filesystem, most of time, run fsck to fix it. It helps if you
have inode info of the filesystem in hand.
This is another big topic, I'll have another article for it.
Good luck. Anytime you pass any sort of command to this file, it's going to interpret it
as a flag. You can't fool rm, echo, sed, or anything else into actually deeming this a file
at this point. You do, however, have a inode for every file.
Traditional methods fail:
[eriks@jaded: ~]$ rm -f –fooface
rm: unrecognized option '–fooface'
Try `rm ./–fooface' to remove the file `–fooface'.
Try `rm –help' for more information.
[eriks@jaded: ~]$ rm -f '–fooface'
rm: unrecognized option '–fooface'
Try `rm ./–fooface' to remove the file `–fooface'.
Try `rm –help' for more information.
So now what, do you live forever with this annoyance of a file sitting inside your
filesystem, never to be removed or touched again? Nah.
We can remove a file, simply by an inode number, but first we must find out the file inode
number:
The author is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a
trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on
SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly
email newsletter .
Run the following command to start the Terminal session recording.
$ script -a my_terminal_activities
Where, -a flag is used to append the output to file or to typescript, retaining the prior
contents. The above command records everything you do in the Terminal and append the output to
a file called 'my_terminal_activities' and save it in your current working directory.
Sample output would be:
Script started, file is my_terminal_activities
Now, run some random Linux commands in your Terminal.
$ mkdir ostechnix
$ cd ostechnix/
$ touch hello_world.txt
$ cd ..
$ uname -r
After running all commands, end the 'script' command's session using command:
$ exit
After typing exit, you will the following output.
exit
Script done, file is my_terminal_activities
As you see, the Terminal activities have been stored in a file called
'my_terminal_activities' and saves it in the current working directory.
You can also save the Terminal activities in a file in different location like below.
$ script -a /home/ostechnix/documents/myscripts.txt
All commands will be stored in /home/ostechnix/documents/myscripts.txt file.
To view your Terminal activities, just open this file in any text editor or simply display
it using the 'cat' command.
$ cat my_terminal_activities
Sample output:
Script started on 2019-10-22 12:07:37+0530
sk@ostechnix:~$ mkdir ostechnix
sk@ostechnix:~$ cd ostechnix/
sk@ostechnix:~/ostechnix$ touch hello_world.txt
sk@ostechnix:~/ostechnix$ cd ..
sk@ostechnix:~$ uname -r
5.0.0-31-generic
sk@ostechnix:~$ exit
exit
Script done on 2019-10-22 12:08:10+0530
As you see in the above output, script command has recorded all my Terminal activities,
including the start and end time of the script command. Awesome, isn't it? The reason to use
script command is it's not just records the commands, but also the commands' output as well. To
put this simply, Script command will record everything you do on the Terminal.
Bonus
tip:
As one of our reader Mr.Alastair Montgomery mentioned in the comment section, we could setup
an alias
with would timestamp the recorded sessions.
Create an alias for the script command like below.
$ alias rec='script -aq ~/term.log-$(date "+%Y%m%d-%H-%M")'
Now simply enter the following command start recording the Terminal.
$ rec
Now, all your Terminal activities will be logged in a text file with timestamp, for example
term.log-20191022-12-16 .
$ find . -size +10M -type f -print0 | xargs -0 ls -Ssh | sort -z
For those wondering, the above command will find and list files bigger than 10 MB in the
current directory and sort them by size. I admit that I couldn't remember this command. I guess
some of you can't remember this command either. This is why we are going to apply a tag to such
kind of commands.
To apply a tag, just type the command and add the comment ( i.e. tag) at the end of the
command as shown below.
$ find . -size +10M -type f -print0 | xargs -0 ls -Ssh | sort -z #ListFilesBiggerThanXSize
Here, #ListFilesBiggerThanXSize is the tag name to the above command. Make sure you have
given a space between the command and tag name. Also, please use the tag name as simple, short
and clear as possible to easily remember it later. Otherwise, you may need another tool to
recall the tags.
To run it again, simply use the tag name like below.
$ !? #ListFilesBiggerThanXSize
Here, the ! (Exclamation mark) and ? (Question mark) operators are used to fetch and run the
command which we tagged earlier from the BASH history.
(businessinsider.com) 121
building its own private cloud software rather than outsourcing to companies like Amazon,
Microsoft, and Google. From a report: The investment, including a $350 million charge in
2017, hasn't been cheap, but it has had a striking payoff, CEO Brian Moynihan said during the
company's third-quarter earnings call. He said the decision helped reduce the firm's servers to
70,000 from 200,000 and its data centers to 23 from 60, and it has resulted in $2 billion in
annual infrastructure savings.
"... the function which converts user id into its username incorrectly treats -1, or its unsigned equivalent 4294967295, as 0, which is always the user ID of root user. ..."
The vulnerability, tracked as CVE-2019-14287 and discovered by Joe Vennix of Apple
Information Security, is more concerning because the sudo utility has been designed to let
users use their own login password to execute commands as a different user without requiring
their password. \
What's more interesting is that this flaw can be exploited by an attacker to
run commands as root just by specifying the user ID "-1" or "4294967295."
That's because the function which
converts user id into its username incorrectly treats -1, or its unsigned equivalent
4294967295, as 0, which is always the user ID of root user.
The vulnerability affects all Sudo versions prior to the latest released version 1.8.28,
which has been released today.
If
you have been blessed with the power to run commands as ANY user you want, then you are still
specially privileged, even though you are not fully privileged.
Its a rare/unusual configuration to say (all, !root) --- the people using this configuration
on their systems should probably KNOW there are going to exist some ways that access can be
abused to ultimately circumvent the intended !root rule - If not within sudo itself, then by
using sudo to get a shell as a different user UID that belongs to some person or program who
DOES have root permissions, and then causing crafted code to run as that user --- For example,
by installing a
Trojanned version of the screen command and modifying files in the home directory of a
legitimate root user to alias the screen command to trojanned version that will log the
password the next time that Other user logs in normally and uses the sudo command.
93 Escort Wagon( 326346 )#59307592)
/etc/sudoers at all - and therefore can't
exploit this bug. And in the simplest configuration (what you're referring to, I imagine),
people who are in/etc/sudoers will have root access already - rendering
this bug pointless for them.
However (assuming I've interpreted this correctly) if you've
given someone only limited sudo permissions, this bug can be exploited by those users to
basically get full root access.
I'm not sure how common that sort of limited sudo access is used, though. I haven't seen
it first hand, but then I've never worked as part of a large group of admins.
Or read TFS carefully. What the bug does is allow someone to choose root as
the uid - even of noroot is set. That doesn't have anything to do with the
password check, and doesn't bypass the password check.
Computer programmer Steve Relles has the poop on what to do when your job is outsourced to
India. Relles has spent the past year making his living scooping up dog droppings as the
"Delmar Dog Butler." "My parents paid for me to get a (degree) in math and now I am a pooper
scooper," "I can clean four to five yards in a hour if they are close together." Relles, who
lost his computer programming job about three years ago ... has over 100 clients who pay $10
each for a once-a-week cleaning of their yard.
Relles competes for business with another local company called "Scoopy Do." Similar
outfits have sprung up across America, including Petbutler.net, which operates in Ohio.
Relles says his business is growing by word of mouth and that most of his clients are women
who either don't have the time or desire to pick up the droppings. "St. Bernard (dogs) are my
favorite customers since they poop in large piles which are easy to find," Relles said. "It
sure beats computer programming because it's flexible, and I get to be outside,"
So you thought you had your files backed up - until it came time to restore. Then you found out that you had bad sectors and
you've lost almost everything because gzip craps out 10% of the way through your archive. The gzip Recovery Toolkit has a program
- gzrecover - that attempts to skip over bad data in a gzip archive. This saved me from exactly the above situation. Hopefully it
will help you as well.
I'm very eager for feedback on this program
. If you download and try it, I'd appreciate and email letting me know what
your results were. My email is
[email protected]. Thanks.
ATTENTION
99% of "corrupted" gzip archives are caused by transferring the file via FTP in ASCII mode instead of binary mode. Please
re-transfer the file in the correct mode first before attempting to recover from a file you believe is corrupted.
Disclaimer and Warning
This program is provided AS IS with absolutely NO WARRANTY. It is not guaranteed to recover anything from your file, nor is
what it does recover guaranteed to be good data. The bigger your file, the more likely that something will be extracted from it.
Also keep in mind that this program gets faked out and is likely to "recover" some bad data. Everything should be manually
verified.
Downloading and Installing
Note that version 0.8 contains major bug fixes and improvements. See the
ChangeLog
for details. Upgrading is recommended. The old
version is provided in the event you run into troubles with the new release.
GNU cpio
(version 2.6 or higher) - Only if your archive is a
compressed tar file and you don't already have this (try "cpio --version" to find out)
First, build and install zlib if necessary. Next, unpack the gzrt sources. Then cd to the gzrt directory and build the
gzrecover program by typing
make
. Install manually by copying to the directory of your choice.
Usage
Run gzrecover on a corrupted .gz file. If you leave the filename blank, gzrecover will read from the standard input. Anything
that can be read from the file will be written to a file with the same name, but with a .recovered appended (any .gz is
stripped). You can override this with the -o
To get a verbose readout of exactly where gzrecover is finding bad bytes, use the -v option to enable verbose mode. This will
probably overflow your screen with text so best to redirect the stderr stream to a file. Once gzrecover has finished, you will
need to manually verify any data recovered as it is quite likely that our output file is corrupt and has some garbage data in it.
Note that gzrecover will take longer than regular gunzip. The more corrupt your data the longer it takes. If your archive is a
tarball, read on.
For tarballs, the tar program will choke because GNU tar cannot handle errors in the file format. Fortunately, GNU cpio
(tested at version 2.6 or higher) handles corrupted files out of the box.
Here's an example:
$ ls *.gz
my-corrupted-backup.tar.gz
$ gzrecover my-corrupted-backup.tar.gz
$ ls *.recovered
my-corrupted-backup.tar.recovered
$ cpio -F my-corrupted-backup.tar.recovered -i -v
Note that newer versions of cpio can spew voluminous error messages to your terminal. You may want to redirect the stderr
stream to /dev/null. Also, cpio might take quite a long while to run.
Copyright
The gzip Recovery Toolkit v0.8
Copyright (c) 2002-2013 Aaron M. Renn (
[email protected])
Recovery is possible but it depends on what caused the corruption.
If the file is just truncated, getting some partial result out is not too hard; just
run
gunzip < SMS.tar.gz > SMS.tar.partial
which will give some output despite the error at the end.
If the compressed file has large missing blocks, it's basically hopeless after the bad
block.
If the compressed file is systematically corrupted in small ways (e.g. transferring the
binary file in ASCII mode, which smashes carriage returns and newlines throughout the file),
it is possible to recover but requires quite a bit of custom programming, it's really only
worth it if you have absolutely no other recourse (no backups) and the data is worth a lot of
effort. (I have done it successfully.) I mentioned this scenario in a previous
question .
The answers for .zip files differ somewhat, since zip archives have multiple
separately-compressed members, so there's more hope (though most commercial tools are rather
bogus, they eliminate warnings by patching CRCs, not by recovering good data). But your
question was about a .tar.gz file, which is an archive with one big member.
,
Here is one possible scenario that we encountered. We had a tar.gz file that would not
decompress, trying to unzip gave the error:
Hi, generally I configure /etc/aliases to forward root messages to my work email address. I
found this useful, because sometimes I become aware of something wrong...
I create specific email filter on my MUA to put everything with "fail" in subject in my
ALERT subfolder, "update" or "upgrade" in my UPGRADE subfolder, and so on.
It is a bit annoying, because with > 50 server, there is lot of "rumor", anyway.
"... Scrum is dead, long live Screm! We need to implement it immediately. We must innovate and stay ahead of the curve! level 7 ..."
"... First you scream, then you ahh. Now you can screm ..."
"... Are you saying quantum synergy coupled with block chain neutral intelligence can not be used to expedite artificial intelligence amalgamation into that will metaphor into cucumber obsession? ..."
We recently implemented DevOps practices, Scrum, and sprints have become the
norm... I swear to god we spend 60% of our time planning our sprints, and 40% of the time doing the work, and
management wonders why our true productivity has fallen through the floor...
level 5
Are you saying quantum synergy coupled with block chain neutral intelligence can not be
used to expedite artificial intelligence amalgamation into that will metaphor into cucumber obsession?
What is it with these people? Someone brought me an "urgent" request (of course there
wasn't a ticket), so I said no worries, I'll help you out. Just open a ticket for me so we can track the work and document
the conversation. We got that all knocked out and everyone was happy.
So a day or two later, I suddenly get an instant message for yet another "urgent"
issue. ... Ok ... Open a ticket, and I'll get it assigned to one of my team members to take a look.
And a couple days later ... he's back and I'm being asked for help troubleshooting an
application that we don't own. At least there's a ticket and an email thread... but wtf man.
What the heck man?
This is like when you get a free drink or dessert from your waiter. Don't keep coming
back and asking for more free pie. You know damn well you're supposed to pay for pie. Be cool. I'll help you out when
you're really in a tight spot, but the more you cry "urgent", the less I care about your issues.
Hey
r/Sysadmin
, please don't suffer in silence. I know the job can be very difficult at times, especially with competing
objectives, tight (or impossible) deadlines, bad bosses and needy end users, but please - always remember that there are
ways to manage that stress. Speaking to friends and family regularly to vent, getting a therapist, or taking time off.
Yes, you do have the ability to take personal leave/medical leave if its that bad. No,
it doesn't matter what your colleagues or boss will think..and no, you are not a quitter, weak, or a loser if you take
time for yourself - to heal mentally, physically or emotionally.
EDIT: Holy Cow! Thanks for the silver and platinum kind strangers. All i wanted to do
was to get some more awareness on this subject, and create a reminder that we all deserve happiness and peace of mind. A
reminder that hopefully sticks with you for the days and weeks to come.
We, sysadmins, have times when we don't really have nothing to do but maintenance. BUT,
there are times when it seems like chaos comes out of nowhere. When I have a lot of tasks to do, I tend to get slower. The
more tasks I have pending, the slower I become. I cannot avoid to start thinking about 3 or 4 different problems at the
same time, and I can't focus! I only have 2 years of experiences as sysadmin.
Have you ever wondered if your whole career will be related to IT stuff? I have, since
my early childhood. It was more than 30 years ago - in the marvelous world of an 8-bit era. After writing my first code
(10 PRINT "
my_name
" : 20 GOTO 10) I exactly knew what I wanted to do in the
future. Now, after spending 18 years in this industry, which is half of my age, I'm not so sure about it.
I had plenty of time to do almost everything. I was writing software for over 100K
users and I was covered in dust while drilling holes for ethernet cables in houses of our customers. I was a main network
administrator for a small ISP and systems administrator for a large telecom operator. I made few websites and I was
managing a team of technical support specialists. I was teaching people - on individual courses on how to use Linux and
made some trainings for admins on how to troubleshoot multicast transmissions in their own networks. I was active in some
Open Source communities, including running forums about one of Linux distributions (the forum was quite popular in my
country) and I was punching endless Ctrl+C/Ctrl+V combos from Stack Overflow. I even fixed my aunt's computer!
And suddenly I realised that I don't want to do this any more. I've completely burnt
out. It was like a snap of a finger.
During many years I've collected a wide range of skills that are (or will be) obsolete.
I don't want to spend rest of my life maintaining a legacy code written in C or PHP or learning a new language which is
currently on top and forcing myself to write in a coding style I don't really like. That's not all... If you think you'll
enjoy setting up vlans on countless switches, you're probably wrong. If you think that managing clusters of virtual
machines is an endless fun, you'll probably be disappointed. If you love the smell of a brand new blade server and the
"click" sound it makes when you mount it into the rack, you'll probably get fed up with it. Sooner or later.
But there's a good side of having those skills. With skills come experience, knowledge
and good premonition. And these features don't get old. Remember that!
My employer offered me a position of a project manager and I eagerly agreed to it. It
means that I'm leaving the world of "hardcore IT" I'll be doing some other, less crazy stuff. I'm logging out of my
console and I'll run Excel. But I'll keep all good memories from all those years. I'd like to thank all of you for doing
what you're doing, because it's really amazing. Good luck! The world lies in your hands!
254 comments
450
Posted by
u/remrinds
1 day ago
General Discussion
UPDATE: So our cloud exchange server was down for 17 hours on friday
my original post got deleted because i behaved wrongly and posted some slurs. I
apologise for that.
anyway, so, my companie is using Office365 ProPlus and we migrated our on premise
exchange server to cloud a while ago, and on friday last week, all of our user (1000 or so) could not access their
exchange box, we are a TV broadcasting station so you can only imagine the damage when we could not use our mailing
system.
initially, we opened a ticket with microsoft and they just kept us on hold for 12 hours
(we are in japan so they had to communicate with US and etc which took time), and then they told us its our network infra
thats wrong when we kept telling them its not. we asked them to check their envrionment at least once which they did not
until 12 hours later.
in the end, it was their exchange server that was the problem, i will copy and paste
the whole incident report below
Title: Can't access Exchange
User Impact: Users are unable to access the Exchange Online service.
Current status: We've determined that a recent sync between Exchange Online and Azure Active Directory (AAD) inadvertently resulted in access issues with the Exchange Online service. We've restored the affected environment and updated the Global Location Service (GLS) records, which we believe has resolved the issue. We're awaiting confirmation from your representatives that this issue is resolved.
Scope of impact: Your organization is affected by this event, and this issue impacts all users.
Start time: Friday, October 4, 2019, 4:51 AM
Root cause: A recent Service Intelligence (SI) move inadvertently resulted in access issues with the Exchange Online service.
they wont explain further than what they posted on the incident page but if anyone here
is good with microsofts cloud envrionment, can anyone tell me what was the root cause of this? from what i can gather, the
AAD and exchange server couldnt sync but they wont tell us what the actual problem is, what the hell is Service
intelligence and how does it fix our exchange server when they updated the global location service?
any insight on these report would be more than appreciated
I rolled out this patch this weekend to my test group and it appears that some of the
workstations this was applied to are having print spooler issues.
I hadn't found a use case for containers in my environment so I had put off learning
Docker for a while. But, I'm writing a rails app to simplify/automate some of our administrative tasks. Setting up my
different dev and test environments was definitely non trivial, and I plan on onboarding another person or 2 so they can
help me out and add it to their resume.
I installed Docker desktop on my Mac, wrote 2 files essentially copied from Docker's
website, built it, then ran it. It took a total of 10 minutes to go from zero Docker to fully configured and running. It's
really that easy to start using it. So, now I've decided to set up Kubernetes at work this week and see what I can find to
do with it.
Let me tell you about the Monday from hell I encountered yesterday.
I work for
xyz corp
which is an MSP for IT
services. One of the companies we support, we'll call them
abc corp
.
I come in to work Monday morning and look at my alerts report from the previous day and
find that all of the servers (about 12+) at
abc corp
are showing offline. Manager
asks me to go on site to investigate, it's around the corner so
nbd
.
I get to the client, head over to the server room and open up the KVM console. I switch
inputs and see no issues with the ESX hosts. I then switch over to the (for some reason, physical) vCenter server and find
this lovely little message:
Now, I've never seen this before and it looks sus but just in case, i reboot the
machine -
same message
. Do a
quick google search and found that the server was hit with an MBR level ransomware encryption. I then quickly switched
over to the server that manages the backups and found that
it's also encrypted -
f*ck.
At this point, I call
Mr. CEO
and account
manager to come on site. While waiting for them, I found that the SANs had also been logged in to and had all data deleted
and snapshots deleted off the datastores and the EQL volume was also encrypted -
PERFECT!
At this point, I'm basically freaking out.
ABC Corp
is owned by a parent company who apparently also got hit however we don't manage them *phew*.
Our only saving grace at this point is the offsite backups. I log in to the server and
wouldn't ya know it, I see this lovely message:
Last replication time: 6/20/2019 13:00:01
BackupsTech
had a script that ran to report on
replication status daily and the reports were showing that they were up to date. Obviously, they weren't so at this point
we're basically f*cked.
We did eventually find out this originated from
parentcompany
and that the accounts used were from the old IT Manager that recently left a few weeks ago.
Unfortunately, they never disabled the accounts in either domain and the account used was a domain admin account.
We're currently going through and attempting to undelete the VMFS data to regain access
to the VM files. If anyone has any suggestions on this, feel free to let me know.
Sick and tired of listening to these so called architects and full stack developers who
watch bunch of videos on YouTube and Pluralsight, find articles online. They go around workplace throwing words like
containers, devops, NoOps, azure, infrastructure as code, serverless, etc, they don't understand half of the stuff. I do some
of the devops tasks in our company, I understand what it takes to implement and manage these technologies. Every meeting is
infested with these A holes.
1.0k comments
91% Upvoted
What are your thoughts? Log in or Sign up
log
in
sign
up
Sort by
level 1
Your best defense against these is to come up with non-sarcastic and
quality questions to ask these people during the meeting, and watch them not have a clue how to answer them.
For example, a friend of mine worked at a smallish company, some manager
really wanted to move more of their stuff into Azure including AD and Exchange environment. But they had
common problems with their internet connection due to limited bandwidth and them not wanting to spend more. So
during a meeting my friend asked a question something like this:
"You said on this slide that moving the AD environment and Exchange
environment to Azure will save us money. Did you take into account that we will need to increase our internet
speed by a factor of at least 4 in order to accommodate the increase in traffic going out to the Azure cloud?
"
Of course, they hadn't. So the CEO asked my friend if he had the numbers,
which he had already done his homework, and it was a significant increase in cost every month and taking into
account the cost for Azure and the increase in bandwidth wiped away the manager's savings.
I know this won't work for everyone. Sometimes there is real savings in
moving things to the cloud. But often times there really isn't. Calling the uneducated people out on what they
see as facts can be rewarding.
level 2
my previous boss was that kind of a guy. he waited till other people were
done throwing their weight around in a meeting and then calmly and politely dismantled them with facts.
no amount of corporate pressuring or bitching could ever stand up to that.
level 3
This is my approach. I don't yell or raise my voice, I just wait. Then I
start asking questions that they generally cannot answer and slowly take them apart. I don't have to be loud
to get my point across.
level 4
This tactic is called "the box game". Just continuously ask them logical
questions that can't be answered with their stupidity. (Box them in), let them be their own argument against
themselves.
Not to mention downtime. We have two ISPs in our area. Most of our clients
have both in order to keep a fail-over. However, depending on where the client is located, one ISP is fast but
goes down every time it rains and the other is solid but slow. Now our only AzureAD customers are those who
have so many remote workers that they throw their hands up and deal with the outages as they come. Maybe this
works in Europe or South Korea, but this here 'Murica got too many internet holes.
level 3
Yup. If you're in a city with fiber it can probably work. If you have even
one remote site, and all they have is DSL (or worse, satellite, as a few offices I once supported were
literally
in the woods when I worked for a timber company) then even
Citrix becomes out of the question.
Definitely this, if you know your stuff and can wrap some numbers around it
you can regain control of the conversation.
I use my dad as a prime example, he was an electrical engineer for ~40
years, ended up just below board level by the time he retired. He sat in on a product demo once, the kit they
were showing off would speed up jointing cable in the road by 30 minutes per joint. My dad asked 3 questions
and shut them down:
"how much will it cost to supply all our jointing teams?" £14million
"how many joints do our teams complete each day?" (this they couldn't
answer so my dad helped them out) 3
"So are we going to tell the jointers that they get an extra hour and a
half hour lunch break or a pay cut?"
Room full of executives that had been getting quite excited at this awesome
new investment were suddenly much more interested in showing these guys the door and getting to their next
meeting.
level 3
I think they did 3 as that was the workload so being able to do 4 isn't
relevant if there isn't a fourth to do.
That's what I get out of his story anyway.
And also if it was going to be 14 million in costs to equip everyone, the
savings have to be there. If adding 1 unit of productivity per day didn't save 14 million in a year or two,
it's not really worth it.
level 5
That was basically what I figured was the missing piece - the logistical
inability to process 4 units.
As far as the RoI, I had to assume that the number of teams involved and
their operational costs had already factored into whether or not 14m was even a price anyone could consider
paying. In other words, by virtue of the meeting even happening I figured that the initial costing had not
already been laughed out of the room, but perhaps that's a bit too much of an assumption to make.
level 6
In my limited experience they slow roll actually pricing anything. Of
course physical equipment pricing might be more straightforward, which would explain why his dad got a number
instead of a discussion of licensing options.
level 5
And also if it was going to be 14 million in costs to equip everyone,
the savings have to be there. If adding 1 unit of productivity per day didn't save 14 million in a year or
two, it's not really worth it.
That entirely depends. If you have 10 people producing 3 joints a day, with
this new kit you could reduce your headcount by 2 and still produce the same, or take on additional workload
and increase your production. Not to mention that you don't need to equip everyone with these kits either, you
could save them for the projects which needed more daily production thus saving money on the kits and
increasing production on an as needed basis.
They story is missing a lot of specifics and while it sounds great, I'm
quite certain there was likely a business case to be made.
He's saying they get 3 done in a day, and the product would save them 30
minutes per joint. That's an hour and a half saved per day, not even enough time to finish a fourth joint,
hence the "so do i just give my workers an extra 30 min on lunch"? He just worded it all really weird.
level 4
Your ignoring travel time in there, there are also factors to do with
outside contractors carrying out the digging and reinstatement works and getting sign off to actually dig the
hole in the road in the first place.
There is also the possibility I'm remembering the time wrong... it's been a
while!
level 5
Travel time actually works in my favour. If it takes more time to go from
job to job, then the impact of the enhancement is magnified because the total time per job shrinks.
level 4
That seems like a poor example. Why would you ignore efficiency
improvements just to give your workers something to do? Why not find another task for them or figure out a way
to consolidate the teams some? We fight this same mentality on our manufacturing floors, the idea that if we
automate a process someone will lose their job or we wont have enough work for everyone. Its never the case.
However, because of the automation improvements we have done in the last 10 years, we are doing 2.5x the
output with only a 10% increase in the total number of laborers.
So maybe in your example for a time they would have nothing for these
people to do. Thats a management problem. Have them come back and sweep the floor or wash their trucks.
Eventually you will be at a point where there is more work, and that added efficiency will save you from
needing to put more crews on the road.
Calling the uneducated people out on what they see as facts can be
rewarding.
I wouldnt call them all uneducated. I think what they are is basically
brainwashed. They constantly hear from the sales teams of vendors like Microsoft pitching them the idea of
moving everything to Azure.
They do not hear the cons. They do not hear from the folks who know their
environment and would know if something is a good fit. At least, they dont hear it enough, and they never see
it first hand.
Now, I do think this is their fault... they need to seek out that info
more, weigh things critically, and listen to what's going on with their teams more. Isolation from the team is
their own doing.
After long enough standing on the edge and only hearing "jump!!", something
stupid happens.
level 3
There's little downside to containers by themselves. They're just a method
of sandboxing processes and packaging a filesystem as a distributable image. From a performance perspective
the impact is near negligible (unless you're doing some truly intensive disk I/O).
What can be problematic is taking a process that was designed to run on
exactly n dedicated servers and converting it to a modern 2 to n autoscaling deployment that shares hosting
with other apps on n a platform like Kubernetes. It's a significant challenge that requires a lot of expertise
and maintenance, so there needs to be a clear business advantage to justify hiring at least one additional
full time engineer to deal with it.
level 5
Containers are great for stateless stuff. So your webservers/application
servers can be shoved into containers. Think of containers as being the modern version of statically linked
binaries or fat applications. Static binaries have the problem that any security vulnerability requires a full
rebuild of the application, and that problem is escalated in containers (where you might not even know that a
broken library exists)
If you are using the typical business application, you need one or more
storage components for data which needs to be available, possibly changed and access controlled.
Containers are a bad fit for stateful databases, or any stateful component,
really.
Containers also enable microservices, which are great ideas at a certain
organisation size (if you aren't sure you need microservices, just use a simple monolithic architecture). The
problem with microservices is that you replace complexity in your code with complexity in the communications
between the various components, and that is harder to see and debug.
level 5
Containers are fine for stateful services -- you can manage persistence at
the storage layer the same way you would have to manage it if you were running the process directly on the
host.
Backing up containers can be a pain, so you don't want to use them for
valuable data unless the data is stored elsewhere, like a database or even a file server.
For spinning up stateless applications to take workload behind a load
balancer, containers are excellent.
The problem is that there is an overwhelming din from vendors. Everybody
and their brother, sister, mother, uncle, cousin, dog, cat, and gerbil is trying to sell you some
pay-by-the-month cloud "solution".
The reason is that the cloud forces people into monthly payments, which is
a guarenteed income for companies, but costs a lot more in the long run, and if something happens and one
can't make the payments, business is halted, ensuring that bankruptcies hit hard and fast. Even with the
mainframe, a company could limp along without support for a few quarters until they could get cash flow
enough.
If we have a serious economic downturn, the fact that businesses will be
completely shuttered if they can't afford their AWS bill just means fewer companies can limp along when the
economy is bad, which will intensify a downturn.
Our company viewed the move to Azure less as a cost savings measure and
more of a move towards agility and "right now" sizing of our infrastructure.
Your point is very accurate, as an example our location is wholly incapable
of moving moving much to the cloud due to half of us being connnected via satellite network and the other half
being bent over the barrel by the only ISP in town.
level 2
I'm sorry, but I find management these days around tech wholly inadequate.
The idea that you can get an MBA and manage shit you have no idea about is absurd and just wastes everyone
elses time for them to constantly ELI5 so manager can do their job effectively.
level 2
Calling the uneducated people out on what they see as facts can be
rewarding
Aaand political suicide in a corporate environment. Instead I use the
following:
"I love this idea! We've actually been looking into a similar solution
however we weren't able to overcome some insurmountable cost sinkholes (remember: nothing is impossible; just
expensive). Will this idea require an increase in internet speed to account for the traffic going to the azure
cloud?"
level 3
This exactly, you can't compromise your own argument to the extent that
it's easy to shoot down in the name of giving your managers a way of saving face, and if you deliver the facts
after that sugar coating it will look even worse, as it will be interpreted as you setting them up to look
like idiots. Being frank, objective and non-blaming is always the best route.
level 4
I think it's quite an american thing to do it so enthusiastically; to hurt
no one, but the result is so condescending. It must be annoying to walk on egg shells to survive a day in the
office.
And this is not a rant against soft skills in IT, at all.
level 4
We work with Americans and they're always so positive, it's kinda annoying.
They enthusiastically say "This is very interesting" when in reality it sucks and they know it.
Another less professional example, one of my (non-american) co-workers
always wants to go out for coffee (while we have free and better coffee in the office), and the American
coworker is always nice like "I'll go with you but I'm not having any" and I just straight up reply "No. I'm
not paying for shitty coffee, I'll make a brew in the office". And that's that. Sometimes telling it as it is
makes the whole conversation much shorter :D
level 5
Maybe the american would appreciate the break and a chance to spend some
time with a coworker away from screens, but also doesn't want the shit coffee?
Yes. "Go out for coffee" is code for "leave the office so we can complain
about management/company/customer/Karen". Some conversations shouldn't happen inside the building.
level 7
Inferior American - please compute this - the sole intention was
consumption of coffee. Therefore due to existence of coffee in office, trip to coffee shop is not sane.
Resistance to my reasoning is futile.
level 7
Coffee is not the sole intention. If that was the case, then there wouldn't
have been an invitation.
Another intention would be the social aspect - which americans are known to
love, especially favoring it over doing any actual work in the context of a typical 9-5 corporate job.
I've effectively resisted your reasoning, therefore [insert ad hominem
insult about inferior logic].
There is still value to tact in your delivery, but, don't slit your own
throat. Remind them they hired you for a reason.
"I appreciate the ideas being raised here by management for cost savings
and it certainly merits a discussion point. As a business, we have many challenges and one of them includes
controlling costs. Bridging these conversations with subject matter experts and management this early can
really help fill out the picture. I'd like to try to provide some of that value to the conversation here"
level 3
If it's political suicide to point out potential downsides, then you need
to work somewhere else.
Especially since your response, in my experience, won't get anything done
(people will either just say "no, that's not an issue", or they'll find your tone really condescending) and
will just piss people off.
I worked with someone like that would would always be super passive
aggressive in how she brought things up and it pissed me off to no end, because it felt less like bringing up
potential issues and more like being belittling.
level 4
Feels good to get to a point in my career where I can call people our
whenever the hell I feel like it. I've got recruiters banging down my door, I couldn't swing a stick without
hitting a job offer or three.
Of course you I'm not suggesting problem be combative for no reason and to
be tactful about it but if you don't call out fools like that then you're being negligent in your duties.
level 4
"I am resolute in my ability to elevate this collaborative,
forward-thinking team into the revenue powerhouse that I believe it can be. We will transition into a DevOps
team specialising in migrating our existing infrastructure entirely to code and go completely serverless!" -
CFO that outsources IT
level 2
We recently implemented DevOps practices, Scrum, and sprints have become
the norm... I swear to god we spend 60% of our time planning our sprints, and 40% of the time doing the work,
and management wonders why our true productivity has fallen through the floor...
level 5
If you spend three whole days out of every five in planning meetings, this
is a problem with your meeting planners, not with screm. If these people stay in charge, you'll be stuck in
planning hell no matter what framework or buzzwords they try to fling around.
level 6
My last company used screm. No 3 day meeting events, 20min of loose
direction and we were off to the races. We all came back with parts to different projects. SYNERGY.
level 7
Are you saying quantum synergy coupled with block chain neutral
intelligence can not be used to expedite artificial intelligence amalgamation into that will metaphor into
cucumber obsession?
What is it with these people? Someone brought me an "urgent" request (of course there
wasn't a ticket), so I said no worries, I'll help you out. Just open a ticket for me so we can track the work and document
the conversation. We got that all knocked out and everyone was happy.
So a day or two later, I suddenly get an instant message for yet another "urgent"
issue. ... Ok ... Open a ticket, and I'll get it assigned to one of my team members to take a look.
And a couple days later ... he's back and I'm being asked for help troubleshooting an
application that we don't own. At least there's a ticket and an email thread... but wtf man.
What the heck man?
This is like when you get a free drink or dessert from your waiter. Don't keep coming
back and asking for more free pie. You know damn well you're supposed to pay for pie. Be cool. I'll help you out when
you're really in a tight spot, but the more you cry "urgent", the less I care about your issues.
Hey
r/Sysadmin
, please don't suffer in silence. I know the job can be very difficult at times, especially with competing
objectives, tight (or impossible) deadlines, bad bosses and needy end users, but please - always remember that there are
ways to manage that stress. Speaking to friends and family regularly to vent, getting a therapist, or taking time off.
Yes, you do have the ability to take personal leave/medical leave if its that bad. No,
it doesn't matter what your colleagues or boss will think..and no, you are not a quitter, weak, or a loser if you take
time for yourself - to heal mentally, physically or emotionally.
EDIT: Holy Cow! Thanks for the silver and platinum kind strangers. All i wanted to do
was to get some more awareness on this subject, and create a reminder that we all deserve happiness and peace of mind. A
reminder that hopefully sticks with you for the days and weeks to come.
We, sysadmins, have times when we don't really have nothing to do but maintenance. BUT,
there are times when it seems like chaos comes out of nowhere. When I have a lot of tasks to do, I tend to get slower. The
more tasks I have pending, the slower I become. I cannot avoid to start thinking about 3 or 4 different problems at the
same time, and I can't focus! I only have 2 years of experiences as sysadmin.
Have you ever wondered if your whole career will be related to IT stuff? I have, since
my early childhood. It was more than 30 years ago - in the marvelous world of an 8-bit era. After writing my first code
(10 PRINT "
my_name
" : 20 GOTO 10) I exactly knew what I wanted to do in the
future. Now, after spending 18 years in this industry, which is half of my age, I'm not so sure about it.
I had plenty of time to do almost everything. I was writing software for over 100K
users and I was covered in dust while drilling holes for ethernet cables in houses of our customers. I was a main network
administrator for a small ISP and systems administrator for a large telecom operator. I made few websites and I was
managing a team of technical support specialists. I was teaching people - on individual courses on how to use Linux and
made some trainings for admins on how to troubleshoot multicast transmissions in their own networks. I was active in some
Open Source communities, including running forums about one of Linux distributions (the forum was quite popular in my
country) and I was punching endless Ctrl+C/Ctrl+V combos from Stack Overflow. I even fixed my aunt's computer!
And suddenly I realised that I don't want to do this any more. I've completely burnt
out. It was like a snap of a finger.
During many years I've collected a wide range of skills that are (or will be) obsolete.
I don't want to spend rest of my life maintaining a legacy code written in C or PHP or learning a new language which is
currently on top and forcing myself to write in a coding style I don't really like. That's not all... If you think you'll
enjoy setting up vlans on countless switches, you're probably wrong. If you think that managing clusters of virtual
machines is an endless fun, you'll probably be disappointed. If you love the smell of a brand new blade server and the
"click" sound it makes when you mount it into the rack, you'll probably get fed up with it. Sooner or later.
But there's a good side of having those skills. With skills come experience, knowledge
and good premonition. And these features don't get old. Remember that!
My employer offered me a position of a project manager and I eagerly agreed to it. It
means that I'm leaving the world of "hardcore IT" I'll be doing some other, less crazy stuff. I'm logging out of my
console and I'll run Excel. But I'll keep all good memories from all those years. I'd like to thank all of you for doing
what you're doing, because it's really amazing. Good luck! The world lies in your hands!
254 comments
450
Posted by
u/remrinds
1 day ago
General Discussion
UPDATE: So our cloud exchange server was down for 17 hours on friday
my original post got deleted because i behaved wrongly and posted some slurs. I
apologise for that.
anyway, so, my companie is using Office365 ProPlus and we migrated our on premise
exchange server to cloud a while ago, and on friday last week, all of our user (1000 or so) could not access their
exchange box, we are a TV broadcasting station so you can only imagine the damage when we could not use our mailing
system.
initially, we opened a ticket with microsoft and they just kept us on hold for 12 hours
(we are in japan so they had to communicate with US and etc which took time), and then they told us its our network infra
thats wrong when we kept telling them its not. we asked them to check their envrionment at least once which they did not
until 12 hours later.
in the end, it was their exchange server that was the problem, i will copy and paste
the whole incident report below
Title: Can't access Exchange
User Impact: Users are unable to access the Exchange Online service.
Current status: We've determined that a recent sync between Exchange Online and Azure Active Directory (AAD) inadvertently resulted in access issues with the Exchange Online service. We've restored the affected environment and updated the Global Location Service (GLS) records, which we believe has resolved the issue. We're awaiting confirmation from your representatives that this issue is resolved.
Scope of impact: Your organization is affected by this event, and this issue impacts all users.
Start time: Friday, October 4, 2019, 4:51 AM
Root cause: A recent Service Intelligence (SI) move inadvertently resulted in access issues with the Exchange Online service.
they wont explain further than what they posted on the incident page but if anyone here
is good with microsofts cloud envrionment, can anyone tell me what was the root cause of this? from what i can gather, the
AAD and exchange server couldnt sync but they wont tell us what the actual problem is, what the hell is Service
intelligence and how does it fix our exchange server when they updated the global location service?
any insight on these report would be more than appreciated
I rolled out this patch this weekend to my test group and it appears that some of the
workstations this was applied to are having print spooler issues.
I hadn't found a use case for containers in my environment so I had put off learning
Docker for a while. But, I'm writing a rails app to simplify/automate some of our administrative tasks. Setting up my
different dev and test environments was definitely non trivial, and I plan on onboarding another person or 2 so they can
help me out and add it to their resume.
I installed Docker desktop on my Mac, wrote 2 files essentially copied from Docker's
website, built it, then ran it. It took a total of 10 minutes to go from zero Docker to fully configured and running. It's
really that easy to start using it. So, now I've decided to set up Kubernetes at work this week and see what I can find to
do with it.
Let me tell you about the Monday from hell I encountered yesterday.
I work for
xyz corp
which is an MSP for IT
services. One of the companies we support, we'll call them
abc corp
.
I come in to work Monday morning and look at my alerts report from the previous day and
find that all of the servers (about 12+) at
abc corp
are showing offline. Manager
asks me to go on site to investigate, it's around the corner so
nbd
.
I get to the client, head over to the server room and open up the KVM console. I switch
inputs and see no issues with the ESX hosts. I then switch over to the (for some reason, physical) vCenter server and find
this lovely little message:
Now, I've never seen this before and it looks sus but just in case, i reboot the
machine -
same message
. Do a
quick google search and found that the server was hit with an MBR level ransomware encryption. I then quickly switched
over to the server that manages the backups and found that
it's also encrypted -
f*ck.
At this point, I call
Mr. CEO
and account
manager to come on site. While waiting for them, I found that the SANs had also been logged in to and had all data deleted
and snapshots deleted off the datastores and the EQL volume was also encrypted -
PERFECT!
At this point, I'm basically freaking out.
ABC Corp
is owned by a parent company who apparently also got hit however we don't manage them *phew*.
Our only saving grace at this point is the offsite backups. I log in to the server and
wouldn't ya know it, I see this lovely message:
Last replication time: 6/20/2019 13:00:01
BackupsTech
had a script that ran to report on
replication status daily and the reports were showing that they were up to date. Obviously, they weren't so at this point
we're basically f*cked.
We did eventually find out this originated from
parentcompany
and that the accounts used were from the old IT Manager that recently left a few weeks ago.
Unfortunately, they never disabled the accounts in either domain and the account used was a domain admin account.
We're currently going through and attempting to undelete the VMFS data to regain access
to the VM files. If anyone has any suggestions on this, feel free to let me know.
Sick and tired of listening to these so called architects and full stack developers who
watch bunch of videos on YouTube and Pluralsight, find articles online. They go around workplace throwing words like
containers, devops, NoOps, azure, infrastructure as code, serverless, etc, they don't understand half of the stuff. I do some
of the devops tasks in our company, I understand what it takes to implement and manage these technologies. Every meeting is
infested with these A holes.
1.0k comments
91% Upvoted
What are your thoughts? Log in or Sign up
log
in
sign
up
Sort by
level 1
Your best defense against these is to come up with non-sarcastic and
quality questions to ask these people during the meeting, and watch them not have a clue how to answer them.
For example, a friend of mine worked at a smallish company, some manager
really wanted to move more of their stuff into Azure including AD and Exchange environment. But they had
common problems with their internet connection due to limited bandwidth and them not wanting to spend more. So
during a meeting my friend asked a question something like this:
"You said on this slide that moving the AD environment and Exchange
environment to Azure will save us money. Did you take into account that we will need to increase our internet
speed by a factor of at least 4 in order to accommodate the increase in traffic going out to the Azure cloud?
"
Of course, they hadn't. So the CEO asked my friend if he had the numbers,
which he had already done his homework, and it was a significant increase in cost every month and taking into
account the cost for Azure and the increase in bandwidth wiped away the manager's savings.
I know this won't work for everyone. Sometimes there is real savings in
moving things to the cloud. But often times there really isn't. Calling the uneducated people out on what they
see as facts can be rewarding.
level 2
my previous boss was that kind of a guy. he waited till other people were
done throwing their weight around in a meeting and then calmly and politely dismantled them with facts.
no amount of corporate pressuring or bitching could ever stand up to that.
level 3
This is my approach. I don't yell or raise my voice, I just wait. Then I
start asking questions that they generally cannot answer and slowly take them apart. I don't have to be loud
to get my point across.
level 4
This tactic is called "the box game". Just continuously ask them logical
questions that can't be answered with their stupidity. (Box them in), let them be their own argument against
themselves.
Not to mention downtime. We have two ISPs in our area. Most of our clients
have both in order to keep a fail-over. However, depending on where the client is located, one ISP is fast but
goes down every time it rains and the other is solid but slow. Now our only AzureAD customers are those who
have so many remote workers that they throw their hands up and deal with the outages as they come. Maybe this
works in Europe or South Korea, but this here 'Murica got too many internet holes.
level 3
Yup. If you're in a city with fiber it can probably work. If you have even
one remote site, and all they have is DSL (or worse, satellite, as a few offices I once supported were
literally
in the woods when I worked for a timber company) then even
Citrix becomes out of the question.
Definitely this, if you know your stuff and can wrap some numbers around it
you can regain control of the conversation.
I use my dad as a prime example, he was an electrical engineer for ~40
years, ended up just below board level by the time he retired. He sat in on a product demo once, the kit they
were showing off would speed up jointing cable in the road by 30 minutes per joint. My dad asked 3 questions
and shut them down:
"how much will it cost to supply all our jointing teams?" £14million
"how many joints do our teams complete each day?" (this they couldn't
answer so my dad helped them out) 3
"So are we going to tell the jointers that they get an extra hour and a
half hour lunch break or a pay cut?"
Room full of executives that had been getting quite excited at this awesome
new investment were suddenly much more interested in showing these guys the door and getting to their next
meeting.
level 3
I think they did 3 as that was the workload so being able to do 4 isn't
relevant if there isn't a fourth to do.
That's what I get out of his story anyway.
And also if it was going to be 14 million in costs to equip everyone, the
savings have to be there. If adding 1 unit of productivity per day didn't save 14 million in a year or two,
it's not really worth it.
level 5
That was basically what I figured was the missing piece - the logistical
inability to process 4 units.
As far as the RoI, I had to assume that the number of teams involved and
their operational costs had already factored into whether or not 14m was even a price anyone could consider
paying. In other words, by virtue of the meeting even happening I figured that the initial costing had not
already been laughed out of the room, but perhaps that's a bit too much of an assumption to make.
level 6
In my limited experience they slow roll actually pricing anything. Of
course physical equipment pricing might be more straightforward, which would explain why his dad got a number
instead of a discussion of licensing options.
level 5
And also if it was going to be 14 million in costs to equip everyone,
the savings have to be there. If adding 1 unit of productivity per day didn't save 14 million in a year or
two, it's not really worth it.
That entirely depends. If you have 10 people producing 3 joints a day, with
this new kit you could reduce your headcount by 2 and still produce the same, or take on additional workload
and increase your production. Not to mention that you don't need to equip everyone with these kits either, you
could save them for the projects which needed more daily production thus saving money on the kits and
increasing production on an as needed basis.
They story is missing a lot of specifics and while it sounds great, I'm
quite certain there was likely a business case to be made.
He's saying they get 3 done in a day, and the product would save them 30
minutes per joint. That's an hour and a half saved per day, not even enough time to finish a fourth joint,
hence the "so do i just give my workers an extra 30 min on lunch"? He just worded it all really weird.
level 4
Your ignoring travel time in there, there are also factors to do with
outside contractors carrying out the digging and reinstatement works and getting sign off to actually dig the
hole in the road in the first place.
There is also the possibility I'm remembering the time wrong... it's been a
while!
level 5
Travel time actually works in my favour. If it takes more time to go from
job to job, then the impact of the enhancement is magnified because the total time per job shrinks.
level 4
That seems like a poor example. Why would you ignore efficiency
improvements just to give your workers something to do? Why not find another task for them or figure out a way
to consolidate the teams some? We fight this same mentality on our manufacturing floors, the idea that if we
automate a process someone will lose their job or we wont have enough work for everyone. Its never the case.
However, because of the automation improvements we have done in the last 10 years, we are doing 2.5x the
output with only a 10% increase in the total number of laborers.
So maybe in your example for a time they would have nothing for these
people to do. Thats a management problem. Have them come back and sweep the floor or wash their trucks.
Eventually you will be at a point where there is more work, and that added efficiency will save you from
needing to put more crews on the road.
Calling the uneducated people out on what they see as facts can be
rewarding.
I wouldnt call them all uneducated. I think what they are is basically
brainwashed. They constantly hear from the sales teams of vendors like Microsoft pitching them the idea of
moving everything to Azure.
They do not hear the cons. They do not hear from the folks who know their
environment and would know if something is a good fit. At least, they dont hear it enough, and they never see
it first hand.
Now, I do think this is their fault... they need to seek out that info
more, weigh things critically, and listen to what's going on with their teams more. Isolation from the team is
their own doing.
After long enough standing on the edge and only hearing "jump!!", something
stupid happens.
level 3
There's little downside to containers by themselves. They're just a method
of sandboxing processes and packaging a filesystem as a distributable image. From a performance perspective
the impact is near negligible (unless you're doing some truly intensive disk I/O).
What can be problematic is taking a process that was designed to run on
exactly n dedicated servers and converting it to a modern 2 to n autoscaling deployment that shares hosting
with other apps on n a platform like Kubernetes. It's a significant challenge that requires a lot of expertise
and maintenance, so there needs to be a clear business advantage to justify hiring at least one additional
full time engineer to deal with it.
level 5
Containers are great for stateless stuff. So your webservers/application
servers can be shoved into containers. Think of containers as being the modern version of statically linked
binaries or fat applications. Static binaries have the problem that any security vulnerability requires a full
rebuild of the application, and that problem is escalated in containers (where you might not even know that a
broken library exists)
If you are using the typical business application, you need one or more
storage components for data which needs to be available, possibly changed and access controlled.
Containers are a bad fit for stateful databases, or any stateful component,
really.
Containers also enable microservices, which are great ideas at a certain
organisation size (if you aren't sure you need microservices, just use a simple monolithic architecture). The
problem with microservices is that you replace complexity in your code with complexity in the communications
between the various components, and that is harder to see and debug.
level 5
Containers are fine for stateful services -- you can manage persistence at
the storage layer the same way you would have to manage it if you were running the process directly on the
host.
Backing up containers can be a pain, so you don't want to use them for
valuable data unless the data is stored elsewhere, like a database or even a file server.
For spinning up stateless applications to take workload behind a load
balancer, containers are excellent.
The problem is that there is an overwhelming din from vendors. Everybody
and their brother, sister, mother, uncle, cousin, dog, cat, and gerbil is trying to sell you some
pay-by-the-month cloud "solution".
The reason is that the cloud forces people into monthly payments, which is
a guarenteed income for companies, but costs a lot more in the long run, and if something happens and one
can't make the payments, business is halted, ensuring that bankruptcies hit hard and fast. Even with the
mainframe, a company could limp along without support for a few quarters until they could get cash flow
enough.
If we have a serious economic downturn, the fact that businesses will be
completely shuttered if they can't afford their AWS bill just means fewer companies can limp along when the
economy is bad, which will intensify a downturn.
Our company viewed the move to Azure less as a cost savings measure and
more of a move towards agility and "right now" sizing of our infrastructure.
Your point is very accurate, as an example our location is wholly incapable
of moving moving much to the cloud due to half of us being connnected via satellite network and the other half
being bent over the barrel by the only ISP in town.
level 2
I'm sorry, but I find management these days around tech wholly inadequate.
The idea that you can get an MBA and manage shit you have no idea about is absurd and just wastes everyone
elses time for them to constantly ELI5 so manager can do their job effectively.
level 2
Calling the uneducated people out on what they see as facts can be
rewarding
Aaand political suicide in a corporate environment. Instead I use the
following:
"I love this idea! We've actually been looking into a similar solution
however we weren't able to overcome some insurmountable cost sinkholes (remember: nothing is impossible; just
expensive). Will this idea require an increase in internet speed to account for the traffic going to the azure
cloud?"
level 3
This exactly, you can't compromise your own argument to the extent that
it's easy to shoot down in the name of giving your managers a way of saving face, and if you deliver the facts
after that sugar coating it will look even worse, as it will be interpreted as you setting them up to look
like idiots. Being frank, objective and non-blaming is always the best route.
level 4
I think it's quite an american thing to do it so enthusiastically; to hurt
no one, but the result is so condescending. It must be annoying to walk on egg shells to survive a day in the
office.
And this is not a rant against soft skills in IT, at all.
level 4
We work with Americans and they're always so positive, it's kinda annoying.
They enthusiastically say "This is very interesting" when in reality it sucks and they know it.
Another less professional example, one of my (non-american) co-workers
always wants to go out for coffee (while we have free and better coffee in the office), and the American
coworker is always nice like "I'll go with you but I'm not having any" and I just straight up reply "No. I'm
not paying for shitty coffee, I'll make a brew in the office". And that's that. Sometimes telling it as it is
makes the whole conversation much shorter :D
level 5
Maybe the american would appreciate the break and a chance to spend some
time with a coworker away from screens, but also doesn't want the shit coffee?
Yes. "Go out for coffee" is code for "leave the office so we can complain
about management/company/customer/Karen". Some conversations shouldn't happen inside the building.
level 7
Inferior American - please compute this - the sole intention was
consumption of coffee. Therefore due to existence of coffee in office, trip to coffee shop is not sane.
Resistance to my reasoning is futile.
level 7
Coffee is not the sole intention. If that was the case, then there wouldn't
have been an invitation.
Another intention would be the social aspect - which americans are known to
love, especially favoring it over doing any actual work in the context of a typical 9-5 corporate job.
I've effectively resisted your reasoning, therefore [insert ad hominem
insult about inferior logic].
There is still value to tact in your delivery, but, don't slit your own
throat. Remind them they hired you for a reason.
"I appreciate the ideas being raised here by management for cost savings
and it certainly merits a discussion point. As a business, we have many challenges and one of them includes
controlling costs. Bridging these conversations with subject matter experts and management this early can
really help fill out the picture. I'd like to try to provide some of that value to the conversation here"
level 3
If it's political suicide to point out potential downsides, then you need
to work somewhere else.
Especially since your response, in my experience, won't get anything done
(people will either just say "no, that's not an issue", or they'll find your tone really condescending) and
will just piss people off.
I worked with someone like that would would always be super passive
aggressive in how she brought things up and it pissed me off to no end, because it felt less like bringing up
potential issues and more like being belittling.
level 4
Feels good to get to a point in my career where I can call people our
whenever the hell I feel like it. I've got recruiters banging down my door, I couldn't swing a stick without
hitting a job offer or three.
Of course you I'm not suggesting problem be combative for no reason and to
be tactful about it but if you don't call out fools like that then you're being negligent in your duties.
level 4
"I am resolute in my ability to elevate this collaborative,
forward-thinking team into the revenue powerhouse that I believe it can be. We will transition into a DevOps
team specialising in migrating our existing infrastructure entirely to code and go completely serverless!" -
CFO that outsources IT
level 2
We recently implemented DevOps practices, Scrum, and sprints have become
the norm... I swear to god we spend 60% of our time planning our sprints, and 40% of the time doing the work,
and management wonders why our true productivity has fallen through the floor...
level 5
If you spend three whole days out of every five in planning meetings, this
is a problem with your meeting planners, not with screm. If these people stay in charge, you'll be stuck in
planning hell no matter what framework or buzzwords they try to fling around.
level 6
My last company used screm. No 3 day meeting events, 20min of loose
direction and we were off to the races. We all came back with parts to different projects. SYNERGY.
level 7
Are you saying quantum synergy coupled with block chain neutral
intelligence can not be used to expedite artificial intelligence amalgamation into that will metaphor into
cucumber obsession?
Everyone says this, meaning "the way
I
do Agile is good, the way everyone else does it sucks. Buy my Agile book! Or my Agile training course! Only
$199.99".
level 8
There are different ways to do Agile? From the past couple of places I
worked at I thought Agile was just standing in a corner for 5 minutes each morning. Do some people sit?
level 9
Wait until they have you doing "retrospectives" on a Friday afternoon with
a bunch of alcohol involved. By Monday morning nobody remembers what the fuck they retrospected about on
Friday.
level 10
No, that's what it's supposed to look like. A quick 'Is anyone blocked?
Does anyone need anything/can anyone chip in with X? Ok get back to it'
What it usually looks like is a round table 'Tell us what you're working
on' that takes at least 30, and depending on team size, closer to an hour.
level 10
our weekly 'stand-up' is often 60-90 minutes long, because they treat it
like not only a roundtable discussion about what you're working on, but an opportunity to hash out every
discussion to death, in front of C-levels.
To me agile is an unfortunate framework to confront and dismantle a lot of
hampering low value business processes. I call it a "get-er-done" framework. But yes theres not all Rose's and
sunshine in agile. But it's important to destroy processes that make delivering value impossible
Like all such things - it's a useful technique, that turns into a colossal
pile of wank if it's misused. This is true of practically every buzzword laden methodology I've seen
introduced in the last 20 years.
level 5
Fro me, the fact that my team is moderately scrummy is a decent treatment
for my ADHD. The patterns are right up there with ritalin in terms of making me less neurologically crippled.
level 5
I think I'm going to snap if I have one more meting that discusses seamless migrations
and seamless movement across a complex multi forest non-standardized network.
Props to the
artist who actually found a way to visualize most of this meaningless corporate lingo. I'm sure it wasn't easy to come up
with everything.
He missed "sea
change" and "vertical integration". Otherwise, that was pretty much all of the useless corporate meetings I've ever attended
distilled down to 4.5 minutes. Oh, and you're getting laid off and/or no raises this year.
For those too
young to get the joke, this is a style parody of Crosby, Stills & Nash, a folk-pop super-group from the 60's. They were
hippies who spoke out against corporate interests, war, and politics. Al took their sound (flawlessly), and wrote a song in
corporate jargon (the exact opposite of everything CSN was about). It's really brilliant, to those who get the joke.
"The company has
undergone organization optimization due to our strategy modification, which includes empowering the support to the
operation in various global markets" - Red 5 on why they laid off 40 people suddenly. Weird Al would be proud.
In his big long
career this has to be one of the best songs Weird Al's ever done. Very ambitious rendering of one of the most
ambitious songs in pop music history.
This should be
played before corporate meetings to shame anyone who's about to get up and do the usual corporate presentation. Genius
as usual, Mr. Yankovic!
There's a quote
it goes something like: A politician is someone who speaks for hours while saying nothing at all. And this is exactly
it and it's brilliant.
From the current
Gamestop earnings call "address the challenges that have impacted our results, and execute both deliberately and with
urgency. We believe we will transform the business and shape the strategy for the GameStop of the future. This will be
driven by our go-forward leadership team that is now in place, a multi-year transformation effort underway, a commitment
to focusing on the core elements of our business that are meaningful to our future, and a disciplined approach to
capital allocation."" yeah Weird Al totally nailed it
Excuse me, but
"proactive" and "paradigm"? Aren't these just buzzwords that dumb people use to sound important? Not that I'm accusing you
of anything like that. [pause] I'm fired, aren't I?~George Meyer
I watch this at
least once a day to take the edge of my job search whenever I have to decipher fifteen daily want-ads claiming to
seek "Hospitality Ambassadors", "Customer Satisfaction Specialists", "Brand Representatives" and "Team Commitment
Associates" eventually to discover they want someone to run a cash register and sweep up.
The irony is a
song about Corporate Speak in the style of tie-died, hippie-dippy CSN (+/- )Y four-part harmony. Suite Judy Blue Eyes
via Almost Cut My Hair filtered through Carry On. "Fantastic" middle finger to Wall Street,The City, and the monstrous
excesses of Unbridled Capitalism.
If you
understand who and what he's taking a jab at, this is one of the greatest songs and videos of all time. So spot on.
This and Frank's 2000 inch tv are my favorite songs of yours. Thanks Al!
hahaha,
"Client-Centric Solutions...!" (or in my case at the time, 'Customer-Centric' solutions) now THAT's a term i haven't
heard/read/seen in years, since last being an office drone. =D
When I interact
with this musical visual medium I am motivated to conceptualize how the English language can be better compartmentalized
to synergize with the client-centric requirements of the microcosmic community focussed social entities that I
administrate on social media while interfacing energetically about the inherent shortcomings of the current
socio-economic and geo-political order in which we co-habitate. Now does this tedium flow in an effortless stream of
coherent verbalisations capable of comprehension?
When I bought
"Mandatory Fun", put it in my car, and first heard this song, I busted a gut, laughing so hard I nearly crashed.
All the corporate buzzwords!
(except "pivot", apparently).
"I am resolute in my ability to elevate this collaborative, forward-thinking team into the
revenue powerhouse that I believe it can be. We will transition into a DevOps team specialising
in migrating our existing infrastructure entirely to code and go completely serverless!" - CFO
that outsources IT level 2 OpenScore Sysadmin 527 points ·
4 days ago
"We will utilize Artificial Intelligence, machine learning, Cloud technologies, python, data
science and blockchain to achieve business value"
I agree with the sentiment. This talk of going serverless or getting rid of traditional
IT admins has gotten very old. In some ways it is true, but in many ways it is greatly exaggerated. There will always be a
need for onsite technical support. There are still users today that cannot plug in a mouse or keyboard into a USB port. Not
to mention layer 1 issues; good luck getting your cloud provider to run a cable drop for you. Besides, who is going to
manage your cloud instances? They don't just operate and manage themselves.
They say, No more IT or system or server admins needed very soon...
Sick and tired of listening to these so called architects and full stack developers who watch bunch of videos on YouTube and Pluralsight,
find articles online. They go around workplace throwing words like containers, devops, NoOps, azure, infrastructure as code, serverless,
etc, they don't understand half of the stuff. I do some of the devops tasks in our company, I understand what it takes to implement
and manage these technologies. Every meeting is infested with these A holes.
Your best defense against these is to come up with non-sarcastic and quality questions to ask these people during the meeting,
and watch them not have a clue how to answer them.
For example, a friend of mine worked at a smallish company, some manager really wanted to move more of their stuff into Azure
including AD and Exchange environment. But they had common problems with their internet connection due to limited bandwidth and
them not wanting to spend more. So during a meeting my friend asked a question something like this:
"You said on this slide that moving the AD environment and Exchange environment to Azure will save us money. Did you take into
account that we will need to increase our internet speed by a factor of at least 4 in order to accommodate the increase in traffic
going out to the Azure cloud? "
Of course, they hadn't. So the CEO asked my friend if he had the numbers, which he had already done his homework, and it was
a significant increase in cost every month and taking into account the cost for Azure and the increase in bandwidth wiped away
the manager's savings.
I know this won't work for everyone. Sometimes there is real savings in moving things to the cloud. But often times there really
isn't. Calling the uneducated people out on what they see as facts can be rewarding. level 2
my previous boss was that kind of a guy. he waited till other people were done throwing their weight around in a meeting and
then calmly and politely dismantled them with facts.
no amount of corporate pressuring or bitching could ever stand up to that. level 3
Ive been trying to do this. Problem is that everyone keeps talking all the way to the end of the meeting leaving no room for
rational facts. level 4 PuzzledSwitch 35 points ·
4 days ago
This is my approach. I don't yell or raise my voice, I just wait. Then I start asking questions that they generally cannot
answer and slowly take them apart. I don't have to be loud to get my point across. level 4
This tactic is called "the box game". Just continuously ask them logical questions that can't be answered with their stupidity.
(Box them in), let them be their own argument against themselves.
Most DevOps I've met are devs trying to bypass the sysadmins. This, and the Cloud fad, are
burning serious amount of money from companies managed by stupid people that get easily impressed by PR stunts and shiny conferences.
Then when everything goes to shit, they call the infrastructure team to fix it...
" Hatred is the most accessible and comprehensive of all the unifying agents Mass
movements can rise and spread without belief in a god, but never without a belief in a
devil. " ~ Eric Hoffer,
The True Believer: Thoughts on the Nature of Mass Movements
(This article was reprinted in the online magazine of the Institute for Ethics &
Emerging Technologies, October 19, 2017.)
Eric Hoffer (1898
– 1983) was an American moral and social philosopher who worked for more than twenty
years as longshoremen in San Francisco. The author of ten books, he was awarded the Presidential Medal
of Freedom in 1983. His first book,
The True Believer: Thoughts on the Nature of Mass Movements (1951), is a work in social psychology which discusses the
psychological causes of fanaticism. It is widely considered a classic.
Overview
The first lines of Hoffer's book clearly state its purpose:
This book deals with some peculiarities common to all mass movements, be they religious
movements, social revolutions or nationalist movements. It does not maintain that all movements
are identical, but that they share certain essential characteristics which give them a family
likeness.
All mass movements generate in their adherents a readiness to die and a proclivity for
united action; all of them, irrespective of the doctrine they preach and the program they
project, breed fanaticism, enthusiasm, fervent hope, hatred and intolerance; all of them are
capable of releasing a powerful flow of activity in certain departments of life; all of them
demand blind faith and single-hearted allegiance
The assumption that mass movements have many traits in common does not imply that all
movements are equally beneficent or poisonous. The book passes no judgments, and expresses no
preferences. It merely tries to explain (pp. xi-xiii)
Part 1 – The Appeal of Mass
Movements
Hoffer says that mass movements begin when discontented, frustrated, powerless people lose
faith in existing institutions and demand change. Feeling hopeless, such people participate in
movements that allow them to become part of a larger collective. They become true believers in
a mass movement that "appeals not to those intent on bolstering and advancing a cherished self,
but to those who crave to be rid of an unwanted self because it can satisfy the passion for
self-renunciation." (p. 12)
Put another way, Hoffer says: "Faith in a holy cause is to a considerable extent a
substitute for the loss of faith in ourselves." (p. 14) Leaders inspire these movements, but
the seeds of mass movements must already exist for the leaders to be successful. And while mass
movements typically blend nationalist, political and religious ideas, they all compete for
angry and/or marginalized people.
Part 2 – The Potential Converts
The destitute are not usually converts to mass movements; they are too busy trying to
survive to become engaged. But what Hoffer calls the "new poor," those who previously had
wealth or status but who believe they have now lost it, are potential converts. Such people are
resentful and blame others for their problems.
Mass movements also attract the partially assimilated -- those who feel alienated from
mainstream culture. Others include misfits, outcasts, adolescents, and sinners, as well as the
ambitious, selfish, impotent and bored. What all converts all share is the feeling that their
lives are meaningless and worthless.
A rising mass movement attracts and holds a following not by its doctrine and promises but
by the refuge it offers from the anxieties, barrenness, and meaninglessness of an individual
existence. It cures the poignantly frustrated not by conferring on them an absolute truth or
remedying the difficulties and abuses which made their lives miserable, but by freeing them
from their ineffectual selves -- and it does this by enfolding and absorbing them into a
closely knit and exultant corporate whole. (p. 41)
Hoffer emphasizes that creative people -- those who experience creative flow -- aren't
usually attracted to mass movements. Creativity provides inner joy which both acts as an
antidote to the frustrations with external hardships. Creativity also relieves boredom, a major
cause of mass movements:
There is perhaps no more reliable indicator of a society's ripeness for a mass movement than
the prevalence of unrelieved boredom. In almost all the descriptions of the periods preceding
the rise of mass movements there is reference to vast ennui; and in their earliest stages mass
movements are more likely to find sympathizers and
support among the bored than among the exploited and oppressed. To a deliberate fomenter of
mass upheavals, the report that people are bored still should be at least as encouraging as
that they are suffering from intolerable economic or political abuses. (pp. 51-52)
Part 3
– United Action and Self-Sacrifice
Mass movements demand of their followers a "total surrender of a distinct self." (p. 117)
Thus a follower identifies as "a member of a certain tribe or family." (p. 62) Furthermore,
mass movements denigrate and "loathe the present." (p. 74) By regarding the modern world as
worthless, the movement inspires a battle against it.
What surprises one, when listening to the frustrated as the decry the present and all its
works, is the enormous joy they derive from doing so. Such delight cannot come from the mere
venting of a grievance. There must be something more -- and there is. By expiating upon the
incurable baseness and vileness of the times, the frustrated soften their feeling of failure
and isolation (p. 75)
Mass movements also promote faith over reason and serve as "fact-proof screens between the
faithful and the realities of the world." (p. 79)
The effectiveness of a doctrine does not come from its meaning but from its certitude
presented as the embodiment of the one and only truth. If a doctrine is not unintelligible, it
has to be vague; and if neither unintelligible nor vague, it has to be unverifiable. One has to
get to heaven or the distant future to determine the truth of an effective doctrine simple
words are made pregnant with meaning and made to look like symbols in a secret message. There
is thus an illiterate air about the most literate true believer. (pp. 80-81).
So believers ignore truths that contradict their fervent beliefs, but this hides the fact
that,
The fanatic is perpetually incomplete and insecure. He cannot generate self-assurance out of
his individual sources but finds it only by clinging passionately to whatever support he
happens to embrace. The passionate attachment is the essence of his blind devotion and
religiosity, and he sees in it the sources of all virtue and strength He sacrifices his life to
prove his worth The fanatic cannot be weaned away from his cause by an appeal to reason or his
moral sense. He fears compromise and cannot be persuaded to qualify the certitude and
righteousness of his holy cause. (p. 85).
Thus the doctrines of the mass movement must not be questioned -- they are regarded with
certitude -- and they are spread through "persuasion, coercion, and proselytization."
Persuasion works best on those already sympathetic to the doctrines, but it must be vague
enough to allow "the frustrated to hear the echo of their own musings in impassioned double
talk." (p. 106) Hoffer quotes Nazi propagandist Joseph Goebbels : "a sharp sword must
always stand behind propaganda if it is to be really effective." (p. 106) The urge to
proselytize comes not from a deeply held belief in the truth of doctrine but from an urge of
the fanatic to "strengthen his own faith by converting others." (p. 110)
Moreover, mass movements need an object of hate which unifies believers, and "the ideal
devil is a foreigner." (p. 93) Mass movements need a devil. But in reality, the "hatred of a
true believer is actually a disguised self-loathing " and "the fanatic is perpetually
incomplete and insecure." (p. 85) Through their fanatical action and personal sacrifice, the
fanatic tries to give their life meaning.
Part 4 – Beginning and End
Hoffer states that three personality types typically lead mass movements: "men of words",
"fanatics", and "practical men of action." Men of words try to "discredit the prevailing
creeds" and creates a "hunger for faith" which is then fed by "doctrines and slogans of the new
faith." (p. 140) (In the USA think of the late William F. Buckley.) Slowly followers
emerge.
Then fanatics take over. (In the USA think of the Koch brothers, Murdoch, Limbaugh,
O'Reilly, Hannity, Alex Jones, etc.) Fanatics don't find solace in literature, philosophy or
art. Instead, they are characterized by viciousness, the urge to destroy, and the perpetual
struggle for power. But after mass movements transform the social order, the insecurity of
their followers is not ameliorated. At this point, the "practical men of action" take over and
try to lead the new order by further controlling their followers. (Think Steve Bannon, Mitch
McConnell, Steve Miller, etc.)
In the end mass movements that succeed often bring about a social order worse than the
previous one. (This was one of Will Durant's findings in The Lessons of History .) As Hoffer puts it near the end of his work: "All mass
movements irrespective of the doctrine they preach and the program they project, breed
fanaticism, enthusiasm, fervent hope, hatred, and intolerance." (p. 141)
Quotes from
Hoffer, Eric (2002). The True Believer: Thoughts on the Nature of Mass Movements .
Harper Perennial Modern Classics. ISBN 978-0-060-50591-2 .
Can I recover a RAID 5 array if two drives have failed?Ask Question Asked 9 years ago Active
2 years, 3 months ago Viewed 58k times I have a Dell 2600 with 6 drives configured in a
RAID 5 on a PERC 4 controller. 2 drives failed at the same time, and according to what I know a
RAID 5 is recoverable if 1 drive fails. I'm not sure if the fact I had six drives in the array
might save my skin.
I bought 2 new drives and plugged them in but no rebuild happened as I expected. Can anyone
shed some light? raid
raid5 dell-poweredge share Share a link to this question
11 Regardless of how many drives are in use, a RAID 5 array only allows
for recovery in the event that just one disk at a time fails.
What 3molo says is a fair point but even so, not quite correct I think - if two disks in a
RAID5 array fail at the exact same time then a hot spare won't help, because a hot spare
replaces one of the failed disks and rebuilds the array without any intervention, and a rebuild
isn't possible if more than one disk fails.
For now, I am sorry to say that your options for recovering this data are going to involve
restoring a backup.
For the future you may want to consider one of the more robust forms of RAID (not sure what
options a PERC4 supports) such as RAID 6 or a nested RAID array . Once you get above a
certain amount of disks in an array you reach the point where the chance that more than one of
them can fail before a replacement is installed and rebuilt becomes unacceptably high.
share Share a link to this
answer Copy link | improve this answer edited Jun 8 '12 at 13:37
longneck 21.1k 3 3 gold badges 43 43 silver
badges 76 76 bronze badges answered Sep 21 '10 at 14:43 Rob Moir Rob Moir 30k 4 4 gold badges 53 53
silver badges 84 84 bronze badges
1 thanks robert I will take this advise into consideration when I rebuild the server,
lucky for me I full have backups that are less than 6 hours old. regards – bonga86 Sep 21 '10 at
15:00
If this is (somehow) likely to occur again in the future, you may consider RAID6. Same
idea as RAID5 but with two Parity disks, so the array can survive any two disks failing.
– gWaldo Sep 21
'10 at 15:04
g man(mmm...), i have recreated the entire system from scratch with a RAID 10. So
hopefully if 2 drives go out at the same time again the system will still function? Otherwise
everything has been restored and working thanks for ideas and input – bonga86 Sep 23 '10 at
11:34
Depends which two drives go... RAID 10 means, for example, 4 drives in two mirrored pairs
(2 RAID 1 mirrors) striped together (RAID 0) yes? If you lose both disks in 1 of the mirrors
then you've still got an outage. – Rob Moir Sep 23 '10 at 11:43
add a comment | 2 You can try to force one or both of the failed
disks to be online from the BIOS interface of the controller. Then check that the data and the
file system are consistent. share Share a link to this answer Copy link | improve this answer answered Sep 21 '10 at
15:35 Mircea
Vutcovici Mircea Vutcovici 13.6k 3 3 gold badges 42 42 silver badges 69 69 bronze badges
2 Dell systems, especially, in my experience, built on PERC3 or PERC4 cards had a nasty
tendency to simply have a hiccup on the SCSI bus which would know two or more drives
off-line. A drive being offline does NOT mean it failed. I've never had a two drives fail at
the same time, but probably a half dozen times, I've had two or more drives go off-line. I
suggest you try Mircea's suggestion first... could save you a LOT of time. – Multiverse IT Sep 21 '10 at
16:32
Hey guys, i tried the force option many times. Both "failed" drives would than come back
online, but when I do a restart it says logical drive :degraded and obviously because of that
they system still could not boot. – bonga86 Sep 23 '10 at 11:27
add a comment | 2 Direct answer is "No". In-direct -- "It depends".
Mainly it depends on whether disks are partially out of order, or completely. In case there're
partially broken, you can give it a try -- I would copy (using tool like ddrescue) both failed
disks. Then I'd try to run the bunch of disks using Linux SoftRAID -- re-trying with proper
order of disks and stripe-size in read-only mode and counting CRC mismatches. It's quite
doable, I should say -- this text in Russian mentions 12 disk RAID50's
recovery using LSR , for example. share Share a link to this answer Copy link | improve this answer edited Jun 8 '12 at 15:12
Skyhawk 13.5k 3 3 gold badges 45 45 silver
badges 91 91 bronze badges answered Jun 8 '12 at 14:11 poige poige 7,370 2 2 gold badges
16 16 silver badges 38 38 bronze badges add a comment | 0 It is possible if raid was with one spare drive ,
and one of your failed disks died before the second one. So, you just need need to try
reconstruct array virtually with 3d party software . Found small article about this process on
this page: http://www.angeldatarecovery.com/raid5-data-recovery/
And, if you realy need one of died drives you can send it to recovery shops. With of this
images you can reconstruct raid properly with good channces.
In a remote office location, corporate's network security scans can cause many false alarms
and even take down services if they are tickled the wrong way. Dropping all traffic from the
scanner's IP is a great time/resource-saver. No vulnerability reports, no follow-ups with
corporate. No time for that.
12 comments 93% Upvoted What are your thoughts? Log in or Sign up
log in sign up Sort by level 1 name_censored_ 9 points ·
1 month ago
Seems a bit like a bandaid to me.
A good shitty sysadmin breaks the corporate scanner's SMTP, so it can't report back.
A great shitty sysadmin spins up their own scanner instance (rigged to always report
AOK) and fiddles with arp/routing/DNS to hijack the actual scanner.
A 10x shitty sysadmin installs a virus on the scanner instance, thus discrediting the
corporate security team for years.
Good ideas, but sounds like a lot of work. Just dropping their packets had the desired
effect and took 30 seconds. level 3 name_censored_ 5 points ·
1 month ago
No-one ever said being lazy was supposed to be easy. level 2 spyingwind 2 points ·
1 month ago
To be serious, closing of unused ports is good practice. Even better if used services can
only be accessed from know sources. Such as the DB only allows access from the App server. A
jump box, like a guacd server for remote access for things like RDP and SSH, would help reduce
the threat surface. Or go further and setup Ansible/Chef/etc to allow only authorized changes.
level 3 gortonsfiJr 2
points ·
1 month ago
Except, seriously, in my experience the security teams demand that you make big security
holes for them in your boxes, so that they can hammer away at them looking for security holes.
level 4 asmiggs 1 point
·
1 month ago
Security teams will always invoke the worst case scenario, 'what if your firewall is
borked?', 'what if your jumpbox is hacked?' etc. You can usually give their scanner exclusive
access to get past these things but surprise surprise the only worst case scenario I've faced
is 'what if your security scanner goes rogue?'. level 5 gortonsfiJr 1 point ·
1 month ago
What if you lose control of your AD domain and some rogue agent gets domain admin rights?
Also, we're going to need domain admin rights.
What if an attacker was pretending o be a security company? No DA access! You can plug in
anywhere, but if port security blocks your scanner, then I can't help. Also only 80 and 443 are
allowed into our network. level 3 TBoneJeeper 1 point ·
1 month ago
Agree. But in rare cases, the ports/services are still used (maybe rarely), yet have
"vulnerabilities" that are difficult to address. Some of these scanners hammer services so
hard, trying every CGI/PHP/java exploit known to man in rapid succession, and older
hardware/services cannot keep up and get wedged. I remember every Tuesday night I would have to
go restart services because this is when they were scanned. Either vendor support for this
software version was no longer available, or would simply require too much time to open vendor
support cases to report the issues, argue with 1st level support, escalate, work with
engineering, test fixes, etc. level 1 rumplestripeskin 1 point ·
1 month ago
Yes... and use Ansible to update iptables on each of your Linux VMs. level 1 rumplestripeskin 1 point
·
1 month ago
In this article we will talk about foremost , a very useful open source
forensic utility which is able to recover deleted files using the technique called data
carving . The utility was originally developed by the United States Air Force Office of
Special Investigations, and is able to recover several file types (support for specific file
types can be added by the user, via the configuration file). The program can also work on
partition images produced by dd or similar tools.
Software Requirements and Linux Command Line Conventions
Category
Requirements, Conventions or Software Version Used
System
Distribution-independent
Software
The "foremost" program
Other
Familiarity with the command line interface
Conventions
# - requires given linux commands to be executed with root
privileges either directly as a root user or by use of sudo command $ - requires given linux commands to be executed as a regular
non-privileged user
Installation
Since foremost is already present in all the major Linux distributions
repositories, installing it is a very easy task. All we have to do is to use our favorite
distribution package manager. On Debian and Ubuntu, we can use apt :
$ sudo apt install foremost
In recent versions of Fedora, we use the dnf package manager to install
packages , the dnf is a successor of yum . The name of the
package is the same:
$ sudo dnf install foremost
If we are using ArchLinux, we can use pacman to install foremost .
The program can be found in the distribution "community" repository:
$ sudo pacman -S foremost
SUBSCRIBE TO NEWSLETTER
Subscribe to Linux Career NEWSLETTER and
receive latest Linux news, jobs, career advice and tutorials.
WARNING
No matter which file recovery tool or process your are going to use to recover your files,
before you begin it is recommended to perform a low level hard drive or partition backup,
hence avoiding an accidental data overwrite !!! In this case you may re-try to recover your
files even after unsuccessful recovery attempt. Check the following dd command guide on
how to perform hard drive or partition low level backup.
The foremost utility tries to recover and reconstruct files on the base of
their headers, footers and data structures, without relying on filesystem metadata
. This forensic technique is known as file carving . The program supports various
types of files, as for example:
jpg
gif
png
bmp
avi
exe
mpg
wav
riff
wmv
mov
pdf
ole
doc
zip
rar
htm
cpp
The most basic way to use foremost is by providing a source to scan for deleted
files (it can be either a partition or an image file, as those generated with dd
). Let's see an example. Imagine we want to scan the /dev/sdb1 partition: before
we begin, a very important thing to remember is to never store retrieved data on the same
partition we are retrieving the data from, to avoid overwriting delete files still present on
the block device. The command we would run is:
$ sudo foremost -i /dev/sdb1
By default, the program creates a directory called output inside the directory
we launched it from and uses it as destination. Inside this directory, a subdirectory for each
supported file type we are attempting to retrieve is created. Each directory will hold the
corresponding file type obtained from the data carving process:
When foremost completes its job, empty directories are removed. Only the ones
containing files are left on the filesystem: this let us immediately know what type of files
were successfully retrieved. By default the program tries to retrieve all the supported file
types; to restrict our search, we can, however, use the -t option and provide a
list of the file types we want to retrieve, separated by a comma. In the example below, we
restrict the search only to gif and pdf files:
$ sudo foremost -t gif,pdf -i /dev/sdb1
https://www.youtube.com/embed/58S2wlsJNvo
In this video we will test the forensic data recovery program Foremost to
recover a single png file from /dev/sdb1 partition formatted with the
EXT4 filesystem.
As we already said, if a destination is not explicitly declared, foremost creates an
output directory inside our cwd . What if we want to specify an
alternative path? All we have to do is to use the -o option and provide said path
as argument. If the specified directory doesn't exist, it is created; if it exists but it's not
empty, the program throws a complain:
ERROR: /home/egdoc/data is not empty
Please specify another directory or run with -T.
To solve the problem, as suggested by the program itself, we can either use another
directory or re-launch the command with the -T option. If we use the
-T option, the output directory specified with the -o option is
timestamped. This makes possible to run the program multiple times with the same destination.
In our case the directory that would be used to store the retrieved files would be:
/home/egdoc/data_Thu_Sep_12_16_32_38_2019
The configuration file
The foremost configuration file can be used to specify file formats not
natively supported by the program. Inside the file we can find several commented examples
showing the syntax that should be used to accomplish the task. Here is an example involving the
png type (the lines are commented since the file type is supported by
default):
# PNG (used in web pages)
# (NOTE THIS FORMAT HAS A BUILTIN EXTRACTION FUNCTION)
# png y 200000 \x50\x4e\x47? \xff\xfc\xfd\xfe
The information to provide in order to add support for a file type, are, from left to right,
separated by a tab character: the file extension ( png in this case), whether the
header and footer are case sensitive ( y ), the maximum file size in Bytes (
200000 ), the header ( \x50\x4e\x47? ) and and the footer (
\xff\xfc\xfd\xfe ). Only the latter is optional and can be omitted.
If the path of the configuration file it's not explicitly provided with the -c
option, a file named foremost.conf is searched and used, if present, in the
current working directory. If it is not found the default configuration file,
/etc/foremost.conf is used instead.
Adding the support for a file type
By reading the examples provided in the configuration file, we can easily add support for a
new file type. In this example we will add support for flac audio files.
Flac (Free Lossless Audio Coded) is a non-proprietary lossless audio format which
is able to provide compressed audio without quality loss. First of all, we know that the header
of this file type in hexadecimal form is 66 4C 61 43 00 00 00 22 (
fLaC in ASCII), and we can verify it by using a program like hexdump
on a flac file:
As you can see the file signature is indeed what we expected. Here we will assume a maximum
file size of 30 MB, or 30000000 Bytes. Let's add the entry to the file:
flac y 30000000 \x66\x4c\x61\x43\x00\x00\x00\x22
The footer signature is optional so here we didn't provide it. The program
should now be able to recover deleted flac files. Let's verify it. To test that
everything works as expected I previously placed, and then removed, a flac file from the
/dev/sdb1 partition, and then proceeded to run the command:
As expected, the program was able to retrieve the deleted flac file (it was the only file on
the device, on purpose), although it renamed it with a random string. The original filename
cannot be retrieved because, as we know, files metadata is contained in the filesystem, and not
in the file itself:
The audit.txt file contains information about the actions performed by the program, in this
case:
Foremost version 1.5.7 by Jesse Kornblum, Kris
Kendall, and Nick Mikus
Audit File
Foremost started at Thu Sep 12 23:47:04 2019
Invocation: foremost -i /dev/sdb1 -o /home/egdoc/Documents/output
Output directory: /home/egdoc/Documents/output
Configuration file: /etc/foremost.conf
------------------------------------------------------------------
File: /dev/sdb1
Start: Thu Sep 12 23:47:04 2019
Length: 200 MB (209715200 bytes)
Num Name (bs=512) Size File Offset Comment
0: 00020482.flac 28 MB 10486784
Finish: Thu Sep 12 23:47:04 2019
1 FILES EXTRACTED
flac:= 1
------------------------------------------------------------------
Foremost finished at Thu Sep 12 23:47:04 2019
Conclusion
In this article we learned how to use foremost, a forensic program able to retrieve deleted
files of various types. We learned that the program works by using a technique called
data carving , and relies on files signatures to achieve its goal. We saw an
example of the program usage and we also learned how to add the support for a specific file
type using the syntax illustrated in the configuration file. For more information about the
program usage, please consult its manual page.
It's easier than you think to get started automating your tasks with Ansible. This gentle introduction
gives you the basics you need to begin streamlining your administrative life.
In the end of 2015 and the beginning of 2016, we decided to use
Red Hat Enterprise Linux (RHEL)
as our third operating system, next to Solaris and Microsoft Windows. I was part of the team that
tested RHEL, among other distributions, and would engage in the upcoming operation of the new OS.
Thinking about a fast-growing number of Red Hat Enterprise Linux systems, it came to my mind that I
needed a tool to automate things because without automation the number of hosts I can manage is
limited.
I had experience with Puppet back in the day but did not like that tool because of its complexity.
We had more modules and classes than hosts to manage back then. So, I took a look at
Ansible
version 2.1.1.0 in July 2016.
What I liked about Ansible and still do is that it is push-based. On a target node, only Python and
SSH access are needed to control the node and push configuration settings to it. No agent needs to be
removed if you decide that Ansible isn't the right tool for you. The
YAML
syntax is easy to read and
write, and the option to use playbooks as well as ad hoc commands makes Ansible a flexible solution
that helps save time in our day-to-day business. So, it was at the end of 2016 when we decided to
evaluate Ansible in our environment.
First steps
As a rule of thumb, you should begin automating things that you have to do on a daily or at least a
regular basis. That way, automation saves time for more interesting or more important things. I
followed this rule by using Ansible for the following tasks:
Set a baseline configuration for newly provisioned hosts (set DNS, time, network, sshd, etc.)
Test how useful the ad hoc commands are, and where we could benefit from them.
Baseline Ansible configuration
For us,
baseline configuration
is the configuration every newly provisioned host gets.
This practice makes sure the host fits into our environment and is able to communicate on the network.
Because the same configuration steps have to be made for each new host, this is an awesome step to get
started with automation.
Make sure a certain set of packages were installed
Configure Postfix to be able to send mail in our environment
Configure firewalld
Configure SELinux
(Some of these steps are already published here on Enable Sysadmin, as you can see, and others
might follow soon.)
All of these tasks have in common that they are small and easy to start with, letting you gather
experience with using different kinds of Ansible modules, roles, variables, and so on. You can run
each of these roles and tasks standalone, or tie them all together in one playbook that sets the
baseline for your newly provisioned system.
Red Hat Enterprise Linux Server
patch management with Ansible
As I explained on my GitHub page for
ansible-role-rhel-patchmanagement
, in our environment, we deploy Red Hat Enterprise Linux Servers
for our operating departments to run their applications.
This role was written to provide a mechanism to install Red Hat Security Advisories on target nodes
once a month. In our special use case, only RHSAs are installed to ensure a minimum security limit.
The installation is enforced once a month. The advisories are summarized in "Patch-Sets." This way, it
is ensured that the same advisories are used for all stages during a patch cycle.
The Ansible Inventory nodes are summarized in one of the following groups, each of which defines
when a node is scheduled for patch installation:
[rhel-patch-phase1] - On the second Tuesday of a month.
[rhel-patch-phase2] - On the third Tuesday of a month.
[rhel-patch-phase3] - On the fourth Tuesday of a month.
[rhel-patch-phase4] - On the fourth Wednesday of a month.
In case packages were updated on target nodes, the hosts will reboot afterward.
Because the production systems are most important, they are divided into two separate groups
(phase3 and phase4) to decrease the risk of failure and service downtime due to advisory installation.
Updating and patch management are tasks every sysadmin has to deal with. With these roles, Ansible
helped me get this task done every month, and I don't have to care about it anymore. Only when a
system is not reachable, or yum has a problem, do I get an email report telling me to take a look.
But, I got lucky, and have not yet received any mail report for the last couple of months, now. (Yes,
of course, the system is able to send mail.)
Ad hoc commands
The possibility to run ad hoc commands for quick (and dirty) tasks was one of the reasons I chose
Ansible. You can use these commands to gather information when you need them or to get things done
without the need to write a playbook first.
I used ad hoc commands in cron jobs until I found the time to write playbooks for them. But, with
time comes practice, and today I try to use playbooks and roles for every task that has to run more
than once.
Here are small examples of ad hoc commands that provide quick information about your nodes.
ansible all -m command -a'/usr/bin/cat /etc/os-release'
Query running kernel version
ansible all -m command -a'/usr/bin/uname -r'
Query DNS servers in use by nodes
ansible all -m command -a'/usr/bin/cat /etc/resolv.conf' | grep 'SUCCESS\|nameserver'
Hopefully, these samples give you an idea for what ad hoc commands can be used.
Summary
It's not hard to start with automation. Just look for small and easy tasks you do every single day,
or even more than once a day, and let Ansible do these tasks for you.
Eventually, you will be able to solve more complex tasks as your automation skills grow. But keep
things as simple as possible. You gain nothing when you have to troubleshoot a playbook for three days
when it solves a task you could have done in an hour.
[Want to learn more about Ansible? Check out these
free e-books
.]
perhaps, just like proponents of AI and self driving cars. They just love the technology,
financially and emotionally invested in it so much they can't see the forest from the
trees.
I like technology, I studied engineering. But the myopic drive to profitability and
naivety to unintended consequences are pushing these tech out into the world before they are
ready.
engineering used to be a discipline with ethics and responsibilities... But now anybody
who could write two lines of code can call themselves a software engineer....
10 Ansible modules you need to knowSee examples and learn the most important
modules for automating everyday tasks with Ansible. 11 Sep 2019 DirectedSoul (Red Hat)Feed 25
up4 comments x
Subscribe now
Get the highlights in your inbox every week.
https://opensource.com/eloqua-embedded-email-capture-block.html?offer_id=70160000000QzXNAA0
Ansible is an open source IT
configuration management and automation platform. It uses human-readable YAML templates so
users can program repetitive tasks to happen automatically without having to learn an advanced
programming language.
Ansible is agentless, which means the nodes it manages do not require any software to be
installed on them. This eliminates potential security vulnerabilities and makes overall
management smoother.
Ansible modules are standalone
scripts that can be used inside an Ansible playbook. A playbook consists of a play, and a play
consists of tasks. These concepts may seem confusing if you're new to Ansible, but as you begin
writing and working more with playbooks, they will become familiar.
There are some modules that are frequently used in automating everyday tasks; those are
the ones that we will cover in this article.
Ansible has three main files that you need to consider:
Host/inventory file: Contains the entry of the nodes that need to be managed
Ansible.cfg file: Located by default at /etc/ansible/ansible.cfg , it has the necessary
privilege escalation options and the location of the inventory file
Main file: A playbook that has modules that perform various tasks on a host listed in an
inventory or host file
Module 1: Package management
There is a module for most popular package managers, such as DNF and APT, to enable you to
install any package on a system. Functionality depends entirely on the package manager, but
usually these modules can install, upgrade, downgrade, remove, and list packages. The names of
relevant modules are easy to guess. For example, the DNF module is dnf_module , the old YUM
module (required for Python 2 compatibility) is yum_module , while the
APT module is apt_module , the Slackpkg
module is slackpkg_module ,
and so on.
Example 1:
- name : install the latest version of Apache and MariaDB
dnf :
name :
- httpd
- mariadb-server
state : latest
This installs the Apache web server and the MariaDB SQL database.
Example 2: -
name : Install a list of packages
yum :
name :
- nginx
- postgresql
- postgresql-server
state : present
This installs the list of packages and helps download multiple packages.
Module 2:
Service
After installing a package, you need a module to start it. The service module
enables you to start, stop, and reload installed packages; this comes in pretty
handy.
Example 1: - name : Start service foo, based on running process
/usr/bin/foo
service :
name : foo
pattern : /usr/bin/foo
state : started
This starts the service foo .
Example 2: - name : Restart network service for
interface eth0
service :
name : network
state : restarted
args : eth0
This restarts the network service of the interface eth0 .
Module 3: Copy
The copy module copies a
file from the local or remote machine to a location on the remote machine.
Example 1:
- name : Copy a new "ntp.conf file into place, backing up the original if it differs from the
copied version
copy:
src: /mine/ntp.conf
dest: /etc/ntp.conf
owner: root
group: root
mode: '0644'
backup: yes Example 2: - name : Copy file with owner and permission, using symbolic
representation
copy :
src : /srv/myfiles/foo.conf
dest : /etc/foo.conf
owner : foo
group : foo
mode : u=rw,g=r,o=r Module 4: Debug
The debug module prints
statements during execution and can be useful for debugging variables or expressions without
having to halt the playbook.
Example 1: - name : Display all variables/facts known
for a host
debug :
var : hostvars [ inventory_hostname ]
verbosity : 4
This displays all the variable information for a host that is defined in the inventory
file.
Example 2: - name : Write some content in a file /tmp/foo.txt
copy :
dest : /tmp/foo.txt
content : |
Good Morning!
Awesome sunshine today.
register : display_file_content
- name : Debug display_file_content
debug :
var : display_file_content
verbosity : 2
This registers the content of the copy module output and displays it only when you specify
verbosity as 2. For example:
ansible-playbook demo.yaml -vv
Module 5: File
The file module manages the
file and its properties.
It sets attributes of files, symlinks, or directories.
It also removes files, symlinks, or directories.
Example 1: - name : Change file ownership, group and permissions
file :
path : /etc/foo.conf
owner : foo
group : foo
mode : '0644'
This creates a file named foo.conf and sets the permission to 0644 .
Example 2: -
name : Create a directory if it does not exist
file :
path : /etc/some_directory
state : directory
mode : '0755'
This creates a directory named some_directory and sets the permission to 0755 .
It ensures a particular line is in a file or replaces an existing line using a
back-referenced regular expression.
It's primarily useful when you want to change just a single line in a file.
Example 1: - name : Ensure SELinux is set to enforcing mode
lineinfile :
path : /etc/selinux/config
regexp : '^SELINUX='
line : SELINUX=enforcing
This sets the value of SELINUX=enforcing .
Example 2: - name : Add a line to a
file if the file does not exist, without passing regexp
lineinfile :
path : /etc/resolv.conf
line : 192.168.1.99 foo.lab.net foo
create : yes
This adds an entry for the IP and hostname in the resolv.conf file.
Module 7: Git
The git module
manages git checkouts of repositories to deploy files or software.
Example 1: #
Example Create git archive from repo
- git :
repo : https://github.com/ansible/ansible-examples.git
dest : /src/ansible-examples
archive : /tmp/ansible-examples.zip Example 2: - git :
repo : https://github.com/ansible/ansible-examples.git
dest : /src/ansible-examples
separate_git_dir : /src/ansible-examples.git
This clones a repo with a separate Git directory.
Module 8: Cli_command
The cli_command
module , first available in Ansible 2.7, provides a platform-agnostic way of pushing
text-based configurations to network devices over the network_cli connection
plugin.
Example 1: - name : commit with comment
cli_config :
config : set system host-name foo
commit_comment : this is a test
This sets the hostname for a switch and exits with a commit message.
This backs up a config to a different destination file.
Module 9: Archive
The archive module
creates a compressed archive of one or more files. By default, it assumes the compression
source exists on the target.
Example 1: - name : Compress directory /path/to/foo/
into /path/to/foo.tgz
archive :
path : /path/to/foo
dest : /path/to/foo.tgz Example 2: - name : Create a bz2 archive of multiple files,
rooted at /path
archive :
path :
- /path/to/foo
- /path/wong/foo
dest : /path/file.tar.bz2
format : bz2 Module 10: Command
One of the most basic but useful modules, the command module takes
the command name followed by a list of space-delimited arguments.
Example 1: - name :
return motd to registered var
command : cat /etc/motd
register : mymotd Example 2: - name : Change the working directory to somedir/ and run
the command as db_owner if /path/to/database does not exist.
command : /usr/bin/make_database.sh db_user db_name
become : yes
become_user : db_owner
args :
chdir : somedir/
creates : /path/to/database Conclusion
There are tons of modules available in Ansible, but these ten are the most basic and
powerful ones you can use for an automation job. As your requirements change, you can learn
about other useful modules by entering ansible-doc <module-name> on the command line or
refer to the official documentation
.
Artistic Style is a source code indenter, formatter, and beautifier for the C, C++, C++/CLI,
Objective‑C, C# and Java programming languages.
When indenting source code, we as programmers have a tendency to use both spaces and tab
characters to create the wanted indentation. Moreover, some editors by default insert spaces
instead of tabs when pressing the tab key. Other editors (Emacs for example) have the ability
to "pretty up" lines by automatically setting up the white space before the code on the line,
possibly inserting spaces in code that up to now used only tabs for indentation.
The NUMBER of spaces for each tab character in the source code can change between editors
(unless the user sets up the number to his liking...). One of the standard problems programmers
face when moving from one editor to another is that code containing both spaces and tabs, which
was perfectly indented, suddenly becomes a mess to look at. Even if you as a programmer take
care to ONLY use spaces or tabs, looking at other people's source code can still be
problematic.
To address this problem, Artistic Style was created – a filter written in C++ that
automatically re-indents and re-formats C / C++ / Objective‑C / C++/CLI / C# / Java
source files. It can be used from a command line, or it can be incorporated as a library in
another program.
Vim can indent bash scripts. But not reformat them before indenting.
Backup your bash script, open it with vim, type gg=GZZ and indent will be
corrected. (Note for the impatient: this overwrites the file, so be sure to do that backup!)
Though, some bugs with << (expecting EOF as first character on a line)
e.g.
The granddaddy of HTML tools, with support for modern standards.
There used to be a fork called tidy-html5 which since became the official thing. Here is its
GitHub repository
.
Tidy is a console application for Mac OS X, Linux, Windows, UNIX, and more. It corrects and
cleans up HTML and XML documents by fixing markup errors and upgrading legacy code to modern
standards.
For your needs, here is the command line to call Tidy:
This impostor definitely demonstrated programming abilities, although at the time there was
not such ter :-)
Notable quotes:
"... "We wrote it down. ..."
