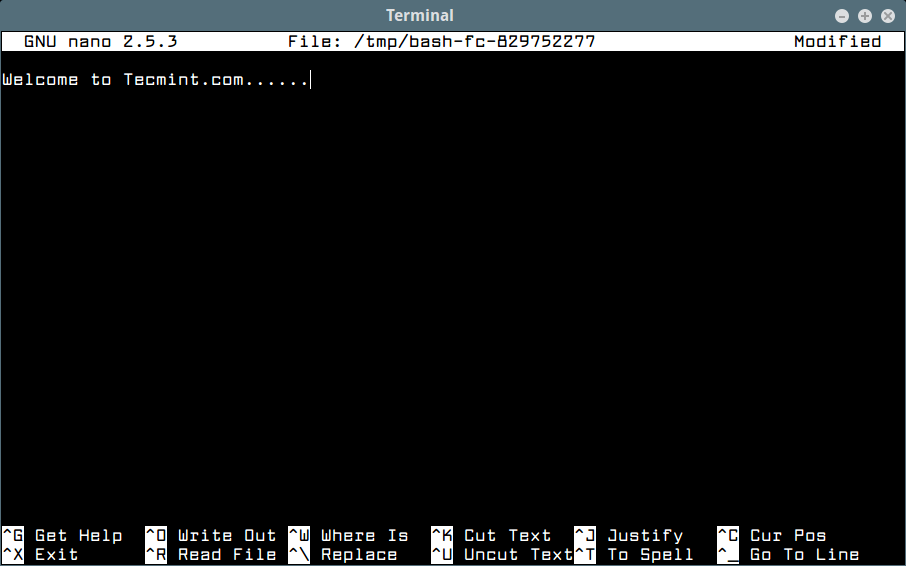
"... By far the biggest act of wage slavery rebellion, don't buy shit. The less you buy, the less you need to earn. Holidays by far the minority of your life should not be a desperate escape from the majority of your life. Spend less, work less and actually really enjoy living more. ..."
"... How about don't shop at Walmart (they helped boost the Chinese economy while committing hari kari on the American Dream) and actually engaging in proper labour action? Calling in sick is just plain childish. ..."
"... I'm all for sticking it to "the man," but when you call into work for a stupid reason (and a hangover is a very stupid reason), it is selfish, and does more damage to the cause of worker's rights, not less. I don't know about where you work, but if I call in sick to my job, other people have to pick up my slack. I work for a public library, and we don't have a lot of funds, so we have the bear minimum of employees we can have and still work efficiently. As such, if anybody calls in, everyone else, up to and including the library director, have to take on more work. ..."
"Phoning in sick is a revolutionary act." I loved that slogan. It came to me, as so many good things did, from Housmans, the radical
bookshop in King's Cross. There you could rummage through all sorts of anarchist pamphlets and there I discovered, in the early 80s,
the wondrous little magazine Processed World. It told you basically how to screw up your workplace. It was smart and full of small
acts of random subversion. In many ways it was ahead of its time as it was coming out of San Francisco and prefiguring Silicon Valley.
It saw the machines coming. Jobs were increasingly boring and innately meaningless. Workers were "data slaves" working for IBM ("Intensely
Boring Machines").
What Processed World was doing was trying to disrupt the identification so many office workers were meant to feel with their management,
not through old-style union organising, but through small acts of subversion. The modern office, it stressed, has nothing to do with
human need. Its rebellion was about working as little as possible, disinformation and sabotage. It was making alienation fun. In
1981, it could not have known that a self-service till cannot ever phone in sick.
I was thinking of this today, as I wanted to do just that. I have made myself ill with a hangover. A hangover, I always feel,
is nature's way of telling you to have a day off. One can be macho about it and eat your way back to sentience via the medium of
bacon sandwiches and Maltesers. At work, one is dehydrated, irritable and only semi-present. Better, surely, though to let the day
fall through you and dream away.
Having worked in America, though, I can say for sure that they brook no excuses whatsoever. When I was late for work and said
things like, "My alarm clock did not go off", they would say that this was not a suitable explanation, which flummoxed me. I had
to make up others. This was just to work in a shop.
This model of working – long hours, very few holidays, few breaks, two incomes needed to raise kids, crazed loyalty demanded by
huge corporations, the American way – is where we're heading. Except now the model is even more punishing. It is China. We are expected
to compete with an economy whose workers are often closer to indentured slaves than anything else.
This is what striving is, then: dangerous, demoralising, often dirty work. Buckle down. It's the only way forward, apparently,
which is why our glorious leaders are sucking up to China, which is immoral, never mind ridiculously short-term thinking.
So again I must really speak up for the skivers. What we have to understand about austerity is its psychic effects. People must
have less. So they must have less leisure, too. The fact is life is about more than work and work is rapidly changing. Skiving in
China may get you killed but here it may be a small act of resistance, or it may just be that skivers remind us that there is meaning
outside wage-slavery.
Work is too often discussed by middle-class people in ways that are simply unrecognisable to anyone who has done crappy jobs.
Much work is not interesting and never has been. Now that we have a political and media elite who go from Oxbridge to working for
a newspaper or a politician, a lot of nonsense is spouted. These people have not cleaned urinals on a nightshift. They don't sit
lonely in petrol stations manning the till. They don't have to ask permission for a toilet break in a call centre. Instead, their
work provides their own special identity. It is very important.
Low-status jobs, like caring, are for others. The bottom-wipers of this world do it for the glory, I suppose. But when we talk
of the coming automation that will reduce employment, bottom-wiping will not be mechanised. Nor will it be romanticised, as old male
manual labour is. The mad idea of reopening the coal mines was part of the left's strange notion of the nobility of labour. Have
these people ever been down a coal mine? Would they want that life for their children?
Instead we need to talk about the dehumanising nature of work. Bertrand Russell and Keynes thought our goal should be less work,
that technology would mean fewer hours.
Far from work giving meaning to life, in some surveys 40% of us say that our jobs are meaningless. Nonetheless, the art of skiving
is verboten as we cram our children with ever longer hours of school and homework. All this striving is for what exactly? A soul-destroying
job?
Just as education is decided by those who loved school, discussions about work are had by those to whom it is about more than
income.
The parts of our lives that are not work – the places we dream or play or care, the space we may find creative – all these are
deemed outside the economy. All this time is unproductive. But who decides that?
Skiving work is bad only to those who know the price of everything and the value of nothing.
So go on: phone in sick. You know you want to.
friedad 23 Oct 2015 18:27
We now exist in a society in which the Fear Cloud is wrapped around each citizen. Our proud history of Union and Labor, fighting
for decent wages and living conditions for all citizens, and mostly achieving these aims, a history, which should be taught to
every child educated in every school in this country, now gradually but surely eroded by ruthless speculators in government, is
the future generations are inheriting. The workforce in fear of taking a sick day, the young looking for work in fear of speaking
out at diminishing rewards, definitely this 21st Century is the Century of Fear. And how is this fear denied, with mind blowing
drugs, regardless if it is is alcohol, description drugs, illicit drugs, a society in denial. We do not require a heavenly object
to destroy us, a few soulless monsters in our mist are masters of manipulators, getting closer and closer to accomplish their
aim of having zombies doing their beckoning. Need a kidney, no worries, zombie dishwasher, is handy for one. Oh wait that time
is already here.
Hemulen6 23 Oct 2015 15:06
Oh join the real world, Suzanne! Many companies now have a limit to how often you can be sick. In the case of the charity I
work for it's 9 days a year. I overstepped it, I was genuinely sick, and was hauled up in front of Occupational Health. That will
now go on my record and count against me. I work for a cancer care charity. Irony? Surely not.
AlexLeo -> rebel7 23 Oct 2015 13:34
Which is exactly my point. You compete on relevant job skills and quality of your product, not what school you have attended.
Yes, there are thousands, tens of thousands of folks here around San Jose who barely speak English, but are smart and hard
working as hell and it takes them a few years to get to 150-200K per year, Many of them get to 300-400K, if they come from strong
schools in their countries of origin, compared to the 10k or so where they came from, but probably more than the whining readership
here.
This is really difficult to swallow for the Brits back in Britain, isn't it. Those who have moved over have experiences the
type of social mobility unthinkable in Britain, but they have had to work hard and get to 300K-700K per year, much better than
the 50-100K their parents used to make back in GB. These are averages based on personal interactions with say 50 Brits in the
last 15 + years, all employed in the Silicon Valley in very different jobs and roles.
Todd Owens -> Scott W 23 Oct 2015 11:00
I get what you're saying and I agree with a lot of what you said. My only gripe is most employees do not see an operation from
a business owner or managerial / financial perspective. They don't understand the costs associated with their performance or lack
thereof. I've worked on a lot of projects that we're operating at a loss for a future payoff. When someone decides they don't
want to do the work they're contracted to perform that can have a cascading effect on the entire company.
All in all what's being described is for the most part misguided because most people are not in the position or even care to
evaluate the particulars. So saying you should do this to accomplish that is bullshit because it's rarely such a simple equation.
If anything this type of tactic will leaf to MORE loss and less money for payroll.
weematt -> Barry1858 23 Oct 2015 09:04
Sorry you just can't have a 'nicer' capitalism.
War ( business by other means) and unemployment ( you can't buck the market), are inevitable concomitants of capitalist competition
over markets, trade routes and spheres of interests. (Remember the war science of Nagasaki and Hiroshima from the 'good guys'
?)
"..capital comes dripping from head to foot, from every pore, with blood and dirt". (Marx)
You can't have full employment, or even the 'Right to Work'.
There is always ,even in boom times a reserve army of unemployed, to drive down wages. (If necessary they will inject inflation
into the economy)
Unemployment is currently 5.5 percent or 1,860,000 people. If their "equilibrium rate" of unemployment is 4% rather than 5% this
would still mean 1,352,000 "need be unemployed". The government don't want these people to find jobs as it would strengthen workers'
bargaining position over wages, but that doesn't stop them harassing them with useless and petty form-filling, reporting to the
so-called "job centre" just for the sake of it, calling them scroungers and now saying they are mentally defective.
Government is 'over' you not 'for' you.
Governments do not exist to ensure 'fair do's' but to manage social expectations with the minimum of dissent, commensurate
with the needs of capitalism in the interests of profit.
Worker participation amounts to self managing workers self exploitation for the maximum of profit for the capitalist class.
Exploitation takes place at the point of production.
" Instead of the conservative motto, 'A fair day's wage for a fair day's work!' they ought to inscribe on their banner the
revolutionary watchword, 'Abolition of the wages system!'"
Karl Marx [Value, Price and Profit]
John Kellar 23 Oct 2015 07:19
Fortunately; as a retired veteran I don't have to worry about phoning in sick.However; during my Air Force days if you were
sick, you had to get yourself to the Base Medical Section and prove to a medical officer that you were sick. If you convinced
the medical officer of your sickness then you may have been luck to receive on or two days sick leave. For those who were very
sick or incapable of getting themselves to Base Medical an ambulance would be sent - promptly.
Rchrd Hrrcks -> wumpysmum 23 Oct 2015 04:17
The function of civil disobedience is to cause problems for the government. Let's imagine that we could get 100,000 people
to agree to phone in sick on a particular date in protest at austerity etc. Leaving aside the direct problems to the economy that
this would cause. It would also demonstrate a willingness to take action. It would demonstrate a capability to organise mass direct
action. It would demonstrate an ability to bring people together to fight injustice. In and of itself it might not have much impact,
but as a precedent set it could be the beginning of something massive, including further acts of civil disobedience.
wumpysmum Rchrd Hrrcks 23 Oct 2015 03:51
There's already a form of civil disobedience called industrial action, which the govt are currently attacking by attempting
to change statute. Random sickies as per my post above are certainly not the answer in the public sector at least, they make no
coherent political point just cause problems for colleagues. Sadly too in many sectors and with the advent of zero hours contracts
sickies put workers at risk of sanctions and lose them earnings.
Alyeska 22 Oct 2015 22:18
I'm American. I currently have two jobs and work about 70 hours a week, and I get no paid sick days. In fact, the last time
I had a job with a paid sick day was 2001. If I could afford a day off, you think I'd be working 70 hours a week?
I barely make rent most months, and yes... I have two college degrees. When I try to organize my coworkers to unionize for
decent pay and benefits, they all tell me not to bother.... they are too scared of getting on management's "bad side" and "getting
in trouble" (yes, even though the law says management can't retaliate.)
Unions are different in the USA than in the UK. The workforce has to take a vote to unionize the company workers; you can't
"just join" a union here. That's why our pay and working conditions have gotten worse, year after year.
rtb1961 22 Oct 2015 21:58
By far the biggest act of wage slavery rebellion, don't buy shit. The less you buy, the less you need to earn. Holidays
by far the minority of your life should not be a desperate escape from the majority of your life. Spend less, work less and actually
really enjoy living more.
Pay less attention to advertising and more attention to the enjoyable simplicity of life, of real direct human relationships,
all of them, the ones in passing where you wish a stranger well, chats with service staff to make their life better as well as
your own, exchange thoughts and ideas with others, be a human being and share humanity with other human beings.
Mkjaks 22 Oct 2015 20:35
How about don't shop at Walmart (they helped boost the Chinese economy while committing hari kari on the American Dream)
and actually engaging in proper labour action? Calling in sick is just plain childish.
toffee1 22 Oct 2015 19:13
It is only considered productive if it feeds the beast, that is, contribute to the accumulation of capital so that the beast
can have more power over us. The issue here is the wage labor. The 93 percent of the U.S. working population perform wage labor
(see BLS site). It is the highest proportion in any society ever came into history. Under the wage labor (employment) contract,
the worker gives up his/her decision making autonomy. The worker accepts the full command of his/her employer during the labor
process. The employer directs and commands the labor process to achieve the goals set by himself. Compare this, for example, self-employed
providing a service (for example, a plumber). In this case, the customer describes the problem to the service provider but the
service provider makes all the decisions on how to organize and apply his labor to solve the problem. Or compare it to a democratically
organized coop, where workers make all the decisions collectively, where, how and what to produce. Under the present economic
system, a great majority of us are condemned to work in large corporations performing wage labor. The system of wage labor stripping
us from autonomy on our own labor, creates all the misery in our present world through alienation. Men and women lose their humanity
alienated from their own labor. Outside the world of wage labor, labor can be a source self-realization and true freedom. Labor
can be the real fulfillment and love. Labor together our capacity to love make us human. Bourgeoisie dehumanized us steeling our
humanity. Bourgeoisie, who sold her soul to the beast, attempting to turn us into ever consuming machines for the accumulation
of capital.
patimac54 -> Zach Baker 22 Oct 2015 17:39
Well said. Most retail employers have cut staff to the minimum possible to keep the stores open so if anyone is off sick, it's
the devil's own job trying to just get customers served. Making your colleagues work even harder than they normally do because
you can't be bothered to act responsibly and show up is just plain selfish.
And sorry, Suzanne, skiving work is nothing more than an act of complete disrespect for those you work with. If you don't understand
that, try getting a proper job for a few months and learn how to exercise some self control.
TettyBlaBla -> FranzWilde 22 Oct 2015 17:25
It's quite the opposite in government jobs where I am in the US. As the fiscal year comes to a close, managers look at their
budgets and go on huge spending sprees, particularly for temp (zero hours in some countries) help and consultants. They fear if
they don't spend everything or even a bit more, their spending will be cut in the next budget. This results in people coming in
to do work on projects that have no point or usefulness, that will never be completed or even presented up the food chain of management,
and ends up costing taxpayers a small fortune.
I did this one year at an Air Quality Agency's IT department while the paid employees sat at their desks watching portable
televisions all day. It was truly demeaning.
oommph -> Michael John Jackson 22 Oct 2015 16:59
Thing is though, children - dependents to pay for - are the easiest way to keep yourself chained to work.
The homemaker model works as long as your spouse's employer retains them (and your spouse retains you in an era of 40% divorce).
You are just as dependent on an employer and "work" but far less in control of it now.
Zach Baker 22 Oct 2015 16:41
I'm all for sticking it to "the man," but when you call into work for a stupid reason (and a hangover is a very stupid
reason), it is selfish, and does more damage to the cause of worker's rights, not less. I don't know about where you work, but
if I call in sick to my job, other people have to pick up my slack. I work for a public library, and we don't have a lot of funds,
so we have the bear minimum of employees we can have and still work efficiently. As such, if anybody calls in, everyone else,
up to and including the library director, have to take on more work. If I found out one of my co-workers called in because
of a hangover, I'd be pissed. You made the choice to get drunk, knowing that you had to work the following morning. Putting it
into the same category of someone who is sick and may not have the luxury of taking off because of a bad employer is insulting.
"... The book talks about how checklists reduce major errors in surgery. Hospitals that use checklists are drastically less likely to amputate the wrong leg . ..."
"... any checklist should start off verifying that what you "know" to be true is true ..."
"... Before starting, ask the "Is it plugged in?" question first. What happened today was an example of when asking "Is it plugged in?" would have helped. ..."
"... moral of the story: Make sure that your understanding of the current state is correct. If you're a developer trying to fix a problem, make sure that you are actually able to understand the problem first. ..."
The book talks about how checklists reduce major errors in surgery. Hospitals that use
checklists are drastically less likely to
amputate the wrong leg .
So, the takeaway for me is this: any checklist should start off verifying that what you
"know" to be true is true . (Thankfully, my errors can be backed out with very little long
term consequences, but I shouldn't use this as an excuse to forego checklists.)
Before starting, ask the "Is it plugged in?" question first. What happened today was an
example of when asking "Is it plugged in?" would have helped.
Today I was testing the thumbnailing of some MediaWiki code and trying to understand the
$wgLocalFileRepo variable.
I copied part of an /images/ directory over from another wiki to my test wiki. I
verified that it thumbnailed correctly.
So far so good.
Then I changed the directory parameter and tested. No thumbnail. Later, I realized this is
to be expected because I didn't copy over the original images. So that is one issue.
I erased (what I thought was) the thumbnail image and tried again on the main repo. It
worked again–I got a thumbnail.
I tried copying over the images directory to the new directory, but it the new thumbnailing
directory structure didn't produce a thumbnail.
I tried over and over with the same thumbnail and was confused because it kept telling me
the same thing.
I added debugging statements and still got no where.
Finally, I just did an ls on the directory to verify it was there. It
was. And it had files in it.
But not the file I was trying to produce a thumbnail of.
The system that "worked" had the thumbnail, but not the original file.
So, moral of the story: Make sure that your understanding of the current state is
correct. If you're a developer trying to fix a problem, make sure that you are actually able to
understand the problem first.
Maybe your perception of reality is wrong. Mine was. I was sure that the thumbnails
were being generated each time until I discovered that I hadn't deleted the thumbnails, I had
deleted the original.
# aliases
alias la="ls -la --group-directories-first --color"
# clear terminal
alias cls="clear"
#
alias sup="sudo apt update && sudo apt upgrade"
# search for package
alias apts='apt-cache search'
# start x session
alias x="startx"
# download mp3 in best quality from YouTube
# usage: ytmp3 https://www.youtube.com/watch?v=LINK
alias ytmp3="youtube-dl -f bestaudio --extract-audio --audio-format mp3 --audio-quality 0"
# perform 'la' after 'cd'
alias cd="listDir"
listDir() {
builtin cd "$*"
RESULT=$?
if [ "$RESULT" -eq 0 ]; then
la
fi
}
# type "extract filename" to extract the file
extract () {
if [ -f $1 ] ; then
case $1 in
*.tar.bz2) tar xvjf $1 ;;
*.tar.gz) tar xvzf $1 ;;
*.bz2) bunzip2 $1 ;;
*.rar) unrar x $1 ;;
*.gz) gunzip $1 ;;
*.tar) tar xvf $1 ;;
*.tbz2) tar xvjf $1 ;;
*.tgz) tar xvzf $1 ;;
*.zip) unzip $1 ;;
*.Z) uncompress $1 ;;
*.7z) 7z x $1 ;;
*) echo "don't know how to extract '$1'..." ;;
esac
else
echo "'$1' is not a valid file!"
fi
}
# obvious one
alias ..="cd .."
alias ...="cd ../.."
alias ....="cd ../../.."
alias .....="cd ../../../.."
# tail all logs in /var/log
alias logs="find /var/log -type f -exec file {} \; | grep 'text' | cut -d' ' -f1 | sed -e's/:$//g' | grep -v '[0-9]$' | xargs
tail -f"
extract () {
if [ -f $1 ] ; then
case $1 in
*.tar.bz2) tar xvjf $1 ;;
*.tar.gz) tar xvzf $1 ;;
*.bz2) bunzip2 $1 ;;
*.rar) unrar x $1 ;;
*.gz) gunzip $1 ;;
*.tar) tar xvf $1 ;;
*.tbz2) tar xvjf $1 ;;
*.tgz) tar xvzf $1 ;;
*.zip) unzip $1 ;;
*.Z) uncompress $1 ;;
*.7z) 7z x $1 ;;
*) echo "don't know how to extract '$1'..." ;;
esac
else
echo "'$1' is not a valid file!"
fi
}
Erm, did you know that `tar` autoextracts these days? This will work for pretty much anything:
The mnt function acts like a poor person's arch-chroot and will bind mount /proc /sys & /dev before chrooting then tear it down afterwards.
The mkiso function builds a UEFI-capable Debian live system (with the name of the image given as the first argument).
The only other stuff I have are aliases, not really worth posting.
dbruce wrote: Ubuntu forums try to be like a coffee shop in Seattle. Debian forums strive for the charm and ambience
of a skinhead bar in Bacau. We intend to keep it that way.
i have a LOT of stuff in my /etc/bash.bashrc, because i want it to be available for the root user too.
i won't post everything, but here's a "best of" from both /etc/bash.bashrc and ~/.bashrc:
# Bash won't get SIGWINCH if another process is in the foreground.
# Enable checkwinsize so that bash will check the terminal size when
# it regains control.
# http://cnswww.cns.cwru.edu/~chet/bash/FAQ (E11)
shopt -s checkwinsize
# forums.bunsenlabs.org/viewtopic.php?pid=27494#p27494
# also see aliases '...' and '....'
shopt -s autocd
# opensource.com/article/18/5/bash-tricks
shopt -s cdspell
# as big as possible!!!
HISTSIZE=500000
HISTFILESIZE=2000000
man() {
env LESS_TERMCAP_mb=$(printf "\e[1;31m") \
LESS_TERMCAP_md=$(printf "\e[1;31m") \
LESS_TERMCAP_me=$(printf "\e[0m") \
LESS_TERMCAP_se=$(printf "\e[0m") \
LESS_TERMCAP_so=$(printf "\e[7m") \
LESS_TERMCAP_ue=$(printf "\e[0m") \
LESS_TERMCAP_us=$(printf "\e[1;32m") \
man "$@"
}
#LESS_TERMCAP_so=$(printf "\e[1;44;33m")
# that used to be in the man function for less's annoyingly over-colorful status line.
# changed it to simple reverse video (tput rev)
alias ls='ls --group-directories-first -hF --color=auto'
alias ll='ls --group-directories-first -hF --color=auto -la'
alias mpf='/usr/bin/ls -1 | mpv --playlist=-'
alias ruler='slop -o -c 1,0.3,0'
alias xmeasure='slop -o -c 1,0.3,0'
alias obxprop='obxprop | grep -v _NET_WM_ICON'
alias sx='exec startx > ~/.local/share/xorg/xlog 2>&1'
alias pngq='pngquant --nofs --speed 1 --skip-if-larger --strip '
alias screencap='ffmpeg -r 15 -s 1680x1050 -f x11grab -i :0.0 -vcodec msmpeg4v2 -qscale 2'
alias su='su -'
alias fblc='fluxbox -list-commands | column'
alias torrench='torrench -t -k -s -x -r -l -i -b --sorted'
alias F5='while sleep 60; do notify-send -u low "Pressed F5 on:" "$(xdotool getwindowname $(xdotool getwindowfocus))"; xdotool
key F5; done'
alias aurs='aurman --sort_by_name -Ss'
alias cal3='cal -3 -m -w --color'
alias mkdir='mkdir -p -v'
alias ping='ping -c 5'
alias cd..='cd ..'
alias off='systemctl poweroff'
alias xg='xgamma -gamma'
alias find='find 2>/dev/null'
alias stressme='stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout'
alias hf='history|grep'
alias du1='du -m --max-depth=1|sort -g|sed "s/\t./M\t/g ; s/\///g"'
alias zipcat='gunzip -c'
If you're new to the career, chances are you'll be saying "yes" to everything. However, as you gain experience and put in your
time, the word "no" needs to creep into your vocabulary. Otherwise, you'll be exploited.
Of course, you have to use this word with caution. Should the CTO approach and set a task before you, the "no" response might
not be your best choice. But if you find end users-and friends-taking advantage of the word "yes," you'll wind up frustrated and
exhausted at the end of the day.
Be done at the end of the day
I used to have a ritual at the end of every day. I would take off my watch and, at that point,
I was done... no more work. That simple routine saved my sanity more often than not. I highly suggest you develop the means to
inform yourself that, at some point, you are done for the day. Do not be that person who is willing to work through the evening
and into the night... or you'll always be that person.
Don't beat yourself up over mistakes made
You are going to make mistakes. Sometimes will be simple and can be quickly repaired.
Others may lean toward the catastrophic. But when you finally call your IT career done, you will have made plenty of mistakes.
Beating yourself up over them will prevent you from moving forward. Instead of berating yourself, learn from the mistakes so you
don't repeat them.
Always have something nice to say
You work with others on a daily basis. Too many times I've watched IT pros become bitter,
jaded people who rarely have anything nice or positive to say. Don't be that person. If you focus on the positive, people will
be more inclined to enjoy working with you, companies will want to hire you, and the daily grind will be less "grindy."
Measure twice, cut once
How many times have you issued a command or clicked OK before you were absolutely sure you should?
The old woodworking adage fits perfectly here. Considering this simple sentence-before you click OK-can save you from quite a
lot of headache. Rushing into a task is never the answer, even during an emergency. Always ask yourself: Is this the right solution?
At every turn, be honest
I've witnessed engineers lie to avoid the swift arm of justice. In the end, however, you must remember
that log files don't lie. Too many times there is a trail that can lead to the truth. When the CTO or your department boss discovers
this truth, one that points to you lying, the arm of justice will be that much more forceful. Even though you may feel like your
job is in jeopardy, or the truth will cause you added hours of work, always opt for the truth. Always.
Make sure you're passionate about what you're doing
Ask yourself this question: Am I passionate about technology? If not,
get out now; otherwise, that job will beat you down. A passion for technology, on the other hand, will continue to drive you forward.
Just know this: The longer you are in the field, the more likely that passion is to falter. To prevent that from happening, learn
something new.
Don't stop learning
Quick-how many operating systems have you gone through over the last decade? No career evolves faster
than technology. The second you believe you have something perfected, it changes. If you decide you've learned enough, it's time
to give up the keys to your kingdom. Not only will you find yourself behind the curve, all those servers and desktops you manage
could quickly wind up vulnerable to every new attack in the wild. Don't fall behind.
When you feel your back against a wall, take a breath and regroup
This will happen to you. You'll be tasked to upgrade a
server farm and one of the upgrades will go south. The sweat will collect, your breathing will reach panic level, and you'll lock
up like Windows Me. When this happens... stop, take a breath, and reformulate your plan. Strangely enough, it's that breath taken
in the moment of panic that will help you survive the nightmare. If a single, deep breath doesn't help, step outside and take
in some fresh air so that you are in a better place to change course.
Don't let clients see you Google a solution
This should be a no-brainer... but I've watched it happen far too many times.
If you're in the middle of something and aren't sure how to fix an issue, don't sit in front of a client and Google the solution.
If you have to, step away, tell the client you need to use the restroom and, once in the safety of a stall, use your phone to
Google the answer. Clients don't want to know you're learning on their dime.
Economists report that workers are starting to act like millennials on Tinder: They're
ditching jobs with nary a text. "A number of contacts said that they had been 'ghosted,' a
situation in which a worker stops coming to work without notice and then is impossible to
contact," the Federal Reserve Bank of Chicago noted in December's Beige Book report,
which tracks employment trends. Advertisement > National data on economic "ghosting" is
lacking. The term, which normally applies to dating, first surfaced on Dictionary.com in 2016. But companies across
the country say silent exits are on the rise. Analysts blame America's increasingly tight labor
market. Job openings have surpassed the number of seekers for eight straight months, and the
unemployment rate has clung to a 49-year low of 3.7% since September. Janitors, baristas,
welders, accountants, engineers -- they're all in demand, said Michael Hicks, a labor economist
at Ball State University in Indiana. More people may opt to skip tough conversations and slide
right into the next thing. "Why hassle with a boss and a bunch of out-processing," he said,
"when literally everyone has been hiring?" Recruiters at global staffing firm Robert Half have
noticed a 10% to 20% increase in ghosting over the last year, D.C. district President Josh
Howarth said. Applicants blow off interviews. New hires turn into no-shows. Workers leave one
evening and never return. "You feel like someone has a high level of interest, only for them to
just disappear," Howarth said. Over the summer, woes he heard from clients emerged in his own
life. A job candidate for a recruiter role asked for a day to mull over an offer, saying she
wanted to discuss the terms with her spouse. Then she halted communication. "In fairness,"
Howarth said, "there are some folks who might have so many opportunities they're considering,
they honestly forget." Keith Station, director of business relations at Heartland Workforce
Solutions, which connects job hunters with companies in Omaha, said workers in his area are
most likely to skip out on low-paying service positions. "People just fall off the face of the
Earth," he said of the area, which has an especially low unemployment rate of 2.8%. Some
employers in Nebraska are trying to head off unfilled shifts by offering apprentice programs
that guarantee raises and additional training over time. "Then you want to stay and watch your
wage grow," Station said. Advertisement > Other recruitment businesses point to solutions
from China, where ghosting took off during the last decade's explosive growth. "We generally
make two offers for every job because somebody doesn't show up," said Rebecca Henderson, chief
executive of Randstad Sourceright, a talent acquisition firm. And if both hires stick around,
she said, her multinational clients are happy to deepen the bench. Though ghosting in the
United States does not yet require that level of backup planning, consultants urge employers to
build meaningful relationships at every stage of the hiring process. Someone who feels invested
in an enterprise is less likely to bounce, said Melissa and Johnathan Nightingale, who have
written about leadership and dysfunctional management. "Employees leave jobs that suck," they
said in an email. "Jobs where they're abused. Jobs where they don't care about the work. And
the less engaged they are, the less need they feel to give their bosses any warning." Some
employees are simply young and restless, said James Cooper, former manager of the Old Faithful
Inn at Yellowstone National Park, where he said people ghosted regularly. A few of his staffers
were college students who lived in park dormitories for the summer. "My favorite," he said,
"was a kid who left a note on the floor in his dorm room that said, 'Sorry bros, had to ghost.'
" Other ghosters describe an inner voice that just says: Nah. Zach Keel, a 26-year-old server
in Austin, Texas, made the call last year to flee a combination bar and cinema after realizing
he would have to clean the place until sunrise. More work, he calculated, was always around the
corner. "I didn't call," Keel said. "I didn't show up. I figured: No point in feeling guilty
about something that wasn't that big of an issue. Turnover is so high, anyway."
But the more common situation is that applicants are ghosted by companies. They apply for a
job and never hear anything in response, not even a rejection. In the U.S., companies are
generally not legally obligated to deliver bad news to job candidates, so many don't.
They also don't provide feedback, because it could open the company up to a legal risk if it
shows that they decided against a candidate for discriminatory reasons protected by law such as
race, gender or disability.
Hiring can be a lengthy process, and rejecting 99 candidates is much more work than
accepting one. But a consistently poor hiring process that leaves applicants hanging can cause
companies to lose out on the best talent and even damage perception of their brand.
Here's what companies can do differently to keep applicants in the loop, and how job seekers
can know that it's time to cut their losses.
What companies can do differently
There are many ways that technology can make the hiring process easier for both HR
professionals and applicants.
Only about half of all companies get back to the candidates they're not planning to
interview, Natalia Baryshnikova, director of product management on the enterprise product team
at SmartRecruiters, tells CNBC Make It .
"Technology has defaults, one change is in the default option," Baryshnikova says. She said
that SmartRecruiters changed the default on its technology from "reject without a note" to
"reject with a note," so that candidates will know they're no longer involved in the
process.
Companies can also use technology as a reminder to prioritize rejections. For the company,
rejections are less urgent than hiring. But for a candidate, they are a top priority. "There
are companies out there that get back to 100 percent of candidates, but they are not yet
common," Baryshnikova says.
How one company is trying to help
WayUp was founded to make the process of applying for a job simpler.
"The No. 1 complaint from candidates we've heard, from college students and recent grads
especially, is that their application goes into a black hole," Liz Wessel, co-founder and CEO
of WayUp, a platform that connects college students and recent graduates with employers, tells
CNBC Make It .
WayUp attempts to increase transparency in hiring by helping companies source and screen
applicants, and by giving applicants feedback based on soft skills. They also let applicants
know if they have advanced to the next round of interviewing within 24 hours.
Wessel says that in addition to creating a better experience for applicants, WayUp's system
helps companies address bias during the resume-screening processes. Resumes are assessed for
hard skills up front, then each applicant participates in a phone screening before their
application is passed to an employer. This ensures that no qualified candidate is passed over
because their resume is different from the typical hire at an organization – something
that can happen in a company that uses computers instead of people to scan resumes .
"The companies we work with see twice as many minorities getting to offer letter," Wessel
said.
When you can safely assume that no news is bad news
First, if you do feel that you're being ghosted by a company after sending in a job
application, don't despair. No news could be good news, so don't assume right off the
bat that silence means you didn't get the job.
Hiring takes time, especially if you're applying for roles where multiple people could be
hired, which is common in entry-level positions. It's possible that an HR team is working
through hundreds or even thousands of resumes, and they might not have gotten to yours yet. It
is not unheard of to hear back about next steps months after submitting an initial
application.
If you don't like waiting, you have a few options. Some companies have application tracking
in their HR systems, so you can always check to see if the job you've applied for has that and
if there's been an update to the status of your application.
Otherwise, if you haven't heard anything, Wessel said that the only way to be sure that you
aren't still in the running for the job is to determine if the position has started. Some
companies will publish their calendar timelines for certain jobs and programs, so check that
information to see if your resume could still be in review.
"If that's the case and the deadline has passed," Wessel says, it's safe to say you didn't
get the job.
And finally, if you're still unclear on the status of your application, she says there's no
problem with emailing a recruiter and asking outright.
I have a script which, when I run it from PuTTY, it scrolls the screen. Now, I want to go
back to see the errors, but when I scroll up, I can see the past commands, but not the output
of the command.
I would recommend using screen if you want to have good control over the
scroll buffer on a remote shell.
You can change the scroll buffer size to suit your needs by setting:
defscrollback 4000
in ~/.screenrc , which will specify the number of lines you want to be
buffered (4000 in this case).
Then you should run your script in a screen session, e.g. by executing screen
./myscript.sh or first executing screen and then
./myscript.sh inside the session.
It's also possible to enable logging of the console output to a file. You can find more
info on the screen's man page
.
,
From your descript, it sounds like the "problem" is that you are using screen, tmux, or
another window manager dependent on them (byobu). Normally you should be able to scroll back
in putty with no issue. Exceptions include if you are in an application like less or nano
that creates it's own "window" on the terminal.
With screen and tmux you can generally scroll back with SHIFT + PGUP (same as
you could from the physical terminal of the remote machine). They also both have a "copy"
mode that frees the cursor from the prompt and lets you use arrow keys to move it around (for
selecting text to copy with just the keyboard). It also lets you scroll up and down with the
PGUP and PGDN keys. Copy mode under byobu using screen or tmux
backends is accessed by pressing F7 (careful, F6 disconnects the
session). To do so directly under screen you press CTRL + a then
ESC or [ . You can use ESC to exit copy mode. Under
tmux you press CTRL + b then [ to enter copy mode and
] to exit.
The simplest solution, of course, is not to use either. I've found both to be quite a bit
more trouble than they are worth. If you would like to use multiple different terminals on a
remote machine simply connect with multiple instances of putty and manage your windows using,
er... Windows. Now forgive me but I must flee before I am burned at the stake for my
heresy.
EDIT: almost forgot, some keys may not be received correctly by the remote terminal if
putty has not been configured correctly. In your putty config check Terminal ->
Keyboard . You probably want the function keys and keypad set to be either
Linux or Xterm R6 . If you are seeing strange characters on the
terminal when attempting the above this is most likely the problem.
That's a very primitive thinking. If RHEL is royally screwed, like is the case with RHEL7,
that affects Kubernetes -- it does not exists outside the OS
There is a separate
reboot command
but you don't need to learn a new command just for rebooting the system. You can use the Linux
shutdown command for rebooting as wel.
To reboot a system using the shutdown command, use the -r option.
sudo shutdown -r
The behavior is the same as the regular shutdown command. It's just that instead of a shutdown, the system will be
restarted.
So, if you used shutdown -r without any time argument, it will schedule a reboot after one minute.
You can schedule reboots the same way you did with shutdown.
sudo shutdown -r +30
You can also reboot the system immediately with shutdown command:
sudo shutdown -r now
4. Broadcast a custom message
If you are in a multi-user environment and there are several users logged on the system, you can send them a
custom broadcast message with the shutdown command.
By default, all the logged users will receive a notification about scheduled shutdown and its time. You can
customize the broadcast message in the shutdown command itself:
sudo shutdown 16:00 "systems will be shutdown for hardware upgrade, please save your work"
Fun Stuff: You
can use the shutdown command with -k option to initiate a 'fake shutdown'. It won't shutdown the system but the
broadcast message will be sent to all logged on users.
5. Cancel a scheduled shutdown
If you scheduled a shutdown, you don't have to live with it. You can always cancel a shutdown with option -c.
sudo shutdown -c
And if you had broadcasted a messaged about the scheduled shutdown, as a good sysadmin, you might also want to
notify other users about
cancelling
the scheduled shutdown.
sudo shutdown -c "planned shutdown has been cancelled"
Halt vs Power off
Halt (option -H): terminates all processes and shuts down the
cpu
.
Power off (option -P): Pretty much like halt but it also turns off the unit itself (lights and everything on the
system).
Historically, the earlier computers used to halt the system and then print a message like "it's ok to power off now"
and then the computers were turned off through physical switches.
These days,
halt
should
automically
power off the system thanks to
ACPI
.
These were the most common and the most useful examples of the Linux shutdown command. I hope you have learned how
to shut down a Linux system via command line. You might also like reading about the
less command usage
or browse through the
list of Linux commands
we have covered so far.
If you have any questions or suggestions, feel free to let me know in the comment section.
"... Shadow IT broadly refers to technology introduced into an organisation that has not passed through the IT department. ..."
"... The result is first; no proactive recommendations from the IT department and second; long approval periods while IT teams evaluate solutions that the business has proposed. Add an over-defensive approach to security, and it is no wonder that some departments look outside the organisation for solutions. ..."
Shadow IT broadly refers to technology introduced into an organisation that has not passed
through the IT department. A familiar example of this is BYOD but, significantly, Shadow IT now
includes enterprise grade software and hardware, which is increasingly being sourced and
managed outside of the direct control of the organisation's IT department and CIO.
Examples
include enterprise wide CRM solutions and marketing automation systems procured by the
marketing department, as well as data warehousing, BI and analysis services sourced by finance
officers.
So why have so many technology solutions slipped through the hands of so many CIOs? I
believe a confluence of events is behind the trend; there is the obvious consumerisation of IT,
which has resulted in non-technical staff being much more aware of possible solutions to their
business needs – they are more tech-savvy. There is also the fact that some CIOs and
technology departments have been too slow to react to the business's technology needs.
The reason for this slow reaction is that very often IT Departments are just too busy
running day-to-day infrastructure operations such as network and storage management along with
supporting users and software. The result is first; no proactive recommendations from the IT
department and second; long approval periods while IT teams evaluate solutions that the
business has proposed. Add an over-defensive approach to security, and it is no wonder that
some departments look outside the organisation for solutions.
Might just be a Debian thing as I haven't looked into it, but I have enough suspicion towards
systemd that I find it worth mentioning. Until fairly recently (in terms of Debian releases),
the default configuration was to murder a user's processes when they log out. This includes
things such as screen and tmux, and I seem to recall it also murdering disowned and NOHUPed
processes as well.
A dilemma for a Really Enterprise Dependant Huge Applications Technology company - The
technology they provide is open, so almost anyone could supply and support it. To continue
growing, and maintain a healthy profit they could consider locking their existing customer
base in; but they need to stop other suppliers moving in, who might offer a better and
cheaper alternative, so they would like more control of the whole ecosystem. The scene: An
imaginary high-level meeting somewhere - The agenda: Let's turn Linux into Windows - That
makes a lot of money:-
Q: Windows is a monopoly, so how are we going to monopolise something that is free and
open, because we will have to supply source code for anything that will do that? A: We make
it convoluted and obtuse, then we will be the only people with the resources to offer it
commercially; and to make certain, we keep changing it with dependencies to "our" stuff
everywhere - Like Microsoft did with the Registry.
Q: How are we going to sell that idea? A: Well, we could create a problem and solve it -
The script kiddies who like this stuff, keep fiddling with things and rebooting all of the
time. They don't appear to understand the existing systems - Sell the idea they do not need
to know why *NIX actually works.
Q: *NIX is designed to be dependable, and go for long periods without rebooting, How do we
get around that. A: That is not the point, the kids don't know that; we can sell them the
idea that a minute or two saved every time that they reboot is worth it, because they
reboot lots of times in every session - They are mostly running single user laptops, and not
big multi-user systems, so they might think that that is important - If there is
somebody who realises that this is trivial, we sell them the idea of creating and
destroying containers or stopping and starting VMs.
Q: OK, you have sold the concept, how are we going to make it happen? A: Well, you know
that we contribute quite a lot to "open" stuff. Let's employ someone with a reputation for
producing fragile, barely functioning stuff for desktop systems, and tell them that we need a
"fast and agile" approach to create "more advanced" desktop style systems - They would lead a
team that will spread this everywhere. I think I know someone who can do it - We can have
almost all of the enterprise market.
Q: What about the other large players, surely they can foil our plan? A: No, they won't
want to, they are all big companies and can see the benefit of keeping newer, efficient
competitors out of the market. Some of them sell equipment and system-wide consulting, so
they might just use our stuff with a suitable discount/mark-up structure anyway.
This is scarily possible and undeserving of the troll icon.
Harkens easily to non-critical software developers intentionally putting undocumented,
buggy code into production systems, forcing the company to keep the guy on payroll to keep
the wreck chugging along.
But replacing it with systemd is akin to "fixing" the restrictions of travel by bicycle
(limited speed and range, ending up sweaty at your destination, dangerous in heavy traffic)
by replacing it with an Apache helicopter gunship that has a whole new set of restrictions
(need for expensive fuel, noisy and pisses off the neighbors, need a crew of trained
mechanics to keep it running, local army base might see you as a threat and shoot missiles at
you)
Too bad we didn't get the equivalent of a bicycle with an electric motor, or perhaps a
moped.
Those who do not understand Unix are condemned to reinvent it, poorly.
"It sounds super basic, but actually it is much more complex than people think,"
Poettering said. "Because Systemd knows which service a process belongs to, it can shut down
that process."
Init has had the groundwork for most of the missing features since the early 1980s. For
example the "id" field in /etc/inittab was intended for a "makefile" like syntax to fix most
of these problems but was dropped in the early days of System V because it wasn't needed.
That is the main problem. With different processes you get different results. For all its
faults, SysV init and RC scripts was understandable to some extent. My (cursory)
understanding of systemd is that it appears more complicated to UNDERSTAND than the init
stuff.
The init scripts are nice text scripts which are executed by a nice well documented shell
(bash mostly). Systemd has all sorts of blobs that somehow do things and are totally
confusing to me. It suffers from "anti- kiss "
Perhaps a nice book could be written WITH example to show what is going on.
Now let's see does audio come before or after networking (or at the same time)?
If they removed logging from the systemd core and went back to good ol' plaintext
syslog[-ng], I'd have very little bad to say about Lennart's monolithic pet project. Indeed,
I much prefer writing unit files than buggering about getting rcorder right in the old SysV
init.
Now, if someone wanted to nuke pulseaudio from orbit and do multiplexing in the kernel a
la FreeBSD, I'll chip in with a contribution to the warhead fund. Needing a userland daemon
just to pipe audio to a device is most certainly a solution in search of a problem.
From now on, I will call Systemd-based Linux distros "SNU Linux". Because Systemd's Not
Unix-like.
It's not clever, but it's the future. From now on, all major distributions will be called
SNU Linux. You can still freely choose to use a non-SNU linux distro, but if you want to use
any of the "normal" ones, you will have to call it "SNU" whether you like it or not. It's for
your own good. You'll thank me later.
However, I don't recall any major agreement that init needed fixing. Between BSD and SysV
inits, probably 99.999% of all use cases were covered. In the 1 in 100,000 use case, a little
bit of C (stand alone code, or patching init itself) covered the special case. In the case of
Slackware's SysV/BSD amalgam, I suspect it was more like one in ten million.
So in all reality, systemd is an answer to a problem that nobody had. There was no reason
for it in the first place. There still isn't a reason for it ... especially not in the
999,999 places out of 1,000,000 where it is being used. Throw in the fact that it's sticking
its tentacles[0] into places where nobody in their right mind would expect an init as a
dependency (disk partitioning software? WTF??), can you understand why us "old guard" might
question the sanity of people singing it's praises?
[0] My spall chucker insists that the word should be "testicles". Tempting ...
It's a pretty polarizing debate: either you see Systemd as a modern, clean, and coherent
management toolkit
Very, very few Linux users see it that way.
or an unnecessary burden running roughshod over the engineering maxim: if it ain't
broke, don't fix it.
Seen as such by 90% of Linux users because it demonstrably is.
Truthfully Systemd is flawed at a deeply fundamental level. While there are a very few
things it can do that init couldn't - the killing off processes owned by a service mentioned
as an example in this article is handled just fine by a well written init script - the
tradeoffs just aren't worth it. For example: fscking BINARY LOGS. Even if all of Systemd's
numerous other problems were fixed that one would keep it forever on my list of things to
avoid if at all possible, and the fact that the Systemd team thought it a good idea to make
the logs binary shows some very troubling flaws in their thinking at a very fundamental
level.
WRT grep and logs I'm the same way which is why I hate json so much. My saying has been
along the lines of "if it's not friends with grep/sed then it's not friends with me". I have
whipped some some whacky sed stuff to generate a tiny bit of json to read into chef for
provisioning systems though.
XML is similar though I like XML a lot more at least the closing tags are a lot easier to
follow then trying to count the nested braces in json.
I haven't had the displeasure much of dealing with the systemd binary logs yet myself.
> I haven't had the displeasure much of dealing with the systemd binary logs yet
myself.
"I have no clue what I'm talking about or what's a robust solution but dear god, that
won't stop me!" – why is it that all the people complaining about journald sound like
that?
systemd works just fine with regular syslog-ng, without journald (that's the thing that
has binary logs) in sight
"systemd works just fine with regular syslog-ng, without journald (that's the thing that
has binary logs) in sight"
Journald can't be switched off, only redirected to /dev/null. It still generates binary
log data (which has caused me at least one system hang due to the absurd amount of data it
was generating on a system that was otherwise functioning correctly) and consumes system
resources. That isn't my idea of "works just fine".
""I have no clue what I'm talking about or what's a robust solution but dear god, that
won't stop me!" – why is it that all the people complaining about journald sound like
that?"
Nice straw man. Most of the complaints I've seen have been from experienced people who do
know what they're talking about.
"I have no clue what I'm talking about or what's a robust solution but dear god, that
won't stop me!" – why is it that all the people complaining about journald sound like
that?
I have had the displeasure of dealing with journald and it is every bit as bad as everyone
says and worse.
systemd works just fine with regular syslog-ng, without journald (that's the thing that
has binary logs) in sight
Yeah, I've tried that. It caused problems. It wasn't a viable option.
Parking U$5bn in redhad for a few months will fix this...
So it's now been 4 years since they first tried to force that shoddy desk-top init system
into our servers? And yet they still feel compelled to tell everyone, look it really isn't
that terrible. That should tell you something. Unless you are tone death like Redhat.
Surprised people didn't start walking out when Poettering outlined his plans for the next
round of systemD power grabs...
Anyway the only way this farce will end is with shareholder activism. Some hedge fund to
buy 10-15 percent of redhat (about the amount you need to make life difficult for management)
and force them to sack that "stable genius" Poettering. So market cap is 30bn today. Anyone
with 5bn spare to park for a few months wanna step forward and do some good?
Early on I warned that he was trying to solve a very large problem space. He insisted he
could do it with his 10 or so "correct" ways of doing things, which quickly became 20, then
30, then 50, then 90, etc.. etc. I asked for some of the features we had in init, he said "no
valid use case". Then, much later (years?), he implements it (no use case provided btw).
Interesting fellow. Very bitter. And not a good listener. But you don't need to listen
when you're always right.
Now, you see, you just summed up the whole problem. Like systemd's author, you think you
know better than the admin how to run his machine, without knowing, or caring to ask, what
he's trying to achieve. Nobody ever runs a computer, to achieve running systemd do
they.
I don't claim I know better, but I do know that I never saw a non-distribution provided
init script that handled correctly the basic of corner cases – service already running,
run file left-over but process dead, service restart – let alone the more obscure ones,
like application double forking when it shouldn't (even when that was the failure mode of the
application the script was provided with). So maybe, just maybe, you haven't experienced
everything there is to experience, so your opinion is subjective?
Yes, the sides of the discussion should talk more, but this applies to both sides. "La,
la, la, sysv is working fine on my machine, thankyouverymuch" is not what you can call
"participating in discussion". So is quoting well known and long discussed (and disproven)
points. (and then downvoting people into oblivion for daring to point this things out).
now in the real world, people that have to deal with init systems on daily basis, as
distribution maintainers, by large, have chosen to switch their distributions to systemd, so
the whole situation I can sum up one way:
I do know that I never saw a non-distribution provided init script that handled
correctly the basic of corner cases – service already running
This only shows that you don't have much real life experience managing lots of hosts.
like application double forking when it shouldn't
If this is a problem in the init script, this should be fixed in the init script. If this
is a problem in the application itself, it should be fixed in the application,
not worked around by the init mechanism. If you're suggesting the latter, you
should not be touching any production box.
"La, la, la, sysv is working fine on my machine, thankyouverymuch" is not what you
can call "participating in discussion".
Shoving down systemd down people's throat as a solution to a non-existing problem, is not
a discussion either; it is the very definition of 'my way or the highway' thinking.
now in the real world, people that have to deal with init systems on daily
basis
Indeed and having a bunch of sub-par developers, focused on the 'year of the Linux
desktop' to decide what the best way is for admins to manage their enterprise environment is
not helping.
"the dogs may bark, but the caravan moves on"
Indeed. It's your way or the highway; I thought you were just complaining about the people
complaining about systemd not wanting to have a discussion, while all the while it's systemd
proponents ignoring and dismissing very valid complaints.
"I never saw ... run file left-over but process dead, service restart ..."
Seriously? I wrote one last week! You use an OS atomic lock on the pidfile and exec the
service if the lock succeeded. The lock dies with the process. It's a very small
shellscript.
I shot a systemd controlled service. Systemd put it into error state and wouldn't restart
it unless I used the right runes. That is functionally identical to the thing you just
complained about.
"application double forking when it shouldn't"
I'm going to have to guess what that means, and then point you at DJB's daemontools. You
leave a FD open in the child. They can fork all they like. You'll still track when the last
dies as the FD will cause an event on final close.
"So maybe, just maybe, you haven't experienced everything there is to
experience"
You realise that's the conspiracy theorist argument "You don't know everything, therefore
I am right". Doubt is never proof of anything.
"La, la, la, sysv is working fine" is not what you can call "participating in
discussion".
Well, no.. it's called evidence. Evidence that things are already working fine, thanks.
Evidence that the need for discussion has not been displayed. Would you like a discussion
about the Earth being flat? Why not? Are you refusing to engage in a constructive discussion?
How obstructive!
"now in the real world..."
In the *real* world people run Windows and Android, so you may want to rethink the "we
outnumber you, so we must be right" angle. You're claiming an awful lot of highground you don't seem to actually know your way
around, while trying to wield arguments you don't want to face yourself...
"(and then downvoting people into oblivion for daring to point this things
out)"
It's not some denialist conspiracy to suppress your "daring" Truth - you genuinely deserve
those downvotes.
I have no idea how or why systemd ended up on servers. Laptops I can see the appeal for "this
is the year of the linux desktop" - for when you want your rebooted machine to just be there
as fast as possible (or fail mysteriously as fast as possible). Servers, on the other hand,
which take in the order of 10+ minutes to get through POST, initialising whatever LOM, disk
controllers, and whatever exotica hardware you may also have connected, I don't see a benefit
in Linux starting (or failing to start) a wee bit more quickly. You're only going to reboot
those beasts when absolutely necessary. And it should boot the same as it booted last time.
PID1 should be as simple as possible.
I only use CentOS these days for FreeIPA but now I'm questioning my life decisions even
here. That Debian adopted systemd too is a real shame. It's actually put me off the whole
game. Time spent learning systemd is time that could have been spent doing something useful
that won't end up randomly breaking with a "will not fix" response.
Systemd should be taken out back and put out of our misery.
"... Another thing bit us with systemd recently as well again going back to bind. Someone on the team upgraded our DNS systems to systemd and the startup parameters for bind were not preserved because systemd ignores the /etc/default/bind file. As a result we had tons of DNS failures when bind was trying to reach out to IPv6 name servers(ugh), when there is no IPv6 connectivity in the network (the solution is to start bind with a -4 option). ..."
"... I'm sure I've only scratched the surface of systemd pain. I'm sure it provides good value to some people, I hear it's good with containers (I have been running LXC containers for years now, I see nothing with systemd that changes that experience so far). ..."
"... If systemd is a solution to any set of problems, I'd love to have those problems back! ..."
(20 of which on Debian, before that was Slackware)
I am new to systemd, maybe 3 or 4 months now tops on Ubuntu, and a tiny bit on Debian
before that.
I was confident I was going to hate systemd before I used it just based on the comments I
had read over the years, I postponed using it as long as I could. Took just a few minutes of
using it to confirm my thoughts. Now to be clear, if I didn't have to mess with the systemd
to do stuff then I really wouldn't care since I don't interact with it (which is the case on
my laptop at least though laptop doesn't have systemd anyway). I manage about 1,000 systems
running Ubuntu for work, so I have to mess with systemd, and init etc there. If systemd would
just do ONE thing I think it would remove all of the pain that it has inflicted on me over
the past several months and I could learn to accept it.
That one thing is, if there is an init script, RUN IT. Not run it like systemd does now.
But turn off ALL intelligence systemd has when it finds that script and run it. Don't put it
on any special timers, don't try to detect if it is running already, or stopped already or
whatever, fire the script up in blocking mode and wait till it exits.
My first experience with systemd was on one of my home servers, I re-installed Debian on
it last year, rebuilt the hardware etc and with it came systemd. I believe there is a way to
turn systemd off but I haven't tried that yet. The first experience was with bind. I have a
slightly custom init script (from previous debian) that I have been using for many years. I
copied it to the new system and tried to start bind. Nothing. I looked in the logs and it
seems that it was trying to interface with rndc(internal bind thing) for some reason, and
because rndc was not working(I never used it so I never bothered to configure it) systemd
wouldn't launch bind. So I fixed rndc and systemd would now launch bind, only to stop it
within 1 second of launching. My first workaround was just to launch bind by hand at the CLI
(no init script), left it running for a few months. Had a discussion with a co-worker who
likes systemd and he explained that making a custom unit file and using the type=forking
option may fix it.. That did fix the issue.
Next issue came up when dealing with MySQL clusters. I had to initialize the cluster with
the "service mysql bootstrap-pxc" command (using the start command on the first cluster
member is a bad thing). Run that with systemd, and systemd runs it fine. But go to STOP the
service, and systemd thinks the service is not running so doesn't even TRY to stop the
service(the service is running). My workaround for my automation for mysql clusters at this
point is to just use mysqladmin to shut the mysql instances down. Maybe newer mysql versions
have better systemd support though a co-worker who is our DBA and has used mysql for many
years says even the new Maria DB builds don't work well with systemd. I am working with Mysql
5.6 which is of course much much older.
Next issue came up with running init scripts that have the same words in them, in the case
of most recently I upgraded systems to systemd that run OSSEC. OSSEC has two init scripts for
us on the server side (ossec and ossec-auth). Systemd refuses to run ossec-auth because it
thinks there is a conflict with the ossec service. I had the same problem with multiple
varnish instances running on the same system (varnish instances were named varnish-XXX and
varnish-YYY). In the varnish case using custom unit files I got systemd to the point where it
would start the service but it still refuses to "enable" the service because of the name
conflict (I even changed the name but then systemd was looking at the name of the binary
being called in the unit file and said there is a conflict there).
fucking a. Systemd shut up, just run the damn script. It's not hard.
Later a co-worker explained the "systemd way" for handling something like multiple varnish
instances on the system but I'm not doing that, in the meantime I just let chef start the
services when it runs after the system boots(which means they start maybe 1 or 2 mins after
bootup).
Another thing bit us with systemd recently as well again going back to bind. Someone on
the team upgraded our DNS systems to systemd and the startup parameters for bind were not
preserved because systemd ignores the /etc/default/bind file. As a result we had tons of DNS
failures when bind was trying to reach out to IPv6 name servers(ugh), when there is no IPv6
connectivity in the network (the solution is to start bind with a -4 option).
I believe I have also caught systemd trying to mess with file systems(iscsi mount points).
I have lots of automation around moving data volumes on the SAN between servers and attaching
them via software iSCSI directly to the VMs themselves(before vsphere 4.0 I attached them via
fibre channel to the hypervisor but a feature in 4.0 broke that for me). I noticed on at
least one occasion when I removed the file systems from a system that SOMETHING (I assume
systemd) mounted them again, and it was very confusing to see file systems mounted again for
block devices that DID NOT EXIST on the server at the time. I worked around THAT one I
believe with the "noauto" option in fstab again. I had to put a lot of extra logic in my
automation scripts to work around systemd stuff.
I'm sure I've only scratched the surface of systemd pain. I'm sure it provides good value
to some people, I hear it's good with containers (I have been running LXC containers for
years now, I see nothing with systemd that changes that experience so far).
But if systemd would just do this one thing and go into dumb mode with init scripts I
would be quite happy.
Now more seriously: it really strikes me that complaints about systemd come from people
managing non-trivial setups like the one you describe. While it might have been a PITA to get
this done with the old init mechanism, you could make it work reliably.
If systemd is a solution to any set of problems, I'd love to have those problems
back!
I knew systemd was coming thanks to playing with Fedora. The quicker start-up times were
welcomed. That was about it! I have had to kickstart many of my CentOS 7 builds to disable
IPv6 (NFS complains bitterly), kill the incredibly annoying 'biosdevname' that turns sensible
eth0/eth1 into some daftly named nonsense, replace Gnome 3 (shudder) with MATE, and fudge
start-up processes. In a previous job, I maintained 2 sets of CentOS 7 'infrastructure'
servers that provided DNS, DHCP, NTP, and LDAP to a large number of historical vlans. Despite
enabling the systemd-network wait online option, which is supposed to start all networks
*before* listening services, systemd would run off flicking all the "on" switches having only
set-up a couple of vlans. Result: NTP would only be listening on one or two vlan interfaces.
The only way I found to get around that was to enable rc.local and call systemd to restart
the NTP daemon after 20 seconds. I never had the time to raise a bug with Red Hat, and I
assume the issue still persists as no-one designed systemd to handle 15-odd vlans!?
I can't remember if it's HPE or Dell (or both) where you can use set the kernel option
biosdevname=0 during build/boot to turn all that renaming stuff off and revert to ethX.
However on (RHEL?)/CentOS 7 I've found that if you build a server like that, and then try
to renam/swap the interfaces it will refuse point blank to allow you to swap the interfaces
round so that something else can be eth0. In the end we just gave up and renamed everything
lanX instead which it was quite happy with.
"I can't remember if it's HPE or Dell (or both) where you can use set the kernel option
biosdevname=0 during build/boot to turn all that renaming stuff off and revert to ethX."
I'm using this on my Debian 9 systems. IIRC the option to do so will be removed in Debian
10.
I'm not really bothered about whether init was perfect from the beginning - for as long as
I've been using Linux (20 years) until now, I have never known the init system to be the
cause of major issues. Since in my experience it's not been seriously broken for two decades,
why throw it out now for something that is orders of magnitude more complex and ridiculously
overreaching?
Like many here I bet, I am barely tolerating SystemD on some servers because RHEL/CentOS 7
is the dominant business distro with a decent support life - but this is also the first time
I can recall ever having serious unpredictable issues with startup and shutdown on Linux
servers.
stiine, Thursday 10th May 2018 15:38 GMT
sysV init
I've been using Linux ( RedHat, CentOS, Ubuntu), BSD (Solaris, SunOS, freeBSD) and Unix ( aix, sysv all of the way back to
AT&T 3B2 servers) in farms of up to 400 servers since 1988 and I never, ever had issues with eth1 becoming eth0 after a
reboot. I also never needed to run ifconfig before configuring an interface just to determine what the inteface was going to
be named on a server at this time. Then they hired Poettering... now, if you replace a failed nic, 9 times out of 10, the
interface is going to have a randomly different name.
Well, I am compelled to agree with most everything you wrote except one niche area that
systemd does better: Remember putzing about with the amd? One line in fstab:
No worries, as has happened with every workaround to make systemD simply mount cifs or NFS
at boot, yours will fail as soon as the next change happens, yet it will remain on the 'net
to be tried over and over as have all the other "fixes" for Poettering's arrogant
breakages.
The last one I heard from him on this was "don't mount shares at boot, it's not reliable
WONTFIX".
Which is why we're all bitching.
Break my stuff.
Web shows workaround.
Break workaround without fixing the original issue, really.
Never ensure one place for current dox on what works now.
Repeat above endlessly.
Fine if all you do is spin up endless identical instances in some cloud (EG a big chunk of
RH customers - but not Debian for example). If like me you have 20+ machines customized to
purpose...for which one workaround works on some but not others, and every new release of
systemD seems to break something new that has to be tracked down and fixed, it's not
acceptable - it's actually making proprietary solutions look more cost effective and less
blood pressure raising.
The old init scripts worked once you got them right, and stayed working. A new distro
release didn't break them, nor did a systemD update (because there wasn't one). This feels
more like sabotage.
Quite understandable that people who don't know anything else would accept systemd. For
everyone else it has nothing to do with old school but everything to do with unpredictability
of systemd.
Today I've kickstarted RHEL7 on a rack of 40 identical servers using same script. On about
25 out of 40 postinstall script added to rc.local failed to run with some obscure error about
script being terminated because something unintelligible did not like it. It never ever
happened on RHEL6, it happens all the time on RHEL7. And that's exactly the reason I
absolutely hate it both RHEL7 and systemd.
Poettering still doesn't get it... Pid 1 is for people wearing big boy pants.
"And perhaps, in the process, you may warm up a bit more to the tool"
Like from LNG to Dry Ice? and by tool does he mean Poettering or systemd?
I love the fact that they aren't trying to address the huge and legitimate issues with
Systemd, while still plowing ahead adding more things we don't want Systemd to touch into
it's ever expanding sprawl.
The root of the issue with Systemd is the problems it causes, not the lack of
"enhancements" initd offered. Replacing Init didn't require the breaking changes and
incompatibility induced by Poettering's misguided handiwork. A clean init replacement would
have made Big Linux more compatible with both it's roots and the other parts of the broader
Linux/BSD/Unix world. As a result of his belligerent incompetence, other peoples projects
have had to be re-engineered, resulting in incompatibility, extra porting work, and security
problems. In short were stuck cleaning up his mess, and the consequences of his security
blunders
A worthy Init replacement should have moved to compiled code and given us asynchronous
startup, threading, etc, without senselessly re-writing basic command syntax or
compatibility. Considering the importance of PID 1, it should have used a formal development
process like the BSD world.
Fedora needs to stop enabling his prima donna antics and stop letting him touch things
until he admits his mistakes and attempts to fix them. The flame wars not going away till he
does.
Re: Poettering still doesn't get it... Pid 1 is for people wearing big boy pants.
SystemD is corporate money (Redhat support dollars) triumphing over the long hairs sadly.
Enough money can buy a shitload of code and you can overwhelm the hippies with hairball
dependencies (the key moment was udev being dependent on systemd) and soon get as much FOSS
as possible dependent on the Linux kernel. This has always been the end game as Red Hat makes
its bones on Linux specifically not on FOSS in general (that say runs on Solaris or HP-UX).
The tighter they can glue the FOSS ecosystem and the Linux kernel together ala Windows lite
style the better for their bottom line. Poettering is just being a good employee asshat
extraordinaire he is.
Raise your hand if you've been completely locked out of a server or laptop (as in, break out
the recovery media and settle down, it'll be a while) because systemd:
1.) Couldn't raise a network interface
2.) Farted and forgot the UUID for a disk, then refused to give a recovery shell
3.) Decided an unimportant service (e.g. CUPS or avahi) was too critical to start before
giving a login over SSH or locally, then that service stalls forever
4.) Decided that no, you will not be network booting your server today. No way to recover
and no debug information, just an interminable hang as it raises wrong network interfaces and
waits for DHCP addresses that will never come.
And lest the fun be restricted to startup, on shutdown systemd can quite happily hang
forever doing things like stopping nonessential services, *with no timeout and no way to
interrupt*. Then you have to Magic Sysreq the machine, except that sometimes secure servers
don't have that ability, at least not remotely. Cue data loss and general excitement.
And that's not even going into the fact that you need to *reboot the machine* to patch the
*network enabled* and highly privileged systemd, or that it seems to have the attack surface
of Jupiter.
Upstart was better than this. SysV was better than this. Mac is better than this. Windows
is better than this.
I honestly would love someone to lay out the problems it solves. Solaris has a similar
parallellised startup system, with some similar problems, but it didn't need pid 1.
Agreed, Solaris svcadm and svcs etc are an example of how it should be done. A layered
approach maintaining what was already there, while adding functionality for management
purposes. Keeps all the old text based log files and uses xml scripts (human readable and
editable) for higher level functions. Afaics, systemd is a power grab by red hat and an ego
trip for it's primary developer. Dumped bloatware Linux in favour of FreeBSD and others after
Suse 11.4, though that was bad enough with Gnome 3...
hh uses shell history to provide suggest box like functionality for commands used in the
past. By default it parses .bash-history file that is filtered as you type a command substring. Commands are not just filtered, but also ordered by a ranking algorithm that considers number
of occurrences, length and timestamp. Favorite and frequently used commands can be
bookmarked . In addition hh allows removal of commands from history - for instance with a
typo or with a sensitive content.
export HH_CONFIG=hicolor # get more colors
shopt -s histappend # append new history items to .bash_history
export HISTCONTROL=ignorespace # leading space hides commands from history
export HISTFILESIZE=10000 # increase history file size (default is 500)
export HISTSIZE=${HISTFILESIZE} # increase history size (default is 500)
export PROMPT_COMMAND="history -a; history -n; ${PROMPT_COMMAND}"
# if this is interactive shell, then bind hh to Ctrl-r (for Vi mode check doc)
if [[ $- =~ .*i.* ]]; then bind '"\C-r": "\C-a hh -- \C-j"'; fi
The prompt command ensures synchronization of the history between BASH memory and history
file.
export HISTFILE=~/.zsh_history # ensure history file visibility
export HH_CONFIG=hicolor # get more colors
bindkey -s "\C-r" "\eqhh\n" # bind hh to Ctrl-r (for Vi mode check doc, experiment with --)
Is Glark a Better Grep? GNU grep is one of my go-to tools on any
Linux box. But grep isn't the only tool in town. If you want to try something a
bit different, check out glark a grep alternative that might
might be better in some situations.
What is glark? Basically, it's a utility that's similar to grep, but it has a few features
that grep does not. This includes complex expressions, Perl-compatible regular expressions, and
excluding binary files. It also makes showing contextual lines a bit easier. Let's take a
look.
I installed glark (yes, annoyingly it's yet another *nix utility that has no initial cap) on
Linux Mint 11. Just grab it with apt-get install glark and you should be good to
go.
Simple searches work the same way as with grep : glark
stringfilenames . So it's pretty much a drop-in replacement for those.
But you're interested in what makes glark special. So let's start with a
complex expression, where you're looking for this or that term:
glark -r -o thing1 thing2 *
This will search the current directory and subdirectories for "thing1" or "thing2." When the
results are returned, glark will colorize the results and each search term will be
highlighted in a different color. So if you search for, say "Mozilla" and "Firefox," you'll see
the terms in different colors.
You can also use this to see if something matches within a few lines of another term. Here's
an example:
glark --and=3 -o Mozilla Firefox -o ID LXDE *
This was a search I was using in my directory of Linux.com stories that I've edited. I used
three terms I knew were in one story, and one term I knew wouldn't be. You can also just use
the --and option to spot two terms within X number of lines of each other, like
so:
glark --and=3 term1 term2
That way, both terms must be present.
You'll note the --and option is a bit simpler than grep's context line options.
However, glark tries to stay compatible with grep, so it also supports the -A ,
-B and -C options from grep.
Miss the grep output format? You can tell glark to use grep format with the
--grep option.
Most, if not all, GNU grep options should work with glark .
Before and
After
If you need to search through the beginning or end of a file, glark has the
--before and --after options (short versions, -b and
-a ). You can use these as percentages or as absolute number of lines. For
instance:
glark -a 20 expression *
That will find instances of expression after line 20 in a file.
The glark
Configuration File
Note that you can have a ~/.glarkrc that will set common options for each use
of glark (unless overridden at the command line). The man page for glark does
include some examples, like so:
after-context: 1
before-context: 6
context: 5
file-color: blue on yellow
highlight: off
ignore-case: false
quiet: yes
text-color: bold reverse
line-number-color: bold
verbose: false
grep: true
Just put that in your ~/.glarkrc and customize it to your heart's content. Note
that I've set mine to grep: false and added the binary-files:
without-match option. You'll definitely want the quiet option to suppress all the notes
about directories, etc. See the man page for more options. It's probably a good idea to spend
about 10 minutes on setting up a configuration file.
Final Thoughts
One thing that I have noticed is that glark doesn't seem as fast as
grep . When I do a recursive search through a bunch of directories containing
(mostly) HTML files, I seem to get results a lot faster with grep . This is not
terribly important for most of the stuff I do with either utility. However, if you're doing
something where performance is a major factor, then you may want to see if grep
fits the bill better.
Is glark "better" than grep? It depends entirely on what you're doing. It has a few features
that give it an edge over grep, and I think it's very much worth trying out if you've never
given it a shot.
1. Introduction The GridFTP User's Guide provides general end user-oriented information. 2. Usage scenarios2.1.
Basic procedure for using GridFTP (globus-url-copy) If you just want the "rules of thumb" on getting started (without all the
details), the following options using globus-url-copy will normally give acceptable performance:
The source/destination URLs will normally be one of the following:
file:///path/to/my/file if you are accessing a file on a file system accessible by the host on which
you are running your
client
.
gsiftp://hostname/path/to/remote/file if you are accessing a file from a GridFTP
server
.
2.1.1. Putting files One of the most basic tasks in GridFTP is to "put" files, i.e., moving a file from your file system to
the server. So for example, if you want to move the file /tmp/foo from a file system accessible to the host on which
you are running your client to a file name /tmp/bar on a host named remote.machine.my.edu running a GridFTP
server, you would use this command:
In theory, remote.machine.my.edu could be the same host as the one on which you
are running your client, but that is normally only done in testing situations.
2.1.2. Getting files A get, i.e, moving a file from a server to your file system, would just reverse the source and destination
URLs:
2.1.3. Third party transfers Finally, if you want to move a file between two GridFTP servers (a
third party transfer ), both URLs would use gsiftp: as the protocol:
2.1.4. For more information If you want more information and details on URLs and the
command line options
, the Key Concepts Guide gives basic definitions and
an overview of the GridFTP protocol as well as our implementation of it. 2.2. Accessing data in...2.2.1. Accessing data
in a non-POSIX file data source that has a POSIX interface If you want to access data in a non-POSIX file data source that has
a POSIX interface, the standard server will do just fine. Just make sure it is really POSIX-like (out of order writes, contiguous
byte writes, etc). 2.2.2. Accessing data in HPSS The following information is helpful if you want to use GridFTP to access
data in HPSS. Architecturally, the Globus GridFTP
server
can be divided into 3 modules:
the GridFTP protocol module,
the (optional) data transform module, and
the Data Storage Interface (DSI).
In the GT4.0.x implementation, the data transform module and the DSI have been merged, although we plan to have separate, chainable,
data transform modules in the future.
Note
This architecture does NOT apply to the WU-FTPD implementation (GT3.2.1 and lower).
2.2.2.1. GridFTP Protocol Module
The GridFTP protocol module is the module that reads and writes to the network and implements the GridFTP protocol. This module should
not need to be modified since to do so would make the server non-protocol compliant, and unable to communicate with other servers.
2.2.2.2. Data Transform Functionality
The data transform functionality is invoked by using the ERET (extended retrieve) and ESTO (extended store) commands. It is seldom
used and bears careful consideration before it is implemented, but in the right circumstances can be very useful. In theory, any
computation could be invoked this way, but it was primarily intended for cases where some simple pre-processing (such as a partial
get or sub-sampling) can greatly reduce the network load. The disadvantage to this is that you remove any real option for planning,
brokering, etc., and any significant computation could adversely affect the data transfer performance. Note that the
client
must also support the ESTO/ERET functionality as well.
2.2.2.3. Data Storage Interface (DSI) / Data Transform module
The Data Storage Interface (DSI) / Data Transform module knows how to read and write to the "local" storage system and can optionally
transform the data. We put local in quotes because in a complicated storage system, the storage may not be directly attached, but
for performance reasons, it should be relatively close (for instance on the same LAN). The interface consists of functions to be
implemented such as send (get), receive (put), command (simple commands that simply succeed or fail like mkdir), etc.. Once these
functions have been implemented for a specific storage system, a client should not need to know or care what is actually providing
the data. The server can either be configured specifically with a specific DSI, i.e., it knows how to interact with a single class
of storage system, or one particularly useful function for the ESTO/ERET functionality mentioned above is to load and configure a
DSI on the fly.
2.2.2.4. HPSS info
Last Update: August 2005 Working with Los Alamos National Laboratory and the High Performance Storage System (HPSS) collaboration
( http://www.hpss-collaboration.org ), we have written a Data Storage
Interface (DSI) for read/write access to HPSS. This DSI would allow an existing application that uses a GridFTP compliant client
to utilize an HPSS data resources. This DSI is currently in testing. Due to changes in the HPSS security mechanisms, it requires
HPSS 6.2 or later, which is due to be released in Q4 2005. Distribution for the DSI has not been worked out yet, but it will *probably*
be available from both Globus and the HPSS collaboration. While this code will be open source, it requires underlying HPSS libraries
which are NOT open source (proprietary).
Note
This is a purely server side change, the client does not know what DSI is running, so only a
site that is already running HPSS and wants to allow GridFTP access needs to worry about access to these proprietary libraries.
2.2.3. Accessing data in SRB The following information is helpful if you want to use GridFTP to access data in SRB. Architecturally,
the Globus GridFTP server can be divided into 3 modules:
the GridFTP protocol module,
the (optional) data transform module, and
the Data Storage Interface (DSI).
In the GT4.0.x implementation, the data transform module and the DSI have been merged, although we plan to have separate, chainable,
data transform modules in the future.
Note
This architecture does NOT apply to the WU-FTPD implementation (GT3.2.1 and lower).
2.2.3.1. GridFTP Protocol Module
The GridFTP protocol module is the module that reads and writes to the network and implements the GridFTP protocol. This module should
not need to be modified since to do so would make the server non-protocol compliant, and unable to communicate with other servers.
2.2.3.2. Data Transform Functionality
The data transform functionality is invoked by using the ERET (extended retrieve) and ESTO (extended store) commands. It is seldom
used and bears careful consideration before it is implemented, but in the right circumstances can be very useful. In theory, any
computation could be invoked this way, but it was primarily intended for cases where some simple pre-processing (such as a partial
get or sub-sampling) can greatly reduce the network load. The disadvantage to this is that you remove any real option for planning,
brokering, etc., and any significant computation could adversely affect the data transfer performance. Note that the
client
must also support the ESTO/ERET functionality as well.
2.2.3.3. Data Storage Interface (DSI) / Data Transform module
The Data Storage Interface (DSI) / Data Transform module knows how to read and write to the "local" storage system and can optionally
transform the data. We put local in quotes because in a complicated storage system, the storage may not be directly attached, but
for performance reasons, it should be relatively close (for instance on the same LAN). The interface consists of functions to be
implemented such as send (get), receive (put), command (simple commands that simply succeed or fail like mkdir), etc.. Once these
functions have been implemented for a specific storage system, a client should not need to know or care what is actually providing
the data. The server can either be configured specifically with a specific DSI, i.e., it knows how to interact with a single class
of storage system, or one particularly useful function for the ESTO/ERET functionality mentioned above is to load and configure a
DSI on the fly.
2.2.3.4. SRB info
Last Update: August 2005 Working with the SRB team at the San Diego Supercomputing Center, we have written a Data Storage Interface
(DSI) for read/write access to data in the Storage Resource Broker (SRB) (http://www.npaci.edu/DICE/SRB). This DSI will enable GridFTP
compliant clients to read and write data to an SRB server, similar in functionality to the sput/sget commands. This DSI is currently
in testing and is not yet publicly available, but will be available from both the SRB web site (here) and the Globus web site (here).
It will also be included in the next stable release of the toolkit. We are working on performance tests, but early results indicate
that for wide area network (WAN) transfers, the performance is comparable. When might you want to use this functionality:
You have existing tools that use GridFTP clients and you want to access data that is in SRB
You have distributed data sets that have some of the data in SRB and some of the data available from GridFTP servers.
2.2.4. Accessing data in some other non-POSIX data source The following information is helpful If you want to use GridFTP
to access data in a non-POSIX data source. Architecturally, the Globus GridFTP
server
can be divided into 3 modules:
the GridFTP protocol module,
the (optional) data transform module, and
the Data Storage Interface (DSI).
In the GT4.0.x implementation, the data transform module and the DSI have been merged, although we plan to have separate, chainable,
data transform modules in the future.
Note
This architecture does NOT apply to the WU-FTPD implementation (GT3.2.1 and lower).
2.2.4.1. GridFTP Protocol Module
The GridFTP protocol module is the module that reads and writes to the network and implements the GridFTP protocol. This module should
not need to be modified since to do so would make the server non-protocol compliant, and unable to communicate with other servers.
2.2.4.2. Data Transform Functionality
The data transform functionality is invoked by using the ERET (extended retrieve) and ESTO (extended store) commands. It is seldom
used and bears careful consideration before it is implemented, but in the right circumstances can be very useful. In theory, any
computation could be invoked this way, but it was primarily intended for cases where some simple pre-processing (such as a partial
get or sub-sampling) can greatly reduce the network load. The disadvantage to this is that you remove any real option for planning,
brokering, etc., and any significant computation could adversely affect the data transfer performance. Note that the
client
must also support the ESTO/ERET functionality as well.
2.2.4.3. Data Storage Interface (DSI) / Data Transform module
The Data Storage Interface (DSI) / Data Transform module knows how to read and write to the "local" storage system and can
optionally transform the data. We put local in quotes because in a complicated storage system, the storage may not be directly
attached, but for performance reasons, it should be relatively close (for instance on the same LAN).
The interface consists of functions to be implemented such as send (get), receive (put), command (simple commands that simply
succeed or fail like mkdir), etc..
Once these functions have been implemented for a specific storage system, a client should not need to know or care what is
actually providing the data. The server can either be configured specifically with a specific DSI, i.e., it knows how to interact
with a single class of storage system, or one particularly useful function for the ESTO/ERET functionality mentioned above is
to load and configure a DSI on the fly. 3. Command line tools
I am trying to backup my file server to a
remove file server using rsync. Rsync is not
successfully resuming when a transfer is
interrupted. I used the partial option but
rsync doesn't find the file it already
started because it renames it to a temporary
file and when resumed it creates a new file
and starts from beginning.
When this command is ran, a backup file
named
OldDisk.dmg
from my
local machine get created on the remote
machine as something like
.OldDisk.dmg.SjDndj23
.
Now when the internet connection gets
interrupted and I have to resume the
transfer, I have to find where rsync left
off by finding the temp file like
.OldDisk.dmg.SjDndj23
and rename it
to
OldDisk.dmg
so that it
sees there already exists a file that it can
resume.
How do I fix this so I don't have to
manually intervene each time?
TL;DR
: Use
--timeout=X
(X in seconds) to
change the default rsync server timeout,
not
--inplace
.
The issue
is the rsync server processes (of which
there are two, see
rsync --server
...
in
ps
output on
the receiver) continue running, to wait
for the rsync client to send data.
If the rsync server processes do not
receive data for a sufficient time, they
will indeed timeout, self-terminate and
cleanup by moving the temporary file to
it's "proper" name (e.g., no temporary
suffix). You'll then be able to resume.
If you don't want to wait for the
long default timeout to cause the rsync
server to self-terminate, then when your
internet connection returns, log into
the server and clean up the rsync server
processes manually. However, you
must politely terminate
rsync --
otherwise, it will not move the partial
file into place; but rather, delete it
(and thus there is no file to resume).
To politely ask rsync to terminate, do
not
SIGKILL
(e.g.,
-9
),
but
SIGTERM
(e.g.,
pkill -TERM -x rsync
- only an
example, you should take care to match
only the rsync processes concerned with
your client).
Fortunately there is an easier way:
use the
--timeout=X
(X in
seconds) option; it is passed to the
rsync server processes as well.
For example, if you specify
rsync ... --timeout=15 ...
, both
the client and server rsync processes
will cleanly exit if they do not
send/receive data in 15 seconds. On the
server, this means moving the temporary
file into position, ready for resuming.
I'm not sure of the default timeout
value of the various rsync processes
will try to send/receive data before
they die (it might vary with operating
system). In my testing, the server rsync
processes remain running longer than the
local client. On a "dead" network
connection, the client terminates with a
broken pipe (e.g., no network socket)
after about 30 seconds; you could
experiment or review the source code.
Meaning, you could try to "ride out" the
bad internet connection for 15-20
seconds.
If you do not clean up the server
rsync processes (or wait for them to
die), but instead immediately launch
another rsync client process, two
additional server processes will launch
(for the other end of your new client
process). Specifically, the new rsync
client
will not
re-use/reconnect to the existing rsync
server processes. Thus, you'll have two
temporary files (and four rsync server
processes) -- though, only the newer,
second temporary file has new data being
written (received from your new rsync
client process).
Interestingly, if you then clean up
all rsync server processes (for example,
stop your client which will stop the new
rsync servers, then
SIGTERM
the older rsync servers, it appears to
merge (assemble) all the partial files
into the new proper named file. So,
imagine a long running partial copy
which dies (and you think you've "lost"
all the copied data), and a short
running re-launched rsync (oops!).. you
can stop the second client,
SIGTERM
the first servers, it
will merge the data, and you can resume.
Finally, a few short remarks:
Don't use
--inplace
to workaround this. You will
undoubtedly have other problems as a
result,
man rsync
for
the details.
It's trivial, but
-t
in your rsync options is redundant,
it is implied by
-a
.
An already compressed disk image
sent over rsync
without
compression might result in shorter
transfer time (by avoiding double
compression). However, I'm unsure of
the compression techniques in both
cases. I'd test it.
As far as I understand
--checksum
/
-c
,
it won't help you in this case. It
affects how rsync decides if it
should
transfer a file. Though,
after a first rsync completes, you
could run a
second
rsync
with
-c
to insist on
checksums, to prevent the strange
case that file size and modtime are
the same on both sides, but bad data
was written.
I
didn't test how the
server-side rsync handles
SIGINT, so I'm not sure it
will keep the partial file -
you could check. Note that
this doesn't have much to do
with
Ctrl-c
; it
happens that your terminal
sends
SIGINT
to
the foreground process when
you press
Ctrl-c
,
but the server-side rsync
has no controlling terminal.
You must log in to the
server and use
kill
.
The client-side rsync will
not send a message to the
server (for example, after
the client receives
SIGINT
via your
terminal
Ctrl-c
)
- might be interesting
though. As for
anthropomorphizing, not sure
what's "politer". :-)
–
Richard
Michael
Dec 29 '13 at 22:34
I
just tried this timeout
argument
rsync -av
--delete --progress --stats
--human-readable --checksum
--timeout=60 --partial-dir /tmp/rsync/
rsync://$remote:/ /src/
but then it timed out during
the "receiving file list"
phase (which in this case
takes around 30 minutes).
Setting the timeout to half
an hour so kind of defers
the purpose. Any workaround
for this?
–
d-b
Feb 3 '15 at 8:48
@user23122
--checksum
reads all data when
preparing the file list,
which is great for many
small files that change
often, but should be done
on-demand for large files.
–
Cees
Timmerman
Sep 15 '15 at 17:10
How do I find out running processes were associated with each open port? How do I find out what process has open tcp port 111
or udp port 7000 under Linux?
You can the following programs to find out about port numbers and its associated process:
netstat – a command-line tool that displays network connections, routing tables, and a number of network interface statistics.
fuser – a command line tool to identify processes using files or sockets.
lsof – a command line tool to list open files under Linux / UNIX to report a list of all open files and the processes that
opened them.
/proc/$pid/ file system – Under Linux /proc includes a directory for each running process (including kernel processes) at
/proc/PID, containing information about that process, notably including the processes name that opened port.
You must run above command(s) as the root user.
netstat example
Type the following command: # netstat -tulpn
Sample outputs:
OR try the following ps command: # ps -eo pid,user,group,args,etime,lstart | grep '[3]813'
Sample outputs:
3813 vivek vivek transmission 02:44:05 Fri Oct 29 10:58:40 2010
Another option is /proc/$PID/environ, enter: # cat /proc/3813/environ
OR # grep --color -w -a USER /proc/3813/environ
Sample outputs (note –colour option): Fig.01: grep output
Now, you get more information about pid # 1607 or 1616 and so on: # ps aux | grep '[1]616'
Sample outputs: www-data 1616 0.0 0.0 35816 3880 ? S 10:20 0:00 /usr/sbin/apache2 -k start
I recommend the following command to grab info about pid # 1616: # ps -eo pid,user,group,args,etime,lstart | grep '[1]616'
Sample outputs:
/usr/sbin/apache2 -k start : The command name and its args
03:16:22 : Elapsed time since the process was started, in the form [[dd-]hh:]mm:ss.
Fri Oct 29 10:20:17 2010 : Time the command started.
Help: I Discover an Open Port Which I Don't Recognize At All
The file /etc/services is used to map port numbers and protocols to service names. Try matching port numbers: $ grep port /etc/services
$ grep 443 /etc/services
Sample outputs:
https 443/tcp # http protocol over TLS/SSL
https 443/udp
Check For rootkit
I strongly recommend that you find out which processes are really running, especially servers connected to the high speed Internet
access. You can look for rootkit which is a program designed to take fundamental control (in Linux / UNIX terms "root" access, in
Windows terms "Administrator" access) of a computer system, without authorization by the system's owners and legitimate managers.
See how to detecting
/ checking rootkits under Linux .
Keep an Eye On Your Bandwidth Graphs
Usually, rooted servers are used to send a large number of spam or malware or DoS style attacks on other computers.
See also:
See the following man pages for more information: $ man ps
$ man grep
$ man lsof
$ man netstat
$ man fuser
The -w option means I am specifying the node(s) that will run the command. In this case, I specified the IP address
of the node (192.168.1.250). After the list of nodes, I add the command I want to run, which is uname -r in this case.
Notice that pdsh starts the output line by identifying the node name.
If you need to mix rcmd modules in a single command, you can specify which module to use in the command line,
by putting the rcmd module before the node name. In this case, I used ssh and typical ssh syntax.
A very common way of using pdsh is to set the environment variable WCOLL to point to the file that contains the list
of hosts you want to use in the pdsh command. For example, I created a subdirectory PDSH where I create a file
hosts that lists the hosts I want to use:
[laytonjb@home4 ~]$ mkdir PDSH
[laytonjb@home4 ~]$ cd PDSH
[laytonjb@home4 PDSH]$ vi hosts
[laytonjb@home4 PDSH]$ more hosts
192.168.1.4
192.168.1.250
I'm only using two nodes: 192.168.1.4 and 192.168.1.250. The first is my test system (like a cluster head node), and the second
is my test compute node. You can put hosts in the file as you would on the command line separated by commas. Be sure not to put a
blank line at the end of the file because pdsh will try to connect to it. You can put the environment variable WCOLL
in your .bashrc file:
export WCOLL=/home/laytonjb/PDSH/hosts
As before, you can source your .bashrc file, or you can log out and log back in. Specifying Hosts
I won't list all the several other ways to specify a list of nodes, because the pdsh website
[9] discusses virtually
all of them; however, some of the methods are pretty handy. The simplest way is to specify the nodes on the command line is to use
the -w option:
In this case, I specified the node names separated by commas. You can also use a range of hosts as follows:
pdsh -w host[1-11]
pdsh -w host[1-4,8-11]
In the first case, pdsh expands the host range to host1, host2, host3, , host11. In the second case, it expands the hosts similarly
(host1, host2, host3, host4, host8, host9, host10, host11). You can go to the pdsh website for more information on hostlist expressions
[10] .
Another option is to have pdsh read the hosts from a file other than the one to which WCOLL points. The command shown in
Listing 2 tells
pdsh to take the hostnames from the file /tmp/hosts , which is listed after -w ^ (with no space between
the "^" and the filename). You can also use several host files,
Listing 2 Read Hosts from File
$ more /tmp/hosts
192.168.1.4
$ more /tmp/hosts2
192.168.1.250
$ pdsh -w ^/tmp/hosts,^/tmp/hosts2 uname -r
192.168.1.4: 2.6.32-431.17.1.el6.x86_64
192.168.1.250: 2.6.32-431.11.2.el6.x86_64
The option -w -192.168.1.250 excluded node 192.168.1.250 from the list and only output the information for 192.168.1.4.
You can also exclude nodes using a node file:
or a list of hostnames to be excluded from the command to run also works.
More Useful pdsh Commands
Now I can shift into second gear and try some fancier pdsh tricks. First, I want to run a more complicated command on all of the
nodes ( Listing 3
). Notice that I put the entire command in quotes. This means the entire command is run on each node, including the first (
cat /proc/cpuinfo ) and second ( grep bogomips ) parts.
Listing 3 Quotation Marks 1
In the output, the node precedes the command results, so you can tell what output is associated with which node. Notice that the
BogoMips values are different on the two nodes, which is perfectly understandable because the systems are different. The first node
has eight cores (four cores and four Hyper-Thread cores), and the second node has four cores.
You can use this command across a homogeneous cluster to make sure all the nodes are reporting back the same BogoMips value. If
the cluster is truly homogeneous, this value should be the same. If it's not, then I would take the offending node out of production
and check it.
A slightly different command shown in
Listing 4 runs
the first part contained in quotes, cat /proc/cpuinfo , on each node and the second part of the command, grep
bogomips , on the node on which you issue the pdsh command.
Listing 4 Quotation Marks 2
The point here is that you need to be careful on the command line. In this example, the differences are trivial, but other commands
could have differences that might be difficult to notice.
One very important thing to note is that pdsh does not guarantee a return of output in any particular order. If you have a list
of 20 nodes, the output does not necessarily start with node 1 and increase incrementally to node 20. For example, in
Listing 5 , I run
vmstat on each node and get three lines of output from each node.
"... Download the authoritative guide: Cloud Computing 2018: Using the Cloud to Transform
Your Business ..."
Notable quotes:
"... Download the authoritative guide: Cloud Computing 2018: Using the Cloud to Transform Your Business ..."
"... Edge computing is a term you are going to hear more of in the coming years because it precedes another term you will be hearing a lot, the Internet of Things (IoT). You see, the formally adopted definition of edge computing is a form of technology that is necessary to make the IoT work. ..."
"... Tech research firm IDC defines edge computing is a "mesh network of micro data centers that process or store critical data locally and push all received data to a central data center or cloud storage repository, in a footprint of less than 100 square feet." ..."
The term
cloud computing is now as firmly lodged in our technical lexicon as email and Internet, and
the concept has taken firm hold in business as well. By 2020, Gartner estimates that a "no
cloud" policy will be as prevalent in business as a "no Internet" policy. Which is to say no
one who wants to stay in business will be without one.
You are likely hearing a new term now, edge computing . One of the problems with technology
is terms tend to come before the definition. Technologists (and the press, let's be honest)
tend to throw a word around before it is well-defined, and in that vacuum come a variety of
guessed definitions, of varying accuracy.
Edge computing is a term you are going to hear more of in the coming years because it
precedes another term you will be hearing a lot, the Internet of Things
(IoT). You see, the formally adopted definition of edge computing is a form of technology
that is necessary to make the IoT work.
Tech research firm IDC defines edge computing is a "mesh network of micro data
centers that process or store critical data locally and push all received data to a central
data center or cloud storage repository, in a footprint of less than 100 square
feet."
It is typically used in IoT use cases, where edge devices collect data from IoT devices and
do the processing there, or send it back to a data center or the cloud for processing. Edge
computing takes some of the load off the central data center, reducing or even eliminating the
processing work at the central location.
IoT Explosion in the Cloud Era
To understand the need for edge computing you must understand the explosive growth in IoT in
the coming years, and it is coming on big. There have been a number of estimates of the growth
in devices, and while they all vary, they are all in the billions of devices.
Gartner estimates there were 6.4 billion connected devices in 2016 will it reach 20.8
billion by 2020. It estimates that in 2016, 5.5 million new "things" were connected every
day.
IDC predicts global IoT revenue will grow from $2.71 billion in 2015 to $7.065 billion by
2020, with the total installed base of devices reaching 28.1 billion in 2020.
IHS Markit forecasts that the IoT market will grow from an installed base of 15.4 billion
devices in 2015 to 30.7 billion devices by 2020 and 75.4 billion in 2025.
McKinsey estimates the total IoT market size was about $900 million in 2015 and will grow
to $3.7 billion by 2020.
This is taking place in a number of areas, most notably cars and industrial equipment. Cars
are becoming increasingly more computerized and more intelligent. Gone are the days when the
"Check engine" warning light came on and you had to guess what was wrong. Now it tells you
which component is failing.
The industrial sector is a broad one and includes sensors, RFID, industrial robotics, 3D
printing, condition monitoring, smart meters, guidance, and more. This sector is sometimes
called the Industrial Internet of Things (IIoT) and the overall market is expected to grow from
$93.9 billion in 2014 to $151.01 billion by 2020.
All of these sensors are taking in data but they are not processing it. Your car does some
of the processing of sensor data but much of it has to be sent in to a data center for
computation, monitoring and logging.
The problem is that this would overload networks and data centers. Imaging the millions of
cars on the road sending in data to data centers around the country. The 4G network would be
overwhelmed, as would the data centers. And if you are in California and the car maker's data
center is in Texas, that's a long round trip.
However, cloud-hosted information assets must still be accessed by users over existing WAN infrastructures, where there are performance
issues due to bandwidth and latency constraints.
How should you troubleshoot WAN performance issues. Your MPLS or VPLS network and your
clients in field offices are complaining about slow WAN performance. Your network should be
performing better and you can't figure out what the problem is. You can contact SD-WAN-Experts to have their
engineers solve your problem, but you want to try to solve the problems yourself.
The first thing to check, seems trivial, but you need to confirm that the ports on your
router and switch ports are configured for the same speed and duplex. Log into your switches
and check the logs for mismatches of speed or duplex. Auto-negotiation sometimes does not work
properly, so a 10M port connected to a 100M port is mismatched. Or you might have a half-duplex
port connected to a full-duplex port. Don't assume that a 10/100/1000 port is auto-negotiating
correctly!
Is your WAN performance problem consistent? Does it occur at roughly the same time of
day? Or is it completely random? If you don't have the monitoring tools to measure this, you
are at a big disadvantage in resolving the issues on your own.
Do you have Class of Service configured on your WAN? Do you have DSCP configured on your
LAN? What is the mapping of your DSCP values to CoS?
What kind of applications are traversing your WAN? Are there specific apps that work
better than others?
Have your reviewed bandwidth utilization on your carrier's web portal to determine if you
are saturating the MPLS port of any locations? Even brief peaks will be enough to generate
complaints. Large files, such as CAD drawings, can completely saturate a WAN link.
Are you backing up or synchronizing data over the WAN? Have you confirmed 100% that this
work is completed before the work day begins.
Might your routing be taking multiple paths and not the most direct path? Look at your
routing tables.
Next, you want to see long term trend statistics. This means monitoring the SNMP streams
from all your routers, using tools such as MRTG, NTOP or Cacti. A two week sampling should
provide a very good picture of what is happening on your network to help troubleshoot your
WAN.
Show network traffic sorted according to various criteria
Display traffic statistics
Store on disk persistent traffic statistics in RRD format
Identify the identity (e.g. email address) of computer users
Passively (i.e. without sending probe packets) identify the host OS
Show IP traffic distribution among the various protocols
Analyse IP traffic and sort it according to the source/destination
Display IP Traffic Subnet matrix (who's talking to who?)
Report IP protocol usage sorted by protocol type
Act as a NetFlow/ sFlow collector for
flows generated by routers (e.g. Cisco and Juniper) or switches (e.g. Foundry Networks)
Produce RMON-like network traffic statistic
MRTG (Multi-Router Traffic
Grapher) provides easy to understand graphs of your network bandwidth utilization.
Cacti requires a MySQL
database. It is a complete network graphing solution designed to harness the power of
RRDTool 's data storage and graphing
functionality. Cacti provides a fast poller, advanced graph templating, multiple data
acquisition methods, and user management features out of the box. All of this is wrapped in an
intuitive, easy to use interface that makes sense for LAN-sized installations up to complex
networks with hundreds of devices.
Both NTOP and MRTG are freeware applications to help troubleshoot your WAN that will run on
the freeware versions of Linux. As a result, they can be installed on almost any desktop
computer that has out-lived its value as a Windows desktop machine. If you are skilled with
Linux and networking, and you have the time, you can install this monitoring system on your
own. You will need to get your carrier to provide read-only access to your router SNMP
traffic.
But you might find it more cost effective to have the engineers at SD-WAN-Experts do the
work for you. All you need to do is provide an available machine with a Linux install (Ubuntu,
CentOS, RedHat, etc) with remote access via a VPN. Our engineers will then download all the
software remotely, install and configure the machine. When we are done with the monitoring,
beside understanding how to solve your problem (and solving it!) you will have your own network
monitoring system installed for your use on a daily basis. We'll teach you how to use it, which
is quite simple using the web based tools, so you can view it from any machine on your
network.
Storage is one
of the most popular uses of cloud computing, particularly for consumers. The user-friendly
design of service-based companies have helped make "cloud" a pretty normal term -- even
reaching meme
status in 2016.
However, cloud storage means something very different to businesses. Big data and the
Internet of
Things (IoT) have made it difficult to appraise the value of data until long after it's
originally stored -- when finding that piece of data becomes the key to revealing valuable
business insights or unlocking an application's new feature. Even after enterprises decide
where to store their data in the cloud (on-premise, off-premise, public, or private), they
still have to decide how they're going to store it. What good is data that can't be
found?
It's common to store data in the cloud using software-defined
storage . Software-defined storage decouples storage software from hardware so you can
abstract and consolidate storage capacity in a cloud. It allows you to scale beyond whatever
individual hardware components your cloud is built on.
Two of the more common software-defined storage solutions include Ceph for structured data
and Gluster for unstructured data. Ceph is a massively scalable,
programmable storage system that works well with clouds -- particularly those deployed using
OpenStack® -- because of its ability to unify object, block, and file storage into 1 pool
of resources. Gluster is designed to handle the
requirements of traditional file storage and is particularly adept at provisioning and managing
elastic storage for container-based applications.
"... The recent widespread of edge computing in some 5G showcases, like the major sports events, has generated the ongoing discussion about the possibility of edge computing to replace cloud computing. ..."
"... For instance, Satya Nadella, the CEO of Microsoft, announced in Microsoft Build 2017 that the company will focus its strategy on edge computing. Indeed, edge computing will be the key for the success of smart home and driverless vehicles ..."
"... the edge will be the first to process and store the data generated by user devices. This will reduce the latency for the data to travel to the cloud. In other words, the edge optimizes the efficiency for the cloud. ..."
The recent widespread of edge computing in some 5G showcases, like the major sports events,
has generated the ongoing discussion about the possibility of edge computing to replace cloud
computing.
In fact, there have been announcements from global tech leaders like Nokia and
Huawei demonstrating increased efforts and resources in developing edge computing.
For
instance, Satya Nadella, the CEO of Microsoft, announced in Microsoft Build 2017 that the
company will focus its strategy on edge computing. Indeed, edge computing will be the key for
the success of smart home and driverless vehicles.
... ... ...
Cloud or edge, which will lead the future?
The answer to that question is "Cloud – Edge Mixing". The cloud and the edge will
complement each other to offer the real IoT experience. For instance, while the cloud
coordinates all the technology and offers SaaS to users, the edge will be the first to process
and store the data generated by user devices. This will reduce the latency for the data to
travel to the cloud. In other words, the edge optimizes the efficiency for the cloud.
It is strongly suggested to implement open architecture white-box servers for both cloud and
edge, to minimize the latency for cloud-edge synchronization and optimize the compatibility
between the two. For example, Lanner Electronics offers a wide range of Intel x86 white box
appliances for data centers and edge uCPE/vCPE.
"... OpenStack's core value is to gather a pool of hypervisor-enabled computers and enable the delivery of virtual machines (VMs) on demand to users. ..."
Both OpenStack and Docker were conceived to make IT more agile. OpenStack has
strived to do this by turning hitherto static IT resources into elastic infrastructure, whereas
Docker has reached for this goal by harmonizing development, test, and production resources, as
Red Hat's Neil Levine suggests .
But while Docker adoption has soared, OpenStack is still largely stuck in neutral. OpenStack
is kept relevant by so many wanting to believe its promise, but never hitting its stride
due to a host of factors , including complexity.
And yet Docker could be just the thing to turn OpenStack's popularity into productivity.
Whether a Docker-plus-OpenStack pairing is right for your enterprise largely depends on the
kind of capacity your enterprise hopes to deliver. If simply Docker, OpenStack is probably
overkill.
An open source approach to delivering virtual machines
OpenStack is an operational model for delivering virtualized compute capacity.
Sure, some give it a more grandiose definition ("OpenStack
is a set of software tools for building and managing cloud computing platforms for public and
private clouds"), but if we ignore secondary services like Cinder, Heat, and Magnum, for
example, OpenStack's core value is to gather a pool of hypervisor-enabled computers and
enable the delivery of virtual machines (VMs) on demand to users.
That's it.
Not that this is a small thing. After all, without OpenStack, the hypervisor sits idle,
lonesome on a single computer, with no way to expose that capacity programmatically (or
otherwise) to users.
Before cloudy systems like OpenStack or Amazon's EC2, users would typically file a help
ticket with IT. An IT admin, in turn, would use a GUI or command line to create a VM, and then
share the credentials with the user.
Systems like OpenStack significantly streamline this process, enabling IT to
programmatically deliver capacity to users. That's a big deal.
Docker peanut butter, meet
OpenStack jelly
Docker, the darling of the containers world, is similar to the VM in the IaaS picture
painted above.
A Docker host is really the unit of compute capacity that users need, and not the container
itself. Docker addresses what you do with a host once you've got it, but it doesn't really help
you get the host in the first place.
A Docker machine provides a client-side tool that lets you request Docker hosts from an IaaS
provider (like EC2 or OpenStack or vSphere), but it's far from a complete solution. In part,
this stems from the fact that Docker doesn't have a tenancy model.
With a hypervisor, each VM is a tenant. But in Docker, the Docker host is a tenant. You
typically don't want multiple users sharing a Docker host because then they see each others'
containers. So typically an enterprise will layer a cloud system underneath Docker to add
tenancy. This yields a stack that looks like: hardware > hypervisor > Docker host >
container.
A common approach today would be to take OpenStack and use it as the enterprise platform to
deliver capacity on demand to users. In other words, users rely on OpenStack to request a
Docker host, and then they use Docker to run containers in their Docker host.
So far, so good.
If all you need is Docker...
Things get more complicated when we start parsing what capacity needs delivering.
When an enterprise wants to use Docker, they need to get Docker hosts from a data center.
OpenStack can do that, and it can do it alongside delivering all sorts of other capacity to the
various teams within the enterprise.
But if all an enterprise IT team needs is Docker containers delivered, then OpenStack -- or
a similar orchestration tool -- may be overkill, as VMware executive Jared Rosoff told me.
For this sort of use case, we really need a new platform. This platform could take the form
of a piece of software that an enterprise installs on all of its computers in the data center.
It would expose an interface to developers that lets them programmatically create Docker hosts
when they need them, and then use Docker to create containers in those hosts.
Google has a vision for something like this with its Google Container Engine . Amazon has something
similar in its EC2 Container Service
. These are both API's that developers can use to provision some Docker-compatible capacity
from their data center.
As for Docker, the company behind Docker, the technology, it seems to have punted on this
problem. focusing instead on what happens on the host itself.
While we probably don't need to build up a big OpenStack cloud simply to manage Docker
instances, it's worth asking what OpenStack should look like if what we wanted to deliver was
only Docker hosts, and not VMs.
Again, we see Google and Amazon tackling the problem, but when will OpenStack, or one of its
supporters, do the same? The obvious candidate would be VMware, given its longstanding
dominance of tooling around virtualization. But the company that solves this problem first, and
in a way that comforts traditional IT with familiar interfaces yet pulls them into a cloudy
future, will win, and win big.
A hybrid cloud is a combination of a private cloud combined with the use of public
cloud services where one or several touch points exist between the environments. The goal is to
combine services and data from a variety of cloud models to create a unified, automated, and
well-managed computing environment.
Combining public services with private clouds and the data center as a hybrid is the new
definition of corporate computing. Not all companies that use some public and some
private cloud services have a hybrid cloud. Rather, a hybrid cloud is an environment where the
private and public services are used together to create value.
A cloud is hybrid
If a company uses a public development platform that sends data to a private cloud or a
data center–based application.
When a company leverages a number of SaaS (Software as a Service) applications and moves
data between private or data center resources.
When a business process is designed as a service so that it can connect with
environments as though they were a single environment.
A cloud is not hybrid
If a few developers in a company use a public cloud service to prototype a new
application that is completely disconnected from the private cloud or the data center.
If a company is using a SaaS application for a project but there is no movement of data
from that application into the company's data center.
"... "There's a big transformation happening," says Thomas Humphrey, segment director for edge computing at APC . "Technologies like IoT have started to require that some local computing and storage happen out in that distributed IT architecture." ..."
"... In retail, for example, edge computing will become more important as stores find success with IoT technologies such as mobile beacons, interactive mirrors and real-time tools for customer experience, behavior monitoring and marketing . ..."
Enterprises are deploying self-contained micro data centers to power computing at the
network edge.
The location for data processing has changed significantly throughout the history of
computing. During the mainframe era, data was processed centrally, but client/server
architectures later decentralized computing. In recent years, cloud computing centralized many
processing workloads, but digital transformation and the Internet of Things are poised to move
computing to new places, such as the network edge .
"There's a big transformation happening," says Thomas Humphrey, segment director for edge
computing at APC .
"Technologies like IoT have started to require that some local computing and storage happen out
in that distributed IT architecture."
For example, some IoT systems require processing of data at remote locations rather than a
centralized data center , such as at a retail store instead of a corporate headquarters.
To meet regulatory requirements and business needs, IoT solutions often need low latency,
high bandwidth, robust security and superior reliability . To meet these demands, many
organizations are deploying micro data centers: self-contained solutions that provide not only
essential infrastructure, but also physical security, power and cooling and remote management
capabilities.
"Digital transformation happens at the network edge, and edge computing will happen inside
micro data centers ," says Bruce A. Taylor, executive vice president at Datacenter Dynamics . "This will probably be one
of the fastest growing segments -- if not the fastest growing segment -- in data centers for
the foreseeable future."
What Is a Micro Data Center?
Delivering the IT capabilities needed for edge computing represents a significant challenge
for many organizations, which need manageable and secure solutions that can be deployed easily,
consistently and close to the source of computing . Vendors such as APC have begun to create
comprehensive solutions that provide these necessary capabilities in a single, standardized
package.
"From our perspective at APC, the micro data center was a response to what was happening in
the market," says Humphrey. "We were seeing that enterprises needed more robust solutions at
the edge."
Most micro data center solutions rely on hyperconverged
infrastructure to integrate computing, networking and storage technologies within a compact
footprint . A typical micro data center also incorporates physical infrastructure (including
racks), fire suppression, power, cooling and remote management capabilities. In effect, the
micro data center represents a sweet spot between traditional IT closets and larger modular
data centers -- giving organizations the ability to deploy professional, powerful IT resources
practically anywhere .
Standardized Deployments Across the Country
Having robust IT resources at the network edge helps to improve reliability and reduce
latency, both of which are becoming more and more important as analytics programs require that
data from IoT deployments be processed in real time .
"There's always been edge computing," says Taylor. "What's new is the need to process
hundreds of thousands of data points for analytics at once."
Standardization, redundant deployment and remote management are also attractive features,
especially for large organizations that may need to deploy tens, hundreds or even thousands of
micro data centers. "We spoke to customers who said, 'I've got to roll out and install 3,500 of
these around the country,'" says Humphrey. "And many of these companies don't have IT staff at
all of these sites." To address this scenario, APC designed standardized, plug-and-play micro
data centers that can be rolled out seamlessly. Additionally, remote management capabilities
allow central IT departments to monitor and troubleshoot the edge infrastructure without costly
and time-intensive site visits.
In part because micro data centers operate in far-flung environments, security is of
paramount concern. The self-contained nature of micro data centers ensures that only authorized
personnel will have access to infrastructure equipment , and security tools such as video
surveillance provide organizations with forensic evidence in the event that someone attempts to
infiltrate the infrastructure.
How Micro Data Centers Can Help in Retail, Healthcare
Micro data centers make business sense for any organization that needs secure IT
infrastructure at the network edge. But the solution is particularly appealing to organizations
in fields such as retail, healthcare and finance , where IT environments are widely distributed
and processing speeds are often a priority.
In retail, for example, edge computing will become more important as stores find success
with IoT technologies such as mobile beacons, interactive mirrors and real-time tools for
customer experience, behavior monitoring and marketing .
"It will be leading-edge companies driving micro data center adoption, but that doesn't
necessarily mean they'll be technology companies," says Taylor. "A micro data center can power
real-time analytics for inventory control and dynamic pricing in a supermarket."
In healthcare,
digital transformation is beginning to touch processes and systems ranging from medication
carts to patient records, and data often needs to be available locally; for example, in case of
a data center outage during surgery. In finance, the real-time transmission of data can have
immediate and significant financial consequences. And in both of these fields, regulations
governing data privacy make the monitoring and security features of micro data centers even
more important.
Micro data centers also have enormous potential to power smart city initiatives and to give
energy companies a cost-effective way of deploying resources in remote locations , among other
use cases.
"The proliferation of edge computing will be greater than anything we've seen in the past,"
Taylor says. "I almost can't think of a field where this won't matter."
Learn
more about how solutions and services from CDW and APC can help your organization overcome
its data center challenges.
Micro Data Centers Versus IT Closets
Think the micro data center is just a glorified update on the traditional IT closet? Think
again.
"There are demonstrable differences," says Bruce A. Taylor, executive vice president at
Datacenter Dynamics. "With micro data centers, there's a tremendous amount of computing
capacity in a very small, contained space, and we just didn't have that capability previously
."
APC identifies three key differences between IT closets and micro data centers:
Difference #1: Uptime Expectations. APC notes that, of the nearly 3 million IT closets in
the U.S., over 70 percent report outages directly related to human error. In an unprotected
IT closet, problems can result from something as preventable as cleaning staff unwittingly
disconnecting a cable. Micro data centers, by contrast, utilize remote monitoring, video
surveillance and sensors to reduce downtime related to human error.
Difference #2: Cooling Configurations. The cooling of IT wiring closets is often
approached both reactively and haphazardly, resulting in premature equipment failure. Micro
data centers are specifically designed to assure cooling compatibility with anticipated
loads.
Difference #3: Power Infrastructure. Unlike many IT closets, micro data centers
incorporate uninterruptible power supplies, ensuring that infrastructure equipment has the
power it needs to help avoid downtime.
Calvin Hennick is a freelance journalist who specializes in business and technology
writing. He is a contributor to the CDW family of technology magazines.
"... most of the Office365 deployments face network related problems - typically manifesting as screen freezes. Limited WAN optimization capability further complicates the problems for most SaaS applications. ..."
"... Why enterprises overlook the importance of strategically placing cloud gateways ..."
About this webinar Major research highlights that most of the Office365 deployments face network related problems - typically
manifesting as screen freezes. Limited WAN optimization capability further complicates the problems for most SaaS applications. To
compound the issue, different SaaS applications issue different guidelines for solving performance issues. We will investigate the
major reasons for these problems.
SD-WAN provides an essential set of features that solves these networking issues related to Office 365 and SaaS applications.
This session will cover the following major topics:
How traditional networks impair O365 performance, and why?
Why enterprises overlook the importance of strategically placing cloud gateways
Understanding tradeoffs among reliability, performance and user-experience when architecting the WAN for your cloud
Best practice architectures for different kinds of SaaS applications
"... We already know that computing at the edge pushes most of the data processing out to the edge of the network, close to the source of the data. Then it's a matter of dividing the processing between the edge and the centralized system, meaning a public cloud such as Amazon Web Services, Google Cloud, or Microsoft Azure. ..."
"... The goal is to process near the device the data that it needs quickly, such as to act on. There are hundreds of use cases where reaction time is the key value of the IoT system, and consistently sending the data back to a centralized cloud prevents that value from happening. ..."
The internet of things is real, and it's a real part of the cloud. A key challenge is how you can get data processed from
so many devices. Cisco Systems predicts that cloud traffic is likely to rise nearly fourfold by 2020, increasing 3.9
zettabytes (ZB) per year in 2015 (the latest full year for which data is available) to 14.1ZB per year by 2020.
As a
result, we could have the cloud computing perfect storm from the growth of IoT. After all, IoT is about processing
device-generated data that is meaningful, and cloud computing is about using data from centralized computing and storage.
Growth rates of both can easily become unmanageable.
So what do we do? The answer is something called "edge computing." We already know that computing at the edge pushes most
of the data processing out to the edge of the network, close to the source of the data. Then it's a matter of dividing the
processing between the edge and the centralized system, meaning a public cloud such as Amazon Web Services, Google Cloud,
or Microsoft Azure.
That may sound a like a client/server architecture, which also involved figuring out what to do at the client versus at
the server. For IoT and any highly distributed applications, you've essentially got a client/network edge/server
architecture going on, or -- if your devices can't do any processing themselves, a network edge/server architecture.
The goal is to process near the device the data that it needs quickly, such as to act on. There are hundreds of use
cases where reaction time is the key value of the IoT system, and consistently sending the data back to a centralized cloud
prevents that value from happening.
You would still use the cloud for processing that is either not as time-sensitive or is not needed by the device, such
as for big data analytics on data from all your devices.
There's another dimension to this: edge computing and cloud computing are two very different things. One does not
replace the other. But too many articles confuse IT pros by suggesting that edge computing will displace cloud computing.
It's no more true than saying PCs would displace the datacenter.
It makes perfect sense to create purpose-built edge computing-based applications, such as an app that places data
processing in a sensor to quickly process reactions to alarms. But you're not going to place your inventory-control data
and applications at the edge -- moving all compute to the edge would result in a distributed, unsecured, and unmanageable
mess.
All the public cloud providers have IoT strategies and technology stacks that include, or will include, edge computing.
Edge and cloud computing can and do work well together, but edge computing is for purpose-built systems with special
needs. Cloud computing is a more general-purpose platform that also can work with purpose-built systems in that old
client/server model.
David S. Linthicum is a chief cloud strategy officer at Deloitte Consulting, and an internationally
recognized industry expert and thought leader. His views are his own.
The open source Globus® Toolkit is a fundamental enabling technology for the "Grid,"
letting people share computing power, databases, and other tools securely online across
corporate, institutional, and geographic boundaries without sacrificing local autonomy. The
toolkit includes software services and libraries for resource monitoring, discovery, and
management, plus security and file management. In addition to being a central part of science
and engineering projects that total nearly a half-billion dollars internationally, the Globus
Toolkit is a substrate on which leading IT companies are building significant commercial Grid
products.
The toolkit includes software for security, information infrastructure, resource management,
data management, communication, fault detection, and portability. It is packaged as a set of
components that can be used either independently or together to develop applications. Every
organization has unique modes of operation, and collaboration between multiple organizations is
hindered by incompatibility of resources such as data archives, computers, and networks. The
Globus Toolkit was conceived to remove obstacles that prevent seamless collaboration. Its core
services, interfaces and protocols allow users to access remote resources as if they were
located within their own machine room while simultaneously preserving local control over who
can use resources and when.
The Globus Toolkit has grown through an open-source strategy similar to the Linux operating
system's, and distinct from proprietary attempts at resource-sharing software. This encourages
broader, more rapid adoption and leads to greater technical innovation, as the open-source
community provides continual enhancements to the product.
Essential background is contained in the papers " Anatomy of the Grid "
by Foster, Kesselman and Tuecke and " Physiology of the Grid "
by Foster, Kesselman, Nick and Tuecke.
Acclaim for the Globus Toolkit
From version 1.0 in 1998 to the 2.0 release in 2002 and now the latest 4.0 version based on
new open-standard Grid services, the Globus Toolkit has evolved rapidly into what The New York
Times called "the de facto
standard" for Grid computing. In 2002 the project earned a prestigious R&D 100 award, given
by R&D Magazine in a ceremony where the Globus Toolkit was named "Most Promising New
Technology" among the year's top 100 innovations. Other honors include project leaders Ian
Foster of Argonne National Laboratory and the University of Chicago, Carl Kesselman of the
University of Southern California's Information Sciences Institute (ISI), and Steve Tuecke of
Argonne being named among 2003's top ten innovators by InfoWorld magazine, and a similar honor
from MIT Technology Review, which named Globus Toolkit-based Grid computing one of "Ten
Technologies That Will Change the World." The Globus Toolkit also GridFTP is a
high-performance, secure, reliable data transfer protocol optimized for high-bandwidth
wide-area networks . The GridFTP protocol is based on FTP, the highly-popular Internet
file transfer protocol. We have selected a set of protocol features and extensions defined
already in IETF RFCs and added a few additional features to meet requirements from current data
grid projects.
The following guides are available for this component:
Aspera Sync is an elite, versatile, multi-directional no concurrent record replication and
synchronization. It is intended to conquer the execution and versatility inadequacies of
conventional synchronization instruments like Rsync. Aspera Sync can scale up and out for most
extreme rate replication and synchronization over WANs. Prominent capacities are The FASP
advantage, superior, smart trade for Rsync, underpins complex synchronization arrangements,
propelled record taking care of, and so on. Aspera Sync is reason worked by Aspera for elite,
versatile, multi-directional offbeat record replication and synchronization. Intended to beat
the execution and adaptability deficiencies of conventional synchronization instruments like
Rsync, Aspera Sync can scale up and out for greatest pace replication and synchronization over
WANs, for now,'s biggest vast information record stores -- from a great many individual
documents to the most significant document sizes. Hearty reinforcement and recuperation
strategies secure business necessary information and frameworks so undertakings can rapidly
recoup necessary documents, structures or a whole site in the occasion if a calamity. Be that
as it may, these strategies can be undermined by average exchange speeds amongst essential and
reinforcement locales, bringing about fragmented reinforcements and augmented recuperation
times. With FASP – controlled transactions, replication fits inside the little
operational window so you can meet your recuperation point objective (RPO) and recovery time
objective (RTO).
1. Syncthing
Syncthing replaces exclusive synchronize and cloud administrations with something open,
reliable and decentralized. Your information is your information alone, and you should pick
where it is put away if it is imparted to some outsider and how it's transmitted over the
Internet. Syncthing is a record sharing application that permits you to share reports between
various gadgets in an advantageous way. Its online Graphical User Interface (GUI) makes it
conceivable WebsiteSyncthing Alternatives
I used rsync to copy a large number of files, but my OS (Ubuntu) restarted unexpectedly.
After reboot, I ran rsync again, but from the output on the terminal, I found that rsync still copied
those already copied before. But I heard that rsync is able to find differences between source and destination, and
therefore to just copy the differences. So I wonder in my case if rsync can resume what was left last time?
Yes, rsync won't copy again files that it's already copied. There are a few edge cases where its detection can fail. Did it copy
all the already-copied files? What options did you use? What were the source and target filesystems? If you run rsync again after
it's copied everything, does it copy again? – Gilles
Sep 16 '12 at 1:56
@Gilles: Thanks! (1) I think I saw rsync copied the same files again from its output on the terminal. (2) Options are same as
in my other post, i.e. sudo rsync -azvv /home/path/folder1/ /home/path/folder2 . (3) Source and target are both NTFS,
buy source is an external HDD, and target is an internal HDD. (3) It is now running and hasn't finished yet. –
Tim
Sep 16 '12 at 2:30
@Tim Off the top of my head, there's at least clock skew, and differences in time resolution (a common issue with FAT filesystems
which store times in 2-second increments, the --modify-window option helps with that). –
Gilles
Sep 19 '12 at 9:25
First of all, regarding the "resume" part of your question, --partial just tells the receiving end to keep partially
transferred files if the sending end disappears as though they were completely transferred.
While transferring files, they are temporarily saved as hidden files in their target folders (e.g. .TheFileYouAreSending.lRWzDC
), or a specifically chosen folder if you set the --partial-dir switch. When a transfer fails and --partial
is not set, this hidden file will remain in the target folder under this cryptic name, but if --partial is set, the
file will be renamed to the actual target file name (in this case, TheFileYouAreSending ), even though the file isn't
complete. The point is that you can later complete the transfer by running rsync again with either --append or
--append-verify .
So, --partial doesn't itself resume a failed or cancelled transfer. To resume it, you'll have to use
one of the aforementioned flags on the next run. So, if you need to make sure that the target won't ever contain files that appear
to be fine but are actually incomplete, you shouldn't use --partial . Conversely, if you want to make sure you never
leave behind stray failed files that are hidden in the target directory, and you know you'll be able to complete the transfer
later, --partial is there to help you.
With regards to the --append switch mentioned above, this is the actual "resume" switch, and you can use it whether
or not you're also using --partial . Actually, when you're using --append , no temporary files are ever
created. Files are written directly to their targets. In this respect, --append gives the same result as --partial
on a failed transfer, but without creating those hidden temporary files.
So, to sum up, if you're moving large files and you want the option to resume a cancelled or failed rsync operation from the
exact point that rsync stopped, you need to use the --append or --append-verify switch
on the next attempt.
As @Alex points out below, since version 3.0.0 rsync now has a new option, --append-verify , which
behaves like --append did before that switch existed. You probably always want the behaviour of --append-verify
, so check your version with rsync --version . If you're on a Mac and not using rsync from homebrew
, you'll (at least up to and including El Capitan) have an older version and need to use --append rather than
--append-verify . Why they didn't keep the behaviour on --append and instead named the newcomer
--append-no-verify is a bit puzzling. Either way, --append on rsync before version 3 is
the same as --append-verify on the newer versions.
--append-verify isn't dangerous: It will always read and compare the data on both ends and not just assume they're
equal. It does this using checksums, so it's easy on the network, but it does require reading the shared amount of data on both
ends of the wire before it can actually resume the transfer by appending to the target.
Second of all, you said that you "heard that rsync is able to find differences between source and destination, and therefore
to just copy the differences."
That's correct, and it's called delta transfer, but it's a different thing. To enable this, you add the -c , or
--checksum switch. Once this switch is used, rsync will examine files that exist on both ends of the wire. It does
this in chunks, compares the checksums on both ends, and if they differ, it transfers just the differing parts of the file. But,
as @Jonathan points out below, the comparison is only done when files are of the same size on both ends -- different sizes will
cause rsync to upload the entire file, overwriting the target with the same name.
This requires a bit of computation on both ends initially, but can be extremely efficient at reducing network load if for example
you're frequently backing up very large files fixed-size files that often contain minor changes. Examples that come to mind are
virtual hard drive image files used in virtual machines or iSCSI targets.
It is notable that if you use --checksum to transfer a batch of files that are completely new to the target system,
rsync will still calculate their checksums on the source system before transferring them. Why I do not know :)
So, in short:
If you're often using rsync to just "move stuff from A to B" and want the option to cancel that operation and later resume
it, don't use --checksum , but do use --append-verify .
If you're using rsync to back up stuff often, using --append-verify probably won't do much for you, unless you're
in the habit of sending large files that continuously grow in size but are rarely modified once written. As a bonus tip, if you're
backing up to storage that supports snapshotting such as btrfs or zfs , adding the --inplace
switch will help you reduce snapshot sizes since changed files aren't recreated but rather the changed blocks are written directly
over the old ones. This switch is also useful if you want to avoid rsync creating copies of files on the target when only minor
changes have occurred.
When using --append-verify , rsync will behave just like it always does on all files that are the same size. If
they differ in modification or other timestamps, it will overwrite the target with the source without scrutinizing those files
further. --checksum will compare the contents (checksums) of every file pair of identical name and size.
UPDATED 2015-09-01 Changed to reflect points made by @Alex (thanks!)
UPDATED 2017-07-14 Changed to reflect points made by @Jonathan (thanks!)
According to the documentation--append does not
check the data, but --append-verify does. Also, as @gaoithe points out in a comment below, the documentation claims
--partialdoes resume from previous files. –
Alex
Aug 28 '15 at 3:49
Thank you @Alex for the updates. Indeed, since 3.0.0, --append no longer compares the source to the target file before
appending. Quite important, really! --partial does not itself resume a failed file transfer, but rather leaves it
there for a subsequent --append(-verify) to append to it. My answer was clearly misrepresenting this fact; I'll update
it to include these points! Thanks a lot :) –
DanielSmedegaardBuus
Sep 1 '15 at 13:29
@CMCDragonkai Actually, check out Alexander's answer below about --partial-dir -- looks like it's the perfect bullet
for this. I may have missed something entirely ;) –
DanielSmedegaardBuus
May 10 '16 at 19:31
What's your level of confidence in the described behavior of --checksum ? According to the
man it has more to do with deciding which files to
flag for transfer than with delta-transfer (which, presumably, is rsync 's default behavior). –
Jonathan Y.
Jun 14 '17 at 5:48
Personally, I don't like yum plugins because they don't work a lot of the time, in my experience.
You can use the yum history command to view your yum history.
[root@testbox ~]# yum history
Loaded plugins: product-id, rhnplugin, search-disabled-repos, subscription-manager, verify, versionlock
ID | Login user | Date and time | Action(s) | Altered
----------------------------------------------------------------------------------
19 | Jason <jason> | 2016-06-28 09:16 | Install | 10
You can find info about the transaction by doing yum history info <transaction id> . So:
yum history info 19 would tell you all the packages that were installed with transaction 19 and the command line
that was used to install the packages. If you want to undo transaction 19, you would run yum history undo 19 .
Alternatively, if you just wanted to undo the last transaction you did (you installed a software package and didn't like it),
you could just do yum history undo last
Firstly, thank you for your excellent answer. And secondly, when I did sudo yum history , it showed only actions
with id 30 through 49. Is there a way to view all actions history (including with id 1-29)? –
ukll
Aug 16 '16 at 18:34
To use it download the tarball, unpack it and run ./INSTALL
Collectl now supports OpenStack Clouds
Colmux now part of collectl package
Looking for colplot ? It's now here!
There are a number of times in which you find yourself needing performance data. These can
include benchmarking, monitoring a system's general heath or trying to determine what your
system was doing at some time in the past. Sometimes you just want to know what the system is
doing right now. Depending on what you're doing, you often end up using different tools, each
designed to for that specific situation.
Unlike most monitoring tools that either focus on a small set of statistics, format their
output in only one way, run either interatively or as a daemon but not both, collectl tries to
do it all. You can choose to monitor any of a broad set of subsystems which currently include
buddyinfo, cpu, disk, inodes, infiniband, lustre, memory, network, nfs, processes, quadrics,
slabs, sockets and tcp.
The following is an example taken while writing a large file and running the collectl
command with no arguments. By default it shows cpu, network and disk stats in brief
format . The key point of this format is all output appears on a single line making it much
easier to spot spikes or other anomalies in the output:
In this example, taken while writing to an NFS mounted filesystem, collectl displays
interrupts, memory usage and nfs activity with timestamps. Keep in mind that you can mix and match
any data and in the case of brief format you simply need to have a window wide enough to
accommodate your output.
You can also display the same information in verbose format , in which case you get a
single line for each type of data at the expense of more screen real estate, as can be seen in this
example of network data during NFS writes. Note how you can actually see the network traffic stall
while waiting for the server to physically write the data.
In this last example we see what detail format looks like where we see multiple lines
of output for a partitular type of data, which in this case is interrupts. We've also elected to
show the time in msecs as well.
Collectl output can also be saved in a rolling set of logs for later playback or displayed
interactively in a variety of formats. If all that isn't enough there are plugins that allow you to
report data in alternate formats or even send them over a socket to remote tools such as ganglia or
graphite. You can even create files in space-separated format for plotting with external packages
like gnuplot. The one below was created with colplot, part of the collectl utilities project, which provides a web-based
interface to gnuplot.
Are you a big user of the top command? Have you ever wanted to look across a cluster to see
what the top processes are? Better yet, how about using iostat across a cluster? Or maybe
vmstat or even looking at top network interfaces across a cluster? Look no more because if
collectl reports it for one node, colmux can do it across a cluster AND you can
sort by any column of your choice by simply using the right/left arrow keys.
Collectl and Colmux run on all linux distros and are available in redhat and debian
respositories and so getting it may be as simple as running yum or apt-get. Note that since
colmux has just been merged into the collectl V4.0.0 package it may not yet be available in the
repository of your choice and you should install collectl-utils V4.8.2 or earlier to get it for the
time being.
Collectl requires perl which is usually installed by default on all major Linux distros and
optionally uses Time::Hires which is also usually installed and
allows collectl to use fractional intervals and display timestamps in msec. The Compress::Zlib module is usually
installed as well and if present the recorded data will be compressed and therefore use on
average 90% less storage when recording to a file.
If you're still not sure if collectl is right for you, take a couple of minutes to look at
the Collectl
Tutorial to get a better feel for what collectl can do. Also be sure to check back and see
what's new on the website, sign up for a Mailing List or watch the Forums .
"I absolutely love it and have been using it extensively for
months."
How can I find which process is constantly writing to disk?
I like my workstation to be close to silent and I just build a new system (P8B75-M + Core i5 3450s -- the 's' because it has
a lower max TDP) with quiet fans etc. and installed Debian Wheezy 64-bit on it.
And something is getting on my nerve: I can hear some kind of pattern like if the hard disk was writing or seeking someting
( tick...tick...tick...trrrrrr rinse and repeat every second or so).
In the past I had a similar issue in the past (many, many years ago) and it turned out it was some CUPS log or something and
I simply redirected that one (not important) logging to a (real) RAM disk.
But here I'm not sure.
I tried the following:
ls -lR /var/log > /tmp/a.tmp && sleep 5 && ls -lR /var/log > /tmp/b.tmp && diff /tmp/?.tmp
but nothing is changing there.
Now the strange thing is that I also hear the pattern when the prompt asking me to enter my LVM decryption passphrase is showing.
Could it be something in the kernel/system I just installed or do I have a faulty harddisk?
hdparm -tT /dev/sda report a correct HD speed (130 GB/s non-cached, sata 6GB) and I've already installed and compiled
from big sources (Emacs) without issue so I don't think the system is bad.
