|
|
Home | Switchboard | Unix Administration | Red Hat | TCP/IP Networks | Neoliberalism | Toxic Managers |
| (slightly skeptical) Educational society promoting "Back to basics" movement against IT overcomplexity and bastardization of classic Unix | |||||||
|
|
|
|
Grid Engine which is often called Sun Grid Engine (SGE) is a software classic. It is a batch jobs controller like batch command on steroids, not so much a typical scheduler. At one point Sun open source the code, so open source version exists. It is the most powerful (albeit specialized) open source scheduler in existence. This is one of most valuable contributions of Sun to open source community as it provides industrial strength batch scheduler for Unix/Linux.
Again this is one of the few classic Unix software systems. SGE 6.2u7 as released by Sun has all signs of the software classic. It inherited from Sun days a fairly good documentation (although software vandals form Oracle destroyed a lot of valuable Sun documents). Any engineer or scientist can read the SGE User Manual and Installation Guide. Then install it (it set up a single queue all.q that can be used immediately), and start using it for his/her needs in a day or two using the defaults without any training. As long as the networking is reliable and jobs are submitted correctly, SGE runs them with nearly zero administration.
SGE is an very powerful and flexible batch system, that probably should became standard Linux subsystem replacing or supplementing very basic batch command. It is available in several Linux distributions such as Debian and Ubuntu as installable software package from the main depository. It is available from "other" depositories for CentOS, RHEL and Suse.
SGE has many options to help effectively use all of computational resources -- grid consisting of head node and computational nodes, each with certain number of cores (aka slots).
But the back side of power and flexibility is complexity. It is a complex system that requires study. You need carefully study the man pages and manuals to get most out of it. The SGE mailing list is also a great educational resource. Don't hesitate to ask questions. Then when you become an expert you can help others to get to speed with the product. Installation is easy, but it usually take a from six month to a year for an isolated person to master the basics (much less if you have at least one expert on the floor). But like with any complex and powerful system even admins with 10years experience probably know only 60-70% of the SGE.
Now that the pieces are falling into place, after Oracle's acquisition of Sun Microsystems and then abandoning the product, we can see that open source can help "vendor-proof" important parts of Unix. Unix did not have a decent batch scheduler before Grid Engine and now it has it. Grid Engine is alive and well, with a blog, a mailing list, a git repository, and even commercial version from Univa. Source code repositories can also be found from the Open Grid Scheduler (Grid Engine 2011.11 is compatible with Sun Grid Engine 6.2u7 ) and Son of Grid Engine projects. Open Grid Scheduler looks like abandonware (user group is active), while Son of Grid Engine is actively developed and currently represents the most viable open source SGE implementation.
As of version 8.1.8 it is the most well debugged open source distribution. It might be especially attractive for those who what have experience with building software, but can be used by everybody on RHEL for which precompiled binaries exist.
Installation is pretty raw, but I tried to compensate for that by creating several pages which together document installation process of RHEL 6.5 or 6.6 pretty well:
Even in the present form they are definitely more clear and useful then old Sun 6.2u5 installation documentation ;-).
Most of the SGE discussion uses the term cluster, but SGE is not linked to cluster technology in any meaningful way. In reality it designed to operate on a heterogeneous server farm.
We will use the term "server farm" here as an alternative and less ambitious term then the term "grid".
The default installation of Grid Engine assumes that the $SGE_ROOT directory (root directory for Grid Engine installation) is on a shared (for example by NFS) filesystem accessible by all hosts.
Right now SGE exists in several competing versions (see SGE implementations) but the last version of Son of Grid engine produced was 8.1.9. After that Dave Love abandoned the project. So while it can be installed on RHEL7 and works, the future of SGE is again in limbo.
The last version of Son grid engine was released in March 2016 (all versions listed below are also downloadable from Son of Grid Engine (SGE) - Browse -SGE-releases at SourceForge.net):
2016-03-02: Version 8.1.9 available. Note that this changes the communication protocol due to the MUNGE support, and really should have been labelled 8.2 in hindsight — ensure you close down execds before upgrading.
2014-11-03: Version 8.1.8 available.
2014-06-01: Version 8.1.7 available.
2013-11-01: Version 8.1.6 available, fixing various bugs.
2013-09-29: Version 8.1.5 available, mainly to fix MS Windows build problems.
2013-08-30: Version 8.1.4available; bug fixes and some enhancements, now with over 1000 patches since Oracle pulled the plug.
2013-02-27: Version 8.1.3available; bug fixes and a few enhancements, plus Debian packaging (as an add-on).
2013-01: The gridengine.debian repository contains proposed new packaging for Debian (as opposed to the standalone packaging now in the sge repository).
The Grid Engine system has functions typical for any powerful batch system:
But as a powerful batch system it is oriented on running multiple jobs optimally on the available resources Typically multiple computers(nodes) of a computational cluster. In its simplest form, a grid appears to users as a large system that provides a single point of access to multiple computers.
In other words grid is just a loose confederation of different computers which can run different OSes connected by regular TCP/IP links. In this sense it is close to the concept of a server farm. Grid engine does not care about uniformity of a server farm and along with scheduling provides some central administration and monitoring capabilities to server farm environment.
SGE enables to distribute jobs across a grid and treat the grid as a single computational resource. It accepts jobs submitted by user(s) and schedule them to be run on appropriate systems in the grid. Users can submit as many jobs at a time as they want without being concerned about where the jobs run.
The main purpose of a batch system like SGE is to optimally utilize system resources that are present in a server farm. To schedule jobs ob available nodes in the most efficient way possible.
Every aspect of the batch system is accessible through the perl API. There is almost no documentation but a few sample scripts in gridengine/source/experimental/perlgui and on Internet such as by Wolfgand Frieebel from DESY ( see ifh.de) can be used as a guidance
Grid Engine architecture is structured around two main concepts:
A queue is a container for a class of jobs that are allowed to run on one or more hosts concurrently. Logically queue is a child of parallel environment (see below) although it can have several such parents. It defines set of hosts and limitation of resources on those hosts.
A queue can reside on a single host, or a queue can extend across multiple hosts. The latter are called server farm queues. Server farm queues enable users and administrators to work with a server farm of execution hosts by means of a single queue configuration. Each host that is attached to the head node can belong to one of more queues
A queue determines certain job attributes. Association with a queue affects some of the things that can happen to a job. For example, if a queue is suspended, all jobs associated with that queue are also suspended.
Grid Engine has always have one default queue called all.q, which is created during the initial installation and updated each time you add another execution host. You can can have several additional queries each of them defining the set of host to run the jobs each with own computational requirements, for example, number of CPUs (ala slots) . The problem here is that without special measures queues are independent and if they contain the same set of nodes oversubscription can easily occur.
Each job should not exceed maximum parameters defined in queue (directly or indirectly via parralal environment). Then SGE scheduler can optimize the job mix for available resources by selecting the most suitable job from the input query and sending it to the most appropriate node of a grid.
Queue defines class of jobs that consume computer resources in a similar way. It also define list of computational nodes on which such jobs can be run.
Jobs typically are submitted to a queue.
In the book Building N1™ Grid Solutions Preparing, Architecting, and Implementing Service-Centric Data Centers we can find an interesting although overblown statement:
The N1 part of the name was never intended to be a product name or a strategy name visible outside of Sun. The name leaked out and stuck. It is the abbreviation for the original project name “Network-1.” The SUN1 workstation was Sun's first workstation. It was designed specifically to be connected to the network.
N1 Grid systems are the first systems intended to be built with the network at their core and be based on the principle that an IP-based network is effectively the system bus.
Parallel environment (PE) is the central notion of SGE and represents a set of settings that tell Grid Engine how to start, stop, and manage jobs run by the class of queues that are using this PE.
It sets the maximum number of slot that can be assigned to all jobs within a given queue. It also set some parameters for parallel messaging framework such as MPI, that is used by parallel jobs.
|
|
The usual syntax applies:
Parallel environment is the defining characteristic of each queue. Needs to be specified in correctly for queue to work. It is specified in pe_list attribute which can contain a single PE or list of PEs. For example:
pe_list make mpi mpi_fill_up
Each parallel environment determines a class of queues that use it and has several important attributes are:
If wallclock accounting is used (execd_params ACCT_RESERVED_USAGE and/or SHARETREE_RESERVED_USAGE set to TRUE) and control_slaves
is set to FALSE, the job_is_first_task parameter influences the accounting for the job: A value of TRUE means that accounting
for cpu and requested memory gets multiplied by the number of slots requested with the -pe switch, if job_is_first_task is
set to FALSE, the accounting information gets multiplied by number of slots + 1.
The accounting_summary parameter can be set to TRUE or FALSE. A value of TRUE indicates that only a single accounting record
is written to the accounting(5) file, containing the accounting summary of the whole job including all slave tasks, while
a value of FALSE indicates an individual accounting(5) record is written for every slave task, as well as for the master task.
Note: When running tightly integrated jobs with SHARETREE_RESERVED_USAGE set, and with having accounting_summary
enabled in the parallel environment, reserved usage will only be reported by the master task of the parallel job. No per parallel
task usage records will be sent from execd to qmaster, which can significantly reduce load on qmaster when running large tightly
integrated parallel jobs.
Some important details are well explained in the blog post Configuring a New Parallel Environment
Grid generally consists of a head node and computational nodes. Head node typically runs sge_master and often called master host. Master host can and often is be the source of export of NFS to computational nodes but this is not necessary.
qconf -ah <hostname>
Two daemons provide the functionality of the Grid Engine system. They are started via init scripts.
Documentation for such a complex and powerful system is fragmentary and generally is of low quality. Even some man pages contain questionable information. Many does not explain features available well, or at all.
This is actually why this set of pages was created: to compensate for insufficient documentation for SGE.
Although version of SGE generally are compatible, some features implementation depends on version used. See history for the list of major implementations.
Documentation to the last opensource version produced by Sun (version 6.2u5) is floating on the Internet. See, for example:
There are docs for older versions too,
And some presentations
Some old Sun Blueprints about SGe still can be found too. But generally Oracle behaved horribly bad as a trustee of Sun documentation portal. They proved to be simply vandals in this particular respect: discarding almost everything without mercy, destroying considerable value and an important part of Sun heritage.
Moreover, those documents organized into historical website might still can earn some money (and respect, which is solely missing now, after this vandalism) for Oracle if they preserved the website. No they discarded everything mercilessly.
Documentation for Oracle Grid Engine which is now abandonware might also floating around.
For more information see
See also SGE Documentation
|
|
Switchboard | ||||
| Latest | |||||
| Past week | |||||
| Past month | |||||
Jan 29, 2021 | finance.yahoo.com
So it now owns the only commercial SGE offering along with PBSpro. Univa Grid Engine will now be referred to as Altair Grid Engine.
Altair will continue to invest in Univa's technology to support existing customers while integrating with Altair's HPC and data analytics solutions. These efforts will further enhance the capability and performance requirements for all Altair customers and solidify the company's leadership in workload management and cloud enablement for HPC. Univa has two flagship products:
· Univa ® Grid Engine ® is a leading distributed resource management system to optimize workloads and resources in thousands of data centers, improving return-on-investment and delivering better results faster.
Dec 16, 2018 | liv.ac.uk
Index of /downloads/SGE/releases/8.1.9
This is Son of Grid Engine version v8.1.9. See <http://arc.liv.ac.uk/repos/darcs/sge-release/NEWS> for information on recent changes. See <https://arc.liv.ac.uk/trac/SGE> for more information. The .deb and .rpm packages and the source tarball are signed with PGP key B5AEEEA9. * sge-8.1.9.tar.gz, sge-8.1.9.tar.gz.sig: Source tarball and PGP signature * RPMs for Red Hat-ish systems, installing into /opt/sge with GUI installer and Hadoop support: * gridengine-8.1.9-1.el5.src.rpm: Source RPM for RHEL, Fedora * gridengine-*8.1.9-1.el6.x86_64.rpm: RPMs for RHEL 6 (and CentOS, SL) See <https://copr.fedorainfracloud.org/coprs/loveshack/SGE/> for hwloc 1.6 RPMs if you need them for building/installing RHEL5 RPMs. * Debian packages, installing into /opt/sge, not providing the GUI installer or Hadoop support: * sge_8.1.9.dsc, sge_8.1.9.tar.gz: Source packaging. See <http://wiki.debian.org/BuildingAPackage>, and see <http://arc.liv.ac.uk/downloads/SGE/support/> if you need (a more recent) hwloc. * sge-common_8.1.9_all.deb, sge-doc_8.1.9_all.deb, sge_8.1.9_amd64.deb, sge-dbg_8.1.9_amd64.deb: Binary packages built on Debian Jessie. * debian-8.1.9.tar.gz: Alternative Debian packaging, for installing into /usr. * arco-8.1.6.tar.gz: ARCo source (unchanged from previous version) * dbwriter-8.1.6.tar.gz: compiled dbwriter component of ARCo (unchanged from previous version) More RPMs (unsigned, unfortunately) are available at <http://copr.fedoraproject.org/coprs/loveshack/SGE/>.
Dec 16, 2018 | github.com
docker-sge
Dockerfile to build a container with SGE installed.
To build type:
git clone [email protected]:gawbul/docker-sge.git cd docker-sge docker build -t gawbul/docker-sge .To pull from the Docker Hub type:
docker pull gawbul/docker-sgeTo run the image in a container type:
docker run -it --rm gawbul/docker-sge login -f sgeadminYou need the
login -f sgeadminas root isn't allowed to submit jobsTo submit a job run:
echo "echo Running test from $HOSTNAME" | qsub
Dec 16, 2018 | hub.docker.com
Docker SGE (Son of Grid Engine) Kubernetes All-in-One Usage
Kubernetes Step-by-Step Usage
- Setup Kubernetes cluster, DNS service, and SGE cluster
Set
KUBE_SERVER,DNS_DOMAIN, andDNS_SERVER_IPcurrectly. And run./kubernetes/setup_all.shwith number of SGE workers.export KUBE_SERVER=xxx.xxx.xxx.xxx export DNS_DOMAIN=xxxx.xxxx export DNS_SERVER_IP=xxx.xxx.xxx.xxx ./kubernetes/setup_all.sh 20- Submit Job
kubectl exec sgemaster -- sudo su sgeuser bash -c '. /etc/profile.d/sge.sh; echo "/bin/hostname" | qsub' kubectl exec sgemaster -- sudo su sgeuser bash -c 'cat /home/sgeuser/STDIN.o1'- Add SGE workers
./kubernetes/add_sge_workers.sh 10Simple Docker Command Usage
- Setup Kubernetes cluster
./kubernetes/setup_k8s.sh- Setup DNS service
Set
KUBE_SERVER,DNS_DOMAIN, andDNS_SERVER_IPcurrectlyexport KUBE_SERVER=xxx.xxx.xxx.xxx export DNS_DOMAIN=xxxx.xxxx export DNS_SERVER_IP=xxx.xxx.xxx.xxx ./kubernetes/setup_dns.sh- Check DNS service
- Boot test client
kubectl create -f ./kubernetes/skydns/busybox.yaml
- Check normal lookup
kubectl exec busybox -- nslookup kubernetes
- Check reverse lookup
kubectl exec busybox -- nslookup 10.0.0.1- Check pod name lookup
kubectl exec busybox -- nslookup busybox.default- Setup SGE cluster
Run
./kubernetes/setup_sge.shwith number of SGE workers../kubernetes/setup_sge.sh 10- Submit job
kubectl exec sgemaster -- sudo su sgeuser bash -c '. /etc/profile.d/sge.sh; echo "/bin/hostname" | qsub' kubectl exec sgemaster -- sudo su sgeuser bash -c 'cat /home/sgeuser/STDIN.o1'- Add SGE workers
./kubernetes/add_sge_workers.sh 10
- Load nfsd module
modprobe nfsd- Boot DNS server
docker run -d --hostname resolvable -v /var/run/docker.sock:/tmp/docker.sock -v /etc/resolv.conf:/tmp/resolv.conf mgood/resolvable- Boot NFS servers
docker run -d --name nfshome --privileged cpuguy83/nfs-server /exports docker run -d --name nfsopt --privileged cpuguy83/nfs-server /exports- Boot SGE master
docker run -d -h sgemaster --name sgemaster --privileged --link nfshome:nfshome --link nfsopt:nfsopt wtakase/sge-master:ubuntu- Boot SGE workers
docker run -d -h sgeworker01 --name sgeworker01 --privileged --link sgemaster:sgemaster --link nfshome:nfshome --link nfsopt:nfsopt wtakase/sge-worker:ubuntu docker run -d -h sgeworker02 --name sgeworker02 --privileged --link sgemaster:sgemaster --link nfshome:nfshome --link nfsopt:nfsopt wtakase/sge-worker:ubuntu- Submit job
docker exec -u sgeuser -it sgemaster bash -c '. /etc/profile.d/sge.sh; echo "/bin/hostname" | qsub' docker exec -u sgeuser -it sgemaster cat /home/sgeuser/STDIN.o1
Nov 08, 2018 | liv.ac.uk
I installed SGE on Centos 7 back in January this year. If my recolection is correct, the procedure was analogous to the instructions for Centos 6. There were some issues with the firewalld service (make sure that it is not blocking SGE), as well as some issues with SSL.
Check out these threads for reference:http://arc.liv.ac.uk/pipermail/sge-discuss/2017-January/001050.html
Max
Sep 07, 2018 | auckland.ac.nz
Experiences with Sun Grid Engine
In October 2007 I updated the Sun Grid Engine installed here at the Department of Statistics and publicised its presence and how it can be used. We have a number of computation hosts (some using Māori fish names as fish are often fast) and a number of users who wish to use the computation power. Matching users to machines has always been somewhat problematic.