"... The next phrase was: ..."
"... " ' Booki fai kiz soy ?' " said Whitey. "It means 'Do you surrender?' " ..."
"... " ' Mizi pok loi ooni rak tong zin ?' 'Where are your comrades?' " ..."
"... "Tong what ?" rasped the colonel. ..."
"... "Tong zin , sir," our instructor replied, rolling chalk between his palms. He arched his eyebrows, as though inviting another question. There was one. The adjutant asked, "What's that gizmo on the end?" ..."
"... Of course, it might have been a Japanese newspaper. Whitey's claim to be a linguist was the last of his status symbols, and he clung to it desperately. Looking back, I think his improvisations on the Morton fantail must have been one of the most heroic achievements in the history of confidence men -- which, as you may have gathered by now, was Whitey's true profession. Toward the end of our tour of duty on the 'Canal he was totally discredited with us and transferred at his own request to the 81-millimeter platoon, where our disregard for him was no stigma, since the 81 millimeter musclemen regarded us as a bunch of eight balls anyway. Yet even then, even after we had become completely disillusioned with him, he remained a figure of wonder among us. We could scarcely believe that an impostor could be clever enough actually to invent a language -- phonics, calligraphy, and all. It had looked like Japanese and sounded like Japanese, and during his seventeen days of lecturing on that ship Whitey had carried it all in his head, remembering every variation, every subtlety, every syntactic construction. ..."
a fabulous tale of the South Pacific by William Manchester
The Man Who Could Speak Japanese
"We wrote it down.
The next phrase was:
" ' Booki fai kiz soy ?' " said Whitey. "It means 'Do you surrender?' "
Then:
" ' Mizi pok loi ooni rak tong zin ?' 'Where are your comrades?' "
"Tong what ?" rasped the colonel.
"Tong zin , sir," our instructor replied, rolling chalk between his palms. He arched
his eyebrows, as though inviting another question. There was one. The adjutant asked,
"What's that gizmo on the end?"
Of course, it might have been a Japanese newspaper. Whitey's claim to be a linguist
was the last of his status symbols, and he clung to it desperately. Looking back, I think
his improvisations on the Morton fantail must have been one of the most heroic achievements
in the history of confidence men -- which, as you may have gathered by now, was Whitey's
true profession. Toward the end of our tour of duty on the 'Canal he was totally
discredited with us and transferred at his own request to the 81-millimeter platoon, where
our disregard for him was no stigma, since the 81 millimeter musclemen regarded us as a
bunch of eight balls anyway. Yet even then, even after we had become completely
disillusioned with him, he remained a figure of wonder among us. We could scarcely believe
that an impostor could be clever enough actually to invent a language -- phonics,
calligraphy, and all. It had looked like Japanese and sounded like Japanese, and during his
seventeen days of lecturing on that ship Whitey had carried it all in his head, remembering
every variation, every subtlety, every syntactic construction.
Ansible
is a multiplier, a tool that automates
and scales infrastructure of every size. It is considered to be a configuration management,
orchestration, and deployment tool. It is easy to get up and running with Ansible. Even a new sysadmin
could start automating with Ansible in a matter of a few hours.
Ansible automates using the SSH
protocol. The control machine uses an SSH connection to communicate with its target hosts, which are
typically Linux hosts. If you're a Windows sysadmin, you can still use Ansible to automate your
Windows environments using
WinRM
as opposed
to SSH. Presently, though, the control machine still needs to run Linux.
As a new sysadmin, you might start with just a few playbooks. But as your automation skills
continue to grow, and you become more familiar with Ansible, you will learn best practices and further
realize that as your playbooks increase, using
Ansible Galaxy
becomes invaluable.
In this article, you will learn a bit about Ansible Galaxy, its structure, and how and when you can
put it to use.
What Ansible does
Common sysadmin tasks that can be performed with Ansible include patching, updating systems, user
and group management, and provisioning. Ansible presently has a huge footprint in IT Automation -- if not
the largest presently -- and is considered to be the most popular and widely used configuration
management, orchestration, and deployment tool available today.
One of the main reasons for its popularity is its simplicity. It's simple, powerful, and agentless.
Which means a new or entry-level sysadmin can hit the ground automating in a matter of hours. Ansible
allows you to scale quickly, efficiently, and cross-functionally.
Create roles with Ansible Galaxy
Ansible Galaxy is essentially a large public repository of Ansible roles. Roles ship with READMEs
detailing the role's use and available variables. Galaxy contains a large number of roles that are
constantly evolving and increasing.
Galaxy can use git to add other role sources, such as GitHub. You can initialize a new galaxy role
using
ansible-galaxy init
, or you can install a role directly from the Ansible Galaxy
role store by executing the command
ansible-galaxy install <name of role>
.
Here are some helpful
ansible-galaxy
commands you might use from time to time:
ansible-galaxy list
displays a list of installed roles, with version numbers.
ansible-galaxy remove <role>
removes an installed role.
ansible-galaxy info
provides a variety of information about Ansible Galaxy.
ansible-galaxy init
can be used to create a role template suitable for submission
to Ansible Galaxy.
To create an Ansible role using Ansible Galaxy, we need to use the
ansible-galaxy
command and its templates. Roles must be downloaded before they can be used in playbooks, and they are
placed into the default directory
/etc/ansible/roles
. You can find role examples at
https://galaxy.ansible.com/geerlingguy
:
Image
Create collections
While Ansible Galaxy has been the go-to tool for constructing and managing roles, with new
iterations of Ansible you are bound to see changes or additions. On Ansible version 2.8 you get the
new feature of
collections
.
What are collections and why are they worth mentioning? As the Ansible documentation states:
Collections are a distribution format for Ansible content. They can be used to package and
distribute playbooks, roles, modules, and plugins.
The
ansible-galaxy-collection
command implements the following commands. Notably, a few of the
subcommands are the same as used with
ansible-galaxy
:
init
creates a basic collection skeleton based on the default template included
with Ansible, or your own template.
build
creates a collection artifact that can be uploaded to Galaxy, or your own
repository.
publish
publishes a built collection artifact to Galaxy.
install
installs one or more collections.
In order to determine what can go into a collection, a great resource can be found
here
.
Conclusion
Establish yourself as a stellar sysadmin with an automation solution that is simple, powerful,
agentless, and scales your infrastructure quickly and efficiently. Using Ansible Galaxy to create
roles is superb thinking, and an ideal way to be organized and thoughtful in managing your
ever-growing playbooks.
The only way to improve your automation skills is to work with a dedicated tool and prove the value
and positive impact of automation on your infrastructure.
Dell EMC OpenManage Ansible Modules provide customers the ability to automate the Out-of-Band configuration management, deployment
and updates for Dell EMC PowerEdge Servers using Ansible by leeveragin the management automation built into the iDRAC with Lifecycle
Controller. iDRAC provides both REST APIs based on DMTF RedFish industry standard and WS-Management (WS-MAN) for management automation
of PowerEdge Servers.
With OpenManage Ansible modules, you can do:
Server administration
Configure iDRAC's settings such as:
iDRAC Network Settings
SNMP and SNMP Alert Settings
Timezone and NTP Settings
System settings such as server topology
LC attributes such as CSIOR etc.
Perform User administration
BIOS and Boot Order configuration
RAID Configuration
OS Deployment
Firmware Updates
1.1 How OpenManage Ansible Modules work?
OpenManage Ansible modules extensively uses the Server Configuration Profile (SCP) for most of the configuration management, deployment
and update of PowerEdge Servers. Lifecycle Controller 2 version 1.4 and later adds support for SCP. A SCP contains all BIOS, iDRAC,
Lifecycle Controller, Network amd Storage settings of a PowerEdge server and can be applied to multiple servers, enabling rapid,
reliable and reproducible configuration.
A SCP operation can be performed using any of the following methods:
Export/Import to/from a remote network share via CIFS, NFS
Export/Import to/from a remote network share via HTTP, HTTPS (iDRAC firmware 3.00.00.00 and above)
Export/Import to/from via local file streaming (iDRAC firmware 3.00.00.00 and above)
NOTE : This BETA release of OpenManage Ansible Module supports only the first option listed above for SCP operations i.e. export/import
to/from a remote network share via CIFS or NFS. Future releases will support all the options for SCP operations.
Setting up a local mount point for a remote network share
Since OpenManage Ansible modules extensively uses SCP to automate and orchestrate configuration, deployment and update on PowerEdge
servers, you must locally mount the remote network share (CIFS or NFS) on the ansible server where you will be executing the playbook
or modules. Local mount point also should have read-write privileges in order for OpenManage Ansible modules to write a SCP file
to remote network share that will be imported by iDRAC.
You can use either of the following ways to setup a local mount point:
Use the mount command to mount a remote network share
# Mount a remote CIFS network share on the local ansible machine.
# In the below command, 192.168.10.10 is the IP address of the CIFS file
# server (you can provide a hostname as well), Share is the directory that
# is being shared, and /mnt/CIFS is the location to mount the file system
# on the local ansible machine
sudo mount -t cifs \\\\192.168.10.10\\Share -o username=user1,password=password,dir_mode=0777,file_mode=0666 /mnt/CIFS
# Mount a remote NFS network share on the local ansible machine.
# In the below command, 192.168.10.10 is the IP address of the NFS file
# server (you can provide a hostname as well), Share is the directory that
# is being exported, and /mnt/NFS is the location to mount the file system
# on the local ansible machine. Please note that NFS checks access
# permissions against user ids (UIDs). For granting the read-write
# privileges on the local mount point, the UID and GID of the user on your
# local ansible machine needs to match the UID and GID of the owner of the
# folder you are trying to access on the server. Other option for granting
# the rw privileges would be to use all_squash option.
sudo mount -t nfs 192.168.10.11:/Share /mnt/NFS -o rw,user,auto
Alternate and preferred way would be to use the /etc/fstab for mounting the remote network share. That way, you
won't have to mount the network share after a reboot and remember all the options. General syntax for mounting the network share
in /etc/fstab would be as follows:
We can also include our own custom configuration file(s) in our custom
packages, thus allowing updating client monitoring configuration in a centralized and automated
way. Keeping that in mind, we'll configure the client in /etc/nrpe.d/custom.cfg on
all distributions in the following examples.
NRPE does not accept any commands other then localhost by default. This is for
security reasons. To allow command execution from a server, we need to set the server's IP
address as an allowed address. In our case the server is a Nagios server, with IP address
10.101.20.34 . We add the following to our client configuration:
Multiple addresses or hostnames can be added, separated by commas. Note that the above logic
requires static address for the monitoring server. Using dhcp on the monitoring
server will surely break your configuration, if you use IP address here. The same applies to
the scenario where you use hostnames, and the client can't resolve the server's
hostname.
Configuring a custom check on the server and client side
To demonstrate our monitoring setup's capabilites, let's say we would like to know if the
local postfix system delivers a mail on a client for user root . The mail could
contain a cronjob output, some report, or something that is written to the
STDERR and is delivered as a mail by default. For instance, abrt
sends a crash report to root by default on a process crash. We did not setup a
mail relay, but we still would like to know if a mail arrives. Let's write a custom check to
monitor that.
Our first piece of the puzzle is the check itself. Consider the following simple
bash
script called check_unread_mail :
#!/bin/bash
USER=root
if [ "$(command -v finger >> /dev/null; echo $?)" -gt 0 ]; then
echo "UNKNOWN: utility finger not found"
exit 3
fi
if [ "$(id "$USER" >> /dev/null ; echo $?)" -gt 0 ]; then
echo "UNKNOWN: user $USER does not exist"
exit 3
fi
## check for mail
if [ "$(finger -pm "$USER" | tail -n 1 | grep -ic "No mail.")" -gt 0 ]; then
echo "OK: no unread mail for user $USER"
exit 0
else
echo "WARNING: unread mail for user $USER"
exit 1
fi
This simple check uses the finger utility to check for unread mail for user
root . Output of the finger -pm may vary by version and thus
distribution, so some adjustments may be needed.
For example on Fedora 30, last line of the output of finger -pm
<username> is "No mail.", but on openSUSE Leap 15.1 it would be "No Mail."
(notice the upper case Mail). In this case the grep -i handles this
difference, but it shows well that when working with different distributions and versions,
some additional work may be needed.
We'll need finger to make this check work. The package's name is the same on
all distributions, so we can install it with apt , zypper ,
dnf or yum .
We need to set the check executable:
# chmod +x check_unread_mail
We'll place the check into the /usr/lib64/nagios/plugins directory, the
common place for nrpe checks. We'll reference it later.
We'll call our command check_mail_root . Let's place another line into our
custom client configuration, where we tell nrpe what commands we accept, and
what need to be done when a given command arrives:
With this our client configuration is complete. We can start the service on the client
with systemd . The service name is nagios-nrpe-server on Debian
derivatives, and simply nrpe on other distributions.
# systemctl start nagios-nrpe-server
# systemctl status nagios-nrpe-server
● nagios-nrpe-server.service - Nagios Remote Plugin Executor
Loaded: loaded (/lib/systemd/system/nagios-nrpe-server.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2019-09-10 13:03:10 CEST; 1min 51s ago
Docs: http://www.nagios.org/documentation
Main PID: 3782 (nrpe)
Tasks: 1 (limit: 3549)
CGroup: /system.slice/nagios-nrpe-server.service
└─3782 /usr/sbin/nrpe -c /etc/nagios/nrpe.cfg -f
szept 10 13:03:10 mail-test-client systemd[1]: Started Nagios Remote Plugin Executor.
szept 10 13:03:10 mail-test-client nrpe[3782]: Starting up daemon
szept 10 13:03:10 mail-test-client nrpe[3782]: Server listening on 0.0.0.0 port 5666.
szept 10 13:03:10 mail-test-client nrpe[3782]: Server listening on :: port 5666.
szept 10 13:03:10 mail-test-client nrpe[3782]: Listening for connections on port 5666
Now we can configure the server side. If we don't have one already, we can define a
command that calls a remote nrpe instance with a command as it's sole argument:
# this command runs a program $ARG1$ with no arguments
define command {
command_name check_nrpe_1arg
command_line $USER1$/check_nrpe -H $HOSTADDRESS$ -t 60 -c $ARG1$ 2>/dev/null
}
We also define the client as a host:
define host {
use linux-server
host_name mail-test-client
alias mail-test-client
address mail-test-client
}
The address can be an IP address or hostname. In the later case we need to ensure it can be
resolved by the monitoring server.
We can define a service on the above host using the Nagios side command and the client
side command:
define service {
use generic-service
host_name mail-test-client
service_description OS:unread mail for root
check_command check_nrpe_1arg!check_mail_root
}
These adjustments can be placed to any configuration file the Nagios server reads on startup,
but it is a good practice to keep configuration files tidy.
We verify our new Nagios configuration:
# nagios -v /etc/nagios/nagios.cfg
If "Things look okay", we can apply the configuration with a server reload:
DiffMerge is a cross-platform GUI application for comparing and merging files. It has two
functionality engines, the Diff engine which shows the difference between two files, which
supports intra-line highlighting and editing and a Merge engine which outputs the changed lines
between three files.
Meld is a lightweight GUI diff and merge tool. It enables users to compare files,
directories plus version controlled programs. Built specifically for developers, it comes with
the following features:
Two-way and three-way comparison of files and directories
Update of file comparison as a users types more words
Makes merges easier using auto-merge mode and actions on changed blocks
Easy comparisons using visualizations
Supports Git, Mercurial, Subversion, Bazaar plus many more
Diffuse is another popular, free, small and simple GUI diff and merge tool that you can use
on Linux. Written in Python, It offers two major functionalities, that is: file comparison and
version control, allowing file editing, merging of files and also output the difference between
files.
You can view a comparison summary, select lines of text in files using a mouse pointer,
match lines in adjacent files and edit different file. Other features include:
Syntax highlighting
Keyboard shortcuts for easy navigation
Supports unlimited undo
Unicode support
Supports Git, CVS, Darcs, Mercurial, RCS, Subversion, SVK and Monotone
XXdiff is a free, powerful file and directory comparator and merge tool that runs on Unix
like operating systems such as Linux, Solaris, HP/UX, IRIX, DEC Tru64. One limitation of XXdiff
is its lack of support for unicode files and inline editing of diff files.
It has the following list of features:
Shallow and recursive comparison of two, three file or two directories
Horizontal difference highlighting
Interactive merging of files and saving of resulting output
Supports merge reviews/policing
Supports external diff tools such as GNU diff, SIG diff, Cleareddiff and many more
Extensible using scripts
Fully customizable using resource file plus many other minor features
KDiff3 is yet another cool, cross-platform diff and merge tool made from KDevelop . It works
on all Unix-like platforms including Linux and Mac OS X, Windows.
It can compare or merge two to three files or directories and has the following notable
features:
Indicates differences line by line and character by character
Supports auto-merge
In-built editor to deal with merge-conflicts
Supports Unicode, UTF-8 and many other codecs
Allows printing of differences
Windows explorer integration support
Also supports auto-detection via byte-order-mark "BOM"
TkDiff is also a cross-platform, easy-to-use GUI wrapper for the Unix diff tool. It provides
a side-by-side view of the differences between two input files. It can run on Linux, Windows
and Mac OS X.
Additionally, it has some other exciting features including diff bookmarks, a graphical map
of differences for easy and quick navigation plus many more.
Having read this review of some of the best file and directory comparator and merge tools,
you probably want to try out some of them. These may not be the only diff tools available you
can find on Linux, but they are known to offer some the best features, you may also want to let
us know of any other diff tools out there that you have tested and think deserve to be
mentioned among the best.
Given a filename in the form
someletters_12345_moreleters.ext
, I want to extract the 5
digits and put them into a variable.
So to emphasize the point, I have a filename with x number of
characters then a five digit sequence surrounded by a single underscore on either side then another
set of x number of characters. I want to take the 5 digit number and put that into a variable.
I am very interested in the number of different ways that this can be accomplished.
If
x
is constant, the following parameter expansion performs substring extraction:
b=${a:12:5}
where
12
is the offset (zero-based) and
5
is the length
If the underscores around the digits are the only ones in the input, you can strip off the
prefix and suffix (respectively) in two steps:
tmp=${a#*_} # remove prefix ending in "_"
b=${tmp%_*} # remove suffix starting with "_"
If there are other underscores, it's probably feasible anyway, albeit more tricky. If anyone
knows how to perform both expansions in a single expression, I'd like to know too.
Both solutions presented are pure bash, with no process spawning involved, hence very fast.
In case someone wants more rigorous information, you can also search it in man bash like this
$ man bash [press return key]
/substring [press return key]
[press "n" key]
[press "n" key]
[press "n" key]
[press "n" key]
Result:
${parameter:offset}
${parameter:offset:length}
Substring Expansion. Expands to up to length characters of
parameter starting at the character specified by offset. If
length is omitted, expands to the substring of parameter start‐
ing at the character specified by offset. length and offset are
arithmetic expressions (see ARITHMETIC EVALUATION below). If
offset evaluates to a number less than zero, the value is used
as an offset from the end of the value of parameter. Arithmetic
expressions starting with a - must be separated by whitespace
from the preceding : to be distinguished from the Use Default
Values expansion. If length evaluates to a number less than
zero, and parameter is not @ and not an indexed or associative
array, it is interpreted as an offset from the end of the value
of parameter rather than a number of characters, and the expan‐
sion is the characters between the two offsets. If parameter is
@, the result is length positional parameters beginning at off‐
set. If parameter is an indexed array name subscripted by @ or
*, the result is the length members of the array beginning with
${parameter[offset]}. A negative offset is taken relative to
one greater than the maximum index of the specified array. Sub‐
string expansion applied to an associative array produces unde‐
fined results. Note that a negative offset must be separated
from the colon by at least one space to avoid being confused
with the :- expansion. Substring indexing is zero-based unless
the positional parameters are used, in which case the indexing
starts at 1 by default. If offset is 0, and the positional
parameters are used, $0 is prefixed to the list.
Note: the above is a regular expression and is restricted to your specific scenario of five
digits surrounded by underscores. Change the regular expression if you need different matching.
I have a filename with x number of characters then a five digit sequence surrounded by a
single underscore on either side then another set of x number of characters. I want to take
the 5 digit number and put that into a variable.
Here's a prefix-suffix solution (similar to the solutions given by JB and Darron) that matches
the first block of digits and does not depend on the surrounding underscores:
str='someletters_12345_morele34ters.ext'
s1="${str#"${str%%[[:digit:]]*}"}" # strip off non-digit prefix from str
s2="${s1%%[^[:digit:]]*}" # strip off non-digit suffix from s1
echo "$s2" # 12345
A slightly more general option would be
not
to assume that you have an
underscore
_
marking the start of your digits sequence, hence for instance stripping
off all non-numbers you get before your sequence:
s/[^0-9]\+\([0-9]\+\).*/\1/p
.
> man sed | grep s/regexp/replacement -A 2
s/regexp/replacement/
Attempt to match regexp against the pattern space. If successful, replace that portion matched with replacement. The replacement may contain the special character & to
refer to that portion of the pattern space which matched, and the special escapes \1 through \9 to refer to the corresponding matching sub-expressions in the regexp.
More on this, in case you're not too confident with regexps:
s
is for _s_ubstitute
[0-9]+
matches 1+ digits
\1
links to the group n.1 of the regex output (group 0 is the whole match,
group 1 is the match within parentheses in this case)
p
flag is for _p_rinting
All escapes
\
are there to make
sed
's regexp processing work.
This will be more efficient if you want to extract something that has any chars like
abc
or any special characters like
_
or
-
. For example: If your string is
like this and you want everything that is after
someletters_
and before
_moreleters.ext
:
str="someletters_123-45-24a&13b-1_moreleters.ext"
With my code you can mention what exactly you want. Explanation:
#*
It will remove the preceding string including the matching key. Here the key
we mentioned is
_
%
It will remove the following string including the
matching key. Here the key we mentioned is '_more*'
Do some experiments yourself and you would find this interesting.
Ok, here goes pure Parameter Substitution with an empty string. Caveat is that I have defined
someletters
and
moreletters
as only characters. If they are
alphanumeric, this will not work as it is.
Can anyone recommend a safe solution to recursively replace spaces with underscores in file
and directory names starting from a given root directory? For example:
$ tree
.
|-- a dir
| `-- file with spaces.txt
`-- b dir
|-- another file with spaces.txt
`-- yet another file with spaces.pdf
Use rename (aka prename ) which is a Perl script
which may be on
your system already. Do it in two steps:
find -name "* *" -type d | rename 's/ /_/g' # do the directories first
find -name "* *" -type f | rename 's/ /_/g'
Based on Jürgen's answer and able to handle multiple layers of files and directories
in a single bound using the "Revision 1.5 1998/12/18 16:16:31 rmb1" version of
/usr/bin/rename (a Perl script):
This one does a little bit more. I use it to rename my downloaded torrents (no special
characters (non-ASCII), spaces, multiple dots, etc.).
#!/usr/bin/perl
&rena(`find . -type d`);
&rena(`find . -type f`);
sub rena
{
($elems)=@_;
@t=split /\n/,$elems;
for $e (@t)
{
$_=$e;
# remove ./ of find
s/^\.\///;
# non ascii transliterate
tr [\200-\377][_];
tr [\000-\40][_];
# special characters we do not want in paths
s/[ \-\,\;\?\+\'\"\!\[\]\(\)\@\#]/_/g;
# multiple dots except for extension
while (/\..*\./)
{
s/\./_/;
}
# only one _ consecutive
s/_+/_/g;
next if ($_ eq $e ) or ("./$_" eq $e);
print "$e -> $_\n";
rename ($e,$_);
}
}
I just make one for my own purpose. You may can use it as reference.
#!/bin/bash
cd /vzwhome/c0cheh1/dev_source/UB_14_8
for file in *
do
echo $file
cd "/vzwhome/c0cheh1/dev_source/UB_14_8/$file/Configuration/$file"
echo "==> `pwd`"
for subfile in *\ *; do [ -d "$subfile" ] && ( mv "$subfile" "$(echo $subfile | sed -e 's/ /_/g')" ); done
ls
cd /vzwhome/c0cheh1/dev_source/UB_14_8
done
for i in `IFS="";find /files -name *\ *`
do
echo $i
done > /tmp/list
while read line
do
mv "$line" `echo $line | sed 's/ /_/g'`
done < /tmp/list
rm /tmp/list
Programming skills are somewhat similar to the skills of people who play violin or piano. As
soon a you stop playing violin or piano still start to evaporate. First slowly, then quicker. In
two yours you probably will lose 80%.
Notable quotes:
"... I happened to look the other day. I wrote 35 programs in January, and 28 or 29 programs in February. These are small programs, but I have a compulsion. I love to write programs and put things into it. ..."
Dijkstra said he was proud to be a programmer. Unfortunately he changed his attitude
completely, and I think he wrote his last computer program in the 1980s. At this conference I
went to in 1967 about simulation language, Chris Strachey was going around asking everybody at
the conference what was the last computer program you wrote. This was 1967. Some of the people
said, "I've never written a computer program." Others would say, "Oh yeah, here's what I did
last week." I asked Edsger this question when I visited him in Texas in the 90s and he said,
"Don, I write programs now with pencil and paper, and I execute them in my head." He finds that
a good enough discipline.
I think he was mistaken on that. He taught me a lot of things, but I really think that if he
had continued... One of Dijkstra's greatest strengths was that he felt a strong sense of
aesthetics, and he didn't want to compromise his notions of beauty. They were so intense that
when he visited me in the 1960s, I had just come to Stanford. I remember the conversation we
had. It was in the first apartment, our little rented house, before we had electricity in the
house.
We were sitting there in the dark, and he was telling me how he had just learned about the
specifications of the IBM System/360, and it made him so ill that his heart was actually
starting to flutter.
He intensely disliked things that he didn't consider clean to work with. So I can see that
he would have distaste for the languages that he had to work with on real computers. My
reaction to that was to design my own language, and then make Pascal so that it would work well
for me in those days. But his response was to do everything only intellectually.
So, programming.
I happened to look the other day. I wrote 35 programs in January, and 28 or 29 programs
in February. These are small programs, but I have a compulsion. I love to write programs and
put things into it. I think of a question that I want to answer, or I have part of my book
where I want to present something. But I can't just present it by reading about it in a book.
As I code it, it all becomes clear in my head. It's just the discipline. The fact that I have
to translate my knowledge of this method into something that the machine is going to understand
just forces me to make that crystal-clear in my head. Then I can explain it to somebody else
infinitely better. The exposition is always better if I've implemented it, even though it's
going to take me more time.
So I had a programming hat when I was outside of Cal Tech, and at Cal Tech I am a
mathematician taking my grad studies. A startup company, called Green Tree Corporation because
green is the color of money, came to me and said, "Don, name your price. Write compilers for us
and we will take care of finding computers for you to debug them on, and assistance for you to
do your work. Name your price." I said, "Oh, okay. $100,000.", assuming that this was In that
era this was not quite at Bill Gate's level today, but it was sort of out there.
The guy didn't blink. He said, "Okay." I didn't really blink either. I said, "Well, I'm not
going to do it. I just thought this was an impossible number."
At that point I made the decision in my life that I wasn't going to optimize my income; I
was really going to do what I thought I could do for well, I don't know. If you ask me what
makes me most happy, number one would be somebody saying "I learned something from you". Number
two would be somebody saying "I used your software". But number infinity would be Well, no.
Number infinity minus one would be "I bought your book". It's not as good as "I read your
book", you know. Then there is "I bought your software"; that was not in my own personal value.
So that decision came up. I kept up with the literature about compilers. The Communications of
the ACM was where the action was. I also worked with people on trying to debug the ALGOL
language, which had problems with it. I published a few papers, like "The Remaining Trouble
Spots in ALGOL 60" was one of the papers that I worked on. I chaired a committee called
"Smallgol" which was to find a subset of ALGOL that would work on small computers. I was active
in programming languages.
Frana: You have made the comment several times that maybe 1 in 50 people have the
"computer scientist's mind." Knuth: Yes. Frana: I am wondering if a large number of those
people are trained professional librarians? [laughter] There is some strangeness there. But can
you pinpoint what it is about the mind of the computer scientist that is....
Knuth: That is different?
Frana: What are the characteristics?
Knuth: Two things: one is the ability to deal with non-uniform structure, where you
have case one, case two, case three, case four. Or that you have a model of something where the
first component is integer, the next component is a Boolean, and the next component is a real
number, or something like that, you know, non-uniform structure. To deal fluently with those
kinds of entities, which is not typical in other branches of mathematics, is critical. And the
other characteristic ability is to shift levels quickly, from looking at something in the large
to looking at something in the small, and many levels in between, jumping from one level of
abstraction to another. You know that, when you are adding one to some number, that you are
actually getting closer to some overarching goal. These skills, being able to deal with
nonuniform objects and to see through things from the top level to the bottom level, these are
very essential to computer programming, it seems to me. But maybe I am fooling myself because I
am too close to it.
Frana: It is the hardest thing to really understand that which you are existing
within.
Knuth: I can be a writer, who tries to organize other people's ideas into some kind of a
more coherent structure so that it is easier to put things together. I can see that I could be
viewed as a scholar that does his best to check out sources of material, so that people get
credit where it is due. And to check facts over, not just to look at the abstract of something,
but to see what the methods were that did it and to fill in holes if necessary. I look at my
role as being able to understand the motivations and terminology of one group of specialists
and boil it down to a certain extent so that people in other parts of the field can use it. I
try to listen to the theoreticians and select what they have done that is important to the
programmer on the street; to remove technical jargon when possible.
But I have never been good at any kind of a role that would be making policy, or advising
people on strategies, or what to do. I have always been best at refining things that are there
and bringing order out of chaos. I sometimes raise new ideas that might stimulate people, but
not really in a way that would be in any way controlling the flow. The only time I have ever
advocated something strongly was with literate programming; but I do this always with the
caveat that it works for me, not knowing if it would work for anybody else.
When I work with a system that I have created myself, I can always change it if I don't like
it. But everybody who works with my system has to work with what I give them. So I am not able
to judge my own stuff impartially. So anyway, I have always felt bad about if anyone says,
'Don, please forecast the future,'...
The Bash options for debugging are turned off by default, but once they are turned on by
using the set command, they stay on until explicitly turned off. If you are not sure which
options are enabled, you can examine the $- variable to see the current state of
all the variables.
$ echo $-
himBHs
$ set -xv && echo $-
himvxBHs
There is another useful switch we can use to help us find variables referenced without
having any value set. This is the -u switch, and just like -x and
-v it can also be used on the command line, as we see in the following
example:
We mistakenly assigned a value of 7 to the variable called "level" then tried to echo a
variable named "score" that simply resulted in printing nothing at all to the screen.
Absolutely no debug information was given. Setting our -u switch allows us to see
a specific error message, "score: unbound variable" that indicates exactly what went wrong.
We can use those options in short Bash scripts to give us debug information to identify
problems that do not otherwise trigger feedback from the Bash interpreter. Let's walk through a
couple of examples.
#!/bin/bash
read -p "Path to be added: " $path
if [ "$path" = "/home/mike/bin" ]; then
echo $path >> $PATH
echo "new path: $PATH"
else
echo "did not modify PATH"
fi
In the example above we run the addpath script normally and it simply does not modify our
PATH . It does not give us any indication of why or clues to mistakes made.
Running it again using the -x option clearly shows us that the left side of our
comparison is an empty string. $path is an empty string because we accidentally
put a dollar sign in front of "path" in our read statement. Sometimes we look right at a
mistake like this and it doesn't look wrong until we get a clue and think, "Why is
$path evaluated to an empty string?"
Looking this next example, we also get no indication of an error from the interpreter. We
only get one value printed per line instead of two. This is not an error that will halt
execution of the script, so we're left to simply wonder without being given any clues. Using
the -u switch,we immediately get a notification that our variable j
is not bound to a value. So these are real time savers when we make mistakes that do not result
in actual errors from the Bash interpreter's point of view.
Now surely you are thinking that sounds fine, but we seldom need help debugging mistakes
made in one-liners at the command line or in short scripts like these. We typically struggle
with debugging when we deal with longer and more complicated scripts, and we rarely need to set
these options and leave them set while we run multiple scripts. Setting -xv
options and then running a more complex script will often add confusion by doubling or tripling
the amount of output generated.
Fortunately we can use these options in a more precise way by placing them inside our
scripts. Instead of explicitly invoking a Bash shell with an option from the command line, we
can set an option by adding it to the shebang line instead.
#!/bin/bash -x
This will set the -x option for the entire file or until it is unset during the
script execution, allowing you to simply run the script by typing the filename instead of
passing it to Bash as a parameter. A long script or one that has a lot of output will still
become unwieldy using this technique however, so let's look at a more specific way to use
options.
For a more targeted approach, surround only the suspicious blocks of code with the options
you want. This approach is great for scripts that generate menus or detailed output, and it is
accomplished by using the set keyword with plus or minus once again.
#!/bin/bash
read -p "Path to be added: " $path
set -xv
if [ "$path" = "/home/mike/bin" ]; then
echo $path >> $PATH
echo "new path: $PATH"
else
echo "did not modify PATH"
fi
set +xv
We surrounded only the blocks of code we suspect in order to reduce the output, making our
task easier in the process. Notice we turn on our options only for the code block containing
our if-then-else statement, then turn off the option(s) at the end of the suspect block. We can
turn these options on and off multiple times in a single script if we can't narrow down the
suspicious areas, or if we want to evaluate the state of variables at various points as we
progress through the script. There is no need to turn off an option If we want it to continue
for the remainder of the script execution.
For completeness sake we should mention also that there are debuggers written by third
parties that will allow us to step through the code execution line by line. You might want to
investigate these tools, but most people find that that they are not actually needed.
As seasoned programmers will suggest, if your code is too complex to isolate suspicious
blocks with these options then the real problem is that the code should be refactored. Overly
complex code means bugs can be difficult to detect and maintenance can be time consuming and
costly.
One final thing to mention regarding Bash debugging options is that a file globbing option
also exists and is set with -f . Setting this option will turn off globbing
(expansion of wildcards to generate file names) while it is enabled. This -f
option can be a switch used at the command line with bash, after the shebang in a file or, as
in this example to surround a block of code.
#!/bin/bash
echo "ignore fileglobbing option turned off"
ls *
echo "ignore file globbing option set"
set -f
ls *
set +f
There are more involved techniques worth considering if your scripts are complicated,
including using an assert function as mentioned earlier. One such method to keep in mind is the
use of trap. Shell scripts allow us to trap signals and do something at that point.
A simple but useful example you can use in your Bash scripts is to trap on EXIT
.
#!/bin/bash
trap 'echo score is $score, status is $status' EXIT
if [ -z ]; then
status="default"
else
status=
fi
score=0
if [ ${USER} = 'superman' ]; then
score=99
elif [ $# -gt 1 ]; then
score=
fi
As you can see just dumping the current values of variables to the screen can be useful to
show where your logic is failing. The EXIT signal obviously does not need an
explicit exit statement to be generated; in this case the echo
statement is executed when the end of the script is reached.
Another useful trap to use with Bash scripts is DEBUG . This happens after
every statement, so it can be used as a brute force way to show the values of variables at each
step in the script execution.
#!/bin/bash
trap 'echo "line ${LINENO}: score is $score"' DEBUG
score=0
if [ "${USER}" = "mike" ]; then
let "score += 1"
fi
let "score += 1"
if [ "" = "7" ]; then
score=7
fi
exit 0
When you notice your Bash script not behaving as expected and the reason is not clear to you
for whatever reason, consider what information would be useful to help you identify the cause
then use the most comfortable tools available to help you pinpoint the issue. The xtrace option
-x is easy to use and probably the most useful of the options presented here, so
consider trying it out next time you're faced with a script that's not doing what you thought
it would
"... When you're writing a document for a human being to understand, the human being will look at it and nod his head and say, "Yeah, this makes sense." But then there's all kinds of ambiguities and vagueness that you don't realize until you try to put it into a computer. Then all of a sudden, almost every five minutes as you're writing the code, a question comes up that wasn't addressed in the specification. "What if this combination occurs?" ..."
"... When you're faced with implementation, a person who has been delegated this job of working from a design would have to say, "Well hmm, I don't know what the designer meant by this." ..."
...I showed the second version of this design to two of my graduate students, and I said,
"Okay, implement this, please, this summer. That's your summer job." I thought I had specified
a language. I had to go away. I spent several weeks in China during the summer of 1977, and I
had various other obligations. I assumed that when I got back from my summer trips, I would be
able to play around with TeX and refine it a little bit. To my amazement, the students, who
were outstanding students, had not competed [it]. They had a system that was able to do about
three lines of TeX. I thought, "My goodness, what's going on? I thought these were good
students." Well afterwards I changed my attitude to saying, "Boy, they accomplished a
miracle."
Because going from my specification, which I thought was complete, they really had an
impossible task, and they had succeeded wonderfully with it. These students, by the way, [were]
Michael Plass, who has gone on to be the brains behind almost all of Xerox's Docutech software
and all kind of things that are inside of typesetting devices now, and Frank Liang, one of the
key people for Microsoft Word.
He did important mathematical things as well as his hyphenation methods which are quite used
in all languages now. These guys were actually doing great work, but I was amazed that they
couldn't do what I thought was just sort of a routine task. Then I became a programmer in
earnest, where I had to do it. The reason is when you're doing programming, you have to explain
something to a computer, which is dumb.
When you're writing a document for a human being to understand, the human being will
look at it and nod his head and say, "Yeah, this makes sense." But then there's all kinds of
ambiguities and vagueness that you don't realize until you try to put it into a computer. Then
all of a sudden, almost every five minutes as you're writing the code, a question comes up that
wasn't addressed in the specification. "What if this combination occurs?"
It just didn't occur to the person writing the design specification. When you're faced
with implementation, a person who has been delegated this job of working from a design would
have to say, "Well hmm, I don't know what the designer meant by this."
If I hadn't been in China they would've scheduled an appointment with me and stopped their
programming for a day. Then they would come in at the designated hour and we would talk. They
would take 15 minutes to present to me what the problem was, and then I would think about it
for a while, and then I'd say, "Oh yeah, do this. " Then they would go home and they would
write code for another five minutes and they'd have to schedule another appointment.
I'm probably exaggerating, but this is why I think Bob Floyd's Chiron compiler never got
going. Bob worked many years on a beautiful idea for a programming language, where he designed
a language called Chiron, but he never touched the programming himself. I think this was
actually the reason that he had trouble with that project, because it's so hard to do the
design unless you're faced with the low-level aspects of it, explaining it to a machine instead
of to another person.
Forsythe, I think it was, who said, "People have said traditionally that you don't
understand something until you've taught it in a class. The truth is you don't really
understand something until you've taught it to a computer, until you've been able to program
it." At this level, programming was absolutely important
Knuth: No, I stopped going to conferences. It was too discouraging. Computer programming
keeps getting harder because more stuff is discovered. I can cope with learning about one new
technique per day, but I can't take ten in a day all at once. So conferences are depressing; it
means I have so much more work to do. If I hide myself from the truth I am much happier.
"... Also, Addison-Wesley was the people who were asking me to do this book; my favorite textbooks had been published by Addison Wesley. They had done the books that I loved the most as a student. For them to come to me and say, "Would you write a book for us?", and here I am just a secondyear gradate student -- this was a thrill. ..."
"... But in those days, The Art of Computer Programming was very important because I'm thinking of the aesthetical: the whole question of writing programs as something that has artistic aspects in all senses of the word. The one idea is "art" which means artificial, and the other "art" means fine art. All these are long stories, but I've got to cover it fairly quickly. ..."
Knuth: This is, of course, really the story of my life, because I hope to live long enough
to finish it. But I may not, because it's turned out to be such a huge project. I got married
in the summer of 1961, after my first year of graduate school. My wife finished college, and I
could use the money I had made -- the $5000 on the compiler -- to finance a trip to Europe for
our honeymoon.
We had four months of wedded bliss in Southern California, and then a man from
Addison-Wesley came to visit me and said "Don, we would like you to write a book about how to
write compilers."
The more I thought about it, I decided "Oh yes, I've got this book inside of me."
I sketched out that day -- I still have the sheet of tablet paper on which I wrote -- I
sketched out 12 chapters that I thought ought to be in such a book. I told Jill, my wife, "I
think I'm going to write a book."
As I say, we had four months of bliss, because the rest of our marriage has all been devoted
to this book. Well, we still have had happiness. But really, I wake up every morning and I
still haven't finished the book. So I try to -- I have to -- organize the rest of my life
around this, as one main unifying theme. The book was supposed to be about how to write a
compiler. They had heard about me from one of their editorial advisors, that I knew something
about how to do this. The idea appealed to me for two main reasons. One is that I did enjoy
writing. In high school I had been editor of the weekly paper. In college I was editor of the
science magazine, and I worked on the campus paper as copy editor. And, as I told you, I wrote
the manual for that compiler that we wrote. I enjoyed writing, number one.
Also, Addison-Wesley was the people who were asking me to do this book; my favorite
textbooks had been published by Addison Wesley. They had done the books that I loved the most
as a student. For them to come to me and say, "Would you write a book for us?", and here I am
just a secondyear gradate student -- this was a thrill.
Another very important reason at the time was that I knew that there was a great need for a
book about compilers, because there were a lot of people who even in 1962 -- this was January
of 1962 -- were starting to rediscover the wheel. The knowledge was out there, but it hadn't
been explained. The people who had discovered it, though, were scattered all over the world and
they didn't know of each other's work either, very much. I had been following it. Everybody I
could think of who could write a book about compilers, as far as I could see, they would only
give a piece of the fabric. They would slant it to their own view of it. There might be four
people who could write about it, but they would write four different books. I could present all
four of their viewpoints in what I would think was a balanced way, without any axe to grind,
without slanting it towards something that I thought would be misleading to the compiler writer
for the future. I considered myself as a journalist, essentially. I could be the expositor, the
tech writer, that could do the job that was needed in order to take the work of these brilliant
people and make it accessible to the world. That was my motivation. Now, I didn't have much
time to spend on it then, I just had this page of paper with 12 chapter headings on it. That's
all I could do while I'm a consultant at Burroughs and doing my graduate work. I signed a
contract, but they said "We know it'll take you a while." I didn't really begin to have much
time to work on it until 1963, my third year of graduate school, as I'm already finishing up on
my thesis. In the summer of '62, I guess I should mention, I wrote another compiler. This was
for Univac; it was a FORTRAN compiler. I spent the summer, I sold my soul to the devil, I guess
you say, for three months in the summer of 1962 to write a FORTRAN compiler. I believe that the
salary for that was $15,000, which was much more than an assistant professor. I think assistant
professors were getting eight or nine thousand in those days.
Feigenbaum: Well, when I started in 1960 at [University of California] Berkeley, I was
getting $7,600 for the nine-month year.
Knuth: Knuth: Yeah, so you see it. I got $15,000 for a summer job in 1962 writing a
FORTRAN compiler. One day during that summer I was writing the part of the compiler that looks
up identifiers in a hash table. The method that we used is called linear probing. Basically you
take the variable name that you want to look up, you scramble it, like you square it or
something like this, and that gives you a number between one and, well in those days it would
have been between 1 and 1000, and then you look there. If you find it, good; if you don't find
it, go to the next place and keep on going until you either get to an empty place, or you find
the number you're looking for. It's called linear probing. There was a rumor that one of
Professor Feller's students at Princeton had tried to figure out how fast linear probing works
and was unable to succeed. This was a new thing for me. It was a case where I was doing
programming, but I also had a mathematical problem that would go into my other [job]. My winter
job was being a math student, my summer job was writing compilers. There was no mix. These
worlds did not intersect at all in my life at that point. So I spent one day during the summer
while writing the compiler looking at the mathematics of how fast does linear probing work. I
got lucky, and I solved the problem. I figured out some math, and I kept two or three sheets of
paper with me and I typed it up. ["Notes on 'Open' Addressing', 7/22/63] I guess that's on the
internet now, because this became really the genesis of my main research work, which developed
not to be working on compilers, but to be working on what they call analysis of algorithms,
which is, have a computer method and find out how good is it quantitatively. I can say, if I
got so many things to look up in the table, how long is linear probing going to take. It dawned
on me that this was just one of many algorithms that would be important, and each one would
lead to a fascinating mathematical problem. This was easily a good lifetime source of rich
problems to work on. Here I am then, in the middle of 1962, writing this FORTRAN compiler, and
I had one day to do the research and mathematics that changed my life for my future research
trends. But now I've gotten off the topic of what your original question was.
Feigenbaum: We were talking about sort of the.. You talked about the embryo of The Art of
Computing. The compiler book morphed into The Art of Computer Programming, which became a
seven-volume plan.
Knuth: Exactly. Anyway, I'm working on a compiler and I'm thinking about this. But now I'm
starting, after I finish this summer job, then I began to do things that were going to be
relating to the book. One of the things I knew I had to have in the book was an artificial
machine, because I'm writing a compiler book but machines are changing faster than I can write
books. I have to have a machine that I'm totally in control of. I invented this machine called
MIX, which was typical of the computers of 1962.
In 1963 I wrote a simulator for MIX so that I could write sample programs for it, and I
taught a class at Caltech on how to write programs in assembly language for this hypothetical
computer. Then I started writing the parts that dealt with sorting problems and searching
problems, like the linear probing idea. I began to write those parts, which are part of a
compiler, of the book. I had several hundred pages of notes gathering for those chapters for
The Art of Computer Programming. Before I graduated, I've already done quite a bit of writing
on The Art of Computer Programming.
I met George Forsythe about this time. George was the man who inspired both of us [Knuth and
Feigenbaum] to come to Stanford during the '60s. George came down to Southern California for a
talk, and he said, "Come up to Stanford. How about joining our faculty?" I said "Oh no, I can't
do that. I just got married, and I've got to finish this book first." I said, "I think I'll
finish the book next year, and then I can come up [and] start thinking about the rest of my
life, but I want to get my book done before my son is born." Well, John is now 40-some years
old and I'm not done with the book. Part of my lack of expertise is any good estimation
procedure as to how long projects are going to take. I way underestimated how much needed to be
written about in this book. Anyway, I started writing the manuscript, and I went merrily along
writing pages of things that I thought really needed to be said. Of course, it didn't take long
before I had started to discover a few things of my own that weren't in any of the existing
literature. I did have an axe to grind. The message that I was presenting was in fact not going
to be unbiased at all. It was going to be based on my own particular slant on stuff, and that
original reason for why I should write the book became impossible to sustain. But the fact that
I had worked on linear probing and solved the problem gave me a new unifying theme for the
book. I was going to base it around this idea of analyzing algorithms, and have some
quantitative ideas about how good methods were. Not just that they worked, but that they worked
well: this method worked 3 times better than this method, or 3.1 times better than this method.
Also, at this time I was learning mathematical techniques that I had never been taught in
school. I found they were out there, but they just hadn't been emphasized openly, about how to
solve problems of this kind.
So my book would also present a different kind of mathematics than was common in the
curriculum at the time, that was very relevant to analysis of algorithm. I went to the
publishers, I went to Addison Wesley, and said "How about changing the title of the book from
'The Art of Computer Programming' to 'The Analysis of Algorithms'." They said that will never
sell; their focus group couldn't buy that one. I'm glad they stuck to the original title,
although I'm also glad to see that several books have now come out called "The Analysis of
Algorithms", 20 years down the line.
But in those days, The Art of Computer Programming was very important because I'm
thinking of the aesthetical: the whole question of writing programs as something that has
artistic aspects in all senses of the word. The one idea is "art" which means artificial, and
the other "art" means fine art. All these are long stories, but I've got to cover it fairly
quickly.
I've got The Art of Computer Programming started out, and I'm working on my 12 chapters. I
finish a rough draft of all 12 chapters by, I think it was like 1965. I've got 3,000 pages of
notes, including a very good example of what you mentioned about seeing holes in the fabric.
One of the most important chapters in the book is parsing: going from somebody's algebraic
formula and figuring out the structure of the formula. Just the way I had done in seventh grade
finding the structure of English sentences, I had to do this with mathematical sentences.
Chapter ten is all about parsing of context-free language, [which] is what we called it at
the time. I covered what people had published about context-free languages and parsing. I got
to the end of the chapter and I said, well, you can combine these ideas and these ideas, and
all of a sudden you get a unifying thing which goes all the way to the limit. These other ideas
had sort of gone partway there. They would say "Oh, if a grammar satisfies this condition, I
can do it efficiently." "If a grammar satisfies this condition, I can do it efficiently." But
now, all of a sudden, I saw there was a way to say I can find the most general condition that
can be done efficiently without looking ahead to the end of the sentence. That you could make a
decision on the fly, reading from left to right, about the structure of the thing. That was
just a natural outgrowth of seeing the different pieces of the fabric that other people had put
together, and writing it into a chapter for the first time. But I felt that this general
concept, well, I didn't feel that I had surrounded the concept. I knew that I had it, and I
could prove it, and I could check it, but I couldn't really intuit it all in my head. I knew it
was right, but it was too hard for me, really, to explain it well.
So I didn't put in The Art of Computer Programming. I thought it was beyond the scope of my
book. Textbooks don't have to cover everything when you get to the harder things; then you have
to go to the literature. My idea at that time [is] I'm writing this book and I'm thinking it's
going to be published very soon, so any little things I discover and put in the book I didn't
bother to write a paper and publish in the journal because I figure it'll be in my book pretty
soon anyway. Computer science is changing so fast, my book is bound to be obsolete.
It takes a year for it to go through editing, and people drawing the illustrations, and then
they have to print it and bind it and so on. I have to be a little bit ahead of the
state-of-the-art if my book isn't going to be obsolete when it comes out. So I kept most of the
stuff to myself that I had, these little ideas I had been coming up with. But when I got to
this idea of left-to-right parsing, I said "Well here's something I don't really understand
very well. I'll publish this, let other people figure out what it is, and then they can tell me
what I should have said." I published that paper I believe in 1965, at the end of finishing my
draft of the chapter, which didn't get as far as that story, LR(k). Well now, textbooks of
computer science start with LR(k) and take off from there. But I want to give you an idea
of
Is there any directory bookmarking utility for bash to allow move around faster on the command
line?
UPDATE
Thanks guys for the feedback however I created my own simple shell script (feel free to modify/expand
it)
function cdb() {
USAGE="Usage: cdb [-c|-g|-d|-l] [bookmark]" ;
if [ ! -e ~/.cd_bookmarks ] ; then
mkdir ~/.cd_bookmarks
fi
case $1 in
# create bookmark
-c) shift
if [ ! -f ~/.cd_bookmarks/$1 ] ; then
echo "cd `pwd`" > ~/.cd_bookmarks/"$1" ;
else
echo "Try again! Looks like there is already a bookmark '$1'"
fi
;;
# goto bookmark
-g) shift
if [ -f ~/.cd_bookmarks/$1 ] ; then
source ~/.cd_bookmarks/"$1"
else
echo "Mmm...looks like your bookmark has spontaneously combusted. What I mean to say is that your bookmark does not exist." ;
fi
;;
# delete bookmark
-d) shift
if [ -f ~/.cd_bookmarks/$1 ] ; then
rm ~/.cd_bookmarks/"$1" ;
else
echo "Oops, forgot to specify the bookmark" ;
fi
;;
# list bookmarks
-l) shift
ls -l ~/.cd_bookmarks/ ;
;;
*) echo "$USAGE" ;
;;
esac
}
INSTALL
1./ create a file ~/.cdb and copy the above script into it.
A colon-separated list of search paths available to the cd command, similar in function to
the $PATH variable for binaries. The $CDPATH variable may be set in the local ~/.bashrc file.
ash$ cd bash-doc
bash: cd: bash-doc: No such file or directory
bash$ CDPATH=/usr/share/doc
bash$ cd bash-doc
/usr/share/doc/bash-doc
bash$ echo $PWD
/usr/share/doc/bash-doc
and
cd -
It's the command-line equivalent of the back button (takes you to the previous directory you
were in).
It primarily allows you to "fuzzy-find" files in a number of ways, but it also allows to feed
arbitrary text data to it and filter this data. So, the shortcuts idea is simple: all we need
is to maintain a file with paths (which are shortcuts), and fuzzy-filter this file. Here's how
it looks: we type cdg command (from "cd global", if you like), get a list of our
bookmarks, pick the needed one in just a few keystrokes, and press Enter. Working directory is
changed to the picked item:
It is extremely fast and convenient: usually I just type 3-4 letters of the needed item, and
all others are already filtered out. Additionally, of course we can move through list with arrow
keys or with vim-like keybindings Ctrl+j / Ctrl+k .
It is possible to use it for GUI applications as well (via xterm): I use that for my GUI file
manager Double Commander . I have
plans to write an article about this use case, too.
Inspired by the question and answers here, I added the lines below to my ~/.bashrc
file.
With this you have a favdir command (function) to manage your favorites and a
autocompletion function to select an item from these favorites.
# ---------
# Favorites
# ---------
__favdirs_storage=~/.favdirs
__favdirs=( "$HOME" )
containsElement () {
local e
for e in "${@:2}"; do [[ "$e" == "$1" ]] && return 0; done
return 1
}
function favdirs() {
local cur
local IFS
local GLOBIGNORE
case $1 in
list)
echo "favorite folders ..."
printf -- ' - %s\n' "${__favdirs[@]}"
;;
load)
if [[ ! -e $__favdirs_storage ]] ; then
favdirs save
fi
# mapfile requires bash 4 / my OS-X bash vers. is 3.2.53 (from 2007 !!?!).
# mapfile -t __favdirs < $__favdirs_storage
IFS=$'\r\n' GLOBIGNORE='*' __favdirs=($(< $__favdirs_storage))
;;
save)
printf -- '%s\n' "${__favdirs[@]}" > $__favdirs_storage
;;
add)
cur=${2-$(pwd)}
favdirs load
if containsElement "$cur" "${__favdirs[@]}" ; then
echo "'$cur' allready exists in favorites"
else
__favdirs+=( "$cur" )
favdirs save
echo "'$cur' added to favorites"
fi
;;
del)
cur=${2-$(pwd)}
favdirs load
local i=0
for fav in ${__favdirs[@]}; do
if [ "$fav" = "$cur" ]; then
echo "delete '$cur' from favorites"
unset __favdirs[$i]
favdirs save
break
fi
let i++
done
;;
*)
echo "Manage favorite folders."
echo ""
echo "usage: favdirs [ list | load | save | add | del ]"
echo ""
echo " list : list favorite folders"
echo " load : load favorite folders from $__favdirs_storage"
echo " save : save favorite directories to $__favdirs_storage"
echo " add : add directory to favorites [default pwd $(pwd)]."
echo " del : delete directory from favorites [default pwd $(pwd)]."
esac
} && favdirs load
function __favdirs_compl_command() {
COMPREPLY=( $( compgen -W "list load save add del" -- ${COMP_WORDS[COMP_CWORD]}))
} && complete -o default -F __favdirs_compl_command favdirs
function __favdirs_compl() {
local IFS=$'\n'
COMPREPLY=( $( compgen -W "${__favdirs[*]}" -- ${COMP_WORDS[COMP_CWORD]}))
}
alias _cd='cd'
complete -F __favdirs_compl _cd
Within the last two lines, an alias to change the current directory (with autocompletion) is
created. With this alias ( _cd ) you are able to change to one of your favorite directories.
May you wan't to change this alias to something which fits your needs .
With the function favdirs you can manage your favorites (see usage).
$ favdirs
Manage favorite folders.
usage: favdirs [ list | load | save | add | del ]
list : list favorite folders
load : load favorite folders from ~/.favdirs
save : save favorite directories to ~/.favdirs
add : add directory to favorites [default pwd /tmp ].
del : delete directory from favorites [default pwd /tmp ].
@getmizanur I used your cdb script. I enhanced it slightly by adding bookmarks tab completion.
Here's my version of your cdb script.
_cdb()
{
local _script_commands=$(ls -1 ~/.cd_bookmarks/)
local cur=${COMP_WORDS[COMP_CWORD]}
COMPREPLY=( $(compgen -W "${_script_commands}" -- $cur) )
}
complete -F _cdb cdb
function cdb() {
local USAGE="Usage: cdb [-h|-c|-d|-g|-l|-s] [bookmark]\n
\t[-h or no args] - prints usage help\n
\t[-c bookmark] - create bookmark\n
\t[-d bookmark] - delete bookmark\n
\t[-g bookmark] - goto bookmark\n
\t[-l] - list bookmarks\n
\t[-s bookmark] - show bookmark location\n
\t[bookmark] - same as [-g bookmark]\n
Press tab for bookmark completion.\n"
if [ ! -e ~/.cd_bookmarks ] ; then
mkdir ~/.cd_bookmarks
fi
case $1 in
# create bookmark
-c) shift
if [ ! -f ~/.cd_bookmarks/$1 ] ; then
echo "cd `pwd`" > ~/.cd_bookmarks/"$1"
complete -F _cdb cdb
else
echo "Try again! Looks like there is already a bookmark '$1'"
fi
;;
# goto bookmark
-g) shift
if [ -f ~/.cd_bookmarks/$1 ] ; then
source ~/.cd_bookmarks/"$1"
else
echo "Mmm...looks like your bookmark has spontaneously combusted. What I mean to say is that your bookmark does not exist." ;
fi
;;
# show bookmark
-s) shift
if [ -f ~/.cd_bookmarks/$1 ] ; then
cat ~/.cd_bookmarks/"$1"
else
echo "Mmm...looks like your bookmark has spontaneously combusted. What I mean to say is that your bookmark does not exist." ;
fi
;;
# delete bookmark
-d) shift
if [ -f ~/.cd_bookmarks/$1 ] ; then
rm ~/.cd_bookmarks/"$1" ;
else
echo "Oops, forgot to specify the bookmark" ;
fi
;;
# list bookmarks
-l) shift
ls -1 ~/.cd_bookmarks/ ;
;;
-h) echo -e $USAGE ;
;;
# goto bookmark by default
*)
if [ -z "$1" ] ; then
echo -e $USAGE
elif [ -f ~/.cd_bookmarks/$1 ] ; then
source ~/.cd_bookmarks/"$1"
else
echo "Mmm...looks like your bookmark has spontaneously combusted. What I mean to say is that your bookmark does not exist." ;
fi
;;
esac
}
Anc stands for anchor, but anc's anchors are really just bookmarks.
It's designed for ease of use and there're multiple ways of navigating, either by giving a
text pattern, using numbers, interactively, by going back, or using [TAB] completion.
I'm actively working on it and open to input on how to make it better.
Allow me to paste the examples from anc's github page here:
# make the current directory the default anchor:
$ anc s
# go to /etc, then /, then /usr/local and then back to the default anchor:
$ cd /etc; cd ..; cd usr/local; anc
# go back to /usr/local :
$ anc b
# add another anchor:
$ anc a $HOME/test
# view the list of anchors (the default one has the asterisk):
$ anc l
(0) /path/to/first/anchor *
(1) /home/usr/test
# jump to the anchor we just added:
# by using its anchor number
$ anc 1
# or by jumping to the last anchor in the list
$ anc -1
# add multiple anchors:
$ anc a $HOME/projects/first $HOME/projects/second $HOME/documents/first
# use text matching to jump to $HOME/projects/first
$ anc pro fir
# use text matching to jump to $HOME/documents/first
$ anc doc fir
# add anchor and jump to it using an absolute path
$ anc /etc
# is the same as
$ anc a /etc; anc -1
# add anchor and jump to it using a relative path
$ anc ./X11 #note that "./" is required for relative paths
# is the same as
$ anc a X11; anc -1
# using wildcards you can add many anchors at once
$ anc a $HOME/projects/*
# use shell completion to see a list of matching anchors
# and select the one you want to jump to directly
$ anc pro[TAB]
Bashmarks
is an amazingly simple and intuitive utility. In short, after installation, the usage is:
s <bookmark_name> - Saves the current directory as "bookmark_name"
g <bookmark_name> - Goes (cd) to the directory associated with "bookmark_name"
p <bookmark_name> - Prints the directory associated with "bookmark_name"
d <bookmark_name> - Deletes the bookmark
l - Lists all available bookmarks
,
For short term shortcuts, I have a the following in my respective init script (Sorry. I can't
find the source right now and didn't bother then):
function b() {
alias $1="cd `pwd -P`"
}
Usage:
In any directory that you want to bookmark type
b THEDIR # <THEDIR> being the name of your 'bookmark'
It will create an alias to cd (back) to here.
To return to a 'bookmarked' dir type
THEDIR
It will run the stored alias and cd back there.
Caution: Use only if you understand that this might override existing shell aliases
and what that means.
Using an trap to cleanup is simple enough. Here is an example of using trap to clean up a
temporary file on exit of the script.
#!/bin/bash
trap "rm -f /tmp/output.txt" EXIT
yum -y update > /tmp/output.txt
if grep -qi "kernel" /tmp/output.txt; then
mail -s "KERNEL UPDATED" [email protected] < /tmp/output.txt
fi
NOTE: It is important that the trap statement be placed at the beginning of the script to
function properly. Any commands above the trap can exit and not be caught in the trap.
Now if the script exits for any reason, it will still run the rm command to delete the file.
Here is an example of me sending SIGINT (CTRL+C) while the script was
running.
# ./test.sh
^Cremoved '/tmp/output.txt'
NOTE: I added verbose ( -v ) output to the rm command so it prints "removed". The ^C
signifies where I hit CTRL+C to send SIGINT.
This is a much cleaner and safer way to ensure the cleanup occurs when the script exists.
Using EXIT ( 0 ) instead of a single defined signal (i.e. SIGINT – 2) ensures the cleanup
happens on any exit, even successful completion of the script.
The Linux exec command is a
bash builtin
and a very interesting
utility. It is not something most people who are new to Linux know. Most seasoned admins understand it but only use it occasionally.
If you are a developer, programmer or DevOp engineer it is probably something you use more often. Lets take a deep dive into the
builtin exec command, what it does and how to use it.
In order to understand the exec command, you need a fundamental understanding of how sub-shells work.
... ... ...
What the Exec Command Does
In it's most basic function the exec command changes the default behavior of creating a sub-shell to run a command. If you run
exec followed by a command, that command will REPLACE the original process, it will NOT create a sub-shell.
An additional feature of the exec command, is
redirection
and manipulation
of
file descriptors
. Explaining redirection and file descriptors is outside the scope of this tutorial. If these are new to you please read "
Linux IO, Standard Streams and
Redirection
" to get acquainted with these terms and functions.
In the following sections we will expand on both of these functions and try to demonstrate how to use them.
How to Use the Exec Command with Examples
Let's look at some examples of how to use the exec command and it's options.
Basic Exec Command Usage – Replacement of Process
If you call exec and supply a command without any options, it simply replaces the shell with
command
.
Let's run an experiment. First, I ran the ps command to find the process id of my second terminal window. In this case it was
17524. I then ran "exec tail" in that second terminal and checked the ps command again. If you look at the screenshot below, you
will see the tail process replaced the bash process (same process ID).
Screenshot 3
Since the tail command replaced the bash shell process, the shell will close when the tail command terminates.
Exec Command Options
If the -l option is supplied, exec adds a dash at the beginning of the first (zeroth) argument given. So if we ran the following
command:
exec -l tail -f /etc/redhat-release
It would produce the following output in the process list. Notice the highlighted dash in the CMD column.
The -c option causes the supplied command to run with a empty environment. Environmental variables like
PATH
, are cleared before the command it run.
Let's try an experiment. We know that the printenv command prints all the settings for a users environment. So here we will open
a new bash process, run the printenv command to show we have some variables set. We will then run printenv again but this time with
the exec -c option.
In the example above you can see that an empty environment is used when using exec with the -c option. This is why there was no
output to the printenv command when ran with exec.
The last option, -a [name], will pass
name
as the first argument to
command
. The command will still run as expected,
but the name of the process will change. In this next example we opened a second terminal and ran the following command:
exec -a PUTORIUS tail -f /etc/redhat-release
Here is the process list showing the results of the above command:
Screenshot 5
As you can see, exec passed PUTORIUS as first argument to
command
, therefore it shows in the process list with that name.
Using the Exec Command for Redirection & File Descriptor Manipulation
The exec command is often used for redirection. When a file descriptor is redirected with exec it affects the current shell. It
will exist for the life of the shell or until it is explicitly stopped.
If no
command
is specified, redirections may be used to affect the current shell environment.
– Bash Manual
Here are some examples of how to use exec for redirection and manipulating file descriptors. As we stated above, a deep dive into
redirection and file descriptors is outside the scope of this tutorial. Please read "
Linux IO, Standard Streams and
Redirection
" for a good primer and see the resources section for more information.
Redirect all standard output (STDOUT) to a file:
exec >file
In the example animation below, we use exec to redirect all standard output to a file. We then enter some commands that should
generate some output. We then use exec to redirect STDOUT to the /dev/tty to restore standard output to the terminal. This effectively
stops the redirection. Using the
cat
command
we can see that the file contains all the redirected output.
Open a file as file descriptor 6 for writing:
exec 6> file2write
Open file as file descriptor 8 for reading:
exec 8< file2read
Copy file descriptor 5 to file descriptor 7:
exec 7<&5
Close file descriptor 8:
exec 8<&-
Conclusion
In this article we covered the basics of the exec command. We discussed how to use it for process replacement, redirection and
file descriptor manipulation.
In the past I have seen exec used in some interesting ways. It is often used as a wrapper script for starting other binaries.
Using process replacement you can call a binary and when it takes over there is no trace of the original wrapper script in the process
table or memory. I have also seen many System Administrators use exec when transferring work from one script to another. If you call
a script inside of another script the original process stays open as a parent. You can use exec to replace that original script.
I am sure there are people out there using exec in some interesting ways. I would love to hear your experiences with exec. Please
feel free to leave a comment below with anything on your mind.
Type the following command to display the seconds since the epoch:
date +%s
date +%s
Sample outputs: 1268727836
Convert Epoch To Current Time
Type the command:
date -d @Epoch
date -d @1268727836
date -d "1970-01-01 1268727836 sec GMT"
date -d @Epoch date -d @1268727836 date -d "1970-01-01 1268727836 sec GMT"
Sample outputs:
Tue Mar 16 13:53:56 IST 2010
Please note that @ feature only works with latest version of date (GNU coreutils v5.3.0+).
To convert number of seconds back to a more readable form, use a command like this:
In ksh93 however, the argument is taken as a date expression where various
and hardly documented formats are supported.
For a Unix epoch time, the syntax in ksh93 is:
printf '%(%F %T)T\n' '#1234567890'
ksh93 however seems to use its own algorithm for the timezone and can get it
wrong. For instance, in Britain, it was summer time all year in 1970, but:
Time conversion using Bash This article show how you can obtain the UNIX epoch time
(number of seconds since 1970-01-01 00:00:00 UTC) using the Linux bash "date" command. It also
shows how you can convert a UNIX epoch time to a human readable time.
Obtain UNIX epoch time using bash
Obtaining the UNIX epoch time using bash is easy. Use the build-in date command and instruct it
to output the number of seconds since 1970-01-01 00:00:00 UTC. You can do this by passing a
format string as parameter to the date command. The format string for UNIX epoch time is
'%s'.
lode@srv-debian6:~$ date "+%s"
1234567890
To convert a specific date and time into UNIX epoch time, use the -d parameter.
The next example shows how to convert the timestamp "February 20th, 2013 at 08:41:15" into UNIX
epoch time.
lode@srv-debian6:~$ date "+%s" -d "02/20/2013 08:41:15"
1361346075
Converting UNIX epoch time to human readable time
Even though I didn't find it in the date manual, it is possible to use the date command to
reformat a UNIX epoch time into a human readable time. The syntax is the following:
lode@srv-debian6:~$ date -d @1234567890
Sat Feb 14 00:31:30 CET 2009
The same thing can also be achieved using a bit of perl programming:
lode@srv-debian6:~$ perl -e 'print scalar(localtime(1234567890)), "\n"'
Sat Feb 14 00:31:30 2009
Please note that the printed time is formatted in the timezone in which your Linux system is
configured. My system is configured in UTC+2, you can get another output for the same
command.
The Code-TidyAll
distribution provides a command line script called tidyall that will use
Perl::Tidy to change the
layout of the code.
This tandem needs 2 configuration file.
The .perltidyrc file contains the instructions to Perl::Tidy that describes the layout of a
Perl-file. We used the following file copied from the source code of the Perl Maven
project.
-pbp
-nst
-et=4
--maximum-line-length=120
# Break a line after opening/before closing token.
-vt=0
-vtc=0
The tidyall command uses a separate file called .tidyallrc that describes which files need
to be beautified.
Once I installed Code::TidyAll and placed those files in
the root directory of the project, I could run tidyall -a .
That created a directory called .tidyall.d/ where it stores cached versions of the files,
and changed all the files that were matches by the select statements in the .tidyallrc
file.
Then, I added .tidyall.d/ to the .gitignore file to avoid adding that subdirectory to the
repository and ran tidyall -a again to make sure the .gitignore file is sorted.
Vim can indent bash scripts. But not reformat them before indenting.
Backup your bash script, open it with vim, type gg=GZZ and indent will be
corrected. (Note for the impatient: this overwrites the file, so be sure to do that backup!)
Though, some bugs with << (expecting EOF as first character on a line)
e.g.
A shell parser, formatter and interpreter. Supports
POSIX Shell
,
Bash
and
mksh
. Requires Go 1.11 or later.
Quick start
To parse shell scripts, inspect them, and print them out, see the
syntax examples
.
For high-level operations like performing shell expansions on strings, see the
shell examples
.
shfmt
Go 1.11 and later can download the latest v2 stable release:
cd $(mktemp -d); go mod init tmp; go get mvdan.cc/sh/cmd/shfmt
The latest v3 pre-release can be downloaded in a similar manner, using the
/v3
module:
cd $(mktemp -d); go mod init tmp; go get mvdan.cc/sh/v3/cmd/shfmt
Finally, any older release can be built with their respective older Go versions by manually cloning,
checking out a tag, and running
go build ./cmd/shfmt
.
shfmt
formats shell programs. It can use tabs or any number of spaces to indent. See
canonical.sh
for a quick look at its
default style.
You can feed it standard input, any number of files or any number of directories to recurse into. When
recursing, it will operate on
.sh
and
.bash
files and ignore files starting with a
period. It will also operate on files with no extension and a shell shebang.
shfmt -l -w script.sh
Typically, CI builds should use the command below, to error if any shell scripts in a project don't adhere
to the format:
shfmt -d .
Use
-i N
to indent with a number of spaces instead of tabs. There are other formatting options
- see
shfmt -h
. For example, to get the formatting appropriate for
Google's Style
guide, use
shfmt -i 2 -ci
.
bash -n
can be useful to check for syntax errors in shell scripts. However,
shfmt
>/dev/null
can do a better job as it checks for invalid UTF-8 and does all parsing statically, including
checking POSIX Shell validity:
$((
and
((
ambiguity is not supported. Backtracking would complicate the
parser and make streaming support via
io.Reader
impossible. The POSIX spec recommends to
space the operands
if
$( (
is meant.
$ echo '$((foo); (bar))' | shfmt
1:1: reached ) without matching $(( with ))
Some builtins like
export
and
let
are parsed as keywords. This is to allow
statically parsing them and building their syntax tree, as opposed to just keeping the arguments as a slice
of arguments.
JavaScript
A subset of the Go packages are available as an npm package called
mvdan-sh
. See the
_js
directory for more information.
Docker
To build a Docker image, checkout a specific version of the repository and run:
Method-2: Exclude Packages with yum Command Permanently
If you are frequently performing the patch update,You can use this permanent method.
To do so, add the required packages in /etc/yum.conf to disable packages updates
permanently.
Once you add an entry, you don't need to specify these package each time you run yum update
command. Also, this prevents packages from any accidental update.
Before EFI, the standard boot process
for virtually all PC systems was called "MBR", for Master Boot Record; today you are likely to
hear it referred to as "Legacy Boot". This process depended on using the first physical block
on a disk to hold some information needed to boot the computer (thus the name Master Boot
Record); specifically, it held the disk address at which the actual bootloader could be found,
and the partition table that defined the layout of the disk. Using this information, the PC
firmware could find and execute the bootloader, which would then bring up the computer and run
the operating system.
This system had a number of rather obvious weaknesses and shortcomings. One of the biggest
was that you could only have one bootable object on each physical disk drive (at least as far
as the firmware boot was concerned). Another was that if that first sector on the disk became
corrupted somehow, you were in deep trouble.
Over time, as part of the Extensible Firmware Interface, a new approach to boot
configuration was developed. Rather than storing critical boot configuration information in a
single "magic" location, EFI uses a dedicated "EFI boot partition" on the desk. This is a
completely normal, standard disk partition, the same as which may be used to hold the operating
system or system recovery data.
The only requirement is that it be FAT formatted, and it should have the boot and
esp partition flags set (esp stands for EFI System Partition). The specific data and
programs necessary for booting is then kept in directories on this partition, typically in
directories named to indicate what they are for. So if you have a Windows system, you would
typically find directories called 'Boot' and 'Microsoft' , and perhaps one named for the
manufacturer of the hardware, such as HP. If you have a Linux system, you would find
directories called opensuse, debian, ubuntu, or any number of others depending on what
particular Linux distribution you are using.
It should be obvious from the description so far that it is perfectly possible with the EFI
boot configuration to have multiple boot objects on a single disk drive.
Before going any further, I should make it clear that if you install Linux as the only
operating system on a PC, it is not necessary to know all of this configuration information in
detail. The installer should take care of setting all of this up, including creating the EFI
boot partition (or using an existing EFI boot partition), and further configuring the system
boot list so that whatever system you install becomes the default boot target.
If you were to take a brand new computer with UEFI firmware, and load it from scratch with
any of the current major Linux distributions, it would all be set up, configured, and working
just as it is when you purchase a new computer preloaded with Windows (or when you load a
computer from scratch with Windows). It is only when you want to have more than one bootable
operating system – especially when you want to have both Linux and Windows on the same
computer – that things may become more complicated.
The problems that arise with such "multiboot" systems are generally related to getting the
boot priority list defined correctly.
When you buy a new computer with Windows, this list typically includes the Windows
bootloader on the primary disk, and then perhaps some other peripheral devices such as USB,
network interfaces and such. When you install Linux alongside Windows on such a computer, the
installer will add the necessary information to the EFI boot partition, but if the boot
priority list is not changed, then when the system is rebooted after installation it will
simply boot Windows again, and you are likely to think that the installation didn't work.
There are several ways to modify this boot priority list, but exactly which ones are
available and whether or how they work depends on the firmware of the system you are using, and
this is where things can get really messy. There are just about as many different UEFI firmware
implementations as there are PC manufacturers, and the manufacturers have shown a great deal of
creativity in the details of this firmware.
First, in the simplest case, there is a software utility included with Linux called
efibootmgr that can be used to modify, add or delete the boot priority list. If this
utility works properly, and the changes it makes are permanent on the system, then you would
have no other problems to deal with, and after installing it would boot Linux and you would be
happy. Unfortunately, while this is sometimes the case it is frequently not. The most common
reason for this is that changes made by software utilities are not actually permanently stored
by the system BIOS, so when the computer is rebooted the boot priority list is restored to
whatever it was before, which generally means that Windows gets booted again.
The other common way of modifying the boot priority list is via the computer BIOS
configuration program. The details of how to do this are different for every manufacturer, but
the general procedure is approximately the same. First you have to press the BIOS configuration
key (usually F2, but not always, unfortunately) during system power-on (POST). Then choose the
Boot item from the BIOS configuration menu, which should get you to a list of boot targets
presented in priority order. Then you need to modify that list; sometimes this can be done
directly in that screen, via the usual F5/F6 up/down key process, and sometimes you need to
proceed one level deeper to be able to do that. I wish I could give more specific and detailed
information about this, but it really is different on every system (sometimes even on different
systems produced by the same manufacturer), so you just need to proceed carefully and figure
out the steps as you go.
I have seen a few rare cases of systems where neither of these methods works, or at least
they don't seem to be permanent, and the system keeps reverting to booting Windows. Again,
there are two ways to proceed in this case. The first is by simply pressing the "boot
selection" key during POST (power-on). Exactly which key this is varies, I have seen it be F12,
F9, Esc, and probably one or two others. Whichever key it turns out to be, when you hit it
during POST you should get a list of bootable objects defined in the EFI boot priority list, so
assuming your Linux installation worked you should see it listed there. I have known of people
who were satisfied with this solution, and would just use the computer this way and have to
press boot select each time they wanted to boot Linux.
The alternative is to actually modify the files in the EFI boot partition, so that the
(unchangeable) Windows boot procedure would actually boot Linux. This involves overwriting the
Windows file bootmgfw.efi with the Linux file grubx64.efi. I have done this, especially in the
early days of EFI boot, and it works, but I strongly advise you to be extremely careful if you
try it, and make sure that you keep a copy of the original bootmgfw.efi file. Finally, just as
a final (depressing) warning, I have also seen systems where this seemed to work, at least for
a while, but then at some unpredictable point the boot process seemed to notice that something
had changed and it restored bootmgfw.efi to its original state – thus losing the Linux
boot configuration again. Sigh.
So, that's the basics of EFI boot, and how it can be configured. But there are some
important variations possible, and some caveats to be aware of.
Interesting. Sorry you had that experience. I'm not sure what you mean by a "multi-line
text widget". I can tell you that early versions of OpenMOTIF were very very buggy in my
experience. You probably know this, but after OpenMOTIF was completed and revved a few times
the original MOTIF code was released as open-source. Many of the bugs I'd been seeing (and
some just strange visual artifacts) disappeared. I know a lot of people love QT and it's
produced real apps and real results - I won't poo-poo it. How
Even if you don't like C++ much, The Design and
Evolution of C++ [amazon.com] is a great book for understanding why pretty much any
language ends up the way it does, seeing the tradeoffs and how a language comes to grow and
expand from simple roots. It's way more interesting to read than you might expect (not very
dry, and more about human interaction than you would expect).
Other than that reading through back posts in a lot of coding blogs that have been around
a long time is probably a really good idea.
You young whippersnappers don't 'preciate how good you have it!
Back in my day, the only book about programming was the 1401 assembly language manual!
But seriously, folks, it's pretty clear we still don't know shite about how to program
properly. We have some fairly clear success criteria for improving the hardware, but the
criteria for good software are clear as mud, and the criteria for ways to produce good
software are much muddier than that.
Having said that, I will now peruse the thread rather carefully
Couldn't find any mention of Guy Steele, so I'll throw in The New Hacker's
Dictionary , which I once owned in dead tree form. Not sure if Version 4.4.7 http://catb.org/jargon/html/ [catb.org] is
the latest online... Also remember a couple of his language manuals. Probably used the Common
Lisp one the most...
Didn't find any mention of a lot of books that I consider highly relevant, but that may
reflect my personal bias towards history. Not really relevant for most programmers.
I've been programming for the past ~40 years and I'll try to summarize what I believe are
the most important bits about programming (pardon the pun.) Think of this as a META: " HOWTO:
Be A Great Programmer " summary. (I'll get to the books section in a bit.)
1. All code can be summarized as a trinity of 3 fundamental concepts:
* Linear ; that is, sequence: A, B, C
* Cyclic ; that is, unconditional jumps: A-B-C-goto B
* Choice ; that is, conditional jumps: if A then B
2. ~80% of programming is NOT about code; it is about Effective Communication. Whether
that be:
* with your compiler / interpreter / REPL
* with other code (levels of abstraction, level of coupling, separation of concerns,
etc.)
* with your boss(es) / manager(s)
* with your colleagues
* with your legal team
* with your QA dept
* with your customer(s)
* with the general public
The other ~20% is effective time management and design. A good programmer knows how to
budget their time. Programming is about balancing the three conflicting goals of the
Program
Management Triangle [wikipedia.org]: You can have it on time, on budget, on quality.
Pick two.
3. Stages of a Programmer
There are two old jokes:
In Lisp all code is data. In Haskell all data is code.
And:
Progression of a (Lisp) Programmer:
* The newbie realizes that the difference between code and data is trivial.
* The expert realizes that all code is data.
* The true master realizes that all data is code.
(Attributed to Aristotle Pagaltzis)
The point of these jokes is that as you work with systems you start to realize that a
data-driven process can often greatly simplify things.
4. Know Thy Data
Fred Books once wrote
"Show me your flowcharts (source code), and conceal your tables (domain model), and I shall
continue to be mystified; show me your tables (domain model) and I won't usually need your
flowcharts (source code): they'll be obvious."
A more modern version would read like this:
Show me your code and I'll have to see your data,
Show me your data and I won't have to see your code.
The importance of data can't be understated:
* Optimization STARTS with understanding HOW the data is being generated and used, NOT the
code as has been traditionally taught.
* Post 2000 "Big Data" has been called the new oil. We are generating upwards to millions of
GB of data every second. Analyzing that data is import to spot trends and potential
problems.
5. There are three levels of optimizations. From slowest to fastest run-time:
a) Bit-twiddling hacks
[stanford.edu]
b) Algorithmic -- Algorithmic complexity or Analysis of algorithms
[wikipedia.org] (such as Big-O notation)
c) Data-Orientated
Design [dataorienteddesign.com] -- Understanding how hardware caches such as instruction
and data caches matter. Optimize for the common case, NOT the single case that OOP tends to
favor.
Optimizing is understanding Bang-for-the-Buck. 80% of code execution is spent in 20% of
the time. Speeding up hot-spots with bit twiddling won't be as effective as using a more
efficient algorithm which, in turn, won't be as efficient as understanding HOW the data is
manipulated in the first place.
6. Fundamental Reading
Since the OP specifically asked about books -- there are lots of great ones. The ones that
have impressed me that I would mark as "required" reading:
* The Mythical Man-Month
* Godel, Escher, Bach
* Knuth: The Art of Computer Programming
* The Pragmatic Programmer
* Zero Bugs and Program Faster
* Writing Solid Code / Code Complete by Steve McConnell
* Game Programming
Patterns [gameprogra...tterns.com] (*)
* Game Engine Design
* Thinking in Java by Bruce Eckel
* Puzzles for Hackers by Ivan Sklyarov
(*) I did NOT list Design Patterns: Elements of Reusable Object-Oriented Software
as that leads to typical, bloated, over-engineered crap. The main problem with "Design
Patterns" is that a programmer will often get locked into a mindset of seeing
everything as a pattern -- even when a simple few lines of code would solve th
eproblem. For example here is 1,100+ of Crap++ code such as Boost's over-engineered
CRC code
[boost.org] when a mere ~25 lines of SIMPLE C code would have done the trick. When was the
last time you ACTUALLY needed to _modify_ a CRC function? The BIG picture is that you are
probably looking for a BETTER HASHING function with less collisions. You probably would be
better off using a DIFFERENT algorithm such as SHA-2, etc.
7. Do NOT copy-pasta
Roughly 80% of bugs creep in because someone blindly copied-pasted without thinking. Type
out ALL code so you actually THINK about what you are writing.
8. K.I.S.S.
Over-engineering and aka technical debt, will be your Achilles' heel. Keep It Simple,
Silly.
9. Use DESCRIPTIVE variable names
You spend ~80% of your time READING code, and only ~20% writing it. Use good, descriptive
variable names. Far too programmers write usless comments and don't understand the difference
between code and comments:
Code says HOW, Comments say WHY
A crap comment will say something like: // increment i
No, Shit Sherlock! Don't comment the obvious!
A good comment will say something like: // BUGFIX: 1234:
Work-around issues caused by A, B, and C.
10. Ignoring Memory Management doesn't make it go away -- now you have two problems. (With
apologies to JWZ)
If you don't understand both the pros and cons of these programming paradigms
...
* Procedural
* Object-Orientated
* Functional, and
* Data-Orientated Design
... then you will never really understand programming, nor abstraction,
at a deep level, along with how and when it should and shouldn't be used.
12. Multi-disciplinary POV
ALL non-trivial code has bugs. If you aren't using static code analysis
[wikipedia.org] then you are not catching as many bugs as the people who are.
Also, a good programmer looks at his code from many different angles. As a programmer you
must put on many different hats to find them:
* Architect -- design the code
* Engineer / Construction Worker -- implement the code
* Tester -- test the code
* Consumer -- doesn't see the code, only sees the results. Does it even work?? Did you VERIFY
it did BEFORE you checked your code into version control?
13. Learn multiple Programming Languages
Each language was designed to solve certain problems. Learning different languages, even
ones you hate, will expose you to different concepts. e.g. If you don't how how to read
assembly language AND your high level language then you will never be as good as the
programmer who does both.
14. Respect your Colleagues' and Consumers Time, Space, and Money.
Mobile game are the WORST at respecting people's time, space and money turning "players
into payers." They treat customers as whales. Don't do this. A practical example: If you are
a slack channel with 50+ people do NOT use @here. YOUR fire is not their emergency!
15. Be Passionate
If you aren't passionate about programming, that is, you are only doing it for the money,
it will show. Take some pride in doing a GOOD job.
16. Perfect Practice Makes Perfect.
If you aren't programming every day you will never be as good as someone who is.
Programming is about solving interesting problems. Practice solving puzzles to develop your
intuition and lateral thinking. The more you practice the better you get.
"Sorry" for the book but I felt it was important to summarize the "essentials" of
programming.
--
Hey Slashdot. Fix your shitty filter so long lists can be posted.: "Your comment has too few
characters per line (currently 37.0)."
You crammed a lot of good ideas into a short post.
I'm sending my team at work a link to your post.
You mentioned code can data. Linus Torvalds had this to say:
"I'm a huge proponent of designing your code around the data, rather than the other way
around, and I think it's one of the reasons git has been fairly successful [â¦] I
will, in fact, claim that the difference between a bad programmer and a good one is whether
he considers his code or his data structures more important."
"Bad programmers worry about the code. Good programmers worry about data structures and
their relationships."
I'm inclined to agree. Once the data structure is right, the code oftem almost writes
itself. It'll be easy to write and easy to read because it's obvious how one would handle
data structured in that elegant way.
Writing the code necessary to transform the data from the input format into the right
structure can be non-obvious, but it's normally worth it.
i learnt to program at school from a Ph.D computer scientist. We never even had computers
in the class. We learnt to break the problem down into sections using flowcharts or
pseudo-code and then we would translate that program into whatever coding language we were
using. I still do this usually in my notebook where I figure out all the things I need to do
and then write the skeleton of the code using a series of comments for what each section of
my program and then I fill in the code for each section. It is a combination of top down and
bottom up programming, writing routines that can be independently tested and validated.
Parsing bash script options with getopts Posted on January 4, 2015 | 5 minutes |
Kevin Sookocheff A common task in shell scripting is to parse command line arguments to your
script. Bash provides the getopts built-in function to do just that. This tutorial
explains how to use the getopts built-in function to parse arguments and options
to a bash script.
The getopts function takes three parameters. The first is a specification of
which options are valid, listed as a sequence of letters. For example, the string
'ht' signifies that the options -h and -t are valid.
The second argument to getopts is a variable that will be populated with the
option or argument to be processed next. In the following loop, opt will hold the
value of the current option that has been parsed by getopts .
while getopts ":ht" opt; do
case ${opt} in
h ) # process option a
;;
t ) # process option t
;;
\? ) echo "Usage: cmd [-h] [-t]"
;;
esac
done
This example shows a few additional features of getopts . First, if an invalid
option is provided, the option variable is assigned the value ? . You can catch
this case and provide an appropriate usage message to the user. Second, this behaviour is only
true when you prepend the list of valid options with : to disable the default
error handling of invalid options. It is recommended to always disable the default error
handling in your scripts.
The third argument to getopts is the list of arguments and options to be
processed. When not provided, this defaults to the arguments and options provided to the
application ( $@ ). You can provide this third argument to use
getopts to parse any list of arguments and options you provide.
Shifting
processed options
The variable OPTIND holds the number of options parsed by the last call to
getopts . It is common practice to call the shift command at the end
of your processing loop to remove options that have already been handled from $@
.
shift $((OPTIND -1))
Parsing options with arguments
Options that themselves have arguments are signified with a : . The argument to
an option is placed in the variable OPTARG . In the following example, the option
t takes an argument. When the argument is provided, we copy its value to the
variable target . If no argument is provided getopts will set
opt to : . We can recognize this error condition by catching the
: case and printing an appropriate error message.
while getopts ":t:" opt; do
case ${opt} in
t )
target=$OPTARG
;;
\? )
echo "Invalid option: $OPTARG" 1>&2
;;
: )
echo "Invalid option: $OPTARG requires an argument" 1>&2
;;
esac
done
shift $((OPTIND -1))
An extended example – parsing nested arguments and options
Let's walk through an extended example of processing a command that takes options, has a
sub-command, and whose sub-command takes an additional option that has an argument. This is a
mouthful so let's break it down using an example. Let's say we are writing our own version of
the pip command . In
this version you can call pip with the -h option to display a help
message.
> pip -h
Usage:
pip -h Display this help message.
pip install Install a Python package.
We can use getopts to parse the -h option with the following
while loop. In it we catch invalid options with \? and
shift all arguments that have been processed with shift $((OPTIND
-1)) .
while getopts ":h" opt; do
case ${opt} in
h )
echo "Usage:"
echo " pip -h Display this help message."
echo " pip install Install a Python package."
exit 0
;;
\? )
echo "Invalid Option: -$OPTARG" 1>&2
exit 1
;;
esac
done
shift $((OPTIND -1))
Now let's add the sub-command install to our script. install takes
as an argument the Python package to install.
> pip install urllib3
install also takes an option, -t . -t takes as an
argument the location to install the package to relative to the current directory.
> pip install urllib3 -t ./src/lib
To process this line we must find the sub-command to execute. This value is the first
argument to our script.
subcommand=$1
shift # Remove `pip` from the argument list
Now we can process the sub-command install . In our example, the option
-t is actually an option that follows the package argument so we begin by removing
install from the argument list and processing the remainder of the line.
case "$subcommand" in
install)
package=$1
shift # Remove `install` from the argument list
;;
esac
After shifting the argument list we can process the remaining arguments as if they are of
the form package -t src/lib . The -t option takes an argument itself.
This argument will be stored in the variable OPTARG and we save it to the variable
target for further work.
case "$subcommand" in
install)
package=$1
shift # Remove `install` from the argument list
while getopts ":t:" opt; do
case ${opt} in
t )
target=$OPTARG
;;
\? )
echo "Invalid Option: -$OPTARG" 1>&2
exit 1
;;
: )
echo "Invalid Option: -$OPTARG requires an argument" 1>&2
exit 1
;;
esac
done
shift $((OPTIND -1))
;;
esac
Putting this all together, we end up with the following script that parses arguments to our
version of pip and its sub-command install .
package="" # Default to empty package
target="" # Default to empty target
# Parse options to the `pip` command
while getopts ":h" opt; do
case ${opt} in
h )
echo "Usage:"
echo " pip -h Display this help message."
echo " pip install <package> Install <package>."
exit 0
;;
\? )
echo "Invalid Option: -$OPTARG" 1>&2
exit 1
;;
esac
done
shift $((OPTIND -1))
subcommand=$1; shift # Remove 'pip' from the argument list
case "$subcommand" in
# Parse options to the install sub command
install)
package=$1; shift # Remove 'install' from the argument list
# Process package options
while getopts ":t:" opt; do
case ${opt} in
t )
target=$OPTARG
;;
\? )
echo "Invalid Option: -$OPTARG" 1>&2
exit 1
;;
: )
echo "Invalid Option: -$OPTARG requires an argument" 1>&2
exit 1
;;
esac
done
shift $((OPTIND -1))
;;
esac
After processing the above sequence of commands, the variable package will hold
the package to install and the variable target will hold the target to install the
package to. You can use this as a template for processing any set of arguments and options to
your scripts.
Update: It's been more than 5 years since I started this answer. Thank you for LOTS of great
edits/comments/suggestions. In order save maintenance time, I've modified the code block to
be 100% copy-paste ready. Please do not post comments like "What if you changed X to Y ".
Instead, copy-paste the code block, see the output, make the change, rerun the script, and
comment "I changed X to Y and " I don't have time to test your ideas and tell you if they
work.
Method #1: Using bash without getopt[s]
Two common ways to pass key-value-pair arguments are:
cat >/tmp/demo-space-separated.sh <<'EOF'
#!/bin/bash
POSITIONAL=()
while [[ $# -gt 0 ]]
do
key="$1"
case $key in
-e|--extension)
EXTENSION="$2"
shift # past argument
shift # past value
;;
-s|--searchpath)
SEARCHPATH="$2"
shift # past argument
shift # past value
;;
-l|--lib)
LIBPATH="$2"
shift # past argument
shift # past value
;;
--default)
DEFAULT=YES
shift # past argument
;;
*) # unknown option
POSITIONAL+=("$1") # save it in an array for later
shift # past argument
;;
esac
done
set -- "${POSITIONAL[@]}" # restore positional parameters
echo "FILE EXTENSION = ${EXTENSION}"
echo "SEARCH PATH = ${SEARCHPATH}"
echo "LIBRARY PATH = ${LIBPATH}"
echo "DEFAULT = ${DEFAULT}"
echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l)
if [[ -n $1 ]]; then
echo "Last line of file specified as non-opt/last argument:"
tail -1 "$1"
fi
EOF
chmod +x /tmp/demo-space-separated.sh
/tmp/demo-space-separated.sh -e conf -s /etc -l /usr/lib /etc/hosts
output from copy-pasting the block above:
FILE EXTENSION = conf
SEARCH PATH = /etc
LIBRARY PATH = /usr/lib
DEFAULT =
Number files in SEARCH PATH with EXTENSION: 14
Last line of file specified as non-opt/last argument:
#93.184.216.34 example.com
cat >/tmp/demo-equals-separated.sh <<'EOF'
#!/bin/bash
for i in "$@"
do
case $i in
-e=*|--extension=*)
EXTENSION="${i#*=}"
shift # past argument=value
;;
-s=*|--searchpath=*)
SEARCHPATH="${i#*=}"
shift # past argument=value
;;
-l=*|--lib=*)
LIBPATH="${i#*=}"
shift # past argument=value
;;
--default)
DEFAULT=YES
shift # past argument with no value
;;
*)
# unknown option
;;
esac
done
echo "FILE EXTENSION = ${EXTENSION}"
echo "SEARCH PATH = ${SEARCHPATH}"
echo "LIBRARY PATH = ${LIBPATH}"
echo "DEFAULT = ${DEFAULT}"
echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l)
if [[ -n $1 ]]; then
echo "Last line of file specified as non-opt/last argument:"
tail -1 $1
fi
EOF
chmod +x /tmp/demo-equals-separated.sh
/tmp/demo-equals-separated.sh -e=conf -s=/etc -l=/usr/lib /etc/hosts
output from copy-pasting the block above:
FILE EXTENSION = conf
SEARCH PATH = /etc
LIBRARY PATH = /usr/lib
DEFAULT =
Number files in SEARCH PATH with EXTENSION: 14
Last line of file specified as non-opt/last argument:
#93.184.216.34 example.com
To better understand ${i#*=} search for "Substring Removal" in this guide . It is
functionally equivalent to `sed 's/[^=]*=//' <<< "$i"` which calls a
needless subprocess or `echo "$i" | sed 's/[^=]*=//'` which calls two
needless subprocesses.
More recent getopt versions don't have these limitations.
Additionally, the POSIX shell (and others) offer getopts which doesn't have
these limitations. I've included a simplistic getopts example.
Usage demo-getopts.sh -vf /etc/hosts foo bar
cat >/tmp/demo-getopts.sh <<'EOF'
#!/bin/sh
# A POSIX variable
OPTIND=1 # Reset in case getopts has been used previously in the shell.
# Initialize our own variables:
output_file=""
verbose=0
while getopts "h?vf:" opt; do
case "$opt" in
h|\?)
show_help
exit 0
;;
v) verbose=1
;;
f) output_file=$OPTARG
;;
esac
done
shift $((OPTIND-1))
[ "${1:-}" = "--" ] && shift
echo "verbose=$verbose, output_file='$output_file', Leftovers: $@"
EOF
chmod +x /tmp/demo-getopts.sh
/tmp/demo-getopts.sh -vf /etc/hosts foo bar
output from copy-pasting the block above:
verbose=1, output_file='/etc/hosts', Leftovers: foo bar
The advantages of getopts are:
It's more portable, and will work in other shells like dash .
It can handle multiple single options like -vf filename in the typical
Unix way, automatically.
The disadvantage of getopts is that it can only handle short options (
-h , not --help ) without additional code.
There is a getopts tutorial which explains
what all of the syntax and variables mean. In bash, there is also help getopts ,
which might be informative.
No answer mentions enhanced getopt . And the top-voted answer is misleading: It either
ignores -vfd style short options (requested by the OP) or options after
positional arguments (also requested by the OP); and it ignores parsing-errors. Instead:
Use enhanced getopt from util-linux or formerly GNU glibc .
1
It works with getopt_long() the C function of GNU glibc.
Has all useful distinguishing features (the others don't have them):
handles spaces, quoting characters and even binary in arguments
2 (non-enhanced getopt can't do this)
it can handle options at the end: script.sh -o outFile file1 file2 -v
( getopts doesn't do this)
allows = -style long options: script.sh --outfile=fileOut
--infile fileIn (allowing both is lengthy if self parsing)
allows combined short options, e.g. -vfd (real work if self
parsing)
allows touching option-arguments, e.g. -oOutfile or
-vfdoOutfile
Is so old already 3 that no GNU system is missing this (e.g. any
Linux has it).
You can test for its existence with: getopt --test → return value
4.
