|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
| News | Pipes | Recommended Links | Pipe Debugging | Filters | Coroutines | Sockets |
| cut | tr | expand | tee | sort | uniq | script |
| pv - pipe viewer | netcat | awk one liners | perl one liners | History | Humor | Etc |
|
|
Component model that stages of pipe implement lend itself to a specific form of debugging, called staged debugging. The existence of this method of debugging as an advantage of pipe/coroutine concept was noted in the original paper by Melvin Conway that introduced the concept of coroutines ( "Design of a Separable Transition-Diagram Compiler", CACM 6 (1963), 396-408)
|
|
That means you debug each pipe stage on different datasets separately as a single program using as input file written by previous stage for specific dataset until output of this stage fully satisfies you. After that you move to the next stage. And so on until the whole pipe is debugged.
You can use tee on any stage of the pipe to divert output to a file.
An additional useful component that simplifies pipe debugging is pv (Pipe Viewer). Here is how Martin Streicher, former editor-in-chief of Linux Journal, characterizes it:
Pipe Viewer is one of those little-known gems that once you find it, you can't recall how you lived without it. You may find some applications of pv in your daily command-line use, but you are likely to find oodles of uses for it in your automation scripts. Rather than stare at a blinking cursor waiting patiently for some indication that all is well, you can now insert a probe to give you real-time feedback. Pipe Viewer adds a heartbeat to the soul of the machine.
Nov 03, 2009
Summary: The pipe operator connects one UNIX® command to another to create ad hoc programs right on the command line. But a pipe is something of a black box, occluding the data flowing from one utility to the next. Pipe Viewer provides a peek into the pipeline. Here's how to use it in day-to-day tasks.
One of the cleverest and most powerful innovations in UNIX is the shell. It's more efficient than a GUI, and you can write scripts to automate many tasks. Better yet, the pipe operator assembles ad hoc programs right at the command line. The pipe chains commands in sequence, where the output of an earlier command becomes the input of a subsequent command. But the pipe has one major detractor: It's something of a black box. If you string commands together, the only evidence of progress is the output that the last command in the series generates. Yes, you can interject tee in the sequence, and you can watch an output file grow with tail, but those solutions work best once, lest the standard output (stdout) and standard error (stderr) of multiple phases commingle. Further, both solutions are crude indicators and likely mask how much computation each step requires.
Of course, you could deconstruct a complex sequence into multiple individual steps, each with its own interim output file. And indeed, if you want to verify results at each interval, decomposition is ideal. Write a script, produce one data file for each step, use a data file between each pair of steps as input, and collect the final file as the ultimate result. However, such a practice is not well suited to the impromptu nature of the command line.
What's needed is a progress meter that you can embed in the command line to measure throughput. Ideally, the meter could be repeated to benchmark each step-and because the sky's the limit, the tool would be open source and portable to multiple UNIX variants, such as Linux® and Mac OS X.
Well, wish no more: Pipe Viewer (pv), written by systems administrator Andrew Wood and enhanced by many other developers over the course of the past four years, provides a peek into command-line "plumbing." As stated on its project page, pv "can be inserted into [a] pipeline between two processes to give a visual indication of how quickly data is passing through, how much time has elapsed so far, and how near completion [it is]." Remarkably, you can also insert multiple instances of pv into the same command line to show relative throughput.
This article shows you how to build pv on a UNIX system and apply it to simple and complex command-line combinations. Let's start, though, with a review of how pipes connect processes.
UNIX pipes: Plumbing for processes
Figure 1 shows the steps for creating a pipe to connect two independent processes.