Fortunately for us, SGE automatically finds a machine to run compute jobs on . When you submit your job you can define certain characteristics, eg, the genetics people like to have at least 2GB of real free RAM per job, so SGE finds you a machine with that much free memory. All problems solved!
Let's find out how to submit jobs ! (The installation and administration section probably won't interest you much.)
I gave a talk on 19 February 2008-02-19 to the Department, giving a quick overview of the need for the grid and how to rearrange tasks to better make use of parallelism.
- Installation
- Administration
- Submitting jobs
- Thrashing the Grid
- Advanced methods of queue submission
- Talk at Department Retreat
- Talk for Department Seminar
- Summary
Installation
My installation isn't as polished as Werner's setup, but it comes with more carrots and sticks and informational emails to heavy users of computing resources.
For this very simple setup I first selected a master host, stat1. This is also the submit host. The documentation explains how to go about setting up a master host.
Installation for the master involved:
- Setting up a configuration file, based on the default configuration.
- Uncompressing the common and architecture-specific binaries into /opt/sge
- Running the installation. (Correcting mistakes, running again.)
- Success!
With the master setup I was ready to add compute hosts. This procedure was repeated for each host. (Thankfully a quick for loop in bash with an ssh command made this step very easy.)
- Login to the host
- Create
/opt/sge.- Uncompress the common and architecture-specific binaries into
/opt/sge- Copy across the cluster configuration from
/opt/sge/default/common. (I'm not so sure on this step, but I get strange errors if I don't do this.)- Add the host to the cluster. (Run qhost on the master.)
- Run the installation, using the configuration file from step 1 of the master. (Correcting mistakes, running again. Mistakes are hidden in
/tmp/install_execd.*until the installation finishes. There's a problem where if/opt/sge/default/common/install_logsis not writeable by the user running the installation then it will be silently failing and retrying in the background. Installation is pretty much instantaneous, unless it's failing silently.)
- As a sub-note, you receive architecture errors on Fedora Core. You can fix this by editing
/opt/sge/util/archand changing line 248 that reads3|4|5)to3|4|5|6).- Success!
If you are now to run qhost on some host, eg, the master, you will now see all your hosts sitting waiting for instructions.
Administration
The fastest way to check if the Grid is working is to run qhost , which lists all the hosts in the Grid and their status. If you're seeing hyphens it means that host has disappeared. Is the daemon stopped, or has someone killed the machine?
The glossiest way to keep things up to date is to use qmon . I have it listed as an application in X11.app on my Mac. The application command is as follows. Change 'master' to the hostname of the Grid master. I hope you have SSH keys already setup.
ssh master -Y . /opt/sge/default/common/settings.sh \; qmonWant to gloat about how many CPUs you have in your cluster? (Does not work with machines that have > 100 CPU cores.)
admin@master:~$ qhost | sed -e 's/^.\{35\}[^0-9]\+//' | cut -d" " -f1Adding Administrators
SGE will probably run under a user you created it known as "sgeadmin". "root" does not automatically become all powerful in the Grid's eyes, so you probably want to add your usual user account as a Manager or Operator. (Have a look in the manual for how to do this.) It will make your life a lot easier.
Automatically sourcing environment
Normally you have to manually source the environment variables, eg, SGE_ROOT, that make things work. On your submit hosts you can have this setup to be done automatically for you.
Create links from /etc/profile.d to the settings files in /opt/sge/default/common and they'll be automatically sourced for bash and tcsh (at least on Redhat).
Slots
The fastest processing you'll do is when you have one CPU core working on one problem. This is how the Grid is setup by default. Each CPU core on the Grid is a slot into which a job can be put.
If you have people logging on to the machines and checking their email, or being naughty and running jobs by hand instead of via the Grid engine, these calculations get mucked up. Yes, there still is a slot there, but it is competing with something being run locally. The Grid finds a machine with a free slot and the lowest load for when it runs your job so this won't be a problem until the Grid is heavily laden.
Setting up queues
Queues are useful for doing crude prioritisation. Typically a job gets put in the default queue and when a slot becomes free it runs.
If the user has access to more than one queue, and there is a free slot in that queue, then the job gets bumped into that slot.
A queue instance is the queue on a host that it can be run on. 10 hosts, 3 queues = 30 queue instances. In the below example you can see three queues and seven queue instances : all.q@paikea, dnetc.q@paikea, beagle.q@paikea, all.q@exec1, dnetc.q@exec1, all.q@exec2, dnetc.q@exec2. Each queue can have a list of machines it runs on so, for example, the heavy genetics work in beagle.q can be run only on the machines attached to the SAN holding the genetics data. A queue does not have to include all hosts, ie, @allhosts.)
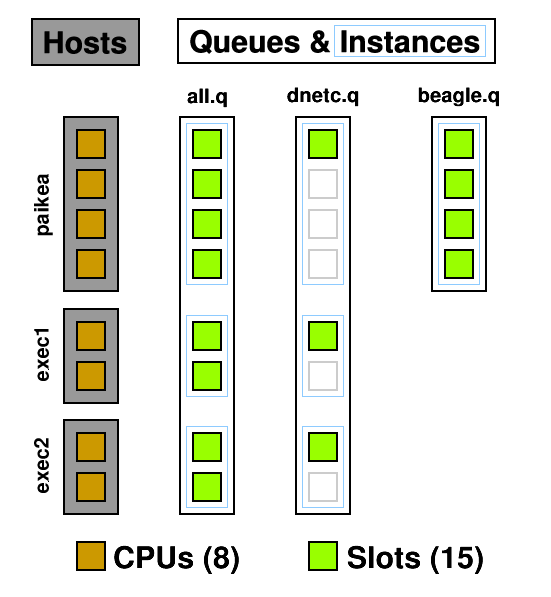
From this diagram you can see how CPUs can become oversubscribed. all.q covers every CPU. dnetc.q covers some of those CPUs a second time. Uh-oh! (dnetc.q is setup to use one slot per queue instance. That means that even if there are 10 CPUs on a given host, it will only use 1 of those.) This is something to consider when setting up queues and giving users access to them. Users can't put jobs into queues they don't have access to, so the only people causing contention are those with access to multiple queues but don't specify a queue ( -q ) when submitting.
Another use for queues are subordinate queues . I run low priority jobs in dnetc.q. When the main queue gets busy, all the jobs in dnetc.q are suspended until the main queue's load decreases. To do this I edited all.q, and under Subordinates added dnetc.q.
So far the shortest queue I've managed to make is one that uses 1 slot on each host it is allowed to run on. There is some talk in the documentation regarding user defined resources ( complexes ) which, much like licenses, can be "consumed" by jobs, thus limiting the number of concurrent jobs that can be run. (This may be useful for running an instance of Folding@Home, as it is not thread-safe , so you can set it up with a single "license".)
You can also change the default nice value of processes, but possibly the most useful setting is to turn on "rerunnable", which allows a task to be killed and run again on a different host.
Parallel Environment
Something that works better than queues and slots is to set up a
parallel environment. This can have a limited number of slots which counts over the entire grid and over every queue instance. As an example, Folding@Home is not thread safe. Each running thread needs its own work directory.How can you avoid contention in this case? Make each working directory a parallel environment, and limit the number of slots to 1.
I have four working directories named fah-a to fah-d . Each contains its own installation of the Folding@Home client:
$ ls ~/grid/fah-a/ fah-a client.cfg FAH504-Linux.exe workFor each of these directories I have created a parallel environment:
admin@master:~$ qconf -sp fah-a pe_name fah-a slots 1 user_lists fahThese parallel environments are made available to all queues that the job can be run in and all users that have access to the working directory - which is just me.
The script to run the client is a marvel of grid arguments. It requests the parallel environment, bills the job to the Folding@Home project, names the project, etc. See for yourself:
#!/bin/sh # use bash #$ -S /bin/sh # current directory #$ -cwd # merge output #$ -j y # mail at end #$ -m e # project #$ -P fah # name in queue #$ -N fah-a # parallel environment #$ -pe fah-a 1 ./FAH504-Linux.exe -oneunitNote the -pe argument that says this job requires one slot worth of fah-a please.
Not a grid option, but the -oneunit flag for the folding client is important as this causes the job to quit after one work unit and the next work unit can be shuffled around to an appropriate host with a low load whose queue isn't disabled. Otherwise the client could end up running in a disabled queue for a month without nearing an end.
With the grid taking care of the parallel environment I no longer need to worry about manually setting up job holds so that I can enqueue multiple units for the same work directory. -t 1-20 ahoy!
Complex Configuration
An alternative to the parallel environment is to use a Complex. You create a new complex, say how many slots are available, and then let people consume them!
- In the QMON Complex Configuration, add a complex called "fah_l", type INT, relation <=, requestable YES, consumable YES, default 0. Add, then Commit.
- I can't manage to get this through QMON, so I do it from the command line. qconf -me global and then add fah_l=1 to the complex_values.
- Again through the command line. qconf -mq all.q and then add fah_l=1 to the complex_values. Change this value for the other queues. (Note that a value of 0 means jobs requesting this complex cannot be run in this queue.)
- When starting a job, add -l fah_l=1 to the requirements.
I had a problem to start off with, where qstat was telling me that -25 licenses were available. However this is due to the default value, so make sure that is 0!
Using Complexes I have set up license handling for Matlab and Splus .
- -l splus=1 (to request a Splus license)
- -l matlab=1 (to request a Matlab license)
- -l ml=1,matlabc=1 (to request a Matlab license and a Matlab Compiler license)
- -l ml=1,matlabst=1 (to request a Matlab license and a Matlab Statistics Toolbox license)
As one host group does not have Splus installed on them I simply set that host group to have 0 Splus licenses available. A license will never be available on the @gradroom host group, thus Splus jobs will never be queued there.
Quotas
Instead of Complexes and parallel environments, you could try a quota!
Please excuse the short details:
admin@master$ qconf -srqsl admin@master$ qconf -mrqs lm2007_slots { name lm2007_slots description Limit the lm2007 project to 20 slots across the grid enabled TRUE limit projects lm2007 to slots=20 }Pending jobs
Want to know why a job isn't running?
- Job Control
- Pending Jobs
- Select a job
- Why ?
This is the same as qstat -f , shown at the bottom of this page.
Using Calendars
A calendar is a list of days and times along with states: off or suspended. Unless specified the state is on.
A queue, or even a single queue instance, can have a calendar attached to it. When the calendar says that the queue should now be "off" then the queue enters the disabled (D) state. Running jobs can continue, but no new jobs are started. If the calendar says it should be suspended then the queue enters the suspended (S) state and all currently running jobs are stopped (SIGSTOP).
First, create the calendar. We have an upgrade for paikea scheduled for 17 January:
admin@master$ qconf -scal paikeaupgrade calendar_name paikeaupgrade year 17.1.2008=off week NONEBy the time we get around to opening up paikea's case and pull out the memory jobs will have had several hours to complete after the queue is disabled. Now, we have to apply this calendar to every queue instance on this host. You can do this all through qmon but I'm doing it from the command line because I can. Simply edit the calendar line to append the hostname and calendar name:
admin@master$ qconf -mq all.q ... calendar NONE,[paikea=paikeaupgrade] ...Repeat this for all the queues.
There is a user who likes to use one particular machine and doesn't like jobs running while he's at the console. Looking at the usage graphs I've found out when he is using the machine and created a calendar based on this:
admin@master$ qconf -scal michael calendar_name michael year NONE week mon-sat=13-21=offThis calendar is obviously recurring weekly. As in the above example it was applied to queues on his machine. Note that the end time is 21, which covers the period from 2100 to 2159.
Suspending jobs automatically
Due to the number of slots being equal to the number of processors, system load is theoretically not going to exceed 1.00 (when divided by the number of processors). This value can be found in the np_load_* complexes .
But (and this is a big butt) there are a number of ways in which the load could go past a reasonable level:
- There are interactive users: all of the machines in the grad room (@gradroom) have console access.
- Someone logged in when they should not have: we're planning to disable ssh access to @ngaika except for %admins.
- A job is multi-threaded, and the submitter didn't mention this. If your Java program is using 'new Thread' somewhere, then it's likely you'll end up using multiple CPUs. Request more than one CPU when you're submitting the job. (-l slots=4 does not work.)
For example, with paikea , there are three queues:
- all.q (4 slots)
- paikea.q (4 slots)
- beagle.q (overlapping with the other two queues)
all.q is filled first, then paikea.q. beagle.q, by project and owner restrictions, is only available to the sponsor of the hardware. When their jobs come in, they can get put into beagle.q, even if the other slots are full. When the load average comes up, other tasks get suspended: first in paikea.q, then in all.q.
Let's see the configuration:
qname beagle.q hostlist paikea.stat.auckland.ac.nz priority 19,[paikea.stat.auckland.ac.nz=15] user_lists beagle projects beagleWe have the limited access to this queue through both user lists and projects. Also, we're setting the Unix process priority to be higher than the other queues.
qname paikea.q hostlist paikea.stat.auckland.ac.nz suspend_thresholds NONE,[paikea.stat.auckland.ac.nz=np_load_short=1.01] nsuspend 1 suspend_interval 00:05:00 slots 0,[paikea.stat.auckland.ac.nz=4]The magic here being that suspend_thresholds is set to 1.01 for np_load_short. This is checked every 5 minutes, and 1 process is suspended at a time. This value can be adjusted to get what you want, but it seems to be doing the trick according to graphs and monitoring the load. np_load_short is chosen because it updates the most frequently (every minute), more than np_load_medium (every five), and np_load_long (every fifteen minutes).
all.q is fairly unremarkable. It just defines four slots on paikea.
Submitting jobs Jobs are submitted to the Grid using qsub . Jobs are shell scripts containing commands to be run.
If you would normally run your job by typing ./runjob , you can submit it to the Grid and have it run by typing: qsub -cwd ./runjob
Jobs can be submitted while logged on to any submit host: sge-submit.stat.auckland.ac.nz .
For all the commands on this page I'm going to assume the settings are all loaded and you are logged in to a submit host. If you've logged in to a submit host then they'll have been sourced for you. You can source the settings yourself if required: . /opt/sge/default/common/settings.sh - the dot and space at the front are important .
Depending on the form your job is currently in they can be very easy to submit. I'm just going to go ahead and assume you have a shell script that runs the CPU-intensive computations you want and spits them out to the screen. For example, this tiny test.sh :
#!/bin/sh expr 3 + 5This computation is very CPU intensive!
Please note that the Sun Grid Engine ignores the bang path at the top of the script and will simply run the file using the queue's default shell which is csh. If you want bash, then request it by adding the very cryptic line: #$ -S /bin/sh
Now, let's submit it to the grid for running: Skip submission output
user@submit:~$ qsub test.sh Your job 464 ("test.sh") has been submitted user@submit:~$ qstat job-ID prior name user state submit/start at queue slots ja-task-ID ------------------------------------------------------------------------------------------------------- 464 0.00000 test.sh user qw 01/10/2008 10:48:03 1There goes our job, waiting in the queue to be run. We can run qstat a few more times to see it as it goes. It'll be run on some host somewhere, then disappear from the list once it is completed. You can find the output by looking in your home directory: Skip finding output
user@submit:~$ ls test.sh* test.sh test.sh.e464 test.sh.o464 user@submit:~$ cat test.sh.o464 8The output file is named based on the name of the job, the letter o , and the number of the job.
If your job had problems running have a look in these files. They probably explain what went wrong.
Easiest way to submit R jobs
Here are two scripts and a symlink I created to make it easy as possible to submit R jobs to your Grid:
qsub-R
If you normally do something along the lines of:
user@exec:~$ nohup nice R CMD BATCH toodles.RNow all you need to do is:
user@submit:~$ qsub-R toodles.R Your job 3540 ("toodles.R") has been submittedqsub-R is linked to submit-R, a script I wrote. It calls qsub and submits a simple shell wrapper with the R file as an argument. It ends up in the queue and eventually your output arrives in the current directory: toodles.R.o3540
Download it and install it. You'll need to make the ' qsub-R ' symlink to ' 3rd_party/uoa-dos/submit-R ' yourself, although there is one in the package already for lx24-x86: qsub-R.tar (10 KiB, tar)
Thrashing the Grid
Sometimes you just want to give something a good thrashing, right? Never experienced that? Maybe it's just me. Anyway, here are two ideas for submitting lots and lots of jobs:
- Write a script that creates jobs and submits them
- Submit the same thing a thousand times
There are merits to each of these methods, and both of them mimic typical operation of the grid, so I'm going to explain them both.
Computing every permutation
If you have two lists of values and wish to calculate every permutation, then this method will do the trick. There's a more complicated solution below .
qsub will happily pass on arguments you supply to the script when it runs. Let us modify our test.sh to take advantage of this:
#!/bin/sh #$ -S /bin/sh echo Factors $1 and $2 expr $1 + $2Now, we just need to submit every permutation to Grid:
user@submit:~$ for A in 1 2 3 4 5 ; do for B in 1 2 3 4 5 ; do qsub test.sh $A $B ; done ; doneAway the jobs go to be computed. If we have a look at different jobs we can see that it works. For example, job 487 comes up with:
user@submit:~$ cat test.sh.?487 Factors 3 and 5 8Right on, brother! That's the same answer as we got previously when we hard coded the values of 3 and 5 into the file. We have algorithm correctness!