Other getopt or shell-builtin getopts are of limited
use.
verbose: y, force: y, debug: y, in: ./foo/bar/someFile, out: /fizz/someOtherFile
with the following myscript
#!/bin/bash
# saner programming env: these switches turn some bugs into errors
set -o errexit -o pipefail -o noclobber -o nounset
# -allow a command to fail with !'s side effect on errexit
# -use return value from ${PIPESTATUS[0]}, because ! hosed $?
! getopt --test > /dev/null
if [[ ${PIPESTATUS[0]} -ne 4 ]]; then
echo 'I'm sorry, `getopt --test` failed in this environment.'
exit 1
fi
OPTIONS=dfo:v
LONGOPTS=debug,force,output:,verbose
# -regarding ! and PIPESTATUS see above
# -temporarily store output to be able to check for errors
# -activate quoting/enhanced mode (e.g. by writing out "--options")
# -pass arguments only via -- "$@" to separate them correctly
! PARSED=$(getopt --options=$OPTIONS --longoptions=$LONGOPTS --name "$0" -- "$@")
if [[ ${PIPESTATUS[0]} -ne 0 ]]; then
# e.g. return value is 1
# then getopt has complained about wrong arguments to stdout
exit 2
fi
# read getopt's output this way to handle the quoting right:
eval set -- "$PARSED"
d=n f=n v=n outFile=-
# now enjoy the options in order and nicely split until we see --
while true; do
case "$1" in
-d|--debug)
d=y
shift
;;
-f|--force)
f=y
shift
;;
-v|--verbose)
v=y
shift
;;
-o|--output)
outFile="$2"
shift 2
;;
--)
shift
break
;;
*)
echo "Programming error"
exit 3
;;
esac
done
# handle non-option arguments
if [[ $# -ne 1 ]]; then
echo "$0: A single input file is required."
exit 4
fi
echo "verbose: $v, force: $f, debug: $d, in: $1, out: $outFile"
1 enhanced getopt is available on most "bash-systems", including
Cygwin; on OS X try brew install gnu-getopt or sudo port
install getopt 2 the POSIX exec() conventions have no reliable way to
pass binary NULL in command line arguments; those bytes prematurely end the argument 3 first version released in 1997 or before (I only tracked it back to
1997)
#!/bin/bash
for i in "$@"
do
case $i in
-p=*|--prefix=*)
PREFIX="${i#*=}"
;;
-s=*|--searchpath=*)
SEARCHPATH="${i#*=}"
;;
-l=*|--lib=*)
DIR="${i#*=}"
;;
--default)
DEFAULT=YES
;;
*)
# unknown option
;;
esac
done
echo PREFIX = ${PREFIX}
echo SEARCH PATH = ${SEARCHPATH}
echo DIRS = ${DIR}
echo DEFAULT = ${DEFAULT}
To better understand ${i#*=} search for "Substring Removal" in this guide . It is
functionally equivalent to `sed 's/[^=]*=//' <<< "$i"` which calls a
needless subprocess or `echo "$i" | sed 's/[^=]*=//'` which calls two
needless subprocesses.
I'm about 4 years late to this question, but want to give back. I used the earlier answers as
a starting point to tidy up my old adhoc param parsing. I then refactored out the following
template code. It handles both long and short params, using = or space separated arguments,
as well as multiple short params grouped together. Finally it re-inserts any non-param
arguments back into the $1,$2.. variables. I hope it's useful.
#!/usr/bin/env bash
# NOTICE: Uncomment if your script depends on bashisms.
#if [ -z "$BASH_VERSION" ]; then bash $0 $@ ; exit $? ; fi
echo "Before"
for i ; do echo - $i ; done
# Code template for parsing command line parameters using only portable shell
# code, while handling both long and short params, handling '-f file' and
# '-f=file' style param data and also capturing non-parameters to be inserted
# back into the shell positional parameters.
while [ -n "$1" ]; do
# Copy so we can modify it (can't modify $1)
OPT="$1"
# Detect argument termination
if [ x"$OPT" = x"--" ]; then
shift
for OPT ; do
REMAINS="$REMAINS \"$OPT\""
done
break
fi
# Parse current opt
while [ x"$OPT" != x"-" ] ; do
case "$OPT" in
# Handle --flag=value opts like this
-c=* | --config=* )
CONFIGFILE="${OPT#*=}"
shift
;;
# and --flag value opts like this
-c* | --config )
CONFIGFILE="$2"
shift
;;
-f* | --force )
FORCE=true
;;
-r* | --retry )
RETRY=true
;;
# Anything unknown is recorded for later
* )
REMAINS="$REMAINS \"$OPT\""
break
;;
esac
# Check for multiple short options
# NOTICE: be sure to update this pattern to match valid options
NEXTOPT="${OPT#-[cfr]}" # try removing single short opt
if [ x"$OPT" != x"$NEXTOPT" ] ; then
OPT="-$NEXTOPT" # multiple short opts, keep going
else
break # long form, exit inner loop
fi
done
# Done with that param. move to next
shift
done
# Set the non-parameters back into the positional parameters ($1 $2 ..)
eval set -- $REMAINS
echo -e "After: \n configfile='$CONFIGFILE' \n force='$FORCE' \n retry='$RETRY' \n remains='$REMAINS'"
for i ; do echo - $i ; done
> ,
I have found the matter to write portable parsing in scripts so frustrating that I have
written Argbash - a FOSS
code generator that can generate the arguments-parsing code for your script plus it has some
nice features:
Example:6) Forcefully overwrite write protected file at destination (mv -f)
Use '-f' option in mv command to forcefully overwrite the write protected file at
destination. Let's assumes we have a file named " bands.txt " in our present working directory
and in /tmp/sysadmin.
[linuxbuzz@web ~]$ ls -l bands.txt /tmp/sysadmin/bands.txt
-rw-rw-r--. 1 linuxbuzz linuxbuzz 0 Aug 25 00:24 bands.txt
-r--r--r--. 1 linuxbuzz linuxbuzz 0 Aug 25 00:24 /tmp/sysadmin/bands.txt
[linuxbuzz@web ~]$
As we can see under /tmp/sysadmin, bands.txt is write protected file,
Example:8) Create backup at destination while using mv command (mv -b)
Use '-b' option to take backup of a file at destination while performing mv command, at
destination backup file will be created with tilde character appended to it, example is shown
below,
Example:9) Move file only when its newer than destination (mv -u)
There are some scenarios where we same file at source and destination and we wan to move the
file only when file at source is newer than the destination, so to accomplish, use -u option in
mv command. Example is shown below
[linuxbuzz@web ~]$ ls -l tools.txt /tmp/sysadmin/tools.txt
-rw-rw-r--. 1 linuxbuzz linuxbuzz 55 Aug 25 00:55 /tmp/sysadmin/tools.txt
-rw-rw-r--. 1 linuxbuzz linuxbuzz 87 Aug 25 00:57 tools.txt
[linuxbuzz@web ~]$
Execute below mv command to mv file only when its newer than destination,
We take our first glimpse at the Ansible
documentation on the official website. While Ansible can be overwhelming with so many
immediate options, let's break down what is presented to us here. Putting our attention on the
page's main pane, we are given five offerings from Ansible. This pane is a central location, or
one-stop-shop, to maneuver through the documentation for products like Ansible Tower, Ansible
Galaxy, and Ansible Lint: Image
We can even dive into Ansible Network for specific module documentation that extends the
power and ease of Ansible automation to network administrators. The focal point of the rest of
this article will be around Ansible Project, to give us a great starting point into our
automation journey:
Image
Once we click the Ansible Documentation tile under the Ansible Project section, the first
action we should take is to ensure we are viewing the documentation's correct version. We can
get our current version of Ansible from our control node's command line by running
ansible --version . Armed with the version information provided by the output, we
can select the matching version in the site's upper-left-hand corner using the drop-down menu,
that by default says latest :
An array variable whose members are the line numbers in source files corresponding to each member of FUNCNAME .
${BASH_LINENO[$i]} is the line number in the source file where ${FUNCNAME[$i]} was called. The corresponding
source file name is ${BASH_SOURCE[$i]} . Use LINENO to obtain the current line number.
I have a test script which has a lot of commands and will generate lots of output, I use
set -x or set -v and set -e , so the script would stop
when error occurs. However, it's still rather difficult for me to locate which line did the
execution stop in order to locate the problem. Is there a method which can output the line
number of the script before each line is executed? Or output the line number before the
command exhibition generated by set -x ? Or any method which can deal with my
script line location problem would be a great help. Thanks.
You mention that you're already using -x . The variable PS4 denotes
the value is the prompt printed before the command line is echoed when the -x
option is set and defaults to : followed by space.
You can change PS4 to emit the LINENO (The line number in the
script or shell function currently executing).
For example, if your script reads:
$ cat script
foo=10
echo ${foo}
echo $((2 + 2))
Executing it thus would print line numbers:
$ PS4='Line ${LINENO}: ' bash -x script
Line 1: foo=10
Line 2: echo 10
10
Line 3: echo 4
4
Simple (but powerful) solution: Place echo around the code you think that causes
the problem and move the echo line by line until the messages does not appear
anymore on screen - because the script has stop because of an error before.
Even more powerful solution: Install bashdb the bash debugger and debug the
script line by line
In a fairly sophisticated script I wouldn't like to see all line numbers; rather I would
like to be in control of the output.
Define a function
echo_line_no () {
grep -n "$1" $0 | sed "s/echo_line_no//"
# grep the line(s) containing input $1 with line numbers
# replace the function name with nothing
} # echo_line_no
Use it with quotes like
echo_line_no "this is a simple comment with a line number"
Output is
16 "this is a simple comment with a line number"
if the number of this line in the source file is 16.
Sure. Why do you need this? How do you work with this? What can you do with this? Is this
simple approach really sufficient or useful? Why do you want to tinker with this at all?
~/.config/gogo/gogo.conf
file (which should be auto created if it doesn't exist) and has the following syntax.
# Comments are lines that start from '#' character.
default = ~/something
alias = /desired/path
alias2 = /desired/path with space
alias3 = "/this/also/works"
zażółć = "unicode/is/also/supported/zażółć gęślą jaźń"
If you run gogo run without any arguments, it will go to the directory specified in default;
this alias is always available, even if it's not in the configuration file, and points to $HOME
directory.
To display the current aliases, use the -l switch. From the following
screenshot, you can see that default points to ~/home/tecmint which is user
tecmint's home directory on the system.
You can also create aliases for connecting directly into directories on a remote Linux
servers. To do this, simple add the following lines to gogo configuration file, which can be
accessed using -e flag, this will use the editor specified in the $EDITOR env variable.
$ gogo -e
One configuration file opens, add these following lines to it.
The bulk of what this tool does can be replaced with a shell function that does `
cd $(grep -w ^$1 ~/.config/gogo.conf | cut -f2 -d' ') `, where
`$1` is the argument supplied to the function.
If you've already installed fzf (and you really should), then you can get a far better
experience than even zsh's excellent "completion" facilities. I use something like `
cd $(fzf -1 +m -q "$1" < ~/.cache/to) ` (My equivalent of gogo.conf is `
~/.cache/to `).
Tutorial on using exit codes from Linux or UNIX commands. Examples of how to get the exit code of a command,
how to set the exit code and how to suppress exit codes.
Estimated reading time: 3 minutes
Table of contents
What is an exit code in the UNIX or Linux shell?
An exit code, or sometimes known as a return code, is the code returned to a parent process by an executable. On
POSIX
systems the standard exit code is
0
for success and any number from
1
to
255
for
anything else.
Exit codes can be interpreted by machine scripts to adapt in the event of successes of failures. If exit codes are not set the
exit code will be the exit code of the last run command.
How to get the exit code of a command
To get the exit code of a command type
echo $?
at the command prompt. In the following example a file is printed
to the terminal using the
cat
command.
cat file.txt
hello world
echo $?
0
The command was successful. The file exists and there are no errors in reading the file or writing it to the terminal. The
exit code is therefore
0
.
In the following example the file does not exist.
cat doesnotexist.txt
cat: doesnotexist.txt: No such file or directory
echo $?
1
The exit code is
1
as the operation was not successful.
How to use exit codes in scripts
To use exit codes in scripts an
if
statement can be used to see if an operation was successful.
#!/bin/bash
cat file.txt
if [ $? -eq 0 ]
then
echo "The script ran ok"
exit 0
else
echo "The script failed" >&2
exit 1
fi
If the command was unsuccessful the exit code will be
0
and 'The script ran ok' will be printed to the terminal.
How to set an exit code
To set an exit code in a script use
exit 0
where
0
is the number you want to return. In the
following example a shell script exits with a
1
. This file is saved as
exit.sh
.
#!/bin/bash
exit 1
Executing this script shows that the exit code is correctly set.
bash exit.sh
echo $?
1
What exit code should I use?
The Linux Documentation Project has a list of
reserved codes
that also offers advice on what code to use for specific scenarios. These are the standard error codes in
Linux or UNIX.
1
- Catchall for general errors
2
- Misuse of shell builtins (according to Bash documentation)
126
- Command invoked cannot execute
127
- "command not found"
128
- Invalid argument to exit
128+n
- Fatal error signal "n"
130
- Script terminated by Control-C
255\*
- Exit status out of range
How to suppress exit statuses
Sometimes there may be a requirement to suppress an exit status. It may be that a command is being run within another script
and that anything other than a
0
status is undesirable.
In the following example a file is printed to the terminal using
cat
.
This file does not exist so will cause an exit status of
1
.
To suppress the error message any output to standard error is sent to
/dev/null
using
2>/dev/null
.
If the cat command fails an
OR
operation can be used to provide a fallback -
cat file.txt || exit 0
.
In this case an exit code of
0
is returned even if there is an error.
Combining both the suppression of error output and the
OR
operation the following script returns a status code of
0
with no output even though the file does not exist.
Exit codes are a number between 0 and 255, which is returned by any Unix command when it
returns control to its parent process.
Other numbers can be used, but these are treated modulo 256, so exit -10 is
equivalent to exit 246 , and exit 257 is equivalent to exit
1 .
These can be used within a shell script to change the flow of execution depending on the
success or failure of commands executed. This was briefly introduced in Variables - Part II . Here we shall look
in more detail in the available interpretations of exit codes.
Success is traditionally represented with exit 0 ; failure is
normally indicated with a non-zero exit-code. This value can indicate different reasons for
failure.
For example, GNU grep returns 0 on success, 1 if no
matches were found, and 2 for other errors (syntax errors, non-existent input
files, etc).
We shall look at three different methods for checking error status, and discuss the pros and
cons of each approach.
Firstly, the simple approach:
#!/bin/sh
# First attempt at checking return codes
USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1`
if [ "$?" -ne "0" ]; then
echo "Sorry, cannot find user ${1} in /etc/passwd"
exit 1
fi
NAME=`grep "^${1}:" /etc/passwd|cut -d":" -f5`
HOMEDIR=`grep "^${1}:" /etc/passwd|cut -d":" -f6`
echo "USERNAME: $USERNAME"
echo "NAME: $NAME"
echo "HOMEDIR: $HOMEDIR"
This script works fine if you supply a valid username in /etc/passwd . However, if
you enter an invalid code, it does not do what you might at first expect - it keeps running,
and just shows:
USERNAME:
NAME:
HOMEDIR:
Why is this? As mentioned, the $? variable is set to the return code of the
last executed command . In this case, that is cut . cut had no
problems which it feels like reporting - as far as I can tell from testing it, and reading the
documentation, cut returns zero whatever happens! It was fed an empty string, and
did its job - returned the first field of its input, which just happened to be the empty
string.
So what do we do? If we have an error here, grep will report it, not
cut . Therefore, we have to test grep 's return code, not
cut 's.
#!/bin/sh
# Second attempt at checking return codes
grep "^${1}:" /etc/passwd > /dev/null 2>&1
if [ "$?" -ne "0" ]; then
echo "Sorry, cannot find user ${1} in /etc/passwd"
exit 1
fi
USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1`
NAME=`grep "^${1}:" /etc/passwd|cut -d":" -f5`
HOMEDIR=`grep "^${1}:" /etc/passwd|cut -d":" -f6`
echo "USERNAME: $USERNAME"
echo "NAME: $NAME"
echo "HOMEDIR: $HOMEDIR"
This fixes the problem for us, though at the expense of slightly longer code.
That is the basic way which textbooks might show you, but it is far from being all there is to
know about error-checking in shell scripts. This method may not be the most suitable to your
particular command-sequence, or may be unmaintainable. Below, we shall investigate two
alternative approaches.
As a second approach, we can tidy this somewhat by putting the test into a separate
function, instead of littering the code with lots of 4-line tests:
#!/bin/sh
# A Tidier approach
check_errs()
{
# Function. Parameter 1 is the return code
# Para. 2 is text to display on failure.
if [ "${1}" -ne "0" ]; then
echo "ERROR # ${1} : ${2}"
# as a bonus, make our script exit with the right error code.
exit ${1}
fi
}
### main script starts here ###
grep "^${1}:" /etc/passwd > /dev/null 2>&1
check_errs $? "User ${1} not found in /etc/passwd"
USERNAME=`grep "^${1}:" /etc/passwd|cut -d":" -f1`
check_errs $? "Cut returned an error"
echo "USERNAME: $USERNAME"
check_errs $? "echo returned an error - very strange!"
This allows us to test for errors 3 times, with customised error messages, without having to
write 3 individual tests. By writing the test routine once. we can call it as many times as we
wish, creating a more intelligent script, at very little expense to the programmer. Perl
programmers will recognise this as being similar to the die command in Perl.
As a third approach, we shall look at a simpler and cruder method. I tend to use this for
building Linux kernels - simple automations which, if they go well, should just get on with it,
but when things go wrong, tend to require the operator to do something intelligent (ie, that
which a script cannot do!):
#!/bin/sh
cd /usr/src/linux && \
make dep && make bzImage && make modules && make modules_install && \
cp arch/i386/boot/bzImage /boot/my-new-kernel && cp System.map /boot && \
echo "Your new kernel awaits, m'lord."
This script runs through the various tasks involved in building a Linux kernel (which can
take quite a while), and uses the && operator to check for success. To do this
with if would involve:
#!/bin/sh
cd /usr/src/linux
if [ "$?" -eq "0" ]; then
make dep
if [ "$?" -eq "0" ]; then
make bzImage
if [ "$?" -eq "0" ]; then
make modules
if [ "$?" -eq "0" ]; then
make modules_install
if [ "$?" -eq "0" ]; then
cp arch/i386/boot/bzImage /boot/my-new-kernel
if [ "$?" -eq "0" ]; then
cp System.map /boot/
if [ "$?" -eq "0" ]; then
echo "Your new kernel awaits, m'lord."
fi
fi
fi
fi
fi
fi
fi
fi
... which I, personally, find pretty difficult to follow.
The && and || operators are the shell's equivalent of AND and
OR tests. These can be thrown together as above, or:
Only one command can be in each part. This method is handy for simple success / fail
scenarios, but if you want to check on the status of the echo commands themselves,
it is easy to quickly become confused about which && and ||
applies to which command. It is also very difficult to maintain. Therefore this construct is
only recommended for simple sequencing of commands.
In earlier versions, I had suggested that you can use a subshell to execute multiple
commands depending on whether the cp command succeeded or failed:
cp /foo /bar && ( echo Success ; echo Success part II; ) || ( echo Failed ; echo Failed part II )
But in fact, Marcel found that this does not work properly. The syntax for a subshell
is:
( command1 ; command2; command3 )
The return code of the subshell is the return code of the final command (
command3 in this example). That return code will affect the overall command. So
the output of this script:
cp /foo /bar && ( echo Success ; echo Success part II; /bin/false ) || ( echo Failed ; echo Failed part II )
Is that it runs the Success part (because cp succeeded, and then - because
/bin/false returns failure, it also executes the Failure part:
Success
Success part II
Failed
Failed part II
So if you need to execute multiple commands as a result of the status of some other
condition, it is better (and much clearer) to use the standard if ,
then , else syntax.
First of all, stop executing everything as root . You never really need to do this. Only run
individual commands with sudo if you need to. If a normal command doesn't work
without sudo, just call sudo !! to execute it again.
If you're paranoid about rm , mv and other operations while
running as root, you can add the following aliases to your shell's configuration file:
[ $UID = 0 ] && \
alias rm='rm -i' && \
alias mv='mv -i' && \
alias cp='cp -i'
These will all prompt you for confirmation ( -i ) before removing a file or
overwriting an existing file, respectively, but only if you're root (the user
with ID 0).
Don't get too used to that though. If you ever find yourself working on a system that
doesn't prompt you for everything, you might end up deleting stuff without noticing it. The
best way to avoid mistakes is to never run as root and think about what exactly you're doing
when you use sudo .
I am using rm within a BASH script to delete many files. Sometimes the files are
not present, so it reports many errors. I do not need this message. I have searched the man
page for a command to make rm quiet, but the only option I found is
-f , which from the description, "ignore nonexistent files, never prompt", seems
to be the right choice, but the name does not seem to fit, so I am concerned it might have
unintended consequences.
Is the -f option the correct way to silence rm ? Why isn't it
called -q ?
The main use of -f is to force the removal of files that would not be removed
using rm by itself (as a special case, it "removes" non-existent files, thus
suppressing the error message).
You can also just redirect the error message using
$ rm file.txt 2> /dev/null
(or your operating system's equivalent). You can check the value of $?
immediately after calling rm to see if a file was actually removed or not.
As far as rm -f doing "anything else", it does force ( -f is
shorthand for --force ) silent removal in situations where rm would
otherwise ask you for confirmation. For example, when trying to remove a file not writable by
you from a directory that is writable by you.
Any one can let me know the possible return codes for the command rm -rf other than zero i.e,
possible return codes for failure cases. I want to know more detailed reason for the failure
of the command unlike just the command is failed(return other than 0).
To see the return code, you can use echo $? in bash.
To see the actual meaning, some platforms (like Debian Linux) have the perror
binary available, which can be used as follows:
$ rm -rf something/; perror $?
rm: cannot remove `something/': Permission denied
OS error code 1: Operation not permitted
rm -rf automatically suppresses most errors. The most likely error you will
see is 1 (Operation not permitted), which will happen if you don't have
permissions to remove the file. -f intentionally suppresses most errors
Enterprises are deploying self-contained micro data centers to power computing at the
network edge.
Calvin Hennick is a freelance journalist who specializes in business and technology
writing. He is a contributor to the CDW family of technology magazines.
The location for data processing has changed significantly throughout the history of
computing. During the mainframe era, data was processed centrally, but client/server
architectures later decentralized computing. In recent years, cloud computing centralized many
processing workloads, but digital transformation and the Internet of Things are poised to move
computing to new places, such as the network edge .
"There's a big transformation happening," says Thomas Humphrey, segment director for edge
computing at APC .
"Technologies like IoT have started to require that some local computing and storage happen out
in that distributed IT architecture."
For example, some IoT systems require processing of data at remote locations rather than a
centralized data center , such as at a retail store instead of a corporate headquarters.
To meet regulatory requirements and business needs, IoT solutions often need low latency,
high bandwidth, robust security and superior reliability . To meet these demands, many
organizations are deploying micro data centers: self-contained solutions that provide not only
essential infrastructure, but also physical security, power and cooling and remote management
capabilities.
"Digital transformation happens at the network edge, and edge computing will happen inside
micro data centers ," says Bruce A. Taylor, executive vice president at Datacenter Dynamics . "This will probably be one
of the fastest growing segments -- if not the fastest growing segment -- in data centers for
the foreseeable future."
What Is a Micro Data Center?
Delivering the IT capabilities needed for edge computing represents a significant challenge
for many organizations, which need manageable and secure solutions that can be deployed easily,
consistently and close to the source of computing . Vendors such as APC have begun to create
comprehensive solutions that provide these necessary capabilities in a single, standardized
package.
"From our perspective at APC, the micro data center was a response to what was happening in
the market," says Humphrey. "We were seeing that enterprises needed more robust solutions at
the edge."
Most micro data center solutions rely on hyperconverged
infrastructure to integrate computing, networking and storage technologies within a compact
footprint . A typical micro data center also incorporates physical infrastructure (including
racks), fire suppression, power, cooling and remote management capabilities. In effect, the
micro data center represents a sweet spot between traditional IT closets and larger modular
data centers -- giving organizations the ability to deploy professional, powerful IT resources
practically anywhere .
Standardized Deployments Across the Country
Having robust IT resources at the network edge helps to improve reliability and reduce
latency, both of which are becoming more and more important as analytics programs require that
data from IoT deployments be processed in real time .
"There's always been edge computing," says Taylor. "What's new is the need to process
hundreds of thousands of data points for analytics at once."
Standardization, redundant deployment and remote management are also attractive features,
especially for large organizations that may need to deploy tens, hundreds or even thousands of
micro data centers. "We spoke to customers who said, 'I've got to roll out and install 3,500 of
these around the country,'" says Humphrey. "And many of these companies don't have IT staff at
all of these sites." To address this scenario, APC designed standardized, plug-and-play micro
data centers that can be rolled out seamlessly. Additionally, remote management capabilities
allow central IT departments to monitor and troubleshoot the edge infrastructure without costly
and time-intensive site visits.
In part because micro data centers operate in far-flung environments, security is of
paramount concern. The self-contained nature of micro data centers ensures that only authorized
personnel will have access to infrastructure equipment , and security tools such as video
surveillance provide organizations with forensic evidence in the event that someone attempts to
infiltrate the infrastructure.
How Micro Data Centers Can Help in Retail, Healthcare
Micro data centers make business sense for any organization that needs secure IT
infrastructure at the network edge. But the solution is particularly appealing to organizations
in fields such as retail, healthcare and finance , where IT environments are widely distributed
and processing speeds are often a priority.
In retail, for example, edge computing will become more important as stores find success
with IoT technologies such as mobile beacons, interactive mirrors and real-time tools for
customer experience, behavior monitoring and marketing .
"It will be leading-edge companies driving micro data center adoption, but that doesn't
necessarily mean they'll be technology companies," says Taylor. "A micro data center can power
real-time analytics for inventory control and dynamic pricing in a supermarket."
In healthcare,
digital transformation is beginning to touch processes and systems ranging from medication
carts to patient records, and data often needs to be available locally; for example, in case of
a data center outage during surgery. In finance, the real-time transmission of data can have
immediate and significant financial consequences. And in both of these fields, regulations
governing data privacy make the monitoring and security features of micro data centers even
more important.
Micro data centers also have enormous potential to power smart city initiatives and to give
energy companies a cost-effective way of deploying resources in remote locations , among other
use cases.
"The proliferation of edge computing will be greater than anything we've seen in the past,"
Taylor says. "I almost can't think of a field where this won't matter."
Learn
more about how solutions and services from CDW and APC can help your organization overcome
its data center challenges.
Micro Data Centers Versus IT Closets
Think the micro data center is just a glorified update on the traditional IT closet? Think
again.
"There are demonstrable differences," says Bruce A. Taylor, executive vice president at
Datacenter Dynamics. "With micro data centers, there's a tremendous amount of computing
capacity in a very small, contained space, and we just didn't have that capability previously
."
APC identifies three key differences between IT closets and micro data centers:
Difference #1: Uptime Expectations. APC notes that, of the nearly 3 million IT closets in
the U.S., over 70 percent report outages directly related to human error. In an unprotected IT
closet, problems can result from something as preventable as cleaning staff unwittingly
disconnecting a cable. Micro data centers, by contrast, utilize remote monitoring, video
surveillance and sensors to reduce downtime related to human error.
Difference #2: Cooling Configurations. The cooling of IT wiring closets is often approached
both reactively and haphazardly, resulting in premature equipment failure. Micro data centers
are specifically designed to assure cooling compatibility with anticipated loads.
Difference #3: Power Infrastructure. Unlike many IT closets, micro data centers incorporate
uninterruptible power supplies, ensuring that infrastructure equipment has the power it needs
to help avoid downtime.
I want to insert some items into mc menu (which is opened by F2) grouped together. Is it
possible to insert some sort of separator before them or put them into some submenu?
Probably, not.
The format of the menu file is very simple. Lines that start with anything but
space or tab are considered entries for the menu (in order to be able to use
it like a hot key, the first character should be a letter). All the lines that
start with a space or a tab are the commands that will be executed when the
entry is selected.
But MC allows you to make multiple menu entries with same shortcut and title, so you can
make a menu entry that looks like separator and does nothing, like:
a hello
echo world
- --------
b world
echo hello
- --------
c superuser
ls /
The above would compress the current directory (%d) to a file also in the current directory. If you want to compress the directory
pointed to by the cursor rather than the current directory, use %f instead:
tar -czf %f_$(date '+%%Y%%m%%d').tar.gz %f
mc handles escaping of special characters so there is no need to put %f in quotes.
By the way, midnight commander's special treatment of percent signs occurs not just in the user menu file but also at the command
line. This is an issue when using shell commands with constructs like ${var%.c} . At the command line, the same as
in the user menu file, percent signs can be escaped by doubling them.
I need to copy all the *.c files from local laptop named hostA to hostB including all directories. I am using the following scp
command but do not know how to exclude specific files (such as *.out): $ scp -r ~/projects/ user@hostB:/home/delta/projects/
How do I tell scp command to exclude particular file or directory at the Linux/Unix command line? One can use scp command to securely
copy files between hosts on a network. It uses ssh for data transfer and authentication purpose. Typical scp command syntax is as
follows: scp file1 user@host:/path/to/dest/ scp -r /path/to/source/ user@host:/path/to/dest/ scp [options] /dir/to/source/
user@host:/dir/to/dest/
Scp exclude files
I don't think so you can filter or exclude files when using scp command. However, there is a great workaround to exclude files
and copy it securely using ssh. This page explains how to filter or excludes files when using scp to copy a directory recursively.
-a : Recurse into directories i.e. copy all files and subdirectories. Also, turn on archive mode and all other
options (-rlptgoD)
-v : Verbose output
-e ssh : Use ssh for remote shell so everything gets encrypted
--exclude='*.out' : exclude files matching PATTERN e.g. *.out or *.c and so on.
Example of rsync command
In this example copy all file recursively from ~/virt/ directory but exclude all *.new files: $ rsync -av -e ssh --exclude='*.new' ~/virt/ root@centos7:/tmp
It is documented in the help, the node is "Edit Menu File" under "Command Menu"; if you
scroll down you should find "Addition Conditions":
If the condition begins with '+' (or '+?') instead of '=' (or '=?') it is an addition
condition. If the condition is true the menu entry will be included in the menu. If the
condition is false the menu entry will not be included in the menu.
This is preceded by "Default conditions" (the = condition), which determine
which entry will be highlighted as the default choice when the menu appears. Anyway, by way
of example:
+ t r & ! t t
t r means if this is a regular file ("t(ype) r"), and ! t t
means if the file has not been tagged in the interface.
As I understand pipes and commands, bash takes each command, spawns a process for each one
and connects stdout of the previous one with the stdin of the next one.
For example, in "ls -lsa | grep feb", bash will create two processes, and connect the
output of "ls -lsa" to the input of "grep feb".
When you execute a background command like "sleep 30 &" in bash, you get the pid of
the background process running your command. Surprisingly for me, when I wrote "ls -lsa |
grep feb &" bash returned only one PID.
How should this be interpreted? A process runs both "ls -lsa" and "grep feb"? Several
process are created but I only get the pid of one of them?
When you run a job in the background, bash prints the process ID of its subprocess, the one
that runs the command in that job. If that job happens to create more subprocesses, that's
none of the parent shell's business.
When the background job is a pipeline (i.e. the command is of the form something1 |
something2 & , and not e.g. { something1 | something2; } & ),
there's an optimization which is strongly suggested by POSIX and performed by most shells
including bash: each of the elements of the pipeline are executed directly as subprocesses of
the original shell. What POSIX mandates is that the variable
$! is set to the last command in the pipeline in this case. In most shells,
that last command is a subprocess of the original process, and so are the other commands in
the pipeline.
When you run ls -lsa | grep feb , there are three processes involved: the one
that runs the left-hand side of the pipe (a subshell that finishes setting up the pipe then
executes ls ), the one that runs the right-hand side of the pipe (a subshell
that finishes setting up the pipe then executes grep ), and the original process
that waits for the pipe to finish.
You can watch what happens by tracing the processes:
use grep [n]ame to remove that grep -v name this is first... Sec using xargs in the way how
it is up there is wrong to rnu whatever it is piped you have to use -i ( interactive mode)
otherwise you may have issues with the command.
I start a background process from my shell script, and I would like to kill this process when my script finishes.
How to get the PID of this process from my shell script? As far as I can see variable $! contains the PID of the
current script, not the background process.
You need to save the PID of the background process at the time you start it:
foo &
FOO_PID=$!
# do other stuff
kill $FOO_PID
You cannot use job control, since that is an interactive feature and tied to a controlling terminal. A script will not necessarily
have a terminal attached at all so job control will not necessarily be available.
An even simpler way to kill all child process of a bash script:
pkill -P $$
The -P flag works the same way with pkill and pgrep - it gets child processes, only
with pkill the child processes get killed and with pgrep child PIDs are printed to stdout.
this is what I have done. Check it out, hope it can help.
#!/bin/bash
#
# So something to show.
echo "UNO" > UNO.txt
echo "DOS" > DOS.txt
#
# Initialize Pid List
dPidLst=""
#
# Generate background processes
tail -f UNO.txt&
dPidLst="$dPidLst $!"
tail -f DOS.txt&
dPidLst="$dPidLst $!"
#
# Report process IDs
echo PID=$$
echo dPidLst=$dPidLst
#
# Show process on current shell
ps -f
#
# Start killing background processes from list
for dPid in $dPidLst
do
echo killing $dPid. Process is still there.
ps | grep $dPid
kill $dPid
ps | grep $dPid
echo Just ran "'"ps"'" command, $dPid must not show again.
done
Then just run it as: ./bgkill.sh with proper permissions of course
root@umsstd22 [P]:~# ./bgkill.sh
PID=23757
dPidLst= 23758 23759
UNO
DOS
UID PID PPID C STIME TTY TIME CMD
root 3937 3935 0 11:07 pts/5 00:00:00 -bash
root 23757 3937 0 11:55 pts/5 00:00:00 /bin/bash ./bgkill.sh
root 23758 23757 0 11:55 pts/5 00:00:00 tail -f UNO.txt
root 23759 23757 0 11:55 pts/5 00:00:00 tail -f DOS.txt
root 23760 23757 0 11:55 pts/5 00:00:00 ps -f
killing 23758. Process is still there.
23758 pts/5 00:00:00 tail
./bgkill.sh: line 24: 23758 Terminated tail -f UNO.txt
Just ran 'ps' command, 23758 must not show again.
killing 23759. Process is still there.
23759 pts/5 00:00:00 tail
./bgkill.sh: line 24: 23759 Terminated tail -f DOS.txt
Just ran 'ps' command, 23759 must not show again.
root@umsstd22 [P]:~# ps -f
UID PID PPID C STIME TTY TIME CMD
root 3937 3935 0 11:07 pts/5 00:00:00 -bash
root 24200 3937 0 11:56 pts/5 00:00:00 ps -f
This typically gives a text representation of all the processes for the "user" and the -p option gives the process-id. It does
not depend, as far as I understand, on having the processes be owned by the current shell. It also shows forks.
pgrep can get you all of the child PIDs of a parent process. As mentioned earlier $$ is the current
scripts PID. So, if you want a script that cleans up after itself, this should do the trick:
"... You can create hard links and symbolic links using C-x l and C-x s keyboard shortcuts. However, these two shortcuts invoke two completely different dialogs. ..."
"... he had also uploaded a sample mc user menu script ( local copy ), which works wonderfully! ..."
You can create hard links and symbolic links using C-x l and C-x s keyboard shortcuts.
However, these two shortcuts invoke two completely different dialogs.
While for C-x s you get 2 pre-populated fields (path to the existing file, and path to the
link – which is pre-populated with your opposite file panel path plus the name of the
file under cursor; simply try it to see what I mean), for C-x l you only get 1 empty field:
path of the hard link to create for a file under cursor. Symlink's behaviour would be much more
convenient
Fortunately, a good man called Wiseman1024 created a feature request in the MC's bug tracker 6
years ago. Not only had he done so, but he had also uploaded a sample mc user
menu script ( local copy ), which
works wonderfully! You can select multiple files, then F2 l (lower-case L), and hard-links to
your selected files (or a file under cursor) will be created in the opposite file panel. Great,
thank you Wiseman1024 !
Word of warning: you must know what hard links are and what their limitations are
before using this menu script. You also must check and understand the user menu code before
adding it to your mc (by F9 C m u , and then pasting the script from the file).
Word of hope: 4 years ago Wiseman's feature request was assigned to Future Releases
version, so a more convenient C-x l will (sooner or later) become the part of mc. Hopefully
[ -n file.txt ] doesn't check its size , it checks that the string file.txt is
non-zero length, so it will always succeed.
If you want to say " size is non-zero", you need [ -s file.txt ] .
To get a file's size , you can use wc -c to get the size ( file length) in bytes:
file=file.txt
minimumsize=90000
actualsize=$(wc -c <"$file")
if [ $actualsize -ge $minimumsize ]; then
echo size is over $minimumsize bytes
else
echo size is under $minimumsize bytes
fi
In this case, it sounds like that's what you want.
But FYI, if you want to know how much disk space the file is using, you could use du -k to get the
size (disk space used) in kilobytes:
file=file.txt
minimumsize=90
actualsize=$(du -k "$file" | cut -f 1)
if [ $actualsize -ge $minimumsize ]; then
echo size is over $minimumsize kilobytes
else
echo size is under $minimumsize kilobytes
fi
If you need more control over the output format, you can also look at stat . On Linux, you'd start with something
like stat -c '%s' file.txt , and on BSD/Mac OS X, something like stat -f '%z' file.txt .
--Mikel
5 Why du -b "$file" | cut -f 1 instead of stat -c '%s' "$file" ? Or stat --printf="%s" "$file"
? – mivk Dec
14 '13 at 11:00
It surprises me that no one mentioned stat to check file size. Some methods are definitely better: using -s
to find out whether the file is empty or not is easier than anything else if that's all you want. And if you want to
find files of a size, then find is certainly the way to go.
I also like du a lot to get file size in kb, but, for bytes, I'd use stat :
size=$(stat -f%z $filename) # BSD stat
size=$(stat -c%s $filename) # GNU stat?
alternative solution with awk and double parenthesis:
FILENAME=file.txt
SIZE=$(du -sb $FILENAME | awk '{ print $1 }')
if ((SIZE<90000)) ; then
echo "less";
else
echo "not less";
fi
Alright, so simple problem here. I'm working on a simple back up code. It works fine except
if the files have spaces in them. This is how I'm finding files and adding them to a tar
archive:
find . -type f | xargs tar -czvf backup.tar.gz
The problem is when the file has a space in the name because tar thinks that it's a
folder. Basically is there a way I can add quotes around the results from find? Or a
different way to fix this?
For anyone that has found this post through numerous googling, I found a way to not only
find specific files given a time range, but also NOT include the relative paths OR
whitespaces that would cause tarring errors. (THANK YOU SO MUCH STEVE.)
find . -name "*.pdf" -type f -mtime 0 -printf "%f\0" | tar -czvf /dir/zip.tar.gz --null -T -
. relative directory
-name "*.pdf" look for pdfs (or any file type)
-type f type to look for is a file
-mtime 0 look for files created in last 24 hours
-printf "%f\0" Regular -print0 OR -printf "%f"
did NOT work for me. From man pages:
This quoting is performed in the same way as for GNU ls. This is not the same quoting
mechanism as the one used for -ls and -fls. If you are able to decide what format to use
for the output of find then it is normally better to use '\0' as a terminator than to use
newline, as file names can contain white space and newline characters.
-czvf create archive, filter the archive through gzip , verbosely list
files processed, archive name
Some versions of tar, for example, the default versions on HP-UX (I tested 11.11 and 11.31),
do not include a command line option to specify a file list, so a decent work-around is to do
this:
On Solaris, you can use the option -I to read the filenames that you would normally state on
the command line from a file. In contrast to the command line, this can create tar archives
with hundreds of thousands of files (just did that).
Is there a simple shell command/script that supports excluding certain files/folders from
being archived?
I have a directory that need to be archived with a sub directory that has a number of very
large files I do not need to backup.
Not quite solutions:
The tar --exclude=PATTERN command matches the given pattern and excludes
those files, but I need specific files & folders to be ignored (full file path),
otherwise valid files might be excluded.
I could also use the find command to create a list of files and exclude the ones I don't
want to archive and pass the list to tar, but that only works with for a small amount of
files. I have tens of thousands.
I'm beginning to think the only solution is to create a file with a list of files/folders
to be excluded, then use rsync with --exclude-from=file to copy all the files to
a tmp directory, and then use tar to archive that directory.
Can anybody think of a better/more efficient solution?
EDIT: Charles Ma 's solution works well. The big gotcha is that the
--exclude='./folder' MUST be at the beginning of the tar command. Full command
(cd first, so backup is relative to that directory):
cd /folder_to_backup
tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz .
so, you want to make a tar file that contain everyting inside /home/ftp/mysite (to move
the site to a new server), but file3 is just junk, and everything in
folder3 is also not needed, so we will skip those two.
we use the format
tar -czvf <name of tar file> <what to tar> <any excludes>
where the c = create, z = zip, and v = verbose (you can see the files as they are entered,
usefull to make sure none of the files you exclude are being added). and f= file.
so, my command would look like this
cd /home/ftp/
tar -czvf mysite.tar.gz mysite --exclude='file3' --exclude='folder3'
note the files/folders excluded are relatively to the root of your tar (I have tried full
path here relative to / but I can not make that work).
hope this will help someone (and me next time I google it)
I've experienced that, at least with the Cygwin version of tar I'm using
("CYGWIN_NT-5.1 1.7.17(0.262/5/3) 2012-10-19 14:39 i686 Cygwin" on a Windows XP Home Edition
SP3 machine), the order of options is important.
While this construction worked for me:
tar cfvz target.tgz --exclude='<dir1>' --exclude='<dir2>' target_dir
that one didn't work:
tar cfvz --exclude='<dir1>' --exclude='<dir2>' target.tgz target_dir
This, while tar --help reveals the following:
tar [OPTION...] [FILE]
So, the second command should also work, but apparently it doesn't seem to be the
case...
I found this somewhere else so I won't take credit, but it worked better than any of the
solutions above for my mac specific issues (even though this is closed):
tar zc --exclude __MACOSX --exclude .DS_Store -f <archive> <source(s)>
$ tar --exclude='./folder_or_file' --exclude='file_pattern' --exclude='fileA'
A word of warning for a side effect that I did not find immediately obvious: The exclusion
of 'fileA' in this example will search for 'fileA' RECURSIVELY!
Example:A directory with a single subdirectory containing a file of the same name
(data.txt)
If using --exclude='data.txt' the archive will not contain EITHER data.txt
file. This can cause unexpected results if archiving third party libraries, such as a
node_modules directory.
To avoid this issue make sure to give the entire path, like
--exclude='./dirA/data.txt'
To avoid possible 'xargs: Argument list too long' errors due to the use of
find ... | xargs ... when processing tens of thousands of files, you can pipe
the output of find directly to tar using find ... -print0 |
tar --null ... .
# archive a given directory, but exclude various files & directories
# specified by their full file paths
find "$(pwd -P)" -type d \( -path '/path/to/dir1' -or -path '/path/to/dir2' \) -prune \
-or -not \( -path '/path/to/file1' -or -path '/path/to/file2' \) -print0 |
gnutar --null --no-recursion -czf archive.tar.gz --files-from -
#bsdtar --null -n -czf archive.tar.gz -T -
Use the find command in conjunction with the tar append (-r) option. This way you can add
files to an existing tar in a single step, instead of a two pass solution (create list of
files, create tar).
You can use cpio(1) to create tar files. cpio takes the files to archive on stdin, so if
you've already figured out the find command you want to use to select the files the archive,
pipe it into cpio to create the tar file:
gnu tar v 1.26 the --exclude needs to come after archive file and backup directory arguments,
should have no leading or trailing slashes, and prefers no quotes (single or double). So
relative to the PARENT directory to be backed up, it's:
tar cvfz /path_to/mytar.tgz ./dir_to_backup
--exclude=some_path/to_exclude
After reading all this good answers for different versions and having solved the problem for
myself, I think there are very small details that are very important, and rare to GNU/Linux
general use , that aren't stressed enough and deserves more than comments.
So I'm not going to try to answer the question for every case, but instead, try to
register where to look when things doesn't work.
IT IS VERY IMPORTANT TO NOTICE:
THE ORDER OF THE OPTIONS MATTER: it is not the same put the --exclude before than after
the file option and directories to backup. This is unexpected at least to me, because in my
experience, in GNU/Linux commands, usually the order of the options doesn't matter.
Different tar versions expects this options in different order: for instance,
@Andrew's answer indicates that in GNU tar v 1.26 and 1.28 the excludes comes last,
whereas in my case, with GNU tar 1.29, it's the other way.
THE TRAILING SLASHES MATTER : at least in GNU tar 1.29, it shouldn't be any .
In my case, for GNU tar 1.29 on Debian stretch, the command that worked was
tar --exclude="/home/user/.config/chromium" --exclude="/home/user/.cache" -cf file.tar /dir1/ /home/ /dir3/
The quotes didn't matter, it worked with or without them.
tar -cvzf destination_folder source_folder -X /home/folder/excludes.txt
-X indicates a file which contains a list of filenames which must be excluded from the
backup. For Instance, you can specify *~ in this file to not include any filenames ending
with ~ in the backup.
Possible redundant answer but since I found it useful, here it is:
While a FreeBSD root (i.e. using csh) I wanted to copy my whole root filesystem to /mnt
but without /usr and (obviously) /mnt. This is what worked (I am at /):
tar --exclude ./usr --exclude ./mnt --create --file - . (cd /mnt && tar xvd -)
My whole point is that it was necessary (by putting the ./ ) to specify to tar that
the excluded directories where part of the greater directory being copied.
I had no luck getting tar to exclude a 5 Gigabyte subdirectory a few levels deep. In the end,
I just used the unix Zip command. It worked a lot easier for me.
So for this particular example from the original post
(tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz . )
The equivalent would be:
zip -r /backup/filename.zip . -x upload/folder/**\* upload/folder2/**\*
The following bash script should do the trick. It uses the answer given
here by Marcus Sundman.
#!/bin/bash
echo -n "Please enter the name of the tar file you wish to create with out extension "
read nam
echo -n "Please enter the path to the directories to tar "
read pathin
echo tar -czvf $nam.tar.gz
excludes=`find $pathin -iname "*.CC" -exec echo "--exclude \'{}\'" \;|xargs`
echo $pathin
echo tar -czvf $nam.tar.gz $excludes $pathin
This will print out the command you need and you can just copy and paste it back in. There
is probably a more elegant way to provide it directly to the command line.
Just change *.CC for any other common extension, file name or regex you want to exclude
and this should still work.
EDIT
Just to add a little explanation; find generates a list of files matching the chosen regex
(in this case *.CC). This list is passed via xargs to the echo command. This prints --exclude
'one entry from the list'. The slashes () are escape characters for the ' marks.
I've got a job running on my server at the command line prompt for a two days now:
find data/ -name filepattern-*2009* -exec tar uf 2009.tar {} ;
It is taking forever , and then some. Yes, there are millions of files in the
target directory. (Each file is a measly 8 bytes in a well hashed directory structure.) But
just running...
...takes only two hours or so. At the rate my job is running, it won't be finished for a
couple of weeks .. That seems unreasonable. Is there a more efficient to do this?
Maybe with a more complicated bash script?
A secondary questions is "why is my current approach so slow?"
If you already did the second command that created the file list, just use the
-T option to tell tar to read the files names from that saved file list. Running
1 tar command vs N tar commands will be a lot better.
Here's a find-tar combination that can do what you want without the use of xargs or exec
(which should result in a noticeable speed-up):
tar --version # tar (GNU tar) 1.14
# FreeBSD find (on Mac OS X)
find -x data -name "filepattern-*2009*" -print0 | tar --null --no-recursion -uf 2009.tar --files-from -
# for GNU find use -xdev instead of -x
gfind data -xdev -name "filepattern-*2009*" -print0 | tar --null --no-recursion -uf 2009.tar --files-from -
# added: set permissions via tar
find -x data -name "filepattern-*2009*" -print0 | \
tar --null --no-recursion --owner=... --group=... --mode=... -uf 2009.tar --files-from -
Guessing why it is slow is hard as there is not much information. What is the structure of
the directory, what filesystem do you use, how it was configured on creating. Having milions
of files in single directory is quite hard situation for most filesystems.
To correctly handle file names with weird (but legal) characters (such as newlines, ...) you
should write your file list to filesOfInterest.txt using find's -print0:
find -x data -name "filepattern-*2009*" -print0 > filesOfInterest.txt
tar --null --no-recursion -uf 2009.tar --files-from filesOfInterest.txt
The way you currently have things, you are invoking the tar command every single time it
finds a file, which is not surprisingly slow. Instead of taking the two hours to print plus
the amount of time it takes to open the tar archive, see if the files are out of date, and
add them to the archive, you are actually multiplying those times together. You might have
better success invoking the tar command once, after you have batched together all the names,
possibly using xargs to achieve the invocation. By the way, I hope you are using
'filepattern-*2009*' and not filepattern-*2009* as the stars will be expanded by the shell
without quotes.
You should check if most of your time are being spent on CPU or in I/O. Either way, there are
ways to improve it:
A: don't compress
You didn't mention "compression" in your list of requirements so try dropping the "z" from
your arguments list: tar cf . This might be speed up things a bit.
There are other techniques to speed-up the process, like using "-N " to skip files you
already backed up before.
B: backup the whole partition with dd
Alternatively, if you're backing up an entire partition, take a copy of the whole disk
image instead. This would save processing and a lot of disk head seek time.
tar and any other program working at a higher level have a overhead of having to
read and process directory entries and inodes to find where the file content is and to do
more head disk seeks , reading each file from a different place from the disk.
To backup the underlying data much faster, use:
dd bs=16M if=/dev/sda1 of=/another/filesystem
(This assumes you're not using RAID, which may change things a bit)
,
To repeat what others have said: we need to know more about the files that are being backed
up. I'll go with some assumptions here. Append to the tar file
If files are only being added to the directories (that is, no file is being deleted), make
sure you are appending to the existing tar file rather than re-creating it every time. You
can do this by specifying the existing archive filename in your tar command
instead of a new one (or deleting the old one).
Write to a different disk
Reading from the same disk you are writing to may be killing performance. Try writing to a
different disk to spread the I/O load. If the archive file needs to be on the same disk as
the original files, move it afterwards.
Don't compress
Just repeating what @Yves said. If your backup files are already compressed, there's not
much need to compress again. You'll just be wasting CPU cycles.
10 YAML tips for people who hate YAML
Do you hate YAML? These tips might ease your pain.
Posted June 10, 2019
|
by
Seth Kenlon
(Red Hat)
Image
There are lots of formats for configuration files: a list of values, key and value pairs, INI files,
YAML, JSON, XML, and many more. Of these, YAML sometimes gets cited as a particularly difficult one to
handle for a few different reasons. While its ability to reflect hierarchical values is significant
and its minimalism can be refreshing to some, its Python-like reliance upon syntactic whitespace can
be frustrating.
However, the open source world is diverse and flexible enough that no one has to
suffer through abrasive technology, so if you hate YAML, here are 10 things you can (and should!) do
to make it tolerable. Starting with zero, as any sensible index should.
0. Make your editor do the work
Whatever text editor you use probably has plugins to make dealing with syntax easier. If you're not
using a YAML plugin for your editor, find one and install it. The effort you spend on finding a plugin
and configuring it as needed will pay off tenfold the very next time you edit YAML.
For example, the
Atom
editor comes with a YAML mode
by default, and while GNU Emacs ships with minimal support, you can add additional packages like
yaml-mode
to help.
Emacs
in YAML and whitespace mode.
If your favorite text editor lacks a YAML mode, you can address some of your grievances with small
configuration changes. For instance, the default text editor for the GNOME desktop, Gedit, doesn't
have a YAML mode available, but it does provide YAML syntax highlighting by default and features
configurable tab width:
Configuring
tab width and type in Gedit.
With the
drawspaces
Gedit plugin package, you can make white space visible in the form of leading
dots, removing any question about levels of indentation.
Take some time to research your favorite text editor. Find out what the editor, or its community,
does to make YAML easier, and leverage those features in your work. You won't be sorry.
1. Use a linter
Ideally, programming languages and markup languages use predictable syntax. Computers tend to do
well with predictability, so the concept of a
linter
was invented in 1978. If you're not using a linter for YAML, then it's time to adopt this 40-year-old
tradition and use
yamllint
.
Invoking
yamllint
is as simple as telling it to check a file. Here's an example of
yamllint
's response to a YAML file containing an error:
$ yamllint errorprone.yaml
errorprone.yaml
23:10 error syntax error: mapping values are not allowed here
23:11 error trailing spaces (trailing-spaces)
That's not a time stamp on the left. It's the error's line and column number. You may or may not
understand what error it's talking about, but now you know the error's location. Taking a second look
at the location often makes the error's nature obvious. Success is eerily silent, so if you want
feedback based on the lint's success, you can add a conditional second command with a double-ampersand
(
&&
). In a POSIX shell,
&&
fails if a command returns anything
but
0, so upon success, your
echo
command makes that clear. This tactic is somewhat
superficial, but some users prefer the assurance that the command did run correctly, rather than
failing silently. Here's an example:
$ yamllint perfect.yaml && echo "OK"
OK
The reason
yamllint
is so silent when it succeeds is that it returns 0 errors when
there are no errors.
2. Write in Python, not YAML
If you really hate YAML, stop writing in YAML, at least in the literal sense. You might be stuck
with YAML because that's the only format an application accepts, but if the only requirement is to end
up in YAML, then work in something else and then convert. Python, along with the excellent
pyyaml
library, makes this easy, and you have two
methods to choose from: self-conversion or scripted.
Self-conversion
In the self-conversion method, your data files are also Python scripts that produce YAML. This
works best for small data sets. Just write your JSON data into a Python variable, prepend an
import
statement, and end the file with a simple three-line output statement.
#!/usr/bin/python3
import yaml
d={
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
f=open('output.yaml','w')
f.write(yaml.dump(d))
f.close
Run the file with Python to produce a file called
output.yaml
file.
$ python3 ./example.json
$ cat output.yaml
glossary:
GlossDiv:
GlossList:
GlossEntry:
Abbrev: ISO 8879:1986
Acronym: SGML
GlossDef:
GlossSeeAlso: [GML, XML]
para: A meta-markup language, used to create markup languages such as DocBook.
GlossSee: markup
GlossTerm: Standard Generalized Markup Language
ID: SGML
SortAs: SGML
title: S
title: example glossary
This output is perfectly valid YAML, although
yamllint
does issue a warning that the
file is not prefaced with
---
, which is something you can adjust either in the Python
script or manually.
Scripted conversion
In this method, you write in JSON and then run a Python conversion script to produce YAML. This
scales better than self-conversion, because it keeps the converter separate from the data.
Create a JSON file and save it as
example.json
. Here is an example from
json.org
:
{
"glossary": {
"title": "example glossary",
"GlossDiv": {
"title": "S",
"GlossList": {
"GlossEntry": {
"ID": "SGML",
"SortAs": "SGML",
"GlossTerm": "Standard Generalized Markup Language",
"Acronym": "SGML",
"Abbrev": "ISO 8879:1986",
"GlossDef": {
"para": "A meta-markup language, used to create markup languages such as DocBook.",
"GlossSeeAlso": ["GML", "XML"]
},
"GlossSee": "markup"
}
}
}
}
}
Create a simple converter and save it as
json2yaml.py
. This script imports both the
YAML and JSON Python modules, loads a JSON file defined by the user, performs the conversion, and then
writes the data to
output.yaml
.
Save this script in your system path, and execute as needed:
$ ~/bin/json2yaml.py example.json
3. Parse early, parse often
Sometimes it helps to look at a problem from a different angle. If your problem is YAML, and you're
having a difficult time visualizing the data's relationships, you might find it useful to restructure
that data, temporarily, into something you're more familiar with.
If you're more comfortable with dictionary-style lists or JSON, for instance, you can convert YAML
to JSON in two commands using an interactive Python shell. Assume your YAML file is called
mydata.yaml
.
There are many other examples, and there are plenty of online converters and local parsers, so
don't hesitate to reformat data when it starts to look more like a laundry list than markup.
4. Read the spec
After I've been away from YAML for a while and find myself using it again, I go straight back to
yaml.org
to re-read the spec. If
you've never read the specification for YAML and you find YAML confusing, a glance at the spec may
provide the clarification you never knew you needed. The specification is surprisingly easy to read,
with the requirements for valid YAML spelled out with lots of examples in
chapter 6
.
5. Pseudo-config
Before I started writing my book,
Developing Games on the
Raspberry Pi
, Apress, 2019, the publisher asked me for an outline. You'd think an outline would be
easy. By definition, it's just the titles of chapters and sections, with no real content. And yet, out
of the 300 pages published, the hardest part to write was that initial outline.
YAML can be the same way. You may have a notion of the data you need to record, but that doesn't
mean you fully understand how it's all related. So before you sit down to write YAML, try doing a
pseudo-config instead.
A pseudo-config is like pseudo-code. You don't have to worry about structure or indentation,
parent-child relationships, inheritance, or nesting. You just create iterations of data in the way you
currently understand it inside your head.
A
pseudo-config.
Once you've got your pseudo-config down on paper, study it, and transform your results into valid
YAML.
6. Resolve the spaces vs. tabs debate
OK, maybe you won't
definitively
resolve the
spaces-vs-tabs debate
,
but you should at least resolve the debate within your project or organization. Whether you resolve
this question with a post-process
sed
script, text editor configuration, or a blood-oath
to respect your linter's results, anyone in your team who touches a YAML project must agree to use
spaces (in accordance with the YAML spec).
Any good text editor allows you to define a number of spaces instead of a tab character, so the
choice shouldn't negatively affect fans of the
Tab
key.
Tabs and spaces are, as you probably know all too well, essentially invisible. And when something
is out of sight, it rarely comes to mind until the bitter end, when you've tested and eliminated all
of the "obvious" problems. An hour wasted to an errant tab or group of spaces is your signal to create
a policy to use one or the other, and then to develop a fail-safe check for compliance (such as a Git
hook to enforce linting).
7. Less is more (or more is less)
Some people like to write YAML to emphasize its structure. They indent vigorously to help
themselves visualize chunks of data. It's a sort of cheat to mimic markup languages that have explicit
delimiters.
For some users, this approach is a helpful way to lay out a YAML document, while other users miss
the structure for the void of seemingly gratuitous white space.
If you own and maintain a YAML document, then
you
get to define what "indentation" means.
If blocks of horizontal white space distract you, then use the minimal amount of white space required
by the YAML spec. For example, the same YAML from the Ansible documentation can be represented with
fewer indents without losing any of its validity or meaning:
I'm a big fan of repetition breeding familiarity, but sometimes repetition just breeds repeated
stupid mistakes. Luckily, a clever peasant woman experienced this very phenomenon back in 396 AD
(don't fact-check me), and invented the concept of the
recipe
.
If you find yourself making YAML document mistakes over and over, you can embed a recipe or
template in the YAML file as a commented section. When you're adding a section, copy the commented
recipe and overwrite the dummy data with your new real data. For example:
I'm a fan of YAML, generally, but sometimes YAML isn't the answer. If you're not locked into YAML
by the application you're using, then you might be better served by some other configuration format.
Sometimes config files outgrow themselves and are better refactored into simple Lua or Python scripts.
YAML is a great tool and is popular among users for its minimalism and simplicity, but it's not the
only tool in your kit. Sometimes it's best to part ways. One of the benefits of YAML is that parsing
libraries are common, so as long as you provide migration options, your users should be able to adapt
painlessly.
If YAML is a requirement, though, keep these tips in mind and conquer your YAML hatred once and for
all!
What to read next
Skip to
main content
We use cookies on our websites to deliver our online services. Details about how we use cookies and how you may disable
them are set out in our
Privacy Statement
. By using
this website you agree to our use of cookies.
×
Search
Enable SysAdmin
Ansible
is an open source tool for software provisioning, application deployment, orchestration,
configuration, and administration. Its purpose is to help you automate your configuration processes
and simplify the administration of multiple systems. Thus, Ansible essentially pursues the same goals
as Puppet, Chef, or Saltstack.
What I like about Ansible is that it's flexible, lean, and easy to start with. In most use cases,
it keeps the job simple.
I chose to use Ansible back in 2016 because no agent has to be installed on the managed nodes -- a
node is what Ansible calls a managed remote system. All you need to start managing a remote system
with Ansible is SSH access to the system, and Python installed on it. Python is preinstalled on most
Linux systems, and I was already used to managing my hosts via SSH, so I was ready to start right
away. And if the day comes where I decide not to use Ansible anymore, I just have to delete my Ansible
controller machine (control node) and I'm good to go. There are no agents left on the managed nodes
that have to be removed.
Ansible offers two ways to control your nodes. The first one uses
playbooks
.
These are simple ASCII files written in
Yet Another Markup Language (YAML)
, which is easy to read and write. And second, there are the
ad-hoc
commands
, which allow you to run a command or
module
without having to create a playbook first.
You organize the hosts you would like to manage and control in an
inventory
file, which offers flexible format options. For example, this could be an INI-like file
that looks like:
I would like to give you two small examples of how to use Ansible. I started with these really
simple tasks before I used Ansible to take control of more complex tasks in my infrastructure.
Ad-hoc: Check if Ansible can remote manage
a system
As you might recall from the beginning of this article, all you need to manage a remote host is SSH
access to it, and a working Python interpreter on it. To check if these requirements are fulfilled,
run the following ad-hoc command against a host from your inventory:
Playbook: Register a system and attach a
subscription
This example shows how to use a playbook to keep installed packages up to date. The playbook is an
ASCII text file which looks like this:
---
# Make sure all packages are up to date
- name: Update your system
hosts: mail.example.com
tasks:
- name: Make sure all packages are up to date
yum:
name: "*"
state: latest
Now, we are ready to run the playbook:
[jkastning@ansible]$ ansible-playbook yum_update.yml
PLAY [Update your system] **************************************************************************
TASK [Gathering Facts] *****************************************************************************
ok: [mail.example.com]
TASK [Make sure all packages are up to date] *******************************************************
ok: [mail.example.com]
PLAY RECAP *****************************************************************************************
mail.example.com : ok=2 changed=0 unreachable=0 failed=0
Here everything is ok and there is nothing else to do. All installed packages are already the
latest version.
Today, Ansible saves me a lot of time and supports my day-to-day work tasks quite well. So what are
you waiting for? Try it, use it, and feel a bit more comfortable at work.
What to read next
Image
10 YAML tips for people who hate YAML
Do you hate YAML? These tips might ease your pain.
Posted:
June 10, 2019
Author:
Seth Kenlon
(Red Hat)
Topics:
Automation
Ansible
AUTOMATION FOR EVERYONE
Getting started with Ansible
Get started
Jörg Kastning
Joerg is a sysadmin for over ten years now. He is a member of the Red Hat Accelerators and runs
his own blog at https://www.my-it-brain.de.
More
about me
Related Content
Image
10 YAML
tips for people who hate YAML
Do you hate YAML? These tips might ease your pain.
Posted:
June 10, 2019
Author:
Seth Kenlon
(Red Hat)
OUR BEST CONTENT, DELIVERED TO YOUR INBOX
https://www.redhat.com/sysadmin/eloqua-embedded-subscribe.html?offer_id=701f20000012gE7AAI
The opinions expressed on this website are those of each author, not of the author's employer or of Red Hat.
Red Hat and the Red Hat logo are trademarks of Red Hat, Inc., registered in the United States and other
countries.
There are several different applications available for free use which will allow you to flash ISO images to USB drives. In this
example, we will use Etcher. It is a free and open-source utility for flashing images to SD cards & USB drives and supports Windows,
macOS, and Linux.
Head over to the Etcher downloads page , and download the
most recent Etcher version for your operating system. Once the file is downloaded, double-click on it and follow the installation
wizard.
Creating Bootable Linux USB Drive using Etcher is a relatively straightforward process, just follow the steps outlined below:
Connect the USB flash drive to your system and Launch Etcher.
Click on the Select image button and locate the distribution .iso file.
If only one USB drive is attached to your machine, Etcher will automatically select it. Otherwise, if more than one SD cards
or USB drives are connected make sure you have selected the correct USB drive before flashing the image.
I'm trying to tar a collection of files in a directory called 'my_directory' and
remove the originals by using the command:
tar -cvf files.tar my_directory --remove-files
However it is only removing the individual files inside the directory and not the
directory itself (which is what I specified in the command). What am I missing here?
EDIT:
Yes, I suppose the 'remove-files' option is fairly literal. Although I too found the man
page unclear on that point. (In linux I tend not to really distinguish much between
directories and files that much, and forget sometimes that they are not the same thing). It
looks like the consensus is that it doesn't remove directories.
However, my major prompting point for asking this question stems from tar's handling of
absolute paths. Because you must specify a relative path to a file/s to be compressed, you
therefore must change to the parent directory to tar it properly. As I see it using any kind
of follow-on 'rm' command is potentially dangerous in that situation. Thus I was hoping to
simplify things by making tar itself do the remove.
For example, imagine a backup script where the directory to backup (ie. tar) is included
as a shell variable. If that shell variable value was badly entered, it is possible that the
result could be deleted files from whatever directory you happened to be in last.
logFile={path to a run log that captures status messages}
Then you could execute something along the lines of:
cd ${parent}
tar cvf Tar_File.`date%Y%M%D_%H%M%S` ${source}
if [ $? != 0 ]
then
echo "Backup FAILED for ${source} at `date` >> ${logFile}
else
echo "Backup SUCCESS for ${source} at `date` >> ${logFile}
rm -rf ${source}
fi
Also the word "file" is ambigous in this case. But because this is a command line switch I
would it expect to mean also directories, because in unix/lnux everything is a file, also a
directory. (The other interpretation is of course also valid, but It makes no sense to keep
directories in such a case. I would consider it unexpected and confusing behavior.)
But I have found that in gnu tar on some distributions gnu tar actually removes the
directory tree. Another indication that keeping the tree was a bug. Or at least some
workaround until they fixed it.
This is what I tried out on an ubuntu 10.04 console:
Mounting archives with FUSE and archivemount Author: Ben Martin The archivemount FUSE filesystem lets you mount a possibly compressed tarball
as a filesystem. Because FUSE exposes its filesystems through the Linux kernel, you can use any
application to load and save files directly into such mounted archives. This lets you use your
favourite text editor, image viewer, or music player on files that are still inside an archive
file. Going one step further, because archivemount also supports write access for some archive
formats, you can edit a text file directly from inside an archive too.
I couldn't find any packages that let you easily install archivemount for mainstream
distributions. Its distribution includes a single source file
and a Makefile.
archivemount depends on libarchive for the heavy lifting.
Packages of libarchive exist for Ubuntu Gutsy and openSUSE
for not for Fedora. To compile libarchive you need to have uudecode installed; my version came
with the sharutils package on Fedora 8. Once you have uudecode, you can build libarchive using
the standard ./configure; make; sudo make install process.
With libarchive installed, either from source or from packages, simply invoke
make to build archivemount itself. To install archivemount, copy its binary into
/usr/local/bin and set permissions appropriately. A common setup on Linux distributions is to
have a fuse group that a user must be a member of in order to mount a FUSE filesystem. It makes
sense to have the archivemount command owned by this group as a reminder to users that they
require that permission in order to use the tool. Setup is shown below:
To show how you can use archivemount I'll first create a trivial compressed tarball, then
mount it with archivemount. You can then explore the directory structure of the contents of the
tarball with the ls command, and access a file from the archive directly with cat.
$ mkdir
-p /tmp/archivetest
$ cd /tmp/archivetest
$ date >datefile1
$ date >datefile2
$ mkdir subA
$ date >subA/foobar
$ cd /tmp
$ tar czvf archivetest.tar.gz archivetest
$ mkdir testing
$ archivemount archivetest.tar.gz testing
$ ls -l testing/archivetest/
-rw-r--r-- 0 root root 29 2008-04-02 21:04 datefile1
-rw-r--r-- 0 root root 29 2008-04-02 21:04 datefile2
drwxr-xr-x 0 root root 0 2008-04-02 21:04 subA
$ cat testing/archivetest/datefile2
Wed Apr 2 21:04:08 EST 2008
Next, I'll create a new file in the archive and read its contents back again. Notice that
the first use of the tar command directly on the tarball does not show that the newly created
file is in the archive. This is because archivemount delays all write operations until the
archive is unmounted. After issuing the fusermount -u command, the new file is
added to the archive itself.
When you unmount a FUSE filesystem, the unmount command can return before the FUSE
filesystem has fully exited. This can lead to a situation where the FUSE filesystem might run
into an error in some processing but not have a good place to report that error. The
archivemount documentation warns that if there is an error writing changes to an archive during
unmount then archivemount cannot be blamed for a loss of data. Things are not quite as grim as
they sound though. I mounted a tar.gz archive to which I had only read access and attempted to
create new files and write to existing ones. The operations failed immediately with a
"Read-only filesystem" message.
In an effort to trick archivemount into losing data, I created an archive in a format that
libarchive has only read support for. I created archivetest.zip with the original contents of
the archivetest directory and mounted it. Creating a new file worked, and reading it back was
fine. As expected from the warnings on the README file for archivemount, I did not see any
error message when I unmounted the zip file. However, attempting to view the manifest of the
zip file with unzip -l failed. It turns out that my archivemount operations had
turned the file into archivetest.zip, which was now a non-compressed POSIX tar archive. Using
tar tvf I saw that the manifest of the archivetest.zip tar archive included the
contents including the new file that I created. There was also a archivetest.zip.orig which was
in zip format and contained the contents of the zip archive when I mounted it with
archivemount.
So it turns out to be fairly tricky to get archivemount to lose data. Mounting a read-only
archive file didn't work, and modifying an archive format that libarchive could only read from
didn't work, though in the last case you will have to contend with the archive format being
silently changed. One other situation could potentially trip you up: Because archivemount
creates a new archive at unmount time, you should make sure that you will not run out of disk
space where the archives are stored.
To test archivemount's performance, I used the bonnie++ filesystem benchmark version 1.03. Because
archivemount holds off updating the actual archive until the filesystem is unmounted, you will
get good performance when accessing and writing to a mounted archive. As shown below, when
comparing the use of archivemount on an archive file stored in /tmp to direct access to a
subdirectory in /tmp, seek times for archivemount were halved on average relative to direct
access, and you can expect about 70% of the performance of direct access when using
archivemount for rewriting. The bonnie++ documentation explains that for the rewrite test, a
chunk of data is a read, dirtied, and written back to a file, and this requires a seek, so
archivemount's slower seek performance likely causes this benchmark to be slower as well.
When you want to pluck a few files out of a tarball, archivemount might be just the command
for the job. Instead of expanding the archive into /tmp just to load a few files into Emacs,
just mount the archive and run Emacs directly on the archivemount filesystem. As the bonnie++
benchmarks above show, an application using an archivemount filesystem does not necessarily
suffer a performance hit.
In the last chapter, you learned about the first three operations to tar . This
chapter presents the remaining five operations to tar : `--append' ,
`--update' , `--concatenate' , `--delete' , and
`--compare' .
You are not likely to use these operations as frequently as those covered in the last
chapter; however, since they perform specialized functions, they are quite useful when you do
need to use them. We will give examples using the same directory and files that you created in
the last chapter. As you may recall, the directory is called `practice' , the files
are `jazz' , `blues' , `folk' , and the two archive
files you created are `collection.tar' and `music.tar' .
We will also use the archive files `afiles.tar' and `bfiles.tar' .
The archive `afiles.tar' contains the members `apple' ,
`angst' , and `aspic' ; `bfiles.tar' contains the
members `./birds' , `baboon' , and `./box' .
Unless we state otherwise, all practicing you do and examples you follow in this chapter
will take place in the `practice' directory that you created in the previous chapter;
see Preparing a Practice
Directory for Examples . (Below in this section, we will remind you of the state of the
examples where the last chapter left them.)
The five operations that we will cover in this chapter are:
`--append'
`-r'
Add new entries to an archive that already exists.
`--update'
`-u'
Add more recent copies of archive members to the end of an archive, if they exist.
`--concatenate'
`--catenate'
`-A'
Add one or more pre-existing archives to the end of another archive.
`--delete'
Delete items from an archive (does not work on tapes).
`--compare'
`--diff'
`-d'
Compare archive members to their counterparts in the file system.
4.2.2 How to Add Files to Existing Archives: `--append'
If you want to add files to an existing archive, you don't need to create a new archive; you
can use `--append' ( `-r' ). The archive must already exist in order
to use `--append' . (A related operation is the `--update' operation;
you can use this to add newer versions of archive members to an existing archive. To learn how
to do this with `--update' , see section Updating an
Archive .)
If you use `--append' to add a file that has the same name as an archive member
to an archive containing that archive member, then the old member is not deleted. What does
happen, however, is somewhat complex. tarallows you to have infinite
number of files with the same name. Some operations treat these same-named members no
differently than any other set of archive members: for example, if you view an archive with
`--list' ( `-t' ), you will see all of those members listed, with
their data modification times, owners, etc.
Other operations don't deal with these members as perfectly as you might prefer; if you were
to use `--extract' to extract the archive, only the most recently added copy of a
member with the same name as other members would end up in the working directory. This is
because `--extract' extracts an archive in the order the members appeared in the
archive; the most recently archived members will be extracted last. Additionally, an extracted
member will replace a file of the same name which existed in the directory already, and
tar will not prompt you about this (10) . Thus,
only the most recently archived member will end up being extracted, as it will replace the one
extracted before it, and so on.
There exists a special option that allows you to get around this behavior and extract (or
list) only a particular copy of the file. This is `--occurrence' option. If you
run tar with this option, it will extract only the first copy of the file. You may
also give this option an argument specifying the number of copy to be extracted. Thus, for
example if the archive `archive.tar' contained three copies of file `myfile'
, then the command
tar --extract --file archive.tar --occurrence=2 myfile
would extract only the second copy. See section --occurrence , for
the description of `--occurrence' option.
See hag - you might want to incorporate some of the above into the MMwtSN node; not
sure. i didn't know how to make it simpler...
There are a few ways to get around this. Xref to Multiple Members with the Same Name,
maybe.
If you want to replace an archive member, use `--delete' to delete the member
you want to remove from the archive, and then use `--append' to add the member you
want to be in the archive. Note that you can not change the order of the archive; the most
recently added member will still appear last. In this sense, you cannot truly "replace" one
member with another. (Replacing one member with another will not work on certain types of
media, such as tapes; see Removing Archive
Members Using `--delete' and Tapes and Other
Archive Media , for more information.)
The simplest way to add a file to an already existing archive is the `--append'
( `-r' ) operation, which writes specified files into the archive whether or not
they are already among the archived files.
When you use `--append' , you must specify file name arguments, as there
is no default. If you specify a file that already exists in the archive, another copy of the
file will be added to the end of the archive. As with other operations, the member names of the
newly added files will be exactly the same as their names given on the command line. The
`--verbose' ( `-v' ) option will print out the names of the files as
they are written into the archive.
`--append' cannot be performed on some tape drives, unfortunately, due to
deficiencies in the formats those tape drives use. The archive must be a valid tar
archive, or else the results of using this operation will be unpredictable. See section
Tapes and Other
Archive Media .
To demonstrate using `--append' to add a file to an archive, create a file
called `rock' in the `practice' directory. Make sure you are in the
`practice' directory. Then, run the following tar command to add
`rock' to `collection.tar' :
$ tar --append --file=collection.tar rock
If you now use the `--list' ( `-t' ) operation, you will see that
`rock' has been added to the archive:
$ tar --list --file=collection.tar
-rw-r--r-- me/user 28 1996-10-18 16:31 jazz
-rw-r--r-- me/user 21 1996-09-23 16:44 blues
-rw-r--r-- me/user 20 1996-09-23 16:44 folk
-rw-r--r-- me/user 20 1996-09-23 16:44 rock
4.2.2.2 Multiple Members with the Same Name
You can use `--append' ( `-r' ) to add copies of files which have
been updated since the archive was created. (However, we do not recommend doing this since
there is another tar option called `--update' ; See section
Updating an
Archive , for more information. We describe this use of `--append' here for
the sake of completeness.) When you extract the archive, the older version will be effectively
lost. This works because files are extracted from an archive in the order in which they were
archived. Thus, when the archive is extracted, a file archived later in time will replace a
file of the same name which was archived earlier, even though the older version of the file
will remain in the archive unless you delete all versions of the file.
Supposing you change the file `blues' and then append the changed version to
`collection.tar' . As you saw above, the original `blues' is in the archive
`collection.tar' . If you change the file and append the new version of the file to
the archive, there will be two copies in the archive. When you extract the archive, the older
version of the file will be extracted first, and then replaced by the newer version when it is
extracted.
You can append the new, changed copy of the file `blues' to the archive in this
way:
$ tar --append --verbose --file=collection.tar blues
blues
Because you specified the `--verbose' option, tar has printed the
name of the file being appended as it was acted on. Now list the contents of the archive:
$ tar --list --verbose --file=collection.tar
-rw-r--r-- me/user 28 1996-10-18 16:31 jazz
-rw-r--r-- me/user 21 1996-09-23 16:44 blues
-rw-r--r-- me/user 20 1996-09-23 16:44 folk
-rw-r--r-- me/user 20 1996-09-23 16:44 rock
-rw-r--r-- me/user 58 1996-10-24 18:30 blues
The newest version of `blues' is now at the end of the archive (note the different
creation dates and file sizes). If you extract the archive, the older version of the file
`blues' will be replaced by the newer version. You can confirm this by extracting the
archive and running `ls' on the directory.
If you wish to extract the first occurrence of the file `blues' from the archive,
use `--occurrence' option, as shown in the following example:
$ tar --extract -vv --occurrence --file=collection.tar blues
-rw-r--r-- me/user 21 1996-09-23 16:44 blues
In the previous section, you learned how to use `--append' to add a file to an
existing archive. A related operation is `--update' ( `-u' ). The
`--update' operation updates a tar archive by comparing the date of
the specified archive members against the date of the file with the same name. If the file has
been modified more recently than the archive member, then the newer version of the file is
added to the archive (as with `--append' ).
Unfortunately, you cannot use `--update' with magnetic tape drives. The
operation will fail.
See other examples of media on which -update will fail? need to ask charles and/or
mib/thomas/dave shevett..
Both `--update' and `--append' work by adding to the end of the
archive. When you extract a file from the archive, only the version stored last will wind up in
the file system, unless you use the `--backup' option. See section Multiple
Members with the Same Name , for a detailed discussion.
4.2.3.1 How to Update an
Archive Using `--update'
You must use file name arguments with the `--update' ( `-u' )
operation. If you don't specify any files, tar won't act on any files and won't
tell you that it didn't do anything (which may end up confusing you).
To see the `--update' option at work, create a new file, `classical' ,
in your practice directory, and some extra text to the file `blues' , using any text
editor. Then invoke tar with the `update' operation and the
`--verbose' ( `-v' ) option specified, using the names of all the
files in the `practice' directory as file name arguments:
$ tar --update -v -f collection.tar blues folk rock classical
blues
classical
$
Because we have specified verbose mode, tar prints out the names of the files
it is working on, which in this case are the names of the files that needed to be updated. If
you run `tar --list' and look at the archive, you will see `blues' and
`classical' at its end. There will be a total of two versions of the member
`blues' ; the one at the end will be newer and larger, since you added text before
updating it.
The reason tar does not overwrite the older file when updating it is that
writing to the middle of a section of tape is a difficult process. Tapes are not designed to go
backward. See section Tapes and Other
Archive Media , for more information about tapes.
`--update' ( `-u' ) is not suitable for performing backups for two
reasons: it does not change directory content entries, and it lengthens the archive every time
it is used. The GNU tar options intended specifically for
backups are more efficient. If you need to run backups, please consult Performing Backups and
Restoring Files .
Sometimes it may be convenient to add a second archive onto the end of an archive rather
than adding individual files to the archive. To add one or more archives to the end of another
archive, you should use the `--concatenate' ( `--catenate' ,
`-A' ) operation.
To use `--concatenate' , give the first archive with `--file'
option and name the rest of archives to be concatenated on the command line. The members, and
their member names, will be copied verbatim from those archives to the first one (11) . The new,
concatenated archive will be called by the same name as the one given with the
`--file' option. As usual, if you omit `--file' , tar
will use the value of the environment variable TAPE , or, if this has not been
set, the default archive name.
See There is no way to specify a new name...
To demonstrate how `--concatenate' works, create two small archives called
`bluesrock.tar' and `folkjazz.tar' , using the relevant files from
`practice' :
$ tar -cvf bluesrock.tar blues rock
blues
rock
$ tar -cvf folkjazz.tar folk jazz
folk
jazz
If you like, You can run `tar --list' to make sure the archives contain what
they are supposed to:
$ tar -tvf bluesrock.tar
-rw-r--r-- melissa/user 105 1997-01-21 19:42 blues
-rw-r--r-- melissa/user 33 1997-01-20 15:34 rock
$ tar -tvf jazzfolk.tar
-rw-r--r-- melissa/user 20 1996-09-23 16:44 folk
-rw-r--r-- melissa/user 65 1997-01-30 14:15 jazz
We can concatenate these two archives with tar :
$ cd ..
$ tar --concatenate --file=bluesrock.tar jazzfolk.tar
If you now list the contents of the `bluesrock.tar' , you will see that now it also
contains the archive members of `jazzfolk.tar' :
$ tar --list --file=bluesrock.tar
blues
rock
folk
jazz
When you use `--concatenate' , the source and target archives must already
exist and must have been created using compatible format parameters. Notice, that
tar does not check whether the archives it concatenates have compatible formats,
it does not even check if the files are really tar archives.
Like `--append' ( `-r' ), this operation cannot be performed on
some tape drives, due to deficiencies in the formats those tape drives use.
It may seem more intuitive to you to want or try to use cat to concatenate two
archives instead of using the `--concatenate' operation; after all,
cat is the utility for combining files.
However, tar archives incorporate an end-of-file marker which must be removed
if the concatenated archives are to be read properly as one archive.
`--concatenate' removes the end-of-archive marker from the target archive before
each new archive is appended. If you use cat to combine the archives, the result
will not be a valid tar format archive. If you need to retrieve files from an
archive that was added to using the cat utility, use the
`--ignore-zeros' ( `-i' ) option. See section Ignoring Blocks
of Zeros , for further information on dealing with archives improperly combined using the
cat shell utility.
You can remove members from an archive by using the `--delete' option. Specify
the name of the archive with `--file' ( `-f' ) and then specify the
names of the members to be deleted; if you list no member names, nothing will be deleted. The
`--verbose' option will cause tar to print the names of the members
as they are deleted. As with `--extract' , you must give the exact member names
when using `tar --delete' . `--delete' will remove all versions of
the named file from the archive. The `--delete' operation can run very slowly.
Unlike other operations, `--delete' has no short form.
This operation will rewrite the archive. You can only use `--delete' on an
archive if the archive device allows you to write to any point on the media, such as a disk;
because of this, it does not work on magnetic tapes. Do not try to delete an archive member
from a magnetic tape; the action will not succeed, and you will be likely to scramble the
archive and damage your tape. There is no safe way (except by completely re-writing the
archive) to delete files from most kinds of magnetic tape. See section Tapes and Other
Archive Media .
To delete all versions of the file `blues' from the archive
`collection.tar' in the `practice' directory, make sure you are in that
directory, and then,
$ tar --list --file=collection.tar
blues
folk
jazz
rock
$ tar --delete --file=collection.tar blues
$ tar --list --file=collection.tar
folk
jazz
rock
See Check if the above listing is actually produced after running all the examples on
collection.tar.
The `--delete' option has been reported to work properly when tar
acts as a filter from stdin to stdout .
4.2.6 Comparing Archive
Members with the File System
The `--compare' ( `-d' ), or `--diff' operation
compares specified archive members against files with the same names, and then reports
differences in file size, mode, owner, modification date and contents. You should only
specify archive member names, not file names. If you do not name any members, then
tar will compare the entire archive. If a file is represented in the archive but
does not exist in the file system, tar reports a difference.
You have to specify the record size of the archive when modifying an archive with a
non-default record size.
tar ignores files in the file system that do not have corresponding members in
the archive.
The following example compares the archive members `rock' , `blues' and
`funk' in the archive `bluesrock.tar' with files of the same name in the file
system. (Note that there is no file, `funk' ; tar will report an error
message.)
$ tar --compare --file=bluesrock.tar rock blues funk
rock
blues
tar: funk not found in archive
The spirit behind the `--compare' ( `--diff' , `-d' )
option is to check whether the archive represents the current state of files on disk, more than
validating the integrity of the archive media. For this latter goal, see Verifying Data
as It is Stored .
With tar.gz to extract a file archiver first creates an intermediary tarball x.tar file from
x.tar.gz by uncompressing the whole archive then unpack requested files from this intermediary
tarball. In tar.gz archive is large unpacking can take several hours or even days.
@ChristopheDeTroyer Tarballs are compressed in such a way that you have to decompress
them in full, then take out the file you want. I think that .zip folders are different, so if
you want to be able to take out individual files fast, try them. – GKFX
Jun 3 '16 at 13:04
You must be aware of process name, before killing and entering a wrong process name may screw you.
# pkill mysqld
Kill more than one process at a time.
# kill PID1 PID2 PID3
or
# kill -9 PID1 PID2 PID3
or
# kill -SIGKILL PID1 PID2 PID3
What if a process have too many instances and a number of child processes, we have a command ' killall '. This is the only command
of this family, which takes process name as argument in-place of process number.
Syntax:
# killall [signal or option] Process Name
To kill all mysql instances along with child processes, use the command as follow.
# killall mysqld
You can always verify the status of the process if it is running or not, using any of the below command.
# service mysql status
# pgrep mysql
# ps -aux | grep mysql
That's all for now, from my side. I will soon be here again with another Interesting and Informative topic. Till Then, stay tuned,
connected to Tecmint and healthy. Don't forget to give your valuable feedback in comment section.
The locate command also accepts patterns containing globbing characters such as
the wildcard character * . When the pattern contains no globbing characters the
command searches for *PATTERN* , that's why in the previous example all files
containing the search pattern in their names were displayed.
The wildcard is a symbol used to represent zero, one or more characters. For example, to
search for all .md files on the system you would use:
locate *.md
To limit the search results use the -n option followed by the number of results
you want to be displayed. For example, the following command will search for all
.py files and display only 10 results:
locate -n 10 *.py
By default, locate performs case-sensitive searches. The -i (
--ignore-case ) option tels locate to ignore case and run
case-insensitive search.
To display the count of all matching entries, use the -c ( --count
) option. The following command would return the number of all files containing
.bashrc in their names:
locate -c .bashrc
6
By default, locate doesn't check whether the found files still exist on the
file system. If you deleted a file after the latest database update if the file matches the
search pattern it will be included in the search results.
To display only the names of the files that exist at the time locate is run use
the -e ( --existing ) option. For example, the following would return
only the existing .json files:
locate -e *.json
If you need to run a more complex search you can use the -r (
--regexp ) option which allows you to search using a basic regexp instead of
patterns. This option can be specified multiple times.
For example, to search for all .mp4 and .avi files on your system and
ignore case you would run:
cd my_directory/ && tar -zcvf ../my_dir.tgz . && cd -
should do the job in one line. It works well for hidden files as well. "*" doesn't expand
hidden files by path name expansion at least in bash. Below is my experiment:
$ mkdir my_directory
$ touch my_directory/file1
$ touch my_directory/file2
$ touch my_directory/.hiddenfile1
$ touch my_directory/.hiddenfile2
$ cd my_directory/ && tar -zcvf ../my_dir.tgz . && cd ..
./
./file1
./file2
./.hiddenfile1
./.hiddenfile2
$ tar ztf my_dir.tgz
./
./file1
./file2
./.hiddenfile1
./.hiddenfile2
The -C my_directory tells tar to change the current directory to
my_directory , and then . means "add the entire current directory"
(including hidden files and sub-directories).
Make sure you do -C my_directory before you do . or else you'll
get the files in the current directory.
With some conditions (archive only files, dirs and symlinks):
find /my/dir/ -printf "%P\n" -type f -o -type l -o -type d | tar -czf mydir.tgz --no-recursion -C /my/dir/ -T -
Explanation
The below unfortunately includes a parent directory ./ in the archive:
tar -czf mydir.tgz -C /my/dir .
You can move all the files out of that directory by using the --transform
configuration option, but that doesn't get rid of the . directory itself. It
becomes increasingly difficult to tame the command.
You could use $(find ...) to add a file list to the command (like in
magnus' answer ),
but that potentially causes a "file list too long" error. The best way is to combine it with
tar's -T option, like this:
find /my/dir/ -printf "%P\n" -type f -o -type l -o -type d | tar -czf mydir.tgz --no-recursion -C /my/dir/ -T -
Basically what it does is list all files ( -type f ), links ( -type
l ) and subdirectories ( -type d ) under your directory, make all
filenames relative using -printf "%P\n" , and then pass that to the tar command
(it takes filenames from STDIN using -T - ). The -C option is
needed so tar knows where the files with relative names are located. The
--no-recursion flag is so that tar doesn't recurse into folders it is told to
archive (causing duplicate files).
If you need to do something special with filenames (filtering, following symlinks etc),
the find command is pretty powerful, and you can test it by just removing the
tar part of the above command:
$ find /my/dir/ -printf "%P\n" -type f -o -type l -o -type d
> textfile.txt
> documentation.pdf
> subfolder2
> subfolder
> subfolder/.gitignore
For example if you want to filter PDF files, add ! -name '*.pdf'
$ find /my/dir/ -printf "%P\n" -type f ! -name '*.pdf' -o -type l -o -type d
> textfile.txt
> subfolder2
> subfolder
> subfolder/.gitignore
Non-GNU find
The command uses printf (available in GNU find ) which tells
find to print its results with relative paths. However, if you don't have GNU
find , this works to make the paths relative (removes parents with
sed ):
find /my/dir/ -type f -o -type l -o -type d | sed s,^/my/dir/,, | tar -czf mydir.tgz --no-recursion -C /my/dir/ -T -
This Answer should work in
most situations. Notice however how the filenames are stored in the tar file as, for example,
./file1 rather than just file1 . I found that this caused problems
when using this method to manipulate tarballs used as package files in BuildRoot .
One solution is to use some Bash globs to list all files except for .. like
this:
Now tar will return an error if there are no files matching ..?* or
.[^.]* , but it will still work. If the error is a problem (you are checking for
success in a script), this works:
I would propose the following Bash function (first argument is the path to the dir, second
argument is the basename of resulting archive):
function tar_dir_contents ()
{
local DIRPATH="$1"
local TARARCH="$2.tar.gz"
local ORGIFS="$IFS"
IFS=$'\n'
tar -C "$DIRPATH" -czf "$TARARCH" $( ls -a "$DIRPATH" | grep -v '\(^\.$\)\|\(^\.\.$\)' )
IFS="$ORGIFS"
}
You can run it in this way:
$ tar_dir_contents /path/to/some/dir my_archive
and it will generate the archive my_archive.tar.gz within current directory.
It works with hidden (.*) elements and with elements with spaces in their filename.
# tar all files within and deeper in a given directory
# with no prefixes ( neither <directory>/ nor ./ )
# parameters: <source directory> <target archive file>
function tar_all_in_dir {
{ cd "$1" && find -type f -print0; } \
| cut --zero-terminated --characters=3- \
| tar --create --file="$2" --directory="$1" --null --files-from=-
}
Safely handles filenames with spaces or other unusual characters. You can optionally add a
-name '*.sql' or similar filter to the find command to limit the files
included.
Yes, just give the full stored path of the file after the tarball name.
Example: suppose you want file etc/apt/sources.list from etc.tar
:
tar -xf etc.tar etc/apt/sources.list
Will extract sources.list and create directories etc/apt under
the current directory.
You can use the -t listing option instead of -x , maybe along
with grep , to find the path of the file you want
You can also extract a single directory
tar has other options like --wildcards , etc. for more advanced
partial extraction scenarios; see man tar
2. Extract it with the Archive Manager
Open the tar in Archive Manager from Nautilus, go down into the folder hierarchy to find
the file you need, and extract it.
On a server or command-line system, use a text-based file manager such as Midnight
Commander ( mc ) to accomplish the same.
3. Using Nautilus/Archive-Mounter
Right-click the tar in Nautilus, and select Open with ArchiveMounter.
The tar will now appear similar to a removable drive on the left, and you can
explore/navigate it like a normal drive and drag/copy/paste any file(s) you need to any
destination.
Midnight Commander uses virtual filesystem ( VFS ) for displying
files, such as contents of a .tar.gz archive, or of .iso image.
This is configured in mc.ext with rules such as this one ( Open is
Enter , View is F3 ):
This is a small tip, to find specific files in tar archives and how to extract those specific
files from said archive. Usefull when you have a 2 GB large tar file with millions of small
files, and you need just one.
Using the command line flags -ft (long flags are --file --list )
we can list the contents of an archive. Using grep you can search that list for
the correct file. Example:
tar -ft large_file.tar.gz | grep "the-filename-you-want"
With a modern tar on modern linux you can omit the flags for compressed archives and just
pass a .tar.gz or .tar.bz2 file directly.
Extracting one file
from a tar archive
When extracting a tar archive, you can specify the filename of the file you want (full path,
use the command above to find it), as the second command line option. Example:
tar -xf large_file.tar.gz "full-path/to-the-file/in-the-archive/the-filename-you-want"
It might just take a long time, at least for my 2 GB file it took a while.
An alternative is to use "mc" (midnight commander), which can open archive files just a a
local folder.
Another tool that can save you time is Midnight Commander's user menu. Go back to
/tmp/test where you created nine files. Press F2 and bring up the user menu. Select
Compress the current subdirectory (tar.gz) . After you choose the name for the archive,
this will be created in /tmp (one level up from the directory being
compressed). If you highlight the .tar.gz file and press ENTER you'll notice it will open
like a regular directory. This allows you to browse archives and extract files by simply
copying them ( F5 ) to the opposite panel's working directory.
To find out the size of a directory (actually, the size of all the files it contains),
highlight the directory and then press CTRL+SPACE .
To search, go up in your directory tree until you reach the top level, / ,
called root directory. Now press F9 , then c , followed by f . After the Find File dialog
opens, type *.gz . This will find any accessible gzip archive on the system. In
the results dialog, press l (L) for Panelize . All the results will be fed to one of your
panels so you can easily browse, copy, view and so on. If you enter a directory from that
list, you lose the list of found files, but you can easily return to it with F9 , l (L) then
z (to select Panelize from the Left menu).
Managing files is not always done locally. Midnight Commander also supports accessing
remote filesystems through SSH's Secure File Transfer Protocol, SFTP . This way you
can easily transfer files between servers.
Press F9 , followed by l (L), then select the SFTP link menu entry. In the dialog box
titled SFTP to machine enter sftp://[email protected] . Replace
example with the username you have created on the remote machine and
203.0.113.1 with the IP address of your server. This will work only if the
server at the other end accepts password logins. If you're logging in with SSH keys, then
you'll first need to create and/or edit ~/.ssh/config . It could look
something like this:
~/.ssh/config
1
2
3
4
5
Host sftp_server
HostName 203.0.113.1
Port 22
User your_user
IdentityFile ~/.ssh/id_rsa
You can choose whatever you want as the Host value, it's only an identifier.
IdentityFile is the path to your private SSH key.
After the config file is setup, access your SFTP server by typing the identifier value
you set after Host in the SFTP to machine dialog. In this example, enter
sftp_server .
Midnight Commander how to compress a file/directory; Make a tar archive with midnight
commander
To compress a file in Midnight Commader (e.g. to make a tar.gz archive) navigate
to the directory you want to pack and press 'F2'. This will bring up the 'User menu'. Choose
the option 'Compress the current subdirectory'. This will compress the WHOLE directory you're
currently in - not the highlighted directory.
"... The sort command option "k" specifies a field, not a column. ..."
"... In gnu sort, the default field separator is 'blank to non-blank transition' which is a good default to separate columns. ..."
"... What is probably missing in that article is a short warning about the effect of the current locale. It is a common mistake to assume that the default behavior is to sort according ASCII texts according to the ASCII codes. ..."
Sort also has built in functionality to arrange by month. It recognizes several formats based on locale-specific information.
I tried to demonstrate some unqiue tests to show that it will arrange by date-day, but not year. Month abbreviations display before
full-names.
Here is the sample text file in this example:
March
Feb
February
April
August
July
June
November
October
December
May
September
1
4
3
6
01/05/19
01/10/19
02/06/18
Let's sort it by months using the -M option:
sort filename.txt -M
Here's the output you'll see:
01/05/19
01/10/19
02/06/18
1
3
4
6
Jan
Feb
February
March
April
May
June
July
August
September
October
November
December
... ... ...
7. Sort Specific Column [option -k]
If you have a table in your file, you can use the -k option to specify which column to sort. I added some arbitrary
numbers as a third column and will display the output sorted by each column. I've included several examples to show the variety of
output possible. Options are added following the column number.
1. MX Linux 100
2. Manjaro 400
3. Mint 300
4. elementary 500
5. Ubuntu 200
sort filename.txt -k 2
This will sort the text on the second column in alphabetical order:
4. elementary 500
2. Manjaro 400
3. Mint 300
1. MX Linux 100
5. Ubuntu 200
sort filename.txt -k 3n
This will sort the text by the numerals on the third column.
1. MX Linux 100
5. Ubuntu 200
3. Mint 300
2. Manjaro 400
4. elementary 500
sort filename.txt -k 3nr
Same as the above command just that the sort order has been reversed.
4. elementary 500
2. Manjaro 400
3. Mint 300
5. Ubuntu 200
1. MX Linux 100
8. Sort and remove duplicates [option -u]
If you have a file with potential duplicates, the -u option will make your life much easier. Remember that sort will
not make changes to your original data file. I chose to create a new file with just the items that are duplicates. Below you'll see
the input and then the contents of each file after the command is run.
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
sort filename.txt -u > filename_duplicates.txt
Here's the output files sorted and without duplicates.
1. MX Linux
2. Manjaro
3. Mint
4. elementary
5. Ubuntu
9. Ignore case while sorting [option -f]
Many modern distros running sort will implement ignore case by default. If yours does not, adding the -f option will
produce the expected results.
sort filename.txt -f
Here's the output where cases are ignored by the sort command:
alpha
alPHa
Alpha
ALpha
beta
Beta
BEta
BETA
10. Sort by human numeric values [option -h]
This option allows the comparison of alphanumeric values like 1k (i.e. 1000).
sort filename.txt -h
Here's the sorted output:
10.0
100
1000.0
1k
I hope this tutorial helped you get the basic usage of the sort command in Linux. If you have some cool sort trick, why not share
it with us in the comment section?
Christopher works as a Software Developer in Orlando, FL. He loves open source, Taco Bell, and a Chi-weenie named Max. Visit
his website for more information or connect with him on social media.
John
The sort command option "k" specifies a field, not a column. In your example all five lines have the same character in
column 2 – a "."
Stephane Chauveau
In gnu sort, the default field separator is 'blank to non-blank transition' which is a good default to separate columns.
In his example, the "." is part of the first column so it should work fine. If –debug is used then the range of characters used
as keys is dumped.
What is probably missing in that article is a short warning about the effect of the current locale. It is a common mistake
to assume that the default behavior is to sort according ASCII texts according to the ASCII codes. For example, the command
echo `printf ".nxn0nXn@në" | sort` produces ". 0 @ X x ë" with LC_ALL=C but ". @ 0 ë x X" with LC_ALL=en_US.UTF-8.
Type the following vmstat command: # vmstat
# vmstat 1 5
... ... ...
Vivek Gite is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a
trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on
SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly email newsletter.
The choice of shell as a programming language is strange, but the idea is good...