Figure 1. Creating a pipe to connect two processes
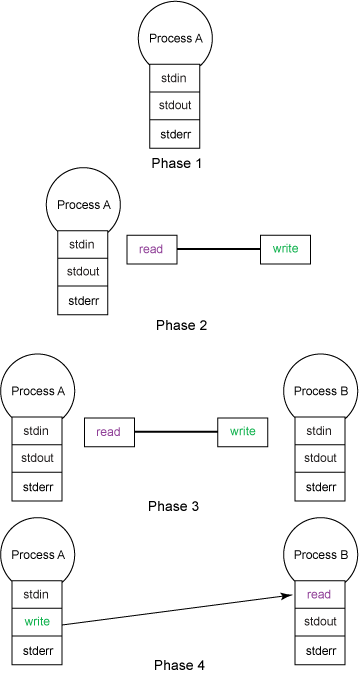
At the outset, Phase 1, the progenitor process reads from standard input stdin, writes output to stdout, and emits errors to stderr. Each of stdin, stdout, and stderr is a file descriptor, or a handle to a file. Each operation on a file handle-open, read, write, rewind, truncate, and close, for example-affects the state of the file.
Next, in Phase 2, the progenitor creates a pipe. A pipe is composed of a queue and two file descriptors-one to enqueue data and the other to dequeue data. A pipe is a first-in-first out (FIFO) data structure.
By itself, a pipe has little use; its purpose is to connect a producer to a consumer. Hence, the progenitor forks, or creates, a second process in Phase 3 to act as a counterpart.
In Phase 4 (and assuming that the new process is the consumer), the original process replaces its stdout with the producer end of the pipe and rewires the newly forked process to treat the consumer end of the pipe and its stdin. After these adjustments, each write by the original process (now the producer) is enqueued and subsequently read by the new process (now the consumer).
Phases 1 through 4 mirror the process your shell uses to connect one utility to another with the command-line pipe operator (|), although the shell spawns a new process for each utility and leaves itself untouched to perform job control.
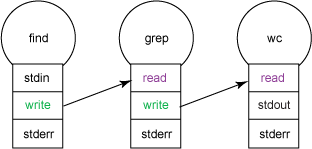
For example, Figure 2 shows how a find, grep, and wc command might be connected via pipes to find and count all files with names that begin with lowercase a. The shell remains independent; find is a producer, grep acts as a consumer (for find) and as a producer (for wc). wc acts a consumer and producer, too: It consumes from grep and produces output to stdout. Typically, the shell connects stdout to a terminal, but redirection can reroute the output to a file.
Figure 2. Connecting commands using pipes
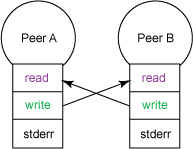
If you want to peer into two UNIX processes, the create two pipes and rewire the file descriptors of each process to act both as a producer and a consumer. Figure 3 shows an interprocess exchange that overrides both processes' stdin and stdout.
Figure 3. Looking into two UNIX processes
Given that brief review, let's look at Pipe Viewer.
Pipe Viewer: Conspicuous conduit
Pipe Viewer is an open source application. You can download its source code and build the application from scratch or, if available, pull an existing binary from your UNIX distribution's repository.
To build from scratch, download the latest source tarball from the Pipe Viewer project page (see Resources). As of mid-September 2009, the latest version of the code is 1.1.4. Unpack the tarball, change to the newly created directory, and type ./configure followed by make and sudo make install. By default, the build process installs the executable named pv into /usr/local/bin. (For a list of configuration options, type ./configure --help.) Listing 1 shows the installation code.