If we use qacct to look up the job information we find that it was computed on host mako (shark) and used 1 units of wallclock and 0 units of CPU.
Computing every permutation, with R
This method of creating job scripts and running them will allow you to compute every permutation of two variables. Note that you can supply arguments to your script, so it is not actually necessary to over-engineer your solution quite this much. This script has the added advantage of not clobbering previous computations. I wrote this solution for Yannan Jiang and Chris Wild and posted it to the r-downunder mailing list in December 2007. ( There is another method of doing this! )
In this particular example the output of the R command is deterministic, so it does not matter that a previous run (which could have taken days of computing time) gets overwritten, however I also work around this problem.
To start with I have my simple template of R commands (template.R):
alpha <- ALPHA beta <- c(BETA) # magic happens here alpha betaThe ALPHA and BETA parameters change for each time this simulation is run. I have these values stored, one per line, in the files ALPHA and BETA.
ALPHA:
0.9 0.8 0.7BETA (please note that these contents must work both in filenames, bash commands, and R commands):
0,0,1 0,1,0 1,0,0I have a shell script that takes each combination of ALPHA x BETA, creates a .R file based on the template, and submits the job to the Grid. This is called submit.sh:
#!/bin/sh if [ "X${SGE_ROOT}" == "X" ] ; then echo Run: . /opt/sge/default/common/settings.sh exit fi cat ALPHA | while read ALPHA ; do cat BETA | while read BETA ; do FILE="t-${ALPHA}-${BETA}" # create our R file cat template.R | sed -e "s/ALPHA/${ALPHA}/" -e "s/BETA/${BETA}/" > ${FILE}.R # create a script echo \#!/bin/sh > ${FILE}.sh echo \#$ -S /bin/sh >> ${FILE}.sh echo "if [ -f ${FILE}.Rout ] ; then echo ERROR: output file exists already ; exit 5 ; fi" >> ${FILE}.sh echo R CMD BATCH ${FILE}.R ${FILE}.Rout >> ${FILE}.sh chmod +x ${FILE}.sh # submit job to grid qsub -j y -cwd ${FILE}.sh done done qstatWhen this script runs it will, for each permutation of ALPHA and BETA,
- create an R file based on the template, filling in the values of ALPHA and BETA,
- create a script that checks if this permutation has been calculated and then calls R,
- submits this job to the queue
... and finally shows the jobs waiting in the queue to execute.
Once computation is complete you will have a lot of files waiting in your directory. You will have:
- template.R -- our R commands template
- t-ALPHA-BETA.sh -- generated shell script that calls R
- t-ALPHA-BETA.R -- generated (from template) R commands
- t-ALPHA-BETA.Rout -- output from the command; this is a quirk of R
- t-ALPHA-BETA.sh.oNNN -- any output or errors from job (merged using qsub -j y )
The output files, stderr and stdout from when R was run, are always empty (unless something goes terribly wrong). For each permutation we receive four files. There are nine permutations (n ALPHA = 3, n BETA = 3, 3 × 3 = 9). A total of 36 files are created. (This example has been pared down from the original for purposes of demonstration.)
My initial question to the r-downunder list was how to get the output from R to stdout and thus t-ALPHA-BETA.sh.oNNN instead of t-ALPHA-BETA.Rout, however in this particular case, I have dodged that. In fact, being deterministic it is better that this job writes its output to a known filename, so I can do a one line test to see if the job has already been run.
I should also point out the -cwd option to the qsub command, which causes the job to be run in the current directory (which if it is in your home directory is accessible in the same place on all machines), rather than in /tmp/* . This allows us to find the R output, since R writes it to the directory it is currently in. Otherwise it could be discarded as a temporary file once the job ends!
Submit the same thing a thousand times
Say you have a job that, for example, pulls in random numbers and runs a simulation, or it grabs a work unit from a server, computes it, then quits. ( FAH -oneunit springs to mind, although it cannot be run in parallel. Refer to the parallel environment setup .) The script is identical every time.
SGE sets the SGE_JOB_ID environment variable which tells you the job number. You can use this as some sort of crude method for generating a unique file name for your output. However, the best way is to write everything to standard output (stdout) and let the Grid take care of returning it to you.
There are also Array Jobs which are
identical tasks being differentiated only by an index number, available through the -t option on qsub . This sets the environment variable of SGE_TASK_ID.For this example I will be using the Distributed Sleep Server . The Distributed Sleep Project passes out work units, packages of time, to clients who then process the unit. The Distributed Sleep Client, dsleepc , connects to the server to fetch a work unit. They can then be processed using the sleep command. A sample script: Skip sample script
#!/bin/sh #$ -S /bin/sh WORKUNIT=`dsleepc` sleep $WORKUNIT && echo Processed $WORKUNIT secondsWork units of 300 seconds typically take about five minutes to complete, but are known to be slower on Windows. (The more adventurous can add the -bigunit option to get a larger package for themselves, but note that they take longer to process.)
So, let us submit an array job to the Grid. We are going to submit one job with 100 tasks, and they will be numbered 1 to 100:
user@submit:~$ qsub -t 1-100 dsleep Your job-array 490.1-100:1 ("dsleep") has been submittedJob 490, tasks 1 to 100, are waiting to run. Later we can come back and pick up our output from our home directory. You can also visit the Distributed Sleep Project and check the statistics server to see if your work units have been received.
Note that running 100 jobs will fill the default queue, all.q. This has two effects. First, if you have any other queues that you can access jobs will be added to those queues and then run. (As the current setup of queues overlaps with CPUs this can lead to over subscription of processing resources. This can cause jobs to be paused, depending on how the queue is setup.) Second, any subordinate queues to all.q will be put on hold until the jobs get freed up.
Array jobs, with R
Using the above method of submitting multiple jobs, we can access this and use it in our R script, as follows: Skip R script
# alpha+1 is found in the SGE TASK number (qsub -t) alphaenv <- Sys.getenv("SGE_TASK_ID") alpha <- (as.numeric(alphaenv)-1)Here the value of alpha is being pulled from the task number. Some manipulation is done of it, first to turn it from a string into a number, and secondly to change it into the expected form. Task numbers run from 1+, but in this case the code wants them to run from 0+.
Similar can be done with Java, by adding the environment value as an argument to invocation of the main class.
Advanced methods of queue submission
When you submit your job you have a lot of flexibility over it. Here are some options to consider that may make your life easier. Remember you can always look in the man page for qsub for more options and explanations.
qsub -N timmy test.shHere the job is called "timmy" and runs the script test.sh . Your the output files will be in timmy.[oe]*
The working directory is usually somewhere in /tmp on the execution host. To use a different working directory, eg, the current directory, use -cwd
qsub -cwd test.shTo request specific characteristics of the execution host, for example, sufficient memory, use the -l argument.
qsub -l mem_free=2500M test.shThis above example requests 2500 megabytes (M = 1024x1024, m = 1000x1000) of free physical memory (mem_free) on the remote host. This means it won't be run on a machine that has 2.0GB of memory, and will instead be put onto a machine with sufficient amounts of memory for BEAGLE Genetic Analysis . There are two other options for ensuring you get enough memory:
- Submit your job to the BEAGLE queue: -q beagle.q . This queue is specifically setup only on machines with a lot of free memory, and has 10 slots. You do have to be one of the allowed BEAGLE users to put jobs into this queue.
- Specify the amount of memory required in your script:
#$ -l mem=2500If your binary is architecture dependent you can ask for a particular architecture.
qsub -l arch=lx24-amd64 test.binThis can also be done in the script that calls the binary so you don't accidentally forget about including it.
#$ -l arch=lx24-amd64This requesting of resources can also be used to ask for a specific host, which goes against the idea of using the Grid to alleviate finding a host to use! Don't do this!
qsub -l hostname=mako test.shIf your job needs to be run multiple times then you can create an array job. You ask for a job to be run several times, and each run (or task) is given a unique task number which can be accessed through the environment variable SGE_TASK_ID. In each of these examples the script is run 50 times:
qsub -t 1-50 test.sh qsub -t 75-125 test.shYou can request a specific queue. Different queues have different characteristics.
- lm2007.q uses a maximum of one slot per host (although once I figure out how to configure it, it will use a maximum of six slots Grid-wide).
- dnetc.q is suspended when the main queue (all.q) is busy.
- beagle.q runs only on machines with enough memory to handle the data (although this can be requested with -l , as shown above).
qsub -q dnetc.q test.shA job can be held until a previous job completes. For example, this job will not run until job 380 completes:
qsub -hold_jid 380 test.shCan't figure out why your job isn't running? qstat can tell you:
qstat -j 490 ... lots of output ... scheduling info: queue instance "[email protected]" dropped because it is temporarily not available queue instance "[email protected]" dropped because it is full cannot run in queue "all.q" because it is not contained in its hard queue list (-q)Requesting licenses
Should you be using software that requires licenses then you should specify this when you submit the job. We have two licenses currently set up but can easily add more as requested:
- -l splus=1 (to request a Splus license)
- -l matlab=1 (to request a Matlab license)
- -l ml=1,matlabc=1 (to request a Matlab license and a Matlab Compiler license)
- -l ml=1,matlabst=1 (to request a Matlab license and a Matlab Statistics Toolbox license)
The Grid engine will hold your job until a Splus license or Matlab license becomes available.
Note: The Grid engine keeps track of the license pool independently of the license manager. If someone is using a license that the Grid doesn't know about, eg, an interactive session you left running on your desktop, then the count will be off. Believing a license is available, the Grid will run your job, but Splus will not run and your job will end. Here is a job script that will detect this error and then allow your job to be retried later: Skip Splus script
#!/bin/sh #$ -S /bin/bash # run in current directory, merge output #$ -cwd -j y # name the job #$ -N Splus-lic # require a single Splus license please #$ -l splus=1 Splus -headless < $1 RETVAL=$? if [ $RETVAL == 1 ] ; then echo No license for Splus sleep 60 exit 99 fi if [ $RETVAL == 127 ] ; then echo Splus not installed on this host # you could try something like this: #qalter -l splus=1,h=!`hostname` $JOB_ID sleep 60 exit 99 fi exit $RETVALPlease note that the script exits with code 99 to tell the Grid to reschedule this job (or task) later. Note also that the script, upon receiving the error, sleeps for a minute before exiting, thus slowing the loop of errors as the Grid continually reschedules the job until it runs successfully. Alternatively you can exit with error 100, which will cause the job to be held in the error (E) state until manually cleared to run again.
You can clear a job's error state by using qmod -c jobid .
Here's the same thing for Matlab. Only minor differences from running Splus: Skip Matlab script
#!/bin/sh #$ -S /bin/sh # run in current directory, merge output #$ -cwd -j y # name the job #$ -N ml # require a single Matlab license please #$ -l matlab=1 matlab -nodisplay < $1 RETVAL=$? if [ $RETVAL == 1 ] ; then echo No license for Matlab sleep 60 exit 99 fi if [ $RETVAL == 127 ] ; then echo Matlab not installed on this host, `hostname` # you could try something like this: #qalter -l matlab=1,h=!`hostname` $JOB_ID sleep 60 exit 99 fi exit $RETVALSave this as "run-matlab". To run your matlab.m file, submit with: qsub run-matlab matlab.m
Processing partial parts of input files in Java
Here is some code I wrote for Lyndon Walker to process a partial dataset in Java.
It comes with two parts: a job script that passes the correct arguments to Java, and some Java code that extracts the correct information from the dataset for processing.
First, the job script gives some Grid task environment variables to Java. Our job script is merely translating from the Grid to the simulation:
java Simulation $@ $SGE_TASK_ID $SGE_TASK_LASTThis does assume your shell is bash, not csh. If your job is in 10 tasks, then SGE_TASK_ID will be a number between 1 and 10, and SGE_TASK_LAST will be 10. I'm also assuming that you are starting your jobs from 1, but you can also change that setting and examine SGE_TASK_FIRST.
Within Java we now read these variables and act upon them:
sge_task_id = Integer.parseInt(args[args.length-2]); sge_task_last = Integer.parseInt(args[args.length-1]);For a more complete code listing, refer to sun-grid-qsub-java-partial.java (Simulation.java).
Preparing confidential datasets
The Grid setup here includes machines on which users can login. That creates the problem where someone might be able to snag a confidential dataset that is undergoing processing. One particular way to keep the files secure is as follows:
- Check we are able to securely delete files
- Locate a safe place to store files locally (the Grid sets up ${TMPDIR} to be unique for this job and task)
- Copy over dataset; it is expected you have setup password-less scp
- Preprocess dataset, eg, unencrypt
- Process dataset
- Delete dataset
A script that does this would look like the following: Skip dataset preparation script
#!/bin/sh #$ -S /bin/sh DATASET=confidential.csv # check our environment umask 0077 cd ${TMPDIR} chmod 0700 . # find srm SRM=`which srm` NOSRM=$? if [ $NOSRM -eq 1 ] ; then echo system srm not found on this host, exiting >> /dev/stderr exit 99 fi # copy files from data store RETRIES=0 while [ ${RETRIES} -lt 5 ] ; do ((RETRIES++)) scp user@filestore:/store/confidential/${DATASET} . if [ $? -eq 0 ] ; then RETRIES=5000 else # wait for up to a minute (MaxStartups 10 by default) sleep `expr ${RANDOM} / 542` fi done if [ ! -f ${DATASET} ] ; then # unable to copy dataset after 5 retries, quit but retry later echo unable to copy dataset from store >> /dev/stderr exit 99 fi # if you were decrypting the dataset, you would do that here # copy our code over too cp /mount/code/*.class . # process data java Simulation ${DATASET} # collect results # (We are just printing to the screen.) # clean up ${SRM} -v ${DATASET} >> /dev/stderr echo END >> /dev/stderrCode will need to be adjusted to match your particular requirements, but the basic form is sketched out above.
As the confidential data is only in files and directories that root and the running user can access, and the same precaution is taken with the datastore, then only the system administrator and the user who has the dataset has access to these files.
The one problem here is how to manage the password-less scp securely. As this is run unattended, it would not be possible to have a password on a file, nor to forward authentication to some local agent. It may be possible to grab the packets that make up the key material. There must be a better way to do this. Remember that the job script is stored world-readable in the Grid cell's spool, so nothing secret can be put in there either.
Talk at Department Retreat
I gave a talk about the Sun Grid Engine on 19 February 2008-02-19 to the Department, giving a quick overview of the need for the grid and how to rearrange tasks to better make use of parallelism. It was aimed at end users and summarises into neat slides the reason for using the grid engine as well as a tutorial and example on how to use it all.
Download: Talk (with notes) PDF 5.9MiB
Question time afterwards was very good. Here are, as I recall them, the questions and answers.
Which jobs are better suited to parallelism?
Q (Ross Ihaka): Which jobs are better suited to parallelism? (Jobs with large data sets do not lend themselves to this sort of parallelism due to I/O overheads.)
A: Most of the jobs being used here are CPU intensive. The grid copies your script to /tmp on the local machine on which it runs. You could copy your data file across as well at the start of the job, thus all your later I/O is local.
(This is a bit of a poor answer. I wasn't really expecting it.) Bayesian priors and multiple identical simulations (eg, MCMC differing only by random numbers) lend themselves well to being parallelised.
Can I make sure I always run on the fastest machine?
A: The grid finds the machine with the least load to run jobs on. If you pile all jobs onto one host, then that host will slow down and become the slowest overall. Submit it through the grid and some days you'll get the fast host, and some days you'll get the slow host, and it is better in the long run. Also it is fair for other users. You can force it with -l, however, it is selfish.
Preemptable queues?
Q (Nicholas Horton): Is there support for preemptable queues? A person who paid for a certain machine might like it to be available only to them when they require it all for themselves.
A: Yes, the Grid has support for queues like that. It can all be configured. This particular example will have to be looked in to further. Beagle.q, as an example, only runs on paikea and overlaps with all.q . Also when the load on paikea , again using that as an example, gets too high, jobs in a certain queue (dnetc.q) are stopped.
An updated answer: the owner of a host can have an exclusive queue that preempts the other queues on the host. When the system load is too high, less important jobs can be suspended using suspend_thresholds .
Is my desktop an execution host?
Q (Ross Ihaka): Did I see my desktop listed earlier?
A: No. So far the grid is only running on the servers in the basement and the desktops in the grad room. Desktops in staff offices and used by PhD candidates will have to opt in.
(Ross Ihaka) Offering your desktop to run as an execution host increases the total speed of the grid, but your desktop may run slower at times. It is a two way street.
Is there job migration?
A: It's crude, and depends on your job. If something goes wrong (eg, the server crashes, power goes out) your job can be restarted on another host. When queue instances become unavailable (eg, we're upgrading paikea) they can send a signal to your job, telling it to save its work and quit, then can be restarted on another host.
Migration to faster hosts
Q (Chris Wild): What happens if a faster host becomes available while my job is running?
A: Nothing. Your job will continue running on the host it is on until it ends. If a host is overloaded, and not due to the grid's fault, some jobs can be suspended until load decreases . The grid isn't migrating jobs. The best method is to break your job down into smaller jobs, so that when the next part of the job is started it gets put onto what is currently the best available host.
Over sufficient jobs it will become apparent that the faster host is processing more jobs than a slower host.
Desktops and calendars
Q (Stephane Guindon): What about when I'm not at my desktop. Can I have my machine be on the grid then, and when I get to the desktop the jobs are migrated?