Notable quotes:
"... The tool is developed by Igor Chubin, also known for its console-oriented weather forecast service wttr.in , which can be used to retrieve the weather from the console using only cURL or Wget. ..."
While it does have its own cheat sheet repository too, the project is actually concentrated around the creation of a unified mechanism
to access well developed and maintained cheat sheet repositories.
The tool is developed by Igor Chubin, also known for its
console-oriented weather forecast
service wttr.in , which can be used to retrieve the weather from the console using
only cURL or Wget.
It's worth noting that cheat.sh is not new. In fact it had its initial commit around May, 2017, and is a very popular repository
on GitHub. But I personally only came across it recently, and I found it very useful, so I figured there must be some Linux Uprising
readers who are not aware of this cool gem.
cheat.sh features & more
cheat.sh major features:
Supports 58 programming
languages , several DBMSes, and more than 1000 most important UNIX/Linux commands
Very fast, returns answers within 100ms
Simple curl / browser interface
An optional command line client (cht.sh) is available, which allows you to quickly search cheat sheets and easily copy
snippets without leaving the terminal
Can be used from code editors, allowing inserting code snippets without having to open a web browser, search for the code,
copy it, then return to your code editor and paste it. It supports Vim, Emacs, Visual Studio Code, Sublime Text and IntelliJ Idea
Comes with a special stealth mode in which any text you select (adding it into the selection buffer of X Window System
or into the clipboard) is used as a search query by cht.sh, so you can get answers without touching any other keys
The command line client features a special shell mode with a persistent queries context and readline support. It also has a query
history, it integrates with the clipboard, supports tab completion for shells like Bash, Fish and Zsh, and it includes the stealth
mode I mentioned in the cheat.sh features.
The web, curl and cht.sh (command line) interfaces all make use of https://cheat.sh/
but if you prefer, you can self-host it .
It should be noted that each editor plugin supports a different feature set (configurable server, multiple answers, toggle comments,
and so on). You can view a feature comparison of each cheat.sh editor plugin on the
Editors integration section of the project's
GitHub page.
Want to contribute a cheat sheet? See the cheat.sh guide on
editing or adding a new cheat sheet.
cheat.sh curl / command line client usage examples Examples of using cheat.sh using the curl interface (this requires having curl installed as you'd expect) from the command
line:
Show the tar command cheat sheet:
curl cheat.sh/tar
Example with output:
$ curl cheat.sh/tar
# To extract an uncompressed archive:
tar -xvf /path/to/foo.tar
# To create an uncompressed archive:
tar -cvf /path/to/foo.tar /path/to/foo/
# To extract a .gz archive:
tar -xzvf /path/to/foo.tgz
# To create a .gz archive:
tar -czvf /path/to/foo.tgz /path/to/foo/
# To list the content of an .gz archive:
tar -ztvf /path/to/foo.tgz
# To extract a .bz2 archive:
tar -xjvf /path/to/foo.tgz
# To create a .bz2 archive:
tar -cjvf /path/to/foo.tgz /path/to/foo/
# To extract a .tar in specified Directory:
tar -xvf /path/to/foo.tar -C /path/to/destination/
# To list the content of an .bz2 archive:
tar -jtvf /path/to/foo.tgz
# To create a .gz archive and exclude all jpg,gif,... from the tgz
tar czvf /path/to/foo.tgz --exclude=\*.{jpg,gif,png,wmv,flv,tar.gz,zip} /path/to/foo/
# To use parallel (multi-threaded) implementation of compression algorithms:
tar -z ... -> tar -Ipigz ...
tar -j ... -> tar -Ipbzip2 ...
tar -J ... -> tar -Ipixz ...
cht.sh also works instead of cheat.sh:
curl cht.sh/tar
Want to search for a keyword in all cheat sheets? Use:
curl cheat.sh/~keyword
List the Python programming language cheat sheet for random list :
curl cht.sh/python/random+list
Example with output:
$ curl cht.sh/python/random+list
# python - How to randomly select an item from a list?
#
# Use random.choice
# (https://docs.python.org/2/library/random.htmlrandom.choice):
import random
foo = ['a', 'b', 'c', 'd', 'e']
print(random.choice(foo))
# For cryptographically secure random choices (e.g. for generating a
# passphrase from a wordlist), use random.SystemRandom
# (https://docs.python.org/2/library/random.htmlrandom.SystemRandom)
# class:
import random
foo = ['battery', 'correct', 'horse', 'staple']
secure_random = random.SystemRandom()
print(secure_random.choice(foo))
# [Pēteris Caune] [so/q/306400] [cc by-sa 3.0]
Replace python with some other programming language supported by cheat.sh, and random+list with the cheat
sheet you want to show.
Want to eliminate the comments from your answer? Add ?Q at the end of the query (below is an example using the same
/python/random+list):
For more flexibility and tab completion you can use cht.sh, the command line cheat.sh client; you'll find instructions for how to
install it further down this article. Examples of using the cht.sh command line client:
Show the tar command cheat sheet:
cht.sh tar
List the Python programming language cheat sheet for random list :
cht.sh python random list
There is no need to use quotes with multiple keywords.
You can start the cht.sh client in a special shell mode using:
cht.sh --shell
And then you can start typing your queries. Example:
$ cht.sh --shell
cht.sh> bash loop
If all your queries are about the same programming language, you can start the client in the special shell mode, directly in that
context. As an example, start it with the Bash context using:
cht.sh --shell bash
Example with output:
$ cht.sh --shell bash
cht.sh/bash> loop
...........
cht.sh/bash> switch case
Want to copy the previously listed answer to the clipboard? Type c , then press Enter to copy the whole
answer, or type C and press Enter to copy it without comments.
Type help in the cht.sh interactive shell mode to see all available commands. Also look under the
Usage section from the cheat.sh GitHub project page for more
options and advanced usage.
How to install cht.sh command line client
You can use cheat.sh in a web browser, from the command line with the help of curl and without having to install anything else, as
explained above, as a code editor plugin, or using its command line client which has some extra features, which I already mentioned.
The steps below are for installing this cht.sh command line client.
If you'd rather install a code editor plugin for cheat.sh, see the
Editors integration page.
1. Install dependencies.
To install the cht.sh command line client, the curl command line tool will be used, so this needs to be installed
on your system. Another dependency is rlwrap , which is required by the cht.sh special shell mode. Install these dependencies
as follows.
Debian, Ubuntu, Linux Mint, Pop!_OS, and any other Linux distribution based on Debian or Ubuntu:
sudo apt install curl rlwrap
Fedora:
sudo dnf install curl rlwrap
Arch Linux, Manjaro:
sudo pacman -S curl rlwrap
openSUSE:
sudo zypper install curl rlwrap
The packages seem to be named the same on most (if not all) Linux distributions, so if your Linux distribution is not on this list,
just install the curl and rlwrap packages using your distro's package manager.
2. Download and install the cht.sh command line interface.
You can install this either for your user only (so only you can run it), or for all users:
Install it for your user only. The command below assumes you have a ~/.bin folder added to your PATH
(and the folder exists). If you have some other local folder in your PATH where you want to install cht.sh, change
install path in the commands:
Install it for all users (globally, in /usr/local/bin ):
curl https://cht.sh/:cht.sh | sudo tee /usr/local/bin/cht.sh
sudo chmod +x /usr/local/bin/cht.sh
If the first command appears to have frozen displaying only the cURL output, press the Enter key and you'll be prompted
to enter your password in order to save the file to /usr/local/bin .
You may also download and install the cheat.sh command completion for Bash or Zsh:
In technical terms, "/dev/null" is a virtual device file. As far as programs are concerned, these are treated just like real files.
Utilities can request data from this kind of source, and the operating system feeds them data. But, instead of reading from disk,
the operating system generates this data dynamically. An example of such a file is "/dev/zero."
In this case, however, you will write to a device file. Whatever you write to "/dev/null" is discarded, forgotten, thrown into
the void. To understand why this is useful, you must first have a basic understanding of standard output and standard error in Linux
or *nix type operating systems.
A command-line utility can generate two types of output. Standard output is sent to stdout. Errors are sent to stderr.
By default, stdout and stderr are associated with your terminal window (or console). This means that anything sent to stdout and
stderr is normally displayed on your screen. But through shell redirections, you can change this behavior. For example, you can redirect
stdout to a file. This way, instead of displaying output on the screen, it will be saved to a file for you to read later – or you
can redirect stdout to a physical device, say, a digital LED or LCD display.
Since there are two types of output, standard output and standard error, the first use case is to filter out one type or the other.
It's easier to understand through a practical example. Let's say you're looking for a string in "/sys" to find files that refer to
power settings.
grep -r power /sys/
There will be a lot of files that a regular, non-root user cannot read. This will result in many "Permission denied" errors.
These clutter the output and make it harder to spot the results that you're looking for. Since "Permission denied"
errors are part of stderr, you can redirect them to "/dev/null."
grep -r power /sys/ 2>/dev/null
As you can see, this is much easier to read.
In other cases, it might be useful to do the reverse: filter out standard output so you can only see errors.
ping google.com 1>/dev/null
The screenshot above shows that, without redirecting, ping displays its normal output when it can reach the destination
machine. In the second command, nothing is displayed while the network is online, but as soon as it gets disconnected, only error
messages are displayed.
You can redirect both stdout and stderr to two different locations.
ping google.com 1>/dev/null 2>error.log
In this case, stdout messages won't be displayed at all, and error messages will be saved to the "error.log" file.
Redirect All Output to /dev/null
Sometimes it's useful to get rid of all output. There are two ways to do this.
grep -r power /sys/ >/dev/null 2>&1
The string >/dev/null means "send stdout to /dev/null," and the second part, 2>&1 , means send stderr
to stdout. In this case you have to refer to stdout as "&1" instead of simply "1." Writing "2>1" would just redirect stdout to a
file named "1."
What's important to note here is that the order is important. If you reverse the redirect parameters like this:
grep -r power /sys/ 2>&1 >/dev/null
it won't work as intended. That's because as soon as 2>&1 is interpreted, stderr is sent to stdout and displayed
on screen. Next, stdout is supressed when sent to "/dev/null." The final result is that you will see errors on the screen instead
of suppressing all output. If you can't remember the correct order, there's a simpler redirect that is much easier to type:
grep -r power /sys/ &>/dev/null
In this case, &>/dev/null is equivalent to saying "redirect both stdout and stderr to this location."
Other Examples Where It Can Be Useful to Redirect to /dev/null
Say you want to see how fast your disk can read sequential data. The test is not extremely accurate but accurate enough. You can
use dd for this, but dd either outputs to stdout or can be instructed to write to a file. With of=/dev/null
you can tell dd to write to this virtual file. You don't even have to use shell redirections here. if= specifies
the location of the input file to be read; of= specifies the name of the output file, where to write.
In some scenarios, you may want to see how fast you can download from a server. But you don't want to write to your disk unnecessarily.
Simply enough, don't write to a regular file, write to "/dev/null."
Type the following netstat command sudo netstat -tulpn | grep LISTEN
... ... ...
For example, TCP port 631 opened by cupsd process and cupsd only listing on the loopback
address (127.0.0.1). Similarly, TCP port 22 opened by sshd process and sshd listing on all IP
address for ssh connections:
Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 0 43385 1821/cupsd
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 0 44064 1823/sshd
Where,
-t : All TCP ports
-u : All UDP ports
-l : Display listening server sockets
-p : Show the PID and name of the program to which each socket belongs
-n : Don't resolve names
| grep LISTEN : Only display open ports by applying grep command filter.
Use ss to list open ports
The ss command is used to dump socket statistics. It allows showing information similar to
netstat. It can display more TCP and state information than other tools. The syntax is: sudo ss -tulpn
... ... ...
Vivek Gite is the creator of nixCraft and a seasoned sysadmin, DevOps engineer, and a
trainer for the Linux operating system/Unix shell scripting. Get the latest tutorials on
SysAdmin, Linux/Unix and open source topics via RSS/XML feed or weekly email newsletter.
"Dangerous" commands like dd should probably be always typed first in the editor and only when you verity
that you did not make a blunder , executed...
A good decision was to go home and think the situation over, not to aggravate it with impulsive attempts to correct the
situation, which typically only make it worse.
Lack of checking of the health of backups suggest that this guy is an arrogant sucker, despite his 20 years of sysadmin
experience.
Notable quotes:
"... I started dd as root , over the top of an EXISTING DISK ON A RUNNING VM. What kind of idiot does that?! ..."
"... Since my VMs were still running, and I'd already done enough damage for one night, I stopped touching things and went home. ..."
See, my RHEV manager was a VM running on a stand-alone Kernel-based Virtual Machine (KVM) host, separate from the
cluster it manages. I had been running RHEV since version 3.0, before hosted engines were a
thing, and I hadn't gone through the effort of migrating. I was already in the process of
building a new set of clusters with a new manager, but this older manager was still controlling
most of our production VMs. It had filled its disk again, and the underlying database had
stopped itself to avoid corruption.
See, for whatever reason, we had never set up disk space monitoring on this system. It's not
like it was an important box, right?
So, I logged into the KVM host that ran the VM, and started the well-known procedure of
creating a new empty disk file, and then attaching it via virsh . The procedure
goes something like this: Become root , use dd to write a stream of
zeros to a new file, of the proper size, in the proper location, then use virsh to
attach the new disk to the already running VM. Then, of course, log into the VM and do your
disk expansion.
I logged in, ran sudo -i , and started my work. I ran cd
/var/lib/libvirt/images , ran ls -l to find the existing disk images, and
then started carefully crafting my dd command:
Which was the next disk again? <Tab> of=vmname-disk2.img <Back arrow, Back
arrow, Back arrow, Back arrow, Backspace> Don't want to dd over the
existing disk, that'd be bad. Let's change that 2 to a 3 , and
Enter . OH CRAP, I CHANGED THE 2 TO A 2 NOT A
3 !
<Ctrl+C><Ctrl+C><Ctrl+C><Ctrl+C><Ctrl+C><Ctrl+C>
I still get sick thinking about this. I'd done the stupidest thing I possibly could have
done, I started dd as root , over the top of an EXISTING DISK ON A
RUNNING VM. What kind of idiot does that?! (The kind that's at work late, trying to get this
one little thing done before he heads off to see his friend. The kind that thinks he knows
better, and thought he was careful enough to not make such a newbie mistake. Gah.)
So, how fast does dd start writing zeros? Faster than I can move my fingers
from the Enter key to the Ctrl+C keys. I tried a number of things to
recover the running disk from memory, but all I did was make things worse, I think. The system
was still up, but still broken like it was before I touched it, so it was useless.
Since my VMs were still running, and I'd already done enough damage for one night, I stopped
touching things and went home. The next day I owned up to the boss and co-workers pretty much
the moment I walked in the door. We started taking an inventory of what we had, and what was
lost. I had taken the precaution of setting up backups ages ago. So, we thought we had that to
fall back on.
I opened a ticket with Red Hat support and filled them in on how dumb I'd been. I can only
imagine the reaction of the support person when they read my ticket. I worked a help desk for
years, I know how this usually goes. They probably gathered their closest coworkers to mourn
for my loss, or get some entertainment out of the guy who'd been so foolish. (I say this in
jest. Red Hat's support was awesome through this whole ordeal, and I'll tell you how soon.
)
So, I figured the next thing I would need from my broken server, which was still running,
was the backups I'd diligently been collecting. They were on the VM but on a separate virtual
disk, so I figured they were safe. The disk I'd overwritten was the last disk I'd made to
expand the volume the database was on, so that logical volume was toast, but I've always set up
my servers such that the main mounts -- / , /var , /home
, /tmp , and /root -- were all separate logical volumes.
In this case, /backup was an entirely separate virtual disk. So, I scp
-r 'd the entire /backup mount to my laptop. It copied, and I felt a little
sigh of relief. All of my production systems were still running, and I had my backup. My hope
was that these factors would mean a relatively simple recovery: Build a new VM, install RHEV-M,
and restore my backup. Simple right?
By now, my boss had involved the rest of the directors, and let them know that we were
looking down the barrel of a possibly bad time. We started organizing a team meeting to discuss
how we were going to get through this. I returned to my desk and looked through the backups I
had copied from the broken server. All the files were there, but they were tiny. Like, a couple
hundred kilobytes each, instead of the hundreds of megabytes or even gigabytes that they should
have been.
Happy feeling, gone.
Turns out, my backups were running, but at some point after an RHEV upgrade, the database
backup utility had changed. Remember how I said this system had existed since version 3.0?
Well, 3.0 didn't have an engine-backup utility, so in my RHEV training, we'd learned how to
make our own. Mine broke when the tools changed, and for who knows how long, it had been
getting an incomplete backup -- just some files from /etc .
No database. Ohhhh ... Fudge. (I didn't say "Fudge.")
I updated my support case with the bad news and started wondering what it would take to
break through one of these 4th-floor windows right next to my desk. (Ok, not really.)
At this point, we basically had three RHEV clusters with no manager. One of those was for
development work, but the other two were all production. We started using these team meetings
to discuss how to recover from this mess. I don't know what the rest of my team was thinking
about me, but I can say that everyone was surprisingly supportive and un-accusatory. I mean,
with one typo I'd thrown off the entire department. Projects were put on hold and workflows
were disrupted, but at least we had time: We couldn't reboot machines, we couldn't change
configurations, and couldn't get to VM consoles, but at least everything was still up and
operating.
Red Hat support had escalated my SNAFU to an RHEV engineer, a guy I'd worked with in the
past. I don't know if he remembered me, but I remembered him, and he came through yet again.
About a week in, for some unknown reason (we never figured out why), our Windows VMs started
dropping offline. They were still running as far as we could tell, but they dropped off the
network, Just boom. Offline. In the course of a workday, we lost about a dozen windows systems.
All of our RHEL machines were working fine, so it was just some Windows machines, and not even
every Windows machine -- about a dozen of them.
Well great, how could this get worse? Oh right, add a ticking time bomb. Why were the
Windows servers dropping off? Would they all eventually drop off? Would the RHEL systems
eventually drop off? I made a panicked call back to support, emailed my account rep, and called
in every favor I'd ever collected from contacts I had within Red Hat to get help as quickly as
possible.
I ended up on a conference call with two support engineers, and we got to work. After about
30 minutes on the phone, we'd worked out the most insane recovery method. We had the newer RHEV
manager I mentioned earlier, that was still up and running, and had two new clusters attached
to it. Our recovery goal was to get all of our workloads moved from the broken clusters to
these two new clusters.
Want to know how we ended up doing it? Well, as our Windows VMs were dropping like flies,
the engineers and I came up with this plan. My clusters used a Fibre Channel Storage Area
Network (SAN) as their storage domains. We took a machine that was not in use, but had a Fibre
Channel host bus adapter (HBA) in it, and attached the logical unit numbers (LUNs) for both the
old cluster's storage domains and the new cluster's storage domains to it. The plan there was
to make a new VM on the new clusters, attach blank disks of the proper size to the new VM, and
then use dd (the irony is not lost on me) to block-for-block copy the old broken
VM disk over to the newly created empty VM disk.
I don't know if you've ever delved deeply into an RHEV storage domain, but under the covers
it's all Logical Volume Manager (LVM). The problem is, the LV's aren't human-readable. They're
just universally-unique identifiers (UUIDs) that the RHEV manager's database links from VM to
disk. These VMs are running, but we don't have the database to reference. So how do you get
this data?
virsh ...
Luckily, I managed KVM and Xen clusters long before RHEV was a thing that was viable. I was
no stranger to libvirt 's virsh utility. With the proper
authentication -- which the engineers gave to me -- I was able to virsh dumpxml on
a source VM while it was running, get all the info I needed about its memory, disk, CPUs, and
even MAC address, and then create an empty clone of it on the new clusters.
Once I felt everything was perfect, I would shut down the VM on the broken cluster with
either virsh shutdown , or by logging into the VM and shutting it down. The catch
here is that if I missed something and shut down that VM, there was no way I'd be able to power
it back on. Once the data was no longer in memory, the config would be completely lost, since
that information is all in the database -- and I'd hosed that. Once I had everything, I'd log
into my migration host (the one that was connected to both storage domains) and use
dd to copy, bit-for-bit, the source storage domain disk over to the destination
storage domain disk. Talk about nerve-wracking, but it worked! We picked one of the broken
windows VMs and followed this process, and within about half an hour we'd completed all of the
steps and brought it back online.
We did hit one snag, though. See, we'd used snapshots here and there. RHEV snapshots are
lvm snapshots. Consolidating them without the RHEV manager was a bit of a chore,
and took even more leg work and research before we could dd the disks. I had to
mimic the snapshot tree by creating symbolic links in the right places, and then start the
dd process. I worked that one out late that evening after the engineers were off,
probably enjoying time with their families. They asked me to write the process up in detail
later. I suspect that it turned into some internal Red Hat documentation, never to be given to
a customer because of the chance of royally hosing your storage domain.
Somehow, over the course of 3 months and probably a dozen scheduled maintenance windows, I
managed to migrate every single VM (of about 100 VMs) from the old zombie clusters to the
working clusters. This migration included our Zimbra collaboration system (10 VMs in itself),
our file servers (another dozen VMs), our Enterprise Resource Planning (ERP) platform, and even
Oracle databases.
We didn't lose a single VM and had no more unplanned outages. The Red Hat Enterprise Linux
(RHEL) systems, and even some Windows systems, never fell to the mysterious drop-off that those
dozen or so Windows servers did early on. During this ordeal, though, I had trouble sleeping. I
was stressed out and felt so guilty for creating all this work for my co-workers, I even had
trouble eating. No exaggeration, I lost 10lbs.
So, don't be like Nate. Monitor your important systems, check your backups, and for all
that's holy, double-check your dd output file. That way, you won't have drama, and
can truly enjoy Sysadmin Appreciation Day!
Nathan Lager is an experienced sysadmin, with 20 years in the industry. He runs his own blog at undrground.org, and
hosts the Iron Sysadmin Podcast. More
about me
Yves here. You have to read
a bit into this article on occupational decline, aka, "What happens to me after the robots take
my job?" to realize that the authors studied Swedish workers. One has to think that the
findings would be more pronounced in the US, due both to pronounced regional and urban/rural
variations, as well as the weakness of social institutions in the US. While there may be small
cities in Sweden that have been hit hard by the decline of a key employer, I don't have the
impression that Sweden has areas that have suffered the way our Rust Belt has. Similarly, in
the US, a significant amount of hiring starts with resume reviews with the job requirements
overspecified because the employer intends to hire someone who has done the same job somewhere
else and hence needs no training (which in practice is an illusion; how companies do things is
always idiosyncratic and new hires face a learning curve). On top of that, many positions are
filled via personal networks, not formal recruiting. Some studies have concluded that having a
large network of weak ties is more helpful in landing a new post than fewer close connections.
It's easier to know a lot of people casually in a society with strong community
institutions.
The article does not provide much in the way of remedies; it hints at "let them eat
training" when programs have proven to be ineffective. One approach would be aggressive
enforcement of laws against age discrimination. And even though some readers dislike a Job
Guarantee, not only would it enable people who wanted to work to keep working, but private
sector employers are particularly loath to employ someone who has been out of work for more
than six months, so a Job Guarantee post would also help keep someone who'd lost a job from
looking like damaged goods.
By Per-Anders Edin, Professor of Industrial Relations, Uppsala University; Tiernan Evans,
Economics MRes/PhD Candidate, LSE; Georg Graetz, Assistant Professor in the Department of
Economics, Uppsala University; Sofia Hernnäs, PhD student, Department of Economics,
Uppsala University; Guy Michaels,Associate Professor in the Department of Economics, LSE.
Originally published at VoxEU
As new technologies replace human labour in a growing number of tasks, employment in some
occupations invariably falls. This column compares outcomes for similar workers in similar
occupations over 28 years to explore the consequences of large declines in occupational
employment for workers' careers. While mean losses in earnings and employment for those
initially working in occupations that later declined are relatively moderate, low-earners lose
significantly more.
How costly is it for workers when demand for their occupation declines? As new technologies
replace human labour in a growing number of tasks, employment in some occupations invariably
falls. Until recently, technological change mostly automated routine production and clerical
work (Autor et al. 2003). But machines' capabilities are expanding, as recent developments
include self-driving vehicles and software that outperforms professionals in some tasks.
Debates on the labour market implications of these new technologies are ongoing (e.g.
Brynjolfsson and McAfee 2014, Acemoglu and Restrepo 2018). But in these debates, it is
important to ask not only "Will robots take my job?", but also "What would happen to my career
if robots took my job?"
Much is at stake. Occupational decline may hurt workers and their families, and may also
have broader consequences for economic inequality, education, taxation, and redistribution. If
it exacerbates differences in outcomes between economic winners and losers, populist forces may
gain further momentum (Dal Bo et al. 2019).
In a new paper (Edin et al. 2019) we explore the consequences of large declines in
occupational employment for workers' careers. We assemble a dataset with forecasts of
occupational employment changes that allow us to identify unanticipated declines,
population-level administrative data spanning several decades, and a highly detailed
occupational classification. These data allow us to compare outcomes for similar workers who
perform similar tasks and have similar expectations of future occupational employment
trajectories, but experience different actual occupational changes.
Our approach is distinct from previous work that contrasts career outcomes of routine and
non-routine workers (e.g. Cortes 2016), since we compare workers who perform similar tasks and
whose careers would likely have followed similar paths were it not for occupational decline.
Our work is also distinct from studies of mass layoffs (e.g. Jacobson et al. 1993), since
workers who experience occupational decline may take action before losing their jobs.
In our analysis, we follow individual workers' careers for almost 30 years, and we find that
workers in declining occupations lose on average 2-5% of cumulative earnings, compared to other
similar workers. Workers with low initial earnings (relative to others in their occupations)
lose more – about 8-11% of mean cumulative earnings. These earnings losses reflect both
lost years of employment and lower earnings conditional on employment; some of the employment
losses are due to increased time spent in unemployment and retraining, and low earners spend
more time in both unemployment and retraining.
Estimating the Consequences of Occupational Decline
We begin by assembling data from the Occupational Outlook Handbooks (OOH), published by the
US Bureau of Labor Statistics, which cover more than 400 occupations. In our main analysis we
define occupations as declining if their employment fell by at least 25% from 1984-2016,
although we show that our results are robust to using other cutoffs. The OOH also provides
information on technological change affecting each occupation, and forecasts of employment over
time. Using these data, we can separate technologically driven declines, and also unanticipated
declines. Occupations that declined include typesetters, drafters, proof readers, and various
machine operators.
We then match the OOH data to detailed Swedish occupations. This allows us to study the
consequences of occupational decline for workers who, in 1985, worked in occupations that
declined over the subsequent decades. We verify that occupations that declined in the US also
declined in Sweden, and that the employment forecasts that the BLS made for the US have
predictive power for employment changes in Sweden.
Detailed administrative micro-data, which cover all Swedish workers, allow us to address two
potential concerns for identifying the consequences of occupational decline: that workers in
declining occupations may have differed from other workers, and that declining occupations may
have differed even in absence of occupational decline. To address the first concern, about
individual sorting, we control for gender, age, education, and location, as well as 1985
earnings. Once we control for these characteristics, we find that workers in declining
occupations were no different from others in terms of their cognitive and non-cognitive test
scores and their parents' schooling and earnings. To address the second concern, about
occupational differences, we control for occupational earnings profiles (calculated using the
1985 data), the BLS forecasts, and other occupational and industry characteristics.
Assessing the losses and how their incidence varied
We find that prime age workers (those aged 25-36 in 1985) who were exposed to occupational
decline lost about 2-6 months of employment over 28 years, compared to similar workers whose
occupations did not decline. The higher end of the range refers to our comparison between
similar workers, while the lower end of the range compares similar workers in similar
occupations. The employment loss corresponds to around 1-2% of mean cumulative employment. The
corresponding earnings losses were larger, and amounted to around 2-5% of mean cumulative
earnings. These mean losses may seem moderate given the large occupational declines, but the
average outcomes do not tell the full story. The bottom third of earners in each occupation
fared worse, losing around 8-11% of mean earnings when their occupations declined.
The earnings and employment losses that we document reflect increased time spent in
unemployment and government-sponsored retraining – more so for workers with low initial
earnings. We also find that older workers who faced occupational decline retired a little
earlier.
We also find that workers in occupations that declined after 1985 were less likely to remain
in their starting occupation. It is quite likely that this reduced supply to declining
occupations contributed to mitigating the losses of the workers that remained there.
We show that our main findings are essentially unchanged when we restrict our analysis to
technology-related occupational declines.
Further, our finding that mean earnings and employment losses from occupational decline are
small is not unique to Sweden. We find similar results using a smaller panel dataset on US
workers, using the National Longitudinal Survey of Youth 1979.
Theoretical implications
Our paper also considers the implications of our findings for Roy's (1951) model, which is a
workhorse model for labour economists. We show that the frictionless Roy model predicts that
losses are increasing in initial occupational earnings rank, under a wide variety of
assumptions about the skill distribution. This prediction is inconsistent with our finding that
the largest earnings losses from occupational decline are incurred by those who earned the
least. To reconcile our findings, we add frictions to the model: we assume that workers who
earn little in one occupation incur larger time costs searching for jobs or retraining if they
try to move occupations. This extension of the model, especially when coupled with the addition
of involuntary job displacement, allows us to reconcile several of our empirical findings.
Conclusions
There is a vivid academic and public debate on whether we should fear the takeover of human
jobs by machines. New technologies may replace not only factory and office workers but also
drivers and some professional occupations. Our paper compares similar workers in similar
occupations over 28 years. We show that although mean losses in earnings and employment for
those initially working in occupations that later declined are relatively moderate (2-5% of
earnings and 1-2% of employment), low-earners lose significantly more.
The losses that we find from occupational decline are smaller than those suffered by workers
who experience mass layoffs, as reported in the existing literature. Because the occupational
decline we study took years or even decades, its costs for individual workers were likely
mitigated through retirements, reduced entry into declining occupations, and increased
job-to-job exits to other occupations. Compared to large, sudden shocks, such as plant
closures, the decline we study may also have a less pronounced impact on local economies.
While the losses we find are on average moderate, there are several reasons why future
occupational decline may have adverse impacts. First, while we study unanticipated declines,
the declines were nevertheless fairly gradual. Costs may be larger for sudden shocks following,
for example, a quick evolution of machine learning. Second, the occupational decline that we
study mainly affected low- and middle-skilled occupations, which require less human capital
investment than those that may be impacted in the future. Finally, and perhaps most
importantly, our findings show that low-earning individuals are already suffering considerable
(pre-tax) earnings losses, even in Sweden, where institutions are geared towards mitigating
those losses and facilitating occupational transitions. Helping these workers stay productive
when they face occupational decline remains an important challenge for governments.
by editor ·
Published June 24, 2019 · Updated June 24, 2019
Package managers provide a way of packaging, distributing, installing, and maintaining apps
in an operating system. With modern desktop, server and IoT applications of the Linux operating
system and the hundreds of different distros that exist, it becomes necessary to move away from
platform specific packaging methods to platform agnostic ones. This post explores 3 such tools,
namely AppImage , Snap and Flatpak , that each aim to be the future of software deployment and
management in Linux. At the end we summarize a few key findings.
1. AppImage
AppImage follows a concept called "One app = one file" . This is to be understood as an
AppImage being a regular independent "file" containing one application with everything it needs
to run in the said file. Once made executable, the AppImage can be run like any application in
a computer by simply double-clicking it in the users file system.[1]
It is a format for creating portable software for Linux without requiring the user to
install the said application. The format allows the original developers of the software
(upstream developers) to create a platform and distribution independent (also called a
distribution-agnostic binary) version of their application that will basically run on any
flavor of Linux.
AppImage has been around for a long time. Klik , a predecessor of AppImage was created by
Simon Peter in 2004. The project was shut down in 2011 after not having passed the beta stage.
A project named PortableLinuxApps was created by Simon around the same time and the format was
picked up by a few portals offering software for Linux users. The project was renamed again in
2013 to its current name AppImage and a repository has been maintained in GitHub (project
link ) with all the latest
changes to the same since 2018.[2][3]
Written primarily in C and donning the MIT license since 2013, AppImage is currently
developed by The AppImage project . It is a very convenient way to use applications as
demonstrated by the following features:
AppImages can run on virtually any Linux system. As mentioned before applications derive
a lot of functionality from the operating system and a few common libraries. This is a common
practice in the software world since if something is already done, there is no point in doing
it again if you can pick and choose which parts from the same to use. The problem is that
many Linux distros might not have all the files a particular application requires to run
since it is left to the developers of that particular distro to include the necessary
packages. Hence developers need to separately include the dependencies of the application for
each Linux distro they are publishing their app for. Using the AppImage format developers can
choose to include all the libraries and files that they cannot possibly hope the target
operating system to have as part of the AppImage file. Hence the same AppImage format file
can work on different operating systems and machines without needing granular control.
The one app one file philosophy means that user experience is simple and elegant in that
users need only download and execute one file that will serve their needs for using the
application.
No requirement of root access . System administrators will require people to have root
access to stop them from messing with computers and their default setup. This also means that
people with no root access or super user privileges cannot install the apps they need as they
please. The practice is common in a public setting (such as library or university computers
or on enterprise systems). The AppImage file does not require users to "install" anything and
hence users need only download the said file and make it executable to start using it. This
removes the access dilemmas that system administrators have and makes their job easier
without sacrificing user experience.
No effect on core operating system . The AppImage-application format allows using
applications with their full functionality without needing to change or even access most
system files. Meaning whatever the applications do, the core operating system setup and files
remain untouched.
An AppImage can be made by a developer for a particular version of their application. Any
updated version is made as a different AppImage. Hence users if need be can test multiple
versions of the same application by running different instances using different AppImages.
This is an invaluable feature when you need to test your applications from an end-user POV to
notice differences.
Take your applications where you go. As mentioned previously AppImages are archived files
of all the files that an application requires and can be used without installing or even
bothering about the distribution the system uses. Hence if you have a set of apps that you
use regularly you may even mount a few AppImage files on a thumb drive and take it with you
to use on multiple computers running multiple different distros without worrying whether
they'll work or not.
Furthermore, the AppImageKit allows users from all backgrounds to build their own AppImages
from applications they already have or for applications that are not provided an AppImage by
their upstream developer.
The package manager is platform independent but focuses primarily on software distribution
to end users on their desktops with a dedicated daemon AppImaged for integrating the AppImage
formats into respective desktop environments. AppImage is supported natively now by a variety
of distros such as Ubuntu, Debian, openSUSE, CentOS, Fedora etc. and others may set it up as
per their needs. AppImages can also be run on servers with limited functionality via the CLI
tools included.
Snappy is a software deployment and package management system like AppImage or any other
package manager for that instance. It is originally designed for the now defunct Ubuntu Touch
Operating system. Snappy lets developers create software packages for use in a variety of Linux
based distributions. The initial intention behind creating Snappy and deploying "snaps" on
Ubuntu based systems is to obtain a unified single format that could be used in everything from
IoT devices to full-fledged computer systems that ran some version of Ubuntu and in a larger
sense Linux itself.[4]
The lead developer behind the project is Canonical , the same company that pilots the Ubuntu
project. Ubuntu had native snap support from version 16.04 LTS with more and more distros
supporting it out of the box or via a simple setup these days. If you use Arch or Debian or
openSUSE you'll find it easy to install support for the package manager using simple commands
in the terminal as explained later in this section. This is also made possible by making the
necessary snap platform files available on the respective repos.[5]
Snappy has the following important components that make up the entire package manager
system.[6]
Snap – is the file format of the packages themselves. Individual applications that
are deployed using Snappy are called "Snaps". Any application may be packaged using the tools
provided to make a snap that is intended to run on a different system running Linux. Snap,
similar to AppImage is an all-inclusive file and contains all dependencies the application
needs to run without assuming them to part of the target system.
Snapcraft – is the tool that lets developers make snaps of their applications. It
is basically a command that is part of the snap system as well as a framework that will let
you build your own snaps.
Snapd – is the background daemon that maintains all the snaps that are installed in
your system. It integrates into the desktop environment and manages all the files and
processes related to working with snaps. The snapd daemon also checks for updates normally 4
times a day unless set otherwise.
Snap Store – is an online
gallery of sorts that lets developers upload their snaps into the repository. Snap store is
also an application discovery medium for users and will let users see and experience the
application library before downloading and installing them.
The snapd component is written primarily in C and Golang whereas the Snapcraft framework is
built using Python . Although both the modules use the GPLv3 license it is to be noted that
snapd has proprietary code from Canonical for its server-side operations with just the client
side being published under the GPL license. This is a major point of contention with developers
since this involves developers signing a CLA form to participate in snap development.[7]
Going deeper into the finer details of the Snappy package manager the following may be
noted:
Snaps as noted before are all inclusive and contain all the necessary files
(dependencies) that the application needs to run. Hence, developers need not to make
different snaps for the different distros that they target. Being mindful of the runtimes is
all that's necessary if base runtimes are excluded from the snap.
Snappy packages are meant to support transactional updates. Such a transactional update
is atomic and fully reversible, meaning you can use the application while its being updated
and that if an update does not behave the way its supposed to, you can reverse the same with
no other effects whatsoever. The concept is also called as delta programming in which only
changes to the application are transmitted as an update instead of the whole package. An
Ubuntu derivative called Ubuntu Core actually promises the snappy update protocol to the OS
itself.[8]
A key point of difference between snaps and AppImages, is how they handle version
differences. Using AppImages different versions of the application will have different
AppImages allowing you to concurrently use 2 or more different versions of the same
application at the same time. However, using snaps means conforming to the transactional or
delta update system. While this means faster updates, it keeps you from running two instances
of the same application at the same time. If you need to use the old version of an app you'll
need to reverse or uninstall the new version. Snappy does support a feature called
"parallel install" which will let users accomplish similar goals, however, it is still in
an experimental stage and cannot be considered to be a stable implementation. Snappy also
makes use of channels meaning you can use the beta or the nightly build of an app and the
stable version at the same time.[9]
Extensive support from major Linux distros and major developers including Google,
Mozilla, Microsoft, etc.[4]
Snapd the desktop integration tool supports taking "snapshots" of the current state of
all the installed snaps in the system. This will let users save the current configuration
state of all the applications that are installed via the Snappy package manager and let users
revert to that state whenever they desire so. The same feature can also be set to
automatically take snapshots at a frequency deemed necessary by the user. Snapshots can be
created using the snap save command in the snapd framework.[10]
Snaps are designed to be sandboxed during operation. This provides a much-required layer
of security and isolation to users. Users need not worry about snap-based applications
messing with the rest of the software on their computer. Sandboxing is implemented using
three levels of isolation viz, classic , strict and devmode . Each level of isolation allows
the app different levels of access within the file system and computer.[11]
On the flip side of things, snaps are widely criticized for being centered around
Canonical's modus operandi . Most of the commits to the project are by Canonical employees or
contractors and other contributors are required to sign a release form (CLA). The sandboxing
feature, a very important one indeed from a security standpoint, is flawed in that the
sandboxing actually requires certain other core services to run (such as Mir) while
applications running the X11 desktop won't support the said isolation, hence making the said
security feature irrelevant. Questionable press releases and other marketing efforts from
Canonical and the "central" and closed app repository are also widely criticized aspects of
Snappy. Furthermore, the file sizes of the different snaps are also comparatively very large
compared to the app sizes of the packages made using AppImage.[7]
Like the Snap/Snappy listed above, Flatpak is also a software deployment tool that aims to
ease software distribution and use in Linux. Flatpak was previously known as "xdg-app" and was
based on concept proposed by Lennart Poettering in 2004. The idea was to contain applications
in a secure virtual sandbox allowing for using applications without the need of root privileges
and without compromising on the systems security. Alex started tinkering with Klik (thought to
be a former version of AppImage) and wanted to implement the concept better. Alexander Larsson
who at the time was working with Red Hat wrote an implementation called xdg-app in 2015 that
acted as a pre-cursor to the current Flatpak format.
Flatpak officially came out in 2016 with backing from Red Hat, Endless Computers and
Collabora. Flathub is the official repository of all Flatpak application packages. At its
surface Flatpak like the other is a framework for building and packaging distribution agnostic
applications for Linux. It simply requires the developers to conform to a few desktop
environment guidelines in order for the application to be successfully integrated into the
Flatpak environment.
Targeted primarily at the three popular desktop implementations FreeDesktop , KDE , and
GNOME , the Flatpak framework itself is written in C and works on a LGPL license. The
maintenance repository can be accessed via the GitHub link here .
A few features of Flatpak that make it stand apart are mentioned below. Notice that features
Flatpak shares with AppImage and Snappy are omitted here.
Deep integration into popular Linux desktop environments such as GNOME & KDE so that
users can simply use Flatpaks using Graphical software management tools instead of resorting
to the terminal. Flatpak can be installed from the default repositories of major desktop
environments now and once the apps themselves are set-up they can be used and provide
features similar to normal desktop applications.[12][13]
Forward-compatibility – Flatpaks are built from the ground up keeping the operating
systems core kernel and runtimes in mind. Hence, even if you upgrade or update your distro
the Flatpaks you have should still work unless there is a core update. This is especially
crucial for people who prefer staying on rolling betas or development versions of their
distros. For such people, since the kinks of the OS itself isn't ironed out usually, the
Flatpak application will run seamlessly without having to depend on the OS files or libraries
for its operation.[13]
Sandboxing using Bubblewrap – snaps are also by default sandboxed in that they run
in isolation from the rest of the applications running while you're using your computer.
However, Flatpaks fully seal the application from accessing OS files and user files during
its operation by default. This essentially means that system administrators can be certain
that Flatpaks that are installed in their systems cannot exploit the computer and the files
it contains whereas for end users this will mean that in order to access a few specific
functions or user data root permission is required.[14]
Flatpak supports decentralized distribution of application natively however the team
behind Flatpak still maintains a central online repository of apps/Flatpaks called Flathub .
Users may in fact configure Flatpak to use multiple remote repositories as they see
necessary. As opposed to snap you can have multiple repositories.[13]
Modular access through the sandbox. Although this capability comes at a great potential
cost to the integrity of the system, Flatpak framework allows for channels to be created
through the sandbox for exchange of specific information from within the sandbox to the host
system or vice versa. The channel is in this case referred to as a portal. A con to this
feature is discussed later in the section.[14]
One of the most criticized aspects of Flatpak however is it's the sandbox feature itself.
Sandboxing is how package managers such as Snappy and Flatpak implement important security
features. Sandboxing essentially isolates the application from everything else in the system
only allowing for user defined exchange of information from within the sandbox to outside. The
flaw with the concept being that the sandbox cannot be inherently impregnable. Data has to be
eventually transferred between the two domains and simple Linux commands can simply get rid of
the sandbox restriction meaning that malicious applications might potentially jump out of the
said sandbox.[15]
This combined with the worse than expected commitment to rolling out security updates for
Flatpak has resulted in widespread criticism of the team's tall claim of providing a secure
framework. The blog (named flatkill ) linked at the end of this guide in fact mentions a couple
of exploits that were not addressed by the Flatpak team as soon as they should've been.[15]
While all three of these platforms have a lot in common with each other and aim to be
platform agnostic in approach, they offer different levels of competencies in a few areas.
While Snaps can run on a variety of devices including embedded ones, AppImages and Flatpaks are
built with the desktop user in mind. AppImages of popular applications on the other had have
superior packaging sizes and portability whereas Flatpak really shines with its forward
compatibility when its used in a set it and forget it system.
If there are any flaws in this guide, please let us know in the comment section below. We
will update the guide accordingly.
"... There is effectively no CPU time spent tarring, so it wouldn't help much. The tar format is just a copy of the input file with header blocks in between files. ..."
"... You can also use the tar flag "--use-compress-program=" to tell tar what compression program to use. ..."
I normally compress using tar zcvf and decompress using tar zxvf
(using gzip due to habit).
I've recently gotten a quad core CPU with hyperthreading, so I have 8 logical cores, and I
notice that many of the cores are unused during compression/decompression.
Is there any way I can utilize the unused cores to make it faster?
The solution proposed by Xiong Chiamiov above works beautifully. I had just backed up my
laptop with .tar.bz2 and it took 132 minutes using only one cpu thread. Then I compiled and
installed tar from source: gnu.org/software/tar I included the options mentioned
in the configure step: ./configure --with-gzip=pigz --with-bzip2=lbzip2 --with-lzip=plzip I
ran the backup again and it took only 32 minutes. That's better than 4X improvement! I
watched the system monitor and it kept all 4 cpus (8 threads) flatlined at 100% the whole
time. THAT is the best solution. – Warren Severin
Nov 13 '17 at 4:37
You can use pigz instead of gzip, which
does gzip compression on multiple cores. Instead of using the -z option, you would pipe it
through pigz:
tar cf - paths-to-archive | pigz > archive.tar.gz
By default, pigz uses the number of available cores, or eight if it could not query that.
You can ask for more with -p n, e.g. -p 32. pigz has the same options as gzip, so you can
request better compression with -9. E.g.
pigz does use multiple cores for decompression, but only with limited improvement over a
single core. The deflate format does not lend itself to parallel decompression.
The
decompression portion must be done serially. The other cores for pigz decompression are used
for reading, writing, and calculating the CRC. When compressing on the other hand, pigz gets
close to a factor of n improvement with n cores.
There is effectively no CPU time spent tarring, so it wouldn't help much. The tar format is just a copy of the input file
with header blocks in between files.
Unfortunately by doing so the concurrent feature of pigz is lost. You can see for yourself by
executing that command and monitoring the load on each of the cores. – Valerio
Schiavoni
Aug 5 '14 at 22:38
I prefer tar - dir_to_zip | pv | pigz > tar.file pv helps me estimate, you
can skip it. But still it easier to write and remember. – Offenso
Jan 11 '17 at 17:26
-I, --use-compress-program PROG
filter through PROG (must accept -d)
You can use multithread version of archiver or compressor utility.
Most popular multithread archivers are pigz (instead of gzip) and pbzip2 (instead of bzip2). For instance:
$ tar -I pbzip2 -cf OUTPUT_FILE.tar.bz2 paths_to_archive
$ tar --use-compress-program=pigz -cf OUTPUT_FILE.tar.gz paths_to_archive
Archiver must accept -d. If your replacement utility hasn't this parameter and/or you need
specify additional parameters, then use pipes (add parameters if necessary):
$ tar cf - paths_to_archive | pbzip2 > OUTPUT_FILE.tar.gz
$ tar cf - paths_to_archive | pigz > OUTPUT_FILE.tar.gz
Input and output of singlethread and multithread are compatible. You can compress using
multithread version and decompress using singlethread version and vice versa.
p7zip
For p7zip for compression you need a small shell script like the following:
#!/bin/sh
case $1 in
-d) 7za -txz -si -so e;;
*) 7za -txz -si -so a .;;
esac 2>/dev/null
Save it as 7zhelper.sh. Here the example of usage:
$ tar -I 7zhelper.sh -cf OUTPUT_FILE.tar.7z paths_to_archive
$ tar -I 7zhelper.sh -xf OUTPUT_FILE.tar.7z
xz
Regarding multithreaded XZ support. If you are running version 5.2.0 or above of XZ Utils,
you can utilize multiple cores for compression by setting -T or
--threads to an appropriate value via the environmental variable XZ_DEFAULTS
(e.g. XZ_DEFAULTS="-T 0" ).
This is a fragment of man for 5.1.0alpha version:
Multithreaded compression and decompression are not implemented yet, so this option has
no effect for now.
However this will not work for decompression of files that haven't also been compressed
with threading enabled. From man for version 5.2.2:
Threaded decompression hasn't been implemented yet. It will only work on files that
contain multiple blocks with size information in block headers. All files compressed in
multi-threaded mode meet this condition, but files compressed in single-threaded mode don't
even if --block-size=size is used.
Recompiling with replacement
If you build tar from sources, then you can recompile with parameters
After recompiling tar with these options you can check the output of tar's help:
$ tar --help | grep "lbzip2\|plzip\|pigz"
-j, --bzip2 filter the archive through lbzip2
--lzip filter the archive through plzip
-z, --gzip, --gunzip, --ungzip filter the archive through pigz
I just found pbzip2 and
mpibzip2 . mpibzip2 looks very
promising for clusters or if you have a laptop and a multicore desktop computer for instance.
– user1985657
Apr 28 '15 at 20:57
find /my/path/ -type f -name "*.sql" -o -name "*.log" -exec
This command will look for the files you want to archive, in this case
/my/path/*.sql and /my/path/*.log . Add as many -o -name
"pattern" as you want.
-exec will execute the next command using the results of find :
tar
Step 2: tar
tar -P --transform='s@/my/path/@@g' -cf - {} +
--transform is a simple string replacement parameter. It will strip the path
of the files from the archive so the tarball's root becomes the current directory when
extracting. Note that you can't use -C option to change directory as you'll lose
benefits of find : all files of the directory would be included.
-P tells tar to use absolute paths, so it doesn't trigger the
warning "Removing leading `/' from member names". Leading '/' with be removed by
--transform anyway.
-cf - tells tar to use the tarball name we'll specify later
{} + uses everyfiles that find found previously
Step 3:
pigz
pigz -9 -p 4
Use as many parameters as you want. In this case -9 is the compression level
and -p 4 is the number of cores dedicated to compression. If you run this on a
heavy loaded webserver, you probably don't want to use all available cores.
An important test is done using rsync. It requires two partitions: the original one, and a
spare partition where to restore the archive. It allows to know whether or not there are
differences between the original and the restored filesystem. rsync is able to compare both the
files contents, and files attributes (timestamps, permissions, owner, extended attributes, acl,
), so that's a very good test. The following command can be used to know whether or not files
are the same (data and attributes) on two file-systems:
Tmux is a screen
multiplexer, meaning that it provides your terminal with virtual terminals, allowing you to
switch from one virtual session to another. Modern terminal emulators feature a tabbed UI,
making the use of Tmux seem redundant, but Tmux has a few peculiar features that still prove
difficult to match without it.
First of all, you can launch Tmux on a remote machine, start a process running, detach from
Tmux, and then log out. In a normal terminal, logging out would end the processes you started.
Since those processes were started in Tmux, they persist even after you leave.
Secondly, Tmux can "mirror" its session on multiple screens. If two users log into the same
Tmux session, then they both see the same output on their screens in real time.
Tmux is a lightweight, simple, and effective solution in cases where you're training someone
remotely, debugging a command that isn't working for them, reviewing text, monitoring services
or processes, or just avoiding the ten minutes it sometimes takes to read commands aloud over a
phone clearly enough that your user is able to accurately type them.
To try this option out, you must have two computers. Assume one computer is owned by Alice,
and the other by Bob. Alice remotely logs into Bob's PC and launches a Tmux session:
alice$ ssh bob.local
alice$ tmux
On his PC, Bob starts Tmux, attaching to the same session:
bob$ tmux attach
When Alice types, Bob sees what she is typing, and when Bob types, Alice sees what he's
typing.
It's a simple but effective trick that enables interactive live sessions between computer
users, but it is entirely text-based.
Collaboration
With these two applications, you have access to some powerful methods of supporting users.
You can use these tools to manage systems remotely, as training tools, or as support tools, and
in every case, it sure beats wandering around the office looking for somebody's desk. Get
familiar with SSH and Tmux, and start using them today.
/run is home to a wide assortment of data. For example, if you take a look at /run/user, you
will notice a group of directories with numeric names.
$ ls /run/user
1000 1002 121
A long file listing will clarify the significance of these numbers.
$ ls -l
total 0
drwx------ 5 shs shs 120 Jun 16 12:44 1000
drwx------ 5 dory dory 120 Jun 16 16:14 1002
drwx------ 8 gdm gdm 220 Jun 14 12:18 121
This allows us to see that each directory is related to a user who is currently logged in or
to the display manager, gdm. The numbers represent their UIDs. The content of each of these
directories are files that are used by running processes.
The /run/user files represent only a very small portion of what you'll find in /run. There
are lots of other files, as well. A handful contain the process IDs for various system
processes.
"... A suicide occurs in the United States roughly once every 12 minutes . What's more, after decades of decline, the rate of self-inflicted deaths per 100,000 people annually -- the suicide rate -- has been increasing sharply since the late 1990s. Suicides now claim two-and-a-half times as many lives in this country as do homicides , even though the murder rate gets so much more attention. ..."
"... In some states the upsurge was far higher: North Dakota (57.6%), New Hampshire (48.3%), Kansas (45%), Idaho (43%). ..."
"... Since 2008 , suicide has ranked 10th among the causes of death in this country. For Americans between the ages of 10 and 34, however, it comes in second; for those between 35 and 45, fourth. The United States also has the ninth-highest rate in the 38-country Organization for Economic Cooperation and Development. Globally , it ranks 27th. ..."
"... The rates in rural counties are almost double those in the most urbanized ones, which is why states like Idaho, Kansas, New Hampshire, and North Dakota sit atop the suicide list. Furthermore, a far higher percentage of people in rural states own guns than in cities and suburbs, leading to a higher rate of suicide involving firearms, the means used in half of all such acts in this country. ..."
"... Education is also a factor. The suicide rate is lowest among individuals with college degrees. Those who, at best, completed high school are, by comparison, twice as likely to kill themselves. Suicide rates also tend to be lower among people in higher-income brackets. ..."
"... Evidence from the United States , Brazil , Japan , and Sweden does indicate that, as income inequality increases, so does the suicide rate. ..."
"... One aspect of the suicide epidemic is puzzling. Though whites have fared far better economically (and in many other ways) than African Americans, their suicide rate is significantly higher . ..."
"... The higher suicide rate among whites as well as among people with only a high school diploma highlights suicide's disproportionate effect on working-class whites. This segment of the population also accounts for a disproportionate share of what economists Anne Case and Angus Deaton have labeled " deaths of despair " -- those caused by suicides plus opioid overdoses and liver diseases linked to alcohol abuse. Though it's hard to offer a complete explanation for this, economic hardship and its ripple effects do appear to matter. ..."
"... Trump has neglected his base on pretty much every issue; this one's no exception. ..."
Yves here. This post describes how the forces driving the US suicide surge started well before the Trump era, but explains how
Trump has not only refused to acknowledge the problem, but has made matters worse.
However, it's not as if the Democrats are embracing this issue either.
BY Rajan Menon, the Anne and Bernard Spitzer Professor of International Relations at the Powell School, City College of New
York, and Senior Research Fellow at Columbia University's Saltzman Institute of War and Peace Studies. His latest book is The Conceit of Humanitarian Intervention
Originally published at
TomDispatch .
We hear a lot about suicide when celebrities like
Anthony Bourdain and
Kate Spade die by their own hand.
Otherwise, it seldom makes the headlines. That's odd given the magnitude of the problem.
In 2017, 47,173 Americans killed themselves.
In that single year, in other words, the suicide count was nearly
seven times greater than the number
of American soldiers killed in the Afghanistan and Iraq wars between 2001 and 2018.
A suicide occurs in the United States roughly once every
12 minutes . What's more, after decades
of decline, the rate of self-inflicted deaths per 100,000 people annually -- the suicide rate -- has been increasing sharply since
the late 1990s. Suicides now claim two-and-a-half times as many lives in this country as do
homicides , even
though the murder rate gets so much more attention.
In other words, we're talking about a national
epidemic of self-inflicted
deaths.
Worrisome Numbers
Anyone who has lost a close relative or friend to suicide or has worked on a suicide hotline (as I have) knows that statistics
transform the individual, the personal, and indeed the mysterious aspects of that violent act -- Why this person? Why now? Why in
this manner? -- into depersonalized abstractions. Still, to grasp how serious the suicide epidemic has become, numbers are a necessity.
According to a 2018 Centers for Disease Control study , between
1999 and 2016, the suicide rate increased in every state in the union except Nevada, which already had a remarkably high rate. In
30 states, it jumped by 25% or more; in 17, by at least a third. Nationally, it increased
33% . In some states the upsurge was far
higher: North Dakota (57.6%), New Hampshire (48.3%), Kansas (45%), Idaho (43%).
Alas, the news only gets grimmer.
Since 2008 , suicide has ranked 10th
among the causes of death in this country. For Americans between the ages of 10 and 34, however, it comes in second; for those between
35 and 45, fourth. The United States also has the ninth-highest
rate in the 38-country Organization for Economic Cooperation and Development.
Globally , it ranks 27th.
More importantly, the trend in the United States doesn't align with what's happening elsewhere in the developed world. The World
Health Organization, for instance, reports
that Great Britain, Canada, and China all have notably lower suicide rates than the U.S.,
as do all but
six countries in the European Union. (Japan's is only slightly lower.)
World Bank statistics show that, worldwide,
the suicide rate fell from 12.8 per 100,000 in 2000 to 10.6 in 2016. It's been falling in
China ,
Japan
(where it has declined steadily for nearly a
decade and is at its lowest point in 37 years), most of Europe, and even countries like
South Korea and
Russia that
have a significantly higher suicide rate than the United States. In Russia, for instance, it has dropped by nearly 26% from a
high point of 42 per 100,000 in
1994 to 31 in 2019.
We know a fair amount about the patterns
of suicide in the United States. In 2017, the rate was highest for men between the ages of 45 and 64 (30 per 100,000) and those 75
and older (39.7 per 100,000).
The rates in rural counties are almost double those in the most urbanized ones, which is why states like Idaho, Kansas, New
Hampshire, and North Dakota sit atop the suicide list. Furthermore, a far higher percentage of people in rural states own
guns than in cities and suburbs, leading to a
higher rate of suicide involving firearms, the means used in half
of all such acts in this country.
There are gender-based differences as well.
From 1999 to 2017, the rate for men was substantially higher than for women -- almost four-and-a-half times higher in the first of
those years, slightly more than three-and-a-half times in the last.
Education is also a factor. The suicide rate is
lowest among individuals with college degrees. Those who, at best, completed high school are, by comparison, twice as likely to kill
themselves. Suicide rates also tend to be lower
among people in higher-income brackets.
The Economics of Stress
This surge in the suicide rate has taken place in years during which the working class has experienced greater economic hardship
and psychological stress. Increased competition from abroad and outsourcing, the results of globalization, have contributed to job
loss, particularly in economic sectors like manufacturing, steel, and mining that had long been mainstays of employment for such
workers. The jobs still available often paid less and provided fewer benefits.
Technological change, including computerization, robotics, and the coming of artificial intelligence, has similarly begun to displace
labor in significant ways, leaving Americans without college degrees, especially those 50 and older, in
far more difficult straits when it comes to
finding new jobs that pay
well. The lack of anything resembling an
industrial policy of a sort that exists in Europe
has made these dislocations even more painful for American workers, while a sharp decline in private-sector union membership
-- down
from nearly 17% in 1983 to 6.4% today -- has reduced their ability to press for higher wages through collective bargaining.
Furthermore, the inflation-adjusted median wage has barely budged
over the last four decades (even as
CEO salaries have soared). And a decline in worker productivity doesn't explain it: between 1973 and 2017 productivity
increased by 77%, while a worker's average hourly wage only
rose by 12.4%. Wage stagnation has made it
harder for working-class
Americans to get by, let alone have a lifestyle comparable to that of their parents or grandparents.
The gap in earnings between those at the top and bottom of American society has also increased -- a lot. Since 1979, the
wages of Americans in the 10th percentile increased by a pitiful
1.2%. Those in the 50th percentile did a bit better, making a gain of 6%. By contrast, those in the 90th percentile increased by
34.3% and those near the peak of the wage pyramid -- the top 1% and especially the rarefied 0.1% -- made far more
substantial
gains.
And mind you, we're just talking about wages, not other forms of income like large stock dividends, expensive homes, or eyepopping
inheritances. The share of net national wealth held by the richest 0.1%
increased from 10% in the 1980s to 20% in 2016.
By contrast, the share of the bottom 90% shrank in those same decades from about 35% to 20%. As for the top 1%, by 2016 its share
had increased to almost 39% .
The precise relationship between economic inequality and suicide rates remains unclear, and suicide certainly can't simply be
reduced to wealth disparities or financial stress. Still, strikingly, in contrast to the United States, suicide rates are noticeably
lower and have been declining in
Western
European countries where income inequalities are far less pronounced, publicly funded healthcare is regarded as a right (not
demonized as a pathway to serfdom), social safety nets far more extensive, and
apprenticeships and worker
retraining programs more widespread.
Evidence from the United States
, Brazil ,
Japan , and
Sweden does indicate that, as income inequality increases,
so does the suicide rate. If so, the good news is that progressive economic policies -- should Democrats ever retake the White
House and the Senate -- could make a positive difference. A study
based on state-by-state variations in the U.S. found that simply boosting the minimum wage and Earned Income Tax Credit by 10%
appreciably reduces the suicide rate among people without college degrees.
The Race Enigma
One aspect of the suicide epidemic is puzzling. Though whites have fared far better economically (and in many other ways)
than African Americans, their suicide rate is significantly
higher . It increased from 11.3 per 100,000
in 2000 to 15.85 per 100,000 in 2017; for African Americans in those years the rates were 5.52 per 100,000 and 6.61 per 100,000.
Black men are
10 times more likely to be homicide victims than white men, but the latter are two-and-half times more likely to kill themselves.
The higher suicide rate among whites as well as among people with only a high school diploma highlights suicide's disproportionate
effect on working-class whites. This segment of the population also accounts for a disproportionate share of what economists Anne
Case and Angus Deaton have labeled "
deaths of despair
" -- those caused by suicides plus
opioid overdoses
and liver diseases linked to alcohol abuse. Though it's hard to offer a complete explanation for this, economic hardship and
its ripple effects do appear to matter.
According to a study by the
St. Louis Federal Reserve , the white working class accounted for 45% of all income earned in the United States in 1990, but
only 27% in 2016. In those same years, its share of national wealth plummeted, from 45% to 22%. And as inflation-adjusted wages have
decreased for
men without college degrees, many white workers seem to have
lost hope of success of
any sort. Paradoxically, the sense of failure and the accompanying stress may be greater for white workers precisely because they
traditionally were much
better off economically than their African American and Hispanic counterparts.
In addition, the fraying of communities knit together by employment in once-robust factories and mines has increased
social isolation
among them, and the evidence that it -- along with
opioid addiction and
alcohol abuse -- increases the risk of suicide
is strong . On top of that,
a significantly higher proportion of
whites than blacks and Hispanics own firearms, and suicide rates are markedly higher in states where gun
ownership is more widespread.
Trump's Faux Populism
The large increase in suicide within the white working class began a couple of decades before Donald Trump's election. Still,
it's reasonable to ask what he's tried to do about it, particularly since votes from these Americans helped propel him to the White
House. In 2016, he received
64% of the votes of whites without college degrees; Hillary Clinton, only 28%. Nationwide, he beat Clinton in
counties where deaths of despair rose significantly between 2000 and 2015.
White workers will remain crucial to Trump's chances of winning in 2020. Yet while he has spoken about, and initiated steps aimed
at reducing, the high suicide rate among
veterans , his speeches and tweets have never highlighted the national suicide epidemic or its inordinate impact on white workers.
More importantly, to the extent that economic despair contributes to their high suicide rate, his policies will only make matters
worse.
The real benefits from the December 2017 Tax Cuts and Jobs Act championed by the president and congressional Republicans flowed
to those on the top steps of the economic ladder. By 2027, when the Act's provisions will run out, the wealthiest Americans are expected
to have captured
81.8% of the gains. And that's not counting the windfall they received from recent changes in taxes on inheritances. Trump and
the GOP
doubled the annual amount exempt from estate taxes -- wealth bequeathed to heirs -- through 2025 from $5.6 million per individual
to $11.2 million (or $22.4 million per couple). And who benefits most from this act of generosity? Not workers, that's for sure,
but every household with an estate worth $22 million or more will.
As for job retraining provided by the Workforce Innovation and Opportunity Act, the president
proposed
cutting that program by 40% in his 2019 budget, later settling for keeping it at 2017 levels. Future cuts seem in the cards as
long as Trump is in the White House. The Congressional Budget Office
projects that his tax cuts alone will produce even bigger budget
deficits in the years to come. (The shortfall last year was
$779 billion and it is expected to
reach $1 trillion by 2020.) Inevitably, the president and congressional Republicans will then demand additional reductions in spending
for social programs.
This is all the more likely because Trump and those Republicans also
slashed corporate taxes
from 35% to 21% -- an estimated
$1.4
trillion in savings for corporations over the next decade. And unlike the income tax cut, the corporate tax has
no end
date . The president assured his base that the big bucks those companies had stashed abroad would start flowing home and produce
a wave of job creation -- all without adding to the deficit. As it happens, however, most of that repatriated cash has been used
for corporate stock buy-backs, which totaled more than
$800 billion last year. That, in turn, boosted share prices, but didn't exactly rain money down on workers. No surprise, of course,
since the wealthiest 10% of Americans own at least
84% of all stocks and the bottom
60% have less than
2% of them.
And the president's corporate tax cut hasn't produced the tsunami of job-generating investments he predicted either. Indeed, in
its aftermath, more than 80% of American
companies stated that their plans for investment and hiring hadn't changed. As a result, the monthly increase in jobs has proven
unremarkable compared to President Obama's
second term, when the economic recovery that Trump largely inherited began. Yes, the economy did grow
2.3%
in 2017 and
2.9% in 2018 (though not
3.1% as the president claimed). There wasn't, however, any "unprecedented economic boom -- a boom that has rarely been seen before"
as he insisted in this year's State of the Union
Address .
Anyway, what matters for workers struggling to get by is growth in real wages, and there's nothing to celebrate on that front:
between 2017 and mid-2018 they actually
declined by 1.63% for white workers and 2.5% for African Americans, while they rose for Hispanics by a measly 0.37%. And though
Trump insists that his beloved tariff hikes are going to help workers, they will actually raise the prices of goods, hurting the
working class and other low-income Americans
the most .
Then there are the obstacles those susceptible to suicide face in receiving insurance-provided mental-health care. If you're a
white worker without medical coverage or have a policy with a deductible and co-payments that are high and your income, while low,
is too high to qualify for Medicaid, Trump and the GOP haven't done anything for you. Never mind the president's
tweet proclaiming that "the Republican Party Will Become 'The Party of Healthcare!'"
Let me amend that: actually, they have done something. It's just not what you'd call helpful. The
percentage of uninsured
adults, which fell from 18% in 2013 to 10.9% at the end of 2016, thanks in no small measure to
Obamacare , had risen to 13.7% by the end of last year.
The bottom line? On a problem that literally has life-and-death significance for a pivotal portion of his base, Trump has been
AWOL. In fact, to the extent that economic strain contributes to the alarming suicide rate among white workers, his policies are
only likely to exacerbate what is already a national crisis of epidemic proportions.
Trump is running on the claim that he's turned the economy around; addressing suicide undermines this (false) claim. To state
the obvious, NC readers know that Trump is incapable of caring about anyone or anything beyond his in-the-moment interpretation
of his self-interest.
Not just Trump. Most of the Republican Party and much too many Democrats have also abandoned this base, otherwise known as
working class Americans.
The economic facts are near staggering and this article has done a nice job of summarizing these numbers that are spread out
across a lot of different sites.
I've experienced this rise within my own family and probably because of that fact I'm well aware that Trump is only a symptom
of an entire political system that has all but abandoned it's core constituency, the American Working Class.
Yep It's not just Trump. The author mentions this, but still focuses on him for some reason. Maybe accurately attributing the
problems to a failed system makes people feel more hopeless. Current nihilists in Congress make it their duty to destroy once
helpful institutions in the name of "fiscal responsibility," i.e., tax cuts for corporate elites.
I'd assumed, the "working class" had dissappeared, back during Reagan's Miracle? We'd still see each other, sitting dazed on
porches & stoops of rented old places they'd previously; trying to garden, fix their car while smoking, drinking or dazed on something?
Those able to morph into "middle class" lives, might've earned substantially less, especially benefits and retirement package
wise. But, a couple decades later, it was their turn, as machines and foreigners improved productivity. You could lease a truck
to haul imported stuff your kids could sell to each other, or help robots in some warehouse, but those 80s burger flipping, rent-a-cop
& repo-man gigs dried up. Your middle class pals unemployable, everybody in PayDay Loan debt (without any pay day in sight?) SHTF
Bug-out bags® & EZ Credit Bushmasters began showing up at yard sales, even up North. Opioids became the religion of the proletariat
Whites simply had much farther to fall, more equity for our betters to steal. And it was damned near impossible to get the cops
to shoot you?
Man, this just ain't turning out as I'd hoped. Need coffee!
We especially love the euphemism "Deaths O' Despair." since it works so well on a Chyron, especially supered over obese crackers
waddling in crusty MossyOak™ Snuggies®
This is a very good article, but I have a comment about the section titled, "The Race Enigma." I think the key to understanding
why African Americans have a lower suicide rate lies in understanding the sociological notion of community, and the related concept
Emil Durkheim called social solidarity. This sense of solidarity and community among African Americans stands in contrast to the
"There is no such thing as society" neoliberal zeitgeist that in fact produces feelings of extreme isolation, failure, and self-recriminations.
An aside: as a white boy growing up in 1950s-60s Detroit I learned that if you yearned for solidarity and community what you had
to do was to hang out with black people.
" if you yearned for solidarity and community what you had to do was to hang out with black people."
amen, to that. in my case rural black people.
and I'll add Hispanics to that.
My wife's extended Familia is so very different from mine.
Solidarity/Belonging is cool.
I recommend it.
on the article we keep the scanner on("local news").we had a 3-4 year rash of suicides and attempted suicides(determined by chisme,
or deduction) out here.
all of them were despair related more than half correlated with meth addiction itself a despair related thing.
ours were equally male/female, and across both our color spectrum.
that leaves economics/opportunity/just being able to get by as the likely cause.
Actually, in the article it states:
"There are gender-based differences as well. From 1999 to 2017, the rate for men was substantially higher than for women -- almost
four-and-a-half times higher in the first of those years, slightly more than three-and-a-half times in the last."
which in some sense makes despair the wrong word, as females are actually quite a bit more likely to be depressed for instance,
but much less likely to "do the deed". Despair if we mean a certain social context maybe, but not just a psychological state.
Suicide deaths are a function of the suicide attempt rate and the efficacy of the method used. A unique aspect of the US is
the prevalence of guns in the society and therefore the greatly increased usage of them in suicide attempts compared to other
countries. Guns are a very efficient way of committing suicide with a very high "success" rate. As of 2010, half of US suicides
were using a gun as opposed to other countries with much lower percentages. So if the US comes even close to other countries in
suicide rates then the US will surpass them in deaths.
https://en.wikipedia.org/wiki/Suicide_methods#Firearms
Now we can add in opiates, especially fentanyl, that can be quite effective as well.
The economic crisis hitting middle America over the past 30 years has been quite focused on the states and populations that
also tend to have high gun ownership rates. So suicide attempts in those populations have a high probability of "success".
I would just take this opportunity to add that the police end up getting called in to prevent on lot of suicide attempts, and
just about every successful one.
In the face of so much blanket demonization of the police, along with justified criticism, it's important to remember that.
As someone who works in the mental health treatment system, acute inpatient psychiatry to be specific, I can say that of the
25 inpatients currently here, 11 have been here before, multiple times. And this is because of several issues, in my experience:
inadequate inpatient resources, staff burnout, inadequate support once they leave the hospital, and the nature of their illnesses.
It's a grim picture here and it's been this way for YEARS. Until MAJOR money is spent on this issue it's not going to get better.
This includes opening more facilities for people to live in long term, instead of closing them, which has been the trend I've
seen.
One last thing the CEO wants "asses in beds", aka census, which is the money maker. There's less profit if people get better
and don't return. And I guess I wouldn't have a job either. Hmmmm: sickness generates wealth.
Before proceeding further, let me give you one tip. In the example above the shell tried to
expand a non-existing variable, producing a blank result. This can be very dangerous,
especially when working with path names, therefore, when writing scripts, it's always
recommended to use the nounset option which causes the shell to exit with error
whenever a non existing variable is referenced:
$ set -o nounset
$ echo "You are reading this article on $site_!"
bash: site_: unbound variable
Working with indirection
The use of the ${!parameter} syntax, adds a level of indirection to our
parameter expansion. What does it mean? The parameter which the shell will try to expand is not
parameter ; instead it will try to use the the value of parameter as
the name of the variable to be expanded. Let's explain this with an example. We all know the
HOME variable expands in the path of the user home directory in the system,
right?
$ echo "${HOME}"
/home/egdoc
Very well, if now we assign the string "HOME", to another variable, and use this type of
expansion, we obtain:
As you can see in the example above, instead of obtaining "HOME" as a result, as it would
have happened if we performed a simple expansion, the shell used the value of
variable_to_inspect as the name of the variable to expand, that's why we talk
about a level of indirection.
Case modification expansion
This parameter expansion syntax let us change the case of the alphabetic characters inside
the string resulting from the expansion of the parameter. Say we have a variable called
name ; to capitalize the text returned by the expansion of the variable we would
use the ${parameter^} syntax:
$ name="egidio"
$ echo "${name^}"
Egidio
What if we want to uppercase the entire string, instead of capitalize it? Easy! we use the
${parameter^^} syntax:
$ echo "${name^^}"
EGIDIO
Similarly, to lowercase the first character of a string, we use the
${parameter,} expansion syntax:
$ name="EGIDIO"
$ echo "${name,}"
eGIDIO
To lowercase the entire string, instead, we use the ${parameter,,} syntax:
$ name="EGIDIO"
$ echo "${name,,}"
egidio
In all cases a pattern to match a single character can also be provided. When
the pattern is provided the operation is applied only to the parts of the original string that
matches it:
In the example above we enclose the characters in square brackets: this causes anyone of
them to be matched as a pattern.
When using the expansions we explained in this paragraph and the parameter is
an array subscripted by @ or * , the operation is applied to all the
elements contained in it:
$ my_array=(one two three)
$ echo "${my_array[@]^^}"
ONE TWO THREE
When the index of a specific element in the array is referenced, instead, the operation is
applied only to it:
$ my_array=(one two three)
$ echo "${my_array[2]^^}"
THREE
Substring removal
The next syntax we will examine allows us to remove a pattern from the
beginning or from the end of string resulting from the expansion of a parameter.
Remove
matching pattern from the beginning of the string
The next syntax we will examine, ${parameter#pattern} , allows us to remove a
pattern from the beginning of the string resulting from the parameter
expansion:
$ name="Egidio"
$ echo "${name#Egi}"
dio
A similar result can be obtained by using the "${parameter##pattern}" syntax,
but with one important difference: contrary to the one we used in the example above, which
removes the shortest matching pattern from the beginning of the string, it removes the longest
one. The difference is clearly visible when using the * character in the
pattern :
$ name="Egidio Docile"
$ echo "${name#*i}"
dio Docile
In the example above we used * as part of the pattern that should be removed
from the string resulting by the expansion of the name variable. This
wildcard matches any character, so the pattern itself translates in "'i' character
and everything before it". As we already said, when we use the
${parameter#pattern} syntax, the shortest matching pattern is removed, in this
case it is "Egi". Let's see what happens when we use the "${parameter##pattern}"
syntax instead:
$ name="Egidio Docile"
$ echo "${name##*i}"
le
This time the longest matching pattern is removed ("Egidio Doci"): the longest possible
match includes the third 'i' and everything before it. The result of the expansion is just
"le".
Remove matching pattern from the end of the string
The syntax we saw above remove the shortest or longest matching pattern from the beginning
of the string. If we want the pattern to be removed from the end of the string, instead, we
must use the ${parameter%pattern} or ${parameter%%pattern}
expansions, to remove, respectively, the shortest and longest match from the end of the
string:
In this example the pattern we provided roughly translates in "'i' character and everything
after it starting from the end of the string". The shortest match is "ile", so what is returned
is "Egidio Doc". If we try the same example but we use the syntax which removes the longest
match we obtain:
$ name="Egidio Docile"
$ echo "${name%%i*}"
Eg
In this case the once the longest match is removed, what is returned is "Eg".
In all the expansions we saw above, if parameter is an array and it is
subscripted with * or @ , the removal of the matching pattern is
applied to all its elements:
$ my_array=(one two three)
$ echo "${my_array[@]#*o}"
ne three
We used the previous syntax to remove a matching pattern from the beginning or from the end
of the string resulting from the expansion of a parameter. What if we want to replace
pattern with something else? We can use the
${parameter/pattern/string} or ${parameter//pattern/string} syntax.
The former replaces only the first occurrence of the pattern, the latter all the
occurrences:
$ phrase="yellow is the sun and yellow is the
lemon"
$ echo "${phrase/yellow/red}"
red is the sun and yellow is the lemon
The parameter (phrase) is expanded, and the longest match of the
pattern (yellow) is matched against it. The match is then replaced by the provided
string (red). As you can observe only the first occurrence is replaced, so the
lemon remains yellow! If we want to change all the occurrences of the pattern, we must prefix
it with the / character:
$ phrase="yellow is the sun and yellow is the
lemon"
$ echo "${phrase//yellow/red}"
red is the sun and red is the lemon
This time all the occurrences of "yellow" has been replaced by "red". As you can see the
pattern is matched wherever it is found in the string resulting from the expansion of
parameter . If we want to specify that it must be matched only at the beginning or
at the end of the string, we must prefix it respectively with the # or
% character.
Just like in the previous cases, if parameter is an array subscripted by either
* or @ , the substitution happens in each one of its elements:
$ my_array=(one two three)
$ echo "${my_array[@]/o/u}"
une twu three
Substring expansion
The ${parameter:offset} and ${parameter:offset:length} expansions
let us expand only a part of the parameter, returning a substring starting at the specified
offset and length characters long. If the length is not specified the
expansion proceeds until the end of the original string. This type of expansion is called
substring expansion :
$ name="Egidio Docile"
$ echo "${name:3}"
dio Docile
In the example above we provided just the offset , without specifying the
length , therefore the result of the expansion was the substring obtained by
starting at the character specified by the offset (3).
If we specify a length, the substring will start at offset and will be
length characters long:
$ echo "${name:3:3}"
dio
If the offset is negative, it is calculated from the end of the string. In this
case an additional space must be added after : otherwise the shell will consider
it as another type of expansion identified by :- which is used to provide a
default value if the parameter to be expanded doesn't exist (we talked about it in the
article
about managing the expansion of empty or unset bash variables ):
$ echo "${name: -6}"
Docile
If the provided length is negative, instead of being interpreted as the total
number of characters the resulting string should be long, it is considered as an offset to be
calculated from the end of the string. The result of the expansion will therefore be a
substring starting at offset and ending at length characters from the
end of the original string:
$ echo "${name:7:-3}"
Doc
When using this expansion and parameter is an indexed array subscribed by
* or @ , the offset is relative to the indexes of the
array elements. For example:
$ my_array=(one two three)
$ echo "${my_array[@]:0:2}"
one two
$ echo "${my_array[@]: -2}"
two three
Accessing remote desktops Need to see what's happening on someone else's screen? Here's what you need to know about accessing
remote desktops.
Posted June 13, 2019 | by Seth Kenlon (Red Hat)
Anyone who's worked a support desk has had the experience: sometimes, no matter how descriptive your instructions,
and no matter how concise your commands, it's just easier and quicker for everyone involved to share screens. Likewise, anyone who's
ever maintained a server located in a loud and chilly data center -- or across town, or the world -- knows that often a remote viewer
is the easiest method for viewing distant screens.
Linux is famously capable of being managed without seeing a GUI, but that doesn't mean you have to manage your box that
way. If you need to see the desktop of a computer that you're not physically in front of, there are plenty of tools for the job.
Barriers
Half the battle of successfully screen sharing is getting into the target computer. That's by design, of course. It should
be difficult to get into a computer without explicit consent.
Usually, there are up to 3 blockades for accessing a remote machine:
The network firewall
The target computer's firewall
Screen share settings
Specific instruction on how to get past each barrier is impossible. Every network and every computer is configured uniquely, but
here are some possible solutions.
Barrier 1: The network firewall
A network firewall is the target computer's LAN entry point, often a part of the router (whether an appliance from an Internet
Service Provider or a dedicated server in a rack). In order to pass through the firewall and access a computer remotely, your network
firewall must be configured so that the appropriate port for the remote desktop protocol you're using is accessible.
The most common, and most universal, protocol for screen sharing is VNC.
If the network firewall is on a Linux server you can access, you can broadly allow VNC traffic to pass through using firewall-cmd
, first by getting your active zone, and then by allowing VNC traffic in that zone:
If you're not comfortable allowing all VNC traffic into the network, add a rich rule to firewalld in order to let
in VNC traffic from only your IP address. For example, using an example IP address of 93.184.216.34, a rule to allow VNC traffic
is:
To ensure the firewall changes were made, reload the rules:
$ sudo firewall-cmd --reload
If network reconfiguration isn't possible, see the section "Screen sharing through a browser."
Barrier 2: The computer's firewall
Most personal computers have built-in firewalls. Users who are mindful of security may actively manage their firewall. Others,
though, blissfully trust their default settings. This means that when you're trying to access their computer for screen sharing,
their firewall may block incoming remote connection requests without the user even realizing it. Your request to view their screen
may successfully pass through the network firewall only to be silently dropped by the target computer's firewall.
Changing zones in Linux.
To remedy this problem, have the user either lower their firewall or, on Fedora and RHEL, place their computer into the trusted
zone. Do this only for the duration of the screen sharing session. Alternatively, have them add either one of the rules you added
to the network firewall (if your user is on Linux).
A reboot is a simple way to ensure the new firewall setting is instantiated, so that's probably the easiest next step for your
user. Power users can instead reload the firewall rules manually :
$ sudo firewall-cmd --reload
If you have a user override their computer's default firewall, remember to close the session by instructing them to re-enable
the default firewall zone. Don't leave the door open behind you!
Barrier 3: The computer's screen share settings
To share another computer's screen, the target computer must be running remote desktop software (technically, a remote desktop
server , since this software listens to incoming requests). Otherwise, you have nothing to connect to.
Some desktops, like GNOME, provide screen sharing options, which means you don't have to launch a separate screen sharing application.
To activate screen sharing in GNOME, open Settings and select Sharing from the left column. In the Sharing panel, click on Screen
Sharing and toggle it on:
Remote desktop viewers
There are a number of remote desktop viewers out there. Here are some of the best options.
GNOME Remote Desktop Viewer
The GNOME Remote Desktop Viewer application is codenamed Vinagre
. It's a simple application that supports multiple protocols, including VNC, Spice, RDP, and SSH. Vinagre's interface is intuitive,
and yet this application offers many options, including whether you want to control the target computer or only view it.
If Vinagre's not already installed, use your distribution's package manager to add it. On
Red Hat Enterprise Linux and
Fedora , use:
$ sudo dnf install vinagre
In order to open Vinagre, go to the GNOME desktop's Activities menu and launch Remote Desktop Viewer . Once it opens, click the
Connect button in the top left corner. In the Connect window that appears, select the VNC protocol. In the Host field, enter the
IP address of the computer you're connecting to. If you want to use the computer's hostname instead, you must have a valid DNS service
in place, or Avahi , or entries in /etc/hosts . Do not prepend
your entry with a username.
Select any additional options you prefer, and then click Connect .
If you use the GNOME Remote Desktop Viewer as a full-screen application, move your mouse to the screen's top center to reveal
additional controls. Most importantly, the exit fullscreen button.
If you're connecting to a Linux virtual machine, you can use the Spice protocol instead. Spice is robust, lightweight, and transmits
both audio and video, usually with no noticeable lag.
TigerVNC and TightVNC
Sometimes you're not on a Linux machine, so the GNOME Remote Desktop Viewer isn't available. As usual, open source has an answer.
In fact, open source has several answers, but two popular ones are TigerVNC and
TightVNC , which are both cross-platform VNC viewers. TigerVNC
offers separate downloads for each platform, while TightVNC has a universal Java client.
Both of these clients are simple, with additional options included in case you need them. The defaults are generally acceptable.
In order for these particular clients to connect, turn off the encryption setting for GNOME's embedded VNC server (codenamed Vino)
as follows:
$ gsettings set org.gnome.Vino require-encryption false
This modification must be done on the target computer before you attempt to connect, either in person or over SSH.
Red Hat Enterprise Linux 7 remoted to RHEL 8 with TightVNC
Use the option for an SSH tunnel to ensure that your VNC connection is fully encrypted.
Screen sharing through a browser
If network re-configuration is out of the question, sharing over an online meeting or collaboration platform is yet another option.
The best open source platform for this is Nextcloud , which offers screen sharing
over plain old HTTPS. With no firewall exceptions and no additional encryption required,
Nextcloud's Talk app provides video and audio chat, plus whole-screen sharing
using WebRTC technology.
This option requires a Nextcloud installation, but given that it's the best open source groupware package out there, it's probably
worth looking at if you're not already running an instance. You can install Nextcloud yourself, or you can purchase hosting from
Nextcloud.
To install the Talk app, go to Nextcloud's app store. Choose the Social & Communication category and then select the Talk plugin.
Next, add a user for the target computer's owner. Have them log into Nextcloud, and then click on the Talk app in the top left
of the browser window.
When you start a new chat with your user, they'll be prompted by their browser to allow notifications from Nextcloud. Whether
they accept or decline, Nextcloud's interface alerts them of the incoming call in the notification area at the top right corner.
Once you're in the call with your remote user, have them click on the Share screen button at the bottom of their chat window.
Remote screens
Screen sharing can be an easy method of support as long as you plan ahead so your network and clients support it from trusted
sources. Integrate VNC into your support plan early, and use screen sharing to help your users get better at what they do. Topics:
Linux Seth Kenlon Seth Kenlon is a free culture
advocate and UNIX geek.
OUR BEST CONTENT, DELIVERED TO YOUR INBOX
https://www.redhat.com/sysadmin/eloqua-embedded-subscribe.html?offer_id=701f20000012gE7AAI The opinions expressed on this website
are those of each author, not of the author's employer or of Red Hat.
Red Hat and the Red Hat logo are trademarks of Red Hat, Inc., registered in the United States and other countries.
`tee` command can be used to store the output of any command into more than one
files. You have to write the file names with space to do this task. Run the following
commands to store the output of `date` command into two files, output1.txt, and
output2.txt.
$ date | tee output1.txt output2.txt
$ cat output1.txt output2.txt
... ... ...
Example-4: Ignoring interrupt signal
`tee` command with '-i' option is used in this example to ignore any interrupt at the
time of command execution. So, the command will execute properly even the user presses
CTRL+C. Run the following commands from the terminal and check the output.
Example-5: Passing `tee` command output into another command
The output of the `tee` command can be passed to another command by using the pipe. In this
example, the first command output is passed to `tee` command and the output of `tee` command is
passed to another command. Run the following commands from the terminal.
$ ls | tee output4.txt | wc -lcw
$ ls
$ cat output4.txt
Screen Command
Examples To Manage Multiple Terminal Sessions
by
sk
· Published
June 6, 2019
· Updated
June 7, 2019
GNU Screen
is a terminal multiplexer (window manager). As the name says, Screen
multiplexes the physical terminal between multiple interactive shells, so we can perform different
tasks in each terminal session. All screen sessions run their programs completely independent. So, a
program or process running inside a screen session will keep running even if the session is
accidentally closed or disconnected. For instance, when
upgrading Ubuntu
server via SSH, Screen command will keep running the upgrade
process just in case your SSH session is terminated for any reason.
The GNU Screen allows us to
easily create multiple screen sessions, switch between different sessions, copy text between sessions,
attach or detach from a session at any time and so on. It is one of the important command line tool
every Linux admins should learn and use wherever necessary. In this brief guide, we will see the basic
usage of Screen command with examples in Linux.
Installing GNU Screen
GNU Screen is available in the default repositories of most Linux operating systems.
To install GNU Screen on Arch Linux, run:
$ sudo pacman -S screen
On Debian, Ubuntu, Linux Mint:
$ sudo apt-get install screen
On Fedora:
$ sudo dnf install screen
On RHEL, CentOS:
$ sudo yum install screen
On SUSE/openSUSE:
$ sudo zypper install screen
Let us go ahead and see some screen command examples.
Screen Command Examples To Manage
Multiple Terminal Sessions
The default prefix shortcut to all commands in Screen is
Ctrl+a
. You need to use
this shortcut a lot when using Screen. So, just remember this keyboard shortcut.
Create new Screen session
Let us create a new Screen session and attach to it. To do so, type the following command in
terminal:
screen
Now, run any program or process inside this session. The running process or program will keep
running even if you're disconnected from this session.
Detach from Screen sessions
To detach from inside a screen session, press
Ctrl+a
and
d
. You
don't have to press the both key combinations at the same time. First press
Ctrl+a
and then press
d
. After detaching from a session, you will see an output something
like below.
[detached from 29149.pts-0.sk]
Here,
29149
is the
screen ID
and
pts-0.sk
is the
name of the screen session. You can attach, detach and kill Screen sessions using either screen ID or
name of the respective session.
Create a named session
You can also create a screen session with any custom name of your choice other than the default
username like below.
screen -S ostechnix
The above command will create a new screen session with name
"xxxxx.ostechnix"
and
attach to it immediately. To detach from the current session, press
Ctrl+a
followed
by
d
.
Naming screen sessions can be helpful when you want to find which processes are running on which
sessions. For example, when a setup LAMP stack inside a session, you can simply name it like below.
screen -S lampstack
Create detached sessions
Sometimes, you might want to create a session, but don't want to attach it automatically. In such
cases, run the following command to create detached session named
"senthil"
:
screen -S senthil -d -m
Or, shortly:
screen -dmS senthil
The above command will create a session called "senthil", but won't attach to it.
List Screen sessions
To list all running sessions (attached or detached), run:
screen -ls
Sample output:
There are screens on:
29700.senthil (Detached)
29415.ostechnix (Detached)
29149.pts-0.sk (Detached)
3 Sockets in /run/screens/S-sk.
As you can see, I have three running sessions and all are detached.
Attach to Screen sessions
If you want to attach to a session at any time, for example
29415.ostechnix
,
simply run:
screen -r 29415.ostechnix
Or,
screen -r ostechnix
Or, just use the screen ID:
screen -r 29415
To verify if we are attached to the aforementioned session, simply list the open sessions and
check.
screen -ls
Sample output:
There are screens on:
29700.senthil (Detached)
29415.ostechnix (Attached)
29149.pts-0.sk (Detached)
3 Sockets in /run/screens/S-sk.
As you see in the above output, we are currently attached to
29415.ostechnix
session. To exit from the current session, press ctrl+a, d.
Create nested sessions
When we run "screen" command, it will create a single session for us. We can, however, create
nested sessions (a session inside a session).
First, create a new session or attach to an opened session. I am going to create a new session
named "nested".
screen -S nested
Now, press
Ctrl+a
and
c
inside the session to create another
session. Just repeat this to create any number of nested Screen sessions. Each session will be
assigned with a number. The number will start from
0
.
You can move to the next session by pressing
Ctrl+n
and move to previous by
pressing
Ctrl+p
.
Here is the list of important Keyboard shortcuts to manage nested sessions.
Ctrl+a "
– List all sessions
Ctrl+a 0
– Switch to session number 0
Ctrl+a n
– Switch to next session
Ctrl+a p
– Switch to the previous session
Ctrl+a S
– Split current region horizontally into two regions
Ctrl+a l
– Split current region vertically into two regions
Ctrl+a Q
– Close all sessions except the current one
Ctrl+a X
– Close the current session
Ctrl+a \
– Kill all sessions and terminate Screen
Ctrl+a ?
– Show keybindings. To quit this, press ENTER.
Lock sessions
Screen has an option to lock a screen session. To do so, press
Ctrl+a
and
x
. Enter your Linux password to lock the screen.
Screen used by sk <sk> on ubuntuserver.
Password:
Logging sessions
You might want to log everything when you're in a Screen session. To do so, just press
Ctrl+a
and
H
.
Alternatively, you can enable the logging when starting a new session using
-L
parameter.
screen -L
From now on, all activities you've done inside the session will recorded and stored in a file named
screenlog.x
in your $HOME directory. Here,
x
is a number.
You can view the contents of the log file using
cat
command or any text viewer
applications.
We should object to the neoliberal complete "instumentalization" of education: education became just a mean to get nicely paid job.
And even this hope is mostly an illusion for all but the top 5% of students...
And while students share their own part of responsibility for accumulating the debt the predatory behaviour of neoliberal universities
is an important factor that should not be discounted and perpetrators should be held responsible. Especially dirty tricks of ballooning
its size and pushing students into "hopeless" specialties, which would be fine, if they were sons or daughters of well to do and parent
still support then financially.
Actually neoliberalism justifies predatory behaviour and as such is a doomed social system as without solidarity some members of
financial oligarchy that rules the country sooner or later might hand from the lampposts.
Notable quotes:
"... It also never ceases to amaze me the number of anti-educational opinions which flare up when the discussion of student loan default arises. There are always those who will prophesize there is no need to attain a higher level of education as anyone could be something else and be successful and not require a higher level of education. Or they come forth with the explanation on how young 18 year-olds and those already struggling should be able to ascertain the risk of higher debt when the cards are already stacked against them legally. ..."
"... There does not appear to be much movement on the part of Congress to reconcile the issues in favor of students as opposed to the non-profit and for profit institutes. ..."
"... It's easy to explain, really. According to the Department of Education ( https://studentaid.ed.gov/sa/repay-loans/understand/plans ) you're going to be paying off that loan at minimum payments for 25 years. Assuming your average bachelor's degree is about $30k if you go all-loans ( http://collegecost.ed.gov/catc/ ) and the average student loan interest rate is a generous 5% ( http://www.direct.ed.gov/calc.html ), you're going to be paying $175 a month for a sizable chunk of your adult life. ..."
"... Majoring in IT or Computer Science would have a been a great move in the late 1990's; however, if you graduated around 2000, you likely would have found yourself facing a tough job market.. Likewise, majoring in petroleum engineering or petroleum geology would have seemed like a good move a couple of years ago; however, now that oil prices are crashing, it's presumably a much tougher job market. ..."
"... To confuse going to college with vocational education is to commit a major category error. I think bright, ambitious high school graduates– who are looking for upward social mobility– would be far better served by a plumbing or carpentry apprenticeship program. A good plumber can earn enough money to send his or her children to Yale to study Dante, Boccaccio, and Chaucer. ..."
"... A bright working class kid who goes off to New Haven, to study medieval lit, will need tremendous luck to overcome the enormous class prejudice she will face in trying to establish herself as a tenure-track academic. If she really loves medieval literature for its own sake, then to study it deeply will be "worth it" even if she finds herself working as a barista or store-clerk. ..."
"... As a middle-aged doctoral student in the humanities you should not even be thinking much about your loans. Write the most brilliant thesis that you can, get a book or some decent articles published from it– and swim carefully in the shark-infested waters of academia until you reach the beautiful island of tenured full-professorship. If that island turns out to be an ever-receding mirage, sell your soul to our corporate overlords and pay back your loans! Alternatively, tune in, drop out, and use your finely tuned research and rhetorical skills to help us overthrow the kleptocratic regime that oppresses us all!! ..."
"... Genuine education should provide one with profound contentment, grateful for the journey taken, and a deep appreciation of life. ..."
"... Instead many of us are left confused – confusing career training (redundant and excessive, as it turned out, unfortunate for the student, though not necessarily bad for those on the supply side, one must begrudgingly admit – oops, there goes one's serenity) with enlightenment. ..."
"... We all should be against Big Educational-Complex and its certificates-producing factory education that does not put the student's health and happiness up there with co-existing peacefully with Nature. ..."
"... Remember DINKs? Dual Income No Kids. Dual Debt Bad Job No House No Kids doesn't work well for acronyms. Better for an abbreviated hash tag? ..."
"... I graduated law school with $100k+ in debt inclusive of undergrad. I've never missed a loan payment and my credit score is 830. my income has never reached $100k. my payments started out at over $1000 a month and through aggressive payment and refinancing, I've managed to reduce the payments to $500 a month. I come from a lower middle class background and my parents offered what I call 'negative help' throughout college. ..."
"... my unfortunate situation is unique and I wouldn't wish my debt on anyone. it's basically indentured servitude. it's awful, it's affects my life and health in ways no one should have to live, I have all sorts of stress related illnesses. I'm basically 2 months away from default of everything. my savings is negligible and my net worth is still negative 10 years after graduating. ..."
"... My story is very similar to yours, although I haven't had as much success whittling down my loan balances. But yes, it's made me a socialist as well; makes me wonder how many of us, i.e. ppl radicalized by student loans, are out there. Perhaps the elites' grand plan to make us all debt slaves will eventually backfire in more ways than via the obvious economic issues? ..."
It also never ceases to amaze me the number of anti-educational opinions which flare up when the discussion of student loan
default arises. There are always those who will prophesize there is no need to attain a higher level of education as anyone could
be something else and be successful and not require a higher level of education. Or they come forth with the explanation on how young
18 year-olds and those already struggling should be able to ascertain the risk of higher debt when the cards are already stacked
against them legally. In any case during a poor economy, those with more education appear to be employed at a higher rate than
those with less education. The issue for those pursuing an education is the ever increasing burden and danger of student loans and
associated interest rates which prevent younger people from moving into the economy successfully after graduation, the failure of
the government to support higher education and protect students from for-profit fraud, the increased risk of default and becoming
indentured to the government, and the increased cost of an education which has surpassed healthcare in rising costs.
There does not appear to be much movement on the part of Congress to reconcile the issues in favor of students as opposed
to the non-profit and for profit institutes.
Ranger Rick, November 9, 2015 at 11:34 am
It's easy to explain, really. According to the Department of Education (
https://studentaid.ed.gov/sa/repay-loans/understand/plans
) you're going to be paying off that loan at minimum payments for 25 years. Assuming your average bachelor's degree is about $30k
if you go all-loans ( http://collegecost.ed.gov/catc/ ) and the
average student loan interest rate is a generous 5% ( http://www.direct.ed.gov/calc.html
), you're going to be paying $175 a month for a sizable chunk of your adult life.
If you're merely hitting the median income of a bachelor's degree after graduation, $55k (http://nces.ed.gov/fastfacts/display.asp?id=77
), and good luck with that in this economy, you're still paying ~31.5% of that in taxes (http://www.oecd.org/ctp/tax-policy/taxing-wages-20725124.htm
) you're left with $35.5k before any other costs. Out of that, you're going to have to come up with the down payment to buy a
house and a car after spending more money than you have left (http://www.bls.gov/cex/csxann13.pdf).
Louis, November 9, 2015 at 12:33 pm
The last paragraph sums it up perfectly, especially the predictable counterarguments. Accurately assessing what job in demand
several years down the road is very difficult, if not impossible.
Majoring in IT or Computer Science would have a been a great move in the late 1990's; however, if you graduated around
2000, you likely would have found yourself facing a tough job market.. Likewise, majoring in petroleum engineering or petroleum
geology would have seemed like a good move a couple of years ago; however, now that oil prices are crashing, it's presumably a
much tougher job market.