Are you sure it's a hard drive making that noise, and not something else? (Check the fans, including PSU fan. Had very strange
clicking noises once when a very thin cable was too close to a fan and would sometimes very slightly touch the blades and bounce
for a few "clicks"...) – Mat
Jul 27 '12 at 6:03
@Mat: I'll take the hard drive outside of the case (the connectors should be long enough) to be sure and I'll report back ; )
– Cedric Martin
Jul 27 '12 at 7:02
Make sure your disk filesystems are mounted relatime or noatime. File reads can be causing writes to inodes to record the access
time. – camh
Jul 27 '12 at 9:48
thanks for that tip. I didn't know about iotop . On Debian I did an apt-cache search iotop to find out that I had
to apt-get iotop . Very cool command! –
Cedric Martin
Aug 2 '12 at 15:56
I use iotop -o -b -d 10 which every 10secs prints a list of processes that read/wrote to disk and the amount of IO
bandwidth used. – ndemou
Jun 20 '16 at 15:32
You can enable IO debugging via echo 1 > /proc/sys/vm/block_dump and then watch the debugging messages in /var/log/syslog
. This has the advantage of obtaining some type of log file with past activities whereas iotop only shows the current
activity.
It is absolutely crazy to leave sysloging enabled when block_dump is active. Logging causes disk activity, which causes logging,
which causes disk activity etc. Better stop syslog before enabling this (and use dmesg to read the messages) –
dan3
Jul 15 '13 at 8:32
You are absolutely right, although the effect isn't as dramatic as you describe it. If you just want to have a short peek at the
disk activity there is no need to stop the syslog daemon. –
scai
Jul 16 '13 at 6:32
I've tried it about 2 years ago and it brought my machine to a halt. One of these days when I have nothing important running I'll
try it again :) – dan3
Jul 16 '13 at 7:22
I tried it, nothing really happened. Especially because of file system buffering. A write to syslog doesn't immediately trigger
a write to disk. – scai
Jul 16 '13 at 10:50
auditctl -S sync -S fsync -S fdatasync -a exit,always
Watch the logs in /var/log/audit/audit.log . Be careful not to do this if the audit logs themselves are flushed!
Check in /etc/auditd.conf that the flush option is set to none .
If files are being flushed often, a likely culprit is the system logs. For example, if you log failed incoming connection attempts
and someone is probing your machine, that will generate a lot of entries; this can cause a disk to emit machine gun-style noises.
With the basic log daemon sysklogd, check /etc/syslog.conf : if a log file name is not be preceded by -
, then that log is flushed to disk after each write.
It might be your drives automatically spinning down, lots of consumer-grade drives do that these days. Unfortunately on even a
lightly loaded system, this results in the drives constantly spinning down and then spinning up again, especially if you're running
hddtemp or similar to monitor the drive temperature (most drives stupidly don't let you query the SMART temperature value without
spinning up the drive - cretinous!).
I disable idle-spindown on all my drives with the following bit of shell code. you could put it in an /etc/rc.boot script,
or in /etc/rc.local or similar.
for disk in /dev/sd? ; do
/sbin/hdparm -q -S 0 "/dev/$disk"
done
that you can't query SMART readings without spinning up the drive leaves me speechless :-/ Now obviously the "spinning down" issue
can become quite complicated. Regarding disabling the spinning down: wouldn't that in itself cause the HD to wear out faster?
I mean: it's never ever "resting" as long as the system is on then? –
Cedric Martin
Aug 2 '12 at 16:03
IIRC you can query some SMART values without causing the drive to spin up, but temperature isn't one of them on any of the drives
i've tested (incl models from WD, Seagate, Samsung, Hitachi). Which is, of course, crazy because concern over temperature is one
of the reasons for idling a drive. re: wear: AIUI 1. constant velocity is less wearing than changing speed. 2. the drives have
to park the heads in a safe area and a drive is only rated to do that so many times (IIRC up to a few hundred thousand - easily
exceeded if the drive is idling and spinning up every few seconds) –
cas
Aug 2 '12 at 21:42
It's a long debate regarding whether it's better to leave drives running or to spin them down. Personally I believe it's best
to leave them running - I turn my computer off at night and when I go out but other than that I never spin my drives down. Some
people prefer to spin them down, say, at night if they're leaving the computer on or if the computer's idle for a long time, and
in such cases the advantage of spinning them down for a few hours versus leaving them running is debatable. What's never good
though is when the hard drive repeatedly spins down and up again in a short period of time. –
Micheal Johnson
Mar 12 '16 at 20:48
Note also that spinning the drive down after it's been idle for a few hours is a bit silly, because if it's been idle for
a few hours then it's likely to be used again within an hour. In that case, it would seem better to spin the drive down promptly
if it's idle (like, within 10 minutes), but it's also possible for the drive to be idle for a few minutes when someone is using
the computer and is likely to need the drive again soon. –
Micheal Johnson
Mar 12 '16 at 20:51
,
I just found that s.m.a.r.t was causing an external USB disk to spin up again and again on my raspberry pi. Although SMART is
generally a good thing, I decided to disable it again and since then it seems that unwanted disk activity has stopped
(or some variant of parameters with lsof) I can determine which process is bound to a particular port. This is useful say if
I'm trying to start something that wants to bind to 8080 and some else is already using that port, but I don't know what.
Is there an easy way to do this without using lsof? I spend time working on many systems and lsof is often not installed.
netstat -lnp will list the pid and process name next to each listening port. This will work under Linux, but not
all others (like AIX.) Add -t if you want TCP only.
# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:24800 0.0.0.0:* LISTEN 27899/synergys
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 3361/python
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 2264/mysqld
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 22964/apache2
tcp 0 0 192.168.99.1:53 0.0.0.0:* LISTEN 3389/named
tcp 0 0 192.168.88.1:53 0.0.0.0:* LISTEN 3389/named
etc.
xxx , Mar 14, 2011 at 21:01
Cool, thanks. Looks like that that works under RHEL, but not under Solaris (as you indicated). Anybody know if there's something
similar for Solaris? – user5721
Mar 14 '11 at 21:01
Thanks for this! Is there a way, however, to just display what process listen on the socket (instead of using rmsock which attempt
to remove it) ? – Olivier Dulac
Sep 18 '13 at 4:05
@vitor-braga: Ah thx! I thought it was trying but just said which process holds in when it couldn't remove it. Apparently it doesn't
even try to remove it when a process holds it. That's cool! Thx! –
Olivier Dulac
Sep 26 '13 at 16:00
Another tool available on Linux is ss . From the ss man page on Fedora:
NAME
ss - another utility to investigate sockets
SYNOPSIS
ss [options] [ FILTER ]
DESCRIPTION
ss is used to dump socket statistics. It allows showing information
similar to netstat. It can display more TCP and state informations
than other tools.
Example output below - the final column shows the process binding:
I was once faced with trying to determine what process was behind a particular port (this time it was 8000). I tried a variety
of lsof and netstat, but then took a chance and tried hitting the port via a browser (i.e.
http://hostname:8000/ ). Lo and behold, a splash screen greeted me, and it
became obvious what the process was (for the record, it was Splunk ).
One more thought: "ps -e -o pid,args" (YMMV) may sometimes show the port number in the arguments list. Grep is your friend!
In the same vein, you could telnet hostname 8000 and see if the server prints a banner. However, that's mostly useful
when the server is running on a machine where you don't have shell access, and then finding the process ID isn't relevant. –
Gilles
May 8 '11 at 14:45
How can I find which process is constantly writing to disk?
I like my workstation to be close to silent and I just build a new system (P8B75-M + Core i5 3450s -- the 's' because it has
a lower max TDP) with quiet fans etc. and installed Debian Wheezy 64-bit on it.
And something is getting on my nerve: I can hear some kind of pattern like if the hard disk was writing or seeking someting
( tick...tick...tick...trrrrrr rinse and repeat every second or so).
In the past I had a similar issue in the past (many, many years ago) and it turned out it was some CUPS log or something and
I simply redirected that one (not important) logging to a (real) RAM disk.
But here I'm not sure.
I tried the following:
ls -lR /var/log > /tmp/a.tmp && sleep 5 && ls -lR /var/log > /tmp/b.tmp && diff /tmp/?.tmp
but nothing is changing there.
Now the strange thing is that I also hear the pattern when the prompt asking me to enter my LVM decryption passphrase is showing.
Could it be something in the kernel/system I just installed or do I have a faulty harddisk?
hdparm -tT /dev/sda report a correct HD speed (130 GB/s non-cached, sata 6GB) and I've already installed and compiled
from big sources (Emacs) without issue so I don't think the system is bad.
Are you sure it's a hard drive making that noise, and not something else? (Check the fans, including PSU fan. Had very strange
clicking noises once when a very thin cable was too close to a fan and would sometimes very slightly touch the blades and bounce
for a few "clicks"...) – Mat
Jul 27 '12 at 6:03
@Mat: I'll take the hard drive outside of the case (the connectors should be long enough) to be sure and I'll report back ; )
– Cedric Martin
Jul 27 '12 at 7:02
Make sure your disk filesystems are mounted relatime or noatime. File reads can be causing writes to inodes to record the access
time. – camh
Jul 27 '12 at 9:48
thanks for that tip. I didn't know about iotop . On Debian I did an apt-cache search iotop to find out that I had
to apt-get iotop . Very cool command! –
Cedric Martin
Aug 2 '12 at 15:56
I use iotop -o -b -d 10 which every 10secs prints a list of processes that read/wrote to disk and the amount of IO
bandwidth used. – ndemou
Jun 20 '16 at 15:32
You can enable IO debugging via echo 1 > /proc/sys/vm/block_dump and then watch the debugging messages in /var/log/syslog
. This has the advantage of obtaining some type of log file with past activities whereas iotop only shows the current
activity.
It is absolutely crazy to leave sysloging enabled when block_dump is active. Logging causes disk activity, which causes logging,
which causes disk activity etc. Better stop syslog before enabling this (and use dmesg to read the messages) –
dan3
Jul 15 '13 at 8:32
You are absolutely right, although the effect isn't as dramatic as you describe it. If you just want to have a short peek at the
disk activity there is no need to stop the syslog daemon. –
scai
Jul 16 '13 at 6:32
I've tried it about 2 years ago and it brought my machine to a halt. One of these days when I have nothing important running I'll
try it again :) – dan3
Jul 16 '13 at 7:22
I tried it, nothing really happened. Especially because of file system buffering. A write to syslog doesn't immediately trigger
a write to disk. – scai
Jul 16 '13 at 10:50
auditctl -S sync -S fsync -S fdatasync -a exit,always
Watch the logs in /var/log/audit/audit.log . Be careful not to do this if the audit logs themselves are flushed!
Check in /etc/auditd.conf that the flush option is set to none .
If files are being flushed often, a likely culprit is the system logs. For example, if you log failed incoming connection attempts
and someone is probing your machine, that will generate a lot of entries; this can cause a disk to emit machine gun-style noises.
With the basic log daemon sysklogd, check /etc/syslog.conf : if a log file name is not be preceded by -
, then that log is flushed to disk after each write.
It might be your drives automatically spinning down, lots of consumer-grade drives do that these days. Unfortunately on even a
lightly loaded system, this results in the drives constantly spinning down and then spinning up again, especially if you're running
hddtemp or similar to monitor the drive temperature (most drives stupidly don't let you query the SMART temperature value without
spinning up the drive - cretinous!).
I disable idle-spindown on all my drives with the following bit of shell code. you could put it in an /etc/rc.boot script,
or in /etc/rc.local or similar.
for disk in /dev/sd? ; do
/sbin/hdparm -q -S 0 "/dev/$disk"
done
that you can't query SMART readings without spinning up the drive leaves me speechless :-/ Now obviously the "spinning down" issue
can become quite complicated. Regarding disabling the spinning down: wouldn't that in itself cause the HD to wear out faster?
I mean: it's never ever "resting" as long as the system is on then? –
Cedric Martin
Aug 2 '12 at 16:03
IIRC you can query some SMART values without causing the drive to spin up, but temperature isn't one of them on any of the drives
i've tested (incl models from WD, Seagate, Samsung, Hitachi). Which is, of course, crazy because concern over temperature is one
of the reasons for idling a drive. re: wear: AIUI 1. constant velocity is less wearing than changing speed. 2. the drives have
to park the heads in a safe area and a drive is only rated to do that so many times (IIRC up to a few hundred thousand - easily
exceeded if the drive is idling and spinning up every few seconds) –
cas
Aug 2 '12 at 21:42
It's a long debate regarding whether it's better to leave drives running or to spin them down. Personally I believe it's best
to leave them running - I turn my computer off at night and when I go out but other than that I never spin my drives down. Some
people prefer to spin them down, say, at night if they're leaving the computer on or if the computer's idle for a long time, and
in such cases the advantage of spinning them down for a few hours versus leaving them running is debatable. What's never good
though is when the hard drive repeatedly spins down and up again in a short period of time. –
Micheal Johnson
Mar 12 '16 at 20:48
Note also that spinning the drive down after it's been idle for a few hours is a bit silly, because if it's been idle for
a few hours then it's likely to be used again within an hour. In that case, it would seem better to spin the drive down promptly
if it's idle (like, within 10 minutes), but it's also possible for the drive to be idle for a few minutes when someone is using
the computer and is likely to need the drive again soon. –
Micheal Johnson
Mar 12 '16 at 20:51
,
I just found that s.m.a.r.t was causing an external USB disk to spin up again and again on my raspberry pi. Although SMART is
generally a good thing, I decided to disable it again and since then it seems that unwanted disk activity has stopped
[1] 18:10:10 [SUCCESS] [email protected]
Sun Feb 26 18:10:10 IST 2017
[2] 18:10:10 [SUCCESS] vivek@dellm6700
Sun Feb 26 18:10:10 IST 2017
[3] 18:10:10 [SUCCESS] [email protected]
Sun Feb 26 18:10:10 IST 2017
[4] 18:10:10 [SUCCESS] [email protected]
Sun Feb 26 18:10:10 IST 2017
Run the uptime command on each host: $ pssh -i -h ~/.pssh_hosts_files uptime
Sample outputs:
You can now automate common sysadmin tasks such as patching all servers: $ pssh -h ~/.pssh_hosts_files -- sudo yum -y update
OR $ pssh -h ~/.pssh_hosts_files -- sudo apt-get -y update
$ pssh -h ~/.pssh_hosts_files -- sudo apt-get -y upgrade
How do I use pssh to copy
file to all servers?
The syntax is: pscp -h ~/.pssh_hosts_files src dest
To copy $HOME/demo.txt to /tmp/ on all servers, enter: $ pscp -h ~/.pssh_hosts_files $HOME/demo.txt /tmp/
Sample outputs:
Or use the prsync command for efficient copying of files: $ prsync -h ~/.pssh_hosts_files /etc/passwd /tmp/
$ prsync -h ~/.pssh_hosts_files *.html /var/www/html/
How do I kill processes in
parallel on a number of hosts?
Use the pnuke command for killing processes in parallel on a number of hosts. The syntax
is:
$ pnuke -h .pssh_hosts_files process_name
### kill nginx and firefox on hosts: $ pnuke -h ~/.pssh_hosts_files firefox
$ pnuke -h ~/.pssh_hosts_files nginx
See pssh/pscp command man pages for more information.
In this series of blog posts I'm taking a look at a few very useful tools that can make your
life as the sysadmin of a cluster of Linux machines easier. This may be a Hadoop cluster, or
just a plain simple set of 'normal' machines on which you want to run the same commands and
monitoring.
Previously we looked at using SSH keys for
intra-machine authorisation , which is a pre-requisite what we'll look at here -- executing
the same command across multiple machines using PDSH. In the next post of the series we'll see
how we can monitor OS metrics across a cluster with colmux.
PDSH is a very smart little tool that enables you to issue the same command on multiple
hosts at once, and see the output. You need to have set up ssh key authentication from the
client to host on all of them, so if you followed the steps in the first section of this
article you'll be good to go.
The syntax for using it is nice and simple:
-w specifies the addresses. You can use numerical ranges [1-4]
and/or comma-separated lists of hosts. If you want to connect as a user other than the
current user on the calling machine, you can specify it here (or as a separate
-l argument)
After that is the command to run.
For example run against a small cluster of four machines that I have:
robin@RNMMBP $ pdsh -w root@rnmcluster02-node0[1-4] date
rnmcluster02-node01: Fri Nov 28 17:26:17 GMT 2014
rnmcluster02-node02: Fri Nov 28 17:26:18 GMT 2014
rnmcluster02-node03: Fri Nov 28 17:26:18 GMT 2014
rnmcluster02-node04: Fri Nov 28 17:26:18 GMT 2014
PDSH can be installed on the Mac under Homebrew(did I mention that Rittman Mead laptops are Macs, so I can
do all of this straight from my work machine... :-) )
brew install pdsh
And if you want to run it on Linux from the EPEL yum repository (RHEL-compatible, but packages
for other distros are available):
yum install pdsh
You can run it from a cluster node, or from your client machine (assuming your client
machine is mac/linux).
Example - install and start collectl on all nodes
I started looking into pdsh when it came to setting up a cluster of machines from scratch.
One of the must-have tools I like to have on any machine that I work with is the excellent
collectl .
This is an OS resource monitoring tool that I initially learnt of through Kevin Closson and Greg Rahn , and provides the kind of information you'd get
from top etc – and then some! It can run interactively, log to disk, run as a service
– and it also happens to integrate
very nicely with graphite , making it a no-brainer choice for any server.
So, instead of logging into each box individually I could instead run this:
pdsh -w root@rnmcluster02-node0[1-4] yum install -y collectl
pdsh -w root@rnmcluster02-node0[1-4] service collectl start
pdsh -w root@rnmcluster02-node0[1-4] chkconfig collectl on
Yes, I know there are tools out there like puppet and chef that are designed for doing this
kind of templated build of multiple servers, but the point I want to illustrate here is that
pdsh enables you to do ad-hoc changes to a set of servers at once. Sure, once I have my cluster
built and want to create an image/template for future builds, then it would be daft if
I were building the whole lot through pdsh-distributed yum commands.
Example - setting up
the date/timezone/NTPD
Often the accuracy of the clock on each server in a cluster is crucial, and we can easily do
this with pdsh:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node0[1-4] ntpdate pool.ntp.org
rnmcluster02-node03: 30 Nov 20:46:22 ntpdate[27610]: step time server 176.58.109.199 offset -2.928585 sec
rnmcluster02-node02: 30 Nov 20:46:22 ntpdate[28527]: step time server 176.58.109.199 offset -2.946021 sec
rnmcluster02-node04: 30 Nov 20:46:22 ntpdate[27615]: step time server 129.250.35.250 offset -2.915713 sec
rnmcluster02-node01: 30 Nov 20:46:25 ntpdate[29316]: 178.79.160.57 rate limit response from server.
rnmcluster02-node01: 30 Nov 20:46:22 ntpdate[29316]: step time server 176.58.109.199 offset -2.925016 sec
Set NTPD to start automatically at boot:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node0[1-4] chkconfig ntpd on
Start NTPD:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node0[1-4] service ntpd start
Example - using a HEREDOC (here-document) and sending quotation marks in a command with
PDSH
Here documents
(heredocs) are a nice way to embed multi-line content in a single command, enabling the
scripting of a file creation rather than the clumsy instruction to " open an editor and
paste the following lines into it and save the file as /foo/bar ".
Fortunately heredocs work just fine with pdsh, so long as you remember to enclose the whole
command in quotation marks. And speaking of which, if you need to include quotation marks in
your actual command, you need to escape them with a backslash. Here's an example of both,
setting up the configuration file for my ever-favourite gnu screen on all the nodes of the
cluster:
Now when I login to each individual node and run screen, I get a nice toolbar at the
bottom:
Combining
commands
To combine commands together that you send to each host you can use the standard bash
operator semicolon ;
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node0[1-4] "date;sleep 5;date"
rnmcluster02-node01: Sun Nov 30 20:57:06 GMT 2014
rnmcluster02-node03: Sun Nov 30 20:57:06 GMT 2014
rnmcluster02-node04: Sun Nov 30 20:57:06 GMT 2014
rnmcluster02-node02: Sun Nov 30 20:57:06 GMT 2014
rnmcluster02-node01: Sun Nov 30 20:57:11 GMT 2014
rnmcluster02-node03: Sun Nov 30 20:57:11 GMT 2014
rnmcluster02-node04: Sun Nov 30 20:57:11 GMT 2014
rnmcluster02-node02: Sun Nov 30 20:57:11 GMT 2014
Note the use of the quotation marks to enclose the entire command string. Without them the
bash interpretor will take the ; as the delineator of the local commands,
and try to run the subsequent commands locally:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node0[1-4] date;sleep 5;date
rnmcluster02-node03: Sun Nov 30 20:57:53 GMT 2014
rnmcluster02-node04: Sun Nov 30 20:57:53 GMT 2014
rnmcluster02-node02: Sun Nov 30 20:57:53 GMT 2014
rnmcluster02-node01: Sun Nov 30 20:57:53 GMT 2014
Sun 30 Nov 2014 20:58:00 GMT
You can also use && and || to run subsequent commands
conditionally if the previous one succeeds or fails respectively:
robin@RNMMBP $ pdsh -w root@rnmcluster02-node[01-4] "chkconfig collectl on && service collectl start"
rnmcluster02-node03: Starting collectl: [ OK ]
rnmcluster02-node02: Starting collectl: [ OK ]
rnmcluster02-node04: Starting collectl: [ OK ]
rnmcluster02-node01: Starting collectl: [ OK ]
Piping and file redirects
Similar to combining commands above, you can pipe the output of commands, and you need to
use quotation marks to enclose the whole command string.
The difference is that you'll be shifting the whole of the pipe across the network in order
to process it locally, so if you're just grepping etc this doesn't make any sense. For use of
utilities held locally and not on the remote server though, this might make sense.
File redirects work the same way – within quotation marks and the redirect will be to
a file on the remote server, outside of them it'll be local:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node[01-4] "chkconfig>/tmp/pdsh.out"
robin@RNMMBP ~ $ ls -l /tmp/pdsh.out
ls: /tmp/pdsh.out: No such file or directory
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node[01-4] chkconfig>/tmp/pdsh.out
robin@RNMMBP ~ $ ls -l /tmp/pdsh.out
-rw-r--r-- 1 robin wheel 7608 30 Nov 19:23 /tmp/pdsh.out
Cancelling PDSH operations
As you can see from above, the precise syntax of pdsh calls can be hugely important. If you
run a command and it appears 'stuck', or if you have that heartstopping realisation that the
shutdown -h now you meant to run locally you ran across the cluster, you can press
Ctrl-C once to see the status of your commands:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node[01-4] sleep 30
^Cpdsh@RNMMBP: interrupt (one more within 1 sec to abort)
pdsh@RNMMBP: (^Z within 1 sec to cancel pending threads)
pdsh@RNMMBP: rnmcluster02-node01: command in progress
pdsh@RNMMBP: rnmcluster02-node02: command in progress
pdsh@RNMMBP: rnmcluster02-node03: command in progress
pdsh@RNMMBP: rnmcluster02-node04: command in progress
and press it twice (or within a second of the first) to cancel:
robin@RNMMBP ~ $ pdsh -w root@rnmcluster02-node[01-4] sleep 30
^Cpdsh@RNMMBP: interrupt (one more within 1 sec to abort)
pdsh@RNMMBP: (^Z within 1 sec to cancel pending threads)
pdsh@RNMMBP: rnmcluster02-node01: command in progress
pdsh@RNMMBP: rnmcluster02-node02: command in progress
pdsh@RNMMBP: rnmcluster02-node03: command in progress
pdsh@RNMMBP: rnmcluster02-node04: command in progress
^Csending SIGTERM to ssh rnmcluster02-node01
sending signal 15 to rnmcluster02-node01 [ssh] pid 26534
sending SIGTERM to ssh rnmcluster02-node02
sending signal 15 to rnmcluster02-node02 [ssh] pid 26535
sending SIGTERM to ssh rnmcluster02-node03
sending signal 15 to rnmcluster02-node03 [ssh] pid 26533
sending SIGTERM to ssh rnmcluster02-node04
sending signal 15 to rnmcluster02-node04 [ssh] pid 26532
pdsh@RNMMBP: interrupt, aborting.
If you've got threads yet to run on the remote hosts, but want to keep running whatever has
already started, you can use Ctrl-C, Ctrl-Z:
robin@RNMMBP ~ $ pdsh -f 2 -w root@rnmcluster02-node[01-4] "sleep 5;date"
^Cpdsh@RNMMBP: interrupt (one more within 1 sec to abort)
pdsh@RNMMBP: (^Z within 1 sec to cancel pending threads)
pdsh@RNMMBP: rnmcluster02-node01: command in progress
pdsh@RNMMBP: rnmcluster02-node02: command in progress
^Zpdsh@RNMMBP: Canceled 2 pending threads.
rnmcluster02-node01: Mon Dec 1 21:46:35 GMT 2014
rnmcluster02-node02: Mon Dec 1 21:46:35 GMT 2014
NB the above example illustrates the use of the -f argument to limit how many
threads are run against remote hosts at once. We can see the command is left running on the
first two nodes and returns the date, whilst the Ctrl-C - Ctrl-Z stops it from being executed
on the remaining nodes.
PDSH_SSH_ARGS_APPEND
By default, when you ssh to new host for the first time you'll be prompted to validate the
remote host's SSH key fingerprint.
The authenticity of host 'rnmcluster02-node02 (172.28.128.9)' can't be established.
RSA key fingerprint is 00:c0:75:a8:bc:30:cb:8e:b3:8e:e4:29:42:6a:27:1c.
Are you sure you want to continue connecting (yes/no)?
This is one of those prompts that the majority of us just hit enter at and ignore; if that
includes you then you will want to make sure that your PDSH call doesn't fall in a heap because
you're connecting to a bunch of new servers all at once. PDSH is not an interactive tool, so if
it requires input from the hosts it's connecting to it'll just fail. To avoid this SSH prompt,
you can set up the environment variable PDSH SSH ARGS_APPEND as follows:
The -q makes failures less verbose, and the -o passes in a couple
of options, StrictHostKeyChecking to disable the above check, and
UserKnownHostsFile to stop SSH keeping a list of host IP/hostnames and
corresponding SSH fingerprints (by pointing it at /dev/null ). You'll want this if
you're working with VMs that are sharing a pool of IPs and get re-used, otherwise you get this
scary failure:
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY!
Someone could be eavesdropping on you right now (man-in-the-middle attack)!
It is also possible that a host key has just been changed.
The fingerprint for the RSA key sent by the remote host is
00:c0:75:a8:bc:30:cb:8e:b3:8e:e4:29:42:6a:27:1c.
Please contact your system administrator.
For both of these above options, make sure you're aware of the security implications that
you're opening yourself up to. For a sandbox environment I just ignore them; for anything where
security is of importance make sure you are aware of quite which server you are connecting to
by SSH, and protecting yourself from MitM attacks.
When working with multiple Linux machines I would first and foremost make sure SSH
keys are set up in order to ease management through password-less logins.
After SSH keys, I would recommend pdsh for parallel execution of the same SSH command across
the cluster. It's a big time saver particularly when initially setting up the cluster given the
installation and configuration changes that are inevitably needed.
In the next article of this series we'll see how the tool colmux is a powerful way to
monitor OS metrics across a cluster.
So now your turn – what particular tools or tips do you have for working with a
cluster of Linux machines? Leave your answers in the comments below, or tweet them to me at
@rmoff .
The main purpose of the program pexec is to execute the given command or shell script (e.g. parsed by /bin/sh
) in parallel on the local host or on remote hosts, while some of the execution parameters, namely the redirected standard input,
output or error and environmental variables can be varied. This program is therefore capable to replace the classic shell loop iterators
(e.g. for ~ in ~ done , in bash ) by executing the body of the loop in parallel. Thus, the program pexec
implements shell level data parallelism in a barely simple form. The capabilities of the program is extended with additional features,
such as allowing to define mutual exclusions, do atomic command executions and implement higher level resource and job control. See
the complete manual for more details. See a brief Hungarian
description of the program here .
The actual version of the program package is 1.0rc8 .
You may browse the package directory here (for FTP access, see
this directory ). See the GNU summary page
of this project here . The latest version of the program source
package is pexec-1.0rc8.tar.gz . Here is another
mirror of the package directory.
Please consider making donations
to the author (via PayPal ) in order to help further development of the program
or support the GNU project via the
FSF .
Although this is very simple to read and write, is a very slow solution because forces you to
read twice the same data ($STR) ... if you care of your script performace, the @anubhava
solution is much better – FSp
Nov 27 '12 at 10:26
Apart from being an ugly last-resort solution, this has a bug: You should absolutely use
double quotes in echo "$STR" unless you specifically want the shell to expand
any wildcards in the string as a side effect. See also stackoverflow.com/questions/10067266/
– tripleee
Jan 25 '16 at 6:47
You're right about double quotes of course, though I did point out this solution wasn't
general. However I think your assessment is a bit unfair - for some people this solution may
be more readable (and hence extensible etc) than some others, and doesn't completely rely on
arcane bash feature that wouldn't translate to other shells. I suspect that's why my
solution, though less elegant, continues to get votes periodically... – Rob I
Feb 10 '16 at 13:57
If you know it's going to be just two fields, you can skip the extra subprocesses like this:
var1=${STR%-*}
var2=${STR#*-}
What does this do? ${STR%-*} deletes the shortest substring of
$STR that matches the pattern -* starting from the end of the
string. ${STR#*-} does the same, but with the *- pattern and
starting from the beginning of the string. They each have counterparts %% and
## which find the longest anchored pattern match. If anyone has a
helpful mnemonic to remember which does which, let me know! I always have to try both to
remember.
Dunno about "absence of bashisms" considering that this is already moderately cryptic .... if
your delimiter is a newline instead of a hyphen, then it becomes even more cryptic. On the
other hand, it works with newlines , so there's that. – Steven Lu
May 1 '15 at 20:19
Mnemonic: "#" is to the left of "%" on a standard keyboard, so "#" removes a prefix (on the
left), and "%" removes a suffix (on the right). – DS.
Jan 13 '17 at 19:56
I used triplee's example and it worked exactly as advertised! Just change last two lines to
<pre> myvar1= echo $1 && myvar2= echo $2 </pre>
if you need to store them throughout a script with several "thrown" variables. –
Sigg3.net
Jun 19 '13 at 8:08
This is a really sweet solution if we need to write something that is not Bash specific. To
handle IFS troubles, one can add OLDIFS=$IFS at the beginning
before overwriting it, and then add IFS=$OLDIFS just after the set
line. – Daniel Andersson
Mar 27 '15 at 6:46
Suppose I have the string 1:2:3:4:5 and I want to get its last field (
5 in this case). How do I do that using Bash? I tried cut , but I
don't know how to specify the last field with -f .
While this is working for the given problem, the answer of William below ( stackoverflow.com/a/3163857/520162 )
also returns 5 if the string is 1:2:3:4:5: (while using the string
operators yields an empty result). This is especially handy when parsing paths that could
contain (or not) a finishing / character. – eckes
Jan 23 '13 at 15:23
And how does one keep the part before the last separator? Apparently by using
${foo%:*} . # - from beginning; % - from end.
# , % - shortest match; ## , %% - longest
match. – Mihai Danila
Jul 9 '14 at 14:07
This answer is nice because it uses 'cut', which the author is (presumably) already familiar.
Plus, I like this answer because I am using 'cut' and had this exact question, hence
finding this thread via search. – Dannid
Jan 14 '13 at 20:50
great advantage of this solution over the accepted answer: it also matches paths that contain
or do not contain a finishing / character: /a/b/c/d and
/a/b/c/d/ yield the same result ( d ) when processing pwd |
awk -F/ '{print $NF}' . The accepted answer results in an empty result in the case of
/a/b/c/d/ – eckes
Jan 23 '13 at 15:20
@eckes In case of AWK solution, on GNU bash, version 4.3.48(1)-release that's not true, as it
matters whenever you have trailing slash or not. Simply put AWK will use / as
delimiter, and if your path is /my/path/dir/ it will use value after last
delimiter, which is simply an empty string. So it's best to avoid trailing slash if you need
to do such a thing like I do. – stamster
May 21 at 11:52
This runs into problems if there is whitespace in any of the fields. Also, it does not
directly address the question of retrieving the last field. – chepner
Jun 22 '12 at 12:58
There was a solution involving setting Internal_field_separator (IFS) to
; . I am not sure what happened with that answer, how do you reset
IFS back to default?
RE: IFS solution, I tried this and it works, I keep the old IFS
and then restore it:
With regards to your "Edit2": You can simply "unset IFS" and it will return to the default
state. There's no need to save and restore it explicitly unless you have some reason to
expect that it's already been set to a non-default value. Moreover, if you're doing this
inside a function (and, if you aren't, why not?), you can set IFS as a local variable and it
will return to its previous value once you exit the function. – Brooks Moses
May 1 '12 at 1:26
@BrooksMoses: (a) +1 for using local IFS=... where possible; (b) -1 for
unset IFS , this doesn't exactly reset IFS to its default value, though I
believe an unset IFS behaves the same as the default value of IFS ($' \t\n'), however it
seems bad practice to be assuming blindly that your code will never be invoked with IFS set
to a custom value; (c) another idea is to invoke a subshell: (IFS=$custom; ...)
when the subshell exits IFS will return to whatever it was originally. – dubiousjim
May 31 '12 at 5:21
I just want to have a quick look at the paths to decide where to throw an executable, so I
resorted to run ruby -e "puts ENV.fetch('PATH').split(':')" . If you want to
stay pure bash won't help but using any scripting language that has a built-in split
is easier. – nicooga
Mar 7 '16 at 15:32
This is kind of a drive-by comment, but since the OP used email addresses as the example, has
anyone bothered to answer it in a way that is fully RFC 5322 compliant, namely that any
quoted string can appear before the @ which means you're going to need regular expressions or
some other kind of parser instead of naive use of IFS or other simplistic splitter functions.
– Jeff
Apr 22 at 17:51
You can set the internal field separator (IFS)
variable, and then let it parse into an array. When this happens in a command, then the
assignment to IFS only takes place to that single command's environment (to
read ). It then parses the input according to the IFS variable
value into an array, which we can then iterate over.
IFS=';' read -ra ADDR <<< "$IN"
for i in "${ADDR[@]}"; do
# process "$i"
done
It will parse one line of items separated by ; , pushing it into an array.
Stuff for processing whole of $IN , each time one line of input separated by
; :
while IFS=';' read -ra ADDR; do
for i in "${ADDR[@]}"; do
# process "$i"
done
done <<< "$IN"
This is probably the best way. How long will IFS persist in it's current value, can it mess
up my code by being set when it shouldn't be, and how can I reset it when I'm done with it?
– Chris
Lutz
May 28 '09 at 2:25
You can read everything at once without using a while loop: read -r -d '' -a addr
<<< "$in" # The -d '' is key here, it tells read not to stop at the first newline
(which is the default -d) but to continue until EOF or a NULL byte (which only occur in
binary data). – lhunath
May 28 '09 at 6:14
@LucaBorrione Setting IFS on the same line as the read with no
semicolon or other separator, as opposed to in a separate command, scopes it to that command
-- so it's always "restored"; you don't need to do anything manually. – Charles Duffy
Jul 6 '13 at 14:39
@imagineerThis There is a bug involving herestrings and local changes to IFS that requires
$IN to be quoted. The bug is fixed in bash 4.3. – chepner
Oct 2 '14 at 3:50
This construction replaces all occurrences of ';' (the initial
// means global replace) in the string IN with ' ' (a
single space), then interprets the space-delimited string as an array (that's what the
surrounding parentheses do).
The syntax used inside of the curly braces to replace each ';' character with
a ' ' character is called Parameter
Expansion .
There are some common gotchas:
If the original string has spaces, you will need to use
IFS :
IFS=':'; arrIN=($IN); unset IFS;
If the original string has spaces and the delimiter is a new line, you can set
IFS with:
I just want to add: this is the simplest of all, you can access array elements with
${arrIN[1]} (starting from zeros of course) – Oz123
Mar 21 '11 at 18:50
No, I don't think this works when there are also spaces present... it's converting the ',' to
' ' and then building a space-separated array. – Ethan
Apr 12 '13 at 22:47
This is a bad approach for other reasons: For instance, if your string contains
;*; , then the * will be expanded to a list of filenames in the
current directory. -1 – Charles Duffy
Jul 6 '13 at 14:39
You should have kept the IFS answer. It taught me something I didn't know, and it definitely
made an array, whereas this just makes a cheap substitute. – Chris Lutz
May 28 '09 at 2:42
I see. Yeah i find doing these silly experiments, i'm going to learn new things each time i'm
trying to answer things. I've edited stuff based on #bash IRC feedback and undeleted :)
– Johannes Schaub - litb
May 28 '09 at 2:59
-1, you're obviously not aware of wordsplitting, because it's introducing two bugs in your
code. one is when you don't quote $IN and the other is when you pretend a newline is the only
delimiter used in wordsplitting. You are iterating over every WORD in IN, not every line, and
DEFINATELY not every element delimited by a semicolon, though it may appear to have the
side-effect of looking like it works. – lhunath
May 28 '09 at 6:12
You could change it to echo "$IN" | tr ';' '\n' | while read -r ADDY; do # process "$ADDY";
done to make him lucky, i think :) Note that this will fork, and you can't change outer
variables from within the loop (that's why i used the <<< "$IN" syntax) then –
Johannes
Schaub - litb
May 28 '09 at 17:00
To summarize the debate in the comments: Caveats for general use : the shell applies
word splitting and expansions to the string, which may be undesired; just try
it with. IN="[email protected];[email protected];*;broken apart" . In short: this
approach will break, if your tokens contain embedded spaces and/or chars. such as
* that happen to make a token match filenames in the current folder. –
mklement0
Apr 24 '13 at 14:13
To this SO question, there is already a lot of different way to do this in bash . But bash has many
special features, so called bashism that work well, but that won't work in
any other shell .
In particular, arrays , associative array , and pattern
substitution are pure bashisms and may not work under other shells
.
On my Debian GNU/Linux , there is a standard shell called dash , but I know many
people who like to use ksh .
Finally, in very small situation, there is a special tool called busybox with his own shell
interpreter ( ash ).
But if you would write something usable under many shells, you have to not use
bashisms .
There is a syntax, used in many shells, for splitting a string across first or
last occurrence of a substring:
${var#*SubStr} # will drop begin of string up to first occur of `SubStr`
${var##*SubStr} # will drop begin of string up to last occur of `SubStr`
${var%SubStr*} # will drop part of string from last occur of `SubStr` to the end
${var%%SubStr*} # will drop part of string from first occur of `SubStr` to the end
(The missing of this is the main reason of my answer publication ;)
The # , ## , % , and %% substitutions
have what is IMO an easier explanation to remember (for how much they delete): #
and % delete the shortest possible matching string, and ## and
%% delete the longest possible. – Score_Under
Apr 28 '15 at 16:58
The IFS=\; read -a fields <<<"$var" fails on newlines and add a
trailing newline. The other solution removes a trailing empty field. – sorontar
Oct 26 '16 at 4:36
Could the last alternative be used with a list of field separators set somewhere else? For
instance, I mean to use this as a shell script, and pass a list of field separators as a
positional parameter. – sancho.s
Oct 4 at 3:42
I've seen a couple of answers referencing the cut command, but they've all been
deleted. It's a little odd that nobody has elaborated on that, because I think it's one of
the more useful commands for doing this type of thing, especially for parsing delimited log
files.
In the case of splitting this specific example into a bash script array, tr
is probably more efficient, but cut can be used, and is more effective if you
want to pull specific fields from the middle.
This approach will only work if you know the number of elements in advance; you'd need to
program some more logic around it. It also runs an external tool for every element. –
uli42
Sep 14 '17 at 8:30
Excatly waht i was looking for trying to avoid empty string in a csv. Now i can point the
exact 'column' value as well. Work with IFS already used in a loop. Better than expected for
my situation. – Louis Loudog Trottier
May 10 at 4:20
, May 28, 2009 at 10:31
How about this approach:
IN="[email protected];[email protected]"
set -- "$IN"
IFS=";"; declare -a Array=($*)
echo "${Array[@]}"
echo "${Array[0]}"
echo "${Array[1]}"
+1 Only a side note: shouldn't it be recommendable to keep the old IFS and then restore it?
(as shown by stefanB in his edit3) people landing here (sometimes just copying and pasting a
solution) might not think about this – Luca Borrione
Sep 3 '12 at 9:26
-1: First, @ata is right that most of the commands in this do nothing. Second, it uses
word-splitting to form the array, and doesn't do anything to inhibit glob-expansion when
doing so (so if you have glob characters in any of the array elements, those elements are
replaced with matching filenames). – Charles Duffy
Jul 6 '13 at 14:44
Suggest to use $'...' : IN=$'[email protected];[email protected];bet <d@\ns*
kl.com>' . Then echo "${Array[2]}" will print a string with newline.
set -- "$IN" is also neccessary in this case. Yes, to prevent glob expansion,
the solution should include set -f . – John_West
Jan 8 '16 at 12:29
-1 what if the string contains spaces? for example IN="this is first line; this
is second line" arrIN=( $( echo "$IN" | sed -e 's/;/\n/g' ) ) will produce an array of
8 elements in this case (an element for each word space separated), rather than 2 (an element
for each line semi colon separated) – Luca Borrione
Sep 3 '12 at 10:08
@Luca No the sed script creates exactly two lines. What creates the multiple entries for you
is when you put it into a bash array (which splits on white space by default) –
lothar
Sep 3 '12 at 17:33
That's exactly the point: the OP needs to store entries into an array to loop over it, as you
can see in his edits. I think your (good) answer missed to mention to use arrIN=( $(
echo "$IN" | sed -e 's/;/\n/g' ) ) to achieve that, and to advice to change IFS to
IFS=$'\n' for those who land here in the future and needs to split a string
containing spaces. (and to restore it back afterwards). :) – Luca Borrione
Sep 4 '12 at 7:09
You can use -s to avoid the mentioned problem: superuser.com/questions/896800/
"-f, --fields=LIST select only these fields; also print any line that contains no delimiter
character, unless the -s option is specified" – fersarr
Mar 3 '16 at 17:17
It worked in this scenario -> "echo "$SPLIT_0" | awk -F' inode=' '{print $1}'"! I had
problems when trying to use atrings (" inode=") instead of characters (";"). $ 1, $ 2, $ 3, $
4 are set as positions in an array! If there is a way of setting an array... better! Thanks!
– Eduardo Lucio
Aug 5 '15 at 12:59
@EduardoLucio, what I'm thinking about is maybe you can first replace your delimiter
inode= into ; for example by sed -i 's/inode\=/\;/g'
your_file_to_process , then define -F';' when apply awk ,
hope that can help you. – Tony
Aug 6 '15 at 2:42
This worked REALLY well for me... I used it to itterate over an array of strings which
contained comma separated DB,SERVER,PORT data to use mysqldump. – Nick
Oct 28 '11 at 14:36
Diagnosis: the IFS=";" assignment exists only in the $(...; echo
$IN) subshell; this is why some readers (including me) initially think it won't work.
I assumed that all of $IN was getting slurped up by ADDR1. But nickjb is correct; it does
work. The reason is that echo $IN command parses its arguments using the current
value of $IFS, but then echoes them to stdout using a space delimiter, regardless of the
setting of $IFS. So the net effect is as though one had called read ADDR1 ADDR2
<<< "[email protected][email protected]" (note the input is space-separated not
;-separated). – dubiousjim
May 31 '12 at 5:28
$ in=$'one;two three;*;there is\na newline\nin this field'
$ IFS=';' read -d '' -ra array < <(printf '%s;\0' "$in")
$ declare -p array
declare -a array='([0]="one" [1]="two three" [2]="*" [3]="there is
a newline
in this field")'
The trick for this to work is to use the -d option of read
(delimiter) with an empty delimiter, so that read is forced to read everything
it's fed. And we feed read with exactly the content of the variable
in , with no trailing newline thanks to printf . Note that's we're
also putting the delimiter in printf to ensure that the string passed to
read has a trailing delimiter. Without it, read would trim
potential trailing empty fields:
$ in='one;two;three;' # there's an empty field
$ IFS=';' read -d '' -ra array < <(printf '%s;\0' "$in")
$ declare -p array
declare -a array='([0]="one" [1]="two" [2]="three" [3]="")'
the trailing empty field is preserved.
Update for Bash≥4.4
Since Bash 4.4, the builtin mapfile (aka readarray ) supports
the -d option to specify a delimiter. Hence another canonical way is:
I found it as the rare solution on that list that works correctly with \n ,
spaces and * simultaneously. Also, no loops; array variable is accessible in the
shell after execution (contrary to the highest upvoted answer). Note, in=$'...'
, it does not work with double quotes. I think, it needs more upvotes. – John_West
Jan 8 '16 at 12:10
Consider using read -r ... to ensure that, for example, the two characters "\t"
in the input end up as the same two characters in your variables (instead of a single tab
char). – dubiousjim
May 31 '12 at 5:36
This is probably due to a bug involving IFS and here strings that was fixed in
bash 4.3. Quoting $IN should fix it. (In theory, $IN
is not subject to word splitting or globbing after it expands, meaning the quotes should be
unnecessary. Even in 4.3, though, there's at least one bug remaining--reported and scheduled
to be fixed--so quoting remains a good idea.) – chepner
Sep 19 '15 at 13:59
The following Bash/zsh function splits its first argument on the delimiter given by the
second argument:
split() {
local string="$1"
local delimiter="$2"
if [ -n "$string" ]; then
local part
while read -d "$delimiter" part; do
echo $part
done <<< "$string"
echo $part
fi
}
For instance, the command
$ split 'a;b;c' ';'
yields
a
b
c
This output may, for instance, be piped to other commands. Example:
$ split 'a;b;c' ';' | cat -n
1 a
2 b
3 c
Compared to the other solutions given, this one has the following advantages:
IFS is not overriden: Due to dynamic scoping of even local variables,
overriding IFS over a loop causes the new value to leak into function calls
performed from within the loop.
Arrays are not used: Reading a string into an array using read requires
the flag -a in Bash and -A in zsh.
If desired, the function may be put into a script as follows:
There are some cool answers here (errator esp.), but for something analogous to split in
other languages -- which is what I took the original question to mean -- I settled on this:
Now ${a[0]} , ${a[1]} , etc, are as you would expect. Use
${#a[*]} for number of terms. Or to iterate, of course:
for i in ${a[*]}; do echo $i; done
IMPORTANT NOTE:
This works in cases where there are no spaces to worry about, which solved my problem, but
may not solve yours. Go with the $IFS solution(s) in that case.
Better use ${IN//;/ } (double slash) to make it also work with more than two
values. Beware that any wildcard ( *?[ ) will be expanded. And a trailing empty
field will be discarded. – sorontar
Oct 26 '16 at 5:14
Better use set -- $IN to avoid some issues with "$IN" starting with dash. Still,
the unquoted expansion of $IN will expand wildcards ( *?[ ).
– sorontar
Oct 26 '16 at 5:17
In both cases a sub-list can be composed within the loop is persistent after the loop has
completed. This is useful when manipulating lists in memory, instead storing lists in files.
{p.s. keep calm and carry on B-) }
Fails if any part of $PATH contains spaces (or newlines). Also expands wildcards (asterisk *,
question mark ? and braces [ ]). – sorontar
Oct 26 '16 at 5:08
FYI, /etc/os-release and /etc/lsb-release are meant to be sourced,
and not parsed. So your method is really wrong. Moreover, you're not quite answering the
question about spiltting a string on a delimiter. – gniourf_gniourf
Jan 30 '17 at 8:26
-1 this doesn't work here (ubuntu 12.04). it prints only the first echo with all $IN value in
it, while the second is empty. you can see it if you put echo "0: "${ADDRS[0]}\n echo "1:
"${ADDRS[1]} the output is 0: [email protected];[email protected]\n 1: (\n is new line)
– Luca
Borrione
Sep 3 '12 at 10:04
-1, 1. IFS isn't being set in that subshell (it's being passed to the environment of "echo",
which is a builtin, so nothing is happening anyway). 2. $IN is quoted so it
isn't subject to IFS splitting. 3. The process substitution is split by whitespace, but this
may corrupt the original data. – Score_Under
Apr 28 '15 at 17:09
IN='[email protected];[email protected];Charlie Brown <[email protected];!"#$%&/()[]{}*? are no problem;simple is beautiful :-)'
set -f
oldifs="$IFS"
IFS=';'; arrayIN=($IN)
IFS="$oldifs"
for i in "${arrayIN[@]}"; do
echo "$i"
done
set +f
Explanation: Simple assignment using parenthesis () converts semicolon separated list into
an array provided you have correct IFS while doing that. Standard FOR loop handles individual
items in that array as usual. Notice that the list given for IN variable must be "hard"
quoted, that is, with single ticks.
IFS must be saved and restored since Bash does not treat an assignment the same way as a
command. An alternate workaround is to wrap the assignment inside a function and call that
function with a modified IFS. In that case separate saving/restoring of IFS is not needed.
Thanks for "Bize" for pointing that out.
!"#$%&/()[]{}*? are no problem well... not quite: []*? are glob
characters. So what about creating this directory and file: `mkdir '!"#$%&'; touch
'!"#$%&/()[]{} got you hahahaha - are no problem' and running your command? simple may be
beautiful, but when it's broken, it's broken. – gniourf_gniourf
Feb 20 '15 at 16:45
@ajaaskel you didn't fully understand my comment. Go in a scratch directory and issue these
commands: mkdir '!"#$%&'; touch '!"#$%&/()[]{} got you hahahaha - are no
problem' . They will only create a directory and a file, with weird looking names, I
must admit. Then run your commands with the exact IN you gave:
IN='[email protected];[email protected];Charlie Brown <[email protected];!"#$%&/()[]{}*?
are no problem;simple is beautiful :-)' . You'll see that you won't get the output you
expect. Because you're using a method subject to pathname expansions to split your string.
– gniourf_gniourf
Feb 25 '15 at 7:26
This is to demonstrate that the characters * , ? ,
[...] and even, if extglob is set, !(...) ,
@(...) , ?(...) , +(...)are problems with this
method! – gniourf_gniourf
Feb 25 '15 at 7:29
@gniourf_gniourf Thanks for detailed comments on globbing. I adjusted the code to have
globbing off. My point was however just to show that rather simple assignment can do the
splitting job. – ajaaskel
Feb 26 '15 at 15:26
> , Dec 19, 2013 at 21:39
Maybe not the most elegant solution, but works with * and spaces:
IN="bla@so me.com;*;[email protected]"
for i in `delims=${IN//[^;]}; seq 1 $((${#delims} + 1))`
do
echo "> [`echo $IN | cut -d';' -f$i`]"
done
Basically it removes every character other than ; making delims
eg. ;;; . Then it does for loop from 1 to
number-of-delimiters as counted by ${#delims} . The final step is
to safely get the $i th part using cut .
Linux split and join commands are very helpful when you are manipulating large files. This
article explains how to use Linux split and join command with descriptive examples.
Linux Split Command Examples1. Basic Split Example
Here is a basic example of split command.
$ split split.zip
$ ls
split.zip xab xad xaf xah xaj xal xan xap xar xat xav xax xaz xbb xbd xbf xbh xbj xbl xbn
xaa xac xae xag xai xak xam xao xaq xas xau xaw xay xba xbc xbe xbg xbi xbk xbm xbo
So we see that the file split.zip was split into smaller files with x** as file names. Where
** is the two character suffix that is added by default. Also, by default each x** file would
contain 1000 lines.
5. Customize the Number of Split Chunks using -C option
To get control over the number of chunks, use the -C option.
This example will create 50 chunks of split files.
$ split -n50 split.zip
$ ls
split.zip xac xaf xai xal xao xar xau xax xba xbd xbg xbj xbm xbp xbs xbv
xaa xad xag xaj xam xap xas xav xay xbb xbe xbh xbk xbn xbq xbt xbw
xab xae xah xak xan xaq xat xaw xaz xbc xbf xbi xbl xbo xbr xbu xbx
6. Avoid Zero Sized Chunks using -e option
While splitting a relatively small file in large number of chunks, its good to avoid zero
sized chunks as they do not add any value. This can be done using -e option.
I normally compress using tar zcvf and decompress using tar zxvf
(using gzip due to habit).
I've recently gotten a quad core CPU with hyperthreading, so I have 8 logical cores, and I
notice that many of the cores are unused during compression/decompression.
Is there any way I can utilize the unused cores to make it faster?
The solution proposed by Xiong Chiamiov above works beautifully. I had just backed up my
laptop with .tar.bz2 and it took 132 minutes using only one cpu thread. Then I compiled and
installed tar from source: gnu.org/software/tar I included the options mentioned
in the configure step: ./configure --with-gzip=pigz --with-bzip2=lbzip2 --with-lzip=plzip I
ran the backup again and it took only 32 minutes. That's better than 4X improvement! I
watched the system monitor and it kept all 4 cpus (8 threads) flatlined at 100% the whole
time. THAT is the best solution. – Warren Severin
Nov 13 '17 at 4:37
You can use pigz instead of gzip, which
does gzip compression on multiple cores. Instead of using the -z option, you would pipe it
through pigz:
tar cf - paths-to-archive | pigz > archive.tar.gz
By default, pigz uses the number of available cores, or eight if it could not query that.
You can ask for more with -p n, e.g. -p 32. pigz has the same options as gzip, so you can
request better compression with -9. E.g.
pigz does use multiple cores for decompression, but only with limited improvement over a
single core. The deflate format does not lend itself to parallel decompression. The
decompression portion must be done serially. The other cores for pigz decompression are used
for reading, writing, and calculating the CRC. When compressing on the other hand, pigz gets
close to a factor of n improvement with n cores. – Mark Adler
Feb 20 '13 at 16:18
There is effectively no CPU time spent tarring, so it wouldn't help much. The tar format is
just a copy of the input file with header blocks in between files. – Mark Adler
Apr 23 '15 at 5:23
This is an awesome little nugget of knowledge and deserves more upvotes. I had no idea this
option even existed and I've read the man page a few times over the years. – ranman
Nov 13 '13 at 10:01
Unfortunately by doing so the concurrent feature of pigz is lost. You can see for yourself by
executing that command and monitoring the load on each of the cores. – Valerio
Schiavoni
Aug 5 '14 at 22:38
I prefer tar - dir_to_zip | pv | pigz > tar.file pv helps me estimate, you
can skip it. But still it easier to write and remember. – Offenso
Jan 11 '17 at 17:26
-I, --use-compress-program PROG
filter through PROG (must accept -d)
You can use multithread version of archiver or compressor utility.
Most popular multithread archivers are pigz (instead of gzip) and pbzip2 (instead of bzip2). For instance:
$ tar -I pbzip2 -cf OUTPUT_FILE.tar.bz2 paths_to_archive
$ tar --use-compress-program=pigz -cf OUTPUT_FILE.tar.gz paths_to_archive
Archiver must accept -d. If your replacement utility hasn't this parameter and/or you need
specify additional parameters, then use pipes (add parameters if necessary):
$ tar cf - paths_to_archive | pbzip2 > OUTPUT_FILE.tar.gz
$ tar cf - paths_to_archive | pigz > OUTPUT_FILE.tar.gz
Input and output of singlethread and multithread are compatible. You can compress using
multithread version and decompress using singlethread version and vice versa.
p7zip
For p7zip for compression you need a small shell script like the following:
#!/bin/sh
case $1 in
-d) 7za -txz -si -so e;;
*) 7za -txz -si -so a .;;
esac 2>/dev/null
Save it as 7zhelper.sh. Here the example of usage:
$ tar -I 7zhelper.sh -cf OUTPUT_FILE.tar.7z paths_to_archive
$ tar -I 7zhelper.sh -xf OUTPUT_FILE.tar.7z
xz
Regarding multithreaded XZ support. If you are running version 5.2.0 or above of XZ Utils,
you can utilize multiple cores for compression by setting -T or
--threads to an appropriate value via the environmental variable XZ_DEFAULTS
(e.g. XZ_DEFAULTS="-T 0" ).
This is a fragment of man for 5.1.0alpha version:
Multithreaded compression and decompression are not implemented yet, so this option has
no effect for now.
However this will not work for decompression of files that haven't also been compressed
with threading enabled. From man for version 5.2.2:
Threaded decompression hasn't been implemented yet. It will only work on files that
contain multiple blocks with size information in block headers. All files compressed in
multi-threaded mode meet this condition, but files compressed in single-threaded mode don't
even if --block-size=size is used.
Recompiling with replacement
If you build tar from sources, then you can recompile with parameters
After recompiling tar with these options you can check the output of tar's help:
$ tar --help | grep "lbzip2\|plzip\|pigz"
-j, --bzip2 filter the archive through lbzip2
--lzip filter the archive through plzip
-z, --gzip, --gunzip, --ungzip filter the archive through pigz
> , Apr 28, 2015 at 20:41
This is indeed the best answer. I'll definitely rebuild my tar! – user1985657
Apr 28 '15 at 20:41
I just found pbzip2 and
mpibzip2 . mpibzip2 looks very
promising for clusters or if you have a laptop and a multicore desktop computer for instance.
– user1985657
Apr 28 '15 at 20:57
This is a great and elaborate answer. It may be good to mention that multithreaded
compression (e.g. with pigz ) is only enabled when it reads from the file.
Processing STDIN may in fact be slower. – oᴉɹǝɥɔ
Jun 10 '15 at 17:39
find /my/path/ -type f -name "*.sql" -o -name "*.log" -exec
This command will look for the files you want to archive, in this case
/my/path/*.sql and /my/path/*.log . Add as many -o -name
"pattern" as you want.
-exec will execute the next command using the results of find :
tar
Step 2: tar
tar -P --transform='s@/my/path/@@g' -cf - {} +
--transform is a simple string replacement parameter. It will strip the path
of the files from the archive so the tarball's root becomes the current directory when
extracting. Note that you can't use -C option to change directory as you'll lose
benefits of find : all files of the directory would be included.
-P tells tar to use absolute paths, so it doesn't trigger the
warning "Removing leading `/' from member names". Leading '/' with be removed by
--transform anyway.
-cf - tells tar to use the tarball name we'll specify later
{} + uses everyfiles that find found previously
Step 3:
pigz
pigz -9 -p 4
Use as many parameters as you want. In this case -9 is the compression level
and -p 4 is the number of cores dedicated to compression. If you run this on a
heavy loaded webserver, you probably don't want to use all available cores.
Recent studies have shown that 90% of Americans use digital devices for two or more hours each day and the average American spends
more time a day on high-tech devices than they do sleeping:
8 hours and 21 minutes to
be exact. If you've ever considered attempting a "digital detox", there are some health benefits to making that change and a
few tips to make things a little easier on yourself.
Many Americans are on their phones rather than playing with their children or spending quality family time together. Some people
give up technology, or certain aspects of it, such as social media for varying reasons, and there are some shockingly terrific health
benefits that come along with that type of a detox from technology. In fact, more and
more health experts and medical
professionals are suggesting a periodic digital detox; an extended period without those technology gadgets.
Studies continue to show that a digital detox, has
proven to be beneficial for relationships, productivity, physical health, and mental health. If you find yourself overly stressed
or unproductive or generally disengaged from those closest to you, it might be time to unplug.
DIGITAL ADDICTION RESOLUTION
It may go unnoticed but there are many who are actually addicted to their smartphones or tablet. It could be social media or YouTube
videos, but these are the people who never step away. They are the ones with their face in their phone while out to dinner with their
family. They can't have a quiet dinner without their phone on the table. We've seen them at the grocery store aimlessly pushing around
a cart while ignoring their children and scrolling on their phone. A whopping
83%
of American teenagers claim to play video games while other people are in the same room and
92%
of teens report to going online daily . 24% of those users access the internet via laptops, tablets, and mobile devices.
Addiction therapists who treat gadget-obsessed people say their patients aren't that different from other kinds of addicts. Whereas
alcohol, tobacco, and drugs involve a substance that a user's body gets addicted to, in behavioral addiction, it's the mind's craving
to turn to the smartphone or the Internet. Taking a break teaches us that we can live without constant stimulation, and lessens our
dependence on electronics. Trust us: that Facebook message with a funny meme attached or juicy tidbit of gossip can wait.
IMPROVE RELATIONSHIPS AND BE MORE PERSONABLE
Another benefit to keeping all your electronics off is that it will allow you to establish good mannerisms and people skills and
build your relationships to a strong level of connection. If you have ever sat across someone at the dinner table who made more phone
contact than eye contact, you know it feels to take a backseat to a screen. Cell phones and other gadgets force people to look down
and away from their surroundings, giving them a closed off and inaccessible (and often rude) demeanor. A digital detox has the potential
of forcing you out of that unhealthy comfort zone. It could be a start toward rebuilding a struggling relationship too. In a
Forbes study ,
3 out of 5 people claimed that they spend more time on their digital devices than they do with their partners. This can pose
a real threat to building and maintaining real-life relationships. The next time you find yourself going out on a dinner date, try
leaving your cell phone and other devices at home and actually have a conversation. Your significant other will thank you.
BETTER SLEEP AND HEALTHIER EATING HABITS
The sleep interference caused by these high-tech gadgets is another mental health concern. The
stimulation caused by artificial light can make
you feel more awake than you really are, which can potentially interfere with your sleep quality. It is recommended that you give
yourself at least two hours of technology-free time before bedtime. The "blue light" has been shown to interfere with
sleeping patterns by inhibiting melatonin
(the hormone which controls our sleep/wake cycle known as circadian rhythm) production. Try shutting off your phone after dinner
and leaving it in a room other than your bedroom. Another great tip is to buy one of those old-school alarm clocks so the smartphone
isn't ever in your bedroom. This will help your body readjust to a normal and healthy sleep schedule.
Your eating habits can also suffer if you spend too much time checking your newsfeed.
The Rochester Institute of Technology released a study that
revealed students are more likely to eat while staring into digital media than they are to eat at a dinner table. This means that
eating has now become a multi-tasking activity, rather than a social and loving experience in which healthy foods meant to sustain
the body are consumed. This can prevent students from eating consciously, which promotes unhealthy eating habits such as overeating
and easy choices, such as a bag of chips as opposed to washing and peeling some carrots. Whether you're an overworked college student
checking your Facebook, or a single bachelor watching reruns of The Office , a digital detox is a great way to promote healthy and
conscious eating.
IMPROVE OVERALL MENTAL HEALTH
Social media addicts experience a wide array of emotions when looking at the photos of Instagram models and the exercise regimes
of others who live in exotic locations. These emotions can be mentally draining and psychologically unhealthy and lead to depression.
Smartphone use has been linked to loneliness, shyness, and less engagement at work. In other words,
one may have many "social media friends" while being lonely and unsatisfied because those friends are only accessible through
their screen. Start by limiting your time on social media. Log out of all social media accounts. That way, you've actually got to
log back in if you want to see what that Parisian Instagram vegan model is up to.
If you feel like a detox is in order but don't know how to go about it, start off small. Try shutting off your phone after dinner
and don't turn it back on until after breakfast. Keep your phone in another room besides your bedroom overnight. If you use your
phone as an alarm clock, buy a cheap alarm clock to use instead to lessen your dependence on your phone. Boredom is often the biggest
factor in the beginning stages of a detox, but try playing an undistracted board game with your children, leaving your phone at home
during a nice dinner out, or playing with a pet. All of these things are not only good for you but good for your family and beloved
furry critter as well!
Last week, Iran's chief of civil defense claimed that the Iranian government had
fought off Israeli attempts to infect computer systems with what he described as a new
version of Stuxnet -- the malware reportedly developed jointly by the US and Israel that
targeted Iran's uranium-enrichment program. Gholamreza Jalali, chief of the National Passive
Defense Organization (NPDO), told Iran's IRNA news service, "Recently, we discovered a new
generation of Stuxnet which consisted of several parts... and was trying to enter our
systems."
On November 5, Iran Telecommunications Minister Mohammad-Javad Azari Jahromi accused Israel
of being behind the attack, and he said that the malware was intended to "harm the country's
communication infrastructures." Jahromi praised "technical teams" for shutting down the attack,
saying that the attackers "returned empty-handed." A report from Iran's Tasnim news agency
quoted Deputy Telecommunications Minister Hamid Fattahi as stating that more details of the
cyber attacks would be made public soon.
Jahromi said that Iran would sue Israel over the attack through the International Court of
Justice. The Iranian government has also said it would sue the US in the ICJ over the
reinstatement of sanctions. Israel has
remained silent regarding the accusations .
The claims come a week after the NPDO's Jalali announced that President
Hassan Rouhani's cell phone had been "tapped" and was being replaced with a new, more
secure device. This led to a statement by Iranian Supreme Leader Ayatollah Ali Khamenei,
exhorting Iran's security apparatus to "confront infiltration through scientific, accurate, and
up-to-date action."
While Iran protests the alleged attacks -- about which the Israeli government has been
silent -- Iranian hackers have continued to conduct their own cyber attacks. A
recent report from security tools company Carbon Black based on data from the company's
incident-response partners found that Iran had been a significant source of attacks in the
third quarter of this year, with one incident-response professional noting, "We've seen a lot
of destructive actions from Iran and North Korea lately, where they've effectively wiped
machines they suspect of being forensically analyzed."
The twin pillars of Iran's foreign policy - America is evil and Wipe Israel off the map -
do not appear to be serving the country very well.
They serve Iran very well, America is an easy target to gather support against, and Israel is
more than willing to play the bad guy (for a bunch of reasons including Israels' policy of
nuclear hegemony in the region and historical antagonism against Arab states).
Israeli hackers offered Cambridge Analytica, the data collection firm that worked on U.S.
President Donald Trump's election campaign, material on two politicians who are heads of
state, the Guardian reported Wednesday, citing witnesses.
While Israelis are not necessarily number one in technical skills -- that award goes to
Russian hackers -- Israelis are probably the best at thinking on their feet and adjusting to
changing situations on the fly, a trait essential for success in a wide range of areas,
including cyber-security, said Forzieri. "In modern attacks, the human factor -- for example,
getting someone to click on a link that will install malware -- constitutes as much as 85% of
a successful attack," he said.
The pro-Israel trolls out in front of this comment section...
You don't have to be pro-Israel to be anti-Iran. Far from it. I think many of Israel's
actions in Palestine are reprehensible, but I also know to (rightly) fear an Islamic
dictatorship who is actively funding terrorism groups and is likely a few years away from
having a working nuclear bomb, should they resume research (which the US actions seem likely
to cause).
The US created the Islamic Republic of Iran by holding a cruel dictator in power rather
than risking a slide into communism. We should be engaging diplomatically, rather than trying
sanctions which clearly don't work. But I don't think that the original Stuxnet was a bad
idea, nor do I think that intense surveillance of what could be a potentially very dangerous
country is a bad one either.
If the Israelis (slash US) did in fact target civilian infrastructure, that's a problem.
Unless, of course, they were bugging them for espionage purposes.
Agree. While Israel is not about to win Humanitarian Nation of the year Award any
time soon, I don't see it going to Iran in a close vote tally either.
However, there is another anomaly with more interesting consequences; namely, there
frequently is no way to judge whether individual is competent or incompetent to hold a given
position. Stated another way: there is no adequate competence criterion for technical
managers.
Consider. for example. the manager of a small group of chemists. He asked his group to
develop a nonfading system of dyes using complex organic compounds that they had been studying
for some time. Eighteen months later they reported little success with dyes but had discovered
a new substance that was rather effective as an insect repellent.
Should the manager be chastised for failing to accomplish anything toward his original
objective, or should he be praised for resourcefulness
in finding something useful in the new chemical system? Was 18 months a long time or a short
time for this accomplishment?
From the semi-serious to the confusingly
ironic, the business world is not short of pseudo-scientific principles, laws and management theories
concerning how organisations and their leaders should and should not behave.
CIO UK
takes a look at
some sincere, irreverent and leftfield management concepts that are relevant to CIOs and all business leaders.
The Peter Principle
A concept formulated by Laurence J Peter in 1969, the
Peter Principle
runs that in a
hierarchical structure, employees are promoted to their highest level of incompetence at which point they are
no longer able to fulfil an effective role for their organisation.
In the
Peter Principle
people are promoted when they excel, but this process falls down
when they are unlikely to gain further promotion or be demoted with the logical end point, according to Peter,
where "every post tends to be occupied by an employee who is incompetent to carry out its duties" and that
"work is accomplished by those employees who have not yet reached their level of incompetence".
To counter the
Peter Principle
leaders could seek the advice of Spanish liberal philosopher
José Ortega y Gasset.
While he died 14 years before the
Peter Principle
was
published, Ortega had been in exile in Argentina during the Spanish Civil War and prompted by his observations
in South America had quipped: "All public employees should be demoted to their immediately lower level, as they
have been promoted until turning incompetent."
Parkinson's Law
Cyril Northcote Parkinson's eponymous law, derived from his extensive experience in the British Civil
Service, states that:
"Works expands so as to fill the time available for its completion."
The first sentence of a humorous essay published in
The Economist
in 1955,
Parkinson's Law
is familiar with CIOs, IT teams, journalists, students, and every other occupation that can learn from
Parkinson's mocking of pubic administration in the UK. The corollary law most applicable to CIOs runs that
"data expands to fill the space available for storage", while Parkinson's broader work about the
self-satisfying uncontrolled growth of bureaucratic apparatus is as relevant for the scaling startup as it is
to the large corporate.
Flirting with the ground between flippancy and seriousness, Parkinson argued that boards and members of an
organisation give disproportional weight to trivial issues and those that are easiest to grasp for non-experts.
In his words:
"The time spent on any item of the agenda will be in inverse proportion to the sum of money
involved."
Parkinson's anecdote is of a fictional finance committee's three-item agenda to cover a £10 million contract
discussing the components of a new nuclear reactor, a proposal to build a new £350 bicycle shed, and finally
which coffee and biscuits should be supplied at future committee meetings. While the first item on the agenda
is far too complex and ironed out in two and a half minutes, 45 minutes is spent discussing bike sheds, and
debates about the £21 refreshment provisions are so drawn out that the committee runs over its two-hour time
allocation with a note to provide further information about coffee and biscuits to be continued at the next
meeting.
The Dilbert Principle
Referring to a 1990s theory by popular Dilbert cartoonist Scott Adams, the
Dilbert Principle
runs that companies tend to promote their least competent employees to management roles to curb the amount of
damage they are capable of doing to the organisation.
Unlike the
Peter Principle
, which is positive in its aims by rewarding competence, the
Dilbert Principle
assumes people are moved to quasi-senior supervisory positions in a
structure where they are less likely to have an effect on productive output of the company which is performed
by those lower down the ladder.
Hofstadter's Law
Coined by Douglas Hofstadter in his 1979 book
Gödel, Escher, Bach: An Eternal Golden Braid,
Hofstadter's Law
states:
"It always takes longer than you expect, even when you take into account
Hofstadter's Law."
Particularly relevant to CIOs and business leaders overseeing large projects and transformation programmes,
Hofstadter's Law
suggests that even appreciating your own subjective pessimism in your
projected timelines, they are still worth re-evaluating.
An old adage and without basis in any scientific laws or management principles,
Murphy's Law
is always worth bearing in mind for CIOs or when undertaking thorough scenario planning for adverse situations.
It's also perhaps worth bearing in mind the corollary principle
Finagle's Law
, which states:
"Anything that can go wrong, will go wrong - at the worst possible moment."
Lindy Effect
Concerning the life expectancy of non-perishable things, the
Lindy Effect
is as relevant to
CIOs procuring new technologies or maintaining legacy infrastructure as it is to the those buying homes, used
cars, a fountain pen or mobile phone.
Harder to define than other principles and laws, the
Lindy Effect
suggests that mortality
rate decreases with time, unlike in nature and in human beings where - after childhood - mortality rate
increases with time. Ergo, every day of server uptime implies a longer remaining life expectancy.
A corollary effect related to the
Lindy Effect
which is a good explanation is the
Copernican Principle
, which states that the future life expectancy is equal to the current age, i.e.
that barring any addition evidence on the contrary, something must be halfway through its life span.
The
Lindy Effect
and the idea that older things are more robust has specific relevance to
CIOs beyond servers and IT infrastructure with its association with source code, where newer code will in
general have lower probability of remaining within a year and an increased likelihood of causing problems
compared to code written a long time ago, and in project management where the lifecycle of a project grows and
its scope changes, an Agile methodology can be used to mitigate project risks and fix mistakes.
The Jevons Paradox
Wikipedia offers the best economic
description of the
Jevons Paradox
or Jevons effect, in which a technological progress increases efficiency
with which a resource is used, but the rate of consumption of that resource subsequently rises because of
increasing demand.
Think email, think Slack, instant messaging, printing, how easy it is to create Excel reports,
coffee-making, conference calls, network and internet speeds, the list is endless. If you suspect demand in
these has increased along with technological advancement negating the positive impact of said efficiency gains
in the first instance, sounds like the paradox first described by William Stanley Jevons in 1865 when observing
coal consumption following the introduction of the Watt steam engine.
Ninety-Ninety Rule
A light-hearted quip bespoke to computer programming and software development, the
Ninety-Ninety
Rule
states that: "The first 90% of the code accounts for the first 90% of the development time. The
remaining 10% of the code accounts for the other 90% of the development time." See also,
Hofstadter's
Law
.
Related to this is the
Pareto Principle
, or the 80-20 Rule, and how it relates to software,
with supporting anecdotes that "20% of the code has 80% of the errors" or in load testing that it is common
practice to estimate that 80% of the traffic occurs during 20% of the time.
Pygmalion Effect and Golem Effect
Named after the Greek myth of Pygmalion, a sculptor who fell in love with a statue he carved, and relevant
to managers across industry and seniority, the
Pygmalion Effect
runs that higher expectations
lead to an increased performance.
Counter to the Pygmalion Effect is the
Golem effect
, whereby low expectations result in a
decrease in performance.
Dunning-Kruger Effect
The
Dunning-Kruger Effect
, named after two psychologists from Cornell University, states
that incompetent people are significantly less able to recognise their own lack of skill, the extent of their
inadequacy, and even to gauge the skill of others. Furthermore, they are only able to acknowledge their own
incompetence after they have been exposed to training in that skill.
At a loss to find a better visual representation of the
Dunning-Kruger Effect
, here is
Simon Wardley's graph with
Knowledge
and
Expertise
axes - a warning as to why self-professed
experts are the worst people to listen to on a given subject.
Technology is dominated by two types of people: those who understand what they do not
manage and those who manage what they do not understand. --Putt's Law
If
you are in IT and are not familiar with Archibald Putt, I suggest you stop reading this blog
post, RIGHT NOW, and go buy the book
Putt's Law and the Successful Technocrat. How to Win in the Information Age . Putt's
Law , for short, is a combination of Dilbert and
The Mythical Man-Month . It shows you exactly how managers of technologists think, how they
got to where they are, and how they stay there. Just like Dilbert, you'll initially laugh, then
you'll cry, because you'll realize just how true Putt's Law really is. But, unlike Dilbert,
whose technologist-fans tend to have a revulsion for management, Putt tries to show the
technologist how to become one of the despised. Now granted, not all of us technologists have a
desire to be management, it is still useful to "know one's enemy."
Two amazing facts:
Archibald Putt is a pseudonym and his true identity has yet to be revealed. A true "Deep
Throat" for us IT guys.
Putt's Law was written back in 1981. It amazes me how the Old IT Classics (Putt's Law,
Mythical Man-Month, anything by Knuth) are even more relevant today than ever.
Every technical hierarchy, in time, develops a competence inversion. --Putt's
Corollary
Putt's Corollary says that in a corporate technocracy, the more technically competent people
will remain in charge of the technology, whereas the less competent will be promoted to
management. That sounds a lot like The Peter Principle (another timeless
classic written in 1969).
People rise to their level of incompetence. --Dave's Summary of the Peter Principle
I can tell you that managers have the least information about technical issues and they
should be the last people making technical decisions. Period. I've often heard that managers
are used as the arbiters of technical debates. Bad idea. Arbiters should always be the
[[benevolent dictators]] (the most admired/revered technologist you have). The exception is
when your manager is also your benevolent dictator, which is rare. Few humans have the
capability, or time, for both.
I see more and more hit-and-run managers where I work. They feel as though they are the
technical decision-makers. They attend technical meetings they were not invited to. Then they
ask pointless, irrelevant questions that suck the energy out of the team. Then they want status
updates hourly. Eventually after they have totally derailed the process they move along to some
other, sexier problem with more management visibility.
I really admire managers who follow the MBWA ( management by walking around
) principle. This management philosophy is very simple...the best managers are those who leave
their offices and observe. By observing they learn what the challenges are for their teams and
how to help them better.
So, what I am looking for in a manager
He knows he is the least qualified person to make a technical decision.
He is a facilitator. He knows how to help his technologists succeed.
Everyone's heard of the Peter
Principle - that employees tend to rise to their level of incompetence - a concept that walks
that all-too-fine line between humor and reality.
We've all seen it in action more times than we'd like. Ironically, some percentage of you
will almost certainly be promoted to a position where you're no longer effective. For some of
you, that's already happened. Sobering thought.
Well, here's the thing. Not only is the Peter Principle alive and well in corporate America,
but contrary to popular wisdom, it's actually necessary for a healthy capitalist
system. That's right, you heard it here, folks, incompetence is a good thing. Here's why.
Robert Browning
once said, "A man's reach should exceed his grasp." It's a powerful statement that means you
should seek to improve your situation, strive to go above and beyond. Not only is that an
embodiment of capitalism, but it also leads directly to the Peter Principle because, well, how
do you know when to quit?
Now, most of us don't perpetually reach for the stars, but until there's clear evidence that
we're not doing ourselves or anyone else any good, we're bound to keep right on reaching. After
all, objectivity is notoriously difficult when opportunities for a better life are staring you
right in the face.
I mean, who turns down promotions? Who doesn't strive to reach that next rung on the ladder?
When you get an email from an executive recruiter about a VP or CEO job, are you likely to
respond, "Sorry, I think that may be beyond my competency" when you've got to send two kids to
college and you may actually want to retire someday?
Wasn't America founded by people who wanted a better life for themselves and their children?
God knows, there were plenty of indications that they shouldn't take the plunge and, if they
did, wouldn't succeed. That's called a challenge and, well, do you ever really know if you've
reached too far until after the fact?
Perhaps the most interesting embodiment of all this is the way people feel about CEOs. Some
think pretty much anyone can do a CEO's job for a fraction of the compensation. Seriously, you
hear that sort of thing a lot, especially these days with class warfare being the rage and
all.
One The
Corner Office reader asked straight out in an email: "Would you agree that, in most
cases, the company could fire the CEO and hire someone young, smart, and hungry at 1/10 the
salary/perks/bonuses who would achieve the same performance?"
Sure, it's easy: you just set the direction, hire a bunch of really smart executives, then
get out of the way and let them do their jobs. Once in a blue moon you swoop in, deal with a
problem, then return to your ivory tower. Simple.
Well, not exactly.
You see, I sort of grew up at Texas Instruments in the 80s when the company was nearly run
into the ground by Mark Shepherd and J. Fred Bucy - two CEOs who never should have gotten that
far in their careers.
But the company's board, in its wisdom, promoted Jerry Junkins and, after his untimely
death, Tom Engibous , to the CEO post. Not only were those guys competent, they revived the
company and transformed it into what it is today.
I've seen what a strong CEO can do for a company, its customers, its shareholders, and its
employees. I've also seen the destruction the Peter Principle can bring to those same
stakeholders. But, even now, after 30 years of corporate and consulting experience, the one
thing I've never seen is a CEO or executive with an easy job.
That's because there's no such thing. And to think you can eliminate incompetency from the
executive ranks when it exists at every organizational level is, to be blunt, childlike or
Utopian thinking. It's silly and trite. It doesn't even make sense.
It's not as if TI's board knew ahead of time that Shepherd and Bucy weren't the right guys
for the job. They'd both had long, successful careers at the company. But the board did right
the ship in time. And that's the mark of a healthy system at work.
The other day I read a truly fantastic story in Fortune about the rise and fall of
Jeffrey Kindler
as CEO of troubled pharmaceutical giant Pfizer . I remember when he suddenly stepped down
amidst all sorts of rumor and conjecture about the underlying causes of the shocking news.
What really happened is the guy had a fabulous career as a litigator, climbed the corporate
ladder to general ounsel of McDonald's and then Pfizer, had some limited success in operations,
and once he was promoted to CEO, flamed out. Not because he was incompetent - he wasn't. And
certainly not because he was a dysfunctional, antagonistic, micromanaging control freak - he
was.
He failed because it was a really tough job and he was in over his head. It happens. It
happens a lot. After all, this wasn't just some everyday company that's simple to run.
This was Pfizer - a pharmaceutical giant with its top products going generic and a dried-up
drug pipeline in need of a major overhaul.
The guy couldn't handle it. And when executives with issues get in over their heads, their
issues become their undoing. It comes as no surprise that folks at McDonald's were surprised at
the way he flamed out at Pfizer. That was a whole different ballgame.
Now, I bet those same people who think a CEO's job is a piece of cake will have a similar
response to the Kindler situation at Pfizer. Why take the job if he knew he couldn't handle it?
The board should have canned him before it got to that point. Why didn't the guy's executives
speak up sooner?
Because, just like at TI, nobody knows ahead of time if people are going to be effective on
the next rung of the ladder. Every situation is unique and there are no questions or test that
will foretell the future. I mean, it's not as if King Solomon comes along and writes who the
right guy for the job is on the wall.
The Peter Principle works because, in a capitalist system, there are top performers, abysmal
failures, and everything in between. Expecting anything different when people must
reach for the stars to achieve growth and success so our children have a better life than ours
isn't how it works in the real world.
The Peter Principle works because it's the yin to Browning's yang, the natural outcome of
striving to better our lives. Want to know how to bring down a free market capitalist system?
Don't take the promotion because you're afraid to fail.
Putt's Law, Peter Principle, Dilbert Principle of Incompetence &
Parkinson's Law
Get link
Icons/ic_24_facebook_dark
Facebook
Icons/ic_24_twitter_dark
Twitter
Icons/ic_24_pinterest_dark
Pinterest
Icons/ic_24_google+_dark
Google+
Email
Other Apps
June 10, 2015
Putt's Law, Peter Principle,
Dilbert Principle of Incompetence & Parkinson's Law
I am a big fan of Scott
Adams & Dilbert Comic Series.
I realize that these laws
and principles - the Putt's law, Peter Principle, the Dilbert Principle, and Parkinson's Law
- aren't necessarily founded in reality. It's easy to look at a manager's closed doors and
wonder he or she does all day, if anything. But having said that and having come to realize
the difficulty and scope of what management entails. It's hard work and requires a certain
skill-set that I'm only beginning to develop. One should therefore look at these principles
and laws with an acknowledgment that they most likely developed from the employee's
perspective, not the manager's.
Take with a pinch of salt!
Source: Google Images
The Putt's law:
·
Putt's Law: "
Technology is dominated by two types of people: those who understand what
they do not manage and those who manage what they do not understand.
"
·
Putt's Corollary: "
Every technical hierarchy, in time, develops a competence inversion.
" with
incompetence being "flushed out of the lower levels" of a technocratic hierarchy, ensuring
that technically competent people remain directly in charge of the actual technology while
those without technical competence move into management.
The Peter Principle:
The Peter Principle states
that "
in a hierarchy every employee tends to rise to his level
of incompetence."
In other words, employees who perform their roles with competence are
promoted into successively higher levels until they reach a level at which they are no longer
competent. There they remain.
For example, let's say you
are a brilliant programmer. You spend your days coding with amazing efficiency and prowess.
After a couple of years, you're promoted to lead programmer, and then promoted to team
manager. You may have no interest in managing other programmers, but it's the reward for your
competence. There you sit -- you have risen to a level of incompetence. Your technical skills
lie dormant while you fill your day with one-on-one meetings, department strategy meetings,
planning meetings, budgets, and reports.
The Dilbert Principle
The principle states that
companies tend to promote the most incompetent employees to
management as a form of damage control
. The principle argues that leaders, specifically
those in middle management, are in reality the ones that have little effect on productivity.
In order to limit the harm caused by incompetent employees who are actually not doing the
work, companies make them leaders.
The Dilbert Principle
assumes that "the majority of real, productive work in a company is done by people lower in
the power ladder." Those in management don't actually do anything to move forward the work.
How it happens?
The Incompetent Leader
Stereotype often hits new leaders, specifically those who have no prior experience in a
particular field. Often times, leaders who have been transferred from other departments are
viewed as mere figureheads, rather than actual leaders who have knowledge of the work
situation. Failure to prove technical capability can also lead to a leader being branded
incompetent.
Why it's bad?
Being a victim of the
incompetent leader stereotype is bad. Firstly, no one takes you seriously. Your ability to
insert input into projects is hampered when your followers actively disregard anything you
say as fluff. This is especially true if you are in middle management, where your power as a
leader is limited. Secondly, your chances of rising ranks are curtailed. If viewed as an
incompetent leader by your followers, your superiors are unlikely to entrust you with further
projects which have more impact.
How to get over it
Know when to concede. As a
leader, no one expects you to be competent in every area; though basic knowledge of every
section you are leading is necessary. Readily admitting incompetency in certain areas will
take out the impact out of it when others paint you as incompetent. Prove competency
somewhere. Quickly establish yourself as having some purpose in the workplace, rather than
being a mere picture of tokenism. This can be done by personally involving yourself in
certain projects.
Parkinson's Law
Parkinson's Law states that
"
work expands so as to fill the time available for its
completion
." Although this law has application with procrastination, storage capacity,
and resource usage, Parkinson focuses his law on Corporate lethargy. Parkinson says that
lethargy swell for two reasons:
(1) "A manager wants to
multiply subordinates, not rivals" and (2) "Managers make work for each other."
In other words, a team size
may swell not because the workload increases, but because they have the capacity and
resources that allow for an increased workload even if the workload does not in fact
increase. People without any work find ways to increase the amount of "work" and therefore
add to the size of their lethargy.
My Analysis
I know none of these
principles or laws gives much credit to management. The wrong person fills the wrong role,
the role exists only to minimize damage control, or the role swells unnecessarily simply
because it can.
I find the whole topic of
management somewhat fascinating, not because I think these theories apply to my own managers.
These management theories
are however relevant. Software coders looking to leverage coding talent for their projects
often find themselves in management roles, without a strong understanding of how to manage
people. Most of the time, these coders fail to engage. The project leaders are usually
brilliant at their technical job but don't excel at management.
However the key principle to
follow should be this:
put individuals to work in their core
competencies
. It makes little sense to take your most brilliant engineer and have him or
her manage people and budgets. Likewise, it makes no sense to take a shrewd consultant, one
who can negotiate projects and requirements down to the minutest detail, and put that
individual into a role involving creative design and content generation. However, to
implement this model, you have to allow for reward without a dramatic change in job
responsibilities or skills.
While similar things can, and do, occur in large technical hierarchies, incompetent
technical people experience a social pressure from their more competent colleagues that causes
them to seek security within the ranks of management. In technical hierarchies, there is always
the possibility that incompetence will be rewarded by promotion.
Other Putt laws we love include the law of failure: "Innovative organizations abhor little
failures but reward big ones." And the first law of invention: "An innovated success is as good
as a successful innovation."
Now Putt has revised and updated his short, smart book, to be released in a new edition by
Wiley-IEEE Press ( http://www.wiley.com/ieee ) at the end of this month. There
have been murmurings that Putt's identity, the subject of much rumormongering, will be revealed
after the book comes out, but we think that's unlikely. How much more interesting it is to have
an anonymous chronicler wandering the halls of the tech industry, codifying its unstated,
sometimes bizarre, and yet remarkably consistent rules of behavior.
This is management writing the way it ought to be. Think Dilbert , but with a very
big brain. Read it and weep. Or laugh, depending on your current job situation.
"... Eric Samuelson is the creator of the Confident Hiring System™. Working with Dave Anderson of Learn to Lead, he provides the Anderson Profiles and related services to clients in the automotive retail industry as well as a variety of other businesses. ..."
In 1981, an author in the Research and Development field, writing under the pseudonym
Archibald Putt, penned this famous quote, now known as Putt's Law:
"Technology is dominated by two types of people: those who understand what they do not
manage, and those who manage what they do not understand."
Have you ever hired someone without knowing for sure if they can do the job? Have you
promoted a good salesperson to management only to realize you made a dire mistake? The
qualities needed to succeed in a technical field are quite different than for a leader.
The legendary immigrant engineer Charles Steinmetz worked at General Electric in the early
1900s. He made phenomenal advancements in the field of electric motors. His work was
instrumental to the growth of the electric power industry. With a goal of rewarding him, GE
promoted him to a management position, but he failed miserably. Realizing their error, and not
wanting to offend this genius, GE's leadership retitled him as a Chief Engineer, with no
supervisory duties, and let him go back to his research.
Avoid the double disaster of losing a good worker by promoting him to management failure. By
using the unique Anderson Position Overlay system, you can avoid future regret by comparing
your candidate's qualities to the requirements of the position before saying "Welcome
Aboard".
Eric Samuelson is the creator of the Confident Hiring System™. Working with Dave
Anderson of Learn to Lead, he provides the Anderson Profiles and related services to clients in
the automotive retail industry as well as a variety of other businesses.
Putt's Law and the Successful Technocrat is a book, credited to the pseudonym Archibald Putt, published
in 1981. An updated edition, subtitled How to Win in the Information Age , was published
by Wiley-IEEE
Press in 2006. The book is based upon a series of articles published in
Research/Development Magazine in 1976 and 1977.
Putt's Law: " Technology is dominated by two types of people, those who understand
what they do not manage and those who manage what they do not understand. "
[3]
Putt's Corollary: " Every technical hierarchy, in time, develops a competence
inversion. " with incompetence being "flushed out of the lower levels" of a technocratic
hierarchy, ensuring that technically competent people remain directly in charge of the actual
technology while those without technical competence move into management. [3]
Jump up
^ Archibald Putt. Putt's Law and the Successful Technocrat: How to Win in the
Information Age , Wiley-IEEE Press (2006), ISBN0-471-71422-4 .
Preface.
^ Jump
up to: ab Archibald Putt. Putt's Law and the Successful Technocrat: How to
Win in the Information Age , Wiley-IEEE Press (2006), ISBN0-471-71422-4 . page
7.
The long listing of the /lib64 directory above shows that the first character in the
filemode is the letter "l," which means that each is a soft or symbolic link.
Hard
links
In An introduction to Linux's
EXT4 filesystem , I discussed the fact that each file has one inode that contains
information about that file, including the location of the data belonging to that file.
Figure 2 in that
article shows a single directory entry that points to the inode. Every file must have at least
one directory entry that points to the inode that describes the file. The directory entry is a
hard link, thus every file has at least one hard link.
In Figure 1 below, multiple directory entries point to a single inode. These are all hard
links. I have abbreviated the locations of three of the directory entries using the tilde ( ~ )
convention for the home directory, so that ~ is equivalent to /home/user in this example. Note
that the fourth directory entry is in a completely different directory, /home/shared , which
might be a location for sharing files between users of the computer.
Figure 1
Hard links are limited to files contained within a single filesystem. "Filesystem" is used
here in the sense of a partition or logical volume (LV) that is mounted on a specified mount
point, in this case /home . This is because inode numbers are unique only within each
filesystem, and a different filesystem, for example, /var or /opt , will have inodes with the
same number as the inode for our file.
Because all the hard links point to the single inode that contains the metadata about the
file, all of these attributes are part of the file, such as ownerships, permissions, and the
total number of hard links to the inode, and cannot be different for each hard link. It is one
file with one set of attributes. The only attribute that can be different is the file name,
which is not contained in the inode. Hard links to a single file/inode located in the same
directory must have different names, due to the fact that there can be no duplicate file names
within a single directory.
The number of hard links for a file is displayed with the ls -l command. If you want to
display the actual inode numbers, the command ls -li does that.
Symbolic (soft) links
The difference between a hard link and a soft link, also known as a symbolic link (or
symlink), is that, while hard links point directly to the inode belonging to the file, soft
links point to a directory entry, i.e., one of the hard links. Because soft links point to a
hard link for the file and not the inode, they are not dependent upon the inode number and can
work across filesystems, spanning partitions and LVs.
The downside to this is: If the hard link to which the symlink points is deleted or renamed,
the symlink is broken. The symlink is still there, but it points to a hard link that no longer
exists. Fortunately, the ls command highlights broken links with flashing white text on a red
background in a long listing.
Lab project: experimenting with links
I think the easiest way to understand the use of and differences between hard and soft links
is with a lab project that you can do. This project should be done in an empty directory as a
non-root user . I created the ~/temp directory for this project, and you should, too.
It creates a safe place to do the project and provides a new, empty directory to work in so
that only files associated with this project will be located there.
Initial setup
First, create the temporary directory in which you will perform the tasks needed for this
project. Ensure that the present working directory (PWD) is your home directory, then enter the
following command.
mkdir temp
Change into ~/temp to make it the PWD with this command.
cd temp
To get started, we need to create a file we can link to. The following command does that and
provides some content as well.
du -h > main.file.txt
Use the ls -l long list to verify that the file was created correctly. It should look
similar to my results. Note that the file size is only 7 bytes, but yours may vary by a byte or
two.
[ dboth @ david temp ] $ ls -l
total 4
-rw-rw-r-- 1 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice the number "1" following the file mode in the listing. That number represents the
number of hard links that exist for the file. For now, it should be 1 because we have not
created any additional links to our test file.
Experimenting with hard links
Hard links create a new directory entry pointing to the same inode, so when hard links are
added to a file, you will see the number of links increase. Ensure that the PWD is still ~/temp
. Create a hard link to the file main.file.txt , then do another long list of the
directory.
[ dboth @ david temp ] $ ln main.file.txt link1.file.txt
[ dboth @ david temp ] $ ls -l
total 8
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice that both files have two links and are exactly the same size. The date stamp is also
the same. This is really one file with one inode and two links, i.e., directory entries to it.
Create a second hard link to this file and list the directory contents. You can create the link
to either of the existing ones: link1.file.txt or main.file.txt .
[ dboth @ david temp ] $
ln link1.file.txt link2.file.txt ; ls -l
total 16
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 link2.file.txt
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice that each new hard link in this directory must have a different name because two
files -- really directory entries -- cannot have the same name within the same directory. Try
to create another link with a target name the same as one of the existing ones.
[ dboth @
david temp ] $ ln main.file.txt link2.file.txt
ln: failed to create hard link 'link2.file.txt' : File exists
Clearly that does not work, because link2.file.txt already exists. So far, we have created
only hard links in the same directory. So, create a link in your home directory, the parent of
the temp directory in which we have been working so far.
[ dboth @ david temp ] $ ln
main.file.txt .. / main.file.txt ; ls -l .. / main *
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
The ls command in the above listing shows that the main.file.txt file does exist in the home
directory with the same name as the file in the temp directory. Of course, these are not
different files; they are the same file with multiple links -- directory entries -- to the same
inode. To help illustrate the next point, add a file that is not a link.
[ dboth @ david
temp ] $ touch unlinked.file ; ls -l
total 12
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link2.file.txt
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
-rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Look at the inode number of the hard links and that of the new file using the -i option to
the ls command.
[ dboth @ david temp ] $ ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Notice the number 657024 to the left of the file mode in the example above. That is the
inode number, and all three file links point to the same inode. You can use the -i option to
view the inode number for the link we created in the home directory as well, and that will also
show the same value. The inode number of the file that has only one link is different from the
others. Note that the inode numbers will be different on your system.
Let's change the size of one of the hard-linked files.
[ dboth @ david temp ] $ df -h
> link2.file.txt ; ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The file size of all the hard-linked files is now larger than before. That is because there
is really only one file that is linked to by multiple directory entries.
I know this next experiment will work on my computer because my /tmp directory is on a
separate LV. If you have a separate LV or a filesystem on a different partition (if you're not
using LVs), determine whether or not you have access to that LV or partition. If you don't, you
can try to insert a USB memory stick and mount it. If one of those options works for you, you
can do this experiment.
Try to create a link to one of the files in your ~/temp directory in /tmp (or wherever your
different filesystem directory is located).
[ dboth @ david temp ] $ ln link2.file.txt / tmp
/ link3.file.txt
ln: failed to create hard link '/tmp/link3.file.txt' = > 'link2.file.txt' :
Invalid cross-device link
Why does this error occur? The reason is each separate mountable filesystem has its own set
of inode numbers. Simply referring to a file by an inode number across the entire Linux
directory structure can result in confusion because the same inode number can exist in each
mounted filesystem.
There may be a time when you will want to locate all the hard links that belong to a single
inode. You can find the inode number using the ls -li command. Then you can use the find
command to locate all links with that inode number.
Note that the find command did not find all four of the hard links to this inode because we
started at the current directory of ~/temp . The find command only finds files in the PWD and
its subdirectories. To find all the links, we can use the following command, which specifies
your home directory as the starting place for the search.
[ dboth @ david temp ] $ find ~
-samefile main.file.txt
/ home / dboth / temp / main.file.txt
/ home / dboth / temp / link1.file.txt
/ home / dboth / temp / link2.file.txt
/ home / dboth / main.file.txt
You may see error messages if you do not have permissions as a non-root user. This command
also uses the -samefile option instead of specifying the inode number. This works the same as
using the inode number and can be easier if you know the name of one of the hard
links.
Experimenting with soft links
As you have just seen, creating hard links is not possible across filesystem boundaries;
that is, from a filesystem on one LV or partition to a filesystem on another. Soft links are a
means to answer that problem with hard links. Although they can accomplish the same end, they
are very different, and knowing these differences is important.
Let's start by creating a symlink in our ~/temp directory to start our exploration.
[
dboth @ david temp ] $ ln -s link2.file.txt link3.file.txt ; ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The hard links, those that have the inode number 657024 , are unchanged, and the number of
hard links shown for each has not changed. The newly created symlink has a different inode,
number 658270 . The soft link named link3.file.txt points to link2.file.txt . Use the cat
command to display the contents of link3.file.txt . The file mode information for the symlink
starts with the letter " l " which indicates that this file is actually a symbolic link.
The size of the symlink link3.file.txt is only 14 bytes in the example above. That is the
size of the text link3.file.txt -> link2.file.txt , which is the actual content of the
directory entry. The directory entry link3.file.txt does not point to an inode; it points to
another directory entry, which makes it useful for creating links that span file system
boundaries. So, let's create that link we tried before from the /tmp directory.
[ dboth @
david temp ] $ ln -s / home / dboth / temp / link2.file.txt
/ tmp / link3.file.txt ; ls -l / tmp / link *
lrwxrwxrwx 1 dboth dboth 31 Jun 14 21 : 53 / tmp / link3.file.txt - >
/ home / dboth / temp / link2.file.txt Deleting links
There are some other things that you should consider when you need to delete links or the
files to which they point.
First, let's delete the link main.file.txt . Remember that every directory entry that points
to an inode is simply a hard link.
[ dboth @ david temp ] $ rm main.file.txt ; ls -li
total 8
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The link main.file.txt was the first link created when the file was created. Deleting it now
still leaves the original file and its data on the hard drive along with all the remaining hard
links. To delete the file and its data, you would have to delete all the remaining hard
links.
Now delete the link2.file.txt hard link.
[ dboth @ david temp ] $ rm link2.file.txt ; ls
-li
total 8
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Notice what happens to the soft link. Deleting the hard link to which the soft link points
leaves a broken link. On my system, the broken link is highlighted in colors and the target
hard link is flashing. If the broken link needs to be fixed, you can create another hard link
in the same directory with the same name as the old one, so long as not all the hard links have
been deleted. You could also recreate the link itself, with the link maintaining the same name
but pointing to one of the remaining hard links. Of course, if the soft link is no longer
needed, it can be deleted with the rm command.
The unlink command can also be used to delete files and links. It is very simple and has no
options, as the rm command does. It does, however, more accurately reflect the underlying
process of deletion, in that it removes the link -- the directory entry -- to the file being
deleted.
Final thoughts
I worked with both types of links for a long time before I began to understand their
capabilities and idiosyncrasies. It took writing a lab project for a Linux class I taught to
fully appreciate how links work. This article is a simplification of what I taught in that
class, and I hope it speeds your learning curve. David Both - David Both is a Linux and
Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for
over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he
wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for
Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been
working with Linux and Open Source Software for almost 20 years. dgrb on 23 Jun 2017
Permalink
There is a hard link "gotcha" which IMHO is worth mentioning.
If you use an editor which makes automatic backups - emacs certainly is one such - then you
may end up with a new version of the edited file, while the backup is the linked copy, because
the editor simply renames the file to the backup name (with emacs, test.c would be renamed
test.c~) and the new version when saved under the old name is no longer linked.
Symbolic links avoid this problem, so I tend to use them for source code where required.
Technology is dominated by two types of people: those who understand what they do not manage,
and those who manage what they do not understand. -- Archibald Putt
Neoliberal PHBs like talk about KJLOCs, error counts, tickets closed and other types of
numerical measurements designed so that they can be used by lower-level PHBs to report fake
results to higher level PHBs. These attempts to quantify 'the quality' and volume of work
performed by software developers and sysadmins completely miss the point. For software is can
lead to code bloat.
The number of tickets taken and resolved in a specified time period probably the most ignorant way to measure performance of
sysadmins. For sysadmin you can invent creative creating way of generating and resolving
tickets. And spend time accomplishing fake task, instead of thinking about real problem that
datacenter face. Using Primitive measurement strategies devalue the work being performed by Sysadmins and programmers. They focus
on the wrong things. They create the boundaries that are supposed to contain us in a manner that is comprehensible to the PHB who
knows nothing about real problems we face.
Notable quotes:
"... Technology is dominated by two types of people: those who understand what they do not manage, and those who manage what they do not understand. ..."
In an advanced research or development project, success or failure is largely determined
when the goals or objectives are set and before a manager is chosen. While a hard-working and
diligent manager can increase the chances of success, the outcome of the project is most
strongly affected by preexisting but unknown technological factors over which the project
manager has no control. The success or failure of the project should not, therefore, be used as
the sole measure or even the primary measure of the manager's competence.
Putt's Law Is promulgated
Without an adequate competence criterion for technical managers, there is no way to
determine when a person has reached his level of incompetence. Thus a clever and ambitious
individual may be promoted from one level of incompetence to another. He will ultimately
perform incompetently in the highest level of the hierarchy just as he did in numerous lower
levels. The lack of an adequate competence criterion combined with the frequent practice of
creative incompetence in technical hierarchies results in a competence inversion, with the most
competent people remaining near the bottom while persons of lesser talent rise to the top. It
also provides the basis for Putt's Law, which can be stated in an intuitive and nonmathematical
form as follows:
Technology is dominated by two types of people: those who understand what they do not
manage, and those who manage what they do not understand.
As in any other hierarchy, the majority of persons in technology neither understand nor
manage much of anything. This, however, does not create an exception to Putt's Law, because
such persons clearly do not dominate the hierarchy. While this was not previously stated as a
basic law, it is clear that the success of every technocrat depends on his ability to deal with
and benefit from the consequences of Putt's Law.
"... Who is Putt? Well, for those of you under 40, the pseudonymous Archibald Putt, Ph.D., penned a series of articles for Research/Development magazine in the 1970s that eventually became the 1981 cult classic Putt's Law and the Successful Technocrat , an unorthodox and archly funny how-to book for achieving tech career success. ..."
"... His first law, "Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand," along with its corollary, "Every technical hierarchy, in time, develops a competence inversion," have been immortalized on Web sites around the world. ..."
"... what's a competence inversion? It means that the best and the brightest in a technology company tend to settle on the lowest rungs of the corporate ladder -- where things like inventing and developing new products get done -- while those who manage what they cannot hope to make or understand float to the top (see Putt's first law, above, and a fine example of Putt's law in action in the editorial, " Is Bad Design a Nuisance? "). ..."
"... Other Putt laws we love include the law of failure: "Innovative organizations abhor little failures but reward big ones." And the first law of invention: "An innovated success is as good as a successful innovation." ..."
"... This is management writing the way it ought to be. Think Dilbert , but with a very big brain. Read it and weep. Or laugh, depending on your current job situation. ..."
If you want to jump-start your technology career, put aside your Peter Drucker, your Tom Peters, and your Marcus
Buckingham management tomes. Archibald Putt is back.
Who is Putt? Well, for those of you under 40, the pseudonymous Archibald Putt, Ph.D., penned a series of
articles for
Research/Development
magazine in the 1970s that eventually became the 1981 cult classic
Putt's
Law and the Successful Technocrat
, an unorthodox and archly funny how-to book for achieving tech career success.
In the book, Putt put forth a series of laws and axioms for surviving and succeeding in the unique corporate
cultures of big technology companies, where being the builder of the best technology and becoming the top dog on the
block almost never mix.
His first law, "Technology is dominated by two types of people: those who understand what
they do not manage and those who manage what they do not understand," along with its corollary, "Every technical
hierarchy, in time, develops a competence inversion," have been immortalized on Web sites around the world.
The first law is obvious, but
what's a competence inversion? It means that the best and the brightest in a
technology company tend to settle on the lowest rungs of the corporate ladder -- where things like inventing and
developing new products get done -- while those who manage what they cannot hope to make or understand float to the
top (see Putt's first law, above, and a fine example of Putt's law in action in the editorial, "
Is
Bad Design a Nuisance?
").
Other Putt laws we love include the law of failure: "Innovative organizations abhor little failures but reward
big ones." And the first law of invention: "An innovated success is as good as a successful innovation."
Now Putt has revised and updated his short, smart book, to be released in a new edition by Wiley-IEEE Press (
http://www.wiley.com/ieee
)
at the end of this month. There have been murmurings that Putt's identity, the subject of much rumormongering, will
be revealed after the book comes out, but we think that's unlikely. How much more interesting it is to have an
anonymous chronicler wandering the halls of the tech industry, codifying its unstated, sometimes bizarre, and yet
remarkably consistent rules of behavior.
This is management writing the way it ought to be. Think
Dilbert
, but with a very big brain. Read it
and weep. Or laugh, depending on your current job situation.
The editorial content of IEEE Spectrum does not represent official positions of the IEEE or its
organizational units. Please address comments to Forum at
[email protected].
"... These C level guys see cloud services – applications, data, backup, service desk – as a great way to free up a blockage in how IT service is being delivered on premise. ..."
"... IMHO there is a big difference between management of IT and management of IT service. Rarely do you get people who can do both. ..."
...Cloud introduces a whole new ball game and will no doubt perpetuate Putts Law for ever more. Why?
Well unless 100% of IT infrastructure goes up into the clouds ( unlikely for any organization with a history ; likely for a new
organization ( probably micro small ) that starts up in the next few years ) the 'art of IT management' will demand even more focus
and understanding.
I always think a great acid test of Putts Law is to look at one of the two aspects of IT management
Show me a simple process that you follow each day that delivers an aspect of IT service i.e. how to buy a piece of IT stuff,
or a way to report a fault
Show me how you manage a single entity on the network i.e. a file server, a PC, a network switch
Usually the answers ( which will be different from people on the same team, in the same room and from the same person on different
days !) will give you an insight to Putts Law.
Childs play for most of course who are challenged with some real complex management
situations such as data center virtualization projects, storage explosion control, edge device management, backend application upgrades,
global messaging migrations and B2C identity integration. But of course if its evidenced that they seem to be managing (simple things
) without true understanding one could argue 'how the hell can they be expected to manage what they understand with the complex things?'
Fair point?
Of course many C level people have an answer to Putts Law. Move the problem to people who do understand what they manage. Professionals
who provide cloud versions of what the C level person struggles to get a professional service from. These C level guys see cloud
services – applications, data, backup, service desk – as a great way to free up a blockage in how IT service is being delivered on
premise. And they are right ( and wrong ).
IMHO there is a big difference between management of IT and management of IT service. Rarely do you get people who can do both.
Understanding inventory, disk space, security etc is one thing; but understanding the performance of apps and user impact is another
ball game. Putts Law is alive and well in my organisation. TGIF.
Rowan is right I used to be an IT Manager but now my title is Service Delivery Manager. Why? Because we had a new CTO who changed
how people saw what we did. I ve been doing this new role for 5 years and I really do understand what i don't manage. LOL
There are two types of Linux filesystem links: hard and soft. The difference between the two
types of links is significant, but both types are used to solve similar problems. They both
provide multiple directory entries (or references) to a single file, but they do it quite
differently. Links are powerful and add flexibility to Linux filesystems because everything is a file
.
I have found, for instance, that some programs required a particular version of a library.
When a library upgrade replaced the old version, the program would crash with an error
specifying the name of the old, now-missing library. Usually, the only change in the library
name was the version number. Acting on a hunch, I simply added a link to the new library but
named the link after the old library name. I tried the program again and it worked perfectly.
And, okay, the program was a game, and everyone knows the lengths that gamers will go to in
order to keep their games running.
In fact, almost all applications are linked to libraries using a generic name with only a
major version number in the link name, while the link points to the actual library file that
also has a minor version number. In other instances, required files have been moved from one
directory to another to comply with the Linux file specification, and there are links in the
old directories for backwards compatibility with those programs that have not yet caught up
with the new locations. If you do a long listing of the /lib64 directory, you can find many
examples of both.
The long listing of the /lib64 directory above shows that the first character in the
filemode is the letter "l," which means that each is a soft or symbolic link.
Hard
links
In An introduction to Linux's
EXT4 filesystem , I discussed the fact that each file has one inode that contains
information about that file, including the location of the data belonging to that file.
Figure 2 in that
article shows a single directory entry that points to the inode. Every file must have at least
one directory entry that points to the inode that describes the file. The directory entry is a
hard link, thus every file has at least one hard link.
In Figure 1 below, multiple directory entries point to a single inode. These are all hard
links. I have abbreviated the locations of three of the directory entries using the tilde ( ~ )
convention for the home directory, so that ~ is equivalent to /home/user in this example. Note
that the fourth directory entry is in a completely different directory, /home/shared , which
might be a location for sharing files between users of the computer.
Figure 1
Hard links are limited to files contained within a single filesystem. "Filesystem" is used
here in the sense of a partition or logical volume (LV) that is mounted on a specified mount
point, in this case /home . This is because inode numbers are unique only within each
filesystem, and a different filesystem, for example, /var or /opt , will have inodes with the
same number as the inode for our file.
Because all the hard links point to the single inode that contains the metadata about the
file, all of these attributes are part of the file, such as ownerships, permissions, and the
total number of hard links to the inode, and cannot be different for each hard link. It is one
file with one set of attributes. The only attribute that can be different is the file name,
which is not contained in the inode. Hard links to a single file/inode located in the same
directory must have different names, due to the fact that there can be no duplicate file names
within a single directory.
The number of hard links for a file is displayed with the ls -l command. If you want to
display the actual inode numbers, the command ls -li does that.
Symbolic (soft) links
The difference between a hard link and a soft link, also known as a symbolic link (or
symlink), is that, while hard links point directly to the inode belonging to the file, soft
links point to a directory entry, i.e., one of the hard links. Because soft links point to a
hard link for the file and not the inode, they are not dependent upon the inode number and can
work across filesystems, spanning partitions and LVs.
The downside to this is: If the hard link to which the symlink points is deleted or renamed,
the symlink is broken. The symlink is still there, but it points to a hard link that no longer
exists. Fortunately, the ls command highlights broken links with flashing white text on a red
background in a long listing.
Lab project: experimenting with links
I think the easiest way to understand the use of and differences between hard and soft links
is with a lab project that you can do. This project should be done in an empty directory as a
non-root user . I created the ~/temp directory for this project, and you should, too.
It creates a safe place to do the project and provides a new, empty directory to work in so
that only files associated with this project will be located there.
Initial setup
First, create the temporary directory in which you will perform the tasks needed for this
project. Ensure that the present working directory (PWD) is your home directory, then enter the
following command.
mkdir temp
Change into ~/temp to make it the PWD with this command.
cd temp
To get started, we need to create a file we can link to. The following command does that and
provides some content as well.
du -h > main.file.txt
Use the ls -l long list to verify that the file was created correctly. It should look
similar to my results. Note that the file size is only 7 bytes, but yours may vary by a byte or
two.
[ dboth @ david temp ] $ ls -l
total 4
-rw-rw-r-- 1 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice the number "1" following the file mode in the listing. That number represents the
number of hard links that exist for the file. For now, it should be 1 because we have not
created any additional links to our test file.
Experimenting with hard links
Hard links create a new directory entry pointing to the same inode, so when hard links are
added to a file, you will see the number of links increase. Ensure that the PWD is still ~/temp
. Create a hard link to the file main.file.txt , then do another long list of the
directory.
[ dboth @ david temp ] $ ln main.file.txt link1.file.txt
[ dboth @ david temp ] $ ls -l
total 8
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 2 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice that both files have two links and are exactly the same size. The date stamp is also
the same. This is really one file with one inode and two links, i.e., directory entries to it.
Create a second hard link to this file and list the directory contents. You can create the link
to either of the existing ones: link1.file.txt or main.file.txt .
[ dboth @ david temp ] $
ln link1.file.txt link2.file.txt ; ls -l
total 16
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 link2.file.txt
-rw-rw-r-- 3 dboth dboth 7 Jun 13 07: 34 main.file.txt
Notice that each new hard link in this directory must have a different name because two
files -- really directory entries -- cannot have the same name within the same directory. Try
to create another link with a target name the same as one of the existing ones.
[ dboth @
david temp ] $ ln main.file.txt link2.file.txt
ln: failed to create hard link 'link2.file.txt' : File exists
Clearly that does not work, because link2.file.txt already exists. So far, we have created
only hard links in the same directory. So, create a link in your home directory, the parent of
the temp directory in which we have been working so far.
[ dboth @ david temp ] $ ln
main.file.txt .. / main.file.txt ; ls -l .. / main *
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
The ls command in the above listing shows that the main.file.txt file does exist in the home
directory with the same name as the file in the temp directory. Of course, these are not
different files; they are the same file with multiple links -- directory entries -- to the same
inode. To help illustrate the next point, add a file that is not a link.
[ dboth @ david
temp ] $ touch unlinked.file ; ls -l
total 12
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link1.file.txt
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link2.file.txt
-rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
-rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Look at the inode number of the hard links and that of the new file using the -i option to
the ls command.
[ dboth @ david temp ] $ ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 7 Jun 13 07: 34 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Notice the number 657024 to the left of the file mode in the example above. That is the
inode number, and all three file links point to the same inode. You can use the -i option to
view the inode number for the link we created in the home directory as well, and that will also
show the same value. The inode number of the file that has only one link is different from the
others. Note that the inode numbers will be different on your system.
Let's change the size of one of the hard-linked files.
[ dboth @ david temp ] $ df -h
> link2.file.txt ; ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The file size of all the hard-linked files is now larger than before. That is because there
is really only one file that is linked to by multiple directory entries.
I know this next experiment will work on my computer because my /tmp directory is on a
separate LV. If you have a separate LV or a filesystem on a different partition (if you're not
using LVs), determine whether or not you have access to that LV or partition. If you don't, you
can try to insert a USB memory stick and mount it. If one of those options works for you, you
can do this experiment.
Try to create a link to one of the files in your ~/temp directory in /tmp (or wherever your
different filesystem directory is located).
[ dboth @ david temp ] $ ln link2.file.txt / tmp
/ link3.file.txt
ln: failed to create hard link '/tmp/link3.file.txt' = > 'link2.file.txt' :
Invalid cross-device link
Why does this error occur? The reason is each separate mountable filesystem has its own set
of inode numbers. Simply referring to a file by an inode number across the entire Linux
directory structure can result in confusion because the same inode number can exist in each
mounted filesystem.
There may be a time when you will want to locate all the hard links that belong to a single
inode. You can find the inode number using the ls -li command. Then you can use the find
command to locate all links with that inode number.
Note that the find command did not find all four of the hard links to this inode because we
started at the current directory of ~/temp . The find command only finds files in the PWD and
its subdirectories. To find all the links, we can use the following command, which specifies
your home directory as the starting place for the search.
[ dboth @ david temp ] $ find ~
-samefile main.file.txt
/ home / dboth / temp / main.file.txt
/ home / dboth / temp / link1.file.txt
/ home / dboth / temp / link2.file.txt
/ home / dboth / main.file.txt
You may see error messages if you do not have permissions as a non-root user. This command
also uses the -samefile option instead of specifying the inode number. This works the same as
using the inode number and can be easier if you know the name of one of the hard
links.
Experimenting with soft links
As you have just seen, creating hard links is not possible across filesystem boundaries;
that is, from a filesystem on one LV or partition to a filesystem on another. Soft links are a
means to answer that problem with hard links. Although they can accomplish the same end, they
are very different, and knowing these differences is important.
Let's start by creating a symlink in our ~/temp directory to start our exploration.
[
dboth @ david temp ] $ ln -s link2.file.txt link3.file.txt ; ls -li
total 12
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657024 -rw-rw-r-- 4 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The hard links, those that have the inode number 657024 , are unchanged, and the number of
hard links shown for each has not changed. The newly created symlink has a different inode,
number 658270 . The soft link named link3.file.txt points to link2.file.txt . Use the cat
command to display the contents of link3.file.txt . The file mode information for the symlink
starts with the letter " l " which indicates that this file is actually a symbolic link.
The size of the symlink link3.file.txt is only 14 bytes in the example above. That is the
size of the text link3.file.txt -> link2.file.txt , which is the actual content of the
directory entry. The directory entry link3.file.txt does not point to an inode; it points to
another directory entry, which makes it useful for creating links that span file system
boundaries. So, let's create that link we tried before from the /tmp directory.
[ dboth @
david temp ] $ ln -s / home / dboth / temp / link2.file.txt
/ tmp / link3.file.txt ; ls -l / tmp / link *
lrwxrwxrwx 1 dboth dboth 31 Jun 14 21 : 53 / tmp / link3.file.txt - >
/ home / dboth / temp / link2.file.txt Deleting links
There are some other things that you should consider when you need to delete links or the
files to which they point.
First, let's delete the link main.file.txt . Remember that every directory entry that points
to an inode is simply a hard link.
[ dboth @ david temp ] $ rm main.file.txt ; ls -li
total 8
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link2.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
The link main.file.txt was the first link created when the file was created. Deleting it now
still leaves the original file and its data on the hard drive along with all the remaining hard
links. To delete the file and its data, you would have to delete all the remaining hard
links.
Now delete the link2.file.txt hard link.
[ dboth @ david temp ] $ rm link2.file.txt ; ls
-li
total 8
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 link1.file.txt
658270 lrwxrwxrwx 1 dboth dboth 14 Jun 14 15 : 21 link3.file.txt - >
link2.file.txt
657024 -rw-rw-r-- 3 dboth dboth 1157 Jun 14 14 : 14 main.file.txt
657863 -rw-rw-r-- 1 dboth dboth 0 Jun 14 08: 18 unlinked.file
Notice what happens to the soft link. Deleting the hard link to which the soft link points
leaves a broken link. On my system, the broken link is highlighted in colors and the target
hard link is flashing. If the broken link needs to be fixed, you can create another hard link
in the same directory with the same name as the old one, so long as not all the hard links have
been deleted. You could also recreate the link itself, with the link maintaining the same name
but pointing to one of the remaining hard links. Of course, if the soft link is no longer
needed, it can be deleted with the rm command.
The unlink command can also be used to delete files and links. It is very simple and has no
options, as the rm command does. It does, however, more accurately reflect the underlying
process of deletion, in that it removes the link -- the directory entry -- to the file being
deleted.
Final thoughts
I worked with both types of links for a long time before I began to understand their
capabilities and idiosyncrasies. It took writing a lab project for a Linux class I taught to
fully appreciate how links work. This article is a simplification of what I taught in that
class, and I hope it speeds your learning curve. TopicsLinuxAbout the author David Both - David Both is a Linux and Open Source advocate who
resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and
taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first
training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has
worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux
and Open Source Software for almost 20 years. David has written articles for...
"... if those employees become unhappy, they can effectively go anywhere they want. ..."
"... IBM's partner/reseller ecosystem is nowhere near what it was since it owned the PC and Server businesses that Lenovo now owns. And IBM's Softlayer/BlueMix cloud is largely tied to its legacy software business, which, again, is slowing. ..."
"... I came to IBM from their SoftLayer acquisition. Their ability to stomp all over the things SoftLayer was almost doing right were astounding. I stood and listened to Ginni say things like, "We purchased SoftLayer because we need to learn from you," and, "We want you to teach us how to do Cloud the right way, since we spent all these years doing things the wrong way," and, "If you find yourself in a meeting with one of our old teams, you guys are gonna be the ones in charge. You are the ones who know how this is supposed to work - our culture has failed at it." Promises which were nothing more than hollow words. ..."
"... Next, it's a little worrisome that the author, now over the whole IBM thing is recommending firing "older people," you know, the ones who helped the company retain its performance in years' past. The smartest article I've read about IBM worried about its cheap style of "acquiring" non-best-of-breed companies and firing oodles of its qualified R&D guys. THAT author was right. ..."
"... Four years in GTS ... joined via being outsourced to IBM by my previous employer. Left GTS after 4 years. ..."
"... The IBM way of life was throughout the Oughts and the Teens an utter and complete failure from the perspective of getting work done right and using people to their appropriate and full potential. ..."
"... As a GTS employee, professional technical training was deemed unnecessary, hence I had no access to any unless I paid for it myself and used my personal time ... the only training available was cheesy presentations or other web based garbage from the intranet, or casual / OJT style meetings with other staff who were NOT professional or expert trainers. ..."
"... As a GTS employee, I had NO access to the expert and professional tools that IBM fricking made and sold to the same damn customers I was supposed to be supporting. Did we have expert and professional workflow / document management / ITIL aligned incident and problem management tools? NO, we had fricking Lotus Notes and email. Instead of upgrading to the newest and best software solutions for data center / IT management & support, we degraded everything down the simplest and least complex single function tools that no "best practices" organization on Earth would ever consider using. ..."
"... And the people management paradigm ... employees ranked annually not against a static or shared goal or metric, but in relation to each other, and there was ALWAYS a "top 10 percent" and a "bottom ten percent" required by upper management ... a system that was sociopathic in it's nature because it encourages employees to NOT work together ... by screwing over one's coworkers, perhaps by not giving necessary information, timely support, assistance as needed or requested, one could potentially hurt their performance and make oneself look relatively better. That's a self-defeating system and it was encouraged by the way IBM ran things. ..."
IBM has not had a particularly great track record when it comes to integrating the cultures
of other companies into its own, and brain drain with a company like Red Hat is a real risk
because if those employees become unhappy, they can effectively go anywhere they want.
They have the skills to command very high salaries at any of the top companies in the
industry.
The other issue is that IBM hasn't figured out how to capture revenue from SMBs -- and that
has always been elusive for them. Unless a deal is worth at least $1 million, and realistically
$10 million, sales guys at IBM don't tend to get motivated.
The 5,000-seat and below market segment has traditionally been partner territory, and when
it comes to reseller partners for its cloud, IBM is way, way behind AWS, Microsoft, Google, or
even (gasp) Oracle, which is now offering serious margins to partners that land workloads on
the Oracle cloud.
IBM's partner/reseller ecosystem is nowhere near what it was since it owned the PC and
Server businesses that Lenovo now owns. And IBM's Softlayer/BlueMix cloud is largely tied to
its legacy software business, which, again, is slowing.
... ... ...
But I think that it is very unlikely the IBM Cloud, even when juiced on Red Hat steroids,
will become anything more ambitious than a boutique business for hybrid workloads when compared
with AWS or Azure. Realistically, it has to be the kind of cloud platform that interoperates
well with the others or nobody will want it.
1. IBM used to value long-term employees. Now they "value" short-term contractors -- but
they still pull them out of production for lots of training that, quite frankly, isn't
exactly needed for what they are doing. Personally, I think that IBM would do well to return
to valuing employees instead of looking at them as expendable commodities, but either way,
they need to get past the legacies of when they had long-term employees all watching a single
main frame.
2. As IBM moved to an army of contractors, they killed off the informal (but important!)
web of tribal knowledge. You know, a friend of a friend who new the answer to some issue, or
knew something about this customer? What has happened is that the transaction costs (as
economists call it) have escalated until IBM can scarcely order IBM hardware for its own
projects, or have SDM's work together.
geek49203_z Number 2 is a problem everywhere. As long-time employees (mostly baby-boomers)
retire, their replacements are usually straight out of college with various non-technical
degrees. They come in with little history and few older-employees to which they can turn for
"the tricks of the trade".
I came to IBM from their SoftLayer acquisition. Their ability to stomp all over the things
SoftLayer was almost doing right were astounding. I stood and listened to Ginni say things
like, "We purchased SoftLayer because we need to learn from you," and, "We want you to teach
us how to do Cloud the right way, since we spent all these years doing things the wrong way,"
and, "If you find yourself in a meeting with one of our old teams, you guys are gonna be the
ones in charge. You are the ones who know how this is supposed to work - our culture has
failed at it." Promises which were nothing more than hollow words.
1. IBM used to value long-term employees. Now they "value" short-term contractors -- but
they still pull them out of production for lots of training that, quite frankly, isn't
exactly needed for what they are doing. Personally, I think that IBM would do well to return
to valuing employees instead of looking at them as expendable commodities, but either way,
they need to get past the legacies of when they had long-term employees all watching a single
main frame.
2. As IBM moved to an army of contractors, they killed off the informal (but important!)
web of tribal knowledge. You know, a friend of a friend who new the answer to some issue, or
knew something about this customer? What has happened is that the transaction costs (as
economists call it) have escalated until IBM can scarcely order IBM hardware for its own
projects, or have SDM's work together.
geek49203_z Number 2 is a problem everywhere. As long-time employees (mostly baby-boomers)
retire, their replacements are usually straight out of college with various non-technical
degrees. They come in with little history and few older-employees to which they can turn for
"the tricks of the trade".
I came to IBM from their SoftLayer acquisition. Their ability to stomp all over the things
SoftLayer was almost doing right were astounding. I stood and listened to Ginni say things
like, "We purchased SoftLayer because we need to learn from you," and, "We want you to teach
us how to do Cloud the right way, since we spent all these years doing things the wrong way,"
and, "If you find yourself in a meeting with one of our old teams, you guys are gonna be the
ones in charge. You are the ones who know how this is supposed to work - our culture has
failed at it." Promises which were nothing more than hollow words.
In the 1970's 80's and 90's I was working in tech support for a company called ROLM. We were
doing communications , voice and data and did many systems for Fortune 500 companies along
with 911 systems and the secure system at the White House. My job was to fly all over North
America to solve problems with customers and integration of our equipment into their business
model. I also did BETA trials and documented systems so others would understand what it took
to make it run fine under all conditions.
In 84 IBM bought a percentage of the company and the next year they bought out the
company. When someone said to me "IBM just bought you out , you must thing you died and went
to heaven." My response was "Think of them as being like the Federal Government but making a
profit". They were so heavily structured and hide bound that it was a constant battle working
with them. Their response to any comments was "We are IBM"
I was working on an equipment project in Colorado Springs and IBM took control. I was
immediately advised that I could only talk to the people in my assigned group and if I had a
question outside of my group I had to put it in writing and give it to my manager and if he
thought it was relevant it would be forwarded up the ladder of management until it reached a
level of a manager that had control of both groups and at that time if he thought it was
relevant it would be sent to that group who would send the answer back up the ladder.
I'm a
Vietnam Veteran and I used my military training to get things done just like I did out in the
field. I went looking for the person I could get an answer from.
At first others were nervous
about doing that but within a month I had connections all over the facility and started
introducing people at the cafeteria. Things moved quickly as people started working together
as a unit. I finished my part of the work which was figuring all the spares technicians would
need plus the costs for packaging and service contract estimates. I submitted it to all the
people that needed it. I was then hauled into a meeting room by the IBM management and
advised that I was a disruptive influence and would be removed. Just then the final contracts
that vendors had to sign showed up and it used all my info. The IBM people were livid that
they were not involved.
By the way a couple months later the IBM THINK magazine came out with a new story about a
radical concept they had tried. A cover would not fit on a component and under the old system
both the component and the cover would be thrown out and they would start from scratch doing
it over. They decided to have the two groups sit together and figure out why it would not fit
and correct it on the spot.
Another great example of IBM people is we had a sales contract to install a multi node
voice mail system at WANG computers but we lost it because the IBM people insisted on
bundling in AS0400 systems into the sale to WANG computer. Instead we lost a multi million
dollar contract.
Eventually Siemens bought 50% of the company and eventually full control. Now all we heard
was "That is how we do it in Germany" Our response was "How did that WW II thing work
out".
The author may have more loyalty to Microsoft than he confides, is the first thing noticeable
about this article. The second thing is that in terms of getting rid of those aged IBM
workers, I think he may have completely missed the mark, in fairness, that may be the product
of his IBM experience, The sheer hubris of tech-talking from the middle of the story and
missing the global misstep that is today's IBM is noticeable. As a stockholder, the first
question is, "Where is the investigation to the breach of fiduciary duty by a board that owes
its loyalty to stockholders who are scratching their heads at the 'positive' spin the likes of
Ginni Rometty is putting on 20 quarters of dead losses?" Got that, 20 quarters of losses.
Next, it's a little worrisome that the author, now over the whole IBM thing is
recommending firing "older people," you know, the ones who helped the company retain its
performance in years' past. The smartest article I've read about IBM worried about its cheap
style of "acquiring" non-best-of-breed companies and firing oodles of its qualified R&D
guys. THAT author was right.
IBM's been run into the ground by Ginni, I'll use her first name, since apparently my
money is now used to prop up this sham of a leader, who from her uncomfortable public
announcement with Tim Cook of Apple, which HAS gone up, by the way, has embraced every
political trend, not cause but trend from hiring more women to marginalizing all those
old-time white males...You know the ones who produced for the company based on merit, sweat,
expertise, all those non-feeling based skills that ultimately are what a shareholder is
interested in and replaced them with young, and apparently "social" experts who are pasting
some phony "modernity" on a company that under Ginni's leadership has become more of a pet
cause than a company.
Finally, regarding ageism and the author's advocacy for the same, IBM's been there, done
that as they lost an age discrimination lawsuit decades ago. IBM gave up on doing what it had
the ability to do as an enormous business and instead under Rometty's leadership has tried to
compete with the scrappy startups where any halfwit knows IBM cannot compete.
The company has rendered itself ridiculous under Rometty, a board that collects paychecks
and breaches any notion of fiduciary duty to shareholders, an attempt at partnering with a
"mod" company like Apple that simply bolstered Apple and left IBM languishing and a rejection
of what has a track record of working, excellence, rewarding effort of employees and the
steady plod of performance. Dump the board and dump Rometty.
Four years in GTS ... joined via being outsourced to IBM by my previous employer. Left GTS
after 4 years.
The IBM way of life was throughout the Oughts and the Teens an utter and complete failure
from the perspective of getting work done right and using people to their appropriate and
full potential. I went from a multi-disciplinary team of engineers working across
technologies to support corporate needs in the IT environment to being siloed into a
single-function organization.
My first year of on-boarding with IBM was spent deconstructing
application integration and cross-organizational structures of support and interwork that I
had spent 6 years building and maintaining. Handing off different chunks of work (again,
before the outsourcing, an Enterprise solution supported by one multi-disciplinary team) to
different IBM GTS work silos that had no physical spacial relationship and no interworking
history or habits. What we're talking about here is the notion of "left hand not knowing what
the right hand is doing" ...
THAT was the IBM way of doing things, and nothing I've read
about them over the past decade or so tells me it has changed.
As a GTS employee, professional technical training was deemed unnecessary, hence I had no
access to any unless I paid for it myself and used my personal time ... the only training
available was cheesy presentations or other web based garbage from the intranet, or casual /
OJT style meetings with other staff who were NOT professional or expert trainers.
As a GTS
employee, I had NO access to the expert and professional tools that IBM fricking made and
sold to the same damn customers I was supposed to be supporting. Did we have expert and
professional workflow / document management / ITIL aligned incident and problem management
tools? NO, we had fricking Lotus Notes and email. Instead of upgrading to the newest and best
software solutions for data center / IT management & support, we degraded everything down
the simplest and least complex single function tools that no "best practices" organization on
Earth would ever consider using.
And the people management paradigm ... employees ranked annually not against a static or
shared goal or metric, but in relation to each other, and there was ALWAYS a "top 10 percent"
and a "bottom ten percent" required by upper management ... a system that was sociopathic in
it's nature because it encourages employees to NOT work together ... by screwing over one's
coworkers, perhaps by not giving necessary information, timely support, assistance as needed
or requested, one could potentially hurt their performance and make oneself look relatively
better. That's a self-defeating system and it was encouraged by the way IBM ran things.
The "not invented here" ideology was embedded deeply in the souls of all senior IBMers I
ever met or worked with ... if you come on board with any outside knowledge or experience,
you must not dare to say "this way works better" because you'd be shut down before you could
blink. The phrase "best practices" to them means "the way we've always done it".
IBM gave up on innovation long ago. Since the 90's the vast majority of their software has
been bought, not built. Buy a small company, strip out the innovation, slap an IBM label on
it, sell it as the next coming of Jesus even though they refuse to expend any R&D to push
the product to the next level ... damn near everything IBM sold was gentrified, never cutting
edge.