A: Yes, we can set up calendars so that at certain times no new jobs will be started on your machine. Jobs that are already running will continue until they end. (Disabling the queue.) Since some jobs run for days this can appear to have no influence on how many jobs are running. Alternatively jobs can be paused, which frees up the CPU, but leaves the job sitting almost in limbo. (Suspending the queue.) Remember the grid isn't doing migration. It can stop your job and run it elsewhere (if you're using the -notify option on submission and handling the USR1 signal).
Jobs under the grid
Q (Sharon Browning): How can I tell if a job is running under the grid's control? It doesn't show this under top .
A: Try ps auxf . You will see the job taking a lot of CPU time, the parent script, and above that the grid (sge_shepherd and sge_execd).
Talk for Department Seminar
On September 11 I gave a talk to the Department covering:
- Trends in Supercomputing
- Increase in power
- Increase in power consumption
- Increase in data
- Collection of servers
- Workflows
- Published services
- Collaboration
- How to use it
- Jargon
- Taking advantage of more CPUs
- Rewriting your code
- Case Studies
- Increasing your Jargon
- Question time
Download slides with extensive notes: Supercomputing and You (PDF 3MiB)
A range of good questions:
- What about psuedo-random number generators being initialised with the same seed?
- How do I get access to these resources if I'm not a researcher here?
- How do I get access to this Department's resources?
- Do Windows programs (eg, WinBUGS) run on the Grid?
Summary
In summary, I heartily recommend the Sun Grid Engine. After a few days installation, configuring, messing around, I am very impressed with what can be done with it.
Try it today.
Aug 17, 2018 | www.rocksclusters.org
Operating System Base
Rocks 7.0 (Manzanita) x86_64 is based upon CentOS 7.4 with all updates available as of 1 Dec 2017.
Building a bare-bones compute clusterBuilding a more complex cluster
- Boot your frontend with the kernel roll
- Then choose the following rolls: base , core , kernel , CentOS and Updates-CentOS
In addition to above, select the following rolls:
Building Custom Clusters
- area51
- fingerprint
- ganglia
- kvm (used for virtualization)
- hpc
- htcondor (used independently or in conjunction with sge)
- perl
- python
- sge
- zfs-linux (used to build reliable storage systems)
If you wish to build a custom cluster, you must choose from our a la carte selection, but make sure to download the required base , kernel and both CentOS rolls. The CentOS rolls include CentOS 7.4 w/updates pre-applied. Most users will want the full updated OS so that other software can be added.
MD5 ChecksumsPlease double check the MD5 checksums for all the rolls you download.
DownloadsAll ISOs are available for downloads from here . Individual links are listed below.
Name Description Name Description kernel Rocks Bootable Kernel Roll required zfs-linux ZFS On Linux Roll. Build and Manage Multi Terabyte File Systems. base Rocks Base Roll required fingerprint Fingerprint application dependencies core Core Roll required hpc Rocks HPC Roll CentOS CentOS Roll required htcondor HTCondor High Throughput Computing (version 8.2.8) Updates-CentOS CentOS Updates Roll required sge Sun Grid Engine (Open Grid Scheduler) job queueing system kvm Support for building KVM VMs on cluster nodes perl Support for Newer Version of Perl ganglia Cluster monitoring system from UCB python Python 2.7 and Python 3.x area51 System security related services and utilities openvswitch Rocks integration of OpenVswitch
Oct 15, 2017 | biohpc.blogspot.com
Installation of Son of Grid Engine(SGE) on CentOS7
SGE Master installation
master# hostnamectl set-hostname qmaster.local
master# vi /etc/hosts
192.168.56.101 qmaster.local qmaster
192.168.56.102 compute01.local compute01master# mkdir -p /BiO/src
master# yum -y install epel-release
master# yum -y install jemalloc-devel openssl-devel ncurses-devel pam-devel libXmu-devel hwloc-devel hwloc hwloc-libs java-devel javacc ant-junit libdb-devel motif-devel csh ksh xterm db4-utils perl-XML-Simple perl-Env xorg-x11-fonts-ISO8859-1-100dpi xorg-x11-fonts-ISO8859-1-75dpi
master# groupadd -g 490 sgeadmin
master# useradd -u 495 -g 490 -r -m -d /home/sgeadmin -s /bin/bash -c "SGE Admin" sgeadmin
master# visudo
%sgeadmin ALL=(ALL) NOPASSWD: ALL
master# cd /BiO/src
master# wget http://arc.liv.ac.uk/downloads/SGE/releases/8.1.9/sge-8.1.9.tar.gz
master# tar zxvfp sge-8.1.9.tar.gz
master# cd sge-8.1.9/source/
master# sh scripts/bootstrap.sh && ./aimk && ./aimk -man
master# export SGE_ROOT=/BiO/gridengine && mkdir $SGE_ROOT
master# echo Y | ./scripts/distinst -local -allall -libs -noexit
master# chown -R sgeadmin.sgeadmin /BiO/gridenginemaster# cd $SGE_ROOT
master# ./install_qmaster
press enter at the intro screen
press "y" and then specify sgeadmin as the user id
leave the install dir as /BiO/gridengine
You will now be asked about port configuration for the master, normally you would choose the default (2) which uses the /etc/services file
accept the sge_qmaster info
You will now be asked about port configuration for the master, normally you would choose the default (2) which uses the /etc/services file
accept the sge_execd info
leave the cell name as "default"
Enter an appropriate cluster name when requested
leave the spool dir as is
press "n" for no windows hosts!
press "y" (permissions are set correctly)
press "y" for all hosts in one domain
If you have Java available on your Qmaster and wish to use SGE Inspect or SDM then enable the JMX MBean server and provide the requested information - probably answer "n" at this point!
press enter to accept the directory creation notification
enter "classic" for classic spooling (berkeleydb may be more appropriate for large clusters)
press enter to accept the next notice
enter "20000-20100" as the GID range (increase this range if you have execution nodes capable of running more than 100 concurrent jobs)
accept the default spool dir or specify a different folder (for example if you wish to use a shared or local folder outside of SGE_ROOT
enter an email address that will be sent problem reports
press "n" to refuse to change the parameters you have just configured
press enter to accept the next notice
press "y" to install the startup scripts
press enter twice to confirm the following messages
press "n" for a file with a list of hosts
enter the names of your hosts who will be able to administer and submit jobs (enter alone to finish adding hosts)
skip shadow hosts for now (press "n")
choose "1" for normal configuration and agree with "y"
press enter to accept the next message and "n" to refuse to see the previous screen again and then finally enter to exit the installermaster# cp /BiO/gridengine/default/common/settings.sh /etc/profile.d/
master# qconf -ah compute01.local
compute01.local added to administrative host listmaster# yum -y install nfs-utils
master# vi /etc/exports
/BiO 192.168.56.0/24(rw,no_root_squash)master# systemctl start rpcbind nfs-server
master# systemctl enable rpcbind nfs-serverSGE Client installation
compute01# yum -y install hwloc-devel
compute01# hostnamectl set-hostname compute01.local
compute01# vi /etc/hosts
192.168.56.101 qmaster.local qmaster
192.168.56.102 compute01.local compute01compute01# groupadd -g 490 sgeadmin
compute01# useradd -u 495 -g 490 -r -m -d /home/sgeadmin -s /bin/bash -c "SGE Admin" sgeadmincompute01# yum -y install nfs-utils
compute01# systemctl start rpcbind
compute01# systemctl enable rpcbind
compute01# mkdir /BiO
compute01# mount -t nfs 192.168.56.101:/BiO /BiO
compute01# vi /etc/fstab
192.168.56.101:/BiO /BiO nfs defaults 0 0compute01# export SGE_ROOT=/BiO/gridengine
compute01# export SGE_CELL=default
compute01# cd $SGE_ROOT
compute01# ./install_execd
compute01# cp /BiO/gridengine/default/common/settings.sh /etc/profile.d/
Apr 25, 2018 | github.com
nicoulaj commented
on Dec 1 2016 FYI, I got a working version with SGE on CentOS 7 on my linked branch.
This is quick and dirty because I need it working right now, there are several issues:
- I inverted the SGE setup/NFS export order due to #347 , so Debian support is probably broken
- The RPMs for RHEL do not contain systemd init files, so there are some workarounds to start
sge_execdmanually- I used
set_factto set global variables forSGE_ROOT, maybe there is a cleaner way ? I never used Ansible until now, I don't know the good practices...
Apr 24, 2018 | liv.ac.uk
From: JuanEsteban.Jimenez at mdc-berlin.de [mailto: JuanEsteban.Jimenez at mdc-berlin.de ]
Sent: 27 April 2017 03:54 PM
To: yasir at orionsolutions.co.in ; 'Maximilian Friedersdorff'; sge-discuss at liverpool.ac.uk
Subject: Re: [SGE-discuss] SGE Installation on Centos 7I am running SGE on nodes with both 7.1 and 7.3. Works fine on both.
Just make sure that if you are using Active Directory/Kerberos for authentication and authorization, your DC's are capable of handling a lot of traffic/requests. If not, things like DRMAA will uncover any shortcomings.
Mfg,
Juan Jimenez
System Administrator, BIH HPC Cluster
MDC Berlin / IT-Dept.
Tel.: +49 30 9406 2800====================
I installed SGE on Centos 7 back in January this year. If my recolection is correct, the procedure was analogous to the instructions for Centos 6. There were some issues with the firewalld service (make sure that it is not blocking SGE), as well as some issues with SSL.
Check out these threads for reference:http://arc.liv.ac.uk/pipermail/sge-discuss/2017-January/001047.html
http://arc.liv.ac.uk/pipermail/sge-discuss/2017-January/001050.html
May 08, 2017 | ctbp.ucsd.edu
- An example of simple APBS serial job.
#!/bin/csh -f #$ -cwd # #$ -N serial_test_job #$ -m e #$ -e sge.err #$ -o sge.out # requesting 12hrs wall clock time #$ -l h_rt=12:00:00 /soft/linux/pkg/apbs/bin/apbs inputfile >& outputfile- An example script for running executable
a.outin parallel on 8 CPUs. (Note: For your executable to run in parallel it must be compiled with parallel library like MPICH, LAM/MPI, PVM, etc.) This script shows file staging, i.e., using fast local filesystem/scratchon the compute node in order to eliminate speed bottlenecks.#!/bin/csh -f #$ -cwd # #$ -N parallel_test_job #$ -m e #$ -e sge.err #$ -o sge.out #$ -pe mpi 8 # requesting 10hrs wall clock time #$ -l h_rt=10:00:00 # echo Running on host `hostname` echo Time is `date` echo Directory is `pwd` set orig_dir=`pwd` echo This job runs on the following processors: cat $TMPDIR/machines echo This job has allocated $NSLOTS processors # copy input and support files to a temporary directory on compute node set temp_dir=/scratch/`whoami`.$$ mkdir $temp_dir cp input_file support_file $temp_dir cd $temp_dir /opt/mpich/intel/bin/mpirun -v -machinefile $TMPDIR/machines \ -np $NSLOTS $HOME/a.out ./input_file >& output_file # copy files back and clean up cp * $orig_dir rm -rf $temp_dir- An example of SGE script for Amber users (parallel run, 4 CPUs, with input file generated on the fly):
#!/bin/csh -f #$ -cwd # #$ -N amber_test_job #$ -m e #$ -e sge.err #$ -o sge.out #$ -pe mpi 4 # requesting 6hrs wall clock time #$ -l h_rt=6:00:00 # setenv MPI_MAX_CLUSTER_SIZE 2 # export all environment variables to SGE #$ -V echo Running on host `hostname` echo Time is `date` echo Directory is `pwd` echo This job runs on the following processors: cat $TMPDIR/machines echo This job has allocated $NSLOTS processors set in=./mdin set out=./mdout set crd=./inpcrd.equil cat <<eof > $in short md, nve ensemble &cntrl ntx=7, irest=1, ntc=2, ntf=2, tol=0.0000001, nstlim=1000, ntpr=10, ntwr=10000, dt=0.001, vlimit=10.0, cut=9., ntt=0, temp0=300., &end &ewald a=62.23, b=62.23, c=62.23, nfft1=64,nfft2=64,nfft3=64, skinnb=2., &end eof set sander=/soft/linux/pkg/amber8/exe.parallel/sander set mpirun=/opt/mpich/intel/bin/mpirun # needs prmtop and inpcrd.equil files $mpirun -v -machinefile $TMPDIR/machines -np $NSLOTS \ $sander -O -i $in -c $crd -o $out < /dev/null /bin/rm -f $in restrt
Please note that if you are running parallel amber8 you must include the following in your.cshrc:# Set P4_GLOBMEMSIZE environment variable used to reserve memory in bytes # for communication with shared memory on dual nodes # (optimum/minimum size may need experimentation) setenv P4_GLOBMEMSIZE 32000000- An example of SGE script for APBS job (parallel run, 8 CPUs, running example input file which is included in APBS distribution (/soft/linux/src/apbs-0.3.1/examples/actin-dimer):
#!/bin/csh -f #$ -cwd # #$ -N apbs-PARALLEL #$ -e apbs-PARALLEL.errout #$ -o apbs-PARALLEL.errout # # requesting 8 processors #$ -pe mpi 8 echo -n "Running on: " hostname setenv APBSBIN_PARALLEL /soft/linux/pkg/apbs/bin/apbs-icc-parallel setenv MPIRUN /opt/mpich/intel/bin/mpirun echo "Starting apbs-PARALLEL calculation ..." $MPIRUN -v -machinefile $TMPDIR/machines -np 8 \ $APBSBIN_PARALLEL apbs-PARALLEL.in >& apbs-PARALLEL.out echo "Done."- An example of SGE script for parallel CHARMM job (4 processors):
#!/bin/csh -f #$ -cwd # #$ -N charmm-test #$ -e charmm-test.errout #$ -o charmm-test.errout # # requesting 4 processors #$ -pe mpi 4 # requesting 2hrs wall clock time #$ -l h_rt=2:00:00 # echo -n "Running on: " hostname setenv CHARMM /soft/linux/pkg/c31a1/bin/charmm.parallel.092204 setenv MPIRUN /soft/linux/pkg/mpich-1.2.6/intel/bin/mpirun echo "Starting CHARMM calculation (using $NSLOTS processors)" $MPIRUN -v -machinefile $TMPDIR/machines -np $NSLOTS \ $CHARMM < mbcodyn.inp > mbcodyn.out echo "Done."- An example of SGE script for parallel NAMD job (8 processors):
#!/bin/csh -f #$ -cwd # #$ -N namd-job #$ -e namd-job.errout #$ -o namd-job.out # # requesting 8 processors #$ -pe mpi 8 # requesting 12hrs wall clock time #$ -l h_rt=12:00:00 # echo -n "Running on: " hostname /soft/linux/pkg/NAMD/namd2.sh namd_input_file > namd2.log echo "Done."- An example of SGE script for parallel Gromacs job (4 processors):
#!/bin/csh -f #$ -cwd # #$ -N gromacs-job #$ -e gromacs-job.errout #$ -o gromacs-job.out # # requesting 4 processors #$ -pe mpich 4 # requesting 8hrs wall clock time #$ -l h_rt=8:00:00 # echo -n "Running on: " cat $TMPDIR/machines setenv MDRUN /soft/linux/pkg/gromacs/bin/mdrun-mpi setenv MPIRUN /soft/linux/pkg/mpich/intel/bin/mpirun $MPIRUN -v -machinefile $TMPDIR/machines -np $NSLOTS \ $MDRUN -v -nice 0 -np $NSLOTS -s topol.tpr -o traj.trr \ -c confout.gro -e ener.edr -g md.log echo "Done."
biowiki.org
After submitting your job to Grid Engine you may track its status by using either the qstat command, the GUI interface QMON, or by email.
Monitoring with qstatThe qstat command provides the status of all jobs and queues in the cluster. The most useful options are:
- qstat: Displays list of all jobs with no queue status information.
- qstat -u hpc1***: Displays list of all jobs belonging to user hpc1***
- qstat -f: gives full information about jobs and queues.
- qstat -j [job_id]: Gives the reason why the pending job (if any) is not being scheduled.
You can refer to the man pages for a complete description of all the options of the qstat command.
Monitoring Jobs by Electronic MailAnother way to monitor your jobs is to make Grid Engine notify you by email on status of the job.
In your batch script or from the command line use the -m option to request that an email should be send and -M option to precise the email address where this should be sent. This will look like:
#$ -M myaddress@work
#$ -m beasWhere the (-m) option can select after which events you want to receive your email. In particular you can select to be notified at the beginning/end of the job, or when the job is aborted/suspended (see the sample script lines above).
And from the command line you can use the same options (for example):
qsub -M myaddress@work -m be job.sh
How do I control my jobsBased on the status of the job displayed, you can control the job by the following actions:
Monitoring and controlling with QMON
Modify a job: As a user, you have certain rights that apply exclusively to your jobs. The Grid Engine command line used is qmod. Check the man pages for the options that you are allowed to use.
- Suspend/(or Resume) a job: This uses the UNIX kill command, and applies only to running jobs, in practice you type
qmod -s/(or-r)job_id (where job_id is given by qstat or qsub).
- Delete a job: You can delete a job that is running or spooled in the queue by using the qdel command like this
qdel job_id (where job_id is given by qstat or qsub).
You can also use the GUI QMON, which gives a convenient window dialog specifically designed for monitoring and controlling jobs, and the buttons are self explanatory.
For further information, see the SGE User's Guide ( PDF, HTML).