Do we blame the computer science majors graduating in 2000 or the graduates struggling to break into the energy industry, now
that oil prices have dropped, for majoring in "useless" degrees? It's much easier to create a strawman about useless degrees that
accept the fact that there is a element of chance in terms of what the job market will look like upon graduation.
The cost of higher education is absurd and there simply aren't enough good jobs to go around-there are people out there who
majored in the "right" fields and have found themselves underemployed or unemployed-so I'm not unsympathetic to the plight of
many people in my generation.
At the same time, I do believe in personal responsibility-I'm wary of creating a moral hazard if people can discharge loans
in bankruptcy. I've been paying off my student loans (grad school) for a couple of years-I kept the level debt below any realistic
starting salary-and will eventually have the loans paid off, though it may be a few more years.
I am really conflicted between believing in personal responsibility but also seeing how this generation has gotten screwed.
I really don't know what the right answer is.
Ulysses, November 9, 2015 at 1:47 pm
"The cost of higher education is absurd and there simply aren't enough good jobs to go around-there are people out there who
majored in the "right" fields and have found themselves underemployed or unemployed-so I'm not unsympathetic to the plight of
many people in my generation."
To confuse going to college with vocational education is to commit a major category error. I think bright, ambitious high
school graduates– who are looking for upward social mobility– would be far better served by a plumbing or carpentry apprenticeship
program. A good plumber can earn enough money to send his or her children to Yale to study Dante, Boccaccio, and Chaucer.
A bright working class kid who goes off to New Haven, to study medieval lit, will need tremendous luck to overcome the
enormous class prejudice she will face in trying to establish herself as a tenure-track academic. If she really loves medieval
literature for its own sake, then to study it deeply will be "worth it" even if she finds herself working as a barista or store-clerk.
None of this, of course, excuses the outrageously high tuition charges, administrative salaries, etc. at the "top schools."
They are indeed institutions that reinforce class boundaries. My point is that strictly career education is best begun at a less
expensive community college. After working in the IT field, for example, a talented associate's degree-holder might well find
that her employer will subsidize study at an elite school with an excellent computer science program.
My utopian dream would be a society where all sorts of studies are open to everyone– for free. Everyone would have a basic
Job or Income guarantee and could study as little, or as much, as they like!
Ulysses, November 9, 2015 at 2:05 pm
As a middle-aged doctoral student in the humanities you should not even be thinking much about your loans. Write the most
brilliant thesis that you can, get a book or some decent articles published from it– and swim carefully in the shark-infested
waters of academia until you reach the beautiful island of tenured full-professorship.
If that island turns out to be an ever-receding mirage, sell your soul to our corporate overlords and pay back your loans!
Alternatively, tune in, drop out, and use your finely tuned research and rhetorical skills to help us overthrow the kleptocratic
regime that oppresses us all!!
subgenius, November 9, 2015 at 3:07 pm
except (in my experience) the corporate overlords want young meat.
I have 2 masters degrees 2 undergraduate degrees and a host of random diplomas – but at 45, I am variously too old, too qualified,
or lacking sufficient recent corporate experience in the field to get hired
Trying to get enough cash to get a contractor license seems my best chance at anything other than random day work.
MyLessThanPrimeBeef, November 9, 2015 at 3:41 pm
Genuine education should provide one with profound contentment, grateful for the journey taken, and a deep appreciation
of life.
Instead many of us are left confused – confusing career training (redundant and excessive, as it turned out, unfortunate
for the student, though not necessarily bad for those on the supply side, one must begrudgingly admit – oops, there goes one's
serenity) with enlightenment.
"I would spend another 12 soul-nourishing years pursuing those non-profit degrees' vs 'I can't feed my family with those paper
certificates.'
jrs, November 9, 2015 at 2:55 pm
I am anti-education as the solution to our economic woes. We need jobs or a guaranteed income. And we need to stop outsourcing
the jobs that exist. And we need a much higher minimum wage. And maybe we need work sharing. I am also against using screwdrivers
to pound in a nail. But why are you so anti screwdriver anyway?
And I see calls for more and more education used to make it seem ok to pay people without much education less than a living
wage. Because they deserve it for being whatever drop outs. And it's not ok.
I don't actually have anything against the professors (except their overall political cowardice in times demanding radicalism!).
Now the administrators, yea I can see the bloat and the waste there. But mostly, I have issues with more and more education being
preached as the answer to a jobs and wages crisis.
MyLessThanPrimeBeef -> jrs, November 9, 2015 at 3:50 pm
We all should be against Big Educational-Complex and its certificates-producing factory education that does not put the
student's health and happiness up there with co-existing peacefully with Nature.
"You must be lazy – you're not educated."
"Sorry, you are too stupid for our elite university to admit, just as your brother was too poor for our rich club to let
in."
"I am going to kill you intellectually. I will annihilate you intellectually. My idea will destroy you and I don't have
to feel sorry at all."
Kris Alman, November 9, 2015 at 11:11 am
Remember DINKs? Dual Income No Kids. Dual Debt Bad Job No House No Kids doesn't work well for acronyms. Better for an abbreviated
hash tag?
debitor serf, November 9, 2015 at 7:17 pm
I graduated law school with $100k+ in debt inclusive of undergrad. I've never missed a loan payment and my credit score
is 830. my income has never reached $100k. my payments started out at over $1000 a month and through aggressive payment and refinancing,
I've managed to reduce the payments to $500 a month. I come from a lower middle class background and my parents offered what I
call 'negative help' throughout college.
my unfortunate situation is unique and I wouldn't wish my debt on anyone. it's basically indentured servitude. it's awful,
it's affects my life and health in ways no one should have to live, I have all sorts of stress related illnesses. I'm basically
2 months away from default of everything. my savings is negligible and my net worth is still negative 10 years after graduating.
student loans, combined with a rigged system, turned me into a closeted socialist. I am smart, hard working and resourceful.
if I can't make it in this world, heck, then who can? few, because the system is rigged!
I have no problems at all taking all the wealth of the oligarchs and redistributing it. people look at me like I'm crazy. confiscate
it all I say, and reset the system from scratch. let them try to make their billions in a system where things are fair and not
rigged...
Ramoth, November 9, 2015 at 9:23 pm
My story is very similar to yours, although I haven't had as much success whittling down my loan balances. But yes, it's
made me a socialist as well; makes me wonder how many of us, i.e. ppl radicalized by student loans, are out there. Perhaps the
elites' grand plan to make us all debt slaves will eventually backfire in more ways than via the obvious economic issues?
How is it that that can be a point of contention ? Name me one country in this world that
doesn't favor local companies.
These people company representatives who are complaining about local
favoritism would be howling like wolves if Huawei was given favor in the US over any one of
them.
I'm not saying that there are no reasons to be unhappy about business with China, but that
is not one of them. 60Reply
" The Trump administration, backed by US cyber defense experts, believes that Huawei
equipment can't be trusted " .. as distinct from Cisco which we already have backdoored
:]
The USA isn't annoyed at Huawei spying, they are annoyed that Huawei isn't spying for
them . If you don't use Huawei who would you use instead? Cisco? Yes, just open up and let
the NSA ream your ports. Oooo, filthy.
If you don't know the chip design, can't verify the construction, don't know the code and
can't verify the deployment to the hardware; you are already owned.
The only question is, but which state actor; China, USA, Israel, UK.....? Anonymous
Coward
..and we're all going to be poorer for it. Americans, Chinese and bystanders.
I was recently watching the WW1 channel on youtube (awesome thing, go Indy and team!) - the
delusion, lack of situational understanding and short sightedness underscoring the actions of
the main actors that started the Great War can certainly be paralleled to the situation
here.
The very idea that you can manage to send China 40 years back in time with no harm on your
side is bonkers.
You can put backdoor in the router. The problem is that you will never be able to access it.
also for improtant deployment countires inpect the source code of firmware. USA is playing dirty
games here., no matter whether Chinese are right or wrong.
They're not necessarily silos. If you design a network as a flat space with all interactions
peer to peer then you have set yourself the problem of ensuring all nodes on that network are
secure and enforcing traffic rules equally on each node. This is impractical -- its not that if
couldn't be done but its a huge waste of resources. A more practical strategy is to layer the
network, providing choke points where traffic can be monitored and managed. We currently do
this with firewalls and demilitarized zones, the goal being normally to prevent unwanted
traffic coming in (although it can be used to monitor and control traffic going out). This has
nothing to do with incompatible standards.
I'm not sure about the rest of the FUD in this article. Yes, its all very complicated. But
just as we have to know how to layer our networks we also know how to manage our information.
For example, anyone who as a smartphone that they co-mingle sensitive data and public access
on, relying on the integrity of its software to keep everything separate, is just plain asking
for trouble. Quite apart from the risk of data leakage between applications its a portable
device that can get lost, stolen or confiscated (and duplicated.....). Use common sense. Manage
your data.
"... The real issue is the semiconductors - the actual silicon. ..."
"... China has some fabs now, but far too few to handle even just their internal demand - and tech export restrictions have long kept their leading edge capabilities significantly behind the cutting edge. ..."
"... On the flip side: Foxconn, Huawei et al are so ubiquitous in the electronics global supply chain that US retail tech companies - specifically Apple - are going to be severely affected, or at least extremely vulnerable to being pushed forward as a hostage. ..."
Internet, phones, Android aren't the issue - except if the US is able to push China out of
GSM/ITU.
The real issue is the semiconductors - the actual silicon.
The majority of raw silicon wafers as well as the finished chips are created in the US or
its most aligned allies: Japan, Taiwan. The dominant manufacturers of semiconductor equipment
are also largely US with some Japanese and EU suppliers.
If Fabs can't sell to China, regardless of who actually paid to manufacture the chips,
because Applied Materials has been banned from any business related to China, this is pretty
severe for 5-10 years until the Chinese can ramp up their capacity.
China has some fabs now, but far too few to handle even just their internal demand - and
tech export restrictions have long kept their leading edge capabilities significantly behind
the cutting edge.
On the flip side: Foxconn, Huawei et al are so ubiquitous in the electronics global supply
chain that US retail tech companies - specifically Apple - are going to be severely affected,
or at least extremely vulnerable to being pushed forward as a hostage.
"... The British aerospace sector (not to be confused with the company of a similar name but more Capital Letters) developed, amongst other things, the all-flying tailplane, successful jet-powered VTOL flight, noise-and drag-reducing rotor blades and the no-tailrotor systems and were promised all sorts of crunchy goodness if we shared it with our wonderful friends across the Atlantic. ..."
"... We shared and the Americans shafted us. Again. And again. And now *they* are bleating about people not respecting Intellectual Property Rights? ..."
"Without saying so publicly, they're glad there's finally some effort to deal with longstanding issues
like government favoritism toward local companies, intellectual property theft, and forced technology
transfers."
The British aerospace sector (not to be confused with the company of a similar name but more Capital
Letters) developed, amongst other things, the all-flying tailplane, successful jet-powered VTOL flight,
noise-and drag-reducing rotor blades and the no-tailrotor systems and were promised all sorts of crunchy
goodness if we shared it with our wonderful friends across the Atlantic.
We shared and the Americans shafted us. Again. And again. And now *they* are bleating about people not
respecting Intellectual Property Rights?
And as for moaning about backdoors in Chinese kit, who do Cisco et al report to again? Oh yeah, those
nice Three Letter Acronym people loitering in Washington and Langley...
A claimed deliberate spying "backdoor" in Huawei routers used in the core of Vodafone
Italy's 3G network was, in fact, a Telnet -based remote debug interface.
The Bloomberg financial newswire reported this morning that Vodafone had found
"vulnerabilities going back years with equipment supplied by Shenzhen-based Huawei for the
carrier's Italian business".
"Europe's biggest phone company identified hidden backdoors in the software that could have
given Huawei unauthorized access to the carrier's fixed-line network in Italy,"
wailed the newswire.
Unfortunately for Bloomberg, Vodafone had a far less alarming explanation for the deliberate
secret "backdoor" – a run-of-the-mill LAN-facing diagnostic service, albeit a hardcoded
undocumented one.
"The 'backdoor' that Bloomberg refers to is Telnet, which is a protocol that is commonly
used by many vendors in the industry for performing diagnostic functions. It would not have
been accessible from the internet," said the telco in a statement to The Register ,
adding: "Bloomberg is incorrect in saying that this 'could have given Huawei unauthorized
access to the carrier's fixed-line network in Italy'.
"This was nothing more than a failure to remove a diagnostic function after
development."
It added the Telnet service was found during an audit, which means it can't have been that
secret or hidden: "The issues were identified by independent security testing, initiated by
Vodafone as part of our routine security measures, and fixed at the time by Huawei."
Huawei itself told us: "We were made aware of historical vulnerabilities in 2011 and 2012
and they were addressed at the time. Software vulnerabilities are an industry-wide challenge.
Like every ICT vendor we have a well-established public notification and patching process, and
when a vulnerability is identified we work closely with our partners to take the appropriate
corrective action."
Prior to removing the Telnet server, Huawei was said to have insisted in 2011 on using the
diagnostic service to configure and test the network devices. Bloomberg reported, citing a
leaked internal memo from then-Vodafone CISO Bryan Littlefair, that the Chinese manufacturer
thus refused to completely disable the service at first:
Vodafone said Huawei then refused
to fully remove the backdoor, citing a manufacturing requirement. Huawei said it needed the
Telnet service to configure device information and conduct tests including on Wi-Fi, and
offered to disable the service after taking those steps, according to the document.
El Reg understands that while Huawei indeed resisted removing the Telnet
functionality from the affected items – broadband network gateways in the core of
Vodafone Italy's 3G network – this was done to the satisfaction of all involved parties
by the end of 2011, with another network-level product de-Telnet-ised in 2012.
Broadband network gateways in 3G UMTS mobile networks are described in technical detail in
this Cisco (sorry)
PDF . The devices are also known as Broadband Remote Access Servers and sit at the edge of
a network operator's core.
Plenty of other things (cough, cough, Cisco) to panic about
Characterising this sort of Telnet service as a covert backdoor for government spies is a
bit like describing your catflap as an access portal that allows multiple species to pass
unhindered through a critical home security layer. In other words, massively over-egging the
pudding.
Many Reg readers won't need it explaining, but Telnet is a routinely used method of
connecting to remote devices for management purposes. When deployed with appropriate security
and authentication controls in place, it can be very useful. In Huawei's case, the Telnet
service wasn't facing the public internet, and was used to set up and test devices.
Look, it's not great that this was hardcoded into the equipment and undocumented – it
was, after all, declared a security risk – and had to be removed after some pressure.
However, it's not quite the hidden deliberate espionage backdoor for Beijing that some
fear.
Twitter-enabled infoseccer Kevin Beaumont also shared his thoughts on the story,
highlighting the number of vulns in equipment from Huawei competitor Cisco, a US firm:
For example, a pretty bad remote access hole was discovered in some Cisco
gear , which the mainstream press didn't seem too fussed about. Ditto hardcoded root
logins in Cisco video surveillance boxes. Lots of things unfortunately ship with insecure
remote access that ought to be removed; it's not evidence of a secret backdoor for state
spies.
Given Bloomberg's previous history of trying to break tech news, when it claimed that tiny
spy chips were being secretly planted on
Supermicro server motherboards – something that left the rest of the tech world
scratching its collective head once the initial dust had settled – it may be best to take
this latest revelation with a pinch of salt. Telnet wasn't even mentioned in
the latest report from the UK's Huawei Cyber Security Evaluation Centre, which savaged
Huawei's pisspoor software development practices.
While there is ample evidence in the public domain that Huawei is doing badly on the
basics of secure software development, so far there has been little that tends to show it
deliberately implements hidden espionage backdoors. Rhetoric from the US alleging Huawei is a
threat to national security seems to be having the opposite effect around the world.
With Bloomberg, an American company, characterising Vodafone's use of Huawei equipment as
"defiance" showing "that countries across Europe are willing to risk rankling the US in the
name of 5G preparedness," it appears that the US-Euro-China divide on 5G technology suppliers
isn't closing up any time soon. ®
Bootnote
This isn't shaping up to be a good week for Bloomberg. Only yesterday High Court judge Mr
Justice Nicklin
ordered the company to pay up £25k for the way it reported a live and ongoing
criminal investigation.
"... Like many of its Wall Street counterparts, Boeing also used complexity as a mechanism to obfuscate and conceal activity that is incompetent, nefarious and/or harmful to not only the corporation itself but to society as a whole (instead of complexity being a benign byproduct of a move up the technology curve). ..."
"... The economists who built on Friedman's work, along with increasingly aggressive institutional investors, devised solutions to ensure the primacy of enhancing shareholder value, via the advocacy of hostile takeovers, the promotion of massive stock buybacks or repurchases (which increased the stock value), higher dividend payouts and, most importantly, the introduction of stock-based pay for top executives in order to align their interests to those of the shareholders. These ideas were influenced by the idea that corporate efficiency and profitability were impinged upon by archaic regulation and unionization, which, according to the theory, precluded the ability to compete globally. ..."
"... "Return on Net Assets" (RONA) forms a key part of the shareholder capitalism doctrine. ..."
"... If the choice is between putting a million bucks into new factory machinery or returning it to shareholders, say, via dividend payments, the latter is the optimal way to go because in theory it means higher net returns accruing to the shareholders (as the "owners" of the company), implicitly assuming that they can make better use of that money than the company itself can. ..."
"... It is an absurd conceit to believe that a dilettante portfolio manager is in a better position than an aviation engineer to gauge whether corporate investment in fixed assets will generate productivity gains well north of the expected return for the cash distributed to the shareholders. But such is the perverse fantasy embedded in the myth of shareholder capitalism ..."
"... When real engineering clashes with financial engineering, the damage takes the form of a geographically disparate and demoralized workforce: The factory-floor denominator goes down. Workers' wages are depressed, testing and quality assurance are curtailed. ..."
The fall of the Berlin Wall and the corresponding end of the Soviet Empire gave the fullest impetus imaginable to the forces of
globalized capitalism, and correspondingly unfettered access to the world's cheapest labor. What was not to like about that? It afforded
multinational corporations vastly expanded opportunities to fatten their profit margins and increase the bottom line with seemingly
no risk posed to their business model.
Or so it appeared. In 2000, aerospace engineer L.J. Hart-Smith's remarkable paper, sardonically titled
"Out-Sourced Profits – The Cornerstone of Successful Subcontracting," laid
out the case against several business practices of Hart-Smith's previous employer, McDonnell Douglas, which had incautiously ridden
the wave of outsourcing when it merged with the author's new employer, Boeing. Hart-Smith's intention in telling his story was a
cautionary one for the newly combined Boeing, lest it follow its then recent acquisition down the same disastrous path.
Of the manifold points and issues identified by Hart-Smith, there is one that stands out as the most compelling in terms of understanding
the current crisis enveloping Boeing: The embrace of the metric "Return on Net Assets" (RONA). When combined with the relentless
pursuit of cost reduction (via offshoring), RONA taken to the extreme can undermine overall safety standards.
Related to this problem is the intentional and unnecessary use of complexity as an instrument of propaganda. Like many of its
Wall Street counterparts, Boeing also used complexity as a mechanism to obfuscate and conceal activity that is incompetent, nefarious
and/or harmful to not only the corporation itself but to society as a whole (instead of complexity being a benign byproduct of a
move up the technology curve).
All of these pernicious concepts are branches of the same poisoned tree: "
shareholder capitalism ":
[A] notion best epitomized by Milton Friedman that the only social
responsibility of a corporation is to increase its profits, laying the groundwork for the idea that shareholders, being the owners
and the main risk-bearing participants, ought therefore to receive the biggest rewards. Profits therefore should be generated
first and foremost with a view toward maximizing the interests of shareholders, not the executives or managers who (according
to the theory) were spending too much of their time, and the shareholders' money, worrying about employees, customers, and the
community at large. The economists who built on Friedman's work, along with increasingly aggressive institutional investors, devised
solutions to ensure the primacy of enhancing shareholder value, via the advocacy of hostile takeovers, the promotion of massive
stock buybacks or repurchases (which increased the stock value), higher dividend payouts and, most importantly, the introduction
of stock-based pay for top executives in order to align their interests to those of the shareholders. These ideas were influenced
by the idea that corporate efficiency and profitability were impinged upon by archaic regulation and unionization, which, according
to the theory, precluded the ability to compete globally.
"Return on Net Assets" (RONA) forms a key part of the shareholder capitalism doctrine. In essence, it means maximizing the returns
of those dollars deployed in the operation of the business. Applied to a corporation, it comes down to this: If the choice is between
putting a million bucks into new factory machinery or returning it to shareholders, say, via dividend payments, the latter is the
optimal way to go because in theory it means higher net returns accruing to the shareholders (as the "owners" of the company), implicitly
assuming that they can make better use of that money than the company itself can.
It is an absurd conceit to believe that a dilettante
portfolio manager is in a better position than an aviation engineer to gauge whether corporate investment in fixed assets will generate
productivity gains well north of the expected return for the cash distributed to the shareholders. But such is the perverse fantasy
embedded in the myth of shareholder capitalism.
Engineering reality, however, is far more complicated than what is outlined in university MBA textbooks. For corporations like
McDonnell Douglas, for example, RONA was used not as a way to prioritize new investment in the corporation but rather to justify
disinvestment in the corporation. This disinvestment ultimately degraded the company's underlying profitability and the quality
of its planes (which is one of the reasons the Pentagon helped to broker the merger with Boeing; in another perverse echo of the
2008 financial disaster, it was a politically engineered bailout).
RONA in Practice
When real engineering clashes with financial engineering, the damage takes the form of a geographically disparate and demoralized
workforce: The factory-floor denominator goes down. Workers' wages are depressed, testing and quality assurance are curtailed. Productivity
is diminished, even as labor-saving technologies are introduced. Precision machinery is sold off and replaced by inferior, but cheaper,
machines. Engineering quality deteriorates. And the upshot is that a reliable plane like Boeing's 737, which had been a tried and
true money-spinner with an impressive safety record since 1967, becomes a high-tech death trap.
The drive toward efficiency is translated into a drive to do more with less. Get more out of workers while paying them less. Make
more parts with fewer machines. Outsourcing is viewed as a way to release capital by transferring investment from skilled domestic
human capital to offshore entities not imbued with the same talents, corporate culture and dedication to quality. The benefits to
the bottom line are temporary; the long-term pathologies become embedded as the company's market share begins to shrink, as the airlines
search for less shoddy alternatives.
You must do one more thing if you are a Boeing director: you must erect barriers to bad news, because there is nothing that bursts
a magic bubble faster than reality, particularly if it's bad reality.
The illusion that Boeing sought to perpetuate was that it continued to produce the same thing it had produced for decades: namely,
a safe, reliable, quality airplane. But it was doing so with a production apparatus that was stripped, for cost reasons, of many
of the means necessary to make good aircraft. So while the wine still came in a bottle signifying Premier Cru quality, and still
carried the same price, someone had poured out the contents and replaced them with cheap plonk.
And that has become remarkably easy to do in aviation. Because Boeing is no longer subject to proper independent regulatory scrutiny.
This is what happens when you're allowed to "
self-certify" your own airplane , as the Washington Post described: "One Boeing engineer would conduct a test of a particular
system on the Max 8, while another Boeing engineer would act as the FAA's representative, signing on behalf of the U.S. government
that the technology complied with federal safety regulations."
This is a recipe for disaster. Boeing relentlessly cut costs, it outsourced across the globe to workforces that knew nothing about
aviation or aviation's safety culture. It sent things everywhere on one criteria and one criteria only: lower the denominator. Make
it the same, but cheaper. And then self-certify the plane, so that nobody, including the FAA, was ever the wiser.
Boeing also greased the wheels in Washington to ensure the continuation of this convenient state of regulatory affairs for the
company. According to OpenSecrets.org ,
Boeing and its affiliates spent $15,120,000 in lobbying expenses in 2018, after spending, $16,740,000 in 2017 (along with a further
$4,551,078 in 2018 political contributions, which placed the company 82nd out of a total of 19,087 contributors). Looking back at
these figures over the past four elections (congressional and presidential) since 2012, these numbers represent fairly typical spending
sums for the company.
But clever financial engineering, extensive political lobbying and self-certification can't perpetually hold back the effects
of shoddy engineering. One of the sad byproducts of the FAA's acquiescence to "self-certification" is how many things fall through
the cracks so easily.
Pentagon serves Wall Street and is controlled by CIA which is actually can be viewed as a
Wall Street arm as well.
Notable quotes:
"... This time, though, the general got to talking about Russia. So I perked up. He made it crystal clear that he saw Moscow as an adversary to be contained, checked, and possibly defeated. There was no nuance, no self-reflection, not even a basic understanding of the general complexity of geopolitics in the 21st century. ..."
"... General It-Doesn't-Matter-His-Name thundered that we need not worry, however, because his tanks and troops could "mop the floor" with the Russians, in a battle that "wouldn't even be close." It was oh-so-typical, another U.S. Army general -- who clearly longs for the Cold War fumes that defined his early career -- overestimating the Russian menace and underestimating Russian military capability . ..."
"... The problem with the vast majority of generals, however, is that they don't think strategically. What they call strategy is really large-scale operations -- deploying massive formations and winning campaigns replete with battles. Many remain mired in the world of tactics, still operating like lieutenants or captains and proving the Peter Principle right, as they get promoted past their respective levels of competence. ..."
"... If America's generals, now and over the last 18 years, really were strategic thinkers, they'd have spoken out about -- and if necessary resigned en masse over -- mission sets that were unwinnable, illegal (in the case of Iraq), and counterproductive . Their oath is to the Constitution, after all, not Emperors Bush, Obama, and Trump. Yet few took that step. It's all symptomatic of the disease of institutionalized intellectual mediocrity. ..."
"... Let's start with Mattis. "Mad Dog" Mattis was so anti-Iran and bellicose in the Persian Gulf that President Barack Obama removed him from command of CENTCOM. ..."
"... Furthermore, the supposedly morally untainted, "intellectual" " warrior monk " chose, when he finally resigned, to do so in response to Trump's altogether reasonable call for a modest troop withdrawal from Afghanistan and Syria. ..."
The two-star army general strode across the stage in his rumpled combat fatigues, almost
like George Patton -- all that was missing was the cigar and riding crop. It was 2017 and I was
in the audience, just another mid-level major attending yet another mandatory lecture in the
auditorium of the Command and General Staff College at Fort Leavenworth, Kansas.
The general then commanded one of the Army's two true armored divisions and had plenty of
his tanks forward deployed in Eastern Europe, all along the Russian frontier. Frankly, most
CGSC students couldn't stand these talks. Substance always seemed lacking, as each general
reminded us to "take care of soldiers" and "put the mission first," before throwing us a few
nuggets of conventional wisdom on how to be good staff officers should we get assigned to his
vaunted command.
This time, though, the general got to talking about Russia. So I perked up. He made it
crystal clear that he saw Moscow as an adversary to be contained, checked, and possibly
defeated. There was no nuance, no self-reflection, not even a basic understanding of the
general complexity of geopolitics in the 21st century. Generals can be like that --
utterly "in-the-box," "can-do" thinkers. They take pride in how little they discuss policy and
politics, even when they command tens of thousands of troops and control entire districts,
provinces, or countries. There is some value in this -- we'd hardly want active
generals meddling in U.S. domestic affairs. But they nonetheless can take the whole "aw shucks"
act a bit too far.
General It-Doesn't-Matter-His-Name thundered that we need not worry, however, because
his tanks and troops could "mop the floor" with the Russians, in a battle that "wouldn't even
be close." It was oh-so-typical, another U.S. Army general -- who clearly longs for the Cold
War fumes that defined his early career -- overestimating the Russian menace and
underestimating Russian military
capability . Of course, it was all cloaked in the macho bravado so common among
generals who think that talking like sergeants will win them street cred with the troops.
(That's not their job anymore, mind you.) He said nothing, of course, about the role
of mid- and long-range nuclear weapons that could be the catastrophic consequence of an
unnecessary war with the Russian Bear.
I got to thinking about that talk recently as I reflected in wonder at how the latest
generation of mainstream "liberals" loves to fawn over generals, admirals -- any flag officers,
really -- as alternatives to President Donald Trump. The irony of that alliance should not be
lost on us. It's built on the standard Democratic fear of looking "soft" on terrorism,
communism, or whatever-ism, and their visceral, blinding hatred of Trump. Some of this is
understandable. Conservative Republicans masterfully paint liberals as "weak sisters" on
foreign policy, and Trump's administration is, well, a wild card in world affairs.
The problem with the vast majority of generals, however, is that they don't think
strategically. What they call strategy is really large-scale operations -- deploying massive
formations and winning campaigns replete with battles. Many remain mired in the world of
tactics, still operating like lieutenants or captains and proving the Peter Principle right, as they
get promoted past their respective levels of competence.
If America's generals, now and over the last 18 years, really were strategic thinkers,
they'd have spoken out about -- and if necessary resigned en masse over -- mission sets that
were unwinnable, illegal (in the case of Iraq), and counterproductive . Their oath is to
the Constitution, after all, not
Emperors Bush, Obama, and Trump. Yet few took that step. It's all symptomatic of the
disease of institutionalized intellectual mediocrity. More of the same is all they know:
their careers were built on fighting "terror" anywhere it raised its evil head. Some, though no
longer most, still subscribe to the faux intellectualism of General Petraeus and his legion of
Coindinistas
, who never saw a problem that a little regime change, followed by expert counterinsurgency,
couldn't solve. Forget that they've been proven wrong time and again and can count
zero victories since 2002. Generals (remember this!) are never held accountable.
Flag officers also rarely seem to recognize that they owe civilian policymakers more than
just tactical "how" advice. They ought to be giving "if" advice -- if we invade Iraq,
it will take 500,000 troops to occupy the place, and even then we'll ultimately destabilize the
country and region, justify al-Qaeda's worldview, kick off a nationalist insurgency, and become
immersed in an unwinnable war. Some, like Army Chief General Eric Shinseki and CENTCOM head
John Abizaid, seemed to
know this deep down. Still, Shinseki quietly retired after standing up to Secretary of
Defense Donald Rumsfeld, and Abizaid rode out his tour to retirement.
Generals also love to tell the American people that victory is
"just around the corner," or that there's a "light at the end of the tunnel." General
William Westmoreland used the very same language when predicting imminent victory in Vietnam.
Two months later, the North Vietnamese and Vietcong unleashed the largest uprising of the war,
the famed Tet Offensive.
Take Afghanistan as exhibit A: 17 or so generals have now commanded U.S. troops in this,
America's longest war. All have commanded within the system and framework of their
predecessors. Sure, they made marginal operational and tactical changes -- some preferred
surges, others advising, others counterterror -- but all failed to achieve anything close to
victory, instead laundering failure into false optimism. None refused to play the same-old game
or question the very possibility of victory in landlocked, historically xenophobic Afghanistan.
That would have taken real courage, which is in short supply among senior officers.
Exhibit B involves Trump's former cabinet generals -- National Security Advisor H.R.
McMaster, Chief of Staff John Kelley, and Defense Secretary Jim Mattis -- whom adoring and
desperate liberals took as saviors and canonized as the supposed adults
in the room . They were no such thing. The generals' triumvirate consisted ultimately of
hawkish conventional thinkers married to the dogma of American exceptionalism and empire.
Period.
Let's start with Mattis. "Mad Dog" Mattis was so anti-Iran and bellicose in the Persian
Gulf that President Barack Obama
removed him from command of CENTCOM.
Furthermore, the supposedly morally untainted, "intellectual" " warrior
monk " chose, when he finally resigned, to do so in response to Trump's altogether
reasonable call for a modest troop withdrawal from Afghanistan and Syria.
Helping Saudi Arabia terror bomb Yemen and starve 85,000 children to death? Mattis rebuked
Congress and
supported that. He never considered resigning in opposition to that war crime. No, he fell
on his "courageous" sword over downgrading a losing 17-year-old war in Afghanistan. Not to
mention he came to Trump's cabinet straight from the board of contracting giant General
Dynamics, where he collected hundreds of thousands of military-industrial complex dollars.
Then there was John Kelley, whom Press Secretary Sarah Sanders implied
was above media questioning because he was once a four-star marine general. And there's
McMaster, another lauded intellectual who once wrote an interesting book and taught history at
West Point. Yet he still drew all
the wrong conclusions in his famous book on Vietnam -- implying that more troops, more
bombing, and a mass invasion of North Vietnam could have won the war. Furthermore, his work
with Mattis on Trump's unhinged
, imperial National Defense Strategy proved that he was, after all, just another devotee of
American hyper-interventionism.
So why reflect on these and other Washington generals? It's simple: liberal veneration for
these, and seemingly all, military flag officers is a losing proposition and a formula for more
intervention, possible war with other great powers, and the creeping militarization of the
entire U.S. government. We know what the generals expect -- and potentially
want -- for America's foreign policy future.
Just look at the curriculum at the various war and staff colleges from Kansas to Rhode
Island. Ten years ago, they were all running war games focused on counterinsurgency in the
Middle East and Africa. Now those same schools are drilling for future "contingencies" in the
Baltic, Caucasus, and in the South China Sea. Older officers have always lamented the end of
the Cold War "good old days," when men were men and the battlefield was "simple." A return to a
state of near-war with Russia and China is the last thing real progressives should be
pushing for in 2020.
The bottom line is this: the faint hint that mainstream libs would relish a Six Days in May– style military coup is more than a little disturbing, no matter what you think
of Trump. Democrats must know the damage such a move would do to our ostensible republic. I
say: be a patriot. Insist on civilian control of foreign affairs. Even if that
means two more years of The Donald.
Danny Sjursen is a retired U.S. Army Major and regular contributor to Truthdig . His
work has also appeared in Harper's, the Los Angeles Times , The Nation , Tom Dispatch , and The
Hill . He served combat tours in Iraq and Afghanistan, and later taught history at his alma
mater, West Point. He is the author of Ghostriders of
Baghdad: Soldiers, Civilians, and the Myth of the Surge . Follow him on Twitter @SkepticalVet .
[ Note: The views expressed in this article are those of the author, expressed in an
unofficial capacity, and do not reflect the official policy or position of the Department of
the Army, Department of Defense, or the U.S. government.]
"... We are having a propaganda barrage about the great Trump economy. We have been hearing about the great economy for a decade while the labor force participation rate declined, real family incomes stagnated, and debt burdens rose. The economy has been great only for large equity owners whose stock ownership benefited from the trillions of dollars the Fed poured into financial markets and from buy-backs by corporations of their own stocks. ..."
"... Federal Reserve data reports that a large percentage of the younger work force live at home with parents, because the jobs available to them are insufficient to pay for an independent existence. How then can the real estate, home furnishings, and appliance markets be strong? ..."
"... In contrast, Robotics, instead of displacing labor, eliminates it. Unlike jobs offshoring which shifted jobs from the US to China, robotics will cause jobs losses in both countries. If consumer incomes fall, then demand for output also falls, and output will fall. Robotics, then, is a way to shrink gross domestic product. ..."
"... The tech nerds and corporations who cannot wait for robotics to reduce labor cost in their profits calculation are incapable of understanding that when masses of people are without jobs, there is no consumer income with which to purchase the products of robots. The robots themselves do not need housing, food, clothing, entertainment, transportation, and medical care. The mega-rich owners of the robots cannot possibly consume the robotic output. An economy without consumers is a profitless economy. ..."
"... A country incapable of dealing with real problems has no future. ..."
We are having a propaganda barrage about the great Trump economy. We have been hearing
about the great economy for a decade while the labor force participation rate declined, real
family incomes stagnated, and debt burdens rose. The economy has been great only for large
equity owners whose stock ownership benefited from the trillions of dollars the Fed poured into
financial markets and from buy-backs by corporations of their own stocks.
I have pointed out for years that the jobs reports are fabrications and that the jobs that
do exist are lowly paid domestic service jobs such as waitresses and bartenders and health care
and social assistance. What has kept the American economy going is the expansion of consumer
debt, not higher pay from higher productivity. The reported low unemployment rate is obtained
by not counting discouraged workers who have given up on finding a job.
Do you remember all the corporate money that the Trump tax cut was supposed to bring back to
America for investment? It was all BS. Yesterday I read reports that Apple is losing its
trillion dollar market valuation because Apple is using its profits to buy back its own stock.
In other words, the demand for Apple's products does not justify more investment. Therefore,
the best use of the profit is to repurchase the equity shares, thus shrinking Apple's
capitalization. The great economy does not include expanding demand for Apple's products.
I read also of endless store and mall closings, losses falsely attributed to online
purchasing, which only accounts for a small percentage of sales.
Federal Reserve data reports that a large percentage of the younger work force live at
home with parents, because the jobs available to them are insufficient to pay for an
independent existence. How then can the real estate, home furnishings, and appliance markets be
strong?
When a couple of decades ago I first wrote of the danger of jobs offshoring to the American
middle class, state and local government budgets, and pension funds, idiot critics raised the
charge of Luddite.
The Luddites were wrong. Mechanization raised the productivity of labor and real wages, but
jobs offshoring shifts jobs from the domestic economy to abroad. Domestic labor is displaced,
but overseas labor gets the jobs, thus boosting jobs there. In other words, labor income
declines in the country that loses jobs and rises in the country to which the jobs are
offshored. This is the way American corporations spurred the economic development of China. It
was due to jobs offshoring that China developed far more rapidly than the CIA expected.
In contrast, Robotics, instead of displacing labor, eliminates it. Unlike jobs
offshoring which shifted jobs from the US to China, robotics will cause jobs losses in both
countries. If consumer incomes fall, then demand for output also falls, and output will fall.
Robotics, then, is a way to shrink gross domestic product.
The tech nerds and corporations who cannot wait for robotics to reduce labor cost in
their profits calculation are incapable of understanding that when masses of people are without
jobs, there is no consumer income with which to purchase the products of robots. The robots
themselves do not need housing, food, clothing, entertainment, transportation, and medical
care. The mega-rich owners of the robots cannot possibly consume the robotic output. An economy
without consumers is a profitless economy.
One would think that there would be a great deal of discussion about the economic effects of
robotics before the problems are upon us, just as one would think there would be enormous
concern about the high tensions Washington has caused between the US and Russia and China, just
as one would think there would be preparations for the adverse economic consequences of global
warming, whatever the cause. Instead, the US, a country facing many crises, is focused on
whether President Trump obstructed investigation of a crime that the special prosecutor said
did not take place.
A country incapable of dealing with real problems has no future.
As is usual, the headline economic number is always the
rosiest number .
Wages for production and nonsupervisory workers accelerated to a 3.4 percent annual pace,
signaling gains for lower-paid employees.
That sounds pretty good. Except for the part where it is a lie. For starters, it doesn't account for
inflation .
Labor Department numbers released Wednesday show that real average hourly earnings, which
compare the nominal rise in wages with the cost of living, rose 1.7 percent in January on a
year-over-year basis.
1.7% is a lot less than 3.4%. While the financial news was bullish, the
actual professionals took the news differently.
Wage inflation was also muted with average hourly earnings rising six cents, or 0.2% in April
after rising by the same margin in March. Average hourly earnings "were disappointing," said Ian Lyngen, head of U.S. rates strategy at
BMO Capital Markets in New York.
Secondly, 1.7% is an average, not a median.
For instance, none of this applied to you if you are an
older
worker .
Weekly earnings for workers aged 55 to 64 were only 0.8% higher in the first quarter of 2019
than they were in the first quarter of 2007, after accounting for inflation, they found.
For comparison, earnings rose 4.7% during that same period for workers between the ages of 35
and 54.
On the other hand, if you worked for a
bank your wages went up at a rate far above average. This goes double if you are in
management.
Among the biggest standouts: commercial banks, which employ an estimated 1.3 million people in
the U.S. Since Trump took office in January 2017, they have increased their average hourly wage
at an annualized pace of almost 11 percent, compared with just 3.3 percent under Obama.
Finally, there is the reason for this incredibly small wage increase fo regular workers.
Hint: it wasn't because of capitalism and all the bullsh*t jobs it creates.
The tiny wage increase that the working class has seen is because of what the capitalists said
was a
terrible idea .
For Americans living in the 21 states where the federal minimum wage is binding, inflation
means that the minimum wage has lost 16 percent of its purchasing power.
But elsewhere, many workers and employers are experiencing a minimum wage well above 2009
levels. That's because state capitols and, to an unprecedented degree, city halls have become
far more active in setting their own minimum wages. ... Averaging across all of these federal, state and local minimum wage laws, the effective minimum
wage in the United States -- the average minimum wage binding each hour of minimum wage work --
will be $11.80 an hour in 2019. Adjusted for inflation, this is probably the highest minimum
wage in American history. The effective minimum wage has not only outpaced inflation in recent years, but it has also
grown faster than typical wages. We can see this from the Kaitz index, which compares the
minimum wage with median overall wages.
So if you are waiting for capitalism to trickle down on you, it's never going to happen.
span y gjohnsit on Fri, 05/03/2019 - 6:21pm
Thousands of South Carolina teachers rallied outside their state capitol Wednesday, demanding
pay raises, more planning time, increased school funding -- and, in a twist, more legal
protections for their freedom of speech SC for Ed, the grassroots activist group that organized Wednesday's demonstration, told CNN
that many teachers fear protesting or speaking up about education issues, worrying they'll
face retaliation at work. Saani Perry, a teacher in Fort Mill, S.C., told CNN that people in
his profession are "expected to sit in the classroom and stay quiet and not speak [their]
mind."
To address these concerns, SC for Ed is lobbying for the Teachers' Freedom of Speech Act,
which was introduced earlier this year in the state House of Representatives. The bill would
specify that "a public school district may not willfully transfer, terminate or fail to renew
the contract of a teacher because the teacher has publicly or privately supported a public
policy decision of any kind." If that happens, teachers would be able to sue for three times
their salary.
Teachers across the country are raising similar concerns about retaliation. Such fears
aren't unfounded: Lawmakers in some states that saw strikes last year have introduced bills
this year that would punish educators for skipping school to protest.
If your Redhat server is not connected to the official RHN repositories, you will need to
configure your own private repository which you can later use to install packages. The
procedure of creating a Redhat repository is quite simple task. In this article we will show
you how to create a local file Redhat repository as well as remote HTTP repository.
Using
Official Redhat DVD as repository
After default installation and without registering your server to official RHN repositories
your are left without any chance to install new packages from redhat repository as your
repository list will show 0 entries:
# yum repolist
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
repolist: 0
At this point the easiest thing to do is to attach your Redhat installation DVD as a local
repository. To do that, first make sure that your RHEL DVD is mounted:
# mount | grep iso9660
/dev/sr0 on /media/RHEL_6.4 x86_64 Disc 1 type iso9660 (ro,nosuid,nodev,uhelper=udisks,uid=500,gid=500,iocharset=utf8,mode=0400,dmode=0500)
The directory which most interests us at the moment is " /media/RHEL_6.4 x86_64 Disc
1/repodata " as this is the directory which contains information about all packages found on
this particular DVD disc.
Next we need to define our new repository pointing to " /media/RHEL_6.4 x86_64 Disc 1/ " by
creating a repository entry in /etc/yum.repos.d/. Create a new file called:
/etc/yum.repos.d/RHEL_6.4_Disc.repo using vi editor and insert a following text:
Once file was created your local Redhat DVD repository should be ready to use:
# yum repolist
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
repo id repo name status
RHEL_6.4_Disc RHEL_6.4_x86_64_Disc 3,648
repolist: 3,648
SUBSCRIBE TO NEWSLETTER
Subscribe to Linux Career NEWSLETTER and
receive latest Linux news, jobs, career advice and tutorials.
Normally having a Redhat DVD repository will be enough to get you started however, the only
disadvantage is that you are not able to alter your repository in any way and thus not able to
insert new/updated packages into it. The resolve this issue we can create a local file
repository sitting somewhere on the filesystem. To aid us with this plan we will use a
createrepo utility.
By default createrepo may not be installed on your system:
# yum list installed | grep createrepo
#
No output indicates that this packages is currently not present in your system. If you have
followed a previous section on how to attach RHEL official DVD as your system's repository,
then to install createrepo package simply execute:
# yum install createrepo
The above command will install createrepo utility along with all prerequisites. In case that
you do not have your repository defined yet, you can install createrepo manually:
Using your mounted RedHat DVD first install prerequisites:
You are also able to create Redhat repository on any debian-like Linux system such as
Debian, Ubuntu or mint. The procedure is the same except that installation of createrepo
utility will be: # apt-get install createrepo
# yum repolist
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
rhel_repo | 2.9 kB 00:00 ...
rhel_repo/primary_db | 367 kB 00:00 ...
repo id repo name status
RHEL_6.4_Disc RHEL_6.4_x86_64_Disc 3,648
rhel_repo RHEL_6.4_x86_64_Local 3,648
Creating a remote HTTP Redhat repository
If you have multiple Redhat servers you may want to create a single Redhat repository
accessible by all other servers on the network. For this you will need apache web server.
Detailed installation and configuration of Apache web server is beyond the scope of this guide
therefore, we assume that your httpd daemon ( Apache webserver ) is already configured. In
order to make your new repository accessible via http configure your apache with /rhel_repo/
directory created in previous section as document root directory or simply copy entire
directory to: /var/www/html/ ( default document root ).
Then create a new yum repository entry on your client system by creating a new repo
configuration file:
vi /etc/yum.repos.d/rhel_http_repo.repo
with a following content, where my host is a IP address or hostname of your Redhat
repository server:
Confirm the correctness of your new repository by:
# yum repolist
Loaded plugins: product-id, refresh-packagekit, security, subscription-manager
This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register.
repo id repo name status
rhel_repo_http RHEL_6.4_x86_64_HTTP 3,648
repolist: 3,648
Conclusion
Creating your own package repository gives you more options on how to manage packages on
your Redhat system even without paid RHN subscription. When using a remote HTTP Redhat
repository you may also want to configure GPGCHECK as part of your repository to make sure that
no packages had been tampered to prior their installation.
...I suspect that for
both of those, when they hit, you need to resolve things quickly and efficiently, with panic
being the worst enemy.
Panic in my experience stems from a number of things here, but two crucial ones are:
– input overload
– not knowing what to do, or learned actions not having any effect
Both of them can be, to a very large extent, overcome with training, training, and more
training (of actually practising the emergency situation, not just reading about it and
filling questionairres).
The New York Times has an
illuminating article today summarizing recent research on the gender effects of
mandatory overwork in professional jobs. Lawyers, people in finance and other
client-centered occupations are increasingly required to be available round-the-clock, with
50-60 or more hours of work per week the norm. Among other costs, the impact on wage inequality
between men and women is severe. Since women are largely saddled with primary responsibility
for child care, even when couples ostensibly embrace equality on a theoretical level, the
workaholic jobs are allocated to men. This shows up in dramatic differences between typical
male and female career paths. The article doesn't discuss comparable issues in working class
employment, but availability for last-minute changes in work schedules and similar demands are
likely to impact men and women differentially as well.
What the article doesn't point out is that the situation it describes is a classic prisoners
dilemma.* Consider law firms. They compete for clients, and clients prefer attorneys who are
available on call, always prepared and willing to adjust to whatever schedule the client throws
at them. Assume that most lawyers want sane, predictable work hours if they are offered without
a severe penalty in pay. If law firms care about the well-being of their employees but also
about profits, we have all the ingredients to construct a standard PD payoff matrix:
There is a penalty to unilateral cooperation, cutting work hours back to a work-life balance
level. If your firm does it and the others don't, you lose clients to them.
There is a benefit to unilateral defection. If everyone else is cutting hours but you don't,
you scoop up the lion's share of the clients.
Mutual cooperation is preferred to mutual defection. Law firms, we are assuming, would
prefer a world in which overwork was removed from the contest for competitive advantage. They
would compete for clients as before, but none would require their staff to put in soul-crushing
hours. The alternative equilibrium, in which competition is still on the basis of the quality
of work but everyone is on call 24/7 is inferior.
If the game is played once, mutual defection dominates. If it is played repeatedly there is
a possibility for mutual cooperation to establish itself, but only under favorable conditions
(which apparently don't exist in the world of NY law firms). The logical solution is some
form of binding regulation.
The reason for bringing this up is that it strengthens the case for collective action rather
than placing all the responsibility on individuals caught in the system, including for that
matter individual law firms. Or, the responsibility is political, to demand constraints on the
entire industry. One place to start would be something like France's
right-to-disconnect law .
*I haven't read the studies by economists and sociologists cited in the article, but I
suspect many of them make the same point I'm making here.
The infatuation with AI makes people overlook three AI's built-in glitches. AI is software.
Software bugs. Software doesn't autocorrect bugs. Men correct bugs. A bugging self-driving
car leads its passengers to death. A man driving a car can steer away from death. Humans love
to behave in erratic ways, it is just impossible to program AI to respond to all possible
erratic human behaviour. Therefore, instead of adapting AI to humans, humans will be forced
to adapt to AI, and relinquish a lot of their liberty as humans. Humans have moral qualms
(not everybody is Hillary Clinton), AI being strictly utilitarian, will necessarily be
"psychopathic".
In short AI is the promise of communism raised by several orders of magnitude. Welcome
to the "Brave New World".
@Vojkan
You've raised some interesting objections, Vojkan. But here are a few quibbles:
1) AI is software. Software bugs. Software doesn't autocorrect bugs. Men correct bugs. A
bugging self-driving car leads its passengers to death. A man driving a car can steer away
from death.
Learn to code! Seriously, until and unless the AI devices acquire actual power over their
human masters (as in The Matrix ), this is not as big a problem as you think. You
simply test the device over and over and over until the bugs are discovered and worked out --
in other words, we just keep on doing what we've always done with software: alpha, beta,
etc.
2) Humans love to behave in erratic ways, it is just impossible to program AI to respond
to all possible erratic human behaviour. Therefore, instead of adapting AI to humans,
humans will be forced to adapt to AI, and relinquish a lot of their liberty as humans.
There's probably some truth to that. This reminds me of the old Marshall McCluhan saying
that "the medium is the message," and that we were all going to adapt our mode of cognition
(somewhat) to the TV or the internet, or whatever. Yeah, to some extent that has happened.
But to some extent, that probably happened way back when people first began domesticating
horses and riding them. Human beings are 'programmed', as it were, to adapt to their
environments to some extent, and to condition their reactions on the actions of other
things/creatures in their environment.
However, I think you may be underestimating the potential to create interfaces that allow
AI to interact with a human in much more complex ways, such as how another human would
interact with human: sublte visual cues, pheromones, etc. That, in fact, was the essence of
the old Turing Test, which is still the Holy Grail of AI:
3) Humans have moral qualms (not everybody is Hillary Clinton), AI being strictly
utilitarian, will necessarily be "psychopathic".
I don't see why AI devices can't have some moral principles -- or at least moral biases --
programmed into them. Isaac Asimov didn't think this was impossible either:
You simply test the device over and over and over until the bugs are discovered and
worked out -- in other words, we just keep on doing what we've always done with software:
alpha, beta, etc.
Some bugs stay dormant for decades. I've seen one up close.
What's new with AI is the amount of damage a faulty software multiplied many times over
can do. My experience was pretty horrible (I was one of the two humans overseeing the system,
but it was a pretty horrifying experience), but if the system was fully autonomous, it'd have
driven my employer bankrupt.
Now I'm not against using AI in any form whatsoever; I also think that it's inevitable
anyway. I'd support AI driving cars or flying planes, because they are likely safer than
humans, though it's of course changing a manageable risk for a very small probability tail
risk. But I'm pretty worried about AI in general.
Luckily most of it was backed up with a custom-built user profile roaming system, but
still it was down for an hour and a half and degraded for more...
Monitoring Specific Storage Devices or Partitions with iostat:
By default, iostat monitors all the storage devices of your computer. But, you can monitor
specific storage devices (such as sda, sdb etc) or specific partitions (such as sda1, sda2,
sdb4 etc) with iostat as well.
For example, to monitor the storage device sda only, run iostat as follows:
$ sudo iostat
sda
Or
$ sudo iostat -d 2 sda
As you can see, only the storage device sda is monitored.
You can also monitor multiple storage devices with iostat.
For example, to monitor the storage devices sda and sdb , run iostat as follows:
$ sudo
iostat sda sdb
Or
$ sudo iostat -d 2 sda sdb
If you want to monitor specific partitions, then you can do so as well.
For example, let's say, you want to monitor the partitions sda1 and sda2 , then run iostat
as follows:
$ sudo iostat sda1 sda2
Or
$ sudo iostat -d 2 sda1 sda2
As you can see, only the partitions sda1 and sda2 are monitored.
Monitoring
LVM Devices with iostat:
You can monitor the LVM devices of your computer with the -N option of iostat.
To monitor the LVM devices of your Linux machine as well, run iostat as follows:
$ sudo
iostat -N -d 2
You can also monitor specific LVM logical volume as well.
For example, to monitor the LVM logical volume centos-root (let's say), run iostat as
follows:
$ sudo iostat -N -d 2 centos-root
Changing
the Units of iostat:
By default, iostat generates reports in kilobytes (kB) unit. But there are options that you
can use to change the unit.
For example, to change the unit to megabytes (MB), use the -m option of iostat.
You can also change the unit to human readable with the -h option of iostat. Human readable
format will automatically pick the right unit depending on the available data.
To change the unit to megabytes, run iostat as follows:
$ sudo iostat -m -d 2 sda
To change the unit to human readable format, run iostat as follows:
$ sudo iostat -h -d 2
sda
I copied as file and as you can see, the unit is now in megabytes (MB).
It changed to kilobytes (kB) as soon as the file copy is over.
Extended
Display of iostat:
If you want, you can display a lot more information about disk i/o with iostat. To do that,
use the -x option of iostat.
For example, to display extended information about disk i/o, run iostat as follows:
$
sudo iostat -x -d 2 sda
You can find what each of these fields (rrqm/s, %wrqm etc) means in the man page of
iostat.
Getting
Help:
If you need more information on each of the supported options of iostat and what each of the
fields of iostat means, I recommend you take a look at the man page of iostat.
You can access the man page of iostat with the following command:
$ man iostat
So, that's how you use iostat in Linux. Thanks for reading this article.
Cat can also number a file's lines during output. There are two commands to do this, as shown in the help documentation: -b, --number-nonblank
number nonempty output lines, overrides -n
-n, --number number all output lines
If I use the -b command with the hello.world file, the output will be numbered like this:
$ cat -b hello.world
1 Hello World !
In the example above, there is an empty line. We can determine why this empty line appears by using the -n argument:
$ cat -n hello.world
1 Hello World !
2
$
Now we see that there is an extra empty line. These two arguments are operating on the final output rather than the file contents,
so if we were to use the -n option with both files, numbering will count lines as follows:
$ cat -n hello.world goodbye.world
1 Hello World !
2
3 Good Bye World !
4
$
One other option that can be useful is -s for squeeze-blank . This argument tells cat to reduce repeated empty line output
down to one line. This is helpful when reviewing files that have a lot of empty lines, because it effectively fits more text on the
screen. Suppose I have a file with three lines that are spaced apart by several empty lines, such as in this example, greetings.world
:
$ cat greetings.world
Greetings World !
Take me to your Leader !
We Come in Peace !
$
Using the -s option saves screen space:
$ cat -s greetings.world
Cat is often used to copy contents of one file to another file. You may be asking, "Why not just use cp ?" Here is how I could
create a new file, called both.files , that contains the contents of the hello and goodbye files:
$ cat hello.world goodbye.world > both.files
$ cat both.files
Hello World !
Good Bye World !
$
zcat
There is another variation on the cat command known as zcat . This command is capable of displaying files that have been compressed
with Gzip without needing to uncompress the files with the gunzip
command. As an aside, this also preserves disk space, which is the entire reason files are compressed!
The zcat command is a bit more exciting because it can be a huge time saver for system administrators who spend a lot of time
reviewing system log files. Where can we find compressed log files? Take a look at /var/log on most Linux systems. On my system,
/var/log contains several files, such as syslog.2.gz and syslog.3.gz . These files are the result of the log
management system, which rotates and compresses log files to save disk space and prevent logs from growing to unmanageable file sizes.
Without zcat , I would have to uncompress these files with the gunzip command before viewing them. Thankfully, I can use zcat :
$ cd / var / log
$ ls * .gz
syslog.2.gz syslog.3.gz
$
$ zcat syslog.2.gz | more
Jan 30 00:02: 26 workstation systemd [ 1850 ] : Starting GNOME Terminal Server...
Jan 30 00:02: 26 workstation dbus-daemon [ 1920 ] : [ session uid = 2112 pid = 1920 ] Successful
ly activated service 'org.gnome.Terminal'
Jan 30 00:02: 26 workstation systemd [ 1850 ] : Started GNOME Terminal Server.
Jan 30 00:02: 26 workstation org.gnome.Terminal.desktop [ 2059 ] : # watch_fast: "/org/gno
me / terminal / legacy / " (establishing: 0, active: 0)
Jan 30 00:02:26 workstation org.gnome.Terminal.desktop[2059]: # unwatch_fast: " / org / g
nome / terminal / legacy / " (active: 0, establishing: 1)
Jan 30 00:02:26 workstation org.gnome.Terminal.desktop[2059]: # watch_established: " /
org / gnome / terminal / legacy / " (establishing: 0)
--More--
We can also pass both files to zcat if we want to review both of them uninterrupted. Due to how log rotation works, you need to
pass the filenames in reverse order to preserve the chronological order of the log contents:
$ ls -l * .gz
-rw-r----- 1 syslog adm 196383 Jan 31 00:00 syslog.2.gz
-rw-r----- 1 syslog adm 1137176 Jan 30 00:00 syslog.3.gz
$ zcat syslog.3.gz syslog.2.gz | more
The cat command seems simple but is very useful. I use it regularly. You also don't need to feed or pet it like a real cat. As
always, I suggest you review the man pages ( man cat ) for the cat and zcat commands to learn more about how it can be used. You
can also use the --help argument for a quick synopsis of command line arguments.
Interesting article but please don't misuse cat to pipe to more......
I am trying to teach people to use less pipes and here you go abusing cat to pipe to other commands. IMHO, 99.9% of the time
this is not necessary!
In stead of "cat file | command" most of the time, you can use "command file" (yes, I am an old dinosaur
from a time where memory was very expensive and forking multiple commands could fill it all up)
Several Pilots repeatedly warned federal authorities of safety concerns over the now-grounded
Boeing 737 Max 8 for months leading up to the
second deadly disaster
involving the plane, according to an investigation by the
Dallas Morning News
.
One captain even called the Max 8's flight manual "
inadequate
and almost criminally insufficient
," according to the report.
"
The fact that this airplane requires such jury-rigging to fly is a red flag.
Now we know the systems employed are error-prone -- even if the pilots aren't sure what those
systems are, what redundancies are in place and failure modes. I am left to wonder: what else don't
I know?" wrote the captain.
At least
five complaints
about the Boeing jet were found in a
federal
database
which pilots routinely use to report aviation incidents without fear of
repercussions.
The complaints are about the safety mechanism cited in
preliminary reports
for an October plane crash in Indonesia that killed 189.
The disclosures found by
The News
reference problems during flights of Boeing 737 Max
8s with an autopilot system during takeoff and nose-down situations while trying to gain
altitude. While records show these flights occurred during October and November, information
regarding which airlines the pilots were flying for at the time is redacted from the database. -
Dallas
Morning News
One captain who flies the Max 8 said in November that it was "unconscionable" that Boeing and
federal authorities have allowed pilots to fly the plane without adequate training - including a
failure to fully disclose how its systems were distinctly different from other planes.
An FAA spokesman said the reporting system is directly filed to NASA, which serves as an neutral
third party in the reporting of grievances.
"The FAA analyzes these reports along with other safety data gathered through programs the FAA
administers directly, including the Aviation Safety Action Program, which includes all of the major
airlines including Southwest and American," said FAA southwest regional spokesman Lynn Lunsford.
Meanwhile, despite several airlines and foreign countries grounding the Max 8, US regulators
have so far declined to follow suit. They have, however, mandated that Boeing upgrade the plane's
software by April.
Sen. Ted Cruz (R-TX), who chairs a Senate subcommittee overseeing aviation, called for the
grounding of the Max 8 in a Thursday statement.
"Further investigation may reveal that mechanical issues were not the cause, but until that
time, our first priority must be the safety of the flying public," said Cruz.
At least 18 carriers -- including American Airlines and Southwest Airlines, the two largest
U.S. carriers flying the 737 Max 8 --
have also declined to ground planes
,
saying they are confident in the safety and "airworthiness" of their fleets. American and
Southwest have 24 and 34 of the aircraft in their fleets, respectively. -
Dallas
Morning News
The United States should be leading the world in aviation safety,"
said Transport Workers Union president John Samuelsen. "
And
yet, because of the lust for profit in the American aviation, we're
still flying planes that dozens of other countries and airlines have
now said need to grounded
."
Tags
Disaster Accident
The automatic trim we described last week has a name, MCAS, or Maneuvering Characteristics
Automation System.
It's unique to the MAX because the 737 MAX no longer has the docile pitch characteristics of
the 737NG at high Angles Of Attack (AOA). This is caused by the larger engine nacelles covering
the higher bypass LEAP-1B engines.
The nacelles for the MAX are larger and placed higher and further forward of the wing,
Figure 1.
Figure 1. Boeing 737NG (left) and MAX (right) nacelles compared. Source: Boeing 737 MAX
brochure.
By placing the nacelle further forward of the wing, it could be placed higher. Combined with
a higher nose landing gear, which raises the nacelle further, the same ground clearance could
be achieved for the nacelle as for the 737NG.
The drawback of a larger nacelle, placed further forward, is it destabilizes the aircraft in
pitch. All objects on an aircraft placed ahead of the Center of Gravity (the line in Figure 2,
around which the aircraft moves in pitch) will contribute to destabilize the aircraft in
pitch.
... ... ...
The 737 is a classical flight control aircraft. It relies on a naturally stable base
aircraft for its flight control design, augmented in selected areas. Once such area is the
artificial yaw damping, present on virtually all larger aircraft (to stop passengers getting
sick from the aircraft's natural tendency to Dutch Roll = Wagging its tail).
Until the MAX, there was no need for artificial aids in pitch. Once the aircraft entered a
stall, there were several actions described last week which assisted the pilot to exit the
stall. But not in normal flight.
The larger nacelles, called for by the higher bypass LEAP-1B engines, changed this. When
flying at normal angles of attack (3° at cruise and say 5° in a turn) the destabilizing
effect of the larger engines are not felt.
The nacelles are designed to not generate lift in normal flight. It would generate
unnecessary drag as the aspect ratio of an engine nacelle is lousy. The aircraft designer
focuses the lift to the high aspect ratio wings.
But if the pilot for whatever reason manoeuvres the aircraft hard, generating an angle of
attack close to the stall angle of around 14°, the previously neutral engine nacelle
generates lift. A lift which is felt by the aircraft as a pitch up moment (as its ahead of the
CG line), now stronger than on the 737NG. This destabilizes the MAX in pitch at higher Angles
Of Attack (AOA). The most difficult situation is when the maneuver has a high pitch ratio. The
aircraft's inertia can then provoke an over-swing into stall AOA.
To counter the MAX's lower stability margins at high AOA, Boeing introduced MCAS. Dependent
on AOA value and rate, altitude (air density) and Mach (changed flow conditions) the MCAS,
which is a software loop in the Flight Control computer, initiates a nose down trim above a
threshold AOA.
It can be stopped by the Pilot counter-trimming on the Yoke or by him hitting the CUTOUT
switches on the center pedestal. It's not stopped by the Pilot pulling the Yoke, which for
normal trim from the autopilot or runaway manual trim triggers trim hold sensors. This would
negate why MCAS was implemented, the Pilot pulling so hard on the Yoke that the aircraft is
flying close to stall.
It's probably this counterintuitive characteristic, which goes against what has been trained
many times in the simulator for unwanted autopilot trim or manual trim runaway, which has
confused the pilots of JT610. They learned that holding against the trim stopped the nose down,
and then they could take action, like counter-trimming or outright CUTOUT the trim servo. But
it didn't. After a 10 second trim to a 2.5° nose down stabilizer position, the trimming
started again despite the Pilots pulling against it. The faulty high AOA signal was still
present.
How should they know that pulling on the Yoke didn't stop the trim? It was described
nowhere; neither in the aircraft's manual, the AFM, nor in the Pilot's manual, the FCOM. This
has created strong reactions from airlines with the 737 MAX on the flight line and their
Pilots. They have learned the NG and the MAX flies the same. They fly them interchangeably
during the week.
They do fly the same as long as no fault appears. Then there are differences, and the
Pilots should have been informed about the differences.
Bruce Levitt
November 14, 2018
In figure 2 it shows the same center of gravity for the NG as the Max. I find this a bit
surprising as I would have expected that mounting heavy engines further forward would have
cause a shift forward in the center of gravity that would not have been offset by the
longer tailcone, which I'm assuming is relatively light even with APU installed.
Based on what is coming out about the automatic trim, Boeing must be counting its lucky
stars that this incident happened to Lion Air and not to an American aircraft. If this had
happened in the US, I'm pretty sure the fleet would have been grounded by the FAA and the
class action lawyers would be lined up outside the door to get their many pounds of
flesh.
This is quite the wake-up call for Boeing.
OV-099
November 14, 2018
If the FAA is not going to comprehensively review the certification for the 737 MAX, I
would not be surprised if EASA would start taking a closer look at the aircraft and why
the FAA seemingly missed the seemingly inadequate testing of the automatic trim when
they decided to certified the 737 MAX 8.
Reply
Doubting Thomas
November 16, 2018
One wonders if there are any OTHER goodies in the new/improved/yet identical handling
latest iteration of this old bird that Boeing did not disclose so that pilots need
not be retrained.
EASA & FAA likely already are asking some pointed questions and will want to
verify any statements made by the manufacturer.
Depending on the answers pilot training requirements are likely to change
materially.
jbeeko
November 14, 2018
CG will vary based on loading. I'd guess the line is the rear-most allowed CG.
Sebina Muwanga
November 17, 2018
Hi Bruce, expect product liability litigation in the US courts even if the accident
occured outside the US. Boeing is domiciled in the US and US courts have jurisdiction.
In my opinion, even the FAA should be a defendant for certifying the aircraft and
endangering the lives of the unsuspecting public.
Take time to read this article i published last year and let me know what you
think.
ahmed
November 18, 2018
hi dears
I think that even the pilot didnt knew about the MCAS ; this case can be corrected by
only applying the boeing check list (QRH) stabilizer runaway.
the pilot when they noticed that stabilizer are trimming without a knewn input ( from
pilot or from Auto pilot ) ; shout put the cut out sw in the off position according to
QRH.
Reply
TransWorld
November 19, 2018
Please note that the first actions pulling back on the yoke to stop it.
Also keep in mind the aircraft is screaming stall and the stick shaker is
activated.
Pulling back on the yoke in that case is the WRONG thing to do if you are
stalled.
The Pilot has to then determine which system is lading.
At the same time its chaning its behavior from previous training, every 5
seconds, it does it again.
There also was another issue taking place at the same time.
So now you have two systems lying to you, one that is actively trying to kill
you.
If the Pitot static system is broken, you also have several key instruments
feeding you bad data (VSI, altitude and speed)
Pilots are trained to immediately deal with emergency issues (engine loss etc)
Then there is a follow up detailed instructions for follow on actions (if any).
Simulators are wonderful things because you can train lethal scenes without lethal
results.
In this case, with NO pilot training let alone in the manuals, pilots have to either
be really quick in the situation or you get the result you do. Some are better at it
than others (Sullenbergers along with other aspects elected to turn on his APU even
though it was not part of the engine out checklist)
The other one was to ditch, too many pilots try to turn back even though we are
trained not to.
What I can tell you from personal expereince is having got myself into a spin
without any training, I was locked up logic wise (panic) as suddenly nothing was
working the way it should.
I was lucky I was high enough and my brain kicked back into cold logic mode and I
knew the counter to a spin from reading)
Another 500 feet and I would not be here to post.
While I did parts of the spin recovery wrong, fortunately in that aircraft it did
not care, right rudder was enough to stop it.
OV-099
November 14, 2018
It's starting to look as if Boeing will not be able to just pay victims' relatives in the
form of "condolence money", without admitting liability.
Reply
Dukeofurl
November 14, 2018
Im pretty sure, even though its an Indonesian Airline, any whiff of fault with the plane
itself will have lawyers taking Boeing on in US courts.
Tech-guru
November 14, 2018
Astonishing to say the least. It is quite unlike Boeing. They are normally very good in the
documentation and training. It makes everyone wonder how such vital change on the MAX
aircraft was omitted from books as weel as in crew training.
Your explanation is very good as to why you need this damn MCAS. But can you also tell us how
just one faulty sensor can trigger this MCAS. In all other Boeing models like B777, the two
AOA sensor signals are compared with a calculated AOA and choose the mid value within the
ADIRU. It eliminates a drastic mistake of following a wrong sensor input.
it's not sure it's a one sensor fault. One sensor was changed amid information there
was a 20 degree diff between the two sides. But then it happened again. I think we
might be informed something else is at the root of this, which could also trip such a
plausibility check you mention. We just don't know. What we know is the MCAS function
was triggered without the aircraft being close to stall.
Matthew
November 14, 2018
If it's certain that the MCAS was doing unhelpful things, that coupled with the
fact that no one was telling pilots anything about it suggests to me that this is
already effectively an open-and-shut case so far as liability, regulatory remedies
are concerned.
The tecnical root cause is also important, but probably irrelevant so far as
estbalishing the ultimate reason behind the crash.
"... The key point I want to pick up on from that earlier post is this: the Boeing 737 Max includes a new "safety" feature about which the company failed to inform the Federal Aviation Administration (FAA). ..."
"... Boeing Co. withheld information about potential hazards associated with a new flight-control feature suspected of playing a role in last month's fatal Lion Air jet crash, according to safety experts involved in the investigation, as well as midlevel FAA officials and airline pilots. ..."
"... Notice that phrase: "under unusual conditions". Seems now that the pilots of two of these jets may have encountered such unusual conditions since October. ..."
"... Why did Boeing neglect to tell the FAA – or, for that matter, other airlines or regulatory authorities – about the changes to the 737 Max? Well, the airline marketed the new jet as not needing pilots to undergo any additional training in order to fly it. ..."
"... In addition to considerable potential huge legal liability, from both the Lion Air and Ethiopian Airlines crashes, Boeing also faces the commercial consequences of grounding some if not all 737 Max 8 'planes currently in service – temporarily? indefinitely? -and loss or at minimum delay of all future sales of this aircraft model. ..."
"... If this tragedy had happened on an aircraft of another manufacturer other than big Boeing, the fleet would already have been grounded by the FAA. The arrogance of engineers both at Airbus and Boeing, who refuse to give the pilots easy means to regain immediate and full authority over the plane (pitch and power) is just appalling. ..."
"... Boeing has made significant inroads in China with its 737 MAX family. A dozen Chinese airlines have ordered 180 of the planes, and 76 of them have been delivered, according Boeing. About 85% of Boeing's unfilled Chinese airline orders are for 737 MAX planes. ..."
"... "It's pretty asinine for them to put a system on an airplane and not tell the pilots who are operating the airplane, especially when it deals with flight controls," Captain Mike Michaelis, chairman of the safety committee for the Allied Pilots Association, told the Wall Street Journal. ..."
"... The aircraft company concealed the new system and minimized the differences between the MAX and other versions of the 737 to boost sales. On the Boeing website, the company claims that airlines can save "millions of dollars" by purchasing the new plane "because of its commonality" with previous versions of the plane. ..."
"... "Years of experience representing hundreds of victims has revealed a common thread through most air disaster cases," said Charles Herrmann the principle of Herrmann Law. "Generating profit in a fiercely competitive market too often involves cutting safety measures. In this case, Boeing cut training and completely eliminated instructions and warnings on a new system. Pilots didn't even know it existed. I can't blame so many pilots for being mad as hell." ..."
"... The Air France Airbus disaster was jumped on – Boeing's traditional hydraulic links between the sticks for the two pilots ensuring they move in tandem; the supposed comments by Captain Sully that the Airbus software didn't allow him to hit the water at the optimal angle he wanted, causing the rear rupture in the fuselage both showed the inferiority of fly-by-wire until Boeing started using it too. (Sully has taken issue with the book making the above point and concludes fly-by-wire is a "mixed blessing".) ..."
Posted on
March 11, 2019 by Jerri-Lynn ScofieldBy
Jerri-Lynn Scofield, who has worked as a securities lawyer and a derivatives trader. She is
currently writing a book about textile artisans.
Yesterday, an Ethiopian Airlines flight crashed minutes after takeoff, killing all 157
passengers on board.
The crash occurred less than five months after a Lion Air jet crashed near Jakarta,
Indonesia, also shortly after takeoff, and killed all 189 passengers.
The state-owned airline is among the early operators of Boeing's new 737 MAX single-aisle
workhorse aircraft, which has been delivered to carriers around the world since 2017. The 737
MAX represents about two-thirds of Boeing's future deliveries and an estimated 40% of its
profits, according to analysts.
Having delivered 350 of the 737 MAX planes as of January, Boeing has booked orders for
about 5,000 more, many to airlines in fast-growing emerging markets around the world.
The voice and data recorders for the doomed flight have already been recovered, the New York
Times reported in Ethiopian
Airline Crash Updates: Data and Voice Recorders Recovered . Investigators will soon be able
to determine whether the same factors that caused the Lion Air crash also caused the latest
Ethiopian Airlines tragedy.
Boeing, Crapification, Two 737 Max Crashes Within Five Months
Yves wrote a post in November, Boeing,
Crapification, and the Lion Air Crash , analyzing a devastating Wall Street Journal report
on that earlier crash. I will not repeat the details of her post here, but instead encourage
interested readers to read it iin full.
The key point I want to pick up on from that earlier post is this: the Boeing 737 Max
includes a new "safety" feature about which the company failed to inform the Federal Aviation
Administration (FAA). As Yves wrote:
The short version of the story is that Boeing had implemented a new "safety" feature that
operated even when its plane was being flown manually, that if it went into a stall, it would
lower the nose suddenly to pick airspeed and fly normally again. However, Boeing didn't tell
its buyers or even the FAA about this new goodie. It wasn't in pilot training or even the
manuals. But even worse, this new control could force the nose down so far that it would be
impossible not to crash the plane. And no, I am not making this up. From the Wall Street
Journal:
Boeing Co. withheld information about potential hazards associated with a new
flight-control feature suspected of playing a role in last month's fatal Lion Air jet
crash, according to safety experts involved in the investigation, as well as midlevel FAA
officials and airline pilots.
The automated stall-prevention system on Boeing 737 MAX 8 and MAX 9 models -- intended
to help cockpit crews avoid mistakenly raising a plane's nose dangerously high -- under
unusual conditions can push it down unexpectedly and so strongly that flight crews can't
pull it back up. Such a scenario, Boeing told airlines in a world-wide safety bulletin
roughly a week after the accident, can result in a steep dive or crash -- even if pilots
are manually flying the jetliner and don't expect flight-control computers to kick in.
Notice that phrase: "under unusual conditions". Seems now that the pilots of two of these
jets may have encountered such unusual conditions since October.
Why did Boeing neglect to tell the FAA – or, for that matter, other airlines or
regulatory authorities – about the changes to the 737 Max? Well, the airline marketed the new jet as not needing pilots to undergo any additional
training in order to fly it.
I see. Why Were 737 Max Jets Still in Service? Today, Boeing executives no doubt rue not pulling all 737 Max 8 jets out of service after
the October Lion Air crash, to allow their engineers and engineering safety regulators to make
necessary changes in the 'plane's design or to develop new training protocols.
In addition to
considerable potential huge legal liability, from both the Lion Air and Ethiopian Airlines
crashes, Boeing also faces the commercial consequences of grounding some if not all 737 Max 8
'planes currently in service – temporarily? indefinitely? -and loss or at minimum delay
of all future sales of this aircraft model.
Over to Yves again, who in her November post cut to the crux:
And why haven't the planes been taken out of service? As one Wall Street Journal reader
put it:
If this tragedy had happened on an aircraft of another manufacturer other than big
Boeing, the fleet would already have been grounded by the FAA. The arrogance of engineers
both at Airbus and Boeing, who refuse to give the pilots easy means to regain immediate and
full authority over the plane (pitch and power) is just appalling.
Accident and incident
records abound where the automation has been a major contributing factor or precursor.
Knowing our friends at Boeing, it is highly probable that they will steer the investigation
towards maintenance deficiencies as primary cause of the accident
The commercial consequences of grounding the 737 Max in China alone are significant,
according to this CNN account, Why
grounding 737 MAX jets is a big deal for Boeing . The 737 Max is Boeing's most important
plane; China is also the company's major market:
"A suspension in China is very significant, as this is a major market for Boeing," said
Greg Waldron, Asia managing editor at aviation research firm FlightGlobal.
Boeing has predicted that China will soon become the world's first trillion-dollar market
for jets. By 2037, Boeing estimates China will need 7,690 commercial jets to meet its travel
demands.
Airbus (EADSF) and Commercial Aircraft Corporation of China, or Comac, are vying with
Boeing for the vast and rapidly growing Chinese market.
Comac's first plane, designed to compete with the single-aisle Boeing 737 MAX and Airbus
A320, made its first test flight in 2017. It is not yet ready for commercial service, but
Boeing can't afford any missteps.
Boeing has made significant inroads in China with its 737 MAX family. A dozen Chinese
airlines have ordered 180 of the planes, and 76 of them have been delivered, according
Boeing. About 85% of Boeing's unfilled Chinese airline orders are for 737 MAX planes.
The 737 has been Boeing's bestselling product for decades. The company's future depends on
the success the 737 MAX, the newest version of the jet. Boeing has 4,700 unfilled orders for
737s, representing 80% of Boeing's orders backlog. Virtually all 737 orders are for MAX
versions.
As of the time of posting, US airlines have yet to ground their 737 Max 8 fleets. American
Airlines, Alaska Air, Southwest Airlines, and United Airlines have ordered a combined 548 of
the new 737 jets, of which 65 have been delivered, according to CNN.
Legal Liability?
Prior to Sunday's Ethiopian Airlines crash, Boeing already faced considerable potential
legal liability for the October Lion Air crash. Just last Thursday, the Hermann Law Group of
personal injury lawyers filed suit against Boeing on behalf of the families of 17 Indonesian
passengers who died in that crash.
"It's pretty asinine for them to put a system on an airplane and not tell the pilots who
are operating the airplane, especially when it deals with flight controls," Captain Mike
Michaelis, chairman of the safety committee for the Allied Pilots Association, told the Wall
Street Journal.
The president of the pilots union at Southwest Airlines, Jon Weaks, said, "We're pissed
that Boeing didn't tell the companies, and the pilots didn't get notice."
The aircraft company concealed the new system and minimized the differences between the
MAX and other versions of the 737 to boost sales. On the Boeing website, the company claims
that airlines can save "millions of dollars" by purchasing the new plane "because of its
commonality" with previous versions of the plane.
"Years of experience representing hundreds of victims has revealed a common thread through
most air disaster cases," said Charles Herrmann the principle of Herrmann Law. "Generating
profit in a fiercely competitive market too often involves cutting safety measures. In this
case, Boeing cut training and completely eliminated instructions and warnings on a new
system. Pilots didn't even know it existed. I can't blame so many pilots for being mad as
hell."
Additionally, the complaint alleges the United States Federal Aviation Administration is
partially culpable for negligently certifying Boeing's Air Flight Manual without requiring
adequate instruction and training on the new system. Canadian and Brazilian authorities did
require additional training.
What's Next?
The consequences for Boeing could be serious and will depend on what the flight and voice
data recorders reveal. I also am curious as to what additional flight training or instructions,
if any, the Ethiopian Airlines pilots received, either before or after the Lion Air crash,
whether from Boeing, an air safety regulator, or any other source.
Of course we shouldn't engage in speculation, but we will anyway 'cause we're human. If
fly-by-wire and the ability of software to over-ride pilots are indeed implicated in the 737
Max 8 then you can bet the Airbus cheer-leaders on YouTube videos will engage in huge
Schaudenfreude.
I really shouldn't even look at comments to YouTube videos – it's bad for my blood
pressure. But I occasionally dip into the swamp on ones in areas like airlines. Of course
– as you'd expect – you get a large amount of "flag waving" between Europeans and
Americans. But the level of hatred and suspiciously similar comments by the "if it ain't
Boeing I ain't going" brigade struck me as in a whole new league long before the "SJW" troll
wars regarding things like Captain Marvel etc of today.
The Air France Airbus disaster was
jumped on – Boeing's traditional hydraulic links between the sticks for the two pilots
ensuring they move in tandem; the supposed comments by Captain Sully that the Airbus software
didn't allow him to hit the water at the optimal angle he wanted, causing the rear rupture in
the fuselage both showed the inferiority of fly-by-wire until Boeing started using it too.
(Sully has taken issue with the book making the above point and concludes fly-by-wire is a
"mixed blessing".)
I'm going to try to steer clear of my YouTube channels on airlines. Hopefully NC will
continue to provide the real evidence as it emerges as to what's been going on here.
It is really disheartening how an idea as reasonable as "a just society" has been so
thoroughly discredited among a large swath of the population.
No wonder there is such a wide interest in primitive construction and technology on
YouTube. This society is very sick and it is nice to pretend there is a way to opt out.
Indeed. The NTSB usually works with local investigation teams (as well as a manufacturers
rep) if the manufacturer is located in the US, or if specifically requested by the local
authorities. I'd like to see their report. I don't care what the FAA or Boeing says about
it.
. .. . .. -- .
Contains a link to a Seattle Times report as a "comprehensive wrap": Speaking before China's announcement, Cox, who previously served as the top safety
official for the Air Line Pilots Association, said it's premature to think of grounding the
737 MAX fleet.
"We don't know anything yet. We don't have close to sufficient information to consider
grounding the planes," he said. "That would create economic pressure on a number of the
airlines that's unjustified at this point.
China has grounded them . US? Must not create undue economic pressure on the airlines.
Right there in black and white. Money over people.
I just emailed southwest about an upcoming flight asking about my choices for refusal to
board MAX 8/9 planes based on this "feature". I expect pro forma policy recitation, but
customer pressure could trump too big to fail sweeping the dirt under the carpet. I hope.
We got the "safety of our customers is our top priority and we are remaining vigilant and
are in touch with Boeing and the Civial Aviation Authority on this matter but will not be
grounding the aircraft model until further information on the crash becomes available" speech
from a local airline here in South Africa. It didn't take half a day for customer pressure to
effect a swift reversal of that blatant disregard for their "top priority", the model is
grounded so yeah, customer muscle flexing will do it
On PPRUNE.ORG (where a lot of pilots hang out), they reported that after the Lion Air
crash, Southwest added an extra display (to indicate when the two angle of attack sensors
were disagreeing with each other) that the folks on PPRUNE thought was an extremely good idea
and effective.
Of course, if the Ethiopian crash was due to something different from the Lion Air crash,
that extra display on the Southwest planes may not make any difference.
Take those comments with a large dose of salt. Not to say everyone commenting on PPRUNE
and sites like PPRUNE are posers, but PPRUNE.org is where a lot of wanna-be pilots and guys
that spend a lot of time in basements playing flight simulator games hang out. The "real
pilots" on PPRUNE are more frequently of the aspiring airline pilot type that fly smaller,
piston-powered planes.
We will have to wait and see what the final investigation reveals. However this does not
look good for Boeing at all.
The Maneuvering Characteristics Augmentation System (MCAS) system was implicated in the
Lion Air crash. There have been a lot of complaints about the system on many of the pilot
forums, suggesting at least anecdotally that there are issues. It is highly suspected that
the MCAS system is responsible for this crash too.
Keep in mind that Ethiopian Airlines is a pretty well-known and regarded airline. This is
not a cut rate airline we are talking about.
At this point, all we can do is to wait for the investigation results.
one other minor thing. you remember that shut down? seems that would have delayed any
updates from Boeing. seems thats one of the things the pilots pointed out when it shutdown
was in progress
What really is the icing on this cake is the fact the new, larger engines on the "Max"
changed the center of gravity of the plane and made it unstable. From what I've read on
aviation blogs, this is highly unusual for a commercial passenger jet. Boeing then created
the new "safety" feature which makes the plane fly nose down to avoid a stall. But of course
garbage in, garbage out on sensors (remember AF447 which stalled right into the S.
Atlantic?).
It's all politics anyway .if Boeing had been forthcoming about the "Max" it would have
required additional pilot training to certify pilots to fly the airliner. They didn't and now
another 189 passengers are D.O.A.
I wouldn't fly on one and wouldn't let family do so either.
If I have read correctly, the MCAS system (not known of by pilots until after the Lion Air
crash) is reliant on a single Angle of Attack sensor, without redundancy (!). It's too
early
to say if MCAS was an issue in the crashes, I guess, but this does not look good.
If it was some other issue with the plane, that will be almost worse for Boeing. Two
crash-causing flaws would require grounding all of the planes, suspending production, then
doing some kind of severe testing or other to make sure that there isn't a third flaw waiting
to show up.
If MCAS relies only on one Angle of Attack (AoA) sensor, then it might have been an error
in the system design an the safety assessment, from which Boeing may be liable.
It appears that a failure of the AoA can produce an unannuntiated erroneous pitch
trim:
a) If the pilots had proper traning and awareness, this event would "only" increase their
workload,
b) But for an unaware or untrained pilot, the event would impair its ability to fly and
introduce excessive workload.
The difference is important, because according to standard civil aviation safety
assessment (see for instance EASA AMC 25.1309 Ch. 7), the case a) should be classified as
"Major" failure, whereas b) should be classified as "Hazardous". "Hazardous" failures are
required to have much lower probability, which means MCAS needs two AoA sensors.
In summary: a safe MCAS would need either a second AoA or pilot training. It seems that it
had neither.
What are the ways an ignorant lay air traveler can find out about whether a particular
airline has these new-type Boeing 737 MAXes in its fleet? What are the ways an ignorant air
traveler can find out which airlines do not have ANY of these airplanes in their fleet?
What are the ways an ignorant air traveler can find out ahead of time, when still planning
herm's trip, which flights use a 737 MAX as against some other kind of plane?
The only way the flying public could possibly torture the airlines into grounding these
planes until it is safe to de-ground them is a total all-encompassing "fearcott" against this
airplane all around the world. Only if the airlines in the "go ahead and fly it" countries
sell zero seats, without exception, on every single 737 MAX plane that flies, will the
airlines themselves take them out of service till the issues are resolved.
Hence my asking how people who wish to save their own lives from future accidents can tell
when and where they might be exposed to the risk of boarding a Boeing 737 MAX plane.
Stop flying. Your employer requires it? Tell'em where to get off. There are alternatives.
The alternatives are less polluting and have lower climate impact also. Yes, this is a hard
pill to swallow. No, I don't travel for employment any more, I telecommute. I used to enjoy
flying, but I avoid it like plague any more. Crapification.
Additional training won't do. If they wanted larger engines, they needed a different
plane. Changing to an unstable center of gravity and compensating for it with new software
sounds like a joke except for the hundreds of victims. I'm not getting on that plane.
Has there been any study of crapification as a broad social phenomenon? When I Google the
word I only get links to NC and sites that reference NC. And yet, this seems like one of the
guiding concepts to understand our present world (the crapification of UK media and civil
service go a long way towards understanding Brexit, for instance).
I mean, my first thought is, why would Boeing commit corporate self-harm for the sake of a
single bullet in sales materials (requires no pilot retraining!). And the answer, of course,
is crapification: the people calling the shots don't know what they're doing.
Google Books finds the word "crapification" quoted (from a 2004) in a work of literary
criticism published in 2008 (Literature, Science and a New Humanities, by J. Gottschall).
From 2013 it finds the following in a book by Edward Keenan, Some Great Idea: "Policy-wise,
it represented a shift in momentum, a slowing down of the childish, intentional crapification
of the city ." So there the word appears clearly in the sense understood by regular readers
here (along with an admission that crapfication can be intentional and not just inadvertent).
To illustrate that sense, Google Books finds the word used in Misfit Toymakers, by Keith T.
Jenkins (2014): "We had been to the restaurant and we had water to drink, because after the
takeover's, all of the soda makers were brought to ruination by the total crapification of
their product, by government management." But almost twenty years earlier the word
"crapification" had occurred in a comic strip published in New York Magazine (29 January
1996, p. 100): "Instant crapification! It's the perfect metaphor for the mirror on the soul
of America!" The word has been used on television. On 5 January 2010 a sketch subtitled
"Night of Terror – The Crapification of the American Pant-scape" ran on The Colbert
Report per: https://en.wikipedia.org/wiki/List_of_The_Colbert_Report_episodes_(2010)
. Searching the internet, Google results do indeed show many instances of the word
"crapification" on NC, or quoted elsewhere from NC posts. But the same results show it used
on many blogs since ca. 2010. Here, at http://nyceducator.com/2018/09/the-crapification-factor.html
, is a recent example that comments on the word's popularization: "I stole that word,
"crapification," from my friend Michael Fiorillo, but I'm fairly certain he stole it from
someone else. In any case, I think it applies to our new online attendance system." A comment
here, https://angrybearblog.com/2017/09/open-thread-sept-26-2017.html
, recognizes NC to have been a vector of the word's increasing usage. Googling shows that
there have been numerous instances of the verb "crapify" used in computer-programming
contexts, from at least as early as 2006. Google Books finds the word "crapified" used in a
novel, Sonic Butler, by James Greve (2004). The derivation, "de-crapify," is also attested.
"Crapify" was suggested to Merriam-Webster in 2007 per:
http://nws.merriam-webster.com/opendictionary/newword_display_alpha.php?letter=Cr&last=40
. At that time the suggested definition was, "To make situations/things bad." The verb was
posted to Urban Dictionary in 2003: https://www.urbandictionary.com/define.php?term=crapify
. The earliest serious discussion I could quickly find on crapificatjon as a phenomenon was
from 2009 at https://www.cryptogon.com/?p=10611 . I have found
only two attempts to elucidate the causes of crapification:
http://malepatternboldness.blogspot.com/2017/03/my-jockey-journey-or-crapification-of.html
(an essay on undershirts) and https://twilightstarsong.blogspot.com/2017/04/complaints.html
(a comment on refrigerators). This essay deals with the mechanics of job crapification:
http://asserttrue.blogspot.com/2015/10/how-job-crapification-works.html
(relating it to de-skilling). An apparent Americanism, "crapification" has recently been
'translated' into French: "Mon bled est en pleine urbanisation, comprends : en pleine
emmerdisation" [somewhat literally -- My hole in the road is in the midst of development,
meaning: in the midst of crapification]: https://twitter.com/entre2passions/status/1085567796703096832
Interestingly, perhaps, a comprehensive search of amazon.com yields "No results for
crapification."
This seems more like a specific bussiness conspiracy than like general crapification. This
isn't " they just don't make them like they used to". This is like Ford deliberately selling
the Crash and Burn Pinto with its special explode-on-impact gas-tank feature
Maybe some Trump-style insults should be crafted for this plane so they can get memed-up
and travel faster than Boeing's ability to manage the story. Epithets like " the new Boeing
crash-a-matic dive-liner
with nose-to-the-ground pilot-override autocrash built into every plane." It seems unfair,
but life and safety should come before fairness, and that will only happen if a world wide
wave of fear MAKES it happen.
I think crapification is the end result of a self-serving belief in the unfailing goodness
and superiority of Ivy faux-meritocracy and the promotion/exaltation of the do-nothing,
know-nothing, corporate, revolving-door MBA's and Psych-major HR types over people with many
years of both company and industry experience who also have excellent professional track
records. The latter group was the group in charge of major corporations and big decisions in
the 'good old days', now it's the former. These morally bankrupt people and their vapid,
self-righteous culture of PR first, management science second, and what-the-hell-else-matters
anyway, are the prime drivers of crapification. Read the bio of an old-school celebrated CEO
like Gordon Bethune (Continental CEO with corporate experience at Boeing) who skipped college
altogether and joined the Navy at 17, and ask yourself how many people like that are in
corporate board rooms today? I'm not saying going back to a 'Good Ole Boy's Club' is the best
model of corporate governnace either but at least people like Bethune didn't think they were
too good to mix with their fellow employees, understood leadership, the consequences of
bullshit, and what 'The buck stops here' thing was really about. Corporate types today sadly
believe their own propaganda, and when their fraudulent schemes, can-kicking, and head-in-the
sand strategies inevitably blow up in their faces, they accept no blame and fail upwards to
another posh corporate job or a nice golden parachute. The wrong people are in charge almost
everywhere these days, hence crapification. Bad incentives, zero white collar crime
enforcement, self-replicating board rooms, group-think, begets toxic corporate culture, which
equals crapification.
As a son of a deceased former Boeing aeronautic engineer, this is tragic. It highlights
the problem of financialization, neoliberalism, and lack of corporate responsibility pointed
out daily here on NC. The crapification was signaled by the move of the headquarters from
Seattle to Chicago and spending billions to build a second 787 line in South Carolina to bust
their Unions. Boeing is now an unregulated multinational corporation superior to sovereign
nations. However, if the 737 Max crashes have the same cause, this will be hard to whitewash.
The design failure of windows on the de Havilland Comet killed the British passenger aircraft
business. The EU will keep a discrete silence since manufacturing major airline passenger
planes is a duopoly with Airbus. However, China hasn't (due to the trade war with the USA)
even though Boeing is building a new assembly line there. Boeing escaped any blame for the
loss of two Malaysian Airline's 777s. This may be an existential crisis for American
aviation. Like a President who denies calling Tim Cook, Tim Apple, or the soft coup ongoing
in DC against him, what is really happening globally is not factually reported by corporate
media.
Sorry, but 'sovereign' nations were always a scam. Nothing than a excuse to build capital
markets, which are the underpinning of capitalism. Capital Markets are what control countries
and have since the 1700's. Maybe you should blame the monarchies for selling out to the
bankers in the late middle ages. Sovereign nations are just economic units for the bankers,
their businesses they finance and nothing more. I guess they figured out after the Great
Depression, they would throw a bunch of goodies at "Indo Europeans" face in western europe
,make them decadent and jaded via debt expansion. This goes back to my point about the yellow
vests ..me me me me me. You reek of it. This stuff with Boeing is all profit based. It could
have happened in 2000, 1960 or 1920. It could happen even under state control. Did you love
Hitler's Voltswagon?
As for the soft coup .lol you mean Trumps soft coup for his allies in Russia and the
Middle East viva la Saudi King!!!!!? Posts like these represent the problem with this board.
The materialist over the spiritualist. Its like people who still don't get some of the
biggest supporters of a "GND" are racialists and being somebody who has long run the
environmentalist rally game, they are hugely in the game. Yet Progressives completely seem
blind to it. The media ignores them for con men like David Duke(who's ancestry is not clean,
no its not) and "Unite the Right"(or as one friend on the environmental circuit told me,
Unite the Yahweh apologists) as whats "white". There is a reason they do this.
You need to wake up and stop the self-gratification crap. The planet is dying due to
mishandlement. Over urbanization, over population, constant need for me over ecosystem. It
can only last so long. That is why I like Zombie movies, its Gaia Theory in a nutshell. Good
for you Earth .or Midgard. Which ever you prefer.
Spot on comment VietnamVet, a lot of chickens can be seen coming home to roost in this
latest Boeing disaster. Remarkable how not many years ago the government could regulate the
aviation industry without fear of killing it, since there was more than one aerospace
company, not anymore! The scourge of monsopany/monopoly power rears its head and bites in
unexpected places.
More detail on the "MCAS" system responsible for the previous Lion Air crash
here (theaircurrent.com)
It says the bigger and repositioned engine, which give the new model its fuel efficiency,
and wing angle tweaks needed to fit the engine vs landing gear and clearance,
change the amount of pitch trim it needs in turns to remain level.
The auto system was added top neutralize the pitch trim during turns, too make it handle
like the old model.
There is another pitch trim control besides the main "stick". To deactivate the auto
system, this other trim control has to be used, the main controls do not deactivate it
(perhaps to prevent it from being unintentionally deactivated, which would be equally bad).
If the sensor driving the correction system gives a false reading and the pilot were unaware,
there would be seesawing and panic
Actually, if this all happened again I would be very surprised. Nobody flying a 737 would
not know after the previous crash. Curious what they find.
While logical, If your last comment were correct, it should have prevented this most
recent crash. It appears that the "seesawing and panic" continue.
I assume it has now gone beyond the cockpit, and beyond the design, and sales teams and
reached the Boeing board room. From there, it is likely to travel to the board rooms of every
airline flying this aircraft or thinking of buying one, to their banks and creditors, and to
those who buy or recommend their stock. But it may not reach the FAA for some time.
"Canadian and Brazilian authorities did require additional training" from the quote at the
bottom is not
something I've seen before. What did they know and when did they know it?
They probably just assumed that the changes in the plane from previous 737s were big
enough to warrant treating it like a major change requiring training.
Both countries fly into remote areas with highly variable weather conditions and some
rugged terrain.
For what it's worth, the quoted section says that Boeing withheld info about the MCAS from
"midlevel FAA officials", while Jerri-Lynn refers to the FAA as a whole.
This makes me wonder if top-level FAA people certified the system.
FAA action follows finding of new cracks in pylon aft bulkhead forward flange; crash
investigation continues
Suspension of the McDonnell Douglas DC-10's type certificate last week followed a
separate grounding order from a federal court as government investigators were narrowing
the scope of their investigation of the American Airlines DC-10 crash May 25 in
Chicago.
The American DC-10-10, registration No. N110AA, crashed shortly after takeoff from
Chicago's O'Hare International Airport, killing 259 passengers, 13 crewmembers and three
persons on the ground. The 275 fatalities make the crash the worst in U.S. history.
The controversies surrounding the grounding of the entire U.S. DC-10 fleet and, by
extension, many of the DC-10s operated by foreign carriers, by Federal Aviation
Administrator Langhorne Bond on the morning of June 6 to revolve around several issues.
Yes, I remember back when the FAA would revoke a type certificate if a plane was a danger
to public safety. It wasn't even that long ago. Now their concern is any threat to
Boeing™. There's a name for that
Leeham news is the best site for info on this. For those of you interested in the tech
details got to Bjorns Corner, where he writes about aeronautic design issues.
I was somewhat horrified to find that modern aircraft flying at near mach speeds have a
lot of somewhat pasted on pilot assistances. All of them. None of them fly with nothing but
good old stick-and-rudder. Not Airbus (which is actually fully Fly By wire-all pilot inputs
got through a computer) and not Boeing, which is somewhat less so.
This latest "solution came about becuse the larger engines (and nacelles) fitted on the
Max increased lift ahead of the center of gravity in a pitchup situation, which was
destabilizing. The MCAS uses inputs from air speed and angle of attack sensors to put a pitch
down input to the horizonatal stablisizer.
A faluty AofA sensor lead to Lion Air's Max pushing the nose down against the pilots
efforts all the way into the sea.
One guy said last night on TV that Boeing had eight years of back orders for this aircraft
so you had better believe that this crash will be studied furiously. Saw a picture of the
crash site and it looks like it augured in almost straight down. There seems to be a large
hole and the wreckage is not strew over that much area. I understand that they were digging
out the cockpit as it was underground. Strange that.
It's not true that Boeing hid the existence of the MCAS. They documented it in the
January 2017 rev of the NG/MAX
differences manual and probably earlier than that. One can argue whether the description
was adequate, but the system was in no way hidden.
Looks like, for now, we're stuck between your "in no way hidden", and numerous 737 pilots'
claims on various online aviation boards that they knew nothing about MCAS. Lots of money
involved, so very cloudy weather expected. For now I'll stick with the pilots.
To the best of my understanding and reading on the subject, the system was well documented
in the Boeing technical manuals, but not in the pilots' manuals, where it was only briefly
mentioned, at best, and not by all airlines. I'm not an airline pilot, but from what I've
read, airlines often write their own additional operators manuals for aircraft models they
fly, so it was up to them to decide the depth of documentation. These are in theory
sufficient to safely operate the plane, but do not detail every aircraft system exhaustively,
as a modern aircraft is too complex to fully understand. Other technical manuals detail how
the systems work, and how to maintain them, but a pilot is unlikely to read them as they are
used by maintenance personnel or instructors. The problem with these cases (if investigations
come to the same conclusions) is that insufficient information was included in the pilots
manual explaining the MCAS, even though the information was communicated via other technical
manuals.
A friend of mine is a commercial pilot who's just doing a 'training' exercise having moved
airlines.
He's been flying the planes in question most of his life, but the airline is asking him to
re-do it all according to their manuals and their rules. If the airline manual does not bring
it up, then the pilots will not read it – few of them have time to go after the actual
technical manuals and read those in addition to what the airline wants. [oh, and it does not
matter that he has tens of thousands of hours on the airplane in question, if he does not do
something in accordance with his new airline manual, he'd get kicked out, even if he was
right and the airline manual wrong]
I believe (but would have to check with him) that some countries regulators do their own
testing over and above the airlines, but again, it depends on what they put in.
Good to head my understanding was correct. My take on the whole situation was that Boeing
was negligent in communicating the significance of the change, given human psychology and
current pilot training. The reason was to enable easier aircraft sales. The purpose of the
MCAS system is however quite legitimate – it enables a more fuel efficient plane while
compensating for a corner case of the flight envelope.
The link is to the actual manual. If that doesn't make you reconsider, nothing will. Maybe
some pilots aren't expected to read the manuals, I don't know.
Furthermore, the post stated that Boeing failed to inform the FAA about the MCAS. Surely
the FAA has time to read all of the manuals.
Nobody reads instruction manuals. They're for reference. Boeing needed to yell at the
pilots to be careful to read new pages 1,576 through 1,629 closely. They're a lulu.
Also, what's with screwing with the geometry of a stable plane so that it will fall out of
the sky without constant adjustments by computer software? It's like having a car designed to
explode but don't worry. We've loaded software to prevent that. Except when there's an error.
But don't worry. We've included reboot instructions. It takes 15 minutes but it'll be OK. And
you can do it with one hand and drive with the other. No thanks. I want the car not designed
to explode.
The FAA is already leaping to the defense of the Boeing 737 Max 8 even before they have a
chance to open up the black boxes. Hope that nothing "happens" to those recordings.
I don't know, crapification, at least for me, refers to products, services, or
infrastructure that has declined to the point that it has become a nuisance rather than a
benefit it once was. This case with Boeing borders on criminal negligence.
1. It's really kind of amazing that we can fly to the other side of the world in a few
hours – a journey that in my grandfather's time would have taken months and been pretty
unpleasant and risky – and we expect perfect safety.
2. Of course the best-selling jet will see these issues. It's the law of large
numbers.
3. I am not a fan of Boeing's corporate management, but still, compared to Wall Street and
Defense Contractors and big education etc. they still produce an actual technical useful
artifact that mostly works, and at levels of performance that in other fields would be
considered superhuman.
4. Even for Boeing, one wonders when the rot will set in. Building commercial airliners is
hard! So many technical details, nowhere to hide if you make even one mistake so easy to just
abandon the business entirely. Do what the (ex) US auto industry did, contract out to foreign
manufacturers and just slap a "USA" label on it and double down on marketing. Milk the
cost-plus cash cow of the defense market. Or just financialize the entire thing and become
too big to fail and walk away with all the profits before the whole edifice crumbles. Greed
is good, right?
"Of course the best-selling jet will see these issues. It's the law of large numbers."
2 crashes of a new model in vary similar circumstances is very unusual. And FAA admits
they are requiring a FW upgrade sometime in April. Pilots need to be hyperaware of what this
MCAS system is doing. And they currently aren't.
if it went into a stall, it would lower the nose suddenly to pick airspeed and fly
normally again.
A while before I read this post, I listened to a news clip that reported that the plane
was observed "porpoising" after takeoff. I know only enough about planes and aviation to be a
more or less competent passenger, but it does seem like that is something that might happen
if the plane had such a feature and the pilot was not familiar with it and was trying to
fight it? The below link is not to the story I saw I don't think, but another one I just
found.
if it went into a stall, it would lower the nose suddenly to pick airspeed and fly
normally again.
At PPRUNE.ORG, many of the commentators are skeptical of what witnesses of airplane
crashes say they see, but more trusting of what they say they hear.
The folks at PPRUNE.ORG who looked at the record of the flight from FlightRadar24, which only
covers part of the flight because FlightRadar24's coverage in that area is not so good and
the terrain is hilly, see a plane flying fast in a straight line very unusually low.
The dodge about making important changes that affect aircraft handling but not disclosing
them – so as to avoid mandatory pilot training, which would discourage airlines from
buying the modified aircraft – is an obvious business-over-safety choice by an ethics
and safety challenged corporation.
But why does even a company of that description, many of whose top managers, designers,
and engineers live and breathe flight, allow its s/w engineers to prevent the pilots from
overriding a supposed "safety" feature while actually flying the aircraft? Was it because it
would have taken a little longer to write and test the additional s/w or because completing
the circle through creating a pilot override would have mandated disclosure and additional
pilot training?
Capt. "Sully" Sullenberger and his passengers and crew would have ended up in pieces at
the bottom of the Hudson if the s/w on his aircraft had prohibited out of the ordinary flight
maneuvers that contradicted its programming.
If you carefully review the over all airframe of the 737 it has not hardly changed over
the past 20 years or so, for the most part Boeing 737
specifications . What I believe the real issue here is the Avionics upgrades over the
years has changed dramatically. More and more precision avionics are installed with less and
less pilot input and ultimately no control of the aircraft. Though Boeing will get the brunt
of the lawsuits, the avionics company will be the real culprit. I believe the avionics on the
Boeing 737 is made by Rockwell Collins, which you guessed it, is owned by Boeing.
United Technologies, UTX, I believe. If I knew how to short, I'd probably short this
'cause if they aren't partly liable, they'll still be hurt if Boeing has to slow (or, horror,
halt) production.
Using routine risk management protocols, the American FAA should need continuing "data" on
an aircraft for it to maintain its airworthiness certificate. Its current press materials on
the Boeing 737 Max 8 suggest it needs data to yank it or to ground the aircraft pending
review. Has it had any other commercial aircraft suffer two apparently similar catastrophic
losses this close together within two years of the aircraft's launch?
I am raising an issue with "crapification" as a meme. Crapification is a symptom of a
specific behaviour.
GREED.
Please could you reconsider your writing to invlude this very old, tremendously venal, and
"worst" sin?
US incentiveness of inventing a new word, "crapification" implies that some error cuould
be corrected. If a deliberate sin, it requires atonement and forgiveness, and a sacrifice of
wolrdy assets, for any chance of forgiveness and redemption.
Something else that will be interesting to this thread is that Boeing doesn't seem to mind
letting the Boeing 737 Max aircraft remain for sale on the open market
Experienced private pilot here. Lots of commercial pilot friends. First, the EU suspending
the MAX 8 is politics. Second, the FAA mandated changes were already in the pipeline. Three,
this won't stop the ignorant from staking out a position on this, and speculating about it on
the internet, of course. Fourth, I'd hop a flight in a MAX 8 without concern –
especially with a US pilot on board. Why? In part because the Lion Air event a few months
back led to pointed discussion about the thrust line of the MAX 8 vs. the rest of the 737
fleet and the way the plane has software to help during strong pitch up events (MAX 8 and 9
have really powerful engines).
Basically, pilots have been made keenly aware of the issue and trained in what to do.
Another reason I'd hop a flight in one right now is because there have been more than 31,000
trouble free flights in the USA in this new aircraft to date. My point is, if there were a
systemic issue we'd already know about it. Note, the PIC in the recent crash had +8000 hours
but the FO had about 200 hours and there is speculation he was flying. Speculation.
Anyway, US commercial fleet pilots are very well trained to deal with runaway trim or
uncommanded flight excursions. How? Simple, by switching the breaker off. It's right near
your fingers. Note, my airplane has an autopilot also. In the event the autopilot does
something unexpected, just like the commercial pilot flying the MAX 8, I'm trained in what to
do (the very same thing, switch the thing off).
Moreover, I speak form experience because I've had it happen twice in 15 years –
once an issue with a servo causing the plane to slowly drift right wing low, and once a
connection came loose leaving the plane trimmed right wing low (coincidence). My reaction
is/was about the same as that of a experienced typist automatically hitting backspace on the
keyboard upon realizing they mistyped a word, e.g. not reflex but nearly so. In my case, it
was to throw the breaker to power off the autopilot as I leveled the plane. No big deal.
Finally, as of yet there been no analysis from the black boxes. I advise holding off on
the speculation until they do. They've been found and we'll learn something soon. The
yammering and near hysteria by non-pilots – especially with this thread – reminds
me of the old saw about now knowing how smart or ignorant someone is until they open their
mouth.
While Boeing is designing a new 787, Airbus redesigns the A320. Boeing cannot compete with
it, so instead of redesigning the 737 properly, they put larger engines on it further
forward, which is never intended in the original design. So to compensate they use software
with two sensors, not three, making it mathematically impossible to know if you have a faulty
sensor which one it would be, to automatically adjust the pitch to prevent a stall, and this
is the only true way to prevent a stall. But since you can kill the breaker and disable it if
you have a bad sensor and can't possibly know which one, everything is ok. And now that the
pilots can disable a feature required for certification, we should all feel good about these
brand new planes, that for the first time in history, crashed within 5 months.
And the FAA, which hasn't had a Director in 14 months, knows better than the UK, Europe,
China, Australia, Singapore, India, Indonesia, Africa and basically every other country in
the world except Canada. And the reason every country in the world except Canada has grounded
the fleet is political? Singapore put Silk Air out of business because of politics?
How many people need to be rammed into the ground at 500 mph from 8000 feet before
yammering and hysteria are justified here? 400 obviously isn't enough.
Overnight since my first post above, the 737 Max 8 crash has become political. The black
boxes haven't been officially read yet. Still airlines and aviation authorities have grounded
the airplane in Europe, India, China, Mexico, Brazil, Australia and S.E. Asia in opposition
to FAA's "Continued Airworthiness Notification to the International Community" issued
yesterday.
I was wrong. There will be no whitewash. I thought they would remain silent. My guess this
is a result of an abundance of caution plus greed (Europeans couldn't help gutting Airbus's
competitor Boeing). This will not be discussed but it is also a manifestation of Trump
Derangement Syndrome (TDS). Since the President has started dissing Atlantic Alliance
partners, extorting defense money, fighting trade wars, and calling 3rd world countries
s***-holes; there is no sympathy for the collapsing hegemon. Boeing stock is paying the
price. If the cause is the faulty design of the flight position sensors and fly by wire
software control system, it will take a long while to design and get approval of a new safe
redundant control system and refit the airplanes to fly again overseas. A real disaster for
America's last manufacturing industry.
Too much automation and too complex flight control computer engager life of pilots and passengers...
Notable quotes:
"... When systems (like those used to fly giant aircraft) become too automatic while remaining essentially stupid or limited by the feedback systems, they endanger the airplane and passengers. These two "accidents" are painful warnings for air passengers and voters. ..."
"... This sort of problem is not new. Search the web for pitot/static port blockage, erroneous stall / overspeed indications. Pilots used to be trained to handle such emergencies before the desk-jockey suits decided computers always know best. ..."
"... @Sky Pilot, under normal circumstances, yes. but there are numerous reports that Boeing did not sufficiently test the MCAS with unreliable or incomplete signals from the sensors to even comply to its own quality regulations. ..."
"... Boeing did cut corners when designing the B737 MAX by just replacing the engines but not by designing a new wing which would have been required for the new engine. ..."
"... I accept that it should be easier for pilots to assume manual control of the aircraft in such situations but I wouldn't rush to condemn the programmers before we get all the facts. ..."
I want to know if Boeing 767s, as well as the new 737s, now has the Max 8 flight control
computer installed with pilots maybe not being trained to use it or it being uncontrollable.
A 3rd Boeing - not a passenger plane but a big 767 cargo plane flying a bunch of stuff for
Amazon crashed near Houston (where it was to land) on 2-23-19. The 2 pilots were killed.
Apparently there was no call for help (at least not mentioned in the AP article about it I
read).
'If' the new Max 8 system had been installed, had either Boeing or the owner of the
cargo plane business been informed of problems with Max 8 equipment that had caused a crash
and many deaths in a passenger plane (this would have been after the Indonesian crash)? Was
that info given to the 2 pilots who died if Max 8 is also being used in some 767s? Did Boeing
get the black box from that plane and, if so, what did they find out?
Those 2 pilots' lives
matter also - particularly since the Indonesian 737 crash with Max 8 equipment had already
happened. Boeing hasn't said anything (yet, that I've seen) about whether or not the Max 8
new configuration computer and the extra steps to get manual control is on other of their
planes.
I want to know about the cause of that 3rd Boeing plane crashing and if there have
been crashes/deaths in other of Boeing's big cargo planes. What's the total of all Boeing
crashes/fatalies in the last few months and how many of those planes had Max 8?
Gentle readers: In the aftermath of the Lion Air crash, do you think it possible that all
737Max pilots have not received mandatory training review in how to quickly disconnect the
MCAS system and fly the plane manually?
Do you think it possible that every 737Max pilot does
not have a "disconnect review" as part of his personal checklist? Do you think it possible
that at the first hint of pitch instability, the pilot does not first think of the MCAS
system and whether to disable it?
Compare the altitude fluctuations with those from Lion Air in NYTimes excellent coverage(
https://www.nytimes.com/interactive/2018/11/16/world/asia/lion-air-crash-cockpit.html
), and they don't really suggest to me a pilot struggling to maintain proper pitch. Maybe the
graph isn't detailed enough, but it looks more like a major, single event rather than a
number of smaller corrections. I could be wrong.
Reports of smoke and fire are interesting;
there is nothing in the modification that (we assume) caused Lion Air's crash that would
explain smoke and fire. So I would hesitate to zero in on the modification at this point.
Smoke and fire coming from the luggage bay suggest a runaway Li battery someone put in their
suitcase. This is a larger issue because that can happen on any aircraft, Boeing, Airbus, or
other.
Is is a shame that Boeing will not ground this aircraft knowing they introduced the MCAS
component to automate the stall recovery of the 737 MAX and is behind these accidents in my
opinion. Stall recovery has always been a step all pilots handled when the stick shaker and
other audible warnings were activated to alert the pilots.
Now, Boeing invented MCAS as a
"selling and marketing point" to a problem that didn't exist. MCAS kicks in when the aircraft
is about to enter the stall phase and places the aircraft in a nose dive to regain speed.
This only works when the air speed sensors are working properly. Now imagine when the air
speed sensors have a malfunction and the plane is wrongly put into a nose dive.
The pilots
are going to pull back on the stick to level the plane. The MCAS which is still getting
incorrect air speed data is going to place the airplane back into a nose dive. The pilots are
going to pull back on the stick to level the aircraft. This repeats itself till the airplane
impacts the ground which is exactly what happened.
Add the fact that Boeing did not disclose
the existence of the MCAS and its role to pilots. At this point only money is keeping the 737
MAX in the air. When Boeing talks about safety, they are not referring to passenger safety
but profit safety.
1. The procedure to allow a pilot to take complete control of the aircraft from auto-pilot
mode should have been a standard eg pull back on the control column. It is not reasonable to
expect a pilot to follow some checklist to determine and then turn off a misbehaving module
especially in emergency situations. Even if that procedure is written in fine print in a
manual. (The number of modules to disable may keep increasing if this is allowed).
2. How are
US airlines confident of the safety of the 737 MAX right now when nothing much is known about
the cause of the 2nd crash? What is known if that both the crashed aircraft were brand new,
and we should be seeing news articles on how the plane's brand-new advanced technology saved
the day from the pilot and not the other way round
3. In the first crash, the plane's
advanced technology could not even recognize that either the flight path was abnormal and/or
the airspeed readings were too erroneous and mandate the pilot to therefore take complete
control immediately!
It's straightforward to design for standard operation under normal circumstances. But when
bizarre operation occurs resulting in extreme circumstances a lot more comes into play. Not
just more variables interacting more rapidly, testing system response times, but much
happening quickly, testing pilot response times and experience. It is doubtful that the FAA
can assess exactly what happened in these crashes. It is a result of a complex and rapid
succession of man-machine-software-instrumentation interactions, and the number of
permutations is huge. Boeing didn't imagine all of them, and didn't test all those it did
think of.
The FAA is even less likely to do so. Boeing eventually will fix some of the
identified problems, and make pilot intervention more effective. Maybe all that effort to
make the new cockpit look as familiar as the old one will be scrapped? Pilot retraining will
be done? Redundant sensors will be added? Additional instrumentation? Software re-written?
That'll increase costs, of course. Future deliveries will cost more. Looks likely there will
be some downtime. Whether the fixes will cover sufficient eventualities, time will tell.
Whether Boeing will be more scrupulous in future designs, less willing to cut corners without
evaluating them? Will heads roll? Well, we'll see...
Boeing has been in trouble technologically since its merger with McDonnell Douglas, which
some industry analysts called a takeover, though it isn't clear who took over whom since MD
got Boeing's name while Boeing took the MD logo and moved their headquarters from Seattle to
Chicago.
In addition to problems with the 737 Max, Boeing is charging NASA considerably more
than the small startup, SpaceX, for a capsule designed to ferry astronauts to the space
station. Boeing's Starliner looks like an Apollo-era craft and is launched via a 1960's-like
ATLAS booster.
Despite using what appears to be old technology, the Starliner is well behind
schedule and over budget while the SpaceX capsule has already docked with the space station
using state-of-art reusable rocket boosters at a much lower cost. It seems Boeing is in
trouble, technologically.
When you read that this model of the Boeing 737 Max was more fuel efficient, and view the
horrifying graphs (the passengers spent their last minutes in sheer terror) of the vertical
jerking up and down of both air crafts, and learn both crashes occurred minutes after take
off, you are 90% sure that the problem is with design, or design not compatible with pilot
training. Pilots in both planes had received permission to return to the airports. The likely
culprit. to a trained designer, is the control system for injecting the huge amounts of fuel
necessary to lift the plane to cruising altitude. Pilots knew it was happening and did not
know how to override the fuel injection system.
These two crashes foretell what will happen
if airlines, purely in the name of saving money, elmininate human control of aircraft. There
will be many more crashes.
These ultra-complicated machines which defy gravity and lift
thousands of pounds of dead weight into the stratesphere to reduce friction with air, are
immensely complex and common. Thousands of flight paths cover the globe each day. Human
pilots must ultimately be in charge - for our own peace of mind, and for their ability to
deal with unimaginable, unforeseen hazards.
When systems (like those used to fly giant
aircraft) become too automatic while remaining essentially stupid or limited by the feedback
systems, they endanger the airplane and passengers. These two "accidents" are painful
warnings for air passengers and voters.
2. Deactivate the ability of the automated system to override pilot
inputs, which it apparently can do even with the autopilot disengaged.
3. Make sure that the
autopilot disengage button on the yoke (pickle switch) disconnects ALL non-manual control
inputs.
4. I do not know if this version of the 737 has direct input ("rope start")
gyroscope, airspeed and vertical speed inticators for emergencies such as failure of the
electronic wonder-stuff. If not, install them. Train pilots to use them.
5. This will cost
money, a lot of money, so we can expect more self-serving excuses until the FAA forces Boeing
to do the right thing.
6. This sort of problem is not new. Search the web for pitot/static
port blockage, erroneous stall / overspeed indications. Pilots used to be trained to handle
such emergencies before the desk-jockey suits decided computers always know
best.
I flew big jets for 34 years, mostly Boeing's. Boeing added new logic to the trim system
and was allowed to not make it known to pilots. However it was in maintenance manuals. Not
great, but these airplanes are now so complex there are many systems that pilots don't know
all of the intimate details.
NOT IDEAL, BUT NOT OVERLY SIGNIFICANT. Boeing changed one of the
ways to stop a runaway trim system by eliminating the control column trim brake, ie airplane
nose goes up, push down (which is instinct) and it stops the trim from running out of
control.
BIG DEAL BOIENG AND FAA, NOT TELLING PILOTS. Boeing produces checklists for almost
any conceivable malfunction. We pilots are trained to accomplish the obvious then go
immediately to the checklist. Some items on the checklist are so important they are called
"Memory Items" or "Red Box Items".
These would include things like in an explosive
depressurization to put on your o2 mask, check to see that the passenger masks have dropped
automatically and start a descent.
Another has always been STAB TRIM SWITCHES ...... CUTOUT
which is surrounded by a RED BOX.
For very good reasons these two guarded switches are very
conveniently located on the pedestal right between the pilots.
So if the nose is pitching
incorrectly, STAB TRIM SWITCHES ..... CUTOUT!!! Ask questions later, go to the checklist.
THAT IS THE PILOTS AND TRAINING DEPARTMENTS RESPONSIBILITY. At this point it is not important
as to the cause.
If these crashes turn out to result from a Boeing flaw, how can that company continue to
stay in business? It should be put into receivership and its executives prosecuted. How many
deaths are persmissable?
The emphasis on software is misplaced. The software intervention is triggered by readings
from something called an Angle of Attack sensor. This sensor is relatively new on airplanes.
A delicate blade protrudes from the fuselage and is deflected by airflow. The direction of
the airflow determines the reading. A false reading from this instrument is the "garbage in"
input to the software that takes over the trim function and directs the nose of the airplane
down. The software seems to be working fine. The AOA sensor? Not so much.
The basic problem seems to be that the 737 Max 8 was not designed for the larger engines
and so there are flight characteristics that could be dangerous. To compensate for the flaw,
computer software was used to control the aircraft when the situation was encountered. The
software failed to prevent the situation from becoming a fatal crash.
A work around that may
be the big mistake of not redesigning the aircraft properly for the larger engines in the
first place. The aircraft may need to be modified at a cost that would be not realistic and
therefore abandoned and a entirely new aircraft design be implemented. That sounds very
drastic but the only other solution would be to go back to the original engines. The Boeing
Company is at a crossroad that could be their demise if the wrong decision is
made.
It may be a training issue in that the 737 Max has several systems changes from previous
737 models that may not be covered adequately in differences training, checklists, etc. In
the Lyon Air crash, a sticky angle-of-attack vane caused the auto-trim to force the nose down
in order to prevent a stall. This is a worthwhile safety feature of the Max, but the crew was
slow (or unable) to troubleshoot and isolate the problem. It need not have caused a crash. I
suspect the same thing happened with Ethiopian Airlines. The circumstances are temptingly
similar.
@Sky Pilot, under normal circumstances, yes. but there are numerous reports that Boeing
did not sufficiently test the MCAS with unreliable or incomplete signals from the sensors to
even comply to its own quality regulations. And that is just one of the many quality issues
with the B737 MAX that have been in the news for a long time and have been of concern to some
of the operators while at the same time being covered up by the FAA.
Just look at the
difference in training requirements between the FAA and the Brazilian aviation authority.
Brazilian pilots need to fully understand the MCAS and how to handle it in emergency
situations while FAA does not even require pilots to know about it.
This is yet another beautiful example of the difference in approach between Europeans and
US Americans. While Europeans usually test their before they deliver the product thoroughly
in order to avoid any potential failures of the product in their customers hands, the US
approach is different: It is "make it work somehow and fix the problems when the client has
them".
Which is what happened here as well. Boeing did cut corners when designing the B737
MAX by just replacing the engines but not by designing a new wing which would have been
required for the new engine.
So the aircraft became unstable to fly at low speedy and tight
turns which required a fix by implementing the MCAS which then was kept from recertification
procedures for clients for reasons competitive sales arguments. And of course, the FAA played
along and provided a cover for this cutting of corners as this was a product of a US company.
Then the proverbial brown stuff hit the fan, not once but twice. So Boeing sent its "thoughts
and prayers" and started to hope for the storm to blow over and for finding a fix that would
not be very expensive and not eat the share holder value away.
Sorry, but that is not the way
to design and maintain aircraft. If you do it, do it right the first time and not fix it
after more than 300 people died in accidents. There is a reason why China has copied the
Airbus A-320 and not the Boeing B737 when building its COMAC C919. The Airbus is not a cheap
fix, still tested by customers.
@Thomas And how do you know that Boeing do not test the aircrafts before delivery? It is a
requirement by FAA for all complete product, systems, parts and sub-parts to be tested before
delivery. However it seems Boeing has not approached the problem (or maybe they do not know
the real issue).
As for the design, are you an engineer that can say whatever the design and
use of new engines without a complete re-design is wrong? Have you seen the design drawings
of the airplane? I do work in an industry in which our products are use for testing different
parts of aircratfs and Boeing is one of our customers.
Our products are use during
manufacturing and maintenance of airplanes. My guess is that Boeing has no idea what is going
on. Your biased opinion against any US product is evident. There are regulations in the USA
(and not in other Asia countries) that companies have to follow. This is not a case of
untested product, it is a case of unknown problem and Boeing is really in the dark of what is
going on...
Boeing and Regulators continue to exhibit criminal behaviour in this case. Ethical
responsibility expects that when the first brand new MAX 8 fell for potentially issues with
its design, the fleet should have been grounded. Instead, money was a priority; and
unfortunately still is. They are even now flying. Disgraceful and criminal
behaviour.
A terrible tragedy for Ethiopia and all of the families affected by this disaster. The
fact that two 737 Max jets have crashed in one year is indeed suspicious, especially as it
has long been safer to travel in a Boeing plane than a car or school bus. That said, it is
way too early to speculate on the causes of the two crashes being identical. Eyewitness
accounts of debris coming off the plane in mid-air, as has been widely reported, would not
seem to square with the idea that software is again at fault. Let's hope this puzzle can be
solved quickly.
@Singh the difference is consumer electronic products usually have a smaller number of
components and wiring compared to commercial aircraft with miles of wiring and multitude of
sensors and thousands of components. From what I know they usually have a preliminary report
that comes out in a short time. But the detailed reported that takes into account analysis
will take over one year to be written.
The engineers and management at Boeing need a crash course in ethics. After the crash in
Indonesia, Boeing was trying to pass the blame rather than admit responsibility. The planes
should all have been grounded then. Now the chickens have come to roost. Boeing is in serious
trouble and it will take a long time to recover the reputation. Large multinationals never
learn.
@John A the previous pilot flying the Lion jet faced the same problem but dealt with it
successfully. The pilot on the ill fated flight was less experienced and unfortunately
failed.
@Imperato Solving a repeat problem on an airplane type must not solely depend upon a pilot
undertaking an emergency response! That is nonsense even to a non-pilot! This implies that
Boeing allows a plane to keep flying which it knows has a fatal flaw! Shouldn't it be
grounding all these planes until it identifies and solves the same problem?
Something is wrong with those two graphs of altitude and vertical speed. For example, both
are flat at the end, even though the vertical speed graph indicates that the plane was
climbing rapidly. So what is the source of those numbers? Is it ground-based radar, or
telemetry from onboard instruments? If the latter, it might be a clue to the
problem.
I wonder if, somewhere, there is a a report from some engineers saying that the system
pushed by administrative-types to get the plane on the market quickly, will results in
serious problems down the line.
If we don't know why the first two 737 Max Jets crashed, then we don't know how long it
will be before another one has a catastrophic failure. All the planes need to be grounded
until the problem can be duplicated and eliminated.
@Rebecca And if it is something about the plane itself - and maybe an interaction with the
new software - then someone has to be ready to volunteer to die to replicate what's
happened.....
@Shirley Heavens no. When investigating failures, duplicating the problem helps develop
the solution. If you can't recreate the problem, then there is nothing to solve. Duplicating
the problem generally is done through analysis and simulations, not with actual planes and
passengers.
Computer geeks can be deadly. This is clearly a software problem. The more software goes
into a plane, the more likely it is for a software failure to bring down a plane. And
computer geeks are always happy to try "new things" not caring what the effects are in the
real world. My PC has a feature that controls what gets typed depending on the speed and
repetitiveness of what I type. The darn thing is a constant source of annoyance as I sit at
my desk, and there is absolutely no way to neutralize it because a computer geek so decided.
Up in an airliner cockpit, this same software idiocy is killing people like
flies.
@Sisifo Software that goes into critical systems like aircraft have a lot more
constraints. Comparing it to the user interface on your PC doesn't make any sense. It's
insulting to assume programmers are happy to "try new things" at the expense of lives. If
you'd read about the Lion Air crash carefully you'd remember that there were faulty sensors
involved. The software was doing what it was designed to do but the input it was getting was
incorrect. I accept that it should be easier for pilots to assume manual control of the
aircraft in such situations but I wouldn't rush to condemn the programmers before we get all
the facts.
@Pooja Mistakes happen. If humans on board can't respond to terrible situations then there
is something wrong with the aircraft and its computer systems. By definition.
Airbus had its own experiences with pilot "mode confusion" in the 1990's with at least 3
fatal crashes in the A320, but was able to control the media narrative until they resolved
the automation issues. Look up Air Inter 148 in Wikipedia to learn the
similarities.
Opinioned! NYC -- currently wintering in the Pacific March 11
"Commands issued by the plane's flight control computer that bypasses the pilots." What
could possibly go wrong? Now let's see whether Boeing's spin doctors can sell this as a
feature, not a bug.
It is telling that the Chinese government grounded their fleet of 737 Max 8 aircraft
before the US government. The world truly has turned upside down when it potentially is safer
to fly in China than the US. Oh, the times we live in. Chris Hartnett Datchet, UK (formerly
Minneapolis)
As a passenger who likes his captains with a head full of white hair, even if the plane is
nosediving to instrument failure, does not every pilot who buckles a seat belt worldwide know
how to switch off automatic flight controls and fly the airplane manually?
Even if this were
1000% Boeing's fault pilots should be able to override electronics and fly the plane safely
back to the airport. I'm sure it's not that black and white in the air and I know it's
speculation at this point but can any pilots add perspective regarding human
responsibility?
@Hollis I'm not a pilot nor an expert, but my understanding is that planes these days are
"fly by wire", meaning the control surfaces are operated electronically, with no mechanical
connection between the pilot's stick and the wings. So if the computer goes down, the ability
to control the plane goes with it.
@Hollis The NYT's excellent reporting on the Lion Air crash indicated that in nearly all
other commercial aircraft, manual control of the pilot's yoke would be sufficient to override
the malfunctioning system (which was controlling the tail wings in response to erroneous
sensor data). Your white haired captain's years of training would have ingrained that
impulse.
Unfortunately, on the Max 8 that would not sufficiently override the tail wings
until the pilots flicked a switch near the bottom of the yoke. It's unclear whether
individual airlines made pilots aware of this. That procedure existed in older planes but may
not have been standard practice because the yoke WOULD sufficiently override the tail wings.
Boeing's position has been that had pilots followed the procedure, a crash would not have
occurred.
@Hollis No, that is the entire crux of this problem; switching from auto-pilot to manual
does NOT solve it. Hence the danger of this whole system. T
his new Boeing 737-Max series are
having the engines placed a bit further away than before and I don't know why they did this,
but the result is that there can be some imbalance in air, which they then tried to correct
with this strange auto-pilot technical adjustment.
Problem is that it stalls the plane (by
pushing its nose down and even flipping out small wings sometimes) even when it shouldn't,
and even when they switch to manual this system OVERRULES the pilot and switches back to
auto-pilot, continuing to try to 'stabilize' (nose dive) the plane. That's what makes it so
dangerous.
It was designed to keep the plane stable but basically turned out to function more
or less like a glitch once you are taking off and need the ascend. I don't know why it only
happens now and then, as this plane had made many other take-offs prior, but when it hits, it
can be deadly. So far Boeings 'solution' is sparsely sending out a HUGE manual for pilots
about how to fight with this computer problem.
Which are complicated to follow in a situation
of stress with a plane computer constantly pushing the nose of your plane down. Max'
mechanism is wrong and instead of correcting it properly, pilots need special training. Or a
new technical update may help... which has been delayed and still hasn't been
provided.
Is it the inability of the two airlines to maintain one of the plane's fly-by-wire systems
that is at fault, not the plane itself? Or are both crashes due to pilot error, not knowing
how to operate the system and then overreacting when it engages? Is the aircraft merely too
advanced for its own good? None of these questions seems to have been answered
yet.
This is such a devastating thing for Ethiopian Airlines, which has been doing critical
work in connecting Africa internally and to the world at large. This is devastating for the
nation of Ethiopia and for all the family members of those killed. May the memory of every
passenger be a blessing. We should all hope a thorough investigation provides answers to why
this make and model of airplane keep crashing so no other people have to go through this
horror again.
A possible small piece of a big puzzle: Bishoftu is a city of 170,000 that is home to the
main Ethiopian air force base, which has a long runway. Perhaps the pilot of Flight 302 was
seeking to land there rather than returning to Bole Airport in Addis Ababa, a much larger and
more densely populated city than Bishoftu. The pilot apparently requested return to Bole, but
may have sought the Bishoftu runway when he experienced further control problems. Detailed
analysis of radar data, conversations between pilot and control tower, flight path, and other
flight-related information will be needed to establish the cause(s) of this
tragedy.
The business of building and selling airplanes is brutally competitive. Malfunctions in
the systems of any kind on jet airplanes ("workhorses" for moving vast quantities of people
around the earth) lead to disaster and loss of life. Boeing's much ballyhooed and vaunted MAX
8 737 jet planes must be grounded until whatever computer glitches brought down Ethiopian Air
and LION Air planes -- with hundreds of passenger deaths -- are explained and fixed.
In 1946,
Arthur Miller's play, "All My Sons", brought to life guilt by the airplane industry leading
to deaths of WWII pilots in planes with defective parts. Arthur Miller was brought before the
House UnAmerican Activities Committee because of his criticism of the American Dream. His
other seminal American play, "Death of a Salesman", was about an everyman to whom attention
must be paid. Attention must be paid to our aircraft industry. The American dream must be
repaired.
Meanwhile, human drivers killed 40,000 and injured 4.5 million people in 2018... For
comparison, 58,200 American troops died in the entire Vietnam war. Computers do not fall
asleep, get drunk, drive angry, or get distracted. As far as I am concerned, we cannot get
unreliable humans out from behind the wheel fast enough.
The irony here seems to be that in attempting to make the aircraft as safe as possible
(with systems updates and such) Boeing may very well have made their product less safe. Since
the crashes, to date, have been limited to the one product that product should be grounded
until a viable determination has been made. John~ American Net'Zen
Knowing quite a few Boeing employees and retirees, people who have shared numerous stories
of concerns about Boeing operations -- I personally avoid flying. As for the assertion: "The
business of building and selling jets is brutally competitive" -- it is monopolistic
competition, as there are only two players. That means consumers (in this case airlines) do
not end up with the best and widest array of airplanes. The more monopolistic a market, the
more it needs to be regulated in the public interest -- yet I seriously doubt the FAA or any
governmental agency has peeked into all the cost cutting measures Boeing has implemented in
recent years
@cosmos Patently ridiculous. Your odds are greater of dying from a lightning strike, or in
a car accident. Or even from food poisoning. Do you avoid driving? Eating? Something about
these major disasters makes people itching to abandon all sense of probability and
statistics.
When the past year was the dealiest one in decades, and when there are two disasters
involved the same plane within that year, how can anyone not draw an inference that there are
something wrong with the plane? In statistical studies of a pattern, this is a very very
strong basis for a logical reasoning that something is wrong with the plane. When the number
involves human lives, we must take very seriously the possibility of design flaws. The MAX
planes should be all grounded for now. Period.
@Bob couldn't agree more - however the basic design and engineering of the 737 is proven
to be dependable over the past ~ 6 decades......not saying that there haven't been accidents
- but these probably lie well within the industry / type averages. the problems seems to have
arisen with the introduction of systems which have purportedly been introduced to take a part
of the work-load off the pilots & pass it onto a central compuertised system.
Maybe the
'automated anti-stalling ' programme installed into the 737 Max, due to some erroneous inputs
from the sensors, provide inaccurate data to the flight management controls leading to
stalling of the aircraft. It seems that the manufacturer did not provide sufficent technical
data about the upgraded software, & incase of malfunction, the corrective procedures to
be followed to mitigate such diasters happening - before delivery of the planes to customers.
The procedure for the pilot to take full control of the aircraft by disengaging the central
computer should be simple and fast to execute. Please we don't want Tesla driverless vehicles
high up in the sky !
All we know at the moment is that a 737 Max crashed in Africa a few minutes after taking
off from a high elevation airport. Some see similarities with the crash of Lion Air's 737 Max
last fall -- but drawing a line between the only two dots that exist does not begin to
present a useful picture of the situation.
Human nature seeks an explanation for an event,
and may lead some to make assumptions that are without merit in order to provide closure.
That tendency is why following a dramatic event, when facts are few, and the few that exist
may be misleading, there is so much cocksure speculation masquerading as solid, reasoned,
analysis. At this point, it's best to keep an open mind and resist connecting
dots.
@James Conner 2 deadly crashes after the introduction of a new airplane has no precedence
in recent aviation history. And the time it has happened (with Comet), it was due to a faulty
aircraft design. There is, of course, some chance that there is no connection between the two
accidents, but if there is, the consequences are huge. Especially because the two events
happened with very similar fashion (right after takeoff, with wild altitude changes), so
there is more similarities than just the type of the plane. So there is literally no reason
to keep this model in the air until the investigation is concluded. Oh well, there is: money.
Over human lives.
It might be a wrong analogy, but if Toyota/Lexus recall over 1.5 million vehicles due to
at least over 20 fatalities in relations to potentially fawlty airbags, Boeing should -- after
over 300 deaths in just about 6 months -- pull their product of the market voluntarily until it
is sorted out once and for all.
This tragic situation recalls the early days of the de
Havilland Comet, operated by BOAC, which kept plunging from the skies within its first years
of operation until the fault was found to be in the rectangular windows, which did not
withstand the pressure due its jet speed and the subsequent cracks in body ripped the planes
apart in midflight.
A third crash may have the potential to take the aircraft manufacturer out of business, it
is therefore unbelievable that the reasons for the Lion Air crash haven't been properly
established yet. With more than a 100 Boeing 737 Max already grounded, I would expect crash
investigations now to be severely fast tracked.
And the entire fleet should be grounded on
the principle of "better safe than sorry". But then again, that would cost Boeing money,
suggesting that the company's assessment of the risks involved favours continued operations
above the absolute safety of passengers.
@Thore Eilertsen This is also not a case for a secretive and extended crash investigation
process. As soon as the cockpit voice recording is extracted - which might be later today -
it should be made public. We also need to hear the communications between the controllers and
the aircraft and to know about the position regarding the special training the pilots
received after the Lion Air crash.
@Thore Eilertsen I would imagine that Boeing will be the first to propose grounding these
planes if they believe with a high degree of probability that it's their issue. They have the
most to lose. Let logic and patience prevail.
It is very clear, even in these early moments, that aircraft makers need far more
comprehensive information on everything pertinent that is going on in cockpits when pilots
encounter problems. That information should be continually transmitted to ground facilities
in real time to permit possible ground technical support.
They know, however, that they've been conned, played, and they're absolute fools in the
game.
Thank you Mr. Black for the laugh this morning. They know exactly what they have been
doing. Whether it was deregulating so that Hedge funds and vulture capitalism can thrive, or
making sure us peons cannot discharge debts, or making everything about financalization. This
was all done on purpose, without care for "winning the political game". Politics is
economics, and the Wall Street Democrats have been winning.
For sure. I'm quite concerned at the behavior of the DNC leadership and pundits. They are
doubling down on blatant corporatist agendas. They are acting like they have this in the bag
when objective evidence says they do not and are in trouble. Assuming they are out of touch is
naive to me. I would assume the opposite, they know a whole lot more than what they are letting
on.
I think the notion that the DNC and the Democrat's ruling class would rather lose to a
like-minded Republican corporatist than win with someone who stands for genuine progressive
values offering "concrete material benefits." I held my nose and read comments at the kos straw
polls (where Sanders consistently wins by a large margin) and it's clear to me that the
Clintonista's will do everything in their power to derail Bernie.
Keynes' "animal spirits" and the "tragedy of the commons" (Lloyd, 1833 and Hardin, 1968)
both implied that economics was messier than Samuelson and Friedman would have us believe
because there are actual people with different short- and long-term interests.
The behavioral folks (Kahnemann, Tversky, Thaler etc.) have all shown that people are even
messier than we would have thought. So most macro-economic stuff over the past half-century has
been largely BS in justifying trickle-down economics, deregulation etc.
There needs to be some inequality as that provides incentives via capitalism but
unfettered it turns into France 1989 or the Great Depression. It is not coincidence that the
major experiment in this in the late 90s and early 2000s required massive government
intervention to keep the ship from sinking less than a decade after the great unregulated
creative forces were unleashed.
MMT is likely to be similar where productive uses of deficits can be beneficial, but if the
money is wasted on stupid stuff like unnecessary wars, then the loss of credibility means that
the fiat currency won't be quite as fiat anymore. Britain was unbelievably economically
powerfully in the late 1800s but in half a century went to being an economic afterthought
hamstrung by deficits after two major wars and a depression.
So it is good that people like Brad DeLong are coming to understand that the pretty
economic theories have some truths but are utter BS (and dangerous) when extrapolated without
accounting for how people and societies actually behave.
I never understood the incentive to make more money -- that only works if money = true value
and that is the implication of living in a capitalist society (not economy)–everything
then becomes a commodity and alienation results and all the depression, fear, anxiety that I
see around me. Whereas human happiness actually comes from helping others and finding meaning
in life not money or dominating others. That's what social science seems to be telling us.
" He says we are discredited. Our policies have failed. And they've failed because
we've been conned by the Republicans."
That's welcome, but it's still making excuses. Neoliberal policies have failed because
the economics were wrong, not because "we've been conned by the Republicans." Furthermore, this
may be important – if it isn't acknowledged, those policies are quite likely to come
sneaking back, especially if Democrats are more in the ascendant., as they will be, given the
seesaw built into the 2-Party.
Might be right there. Groups like the neocons were originally attached the the left side of
politics but when the winds changed, detached themselves and went over to the Republican right.
The winds are changing again so those who want power may be going over to what is called the
left now to keep their grip on power. But what you say is quite true. It is not really the
policies that failed but the economics themselves that were wrong and which, in an honest
debate, does not make sense either.
"And they've failed because we've been conned by the Republicans.""
Not at all. What about the "free trade" hokum that DeJong and his pal Krugman have been
peddling since forever? History and every empirical test in the modern era shows that it fails
in developing countries and only exacerbates inequality in richer ones.
That's just a failed policy.
I'm still waiting for an apology for all those years that those two insulted anyone who
questioned their dogma as just "too ignorant to understand."
It's intriguing, but two other voices come to mind. One is Never Let a Serious Crisis Go To
Waste by Mirowski and the other is Generation Like by Doug Rushkoff.
Neoliberalism is partially entrepreneurial self-conceptions which took a long time to
promote. Rushkoff's Frontline shows the Youtube culture. There is a girl with a "leaderboard"
on the wall of her suburban room, keeping track of her metrics.
There's a devastating VPRO Backlight film on the same topic. Internet-platform
neoliberalism does not have much to do with the GOP.
It's going to be an odd hybrid at best – you could have deep-red communism but enacted
for and by people whose self-conception is influenced by decades of Becker and Hayek? One place
this question leads is to ask what's the relationship between the set of ideas and material
conditions-centric philosophies? If new policies pass that create a different possibility
materially, will the vise grip of the entrepreneurial self loosen?
Partially yeah, maybe, a Job Guarantee if it passes and actually works, would be an
anti-neoliberal approach to jobs, which might partially loosen the regime of neoliberal advice
for job candidates delivered with a smug attitude that There Is No Alternative. (Described by
Gershon). We take it seriously because of a sense of dread that it might actually be powerful
enough to lock us out if we don't, and an uncertainty of whether it is or not.
There has been deep damage which is now a very broad and resilient base. It is one of the
prongs of why 2008 did not have the kind of discrediting effect that 1929 did. At least that's
what I took away from _Never Let_.
Brad DeLong handing the baton might mean something but it is not going to ameliorate the
sense-of-life that young people get from managing their channels and metrics.
Take the new 1099 platforms as another focal point. Suppose there were political measures
that splice in on the platforms and take the edge off materially, such as underwritten
healthcare not tied to your job. The platforms still use star ratings, make star ratings seem
normal, and continually push a self-conception as a small business. If you have overt DSA plus
covert Becker it is, again, a strange hybrid,
Your comment is very insightful. Neoliberalism embeds its mindset into the very fabric of
our culture and self-concepts. It strangely twists many of our core myths and beliefs.
This is nothing but a Trojan horse to 'co-opt' and 'subvert'. Neoliberals sense a risk to
their neo feudal project and are simply attempting to infiltrate and hollow out any threats
from within.
There are the same folks who have let entire economics departments becomes mouthpieces for
corporate propaganda and worked with thousands of think tanks and international organizations
to mislead, misinform and cause pain to millions of people.
They have seeded decontextualized words like 'wealth creators' and 'job creators' to
create a halo narrative for corporate interests and undermine society, citizenship, the social
good, the environment that make 'wealth creation' even possible. So all those take a backseat
to 'wealth creator' interests. Since you can't create wealth without society this is some
achievement.
Its because of them that we live in a world where the most important economic idea is
protecting people like Kochs business and personal interests and making sure government is not
'impinging on their freedom'. And the corollary a fundamental anti-human narrative where
ordinary people and workers are held in contempt for even expecting living wages and conditions
and their access to basics like education, health care and living conditions is hollowed out
out to promote privatization and become 'entitlements'.
Neoliberalism has left us with a decontextualized highly unstable world that exists in a
collective but is forcefully detached into a context less individual existence. These are not
mistakes of otherwise 'well meaning' individuals, there are the results of hard core ideologues
and high priests of power.
Two thumbs up. This has been an ongoing agenda for decades and it has succeeded in
permeating every aspect of society, which is why the United States is such a vacuous,
superficial place. And it's exporting that superficiality to the rest of the world.
I read Brad DeLong's and Paul Krugman's blogs until their contradictions became too
great. If anything, we need more people seeing the truth. The Global War on Terror is into its
18th year. In October the USA will spend approximately $6 trillion and will have accomplish
nothing except to create blow back. The Middle Class is disappearing. Those who remain in their
homes are head over heels in debt.
The average American household carries $137,063 in debt. The wealthy are getting richer.
The Jeff Bezos, Warren Buffett and Bill Gates families together have as much wealth as the
lowest half of Americans. Donald Trump's Presidency and Brexit document that neoliberal
politicians have lost contact with reality. They are nightmares that there is no escaping. At
best, perhaps, Roosevelt Progressives will be reborn to resurrect regulated capitalism and debt
forgiveness.
But more likely is a middle-class revolt when Americans no longer can pay for water,
electricity, food, medicine and are jailed for not paying a $1,500 fine for littering the
Beltway.
A civil war inside a nuclear armed nation state is dangerous beyond belief. France is
approaching this.
I use Tilda (drop-down terminal) on Ubuntu as my "command central" - pretty much the way
others might use GNOME Do, Quicksilver or Launchy.
However, I'm struggling with how to completely detach a process (e.g. Firefox) from the
terminal it's been launched from - i.e. prevent that such a (non-)child process
is terminated when closing the originating terminal
"pollutes" the originating terminal via STDOUT/STDERR
For example, in order to start Vim in a "proper" terminal window, I have tried a simple
script like the following:
exec gnome-terminal -e "vim $@" &> /dev/null &
However, that still causes pollution (also, passing a file name doesn't seem to work).
First of all; once you've started a process, you can background it by first stopping it (hit
Ctrl - Z ) and then typing bg to let it resume in the
background. It's now a "job", and its stdout / stderr /
stdin are still connected to your terminal.
You can start a process as backgrounded immediately by appending a "&" to the end of
it:
firefox &
To run it in the background silenced, use this:
firefox </dev/null &>/dev/null &
Some additional info:
nohup is a program you can use to run your application with such that its
stdout/stderr can be sent to a file instead and such that closing the parent script won't
SIGHUP the child. However, you need to have had the foresight to have used it before you
started the application. Because of the way nohup works, you can't just apply
it to a running process .
disown is a bash builtin that removes a shell job from the shell's job list.
What this basically means is that you can't use fg , bg on it
anymore, but more importantly, when you close your shell it won't hang or send a
SIGHUP to that child anymore. Unlike nohup , disown is
used after the process has been launched and backgrounded.
What you can't do, is change the stdout/stderr/stdin of a process after having
launched it. At least not from the shell. If you launch your process and tell it that its
stdout is your terminal (which is what you do by default), then that process is configured to
output to your terminal. Your shell has no business with the processes' FD setup, that's
purely something the process itself manages. The process itself can decide whether to close
its stdout/stderr/stdin or not, but you can't use your shell to force it to do so.
To manage a background process' output, you have plenty of options from scripts, "nohup"
probably being the first to come to mind. But for interactive processes you start but forgot
to silence ( firefox < /dev/null &>/dev/null & ) you can't do
much, really.
I recommend you get GNU screen . With screen you can just close your running
shell when the process' output becomes a bother and open a new one ( ^Ac ).
Oh, and by the way, don't use " $@ " where you're using it.
$@ means, $1 , $2 , $3 ..., which
would turn your command into:
gnome-terminal -e "vim $1" "$2" "$3" ...
That's probably not what you want because -e only takes one argument. Use $1
to show that your script can only handle one argument.
It's really difficult to get multiple arguments working properly in the scenario that you
gave (with the gnome-terminal -e ) because -e takes only one
argument, which is a shell command string. You'd have to encode your arguments into one. The
best and most robust, but rather cludgy, way is like so:
Reading these answers, I was under the initial impression that issuing nohup
<command> & would be sufficient. Running zsh in gnome-terminal, I found that
nohup <command> & did not prevent my shell from killing child
processes on exit. Although nohup is useful, especially with non-interactive
shells, it only guarantees this behavior if the child process does not reset its handler for
the SIGHUP signal.
In my case, nohup should have prevented hangup signals from reaching the
application, but the child application (VMWare Player in this case) was resetting its
SIGHUP handler. As a result when the terminal emulator exits, it could still
kill your subprocesses. This can only be resolved, to my knowledge, by ensuring that the
process is removed from the shell's jobs table. If nohup is overridden with a
shell builtin, as is sometimes the case, this may be sufficient, however, in the event that
it is not...
disown is a shell builtin in bash , zsh , and
ksh93 ,
<command> &
disown
or
<command> &; disown
if you prefer one-liners. This has the generally desirable effect of removing the
subprocess from the jobs table. This allows you to exit the terminal emulator without
accidentally signaling the child process at all. No matter what the SIGHUP
handler looks like, this should not kill your child process.
After the disown, the process is still a child of your terminal emulator (play with
pstree if you want to watch this in action), but after the terminal emulator
exits, you should see it attached to the init process. In other words, everything is as it
should be, and as you presumably want it to be.
What to do if your shell does not support disown ? I'd strongly advocate
switching to one that does, but in the absence of that option, you have a few choices.
screen and tmux can solve this problem, but they are much
heavier weight solutions, and I dislike having to run them for such a simple task. They are
much more suitable for situations in which you want to maintain a tty, typically on a
remote machine.
For many users, it may be desirable to see if your shell supports a capability like
zsh's setopt nohup . This can be used to specify that SIGHUP
should not be sent to the jobs in the jobs table when the shell exits. You can either apply
this just before exiting the shell, or add it to shell configuration like
~/.zshrc if you always want it on.
Find a way to edit the jobs table. I couldn't find a way to do this in
tcsh or csh , which is somewhat disturbing.
Write a small C program to fork off and exec() . This is a very poor
solution, but the source should only consist of a couple dozen lines. You can then pass
commands as commandline arguments to the C program, and thus avoid a process specific entry
in the jobs table.
I've been using number 2 for a very long time, but number 3 works just as well. Also,
disown has a 'nohup' flag of '-h', can disown all processes with '-a', and can disown all
running processes with '-ar'.
Silencing is accomplished by '$COMMAND &>/dev/null'.
in tcsh (and maybe in other shells as well), you can use parentheses to detach the process.
Compare this:
> jobs # shows nothing
> firefox &
> jobs
[1] + Running firefox
To this:
> jobs # shows nothing
> (firefox &)
> jobs # still shows nothing
>
This removes firefox from the jobs listing, but it is still tied to the terminal; if you
logged in to this node via 'ssh', trying to log out will still hang the ssh process.
,
To disassociate tty shell run command through sub-shell for e.g.
(command)&
When exit used terminal closed but process is still alive.
Have a look at reptyr ,
which does exactly that. The github page has all the information.
reptyr - A tool for "re-ptying" programs.
reptyr is a utility for taking an existing running program and attaching it to a new
terminal. Started a long-running process over ssh, but have to leave and don't want to
interrupt it? Just start a screen, use reptyr to grab it, and then kill the ssh session
and head on home.
USAGE
reptyr PID
"reptyr PID" will grab the process with id PID and attach it to your current
terminal.
After attaching, the process will take input from and write output to the new
terminal, including ^C and ^Z. (Unfortunately, if you background it, you will still have
to run "bg" or "fg" in the old terminal. This is likely impossible to fix in a reasonable
way without patching your shell.)
EDIT : As Stephane Gimenez said, it's not that simple. It's only allowing you to print to a
different terminal.
You can try to write to this process using /proc . It should be located in
/proc/ pid /fd/0 , so a simple :
echo "hello" > /proc/PID/fd/0
should do it. I have not tried it, but it should work, as long as this process still has a
valid stdin file descriptor. You can check it with ls -l on /proc/ pid
/fd/ .
if it's a link to /dev/null => it's closed
if it's a link to /dev/pts/X or a socket => it's open
See nohup for more
details about how to keep processes running.
Just ending the command line with & will not completely detach the process,
it will just run it in the background. (With zsh you can use &!
to actually detach it, otherwise you have do disown it later).
When a process runs in the background, it won't receive input from its controlling
terminal anymore. But you can send it back into the foreground with fg and then
it will read input again.
Otherwise, it's not possible to externally change its filedescriptors (including stdin) or
to reattach a lost controlling terminal unless you use debugging tools (see Ansgar's answer , or have a
look at the retty command).
Since a few days I'm successfully running the new Minecraft Bedrock Edition dedicated
server on my Ubuntu 18.04 LTS home server. Because it should be available 24/7 and
automatically startup after boot I created a systemd service for a detached tmux session:
Everything works as expected but there's one tiny thing that keeps bugging me:
How can I prevent tmux from terminating it's whole session when I press
Ctrl+C ? I just want to terminate the Minecraft server process itself instead of
the whole tmux session. When starting the server from the command line in a manually
created tmux session this does work (session stays alive) but not when the session was
brought up by systemd .
When starting the server from the command line in a manually created tmux session this
does work (session stays alive) but not when the session was brought up by systemd
.
The difference between these situations is actually unrelated to systemd. In one case,
you're starting the server from a shell within the tmux session, and when the server
terminates, control returns to the shell. In the other case, you're starting the server
directly within the tmux session, and when it terminates there's no shell to return to, so
the tmux session also dies.
tmux has an option to keep the session alive after the process inside it dies (look for
remain-on-exit in the manpage), but that's probably not what you want: you want
to be able to return to an interactive shell, to restart the server, investigate why it died,
or perform maintenance tasks, for example. So it's probably better to change your command to
this:
That is, first run the server, and then, after it terminates, replace the process (the
shell which tmux implicitly spawns to run the command, but which will then exit) with
another, interactive shell. (For some other ways to get an interactive shell after the
command exits, see e. g. this question – but note that the
<(echo commands) syntax suggested in the top answer is not available in
systemd unit files.)
As you know linux implements some type of mechanism
to gracefully shutdown and reboot, this means the daemons are stopping, usually linux stops
them one by one, the file cache is synced to disk.
But what sometimes happens is that the system will not reboot or shutdown no mater how many
times you issue the shutdown or reboot command.
If the server is close to you, you can always just do a physical reset, but what if it's far
away from you, where you can't reach it, sometimes it's not feasible, why if the OpenSSH server
crashes and you cannot log in again in the system.
If you ever find yourself in a situation like that, there is another option to force the
system to reboot or shutdown.
The magic SysRq key is a key combination understood by the Linux kernel, which allows the
user to perform various low-level commands regardless of the system's state. It is often used
to recover from freezes, or to reboot a computer without corrupting the filesystem.
Description
QWERTY
Immediately reboot the system, without unmounting or syncing filesystems
b
Sync all mounted filesystems
s
Shut off the system
o
Send the SIGKILL signal to all processes except init
i
So if you are in a situation where you cannot reboot or shutdown the server, you can force
an immediate reboot by issuing
echo 1 > /proc/sys/kernel/sysrq
echo b > /proc/sysrq-trigger
If you want you can also force a sync before rebooting by issuing these commands
echo 1 > /proc/sys/kernel/sysrq
echo s > /proc/sysrq-trigger
echo b > /proc/sysrq-trigger
These are called magic commands , and they're pretty much
synonymous with holding down Alt-SysRq and another key on older keyboards. Dropping 1 into
/proc/sys/kernel/sysrq tells the kernel that you want to enable SysRq access (it's usually
disabled). The second command is equivalent to pressing * Alt-SysRq-b on a QWERTY
keyboard.
If you want to keep SysRq enabled all the time, you can do that with an entry in your
server's sysctl.conf:
Since I was looking at this
already and had a few things to investigate and fix in our systemd-using hosts, I checked how
plausible it is to insert a molly-guard-like password prompt as part of the reboot/shutdown
process on CentOS 7 (i.e. using systemd).
Problems encountered include:
Asking for a password from a service/unit in systemd -- Use
systemd-ask-password and needs some agent setup to reply to this
correctly?
The reboot command always walls a message to all logged in users before it
even runs the new reboot-molly unit, as it expects a reboot to happen. The argument
--no-wall stops this but that requires a change to the reboot command. Hence
back to the original problem of replacing packaged files/symlinks with RPM
The reboot.target unit is a "systemd.special"
unit, which means that it has some special behaviour and cannot be renamed. We can modify it,
of course, by editing the reboot.target file.
How do we get a systemd unit to run first and block anything later from running until it
is complete? (In fact to abort the reboot but just for this time rather than being set as
permanently failed. Reboot failing is a bit of a strange situation for it to be in ) The
dependencies appear to work but the reboot target is quite keen on running other items from
the dependency list -- I'm more than likely doing something wrong here!
So for now this is shelved. It would be nice to have a solution though, so any hints from
systemd experts are gratefully received!
(Note that CentOS 7 uses systemd 208, so new features in later versions which help won't be
available to us) This entry was posted in Uncategorized by dg12158 . Bookmark the permalink .
molly-guard installs a shell script that overrides the existing
shutdown/reboot/halt/poweroff commands and first runs a set of scripts, which all have to exit
successfully, before molly-guard invokes the real command.
One of the scripts checks for existing SSH sessions. If any of the four commands are called
interactively over an SSH session, the shell script prompts you to enter the name of the host
you wish to shut down. This should adequately prevent you from accidental shutdowns and
reboots.
This shell script passes through the commands to the respective binaries in /sbin and should
thus not get in the way if called non-interactively, or locally.
The tool is basically a replacement for halt, reboot and shutdown to prevent such
accidents.
Now that it's installed, try it out (on a non production box). Here you can see it save me
from rebooting the box Ubuntu-test
Ubuntu-test:~$ sudo reboot
W: molly-guard: SSH session detected!
Please type in hostname of the machine to reboot: ruchi
Good thing I asked; I won't reboot Ubuntu-test ...
W: aborting reboot due to 30-query-hostname exiting with code 1.
Ubuntu-Test:~$
By default you're only protected on sessions that look like SSH sessions (have
$SSH_CONNECTION set). If, like us, you use alot of virtual machines and RILOE cards, edit
/etc/molly-guard/rc and uncomment ALWAYS_QUERY_HOSTNAME=true. Now you should be prompted for
any interactive session.
"... rushing to leave and was still logged into a server so I wanted to shutdown my laptop, but what I didn't notice is that I was still connected to the remote server. ..."
rushing to leave and
was still logged into a server so I wanted to shutdown my laptop, but what I didn't notice is
that I was still connected to the remote server. Luckily before pressing enter I noticed I'm
not on my machine but on a remote server. So I was thinking there should be a very easy way to
prevent it from happening again, to me or to anyone else.
So first thing we need to create a new bash script at /usr/local/bin/confirm with the
contents bellow and with execution permissions
#!/usr/bin/env bash
echo "About to execute $1 command"
echo -n "Would you like to proceed y/n? "
read reply
if [ "$reply" = y -o "$reply" = Y ]
then
$1 "${@:2}"
else
echo "$1 ${@:2} cancelled"
fi
Now only thing left to do is to setup the aliases so they go through this command to confirm
instead of directly calling the command.
So I create the following files
/etc/profile.d/confirm-shutdown.sh
alias shutdown="/usr/local/bin/confirm /sbin/shutdown"
/etc/profile.d/confirm-reboot.sh
alias reboot="/usr/local/bin/confirm /sbin/reboot"
Now when I actually try to do a shutdown/reboot it will prompt me like so.
ilijamt@x1 ~ $ reboot
Before proceeding to perform /sbin/reboot, please ensure you have approval to perform this task
Would you like to proceed y/n? n
/sbin/reboot cancelled
"... While the Tea Party was critical of status-quo neoliberalism -- especially its cosmopolitanism and embrace of globalization and diversity, which was perfectly embodied by Obama's election and presidency -- it was not exactly anti-neoliberal. Rather, it was anti-left neoliberalism-, it represented a more authoritarian, right [wing] version of neoliberalism. ..."
"... Within the context of the 2016 election, Clinton embodied the neoliberal center that could no longer hold. Inequality. Suffering. Collapsing infrastructures. Perpetual war. Anger. Disaffected consent. ..."
"... Both Sanders and Trump were embedded in the emerging left and right responses to neoliberalism's crisis. Specifically, Sanders' energetic campaign -- which was undoubtedly enabled by the rise of the Occupy movement -- proposed a decidedly more "commongood" path. Higher wages for working people. Taxes on the rich, specifically the captains of the creditocracy. ..."
"... In other words, Trump supporters may not have explicitly voted for neoliberalism, but that's what they got. In fact, as Rottenberg argues, they got a version of right neoliberalism "on steroids" -- a mix of blatant plutocracy and authoritarianism that has many concerned about the rise of U.S. fascism. ..."
"... We can't know what would have happened had Sanders run against Trump, but we can think seriously about Trump, right and left neoliberalism, and the crisis of neoliberal hegemony. In other words, we can think about where and how we go from here. As I suggested in the previous chapter, if we want to construct a new world, we are going to have to abandon the entangled politics of both right and left neoliberalism; we have to reject the hegemonic frontiers of both disposability and marketized equality. After all, as political philosopher Nancy Fraser argues, what was rejected in the election of 2016 was progressive, left neoliberalism. ..."
"... While the rise of hyper-right neoliberalism is certainly nothing to celebrate, it does present an opportunity for breaking with neoliberal hegemony. We have to proceed, as Gary Younge reminds us, with the realization that people "have not rejected the chance of a better world. They have not yet been offered one."' ..."
In Chapter 1, we traced the rise of our neoliberal conjuncture back to the crisis of liberalism during the late nineteenth and
early twentieth centuries, culminating in the Great Depression. During this period, huge transformations in capitalism proved impossible
to manage with classical laissez-faire approaches. Out of this crisis, two movements emerged, both of which would eventually shape
the course of the twentieth century and beyond. The first, and the one that became dominant in the aftermath of the crisis, was the
conjuncture of embedded liberalism. The crisis indicated that capitalism wrecked too much damage on the lives of ordinary citizens.
People (white workers and families, especially) warranted social protection from the volatilities and brutalities of capitalism.
The state's public function was expanded to include the provision of a more substantive social safety net, a web of protections for
people and a web of constraints on markets. The second response was the invention of neoliberalism. Deeply skeptical of the common-good
principles that undergirded the emerging social welfare state, neoliberals began organizing on the ground to develop a "new" liberal
govemmentality, one rooted less in laissez-faire principles and more in the generalization of competition and enterprise. They worked
to envision a new society premised on a new social ontology, that is, on new truths about the state, the market, and human beings.
Crucially, neoliberals also began building infrastructures and institutions for disseminating their new' knowledges and theories
(i.e., the Neoliberal Thought Collective), as well as organizing politically to build mass support for new policies (i.e., working
to unite anti-communists, Christian conservatives, and free marketers in common cause against the welfare state). When cracks in
embedded liberalism began to surface -- which is bound to happen with any moving political equilibrium -- neoliberals were there
with new stories and solutions, ready to make the world anew.
We are currently living through the crisis of neoliberalism. As I write this book, Donald Trump has recently secured the U.S.
presidency, prevailing in the national election over his Democratic opponent Hillary Clinton. Throughout the election, I couldn't
help but think back to the crisis of liberalism and the two responses that emerged. Similarly, after the Great Recession of 2008,
we've saw two responses emerge to challenge our unworkable status quo, which dispossesses so many people of vital resources for individual
and collective life. On the one hand, we witnessed the rise of Occupy Wall Street. While many continue to critique the movement for
its lack of leadership and a coherent political vision, Occupy was connected to burgeoning movements across the globe, and our current
political horizons have been undoubtedly shaped by the movement's success at repositioning class and economic inequality within our
political horizon. On the other hand, we saw' the rise of the Tea Party, a right-wing response to the crisis. While the Tea Party
was critical of status-quo neoliberalism -- especially its cosmopolitanism and embrace of globalization and diversity, which was
perfectly embodied by Obama's election and presidency -- it was not exactly anti-neoliberal. Rather, it was anti-left neoliberalism-,
it represented a more authoritarian, right [wing] version of neoliberalism.
Within the context of the 2016 election, Clinton embodied the neoliberal center that could no longer hold. Inequality. Suffering.
Collapsing infrastructures. Perpetual war. Anger. Disaffected consent. There were just too many fissures and fault lines in
the glossy, cosmopolitan world of left neoliberalism and marketized equality. Indeed, while Clinton ran on status-quo stories of
good governance and neoliberal feminism, confident that demographics and diversity would be enough to win the election, Trump effectively
tapped into the unfolding conjunctural crisis by exacerbating the cracks in the system of marketized equality, channeling political
anger into his celebrity brand that had been built on saying "f*** you" to the culture of left neoliberalism (corporate diversity,
political correctness, etc.) In fact, much like Clinton's challenger in the Democratic primary, Benie Sanders, Trump was a crisis
candidate.
Both Sanders and Trump were embedded in the emerging left and right responses to neoliberalism's crisis. Specifically, Sanders'
energetic campaign -- which was undoubtedly enabled by the rise of the Occupy movement -- proposed a decidedly more "commongood"
path. Higher wages for working people. Taxes on the rich, specifically the captains of the creditocracy.
Universal health care. Free higher education. Fair trade. The repeal of Citizens United. Trump offered a different response to
the crisis. Like Sanders, he railed against global trade deals like NAFTA and the Trans-Pacific Partnership (TPP). However, Trump's
victory was fueled by right neoliberalism's culture of cruelty. While Sanders tapped into and mobilized desires for a more egalitarian
and democratic future, Trump's promise was nostalgic, making America "great again" -- putting the nation back on "top of the world,"
and implying a time when women were "in their place" as male property, and minorities and immigrants were controlled by the state.
Thus, what distinguished Trump's campaign from more traditional Republican campaigns was that it actively and explicitly pitted
one group's equality (white men) against everyone else's (immigrants, women, Muslims, minorities, etc.). As Catherine Rottenberg
suggests, Trump offered voters a choice between a multiracial society (where folks are increasingly disadvantaged and dispossessed)
and white supremacy (where white people would be back on top). However, "[w]hat he neglected to state," Rottenberg writes,
is that neoliberalism flourishes in societies where the playing field is already stacked against various segments of society,
and that it needs only a relatively small select group of capital-enhancing subjects, while everyone else is ultimately dispensable.
1
In other words, Trump supporters may not have explicitly voted for neoliberalism, but that's what they got. In fact, as Rottenberg
argues, they got a version of right neoliberalism "on steroids" -- a mix of blatant plutocracy and authoritarianism that has many
concerned about the rise of U.S. fascism.
We can't know what would have happened had Sanders run against Trump, but we can think seriously about Trump, right and left
neoliberalism, and the crisis of neoliberal hegemony. In other words, we can think about where and how we go from here. As I suggested
in the previous chapter, if we want to construct a new world, we are going to have to abandon the entangled politics of both right
and left neoliberalism; we have to reject the hegemonic frontiers of both disposability and marketized equality. After all, as political
philosopher Nancy Fraser argues, what was rejected in the election of 2016 was progressive, left neoliberalism.
While the rise of hyper-right neoliberalism is certainly nothing to celebrate, it does present an opportunity for breaking
with neoliberal hegemony. We have to proceed, as Gary Younge reminds us, with the realization that people "have not rejected the
chance of a better world. They have not yet been offered one."'
Mark Fisher, the author of Capitalist Realism, put it this way:
The long, dark night of the end of history has to be grasped as an enormous opportunity. The very oppressive pervasiveness
of capitalist realism means that even glimmers of alternative political and economic possibilities can have a disproportionately
great effect. The tiniest event can tear a hole in the grey curtain of reaction which has marked the horizons of possibility under
capitalist realism. From a situation in which nothing can happen, suddenly anything is possible again.4
I think that, for the first time in the history of U.S. capitalism, the vast majority of people might sense the lie of liberal,
capitalist democracy. They feel anxious, unfree, disaffected. Fantasies of the good life have been shattered beyond repair for most
people. Trump and this hopefully brief triumph of right neoliberalism will soon lay this bare for everyone to see. Now, with Trump,
it is absolutely clear: the rich rule the world; we are all disposable; this is no democracy. The question becomes: How will we show
up for history? Will there be new stories, ideas, visions, and fantasies to attach to? How can we productively and meaningful intervene
in the crisis of neoliberalism? How can we "tear a hole in the grey curtain" and open up better worlds? How can we put what we've
learned to use and begin to imagine and build a world beyond living in competition? I hope our critical journey through the neoliberal
conjuncture has enabled you to begin to answer these questions.
More specifically, in recent decades, especially since the end of the Cold War, our common-good sensibilities have been channeled
into neoliberal platforms for social change and privatized action, funneling our political energies into brand culture and marketized
struggles for equality (e.g., charter schools, NGOs and non-profits, neoliberal antiracism and feminism). As a result, despite our
collective anger and disaffected consent, we find ourselves stuck in capitalist realism with no real alternative. Like the neoliberal
care of the self, we are trapped in a privatized mode of politics that relies on cruel optimism; we are attached, it seems, to politics
that inspire and motivate us to action, while keeping us living in competition.
To disrupt the game, we need to construct common political horizons against neoliberal hegemony. We need to use our common stories
and common reason to build common movements against precarity -- for within neoliberalism, precarity is what ultimately has the potential
to thread all of our lives together. Put differently, the ultimate fault line in the neoliberal conjiuicture is the way it subjects
us all to precarity and the biopolitics of disposability, thereby creating conditions of possibility for new coalitions across race,
gender, citizenship, sexuality, and class. Recognizing this potential for coalition in the face of precarization is the most pressing
task facing those who are yearning for a new world. The question is: How do we get there? How do we realize these coalitional potentialities
and materialize common horizons?
Ultimately, mapping the neoliberal conjuncture through everyday life in enterprise culture has not only provided some direction
in terms of what we need; it has also cultivated concrete and practical intellectual resources for political interv ention and social
interconnection -- a critical toolbox for living in common. More specifically, this book has sought to provide resources for thinking
and acting against the four Ds: resources for engaging in counter-conduct, modes of living that refuse, on one hand, to conduct one's
life according to the norm of enterprise, and on the other, to relate to others through the norm of competition. Indeed, we need
new ways of relating, interacting, and living as friends, lovers, workers, vulnerable bodies, and democratic people if we are to
write new stories, invent new govemmentalities, and build coalitions for new worlds.
Against Disimagination: Educated Hope and Affirmative Speculation
We need to stop turning inward, retreating into ourselves, and taking personal responsibility for our lives (a task which is ultimately
impossible). Enough with the disimagination machine! Let's start looking outward, not inward -- to the broader structures that undergird
our lives. Of course, we need to take care of ourselves; we must survive. But I firmly believe that we can do this in ways both big
and small, that transform neoliberal culture and its status-quo stories.
Here's the thing I tell my students all the time. You cannot escape neoliberalism. It is the air we breathe, the water in which
we swim. No job, practice of social activism, program of self-care, or relationship will be totally free from neoliberal impingements
and logics. There is no pure "outside" to get to or work from -- that's just the nature of the neoliberalism's totalizing cultural
power. But let's not forget that neoliberalism's totalizing cultural power is also a source of weakness. Potential for resistance
is everywhere, scattered throughout our everyday lives in enterprise culture. Our critical toolbox can help us identify these potentialities
and navigate and engage our conjuncture in ways that tear open up those new worlds we desire.
In other words, our critical perspective can help us move through the world with what Henry Giroux calls educated hope. Educated
hope means holding in tension the material realities of power and the contingency of history. This orientation of educated hope knows
very well what we're up against. However, in the face of seemingly totalizing power, it also knows that neoliberalism can never become
total because the future is open. Educated hope is what allows us to see the fault lines, fissures, and potentialities of the present
and emboldens us to think and work from that sliver of social space where we do have political agency and freedom to construct a
new world. Educated hope is what undoes the power of capitalist realism. It enables affirmative speculation (such as discussed in
Chapter 5), which does not try to hold the future to neoliberal horizons (that's cruel optimism!), but instead to affirm our commonalities
and the potentialities for the new worlds they signal. Affirmative speculation demands a different sort of risk calculation and management.
It senses how little we have to lose and how much we have to gain from knocking the hustle of our lives.
Against De-democratization: Organizing and Collective Coverning
We can think of educated hope and affirmative speculation as practices of what Wendy Brown calls "bare democracy" -- the basic
idea that ordinary' people like you and me should govern our lives in common, that we should critique and try to change our world,
especially the exploitative and oppressive structures of power that maintain social hierarchies and diminish lives. Neoliberal culture
works to stomp out capacities for bare democracy by transforming democratic desires and feelings into meritocratic desires and feelings.
In neoliberal culture, utopian sensibilities are directed away from the promise of collective utopian sensibilities are directed
away from the promise of collective governing to competing for equality.
We have to get back that democractic feeling! As Jeremy Gilbert taught us, disaffected consent is a post-democratic orientation.
We don't like our world, but we don't think we can do anything about it. So, how do we get back that democratic feeling? How do we
transform our disaffected consent into something new? As I suggested in the last chapter, we organize. Organizing is simply about
people coming together around a common horizon and working collectively to materialize it. In this way, organizing is based on the
idea of radical democracy, not liberal democracy. While the latter is based on formal and abstract rights guaranteed by the state,
radical democracy insists that people should directly make the decisions that impact their lives, security, and well-being. Radical
democracy is a practice of collective governing: it is about us hashing out, together in communities, what matters, and working in
common to build a world based on these new sensibilities.
The work of organizing is messy, often unsatisfying, and sometimes even scary. Organizing based on affirmative speculation and
coalition-building, furthermore, will have to be experimental and uncertain. As Lauren Berlant suggests, it means "embracing the
discomfort of affective experience in a truly open social life that no
one has ever experienced." Organizing through and for the common "requires more adaptable infrastructures. Keep forcing the existing
infrastructures to do what they don't know how to do. Make new ways to be local together, where local doesn't require a physical
neighborhood." 5 What Berlant is saying is that the work of bare democracy requires unlearning, and detaching from, our
current stories and infrastructures in order to see and make things work differently. Organizing for a new world is not easy -- and
there are no guarantees -- but it is the only way out of capitalist realism.
Getting back democratic feeling will at once require and help us lo move beyond the biopolitics of disposability and entrenched
systems of inequality. On one hand, organizing will never be enough if it is not animated by bare democracy, a sensibility that each
of us is equally important when it comes to the project of determining our lives in common. Our bodies, our hurts, our dreams, and
our desires matter regardless of our race, gender, sexuality, or citizenship, and regardless of how r much capital (economic,
social, or cultural) we have. Simply put, in a radical democracy, no one is disposable. This bare-democratic sense of equality must
be foundational to organizing and coalition-building. Otherwise, we will always and inevitably fall back into a world of inequality.
On the other hand, organizing and collective governing will deepen and enhance our sensibilities and capacities for radical equality.
In this context, the kind of self-enclosed individualism that empowers and underwrites the biopolitics of disposability melts away,
as we realize the interconnectedness of our lives and just how amazing it feels to
fail, we affirm our capacities for freedom, political intervention, social interconnection, and collective social doing.
Against Dispossession: Shared Security and Common Wealth
Thinking and acting against the biopolitics of disposability goes hand-in-hand with thinking and acting against dispossession.
Ultimately, when we really understand and feel ourselves in relationships of interconnection with others, we want for them as we
want for ourselves. Our lives and sensibilities of what is good and just are rooted in radical equality, not possessive or self-appreciating
individualism. Because we desire social security and protection, we also know others desire and deserve the same.
However, to really think and act against dispossession means not only advocating for shared security and social protection, but
also for a new society that is built on the egalitarian production and distribution of social wealth that we all produce. In this
sense, we can take Marx's critique of capitalism -- that wealth is produced collectively but appropriated individually -- to heart.
Capitalism was built on the idea that one class -- the owners of the means of production -- could exploit and profit from the collective
labors of everyone else (those who do not own and thus have to work), albeit in very different ways depending on race, gender, or
citizenship. This meant that, for workers of all stripes, their lives existed not for themselves, but for others (the appropriating
class), and that regardless of what we own as consumers, we are not really free or equal in that bare-democratic sense of the word.
If we want to be really free, we need to construct new material and affective social infrastructures for our common wealth. In
these new infrastructures, wealth must not be reduced to economic value; it must be rooted in social value. Here, the production
of wealth does not exist as a separate sphere from the reproduction of our lives. In other words, new infrastructures, based on the
idea of common wealth, will not be set up to exploit our labor, dispossess our communities, or to divide our lives. Rather, they
will work to provide collective social resources and care so that we may all be free to pursue happiness, create beautiful and/or
useful things, and to realize our potential within a social world of living in common. Crucially, to create the conditions for these
new, democratic forms of freedom rooted in radical equality, we need to find ways to refuse and exit the financial networks of Empire
and the dispossessions of creditocracy, building new systems that invite everyone to participate in the ongoing production of new
worlds and the sharing of the wealth that we produce in common.
It's not up to me to tell you exactly where to look, but I assure you that potentialities for these new worlds are everywhere
around you.
rm is a powerful *nix tool that simply drops a file from the drive index. It
doesn't delete it or put it in a Trash can, it just de-indexes it which makes the file hard to
recover unless you want to put in the work, and pretty easy to recover if you are willing to
spend a few hours trying (use shred to actually secure erase files).
careful_rm.py is inspired by the -I interactive mode of
rm and by safe-rm . safe-rm adds a recycle
bin mode to rm, and the -I interactive mode adds a prompt if you delete more than
a handful of files or recursively delete a directory. ZSH also has an option to
warn you if you recursively rm a directory.
These are all great, but I found them unsatisfying. What I want is for rm to be quick and
not bother me for single file deletions (so rm -i is out), but to let me know when
I am deleting a lot of files, and to actually print a list of files that are about to be
deleted . I also want it to have the option to trash/recycle my files instead of just
straight deleting them.... like safe-rm , but not so intrusive (safe-rm defaults
to recycle, and doesn't warn).
careful_rm.py is fundamentally a simple rm wrapper, that accepts
all of the same commands as rm , but with a few additional options features. In
the source code CUTOFF is set to 3 , so deleting more files than that will prompt
the user. Also, deleting a directory will prompt the user separately with a count of all files
and subdirectories within the folders to be deleted.
Furthermore, careful_rm.py implements a fully integrated trash mode that can be
toggled on with -c . It can also be forced on by adding a file at
~/.rm_recycle , or toggled on only for $HOME (the best idea), by
~/.rm_recycle_home . The mode can be disabled on the fly by passing
--direct , which forces off recycle mode.
The recycle mode tries to find the best location to recycle to on MacOS or Linux, on MacOS
it also tries to use Apple Script to trash files, which means the original location is
preserved (note Applescript can be slow, you can disable it by adding a
~/.no_apple_rm file, but Put Back won't work). The best location for
trashes goes in this order:
$HOME/.Trash on Mac or $HOME/.local/share/Trash on Linux
<mountpoint>/.Trashes on Mac or
<mountpoint>/.Trash-$UID on Linux
/tmp/$USER_trash
Always the best trash can to avoid Volume hopping is favored, as moving across file systems
is slow. If the trash does not exist, the user is prompted to create it, they then also have
the option to fall back to the root trash ( /tmp/$USER_trash ) or just
rm the files.
/tmp/$USER_trash is almost always used for deleting system/root files, but note
that you most likely do not want to save those files, and straight rm is generally
better.
The rm='rm -i' alias is an horror because after a while using it, you will
expect rm to prompt you by default before removing files. Of course, one day
you'll run it with an account that hasn't that alias set and before you understand what's going
on, it is too late.
... ... ...
If you want save aliases, but don't want to risk getting used to the commands working
differently on your system than on others, you can to disable rm like this
alias rm='echo "rm is disabled, use remove or trash or /bin/rm instead."'
Trash-cli package provides a command line interface trashcan utility compliant with the
FreeDesktop.org Trash Specification. It remembers the name, original path, deletion date,
and permissions of each trashed file.
ARGUMENTS
Names of files or directory to move in the trashcan.
EXAMPLES
$ cd /home/andrea/
$ touch foo bar
$ trash foo bar
BUGS
Report bugs to http://code.google.com/p/trash-cli/issues
trash-list(1), trash-restore(1), trash-empty(1), and the FreeDesktop.org Trash
Specification at http://www.ramendik.ru/docs/trashspec.html.
Both are released under the GNU General Public License, version 2 or later.
By Alvin Alexander. Last updated: June 22 2017 Unix/Linux bash shell script FAQ: How do I
prompt a user for input from a shell script (Bash shell script), and then read the input the
user provides?
Answer: I usually use the shell script read function to read input from a shell
script. Here are two slightly different versions of the same shell script. This first version
prompts the user for input only once, and then dies if the user doesn't give a correct Y/N
answer:
# (1) prompt user, and read command line argument
read -p "Run the cron script now? " answer
# (2) handle the command line argument we were given
while true
do
case $answer in
[yY]* ) /usr/bin/wget -O - -q -t 1 http://www.example.com/cron.php
echo "Okay, just ran the cron script."
break;;
[nN]* ) exit;;
* ) echo "Dude, just enter Y or N, please."; break ;;
esac
done
This second version stays in a loop until the user supplies a Y/N answer:
while true
do
# (1) prompt user, and read command line argument
read -p "Run the cron script now? " answer
# (2) handle the input we were given
case $answer in
[yY]* ) /usr/bin/wget -O - -q -t 1 http://www.example.com/cron.php
echo "Okay, just ran the cron script."
break;;
[nN]* ) exit;;
* ) echo "Dude, just enter Y or N, please.";;
esac
done
I prefer the second approach, but I thought I'd share both of them here. They are subtly
different, so not the extra break in the first script.
This Linux Bash 'read' function is nice, because it does both things, prompting the user for
input, and then reading the input. The other nice thing it does is leave the cursor at the end
of your prompt, as shown here:
Run the cron script now? _
(This is so much nicer than what I had to do years ago.)
It is unclear how long this vulnerability exists, but this is pretty serious staff that shows
how Hillary server could be hacked via Abedin account. As Abedin technical level was lower then
zero, to hack into her home laptop just just trivial.
Microsoft also patched
Exchange against a vulnerability that allowed remote attackers with little more than an
unprivileged mailbox account to gain administrative control over the server. Dubbed
PrivExchange, CVE-2019-0686 was publicly disclosed last month , along with
proof-of-concept code that exploited it. In Tuesday's
advisory , Microsoft officials said they haven't seen active exploits yet but that they
were "likely."
I am trying to backup my file server to a remove file server using rsync. Rsync is not successfully resuming when a transfer is
interrupted. I used the partial option but rsync doesn't find the file it already started because it renames it to a temporary
file and when resumed it creates a new file and starts from beginning.
When this command is ran, a backup file named OldDisk.dmg from my local machine get created on the remote machine as something
like .OldDisk.dmg.SjDndj23 .
Now when the internet connection gets interrupted and I have to resume the transfer, I have to find where rsync left off by
finding the temp file like .OldDisk.dmg.SjDndj23 and rename it to OldDisk.dmg so that it sees there already exists a file that
it can resume.
How do I fix this so I don't have to manually intervene each time?
TL;DR : Use --timeout=X (X in seconds) to change the default rsync server timeout, not --inplace .
The issue is the rsync server processes (of which there are two, see rsync --server ... in ps output
on the receiver) continue running, to wait for the rsync client to send data.
If the rsync server processes do not receive data for a sufficient time, they will indeed timeout, self-terminate and cleanup
by moving the temporary file to it's "proper" name (e.g., no temporary suffix). You'll then be able to resume.
If you don't want to wait for the long default timeout to cause the rsync server to self-terminate, then when your internet
connection returns, log into the server and clean up the rsync server processes manually. However, you
must politely terminate rsync -- otherwise,
it will not move the partial file into place; but rather, delete it (and thus there is no file to resume). To politely ask rsync
to terminate, do not SIGKILL (e.g., -9 ), but SIGTERM (e.g., pkill -TERM -x rsync
- only an example, you should take care to match only the rsync processes concerned with your client).
Fortunately there is an easier way: use the --timeout=X (X in seconds) option; it is passed to the rsync server
processes as well.
For example, if you specify rsync ... --timeout=15 ... , both the client and server rsync processes will cleanly
exit if they do not send/receive data in 15 seconds. On the server, this means moving the temporary file into position, ready
for resuming.
I'm not sure of the default timeout value of the various rsync processes will try to send/receive data before they die (it
might vary with operating system). In my testing, the server rsync processes remain running longer than the local client. On a
"dead" network connection, the client terminates with a broken pipe (e.g., no network socket) after about 30 seconds; you could
experiment or review the source code. Meaning, you could try to "ride out" the bad internet connection for 15-20 seconds.
If you do not clean up the server rsync processes (or wait for them to die), but instead immediately launch another rsync client
process, two additional server processes will launch (for the other end of your new client process). Specifically, the new rsync
client will not re-use/reconnect to the existing rsync server processes. Thus, you'll have two temporary files (and four rsync
server processes) -- though, only the newer, second temporary file has new data being written (received from your new rsync client
process).
Interestingly, if you then clean up all rsync server processes (for example, stop your client which will stop the new rsync
servers, then SIGTERM the older rsync servers, it appears to merge (assemble) all the partial files into the new
proper named file. So, imagine a long running partial copy which dies (and you think you've "lost" all the copied data), and a
short running re-launched rsync (oops!).. you can stop the second client, SIGTERM the first servers, it will merge
the data, and you can resume.
Finally, a few short remarks:
Don't use --inplace to workaround this. You will undoubtedly have other problems as a result, man rsync
for the details.
It's trivial, but -t in your rsync options is redundant, it is implied by -a .
An already compressed disk image sent over rsync without compression might result in shorter transfer time (by
avoiding double compression). However, I'm unsure of the compression techniques in both cases. I'd test it.
As far as I understand --checksum / -c , it won't help you in this case. It affects how rsync
decides if it should transfer a file. Though, after a first rsync completes, you could run a second rsync
with -c to insist on checksums, to prevent the strange case that file size and modtime are the same on both sides,
but bad data was written.
I didn't test how the server-side rsync handles SIGINT, so I'm not sure it will keep the partial file - you could check. Note
that this doesn't have much to do with Ctrl-c ; it happens that your terminal sends SIGINT to the foreground
process when you press Ctrl-c , but the server-side rsync has no controlling terminal. You must log in to the server
and use kill . The client-side rsync will not send a message to the server (for example, after the client receives
SIGINT via your terminal Ctrl-c ) - might be interesting though. As for anthropomorphizing, not sure
what's "politer". :-) – Richard Michael
Dec 29 '13 at 22:34
I just tried this timeout argument rsync -av --delete --progress --stats --human-readable --checksum --timeout=60 --partial-dir
/tmp/rsync/ rsync://$remote:/ /src/ but then it timed out during the "receiving file list" phase (which in this case takes
around 30 minutes). Setting the timeout to half an hour so kind of defers the purpose. Any workaround for this? –
d-b
Feb 3 '15 at 8:48
@user23122 --checksum reads all data when preparing the file list, which is great for many small files that change
often, but should be done on-demand for large files. –
Cees Timmerman
Sep 15 '15 at 17:10
prsync is a program for copying files in parallel to a number of hosts using the popular
rsync program. It provides features such as passing a password to ssh, saving output to files,
and timing out.
Read hosts from the given host_file . Lines in the host file are of the form [
user @] host [: port ] and can include blank lines and comments (lines
beginning with "#"). If multiple host files are given (the -h option is used more than once), then prsync
behaves as though these files were concatenated together. If a host is specified multiple
times, then prsync will connect the given number of times.
Save standard output to files in the given directory. Filenames are of the form [
user @] host [: port ][. num ] where the user and port are only
included for hosts that explicitly specify them. The number is a counter that is incremented
each time for hosts that are specified more than once.
Passes extra rsync command-line arguments (see the rsync(1) man page for more information about rsync
arguments). This option may be specified multiple times. The arguments are processed to split
on whitespace, protect text within quotes, and escape with backslashes. To pass arguments
without such processing, use the -X option instead.
Passes a single rsync command-line argument (see the rsync(1) man page for more information about rsync
arguments). Unlike the -x
option, no processing is performed on the argument, including word splitting. To pass
multiple command-line arguments, use the option once for each argument.
SSH options in the format used in the SSH configuration file (see the ssh_config(5) man page for more information).
This option may be specified multiple times.
Prompt for a password and pass it to ssh. The password may be used for either to unlock a
key or for password authentication. The password is transferred in a fairly secure manner
(e.g., it will not show up in argument lists). However, be aware that a root user on your
system could potentially intercept the password.
Passes extra SSH command-line arguments (see the ssh(1) man page for more information about SSH
arguments). The given value is appended to the ssh command (rsync's -e option) without any processing.
The ssh_config file can include an arbitrary number of Host sections. Each host entry
specifies ssh options which apply only to the given host. Host definitions can even behave like
aliases if the HostName option is included. This ssh feature, in combination with pssh host
files, provides a tremendous amount of flexibility.
Nagios is an opensource software used for network and infrastructure monitoring . Nagios
will monitor servers, switches, applications and services . It alerts the System Administrator
when something went wrong and also alerts back when the issues has been rectified.
View also: How to Enable EPEL Repository for RHEL/CentOS 6/5
yum install nagios nagios-devel nagios-plugins* gd gd-devel httpd php gcc glibc
glibc-common
Bydefualt on doing yum install nagios, in cgi.cfg file, authorized user name nagiosadmin is
mentioned and for htpasswd file /etc/nagios/passwd file is used.So for easy steps I am using
the same name.
# htpasswd -c /etc/nagios/passwd nagiosadmin
Check the below given values in /etc/nagios/cgi.cfg
nano /etc/nagios/cgi.cfg
# AUTHENTICATION USAGE
use_authentication=1
# SYSTEM/PROCESS INFORMATION ACCESS
authorized_for_system_information=nagiosadmin
# CONFIGURATION INFORMATION ACCESS
authorized_for_configuration_information=nagiosadmin
# SYSTEM/PROCESS COMMAND ACCESS
authorized_for_system_commands=nagiosadmin
# GLOBAL HOST/SERVICE VIEW ACCESS
authorized_for_all_services=nagiosadmin
authorized_for_all_hosts=nagiosadmin
# GLOBAL HOST/SERVICE COMMAND ACCESS
authorized_for_all_service_commands=nagiosadmin
authorized_for_all_host_commands=nagiosadmin
For provoding the access to nagiosadmin user in http, /etc/httpd/conf.d/nagios.conf file
exist. Below is the nagios.conf configuration for nagios server.
cat /etc/http/conf.d/nagios.conf
# SAMPLE CONFIG SNIPPETS FOR APACHE WEB SERVER
# Last Modified: 11-26-2005
#
# This file contains examples of entries that need
# to be incorporated into your Apache web server
# configuration file. Customize the paths, etc. as
# needed to fit your system.
ScriptAlias /nagios/cgi-bin/ "/usr/lib/nagios/cgi-bin/"
# SSLRequireSSL
Options ExecCGI
AllowOverride None
Order allow,deny
Allow from all
# Order deny,allow
# Deny from all
# Allow from 127.0.0.1
AuthName "Nagios Access"
AuthType Basic
AuthUserFile /etc/nagios/passwd
Require valid-user
Alias /nagios "/usr/share/nagios/html"
# SSLRequireSSL
Options None
AllowOverride None
Order allow,deny
Allow from all
# Order deny,allow
# Deny from all
Allow from 127.0.0.1
AuthName "Nagios Access"
AuthType Basic
AuthUserFile /etc/nagios/passwd
Require valid-user
Start the httpd and nagios /etc/init.d/httpd start /etc/init.d/nagios start [warn]Note:
SELINUX and IPTABLE are disabled.[/warn] Access the nagios server by
http://nagios_server_ip-address/nagios Give the username = nagiosadmin and password which you
have given to nagiosadmin user.
In theory, you could reduce the size of sda1, increase the size of the extended partition, shift the contents
of the extended partition down, then increase the size of the PV on the extended partition and you'd have the extra
room.
However, the number of possible things that can go wrong there is just astronomical
So I'd recommend either buying a second
hard drive (and possibly transferring everything onto it in a more sensible layout, then repartitioning your current drive better)
or just making some bind mounts of various bits and pieces out of /home into / to free up a bit more space.
Last modified
2
years ago Integration mc with mc2(Lua)
Description I think that it is necessary that code base mc and mc2 correspond
each other. mooffie? can you check that patches from andrew_b easy merged with mc2 and if some
patch conflict with mc2 code hold this changes by writing about in corresponding ticket.
zaytsev can you help automate this( continues integration, travis and so on). Sorry, but some
words in Russian:
Ребята, я не
пытаюсь давать
ЦУ, Вы делаете
классную
работу. Просто
яхотел
обратить
внимание, что
Муфья пытается
поддерживать
свой код в
актуальном
состоянии, но
видя как у него
возникают
проблемы на
ровном месте
боюсь
энтузиазм у
него может
пропасть.
I have asked what plans does mooffie have for mc 2 sometime ago and never got an
answer. Note that I totally don't blame him for that. Everyone here is working at their own
pace. Sometimes I disappear for weeks or months, because I can't get a spare 5 minutes not even
speaking of several hours due to the non-mc related workload. I hope that one day we'll figure
out the way towards merging it, and eventually get it done.
In the mean time, he's working together with us by offering extremely important and
well-prepared contributions, which are a pleasure to deal with and we are integrating them as
fast as we can, so it's not like we are at war and not talking to each other.
Anyways, creating random noise in the ticket tracking system will not help to advance your
cause. The only way to influence the process is to invest serious amount of time in the
development.
Asked whether they have confidence in CEO Sundar Pichai and his management team to
"effectively lead in the future," 74 percent of employees responded "positive," as opposed to
"neutral" or "negative," in late 2018, down from 92 percent "positive" the year before. The
18-point drop left employee confidence at its lowest point in at least six years. The results
of the survey, known internally as Googlegeist, also showed a decline in employees'
satisfaction with their compensation, with 54 percent saying they were satisfied, compared with
64 percent the prior year.
The drop in employee sentiment helps explain why internal debate around compensation, pay
equity, and trust in executives has heated up in recent weeks -- and why an HR presentation
from 2016 went viral inside the company three years later.
The presentation, first reported by Bloomberg and
reviewed by WIRED, dates from July 2016, about a year after Google started an internal effort
to curb
spending . In the slide deck, Google's human-resources department presents potential ways
to cut the company's $20 billion compensation budget. Ideas include: promoting fewer people,
hiring proportionately more low-level employees, and conducting an audit to make sure Google is
paying benefits "(only) for the right people." In some cases, HR suggested ways to implement
changes while drawing little attention, or tips on how to sell the changes to Google employees.
Some of the suggestions were implemented, like eliminating the annual employee holiday gift;
most were not.
Another, more radical proposal floated inside the company around the same time didn't appear
in the deck. That suggested converting some full-time employees to contractors to save money. A
person familiar with the situation said this proposal was not implemented. In July,
Bloomberg
reported that, for the first time, more than 50 percent of Google's workforce were temps,
contractors, and vendors.
Unlike most monitoring tools that either focus on a small set of statistics, format their
output in only one way, run either interactively or as a daemon but not both, collectl tries to
do it all. You can choose to monitor any of a broad set of subsystems which currently include
buddyinfo, cpu, disk, inodes, InfiniBand, lustre, memory, network, nfs, processes, quadrics,
slabs, sockets and tcp.
Installing collectl
The collectl community project is maintained at http://collectl.sourceforge.net/ as well as provided in
the Fedora community project. For Red Hat Enterprise Linux 6 and 7, the easiest way to install
collectl is via the EPEL repositories (Extra Packages for Enterprise Linux) maintained by the
Fedora community.
Once set up, collectl can be installed with the following command:
# yum install collectl
The packages are also available for direct download using the following links:
The collectl utility can be run manually via the command line or as a service. Data will be
logged to /var/log/collectl/*.raw.gz . The logs will be rotated every 24 hours by default. To
run as a service:
# chkconfig collectl on # [optional, to start at boot time]
# service collectl start
Sample Intervals
When run manually from the command line, the first Interval value is 1 . When running as a
service, default sample intervals are as show below. It might sometimes be desired to lower
these to avoid averaging, such as 1,30,60.