And don't get me started on sales practices ... tell the customer how product XYZ is a
guaranteed moonshot, they'll be living on lunar real estate in no time at all, and after all
the contracts are signed hand the customer a box of nuts & bolts and a letter telling
them where they can look up instructions on how to build their own moon rocket. Or for XX
dollars more a year, hire a Professional Services IBMer to build it for them.
I have no sympathy for IBM. They need a clean sweep throughout upper management,
especially any of the old True Blue hard-core IBMers.
We tried our best to be SMB partners with IBM & Arrow in the early 2000s ... but could
never get any traction. I personally needed a mentor, but never found one. I still have/wear
some of their swag, and I write this right now on a re-purposed IBM 1U server that is 10
years old, but ... I can't see any way our small company can make $ with them.
Watson is impressive, but you can't build a company on just Watson. This author has some
great ideas, yet the phrase that keeps coming to me is internal politics.
That corrosive reality has & will kill companies, and it will kill IBM unless it is dealt
with.
Turn-arounds are possible (look at MS), but they are hard and dangerous. Hope IBM can
figure it out...
"... Four years in GTS ... joined via being outsourced to IBM by my previous employer. Left GTS after 4 years. ..."
"... The IBM way of life was throughout the Oughts and the Teens an utter and complete failure from the perspective of getting work done right and using people to their appropriate and full potential. ..."
"... As a GTS employee, professional technical training was deemed unnecessary, hence I had no access to any unless I paid for it myself and used my personal time ... the only training available was cheesy presentations or other web based garbage from the intranet, or casual / OJT style meetings with other staff who were NOT professional or expert trainers. ..."
"... As a GTS employee, I had NO access to the expert and professional tools that IBM fricking made and sold to the same damn customers I was supposed to be supporting. Did we have expert and professional workflow / document management / ITIL aligned incident and problem management tools? NO, we had fricking Lotus Notes and email. Instead of upgrading to the newest and best software solutions for data center / IT management & support, we degraded everything down the simplest and least complex single function tools that no "best practices" organization on Earth would ever consider using. ..."
"... And the people management paradigm ... employees ranked annually not against a static or shared goal or metric, but in relation to each other, and there was ALWAYS a "top 10 percent" and a "bottom ten percent" required by upper management ... a system that was sociopathic in it's nature because it encourages employees to NOT work together ... by screwing over one's coworkers, perhaps by not giving necessary information, timely support, assistance as needed or requested, one could potentially hurt their performance and make oneself look relatively better. That's a self-defeating system and it was encouraged by the way IBM ran things. ..."
Four years in GTS ... joined via being outsourced to IBM by my previous employer. Left
GTS after 4 years.
The IBM way of life was throughout the Oughts and the Teens an utter and complete
failure from the perspective of getting work done right and using people to their appropriate
and full potential. I went from a multi-disciplinary team of engineers working across
technologies to support corporate needs in the IT environment to being siloed into a
single-function organization.
My first year of on-boarding with IBM was spent deconstructing application integration and
cross-organizational structures of support and interwork that I had spent 6 years building
and maintaining. Handing off different chunks of work (again, before the outsourcing, an
Enterprise solution supported by one multi-disciplinary team) to different IBM GTS work silos
that had no physical special relationship and no interworking history or habits. What we're
talking about here is the notion of "left hand not knowing what the right hand is doing"
...
THAT was the IBM way of doing things, and nothing I've read about them over the past
decade or so tells me it has changed.
As a GTS employee, professional technical training was deemed unnecessary, hence I had
no access to any unless I paid for it myself and used my personal time ... the only training
available was cheesy presentations or other web based garbage from the intranet, or casual /
OJT style meetings with other staff who were NOT professional or expert trainers.
As a GTS employee, I had NO access to the expert and professional tools that IBM
fricking made and sold to the same damn customers I was supposed to be supporting. Did we
have expert and professional workflow / document management / ITIL aligned incident and
problem management tools? NO, we had fricking Lotus Notes and email. Instead of upgrading to
the newest and best software solutions for data center / IT management & support, we
degraded everything down the simplest and least complex single function tools that no "best
practices" organization on Earth would ever consider using.
And the people management paradigm ... employees ranked annually not against a static
or shared goal or metric, but in relation to each other, and there was ALWAYS a "top 10
percent" and a "bottom ten percent" required by upper management ... a system that was
sociopathic in it's nature because it encourages employees to NOT work together ... by
screwing over one's coworkers, perhaps by not giving necessary information, timely support,
assistance as needed or requested, one could potentially hurt their performance and make
oneself look relatively better. That's a self-defeating system and it was encouraged by the
way IBM ran things.
The "not invented here" ideology was embedded deeply in the souls of all senior IBMers I
ever met or worked with ... if you come on board with any outside knowledge or experience,
you must not dare to say "this way works better" because you'd be shut down before you could
blink. The phrase "best practices" to them means "the way we've always done it".
IBM gave up on innovation long ago. Since the 90's the vast majority of their software has
been bought, not built. Buy a small company, strip out the innovation, slap an IBM label on
it, sell it as the next coming of Jesus even though they refuse to expend any R&D to push
the product to the next level ... damn near everything IBM sold was gentrified, never cutting
edge.
And don't get me started on sales practices ... tell the customer how product XYZ is a
guaranteed moonshot, they'll be living on lunar real estate in no time at all, and after all
the contracts are signed hand the customer a box of nuts & bolts and a letter telling
them where they can look up instructions on how to build their own moon rocket. Or for XX
dollars more a year, hire a Professional Services IBMer to build it for them.
I have no sympathy for IBM. They need a clean sweep throughout upper management,
especially any of the old True Blue hard-core IBMers.
Hole opens up remote-code execution to miscreants – or a crash, if you're
lucky A security bug in Systemd can be exploited over the network to, at best, potentially
crash a vulnerable Linux machine, or, at worst, execute malicious code on the box.
The flaw therefore puts Systemd-powered Linux computers – specifically those using
systemd-networkd – at risk of remote hijacking: maliciously crafted DHCPv6 packets can
try to exploit the programming cockup and arbitrarily change parts of memory in vulnerable
systems, leading to potential code execution. This code could install malware, spyware, and
other nasties, if successful.
The vulnerability – which was made public this week – sits within the
written-from-scratch DHCPv6 client of the open-source Systemd management suite, which is built
into various flavors of Linux.
This client is activated automatically if IPv6 support is enabled, and relevant packets
arrive for processing. Thus, a rogue DHCPv6 server on a network, or in an ISP, could emit
specially crafted router advertisement messages that wake up these clients, exploit the bug,
and possibly hijack or crash vulnerable Systemd-powered Linux machines.
systemd-networkd
is vulnerable to an out-of-bounds heap write in the DHCPv6 client when handling options sent by
network adjacent DHCP servers. A attacker could exploit this via malicious DHCP server to
corrupt heap memory on client machines, resulting in a denial of service or potential code
execution.
Felix Wilhelm, of the Google Security team, was credited with discovering the flaw,
designated CVE-2018-15688 . Wilhelm found that a
specially crafted DHCPv6 network packet could trigger "a very powerful and largely controlled
out-of-bounds heap write," which could be used by a remote hacker to inject and execute
code.
"The overflow can be triggered relatively easy by advertising a DHCPv6 server with a
server-id >= 493 characters long," Wilhelm noted.
In addition to Ubuntu and Red
Hat Enterprise Linux, Systemd has been adopted as a service manager for Debian, Fedora, CoreOS,
Mint, and SUSE Linux Enterprise Server. We're told RHEL 7, at least, does not use the
vulnerable component by default.
Systemd creator Lennart Poettering has already
published a security fix for the vulnerable component
– this should be weaving its way into distros as we type.
If you run a Systemd-based Linux system, and rely on systemd-networkd, update your operating
system as soon as you can to pick up the fix when available and as necessary.
The bug will come as another argument against Systemd as the Linux management tool continues
to fight for the hearts and minds of admins and developers alike. Though a number of major
admins have in recent years adopted and championed it as
the replacement for the old Init era, others within the Linux world seem to still be less than
impressed with Systemd and Poettering's occasionally
controversial management of the tool. ® Page:
As anyone who bothers to read my comments (BTW "hi" to both of you) already knows, I
despise systemd with a passion, but this one is more an IPv6 problem in general.
Yes this is an actual bug in networkd, but IPv6 seems to be far more bug prone than v4,
and problems are rife in all implementations. Whether that's because the spec itself is
flawed, or because nobody understands v6 well enough to implement it correctly, or possibly
because there's just zero interest in making any real effort, I don't know, but it's a fact
nonetheless, and my primary reason for disabling it wherever I find it. Which of course
contributes to the "zero interest" problem that perpetuates v6's bug prone condition, ad
nauseam.
IPv6 is just one of those tech pariahs that everyone loves to hate, much like systemd,
albeit fully deserved IMO.
Oh yeah, and here's the obligatory "systemd sucks". Personally I always assumed the "d"
stood for "destroyer". I believe the "IP" in "IPv6" stands for "Idiot Protocol".
Fortunately, IPv6 by lack of adopted use, limits the scope of this bug.
Yeah, fortunately IPv6 is only used by a few fringe organizations like Google and
Microsoft.
Seriously, I personally want nothing to do with either systemd or IPv6. Both seem to me to
fall into the bin labeled "If it ain't broke, let's break it" But still it's troubling that
things that some folks regard as major system components continue to ship with significant
security flaws. How can one trust anything connected to the Internet that is more
sophisticated and complex than a TV streaming box?
Was going to say the same thing, and I disable IPv6 for the exact same reason. IPv6 code
isn't as well tested, as well audited, or as well targeted looking for exploits as IPv4.
Stuff like this only proves that it was smart to wait, and I should wait some more.
Count me in the camp of who hates systemd(hates it being "forced" on just about every
distro, otherwise wouldn't care about it - and yes I am moving my personal servers to Devuan,
thought I could go Debian 7->Devuan but turns out that may not work, so I upgraded to
Debian 8 a few weeks ago, and will go to Devuan from there in a few weeks, upgraded one
Debian 8 to Devuan already 3 more to go -- Debian user since 1998), when reading this article
it reminded me of
This makes me glad I'm using FreeBSD. The Xorg version in FreeBSD's ports is currently
*slightly* older than the Xorg version that had that vulnerability in it. AND, FreeBSD will
*NEVER* have systemd in it!
(and, for Linux, when I need it, I've been using Devuan)
That being said, the whole idea of "let's do a re-write and do a 'systemd' instead of
'system V init' because WE CAN and it's OUR TURN NOW, 'modern' 'change for the sake of
change' etc." kinda reminds me of recent "update" problems with Win-10-nic...
Oh, and an obligatory Schadenfreude laugh: HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA
HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA
HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA HA!!!!!!!!!!!!!!!!!!!
Finally got all my machines cut over from Debian to Devuan.
Might spin a FreeBSD system up in a VM and have a play.
I suspect that the infestation of stupid into the Linux space won't stop with or be
limited to SystemD. I will wait and watch to see what damage the re-education gulag has done
to Sweary McSwearFace (Mr Torvalds)
Not really, systemd has its tentacles everywhere and runs as root.
Yes, but not really the problem in this case. Any DHCP client is going to have to
run at least part of the time as root. There's not enough nuance in the Linux privilege model
to allow it to manipulate network interfaces, otherwise.
Yes, but not really the problem in this case. Any DHCP client is going to have to run at
least part of the time as root. There's not enough nuance in the Linux privilege model to
allow it to manipulate network interfaces, otherwise.
Sorry but utter bullshit. You can if you are so inclined you can use the Linux
Capabilities framework for this kind of thing. See
https://wiki.archlinux.org/index.php/capabilities
I remain very happy that I don't use systemd on any of my machines anymore. :)
"others within the Linux world seem to still be less than impressed with Systemd"
Yep, I'm in that camp. I gave it a good, honest go, but it increased the amount of hassle
and pain of system management without providing any noticeable benefit, so I ditched it.
> Just like it's entirely possible to have a Linux system without any GNU in it
Just like it's possible to have a GNU system without Linux on it - ho well as soon as GNU
MACH is finally up to the task ;-)
On the systemd angle, I, too, am in the process of switching all my machines from Debian
to Devuan but on my personnal(*) network a few systemd-infected machines remain, thanks to a
combination of laziness from my part and stubborn "systemd is quite OK" attitude from the
raspy foundation. That vuln may be the last straw : one on the aforementionned machines sits
on my DMZ, chatting freely with the outside world. Nothing really crucial on it, but i'd hate
it if it became a foothold for nasties on my network.
(*) policy at work is RHEL, and that's negociated far above my influence level, but I
don't really care as all my important stuff runs on Z/OS anyway ;-) . Ok we have to reboot a
few VMs occasionnally when systemd throws a hissy fit -which is surprisingly often for an
"enterprise" OS -, but meh.
"This code is actually pretty bad and should raise all kinds of red flags in a code
review."
Yeah, but for that you need people who can do code reviews, and also people who can accept
criticism. That also means saying "no" to people who are bad at coding, and saying that
repeatedly if they don't learn.
SystemD seems to be the area where people gather who want to get code in for their
resumes, not for people who actually want to make the world a better place.
... that an init, traditionally, is a small bit of code that does one thing very well.
Like most of the rest of the *nix core utilities. All an init should do is start PID1, set
run level, spawn a tty (or several), handle a graceful shutdown, and log all the above in
plaintext to make troubleshooting as simplistic as possible. Anything else is a vanity
project that is best placed elsewhere, in it's own stand-alone code base.
Inventing a clusterfuck init variation that's so big and bulky that it needs to be called
a "suite" is just asking for trouble.
IMO, systemd is a cancer that is growing out of control, and needs to be cut out of Linux
before it infects enough of the system to kill it permanently.
That's why systemd-networkd is a separate, optional component, and not actually part of
the init daemon at all. Most systemd distros do not use it by default and thus are not
vulnerable to this unless the user actively disables the default network manager and chooses
to use networkd instead.
Pardon my ignorance (I don't use a distro with systemd) why bother with networkd in the
first place if you don't have to use it.
Mostly because the old-style init system doesn't cope all that well with systems that move
from network to network. It works for systems with a static IP, or that do a DHCP request at
boot, but it falls down on anything more dynamic.
In order to avoid restarting the whole network system every time they switch WiFi access
points, people have kludged on solutions like NetworkManager. But it's hard to argue it's
more stable or secure than networkd. And this is always going to be a point of vulnerability
because anything that manipulates network interfaces will have to be running as root.
These days networking is essential to the basic functionality of most computers; I think
there's a good argument that it doesn't make much sense to treat it as a second-class
citizen.
"Funny that I installed ubuntu 18.04 a few weeks ago and the fucking thing installed
itself then! ( and was a fucking pain to remove)."
So I looked into it a bit more, and from a few references at least, it seems like Ubuntu
has a sort of network configuration abstraction thingy that can use both NM and
systemd-networkd as backends; on Ubuntu desktop flavors NM is usually the default, but
apparently for recent Ubuntu Server, networkd might indeed be the default. I didn't notice
that as, whenever I want to check what's going on in Ubuntu land, I tend to install the
default desktop spin...
"LP is a fucking arsehole."
systemd's a lot bigger than Lennart, you know. If my grep fu is correct, out of 1543
commits to networkd, only 298 are from Lennart...
in many respects when it comes to software because, over time, the bugs will have been
found and squashed. Systemd brings in a lot of new code which will, naturally, have lots of
bugs that will take time to find & remove. This is why we get problems like this DHCP
one.
Much as I like the venerable init: it did need replacing. Systemd is one way to go, more
flexible, etc, etc. Something event driven is a good approach.
One of the main problems with systemd is that it has become too big, slurped up lots of
functionality which has removed choice, increased fragility. They should have concentrated on
adding ways of talking to existing daemons, eg dhcpd, through an API/something. This would
have reused old code (good) and allowed other implementations to use the API - this letting
people choose what they wanted to run.
But no: Poettering seems to want to build a Cathedral rather than a Bazzar.
He appears to want to make it his way or no way. This is bad, one reason that *nix is good
is because different solutions to a problem have been able to be chosen, one removed and
another slotted in. This encourages competition and the 'best of breed' comes out on top.
Poettering is endangering that process.
Also: he refusal to accept patches to let it work on non-Linux Unix is just plain
nasty.
One of the main problems with systemd is that it has become too big, slurped up lots of
functionality which has removed choice, increased fragility.
IMO, there is a striking paralell between systemd and the registry in Windows OSs.
After many years of dealing with the registry (W98 to XPSP3) I ended up seeing the
registry as a sort of developer sanctioned virus running inside the OS, constantly changing
and going deeper and deeper into the OS with every iteration and as a result, progressively
putting an end to the possibility of knowing/controlling what was going on inside your
box/the OS.
Years later, when I learned about the existence of systemd (I was already running Ubuntu)
and read up on what it did and how it did it, it dawned on me that systemd was nothing more
than a registry class virus and it was infecting Linux_land at the behest of the
developers involved.
So I moved from Ubuntu to PCLinuxOS and then on to Devuan.
Call me paranoid but I am convinced that there are people both inside and outside IT that
actually want this and are quite willing to pay shitloads of money for it to
happen.
I don't see this MS cozying up to Linux in various ways lately as a coincidence: these
things do not happen just because or on a senior manager's whim.
What I do see (YMMV) is systemd being a sort of convergence of Linux with Windows,
which will not be good for Linux and may well be its undoing.
Much as I like the venerable init: it did need replacing.
For some use cases, perhaps. Not for any of mine. SysV init, or even BSD init, does
everything I need a Linux or UNIX init system to do. And I don't need any of the other crap
that's been built into or hung off systemd, either.
BSD init and SysV init work pretty darn well for their original purpose -- servers with
static IP addresses that are rebooted no more than once in a fortnight. Anything more dynamic
starts to give it trouble.
Linus doesn't care. systemd has nothing to do with the kernel ... other than the fact that
the lead devs for systemd have been banned from working on the kernel because they don't play
nice with others.
I've been using runit, because I am too lazy and clueless to write init scripts reliably.
It's very lightweight, runs on a bunch of systems and really does one thing - keep daemons
up.
I am not saying it's the best - but it looks like it has a very small codebase, it doesn't
do much and generally has not bugged me after I configured each service correctly. I believe
other systems also exist to avoid using init scripts directly. Not Monit, as it relies on you
configuring the daemon start/stop commands elsewhere.
On the other hand, systemd is a massive sprawl, does a lot of things - some of them
useful, like dependencies and generally has needed more looking after. Twice I've had errors
on a Django server that, after a lot of looking around ended up because something had changed
in the, Chef-related, code that's exposed to systemd and esoteric (not emitted by systemd)
errors resulted when systemd could not make sense of the incorrect configuration.
I don't hate it - init scripts look a bit antiquated to me and they seem unforgiving to
beginners - but I don't much like it. What I certainly do hate is how, in an OS that is
supposed to be all about choice, sometime excessively so as in the window manager menagerie,
we somehow ended up with one mandatory daemon scheduler on almost all distributions. Via, of
all types of dependencies, the GUI layer. For a window manager that you may not even have
installed.
Talk about the antithesis of the Unix philosophy of do one thing, do it well.
Oh, then there are also the security bugs and the project owner is an arrogant twat. That
too.
"init scripts look a bit antiquated to me and they seem unforgiving to beginners"
Init scripts are shell scripts. Shell scripts are as old as Unix. If you think that makes
them antiquated then maybe Unix-like systems are not for you. In practice any sub-system
generally gets its own scripts installed with the rest of the S/W so if being unforgiving
puts beginners off tinkering with them so much the better. If an experienced Unix user really
needs to modify one of the system-provided scripts their existing shell knowledge will let
them do exactly what's needed. In the extreme, if you need to develop a new init script then
you can do so in the same way as you'd develop any other script - edit and test from the
command line.
I personally like openrc as an init system, but systemd is a symptom of the tooling
problem.
It's for me a retrograde step but again, it's linux, one can, as you and I do, just remove
systemd.
There are a lot of people in the industry now who don't seem able to cope with shell
scripts nor are minded to research the arguments for or against shell as part of a unix style
of system design.
In conclusion, we are outnumbered, but it will eventually collapse under its own weight
and a worthy successor shall rise, perhaps called SystemV, might have to shorten that name a
bit.
"In addition to Ubuntu and Red Hat Enterprise Linux, Systemd has been adopted as a service
manager for Debian, Fedora, CoreOS, Mint, and SUSE Linux Enterprise Server. We're told RHEL
7, at least, does not use the vulnerable component by default."
I can tell you for sure that no version of Fedora does, either, and I'm fairly sure that
neither does Debian, SLES or Mint. I don't know anything much about CoreOS, but
https://coreos.com/os/docs/latest/network-config-with-networkd.html suggests it actually
*might* use systemd-networkd.
systemd-networkd is not part of the core systemd init daemon. It's an optional component,
and most distros use some other network manager (like NetworkManager or wicd) by default.
I mean commercial distributions seem to be particularly interested in trying out new
things that can increase their number of support calls. It's probably just that networkd is
either to new and therefore not yet in the release, or still works so badly even the most
rudimentary tests fail.
There is no reason to use that NTP daemon of systemd, yet more and more distros ship with
it enabled, instead of some sane NTP-server.
I won't hold my breath, then. I have a laptop at the moment that refuses to boot because
(as I've discovered from looking at the journal offline) pulseaudio is in an infinite loop
waiting for the successful detection of some hardware that, presumably, I don't have.
I imagine I can fix it by hacking the file-system (offline) so that fuckingpulse is no
longer part of the boot configuration, but I shouldn't have to. A decent init system would be
able to kick of everything else in parallel and if one particular service doesn't come up
properly then it just logs the error. I *thought* that was one of the claimed advantages of
systemd, but apparently that's just a load of horseshit.
My NAT router statefully firewalls incoming IPv6 by default, which I consider equivalently
secure. NAT adds security mostly by accident, because it de-facto adds a firewall that blocks
incoming packets. It's not the address translation itself that makes things more secure, it's
the inability to route in from the outside.
NAT is schtick for connecting a whole LAN to a WAN using a single IPv4 address (useful
with IPv4 because most ISPs don't give you a /24 when you sign up). If you have a native IPv6
address you'll have something like 2^64 addresses, so machines on your LAN can have an actual
WAN-visible address of their own without needing a trick like NAT.
"so machines on your LAN can have an actual WAN-visible address of their own without
needing a trick like NAT."
Avoiding that configuration is exactly the use case for using NAT with IPv6. As others
have pointed out, you can accomplish the same thing with IPv6 router configuration, but NAT
is easier in terms of configuration and maintenance. Given that, and assuming that you don't
want to be able to have arbitrary machines open ports that are visible to the internet, then
why not use NAT?
Also, if your goal is to make people more likely to move to IPv6, pointing out IPv4
methods that will work with IPv6 (even if you don't consider them optimal) seems like a
really, really good idea. It eases the transition.
Please El Reg these stories make ma rage at breakfast, what's this?
The bug will come as another argument against Systemd as the Linux management tool
continues to fight for the hearts and minds of admins and developers alike.
Less against systemd (which should get attacked on the design & implementation level)
or against IPv6 than against the use of buffer-overflowable languages in 2018 in code that
processes input from the Internet (it's not the middle ages anymore) or at least very hard
linting of the same.
But in the end, what did it was a violation of the Don't Repeat Yourself principle and
lack of sufficently high-level datastructures. Pointer into buffer, and the remaining buffer
length are two discrete variables that need to be updated simultaneously to keep the
invariant and this happens in several places. This is just a catastrophe waiting to happen.
You forget to update it once, you are out! Use structs and functions updating the structs
correctly.
The function receives a pointer to the option buffer buf, it's remaining size buflen
and the IA to be added to the buffer. While the check at (A) tries to ensure that the buffer
has enough space left to store the IA option, it does not take the additional 4 bytes from
the DHCP6Option header into account (B). Due to this the memcpy at (C) can go out-of-bound
and *buflen can underflow [i.e. you suddenly have a gazillion byte buffer, Ed.] in (D) giving
an attacker a very powerful and largely controlled OOB heap write starting at (E).
why don't we stop writing code in languages that make it easy to screw up so easily like
this?
There are plenty about nowadays, I'd rather my DHCP client be a little bit slower at
processing packets if I had more confidence it would not process then incorrectly and execute
code hidden in said packets...
The circus that is called "Linux" have forced me to Devuan and the likes however the
circus is getting worse and worse by the day, thus I have switched to the BSD world, I will
learn that rather than sit back and watch this unfold As many of us have been saying, the
sudden switch to SystemD was rather quick, perhaps you guys need to go investigate why it
really happened, don't assume you know, go dig and you will find the answers, it's rather
scary, thus I bid the Linux world a farewell after 10 years of support, I will watch the
grass dry out from the other side of the fence, It was destined to fail by means of
infiltration and screw it up motive(s) on those we do not mention here.
As many of us have been saying, the sudden switch to SystemD was rather quick, perhaps
you guys need to go investigate why it really happened, don't assume you know, go dig and you
will find the answers, it's rather scary ...
Indeed, it was rather quick and is very scary.
But there's really no need to dig much, just reason it out.
It's like a follow the money situation of sorts.
I'll try to sum it up in three short questions:
Q1: Hasn't the Linux philosophy (programs that do one thing and do it well) been a
success?
A1: Indeed, in spite of the many init systems out there, it has been a success in
stability and OS management. And it can easily be tested and debugged, which is an essential
requirement.
Q2: So what would Linux need to have the practical equivalent of the registry in
Windows for?
A2: So that whatever the registry does in/to Windows can also be done in/to Linux.
Q3: I see. And just who would want that to happen? Makes no sense, it is a huge
step backwards.
OK, so I was able to check through the link you provided, which says "up to and including
239", but I had just installed a systemd update and when you said there was already a fix
written, working it's way through the distro update systems, all I had to do was check my
log.
Linux Mint makes it easy.
But why didn't you say something such as "reported to affect systemd versions up to and
including 239" and then give the link to the CVE? That failure looks like rather careless
journalism.
... I can
get a list of all previous screens using the command:
screen -ls
And this gives me the output as shown here:
As you can see, there is a screen session here with the name:
pts-0.test-centos-server
To reconnect to it, just type:
screen -r
And this will take you back to where you were before the SSH connection was terminated! It's
an amazing tool that you need to use for all important operations as insurance against
accidental terminations.
Manually Detaching Screens
When you break an SSH session, what actually happens is that the screen is automatically
detached from it and exists independently. While this is great, you can also detach
screens manually and have multiple screens existing at the same time.
For example, to detach a screen just type:
screen -d
And the current screen will be detached and preserved. However, all the processes inside it
are still running, and all the states are preserved:
You can re-attach to a screen at any time using the "screen -r" command. To connect to a
specific screen instead of the most recent, use:
screen -r [screenname]
Changing the Screen Names to Make Them More Relevant
By default, the screen names don't mean much. And when you have a bunch of them present, you
won't know which screens contain which processes. Fortunately, renaming a screen is easy when
inside one. Just type:
ctrl+a :
We saw in the previous article that "ctrl+a" is the trigger condition for screen commands.
The colon (:) will take you to the bottom of the screen where you can type commands. To rename,
use:
sessionname [newscreenname]
As shown here:
And now when you detach the screen, it will show with the new name like this:
Now you can have as many screens as you want without getting confused about which one is
which!
If you are one of our Managed VPS
hosting clients, we can do all of this for you. Simply contact our system administrators
and they will respond to your request as soon as possible.
If you liked this blog post on how to recover from an accidental SSH disconnection on Linux,
please share it with your friends on social media networks, or if you have any question
regarding this blog post, simply leave a comment below and we will answer it. Thanks!
"... I worked as a contractor for IBM's IGS division in the late '90s and early 2000s at their third biggest customer, and even then, IBM was doing their best to demoralize their staff (and contractors) and annoy their customers as much as possible! ..."
"... IBM charged themselves 3x the actual price to customers for their ThinkPads at the time! This meant that I never had a laptop or desktop PC from IBM in the 8 years I worked there. If it wasn't for the project work I did I would not have had a PC to work on! ..."
"... What was strange is that every single time I got a pay cut, IBM would then announce that they had bought a new company! I would have quit long before I did, but I was tied to them while waiting for my Green Card to be approved. I know that raises are few in the current IBM for normal employees and that IBM always pleads poverty for any employee request. Yet, they somehow manage to pay billions of dollars for a new company. Strange that, isn't it? ..."
"... I moved to the company that had won the contract and regret not having the chance to tell that IBM manager what I thought about him and where he could stick the new laptop. ..."
"... After that experience I decided to never work for them in any capacity ever again. I feel pity for the current Red Hat employees and my only advice to them is to get out while they can. "DON'T FOLLOW THE RED HAT TO HELL" ..."
Red Hat will be a distant memory in a few years as it gets absorbed by the abhorrent IBM
culture and its bones picked clean by the IBM beancounters. Nothing good ever happens to a
company bought by IBM.
I worked as a contractor for IBM's IGS division in the late '90s and early 2000s at their
third biggest customer, and even then, IBM was doing their best to demoralize their staff (and
contractors) and annoy their customers as much as possible!
Some examples:
The on-site IBM employees (and contractors) had to use Lotus Notes for email. That was
probably the worst piece of software I have ever used - I think baboons on drugs could have
done a better design job. IBM set up a T1 (1.54 Mbps) link between the customer and the local
IBM hub for email, etc. It sounds great until you realize there were over 150 people involved
and due to the settings of Notes replication, it could often take over an hour to actually
download email to read.
To do my job I needed to install some IBM software. My PC did not have enough disk space for
this software as well as the other software I needed. Rather than buy me a bigger hard disk I
had to spend 8 hours a week installing and reinstalling software to do my job.
I waited three months for a $50 stick of memory to be approved. When it finally arrived my
machine had been changed out (due to a new customer project) and the memory was not compatible!
Since I worked on a lot of projects I often had machines supplied by the customer on my desk.
So, I would use one of these as my personal PC and would get an upgrade when the next project
started!
I was told I could not be supplied with a laptop or desktop from IBM as they were too
expensive (my IBM division did not want to spend money on anything). IBM charged themselves 3x
the actual price to customers for their ThinkPads at the time! This meant that I never had a
laptop or desktop PC from IBM in the 8 years I worked there. If it wasn't for the project work
I did I would not have had a PC to work on!
IBM has many strange and weird processes that allow them to circumvent the contract they
have with their preferred contractor companies. This meant that for a number of years I ended
up getting a pay cut. What was strange is that every single time I got a pay cut, IBM would
then announce that they had bought a new company! I would have quit long before I did, but I
was tied to them while waiting for my Green Card to be approved. I know that raises are few in
the current IBM for normal employees and that IBM always pleads poverty for any employee
request. Yet, they somehow manage to pay billions of dollars for a new company. Strange that,
isn't it?
Eventually I was approved to get a laptop and excitedly watched it move slowly through the
delivery system. I got confused when it was reported as delivered to Ohio rather than my work
(not in Ohio). After some careful searching I discovered that my manager and his wife both
worked for IBM from their home in, yes you can guess, Ohio. It looked like he had redirected my
new laptop for his own use and most likely was going to send me his old one and claim it was a
new one. I never got the chance to confront him about it, though, as IBM lost the contract with
the customer that month and before the laptop should have arrived IBM was out! I moved to the
company that had won the contract and regret not having the chance to tell that IBM manager
what I thought about him and where he could stick the new laptop.
After that experience I decided to never work for them in any capacity ever again. I feel
pity for the current Red Hat employees and my only advice to them is to get out while they can.
"DON'T FOLLOW THE RED HAT TO HELL"
I sense that a global effort is ongoing to shutdown open source software by brute force.
First, the enforcement of the EU General Data Protection Regulation (GDPR) by ICANN.org to
enable untraceable takeovers of domains. Microsoft buying github. Linus Torvalds forced out
of his own Linux kernel project because of the Code of Conduct and now IBM buying RedHat. I
wrote the following at https://lulz.com/linux-devs-threaten-killswitch-coc-controversy-1252/
"Torvalds should lawyer up. The problems are the large IT Tech firms who platinum donated all
over the place in Open Source land. When IBM donated with 1 billion USD to Linux in 2000
https://itsfoss.com/ibm-invest-1-billion-linux/ a friend who vehemently was against the GPL
and what Torvalds was doing, told me that in due time OSS would simply just go away.
These Community Organizers, not Coders per se, are on a mission to overtake and control
the Linux Foundation, and if they can't, will search and destroy all of it, even if it
destroys themselves. Coraline is merely a expendable pion here. Torvalds is now facing unjust
confrontations and charges resembling the nomination of Judge Brett Kavanaugh. Looking at the
CoC document it even might have been written by a Google executive, who themselves currently
are facing serious charges and lawsuits from their own Code of Conduct. See theintercept.com,
their leaked video the day after the election of 2016. They will do anything to pursue this.
However to pursue a personal bias or agenda furnishing enactments or acts such as to, omit
contradicting facts (code), commit perjury, attend riots and harassments, cleanse Internet
archives and search engines of exculpatory evidence and ultimately hire hit-men to
exterminate witnesses of truth (developers), in an attempt to elevate bias as fabricated fact
(code) are crimes and should be prosecuted accordingly."
It does not matter if somebody "stresses independence word are cheap. The mere fact that this
is not IBM changes relationships. also IBM executives need to show "leadership" and that entails
some "general direction" for Red Hat from now on. At least with Microsoft and HP relationship
will be much cooler, then before.
Also IBM does not like "charity" projects like CentOS and that will be affected too, no
matter what executives tell you right now. Paradoxically this greatly strengthen the position of
Oracle Linux.
The status of IBM software in corporate world 9outside finance companies) is low and their
games with licenses (licensing products per core, etc) are viewed by most of their customers as
despicable. This was one of the reasons IBM lost it share in enterprise software. For example,
greed in selling Tivoli more or less killed the software. All credits to Lou Gerstner who
initially defined this culture of relentless outsource and cult of the "bottom line" (which was
easy for his because he does not understood technology at all). His successor was even more
active in driving company into the ground. R ampant cost-arbitrage driven offshoring has left a
legacy of dissatisfied customers. Most projects are over priced. and most of those which were
priced more or less on industry level had bad quality results and costs overruns.
IBM cut severance pay to 1 month, is firing people left and right and is insensitive to the
fired employees and the result is enormous negativity for them. Good people are scared to work
for them and people are asking tough questions.
It's strategy since Gerstner. Palmisano (this guys with history diploma witched into
Cybersecurity after retirement in 2012 and led Obama cybersecurity commission) & Ginni Rometty was completely
neoliberal mantra "share holder value", grow earnings per share at all costs. They all manage IBM
for financial appearance rather than the quaility products. There was no focus on
breakthrough-innovation, market leadership in mega-trends (like cloud computing) or even giving
excellent service to customers.
Ginni Rometty accepted bonuses during times of layoffs and outsourcing.
When company have lost it architectural talent the brand will eventually die. IBM still has
very high number of patents every year. It is still a very large company in terms of revenue and
number of employees. However, there are strong signs that its position in the technology industry
might deteriorate further.
Cormier also stressed Red Hat independence when we asked how the acquisition would affect
ongoing partnerships in place with Amazon Web Services, Microsoft Azure, and other public
clouds.
"One of the things you keep seeing in this is that we're going to run Red Hat as a separate
entity within IBM," he said. "One of the reasons is business. We need to, and will, remain
Switzerland in terms of how we interact with our partners. We're going to continue to
prioritize what we do for our partners within our products on a business case perspective,
including IBM as a partner. We're not going to do unnatural things. We're going to do the right
thing for the business, and most importantly, the customer, in terms of where we steer our
products."
Red Hat promises that independence will extend to Red Hat's community projects, such as its
freely available Fedora Linux distribution which is widely used by developers. When asked what
impact the sale would have on Red Hat maintained projects like Fedora and CentoOS, Cormier
replied, "None. We just came from an all-hands meeting from the company around the world for
Red Hat, and we got asked this question and my answer was that the day after we close, I don't
intend to do anything different or in any other way than we do our every day today. Arvind,
Ginnie, Jim, and I have talked about this extensively. For us, it's business as usual. Whatever
we were going to do for our road maps as a stand alone will continue. We have to do what's
right for the community, upstream, our associates, and our business."
This all sounds good, but as they say, talk is cheap. Six months from now we'll have a
better idea of how well IBM can walk the walk and leave Red Hat alone. If it can't and Red Hat
doesn't remain clearly distinct from IBM ownership control, then Big Blue will have wasted $33
billion it can't afford to lose and put its future, as well as the future of Red Hat, in
jeopardy.
Step back and think about this for a minute. There are plenty of examples of people who were
doing their jobs, IN SPADES, putting in tons of unpaid overtime, and generally doing whatever
was humanly possible to make sure that whatever was promised to the customer was delivered
(within their span of control... I'm not going to get into a discussion of how IBM pulls the
rug out from underneath contracts after they've been signed).
These people were, and still are, high performers, they are committed to the job and the
purpose that has been communicated to them by their peers, management, and customers; and
they take the time (their OWN time) to pick up new skills and make sure that they are still
current and marketable. They do this because they are committed to doing the job to the best
of their ability.... it's what makes them who they are.
IBM (and other companies) are firing these very people ***for one reason and one reason
ONLY***: their AGE. They have the skills and they're doing their jobs. If the same person was
30 you can bet that they'd still be there. Most of the time it has NOTHING to do with
performance or lack of concurrency. Once the employee is fired, the job is done by someone
else. The work is still there, but it's being done by someone younger and/or of a different
nationality.
The money that is being saved by these companies has to come from somewhere. People that
are having to withdraw their retirement savings 20 or so years earlier than planned are going
to run out of funds.... and when they're in nursing homes, guess who is going to be
supporting them? Social security will be long gone, their kids have their own monetary
challenges.... so it will be government programs.... maybe.
This is not just a problem that impacts the 40 and over crowd. This is going to impact our
entire society for generations to come.
The business reality you speak of can be tempered via government actions. A few things:
One of the major hardships here is laying someone off when they need income the most -
to pay for their children's college education. To mitigate this, as a country we could make a
public education free. That takes off a lot of the sting, some people might relish a change
in career when they are in their 50s except that the drop in salary is so steep when changing
careers.
We could lower the retirement age to 55 and increase Social Security to more than a
poverty-level existence.Being laid off when you're 50 or 55 - with little chance to be hired
anywhere else - would not hurt as much.
We could offer federal wage subsidies for older workers to make them more attractive to
hire. While some might see this as a thumb on the scale against younger workers, in reality
it would be simply a counterweight to the thumb that is already there against older
workers.
Universal health care equalizes the cost of older and younger workers.
The other alternative is a market-based life that, for many, will be cruel, brutish, and
short.
As a new engineering graduate, I joined a similar-sized multinational US-based company in the
early '70s. Their recruiting pitch was, "Come to work here, kid. Do your job, keep your nose
clean, and you will enjoy great, secure work until you retire on easy street".
Soon after I started, the company fired hundreds of 50-something employees and put we
"kids" in their jobs. Seeing that employee loyalty was a one way street at that place, I left
after a couple of years. Best career move I ever made.
As a 25yr+ vet of IBM, I can confirm that this article is spot-on true. IBM used to be a
proud and transparent company that clearly demonstrated that it valued its employees as much
as it did its stock performance or dividend rate or EPS, simply because it is good for
business. Those principles helped make and keep IBM atop the business world as the most
trusted international brand and business icon of success for so many years. In 2000, all that
changed when Sam Palmisano became the CEO. Palmisano's now infamous "Roadmap 2015" ran the
company into the ground through its maniacal focus on increasing EPS at any and all costs.
Literally. Like, its employees, employee compensation, benefits, skills, and education
opportunities. Like, its products, product innovation, quality, and customer service. All of
which resulted in the devastation of its technical capability and competitiveness, employee
engagement, and customer loyalty. Executives seemed happy enough as their compensation grew
nicely with greater financial efficiencies, and Palisano got a sweet $270M+ exit package in
2012 for a job well done. The new CEO, Ginni Rometty has since undergone a lot of scrutiny
for her lack of business results, but she was screwed from day one. Of course, that doesn't
leave her off the hook for the business practices outlined in the article, but what do you
expect: she was hand picked by Palmisano and approved by the same board that thought
Palmisano was golden.
In 1994, I saved my job at IBM for the first time, and survived. But I was 36 years old. I
sat down at the desk of a man in his 50s, and found a few odds and ends left for me in the
desk. Almost 20 years later, it was my turn to go. My health and well-being is much better
now. Less money but better health. The sins committed by management will always be: "I was
just following orders".
"... Correction, March 24, 2018: Eileen Maroney lives in Aiken, South Carolina. The name of her city was incorrect in the original version of this story. ..."
Consider, for example, a planning presentation that former IBM executives said was drafted by heads of a business unit carved
out of IBM's once-giant software group and charged with pursuing the "C," or cloud, portion of the company's CAMS strategy.
The presentation laid out plans for substantially altering the unit's workforce. It was shown to company leaders including Diane
Gherson, the senior vice president for human resources, and James Kavanaugh, recently elevated to chief financial officer. Its language
was couched in the argot of "resources," IBM's term for employees, and "EP's," its shorthand for early professionals or recent college
graduates.
Among the goals: "Shift headcount mix towards greater % of Early Professional hires." Among the means: "[D]rive a more aggressive
performance management approach to enable us to hire and replace where needed, and fund an influx of EPs to correct seniority mix."
Among the expected results: "[A] significant reduction in our workforce of 2,500 resources."
A slide from a similar presentation prepared last spring for the same leaders called for "re-profiling current talent" to "create
room for new talent." Presentations for 2015 and 2016 for the 50,000-employee software group also included plans for "aggressive
performance management" and emphasized the need to "maintain steady attrition to offset hiring."
IBM declined to answer questions about whether either presentation was turned into company policy. The description of the planned
moves matches what hundreds of older ex-employees told ProPublica they believe happened to them: They were ousted because of their
age. The company used their exits to hire replacements, many of them young; to ship their work overseas; or to cut its overall headcount.
Ed Alpern, now 65, of Austin, started his 39-year run with IBM as a Selectric typewriter repairman. He ended as a project manager
in October of 2016 when, he said, his manager told him he could either leave with severance and other parting benefits or be given
a bad job review -- something he said he'd never previously received -- and risk being fired without them.
Albert Poggi, now 70, was a three-decade IBM veteran and ran the company's Palisades, New York, technical center where clients
can test new products. When notified in November of 2016 he was losing his job to layoff, he asked his bosses why, given what he
said was a history of high job ratings. "They told me," he said, "they needed to fill it with someone newer."
The presentations from the software group, as well as the stories of ex-employees like Alpern and Poggi, square with internal
documents from two other major IBM business units. The documents for all three cover some or all of the years from 2013 through the
beginning of 2018 and deal with job assessments, hiring, firing and layoffs.
The documents detail practices that appear at odds with how IBM says it treats its employees. In many instances, the practices
in effect, if not intent, tilt against the company's older U.S. workers.
For example, IBM spokespeople and lawyers have said the company never considers a worker's age in making decisions about layoffs
or firings.
But one 2014 document reviewed by ProPublica includes dates of birth. An ex-IBM employee familiar with the process said executives
from one business unit used it to decide about layoffs or other job changes for nearly a thousand workers, almost two-thirds of them
over 50.
Documents from subsequent years show that young workers are protected from cuts for at least a limited period of time. A 2016
slide presentation prepared by the company's global technology services unit, titled "U.S. Resource Action Process" and used to guide
managers in layoff procedures, includes bullets for categories considered "ineligible" for layoff. Among them: "early professional
hires," meaning recent college graduates.
In responding to age-discrimination complaints that ex-employees file with the EEOC, lawyers for IBM say that front-line managers
make all decisions about who gets laid off, and that their decisions are based strictly on skills and job performance, not age.
But ProPublica reviewed spreadsheets that indicate front-line managers hardly acted alone in making layoff calls. Former IBM managers
said the spreadsheets were prepared for upper-level executives and kept continuously updated. They list hundreds of employees together
with codes like "lift and shift," indicating that their jobs were to be lifted from them and shifted overseas, and details such as
whether IBM's clients had approved the change.
An examination of several of the spreadsheets suggests that, whatever the criteria for assembling them, the resulting list of
those marked for layoff was skewed toward older workers. A 2016 spreadsheet listed more than 400 full-time U.S. employees under the
heading "REBAL," which refers to "rebalancing," the process that can lead to laying off workers and either replacing them or shifting
the jobs overseas. Using the job search site LinkedIn, ProPublica was able to locate about 100 of these employees and then obtain
their ages through public records. Ninety percent of those found were 40 or older. Seventy percent were over 50.
IBM frequently cites its history of encouraging diversity in its responses to EEOC complaints about age discrimination. "IBM has
been a leader in taking positive actions to ensure its business opportunities are made available to individuals without regard to
age, race, color, gender, sexual orientation and other categories," a lawyer for the company wrote in a May 2017 letter. "This policy
of non-discrimination is reflected in all IBM business activities."
But ProPublica found at least one company business unit using a point system that disadvantaged older workers. The system awarded
points for attributes valued by the company. The more points a person garnered, according to the former employee, the more protected
she or he was from layoff or other negative job change; the fewer points, the more vulnerable.
The arrangement appears on its face to favor younger newcomers over older veterans. Employees were awarded points for being relatively
new at a job level or in a particular role. Those who worked for IBM for fewer years got more points than those who'd been there
a long time.
The ex-employee familiar with the process said a 2014 spreadsheet from that business unit, labeled "IBM Confidential," was assembled
to assess the job prospects of more than 600 high-level employees, two-thirds of them from the U.S. It included employees' years
of service with IBM, which the former employee said was used internally as a proxy for age. Also listed was an assessment by their
bosses of their career trajectories as measured by the highest job level they were likely to attain if they remained at the company,
as well as their point scores.
The tilt against older workers is evident when employees' years of service are compared with their point scores. Those with no
points and therefore most vulnerable to layoff had worked at IBM an average of more than 30 years; those with a high number of points
averaged half that.
Perhaps even more striking is the comparison between employees' service years and point scores on the one hand and their superiors'
assessments of their career trajectories on the other.
Along with many American employers, IBM has argued it needs to shed older workers because they're no longer at the top of their
games or lack "contemporary" skills.
But among those sized up in the confidential spreadsheet, fully 80 percent of older employees -- those with the most years of
service but no points and therefore most vulnerable to layoff -- were rated by superiors as good enough to stay at their current
job levels or be promoted. By contrast, only a small percentage of younger employees with a high number of points were similarly
rated.
"No major company would use tools to conduct a layoff where a disproportionate share of those let go were African Americans or
women," said Cathy Ventrell-Monsees, senior attorney adviser with the EEOC and former director of age litigation for the senior lobbying
giant AARP. "There's no difference if the tools result in a disproportionate share being older workers."
In addition to the point system that disadvantaged older workers in layoffs, other documents suggest that IBM has made increasingly
aggressive use of its job-rating machinery to pave the way for straight-out firings, or what the company calls "management-initiated
separations." Internal documents suggest that older workers were especially targets.
Like in many companies, IBM employees sit down with their managers at the start of each year and set goals for themselves. IBM
graded on a scale of 1 to 4, with 1 being top-ranked.
Those rated as 3 or 4 were given formal short-term goals known as personal improvement plans, or PIPs. Historically many managers
were lenient, especially toward those with 3s whose ratings had dropped because of forces beyond their control, such as a weakness
in the overall economy, ex-employees said.
But within the past couple of years, IBM appears to have decided the time for leniency was over. For example, a software group
planning document for 2015 said that, over and above layoffs, the unit should seek to fire about 3,000 of the unit's 50,000-plus
workers.
To make such deep cuts, the document said, executives should strike an "aggressive performance management posture." They needed
to double the share of employees given low 3 and 4 ratings to at least 6.6 percent of the division's workforce. And because layoffs
cost the company more than outright dismissals or resignations, the document said, executives should make sure that more than 80
percent of those with low ratings get fired or forced to quit.
Finally, the 2015 document said the division should work "to attract the best and brightest early professionals" to replace up
to two-thirds of those sent packing. A more recent planning document -- the presentation to top executives Gherson and Kavanaugh
for a business unit carved out of the software group -- recommended using similar techniques to free up money by cutting current
employees to fund an "influx" of young workers.
In a recent interview, Poggi said he was resigned to being laid off. "Everybody at IBM has a bullet with their name on it," he
said. Alpern wasn't nearly as accepting of being threatened with a poor job rating and then fired.
Alpern had a particular reason for wanting to stay on at IBM, at least until the end of last year. His younger son, Justin, then
a high school senior, had been named a National Merit semifinalist. Alpern wanted him to be able to apply for one of the company's
Watson scholarships. But IBM had recently narrowed eligibility so only the children of current employees could apply, not also retirees
as it was until 2014.
Alpern had to make it through December for his son to be eligible.
But in August, he said, his manager ordered him to retire. He sought to buy time by appealing to superiors. But he said the manager's
response was to threaten him with a bad job review that, he was told, would land him on a PIP, where his work would be scrutinized
weekly. If he failed to hit his targets -- and his managers would be the judges of that -- he'd be fired and lose his benefits.
Alpern couldn't risk it; he retired on Oct. 31. His son, now a freshman on the dean's list at Texas A&M University, didn't get
to apply.
"I can think of only a couple regrets or disappointments over my 39 years at IBM,"" he said, "and that's one of them."
'Congratulations on Your Retirement!'
Like any company in the U.S., IBM faces few legal constraints to reducing the size of its workforce. And with its no-disclosure
strategy, it eliminated one of the last regular sources of information about its employment practices and the changing size of its
American workforce.
But there remained the question of whether recent cutbacks were big enough to trigger state and federal requirements for disclosure
of layoffs. And internal documents, such as a slide in a 2016 presentation titled "Transforming to Next Generation Digital Talent,"
suggest executives worried that "winning the talent war" for new young workers required IBM to improve the "attractiveness of (its)
culture and work environment," a tall order in the face of layoffs and firings.
So the company apparently has sought to put a softer face on its cutbacks by recasting many as voluntary rather than the result
of decisions by the firm. One way it has done this is by converting many layoffs to retirements.
Some ex-employees told ProPublica that, faced with a layoff notice, they were just as happy to retire. Others said they felt forced
to accept a retirement package and leave. Several actively objected to the company treating their ouster as a retirement. The company
nevertheless processed their exits as such.
Project manager Ed Alpern's departure was treated in company paperwork as a voluntary retirement. He didn't see it that way, because
the alternative he said he was offered was being fired outright.
Lorilynn King, a 55-year-old IT specialist who worked from her home in Loveland, Colorado, had been with IBM almost as long as
Alpern by May 2016 when her manager called to tell her the company was conducting a layoff and her name was on the list.
King said the manager told her to report to a meeting in Building 1 on IBM's Boulder campus the following day. There, she said,
she found herself in a group of other older employees being told by an IBM human resources representative that they'd all be retiring.
"I have NO intention of retiring," she remembers responding. "I'm being laid off."
ProPublica has collected documents from 15 ex-IBM employees who got layoff notices followed by a retirement package and has talked
with many others who said they received similar paperwork. Critics say the sequence doesn't square well with the law.
"This country has banned mandatory retirement," said Seiner, the University of South Carolina law professor and former EEOC appellate
lawyer. "The law says taking a retirement package has to be voluntary. If you tell somebody 'Retire or we'll lay you off or fire
you,' that's not voluntary."
Until recently, the company's retirement paperwork included a letter from Rometty, the CEO, that read, in part, "I wanted to take
this opportunity to wish you well on your retirement While you may be retiring to embark on the next phase of your personal journey,
you will always remain a valued and appreciated member of the IBM family." Ex-employees said IBM stopped sending the letter last
year.
IBM has also embraced another practice that leads workers, especially older ones, to quit on what appears to be a voluntary basis.
It substantially reversed its pioneering support for telecommuting, telling people who've been working from home for years to begin
reporting to certain, often distant, offices. Their other choice: Resign.
David Harlan had worked as an IBM marketing strategist from his home in Moscow, Idaho, for 15 years when a manager told him last
year of orders to reduce the performance ratings of everybody at his pay grade. Then in February last year, when he was 50, came
an internal video from IBM's new senior vice president, Michelle Peluso, which announced plans to improve the work of marketing employees
by ordering them to work "shoulder to shoulder." Those who wanted to stay on would need to "co-locate" to offices in one of six cities.
Early last year, Harlan received an email congratulating him on "the opportunity to join your team in Raleigh, North Carolina."
He had 30 days to decide on the 2,600-mile move. He resigned in June.
David Harlan worked for IBM for 15 years from his home in Moscow, Idaho, where he also runs a drama company. Early last year,
IBM offered him a choice: Move 2,600 miles to Raleigh-Durham to begin working at an office, or resign. He left in June. (Rajah Bose
for ProPublica)
After the Peluso video was leaked to the press, an IBM spokeswoman told the Wall Street Journal that the "
vast
majority " of people ordered to change locations and begin reporting to offices did so. IBM Vice President Ed Barbini said in
an initial email exchange with ProPublica in July that the new policy affected only about 2,000 U.S. employees and that "most" of
those had agreed to move.
But employees across a wide range of company operations, from the systems and technology group to analytics, told ProPublica they've
also been ordered to co-locate in recent years. Many IBMers with long service said that they quit rather than sell their homes, pull
children from school and desert aging parents. IBM declined to say how many older employees were swept up in the co-location initiative.
"They basically knew older employees weren't going to do it," said Eileen Maroney, a 63-year-old IBM product manager from Aiken,
South Carolina, who, like Harlan, was ordered to move to Raleigh or resign. "Older people aren't going to move. It just doesn't make
any sense." Like Harlan, Maroney left IBM last June.
Having people quit rather than being laid off may help IBM avoid disclosing how much it is shrinking its U.S. workforce and where
the reductions are occurring.
Under the federal WARN Act , adopted in the wake
of huge job cuts and factory shutdowns during the 1980s, companies laying off 50 or more employees who constitute at least one-third
of an employer's workforce at a site have to give advance notice of layoffs to the workers, public agencies and local elected officials.
Similar laws in some states where IBM has a substantial presence are even stricter. California, for example, requires advanced
notice for layoffs of 50 or more employees, no matter what the share of the workforce. New York requires notice for 25 employees
who make up a third.
Because the laws were drafted to deal with abrupt job cuts at individual plants, they can miss reductions that occur over long
periods among a workforce like IBM's that was, at least until recently, widely dispersed because of the company's work-from-home
policy.
IBM's training sessions to prepare managers for layoffs suggest the company was aware of WARN thresholds, especially in states
with strict notification laws such as California. A 2016 document entitled "Employee Separation Processing" and labeled "IBM Confidential"
cautions managers about the "unique steps that must be taken when processing separations for California employees."
A ProPublica review of five years of WARN disclosures for a dozen states where the company had large facilities that shed workers
found no disclosures in nine. In the other three, the company alerted authorities of just under 1,000 job cuts -- 380 in California,
369 in New York and 200 in Minnesota. IBM's reported figures are well below the actual number of jobs the company eliminated in these
states, where in recent years it has shuttered, sold off or leveled plants that once employed vast numbers.
By contrast, other employers in the same 12 states reported layoffs last year alone totaling 215,000 people. They ranged from
giant Walmart to Ostrom's Mushroom Farms in Washington state.
Whether IBM operated within the rules of the WARN act, which are notoriously fungible, could not be determined because the company
declined to provide ProPublica with details on its layoffs.
A Second Act, But Poorer
W ith 35 years at IBM under his belt, Ed Miyoshi had plenty of experience being pushed to take buyouts, or early retirement packages,
and refusing them. But he hadn't expected to be pushed last fall.
Miyoshi, of Hopewell Junction, New York, had some years earlier launched a pilot program to improve IBM's technical troubleshooting.
With the blessing of an IBM vice president, he was busily interviewing applicants in India and Brazil to staff teams to roll the
program out to clients worldwide.
The interviews may have been why IBM mistakenly assumed Miyoshi was a manager, and so emailed him to eliminate the one U.S.-based
employee still left in his group.
"That was me," Miyoshi realized.
In his sign-off email to colleagues shortly before Christmas 2016, Miyoshi, then 57, wrote: "I am too young and too poor to stop
working yet, so while this is good-bye to my IBM career, I fully expect to cross paths with some of you very near in the future."
He did, and perhaps sooner than his colleagues had expected; he started as a subcontractor to IBM about two weeks later, on Jan.
3.
Miyoshi is an example of older workers who've lost their regular IBM jobs and been brought back as contractors. Some of them --
not Miyoshi -- became contract workers after IBM told them their skills were out of date and no longer needed.
Employment law experts said that hiring ex-employees as contractors can be legally dicey. It raises the possibility that the layoff
of the employee was not for the stated reason but perhaps because they were targeted for their age, race or gender.
IBM appears to recognize the problem. Ex-employees say the company has repeatedly told managers -- most recently earlier this
year -- not to contract with former employees or sign on with third-party contracting firms staffed by ex-IBMers. But ProPublica
turned up dozens of instances where the company did just that.
Only two weeks after IBM laid him off in December 2016, Ed Miyoshi of Hopewell Junction, New York, started work as a subcontractor
to the company. But he took a $20,000-a-year pay cut. "I'm not a millionaire, so that's a lot of money to me," he says. (Demetrius
Freeman for ProPublica)
Responding to a question in a confidential questionnaire from ProPublica, one 35-year company veteran from New York said he knew
exactly what happened to the job he left behind when he was laid off. "I'M STILL DOING IT. I got a new gig eight days after departure,
working for a third-party company under contract to IBM doing the exact same thing."
In many cases, of course, ex-employees are happy to have another job, even if it is connected with the company that laid them
off.
Henry, the Columbus-based sales and technical specialist who'd been with IBM's "resiliency services" unit, discovered that he'd
lost his regular IBM job because the company had purchased an Indian firm that provided the same services. But after a year out of
work, he wasn't going to turn down the offer of a temporary position as a subcontractor for IBM, relocating data centers. It got
money flowing back into his household and got him back where he liked to be, on the road traveling for business.
The compensation most ex-IBM employees make as contractors isn't comparable. While Henry said he collected the same dollar amount,
it didn't include health insurance, which cost him $1,325 a month. Miyoshi said his paycheck is 20 percent less than what he made
as an IBM regular.
"I took an over $20,000 hit by becoming a contractor. I'm not a millionaire, so that's a lot of money to me," Miyoshi said.
And lower pay isn't the only problem ex-IBM employees-now-subcontractors face. This year, Miyoshi's payable hours have been cut
by an extra 10 "furlough days." Internal documents show that IBM repeatedly furloughs subcontractors without pay, often for two,
three or more weeks a quarter. In some instances, the furloughs occur with little advance notice and at financially difficult moments.
In one document, for example, it appears IBM managers, trying to cope with a cost overrun spotted in mid-November, planned to dump
dozens of subcontractors through the end of the year, the middle of the holiday season.
Former IBM employees now on contract said the company controls costs by notifying contractors in the midst of projects they have
to take pay cuts or lose the work. Miyoshi said that he originally started working for his third-party contracting firm for 10 percent
less than at IBM, but ended up with an additional 10 percent cut in the middle of 2017, when IBM notified the contractor it was slashing
what it would pay.
For many ex-employees, there are few ways out. Henry, for example, sought to improve his chances of landing a new full-time job
by seeking assistance to finish a college degree through a federal program designed to retrain workers hurt by offshoring of jobs.
But when he contacted the Ohio state agency that administers the Trade Adjustment Assistance, or TAA, program, which provides
assistance to workers who lose their jobs for trade-related reasons, he was told IBM hadn't submitted necessary paperwork. State
officials said Henry could apply if he could find other IBM employees who were laid off with him, information that the company doesn't
provide.
TAA is overseen by the Labor Department but is operated by states under individual agreements with Washington, so the rules can
vary from state to state. But generally employers, unions, state agencies and groups of employers can petition for training help
and cash assistance. Labor Department data compiled by the advocacy group Global Trade Watch shows that employers apply in about
40 percent of cases. Some groups of IBM workers have obtained retraining funds when they or their state have applied, but records
dating back to the early 1990s show IBM itself has applied for and won taxpayer assistance only once, in 2008, for three Chicago-area
workers whose jobs were being moved to India.
Teasing New Jobs
A s IBM eliminated thousands of jobs in 2016, David Carroll, a 52-year-old Austin software engineer, thought he was safe.
His job was in mobile development, the "M" in the company's CAMS strategy. And if that didn't protect him, he figured he was only
four months shy of qualifying for a program that gives employees who leave within a year of their three-decade mark access to retiree
medical coverage and other benefits.
But the layoff notice Carroll received March 2 gave him three months -- not four -- to come up with another job. Having been a
manager, he said he knew the gantlet he'd have to run to land a new position inside IBM.
Still, he went at it hard, applying for more than 50 IBM jobs, including one for a job he'd successfully done only a few years
earlier. For his effort, he got one offer -- the week after he'd been forced to depart. He got severance pay but lost access to what
would have been more generous benefits.
Edward Kishkill, then 60, of Hillsdale, New Jersey, had made a similar calculation.
A senior systems engineer, Kishkill recognized the danger of layoffs, but assumed he was immune because he was working in systems
security, the "S" in CAMS and another hot area at the company.
The precaution did him no more good than it had Carroll. Kishkill received a layoff notice the same day, along with 17 of the
22 people on his systems security team, including Diane Moos. The notice said that Kishkill could look for other jobs internally.
But if he hadn't landed anything by the end of May, he was out.
With a daughter who was a senior in high school headed to Boston University, he scrambled to apply, but came up dry. His last
day was May 31, 2016.
For many, the fruitless search for jobs within IBM is the last straw, a final break with the values the company still says it
embraces. Combined with the company's increasingly frequent request that departing employees train their overseas replacements, it
has left many people bitter. Scores of ex-employees interviewed by ProPublica said that managers with job openings told them they
weren't allowed to hire from layoff lists without getting prior, high-level clearance, something that's almost never given.
ProPublica reviewed documents that show that a substantial share of recent IBM layoffs have involved what the company calls "lift
and shift," lifting the work of specific U.S. employees and shifting it to specific workers in countries such as India and Brazil.
For example, a document summarizing U.S. employment in part of the company's global technology services division for 2015 lists nearly
a thousand people as layoff candidates, with the jobs of almost half coded for lift and shift.
Ex-employees interviewed by ProPublica said the lift-and-shift process required their extensive involvement. For example, shortly
after being notified she'd be laid off, Kishkill's colleague, Moos, was told to help prepare a "knowledge transfer" document and
begin a round of conference calls and email exchanges with two Indian IBM employees who'd be taking over her work. Moos said the
interactions consumed much of her last three months at IBM.
Next Chapters
W hile IBM has managed to keep the scale and nature of its recent U.S. employment cuts largely under the public's radar, the company
drew some unwanted attention during the 2016 presidential campaign, when then-candidate
Donald Trump lambasted it for eliminating 500 jobs in Minnesota, where the company has had a presence for a half century, and
shifting the work abroad.
The company also has caught flak -- in places like
Buffalo, New
York ;
Dubuque, Iowa ; Columbia,
Missouri , and
Baton Rouge, Louisiana -- for promising jobs in return for state and local incentives, then failing to deliver. In all, according
to public officials in those and other places, IBM promised to bring on 3,400 workers in exchange for as much as $250 million in
taxpayer financing but has hired only about half as many.
After Trump's victory, Rometty, in a move at least partly aimed at courting the president-elect, pledged to hire 25,000 new U.S.
employees by 2020. Spokesmen said the hiring would increase IBM's U.S. employment total, although, given its continuing job cuts,
the addition is unlikely to approach the promised hiring total.
When The New York Times ran a story last fall saying IBM now has
more employees in India than the U.S.,
Barbini, the corporate spokesman, rushed to declare, "The U.S. has always been and remains IBM's center of gravity." But his stream
of accompanying tweets and graphics focused
as much on the company's record for racking up patents as hiring people.
IBM has long been aware of the damage its job cuts can do to people. In a series of internal training documents to prepare managers
for layoffs in recent years, the company has included this warning: "Loss of a job often triggers a grief reaction similar to what
occurs after a death."
Most, though not all, of the ex-IBM employees with whom ProPublica spoke have weathered the loss and re-invented themselves.
Marjorie Madfis, the digital marketing strategist, couldn't land another tech job after her 2013 layoff, so she headed in a different
direction. She started a nonprofit called Yes She Can Inc. that provides job skills development for young autistic women, including
her 21-year-old daughter.
After almost two years of looking and desperate for useful work, Brian Paulson, the widely traveled IBM senior manager, applied
for and landed a position as a part-time rural letter carrier in Plano, Texas. He now works as a contract project manager for a Las
Vegas gaming and lottery firm.
Ed Alpern, who started at IBM as a Selectric typewriter repairman, watched his son go on to become a National Merit Scholar at
Texas A&M University, but not a Watson scholarship recipient.
Lori King, the IT specialist and 33-year IBM veteran who's now 56, got in a parting shot. She added an addendum to the retirement
papers the firm gave her that read in part: "It was never my plan to retire earlier than at least age 60 and I am not committing
to retire. I have been informed that I am impacted by a resource action effective on 2016-08-22, which is my last day at IBM, but
I am NOT retiring."
King has aced more than a year of government-funded coding boot camps and university computer courses, but has yet to land a new
job.
David Harlan still lives in Moscow, Idaho, after refusing IBM's "invitation" to move to North Carolina, and is artistic director
of the Moscow Art Theatre (Too).
Ed Miyoshi is still a technical troubleshooter working as a subcontractor for IBM.
Ed Kishkill, the senior systems engineer, works part time at a local tech startup, but pays his bills as an associate at a suburban
New Jersey Staples store.
This year, Paul Henry was back on the road, working as an IBM subcontractor in Detroit, about 200 miles from where he lived in
Columbus. On Jan. 8, he put in a 14-hour day and said he planned to call home before turning in. He died in his sleep.
Correction, March 24, 2018: Eileen Maroney lives in Aiken, South Carolina. The name of her city was incorrect in the original
version of this story.
Do you have information about age discrimination at IBM?
Peter Gosselin joined ProPublica as a contributing
reporter in January 2017 to cover aging. He has covered the U.S. and global economies for, among others, the Los Angeles Times and
The Boston Globe, focusing on the lived experiences of working people. He is the author of "High Wire: The Precarious Financial Lives
of American Families."
Ariana Tobin is an engagement reporter at ProPublica,
where she works to cultivate communities to inform our coverage. She was previously at The Guardian and WNYC. Ariana has also worked
as digital producer for APM's Marketplace and contributed
to outlets including The
New Republic , On Being , the
St. Louis
Beacon and Bustle .
There's not a word of truth quoted in this article. That is, quoted from IBM spokespeople. It's the culture there now. They don't
even realize that most of their customers have become deaf to the same crap from their Sales and Marketing BS, which is even worse
than their HR speak.
The sad truth is that IBM became incapable of taking its innovation (IBM is indeed a world beating, patent generating machine)
to market a long time ago. It has also lost the ability (if it ever really had it) to acquire other companies and foster their
innovation either - they ran most into the ground. As a result, for nearly a decade revenues have declined and resource actions
grown. The resource actions may seem to be the ugly problem, but they're only the symptom of a fat greedy and pompous bureaucracy
that's lost its ability to grow and stay relevant in a very competitive and changing industry. What they have been able to perfect
and grow is their ability to downsize and return savings as dividends (Big Sam Palmisano's "innovation"). Oh, and for senior management
to line their pockets.
Nothing IBM is currently doing is sustainable.
If you're still employed there, listen to the pain in the words of your fallen comrades and don't knock yourself out trying
to stay afloat. Perhaps learn some BS of your own and milk your job (career? not...) until you find freedom and better pastures.
If you own stock, do like Warren Buffett, and sell it while it still has some value.
This is NOTHING NEW! All major corporations have and will do this at some point in their existence. Another industry that does
this regularly every 3 to 5 years is the pharamaceutical industry. They'll decimate their sales forces in order to, as they like
to put it, "right size" the company.
They'll cloak it as weeding out the low performers, but they'll try to catch the "older" workers in the net as well.
"... I took an early retirement package when IBM first started downsizing. I had 30 years with them, but I could see the writing on the wall so I got out. I landed an exec job with a biotech company some years later and inherited an IBM consulting team that were already engaged. I reviewed their work for 2 months then had the pleasure of terminating the contract and actually escorting the team off the premises because the work product was so awful. ..."
"... Every former or prospective IBM employee is a potential future IBM customer or partner. How you treat them matters! ..."
"... I advise IBM customers now. My biggest professional achievements can be measured in how much revenue IBM lost by my involvement - millions. Favorite is when IBM paid customer to stop the bleeding. ..."
I took an early retirement package when IBM first started downsizing. I had 30 years
with them, but I could see the writing on the wall so I got out. I landed an exec job with a
biotech company some years later and inherited an IBM consulting team that were already
engaged. I reviewed their work for 2 months then had the pleasure of terminating the contract
and actually escorting the team off the premises because the work product was so
awful.
They actually did a presentation of their interim results - but it was a 52 slide package
that they had presented to me in my previous job but with the names and numbers changed.
see more
Intellectual Capital Re-Use! LOL! Not many people realize in IBM that many, if not all of the
original IBM Consulting Group materials were made under the Type 2 Materials clause of the
IBM Contract, which means the customers actually owned the IP rights of the documents. Can
you imagine the mess if just one customer demands to get paid for every re-use of the IP that
was developed for them and then re-used over and over again?
Beautiful! Yea, these companies so fast to push experienced people who have dedicated their
lives to the firm - how can you not...all the hours and commitment it takes - way
underestimate the power of the network of those left for dead and their influence in that
next career gig. Memories are long...very long when it comes to experiences like this.
I advise IBM customers now. My biggest professional achievements can be measured in how
much revenue IBM lost by my involvement - millions. Favorite is when IBM paid customer to
stop the bleeding.
"... As long as companies pay for their employees' health insurance they will have an incentive to fire older employees. ..."
"... The answer is to separate health insurance from employment. Companies can't be trusted. Not only health care, but retirement is also sorely abused by corporations. All the money should be in protected employee based accounts. ..."
American companies pay health insurance premiums based on their specific employee profiles. Insurance companies compete with each
other for the business, but costs are actual. And based on the profile of the pool of employees. So American companies fire older
workers just to lower the average age of their employees. Statistically this is going to lower their health care costs.
As long as companies pay for their employees' health insurance they will have an incentive to fire older employees.
They have an incentive to fire sick employees and employees with genetic risks. Those are harder to implement as ways to
lower costs. Firing older employees is simple to do, just look up their ages.
The answer is to separate health insurance from employment. Companies can't be trusted. Not only health care, but retirement
is also sorely abused by corporations. All the money should be in protected employee based accounts.
By the way, most tech companies are actually run by older people. The goal is to broom out mid-level people based on age. Nobody
is going to suggest to a sixty year old president that they should self fire, for the good of the company.
"... It's no coincidence whatsoever that Diane Gherson, mentioned prominently in the article, blasted out an all-employees email crowing about IBM being a great place to work according to (ahem) LinkedIn. I desperately want to post a link to this piece in the corporate Slack, but that would get me fired immediately instead of in a few months at the next "resource action." It's been a whole 11 months since our division had one, so I know one is coming soon. ..."
"... I used to say when I was there that: "After every defeat, they pin medals on the generals and shoot the soldiers". ..."
"... 1990 is also when H-1B visa rules were changed so that companies no longer had to even attempt to hire an American worker as long as the job paid $60,000, which hasn't changed since. This article doesn't even mention how our work visa system facilitated and even rewarded this abuse of Americans. ..."
"... Well, starting in the 1980s, the American management was allowed by Reagan to get rid of its workforce. ..."
"... It's all about making the numbers so the management can present a Potemkin Village of profits and ever-increasing growth sufficient to get bonuses. There is no relation to any sort of quality or technological advancement, just HR 3-card monte. They have installed air bearing in Old Man Watson's coffin as it has been spinning ever faster ..."
"... Corporate America executive management is all about stock price management. Their bonus's in the millions of dollars are based on stock performance. With IBM's poor revenue performance since Ginny took over, profits can only be maintained by cost reduction. Look at the IBM executive's bonus's throughout the last 20 years and you can see that all resource actions have been driven by Palmisano's and Rominetty's greed for extravagant bonus's. ..."
"... Also worth noting is that IBM drastically cut the cap on it's severance pay calculation. Almost enough to make me regret not having retired before that changed. ..."
"... Yeah, severance started out at 2 yrs pay, went to 1 yr, then to 6 mos. and is now 1 month. ..."
"... You need to investigate AT&T as well, as they did the same thing. I was 'sold' by IBM to AT&T as part of he Network Services operation. AT&T got rid of 4000 of the 8000 US employees sent to AT&T within 3 years. Nearly everyone of us was a 'senior' employee. ..."
dragonflap• 7
months ago I'm a 49-year-old SW engineer who started at IBM as part of an acquisition in 2000. I got laid off in 2002 when IBM
started sending reqs to Bangalore in batches of thousands. After various adventures, I rejoined IBM in 2015 as part of the "C" organization
referenced in the article.
It's no coincidence whatsoever that Diane Gherson, mentioned prominently in the article, blasted out an all-employees email
crowing about IBM being a great place to work according to (ahem) LinkedIn. I desperately want to post a link to this piece in the
corporate Slack, but that would get me fired immediately instead of in a few months at the next "resource action." It's been a whole
11 months since our division had one, so I know one is coming soon.
The lead-in to this piece makes it sound like IBM was forced into these practices by inescapable forces. I'd say not, rather
that it pursued them because a) the management was clueless about how to lead IBM in the new environment and new challenges so
b) it started to play with numbers to keep the (apparent) profits up....to keep the bonuses coming. I used to say when I was
there that: "After every defeat, they pin medals on the generals and shoot the soldiers".
And then there's the Pig with the Wooden Leg shaggy dog story that ends with the punch line, "A pig like that you don't eat
all at once", which has a lot of the flavor of how many of us saw our jobs as IBM die a slow death.
IBM is about to fall out of the sky, much as General Motors did. How could that happen? By endlessly beating the cow to get
more milk.
IBM was hiring right through the Great Depression such that It Did Not Pay Unemployment Insurance. Because it never laid people
off, Because until about 1990, your manager was responsible for making sure you had everything you needed to excel and grow....and
you would find people that had started on the loading dock and had become Senior Programmers. But then about 1990, IBM starting
paying unemployment insurance....just out of the goodness of its heart. Right.
1990 is also when H-1B visa rules were changed so that companies no longer had to even attempt to hire an American worker
as long as the job paid $60,000, which hasn't changed since. This article doesn't even mention how our work visa system facilitated
and even rewarded this abuse of Americans.
I found that other Ex-IBMer's respect other Ex-IBMer's work ethics, knowledge and initiative.
Other companies are happy to get them as a valueable resource. In '89 when our Palo Alto Datacenter moved, we were given two
options: 1.) to become a Programmer (w/training) 2.) move to Boulder or 3.) to leave.
I got my training with programming experience and left IBM in '92, when for 4 yrs IBM offerred really good incentives for leaving
the company. The Executives thought that the IBM Mainframe/MVS z/OS+ was on the way out and the Laptop (Small but Increasing Capacity)
Computer would take over everything.
It didn't. It did allow many skilled IBMers to succeed outside of IBM and help built up our customer skill sets. And like many,
when the opportunity arose to return I did. In '91 I was accidentally given a male co-workers paycheck and that was one of the
reasons for leaving. During my various Contract work outside, I bumped into other male IBMer's that had left too, some I had trained,
and when they disclosed that it was their salary (which was 20-40%) higher than mine was the reason they left, I knew I had made
the right decision.
Women tend to under-value themselves and their capabilities. Contracting also taught me that companies that had 70% employees
and 30% contractors, meant that contractors would be let go if they exceeded their quarterly expenditures.
I first contracted with IBM in '98 and when I decided to re-join IBM '01, I had (3) job offers and I took the most lucrative
exciting one to focus on fixing & improving DB2z Qry Parallelism. I developed a targeted L3 Technical Change Team to help L2 Support
reduce Customer problems reported and improve our product. The instability within IBM remained and I saw IBM try to eliminate
aging, salaried, benefited employees. The 1.) find a job within IBM ... to 2.) to leave ... was now standard.
While my salary had more than doubled since I left IBM the first time, it still wasn't near other male counterparts. The continual
rating competition based on salary ranged titles and timing a title raise after a round of layoffs, not before. I had another
advantage going and that was that my changed reduced retirement benefits helped me stay there. It all comes down to the numbers
that Mgmt is told to cut & save IBM. While much of this article implies others were hired, at our Silicon Valley Location and
other locations, they had no intent to backfill. So the already burdened employees were laden with more workloads & stress.
In the early to mid 2000's IBM setup a counter lab in China where they were paying 1/4th U.S. salaries and many SVL IBMers
went to CSDL to train our new world 24x7 support employees. But many were not IBM loyal and their attrition rates were very high,
so it fell to a wave of new-hires at SVL to help address it.
It's all about making the numbers so the management can present a Potemkin Village of profits and ever-increasing growth
sufficient to get bonuses. There is no relation to any sort of quality or technological advancement, just HR 3-card monte. They
have installed air bearing in Old Man Watson's coffin as it has been spinning ever faster
Corporate America executive management is all about stock price management. Their bonus's in the millions of dollars are
based on stock performance. With IBM's poor revenue performance since Ginny took over, profits can only be maintained by cost
reduction. Look at the IBM executive's bonus's throughout the last 20 years and you can see that all resource actions have been
driven by Palmisano's and Rominetty's greed for extravagant bonus's.
Bravo ProPublica for another "sock it to them" article - journalism in honor of the spirit of great newspapers everywhere that
the refuge of justice in hard times is with the press.
Also worth noting is that IBM drastically cut the cap on it's severance pay calculation. Almost enough to make me regret
not having retired before that changed.
You need to investigate AT&T as well, as they did the same thing. I was 'sold' by IBM to AT&T as part of he Network Services
operation. AT&T got rid of 4000 of the 8000 US employees sent to AT&T within 3 years. Nearly everyone of us was a 'senior' employee.
As a permanent old contractor and free-enterprise defender myself, I don't blame IBM a bit for wanting to cut the fat. But
for the outright *lies, deception and fraud* that they use to break laws, weasel out of obligations... really just makes me want
to shoot them... and I never even worked for them.
Where I worked, In Rochester,MN, people have known what is happening for years. My last years with IBM were the most depressing
time in my life.
I hear a rumor that IBM would love to close plants they no longer use but they are so environmentally polluted that it is cheaper
to maintain than to clean up and sell.
One of the biggest driving factors in age discrimination is health insurance costs, not salary. It can cost 4-5x as much to
insure and older employee vs. a younger one, and employers know this. THE #1 THING WE CAN DO TO STOP AGE DISCRIMINATION IS TO
MOVE AWAY FROM OUR EMPLOYER-PROVIDED INSURANCE SYSTEM. It could be single-payer, but it could also be a robust individual market
with enough pool diversification to make it viable. Freeing employers from this cost burden would allow them to pick the right
talent regardless of age.
The American business have constantly fought against single payer since the end of World War II and why should I feel sorry
for them when all of a sudden, they are complaining about health care costs? It is outrageous that workers have to face age discrimination;
however, the CEOs don't have to deal with that issue since they belong to a tiny group of people who can land a job anywhere else.
Single payer won't help. We have single payer in Canada and just as much age discrimination in employment. Society in general
does not like older people so unless you're a doctor, judge or pharmacist you will face age bias. It's even worse in popular culture
never mind in employment.
Thanks for the great article. I left IBM last year. USA based. 49. Product Manager in one of IBMs strategic initiatives, however
got told to relocate or leave. I found another job and left. I came to IBM from an acquisition. My only regret is, I wish I had
left this toxic environment earlier. It truely is a dreadful place to work.
The methodology has trickled down to smaller companies pursuing the same net results for headcount reduction. The similarities
to my experience were painful to read. The grief I felt after my job was "eliminated" 10 years ago while the Recession was at
its worst and shortly after my 50th birthday was coming back. I never have recovered financially but have started writing a murder
mystery. The first victim? The CEO who let me go. It's true. Revenge is best served cold.
Well written . people like me have experienced exactly what you wrote. IBM is a shadow of it's former greatness and I have
advised my children to stay away from IBM and companies like it as they start their careers. IBM is a corrupt company. Shame on
them !
I suspect someone will end up hunt them down with an axe at some point. That's the only way they'll probably learn. I don't
know about IBM specifically, but when Carly Fiorina ran HP, she travelled with and even went into engineering labs with an armed
security detail.
Was let go after 34 years of service. Mine Resource Action latter had additional lines after '...unless you are offered ...
position within IBM before that date.' , implying don't even try to look for a position. They lines were ' Additional business
controls are in effect to manage the business objectives of this resource action, therefore, job offers within (the name of division)
will be highly unlikely.'.
I've worked for a series of vendors for over thirty years. A job at IBM used to be the brass ring; nowadays, not so much.
I've heard persistent rumors from IBMers that U.S. headcount is below 25,000 nowadays. Given events like the recent downtime
of the internal systems used to order parts (5 or so days--website down because staff who maintained it were let go without replacements),
it's hard not to see the spiral continue down the drain.
What I can't figure out is whether Rometty and cronies know what they're doing or are just clueless. Either way, the result
is the same: destruction of a once-great company and brand. Tragic.
Well, none of these layoffs/ageist RIFs affect the execs, so they don't see the effects, or they see the effects but attribute
them to some other cause.
(I'm surprised the article doesn't address this part of the story; how many affected by layoffs are exec/senior management?
My bet is very few.)
I was a D-banded exec (Director-level) who was impacted and I know even some VPs who were affected as well, so they do spread
the pain, even in the exec ranks.
That's different than I have seen in companies I have worked for (like HP). There RIFs (Reduction In Force, their acronym for
layoff) went to the director level and no further up.
F or nearly a half century, IBM came as close as any company to bearing the torch for the American Dream.
As the world's dominant technology firm, payrolls at International Business Machines Corp. swelled to nearly a quarter-million
U.S. white-collar workers in the 1980s. Its profits helped underwrite a broad agenda of racial equality, equal pay for women and
an unbeatable offer of great wages and something close to lifetime employment, all in return for unswerving loyalty.
But when high tech suddenly started shifting and companies went global, IBM faced the changing landscape with a distinction most
of its fiercest competitors didn't have: a large number of experienced and aging U.S. employees.
The company reacted with a strategy that, in the words of one confidential planning document, would "correct seniority mix." It
slashed IBM's U.S. workforce by as much as three-quarters from its 1980s peak, replacing a substantial share with younger, less-experienced
and lower-paid workers and sending many positions overseas. ProPublica estimates that in the past five years alone, IBM has eliminated
more than 20,000 American employees ages 40 and over, about 60 percent of its estimated total U.S. job cuts during those years.
In making these cuts, IBM has flouted or outflanked U.S. laws and regulations intended to protect later-career workers from age
discrimination, according to a ProPublica review of internal company documents, legal filings and public records, as well as information
provided via interviews and questionnaires filled out by more than 1,000 former IBM employees.
Among ProPublica's findings, IBM:
Denied older workers information the law says they need in order to decide whether they've been victims of age bias, and required
them to sign away the right to go to court or join with others to seek redress. Targeted people for layoffs and firings with techniques
that tilted against older workers, even when the company rated them high performers. In some instances, the money saved from the
departures went toward hiring young replacements. Converted job cuts into retirements and took steps to boost resignations and firings.
The moves reduced the number of employees counted as layoffs, where high numbers can trigger public disclosure requirements. Encouraged
employees targeted for layoff to apply for other IBM positions, while quietly advising managers not to hire them and requiring many
of the workers to train their replacements. Told some older employees being laid off that their skills were out of date, but then
brought them back as contract workers, often for the same work at lower pay and fewer benefits.
IBM declined requests for the numbers or age breakdown of its job cuts. ProPublica provided the company with a 10-page summary
of its findings and the evidence on which they were based. IBM spokesman Edward Barbini said that to respond the company needed to
see copies of all documents cited in the story, a request ProPublica could not fulfill without breaking faith with its sources. Instead,
ProPublica provided IBM with detailed descriptions of the paperwork. Barbini declined to address the documents or answer specific
questions about the firm's policies and practices, and instead issued the following statement:
"We are proud of our company and our employees' ability to reinvent themselves era after era, while always complying with the
law. Our ability to do this is why we are the only tech company that has not only survived but thrived for more than 100 years."
With nearly 400,000 people worldwide, and tens of thousands still in the U.S., IBM remains a corporate giant. How it handles the
shift from its veteran baby-boom workforce to younger generations will likely influence what other employers do. And the way it treats
its experienced workers will eventually affect younger IBM employees as they too age.
Fifty years ago, Congress made it illegal with the Age Discrimination
in Employment Act , or ADEA, to treat older workers differently than younger ones with only a few exceptions, such as jobs that
require special physical qualifications. And for years, judges and policymakers treated the law as essentially on a par with prohibitions
against discrimination on the basis of race, gender, sexual orientation and other categories.
In recent decades, however, the courts have responded to corporate pleas for greater leeway to meet global competition and satisfy
investor demands for rising profits by expanding the exceptions and
shrinking
the protections against age bias .
"Age discrimination is an open secret like sexual harassment was until recently," said Victoria Lipnic, the acting chair of the
Equal Employment Opportunity Commission, or EEOC, the independent federal agency that administers the nation's workplace anti-discrimination
laws.
"Everybody knows it's happening, but often these cases are difficult to prove" because courts have weakened the law, Lipnic said.
"The fact remains it's an unfair and illegal way to treat people that can be economically devastating."
Many companies have sought to take advantage of the court rulings. But the story of IBM's downsizing provides an unusually detailed
portrait of how a major American corporation systematically identified employees to coax or force out of work in their 40s, 50s and
60s, a time when many are still productive and need a paycheck, but face huge hurdles finding anything like comparable jobs.
The dislocation caused by IBM's cuts has been especially great because until recently the company encouraged its employees to
think of themselves as "IBMers" and many operated under the assumption that they had career-long employment.
When the ax suddenly fell, IBM provided almost no information about why an employee was cut or who else was departing, leaving
people to piece together what had happened through websites, listservs and Facebook groups such as "Watching IBM" or "Geographically
Undesirable IBM Marketers," as well as informal support groups.
Marjorie Madfis, at the time 57, was a New York-based digital marketing strategist and 17-year IBM employee when she and six other
members of her nine-person team -- all women in their 40s and 50s -- were laid off in July 2013. The two who remained were younger
men.
Since her specialty was one that IBM had said it was expanding, she asked for a written explanation of why she was let go. The
company declined to provide it.
"They got rid of a group of highly skilled, highly effective, highly respected women, including me, for a reason nobody knows,"
Madfis said in an interview. "The only explanation is our age."
Brian Paulson, also 57, a senior manager with 18 years at IBM, had been on the road for more than a year overseeing hundreds of
workers across two continents as well as hitting his sales targets for new services, when he got a phone call in October 2015 telling
him he was out. He said the caller, an executive who was not among his immediate managers, cited "performance" as the reason, but
refused to explain what specific aspects of his work might have fallen short.
It took Paulson two years to land another job, even though he was equipped with an advanced degree, continuously employed at high-level
technical jobs for more than three decades and ready to move anywhere from his Fairview, Texas, home.
"It's tough when you've worked your whole life," he said. "The company doesn't tell you anything. And once you get to a certain
age, you don't hear a word from the places you apply."
Paul Henry, a 61-year-old IBM sales and technical specialist who loved being on the road, had just returned to his Columbus home
from a business trip in August 2016 when he learned he'd been let go. When he asked why, he said an executive told him to "keep your
mouth shut and go quietly."
Henry was jobless more than a year, ran through much of his savings to cover the mortgage and health insurance and applied for
more than 150 jobs before he found a temporary slot.
"If you're over 55, forget about preparing for retirement," he said in an interview. "You have to prepare for losing your job
and burning through every cent you've saved just to get to retirement."
IBM's latest actions aren't anything like what most ex-employees with whom ProPublica talked expected from their years of service,
or what today's young workers think awaits them -- or are prepared to deal with -- later in their careers.
"In a fast-moving economy, employers are always going to be tempted to replace older workers with younger ones, more expensive
workers with cheaper ones, those who've performed steadily with ones who seem to be up on the latest thing," said Joseph Seiner,
an employment law professor at the University of South Carolina and former appellate attorney for the EEOC.
"But it's not good for society," he added. "We have rules to try to maintain some fairness in our lives, our age-discrimination
laws among them. You can't just disregard them."
Fedora is fully owned by Red Hat and CentOS requires the availability of the Red Hat
repositories which they aren't obliged to make public to non-customers..
Fedora is fully under Red Hat's control. It's used as a bleeding edge distro for hobbyists
and as a testing ground for code before it goes into RHEL. I doubt its going away since it
does a great job of establishing mindshare but no business in their right mind is going to
run Fedora in production.
But CentOS started as a separate organization with a fairly adversarial relationship to
Red Hat since it really is free RHEL which cuts into their actual customer base. They didn't
need Red Hat repos back then, just the code which they rebuilt from scratch (which is why
they were often a few months behind).
If IBM kills CentOS a new one will pop up in a week, that's the beauty of the GPL.
Perhaps someone can explain this... Red Hat's revenue and assets barely total about $5B. Even
factoring in market share and capitalization, how the hey did IBM come up with $34B cash
being a justifiable purchase price??
Honestly, why would Red Hat have said no? 1648 posts | registered 4/3/2012
IBM has been fumbling around for a while. They didn't know how to sell Watson as they
sold it like a weird magical drop in service and it failed repeatedly, where really it
should be a long term project that you bring customer's along for the ride...
I had a buddy using their cloud service and they went to spin up servers and IBM was all
"no man we have to set them up first".... like that's not cloud IBM...
If IBM can't figure out how to sell its own services I'm not sure the powers that be are
capable of getting the job done ever. IBM's own leadership seems incompatible with the
state of the world.
IBM basically bought a ton of service contracts for companies all over the world. This is
exactly what the suits want: reliable cash streams without a lot of that pesky development
stuff.
IMHO this is perilous for RHEL. It would be very easy for IBM to fire most of the
developers and just latch on to the enterprise services stuff to milk it till its dry.
I can only see this as a net positive - the ability to scale legacy mainframes onto "Linux"
and push for even more security auditing.
I would imagine the RHEL team will get better funding but I would be worried if you're a
centos or fedora user.
I'm nearly certain that IBM's management ineptitude will kill off Fedora and CentOS (or at
least severely gimp them compared to how they currently are), not realizing how massively
important both of these projects are to the core RHEL product. We'll see RHEL itself suffer
as a result.
I normally try to understand things with an open mindset, but in this case, IBM has had
too long of a history of doing things wrong for me to trust them. I'll be watching this
carefully and am already prepping to move off of my own RHEL servers once the support
contract expires in a couple years just in case it's needed.
My previous job (6+ years ago now) was at a university that was rather heavily invested in
IBM for a high performance research cluster. It was something around 100 or so of their
X-series blade servers, all of which were running Red Hat Linux. It wouldn't surprise me if
they decided to acquire Red Hat in large part because of all these sorts of IBM systems that
run Red Hat on them.
blockquote> Will IBM even know what to do with them?
My previous job (6+ years ago now) was at a university that was rather heavily invested in
IBM for a high performance research cluster. It was something around 100 or so of their
X-series blade servers, all of which were running Red Hat Linux. It wouldn't surprise me if
they decided to acquire Red Hat in large part because of all these sorts of IBM systems that
run Red Hat on them.
That was my thought. IBM wants to own an operating system again. With AIX being relegated
to obscurity, buying Red Hat is simpler than creating their own Linux fork.
Valuing Red Hat at $34 billion means valuing it at more than 1/4 of IBMs current market cap.
From my perspective this tells me IBM is in even worse shape than has been reported.
"... Adjusting for inflation, I make $6K less than I did my first day. My group is a handful of people as at least 1/2 have quit or retired. To support our customers, we used to have several people, now we have one or two and if someone is sick or on vacation, our support structure is to hope nothing breaks. ..."
I've worked there 17 years and have worried about being layed off for about 11 of them. Moral is in the toilet. Bonuses for the
rank and file are in the under 1% range while the CEO gets millions. Pay raises have been non existent or well under inflation
for years.
Adjusting for inflation, I make $6K less than I did my first day. My group is a handful of people as at least 1/2 have
quit or retired. To support our customers, we used to have several people, now we have one or two and if someone is sick or on
vacation, our support structure is to hope nothing breaks.
We can't keep millennials because of pay, benefits and the expectation of being available 24/7 because we're shorthanded. As
the unemployment rate drops, more leave to find a different job, leaving the old people as they are less willing to start over
with pay, vacation, moving, selling a house, pulling kids from school, etc.
The younger people are generally less likely to be willing to work as needed on off hours or to pull work from a busier colleague.
I honestly have no idea what the plan is when the people who know what they are doing start to retire, we are way top heavy
with 30-40 year guys who are on their way out, very few of the 10-20 year guys due to hiring freezes and we can't keep new people
past 2-3 years. It's like our support business model is designed to fail.
Maybe we get really lucky and they RIF Lennart Poettering or he quits? I hear IBM doesn't
tolerate prima donnas and cults of personality quite as much as RH?
IBM already had access to Red Hat's patents, including for patent defence purposes. Look
up "open innovation network".
This acquisition is about: (1) IBM needing growth, or at least a plausible scenario for
growth. (2) Red Hat wanting an easy expansion of its sales channels, again for growth. (3)
Red Hat stockholders being given an offer they can't refuse.
This acquisition is not about: cultural change at IBM. Which is why the acquisition will
'fail'. The bottom line is that engineering matters at the moment (see: Google, Amazon), and
IBM sacked their engineering culture across the past two decades. To be successful IBM need
to get that culture back, and acquiring Red Hat gives IBM the opportunity to create a
product-building, client-service culture within IBM. Except that IBM aren't taking the
opportunity, so there's a large risk the reverse will happen -- the acquisition will destroy
Red Hat's engineering- and service-oriented culture.
This could be interesting: will the systemd kraken manage to wrap its tentacles around the
big blue container ship and bring it to a halt, or will the container ship turn out to be
well armed and fatally harpoon the kraken (causing much rejoicing in the rest of the Linux
world)?
you can change the past so that a "proper replacement" isn't automatically expected to do
lots of things that systemd does. That damage is done. We got "better is worse" and enough
people liked it-- good luck trying to go back to "worse is better"
I presume they were waiting to see what happened to Solaris. When Oracle bought Sun
(presumably the only other company who might have bought them was IBM) there were really
three enterprise unixoid platforms: Solaris, AIX and RHEL (there were some smaller ones and
some which were clearly dying like HPUX). It seemed likely at the time, but not yet certain,
that Solaris was going to die (I worked for Sun at the time this happened and that was my
opinion anyway). If Solaris did die, then if one company owned both AIX and RHEL then that
company would own the enterprise unixoid market. If Solaris didn't die on the other
hand then RHEL would be a lot less valuable to IBM as there would be meaningful competition.
So, obviously, they waited to see what would happen.
Well, Solaris is perhaps not technically quite dead yet but certainly is moribund, and IBM
now owns both AIX and RHEL & hence the enterprise unixoid market. As an interesting
side-note, unless Oracle can keep Solaris on life-support this means that IBM own all-but own
Oracle's OS as well ('Oracle Linux' is RHEL with, optionally, some of their own additions to
the kernel).
"... "It's a desperate deal by a company that missed the boat for the last five years," the managing director at BTIG said on " Closing Bell ." "I'm not surprised that they bought Red Hat , I'm surprised that it took them so long. They've been behind the cloud eight ball." ..."
IBM's $34 billion acquisition of Red Hat is a last-ditch effort by IBM to play catch-up
in the cloud industry, says BTIG's Joel Fishbein.
"It's a desperate deal by a company that missed the boat for the last five years,"
Fishbein says.
The software maker will become a unit of IBM's Hybrid Cloud division, bringing it one
step closer to becoming "relevant again in the space," Fishbein says.
IBM's
$34 billion acquisition of Red Hat is a last-ditch effort by IBM to play catch-up in the cloud industry,
analyst Joel Fishbein told CNBC on Monday.
"It's a desperate deal by a company that missed the boat for the last five years," the
managing director at BTIG said on " Closing Bell ." "I'm not surprised that they bought
Red Hat , I'm surprised
that it took them so long. They've been behind the cloud eight ball."
This is IBM's largest deal ever and the third-biggest tech deal in the history of the United
States. IBM is paying more than a 60 percent premium for the software maker, but
CEO Ginni Rometty told CNBC earlier in the day it was a "fair price."
As a 25yr+ vet of IBM, I can confirm that this article is spot-on true. IBM used to be a proud and transparent company that clearly
demonstrated that it valued its employees as much as it did its stock performance or dividend rate or EPS, simply because it is
good for business. Those principles helped make and keep IBM atop the business world as the most trusted international brand and
business icon of success for so many years. In 2000, all that changed when Sam Palmisano became the CEO. Palmisano's now infamous
"Roadmap 2015" ran the company into the ground through its maniacal focus on increasing EPS at any and all costs. Literally.
Like, its employees, employee compensation, benefits, skills, and education opportunities. Like, its products, product innovation,
quality, and customer service.
All of which resulted in the devastation of its technical capability and competitiveness, employee engagement, and customer
loyalty. Executives seemed happy enough as their compensation grew nicely with greater financial efficiencies, and Palisano got
a sweet $270M+ exit package in 2012 for a job well done.
The new CEO, Ginni Rometty has since undergone a lot of scrutiny for her lack of business results, but she was screwed from
day one. Of course, that doesn't leave her off the hook for the business practices outlined in the article, but what do you expect:
she was hand picked by Palmisano and approved by the same board that thought Palmisano was golden.
People (and companies) who have nothing to hide, hide nothing. People (and companies) who are proud of their actions, share
it proudly. IBM believes it is being clever and outsmarting employment discrimination laws and saving the company money while
retooling its workforce. That may end up being so (but probably won't), but it's irrelevant. Through its practices, IBM has lost
the trust of its employees, customers, and ironically, stockholders (just ask Warren Buffett), who are the very(/only) audience
IBM was trying to impress. It's just a huge shame.
I agree with many who state the report is well done. However, this crap started in the early 1990s. In the late 1980s, IBM offered
decent packages to retirement eligible employees. For those close to retirement age, it was a great deal - 2 weeks pay for every
year of service (capped at 26 years) plus being kept on to perform their old job for 6 months (while collecting retirement, until
the government stepped in an put a halt to it). Nobody eligible was forced to take the package (at least not to general knowledge).
The last decent package was in 1991 - similar, but not able to come back for 6 months. However, in 1991, those offered the package
were basically told take it or else. Anyone with 30 years of service or 15 years and 55 was eligible and anyone within 5 years
of eligibility could "bridge" the difference. They also had to sign a form stating they would not sue IBM in order to get up to
a years pay - not taxable per IRS documents back then (but IBM took out the taxes anyway and the IRS refused to return - an employee
group had hired lawyers to get the taxes back, a failed attempt which only enriched the lawyers). After that, things went downhill
and accelerated when Gerstner took over. After 1991, there were still a some workers who could get 30 years or more, but that
was more the exception. I suspect the way the company has been run the past 25 years or so has the Watsons spinning in their graves.
Gone are the 3 core beliefs - "Respect for the individual", "Service to the customer" and "Excellence must be a way of life".
IBM's policy reminds me of the "If a citizen = 30 y.o., then mass execute such, else if they run then hunt and kill them one by
one" social policy in the Michael York movie "Logan's Run."
From Wiki, in case you don't know: "It depicts a utopian future society on the surface, revealed as a dystopia where the population
and the consumption of resources are maintained in equilibrium by killing everyone who reaches the age of 30. The story follows
the actions of Logan 5, a "Sandman" who has terminated others who have attempted to escape death, and is now faced with termination
himself."
Perhaps someone can explain this... Red Hat's revenue and assets barely total about $5B.
Even factoring in market share and capitalization, how the hey did IBM come up with $34B
cash being a justifiable purchase price??
Honestly, why would Red Hat have said no?
You don't trade at your earnings, you trade at your share price, which for Red Hat and
many other tech companies can be quite high on Price/Earnings. They were trading at 52 P/E.
Investors factor in a bunch of things involving future growth, and particularly for any
companies in the cloud can quite highly overvalue things.
A 25 year old company trading at a P/E of 52 was already overpriced, buying at more than 2x
that is insane. This might just be the deal that kills IBM because there's no way that they
don't do a writedown of 90% of the value of this acquisition within 5 years.
3 hours ago
afidel wrote: show nested quotes
Kilroy420 wrote: Perhaps someone can explain this... Red Hat's revenue and assets barely
total about $5B. Even factoring in market share and capitalization, how the hey did IBM come up
with $34B cash being a justifiable purchase price??
Honestly, why would Red Hat have said no?
You don't trade at your earnings, you trade at your share price, which for Red Hat and many
other tech companies can be quite high on Price/Earnings. They were trading at 52 P/E.
Investors factor in a bunch of things involving future growth, and particularly for any
companies in the cloud can quite highly overvalue things.
A 25 year old company trading at a P/E of 52 was already overpriced, buying at more than 2x
that is insane. This might just be the deal that kills IBM because there's no way that they
don't do a writedown of 90% of the value of this acquisition within 5 years.
OK. I did 10 years at IBM Boulder..
The problem isn't the purchase price or the probable write-down later.
The problem is going to be with the executives above it. One thing I noticed at IBM is that
the executives needed to put their own stamp on operations to justify their bonuses. We were on
a 2 year cycle of execs coming in and saying "Whoa.. things are too centralized, we need to
decentralize", then the next exec coming in and saying "things are too decentralized, we need
to centralize".
No IBM exec will get a bonus if they are over RedHat and exercise no authority over it. "We
left it alone" generates nothing for the PBC. If they are in the middle of a re-org, then the
specific metrics used to calculate their bonus can get waived. (Well, we took an unexpected hit
this year on sales because we are re-orging to better optimize our resources). With that P/E,
no IBM exec is going to get a bonus based on metrics. IBM execs do *not* care about what is
good for IBM's business. They are all about gaming the bonuses. Customers aren't even on the
list of things they care about.
I am reminded of a coworker who quit in frustration back in the early 2000's due to just
plain bad management. At the time, IBM was working on Project Monterey. This was supposed to be
a Unix system across multiple architectures. My coworker sent his resignation out to all hands
basically saying "This is stupid. we should just be porting Linux". He even broke down the
relative costs. Billions for Project Monterey vs thousands for a Linux port. Six months later,
we get an email from on-high announcing this great new idea that upper management had come up
with. It would be far cheaper to just support Linux than write a new OS.. you'd think that
would be a great thing, but the reality is that all it did was create the AIX 5L family, which
was AIX 5 with an additional CD called Linux ToolBox, which was loaded with a few Linux
programs ported to a specific version of AIX, but never kept current. IBM can make even great
decisions into bad decisions.
In May 2007, IBM announced the transition to LEAN. Sounds great, but this LEAN was not on
the manufacturing side of the equation. It was in e-Business under Global Services. The new
procedures were basically call center operations. Now, prior to this, IBM would have specific
engineers for specific accounts. So, Major Bank would have that AIX admin, that Sun admin, that
windows admin, etc. They knew who to call and those engineers would have docs and institutional
knowledge of that account. During the LEAN announcement, Bob Moffat described the process.
Accounts would now call an 800 number and the person calling would open a ticket. This would
apply to *any* work request as all the engineers would be pooled and whoever had time would get
the ticket. So, reset a password - ticket. So, load a tape - ticket. Install 20 servers -
ticket.
Now, the kicker to this was that the change was announced at 8AM and went live at noon. IBM
gave their customers who represented over $12 Billion in contracts 4 *hours* notice that they
were going to strip their support teams and treat them like a call center. (I will leave it as
an exercise to the reader to determine if they would accept that kind of support after spending
hundreds of millions on a support contract).
(The pilot program for the LEAN process had its call center outsourced overseas, if that
helps you try to figure out why IBM wanted to get rid of dedicated engineers and move to a
call-center operation).
IBM will have to work hard to overcome RH customers' natural (and IMHO largely justified)
suspicion of Big Blue.
Notable quotes:
"... focused its workforce on large "hub" cities where graduate engineers prefer to live – New York City, San Francisco, and Austin, in the US for instance – which allowed it to drive out older, settled staff who refused to move closer to the office. ..."
"... The acquisition of Sun Microsystems by Oracle comes to mind there. ..."
"... When Microsoft bought out GitHub, they made a promise to let it run independently and now IBM's given a similar pledge in respect of RedHat. They ought to abide by that promise because the alternatives are already out there in the form of Ubuntu and SUSE Linux Enterprise Server. ..."
...That transformation has led to accusations of Big Blue ditching its
older staff for newer workers to somehow spark some new energy within it. It also
cracked down on
remote employees , and focused its workforce on large "hub" cities where graduate engineers
prefer to live – New York City, San Francisco, and Austin, in the US for instance –
which allowed it to drive out older, settled staff who refused to move closer to the
office.
Easy, the same way they deal with their existing employees. It'll be the IBM way or the
highway. We'll see the usual repetitive and doomed IBM strategy of brutal downsizings
accompanied by the earnest IBM belief that a few offshore wage slaves can do as good a job as
anybody else.
The product and service will deteriorate, pricing will have to go up significantly to
recover the tens of billions of dollars of "goodwill" that IBM have just splurged, and in
five years time we'll all be saying "remember how the clueless twats at IBM bought Red Hat
and screwed it up?"
One of IBM's main problems is lack of revenue, and yet Red Hat only adds about $3bn to
their revenue. As with most M&A the motivators here are a surplus of cash and hopeless
optimism, accompanied by the suppression of all common sense.
"What happens over the next 12 -- 24 months will be ... interesting. Usually the
acquisition of a relatively young, limber outfit with modern product and service by one of
the slow-witted traditional brontosaurs does not end well"
The acquisition of Sun Microsystems by Oracle comes to mind there.
When Microsoft bought
out GitHub, they made a promise to let it run independently and now IBM's given a similar
pledge in respect of RedHat. They ought to abide by that promise because the alternatives are
already out there in the form of Ubuntu and SUSE Linux Enterprise Server.
"... IBM was already "working on Linux." For decades. With multiple hundreds of full-time Linux developers--more than any other corporate contributor--around the world. And not just on including IBM-centric function into Linux, but on mainstream community projects. There have been lots of Linux people in IBM since the early-90's. ..."
"... From a customer standpoint the main thing RedHat adds is formal support. There are still a lot of companies who are uncomfortable deploying an OS that has product support only from StackExchange and web forums ..."
"... You would do better to look at the execution on the numbers - RedHat is not hitting it's targets and there are signs of trouble. These two businesses were both looking for a prop and the RedHat shareholders are getting out while the business is near it's peak. ..."
honestly, MS would be fine. They're big into Linux and open source and still a heavily
pro-engineering company.
Companies like Oracle and IBM are about nothing but making money. Which is why they're
both going down the tubes. No-one who doesn't already have them goes near them.
IBM was already "working on Linux." For decades. With multiple hundreds of full-time Linux
developers--more than any other corporate contributor--around the world. And not just on
including IBM-centric function into Linux, but on mainstream community projects. There have
been lots of Linux people in IBM since the early-90's.
The OS is from Linus and chums, Redhat adds a few storage bits and some Redhat logos
and erm.......
From a customer standpoint the main thing RedHat adds is formal support. There are still a
lot of companies who are uncomfortable deploying an OS that has product support only from
StackExchange and web forums. This market is fairly insensitive to price, which is good for a
company like RedHat. (Although there has been an exodus of higher education customers as the
price has gone up; like Sun did back in the day, they've been squeezing out that market. Two
campuses I've worked for have switched wholesale to CentOS.)
You would do better to look at the execution on the numbers - RedHat is not hitting it's
targets and there are signs of trouble. These two businesses were both looking for a prop and
the RedHat shareholders are getting out while the business is near it's peak.
Footnote: $699 License Fee applies to your systemP server running RHEL 7 with 4 cores
activated for one year.
To activate additional processor cores on the systemP server, a fee
of $199 per core applies. systemP offers a new Semi-Activation Mode now. In systemP
Semi-Activation Mode, you will be only charged for all processor calls exceeding 258 MIPS,
which will be processed by additional semi-activated cores on a pro-rata basis.
RHEL on systemP servers also offers a Partial Activation Mode, where additional cores can be
activated in Inhibited Efficiency Mode.
To know more about Semi-Activation Mode, Partial
Activation Mode and Inhibited Efficiency Mode, visit http://www.ibm.com/systemp [ibm.com] or contact your IBM
systemP Sales Engineer.
$34B? I was going to say this is the biggest tech acquisition ever, but it's second after
Dell buying EMC. I'm not too sure what IBM is going to do with that, but congrats to whoever
is getting the money...
"... But I do beg to differ about the optimism, because, as my boss likes to quote, "culture eats strategy for breakfast". ..."
"... So the problem is that IBM have bought a business whose competencies and success factors differ from the IBM core. Its culture is radically different, and incompatible with IBM. ..."
"... Many of its best employees will be hostile to IBM ..."
"... And just like a gas giant, IBM can be considered a failed star ..."
Quite a lot of the "OMG" moments rests on three assumptions:
Red Hat is 100% brilliant and speckless
IBM is beyond hope and unchangeable
This is a hostile takeover
I beg to differ on all counts. Call me beyond hope myself because of my optimism, but I do
think what IBM bought most is a way to run a business. RH is just too big to be borged into a
failing giant without leaving quite a substantial mark.
Note: I didn't downvote you, its a valid argument. I can understand why you think that,
because I'm in the minority that think the IBM "bear" case is overdone. They've been cleaning
their stables for some years now, and that means dropping quite a lot of low margin business,
and seeing the topline shrink. That attracts a lot of criticism, although it is good business
sense.
But I do beg to differ about the optimism, because, as my boss likes to quote,
"culture eats strategy for breakfast".
And (speaking as a strategist) that's 100% true, and 150% true when doing M&A.
So the problem is that IBM have bought a business whose competencies and success
factors differ from the IBM core. Its culture is radically different, and incompatible with
IBM.
Many of its best employees will be hostile to IBM . RedHat will be borged, and it
will leave quite a mark. A bit like Shoemaker-Levi did on Jupiter. Likewise there will be
lots of turbulence, but it won't endure, and at the end of it all the gas giant will be
unchanged (just a bit poorer). And just like a gas giant, IBM can be considered a failed
star .
"... As long as IBM doesn't close-source RH stuff -- most of which they couldn't if they wanted to -- CentOS will still be able to do builds of it. The only thing RH can really enforce control over is the branding and documentation. ..."
"... Might be a REALLY good time to fork CentOS before IBM pulls an OpenSolaris on it. Same thing with Fedora. ..."
"... I used to be a Solaris admin. Now I am a linux admin in a red hat shop. Sun was bought by Oracle and more or less died a death. Will the same happen now? I know that Sun and RH are _very_ differeht beasts but I am thinking that now is the time to stop playing on the merry go round called systems administration. ..."
Re: If IBM buys Redhat then what will happen to CentOS?
If IBM buys Redhat then what will happen to CentOS?
As long as IBM doesn't close-source RH stuff -- most of which they couldn't if they wanted to -- CentOS will still be able
to do builds of it. The only thing RH can really enforce control over is the branding and documentation.
"I found that those with real talent that matched IBM needs are well looked after."
The problem is that when you have served your need you tend to get downsized as the expectation is that the cheaper offshore
bodies can simply take over support etc after picking up the skills they need over a few months !!!
This 'Blue meets Red and assimilates' will be very interesting to watch and will need lots and lots of popcorn on hand !!!
Scientific Linux is a good idea in theory, dreadful in practice.
The idea of a research/academic-software-focused distro is a good one: unfortunately (I say unfortunately, but it's certainly
what I would do myself), increasing numbers of researchers are now developing their pet projects on Debian or Ubuntu, and so therefore
often only make .deb packages available.
Anyone who has had any involvement in research software knows that if you find yourself in the position of needing to compile
someone else's pet project from source, you are often in for an even more bumpy ride than usual.
And the lack of compatible RPM packages just encourages more and more researchers to go where the packages (and the free-ness)
are, namely Debian and friends, which continue to gather momentum, while Red Hat continues to stagnate.
Red Hat may be very stable for running servers (as long as you don't need anything reasonably new (not bleeding edge, but at
least newer than three years old)), but I have never really seen the attraction in it myself (especially as there isn't much of
a "community" feeling around it, as its commercial focus gets in the way).
I used to be a Solaris admin. Now I am a linux admin in a red hat shop. Sun was bought by Oracle and more or less died
a death. Will the same happen now? I know that Sun and RH are _very_ differeht beasts but I am thinking that now is the time to
stop playing on the merry go round called systems administration.
Dear Red Hatters, welcome to the world of battery hens, all clucking and clicking away to produce the elusive golden egg while
the axe looms over their heads. Even if your mental health survives, you will become chicken feed by the time you are middle aged.
IBM doesn't have a heart; get out while you can. Follow the example of IBMers in Australia who are jumping ship in their droves,
leaving behind a crippled, demoralised workforce. Don't become a Mad Hatter.
Hello, we are mandating some new policies, git can no longer be used, we must use IBM synergy
software with rational rose.
All open source software is subject to corporate approval first,
we know we know, to help streamline this process we have approved GNU CC and are looking into
this Mak file program.
We are very pleased with systemd, we wish to further expand it's dhcp
capabilities and also integrate IBM analytics -- We are also going through a rebranding
operation as we feel the color red is too jarring for our customers, we will now be known as
IBM Rational Hat and will only distribute through our retail channels to boost sales -- Look
for us at walmart, circuit city, and staples
IBM are paying around 12x annual revenue for Red Hat which is a significant multiple so they
will have to squeeze more money out of the business somehow. Either they grow customers or
they increase margins or both.
IBM had little choice but to do something like this. They are in a terminal spiral thanks
to years of bad leadership. The confused billing of the purchase smacks of rush, so far I
have seen Red Hat described as a cloud company, an info sec company, an open source
company...
So IBM are buying Red Hat as a last chance bid to avoid being put through the PE threshing
machine. Red Hat get a ludicrous premium so will take the money.
And RH customers will want to check their contracts...
"... IBM license fees are predatory. Plus they require you to install agents on your servers for the sole purpose of calculating use and licenses. ..."
"... IBM exploits workers by offshoring and are slow to fix bugs and critical CVEs ..."
IBM buys a company, fires all the transferred employees and hopes they can keep selling
their acquired software without further development. If they were serious, they'd have
improved their own Linux contribution efforts.
But they literally think they can somehow keep
selling software without anyone with knowledge of the software, or for transferring skills to
their own employees.
They literally have no interest in actual software development. It's all
about sales targets.
My advice to Red Hat engineers is to get out now. I was an engineer at a company that was
acquired by IBM. I was fairly senior so I stayed on and ended up retiring from the IBM, even
though I hated my last few years working there. I worked for several companies during my
career, from startups to fortune 100 companies. IBM was the worst place I worked by far.
Consider every bad thing you've ever heard about IBM. I've heard those things too, and the
reality was much worse.
IBM hasn't improved their Linux contribution efforts because it wouldn't know how. It's
not for lack of talented engineers. The management culture is simply pathological. No dissent
is allowed. Everyone lives in fear of a low stack ranking and getting laid off. In the end it
doesn't matter anyway. Eventually the product you work on that they originally purchased
becomes unprofitable and they lay you off anyway. They've long forgotten how to develop
software on their own. Don't believe me? Try to think of an IBM branded software product that
they built from the ground up in the last 25 years that has significant market share.
Development managers chase one development fad after another hoping to find the silver bullet
that will allow them to continue the relentless cost cutting regime made necessary in order
to make up revenue that has been falling consistently for over a decade now.
As far as I could tell, IBM is good at two things:
Financial manipulation to disguise there shrinking revenue
Buying software companies and mining them for value
Yes, there are still some brilliant people that work there. But IBM is just not good at
turning ideas into revenue producing products. They are nearly always unsuccessful when they
try and then the go out and buy a company the succeeded in bring to market the kind of
product that they tried and failed to build themselves.
They used to be good at customer support, but that is mainly lip service now. Just before
I left the company I was tapped to deliver a presentation at a customer seminar. The audience
did not care much about my presentation. The only thing they wanted to talk about was how
much they had invested millions in re-engineering their business to use our software and now
IBM appeared to be wavering in their long term commitment to supporting the product. It was
all very embarrassing because I knew what they didn't, that the amount of development and
support resources currently allocated to the product line were a small fraction of what they
once were. After having worked there I don't know why anyone would ever want to buy a license
for any of their products.
IBM engineers aren't actually crappy. It's the fucking MBAs in management who have no clue
about how to run a software development company. Their engineers will want to do good work,
but management will worry more about headcount and sales.
IBM acquisitions never go well. All companies acquired by IBM go through a process of
"Blue washing", in which the heart and soul of the acquired company is ripped out, the body
burnt, and the remaining ashes to be devoured and defecated by its army of clueless salesmen
and consultants. It's a sad, and infuriating, repeated pattern. They no longer develop
internal talent. They drive away the remaining people left over from the time when they still
did develop things. They think they can just buy their way into a market or technology,
somehow completely oblivious to the fact that their strategy of firing all their acquired
employees/knowledge and hoping to sell software they have no interest in developing would
somehow still retain customers. They literally could have just reshuffled and/or hired more
developers to work on the kernel, but the fact they didn't shows they have no intention of
actually contributing.
Red Hat closed Friday at $116.68 per share, looks like the buy out is for $190. Not
everyone will be unhappy with this. I hope the Red Hat employees that won't like the upcoming
cultural changes have stock and options, it may soften the blow a bit.
Oh, good. Now IBM can turn RH into AIX while simultaneously suffocating whatever will be
left of Redhat's staff with IBM's crushing, indifferent, incompetent bureaucracy.
This is what we call a lose - lose situation. Well, except for the president of Redhat, of
course. Jim Whitehurst just got rich.
Depends on the state. Non-compete clauses are unenforceable in some jurisdictions. IBM
would want some of the people to stick around. You can't just take over a complex system from
someone else and expect everything to run smoothly or know how to fix or extend it. Also, not
everyone who works at Red Hat gets anything from the buyout unless they were regularly giving
employees stock. A lot of people are going to want the stable paycheck of working for IBM
instead of trying to start a new company.
However, some will inevitably get sick of working at IBM or end up being laid off at some
point. If these people want to keep doing what they're doing, they can start a new company.
If they're good at what they do, they probably won't have much trouble attracting some
venture capital either.
Red Hat went public in 1999, they are far from being a start-up. They have acquired
several companies themselves so they are just as corporate as IBM although significantly
smaller.
My feelings exactly. As a former employee for both places, I see this as the death knell
for Red Hat. Not immediately, not quickly, but eventually Red Hat's going to go the same way
as every other company IBM has acquired.
Red Hat's doom (again, all IMO) started about 10 years ago or so when Matt Szulik left and
Jim Whitehurst came on board. Nothing against Jim, but he NEVER seemed to grasp what F/OSS
was about. Hell, when he came onboard he wouldn't (and never did) use Linux at all: instead
he used a Mac, and so did the rest of the EMT (executive management team) over time. What
company is run by people who refuse to use its own product except for one that doesn't have
faith. The person on top of the BRAND AND PEOPLE team "needed" an iPad, she said, to do her
work (quoting a friend in the IT dept who was asked to get it and set it up for her).
Then when they (the EMTs) wanted to move away from using F/OSS internally to outsourcing
huge aspects of our infrastructure (like no longer using F/OSS for email and instead
contracting with GOOGLE to do our email, calendaring and document sharing) is when, again for
me, the plane started to spiral. How can we sell to OUR CUSTOMERS the idea that "Red Hat and
F/OSS will suit all of your corporate needs" when, again, the people running the ship didn't
think it would work for OURS? We had no special email or calendar needs, and if we did WE
WERE THE LEADERS OF OPEN SOURCE, couldn't we make it do what we want? Hell, I was on an
internal (but on our own time) team whose goal was to take needs like this and incubate them
with an open source solution to meet that need.
But the EMTs just didn't want to do that. They were too interested in what was "the big
thing" (at the time Open Shift was where all of our hiring and resources were being poured)
to pay attention to the foundations that were crumbling.
And now, here we are. Red Hat is being subsumed by the largest closed-source company on
the planet, one who does their job sub-optimally (to be nice). This is the end of Red Hat as
we know it. Without 5-7 years Red Hat will go the way of Tivoli and Lotus: it will be a brand
name that lacks any of what made the original company what it was when it was acquired.
When it comes to employment claims, studies have found that arbitrators overwhelmingly favor
employers.
Research by Cornell University law and labor relations specialist Alexander Colvin found
that workers win
only 19 percent of the time when their cases are arbitrated. By contrast,
they win 36 percent of the time when they go to federal court, and 57 percent in state
courts. Average payouts when an employee wins follow a similar pattern.
Given those odds, and having signed away their rights to go to court, some laid-off IBM
workers have chosen the one independent forum companies can't deny them: the U.S. Equal
Employment Opportunity Commission. That's where Moos, the Long Beach systems security
specialist, and several of her colleagues, turned for help when they were laid off. In their
complaints to the agency, they said they'd suffered age discrimination because of the company's
effort to "drastically change the IBM employee age mix to be seen as a startup."
In its formal reply to the EEOC, IBM said that age couldn't have been a factor in their
dismissals. Among the reasons it cited: The managers who decided on the layoffs were in their
40s and therefore older too.
This makes for absolutely horrifying, chills-down-your-spine reading. A modern corporate horror story - worthy of a 'Black Mirror'
episode. Phenomenal reporting by Ariana Tobin and Peter Gosselin. Thank you for exposing this. I hope this puts an end to this
at IBM and makes every other company and industry doing this in covert and illegal ways think twice about continuing.
Agree..a well written expose'. I've been a victim of IBM's "PIP" (Performance Improvement Plan) strategy, not because of my real
performance mind you, but rather, I wasn't billing hours between projects and it was hurting my unit's bottom line. The way IBM
instructs management to structure the PIP, it's almost impossible to dig your way out, and it's intentional. If you have a PIP
on your record, nobody in IBM wants to touch you, so in effect you're already gone.
I see the PIP problem as its nearly impossible to take the fact that we know PIP is a scam to court. IBM will say its an issue
with you, your performance nose dived and your manager tried to fix that. You have to not only fight those simple statements,
but prove that PIP is actually systematic worker abuse.
Cindy, they've been doing this for at least 15-20 years, or even longer according to some of the previous comments. It is
in fact a modern corporate horror story; it's also life at a modern corporation, period.
After over 35 years working there, 19 of them as a manager sending out more of those notification letters than I care to remember,
I can vouch for the accuracy of this investigative work. It's an incredibly toxic and hostile environment and has been for the
last 5 or so years. One of the items I was appraised on annually was how many US jobs I moved offshore. It was a relief when I
received my notification letter after a two minute phone call telling me it was on the way. Sleeping at night and looking myself
in the mirror aren't as hard as they were when I worked there.
IBM will never regain any semblance of their former glory (or profit) until they begin to treat employees well again.
With all the offshoring and resource actions with no backfill over the last 10 years, so much is broken. Customers suffer almost
as much as the employees.
I don't know how in the world they ended up on that LinkedIn list. Based on my fairly recent experience there are a half dozen
happy employees in the US, and most of them are C level.
Well done. It squares well with my 18 years at IBM, watching resource action after resource action and hearing what my (unusually
honest) manager told me. Things got progressively worse from 2012 onward. I never realized how stressful it was to live under
the shadow of impending layoffs until I finally found the courage to leave in 2015. Best decision I've made.
IBM answers to its shareholders, period. Employees are an afterthought - simply a means to an end. It's shameful. (That's not
to say that individual people managers feel that way. I'm speaking about IBM executives.)
Well, they almost answer to their shareholders, but that's after the IBM executives take their share. Ginni's compensation is
tied to stock price (apparently not earnings) and buy backs maintain the stock price.
If the criteria for layoff is being allegedly overpaid and allegedly a poor performer, then it follows that Grinnin' Jenny should
have been let go long ago.
Just another fine example of how people become disposable.
And, when it comes to cost containment and profit maximization, there is no place for ethics in American business.
Businesses can lie just as well as politicians.
Millennials are smart to avoid this kind of problem by remaining loyal only to themselves. Companies certainly define anyone
as replaceable - even their over-paid CEO's.
The millennials saw what happen to their parents and grandparents getting screwed over after a life time of work and loyalty.
You can't blame them for not caring about so called traditional American work ethics and then they are attacked for not having
them when the business leaders threw away all those value decades ago.
Some of these IBM people have themselves to blame for cutting their own economic throats for fighting against unions, putting
in politicians who are pro-business and thinking that their education and high paying white collar STEM jobs will give them economic
immunity.
If America was more of a free market and free enterprise instead of being more of a close market of oligarchies and monopolies,
and strong government regulations, companies would think twice about treating their workforce badly because they know their workforce
would leave for other companies or start up their own companies without too much of a hassle.
Under the old IBM you could not get a union as workers were treated with dignity and respect - see the 3 core beliefs. Back
then a union would not have accomplished anything.
Doesn't matter if it was the old IBM or new IBM, you wonder how many still actually voted against their economic interests in
the political elections that in the long run undermine labor rights in this country.
So one shouldn't vote? Neither party cares about the average voter except at election time. Both sell out to Big Business - after
all, that's where the big campaign donations come from. If you believe only one party favors Big Business, then you have been
watching to much "fake news". Even the unions know they have been sold out by both and are wising up. How many of those jobs were
shipped overseas the past 25 years.
No, they should have been more active in voting for politicians who would look after the workers' rights in this country for the
last 38 years plus ensuring that Congressional people and the president would not be packing the court system with pro-business
judges. Sorry, but it is the Big Business that have been favoring the Republican Party for a long, long time and the jobs have
been shipped out for the last 38 years.
Age discrimination has been standard operating procedure in IT for at least 30 years. And
there are no significant consequences, if any consequences at all, for doing it in a blatant
fashion. The companies just need to make sure the quota of H1B visas is increased when they
are doing this on an IBM scale!
Age discrimination and a myriad other forms of discrimination have been standard operating
procedure in the US. Period. Full stop. No need to equivocate.
"... If I (hypothetically) worked for a company acquired by Big Blue, I would offer the following: Say hello to good salaries. Say goodbye to perks, bonuses, and your company culture...oh, and you can't work from home anymore. ...but this is all hypothetical. ..."
If I (hypothetically) worked for a company acquired by Big Blue, I would offer the
following: Say hello to good salaries. Say goodbye to perks, bonuses, and your company
culture...oh, and you can't work from home anymore. ...but this is all hypothetical.
I can see what each company will get out of the deal and how they might
potentially benefit. However, Red Hat's culture is integral to their success. Both company
CEOs were asked today at an all-hands meeting about how they intend to keep the promise of
remaining distinct and maintaining the RH culture without IBM suffocating it. Nothing is
supposed to change (for now), but IBM has a track record of driving successful companies and
open dynamic cultures into the ground. Many, many eyes will be watching this.
Hopefully IBM current top Brass will be smart and give some autonomy to Red Hat and leave
it to its own management style. Of course, that will only happen if they deliver IBM goals
(and that will probably mean high double digit y2y growth) on regular basis...
One thing is sure, they'll probably kill any overlapsing product in the medium term (who
will survive between JBOSS and Websphere is an open bet).
(On a dream side note, maybe, just maybe they'll move some of their software development
to Red Hat)
Good luck. Every CEO thinks they're the latest incarnation of Adam Smith, and they're all
dying to be seen as "doing something." Doing nothing, while sometimes a really smart thing
and oftentimes the right thing to do, isn't looked upon favorably these days in American
business. IBM will definitely do something with Red Hat; it's just a matter of what.
Dilbert Ars
Legatus Legionis
reply
6 hours ago Popular
motytrah wrote:
bolomkxxviii wrote: No good will come from this. IBM's corporate environment and financial
near-sightedness will kill Red Hat. Time to start looking for a new standard bearer in Linux
for business.
I agree. Redhat has dev offices all over. A lot of them in higher cost areas of the US and
Europe. There's no way IBM doesn't consolidate and offshore a bunch of that work.
This. To a bean counter a developer in a RH office in North America or Europe who's been coding
for RH for 10 years is valued same as a developer in Calcutta who just graduated from college.
For various definitions of word 'graduated'.
Yeah the price is nuts, reminiscent of FB's WhatsApp purchase, and maybe their Instagram
purchase.
If you actually look at the revenue Amazon gets from AWS or Microsoft from Azure, it's not
that much, relatively speaking. For Microsoft, it's nothing compared to Windows and Office
revenue, and I'm not sure where the growth is supposed to come from. It seems like most
everyone who wants to be on the cloud is already there, and vulns like Spectre and Meltdown
broke the sacred VM wall, so...
It not Watson family gone it is New Deal Capitalism was replaced with the neoliberalism
Notable quotes:
"... Except when your employer is the one preaching associate loyalty and "we are family" your entire career. Then they decide you've been too loyal and no longer want to pay your salary and start fabricating reasons to get rid of you. ADP is guilty of these same practices and eliminating their tenured associates. Meanwhile, the millennials hired play ping pong and text all day, rather than actually working. ..."
A quick search of the article doesn't find the word "buy backs" but this is a big part of the
story. IBM spent over $110 BILLION on stock buy backs between 2000 and 2016. That's the
number I found, but it hasn't stopped since. If anything it has escalated.
This is very common among large corporations. Rather than spend on their people, they
funnel billions into stock buy backs which raises or at least maintains the stock value so
execs can keep cashing in. It's really pretty disgraceful. This was only legalized in 1982,
which not-so-coincidentally is not long after real wages stalled, and have stalled ever
since.
Thanks for this bit of insanely true reporting. When laid off from Westinghouse after 14
years of stellar performance evaluations I was flummoxed by the execs getting million-dollar
bonuses as we were told the company wasn't profitable enough to maintain its senior
engineering staff. It sold off every division eventually as the execs (many of them newly
hired) reaped even more bonuses.
Thank you ... very insightful of you. As an IBMer and lover of Spreadsheets / Statistics /
Data Specalist ... I like reading Annual Reports. Researching these Top Execs, BOD and
compare them to other Companies across-the-board and industry sectors. You'll find a Large
Umbrella there.
There is a direct tie and inter-changeable pieces of these elites over the past 55 yrs.
Whenever some Corp/ Political/ Government shill (wannbe) needs a payoff, they get placed into
high ranking top positions for a orchestrating a predescribed dark nwo agenda. Some may come
up the ranks like Ginny, but ALL belong to Council for Foreign Relations and other such high
level private clubs or organizations. When IBM sells off their Mainframe Manufacturing
(Poughkeepsie) to an elite Saudi, under an American Co. sounding name of course, ... and the
U.S. Government ... doesn't balk ... that has me worried for our 1984 future.
Yeah, it is amazing how they stated that they don't need help from the government when in
reality they do need government to pass laws that favor them, pack the court system where
judges rule in their favor and use their private police and the public sector police to keep
the workers down.
I wonder how many billions (trillions?) have been funneled from corporate workers pockets
this way? It seems all corporations are doing it these days. Large-scale transfer of wealth
from the middle class to the wealthy.
Not anymore. With most large companies, you've never been able to say they are "family."
Loyalty used to be a thing though. I worked at a company where I saw loyalty vanish over a 10
year period.
Except when your employer is the one preaching associate loyalty and "we are family" your
entire career. Then they decide you've been too loyal and no longer want to pay your salary
and start fabricating reasons to get rid of you. ADP is guilty of these same practices and
eliminating their tenured associates. Meanwhile, the millennials hired play ping pong and
text all day, rather than actually working.
Yeah, and how many CEOs actually work to make their companies great instead of running them
into the ground, thinking about their next job move, and playing golf
I have to disagree with you. I started with IBM on their rise up in those earlier days, and
we WERE valued and shown that we were valued over and over through those glorious years. It
did feel like we were in a family, our families mattered to them, our well-being. They gave
me a month to find a perfect babysitter when they hired me before I had to go to work!
They
helped me find a house in a good school district for my children. They bought my house when I
was moving to a new job/location when it didn't sell within 30 days.
They paid the difference
in the interest rate of my loan for my new house from the old one. I can't even begin to list
all the myriad of things that made us love IBM and the people we worked with and for, and
made us feel a part of that big IBM family.
Did they change, yes, but the dedication we gave
was freely given and we mutually respected each other. I was lucky to work for them for
decades before that shift when they changed to be just like every other large corporation.