May 07, 2017 | biowiki.org
Does your job show "Eqw" or "qw" state when you run qstat , and just sits there refusing to run? Get more info on what's wrong with it using:
$ qstat -j <job number>
Does your job actually get dispatched and run (that is, qstat no longer shows it - because it was sent to an exec host, ran, and exited), but something else isn't working right? Get more info on what's wrong with it using:
$ qacct -j <job number> (especially see the lines "failed" and "exit_status")
If any of the above have an "access denied" message in them, it's probably a permissions problem. Your user account does not have the privileges to read from/write to where you told it (this happens with the -e and -o options to qsub often). So, check to make sure you do. Try, for example, to SSH into the node on which the job is trying to run (or just any node) and make sure that you can actually read from/write to the desired directories from there. While you're at it, just run the job manually from that node, see if it runs - maybe there's some library it needs that the particular node is missing.
To avoid permissions problems, cd into the directory on the NFS where you want your job to run, and submit from there using qsub -cwd to make sure it runs in that same directory on all the nodes.
Not a permissions problem? Well, maybe the nodes or the queues are unreachable. Check with:
qstat -f
or, for even more detail:
qstat -F
If the "state" column in qstat -f has a big E , that host or queue is in an error state due to... well, something. Sometimes an error just occurs and marks the whole queue as "bad", which blocks all jobs from running in that queue, even though there is nothing otherwise wrong with it. Use qmod -c <queue list> to clear the error state for a queue.
Maybe that's not the problem, though. Maybe there is some network problem preventing the SGE master from communicating with the exec hosts, such as routing problems or a firewall misconfiguration. You can troubleshoot these things with qping , which will test whether the SGE processes on the master node and the exec nodes can communicate.
N.B.: remember, the execd process on the exec node is responsible for establishing a TCP/IP connection to the qmaster process on the master node , not the other way around. The execd processes basically "phone home". So you have to run qping from the exec nodes , not the master node!
Syntax example (I am running this on a exec node, and sheridan is the SGE master):
$ qping sheridan 536 qmaster 1
where 536 is the port that qmaster is listening on, and 1 simply means that I am trying to reach a daemon. Can't reach it? Make sure your firewall has a hole on that port, that the routing is correct, that you can ping using the good old ping command, that the qmaster process is actually up, and so on.
Of course, you could ping the exec nodes from the master node, too, e.g. I can see if I can reach exec node kosh like this:
$ qping kosh 537 execd 1
but why would you do such a crazy thing? execd is responsible for reaching qmaster , not the other way around.
If the above checks out, check the messages log in /var/log/sge_messages on the submit and/or master node (on our Babylon Cluster , they're both the node sheridan ):
$ tail /var/log/sge_messages
Personally, I like running:
$ tail -f /var/log/sge_messages
before I submit the job, and then submit a job in a different window. The -f option will update the tail of the file as it grows, so you can see the message log change "live" as your job executes and see what's happening as things take place.
(Note that the above is actually a symbolic link I put in to the messages log in the qmaster spool directory, i.e. /opt/sge/default/spool/qmaster/messages .)
One thing that commonly goes wrong is permissions. Make sure that the user that submitted the job using qsub actually has the permissions to write error, output, and other files to the paths you specified.
For even more precise troubleshooting... maybe the problem is unique only to some nodes(s) or some queue(s)? To pin it down, try to run the job only on some specific node or queue:
$ qsub -l hostname=<node/host name> <other job params>
$ qsub -l qname=<queue name> <other job params>
Maybe you should also try to SSH into the problem nodes directly and run the job locally from there, as your own user, and see if you can get any more detail on why it fails.
If all else fails...Sometimes, the SGE master host will become so FUBARed that we have to resort to brute, traumatizing force to fix it. The following solution is equivalent to fixing a wristwatch with a bulldozer, but seems to cause more good than harm (although I can't guarantee that it doesn't cause long-term harm in favor of a short-term solution).
Basically, you wipe the database that keeps track of SGE jobs on the master host, taking any problem "stuck" jobs with it. (At least that's what I think this does...)
I've found this useful when:
- You submit >10,000 jobs to SGE, which uses too much system resources resulting in their inability to get dispatched to exec hosts, and start getting the "failed receiving gdi request" error on something as simple as qstat . You can't use qdel to wipe the jobs due to the same error.
- A job is stuck in the r state (and if you try to delete it, the dr state) despite the fact that the exec host is not running the job, not is even aware of it. This can happen if you reboot a stuck/unresponsive exec host.
The solution:
ssh sheridan su - service sgemaster stop cd /opt/sge/default/ mv spooldb spooldb.fubared mkdir spooldb cp spooldb.fubared/sge spooldb/ chown -R sgeadmin:sgeadmin spooldb service sgemaster startWipe spooldb.fubared when you are confident that you won't need its contents again.
Feb 08, 2017 | www.biostars.org
Question: Sge,Torque, Pbs : What'S The Best Choise For A Ngs Dedicated Cluster ? 114.4 years ago by abihouee • 110 abihouee • 110 wrote:
Sorry, it may be off topics...
We plan to install a scheduler on our cluster (DELL blade cluster over Infiniband storage on Linux CentOS 6.3). This cluster is dedicated to do NGS data analysis.
It seems to me that the most current is SGE, but since Oracle bougth the stuff, there are several alternative developments ( OpenGridEngine , SonGridEngine , Univa Grid Engine ...)
An other possible scheluler is Torque / PBS .
I' m a little bit lost in this scheduler forest ! Is there someone with any experiment on this or who knows some existing benchmark ?
Thanks a lot. Audrey
next-gen analysis clustering • 15k views ADD COMMENT • link • modified 2.1 years ago by joe.cornish826 ♦ 4.4k • written 4.4 years ago by abihouee • 110 2I worked with SGE for years at a genome center in Vancouver. Seemed to work quite well. Now I'm at a different genome center and we are using LSF but considering switching to SGE, which is ironic because we are trying to transition from Oracle DB to PostGres to get away from Oracle... SGE and LSF seemed to offer similar functionality and performance as far as I can tell. Both clusters have several 1000 cpus.
ADD REPLY • link modified 4.3 years ago • written 4.3 years ago by Malachi Griffith ♦ 14k 1openlava ( source code ) is an open-source fork of LSF that while lacking some features does work fairly well.
ADD REPLY • link written 2.1 years ago by Malachi Griffith ♦ 14k 1Torque is fine, and very well tested; either of the SGE forks are widely used in this sort of environment, and has qmake, which some people are very fond of. SLURM is another good possibility.
ADD REPLY • link modified 2.1 years ago • written 2.1 years ago by Jonathan Dursi • 250 104.4 years ago by matted ♦ 6.3k Boston, United States matted ♦ 6.3k wrote:
I can only offer my personal experiences, with the caveat that we didn't do a ton of testing and so others may have differing opinions.
We use SGE, which installs relatively nicely on Ubuntu with the standard package manager (the gridengine-* packages). I'm not sure what the situation is on CentOS.
We previously used Torque/PBS, but the scheduler performance seemed poor and it bogged down with lots of jobs in the queue. When we switched to SGE, we didn't have any problems. This might be a configuration error on our part, though.
When I last tried out Condor (several years ago), installation was quite painful and I gave up. I believe it claims to work in a cross-platform environment, which might be interesting if for example you want to send jobs to Windows workstations.
LSF is another option, but I believe the licenses cost a lot.
My overall impression is that once you get a system running in your environment, they're mostly interchangeable (once you adapt your submission scripts a bit). The ease with which you can set them up does vary, however. If your situation calls for "advanced" usage (MPI integration, Kerberos authentication, strange network storage, job checkpointing, programmatic job submission with DRMAA, etc. etc.), you should check to see which packages seem to support your world the best.
ADD COMMENT • link written 4.4 years ago by matted ♦ 6.3k 1Recent versions of torque have improved a great deal for large numbers of jobs, but yes, that was a real problem.
I also agree that all are more or less fine once they're up and working, and the main way to decide which to use would be to either (a) just pick something future users are familiar with, or (b) pick some very specific things you want to be able to accomplish with the resource manager/scheduler and start finding out which best support those features/workflows.
ADD REPLY • link written 2.1 years ago by Jonathan Dursi • 250 44.4 years ago by Jeremy Leipzig ♦ 16k Philadelphia, PA Jeremy Leipzig ♦ 16k wrote:
Unlike PBS, SGE has qrsh , which is a command that actually run jobs in the foreground, allowing you to easily inform a script when a job is done. What will they think of next?
This is one area where I think the support you pay for going commercial might be worthwhile. At least you'll have someone to field your complaints.
ADD COMMENT • link modified 2.1 years ago • written 4.4 years ago by Jeremy Leipzig ♦ 16k 2EDIT: Some versions of PBS also have qsub -W block=true that works in a very similar way to SGE qsrh.
ADD REPLY • link modified 4.4 years ago • written 4.4 years ago by Sean Davis ♦ 22kyou must have a newer version than me
ADD REPLY • link modified 4.4 years ago • written 4.4 years ago by Jeremy Leipzig ♦ 16k>qsub -W block=true dothis.sh qsub: Undefined attribute MSG=detected presence of an unknown attribute >qsub --version version: 2.4.11For Torque and perhaps versions of PBS without -W block=true, you can use the following to switches. The behaviour is similar but when called, any embedded options to qsub will be ignored. Also, stderr/stdout is sent to the shell.
qsub -I -x dothis.shADD REPLY • link modified 16 months ago • written 16 months ago by matt.demaere • 0 1My answer should be updated to say that any DRMAA-compatible cluster engine is fine, though running jobs through DRMAA (e.g.
Snakemake --drmaa) instead of with a batch scheduler may anger your sysadmin, especially if they are not familiar with scientific computing standards.using qsub -I just to get a exit code is not ok
ADD REPLY • link written 2.1 years ago by Jeremy Leipzig ♦ 16kTorque definitely allows interactive jobs -
qsub -IAs for Condor, I've never seen it used within a cluster; it was designed back in the day for farming out jobs between diverse resources (e.g., workstations after hours) and would have a lot of overhead for working within a homogeneous cluster. Scheduling jobs between clusters, maybe?
ADD REPLY • link modified 2.1 years ago • written 2.1 years ago by Jonathan Dursi • 250 44.4 years ago by Ashutosh Pandey ♦ 10k Philadelphia Ashutosh Pandey ♦ 10k wrote:
We use Rocks Cluster Distribution that comes with SGE.
http://en.wikipedia.org/wiki/Rocks_Cluster_Distribution
ADD COMMENT • link written 4.4 years ago by Ashutosh Pandey ♦ 10k 1+1 Rocks - If you're setting up a dedicated cluster, it will save you a lot of time and pain.
ADD REPLY • link written 4.3 years ago by mike.thon • 30I'm not a huge rocks fan personally, but one huge advantage, especially (but not only) if you have researchers who use XSEDE compute resources in the US, is that you can use the XSEDE campus bridging rocks rolls which bundle up a large number of relevant software packages as well as the cluster management stuff. That also means that you can directly use XSEDEs extensive training materials to help get the cluster's new users up to speed.
ADD REPLY • link written 2.1 years ago by Jonathan Dursi • 250 34.3 years ago by samsara • 470 The Earth samsara • 470 wrote:
It has been more than a year i have been using SGE for processing NGS data. I have not experienced any problem with it. I am happy with it. I have not used any other scheduler except Slurm few times.
ADD COMMENT • link written 4.3 years ago by samsara • 470 22.1 years ago by richard.deborja • 80 Canada richard.deborja • 80 wrote:
Used SGE at my old institute, currently using PBS and I really wish we had SGE on the new cluster. Things I miss the most, qmake and the "-sync y" qsub option. These two were completely pipeline savers. I also appreciated the integration of MPI with SGE. Not sure how well it works with PBS as we currently don't have it installed.
ADD COMMENT • link written 2.1 years ago by richard.deborja • 80 12.1 years ago by joe.cornish826 ♦ 4.4k United States joe.cornish826 ♦ 4.4k wrote:
NIH's Biowulf system uses PBS, but most of my gripes about PBS are more about the typical user load. PBS always looks for the next smallest job, so your 30 node run that will take an hour can get stuck behind hundreds (and thousands) of single node jobs that take a few hours each. Other than that it seems to work well enough.
In my undergrad our cluster (UMBC Tara) uses SLURM, didn't have as many problems there but usage there was different, more nodes per user (82 nodes with ~100 users) and more MPI/etc based jobs. However, a grad student in my old lab did manage to crash the head nodes because we were rushing to rerun a ton of jobs two days before a conference. I think it was likely a result of the head node hardware and not SLURM. Made for a few good laughs.
ADD COMMENT • link modified 2.1 years ago • written 2.1 years ago by joe.cornish826 ♦ 4.4k 2"PBS always looks for the next smallest job" -- just so people know, that's not something inherent to PBS. That's a configurable choice the scheduler (probably maui in this case) makes, but you can easily configure the scheduler so that bigger jobs so that they don't get starved out by little jobs that get "backfilled" into temporarily open slots.
ADD REPLY • link written 2.1 years ago by Jonathan Dursi • 250Part of it is because Biowulf looks for the next smallest job but also prioritizes by how much cpu time a user has been consuming. If I've run 5 jobs with 30x 24 core nodes each taking 2 hours of wall time, I've used roughly 3600 CPU hours. If someone is using a single core on each node (simple because of memory requirements), they're basically at a 1:1 ratio between wall and cpu time. It will take a while for their CPU hours to catch up to mine.
It is a pain, but unlike math/physics/etc there are fewer programs in bioinformatics that make use of message passing (and when they do, they don't always need low-latency ICs), so it makes more sense to have PBS work for the generic case. This behavior is mostly seen on the ethernet IC nodes, there's a much smaller (245 nodes) system set up with infiniband for jobs that really need it (e.g. MrBayes, structural stuff).
Still I wish they'd try and strike a better balance. I'm guilty of it but it stinks when the queue gets clogged with memory intensive python/perl/R scripts that probably wouldn't need so much memory if they were written in C/C++/etc.
Mar 02, 2016 | liv.ac.uk
README
This is Son of Grid Engine version v8.1.9.
See <http://arc.liv.ac.uk/repos/darcs/sge-release/NEWS> for information on recent changes. See <https://arc.liv.ac.uk/trac/SGE> for more information.
The .deb and .rpm packages and the source tarball are signed with PGP key B5AEEEA9.
* sge-8.1.9.tar.gz, sge-8.1.9.tar.gz.sig: Source tarball and PGP signature * RPMs for Red Hat-ish systems, installing into /opt/sge with GUI installer and Hadoop support: * gridengine-8.1.9-1.el5.src.rpm: Source RPM for RHEL, Fedora * gridengine-*8.1.9-1.el6.x86_64.rpm: RPMs for RHEL 6 (and CentOS, SL) See < https://copr.fedorainfracloud.org/coprs/loveshack/SGE/ > for hwloc 1.6 RPMs if you need them for building/installing RHEL5 RPMs. * Debian packages, installing into /opt/sge, not providing the GUI installer or Hadoop support: * sge_8.1.9.dsc, sge_8.1.9.tar.gz: Source packaging. See <http://wiki.debian.org/BuildingAPackage> , and see < http://arc.liv.ac.uk/downloads/SGE/support/ > if you need (a more recent) hwloc. * sge-common_8.1.9_all.deb, sge-doc_8.1.9_all.deb, sge_8.1.9_amd64.deb, sge-dbg_8.1.9_amd64.deb: Binary packages built on Debian Jessie. * debian-8.1.9.tar.gz: Alternative Debian packaging, for installing into /usr. * arco-8.1.6.tar.gz: ARCo source (unchanged from previous version) * dbwriter-8.1.6.tar.gz: compiled dbwriter component of ARCo (unchanged from previous version)More RPMs (unsigned, unfortunately) are available at < http://copr.fedoraproject.org/coprs/loveshack/SGE/ >.
[gridengine users] Undocumented Feature of load sensors
Fritz Ferstl fferstl at univa.com
Thu Apr 16 15:15:36 UTC 2015
•Previous message: [gridengine users] Undocumented Feature of load sensors
•Next message: [gridengine users] Undocumented Feature of load sensors
• Messages sorted by: [ date ] [ thread ] [ subject ] [ author ]It is certainly an intended feature, William. Always was since load
sensor were introduced in the late 90s.The thought behind it was that you might have central system management
services which maintain host level information. You can then put the
load sensor on the system management server instead of having 1000s of
hosts query it. But you can use it for other stuff as well, of course.Cheers,
Fritz
William Hay schrieb:
> It appears that you can have load sensors report values for individual hosts other than the one on which it runs. I've tested this by having a load sensor run on one host report different values for two different hosts and used qhost -F to verify that gridengine reports them.
>
> The possibility of doing this is implied by the format of load sensor reports but I've never seen it explicitly documented as possible or used elsewhere.
>
> Being able to use this would simplify certain aspects of the configuration of our production cluster so it would be useful to know if this is intended behavior
> and therefore something I can rely on or an implementation quirk.
>
> Opinions?
Reuti reuti at staff.uni-marburg.de
Thu Apr 9 21:19:12 UTC 2015
- Previous message: [gridengine users] Anyone have scripts for detecting users who bypass grid engine?
- Next message: [gridengine users] Anyone have scripts for detecting users who bypass grid engine?