Listing 1. Pipe Viewer installation code
$ wget http://pipeviewer.googlecode.com/files/pv-1.1.4.tar.bz2 $ tar xjf pv-1.1.4.tar.bz2 $ cd pv-1.1.4 $ ./configure $ make $ sudo make install $ which pv /usr/local/bin/pvTo pull the pv binary from a repository, use your distribution's package manager and search for either pv or pipe viewer. For example, a search using Ubuntu version 9's APT package manager yields this match:
$ apt-cache search part viewer pv - Shell pipeline element to meter data passing throughTo continue, use your package manager to download and install the package. For Ubuntu, the command is apt-get install:
$ sudo apt-get install pvOnce installed, give pv a try. The simplest use replaces the traditional cat utility with pv to feed bytes to another program and measure overall throughput. For instance, you can use pv to monitor a lengthy compress operation:$ ls -lh listings.txt -r--r--r-- 1 supergiantrobot staff 109M Sep 1 20:47 listings.txt $ pv listings.txt | gzip > listings.gz 96.1MB 0:00:09 [11.3MB/s] [=====================> ] 87% ETA 0:00:01When the command launches, pv posts a progress bar and continually updates the gauge to show headway. From left to right, the typical pv display shows how much data has been processed so far, the time elapsed, throughput in megabytes/second, a visual and numeric representation of work complete, and an estimate of how much time remains. In the display above, 96.1MB of 109MB has been processed, leaving about 13 percent of the file to go after 9 seconds of work.By default, pv renders all the status indicators for which it is able to calculate values. For instance, if the input to pv is not a file and no specific size is manually specified, the progress bar advances from left to right to show activity, but it cannot measure the percent complete without a baseline. Here's an example:
$ ssh faraway tar cf - projectx | pv --wait > projectx.tar Password: 4.34MB 0:00:07 [ 611kB/s] [ <=> ]This example runs tar on a remote machine and sends the output of the remote command to the local system to create projectx.tar. Because pv cannot calculate the total number of bytes to expect in the transfer, it shows throughput so far, time elapsed, and a special indicator that reflects activity. The little "car" (<=>) travels left to right as long as data is streaming through.The --wait option delays the rendering of the progress meter(s) until the first byte is actually received. Here, --wait is useful, because the ssh command may prompt for a password.
You can enable individual indicators at your discretion with eponymous flags:
>$ ssh faraway tar cf - projectx | \ pv --wait --bytes > projectx.tar Password: 268kBThe latter command enables the running byte count with --bytes. The other options are --progress, --timer, --eta, --rate, and --numeric. If you specify one or more display options, all remaining (unnamed) indicators are automatically disabled.There is one other simple use of pv. The --rate-limit option can throttle throughput. The argument to this option is a number and a suffix, such as m to indicate megabytes/second:
$ ssh faraway tar cf - projectx | \ pv --wait --quiet --rate-limit 1m > projectx.tarThe previous command hides all indicators (--quiet) and limits throughout to 1MB/s.
So far, the examples shown employ a single instance of Pipe Viewer as the producer or consumer in a pair of commands. However, more complex combinations are also possible. You can use pv multiple times in the same command line, with some provisos. Specifically, you must name each instance of pv using --name, and you must enable multiline mode with --cursor. Combined, the two options create a series of labeled indicators, one indicator per named instance.
For example, imagine you want to monitor the progress of a data transfer and its compression separately and simultaneously. You can assign one instance of pv to the former operation and another to the latter, like so:
$ ssh faraway tar cf - projectx | pv --wait --name ssh | \ gzip | pv --wait --name gzip > projectx.tgzAfter you type a password, the Pipe Viewer commands produce a two-line progress meter:
ssh: 4.17MB 0:00:07 [ 648kB/s] [ <=> ] gzip: 592kB 0:00:06 [62.1kB/s] [ <=> ]The first line is labeled ssh and shows the progress of the transfer; the second line, tagged gzip, shows the progression of the compression. Because each command cannot determine the number of bytes in its respective operation, the accumulated totals and the activity bar are shown on each line.
If you know or are able to approximate or calculate the number of bytes in an operation, use the --size option. Adding this option provides some finer-grained detail in the progress bars.
For instance, if you want to monitor the progress of a significant archiving task, you can use other UNIX utilities to approximate the total size of the original files. The df utility can show statistics for an entire file system, while du can calculate the size of an arbitrarily deep hierarchy:
$ tar cf - work | pv --size `du -sh work | cut -f1` > work.tarHere, the subshell command du -sh work | cut -f1 yields the total size of the work directory in a format compatible with pv. Namely, du -h produces a human-readable format such as 17M for 17 megabytes-perfect for use with pv. (The ls and df commands also support -h for human-readable format.) Because pv now expects a specific number of bytes to transit through the pipe, it can render a true progress bar:
700kB 0:00:07 [ 100kB/s] [> ] 4% ETA 0:02:47Finally, there is one additional technique you're sure to find useful. Beside counting bytes, Pipe Viewer can visualize progress by counting lines. If you specify the modifier --line-mode, pv advances the progress meter each time a newline is encountered. You can also provide --size, and the number is interpreted as the expected number of lines.