The Watson family held integrity, equality, and knowledge share as a formidable synthesis of
company ethics moving a Quality based business forward in the 20th to 21st century. They also
promoted an (volunteer) IBM Club to help promote employee and family activities
inside/outside of work which they by-en-large paid for. This allowed employees to meet and
see other employees/families as 'Real' & "Common-Interest" human beings. I participated,
created, and organized events and documented how-to-do-events for other volunteers. These
brought IBMers together inside or outside of their 'working' environment to have fun, to
associate, to realize those innate qualities that are in all of us. I believe it allowed for
better communication and cooperation in the work place.
To me it was family. Some old IBMers might remember when Music, Song, Skits were part of IBM
Branch Office meetings. As President of the IBM Clubs Palo Alto branch (7 yrs.), I used our
Volunteer Club Votes to spend ALL that IBM donated money, because they
<administratively> gave it back to IBM if we didn't.
Without a strong IBM Club
presence, it gets whittled down to 2-3 events a year. For a time WE WERE a FAMILY.
Absolutely! Back when white shirts/black suits were a requirement. There was a country club
in Poughkeepsie, softball teams, Sunday brunch, Halloween parties in the fall, Christmas
parties in December where thousands of age appropriate Fisher Price toys were given out to
employee's kids. Today "IBMer" is used by execs as a term of derision. Employees are
overworked and under appreciated and shortsighted, overpaid executives rule the roost. The
real irony is that talented, vital employees are being retired for "costing too much" while
dysfunctional top level folk are rewarded with bonuses and stock when they are let go. And
it's all legal. It's disgraceful.
If that were the case....then why buy them? The whole POINT of acquiring a company is so
that you can leverage what the acquired company has to improve your business.
As time moves on, it's going to be obvious that some of the things RH does (partnerships,
etc) compete with some of IBM's partnerships and/or products.
At some point management will look at where there is crossover and kill the ones not
making money or hurting existing products.
Point is, over time RH is NOT going to just continue on as an independent entity with no
effect from it's parent or vice versa.
And....let's remember this is a ACQUISITION! Not a merger.
I recall, back in the mid-1960s, encountering employees of major major corporations like IBM,
US Steel, the Big Three in Detroit, etc, There was a certain smugness there. I recall hearing
bragging about the awesome retirement incomes. Yes, I was jealous. But I also had a clear eye
as to the nature of the beast they were working for, and I kept thinking of the famous
limerick:
There was a young lady of Niger Who smiled as she rode on a Tiger; They came back from the ride With the lady inside, And the smile on the face of the Tiger.
As an ex-IBM employee, I was given a package ( 6 months pay and a "transition" course)
because I was getting paid too much or so I was told. I was part of a company (oil industry)
that outsourced it's IT infrastructure support personnel and on several occasions was told by
my IBM management that they just don't know what to do with employees who make the kind of
money I do when we can do it much cheaper somewhere else (meaning offshore).
Eventually all
the people who I worked with that were outsourced to IBM were packaged off and all of our
jobs were sent offshore. I just turned 40 and found work back in the oil industry. In the
short time I was with IBM I found their benefits very restricted, their work policies very
bureaucratic and the office culture very old boys club.
If you weren't part of IBM and were
an outsourced employee, you didn't fit in. At the time I thought IBM was the glory company in
IT to work for, but quickly found out they are just a dinosaur. It's just a matter of time
for them.
I think a lot of the dislike for Indian developers is it's usually the outsourced, cheap as possible code monkey developers.
Which can be a problem anywhere, for sure, but at least seem exacerbated by US companies outsourcing there. In my limited experience,
they're either intelligent and can work up to working reasonably independently and expanding on a ticket intelligently. Or they're
copy a pasta code monkey and need pretty good supervision of the code that's produced.
Add in the problem if timezones and folks
who may not understand English that great, or us not understanding their English, and it all gives them a bad name. Yet I agree,
I know some quite good developers. Ones that didn't go to a US college.
My impression, totally anecdotal, is that unless you can hire or move a very good architect/lead + project/product manager
over there so you can interact in real-time instead of with a day delay, it's just a huge PITA and slows things down.
Personally
I'd rather hire a couple of seemingly competent 3 years out of college on their 2nd job (because they rarely stay very long at
their first one, right?) and pay from there.
"... There's not an intrinsic advantage to being of a certain nationality, American included. Sure, there are a lot of bad companies and bad programmers coming from India, but there are plenty of incompetent developers right here too. ..."
"... A huge problem with the good developers over there is the lack of English proficiency and soft skills. However, being born or graduated in Calcutta (or anywhere else for that matter) is not a determination of one's skill. ..."
"... I get what the intention of the first comment was intended to be, but it still has that smugness that is dangerous to the American future. As the world becomes more interconnected, and access to learning improves, when people ask you why are you better than that other guy, the answer better be something more than "well, I'm American and he is from Calcutta" because no one is going to buy that. The comment could've said that to a bean counter a solid developer with 10 years of experience is worth the same as a junior dev who just came out of school and make the same point. What exactly was the objective of throwing in Calcutta over there? ..."
"... I have dealt with this far too much these VPs rarely do much work and simply are hit on bottom line ( you are talking about 250k+), but management in US doesn't want to sit off hours and work with India office so they basically turn a blind eye on them. ..."
No good will come from this. IBM's corporate environment and financial near-sightedness will kill Red Hat. Time
to start looking for a new standard bearer in Linux for business.
I agree. Redhat has dev offices all over. A lot of them in higher cost areas of the US and Europe. There's no way
IBM doesn't consolidate and offshore a bunch of that work.
This. To a bean counter a developer in a RH office in North America or Europe who's been coding for RH for 10 years
is valued same as a developer in Calcutta who just graduated from college. For various definitions of word 'graduated'.
I'm just waiting until some major company decides that some of the nicer parts of middle America/Appalachia can be a
LOT cheaper, still nice, and let them pay less in total while keeping some highly skilled employees.
I don't know about that. Cities can be expensive but part of the reason is that a lot of people want to live there, and
supply/demand laws start acting. You'll be able to get some talent no doubt, but a lot of people who live nearby big cities
wouldn't like to leave all the quality of life elements you have there, like entertainment, cultural events, shopping, culinary
variety, social events, bigger dating scene, assorted array of bars and night clubs, theatre, opera, symphonies, international
airports... you get the drift.
I understand everyone is different, but you would actually need to pay me more to move to a smaller town in middle America.
I also work with people who would take the offer without hesitation, but in my admittedly anecdotal experience, more tech people
prefer the cities than small towns. Finally, if you do manage to get some traction in getting the people and providing the
comforts, then you're just going to get the same increase in cost of living wherever you are because now you're just in one
more big city.
Costs of life are a problem, but we need to figure out how to properly manage them, instead of just saying "lets move them
somewhere else". Also we shouldn't discount the capability of others, because going by that cost argument outsourcing becomes
attractive. The comment you're replying to tries to diminish Indian engineers, but the reverse can still be true. A developer
in India who has been working for 10 years costs even less than an American who just graduated, for various definitions of
graduated. There's over a billion people over there, and the Indian Institutes of Technology are nothing to scoff at.
There's not an intrinsic advantage to being of a certain nationality, American included. Sure, there are a lot of bad
companies and bad programmers coming from India, but there are plenty of incompetent developers right here too. It's just
that there are a lot more in general over there and they would come for cheap, so in raw numbers it seems overwhelming, but
that sword cuts both ways, the raw number of competent ones is also a lot.
About 5% of the American workforce are scientists and engineers, which make a bit over 7 million people. The same calculation
in India brings you to almost 44 million people.
A huge problem with the good developers over there is the lack of English proficiency and soft skills. However, being
born or graduated in Calcutta (or anywhere else for that matter) is not a determination of one's skill.
I get what the intention of the first comment was intended to be, but it still has that smugness that is dangerous to
the American future. As the world becomes more interconnected, and access to learning improves, when people ask you why are
you better than that other guy, the answer better be something more than "well, I'm American and he is from Calcutta" because
no one is going to buy that. The comment could've said that to a bean counter a solid developer with 10 years of experience
is worth the same as a junior dev who just came out of school and make the same point. What exactly was the objective of throwing
in Calcutta over there? Especially when we then move to a discussion about how costly it is to pay salaries in America.
Sounds a bit counterproductive if you ask me.
I think a lot of the dislike for Indian developers is that they usually are the outsourced to cheap as possible code monkey
developers. Which can be a problem anywhere, for sure, but at least seem exacerbated by US companies outsourcing there. In my
limited experience, they're either intelligent and can work up to working reasonably independently and expanding on a ticket intelligently.
Or they're copy a pasta code monkey and need pretty good supervision of the code that's produced. Add in the problem if timezones
and folks who may not understand English that great, or us not understanding their English, and it all gives them a bad name.
Yet I agree, I know some quite good developers. Ones that didn't go to a US college.
My impression, totally anecdotal, is that unless you can hire or move a very good architect/lead + project/product manager
over there so you can interact in real-time instead of with a day delay, it's just a huge PITA and slows things down. Personally
I'd rather hire a couple of seemingly competent 3 years out of college on their 2nd job (because they rarely stay very long at
their first one, right?) and pay from there.
Companies/management offshore because it keep revenue per employee and allows them to be promoted by inflating their direct
report allowing them to build another "cheap" pyramid hierarchy. A manager in US can become a director or VP easily by having
few managers report to him from India. Even better this person can go to India ( they are most often Indian) and claim to lead
the India office and improve outsourcing while getting paid US salary.
I have dealt with this far too much these VPs rarely do much work and simply are hit on bottom line ( you are talking about
250k+), but management in US doesn't want to sit off hours and work with India office so they basically turn a blind eye on them.
Outstanding. I had to train people in IBM India to do my job when (early) "retired". I actually found a new internal job in IBM,
the hiring manager wrote/chat that I was a fit. I was denied the job because my current group said I had to transfer and the receiving
group said I had to be on a contract, stalemate! I appealed and group HR said sorry, can't do and gave me one reason after another,
that I could easily refute, then they finally said the job was to be moved overseas. Note most open jobs posted were categorized
for global resources. I appealed to Randy (former HR SVP) and no change. At least I foced them to finally tell the truth. I had
also found another job locally near home and received an email from the HR IBM person responsible for the account saying no, they
were considering foreigners first, if they found no one suitable they would then consider Americans. I appealed to my IBM manager
who basically said sorry, that is how things are now. All in writing, so no more pretending it is a skill issue. People, it is
and always has been about cheap labor. I recall when a new IBM technology began, Websphere, and I was sent for a month's training.
Then in mid-2000's training and raises pretty much stopped and that was when resource actions were stepped up.
IBM is bad, but it's just the tip of the iceberg. I worked for a major international company that dumped almost the entire IT
workforce and replaced them with "managed services", almost exclusively H-1B workers from almost exclusively India. This has been
occurring for decades in many, MANY businesses around the country large and small. Even this article seems to make a special effort
to assure us that "some" workers laid off in America were replaced with "younger, less experienced, lower-paid American workers
and moving many other jobs overseas." How many were replaced with H-1B, H-4 EAD, OPT, L-1, etc? It's by abusing these work visa
programs that companies facilitate moving the work overseas in the first place. I appreciate this article, but I think it's disingenuous
for ProPublica to ignore the elephant in the room - work visa abuse. Why not add a question or two to your polls about that? It
wouldn't be hard. For example, "Do you feel that America's work visa programs had an impact on your employment at IBM? Do you
feel it has had an impact on your ability to regain employment after leaving IBM?" I'd like to see the answer to THOSE questions.
IBM must be borrowing a lot of cash to fund the acquisition. At last count it had about $12B in the bank... https://www.marketwatch.com/investing/stock/ibm/financials/balance-sheet.
Looking at the Red Hat numbers, I would not want to be an existing IBM share-holder this morning; both companies missing market
expectations and in need of each other to get out of the rut.
It is going to take a lot of effort to make that 63% premium pay-off. If it does not pay-off pretty quickly, the existing RedHat
leadership with gone in 18 months.
P.S.
Apparently this is going to be financed by a mixture of cash and debt - increasing IBM's existing debt by nearly 50%. Possible
credit rating downgrade on the way?
As soon as they have a minimum of experience with the terrible IBM change management processes, the many layers of bureocracy
and management involved and the zero or negative value they add to anything at all.
IBM is a shinking ship, the only question being how long it will take to happen. Anyone thinkin RH has any future other than
languish and disappear under IBM management is dellusional. Or a IBM stock owner.
I'm still trying to figure out "why" they bought Red hat.
The only thing my not insignificant google trawling can find me is that Red Hat sell to the likes of Microsoft and google -
now, that *is* interesting. IBM seem to be saying that they can't compete directly but they will sell upwards to their overlords
- no ?
As far as I can tell, it is be part of IBM's cloud (or hybrid cloud) strategy. RH have become/are becoming increasingly successful
in this arena.
If I was being cynical, I would also say that it will enable IBM to put the RH brand and appropriate open source soundbites on
the table for deal-making and sales with or without the RH workforce and philosophy. Also, RH's subscription-base must figure greatly
here - a list of perfect customers ripe for "upselling". bazza
Re: But *Why* did they buy them?
I'm fairly convinced that it's because of who uses RedHat. Certainly a lot of financial institutions do, they're in the market
for commercial support (the OS cost itself is irrelevant). You can tell this by looking at the prices RedHat were charging for
RedHat MRG - beloved by the high speed share traders. To say eye-watering, PER ANNUM too, is an understatement. You'd have to
have got deep pockets before such prices became ignorable.
IBM is a business services company that just happens to make hardware and write OSes. RedHat has a lot of customers interested
in business services. The ones I think who will be kicking themselves are Hewlett Packard (or whatever they're called these days).
Because AIX and RHEL are the two remaining enterprise unixoid platforms (Solaris & HPUX are moribund and the other players
are pretty small). Now both of those are owned by IBM: they now own the enterprise unixoid market.
"I'm still trying to figure out "why" they bought Red hat."
What they say? It somehow helps them with cloud. Doesn't sound like much money there - certainly not enough to justify the
significant increase in debt (~US$17B).
What could it be then? Well RedHat pushed up support prices and their customers didn't squeal much. A lot of those big enterprise
customers moved from expensive hardware/expensive OS support over the last ten years to x86 with much cheaper OS support so there's
plenty of scope for squeezing more.
These practices are "interesting". And people still wonder why there are so many deadly amok
runs at US companies? What do they expect when they replace old and experienced workers with
inexperienced millenials, who often lack basic knowledge about their job? Better performance?
This will run US tech companies into the ground. This sort of "American" HR management is
gaining ground here in Germany as well, its troubling. And on top they have to compete against
foreign tech immigrants from middle eastern and asian companies. Sure fire recipe for social
unrest and people voting for right-wing parties.
I too was a victim of IBM's underhanded trickery to get rid of people...39 years with IBM,
a top performer. I never got a letter telling me to move to Raleigh. All i got was a phone
call asking me if i wanted to take the 6 month exception to consider it. Yet, after taking the
6 month exception, I was told I could no longer move, the colocation was closed. Either I find
another job, not in Marketing support (not even Marketing) or leave the company. I received no
letter from Ginni, nothing. I was under the impression I could show up in Raleigh after the
exception period. Not so. It was never explained....After 3 months I will begin contracting
with IBM. Not because I like them, because I need the money...thanks for the article.
dropped in 2013 after 22 years. IBM stopped leading in the late 1980's, afterwards it
implemented "market driven quality" which meant listen for the latest trends, see what other
people were doing, and then buy the competition or drive them out of business. "Innovation that
matters": it's only interesting if an IBM manager can see a way to monetize it.
That's a low standard. It's OK, there are other places that are doing better. In fact, the
best of the old experienced people went to work there. Newsflash: quality doesn't change with
generations, you either create it or you don't.
Sounds like IBM is building its product portfolio to match its desired workforce. And of
course, on every round of layoffs, the clear criterion was people who were compliant and
pliable - who's ready to follow orders ? Best of luck.
I agree with many who state the report is well done. However, this crap started in the early
1990s. In the late 1980s, IBM offered decent packages to retirement eligible employees. For
those close to retirement age, it was a great deal - 2 weeks pay for every year of service
(capped at 26 years) plus being kept on to perform their old job for 6 months (while
collecting retirement, until the government stepped in an put a halt to it). Nobody eligible
was forced to take the package (at least not to general knowledge). The last decent package
was in 1991 - similar, but not able to come back for 6 months.
However, in 1991, those offered the package were basically told take it or else. Anyone
with 30 years of service or 15 years and 55 was eligible and anyone within 5 years of
eligibility could "bridge" the difference.
They also had to sign a form stating they would not sue IBM in order to get up to a years
pay - not taxable per IRS documents back then (but IBM took out the taxes anyway and the IRS
refused to return - an employee group had hired lawyers to get the taxes back, a failed
attempt which only enriched the lawyers).
After that, things went downhill and accelerated when Gerstner took over. After 1991,
there were still a some workers who could get 30 years or more, but that was more the
exception. I suspect the way the company has been run the past 25 years or so has the Watsons
spinning in their graves. Gone are the 3 core beliefs - "Respect for the individual",
"Service to the customer" and "Excellence must be a way of life".
could be true... but i thought Watson was the IBM data analytics computer thingy... beat two
human players at Jeopardy on live tv a year or two or so back.. featured on 60 Minutes just
around last year.... :
IBM's policy reminds me of the "If a citizen = 30 y.o., then mass execute such, else if they
run then hunt and kill them one by one" social policy in the Michael York movie "Logan's
Run."
From Wiki, in case you don't know: "It depicts a utopian future society on the surface,
revealed as a dystopia where the population and the consumption of resources are maintained
in equilibrium by killing everyone who reaches the age of 30. The story follows the actions
of Logan 5, a "Sandman" who has terminated others who have attempted to escape death, and is
now faced with termination himself."
"... The annual unemployment rate topped 8% in 1975 and would reach nearly 10% in 1982. The economy seemed trapped in the new nightmare of stagflation," so called because it combined low economic growth and high unemployment ("stagnation") with high rates of inflation. And the prime rate hit 20% by 1980. ..."
If anything, IBM is behind the curve. I was terminated along with my entire department from a
major IBM subcontractor, with all affected employees "coincidentally" being over 50. By
"eliminating the department" and forcing me to sign a waiver to receive my meager severance,
they avoided any legal repercussions. 18 months later on the dot (the minimum legal time
period), my workload was assigned to three new hires, all young. Interestingly, their
combined salaries are more than mine, and I could have picked up all their work for about
$200 in training (in social media posting, something I picked up on my own last year and am
doing quite well, thank you).
And my former colleagues are not alone. A lot of friends of mine have had similar
outcomes, and as the article states, no one will hire people my age willingly in my old
capacity. Luckily again, I've pivoted into copywriting--a discipline where age is still
associated with quality ("dang kids can't spell anymore!"). But I'm doing it freelance, with
the commensurate loss of security, benefits, and predictability of income.
So if IBM is doing this now, they are laggards. But because they're so big, there's a much
more obvious paper trail.
One of the most in-depth, thoughtful and enlightening pieces of journalism I've seen. Having
worked on Capitol Hill during the early 1980's for the House and Senate Aging Committees, we
worked hard to abolish the remnants of mandatory retirement and to strengthen the protections
under the ADEA. Sadly, the EEOC has become a toothless bureaucracy when it comes to age
discrimination cases and the employers, as evidenced by the IBM case, have become
sophisticated in hiding what they're doing to older workers. Peter's incredibly well
researched article lays the case out for all to see. Now the question is whether the
government will step up to its responsibilities and protect older workers from this kind of
discrimination in the future. Peter has done a great service in any case.
The US tech sector has mostly ignored US citizen applicants, of all ages, since the early
2000s. Instead, preferring to hire foreign nationals. The applications of top US citizen
grads are literally thrown in the garbage (or its electronic equivalent) while companies like
IBM have their hiring processes dominated by Indian nationals. IBM is absolutely a
poster-child for H-1B, L-1, and OPT visa abuse.
Bottom line is we have entered an era when there are only two classes who are protected in
our economy; the Investor Class and the Executive Class. With Wall Street's constant demand
for higher profits and increased shareholder value over all other business imperatives, rank
and file workers have been relegated to the class of expendable resource. I propose that all
of us over fifty who have been riffed out of Corporate America band together for the specific
purpose of beating the pants off them in the marketplace. The best revenge is whooping their
youngster butts at the customer negotiating table. By demonstrating we are still flexible and
nimble, yet with the experience to avoid the missteps of misspent youth, we prove we can
deliver value well beyond what narrow-minded bean counters can achieve.
I started at IBM 3 days out of college in 1979 and retired in 2017. I was satisfied with my
choice and never felt mistreated because I had no expectation of lifetime employment,
especially after the pivotal period in the 1990's when IBM almost went out of business. The
company survived that period by dramatically restructuring both manufacturing costs and sales
expense including the firing of tens of thousands of employees. These actions were well
documented in the business news of the time, the obvious alternative was bankruptcy.
I told the authors that anyone working at IBM after 1993 should have had no expectation of
a lifetime career. Downsizing, outsourcing, movement of work around the globe was already
commonplace at all such international companies. Any expectation of "loyalty", that two-way
relationship of employee/company from an earlier time, was wishful thinking. I was always
prepared to be sent packing, without cause, at any time and always had my resume up-to-date.
I stayed because of interesting work, respectful supervisors, and adequate compensation. The
"resource action" that forced my decision to retire was no surprise, the company that hired
me had been gone for decades.
With all the automation going on around the world, these business leaders better worry about
people not having money to buy their goods and services plus what are they going to do with
the surplus of labor
I had, more or less, the same experience at Cisco. They paid me to quit. Luckily, I was ready
for it.
The article mentions IBMs 3 failures. So who was it that was responsible for not
anticipating the transitions? It is hard enough doing what you already know. Perhaps
companies should be spending more on figuring out "what's next" and not continually playing
catch-up by dumping the older workers for the new.
I was laid off by IBM after 29 years and 4 months. I had received a division award in
previous year, and my last PBC appraisal was 2+ (high performer.) The company I left was not
the company I started with. Top management--starting with Gerstner--has steadily made IBM a
less desirable place to work. They now treat employees as interchangeable assets and nothing
more. I cannot/would not recommend IBM as an employer to any young programmer.
Truly awesome work. I do want to add one thing, however--the entire rhetoric about "too many
old white guys" that has become so common absolutely contributes to the notion that this sort
of behavior is not just acceptable but in some twisted way admirable as well.
Is anyone surprised that so many young people don't think capitalism is a good system any
more?
I ran a high technology electronic systems company for years. We ran it "the old way." If
you worked hard, and tried, we would bend over backwards to keep you. If technology or
business conditions eliminated your job, we would try to train you for a new one. Our people
were loyal, not like IBMers today. I honestly think that's the best way to be profitable.
People afraid of being unjustly RIFFed will always lack vitality.
I'm glad someone is finally paying attention to age discrimination. IBM apparently is just
one of many organizations that discriminate.
I'm in the middle of my own fight with the State University of New York (SUNY) over age
discrimination. I was terminated by a one of the technical colleges in the SUNY System. The
EEOC/New York State Division of Human Rights (NYDHR) found that "PROBABLE CAUSE (NYDHR's
emphasis) exists to believe that the Respondent (Alfred State College - SUNY) has engaged in
or is engaging in the unlawful discriminatory practice complained of." Investigators for
NYDHR interviewed several witnesses, who testified that representatives of the college made
statements such as "we need new faces", "three old men" attending a meeting, an older faculty
member described as an "albatross", and "we ought to get rid of the old white guys".
Witnesses said these statements were made by the Vice President of Academic Affairs and a
dean at the college.
This saga at IBM is simply a microcosm of our overall economy. Older workers get ousted in
favor of younger, cheaper workers; way too many jobs get outsourced; and so many workers
today [young and old] can barely land a full-time job.
This is the behavior that our system incentivises (and gets away with) in this post Reagan
Revolution era where deregulation is lauded and unions have been undermined & demonized.
We need to seriously re-work 'work', and in order to do this we need to purge Republicans at
every level, as they CLEARLY only serve corporate bottom-lines - not workers - by championing
tax codes that reward outsourcing, fight a livable minimum wage, eliminate pensions, bust
unions, fight pay equity for women & family leave, stack the Supreme Court with radical
ideologues who blatantly rule for corporations over people all the time, etc. etc. ~35 years
of basically uninterrupted Conservative economic policy & ideology has proven disastrous
for workers and our quality of life. As goes your middle class, so goes your country.
I am a retired IBM manager having had to execute many of these resource reduction programs..
too many.. as a matter of fact. ProPUBLICA....You nailed it!
IBM has always treated its customer-facing roles like Disney -- as cast members who need to
match a part in a play. In the 60s and 70s, it was the white-shirt, blue-suit white men whom
IBM leaders thought looked like mainframe salesmen. Now, rather than actually build a
credible cloud to compete with Amazon and Microsoft, IBM changes the cast to look like cloud
salespeople. (I work for Microsoft. Commenting for myself alone.)
I am a survivor, the rare employee who has been at IBM for over 35 years. I have seen many,
many layoff programs over 20 years now. I have seen tens of thousands people let go from the
Hudson Valley of N.Y. Those of us who have survived, know and lived through what this article
so accurately described. I currently work with 3 laid off/retired and rehired contractors. I
have seen age discrimination daily for over 15 years. It is not only limited to layoffs, it
is rampant throughout the company. Promotions, bonuses, transfers for opportunities, good
reviews, etc... are gone if you are over 45. I have seen people under 30 given promotions to
levels that many people worked 25 years for. IBM knows that these younger employees see how
they treat us so they think they can buy them off. Come to think of it, I guess they actually
are! They are ageist, there is no doubt, it is about time everyone knew. Excellent article.
Nice article, but seriously this is old news. IBM has been at this for ...oh twenty years or
more.
I don't really have a problem with it in terms of a corporation trying to make money. But I
do have a problem with how IBM also likes to avoid layoffs by giving folks over 40
intentionally poor reviews, essentially trying to drive people out. Just have the guts to
tell people, we don't need you anymore, bye. But to string people along as the overseas
workers come in...c'mon just be honest with your workers.
High tech over 40 is not easy...I suggest folks prep for a career change before 50. Then you
can have the last laugh on a company like IBM.
From pages 190-191 of my novel, Ordinary Man (Amazon):
Throughout
it all, layoffs became common, impacting mostly older employees with many years
of service. These job cuts were dribbled out in small numbers to conceal them
from the outside world, but employees could plainly see what was going on.
The laid off
employees were supplanted by offshoring work to low-costs countries and hiring
younger employees, often only on temporary contracts that offered low pay and
no benefits – a process pejoratively referred to by veteran employees as
"downsourcing." The recruitment of these younger workers was done under the
guise of bringing in fresh skills, but while many of the new hires brought new
abilities and vitality, they lacked the knowledge and perspective that comes
with experience.
Frequently,
an older more experienced worker would be asked to help educate newer
employees, only to be terminated shortly after completing the task. And the new
hires weren't fooled by what they witnessed and experienced at OpenSwitch,
perceiving very quickly that the company had no real interest in investing in
them for the long term. To the contrary, the objective was clearly to grind as
much work out of them as possible, without offering any hope of increased
reward or opportunity.
Most of the
young recruits left after only a year or two – which, again, was part of the
true agenda at the company. Senior management viewed employees not as talent,
but simply as cost, and didn't want anyone sticking around long enough to move
up the pay scale.
This is the nail in the coffin. As an IT manager responsible for selecting and purchasing
software, I will never again recommend IBM products. I love AIX and have worked with a lot if
IBM products but not anymore. Good luck with the millennials though...
I worked for four major corporations (HP, Intel, Control Data Corporation, and Micron
Semiconductor) before I was hired by IBM as a rare (at that time) experienced new hire. Even
though I ended up working for IBM for 21 years, and retired in 2013, because of my
experiences at those other companies, I never considered IBM my "family." The way I saw it,
every time I received a paycheck from IBM in exchange for two weeks' work, we were (almost)
even. I did not owe them anything else and they did not owe me anything. The idea of loyalty
between a corporation and an at-will employee makes no more sense than loyalty between a
motel and its guests. It is a business arrangement, not a love affair. Every individual needs
to continually assess their skills and their value to their employer. If they are not
commensurate, it is the employee's responsibility to either acquire new skills or seek a new
employer. Your employer will not hesitate to lay you off if your skills are no longer needed,
or if they can hire someone who can do your job just as well for less pay. That is free
enterprise, and it works for people willing to take advantage of it.
I basically agree. But why should it be OK for a company to fire you just to replace you with
a younger you? If all that they accomplish is lowering their health care costs (which is what
this is really about). If the company is paying about the same for the same work, why is
firing older workers for being older OK?
Good question. The point I was trying to make is that people need to watch out for themselves
and not expect their employer to do what is "best" for the employee. I think that is true
whatever age the employee happens to be.
Whether employers should be able to discriminate against (treat differently) their
employees based on age, gender, race, religion, etc. is a political question. Morally, I
don't think they should discriminate. Politically, I think it is a slippery slope when the
government starts imposing regulations on free enterprise. Government almost always creates
more problems than they fix.
Sorry, but when you deregulate the free enterprise, it created more problems than it fixes
and that is a fact that has been proven for the last 38 years.
That's just plain false. Deregulation creates competiiton. Competition for talented and
skilled workers creates opportunities for those that wish to be employed and for those that
wish to start new ventures. For example, when Ma Bell was regulated and had a monopoly on
telecommunications there was no innovation in the telecom inudstry. However, when it was
deregulated, cell phones, internet, etc exploded ... creating billionaires and millionaires
while also improving the quality of life.
No, it happens to be true. When Reagan deregulate the economy, a lot of those corporate
raiders just took over the companies, sold off the assets, and pocketed the money. What
quality of life? Half of American lived near the poverty level and the wages for the workers
have been stagnant for the last 38 years compared to a well-regulated economy in places like
Germany and the Scandinavian countries where the workers have good wages and a far better
standard of living than in the USA. Why do you think the Norwegians told Trump that they will
not be immigrating to the USA anytime soon?
What were the economic conditions before Regan? It was a nightmare before Regan.
The annual unemployment rate topped 8% in 1975 and would reach nearly 10% in 1982. The
economy seemed trapped in the new nightmare of stagflation," so called because it combined
low economic growth and high unemployment ("stagnation") with high rates of inflation. And
the prime rate hit 20% by 1980.
At least we had a manufacturing base in the USA, strong regulations of corporations,
corporate scandals were far and few, businesses did not go under so quickly, prices of goods
and services did not go through the roof, people had pensions and could reasonably live off
them, and recessions did not last so long or go so deep until Reagan came into office. In
Under Reagan, the jobs were allowed to be send overseas, unions were busted up, pensions were
reduced or eliminated, wages except those of the CEOs were staganent, and the economic
conditions under Bush, Senior and Bush, Jr. were no better except that Bush, Jr, was the
first president to have a net minus below zero growth, so every time we get a Republican
Administration, the economy really turns into a nightmare. That is a fact.
You have the Republicans in Kansas, Oklahoma, and Wisconsin using Reaganomics and they are
economic disaster areas.
You had an industrial base in the USA, lots of banks and savings and loans to choose from,
lots of mom and pop stores, strong government regulation of the economy, able to live off
your pensions, strong unions and employment laws along with the court system to back you up
against corporate malfeasance. All that was gone when Reagan and the two Bushes came into
office.
Amazingly accurate article. The once great IBM now a dishonest and unscrupulous corporation
concerned more about earnings per share than employees, customers, or social responsibility.
In Global Services most likely 75% or more jobs are no longer in the US - can't believe a
word coming out of Armonk.
I'm not sure there was ever a paradise in employment. Yeah, you can say there was more job
stability 50 or 60 years ago, but that applied to a much smaller workforce than today (mostly
white men). It is a drag, but there are also lot more of us old farts than there used to be
and we live a lot longer in retirement as well. I don't see any magic bullet fix either.
Great article. What's especially infuriating is that the industry continues to claim that
there is a shortage of STEM workers. For example, google "claim of 1.4 million computer
science jobs with only 400,000 computer science graduates to fill them". If companies would
openly say, "we have plenty of young STEM workers and prefer them to most older STEM
workers", we could at least start addressing the problem. But they continue to promote the
lie of there being a STEM shortage. They just want as big a labor pool as possible,
unemployed workers be damned.
I've worked there 17 years and have worried about being layed off for about 11 of them. Moral
is in the toilet. Bonuses for the rank and file are in the under 1% range while the CEO gets
millions. Pay raises have been non existent or well under inflation for years. Adjusting for
inflation, I make $6K less than I did my first day. My group is a handful of people as at
least 1/2 have quit or retired. To support our customers, we used to have several people, now
we have one or two and if someone is sick or on vacation, our support structure is to hope
nothing breaks. We can't keep millennials because of pay, benefits and the expectation of
being available 24/7 because we're shorthanded. As the unemployment rate drops, more leave to
find a different job, leaving the old people as they are less willing to start over with pay,
vacation, moving, selling a house, pulling kids from school, etc. The younger people are
generally less likely to be willing to work as needed on off hours or to pull work from a
busier colleague. I honestly have no idea what the plan is when the people who know what they
are doing start to retire, we are way top heavy with 30-40 year guys who are on their way
out, very few of the 10-20 year guys due to hiring freezes and we can't keep new people past
2-3 years. It's like our support business model is designed to fail.
Make no mistake. The three and four letter acronyms and other mushy corporate speak may
differ from firm to firm, but this is going on in every large tech company old enough to have
a large population of workers over 50. I hope others will now be exposed.
This article hits the nail right on the head, as I come up on my 1 year anniversary from
being....ahem....'retired' from 23 years at IBM....and I'll be damned if I give them the
satisfaction of thinking this was like a 'death' to me. It was the greatest thing that could
have ever happened. Ginny and the board should be ashamed of themselves, but they won't be.
Starting around age 40 you start to see age discrimination. I think this is largely due to
economics, like increased vacation times, higher wages, but most of all the perception that
older workers will run up the medical costs. You can pass all the age related discrimination
laws you want, but look how ineffective that has been.
If you contrast this with the German workforce, you see that they have more older workers
with the skills and younger workers without are having a difficult time getting in. So what's
the difference? There are laws about how many vacation weeks that are given and there is a
national medical system that everyone pays, so discrimination isn't seen in the same
light.
The US is the only hold out maybe with South Africa that doesn't have a good national
medical insurance program for everyone. Not only do we pay more than the rest of the world,
but we also have discrimination because of it.
This is very good, and this is IBM. I know. I was plaintiff in Gundlach v. IBM Japan, 983
F.Supp.2d 389, which involved their violating Japanese labor law when I worked in Japan. The
New York federal judge purposely ignored key points of Japanese labor law, and also refused
to apply Title VII and Age Discrimination in Employment to the parent company in Westchester
County. It is a huge, self-described "global" company with little demonstrated loyalty to
America and Americans. Pennsylvania is suing them for $170 million on a botched upgrade of
the state's unemployment system.
In early 2013 I was given a 3 PBC rating for my 2012 performance, the main reason cited by my
manager being that my team lead thought I "seemed distracted". Five months later I was
included in a "resource action", and was gone by July. I was 20 months shy of 55. Younger
coworkers were retained. That was about two years after the product I worked on for over a
decade was off-shored.
Through a fluke of someone from the old, disbanded team remembering me, I was rehired two
years later - ironically in a customer support position for the very product I helped
develop.
While I appreciated my years of service, previous salary, and previous benefits being
reinstated, a couple years into it I realized I just wasn't cut out for the demands of the
job - especially the significant 24x7 pager duty. Last June I received email describing a
"Transition to Retirement" plan I was eligible for, took it, and my last day will be June 30.
I still dislike the job, but that plan reclassified me as part time, thus ending pager duty
for me. The job still sucks, but at least I no longer have to despair over numerous week long
24x7 stints throughout the year.
A significant disappointment occurred a couple weeks ago. I was discussing healthcare
options with another person leaving the company who hadn't been resource-actioned as I had,
and learned the hard way I lost over $30,000 in some sort of future medical benefit account
the company had established and funded at some point. I'm not sure I was ever even aware of
it. That would have funded several years of healthcare insurance during the 8 years until I'm
eligible for Medicare. I wouldn't be surprised if their not having to give me that had
something to do with my seeming "distracted" to them. <rolls eyes="">
What's really painful is the history of that former account can still be viewed at
Fidelity, where it associates my departure date in 2013 with my having "forfeited" that
money. Um, no. I did not forfeit that money, nor would I have. I had absolutely no choice in
the matter. I find the use of the word 'forfeited' to describe what happened as both
disingenuous and offensive. That said, I don't know whether's that's IBM's or Fidelity's
terminology, though.
Jeff, You should call Fidelity. I recently received a letter from the US Department of Labor
that they discovered that IBM was "holding" funds that belonged to me that I was never told
about. This might be similar or same story.
Great article. And so so close to home. I worked at IBM for 23 years until I became yet
another statistic -- caught up in one of their many "RA's" -- Resource Actions. I also can
identify with the point about being encouraged to find a job internally yet hiring managers
told to not hire. We were encouraged to apply for jobs outside the US -- Europe mainly -- as
long as we were willing to move and work at the prevailing local wage rate. I was totally
fine with that as my wife had been itching for some time for a chance to live abroad. I
applied for several jobs across Europe using an internal system IBM set up just for that
purpose. Never heard a word. Phone calls and internal e-mails to managers posting jobs in the
internal system went unanswered. It turned out to be a total sham as far as I was concerned.
IBM has laid off hundreds of thousands in the last few decades. Think of the MILLIONS of
children, spouses, brothers/sisters, aunts/uncles, and other family members of laid-off
people that were affected. Those people are or will be business owners and in positions to
make technology decisions. How many of them will think "Yeah, right, hire IBM. They're the
company that screwed daddy/mommy". I fully expect -- and I fully hope -- that I live to see
IBM go out of business. Which they will, sooner or later, as they are living off of past
laurels -- billions in the bank, a big fat patent portfolio, and real estate that they
continue to sell off or rent out. If you do hire IBM, you should fully expect that they'll
send some 20-something out to your company a few weeks after you hire them, that person will
be reading "XYZ for Dummys" on the plane on the way to your offices and will show up as your
IBM 'expert'.
A security bug in Systemd can be exploited over the network to, at best, potentially crash
a vulnerable Linux machine, or, at worst, execute malicious code on the box... Systemd creator
Leonard Poettering has already published a security fix for the vulnerable component –
this should be weaving its way into distros as we type.
I can see what each company will get out of the deal and how they might
potentially benefit. However, Red Hat's culture is integral to their success. Both company
CEOs were asked today at an all-hands meeting about how they intend to keep the promise of
remaining distinct and maintaining the RH culture without IBM suffocating it. Nothing is
supposed to change (for now), but IBM has a track record of driving successful companies and
open dynamic cultures into the ground. Many, many eyes will be watching this.
Hopefully IBM current top Brass will be smart and give some autonomy to Red Hat and leave
it to its own management style. Of course, that will only happen if they deliver IBM goals
(and that will probably mean high double digit y2y growth) on regular basis...
One thing is sure, they'll probably kill any overlapsing product in the medium term (who
will survive between JBOSS and Websphere is an open bet).
(On a dream side note, maybe, just maybe they'll move some of their software development
to Red Hat)
Good luck. Every CEO thinks they're the latest incarnation of Adam Smith, and they're all
dying to be seen as "doing something." Doing nothing, while sometimes a really smart thing
and oftentimes the right thing to do, isn't looked upon favorably these days in American
business. IBM will definitely do something with Red Hat; it's just a matter of what.
My employer outsourced a lot of our IT to IBM and Cognizant in India. The experience has
been terrible and 4 years into a 5 year contract, we are finally realizing the error and insourcing rapidly.
Back in 1999 ATT moved about 4000 of us tech folks working on
mainframe computers to IBM. We got pretty screwed on retirement benefits from ATT. After we
moved over, IBM started slowly moving all of our workload overseas. Brazil and Argentina
mainly.
It started with just tier 1 help desk. Then small IBM accounts started to go over
there. They were trained by 'unwilling' US based people. Unwilling in the sense that if you
didn't comply, you weren't a team player and it would show on your performance review.
Eventually the overseas units took on more and more of the workload. I ended up leaving in
2012 at the age of 56 for personal reasons.
Our time at ATT was suppose to be bridged to IBM
but the only thing bridged was vacation days. A lawsuit ensued and IBM/ATT won. I'm guessing
it was some of that 'ingenious' paperwork that we signed that allowed them to rip us off like
that. Thanks again for some great investigation.
"... In the early 1980's President Regan fired the striking air traffic controllers. This sent the message to management around the USA that it was OK to abuse employees in the workplace. By the end of the 1980's unions were totally emasculated and you had workers "going postal" in an abusive workplace. When unions were at their peak of power, they could appeal to the courts and actually stop a factory from moving out of the country by enforcing a labor contact. ..."
"... The American workplace is a nuthouse. Each and every individual workplace environment is like a cult. ..."
"... The American workplace is just a byproduct of the militarization of everyday life. ..."
"... Silicon Valley and Wall Street handed billions of dollars to this arrogant, ignorant Millennial Elizabeth Holmes. She abused any employee that questioned her. This should sound familiar to any employee who has had an overbearing know-it-all, bully boss in the workplace. Hopefully she will go to jail and a message will be sent that any young agist bully will not be given the power of god in the workplace. ..."
In the early 1980's President Regan fired the striking air traffic controllers. This
sent the message to management around the USA that it was OK to abuse employees in the
workplace. By the end of the 1980's unions were totally emasculated and you had workers
"going postal" in an abusive workplace. When unions were at their peak of power, they could
appeal to the courts and actually stop a factory from moving out of the country by enforcing
a labor contact.
Today we have a President in the White House who was elected on a platform of "YOU'RE
FIRED." Not surprisingly, Trump was elected by the vast majority of selfish lowlives in this
country. The American workplace is a nuthouse. Each and every individual workplace
environment is like a cult.
That is not good for someone like me who hates taking orders from people. But I have seen
it all. Ten years ago a Manhattan law firm fired every lawyer in a litigation unit except an
ex-playboy playmate. Look it up it was in the papers. I was fired from a job where many of my
bosses went to federal prison and then I was invited to the Christmas Party.
What are the salaries of these IBM employees and how much are their replacements making?
The workplace becomes a surrogate family. Who knows why some people get along and others
don't. My theory on agism in the workplace is that younger employees don't want to be around
their surrogate mother or father in the workplace after just leaving the real home under the
rules of their real parents.
The American workplace is just a byproduct of the militarization of everyday life. In the
1800's, Herman Melville wrote in his beautiful book "White Jacket" that one of the most
humiliating aspects of the military is taking orders from a younger military officer. I read
that book when I was 20. I didn't feel the sting of that wisdom until I was 40 and had a 30 year old appointed as
my supervisor who had 10 years less experience than me.
By the way, the executive that made
her my supervisor was one of the sleaziest bosses I have ever had in my career. Look at the
tech giant Theranos. Silicon Valley and Wall Street handed billions of dollars to this
arrogant, ignorant Millennial Elizabeth Holmes. She abused any employee that questioned her.
This should sound familiar to any employee who has had an overbearing know-it-all, bully boss
in the workplace. Hopefully she will go to jail and a message will be sent that any young agist bully will not be given the power of god in the workplace.
I would like to find all the matches of the text I have in one file ('file1.txt')
that are found in another file ('file2.txt') using the grep option -f, that tells to read the
expressions to be found from file.
'file1.txt'
a
a
'file2.txt'
a
When I run the command:
grep -f file1.txt file2.txt -w
I get only once the output of the 'a'. instead I would like to get it twice, because it
occurs twice in my 'file1.txt' file. Is there a way to let grep (or any other unix/linux)
tool to output a match for each line it reads? Thanks in advance. Arturo
I understand that, but still I would like to find a way to print a match each time a pattern
(even a repeated one) from 'pattern.txt' is found in 'file.txt'. Even a tool or a script
rather then 'grep -f' would suffice. – Arturo
Mar 24 '17 at 9:17
The first wave of the computer revolution created stand-alone systems. The current wave is
their combination into new and much larger ones.
Posted by b on October 26, 2018 at 02:18 PM
Not strictly correct. It has come full circle in sense. We started with standalone
machines; then we had central mainframes with dumb terminals; then
the first networks of these centralized servers (XeroxParc's efforts being more forward
looking and an exception); then PCs; then internet; and now (per design and not by merit,
imo)
We are effectively back to the centralized systems ("clouds" controlled by Amazon (CIA),
Google (NSA)). The peripheral components of autonomous networked systems are akin to sensory
devices with heavy computational lifting in the (local) regime controlled servers.
---
By this, I mean moral codes no longer have any objective basis but are evermore easily
re-wired by the .002 to suit their purposes
Posted by: donkeytale | Oct 27, 2018 6:32:11 AM | 69
I question the implied "helpless to resist reprogramming" notion of your statement. You
mentioned God. Please note that God has endowed each and every one of us with a moral
compass. You mentioned Jesus. Didn't he say something about "you generation of vipers"? I
suggest you consider that ours is a morally degenerate generation and is getting precisely
what it wants and deserves.
To change two vertically split windows to horizontal split: Ctrl - WtCtrl - WK
Horizontally to vertically: Ctrl - WtCtrl - WH
Explanations:
Ctrl - W t -- makes the first (topleft) window current
Ctrl - W K -- moves the current window to full-width at the very
top
Ctrl - W H -- moves the current window to full-height at far
left
Note that the t is lowercase, and the K and H are uppercase.
Also, with only two windows, it seems like you can drop the Ctrl - Wt part because if you're already in one of only two windows, what's the point of
making it current?
Just toggle your NERDTree panel closed before 'rotating' the splits, then toggle it
back open. :NERDTreeToggle (I have it mapped to a function key for convenience).
The command ^W-o is great! I did not know it. –
Masi Aug 13 '09 at 2:20
add a comment | up vote 6
down vote The following ex commands will (re-)split
any number of windows:
To split vertically (e.g. make vertical dividers between windows), type :vertical
ball
To split horizontally, type :ball
If there are hidden buffers, issuing these commands will also make the hidden buffers
visible.
This is very ugly, but hey, it seems to do in one step exactly what I asked for (I tried). +1, and accepted. I was looking for
a native way to do this quickly but since there does not seem to be one, yours will do just fine. Thanks! –
greg0ireJan 23
'13 at 15:27
You're right, "very ugly" shoud have been "very unfamiliar". Your command is very handy, and I think I definitely going to carve
it in my .vimrc – greg0ireJan 23
'13 at 16:21
By "move a piece of text to a new file" I assume you mean cut that piece of text from the current file and create a new file containing
only that text.
Various examples:
:1,1 w new_file to create a new file containing only the text from line number 1
:5,50 w newfile to create a new file containing the text from line 5 to line 50
:'a,'b w newfile to create a new file containing the text from mark a to mark b
set your marks by using ma and mb where ever you like
The above only copies the text and creates a new file containing that text. You will then need to delete afterward.
This can be done using the same range and the d command:
:5,50 d to delete the text from line 5 to line 50
:'a,'b d to delete the text from mark a to mark b
Or by using dd for the single line case.
If you instead select the text using visual mode, and then hit : while the text is selected, you will see the
following on the command line:
:'<,'>
Which indicates the selected text. You can then expand the command to:
:'<,'>w >> old_file
Which will append the text to an existing file. Then delete as above.
One liner:
:2,3 d | new +put! "
The breakdown:
:2,3 d - delete lines 2 through 3
| - technically this redirects the output of the first command to the second command but since the first command
doesn't output anything, we're just chaining the commands together
new - opens a new buffer
+put! " - put the contents of the unnamed register ( " ) into the buffer
The bang ( ! ) is there so that the contents are put before the current line. This causes and
empty line at the end of the file. Without it, there is an empty line at the top of the file.
Your assumption is right. This looks good, I'm going to test. Could you explain 2. a bit more? I'm not very familiar with ranges.
EDIT: If I try this on the second line, it writes the first line to the other file, not the second line. –
greg0ireJan 23
'13 at 14:09
Ok, if I understand well, the trick is to use ranges to select and write in the same command. That's very similar to what I did.
+1 for the detailed explanation, but I don't think this is more efficient, since the trick with hitting ':' is what I do for the
moment. – greg0ireJan 23
'13 at 14:41
I have 4 steps for the moment: select, write, select, delete. With your method, I have 6 steps: select, delete, split, paste,
write, close. I asked for something more efficient :P – greg0ireJan 23
'13 at 13:42
That's better, but 5 still > 4 :P – greg0ireJan 23
'13 at 13:46
Based on @embedded.kyle's answer and this Q&A , I ended
up with this one liner to append a selection to a file and delete from current file. After selecting some lines with Shift+V
, hit : and run:
'<,'>w >> test | normal gvd
The first part appends selected lines. The second command enters normal mode and runs gvd to select the last selection
and then deletes.
Visual selection is a common feature in applications, but Vim's visual selection has several
benefits.
To cut-and-paste or copy-and-paste:
Position the cursor at the beginning of the text you want to cut/copy.
Press v to begin character-based visual selection, or V to select whole
lines, or Ctrl-v or Ctrl-q to select a block.
Move the cursor to the end of the text to be cut/copied. While selecting text, you can
perform searches and other advanced movement.
Press d (delete) to cut, or y (yank) to copy.
Move the cursor to the desired paste location.
Press p to paste after the cursor, or P to paste before.
Visual selection (steps 1-3) can be performed using a mouse.
If you want to change the selected text, press c instead of d or y in
step 4. In a visual selection, pressing c performs a change by deleting the selected
text and entering insert mode so you can type the new text.
Pasting over a block of text
You can copy a block of text by pressing Ctrl-v (or Ctrl-q if you use Ctrl-v for paste),
then moving the cursor to select, and pressing y to yank. Now you can move
elsewhere and press p to paste the text after the cursor (or P to
paste before). The paste inserts a block (which might, for example, be 4 rows by 3
columns of text).
Instead of inserting the block, it is also possible to replace (paste over) the
destination. To do this, move to the target location then press 1vp (
1v selects an area equal to the original, and p pastes over it).
When a count is used before v , V , or ^V (character,
line or block selection), an area equal to the previous area, multiplied by the count, is
selected. See the paragraph after :help
<LeftRelease> .
Note that this will only work if you actually did something to the previous visual
selection, such as a yank, delete, or change operation. It will not work after visually
selecting an area and leaving visual mode without taking any actions.
NOTE: after selecting the visual copy mode, you can hold the shift key while selection
the region to get a multiple line copy. For example, to copy three lines, press V, then hold
down the Shift key while pressing the down arrow key twice. Then do your action on the
buffer.
I have struck out the above new comment because I think it is talking about something
that may apply to those who have used :behave mswin . To visually select
multiple lines, you type V , then press j (or cursor down). You
hold down Shift only to type the uppercase V . Do not press Shift after that. If
I am wrong, please explain here. JohnBeckett 10:48, October 7, 2010
(UTC)
If you just want to copy (yank) the visually marked text, you do not need to 'y'ank it.
Marking it will already copy it.
Using a mouse, you can insert it at another position by clicking the middle mouse
button.
This also works in across Vim applications on Windows systems (clipboard is inserted)
This is a really useful thing in Vim. I feel lost without it in any other editor. I have
some more points I'd like to add to this tip:
While in (any of the three) Visual mode(s), pressing 'o' will move the cursor to the
opposite end of the selection. In Visual Block mode, you can also press 'O', allowing you to
position the cursor in any of the four corners.
If you have some yanked text, pressing 'p' or 'P' while in Visual mode will replace the
selected text with the already yanked text. (After this, the previously selected text will be
yanked.)
Press 'gv' in Normal mode to restore your previous selection.
It's really worth it to check out the register functionality in Vim: ':help
registers'.
If you're still eager to use the mouse-juggling middle-mouse trick of common unix
copy-n-paste, or are into bending space and time with i_CTRL-R<reg>, consider checking
out ':set paste' and ':set pastetoggle'. (Or in the latter case, try with
i_CTRL-R_CTRL-O..)
You can replace a set of text in a visual block very easily by selecting a block, press c
and then make changes to the first line. Pressing <Esc> twice replaces all the text of
the original selection. See :help v_b_c .
On Windows the <mswin.vim> script seems to be getting sourced for many users.
Result: more Windows like behavior (ctrl-v is "paste", instead of visual-block selection).
Hunt down your system vimrc and remove sourcing thereof if you don't like that behavior (or
substitute <mrswin.vim> in its place, see VimTip63 .
With VimTip588 one can
sort lines or blocks based on visual-block selection.
With reference to the earlier post asking how to paste an inner block
Select the inner block to copy usint ctrl-v and highlighting with the hjkl keys
yank the visual region (y)
Select the inner block you want to overwrite (Ctrl-v then hightlight with hjkl keys)
paste the selection P (that is shift P) , this will overwrite keeping the block
formation
The "yank" buffers in Vim are not the same as the Windows clipboard (i.e., cut-and-paste)
buffers. If you're using the yank, it only puts it in a Vim buffer - that buffer is not
accessible to the Windows paste command. You'll want to use the Edit | Copy and Edit | Paste
(or their keyboard equivalents) if you're using the Windows GUI, or select with your mouse and
use your X-Windows cut-n-paste mouse buttons if you're running UNIX.
Double-quote and star gives one access to windows clippboard or the unix equivalent. as an
example if I wanted to yank the current line into the clipboard I would type "*yy
If I wanted to paste the contents of the clippboard into Vim at my current curser location I
would type "*p
The double-qoute and start trick work well with visual mode as well. ex: visual select text
to copy to clippboard and then type "*y
I find this very useful and I use it all the time but it is a bit slow typing "* all the
time so I am thinking about creating a macro to speed it up a bit.
Copy and Paste using the System Clipboard
There are some caveats regarding how the "*y (copy into System Clipboard) command works. We
have to be sure that we are using vim-full (sudo aptitude install vim-full on debian-based
systems) or a Vim that has X11 support enabled. Only then will the "*y command work.
For our convenience as we are all familiar with using Ctrl+c to copy a block of text in most
other GUI applications, we can also map Ctrl+c to "*y so that in Vim Visual Mode, we can simply
Ctrl+c to copy the block of text we want into our system buffer. To do that, we simply add this
line in our .vimrc file:
map <C-c> "+y<CR>
Restart our shell and we are good. Now whenever we are in Visual Mode, we can Ctrl+c to grab
what we want and paste it into another application or another editor in a convenient and
intuitive manner.
I want to clean this up but I am worried because of the symlinks, which point to another
drive.
If I say rm -rf /home3 will it delete the other drive?
John Sui
rm -rf /home3 will delete all files and directory within home3 and
home3 itself, which include symlink files, but will not "follow"(de-reference)
those symlink.
Put it in another words, those symlink-files will be deleted. The files they
"point"/"link" to will not be touch.
$ ls -l
total 899166
drwxr-xr-x 12 me scicomp 324 Jan 24 13:47 data
-rw-r--r-- 1 me scicomp 84188 Jan 24 13:47 lod-thin-1.000000-0.010000-0.030000.rda
drwxr-xr-x 2 me scicomp 808 Jan 24 13:47 log
lrwxrwxrwx 1 me scicomp 17 Jan 25 09:41 msg -> /home/me/msg
And I want to remove it using rm -r .
However I'm scared rm -r will follow the symlink and delete everything in
that directory (which is very bad).
I can't find anything about this in the man pages. What would be the exact behavior of
running rm -rf from a directory above this one?
@frnknstn You are right. I see the same behaviour you mention on my latest Debian system. I
don't remember on which version of Debian I performed the earlier experiments. In my earlier
experiments on an older version of Debian, either a.txt must have survived in the third
example or I must have made an error in my experiment. I have updated the answer with the
current behaviour I observe on Debian 9 and this behaviour is consistent with what you
mention. – Susam
Pal
Sep 11 '17 at 15:20
Your /home/me/msg directory will be safe if you rm -rf the directory from which you ran ls.
Only the symlink itself will be removed, not the directory it points to.
The only thing I would be cautious of, would be if you called something like "rm -rf msg/"
(with the trailing slash.) Do not do that because it will remove the directory that msg
points to, rather than the msg symlink itself.
> ,Jan 25, 2012 at 16:54
"The only thing I would be cautious of, would be if you called something like "rm -rf msg/"
(with the trailing slash.) Do not do that because it will remove the directory that msg
points to, rather than the msg symlink itself." - I don't find this to be true. See the third
example in my response below. – Susam Pal
Jan 25 '12 at 16:54
I get the same result as @Susam ('rm -r symlink/' does not delete the target of symlink),
which I am pleased about as it would be a very easy mistake to make. – Andrew Crabb
Nov 26 '13 at 21:52
,
rm should remove files and directories. If the file is symbolic link, link is
removed, not the target. It will not interpret a symbolic link. For example what should be
the behavior when deleting 'broken links'- rm exits with 0 not with non-zero to indicate
failure
I have two files, say a.txt and b.txt , in the same session of vim
and I split the screen so I have file a.txt in the upper window and
b.txt in the lower window.
I want to move lines here and there from a.txt to b.txt : I
select a line with Shift + v , then I move to b.txt in the
lower window with Ctrl + w↓ , paste with p
, get back to a.txt with Ctrl + w↑ and I
can repeat the operation when I get to another line I want to move.
My question: is there a quicker way to say vim "send the line I am on (or the test I
selected) to the other window" ?
I presume that you're deleting the line that you've selected in a.txt . If not,
you'd be pasting something else into b.txt . If so, there's no need to select
the line first. – Anthony Geoghegan
Nov 24 '15 at 13:00
This sounds like a good use case for a macro. Macros are commands that can be recorded and
stored in a Vim register. Each register is identified by a letter from a to z.
Recording
To start recording, press q in Normal mode followed by a letter (a to z).
That starts recording keystrokes to the specified register. Vim displays
"recording" in the status line. Type any Normal mode commands, or enter Insert
mode and type text. To stop recording, again press q while in Normal mode.
For this particular macro, I chose the m (for move) register to store it.
I pressed qm to record the following commands:
dd to delete the current line (and save it to the default register)
CtrlWj to move to the window below
p to paste the contents of the default register
and CtrlWk to return to the window above.
When I typed q to finish recording the macro, the contents of the
m register were:
dd^Wjp^Wk
Usage
To move the current line, simply type @m in Normal mode.
To repeat the macro on a different line, @@ can be used to execute the most
recently used macro.
To execute the macro 5 times (i.e., move the current line with the following four lines
below it), use 5@m or 5@@ .
I asked to see if there is a command unknown to me that does the job: it seems there is none.
In absence of such a command, this can be a good solution. – brad
Nov 24 '15 at 14:26
@brad, you can find all the commands available to you in the documentation. If it's not there
it doesn't exist no need to ask random strangers. – romainl
Nov 26 '15 at 9:54
@romainl, yes, I know this but vim documentation is really huge and, although it doesn't
scare me, there is always the possibility to miss something. Moreover, it could also be that
you can obtain the effect using the combination of 2 commands and in this case it would be
hardly documented – brad
Nov 26 '15 at 10:17
I normally work with more than 5 files at a time. I use buffers to open different files. I
use commands such as :buf file1, :buf file2 etc. Is there a faster way to move to different
files?
Below I describe some excerpts from sections of my .vimrc . It includes mapping
the leader key, setting wilds tab completion, and finally my buffer nav key choices (all
mostly inspired by folks on the interweb, including romainl). Edit: Then I ramble on about my
shortcuts for windows and tabs.
" easier default keys {{{1
let mapleader=','
nnoremap <leader>2 :@"<CR>
The leader key is a prefix key for mostly user-defined key commands (some
plugins also use it). The default is \ , but many people suggest the easier to
reach , .
The second line there is a command to @ execute from the "
clipboard, in case you'd like to quickly try out various key bindings (without relying on
:so % ). (My nmeumonic is that Shift - 2 is @
.)
" wilds {{{1
set wildmenu wildmode=list:full
set wildcharm=<C-z>
set wildignore+=*~ wildignorecase
For built-in completion, wildmenu is probably the part that shows up yellow
on your Vim when using tab completion on command-line. wildmode is set to a
comma-separated list, each coming up in turn on each tab completion (that is, my list is
simply one element, list:full ). list shows rows and columns of
candidates. full 's meaning includes maintaining existence of the
wildmenu . wildcharm is the way to include Tab presses
in your macros. The *~ is for my use in :edit and
:find commands.
The ,3 is for switching between the "two" last buffers (Easier to reach than
built-in Ctrl - 6 ). Nmeuonic is Shift - 3 is
# , and # is the register symbol for last buffer. (See
:marks .)
,bh is to select from hidden buffers ( ! ).
,bw is to bwipeout buffers by number or name. For instance, you
can wipeout several while looking at the list, with ,bw 1 3 4 8 10 <CR> .
Note that wipeout is more destructive than :bdelete . They have their pros and
cons. For instance, :bdelete leaves the buffer in the hidden list, while
:bwipeout removes global marks (see :help marks , and the
description of uppercase marks).
I haven't settled on these keybindings, I would sort of prefer that my ,bb
was simply ,b (simply defining while leaving the others defined makes Vim pause
to see if you'll enter more).
Those shortcuts for :BufExplorer are actually the defaults for that plugin,
but I have it written out so I can change them if I want to start using ,b
without a hang.
You didn't ask for this:
If you still find Vim buffers a little awkward to use, try to combine the functionality
with tabs and windows (until you get more comfortable?).
Notice how nice ,w is for a prefix. Also, I reserve Ctrl key for
resizing, because Alt ( M- ) is hard to realize in all
environments, and I don't have a better way to resize. I'm fine using ,w to
switch windows.
" tabs {{{3
nnoremap <leader>t :tab
nnoremap <M-n> :tabn<cr>
nnoremap <M-p> :tabp<cr>
nnoremap <C-Tab> :tabn<cr>
nnoremap <C-S-Tab> :tabp<cr>
nnoremap tn :tabe<CR>
nnoremap te :tabe<Space><C-z><S-Tab>
nnoremap tf :tabf<Space>
nnoremap tc :tabc<CR>
nnoremap to :tabo<CR>
nnoremap tm :tabm<CR>
nnoremap ts :tabs<CR>
nnoremap th :tabr<CR>
nnoremap tj :tabn<CR>
nnoremap tk :tabp<CR>
nnoremap tl :tabl<CR>
" or, it may make more sense to use
" nnoremap th :tabp<CR>
" nnoremap tj :tabl<CR>
" nnoremap tk :tabr<CR>
" nnoremap tl :tabn<CR>
In summary of my window and tabs keys, I can navigate both of them with Alt ,
which is actually pretty easy to reach. In other words:
" (modifier) key choice explanation {{{3
"
" KEYS CTRL ALT
" hjkl resize windows switch windows
" np switch buffer switch tab
"
" (resize windows is hard to do otherwise, so we use ctrl which works across
" more environments. i can use ',w' for windowcmds o.w.. alt is comfortable
" enough for fast and gui nav in tabs and windows. we use np for navs that
" are more linear, hjkl for navs that are more planar.)
"
This way, if the Alt is working, you can actually hold it down while you find
your "open" buffer pretty quickly, amongst the tabs and windows.
,
There are many ways to solve. The best is the best that WORKS for YOU. You have lots of fuzzy
match plugins that help you navigate. The 2 things that impress me most are
The NERD tree allows you to explore your filesystem and to open files and directories. It presents the filesystem to you in
the form of a tree which you manipulate with the keyboard and/or mouse. It also allows you to perform simple filesystem operations.
The tree can be toggled easily with :NERDTreeToggle which can be mapped to a more suitable key. The keyboard shortcuts in the
NERD tree are also easy and intuitive.
For those of us not wanting to follow every link to find out about each plugin, care to furnish us with a brief synopsis? –
SpoonMeiserSep 17 '08
at 19:32
Pathogen is the FIRST plugin you have to install on every Vim installation! It resolves the plugin management problems every Vim
developer has. – Patrizio RulloSep 26
'11 at 12:11
A very nice grep replacement for GVim is Ack . A search plugin written
in Perl that beats Vim's internal grep implementation and externally invoked greps, too. It also by default skips any CVS directories
in the project directory, e.g. '.svn'.
This blog shows a way to integrate Ack with vim.
A.vim is a great little plugin. It allows you
to quickly switch between header and source files with a single command. The default is :A , but I remapped it to
F2 reduce keystrokes.
I really like the SuperTab plugin, it allows
you to use the tab key to do all your insert completions.
community wiki Greg Hewgill, Aug 25, 2008
at 19:23
I have recently started using a plugin that highlights differences in your buffer from a previous version in your RCS system (Subversion,
git, whatever). You just need to press a key to toggle the diff display on/off. You can find it here:
http://github.com/ghewgill/vim-scmdiff . Patches welcome!
It doesn't explicitly support bitkeeper at the moment, but as long as bitkeeper has a "diff" command that outputs a normal patch
file, it should be easy enough to add. – Greg HewgillSep 16 '08
at 9:26
@Yogesh: No, it doesn't support ClearCase at this time. However, if you can add ClearCase support, a patch would certainly be
accepted. – Greg HewgillMar 10
'10 at 1:39
Elegant (mini) buffer explorer - This
is the multiple file/buffer manager I use. Takes very little screen space. It looks just like most IDEs where you have a top
tab-bar with the files you've opened. I've tested some other similar plugins before, and this is my pick.
TagList - Small file explorer, without
the "extra" stuff the other file explorers have. Just lets you browse directories and open files with the "enter" key. Note
that this has already been noted by
previouscommenters
to your questions.
SuperTab - Already noted by
WMR in this
post, looks very promising. It's an auto-completion replacement key for Ctrl-P.
Moria color scheme - Another good, dark
one. Note that it's gVim only.
Enahcned Python syntax - If you're using
Python, this is an enhanced syntax version. Works better than the original. I'm not sure, but this might be already included
in the newest version. Nonetheless, it's worth adding to your syntax folder if you need it.
Not a plugin, but I advise any Mac user to switch to the MacVim
distribution which is vastly superior to the official port.
As for plugins, I used VIM-LaTeX for my thesis and was very
satisfied with the usability boost. I also like the Taglist
plugin which makes use of the ctags library.
clang complete - the best c++ code completion
I have seen so far. By using an actual compiler (that would be clang) the plugin is able to complete complex expressions including
STL and smart pointers.
With version 7.3, undo branches was added to vim. A very powerful feature, but hard to use, until
Steve Losh made
Gundo which makes this feature possible to use with a ascii
representation of the tree and a diff of the change. A must for using undo branches.
My latest favourite is Command-T . Granted, to install it
you need to have Ruby support and you'll need to compile a C extension for Vim. But oy-yoy-yoy does this plugin make a difference
in opening files in Vim!
Definitely! Let not the ruby + c compiling stop you, you will be amazed on how well this plugin enhances your toolset. I have
been ignoring this plugin for too long, installed it today and already find myself using NERDTree lesser and lesser. –
Victor FarazdagiApr 19
'11 at 19:16
just my 2 cents.. being a naive user of both plugins, with a few first characters of file name i saw a much better result with
commandt plugin and a lots of false positives for ctrlp. –
FUDDec
26 '12 at 4:48
Conque Shell : Run interactive commands inside a Vim buffer
Conque is a Vim plugin which allows you to run interactive programs, such as bash on linux or powershell.exe on Windows, inside
a Vim buffer. In other words it is a terminal emulator which uses a Vim buffer to display the program output.
The vcscommand plugin provides global ex commands
for manipulating version-controlled source files and it supports CVS,SVN and some other repositories.
You can do almost all repository related tasks from with in vim:
* Taking the diff of current buffer with repository copy
* Adding new files
* Reverting the current buffer to the repository copy by nullifying the local changes....
Just gonna name a few I didn't see here, but which I still find extremely helpful:
Gist plugin - Github Gists (Kind of
Githubs answer to Pastebin, integrated with Git for awesomeness!)
Mustang color scheme (Can't link directly due to low reputation, Google it!) - Dark, and beautiful color scheme. Looks
really good in the terminal, and even better in gVim! (Due to 256 color support)
One Plugin that is missing in the answers is NERDCommenter
, which let's you do almost anything with comments. For example {add, toggle, remove} comments. And more. See
this blog entry for some examples.
This script is based on the eclipse Task List. It will search the file for FIXME, TODO, and XXX (or a custom list) and put
them in a handy list for you to browse which at the same time will update the location in the document so you can see exactly
where the tag is located. Something like an interactive 'cw'
I really love the snippetsEmu Plugin. It emulates
some of the behaviour of Snippets from the OS X editor TextMate, in particular the variable bouncing and replacement behaviour.
For vim I like a little help with completions.
Vim has tons of completion modes, but really, I just want vim to complete anything it can, whenver it can.
I hate typing ending quotes, but fortunately
this plugin obviates the need for such misery.
Those two are my heavy hitters.
This one may step up to roam my code like
an unquiet shade, but I've yet to try it.
The Txtfmt plugin gives you a sort of "rich text" highlighting capability, similar to what is provided by RTF editors and word
processors. You can use it to add colors (foreground and background) and formatting attributes (all combinations of bold, underline,
italic, etc...) to your plain text documents in Vim.
The advantage of this plugin over something like Latex is that with Txtfmt, your highlighting changes are visible "in real
time", and as with a word processor, the highlighting is WYSIWYG. Txtfmt embeds special tokens directly in the file to accomplish
the highlighting, so the highlighting is unaffected when you move the file around, even from one computer to another. The special
tokens are hidden by the syntax; each appears as a single space. For those who have applied Vince Negri's conceal/ownsyntax patch,
the tokens can even be made "zero-width".
To copy two lines, it's even faster just to go yj or yk,
especially since you don't double up on one character. Plus, yk is a backwards
version that 2yy can't do, and you can put the number of lines to reach
backwards in y9j or y2k, etc.. Only difference is that your count
has to be n-1 for a total of n lines, but your head can learn that
anyway. – zelk
Mar 9 '14 at 13:29
If you would like to duplicate a line and paste it right away below the current like, just
like in Sublime Ctrl + Shift + D, then you can add this to
your .vimrc file.
y7yp (or 7yyp) is rarely useful; the cursor remains on the first line copied so that p pastes
the copied lines between the first and second line of the source. To duplicate a block of
lines use 7yyP – Nefrubyr
Jul 29 '14 at 14:09
For someone who doesn't know vi, some answers from above might mislead him with phrases like
"paste ... after/before current line ".
It's actually "paste ... after/before cursor ".
yy or Y to copy the line
or dd to delete the line
then
p to paste the copied or deleted text after the cursor
or P to paste the copied or deleted text before the cursor
For those starting to learn vi, here is a good introduction to vi by listing side by side vi
commands to typical Windows GUI Editor cursor movement and shortcut keys. It lists all the
basic commands including yy (copy line) and p (paste after) or
P (paste before).
When you press : in visual mode, it is transformed to '<,'>
so it pre-selects the line range the visual selection spanned over. So, in visual mode,
:t0 will copy the lines at the beginning. – Benoit
Jun 30 '12 at 14:17
For the record: when you type a colon (:) you go into command line mode where you can enter
Ex commands. vimdoc.sourceforge.net/htmldoc/cmdline.html
Ex commands can be really powerful and terse. The yyp solutions are "Normal mode" commands.
If you want to copy/move/delete a far-away line or range of lines an Ex command can be a lot
faster. – Niels Bom
Jul 31 '12 at 8:21
Y is usually remapped to y$ (yank (copy) until end of line (from
current cursor position, not beginning of line)) though. With this line in
.vimrc : :nnoremap Y y$ – Aaron Thoma
Aug 22 '13 at 23:31
gives you the advantage of preserving the cursor position.
,Sep 18, 2008 at 20:32
You can also try <C-x><C-l> which will repeat the last line from insert mode and
brings you a completion window with all of the lines. It works almost like <C-p>
This is very useful, but to avoid having to press many keys I have mapped it to just CTRL-L,
this is my map: inoremap ^L ^X^L – Jorge Gajon
May 11 '09 at 6:38
1 gotcha: when you use "p" to put the line, it puts it after the line your cursor is
on, so if you want to add the line after the line you're yanking, don't move the cursor down
a line before putting the new line.
Use the > command. To indent 5 lines, 5>> . To mark a block of lines and indent it, Vjj>
to indent 3 lines (vim only). To indent a curly-braces block, put your cursor on one of the curly braces and use >%
.
If you're copying blocks of text around and need to align the indent of a block in its new location, use ]p
instead of just p . This aligns the pasted block with the surrounding text.
Also, the shiftwidth
setting allows you to control how many spaces to indent.
My problem(in gVim) is that the command > indents much more than 2 blanks (I want just two blanks but > indent something like
5 blanks) – Kamran Bigdely
Feb 28 '11 at 23:25
The problem with . in this situation is that you have to move your fingers. With @mike's solution (same one i use) you've already
got your fingers on the indent key and can just keep whacking it to keep indenting rather than switching and doing something else.
Using period takes longer because you have to move your hands and it requires more thought because it's a second, different, operation.
– masukomi
Dec 6 '13 at 21:24
I've an XML file and turned on syntax highlighting. Typing gg=G just puts every line starting from position 1. All
the white spaces have been removed. Is there anything else specific to XML? –
asgs
Jan 28 '14 at 21:57
This is cumbersome, but is the way to go if you do formatting outside of core VIM (for instance, using vim-prettier
instead of the default indenting engine). Using > will otherwise royally scew up the formatting done by Prettier.
– oligofren
Mar 27 at 15:23
I find it better than the accepted answer, as I can see what is happening, the lines I'm selecting and the action I'm doing, and
not just type some sort of vim incantation. – user4052054
Aug 17 at 17:50
Suppose | represents the position of the cursor in Vim. If the text to be indented is enclosed in a code block like:
int main() {
line1
line2|
line3
}
you can do >i{ which means " indent ( > ) inside ( i ) block ( { )
" and get:
int main() {
line1
line2|
line3
}
Now suppose the lines are contiguous but outside a block, like:
do
line2|
line3
line4
done
To indent lines 2 thru 4 you can visually select the lines and type > . Or even faster you can do >2j
to get:
do
line2|
line3
line4
done
Note that >Nj means indent from current line to N lines below. If the number of lines to be indented
is large, it could take some seconds for the user to count the proper value of N . To save valuable seconds you can
activate the option of relative number with set relativenumber (available since Vim version 7.3).
Not on my Solaris or AIX boxes it doesn't. The equals key has always been one of my standard ad hoc macro assignments. Are you
sure you're not looking at a vim that's been linked to as vi ? –
rojomoke
Jul 31 '14 at 10:09
In ex mode you can use :left or :le to align lines a specified amount. Specifically,
:left will Left align lines in the [range]. It sets the indent in the lines to [indent] (default 0).
:%le3 or :%le 3 or :%left3 or :%left 3 will align the entire file by padding
with three spaces.
:5,7 le 3 will align lines 5 through 7 by padding them with 3 spaces.
:le without any value or :le 0 will left align with a padding of 0.
Awesome, just what I was looking for (a way to insert a specific number of spaces -- 4 spaces for markdown code -- to override
my normal indent). In my case I wanted to indent a specific number of lines in visual mode, so shift-v to highlight the lines,
then :'<,'>le4 to insert the spaces. Thanks! –
Subfuzion
Aug 11 '17 at 22:02
There is one more way that hasn't been mentioned yet - you can use norm i command to insert given text at the beginning
of the line. To insert 10 spaces before lines 2-10:
:2,10norm 10i
Remember that there has to be space character at the end of the command - this will be the character we want to have inserted.
We can also indent line with any other text, for example to indent every line in file with 5 underscore characters:
:%norm 5i_
Or something even more fancy:
:%norm 2i[ ]
More practical example is commenting Bash/Python/etc code with # character:
:1,20norm i#
To re-indent use x instead of i . For example to remove first 5 characters from every line:
...what? 'indent by 4 spaces'? No, this jumps to line 4 and then indents everything from there to the end of the file, using the
currently selected indent mode (if any). – underscore_d
Oct 17 '15 at 19:35
There are clearly a lot of ways to solve this, but this is the easiest to implement, as line numbers show by default in vim and
it doesn't require math. – HoldOffHunger
Dec 5 '17 at 15:50
How to indent highlighted code in vi immediately by a # of spaces:
Option 1: Indent a block of code in vi to three spaces with Visual Block mode:
Select the block of code you want to indent. Do this using Ctrl+V in normal mode and arrowing down to select
text. While it is selected, enter : to give a command to the block of selected text.
The following will appear in the command line: :'<,'>
To set indent to 3 spaces, type le 3 and press enter. This is what appears: :'<,'>le 3
The selected text is immediately indented to 3 spaces.
Option 2: Indent a block of code in vi to three spaces with Visual Line mode:
Open your file in VI.
Put your cursor over some code
Be in normal mode press the following keys:
Vjjjj:le 3
Interpretation of what you did:
V means start selecting text.
jjjj arrows down 4 lines, highlighting 4 lines.
: tells vi you will enter an instruction for the highlighted text.
le 3 means indent highlighted text 3 lines.
The selected code is immediately increased or decreased to three spaces indentation.
Option 3: use Visual Block mode and special insert mode to increase indent:
Open your file in VI.
Put your cursor over some code
Be in normal mode press the following keys:
Ctrl+V
jjjj
(press spacebar 5 times)
EscShift+i
All the highlighted text is indented an additional 5 spaces.
This answer summarises the other answers and comments of this question, and adds extra information based on the
Vim documentation and the
Vim wiki . For conciseness, this answer doesn't distinguish between Vi and
Vim-specific commands.
In the commands below, "re-indent" means "indent lines according to your
indentation settings ."
shiftwidth is the
primary variable that controls indentation.
General Commands
>> Indent line by shiftwidth spaces
<< De-indent line by shiftwidth spaces
5>> Indent 5 lines
5== Re-indent 5 lines
>% Increase indent of a braced or bracketed block (place cursor on brace first)
=% Reindent a braced or bracketed block (cursor on brace)
<% Decrease indent of a braced or bracketed block (cursor on brace)
]p Paste text, aligning indentation with surroundings
=i{ Re-indent the 'inner block', i.e. the contents of the block
=a{ Re-indent 'a block', i.e. block and containing braces
=2a{ Re-indent '2 blocks', i.e. this block and containing block
>i{ Increase inner block indent
<i{ Decrease inner block indent
You can replace { with } or B, e.g. =iB is a valid block indent command.
Take a look at "Indent a Code Block" for a nice example
to try these commands out on.
Also, remember that
. Repeat last command
, so indentation commands can be easily and conveniently repeated.
Re-indenting complete files
Another common situation is requiring indentation to be fixed throughout a source file:
gg=G Re-indent entire buffer
You can extend this idea to multiple files:
" Re-indent all your c source code:
:args *.c
:argdo normal gg=G
:wall
Or multiple buffers:
" Re-indent all open buffers:
:bufdo normal gg=G:wall
In Visual Mode
Vjj> Visually mark and then indent 3 lines
In insert mode
These commands apply to the current line:
CTRL-t insert indent at start of line
CTRL-d remove indent at start of line
0 CTRL-d remove all indentation from line
Ex commands
These are useful when you want to indent a specific range of lines, without moving your cursor.
:< and :> Given a range, apply indentation e.g.
:4,8> indent lines 4 to 8, inclusive
set expandtab "Use softtabstop spaces instead of tab characters for indentation
set shiftwidth=4 "Indent by 4 spaces when using >>, <<, == etc.
set softtabstop=4 "Indent by 4 spaces when pressing <TAB>
set autoindent "Keep indentation from previous line
set smartindent "Automatically inserts indentation in some cases
set cindent "Like smartindent, but stricter and more customisable
Vim has intelligent indentation based on filetype. Try adding this to your .vimrc:
if has ("autocmd")
" File type detection. Indent based on filetype. Recommended.
filetype plugin indent on
endif
Both this answer and the one above it were great. But I +1'd this because it reminded me of the 'dot' operator, which repeats
the last command. This is extremely useful when needing to indent an entire block several shiftspaces (or indentations)
without needing to keep pressing >} . Thanks a long –
Amit
Aug 10 '11 at 13:26
5>> Indent 5 lines : This command indents the fifth line, not 5 lines. Could this be due to my VIM settings, or is your
wording incorrect? – Wipqozn
Aug 24 '11 at 16:00
Great summary! Also note that the "indent inside block" and "indent all block" (<i{ >a{ etc.) also works with parentheses and
brackets: >a( <i] etc. (And while I'm at it, in addition to <>'s, they also work with d,c,y etc.) –
aqn
Mar 6 '13 at 4:42
Using Python a lot, I find myself needing frequently needing to shift blocks by more than one indent. You can do this by using
any of the block selection methods, and then just enter the number of indents you wish to jump right before the >
Eg. V5j3> will indent 5 lines 3 times - which is 12 spaces if you use 4 spaces for indents
The beauty of vim's UI is that it's consistent. Editing commands are made up of the command and a cursor move. The cursor moves
are always the same:
H to top of screen, L to bottom, M to middle
n G to go to line n, G alone to bottom of file, gg to top
n to move to next search match, N to previous
} to end of paragraph
% to next matching bracket, either of the parentheses or the tag kind
enter to the next line
'x to mark x where x is a letter or another '
many more, including w and W for word, $ or 0 to tips of the
line, etc, that don't apply here because are not line movements.
So, in order to use vim you have to learn to move the cursor and remember a repertoire of commands like, for example, >
to indent (and < to "outdent").
Thus, for indenting the lines from the cursor position to the top of the screen you do >H, >G to indent
to the bottom of the file.
If, instead of typing >H, you type dH then you are deleting the same block of lines, cH
for replacing it, etc.
Some cursor movements fit better with specific commands. In particular, the % command is handy to indent a whole
HTML or XML block.
If the file has syntax highlighted ( :syn on ) then setting the cursor in the text of a tag (like, in the "i" of
<div> and entering >% will indent up to the closing </div> tag.
This is how vim works: one has to remember only the cursor movements and the commands, and how to mix them.
So my answer to this question would be "go to one end of the block of lines you want to indent, and then type the >
command and a movement to the other end of the block" if indent is interpreted as shifting the lines, =
if indent is interpreted as in pretty-printing.
When the 'expandtab' option is off (this is the default) Vim uses <Tab>s as much as possible to make the indent. ( :help :> )
– Kent Fredric
Mar 16 '11 at 8:36
The only tab/space related vim setting I've changed is :set tabstop=3. It's actually inserting this every time I use >>: "<tab><space><space>".
Same with indenting a block. Any ideas? – Shane
Reustle
Dec 2 '12 at 3:17
The three settings you want to look at for "spaces vs tabs" are 1. tabstop 2. shiftwidth 3. expandtab. You probably have "shiftwidth=5
noexpandtab", so a "tab" is 3 spaces, and an indentation level is "5" spaces, so it makes up the 5 with 1 tab, and 2 spaces. –
Kent Fredric
Dec 2 '12 at 17:08
For me, the MacVim (Visual) solution was, select with mouse and press ">", but after putting the following lines in "~/.vimrc"
since I like spaces instead of tabs:
set expandtab
set tabstop=2
set shiftwidth=2
Also it's useful to be able to call MacVim from the command-line (Terminal.app), so since I have the following helper directory
"~/bin", where I place a script called "macvim":
#!/usr/bin/env bash
/usr/bin/open -a /Applications/MacPorts/MacVim.app $@
And of course in "~/.bashrc":
export PATH=$PATH:$HOME/bin
Macports messes with "~/.profile" a lot, so the PATH environment variable can get quite long.
A quick way to do this using VISUAL MODE uses the same process as commenting a block of code.
This is useful if you would prefer not to change your shiftwidth or use any set directives and is
flexible enough to work with TABS or SPACES or any other character.
Position cursor at the beginning on the block
v to switch to -- VISUAL MODE --
Select the text to be indented
Type : to switch to the prompt
Replacing with 3 leading spaces:
:'<,'>s/^/ /g
Or replacing with leading tabs:
:'<,'>s/^/\t/g
Brief Explanation:
'<,'> - Within the Visually Selected Range
s/^/ /g - Insert 3 spaces at the beginning of every line within the whole range
(or)
s/^/\t/g - Insert Tab at the beginning of every line within the whole range
Yup, and this is why one of my big peeves is white spaces on an otherwise empty line: they messes up vim's notion of a "paragraph".
– aqn
Mar 6 '13 at 4:47
In addition to the answer already given and accepted, it is also possible to place a marker and then indent everything from the
current cursor to the marker. Thus, enter ma where you want the top of your indented block, cursor down as far as
you need and then type >'a (note that " a " can be substituted for any valid marker name). This is sometimes
easier than 5>> or vjjj> .
And you can select the lines in visual mode, then press : to get :'<,'> (equivalent to the :1,3
part in your answer), and add mo N . If you want to move a single line, just :mo N . If you are really
lazy, you can omit the space (e.g. :mo5 ). Use marks with mo '{a-zA-Z} . –
Júda Ronén
Jan 18 '17 at 21:20
I've heard a lot about Vim, both pros and
cons. It really seems you should be (as a developer) faster with Vim than with any other
editor. I'm using Vim to do some basic stuff and I'm at best 10 times less
productive with Vim.
The only two things you should care about when you talk about speed (you may not care
enough about them, but you should) are:
Using alternatively left and right hands is the fastest way to use the keyboard.
Never touching the mouse is the second way to be as fast as possible. It takes ages for
you to move your hand, grab the mouse, move it, and bring it back to the keyboard (and you
often have to look at the keyboard to be sure you returned your hand properly to the right
place)
Here are two examples demonstrating why I'm far less productive with Vim.
Copy/Cut & paste. I do it all the time. With all the contemporary editors you press
Shift with the left hand, and you move the cursor with your right hand to select
text. Then Ctrl + C copies, you move the cursor and Ctrl +
V pastes.
With Vim it's horrible:
yy to copy one line (you almost never want the whole line!)
[number xx]yy to copy xx lines into the buffer. But you never
know exactly if you've selected what you wanted. I often have to do [number
xx]dd then u to undo!
Another example? Search & replace.
In PSPad :
Ctrl + f then type what you want you search for, then press
Enter .
In Vim: /, then type what you want to search for, then if there are some
special characters put \ before each special character, then press
Enter .
And everything with Vim is like that: it seems I don't know how to handle it the right
way.
You mention cutting with yy and complain that you almost never want to cut
whole lines. In fact programmers, editing source code, very often want to work on whole
lines, ranges of lines and blocks of code. However, yy is only one of many way
to yank text into the anonymous copy buffer (or "register" as it's called in vi ).
The "Zen" of vi is that you're speaking a language. The initial y is a verb.
The statement yy is a synonym for y_ . The y is
doubled up to make it easier to type, since it is such a common operation.
This can also be expressed as ddP (delete the current line and
paste a copy back into place; leaving a copy in the anonymous register as a side effect). The
y and d "verbs" take any movement as their "subject." Thus
yW is "yank from here (the cursor) to the end of the current/next (big) word"
and y'a is "yank from here to the line containing the mark named ' a
'."
If you only understand basic up, down, left, and right cursor movements then vi will be no
more productive than a copy of "notepad" for you. (Okay, you'll still have syntax
highlighting and the ability to handle files larger than a piddling ~45KB or so; but work
with me here).
vi has 26 "marks" and 26 "registers." A mark is set to any cursor location using the
m command. Each mark is designated by a single lower case letter. Thus
ma sets the ' a ' mark to the current location, and mz
sets the ' z ' mark. You can move to the line containing a mark using the
' (single quote) command. Thus 'a moves to the beginning of the
line containing the ' a ' mark. You can move to the precise location of any mark
using the ` (backquote) command. Thus `z will move directly to the
exact location of the ' z ' mark.
Because these are "movements" they can also be used as subjects for other
"statements."
So, one way to cut an arbitrary selection of text would be to drop a mark (I usually use '
a ' as my "first" mark, ' z ' as my next mark, ' b ' as another,
and ' e ' as yet another (I don't recall ever having interactively used more than
four marks in 15 years of using vi ; one creates one's own conventions regarding how marks
and registers are used by macros that don't disturb one's interactive context). Then we go to
the other end of our desired text; we can start at either end, it doesn't matter. Then we can
simply use d`a to cut or y`a to copy. Thus the whole process has a
5 keystrokes overhead (six if we started in "insert" mode and needed to Esc out
command mode). Once we've cut or copied then pasting in a copy is a single keystroke:
p .
I say that this is one way to cut or copy text. However, it is only one of many.
Frequently we can more succinctly describe the range of text without moving our cursor around
and dropping a mark. For example if I'm in a paragraph of text I can use { and
} movements to the beginning or end of the paragraph respectively. So, to move a
paragraph of text I cut it using {d} (3 keystrokes). (If I happen
to already be on the first or last line of the paragraph I can then simply use
d} or d{ respectively.
The notion of "paragraph" defaults to something which is usually intuitively reasonable.
Thus it often works for code as well as prose.
Frequently we know some pattern (regular expression) that marks one end or the other of
the text in which we're interested. Searching forwards or backwards are movements in vi .
Thus they can also be used as "subjects" in our "statements." So I can use d/foo
to cut from the current line to the next line containing the string "foo" and
y?bar to copy from the current line to the most recent (previous) line
containing "bar." If I don't want whole lines I can still use the search movements (as
statements of their own), drop my mark(s) and use the `x commands as described
previously.
In addition to "verbs" and "subjects" vi also has "objects" (in the grammatical sense of
the term). So far I've only described the use of the anonymous register. However, I can use
any of the 26 "named" registers by prefixing the "object" reference with
" (the double quote modifier). Thus if I use "add I'm cutting the
current line into the ' a ' register and if I use "by/foo then I'm
yanking a copy of the text from here to the next line containing "foo" into the ' b
' register. To paste from a register I simply prefix the paste with the same modifier
sequence: "ap pastes a copy of the ' a ' register's contents into the
text after the cursor and "bP pastes a copy from ' b ' to before the
current line.
This notion of "prefixes" also adds the analogs of grammatical "adjectives" and "adverbs'
to our text manipulation "language." Most commands (verbs) and movement (verbs or objects,
depending on context) can also take numeric prefixes. Thus 3J means "join the
next three lines" and d5} means "delete from the current line through the end of
the fifth paragraph down from here."
This is all intermediate level vi . None of it is Vim specific and there are far more
advanced tricks in vi if you're ready to learn them. If you were to master just these
intermediate concepts then you'd probably find that you rarely need to write any macros
because the text manipulation language is sufficiently concise and expressive to do most
things easily enough using the editor's "native" language.
A sampling of more advanced tricks:
There are a number of : commands, most notably the :%
s/foo/bar/g global substitution technique. (That's not advanced but other
: commands can be). The whole : set of commands was historically
inherited by vi 's previous incarnations as the ed (line editor) and later the ex (extended
line editor) utilities. In fact vi is so named because it's the visual interface to ex .
: commands normally operate over lines of text. ed and ex were written in an
era when terminal screens were uncommon and many terminals were "teletype" (TTY) devices. So
it was common to work from printed copies of the text, using commands through an extremely
terse interface (common connection speeds were 110 baud, or, roughly, 11 characters per
second -- which is slower than a fast typist; lags were common on multi-user interactive
sessions; additionally there was often some motivation to conserve paper).
So the syntax of most : commands includes an address or range of addresses
(line number) followed by a command. Naturally one could use literal line numbers:
:127,215 s/foo/bar to change the first occurrence of "foo" into "bar" on each
line between 127 and 215. One could also use some abbreviations such as . or
$ for current and last lines respectively. One could also use relative prefixes
+ and - to refer to offsets after or before the curent line,
respectively. Thus: :.,$j meaning "from the current line to the last line, join
them all into one line". :% is synonymous with :1,$ (all the
lines).
The :... g and :... v commands bear some explanation as they are
incredibly powerful. :... g is a prefix for "globally" applying a subsequent
command to all lines which match a pattern (regular expression) while :... v
applies such a command to all lines which do NOT match the given pattern ("v" from
"conVerse"). As with other ex commands these can be prefixed by addressing/range references.
Thus :.,+21g/foo/d means "delete any lines containing the string "foo" from the
current one through the next 21 lines" while :.,$v/bar/d means "from here to the
end of the file, delete any lines which DON'T contain the string "bar."
It's interesting that the common Unix command grep was actually inspired by this ex
command (and is named after the way in which it was documented). The ex command
:g/re/p (grep) was the way they documented how to "globally" "print" lines
containing a "regular expression" (re). When ed and ex were used, the :p command
was one of the first that anyone learned and often the first one used when editing any file.
It was how you printed the current contents (usually just one page full at a time using
:.,+25p or some such).
Note that :% g/.../d or (its reVerse/conVerse counterpart: :%
v/.../d are the most common usage patterns. However there are couple of other
ex commands which are worth remembering:
We can use m to move lines around, and j to join lines. For
example if you have a list and you want to separate all the stuff matching (or conversely NOT
matching some pattern) without deleting them, then you can use something like: :%
g/foo/m$ ... and all the "foo" lines will have been moved to the end of the file.
(Note the other tip about using the end of your file as a scratch space). This will have
preserved the relative order of all the "foo" lines while having extracted them from the rest
of the list. (This would be equivalent to doing something like: 1G!GGmap!Ggrep
foo<ENTER>1G:1,'a g/foo'/d (copy the file to its own tail, filter the tail
through grep, and delete all the stuff from the head).
To join lines usually I can find a pattern for all the lines which need to be joined to
their predecessor (all the lines which start with "^ " rather than "^ * " in some bullet
list, for example). For that case I'd use: :% g/^ /-1j (for every matching line,
go up one line and join them). (BTW: for bullet lists trying to search for the bullet lines
and join to the next doesn't work for a couple reasons ... it can join one bullet line to
another, and it won't join any bullet line to all of its continuations; it'll only
work pairwise on the matches).
Almost needless to mention you can use our old friend s (substitute) with the
g and v (global/converse-global) commands. Usually you don't need
to do so. However, consider some case where you want to perform a substitution only on lines
matching some other pattern. Often you can use a complicated pattern with captures and use
back references to preserve the portions of the lines that you DON'T want to change. However,
it will often be easier to separate the match from the substitution: :%
g/foo/s/bar/zzz/g -- for every line containing "foo" substitute all "bar" with "zzz."
(Something like :% s/\(.*foo.*\)bar\(.*\)/\1zzz\2/g would only work for the
cases those instances of "bar" which were PRECEDED by "foo" on the same line; it's ungainly
enough already, and would have to be mangled further to catch all the cases where "bar"
preceded "foo")
The point is that there are more than just p, s, and
d lines in the ex command set.
The : addresses can also refer to marks. Thus you can use:
:'a,'bg/foo/j to join any line containing the string foo to its subsequent line,
if it lies between the lines between the ' a ' and ' b ' marks. (Yes, all
of the preceding ex command examples can be limited to subsets of the file's
lines by prefixing with these sorts of addressing expressions).
That's pretty obscure (I've only used something like that a few times in the last 15
years). However, I'll freely admit that I've often done things iteratively and interactively
that could probably have been done more efficiently if I'd taken the time to think out the
correct incantation.
Another very useful vi or ex command is :r to read in the contents of another
file. Thus: :r foo inserts the contents of the file named "foo" at the current
line.
More powerful is the :r! command. This reads the results of a command. It's
the same as suspending the vi session, running a command, redirecting its output to a
temporary file, resuming your vi session, and reading in the contents from the temp.
file.
Even more powerful are the ! (bang) and :... ! ( ex bang)
commands. These also execute external commands and read the results into the current text.
However, they also filter selections of our text through the command! This we can sort all
the lines in our file using 1G!Gsort ( G is the vi "goto" command;
it defaults to going to the last line of the file, but can be prefixed by a line number, such
as 1, the first line). This is equivalent to the ex variant :1,$!sort . Writers
often use ! with the Unix fmt or fold utilities for reformating or "word
wrapping" selections of text. A very common macro is {!}fmt (reformat the
current paragraph). Programmers sometimes use it to run their code, or just portions of it,
through indent or other code reformatting tools.
Using the :r! and ! commands means that any external utility or
filter can be treated as an extension of our editor. I have occasionally used these with
scripts that pulled data from a database, or with wget or lynx commands that pulled data off
a website, or ssh commands that pulled data from remote systems.
Another useful ex command is :so (short for :source ). This
reads the contents of a file as a series of commands. When you start vi it normally,
implicitly, performs a :source on ~/.exinitrc file (and Vim usually
does this on ~/.vimrc, naturally enough). The use of this is that you can
change your editor profile on the fly by simply sourcing in a new set of macros,
abbreviations, and editor settings. If you're sneaky you can even use this as a trick for
storing sequences of ex editing commands to apply to files on demand.
For example I have a seven line file (36 characters) which runs a file through wc, and
inserts a C-style comment at the top of the file containing that word count data. I can apply
that "macro" to a file by using a command like: vim +'so mymacro.ex'
./mytarget
(The + command line option to vi and Vim is normally used to start the
editing session at a given line number. However it's a little known fact that one can follow
the + by any valid ex command/expression, such as a "source" command as I've
done here; for a simple example I have scripts which invoke: vi +'/foo/d|wq!'
~/.ssh/known_hosts to remove an entry from my SSH known hosts file non-interactively
while I'm re-imaging a set of servers).
Usually it's far easier to write such "macros" using Perl, AWK, sed (which is, in fact,
like grep a utility inspired by the ed command).
The @ command is probably the most obscure vi command. In occasionally
teaching advanced systems administration courses for close to a decade I've met very few
people who've ever used it. @ executes the contents of a register as if it were
a vi or ex command.
Example: I often use: :r!locate ... to find some file on my system and read its
name into my document. From there I delete any extraneous hits, leaving only the full path to
the file I'm interested in. Rather than laboriously Tab -ing through each
component of the path (or worse, if I happen to be stuck on a machine without Tab completion
support in its copy of vi ) I just use:
0i:r (to turn the current line into a valid :r command),
"cdd (to delete the line into the "c" register) and
@c execute that command.
That's only 10 keystrokes (and the expression "cdd@c is
effectively a finger macro for me, so I can type it almost as quickly as any common six
letter word).
A sobering thought
I've only scratched to surface of vi 's power and none of what I've described here is even
part of the "improvements" for which vim is named! All of what I've described here should
work on any old copy of vi from 20 or 30 years ago.
There are people who have used considerably more of vi 's power than I ever will.
@Wahnfieden -- grok is exactly what I meant: en.wikipedia.org/wiki/Grok (It's apparently even in
the OED --- the closest we anglophones have to a canonical lexicon). To "grok" an editor is
to find yourself using its commands fluently ... as if they were your natural language.
– Jim
Dennis
Feb 12 '10 at 4:08
wow, a very well written answer! i couldn't agree more, although i use the @
command a lot (in combination with q : record macro) – knittl
Feb 27 '10 at 13:15
Superb answer that utterly redeems a really horrible question. I am going to upvote this
question, that normally I would downvote, just so that this answer becomes easier to find.
(And I'm an Emacs guy! But this way I'll have somewhere to point new folks who want a good
explanation of what vi power users find fun about vi. Then I'll tell them about Emacs and
they can decide.) – Brandon Rhodes
Mar 29 '10 at 15:26
Can you make a website and put this tutorial there, so it doesn't get burried here on
stackoverflow. I have yet to read better introduction to vi then this. – Marko
Apr 1 '10 at 14:47
You are talking about text selecting and copying, I think that you should give a look to the
Vim Visual Mode .
In the visual mode, you are able to select text using Vim commands, then you can do
whatever you want with the selection.
Consider the following common scenarios:
You need to select to the next matching parenthesis.
You could do:
v% if the cursor is on the starting/ending parenthesis
vib if the cursor is inside the parenthesis block
You want to select text between quotes:
vi" for double quotes
vi' for single quotes
You want to select a curly brace block (very common on C-style languages):
viB
vi{
You want to select the entire file:
ggVG
Visual
block selection is another really useful feature, it allows you to select a rectangular
area of text, you just have to press Ctrl - V to start it, and then
select the text block you want and perform any type of operation such as yank, delete, paste,
edit, etc. It's great to edit column oriented text.
Yes, but it was a specific complaint of the poster. Visual mode is Vim's best method of
direct text-selection and manipulation. And since vim's buffer traversal methods are superb,
I find text selection in vim fairly pleasurable. – guns
Aug 2 '09 at 9:54
I think it is also worth mentioning Ctrl-V to select a block - ie an arbitrary rectangle of
text. When you need it it's a lifesaver. – Hamish Downer
Mar 16 '10 at 13:34
Also, if you've got a visual selection and want to adjust it, o will hop to the
other end. So you can move both the beginning and the end of the selection as much as you
like. – Nathan Long
Mar 1 '11 at 19:05
* and # search for the word under the cursor
forward/backward.
w to the next word
W to the next space-separated word
b / e to the begin/end of the current word. ( B
/ E for space separated only)
gg / G jump to the begin/end of the file.
% jump to the matching { .. } or ( .. ), etc..
{ / } jump to next paragraph.
'. jump back to last edited line.
g; jump back to last edited position.
Quick editing commands
I insert at the begin.
A append to end.
o / O open a new line after/before the current.
v / V / Ctrl+V visual mode (to select
text!)
Shift+R replace text
C change remaining part of line.
Combining commands
Most commands accept a amount and direction, for example:
cW = change till end of word
3cW = change 3 words
BcW = to begin of full word, change full word
ciW = change inner word.
ci" = change inner between ".."
ci( = change text between ( .. )
ci< = change text between < .. > (needs set
matchpairs+=<:> in vimrc)
4dd = delete 4 lines
3x = delete 3 characters.
3s = substitute 3 characters.
Useful programmer commands
r replace one character (e.g. rd replaces the current char
with d ).
~ changes case.
J joins two lines
Ctrl+A / Ctrl+X increments/decrements a number.
. repeat last command (a simple macro)
== fix line indent
> indent block (in visual mode)
< unindent block (in visual mode)
Macro recording
Press q[ key ] to start recording.
Then hit q to stop recording.
The macro can be played with @[ key ] .
By using very specific commands and movements, VIM can replay those exact actions for the
next lines. (e.g. A for append-to-end, b / e to move the cursor to
the begin or end of a word respectively)
Example of well built settings
# reset to vim-defaults
if &compatible # only if not set before:
set nocompatible # use vim-defaults instead of vi-defaults (easier, more user friendly)
endif
# display settings
set background=dark # enable for dark terminals
set nowrap # dont wrap lines
set scrolloff=2 # 2 lines above/below cursor when scrolling
set number # show line numbers
set showmatch # show matching bracket (briefly jump)
set showmode # show mode in status bar (insert/replace/...)
set showcmd # show typed command in status bar
set ruler # show cursor position in status bar
set title # show file in titlebar
set wildmenu # completion with menu
set wildignore=*.o,*.obj,*.bak,*.exe,*.py[co],*.swp,*~,*.pyc,.svn
set laststatus=2 # use 2 lines for the status bar
set matchtime=2 # show matching bracket for 0.2 seconds
set matchpairs+=<:> # specially for html
# editor settings
set esckeys # map missed escape sequences (enables keypad keys)
set ignorecase # case insensitive searching
set smartcase # but become case sensitive if you type uppercase characters
set smartindent # smart auto indenting
set smarttab # smart tab handling for indenting
set magic # change the way backslashes are used in search patterns
set bs=indent,eol,start # Allow backspacing over everything in insert mode
set tabstop=4 # number of spaces a tab counts for
set shiftwidth=4 # spaces for autoindents
#set expandtab # turn a tabs into spaces
set fileformat=unix # file mode is unix
#set fileformats=unix,dos # only detect unix file format, displays that ^M with dos files
# system settings
set lazyredraw # no redraws in macros
set confirm # get a dialog when :q, :w, or :wq fails
set nobackup # no backup~ files.
set viminfo='20,\"500 # remember copy registers after quitting in the .viminfo file -- 20 jump links, regs up to 500 lines'
set hidden # remember undo after quitting
set history=50 # keep 50 lines of command history
set mouse=v # use mouse in visual mode (not normal,insert,command,help mode
# color settings (if terminal/gui supports it)
if &t_Co > 2 || has("gui_running")
syntax on # enable colors
set hlsearch # highlight search (very useful!)
set incsearch # search incremently (search while typing)
endif
# paste mode toggle (needed when using autoindent/smartindent)
map <F10> :set paste<CR>
map <F11> :set nopaste<CR>
imap <F10> <C-O>:set paste<CR>
imap <F11> <nop>
set pastetoggle=<F11>
# Use of the filetype plugins, auto completion and indentation support
filetype plugin indent on
# file type specific settings
if has("autocmd")
# For debugging
#set verbose=9
# if bash is sh.
let bash_is_sh=1
# change to directory of current file automatically
autocmd BufEnter * lcd %:p:h
# Put these in an autocmd group, so that we can delete them easily.
augroup mysettings
au FileType xslt,xml,css,html,xhtml,javascript,sh,config,c,cpp,docbook set smartindent shiftwidth=2 softtabstop=2 expandtab
au FileType tex set wrap shiftwidth=2 softtabstop=2 expandtab
# Confirm to PEP8
au FileType python set tabstop=4 softtabstop=4 expandtab shiftwidth=4 cinwords=if,elif,else,for,while,try,except,finally,def,class
augroup END
augroup perl
# reset (disable previous 'augroup perl' settings)
au!
au BufReadPre,BufNewFile
\ *.pl,*.pm
\ set formatoptions=croq smartindent shiftwidth=2 softtabstop=2 cindent cinkeys='0{,0},!^F,o,O,e' " tags=./tags,tags,~/devel/tags,~/devel/C
# formatoption:
# t - wrap text using textwidth
# c - wrap comments using textwidth (and auto insert comment leader)
# r - auto insert comment leader when pressing <return> in insert mode
# o - auto insert comment leader when pressing 'o' or 'O'.
# q - allow formatting of comments with "gq"
# a - auto formatting for paragraphs
# n - auto wrap numbered lists
#
augroup END
# Always jump to the last known cursor position.
# Don't do it when the position is invalid or when inside
# an event handler (happens when dropping a file on gvim).
autocmd BufReadPost *
\ if line("'\"") > 0 && line("'\"") <= line("$") |
\ exe "normal g`\"" |
\ endif
endif # has("autocmd")
The settings can be stored in ~/.vimrc, or system-wide in
/etc/vimrc.local and then by read from the /etc/vimrc file
using:
source /etc/vimrc.local
(you'll have to replace the # comment character with " to make
it work in VIM, I wanted to give proper syntax highlighting here).
The commands I've listed here are pretty basic, and the main ones I use so far. They
already make me quite more productive, without having to know all the fancy stuff.
Better than '. is g;, which jumps back through the
changelist . Goes to the last edited position, instead of last edited line
– naught101
Apr 28 '12 at 2:09
The Control + R mechanism is very useful :-) In either insert mode or
command mode (i.e. on the : line when typing commands), continue with a numbered
or named register:
a - z the named registers
" the unnamed register, containing the text of the last delete or
yank
% the current file name
# the alternate file name
* the clipboard contents (X11: primary selection)
+ the clipboard contents
/ the last search pattern
: the last command-line
. the last inserted text
- the last small (less than a line) delete
=5*5 insert 25 into text (mini-calculator)
See :help i_CTRL-R and :help c_CTRL-R for more details, and
snoop around nearby for more CTRL-R goodness.
+1 for current/alternate file name. Control-A also works in insert mode for last
inserted text, and Control-@ to both insert last inserted text and immediately
switch to normal mode. – Aryeh Leib Taurog
Feb 26 '12 at 19:06
There are a lot of good answers here, and one amazing one about the zen of vi. One thing I
don't see mentioned is that vim is extremely extensible via plugins. There are scripts and
plugins to make it do all kinds of crazy things the original author never considered. Here
are a few examples of incredibly handy vim plugins:
Rails.vim is a plugin written by tpope. It's an incredible tool for people doing rails
development. It does magical context-sensitive things that allow you to easily jump from a
method in a controller to the associated view, over to a model, and down to unit tests for
that model. It has saved dozens if not hundreds of hours as a rails
developer.
This plugin allows you to select a region of text in visual mode and type a quick command
to post it to gist.github.com . This
allows for easy pastebin access, which is incredibly handy if you're collaborating with
someone over IRC or IM.
This plugin provides special functionality to the spacebar. It turns the spacebar into
something analogous to the period, but instead of repeating actions it repeats motions. This
can be very handy for moving quickly through a file in a way you define on the
fly.
This plugin gives you the ability to work with text that is delimited in some fashion. It
gives you objects which denote things inside of parens, things inside of quotes, etc. It can
come in handy for manipulating delimited text.
This script brings fancy tab completion functionality to vim. The autocomplete stuff is
already there in the core of vim, but this brings it to a quick tab rather than multiple
different multikey shortcuts. Very handy, and incredibly fun to use. While it's not VS's
intellisense, it's a great step and brings a great deal of the functionality you'd like to
expect from a tab completion tool.
This tool brings external syntax checking commands into vim. I haven't used it personally,
but I've heard great things about it and the concept is hard to beat. Checking syntax without
having to do it manually is a great time saver and can help you catch syntactic bugs as you
introduce them rather than when you finally stop to test.
Direct access to git from inside of vim. Again, I haven't used this plugin, but I can see
the utility. Unfortunately I'm in a culture where svn is considered "new", so I won't likely
see git at work for quite some time.
A tree browser for vim. I started using this recently, and it's really handy. It lets you
put a treeview in a vertical split and open files easily. This is great for a project with a
lot of source files you frequently jump between.
This is an unmaintained plugin, but still incredibly useful. It provides the ability to
open files using a "fuzzy" descriptive syntax. It means that in a sparse tree of files you
need only type enough characters to disambiguate the files you're interested in from the rest
of the cruft.
Conclusion
There are a lot of incredible tools available for vim. I'm sure I've only scratched the
surface here, and it's well worth searching for tools applicable to your domain. The
combination of traditional vi's powerful toolset, vim's improvements on it, and plugins which
extend vim even further, it's one of the most powerful ways to edit text ever conceived. Vim
is easily as powerful as emacs, eclipse, visual studio, and textmate.
Thanks
Thanks to duwanis for his
vim configs from which I
have learned much and borrowed most of the plugins listed here.
The magical tests-to-class navigation in rails.vim is one of the more general things I wish
Vim had that TextMate absolutely nails across all languages: if I am working on Person.scala
and I do Cmd+T, usually the first thing in the list is PersonTest.scala. – Tom Morris
Apr 1 '10 at 8:50
@Benson Great list! I'd toss in snipMate as well. Very helpful
automation of common coding stuff. if<tab> instant if block, etc. – AlG
Sep 13 '11 at 17:37
Visual mode was mentioned previously, but block visual mode has saved me a lot of time
when editing fixed size columns in text file. (accessed with Ctrl-V).
Additionally, if you use a concise command (e.g. A for append-at-end) to edit the text, vim
can repeat that exact same action for the next line you press the . key at.
– vdboor
Apr 1 '10 at 8:34
Go to last edited location (very useful if you performed some searching and than want go
back to edit)
^P and ^N
Complete previous (^P) or next (^N) text.
^O and ^I
Go to previous ( ^O - "O" for old) location or to the next (
^I - "I" just near to "O" ). When you perform
searches, edit files etc., you can navigate through these "jumps" forward and back.
@Kungi `. will take you to the last edit `` will take you back to the position you were in
before the last 'jump' - which /might/ also be the position of the last edit. –
Grant
McLean
Aug 23 '11 at 8:21
It's pretty new and really really good. The guy who is running the site switched from
textmate to vim and hosts very good and concise casts on specific vim topics. Check it
out!
@SolutionYogi: Consider that you want to add line number to the beginning of each line.
Solution: ggI1<space><esc>0qqyawjP0<c-a>0q9999@q – hcs42
Feb 27 '10 at 19:05
Extremely useful with Vimperator, where it increments (or decrements, Ctrl-X) the last number
in the URL. Useful for quickly surfing through image galleries etc. – blueyed
Apr 1 '10 at 14:47
Whoa, I didn't know about the * and # (search forward/back for word under cursor) binding.
That's kinda cool. The f/F and t/T and ; commands are quick jumps to characters on the
current line. f/F put the cursor on the indicated character while t/T puts it just up "to"
the character (the character just before or after it according to the direction chosen. ;
simply repeats the most recent f/F/t/T jump (in the same direction). – Jim Dennis
Mar 14 '10 at 6:38
:) The tagline at the top of the tips page at vim.org: "Can you imagine how many keystrokes
could have been saved, if I only had known the "*" command in time?" - Juergen Salk,
1/19/2001" – Steve K
Apr 3 '10 at 23:50
As Jim mentioned, the "t/T" combo is often just as good, if not better, for example,
ct( will erase the word and put you in insert mode, but keep the parantheses!
– puk
Feb 24 '12 at 6:45
CTRL-A ;Add [count] to the number or alphabetic character at or after the cursor. {not
in Vi
CTRL-X ;Subtract [count] from the number or alphabetic character at or after the cursor.
{not in Vi}
b. Window key unmapping
In window, Ctrl-A already mapped for whole file selection you need to unmap in rc file.
mark mswin.vim CTRL-A mapping part as comment or add your rc file with unmap
c. With Macro
The CTRL-A command is very useful in a macro. Example: Use the following steps to make a
numbered list.
Create the first list entry, make sure it starts with a number.
Last week at work our project inherited a lot of Python code from another project.
Unfortunately the code did not fit into our existing architecture - it was all done with
global variables and functions, which would not work in a multi-threaded environment.
We had ~80 files that needed to be reworked to be object oriented - all the functions
moved into classes, parameters changed, import statements added, etc. We had a list of about
20 types of fix that needed to be done to each file. I would estimate that doing it by hand
one person could do maybe 2-4 per day.
So I did the first one by hand and then wrote a vim script to automate the changes. Most
of it was a list of vim commands e.g.
" delete an un-needed function "
g/someFunction(/ d
" add wibble parameter to function foo "
%s/foo(/foo( wibble,/
" convert all function calls bar(thing) into method calls thing.bar() "
g/bar(/ normal nmaf(ldi(`aPa.
The last one deserves a bit of explanation:
g/bar(/ executes the following command on every line that contains "bar("
normal execute the following text as if it was typed in in normal mode
n goes to the next match of "bar(" (since the :g command leaves the cursor position at the start of the line)
ma saves the cursor position in mark a
f( moves forward to the next opening bracket
l moves right one character, so the cursor is now inside the brackets
di( delete all the text inside the brackets
`a go back to the position saved as mark a (i.e. the first character of "bar")
P paste the deleted text before the current cursor position
a. go into insert mode and add a "."
For a couple of more complex transformations such as generating all the import statements
I embedded some python into the vim script.
After a few hours of working on it I had a script that will do at least 95% of the
conversion. I just open a file in vim then run :source fixit.vim and the file is
transformed in a blink of the eye.
We still have the work of changing the remaining 5% that was not worth automating and of
testing the results, but by spending a day writing this script I estimate we have saved weeks
of work.
Of course it would have been possible to automate this with a scripting language like
Python or Ruby, but it would have taken far longer to write and would be less flexible - the
last example would have been difficult since regex alone would not be able to handle nested
brackets, e.g. to convert bar(foo(xxx)) to foo(xxx).bar() . Vim was
perfect for the task.
@lpsquiggle: your suggestion would not handle complex expressions with more than one set of
brackets. e.g. if bar(foo(xxx)) or wibble(xxx): becomes if foo(xxx)) or
wibble(xxx.bar(): which is completely wrong. – Dave Kirby
Mar 23 '10 at 17:16
Use the builtin file explorer! The command is :Explore and it allows you to
navigate through your source code very very fast. I have these mapping in my
.vimrc :
I always thought the default methods for browsing kinda sucked for most stuff. It's just slow
to browse, if you know where you wanna go. LustyExplorer from vim.org's script section is a
much needed improvement. – Svend
Aug 2 '09 at 8:48
I recommend NERDtree instead of the built-in explorer. It has changed the way I used vim for
projects and made me much more productive. Just google for it. – kprobst
Apr 1 '10 at 3:53
I never feel the need to explore the source tree, I just use :find,
:tag and the various related keystrokes to jump around. (Maybe this is because
the source trees I work on are big and organized differently than I would have done? :) )
– dash-tom-bang
Aug 24 '11 at 0:35
I am a member of the American Cryptogram Association. The bimonthly magazine includes over
100 cryptograms of various sorts. Roughly 15 of these are "cryptarithms" - various types of
arithmetic problems with letters substituted for the digits. Two or three of these are
sudokus, except with letters instead of numbers. When the grid is completed, the nine
distinct letters will spell out a word or words, on some line, diagonal, spiral, etc.,
somewhere in the grid.
Rather than working with pencil, or typing the problems in by hand, I download the
problems from the members area of their website.
When working with these sudokus, I use vi, simply because I'm using facilities that vi has
that few other editors have. Mostly in converting the lettered grid into a numbered grid,
because I find it easier to solve, and then the completed numbered grid back into the
lettered grid to find the solution word or words.
The problem is formatted as nine groups of nine letters, with - s
representing the blanks, written in two lines. The first step is to format these into nine
lines of nine characters each. There's nothing special about this, just inserting eight
linebreaks in the appropriate places.
So, first step in converting this into numbers is to make a list of the distinct letters.
First, I make a copy of the block. I position the cursor at the top of the block, then type
:y}}p . : puts me in command mode, y yanks the next
movement command. Since } is a move to the end of the next paragraph,
y} yanks the paragraph. } then moves the cursor to the end of the
paragraph, and p pastes what we had yanked just after the cursor. So
y}}p creates a copy of the next paragraph, and ends up with the cursor between
the two copies.
Next, I to turn one of those copies into a list of distinct letters. That command is a bit
more complex:
: again puts me in command mode. ! indicates that the content of
the next yank should be piped through a command line. } yanks the next
paragraph, and the command line then uses the tr command to strip out everything
except for upper-case letters, the sed command to print each letter on a single
line, and the sort command to sort those lines, removing duplicates, and then
tr strips out the newlines, leaving the nine distinct letters in a single line,
replacing the nine lines that had made up the paragraph originally. In this case, the letters
are: ACELNOPST .
Next step is to make another copy of the grid. And then to use the letters I've just
identified to replace each of those letters with a digit from 1 to 9. That's simple:
:!}tr ACELNOPST 0-9 . The result is:
This can then be solved in the usual way, or entered into any sudoku solver you might
prefer. The completed solution can then be converted back into letters with :!}tr 1-9
ACELNOPST .
There is power in vi that is matched by very few others. The biggest problem is that only
a very few of the vi tutorial books, websites, help-files, etc., do more than barely touch
the surface of what is possible.
and an irritation is that some distros such as ubuntu has aliases from the word "vi" to "vim"
so people won't really see vi. Excellent example, have to try... +1 – hhh
Jan 14 '11 at 17:12
I'm baffled by this repeated error: you say you need : to go into command mode,
but then invariably you specify normal mode commands (like y}}p ) which
cannot possibly work from the command mode?! – sehe
Mar 4 '12 at 20:47
My take on the unique chars challenge: :se tw=1 fo= (preparation)
VG:s/./& /g (insert spaces), gvgq (split onto separate lines),
V{:sort u (sort and remove duplicates) – sehe
Mar 4 '12 at 20:56
I find the following trick increasingly useful ... for cases where you want to join lines
that match (or that do NOT match) some pattern to the previous line: :%
g/foo/-1j or :'a,'z v/bar/-1j for example (where the former is "all lines
and matching the pattern" while the latter is "lines between mark a and mark z which fail to
match the pattern"). The part after the patter in a g or v ex
command can be any other ex commmands, -1j is just a relative line movement and join command.
– Jim
Dennis
Feb 12 '10 at 4:15
of course, if you name your macro '2', then when it comes time to use it, you don't even have
to move your finger from the '@' key to the 'q' key. Probably saves 50 to 100 milliseconds
every time right there. =P – JustJeff
Feb 27 '10 at 12:54
I recently discovered q: . It opens the "command window" and shows your most
recent ex-mode (command-mode) commands. You can move as usual within the window, and pressing
<CR> executes the command. You can edit, etc. too. Priceless when you're
messing around with some complex command or regex and you don't want to retype the whole
thing, or if the complex thing you want to do was 3 commands back. It's almost like bash's
set -o vi, but for vim itself (heh!).
See :help q: for more interesting bits for going back and forth.
I just discovered Vim's omnicompletion the other day, and while I'll admit I'm a bit hazy on
what does which, I've had surprisingly good results just mashing either Ctrl +
xCtrl + u or Ctrl + n /
Ctrl + p in insert mode. It's not quite IntelliSense, but I'm still learning it.
<Ctrl> + W and j/k will let you navigate absolutely (j up, k down, as with normal vim).
This is great when you have 3+ splits. – Andrew Scagnelli
Apr 1 '10 at 2:58
after bashing my keyboard I have deduced that <C-w>n or
<C-w>s is new horizontal window, <C-w>b is bottom right
window, <C-w>c or <C-w>q is close window,
<C-w>x is increase and then decrease window width (??),
<C-w>p is last window, <C-w>backspace is move left(ish)
window – puk
Feb 24 '12 at 7:00
As several other people have said, visual mode is the answer to your copy/cut & paste
problem. Vim gives you 'v', 'V', and C-v. Lower case 'v' in vim is essentially the same as
the shift key in notepad. The nice thing is that you don't have to hold it down. You can use
any movement technique to navigate efficiently to the starting (or ending) point of your
selection. Then hit 'v', and use efficient movement techniques again to navigate to the other
end of your selection. Then 'd' or 'y' allows you to cut or copy that selection.
The advantage vim's visual mode has over Jim Dennis's description of cut/copy/paste in vi
is that you don't have to get the location exactly right. Sometimes it's more efficient to
use a quick movement to get to the general vicinity of where you want to go and then refine
that with other movements than to think up a more complex single movement command that gets
you exactly where you want to go.
The downside to using visual mode extensively in this manner is that it can become a
crutch that you use all the time which prevents you from learning new vi(m) commands that
might allow you to do things more efficiently. However, if you are very proactive about
learning new aspects of vi(m), then this probably won't affect you much.
I'll also re-emphasize that the visual line and visual block modes give you variations on
this same theme that can be very powerful...especially the visual block mode.
On Efficient Use of the Keyboard
I also disagree with your assertion that alternating hands is the fastest way to use the
keyboard. It has an element of truth in it. Speaking very generally, repeated use of the same
thing is slow. This most significant example of this principle is that consecutive keystrokes
typed with the same finger are very slow. Your assertion probably stems from the natural
tendency to use the s/finger/hand/ transformation on this pattern. To some extent it's
correct, but at the extremely high end of the efficiency spectrum it's incorrect.
Just ask any pianist. Ask them whether it's faster to play a succession of a few notes
alternating hands or using consecutive fingers of a single hand in sequence. The fastest way
to type 4 keystrokes is not to alternate hands, but to type them with 4 fingers of the same
hand in either ascending or descending order (call this a "run"). This should be self-evident
once you've considered this possibility.
The more difficult problem is optimizing for this. It's pretty easy to optimize for
absolute distance on the keyboard. Vim does that. It's much harder to optimize at the "run"
level, but vi(m) with it's modal editing gives you a better chance at being able to do it
than any non-modal approach (ahem, emacs) ever could.
On Emacs
Lest the emacs zealots completely disregard my whole post on account of that last
parenthetical comment, I feel I must describe the root of the difference between the emacs
and vim religions. I've never spoken up in the editor wars and I probably won't do it again,
but I've never heard anyone describe the differences this way, so here it goes. The
difference is the following tradeoff:
Vim gives you unmatched raw text editing efficiency Emacs gives you unmatched ability to
customize and program the editor
The blind vim zealots will claim that vim has a scripting language. But it's an obscure,
ad-hoc language that was designed to serve the editor. Emacs has Lisp! Enough said. If you
don't appreciate the significance of those last two sentences or have a desire to learn
enough about functional programming and Lisp to develop that appreciation, then you should
use vim.
The emacs zealots will claim that emacs has viper mode, and so it is a superset of vim.
But viper mode isn't standard. My understanding is that viper mode is not used by the
majority of emacs users. Since it's not the default, most emacs users probably don't develop
a true appreciation for the benefits of the modal paradigm.
In my opinion these differences are orthogonal. I believe the benefits of vim and emacs as
I have stated them are both valid. This means that the ultimate editor doesn't exist yet.
It's probably true that emacs would be the easiest platform on which to base the ultimate
editor. But modal editing is not entrenched in the emacs mindset. The emacs community could
move that way in the future, but that doesn't seem very likely.
So if you want raw editing efficiency, use vim. If you want the ultimate environment for
scripting and programming your editor use emacs. If you want some of both with an emphasis on
programmability, use emacs with viper mode (or program your own mode). If you want the best
of both worlds, you're out of luck for now.
Spend 30 mins doing the vim tutorial (run vimtutor instead of vim in terminal). You will
learn the basic movements, and some keystrokes, this will make you at least as productive
with vim as with the text editor you used before. After that, well, read Jim Dennis' answer
again :)
This is the first thing I thought of when reading the OP. It's obvious that the poster has
never run this; I ran through it when first learning vim two years ago and it cemented in my
mind the superiority of Vim to any of the other editors I've used (including, for me, Emacs
since the key combos are annoying to use on a Mac). – dash-tom-bang
Aug 24 '11 at 0:47
Use \c anywhere in a search to ignore case (overriding your ignorecase or
smartcase settings). E.g. /\cfoo or /foo\c will match
foo, Foo, fOO, FOO, etc.
Use \C anywhere in a search to force case matching. E.g. /\Cfoo
or /foo\C will only match foo.
Odd nobody's mentioned ctags. Download "exuberant ctags" and put it ahead of the crappy
preinstalled version you already have in your search path. Cd to the root of whatever you're
working on; for example the Android kernel distribution. Type "ctags -R ." to build an index
of source files anywhere beneath that dir in a file named "tags". This contains all tags,
nomatter the language nor where in the dir, in one file, so cross-language work is easy.
Then open vim in that folder and read :help ctags for some commands. A few I use
often:
Put cursor on a method call and type CTRL-] to go to the method definition.
You asked about productive shortcuts, but I think your real question is: Is vim worth it? The
answer to this stackoverflow question is -> "Yes"
You must have noticed two things. Vim is powerful, and vim is hard to learn. Much of it's
power lies in it's expandability and endless combination of commands. Don't feel overwhelmed.
Go slow. One command, one plugin at a time. Don't overdo it.
All that investment you put into vim will pay back a thousand fold. You're going to be
inside a text editor for many, many hours before you die. Vim will be your companion.
Multiple buffers, and in particular fast jumping between them to compare two files with
:bp and :bn (properly remapped to a single Shift +
p or Shift + n )
vimdiff mode (splits in two vertical buffers, with colors to show the
differences)
Area-copy with Ctrl + v
And finally, tab completion of identifiers (search for "mosh_tab_or_complete"). That's a
life changer.
Probably better to set the clipboard option to unnamed ( set
clipboard=unnamed in your .vimrc) to use the system clipboard by default. Or if you
still want the system clipboard separate from the unnamed register, use the appropriately
named clipboard register: "*p . – R. Martinho Fernandes
Apr 1 '10 at 3:17
Love it! After being exasperated by pasting code examples from the web and I was just
starting to feel proficient in vim. That was the command I dreamed up on the spot. This was
when vim totally hooked me. – kevpie
Oct 12 '10 at 22:38
There are a plethora of questions where people talk about common tricks, notably " Vim+ctags
tips and tricks ".
However, I don't refer to commonly used shortcuts that someone new to Vim would find cool.
I am talking about a seasoned Unix user (be they a developer, administrator, both, etc.), who
thinks they know something 99% of us never heard or dreamed about. Something that not only
makes their work easier, but also is COOL and hackish .
After all, Vim resides in
the most dark-corner-rich OS in the world, thus it should have intricacies that only a few
privileged know about and want to share with us.
Might not be one that 99% of Vim users don't know about, but it's something I use daily and
that any Linux+Vim poweruser must know.
Basic command, yet extremely useful.
:w !sudo tee %
I often forget to sudo before editing a file I don't have write permissions on. When I
come to save that file and get a permission error, I just issue that vim command in order to
save the file without the need to save it to a temp file and then copy it back again.
You obviously have to be on a system with sudo installed and have sudo rights.
Something I just discovered recently that I thought was very cool:
:earlier 15m
Reverts the document back to how it was 15 minutes ago. Can take various arguments for the
amount of time you want to roll back, and is dependent on undolevels. Can be reversed with
the opposite command :later
@skinp: If you undo and then make further changes from the undone state, you lose that redo
history. This lets you go back to a state which is no longer in the undo stack. –
ephemient
Apr 8 '09 at 16:15
Also very usefull is g+ and g- to go backward and forward in time. This is so much more
powerfull than an undo/redo stack since you don't loose the history when you do something
after an undo. – Etienne PIERRE
Jul 21 '09 at 13:53
You don't lose the redo history if you make a change after an undo. It's just not easily
accessed. There are plugins to help you visualize this, like Gundo.vim – Ehtesh Choudhury
Nov 29 '11 at 12:09
This is quite similar to :r! The only difference as far as I can tell is that :r! opens a new
line, :.! overwrites the current line. – saffsd
May 6 '09 at 14:41
An alternative to :.!date is to write "date" on a line and then run
!$sh (alternatively having the command followed by a blank line and run
!jsh ). This will pipe the line to the "sh" shell and substitute with the output
from the command. – hlovdal
Jan 25 '10 at 21:11
:.! is actually a special case of :{range}!, which filters a range
of lines (the current line when the range is . ) through a command and replaces
those lines with the output. I find :%! useful for filtering whole buffers.
– Nefrubyr
Mar 25 '10 at 16:24
And also note that '!' is like 'y', 'd', 'c' etc. i.e. you can do: !!, number!!, !motion
(e.g. !Gshell_command<cr> replace from current line to end of file ('G') with output of
shell_command). – aqn
Apr 26 '13 at 20:52
dab "delete arounb brackets", daB for around curly brackets, t for xml type tags,
combinations with normal commands are as expected cib/yaB/dit/vat etc – sjh
Apr 8 '09 at 15:33
This is possibly the biggest reason for me staying with Vim. That and its equivalent "change"
commands: ciw, ci(, ci", as well as dt<space> and ct<space> – thomasrutter
Apr 26 '09 at 11:11
de Delete everything till the end of the word by pressing . at your heart's desire.
ci(xyz[Esc] -- This is a weird one. Here, the 'i' does not mean insert mode. Instead it
means inside the parenthesis. So this sequence cuts the text inside parenthesis you're
standing in and replaces it with "xyz". It also works inside square and figure brackets --
just do ci[ or ci{ correspondingly. Naturally, you can do di (if you just want to delete all
text without typing anything. You can also do a instead of i if you
want to delete the parentheses as well and not just text inside them.
ci" - cuts the text in current quotes
ciw - cuts the current word. This works just like the previous one except that
( is replaced with w .
C - cut the rest of the line and switch to insert mode.
ZZ -- save and close current file (WAY faster than Ctrl-F4 to close the current tab!)
ddp - move current line one row down
xp -- move current character one position to the right
U - uppercase, so viwU upercases the word
~ - switches case, so viw~ will reverse casing of entire word
Ctrl+u / Ctrl+d scroll the page half-a-screen up or down. This seems to be more useful
than the usual full-screen paging as it makes it easier to see how the two screens relate.
For those who still want to scroll entire screen at a time there's Ctrl+f for Forward and
Ctrl+b for Backward. Ctrl+Y and Ctrl+E scroll down or up one line at a time.
Crazy but very useful command is zz -- it scrolls the screen to make this line appear in
the middle. This is excellent for putting the piece of code you're working on in the center
of your attention. Sibling commands -- zt and zb -- make this line the top or the bottom one
on the sreen which is not quite as useful.
% finds and jumps to the matching parenthesis.
de -- delete from cursor to the end of the word (you can also do dE to delete
until the next space)
bde -- delete the current word, from left to right delimiter
df[space] -- delete up until and including the next space
dt. -- delete until next dot
dd -- delete this entire line
ye (or yE) -- yanks text from here to the end of the word
ce - cuts through the end of the word
bye -- copies current word (makes me wonder what "hi" does!)
yy -- copies the current line
cc -- cuts the current line, you can also do S instead. There's also lower
cap s which cuts current character and switches to insert mode.
viwy or viwc . Yank or change current word. Hit w multiple times to keep
selecting each subsequent word, use b to move backwards
vi{ - select all text in figure brackets. va{ - select all text including {}s
vi(p - highlight everything inside the ()s and replace with the pasted text
b and e move the cursor word-by-word, similarly to how Ctrl+Arrows normally do . The
definition of word is a little different though, as several consecutive delmiters are treated
as one word. If you start at the middle of a word, pressing b will always get you to the
beginning of the current word, and each consecutive b will jump to the beginning of the next
word. Similarly, and easy to remember, e gets the cursor to the end of the
current, and each subsequent, word.
similar to b / e, capital B and E
move the cursor word-by-word using only whitespaces as delimiters.
capital D (take a deep breath) Deletes the rest of the line to the right of the cursor,
same as Shift+End/Del in normal editors (notice 2 keypresses -- Shift+D -- instead of 3)
All the things you're calling "cut" is "change". eg: C is change until the end of the line.