- Messages sorted by: [ date ] [ thread ] [ subject ] [ author ]
Am 09.04.2015 um 23:09 schrieb Feng Zhang: > I know that some people use ssh as rsh_command, which may have similar problem? Not when you have a tight integration of `ssh` in SGE: https://arc.liv.ac.uk/SGE/htmlman/htmlman5/remote_startup.html section "SSH TIGHT INTEGRATION" Then `ssh` can't spawn any process which escapes form SGE. -- Reuti > On Thu, Apr 9, 2015 at 3:46 PM, Reuti <reuti at staff.uni-marburg.de> wrote: >> Am 09.04.2015 um 21:23 schrieb Chris Dagdigian: >> >>> >>> I'm one of the people who has been arguing for years that technological methods for stopping abuse of GE systems never work in the long term because motivated users always have more time and interest than overworked admins so it's kind of embarrassing to ask this but ... >>> >>> Does anyone have a script that runs on a node and prints out all the userland processes that are not explicitly a child of a sge_sheperd daemon? >>> >>> I'm basically looking for a light way to scan a node just to see if there are users/tasks running that are outside the awareness of the SGE qmaster. Back in the day when we talked about this it seemed that one easy method was just looking for user stuff that was not a child process of a SGE daemon process. >>> >>> The funny thing is that it's not the HPC end users who do this. As the grid(s) get closer and closer to the enterprise I'm starting to see software developers and others trying to play games and then plead ignorance when asked "why did you SSH to a compute node and start a tomcat service out of your home directory?". heh. >> >> Why allow `ssh` to a node at all? In my installations only the admins can do this. If users want to peek around on a node I have an interactive queue with a h_cpu limit of 60 seconds for this. So even login in to a node is controlled by SGE. >> >> -- Reuti >> >> >>> >>> -chris >>> >>> >>> >>> _______________________________________________ >>> users mailing list >>> users at gridengine.org >>> https://gridengine.org/mailman/listinfo/users >> >> >> _______________________________________________ >> users mailing list >> users at gridengine.org >> https://gridengine.org/mailman/listinfo/users > > > > -- > Best, > > Feng >
[gridengine users] Consumable configuration best practices question for hundreds of resources for specific group of nodes
William Hay w.hay at ucl.ac.uk
Mon Mar 30 08:41:10 UTC 2015
•Previous message: [gridengine users] Consumable configuration best practices question for hundreds of resources for specific group of nodes
•Next message: [gridengine users] External Scheduler
• Messages sorted by: [ date ] [ thread ] [ subject ] [ author ]On Sun, 29 Mar 2015 08:50:15 +0000
Yuri Burmachenko <yuribu at mellanox.com> wrote:
>
> Users will care about which cells they are using.Could you confirm my understanding is correct below is correct:
The users of this system care which cells they need to use for reasons other than avoiding oversubscription of the cell.
Cell 25 is fundamentally different from cell 39 even when both are free.
The users want to be able to tell the scheduler which cells to use rather than being able to write a job script that can read a list of cells
to use from a file or similar.If all the above is true then your 300 different complex_values are probably unavoidable but it won't be pretty.
>
> Our partial solution should allow the users to control/monitor/request/free these cells.
>
>
>
> I looked into the links https://arc.liv.ac.uk/trac/SGE/ticket/1426 and http://gridengine.eu/grid-engine-internals/102-univa-grid-engine-810-features-part-2-better-resource-management-with-the-rsmap-complex-2012-05-25 - I see that many consumable resources can be attached on host basis with RSMAP.
>
Not entirely AIUI (and we're not Univa customers) RSMAP resources can be associated with queues or the global host as well. Also you request the number of resources you want but UGE assigns the specific resources(cells in you case) that your job will use. If I'm understanding you correctly that won't work for you.> We need to be able to attach these 300 consumable resources as shared between 4 nodes – is it possible? Maybe a separate queue for these 4 particular hosts with list of complex consumable resources?
That doesn't work because resources defined on a cluster queue exist for each queue instance.
Grid Engine doesn't have a simple way to associate a resource with a group of hosts other than the cluster as a whole. What you can do is define resource availability on the global pseudo host then add a restriction by some means to prevent usage other than on the hosts in question:
*You could define your queue configuration so that all queues on all other nodes have 0 of the resource available while the nodes with access say nothing about availability and therefore have access to the full resources defined on the global host.
*You could define the resources as having 0 availability on hosts other than the ones in question.
*You could probably also do the same with resource quotas.The first of the above is probably simplest/least work assuming your existing queue configuration is simple.
> All cells are different and users will need to know which one they need to request. At this stage they all should be distinct.
OK. If users request a lot of different cells for individual jobs this will probably lead to long delays before jobs start. Said users will almost certainly want to request
a dynamic reservation for their jobs (-R y).
arc.liv.ac.uk
This is Son of Grid Engine version v8.1.7.
See <http://arc.liv.ac.uk/repos/darcs/sge-release/NEWS> for information on recent changes. See <https://arc.liv.ac.uk/trac/SGE> for more information.
The .deb and .rpm packages and the source tarball are signed with PGP key B5AEEEA9. For some reason the el5 signatures won't verify on RHEL5, but they can be verified by transferring the rpms to an RHEL6 system.
- * sge-8.1.7.tar.gz, sge-8.1.7.tar.gz.sig: Source tarball and PGP signature
- * sge-8.1.7a.tar.gz: Source with a fix for building with recent GNU
binutils (RHEL7 and recent Fedora, at least)- * RPMs for Red Hat-ish systems, installing into /opt/sge with GUI
installer and Hadoop support:- * gridengine-8.1.7-1.src.rpm: Source RPM for Red Hat 5/6, Fedora
- * gridengine-*8.1.7-1.el5.x86_64.rpm: RPMs for Red Hat 5 (and
CentOS, SL)- * gridengine-*8.1.7-1.el6.x86_64.rpm: RPMs for Red Hat 6 (and
CentOS, SL)- See <http://arc.liv.ac.uk/downloads/SGE/support/> for source and
binary RPMs of hwloc-1.4.1 for building/installing the RPMs above,
if necessary.- * Debian packages, installing into /opt/sge, not providing the GUI
installer or Hadoop support:- * sge_8.1.7.dsc, sge_8.1.7.tar.gz: Source packaging. See
<http://wiki.debian.org/BuildingAPackage>, and see
<http://arc.liv.ac.uk/downloads/SGE/support/> if you need (a more
recent) hwloc.- * sge-common_8.1.7_all.deb, sge-doc_8.1.7_all.deb,
sge_8.1.7_amd64.deb, sge-dbg_8.1.7_amd64.deb: Binary packages
built on Debian Wheezy.- * sge-8.1.7-common.tar.gz: Common files to accompany binary tarballs
(including GUI installer and Hadoop integration)- * arco-8.1.6.tar.gz: ARCo source (unchanged from last version)
- * dbwriter-8.1.6.tar.gz: compiled dbwriter component of ARCo
(unchanged from last version)More (S)RPMS may be available at http://jur-linux.org/rpms/el-updates/, thanks to Florian La Roche.
Contents
- News
- Repositories/Source
- Building
- Bug reporting, patches, and mail lists
- History
- Copyright and Naming
- Related
- Other Resources
- Contact
The Son of Grid Engine is a community project to continue Sun's old gridengine free software project that used to live at http://gridengine.sunsource.net after Oracle shut down the site and stopped contributing code. (Univa now own the copyright - see below.) It will maintain copies of as much as possible/useful from the old site.
The idea is to encourage sharing, in the spirit of the original project, informed by long experience of free software projects and scientific computing support. Please contribute, and share code or ideas for improvement, especially any ideas for encouraging contribution.
This effort precedes Univa taking over gridengine maintenance and subsequently apparently making it entirely proprietary, rather than the originally-promised 'open core'. What's here was originally based on Univa's free code and was intended to be fed into that.
See also the gridengine.org site, in particular the mail lists hosted there. The gridengine.org users list is probably the best one to use for general gridengine discussions and questions which aren't specific to this project.
Currently most information you find for the gridengine v6.2u5 release will apply to this effort, but the non-free documentation that used to be available from Oracle has been expurgated and no-one has the time/interest to replace it. See also Other Resources, particularly extra information locally, and the download area.
This wiki isn't currently generally editable, but will be when spam protection is in place; yes it needs reorganizing and expanding. If you're a known past contributor to gridengine and would like to help, please get in touch for access or to make any other contributions.
- 2014-06-01: Version 8.1.7 available.
- 2013-11-01: Version 8.1.6 available, fixing various bugs.
- 2013-09-29: Version 8.1.5 available, mainly to fix MS Windows build problems.
- 2013-08-30: Version 8.1.4 available; bug fixes and some enhancements, now with over 1000 patches since Oracle pulled the plug.
- 2013-02-27: Version 8.1.3 available; bug fixes and a few enhancements, plus Debian packaging (as an add-on).
- 2013-01: The gridengine.debian repository contains proposed new packaging for Debian (as opposed to the standalone packaging now in the sge repository).
- 2012-08-28: Version 8.1.2 available, mainly fixing a regression in 8.1.1 and providing Linux cpuset-based containment (NEWS).
- 2012-07-17: Version 8.1.1 available with many changes and extra binaries for Cygwin (only client programs currently usable).
- 2012-06-10: Version 8.1.0 available, with a few stability fixes over 8.0.0e and better RPM packaging as well as adopting different versioning.
Download gridengine-6.2u5-10.el6.4.x86_64.rpm for CentOS 6 / RHEL 6 from EPEL repository. 10. Advanced search. About; Contact; ... /usr/share/gridengine/bin/lx26-amd64/qhost /usr/share/gridengine/bin/lx26 ... 2012-03-15 - Orion Poplawski <[email protected]> 6.2u5-10.2 - Use sge_/SGE_ in man pages.pkgs.org/centos-6-rhel-6/epel-x86_64/gridengine-... More from pkgs.org
What is Grid Engine?
Grid Engine is a job scheduler that has been around for years and it's FREE!! If you are already using it under an open source license you certainly don't need to buy it. Grid Engine started out as a Sun Microsystems product known as Sun Grid Engine (SGE). After Oracle purchased Sun it became Oracle Grid Engine.
Why is another company trying to sell Grid Engine if it is Free?
A small company called Univa has essentially taken away some of the Grid Engine development staff from Oracle is selling support bundled with what they feel is an upgraded source code that is no longer Open Source. This company wants to sell you Grid Engine support instead of you going to Oracle and buying it for essentially the same price. You can even get free Grid Engine Support here with the open source community, and here with the Oracle community.
And you can get the Oracle version here for free which is being developed just like the small company version is but WITH the blessing of Oracle who actually bought this product from Sun.
If you are looking at buying the univa company version of Grid Engine you might ask yourself what you are buying? Is there a free product that is the same? Yes, from Oracle and Source forge. Is there another more reputable version of the same product? Yes, from Oracle. Are there other schedulers out there that are more robust that you can buy? Yes, Platform Computing has an excellent product called LSF that can often be purchased for much less than univa grid engine can be. PBSWorks offers a scheduler that is very good as well as RTDA. There is even a new company that is developing the free Grid Engine source code as well as the core and is actively supporting the free community with support and upgrades called Scalable logic. They have even now come out with an upgraded free version of Grid Engine as Univa has attempted to but this version from Scalable Logic is free and totally open source. It has support for many Operating Systems including even Windows.
Are there risks in going with this version of Grid Engine from Univa?
It's possible that univa may tell you that you could be risking violation of software licensing agreements with Oracle or other parties by using certain versions of Grid Engine for free. They may try to use fear, uncertainty, and doubt (FUD) to scare you into buying with them in thinking that it will protect you from Oracle. It may, but before you buy you may want to check that out with Oracle and the open source community and find out for yourself because that may not be the real risk you face. What you may face with this small company is potentially more operational than legal.
If you think about it, they are essentially trying to make money off of a free open source product. This is not the most lucrative idea in the software world and makes the prospect of making money as a company doing this very difficult if not impossible. You might ask yourself if you think they are going to make it. They have carved out a software product and a team from one of the largest software companies in the world, trying to make money on a free product that Oracle bought with the Sun acquisition. If they do not make it and fail as a company, where will you be with your paid software subscription and product through them? If they do make it and then happen to gain the attention of Oracle and its Lawyers, where will you be if Oracle decides to take legal action against them, or just decides to shut them down? Do you really think that a small company with possibly faulty management and financials would have the resources to remain, let alone still be concerned with your support contract? Would your company be protected or could that liability extend to you as well? These might all be questions you would want to pose to Oracle or at least another party besides Univa if you decided on purchasing Grid Engine.
Either way, univa and its pay version of Grid Engine could be in a tough spot. No matter which way they go they may have a good chance of ending up insolvent or worse. If this happens where would your support contract with them be. Or worse still, what position would you be in with to Oracle at that point? Again, a very good question to ask Oracle. With all these risks it might be better to again look at the free version which even Oracle is offering as they themselves are showing commitment to Grid Engine and the enhancement of the free version.
Effective October 22, 2013, Univa, a leader in Grid Engine technology, will assume product support for Oracle Grid Engine customers for the remaining term of their existing Oracle Grid Engine support contracts.
For continued access to Grid Engine product support from Univa, customers with an active support contract should visit support.univa.com, or contact Univa Support at [email protected] or 800.370.5320.
For more details on this announcement or future sales and support inquiries for Grid Engine, please visit www.univa.com/oracle or contact [email protected].
Son of Grid Engine is a highly-scalable and versatile distributed resource manager for scheduling batch or interactive jobs on clusters or desktop farms. It is a community project to continue Sun's Grid... Engine.
It is competitive against proprietary systems and provides better scheduling features and scalability than other free DRMs like Torque, SLURM, Condor, and Lava
SGE 8.1.0 is available from
http://arc.liv.ac.uk/downloads/SGE/releases/8.1.0
It corrects a few problems with the previous version, takes an overdue opportunity to adopt a more logical numbering now that tracking the Univa repo is irrelevant, and improves the RPM packaging.The RPMs now include the GUI installer and the "herd" Hadoop integration built against a more recent Cloudera distribution. (The GUI installer was previously separate as the original IzPack packaging was non-distributable.)
Generally this distribution has hundreds of improvements not (freely?) available in others, including security fixes, maintained documentation, and easy building at least on recent GNU/Linux.
Yahoo!
Univa, the Data Center Automation Company, announced today the release of Univa Grid Engine Version 8.1, the most widely deployed, distributed resource management software platform used by enterprises and research organizations across the globe. Univa Grid Engine is the industry-leading choice for workload management and integrating Big Data solutions while saving time and money through increased uptime and reduced total cost of ownership. Corporations in the industries of Oil and Energy, Life Sciences and Biology, and Semiconductors rely on Univa Grid Engine when they need mission-critical computing capacity to model and solve complex problems.
Key features include:
- Processor core and NUMA memory binding for jobs which enables applications to run consistently and over 10% faster
- Job Classes describing how applications run in a server farm, slashing the time to onboard and manage workflow
- Resource maps which define how hardware and software resources are ordered and used in the server farm helping to improve throughput and utilization of the server farm
- Improved Job Debugging and Diagnostics allowing administrators discover issues in less time
- New support for Postgres database job spooling that balances speed of submission with reliability in high volume server farms that have lots of small jobs
- Documented and tested integrations with common MPI environments allows for valuable time saved since Univa has done the integration work.
Jeppesen has implemented Univa Grid Engine to support their Crew & Fleet management products for distributing optimization jobs, RAVE compilations and Studio sessions. "Jeppesen has selected Univa Grid Engine as this was the most appealing alternative looking at both cost and Univa's ability to make future enhancements to the product," said Pete Catherall, Business Operations Manager, Jeppesen. "This is another example of that."
April 25, 2012
After Wolfgang left Sun, - many fine people in Sun had to leave at that time - it was frustrating to see how our efforts to have two Sun Grid Engine products (one available by subscription and one available as free Open Source) failed because of management veto. On one hand we were under pressure to be profitable as a unit, on the other hand, our customers appeared to have no reason to pay even one cent for a subscription or license.
Oracle still has IP control of Grid Engine. Both Univa and Oracle decided to make no more contributions to the open source. While in Oracle open source policies are clear, Univa, a champion of open source for many years, has surprised the community. This has created an agitated thread on Grid Engine discussion group.
Sun Grid Engine 6.2 Update 2 introduced the support for Windows Operating systems to run as worker nodes. Sun or Oracle Grid Engine as it's being relabeled now is a distributed resource manager primarily used in HPC environment, but there's more widespread use now with all the new features introduced as part of Update 5.Here I'm going to detail a quick how-to of getting Grid Engine installed and running on Windows hosts. This is more applicable for Windows XP and Windows Server 2003, some of additional prerequisites required on the Windows hosts are now standard in Windows Server 2008 and Windows 7.
Son of Grid Engine is a highly-scalable and versatile distributed resource manager for scheduling batch or interactive jobs on server farms or desktop farms. It is a community project to continue Sun's Grid...
Bio-IT World
...NIBR had already chosen Sun Grid Engine Enterprise Edition (SGEEE) to run on the server farm. The BioTeam was asked to deploy SGEEE and integrate several FLEXlm-licensed scientific applications. Acceptance tests for determining success were rigorous. The server farm had to withstand test cases developed by the researchers while automatically detecting and correcting license-related job errors without human intervention.
The core problem turned out to be the most straightforward to solve. To prevent the NIBR server farm from running jobs when no licenses were available, the Grid Engine scheduler needed to become license aware. This was accomplished via a combination of "load sensor" scripts and specially configured Grid Engine "resources."
· Load sensor scripts give Grid Engine operators the ability to collect additional system measurements to help make scheduling or resource allocation decisions.