Here's an example. Oftentimes, find is helpful for locating a needle in a haystack, such as locating all the uses of a particular system call in a large body of application code. In such circumstances, you might run something like this:
$ find . -type f -name '*.c' -exec grep --files-with-match fopen \{\} \; > resultsThis code finds all C source files and emits the file's name if the string fopen appears anywhere in the file. Output is collected in a file named results. To reflect activity, add pv to the mix:
$ find . -type f -name '*.c' -exec grep --files-with-match fopen \{\} \; | \ pv --line-mode > resultsLine mode is phenomenal, because many UNIX commands, like find, operate on a file's metadata, not on the contents of the file. Line mode is ideal for systems administration scripts that copy or compress large collections of files.
In general, you can inject Pipe Viewer into command lines and scripts whenever rate is measurable. You may have to get creative, though. For example, to measure how quickly a directory is copied, switch from cp -pr to tar:
$ # an equivalent of cp -pr old/somedir new $ (cd old; tar cf - somedir) | pv | (cd new; tar xf - )You might also consider line mode for use with networking utilities such as wget, curl, and scp. For instance, you can use pv to measure the progress of a sizable upload. And because many of the networking tools can take input from a file, you can use the length of such a file as an argument to --size.
Martin Streicher is a freelance Ruby on Rails developer and the former Editor-in-Chief of Linux Magazine. Martin holds a Masters of Science degree in computer science from Purdue University and has programmed UNIX-like systems since 1986. He collects art and toys. You can reach Martin at [email protected].
03-27-2010
tokland
Problem with pipes on infinite streams
--------------------------------------------------------------------------------
Here is an example code that shows the issue I have:
Code:
#!/bin/bash counter() { seq 1000 | while read NUM; do echo $NUM echo "debug: $NUM" >&2 sleep 0.1 # slow it down so we know when this loop really ends done } counter | grep --line-buffered "[27]" | head -n1Code:debug: 1 debug: 2 2 debug: 3 debug: 4 debug: 5 debug: 6 debug: 7If I understand it correctly, "head" finishes on the first match (as expected), but "grep" is not aware of it until it tries to write the next line (the second match). When it does, it finds out the pipe is closed so it also finishes.That's normally not a problem, but if you have an infinite input stream containing only one match, it won't never stop. Any solution?
alister
Hello, tokland:
If using GNU grep:
Code:
counter | grep -m1 '[27]'
If that's not available:
Code:
counter | sed -n '/[27]/{p;q;}'
Regards,
Alistertokland
Hi!
Quote:Originally Posted by alister
If using GNU grep:
Code:
counter | grep -m1 '[27]'
If that's not available:
Code:
counter | sed -n '/[27]/{p;q;}'Thanks, those are good solutions. However, the grep in my code was just an example, let's imagine you cannot change how the stream is generated:
stream_generator | head -n1
By the way, using process substitution "works":
head -n1 <(stream_generator)
but it keeps the generator running on the background until the next match.
alister
You can run the stream generator in the background, asynchronously, and use a named pipe to communicate with it:
Code:
mkfifo sg_pipe
stream_generator > sg_pipe &
head -n1 sg_pipe
kill %?stream
Regards,
Alister---------- Post updated at 10:51 PM ---------- Previous update was at 10:38 PM ----------
For the example code you used in your original post:
Code:
#!/bin/bash
counter() {
seq 1000 | while read NUM; do
echo $NUM
echo "debug: $NUM" >&2
sleep 0.1 # slow it down so we know when this loop really ends
done
}mkfifo p
counter | grep --line-buffered "[27]" > p &
head -n1 p
kill %?counter
Outputs:
Code:
$ ./tokland.sh
debug: 1
debug: 2
2
Alister
Google matched content |
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: March 12, 2019