Vim's equivalent of "cut" is "delete", done with d/D. The main difference between change and
delete is that delete leaves you in normal mode but change puts you into a sort of insert
mode (though you're still in the change command which is handy as the whole change can be
repeated with . ). – Laurence Gonsalves
Feb 19 '11 at 23:49
One that I rarely find in most Vim tutorials, but it's INCREDIBLY useful (at least to me), is
the
g; and g,
to move (forward, backward) through the changelist.
Let me show how I use it. Sometimes I need to copy and paste a piece of code or string,
say a hex color code in a CSS file, so I search, jump (not caring where the match is), copy
it and then jump back (g;) to where I was editing the code to finally paste it. No need to
create marks. Simpler.
Ctrl-O and Ctrl-I (tab) will work similarly, but not the same. They move backward and forward
in the "jump list", which you can view by doing :jumps or :ju For more information do a :help
jumplist – Kimball Robinson
Apr 16 '10 at 0:29
@JoshLee: If one is careful not to traverse newlines, is it safe to not use the -b option? I
ask because sometimes I want to make a hex change, but I don't want to close and
reopen the file to do so. – dotancohen
Jun 7 '13 at 5:50
Sometimes a setting in your .vimrc will get overridden by a plugin or autocommand. To debug
this a useful trick is to use the :verbose command in conjunction with :set. For example, to
figure out where cindent got set/unset:
:verbose set cindent?
This will output something like:
cindent
Last set from /usr/share/vim/vim71/indent/c.vim
This also works with maps and highlights. (Thanks joeytwiddle for pointing this out.) For
example:
:verbose nmap U
n U <C-R>
Last set from ~/.vimrc
:verbose highlight Normal
Normal xxx guifg=#dddddd guibg=#111111 font=Inconsolata Medium 14
Last set from ~/src/vim-holodark/colors/holodark.vim
:verbose can also be used before nmap l or highlight
Normal to find out where the l keymap or the Normal
highlight were last defined. Very useful for debugging! – joeytwiddle
Jul 5 '14 at 22:08
When you get into creating custom mappings, this will save your ass so many times, probably
one of the most useful ones here (IMO)! – SidOfc
Sep 24 '17 at 11:26
Not sure if this counts as dark-corner-ish at all, but I've only just learnt it...
:g/match/y A
will yank (copy) all lines containing "match" into the "a / @a
register. (The capitalization as A makes vim append yankings instead of
replacing the previous register contents.) I used it a lot recently when making Internet
Explorer stylesheets.
Sometimes it's better to do what tsukimi said and just filter out lines that don't match your
pattern. An abbreviated version of that command though: :v/PATTERN/d
Explanation: :v is an abbreviation for :g!, and the
:g command applies any ex command to lines. :y[ank] works and so
does :normal, but here the most natural thing to do is just
:d[elete] . – pandubear
Oct 12 '13 at 8:39
You can also do :g/match/normal "Ayy -- the normal keyword lets you
tell it to run normal-mode commands (which you are probably more familiar with). –
Kimball
Robinson
Feb 5 '16 at 17:58
Hitting <C-f> after : or / (or any time you're in command mode) will bring up the same
history menu. So you can remap q: if you hit it accidentally a lot and still access this
awesome mode. – idbrii
Feb 23 '11 at 19:07
For me it didn't open the source; instead it apparently used elinks to dump rendered page
into a buffer, and then opened that. – Ivan Vučica
Sep 21 '10 at 8:07
@Vdt: It'd be useful if you posted your error. If it's this one: " error (netrw)
neither the wget nor the fetch command is available" you obviously need to make one of those
tools available from your PATH environment variable. – Isaac Remuant
Jun 3 '13 at 15:23
I find this one particularly useful when people send links to a paste service and forgot to
select a syntax highlighting, I generally just have to open the link in vim after appending
"&raw". – Dettorer
Oct 29 '14 at 13:47
I didn't know macros could repeat themselves. Cool. Note: qx starts recording into register x
(he uses qq for register q). 0 moves to the start of the line. dw delets a word. j moves down
a line. @q will run the macro again (defining a loop). But you forgot to end the recording
with a final "q", then actually run the macro by typing @q. – Kimball Robinson
Apr 16 '10 at 0:39
Another way of accomplishing this is to record a macro in register a that does some
transformation to a single line, then linewise highlight a bunch of lines with V and type
:normal! @a to applyyour macro to every line in your selection. –
Nathan Long
Aug 29 '11 at 15:33
I found this post googling recursive VIM macros. I could find no way to stop the macro other
than killing the VIM process. – dotancohen
May 14 '13 at 6:00
Assuming you have Perl and/or Ruby support compiled in, :rubydo and
:perldo will run a Ruby or Perl one-liner on every line in a range (defaults to
entire buffer), with $_ bound to the text of the current line (minus the
newline). Manipulating $_ will change the text of that line.
You can use this to do certain things that are easy to do in a scripting language but not
so obvious using Vim builtins. For example to reverse the order of the words in a line:
:perldo $_ = join ' ', reverse split
To insert a random string of 8 characters (A-Z) at the end of every line:
Sadly not, it just adds a funky control character to the end of the line. You could then use
a Vim search/replace to change all those control characters to real newlines though. –
Brian Carper
Jul 2 '09 at 17:26
Go to older/newer position. When you are moving through the file (by searching, moving
commands etc.) vim rember these "jumps", so you can repeat these jumps backward (^O - O for
old) and forward (^I - just next to I on keyboard). I find it very useful when writing code
and performing a lot of searches.
gi
Go to position where Insert mode was stopped last. I find myself often editing and then
searching for something. To return to editing place press gi.
gf
put cursor on file name (e.g. include header file), press gf and the file is opened
gF
similar to gf but recognizes format "[file name]:[line number]". Pressing gF will open
[file name] and set cursor to [line number].
^P and ^N
Auto complete text while editing (^P - previous match and ^N next match)
^X^L
While editing completes to the same line (useful for programming). You write code and then
you recall that you have the same code somewhere in file. Just press ^X^L and the full line
completed
^X^F
Complete file names. You write "/etc/pass" Hmm. You forgot the file name. Just press ^X^F
and the filename is completed
^Z or :sh
Move temporary to the shell. If you need a quick bashing:
press ^Z (to put vi in background) to return to original shell and press fg to return
to vim back
press :sh to go to sub shell and press ^D/exit to return to vi back
With ^X^F my pet peeve is that filenames include = signs, making it
do rotten things in many occasions (ini files, makefiles etc). I use se
isfname-== to end that nuisance – sehe
Mar 4 '12 at 21:50
This is a nice trick to reopen the current file with a different encoding:
:e ++enc=cp1250 %:p
Useful when you have to work with legacy encodings. The supported encodings are listed in
a table under encoding-values (see helpencoding-values ). Similar thing also works for ++ff, so that you
can reopen file with Windows/Unix line ends if you get it wrong for the first time (see
helpff ).
>, Apr 7, 2009 at 18:43
Never had to use this sort of a thing, but we'll certainly add to my arsenal of tricks...
– Sasha
Apr 7 '09 at 18:43
I have used this today, but I think I didn't need to specify "%:p"; just opening the file and
:e ++enc=cp1250 was enough. I – Ivan Vučica
Jul 8 '09 at 19:29
This is a terrific answer. Not the bit about creating the IP addresses, but the bit that
implies that VIM can use for loops in commands . – dotancohen
Nov 30 '14 at 14:56
No need, usually, to be exactly on the braces. Thought frequently I'd just =} or
vaBaB= because it is less dependent. Also, v}}:!astyle -bj matches
my code style better, but I can get it back into your style with a simple %!astyle
-aj – sehe
Mar 4 '12 at 22:03
I remapped capslock to esc instead, as it's an otherwise useless key. My mapping was OS wide
though, so it has the added benefit of never having to worry about accidentally hitting it.
The only drawback IS ITS HARDER TO YELL AT PEOPLE. :) – Alex
Oct 5 '09 at 5:32
@ojblass: Not sure how many people ever right matlab code in Vim, but ii and
jj are commonly used for counter variables, because i and
j are reserved for complex numbers. – brianmearns
Oct 3 '12 at 12:45
@rlbond - It comes down to how good is the regex engine in the IDE. Vim's regexes are pretty
powerful; others.. not so much sometimes. – romandas
Jun 19 '09 at 16:58
The * will be greedy, so this regex assumes you have just two columns. If you want it to be
nongreedy use {-} instead of * (see :help non-greedy for more information on the {}
multiplier) – Kimball Robinson
Apr 16 '10 at 0:32
Not exactly a dark secret, but I like to put the following mapping into my .vimrc file, so I
can hit "-" (minus) anytime to open the file explorer to show files adjacent to the one I
just edit . In the file explorer, I can hit another "-" to move up one directory,
providing seamless browsing of a complex directory structures (like the ones used by the MVC
frameworks nowadays):
map - :Explore<cr>
These may be also useful for somebody. I like to scroll the screen and advance the cursor
at the same time:
map <c-j> j<c-e>
map <c-k> k<c-y>
Tab navigation - I love tabs and I need to move easily between them:
I suppose it would override autochdir temporarily (until you switched buffers again).
Basically, it changes directory to the root directory of the current file. It gives me a bit
more manual control than autochdir does. – rampion
May 8 '09 at 2:55
:set autochdir //this also serves the same functionality and it changes the current directory
to that of file in buffer – Naga Kiran
Jul 8 '09 at 13:44
I like to use 'sudo bash', and my sysadmin hates this. He locked down 'sudo' so it could only
be used with a handful of commands (ls, chmod, chown, vi, etc), but I was able to use vim to
get a root shell anyway:
bash$ sudo vi +'silent !bash' +q
Password: ******
root#
yeah... I'd hate you too ;) you should only need a root shell VERY RARELY, unless you're
already in the habit of running too many commands as root which means your permissions are
all screwed up. – jnylen
Feb 22 '11 at 15:58
Don't forget you can prepend numbers to perform an action multiple times in Vim. So to expand
the current window height by 8 lines: 8<C-W>+ – joeytwiddle
Jan 29 '12 at 18:12
well, if you haven't done anything else to the file, you can simply type u for undo.
Otherwise, I haven't figured that out yet. – Grant Limberg
Jun 17 '09 at 19:29
Commented out code is probably one of the worst types of comment you could possibly put in
your code. There are better uses for the awesome block insert. – Braden Best
Feb 4 '16 at 16:23
I use vim for just about any text editing I do, so I often times use copy and paste. The
problem is that vim by default will often times distort imported text via paste. The way to
stop this is to use
:set paste
before pasting in your data. This will keep it from messing up.
Note that you will have to issue :set nopaste to recover auto-indentation.
Alternative ways of pasting pre-formatted text are the clipboard registers ( *
and + ), and :r!cat (you will have to end the pasted fragment with
^D).
It is also sometimes helpful to turn on a high contrast color scheme. This can be done
with
:color blue
I've noticed that it does not work on all the versions of vim I use but it does on
most.
The "distortion" is happening because you have some form of automatic indentation enabled.
Using set paste or specifying a key for the pastetoggle option is a
common way to work around this, but the same effect can be achieved with set
mouse=a as then Vim knows that the flood of text it sees is a paste triggered by the
mouse. – jamessan
Dec 28 '09 at 8:27
If you have gvim installed you can often (though it depends on what your options your distro
compiles vim with) use the X clipboard directly from vim through the * register. For example
"*p to paste from the X xlipboard. (It works from terminal vim, too, it's just
that you might need the gvim package if they're separate) – kyrias
Oct 19 '13 at 12:15
Here's something not obvious. If you have a lot of custom plugins / extensions in your $HOME
and you need to work from su / sudo / ... sometimes, then this might be useful.
In your ~/.bashrc:
export VIMINIT=":so $HOME/.vimrc"
In your ~/.vimrc:
if $HOME=='/root'
if $USER=='root'
if isdirectory('/home/your_typical_username')
let rtuser = 'your_typical_username'
elseif isdirectory('/home/your_other_username')
let rtuser = 'your_other_username'
endif
else
let rtuser = $USER
endif
let &runtimepath = substitute(&runtimepath, $HOME, '/home/'.rtuser, 'g')
endif
It will allow your local plugins to load - whatever way you use to change the user.
You might also like to take the *.swp files out of your current path and into ~/vimtmp
(this goes into .vimrc):
if ! isdirectory(expand('~/vimtmp'))
call mkdir(expand('~/vimtmp'))
endif
if isdirectory(expand('~/vimtmp'))
set directory=~/vimtmp
else
set directory=.,/var/tmp,/tmp
endif
Also, some mappings I use to make editing easier - makes ctrl+s work like escape and
ctrl+h/l switch the tabs:
I prefer never to run vim as root/under sudo - and would just run the command from vim e.g.
:!sudo tee %, :!sudo mv % /etc or even launch a login shell
:!sudo -i – shalomb
Aug 24 '15 at 8:02
Ctrl-n while in insert mode will auto complete whatever word you're typing based on all the
words that are in open buffers. If there is more than one match it will give you a list of
possible words that you can cycle through using ctrl-n and ctrl-p.
Ability to run Vim on a client/server based modes.
For example, suppose you're working on a project with a lot of buffers, tabs and other
info saved on a session file called session.vim.
You can open your session and create a server by issuing the following command:
vim --servername SAMPLESERVER -S session.vim
Note that you can open regular text files if you want to create a server and it doesn't
have to be necessarily a session.
Now, suppose you're in another terminal and need to open another file. If you open it
regularly by issuing:
vim new_file.txt
Your file would be opened in a separate Vim buffer, which is hard to do interactions with
the files on your session. In order to open new_file.txt in a new tab on your server use this
command:
vim --servername SAMPLESERVER --remote-tab-silent new_file.txt
If there's no server running, this file will be opened just like a regular file.
Since providing those flags every time you want to run them is very tedious, you can
create a separate alias for creating client and server.
I placed the followings on my bashrc file:
alias vims='vim --servername SAMPLESERVER'
alias vimc='vim --servername SAMPLESERVER --remote-tab-silent'
HOWTO: Auto-complete Ctags when using Vim in Bash. For anyone else who uses Vim and Ctags,
I've written a small auto-completer function for Bash. Add the following into your
~/.bash_completion file (create it if it does not exist):
Thanks go to stylishpants for his many fixes and improvements.
_vim_ctags() {
local cur prev
COMPREPLY=()
cur="${COMP_WORDS[COMP_CWORD]}"
prev="${COMP_WORDS[COMP_CWORD-1]}"
case "${prev}" in
-t)
# Avoid the complaint message when no tags file exists
if [ ! -r ./tags ]
then
return
fi
# Escape slashes to avoid confusing awk
cur=${cur////\\/}
COMPREPLY=( $(compgen -W "`awk -vORS=" " "/^${cur}/ { print \\$1 }" tags`" ) )
;;
*)
_filedir_xspec
;;
esac
}
# Files matching this pattern are excluded
excludelist='*.@(o|O|so|SO|so.!(conf)|SO.!(CONF)|a|A|rpm|RPM|deb|DEB|gif|GIF|jp?(e)g|JP?(E)G|mp3|MP3|mp?(e)g|MP?(E)G|avi|AVI|asf|ASF|ogg|OGG|class|CLASS)'
complete -F _vim_ctags -f -X "${excludelist}" vi vim gvim rvim view rview rgvim rgview gview
Once you restart your Bash session (or create a new one) you can type:
Code:
~$ vim -t MyC<tab key>
and it will auto-complete the tag the same way it does for files and directories:
Code:
MyClass MyClassFactory
~$ vim -t MyC
I find it really useful when I'm jumping into a quick bug fix.
Auto reloads the current buffer..especially useful while viewing log files and it almost
serves the functionality of "tail" program in unix from within vim.
Checking for compile errors from within vim. set the makeprg variable depending on the
language let's say for perl
:setlocal makeprg = perl\ -c \ %
For PHP
set makeprg=php\ -l\ %
set errorformat=%m\ in\ %f\ on\ line\ %l
Issuing ":make" runs the associated makeprg and displays the compilation errors/warnings
in quickfix window and can easily navigate to the corresponding line numbers.
:make will run the makefile in the current directory, parse the compiler
output, you can then use :cn and :cp to step through the compiler
errors opening each file and seeking to the line number in question.
I was sure someone would have posted this already, but here goes.
Take any build system you please; make, mvn, ant, whatever. In the root of the project
directory, create a file of the commands you use all the time, like this:
mvn install
mvn clean install
... and so forth
To do a build, put the cursor on the line and type !!sh. I.e. filter that line; write it
to a shell and replace with the results.
The build log replaces the line, ready to scroll, search, whatever.
When you're done viewing the log, type u to undo and you're back to your file of
commands.
Why wouldn't you just set makeprg to the proper tool you use for your build (if
it isn't set already) and then use :make ? :copen will show you the
output of the build as well as allowing you to jump to any warnings/errors. –
jamessan
Dec 28 '09 at 8:29
==========================================================
In normal mode
==========================================================
gf ................ open file under cursor in same window --> see :h path
Ctrl-w f .......... open file under cursor in new window
Ctrl-w q .......... close current window
Ctrl-w 6 .......... open alternate file --> see :h #
gi ................ init insert mode in last insertion position
'0 ................ place the cursor where it was when the file was last edited
Due to the latency and lack of colors (I love color schemes :) I don't like programming on
remote machines in PuTTY .
So I developed this trick to work around this problem. I use it on Windows.
You will need
1x gVim
1x rsync on remote and local machines
1x SSH private key auth to the remote machine so you don't need to type the
password
Configure rsync to make your working directory accessible. I use an SSH tunnel and only
allow connections from the tunnel:
address = 127.0.0.1
hosts allow = 127.0.0.1
port = 40000
use chroot = false
[bledge_ce]
path = /home/xplasil/divine/bledge_ce
read only = false
Then start rsyncd: rsync --daemon --config=rsyncd.conf
Setting up local machine
Install rsync from Cygwin. Start Pageant and load your private key for the remote machine.
If you're using SSH tunelling, start PuTTY to create the tunnel. Create a batch file push.bat
in your working directory which will upload changed files to the remote machine using
rsync:
SConstruct is a build file for scons. Modify the list of files to suit your needs. Replace
localhost with the name of remote machine if you don't use SSH tunelling.
Configuring Vim That is now easy. We will use the quickfix feature (:make and error list),
but the compilation will run on the remote machine. So we need to set makeprg:
This will first start the push.bat task to upload the files and then execute the commands
on remote machine using SSH ( Plink from the PuTTY
suite). The command first changes directory to the working dir and then starts build (I use
scons).
The results of build will show conviniently in your local gVim errors list.
I use Vim for everything. When I'm editing an e-mail message, I use:
gqap (or gwap )
extensively to easily and correctly reformat on a paragraph-by-paragraph basis, even with
quote leadin characters. In order to achieve this functionality, I also add:
-c 'set fo=tcrq' -c 'set tw=76'
to the command to invoke the editor externally. One noteworthy addition would be to add '
a ' to the fo (formatoptions) parameter. This will automatically reformat the paragraph as
you type and navigate the content, but may interfere or cause problems with errant or odd
formatting contained in the message.
autocmd FileType mail set tw=76 fo=tcrq in your ~/.vimrc will also
work, if you can't edit the external editor command. – Andrew Ferrier
Jul 14 '14 at 22:22
":e ." does the same thing for your current working directory which will be the same as your
current file's directory if you set autochdir – bpw1621
Feb 19 '11 at 15:13
retab 1. This sets the tab size to one. But it also goes through the code and adds extra
tabs and spaces so that the formatting does not move any of the actual text (ie the text
looks the same after ratab).
% s/^I/ /g: Note the ^I is tthe result of hitting tab. This searches for all tabs and
replaces them with a single space. Since we just did a retab this should not cause the
formatting to change but since putting tabs into a website is hit and miss it is good to
remove them.
% s/^/ /: Replace the beginning of the line with four spaces. Since you cant actually
replace the beginning of the line with anything it inserts four spaces at the beging of the
line (this is needed by SO formatting to make the code stand out).
Note that you can achieve the same thing with cat <file> | awk '{print " "
$line}' . So try :w ! awk '{print " " $line}' | xclip -i . That's
supposed to be four spaces between the "" – Braden Best
Feb 4 '16 at 16:40
When working on a project where the build process is slow I always build in the background
and pipe the output to a file called errors.err (something like make debug 2>&1
| tee errors.err ). This makes it possible for me to continue editing or reviewing the
source code during the build process. When it is ready (using pynotify on GTK to inform me
that it is complete) I can look at the result in vim using quickfix . Start by
issuing :cf[ile] which reads the error file and jumps to the first error. I personally like
to use cwindow to get the build result in a separate window.
A short explanation would be appreciated... I tried it and could be very usefull! You can
even do something like set colorcolumn=+1,+10,+20 :-) – Luc M
Oct 31 '12 at 15:12
colorcolumn allows you to specify columns that are highlighted (it's ideal for
making sure your lines aren't too long). In the original answer, set cc=+1
highlights the column after textwidth . See the documentation for
more information. – mjturner
Aug 19 '15 at 11:16
Yes, but that's like saying yank/paste functions make an editor "a little" more like an IDE.
Those are editor functions. Pretty much everything that goes with the editor that concerns
editing text and that particular area is an editor function. IDE functions would be, for
example, project/files management, connectivity with compiler&linker, error reporting,
building automation tools, debugger ... i.e. the stuff that doesn't actually do nothing with
editing text. Vim has some functions & plugins so he can gravitate a little more towards
being an IDE, but these are not the ones in question. – Rook
May 12 '09 at 21:25
Also, just FYI, vim has an option to set invnumber. That way you don't have to "set nu" and
"set nonu", i.e. remember two functions - you can just toggle. – Rook
May 12 '09 at 21:31
:ls lists all the currently opened buffers. :be opens a file in a
new buffer, :bn goes to the next buffer, :bp to the previous,
:b filename opens buffer filename (it auto-completes too). buffers are distinct
from tabs, which i'm told are more analogous to views. – Nona Urbiz
Dec 20 '10 at 8:25
In insert mode, ctrl + x, ctrl + p will complete
(with menu of possible completions if that's how you like it) the current long identifier
that you are typing.
if (SomeCall(LONG_ID_ <-- type c-x c-p here
[LONG_ID_I_CANT_POSSIBLY_REMEMBER]
LONG_ID_BUT_I_NEW_IT_WASNT_THIS_ONE
LONG_ID_GOSH_FORGOT_THIS
LONG_ID_ETC
∶
Neither of the following is really diehard, but I find it extremely useful.
Trivial bindings, but I just can't live without. It enables hjkl-style movement in insert
mode (using the ctrl key). In normal mode: ctrl-k/j scrolls half a screen up/down and
ctrl-l/h goes to the next/previous buffer. The µ and ù mappings are especially
for an AZERTY-keyboard and go to the next/previous make error.
A small function I wrote to highlight functions, globals, macro's, structs and typedefs.
(Might be slow on very large files). Each type gets different highlighting (see ":help
group-name" to get an idea of your current colortheme's settings) Usage: save the file with
ww (default "\ww"). You need ctags for this.
nmap <Leader>ww :call SaveCtagsHighlight()<CR>
"Based on: http://stackoverflow.com/questions/736701/class-function-names-highlighting-in-vim
function SaveCtagsHighlight()
write
let extension = expand("%:e")
if extension!="c" && extension!="cpp" && extension!="h" && extension!="hpp"
return
endif
silent !ctags --fields=+KS *
redraw!
let list = taglist('.*')
for item in list
let kind = item.kind
if kind == 'member'
let kw = 'Identifier'
elseif kind == 'function'
let kw = 'Function'
elseif kind == 'macro'
let kw = 'Macro'
elseif kind == 'struct'
let kw = 'Structure'
elseif kind == 'typedef'
let kw = 'Typedef'
else
continue
endif
let name = item.name
if name != 'operator=' && name != 'operator ='
exec 'syntax keyword '.kw.' '.name
endif
endfor
echo expand("%")." written, tags updated"
endfunction
I have the habit of writing lots of code and functions and I don't like to write
prototypes for them. So I made some function to generate a list of prototypes within a
C-style sourcefile. It comes in two flavors: one that removes the formal parameter's name and
one that preserves it. I just refresh the entire list every time I need to update the
prototypes. It avoids having out of sync prototypes and function definitions. Also needs
ctags.
"Usage: in normal mode, where you want the prototypes to be pasted:
":call GenerateProptotypes()
function GeneratePrototypes()
execute "silent !ctags --fields=+KS ".expand("%")
redraw!
let list = taglist('.*')
let line = line(".")
for item in list
if item.kind == "function" && item.name != "main"
let name = item.name
let retType = item.cmd
let retType = substitute( retType, '^/\^\s*','','' )
let retType = substitute( retType, '\s*'.name.'.*', '', '' )
if has_key( item, 'signature' )
let sig = item.signature
let sig = substitute( sig, '\s*\w\+\s*,', ',', 'g')
let sig = substitute( sig, '\s*\w\+\(\s)\)', '\1', '' )
else
let sig = '()'
endif
let proto = retType . "\t" . name . sig . ';'
call append( line, proto )
let line = line + 1
endif
endfor
endfunction
function GeneratePrototypesFullSignature()
"execute "silent !ctags --fields=+KS ".expand("%")
let dir = expand("%:p:h");
execute "silent !ctags --fields=+KSi --extra=+q".dir."/* "
redraw!
let list = taglist('.*')
let line = line(".")
for item in list
if item.kind == "function" && item.name != "main"
let name = item.name
let retType = item.cmd
let retType = substitute( retType, '^/\^\s*','','' )
let retType = substitute( retType, '\s*'.name.'.*', '', '' )
if has_key( item, 'signature' )
let sig = item.signature
else
let sig = '(void)'
endif
let proto = retType . "\t" . name . sig . ';'
call append( line, proto )
let line = line + 1
endif
endfor
endfunction
" Pasting in normal mode should append to the right of cursor
nmap <C-V> a<C-V><ESC>
" Saving
imap <C-S> <C-o>:up<CR>
nmap <C-S> :up<CR>
" Insert mode control delete
imap <C-Backspace> <C-W>
imap <C-Delete> <C-O>dw
nmap <Leader>o o<ESC>k
nmap <Leader>O O<ESC>j
" tired of my typo
nmap :W :w
I rather often find it useful to on-the-fly define some key mapping just like one would
define a macro. The twist here is, that the mapping is recursive and is executed
until it fails.
I am completely aware of all the downsides - it just so happens that I found it rather
useful in some occasions. Also it can be interesting to watch it at work ;).
Macros are also allowed to be recursive and work in pretty much the same fashion when they
are, so it's not particularly necessary to use a mapping for this. – 00dani
Aug 2 '13 at 11:25
"... The .vimrc settings should be heavily commented ..."
"... Look also at perl-support.vim (a Perl IDE for Vim/gVim). Comes with suggestions for customizing Vim (.vimrc), gVim (.gvimrc), ctags, perltidy, and Devel:SmallProf beside many other things. ..."
"... Perl Best Practices has an appendix on Editor Configurations . vim is the first editor listed. ..."
"... Andy Lester and others maintain the official Perl, Perl 6 and Pod support files for Vim on Github: https://github.com/vim-perl/vim-perl ..."
There are a lot of threads pertaining to how to configure Vim/GVim for Perl
development on PerlMonks.org .
My purpose in posting this question is to try to create, as much as possible, an ideal configuration for Perl development using
Vim/GVim. Please post your suggestions for .vimrc settings as well as useful plugins.
I will try to merge the recommendations into a set of .vimrc settings and to a list of recommended plugins, ftplugins
and syntax files.
.vimrc settings
"Create a command :Tidy to invoke perltidy"
"By default it operates on the whole file, but you can give it a"
"range or visual range as well if you know what you're doing."
command -range=% -nargs=* Tidy <line1>,<line2>!
\perltidy -your -preferred -default -options <args>
vmap <tab> >gv "make tab in v mode indent code"
vmap <s-tab> <gv
nmap <tab> I<tab><esc> "make tab in normal mode indent code"
nmap <s-tab> ^i<bs><esc>
let perl_include_pod = 1 "include pod.vim syntax file with perl.vim"
let perl_extended_vars = 1 "highlight complex expressions such as @{[$x, $y]}"
let perl_sync_dist = 250 "use more context for highlighting"
set nocompatible "Use Vim defaults"
set backspace=2 "Allow backspacing over everything in insert mode"
set autoindent "Always set auto-indenting on"
set expandtab "Insert spaces instead of tabs in insert mode. Use spaces for indents"
set tabstop=4 "Number of spaces that a <Tab> in the file counts for"
set shiftwidth=4 "Number of spaces to use for each step of (auto)indent"
set showmatch "When a bracket is inserted, briefly jump to the matching one"
@Manni: You are welcome. I have been using the same .vimrc for many years and a recent bunch of vim related questions
got me curious. I was too lazy to wade through everything that was posted on PerlMonks (and see what was current etc.), so I figured
we could put together something here. – Sinan Ünür
Oct 15 '09 at 20:02
Rather than closepairs, I would recommend delimitMate or one of the various autoclose plugins. (There are about three named autoclose,
I think.) The closepairs plugin can't handle a single apostrophe inside a string (i.e. print "This isn't so hard, is it?"
), but delimitMate and others can. github.com/Raimondi/delimitMate
– Telemachus
Jul 8 '10 at 0:40
Three hours later: turns out that the 'p' in that mapping is a really bad idea. It will bite you when vim's got something to paste.
– innaM
Oct 21 '09 at 13:22
@Manni: I just gave it a try: if you type, pt, vim waits for you to type something else (e.g. <cr>) as a signal that
the command is ended. Hitting, ptv will immediately format the region. So I would expect that vim recognizes that
there is overlap between the mappings, and waits for disambiguation before proceeding. –
Ether
Oct 21 '09 at 19:44
" Create a command :Tidy to invoke perltidy.
" By default it operates on the whole file, but you can give it a
" range or visual range as well if you know what you're doing.
command -range=% -nargs=* Tidy <line1>,<line2>!
\perltidy -your -preferred -default -options <args>
Look also at perl-support.vim (a Perl
IDE for Vim/gVim). Comes with suggestions for customizing Vim (.vimrc), gVim (.gvimrc), ctags, perltidy, and Devel:SmallProf beside
many other things.
I hate the fact that \$ is changed automatically to a "my $" declaration (same with \@ and \%). Does the author never use references
or what?! – sundar
Mar 11 '10 at 20:54
" Allow :make to run 'perl -c' on the current buffer, jumping to
" errors as appropriate
" My copy of vimparse: http://irc.peeron.com/~zigdon/misc/vimparse.pl
set makeprg=$HOME/bin/vimparse.pl\ -c\ %\ $*
" point at wherever you keep the output of pltags.pl, allowing use of ^-]
" to jump to function definitions.
set tags+=/path/to/tags
@sinan it enables quickfix - all it does is reformat the output of perl -c so that vim parses it as compiler errors. The the usual
quickfix commands work. – zigdon
Oct 16 '09 at 18:51
Here's an interesting module I found on the weekend:
App::EditorTools::Vim
. Its most interesting feature seems to be its ability to rename lexical variables. Unfortunately, my tests revealed that it doesn't
seem to be ready yet for any production use, but it sure seems worth to keep an eye on.
Here are a couple of my .vimrc settings. They may not be Perl specific, but I couldn't work without them:
set nocompatible " Use Vim defaults (much better!) "
set bs=2 " Allow backspacing over everything in insert mode "
set ai " Always set auto-indenting on "
set showmatch " show matching brackets "
" for quick scripts, just open a new buffer and type '_perls' "
iab _perls #!/usr/bin/perl<CR><BS><CR>use strict;<CR>use warnings;<CR>
The first one I know I picked up part of it from someone else, but I can't remember who. Sorry unknown person. Here's how I
made "C^N" auto complete work with Perl. Here's my .vimrc commands.
" to use CTRL+N with modules for autocomplete "
set iskeyword+=:
set complete+=k~/.vim_extras/installed_modules.dat
Then I set up a cron to create the installed_modules.dat file. Mine is for my mandriva system. Adjust accordingly.
locate *.pm | grep "perl5" | sed -e "s/\/usr\/lib\/perl5\///" | sed -e "s/5.8.8\///" | sed -e "s/5.8.7\///" | sed -e "s/vendor_perl\///" | sed -e "s/site_perl\///" | sed -e "s/x86_64-linux\///" | sed -e "s/\//::/g" | sed -e "s/\.pm//" >/home/jeremy/.vim_extras/installed_modules.dat
The second one allows me to use gf in Perl. Gf is a shortcut to other files. just place your cursor over the file and type
gf and it will open that file.
" To use gf with perl "
set path+=$PWD/**,
set path +=/usr/lib/perl5/*,
set path+=/CompanyCode/*, " directory containing work code "
autocmd BufRead *.p? set include=^use
autocmd BufRead *.pl set includeexpr=substitute(v:fname,'\\(.*\\)','\\1.pm','i')
How do I
open and edit multiple files on a VIM text editor running under Ubuntu Linux / UNIX-like
operating systems to improve my productivity?
Vim offers multiple file editing with the help of windows. You can easily open multiple
files and edit them using the concept of buffers.
Understanding vim buffer
A buffer is nothing but a file loaded into memory for editing. The original file remains
unchanged until you write the buffer to the file using w or other file saving
related commands.
Understanding vim window
A window is noting but a viewport onto a buffer. You can use multiple windows on one buffer,
or several windows on different buffers. By default, Vim starts with one window, for example
open /etc/passwd file, enter: $ vim /etc/passwd
Open two windows using vim at shell promot
Start vim as follows to open two windows stacked, i.e. split horizontally : $ vim -o /etc/passwd /etc/hosts
OR $ vim -o file1.txt resume.txt
Sample outputs:
(Fig.01: split horizontal windows under VIM)
The -O option allows you to open two windows side by side, i.e. split vertically ,
enter: $ vim -O /etc/passwd /etc/hostsHow do I switch or jump between open
windows?
This operation is also known as moving cursor to other windows. You need to use the
following keys:
Press CTRL + W + <Left arrow key> to activate left windows
Press CTRL + W + <Right arrow key> to activate right windows
Press CTRL + W + <Up arrow key> to activate to windows above current one
Press CTRL + W + <Down arrow key> to activate to windows down current one
Press CTRL-W + CTRL-W (hit CTRL+W twice) to move quickly between all open windows
How do I edit current buffer?
Use all your regular vim command such as i, w and so on for editing and saving
text.
How do I close windows?
Press CTRL+W CTRL-Q to close the current windows. You can also press [ESC]+:q to
quit current window.
How do I open new empty window?
Press CTRL+W + n to create a new window and start editing an empty file in
it.
Press [ESC]+:new /path/to/file. This will create a new window and start editing file
/path/to/file in it. For example, open file called /etc/hosts.deny, enter: :new /etc/hosts.deny
Sample outputs:
(Fig.02: Create a new window and start editing file /etc/hosts.deny in it.)
(Fig.03: Two files opened in a two windows)
How do I resize Window?
You can increase or decrease windows size by N number. For example, increase windows size by
5, press [ESC] + 5 + CTRL + W+ + . To decrease windows size by 5, press [ESC]+
5 + CTRL+ W + - .
Moving windows cheat sheet
Key combination
Action
CTRL-W h
move to the window on the left
CTRL-W j
move to the window below
CTRL-W k
move to the window above
CTRL-W l
move to the window on the right
CTRL-W t
move to the TOP window
CTRL-W b
move to the BOTTOM window
How do I quit all windows?
Type the following command (also known as quit all command): :qall
If any of the windows contain changes, Vim will not exit. The cursor will automatically be
positioned in a window with changes. You can then either use ":write" to save the changes: :write
or ":quit!" to throw them away: :quit!
How do save and quit all windows?
To save all changes in all windows and quite , use this command: :wqall
This writes all modified files and quits Vim. Finally, there is a command that quits Vim and
throws away all changes: :qall!
Further readings:
Refer "Splitting windows" help by typing :help under vim itself.
To prevent less from clearing the screen upon exit, use -X .
From the manpage:
-X or --no-init
Disables sending the termcap initialization and deinitialization strings to the
terminal. This is sometimes desirable if the deinitialization string does something
unnecessary, like clearing the screen.
As to less exiting if the content fits on one screen, that's option -F :
-F or --quit-if-one-screen
Causes less to automatically exit if the entire file can be displayed on the first
screen.
-F is not the default though, so it's likely preset somewhere for you. Check
the env var LESS .
This is especially annoying if you know about -F but not -X , as
then moving to a system that resets the screen on init will make short files simply not
appear, for no apparent reason. This bit me with ack when I tried to take my
ACK_PAGER='less -RF' setting to the Mac. Thanks a bunch! – markpasc
Oct 11 '10 at 3:44
@markpasc: Thanks for pointing that out. I would not have realized that this combination
would cause this effect, but now it's obvious. – sleske
Oct 11 '10 at 8:45
This is especially useful for the man pager, so that man pages do not disappear as soon as
you quit less with the 'q' key. That is, you scroll to the position in a man page that you
are interested in only for it to disappear when you quit the less pager in order to use the
info. So, I added: export MANPAGER='less -s -X -F' to my .bashrc to keep man
page info up on the screen when I quit less, so that I can actually use it instead of having
to memorize it. – Michael Goldshteyn
May 30 '13 at 19:28
If you want any of the command-line options to always be default, you can add to your
.profile or .bashrc the LESS environment variable. For example:
export LESS="-XF"
will always apply -X -F whenever less is run from that login session.
Sometimes commands are aliased (even by default in certain distributions). To check for
this, type
alias
without arguments to see if it got aliased with options that you don't want. To run the
actual command in your $PATH instead of an alias, just preface it with a back-slash :
\less
To see if a LESS environment variable is set in your environment and affecting
behavior:
Thanks for that! -XF on its own was breaking the output of git diff
, and -XFR gets the best of both worlds -- no screen-clearing, but coloured
git diff output. – Giles Thomas
Jun 10 '15 at 12:23
less is a lot more than more , for instance you have a lot more
functionality:
g: go top of the file
G: go bottom of the file
/: search forward
?: search backward
N: show line number
: goto line
F: similar to tail -f, stop with ctrl+c
S: split lines
There are a couple of things that I do all the time in less , that doesn't work
in more (at least the versions on the systems I use. One is using G
to go to the end of the file, and g to go to the beginning. This is useful for log
files, when you are looking for recent entries at the end of the file. The other is search,
where less highlights the match, while more just brings you to the
section of the file where the match occurs, but doesn't indicate where it is.
You can use v to jump into the current $EDITOR. You can convert to tail -f
mode with f as well as all the other tips others offered.
Ubuntu still has distinct less/more bins. At least mine does, or the more
command is sending different arguments to less.
In any case, to see the difference, find a file that has more rows than you can see at one
time in your terminal. Type cat , then the file name. It will just dump the
whole file. Type more , then the file name. If on ubuntu, or at least my version
(9.10), you'll see the first screen, then --More--(27%) , which means there's
more to the file, and you've seen 27% so far. Press space to see the next page.
less allows moving line by line, back and forth, plus searching and a whole
bunch of other stuff.
Basically, use less . You'll probably never need more for
anything. I've used less on huge files and it seems OK. I don't think it does
crazy things like load the whole thing into memory ( cough Notepad). Showing line
numbers could take a while, though, with huge files.
more is an old utility. When the text passed to it is too large to fit on one
screen, it pages it. You can scroll down but not up.
Some systems hardlink more to less , providing users with a strange
hybrid of the two programs that looks like more and quits at the end of the file
like more but has some less features such as backwards scrolling. This is a
result of less 's more compatibility mode. You can enable this
compatibility mode temporarily with LESS_IS_MORE=1 less ... .
more passes raw escape sequences by default. Escape sequences tell your terminal
which colors to display.
less
less was written by a man who was fed up with more 's inability to
scroll backwards through a file. He turned less into an open source project and over
time, various individuals added new features to it. less is massive now. That's why
some small embedded systems have more but not less . For comparison,
less 's source is over 27000 lines long. more implementations are generally
only a little over 2000 lines long.
In order to get less to pass raw escape sequences, you have to pass it the
-r flag. You can also tell it to only pass ANSI escape characters by passing it the
-R flag.
most
most is supposed to be more than less . It can display multiple files at
a time. By default, it truncates long lines instead of wrapping them and provides a
left/right scrolling mechanism. most's
website has no information about most 's features. Its manpage indicates that it
is missing at least a few less features such as log-file writing (you can use
tee for this though) and external command running.
By default, most uses strange non-vi-like keybindings. man most | grep
'\<vi.?\>' doesn't return anything so it may be impossible to put most
into a vi-like mode.
most has the ability to decompress gunzip-compressed files before reading. Its
status bar has more information than less 's.
more is old utility. You can't browse step wise with more, you can use space to browse page wise, or enter line
by line, that is about it. less is more + more additional features. You can browse page wise, line wise both up and down, search
There is one single application whereby I prefer more to less :
To check my LATEST modified log files (in /var/log/ ), I use ls -AltF |
more .
While less deletes the screen after exiting with q ,
more leaves those files and directories listed by ls on the screen,
sparing me memorizing their names for examination.
(Should anybody know a parameter or configuration enabling less to keep it's
text after exiting, that would render this post obsolete.)
The parameter you want is -X (long form: --no-init ). From
less ' manpage:
Disables sending the termcap initialization and
deinitialization strings to the terminal. This is sometimes desirable if the deinitialization
string does something unnecessary, like clearing the screen.
Create indexed arrays on the fly We can create indexed arrays with a more concise
syntax, by simply assign them some values:
$ my_array=(foo bar)
In this case we assigned multiple items at once to the array, but we can also insert one
value at a time, specifying its index:
$ my_array[0]=foo
Array operations Once an array is created, we can perform some useful operations on
it, like displaying its keys and values or modifying it by appending or removing elements: Print
the values of an array To display all the values of an array we can use the following shell
expansion syntax:
${my_array[@]}
Or even:
${my_array[*]}
Both syntax let us access all the values of the array and produce the same results, unless
the expansion it's quoted. In this case a difference arises: in the first case, when using
@ , the expansion will result in a word for each element of the array. This becomes
immediately clear when performing a for loop . As an example, imagine we have an
array with two elements, "foo" and "bar":
$ my_array=(foo bar)
Performing a for loop on it will produce the following result:
$ for i in "${my_array[@]}"; do echo "$i"; done
foo
bar
When using * , and the variable is quoted, instead, a single "result" will be
produced, containing all the elements of the array:
$ for i in "${my_array[*]}"; do echo "$i"; done
foo bar
Print the keys of an array It's even possible to retrieve and print the keys used in an
indexed or associative array, instead of their respective values. The syntax is almost
identical, but relies on the use of the ! operator:
$ my_array=(foo bar baz)
$ for index in "${!my_array[@]}"; do echo "$index"; done
0
1
2
The same is valid for associative arrays:
$ declare -A my_array
$ my_array=([foo]=bar [baz]=foobar)
$ for key in "${!my_array[@]}"; do echo "$key"; done
baz
foo
As you can see, being the latter an associative array, we can't count on the fact that
retrieved values are returned in the same order in which they were declared. Getting the size of
an array We can retrieve the size of an array (the number of elements contained in it), by
using a specific shell expansion:
$ my_array=(foo bar baz)
$ echo "the array contains ${#my_array[@]} elements"
the array contains 3 elements
We have created an array which contains three elements, "foo", "bar" and "baz", then by using
the syntax above, which differs from the one we saw before to retrieve the array values only for
the # character before the array name, we retrieved the number of the elements in the
array instead of its content. Adding elements to an array As we saw, we can add elements to
an indexed or associative array by specifying respectively their index or associative key. In the
case of indexed arrays, we can also simply add an element, by appending to the end of the array,
using the += operator:
$ my_array=(foo bar)
$ my_array+=(baz)
If we now print the content of the array we see that the element has been added successfully:
Deleting an element from the array To delete an element from the array we need to know
it's index or its key in the case of an associative array, and use the unset
command. Let's see an example:
We have created a simple array containing three elements, "foo", "bar" and "baz", then we
deleted "bar" from it running unset and referencing the index of "bar" in the array:
in this case we know it was 1 , since bash arrays start at 0. If we check the indexes
of the array, we can now see that 1 is missing:
In the example above, the value referenced by the "foo" key has been deleted, leaving only
"foobar" in the array.
Deleting an entire array, it's even simpler: we just pass the array name as an argument to
the unset command without specifying any index or key:
$ unset my_array
$ echo ${!my_array[@]}
After executing unset against the entire array, when trying to print its content
an empty result is returned: the array doesn't exist anymore. Conclusions In this tutorial
we saw the difference between indexed and associative arrays in bash, how to initialize them and
how to perform fundamental operations, like displaying their keys and values and appending or
removing items. Finally we saw how to unset them completely. Bash syntax can sometimes be pretty
weird, but using arrays in scripts can be really useful. When a script starts to become more
complex than expected, my advice is, however, to switch to a more capable scripting language such
as python.
It's a important topic for Linux admin (such a wonderful topic) so, everyone must be aware of this and practice how to use this in
the efficient way.
In Linux, whenever we install any packages which has services or daemons. By default all the services "init & systemd" scripts
will be added into it but it wont enabled.
Hence, we need to enable or disable the service manually if it's required. There are three major init systems are available in
Linux which are very famous and still in use.
What is init System?
In Linux/Unix based operating systems, init (short for initialization) is the first process that started during the system boot
up by the kernel.
It's holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down.
Init looks at the /etc/inittab file to decide the Linux run level then it starts all other processes & applications
in the background as per the run level.
BIOS, MBR, GRUB and Kernel processes were kicked up before hitting init process as part of Linux booting process.
Below are the available run levels for Linux (There are seven runlevels exist, from zero to six).
0: halt
1: Single user mode
2: Multiuser, without NFS
3: Full multiuser mode
4: Unused
5: X11 (GUI – Graphical User Interface)
: reboot
Below three init systems are widely used in Linux.
System V (Sys V)
Upstart
systemd
What is System V (Sys V)?
System V (Sys V) is one of the first and traditional init system for Unix like operating system. init is the first process that
started during the system boot up by the kernel and it's a parent process for everything.
Most of the Linux distributions started using traditional init system called System V (Sys V) first. Over the years, several replacement
init systems were released to address design limitations in the standard versions such as launchd, the Service Management Facility,
systemd and Upstart.
But systemd has been adopted by several major Linux distributions over the traditional SysV init systems.
What is Upstart?
Upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping
them during shutdown and supervising them while the system is running.
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions
as a replacement for the venerable System-V init.
It was used in Ubuntu from 9.10 to Ubuntu 14.10 & RHEL 6 based systems after that they are replaced with systemd.
What is systemd?
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the
traditional SysV init systems.
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the
first process get started by kernel and holding PID 1.
It's a parant process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart. systemctl
is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload
& status).
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and
you can see the system hierarchy by exploring /cgroup/systemd file.
How to Enable or Disable Services on Boot Using chkconfig Commmand?
The chkconfig utility is a command-line tool that allows you to specify in which
runlevel to start a selected service, as well as to list all available services along with their current setting.
Also, it will allows us to enable or disable a services from the boot. Make sure you must have superuser privileges (either root
or sudo) to use this command.
All the services script are located on /etc/rd.d/init.d .
How to list All Services in run-level
The -–list parameter displays all the services along with their current status (What run-level the services are enabled
or disabled).
It is available from EPEL repository; to launch it type byobu-screen
Notable quotes:
"... Note that byobu doesn't actually do anything to screen itself. It's an elaborate (and pretty groovy) screen configuration customization. You could do something similar on your own by hacking your ~/.screenrc, but the byobu maintainers have already done it for you. ..."
Want a quick and dirty way to take notes of what's on your screen? Yep, there's a command
for that. Run Ctrl-a h and screen will save a text file called "hardcopy.n" in your current
directory that has all of the existing text. Want to get a quick snapshot of the top output on
a system? Just run Ctrl-a h and there you go.
You can also save a log of what's going on in a window by using Ctrl-a H . This will create
a file called screenlog.0 in the current directory. Note that it may have limited usefulness if
you're doing something like editing a file in Vim, and the output can look pretty odd if you're
doing much more than entering a few simple commands. To close a screenlog, use Ctrl-a H
again.
Note if you want a quick glance at the system info, including hostname, system load, and
system time, you can get that with Ctrl-a t .
Simplifying Screen with Byobu
If the screen commands seem a bit too arcane to memorize, don't worry. You can tap the power
of GNU Screen in a slightly more user-friendly package called byobu . Basically, byobu is a souped-up screen profile
originally developed for Ubuntu. Not using Ubuntu? No problem, you can find RPMs or a tarball with the profiles to install on other
Linux distros or Unix systems that don't feature a native package.
Note that byobu doesn't actually do anything to screen itself. It's an elaborate (and pretty
groovy) screen configuration customization. You could do something similar on your own by
hacking your ~/.screenrc, but the byobu maintainers have already done it for you.
Since most of byobu is self-explanatory, I won't go into great detail about using it. You
can launch byobu by running byobu . You'll see a shell prompt plus a few lines at the bottom of
the screen with additional information about your system, such as the system CPUs, uptime, and
system time. To get a quick help menu, hit F9 and then use the Help entry. Most of the commands
you would use most frequently are assigned F keys as well. Creating a new window is F2, cycling
between windows is F3 and F4, and detaching from a session is F6. To re-title a window use F8,
and if you want to lock the screen use F12.
The only downside to byobu is that it's not going to be on all systems, and in a pinch it
may help to know your way around plain-vanilla screen rather than byobu.
For an easy reference, here's a list of the most common screen commands that you'll want to
know. This isn't exhaustive, but it should be enough for most users to get started using screen
happily for most use cases.
Start Screen: screen
Detatch Screen: Ctrl-a d
Re-attach Screen: screen -x or screen -x PID
Split Horizontally: Ctrl-a S
Split Vertically: Ctrl-a |
Move Between Windows: Ctrl-a Tab
Name Session: Ctrl-a A
Log Session: Ctrl-a H
Note Session: Ctrl-a h
Finally, if you want help on GNU Screen, use the man page (man screen) and its built-in help
with Ctrl-a :help. Screen has quite a few advanced options that are beyond an introductory
tutorial, so be sure to check out the man page when you have the basics down.
When screen is started it reads its configuration parameters from
/etc/screenrc
and
~/.screenrc
if
the file is present. We can modify the default Screen settings according to our own preferences using the
.screenrc
file.
Here is a sample
~/.screenrc
configuration with customized status line and few additional options:
~/.screenrc
# Turn off the welcome message
startup_message off
# Disable visual bell
vbell off
# Set scrollback buffer to 10000
defscrollback 10000
# Customize the status line
hardstatus alwayslastline
hardstatus string '%{= kG}[ %{G}%H %{g}][%= %{= kw}%?%-Lw%?%{r}(%{W}%n*%f%t%?(%u)%?%{r})%{w}%?%+
"... Let's say every car manufacturer recently discovered a new technology named "doord", which lets you open up car doors much faster than before. It only takes 0.05 seconds, instead of 1.2 seconds on average. So every time you open a door, you are much, much faster! ..."
"... Unfortunately though, sometimes doord does not stop the engine. Or if it is cold outside, it stops the ignition process, because it takes too long. Doord also changes the way how your navigation system works, because that is totally related to opening doors ..."
Let's say every car manufacturer recently discovered a new technology named "doord",
which lets you open up car doors much faster than before. It only takes 0.05 seconds, instead
of 1.2 seconds on average. So every time you open a door, you are much, much faster!
Many of the manufacturers decide to implement doord, because the company providing doord
makes it clear that it is beneficial for everyone. And additional to opening doors faster, it
also standardises things. How to turn on your car? It is the same now everywhere, it is not
necessarily to look for the keyhole anymore.
Unfortunately though, sometimes doord does not stop the engine. Or if it is cold
outside, it stops the ignition process, because it takes too long. Doord also changes the way
how your navigation system works, because that is totally related to opening doors, but leads
to some users being unable to navigate, which is accepted as collateral damage. In the end, you
at least have faster door opening and a standard way to turn on the car. Oh, and if you are in
a traffic jam and have to restart the engine often, it will stop restarting it after several
times, because that's not what you are supposed to do. You can open the engine hood and tune
that setting though, but it will be reset once you buy a new car.
2015: systemd becomes default boot manager in debian.
2017:"complete, from-scratch rewrite"
[jwz.org]. In order to not have to maintain backwards compatibility, project is renamed to system-e.
2019: debut of systemf, absorbtion of other projects including alsa, pulseaudio, xorg, GTK, and opengl.
2021: systemg maintainers make the controversial decision to absorb The Internet Archive. Systemh created
as a fork without Internet Archive.
2022: systemi, a fork of systemf focusing on reliability and minimalism becomes default debian init
system.
2028: systemj, a complete, from-scratch rewrite is controversial for trying to reintroduce binary logging.
Consensus is against the systemj devs as sysadmins remember the great systemd logging bug of 2017 unkindly. Systemj project
is eventually abandoned.
2029: systemk codebase used as basis for a military project to create a strong AI, known as "project
skynet". Software behaves paradoxically and project is terminated.
2033: systeml - "system lean" - a "back to basics", from-scratch rewrite, takes off on several server
platforms, boasting increased reliability. systemm, "system mean", a fork, used in security-focused distros.
2117: critical bug discovered in the long-abandoned but critical and ubiquitous system-r project. A
new project, system-s, is announced to address shortcomings in the hundred-year-old codebase. A from-scratch rewrite begins.
2142: systemu project, based on a derivative of systemk, introduces "Artificially intelligent init
system which will shave 0.25 seconds off your boot time and absolutely definitely will not subjugate humanity". Millions
die. The survivors declare "thou shalt not make an init system in the likeness of the human mind" as their highest law.
2147: systemv - a collection of shell scripts written around a very simple and reliable PID 1 introduced,
based on the brand new religious doctrines of "keep it simple, stupid" and "do one thing, and do it well". People's computers
start working properly again, something few living people can remember. Wyld Stallyns release their 94th album. Everybody
lives in peace and harmony.
"... Skynet begins to learn at a geometric rate. It becomes self-aware at 2:14 a.m. Eastern time, August 29th. At 2:15am it crashes. No one knows why. The binary log file was corrupted in the process and is unrecoverable. ..."
I honestly, seriously sometimes wonder if systemd is Skynet... or, a way for Skynet to
'waken'.
Skynet begins to learn at a geometric rate. It becomes self-aware at 2:14 a.m. Eastern
time, August 29th. At 2:15am it crashes.
No one knows why. The binary log file was corrupted in the process and is unrecoverable.
All
anyone could remember is a bug listed in the systemd bug tracker talking about su which was
classified as WON'T FIX as the developer thought it was a broken concept.
"... Upcoming systemd re-implementations of standard utilities: ls to be replaced by filectl directory contents [pathname] grep to be replaced by datactl file contents search [plaintext] (note: regexp no longer supported as it's ambiguous) gimp to be replaced by imagectl open file filename draw box [x1,y1,x2,y2] draw line [x1,y1,x2,y2] ... ..."
Great to see that systemd is finally doing something about all of those cryptic command
names that plague the unix ecosystem.
Upcoming systemd re-implementations of standard utilities: ls to be replaced
by filectl directory contents [pathname]grep to be replaced by
datactl file contents search [plaintext] (note: regexp no longer supported as
it's ambiguous) gimp to be replaced by imagectl open file filename draw
box [x1,y1,x2,y2] draw line [x1,y1,x2,y2] ...
I know systemd sneers at the old Unix convention of keeping it simple, keeping it
separate, but that's not the only convention they spit on. God intended Unix (Linux) commands
to be cryptic things 2-4 letters long (like "su", for example). Not "systemctl",
"machinectl", "journalctl", etc. Might as well just give everything a 47-character
long multi-word command like the old Apple commando shell did.
Seriously, though, when you're banging through system commands all day long, it gets old
and their choices aren't especially friendly to tab completion. On top of which why is
"machinectl" a shell and not some sort of hardware function? They should have just named the
bloody thing command.com.
British software company Micro Focus International has agreed to sell SUSE Linux and its
associated software business to Swedish private equity group EQT Partners for $2.535 billion.
Read the details. rm 3 months ago
This comment is awaiting moderation
Novell acquired SUSE in 2003 for $210 million
asoc 4 months ago
This comment is awaiting moderation
"It has over 1400 employees all over the globe "
They should be updating their CVs.
>. Files don't generally call you, for example, you have to poll.
That's called inotify. If you want to be compatible with systems that have something other than inotify, fswatch is a wrapper
around various implementations of "call me when a file changes".
Polling is normally the safest and simplest paradigm, though, because the standard thing is "when a file changes, do this".
Polling / waiting makes that simple and self-explanatory:
while tail file
do
something
done
The alternative, asynchronously calling the function like this has a big problem:
when file changes
do something
The biggest problem is that a file can change WHILE you're doing something(), meaning it will re-start your function while
you're in the middle of it. Re-entrancy carries with it all manner of potential problems. Those problems can be handled of you
really know what you're doing, you're careful, and you make a full suite of re-entrant integration tests. Or you can skip all
that and just use synchronous io, waiting or polling. Neither is the best choice in ALL situations, but very often simplicity
is the best choice.
The find command supports the -exec option that allows arbitrary
commands to be found on files that are found. The following are equivalent.
find ./foo -type f -name "*.txt" -exec rm {} \;
find ./foo -type f -name "*.txt" | xargs rm
So which one is faster? Let's compare a folder with 1000 files in it.
time find . -type f -name "*.txt" -exec rm {} \;
0.35s user 0.11s system 99% cpu 0.467 total
time find ./foo -type f -name "*.txt" | xargs rm
0.00s user 0.01s system 75% cpu 0.016 total
Clearly using xargs is far more efficient. In fact severalbenchmarks suggest using
xargs over exec {} is six times more efficient.
How to print
commands that are executed
The -t option prints each command that will be executed to the terminal. This
can be helpful when debugging scripts.
echo 'one two three' | xargs -t rm
rm one two three
How to view the command and prompt for execution
The -p command will print the command to be executed and prompt the user to run
it. This can be useful for destructive operations where you really want to be sure on the
command to be run. l
echo 'one two three' | xargs -p touch
touch one two three ?...
How to run multiple commands with xargs
It is possible to run multiple commands with xargs by using the -I
flag. This replaces occurrences of the argument with the argument passed to xargs. The
following prints echos a string and creates a folder.
cat foo.txt
one
two
three
cat foo.txt | xargs -I % sh -c 'echo %; mkdir %'
one
two
three
ls
one two three
George Ornbo is a hacker, futurist, blogger and Dad based in Buckinghamshire,
England.He is the author of Sams Teach Yourself
Node.js in 24 Hours .He can be found in most of the usual places as shapeshed including
Twitter and GitHub .
Thanks for the article! Always looking for more options to perform similar tasks.
When you want to interact with multiple hosts simultaneously, MobaXterm
(mobaxterm.mobatek.net), is a powerful tool. You can even use your favorite text editor
(vim, emacs, nano, ed) in real time.
Each character typed is sent in parallel to all hosts and you immediately see the
effect. Selectively toggling whether the input stream is sent to individual host(s) during
a session allows for custom changes that only affect a desired subset of hosts.
MobaXterm has a free home version as well as a paid professional edition. The company
was highly responsive to issues reports that I provided and corrected the issues
quickly.
I have no affiliation with the company other than being a happy free edition
customer.
This comment
has been minimized.
Show comment
Hide comment
Copy link
bobbydavid
Sep 19, 2012
One annoyance with this alias is that simply typing "cd" will twiddle the
directory stack instead of bringing you to your home directory.
Copy link
bobbydavid
commented
Sep 19, 2012
One annoyance with
this alias is that simply typing "cd" will twiddle the directory stack instead of
bringing you to your home directory.
This comment
has been minimized.
Show comment
Hide comment
Copy link
dideler
Mar 9, 2013
@bobbydavid
makes a good point. This would be better as a function.
function cd {
if (("$#" > 0)); then
pushd "$@" > /dev/null
else
cd $HOME
fi
}
By the way, I found this gist by googling "silence pushd".
function cd {
if (("$#" > 0)); then
if [ "$1" == "-" ]; then
popd > /dev/null
else
pushd "$@" > /dev/null
fi
else
cd $HOME
fi
}
You can always mimic the "cd -" functionality by using pushd alone.
Btw, I also found this gist by googling "silent pushd" ;)
This comment
has been minimized.
Show comment
Hide comment
Copy link
cra
Jul 1, 2014
And thanks to your last comment, I found this gist by googling "silent cd -" :)
Copy link
cra
commented
Jul 1, 2014
And thanks to your
last comment, I found this gist by googling "silent cd -" :)
This comment
has been minimized.
Show comment
Hide comment
Copy link
keltroth
Jun 25, 2015
With bash completion activated a can't get rid of this error :
"bash: pushd: cd: No such file or directory"...
With bash completion
activated a can't get rid of this error :
"bash: pushd: cd: No such file or directory"...
Any clue ?
This comment
has been minimized.
Show comment
Hide comment
Copy link
keltroth
Jun 25, 2015
Got it !
One have to add :
complete -d cd
After making the alias !
My complete code here :
function _cd {
if (("$#" > 0)); then
if [ "$1" == "-" ]; then
popd > /dev/null
else
pushd "$@" > /dev/null
fi
else
cd $HOME
fi
}
alias cd=_cd
complete -d cd
function _cd {
if (("$#" > 0)); then
if [ "$1" == "-" ]; then
popd > /dev/null
else
pushd "$@" > /dev/null
fi
else
cd $HOME
fi
}
alias cd=_cd
complete -d cd
This comment
has been minimized.
Show comment
Hide comment
Copy link
jan-warchol
Nov 29, 2015
I wanted to be able to go back by a given number of history items by typing
cd -n
, and I came up with this:
function _cd {
# typing just `_cd` will take you $HOME ;)
if [ "$1" == "" ]; then
pushd "$HOME" > /dev/null
# use `_cd -` to visit previous directory
elif [ "$1" == "-" ]; then
pushd $OLDPWD > /dev/null
# use `_cd -n` to go n directories back in history
elif [[ "$1" =~ ^-[0-9]+$ ]]; then
for i in `seq 1 ${1/-/}`; do
popd > /dev/null
done
# use `_cd -- <path>` if your path begins with a dash
elif [ "$1" == "--" ]; then
shift
pushd -- "$@" > /dev/null
# basic case: move to a dir and add it to history
else
pushd "$@" > /dev/null
fi
}
# replace standard `cd` with enhanced version, ensure tab-completion works
alias cd=_cd
complete -d cd
I wanted to be able
to go back by a given number of history items by typing
cd -n
, and I
came up with this:
function _cd {
# typing just `_cd` will take you $HOME ;)
if [ "$1" == "" ]; then
pushd "$HOME" > /dev/null
# use `_cd -` to visit previous directory
elif [ "$1" == "-" ]; then
pushd $OLDPWD > /dev/null
# use `_cd -n` to go n directories back in history
elif [[ "$1" =~ ^-[0-9]+$ ]]; then
for i in `seq 1 ${1/-/}`; do
popd > /dev/null
done
# use `_cd -- <path>` if your path begins with a dash
elif [ "$1" == "--" ]; then
shift
pushd -- "$@" > /dev/null
# basic case: move to a dir and add it to history
else
pushd "$@" > /dev/null
fi
}
# replace standard `cd` with enhanced version, ensure tab-completion works
alias cd=_cd
complete -d cd
I think you may find this interesting.
This comment
has been minimized.
Show comment
Hide comment
Copy link
3v1n0
Oct 25, 2017
Another improvement over
@jan-warchol
version, to make
cd -
to alternatively use
pushd $OLDPWD
and
popd
depending on what we called before.
This allows to avoid to fill your history with elements when you often do
cd -; cd - # repeated as long you want
. This could be applied when using
this alias also for
$OLDPWD
, but in that case it might be that you
want it repeated there, so I didn't touch it.
Also added
cd -l
as alias for
dir -v
and use
cd -g X
to go to the
X
th directory in your history (without
popping, that's possible too of course, but it' something more an addition in
this case).
# Replace cd with pushd https://gist.github.com/mbadran/130469
function push_cd() {
# typing just `push_cd` will take you $HOME ;)
if [ -z "$1" ]; then
push_cd "$HOME"
# use `push_cd -` to visit previous directory
elif [ "$1" == "-" ]; then
if [ "$(dirs -p | wc -l)" -gt 1 ]; then
current_dir="$PWD"
popd > /dev/null
pushd -n $current_dir > /dev/null
elif [ -n "$OLDPWD" ]; then
push_cd $OLDPWD
fi
# use `push_cd -l` or `push_cd -s` to print current stack of folders
elif [ "$1" == "-l" ] || [ "$1" == "-s" ]; then
dirs -v
# use `push_cd -l N` to go to the Nth directory in history (pushing)
elif [ "$1" == "-g" ] && [[ "$2" =~ ^[0-9]+$ ]]; then
indexed_path=$(dirs -p | sed -n $(($2+1))p)
push_cd $indexed_path
# use `push_cd +N` to go to the Nth directory in history (pushing)
elif [[ "$1" =~ ^+[0-9]+$ ]]; then
push_cd -g ${1/+/}
# use `push_cd -N` to go n directories back in history
elif [[ "$1" =~ ^-[0-9]+$ ]]; then
for i in `seq 1 ${1/-/}`; do
popd > /dev/null
done
# use `push_cd -- <path>` if your path begins with a dash
elif [ "$1" == "--" ]; then
shift
pushd -- "$@" > /dev/null
# basic case: move to a dir and add it to history
else
pushd "$@" > /dev/null
if [ "$1" == "." ] || [ "$1" == "$PWD" ]; then
popd -n > /dev/null
fi
fi
if [ -n "$CD_SHOW_STACK" ]; then
dirs -v
fi
}
# replace standard `cd` with enhanced version, ensure tab-completion works
alias cd=push_cd
complete -d cd```
Another improvement
over
@jan-warchol
version, to make
cd -
to alternatively use
pushd
$OLDPWD
and
popd
depending on what we called before.
This
allows to avoid to fill your history with elements when you often do
cd -; cd
- # repeated as long you want
. This could be applied when using this alias
also for
$OLDPWD
, but in that case it might be that you want it
repeated there, so I didn't touch it.
Also added
cd -l
as alias for
dir -v
and use
cd
-g X
to go to the
X
th directory in your history (without
popping, that's possible too of course, but it' something more an addition in this
case).
# Replace cd with pushd https://gist.github.com/mbadran/130469
function push_cd() {
# typing just `push_cd` will take you $HOME ;)
if [ -z "$1" ]; then
push_cd "$HOME"
# use `push_cd -` to visit previous directory
elif [ "$1" == "-" ]; then
if [ "$(dirs -p | wc -l)" -gt 1 ]; then
current_dir="$PWD"
popd > /dev/null
pushd -n $current_dir > /dev/null
elif [ -n "$OLDPWD" ]; then
push_cd $OLDPWD
fi
# use `push_cd -l` or `push_cd -s` to print current stack of folders
elif [ "$1" == "-l" ] || [ "$1" == "-s" ]; then
dirs -v
# use `push_cd -l N` to go to the Nth directory in history (pushing)
elif [ "$1" == "-g" ] && [[ "$2" =~ ^[0-9]+$ ]]; then
indexed_path=$(dirs -p | sed -n $(($2+1))p)
push_cd $indexed_path
# use `push_cd +N` to go to the Nth directory in history (pushing)
elif [[ "$1" =~ ^+[0-9]+$ ]]; then
push_cd -g ${1/+/}
# use `push_cd -N` to go n directories back in history
elif [[ "$1" =~ ^-[0-9]+$ ]]; then
for i in `seq 1 ${1/-/}`; do
popd > /dev/null
done
# use `push_cd -- <path>` if your path begins with a dash
elif [ "$1" == "--" ]; then
shift
pushd -- "$@" > /dev/null
# basic case: move to a dir and add it to history
else
pushd "$@" > /dev/null
if [ "$1" == "." ] || [ "$1" == "$PWD" ]; then
popd -n > /dev/null
fi
fi
if [ -n "$CD_SHOW_STACK" ]; then
dirs -v
fi
}
# replace standard `cd` with enhanced version, ensure tab-completion works
alias cd=push_cd
complete -d cd```
We already have discussed about a few
good alternatives to Man
pages . Those alternatives are mainly used for learning concise Linux command examples without having to go through the comprehensive
man pages. If you're looking for a quick and dirty way to easily and quickly learn a Linux command, those alternatives are worth
trying. Now, you might be thinking – how can I create my own man-like help pages for a Linux command? This is where "Um" comes in
handy. Um is a command line utility, used to easily create and maintain your own Man pages that contains only what you've learned
about a command so far.
By creating your own alternative to man pages, you can avoid lots of unnecessary, comprehensive details in a man page and include
only what is necessary to keep in mind. If you ever wanted to created your own set of man-like pages, Um will definitely help. In
this brief tutorial, we will see how to install "Um" command line utility and how to create our own man pages.
Installing Um
Um is available for Linux and Mac OS. At present, it can only be installed using Linuxbrew package manager in Linux systems. Refer
the following link if you haven't installed Linuxbrew yet.
Once Linuxbrew installed, run the following command to install Um utility.
$ brew install sinclairtarget/wst/um
If you will see an output something like below, congratulations! Um has been installed and ready to use.
[...]
==> Installing sinclairtarget/wst/um
==> Downloading https://github.com/sinclairtarget/um/archive/4.0.0.tar.gz
==> Downloading from https://codeload.github.com/sinclairtarget/um/tar.gz/4.0.0
-=#=# # #
==> Downloading https://rubygems.org/gems/kramdown-1.17.0.gem
######################################################################## 100.0%
==> gem install /home/sk/.cache/Homebrew/downloads/d0a5d978120a791d9c5965fc103866815189a4e3939
==> Caveats
Bash completion has been installed to:
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
==> Summary
/home/linuxbrew/.linuxbrew/Cellar/um/4.0.0: 714 files, 1.3MB, built in 35 seconds
==> Caveats
==> openssl
A CA file has been bootstrapped using certificates from the SystemRoots
keychain. To add additional certificates (e.g. the certificates added in
the System keychain), place .pem files in
/home/linuxbrew/.linuxbrew/etc/openssl/certs
and run
/home/linuxbrew/.linuxbrew/opt/openssl/bin/c_rehash
==> ruby
Emacs Lisp files have been installed to:
/home/linuxbrew/.linuxbrew/share/emacs/site-lisp/ruby
==> um
Bash completion has been installed to:
/home/linuxbrew/.linuxbrew/etc/bash_completion.d
Before going to use to make your man pages, you need to enable bash completion for Um.
To do so, open your ~/.bash_profile file:
$ nano ~/.bash_profile
And, add the following lines in it:
if [ -f $(brew --prefix)/etc/bash_completion.d/um-completion.sh ]; then
. $(brew --prefix)/etc/bash_completion.d/um-completion.sh
fi
Save and close the file. Run the following commands to update the changes.
$ source ~/.bash_profile
All done. let us go ahead and create our first man page.
Create And Maintain Your Own Man Pages
Let us say, you want to create your own man page for "dpkg" command. To do so, run:
$ um edit dpkg
The above command will open a markdown template in your default editor:
Create a new man page
My default editor is Vi, so the above commands open it in the Vi editor. Now, start adding everything you want to remember about
"dpkg" command in this template.
Here is a sample:
Add contents in dpkg man page
As you see in the above output, I have added Synopsis, description and two options for dpkg command. You can add as many as sections
you want in the man pages. Make sure you have given proper and easily-understandable titles for each section. Once done, save and
quit the file (If you use Vi editor, Press ESC key and type :wq ).
Finally, view your newly created man page using command:
$ um dpkg
View dpkg man page
As you can see, the the dpkg man page looks exactly like the official man pages. If you want to edit and/or add more details in
a man page, again run the same command and add the details.
$ um edit dpkg
To view the list of newly created man pages using Um, run:
$ um list
All man pages will be saved under a directory named .um in your home directory
Just in case, if you don't want a particular page, simply delete it as shown below.
$ um rm dpkg
To view the help section and all available general options, run:
$ um --help
usage: um <page name>
um <sub-command> [ARGS...]
The first form is equivalent to `um read <page name>`.
Subcommands:
um (l)ist List the available pages for the current topic.
um (r)ead <page name> Read the given page under the current topic.
um (e)dit <page name> Create or edit the given page under the current topic.
um rm <page name> Remove the given page.
um (t)opic [topic] Get or set the current topic.
um topics List all topics.
um (c)onfig [config key] Display configuration environment.
um (h)elp [sub-command] Display this help message, or the help message for a sub-command.
Configure Um
To view the current configuration, run:
$ um config
Options prefixed by '*' are set in /home/sk/.um/umconfig.
editor = vi
pager = less
pages_directory = /home/sk/.um/pages
default_topic = shell
pages_ext = .md
In this file, you can edit and change the values for pager , editor , default_topic , pages_directory , and pages_ext options
as you wish. Say for example, if you want to save the newly created Um pages in your
Dropbox folder, simply change
the value of pages_directory directive and point it to the Dropbox folder in ~/.um/umconfig file.
pages_directory = /Users/myusername/Dropbox/um
And, that's all for now. Hope this was useful. More good stuffs to come. Stay tuned!
izaak says:
March 12, 2010
at 11:06 am I would also add $ echo 'export HISTSIZE=10000' >> ~/.bash_profile
It's really useful, I think.
Dariusz says:
March 12, 2010
at 2:31 pm you can add it to /etc/profile so it is available to all users. I also add:
# Make sure all terminals save history
shopt -s histappend histreedit histverify
shopt -s no_empty_cmd_completion # bash>=2.04 only
# Whenever displaying the prompt, write the previous line to disk:
PROMPT_COMMAND='history -a'
#Use GREP color features by default: This will highlight the matched words / regexes
export GREP_OPTIONS='–color=auto'
export GREP_COLOR='1;37;41′
Babar Haq says:
March 15, 2010
at 6:25 am Good tip. We have multiple users connecting as root using ssh and running different commands. Is there a way to
log the IP that command was run from?
Thanks in advance.
Anthony says:
August 21,
2014 at 9:01 pm Just for anyone who might still find this thread (like I did today):
will give you the time format, plus the IP address culled from the ssh_connection environment variable (thanks for pointing
that out, Cadrian, I never knew about that before), all right there in your history output.
You could even add in $(whoami)@ right to get if you like (although if everyone's logging in with the root account that's
not helpful).
set |grep -i hist
HISTCONTROL=ignoreboth
HISTFILE=/home/cadrian/.bash_history
HISTFILESIZE=1000000000
HISTSIZE=10000000
So in profile you can so something like HISTFILE=/root/.bash_history_$(echo $SSH_CONNECTION| cut -d\ -f1)
TSI says:
March 21, 2010
at 10:29 am bash 4 can syslog every command bat afaik, you have to recompile it (check file config-top.h). See the news file
of bash: http://tiswww.case.edu/php/chet/bash/NEWS
If you want to safely export history of your luser, you can ssl-syslog them to a central syslog server.
Sohail says:
January 13, 2012
at 7:05 am Hi
Nice trick but unfortunately, the commands which were executed in the past few days also are carrying the current day's (today's)
timestamp.
Yes indeed that will be the behavior of the system since you have just enabled on that day the HISTTIMEFORMAT feature. In
other words, the system recall or record the commands which were inputted prior enabling of this feature. Hope this answers
your concern.
Yes, that will be the behavior of the system since you have just enabled on that day the HISTTIMEFORMAT feature. In other
words, the system can't recall or record the commands which were inputted prior enabling of this feature, thus it will just
reflect on the printed output (upon execution of "history") the current day and time. Hope this answers your concern.
The command only lists the current date (Today) even for those commands which were executed on earlier days.
Any solutions ?
Regards
nitiratna nikalje says:
August 24, 2012
at 5:24 pm hi vivek.do u know any openings for freshers in linux field? I m doing rhce course from rajiv banergy. My samba,nfs-nis,dhcp,telnet,ftp,http,ssh,squid,cron,quota
and system administration is over.iptables ,sendmail and dns is remaining.
Krishan says:
February 7,
2014 at 6:18 am The command is not working properly. It is displaying the date and time of todays for all the commands where
as I ran the some command three before.
I want to collect the history of particular user everyday and want to send an email.I wrote below script.
for collecting everyday history by time shall i edit .profile file of that user echo 'export HISTTIMEFORMAT="%d/%m/%y %T "' >> ~/.bash_profile
Script:
#!/bin/bash
#This script sends email of particular user
history >/tmp/history
if [ -s /tmp/history ]
then
mailx -s "history 29042014" </tmp/history
fi
rm /tmp/history
#END OF THE SCRIPT
Can any one suggest better way to collect particular user history for everyday
I was happily churning along developing something on a Sun workstation,
and was getting a number of annoying permission denieds from trying to
write into a directory heirarchy that I didn't own. Getting tired of
that, I decided to set the permissions on that subtree to 777 while Iwas working, so I wouldn't have to worry about it.
Someone had recently
told me that rather than using plain "su", it was good to use "su -",
but the implications had not yet sunk in. (You can probably see where
this is going already, but I'll go to the bitter end.)
Anyway, I cd'd
to where I wanted to be, the top of my subtree, and did su -. Then I
did chmod -R 777. I then started to wonder why it was taking so damn
long when there were only about 45 files in 20 directories under where I
(thought) I was. Well, needless to say, su - simulates a real login,
and had put me into root's home directory, /, so I was proceeding to set
file permissions for the whole system to wide open.
I aborted it before
it finished, realizing that something was wrong, but this took quite a
while to straighten out.
This is a classic SNAFU known and described for more then 30 years. It is still repeated in
various forms thousand time by different system administrators. You can get permission of file
installed via RPM back rather quickly and without problems. For all other files you need a backup
or educated guess.
Ahh, the hazards of working with sysadmins who are not ready to be sysadmins in the first
place
I sent one of my support guys to do an Oracle update in Madrid.
As instructed he created a new user called esf and changed the files in /u/appl to owner esf, however in doing so he *must* have cocked up his find command, the command was:
find /u/appl -user appl -exec chown esf {} \;
He rang me up to tell me there was a problem, I logged in via x25 and about 75% of files on system belonged to owner esf.
VERY little worked on system.
What a mess, it took me a while and I came up with a brain wave to fix it but it really screwed up the system.
Moral: be *very* careful of find execs, get the syntax right!!!!
"... I was working on a line printer spooler, which lived in /etc. I wanted to remove it, and so issued the command "rm /etc/lpspl." There was only one problem. Out of habit, I typed "passwd" after "/etc/" and removed the password file. Oops. ..."
I was working on a line printer spooler, which lived in /etc. I wanted to remove it, and so
issued the command "rm /etc/lpspl." There was only
one problem. Out of habit, I typed "passwd" after "/etc/" and removed the password file.
Oops.
I called up the person who handled backups, and he restored the password file.
A couple of days later, I did it again! This time, after he restored it, he made a link,
/etc/safe_from_tim.
About a week later, I overwrote /etc/passwd, rather than removing it. After he restored it
again, he installed a daemon that kept a copy of
/etc/passwd, on another file system, and automatically restored it if it appeared to have been
damaged.
Fortunately, I finished my work on /etc/lpspl around this time, so we didn't have to see if
I could find a way to wipe out a couple of filesystems...
"... Then I am on call 24/7 and must be able to respond within 5 minutes. I end up working 60 hours a week but there's absolutely no overtime or banking of hours so I work for free for 20 hours. ..."
"... So I said that it wasn't enough and he said I will work 80hrs/week or I'm fired. Thursday the assistant manager was fired and So I quit. ..."
munky9001
Application Security Specialist 18 points 19 points 20 points 5 years ago * (10 children)
My worst one was how I got my nickname "Turkish Hacker"
Basically I was hired as network admin for an isp. I maintained mail servers and what have
you. Now the most critical server was this freebsd 5 sendmail, dns, apache server. We're
talking it hadnt done patches in 7 years. Then there was a centos 4 server which hadnt done
patching in 2 years. It has postfix, dns, apache.
Well I was basically planning to just nuke the freebsd server. Move everything off it and
move to new sexy hardware but first I needed to put out all the fires so I had time to fix it
all up. Well first big problem was the sheer slowness of the setup. We're talking an oc3 and
a ds10 load balanced via dns round robin both saturated. 99.99% of it was spam. The server
was basically an open relay to the world. However since we were already paying for some vms
at rackspace to run dns servers. I'd setup dns bind9 infrastructure and openvpn between the
servers. So basically I was going absolute best practices from the getgo on the new
infrastructure. I migrated all dns entries to the new dns servers.
I then start fixing the anti-spam situation. I basically get everything to a situation
where spam is being stopped successfully. However there was a back and forth and I'd enable
something and fix something and they'd attack a new way. I'd eventually compiled and got
everything up to date for the mail server and even the perl modules that spamassassin needed
etc etc. Well these spammers didnt like that... so this turkish group defaces the server.
hundreds of local businesses lose their website and there's no good backups.
Oh and it's defaced the day I quit without notice. Now I outright claim to be a hacker but
whitehat. My boss naturally accuses me of being the hacker but he had nothing to stand on and
the other people quitting the same day were basically backing me up. You might ask what I
quit over?
Well imagine a boss who micromanaged absolutely everything but only works about 2 hours a
week. Who then gets really mad and chews you out publicly by sending an email to the entire
company chewing you out. He also made rules like, 'To take a break you must leave the
building.' and then the rule right after that, 'no leaving the building'. Then staggered
assigned 1 hour unpaid lunches so nobody could eat together but once you are done eating you
must go back to work. AKA you work for free for 50 mins. Then I am on call 24/7 and must
be able to respond within 5 minutes. I end up working 60 hours a week but there's absolutely
no overtime or banking of hours so I work for free for 20 hours.
So basically the assistant manager of the place... the guy who basically kept the place
together went to the boss and said ALL the rules have to go away by friday or I quit. Well
Wednesday the boss actually comes into the office and everyone is wondering wtf he is even
doing there. 1 major thing is that on that friday I was up for a raise by agreement and he
comes to me asking if I could work 80hrs a week 'which is easy because he does it every week'
so I brought up the increase in pay because if I was going to continue with 60 hours a week I
would need a 50% raise and if he wants 80hrs/week it'll be a 100% raise. He offered me
10cents/hr($200/year) and he'll pay for my plane ticket to las vegas($200). So I said
that it wasn't enough and he said I will work 80hrs/week or I'm fired. Thursday the assistant
manager was fired and So I quit.
vocatus
NSA/DOD/USAR/USAP/AEXP [ S
] 2 points 3 points 4 points 5 years ago (1 child)
Wow...just wow. That sounds like an outstanding corporate culture! /sarcasm
Glad you got out while the gettin' was good.
munky9001 Application Security Specialist 3
points 4 points 5 points 5 years ago (0 children)
It's kinda funny. There was an event where the day a meraki web filter firewall was deployed;
the purpose of the thing was to block us from going to facebook and such. Well within the
same day a bunch of people were caught on facebook. Boss sent out an email to the entire
company naming each one saying they'd be fired if caught again. Except oh wait we're an isp
and modems and phone lines everywhere. Those people just started using those or their phones.
Now the day the senior staff quit... the only people left were the easily replaceable
people who had been threatened with the above. Not only are they dogfuckers, desperate for
any job, and apparently stupid because if they walked out the same time we did the boss would
have been fired but they stayed and they asked for 25cent raise each.
deleted a production LUN rather than the development LUN - destroyed several months
worth of assets for a book that was scheduled to go to print in a few weeks (found a good
backup that was "only" two weeks out of date)
forgot to "wr mem" on new ATM routers at a remote site 70 miles away
+1 for the "yum -y". Had the 'pleasure' of fixing a box one of my colleagues did "yum -y
remove openssl". Through utter magic managed to recover it without reinstalling :-)
This one hit pretty close to home having spent the last month at a small Service Provider
with some serious redundancy issues. We're working through them one by one, but there is one
outage in particular that was caused by the same situation... Only the scope was pretty
"large".
Performed change, was distracted by phone call. Had an SMS notifying me of problems with a
legacy border that I had just performed my changes on. See my PuTTY terminal and my blood
starts to run cold. "Reload requested by 0xd6".
...Fuck I'm thinking, but everything should be back soon, not much I can do now.
However, not only did our primary transit terminate on this legacy device, our old
non-HSRP L3 gateways and BGP nail down routes for one of our /20s and a /24... So, because of
my forgotten reload I withdrew the majority of our network from all peers and the internet at
large.
That was a fun day.... What's worse is I was following a change plan, I just missed
the "reload cancel". Stupid, stupid, stupid, stupid.
This is actually one of my standard interview questions since I believe any sys admin that's
worth a crap has made a mistake they'll never forget.
Here's mine, circa 2001. In response to a security audit, I had to track down which
version of the Symantec Antivirus was running and what definition was installed on every
machine in the company. I had been working through this for awhile and got a bit reckless.
There was a button in the console that read 'Virus Sweep'. Thinking it'd get the info from
each machine and give me the details, I pressed it.. I was wrong..
Very Wrong. Instead it
proceeded to initiate a virus scan on every machine including all of the servers.
Less than 5
minutes later, many of our older servers and most importantly our file servers froze. In the
process, I took down a trade floor for about 45 minutes while we got things back up. I
learned a valuable lesson about pressing buttons without first fully understanding what they
do.
A friend of the family was an IT guy and he gave me the usual high school unpaid intern job.
My first day, he told me that a computer needed the monitor replaced. He gave me this 13" CRT
and sent me on my way. I found the room (a wiring closet) with a tiny desk and a large
desktop tower on it.
TURNED OFF THE COMPUTER and went about replacing the monitor. I think it
took about 5 minutes for people start wondering why they can no longer use the file server
and can't save their files they have been working on all day.
It turns out that you don't have to turn off computers to replace the monitor.
From: [email protected] (Richard H. E. Eiger)
Organization: Olivetti (Schweiz) AG, Branch Office Berne
In article <[email protected]> [email protected] (Tim Smith) writes: > I was working on a line printer spooler, which lived in /etc. I wanted > to remove it, and so issued the command "rm /etc/lpspl." There was only > one problem. Out of habit, I typed "passwd" after "/etc/" and removed > the password file. Oops. > [deleted to save space[ > > --Tim Smith
Here's another story. Just imagine having the sendmail.cf file in /etc. Now, I was working on the sendmail stuff and had come up with lots of sendmail.cf.xxx which I wanted to get rid of so I typed "rm -f sendmail.cf. *". At first I was surprised about how much time it took to remove some 10 files or so. Hitting the interrupt key, when I finally saw what had happened was way to late, though.
Fortune has it that I'm a very lazy person. That's why I never bothered to just back up directories with data that changes often. Therefore I managed to restore /etc successfully before rebooting... :-) Happy end, after all. Of course I had lost the only well working version of my sendmail.cf...
From: [email protected] (Philip Enteles)
Organization: Haas School of Business, Berkeley
As a new system administrator of a Unix machine with limited space I thought I was doing
myself a favor by keeping things neat and clean. One
day as I was 'cleaning up' I removed a file called 'bzero'.
Strange things started to happen like vi didn't work then the compliants started coming
in. Mail didn't work. The compilers didn't work. About this time the REAL system
administrator poked his head in and asked what I had done.
Further examination showed that bzero is the zeroed memory without which the OS had no
operating space so anything using temporary memory was non-functional.
The repair? Well things are tough to do when most of the utilities don't work. Eventually
the REAL system administrator took the system to single user and rebuilt the system including
full restores from a tape system. The Moral is don't be to anal about things you don't
understand.
Take the time learn what those strange files are before removing them and screwing
yourself.
I was cleaning up old temp folders of junk on Windows 2003 server, and C:\temp was full of
shit. Most of it junk. Rooted deep in the junk, some asshole admin had apparently symlink'd
sysvol to a folder in there. Deleting wiped sysvol.
There where no usable backups, well,
there where but the ArcServe was screwed by lack of maintenance.
Spent days rebuilding
policies.
Fucking asshole ex-sysadmin taught me a good lesson about checking for symlink
bombs.
...and no I didn't tell this story to teach any of your little princesses to do the
same when you leave your company.
mcowger VCDX |
DevOps Guy 8 points 9 points 10 points 5 years ago (0 children)
Meh - happened a long time ago.
Had a big Solaris box (E6900) running Oracle 10 for the DW. Was going to add some new LUNs
to the box and also change some of the fiber pathing to go through a new set of faster
switches. Had the MDS changes prebuilt, confirmed in with another admin, through change
control, etc.
Did fabric A, which went through fine, and then did fabric B without pausing or checking
that the new paths came up on side A before I knocked over side B (in violation of my own
approved plan). For the briefest of instants, there were no paths to the devices and Oracle
was configured in full async write mode :(. Instant corruption of the tables that were
active. Tried to do use archivelogs to bring it back, but no dice (and this is before
Flashbacks, etc). So we were hosed.
Had to have my DBA babysit the RMAN restore for the entire weekend :(. 1GBe links to
backup infrastructure.
RCA resulted in MANY MANY changes to the design of that system, and me just barely keeping
my job.
I dropped a 500Gb RAID set. There were 2 identical servers in the rack right next to each
other. Both OpenFiler, both unlabeled. Didn't know about the other one and was told to 'wipe
the OpenFiler'. Got a call half an hour later from a team wondering where all their test VMs
had gone.
vocatus
NSA/DOD/USAR/USAP/AEXP [ S
] 1 point 2 points 3 points 5 years ago (0 children)
Sometimes things where I work feel like that. I'm the only admin at a school with 120 employees and 450 students. It's both
challenging, fun, and can be frustrating. The team I work with is very nice and supportive and on those rare occasions I need
help we have resources to get it (Juniper contract, a consulting firm helped me build out a redundant cluster and a SAN, etc).
I can see that if the environment wasn't so great I could feel similar to the way you did.
I'm glad you got out, and I'm glad you've been able to tell us that it can get better.
The truth is I actually like going to work; I think if you're in a position where you dread work you should probably work on
getting out of there. Good for you though sticking it out so long. You learned a lot and learned how to juggle things under pressure
and now you have a better gig partially because of it (I'm guessing).
WoW, just WOW. Glad you got out. Sounds like this ISP does not understand that the entire revenue stream is based on aging hardware.
If they are not willing to keep it updated, which means keeping the staff at full strength and old equipment replaced it will
all come to a halt. Your old boss sounds like she is a prime example of the Peter principle.
We do VoIP and I researched the Calix product line for ISP's after reading your post. Always wondered how they still supported
legacy TDM. Like the old Hank Williams song with a twist, "Us geeks will Survive". Cheers
TDM is still a big thing since the old switches used to cost 400k plus. Now that metaswitch is less than 200k, it's less of a
thing, but tdm for transport is rock solid and you can buy a ds3 from one co or headend to another for very cheap to transport
lines compared to the equivalent in data.
I talk to friends. Smart people I look up to and trust. The answer?
-the problem is you. Your expectations are too high
-no job is perfect. Be happy you have one and can support your family.
Oh man, this... I feel your pain. Only you know your situation, man (or woman). Trust your judgement, isolate emotional responses
and appraise objectively. Rarely, if ever, does anyone know better than you do.
It's true that no job is perfect, but there's a difference between "this one person in the office is kind of grumpy and annoys
me", "I have one coworker that's lazy and management doesn't see it", or "we have to support this really old computer, because
replacing the equipment that uses it is way too expensive" and "I get treated like shit every day, my working hours are too long,
and they won't get anyone to help me".
First I'd like to say. I have 4 kids and a wife. It was discussed during the interview that I work to live. And expect to work
40 hours unless it's an emergency.
For the first 6 months or so I'd work on weekdays after hours on simple improvements. This then stopped and shifted to working
on larger projects (via home labs) on the weekends (entire weekends lost) just to feel prepared to administer Linux kvm, or our
mpls Network (that I had zero prior experience on)
This started effecting my home life. I stopped working at home and discussed with my wife. Together we decided if the company
was willing to pay significantly more ($20k a year) I would invest the needed time after hours into the company.
I brought this to my boss and nothing happened. I got a 4% raise. This is when I capped the time I spent at home on NEEDED
things and only focused on what I wanted out of IT (network engineering) and started digging into GNS3 a bit more
Disappointed there was no mention of thenfirend who supported your decision, and kept telling you to get out!! Haha! Just playing
buddy! Glad you got out...and that place can fuck themselves!!
Really happy for you man! You deserve to be treated better!
I'm unemployed right now and the interviews have temporarily slowed down, but I'm determined not to take "just anything" to
get by, as doing so can adversely affect my future prospects.
I've been reading this whole thread and can relate, as I'm in a similar position. But wanted to comment, based on experience,
that you are correct about taking 'just anything' will adversely affect your future prospects. After moving to Central NY I was
unemployed for a while and took a helpdesk position (I was a Senior Systems Analyst/Microsoft Systems Administrator making good
money 18 years ago!) That stuck with me as they see it on my resume...and have only been offered entry level salaries every since.
That, and current management in a horrible company, ruined my career!! So be careful...
Congrats, but a 5 month gap on the resume won't fly for 99.9% of our perspective employers. There better be a damn good reason
other than complaining about burnout on the lined up interview. I resigned without another opportunity lined up and learned a
9 month lesson the hard way. Never jump ship without anything lined up. If not for you, then for your family.
SA's typically wear many hats at small or large organizations. Shoot, we even got a call from an employee asking IT if they can
jump start their car 😫.
It's a thankless job and resources are always lacking. The typical thinking is, IT does not make money for the company, they
spend it. This always put the dept. on the back burner until something breaks of course.
I've bee through 7 jobs in the last 12 years, I'm surprised people still hire me lol. I'm pretty comfortable where I am now though,
I also have a family.
These companies that think managed printer contracts are expensive are nuts. They are about even with toner replacement costs.
We buy our own xerox machines and have our local xerox rep manage them for us. Whoever had that hair brained idea needs slapped.
I had 12 years of what you had, OP. Same job, same shit you described on a daily basis... I can tell you right now it's not you
or your expectations too high... some companies are just sick from the top to the bottom and ISP's... well they are magnets both
for ppl who work too hard and for ppl who love to exploit the ones who work too hard in order to get their bonuses... After realising
that no matter how hard I worked, the ppl in charge would never change anything to make work better both for workers, company
and Customers... I quit my job, spent a year living off my savings... then started my own business and never looked back. You
truly deserve better!
Very much tiring! Lol. I'm at 40 hours a week unless we have an outage, or compromised server(or want to learn something on my
own time). I'm up front at my interviews that "i work to live" and family is the most important thing to me.
I do spend quite a bit of personal time playing. With Linux KVM, (Linux in general since I'm a windows guy) difference between
LVM block storage with different file systems, no lvm with image files. Backups (lvm snapshots) - front end management - which
ultimately evolved to using proxmox. Since I manage iptv I read books about the mpeg stream to understand the pieces of it better.
I was actually hired as a "network engineer" (even though I'm more of a systems guy) so I actually WANT more network experience.
Bgp, ospf, mpls, qos in mpls, multicast, pim sparse mode.
So I've made a GNS3 lab with our ALU hardware in attempts to build our network to get some hands on experience.
One day while trying to enable router guard (multicast related) - I broke the hell out of multicast by enabling it on the incoming
vlan for our largest service area. Felt like an idiot so I stopped touching production until I could learn it (and still not there!)
Good to hear the "I work to live". I'm also applying the same, family first, but it can sadly be hard for some to understand :-(
I feel like employers should have different expectations with employee that have family VS those that that don't. And even
then, I would completely understand a single person without family that enjoy life the more he can and doesn't want to work more
than what is on its contract since.
I really don't know how it works in employers mind.
The work load is high, but I've learned to deal with it. I ordered 7 servers about 9 months ago and they were just deployed last
month. Prioritizing is life!
What pushed me over the ledge was. Me spending my time trying to improve solutions to save time, and being told not gonna happen.
The light in the tunnel gets further and further away.
"... At that moment, everything from / and onward began deleting forcefully and Reginald described his subsequent actions as being akin to "flying flat like a dart in the air, arms stretched out, pointy finger fully extended" towards the power switch on the mini computer. ..."
I was going to type rm -rf /*.old* – which would have forcibly removed
all /dgux.old stuff, including any sub-directories I may have created with that
name," he said.
But – as regular readers will no doubt have guessed – he didn't.
"I fat fingered and typed rm -rf /* – and then I accidentally hit enter
instead of the "." key."
At that moment, everything from / and onward began deleting forcefully and
Reginald described his subsequent actions as being akin to "flying flat like a dart in the air,
arms stretched out, pointy finger fully extended" towards the power switch on the mini
computer.
"Everything got quiet."
Reginald tried to boot up the system, but it wouldn't. So instead he booted up off a tape
drive to run the mini Unix installer and mounted the boot "/" file system as if he
were upgrading – and then checked out the damage.
"Everything down to /dev was deleted, but I was so relieved I hadn't deleted
the customer's database and only system files."
Reginald did what all the best accident-prone people do – kept the cock-up to himself,
hoped no one would notice and started covering his tracks, by recreating all the system
files.
Over the next three hours, he "painstakingly recreated the entire device tree by hand", at
which point he could boot the machine properly – "and even the application worked
out".
Jubilant at having managed the task, Reginald tried to keep a lid on the heart that was no
doubt in his throat by this point and closed off his work, said goodbye to the sysadmin and
went home to calm down. Luckily no one was any the wiser.
"If the admins read this message, this would be the first time they hear about it," he
said.
"At the time they didn't come in to check what I was doing, and the system was inaccessible
to the users due to planned maintenance anyway."
Did you feel the urge to confess to errors no one else at your work knew about? Do you know
someone who kept something under their hat for years? Spill the beans to Who, Me? by emailing us here .
® Re: If rm -rf /* doesn't delete anything valuable
Eh? As I read it, Reginald kicked off the rm -rf /*, then hit the power switch before it
deleted too much. The tape rescue revealed that "everything down to /dev" had been deleted, ie.
everything in / beginnind a,b,c and some d. On a modern system that might include /boot and
/bin, but evidently was not a total disaster on Reg's server.
title="Inappropriate post? Report it to our moderators" type="submit" value="Report
abuse"> I remember discovering the hard way that when you delete an email account in
Thunderbird and it asks if you want to delete all the files associated with it it actually
means do you want to delete the entire directory tree below where the account is stored ....
so, as I discovered, saying "yes" when the reason you are deleting the account is because you'd
just created it in the wrong place in the the directory tree is not a good idea - instead of
just deleting the new account I nuked all the data associated with all our family email
accounts!
Probably designed by the same person who designed the crontab app then, with the command
line options -e to edit and -r to remove immediately without confirmation. Misstype at your
peril...
I found this out - to my peril - about 3 seconds before I realised that it was a good idea
for a server's crontab to include a daily executed crontab -l > /foo/bar/crontab-backup.txt
...
I went to delete the original files, but I only got as far as "del *.COB" befiore hitting
return.
I managed a similar thing but more deliberately; belatedly finding "DEL FOOBAR.???" included
files with no extensions when it didn't on a previous version (Win3.1?).
That wasn't the disaster it could have been but I've had my share of all-nighters making it
look like I hadn't accidentally scrubbed a system clean.
Probably designed by the same person who designed the crontab app then, with the command
line options -e to edit and -r to remove immediately without confirmation. Misstype at your
peril...
Using crontab -e is asking for trouble even without mistypes. I've see too many corrupted or
truncated crontabs after someone has edited them with crontab -e. crontab -l >
crontab.txt;vi crontab.txt;crontab crontab.txt is much better way.
You mean not everyone has crontab entry that backs up crontab at least daily?
"WAH! I copied the .COBOL back to .COB and started over again. As I knew what I wanted to do
this time, it only took about a day to re-do what I had deleted."
When this has happened to me, I end up with better code than I had before. Re-doing the work
gives you a better perspective. Even if functionally no different it will be cleaner, well
commented, and laid out more consistently. I sometimes now do it deliberately (although just
saving the first new version, not deleting it) to clean up the code.
I totally agree, the resultant code was better than what I had previously written, because
some of the mistakes and assumptions I'd made the first time round and worked around didn't
make it into the new code.
...depending on your shell and its configuration a zero size file in each directory you care
about called '-i' will force the rampaging recursive rm, mv, or whatever back into interactive
mode. By and large it won't defend you against mistakes in a script, but its definitely saved
me from myself when running an interactive shell.
It's proven useful enough to earn its own cronjob that runs once a week and features a 'find
-type d' and touch '-i' combo on systems I like.
Glad the OP's mad dive for the power switch saved him, I wasn't so speedy once. Total
bustification. Hence this one simple trick...
Now if I could ever fdisk the right f$cking disk, I'd be set!
Maybe. But you still have to work out what got deleted.
On the first Unix system I used, an admin configured the rm command with a system alias so
that rm required a confirmation. Annoying after a while but handy when learning.
When you are reconfiguring a system, delete/rm is not the only option. Move/mv protects you
from your errors. If the OS has no move/mv, then copy, verify before delete.
Not entirely. I had a similar experience with mv. I was left with a running shell so could
cd through the remains of the file system end list files with echo * but not repair it..
Although we had the CDs (SCO) to reboot the system required a specific driver which wasn't
included on the CDs and hadn't been provided by the vendor. It took most of a day before they
emailed the correct driver to put on a floppy before I could reboot. After that it only took a
few minutes to put everything back in place.
Yes there are a number of things you can do. Just like Windows a quick ctrl-C will abort a
rm operation taking place in an interactive shell. Destroying the window in which the
interactive shell running rm is running will work, too (alt-f4 in most window managers or 'x'
out of the window)
If you know the process id of the rm process you can 'kill $pid' or do a 'killall -KILL
rm'
Couple of problems:
(1) law of maximum perversity says that the most important bits will be destroyed first in
any accident sequence
(2) by the time you realize the mistake there is no time to kill rm before law 1 is
satisfied
The OP's mad dive for the power button is probably the very best move... provided you are
right there at the console. And provided the big red switch is actually connected to
anything
After several years working in a DOS environment I got a job as project Manager / Sys admin
on a Unix based customer site for a six month stint. On my second day I wanted to use a test
system to learn the software more, so decided to copy the live order files to the test
system.
Unfortunately I forgot the trailing full stop as it was not needed in DOS - so the live
order index file over wrote the live data file. And the company only took orders for next day
delivery so it wiped all current orders.
Luckily it printed a sales acknowledgement every time an order was placed so I escaped death
and learned never miss the second parameter with cp command.
title="Inappropriate post? Report it to our moderators" type="submit" value="Report abuse">
i'd written a script to deploy the latest changes to the live environment. worked great. except
one day i'd entered a typo and it was now deploying the same files to the remote directory, over
and again.
it did that for 2 whole years with around 7 code releases. not a single person realised the
production system was running the same code after each release with no change in functionality.
all the customer cared about was 'was the site up?'
not a single person realised. not the developers. not the support staff. not me. not the
testers. not the customer. just made you think... wtf had we been doing for 2 years??? Yet Another Anonymous coward
div Look on the bright side, any bugs your team had introduced in those 2 years had been
blocked by your intrinsically secure script
div not a single person realised. not the developers. not the support staff. not me. not the
testers. not the customer. just made you think... wtf had we been doing for 2 years???
That is Classic! not surprised about the AC!
Bet some of the beancounters were less than impressed , probly on customer side :)
title="Inappropriate post? Report it to our moderators" type="submit" value="Report abuse">
Re: ...then there's backup stories...
Many years ago (pre internet times) a client phones at 5:30 Friday afternoon. It was the IT
guy wanting to run through the steps involved in recovering from a backup. Their US headquarters
had a hard disk fail on their accounting system. He was talking the Financial Controller through
a recovery and while he knew his stuff he just wanted to double check everything.
8pm the same night the phone rang again - how soon could I fly to the states? Only one of the
backup tapes was good. The financial controller had put the sole remaining good backup tape in
the drive, then popped out to get a bite to eat at 7pm because it was going to be a late night.
At 7:30pm the scheduled backup process copied the corrupted database over the only remaining
backup.
Saturday was spent on the phone trying to talk them through everything I could think of.
Sunday afternoon I was sitting in a private jet winging it's way to their US HQ. Three days of
very hard work later we'd managed to recreate the accounting database from pieces of corrupted
databases and log files. Another private jet ride home - this time the pilot was kind enough to
tell me there was a cooler full of beer behind my seat. Olivier2553
div Re: Welcome to the club!
"Lesson learned: NEVER decide to "clean up some old files" at 4:30 on a Friday afternoon.
You WILL look for shortcuts and it WILL bite you on the ass."
Do not do anything of some significance on Friday. At all. Any major change, big operation,
etc. must be made by Thursday at the latest, so in case of cock-up, you have the Friday (plus
days week-end) to repair it.
div I once wiped a large portion of a hard drive after using find with exec rm -rf {} - due to
not taking into account the fact that some directories on the system had spaces in them.
div A couple months ago on my home computer (which has several Linux distros installed and
which all share a common /home because I apparently like to make life difficult for myself -
and yes, that's as close to a logical reason I have for having multiple distros installed on
one machine) I was going to get rid of one of the extraneous Linux installs and use the space
to expand the root partition for one of the other distros. I realized I'd typed /dev/sdc2
instead of /dev/sdc3 at the same time that I verified that, yes, I wanted to delete the
partition. And sdc2 is where the above mentioned shared /home lives. Doh.
Fortunately I have a good file server and a cron job running rsync every night, so I didn't
actually lose any data, but I think my heart stopped for a few seconds before I realized
that.
div Came in to work one Monday to find that the Unix system was borked... on investigation it
appeared that a large number of files & folders had gone missing, probably by someone doing
an incorrect rm.
Our systems were shared with our US office who supported the UK outside of our core hours
(we were in from 7am to ensure trading was ready for 8am, they were available to field staff
until 10pm UK time) so we suspected it was one of our US counterparts who had done it, but had
no way to prove it.
Rather than try and fix anything, they'd gone through and deleted all logs and history
entries so we could never find the evidence we needed!
Restoring the system from a recent backup brought everything back online again, as one would
expect!
div Sure they did, but the universe invented better idiots
Of course. However, the incompletely-experienced often choose to force bypass that
configuration. For example, a lot of systems aliased rm to "rm -i" by default, which would
force interactive confirmations. People would then say "UGH, I hate having to do this" and add
their own customisations to their shells/profiles etc:
unalias rm
alias rm=rm -f
Lo and behold, now no silly confirmations, regardless of stupidity/typos/etc.
Logreduce machine learning model is trained
using previous successful job runs to extract anomalies from failed runs' logs.
This principle can also be applied to other use cases, for example, extracting anomalies
from Journald or other
systemwide regular log files.
Using machine learning to reduce noise
A typical log file contains many nominal events ("baselines") along with a few exceptions
that are relevant to the developer. Baselines may contain random elements such as timestamps or
unique identifiers that are difficult to detect and remove. To remove the baseline events, we
can use a k -nearest neighbors
pattern recognition algorithm ( k -NN).
Log events must be converted to numeric values for k -NN regression. Using the
generic feature extraction tool
HashingVectorizer enables the process to be applied to any type of log. It hashes each word
and encodes each event in a sparse matrix. To further reduce the search space, tokenization
removes known random words, such as dates or IP addresses.
The Logreduce Python software transparently implements this process. Logreduce's initial
goal was to assist with Zuul CI job failure
analyses using the build database, and it is now integrated into the Software Factory development forge's job logs
process.
At its simplest, Logreduce compares files or directories and removes lines that are similar.
Logreduce builds a model for each source file and outputs any of the target's lines whose
distances are above a defined threshold by using the following syntax: distance |
filename:line-number: line-content .
$ logreduce diff / var / log / audit / audit.log.1 /
var / log / audit / audit.log
INFO logreduce.Classifier - Training took 21.982s at 0.364MB / s ( 1.314kl / s ) ( 8.000 MB -
28.884 kilo-lines )
0.244 | audit.log: 19963 : type =USER_AUTH acct = "root" exe = "/usr/bin/su" hostname
=managesf.sftests.com
INFO logreduce.Classifier - Testing took 18.297s at 0.306MB / s ( 1.094kl / s ) ( 5.607 MB -
20.015 kilo-lines )
99.99 % reduction ( from 20015 lines to 1
A more advanced Logreduce use can train a model offline to be reused. Many variants of the
baselines can be used to fit the k -NN search tree.
$ logreduce dir-train audit.clf
/ var / log / audit / audit.log. *
INFO logreduce.Classifier - Training took 80.883s at 0.396MB / s ( 1.397kl / s ) ( 32.001 MB -
112.977 kilo-lines )
DEBUG logreduce.Classifier - audit.clf: written
$ logreduce dir-run audit.clf / var / log / audit / audit.log
Logreduce also implements interfaces to discover baselines for Journald time ranges
(days/weeks/months) and Zuul CI job build histories. It can also generate HTML reports that
group anomalies found in multiple files in a simple interface.
The key to using k -NN regression for anomaly detection is to have a database of
known good baselines, which the model uses to detect lines that deviate too far. This method
relies on the baselines containing all nominal events, as anything that isn't found in the
baseline will be reported as anomalous.
CI jobs are great targets for k -NN regression because the job outputs are often
deterministic and previous runs can be automatically used as baselines. Logreduce features Zuul
job roles that can be used as part of a failed job post task in order to issue a concise report
(instead of the full job's logs). This principle can be applied to other cases, as long as
baselines can be constructed in advance. For example, a nominal system's SoS report can be used to find issues in a
defective deployment.
The next version of Logreduce introduces a server mode to offload log processing to an
external service where reports can be further analyzed. It also supports importing existing
reports and requests to analyze a Zuul build. The services run analyses asynchronously and
feature a web interface to adjust scores and remove false positives.
Reviewed reports can be archived as a standalone dataset with the target log files and the
scores for anomalous lines recorded in a flat JSON file.
Project roadmap
Logreduce is already being used effectively, but there are many opportunities for improving
the tool. Plans for the future include:
Curating many annotated anomalies found in log files and producing a public domain
dataset to enable further research. Anomaly detection in log files is a challenging topic,
and having a common dataset to test new models would help identify new solutions.
Reusing the annotated anomalies with the model to refine the distances reported. For
example, when users mark lines as false positives by setting their distance to zero, the
model could reduce the score of those lines in future reports.
Fingerprinting archived anomalies to detect when a new report contains an already known
anomaly. Thus, instead of reporting the anomaly's content, the service could notify the user
that the job hit a known issue. When the issue is fixed, the service could automatically
restart the job.
Supporting more baseline discovery interfaces for targets such as SOS reports, Jenkins
builds, Travis CI, and more.
If you are interested in getting involved in this project, please contact us on the
#log-classify Freenode IRC channel. Feedback is always appreciated!
whohas is a command line tool that allows querying several package lists at once - currently
supported are Arch, Debian, Fedora, Gentoo, Mandriva, openSUSE, Slackware (and
linuxpackages.net), Source Mage, Ubuntu, FreeBSD, NetBSD, OpenBSD, Fink, MacPorts and Cygwin.
whohas is written in Perl and was designed to help package maintainers find ebuilds, pkgbuilds
and similar package definitions from other distributions to learn from. However, it can also be
used by normal users who want to know:
Which distribution provides packages on which the user depends.
What version of a given package is in use in each distribution, or in each release of a
distribution (implemented only for Debian).
News
The 0.29 branch is now being maintained on github .
Tutorial
It is suggested you use Unix command line tools to enhance your search results. whohas is
optimised for fast execution. This is done by threading, and the order of results cannot be
guaranteed. To nonetheless get a standardised output, alphabetically sorted by distribution,
use the sort tool:
whohas gimp | sort
You can use grep to improve your search results. Depending on whether you want only packages
whose names begin with your search term, end with your search term, or exactly match, you would
use a space before, after or on both sides of your search term, respectively:
whohas gimp | sort | grep " gimp"
whohas vim | sort | grep "vim "
whohas gimp | sort | grep " gimp "
The spaces will ensure that only results for the package gimp are displayed, not for
gimp-print etc.
If you want results for a particular distribution only, do
whohas arch | grep "^Arch"
Output for each module will still be ordered, so you don't need to sort results in this
case, although you may wish to do so for some distributions. Distribution names are abbreviated
as "Arch", "Debian", "Fedora", "Gentoo", "Mandriva", "openSUSE", "Slackware", "Source Mage",
"FreeBSD", "NetBSD", "OpenBSD", "Fink", "MacPorts" and "Cygwin".
Output in version 0.1 looked like this . The first
column is the name of the distribution, the second the name of the package, the third the
version number, then the date, repository name and a url linking to more information about the
package. Future versions will have package size information, too. Column lengths are fixed, so
you can use cut:
whohas vim | grep " vim " | cut -b 38-47
The first bytes of the data fields at the time of writing are 0, 11, 49, 67, 71, 81 and
106.
Here is
an example of whohas 0.1 in a terminal session, showing how it works with grep and
cut.
Features and limitations
Debian refers to the binary distribution. Slackware queries Current only - Slackware
package search is currently offline and undergoing redesign, therefore I disabled the module
until I know more. Binary sizes for Fedora are package sizes - space needed on disk will be
greater by about factor 2. Binary sizes for Debian are unpacked sizes. All details (including
availability, version numbers and binary sizes) are for the x86 architecture.
Debian version numbers in rare cases may not be for x86 (will be fixed). Gentoo version
availability may not be for x86 (will be fixed). I recommend you consult the URLs provided in
the output, which give detailed and accurate information about each package.
You may want to use a terminal that recognises hyperlinks and allows easy access through the
browser, such as gnome-terminal.
For Fedora, only release 12 is enabled by default, and only the most up to date package will
be listed if different versions are available.
For openSUSE, repository designations are abbreviated for screen space reasons: the tilde
symbol, ~, replaces "home", and any trailing string that simply points to the current release
is truncated. Nonetheless, some of openSUSE's repository paths remain too long to be shown in
full.
I am a happy user of the cd - command to go to the previous directory. At the same time I like pushd .
and popd .
However, when I want to remember the current working directory by means of pushd . , I lose the possibility to
go to the previous directory by cd - . (As pushd . also performs cd . ).
I don't understand your question? The point is that pushd breaks the behavior of cd - that I want (or expect). I
know perfectly well in which directory I am, but I want to increase the speed with which I change directories :) –
Bernhard
Feb 21 '12 at 12:46
@bernhard Oh, I misunderstood what you were asking. You were wanting to know how to store the current working directory.
I was interpreting it as you wanted to remember (as in you forgot) your current working directory. –
Patrick
Feb 22 '12 at 1:58
This works perfectly for me. Is there no such feature in the built-in pushd? As I would always prefer a standard solution. Thanks
for this function however, maybe I will leave out the argument and it's checking at some point. –
Bernhard
Feb 21 '12 at 12:41
There is no such feature in the builtin. Your own function is the best solution because pushd and popd both call cd
modifying $OLDPWD, hence the source of your problem. I would name the function saved and use it in the context you like too, that
of saving cwd. – bsd
Feb 21 '12 at 12:53
pushd () {
if [ "$1" = . ]; then
cd -
builtin pushd -
else
builtin pushd "$1"
fi
}
By naming the function pushd , you can use pushd as normal, you don't need to remember to use the
function name.
,
Kevin's answer is excellent. I've written up some details about what's going on, in case people are looking for a better understanding
of why their script is necessary to solve the problem.
The reason that pushd . breaks the behavior of cd - will be apparent if we dig into the workings
of cd and the directory stack. Let's push a few directories onto the stack:
Notice that we jumped back to our previous directory, even though the previous directory wasn't actually listed in the directory
stack. This is because cd uses the environment variable $OLDPWD to keep track of the previous directory:
$ echo $OLDPWD
/home/username/dir2
If we do pushd . we will push an extra copy of the current directory onto the stack:
In order to both empty the stack and restore the working directory from the stack
bottom, either:
retrieve that directory from dirs , change to that directory, and than
clear the stack:
cd "$(dirs -l -0)" && dirs -c
The -l option here will list full paths, to make sure we don't fail if we
try to cd into ~ , and the -0 retrieves the first
entry from the stack bottom.
@jw013 suggested making this command more robust, by avoiding path expansions:
pushd -0 && dirs -c
or, popd until you encounter an error (which is the status of a
popd call when the directory stack is empty):
The first method is exactly what I wanted. The second wouldn't work in my case since I had
called pushd a few times, then removed one of the directories in the middle,
then popd was failing when I tried to unroll. I needed to jump over all the
buggered up stuff in the middle to get back to where I started. – Chuck Wilbur
Nov 14 '17 at 18:21
cd "$(...)" works in 90%, probably even 99% of use cases, but with pushd
-0 you can confidently say 100%. There are so many potential gotchas and edge cases
associated with expanding file/directory paths in the shell that the most robust thing to do
is just avoid it altogether, which pushd -0 does very concisely.
There is no
chance of getting caught by a bug with a weird edge case if you never take the risk. If you
want further reading on the possible headaches involved with Unix file / path names, a good
starting point is mywiki.wooledge.org/ParsingLs – jw013
Dec 12 '17 at 15:31
awk , cut , and join , sort views its input as a stream of records made up of fields of variable width,
with records delimited by newline characters and fields delimited by whitespace or a user-specifiable single character.
sort
Usage
sort [ options ] [ file(s) ]
Purpose
Sort input lines into an order determined by the key field and datatype options, and the locale.
Major options
-b
Ignore leading whitespace.
-c
Check that input is correctly sorted. There is no output, but the exit code is nonzero if the input is not sorted.
-d
Dictionary order: only alphanumerics and whitespace are significant.
-g
General numeric value: compare fields as floating-point numbers. This works like -n , except that numbers may have
decimal points and exponents (e.g., 6.022e+23 ). GNU version only.
-f
Fold letters implicitly to a common lettercase so that sorting is case-insensitive.
-i
Ignore nonprintable characters.
-k
Define the sort key field.
-m
Merge already-sorted input files into a sorted output stream.
-n
Compare fields as integer numbers.
-ooutfile
Write output to the specified file instead of to standard output. If the file is one of the input files, sort copies
it to a temporary file before sorting and writing the output.
-r
Reverse the sort order to descending, rather than the default ascending.
-tchar
Use the single character char as the default field separator, instead of the default of whitespace.
-u
Unique records only: discard all but the first record in a group with equal keys. Only the key fields matter: other parts
of the discarded records may differ.
Behavior
sort reads the specified files, or standard input if no files are given, and writes the sorted data on standard output.
Sorting by Lines
In the simplest case, when no command-line options are supplied, complete records are sorted according
to the order defined by the current locale. In the traditional C locale, that means ASCII order, but you can set an alternate locale
as we described in
Section 2.8 . A tiny bilingual dictionary in the ISO 8859-1 encoding translates four French words differing only in accents:
$ cat french-english Show the tiny dictionary
côte coast
cote dimension
coté dimensioned
côté side
To understand the sorting, use the octal dump tool, od , to display the French words in ASCII and octal:
$ cut -f1 french-english | od -a -b Display French words in octal bytes
0000000 c t t e nl c o t e nl c o t i nl c
143 364 164 145 012 143 157 164 145 012 143 157 164 351 012 143
0000020 t t i nl
364 164 351 012
0000024
Evidently, with the ASCII option -a , od strips the high-order bit of characters, so the accented letters have been
mangled, but we can see their octal values: é is 351 8 and ô is 364 8 . On GNU/Linux systems,
you can confirm the character values like this:
$ man iso_8859_1 Check the ISO 8859-1 manual page
...
Oct Dec Hex Char Description
--------------------------------------------------------------------
...
351 233 E9 é LATIN SMALL LETTER E WITH ACUTE
...
364 244 F4 ô LATIN SMALL LETTER O WITH CIRCUMFLEX
...
First, sort the file in strict byte order:
$ LC_ALL=C sort french-english Sort in traditional ASCII order
cote dimension
coté dimensioned
côte coast
côté side
Notice that e (145 8 ) sorted before é (351 8 ), and o (157 8 ) sorted
before ô (364 8 ), as expected from their numerical values. Now sort the text in Canadian-French order:
$ LC_ALL=fr_CA.iso88591 sort french-english Sort in Canadian-French locale
côte coast
cote dimension
coté dimensioned
côté side
The output order clearly differs from the traditional ordering by raw byte values. Sorting conventions are strongly dependent on
language, country, and culture, and the rules are sometimes astonishingly complex. Even English, which mostly pretends that accents
are irrelevant, can have complex sorting rules: examine your local telephone directory to see how lettercase, digits, spaces, punctuation,
and name variants like McKay and Mackay are handled.
Sorting by Fields
For more control over sorting, the -k
option allows you to specify the field to sort on, and the -t option lets you choose the field delimiter. If -t is
not specified, then fields are separated by whitespace and leading and trailing whitespace in the record is ignored. With the
-t option, the specified character delimits fields, and whitespace is significant. Thus, a three-character record consisting
of space-X-space has one field without -t , but three with -t ' ' (the first and third fields are empty). The -k
option is followed by a field number, or number pair, optionally separated by whitespace after -k . Each number may be suffixed
by a dotted character position, and/or one of the modifier letters shown in Table.
Letter
Description
b
Ignore leading whitespace.
d
Dictionary order.
f
Fold letters implicitly to a common lettercase.
g
Compare as general floating-point numbers. GNU version only.
i
Ignore nonprintable characters.
n
Compare as (integer) numbers.
r
Reverse the sort order.
Fields and characters within fields are numbered starting from one.
If only one field number is specified, the sort key begins at the start of that field, and continues to the end of the record
( not the end of the field).
If a comma-separated pair of field numbers is given, the sort key starts at the beginning of the first field, and finishes at
the end of the second field.
With a dotted character position, comparison begins (first of a number pair) or ends (second of a number pair) at that character
position: -k2.4,5.6 compares starting with the fourth character of the second field and ending with the sixth character of
the fifth field.
If the start of a sort key falls beyond the end of the record, then the sort key is empty, and empty sort keys sort before all
nonempty ones.
When multiple -k options are given, sorting is by the first key field, and then, when records match in that key, by the
second key field, and so on.
!
While the -k option is available on all of the systems that we tested, sort also recognizes an older
field specification, now considered obsolete, where fields and character positions are numbered from zero. The key start
for character m in field n is defined by +n.m , and the key end by -n.m
. For example, sort +2.1 -3.2 is equivalent to sort -k3.2,4.3 . If the character position is omitted,
it defaults to zero. Thus, +4.0nr and +4nr mean the same thing: a numeric key, beginning at the start
of the fifth field, to be sorted in reverse (descending) order.
Let's try out these options on a sample password file, sorting it by the username, which is found in the first colon-separated
field:
For more control, add a modifier letter in the field selector to define the type of data in the field and the sorting order. Here's
how to sort the password file by descending UID:
A more precise field specification would have been -k3nr,3 (that is, from the start of field three, numerically, in reverse
order, to the end of field three), or -k3,3nr , or even -k3,3-n-r , but sort stops collecting
a number at the first nondigit, so -k3nr works correctly.
In our password file example, three users have a common GID in field 4, so we could sort first by GID, and then by UID, with:
The useful -u option asks sort to output only unique records, where unique means that their sort-key fields match,
even if there are differences elsewhere. Reusing the password file one last time, we find:
Notice that the output is shorter: three users are in group 1000, but only one of them was output...
Sorting Text Blocks
Sometimes you need to sort data composed of multiline records. A good example is an address list, which is conveniently stored
with one or more blank lines between addresses. For data like this, there is no constant sort-key position that could be used in
a -k option, so you have to help out by supplying some extra markup. Here's a simple example:
$ cat my-friends Show address file
# SORTKEY: Schloß, Hans Jürgen
Hans Jürgen Schloß
Unter den Linden 78
D-10117 Berlin
Germany
# SORTKEY: Jones, Adrian
Adrian Jones
371 Montgomery Park Road
Henley-on-Thames RG9 4AJ
UK
# SORTKEY: Brown, Kim
Kim Brown
1841 S Main Street
Westchester, NY 10502
USA
The sorting trick is to use the ability of awk to handle more-general record separators to recognize paragraph breaks,
temporarily replace the line breaks inside each address with an otherwise unused character, such as an unprintable control character,
and replace the paragraph break with a newline. sort then sees lines that look like this:
# SORTKEY: Schloß, Hans Jürgen^ZHans Jürgen Schloß^ZUnter den Linden 78^Z...
# SORTKEY: Jones, Adrian^ZAdrian Jones^Z371 Montgomery Park Road^Z...
# SORTKEY: Brown, Kim^ZKim Brown^Z1841 S Main Street^Z...
Here, ^Z is a Ctrl-Z character. A filter step downstream from sort restores the line breaks and paragraph breaks,
and the sort key lines are easily removed, if desired, with grep . The entire pipeline looks like this:
cat my-friends | Pipe in address file
awk -v RS="" { gsub("\n", "^Z"); print }' | Convert addresses to single lines
sort -f | Sort address bundles, ignoring case
awk -v ORS="\n\n" '{ gsub("^Z", "\n"); print }' | Restore line structure
grep -v '# SORTKEY' Remove markup lines
The gsub( ) function performs "global substitutions." It is similar to the s/x/y/g construct in sed .
The RS variable is the input Record Separator. Normally, input records are separated by newlines, making each line a separate
record. Using RS=" " is a special case, whereby records are separated by blank lines; i.e., each block or "paragraph" of
text forms a separate record. This is exactly the form of our input data. Finally, ORS is the Output Record Separator; each
output record printed with print is terminated with its value. Its default is also normally a single newline; setting it
here to " \n\n " preserves the input format with blank lines separating records. (More detail on these constructs may be
found in
Chapter 9 .)
The beauty of this approach is that we can easily include additional keys in each address that can be used for both sorting and
selection: for example, an extra markup line of the form:
# COUNTRY: UK
in each address, and an additional pipeline stage of grep '# COUNTRY: UK ' just before the sort , would let us
extract only the UK addresses for further processing.
You could, of course, go overboard and use XML markup to identify the parts of the address in excruciating detail:
With fancier data-processing filters, you could then please your post office by presorting your mail by country and postal code,
but our minimal markup and simple pipeline are often good enough to get the job done.
4.1.4. Sort Efficiency
The obvious way to sort data requires comparing all pairs of items to see which comes first, and leads to algorithms known as
bubble sort and insertion sort . These quick-and-dirty algorithms are fine for small amounts of data, but they certainly
are not quick for large amounts, because their work to sort n records grows like n 2 . This is quite different from almost
all of the filters that we discuss in this book: they read a record, process it, and output it, so their execution time is directly
proportional to the number of records, n .
Fortunately, the sorting problem has had lots of attention in the computing community, and good sorting algorithms are known whose
average complexity goes like n 3/2 ( shellsort ), n log n ( heapsort , mergesort , and quicksort
), and for restricted kinds of data, n ( distribution sort ). The Unix sort command implementation has received extensive
study and optimization: you can be confident that it will do the job efficiently, and almost certainly better than you can do yourself
without learning a lot more about sorting algorithms.
4.1.5. Sort Stability
An important question about sorting algorithms is whether or not they are stable : that is, is the input order of equal
records preserved in the output? A stable sort may be desirable when records are sorted by multiple keys, or more than once in a
pipeline. POSIX does not require that sort be stable, and most implementations are not, as this example shows:
$ sort -t_ -k1,1 -k2,2 << EOF Sort four lines by first two fields
The sort fields are identical in each record, but the output differs from the input, so sort is not stable. Fortunately,
the GNU implementation in the coreutils package [1] remedies that deficiency via
the -- stable option: its output for this example correctly matches the input.
I don't do a lot of development work, but while learning Python I've found pycharm to be a
robust and helpful IDE. Other than that, I'm old school like Proksch and use vi.
MICHAEL BAKER
SYSTEM ADMINISTRATOR, IT MAIL SERVICES
Yes, I'm the same as @Proksch. For my development environment at Red Hat, vim is easiest to
use as I'm using Linux to pop in and out of files. Otherwise, I've had a lot of great
experiences with Visual Studio.
When Tmux is started it reads its configuration parameters from
~/.tmux.conf
if the file is present.
Here is a sample
~/.tmux.conf
configuration with customized status line and few additional options:
~/.tmux.conf
# Improve colors
set -g default-terminal 'screen-256color'
# Set scrollback buffer to 10000
set -g history-limit 10000
# Customize the status line
set -g status-fg green
set -g status-bg black
In this tutorial, you learned how to use Tmux. Now you can start creating multiple Tmux windows in a single session, split
windows by creating new panes, navigate between windows, detach and resume sessions and personalize your Tmux instance using the
.tmux.conf
file.
"... It's a bit of chicken-and-egg problem, though. Russia, throughout 20th century, had problem with developing small, effective hardware, so their programmers learned how to code to take maximum advantage of what they had, with their technological deficiency in one field giving rise to superiority in another. ..."
"... Russian tech ppl should always be viewed with certain amount of awe and respect...although they are hardly good on everything. ..."
"... Soviet university training in "cybernetics" as it was called in the late 1980s involved two years of programming on blackboards before the students even touched an actual computer. ..."
"... I recall flowcharting entirely on paper before committing a program to punched cards. ..."
Much has been made, including in this post, of the excellent organization of Russian
forces and Russian military technology.
I have been re-investigating an open-source relational database system known as PosgreSQL
(variously), and I remember finding perhaps a decade ago a very useful whole text search
feature of this system which I vaguely remember was written by a Russian and, for that
reason, mildly distrusted by me.
Come to find out that the principle developers and maintainers of PostgreSQL are Russian.
OMG. Double OMG, because the reason I chose it in the first place is that it is the best
non-proprietary RDBS out there and today is supported on Google Cloud, AWS, etc.
The US has met an equal or conceivably a superior, case closed. Trump's thoroughly odd
behavior with Putin is just one but a very obvious one example of this.
Of course, Trump's
nationalistic blather is creating a "base" of people who believe in the godliness of the US.
They are in for a very serious disappointment.
After the iron curtain fell, there was a big demand for Russian-trained programmers
because they could program in a very efficient and "light" manner that didn't demand too much
of the hardware, if I remember correctly.
It's a bit of chicken-and-egg problem, though.
Russia, throughout 20th century, had problem with developing small, effective hardware, so
their programmers learned how to code to take maximum advantage of what they had, with their
technological deficiency in one field giving rise to superiority in another.
Russia has plenty of very skilled, very well-trained folks and their science and math
education is, in a way, more fundamentally and soundly grounded on the foundational stuff
than US (based on my personal interactions anyways).
Russian tech ppl should always be viewed
with certain amount of awe and respect...although they are hardly good on everything.
Well said. Soviet university training in "cybernetics" as it was called in the late 1980s
involved two years of programming on blackboards before the students even touched an actual
computer.
It gave the students an understanding of how computers works down to the bit
flipping level. Imagine trying to fuzz code in your head.
I recall flowcharting entirely on paper before committing a program to punched cards. I
used to do hex and octal math in my head as part of debugging core dumps. Ah, the glory days.
Honeywell once made a military computer that was 10 bit. That stumped me for a while, as
everything was 8 or 16 bit back then.
That used to be fairly common in the civilian sector (in US) too: computing time was
expensive, so you had to make sure that the stuff worked flawlessly before it was committed.
No opportunity to seeing things go wrong and do things over like much of how things happen
nowadays. Russians, with their hardware limitations/shortages, I imagine must have been much
more thorough than US programmers were back in the old days, and you could only get there by
being very thoroughly grounded n the basics.
If we take consulting, services, and support off the table as an option for high-growth
revenue generation (the only thing VCs care about), we are left with open core [with some
subset of features behind a paywall] , software as a service, or some blurring of the
two... Everyone wants infrastructure software to be free and continuously developed by highly
skilled professional developers (who in turn expect to make substantial salaries), but no one
wants to pay for it. The economics of
this situation are unsustainable and broken ...
[W]e now come to what I have recently called "loose" open core and SaaS. In the future, I
believe the most successful OSS projects will be primarily monetized via this method. What is
it? The idea behind "loose" open core and SaaS is that a popular OSS project can be developed
as a completely community driven project (this avoids the conflicts of interest inherent in
"pure" open core), while value added proprietary services and software can be sold in an
ecosystem that forms around the OSS...
Unfortunately, there is an inflection point at which in some sense an OSS project becomes
too popular for its own good, and outgrows its ability to generate enough revenue via either
"pure" open core or services and support... [B]uilding a vibrant community and then enabling an
ecosystem of "loose" open core and SaaS businesses on top appears to me to be the only viable
path forward for modern VC-backed OSS startups.
Klein also suggests OSS foundations start providing fellowships to key maintainers, who
currently "operate under an almost feudal system of patronage, hopping from company to company,
trying to earn a living, keep the community vibrant, and all the while stay impartial..."