· Resources are a Grid Engine concept used primarily by users who require a particular need to be met in order for a job to complete successfully. A user-requested resource could be dynamic ("run job only on a system with at least 2 GB of free memory") or static ("run job on the machine with laser printer attached").
The NIBR plan involved creating custom resource attributes within Grid Engine so that scientists could submit jobs with the requirement "only run this job if a license is available." If licenses were available, the jobs would be dispatched immediately; if not, the jobs would be held until licenses were available.
To this point, the project was easy. Much more difficult - and more interesting - were efforts to meet NIBR acceptance tests.
The first minor headache resulted from trying to accurately automate querying of the FLEXlm license servers. One FLEXlm license server was an older version that only revealed the number of currently in-use licenses. This meant that the total number of available licenses (equally important) needed to be hard-coded into Grid Engine. NIBR researchers felt strongly that this could create server farm management problems, so the license server was upgraded to a version that allowed the load sensor script to learn how many licenses were available.
The next problem was figuring out how to automatically detect jobs that still managed to fail with license-related errors. The root cause of these failures is the loose integration between the FLEXlm license servers and Grid Engine. Race conditions may occur when Grid Engine launches server farm jobs that do not immediately check out their licenses from the FLEXlm server. Delays can cause Grid Engine's internal license values to get slightly out of sync with the real values held by the license server.
Nasty race conditions between license servers and server farm resource management systems such as Grid Engine are mostly unavoidable at present. The solution everyone is hoping for is FLEXlm support of an API (application programming interface) for advance license reservation and checkout. Applications such as Grid Engine could then directly hook into the FLEXlm system rather than rely on external polling methods. Until this occurs, we are left with half-measures and workarounds.
Mar 10, 2011
Back in the day …
Way back in 2009 I placed an aging copy of my Grid Engine Administration training materials online. Response has been fantastic and it's still one of the more popular links on this blog.
Today
Well it's probably past time I did something similar aimed at people actually interested in using Grid Engine rather than just administering it.
It's not comprehensive or all that interesting but I am going to post a bunch of slides cherry picked from the collection of things I build custom training presentations from. Think of them as covering an intro-level view of Grid Engine use and usage.
Intro to Grid Engine Usage & Simple Workflows
There are two slide decks, both of which are mostly stripped of information that is unique to a particular client, customer or Grid Engine server farm.
The first presentation is a short and dry introduction aimed at a user audience – it explains what Grid Engine is, what it does and what the expectations of the users are. It then dives into commands and examples.
The second presentation is also aimed at a basic user audience but talks a bit more about workflows, pipelines and simple SGE features that make life a bit easier for people who need to do more than a few simple 'qsub' actions.
By abstracting end users from the specific machines processing the workload, machine failures can be taken in stride. When a machine fails, the workload it was processing can be requeued and rescheduled. While the machine remains down, new workload is scheduled around that machine, preventing end users from ever noticing the machine failure. In addition to the Oracle Grid Engine product's rich scheduling and workload management capabilities, it also has the ability to share resources among fixed services, such as between two Oracle Grid Engine server farms, resulting in even higher overall data center utilization. Included in this capability is the ability to reach out to a private or public cloud service provider to lease additional resources when needed. During peak workload periods, additional virtual machines can be leased from a cloud service provider to augment the on-site resources. When the workload subsides the leased cloud resources are released back to the cloud, minimizing the costs. Such cloud bursting capabilities allow an enterprise to handle regular and unpredictable peak workloads without resorting to purchasing excess additional
The Son of Grid Engine is a community project to continue Sun's old grid engine free software project that used to live at http://gridengine.sunsource.net, now that Oracle have shut down the site and are not contributing code. It will maintain copies of as much as possible/useful from the old site. Currently we do not have the old mail archives online, though articles from the old gridengine-users list from the last five years or so will be available soon, and Oracle have promised to donate artifacts from the old site, so we should be able to get complete copies of everything.The idea is to encourage sharing, in the spirit of the original project, and informed by long experience of free software projects and scientific computing support. Please contribute, and share code or ideas for improvement, especially any ideas for encouraging contribution.
Currently any information you find for the grid engine v6.2u5 release will apply to this effort, including the v6.2u5 wiki documentation and pointers therefrom, including the grid engine.info site and its wiki. There may eventually also be useful info at the Oracle Grid Engine Forum. You should note its terms of use before posting there; they include even relinquishing moral rights.
This wiki isn't currently generally editable, but will be when spam protection is in place. If you're a known past contributor to grid engine and would like to help, please get in touch for access.
Dec 23, 2010 | DanT's Grid Blog
For the past decade, Oracle Grid Engine has been helping thousands of customers marshal the enterprise technical computing processes at the heart of bringing their products to market. Many customers have achieved outstanding results with it via higher data center utilization and improved performance. The latest release of the product provides best-in-class capabilities for resource management including: Hadoop integration, topology-aware scheduling, and on-demand connectivity to the cloud.
Oracle Grid Engine has a rich history, from helping BMW Oracle Racing prepare for the America's Cup to helping isolate and identify the genes associated with obesity; from analyzing and predicting the world's financial markets to producing the digital effects for the popular Harry Potter series of films. Since 2001, the Grid Engine open source project has made Oracle Grid Engine functionality available for free to open source users. The Grid Engine open source community has grown from a handful of users in 2001 into the strong, self-sustaining community that it is now.
Today, we are entering a new chapter in Oracle Grid Engine's life. Oracle has been working with key members of the open source community to pass on the torch for maintaining the open source code base to the Open Grid Scheduler project hosted on SourceForge. This transition will allow the Oracle Grid Engine engineering team to focus their efforts more directly on enhancing the product. In a matter of days, we will take definitive steps in order to roll out this transition. To ensure on-going communication with the open source community, we will provide the following services:
- Upon the decommissioning of the current open source site on December 31st, 2010, we will begin to transition the information on the open source project to Oracle Technology Network's home page for Oracle Grid Engine. This site will ultimately contain the resources currently available on the open source site, as well as a wealth of additional product resources.
- The Oracle Grid Engine engineering team will be available to answer questions and provide guidance regarding the open source project and Oracle Grid Engine via the online product forum
- The Open Grid Scheduler project will be continuing on the tradition of the Grid Engine open source project. While the Open Grid Scheduler project will remain independent of the Oracle Grid Engine product, the project will have the support of the Oracle team, including making available artifacts from the original Grid Engine open source project.
Oracle is committed to enhancing Oracle Grid Engine as a commercial product and has an exciting road map planned. In addition to developing new features and functionality to continue to improve the customer experience, we also plan to release game-changing integrations with several other Oracle products, including Oracle Enterprise Manager and Oracle Coherence. Also, as Oracle's cloud strategy unfolds, we expect that the Oracle Grid Engine product's role in the overall strategy will continue to grow. To discuss our general plans for the product, we would like to invite you to join us for a live webcast on Oracle Grid Engine's new road map. Click here to register.
Next Steps:
- Visit Oracle Technology Network Oracle Grid Engine center to post questions or regarding open source related issues
- Contact Oracle if you wish to learn more about Oracle Grid Engine
- Join us for a live webcast on Oracle Grid Engine's roadmap
2011-01-19 | eWeek.com
As a result, Univa will offer engineering support for current Oracle Grid Engine deployments and will release a new Univa version of the DRM by March.
Univa revealed Jan. 19 that the principal engineers from the Sun/Oracle Grid Engine team, including Grid Engine founder and original project owner Fritz Ferstl, have left Oracle and are joining the company.
As a result, Univa will now offer engineering support for current Oracle Grid Engine deployments and will release a new Univa version of Grid Engine before the end of the first quarter of 2011.
Oracle Grid Engine software is a distributed resource management (DRM) system that manages the distribution of users' workloads to the best available compute resources within the system. While compute resources in a typical data center have utilization rates that average only 10 percent to 25 percent, the Oracle Grid Engine can help a company increase utilization to 80, 90 or even 95 percent, Oracle said.
This significant improvement comes from the intelligent distribution of workload to the most appropriate available resources.
When users submit their work to Oracle Grid Engine as jobs, the software monitors the current state of all resources in the server farm and is able to assign these jobs to the best-suited resources. Oracle Grid Engine gives administrators both the flexibility to accurately model their computing environments as resources and to translate business rules into policies that govern the use of those resources, Oracle said.
"Combining the Grid Engine and Univa technology offerings was a once-in-a-lifetime opportunity that the new Univa EMEA team and I just couldn't miss," Ferstl said. "Now we'll be able to interact with and serve users worldwide investigating and understanding their data center optimization needs."
Lisle, Ill.-based Univa will concentrate on improving the Grid Engine for technical computing and HPC use cases in addition to promoting the continuity of the Grid Engine open-source community, Univa said.
Nov 30, 2009 | DanT's Grid Blog
Servers tend to be used for one of two purposes: running services or processing workloads. Services tend to be long-running and don't tend to move around much. Workloads, however, such as running calculations, are usually done in a more "on demand" fashion. When a user needs something, he tells the server, and the server does it. When it's done, it's done. For the most part it doesn't matter on which particular machine the calculations are run. All that matters is that the user can get the results. This kind of work is often called batch, offline, or interactive work. Sometimes batch work is called a job. Typical jobs include processing of accounting files, rendering images or movies, running simulations, processing input data, modeling chemical or mechanical interactions, and data mining. Many organizations have hundreds, thousands, or even tens of thousands of machines devoted to running jobs.Now, the interesting thing about jobs is that (for the most part) if you can run one job on one machine, you can run 10 jobs on 10 machines or 100 jobs on 100 machines. In fact, with today's multi-core chips, it's often the case that you can run 4, 8, or even 16 jobs on a single machine. Obviously, the more jobs you can run in parallel, the faster you can get your work done. If one job takes 10 minutes on one machine, 100 jobs still only take ten minutes when run on 100 machines. That's much better than 1000 minutes to run those 100 jobs on a single machine. But there's a problem. It's easy for one person to run one job on one machine. It's still pretty easy to run 10 jobs on 10 machines. Running 1600 jobs on 100 machines is a tremendous amount of work. Now imagine that you have 1000 machines and 100 users all trying to running 1600 jobs each. Chaos and unhappiness would ensue.
To solve the problem of organizing a large number of jobs on a set of machines, distributed resource managers (DRMs) were created. (A DRM is also sometimes called a workload manager. I will stick with the term, DRM.) The role of a DRM is to take a list of jobs to be executed and distributed them across the available machines. The DRM makes life easier for the users because they don't have to track all their jobs themselves, and it makes life easier for the administrators because they don't have to manage users' use of the machines directly. It's also better for the organization in general because a DRM will usually do a much better job of keeping the machines busy than users would on their own, resulting in much higher utilization of the machines. Higher utilization effectively means more compute power from the same set of machines, which makes everyone happy.
Here's a bit more terminology, just to make sure we're all on the same page. A cluster is a group of machines cooperating to do some work. A DRM and the machines it manages compose a cluster. A cluster is also often called a grid. There has historically been some debate about what exactly a grid is, but for most purposes grid can be used interchangeably with cluster. Cloud computing is a hot topic that builds on concepts from grid/cluster computing. One of the defining characteristics of a cloud is the ability to "pay as you go." Sun Grid Engine offers an accounting module that can track and report on fine grained usage of the system. Beyond that, Sun Grid Engine now offers deep integration to other technologies commonly being used in the cloud, such as Apache Hadoop.
Onobre of the best ways to show Sun Grid Engine's flexibility is to take a look a some unusual use cases. These are by no means exhaustive, but they should serve to give you an idea of what can be done with the Sun Grid Engine software.Further Reading
- As the manager of services. A large automotive manufacturer uses their Sun Grid Engine cluster in an interesting way. In addition to using it to process traditional batch jobs, they also use it to manage services. Service instances are submitted to the cluster as jobs. When additional service instances are needed, more jobs are submitted. When too many are running for the current workload, some of the service instances are stopped. The Sun Grid Engine cluster makes sure that the service instances are assigned to the most appropriate machines at the time.
- One of the more interesting configuration techniques for Sun Grid Engine is called a transfer queue. A transfer queue is a queue that, instead of processing jobs itself, actually forwards the jobs on to another service, such as another Sun Grid Engine cluster or some other service. Because the Sun Grid Engine software allows you to configure how every aspect of a job's life cycle is managed, the behavior around starting, stopping, suspending, and resuming a job can be altered arbitrarily, such as by sending jobs off to another service to process. More information about transfer queues can be found on the open source web site.
- A Sun Grid Engine cluster is great for traditional batch and parallel applications, but how can one use it with an application server cluster? There are actually two answers, and both have been prototyped as proofs of concept.
The first approach is to submit the application server instances as jobs to the Sun Grid Engine cluster. The Sun Grid Engine cluster can be configured to handle updating the load balancer automatically as part of the process of starting the application server instance. The Sun Grid Engine cluster can also be configured to monitor the application server cluster for key performance indicators (KPIs), and it can even respond to changes in the KPIs by starting additional or stopping extra application server instances.
The second approach is to use the Sun Grid Engine cluster to do work on behalf of the application server cluster. If the applications being hosted by the application servers need to execute longer-running calculations, those calculations can be sent to the Sun Grid Engine cluster, reducing the load on the application servers. Because of the overhead associated with submitting, scheduling, and launching a job, this technique is best applied to workloads that take at least several seconds to run. This technique is also applicable beyond just application servers, such as with SunRay Virtual Desktop Infrastructure.
- A research group at a Canadian university uses Sun Grid Engine in conjunction with Cobbler to do automated machine profile management. Cobbler allows a machine to be rapidly reprovisioned to a pre-configured profile. By integrating Cobbler into their Sun Grid Engine cluster, they are able to have Sun Grid Engine reprovision machines on demand to meet the needs of pending jobs. If a pending job needs a machine profile that isn't currently available, Sun Grid Engine will pick one of the available machines and use Cobbler to reprovision it into the desired profile.
A similar effect can be achieved through virtual machines. Because Sun Grid Engine allows jobs' life cycles to be flexibly managed, a queue could be configured that starts all jobs in virtual machines. Aside from always having the right OS profile available, jobs started in virtual machines are easy to checkpoint and migrate.
- With the 6.2 update 5 release of the Sun Grid Engine software, Sun Grid Engine can manage Apache Hadoop workloads. In order to do that effectively, the qmaster must be aware of data locality in the Hadoop HDFS. The same principle can the applied to other data repository types such that the Sun Grid Engine cluster can direct jobs (or even data disguised as a job) to the machine that is closest (in network terms) to the appropriate repository.
- One of the strong points of the Sun Grid Engine software is the flexible resource model. In a typical cluster, jobs are scheduled against things like CPU availability, memory availability, system load, license availability, etc. Because the Sun Grid Engine resource model is so flexible, however, any number of custom scheduling and resource management schemes are possible. For example, network bandwidth could be modeled as a resource. When a job requests a given bandwidth, it would only be scheduled on machines that can provide that bandwidth. The cluster could even be configured such that if a job lands on a resource that provides higher bandwidth than the job requires, the bandwidth could be limited to the requested value (such as through the Solaris Resource Manager).
For more information about Sun Grid Engine, here are some useful links:
SGE Grid Job Dependency
It is possible to describe SGE (Sun Grid Engine) job (or any other grid engine) dependency in a DAG (Directed Acyclic Graph) format. By taking advantage of the opensource Graphviz, it is very easy to document this dependency in DOT language format. Below shows you a sample DOT file:$ cat job-dep.dot digraph jobs101 { job_1 -> job_11; job_1 -> job_12; job_1 -> job_13; job_11 -> job_111; job_12 -> job_111; job_2 -> job_13; job_2 -> job_21; job_3 -> job_21; job_3 -> job_31; }With this DOT file, one can generate the graphical representation:
$ dot -Tpng -o job-dep.png job-dep.dot
It is also possible to derive the corresponding SGE commands by the following Tcl script.
$ cat ./dot2sge.tcl #! /usr/local/bin/tclsh if { $argc != 1 } { puts stderr "Usage: $argv0" exit 1 } set dotfile [lindex $argv 0] if { [file exists $dotfile] == 0 } { puts stderr "Error. $dotfile does not exist" exit 2 } # assume simple directed graph a -> b set fp [open $dotfile r] set data [read $fp] close $fp set sge_jobs {} foreach i [split [lindex $data 2] {;}] { if { [regexp {(\w+)\s*->\s*(\w+)} $i x parent child] != 0 } { lappend sge_jobs $parent lappend sge_jobs $child lappend sge_job_rel($parent) $child } } # submit unique jobs, and hold set queue all.q set sge_unique_jobs [lsort -unique $sge_jobs] foreach i $sge_unique_jobs { puts "qsub -h -q $queue -N $i job-submit.sh" } # alter the job dependency, but unhold after all the hold relationships are # established foreach i $sge_unique_jobs { if { [info exists sge_job_rel($i)] } { # with dependency puts "qalter -hold_jid [join $sge_job_rel($i) {,}] $i" } } foreach i $sge_unique_jobs { puts "qalter -h U $i" } Run this Tcl script to generate the SGE submission commands and alternation commands to register the job dependency
$ ./dot2sge.tcl job-dep.dot qsub -h -q all.q -N job_1 job-submit.sh qsub -h -q all.q -N job_11 job-submit.sh qsub -h -q all.q -N job_111 job-submit.sh qsub -h -q all.q -N job_12 job-submit.sh qsub -h -q all.q -N job_13 job-submit.sh qsub -h -q all.q -N job_2 job-submit.sh qsub -h -q all.q -N job_21 job-submit.sh qsub -h -q all.q -N job_3 job-submit.sh qsub -h -q all.q -N job_31 job-submit.sh qalter -hold_jid job_11,job_12,job_13 job_1 qalter -hold_jid job_111 job_11 qalter -hold_jid job_111 job_12 qalter -hold_jid job_13,job_21 job_2 qalter -hold_jid job_21,job_31 job_3 qalter -h U job_1 qalter -h U job_11 qalter -h U job_111 qalter -h U job_12 qalter -h U job_13 qalter -h U job_2 qalter -h U job_21 qalter -h U job_3 qalter -h U job_31Below show the above proof-of-concept in action. So sit back....