Using collectl to troubleshoot disk or SAN storage performance
The defaults of 10s for all but process data which is collected at 60s intervals are best
left as is, even for storage performance analysis.
The SAR Equivalence
Matrix shows common SAR command equivalents to help experienced SAR users learn to use
Collectl. The following example command will view summary detail of the CPU, Network and Disk
from the file /var/log/collectl/HOSTNAME-20190116-164506.raw.gz :
These generate summary, which is the total of ALL data for a particular type
b - buddy info (memory fragmentationc cpu
d - disk
f - nfs
i - inodes
j - interrupts by CPU
l - lustre
m - memory
n - network
s - sockets
t - tcp
x – Interconnect
y – Slabs (system object caches)
These generate detail data, typically but not limited to the device level
C - individual CPUs, including interrupts if sj or sJ
D - individual Disks
E - environmental (fan, power, temp) [requires ipmitool]
F - nfs data
J - interrupts by CPU by interrupt number
L - lustre
M - memory numa/node
N - individual Networks
T - tcp details (lots of data!)
X - interconnect ports/rails (Infiniband/Quadrics)
Y - slabs/slubs
Z - processes
The most useful switches are listed here
-sD detailed disk data
-sC detailed CPU data
-sN detailed network data
-sZ detailed process data
Final Thoughts
Performance Co-Pilot (PCP) is the preferred tool for collecting comprehensive performance
metrics for performance analysis and troubleshooting. It is shipped and supported in Red Hat
Enterprise Linux 6 & 7 and is the preferred recommendation over Collectl or Sar/Sysstat. It
also includes conversion tools between its own performance data and Collectl &
Sar/Syststat.
"... I think some of the design details are insane (I dislike the binary logs, for example) ..."
"... Systemd problems might not have mattered that much, except that GNOME has a similar attitude; they only care for a small subset of the Linux desktop users, and they have historically abandoned some ways of interacting the Desktop in the interest of supporting touchscreen devices and to try to attract less technically sophisticated users. ..."
"... If you don't fall in the demographic of what GNOME supports, you're sadly out of luck. (Or you become a second class citizen, being told that you have to rely on GNOME extensions that may break on every single new version of GNOME.) ..."
"... As a result, many traditional GNOME users have moved over to Cinnamon, XFCE, KDE, etc. But as systemd starts subsuming new functions, components like network-manager will only work on systemd or other components that are forced to be used due to a network of interlocking dependencies; and it may simply not be possible for these alternate desktops to continue to function, because there is [no] viable alternative to systemd supported by more and more distributions. ..."
So what do Linux's leaders think of all this? I asked them and this is what they told
me.
Linus Torvalds said:
"I don't actually have any particularly strong opinions on systemd itself. I've had issues
with some of the core developers that I think are much too cavalier about bugs and
compatibility, and I think some of the design details are insane (I dislike the binary
logs, for example) , but those are details, not big issues."
Theodore "Ted" Ts'o, a leading Linux kernel developer and a Google engineer, sees systemd as
potentially being more of a problem. "The bottom line is that they are trying to solve some
real problems that matter in some use cases. And, [that] sometimes that will break assumptions
made in other parts of the system."
Another concern that Ts'o made -- which I've heard from many other developers -- is that the
systemd move was made too quickly: "The problem is sometimes what they break are in other parts
of the software stack, and so long as it works for GNOME, they don't necessarily consider it
their responsibility to fix the rest of the Linux ecosystem."
This, as Ts'o sees it, feeds into another problem:
" Systemd problems might not have mattered that much, except that GNOME has a similar attitude; they only care for a small
subset of the Linux desktop users, and they have historically abandoned some ways of
interacting the Desktop in the interest of supporting touchscreen devices and to try to
attract less technically sophisticated users.
If you don't fall in the demographic of what GNOME supports, you're sadly out of luck.
(Or you become a second class citizen, being told that you have to rely on GNOME extensions
that may break on every single new version of GNOME.) "
" As a result, many traditional GNOME users have moved over to Cinnamon, XFCE, KDE,
etc. But as systemd starts subsuming new functions, components like network-manager will only
work on systemd or other components that are forced to be used due to a network of
interlocking dependencies; and it may simply not be possible for these alternate desktops to
continue to function, because there is [no] viable alternative to systemd supported by more
and more distributions. "
Of course, Ts'o continued, "None of these nightmare scenarios have happened yet. The people
who are most stridently objecting to systemd are people who are convinced that the nightmare
scenario is inevitable so long as we continue on the same course and altitude."
Ts'o is "not entirely certain it's going to happen, but he's afraid it will.
What I find puzzling about all this is that even though everyone admits that sysvinit needed
replacing and many people dislike systemd, the distributions keep adopting it. Only a few
distributions, including Slackware ,
Gentoo , PCLinuxOS , and Chrome OS , haven't adopted it.
It's not like there aren't alternatives. These include Upstart , runit , and OpenRC .
If systemd really does turn out to be as bad as some developers fear, there are plenty of
replacements waiting in the wings. Indeed, rather than hear so much about how awful systemd is,
I'd rather see developers spending their time working on an alternative.
My company makes an embedded Debian Linux device that boots from an ext3 partition on an
internal SSD drive. Because the device is an embedded "black box", it is usually shut down the
rude way, by simply cutting power to the device via an external switch.
This is normally okay, as ext3's journalling keeps things in order, so other than the
occasional loss of part of a log file, things keep chugging along fine.
However, we've recently seen a number of units where after a number of hard-power-cycles the
ext3 partition starts to develop structural issues -- in particular, we run e2fsck on the ext3
partition and it finds a number of issues like those shown in the output listing at the bottom
of this Question. Running e2fsck until it stops reporting errors (or reformatting the
partition) clears the issues.
My question is... what are the implications of seeing problems like this on an ext3/SSD
system that has been subjected to lots of sudden/unexpected shutdowns?
My feeling is that this might be a sign of a software or hardware problem in our system,
since my understanding is that (barring a bug or hardware problem) ext3's journalling feature
is supposed to prevent these sorts of filesystem-integrity errors. (Note: I understand that
user-data is not journalled and so munged/missing/truncated user-files can happen; I'm
specifically talking here about filesystem-metadata errors like those shown below)
My co-worker, on the other hand, says that this is known/expected behavior because SSD
controllers sometimes re-order write commands and that can cause the ext3 journal to get
confused. In particular, he believes that even given normally functioning hardware and bug-free
software, the ext3 journal only makes filesystem corruption less likely, not impossible, so we
should not be surprised to see problems like this from time to time.
Which of us is right?
Embedded-PC-failsafe:~# ls
Embedded-PC-failsafe:~# umount /mnt/unionfs
Embedded-PC-failsafe:~# e2fsck /dev/sda3
e2fsck 1.41.3 (12-Oct-2008)
embeddedrootwrite contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Invalid inode number for '.' in directory inode 46948.
Fix<y>? yes
Directory inode 46948, block 0, offset 12: directory corrupted
Salvage<y>? yes
Entry 'status_2012-11-26_14h13m41.csv' in /var/log/status_logs (46956) has deleted/unused inode 47075. Clear<y>? yes
Entry 'status_2012-11-26_10h42m58.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47076. Clear<y>? yes
Entry 'status_2012-11-26_11h29m41.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47080. Clear<y>? yes
Entry 'status_2012-11-26_11h42m13.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47081. Clear<y>? yes
Entry 'status_2012-11-26_12h07m17.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47083. Clear<y>? yes
Entry 'status_2012-11-26_12h14m53.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47085. Clear<y>? yes
Entry 'status_2012-11-26_15h06m49.csv' in /var/log/status_logs (46956) has deleted/unused inode 47088. Clear<y>? yes
Entry 'status_2012-11-20_14h50m09.csv' in /var/log/status_logs (46956) has deleted/unused inode 47073. Clear<y>? yes
Entry 'status_2012-11-20_14h55m32.csv' in /var/log/status_logs (46956) has deleted/unused inode 47074. Clear<y>? yes
Entry 'status_2012-11-26_11h04m36.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47078. Clear<y>? yes
Entry 'status_2012-11-26_11h54m45.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47082. Clear<y>? yes
Entry 'status_2012-11-26_12h12m20.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47084. Clear<y>? yes
Entry 'status_2012-11-26_12h33m52.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47086. Clear<y>? yes
Entry 'status_2012-11-26_10h51m59.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47077. Clear<y>? yes
Entry 'status_2012-11-26_11h17m09.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47079. Clear<y>? yes
Entry 'status_2012-11-26_12h54m11.csv.gz' in /var/log/status_logs (46956) has deleted/unused inode 47087. Clear<y>? yes
Pass 3: Checking directory connectivity
'..' in /etc/network/run (46948) is <The NULL inode> (0), should be /etc/network (46953).
Fix<y>? yes
Couldn't fix parent of inode 46948: Couldn't find parent directory entry
Pass 4: Checking reference counts
Unattached inode 46945
Connect to /lost+found<y>? yes
Inode 46945 ref count is 2, should be 1. Fix<y>? yes
Inode 46953 ref count is 5, should be 4. Fix<y>? yes
Pass 5: Checking group summary information
Block bitmap differences: -(208264--208266) -(210062--210068) -(211343--211491) -(213241--213250) -(213344--213393) -213397 -(213457--213463) -(213516--213521) -(213628--213655) -(213683--213688) -(213709--213728) -(215265--215300) -(215346--215365) -(221541--221551) -(221696--221704) -227517
Fix<y>? yes
Free blocks count wrong for group #6 (17247, counted=17611).
Fix<y>? yes
Free blocks count wrong (161691, counted=162055).
Fix<y>? yes
Inode bitmap differences: +(47089--47090) +47093 +47095 +(47097--47099) +(47101--47104) -(47219--47220) -47222 -47224 -47228 -47231 -(47347--47348) -47350 -47352 -47356 -47359 -(47457--47488) -47985 -47996 -(47999--48000) -48017 -(48027--48028) -(48030--48032) -48049 -(48059--48060) -(48062--48064) -48081 -(48091--48092) -(48094--48096)
Fix<y>? yes
Free inodes count wrong for group #6 (7608, counted=7624).
Fix<y>? yes
Free inodes count wrong (61919, counted=61935).
Fix<y>? yes
embeddedrootwrite: ***** FILE SYSTEM WAS MODIFIED *****
embeddedrootwrite: ********** WARNING: Filesystem still has errors **********
embeddedrootwrite: 657/62592 files (24.4% non-contiguous), 87882/249937 blocks
Embedded-PC-failsafe:~#
Embedded-PC-failsafe:~# e2fsck /dev/sda3
e2fsck 1.41.3 (12-Oct-2008)
embeddedrootwrite contains a file system with errors, check forced.
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Directory entry for '.' in ... (46948) is big.
Split<y>? yes
Missing '..' in directory inode 46948.
Fix<y>? yes
Setting filetype for entry '..' in ... (46948) to 2.
Pass 3: Checking directory connectivity
'..' in /etc/network/run (46948) is <The NULL inode> (0), should be /etc/network (46953).
Fix<y>? yes
Pass 4: Checking reference counts
Inode 2 ref count is 12, should be 13. Fix<y>? yes
Pass 5: Checking group summary information
embeddedrootwrite: ***** FILE SYSTEM WAS MODIFIED *****
embeddedrootwrite: 657/62592 files (24.4% non-contiguous), 87882/249937 blocks
Embedded-PC-failsafe:~#
Embedded-PC-failsafe:~# e2fsck /dev/sda3
e2fsck 1.41.3 (12-Oct-2008)
embeddedrootwrite: clean, 657/62592 files, 87882/249937 blocks
I've thought about changing to ext4, at least... would that help address this issue?
Would ZFS be better still? – Jeremy Friesner
Dec 4 '12 at 2:17
1 Neither option would fix this. We still use devices with supercapacitors in ZFS, and
battery or flash-protected cache is recommended for ext4 in server applications. –
ewwhite
Dec 4 '12 at 2:54
add
a comment | 2 Answers 2
active
oldest
votes 10 You're both wrong (maybe?)... ext3 is coping the best it can with having its
underlying storage removed so abruptly.
Your SSD probably has some type of onboard cache. You don't mention the make/model of SSD in
use, but this sounds like a consumer-level SSD versus an enterprise or industrial-grade model .
Either way, the cache is used to help coalesce writes and prolong the life of the drive. If
there are writes in-transit, the sudden loss of power is definitely the source of your
corruption. True enterprise and industrial SSD's have supercapacitors
that maintain power long enough to move data from cache to nonvolatile storage, much in the
same way
battery-backed and flash-backed RAID controller caches work .
If your drive doesn't have a supercap, the in-flight transactions are being lost, hence the
filesystem corruption. ext3 is probably being told that everything is on stable storage, but
that's just a function of the cache. share | improve this answeredited Apr 13 '17 at 12:14Community
♦ 1 answered Dec 4 '12 at 1:24 ewwhite ewwhite 173k 75 364 712
Sorry to you and everyone who upvoted this, but you're just wrong. Handling the loss of
in progress writes is exactly what the journal is for, and as long as the drive correctly
reports whether it has a write cache and obeys commands to flush it, the journal guarantees
that the metadata will not be inconsistent. You only need a supercap or battery backed raid
cache so you can enable write cache without having to enable barriers, which sacrifices some
performance to maintain data correctness. – psusi
Dec 5 '12 at 19:12
@psusi The SSD in use probably has cache explicitly enabled or relies on an internal
buffer regardless of the OS_level setting. The data in that cache is what a supercapacitor-enabled
SSD would protect. – ewwhite
Dec 5 '12 at 19:30
The data in the cache doesn't need protecting if you enable IO barriers. Most consumer
type drives ship with write caching disabled by default and you have to enable it if you want
it, exactly because it causes corruption issues if the OS is not careful. – psusi
Dec 5 '12 at 19:35
@pusi Old now, but you mention this: as long as the drive correctly reports whether
it has a write cache and obeys commands to flush it, the journal guarantees that the metadata
will not be inconsistent. That's the thing: because of storage controllers that tend
to assume older disks, SSDs will sometimes lie about whether data is flushed. You do
need that supercap. – Joel Coel
Aug 9 '15 at 22:01
add a comment | 2 You are right and your coworker is wrong. Barring
something going wrong the journal makes sure you never have inconsistent fs metadata. You might
check with hdparm to see if the drive's write cache is enabled. If it is, and you
have not enabled IO barriers ( off by default on ext3, on by default in ext4 ), then that would
be the cause of the problem.
The barriers are needed to force the drive write cache to flush at the correct time to
maintain consistency, but some drives are badly behaved and either report that their write
cache is disabled when it is not, or silently ignore the flush commands. This prevents the
journal from doing its job. share | improve this answer answered Dec 5 '12 at 19:09
psusi psusi
2,617 11 9
@ewwhite, maybe you should try reading, and actually writing a useful response
instead of this childish insult. – psusi
Dec 5 '12 at 19:36
+1 this answer probably could be improved, as any other answer in any QA. But at least
provides some light and hints. @downvoters: improve the answer yourselves, or comment on
possible flows, but downvoting this answer without proper justification is just disgusting!
– Alberto
Dec 6 '12 at 21:44
i have a problem. yesterday there was a power outage at one of my datacenters, where i
have a relatively large fileserver. 2 arrays, 1 x 14 tb and 1 x 18 tb both in raid6, with a
3ware card.
after the outage, the server came back online, the xfs partitions were mounted, and
everything looked okay. i could access the data and everything seemed just fine.
today i woke up to lots of i/o errors, and when i rebooted the server, the partitions
would not mount:
Oct 14 04:09:17 kp4 kernel:
Oct 14 04:09:17 kp4 kernel: XFS internal error XFS_WANT_CORRUPTED_RETURN
a<ffffffff80056933>] pdflush+0x0/0x1fb
Oct 14 04:09:17 kp4 kernel: [<ffffffff80056a84>] pdflush+0x151/0x1fb
Oct 14 04:09:17 kp4 kernel: [<ffffffff800cd931>] wb_kupdate+0x0/0x16a
Oct 14 04:09:17 kp4 kernel: [<ffffffff80032c2b>] kthread+0xfe/0x132
Oct 14 04:09:17 kp4 kernel: [<ffffffff8005dfc1>] child_rip+0xa/0x11
Oct 14 04:09:17 kp4 kernel: [<ffffffff800a3ab7>] keventd_create_kthread+0x0/0xc4
Oct 14 04:09:17 kp4 kernel: [<ffffffff80032b2d>] kthread+0x0/0x132
Oct 14 04:09:17 kp4 kernel: [<ffffffff8005dfb7>] child_rip+0x0/0x11
Oct 14 04:09:17 kp4 kernel:
Oct 14 04:09:17 kp4 kernel: XFS internal error XFS_WANT_CORRUPTED_RETURN at line 279 of
file fs/xfs/xfs_alloc.c. Caller 0xffffffff88342331
Oct 14 04:09:17 kp4 kernel:
got a bunch of these in dmesg.
The array is fine:
[root@kp4 ~]# tw_cli
//kp4> focus c6
s
//kp4/c6> how
Unit UnitType Status %RCmpl %V/I/M Stripe Size(GB) Cache AVrfy
------------------------------------------------------------------------------
u0 RAID-6 OK - - 256K 13969.8 RiW ON
u1 RAID-6 OK - - 256K 16763.7 RiW ON
VPort Status Unit Size Type Phy Encl-Slot Model
------------------------------------------------------------------------------
p0 OK u1 2.73 TB SATA 0 - Hitachi HDS723030AL
p1 OK u1 2.73 TB SATA 1 - Hitachi HDS723030AL
p2 OK u1 2.73 TB SATA 2 - Hitachi HDS723030AL
p3 OK u1 2.73 TB SATA 3 - Hitachi HDS723030AL
p4 OK u1 2.73 TB SATA 4 - Hitachi HDS723030AL
p5 OK u1 2.73 TB SATA 5 - Hitachi HDS723030AL
p6 OK u1 2.73 TB SATA 6 - Hitachi HDS723030AL
p7 OK u1 2.73 TB SATA 7 - Hitachi HDS723030AL
p8 OK u0 2.73 TB SATA 8 - Hitachi HDS723030AL
p9 OK u0 2.73 TB SATA 9 - Hitachi HDS723030AL
p10 OK u0 2.73 TB SATA 10 - Hitachi HDS723030AL
p11 OK u0 2.73 TB SATA 11 - Hitachi HDS723030AL
p12 OK u0 2.73 TB SATA 12 - Hitachi HDS723030AL
p13 OK u0 2.73 TB SATA 13 - Hitachi HDS723030AL
p14 OK u0 2.73 TB SATA 14 - Hitachi HDS723030AL
Name OnlineState BBUReady Status Volt Temp Hours LastCapTest
---------------------------------------------------------------------------
bbu On Yes OK OK OK 0 xx-xxx-xxxx
i googled for solutions and i think i jumped the horse by doing
xfs_repair -L /dev/sdc
it would not clean it with xfs_repair /dev/sdc, and everybody pretty much says the same
thing.
this is what i was getting when trying to mount the array.
Filesystem Corruption of in-memory data detected. Shutting down filesystem xfs_check
George
Sutherland
Jul 8, 2015 9:58 AM (
in response to RandyBrown ) had similar thing happen with an HVAC tech that confused
the BLACK button that got pushed to exit the room with the RED button clearly marked
EMERGENCY POWER OFF. Clear plastic cover installed with in 24 hours.... after 3 hours of
recovery!
PS... He told his boss that he did not do it.... the camera that focused on the door
told a much different story. He was persona non grata at our site after that.
damateem LQ Newbie
Registered: Dec 2010 Posts: 8
Rep:
Unable to mount root file system after a power failure
[ Log in to get rid of
this advertisement] We had a storm yesterday and the power dropped out, causing my
Ubuntu server to shut off. Now, when booting, I get
[ 0.564310] Kernel panic - not syncing: VFS: Unable to mount root fs on
unkown-block(0,0)
It looks like a file system corruption, but I'm having a hard time fixing the
problem. I'm using Rescue Remix 12-04 to boot from USB and get access to the
system.
Using
sudo fdisk -l
Shows the hard drive as
/dev/sda1: Linux
/dev/sda2: Extended
/dev/sda5: Linux LVM
I can mount sda1 and server1/root and all the files appear normal, although I'm
not really sure what issues I should be looking for. On sda1, I see a grub folder
and several other files. On root, I see the file system as it was before I started
having trouble.
I've ran the following fsck commands and none of them report any errors
syg00 LQ Veteran
Registered: Aug 2003 Location: Australia Distribution: Lots ... Posts: 17,415
Rep:
Might depend a bit on what messages we aren't seeing.
Normally I'd reckon that means that either the filesystem or disk controller
support isn't available. But with something like Ubuntu you'd expect that to all be
in place from the initrd. And that is on the /boot partition, and shouldn't be
subject to update activity in a normal environment. Unless maybe you're
real unlucky and an update was in flight.
Can you chroot into the server (disk) install and run from there successfully
?.
damateem LQ Newbie
Registered: Dec 2010 Posts: 8
Original Poster
Rep:
I had a very hard time getting the Grub menu to appear. There must be a very small
window for detecting the shift key. Holding it down through the boot didn't work.
Repeatedly hitting it at about twice per second didn't work. Increasing the rate to
about 4 hits per second got me into it.
Once there, I was able to select an older kernel (2.6.32-39-server). The
non-booting kernel was 2.6.32-40-server. 39 booted without any problems.
When I initially setup this system, I couldn't send email from it. It wasn't
important to me at the time, so I planned to come back and fix it later. Last week
(before the power drop), email suddenly started working on its own. I was surprised
because I haven't specifically performed any updates. However, I seem to remember
setting up automatic updates, so perhaps an auto update was done that introduced a
problem, but it wasn't seen until the reboot that was forced by the power
outage.
Next, I'm going to try updating to the latest kernel and see if it has the same
problem.
frieza Senior Member Contributing Member
Registered: Feb 2002 Location: harvard, il Distribution: Ubuntu 11.4,DD-WRT micro
plus ssh,lfs-6.6,Fedora 15,Fedora 16 Posts: 3,233
Rep:
imho auto updates are dangerous, if you want my opinion, make sure auto updates are
off, and only have the system tell you there are updates, that way you can chose
not to install them during a power failure
as for a possible future solution for what you went through, unlike other keys,
the shift key being held doesn't register as a stuck key to the best of my
knowledge, so you can hold the shift key to get into grub, after that, edit the
recovery line (the e key) to say at the end, init=/bin/bash then boot the system
using the keys specified on the bottom of the screen, then once booted to a prompt,
you would run
Code:
fsck -f {root partition}
(in this state, the root partition should be either not mounted or mounted read-only, so you
can safely run an fsck on the drive)
note the -f seems to be an undocumented flag that does a more thorough scan than
merely a standard run of fsck.
then reboot, and hopefully that fixes things
glad things seem to be working for the moment though.
suicidaleggroll LQ Guru Contributing Member
Registered: Nov 2010 Location: Colorado Distribution: OpenSUSE, CentOS Posts:
5,573
Rep:
Quote:
Originally Posted by damateem However, I seem to remember setting up automatic updates, so
perhaps an auto update was done that introduced a problem, but it wasn't seen
until the reboot that was forced by the power outage.
I think this is very likely. Delayed reboots after performing an update can
make tracking down errors impossibly difficult. I had a system a while back that
wouldn't boot, turns out it was caused by an update I had done 6 MONTHS earlier,
and the system had simply never been restarted afterward.
damateem LQ Newbie
Registered: Dec 2010 Posts: 8
Original Poster
Rep:
I discovered the root cause of the problem. When I attempted the update, I found
that the boot partition was full. So I suspect that caused issues for the auto
update, but they went undetected until the reboot.
I next tried to purge old kernels using the instructions at
but that failed because a previous install had not completed, but it couldn't
complete because of the full partition. So had no choice but to manually rm the
oldest kernel and it's associated files. With that done, the command
apt-get -f install
got far enough that I could then purge the unwanted kernels. Finally,
"... It mirrors the content of block devices such as hard disks, partitions, logical volumes etc. between servers. ..."
"... It involves a copy of data on two storage devices, such that if one fails, the data on the other can be used. ..."
"... Originally, DRBD was mainly used in high availability (HA) computer clusters, however, starting with version 9, it can be used to deploy cloud storage solutions. In this article, we will show how to install DRBD in CentOS and briefly demonstrate how to use it to replicate storage (partition) on two servers. ..."
The DRBD (stands for Distributed Replicated Block Device ) is a distributed, flexible and versatile replicated storage solution for
Linux. It mirrors the content of block devices such as hard disks, partitions, logical volumes etc. between servers.
It involves a copy of data on two storage devices, such that if one fails, the data on the other can be used.
You can think of it somewhat like a network RAID 1 configuration
with the disks mirrored across servers. However, it operates in a very different way from RAID and even network RAID.
Originally, DRBD was mainly used in high availability (HA) computer clusters, however, starting with version 9, it can be
used to deploy cloud storage solutions. In this article, we will show how to install DRBD in CentOS and briefly demonstrate how to
use it to replicate storage (partition) on two servers.
... ... ...
For the purpose of this article, we are using two nodes cluster for this setup.
DRBD is extremely flexible and versatile, which makes it a storage replication solution suitable for adding HA to just about
any application. In this article, we have shown how to install DRBD in CentOS 7 and briefly demonstrated how to use it to replicate
storage. Feel free to share your thoughts with us via the feedback form below.
Now, I assume most of you here aren't users of MC.
So I won't bore you with description of how Lua makes MC a better file-manager. Instead, I'll just list some details that may
interest
any developer who works on extending some application.
And, as you'll shortly see, you may find mc^2 useful even if you aren't a user of MC!
So, some interesting details:
* Programmer Goodies
- You can restart the Lua system from within MC.
- Since MC has a built-in editor, you can edit Lua code right there and restart Lua. So it's somewhat like a live IDE:
- It comes with programmer utilities: regular expressions; global scope protected by default; good pretty printer for Lua tables;
calculator where you can type Lua expressions; the editor can "lint" Lua code (and flag uses of global variables).
- It installs a /usr/bin/mcscript executable letting you use all the goodies from "outside" MC:
- You can program a UI (user interface) very easily. The API is fun
yet powerful. It has some DOM/JavaScript borrowings in it: you can
attach functions to events like on_click, on_change, etc. The API
uses "properties", so your code tends to be short and readable:
Bash uses Emacs style keyboard shortcuts by default. There is also Vi
mode. Find out how to bind HSTR to a keyboard shortcut based on the style you prefer below.
Check your active Bash keymap with:
bind -v | grep editing-mode
bind -v | grep keymap
To determine character sequence emitted by a pressed key in terminal, type Ctrlv
and then press the key. Check your current bindings using:
bind -S
Bash Emacs Keymap (default)
Bind HSTR to a Bash key e.g. to Ctrlr :
bind '"\C-r": "\C-ahstr -- \C-j"'
or CtrlAltr :
bind '"\e\C-r":"\C-ahstr -- \C-j"'
or CtrlF12 :
bind '"\e[24;5~":"\C-ahstr -- \C-j"'
Bind HSTR to Ctrlr only if it is interactive shell:
if [[ $- =~ .*i.* ]]; then bind '"\C-r": "\C-a hstr -- \C-j"'; fi
You can bind also other HSTR commands like --kill-last-command :
if [[ $- =~ .*i.* ]]; then bind '"\C-xk": "\C-a hstr -k \C-j"'; fi
Bash Vim Keymap
Bind HSTR to a Bash key e.g. to Ctrlr :
bind '"\C-r": "\e0ihstr -- \C-j"'
Zsh Emacs Keymap
Bind HSTR to a zsh key e.g. to Ctrlr :
bindkey -s "\C-r" "\eqhstr --\n"
Alias
If you want to make running of hstr from command line even easier, then define
alias in your ~/.bashrc :
alias hh=hstr
Don't forget to source ~/.bashrc to be able to to use hh
command.
Colors
Let HSTR to use colors:
export HSTR_CONFIG=hicolor
or ensure black and white mode:
export HSTR_CONFIG=monochromatic
Default History View
To show normal history by default (instead of metrics-based view, which is default) use:
export HSTR_CONFIG=raw-history-view
To show favorite commands as default view use:
export HSTR_CONFIG=favorites-view
Filtering
To use regular expressions based matching:
export HSTR_CONFIG=regexp-matching
To use substring based matching:
export HSTR_CONFIG=substring-matching
To use keywords (substrings whose order doesn't matter) search matching (default):
export HSTR_CONFIG=keywords-matching
Make search case sensitive (insensitive by default):
export HSTR_CONFIG=case-sensitive
Keep duplicates in raw-history-view (duplicate commands are discarded by
default):
export HSTR_CONFIG=duplicates
Static favorites
Last selected favorite command is put the head of favorite commands list by default. If you
want to disable this behavior and make favorite commands list static, then use the following
configuration:
export HSTR_CONFIG=static-favorites
Skip favorites comments
If you don't want to show lines starting with # (comments) among favorites,
then use the following configuration:
export HSTR_CONFIG=skip-favorites-comments
Blacklist
Skip commands when processing history i.e. make sure that these commands will not
be shown in any view:
export HSTR_CONFIG=blacklist
Commands to be stored in ~/.hstr_blacklist file with trailing empty line. For
instance:
cd
my-private-command
ls
ll
Confirm on Delete
Do not prompt for confirmation when deleting history items:
export HSTR_CONFIG=no-confirm
Verbosity
Show a message when deleting the last command from history:
export HSTR_CONFIG=verbose-kill
Show warnings:
export HSTR_CONFIG=warning
Show debug messages:
export HSTR_CONFIG=debug
Bash History Settings
Use the following Bash settings to get most out of HSTR.
Increase the size of history maintained by BASH - variables defined below increase the
number of history items and history file size (default value is 500):
This is #1 Google hit but there's controversy in the answer because the question unfortunately asks about delimiting on
, (comma-space) and not a single character such as comma. If you're only interested in the latter, answers here
are easier to follow:
stackoverflow.com/questions/918886/
– antak
Jun 18 '18 at 9:22
Note that the characters in $IFS are treated individually as separators so that in this case fields may be separated
by either a comma or a space rather than the sequence of the two characters. Interestingly though, empty fields aren't
created when comma-space appears in the input because the space is treated specially.
To access an individual element:
echo "${array[0]}"
To iterate over the elements:
for element in "${array[@]}"
do
echo "$element"
done
To get both the index and the value:
for index in "${!array[@]}"
do
echo "$index ${array[index]}"
done
The last example is useful because Bash arrays are sparse. In other words, you can delete an element or add an element and
then the indices are not contiguous.
unset "array[1]"
array[42]=Earth
To get the number of elements in an array:
echo "${#array[@]}"
As mentioned above, arrays can be sparse so you shouldn't use the length to get the last element. Here's how you can in Bash
4.2 and later:
echo "${array[-1]}"
in any version of Bash (from somewhere after 2.05b):
echo "${array[@]: -1:1}"
Larger negative offsets select farther from the end of the array. Note the space before the minus sign in the older form. It
is required.
Just use IFS=', ' , then you don't have to remove the spaces separately. Test: IFS=', ' read -a array <<< "Paris,
France, Europe"; echo "${array[@]}" – l0b0
May 14 '12 at 15:24
Warning: the IFS variable means split by one of these characters , so it's not a sequence of chars to split by. IFS=',
' read -a array <<< "a,d r s,w" => ${array[*]} == a d r s w –
caesarsol
Oct 29 '15 at 14:45
string="1:2:3:4:5"
set -f # avoid globbing (expansion of *).
array=(${string//:/ })
for i in "${!array[@]}"
do
echo "$i=>${array[i]}"
done
The idea is using string replacement:
${string//substring/replacement}
to replace all matches of $substring with white space and then using the substituted string to initialize a array:
(element1 element2 ... elementN)
Note: this answer makes use of the split+glob operator
. Thus, to prevent expansion of some characters (such as * ) it is a good idea to pause globbing for this script.
Used this approach... until I came across a long string to split. 100% CPU for more than a minute (then I killed it). It's a pity
because this method allows to split by a string, not some character in IFS. –
Werner Lehmann
May 4 '13 at 22:32
WARNING: Just ran into a problem with this approach. If you have an element named * you will get all the elements of your cwd
as well. thus string="1:2:3:4:*" will give some unexpected and possibly dangerous results depending on your implementation. Did
not get the same error with (IFS=', ' read -a array <<< "$string") and this one seems safe to use. –
Dieter Gribnitz
Sep 2 '14 at 15:46
1: This is a misuse of $IFS . The value of the $IFS variable is not taken as a single variable-length
string separator, rather it is taken as a set of single-character string separators, where each field that
read splits off from the input line can be terminated by any character in the set (comma or space, in this example).
Actually, for the real sticklers out there, the full meaning of $IFS is slightly more involved. From the
bash manual
:
The shell treats each character of IFS as a delimiter, and splits the results of the other expansions into words using these
characters as field terminators. If IFS is unset, or its value is exactly <space><tab><newline> , the default, then sequences
of <space> , <tab> , and <newline> at the beginning and end of the results of the previous expansions are ignored, and any
sequence of IFS characters not at the beginning or end serves to delimit words. If IFS has a value other than the default,
then sequences of the whitespace characters <space> , <tab> , and <newline> are ignored at the beginning and end of the word,
as long as the whitespace character is in the value of IFS (an IFS whitespace character). Any character in IFS that is not
IFS whitespace, along with any adjacent IFS whitespace characters, delimits a field. A sequence of IFS whitespace characters
is also treated as a delimiter. If the value of IFS is null, no word splitting occurs.
Basically, for non-default non-null values of $IFS , fields can be separated with either (1) a sequence of one
or more characters that are all from the set of "IFS whitespace characters" (that is, whichever of <space> , <tab> , and <newline>
("newline" meaning line feed (LF) ) are present anywhere in
$IFS ), or (2) any non-"IFS whitespace character" that's present in $IFS along with whatever "IFS whitespace
characters" surround it in the input line.
For the OP, it's possible that the second separation mode I described in the previous paragraph is exactly what he wants for
his input string, but we can be pretty confident that the first separation mode I described is not correct at all. For example,
what if his input string was 'Los Angeles, United States, North America' ?
IFS=', ' read -ra a <<<'Los Angeles, United States, North America'; declare -p a;
## declare -a a=([0]="Los" [1]="Angeles" [2]="United" [3]="States" [4]="North" [5]="America")
2: Even if you were to use this solution with a single-character separator (such as a comma by itself, that is, with no following
space or other baggage), if the value of the $string variable happens to contain any LFs, then read
will stop processing once it encounters the first LF. The read builtin only processes one line per invocation. This
is true even if you are piping or redirecting input only to the read statement, as we are doing in this example
with the here-string
mechanism, and thus unprocessed input is guaranteed to be lost. The code that powers the read builtin has no knowledge
of the data flow within its containing command structure.
You could argue that this is unlikely to cause a problem, but still, it's a subtle hazard that should be avoided if possible.
It is caused by the fact that the read builtin actually does two levels of input splitting: first into lines, then
into fields. Since the OP only wants one level of splitting, this usage of the read builtin is not appropriate, and
we should avoid it.
3: A non-obvious potential issue with this solution is that read always drops the trailing field if it is empty,
although it preserves empty fields otherwise. Here's a demo:
string=', , a, , b, c, , , '; IFS=', ' read -ra a <<<"$string"; declare -p a;
## declare -a a=([0]="" [1]="" [2]="a" [3]="" [4]="b" [5]="c" [6]="" [7]="")
Maybe the OP wouldn't care about this, but it's still a limitation worth knowing about. It reduces the robustness and generality
of the solution.
This problem can be solved by appending a dummy trailing delimiter to the input string just prior to feeding it to read
, as I will demonstrate later.
string="1,2,3,4"
array=(`echo $string | sed 's/,/\n/g'`)
These solutions leverage word splitting in an array assignment to split the string into fields. Funnily enough, just like
read , general word splitting also uses the $IFS special variable, although in this case it is implied
that it is set to its default value of <space><tab><newline> , and therefore any sequence of one or more IFS characters (which
are all whitespace characters now) is considered to be a field delimiter.
This solves the problem of two levels of splitting committed by read , since word splitting by itself constitutes
only one level of splitting. But just as before, the problem here is that the individual fields in the input string can already
contain $IFS characters, and thus they would be improperly split during the word splitting operation. This happens
to not be the case for any of the sample input strings provided by these answerers (how convenient...), but of course that doesn't
change the fact that any code base that used this idiom would then run the risk of blowing up if this assumption were ever violated
at some point down the line. Once again, consider my counterexample of 'Los Angeles, United States, North America'
(or 'Los Angeles:United States:North America' ).
Also, word splitting is normally followed by
filename
expansion ( aka pathname expansion aka globbing), which, if done, would potentially corrupt words containing
the characters * , ? , or [ followed by ] (and, if extglob is
set, parenthesized fragments preceded by ? , * , + , @ , or !
) by matching them against file system objects and expanding the words ("globs") accordingly. The first of these three answerers
has cleverly undercut this problem by running set -f beforehand to disable globbing. Technically this works (although
you should probably add set +f afterward to reenable globbing for subsequent code which may depend on it), but it's
undesirable to have to mess with global shell settings in order to hack a basic string-to-array parsing operation in local code.
Another issue with this answer is that all empty fields will be lost. This may or may not be a problem, depending on the application.
Note: If you're going to use this solution, it's better to use the ${string//:/ } "pattern substitution" form
of
parameter expansion , rather than going to the trouble of invoking a command substitution (which forks the shell), starting
up a pipeline, and running an external executable ( tr or sed ), since parameter expansion is purely
a shell-internal operation. (Also, for the tr and sed solutions, the input variable should be double-quoted
inside the command substitution; otherwise word splitting would take effect in the echo command and potentially mess
with the field values. Also, the $(...) form of command substitution is preferable to the old `...`
form since it simplifies nesting of command substitutions and allows for better syntax highlighting by text editors.)
str="a, b, c, d" # assuming there is a space after ',' as in Q
arr=(${str//,/}) # delete all occurrences of ','
This answer is almost the same as #2 . The difference is that the answerer has made the assumption that the fields are delimited
by two characters, one of which being represented in the default $IFS , and the other not. He has solved this rather
specific case by removing the non-IFS-represented character using a pattern substitution expansion and then using word splitting
to split the fields on the surviving IFS-represented delimiter character.
This is not a very generic solution. Furthermore, it can be argued that the comma is really the "primary" delimiter character
here, and that stripping it and then depending on the space character for field splitting is simply wrong. Once again, consider
my counterexample: 'Los Angeles, United States, North America' .
Also, again, filename expansion could corrupt the expanded words, but this can be prevented by temporarily disabling globbing
for the assignment with set -f and then set +f .
Also, again, all empty fields will be lost, which may or may not be a problem depending on the application.
string='first line
second line
third line'
oldIFS="$IFS"
IFS='
'
IFS=${IFS:0:1} # this is useful to format your code with tabs
lines=( $string )
IFS="$oldIFS"
This is similar to #2 and #3 in that it uses word splitting to get the job done, only now the code explicitly sets $IFS
to contain only the single-character field delimiter present in the input string. It should be repeated that this cannot work
for multicharacter field delimiters such as the OP's comma-space delimiter. But for a single-character delimiter like the LF used
in this example, it actually comes close to being perfect. The fields cannot be unintentionally split in the middle as we saw
with previous wrong answers, and there is only one level of splitting, as required.
One problem is that filename expansion will corrupt affected words as described earlier, although once again this can be solved
by wrapping the critical statement in set -f and set +f .
Another potential problem is that, since LF qualifies as an "IFS whitespace character" as defined earlier, all empty fields
will be lost, just as in #2 and #3 . This would of course not be a problem if the delimiter happens to be a non-"IFS whitespace
character", and depending on the application it may not matter anyway, but it does vitiate the generality of the solution.
So, to sum up, assuming you have a one-character delimiter, and it is either a non-"IFS whitespace character" or you don't
care about empty fields, and you wrap the critical statement in set -f and set +f , then this solution
works, but otherwise not.
(Also, for information's sake, assigning a LF to a variable in bash can be done more easily with the $'...' syntax,
e.g. IFS=$'\n'; .)
This solution is effectively a cross between #1 (in that it sets $IFS to comma-space) and #2-4 (in that it uses
word splitting to split the string into fields). Because of this, it suffers from most of the problems that afflict all of the
above wrong answers, sort of like the worst of all worlds.
Also, regarding the second variant, it may seem like the eval call is completely unnecessary, since its argument
is a single-quoted string literal, and therefore is statically known. But there's actually a very non-obvious benefit to using
eval in this way. Normally, when you run a simple command which consists of a variable assignment only , meaning
without an actual command word following it, the assignment takes effect in the shell environment:
IFS=', '; ## changes $IFS in the shell environment
This is true even if the simple command involves multiple variable assignments; again, as long as there's no command
word, all variable assignments affect the shell environment:
IFS=', ' array=($countries); ## changes both $IFS and $array in the shell environment
But, if the variable assignment is attached to a command name (I like to call this a "prefix assignment") then it does not
affect the shell environment, and instead only affects the environment of the executed command, regardless whether it is a builtin
or external:
IFS=', ' :; ## : is a builtin command, the $IFS assignment does not outlive it
IFS=', ' env; ## env is an external command, the $IFS assignment does not outlive it
If no command name results, the variable assignments affect the current shell environment. Otherwise, the variables are
added to the environment of the executed command and do not affect the current shell environment.
It is possible to exploit this feature of variable assignment to change $IFS only temporarily, which allows us
to avoid the whole save-and-restore gambit like that which is being done with the $OIFS variable in the first variant.
But the challenge we face here is that the command we need to run is itself a mere variable assignment, and hence it would not
involve a command word to make the $IFS assignment temporary. You might think to yourself, well why not just add
a no-op command word to the statement like the
: builtin to make the $IFS assignment temporary? This does not work because it would then make the
$array assignment temporary as well:
IFS=', ' array=($countries) :; ## fails; new $array value never escapes the : command
So, we're effectively at an impasse, a bit of a catch-22. But, when eval runs its code, it runs it in the shell
environment, as if it was normal, static source code, and therefore we can run the $array assignment inside the
eval argument to have it take effect in the shell environment, while the $IFS prefix assignment that
is prefixed to the eval command will not outlive the eval command. This is exactly the trick that is
being used in the second variant of this solution:
IFS=', ' eval 'array=($string)'; ## $IFS does not outlive the eval command, but $array does
So, as you can see, it's actually quite a clever trick, and accomplishes exactly what is required (at least with respect to
assignment effectation) in a rather non-obvious way. I'm actually not against this trick in general, despite the involvement of
eval ; just be careful to single-quote the argument string to guard against security threats.
But again, because of the "worst of all worlds" agglomeration of problems, this is still a wrong answer to the OP's requirement.
IFS=', '; array=(Paris, France, Europe)
IFS=' ';declare -a array=(Paris France Europe)
Um... what? The OP has a string variable that needs to be parsed into an array. This "answer" starts with the verbatim contents
of the input string pasted into an array literal. I guess that's one way to do it.
It looks like the answerer may have assumed that the $IFS variable affects all bash parsing in all contexts, which
is not true. From the bash manual:
IFS The Internal Field Separator that is used for word splitting after expansion and to split lines into words with the
read builtin command. The default value is <space><tab><newline> .
So the $IFS special variable is actually only used in two contexts: (1) word splitting that is performed after
expansion (meaning not when parsing bash source code) and (2) for splitting input lines into words by the read
builtin.
Let me try to make this clearer. I think it might be good to draw a distinction between parsing and execution
. Bash must first parse the source code, which obviously is a parsing event, and then later it executes the
code, which is when expansion comes into the picture. Expansion is really an execution event. Furthermore, I take issue
with the description of the $IFS variable that I just quoted above; rather than saying that word splitting is performed
after expansion , I would say that word splitting is performed during expansion, or, perhaps even more precisely,
word splitting is part of the expansion process. The phrase "word splitting" refers only to this step of expansion; it
should never be used to refer to the parsing of bash source code, although unfortunately the docs do seem to throw around the
words "split" and "words" a lot. Here's a relevant excerpt from the
linux.die.net version of the bash manual:
Expansion is performed on the command line after it has been split into words. There are seven kinds of expansion performed:
brace expansion , tilde expansion , parameter and variable expansion , command substitution ,
arithmetic expansion , word splitting , and pathname expansion .
The order of expansions is: brace expansion; tilde expansion, parameter and variable expansion, arithmetic expansion, and
command substitution (done in a left-to-right fashion); word splitting; and pathname expansion.
You could argue the
GNU version
of the manual does slightly better, since it opts for the word "tokens" instead of "words" in the first sentence of the Expansion
section:
Expansion is performed on the command line after it has been split into tokens.
The important point is, $IFS does not change the way bash parses source code. Parsing of bash source code is actually
a very complex process that involves recognition of the various elements of shell grammar, such as command sequences, command
lists, pipelines, parameter expansions, arithmetic substitutions, and command substitutions. For the most part, the bash parsing
process cannot be altered by user-level actions like variable assignments (actually, there are some minor exceptions to this rule;
for example, see the various
compatxx
shell settings , which can change certain aspects of parsing behavior on-the-fly). The upstream "words"/"tokens" that result
from this complex parsing process are then expanded according to the general process of "expansion" as broken down in the above
documentation excerpts, where word splitting of the expanded (expanding?) text into downstream words is simply one step of that
process. Word splitting only touches text that has been spit out of a preceding expansion step; it does not affect literal text
that was parsed right off the source bytestream.
string='first line
second line
third line'
while read -r line; do lines+=("$line"); done <<<"$string"
This is one of the best solutions. Notice that we're back to using read . Didn't I say earlier that read
is inappropriate because it performs two levels of splitting, when we only need one? The trick here is that you can call
read in such a way that it effectively only does one level of splitting, specifically by splitting off only one field per
invocation, which necessitates the cost of having to call it repeatedly in a loop. It's a bit of a sleight of hand, but it works.
But there are problems. First: When you provide at least one NAME argument to read , it automatically ignores
leading and trailing whitespace in each field that is split off from the input string. This occurs whether $IFS is
set to its default value or not, as described earlier in this post. Now, the OP may not care about this for his specific use-case,
and in fact, it may be a desirable feature of the parsing behavior. But not everyone who wants to parse a string into fields will
want this. There is a solution, however: A somewhat non-obvious usage of read is to pass zero NAME arguments.
In this case, read will store the entire input line that it gets from the input stream in a variable named
$REPLY , and, as a bonus, it does not strip leading and trailing whitespace from the value. This is a very robust
usage of read which I've exploited frequently in my shell programming career. Here's a demonstration of the difference
in behavior:
string=$' a b \n c d \n e f '; ## input string
a=(); while read -r line; do a+=("$line"); done <<<"$string"; declare -p a;
## declare -a a=([0]="a b" [1]="c d" [2]="e f") ## read trimmed surrounding whitespace
a=(); while read -r; do a+=("$REPLY"); done <<<"$string"; declare -p a;
## declare -a a=([0]=" a b " [1]=" c d " [2]=" e f ") ## no trimming
The second issue with this solution is that it does not actually address the case of a custom field separator, such as the
OP's comma-space. As before, multicharacter separators are not supported, which is an unfortunate limitation of this solution.
We could try to at least split on comma by specifying the separator to the -d option, but look what happens:
string='Paris, France, Europe';
a=(); while read -rd,; do a+=("$REPLY"); done <<<"$string"; declare -p a;
## declare -a a=([0]="Paris" [1]=" France")
Predictably, the unaccounted surrounding whitespace got pulled into the field values, and hence this would have to be corrected
subsequently through trimming operations (this could also be done directly in the while-loop). But there's another obvious error:
Europe is missing! What happened to it? The answer is that read returns a failing return code if it hits end-of-file
(in this case we can call it end-of-string) without encountering a final field terminator on the final field. This causes the
while-loop to break prematurely and we lose the final field.
Technically this same error afflicted the previous examples as well; the difference there is that the field separator was taken
to be LF, which is the default when you don't specify the -d option, and the <<< ("here-string") mechanism
automatically appends a LF to the string just before it feeds it as input to the command. Hence, in those cases, we sort of
accidentally solved the problem of a dropped final field by unwittingly appending an additional dummy terminator to the input.
Let's call this solution the "dummy-terminator" solution. We can apply the dummy-terminator solution manually for any custom delimiter
by concatenating it against the input string ourselves when instantiating it in the here-string:
a=(); while read -rd,; do a+=("$REPLY"); done <<<"$string,"; declare -p a;
declare -a a=([0]="Paris" [1]=" France" [2]=" Europe")
There, problem solved. Another solution is to only break the while-loop if both (1) read returned failure and
(2) $REPLY is empty, meaning read was not able to read any characters prior to hitting end-of-file.
Demo:
a=(); while read -rd,|| [[ -n "$REPLY" ]]; do a+=("$REPLY"); done <<<"$string"; declare -p a;
## declare -a a=([0]="Paris" [1]=" France" [2]=$' Europe\n')
This approach also reveals the secretive LF that automatically gets appended to the here-string by the <<< redirection
operator. It could of course be stripped off separately through an explicit trimming operation as described a moment ago, but
obviously the manual dummy-terminator approach solves it directly, so we could just go with that. The manual dummy-terminator
solution is actually quite convenient in that it solves both of these two problems (the dropped-final-field problem and the appended-LF
problem) in one go.
So, overall, this is quite a powerful solution. It's only remaining weakness is a lack of support for multicharacter delimiters,
which I will address later.
string='first line
second line
third line'
readarray -t lines <<<"$string"
(This is actually from the same post as #7 ; the answerer provided two solutions in the same post.)
The readarray builtin, which is a synonym for mapfile , is ideal. It's a builtin command which parses
a bytestream into an array variable in one shot; no messing with loops, conditionals, substitutions, or anything else. And it
doesn't surreptitiously strip any whitespace from the input string. And (if -O is not given) it conveniently clears
the target array before assigning to it. But it's still not perfect, hence my criticism of it as a "wrong answer".
First, just to get this out of the way, note that, just like the behavior of read when doing field-parsing,
readarray drops the trailing field if it is empty. Again, this is probably not a concern for the OP, but it could
be for some use-cases. I'll come back to this in a moment.
Second, as before, it does not support multicharacter delimiters. I'll give a fix for this in a moment as well.
Third, the solution as written does not parse the OP's input string, and in fact, it cannot be used as-is to parse it. I'll
expand on this momentarily as well.
For the above reasons, I still consider this to be a "wrong answer" to the OP's question. Below I'll give what I consider to
be the right answer.
Right answer
Here's a naïve attempt to make #8 work by just specifying the -d option:
string='Paris, France, Europe';
readarray -td, a <<<"$string"; declare -p a;
## declare -a a=([0]="Paris" [1]=" France" [2]=$' Europe\n')
We see the result is identical to the result we got from the double-conditional approach of the looping read solution
discussed in #7 . We can almost solve this with the manual dummy-terminator trick:
readarray -td, a <<<"$string,"; declare -p a;
## declare -a a=([0]="Paris" [1]=" France" [2]=" Europe" [3]=$'\n')
The problem here is that readarray preserved the trailing field, since the <<< redirection operator
appended the LF to the input string, and therefore the trailing field was not empty (otherwise it would've been dropped).
We can take care of this by explicitly unsetting the final array element after-the-fact:
readarray -td, a <<<"$string,"; unset 'a[-1]'; declare -p a;
## declare -a a=([0]="Paris" [1]=" France" [2]=" Europe")
The only two problems that remain, which are actually related, are (1) the extraneous whitespace that needs to be trimmed,
and (2) the lack of support for multicharacter delimiters.
The whitespace could of course be trimmed afterward (for example, see
How to trim whitespace
from a Bash variable? ). But if we can hack a multicharacter delimiter, then that would solve both problems in one shot.
Unfortunately, there's no direct way to get a multicharacter delimiter to work. The best solution I've thought of is
to preprocess the input string to replace the multicharacter delimiter with a single-character delimiter that will be guaranteed
not to collide with the contents of the input string. The only character that has this guarantee is the
NUL byte . This is because, in bash (though not in
zsh, incidentally), variables cannot contain the NUL byte. This preprocessing step can be done inline in a process substitution.
Here's how to do it using awk :
There, finally! This solution will not erroneously split fields in the middle, will not cut out prematurely, will not drop
empty fields, will not corrupt itself on filename expansions, will not automatically strip leading and trailing whitespace, will
not leave a stowaway LF on the end, does not require loops, and does not settle for a single-character delimiter.
Trimming solution
Lastly, I wanted to demonstrate my own fairly intricate trimming solution using the obscure -C callback option
of readarray . Unfortunately, I've run out of room against Stack Overflow's draconian 30,000 character post limit,
so I won't be able to explain it. I'll leave that as an exercise for the reader.
function mfcb { local val="$4"; "$1"; eval "$2[$3]=\$val;"; };
function val_ltrim { if [[ "$val" =~ ^[[:space:]]+ ]]; then val="${val:${#BASH_REMATCH[0]}}"; fi; };
function val_rtrim { if [[ "$val" =~ [[:space:]]+$ ]]; then val="${val:0:${#val}-${#BASH_REMATCH[0]}}"; fi; };
function val_trim { val_ltrim; val_rtrim; };
readarray -c1 -C 'mfcb val_trim a' -td, <<<"$string,"; unset 'a[-1]'; declare -p a;
## declare -a a=([0]="Paris" [1]="France" [2]="Europe")
It may also be helpful to note (though understandably you had no room to do so) that the -d option to readarray
first appears in Bash 4.4. – fbicknel
Aug 18 '17 at 15:57
Great answer (+1). If you change your awk to awk '{ gsub(/,[ ]+|$/,"\0"); print }' and eliminate that concatenation
of the final ", " then you don't have to go through the gymnastics on eliminating the final record. So: readarray
-td '' a < <(awk '{ gsub(/,[ ]+/,"\0"); print; }' <<<"$string") on Bash that supports readarray . Note your
method is Bash 4.4+ I think because of the -d in readarray –
dawg
Nov 26 '17 at 22:28
@datUser That's unfortunate. Your version of bash must be too old for readarray . In this case, you can use the second-best
solution built on read . I'm referring to this: a=(); while read -rd,; do a+=("$REPLY"); done <<<"$string,";
(with the awk substitution if you need multicharacter delimiter support). Let me know if you run into any problems;
I'm pretty sure this solution should work on fairly old versions of bash, back to version 2-something, released like two decades
ago. – bgoldst
Feb 23 '18 at 3:37
This does not work as stated. @Jmoney38 or shrimpwagon if you can paste this in a terminal and get the desired output, please
paste the result here. – abalter
Aug 30 '16 at 5:13
Sometimes it happened to me that the method described in the accepted answer didn't work, especially if the separator is a carriage
return.
In those cases I solved in this way:
string='first line
second line
third line'
oldIFS="$IFS"
IFS='
'
IFS=${IFS:0:1} # this is useful to format your code with tabs
lines=( $string )
IFS="$oldIFS"
for line in "${lines[@]}"
do
echo "--> $line"
done
+1 This completely worked for me. I needed to put multiple strings, divided by a newline, into an array, and read -a arr
<<< "$strings" did not work with IFS=$'\n' . –
Stefan van den Akker
Feb 9 '15 at 16:52
While not every solution works for every situation, your mention of readarray... replaced my last two hours with 5 minutes...
you got my vote – Mayhem
Dec 31 '15 at 3:13
The key to splitting your string into an array is the multi character delimiter of ", " . Any solution using
IFS for multi character delimiters is inherently wrong since IFS is a set of those characters, not a string.
If you assign IFS=", " then the string will break on EITHER "," OR " " or any combination
of them which is not an accurate representation of the two character delimiter of ", " .
You can use awk or sed to split the string, with process substitution:
#!/bin/bash
str="Paris, France, Europe"
array=()
while read -r -d $'\0' each; do # use a NUL terminated field separator
array+=("$each")
done < <(printf "%s" "$str" | awk '{ gsub(/,[ ]+|$/,"\0"); print }')
declare -p array
# declare -a array=([0]="Paris" [1]="France" [2]="Europe") output
It is more efficient to use a regex you directly in Bash:
#!/bin/bash
str="Paris, France, Europe"
array=()
while [[ $str =~ ([^,]+)(,[ ]+|$) ]]; do
array+=("${BASH_REMATCH[1]}") # capture the field
i=${#BASH_REMATCH} # length of field + delimiter
str=${str:i} # advance the string by that length
done # the loop deletes $str, so make a copy if needed
declare -p array
# declare -a array=([0]="Paris" [1]="France" [2]="Europe") output...
With the second form, there is no sub shell and it will be inherently faster.
Edit by bgoldst: Here are some benchmarks comparing my readarray solution to dawg's regex solution, and I also
included the read solution for the heck of it (note: I slightly modified the regex solution for greater harmony with
my solution) (also see my comments below the post):
## competitors
function c_readarray { readarray -td '' a < <(awk '{ gsub(/, /,"\0"); print; };' <<<"$1, "); unset 'a[-1]'; };
function c_read { a=(); local REPLY=''; while read -r -d ''; do a+=("$REPLY"); done < <(awk '{ gsub(/, /,"\0"); print; };' <<<"$1, "); };
function c_regex { a=(); local s="$1, "; while [[ $s =~ ([^,]+),\ ]]; do a+=("${BASH_REMATCH[1]}"); s=${s:${#BASH_REMATCH}}; done; };
## helper functions
function rep {
local -i i=-1;
for ((i = 0; i<$1; ++i)); do
printf %s "$2";
done;
}; ## end rep()
function testAll {
local funcs=();
local args=();
local func='';
local -i rc=-1;
while [[ "$1" != ':' ]]; do
func="$1";
if [[ ! "$func" =~ ^[_a-zA-Z][_a-zA-Z0-9]*$ ]]; then
echo "bad function name: $func" >&2;
return 2;
fi;
funcs+=("$func");
shift;
done;
shift;
args=("$@");
for func in "${funcs[@]}"; do
echo -n "$func ";
{ time $func "${args[@]}" >/dev/null 2>&1; } 2>&1| tr '\n' '/';
rc=${PIPESTATUS[0]}; if [[ $rc -ne 0 ]]; then echo "[$rc]"; else echo; fi;
done| column -ts/;
}; ## end testAll()
function makeStringToSplit {
local -i n=$1; ## number of fields
if [[ $n -lt 0 ]]; then echo "bad field count: $n" >&2; return 2; fi;
if [[ $n -eq 0 ]]; then
echo;
elif [[ $n -eq 1 ]]; then
echo 'first field';
elif [[ "$n" -eq 2 ]]; then
echo 'first field, last field';
else
echo "first field, $(rep $[$1-2] 'mid field, ')last field";
fi;
}; ## end makeStringToSplit()
function testAll_splitIntoArray {
local -i n=$1; ## number of fields in input string
local s='';
echo "===== $n field$(if [[ $n -ne 1 ]]; then echo 's'; fi;) =====";
s="$(makeStringToSplit "$n")";
testAll c_readarray c_read c_regex : "$s";
}; ## end testAll_splitIntoArray()
## results
testAll_splitIntoArray 1;
## ===== 1 field =====
## c_readarray real 0m0.067s user 0m0.000s sys 0m0.000s
## c_read real 0m0.064s user 0m0.000s sys 0m0.000s
## c_regex real 0m0.000s user 0m0.000s sys 0m0.000s
##
testAll_splitIntoArray 10;
## ===== 10 fields =====
## c_readarray real 0m0.067s user 0m0.000s sys 0m0.000s
## c_read real 0m0.064s user 0m0.000s sys 0m0.000s
## c_regex real 0m0.001s user 0m0.000s sys 0m0.000s
##
testAll_splitIntoArray 100;
## ===== 100 fields =====
## c_readarray real 0m0.069s user 0m0.000s sys 0m0.062s
## c_read real 0m0.065s user 0m0.000s sys 0m0.046s
## c_regex real 0m0.005s user 0m0.000s sys 0m0.000s
##
testAll_splitIntoArray 1000;
## ===== 1000 fields =====
## c_readarray real 0m0.084s user 0m0.031s sys 0m0.077s
## c_read real 0m0.092s user 0m0.031s sys 0m0.046s
## c_regex real 0m0.125s user 0m0.125s sys 0m0.000s
##
testAll_splitIntoArray 10000;
## ===== 10000 fields =====
## c_readarray real 0m0.209s user 0m0.093s sys 0m0.108s
## c_read real 0m0.333s user 0m0.234s sys 0m0.109s
## c_regex real 0m9.095s user 0m9.078s sys 0m0.000s
##
testAll_splitIntoArray 100000;
## ===== 100000 fields =====
## c_readarray real 0m1.460s user 0m0.326s sys 0m1.124s
## c_read real 0m2.780s user 0m1.686s sys 0m1.092s
## c_regex real 17m38.208s user 15m16.359s sys 2m19.375s
##
Very cool solution! I never thought of using a loop on a regex match, nifty use of $BASH_REMATCH . It works, and
does indeed avoid spawning subshells. +1 from me. However, by way of criticism, the regex itself is a little non-ideal, in that
it appears you were forced to duplicate part of the delimiter token (specifically the comma) so as to work around the lack of
support for non-greedy multipliers (also lookarounds) in ERE ("extended" regex flavor built into bash). This makes it a little
less generic and robust. – bgoldst
Nov 27 '17 at 4:28
Secondly, I did some benchmarking, and although the performance is better than the other solutions for smallish strings, it worsens
exponentially due to the repeated string-rebuilding, becoming catastrophic for very large strings. See my edit to your answer.
– bgoldst
Nov 27 '17 at 4:28
@bgoldst: What a cool benchmark! In defense of the regex, for 10's or 100's of thousands of fields (what the regex is splitting)
there would probably be some form of record (like \n delimited text lines) comprising those fields so the catastrophic
slow-down would likely not occur. If you have a string with 100,000 fields -- maybe Bash is not ideal ;-) Thanks for the benchmark.
I learned a thing or two. – dawg
Nov 27 '17 at 4:46
As others have pointed out in this thread, the OP's question gave an example of a comma delimited string to be parsed into
an array, but did not indicate if he/she was only interested in comma delimiters, single character delimiters, or multi-character
delimiters.
Since Google tends to rank this answer at or near the top of search results, I wanted to provide readers with a strong answer
to the question of multiple character delimiters, since that is also mentioned in at least one response.
If you're in search of a solution to a multi-character delimiter problem, I suggest reviewing
Mallikarjun M 's post, in particular the response
from gniourf_gniourf who provides this elegant
pure BASH solution using parameter expansion:
#!/bin/bash
str="LearnABCtoABCSplitABCaABCString"
delimiter=ABC
s=$str$delimiter
array=();
while [[ $s ]]; do
array+=( "${s%%"$delimiter"*}" );
s=${s#*"$delimiter"};
done;
declare -p array
countries='Paris, France, Europe'
OIFS="$IFS"
IFS=', ' array=($countries)
IFS="$OIFS"
#${array[1]} == Paris
#${array[2]} == France
#${array[3]} == Europe
Bad: subject to word splitting and pathname expansion. Please don't revive old questions with good answers to give bad answers.
– gniourf_gniourf
Dec 19 '16 at 17:22
@GeorgeSovetov: As I said, it's subject to word splitting and pathname expansion. More generally, splitting a string into an
array as array=( $string ) is a (sadly very common) antipattern: word splitting occurs: string='Prague,
Czech Republic, Europe' ; Pathname expansion occurs: string='foo[abcd],bar[efgh]' will fail if you have a
file named, e.g., food or barf in your directory. The only valid usage of such a construct is when
string is a glob. – gniourf_gniourf
Dec 26 '16 at 18:07
Pfft. No. If you're writing scripts large enough for this to matter, you're doing it wrong. In application code, eval is evil.
In shell scripting, it's common, necessary, and inconsequential. –
user1009908
Oct 30 '15 at 4:05
Splitting strings by strings is a pretty boring thing to do using bash. What happens is that we have limited approaches that
only work in a few cases (split by ";", "/", "." and so on) or we have a variety of side effects in the outputs.
The approach below has required a number of maneuvers, but I believe it will work for most of our needs!
#!/bin/bash
# --------------------------------------
# SPLIT FUNCTION
# ----------------
F_SPLIT_R=()
f_split() {
: 'It does a "split" into a given string and returns an array.
Args:
TARGET_P (str): Target string to "split".
DELIMITER_P (Optional[str]): Delimiter used to "split". If not
informed the split will be done by spaces.
Returns:
F_SPLIT_R (array): Array with the provided string separated by the
informed delimiter.
'
F_SPLIT_R=()
TARGET_P=$1
DELIMITER_P=$2
if [ -z "$DELIMITER_P" ] ; then
DELIMITER_P=" "
fi
REMOVE_N=1
if [ "$DELIMITER_P" == "\n" ] ; then
REMOVE_N=0
fi
# NOTE: This was the only parameter that has been a problem so far!
# By Questor
# [Ref.: https://unix.stackexchange.com/a/390732/61742]
if [ "$DELIMITER_P" == "./" ] ; then
DELIMITER_P="[.]/"
fi
if [ ${REMOVE_N} -eq 1 ] ; then
# NOTE: Due to bash limitations we have some problems getting the
# output of a split by awk inside an array and so we need to use
# "line break" (\n) to succeed. Seen this, we remove the line breaks
# momentarily afterwards we reintegrate them. The problem is that if
# there is a line break in the "string" informed, this line break will
# be lost, that is, it is erroneously removed in the output!
# By Questor
TARGET_P=$(awk 'BEGIN {RS="dn"} {gsub("\n", "3F2C417D448C46918289218B7337FCAF"); printf $0}' <<< "${TARGET_P}")
fi
# NOTE: The replace of "\n" by "3F2C417D448C46918289218B7337FCAF" results
# in more occurrences of "3F2C417D448C46918289218B7337FCAF" than the
# amount of "\n" that there was originally in the string (one more
# occurrence at the end of the string)! We can not explain the reason for
# this side effect. The line below corrects this problem! By Questor
TARGET_P=${TARGET_P%????????????????????????????????}
SPLIT_NOW=$(awk -F"$DELIMITER_P" '{for(i=1; i<=NF; i++){printf "%s\n", $i}}' <<< "${TARGET_P}")
while IFS= read -r LINE_NOW ; do
if [ ${REMOVE_N} -eq 1 ] ; then
# NOTE: We use "'" to prevent blank lines with no other characters
# in the sequence being erroneously removed! We do not know the
# reason for this side effect! By Questor
LN_NOW_WITH_N=$(awk 'BEGIN {RS="dn"} {gsub("3F2C417D448C46918289218B7337FCAF", "\n"); printf $0}' <<< "'${LINE_NOW}'")
# NOTE: We use the commands below to revert the intervention made
# immediately above! By Questor
LN_NOW_WITH_N=${LN_NOW_WITH_N%?}
LN_NOW_WITH_N=${LN_NOW_WITH_N#?}
F_SPLIT_R+=("$LN_NOW_WITH_N")
else
F_SPLIT_R+=("$LINE_NOW")
fi
done <<< "$SPLIT_NOW"
}
# --------------------------------------
# HOW TO USE
# ----------------
STRING_TO_SPLIT="
* How do I list all databases and tables using psql?
\"
sudo -u postgres /usr/pgsql-9.4/bin/psql -c \"\l\"
sudo -u postgres /usr/pgsql-9.4/bin/psql <DB_NAME> -c \"\dt\"
\"
\"
\list or \l: list all databases
\dt: list all tables in the current database
\"
[Ref.: https://dba.stackexchange.com/questions/1285/how-do-i-list-all-databases-and-tables-using-psql]
"
f_split "$STRING_TO_SPLIT" "bin/psql -c"
# --------------------------------------
# OUTPUT AND TEST
# ----------------
ARR_LENGTH=${#F_SPLIT_R[*]}
for (( i=0; i<=$(( $ARR_LENGTH -1 )); i++ )) ; do
echo " > -----------------------------------------"
echo "${F_SPLIT_R[$i]}"
echo " < -----------------------------------------"
done
if [ "$STRING_TO_SPLIT" == "${F_SPLIT_R[0]}bin/psql -c${F_SPLIT_R[1]}" ] ; then
echo " > -----------------------------------------"
echo "The strings are the same!"
echo " < -----------------------------------------"
fi
Rather than changing IFS to match our desired delimiter, we can replace all occurrences of our desired delimiter ", "
with contents of $IFS via "${string//, /$IFS}" .
Maybe this will be slow for very large strings though?
I cover this idea in
my
answer ; see Wrong answer #5 (you might be especially interested in my discussion of the eval trick).
Your solution leaves $IFS set to the comma-space value after-the-fact. –
bgoldst
Aug 13 '17 at 22:38
Me: There is a problem with your head-end router, you need to get an engineer to troubleshoot it
Them: no the problem is with your cable modem and router, we can see it fine on our network
Me: That's interesting because I powered it off and disconnected it from the wall before we started this conversation.
Them: Are you sure?
Me: I'm pretty sure that the lack of blinky lights means it's got no power but if you think it's still working fine then I'd suggest
the problem at your end of this phone conversation and not at my end.
Or in other words, a simple, reliable and clear solution (which has some faults due to its age) was replaced with a gigantic KISS
violation. No engineer worth the name will ever do that. And if it needs doing, any good engineer will make damned sure to achieve maximum
compatibility and a clean way back. The systemd people seem to be hell-bent on making it as hard as possible to not use their monster.
That alone is a good reason to stay away from it.
Notable quotes:
"... We are systemd. Lower your memory locks and surrender your processes. We will add your calls and code distinctiveness to our own. Your functions will adapt to service us. Resistance is futile. ..."
"... I think we should call systemd the Master Control Program since it seems to like making other programs functions its own. ..."
"... RHEL7 is a fine OS, the only thing it's missing is a really good init system. ..."
Systemd is nothing but a thinly-veiled plot by Vladimir Putin and Beyonce to import illegal German Nazi immigrants over the
border from Mexico who will then corner the market in kimchi and implement Sharia law!!!
We are systemd. Lower your memory locks and surrender your processes. We will add your calls and code distinctiveness to
our own. Your functions will adapt to service us. Resistance is futile.
My story is about required processes...Need to add DHCP entries
to the DHCP server. Here is the process. Receive request. Write 5 page document (no
exaggeration) detailing who submitted the request, why the request was submitted, what the
solution would be, the detailed steps of the solution including spreadsheet showing how
each field would be completed and backup procedures. Produce second document to include pre
execution test plan, and post execution test plan in minute detail. Submit to CAB board for
review, submit to higher level advisory board for review; attend CAB meeting for formal
approval; attend additional approval board meeting if data center is in freeze; attend post
implementation board for lessons learned...Lesson learned: now I know where our tax dollars
go...
highlord_fox
Moderator | /r/sysadmin Sock Puppet 10 points 11 points 12 points 3 years ago (1 child)
9-10 year old Poweredge 2950. Four drives, 250GB ea, RAID 5. Not even sure the fourth drive
was even part of the array at this point. Backups consist of cloud file-level backup of most
of the server's files. I was working on the server, updating the OS, rebooting it to solve
whatever was ailing it at the time, and it was probably about 7-8PM on a Friday. I powered it
off, and went to power it back on.
Disk Array not found.
SHIT SHIT SHIT SHIT SHIT SHIT SHIT . Power it back off. Power it back on.
Disk Array not found.
I stared at it, and hope I don't have to call for emergency support on the thing. Power it
off and back on a third time.
Windows 2003 is now loading.
OhThankTheGods
I didn't power it off again until I replaced it, some 4-6 months later. And then it stayed
off for a good few weeks, before I had to buy a Perc 5i card off ebay to get it running
again. Long story short, most of the speed issues I was having was due to the card dying. AH
WELL.
Viewing backup logs is vital. Often it only looks that backup is going fine...
Notable quotes:
"... Things looked fine until someone noticed that a directory with critically important and sensitive data was missing. Turned out that some manager had decided to 'secure' the directory by doing 'chmod 000 dir' to protect the data from inquisitive eyes when the data was not being used. ..."
"... Of course, tar complained about the situation and returned with non-null status, but since the backup procedure had seemed to work fine, no one thought it necessary to view the logs... ..."
At an unnamed location it happened thus... The customer had been using a home built 'tar' -based backup system for a long time.
They were informed enough to have even tested and verified that recovery would work also.
Everything had been working fine, and they even had to do a recovery which went fine. Well, one day something evil happened
to a disk and they had to replace the unit and do a full recovery.
Things looked fine until someone noticed that a directory with
critically important and sensitive data was missing. Turned out that some manager had decided to 'secure' the directory by doing
'chmod 000 dir' to protect the data from inquisitive eyes when the data was not being used.
Of course, tar complained about the
situation and returned with non-null status, but since the backup procedure had seemed to work fine, no one thought it necessary
to view the logs...
"... I RECURSIVELY DELETED ALL THE LIVE CORPORATE WEBSITES ON FRIDAY AFTERNOON AT 4PM! ..."
"... This is why it's ALWAYS A GOOD IDEA to use Midnight Commander or something similar to delete directories!! ..."
"... rsync with ssh as the transport mechanism works very well with my nightly LAN backups. I've found this page to be very helpful: http://www.mikerubel.org/computers/rsync_snapshots/ ..."
The Subject, not the content, really brings back memories.
Imagine this, your tasked with complete control over the network in a multi-million dollar company. You've had some experience
in the real world of network maintaince, but mostly you've learned from breaking things at home.
Time comes to implement (yes this was a startup company), a backup routine. You carefully consider the best way to do it and
decide copying data to a holding disk before the tape run would be perfect in the situation, faster restore if the holding disk
is still alive.
So off you go configuring all your servers for ssh pass through, and create the rsync scripts. Then before the trial run you
think it would be a good idea to create a local backup of all the websites.
You logon to the web server, create a temp directory
and start testing your newly advance rsync skills. After a couple of goes, you think your ready for the real thing, but you decide
to run the test one more time.
Everything seems fine so you delete the temp directory. You pause for a second and your month drops
open wider than it has ever opened before, and a feeling of terror overcomes you. You want to hide in a hole and hope you didn't
see what you saw.
I RECURSIVELY DELETED ALL THE LIVE CORPORATE WEBSITES ON FRIDAY AFTERNOON AT 4PM!
Anonymous on Sun, 11/10/2002 - 03:00.
This is why it's ALWAYS A GOOD IDEA to use Midnight Commander or something similar to delete directories!!
...Root for (5) years and never trashed a filesystem yet (knockwoody)...
"... On closer inspection, noticed this power lead was only half in the socket... I connected this back to the original switch, grabbed the "I.T manager" and asked him to "just push the power lead"... his face? Looked like Casper the friendly ghost. ..."
Had to travel from Cheshire to Glasgow (4+hours) at 3am to get to a major high street
store for 8am, an hour before opening. A switch had failed and taken out a whole floor of
the store. So I prepped the new switch, using the same power lead from the failed switch as
that was the only available lead / socket. No power. Initially thought the replacement
switch was faulty and I would be in trouble for not testing this prior to attending site...
On closer inspection, noticed this power lead was only half in the socket... I connected
this back to the original switch, grabbed the "I.T manager" and asked him to "just push the
power lead"... his face? Looked like Casper the friendly ghost.
Problem solved at a massive
expense to the company due to the out of hours charges. Surely that would be the first
thing to check? Obviously not...
The same thing happened in Aberdeen, a 13 hour round trip to resolve a fault on a
"failed router". The router looked dead at first glance, but after taking the side panel
off the cabinet, I discovered it always helps if the router is actually plugged in...
Yet the customer clearly said everything is plugged in as it should be and it "must be
faulty"... It does tend to appear faulty when not supplied with any power...
Shortly after I started my first remote server-monitoring job, I started receiving, one by one, traps for servers that had gone
heartbeat missing/no-ping at a remote site. I looked up the site, and there were 16 total servers there, of which about 4 or 5
(and counting) were already down. Clearly not network issues. I remoted into one of the ones that was still up, and found in the
Windows event viewer that it was beginning to overheat.
I contacted my front-line team and asked them to call the site to find out if the data center air conditioner had gone out,
or if there was something blocking the servers' fans or something. He called, the client at the site checked and said the data
center was fine, so I dispatched IBM (our remote hands) to go to the site and check out the servers. They got there and called
in laughing.
There was construction in the data center, and the contractors, being thoughtful, had draped a painter's dropcloth over the
server racks to keep off saw dust. Of COURSE this caused the servers to overheat. Somehow the client had failed to mention this.
...so after all this went down, the client had the gall to ask us to replace the servers "just in case" there was any damage,
despite the fact that each of them had shut itself down in order to prevent thermal damage. We went ahead and replaced them anyway.
(I'm sure they were rebuilt and sent to other clients, but installing these servers on site takes about 2-3 hours of IBM's time
on site and 60-90 minutes of my remote team's time, not counting the rebuild before recycling.
Oh well. My employer paid me for my time, so no skin off my back.
I was just starting my IT career, and I was told a VIP user couldn't VPN in, and I was asked
to help. Everything checked out with the computer, so I asked the user to try it in front of
me. He took out his RSA token, knew what to do with it, and it worked.
I also knew this user had been complaining of this issue for some time, and I wasn't the
first person to try to fix this. Something wasn't right.
I asked him to walk me through every step he took from when it failed the night before.
"Sure, I get out my laptop, plug in the network cable, get on the internet from home. I
start the VPN client, take out this paper with the code on it, and type it in..." Yup. He wrote
down the RSA token's code before he went home. See that little thing was expensive, and he
didn't want to lose it. I explained that the number changes all time, and that he needed to
have it with him. VPN issue resolved.
"... "Oh my God, the server room is full of smoke!" Somehow they hooked up things wrong and fed 220v instead of 110v to all the circuits. Every single UPS was dead. Several of the server power supplies were fried. ..."
This happened back when we had an individual APC UPS for each
server. Most of the servers were really just whitebox PCs in a rack mount case running a
server OS.
The facilities department was doing some planned maintenance on the electrical panel in
the server room over the weekend. They assured me that they were not going to touch any of
the circuits for the server room, just for the rooms across the hallway. Well, they
disconnected power to the entire panel. Then they called me to let me know what they did. I
was able to remotely verify that everything was running on battery just fine. I let them
know that they had about 20 minutes to restore power or I would need to start shutting down
servers. They called me again and said,
"Oh my God, the server room is full of smoke!"
Somehow they hooked up things wrong and fed 220v instead of 110v to all the circuits. Every
single UPS was dead. Several of the server power supplies were fried.
And a few
motherboards didn't make it either. It took me the rest of the weekend kludging things
together to get the critical systems back online.
Many years ago I worked at an IBM Mainframe site. To make systems more robust they installed
a UPS system for the mainframe with battery bank and a honkin' great diesel generator in the
yard.
During the commissioning of the system, they decided to test the UPS cutover one afternoon -
everything goes *dark* in seconds. Frantic running around to get power back on and MF restarted
and databases recovered (afternoon, remember? during the work day...). Oh! The UPS batteries
were not charged! Oops.
Over the next few weeks, they did two more 'tests' during the working day, with everything
going *dark* in seconds for various reasons. Oops.
Then they decided - perhaps we should test this outside of office hours. (YAY!)
Still took a few more efforts to get everything working - diesel generator wouldn't start
automatically, fixed that and forgot to fill up the diesel tank so cutover was fine until the
fuel ran out.
I was in my main network facility, for a municipal fiber optic ring. Outside were two
technicians replacing our backup air conditioning unit. I walk inside after talking with the
two technicians, turn on the lights and begin walking around just visually checking things
around the room. All of a sudden I started smelling that dreaded electric hot/burning smell.
In this place I have my core switch, primary router, a handful of servers, some customer
equipment and a couple of racks for my service provider. I start running around the place
like a mad man sniffing all the equipment. I even called in the AC technicians to help me
sniff.
After 15 minutes we could not narrow down where it was coming from. Finally I noticed
that one of the florescent lights had not come on. I grabbed a ladder and opened it up.
The
ballast had burned out on the light and it just so happen to be the light right in front of
the AC vent blowing the smell all over the room.
The last time I had smelled that smell in
that room a major piece of equipment went belly up and there was nothing I could do about it.
The exact same thing has happened to me. Nothing quite as terrifying as the sudden smell of
ozone as you're surrounded by critical computers and electrical gear.
eraser_6776 VP
IT/Sec (a damn suit) 9 points 10 points 11 points 3 years ago (1 child)
May 22, 2004. There was a rather massive storm here that spurred one of the [biggest
Tornaodes recorded in Nebraska]( www.tornadochaser.net/hallam.html ) and I was
a sysadmin for a small company. It was a Saturday, aka beer day, and as all hell was breaking
loose my friends and roomates' pagers and phones were all going off. "Ha ha!" I said, looking
at a silent cellphone "sucks to be you!"
Next morning around 10 my phone rings, and I groggily answer it because it's the owner of
the company. "You'd better come in here, none of the computers will turn on" he says. Slight
panic, but I hadn't received any emails. So it must have been breakers, and I can get that
fixed. No problem.
I get into the office and something strikes me. That eery sound of silence. Not a single
machine is on.. why not? Still shaking off too much beer from the night before, I go into the
server room and find out why I didn't get paged. Machines are running, but every switch in
the cabinet is dead. Some servers are dead. Panic sets in.
I start walking around the office trying to turn on machines and.. dead. All of them.
Every last desktop won't power on. That's when panic REALLY set in.
In the aftermath I found out two things - one, when the building was built, it was built
with a steel roof and steel trusses. Two, when my predecessor had the network cabling wired
he hired an idiot who didn't know fire code and ran the network cabling, conveniently, along
the trusses into the ceiling. Thus, when lightning hit the building it had a perfect ground
path to every workstation in the company. Some servers that weren't in the primary cabinet
had been wired to a wall jack (which, in turn, went up into the ceiling then back down into
the cabinet because you know, wire management!). Thankfully they were all "legacy"
servers.
The only thing that saved the main servers was that Cisco 2924 XL-EN's are some badass
mofo's that would die before they let that voltage pass through to the servers in the
cabinet. At least that's what I told myself.
All in all, it ended up being one of the longest work weeks ever as I first had to source
a bunch of switches, fast to get things like mail and the core network back up. Next up was
feeding my buddies a bunch of beer and pizza after we raided every box store in town for
spools of Cat 5 and threw wire along the floor.
Finally I found out that CDW can and would get you a whole lot of desktops delivered to
your door with your software pre-installed in less than 24 hours if you have an open
checkbook. Thanks to a great insurance policy, we did. Shipping and "handling" for those were
more than the cost of the machines (again, this was back in 2004 and they were business
desktops so you can imagine).
Still, for weeks after I had non-stop user complaints that generally involved "..I think
this is related to the lightning ". I drank a lot that summer.
"... Look at the screen, check out what it is doing, realize that the installer had grabbed the backend and he said yeah format all(we are not sure exactly how he did it). ..."
~10 years ago. 100GB drives on a node attached to an 8TB SAN. Cabling is all hooked up as we are adding this new node to manage
the existing data on the SAN. A guy that is training up to help, we let him install RedHat and go through the GUI setup. Did not
pay attention to him, and after a while wonder what is taking so long. Walk over to him and he is still staring at the install
screen and says, "Hey guys, this format sure is taking a while".
Look at the screen, check out what it is doing, realize that the installer had grabbed the backend and he said yeah format
all(we are not sure exactly how he did it).
Middle of the day, better kick off the tape restore for 8TB of data.
I was the on-call technician for the security team supporting a
Fortune 500 logistics company, in fact it was my first time being on-call. My phone rings
at about 2:00 AM and the help desk agent says that the Citrix portal is down for everyone.
This is a big deal because it's a 24/7 shop with people remoting in all around the world.
While not strictly a security appliance, my team was responsible for the Citrix Access
Gateway that was run on a NetScaler. Also on the line are the systems engineers responsible
for the Citrix presentation/application servers.
I log in, check the appliance, look at all
of the monitors, everything is reporting up. After about 4 hours of troubleshooting and
trying everything within my limited knowledge of this system we get my boss on the line to
help.
It came down to this: the Citrix team didn't troubleshoot anything and it was the StoreFront and broker servers that were having the troubles; but since the CAG wouldn't let
people see any applications they instantly pointed the finger at the security team and
blamed us.
I still went to work that day, tired, grumpy and hyped on caffeine teetering between
consciousness and a comatose state because of two reasons: the Citrix team doesn't know how
to do their job and I was too tired to ask the investigating questions like "when did it
stop working? has anything changed? what have you looked at so far?".
Everyone seems to be really paranoid when firing a senior sysadmin. Advice seems to range
from "check for backdoors" to "remove privileges while he is in the severage meeting"
I think it sounds a bit paranoid to be honest. I know media loves these stories, and I
doubt they are that common.
Has anyone actually personally experienced a fired sysadmin who has retaliated?
Many moons ago I worked for a a very large dot com. I won't even call it a startup as they
were pretty big and well used. They were hacked once. The guy did a ransom type of thing and
the company paid him. But they also hired him as a sysadmin with a focus on security. For 6
months he did nothing but surf IRC channels. One thing leads to another and the guy was
fired. A month later I'm looking a an issue on a host and notice a weird port open on the
front end web server (the guy was so good at security that he insisted on no firewalls).
Turns out the guy hacked back into our servers. The next week our primary database goes down
for 24 hours. I wonder how that happened.
He eventually got on the secret services radar for stealing credit card information from
thousands of people. He's now in jail.
It works for the FBI. But it all depends on the TYPE of blackhat you hire. You want the kind
in it just to prove they can do it, not the type that are out for making money.
To be fair, I have a large group of friends that exactly this happened to. From what I hear,
it is kind of cool to be legally allowed to commit purger for the sake of work (infosec).
's career suicide, especially in a smaller IT market.
It ought to be, but it would be libel per se to say that he did this, meaning that if he
sues, you'd have to prove what you said true, or you'd lose by default, and the finding would
assumed by the court to be large. Libel per se is nothing to sneeze at.
I always hated that. We had a guy steal from us, server's, mobile phones, computers, etc. We
caught him with footage, and he was even dumb enough to leave chat logs on his computer
detailing criminal activity like doing drugs in the office late at night and theft . We
were such a small shop at the time. We fired him and nobody followed up and filed any
charges. Around 2 months later we get a call from employment insurance office and they say
the dispute was we claimed him stole office equipment but had no proof. We would have had to
higher lawyers and it just wasn't worth it...we let him go and have his free money. Always
pissed me off.
This is why you press charges. If he'd been convicted of theft, which he almost surely would
have if you had so much evidence, he not only would've had no ground to stand on for that
suit, but he'd be in jail. The best part is, the police handle the pressing of charges,
because criminal prosecution is state v. accused.
Yah I really wish we had. But when your vp of customer service takes support calls, when your
CFO is also a lead programmer and your accountant's primary focus is calling customers to pay
their bills it's easier said then done!
neoice
Principal Linux Systems Engineer 1 point 2 points 3 points 4 years ago (1 child)
I dunno, for criminal proceedings the police do most of the legwork. when my car got stolen,
I had to fill out and sign a statement then the state did the rest.
you probably would have spent a 2-16 hours with a detective going over the evidence and
filing your report. I think that's a pretty low cost to let the wheels of justice spin!
Depending on the position of the person, i.e a manager or in management at the former
employees company, a person "bad mouthing" an ex employee will also be in violation of
anti-blacklistling laws that are in place in many/most states which prohibit companies and
authorized agents of companies (HR, managers etc) from (and I quote from the statute)
using any words that any discharged employees, or attempt[ing] by words or writing, or
any other means whatever, to prevent such discharged employee, or any employee who may have
voluntarily left said company's service from obtaining employment with any other person, or
company. -
So most business to not authorize their managers or HR to do anything other than confirm
dates of employment, job title, and possibly wage.
I'm (only a little) surprised by this. Since you are quoting from statute, can you link me.
I'm curious about that whole section of code. I should assume this is some specific state,
yes?
the quote is from IC 22-5-3-2, which on its face seem to apply only to "Railroads" but
also clearly says "any other company" in the text.
There are some of the standard Libale protections as well for truthful statements, but you
must prove it was truthful, so something like "he was always late" if you have time cards to
prove that would not be in violation, but something like "He smelled bad, was rude and
incompetent" would likely be a violation
Your second example is actually just three opinions which a person cannot sue you for. If I
declare that I thought you smelled bad and where an incompetent employee I'm not making
libelous statements because libel laws don't cover personal opinions. If I say you where late
everyday, that is a factual statement that can either be proven or disproven, so libel law
now applies.
"CaptainDave is a convicted pederast" would be an example of libel per se. It doesn't matter
if I believe it true. It doesn't matter if I am not malicious in my
statement. The statement must be true for it to not be libel. If CaptainDave were to
sue me, I'd have to show proof of that conviction. CaptainDave would not be required to prove
the statement false. The court would not be interested in investigating the matter itself, so
the burden of proof would shift to me . If I were not to succeed in proving this
statement, the court would assume the damages of this class of libel to be high. Generally;
with caveats.
CaptainDave Infrastructure Engineer 0 points
1 point 2 points 4 years ago (1 child)
That's what I was saying: there's no intent element. That's what's meant by "libel per se."
That doesn't shift the burden of proof, it just means there's one less thing to show. You
have burden shifting confused with the affirmative defense that the statement was true;
however, that, as an affirmative defense, is always on the party pressing it. There is thus
no burden shifting. Moreover, you have to prove your damages no matter what; there is no
presumption as to their amount (beyond "nominal," IIRC).
Moreover, you have to prove your damages no matter what; t
These are the actual written instructions given to juries in California:
"Even if [name of plaintiff] has not proved any actual damages for harm to reputation or
shame, mortification or hurt feelings, the law assumes that [he/she] has suffered this
harm . Without presenting evidence of damage, [name of plaintiff] is entitled to receive
compensation for this assumed harm in whatever sum you believe is reasonable."
Juries, of course, are not instructed on an actual amount here. As you say, it might only
be nominal. But in the case of an employer leaving a negative reference about an employee
accusing them of a crime? It won't be as a matter of practice, now will it? The jury has been
told the harm to reputation and mortification is assumed by the law . While this
does not guarantee a sympathetic jury, and obviously the case will have its context, I'll
make the assumption starting right now that you don't want to be on the receiving end of a
legitimate libel per se case, is that fair? :-P
At least in California. I've been told not all states have libel per se laws, but I really
wouldn't know.
As far as my statement that "would be assumed by the court to be large," this was sloppily
worded, yes. Let's just say that, with wording like the above, the only real test is... "is
the jury offended on your behalf?" Because if they are, with instructions like that, and any
actually serious libel per se case, defendant is screwed. It's also a bit of a stinger that
attorney's fees are generally included in libel per se cases (at least according to black
letter law; IANAL, so I'm not acquainted with real case histories).
When we got rid of the last guy I worked with he remoted into one of our servers
People need to know that this is a big no-no. Whether your employer remembered to delete
your accounts or not, attempting to access or accessing servers once you've been termed is
against the law in most places.
Whether you're being malicious or not, accessing or even attempting to access systems you
no longer have permission to access can easily be construed as malicious.
i was working late night in our colo within $LARGE_DATA_RECOVERY_CENTER . one of the
sysadmins (financials) for the hosting company was there telling me about how she was getting
the axe and had to train her overseas counterparts how to do her job. lets say she was less
than gruntled. she mentioned something about "at(1) jobs they'll never find".
years later i read a vague article in an industry journal about insider sabotage at a
local company that caused millions of dollars of downtime..
i'm not sure if that was her, but the details lined up very closely and it makes a lot of
sense that the f500 company would want to sweep this under the rug.
The Childs case is like if you took your average /r/talesfromtechsupport story and mixed
it with about 50% more paranoia and half as much common sense - continuing to refuse requests
for the administrator passwords even after being arrested. If management asked me for the
passwords to all of my systems, they can have them. In fact, in my exit interview, I would be
more than happy to point out each and every remote access method that I have to their
systems, and request that all of those passwords are changed. I don't WANT there to be any
conceivable way for me to get back into a previous employers' environment when I go. Whenever
I leave a team, my last action is deactivating all of my own database logins, removing my
sudo rights, removing myself from any groups with elevated rights, ensuring that the team
will be changing admin passwords ASAP. That way when colleagues and customers come back
pleading for me to fix stuff, I can honestly tell them I no longer have the ability to solve
their problem - go hit up the new guy. They stop calling much quicker that way.
neoice
Principal Linux Systems Engineer 2 points 3 points 4 points 4 years ago (4 children)
Whenever I leave a team, my last action is deactivating all of my own database logins,
removing my sudo rights, removing myself from any groups with elevated rights, ensuring
that the team will be changing admin passwords ASAP.
I <3 our version controlled infrastructure. I could remove my database logins, sudo
rights and lock my user account with a single commit. then I could push another commit to
revoke my commit privs :)
I am envious of your setup. Ours is very fragmented, but cobbled together with tons of
somewhat fragile home-grown scripts, mostly manageable. Somehow configuration management
never seems to make it to the top of the project list ...
neoice
Principal Linux Systems Engineer 0 points 1 point 2 points 4 years ago (0 children)
doooo it. it's so so worth it. even if your initial rollout is just getting a config mgmt
daemon installed and managed. once you get over the initial hurdle of having your config mgmt
infrastructure in place, updates become so cheap and fast. it really will accelerate your
organization.
Most of these "horror stories" are not malicious in nature, but trace back to poor
documentation, and experience.
If an admin has been in the same environment for 10+ years, they know all the quirks, all
of one off scripts that hold critical systems together, how each piece fits with each other
piece, etc.
So when a new person comes in off the street with no time to do a knowledge transfer,
which normally takes months or years in some cases, problems arise and the immediate reaction
is "Ex Employee did this on purpose because we fired them"
I had a warehouse job where I ran into a similar issue. The person I was bring brought in to
replace had been there for 25+ years, and even tho I was being taught by her to replace, I
wasn't up to her speed on a lot of the procedures, and I didn't have the entire warehouse
memorized like she did (She was on the planning team who BUILT the damned thing)
They never understood that I could not do in six months what it took her 25 years to
perfect. "But Kreiger, she's old and retiring, how come you can't do it that fast"
I was hired because of bus factor. My boss crashed his motorcycle and management was forced
to hire someone while he was recovering. But when he returned to work it was back to the old
habits. Even now he leaves me off the all the important stuff and documents nothing. Senior
management is aware and they don't care. Needless to say, I haven't stopped looking.
Well, not being a dick, if I won the lottery, I'd probably stick around doing stuff but
having way, way less stress about any of it. Finish up documentation, wrap up loose ends,
take the team out for dinner and beers, then leave.
Hit by a bus? I'm not going to be doing jack shit if I'm in a casket.
neoice
Principal Linux Systems Engineer 0 points 1 point 2 points 4 years ago (3 children)
my company's bus factor is 1.5-1.75. there are still places where knowledge is stored in a
single head, but we're confident that the other party could figure things out given some
time.
other party could figure things out given some time.
ofcourse, given enough time a qualified person could figure out all systems, that is not
what the bus factor is about.
The Bus Factor is, if you die, quit, or are in some way incapacitated TODAY, can someone
pick up where you left off with out any impact to business operations.
That does not mean "Yes we only have 1 admin for this systems, but the admins of another
system can figure out it over 6 mos" That would be a 1 for a bus factor.
neoice
Principal Linux Systems Engineer 0 points 1 point 2 points 4 years ago (1 child)
I think it would be 3-6mo before anything broke that wasn't bus factor 2. probably 6-9mo for
something actually important.
jhulbe
Citrix Admin 5 points 6 points 7 points 4 years ago (1 child)
yeah, it's usually a lot reseting on one persons shoulders and then he becomes overworked and
resentful of his job but happy to have it. Then if he's ever let go he feels like hes owed
something and gets upset because of all the time has put into his masterpiece.
At a previous job we had a strict password change policy when someone left the company or was
let go. Unfortunately the password change didn't have a task to change it on the backup
system and we had a centralized backup location for all of our customers offsite. An employee
that was let go must have tried all systems and found this one was available. He connected in
and deleted all backup data and stopped them from backing up. He then somehow connected into
the customer somehow (I believe this customer wanted RDP open on a specific port despite our
advice) and used that to connect in and delete their data.
The person tried to make this look like it was not them by using a local public wifi but
it was traced to him since the location it was done at showed he was nearby due to his EZPass
triggering when driving there.
Unfortunately I think today years after this occurred it is still pending investigation
and nothing was really done.
Loki-L
Please contact your System Administrator 7 points 8 points 9 points 4 years ago (2 children)
So far nothing worse than bad online review has ever happened from a co-worker leaving.
Mostly that was because everyone here is sort of a professional and half of the co-workers
that have left, have left to customers or partner companies or otherwise kept in business
contact. There has been very little bridge burning despite a relatively high turnover in the
IT department.
Part of me is hoping that someone would try to do something just so I could have something
to show to the bosses about why I am always talking about having a better exit procedure than
just stopping paying people and having the rest of the company find out by themselves sooner
or later. There have been several instances of me deactivating accounts days or even weeks
after someone stopped working for us because nobody thought to tell anyone....
On the flip-side it appears that if I ever left my current employer I would not need to
sabotage them or withhold any critical information or anything. Based on the fact that they
managed to call me on the first day of my vacation (before I actually planned to get up
really) for something that was both obvious and well documented, I half expect them to simply
collapse by themselves If I stayed away for more than two weeks.
mwerte in
over my head 1 point 2 points 3 points 4 years ago (0 children)
My old company kept paying people on several occasions because nobody bothered to fill out
the 3 form sheet (first, last, date of termination) that was very prominently displayed on
our intranet, send us an email, or even stop by and say "by the way...". It was good times.
It was 1998, and our company had been through another round of layoffs. A few months later, a
rep in member services got a weird error while attempting to log into a large database.
"Please enter in administrative password." She showed it to her supervisor, who had a
password for those types of errors. The manager usually just keyed in the password, which was
used to fix random corrupt or incomplete records. But instead, she paused.
"Why would my rep get this error upon login?"
She called down to the database folks, who did a search and immediately shut down the
database access, which pretty much killed all member service reps from doing any work for the
rest of the day.
Turns out, one of the previous DBA/programmers had released a "time bomb" of sorts into
the database client. Long story short, it was one of those, "if date is greater than [6
months from last build], run a delete query on the primary key upon first login." His mistake
was that the db client was used by a rep who didn't have access to delete records. Had her
manager just typed in a password, they would have wiped and made useless over 50 million
records. Sure, they had backups, but upon restore, it would have done it again.
IIRC, the supervisor and rep got some kind of reward or bonus.
The former DBA was formally charged with whatever the law was back then, but I don't know
what became of him after he was charged.
This isn't a personal experience but was a recent news story that lead to prison time. Guy
ended up with a 4 year prison sentence and a $500k fine.
In June 2012, Mitchell found out he was going to be fired from EnerVest and in response he
decided to reset the company's servers to their original factory settings. He also disabled
cooling equipment for EnerVest's systems and disabled a data-replication process.
Mitchell's actions left EnerVest unable to "fully communicate or conduct business
operations" for about 30 days, according to Booth's office. The company also had to spend
hundreds of thousands of dollars on data-recovery efforts, and part of the information could
not be retrieved.
Maybe that's true, I suppose it depends on circumstance
jdom22
Master of none 6 points 7 points 8 points 4 years ago (2 children)
gaining access to a network you are not permitted to access = federal crime. doing so after a
bitter departure makes you suspect #1. Don't do it. You will get caught, you will go to jail,
you will likely never work in IT again.
Even attempting to access systems you no longer have permission to access can be construed as
malicious in nature and a crime.
lawrish
Automation Lover 5 points 6 points 7 points 4 years ago (0 children)
Once upon a time my company was a mess, they have next to no network infrastructure.
Firewalls? Too fancy. Everything in an external facing server was open. A contractor put a
back door in 4 of those servers, granting root access. Did he ever use it? No idea. I
discovered it 5 years later. Not only that, he was bright enough to upload that really unique
code into github, with his full name and a linkedin profile, linking him to my current
company for 3 months.
here's a tip from a senior sysadmin to anyone considering terminating a peer's employment...
treating someone like garbage is one of the reasons a lot of times the person in question
might put "backdoors" or anything else that could be malicious. i've been fired from a job
before, and you know what i did to "get back at them?" i got another, better job.
be a pro to the person and they'll be a pro to you, even when it's time to move on.
i know one person who retaliated after being fired, and he went to prison for a year. he
was really young and dumb at the time, but it taught me a big lesson on how to act in this
industry. getting mad gets you no where.
I've watched 3 senior IT people fired. All of them were given very cushy severances
(like 4 months) and walked out the door with all sorts of statements like "we are willing to
be a good reference for you" etc etc.
Seen this happen too, but it's usually been when a senior person gets a little crusty around
the edges, starts being an impediment, and refuses to do things the 'new' way.
it has nothing to do with logic, EVERYONE can snap when under the right circumstances. It's
why school shootings, postman shootings even regular road rage and really any craziness
happens, we all have different amount of stress that will make us simply not care, but we're
all capable of losing our shit. Imagine if your wife divorces you, you lose your kids, you
get raped in divorce court, your work suffers, you get fired and you have access to a gun or
in this case a keyboard + admin access... million ways for a person to snap.
and 99.9% of people in 99.9% of cases do, you're missing the simple truth that it can happen
to anyone at anytime, you never know what someone you're firing today has been going through
in the last 6 months. Hence you should worry.
Omega Engineering Corp. ("Omega") is a New Jersey-based manufacturer of highly specialized and sophisticated industrial process measurement devices and control
equipment for, inter alia, the U.S. Navy and NASA. On July 31, 1996, all its design and production computer programs were permanently deleted. About 1,200 computer programs
were deleted and purged, crippling Omega's manufacturing capabilities and resulting in a loss of millions of dollars in sales and contracts.
There's an interesting rumor that because of the insurance payout Omega actually profited
from the sabotage. Maybe that's the real business lesson.
Not a horror story exactly, but, my first IT job I worked for a small non profit as the "IT
Guy" so servers, networks, users, whatever. My manager wanted to get her nephew into IT, so
she "chose not to renew my contract". Her and the HR lady brought me in, told me I wasn't
being renewed and said that for someone in my position they should have someone go to my desk
and clean everything for me and escort me out so I can't damage anything.
I told her, "listen, you both should know I'm not that sort of person, but really, I can
access the entire system from home, easily, if I wanted to trash things I could, but I don't
do that sort of thing. So how about you give me 10 minutes so I can pack up my own personal
things?" They both turned completely white and nodded their heads and I left.
I got emails from the staff for months, the new guy was horrible. My manager was let go a
few months later. Too bad on the timing really as it was a pretty great first IT job.
I used to be a sysadmin at a small web hosting company owned by a family member. When I went
to law school, I asked to take a reduced role. The current management didn't really
understand systems administration, so they asked the outside developer to take on this role.
They then got into a licensing dispute with the developer over ownership of their code.
The dev locked them out and threatened to wipe the servers if he wasn't paid. He started
deleting email accounts and websites as threats. So, I get called the night before the bar exam by the family member.
I walk him through manually changing the root passwords and locking out all the unknown
users. The real annoyance came when I asked the owner some simple information to threaten the
developer. Turns out, the owner didn't even know the guy's full name or address. The checks
were sent to a P.O. box.
I had some minor issues with a co-worker. He got bounced out because he had a bad habit of
changing things and not testing them (and not being around to deal with the fallout). He was
also super high control.
I knew enough about the system (he was actually my "replacement" when my
helpdesk/support/sysadmin job was too big for one person) to head things off at the pass, but
one day I was at the office late doing sysadmin stuff and got bounced off everything. Turns
out he had set "login hours" on my account.
I had one where I was taking over and they still had access; we weren't supposed to cut off
access.
Well they setup backup exclusion and deleted all the backups of a certain directory. This
directory had about 20 scripts which eliminates people's jobs and after about 1 week they
deleted the folder.
Mind you I had no idea it was even there. The disaster started in the morning and
eventually after lunch all I did was log in as their user and restore it from their recycle
bin.
We then kept the story going and asking them for copies of the scripts etc etc. They
played it off like 'oh wow you guys havent even taken over yet and there's a disaster' and
'unfortunately we don't have copies of your scripts.'
It was days before they managed to find them and sent them to us. You also read the things. REM This script is a limited license use to use only if you are
our customer. Copyrights are ours.
So naturally I fix their scripts as there was problems with them and I put GPL at the top.
Month later they contact the CFO with a quote of $40,000 to allow them to keep using their
intellectual property. I wish I got to see their face when they got the email back
saying.
"We caught you deleting the scripts and since it took you too long to respond and provide
us with the scripts we wrote our owned and we licensed this with GPL, because it would be
unethical to do otherwise.
Fortunately since we are not using your scripts and you just sent
them to us without any mention of cost; we owe nothing."
However, slapping the GPL on top of someone else's licensed code doesn't actually GPL
it.
I never said I put GPL on their work. I put GPL on my work. I recreated the scripts from
scratch. I can license my own work however I damned well feel.
In the 1980s, there was a story that went around the computer hobbyist circles about a travel
agency in our area. They were big, and had all kinds of TV ads. Their claim to fame was how
modern they were (for the time), and used computers to find the best deal at the last second,
predict travel cost trends, and so on.
But behind the scenes, all was not well. The person in charge of their computer system was
this older, crotchety bastard who was a former IBM or DEC employee (I forget which). The
stereotype of the BOFH before that was even a thing. He was unfriendly, made his own hours,
and as time went on, demanded more money, less work, more hardware, and management hated him.
They tried to hire him help, but he refused to tell the new guys anything, and after 2-3
years of assistant techs quitting, they finally fired the guy and hired a consulting team to
take over.
The programmer left quietly, didn't create a fuss, and no one suspected anything was
amiss. But at some point, he dialed back into the mainframe and wiped all records and data.
The backup tapes were all blank, too. He didn't document anything.
This pretty much fucked the company. They were out of business within a few months.
The big news about this was at the time, there was no precedence for this type of
behavior, and there were no laws specific to this kind of crime. Essentially, they didn't
have any proof of what he did, and those that could prove it didn't have a case because it
wasn't a crime yet. He couldn't be charged with destruction of property, because no property
was actually touched (from a legal perspective). This led to more modern laws and some of the
first laws in preventing data from being deleted.
I worked for a local government agency and our group acquired a sociopath boss.
My then supervisor (direct report to $Crazy) found another job and gave his notice. On his
last day he admitted that he had considered screwing with things but that the people mostly
hurt by it would be us and his beef was not with us.
$Crazy must have heard because all future leavers in the group (and there was hella
turnover) got put on admin leave the minute they gave notice. E.g. no system access.
This is also more a people/process issue than a technical one.
If your processes are in place to ensure documentation is written, access is listed
somewhere etc. then it shouldn't be an issue.
If the people who are hiring are like this, then there was an issue in the hiring process
- people with these kind of ethics aren't good admins. They're not even admins. They're
chumps.
The guy I actually replaced was leaving on bad terms and let loose Conficker right before he
left and caused a lot of other issues. He is now the Director of IT at another corporation
....
Change admin and the pw of Terminated Domain Admin. Reformat TAD's pcs. Tell Tad he's welcome
to x months of severance as long as Tad doesn't come back or start shit. Worked for us so
far...
I have a horror story from
another IT person. One day they were tasked with adding a new server to a rack in their data
center. They added the server... being careful to not bump a cable to the nearby production
servers, SAN, and network switch. The physical install went well. But when they powered on the
server, the ENTIRE RACK went dark. Customers were not happy:( IT turns out that the power
circuit they attached the server to was already at max capacity and thus they caused the
breaker to trip. Lessons learned... use redundant power and monitor power consumption.
Another issue was being a newbie on a Cisco switch and making a few changes and thinking the
innocent sounding "reload" command would work like Linux does when you restart a daemon.
Watching 48 link activity LEDs go dark on your vmware cluster switch... Priceless
"... "Of course! You told me that I had to stay a couple of extra hours to perform that task," I answered. "Exactly! But you preferred to leave early without finishing that task," he said. "Oh my! I thought it was optional!" I exclaimed. ..."
"... "It was, it was " ..."
"... Even with the best solution that promises to make the most thorough backups, the ghost of the failed restoration can appear, darkening our job skills, if we don't make a habit of validating the backup every time. ..."
In a well-known data center (whose name I do not want to remember), one cold October night we had a production outage in which
thousands of web servers stopped responding due to downtime in the main database. The database administrator asked me, the rookie
sysadmin, to recover the database's last full backup and restore it to bring the service back online.
But, at the end of the process, the database was still broken. I didn't worry, because there were other full backup files in stock.
However, even after doing the process several times, the result didn't change.
With great fear, I asked the senior sysadmin what to do to fix this behavior.
"You remember when I showed you, a few days ago, how the full backup script was running? Something about how important it was
to validate the backup?" responded the sysadmin.
"Of course! You told me that I had to stay a couple of extra hours to perform that task," I answered. "Exactly! But you preferred to leave early without finishing that task," he said. "Oh my! I thought it was optional!" I exclaimed.
"It was, it was "
Moral of the story: Even with the best solution that promises to make the most thorough backups, the ghost of the failed restoration
can appear, darkening our job skills, if we don't make a habit of validating the backup every time.
The most typical danger is dropping of the hard drive on the floor.
Notable quotes:
"... Also, backing up to another disk in the same computer will probably not save you when lighting strikes, as the backup disk is just as likely to be fried as the main disk. ..."
"... In real life, the backup strategy and hardware/software choices to support it is (as most other things) a balancing act. The important thing is that you have a strategy, and that you test it regularly to make sure it works as intended (as the main point is in the article). Also, realizing that achieving 100% backup security is impossible might save a lot of time in setting up the strategy. ..."
Why don't you just buy an extra hard disk and have a copy of your important data there. With
today's prices it doesn't cost anything.
Anonymous on Fri, 11/08/2002 - 03:00. A lot of people seams to have this idea, and in many situations
it should work fine.
However, there is the human factor. Sometimes simple things go wrong (as simple as copying
a file), and it takes a while before anybody notices that the contents of this file is not what
is expected. This means you have to have many "generations" of backup of the file in order to
be able to restore it, and in order to not put all the "eggs in the same basket" each of the file
backups should be on a physical device.
Also, backing up to another disk in the same computer will probably not save you when lighting
strikes, as the backup disk is just as likely to be fried as the main disk.
In real life, the backup strategy and hardware/software choices to support it is (as most other
things) a balancing act. The important thing is that you have a strategy, and that you test it
regularly to make sure it works as intended (as the main point is in the article). Also, realizing
that achieving 100% backup security is impossible might save a lot of time in setting up the strategy.
(I.e. you have to say that this strategy has certain specified limits, like not being able
to restore a file to its intermediate state sometime during a workday, only to the state it had
when it was last backed up, which should be a maximum of xxx hours ago and so on...)
I was reaching down to power up the new UPS as my guy was stepping out from behind the rack
and the whole rack went dark. His foot caught the power cord of the working UPS and pulled it
just enough to break the contacts and since the battery was failed it couldn't provide power
and shut off. It took about 30 minutes to bring everything back up..
Things went much better with the second UPS replacement. :-)
Working for a large UK-based international IT company, I had a call from newest guy in the
internal IT department: "The main server, you know ..."
"Yes?"
"I was cleaning out somebody's homedir ..."
"Yes?"
"Well, the server stopped running properly ..."
"Yes?"
"... and I can't seem to get it to boot now ..."
"Oh-kayyyy. I'll just totter down to you and give it an eye."
I went down to the basement where the IT department was located and had a look at his
terminal screen on his workstation. Going back through the terminal history, just before a
hefty amount of error messages, I found his last command: 'rm -rf /home/johndoe /*'. And I
probably do not have to say that he was root at the time (it was them there days before sudo,
not that that would have helped in his situation).
"Right," I said. "Time to get the backup." I knew I had to leave when I saw his face start
twitching and he whispered: "Backup ...?"
==========
Bonus entries from same company:
It was the days of the 5.25" floppy disks (Wikipedia is your friend, if you belong to the
younger generation). I sometimes had to ask people to send a copy of a floppy to check why
things weren't working properly. Once I got a nice photocopy and another time, the disk came
with a polite note attached ... stapled through the disk, to be more precise!
I'm writing bash script which defines several path constants and will use them for file
and directory manipulation (copying, renaming and deleting). Often it will be necessary to do
something like:
rm -rf "/${PATH1}"
rm -rf "${PATH2}/"*
While developing this script I'd want to protect myself from mistyping names like PATH1
and PATH2 and avoid situations where they are expanded to empty string, thus resulting in
wiping whole disk. I decided to create special wrapper:
rmrf() {
if [[ $1 =~ "regex" ]]; then
echo "Ignoring possibly unsafe path ${1}"
exit 1
fi
shopt -s dotglob
rm -rf -- $1
shopt -u dotglob
}
Which will be called as:
rmrf "/${PATH1}"
rmrf "${PATH2}/"*
Regex (or sed expression) should catch paths like "*", "/*", "/**/", "///*" etc. but allow
paths like "dir", "/dir", "/dir1/dir2/", "/dir1/dir2/*". Also I don't know how to enable
shell globbing in case like "/dir with space/*". Any ideas?
EDIT: this is what I came up with so far:
rmrf() {
local RES
local RMPATH="${1}"
SAFE=$(echo "${RMPATH}" | sed -r 's:^((\.?\*+/+)+.*|(/+\.?\*+)+.*|[\.\*/]+|.*/\.\*+)$::g')
if [ -z "${SAFE}" ]; then
echo "ERROR! Unsafe deletion of ${RMPATH}"
return 1
fi
shopt -s dotglob
if [ '*' == "${RMPATH: -1}" ]; then
echo rm -rf -- "${RMPATH/%\*/}"*
RES=$?
else
echo rm -rf -- "${RMPATH}"
RES=$?
fi
shopt -u dotglob
return $RES
}
Intended use is (note an asterisk inside quotes):
rmrf "${SOMEPATH}"
rmrf "${SOMEPATH}/*"
where $SOMEPATH is not system or /home directory (in my case all such operations are
performed on filesystem mounted under /scratch directory).
CAVEATS:
not tested very well
not intended to use with paths possibly containing '..' or '.'
should not be used with user-supplied paths
rm -rf with asterisk probably can fail if there are too many files or directories
inside $SOMEPATH (because of limited command line length) - this can be fixed with 'for'
loop or 'find' command
I've found a big danger with rm in bash is that bash usually doesn't stop for errors. That
means that:
cd $SOMEPATH
rm -rf *
Is a very dangerous combination if the change directory fails. A safer way would be:
cd $SOMEPATH && rm -rf *
Which will ensure the rf won't run unless you are really in $SOMEPATH. This doesn't
protect you from a bad $SOMEPATH but it can be combined with the advice given by others to
help make your script safer.
EDIT: @placeybordeaux makes a good point that if $SOMEPATH is undefined or empty
cd doesn't treat it as an error and returns 0. In light of that this answer
should be considered unsafe unless $SOMEPATH is validated as existing and non-empty first. I
believe cd with no args should be an illegal command since at best is performs a
no-op and at worse it can lead to unexpected behaviour but it is what it is.
Instead of cd $SOMEPATH , you should write cd "${SOMEPATH?}" . The
${varname?} notation ensures that the expansion fails with a warning-message if
the variable is unset or empty (such that the && ... part is never run);
the double-quotes ensure that special characters in $SOMEPATH , such as
whitespace, don't have undesired effects. – ruakh
Jul 13 '18 at 6:46
There is a set -u bash directive that will cause exit, when uninitialized
variable is used. I read about it here , with
rm -rf as an example. I think that's what you're looking for. And here is
set's manual .
,Jun 14, 2009 at 12:38
I think "rm" command has a parameter to avoid the deleting of "/". Check it out.
Generally, when I'm developing a command with operations such as ' rm -fr ' in
it, I will neutralize the remove during development. One way of doing that is:
RMRF="echo rm -rf"
...
$RMRF "/${PATH1}"
This shows me what should be deleted - but does not delete it. I will do a manual clean up
while things are under development - it is a small price to pay for not running the risk of
screwing up everything.
The notation ' "/${PATH1}" ' is a little unusual; normally, you would ensure
that PATH1 simply contains an absolute pathname.
Using the metacharacter with ' "${PATH2}/"* ' is unwise and unnecessary. The
only difference between using that and using just ' "${PATH2}" ' is that if the
directory specified by PATH2 contains any files or directories with names starting with dot,
then those files or directories will not be removed. Such a design is unlikely and is rather
fragile. It would be much simpler just to pass PATH2 and let the recursive remove do its job.
Adding the trailing slash is not necessarily a bad idea; the system would have to ensure that
$PATH2 contains a directory name, not just a file name, but the extra protection
is rather minimal.
Using globbing with ' rm -fr ' is usually a bad idea. You want to be precise
and restrictive and limiting in what it does - to prevent accidents. Of course, you'd never
run the command (shell script you are developing) as root while it is under development -
that would be suicidal. Or, if root privileges are absolutely necessary, you neutralize the
remove operation until you are confident it is bullet-proof.
To delete subdirectories and files starting with dot I use "shopt -s dotglob". Using rm -rf
"${PATH2}" is not appropriate because in my case PATH2 can be only removed by superuser and
this results in error status for "rm" command (and I verify it to track other errors).
– Max
Jun 14 '09 at 13:09
Then, with due respect, you should use a private sub-directory under $PATH2 that you can
remove. Avoid glob expansion with commands like 'rm -rf' like you would avoid the plague (or
should that be A/H1N1?). – Jonathan Leffler
Jun 14 '09 at 13:37
If it is possible, you should try and put everything into a folder with a hard-coded name
which is unlikely to be found anywhere else on the filesystem, such as '
foofolder '. Then you can write your rmrf() function as:
You don't need to use regular expressions.
Just assign the directories you want to protect to a variable and then iterate over the
variable. eg:
protected_dirs="/ /bin /usr/bin /home $HOME"
for d in $protected_dirs; do
if [ "$1" = "$d" ]; then
rm=0
break;
fi
done
if [ ${rm:-1} -eq 1 ]; then
rm -rf $1
fi
,
Add the following codes to your ~/.bashrc
# safe delete
move_to_trash () { now="$(date +%Y%m%d_%H%M%S)"; mv "$@" ~/.local/share/Trash/files/"$@_$now"; }
alias del='move_to_trash'
# safe rm
alias rmi='rm -i'
Every time you need to rm something, first consider del , you
can change the trash folder. If you do need to rm something, you could go to the
trash folder and use rmi .
One small bug for del is that when del a folder, for example,
my_folder , it should be del my_folder but not del
my_folder/ since in order for possible later restore, I attach the time information in
the end ( "$@_$now" ). For files, it works fine.
Not really a horror story but definitely one of my first "Oh shit" moments. I was the FNG
helpdesk/sysadmin at a company of 150 people. I start getting calls that something (I think
it was Outlook) wasn't working in Citrix, apparently something broken on one of the Citrix
servers. I'm 100% positive it will be fixed with a reboot (I've seen this before on
individual PCs), so I diligently start working to get people off that Citrix server (one of
three) so I can reboot it.
I get it cleared out, hit Reboot... And almost immediately get a call from the call center
manager saying every single person just got kicked off Citrix. Oh shit. But there was nobody
on that server! Apparently that server also housed the Secure Gateway server which my senior
hadn't bothered to tell me or simply didn't know (Set up by a consulting firm). Whoops.
Thankfully the servers were pretty fast and people's sessions reconnected a few minutes
later, no harm no foul. And on the plus side, it did indeed fix the problem.
And that's how I learned to always check with somebody else before rebooting a production
server, no matter how minor it may seem.
Introduction Despite my woeful knowledge of networking, I run my own DNS servers on my own websites run from home. I achieved
this through trial and error and now it requires almost zero maintenance, even though I don't have a static IP at home.
Here I share
how (and why) I persist in this endeavour.
Overview This is an overview of the setup:
This is how I set up my DNS. I:
got a domain from an authority (a .tk domain in my case)
set up glue records to defer DNS queries to my nameservers
set up nameservers with static IPs
set up a dynamic DNS updater from home
How? Walking through step-by-step how I did it: 1) Set up two Virtual Private Servers (VPSes) You will need two stable
machines with static IP addresses. If you're not lucky enough to have these in your possession, then you can set one up on the cloud.
I used this site , but there are plenty out there.
NB I asked them, and their IPs are static per VPS. I use the cheapest cloud VPS (1$/month) and set up debian on there. NOTE: Replace
any mention of DNSIP1 and DNSIP2 below with the first and second static IP addresses you are given. Log on and set up root password SSH to the servers and set up a strong root password.
2) Set up domains You will need
two domains: one for your dns servers, and one for the application running on your host. I use
dot.tk to get free throwaway domains. In this case, I might setup a myuniquedns.tk
DNS domain and a myuniquesite.tk site domain. Whatever you choose, replace your DNS domain when you see YOURDNSDOMAIN
below. Similarly, replace your app domain when you see YOURSITEDOMAIN below. 3) Set up a 'glue' record If you
use dot.tk as above, then to allow you to manage the YOURDNSDOMAIN domain you will need to set up a 'glue' record. What
this does is tell the current domain authority (dot.tk) to defer to your nameservers (the two servers you've set up) for this specific
domain. Otherwise it keeps referring back to the .tk domain for the IP. See
here for a fuller explanation. Another
good explanation is here . To do this you need to check
with the authority responsible how this is done, or become the authority yourself. dot.tk has a web interface for setting up a glue
record, so I used that. There, you need to go to 'Manage Domains' => 'Manage Domain' => 'Management Tools' => 'Register Glue Records'
and fill out the form. Your two hosts will be called ns1.YOURDNSDOMAIN and ns2.YOURDNSDOMAIN , and the
glue records will point to either IP address. Note, you may need to wait a few hours (or longer) for this to take effect. If really
unsure, give it a day.
If you like this post, you might be interested in my book Learn Bash the Hard Way , available
here for just $5.
4) Install bind on the DNS Servers On a Debian machine (for example), and as root, type: apt install
bind9bind is the domain name server software you will be running. 5) Configure bind on the DNS
Servers Now, this is the hairy bit. There are two parts this with two files involved: named.conf.local , and the
db.YOURDNSDOMAIN file. They are both in the /etc/bind folder. Navigate there and edit these files. Part
1 – named.conf.local This file lists the 'zone's (domains) served by your DNS servers. It also defines whether this
bind instance is the 'master' or the 'slave'. I'll assume ns1.YOURDNSDOMAIN is the 'master' and
ns2.YOURDNSDOMAIN
is the 'slave.
Part 1a – the master
On the master/ ns1.YOURNDSDOMAIN , the named.conf.local should be changed to look like this:
zone "YOURDNSDOMAIN" {
type master;
file "/etc/bind/db.YOURDNSDOMAIN";
allow-transfer { DNSIP2; };
};
zone "YOURSITEDOMAIN" {
type master;
file "/etc/bind/YOURDNSDOMAIN";
allow-transfer { DNSIP2; };
};
zone "14.127.75.in-addr.arpa" {
type master;
notify no;
file "/etc/bind/db.75";
allow-transfer { DNSIP2; };
};
logging {
channel query.log {
file "/var/log/query.log";
// Set the severity to dynamic to see all the debug messages.
severity debug 3;
};
category queries { query.log; };
};
The logging at the bottom is optional (I think). I added it a while ago, and I leave it in here for interest. I don't know what the
14.127 zone stanza is about.
On the slave/ ns2.YOURNDSDOMAIN , the named.conf.local should be changed to look like this:
zone "YOURDNSDOMAIN" {
type slave;
file "/var/cache/bind/db.YOURDNSDOMAIN";
masters { DNSIP1; };
};
zone "YOURSITEDOMAIN" {
type slave;
file "/var/cache/bind/db.YOURSITEDOMAIN";
masters { DNSIP1; };
};
zone "14.127.75.in-addr.arpa" {
type slave;
file "/var/cache/bind/db.75";
masters { DNSIP1; };
};
Part 2 – db.YOURDNSDOMAIN
Now we get to the meat – your DNS database is stored in this file.
On the master/ ns1.YOURDNSDOMAIN the db.YOURDNSDOMAIN file looks like this :
$TTL 4800
@ IN SOA ns1.YOURDNSDOMAIN. YOUREMAIL.YOUREMAILDOMAIN. (
2018011615 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns1.YOURDNSDOMAIN.
@ IN NS ns2.YOURDNSDOMAIN.
ns1 IN A DNSIP1
ns2 IN A DNSIP2
YOURSITEDOMAIN. IN A YOURDYNAMICIP
On the slave/ ns2.YOURDNSDOMAIN it's very similar, but has ns1 in the SOA line, and the IN
NS lines reversed. I can't remember if this reversal is needed or not :
$TTL 4800 @ IN SOA ns1.YOURDNSDOMAIN. YOUREMAIL.YOUREMAILDOMAIN. (
2018011615 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
@ IN NS ns1.YOURDNSDOMAIN.
@ IN NS ns2.YOURDNSDOMAIN.
ns1 IN A DNSIP1
ns2IN A DNSIP2
YOURSITEDOMAIN. IN A YOURDYNAMICIP
A few notes on the above:
The dots at the end of lines are not typos – this is how domains are written in bind files. So google.com
is written google.com.
The YOUREMAIL.YOUREMAILDOMAIN. part must be replaced by your own email. For example, my email address: [email protected]
becomes ianmiell.gmail.com. . Note also that the dot between first and last name is dropped. email ignores those
anyway!
YOURDYNAMICIP is the IP address your domain should be pointed to (ie the IP address returned by the DNS server).
It doesn't matter what it is at this point, because .
the next step is to dynamically update the DNS server with your dynamic IP address whenever it changes.
6) Copy ssh keys
Before setting up your dynamic DNS you need to set up your ssh keys so that your home server can access the DNS servers.
NOTE: This is not security advice. Use at your own risk.
First, check whether you already have an ssh key generated:
ls ~/.ssh/id_rsa
If that returns a file, you're all set up. Otherwise, type:
ssh-keygen
and accept the defaults.
Then, once you have a key set up, copy your ssh ID to the nameservers:
ssh-copy-id root@DNSIP1
ssh-copy-id root@DNSIP2
Inputting your root password on each command.
7) Create an IP updater script
Now ssh to both servers and place this script in /root/update_ip.sh :
#!/bin/bash
set -o nounset
sed -i "s/^(.*) IN A (.*)$/1 IN A $1/" /etc/bind/db.YOURDNSDOMAIN
sed -i "s/.*Serial$/ $(date +%Y%m%d%H) ; Serial/" /etc/bind/db.YOURDNSDOMAIN
/etc/init.d/bind9 restart
Make it executable by running:
chmod +x /root/update_ip.sh
Going through it line by line:
set -o nounset
This line throws an error if the IP is not passed in as the argument to the script.
sed -i "s/^(.*) IN A (.*)$/1 IN A $1/" /etc/bind/db.YOURDNSDOMAIN
Replaces the IP address with the contents of the first argument to the script.
This diffs the contents of /tmp/ip.tmp with /tmp/ip (which is yet to be created, and holds the last-updated
ip address). If there is an error (ie there is a new IP address to update on the DNS server), then the subshell is run. This overwrites
the ip address, and then ssh'es onto the
The same process is then repeated for DNSIP2 using separate files ( /tmp/ip.tmp2 and /tmp/ip2
).
Why!?
You may be wondering why I do this in the age of cloud services and outsourcing. There's a few reasons.
It's Cheap
The cost of running this stays at the cost of the two nameservers (24$/year) no matter how many domains I manage and whatever
I want to do with them.
Learning
I've learned a lot by doing this, probably far more than any course would have taught me.
More Control
I can do what I like with these domains: set up any number of subdomains, try my hand at secure mail techniques, experiment
with obscure DNS records and so on.
I could extend this into a service. If you're interested, my rates are very low :)
If you like this post, you might be interested in my book Learn Bash the Hard Way , available
here for just $5.
that diagram shows what happens according to the man page, and not what happens when you actually try it out in real life. This second
diagram more accurately captures the insanity of bash:
See how remote interactive login shells read /etc/bash.bashrc, but normal interactive login shells don't? Sigh.
Finally, here's a repository containing my implementation
and the graphviz files for the above diagram. If your POSIX-compliant shell isn't listed here, or if I've made a horrible mistake
(or just a tiny one), please send me a pull request or make a comment below, and I'll update this post accordingly.
In my experience, if your bash sources /etc/bash.bashrc, odds are good it also sources /etc/bash.bash_logout
or something similar on logout (after ~/.bash_logout, of course).
They don't want to replace the kernel, they are more than happy to leverage Linus's good
work on what they see as a collection of device drivers. No, they want to replace the GNU/X
in the traditional Linux/GNU/X arrangement. All of the command line tools, up to and
including bash are to go, replaced with the more Windows like tools most of the systemd
developers grew up on, while X and the desktop environments all get rubbished for Wayland
and GNOME3.
And I would wish them luck, the world could use more diversity in operating systems. So
long as they stayed the hell over at RedHat and did their grand experiment and I could
still find a Linux/GNU/X distribution to run. But they had to be borg and insist that all
must bend the knee and to that I say HELL NO!
Recently I wanted to deepen my understanding of bash by researching as much of it as
possible. Because I felt bash is an often-used (and under-understood) technology, I ended up
writing a book on it
.
You don't have to look hard on the internet to find plenty of useful one-liners in bash, or
scripts. And there are guides to bash that seem somewhat intimidating through either their
thoroughness or their focus on esoteric detail.
Here I've focussed on the things that either confused me or increased my power and
productivity in bash significantly, and tried to communicate them (as in my book) in a way that
emphasises getting the understanding right.
Enjoy!
1)
`` vs $()
These two operators do the same thing. Compare these two lines:
$ echo `ls`
$ echo $(ls)
Why these two forms existed confused me for a long time.
If you don't know, both forms substitute the output of the command contained within it into
the command.
The principal difference is that nesting is simpler.
Which of these is easier to read (and write)?
$ echo `echo \`echo \\\`echo inside\\\`\``
or:
$ echo $(echo $(echo $(echo inside)))
If you're interested in going deeper, see here or
here .
2) globbing vs regexps
Another one that can confuse if never thought about or researched.
While globs and regexps can look similar, they are not the same.
Consider this command:
$ rename -n 's/(.*)/new$1/' *
The two asterisks are interpreted in different ways.
The first is ignored by the shell (because it is in quotes), and is interpreted as '0 or
more characters' by the rename application. So it's interpreted as a regular expression.
The second is interpreted by the shell (because it is not in quotes), and gets replaced by a
list of all the files in the current working folder. It is interpreted as a glob.
So by looking at man bash can you figure out why these two commands produce
different output?
$ ls *
$ ls .*
The second looks even more like a regular expression. But it isn't!
3) Exit Codes
Not everyone knows that every time you run a shell command in bash, an 'exit code' is
returned to bash.
Generally, if a command 'succeeds' you get an error code of 0 . If it doesn't
succeed, you get a non-zero code. 1 is a 'general error', and others can give you
more information (eg which signal killed it, for example).
But these rules don't always hold:
$ grep not_there /dev/null
$ echo $?
$? is a special bash variable that's set to the exit code of each command after
it runs.
Grep uses exit codes to indicate whether it matched or not. I have to look up every time
which way round it goes: does finding a match or not return 0 ?
Grok this and a lot will click into place in what follows.
4) if
statements, [ and [[
Here's another 'spot the difference' similar to the backticks one above.
What will this output?
if grep not_there /dev/null
then
echo hi
else
echo lo
fi
grep's return code makes code like this work more intuitively as a side effect of its use of
exit codes.
Now what will this output?
a) hihi
b) lolo
c) something else
if [ $(grep not_there /dev/null) = '' ]
then
echo -n hi
else
echo -n lo
fi
if [[ $(grep not_there /dev/null) = '' ]]
then
echo -n hi
else
echo -n lo
fi
The difference between [ and [[ was another thing I never really
understood. [ is the original form for tests, and then [[ was
introduced, which is more flexible and intuitive. In the first if block above, the
if statement barfs because the $(grep not_there /dev/null) is evaluated to
nothing, resulting in this comparison:
[ = '' ]
which makes no sense. The double bracket form handles this for you.
This is why you occasionally see comparisons like this in bash scripts:
if [ x$(grep not_there /dev/null) = 'x' ]
so that if the command returns nothing it still runs. There's no need for it, but that's why
it exists.
5) set s
Bash has configurable options which can be set on the fly. I use two of these all the
time:
set -e
exits from a script if any command returned a non-zero exit code (see above).
This outputs the commands that get run as they run:
set -x
So a script might start like this:
#!/bin/bash
set -e
set -x
grep not_there /dev/null
echo $?
What would that script output?
6) <()
This is my favourite. It's so under-used, perhaps because it can be initially baffling, but
I use it all the time.
It's similar to $() in that the output of the command inside is re-used.
In this case, though, the output is treated as a file. This file can be used as an argument
to commands that take files as an argument.
Quoting's a knotty subject in bash, as it is in many software contexts.
Firstly, variables in quotes:
A='123'
echo "$A"
echo '$A'
Pretty simple – double quotes dereference variables, while single quotes go
literal.
So what will this output?
mkdir -p tmp
cd tmp
touch a
echo "*"
echo '*'
Surprised? I was.
8) Top three shortcuts
There are plenty of shortcuts listed in man bash , and it's not hard to find
comprehensive lists. This list consists of the ones I use most often, in order of how often I
use them.
Rather than trying to memorize them all, I recommend picking one, and trying to remember to
use it until it becomes unconscious. Then take the next one. I'll skip over the most obvious
ones (eg !! – repeat last command, and ~ – your home
directory).
!$
I use this dozens of times a day. It repeats the last argument of the last command. If
you're working on a file, and can't be bothered to re-type it command after command it can save
a lot of work:
grep somestring /long/path/to/some/file/or/other.txt
vi !$
!:1-$
This bit of magic takes this further. It takes all the arguments to the previous command and
drops them in. So:
The ! means 'look at the previous command', the : is a separator,
and the 1 means 'take the first word', the - means 'until' and the
$ means 'the last word'.
Note: you can achieve the same thing with !* . Knowing the above gives you the
control to limit to a specific contiguous subset of arguments, eg with !:2-3 .
:h
I use this one a lot too. If you put it after a filename, it will change that filename to
remove everything up to the folder. Like this:
grep isthere /long/path/to/some/file/or/other.txt
cd !$:h
which can save a lot of work in the course of the day.
9) startup order
The order in which bash runs startup scripts can cause a lot of head-scratching. I keep this
diagram handy (from this great page):
It shows which scripts bash decides to run from the top, based on decisions made about the
context bash is running in (which decides the colour to follow).
So if you are in a local (non-remote), non-login, interactive shell (eg when you run bash
itself from the command line), you are on the 'green' line, and these are the order of files
read:
/etc/bash.bashrc
~/.bashrc
[bash runs, then terminates]
~/.bash_logout
This can save you a hell of a lot of time debugging.
10) getopts (cheapci)
If you go deep with bash, you might end up writing chunky utilities in it. If you do, then
getting to grips with getopts can pay large dividends.
For fun, I once wrote a script called
cheapci which I used to work like a Jenkins job.
The code here implements the
reading of the two required, and 14
non-required arguments . Better to learn this than to build up a bunch of bespoke code that
can get very messy pretty quickly as your utility grows.
(20 of which on Debian, before that was Slackware)
I am new to systemd, maybe 3 or 4 months now tops on Ubuntu, and a tiny bit on Debian before
that.
I was confident I was going to hate systemd before I used it just based on the comments I
had read over the years, I postponed using it as long as I could. Took just a few minutes of
using it to confirm my thoughts. Now to be clear, if I didn't have to mess with the systemd to
do stuff then I really wouldn't care since I don't interact with it (which is the case on my
laptop at least though laptop doesn't have systemd anyway). I manage about 1,000 systems
running Ubuntu for work, so I have to mess with systemd, and init etc there.
If systemd would just do ONE thing I think it would remove all of the pain that it has
inflicted on me over the past several months and I could learn to accept it.
That one thing is, if there is an init script, RUN IT. Not run it like systemd does now. But
turn off ALL intelligence systemd has when it finds that script and run it. Don't put it on any
special timers, don't try to detect if it is running already, or stopped already or whatever,
fire the script up in blocking mode and wait till it exits.
My first experience with systemd was on one of my home servers, I re-installed Debian on it
last year, rebuilt the hardware etc and with it came systemd. I believe there is a way to turn
systemd off but I haven't tried that yet. The first experience was with bind. I have a slightly
custom init script (from previous debian) that I have been using for many years. I copied it to
the new system and tried to start bind. Nothing. I looked in the logs and it seems that it was
trying to interface with rndc(internal bind thing) for some reason, and because rndc was not
working(I never used it so I never bothered to configure it) systemd wouldn't launch bind. So I
fixed rndc and systemd would now launch bind, only to stop it within 1 second of launching. My
first workaround was just to launch bind by hand at the CLI (no init script), left it running
for a few months. Had a discussion with a co-worker who likes systemd and he explained that
making a custom unit file and using the type=forking option may fix it.. That did fix the
issue.
Next issue came up when dealing with MySQL clusters. I had to initialize the cluster with
the "service mysql bootstrap-pxc" command (using the start command on the first cluster member
is a bad thing). Run that with systemd, and systemd runs it fine. But go to STOP the service,
and systemd thinks the service is not running so doesn't even TRY to stop the service(the
service is running). My workaround for my automation for mysql clusters at this point is to
just use mysqladmin to shut the mysql instances down. Maybe newer mysql versions have better
systemd support though a co-worker who is our DBA and has used mysql for many years says even
the new Maria DB builds don't work well with systemd. I am working with Mysql 5.6 which is of
course much much older.
Next issue came up with running init scripts that have the same words in them, in the case
of most recently I upgraded systems to systemd that run OSSEC. OSSEC has two init scripts for
us on the server side (ossec and ossec-auth). Systemd refuses to run ossec-auth because it
thinks there is a conflict with the ossec service. I had the same problem with multiple varnish
instances running on the same system (varnish instances were named varnish-XXX and
varnish-YYY). In the varnish case using custom unit files I got systemd to the point where it
would start the service but it still refuses to "enable" the service because of the name
conflict (I even changed the name but then systemd was looking at the name of the binary being
called in the unit file and said there is a conflict there).
fucking a. Systemd shut up, just run the damn script. It's not hard.
Later a co-worker explained the "systemd way" for handling something like multiple varnish
instances on the system but I'm not doing that, in the meantime I just let chef start the
services when it runs after the system boots(which means they start maybe 1 or 2 mins after
bootup).
Another thing bit us with systemd recently as well again going back to bind. Someone on the
team upgraded our DNS systems to systemd and the startup parameters for bind were not preserved
because systemd ignores the /etc/default/bind file. As a result we had tons of DNS failures
when bind was trying to reach out to IPv6 name servers(ugh), when there is no IPv6 connectivity
in the network (the solution is to start bind with a -4 option).
I believe I have also caught systemd trying to mess with file systems(iscsi mount points). I
have lots of automation around moving data volumes on the SAN between servers and attaching
them via software iSCSI directly to the VMs themselves(before vsphere 4.0 I attached them via
fibre channel to the hypervisor but a feature in 4.0 broke that for me). I noticed on at least
one occasion when I removed the file systems from a system that SOMETHING (I assume systemd)
mounted them again, and it was very confusing to see file systems mounted again for block
devices that DID NOT EXIST on the server at the time. I worked around THAT one I believe with
the "noauto" option in fstab again. I had to put a lot of extra logic in my automation scripts
to work around systemd stuff.
I'm sure I've only scratched the surface of systemd pain. I'm sure it provides good value to
some people, I hear it's good with containers (I have been running LXC containers for years
now, I see nothing with systemd that changes that experience so far).
But if systemd would just do this one thing and go into dumb mode with init scripts I would
be quite happy.
"Shadow files" approach of Solaris 10, where additional functions of init are controlled by XML script that exist in a
separate directory with the same names as init scripts can be improved but architecturally it is much cleaner then systemd
approach.
Notable quotes:
"... Solaris has a similar parallellised startup system, with some similar problems, but it didn't need pid 1. ..."
"... Agreed, Solaris svcadm and svcs etc are an example of how it should be done. A layered approach maintaining what was already there, while adding functionality for management purposes. Keeps all the old text based log files and uses xml scripts (human readable and editable) for higher level functions. ..."
"... AFAICT everyone followed RedHat because they also dominate Gnome, and chose to make Gnome depend on systemd. Thus if one had any aspirations for your distro supporting Gnome in any way, you have to have systemd underneath it all. ..."
Re: Poettering still doesn't get it... Pid 1 is for people wearing big boy pants.
SystemD is corporate money (Redhat support dollars) triumphing over the long hairs sadly.
Enough money can buy a shitload of code and you can overwhelm the hippies with hairball
dependencies (the key moment was udev being dependent on systemd) and soon get as much FOSS as
possible dependent on the Linux kernel.
This has always been the end game as Red Hat makes its
bones on Linux specifically not on FOSS in general (that say runs on Solaris or HP-UX).
The
tighter they can glue the FOSS ecosystem and the Linux kernel together ala Windows lite style
the better for their bottom line. Poettering is just being a good employee asshat
extraordinaire he is.
Re: Ahhh SystemD
I honestly would love someone to lay out the problems it solves.
Solaris has a similar parallellised startup system, with some similar problems, but it didn't need pid 1.
Re: Ahhh SystemD
Agreed, Solaris svcadm and svcs etc are an example of how it should be done. A layered
approach maintaining what was already there, while adding functionality for management
purposes. Keeps all the old text based log files and uses xml scripts (human readable and
editable) for higher level functions.
Afaics, systemd is a power grab by Red Hat and an ego
trip for it's primary developer.
Dumped bloatware Linux in favour of FreeBSD and others after
Suse 11.4, though that was bad enough with Gnome 3...
starbase7, Thursday 10th May 2018 04:36 GMT
SMF?
As an older timer (on my way but not there yet), I never cared for the init.d startup and I dislike the systemd monolithic
architecture.
What I do like is Solaris SMF and wish Linux would have adopted a method such as or similar to that. I still think SMF
was/is a great comprise to the init.d method or systemd manor.
I used SMF professionally, but now I have moved on with Linux professionally as Solaris is, well, dead. I only get to
enjoy SMF on my home systems, and savor it. I'm trying to like Linux over all these years, but this systemd thing is a real
big road block for me to get enthusiastic.
I have a hard time understanding why all the other Linux distros joined hands with Redhat and implemented that thing,
systemd. Sigh.
Anonymous Coward, Thursday 10th May 2018 04:53 GMT
Re: SMF?
You're not alone in liking SMF and Solaris.
AFAICT everyone followed RedHat because they also dominate Gnome, and chose to make Gnome depend on systemd. Thus if
one had any aspirations for your distro supporting Gnome in any way, you have to have systemd underneath it all.
RedHat seem to call the shots these days as to what a Linux distro has. I personally have mixed opinions on this; I think the
vast anarchy of Linux is a bad thing for Linux adoption ("this is the year of the Linux desktop" don't make me laugh), and
Linux would benefit from a significant culling of the vast number of distros out there. However if that did happen and all
that was left was something controlled by RedHat, that would be a bad situation.
Steve Davies, Thursday 10th May 2018 07:30 GMT 3
Re: SMF?
Remember who 'owns' SMF... namely Oracle. They may well have made it impossible for anyone to adopt. That stance is not
unknown now is it...?
As for systemd, I have bit my teeth and learned to tolerate it. I'll never be as comfortable with it as I was with the old
init system but I did start running into issues especially with shutdown syncing with it on some complex systems.
Still not sure if systemd is the right way forward even after four years.
Daggerchild, Thursday 10th May 2018 14:30 GMT
Re: SMF?
SMF should be good, and yet they released it before they'd documented it. Strange priorities...
And XML is *not* a config file format you should let humans at. Finding out the correct order to put the XML elements in
to avoid unexplained "parse error", was *not* a fun game.
And someone correct me, but it looks like there are SMF properties of a running service that can only be modified/added by
editing the file, reloading *and* restarting the service. A metadata and state/dependency tracking system shouldn't require
you to shut down the priority service it's meant to be ensuring... Again, strange priorities...
12 1 Reply
Friday 11th May 2018 07:55 GMTonefangSilver badge
Reply Icon
FAIL
Re: SMF?
"XML is *not* a config file format you should let humans at"
XML is a format you shouldn't let computers at, it was designed to be human readable and writable. It fails totally.
5 1 Reply
Friday 6th July 2018 12:27 GMTHans 1Silver badge
Reply Icon
Re: SMF?
Finding out the correct order to put the XML elements in to avoid unexplained "parse error", was *not* a fun game.
Hm, you do know the grammar is in a dtd ? Yes, XML takes time to learn, but very powerful once mastered.
0 1 Reply
Thursday 10th May 2018 13:24 GMTCrazyOldCatManSilver badge
Reply Icon
Re: SMF?
I have a hard time understanding why all the other Linux distros joined hands with Redhat and implemented that thing, systemd
Several reasons:
A lot of other distros use Redhat (or Fedora) as their base and then customise it.
A lot of other distros include things dependant on systemd (Gnome being the one with biggest dependencies - you can just
about to get it to run without systemd but it's a pain and every update will break your fixes).
By default xargs reads items from standard input as separated by blanks and
executes a command once for each argument. In the following example standard input is piped to
xargs and the mkdir command is run for each argument, creating three folders.
echo 'one two three' | xargs mkdir
ls
one two three
How to use xargs with find
The most common usage of xargs is to use it with the find command. This uses find
to search for files or directories and then uses xargs to operate on the results.
Typical examples of this are removing files, changing the ownership of files or moving
files.
find and xargs can be used together to operate on files that match
certain attributes. In the following example files older than two weeks in the temp folder are
found and then piped to the xargs command which runs the rm command on each file
and removes them.
find /tmp -mtime +14 | xargs rm
xargs v exec {}
The find command supports the -exec option that allows arbitrary
commands to be found on files that are found. The following are equivalent.
find ./foo -type f -name "*.txt" -exec rm {} \;
find ./foo -type f -name "*.txt" | xargs rm
So which one is faster? Let's compare a folder with 1000 files in it.
time find . -type f -name "*.txt" -exec rm {} \;
0.35s user 0.11s system 99% cpu 0.467 total
time find ./foo -type f -name "*.txt" | xargs rm
0.00s user 0.01s system 75% cpu 0.016 total
Clearly using xargs is far more efficient. In fact severalbenchmarks suggest using
xargs over exec {} is six times more efficient.
How to print
commands that are executed
The -t option prints each command that will be executed to the terminal. This
can be helpful when debugging scripts.
echo 'one two three' | xargs -t rm
rm one two three
How to view the command and prompt for execution
The -p command will print the command to be executed and prompt the user to run
it. This can be useful for destructive operations where you really want to be sure on the
command to be run. l
echo 'one two three' | xargs -p touch
touch one two three ?...
How to run multiple commands with xargs
It is possible to run multiple commands with xargs by using the -I
flag. This replaces occurrences of the argument with the argument passed to xargs. The
following prints echos a string and creates a folder.
cat foo.txt
one
two
three
cat foo.txt | xargs -I % sh -c 'echo %; mkdir %'
one
two
three
ls
one two three
Security department often does more damage to the network then any sophisticated hacker can. Especially if they are populated
with morons, as they usually are. One of the most blatant examples is below... Those idiots decided to disable Traceroute
(which means ICMP) in order to increase security.
Notable quotes:
"... Traceroute is disabled on every network I work with to prevent intruders from determining the network structure. Real pain in the neck, but one of those things we face to secure systems. ..."
"... Also really stupid. A competent attacker (and only those manage it into your network, right?) is not even slowed down by things like this. ..."
"... Breaking into a network is a slow process. Slow and precise. Trying to fix problems is a fast reactionary process. Who do you really think you're hurting? Yes another example of how ignorant opinions can become common sense. ..."
"... Disable all ICMP is not feasible as you will be disabling MTU negotiation and destination unreachable messages. You are essentially breaking the TCP/IP protocol. And if you want the protocol working OK, then people can do traceroute via HTTP messages or ICMP echo and reply. ..."
"... You have no fucking idea what you're talking about. I run a multi-regional network with over 130 peers. Nobody "disables ICMP". IP breaks without it. Some folks, generally the dimmer of us, will disable echo responses or TTL expiration notices thinking it is somehow secure (and they are very fucking wrong) but nobody blocks all ICMP, except for very very dim witted humans, and only on endpoint nodes. ..."
"... You have no idea what you're talking about, at any level. "disabled ICMP" - state statement alone requires such ignorance to make that I'm not sure why I'm even replying to ignorant ass. ..."
"... In short, he's a moron. I have reason to suspect you might be, too. ..."
"... No, TCP/IP is not working fine. It's broken and is costing you performance and $$$. But it is not evident because TCP/IP is very good about dealing with broken networks, like yours. ..."
"... It's another example of security by stupidity which seldom provides security, but always buys added cost. ..."
"... A brief read suggests this is a good resource: https://john.albin.net/essenti... [albin.net] ..."
"... Linux has one of the few IP stacks that isn't derived from the BSD stack, which in the industry is considered the reference design. Instead for linux, a new stack with it's own bugs and peculiarities was cobbled up. ..."
"... Reference designs are a good thing to promote interoperability. As far as TCP/IP is concerned, linux is the biggest and ugliest stepchild. A theme that fits well into this whole discussion topic, actually. ..."
Traceroute is disabled on every network I work with to prevent intruders from determining the network structure. Real pain
in the neck, but one of those things we face to secure systems.
They can easily. And often time will compile their own tools, versions of Apache, etc..
At best it slows down incident response and resolution while doing nothing to prevent discovery of their networks. If you only
use Vlans to segregate your architecture you're boned.
Doing something to make things more difficult for a hacker is better than doing nothing to make things more difficult for a
hacker. Unless you're lazy, as many of these things should be done as possible.
Things like this don't slow down "hackers" with even a modicum of network knowledge inside of a functioning network. What they
do slow down is your ability to troubleshoot network problems.
Breaking into a network is a slow process. Slow and precise. Trying to fix problems is a fast reactionary process. Who do you
really think you're hurting? Yes another example of how ignorant opinions can become common sense.
Pretty much my reaction. like WTF? OTON, redhat flavors all still on glibc2 starting to become a regular p.i.t.a. so the chances
of this actually becoming a thing to be concerned about seem very low.
Kinda like gdpr, same kind of groupthink that anyone actually cares or concerns themselves with policy these days.
Disable all ICMP is not feasible as you will be disabling MTU negotiation and destination unreachable messages. You are essentially
breaking the TCP/IP protocol. And if you want the protocol working OK, then people can do traceroute via HTTP messages or ICMP
echo and reply.
Or they can do reverse traceroute at least until the border edge of your firewall via an external site.
You have no fucking idea what you're talking about. I run a multi-regional network with over 130 peers. Nobody "disables ICMP".
IP breaks without it. Some folks, generally the dimmer of us, will disable echo responses or TTL expiration notices thinking it is somehow secure
(and they are very fucking wrong) but nobody blocks all ICMP, except for very very dim witted humans, and only on endpoint nodes.
That's hilarious... I am *the guy* who runs the network. I am our senior network engineer. Every line in every router -- mine.
You have no idea what you're talking about, at any level. "disabled ICMP" - state statement alone requires such ignorance
to make that I'm not sure why I'm even replying to ignorant ass.
Nonsense. I conceded that morons may actually go through the work to totally break their PMTUD, IP error signaling channels,
and make their nodes "invisible"
I understand "networking" at a level I'm pretty sure you only have a foggy understanding of. I write applications that require
layer-2 packet building all the way up to layer-4.
In short, he's a moron. I have reason to suspect you might be, too.
A CDS is MAC. Turning off ICMP toward people who aren't allowed to access your node/network is understandable. They can't get
anything else though, why bother supporting the IP control channel? CDS does *not* say turn off ICMP globally. I deal with CDS,
SSAE16 SOC 2, and PCI compliance daily. If your CDS solution only operates with a layer-4 ACL, it's a pretty simple model, or
You're Doing It Wrong (TM)
No, TCP/IP is not working fine. It's broken and is costing you performance and $$$. But it is not evident because TCP/IP is
very good about dealing with broken networks, like yours.
The problem is that doing this requires things like packet fragmentation which greatly increases router CPU load and reduces
the maximum PPS of your network as well s resulting in dropped packets requiring re-transmission and may also result in widow
collapse fallowed with slow-start, though rapid recovery mitigates much of this, it's still not free.
It's another example of security by stupidity which seldom provides security, but always buys added cost.
As a server engineer I am experiencing this with our network team right now.
Do you have some reading that I might be able to further educate myself? I would like to be able to prove to the directors
why disabling ICMP on the network may be the cause of our issues.
Linux has one of the few IP stacks that isn't derived from the BSD stack, which in the industry is considered the reference
design. Instead for linux, a new stack with it's own bugs and peculiarities was cobbled up.
Reference designs are a good thing to promote interoperability. As far as TCP/IP is concerned, linux is the biggest and
ugliest stepchild. A theme that fits well into this whole discussion topic, actually.
#!/bin/bash
##
## saferm.sh
## Safely remove files, moving them to GNOME/KDE trash instead of deleting.
## Made by Eemil Lagerspetz
## Login <vermind@drache>
##
## Started on Mon Aug 11 22:00:58 2008 Eemil Lagerspetz
## Last update Sat Aug 16 23:49:18 2008 Eemil Lagerspetz
##
version="1.16";
## flags (change these to change default behaviour)
recursive="" # do not recurse into directories by default
verbose="true" # set verbose by default for inexperienced users.
force="" #disallow deleting special files by default
unsafe="" # do not behave like regular rm by default
## possible flags (recursive, verbose, force, unsafe)
# don't touch this unless you want to create/destroy flags
flaglist="r v f u q"
# Colours
blue='\e[1;34m'
red='\e[1;31m'
norm='\e[0m'
## trashbin definitions
# this is the same for newer KDE and GNOME:
trash_desktops="$HOME/.local/share/Trash/files"
# if neither is running:
trash_fallback="$HOME/Trash"
# use .local/share/Trash?
use_desktop=$( ps -U $USER | grep -E "gnome-settings|startkde|mate-session|mate-settings|mate-panel|gnome-shell|lxsession|unity" )
# mounted filesystems, for avoiding cross-device move on safe delete
filesystems=$( mount | awk '{print $3; }' )
if [ -n "$use_desktop" ]; then
trash="${trash_desktops}"
infodir="${trash}/../info";
for k in "${trash}" "${infodir}"; do
if [ ! -d "${k}" ]; then mkdir -p "${k}"; fi
done
else
trash="${trash_fallback}"
fi
usagemessage() {
echo -e "This is ${blue}saferm.sh$norm $version. LXDE and Gnome3 detection.
Will ask to unsafe-delete instead of cross-fs move. Allows unsafe (regular rm) delete (ignores trashinfo).
Creates trash and trashinfo directories if they do not exist. Handles symbolic link deletion.
Does not complain about different user any more.\n";
echo -e "Usage: ${blue}/path/to/saferm.sh$norm [${blue}OPTIONS$norm] [$blue--$norm] ${blue}files and dirs to safely remove$norm"
echo -e "${blue}OPTIONS$norm:"
echo -e "$blue-r$norm allows recursively removing directories."
echo -e "$blue-f$norm Allow deleting special files (devices, ...)."
echo -e "$blue-u$norm Unsafe mode, bypass trash and delete files permanently."
echo -e "$blue-v$norm Verbose, prints more messages. Default in this version."
echo -e "$blue-q$norm Quiet mode. Opposite of verbose."
echo "";
}
detect() {
if [ ! -e "$1" ]; then fs=""; return; fi
path=$(readlink -f "$1")
for det in $filesystems; do
match=$( echo "$path" | grep -oE "^$det" )
if [ -n "$match" ]; then
if [ ${#det} -gt ${#fs} ]; then
fs="$det"
fi
fi
done
}
trashinfo() {
#gnome: generate trashinfo:
bname=$( basename -- "$1" )
fname="${trash}/../info/${bname}.trashinfo"
cat < "${fname}"
[Trash Info]
Path=$PWD/${1}
DeletionDate=$( date +%Y-%m-%dT%H:%M:%S )
EOF
}
setflags() {
for k in $flaglist; do
reduced=$( echo "$1" | sed "s/$k//" )
if [ "$reduced" != "$1" ]; then
flags_set="$flags_set $k"
fi
done
for k in $flags_set; do
if [ "$k" == "v" ]; then
verbose="true"
elif [ "$k" == "r" ]; then
recursive="true"
elif [ "$k" == "f" ]; then
force="true"
elif [ "$k" == "u" ]; then
unsafe="true"
elif [ "$k" == "q" ]; then
unset verbose
fi
done
}
performdelete() {
# "delete" = move to trash
if [ -n "$unsafe" ]
then
if [ -n "$verbose" ];then echo -e "Deleting $red$1$norm"; fi
#UNSAFE: permanently remove files.
rm -rf -- "$1"
else
if [ -n "$verbose" ];then echo -e "Moving $blue$k$norm to $red${trash}$norm"; fi
mv -b -- "$1" "${trash}" # moves and backs up old files
fi
}
askfs() {
detect "$1"
if [ "${fs}" != "${tfs}" ]; then
unset answer;
until [ "$answer" == "y" -o "$answer" == "n" ]; do
echo -e "$blue$1$norm is on $blue${fs}$norm. Unsafe delete (y/n)?"
read -n 1 answer;
done
if [ "$answer" == "y" ]; then
unsafe="yes"
fi
fi
}
complain() {
msg=""
if [ ! -e "$1" -a ! -L "$1" ]; then # does not exist
msg="File does not exist:"
elif [ ! -w "$1" -a ! -L "$1" ]; then # not writable
msg="File is not writable:"
elif [ ! -f "$1" -a ! -d "$1" -a -z "$force" ]; then # Special or sth else.
msg="Is not a regular file or directory (and -f not specified):"
elif [ -f "$1" ]; then # is a file
act="true" # operate on files by default
elif [ -d "$1" -a -n "$recursive" ]; then # is a directory and recursive is enabled
act="true"
elif [ -d "$1" -a -z "${recursive}" ]; then
msg="Is a directory (and -r not specified):"
else
# not file or dir. This branch should not be reached.
msg="No such file or directory:"
fi
}
asknobackup() {
unset answer
until [ "$answer" == "y" -o "$answer" == "n" ]; do
echo -e "$blue$k$norm could not be moved to trash. Unsafe delete (y/n)?"
read -n 1 answer
done
if [ "$answer" == "y" ]
then
unsafe="yes"
performdelete "${k}"
ret=$?
# Reset temporary unsafe flag
unset unsafe
unset answer
else
unset answer
fi
}
deletefiles() {
for k in "$@"; do
fdesc="$blue$k$norm";
complain "${k}"
if [ -n "$msg" ]
then
echo -e "$msg $fdesc."
else
#actual action:
if [ -z "$unsafe" ]; then
askfs "${k}"
fi
performdelete "${k}"
ret=$?
# Reset temporary unsafe flag
if [ "$answer" == "y" ]; then unset unsafe; unset answer; fi
#echo "MV exit status: $ret"
if [ ! "$ret" -eq 0 ]
then
asknobackup "${k}"
fi
if [ -n "$use_desktop" ]; then
# generate trashinfo for desktop environments
trashinfo "${k}"
fi
fi
done
}
# Make trash if it doesn't exist
if [ ! -d "${trash}" ]; then
mkdir "${trash}";
fi
# find out which flags were given
afteropts=""; # boolean for end-of-options reached
for k in "$@"; do
# if starts with dash and before end of options marker (--)
if [ "${k:0:1}" == "-" -a -z "$afteropts" ]; then
if [ "${k:1:2}" == "-" ]; then # if end of options marker
afteropts="true"
else # option(s)
setflags "$k" # set flags
fi
else # not starting with dash, or after end-of-opts
files[++i]="$k"
fi
done
if [ -z "${files[1]}" ]; then # no parameters?
usagemessage # tell them how to use this
exit 0;
fi
# Which fs is trash on?
detect "${trash}"
tfs="$fs"
# do the work
deletefiles "${files[@]}"
Hello,
Is it possible to customize the columns in the single panel view ?
For my default (two panel) view, I have customized it using:
-> Listing Mode
(*) User defined:
half type name | size:15 | mtime
however, when I switch to the single panel view, there are different
columns (obviously):
Permission Nl Owner Group Size Modify time Name
For instance, I need to change the width of "Size" to 15.
No, you can't change the format of the "Long" listing-mode.
(You can make the "User defined" listing-mode display in one panel (by
changing "half" to "full"), but this is not what you want.)
So, you have two options:
(1) Modify the source code (search panel.c for "full perm space" and
tweak it); or:
(2) Use mc^2. It allows you to do this. (It already comes with a
snippet that enlarges the "Size" field a bit so there'd be room for
the commas (or other locale-dependent formatting) it adds. This makes
reading long numbers much easier.)
Subject : Re: Help: meaning of the panelize command in left/right menus
Date : Fri, 17 Feb 2017 15:00:16 +0100
On Thu, Feb 16, 2017 at 01:25:22PM +1300, William Kimber wrote:
Briefly, if you do a search over several directories you can put all those
files into a single panel. Not withstanding that they are from different
directories.
I'm not sure I understand what you mean here; anyway I noticed that if you do a
search using the "Find file" (M-?) command, choose "Panelize" (at the bottom
of the "Find File" popup window), then change to some other directory (thus
exiting from panelized mode), if you now choose Left -> Panelize, you can recall
the panelized view of the last "Find file" results. Is this what you mean?
However this seems to work only with panelized results coming from the
"Find file" command, not with results from the "External panelize" command:
if I change directory, and then choose Left -> Panelize I get an empty panel.
Is this a bug?
Cri
Re: Help: meaning of the panelize command in left/right menus
From : Cristian Rigamonti <cri linux it>
To : mc gnome org
Subject : Re: Help: meaning of the panelize command in left/right menus
Date : Fri, 17 Feb 2017 15:00:16 +0100
On Thu, Feb 16, 2017 at 01:25:22PM +1300, William Kimber wrote:
Briefly, if you do a search over several directories you can put all those
files into a single panel. Not withstanding that they are from different
directories.
I'm not sure I understand what you mean here; anyway I noticed that if you do a
search using the "Find file" (M-?) command, choose "Panelize" (at the bottom
of the "Find File" popup window), then change to some other directory (thus
exiting from panelized mode), if you now choose Left -> Panelize, you can recall
the panelized view of the last "Find file" results. Is this what you mean?
However this seems to work only with panelized results coming from the
"Find file" command, not with results from the "External panelize" command:
if I change directory, and then choose Left -> Panelize I get an empty panel.
Is this a bug?
Cri
Hello,
Is it possible to customize the columns in the single panel view ?
For my default (two panel) view, I have customized it using:
-> Listing Mode
(*) User defined:
half type name | size:15 | mtime
however, when I switch to the single panel view, there are different
columns (obviously):
Permission Nl Owner Group Size Modify time Name
For instance, I need to change the width of "Size" to 15.
No, you can't change the format of the "Long" listing-mode.
(You can make the "User defined" listing-mode display in one panel (by
changing "half" to "full"), but this is not what you want.)
So, you have two options:
(1) Modify the source code (search panel.c for "full perm space" and
tweak it); or:
(2) Use mc^2. It allows you to do this. (It already comes with a
snippet that enlarges the "Size" field a bit so there'd be room for
the commas (or other locale-dependent formatting) it adds. This makes
reading long numbers much easier.)
Hi!
My mc version:
$ mc --version
GNU Midnight Commander 4.8.19
System: Fedora 24
I just want to tell you that %f macro in mcedit is not correct. It
contains the current file name that is selected in the panel but not
the actual file name that is opened in mcedit.
I created the mcedit item to run C++ program:
+= f \.cpp$
r Run
clear
app_path=/tmp/$(uuidgen)
if g++ -o $app_path "%f"; then
$app_path
rm $app_path
fi
echo 'Press any key to exit.'
read -s -n 1
Imagine that I opened the file a.cpp in mcedit.
Then I pressed alt+` and switched to panel.
Then I selected (or even opened in mcedit) the file b.cpp.
Then I pressed alt+` and switched to mcedit with a.cpp.
Then I executed the "Run" item from user menu.
And... The b.cpp will be compiled and run. This is wrong! Why b.cpp???
I executed "Run" from a.cpp!
I propose you to do the new macros for mcedit.
%opened_file
- the file name that is opened in current instance of mcedit.
%opened_file_full_path
- as %opened_file but full path to that file.
I think that %opened_file may be not safe because the current
directory may be changed in mc panel. So it is better to use
%opened_file_full_path.
%opened_file_dir
- full path to directory where %opened_file is.
%save
- save opened file before executing the menu commands. May be useful
in some cases. For example I don't want to press F2 every time before
run changed code.
Thanks for the mc.
Best regards, Sergiy Vovk.
I'd like mc to open /home/keith/Documents/ in the left panel as well whenever I start
mc up, so both panels are showing the /home/keith/Documents/ directory.
Is there some way to tell mc how to do this please?
I think you could use: `mc <path> <path>`, for instance:
`mc /home/keith/Documents/ /tmp`, but of course this requires you to know
the second path to open in addition to your ~/Documents. Not really
satisfying?
Regards,
Hi wwp,
Thanks for your suggestion and that seems to work OK - I just start mc with the following
command:
mc ~/Documents
and both panes are opened at the ~Documents directories now which is fine.
Description I think that it is necessary that code base mc and mc2 correspond
each other. mooffie? can you check that patches from andrew_b easy merged with mc2 and if some
patch conflict with mc2 code hold this changes by writing about in corresponding ticket.
zaytsev can you help automate this( continues integration, travis and so on). Sorry, but some
words in Russian:
Ребята, я не
пытаюсь давать
ЦУ, Вы делаете
классную
работу. Просто
яхотел
обратить
внимание, что
Муфья пытается
поддерживать
свой код в
актуальном
состоянии, но
видя как у него
возникают
проблемы на
ровном месте
боюсь
энтузиазм у
него может
пропасть. Change
Historycomment:1 Changed 2
years ago by zaytsev-work
I have asked what plans does mooffie have for mc 2 sometime ago and never got an
answer. Note that I totally don't blame him for that. Everyone here is working at their own
pace. Sometimes I disappear for weeks or months, because I can't get a spare 5 minutes not even
speaking of several hours due to the non-mc related workload. I hope that one day we'll figure
out the way towards merging it, and eventually get it done.
In the mean time, he's working together with us by offering extremely important and
well-prepared contributions, which are a pleasure to deal with and we are integrating them as
fast as we can, so it's not like we are at war and not talking to each other.
Anyways, creating random noise in the ticket tracking system will not help to advance your
cause. The only way to influence the process is to invest serious amount of time in the
development. comment:2
Changed 2
years ago by zaytsev
Now, I assume most of you here aren't users of MC.
So I won't bore you with description of how Lua makes MC a better
file-manager. Instead, I'll just list some details that may interest
any developer who works on extending some application.
And, as you'll shortly see, you may find mc^2 useful even if you
aren't a user of MC!
So, some interesting details:
* Programmer Goodies
- You can restart the Lua system from within MC.
- Since MC has a built-in editor, you can edit Lua code right there
and restart Lua. So it's somewhat like a live IDE:
- It comes with programmer utilities: regular expressions; global scope
protected by default; good pretty printer for Lua tables; calculator
where you can type Lua expressions; the editor can "lint" Lua code (and
flag uses of global variables).
- It installs a /usr/bin/mcscript executable letting you use all the
goodies from "outside" MC:
- You can program a UI (user interface) very easily. The API is fun
yet powerful. It has some DOM/JavaScript borrowings in it: you can
attach functions to events like on_click, on_change, etc. The API
uses "properties", so your code tends to be short and readable:
I defined my own listing mode and I'd like to make it permanent so that on the next mc
start my defined listing mode will be set. I found no configuration file for mc.
,
You have probably Auto save setup turned off in
Options->Configuration menu.
You can save the configuration manually by Options->Save setup .
Panels setup is saved to ~/.config/mc/panels.ini .
Now, I assume most of you here aren't users of MC.
So I won't bore you with description of how Lua makes MC a better
file-manager. Instead, I'll just list some details that may interest
any developer who works on extending some application.
And, as you'll shortly see, you may find mc^2 useful even if you
aren't a user of MC!
So, some interesting details:
* Programmer Goodies
- You can restart the Lua system from within MC.
- Since MC has a built-in editor, you can edit Lua code right there
and restart Lua. So it's somewhat like a live IDE:
- It comes with programmer utilities: regular expressions; global scope
protected by default; good pretty printer for Lua tables; calculator
where you can type Lua expressions; the editor can "lint" Lua code (and
flag uses of global variables).
- It installs a /usr/bin/mcscript executable letting you use all the
goodies from "outside" MC:
- You can program a UI (user interface) very easily. The API is fun
yet powerful. It has some DOM/JavaScript borrowings in it: you can
attach functions to events like on_click, on_change, etc. The API
uses "properties", so your code tends to be short and readable:
On Fri, 27 Jul 2018 17:01:17 +0300 Sergey Naumov via mc-devel wrote:
I'm curious whether there is a way to change default configuration that is
generated when user invokes mc for the first time?
For example, I want "use_internal_edit" to be true by default instead of
false for any new user.
In vanilla mc the initial value of use_internal_edit is true. Some distros
(Debian and some others) change this to false.
If there is a way to do it, then is it possible to just use lines that I
want to change, not the whole configuration, say
[Midnight-Commander]
use_internal_edit=true
Before first run, ~/.config/mc/ini doesn't exist.
If ~/.config/mc/ini doesn't exist, /etc/mc/mc.ini is used.
If /etc/mc/mc.ini doesn't exist, /usr/share/mc/mc.ini is used.
You can create one of these files with required default settings set.
Unfortunately, there is no info about /etc/mc/mc.ini in the man page.
I'll fix that at this weekend.
Yes, it does, if it has been compiled accordingly.
http://www.linux-databook.info/wp-content/uploads/2015/04/MC-02.jpeg
On Thu, 15 Nov 2018, Fourhundred Thecat wrote:
Hello,
I need to connect to server where I don't have shell access (no ssh)
the server only allows sftp. I can connect with winscp, for instance.
does mc support sftp as well ?
thanks,
_______________________________________________
mc mailing list
https://mail.gnome.org/mailman/listinfo/mc
Hi, I'm wondering why following happens:
In Ubuntu and FreeBSD, when I am pressing Ctrl+J in MC, it puts name
of file on which file cursor is currently on. But this doesn't work in
CentOS and RHEL.
How to fix that in CentOS and RHEL?
Ivan.
Never heard about Ctrl+j, I always used Alt+Enter for that purpose.
Alt+a does the same thing for the path, BTW (just in case you didn't
know). :-)
HTH,
Thomas
_______________________________________________
mc-devel mailing list
https://mail.gnome.org/mailman/listinfo/mc-devel
"... Sometimes, though, a tool is just too fun to pass up; such is the case for Midnight Commander! Of course, we also had numerous requests for it, and that helped, too! Today, let's explore this useful utility. ..."
Quite often, I'm asked how open source deliveries are prioritized at IBM. The answer isn't
simple. Even after we estimate the cost of a project, there are many factors to consider. For
instance, does it enable a specific solution to run? Does it expand a programming language's
abilities? Is it highly-requested by the community or vendors?
Sometimes, though, a tool is just too fun to pass up; such is the case for Midnight
Commander! Of course, we also had numerous requests for it, and that helped, too! Today, let's
explore this useful utility.
... ... ...
Getting Started
Installing Midnight Commander is easy. Once you have the yum package manager , use it to install the 'mc'
package.
In order for the interface to display properly, you'll want to set the LC_ALL environment
variable to a UTF-8 locale. For instance, "EN_US.UTF-8" would work just fine. You can have this
done automatically by putting the following lines in your $HOME/.profile file (or
$HOME/.bash_profile):
Once that's done, you can run 'mc -c' from your SSH
terminal . (You didn't expect this to work from QSH, did you?) If you didn't set up your
environment variables, you can just run 'LC_ALL=EN_US.UTF-8 /QOpenSys/pkgs/bin/mc -c' instead.
I recommend the '-c' option because it enables colors.
A Community Effort
As with many things open source, IBM was not the only contributor. In this particular case, a
"tip of the hat" goes to Jack Woehr. You may remember Jack as the creator of Ublu ,
an open source programming language for IBM i. He also hosts his own RPM repository with lynx,
a terminal-based web browser (perhaps a future topic?). The initial port of Midnight Commander
was collaboratively done with work from both parties. Jack also helped with quality assurance
and worked with project owners to upstream all code changes. In fact, the main code stream for
Midnight Commander can now be built for IBM i with no modifications.
Now that we've delivered hundreds of open source packages, it seems like there's something
for everybody. This seems like one of those tools that is useful for just about anyone. And
with a name like "Midnight Commander," how can you go wrong? Try it today!
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.


1 r/commandline • Posted by u/acksed 6 years ago

Follow
Digital Marketing Executive at LASCO Financial ServicesLet's talk about mental health and stress
r/sysadmin

Eric Hoffer in 1967, in the Oval Office , visiting President Lyndon Baines Johnson
(1951), is a work in social psychology which discusses the psychological causes of fanaticism. It is widely considered a classic.
) As Hoffer puts it near the end of his work: "All mass movements irrespective of the doctrine they preach and the program they project, breed fanaticism, enthusiasm, fervent hope, hatred, and intolerance." (p. 141)
Rob Moir Rob Moir 30k 4 4 gold badges 53 53 silver badges 84 84 bronze badges
<img src=https://linuxconfig.org/images/foremost_manual.png alt=foremost-manual width=1200 height=675 /> Foremost is a forensic data recovery program for Linux used to recover files using their headers, footers, and data structures through a process known as file carving. Software Requirements and Conventions Used
<img aria-describedby="caption-attachment-21311" src="https://www.tecmint.com/wp-content/uploads/2016/07/Kompare-Two-Files-in-Linux.png" alt="Kompare Tool - Compare Two Files in Linux" width="1097" height="701" srcset="https://www.tecmint.com/wp-content/uploads/2016/07/Kompare-Two-Files-in-Linux.png 1097w, https://www.tecmint.com/wp-content/uploads/2016/07/Kompare-Two-Files-in-Linux-768x491.png 768w" sizes="(max-width: 1097px) 100vw, 1097px" />
<img aria-describedby="caption-attachment-21312" src="https://www.tecmint.com/wp-content/uploads/2016/07/DiffMerge-Compare-Files-in-Linux.png" alt="DiffMerge - Compare Files in Linux" width="1078" height="700" srcset="https://www.tecmint.com/wp-content/uploads/2016/07/DiffMerge-Compare-Files-in-Linux.png 1078w, https://www.tecmint.com/wp-content/uploads/2016/07/DiffMerge-Compare-Files-in-Linux-768x499.png 768w" sizes="(max-width: 1078px) 100vw, 1078px" />
<img aria-describedby="caption-attachment-21313" src="https://www.tecmint.com/wp-content/uploads/2016/07/Meld-Diff-Tool-to-Compare-Files-in-Linux.png" alt="Meld - A Diff Tool to Compare File in Linux" width="1028" height="708" srcset="https://www.tecmint.com/wp-content/uploads/2016/07/Meld-Diff-Tool-to-Compare-Files-in-Linux.png 1028w, https://www.tecmint.com/wp-content/uploads/2016/07/Meld-Diff-Tool-to-Compare-Files-in-Linux-768x529.png 768w" sizes="(max-width: 1028px) 100vw, 1028px" />
<img aria-describedby="caption-attachment-21314" src="https://www.tecmint.com/wp-content/uploads/2016/07/DiffUse-Compare-Text-Files-in-Linux.png" alt="DiffUse - A Tool to Compare Text Files in Linux" width="1030" height="795" srcset="https://www.tecmint.com/wp-content/uploads/2016/07/DiffUse-Compare-Text-Files-in-Linux.png 1030w, https://www.tecmint.com/wp-content/uploads/2016/07/DiffUse-Compare-Text-Files-in-Linux-768x593.png 768w" sizes="(max-width: 1030px) 100vw, 1030px" />
<img aria-describedby="caption-attachment-21315" src="https://www.tecmint.com/wp-content/uploads/2016/07/xxdiff-Tool.png" alt="xxdiff Tool" width="718" height="401" />
<img aria-describedby="caption-attachment-21418" src="https://www.tecmint.com/wp-content/uploads/2016/07/KDiff3-Tool-for-Linux.png" alt="KDiff3 Tool for Linux" width="950" height="694" srcset="https://www.tecmint.com/wp-content/uploads/2016/07/KDiff3-Tool-for-Linux.png 950w, https://www.tecmint.com/wp-content/uploads/2016/07/KDiff3-Tool-for-Linux-768x561.png 768w" sizes="(max-width: 950px) 100vw, 950px" />
<img src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at command line" width=1200 height=254 /> Setting
<img src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath script" width=1200 height=417 /> Using
<img src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh script" width=1200 height=291 /> Using
<img src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath script" width=1200 height=469 /> Wrapping options around a block of code in your script
<img src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option" width=1200 height=314 /> Using
<img src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap EXIT" width=1200 height=469 /> Using trap
<img src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap DEBUG" width=1200 height=469 /> Using trap


 Open a file as file descriptor 6 for writing:exec 6> file2writeOpen file as file descriptor 8 for reading:exec 8< file2readCopy file descriptor 5 to file descriptor 7:exec 7<&5Close file descriptor 8:exec 8<&-Conclusion
Open a file as file descriptor 6 for writing:exec 6> file2writeOpen file as file descriptor 8 for reading:exec 8< file2readCopy file descriptor 5 to file descriptor 7:exec 7<&5Close file descriptor 8:exec 8<&-Conclusion
<img aria-describedby="caption-attachment-28848" src="https://www.tecmint.com/wp-content/uploads/2018/03/List-Gogo-Aliases.png" alt="List Gogo Aliases" width="664" height="150" />
<img aria-describedby="caption-attachment-28849" src="https://www.tecmint.com/wp-content/uploads/2018/03/Gogo-Listing.png" alt="Running Gogo Without Options" width="661" height="105" />
<img aria-describedby="caption-attachment-28850" src="https://www.tecmint.com/wp-content/uploads/2018/03/Create-Gogo-Shortcut.png" alt="Create Long Directory Shortcut " width="739" height="270" />
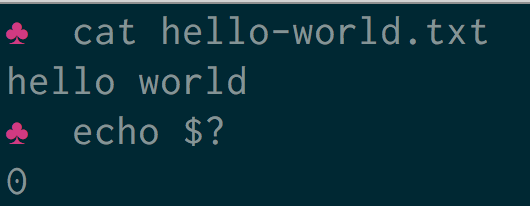


GNU Screen is a terminal multiplexer (window manager). As the name says, Screen multiplexes the physical terminal between multiple interactive shells, so we can perform different tasks in each terminal session. All screen sessions run their programs completely independent. So, a program or process running inside a screen session will keep running even if the session is accidentally closed or disconnected. For instance, when upgrading Ubuntu server via SSH, Screen command will keep running the upgrade process just in case your SSH session is terminated for any reason.
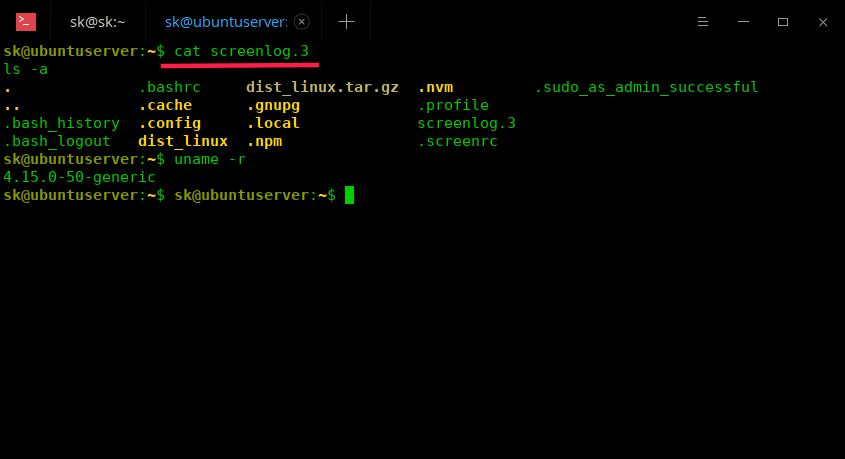
ewwhite 173k 75 364 712 asked Dec 4 '12 at 1:13

07-02-2012, 05:58 AM


However, I seem to remember setting up automatic updates, so perhaps an auto update was done that introduced a problem, but it wasn't seen until the reboot that was forced by the power outage.
Oct 15, 2015; 12:13pm [ANN] mc^2
11 posts






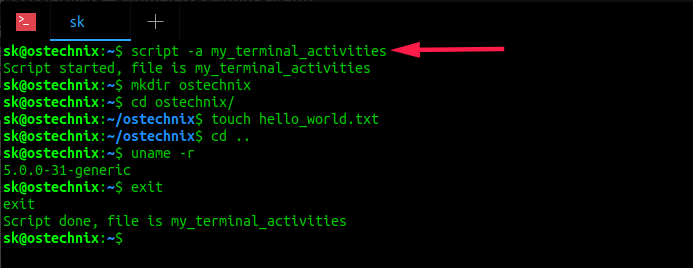
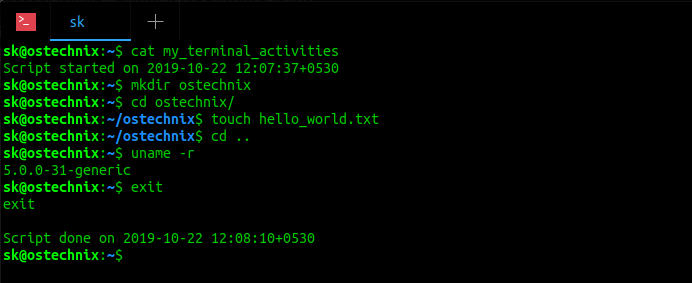
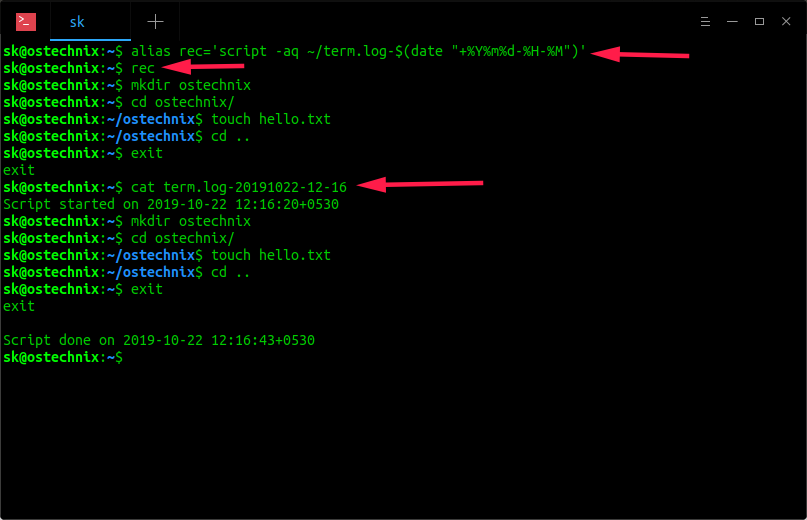
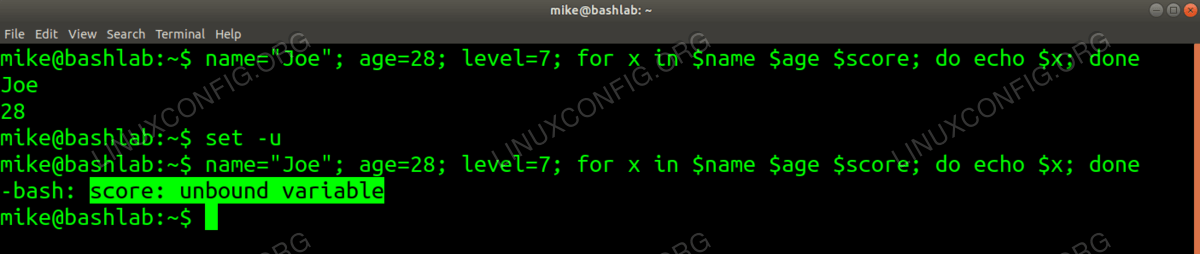 <img
src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at
command line" width=1200 height=254 /> Setting
<img
src=https://linuxconfig.org/images/02-how-to-debug-bash-scripts.png alt="set u option at
command line" width=1200 height=254 /> Setting 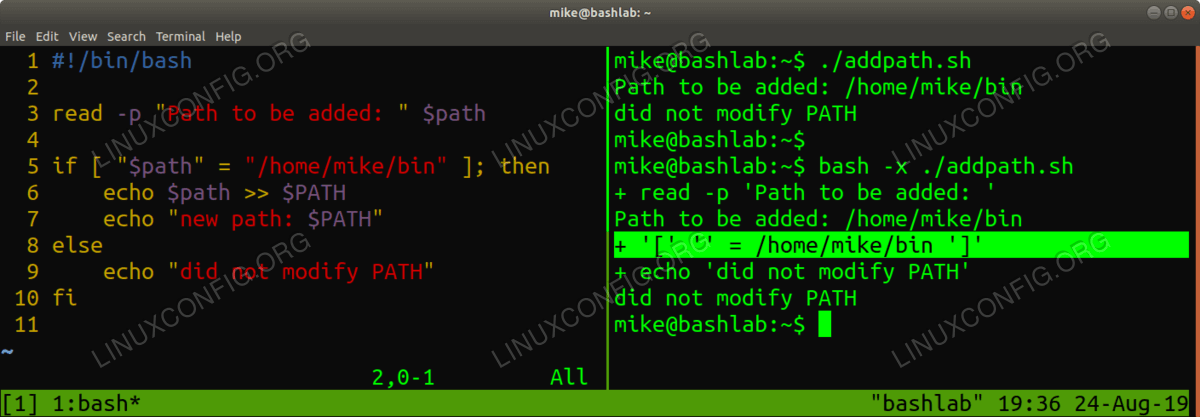 <img
src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=417 /> Using
<img
src=https://linuxconfig.org/images/03-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=417 /> Using  <img
src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh
script" width=1200 height=291 /> Using
<img
src=https://linuxconfig.org/images/04-how-to-debug-bash-scripts.png alt="results from count.sh
script" width=1200 height=291 /> Using 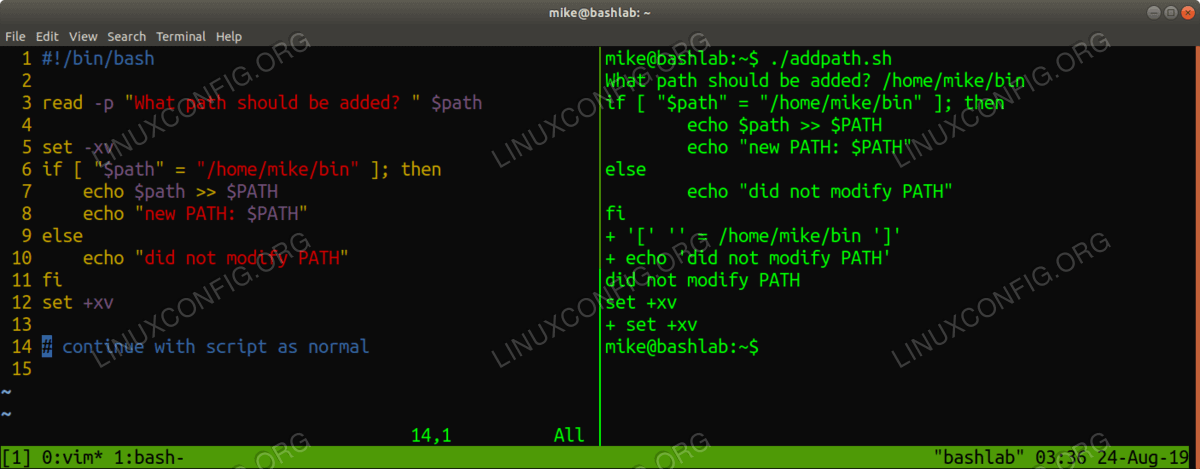 <img
src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=469 /> Wrapping options around a block of code in your script
<img
src=https://linuxconfig.org/images/05-how-to-debug-bash-scripts.png alt="results from addpath
script" width=1200 height=469 /> Wrapping options around a block of code in your script
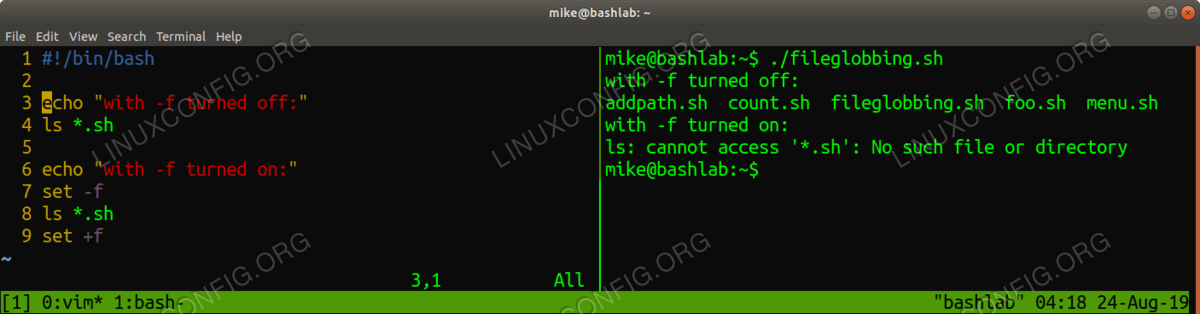 <img
src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option"
width=1200 height=314 /> Using
<img
src=https://linuxconfig.org/images/06-how-to-debug-bash-scripts.png alt="results from -f option"
width=1200 height=314 /> Using  <img
src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap
EXIT" width=1200 height=469 /> Using trap
<img
src=https://linuxconfig.org/images/07-how-to-debug-bash-scripts.png alt="results from using trap
EXIT" width=1200 height=469 /> Using trap 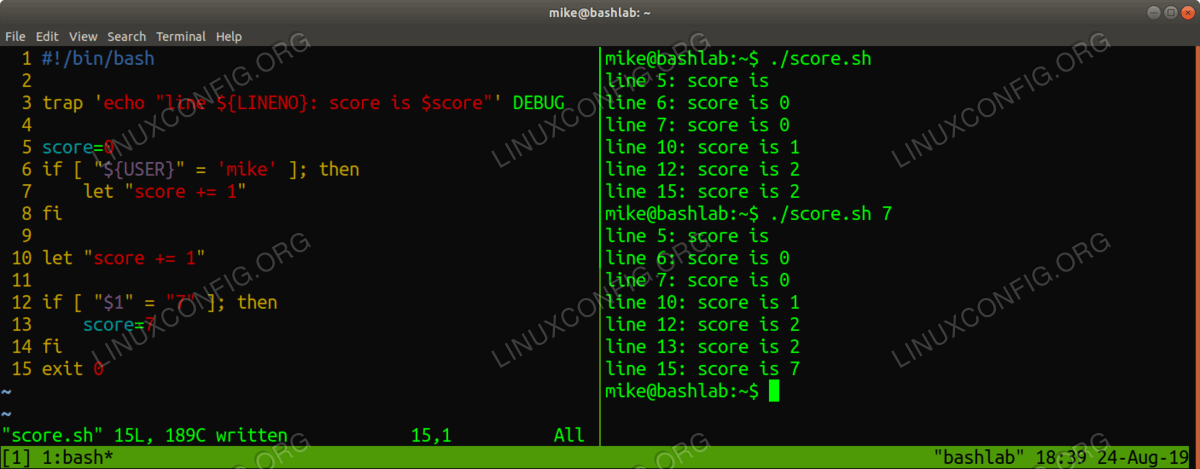 <img
src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap
DEBUG" width=1200 height=469 /> Using trap
<img
src=https://linuxconfig.org/images/08-how-to-debug-bash-scripts.png alt="results from using trap
DEBUG" width=1200 height=469 /> Using trap 


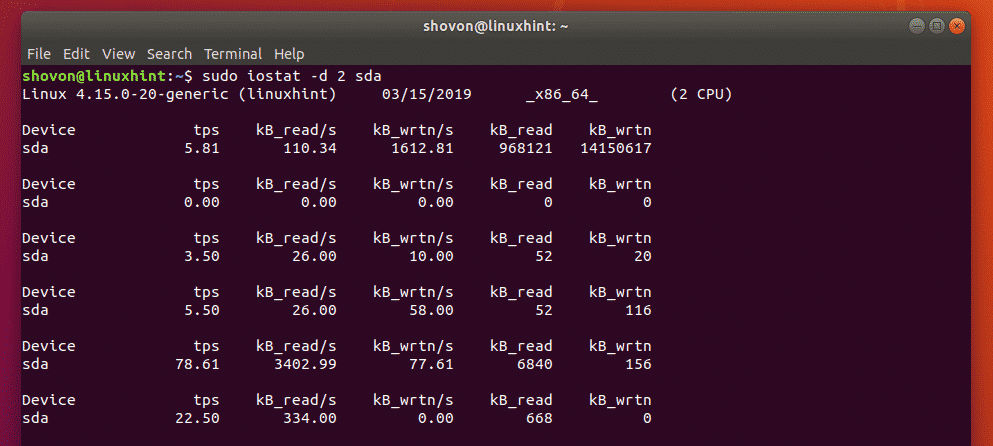


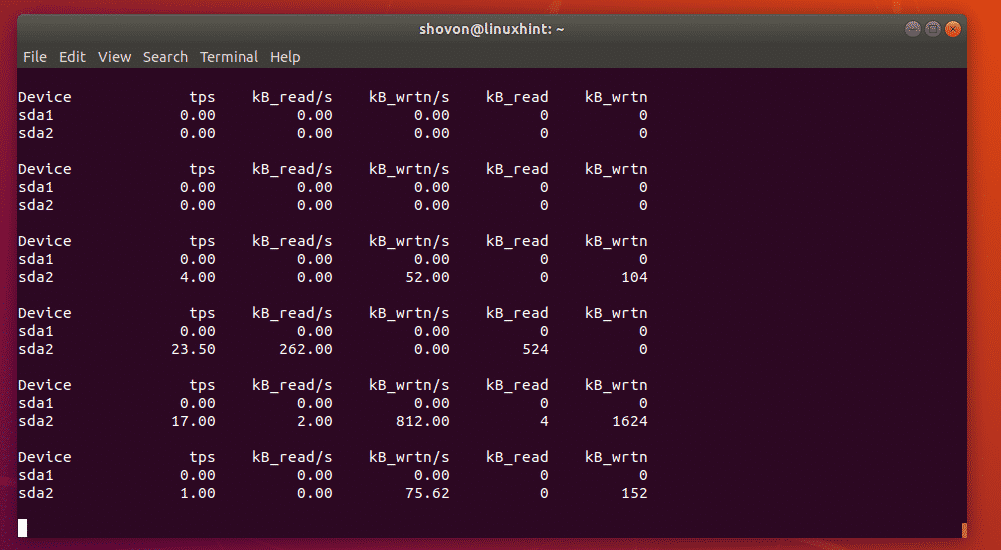
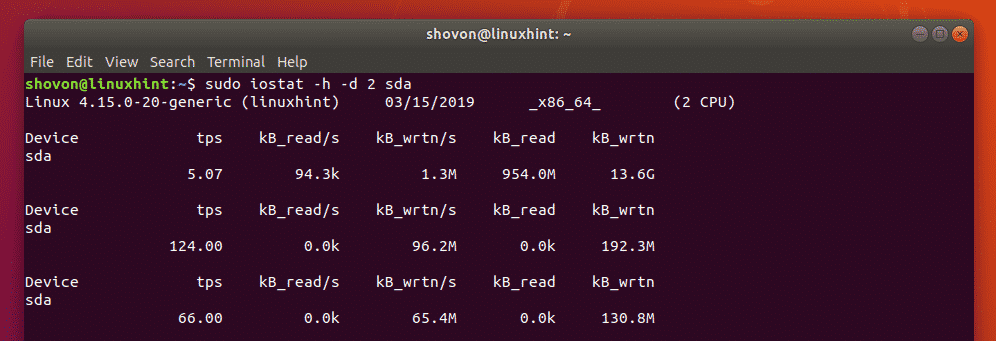
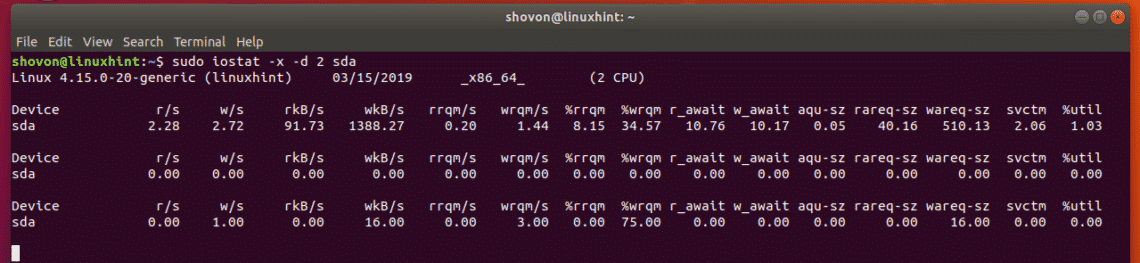
 OV-099
OV-099