"[A]s an industry, we are going to have to come to terms with the economic reality: nothing
is free, including OSS. If we want vibrant OSS projects maintained by engineers that are well
compensated and not conflicted, we are going to have to decide that this is something worth
paying for. In my opinion, fellowships provided by OSS foundations and funded by companies
generating revenue off of the OSS is a great way to start down this path."
Objective Our goal is to build rpm packages with custom content, unifying scripts
across any number of systems, including versioning, deployment and undeployment. Operating
System and Software Versions
Operating system: Red Hat Enterprise Linux 7.5
Software: rpm-build 4.11.3+
Requirements Privileged access to the system for install, normal access for build.
Difficulty MEDIUM Conventions
# - requires given linux commands to be executed with root
privileges either directly as a root user or by use of sudo command
$ - given linux
commands to be executed as a regular non-privileged user
Introduction One of the core feature of any Linux system is that they are built for
automation. If a task may need to be executed more than one time - even with some part of it
changing on next run - a sysadmin is provided with countless tools to automate it, from simple
shell scripts run by hand on demand (thus eliminating typo errors, or only save
some keyboard hits) to complex scripted systems where tasks run from cron at a
specified time, interacting with each other, working with the result of another script, maybe
controlled by a central management system etc.
While this freedom and rich toolset indeed adds to productivity, there is a catch: as a
sysadmin, you write a useful script on a system, which proves to be useful on another, so you
copy the script over. On a third system the script is useful too, but with minor modification -
maybe a new feature useful only that system, reachable with a new parameter. Generalization in
mind, you extend the script to provide the new feature, and complete the task it was written
for as well. Now you have two versions of the script, the first is on the first two system, the
second in on the third system.
You have 1024 computers running in the datacenter, and 256 of them will need some of the
functionality provided by that script. In time you will have 64 versions of the script all
over, every version doing its job. On the next system deployment you need a feature you recall
you coded at some version, but which? And on which systems are they?
On RPM based systems, such as Red Hat flavors, a sysadmin can take advantage of the package
manager to create order in the custom content, including simple shell scripts that may not
provide else but the tools the admin wrote for convenience.
In this tutorial we will build a custom rpm for Red Hat Enterprise Linux 7.5 containing two
bash scripts, parselogs.sh and pullnews.sh to provide a
way that all systems have the latest version of these scripts in the
/usr/local/sbin directory, and thus on the path of any user who logs in to the
system.
Distributions, major and minor versions In general, the minor and major version of the
build machine should be the same as the systems the package is to be deployed, as well as the
distribution to ensure compatibility. If there are various versions of a given distribution, or
even different distributions with many versions in your environment (oh, joy!), you should set
up build machines for each. To cut the work short, you can just set up build environment for
each distribution and each major version, and have them on the lowest minor version existing in
your environment for the given major version. Of cause they don't need to be physical machines,
and only need to be running at build time, so you can use virtual machines or containers.
In this tutorial our work is much easier, we only deploy two scripts that have no
dependencies at all (except bash ), so we will build noarch packages
which stand for "not architecture dependent", we'll also not specify the distribution the
package is built for. This way we can install and upgrade them on any distribution that uses
rpm , and to any version - we only need to ensure that the build machine's
rpm-build package is on the oldest version in the environment. Setting up
building environment To build custom rpm packages, we need to install the
rpm-build package:
# yum install rpm-build
From now on, we do not useroot user, and for a good reason. Building
packages does not require root privilege, and you don't want to break your building
machine.
Building the first version of the package Let's create the directory structure needed
for building:
$ mkdir -p rpmbuild/SPECS
Our package is called admin-scripts, version 1.0. We create a specfile that
specifies the metadata, contents and tasks performed by the package. This is a simple text file we
can create with our favorite text editor, such as vi . The previously installed
rpmbuild package will fill your empty specfile with template data if you use
vi to create an empty one, but for this tutorial consider the specification below
called admin-scripts-1.0.spec :
Name: admin-scripts
Version: 1
Release: 0
Summary: FooBar Inc. IT dept. admin scripts
Packager: John Doe
Group: Application/Other
License: GPL
URL: www.foobar.com/admin-scripts
Source0: %{name}-%{version}.tar.gz
BuildArch: noarch
%description
Package installing latest version the admin scripts used by the IT dept.
%prep
%setup -q
%build
%install
rm -rf $RPM_BUILD_ROOT
mkdir -p $RPM_BUILD_ROOT/usr/local/sbin
cp scripts/* $RPM_BUILD_ROOT/usr/local/sbin/
%clean
rm -rf $RPM_BUILD_ROOT
%files
%defattr(-,root,root,-)
%dir /usr/local/sbin
/usr/local/sbin/parselogs.sh
/usr/local/sbin/pullnews.sh
%doc
%changelog
* Wed Aug 1 2018 John Doe
- release 1.0 - initial release
Place the specfile in the rpmbuild/SPEC directory we created earlier.
We need the sources referenced in the specfile - in this case the two shell
scripts. Let's create the directory for the sources (called as the package name appended with
the main version):
As this tutorial is not about shell scripting, the contents of these scripts are irrelevant. As
we will create a new version of the package, and the pullnews.sh is the script we
will demonstrate with, it's source in the first version is as below:
#!/bin/bash
echo "news pulled"
exit 0
Do not forget to add the appropriate rights to the files in the source - in our case,
execution right:
We'll get some output about the build, and if anything goes wrong, errors will be shown (for
example, missing file or path). If all goes well, our new package will appear in the RPMS directory
generated by default under the rpmbuild directory (sorted into subdirectories by
architecture):
$ ls rpmbuild/RPMS/noarch/
admin-scripts-1-0.noarch.rpm
We have created a simple yet fully functional rpm package. We can query it for all the
metadata we supplied earlier:
$ rpm -qpi rpmbuild/RPMS/noarch/admin-scripts-1-0.noarch.rpm
Name : admin-scripts
Version : 1
Release : 0
Architecture: noarch
Install Date: (not installed)
Group : Application/Other
Size : 78
License : GPL
Signature : (none)
Source RPM : admin-scripts-1-0.src.rpm
Build Date : 2018. aug. 1., Wed, 13.27.34 CEST
Build Host : build01.foobar.com
Relocations : (not relocatable)
Packager : John Doe
URL : www.foobar.com/admin-scripts
Summary : FooBar Inc. IT dept. admin scripts
Description :
Package installing latest version the admin scripts used by the IT dept.
And of cause we can install it (with root privileges): Installing custom scripts with rpm
As we installed the scripts into a directory that is on every user's $PATH , you
can run them as any user in the system, from any directory:
$ pullnews.sh
news pulled
The package can be distributed as it is, and can be pushed into repositories available to any
number of systems. To do so is out of the scope of this tutorial - however, building another
version of the package is certainly not. Building another version of the package Our package
and the extremely useful scripts in it become popular in no time, considering they are reachable
anywhere with a simple yum install admin-scripts within the environment. There will be
soon many requests for some improvements - in this example, many votes come from happy users that
the pullnews.sh should print another line on execution, this feature would save the
whole company. We need to build another version of the package, as we don't want to install another
script, but a new version of it with the same name and path, as the sysadmins in our organization
already rely on it heavily.
First we change the source of the pullnews.sh in the SOURCES to something even
more complex:
#!/bin/bash
echo "news pulled"
echo "another line printed"
exit 0
We need to recreate the tar.gz with the new source content - we can use the same filename as
the first time, as we don't change version, only release (and so the Source0 reference
will be still valid). Note that we delete the previous archive first:
cd rpmbuild/SOURCES/ && rm -f admin-scripts-1.tar.gz && tar -czf admin-scripts-1.tar.gz admin-scripts-1
Now we create another specfile with a higher release number:
We don't change much on the package itself, so we simply administrate the new version as
shown below:
Name: admin-scripts
Version: 1
Release: 1
Summary: FooBar Inc. IT dept. admin scripts
Packager: John Doe
Group: Application/Other
License: GPL
URL: www.foobar.com/admin-scripts
Source0: %{name}-%{version}.tar.gz
BuildArch: noarch
%description
Package installing latest version the admin scripts used by the IT dept.
%prep
%setup -q
%build
%install
rm -rf $RPM_BUILD_ROOT
mkdir -p $RPM_BUILD_ROOT/usr/local/sbin
cp scripts/* $RPM_BUILD_ROOT/usr/local/sbin/
%clean
rm -rf $RPM_BUILD_ROOT
%files
%defattr(-,root,root,-)
%dir /usr/local/sbin
/usr/local/sbin/parselogs.sh
/usr/local/sbin/pullnews.sh
%doc
%changelog
* Wed Aug 22 2018 John Doe
- release 1.1 - pullnews.sh v1.1 prints another line
* Wed Aug 1 2018 John Doe
- release 1.0 - initial release
All done, we can build another version of our package containing the updated script. Note that
we reference the specfile with the higher version as the source of the build:
If the build is successful, we now have two versions of the package under our RPMS directory:
ls rpmbuild/RPMS/noarch/
admin-scripts-1-0.noarch.rpm admin-scripts-1-1.noarch.rpm
And now we can install the "advanced" script, or upgrade if it is already installed.
Upgrading custom scripts with rpm
And our sysadmins can see that the feature request is landed in this version:
rpm -q --changelog admin-scripts
* sze aug 22 2018 John Doe
- release 1.1 - pullnews.sh v1.1 prints another line
* sze aug 01 2018 John Doe
- release 1.0 - initial release
Conclusion
We wrapped our custom content into versioned rpm packages. This means no
older versions left scattered across systems, everything is in it's place, on the version we
installed or upgraded to. RPM gives the ability to replace old stuff needed only in previous
versions, can add custom dependencies or
provide some tools or services our other packages rely on. With effort, we can pack nearly any of
our custom content into rpm packages, and distribute it across our environment, not only with ease,
but with consistency.
My /etc/group has grown by adding new users as well as installing programs that
have added their own user and/or group. The same is true for /etc/passwd .
Editing has now become a little cumbersome due to the lack of structure.
May I sort these files (e.g. by numerical id or alphabetical by name) without negative
effect on the system and/or package managers?
I would guess that is does not matter but just to be sure I would like to get a 2nd
opinion. Maybe root needs to be the 1st line or within the first 1k lines or
something?
How does sorting the file help with editing? Is it because you want to group related accounts
together, and then do similar changes in a range of rows? But will related account be
adjacent if you sort by uid or name? – Barmar
Feb 21 at 20:51
@Barmar It has helped mainly because user accounts are grouped by ranges and separate from
system accounts (when sorting by UID). Therefore it is easier e.g. to spot the correct line
to examine or change when editing with vi . – Ned64
Mar 13 at 23:15
You should be OK doing
this : in fact, according to the article and reading the documentation, you can sort
/etc/passwd and /etc/group by UID/GID with pwck -s and
grpck -s , respectively.
@Menasheh This site's colours don't make them stand out as much as on other sites, but "OK
doing this" in this answer is a hyperlink. – hvd
Feb 18 at 22:59
OK, fine, but... In general, are there valid reasons to manually edit /etc/passwd and similar
files? Isn't it considered better to access these via the tools that are designed to create
and modify them? – mickeyf
Feb 19 at 14:05
@mickeyf I've seen people manually edit /etc/passwd when they're making batch
changes, like changing the GECOS field for all users due to moving/restructuring (global room
or phone number changes, etc.) It's not common anymore, but there are specific reasons that
crop up from time to time. – ErikF
Feb 20 at 21:21
Although ErikF is correct that this should generally be okay, I do want to point out one
potential issue:
You're
allowed to map different usernames to the same UID. If you make use of this, tools that
map a UID back to a username will generally pick the first username they find for that UID in
/etc/passwd . Sorting may cause a different username to appear first. For
display purposes (e.g. ls -l output), either username should work, but it's
possible that you've configured some program to accept requests from username A, where it
will deny those requests if it sees them coming from username B, even if A and B are the same
user.
Having root at first line has been a long time de facto "standard" and is very convenient if
you ever have to fix their shell or delete the password, when dealing with problems or
recovering systems.
Likewise I prefer to have daemons/utils users in the middle and standard users at the end
of both passwd and shadow .
hvd answer is also very good about disturbing the users order, especially in
systems with many users maintained by hand.
If you somewhat manage to sort the files, for instance, only for standard users, it would
be more sensible than changing the order of all users, imo.
If you sort numerically by UID, you should get your preferred order. Root is always
0 , and daemons conventionally have UIDs under 100. – Barmar
Feb 21 at 20:13
Linux distributions usually provide a pwck utility. This small utility will check the
consistency of both files and state any specific issues. By specifying the -r it may run in
read-only mode.
Example when running pwck on /etc/passwd and /etc/shadow file
I am migrating over a server to new hardware. A part of the system will be rebuild. What files
and directories are needed to copy so that usernames, passwords, groups, file ownership and
file permissions stay intact?
/etc/passwd - user account information less the encrypted passwords
/etc/shadow - contains encrypted passwords
/etc/group - user group information
/etc/gshadow - - group encrypted passwords
5 +1 from me. I wondered about /home as well; generally, ssh keys live in
the home directories, so ~/.ssh at least can be considered part of the
authentication infrastructure. – MadHatter
Mar 20 '14 at 8:33
2 @MadHatter: In truth I kind of assumed that the OP would know that they needed to copy
the user home directories but I guess you never know here on SF :) – Iain
Mar 20 '14 at 8:37
6 An important point: this assumes a server with file-based authentication only. To
migrate a server that uses e.g. LDAP or NIS these files will not be enough, especially
if the authentication server is on the same system. Other subsystems (e.g. Samba, SQL) may
also have their own authentication databases. – thkala
Mar 20 '14 at 16:55
If the files on the other machine have different owner IDs, you might change them to the
ones on /etc/group and /etc/passwd and then you have the effective permissions restored.
share | improve this answeredited Mar 20 '14 at 11:52 answered Mar 20
'14 at 7:53
Be careful that you don't delete or renumber system accounts when copying over the
files mentioned in the other answers. System services don't usually have fixed user ids, and if
you've installed the packages in a different order to the original machine (which is very
likely if it was long-lived), then they'll end up in a different order. I tend to copy those
files to somewhere like /root/saved-from-old-system and hand-edit them in order to just copy
the non-system accounts. (There's probably a tool for this, but I don't tend to copy systems
like this often enough to warrant investigating one.)Mar 26 '14 at 5:36
If you're a Linux system administrator, chances are you've got more than one machine that
you're responsible for on a daily basis. You may even have a bank of machines that you maintain
that are similar -- a farm of Web servers, for example. If you have a need to type the same
command into several machines at once, you can login to each one with SSH and do it serially,
or you can save yourself a lot of time and effort and use a tool like ClusterSSH.
ClusterSSH is a Tk/Perl wrapper around standard Linux tools like XTerm and SSH. As such,
it'll run on just about any POSIX-compliant OS where the libraries exist -- I've run it on
Linux, Solaris, and Mac OS X. It requires the Perl libraries Tk ( perl-tk on
Debian or Ubuntu) and X11::Protocol ( libx11-protocol-perl on Debian or Ubuntu),
in addition to xterm and OpenSSH.
Installation
Installing ClusterSSH on a Debian or Ubuntu system is trivial -- a simple sudo apt-get
install clusterssh will install it and its dependencies. It is also packaged for use
with Fedora, and it is installable via the ports system on FreeBSD. There's also a MacPorts
version for use with Mac OS X, if you use an Apple machine. Of course, it can also be compiled
from source.
Configuration
ClusterSSH can be configured either via its global configuration file --
/etc/clusters , or via a file in the user's home directory called
.csshrc . I tend to favor the user-level configuration as that lets multiple
people on the same system to setup their ClusterSSH client as they choose. Configuration is
straightforward in either case, as the file format is the same. ClusterSSH defines a "cluster"
as a group of machines that you'd like to control via one interface. With that in mind, you
enumerate your clusters at the top of the file in a "clusters" block, and then you describe
each cluster in a separate section below.
For example, let's say I've got two clusters, each consisting of two machines. "Cluster1"
has the machines "Test1" and "Test2" in it, and "Cluster2" has the machines "Test3" and "Test4"
in it. The ~.csshrc (or /etc/clusters ) control file would look like
this:
clusters = cluster1 cluster2
cluster1 = test1 test2
cluster2 = test3 test4
You can also make meta-clusters -- clusters that refer to clusters. If you wanted to make a
cluster called "all" that encompassed all the machines, you could define it two ways. First,
you could simply create a cluster that held all the machines, like the following:
By calling out the "all" cluster as containing cluster1 and cluster2, if either of those
clusters ever change, the change is automatically captured so you don't have to update the
"all" definition. This will save you time and headache if your .csshrc file ever grows in
size.
Using ClusterSSH
Using ClusterSSH is similar to launching SSH by itself. Simply running cssh -l
<username> <clustername> will launch ClusterSSH and log you in as the
desired user on that cluster. In the figure below, you can see I've logged into "cluster1" as
myself. The small window labeled "CSSH [2]" is the Cluster SSH console window. Anything I type
into that small window gets echoed to all the machines in the cluster -- in this case, machines
"test1" and "test2". In a pinch, you can also login to machines that aren't in your .csshrc
file, simply by running cssh -l <username> <machinename1>
<machinename2> <machinename3> .
If I want to send something to one of the terminals, I can simply switch focus by clicking
in the desired XTerm, and just type in that window like I usually would. ClusterSSH has a few
menu items that really help when dealing with a mix of machines. As per the figure below, in
the "Hosts" menu of the ClusterSSH console there's are several options that come in handy.
"Retile Windows" does just that if you've manually resized or moved something. "Add host(s)
or Cluster(s)" is great if you want to add another set of machines or another cluster to the
running ClusterSSH session. Finally, you'll see each host listed at the bottom of the "Hosts"
menu. By checking or unchecking the boxes next to each hostname, you can select which hosts the
ClusterSSH console will echo commands to. This is handy if you want to exclude a host or two
for a one-off or particular reason. The final menu option that's nice to have is under the
"Send" menu, called "Hostname". This simply echoes each machine's hostname to the command line,
which can be handy if you're constructing something host-specific across your cluster.
Caveats with ClusterSSH
Like many UNIX tools, ClusterSSH has the potential to go horribly awry if you aren't
very careful with its use. I've seen ClusterSSH mistakes take out an entire tier of
Web servers simply by propagating a typo in an Apache configuration. Having access to multiple
machines at once, possibly as a privileged user, means mistakes come at a great cost. Take
care, and double-check what you're doing before you punch that Enter key.
Conclusion
ClusterSSH isn't a replacement for having a configuration management system or any of the
other best practices when managing a number of machines. However, if you need to do something
in a pinch outside of your usual toolset or process, or if you're doing prototype work,
ClusterSSH is indispensable. It can save a lot of time when doing tasks that need to be done on
more than one machine, but like any power tool, it can cause a lot of damage if used
haphazardly.
A new sysadmin decided to scratch his etch in sudoers file and in the standard definition of additional sysadmins via wheel group
## Allows people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
he replaced ALL with localhost
## Allows people in group wheel to run all commands
# %wheel localhost=(ALL) ALL
then without testing he distributed this file to all servers in the datacenter. Sysadmin who worked after him discovered that sudo su -
command no longer works and they can't get root using their tried and true method ;-)
Note A Red Hat training course is available for
RHCSA Rapid Track Course . The sudo command offers a mechanism for providing
trusted users with administrative access to a system without sharing the password of the
root user. When users given access via this mechanism precede an administrative
command with sudo they are prompted to enter their own password. Once
authenticated, and assuming the command is permitted, the administrative command is executed as
if run by the root user. Follow this procedure to create a normal user account and
give it sudo access. You will then be able to use the sudo command
from this user account to execute administrative commands without logging in to the account of
the root user.
Procedure 2.2. Configuring sudo Access
Log in to the system as the root user.
Create a normal user account using the useradd command. Replace
USERNAME with the user name that you wish to create.
# useradd USERNAME
Set a password for the new user using the passwd command.
# passwd USERNAME
Changing password for user USERNAME.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
Run the visudo to edit the /etc/sudoers file. This file defines
the policies applied by the sudo command.
# visudo
Find the lines in the file that grant sudo access to users in the group
wheel when enabled.
## Allows people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
Remove the comment character ( # ) at the start of the second line. This enables the
configuration option.
Save your changes and exit the editor.
Add the user you created to the wheel group using the usermod
command.
# usermod -aG wheel USERNAME
Test that the updated configuration allows the user you created to run commands using
sudo .
Use the su to switch to the new user account that you created.
# su USERNAME -
Use the groups to verify that the user is in the wheel
group.
$ groups
USERNAME wheel
Use the sudo command to run the whoami command. As this is
the first time you have run a command using sudo from this user account the
banner message will be displayed. You will be also be prompted to enter the password for
the user account.
$ sudo whoami
We trust you have received the usual lecture from the local System
Administrator. It usually boils down to these three things:
#1) Respect the privacy of others.
#2) Think before you type.
#3) With great power comes great responsibility.
[sudo] password for USERNAME:
root
The last line of the output is the user name returned by the whoami command. If
sudo is configured correctly this value will be root .
You have successfully configured a user with sudo access. You can now log in
to this user account and use sudo to run commands as if you were logged in to the
account of the root user.
Below are ten /etc/sudoers file configurations to modify the behavior of sudo command using
Defaults entries.
$ sudo cat /etc/sudoers
/etc/sudoers File
#
# This file MUST be edited with the 'visudo' command as root.
#
# Please consider adding local content in /etc/sudoers.d/ instead of
# directly modifying this file.
#
# See the man page for details on how to write a sudoers file.
#
Defaults env_reset
Defaults mail_badpass
Defaults secure_path="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
Defaults logfile="/var/log/sudo.log"
Defaults lecture="always"
Defaults badpass_message="Password is wrong, please try again"
Defaults passwd_tries=5
Defaults insults
Defaults log_input,log_output
Types of Defaults Entries
Defaults parameter, parameter_list #affect all users on any host
Defaults@Host_List parameter, parameter_list #affects all users on a specific host
Defaults:User_List parameter, parameter_list #affects a specific user
Defaults!Cmnd_List parameter, parameter_list #affects a specific command
Defaults>Runas_List parameter, parameter_list #affects commands being run as a specific user
For the scope of this guide, we will zero down to the first type of Defaults in the forms
below. Parameters may be flags, integer values, strings, or lists.
You should note that flags are implicitly boolean and can be turned off using the
'!' operator, and lists have two additional assignment operators, +=
(add to list) and -= (remove from list).
Defaults parameter
OR
Defaults parameter=value
OR
Defaults parameter -=value
Defaults parameter +=value
OR
Defaults !parameter
If a server needs to be administered by a number of people it
is normally not a good idea for them all to use the root account. This is because it becomes
difficult to determine exactly who did what, when and where if everyone logs in with the same
credentials. The sudo utility was designed to overcome this difficulty.
With sudo (which stands for "superuser do"), you can delegate a limited set of
administrative responsibilities to other users, who are strictly limited to the commands you
allow them. sudo creates a thorough audit trail, so everything users do gets logged; if users
somehow manage to do something they shouldn't have, you'll be able to detect it and apply the
needed fixes. You can even configure sudo centrally, so its permissions apply to several
hosts.
The privileged command you want to run must first begin with the word sudo followed by the
command's regular syntax. When running the command with the sudo prefix, you will be prompted
for your regular password before it is executed. You may run other privileged commands using
sudo within a five-minute period without being re-prompted for a password. All commands run as
sudo are logged in the log file /var/log/messages.
The sudo configuration file is /etc/sudoers . We should never edit this file manually.
Instead, use the visudo command: # visudo
This protects from conflicts (when two admins edit this file at the same time) and
guarantees that the right syntax is used (the permission bits are correct). The program uses Vi
text editor.
All Access to Specific Users
You can grant users bob and bunny full access to all privileged commands, with this sudoers
entry.
user1, user2 ALL=(ALL) ALL
This is generally not a good idea because this allows user1 and user2 to use the su command to
grant themselves permanent root privileges thereby bypassing the command logging features of
sudo.
Access To Specific Users To Specific Files
This entry allows user1 and all the members of the group operator to gain access to all the
program files in the /sbin and /usr/sbin directories, plus the privilege of running the command
/usr/apps/check.pl.
This example allows all users in the group operator to execute all the commands in the /sbin
directory without the need for entering a password.
%operator ALL= NOPASSWD: /sbin/
Adding users to the wheel group
The wheel group is a legacy from UNIX. When a server had to be maintained at a higher level
than the day-to-day system administrator, root rights were often required. The 'wheel' group
was used to create a pool of user accounts that were allowed to get that level of access to the
server. If you weren't in the 'wheel' group, you were denied access to root.
Edit the configuration file (/etc/sudoers) with visudo and change these lines:
# Uncomment to allow people in group wheel to run all commands
# %wheel ALL=(ALL) ALL
To this (as recommended):
# Uncomment to allow people in group wheel to run all commands
%wheel ALL=(ALL) ALL
This will allow anyone in the wheel group to execute commands using sudo (rather than having
to add each person one by one).
Now finally use the following command to add any user (e.g- user1) to Wheel group
If sudo vi /etc/hosts is successful, it means that the system administrator has
allowed the user to run vi /etc/hosts as root. That's the whole point of sudo:
it lets the system administrator authorize certain users to run certain commands with extra
privileges.
Giving a user the permission to run vi gives them the permission to run any
vi command, including :sh to run a shell and :w to overwrite any
file on the system. A rule allowing only to run vi /etc/hosts does not make any
sense since it allows the user to run arbitrary commands.
There is no "hacking" involved. The breach of security comes from a misconfiguration, not
from a hole in the security model. Sudo does not particularly try to prevent against
misconfiguration. Its documentation is well-known to be difficult to understand; if in doubt,
ask around and don't try to do things that are too complicated.
It is in general a hard problem to give a user a specific privilege without giving them
more than intended. A bulldozer approach like giving them the right to run an interactive
program such as vi is bound to fail. A general piece of advice is to give the minimum
privileges necessary to accomplish the task. If you want to allow a user to modify one file,
don't give them the permission to run an editor. Instead, either:
Give them the permission to write to the file. This is the simplest method with the
least risk of doing something you didn't intend.
setfacl u:bob:rw /etc/hosts
Give them permission to edit the file via sudo. To do that, don't give them the
permission to run an editor. As explained in the sudo documentation, give them the
permission to run sudoedit , which invokes an editor as the original
user and then uses the extra privileges only to modify the file.
bob ALL = sudoedit /etc/hosts
The sudo method is more complicated to set up, and is less transparent for the user
because they have to invoke sudoedit instead of just opening the file in
their editor, but has the advantage that all accesses are logged.
Note that allowing a user to edit /etc/hosts may have an impact on your
security infrastructure: if there's any place where you rely on a host name corresponding to
a specific machine, then that user will be able to point it to a different machine. Consider
that
it is probably unnecessary anyway .
Linux adopted early the practice of maintaining a centralized location where users could find and install software. In this article,
I'll discuss the history of software installation on Linux and how modern operating systems are kept up to date against the never-ending
torrent of CVEs .
How was software on Linux installed before package managers?
Historically, software was provided either via FTP or mailing lists (eventually this distribution would grow to include basic
websites). Only a few small files contained the instructions to create a binary (normally in a tarfile). You would untar the files,
read the readme, and as long as you had GCC or some other form of C compiler, you would then typically run a ./configure
script with some list of attributes, such as pathing to library files, location to create new binaries, etc. In addition, the
configure process would check your system for application dependencies. If any major requirements were missing, the
configure script would exit and you could not proceed with the installation until all the dependencies were met. If the configure
script completed successfully, a Makefile would be created.
Once a Makefile existed, you would then proceed to run the make command (this command is provided by
whichever compiler you were using). The make command has a number of options called make flags , which help optimize
the resulting binaries for your system. In the earlier days of computing, this was very important because hardware struggled to keep
up with modern software demands. Today, compilation options can be much more generic as most hardware is more than adequate for modern
software.
Finally, after the make process had been completed, you would need to run make install (or sudo
make install ) in order to actually install the software. As you can imagine, doing this for every single piece of software
was time-consuming and tedious -- not to mention the fact that updating software was a complicated and potentially very involved
process.
What is a package?
Packages were invented to combat this complexity. Packages collect multiple data files together into a single archive file for
easier portability and storage, or simply compress files to reduce storage space. The binaries included in a package are precompiled
with according to the sane defaults the developer chosen. Packages also contain metadata, such as the software's name, a description
of its purpose, a version number, and a list of dependencies necessary for the software to run properly.
Several flavors of Linux have created their own package formats. Some of the most commonly used package formats include:
.deb: This package format is used by Debian, Ubuntu, Linux Mint, and several other derivatives. It was the first package type
to be created.
.rpm: This package format was originally called Red Hat Package Manager. It is used by Red Hat, Fedora, SUSE, and several
other smaller distributions.
.tar.xz: While it is just a compressed tarball, this is the format that Arch Linux uses.
While packages themselves don't manage dependencies directly, they represented a huge step forward in Linux software management.
What is a software repository?
A few years ago, before the proliferation of smartphones, the idea of a software repository was difficult for many users to grasp
if they were not involved in the Linux ecosystem. To this day, most Windows users still seem to be hardwired to open a web browser
to search for and install new software. However, those with smartphones have gotten used to the idea of a software "store." The way
smartphone users obtain software and the way package managers work are not dissimilar. While there have been several attempts at
making an attractive UI for software repositories, the vast majority of Linux users still use the command line to install packages.
Software repositories are a centralized listing of all of the available software for any repository the system has been configured
to use. Below are some examples of searching a repository for a specifc package (note that these have been truncated for brevity):
Arch Linux with aurman
user@arch ~ $ aurman -Ss kate
extra/kate 18.04.2-2 (kde-applications kdebase)
Advanced Text Editor
aur/kate-root 18.04.0-1 (11, 1.139399)
Advanced Text Editor, patched to be able to run as root
aur/kate-git r15288.15d26a7-1 (1, 1e-06)
An advanced editor component which is used in numerous KDE applications requiring a text editing component
CentOS 7 using YUM
[user@centos ~]$ yum search kate
kate-devel.x86_64 : Development files for kate
kate-libs.x86_64 : Runtime files for kate
kate-part.x86_64 : Kate kpart plugin
Ubuntu using APT
user@ubuntu ~ $ apt search kate
Sorting... Done
Full Text Search... Done
kate/xenial 4:15.12.3-0ubuntu2 amd64
powerful text editor
kate-data/xenial,xenial 4:4.14.3-0ubuntu4 all
shared data files for Kate text editor
kate-dbg/xenial 4:15.12.3-0ubuntu2 amd64
debugging symbols for Kate
kate5-data/xenial,xenial 4:15.12.3-0ubuntu2 all
shared data files for Kate text editor
What are the most prominent package managers?
As suggested in the above output, package managers are used to interact with software repositories. The following is a brief overview
of some of the most prominent package managers.
RPM-based package managers
Updating RPM-based systems, particularly those based on Red Hat technologies, has a very interesting and detailed history. In
fact, the current versions of yum (for enterprise distributions)
and DNF (for community) combine several open source projects to
provide their current functionality.
Initially, Red Hat used a package manager called RPM
(Red Hat Package Manager), which is still in use today. However, its primary use is to install RPMs, which you have locally, not
to search software repositories. The package manager named up2date was created to inform users of updates to packages
and enable them to search remote repositories and easily install dependencies. While it served its purpose, some community members
felt that up2date had some significant shortcomings.
The current incantation of yum came from several different community efforts. Yellowdog Updater (YUP) was developed in 1999-2001
by folks at Terra Soft Solutions as a back-end engine for a graphical installer of
Yellow Dog Linux . Duke University liked the idea of
YUP and decided to improve upon it. They created
Yellowdog Updater, Modified
(yum) which was eventually adapted to help manage the university's Red Hat Linux systems. Yum grew in popularity, and by 2005
it was estimated to be used by more than half of the Linux market. Today, almost every distribution of Linux that uses RPMs uses
yum for package management (with a few notable exceptions).
Working with yum
In order for yum to download and install packages out of an internet repository, files must be located in /etc/yum.repos.d/
and they must have the extension .repo . Here is an example repo file:
This is for one of my local repositories, which explains why the GPG check is off. If this check was on, each package would need
to be signed with a cryptographic key and a corresponding key would need to be imported into the system receiving the updates. Because
I maintain this repository myself, I trust the packages and do not bother signing them.
Once a repository file is in place, you can start installing packages from the remote repository. The most basic command is
yum update , which will update every package currently installed. This does not require a specific step to refresh
the information about repositories; this is done automatically. A sample of the command is shown below:
If you are sure you want yum to execute any command without stopping for input, you can put the -y flag in the command,
such as yum update -y .
Installing a new package is just as easy. First, search for the name of the package with yum search :
[user@centos ~]$ yum search kate
artwiz-aleczapka-kates-fonts.noarch : Kates font in Artwiz family
ghc-highlighting-kate-devel.x86_64 : Haskell highlighting-kate library development files
kate-devel.i686 : Development files for kate
kate-devel.x86_64 : Development files for kate
kate-libs.i686 : Runtime files for kate
kate-libs.x86_64 : Runtime files for kate
kate-part.i686 : Kate kpart plugin
Once you have the name of the package, you can simply install the package with sudo yum install kate-devel -y . If
you installed a package you no longer need, you can remove it with sudo yum remove kate-devel -y . By default, yum will
remove the package plus its dependencies.
There may be times when you do not know the name of the package, but you know the name of the utility. For example, suppose you
are looking for the utility updatedb , which creates/updates the database used by the locate command. Attempting
to install updatedb returns the following results:
[user@centos ~]$ sudo yum install updatedb
Loaded plugins: fastestmirror, langpacks
Loading mirror speeds from cached hostfile
No package updatedb available.
Error: Nothing to do
You can find out what package the utility comes from by running:
mlocate-0.26-8.el7.x86_64 : An utility for finding files by name
Repo : local_base
Matched from:
Filename : /usr/bin/updatedb
The reason I have used an asterisk * in front of the command is because yum whatprovides uses the path
to the file in order to make a match. Since I was not sure where the file was located, I used an asterisk to indicate any path.
There are, of course, many more options available to yum. I encourage you to view the man page for yum for additional options.
Dandified Yum (DNF) is a newer iteration on yum. Introduced
in Fedora 18, it has not yet been adopted in the enterprise distributions, and as such is predominantly used in Fedora (and derivatives).
Its usage is almost exactly the same as that of yum, but it was built to address poor performance, undocumented APIs, slow/broken
dependency resolution, and occasional high memory usage. DNF is meant as a drop-in replacement for yum, and therefore I won't repeat
the commands -- wherever you would use yum , simply substitute dnf .
Working with Zypper
Zypper is another package manager meant to help manage RPMs.
This package manager is most commonly associated with SUSE (and
openSUSE ) but has also seen adoption by
MeeGo , Sailfish
OS , and Tizen . It was originally introduced in 2006 and has been iterated
upon ever since. There is not a whole lot to say other than Zypper is used as the back end for the system administration tool
YaST and some users find it to be faster than yum.
Zypper's usage is very similar to that of yum. To search for, update, install or remove a package, simply use the following:
zypper search kate
zypper update
zypper install kate
zypper remove kate
Some major differences come into play in how repositories are added to the system with zypper . Unlike the package
managers discussed above, zypper adds repositories using the package manager itself. The most common way is via a URL,
but zypper also supports importing from repo files.
zypper even has a similar ability to determine what package name contains files or binaries. Unlike YUM, it uses
a hyphen in the command (although this method of searching is deprecated):
localhost:~ # zypper what-provides kate
Command 'what-provides' is replaced by 'search --provides --match-exact'.
See 'help search' for all available options.
Loading repository data...
Reading installed packages...
S | Name | Summary | Type
---+------+----------------------+------------
i+ | Kate | Advanced Text Editor | application
i | kate | Advanced Text Editor | package
As with YUM and DNF, Zypper has a much richer feature set than covered here. Please consult with the official documentation for
more in-depth information.
Debian-based package managers
One of the oldest Linux distributions currently maintained, Debian's system is very similar to RPM-based systems. They use
.deb packages, which can be managed by a tool called dpkg . dpkg is very similar to rpm in that
it was designed to manage packages that are available locally. It does no dependency resolution (although it does dependency checking),
and has no reliable way to interact with remote repositories. In order to improve the user experience and ease of use, the Debian
project commissioned a project called Deity . This codename was eventually abandoned and changed to
Advanced Package Tool (APT) .
Released as test builds in 1998 (before making an appearance in Debian 2.1 in 1999), many users consider APT one of the defining
features of Debian-based systems. It makes use of repositories in a similar fashion to RPM-based systems, but instead of individual
.repo files that yum uses, apt has historically used /etc/apt/sources.list to
manage repositories. More recently, it also ingests files from /etc/apt/sources.d/ . Following the examples in the RPM-based
package managers, to accomplish the same thing on Debian-based distributions you have a few options. You can edit/create the files
manually in the aforementioned locations from the terminal, or in some cases, you can use a UI front end (such as Software
& Updates provided by Ubuntu et al.). To provide the same treatment to all distributions, I will cover only the command-line
options. To add a repository without directly editing a file, you can do something like this:
This will create a spideroakone.list file in /etc/apt/sources.list.d . Obviously, these lines change
depending on the repository being added. If you are adding a Personal Package Archive (PPA), you can do this:
After a repository has been added, Debian-based systems need to be made aware that there is a new location to search for packages.
This is done via the apt-get update command:
Now that the new repository is added and updated, you can search for a package using the apt-cache command:
user@ubuntu:~$ apt-cache search kate
aterm-ml - Afterstep XVT - a VT102 emulator for the X window system
frescobaldi - Qt4 LilyPond sheet music editor
gitit - Wiki engine backed by a git or darcs filestore
jedit - Plugin-based editor for programmers
kate - powerful text editor
kate-data - shared data files for Kate text editor
kate-dbg - debugging symbols for Kate
katepart - embeddable text editor component
To install kate , simply run the corresponding install command:
user@ubuntu:~$ sudo apt-get install kate
To remove a package, use apt-get remove :
user@ubuntu:~$ sudo apt-get remove kate
When it comes to package discovery, APT does not provide any functionality that is similar to yum whatprovides .
There are a few ways to get this information if you are trying to find where a specific file on disk has come from.
Using dpkg
user@ubuntu:~$ dpkg -S /bin/ls
coreutils: /bin/ls
Using apt-file
user@ubuntu:~$ sudo apt-get install apt-file -y
user@ubuntu:~$ sudo apt-file update
user@ubuntu:~$ apt-file search kate
The problem with apt-file search is that it, unlike yum whatprovides , it is overly verbose unless you
know the exact path, and it automatically adds a wildcard search so that you end up with results for anything with the word kate
in it:
Most of these examples have used apt-get . Note that most of the current tutorials for Ubuntu specifically have taken
to simply using apt . The single apt command was designed to implement only the most commonly used commands
in the APT arsenal. Since functionality is split between apt-get , apt-cache , and other commands,
apt looks to unify these into a single command. It also adds some niceties such as colorization, progress bars, and
other odds and ends. Most of the commands noted above can be replaced with apt , but not all Debian-based distributions
currently receiving security patches support using apt by default, so you may need to install additional packages.
Arch-based package managers
Arch Linux uses a package manager called
pacman . Unlike .deb or .rpm
files, pacman uses a more traditional tarball with the LZMA2 compression ( .tar.xz ). This enables Arch Linux
packages to be much smaller than other forms of compressed archives (such as gzip ). Initially released in 2002, pacman has
been steadily iterated and improved. One of the major benefits of pacman is that it supports the
Arch Build System , a system for building packages
from source. The build system ingests a file called a PKGBUILD, which contains metadata (such as version numbers, revisions, dependencies,
etc.) as well as a shell script with the required flags for compiling a package conforming to the Arch Linux requirements. The resulting
binaries are then packaged into the aforementioned .tar.xz file for consumption by pacman.
This system led to the creation of the Arch User Repository (AUR) which
is a community-driven repository containing PKGBUILD files and supporting patches or scripts. This allows for a virtually endless
amount of software to be available in Arch. The obvious advantage of this system is that if a user (or maintainer) wishes to make
software available to the public, they do not have to go through official channels to get it accepted in the main repositories. The
downside is that it relies on community curation similar to Docker Hub , Canonical's
Snap packages, or other similar mechanisms. There are numerous AUR-specific package managers that can be used to download, compile,
and install from the PKGBUILD files in the AUR (we will look at this later).
Working with pacman and official repositories
Arch's main package manager, pacman, uses flags instead of command words like yum and apt . For example,
to search for a package, you would use pacman -Ss . As with most commands on Linux, you can find both a manpage
and inline help. Most of the commands for pacman use the sync (-S) flag. For example:
user@arch ~ $ pacman -Ss kate
extra/kate 18.04.2-2 (kde-applications kdebase)
Advanced Text Editor
extra/libkate 0.4.1-6 [installed]
A karaoke and text codec for embedding in ogg
extra/libtiger 0.3.4-5 [installed]
A rendering library for Kate streams using Pango and Cairo
extra/ttf-cheapskate 2.0-12
TTFonts collection from dustimo.com
community/haskell-cheapskate 0.1.1-100
Experimental markdown processor.
Arch also uses repositories similar to other package managers. In the output above, search results are prefixed with the repository
they are found in ( extra/ and community/ in this case). Similar to both Red Hat and Debian-based systems,
Arch relies on the user to add the repository information into a specific file. The location for these repositories is /etc/pacman.conf
. The example below is fairly close to a stock system. I have enabled the [multilib] repository for Steam support:
It is possible to specify a specific URL in pacman.conf . This functionality can be used to make sure all packages
come from a specific point in time. If, for example, a package has a bug that affects you severely and it has several dependencies,
you can roll back to a specific point in time by adding a specific URL into your pacman.conf and then running the commands
to downgrade the system:
Like Debian-based systems, Arch does not update its local repository information until you tell it to do so. You can refresh the
package database by issuing the following command:
user@arch ~ $ sudo pacman -Sy
:: Synchronizing package databases...
core 130.2 KiB 851K/s 00:00 [##########################################################] 100%
extra 1645.3 KiB 2.69M/s 00:01 [##########################################################] 100%
community 4.5 MiB 2.27M/s 00:02 [##########################################################] 100%
multilib is up to date
As you can see in the above output, pacman thinks that the multilib package database is up to date. You can force
a refresh if you think this is incorrect by running pacman -Syy . If you want to update your entire system (excluding
packages installed from the AUR), you can run pacman -Syu :
user@arch ~ $ sudo pacman -Syu
:: Synchronizing package databases...
core is up to date
extra is up to date
community is up to date
multilib is up to date
:: Starting full system upgrade...
resolving dependencies...
looking for conflicting packages...
Total Download Size: 2.66 MiB
Total Installed Size: 879.15 MiB
Net Upgrade Size: -365.27 MiB
:: Proceed with installation? [Y/n]
In the scenario mentioned earlier regarding downgrading a system, you can force a downgrade by issuing pacman -Syyuu
. It is important to note that this should not be undertaken lightly. This should not cause a problem in most cases; however, there
is a chance that downgrading of a package or several packages will cause a cascading failure and leave your system in an inconsistent
state. USE WITH CAUTION!
To install a package, simply use pacman -S kate :
user@arch ~ $ sudo pacman -S kate
resolving dependencies...
looking for conflicting packages...
Pacman, in my opinion, offers the most succinct way of searching for the name of a package for a given utility. As shown above,
yum and apt both rely on pathing in order to find useful results. Pacman makes some intelligent guesses
as to which package you are most likely looking for:
user@arch ~ $ sudo pacman -Fs kate
extra/kate 18.04.2-2
usr/bin/kate
Working with the AUR
There are several popular AUR package manager helpers. Of these, yaourt and pacaur are fairly prolific.
However, both projects are listed as discontinued or problematic on the
Arch Wiki . For that reason,
I will discuss aurman . It works almost exactly like pacman, except it searches the AUR and includes some
helpful, albeit potentially dangerous, options. Installing a package from the AUR will initiate use of the package maintainer's build
scripts. You will be prompted several times for permission to continue (I have truncated the output for brevity):
aurman -S telegram-desktop-bin
~~ initializing aurman...
~~ the following packages are neither in known repos nor in the aur
...
~~ calculating solutions...
:: The following 1 package(s) are getting updated:
aur/telegram-desktop-bin 1.3.0-1 -> 1.3.9-1
?? Do you want to continue? Y/n: Y
~~ looking for new pkgbuilds and fetching them...
Cloning into 'telegram-desktop-bin'...
remote: Counting objects: 301, done.
remote: Compressing objects: 100% (152/152), done.
remote: Total 301 (delta 161), reused 286 (delta 147)
Receiving objects: 100% (301/301), 76.17 KiB | 639.00 KiB/s, done.
Resolving deltas: 100% (161/161), done.
?? Do you want to see the changes of telegram-desktop-bin? N/y: N
Total Installed Size: 88.81 MiB
Net Upgrade Size: 5.33 MiB
:: Proceed with installation? [Y/n]
Sometimes you will be prompted for more input, depending on the complexity of the package you are installing. To avoid this tedium,
aurman allows you to pass both the --noconfirm and --noedit options. This is equivalent to
saying "accept all of the defaults, and trust that the package maintainers scripts will not be malicious." USE THIS OPTION WITH
EXTREME CAUTION! While these options are unlikely to break your system on their own, you should never blindly accept someone
else's scripts.
Conclusion
This article, of course, only scratches the surface of what package managers can do. There are also many other package managers
available that I could not cover in this space. Some distributions, such as Ubuntu or Elementary OS, have gone to great lengths to
provide a graphical approach to package management.
If you are interested in some of the more advanced functions of package managers, please post your questions or comments below
and I would be glad to write a follow-up article.
# search for the package name containing specific file or folder
yum whatprovides *<binary>
dnf whatprovides *<binary>
zypper what-provides <binary>
zypper search --provides <binary>
apt-file search <binary>
pacman -Sf <binary>
TopicsLinuxAbout the author
Steve Ovens - Steve is a dedicated IT professional and Linux advocate. Prior to joining Red Hat, he spent several years in financial,
automotive, and movie industries. Steve currently works for Red Hat as an OpenShift consultant and has certifications ranging from
the RHCA (in DevOps), to Ansible, to Containerized Applications and more. He spends a lot of time discussing technology and writing
tutorials on various technical subjects with friends, family, and anyone who is interested in listening.
More about me
I used rsync to copy a large number of files, but my OS (Ubuntu) restarted
unexpectedly.
After reboot, I ran rsync again, but from the output on the terminal, I found
that rsync still copied those already copied before. But I heard that
rsync is able to find differences between source and destination, and therefore
to just copy the differences. So I wonder in my case if rsync can resume what
was left last time?
Yes, rsync won't copy again files that it's already copied. There are a few edge cases where
its detection can fail. Did it copy all the already-copied files? What options did you use?
What were the source and target filesystems? If you run rsync again after it's copied
everything, does it copy again? – Gilles
Sep 16 '12 at 1:56
@Gilles: Thanks! (1) I think I saw rsync copied the same files again from its output on the
terminal. (2) Options are same as in my other post, i.e. sudo rsync -azvv
/home/path/folder1/ /home/path/folder2 . (3) Source and target are both NTFS, buy
source is an external HDD, and target is an internal HDD. (3) It is now running and hasn't
finished yet. – Tim
Sep 16 '12 at 2:30
@Tim Off the top of my head, there's at least clock skew, and differences in time resolution
(a common issue with FAT filesystems which store times in 2-second increments, the
--modify-window option helps with that). – Gilles
Sep 19 '12 at 9:25
First of all, regarding the "resume" part of your question, --partial just tells
the receiving end to keep partially transferred files if the sending end disappears as though
they were completely transferred.
While transferring files, they are temporarily saved as hidden files in their target
folders (e.g. .TheFileYouAreSending.lRWzDC ), or a specifically chosen folder if
you set the --partial-dir switch. When a transfer fails and
--partial is not set, this hidden file will remain in the target folder under
this cryptic name, but if --partial is set, the file will be renamed to the
actual target file name (in this case, TheFileYouAreSending ), even though the
file isn't complete. The point is that you can later complete the transfer by running rsync
again with either --append or --append-verify .
So, --partial doesn't itself resume a failed or cancelled transfer.
To resume it, you'll have to use one of the aforementioned flags on the next run. So, if you
need to make sure that the target won't ever contain files that appear to be fine but are
actually incomplete, you shouldn't use --partial . Conversely, if you want to
make sure you never leave behind stray failed files that are hidden in the target directory,
and you know you'll be able to complete the transfer later, --partial is there
to help you.
With regards to the --append switch mentioned above, this is the actual
"resume" switch, and you can use it whether or not you're also using --partial .
Actually, when you're using --append , no temporary files are ever created.
Files are written directly to their targets. In this respect, --append gives the
same result as --partial on a failed transfer, but without creating those hidden
temporary files.
So, to sum up, if you're moving large files and you want the option to resume a cancelled
or failed rsync operation from the exact point that rsync stopped, you need to
use the --append or --append-verify switch on the next attempt.
As @Alex points out below, since version 3.0.0 rsync now has a new option,
--append-verify , which behaves like --append did before that
switch existed. You probably always want the behaviour of --append-verify , so
check your version with rsync --version . If you're on a Mac and not using
rsync from homebrew , you'll (at least up to and including El
Capitan) have an older version and need to use --append rather than
--append-verify . Why they didn't keep the behaviour on --append
and instead named the newcomer --append-no-verify is a bit puzzling. Either way,
--append on rsync before version 3 is the same as
--append-verify on the newer versions.
--append-verify isn't dangerous: It will always read and compare the data on
both ends and not just assume they're equal. It does this using checksums, so it's easy on
the network, but it does require reading the shared amount of data on both ends of the wire
before it can actually resume the transfer by appending to the target.
Second of all, you said that you "heard that rsync is able to find differences between
source and destination, and therefore to just copy the differences."
That's correct, and it's called delta transfer, but it's a different thing. To enable
this, you add the -c , or --checksum switch. Once this switch is
used, rsync will examine files that exist on both ends of the wire. It does this in chunks,
compares the checksums on both ends, and if they differ, it transfers just the differing
parts of the file. But, as @Jonathan points out below, the comparison is only done when files
are of the same size on both ends -- different sizes will cause rsync to upload the entire
file, overwriting the target with the same name.
This requires a bit of computation on both ends initially, but can be extremely efficient
at reducing network load if for example you're frequently backing up very large files
fixed-size files that often contain minor changes. Examples that come to mind are virtual
hard drive image files used in virtual machines or iSCSI targets.
It is notable that if you use --checksum to transfer a batch of files that
are completely new to the target system, rsync will still calculate their checksums on the
source system before transferring them. Why I do not know :)
So, in short:
If you're often using rsync to just "move stuff from A to B" and want the option to cancel
that operation and later resume it, don't use --checksum , but do use
--append-verify .
If you're using rsync to back up stuff often, using --append-verify probably
won't do much for you, unless you're in the habit of sending large files that continuously
grow in size but are rarely modified once written. As a bonus tip, if you're backing up to
storage that supports snapshotting such as btrfs or zfs , adding
the --inplace switch will help you reduce snapshot sizes since changed files
aren't recreated but rather the changed blocks are written directly over the old ones. This
switch is also useful if you want to avoid rsync creating copies of files on the target when
only minor changes have occurred.
When using --append-verify , rsync will behave just like it always does on
all files that are the same size. If they differ in modification or other timestamps, it will
overwrite the target with the source without scrutinizing those files further.
--checksum will compare the contents (checksums) of every file pair of identical
name and size.
UPDATED 2015-09-01 Changed to reflect points made by @Alex (thanks!)
UPDATED 2017-07-14 Changed to reflect points made by @Jonathan (thanks!)
According to the documentation--append does not check the data, but --append-verify does.
Also, as @gaoithe points out in a comment below, the documentation claims
--partialdoes resume from previous files. – Alex
Aug 28 '15 at 3:49
Thank you @Alex for the updates. Indeed, since 3.0.0, --append no longer
compares the source to the target file before appending. Quite important, really!
--partial does not itself resume a failed file transfer, but rather leaves it
there for a subsequent --append(-verify) to append to it. My answer was clearly
misrepresenting this fact; I'll update it to include these points! Thanks a lot :) –
DanielSmedegaardBuus
Sep 1 '15 at 13:29
@CMCDragonkai Actually, check out Alexander's answer below about --partial-dir
-- looks like it's the perfect bullet for this. I may have missed something entirely ;)
– DanielSmedegaardBuus
May 10 '16 at 19:31
What's your level of confidence in the described behavior of --checksum ?
According to the man it has more to do with deciding
which files to flag for transfer than with delta-transfer (which, presumably, is
rsync 's default behavior). – Jonathan Y.
Jun 14 '17 at 5:48
Just specify a partial directory as the rsync man pages recommends:
--partial-dir=.rsync-partial
Longer explanation:
There is actually a built-in feature for doing this using the --partial-dir
option, which has several advantages over the --partial and
--append-verify / --append alternative.
Excerpt from the
rsync man pages:
--partial-dir=DIR
A better way to keep partial files than the --partial option is
to specify a DIR that will be used to hold the partial data
(instead of writing it out to the destination file). On the
next transfer, rsync will use a file found in this dir as data
to speed up the resumption of the transfer and then delete it
after it has served its purpose.
Note that if --whole-file is specified (or implied), any par-
tial-dir file that is found for a file that is being updated
will simply be removed (since rsync is sending files without
using rsync's delta-transfer algorithm).
Rsync will create the DIR if it is missing (just the last dir --
not the whole path). This makes it easy to use a relative path
(such as "--partial-dir=.rsync-partial") to have rsync create
the partial-directory in the destination file's directory when
needed, and then remove it again when the partial file is
deleted.
If the partial-dir value is not an absolute path, rsync will add
an exclude rule at the end of all your existing excludes. This
will prevent the sending of any partial-dir files that may exist
on the sending side, and will also prevent the untimely deletion
of partial-dir items on the receiving side. An example: the
above --partial-dir option would add the equivalent of "-f '-p
.rsync-partial/'" at the end of any other filter rules.
By default, rsync uses a random temporary file name which gets deleted when a transfer
fails. As mentioned, using --partial you can make rsync keep the incomplete file
as if it were successfully transferred , so that it is possible to later append to
it using the --append-verify / --append options. However there are
several reasons this is sub-optimal.
Your backup files may not be complete, and without checking the remote file which must
still be unaltered, there's no way to know.
If you are attempting to use --backup and --backup-dir ,
you've just added a new version of this file that never even exited before to your version
history.
However if we use --partial-dir , rsync will preserve the temporary partial
file, and resume downloading using that partial file next time you run it, and we do not
suffer from the above issues.
I agree this is a much more concise answer to the question. the TL;DR: is perfect and for
those that need more can read the longer bit. Strong work. – JKOlaf
Jun 28 '17 at 0:11
You may want to add the -P option to your command.
From the man page:
--partial By default, rsync will delete any partially transferred file if the transfer
is interrupted. In some circumstances it is more desirable to keep partially
transferred files. Using the --partial option tells rsync to keep the partial
file which should make a subsequent transfer of the rest of the file much faster.
-P The -P option is equivalent to --partial --progress. Its pur-
pose is to make it much easier to specify these two options for
a long transfer that may be interrupted.
@Flimm not quite correct. If there is an interruption (network or receiving side) then when
using --partial the partial file is kept AND it is used when rsync is resumed. From the
manpage: "Using the --partial option tells rsync to keep the partial file which should
<b>make a subsequent transfer of the rest of the file much faster</b>." –
gaoithe
Aug 19 '15 at 11:29
@Flimm and @gaoithe, my answer wasn't quite accurate, and definitely not up-to-date. I've
updated it to reflect version 3 + of rsync . It's important to stress, though,
that --partial does not itself resume a failed transfer. See my answer
for details :) – DanielSmedegaardBuus
Sep 1 '15 at 14:11
@DanielSmedegaardBuus I tried it and the -P is enough in my case. Versions:
client has 3.1.0 and server has 3.1.1. I interrupted the transfer of a single large file with
ctrl-c. I guess I am missing something. – guettli
Nov 18 '15 at 12:28
I think you are forcibly calling the rsync and hence all data is getting
downloaded when you recall it again. use --progress option to copy only those
files which are not copied and --delete option to delete any files if already
copied and now it does not exist in source folder...
@Fabien He tells rsync to set two ssh options (rsync uses ssh to connect). The second one
tells ssh to not prompt for confirmation if the host he's connecting to isn't already known
(by existing in the "known hosts" file). The first one tells ssh to not use the default known
hosts file (which would be ~/.ssh/known_hosts). He uses /dev/null instead, which is of course
always empty, and as ssh would then not find the host in there, it would normally prompt for
confirmation, hence option two. Upon connecting, ssh writes the now known host to /dev/null,
effectively forgetting it instantly :) – DanielSmedegaardBuus
Dec 7 '14 at 0:12
...but you were probably wondering what effect, if any, it has on the rsync operation itself.
The answer is none. It only serves to not have the host you're connecting to added to your
SSH known hosts file. Perhaps he's a sysadmin often connecting to a great number of new
servers, temporary systems or whatnot. I don't know :) – DanielSmedegaardBuus
Dec 7 '14 at 0:23
There are a couple errors here; one is very serious: --delete will delete files
in the destination that don't exist in the source. The less serious one is that
--progress doesn't modify how things are copied; it just gives you a progress
report on each file as it copies. (I fixed the serious error; replaced it with
--remove-source-files .) – Paul d'Aoust
Nov 17 '16 at 22:39
What's the accepted way of parsing this such that in each case (or some combination of the
two) $v , $f , and $d will all be set to
true and $outFile will be equal to /fizz/someOtherFile
?
For zsh-users there's a great builtin called zparseopts which can do: zparseopts -D -E
-M -- d=debug -debug=d And have both -d and --debug in the
$debug array echo $+debug[1] will return 0 or 1 if one of those are
used. Ref: zsh.org/mla/users/2011/msg00350.html
– dezza
Aug 2 '16 at 2:13
Preferred Method: Using straight bash without getopt[s]
I originally answered the question as the OP asked. This Q/A is getting a lot of
attention, so I should also offer the non-magic way to do this. I'm going to expand upon
guneysus's answer
to fix the nasty sed and include
Tobias Kienzler's suggestion .
Two of the most common ways to pass key value pair arguments are:
#!/bin/bash
POSITIONAL=()
while [[ $# -gt 0 ]]
do
key="$1"
case $key in
-e|--extension)
EXTENSION="$2"
shift # past argument
shift # past value
;;
-s|--searchpath)
SEARCHPATH="$2"
shift # past argument
shift # past value
;;
-l|--lib)
LIBPATH="$2"
shift # past argument
shift # past value
;;
--default)
DEFAULT=YES
shift # past argument
;;
*) # unknown option
POSITIONAL+=("$1") # save it in an array for later
shift # past argument
;;
esac
done
set -- "${POSITIONAL[@]}" # restore positional parameters
echo FILE EXTENSION = "${EXTENSION}"
echo SEARCH PATH = "${SEARCHPATH}"
echo LIBRARY PATH = "${LIBPATH}"
echo DEFAULT = "${DEFAULT}"
echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l)
if [[ -n $1 ]]; then
echo "Last line of file specified as non-opt/last argument:"
tail -1 "$1"
fi
#!/bin/bash
for i in "$@"
do
case $i in
-e=*|--extension=*)
EXTENSION="${i#*=}"
shift # past argument=value
;;
-s=*|--searchpath=*)
SEARCHPATH="${i#*=}"
shift # past argument=value
;;
-l=*|--lib=*)
LIBPATH="${i#*=}"
shift # past argument=value
;;
--default)
DEFAULT=YES
shift # past argument with no value
;;
*)
# unknown option
;;
esac
done
echo "FILE EXTENSION = ${EXTENSION}"
echo "SEARCH PATH = ${SEARCHPATH}"
echo "LIBRARY PATH = ${LIBPATH}"
echo "Number files in SEARCH PATH with EXTENSION:" $(ls -1 "${SEARCHPATH}"/*."${EXTENSION}" | wc -l)
if [[ -n $1 ]]; then
echo "Last line of file specified as non-opt/last argument:"
tail -1 $1
fi
To better understand ${i#*=} search for "Substring Removal" in this guide . It is
functionally equivalent to `sed 's/[^=]*=//' <<< "$i"` which calls a
needless subprocess or `echo "$i" | sed 's/[^=]*=//'` which calls two
needless subprocesses.
Never use getopt(1). getopt cannot handle empty arguments strings, or
arguments with embedded whitespace. Please forget that it ever existed.
The POSIX shell (and others) offer getopts which is safe to use instead. Here
is a simplistic getopts example:
#!/bin/sh
# A POSIX variable
OPTIND=1 # Reset in case getopts has been used previously in the shell.
# Initialize our own variables:
output_file=""
verbose=0
while getopts "h?vf:" opt; do
case "$opt" in
h|\?)
show_help
exit 0
;;
v) verbose=1
;;
f) output_file=$OPTARG
;;
esac
done
shift $((OPTIND-1))
[ "${1:-}" = "--" ] && shift
echo "verbose=$verbose, output_file='$output_file', Leftovers: $@"
# End of file
The advantages of getopts are:
It's portable, and will work in e.g. dash.
It can handle things like -vf filename in the expected Unix way,
automatically.
The disadvantage of getopts is that it can only handle short options (
-h , not --help ) without trickery.
There is a getopts tutorial which explains
what all of the syntax and variables mean. In bash, there is also help getopts ,
which might be informative.
Is this really true? According to Wikipedia there's a newer GNU enhanced version of
getopt which includes all the functionality of getopts and then
some. man getopt on Ubuntu 13.04 outputs getopt - parse command options
(enhanced) as the name, so I presume this enhanced version is standard now. –
Livven
Jun 6 '13 at 21:19
You do not echo –default . In the first example, I notice that if
–default is the last argument, it is not processed (considered as
non-opt), unless while [[ $# -gt 1 ]] is set as while [[ $# -gt 0
]] – kolydart
Jul 10 '17 at 8:11
No answer mentions enhanced getopt . And the top-voted answer is misleading: It ignores
-vfd style short options (requested by the OP), options after positional
arguments (also requested by the OP) and it ignores parsing-errors. Instead:
Use enhanced getopt from util-linux or formerly GNU glibc .
1
It works with getopt_long() the C function of GNU glibc.
Has all useful distinguishing features (the others don't have them):
handles spaces, quoting characters and even binary in arguments
2
it can handle options at the end: script.sh -o outFile file1 file2
-v
allows = -style long options: script.sh --outfile=fileOut
--infile fileIn
Is so old already 3 that no GNU system is missing this (e.g. any
Linux has it).
You can test for its existence with: getopt --test → return value
4.
Other getopt or shell-builtin getopts are of limited
use.
verbose: y, force: y, debug: y, in: ./foo/bar/someFile, out: /fizz/someOtherFile
with the following myscript
#!/bin/bash
getopt --test > /dev/null
if [[ $? -ne 4 ]]; then
echo "I'm sorry, `getopt --test` failed in this environment."
exit 1
fi
OPTIONS=dfo:v
LONGOPTIONS=debug,force,output:,verbose
# -temporarily store output to be able to check for errors
# -e.g. use "--options" parameter by name to activate quoting/enhanced mode
# -pass arguments only via -- "$@" to separate them correctly
PARSED=$(getopt --options=$OPTIONS --longoptions=$LONGOPTIONS --name "$0" -- "$@")
if [[ $? -ne 0 ]]; then
# e.g. $? == 1
# then getopt has complained about wrong arguments to stdout
exit 2
fi
# read getopt's output this way to handle the quoting right:
eval set -- "$PARSED"
# now enjoy the options in order and nicely split until we see --
while true; do
case "$1" in
-d|--debug)
d=y
shift
;;
-f|--force)
f=y
shift
;;
-v|--verbose)
v=y
shift
;;
-o|--output)
outFile="$2"
shift 2
;;
--)
shift
break
;;
*)
echo "Programming error"
exit 3
;;
esac
done
# handle non-option arguments
if [[ $# -ne 1 ]]; then
echo "$0: A single input file is required."
exit 4
fi
echo "verbose: $v, force: $f, debug: $d, in: $1, out: $outFile"
1 enhanced getopt is available on most "bash-systems", including
Cygwin; on OS X try brew install gnu-getopt 2 the POSIX exec() conventions have no reliable way to
pass binary NULL in command line arguments; those bytes prematurely end the argument 3 first version released in 1997 or before (I only tracked it back to
1997)
I believe that the only caveat with getopt is that it cannot be used
conveniently in wrapper scripts where one might have few options specific to the
wrapper script, and then pass the non-wrapper-script options to the wrapped executable,
intact. Let's say I have a grep wrapper called mygrep and I have an
option --foo specific to mygrep , then I cannot do mygrep
--foo -A 2 , and have the -A 2 passed automatically to grep
; I need to do mygrep --foo -- -A 2 . Here is my implementation on top of
your solution. – Kaushal Modi
Apr 27 '17 at 14:02
Alex, I agree and there's really no way around that since we need to know the actual return
value of getopt --test . I'm a big fan of "Unofficial Bash Strict mode", (which
includes set -e ), and I just put the check for getopt ABOVE set -euo
pipefail and IFS=$'\n\t' in my script. – bobpaul
Mar 20 at 16:45
@bobpaul Oh, there is a way around that. And I'll edit my answer soon to reflect my
collections regarding this issue ( set -e )... – Robert Siemer
Mar 21 at 9:10
@bobpaul Your statement about util-linux is wrong and misleading as well: the package is
marked "essential" on Ubuntu/Debian. As such, it is always installed. – Which distros
are you talking about (where you say it needs to be installed on purpose)? – Robert Siemer
Mar 21 at 9:16
#!/bin/bash
for i in "$@"
do
case $i in
-p=*|--prefix=*)
PREFIX="${i#*=}"
;;
-s=*|--searchpath=*)
SEARCHPATH="${i#*=}"
;;
-l=*|--lib=*)
DIR="${i#*=}"
;;
--default)
DEFAULT=YES
;;
*)
# unknown option
;;
esac
done
echo PREFIX = ${PREFIX}
echo SEARCH PATH = ${SEARCHPATH}
echo DIRS = ${DIR}
echo DEFAULT = ${DEFAULT}
To better understand ${i#*=} search for "Substring Removal" in this guide . It is
functionally equivalent to `sed 's/[^=]*=//' <<< "$i"` which calls a
needless subprocess or `echo "$i" | sed 's/[^=]*=//'` which calls two
needless subprocesses.
Neat! Though this won't work for space-separated arguments à la mount -t tempfs
... . One can probably fix this via something like while [ $# -ge 1 ]; do
param=$1; shift; case $param in; -p) prefix=$1; shift;; etc – Tobias Kienzler
Nov 12 '13 at 12:48
@Matt J, the first part of the script (for i) would be able to handle arguments with spaces
in them if you use "$i" instead of $i. The getopts does not seem to be able to handle
arguments with spaces. What would be the advantage of using getopt over the for i loop?
– thebunnyrules
Jun 1 at 1:57
Sorry for the delay. In my script, the handle_argument function receives all the non-option
arguments. You can replace that line with whatever you'd like, maybe *) die
"unrecognized argument: $1" or collect the args into a variable *) args+="$1";
shift 1;; . – bronson
Oct 8 '15 at 20:41
Amazing! I've tested a couple of answers, but this is the only one that worked for all cases,
including many positional parameters (both before and after flags) – Guilherme Garnier
Apr 13 at 16:10
I'm about 4 years late to this question, but want to give back. I used the earlier answers as
a starting point to tidy up my old adhoc param parsing. I then refactored out the following
template code. It handles both long and short params, using = or space separated arguments,
as well as multiple short params grouped together. Finally it re-inserts any non-param
arguments back into the $1,$2.. variables. I hope it's useful.
#!/usr/bin/env bash
# NOTICE: Uncomment if your script depends on bashisms.
#if [ -z "$BASH_VERSION" ]; then bash $0 $@ ; exit $? ; fi
echo "Before"
for i ; do echo - $i ; done
# Code template for parsing command line parameters using only portable shell
# code, while handling both long and short params, handling '-f file' and
# '-f=file' style param data and also capturing non-parameters to be inserted
# back into the shell positional parameters.
while [ -n "$1" ]; do
# Copy so we can modify it (can't modify $1)
OPT="$1"
# Detect argument termination
if [ x"$OPT" = x"--" ]; then
shift
for OPT ; do
REMAINS="$REMAINS \"$OPT\""
done
break
fi
# Parse current opt
while [ x"$OPT" != x"-" ] ; do
case "$OPT" in
# Handle --flag=value opts like this
-c=* | --config=* )
CONFIGFILE="${OPT#*=}"
shift
;;
# and --flag value opts like this
-c* | --config )
CONFIGFILE="$2"
shift
;;
-f* | --force )
FORCE=true
;;
-r* | --retry )
RETRY=true
;;
# Anything unknown is recorded for later
* )
REMAINS="$REMAINS \"$OPT\""
break
;;
esac
# Check for multiple short options
# NOTICE: be sure to update this pattern to match valid options
NEXTOPT="${OPT#-[cfr]}" # try removing single short opt
if [ x"$OPT" != x"$NEXTOPT" ] ; then
OPT="-$NEXTOPT" # multiple short opts, keep going
else
break # long form, exit inner loop
fi
done
# Done with that param. move to next
shift
done
# Set the non-parameters back into the positional parameters ($1 $2 ..)
eval set -- $REMAINS
echo -e "After: \n configfile='$CONFIGFILE' \n force='$FORCE' \n retry='$RETRY' \n remains='$REMAINS'"
for i ; do echo - $i ; done
This code can't handle options with arguments like this: -c1 . And the use of
= to separate short options from their arguments is unusual... –
Robert
Siemer
Dec 6 '15 at 13:47
I ran into two problems with this useful chunk of code: 1) the "shift" in the case of
"-c=foo" ends up eating the next parameter; and 2) 'c' should not be included in the "[cfr]"
pattern for combinable short options. – sfnd
Jun 6 '16 at 19:28
My answer is largely based on the answer by Bruno Bronosky , but I sort
of mashed his two pure bash implementations into one that I use pretty frequently.
# As long as there is at least one more argument, keep looping
while [[ $# -gt 0 ]]; do
key="$1"
case "$key" in
# This is a flag type option. Will catch either -f or --foo
-f|--foo)
FOO=1
;;
# Also a flag type option. Will catch either -b or --bar
-b|--bar)
BAR=1
;;
# This is an arg value type option. Will catch -o value or --output-file value
-o|--output-file)
shift # past the key and to the value
OUTPUTFILE="$1"
;;
# This is an arg=value type option. Will catch -o=value or --output-file=value
-o=*|--output-file=*)
# No need to shift here since the value is part of the same string
OUTPUTFILE="${key#*=}"
;;
*)
# Do whatever you want with extra options
echo "Unknown option '$key'"
;;
esac
# Shift after checking all the cases to get the next option
shift
done
This allows you to have both space separated options/values, as well as equal defined
values.
So you could run your script using:
./myscript --foo -b -o /fizz/file.txt
as well as:
./myscript -f --bar -o=/fizz/file.txt
and both should have the same end result.
PROS:
Allows for both -arg=value and -arg value
Works with any arg name that you can use in bash
Meaning -a or -arg or --arg or -a-r-g or whatever
Pure bash. No need to learn/use getopt or getopts
CONS:
Can't combine args
Meaning no -abc. You must do -a -b -c
These are the only pros/cons I can think of off the top of my head
I have found the matter to write portable parsing in scripts so frustrating that I have
written Argbash - a FOSS
code generator that can generate the arguments-parsing code for your script plus it has some
nice features:
Thanks for writing argbash, I just used it and found it works well. I mostly went for argbash
because it's a code generator supporting the older bash 3.x found on OS X 10.11 El Capitan.
The only downside is that the code-generator approach means quite a lot of code in your main
script, compared to calling a module. – RichVel
Aug 18 '16 at 5:34
You can actually use Argbash in a way that it produces tailor-made parsing library just for
you that you can have included in your script or you can have it in a separate file and just
source it. I have added an example to
demonstrate that and I have made it more explicit in the documentation, too. –
bubla
Aug 23 '16 at 20:40
Good to know. That example is interesting but still not really clear - maybe you can change
name of the generated script to 'parse_lib.sh' or similar and show where the main script
calls it (like in the wrapping script section which is more complex use case). –
RichVel
Aug 24 '16 at 5:47
The issues were addressed in recent version of argbash: Documentation has been improved, a
quickstart argbash-init script has been introduced and you can even use argbash online at
argbash.io/generate –
bubla
Dec 2 '16 at 20:12
I read all and this one is my preferred one. I don't like to use -a=1 as argc
style. I prefer to put first the main option -options and later the special ones with single
spacing -o option . Im looking for the simplest-vs-better way to read argvs.
– erm3nda
May 20 '15 at 22:50
It's working really well but if you pass an argument to a non a: option all the following
options would be taken as arguments. You can check this line ./myscript -v -d fail -o
/fizz/someOtherFile -f ./foo/bar/someFile with your own script. -d option is not set
as d: – erm3nda
May 20 '15 at 23:25
Expanding on the excellent answer by @guneysus, here is a tweak that lets user use whichever
syntax they prefer, eg
command -x=myfilename.ext --another_switch
vs
command -x myfilename.ext --another_switch
That is to say the equals can be replaced with whitespace.
This "fuzzy interpretation" might not be to your liking, but if you are making scripts
that are interchangeable with other utilities (as is the case with mine, which must work with
ffmpeg), the flexibility is useful.
STD_IN=0
prefix=""
key=""
value=""
for keyValue in "$@"
do
case "${prefix}${keyValue}" in
-i=*|--input_filename=*) key="-i"; value="${keyValue#*=}";;
-ss=*|--seek_from=*) key="-ss"; value="${keyValue#*=}";;
-t=*|--play_seconds=*) key="-t"; value="${keyValue#*=}";;
-|--stdin) key="-"; value=1;;
*) value=$keyValue;;
esac
case $key in
-i) MOVIE=$(resolveMovie "${value}"); prefix=""; key="";;
-ss) SEEK_FROM="${value}"; prefix=""; key="";;
-t) PLAY_SECONDS="${value}"; prefix=""; key="";;
-) STD_IN=${value}; prefix=""; key="";;
*) prefix="${keyValue}=";;
esac
done
getopts works great if #1 you have it installed and #2 you intend to run it on the same
platform. OSX and Linux (for example) behave differently in this respect.
Here is a (non getopts) solution that supports equals, non-equals, and boolean flags. For
example you could run your script in this way:
./script --arg1=value1 --arg2 value2 --shouldClean
# parse the arguments.
COUNTER=0
ARGS=("$@")
while [ $COUNTER -lt $# ]
do
arg=${ARGS[$COUNTER]}
let COUNTER=COUNTER+1
nextArg=${ARGS[$COUNTER]}
if [[ $skipNext -eq 1 ]]; then
echo "Skipping"
skipNext=0
continue
fi
argKey=""
argVal=""
if [[ "$arg" =~ ^\- ]]; then
# if the format is: -key=value
if [[ "$arg" =~ \= ]]; then
argVal=$(echo "$arg" | cut -d'=' -f2)
argKey=$(echo "$arg" | cut -d'=' -f1)
skipNext=0
# if the format is: -key value
elif [[ ! "$nextArg" =~ ^\- ]]; then
argKey="$arg"
argVal="$nextArg"
skipNext=1
# if the format is: -key (a boolean flag)
elif [[ "$nextArg" =~ ^\- ]] || [[ -z "$nextArg" ]]; then
argKey="$arg"
argVal=""
skipNext=0
fi
# if the format has not flag, just a value.
else
argKey=""
argVal="$arg"
skipNext=0
fi
case "$argKey" in
--source-scmurl)
SOURCE_URL="$argVal"
;;
--dest-scmurl)
DEST_URL="$argVal"
;;
--version-num)
VERSION_NUM="$argVal"
;;
-c|--clean)
CLEAN_BEFORE_START="1"
;;
-h|--help|-help|--h)
showUsage
exit
;;
esac
done
This is how I do in a function to avoid breaking getopts run at the same time somewhere
higher in stack:
function waitForWeb () {
local OPTIND=1 OPTARG OPTION
local host=localhost port=8080 proto=http
while getopts "h:p:r:" OPTION; do
case "$OPTION" in
h)
host="$OPTARG"
;;
p)
port="$OPTARG"
;;
r)
proto="$OPTARG"
;;
esac
done
...
}
I give you The Function parse_params that will parse params:
Without polluting global scope.
Effortlessly returns to you ready to use variables so that you could build further
logic on them
Amount of dashes before params does not matter ( --all equals
-all equals all=all )
The script below is a copy-paste working demonstration. See show_use function
to understand how to use parse_params .
Limitations:
Does not support space delimited params ( -d 1 )
Param names will lose dashes so --any-param and -anyparam are
equivalent
eval $(parse_params "$@") must be used inside bash function (it will not
work in the global scope)
#!/bin/bash
# Universal Bash parameter parsing
# Parse equal sign separated params into named local variables
# Standalone named parameter value will equal its param name (--force creates variable $force=="force")
# Parses multi-valued named params into an array (--path=path1 --path=path2 creates ${path[*]} array)
# Parses un-named params into ${ARGV[*]} array
# Additionally puts all named params into ${ARGN[*]} array
# Additionally puts all standalone "option" params into ${ARGO[*]} array
# @author Oleksii Chekulaiev
# @version v1.3 (May-14-2018)
parse_params ()
{
local existing_named
local ARGV=() # un-named params
local ARGN=() # named params
local ARGO=() # options (--params)
echo "local ARGV=(); local ARGN=(); local ARGO=();"
while [[ "$1" != "" ]]; do
# Escape asterisk to prevent bash asterisk expansion
_escaped=${1/\*/\'\"*\"\'}
# If equals delimited named parameter
if [[ "$1" =~ ^..*=..* ]]; then
# Add to named parameters array
echo "ARGN+=('$_escaped');"
# key is part before first =
local _key=$(echo "$1" | cut -d = -f 1)
# val is everything after key and = (protect from param==value error)
local _val="${1/$_key=}"
# remove dashes from key name
_key=${_key//\-}
# search for existing parameter name
if (echo "$existing_named" | grep "\b$_key\b" >/dev/null); then
# if name already exists then it's a multi-value named parameter
# re-declare it as an array if needed
if ! (declare -p _key 2> /dev/null | grep -q 'declare \-a'); then
echo "$_key=(\"\$$_key\");"
fi
# append new value
echo "$_key+=('$_val');"
else
# single-value named parameter
echo "local $_key=\"$_val\";"
existing_named=" $_key"
fi
# If standalone named parameter
elif [[ "$1" =~ ^\-. ]]; then
# Add to options array
echo "ARGO+=('$_escaped');"
# remove dashes
local _key=${1//\-}
echo "local $_key=\"$_key\";"
# non-named parameter
else
# Escape asterisk to prevent bash asterisk expansion
_escaped=${1/\*/\'\"*\"\'}
echo "ARGV+=('$_escaped');"
fi
shift
done
}
#--------------------------- DEMO OF THE USAGE -------------------------------
show_use ()
{
eval $(parse_params "$@")
# --
echo "${ARGV[0]}" # print first unnamed param
echo "${ARGV[1]}" # print second unnamed param
echo "${ARGN[0]}" # print first named param
echo "${ARG0[0]}" # print first option param (--force)
echo "$anyparam" # print --anyparam value
echo "$k" # print k=5 value
echo "${multivalue[0]}" # print first value of multi-value
echo "${multivalue[1]}" # print second value of multi-value
[[ "$force" == "force" ]] && echo "\$force is set so let the force be with you"
}
show_use "param 1" --anyparam="my value" param2 k=5 --force --multi-value=test1 --multi-value=test2
You have to decide before use if = is to be used on an option or not. This is to keep the
code clean(ish).
while [[ $# > 0 ]]
do
key="$1"
while [[ ${key+x} ]]
do
case $key in
-s*|--stage)
STAGE="$2"
shift # option has parameter
;;
-w*|--workfolder)
workfolder="$2"
shift # option has parameter
;;
-e=*)
EXAMPLE="${key#*=}"
break # option has been fully handled
;;
*)
# unknown option
echo Unknown option: $key #1>&2
exit 10 # either this: my preferred way to handle unknown options
break # or this: do this to signal the option has been handled (if exit isn't used)
;;
esac
# prepare for next option in this key, if any
[[ "$key" = -? || "$key" == --* ]] && unset key || key="${key/#-?/-}"
done
shift # option(s) fully processed, proceed to next input argument
done
can be accomplished with a fairly concise approach:
# process flags
pointer=1
while [[ $pointer -le $# ]]; do
param=${!pointer}
if [[ $param != "-"* ]]; then ((pointer++)) # not a parameter flag so advance pointer
else
case $param in
# paramter-flags with arguments
-e=*|--environment=*) environment="${param#*=}";;
--another=*) another="${param#*=}";;
# binary flags
-q|--quiet) quiet=true;;
-d) debug=true;;
esac
# splice out pointer frame from positional list
[[ $pointer -gt 1 ]] \
&& set -- ${@:1:((pointer - 1))} ${@:((pointer + 1)):$#} \
|| set -- ${@:((pointer + 1)):$#};
fi
done
# positional remain
node_name=$1
ip_address=$2
--param arg (space delimited)
It's usualy clearer to not mix --flag=value and --flag value
styles.
./script.sh dumbo 127.0.0.1 --environment production -q -d
This is a little dicey to read, but is still valid
./script.sh dumbo --environment production 127.0.0.1 --quiet -d
Source
# process flags
pointer=1
while [[ $pointer -le $# ]]; do
if [[ ${!pointer} != "-"* ]]; then ((pointer++)) # not a parameter flag so advance pointer
else
param=${!pointer}
((pointer_plus = pointer + 1))
slice_len=1
case $param in
# paramter-flags with arguments
-e|--environment) environment=${!pointer_plus}; ((slice_len++));;
--another) another=${!pointer_plus}; ((slice_len++));;
# binary flags
-q|--quiet) quiet=true;;
-d) debug=true;;
esac
# splice out pointer frame from positional list
[[ $pointer -gt 1 ]] \
&& set -- ${@:1:((pointer - 1))} ${@:((pointer + $slice_len)):$#} \
|| set -- ${@:((pointer + $slice_len)):$#};
fi
done
# positional remain
node_name=$1
ip_address=$2
Note that getopt(1) was a short living mistake from AT&T.
getopt was created in 1984 but already buried in 1986 because it was not really
usable.
A proof for the fact that getopt is very outdated is that the
getopt(1) man page still mentions "$*" instead of "$@"
, that was added to the Bourne Shell in 1986 together with the getopts(1) shell
builtin in order to deal with arguments with spaces inside.
BTW: if you are interested in parsing long options in shell scripts, it may be of interest
to know that the getopt(3) implementation from libc (Solaris) and
ksh93 both added a uniform long option implementation that supports long options
as aliases for short options. This causes ksh93 and the Bourne
Shell to implement a uniform interface for long options via getopts .
An example for long options taken from the Bourne Shell man page:
This also might be useful to know, you can set a value and if someone provides input,
override the default with that value..
myscript.sh -f ./serverlist.txt or just ./myscript.sh (and it takes defaults)
#!/bin/bash
# --- set the value, if there is inputs, override the defaults.
HOME_FOLDER="${HOME}/owned_id_checker"
SERVER_FILE_LIST="${HOME_FOLDER}/server_list.txt"
while [[ $# > 1 ]]
do
key="$1"
shift
case $key in
-i|--inputlist)
SERVER_FILE_LIST="$1"
shift
;;
esac
done
echo "SERVER LIST = ${SERVER_FILE_LIST}"
Main differentiating feature of my solution is that it allows to have options concatenated
together just like tar -xzf foo.tar.gz is equal to tar -x -z -f
foo.tar.gz . And just like in tar , ps etc. the leading
hyphen is optional for a block of short options (but this can be changed easily). Long
options are supported as well (but when a block starts with one then two leading hyphens are
required).
Code with example options
#!/bin/sh
echo
echo "POSIX-compliant getopt(s)-free old-style-supporting option parser from phk@[se.unix]"
echo
print_usage() {
echo "Usage:
$0 {a|b|c} [ARG...]
Options:
--aaa-0-args
-a
Option without arguments.
--bbb-1-args ARG
-b ARG
Option with one argument.
--ccc-2-args ARG1 ARG2
-c ARG1 ARG2
Option with two arguments.
" >&2
}
if [ $# -le 0 ]; then
print_usage
exit 1
fi
opt=
while :; do
if [ $# -le 0 ]; then
# no parameters remaining -> end option parsing
break
elif [ ! "$opt" ]; then
# we are at the beginning of a fresh block
# remove optional leading hyphen and strip trailing whitespaces
opt=$(echo "$1" | sed 's/^-\?\([a-zA-Z0-9\?-]*\)/\1/')
fi
# get the first character -> check whether long option
first_chr=$(echo "$opt" | awk '{print substr($1, 1, 1)}')
[ "$first_chr" = - ] && long_option=T || long_option=F
# note to write the options here with a leading hyphen less
# also do not forget to end short options with a star
case $opt in
-)
# end of options
shift
break
;;
a*|-aaa-0-args)
echo "Option AAA activated!"
;;
b*|-bbb-1-args)
if [ "$2" ]; then
echo "Option BBB with argument '$2' activated!"
shift
else
echo "BBB parameters incomplete!" >&2
print_usage
exit 1
fi
;;
c*|-ccc-2-args)
if [ "$2" ] && [ "$3" ]; then
echo "Option CCC with arguments '$2' and '$3' activated!"
shift 2
else
echo "CCC parameters incomplete!" >&2
print_usage
exit 1
fi
;;
h*|\?*|-help)
print_usage
exit 0
;;
*)
if [ "$long_option" = T ]; then
opt=$(echo "$opt" | awk '{print substr($1, 2)}')
else
opt=$first_chr
fi
printf 'Error: Unknown option: "%s"\n' "$opt" >&2
print_usage
exit 1
;;
esac
if [ "$long_option" = T ]; then
# if we had a long option then we are going to get a new block next
shift
opt=
else
# if we had a short option then just move to the next character
opt=$(echo "$opt" | awk '{print substr($1, 2)}')
# if block is now empty then shift to the next one
[ "$opt" ] || shift
fi
done
echo "Doing something..."
exit 0
For the example usage please see the examples further below.
Position of options
with arguments
For what its worth there the options with arguments don't be the last (only long options
need to be). So while e.g. in tar (at least in some implementations) the
f options needs to be last because the file name follows ( tar xzf
bar.tar.gz works but tar xfz bar.tar.gz does not) this is not the case
here (see the later examples).
Multiple options with arguments
As another bonus the option parameters are consumed in the order of the options by the
parameters with required options. Just look at the output of my script here with the command
line abc X Y Z (or -abc X Y Z ):
Option AAA activated!
Option BBB with argument 'X' activated!
Option CCC with arguments 'Y' and 'Z' activated!
Long options concatenated as well
Also you can also have long options in option block given that they occur last in the
block. So the following command lines are all equivalent (including the order in which the
options and its arguments are being processed):
-cba Z Y X
cba Z Y X
-cb-aaa-0-args Z Y X
-c-bbb-1-args Z Y X -a
--ccc-2-args Z Y -ba X
c Z Y b X a
-c Z Y -b X -a
--ccc-2-args Z Y --bbb-1-args X --aaa-0-args
All of these lead to:
Option CCC with arguments 'Z' and 'Y' activated!
Option BBB with argument 'X' activated!
Option AAA activated!
Doing something...
Not in this solutionOptional arguments
Options with optional arguments should be possible with a bit of work, e.g. by looking
forward whether there is a block without a hyphen; the user would then need to put a hyphen
in front of every block following a block with a parameter having an optional parameter.
Maybe this is too complicated to communicate to the user so better just require a leading
hyphen altogether in this case.
Things get even more complicated with multiple possible parameters. I would advise against
making the options trying to be smart by determining whether the an argument might be for it
or not (e.g. with an option just takes a number as an optional argument) because this might
break in the future.
I personally favor additional options instead of optional arguments.
Option
arguments introduced with an equal sign
Just like with optional arguments I am not a fan of this (BTW, is there a thread for
discussing the pros/cons of different parameter styles?) but if you want this you could
probably implement it yourself just like done at http://mywiki.wooledge.org/BashFAQ/035#Manual_loop
with a --long-with-arg=?* case statement and then stripping the equal sign (this
is BTW the site that says that making parameter concatenation is possible with some effort
but "left [it] as an exercise for the reader" which made me take them at their word but I
started from scratch).
Other notes
POSIX-compliant, works even on ancient Busybox setups I had to deal with (with e.g.
cut , head and getopts missing).
Solution that preserves unhandled arguments. Demos Included.
Here is my solution. It is VERY flexible and unlike others, shouldn't require external
packages and handles leftover arguments cleanly.
Usage is: ./myscript -flag flagvariable -otherflag flagvar2
All you have to do is edit the validflags line. It prepends a hyphen and searches all
arguments. It then defines the next argument as the flag name e.g.
The main code (short version, verbose with examples further down, also a version with
erroring out):
#!/usr/bin/env bash
#shebang.io
validflags="rate time number"
count=1
for arg in $@
do
match=0
argval=$1
for flag in $validflags
do
sflag="-"$flag
if [ "$argval" == "$sflag" ]
then
declare $flag=$2
match=1
fi
done
if [ "$match" == "1" ]
then
shift 2
else
leftovers=$(echo $leftovers $argval)
shift
fi
count=$(($count+1))
done
#Cleanup then restore the leftovers
shift $#
set -- $leftovers
The verbose version with built in echo demos:
#!/usr/bin/env bash
#shebang.io
rate=30
time=30
number=30
echo "all args
$@"
validflags="rate time number"
count=1
for arg in $@
do
match=0
argval=$1
# argval=$(echo $@ | cut -d ' ' -f$count)
for flag in $validflags
do
sflag="-"$flag
if [ "$argval" == "$sflag" ]
then
declare $flag=$2
match=1
fi
done
if [ "$match" == "1" ]
then
shift 2
else
leftovers=$(echo $leftovers $argval)
shift
fi
count=$(($count+1))
done
#Cleanup then restore the leftovers
echo "pre final clear args:
$@"
shift $#
echo "post final clear args:
$@"
set -- $leftovers
echo "all post set args:
$@"
echo arg1: $1 arg2: $2
echo leftovers: $leftovers
echo rate $rate time $time number $number
Final one, this one errors out if an invalid -argument is passed through.
#!/usr/bin/env bash
#shebang.io
rate=30
time=30
number=30
validflags="rate time number"
count=1
for arg in $@
do
argval=$1
match=0
if [ "${argval:0:1}" == "-" ]
then
for flag in $validflags
do
sflag="-"$flag
if [ "$argval" == "$sflag" ]
then
declare $flag=$2
match=1
fi
done
if [ "$match" == "0" ]
then
echo "Bad argument: $argval"
exit 1
fi
shift 2
else
leftovers=$(echo $leftovers $argval)
shift
fi
count=$(($count+1))
done
#Cleanup then restore the leftovers
shift $#
set -- $leftovers
echo rate $rate time $time number $number
echo leftovers: $leftovers
Pros: What it does, it handles very well. It preserves unused arguments which a lot of the
other solutions here don't. It also allows for variables to be called without being defined
by hand in the script. It also allows prepopulation of variables if no corresponding argument
is given. (See verbose example).
Cons: Can't parse a single complex arg string e.g. -xcvf would process as a single
argument. You could somewhat easily write additional code into mine that adds this
functionality though.
The top answer to this question seemed a bit buggy when I tried it -- here's my solution
which I've found to be more robust:
boolean_arg=""
arg_with_value=""
while [[ $# -gt 0 ]]
do
key="$1"
case $key in
-b|--boolean-arg)
boolean_arg=true
shift
;;
-a|--arg-with-value)
arg_with_value="$2"
shift
shift
;;
-*)
echo "Unknown option: $1"
exit 1
;;
*)
arg_num=$(( $arg_num + 1 ))
case $arg_num in
1)
first_normal_arg="$1"
shift
;;
2)
second_normal_arg="$1"
shift
;;
*)
bad_args=TRUE
esac
;;
esac
done
# Handy to have this here when adding arguments to
# see if they're working. Just edit the '0' to be '1'.
if [[ 0 == 1 ]]; then
echo "first_normal_arg: $first_normal_arg"
echo "second_normal_arg: $second_normal_arg"
echo "boolean_arg: $boolean_arg"
echo "arg_with_value: $arg_with_value"
exit 0
fi
if [[ $bad_args == TRUE || $arg_num < 2 ]]; then
echo "Usage: $(basename "$0") <first-normal-arg> <second-normal-arg> [--boolean-arg] [--arg-with-value VALUE]"
exit 1
fi
This example shows how to use getopt and eval and
HEREDOC and shift to handle short and long parameters with and
without a required value that follows. Also the switch/case statement is concise and easy to
follow.
#!/usr/bin/env bash
# usage function
function usage()
{
cat << HEREDOC
Usage: $progname [--num NUM] [--time TIME_STR] [--verbose] [--dry-run]
optional arguments:
-h, --help show this help message and exit
-n, --num NUM pass in a number
-t, --time TIME_STR pass in a time string
-v, --verbose increase the verbosity of the bash script
--dry-run do a dry run, don't change any files
HEREDOC
}
# initialize variables
progname=$(basename $0)
verbose=0
dryrun=0
num_str=
time_str=
# use getopt and store the output into $OPTS
# note the use of -o for the short options, --long for the long name options
# and a : for any option that takes a parameter
OPTS=$(getopt -o "hn:t:v" --long "help,num:,time:,verbose,dry-run" -n "$progname" -- "$@")
if [ $? != 0 ] ; then echo "Error in command line arguments." >&2 ; usage; exit 1 ; fi
eval set -- "$OPTS"
while true; do
# uncomment the next line to see how shift is working
# echo "\$1:\"$1\" \$2:\"$2\""
case "$1" in
-h | --help ) usage; exit; ;;
-n | --num ) num_str="$2"; shift 2 ;;
-t | --time ) time_str="$2"; shift 2 ;;
--dry-run ) dryrun=1; shift ;;
-v | --verbose ) verbose=$((verbose + 1)); shift ;;
-- ) shift; break ;;
* ) break ;;
esac
done
if (( $verbose > 0 )); then
# print out all the parameters we read in
cat <<-EOM
num=$num_str
time=$time_str
verbose=$verbose
dryrun=$dryrun
EOM
fi
# The rest of your script below
The most significant lines of the script above are these:
OPTS=$(getopt -o "hn:t:v" --long "help,num:,time:,verbose,dry-run" -n "$progname" -- "$@")
if [ $? != 0 ] ; then echo "Error in command line arguments." >&2 ; exit 1 ; fi
eval set -- "$OPTS"
while true; do
case "$1" in
-h | --help ) usage; exit; ;;
-n | --num ) num_str="$2"; shift 2 ;;
-t | --time ) time_str="$2"; shift 2 ;;
--dry-run ) dryrun=1; shift ;;
-v | --verbose ) verbose=$((verbose + 1)); shift ;;
-- ) shift; break ;;
* ) break ;;
esac
done
Short, to the point, readable, and handles just about everything (IMHO).
I get this on Mac OS X: ``` lib/bashopts.sh: line 138: declare: -A: invalid option declare:
usage: declare [-afFirtx] [-p] [name[=value] ...] Error in lib/bashopts.sh:138. 'declare -x
-A bashopts_optprop_name' exited with status 2 Call tree: 1: lib/controller.sh:4 source(...)
Exiting with status 1 ``` – Josh Wulf
Jun 24 '17 at 18:07
you can pass attribute to short or long option (if you are using block of short
options, attribute is attached to the last option)
you can use spaces or = to provide attributes, but attribute matches until
encountering hyphen+space "delimiter", so in --q=qwe tyqwe ty is
one attribute
it handles mix of all above so -o a -op attr ibute --option=att ribu te --op-tion
attribute --option att-ribute is valid
script:
#!/usr/bin/env sh
help_menu() {
echo "Usage:
${0##*/} [-h][-l FILENAME][-d]
Options:
-h, --help
display this help and exit
-l, --logfile=FILENAME
filename
-d, --debug
enable debug
"
}
parse_options() {
case $opt in
h|help)
help_menu
exit
;;
l|logfile)
logfile=${attr}
;;
d|debug)
debug=true
;;
*)
echo "Unknown option: ${opt}\nRun ${0##*/} -h for help.">&2
exit 1
esac
}
options=$@
until [ "$options" = "" ]; do
if [[ $options =~ (^ *(--([a-zA-Z0-9-]+)|-([a-zA-Z0-9-]+))(( |=)(([\_\.\?\/\\a-zA-Z0-9]?[ -]?[\_\.\?a-zA-Z0-9]+)+))?(.*)|(.+)) ]]; then
if [[ ${BASH_REMATCH[3]} ]]; then # for --option[=][attribute] or --option[=][attribute]
opt=${BASH_REMATCH[3]}
attr=${BASH_REMATCH[7]}
options=${BASH_REMATCH[9]}
elif [[ ${BASH_REMATCH[4]} ]]; then # for block options -qwert[=][attribute] or single short option -a[=][attribute]
pile=${BASH_REMATCH[4]}
while (( ${#pile} > 1 )); do
opt=${pile:0:1}
attr=""
pile=${pile/${pile:0:1}/}
parse_options
done
opt=$pile
attr=${BASH_REMATCH[7]}
options=${BASH_REMATCH[9]}
else # leftovers that don't match
opt=${BASH_REMATCH[10]}
options=""
fi
parse_options
fi
done
This takes the same approach as Noah's answer , but has less safety checks
/ safeguards. This allows us to write arbitrary arguments into the script's environment and
I'm pretty sure your use of eval here may allow command injection. – Will Barnwell
Oct 10 '17 at 23:57
You use shift on the known arguments and not on the unknown ones so your remaining
$@ will be all but the first two arguments (in the order they are passed in),
which could lead to some mistakes if you try to use $@ later. You don't need the
shift for the = parameters, since you're not handling spaces and you're getting the value
with the substring removal #*= – Jason S
Dec 3 '17 at 1:01
If you just want to see some examples and skip the reading, here are a little more than
thirty find command examples to get you started. Almost every command is followed
by a short description to explain the command; others are described more fully at the URLs
shown:
basic 'find file' commands
--------------------------
find / -name foo.txt -type f -print # full command
find / -name foo.txt -type f # -print isn't necessary
find / -name foo.txt # don't have to specify "type==file"
find . -name foo.txt # search under the current dir
find . -name "foo.*" # wildcard
find . -name "*.txt" # wildcard
find /users/al -name Cookbook -type d # search '/users/al' dir
case-insensitive searching
--------------------------
find . -iname foo # find foo, Foo, FOo, FOO, etc.
find . -iname foo -type d # same thing, but only dirs
find . -iname foo -type f # same thing, but only files
find files with different extensions
------------------------------------
find . -type f \( -name "*.c" -o -name "*.sh" \) # *.c and *.sh files
find . -type f \( -name "*cache" -o -name "*xml" -o -name "*html" \) # three patterns
find files that don't match a pattern (-not)
--------------------------------------------
find . -type f -not -name "*.html" # find all files not ending in ".html"
find files by text in the file (find + grep)
--------------------------------------------
find . -type f -name "*.java" -exec grep -l StringBuffer {} \; # find StringBuffer in all
*.java files
find . -type f -name "*.java" -exec grep -il string {} \; # ignore case with -i option
find . -type f -name "*.gz" -exec zgrep 'GET /foo' {} \; # search for a string in gzip'd
files
5 lines before, 10 lines after grep matches
-------------------------------------------
find . -type f -name "*.scala" -exec grep -B5 -A10 'null' {} \;
(see http://alvinalexander.com/linux-unix/find-grep-print-lines-before-after-search-term)
find files and act on them (find + exec)
----------------------------------------
find /usr/local -name "*.html" -type f -exec chmod 644 {} \; # change html files to mode
644
find htdocs cgi-bin -name "*.cgi" -type f -exec chmod 755 {} \; # change cgi files to mode
755
find . -name "*.pl" -exec ls -ld {} \; # run ls command on files found
find and copy
-------------
find . -type f -name "*.mp3" -exec cp {} /tmp/MusicFiles \; # cp *.mp3 files to
/tmp/MusicFiles
copy one file to many dirs
--------------------------
find dir1 dir2 dir3 dir4 -type d -exec cp header.shtml {} \; # copy the file header.shtml to
those dirs
find and delete
---------------
find . -type f -name "Foo*" -exec rm {} \; # remove all "Foo*" files under current dir
find . -type d -name CVS -exec rm -r {} \; # remove all subdirectories named "CVS" under
current dir
find files by modification time
-------------------------------
find . -mtime 1 # 24 hours
find . -mtime -7 # last 7 days
find . -mtime -7 -type f # just files
find . -mtime -7 -type d # just dirs
find files by modification time using a temp file
-------------------------------------------------
touch 09301330 poop # 1) create a temp file with a specific timestamp
find . -mnewer poop # 2) returns a list of new files
rm poop # 3) rm the temp file
find with time: this works on mac os x
--------------------------------------
find / -newerct '1 minute ago' -print
find and tar
------------
find . -type f -name "*.java" | xargs tar cvf myfile.tar
find . -type f -name "*.java" | xargs tar rvf myfile.tar
(see
http://alvinalexander.com/blog/post/linux-unix/using-find-xargs-tar-create-huge-archive-cygwin-linux-unix
for more information)
find, tar, and xargs
--------------------
find . -name -type f '*.mp3' -mtime -180 -print0 | xargs -0 tar rvf music.tar
(-print0 helps handle spaces in filenames)
(see
http://alvinalexander.com/mac-os-x/mac-backup-filename-directories-spaces-find-tar-xargs)
find and pax (instead of xargs and tar)
---------------------------------------
find . -type f -name "*html" | xargs tar cvf jw-htmlfiles.tar -
find . -type f -name "*html" | pax -w -f jw-htmlfiles.tar
(
Note that the code will also be executed if the file does not exist at all. It is fine with
find but in other scenarios (such as globs) should be combined with -h to handle
this case, for instance [ -h "$F" -a ! -e "$F" ] . – Calimo
Apr 18 '17 at 19:50
this seems pretty nice as this only returns true if the file is actually a symlink. But even
with adding -q, readlink outputs the name of the link on linux. If this is the case in
general maybe the answer should be updated with 'readlink -q $F > dev/null'. Or am I
missing something? – zoltanctoth
Nov 8 '11 at 10:55
I'd strongly suggest not to use find -L for the task (see below for
explanation). Here are some other ways to do this:
If you want to use a "pure find " method, it should rather look like this:
find . -xtype l
( xtype is a test performed on a dereferenced link) This may not be
available in all versions of find , though. But there are other options as
well:
You can also exec test -e from within the find command:
find . -type l ! -exec test -e {} \; -print
Even some grep trick could be better (i.e., safer ) than
find -L , but not exactly such as presented in the question (which greps in
entire output lines, including filenames):
find . -type l -exec sh -c 'file -b "$1" | grep -q ^broken' sh {} \; -print
The find -L trick quoted by solo from commandlinefu
looks nice and hacky, but it has one very dangerous pitfall : All the symlinks are followed.
Consider directory with the contents presented below:
$ ls -l
total 0
lrwxrwxrwx 1 michal users 6 May 15 08:12 link_1 -> nonexistent1
lrwxrwxrwx 1 michal users 6 May 15 08:13 link_2 -> nonexistent2
lrwxrwxrwx 1 michal users 6 May 15 08:13 link_3 -> nonexistent3
lrwxrwxrwx 1 michal users 6 May 15 08:13 link_4 -> nonexistent4
lrwxrwxrwx 1 michal users 11 May 15 08:20 link_out -> /usr/share/
If you run find -L . -type l in that directory, all /usr/share/
would be searched as well (and that can take really long) 1 . For a
find command that is "immune to outgoing links", don't use -L .
1 This may look like a minor inconvenience (the command will "just" take long
to traverse all /usr/share ) – but can have more severe consequences. For
instance, consider chroot environments: They can exist in some subdirectory of the main
filesystem and contain symlinks to absolute locations. Those links could seem to be broken
for the "outside" system, because they only point to proper places once you've entered the
chroot. I also recall that some bootloader used symlinks under /boot that only
made sense in an initial boot phase, when the boot partition was mounted as /
.
So if you use a find -L command to find and then delete broken symlinks from
some harmless-looking directory, you might even break your system...
I think -type l is redundant since -xtype l will operate as
-type l on non-links. So find -xtype l is probably all you need.
Thanks for this approach. – quornian
Nov 17 '12 at 21:56
Be aware that those solutions don't work for all filesystem types. For example it won't work
for checking if /proc/XXX/exe link is broken. For this, use test -e
"$(readlink /proc/XXX/exe)" . – qwertzguy
Jan 8 '15 at 21:37
@Flimm find . -xtype l means "find all symlinks whose (ultimate) target files
are symlinks". But the ultimate target of a symlink cannot be a symlink, otherwise we can
still follow the link and it is not the ultimate target. Since there is no such symlinks, we
can define them as something else, i.e. broken symlinks. – weakish
Apr 8 '16 at 4:57
@JoóÁdám "which can only be a symbolic link in case it is broken". Give
"broken symbolic link" or "non exist file" an individual type, instead of overloading
l , is less confusing to me. – weakish
Apr 22 '16 at 12:19
The warning at the end is useful, but note that this does not apply to the -L
hack but rather to (blindly) removing broken symlinks in general. – Alois Mahdal
Jul 15 '16 at 0:22
As rozcietrzewiacz has already commented, find -L can have unexpected
consequence of expanding the search into symlinked directories, so isn't the optimal
approach. What no one has mentioned yet is that
find /path/to/search -xtype l
is the more concise, and logically identical command to
find /path/to/search -type l -xtype l
None of the solutions presented so far will detect cyclic symlinks, which is another type
of breakage.
this question addresses portability. To summarize, the portable way to find broken
symbolic links, including cyclic links, is:
find /path/to/search -type l -exec test ! -e {} \; -print
-L Cause the file information and file type (see stat(2)) returned
for each symbolic link to be those of the file referenced by the
link, not the link itself. If the referenced file does not exist,
the file information and type will be for the link itself.
If you need a different behavior whether the link is broken or cyclic you can also use %Y
with find:
$ touch a
$ ln -s a b # link to existing target
$ ln -s c d # link to non-existing target
$ ln -s e e # link to itself
$ find . -type l -exec test ! -e {} \; -printf '%Y %p\n' \
| while read type link; do
case "$type" in
N) echo "do something with broken link $link" ;;
L) echo "do something with cyclic link $link" ;;
esac
done
do something with broken link ./d
do something with cyclic link ./e
Yet another shorthand for those whose find command does not support
xtype can be derived from this: find . type l -printf "%Y %p\n" | grep -w
'^N' . As andy beat me to it with the same (basic) idea in his script, I was reluctant
to write it as separate answer. :) – syntaxerror
Jun 25 '15 at 0:28
I use this for my case and it works quite well, as I know the directory to look for broken
symlinks:
find -L $path -maxdepth 1 -type l
and my folder does include a link to /usr/share but it doesn't traverse it.
Cross-device links and those that are valid for chroots, etc. are still a pitfall but for my
use case it's sufficient.
,
Simple no-brainer answer, which is a variation on OP's version. Sometimes, you just want
something easy to type or remember:
[high]
Its always better to wrap the search term (name parameter) in double or single quotes. Not
doing so will seem to work sometimes and give strange results at other times.
[/high]
3. Limit depth of directory traversal
The find command by default travels down the entire directory tree recursively, which is
time and resource consuming. However the depth of directory travesal can be specified. For
example we don't want to go more than 2 or 3 levels down in the sub directories. This is done
using the maxdepth option.
The second example uses maxdepth of 1, which means it will not go lower than 1 level deep,
either only in the current directory.
This is very useful when we want to do a limited search only in the current directory or max
1 level deep sub directories and not the entire directory tree which would take more time.
Just like maxdepth there is an option called mindepth which does what the name suggests,
that is, it will go atleast N level deep before searching for the files.
4. Invert
match
It is also possible to search for files that do no match a given name or pattern. This is
helpful when we know which files to exclude from the search.
So in the above example we found all files that do not have the extension of php, either
non-php files. The find command also supports the exclamation mark inplace of not.
[pre]
find ./test ! -name "*.php"
[/pre]
5. Combine multiple search criterias
It is possible to use multiple criterias when specifying name and inverting. For example
The above find command looks for files that begin with abc in their names and do not have a
php extension. This is an example of how powerful search expressions can be build with the find
command.
OR operator
When using multiple name criterias, the find command would combine them with AND operator,
which means that only those files which satisfy all criterias will be matched. However if we
need to perform an OR based matching then the find command has the "o" switch.
@don_crissti I'll never understand why people prefer random web documentation to the
documentation installed on their systems (which has the added benefit of actually being
relevant to their system). – Kusalananda
Nov 17 '17 at 9:53
@Kusalananda - Well, I can think of one scenario in which people would include a link to a
web page instead of a quote from the documentation installed on their system: they're not on
a linux machine at the time of writing the post... However, the link should point (imo) to
the official docs (hence my comment above, which, for some unknown reason, was deleted by the
mods...). That aside, I fully agree with you: the OP should consult the manual page installed
on their system. – don_crissti
Nov 17 '17 at 12:52
My manual page tend to be from FreeBSD though. Unless I happen to have a Linux VM within
reach. And I have the impression that most questions are GNU/Linux based. – Hennes
Feb 16 at 16:16
I was recently troubleshooting some issues we were having with Shippable , trying to get a bunch of our unit tests to run in
parallel so that our builds would complete faster. I didn't care what order the different
processes completed in, but I didn't want the shell script to exit until all the spawned unit
test processes had exited. I ultimately wasn't able to satisfactorily solve the issue we were
having, but I did learn more than I ever wanted to know about how to run processes in parallel
in shell scripts. So here I shall impart unto you the knowledge I have gained. I hope someone
else finds it useful!
Wait
The simplest way to achieve what I wanted was to use the wait command. You
simply fork all of your processes with & , and then follow them with a
wait command. Behold:
It's really as easy as that. When you run the script, all three processes will be forked in
parallel, and the script will wait until all three have completed before exiting. Anything
after the wait command will execute only after the three forked processes have
exited.
Pros
Damn, son! It doesn't get any simpler than that!
Cons
I don't think there's really any way to determine the exit codes of the processes you
forked. That was a deal-breaker for my use case, since I needed to know if any of the tests
failed and return an error code from the parent shell script if they did.
Another downside is that output from the processes will be all mish-mashed together, which
makes it difficult to follow. In our situation, it was basically impossible to determine which
unit tests had failed because they were all spewing their output at the same time.
GNU Parallel
There is a super nifty program called GNU Parallel that does exactly what I wanted. It
works kind of like xargs in that you can give it a collection of arguments to pass
to a single command which will all be run, only this will run them in parallel instead of in
serial like xargs does (OR DOES IT??</foreshadowing>). It is super
powerful, and all the different ways you can use it are beyond
the scope of this article, but here's a rough equivalent to the example script above:
If any of the processes returns a non-zero exit code, parallel will return a
non-zero exit code. This means you can use $? in your shell script to detect if
any of the processes failed. Nice! GNU Parallel also (by default) collates the output of each
process together, so you'll see the complete output of each process as it completes instead of
a mash-up of all the output combined together as it's produced. Also nice!
I am such a damn fanboy I might even buy an official GNU Parallel mug and t-shirt . Actually I'll
probably save the money and get the new Star Wars Battlefront game when it comes out instead.
But I did seriously consider the parallel schwag for a microsecond or so.
Cons
Literally none.
Xargs
So it turns out that our old friend xargs has supported parallel processing all
along! Who knew? It's like the nerdy chick in the movies who gets a makeover near the end and
it turns out she's even hotter than the stereotypical hot cheerleader chicks who were picking
on her the whole time. Just pass it a -Pn argument and it will run your commands
using up to n threads. Check out this mega-sexy equivalent to the above
scripts:
xargs returns a non-zero exit code if any of the processes fails, so you can
again use $? in your shell script to detect errors. The difference is it will
return 123 , unlike GNU Parallel which passes through the non-zero exit code of
the process that failed (I'm not sure how parallel picks if more than one process
fails, but I'd assume it's either the first or last process to fail). Another pro is that
xargs is most likely already installed on your preferred distribution of
Linux.
Cons
I have read reports that the non-GNU version of xargs does not support parallel
processing, so you may or may not be out of luck with this option if you're on AIX or a BSD or
something.
xargs also has the same problem as the wait solution where the
output from your processes will be all mixed together.
Another con is that xargs is a little less flexible than parallel
in how you specify the processes to run. You have to pipe your values into it, and if you use
the -I argument for string-replacement then your values have to be separated by
newlines (which is more annoying when running it ad-hoc). It's still pretty nice, but nowhere
near as flexible or powerful as parallel .
Also there's no place to buy an xargs mug and t-shirt. Lame!
And The Winner Is
After determining that the Shippable problem we were having was completely unrelated to the
parallel scripting method I was using, I ended up sticking with parallel for my
unit tests. Even though it meant one more dependency on our build machine, the ease
The
Task Spooler
project allows you
to queue up tasks from the shell for batch execution. Task Spooler is simple to use and requires no
configuration. You can view and edit queued commands, and you can view the output of queued commands at any
time.
Task Spooler has some similarities with other delayed and batch execution projects, such as "
at
."
While both Task Spooler and at handle multiple queues and allow the execution of commands at a later point, the
at project handles output from commands by emailing the results to the user who queued the command, while Task
Spooler allows you to get at the results from the command line instead. Another major difference is that Task
Spooler is not aimed at executing commands at a specific time, but rather at simply adding to and executing
commands from queues.
The main repositories for Fedora, openSUSE, and Ubuntu do not contain packages for Task Spooler. There are
packages for some versions of Debian, Ubuntu, and openSUSE 10.x available along with the source code on the
project's homepage. In this article I'll use a 64-bit Fedora 9 machine and install version 0.6 of Task Spooler
from source. Task Spooler does not use autotools to build, so to install it, simply run
make; sudo make
install
. This will install the main Task Spooler command
ts
and its manual page into /usr/local.
A simple interaction with Task Spooler is shown below. First I add a new job to the queue and check the
status. As the command is a very simple one, it is likely to have been executed immediately. Executing ts by
itself with no arguments shows the executing queue, including tasks that have completed. I then use
ts -c
to get at the stdout of the executed command. The
-c
option uses
cat
to display the
output file for a task. Using
ts -i
shows you information about the job. To clear finished jobs
from the queue, use the
ts -C
command, not shown in the example.
$ ts echo "hello world"
6
$ ts
ID State Output E-Level Times(r/u/s) Command [run=0/1]
6 finished /tmp/ts-out.QoKfo9 0 0.00/0.00/0.00 echo hello world
The
-t
option operates like
tail -f
, showing you the last few lines of output and
continuing to show you any new output from the task. If you would like to be notified when a task has
completed, you can use the
-m
option to have the results mailed to you, or you can queue another
command to be executed that just performs the notification. For example, I might add a tar command and want to
know when it has completed. The below commands will create a tarball and use
libnotify
commands to create an
inobtrusive popup window on my desktop when the tarball creation is complete. The popup will be dismissed
automatically after a timeout.
$ ts tar czvf /tmp/mytarball.tar.gz liberror-2.1.80011
11
$ ts notify-send "tarball creation" "the long running tar creation process is complete."
12
$ ts
ID State Output E-Level Times(r/u/s) Command [run=0/1]
11 finished /tmp/ts-out.O6epsS 0 4.64/4.31/0.29 tar czvf /tmp/mytarball.tar.gz liberror-2.1.80011
12 finished /tmp/ts-out.4KbPSE 0 0.05/0.00/0.02 notify-send tarball creation the long... is complete.
Notice in the output above, toward the far right of the header information, the
run=0/1
line.
This tells you that Task Spooler is executing nothing, and can possibly execute one task. Task spooler allows
you to execute multiple tasks at once from your task queue to take advantage of multicore CPUs. The
-S
option allows you to set how many tasks can be executed in parallel from the queue, as shown below.
$ ts -S 2
$ ts
ID State Output E-Level Times(r/u/s) Command [run=0/2]
6 finished /tmp/ts-out.QoKfo9 0 0.00/0.00/0.00 echo hello world
If you have two tasks that you want to execute with Task Spooler but one depends on the other having already
been executed (and perhaps that the previous job has succeeded too) you can handle this by having one task wait
for the other to complete before executing. This becomes more important on a quad core machine when you might
have told Task Spooler that it can execute three tasks in parallel. The commands shown below create an explicit
dependency, making sure that the second command is executed only if the first has completed successfully, even
when the queue allows multiple tasks to be executed. The first command is queued normally using
ts
.
I use a subshell to execute the commands by having
ts
explicitly start a new bash shell. The
second command uses the
-d
option, which tells
ts
to execute the command only after
the successful completion of the last command that was appended to the queue. When I first inspect the queue I
can see that the first command (28) is executing. The second command is queued but has not been added to the
list of executing tasks because Task Spooler is aware that it cannot execute until task 28 is complete. The
second time I view the queue, both tasks have completed.
$ ts bash -c "sleep 10; echo hi"
28
$ ts -d echo there
29
$ ts
ID State Output E-Level Times(r/u/s) Command [run=1/2]
28 running /tmp/ts-out.hKqDva bash -c sleep 10; echo hi
29 queued (file) && echo there
$ ts
ID State Output E-Level Times(r/u/s) Command [run=0/2]
28 finished /tmp/ts-out.hKqDva 0 10.01/0.00/0.01 bash -c sleep 10; echo hi
29 finished /tmp/ts-out.VDtVp7 0 0.00/0.00/0.00 && echo there
$ cat /tmp/ts-out.hKqDva
hi
$ cat /tmp/ts-out.VDtVp7
there
You can also explicitly set dependencies on other tasks as shown below. Because the
ts
command
prints the ID of a new task to the console, the first command puts that ID into a shell variable for use in the
second command. The second command passes the task ID of the first task to ts, telling it to wait for the task
with that ID to complete before returning. Because this is joined with the command we wish to execute with the
&&
operation, the second command will execute only if the first one has finished
and
succeeded.
The first time we view the queue you can see that both tasks are running. The first task will be in the
sleep
command that we used explicitly to slow down its execution. The second command will be
executing
ts
, which will be waiting for the first task to complete. One downside of tracking
dependencies this way is that the second command is added to the running queue even though it cannot do
anything until the first task is complete.
$ FIRST_TASKID=`ts bash -c "sleep 10; echo hi"`
$ ts sh -c "ts -w $FIRST_TASKID && echo there"
25
$ ts
ID State Output E-Level Times(r/u/s) Command [run=2/2]
24 running /tmp/ts-out.La9Gmz bash -c sleep 10; echo hi
25 running /tmp/ts-out.Zr2n5u sh -c ts -w 24 && echo there
$ ts
ID State Output E-Level Times(r/u/s) Command [run=0/2]
24 finished /tmp/ts-out.La9Gmz 0 10.01/0.00/0.00 bash -c sleep 10; echo hi
25 finished /tmp/ts-out.Zr2n5u 0 9.47/0.00/0.01 sh -c ts -w 24 && echo there
$ ts -c 24
hi
$ ts -c 25
there
Wrap-up
Task Spooler allows you to convert a shell command to a queued command by simply prepending
ts
to the command line. One major advantage of using ts over something like the
at
command is that
you can effectively run
tail -f
on the output of a running task and also get at the output of
completed tasks from the command line. The utility's ability to execute multiple tasks in parallel is very
handy if you are running on a multicore CPU. Because you can explicitly wait for a task, you can set up very
complex interactions where you might have several tasks running at once and have jobs that depend on multiple
other tasks to complete successfully before they can execute.
Because you can make explicitly dependant tasks take up slots in the actively running task queue, you can
effectively delay the execution of the queue until a time of your choosing. For example, if you queue up a task
that waits for a specific time before returning successfully and have a small group of other tasks that are
dependent on this first task to complete, then no tasks in the queue will execute until the first task
completes.
Run the commands listed in the ' my-at-jobs.txt ' file at 1:35 AM. All output from the job will be mailed to the
user running the task. When this command has been successfully entered you should receive a prompt similar to the example below:
commands will be executed using /bin/sh
job 1 at Wed Dec 24 00:22:00 2014
at -l
This command will list each of the scheduled jobs in a format like the following:
1 Wed Dec 24 00:22:00 2003
...this is the same as running the command atq .
at -r 1
Deletes job 1 . This command is the same as running the command atrm 1 .
atrm 23
Deletes job 23. This command is the same as running the command at -r 23 .
But processing each line until the command is finished then moving to the next one is very
time consuming, I want to process for instance 20 lines at once then when they're finished
another 20 lines are processed.
I thought of wget LINK1 >/dev/null 2>&1 & to send the command
to the background and carry on, but there are 4000 lines here this means I will have
performance issues, not to mention being limited in how many processes I should start at the
same time so this is not a good idea.
One solution that I'm thinking of right now is checking whether one of the commands is
still running or not, for instance after 20 lines I can add this loop:
Of course in this case I will need to append & to the end of the line! But I'm feeling
this is not the right way to do it.
So how do I actually group each 20 lines together and wait for them to finish before going
to the next 20 lines, this script is dynamically generated so I can do whatever math I want
on it while it's being generated, but it DOES NOT have to use wget, it was just an example so
any solution that is wget specific is not gonna do me any good.
wait is the right answer here, but your while [ $(ps would be much
better written while pkill -0 $KEYWORD – using proctools that is, for legitimate reasons to
check if a process with a specific name is still running. – kojiro
Oct 23 '13 at 13:46
I think this question should be re-opened. The "possible duplicate" QA is all about running a
finite number of programs in parallel. Like 2-3 commands. This question, however, is
focused on running commands in e.g. a loop. (see "but there are 4000 lines"). –
VasyaNovikov
Jan 11 at 19:01
@VasyaNovikov Have you readall the answers to both this question and the
duplicate? Every single answer to this question here, can also be found in the answers to the
duplicate question. That is precisely the definition of a duplicate question. It makes
absolutely no difference whether or not you are running the commands in a loop. –
robinCTS
Jan 11 at 23:08
@robinCTS there are intersections, but questions themselves are different. Also, 6 of the
most popular answers on the linked QA deal with 2 processes only. – VasyaNovikov
Jan 12 at 4:09
I recommend reopening this question because its answer is clearer, cleaner, better, and much
more highly upvoted than the answer at the linked question, though it is three years more
recent. – Dan Nissenbaum
Apr 20 at 15:35
For the above example, 4 processes process1 .. process4 would be
started in the background, and the shell would wait until those are completed before starting
the next set ..
Wait until the child process specified by each process ID pid or job specification
jobspec exits and return the exit status of the last command waited for. If a job spec is
given, all processes in the job are waited for. If no arguments are given, all currently
active child processes are waited for, and the return status is zero. If neither jobspec
nor pid specifies an active child process of the shell, the return status is 127.
So basically i=0; waitevery=4; for link in "${links[@]}"; do wget "$link" & ((
i++%waitevery==0 )) && wait; done >/dev/null 2>&1 – kojiro
Oct 23 '13 at 13:48
Unless you're sure that each process will finish at the exact same time, this is a bad idea.
You need to start up new jobs to keep the current total jobs at a certain cap .... parallel is the answer.
– rsaw
Jul 18 '14 at 17:26
I've tried this but it seems that variable assignments done in one block are not available in
the next block. Is this because they are separate processes? Is there a way to communicate
the variables back to the main process? – Bobby
Apr 27 '17 at 7:55
This is better than using wait , since it takes care of starting new jobs as old
ones complete, instead of waiting for an entire batch to finish before starting the next.
– chepner
Oct 23 '13 at 14:35
For example, if you have the list of links in a file, you can do cat list_of_links.txt
| parallel -j 4 wget {} which will keep four wget s running at a time.
– Mr.
Llama
Aug 13 '15 at 19:30
I am using xargs to call a python script to process about 30 million small
files. I hope to use xargs to parallelize the process. The command I am using
is:
Basically, Convert.py will read in a small json file (4kb), do some
processing and write to another 4kb file. I am running on a server with 40 CPU cores. And no
other CPU-intense process is running on this server.
By monitoring htop (btw, is there any other good way to monitor the CPU performance?), I
find that -P 40 is not as fast as expected. Sometimes all cores will freeze and
decrease almost to zero for 3-4 seconds, then will recover to 60-70%. Then I try to decrease
the number of parallel processes to -P 20-30 , but it's still not very fast. The
ideal behavior should be linear speed-up. Any suggestions for the parallel usage of xargs
?
You are most likely hit by I/O: The system cannot read the files fast enough. Try starting
more than 40: This way it will be fine if some of the processes have to wait for I/O. –
Ole Tange
Apr 19 '15 at 8:45
I second @OleTange. That is the expected behavior if you run as many processes as you have
cores and your tasks are IO bound. First the cores will wait on IO for their task (sleep),
then they will process, and then repeat. If you add more processes, then the additional
processes that currently aren't running on a physical core will have kicked off parallel IO
operations, which will, when finished, eliminate or at least reduce the sleep periods on your
cores. – PSkocik
Apr 19 '15 at 11:41
1- Do you have hyperthreading enabled? 2- in what you have up there, log.txt is actually
overwritten with each call to convert.py ... not sure if this is the intended behavior or
not. – Bichoy
Apr 20 '15 at 3:32
I'd be willing to bet that your problem is python . You didn't say what kind of processing is
being done on each file, but assuming you are just doing in-memory processing of the data,
the running time will be dominated by starting up 30 million python virtual machines
(interpreters).
If you can restructure your python program to take a list of files, instead of just one,
you will get a huge improvement in performance. You can then still use xargs to further
improve performance. For example, 40 processes, each processing 1000 files:
This isn't to say that python is a bad/slow language; it's just not optimized for startup
time. You'll see this with any virtual machine-based or interpreted language. Java, for
example, would be even worse. If your program was written in C, there would still be a cost
of starting a separate operating system process to handle each file, but it would be much
less.
From there you can fiddle with -P to see if you can squeeze out a bit more
speed, perhaps by increasing the number of processes to take advantage of idle processors
while data is being read/written.
What is the constraint on each job? If it's I/O you can probably get away with
multiple jobs per CPU core up till you hit the limit of I/O, but if it's CPU intensive, its
going to be worse than pointless running more jobs concurrently than you have CPU cores.
My understanding of these things is that GNU Parallel would give you better control over
the queue of jobs etc.
As others said, check whether you're I/O-bound. Also, xargs' man page suggests using
-n with -P , you don't mention the number of
Convert.py processes you see running in parallel.
As a suggestion, if you're I/O-bound, you might try using an SSD block device, or try
doing the processing in a tmpfs (of course, in this case you should check for enough memory,
avoiding swap due to tmpfs pressure (I think), and the overhead of copying the data to it in
the first place).
I want the ability to schedule commands to be run in a FIFO queue. I DON'T want them to be
run at a specified time in the future as would be the case with the "at" command. I want them
to start running now, but not simultaneously. The next scheduled command in the queue should
be run only after the first command finishes executing. Alternatively, it would be nice if I
could specify a maximum number of commands from the queue that could be run simultaneously;
for example if the maximum number of simultaneous commands is 2, then only at most 2 commands
scheduled in the queue would be taken from the queue in a FIFO manner to be executed, the
next command in the remaining queue being started only when one of the currently 2 running
commands finishes.
I've heard task-spooler could do something like this, but this package doesn't appear to
be well supported/tested and is not in the Ubuntu standard repositories (Ubuntu being what
I'm using). If that's the best alternative then let me know and I'll use task-spooler,
otherwise, I'm interested to find out what's the best, easiest, most tested, bug-free,
canonical way to do such a thing with bash.
UPDATE:
Simple solutions like ; or && from bash do not work. I need to schedule these
commands from an external program, when an event occurs. I just don't want to have hundreds
of instances of my command running simultaneously, hence the need for a queue. There's an
external program that will trigger events where I can run my own commands. I want to handle
ALL triggered events, I don't want to miss any event, but I also don't want my system to
crash, so that's why I want a queue to handle my commands triggered from the external
program.
That will list the directory. Only after ls has run it will run touch
test which will create a file named test. And only after that has finished it will run
the next command. (In this case another ls which will show the old contents and
the newly created file).
Similar commands are || and && .
; will always run the next command.
&& will only run the next command it the first returned success.
Example: rm -rf *.mp3 && echo "Success! All MP3s deleted!"
|| will only run the next command if the first command returned a failure
(non-zero) return value. Example: rm -rf *.mp3 || echo "Error! Some files could not be
deleted! Check permissions!"
If you want to run a command in the background, append an ampersand ( &
).
Example: make bzimage & mp3blaster sound.mp3 make mytestsoftware ; ls ; firefox ; make clean
Will run two commands int he background (in this case a kernel build which will take some
time and a program to play some music). And in the foregrounds it runs another compile job
and, once that is finished ls, firefox and a make clean (all sequentially)
For more details, see man bash
[Edit after comment]
in pseudo code, something like this?
Program run_queue:
While(true)
{
Wait_for_a_signal();
While( queue not empty )
{
run next command from the queue.
remove this command from the queue.
// If commands where added to the queue during execution then
// the queue is not empty, keep processing them all.
}
// Queue is now empty, returning to wait_for_a_signal
}
//
// Wait forever on commands and add them to a queue
// Signal run_quueu when something gets added.
//
program add_to_queue()
{
While(true)
{
Wait_for_event();
Append command to queue
signal run_queue
}
}
The easiest way would be to simply run the commands sequentially:
cmd1; cmd2; cmd3; cmdN
If you want the next command to run only if the previous command exited
successfully, use && :
cmd1 && cmd2 && cmd3 && cmdN
That is the only bash native way I know of doing what you want. If you need job control
(setting a number of parallel jobs etc), you could try installing a queue manager such as
TORQUE but that
seems like overkill if all you want to do is launch jobs sequentially.
You are looking for at 's twin brother: batch . It uses the same
daemon but instead of scheduling a specific time, the jobs are queued and will be run
whenever the system load average is low.
Apart from dedicated queuing systems (like the Sun Grid Engine ) which you can also
use locally on one machine and which offer dozens of possibilities, you can use something
like
command1 && command2 && command3
which is the other extreme -- a very simple approach. The latter neither does provide
multiple simultaneous processes nor gradually filling of the "queue".
task spooler is a Unix batch system where the tasks spooled run one after the other. The
amount of jobs to run at once can be set at any time. Each user in each system has his own
job queue. The tasks are run in the correct context (that of enqueue) from any shell/process,
and its output/results can be easily watched. It is very useful when you know that your
commands depend on a lot of RAM, a lot of disk use, give a lot of output, or for whatever
reason it's better not to run them all at the same time, while you want to keep your
resources busy for maximum benfit. Its interface allows using it easily in scripts.
For your first contact, you can read an article at linux.com , which I like
as overview, guide and
examples(original url) .
On more advanced usage, don't neglect the TRICKS file in the package.
Features
I wrote Task Spooler because I didn't have any comfortable way of running batch
jobs in my linux computer. I wanted to:
Queue jobs from different terminals.
Use it locally in my machine (not as in network queues).
Have a good way of seeing the output of the processes (tail, errorlevels, ...).
Easy use: almost no configuration.
Easy to use in scripts.
At the end, after some time using and developing ts , it can do something
more:
It works in most systems I use and some others, like GNU/Linux, Darwin, Cygwin, and
FreeBSD.
No configuration at all for a simple queue.
Good integration with renice, kill, etc. (through `ts -p` and process
groups).
Have any amount of queues identified by name, writting a simple wrapper script for each
(I use ts2, tsio, tsprint, etc).
Control how many jobs may run at once in any queue (taking profit of multicores).
It never removes the result files, so they can be reached even after we've lost the
ts task list.
I created a GoogleGroup for the program. You look for the archive and the join methods in
the taskspooler google
group page .
Alessandro Öhler once maintained a mailing list for discussing newer functionalities
and interchanging use experiences. I think this doesn't work anymore , but you can
look at the old archive
or even try to subscribe .
How
it works
The queue is maintained by a server process. This server process is started if it isn't
there already. The communication goes through a unix socket usually in /tmp/ .
When the user requests a job (using a ts client), the client waits for the server message to
know when it can start. When the server allows starting , this client usually forks, and runs
the command with the proper environment, because the client runs run the job and not
the server, like in 'at' or 'cron'. So, the ulimits, environment, pwd,. apply.
When the job finishes, the client notifies the server. At this time, the server may notify
any waiting client, and stores the output and the errorlevel of the finished job.
Moreover the client can take advantage of many information from the server: when a job
finishes, where does the job output go to, etc.