# # ----------below is a very simple script # $ cat job-submit.sh #! /bin/sh #$ -S /bin/sh date sleep 10 # # ----------run all the qsub to submit jobs, but put them on hold # $ qsub -h -q all.q -N job_1 job-submit.sh Your job 333 ("job_1") has been submitted. $ qsub -h -q all.q -N job_11 job-submit.sh Your job 334 ("job_11") has been submitted. $ qsub -h -q all.q -N job_111 job-submit.sh Your job 335 ("job_111") has been submitted. $ qsub -h -q all.q -N job_12 job-submit.sh Your job 336 ("job_12") has been submitted. $ qsub -h -q all.q -N job_13 job-submit.sh Your job 337 ("job_13") has been submitted. $ qsub -h -q all.q -N job_2 job-submit.sh Your job 338 ("job_2") has been submitted. $ qsub -h -q all.q -N job_21 job-submit.sh Your job 339 ("job_21") has been submitted. $ qsub -h -q all.q -N job_3 job-submit.sh Your job 340 ("job_3") has been submitted. $ qsub -h -q all.q -N job_31 job-submit.sh Your job 341 ("job_31") has been submitted. # # ----------show the status, all jobs are in hold position (hqw) # $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 0/4 0.01 sol-amd64 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 334 0.00000 job_11 chihung hqw 07/19/2007 21:04:34 1 335 0.00000 job_111 chihung hqw 07/19/2007 21:04:34 1 336 0.00000 job_12 chihung hqw 07/19/2007 21:04:34 1 337 0.00000 job_13 chihung hqw 07/19/2007 21:04:34 1 338 0.00000 job_2 chihung hqw 07/19/2007 21:04:34 1 339 0.00000 job_21 chihung hqw 07/19/2007 21:04:34 1 340 0.00000 job_3 chihung hqw 07/19/2007 21:04:34 1 341 0.00000 job_31 chihung hqw 07/19/2007 21:04:34 1 # # ----------register the job dependency # $ qalter -hold_jid job_11,job_12,job_13 job_1 modified job id hold list of job 333 blocking jobs: 334,336,337 exited jobs: NONE $ qalter -hold_jid job_111 job_11 modified job id hold list of job 334 blocking jobs: 335 exited jobs: NONE $ qalter -hold_jid job_111 job_12 modified job id hold list of job 336 blocking jobs: 335 exited jobs: NONE $ qalter -hold_jid job_13,job_21 job_2 modified job id hold list of job 338 blocking jobs: 337,339 exited jobs: NONE $ qalter -hold_jid job_21,job_31 job_3 modified job id hold list of job 340 blocking jobs: 339,341 exited jobs: NONE # # ----------release all the holds and let SGE to sort itself out # $ qalter -h U job_1 modified hold of job 333 $ qalter -h U job_11 modified hold of job 334 $ qalter -h U job_111 modified hold of job 335 $ qalter -h U job_12 modified hold of job 336 $ qalter -h U job_13 modified hold of job 337 $ qalter -h U job_2 modified hold of job 338 $ qalter -h U job_21 modified hold of job 339 $ qalter -h U job_3 modified hold of job 340 $ qalter -h U job_31 modified hold of job 341 # # ----------query SGE stats # $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 0/4 0.01 sol-amd64 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 334 0.00000 job_11 chihung hqw 07/19/2007 21:04:34 1 335 0.00000 job_111 chihung qw 07/19/2007 21:04:34 1 336 0.00000 job_12 chihung hqw 07/19/2007 21:04:34 1 337 0.00000 job_13 chihung qw 07/19/2007 21:04:34 1 338 0.00000 job_2 chihung hqw 07/19/2007 21:04:34 1 339 0.00000 job_21 chihung qw 07/19/2007 21:04:34 1 340 0.00000 job_3 chihung hqw 07/19/2007 21:04:34 1 341 0.00000 job_31 chihung qw 07/19/2007 21:04:34 1 # # ----------some jobs started to run # $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 2/4 0.01 sol-amd64 339 0.55500 job_21 chihung r 07/19/2007 21:05:36 1 341 0.55500 job_31 chihung r 07/19/2007 21:05:36 1 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 1/4 0.01 sol-amd64 335 0.55500 job_111 chihung r 07/19/2007 21:05:36 1 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 337 0.55500 job_13 chihung r 07/19/2007 21:05:36 1 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 334 0.00000 job_11 chihung hqw 07/19/2007 21:04:34 1 336 0.00000 job_12 chihung hqw 07/19/2007 21:04:34 1 338 0.00000 job_2 chihung hqw 07/19/2007 21:04:34 1 340 0.00000 job_3 chihung hqw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 2/4 0.01 sol-amd64 339 0.55500 job_21 chihung r 07/19/2007 21:05:36 1 341 0.55500 job_31 chihung r 07/19/2007 21:05:36 1 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 1/4 0.01 sol-amd64 335 0.55500 job_111 chihung r 07/19/2007 21:05:36 1 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 337 0.55500 job_13 chihung r 07/19/2007 21:05:36 1 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 334 0.00000 job_11 chihung hqw 07/19/2007 21:04:34 1 336 0.00000 job_12 chihung hqw 07/19/2007 21:04:34 1 338 0.00000 job_2 chihung hqw 07/19/2007 21:04:34 1 340 0.00000 job_3 chihung hqw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 0/4 0.01 sol-amd64 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 334 0.00000 job_11 chihung qw 07/19/2007 21:04:34 1 336 0.00000 job_12 chihung qw 07/19/2007 21:04:34 1 338 0.00000 job_2 chihung qw 07/19/2007 21:04:34 1 340 0.00000 job_3 chihung qw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 2/4 0.01 sol-amd64 338 0.55500 job_2 chihung r 07/19/2007 21:05:51 1 340 0.55500 job_3 chihung r 07/19/2007 21:05:51 1 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 1/4 0.01 sol-amd64 334 0.55500 job_11 chihung r 07/19/2007 21:05:51 1 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 336 0.55500 job_12 chihung r 07/19/2007 21:05:51 1 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 2/4 0.01 sol-amd64 338 0.55500 job_2 chihung r 07/19/2007 21:05:51 1 340 0.55500 job_3 chihung r 07/19/2007 21:05:51 1 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 1/4 0.01 sol-amd64 334 0.55500 job_11 chihung r 07/19/2007 21:05:51 1 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 336 0.55500 job_12 chihung r 07/19/2007 21:05:51 1 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung hqw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 0/4 0.01 sol-amd64 ############################################################################ - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS - PENDING JOBS ############################################################################ 333 0.00000 job_1 chihung qw 07/19/2007 21:04:34 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 333 0.55500 job_1 chihung r 07/19/2007 21:06:06 1 $ qstat -f queuename qtype used/tot. load_avg arch states ---------------------------------------------------------------------------- all.q@sgeexec0 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec1 BIP 0/4 0.01 sol-amd64 ---------------------------------------------------------------------------- all.q@sgeexec2 BIP 1/4 0.01 sol-amd64 333 0.55500 job_1 chihung r 07/19/2007 21:06:06 1 # # ----------output of all jobs, you can see job job_1/2/3 finished last # $ grep 2007 job_*.o* job_111.o335:Thu Jul 19 21:05:36 SGT 2007 job_11.o334:Thu Jul 19 21:05:51 SGT 2007 job_12.o336:Thu Jul 19 21:05:51 SGT 2007 job_13.o337:Thu Jul 19 21:05:36 SGT 2007 job_1.o333:Thu Jul 19 21:06:06 SGT 2007 job_21.o339:Thu Jul 19 21:05:36 SGT 2007 job_2.o338:Thu Jul 19 21:05:51 SGT 2007 job_31.o341:Thu Jul 19 21:05:37 SGT 2007 job_3.o340:Thu Jul 19 21:05:52 SGT 2007Another successful proof-of-concept. :-)
Google matched content |
Oracle Grid Engine - Wikipedia, the free encyclopedia
Guide to Using the Grid Engine The Particle Beam Physics Laboratory at the UCLA Department of Physics and Astronomy
How To Use Sun Grid Engine Main Biowiki
SUN Grid Engine - UU/Department of Information Technology
BeocatDocs-SunGridEngine - CIS Support
Sun
Oracle
Univa
What the heck is going on with Grid Engine in 2012 and beyond? If you've found this page and have managed to keep reading, you are probably interested in Grid Engine and what it may look like in the future. This post will attempt to summarize what is currently available.
History of this site
This website was thrown together very quickly in early 2011 when Oracle announced it was taking Oracle Grid Engine in a new "closed source" direction. Very soon after the announcement, the open source SGE codebase was forked by multiple groups. Oracle had also been hosting the popular gridengine.sunsource.net site where documentation, HowTo's and a very active mailing list had become the default support channel for many SGE users and administrators.
This website was seen as a gathering point and central public portal for the various grid engine fork efforts. It was also a natural place to host a new "[email protected]" mailing list in an attempt to recreate the atmosphere found in the old "[email protected]" listserv community.
The new mailing list was a success but efforts to build a "Steering Committee" that would drive some sort of coordinated effort stalled throughout most of 2011. Truth be told, we probably don't need a central site or even a steering committee - the maintainers of the various forks all know each other and can easily trade patches, advice and collaborative efforts among themselves.
It's best simply to recast the gridengine.org site as a convenient place for information broadly of interest to all Grid Engine users, administrators and maintainers – mailing lists, news and pointers to information, software & resources.
Available Grid Engine Options
Open Source
"Son of Grid Engine"
URL: https://arc.liv.ac.uk/trac/SGE
News & Announcements: http://arc.liv.ac.uk/repos/darcs/sge/NEWS
Description: Baseline code comes from the Univa public repo with additional enhancements and improvements added. The maintainer(s) have deep knowledge of SGE source and internals and are committed to the effort. Future releases may start to diverge from Univa as Univa pursues an "open core" development model. Maintainers have made efforts to make building binaries from source easier and the latest release offers RedHat Linux SRPMS and RPM files ready for download.
Support: Supported via the maintainers and the users mailing list."Open Grid Scheduler"
URL: http://gridscheduler.sourceforge.net/
Description: Baseline code comes from the last Oracle open source release with significant additional enhancements and improvements added. The maintainer(s) have deep knowledge of SGE source and internals and are committed to the effort. No pre-compiled "courtesy binaries" available at the SourceForge site (just source code and instructions on how to build Grid Engine locally). In November 2011 a new company ScalableLogic announced plans to offer commercial support options for users of Open Grid Scheduler.
Support: Supported via the maintainers and the users mailing list. Commercial support from ScalableLogic.Commercial
"Univa Grid Engine"
URL: http://www.univa.com/products/grid-engine
Description: Commercial company selling Grid Engine, support and layered products that add features and functionality. Several original SGE developers are now employed by Univa. Evaluation versions and "48 cores for free" are available from the website.
Support: Univa supports their own products."Oracle Grid Engine"
URL: http://www.oracle.com/us/products/tools/oracle-grid-engine-075549.html
Description: Continuation of "Sun Grid Engine" after Oracle purchased Sun. This is the current commercial version of Oracle Grid Engine after Oracle discontinued the open source version of their product and went 100% closed-source.
Support: Oracle supports their own products, a web support forum for Oracle customers can be found at https://forums.oracle.com/forums/forum.jspa?forumID=859
Univa Grid Engine - Wikipedia, the free encyclopedia
Univa Grid Engine - Daniel's Blog about Grid Engine
Society
Groupthink : Two Party System as Polyarchy : Corruption of Regulators : Bureaucracies : Understanding Micromanagers and Control Freaks : Toxic Managers : Harvard Mafia : Diplomatic Communication : Surviving a Bad Performance Review : Insufficient Retirement Funds as Immanent Problem of Neoliberal Regime : PseudoScience : Who Rules America : Neoliberalism : The Iron Law of Oligarchy : Libertarian Philosophy
Quotes
War and Peace : Skeptical Finance : John Kenneth Galbraith :Talleyrand : Oscar Wilde : Otto Von Bismarck : Keynes : George Carlin : Skeptics : Propaganda : SE quotes : Language Design and Programming Quotes : Random IT-related quotes : Somerset Maugham : Marcus Aurelius : Kurt Vonnegut : Eric Hoffer : Winston Churchill : Napoleon Bonaparte : Ambrose Bierce : Bernard Shaw : Mark Twain Quotes
Bulletin:
Vol 25, No.12 (December, 2013) Rational Fools vs. Efficient Crooks The efficient markets hypothesis : Political Skeptic Bulletin, 2013 : Unemployment Bulletin, 2010 : Vol 23, No.10 (October, 2011) An observation about corporate security departments : Slightly Skeptical Euromaydan Chronicles, June 2014 : Greenspan legacy bulletin, 2008 : Vol 25, No.10 (October, 2013) Cryptolocker Trojan (Win32/Crilock.A) : Vol 25, No.08 (August, 2013) Cloud providers as intelligence collection hubs : Financial Humor Bulletin, 2010 : Inequality Bulletin, 2009 : Financial Humor Bulletin, 2008 : Copyleft Problems Bulletin, 2004 : Financial Humor Bulletin, 2011 : Energy Bulletin, 2010 : Malware Protection Bulletin, 2010 : Vol 26, No.1 (January, 2013) Object-Oriented Cult : Political Skeptic Bulletin, 2011 : Vol 23, No.11 (November, 2011) Softpanorama classification of sysadmin horror stories : Vol 25, No.05 (May, 2013) Corporate bullshit as a communication method : Vol 25, No.06 (June, 2013) A Note on the Relationship of Brooks Law and Conway Law
History:
Fifty glorious years (1950-2000): the triumph of the US computer engineering : Donald Knuth : TAoCP and its Influence of Computer Science : Richard Stallman : Linus Torvalds : Larry Wall : John K. Ousterhout : CTSS : Multix OS Unix History : Unix shell history : VI editor : History of pipes concept : Solaris : MS DOS : Programming Languages History : PL/1 : Simula 67 : C : History of GCC development : Scripting Languages : Perl history : OS History : Mail : DNS : SSH : CPU Instruction Sets : SPARC systems 1987-2006 : Norton Commander : Norton Utilities : Norton Ghost : Frontpage history : Malware Defense History : GNU Screen : OSS early history
Classic books:
The Peter Principle : Parkinson Law : 1984 : The Mythical Man-Month : How to Solve It by George Polya : The Art of Computer Programming : The Elements of Programming Style : The Unix Hater’s Handbook : The Jargon file : The True Believer : Programming Pearls : The Good Soldier Svejk : The Power Elite
Most popular humor pages:
Manifest of the Softpanorama IT Slacker Society : Ten Commandments of the IT Slackers Society : Computer Humor Collection : BSD Logo Story : The Cuckoo's Egg : IT Slang : C++ Humor : ARE YOU A BBS ADDICT? : The Perl Purity Test : Object oriented programmers of all nations : Financial Humor : Financial Humor Bulletin, 2008 : Financial Humor Bulletin, 2010 : The Most Comprehensive Collection of Editor-related Humor : Programming Language Humor : Goldman Sachs related humor : Greenspan humor : C Humor : Scripting Humor : Real Programmers Humor : Web Humor : GPL-related Humor : OFM Humor : Politically Incorrect Humor : IDS Humor : "Linux Sucks" Humor : Russian Musical Humor : Best Russian Programmer Humor : Microsoft plans to buy Catholic Church : Richard Stallman Related Humor : Admin Humor : Perl-related Humor : Linus Torvalds Related humor : PseudoScience Related Humor : Networking Humor : Shell Humor : Financial Humor Bulletin, 2011 : Financial Humor Bulletin, 2012 : Financial Humor Bulletin, 2013 : Java Humor : Software Engineering Humor : Sun Solaris Related Humor : Education Humor : IBM Humor : Assembler-related Humor : VIM Humor : Computer Viruses Humor : Bright tomorrow is rescheduled to a day after tomorrow : Classic Computer Humor
The Last but not Least Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt. Ph.D
Copyright © 1996-2021 by Softpanorama Society. www.softpanorama.org was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP) without any remuneration. This document is an industrial compilation designed and created exclusively for educational use and is distributed under the Softpanorama Content License. Original materials copyright belong to respective owners. Quotes are made for educational purposes only in compliance with the fair use doctrine.
FAIR USE NOTICE This site contains copyrighted material the use of which has not always been specifically authorized by the copyright owner. We are making such material available to advance understanding of computer science, IT technology, economic, scientific, and social issues. We believe this constitutes a 'fair use' of any such copyrighted material as provided by section 107 of the US Copyright Law according to which such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free) site written by people for whom English is not a native language. Grammar and spelling errors should be expected. The site contain some broken links as it develops like a living tree...
|
|
You can use PayPal to to buy a cup of coffee for authors of this site |
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or referenced source) and are not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society. We do not warrant the correctness of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be tracked by Google please disable Javascript for this site. This site is perfectly usable without Javascript.
Last modified: February 27, 2021