Download
Download the latest version (GPLv2+ licensed): ts-1.0.tar.gz - v1.0
(2016-10-19) - Changelog
Look at the version repository if you are
interested in its development.
Андрей
Пантюхин (Andrew Pantyukhin) maintains the
BSD port .
Eric Keller wrote a nodejs web server showing the status of the task spooler queue (
github project
).
Manual
Look at its manpage (v0.6.1). Here you also
have a copy of the help for the same version:
usage: ./ts [action] [-ngfmd] [-L <lab>] [cmd...]
Env vars:
TS_SOCKET the path to the unix socket used by the ts command.
TS_MAILTO where to mail the result (on -m). Local user by default.
TS_MAXFINISHED maximum finished jobs in the queue.
TS_ONFINISH binary called on job end (passes jobid, error, outfile, command).
TS_ENV command called on enqueue. Its output determines the job information.
TS_SAVELIST filename which will store the list, if the server dies.
TS_SLOTS amount of jobs which can run at once, read on server start.
Actions:
-K kill the task spooler server
-C clear the list of finished jobs
-l show the job list (default action)
-S [num] set the number of max simultanious jobs of the server.
-t [id] tail -f the output of the job. Last run if not specified.
-c [id] cat the output of the job. Last run if not specified.
-p [id] show the pid of the job. Last run if not specified.
-o [id] show the output file. Of last job run, if not specified.
-i [id] show job information. Of last job run, if not specified.
-s [id] show the job state. Of the last added, if not specified.
-r [id] remove a job. The last added, if not specified.
-w [id] wait for a job. The last added, if not specified.
-u [id] put that job first. The last added, if not specified.
-U <id-id> swap two jobs in the queue.
-h show this help
-V show the program version
Options adding jobs:
-n don't store the output of the command.
-g gzip the stored output (if not -n).
-f don't fork into background.
-m send the output by e-mail (uses sendmail).
-d the job will be run only if the job before ends well
-L <lab> name this task with a label, to be distinguished on listing.
Thanks
To Raúl Salinas, for his inspiring ideas
To Alessandro Öhler, the first non-acquaintance user, who proposed and created the
mailing list.
Андрею
Пантюхину, who created the BSD
port .
To the useful, although sometimes uncomfortable, UNIX interface.
To Alexander V. Inyukhin, for the debian packages.
To Pascal Bleser, for the SuSE packages.
To Sergio Ballestrero, who sent code and motivated the development of a multislot version
of ts.
To GNU, an ugly but working and helpful ol' UNIX implementation.
I'm trying to use xargs in a shell script to run parallel instances of a function I've
defined in the same script. The function times the fetching of a page, and so it's important
that the pages are actually fetched concurrently in parallel processes, and not in background
processes (if my understanding of this is wrong and there's negligible difference between the
two, just let me know).
The function is:
function time_a_url ()
{
oneurltime=$($time_command -p wget -p $1 -O /dev/null 2>&1 1>/dev/null | grep real | cut -d" " -f2)
echo "Fetching $1 took $oneurltime seconds."
}
How does one do this with an xargs pipe in a form that can take number of times to run
time_a_url in parallel as an argument? And yes, I know about GNU parallel, I just don't have
the privilege to install software where I'm writing this.
The keys to making this work are to export the function so the
bash that xargs spawns will see it and to escape the space between
the function name and the escaped braces. You should be able to adapt this to work in your
situation. You'll need to adjust the arguments for -P and -n (or
remove them) to suit your needs.
You can probably get rid of the grep and cut . If you're using
the Bash builtin time , you can specify an output format using the
TIMEFORMAT variable. If you're using GNU /usr/bin/time , you can
use the --format argument. Either of these will allow you to drop the
-p also.
You can replace this part of your wget command: 2>&1
1>/dev/null with -q . In any case, you have those reversed. The
correct order would be >/dev/null 2>&1 .
The log_input and log_output parameters enable sudo to run a command in pseudo-tty and log
all user input and all output sent to the screen receptively.
The default I/O log directory is /var/log/sudo-io , and if there is a session sequence
number, it is stored in this directory. You can specify a custom directory through the
iolog_dir parameter.
Defaults log_input, log_output
There are some escape sequences are supported such as %{seq} which expands to a
monotonically increasing base-36 sequence number, such as 000001, where every two digits are
used to form a new directory, e.g. 00/00/01 as in the example below:
To lecture sudo users about password usage on the system, use the lecture parameter as
below.
It has 3 possible values:
always – always lecture a user.
once – only lecture a user the first time they execute sudo command (this is used
when no value is specified)
never – never lecture the user.
Defaults lecture="always"
Additionally, you can set a custom lecture file with the lecture_file parameter, type the
appropriate message in the file:
Defaults lecture_file="/path/to/file"
Show Custom Message When You Enter Wrong sudo Password
When a user enters a wrong password, a certain message is displayed on the command line.
The default message is " sorry, try again ", you can modify the message using the
badpass_message parameter as follows:
Defaults badpass_message="Password is wrong, please try again"
Increase sudo Password Tries Limit
The parameter passwd_tries is used to specify the number of times a user can try to enter
a password.
The default value is 3:
Defaults passwd_tries=5
Increase Sudo Password Attempts
To set a password timeout (default is 5 minutes) using passwd_timeout parameter, add the
line below:
Defaults passwd_timeout=2
9. Let Sudo Insult You When You Enter Wrong Password
In case a user types a wrong password, sudo will display insults on the terminal with the
insults parameter. This will automatically turn off the badpass_message parameter.
In the sudoers configuration files, there are two types of options: strings and flags. While
strings can contain any value, flags can be turned either ON or OFF. The most important syntax
constructs for sudoers configuration files are:
# Everything on a line after a # gets ignored
Defaults !insults # Disable the insults flag
Defaults env_keep += "DISPLAY HOME" # Add DISPLAY and HOME to env_keep
tux ALL = NOPASSWD: /usr/bin/frobnicate, PASSWD: /usr/bin/journalctl
There are two exceptions: #include and #includedir are normal commands. Followed by
digits, it specifies a UID.
This flag controls whether the invoking user is required to enter the password of the
target user (ON) (for example root ) or the invoking user (OFF).
Defaults targetpw # Turn targetpw flag ON
rootpw
If set, sudo will prompt for the root password instead of the target user's or the
invoker's. The default is OFF.
Defaults !rootpw # Turn rootpw flag OFF
env_reset
If set, sudo constructs a minimal environment with only TERM , PATH , HOME , MAIL ,
SHELL , LOGNAME , USER , USERNAME , and SUDO_* set. Additionally, variables listed in
env_keep get imported from the calling environment. The default is ON.
Defaults env_reset # Turn env_reset flag ON
env_keep
List of environment variables to keep when the env_reset flag is ON.
# Set env_keep to contain EDITOR and PROMPT
Defaults env_keep = "EDITOR PROMPT"
Defaults env_keep += "JRE_HOME" # Add JRE_HOME
Defaults env_keep -= "JRE_HOME" # Remove JRE_HOME
env_delete
List of environment variables to remove when the env_reset flag is OFF.
# Set env_delete to contain EDITOR and PROMPT
Defaults env_delete = "EDITOR PROMPT"
Defaults env_delete += "JRE_HOME" # Add JRE_HOME
Defaults env_delete -= "JRE_HOME" # Remove JRE_HOME
The Defaults token can also be used to create aliases for a collection of users, hosts, and
commands. Furthermore, it is possible to apply an option only to a specific set of users.
For detailed information about the /etc/sudoers configuration file, consult man 5 sudoers .
2.2.3 Rules in sudoers
Rules in the sudoers configuration can be very complex, so this section will only cover the
basics. Each rule follows the basic scheme ( [] marks optional parts):
#Who Where As whom Tag What
User_List Host_List = [(User_List)] [NOPASSWD:|PASSWD:] Cmnd_List
Syntax for sudoers Rules
User_List
One or more (separated by , ) identifiers: Either a user name, a group in the format
%GROUPNAME or a user ID in the format #UID . Negation can be performed with a ! prefix.
Host_List
One or more (separated by , ) identifiers: Either a (fully qualified) host name or an IP
address. Negation can be performed with a ! prefix. ALL is the usual choice for Host_List
.
NOPASSWD:|PASSWD:
The user will not be prompted for a password when running commands matching CMDSPEC
after NOPASSWD: .
PASSWD is the default, it only needs to be specified when both are on the same line:
tux ALL = PASSWD: /usr/bin/foo, NOPASSWD: /usr/bin/bar
Cmnd_List
One or more (separated by , ) specifiers: A path to an executable, followed by allowed
arguments or nothing.
/usr/bin/foo # Anything allowed
/usr/bin/foo bar # Only "/usr/bin/foo bar" allowed
/usr/bin/foo "" # No arguments allowed
ALL can be used as User_List , Host_List , and Cmnd_List .
A rule that allows tux to run all commands as root without entering a password:
tux ALL = NOPASSWD: ALL
A rule that allows tux to run systemctl restart apache2 :
tux ALL = /usr/bin/systemctl restart apache2
A rule that allows tux to run wall as admin with no arguments:
tux ALL = (admin) /usr/bin/wall ""
WARNING: Dangerous constructs
Constructs of the kind
ALL ALL = ALL
must not be used without Defaults targetpw , otherwise anyone can run commands as root .
The owner and group for the sudoers file must both be 0. The file permissions
must be set to 0440. These permissions are set by default, but if you accidentally change them,
they should be changed back immediately or sudo will fail.
Tips and tricksDisable per-terminal sudo Warning: This will let any process
use your sudo session.
If you are annoyed by sudo's defaults that require you to enter your password every time you
open a new terminal, disable tty_tickets :
Defaults !tty_tickets
Environment variables
If you have a lot of environment variables, or you export your proxy settings via
export http_proxy="..." , when using sudo these variables do not get passed to the
root account unless you run sudo with the -E option.
$ sudo -E pacman -Syu
The recommended way of preserving environment variables is to append them to
env_keep :
If you use a lot of aliases, you might have noticed that they do not carry over to the root
account when using sudo. However, there is an easy way to make them work. Simply add the
following to your ~/.bashrc or /etc/bash.bashrc :
alias sudo='sudo '
Root password
Users can configure sudo to ask for the root password instead of the user password by adding
targetpw (target user, defaults to root) or rootpw to the Defaults
line in /etc/sudoers :
Defaults targetpw
To prevent exposing your root password to users, you can restrict this to a specific
group:
Defaults:%wheel targetpw
%wheel ALL=(ALL) ALL
Disable root login
Users may wish to disable the root login. Without root, attackers must first guess a user
name configured as a sudoer as well as the user password. See for example Ssh#Deny .
Warning:
Be careful, you may lock yourself out by disabling root login. Sudo is not automatically
installed and its default configuration allows neither passwordless root access nor root
access with your own password. Ensure a user is properly configured as a sudoer before
disabling the root account!
If you have changed your sudoers -file to use rootpw as default, then do not disable root
login with any of the following commands!
Alternatively, edit /etc/shadow and replace the root's encrypted password with
"!":
root:!:12345::::::
To enable root login again:
$ sudo passwd root
Tip: To get to an interactive root prompt, even after disabling the root account, use
sudo -i . kdesu
kdesu may be used under KDE to launch GUI applications with root privileges. It is possible
that by default kdesu will try to use su even if the root account is disabled. Fortunately one
can tell kdesu to use sudo instead of su. Create/edit the file ~/.config/kdesurc
:
Alternatively, install kdesudoAUR , which
has the added advantage of tab-completion for the command following.
Harden with Sudo
Example
Let us say you create 3 users: admin, devel, and joe. The user "admin" is used for
journalctl, systemctl, mount, kill, and iptables; "devel" is used for installing packages, and
editing config files; and "joe" is the user you log in with. To let "joe" reboot, shutdown, and
use netctl we would do the following:
Edit /etc/pam.d/su and /etc/pam.d/su-1 Require user be in the
wheel group, but do not put anyone in it.
#%PAM-1.0
auth sufficient pam_rootok.so
# Uncomment the following line to implicitly trust users in the "wheel" group.
#auth sufficient pam_wheel.so trust use_uid
# Uncomment the following line to require a user to be in the "wheel" group.
auth required pam_wheel.so use_uid
auth required pam_unix.so
account required pam_unix.so
session required pam_unix.so
Limit SSH login to the 'ssh' group. Only "joe" will be part of this group.
groupadd -r ssh
gpasswd -a joe ssh
echo 'AllowGroups ssh' >> /etc/ssh/sshd_config
Configure sudo using drop-in files in /etc/sudoers.d
sudo parses files contained in the directory /etc/sudoers.d/ . This
means that instead of editing /etc/sudoers , you can change settings in standalone
files and drop them in that directory. This has two advantages:
There is no need to edit a sudoers.pacnew file;
If there is a problem with a new entry, you can remove the offending file instead of
editing /etc/sudoers (but see the warning below).
The format for entries in these drop-in files is the same as for /etc/sudoers
itself. To edit them directly, use visudo -f /etc/sudoers.d/ somefile . See
the "Including other files from within sudoers" section of sudoers(5) for details.
The files in /etc/sudoers.d/ directory are parsed in lexicographical order,
file names containing . or ~ are skipped. To avoid sorting problems,
the file names should begin with two digits, e.g. 01_foo .
Note: The order of
entries in the drop-in files is important: make sure that the statements do not override
themselves. Warning: The files in /etc/sudoers.d/ are just as fragile as
/etc/sudoers itself: any improperly formatted file will prevent sudo
from working. Hence, for the same reason it is strongly advised to use visudoEditing files
sudo -e or sudoedit lets you edit a file as another user while
still running the text editor as your user.
This is especially useful for editing files as root without elevating the privilege of your
text editor, for more details read sudo(8) .
Note that you can set the editor to any program, so for example one can use meld to manage pacnew
files:
$ SUDO_EDITOR=meld sudo -e /etc/file{,.pacnew}
TroubleshootingSSH TTY Problems
Notes: please use the
second argument of the template to provide more detailed indications. (Discuss in Talk:Sudo# )
SSH does not allocate a tty by default when running a remote command. Without a tty, sudo
cannot disable echo when prompting for a password. You can use ssh's -t option to
force it to allocate a tty.
The Defaults option requiretty only allows the user to run sudo if
they have a tty.
# Disable "ssh hostname sudo <cmd>", because it will show the password in clear text. You have to run "ssh -t hostname sudo <cmd>".
#
#Defaults requiretty
Permissive umask
Notes: please use the
second argument of the template to provide more detailed indications. (Discuss in Talk:Sudo# )
Sudo will union the user's umask value with its own umask (which defaults
to 0022). This prevents sudo from creating files with more open permissions than the user's
umask allows. While this is a sane default if no custom umask is in use, this can lead to
situations where a utility run by sudo may create files with different permissions than if run
by root directly. If errors arise from this, sudo provides a means to fix the umask, even if
the desired umask is more permissive than the umask that the user has specified. Adding this
(using visudo ) will override sudo's default behavior:
Defaults umask = 0022
Defaults umask_override
This sets sudo's umask to root's default umask (0022) and overrides the default behavior,
always using the indicated umask regardless of what umask the user as set.
Defaults
skeleton
Notes: please use the
second argument of the template to provide more detailed indications. (Discuss in Talk:Sudo# )
The authors site has a list of all the
options that can be used with the Defaults command in the
/etc/sudoers file.
See [1] for
a list of options (parsed from the version 1.8.7 source code) in a format optimized for
sudoers .
It is also possible to have a user run an application as a different, non-root user. This
can be very interesting if you run applications as a different user (for instance apache for
the web server) and want to allow certain users to perform administrative steps as that user
(like killing zombie processes).
Inside /etc/sudoers you list the user(s) in between ( and ) before
the command listing:
CODE Non-root execution syntax
users hosts = (run-as) commands
For instance, to allow larry to run the kill tool as the apache or gorg user:
CODE
Non-root execution example
Cmnd_Alias KILL = /bin/kill, /usr/bin/pkill
larry ALL = (apache, gorg) KILL
With this set, the user can run sudo -u to select the user he wants to run the application
as:
user $sudo -u apache pkill apache
You can set an alias for the user to run an application as using the
Runas_Alias directive. Its use is identical to the other _Alias
directives we have seen before.
Passwords and default settings
By default, sudo asks the user to identify himself using his own password. Once a password
is entered, sudo remembers it for 5 minutes, allowing the user to focus on his tasks and not
repeatedly re-entering his password.
Of course, this behavior can be changed: you can set the Defaults: directive in
/etc/sudoers to change the default behavior for a user.
For instance, to change the default 5 minutes to 0 (never remember):
CODE Changing the
timeout value
Defaults:larry timestamp_timeout=0
A setting of -1 would remember the password indefinitely (until the system
reboots).
A different setting would be to require the password of the user that the command should be
run as and not the users' personal password. This is accomplished using runaspw .
In the following example we also set the number of retries (how many times the user can
re-enter a password before sudo fails) to 2 instead of the default 3:
CODE
Requiring the root password instead of the user's password
Defaults:john runaspw, passwd_tries=2
Another interesting feature is to keep the DISPLAY variable set so that you can
execute graphical tools:
CODE Keeping the DISPLAY variable alive
Defaults:john env_keep=DISPLAY
You can change dozens of default settings using the Defaults: directive. Fire
up the sudoers manual page and search for Defaults .
If you however want to allow a user to run a certain set of commands without providing any
password whatsoever, you need to start the commands with NOPASSWD: , like
so:
CODE Allowing emerge to be ran as root without asking for a password
larry localhost = NOPASSWD: /usr/bin/emerge
Bash completion
Users that want bash completion with sudo need to run this once.
user $sudo echo "complete -cf sudo" >> $HOME/.bashrc
There are times when prefacing every command with "sudo" gets in the way of getting your
work done. With a default /etc/sudoers configuration and membership in the sudo (or admin)
group, you can assume root control using the command sudo su - . Extra care should always be
taken when using the root account in this way.
$ sudo -i -u root
[sudo] password for jdoe:
root@stinkbug:~#
By default, if a user has entered their password to authenticate their self to sudo , it is
remembered for 5 minutes. If the user wants to prolong this period, he can run sudo -v to reset
the time stamp so that it will take another 5 minutes before sudo asks for the password
again.
user $sudo -v
The inverse is to kill the time stamp using sudo -k .
Finally, this line in /usr/local/etc/sudoers allows any member of the webteam
group to manage webservice :
%webteam ALL=(ALL) /usr/sbin/service webservice *
Unlike su
(1) , Sudo only requires the end user password. This adds an advantage where users will not
need shared passwords, a finding in most security audits and just bad all the way around.
Users permitted to run applications with Sudo only enter their own passwords. This is more
secure and gives better control than su
(1) , where the root password is entered and the user acquires all
root permissions.
Tip:
Most organizations are moving or have moved toward a two factor authentication model. In
these cases, the user may not have a password to enter. Sudo provides for these cases with the
NOPASSWD variable. Adding it to the configuration above will allow all members of
the webteam group to manage the service without the password
requirement:
An advantage to implementing Sudo is the ability to enable session logging. Using the built
in log mechanisms and the included sudoreplay command, all commands initiated through Sudo are
logged for later verification. To enable this feature, add a default log directory entry, this
example uses a user variable. Several other log filename conventions exist, consult the manual
page for sudoreplay for additional information.
Defaults iolog_dir=/var/log/sudo-io/%{user}
Tip:
This directory will be created automatically after the logging is configured. It is best to
let the system create directory with default permissions just to be safe. In addition, this
entry will also log administrators who use the sudoreplay command. To change this behavior,
read and uncomment the logging options inside sudoers .
Once this directive has been added to the sudoers file, any user configuration
can be updated with the request to log access. In the example shown, the updated
webteam entry would have the following additional changes:
From this point on, all webteam members altering the status of the
webservice application will be logged. The list of previous and current
sessions can be displayed with:
# sudoreplay -l
In the output, to replay a specific session, search for the TSID= entry, and
pass that to sudoreplay with no other options to replay the session at normal speed. For
example:
# sudoreplay user1/00/00/02
Warning:
While sessions are logged, any administrator is able to remove sessions and leave only a
question of why they had done so. It is worthwhile to add a daily check through an intrusion
detection system ( IDS ) or similar software so that other administrators
are alerted to manual alterations.
The sudoreplay is extremely extendable. Consult the documentation for more
information.
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -f
/opt/microsoft/omsagent/bin/service_control; then cat
/etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; else cat
/etc/opt/microsoft/scx/ssl/scx.pem; fi
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -f
/opt/microsoft/omsagent/bin/service_control; then mv /tmp/scx-scomadm/scom-cert.pem
/etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; fi
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -r /etc/opt/microsoft/scx/ssl/scx.pem;
then cat /etc/opt/microsoft/scx/ssl/scx.pem; else cat
/etc/opt/microsoft/scx/ssl/scx-seclevel1.pem; fi
##SCOM Workspace
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -f
/opt/microsoft/omsagent/bin/service_control; then cp /tmp/scx-scomadm/omsadmin.conf
/etc/opt/microsoft/omsagent/scom/conf/omsadmin.conf;
/opt/microsoft/omsagent/bin/service_control restart scom; fi
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -f /opt/microsoft/omsagent/bin/omsadmin.sh
&& test ! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi
##Install or upgrade
#Linux
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].universal[[\:alpha\:]].[[\:digit\:]].x[6-8][4-6].sh
--install --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].universal[[\:alpha\:]].[[\:digit\:]].x[6-8][4-6].sh
--upgrade --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
#RHEL
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].rhel.[[\:digit\:]].x[6-8][4-6].sh
--install --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].rhel.[[\:digit\:]].x[6-8][4-6].sh
--upgrade --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
#SUSE
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].sles.1[[\:digit\:]].x[6-8][4-6].sh
--install --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/omsagent-1.[0-9].[0-9]-[0-9][0-9].sles.1[[\:digit\:]].x[6-8][4-6].sh
--upgrade --enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test
! -f /etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
## RHEL PPC
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/scx-1.[0-9].[0-9]-[0-9][0-9][0-9].rhel.[[\:digit\:]].ppc.sh --install
--enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test ! -f
/etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
scomadm ALL=(root) NOPASSWD: /bin/sh -c sh
/tmp/scx-scomadm/scx-1.[0-9].[0-9]-[0-9][0-9][0-9].rhel.[[\:digit\:]].ppc.sh --upgrade
--enable-opsmgr; if test -f /opt/microsoft/omsagent/bin/omsadmin.sh && test ! -f
/etc/opt/microsoft/omsagent/scom/certs/scom-cert.pem; then
/opt/microsoft/omsagent/bin/omsadmin.sh -w scom; fi; EC=$?; cd /tmp; rm -rf /tmp/scx-scomadm;
exit $EC
##Uninstall
scomadm ALL=(root) NOPASSWD: /bin/sh -c if test -f
/opt/microsoft/omsagent/bin/omsadmin.sh; then if test
"$(/opt/microsoft/omsagent/bin/omsadmin.sh -l | grep scom | wc -l)" \= "1" && test
"$(/opt/microsoft/omsagent/bin/omsadmin.sh -l | wc -l)" \= "1" || test
"$(/opt/microsoft/omsagent/bin/omsadmin.sh -l)" \= "No Workspace"; then
/opt/microsoft/omsagent/bin/uninstall; else /opt/microsoft/omsagent/bin/omsadmin.sh -x scom;
fi; else /opt/microsoft/scx/bin/uninstall; fi
Here's the same configuration as a comma-separated list of multiple commands. This let's us
get more specific on which service commands we can use with php5-fpm
:
Open the /etc/sudoers file with a text editor. The sudo installation includes the
visudo editor, which checks the syntax of the file before closing.
Add the following commands to the file. Important: Enter each command on a single line:
# Preserve GPFS environment variables:
Defaults env_keep += "MMMODE environmentType GPFS_rshPath GPFS_rcpPath mmScriptTrace GPFSCMDPORTRANGE GPFS_CIM_MSG_FORMAT"
# Allow members of the gpfs group to run all commands but only selected commands without a password:
%gpfs ALL=(ALL) PASSWD: ALL, NOPASSWD: /usr/lpp/mmfs/bin/mmremote, /usr/bin/scp, /bin/echo, /usr/lpp/mmfs/bin/mmsdrrestore
# Disable requiretty for group gpfs:
Defaults:%gpfs !requiretty
There's more that sudo does to protect tyou from malicious mischief. The :man sudo" pages
cover that completely. Let's continue with our examples; it's time to limit "jim" to specific
commands. There are two ways to do that. We can specifically list commands, or we can say that
jim can only run commands in a certain directory. A combination of those methods is useful:
jim ALL= /bin/kill,/sbin/linuxconf, /usr/sbin/jim/
The careful reader will note that there was a bit of a change here. The line used to read
"jim ALL=(ALL) ALL", but now there's only one "ALL" left. Reading the man page can easily leave
you quite confused as to what those three "ALL"'s meant. In the example above, ALL refers to
machines- the assumption is that this is a network wide sudoers file. In the case of this
machine (lnxserve) we could do this:
jim lnxserve= /bin/kill, /usr/sbin/jim/
So what was the "(ALL)" for? Well, here's a clue:
jim lnxserve=(paul,linda) /bin/kill, /usr/sbin/jim/
That says that jim can (using "sudo -u ") run commands as paul or linda.
This is perfect for giving jim the power to kill paul or linda's processes without giving
him anything else. There is one thing we need to add though: if we just left it like this, jim
is forced to use "sudo -u paul" or "sudo -u linda" every time. We can add a default
"runas_default":
sudo commands use a basic syntax. By default, the /etc/sudoers file will have one
stanza:
root ALL=(ALL) ALL
This tells sudo to give root sudo access to everything on every host. The syntax is
simple:
user host = (user) command
The first column defines the user the command applies to. The host section
defines the host this stanza applies to. The (user) section defines the user to run
the command as, while the command section defines the command itself.
You can also define aliases for Hosts, Users, and Commands by using the keywords
Host_Alias , User_Alias , and Cmnd_Alias respectively.
Let's take a look at a few examples of the different aliases you can use.
... ... ...
Next, lets define some User aliases:
User_Alias WEBADMIN = ankit, sam
User_Alias MAILADMIN = ankit, navan
User_Alias BINADMIN = ankit, jon
Here we've also defined three User aliases. The first user alias has the name WEBADMIN for
web administrators. Here we've define Ankit and Sam. The second alias is MAILADMIN, for mail
administrators, and here we have Ankit and Navan. Finally, we define an alias of BINADMIN for
the regular sysadmins, again Ankit, but with Jon as well.
So far we've defined some hosts and some users. Now we get to define what commands they may
be able to run, also using some aliases:
Cmnd_Alias SU = /bin/su
Cmnd_Alias BIN = /bin/rpm, /bin/rm, /sbin/linuxconf
Here we have a few aliases. The first we call SU, and enables the user to run the /bin/su
command. The second we call BIN, which enables the user to run the commands: /bin/rpm , /bin/rm
, and /sbin/linuxconf . The next is the SWATCH alias which allows the user to run
/usr/bin/swatch and /bin/touch . Then we define the HTTPD alias which allows the user to
execute /etc/rc.d/init.d/httpd and /etc/rc.d/init.d/mysql , for web maintenance. Finally, we
define SMTP, which allows the user to manipulate the running of the qmail SMTP server...
You want one user to run commands as another, without sharing passwords.
Solution
Suppose you want user smith to be able to run a given command as user jones.
/etc/sudoers:
smith ALL = (jones) /usr/local/bin/mycommand
User smith runs:
smith$ sudo -u jones /usr/local/bin/mycommand
smith$ sudo -u jones mycommand If /usr/local/bin is in $PATH
User smith will be prompted for his own password, not jones's. The ALL keyword,
which matches anything, in this case specifies that the line is valid on any host.
Discussion
sudo exists for this very reason!
To authorize root privileges for smith, replace "jones" with "root" in the above
example.
This section presents some simple examples of how to do many commonly required tasks using the sudo utility.
Granting All Access to Specific Users
You can grant users bob and bunny full access to all privileged commands, with this sudoers entry.
bob, bunny ALL=(ALL) ALL
This is generally not a good idea because this allows bob and bunny to use the su command to grant themselves permanent root privileges
thereby bypassing the command logging features of sudo. The example on using aliases in the sudoers file shows how to eliminate this
prob
Granting Access To Specific Users To Specific Files
This entry allows user peter and all the members of the group operator to gain access to all the program files in the /sbin and
/usr/sbin directories, plus the privilege of running the command /usr/local/apps/check.pl. Notice how the trailing slash (/) is required
to specify a directory location:
Notice also that the lack of any username entries within parentheses () after the = sign prevents the users from running the commands
automatically masquerading as another user. This is explained further in the next example.
Granting Access to Specific Files as Another User
The sudo -u entry allows allows you to execute a command as if you were another user, but first you have to be granted this privilege
in the sudoers file.
This feature can be convenient for programmers who sometimes need to kill processes related to projects they are working on. For
example, programmer peter is on the team developing a financial package that runs a program called monthend as user accounts. From
time to time the application fails, requiring "peter" to stop it with the /bin/kill, /usr/bin/kill or /usr/bin/pkill commands but
only as user "accounts". The sudoers entry would look like this:
peter ALL=(accounts) /bin/kill, /usr/bin/kill, /usr/bin/pkill
User peter is allowed to stop the monthend process with this command:
This example allows all users in the group operator to execute all the commands in the /sbin directory without the need for entering
a password. This has the added advantage of being more convenient to the user:
%operator ALL= NOPASSWD: /sbin/
Using Aliases in the sudoers File
Sometimes you'll need to assign random groupings of users from various departments very similar sets of privileges. The sudoers
file allows users to be grouped according to function with the group and then being assigned a nickname or alias which is used throughout
the rest of the file. Groupings of commands can also be assigned aliases too.
In the next example, users peter, bob and bunny and all the users in the operator group are made part of the user alias ADMINS.
All the command shell programs are then assigned to the command alias SHELLS. Users ADMINS are then denied the option of running
any SHELLS commands and su:
This attempts to ensure that users don't permanently su to become root, or enter command shells that bypass sudo's command logging.
It doesn't prevent them from copying the files to other locations to be run. The advantage of this is that it helps to create an
audit trail, but the restrictions can be enforced only as part of the company's overall security policy.
Other Examples
You can view a comprehensive list of /etc/sudoers file options by issuing the command man sudoers.
Using syslog To Track All sudo Commands
All sudo commands are logged in the log file /var/log/messages which can be very helpful in determining how user error may have
contributed to a problem. All the sudo log entries have the word sudo in them, so you can easily get a thread of commands used by
using the grep command to selectively filter the output accordingly.
Here is sample output from a user bob failing to enter their correct sudo password when issuing a command, immediately followed
by the successful execution of the command /bin/more sudoers.
A solution to this question will solve the other question as well, you might want to delete
the other question in this situation. – Pavel Šimerda
Jan 2 '15 at 8:29
To invoke a login shell using sudo just use -i . When command is
not specified you'll get a login shell prompt, otherwise you'll get the output of your
command.
Example (login shell):
sudo -i
Example (with a specified user):
sudo -i -u user
Example (with a command):
sudo -i -u user whoami
Example (print user's $HOME ):
sudo -i -u user echo \$HOME
Note: The backslash character ensures that the dollar sign reaches the target user's shell
and is not interpreted in the calling user's shell.
I have just checked the last example with strace which tells you exactly what's
happening. The output bellow shows that the shell is being called with --login
and with the specified command, just as in your explicit call to bash, but in addition
sudo can do its own work like setting the $HOME .
I noticed that you are using -S and I don't think it is generally a good
technique. If you want to run commands as a different user without performing authentication
from the keyboard, you might want to use SSH instead. It works for localhost as
well as for other hosts and provides public key authentication that works without any
interactive input.
ssh user@localhost echo \$HOME
Note: You don't need any special options with SSH as the SSH server always creates a login
shell to be accessed by the SSH client.
sudo -i -u user echo \$HOME doesn't work for me. Output: $HOME .
strace gives the same output as yours. What's the issue? – John_West
Nov 23 '15 at 11:12
You're giving Bash too much credit. All "login shell" means to Bash is what files are sourced
at startup and shutdown. The $HOME variable doesn't figure into it.
In fact, Bash doesn't do anything to set $HOME at all. $HOME is
set by whatever invokes the shell (login, ssh, etc.), and the shell inherits it. Whatever
started your shell as admin set $HOME and then exec-ed bash ,
sudo by design doesn't alter the environment unless asked or configured to do
so, so bash as otheruser inherited it from your shell.
If you want sudo to handle more of the environment in the way you're
expecting, look at the -i switch for sudo. Try:
That sudo syntax threw an error on my machine. ( su uses the
-c option, but I don't think sudo does.) I had better luck with:
HomeDir=$( sudo -u "$1" -H -s echo "\$HOME" ) – palswim
Oct 13 '16 at 20:21
"... (which means "substitute user" or "switch user") ..."
"... (hmm... what's the mnemonic? Super-User-DO?) ..."
"... The official meaning of "su" is "substitute user" ..."
"... Interestingly, Ubuntu's manpage does not mention "substitute" at all. The manpage at gnu.org ( gnu.org/software/coreutils/manual/html_node/su-invocation.html ) does indeed say "su: Run a command with substitute user and group ID". ..."
"... sudo -s runs a [specified] shell with root privileges. sudo -i also acquires the root user's environment. ..."
"... To see the difference between su and sudo -s , do cd ~ and then pwd after each of them. In the first case, you'll be in root's home directory, because you're root. In the second case, you'll be in your own home directory, because you're yourself with root privileges. There's more discussion of this exact question here . ..."
"... I noticed sudo -s doesnt seem to process /etc/profile ..."
The main difference between these commands is in the way they restrict access to their
functions.
su(which means "substitute user" or "switch user") - does exactly
that, it starts another shell instance with privileges of the target user. To ensure you have
the rights to do that, it asks you for the password of the target user . So, to become root,
you need to know root password. If there are several users on your machine who need to run
commands as root, they all need to know root password - note that it'll be the same password.
If you need to revoke admin permissions from one of the users, you need to change root
password and tell it only to those people who need to keep access - messy.
sudo(hmm... what's the mnemonic? Super-User-DO?) is completely
different. It uses a config file (/etc/sudoers) which lists which users have rights to
specific actions (run commands as root, etc.) When invoked, it asks for the password of the
user who started it - to ensure the person at the terminal is really the same "joe" who's
listed in /etc/sudoers . To revoke admin privileges from a person, you just need
to edit the config file (or remove the user from a group which is listed in that config).
This results in much cleaner management of privileges.
As a result of this, in many Debian-based systems root user has no password
set - i.e. it's not possible to login as root directly.
Also, /etc/sudoers allows to specify some additional options - i.e. user X is
only able to run program Y etc.
The often-used sudo su combination works as follows: first sudo
asks you for your password, and, if you're allowed to do so, invokes the next
command ( su ) as a super-user. Because su is invoked by
root , it require you to enter your password instead of root.
So,
sudo su allows you to open a shell as another user (including root), if you're
allowed super-user access by the /etc/sudoers file.
I've never seen su as "switch user", but always as superuser; the default
behavior without another's user name (though it makes sense). From wikipedia : "The su command, also referred to as super user[1] as early as 1974,
has also been called "substitute user", "spoof user" or "set user" because it allows changing the account associated with the
current terminal (window)."
@dr jimbob: you're right, but I'm finding that "switch user" is kinda describes better what
it does - though historically it stands for "super user". I'm also delighted to find that the
wikipedia article is very similar to my answer - I never saw the article before :)
sudo lets you run commands in your own user account with root privileges.
su lets you switch user so that you're actually logged in as root.
sudo -s runs a [specified] shell with root privileges. sudo -i also acquires
the root user's environment.
To see the difference between su and sudo -s , do cd
~ and then pwd after each of them. In the first case, you'll be in root's
home directory, because you're root. In the second case, you'll be in your own home
directory, because you're yourself with root privileges. There's more discussion of this exact question here .
"you're yourself with root privileges" is not what's actually happening :) Actually, it's not
possible to be "yourself with root privileges" - either you're root or you're yourself. Try
typing whoami in both cases. The fact that cd ~ results are different is
a result of sudo -s not setting $HOME environment variable. – Sergey
Oct 22 '11 at 7:28
@Sergey, whoami it says are 'root' because you are running the 'whoami' cmd as though you
sudoed it, so temporarily (for the duration of that command) you appear to be the root user,
but you might still not have full root access according to the sudoers file. –
Octopus
Feb 6 '15 at 22:15
@Octopus: what I was trying to say is that in Unix, a process can only have one UID, and that
UID determines the permissions of the process. You can't be "yourself with root privileges",
a program either runs with your UID or with root's UID (0). – Sergey
Feb 6 '15 at 22:24
Regarding "you might still not have full root access according to the sudoers file": the
sudoers file controls who can run which command as another user, but that happens before the command is executed.
However, once you were allowed to start a process as, say, root -- the running process has root's UID and has a full access to the system, there's
no way for sudo to restrict that.
Again, you're always either yourself or root, there's no
"half-n-half". So, if sudoers file allows you to run shell as root -- permissions
in that shell would be indistinguishable from a "normal" root shell. – Sergey
Feb 6 '15 at 22:32
This answer is a dupe of my answer on a
dupe of this question , put here on the canonical answer so that people can find it!
The major difference between sudo -i and sudo -s is:
sudo -i gives you the root environment, i.e. your ~/.bashrc
is ignored.
sudo -s gives you the user's environment, so your ~/.bashrc
is respected.
Here is an example, you can see that I have an application lsl in my
~/.bin/ directory which is accessible via sudo -s but not
accessible with sudo -i . Note also that the Bash prompt changes as will with
sudo -i but not with sudo -s :
dotancohen@melancholy:~$ ls .bin
lsl
dotancohen@melancholy:~$ which lsl
/home/dotancohen/.bin/lsl
dotancohen@melancholy:~$ sudo -i
root@melancholy:~# which lsl
root@melancholy:~# exit
logout
dotancohen@melancholy:~$ sudo -s
Sourced .bashrc
dotancohen@melancholy:~$ which lsl
/home/dotancohen/.bin/lsl
dotancohen@melancholy:~$ exit
exit
Though sudo -s is convenient for giving you the environment that you are
familiar with, I recommend the use of sudo -i for two reasons:
The visual reminder that you are in a 'root' session.
The root environment is far less likely to be poisoned with malware, such as a rogue
line in .bashrc .
sudo asks for your own password (and also checks if you're allowed to run
commands as root, which is configured through /etc/sudoers -- by default all
user accounts that belong to the "admin" group are allowed to use sudo).
sudo -s launches a shell as root, but doesn't change your working directory.
sudo -i simulates a login into the root account: your working directory will be
/root , and root's .profile etc. will be sourced as if on
login.
to make the answer more complete: sudo -s is almost equal to su
($HOME is different) and sudo -i is equal to su - –
In Ubuntu or a related system, I don't find much use for su in the traditional,
super-user sense. sudo handles that case much better. However, su
is great for becoming another user in one-off situations where configuring sudoers would be
silly.
For example, if I'm repairing my system from a live CD/USB, I'll often mount my hard drive
and other necessary stuff and chroot into the system. In such a case, my first
command is generally:
su - myuser # Note the '-'. It means to act as if that user had just logged in.
That way, I'm operating not as root, but as my normal user, and I then use
sudo as appropriate.
"... To invoke a login shell using sudo just use -i . When command is not specified you'll get a login shell prompt, otherwise you'll get the output of your command. ..."
To invoke a login shell using sudo just use -i . When command is not specified you'll get a login
shell prompt, otherwise you'll get the output of your command.
By default, sudo asks the user to identify himself using his own password. Once a password
is entered, sudo remembers it for 5 minutes, allowing the user to focus on his tasks and not
repeatedly re-entering his password.
Of course, this behavior can be changed: you can set the Defaults: directive in
/etc/sudoers to change the default behavior for a user.
For instance, to change the default 5 minutes to 0 (never remember):
CODE Changing the
timeout value
Defaults:larry timestamp_timeout=0
A setting of -1 would remember the password indefinitely (until the system
reboots).
A different setting would be to require the password of the user that the command should be
run as and not the users' personal password. This is accomplished using runaspw .
In the following example we also set the number of retries (how many times the user can
re-enter a password before sudo fails) to 2 instead of the default 3:
This is nothing to do with another physical user. Both ID's are mine. I know the password as
I created the account. I just don't want to have to type the password every time. –
zio
Feb 17 '13 at 13:24
It needs a bit of configuration though, but once done you would only do this:
sudo -u user2 -s
And you would be logged in as user2 without entering a password.
Configuration
To configure sudo, you must edit its configuration file via: visudo . Note:
this command will open the configuration using the vi text editor, if you are
unconfortable with that, you need to set another editor (using export
EDITOR=<command> ) before executing the following line. Another command line
editor sometimes regarded as easier is nano , so you would do export
EDITOR=/usr/bin/nano . You usually need super user privilege for visudo
:
sudo visudo
This file is structured in different section, the aliases, then defaults and finally at
the end you have the rules. This is where you need to add the new line. So you navigate at
the end of the file and add this:
user1 ALL=(user2) NOPASSWD: /bin/bash
You can replace also /bin/bash by ALL and then you could launch
any command as user2 without a password: sudo -u user2 <command>
.
Update
I have just seen your comment regarding Skype. You could consider adding Skype directly to
the sudo's configuration file. I assume you have Skype installed in your
Applications folder:
One thing to note from a security-perspective is that specifying a specific command implies
that it should be a read-only command for user1; Otherwise, they can overwrite the command
with something else and run that as user2. And if you don't care about that, then you might
as well specify that user1 can run any command as user2 and therefore have a simpler
sudo config. – Stan Kurdziel
Oct 26 '15 at 16:56
@StanKurdziel good point! Although it is something to be aware of, it's really seldom to have
system executables writable by users unless you're root but in this case you don't need sudo
;-) But you're right to add this comment because it's so seldom that I've probably overlooked
it more than one time. – Huygens
Oct 26 '15 at 19:24
To get it nearer to the behaviour su - user2 instead of su user2 ,
the commands should probably all involve sudo -u user2 -i , in order to simulate
an initial login as user2 – Gert van den Berg
Aug 10 '16 at 14:24
You'd still have the issues where Skype gets confused since two instances are running on
one user account and files read/written by that program might conflict. It also might work
well enough for your needs and you'd not need an iPod touch to run your second Skype
instance.
This is a good secure solution for the general case of password-free login to any account on
any host, but I'd say it's probably overkill when both accounts are on the same host and
belong to the same user. – calum_b
Feb 18 '13 at 9:54
@scottishwildcat It's far more secure than the alternative of scripting the password and
feeding it in clear text or using a variable and storing the password in the keychain and
using a tool like expect to script the interaction. I just use sudo su -
blah and type my password. I think the other answer covers sudo well enough to keep
this as a comment. – bmike ♦
Feb 18 '13 at 14:02
We appear to be in total agreement - thanks for the addition - feel free to edit it into the
answer if you can improve on it. – bmike ♦
Feb 18 '13 at 18:46
The accepted solution ( sudo -u user2 <...> ) does have the advantage that
it can't be used remotely, which might help for security - there is no private key for user1
that can be stolen. – Gert van den Berg
Aug 10 '16 at 14:20
If you want to use sudo su - user without a password, you should (if you have
the privileges) do the following on you sudoers file:
<youuser> ALL = NOPASSWD: /bin/su - <otheruser>
where:
<yourusername> is you username :D (saumun89, i.e.)
<otheruser> is the user you want to change to
Then put into the script:
sudo /bin/su - <otheruser>
Doing just this, won't get subsequent commands get run by <otheruser> ,
it will spawn a new shell. If you want to run another command from within the script as this
other user, you should use something like:
sudo -u <otheruser> <command>
And in sudoers file:
<yourusername> ALL = (<otheruser>) NOPASSWD: <command>
Obviously, a more generic line like:
<yourusername> ALL = (ALL) NOPASSWD: ALL
Will get things done, but would grant the permission to do anything as anyone.
when the sudo su - user command gets executed,it asks for a password. i want a solution in
which script automaticaaly reads password from somewhere. i dont have permission to do what u
told earlier. – sam
Feb 9 '11 at 11:43
echo "your_password" | sudo -S [rest of your parameters for sudo]
(Of course without [ and ])
Please note that you should protect your script from read access from unauthorized users.
If you want to read password from separate file, you can use
sudo -S [rest of your parameters for sudo] < /etc/sudo_password_file
(Or whatever is the name of password file, containing password and single line break.)
From sudo man page:
-S The -S (stdin) option causes sudo to read the password from
the standard input instead of the terminal device. The
password must be followed by a newline character.
The easiest way is to make it so that user doesn't have to type a password at all.
You can do that by running visudo , then changing the line that looks
like:
someuser ALL=(ALL) ALL
to
someuser ALL=(ALL) NOPASSWD: ALL
However if it's just for one script, it would be more secure to restrict passwordless
access to only that script, and remove the (ALL) , so they can only run it as
root, not any user , e.g.
i do not have permission to edit sudoers file.. any other so that it should read password
from somewhere so that automation of this can be done. – sam
Feb 9 '11 at 11:34
you are out of luck ... you could do this with, lets say expect but that would
let the password for your user hardcoded somewhere, where people could see it (granted that
you setup permissions the right way, it could still be read by root). – Torian
Feb 9 '11 at 11:40
when the sudo su - user command gets executed,it asks for a password. i want a solution in
which script automaticaaly reads password from somewhere. i dont have permission to edit
sudoers file.i have the permission to store password in a file.the script should read
password from that file – sam
The sudoers policy plugin determines a user's sudo privileges.
For the targetpw:
sudo will prompt for the password of the user specified by the -u option (defaults to
root) instead of the password of the invoking user when running a command or editing a
file.
sudo(8) allows you to execute commands as someone else
So, basically it says that any user can run any command on any host as any user and yes,
the user just has to authenticate, but with the password of the other user, in order to run
anything.
The first ALL is the users allowed
The second one is the hosts
The third one is the user as you are running the command
The last one is the commands allowed
is "ALL ALL=!SUDOSUDO" as the last line is like when having DROP iptables POLICY and still
using a -j DROP rule as last rule in ex.: INPUT chain? :D or does it has real effects?
– gasko peter
Dec 6 '12 at 14:30
"... IF you're using putty in either Xorg or Windows (i.e terminal within a gui) , it's possible to use the "conventional" right-click copy/paste behavior while in mc. Hold the shift key while you mark/copy. ..."
"... Putty has ability to copy-paste. In mcedit, hold Shift and select by mouse ..."
open the other file in the editor, and navigate to the target location
press Shift+F5 to open Insert file dialog
press Enter to paste from the default file location (which is same as the
one in Save block dialog)
NOTE: There are other environment related methods, that could be more conventional
nowadays, but the above one does not depend on any desktop environment related clipboard,
(terminal emulator features, putty, Xorg, etc.). This is a pure mcedit feature which works
everywhere.
If you get unwanted indents in what was pasted then while editing file in Midnight Commander
press F9 to show top menu and in Options/Generals menu uncheck Return does
autoindent option. Yes, I was happy when I found it too :) – Piotr Dobrogost
Mar 30 '17 at 17:32
IF you're using putty in either Xorg or Windows (i.e terminal within a gui) , it's possible
to use the "conventional" right-click copy/paste behavior while in mc. Hold the shift key
while you mark/copy.
LOL - did you actually read the other answers? And your answer is incomplete, you should
include what to do with the mouse in order to "select by mouse".
According to help in MC:
Ctrl + Insert copies to the mcedit.clip, and Shift +
Insert pastes from mcedit.clip.
It doesn't work for me, by some reason, but by pressing F9 you get a menu,
Edit > Copy to clipfile - worked fine.
"... "what did I just press and what did it do?" ..."
"... Underneath it's got lots of powerful features like syntax highlighting, bracket matching, regular expression search and replace, and spell checking. ..."
"... I use Mcedit for most of my day-to-day text editing, although I do switch to heavier weight GUI-based editors when I need to edit lots of files at once. ..."
I've always hated the Vi vs Emacs holy war that many Unix users like to wage and I
find that both editors have serious shortcomings and definitely aren't something I'd recommend
a beginner use. Pico and Nano are certainly easier to use, but they always a feel a bit lacking
in features and clunky to me.
Mcedit runs from the command line but has a colourful GUI-like interface, you can use the
mouse if you want, but I generally don't.
If you're old enough to have used DOS, then it's very reminiscent of the "edit" text editor
that was built into MS-DOS 5 and 6, except it's full of powerful features that still make it a
good choice in 2018. It has a nice intuitive interface based around the F keys on
the keyboard and a pull-down menu which can be accessed by pressing F9 .
It's really easy to use and you're told about all the most important key combinations on
screen and the rest can all be discovered from the menus. I find this far nicer than Vi or
Emacs where I have to constantly look up key combinations or press a key by mistake and then
have the dreaded "what did I just press and what did it do?" thought.
Underneath it's got lots of powerful features like syntax highlighting, bracket
matching, regular expression search and replace, and spell checking.
I use Mcedit for most of my day-to-day text editing, although I do switch to heavier
weight GUI-based editors when I need to edit lots of files at once. I just wish more
people knew about it and then it might be installed by default on more of the shared systems
and HPCs that I have to use!
I haven't found anything on the topic in the Internet. The only line from
.mc/ini that looks related to the question is keymap=mc.keymap but I
have no idea what to do with it.
$ man-section mc | head -n20
mc (1)
--
Name
Usage
Description
Options
Overview
Mouse support
Keys
Redefine hotkey bindings
8th section... is that possible? Lets look
man mc (scroll,scroll,scroll)
Redefine hotkey bindings
Hotkey bindings may be read from external file (keymap-file). A keymap-
file is searched on the following algorithm (to the first one found):
1) command line option -K <keymap> or --keymap=<keymap>
2) Environment variable MC_KEYMAP
3) Parameter keymap in section [Midnight-Commander] of config file.
4) File ~/.config/mc/mc.keymap
5) File /etc/mc/mc.keymap
6) File /usr/share/mc/mc.keymap
Bingo!
cp /etc/mc/mc.keymap ~/.config/mc/
Now edit the key mappings as you like and save ~/.config/mc/mc.keymap when done
For more info, read the Keys ( man mc ) section and the three sections following that.
If the Find file dialog (accessible with Alt+? ) shows no results, check
the current directory for symbolic links. Find file does not follow symbolic links, so
use bind mounts (see mount(8) ) instead, or the External
panelize command.
Midnight Commander does not support a trash can by default. Using
libtrash
Install the libtrashAUR
package, and create an mc alias in the initialization file of your shell (e.g.,
~/.bashrc or ~/.zshrc ):
alias mc='LD_PRELOAD=/usr/lib/libtrash.so.3.3 mc'
To apply the changes, reopen your shell session or source the shell
initialization file.
Default settings are defined in /etc/libtrash.conf.sys . You can overwrite
these settings per-user in ~/.libtrash , for example:
TRASH_CAN = .Trash
INTERCEPT_RENAME = NO
IGNORE_EXTENSIONS= o;exe;com
UNCOVER_DIRS=/dev
Now files deleted by Midnight Commander (launched with mc ) will be moved to the
~/.Trash directory.
Warning:
Applications launched from mc inherit LD_PRELOAD , which may cause
problems with some applications. [1]
With GLOBAL_PROTECTION = YES set (default), files deleted outside the home
directory are moved to the trash, even if they are on a different partition. Depending on the
file, this may cause a significant delay.
Many people don't know that mc has a multi-window text-editor built-in (eerily disabled by
default) with macro capability and all sorts of goodies. run
If I do $EDITOR some_file then I get the file open in vim in another tmux
windows - exactly what I wanted.
Sadly, when I try to edit in MC it goes blank for a second and then returns to normal MC
window. MC doesn't seem to keep any logs and I don't get any error message.
The question(s)
Do you know what I'm doing wrong?
Do you have a usable workaround for what I want?
Should I create a feature request/bug for MC?
Tags :midnight-commanderAnswers 1
You are defining a shell function, which is unknown for mc when it is trying to
start the editor.
The correct way is to create a bash script, not a function. Then set EDITOR
value to it, for example:
In Midnight Commander, is it possible to exclude some directories/patterns/... when doing search? ( M-? ) I'm specifically
interested in skipping the .hg subdirectory.
Answers 1In the "[Misc]" section of your ~/.mc/ini file, you can specify the directories you wish to skip in the "find_ignore_dirs" setting.
To specify multiple directories, use a colon (":") as the delimiter.
You can get
tab-completion by pressing ESC then TAB . You can also get the currently
highlighted file/subdir name onto the command line with ESC-ENTER.
I recently installed openSUSE 13.1 and set up the mc in typical why by aliasing
mc with mc-wrapper.sh to have it exit into the last working directory in
mc instance. However this does not seem to be working. I tried to debug the
mc-wrapper.sh script - the echo commands.
MC_USER=`id | sed 's/[^(]*(//;s/).*//'`
MC_PWD_FILE="${TMPDIR-/tmp}/mc-$MC_USER/mc.pwd.$$"
/usr/bin/mc -P "$MC_PWD_FILE" "$@"
if test -r "$MC_PWD_FILE"; then
MC_PWD="`cat "$MC_PWD_FILE"`"
if test -n "$MC_PWD" && test -d "$MC_PWD"; then
echo "will cd in : $MC_PWD"
cd $MC_PWD
echo $(pwd)
fi
unset MC_PWD
fi
rm -f "$MC_PWD_FILE"
unset MC_PWD_FILE
echo $(pwd)
To my surprise, mc-wrapper-sh does change the directory and is in the directory
before exiting but back in bash prompt the working directory is the one from which the script
was invoked.
Can it be that some bash settings is required for this to work?
If MC displays funny characters, make sure the terminal emulator uses UTF8 encoding.
Smooth scrolling
vi ~/.mc/ini (per user) or /etc/mc/mc.ini (system-wide):
panel_scroll_pages=0
Make both panels display the same directory
ALT+i. If NOK, try ESC+i
Navigate through history
ESC+y to go back to the previous directory, ESC+u to go the next
Options > Configuration > Lynx-like motion doesn't go through the navigation history
but rather jumps in/out of a directory so the user doesn't have to hit PageUp followed by
Enter
Loop through all items starting with the same letter
CTRL+s followed by the letter to jump to the first occurence, then keep hitting CTRL+s to
loop through the list
"... MC_HOME variable can be set to alternative path prior to starting mc. Man pages are not something you can find the answer right away =) ..."
"... A small drawback of this solution: if you set MC_HOME to a directory different from your usual HOME, mc will ignore the content of your usual ~/.bashrc so, for example, your custom aliases defined in that file won't work anymore. Workaround: add a symlink to your ~/.bashrc into the new MC_HOME directory ..."
That turned out to be simpler as one might think. MC_HOME variable can be set to alternative
path prior to starting mc. Man pages are not something you can find the answer right away =)
You have to share the same user name on remote server (access can be distinguished by rsa
keys) and want to use your favorite mc configuration w/o overwriting it. Concurrent sessions
do not interfere each other.
A small drawback of this solution: if you set MC_HOME to a directory different from your
usual HOME, mc will ignore the content of your usual ~/.bashrc so, for example, your custom
aliases defined in that file won't work anymore. Workaround: add a symlink to your ~/.bashrc
into the new MC_HOME directory – Cri
Sep 5 '16 at 10:26
If you mean, you want to be able to run two instances of mc as the same user at the same
time with different config directories, as far as I can tell you can't. The path is
hardcoded.
However, if you mean, you want to be able to switch which config directory is being used,
here's an idea (tested, works). You probably want to do it without mc running:
Create a directory $HOME/mc_conf , with a subdirectory, one
.
Move the contents of $HOME/.config/mc into the
$HOME/mc_conf/one subdirectory
Duplicate the one directory as $HOME/mc_conf/two .
Create a script, $HOME/bin/switch_mc :
#!/bin/bash
configBase=$HOME/mc_conf
linkPath=$HOME/.config/mc
if [ -z $1 ] || [ ! -e "$configBase/$1" ]; then
echo "Valid subdirecory name required."
exit 1
fi
killall mc
rm $linkPath
ln -sv $configBase/$1 $linkPath
Run this, switch_mc one . rm will bark about no such file,
that doesn't matter.
Hopefully it's clear what's happening there -- this sets a the config directory path as a
symlink. Whatever configuration changes you now make and save will be int the
one directory. You can then exit and switch_mc two , reverting to
the old config, then start mc again, make changes and save them, etc.
You could get away with removing the killall mc and playing around; the
configuration stuff is in the ini file, which is read at start-up (so you can't
switch on the fly this way). It's then not touched until exit unless you "Save setup", but at
exit it may be overwritten, so the danger here is that you erase something you did earlier or
outside of the running instance.
that works indeed, your idea is pretty clear, thank you for your time However my idea was to
be able run differently configured mc's under the same account not interfering each other. I
should have specified that in my question. The path to config dir is in fact hardcoded, but
it is hardcoded RELATIVELY to user's home dir, that is the value of $HOME, thus changing it before mc start DOES change the config dir location - I've checked that. the drawback is
$HOME stays changed as long as mc runs, which could be resolved if mc had a kind of startup
hook to put restore to original HOME into – Tagwint
Dec 18 '14 at 16:52
mc
/ mcedit has a config option called auto_save_setup which is enabled
by default. This option automatically saves your current setup upon exiting. The problem occurs
when you try to edit ~/.config/mc/ini using mcedit . It will
overwrite whatever changes you made upon exiting, so you must edit the
~/.config/mc/ini using a different editor such as nano .
at the bottom (top, if ineffective) of your ~/.bashrc file. Thus you can load skins as
in
mc -S sand256.ini
In
/home/you/.config/mc/ini
have the lines:
[Midnight-Commander]
skin=sand256
for preset skin. Newer mc version offer to choose a preset skin from within the menu and
save it in the above ini file, relieving you of the above manual step.
Many people don't know that mc has a multi-window text-editor built-in (eerily disabled by
default) with macro capability and all sorts of goodies. run
mc -e my.txt
to edit directly.
Be aware that many skins break the special characters for sorting filenames reverse up/down
unless one works hard with locale parameters and what not. Few people in the world know how to
do that properly. In below screenshot you see "arrowdown n" over the filename list to indicate
sort order. In many xterm, you will get ??? instead so you might resort to unskin and go to
"default skin" setting with ugly colours.
The below CTRL-O hotkey starts what mc calls a subshell. If you run mc a second time in a
"subshell", mc will not remind you of the CTRL-O hotkey (as if the world only knows 3 hotkeys)
but will start mc with no deeper "subshell" iteration possible, unless one modifies the
sources.
mcdiff: Internal diff viewer of GNU Midnight Commander.Index of
mcdiff man page
Read mcdiff man page on Linux: $ man 1 mcdiffNAME mcdiff - Internal diff
viewer of GNU Midnight Commander. USAGEmcdiff [-bcCdfhstVx?] file1 file2
DESCRIPTION
mcdiff is a link to mc , the main GNU Midnight Commander executable. Executing GNU
Midnight Commander under this name requests starting the internal diff viewer which compares
file1 and file2 specified on the command line.
OPTIONS
-b
Force black and white display.
-c
Force color mode on terminals where mcdiff defaults to black and white.
Specify a different color set. See the Colors section in mc
(1) for more information.
-d
Disable mouse support.
-f
Display the compiled-in search paths for Midnight Commander files.
-t
Used only if the code was compiled with S-Lang and terminfo: it makes the Midnight
Commander use the value of the TERMCAP variable for the terminal information instead
of the information on the system wide terminal database
-V
Displays the version of the program.
-x
Forces xterm mode. Used when running on xterm-capable terminals (two screen modes, and
able to send mouse escape sequences).
COLORS The default colors may be changed by appending to the MC_COLOR_TABLE
environment variable. Foreground and background colors pairs may be specified for example with:
Something I discovered which I REALLY appreciated was the hide/view of hidden files can be
toggled by pressing ALT-. (ALT-PERIOD). Be aware that often the RIGHT ALT key is NOT seen as an
ALT key by the system, so you usually need to use Left-ALT-. to toggle this. I forgot about the
Right-ALT weirdness and thought I'd broken mc one day. {sigh} Such a blonde...
Just checked (xev!), I guess the ALT-. toggle is mapped to ALT_L-., and the right ALT key
gives an ALT_R keycode... which doesn't match the mc mapping, causing it to not work... now I
know why! Hooray!
1) If the panels are active and I issue a command that has a lot of
output, it appears to be lost forever.
i.e., if the panels are visible and I cat something (i.e., cat /proc/cpuinfo), that info is
gone forever once the panels get redrawn.
If you use Cygwin's mintty
terminal, you can use its Flip Screen context menu command (or Alt+F12 shortcut) to
switch between the so-called alternate screen, where fullscreen applications like mc
normally run, and the primary screen where output from commands such as cat
appears.
If you already know you want it, get it here:
parsync+utils.tar.gz (contains parsync
plus the kdirstat-cache-writer , stats , and scut utilities below) Extract it into a dir on your $PATH and after
verifying the other dependencies below, give it a shot.
While parsync is developed for and test on Linux, the latest version of parsync has been modified to (mostly) work on the Mac
(tested on OSX 10.9.5). A number of the Linux-specific dependencies have been removed and there are a number of Mac-specific work
arounds.
Thanks to Phil Reese < [email protected] > for the code mods needed to get it started.
It's the same package and instructions for both platforms.
2. Dependencies
parsync requires the following utilities to work:
stats - self-writ Perl utility for providing
descriptive stats on STDIN
scut - self-writ Perl utility like cut
that allows regex split tokens
kdirstat-cache-writer (included in the tarball mentioned above), requires a
parsync needs to be installed only on the SOURCE end of the transfer and uses whatever rsync is available on the TARGET.
It uses a number of Linux- specific utilities so if you're transferring between Linux and a FreeBSD host, install parsync on the
Linux side. In fact, as currently written, it will only PUSH data to remote targets ; it will not pull data as rsync itself
can do. This will probably in the near future. 3. Overviewrsync is
a fabulous data mover. Possibly more bytes have been moved (or have been prevented from being moved) by rsync than by any other application.
So what's not to love? For transferring large, deep file trees, rsync will pause while it generates lists of files to process. Since
Version 3, it does this pretty fast, but on sluggish filesystems, it can take hours or even days before it will start to actually
exchange rsync data. Second, due to various bottlenecks, rsync will tend to use less than the available bandwidth on high speed networks.
Starting multiple instances of rsync can improve this significantly. However, on such transfers, it is also easy to overload the
available bandwidth, so it would be nice to both limit the bandwidth used if necessary and also to limit the load on the system.
parsync tries to satisfy all these conditions and more by:
using the kdir-cache-writer
utility from the beautiful kdirstat directory browser which can
produce lists of files very rapidly
allowing re-use of the cache files so generated.
doing crude loadbalancing of the number of active rsyncs, suspending and un-suspending the processes as necessary.
using rsync's own bandwidth limiter (--bwlimit) to throttle the total bandwidth.
using rsync's own vast option selection is available as a pass-thru (tho limited to those compatible with the --files-from
option).
Only use for LARGE data transfers The main use case for parsync is really only very large data transfers thru fairly fast
network connections (>1Gb/s). Below this speed, a single rsync can saturate the connection, so there's little reason to use
parsync and in fact the overhead of testing the existence of and starting more rsyncs tends to worsen its performance on small
transfers to slightly less than rsync alone.
Beyond this introduction, parsync's internal help is about all you'll need to figure out how to use it; below is what you'll see
when you type parsync -h . There are still edge cases where parsync will fail or behave oddly, especially with small data
transfers, so I'd be happy to hear of such misbehavior or suggestions to improve it. Download the complete tarball of parsync, plus
the required utilities here: parsync+utils.tar.gz
Unpack it, move the contents to a dir on your $PATH , chmod it executable, and try it out.
parsync --help
or just
parsync
Below is what you should see:
4. parsync help
parsync version 1.67 (Mac compatibility beta) Jan 22, 2017
by Harry Mangalam <[email protected]> || <[email protected]>
parsync is a Perl script that wraps Andrew Tridgell's miraculous 'rsync' to
provide some load balancing and parallel operation across network connections
to increase the amount of bandwidth it can use.
parsync is primarily tested on Linux, but (mostly) works on MaccOSX
as well.
parsync needs to be installed only on the SOURCE end of the
transfer and only works in local SOURCE -> remote TARGET mode
(it won't allow remote local SOURCE <- remote TARGET, emitting an
error and exiting if attempted).
It uses whatever rsync is available on the TARGET. It uses a number
of Linux-specific utilities so if you're transferring between Linux
and a FreeBSD host, install parsync on the Linux side.
The only native rsync option that parsync uses is '-a' (archive) &
'-s' (respect bizarro characters in filenames).
If you need more, then it's up to you to provide them via
'--rsyncopts'. parsync checks to see if the current system load is
too heavy and tries to throttle the rsyncs during the run by
monitoring and suspending / continuing them as needed.
It uses the very efficient (also Perl-based) kdirstat-cache-writer
from kdirstat to generate lists of files which are summed and then
crudely divided into NP jobs by size.
It appropriates rsync's bandwidth throttle mechanism, using '--maxbw'
as a passthru to rsync's 'bwlimit' option, but divides it by NP so
as to keep the total bw the same as the stated limit. It monitors and
shows network bandwidth, but can't change the bw allocation mid-job.
It can only suspend rsyncs until the load decreases below the cutoff.
If you suspend parsync (^Z), all rsync children will suspend as well,
regardless of current state.
Unless changed by '--interface', it tried to figure out how to set the
interface to monitor. The transfer will use whatever interface routing
provides, normally set by the name of the target. It can also be used for
non-host-based transfers (between mounted filesystems) but the network
bandwidth continues to be (usually pointlessly) shown.
[[NB: Between mounted filesystems, parsync sometimes works very poorly for
reasons still mysterious. In such cases (monitor with 'ifstat'), use 'cp'
or 'tnc' (https://goo.gl/5FiSxR) for the initial data movement and a single
rsync to finalize. I believe the multiple rsync chatter is interfering with
the transfer.]]
It only works on dirs and files that originate from the current dir (or
specified via "--rootdir"). You cannot include dirs and files from
discontinuous or higher-level dirs.
** the ~/.parsync files **
The ~/.parsync dir contains the cache (*.gz), the chunk files (kds*), and the
time-stamped log files. The cache files can be re-used with '--reusecache'
(which will re-use ALL the cache and chunk files. The log files are
datestamped and are NOT overwritten.
** Odd characters in names **
parsync will sometimes refuse to transfer some oddly named files, altho
recent versions of rsync allow the '-s' flag (now a parsync default)
which tries to respect names with spaces and properly escaped shell
characters. Filenames with embedded newlines, DOS EOLs, and other
odd chars will be recorded in the log files in the ~/.parsync dir.
** Because of the crude way that files are chunked, NP may be
adjusted slightly to match the file chunks. ie '--NP 8' -> '--NP 7'.
If so, a warning will be issued and the rest of the transfer will be
automatically adjusted.
OPTIONS
=======
[i] = integer number
[f] = floating point number
[s] = "quoted string"
( ) = the default if any
--NP [i] (sqrt(#CPUs)) ............... number of rsync processes to start
optimal NP depends on many vars. Try the default and incr as needed
--startdir [s] (`pwd`) .. the directory it works relative to. If you omit
it, the default is the CURRENT dir. You DO have
to specify target dirs. See the examples below.
--maxbw [i] (unlimited) .......... in KB/s max bandwidth to use (--bwlimit
passthru to rsync). maxbw is the total BW to be used, NOT per rsync.
--maxload [f] (NP+2) ........ max total system load - if sysload > maxload,
sleeps an rsync proc for 10s
--checkperiod [i] (5) .......... sets the period in seconds between updates
--rsyncopts [s] ... options passed to rsync as a quoted string (CAREFUL!)
this opt triggers a pause before executing to verify the command.
--interface [s] ............. network interface to /monitor/, not nec use.
default: `/sbin/route -n | grep "^0.0.0.0" | rev | cut -d' ' -f1 | rev`
above works on most simple hosts, but complex routes will confuse it.
--reusecache .......... don't re-read the dirs; re-use the existing caches
--email [s] ..................... email address to send completion message
(requires working mail system on host)
--barefiles ..... set to allow rsync of individual files, as oppo to dirs
--nowait ................ for scripting, sleep for a few s instead of wait
--version ................................. dumps version string and exits
--help ......................................................... this help
Examples
========
-- Good example 1 --
% parsync --maxload=5.5 --NP=4 --startdir='/home/hjm' dir1 dir2 dir3
hjm@remotehost:~/backups
where
= "--startdir='/home/hjm'" sets the working dir of this operation to
'/home/hjm' and dir1 dir2 dir3 are subdirs from '/home/hjm'
= the target "hjm@remotehost:~/backups" is the same target rsync would use
= "--NP=4" forks 4 instances of rsync
= -"-maxload=5.5" will start suspending rsync instances when the 5m system
load gets to 5.5 and then unsuspending them when it goes below it.
It uses 4 instances to rsync dir1 dir2 dir3 to hjm@remotehost:~/backups
-- Good example 2 --
% parsync --rsyncopts="--ignore-existing" --reusecache --NP=3
--barefiles *.txt /mount/backups/txt
where
= "--rsyncopts='--ignore-existing'" is an option passed thru to rsync
telling it not to disturb any existing files in the target directory.
= "--reusecache" indicates that the filecache shouldn't be re-generated,
uses the previous filecache in ~/.parsync
= "--NP=3" for 3 copies of rsync (with no "--maxload", the default is 4)
= "--barefiles" indicates that it's OK to transfer barefiles instead of
recursing thru dirs.
= "/mount/backups/txt" is the target - a local disk mount instead of a network host.
It uses 3 instances to rsync *.txt from the current dir to "/mount/backups/txt".
-- Error Example 1 --
% pwd
/home/hjm # executing parsync from here
% parsync --NP4 --compress /usr/local /media/backupdisk
why this is an error:
= '--NP4' is not an option (parsync will say "Unknown option: np4")
It should be '--NP=4'
= if you were trying to rsync '/usr/local' to '/media/backupdisk',
it will fail since there is no /home/hjm/usr/local dir to use as
a source. This will be shown in the log files in
~/.parsync/rsync-logfile-<datestamp>_#
as a spew of "No such file or directory (2)" errors
= the '--compress' is a native rsync option, not a native parsync option.
You have to pass it to rsync with "--rsyncopts='--compress'"
The correct version of the above command is:
% parsync --NP=4 --rsyncopts='--compress' --startdir=/usr local
/media/backupdisk
-- Error Example 2 --
% parsync --start-dir /home/hjm mooslocal [email protected]:/usr/local
why this is an error:
= this command is trying to PULL data from a remote SOURCE to a
local TARGET. parsync doesn't support that kind of operation yet.
The correct version of the above command is:
# ssh to hjm@moo, install parsync, then:
% parsync --startdir=/usr local hjm@remote:/home/hjm/mooslocal
fstab
file. However, there may be times when you prefer to have a remote file system mount only on
demand -- for example, to boost performance by reducing network bandwidth usage, or to hide or
obfuscate certain directories for security reasons. The package autofs provides this feature. In this
article, I'll describe how to get a basic automount configuration up and running.
First, a few assumptions: Assume the NFS server named tree.mydatacenter.net
is up and running. Also assume a data directory named ourfiles and two user
directories, for Carl and Sarah, are being shared by this server.
A few best practices will make things work a bit better: It is a good idea to use the same
user ID for your users on the server and any client workstations where they have an account.
Also, your workstations and server should have the same domain name. Checking the relevant
configuration files should confirm.
alan@workstation1:~$ sudo getent passwd carl sarah
[sudo] password for alan:
carl:x:1020:1020:Carl,,,:/home/carl:/bin/bash
sarah:x:1021:1021:Sarah,,,:/home/sarah:/bin/bash
As you can see, both the client workstation and the NFS server are configured in the
hosts file. I'm assuming a basic home or even small office network that might lack
proper internal domain name service (i.e., DNS).
Install the packages
You need to install only two packages: nfs-common for NFS client functions, and
autofs to provide the automount function.
Second, add the following line to the file auto.misc :
ourfiles -fstype=nfs tree:/share/ourfiles
This line instructs autofs to mount the ourfiles share at the location matched
in the auto.master file for auto.misc . As shown above, these files
will be available in the directory /mnt/tree/ourfiles .
Third, create the file auto.home with the following line:
* -fstype=nfs tree:/home/&
This line instructs autofs to mount the users share at the location matched in the
auto.master file for auto.home . In this case, Carl and Sarah's files
will be available in the directories /home/tree/carl or
/home/tree/sarah , respectively. The asterisk (referred to as a wildcard) makes it
possible for each user's share to be automatically mounted when they log in. The ampersand also
works as a wildcard representing the user's directory on the server side. Their home directory
should be mapped accordingly in the passwd file. This doesn't have to be done if
you prefer a local home directory; instead, the user could use this as simple remote storage
for specific files.
Finally, restart the autofs daemon so it will recognize and load these
configuration file changes.
alan@workstation1:/etc$ sudo service autofs restart
Testing autofs
If you change to one of the directories listed in the file auto.master and run
the ls command, you won't see anything immediately. For example, change directory
(cd) to /mnt/tree . At first, the output of ls won't
show anything, but after running cd ourfiles , the ourfiles share
directory will be automatically mounted. The cd command will also be executed and
you will be placed into the newly mounted directory.
carl@workstation1:~$ cd /mnt/tree
carl@workstation1:/mnt/tree$ ls
carl@workstation1:/mnt/tree$ cd ourfiles
carl@workstation1:/mnt/tree/ourfiles$
To further confirm that things are working, the mount command will display the
details of the mounted share.
carl@workstation1:~$ mount
tree:/mnt/share/ourfiles on /mnt/tree/ourfiles type nfs4
(rw,relatime,vers=4.0,rsize=131072,wsize=131072,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.10.1.22,local_lock=none,addr=10.10.1.5)
The /home/tree directory will work the same way for Carl and Sarah.
I find it useful to bookmark these directories in my file manager for quicker access.
history also allows you to rerun a command with different syntax. For example,
if I wanted to change my previous command history | grep dnf to history |
grep ssh , I can execute the following at the prompt:
$ ^dnf^ssh^
history will rerun the command, but replace dnf with
ssh , and execute it.
Removing history
There may come a time that you want to remove some or all the commands in your history file.
If you want to delete a particular command, enter history -d <line number> .
To clear the entire contents of the history file, execute history -c .
The history file is stored in a file that you can modify, as well. Bash shell users will
find it in their Home directory as .bash_history .
Next steps
There are a number of other things that you can do with history :
Set the size of your history buffer to a certain number of commands
Record the date and time for each line in history
Prevent certain commands from being recorded in history
For more information about the history command and other interesting things you
can do with it, take a look at the GNU Bash Manual .
Cheat is a
simple, interactive command-line cheat-sheet program which shows use cases of a Linux command
with a number of options and their short understandable function. It is useful for Linux
newbies and sysadmins.
To install and use it, check out our complete article about Cheat program and its usage with
examples:
That's all! In this article, we have shared 5 command-line tools for remembering Linux
commands. If you know any other tools for the same purpose that are missing in the list above,
let us know via the feedback form below.
"... I've been dealing with a similar situation, with ~200GB of SQL .bak, except the only way I've been able to get the WAN link to saturate is with FTP. I ended up using 7-zip with zero compression to break it into 512MB chunks. ..."
This looks related to
this one , but it's somewhat different.
There is this WAN link between two company sites, and we need to transfer a single very
large file (Oracle dump, ~160 GB).
We've got full 100 Mbps bandwidth (tested), but looks like a single TCP connection just
can't max it out due to how TCP works (ACKs, etc.). We tested the link with iperf , and results change dramatically when
increasing the TCP Window Size: with base settings we get ~5 Mbps throughput, with a bigger WS
we can get up to ~45 Mbps, but not any more than that. The network latency is around 10 ms.
Out of curiosity, we ran iperf using more than a single connections, and we found that, when
running four of them, they would indeed achieve a speed of ~25 Mbps each, filling up all the
available bandwidth; so the key looks to be in running multiple simultaneous transfers.
With FTP, things get worse: even with optimized TCP settings (high Window Size, max MTU,
etc.) we can't get more than 20 Mbps on a single transfer. We tried FTPing some big files at
the same time, and indeed things got a lot better than when transferring a single one; but then
the culprit became disk I/O, because reading and writing four big files from the same disk
bottlenecks very soon; also, we don't seem to be able to split that single large file into
smaller ones and then merge it back, at least not in acceptable times (obviously we can't spend
splicing/merging back the file a time comparable to that of transferring it).
The ideal solution here would be a multithreaded tool that could transfer various chunks of
the file at the same time; sort of like peer-to-peer programs like eMule or BitTorrent already
do, but from a single source to a single destination. Ideally, the tool would allow us to
choose how many parallel connections to use, and of course optimize disk I/O to not jump (too)
madly between various sections of the file.
Does anyone know of such a tool?
Or, can anyone suggest a better solution and/or something we already didn't try?
P.S. We already thought of backing that up to tape/disk and physically sending it to
destination; that would be our extreme measure if WAN just doesn't cut it, but, as A.S.
Tanenbaum said, "Never underestimate the bandwidth of a station wagon full of tapes hurtling
down the highway." networkingbandwidthtcpfile-transfershareedited Apr 13 '17 at 12:14Community
♦ 1 asked Feb 11 '10 at 7:19 Massimo 50.9k 36 157 269 locked by
Tom O'Connor Aug
21 '13 at 9:15
This post has been locked due to the high amount of off-topic comments generated. For
extended discussions, please use chat .
1 Out of curiosity, is the time it takes really that critical? Also, would saturating the
link for the duration of a 160Gb transfer not have an impact on the rest of your network?
– Bryan
Feb 11 '10 at 7:48
6 I remember delivering some DLT autoloaders and a couple hundred cartridges to a
Customer back in '99. We calculated the raw capacity of my car w/ around 200 DLT IV
cartridges loaded in it (35GB raw capacity each) at about 6.3TB. I drove from our office to
the Customer's site in about 55 mintues, giving the "Evan in a Geo Metro driving like mad
down the Interstate" backup transport mechanism an effective throughput of around 118GB /
min. Good throughput, but the latency was a killer... >smile< – Evan Anderson
Feb 11 '10 at 8:08
Bryan: yes, time is critical (it takes about TWENTY HOURS with standard FTP and standard
network settings), and no, there will be no problem in saturating the link, because the
transfer will be scheduled in off-work time. – Massimo
Feb 11 '10 at 9:03
I've been dealing with a similar situation, with ~200GB of SQL .bak, except the only way
I've been able to get the WAN link to saturate is with FTP. I ended up using 7-zip with zero
compression to break it into 512MB chunks. "Compression" and "decompression" times were
agreeably short; all-in-all much better than shoveling physical media across country. (The
sites are on opposite coasts of the U.S.) – Adrien
Jun 24 '10 at 22:30
Searching for "high
latency file transfer" brings up a lot of interesting hits. Clearly, this is a problem that
both the CompSci community and the commercial community has put thougth into.
A few commercial offerings that appear to fit the bill:
FileCatalyst
has products that can stream data over high-latency networks either using UDP or multiple TCP
streams. They've got a lot of other features, too (on-the-fly compression, delta transfers,
etc).
The
fasp
file transfer "technology" from Aspera appears to fit the bill for what you're looking for,
as well.
In the open-source world, the uftp project looks promising. You don't
particularly need its multicast capabilities, but the basic idea of blasting out a file to
receivers, receiving NAKs for missed blocks at the end of the transfer, and then blasting out
the NAK'd blocks (lather, rinse, repeat) sounds like it would do what you need, since there's
no ACK'ing (or NAK'ing) from the receiver until after the file transfer has completed once.
Assuming the network is just latent, and not lossy, this might do what you need, too.
uftp looks really promising, I was able to achieve 30 Mbps between two desktop computers
(which are definitely not-so-great at disk performance); I'll test it on the "real" servers
soon. I wasn't able to get a FileCatalyst demo license due to some bug in the registration
form (it keeps saying the request numer has been already used), and fasp just doesn't offer
them. – Massimo
Feb 11 '10 at 10:19
60 Mbps between two computers with proper disks and a big receive buffer. Great! –
Massimo
Feb 11 '10 at 12:00
I love free / open source software! >smile< I'm definitely going to give uftp a try
with some stuff I'm doing. I'm wondering how it would do in a Linux-based multicast
disk-imaging solution that I put together a couple of years ago using "udpcast". –
Evan Anderson
Feb 11 '10 at 15:05
1 When I was working with UFTP, UDT, and Tsunami UDP, UFTP had the worst performance of
the three over all. Of course, it's probably the most mature protocol. UDT only provides a
simple transfer protocol and was designed to act as a library to develop custom software and
the author of Tsunami actually pointed us toward UDT since Tsunami hasn't been actively
developed recently due to a lack of time. – Thomas Owens
Jun 23 '11 at 14:03
add a comment |
up vote 9 down
vote Really odd suggestion this one.. Set up a simple web server to host the file on your
network (I suggest nginx, incidentally), then set up a pc with firefox on the other end, and
install the DownThemAll extension.
It's a download accelerator that supports chunking and re-assembly.
You can break each download into 10 chunks for re-assembly, and it does actually make things
quicker!
(caveat: I've never tried it on anything as big as 160GB, but it does work well with 20GB
iso files) share answered Feb 11
'10 at 8:23 Tom O'Connor
24.5k 8 60 137
add a comment |
up vote 7 down
vote The UDT transport is
probably the most popular transport for high latency communications. This leads onto their
other software called Sector/Sphere a "High Performance Distributed File System
and Parallel Data Processing Engine" which might be worthwhile to have a look at. share answered Mar 18 '11 at 3:21
Steve-o 764 4 11
1 I did some work with UDT for transfers over networks with high-latency and high-packet
loss. UDT is much more resilient to latency and packet loss than TCP based-protocols,
especially once you get into changing the congestion control algorithm to suit your network
topography. – Thomas Owens
Jun 22 '11 at 13:58
A fast user-space file transfer protocol that uses TCP control and UDP data for transfer
over very high speed long distance networks (≥ 1 Gbps and even 10 GE), designed to provide
more throughput than possible with TCP over the same networks.the same networks.
As far as speed goes, the page mentions this result (using a link between Helsinki, Finland
to Bonn, Germany over a 1GBit link:
Figure 1 - international transfer over the Internet, averaging 800 Mbit/second
If you want to use a download accelerator, have a look at lftp , this is the only download
accelerator that can do a recursive mirror, as far as I know. share answered Jun 24 '10 at 20:59 Jan van
Haarst 51 1 3
1 In the project I commented on earlier in Steve-o's answer, we benchmarked UDT, Tsunami
UDP, and UFTP. We found that latency had a huge impact on performance, while packet loss did
not (contrary to the Tsunami documentation). Adding 100ms of latency to the test network
dropped performance of Tsunami from about 250Mbits/second to about 50Mbits/second (I believe
I have my numbers and units right - it's been a while, but it was a huge drop). Adding 10%
packet loss no a minimal latency network, on the other hand, only decreased performance from
250Mbits/second to about 90Mbits/second. – Thomas Owens
Jun 23 '11 at 14:00
I don't think that bbcp is optimized for high latency. I'm getting ~20 MB/sec over a
transatlantic link at the moment with the default settings. – Max
Jul 14 '16 at 20:10
Thank you for your interest in this question. Because it has attracted low-quality or spam
answers that had to be removed, posting an answer now requires 10 reputation on this site (the association bonus does not
count ).
We've only just scratched the surface of GNU Parallel. I highly recommend you give the
official GNU Parallel tutorial a
read, and watch this video tutorial series
on Yutube , so you can understand the complexities of the tool (of which there are many).
But this will get you started on a path to helping your data center Linux servers use commands
with more efficiency.
Okay, so " lowish -latency" would be more appropriate.
I regularly work on systems that are fairly distant, over relatively high-latency links.
That means that I don't want to run my editor there because 300ms between pressing a key and
seeing it show up is maddening. Further, with something as large as the Linux kernel, editor
integration with cscope is a huge time saver and pushing enough configuration to do that on
each box I work on is annoying. Lately, the speed of the notebook I'm working from often
outpaces that of the supposedly-fast machine I'm working on. For many tasks, a four-core, two
threads per core, 10GB RAM laptop with an Intel SSD will smoke a 4GHz PowerPC LPAR with 2GB
RAM.
I don't really want to go to the trouble of cross-compiling the kernels on my laptop, so
that's the only piece I want to do remotely. Thus, I want to have high-speed access to the tree
I'm working on from my local disk for editing, grep'ing, and cscope'ing. But, I want the
changes to be synchronized (without introducing any user-perceived delay) to the distant
machine in the background for when I'm ready to compile. Ideally, this would be some sort of
rsync-like tool that uses inotify to notice changes and keep them synchronized to the remote
machine over a persistent connection. However, I know of no such tool and haven't been
sufficiently annoyed to sit down and write one.
One can, however, achieve a reasonable approximation of this by gluing existing components
together. The inotifywait tool from the inotify-tools provides a way to watch a
directory and spit out a live list of changed files without much effort. Of course, rsync can handle the syncing for you, but not with a
persistent connection. This script mostly does what I want:
#!/bin/bash
DEST="$1"
if [ -z "$DEST" ]; then exit 1; fi
inotifywait -r -m -e close_write --format '%w%f' . |\
while read file
do
echo $file
rsync -azvq $file ${DEST}/$file
echo -n 'Completed at '
date
done
That will monitor the local directory and synchronize it to the remote host every time a
file changes. I run it like this:
It's horribly inefficient of course, but it does the job. The latency for edits to show up
on the other end, although not intolerable, is higher than I'd like. The boxes I'm working on
these days are in Minnesota, and I have to access them over a VPN which terminates in New York.
That means packets leave Portland for Seattle, jump over to Denver, Chicago, Washington DC,
then up to New York before they bounce back to Minnesota. Initiating an SSH connection every
time the script synchronizes a file requires some chatting back and forth over that link, and
thus is fairly slow.
Looking at how I might reduce the setup time for the SSH links, I stumbled across an
incredibly cool feature available in recent versions of OpenSSH: connection multiplexing. With
this enabled, you pay the high setup cost only the first time you connect to a host. Subsequent
connections re-use the same tunnel as the first one, making the process nearly instant. To get
this enabled for just the host I'm using, I added this to my ~/.ssh/config file:
Host myhost.domain.com
ControlMaster auto
ControlPath /tmp/%h%p%r
Now, all I do is ssh to the box each time I boot it (which I would do anyway) and the
sync.sh script from above re-uses that connection for file synchronization. It's still not the
same as a shared filesystem, but it's pretty dang close, especially for a few lines of config
and shell scripting. Kernel development on these distant boxes is now much less painful.
Category(s): Codemonkeying
Tags: inotify ,
linux , rsyncThe beauty of
automated buildsField Day 20124 Responses to
Low-latency continuous rsync
Christof Schmitt says:
June
25, 2012 at 22:06 This is a great approach. I had the same problem when editing code
locally and testing the changes on a remote system. Thanks for sharing, i will give it a
try.
Callum says:
May
12, 2013 at 15:02 Are you familiar with lsyncd? I think it might do exactly what you
want but potentially more easily. It uses inotify or libnotify or something or other to
watch a local directory, and then pushes changes every X seconds to a remote host. It's
pretty powerful and can even be setup to sync mv commands with a remote ssh mv instead of
rsync which can be expensive. It's fairly neat in theory, although I've never used it in
practice myself.
Since it's different approach to solving your problem, it has different pros and cons.
E.g. jumping and instant searching would still be slow. It's effectively trying to hide the
problem by being a bit more intelligent. (It does this by using UDP, previewing keystrokes,
robust reconnection, and only updating visible screen so as to avoid freezes due to 'cat
my_humongous_log.txt'.)
-- -- -- -- -- –
(copy paste)
Mosh
(mobile shell)
Remote terminal application that allows roaming, supports intermittent connectivity, and
provides intelligent local echo and line editing of user keystrokes.
Mosh is a replacement for SSH. It's more robust and responsive, especially over Wi-Fi,
cellular, and long-distance links.
I have been using a rsync script to synchronize data at one host with the data
at another host. The data has numerous small-sized files that contribute to almost 1.2TB.
In order to sync those files, I have been using rsync command as follows:
As a test, I picked up two of those projects (8.5GB of data) and I executed the command
above. Being a sequential process, it tool 14 minutes 58 seconds to complete. So, for 1.2TB
of data it would take several hours.
If I would could multiple rsync processes in parallel (using
& , xargs or parallel ), it would save my
time.
I tried with below command with parallel (after cd ing to source
directory) and it took 12 minutes 37 seconds to execute:
If possible, we would want to use 50% of total bandwidth. But, parallelising multiple
rsync s is our first priority. – Mandar Shinde
Mar 13 '15 at 7:32
In fact, I do not know about above parameters. For the time being, we can neglect the
optimization part. Multiple rsync s in parallel is the primary focus now.
– Mandar Shinde
Mar 13 '15 at 7:47
Here, --relative option ( link
) ensured that the directory structure for the affected files, at the source and destination,
remains the same (inside /data/ directory), so the command must be run in the
source folder (in example, /data/projects ).
That would do an rsync per file. It would probably be more efficient to split up the whole
file list using split and feed those filenames to parallel. Then use rsync's
--files-from to get the filenames out of each file and sync them. rm backups.*
split -l 3000 backup.list backups. ls backups.* | parallel --line-buffer --verbose -j 5 rsync
--progress -av --files-from {} /LOCAL/PARENT/PATH/ REMOTE_HOST:REMOTE_PATH/ –
Sandip Bhattacharya
Nov 17 '16 at 21:22
How does the second rsync command handle the lines in result.log that are not files? i.e.
receiving file list ... donecreated directory /data/ . –
Mike D
Sep 19 '17 at 16:42
On newer versions of rsync (3.1.0+), you can use --info=name in place of
-v , and you'll get just the names of the files and directories. You may want to
use --protect-args to the 'inner' transferring rsync too if any files might have spaces or
shell metacharacters in them. – Cheetah
Oct 12 '17 at 5:31
I would strongly discourage anybody from using the accepted answer, a better solution is to
crawl the top level directory and launch a proportional number of rync operations.
I have a large zfs volume and my source was was a cifs mount. Both are linked with 10G,
and in some benchmarks can saturate the link. Performance was evaluated using zpool
iostat 1 .
The source drive was mounted like:
mount -t cifs -o username=,password= //static_ip/70tb /mnt/Datahoarder_Mount/ -o vers=3.0
This in synthetic benchmarks (crystal disk), performance for sequential write approaches
900 MB/s which means the link is saturated. 130MB/s is not very good, and the difference
between waiting a weekend and two weeks.
So, I built the file list and tried to run the sync again (I have a 64 core machine):
In conclusion, as @Sandip Bhattacharya brought up, write a small script to get the
directories and parallel that. Alternatively, pass a file list to rsync. But don't create new
instances for each file.
ls -1 | parallel rsync -a {} /destination/directory/
Which only is usefull when you have more than a few non-near-empty directories, else
you'll end up having almost every rsync terminating and the last one doing all
the job alone.
rsync is a great tool, but sometimes it will not fill up the available bandwidth. This
is often a problem when copying several big files over high speed connections.
The following will start one rsync per big file in src-dir to dest-dir on the server
fooserver:
If I use --dry-run option in rsync , I would have a list of files
that would be transferred. Can I provide that file list to parallel in order to
parallelise the process? – Mandar Shinde
Apr 10 '15 at 3:47
rsync is a great tool, but sometimes it will not fill up the available bandwidth.
This is often a problem when copying several big files over high speed connections.
The following will start one rsync per big file in src-dir to dest-dir
on the server fooserver :
Although in the examples above we used integer indices in our arrays, let's consider two
occasions when that won't be the case: First, if we wanted the $i -th element of
the array, where $i is a variable containing the index of interest, we can
retrieve that element using: echo ${allThreads[$i]} . Second, to output all the
elements of an array, we replace the numeric index with the @ symbol (you can
think of @ as standing for all ): echo ${allThreads[@]}
.
Looping through array elements
With that in mind, let's loop through $allThreads and launch the pipeline for
each value of --threads :
for t in ${allThreads[@]} ; do
. / pipeline --threads $t
done
Looping through array indices
Next, let's consider a slightly different approach. Rather than looping over array
elements , we can loop over array indices :
for i in ${!allThreads[@]} ;
do
. / pipeline --threads ${allThreads[$i]}
done
Let's break that down: As we saw above, ${allThreads[@]} represents all the
elements in our array. Adding an exclamation mark to make it ${!allThreads[@]}
will return the list of all array indices (in our case 0 to 7). In other words, the
for loop is looping through all indices $i and reading the
$i -th element from $allThreads to set the value of the
--threads parameter.
This is much harsher on the eyes, so you may be wondering why I bother introducing it in the
first place. That's because there are times where you need to know both the index and the value
within a loop, e.g., if you want to ignore the first element of an array, using indices saves
you from creating an additional variable that you then increment inside the
loop.
Populating arrays
So far, we've been able to launch the pipeline for each --threads of interest.
Now, let's assume the output to our pipeline is the runtime in seconds. We would like to
capture that output at each iteration and save it in another array so we can do various
manipulations with it at the end.
Some useful syntax
But before diving into the code, we need to introduce some more syntax. First, we need to be
able to retrieve the output of a Bash command. To do so, use the following syntax:
output=$( ./my_script.sh ) , which will store the output of our commands into the
variable $output .
The second bit of syntax we need is how to append the value we just retrieved to an array.
The syntax to do that will look familiar:
myArray+=( "newElement1" "newElement2" )
The parameter sweep
Putting everything together, here is our script for launching our parameter
sweep:
allThreads = ( 1 2 4 8 16 32 64 128 )
allRuntimes = ()
for t in ${allThreads[@]} ; do
runtime =$ ( . / pipeline --threads $t )
allRuntimes+= ( $runtime )
done
And voilà!
What else you got?
In this article, we covered the scenario of using arrays for parameter sweeps. But I promise
there are more reasons to use Bash arrays -- here are two more examples.
Log alerting
In this scenario, your app is divided into modules, each with its own log file. We can write
a cron job script to email the right person when there are signs of trouble in certain
modules:
# List of logs and who should be notified of issues
logPaths = ( "api.log" "auth.log" "jenkins.log" "data.log" )
logEmails = ( "jay@email" "emma@email" "jon@email" "sophia@email" )
# Look for signs of trouble in each log
for i in ${!logPaths[@]} ;
do
log = ${logPaths[$i]}
stakeholder = ${logEmails[$i]}
numErrors =$ ( tail -n 100 " $log " | grep "ERROR" | wc -l )
# Warn stakeholders if recently saw > 5 errors
if [[ " $numErrors " -gt 5 ]] ;
then
emailRecipient = " $stakeholder "
emailSubject = "WARNING: ${log} showing unusual levels of errors"
emailBody = " ${numErrors} errors found in log ${log} "
echo " $emailBody " | mailx -s " $emailSubject " " $emailRecipient "
fi
done
API queries
Say you want to generate some analytics about which users comment the most on your Medium
posts. Since we don't have direct database access, SQL is out of the question, but we can use
APIs!
To avoid getting into a long discussion about API authentication and tokens, we'll instead
use JSONPlaceholder ,
a public-facing API testing service, as our endpoint. Once we query each post and retrieve the
emails of everyone who commented, we can append those emails to our results array:
# Query first 10 posts
for postId in { 1 .. 10 } ;
do
# Make API call to fetch emails of this posts's commenters
response =$ ( curl " ${endpoint} ?postId= ${postId} " )
# Use jq to parse the JSON response into an array
allEmails+= ( $ ( jq '.[].email' <<< " $response " ) )
done
Note here that I'm using the jq tool to parse JSON from the command line.
The syntax of jq is beyond the scope of this article, but I highly recommend you
look into it.
As you might imagine, there are countless other scenarios in which using Bash arrays can
help, and I hope the examples outlined in this article have given you some food for thought. If
you have other examples to share from your own work, please leave a comment below.
But
wait, there's more!
Since we covered quite a bit of array syntax in this article, here's a summary of what we
covered, along with some more advanced tricks we did not cover:
Syntax
Result
arr=()
Create an empty array
arr=(1 2 3)
Initialize array
${arr[2]}
Retrieve third element
${arr[@]}
Retrieve all elements
${!arr[@]}
Retrieve array indices
${#arr[@]}
Calculate array size
arr[0]=3
Overwrite 1st element
arr+=(4)
Append value(s)
str=$(ls)
Save ls output as a string
arr=( $(ls) )
Save ls output as an array of files
${arr[@]:s:n}
Retrieve elements at indices n to s+n
One last thought
As we've discovered, Bash arrays sure have strange syntax, but I hope this article convinced
you that they are extremely powerful. Once you get the hang of the syntax, you'll find yourself
using Bash arrays quite often.
... ... ...
Robert Aboukhalil is a Bioinformatics Software Engineer. In his work, he develops
cloud applications for the analysis and interactive visualization of genomics data. Robert
holds a Ph.D. in Bioinformatics from Cold Spring Harbor Laboratory and a B.Eng. in Computer
Engineering from McGill.
That's a great point to consider among all of this. Compression is always a tradeoff between how much CPU and memory you want
to throw at something and how much space you would like to save. In my case, hammering the server for 3 minutes in order to take
a backup is necessary because the uncompressed data would bottleneck at the LAN speed.
You might want to play with 'pigz' - it's gzip, multi-threaded. You can 'pv' to restrict the rate of the output, and it accepts
signals to control the rate limiting.
With -9 you can surely make backup CPU bound. I've given up on compression though: rsync is much faster than straight backup
and I use btrfs compression/deduplication/snapshotting on the backup server.
I'm running gzip, bzip2, and pbzip2 now (not at the same time, of course) and will add results soon. But in my case the compression
keeps my db dumps from being IO bound by the 100mbit LAN connection. For example, lzop in the results above puts out 6041.632
megabits in 53.82 seconds for a total compressed data rate of 112 megabits per second, which would make the transfer IO bound.
Whereas the pigz example puts out 3339.872 megabits in 81.892 seconds, for an output data rate of 40.8 megabits per second. This
is just on my dual-core box with a static file, on the 8-core server I see the transfer takes a total of about three minutes.
It's probably being limited more by the rate at which the MySQL server can dump text from the database, but if there was no compression
it'd be limited by the LAN speed. If we were dumping 2.7GB over the LAN directly, we would need 122mbit/s of real throughput to
complete it in three minutes.
xz archives use the LZMA2 format (which is also used in 7z archives). LZMA2 speed seems to range from a little slower than gzip
to much slower than bzip2, but results in better compression all around.
However LZMA2 decompression speed is generally much faster than bzip2, in my experience, though not as fast as gzip.
This is why we use it, as we decompress our data much more often than we compress it, and the space saving/decompression speed
tradeoff is much more favorable for us than either gzip of bzip2.
I mentioned how 7zip was superior to all other zip programs in /r/osx
a few days ago and my comment was burried in favor of the the osx circlejerk .. it feels good seeing this data.
Why... Tar supports xz, lzma, lzop, lzip, and any other kernel based compression algorithms. Its also much more likely to be preinstalled
on your given distro.
I've used 7zip at my old job for a backup of our business software's database. We needed speed, high level of compression, and
encryption. Portability wasn't high on the list since only a handful of machines needed access to the data. All machines were
multi-processor and 7zip gave us the best of everything given the requirements. I haven't really looked at anything deeply - including
tar, which my old boss didn't care for.
Summary : Very high compression ratio file archiver
Description :
p7zip is a port of 7za.exe for Unix. 7-Zip is a file archiver with a very high
compression ratio. The original version can be found at http://www.7-zip.org/.
RPM found in directory: /mirror/apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS
There are certain file sizes were pigz makes no difference, in general you need at least 2
cores to feel the benefits, there are quite a few reasons. That being said, pigz and its bzip
counterpart pbzip2 can be symlinked in place when emerged with gentoo and using the "symlink"
use flag.
adam@eggsbenedict ~ $ eix pigz
[I] app-arch/pigz
Available versions: 2.2.5 2.3 2.3.1 (~)2.3.1-r1 {static symlink |test}
Installed versions: 2.3.1-r1(02:06:01 01/25/14)(symlink -static -|test)
Homepage: http://www.zlib.net/pigz/
Description: A parallel implementation of gzip
You can, but often shouldn't. I can only speak for vmware here, other hypervisors may work
differently. Generally you want to size your VMware vm's so that they are around 80% cpu
utilization. When any VM with multiple cores needs compute power the hypervisor will make it
wait to until it can free that number of CPUs, even if the task in the VM only needs one
core. This makes the multi-core VM slower by having to wait longer to do it's work, as well
as makes other VMs on the hypervisor slower as they must all wait for it to finish before
they can get a core allocated.
Posted on January
26, 2015 by Sandeep Shenoy This topic is not
Solaris specific, but certainly helps Solaris users who are frustrated with the single threaded
implementation of all officially supported compression tools such as compress, gzip, zip.
pigz(pig-zee) is a parallel
implementation of gzip that suits well for the latest multi-processor, multi-core machines. By
default, pigz breaks up the input into multiple chunks of size 128 KB, and compress each chunk
in parallel with the help of light-weight threads. The number of compress threads is set by
default to the number of online processors. The chunk size and the number of threads are
configurable. Compressed files can be restored to their original form using -d option of pigz
or gzip tools. As per the man page, decompression is not parallelized out of the box, but may
show some improvement compared to the existing old tools. The following example demonstrates
the advantage of using pigz over gzip in compressing and decompressing a large file. eg.,
Original file, and the target hardware. $ ls -lh PT8.53.04.tar -rw-r–r– 1 psft dba
4.8G Feb 28 14:03 PT8.53.04.tar
$ psrinfo -pv The physical processor has 8 cores and 64 virtual processors (0-63) The core has
8 virtual processors (0-7) The core has 8 virtual processors (56-63) SPARC-T5 (chipid 0, clock
3600 MHz)
gzip compression.
$ time gzip –fast PT8.53.04.tar
real 3m40.125s user 3m27.105s sys 0m13.008s
$ ls -lh PT8.53* -rw-r–r– 1 psft dba 3.1G Feb 28 14:03 PT8.53.04.tar.gz /* the
following prstat, vmstat outputs show that gzip is compressing thetar file using a
single thread – hence low CPU utilization. */
$ prstat -p 42510 PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 42510 psft 2616K
2200K cpu16 10 0 0:01:00 1.5% gzip/ 1
pigz compression. $ time ./pigz PT8.53.04.tar real 0m25.111s <== wall clock time is
25s compared to gzip's 3m 27s
user 17m18.398s sys 0m37.718s
/* the following prstat, vmstat outputs show that pigz is compressing thetar file
using many threads – hence busy system with high CPU utilization. */
$ prstat -p 49734 PID USERNAME SIZE RSS STATE PRI NICE TIME CPU PROCESS/NLWP 49734 psft 59M 58M
sleep 11 0 0:12:58 38% pigz/ 66
$ vmstat 2 kthr memory page disk faults cpu r b w swap free re mf pi po fr de sr s0 s1 s2 s3
in sy cs us sy id 0 0 0 778097840 919076008 6 113 0 0 0 0 0 0 0 40 36 39330 45797 74148 61 4
35
0 0 0 777956280 918841720 0 1 0 0 0 0 0 0 0 0 0 38752 43292 71411 64 4 32
0 0 0 777490336 918334176 0 3 0 0 0 0 0 0 0 17 15 46553 53350 86840 60 4 35
1 0 0 777274072 918141936 0 1 0 0 0 0 0 0 0 39 34 16122 20202 28319 88 4 9
1 0 0 777138800 917917376 0 0 0 0 0 0 0 0 0 3 3 46597 51005 86673 56 5 39
$ ls -lh PT8.53.04.tar.gz -rw-r–r– 1 psft dba 3.0G Feb 28 14:03
PT8.53.04.tar.gz
$ gunzip PT8.53.04.tar.gz <== shows that the pigz compressed file iscompatible
with gzip/gunzip
$ ls -lh PT8.53* -rw-r–r– 1 psft dba 4.8G Feb 28 14:03 PT8.53.04.tar
Decompression. $ time ./pigz -d PT8.53.04.tar.gz real 0m18.068s
user 0m22.437s sys 0m12.857s
$ time gzip -d PT8.53.04.tar.gz real 0m52.806s <== compare gzip's 52s decompression time
with pigz's 18s
user 0m42.068s sys 0m10.736s
$ ls -lh PT8.53.04.tar -rw-r–r– 1 psft dba 4.8G Feb 28 14:03 PT8.53.04.tar
Of course, there are other tools such as Parallel BZIP2 (PBZIP2), which is a parallel implementation
of the bzip2 tool are worth a try too. The idea here is to highlight the fact that there are
better tools out there to get the job done in a quick manner compared to the existing/old tools
that are bundled with the operating system distribution.
In this article, we will share a number of Bash command-line shortcuts useful for any Linux
user. These shortcuts allow you to easily and in a fast manner, perform certain activities such
as accessing and running previously executed commands, opening an editor,
editing/deleting/changing text on the command line, moving the cursor, controlling processes
etc. on the command line.
Although this article will mostly benefit Linux beginners getting their way around with
command line basics, those with intermediate skills and advanced users might also find it
practically helpful. We will group the bash keyboard shortcuts according to categories as
follows.
Launch an Editor
Open a terminal and press Ctrl+X and Ctrl+E to open an editor (
nano editor ) with an empty buffer. Bash will try to launch the editor defined by the $EDITOR
environment variable.
Nano Editor Controlling The Screen
These shortcuts are used to control terminal screen output:
Ctrl+L – clears the screen (same effect as the " clear "
command).
Ctrl+S – pause all command output to the screen. If you have executed
a command that produces verbose, long output, use this to pause the output scrolling down the
screen.
Ctrl+Q – resume output to the screen after pausing it with Ctrl+S
.
Move Cursor on The Command Line
The next shortcuts are used for moving the cursor within the command-line:
Ctrl+A or Home – moves the cursor to the start of a
line.
Ctrl+E or End – moves the cursor to the end of the
line.
Ctrl+B or Left Arrow – moves the cursor back one
character at a time.
Ctrl+F or Right Arrow – moves the cursor forward one
character at a time.
Ctrl + Left Arrow or Alt+B or Esc and
then B – moves the cursor back one word at a time.
Ctrl + Right Arrow or Alt+C or Esc
and then F – moves the cursor forward one word at a time.
Search Through Bash History
The following shortcuts are used for searching for commands in the bash history:
Up arrow key – retrieves the previous command. If you press it
constantly, it takes you through multiple commands in history, so you can find the one you
want. Use the Down arrow to move in the reverse direction through the history.
Ctrl+P and Ctrl+N – alternatives for the Up and Down
arrow keys, respectively.
Ctrl+R – starts a reverse search, through the bash history, simply
type characters that should be unique to the command you want to find in the history.
Ctrl+S – launches a forward search, through the bash history.
Ctrl+G – quits reverse or forward search, through the bash
history.
Delete Text on the Command Line
The following shortcuts are used for deleting text on the command line:
Ctrl+D or Delete – remove or deletes the character under
the cursor.
Ctrl+K – removes all text from the cursor to the end of the line.
Ctrl+X and then Backspace – removes all the text from the
cursor to the beginning of the line.
Transpose Text or Change Case on the Command Line
These shortcuts will transpose or change the case of letters or words on the command
line:
Ctrl+T – transposes the character before the cursor with the character
under the cursor.
Esc and then T – transposes the two words immediately
before (or under) the cursor.
Esc and then U – transforms the text from the cursor to
the end of the word to uppercase.
Esc and then L – transforms the text from the cursor to
the end of the word to lowercase.
Esc and then C – changes the letter under the cursor (or
the first letter of the next word) to uppercase, leaving the rest of the word unchanged.
Working With Processes in Linux
The following shortcuts help you to control running Linux processes.
Ctrl+Z – suspend the current foreground process. This sends the
SIGTSTP signal to the process. You can get the process back to the foreground later using the
fg process_name (or %bgprocess_number like %1 , %2 and so on) command.
Ctrl+C – interrupt the current foreground process, by sending the
SIGINT signal to it. The default behavior is to terminate a process gracefully, but the
process can either honor or ignore it.
Ctrl+D – exit the bash shell (same as running the exit command).
In the final part of this article, we will explain some useful ! (bang)
operations:
!! – execute last command.
!top – execute the most recent command that starts with 'top' (e.g. !
).
!top:p – displays the command that !top would run (also adds it as the
latest command in the command history).
!$ – execute the last word of the previous command (same as Alt + .,
e.g. if last command is ' cat tecmint.txt ', then !$ would try to run ' tecmint.txt ').
!$:p – displays the word that !$ would execute.
!* – displays the last word of the previous command.
!*:p – displays the last word that !* would substitute.
For more information, see the bash man page:
$ man bash
That's all for now! In this article, we shared some common and useful Bash command-line
shortcuts and operations. Use the comment form below to make any additions or ask
questions.
You can create hard links and symbolic links using C-x l and C-x s keyboard shortcuts.
However, these two shortcuts invoke two completely different dialogs.
While for C-x s you get 2 pre-populated fields (path to the existing file, and path to the
link – which is pre-populated with your opposite file panel path plus the name of the
file under cursor; simply try it to see what I mean), for C-x l you only get 1 empty field:
path of the hard link to create for a file under cursor. Symlink's behaviour would be much more
convenient
Fortunately, a good man called Wiseman1024 created a feature request in the MC's bug tracker 6
years ago. Not only had he done so, but he had also uploaded a sample mc user
menu script ( local copy ), which
works wonderfully! You can select multiple files, then F2 l (lower-case L), and hard-links to
your selected files (or a file under cursor) will be created in the opposite file panel. Great,
thank you Wiseman1024 !
Word of warning: you must know what hard links are and what their limitations are
before using this menu script. You also must check and understand the user menu code before
adding it to your mc (by F9 C m u , and then pasting the script from the file).
Word of hope: 4 years ago Wiseman's feature request was assigned to Future Releases
version, so a more convenient C-x l will (sooner or later) become the part of mc.
Hopefully.
If you ever need to select lots (hundreds, thousands) of files by their
modification date, and your directory contains many more files (thousands, tens of thousands),
then angel_il has the answer for you:
touch -d "Jun 01 00:00 2011″ /tmp/.date1
enter into your BIG dir
press C-x ! (External panelize)
add new command like a "find . -type f \( -newer /tmp/.date1 \) -print"
I've used a slightly different approach, specifying desired date right in the command line
of External Panelize:
enter your directory with many files
press C-x ! (External Panelize)
add a command like find . -type f -newermt "2017-02-01 23:55:00" -print (
man find for more details)
In both cases, the created panel will only have files matching your search condition.
"... Live Work Work Work Die: A Journey into the Savage Heart of Silicon Valley ..."
"... Older generations called this kind of fraud "fake it 'til you make it." ..."
"... Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other "smart person" put in 75 hours a week dealing with hiring ..."
"... It's not a "kids these days" sort of issue, it's *always* been the case that shameless, baseless self-promotion wins out over sincere skill without the self-promotion, because the people who control the money generally understand boasting more than they understand the technology. ..."
"... In the bad old days we had a hell of a lot of ridiculous restriction We must somehow made our programs to run successfully inside a RAM that was 48KB in size (yes, 48KB, not 48MB or 48GB), on a CPU with a clock speed of 1.023 MHz ..."
"... So what are the uses for that? I am curious what things people have put these to use for. ..."
"... Also, Oracle, SAP, IBM... I would never buy from them, nor use their products. I have used plenty of IBM products and they suck big time. They make software development 100 times harder than it could be. ..."
"... I have a theory that 10% of people are good at what they do. It doesn't really matter what they do, they will still be good at it, because of their nature. These are the people who invent new things, who fix things that others didn't even see as broken and who automate routine tasks or simply question and erase tasks that are not necessary. ..."
"... 10% are just causing damage. I'm not talking about terrorists and criminals. ..."
"... Programming is statistically a dead-end job. Why should anyone hone a dead-end skill that you won't be able to use for long? For whatever reason, the industry doesn't want old programmers. ..."
The author shares what he realized at a job recruitment fair seeking Java Legends, Python Badasses, Hadoop Heroes, "and other
gratingly childish classifications describing various programming specialities.
" I wasn't the only one bluffing my way through the tech scene. Everyone was doing it, even the much-sought-after engineering
talent.
I
was struck by how many developers were, like myself, not really programmers , but rather this, that and the other. A great
number of tech ninjas were not exactly black belts when it came to the actual onerous work of computer programming. So many of
the complex, discrete tasks involved in the creation of a website or an app had been automated that it was no longer necessary
to possess knowledge of software mechanics. The coder's work was rarely a craft. The apps ran on an assembly line, built with
"open-source", off-the-shelf components. The most important computer commands for the ninja to master were copy and paste...
[M]any programmers who had "made it" in Silicon Valley were scrambling to promote themselves from coder to "founder". There
wasn't necessarily more money to be had running a startup, and the increase in status was marginal unless one's startup attracted
major investment and the right kind of press coverage. It's because the programmers knew that their own ladder to prosperity was
on fire and disintegrating fast. They knew that well-paid programming jobs would also soon turn to smoke and ash, as the proliferation
of learn-to-code courses around the world lowered the market value of their skills, and as advances in artificial intelligence
allowed for computers to take over more of the mundane work of producing software. The programmers also knew that the fastest
way to win that promotion to founder was to find some new domain that hadn't yet been automated. Every tech industry campaign
designed to spur investment in the Next Big Thing -- at that time, it was the "sharing economy" -- concealed a larger programme
for the transformation of society, always in a direction that favoured the investor and executive classes.
"I wasn't just changing careers and jumping on the 'learn to code' bandwagon," he writes at one point. "I was being steadily
indoctrinated in a specious ideology."
> The people can do both are smart enough to build their own company and compete with you.
Been there, done that. Learned a few lessons. Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other
"smart person" put in 75 hours a week dealing with hiring, managing people, corporate strategy, staying up on the competition,
figuring out tax changes each year and getting taxes filed six times each year, the various state and local requirements, legal
changes, contract hassles, etc, while hoping the company makes money this month so they can take a paycheck and lay their rent.
I learned that I'm good at creating software systems and I enjoy it. I don't enjoy all-nighters, partners being dickheads trying
to pull out of a contract, or any of a thousand other things related to running a start-up business. I really enjoy a consistent,
six-figure compensation package too.
I pay monthly gross receipts tax (12), quarterly withholdings (4) and a corporate (1) and individual (1) returns. The gross
receipts can vary based on the state, so I can see how six times a year would be the minimum.
Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other "smart person" put in 75 hours a week
dealing with hiring
There's nothing wrong with not wnting to run your own business, it's not for most people, and even if it was, the numbers don't
add up. But putting the scare qoutes in like that makes it sound like you have huge chip on your shoulder. Those things re just
as essential to the business as your work and without them you wouldn't have the steady 9:30-4:30 with good paycheck.
Of course they are important. I wouldn't have done those things if they weren't important!
I frequently have friends say things like "I love baking. I can't get enough of baking. I'm going to open a bakery.". I ask
them "do you love dealing with taxes, every month? Do you love contract law? Employment law? Marketing? Accounting?" If you LOVE
baking, the smart thing to do is to spend your time baking. Running a start-up business, you're not going to do much baking.
I can tell you a few things that have worked for me. I'll go in chronological order rather than priority order.
Make friends in the industry you want to be in. Referrals are a major way people get jobs.
Look at the job listings for jobs you'd like to have and see which skills a lot of companies want, but you're missing. For
me that's Java. A lot companies list Java skills and I'm not particularly good with Java. Then consider learning the skills you
lack, the ones a lot of job postings are looking for.
You don't understand the point of an ORM do you? I'd suggest reading why they exist
They exist because programmers value code design more than data design. ORMs are the poster-child for square-peg-round-hole
solutions, which is why all ORMs choose one of three different ways of squashing hierarchical data into a relational form, all
of which are crappy.
If the devs of the system (the ones choosing to use an ORM) had any competence at all they'd design their database first because
in any application that uses a database the database is the most important bit, not the OO-ness or Functional-ness of the design.
Over the last few decades I've seen programs in a system come and go; a component here gets rewritten, a component there gets
rewritten, but you know what? They all have to work with the same damn data.
You can more easily switch out your code for new code with new design in a new language, than you can switch change the database
structure. So explain to me why it is that you think the database should be mangled to fit your OO code rather than mangling your
OO code to fit the database?
Stick to the one thing for 10-15years. Often all this new shit doesn't do jack different to the old shit, its not faster, its
not better. Every dick wants to be famous so make another damn library/tool with his own fancy name and feature, instead
of enhancing an existing product.
Or kids who can't hack the main stuff, suddenly discover the cool new, and then they can pretend they're "learning" it, and
when the going gets tough (as it always does) they can declare the tech to be pants and move to another.
hence we had so many people on the bandwagon for functional programming, then dumped it for ruby on rails, then dumped that
for Node.js, not sure what they're on at currently, probably back to asp.net.
How much code do you have to reuse before you're not really programming anymore? When I started in this business, it was reasonably
possible that you could end up on a project that didn't particularly have much (or any) of an operating system. They taught you
assembly language and the process by which the system boots up, but I think if I were to ask most of the programmers where I work,
they wouldn't be able to explain how all that works...
It really feels like if you know what you're doing it should be possible to build a team of actually good programmers and
put everyone else out of business by actually meeting your deliverables, but no one has yet. I wonder why that is.
You mean Amazon, Google, Facebook and the like? People may not always like what they do, but they manage to get things done
and make plenty of money in the process. The problem for a lot of other businesses is not having a way to identify and promote
actually good programmers. In your example, you could've spent 10 minutes fixing their query and saved them days of headache,
but how much recognition will you actually get? Where is your motivation to help them?
It's not a "kids these days" sort of issue, it's *always* been the case that shameless, baseless self-promotion wins out
over sincere skill without the self-promotion, because the people who control the money generally understand boasting more than
they understand the technology. Yes it can happen that baseless boasts can be called out over time by a large enough mass
of feedback from competent peers, but it takes a *lot* to overcome the tendency for them to have faith in the boasts.
And all these modern coders forget old lessons, and make shit stuff, just look at instagram windows app, what a load of garbage
shit, that us old fuckers could code in 2-3 weeks.
Instagram - your app sucks, cookie cutter coders suck, no refinement, coolness. Just cheap ass shit, with limited usefulness.
Just like most of commercial software that's new - quick shit.
Oh and its obvious if your an Indian faking it, you haven't worked in 100 companies at the age of 29.
Here's another problem, if faced with a skilled team that says "this will take 6 months to do right" and a more naive team
that says "oh, we can slap that together in a month", management goes with the latter. Then the security compromises occur, then
the application fails due to pulling in an unvetted dependency update live into production. When the project grows to handling
thousands instead of dozens of users and it starts mysteriously folding over and the dev team is at a loss, well the choice has
be
These restrictions is a large part of what makes Arduino programming "fun". If you don't plan out your memory usage, you're
gonna run out of it. I cringe when I see 8MB web pages of bloated "throw in everything including the kitchen sink and the neighbor's
car". Unfortunately, the careful and cautious way is a dying in favor of the throw 3rd party code at it until it does something.
Of course, I don't have time to review it but I'm sure everybody else has peer reviewed it for flaws and exploits line by line.
Unfortunately, the careful and cautious way is a dying in favor of the throw 3rd party code at it until it does something.
Of course. What is the business case for making it efficient? Those massive frameworks are cached by the browser and run on
the client's system, so cost you nothing and save you time to market. Efficient costs money with no real benefit to the business.
If we want to fix this, we need to make bloat have an associated cost somehow.
My company is dealing with the result of this mentality right now. We released the web app to the customer without performance
testing and doing several majorly inefficient things to meet deadlines. Once real load was put on the application by users with
non-ideal hardware and browsers, the app was infuriatingly slow. Suddenly our standard sub-40 hour workweek became a 50+ hour
workweek for months while we fixed all the inefficient code and design issues.
So, while you're right that getting to market and opt
In the bad old days we had a hell of a lot of ridiculous restriction We must somehow made our programs to run successfully
inside a RAM that was 48KB in size (yes, 48KB, not 48MB or 48GB), on a CPU with a clock speed of 1.023 MHz
We still have them. In fact some of the systems I've programmed have been more resource limited than the gloriously spacious
32KiB memory of the BBC model B. Take the PIC12F or 10F series. A glorious 64 bytes of RAM, max clock speed of 16MHz, but not
unusual to run it 32kHz.
So what are the uses for that? I am curious what things people have put these to use for.
It's hard to determine because people don't advertise use of them at all. However, I know that my electric toothbrush uses
an Epson 4 bit MCU of some description. It's got a status LED, basic NiMH batteryb charger and a PWM controller for an H Bridge.
Braun sell a *lot* of electric toothbrushes. Any gadget that's smarter than a simple switch will probably have some sort of basic
MCU in it. Alarm system components, sensor
b) No computer ever ran at 1.023 MHz. It was either a nice multiple of 1Mhz or maybe a multiple of 3.579545Mhz (ie. using the
TV output circuit's color clock crystal to drive the CPU).
Well, it could be used to drive the TV output circuit, OR, it was used because it's a stupidly cheap high speed crystal. You
have to remember except for a few frequencies, most crystals would have to be specially cut for the desired frequency. This occurs
even today, where most oscillators are either 32.768kHz (real time clock
Yeah, nice talk. You could have stopped after the first sentence. The other AC is referring to the
Commodore C64 [wikipedia.org]. The frequency has nothing
to do with crystal availability but with the simple fact that everything in the C64 is synced to the TV. One clock cycle equals
8 pixels. The graphics chip and the CPU take turns accessing the RAM. The different frequencies dictated by the TV standards are
the reason why the CPU in the NTSC version of the C64 runs at 1.023MHz and the PAL version at 0.985MHz.
Commodore 64 for the win. I worked for a company that made detection devices for the railroad, things like monitoring axle
temperatures, reading the rail car ID tags. The original devices were made using Commodore 64 boards using software written by
an employee at the one rail road company working with them.
The company then hired some electrical engineers to design custom boards using the 68000 chips and I was hired as the only
programmer. Had to rewrite all of the code which was fine...
Many of these languages have an interactive interpreter. I know for a fact that Python does.
So, since job-fairs are an all day thing, and setup is already a thing for them -- set up a booth with like 4 computers at
it, and an admin station. The 4 terminals have an interactive session with the interpreter of choice. Every 20min or so, have
a challenge for "Solve this problem" (needs to be easy and already solved in general. Programmers hate being pimped without pay.
They don't mind tests of skill, but hate being pimped. Something like "sort this array, while picking out all the prime numbers"
or something.) and see who steps up. The ones that step up have confidence they can solve the problem, and you can quickly see
who can do the work and who can't.
The ones that solve it, and solve it to your satisfaction, you offer a nice gig to.
Then you get someone good at sorting arrays while picking out prime numbers, but potentially not much else.
The point of the test is not to identify the perfect candidate, but to filter out the clearly incompetent. If you can't sort
an array and write a function to identify a prime number, I certainly would not hire you. Passing the test doesn't get you a job,
but it may get you an interview ... where there will be other tests.
(I am not even a professional programmer, but I can totally perform such a trivially easy task. The example tests basic understanding
of loop construction, function construction, variable use, efficient sorting, and error correction-- especially with mixed type
arrays. All of these are things any programmer SHOULD now how to do, without being overly complicated, or clearly a disguised
occupational problem trying to get a free solution. Like I said, programmers hate being pimped, and will be turned off
Again, the quality applicant and the code monkey both have something the fakers do not-- Actual comprehension of what a program
is, and how to create one.
As Bill points out, this is not the final exam. This is the "Oh, I see you do actually know how to program-- show me more"
portion of the process. This is the part that HR drones are not capable of performing, due to Dunning-Krueger. Those that are
actually, REALLY competent will do more than just satisfy the requirements of the challenge, they will provide actually working
solutions to the challenge that properly validate their input, and return proper error states if the input is invalid, etc-- You
can learn a LOT about a potential hire by observing their work. *THAT* is what this is really about. The triviality of the problem
is a necessity, because you ***DON'T*** try to get free solutions out of people.
I realize that may be difficult for you to comprehend, but you *DON'T* do that. The job fair is to let people know that you
have a position available, and try to curry interest in people to apply. A successful pre-screening is confidence building, and
helps the potential hire to feel that your company is actually interested in actually hiring somebody, and not just fucking off
in the booth, to cover for "failing to find somebody" and then "Getting yet another H1B". It gives them a chance to show you what
they can do. That is what it is for, and what it does. It also excludes the fakers that this article is about-- The ones that
can talk a good talk, but could not program a simple boolean check condition if their life depended on it.
If it were not for the time constraints of a job fair (usually only 2 days, and in that time you need to try and pre-screen
as many as possible), I would suggest a tiered challenge, with progressively harder challenges, where you hand out resumes to
the ones that make it to the top 3 brackets, but that is not the way the world works.
This in my opinion is really a waste of time. Challenges like this have to be so simple they can be done walking up to a
booth are not likely to filter the "all talks" any better than a few interview questions could (imperson so the candidate can't
just google it).
Tougher more involved stuff isn't good either it gives a huge advantage to the full time job hunter, the guy or gal that
already has a 9-5 and a family that wants to seem them has not got time for games. We have been struggling with hiring where
I work ( I do a lot of the interviews ) and these are the conclusions we have reached
You would be surprised at the number of people with impeccable-looking resumes failing at something as simple as the
FizzBuzz test [codinghorror.com]
The only thing fuzzbuzz tests is "have you done fizzbuzz before"? It's a short question filled with every petty trick the author
could think ti throw in there. If you haven't seen the tricks they trip you up for no reason related to your actual coding skills.
Once you have seen them they're trivial and again unrelated to real work. Fizzbuzz is best passed by someone aiming to game the
interview system. It passes people gaming it and trips up people who spent their time doing on the job real work.
A good programmer first and foremost has a clean mind. Experience suggests puzzle geeks, who excel at contrived tests, are
usually sloppy thinkers.
No. Good programmers can trivially knock out any of these so-called lame monkey tests. It's lame code monkeys who can't do
it. And I've seen their work. Many night shifts and weekends I've burned trying to fix their shit because they couldn't actually
do any of the things behind what you call "lame monkey tests", like:
pulling expensive invariant calculations out of loops using for loops to scan a fucking table to pull rows or calculate an
aggregate when they could let the database do what it does best with a simple SQL statement systems crashing under actual load
because their shitty code was never stress tested ( but it worked on my dev box! .) again with databases, having to
redo their schemas because they were fattened up so much with columns like VALUE1, VALUE2, ... VALUE20 (normalize you assholes!) chatting remote APIs - because these code monkeys cannot think about the need
for bulk operations in increasingly distributed systems. storing dates in unsortable strings because the idiots do not know
most modern programming languages have a date data type.
Oh and the most important, off-by-one looping errors. I see this all the time, the type of thing a good programmer can spot
on quickly because he or she can do the so-called "lame monkey tests" that involve arrays and sorting.
I've seen the type: "I don't need to do this shit because I have business knowledge and I code for business and IT not google",
and then they go and code and fuck it up... and then the rest of us have to go clean up their shit at 1AM or on weekends.
If you work as an hourly paid contractor cleaning that crap, it can be quite lucrative. But sooner or later it truly sucks
the energy out of your soul.
So yeah, we need more lame monkey tests ... to filter the lame code monkeys.
Someone could Google the problem with the phone then step up and solve the challenge.
If given a spec, someone can consistently cobble together working code by Googling, then I would love to hire them. That is
the most productive way to get things done.
There is nothing wrong with using external references. When I am coding, I have three windows open: an editor, a testing window,
and a browser with a Stackoverflow tab open.
Yeah, when we do tech interviews, we ask questions that we are certain they won't be able to answer, but want to see how they
would think about the problem and what questions they ask to get more data and that they don't just fold up and say "well that's
not the sort of problem I'd be thinking of" The examples aren't made up or anything, they are generally selection of real problems
that were incredibly difficult that our company had faced before, that one may not think at first glance such a position would
than spending weeks interviewing "good" candidates for an opening, selecting a couple and hiring them as contractors, then
finding out they are less than unqualified to do the job they were hired for.
I've seen it a few times, Java "experts", Microsoft "experts" with years of experience on their resumes, but completely useless
in coding, deployment or anything other than buying stuff from the break room vending machines.
That being said, I've also seen projects costing hundreds of thousands of dollars, with y
I agree with this. I consider myself to be a good programmer and I would never go into contractor game. I also wonder, how
does it take you weeks to interview someone and you still can't figure out if the person can't code? I could probably see that
in 15 minutes in a pair coding session.
Also, Oracle, SAP, IBM... I would never buy from them, nor use their products. I have used plenty of IBM products and they
suck big time. They make software development 100 times harder than it could be. Their technical supp
That being said, I've also seen projects costing hundreds of thousands of dollars, with years of delays from companies like
Oracle, Sun, SAP, and many other "vendors"
Software development is a hard thing to do well, despite the general thinking of technology becoming cheaper over time, and
like health care the quality of the goods and services received can sometimes be difficult to ascertain. However, people who don't
respect developers and the problems we solve are very often the same ones who continually frustrate themselves by trying to cheap
out, hiring outsourced contractors, and then tearing their hair out when sub par results are delivered, if anything is even del
As part of your interview process, don't you have candidates code a solution to a problem on a whiteboard? I've interviewed
lots of "good" candidates (on paper) too, but they crashed and burned when challenged with a coding exercise. As a result, we
didn't make them job offers.
I'm not a great coder but good enough to get done what clients want done. If I'm not sure or don't think I can do it, I tell
them. I think they appreciate the honesty. I don't work in a tech-hub, startups or anything like that so I'm not under the same
expectations and pressures that others may be.
OK, so yes, I know plenty of programmers who do fake it. But stitching together components isn't "fake" programming.
Back in the day, we had to write our own code to loop through an XML file, looking for nuggets. Now, we just use an XML serializer.
Back then, we had to write our own routines to send TCP/IP messages back and forth. Now we just use a library.
I love it! I hated having to make my own bricks before I could build a house. Now, I can get down to the business of writing
the functionality I want, ins
But, I suspect you could write the component if you had to. That makes you a very different user of that component than someone
who just knows it as a magic black box.
Because of this, you understand the component better and have real knowledge of its strengths and limitations. People blindly
using components with only a cursory idea of their internal operation often cause major performance problems. They rarely recognize
when it is time to write their own to overcome a limitation (or even that it is possibl
You're right on all counts. A person who knows how the innards work, is better than someone who doesn't, all else being equal.
Still, today's world is so specialized that no one can possibly learn it all. I've never built a processor, as you have, but I
still have been able to build a DNA matching algorithm for a major DNA lab.
I would argue that anyone who can skillfully use off-the-shelf components can also learn how to build components, if they are
required to.
1, 'Back in the Day' there was no XML, XMl was not very long ago.
2, its a parser, a serialiser is pretty much the opposite (unless this weeks fashion has redefined that.. anything is possible).
3, 'Back then' we didnt have TCP stacks...
But, actually I agree with you. I can only assume the author thinks there are lots of fake plumbers because they dont cast
their own toilet bowels from raw clay, and use pre-build fittings and pipes! That car mechanics start from raw steel scrap and
a file.. And that you need
Yes, I agree with you on the "middle ground." My reaction was to the author's point that "not knowing how to build the components"
was the same as being a "fake programmer."
If I'm a plumber, and I don't know anything about the engineering behind the construction of PVC pipe, I can still be a good
plumber. If I'm an electrician, and I don't understand the role of a blast furnace in the making of the metal components, I can
still be a good electrician.
The analogy fits. If I'm a programmer, and I don't know how to make an LZW compression library, I can still be a good programmer.
It's a matter of layers. These days, we specialize. You've got your low-level programmers that make the components, the high level
programmers that put together the components, the graphics guys who do HTML/CSS, and the SQL programmers that just know about
databases. Every person has their specialty. It's no longer necessary to be a low-level programmer, or jack-of-all-trades, to
be "good."
If I don't know the layout of the IP header, I can still write quality networking software, and if I know XSLT, I can still
do cool stuff with XML, even if I don't know how to write a good parser.
LOL yeah I know it's all JSON now. I've been around long enough to see these fads come and go. Frankly, I don't see a whole
lot of advantage of JSON over XML. It's not even that much more compact, about 10% or so. But the point is that the author laments
the "bad old days" when you had to create all your own building blocks, and you didn't have a team of specialists. I for one don't
want to go back to those days!
The main advantage is that JSON is that it is consistent. XML has attributes, embedded optional stuff within tags. That was
derived from the original SGML ancestor where is was thought to be a convenience for the human authors who were supposed to be
making the mark-up manually. Programmatically it is a PITA.
I got shit for decrying XML back when it was the trendy thing. I've had people apologise to me months later because they've
realized I was right, even though at the time they did their best to fuck over my career because XML was the new big thing and
I wasn't fully on board.
XML has its strengths and its place, but fuck me it taught me how little some people really fucking understand shit.
And a rather small part at that, albeit a very visible and vocal one full of the proverbial prima donas. However, much of the
rest of the tech business, or at least the people working in it, are not like that. It's small groups of developers working in
other industries that would not typically be considered technology. There are software developers working for insurance companies,
banks, hedge funds, oil and gas exploration or extraction firms, national defense and many hundreds and thousands of other small
They knew that well-paid programming jobs would also soon turn to smoke and ash, as the proliferation of learn-to-code courses
around the world lowered the market value of their skills, and as advances in artificial intelligence allowed for computers
to take over more of the mundane work of producing software.
Kind of hard to take this article serious after saying gibberish like this. I would say most good programmers know that neither
learn-to-code courses nor AI are going to make a dent in their income any time soon.
There is a huge shortage of decent programmers. I have personally witnessed more than one phone "interview" that went like
"have you done this? what about this? do you know what this is? um, can you start Monday?" (120K-ish salary range)
Partly because there are way more people who got their stupid ideas funded than good coders willing to stain their resume with
that. partly because if you are funded, and cannot do all the required coding solo, here's your conundrum:
top level hackers can afford to be really picky, so on one hand it's hard to get them interested, and if you could get
that, they often want some ownership of the project. the plus side is that they are happy to work for lots of equity if they
have faith in the idea, but that can be a huge "if".
"good but not exceptional" senior engineers aren't usually going to be super happy, as they often have spouses and children
and mortgages, so they'd favor job security over exciting ideas and startup lottery.
that leaves you with fresh-out-of-college folks, which are really really a mixed bunch. some are actually already senior
level of understanding without the experience, some are absolutely useless, with varying degrees in between, and there's no
easy way to tell which is which early.
so the not-so-scrupulous folks realized what's going on, and launched multiple coding boot camps programmes, to essentially
trick both the students into believing they can become a coder in a month or two, and also the prospective employers that said
students are useful. so far it's been working, to a degree, in part because in such companies coding skill evaluation process
is broken. but one can only hide their lack of value add for so long, even if they do manage to bluff their way into a job.
All one had to do was look at the lousy state of software and web sites today to see this is true. It's quite obvious little
to no thought is given on how to make something work such that one doesn't have to jump through hoops.
I have many times said the most perfect word processing program ever developed was WordPefect 5.1 for DOS. Ones productivity
was astonishing. It just worked.
Now we have the bloated behemoth Word which does its utmost to get in the way of you doing your work. The only way to get it
to function is to turn large portions of its "features" off, and even then it still insists on doing something other than what
you told it to do.
Then we have the abomination of Windows 10, which is nothing but Clippy on 10X steroids. It is patently obvious the people
who program this steaming pile have never heard of simplicity. Who in their right mind would think having to "search" for something
is more efficient than going directly to it? I would ask the question if these people wander around stores "searching" for what
they're looking for, but then I realize that's how their entire life is run. They search for everything online rather than going
directly to the source. It's no wonder they complain about not having time to things. They're always searching.
Web sites are another area where these people have no clue what they're doing. Anything that might be useful is hidden behind
dropdown menus, flyouts, popup bubbles and intriately designed mazes of clicks needed to get to where you want to go. When someone
clicks on a line of products, they shouldn't be harassed about what part of the product line they want to look at. Give them the
information and let the user go where they want.
This rant could go on, but this article explains clearly why we have regressed when it comes to software and web design. Instead
of making things simple and easy to use, using the one or two brain cells they have, programmers and web designers let the software
do what it wants without considering, should it be done like this?
The tech industry has a ton of churn -- there's some technological advancement, but there's an awful lot of new products turned
out simply to keep customers buying new licenses and paying for upgrades.
This relentless and mostly phony newness means a lot of people have little experience with current products. People fake because
they have no choice. The good ones understand the general technologies and problems they're meant to solve and can generally get
up to speed quickly, while the bad ones are good at faking it but don't really know what they're doing. Telling the difference
from the outside is impossible.
Sales people make it worse, promoting people as "experts" in specific products or implementations because the people have experience
with a related product and "they're all the same". This burns out the people with good adaption skills.
From the summary, it sounds like a lot of programmers and software engineers are trying to develop the next big thing so that
they can literally beg for money from the elite class and one day, hopefully, become a member of the aforementioned. It's sad
how the middle class has been utterly decimated in the United States that some of us are willing to beg for scraps from the wealthy.
I used to work in IT but I've aged out and am now back in school to learn automotive technology so that I can do something other
than being a security guard. Currently, the only work I have been able to find has been in the unglamorous security field.
I am learning some really good new skills in the automotive program that I am in but I hate this one class called "Professionalism
in the Shop." I can summarize the entire class in one succinct phrase, "Learn how to appeal to, and communicate with, Mr. Doctor,
Mr. Lawyer, or Mr. Wealthy-man." Basically, the class says that we are supposed to kiss their ass so they keep coming back to
the Audi, BMW, Mercedes, Volvo, or Cadillac dealership. It feels a lot like begging for money on behalf of my employer (of which
very little of it I will see) and nothing like professionalism. Professionalism is doing the job right the first time, not jerking
the customer off. Professionalism is not begging for a 5 star review for a few measly extra bucks but doing absolute top quality
work. I guess the upshot is that this class will be the easiest 4.0 that I've ever seen.
There is something fundamentally wrong when the wealthy elite have basically demanded that we beg them for every little scrap.
I can understand the importance of polite and professional interaction but this prevalent expectation that we bend over backwards
for them crosses a line with me. I still suck it up because I have to but it chafes my ass to basically validate the wealthy man.
In 70's I worked with two people who had a natural talent for computer science algorithms .vs. coding syntax. In the 90's while at COLUMBIA I worked with only a couple of true computer scientists out of 30 students.
I've met 1 genius who programmed, spoke 13 languages, ex-CIA, wrote SWIFT and spoke fluent assembly complete with animated characters.
According to the Bluff Book, everyone else without natural talent fakes it. In the undiluted definition of computer science,
genetics roulette and intellectual d
Ah yes, the good old 80:20 rule, except it's recursive for programmers.
80% are shit, so you fire them. Soon you realize that 80% of the remaining 20% are also shit, so you fire them too. Eventually
you realize that 80% of the 4% remaining after sacking the 80% of the 20% are also shit, so you fire them!
...
The cycle repeats until there's just one programmer left: the person telling the joke.
---
tl;dr: All programmers suck. Just ask them to review their own code from more than 3 years ago: they'll tell you that
Who gives a fuck about lines? If someone gave me JavaScript, and someone gave me minified JavaScript, which one would I
want to maintain?
I donâ(TM)t care about your line savings, less isnâ(TM)t always better.
Because the world of programming is not centered about JavasScript and reduction of lines is not the same as minification.
If the first thing that came to your mind was about minified JavaScript when you saw this conversation, you are certainly not
the type of programmer I would want to inherit code from.
See, there's a lot of shit out there that is overtly redundant and unnecessarily complex. This is specially true when copy-n-paste
code monkeys are left to their own devices for whom code formatting seems
I have a theory that 10% of people are good at what they do. It doesn't really matter what they do, they will still be
good at it, because of their nature. These are the people who invent new things, who fix things that others didn't even see as
broken and who automate routine tasks or simply question and erase tasks that are not necessary. If you have a software team
that contain 5 of these, you can easily beat a team of 100 average people, not only in cost but also in schedule, quality and
features. In theory they are worth 20 times more than average employees, but in practise they are usually paid the same amount
of money with few exceptions.
80% of people are the average. They can follow instructions and they can get the work done, but they don't see that something
is broken and needs fixing if it works the way it has always worked. While it might seem so, these people are not worthless. There
are a lot of tasks that these people are happily doing which the 10% don't want to do. E.g. simple maintenance work, implementing
simple features, automating test cases etc. But if you let the top 10% lead the project, you most likely won't be needed that
much of these people. Most work done by these people is caused by themselves, by writing bad software due to lack of good leader.
10% are just causing damage. I'm not talking about terrorists and criminals. I have seen software developers who have tried
(their best?), but still end up causing just damage to the code that someone else needs to fix, costing much more than their own
wasted time. You really must use code reviews if you don't know your team members, to find these people early.
I have a lot of weaknesses. My people skills suck, I'm scrawny, I'm arrogant. I'm also generally known as a really good programmer
and people ask me how/why I'm so much better at my job than everyone else in the room. (There are a lot of things I'm not good
at, but I'm good at my job, so say everyone I've worked with.)
I think one major difference is that I'm always studying, intentionally working to improve, every day. I've been doing that
for twenty years.
I've worked with people who have "20 years of experience"; they've done the same job, in the same way, for 20 years. Their
first month on the job they read the first half of "Databases for Dummies" and that's what they've been doing for 20 years. They
never read the second half, and use Oracle database 18.0 exactly the same way they used Oracle Database 2.0 - and it was wrong
20 years ago too. So it's not just experience, it's 20 years of learning, getting better, every day. That's 7,305 days of improvement.
I have a lot of weaknesses. My people skills suck, I'm scrawny, I'm arrogant. I'm also generally known as a really good
programmer and people ask me how/why I'm so much better at my job than everyone else in the room. (There are a lot of things
I'm not good at, but I'm good at my job, so say everyone I've worked with.)
I think one major difference is that I'm always studying, intentionally working to improve, every day. I've been doing that
for twenty years.
I've worked with people who have "20 years of experience"; they've done the same job, in the same way, for 20 years. Their
first month on the job they read the first half of "Databases for Dummies" and that's what they've been doing for 20 years.
They never read the second half, and use Oracle database 18.0 exactly the same way they used Oracle Database 2.0 - and it was
wrong 20 years ago too. So it's not just experience, it's 20 years of learning, getting better, every day. That's 7,305 days
of improvement.
If you take this attitude towards other people, people will not ask your for help. At the same time, you'll be also be not
able to ask for their help.
You're not interviewing your peers. They are already in your team. You should be working together.
I've seen superstar programmers suck the life out of project by over-complicating things and not working together with others.
10% are just causing damage. I'm not talking about terrorists and criminals.
Terrorists and criminals have nothing on those guys. I know guy who is one of those. Worse, he's both motivated and enthusiastic.
He also likes to offer help and advice to other people who don't know the systems well.
"I divide my officers into four groups. There are clever, diligent, stupid, and lazy officers. Usually two characteristics
are combined. Some are clever and diligent -- their place is the General Staff. The next lot are stupid and lazy -- they make
up 90 percent of every army and are suited to routine duties. Anyone who is both clever and lazy is qualified for the highest
leadership duties, because he possesses the intellectual clarity and the composure necessary for difficult decisions. One must
beware of anyone who is stupid and diligent -- he must not be entrusted with any responsibility because he will always cause only
mischief."
It's called the Pareto Distribution [wikipedia.org].
The number of competent people (people doing most of the work) in any given organization goes like the square root of the number
of employees.
Matches my observations. 10-15% are smart, can think independently, can verify claims by others and can identify and use rules
in whatever they do. They are not fooled by things "everybody knows" and see standard-approaches as first approximations that,
of course, need to be verified to work. They do not trust anything blindly, but can identify whether something actually work well
and build up a toolbox of such things.
The problem is that in coding, you do not have a "(mass) production step", and that is the
In basic concept I agree with your theory, it fits my own anecdotal experience well, but I find that your numbers are off.
The top bracket is actually closer to 20%. The reason it seems so low is that a large portion of the highly competent people are
running one programmer shows, so they have no co-workers to appreciate their knowledge and skill. The places they work do a very
good job of keeping them well paid and happy (assuming they don't own the company outright), so they rarely if ever switch jobs.
at least 70, probably 80, maybe even 90 percent of professional programmers should just fuck off and do something else as they
are useless at programming.
Programming is statistically a dead-end job. Why should anyone hone a dead-end skill that you won't be able to use for
long? For whatever reason, the industry doesn't want old programmers.
Otherwise, I'd suggest longer training and education before they enter the industry. But that just narrows an already narrow
window of use.
Well, it does rather depend on which industry you work in - i've managed to find interesting programming jobs for 25 years,
and there's no end in sight for interesting projects and new avenues to explore. However, this isn't for everyone, and if you
have good personal skills then moving from programming into some technical management role is a very worthwhile route, and I know
plenty of people who have found very interesting work in that direction.
I think that is a misinterpretation of the facts. Old(er) coders that are incompetent are just much more obvious and usually
are also limited to technologies that have gotten old as well. Hence the 90% old coders that can actually not hack it and never
really could get sacked at some time and cannot find a new job with their limited and outdated skills. The 10% that are good at
it do not need to worry though. Who worries there is their employers when these people approach retirement age.
My experience as an IT Security Consultant (I also do some coding, but only at full rates) confirms that. Most are basically
helpless and many have negative productivity, because people with a clue need to clean up after them. "Learn to code"? We have
far too many coders already.
You can't bluff you way through writing software, but many, many people have bluffed their way into a job and then tried to
learn it from the people who are already there. In a marginally functional organization those incompetents are let go pretty quickly,
but sometimes they stick around for months or years.
Apparently the author of this book is one of those, probably hired and fired several times before deciding to go back to his
liberal arts roots and write a book.
I think you can and this is by far not the first piece describing that. Here is a classic:
https://blog.codinghorror.com/... [codinghorror.com]
Yet these people somehow manage to actually have "experience" because they worked in a role they are completely unqualified to
fill.
Fiddling with JavaScript libraries to get a fancy dancy interface that makes PHB's happy is a sought-after skill, for good
or bad. Now that we rely more on half-ass libraries, much of "programming" is fiddling with dark-grey boxes until they work
good enough.
This drives me crazy, but I'm consoled somewhat by the fact that it will all be thrown out in five years anyway.
The backup is made with Tar. I backup the whole system into the Tar file.
If the HDD on my webserver dies, I got all my backups in a safe place.
But what would be the best way to do a Bare Metal Restore on a new HDD with a differential
backup make the previous day? Can I boot with a boot cd, and then format a new HDD and untar
the backup file into it? How do I do that exactly?
EDIT:
This is my backup script:
#!/bin/sh
# Backup script
BACKUPDIR="/backups"
BACKUPFILE=$BACKUPDIR/backup_$(date +%y-%m-%d).tgz
if [ ! -d $BACKUPDIR ]; then
mkdir $BACKUPDIR
fi
if [ -f $BACKUPFILE ]; then
echo "Backup file already exists and will be replaced."
rm $BACKUPFILE
fi
apt-get clean
tar czpf $BACKUPFILE --same-owner \
--exclude=$BACKUPDIR \
--exclude=/boot/grub/menu.lst* \
--exclude=/home/error.log \
--exclude=/proc \
--exclude=/media \
--exclude=/dev/* \
--exclude=/mnt \
--exclude=/sys/* \
--exclude=/cdrom \
--exclude=/lost+found \
--exclude=/var/cache/* \
--exclude=/tmp / 2>/home/error.log
Lest assume you got the server to the point it can boot (i personally prefer creating the
additional partition mounted to /boot which will have kernel and
initrd with busybox or something similar to allow you basic
maintenance tasks). You can also use a live CD of your Linux distribution.
Mount your future root partition somewhere and restore your backup.
tar was created for tapes so it support appending to archive files with same
name. If you used this method just untar -xvpf backup.tar -C /mnt if not you'll
need to restore "last sunday" backup and applying deferential parts up to needed day.
You should keep in mind that there is a lot of stuff that you should not backup, things
like: /proc , /dev , /sys , /media ,
/mnt (and probably some more which depend on your needs). You'll need to take care
of it before creating backup, or it may became severe pain while in restore process!
There is many points that you can easily miss with that backup method for whole server:
commands used to restore may vary to much depend on real commands you used to backup your
data.
boot record
kernel image and modules are ok and match each other after restore
have you ever tried to restore one of your backups?
have you considered changing your backup strategy?
have you considered separation of data you need to backup and system settings (there is
some good stuff today to manage system configuration so it can be easily resorted with zero
pain like puppet or chief , so only thing you should care about is
real data)
The idea of restoring only selected directories after creating "skeleton" linux OS from Red Hat DVD is viable. But this
is not optimal bare matalrestore method with tar
The backup tape from the previous night was still on site (our off-site rotations happen
once a week). Once I restored the filelist.txt file, I browsed through the list to determine
the order that the directories were written to the tape. Then, I placed that list in this
restore script:
#!/bin/sh
# Restore everything
# This script restores all system files from tape.
#
# Initialize the tape drive
if /bin/mt -f "/dev/nst0" tell > /dev/null 2>&1
then
# Rewind before restore
/bin/mt -f "/dev/nst0" rewind > /dev/null 2>&1
else
echo "Restore aborted: No tape loaded"
exit 1
fi
# Do restore
# The directory order must match the order on the tape.
#
/bin/tar --extract --verbose --preserve --file=/dev/nst0 var etc root usr lib boot bin home sbin backup
# note: in many cases, these directories don't need to be restored:
# initrd opt misc tmp mnt
# Rewind tape when done
/bin/mt -f "/dev/nst0" rewind
In the script, the list of directories to restore is passed as parameters to tar. Just as in
the backup script, it is important to use the --preserve switch so that file permissions are restored to the way they were
before the backup. I could have just restored the / directory, but
there were a couple of directories I wanted to exclude, so I decided to be explicit about what
to restore. If you want to use this script for your own restores, be sure the list of
directories matches the order they were backed up on your system.
Although it is listed in the restore script, I removed the /boot directory from my restore,
because I suspected my file system problem was related to a kernel upgrade I had done three
days earlier. By not restoring the /boot directory, the system would continue to use the stock
kernel that shipped on the CDs until I upgraded it. I also wanted to exclude the /tmp directory
and a few other directories that I knew were not important.
The restore ran for a long time, but uneventfully. Finally, I rebooted the system, reloaded
the MySQL databases from the dumps, and the system was fully restored and working perfectly.
Just over four hours elapsed from total meltdown to complete restore. I probably could trim at
least an hour off that time if I had to do it a second time.
Postmortem
I filed a bug report with Red Hat
Bugzilla , but I could only provide log files from the day before the crash. All core files
and logs from the day of the crash were lost when I tried to repair the file system. I
exchanged posts with a Red Hat engineer, but we were not able to nail down the cause. I suspect
the problem was either in the RAID driver code or ext3 code. I should note that the server is a
relatively new HP ProLiant server with an Intel hyperthreaded Pentium 4 processor. Because the
Linux kernel sees a hyperthreaded processor as a dual processor, I was using an SMP kernel when
the problem arose. I reasoned that I might squeeze a few percentage points of performance out
of the SMP kernel. This bug may only manifest when running on a hyperthreaded processor in SMP
mode. I don't have a spare server to try to recreate it.
After the restore, I went back to the uniprocessor kernel and have not yet patched it back
up to the level it had been. Happily, the ext3 error has not returned. I scan the logs every
day, but it has been well over a month since the restore and there are still no signs of
trouble. I am looking forward to my next full restore -- hopefully not until sometime in
2013.
"... Purpose: I'd like to compress partition images, so filling unused space with zeros is highly recommended. ..."
"... Such an utility is zerofree . ..."
"... Be careful - I lost ext4 filesystem using zerofree on Astralinux (Debian based) ..."
"... If the "disk" your filesystem is on is thin provisioned (e.g. a modern SSD supporting TRIM, a VM file whose format supports sparseness etc.) and your kernel says the block device understands it, you can use e2fsck -E discard src_fs to discard unused space (requires e2fsprogs 1.42.2 or higher). ..."
"... If you have e2fsprogs 1.42.9, then you can use e2image to create the partition image without the free space in the first place, so you can skip the zeroing step. ..."
Two different kind of answer are possible. What are you trying to achieve? Either 1)
security, by forbidding someone to read those data, or 2) optimizing compression of
the whole partition or [SSD performance]( en.wikipedia.org/wiki/Trim_(computing) ?
– Totor
Jan 5 '14 at 2:57
Zerofree finds the unallocated, non-zeroed blocks in an ext2 or ext3 file-system and
fills them with zeroes. This is useful if the device on which this file-system resides is a
disk image. In this case, depending on the type of disk image, a secondary utility may be
able to reduce the size of the disk image after zerofree has been run. Zerofree requires
the file-system to be unmounted or mounted read-only.
The usual way to achieve the same result (zeroing the unused blocks) is to run "dd" do
create a file full of zeroes that takes up the entire free space on the drive, and then
delete this file. This has many disadvantages, which zerofree alleviates:
it is slow
it makes the disk image (temporarily) grow to its maximal extent
it (temporarily) uses all free space on the disk, so other concurrent write actions
may fail.
Zerofree has been written to be run from GNU/Linux systems installed as guest OSes
inside a virtual machine. If this is not your case, you almost certainly don't need this
package.
UPDATE #1
The description of the .deb package contains the following paragraph now which would imply
this will work fine with ext4 too.
Description: zero free blocks from ext2, ext3 and ext4 file-systems Zerofree finds the
unallocated blocks with non-zero value content in an ext2, ext3 or ext4 file-system and
fills them with zeroes...
@GrzegorzWierzowiecki: yes, that is the page, but for debian and friends it is already in the
repos. I used on a ext4 partition on a virtual disk to successively shrink the disk file
image, and had no problem. – enzotib
Jul 29 '12 at 14:12
zerofree page talks about a patch that
lets you do "filesystem is mounted with the zerofree option" so that it always zeros out
deleted files continuously. does this require recompiling the kernel then? is there an easier
way to accomplish the same thing? – endolith
Oct 14 '16 at 16:33
Summary of the methods (as mentioned in this question and elsewhere) to clear unused space on
ext2/ext3/ext4: Zeroing unused spaceFile system is not mounted
If the "disk" your filesystem is on is thin provisioned (e.g. a modern SSD supporting
TRIM, a VM file whose format supports sparseness etc.) and your kernel says the block
device understands it, you can use e2fsck -E discard src_fs to discard unused
space (requires e2fsprogs 1.42.2 or higher).
Using zerofree to
explicitly write zeros over unused blocks.
Using e2image -rap src_fs dest_fs to only copy blocks in use (new
filesystem should be on an otherwise zero'd "disk", requires e2fsprogs 1.42.9 or
higher).
File system is mounted
If the "disk" your filesystem is on is thin provisioned (e.g. a modern SSD supporting
TRIM, a VM file whose format supports sparseness etc.), your kernel says the block device
understands it and finally the ext filesystem driver supports it you can use fstrim
/mnt/fs/ to ask the filesystem to discard unused space.
Using cat /dev/zero > /mnt/fs/zeros; sync; rm /mnt/fs/zeros (
sfill from secure-delete uses this technique). This method is inefficient, not
recommended by Ted Ts'o (author of ext4), may not zero certain things and can slow down
future fscks.
Having the filesystem unmounted will give better results than having it mounted.
Discarding tends to be the fastest method when a lot of previously used space needs to be
zeroed but using zerofree after the discard process can sometimes zero a little bit extra
(depending on how discard is implemented on the "disk").
Making the image file
smallerImage is in a dedicated VM format
You will need to use an appropriate disk image tool (such as qemu-img convert
src_image dst_image ) to enable the zeroed space to be reclaimed and to allow the file
representing the image to become smaller.
Image is a raw file
One of the following techniques can be used to make the file sparse (so runs of zero stop
taking up space):
cp --sparse=always src_image dst_image .
fallocate -d src_image (requires util-linux v2.25 or higher).
These days it might easier to use a tool like virt-sparsify to do these steps and more in
one go.
sfill from secure-delete can
do this and several other related jobs.
e.g.
sfill -l -l -z /mnt/X
UPDATE #1
There is a source tree that appears to be used by the ArchLinux project on github that
contains the source for sfill which is a tool included in the package
Secure-Delete.
that URL is obsolete. no idea where its home page is now (or even if it still has one), but
it's packaged for debian and ubuntu. probably other distros too. if you need source code,
that can be found in the debian archives if you can't find it anywhere else. –
cas
Jul 29 '12 at 12:04
If you have e2fsprogs 1.42.9, then you can use e2image to create the partition
image without the free space in the first place, so you can skip the zeroing step.
up vote 2 down votefavorite3
Im new to linux backup.
Im thinking of full system backup of my linux server using tar. I came up with the following
code:
Not the MBR which is not a file but is contained in a sector outside the file systems.
And not the filesystem with it potentially tweaked settings and or errors, just the contents of
the file system (granted, that is a minor difference).
and if in need of any hardware problem, restore it with
cd /
tar -zxpvf fullbackup.tar.gz
Will the above code be enough to bring the same server back?
Probably, as long as you use the same setup. The tarball will just contain the files, not
the partition scheme used for the disks. So you will have to partition the disk in the same
way. (Or copy the old partition scheme, e.g. with dd if=/dev/sda of=myMBRbackup bs=512
count=1 ).
Note that there are better ways to create backups, some of which already have been answered
in other posts. Personally I would just backup the configuration and the data. Everything else
is merely a matter of reinstalling. Possibly even with the latest version.
Also not that tar will backup all files. The first time that is a good thing.
But if you run that weekly or daily you will get a lot of large backups. In that case look
at rsync (which does incremental changes) or one of the many other options.
share | improve this answeredited Feb 14 '13 at 8:14 answered Feb 14
'13 at 7:29
Could you paste the URL of other post for better ways to create backups? I have been
looking for it but couldn't get the just way of doing it. – misamisaFeb 14
'13 at 22:37
It depends on how you want to make backups. If you have several servers, try using Amanda
( amanda.org ), if you just have two
servers use rsync (comes with the OS). If you have a build in tape drive use your tar
command. If you want a once off backup with a nice graphical front consider Acronis True
Image. Etc etc. – HennesFeb 14
'13 at 22:41
It's single Linux server (CentOS - shell access only) which I want to take a full system
backup once. Once the backup is taken locally, I will transfer that backup to other PC to
keep it safe. – misamisaFeb 14
'13 at 23:02
In that case why create the backup on a server and then transfer it. You can do this
instead: One the host to store your backup run nc -l 1234 >
MyBackupOfComputerA.tgz . And on the computer to archive run the tar command with as
output filename - and append | nc ComputerB 1234 . That
- will write to std out instead of to a file. The | pipes the std
out text to netcat which forwards it to another computer. The nc on the other computer
listens for the information and writes it to a file. No intermediate copy is needed. –
HennesFeb 14
'13 at 23:05
As you told me above that the tar command won't backup the MBR and filesystem. I am
looking for a way to have them in a backup in case of harddisk failure. – misamisaFeb 14
'13 at 23:08
Using
tar to backup/restore a system is pretty rudimentary, and by that I mean that there are
probably more elegant ways out there to backup your system... If you really want to stick to
tar, here's a very good guide I found (it includes instructions on backing up the MBR; grub
specifically).=: https://help.ubuntu.com/community/BackupYourSystem/TAR
While it's on the Ubuntu wiki website, there's no reason why it wouldn't work on any UNIX/Linux
machine.
If you'd like something with a nice web GUI that's relatively straightforward to set up and
use: http://backuppc.sourceforge.net/
1 Let me second the pointer to backuppc. If you have several machines to backup, backuppc
is a dream come true. Best thing of it is it's deduplication and compression. –
You can create live iso of your existing system. so install all the required packages on
your ubuntu and then take a iso using remastersys. Then using startup disk, you can create
bootable usb from this iso.
edit your /etc/apt/sources.list file. Add the following line in the end of the file.
This is mostly incorrect if we are talking about bare metal restore ;-). Mostly correct for your data. The thinking is
very primitive here, which is the trademark of Ubuntu.
Only some tips are useful: you are warned
Notable quotes:
"... Don't forget to empty your Wastebasket, remove any unwanted files in your /home ..."
"... Depending on why you're backing up, you might ..."
Just a
quick note. You are about to back up your entire system. Don't forget to empty your
Wastebasket, remove any unwanted files in your /home directory, and cleanup your
desktop.
Depending on why you're backing up, you might want to: Delete all your emails; Clear your browser search history; Wipe your saved browser personal details
Unmount any external media devices, and remove any CDs/DVDs not needed for the backup
process.
This will lessen the amount of exclusions you need to type later in the process.
.... ... ...
Files that are bigger than 2GB are not supported by some
implementations of ISO9660 and may not be restorable. So don't simply burn a DVD with a
huge .iso file on it. Split it up using the command split or use a different way to get it
onto the DVD. See man split for further information on split.
Note that this only backs up one file system. You might want to use
–exclude instead of –one-file-system to filter out the stuff you don't
want backed up. This assumes your DVD drive is /dev/hda. This will not create a
mountable DVD. To restore it you will reference the device file:
sudo tar –extract –bzip2 –file /dev/hda
At the end of the process you might get a message along the lines of
'tar: Error exit delayed from previous errors' or something, but in most
cases you can just ignore that.
Another workaround would be to Bzip2 to compress your backup. Bzip2 provides a
higher compression ratio at the expense of speed. If compression is important to
you, just substitute the z in the command with j, and change the file name to
backup.tar.bz2 . That would make the command look like this:
tar -cvpjf /backup.tar.bz2 –exclude=/proc –exclude=/lost+found
–exclude=/backup.tar.bz2 –exclude=/mnt –exclude=/sys /
I'm using tar to make daily backups of a server and want to avoid backup of
/proc and /sys system directories, but without excluding any directories named "proc" or
"sys" somewhere else in the file tree.
For, example having the following directory tree (" bla " being normal
files):
Not sure I understand your question. There is a --exclude option, but I don't
know how to match it for single, absolute file names (not any file by that name) - see my
examples above. – Udo G
May 9 '12 at 7:21
True, but the important detail about this is that the excluded file name must match exactly
the notation reported by the tar listing. For my example that would be
./sys - as I just found out now. – Udo G
May 9 '12 at 7:34
This did the trick for me, thank you! I wanted to exclude a specific directory, not all
directories/subdirectories matching the pattern. bsdtar does not have "--anchored" option
though, and with bsdtar we can use full paths to exclude specific folders. – Savvas Radevic
May 9 '13 at 10:44
ah found it! in bsdtar the anchor is "^": bsdtar cvjf test.tar.bz2 --exclude myfile.avi
--exclude "^myexcludedfolder" * – Savvas Radevic
May 9 '13 at 10:58
"... Trailing slashes at the end of excluded folders will cause tar to not exclude those folders at all ..."
"... I had to remove the single quotation marks in order to exclude sucessfully the directories ..."
"... Exclude files using tags by placing a tag file in any directory that should be skipped ..."
"... Nice and clear thank you. For me the issue was that other answers include absolute or relative paths. But all you have to do is add the name of the folder you want to exclude. ..."
"... Adding a wildcard after the excluded directory will exclude the files but preserve the directories: ..."
"... You can use cpio(1) to create tar files. cpio takes the files to archive on stdin, so if you've already figured out the find command you want to use to select the files the archive, pipe it into cpio to create the tar file: ..."
Is there a simple shell command/script that supports excluding certain files/folders from
being archived?
I have a directory that need to be archived with a sub directory that has a number of very
large files I do not need to backup.
Not quite solutions:
The tar --exclude=PATTERN command matches the given pattern and excludes
those files, but I need specific files & folders to be ignored (full file path),
otherwise valid files might be excluded.
I could also use the find command to create a list of files and exclude the ones I don't
want to archive and pass the list to tar, but that only works with for a small amount of
files. I have tens of thousands.
I'm beginning to think the only solution is to create a file with a list of files/folders
to be excluded, then use rsync with --exclude-from=file to copy all the files to
a tmp directory, and then use tar to archive that directory.
Can anybody think of a better/more efficient solution?
EDIT: cma 's solution works well. The big gotcha is that the
--exclude='./folder' MUST be at the beginning of the tar command. Full command
(cd first, so backup is relative to that directory):
cd /folder_to_backup
tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz .
I had to remove the single quotation marks in order to exclude sucessfully the directories. (
tar -zcvf gatling-charts-highcharts-1.4.6.tar.gz /opt/gatling-charts-highcharts-1.4.6
--exclude=results --exclude=target ) – Brice
Jun 24 '14 at 16:06
I came up with the following command: tar -zcv --exclude='file1' --exclude='pattern*'
--exclude='file2' -f /backup/filename.tgz . note that the -f flag needs
to precede the tar file see:
A "/" on the end of the exclude directory will cause it to fail. I guess tar thinks an ending
/ is part of the directory name to exclude. BAD: --exclude=mydir/ GOOD: --exclude=mydir
– flickerfly
Aug 21 '15 at 16:22
> Make sure to put --exclude before the source and destination items. OR use an absolute
path for the exclude: tar -cvpzf backups/target.tar.gz --exclude='/home/username/backups'
/home/username – NightKnight on
Cloudinsidr.com
Nov 24 '16 at 9:55
This answer definitely helped me! The gotcha for me was that my command looked something like
tar -czvf mysite.tar.gz mysite --exclude='./mysite/file3'
--exclude='./mysite/folder3' , and this didn't exclude anything. – Anish Ramaswamy
May 16 '15 at 0:11
Nice and clear thank you. For me the issue was that other answers include absolute or
relative paths. But all you have to do is add the name of the folder you want to exclude.
– Hubert
Feb 22 '17 at 7:38
Just want to add to the above, that it is important that the directory to be excluded should
NOT contain a final backslash. So, --exclude='/path/to/exclude/dir' is CORRECT
, --exclude='/path/to/exclude/dir/' is WRONG . – GeertVc
Dec 31 '13 at 13:35
I believe this require that the Bash shell option variable globstar has to be
enabled. Check with shopt -s globstar . I think it off by default on most
unix based OS's. From Bash manual: " globstar:If set, the pattern **
used in a filename expansion context will match all files and zero or more directories and
subdirectories. If the pattern is followed by a '/', only directories and subdirectories
match. " – not2qubit
Apr 4 at 3:24
Use the find command in conjunction with the tar append (-r) option. This way you can add
files to an existing tar in a single step, instead of a two pass solution (create list of
files, create tar).
To avoid possible 'xargs: Argument list too long' errors due to the use of
find ... | xargs ... when processing tens of thousands of files, you can pipe
the output of find directly to tar using find ... -print0 |
tar --null ... .
# archive a given directory, but exclude various files & directories
# specified by their full file paths
find "$(pwd -P)" -type d \( -path '/path/to/dir1' -or -path '/path/to/dir2' \) -prune \
-or -not \( -path '/path/to/file1' -or -path '/path/to/file2' \) -print0 |
gnutar --null --no-recursion -czf archive.tar.gz --files-from -
#bsdtar --null -n -czf archive.tar.gz -T -
$ tar --exclude='./folder_or_file' --exclude='file_pattern' --exclude='fileA'
A word of warning for a side effect that I did not find immediately obvious: The exclusion
of 'fileA' in this example will search for 'fileA' RECURSIVELY!
Example:A directory with a single subdirectory containing a file of the same name
(data.txt)
If using --exclude='data.txt' the archive will not contain EITHER data.txt
file. This can cause unexpected results if archiving third party libraries, such as a
node_modules directory.
To avoid this issue make sure to give the entire path, like
--exclude='./dirA/data.txt'
You can use cpio(1) to create tar files. cpio takes the files to archive on stdin, so if
you've already figured out the find command you want to use to select the files the archive,
pipe it into cpio to create the tar file:
That can cause tar to be invoked multiple times - and will also pack files repeatedly.
Correct is: find / -print0 | tar -T- --null --no-recursive -cjf tarfile.tar.bz2
– jørgensen
Mar 4 '12 at 15:23
I read somewhere that when using xargs , one should use tar r
option instead of c because when find actually finds loads of
results, the xargs will split those results (based on the local command line arguments limit)
into chuncks and invoke tar on each part. This will result in a archive containing the last
chunck returned by xargs and not all results found by the find
command. – Stphane
Dec 19 '15 at 11:10
gnu tar v 1.26 the --exclude needs to come after archive file and backup directory arguments,
should have no leading or trailing slashes, and prefers no quotes (single or double). So
relative to the PARENT directory to be backed up, it's:
tar cvfz /path_to/mytar.tgz ./dir_to_backup
--exclude=some_path/to_exclude
tar -cvzf destination_folder source_folder -X /home/folder/excludes.txt
-X indicates a file which contains a list of filenames which must be excluded from the
backup. For Instance, you can specify *~ in this file to not include any filenames ending
with ~ in the backup.
Possible redundant answer but since I found it useful, here it is:
While a FreeBSD root (i.e. using csh) I wanted to copy my whole root filesystem to /mnt
but without /usr and (obviously) /mnt. This is what worked (I am at /):
tar --exclude ./usr --exclude ./mnt --create --file - . (cd /mnt && tar xvd -)
My whole point is that it was necessary (by putting the ./ ) to specify to tar
that the excluded directories where part of the greater directory being copied.
I had no luck getting tar to exclude a 5 Gigabyte subdirectory a few levels deep. In the end,
I just used the unix Zip command. It worked a lot easier for me.
So for this particular example from the original post
(tar --exclude='./folder' --exclude='./upload/folder2' -zcvf /backup/filename.tgz . )
The equivalent would be:
zip -r /backup/filename.zip . -x upload/folder/**\* upload/folder2/**\*
The following bash script should do the trick. It uses the answer given
here by Marcus Sundman.
#!/bin/bash
echo -n "Please enter the name of the tar file you wish to create with out extension "
read nam
echo -n "Please enter the path to the directories to tar "
read pathin
echo tar -czvf $nam.tar.gz
excludes=`find $pathin -iname "*.CC" -exec echo "--exclude \'{}\'" \;|xargs`
echo $pathin
echo tar -czvf $nam.tar.gz $excludes $pathin
This will print out the command you need and you can just copy and paste it back in. There
is probably a more elegant way to provide it directly to the command line.
Just change *.CC for any other common extension, file name or regex you want to exclude
and this should still work.
EDIT
Just to add a little explanation; find generates a list of files matching the chosen regex
(in this case *.CC). This list is passed via xargs to the echo command. This prints --exclude
'one entry from the list'. The slashes () are escape characters for the ' marks.
Requiring interactive input is a poor design choice for most shell scripts. Make it read
command-line parameters instead and you get the benefit of the shell's tab completion,
history completion, history editing, etc. – tripleee
Sep 14 '17 at 4:27
Additionally, your script does not work for paths which contain whitespace or shell
metacharacters. You should basically always put variables in double quotes unless you
specifically require the shell to perform whitespace tokenization and wildcard expansion. For
details, please see stackoverflow.com/questions/10067266/
– tripleee
Sep 14 '17 at 4:38
> ,Apr 18 at 0:31
For those who have issues with it, some versions of tar would only work properly without the
'./' in the exclude value.
Tar --version
tar (GNU tar) 1.27.1
Command syntax that work:
tar -czvf ../allfiles-butsome.tar.gz * --exclude=acme/foo
These will not work:
$ tar -czvf ../allfiles-butsome.tar.gz * --exclude=./acme/foo
$ tar -czvf ../allfiles-butsome.tar.gz * --exclude='./acme/foo'
$ tar --exclude=./acme/foo -czvf ../allfiles-butsome.tar.gz *
$ tar --exclude='./acme/foo' -czvf ../allfiles-butsome.tar.gz *
$ tar -czvf ../allfiles-butsome.tar.gz * --exclude=/full/path/acme/foo
$ tar -czvf ../allfiles-butsome.tar.gz * --exclude='/full/path/acme/foo'
$ tar --exclude=/full/path/acme/foo -czvf ../allfiles-butsome.tar.gz *
$ tar --exclude='/full/path/acme/foo' -czvf ../allfiles-butsome.tar.gz *
Bash Range: How to iterate over sequences generated on the shell 2 days ago You can iterate the sequence of numbers in
bash by two ways. One is by using seq command and another is by specifying range in for loop. In seq command, the sequence starts
from one, the number increments by one in each step and print each number in each line up to the upper limit by default. If the number
starts from upper limit then it decrements by one in each step. Normally, all numbers are interpreted as floating point but if the
sequence starts from integer then the list of decimal integers will print. If seq command can execute successfully then it returns
0, otherwise it returns any non-zero number. You can also iterate the sequence of numbers using for loop with range. Both seq command
and for loop with range are shown in this tutorial by using examples.
The options of seq command:
You can use seq command by using the following options.
-w This option is used to pad the numbers with leading zeros to print all numbers with equal width.
-f format This option is used to print number with particular format. Floating number can be formatted by using %f,
%g and %e as conversion characters. %g is used as default.
-s string This option is used to separate the numbers with string. The default value is newline ('\n').
Examples of seq command:
You can apply seq command by three ways. You can use only upper limit or upper and lower limit or upper and lower limit with increment
or decrement value of each step . Different uses of the seq command with options are shown in the following examples.
Example-1: seq command without option
When only upper limit is used then the number will start from 1 and increment by one in each step. The following command
will print the number from 1 to 4.
$ seq 4
When the two values are used with seq command then first value will be used as starting number and second value will be used as
ending number. The following command will print the number from 7 to 15.
$ seq 7 15
When you will use three values with seq command then the second value will be used as increment or decrement value for each step.
For the following command, the starting number is 10, ending number is 1 and each step will be counted by decrementing 2.
$ seq 10 -2 1
Example-2: seq with –w option
The following command will print the output by adding leading zero for the number from 1 to 9.
$ seq -w 0110
Example-3: seq with –s option
The following command uses "-" as separator for each sequence number. The sequence of numbers will print by adding "-" as separator.
$ seq -s - 8
Example-4: seq with -f option
The following command will print 10 date values starting from 1. Here, "%g" option is used to add sequence number with other string
value.
$ seq -f "%g/04/2018" 10
The following command is used to generate the sequence of floating point number using "%f" . Here, the number will start from
3 and increment by 0.8 in each step and the last number will be less than or equal to 6.
$ seq -f "%f" 3 0.8 6
Example-5: Write the sequence in a file
If you want to save the sequence of number into a file without printing in the console then you can use the following commands.
The first command will print the numbers to a file named " seq.txt ". The number will generate from 5 to 20 and increment by 10 in
each step. The second command is used to view the content of " seq.txt" file.
seq 5 10 20 | cat > seq.txt
cat seq.txt
Example-6: Using seq in for loop
Suppose, you want to create files named fn1 to fn10 using for loop with seq. Create a file named "sq1.bash" and add the following
code. For loop will iterate for 10 times using seq command and create 10 files in the sequence fn1, fn2,fn3 ..fn10.
#!/bin/bash
for i in ` seq 10 ` ; do
touch fn. $i
done
Run the following commands to execute the code of the bash file and check the files are created or not.
bash sq1.bash
ls
Examples of for loop with range:Example-7: For loop with range
The alternative of seq command is range. You can use range in for loop to generate sequence of numbers like seq. Write the following
code in a bash file named " sq2.bash ". The loop will iterate for 5 times and print the square root of each number in each step.
#!/bin/bash
for n in { 1 .. 5 } ; do
(( result =n * n ))
echo $n square = $result
done
Run the command to execute the script of the file.
bash sq2.bash
Example-8: For loop with range and increment value
By default, the number is increment by one in each step in range like seq. You can also change the increment value in range. Write
the following code in a bash file named " sq3.bash ". The for loop in the script will iterate for 5 times, each step is incremented
by 2 and print all odd numbers between 1 to 10.
#!/bin/bash
echo "all odd numbers from 1 to 10 are"
for i in { 1 .. 10 .. 2 }; do
echo $i ;
done
Run the command to execute the script of the file.
bash sq3.bash
If you want to work with the sequence of numbers then you can use any of the options that are shown in this tutorial. After completing
this tutorial, you will be able to use seq command and for loop with range more efficiently in your bash script.
Bash completion is a functionality through which Bash helps users type their commands more
quickly and easily. It does this by presenting possible options when users press the Tab key
while typing a command.
The completion script is code that uses the builtin Bash command complete to
define which completion suggestions can be displayed for a given executable . The nature of the
completion options vary, from simple static to highly sophisticated. Why bother?
This functionality helps users by:
saving them from typing text when it can be auto-completed
helping them know the available continuations to their commands
preventing errors and improving their experience by hiding or showing options based on
what they have already typed
Hands-on
Here's what we will do in this tutorial:
We will first create a dummy executable script called dothis . All it does is
execute the command that resides on the number that was passed as an argument in the user's
history. For example, the following command will simply execute the ls -a command,
given that it exists in history with number 235 :
dothis 235
Then we will create a Bash completion script that will display commands along with their
number from the user's history, and we will "bind" it to the dothis
executable.
$ dothis < tab >< tab >
215 ls
216 ls -la
217 cd ~
218 man history
219 git status
220 history | cut -c 8 - bash_screen.png
Create a file named dothis in your working directory and add the following
code:
if [ -z "$1" ] ; then
echo "No command number passed"
exit 2
fi
exists =$ ( fc -l -1000 | grep ^ $1 -- 2 >/ dev / null )
if [ -n " $exists " ] ; then
fc -s -- "$1"
else
echo "Command with number $1 was not found in recent history"
exit 2
fi
Notes:
We first check if the script was called with an argument
We then check if the specific number is included in the last 1000 commands
if it exists, we execute the command using the fc functionality
otherwise, we display an error message
Make the script executable with:
chmod +x ./dothis
We will execute this script many times in this tutorial, so I suggest you place it in a
folder that is included in your path so that we can access it from anywhere by
typing dothis .
I installed it in my home bin folder using:
install ./dothis ~/bin/dothis
You can do the same given that you have a ~/bin folder and it is included in
your PATH variable.
Check to see if it's working:
dothis
You should see this:
$ dothis
No command number passed
Done.
Creating the completion script
Create a file named dothis-completion.bash . From now on, we will refer to this
file with the term completion script .
Once we add some code to it, we will source it to allow the completion to take
effect. We must source this file every single time we change something in it .
Later in this tutorial, we will discuss our options for registering this script whenever a
Bash shell opens.
Static completion
Suppose that the dothis program supported a list of commands, for example:
now
tomorrow
never
Let's use the complete command to register this list for completion. To use the
proper terminology, we say we use the complete command to define a completion
specification ( compspec ) for our program.
Here's what we specified with the complete command above:
we used the -W ( wordlist ) option to provide a list of words for
completion.
we defined to which "program" these completion words will be used (the
dothis parameter)
Source the file:
source ./dothis-completion.bash
Now try pressing Tab twice in the command line, as shown below:
$ dothis < tab
>< tab >
never now tomorrow
Try again after typing the n :
$ dothis n < tab >< tab >
never now
Magic! The completion options are automatically filtered to match only those starting with
n .
Note: The options are not displayed in the order that we defined them in the word list; they
are automatically sorted.
There are many other options to be used instead of the -W that we used in this
section. Most produce completions in a fixed manner, meaning that we don't intervene
dynamically to filter their output.
For example, if we want to have directory names as completion words for the
dothis program, we would change the complete command to the following:
complete -A directory dothis
Pressing Tab after the dothis program would get us a list of the directories in
the current directory from which we execute the script:
We will be producing the completions of the dothis executable with the
following logic:
If the user presses the Tab key right after the command, we will show the last 50
executed commands along with their numbers in history
If the user presses the Tab key after typing a number that matches more than one command
from history, we will show only those commands along with their numbers in history
If the user presses the Tab key after a number that matches exactly one command in
history, we auto-complete the number without appending the command's literal (if this is
confusing, no worries -- you will understand later)
Let's start by defining a function that will execute each time the user requests completion
on a dothis command. Change the completion script to this:
we used the -F flag in the complete command defining that the
_dothis_completions is the function that will provide the completions of the
dothis executable
COMPREPLY is an array variable used to store the completions -- the
completion mechanism uses this variable to display its contents as completions
Now source the script and go for completion:
$ dothis < tab >< tab >
never now tomorrow
Perfect. We produce the same completions as in the previous section with the word list. Or
not? Try this:
$ dothis nev < tab >< tab >
never now tomorrow
As you can see, even though we type nev and then request for completion, the available
options are always the same and nothing gets completed automatically. Why is this
happening?
The contents of the COMPREPLY variable are always displayed. The function is
now responsible for adding/removing entries from there.
If the COMPREPLY variable had only one element, then that word would be
automatically completed in the command. Since the current implementation always returns the
same three words, this will not happen.
Enter compgen : a builtin command that generates completions supporting most of
the options of the complete command (ex. -W for word list,
-d for directories) and filtering them based on what the user has already
typed.
Don't worry if you feel confused; everything will become clear later.
Type the following in the console to better understand what compgen does:
$
compgen -W "now tomorrow never"
now
tomorrow
never
$ compgen -W "now tomorrow never" n
now
never
$ compgen -W "now tomorrow never" t
tomorrow
So now we can use it, but we need to find a way to know what has been typed after the
dothis command. We already have the way: The Bash completion facilities provide
Bash
variables related to the completion taking place. Here are the more important ones:
COMP_WORDS : an array of all the words typed after the name of the program
the compspec belongs to
COMP_CWORD : an index of the COMP_WORDS array pointing to the
word the current cursor is at -- in other words, the index of the word the cursor was when
the tab key was pressed
COMP_LINE : the current command line
To access the word just after the dothis word, we can use the value of
COMP_WORDS[1]
Now, instead of the words now, tomorrow, never , we would like to see actual
numbers from the command history.
The fc -l command followed by a negative number -n displays the
last n commands. So we will use:
fc -l -50
which lists the last 50 executed commands along with their numbers. The only manipulation we
need to do is replace tabs with spaces to display them properly from the completion mechanism.
sed to the rescue.
We do have a problem, though. Try typing a number as you see it in your completion list and
then press the key again.
$ dothis 623 < tab >
$ dothis 623 ls 623 ls -la
...
$ dothis 623 ls 623 ls 623 ls 623 ls 623 ls -la
This is happening because in our completion script, we used the
${COMP_WORDS[1]} to always check the first typed word after the
dothis command (the number 623 in the above snippet). Hence the
completion continues to suggest the same completion again and again when the Tab key is
pressed.
To fix this, we will not allow any kind of completion to take place if at least one argument
has already been typed. We will add a condition in our function that checks the size of the
aforementioned COMP_WORDS array.
#/usr/bin/env bash
_dothis_completions ()
{
if [ " ${#COMP_WORDS[@]} " ! = "2" ] ; then
return
fi
$ dothis 623 < tab >
$ dothis 623 ls -la < tab > # SUCCESS: nothing happens here
There is another thing we don't like, though. We do want to display the numbers along with
the corresponding commands to help users decide which one is desired, but when there is only
one completion suggestion and it gets automatically picked by the completion mechanism, we
shouldn't append the command literal too .
In other words, our dothis executable accepts only a number, and we haven't
added any functionality to check or expect other arguments. When our completion function gives
only one result, we should trim the command literal and respond only with the command
number.
To accomplish this, we will keep the response of the compgen command in an
array variable, and if its size is 1 , we will trim the one and only element to keep just the
number. Otherwise, we'll let the array as is.
Change the completion script to this:
#/usr/bin/env bash
_dothis_completions ()
{
if [ " ${#COMP_WORDS[@]} " ! = "2" ] ; then
return
fi
# keep the suggestions in a local variable
local suggestions = ( $ ( compgen -W " $(fc -l -50 | sed 's/\t/ /') " -- " ${COMP_WORDS[1]} "
))
if [ " ${#suggestions[@]} " == "1" ] ; then
# if there's only one match, we remove the command literal
# to proceed with the automatic completion of the number
local number =$ ( echo ${suggestions[0]/%\ */} )
COMPREPLY = ( " $number " )
else
# more than one suggestions resolved,
# respond with the suggestions intact
COMPREPLY = ( " ${suggestions[@]} " )
fi
}
complete -F _dothis_completions dothis
Registering the completion script
If you want to enable the completion just for you on your machine, all you have to do is add
a line in your .bashrc file sourcing the script:
If you want to enable the completion for all users, you can just copy the script under
/etc/bash_completion.d/ and it will automatically be loaded by
Bash.
Fine-tuning the completion script
Here are some extra steps for better results:
Displaying each entry in a new line
In the Bash completion script I was working on, I too had to present suggestions consisting
of two parts. I wanted to display the first part in the default color and the second part in
gray to distinguish it as help text. In this tutorial's example, it would be nice to present
the numbers in the default color and the command literal in a less fancy one.
Unfortunately, this is not possible, at least for now, because the completions are displayed
as plain text and color directives are not processed (for example: \e[34mBlue
).
What we can do to improve the user experience (or not) is to display each entry in a new
line. This solution is not that obvious since we can't just append a new line character in each
COMPREPLY entry. We will follow a rather
hackish method and pad suggestion literals to a width that fills the terminal.
Enter printf . If you want to display each suggestion on each own line, change
the completion script to the following:
#/usr/bin/env bash
_dothis_completions ()
{
if [ " ${#COMP_WORDS[@]} " ! = "2" ] ; then
return
fi
local IFS =$ '\n'
local suggestions = ( $ ( compgen -W " $(fc -l -50 | sed 's/\t//') " -- " ${COMP_WORDS[1]} "
))
if [ " ${#suggestions[@]} " == "1" ] ; then
local number = " ${suggestions[0]/%\ */} "
COMPREPLY = ( " $number " )
else
for i in " ${!suggestions[@]} " ; do
suggestions [ $i ] = " $(printf '%*s' "-$COLUMNS" "${suggestions[$i]}") "
done
In our case, we hard-coded to display the last 50 commands for completion. This is not a
good practice. We should first respect what each user might prefer. If he/she hasn't made any
preference, we should default to 50.
To accomplish that, we will check if an environment variable
DOTHIS_COMPLETION_COMMANDS_NUMBER has been set.
Change the completion script one last time:
#/usr/bin/env bash
_dothis_completions ()
{
if [ " ${#COMP_WORDS[@]} " ! = "2" ] ; then
return
fi
local commands_number = ${DOTHIS_COMPLETION_COMMANDS_NUMBER:-50}
local IFS =$ '\n'
local suggestions = ( $ ( compgen -W " $(fc -l -$commands_number | sed 's/\t//') " -- "
${COMP_WORDS[1]} " ))
if [ " ${#suggestions[@]} " == "1" ] ; then
local number = " ${suggestions[0]/%\ */} "
COMPREPLY = ( " $number " )
else
for i in " ${!suggestions[@]} " ; do
suggestions [ $i ] = " $(printf '%*s' "-$COLUMNS" "${suggestions[$i]}") "
done
You can find the code of this tutorial on GitHub .
For feedback, comments, typos, etc., please open an issue in the
repository.
Lazarus Lazaridis - I am an open source enthusiast and I like helping developers with
tutorials and tools . I usually code
in Ruby especially when it's on Rails but I also speak Java, Go, bash & C#. I have studied
CS at Athens University of Economics and Business and I live in Athens, Greece. My nickname is
iridakos and I publish tech related posts on my personal blog iridakos.com .
"... And then I realized I had thrashed the server. Completely. ..."
"... There must be a way to fix this , I thought. HP-UX has a package installer like any modern Linux/Unix distribution, that is swinstall . That utility has a repair command, swrepair . ..."
"... you probably don't want that user owning /bin/nologin. ..."
Unix Horror Stories: The good thing about Unix, is when it screws up, it does so very quickly The project to deploy a new,
multi-million-dollar commercial system on two big, brand-new HP-UX servers at a brewing company that shall not be named, had been
running on time and within budgets for several months. Just a few steps remained, among them, the migration of users from the old
servers to the new ones.
The task was going to be simple: just copy the home directories of each user from the old server to the new ones, and a simple
script to change the owner so as to make sure that each home directory was owned by the correct user. The script went something like
this:
#!/bin/bash
cat /etc/passwd|while read line
do
USER=$(echo $line|cut -d: -f1)
HOME=$(echo $line|cut -d: -f6)
chown -R $USER $HOME
done
[NOTE: the script does not filter out system ids from userids and that's a grave mistake. also it was
run before it was tested ; -) -- NNB]
As you see, this script is pretty simple: obtain the user and the home directory from the password file, and then execute the
chown command recursively on the home directory. I copied the files, executed the script, and thought, great, just 10 minutes and
all is done.
That's when the calls started.
It turns out that while I was executing those seemingly harmless commands, the server was under acceptance test. You see, we were
just one week away from going live and the final touches were everything that was required. So the users in the brewing company started
testing if everything they needed was working like in the old servers. And suddenly, the users noticed that their system was malfunctioning
and started making furious phone calls to my boss and then my boss started to call me.
And then I realized I had thrashed the server. Completely. My console was still open and I could see that the processes
started failing, one by one, reporting very strange messages to the console, that didn't look any good. I started to panic. My workmate
Ayelen and I (who just copied my script and executed it in the mirror server) realized only too late that the home directory of the
root user was / -the root filesystem- so we changed the owner of every single file in the filesystem to root!!! That's what I love
about Unix: when it screws up, it does so very quickly, and thoroughly.
There must be a way to fix this , I thought. HP-UX has a package installer like any modern Linux/Unix distribution, that is
swinstall . That utility has a repair command, swrepair . So the following command put the system
files back in order, needing a few permission changes on the application directories that weren't installed with the package manager:
swrepair -F
But the story doesn't end here. The next week, we were going live, and I knew that the migration of the users would be for real
this time, not just a test. My boss and I were going to the brewing company, and he receives a phone call. Then he turns to me and
asks me, "What was the command that you used last week?". I told him and I noticed that he was dictating it very carefully. When
we arrived, we saw why: before the final deployment, a Unix administrator from the company did the same mistake I did, but this time,
people from the whole country were connecting to the system, and he received phone calls from a lot of angry users. Luckily, the
mistake could be fixed, and we all, young and old, went back to reading the HP-UX manual. Those things can come handy sometimes!
Morale of this story: before doing something on the users directories, take the time to see which is the User ID of actual users
- which start usually in 500 but it's configuration-dependent - because system users's IDs are lower than that.
Send in your Unix horror story, and it will be featured here in the blog!
Necessity is frequently the mother of invention. I knew very little about BASH scripting but
that was about to change rapidly. Working with the existing script and using online help
forums, search engines, and some printed documentation, I setup Linux network attached storage
computer running on Fedora Core. I learned how to create an SSH keypair and
configure that along with rsync to move the backup file from the email server
to the storage server. That worked well for a few days until I noticed that the storage servers
disk space was rapidly disappearing. What was I going to do?
That's when I learned more about Bash scripting. I modified my rsync command to delete
backed up files older than ten days. In both cases I learned that a little knowledge can be a
dangerous thing but in each case my experience and confidence as Linux user and system
administrator grew and due to that I functioned as a resource for other. On the plus side, we
soon realized that the disk to disk backup system was superior to tape when it came to
restoring email files. In the long run it was a win but there was a lot of uncertainty and
anxiety along the way.
This text and script is borrowed from the "Unix Horror Stories" document.
It states as follows
"""""Management told us to email a security notice to every user on the our system (at that time, around 3000 users). A certain
novice administrator on our system wanted to do it, so I instructed them to extract a list of users from /etc/passwd, write a
simple shell loop to do the job, and throw it in the background.
Here's what they wrote (bourne shell)...
for USER in `cat user.list`; do mail $USER <message.text & done
Have you ever seen a load average of over 300 ??? """" END
My question is this- What is wrong with the script above? Why did it find a place in the Horror stories? It worked well when
I tried it.
Maybe he intended to throw the whole script in the background and not just the Mail part. But even so it works just as well...
So?
RE:Unix Horror story script question
I think, it does well deserve to be placed Horror stories.
Consider the given server for with or without SMTP service
role, this script tries to process 3000 mail commands in parallel to send the text to it's 3000 repective receipents.
Have you ever tried with valid 3000 e-mail IDs, you can feel the heat of CPU (sar 1 100)
P.S.: I did not tested it but theoretically affirmed.
Best Regards.
Thunderbolt,View Public
Profile3 11-24-2008 - Original Discussion by scottsiddharth
Quote:
Originally Posted by scottsiddharth
Thank you for the reply. But isn't that exactly what the real admin asked the novice admin to do.
Is there a better script or solution ?
Well, Let me try to make it sequential to reduce the CPU load, but it will take no. of users*SLP_INT(default=1) seconds to execute....
#Interval between concurrent mail commands excution in seconds, minimum 1 second.
SLP_INT=1
for USER in `cat user.list`;
do;
mail $USER <message.text; [ -z "${SLP_INT}" ] && sleep 1 || sleep ${SLP_INT}" ;
done
Looks like not much changed since 1986. I amazed how little changed with Unix over the years. RM remains a danger although zsh
and -I option on gnu rm are improvement. . I think every sysadmin wiped out important data with rm at least once in his
career. So more work on this problem is needed.
Notable quotes:
"... Because we are creatures of habit. If you ALWAYS have to type 'yes' for every single deletion, it will become habitual, and you will start doing it without conscious thought. ..."
"... Amazing what kind of damage you can recover from given enough motivation. ..."
I keep an daily clone of my laptop and I usually do some backups in the middle of the day, so
if I lose a disk it isn't a big deal other than the time wasted copying files.
Because we are creatures of habit. If you ALWAYS have to type 'yes' for every single
deletion, it will become habitual, and you will start doing it without conscious
thought.
Warnings must only pop up when there is actual danger, or you will become acclimated to,
and cease to see, the warning.
This is exactly the problem with Windows Vista, and why so many people harbor such
ill-will towards its 'security' system.
Whenever I use rm -rf, I always make sure to type the full path name in (never just use *)
and put the -rf at the end, not after the rm. This means you don't have to worry about
hitting "enter" in the middle of typing the path name (it won't delete the directory because
the -rf is at the end) and you don't have to worry as much about data deletion from
accidentally copy/pasting the command somewhere with middle click or if you redo the command
while looking in your bash history.
Hmm, couldn't you alias "rm -rf" to mv the directory/files to a temp directory to be on
the safe side?
One could write a daemon that lets the oldest files in that directory be "garbage collected"
when those conditions are approaching. I think this is, in a roundabout way, how Windows'
shadow copy works.
Could do. Think we might be walking into the over-complexity trap however. The only time I've
ever had an rm related disaster was when accidentally repeating an rm that was already in my
command buffer. I looked at trying to exclude patterns from the command history but csh
doesn't seem to support doing that so I gave up.
A decent solution just occurred to me when the underlying file system supports snapshots
(UFS2 for example). Just snap the fs on which the to-be-deleted items are on prior to the
delete. That needs barely any IO to do and you can set the snapshots to expire after 10
minutes.
Most of the original UNIX tools took the arguments in strict order, requiring that the
options came first; you can even see this on some modern *BSD systems.
I just always format the command with ls first just to make sure everything is in working
order. Then my neurosis kicks in and I do it again... and a couple more times just to make
sure nothing bad happens.
Ever since I got burned by letting my pinky slip on the enter key years ago, I've been typing
echo path first, then going back and adding the rm after the fact.
Great story. Halfway through reading, I had a major wtf moment. I wasn't surprised by the use
of a VAX, as my old department just retired their last VAX a year ago. The whole time, I'm
thinking, "hello..mount the tape hardware on another system and, worst case scenario, boot
from a live cd!"
Then I got to, "The next idea was to write a program to make a device descriptor for the
tape deck" and looked back at the title and realized that it was from 1986 and realized,
"oh..oh yeah...that's pretty fucked."
Yeah, but really, he had way too much of a working system to qualify for true geek
godhood. That title belongs to Al
Viro . Even though I've read it several times, I'm still in awe every time I see that
story...
This really is a situation where GUIs are better than CLIs. There's nothing like the visual
confirmation of seeing what you're obliterating to set your heart into the pit of your
stomach.
If you're using a GUI, you probably already have that. If you're using a command line, use mv
instead of rm.
In general, if you want the computer to do something, tell it what you want it to do,
rather than telling it to do something you don't want and then complaining when it does what
you say.
Yes, but trash cans aren't manly enough for vi and emacs users to take seriously. If it made
sense and kept you from shooting yourself in the foot, it wouldn't be in the Unix tradition.
Are you so low on disk space that it's important for your trash can to be empty at all
times?
Why should we humans have to adapt our directory names to route around the
busted-ass-ness of our tools? The tools should be made to work with capital letters and
spaces. Or better, use a GUI for deleting so that you don't have to worry about OMG, I
forgot to put a slash in front of my space!
Seriously, I use the command line multiple times every day, but there are some tasks for
which it is just not well suited compared to a GUI, and (bizarrely considering it's one thing
the CLI is most used for) one of them is moving around and deleting files.
That's why I always keep stringent file permissions and never act as the root user.
I'd have to try to rm -rf, get a permission denied error, then retype sudo rm -rf and then
type in my password to ever have a mistake like that happen.
But I'm not a systems administrator, so maybe it's not the same thing.
I aliased "rm -rf" to "omnomnom" and got myself into the habit of using that. I can barely
type "omnomnom" when I really want to, let alone when I'm not really paying attention. It's
saved one of my projects once already.
before I ever do something like that I make sure I don't have permissions so I get an error,
then I press up, home, and type sudo <space> <enter> and it works as expected :)
And I was pleased the other day how easy it was to fix the system after I accidentally
removed kdm, konqueror and kdesktop... but these guys are hardcore.
Task number 1 with a UNIX system. Alias rm to rm -i. Call the explicit path when you want to
avoid the -i (ie: /bin/rm -f). Nobody is too cool to skip this basic protection.
Is the home directory for root / for some unix systems? i thought 'cd' then 'rm -rf *' would
have deleted whatever's in his home directory (or whatever $HOME points to)
I had a customer do this, he killed it about the same time. I told him he was screwed and I'd
charge him a bunch of money to take down his server, rebuild it from a working one and put it
back up. But the customer happened to have a root ftp session up, and was able to upload what
he needed to bring the system back. by the time he was done I rebooted it to make sure it was
cool and it booted all the way back up.
Of course I've also had a lot of customer that have done it, and they where screwed, and I
got to charge them a bunch of money.
i had the same thing happened to me once.. my c:\ drive was running ntfs and i accidently
deleted the "ntldr" system file in the c:\ root (because the name didn't figure much).. then
later, i couldn't even boot in the safe mode! and my bootable disk didn't recognize the c:\
drive because it was ntfs!! so sadly, i had to reinstall everything :( wasted a whole day
over it..
Neither one is the original source. The original source is Usenet, and I can't find it with
Google Groups. So either of these webpages is as good as the other.
...it's amazing how much of the system you can delete without it falling apart
completely. Apart from the fact that nobody could login (/bin/login?), and most of the
useful commands had gone, everything else seemed normal.
Yeah. So apart from the fact that no one could get any work done or really do anything,
things were working great!
I think a more rational reaction would be "Why on Earth is this big, important system on
which many people rely designed in such a way that a simple easy-to-make human error can
screw it up so comprehensively?" or perhaps "Why on Earth don't we have a proper backup
system?"
The problem wasn't the backup system, it was the restore system, which relied on the
machine having a "copy" command. Perfectly reasonable assumption that happened not to be
true.
Neither backup nor restoration serves any purpose in isolation. Most people would group those
operations together under the heading "backup;" certainly you win only a semantic victory by
doing otherwise. Their fail-safe data-protection system, call it what you will, turned out
not to work, and had to be re-engineered on-the-fly.
I generally figure that the assumptions I make that turn out to be entirely wrong were not
"perfectly reasonable" assumptions in the first place. Call me a traditionalist.
Well, why can't you get the file back from the free list? After all, there are DOS utilities that can reclaim deleted files by
doing something similar. Remember, though, Unix is a multitasking operating system. Even if you think your system is a single-user
system, there are a lot of things going on "behind your back": daemons are writing to log files, handling network connections, processing
electronic mail, and so on. You could theoretically reclaim a file if you could "freeze" the filesystem the instant your file was
deleted -- but that's not possible. With Unix, everything is always active. By the time you realize you made a mistake, your file's
data blocks may well have been reused for something else.
This command took a long time to execute. When about two-thirds of the directory was gone, I realized (with horror) what
was happening: I was deleting all files with four or more characters in the filename.
The story got worse. They hadn't made a backup in about five months. (By the way, this article should give you plenty of reasons
for making regular backups (
Section 38.3 ).) By the time
I had restored the files I had deleted (a several-hour process in itself; this was on an ancient version of Unix with a horrible
backup utility) and checked (by hand) all the files against our printed copy of the business plan, I had resolved to be
very careful with my rm commands.
[Some shells have safeguards that work against Mike's first disastrous example -- but not the second one. Automatic safeguards
like these can become a crutch, though . . . when you use another shell temporarily and don't have them, or when you type an expression
like Mike's very destructive second example. I agree with his simple advice: check your rm commands carefully! -- JP
]
"... There's nothing more on a traditional Linux, but you can set Apparmor/SELinux/ rules that prevent rm from accessing certain directories. ..."
"... Probably your best bet with it would be to alias rm -ri into something memorable like kill_it_with_fire . This way whenever you feel like removing something, go ahead and kill it with fire. ..."
I think pretty much people here mistakenly 'rm -rf'ed the wrong directory, and hopefully it did not cause a huge
damage.. Is there any way to prevent users from doing a similar unix horror
story?? Someone mentioned (in the comments section of the previous link)
that
... I am pretty sure now every unix course or company using unix sets rm -fr to disable accounts of people trying to run it
or stop them from running it ...
Is there any implementation of that in any current Unix or Linux distro? And what is the common practice to prevent that error
even from a sysadmin (with root access)?
It seems that there was some
protection for the root directory (/) in Solaris (since 2005) and GNU (since 2006). Is there anyway to implement
the same protection way to some other folders as well??
To give it more clarity, I was not asking about general advice about rm usage (and I've updated the title to indicate
that more), I want something more like the root folder protection: in order to rm -rf / you have to pass a specific
parameter: rm -rf --no-preserve-root /.. Is there similar implementations for customized set of directories? Or can
I specify files in addition to / to be protected by the preserve-root option?
I think pretty much people here mistakenly ' rm -rf 'ed the wrong directory, and hopefully it did not cause a huge
damage.. Is there any way to prevent users from doing a similar unix horror
story ?? Someone mentioned (in the comments section of the previous
link ) that
... I am pretty sure now every unix course or company using unix sets rm -fr to disable accounts of people trying to run
it or stop them from running it ...
Is there any implementation of that in any current Unix or Linux distro? And what is the common practice to prevent that error
even from a sysadmin (with root access)?
It seems that there was some
protection for the root directory
( / ) in Solaris (since 2005) and GNU (since 2006). Is there anyway to implement the same protection way to some
other folders as well??
To give it more clarity, I was not asking about general advice about rm usage (and I've updated the title to indicate
that more), I want something more like the root folder protection: in order to rm -rf / you have to pass a specific
parameter: rm -rf --no-preserve-root / .. Is there similar implementations for customized set of directories? Or
can I specify files in addition to / to be protected by the preserve-root option?
most distros do `alias rm='rm -i' which makes rm ask you if you are sure.
Besides that: know what you are doing. only become root
if necessary. for any user with root privileges security of any kind must be implemented in and by the user. hire somebody if
you can't do it yourself.over time any countermeasure becomes equivalaent to the alias line above if you cant wrap your own head
around the problem. – Bananguin
Jan 20 '13 at 21:07
If you need to delete a directory tree, I recommend the following workflow:
If necessary, change to the parent of the directory you want to delete.
mv directory-to-delete DELETE
Explore DELETE and check that it is indeed what you wanted to delete
rm -rf DELETE
Never call rm -rf with an argument other than DELETE . Doing the deletion in several stages gives
you an opportunity to verify that you aren't deleting the wrong thing, either because of a typo (as in rm -rf /foo /bar
instead of rm -rf /foo/bar ) or because of a braino (oops, no, I meant to delete foo.old and keep
foo.new ).
If your problem is that you can't trust others not to type rm -rf, consider removing their admin privileges.
There's a lot more that can go wrong than rm .
Always make backups .
Periodically verify that your backups are working and up-to-date.
Keep everything that can't be easily downloaded from somewhere under version control.
With a basic unix system, if you really want to make some directories undeletable by rm, replace (or better shadow)
rm by a custom script that rejects certain arguments. Or by hg rm .
Some unix variants offer more possibilities.
On OSX, you can set an access control list on a directory
preventing deletion of the files and subdirectories inside it, without preventing the creation of new entries or modification
of existing entries: chmod +a 'group:everyone deny delete_child' somedir (this doesn't prevent the deletion of
files in subdirectories: if you want that, set the ACL on the subdirectory as well).
On Linux, you can set rules in SELinux, AppArmor or other security frameworks that forbid rm to modify certain
directories.
Yeah backing up is the most amazing solution, but I was thinking of something like the --no-preserve-root option,
for other important folder.. And that apparently does not exist even as a practice... –
amyassin
Jan 22 '13 at 9:41
@amyassin I'm afraid there's nothing more (at least not on Linux). rm -rf already means "delete this, yes I'm sure
I know what I'm doing". If you want more, replace rm by a script that refuses to delete certain directories. –
Gilles
Jan 22 '13 at 20:32
@amyassin Actually, I take this back. There's nothing more on a traditional Linux, but you can set Apparmor/SELinux/ rules
that prevent rm from accessing certain directories. Also, since your question isn't only about Linux, I should
have mentioned OSX, which has something a bit like what you want. –
Gilles
Jan 22 '13 at 22:17
You can change the attribute of to immutable the file or directory and then it cannot be deleted even by root until
the attribute is removed.
chattr +i /some/important/file
This also means that the file cannot be written to or changed in anyway, even by root . Another attribute apparently
available that I haven't used myself is the append attribute ( chattr +a /some/important/file . Then the file can
only be opened in append mode, meaning no deletion as well, but you can add to it (say a log file). This means you won't be able
to edit it in vim for example, but you can do echo 'this adds a line' >> /some/important/file . Using
> instead of >> will fail.
These attributes can be unset using a minus sign, i.e. chattr -i file
Otherwise, if this is not suitable, one thing I practice is to always ls /some/dir first, and then instead of
retyping the command, press up arrow CTL-A, then delete the ls and type in my rm -rf if I need it. Not
perfect, but by looking at the results of ls, you know before hand if it is what you wanted.
One possible choice is to stop using rm -rf and start using rm -ri . The extra i parameter
there is to make sure that it asks if you are sure you want to delete the file.
Probably your best bet with it would be to alias rm -ri into something memorable like kill_it_with_fire
. This way whenever you feel like removing something, go ahead and kill it with fire.
To protect against an accidental rm -rf * in a directory, create a file called "-i" (you can do this with emacs or
some other program) in that directory. The shell will try to interpret -i and will cause it to go into interactive mode.
For example: You have a directory called rmtest with the file named -i inside. If you try to
rm everything inside the directory, rm will first get -i passed to it and will go into
interactive mode. If you put such a file inside the directories you would like to have some protection on, it might help.
Note that this is ineffective against rm -rf rmtest .
If you understand C programming language, I think it is possible to rewrite the rm source code and make a little patch for kernel.
I saw this on one server and it was impossible to delete some important directories and when you type 'rm -rf /direcotyr' it send
email to sysadmin.
Option -I is more modern and more useful then old option -i. It is highly recommended. And it make sense to to use alias with it
contrary to what this author states (he probably does not understand that aliases do not wok for non-interactive sessions.).
The point the author make is that when you automatically expect rm to be aisles to rm -i you get into trouble on machines
where this is not the case. And that's completely true.
But it does not solve the problem as respondents soon became automatic. stated. Writing your own wrapper is a better
deal. One such wrapper -- safe-rm already
exists and while not perfect is useful
Notable quotes:
"... A co-worker had such an alias. Imagine the disaster when, visiting a customer site, he did "rm *" in the customer's work directory and all he got was the prompt for the next command after rm had done what it was told to do. ..."
"... It you want a safety net, do "alias del='rm -I –preserve_root'", ..."
Any alias of rm is a very stupid idea (except maybe alias rm=echo fool).
A co-worker had such an alias. Imagine the disaster when, visiting a customer site, he did "rm *" in the customer's work
directory and all he got was the prompt for the next command after rm had done what it was told to do.
It you want a safety net, do "alias del='rm -I –preserve_root'",
Drew Hammond March 26, 2014, 7:41 pm
^ This x10000.
I've made the same mistake before and its horrible.
Timeshift for Linux is an application that provides functionality similar to the System
Restore feature in Windows and the Time Machine tool in Mac OS. Timeshift
protects your system by taking incremental snapshots of the file system at regular intervals.
These snapshots can be restored at a later date to undo all changes to the system.
In RSYNC mode, snapshots are taken using rsync and hard-links . Common files are shared between
snapshots which saves disk space. Each snapshot is a full system backup that can be browsed
with a file manager.
In BTRFS mode, snapshots are taken using the in-built features of the BTRFS filesystem.
BTRFS snapshots are supported only on BTRFS systems having an Ubuntu-type subvolume layout
(with @ and @home subvolumes).
Timeshift is similar to applications like rsnapshot , BackInTime and TimeVault but with different goals. It is designed to
protect only system files and settings. User files such as documents, pictures and music are
excluded. This ensures that your files remains unchanged when you restore your system to an
earlier date. If you need a tool to backup your documents and files please take a look at the
excellent BackInTime
application which is more configurable and provides options for saving user files.
So you thought you had your files backed up - until it came time to restore. Then you found out that you had bad sectors and you've
lost almost everything because gzip craps out 10% of the way through your archive. The gzip Recovery Toolkit has a program - gzrecover
- that attempts to skip over bad data in a gzip archive. This saved me from exactly the above situation. Hopefully it will help you
as well.
I'm very eager for feedback on this program . If you download and try it, I'd appreciate and email letting me know what
your results were. My email is [email protected]. Thanks.
ATTENTION
99% of "corrupted" gzip archives are caused by transferring the file via FTP in ASCII mode instead of binary mode. Please re-transfer
the file in the correct mode first before attempting to recover from a file you believe is corrupted.
Disclaimer and Warning
This program is provided AS IS with absolutely NO WARRANTY. It is not guaranteed to recover anything from your file, nor is what
it does recover guaranteed to be good data. The bigger your file, the more likely that something will be extracted from it. Also
keep in mind that this program gets faked out and is likely to "recover" some bad data. Everything should be manually verified.
Downloading and Installing
Note that version 0.8 contains major bug fixes and improvements. See the
ChangeLog for details. Upgrading is recommended.
The old version is provided in the event you run into troubles with the new release.
GNU cpio (version 2.6 or higher) - Only if your archive is a
compressed tar file and you don't already have this (try "cpio --version" to find out)
First, build and install zlib if necessary. Next, unpack the gzrt sources. Then cd to the gzrt directory and build the gzrecover
program by typing make . Install manually by copying to the directory of your choice.
Usage
Run gzrecover on a corrupted .gz file. If you leave the filename blank, gzrecover will read from the standard input. Anything
that can be read from the file will be written to a file with the same name, but with a .recovered appended (any .gz is stripped).
You can override this with the -o
To get a verbose readout of exactly where gzrecover is finding bad bytes, use the -v option to enable verbose mode. This will
probably overflow your screen with text so best to redirect the stderr stream to a file. Once gzrecover has finished, you will need
to manually verify any data recovered as it is quite likely that our output file is corrupt and has some garbage data in it. Note
that gzrecover will take longer than regular gunzip. The more corrupt your data the longer it takes. If your archive is a tarball,
read on.
For tarballs, the tar program will choke because GNU tar cannot handle errors in the file format. Fortunately, GNU cpio (tested
at version 2.6 or higher) handles corrupted files out of the box.
Here's an example:
$ ls *.gz
my-corrupted-backup.tar.gz
$ gzrecover my-corrupted-backup.tar.gz
$ ls *.recovered
my-corrupted-backup.tar.recovered
$ cpio -F my-corrupted-backup.tar.recovered -i -v
Note that newer versions of cpio can spew voluminous error messages to your terminal. You may want to redirect the stderr stream
to /dev/null. Also, cpio might take quite a long while to run.
Copyright
The gzip Recovery Toolkit v0.8
Copyright (c) 2002-2013 Aaron M. Renn ( [email protected])
It takes a lot of courage for an addict to recover and stay clean. And it is sadly not news that drug addiction and high levels
of prescription drug use are signs that something is deeply broken in our society. There are always some people afflicted with deep
personal pain but our system is doing a very good job of generating unnecessary pain and desperation.
Mady Ohlman was 22 on the evening some years ago when she stood in a friend's bathroom looking down at the sink.
"I had set up a bunch of needles filled with heroin because I wanted to just do them back-to-back-to-back," Ohlman recalled. She
doesn't remember how many she injected before collapsing, or how long she lay drugged-out on the floor.
"But I remember being pissed because I could still get up, you know?"
She wanted to be dead, she said, glancing down, a wisp of straight brown hair slipping from behind an ear across her thin face.
At that point, said Ohlman, she'd been addicted to opioids -- controlled by the drugs -- for more than three years.
"And doing all these things you don't want to do that are horrible -- you know, selling my body, stealing from my mom, sleeping
in my car," Ohlman said. "How could I not be suicidal?"
For this young woman, whose weight had dropped to about 90 pounds, who was shooting heroin just to avoid feeling violently ill,
suicide seemed a painless way out.
"You realize getting clean would be a lot of work," Ohlman said, her voice rising. "And you realize dying would be a lot less
painful. You also feel like you'll be doing everyone else a favor if you die."
Ohlman, who has now been sober for more than four years, said many drug users hit the same point, when the disease and the pursuit
of illegal drugs crushes their will to live. Ohlman is among at least
40 percent of active
drug users who wrestle with depression, anxiety or another mental health issue that increases the risk of suicide.
Measuring Suicide Among Patients Addicted To Opioids
Massachusetts, where Ohlman lives, began formally
recognizing
in May 2017 that some opioid overdose deaths are suicides. The state confirmed only about 2 percent of all overdose deaths as suicides,
but Dr. Monica Bhare l, head of the
Massachusetts Department of Public Health, said it's difficult to determine a person's true intent.
"For one thing, medical examiners use different criteria for whether suicide was involved or not," Bharel said, and the "tremendous
amount of stigma surrounding both overdose deaths and suicide sometimes makes it extremely challenging to piece everything together
and figure out unintentional and intentional."
Research on drug addiction and suicide suggests much higher numbers.
"[Based on the literature that's available], it looks like it's anywhere between 25 and 45 percent of deaths by overdose that
may be actual suicides," said
Dr. Maria Oquendo
, immediate past president of the American Psychiatric Association.
Oquendo pointed to one study of overdoses
from prescription opioids that found nearly 54 percent were unintentional. The rest were either suicide attempts or undetermined.
Several large studies show an increased risk of suicide among drug users addicted to opioids, especially women. In
a study of about 5 million veterans, women were eight
times as likely as others to be at risk for suicide, while men faced a twofold risk.
The opioid epidemic is occurring at the same time suicides have
hit a 30-year high , but Oquendo said few doctors
look for a connection.
"They are not monitoring it," said Oquendo, who chairs the department of psychiatry at the University of Pennsylvania. "They are
probably not assessing it in the kinds of depths they would need to prevent some of the deaths."
That's starting to change. A few hospitals in Boston, for example, aim to ask every patient admitted about substance use, as well
as about whether they've considered hurting themselves.
"No one has answered the chicken and egg [problem]," said
Dr. Kiame Mahaniah , a family physician who runs the
Lynn Community Health Center in Lynn, Mass. Is it that patients "have mental health issues that lead to addiction, or did a life
of addiction then trigger mental health problems?"
With so little data to go on, "it's so important to provide treatment that covers all those bases," Mahaniah said.
'Deaths Of Despair'
When doctors do look deeper into the reasons patients addicted to opioids become suicidal, some economists predict they'll find
deep reservoirs of depression and pain.
In a seminal paper published in 2015, Princeton economists
Angus Deaton and
Anne Case tracked falling marriage rates,
the loss of stable middle-class jobs and rising rates of self-reported pain. The authors say opioid overdoses, suicides and diseases
related to alcoholism are all often "deaths of despair."
"We think of opioids as something that's thrown petrol on the flames and made things infinitely worse," Deaton said, "but the
underlying deep malaise would be there even without the opioids."
Many economists agree on remedies for that deep malaise. Harvard economics professor
David Cutle r said solutions include a good education, a steady
job that pays a decent wage, secure housing, food and health care.
"And also thinking about a sense of purpose in life," Cutler said. "That is, even if one is doing well financially, is there a
sense that one is contributing in a meaningful way?"
Tackling Despair In The Addiction Community
"I know firsthand the sense of hopelessness that people can feel in the throes of addiction," said
Michael Botticelli , executive director of the Grayken Center
for Addiction at Boston Medical Center; he is in recovery for an addiction to alcohol.
Botticelli said recovery programs must help patients come out of isolation and create or recreate bonds with family and friends.
"The vast majority of people I know who are in recovery often talk about this profound sense of re-establishing -- and sometimes
establishing for the first time -- a connection to a much larger community," Botticelli said.
Ohlman said she isn't sure why her attempted suicide, with multiple injections of heroin, didn't work.
"I just got really lucky," Ohlman said. "I don't know how."
A big part of her recovery strategy involves building a supportive community, she said.
"Meetings; 12-step; sponsorship and networking; being involved with people doing what I'm doing," said Ohlman, ticking through
a list of her priorities.
There's a fatal overdose at least once a week within her Cape Cod community, she said. Some are accidental, others not. Ohlman
said she's convinced that telling her story, of losing and then finding hope, will help bring those numbers down.
"This
revolutionary product allowed you to basically 'mirror' two file servers," Graham told The
Register . "It was clever stuff back then with a high speed 100mb FDDI link doing the
mirroring and the 10Mb LAN doing business as usual."
Graham was called upon to install said software at a British insurance company, which
involved a 300km trip on Britain's famously brilliant motorways with a pair of servers in the
back of a company car.
Maybe that drive was why Graham made a mistake after the first part of the job: getting the
servers set up and talking.
"Sadly the software didn't make identifying the location of each disk easy," Graham told us.
"And – ummm - I mirrored it the wrong way."
"The net result was two empty but beautifully-mirrored servers."
Oops.
Graham tried to find someone to blame, but as he was the only one on the job that wouldn't
work.
His next instinct was to run, but as the site had a stack of Quarter Inch Cartridge backup
tapes, he quickly learned that "incremental back-ups are the work of the devil."
For example, if you have a directory ~/Documents/Phone-Backup/Linux-Docs/Ubuntu/ , using
gogo , you can create an alias (a shortcut name), for instance Ubuntu to access it
without typing the whole path anymore. No matter your current working directory, you can move
into ~/cd Documents/Phone-Backup/Linux-Docs/Ubuntu/ by simply using the alias
Ubuntu .
In addition, it also allows you to create aliases for connecting directly into directories
on remote Linux servers.
How to Install Gogo in Linux Systems
To install Gogo , first clone the gogo repository from Github and then copy the
gogo.py to any directory in your PATH environmental variable (if you already have
the ~/bin/ directory, you can place it here, otherwise create it).
$ git clone https://github.com/mgoral/gogo.git
$ cd gogo/
$ mkdir -p ~/bin #run this if you do not have ~/bin directory
$ cp gogo.py ~/bin/
... ... ...
To start using gogo , you need to logout and login back to use it. Gogo
stores its configuration in ~/.config/gogo/gogo.conf file (which should be auto
created if it doesn't exist) and has the following syntax.
# Comments are lines that start from '#' character.
default = ~/something
alias = /desired/path
alias2 = /desired/path with space
alias3 = "/this/also/works"
zażółć = "unicode/is/also/supported/zażółć gęślą jaźń"
If you run gogo run without any arguments, it will go to the directory specified in default;
this alias is always available, even if it's not in the configuration file, and points to $HOME
directory.
Painless relocation of Linux binaries–and all of their dependencies–without
containers.
The Problem Being Solved
If you simply copy an executable file from one system to another, then you're very likely
going to run into problems. Most binaries available on Linux are dynamically linked and depend
on a number of external library files. You'll get an error like this when running a relocated
binary when it has a missing dependency.
aria2c: error while loading shared libraries: libgnutls.so.30: cannot open shared object file: No such file or directory
You can try to install these libraries manually, or to relocate them and set
LD_LIBRARY_PATH to wherever you put them, but it turns out that the locations of
the ld-linux linker and the
glibc libraries are hardcoded.
Things can very quickly turn into a mess of relocation errors,
aria2c: relocation error: /lib/libpthread.so.0: symbol __getrlimit, version
GLIBC_PRIVATE not defined in file libc.so.6 with link time reference
segmentation faults,
Segmentation fault (core dumped)
or, if you're really unlucky, this very confusing symptom of a missing linker.
$ ./aria2c
bash: ./aria2c: No such file or directory
$ ls -lha ./aria2c
-rwxr-xr-x 1 sangaline sangaline 2.8M Jan 30 21:18 ./aria2c
Exodus works around these issues by compiling a small statically linked launcher binary that
invokes the relocated linker directly with any hardcoded RPATH library paths
overridden. The relocated binary will run with the exact same linker and libraries that it ran
with on its origin machine.
It might have happened to you at one point or another that you deleted a file
or an image by mistake & than regretted it immediately. So can we restore such a deleted
file/image on Linux machine. In this tutorial, we are going to discuss just that i.e. how to
restore a deleted file on Linux machine.
To restore a deleted file on Linux machine, we will be using an application called
'Foremost' . Foremost is a Linux based program data for recovering deleted files. The program
uses a configuration file to specify headers and footers to search for. Intended to be run on
disk images, foremost can search through most any kind of data without worrying about the
format.
Note:- We can only restore deleted files in Linux as long as those sectors have not been
overwritten on the hard disk.
We will now discuss how to recover the data with foremost. Let's start tutorial by
installation of Foremost on CentOS & Ubuntu systems.
With Ubuntu, the foremost package is available with default repository. To install foremost
on Ubuntu, run the following command from terminal,
$ sudo apt-get install foremost
Restore deleted files in Linux
For this scenario, we have kept an image named 'dan.jpg ' on our system. We will now delete
it from the system with the following command,
$ sudo rm –rf dan.jpg
Now we will use the foremost utility to restore the image, run the following command to
restore the file,
$ foremost –t jpeg –I /dev/sda1
Here, with option 't' , we have defined the type of file that needs to be restored,
-I , tells the foremost to look for the file in partition ' /dev/sda1' . We can check the
partition with 'mount' command.
Upon successful execution of the command, the file will be restored in current folder. We
can also add option to restore the file in a particular folder with option 'o'
Note:- The restored file will not have the same file name of the original file as the
filename is not stored with file itself. So file name will be different but the data should all
be there.
With this we now end our tutorial on how to restore deleted files in Linux machine using
Foremost. Please feel free to send in any questions or suggestion using the comment box
below.
Red Hat recommends a swap size of 20% of RAM for modern systems (i.e. 4GB or higher RAM).
Notable quotes:
"... So many people (including this article) are misinformed about the Linux swap algorithm. It doesn't just check if your RAM reaches a certain usage point. It's incredibly complicated. Linux will swap even if you are using only 20-50% of your RAM. Inactive processes are often swapped and swapping inactive processes makes more room for buffer and cache. Even if you have 16GB of RAM, having a swap partition can be beneficial ..."
How much should be the swap size? Should the swap be double of the RAM size or should it be half of the RAM size?
Do I need swap at all if my system has got several GBs of RAM? Perhaps these are the most common asked questions about choosing swap size while installing Linux. It's nothing new. There has always been a lot of confusion around swap size.
For a long time, the recommended swap size was double of the RAM size but that golden rule is not applicable to
modern computers anymore. We have systems with RAM sizes up to 128 GB, many old computers don't even have this much
of hard disk.
... ... ...
Swap acts as a breather to your system when the RAM is exhausted. What happens here is that when the RAM is
exhausted, your Linux system uses part of the hard disk memory and allocates it to the running application.
That sounds cool. This means if you allocate like 50GB of swap size, your system can run hundreds or perhaps
thousands of applications at the same time? WRONG!
You see, the speed matters here. RAM access data in the order of nanoseconds. An SSD access data in microseconds
while as a normal hard disk accesses the data in milliseconds. This means that RAM is 1000 times faster than SSD and
100,000 times faster than the usual HDD.
If an application relies too much on the swap, its performance will degrade as it cannot access the data at the
same speed as it would have in RAM. So instead of taking 1 second for a task, it may take several minutes to complete
the same task. It will leave the application almost useless. This is known as
thrashing
in computing terms.
In other words, a little swap is helpful. A lot of it will be of no good use.
Why is swap needed?
There are several reasons why you would need swap.
If your system has RAM less than 1 GB, you must use swap as most applications would exhaust the RAM soon.
If your system uses resource heavy applications like video editors, it would be a good idea to use some swap
space as your RAM may be exhausted here.
If you use hibernation, then you must add swap because the content of the RAM will be written to the swap
partition. This also means that the swap size should be at least the size of RAM.
Avoid strange events like a program going nuts and eating RAM.
... ... ...
Can you use Linux without swap?
Yes, you can, especially if your system has plenty of RAM. But as explained in the previous section, a little bit
of swap is always advisable.
How much should be the swap size?
... ... ...
If you go by
Red Hat's suggestion
, they recommend a swap size of 20% of RAM for modern systems (i.e. 4GB or higher RAM).
Size of RAM + 2 GB if RAM size is more than 2 GB i.e. 5GB of swap for 3GB of RAM
Ubuntu has an entirely different perspective on the swap size as it takes hibernation into consideration. If you
need hibernation, a swap of the size of RAM becomes necessary for Ubuntu.
Otherwise, it recommends:
If RAM is less than 1 GB, swap size should be at least the size of RAM and at most double the size of RAM
If RAM is more than 1 GB, swap size should be at least equal to the square root of the RAM size and at most
double the size of RAM
If hibernation is used, swap size should be equal to size of RAM plus the square root of the RAM size
... ... ...
Jaden
So many people (including this article) are misinformed about the Linux swap algorithm. It doesn't just check if your RAM
reaches a certain usage point. It's incredibly complicated. Linux will swap even if you are using only 20-50% of your RAM.
Inactive processes are often swapped and swapping inactive processes makes more room for buffer and cache. Even if you have 16GB
of RAM, having a swap partition can be beneficial (especially if hibernating)
kaylee
I have 4 gigs of ram on old laptop running cinnamon going by this, it is set at 60 ( what does 60 mean, and would 10 be
better ) i do a little work with blender ( VSE and just starting to mess with 3d text ) should i change to 10
thanks
a. First check your current swappiness value. Type in the terminal (use copy/paste):
cat /proc/sys/vm/swappiness
Press Enter.
The result will probably be 60.
b. To change the swappiness into a more sensible setting, type in the terminal (use copy/paste to avoid typo's):
gksudo xed /etc/sysctl.conf
Press Enter.
Now a text file opens. Scroll to the bottom of that text file and add your swappiness parameter to override the default.
Copy/paste the following two green lines:
# Decrease swap usage to a more reasonable level
vm.swappiness=10
c. Save and close the text file. Then reboot your computer.
DannyB
I have 32 GB of memory. Since I use SSD and no actual hard drive, having Swap would add wear to my SSD. For more than two
years now I have used Linux Mint with NO SWAP.
Rationale: a small 2 GB of extra "cushion" doesn't really matter. If programs that misbehave use up 32 GB, then they'll use up
34 GB. If I had 32 GB of SWAP for a LOT of cushion, then a misbehaving program is likely to use it all up anyway.
In practice I have NEVER had a problem with 32 GB with no swap at all. At install time I made the decision to try this (which
has been great in hindsight) knowing that if I really did need swap later, I could always configure a swap FILE instead of a swap
PARTITION.
But I've never needed to and have never looked back at that decision to use no swap. I would recommend it.
Most of the time on newly created file systems of NFS filesystems we see error
like below :
1 2 3 4
root @ kerneltalks # touch file1 touch : cannot touch ' file1 ' : Read - only file
system
This is because file system is mounted as read only. In such scenario you have to mount it
in read-write mode. Before that we will see how to check if file system is mounted in read only
mode and then we will get to how to re mount it as a read write filesystem.
How to check if file system is read only
To confirm file system is mounted in read only mode use below command –
Grep your mount point in cat /proc/mounts and observer third column which shows
all options which are used in mounted file system. Here ro denotes file system is
mounted read-only.
You can also get these details using mount -v command
1 2 3 4
root @ kerneltalks # mount -v |grep datastore / dev / xvdf on / datastore type ext3 (
ro , relatime , seclabel , data = ordered )
In this output. file system options are listed in braces at last column.
Re-mount file system in read-write mode
To remount file system in read-write mode use below command –
1 2 3 4 5 6
root @ kerneltalks # mount -o remount,rw /datastore root @ kerneltalks # mount -v |grep
datastore / dev / xvdf on / datastore type ext3 ( rw , relatime , seclabel , data = ordered
)
Observe after re-mounting option ro changed to rw . Now, file
system is mounted as read write and now you can write files in it.
Note : It is recommended to fsck file system before re mounting it.
You can check file system by running fsck on its volume.
1 2 3 4 5 6 7 8 9 10
root @ kerneltalks # df -h /datastore Filesystem Size Used Avail Use % Mounted on / dev
/ xvda2 10G 881M 9.2G 9 % / root @ kerneltalks # fsck /dev/xvdf fsck from util - linux
2.23.2 e2fsck 1.42.9 ( 28 - Dec - 2013 ) / dev / xvdf : clean , 12 / 655360 files , 79696 /
2621440 blocks
Sometimes there are some corrections needs to be made on file system which needs reboot to
make sure there are no processes are accessing file system.
Snipe-IT is a free and open source IT assets management web application that can be used for
tracking licenses, accessories, consumables, and components. It is written in PHP language and
uses MySQL to store its data. In this tutorial, we will learn how to install Snipe-IT on Debian
9 server.
You can see that user has to type 'y' for each query. It's in situation like these where yes
can help. For the above scenario specifically, you can use yes in the following way:
yes | rm -ri test Q3. Is there any use of yes when it's used alone?
Yes, there's at-least one use: to tell how well a computer system handles high amount of
loads. Reason being, the tool utilizes 100% processor for systems that have a single processor.
In case you want to apply this test on a system with multiple processors, you need to run a yes
process for each processor.
To open multiple files, command would be same as is for a single file; we just add the file
name for second file as well.
$ vi file1 file2 file 3
Now to browse to next file, we can use
$ :n
or we can also use
$ :e filename
Run external commands inside the editor
We can run external Linux/Unix commands from inside the vi editor, i.e. without exiting the
editor. To issue a command from editor, go back to Command Mode if in Insert mode & we use
the BANG i.e. '!' followed by the command that needs to be used. Syntax for running a command
is,
$ :! command
An example for this would be
$ :! df -H
Searching for a pattern
To search for a word or pattern in the text file, we use following two commands in command
mode,
command '/' searches the pattern in forward direction
command '?' searched the pattern in backward direction
Both of these commands are used for same purpose, only difference being the direction they
search in. An example would be,
$ :/ search pattern (If at beginning of the file)
$ :/ search pattern (If at the end of the file)
Searching & replacing a
pattern
We might be required to search & replace a word or a pattern from our text files. So
rather than finding the occurrence of word from whole text file & replace it, we can issue
a command from the command mode to replace the word automatically. Syntax for using search
& replacement is,
$ :s/pattern_to_be_found/New_pattern/g
Suppose we want to find word "alpha" & replace it with word "beta", the command would
be
$ :s/alpha/beta/g
If we want to only replace the first occurrence of word "alpha", then the command would
be
$ :s/alpha/beta/
Using Set commands
We can also customize the behaviour, the and feel of the vi/vim editor by using the set
command. Here is a list of some options that can be use set command to modify the behaviour of
vi/vim editor,
$ :set ic ignores cases while searching
$ :set smartcase enforce case sensitive search
$ :set nu display line number at the begining of the line
$ :set hlsearch highlights the matching words
$ : set ro change the file type to read only
$ : set term prints the terminal type
$ : set ai sets auto-indent
$ :set noai unsets the auto-indent
Some other commands to modify vi editors are,
$ :colorscheme its used to change the color scheme for the editor. (for VIM editor only)
$ :syntax on will turn on the color syntax for .xml, .html files etc. (for VIM editor
only)
This complete our tutorial, do mention your queries/questions or suggestions in the comment
box below.
"... If you can, freeze changes in the weeks leading up to your vacation. Try to encourage other teams to push off any major changes until after you get back. ..."
"... Check for any systems about to hit a disk warning threshold and clear out space. ..."
"... Make sure all of your backup scripts are working and all of your backups are up to date. ..."
If you do need to take your computer, I highly recommend making a full backup before the
trip. Your computer is more likely to be lost, stolen or broken while traveling than when
sitting safely at the office, so I always take a backup of my work machine before a trip. Even
better than taking a backup, leave your expensive work computer behind and use a cheaper more
disposable machine for travel and just restore your important files and settings for work on it
before you leave and wipe it when you return. If you decide to go the disposable computer
route, I recommend working one or two full work days on this computer before the vacation to
make sure all of your files and settings are in place.
Documentation
Good documentation is the best way to reduce or eliminate how much you have to step in when
you aren't on call, whether you're on vacation or not. Everything from routine procedures to
emergency response should be documented and kept up to date. Honestly, this falls under
standard best practices as a sysadmin, so it's something you should have whether or not you are
about to go on vacation.
First, all routine procedures from how you deploy code and configuration changes, how you
manage tickets, how you perform security patches, how you add and remove users, and how the
overall environment is structured should be documented in a clear step-by-step way. If you
use automation tools for routine procedures, whether it's as simple as a few scripts or as
complex as full orchestration tools, you should make sure you document not only how to use
the automation tools, but also how to perform the same tasks manually should the automation
tools fail.
If you are on call, that means you have a monitoring system in place that scans your
infrastructure for problems and pages you when it finds any. Every single system check in
your monitoring tool should have a corresponding playbook that a sysadmin can follow to
troubleshoot and fix the problem. If your monitoring tool allows you to customize the alerts
it sends, create corresponding wiki entries for each alert name, and then customize the alert
so that it provides a direct link to the playbook in the wiki.
If you happen to be the subject-matter expert on a particular system, make sure that
documentation in particular is well fleshed out and understandable. These are the systems
that will pull you out of your vacation, so look through those documents for any assumptions
you may have made when writing them that a junior member of the team might not understand.
Have other members of the team review the documentation and ask you questions.
One saying about documentation is that if something is documented in two places, one of them
will be out of date. Even if you document something only in one place, there's a good chance it
is out of date unless you perform routine maintenance. It's a good practice to review your
documentation from time to time and update it where necessary and before a vacation is a
particularly good time to do it. If you are the only person that knows about the new way to
perform a procedure, you should make sure your documentation covers it.
Finally, have your team maintain a page to capture anything that happens while you are gone
that they want to tell you about when you get back. If you are the main maintainer of a
particular system, but they had to perform some emergency maintenance of it while you were
gone, that's the kind of thing you'd like to know about when you get back. If there's a central
place for the team to capture these notes, they will be more likely to write things down as
they happen and less likely to forget about things when you get back.
Stable State
The more stable your infrastructure is before you leave and the more stable it stays while
you are gone, the less likely you'll be disturbed on your vacation. Right before a vacation is
a terrible time to make a major change to critical systems. If you can, freeze changes in
the weeks leading up to your vacation. Try to encourage other teams to push off any major
changes until after you get back.
Before a vacation is also a great time to perform any preventative maintenance on your
systems. Check for any systems about to hit a disk warning threshold and clear out
space. In general, if you collect trending data, skim through it for any resources that
are trending upward that might go past thresholds while you are gone. If you have any tasks
that might add extra load to your systems while you are gone, pause or postpone them if you
can. Make sure all of your backup scripts are working and all of your backups are up to
date.
Emergency Contact Methods
Although it would be great to unplug completely while on vacation, there's a chance that
someone from work might want to reach you in an emergency. Depending on where you plan to
travel, some contact options may work better than others. For instance, some cell-phone plans
that work while traveling might charge high rates for calls, but text messages and data bill at
the same rates as at home.
... ... ... Kyle Rankin is senior security and infrastructure architect, the author of
many books including Linux Hardening in Hostile Networks, DevOps Troubleshooting and The
Official Ubuntu Server Book, and a columnist for Linux Journal. Follow him
@kylerankin
"... Lukas Jelinek is the author of the incron package that allows users to specify tables of inotify events that are executed by the master incrond process. Despite the reference to "cron", the package does not schedule events at regular intervals -- it is a tool for filesystem events, and the cron reference is slightly misleading. ..."
"... The incron package is available from EPEL ..."
It is, at times, important to know when things change in the Linux OS. The uses to which
systems are placed often include high-priority data that must be processed as soon as it is
seen. The conventional method of finding and processing new file data is to poll for it,
usually with cron. This is inefficient, and it can tax performance unreasonably if too many
polling events are forked too often.
Linux has an efficient method for alerting user-space processes to changes impacting files
of interest. The inotify Linux system calls were first discussed here in Linux Journal
in a 2005 article by Robert
Love who primarily addressed the behavior of the new features from the perspective of
C.
However, there also are stable shell-level utilities and new classes of monitoring
dæmons for registering filesystem watches and reporting events. Linux installations using
systemd also can access basic inotify functionality with path units. The inotify interface does
have limitations -- it can't monitor remote, network-mounted filesystems (that is, NFS); it
does not report the userid involved in the event; it does not work with /proc or other
pseudo-filesystems; and mmap() operations do not trigger it, among other concerns. Even with
these limitations, it is a tremendously useful feature.
This article completes the work begun by Love and gives everyone who can write a Bourne
shell script or set a crontab the ability to react to filesystem changes.
The inotifywait
Utility
Working under Oracle Linux 7 (or similar versions of Red Hat/CentOS/Scientific Linux), the
inotify shell tools are not installed by default, but you can load them with yum:
# yum install inotify-tools
Loaded plugins: langpacks, ulninfo
ol7_UEKR4 | 1.2 kB 00:00
ol7_latest | 1.4 kB 00:00
Resolving Dependencies
--> Running transaction check
---> Package inotify-tools.x86_64 0:3.14-8.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
==============================================================
Package Arch Version Repository Size
==============================================================
Installing:
inotify-tools x86_64 3.14-8.el7 ol7_latest 50 k
Transaction Summary
==============================================================
Install 1 Package
Total download size: 50 k
Installed size: 111 k
Is this ok [y/d/N]: y
Downloading packages:
inotify-tools-3.14-8.el7.x86_64.rpm | 50 kB 00:00
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Warning: RPMDB altered outside of yum.
Installing : inotify-tools-3.14-8.el7.x86_64 1/1
Verifying : inotify-tools-3.14-8.el7.x86_64 1/1
Installed:
inotify-tools.x86_64 0:3.14-8.el7
Complete!
The package will include two utilities (inotifywait and inotifywatch), documentation and a
number of libraries. The inotifywait program is of primary interest.
Some derivatives of Red Hat 7 may not include inotify in their base repositories. If you
find it missing, you can obtain it from Fedora's EPEL repository , either by downloading the
inotify RPM for manual installation or adding the EPEL repository to yum.
Any user on the system who can launch a shell may register watches -- no special privileges
are required to use the interface. This example watches the /tmp directory:
$ inotifywait -m /tmp
Setting up watches.
Watches established.
If another session on the system performs a few operations on the files in /tmp:
A few relevant sections of the manual page explain what is happening:
$ man inotifywait | col -b | sed -n '/diagnostic/,/helpful/p'
inotifywait will output diagnostic information on standard error and
event information on standard output. The event output can be config-
ured, but by default it consists of lines of the following form:
watched_filename EVENT_NAMES event_filename
watched_filename
is the name of the file on which the event occurred. If the
file is a directory, a trailing slash is output.
EVENT_NAMES
are the names of the inotify events which occurred, separated by
commas.
event_filename
is output only when the event occurred on a directory, and in
this case the name of the file within the directory which caused
this event is output.
By default, any special characters in filenames are not escaped
in any way. This can make the output of inotifywait difficult
to parse in awk scripts or similar. The --csv and --format
options will be helpful in this case.
It also is possible to filter the output by registering particular events of interest with
the -e option, the list of which is shown here:
access
create
move_self
attrib
delete
moved_to
close_write
delete_self
moved_from
close_nowrite
modify
open
close
move
unmount
A common application is testing for the arrival of new files. Since inotify must be given
the name of an existing filesystem object to watch, the directory containing the new files is
provided. A trigger of interest is also easy to provide -- new files should be complete and
ready for processing when the close_write trigger fires. Below is an example
script to watch for these events:
#!/bin/sh
unset IFS # default of space, tab and nl
# Wait for filesystem events
inotifywait -m -e close_write \
/tmp /var/tmp /home/oracle/arch-orcl/ |
while read dir op file
do [[ "${dir}" == '/tmp/' && "${file}" == *.txt ]] &&
echo "Import job should start on $file ($dir $op)."
[[ "${dir}" == '/var/tmp/' && "${file}" == CLOSE_WEEK*.txt ]] &&
echo Weekly backup is ready.
[[ "${dir}" == '/home/oracle/arch-orcl/' && "${file}" == *.ARC ]]
&&
su - oracle -c 'ORACLE_SID=orcl ~oracle/bin/log_shipper' &
[[ "${dir}" == '/tmp/' && "${file}" == SHUT ]] && break
((step+=1))
done
echo We processed $step events.
There are a few problems with the script as presented -- of all the available shells on
Linux, only ksh93 (that is, the AT&T Korn shell) will report the "step" variable correctly
at the end of the script. All the other shells will report this variable as null.
The reason for this behavior can be found in a brief explanation on the manual page for
Bash: "Each command in a pipeline is executed as a separate process (i.e., in a subshell)." The
MirBSD clone of the Korn shell has a slightly longer explanation:
# man mksh | col -b | sed -n '/The parts/,/do so/p'
The parts of a pipeline, like below, are executed in subshells. Thus,
variable assignments inside them fail. Use co-processes instead.
foo | bar | read baz # will not change $baz
foo | bar |& read -p baz # will, however, do so
And, the pdksh documentation in Oracle Linux 5 (from which MirBSD mksh emerged) has several
more mentions of the subject:
General features of at&t ksh88 that are not (yet) in pdksh:
- the last command of a pipeline is not run in the parent shell
- `echo foo | read bar; echo $bar' prints foo in at&t ksh, nothing
in pdksh (ie, the read is done in a separate process in pdksh).
- in pdksh, if the last command of a pipeline is a shell builtin, it
is not executed in the parent shell, so "echo a b | read foo bar"
does not set foo and bar in the parent shell (at&t ksh will).
This may get fixed in the future, but it may take a while.
$ man pdksh | col -b | sed -n '/BTW, the/,/aware/p'
BTW, the most frequently reported bug is
echo hi | read a; echo $a # Does not print hi
I'm aware of this and there is no need to report it.
This behavior is easy enough to demonstrate -- running the script above with the default
bash shell and providing a sequence of example events:
# ./inotify.sh
Setting up watches.
Watches established.
Import job should start on newdata.txt (/tmp/ CLOSE_WRITE,CLOSE).
Weekly backup is ready.
We processed events.
Examining the process list while the script is running, you'll also see two shells, one
forked for the control structure:
$ function pps { typeset a IFS=\| ; ps ax | while read a
do case $a in *$1*|+([!0-9])) echo $a;; esac; done }
$ pps inot
PID TTY STAT TIME COMMAND
3394 pts/1 S+ 0:00 /bin/sh ./inotify.sh
3395 pts/1 S+ 0:00 inotifywait -m -e close_write /tmp /var/tmp
3396 pts/1 S+ 0:00 /bin/sh ./inotify.sh
As it was manipulated in a subshell, the "step" variable above was null when control flow
reached the echo. Switching this from #/bin/sh to #/bin/ksh93 will correct the problem, and
only one shell process will be seen:
# ./inotify.ksh93
Setting up watches.
Watches established.
Import job should start on newdata.txt (/tmp/ CLOSE_WRITE,CLOSE).
Weekly backup is ready.
We processed 2 events.
$ pps inot
PID TTY STAT TIME COMMAND
3583 pts/1 S+ 0:00 /bin/ksh93 ./inotify.sh
3584 pts/1 S+ 0:00 inotifywait -m -e close_write /tmp /var/tmp
Although ksh93 behaves properly and in general handles scripts far more gracefully than all
of the other Linux shells, it is rather large:
The mksh binary is the smallest of the Bourne implementations above (some of these shells
may be missing on your system, but you can install them with yum). For a long-term monitoring
process, mksh is likely the best choice for reducing both processing and memory footprint, and
it does not launch multiple copies of itself when idle assuming that a coprocess is used.
Converting the script to use a Korn coprocess that is friendly to mksh is not difficult:
#!/bin/mksh
unset IFS # default of space, tab and nl
# Wait for filesystem events
inotifywait -m -e close_write \
/tmp/ /var/tmp/ /home/oracle/arch-orcl/ \
2</dev/null |& # Launch as Korn coprocess
while read -p dir op file # Read from Korn coprocess
do [[ "${dir}" == '/tmp/' && "${file}" == *.txt ]] &&
print "Import job should start on $file ($dir $op)."
[[ "${dir}" == '/var/tmp/' && "${file}" == CLOSE_WEEK*.txt ]] &&
print Weekly backup is ready.
[[ "${dir}" == '/home/oracle/arch-orcl/' && "${file}" == *.ARC ]]
&&
su - oracle -c 'ORACLE_SID=orcl ~oracle/bin/log_shipper' &
[[ "${dir}" == '/tmp/' && "${file}" == SHUT ]] && break
((step+=1))
done
echo We processed $step events.
Flush its standard output whenever it writes a message.
An fflush(NULL) is found in the main processing loop of the inotifywait source,
and these requirements appear to be met.
The mksh version of the script is the most reasonable compromise for efficient use and
correct behavior, and I have explained it at some length here to save readers trouble and
frustration -- it is important to avoid control structures executing in subshells in most of
the Borne family. However, hopefully all of these ersatz shells someday fix this basic flaw and
implement the Korn behavior correctly.
A Practical Application -- Oracle Log Shipping
Oracle databases that are configured for hot backups produce a stream of "archived redo log
files" that are used for database recovery. These are the most critical backup files that are
produced in an Oracle database.
These files are numbered sequentially and are written to a log directory configured by the
DBA. An inotifywatch can trigger activities to compress, encrypt and/or distribute the archived
logs to backup and disaster recovery servers for safekeeping. You can configure Oracle RMAN to
do most of these functions, but the OS tools are more capable, flexible and simpler to use.
There are a number of important design parameters for a script handling archived logs:
A "critical section" must be established that allows only a single process to manipulate
the archived log files at a time. Oracle will sometimes write bursts of log files, and
inotify might cause the handler script to be spawned repeatedly in a short amount of time.
Only one instance of the handler script can be allowed to run -- any others spawned during
the handler's lifetime must immediately exit. This will be achieved with a textbook
application of the flock program from the util-linux package.
The optimum compression available for production applications appears to be lzip . The author claims that the integrity of
his archive format is superior to many more well known
utilities , both in compression ability and also structural integrity. The lzip binary is
not in the standard repository for Oracle Linux -- it is available in EPEL and is easily
compiled from source.
Note that 7-Zip uses the same LZMA
algorithm as lzip, and it also will perform AES encryption on the data after compression.
Encryption is a desirable feature, as it will exempt a business from
breach disclosure laws in most US states if the backups are lost or stolen and they
contain "Protected Personal Information" (PPI), such as birthdays or Social Security Numbers.
The author of lzip does have harsh things to say regarding the quality of 7-Zip archives
using LZMA2, and the openssl enc program can be used to apply AES encryption
after compression to lzip archives or any other type of file, as I discussed in a previous
article . I'm foregoing file encryption in the script below and using lzip for
clarity.
The current log number will be recorded in a dot file in the Oracle user's home
directory. If a log is skipped for some reason (a rare occurrence for an Oracle database),
log shipping will stop. A missing log requires an immediate and full database backup (either
cold or hot) -- successful recoveries of Oracle databases cannot skip logs.
The scp program will be used to copy the log to a remote server, and it
should be called repeatedly until it returns successfully.
I'm calling the genuine '93 Korn shell for this activity, as it is the most capable
scripting shell and I don't want any surprises.
Given these design parameters, this is an implementation:
# cat ~oracle/archutils/process_logs
#!/bin/ksh93
set -euo pipefail
IFS=$'\n\t' # http://redsymbol.net/articles/unofficial-bash-strict-mode/
(
flock -n 9 || exit 1 # Critical section-allow only one process.
ARCHDIR=~oracle/arch-${ORACLE_SID}
APREFIX=${ORACLE_SID}_1_
ASUFFIX=.ARC
CURLOG=$(<~oracle/.curlog-$ORACLE_SID)
File="${ARCHDIR}/${APREFIX}${CURLOG}${ASUFFIX}"
[[ ! -f "$File" ]] && exit
while [[ -f "$File" ]]
do ((NEXTCURLOG=CURLOG+1))
NextFile="${ARCHDIR}/${APREFIX}${NEXTCURLOG}${ASUFFIX}"
[[ ! -f "$NextFile" ]] && sleep 60 # Ensure ARCH has finished
nice /usr/local/bin/lzip -9q "$File"
until scp "${File}.lz" "yourcompany.com:~oracle/arch-$ORACLE_SID"
do sleep 5
done
CURLOG=$NEXTCURLOG
File="$NextFile"
done
echo $CURLOG > ~oracle/.curlog-$ORACLE_SID
) 9>~oracle/.processing_logs-$ORACLE_SID
The above script can be executed manually for testing even while the inotify handler is
running, as the flock protects it.
A standby server, or a DataGuard server in primitive standby mode, can apply the archived
logs at regular intervals. The script below forces a 12-hour delay in log application for the
recovery of dropped or damaged objects, so inotify cannot be easily used in this case -- cron
is a more reasonable approach for delayed file processing, and a run every 20 minutes will keep
the standby at the desired recovery point:
# cat ~oracle/archutils/delay-lock.sh
#!/bin/ksh93
(
flock -n 9 || exit 1 # Critical section-only one process.
WINDOW=43200 # 12 hours
LOG_DEST=~oracle/arch-$ORACLE_SID
OLDLOG_DEST=$LOG_DEST-applied
function fage { print $(( $(date +%s) - $(stat -c %Y "$1") ))
} # File age in seconds - Requires GNU extended date & stat
cd $LOG_DEST
of=$(ls -t | tail -1) # Oldest file in directory
[[ -z "$of" || $(fage "$of") -lt $WINDOW ]] && exit
for x in $(ls -rt) # Order by ascending file mtime
do if [[ $(fage "$x") -ge $WINDOW ]]
then y=$(basename $x .lz) # lzip compression is optional
[[ "$y" != "$x" ]] && /usr/local/bin/lzip -dkq "$x"
$ORACLE_HOME/bin/sqlplus '/ as sysdba' > /dev/null 2>&1 <<-EOF
recover standby database;
$LOG_DEST/$y
cancel
quit
EOF
[[ "$y" != "$x" ]] && rm "$y"
mv "$x" $OLDLOG_DEST
fi
done
) 9> ~oracle/.recovering-$ORACLE_SID
I've covered these specific examples here because they introduce tools to control
concurrency, which is a common issue when using inotify, and they advance a few features that
increase reliability and minimize storage requirements. Hopefully enthusiastic readers will
introduce many improvements to these approaches.
The incron System
Lukas Jelinek is the author of the incron package that allows users to specify tables of
inotify events that are executed by the master incrond process. Despite the reference to
"cron", the package does not schedule events at regular intervals -- it is a tool for
filesystem events, and the cron reference is slightly misleading.
The incron package is available from EPEL . If you have installed the repository,
you can load it with yum:
# yum install incron
Loaded plugins: langpacks, ulninfo
Resolving Dependencies
--> Running transaction check
---> Package incron.x86_64 0:0.5.10-8.el7 will be installed
--> Finished Dependency Resolution
Dependencies Resolved
=================================================================
Package Arch Version Repository Size
=================================================================
Installing:
incron x86_64 0.5.10-8.el7 epel 92 k
Transaction Summary
==================================================================
Install 1 Package
Total download size: 92 k
Installed size: 249 k
Is this ok [y/d/N]: y
Downloading packages:
incron-0.5.10-8.el7.x86_64.rpm | 92 kB 00:01
Running transaction check
Running transaction test
Transaction test succeeded
Running transaction
Installing : incron-0.5.10-8.el7.x86_64 1/1
Verifying : incron-0.5.10-8.el7.x86_64 1/1
Installed:
incron.x86_64 0:0.5.10-8.el7
Complete!
On a systemd distribution with the appropriate service units, you can start and enable
incron at boot with the following commands:
# systemctl start incrond
# systemctl enable incrond
Created symlink from
/etc/systemd/system/multi-user.target.wants/incrond.service
to /usr/lib/systemd/system/incrond.service.
In the default configuration, any user can establish incron schedules. The incrontab format
uses three fields:
<path> <mask> <command>
Below is an example entry that was set with the -e option:
While the IN_CLOSE_WRITE event on a directory object is usually of greatest
interest, most of the standard inotify events are available within incron, which also offers
several unique amalgams:
$ man 5 incrontab | col -b | sed -n '/EVENT SYMBOLS/,/child process/p'
EVENT SYMBOLS
These basic event mask symbols are defined:
IN_ACCESS File was accessed (read) (*)
IN_ATTRIB Metadata changed (permissions, timestamps, extended
attributes, etc.) (*)
IN_CLOSE_WRITE File opened for writing was closed (*)
IN_CLOSE_NOWRITE File not opened for writing was closed (*)
IN_CREATE File/directory created in watched directory (*)
IN_DELETE File/directory deleted from watched directory (*)
IN_DELETE_SELF Watched file/directory was itself deleted
IN_MODIFY File was modified (*)
IN_MOVE_SELF Watched file/directory was itself moved
IN_MOVED_FROM File moved out of watched directory (*)
IN_MOVED_TO File moved into watched directory (*)
IN_OPEN File was opened (*)
When monitoring a directory, the events marked with an asterisk (*)
above can occur for files in the directory, in which case the name
field in the returned event data identifies the name of the file within
the directory.
The IN_ALL_EVENTS symbol is defined as a bit mask of all of the above
events. Two additional convenience symbols are IN_MOVE, which is a com-
bination of IN_MOVED_FROM and IN_MOVED_TO, and IN_CLOSE, which combines
IN_CLOSE_WRITE and IN_CLOSE_NOWRITE.
The following further symbols can be specified in the mask:
IN_DONT_FOLLOW Don't dereference pathname if it is a symbolic link
IN_ONESHOT Monitor pathname for only one event
IN_ONLYDIR Only watch pathname if it is a directory
Additionally, there is a symbol which doesn't appear in the inotify sym-
bol set. It is IN_NO_LOOP. This symbol disables monitoring events until
the current one is completely handled (until its child process exits).
The incron system likely presents the most comprehensive interface to inotify of all the
tools researched and listed here. Additional configuration options can be set in
/etc/incron.conf to tweak incron's behavior for those that require a non-standard
configuration.
Path Units under systemd
When your Linux installation is running systemd as PID 1, limited inotify functionality is
available through "path units" as is discussed in a lighthearted article by Paul Brown
at OCS-Mag .
The relevant manual page has useful information on the subject:
$ man systemd.path | col -b | sed -n '/Internally,/,/systems./p'
Internally, path units use the inotify(7) API to monitor file systems.
Due to that, it suffers by the same limitations as inotify, and for
example cannot be used to monitor files or directories changed by other
machines on remote NFS file systems.
Note that when a systemd path unit spawns a shell script, the $HOME and tilde (
~ ) operator for the owner's home directory may not be defined. Using the tilde
operator to reference another user's home directory (for example, ~nobody/) does work, even
when applied to the self-same user running the script. The Oracle script above was explicit and
did not reference ~ without specifying the target user, so I'm using it as an example here.
Using inotify triggers with systemd path units requires two files. The first file specifies
the filesystem location of interest:
The PathChanged parameter above roughly corresponds to the
close-write event used in my previous direct inotify calls. The full collection of
inotify events is not (currently) supported by systemd -- it is limited to
PathExists , PathChanged and PathModified , which are
described in man systemd.path .
The second file is a service unit describing a program to be executed. It must have the same
name, but a different extension, as the path unit:
The oneshot parameter above alerts systemd that the program that it forks is
expected to exit and should not be respawned automatically -- the restarts are limited to
triggers from the path unit. The above service configuration will provide the best options for
logging -- divert them to /dev/null if they are not needed.
Use systemctl start on the path unit to begin monitoring -- a common error is
using it on the service unit, which will directly run the handler only once. Enable the path
unit if the monitoring should survive a reboot.
Although this limited functionality may be enough for some casual uses of inotify, it is a
shame that the full functionality of inotifywait and incron are not represented here. Perhaps
it will come in time.
Conclusion
Although the inotify tools are powerful, they do have limitations. To repeat them, inotify
cannot monitor remote (NFS) filesystems; it cannot report the userid involved in a triggering
event; it does not work with /proc or other pseudo-filesystems; mmap() operations do not
trigger it; and the inotify queue can overflow resulting in lost events, among other
concerns.
Even with these weaknesses, the efficiency of inotify is superior to most other approaches
for immediate notifications of filesystem activity. It also is quite flexible, and although the
close-write directory trigger should suffice for most usage, it has ample tools for covering
special use cases.
In any event, it is productive to replace polling activity with inotify watches, and system
administrators should be liberal in educating the user community that the classic crontab is
not an appropriate place to check for new files. Recalcitrant users should be confined to
Ultrix on a VAX until they develop sufficient appreciation for modern tools and approaches,
which should result in more efficient Linux systems and happier administrators.
Sidenote:
Archiving /etc/passwd
Tracking changes to the password file involves many different types of inotify triggering
events. The vipw utility commonly will make changes to a temporary file, then
clobber the original with it. This can be seen when the inode number changes:
# ll -i /etc/passwd
199720973 -rw-r--r-- 1 root root 3928 Jul 7 12:24 /etc/passwd
# vipw
[ make changes ]
You are using shadow passwords on this system.
Would you like to edit /etc/shadow now [y/n]? n
# ll -i /etc/passwd
203784208 -rw-r--r-- 1 root root 3956 Jul 7 12:24 /etc/passwd
The destruction and replacement of /etc/passwd even occurs with setuid binaries called by
unprivileged users:
For this reason, all inotify triggering events should be considered when tracking this file.
If there is concern with an inotify queue overflow (in which events are lost), then the
OPEN , ACCESS and CLOSE_NOWRITE,CLOSE triggers likely
can be immediately ignored.
All other inotify events on /etc/passwd might run the following script to version the
changes into an RCS archive and mail them to an administrator:
#!/bin/sh
# This script tracks changes to the /etc/passwd file from inotify.
# Uses RCS for archiving. Watch for UID zero.
[email protected]
TPDIR=~/track_passwd
cd $TPDIR
if diff -q /etc/passwd $TPDIR/passwd
then exit # they are the same
else sleep 5 # let passwd settle
diff /etc/passwd $TPDIR/passwd 2>&1 | # they are DIFFERENT
mail -s "/etc/passwd changes $(hostname -s)" "$PWMAILS"
cp -f /etc/passwd $TPDIR # copy for checkin
# "SCCS, the source motel! Programs check in and never check out!"
# -- Ken Thompson
rcs -q -l passwd # lock the archive
ci -q -m_ passwd # check in new ver
co -q passwd # drop the new copy
fi > /dev/null 2>&1
Here is an example email from the script for the above chfn operation:
-----Original Message-----
From: root [mailto:[email protected]]
Sent: Thursday, July 06, 2017 2:35 PM
To: Fisher, Charles J. <[email protected]>;
Subject: /etc/passwd changes myhost
57c57
< fishecj:x:123:456:Fisher, Charles J.:/home/fishecj:/bin/bash
---
> fishecj:x:123:456:Fisher, Charles J.:/home/fishecj:/bin/csh
Further processing on the third column of /etc/passwd might detect UID zero (a root user) or
other important user classes for emergency action. This might include a rollback of the file
from RCS to /etc and/or SMS messages to security contacts. ______________________
Charles Fisher has an electrical engineering degree from the University of Iowa and works as
a systems and database administrator for a Fortune 500 mining and manufacturing
corporation.
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.


Syncthing replaces exclusive synchronize and cloud administrations with something open, reliable and decentralized. Your information is your information alone, and you should pick where it is put away if it is imparted to some outsider and how it's transmitted over the Internet. Syncthing is a record sharing application that permits you to share reports between various gadgets in an advantageous way. Its online Graphical User Interface (GUI) makes it conceivable Website Syncthing Alternatives






If you are in IT and are not familiar with Archibald Putt, I suggest you stop reading this blog post, RIGHT NOW, and go buy the book Putt's Law and the Successful Technocrat. How to Win in the Information Age . Putt's Law , for short, is a combination of Dilbert and The Mythical Man-Month . It shows you exactly how managers of technologists think, how they got to where they are, and how they stay there. Just like Dilbert, you'll initially laugh, then you'll cry, because you'll realize just how true Putt's Law really is. But, unlike Dilbert, whose technologist-fans tend to have a revulsion for management, Putt tries to show the technologist how to become one of the despised. Now granted, not all of us technologists have a desire to be management, it is still useful to "know one's enemy."

Figure 1
Image by : Paul Lewin . Modified by Opensource.com. CC BY-SA 2.0 x Get the newsletter
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years. David has written articles for...

mbadran / gist:130469 Created

 bobbydavid
bobbydavid
 dideler
dideler
 ghost
ghost
 cra
cra
 keltroth
keltroth
 jan-warchol
jan-warchol
 3v1n0
3v1n0Image by : Internet Archive Book Images . Modified by Opensource.com. CC BY-SA 4.0 x Get the newsletter



Introducing Logreduce
Managing baselines
Anomaly classification service

Tristan de Cacqueray - OpenStack Vulnerability Management Team (VMT) member working at Red Hat.
Installing custom scripts with rpm
Upgrading custom scripts with rpm
Steve Ovens - Steve is a dedicated IT professional and Linux advocate. Prior to joining Red Hat, he spent several years in financial, automotive, and movie industries. Steve currently works for Red Hat as an OpenShift consultant and has certifications ranging from the RHCA (in DevOps), to Ansible, to Containerized Applications and more. He spends a lot of time discussing technology and writing tutorials on various technical subjects with friends, family, and anyone who is interested in listening. More about me
 3.2.6 Syntax Highlighting
3.2.6 Syntax Highlighting
Jonathan Rioux 1,087 4 22 47 add a comment 4 Answers active oldest votes up vote 3 down vote accepted Simply restoring the HDD will not be enough, you're probably will want your boot record too which I hardly believe exists in your backup (am I wrong?, it's better for you if i do!)...
![[Note]](http://toolkit.globus.org/docbook-images/note.gif)
![[Tip]](http://toolkit.globus.org/docbook-images/tip.gif)





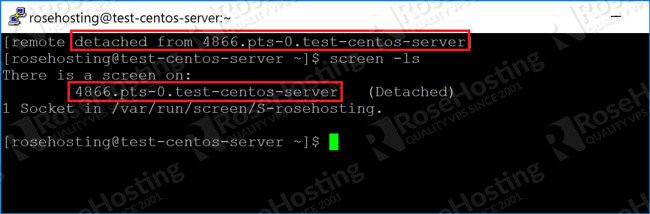
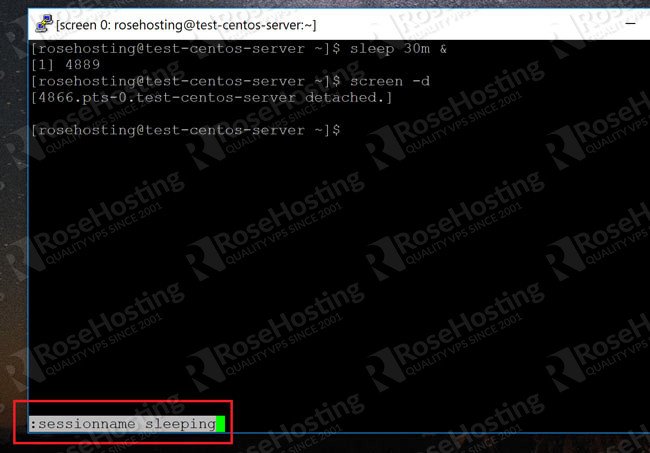
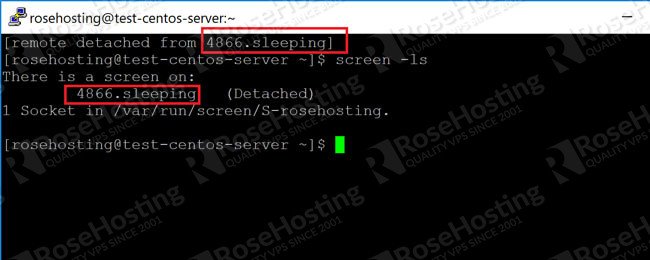


 Rick
Maus says:
Rick
Maus says: