Software Engineering: A study akin to numerology and astrology, but lacking the precision
of the former and the success of the latter.
KISS Principle/kis' prin'si-pl/ n.
"Keep It Simple, Stupid". A maxim often invoked when discussing design to fend off
creeping
featurism and control development complexity. Possibly related to the
marketroid
maxim on sales presentations, "Keep It Short and Simple".
creeping featurism/kree'ping fee'chr-izm/ n.[common]1. Describes a systematic tendency to load more
chrome and
features onto
systems at the expense of whatever elegance they may have possessed when originally designed.
See also
feeping
creaturism. "You know, the main problem with
BSD Unix has always
been creeping featurism." 2. More generally, the tendency for anything complicated to become
even more complicated because people keep saying "Gee, it would be even better if it had this
feature too". (See
feature.) The result is usually a patchwork because it grew one ad-hoc step at a time, rather
than being planned. Planning is a lot of work, but it's easy to add just one extra little feature
to help someone ... and then another ... and another... When creeping featurism gets out of hand,
it's like a cancer. Usually this term is used to describe computer programs, but it could also
be said of the federal government, the IRS 1040 form, and new cars. A similar phenomenon sometimes
afflicts conscious redesigns; see
second-system
effect. See also
creeping
elegance. Jargon file
Software engineering (SE) has probably largest concentration of snake oil salesman after OO
programming and software architecture is far from being an exclusion. Many published software
methodologies/architectures claim to provide the benefits, that most of them can not deliver (UML is
one good example). I see a lot of oversimplification of the real situation and unnecessary (and useless)
formalisms. The main idea advocated here is simplification of software architecture (including
usage of well-understood "Pipe and Filter model") and scripting languages.
There are few quality general architectural resources available from the Net, therefore the list
below represent only some links that I am interested personally. The stress here is on skepticism and
this collection is neither complete, nor up to date. But still it might help students that are trying
to study this complex and interesting subject. Or perhaps, if you already a software architect you might
be able to expand your knowledge of the subject.
Excessive zeal in adopting some fashionable but questionable methodology is a "real and present
danger" in software engineering. This is not a new threat, it started with structured programming
revolution and then verification "holy land" searching with
Edsger W. Dijkstra as a new
prophet of an obsure cult. The main problem here that all those methodologies contain 20% of useful
elements; but the other 80% kill all the useful elements and introduce probably some real disadvantages.
After a dozen or so partially useful but mostly useless methodologies came, were enthusiastically
adopted and went into oblivion we should definitely be skeptical.
All this "extreme programming" idiotism or
CMM Lysenkoism should be treated as we treat dangerous religious sects.
It's undemocratic and stupid to prohibit them but it's equally dangerous and stupid to follow their
recommendations ;-). As Talleyrand advised to junior diplomats: "Above all, gentlemen, not too much
zeal. " By this phrase, Talleyrand was reportedly recommended to his subordinates that important
decisions must be based upon the exercise of cool-headed reason and not upon emotions or any waxing
or waning popular delusion.
One interesting fact about software architecture is that it can't be practiced from the "ivory tower".
Only when you do coding yourself and faces limitations of the tools and hardware you can create a great
architecture. See Real Insights into Architecture Come Only From
Actual Programming
One interesting fact about software architecture is that it can't be practiced from the
"ivory tower". Only when you do coding yourself and faces limitations of the tools and hardware
you can create a great architecture. SeeReal Insights
into Architecture Come Only From Actual Programming
The primary purpose of Software Architecture courses
is to teach students some higher level skills useful in designing and implementing complex software
systems. In usually includes some information about classification (general and domain specific architectures),
analysis and tools. As guys in Breadmear consulting aptly noted in their paper
Who Software Architect Role:
A simplistic view of the role is that architects create architectures,
and their responsibilities encompass all that is involved in doing so. This would include articulating
the architectural vision, conceptualizing and experimenting with alternative architectural approaches,
creating models and component and interface specification documents, and validating the architecture
against requirements and assumptions.
However, any experienced architect knows that the role involves not
just these technical activities, but others that are more political and strategic in nature on the
one hand, and more like those of a consultant, on the other. A sound sense of business and technical
strategy is required to envision the "right" architectural approach to the customer's problem set,
given the business objectives of the architect's organization. Activities in this area include the
creation of technology roadmaps, making assertions about technology directions and determining their
consequences for the technical strategy and hence architectural approach.
Further, architectures are seldom embraced without considerable challenges
from many fronts. The architect thus has to shed any distaste for what may be considered
"organizational politics", and actively work to sell the architecture to its various stakeholders,
communicating extensively and working networks of influence to ensure the ongoing success of the
architecture.
But "buy-in" to the architecture vision is not enough either. Anyone
involved in implementing the architecture needs to understand it. Since weighty architectural
documents are notorious dust-gatherers, this involves creating and teaching tutorials and actively
consulting on the application of the architecture, and being available to explain the rationale behind
architectural choices and to make amendments to the architecture when justified.
Lastly, the architect must lead--the architecture team, the developer
community, and, in its technical direction, the organization.
Again, I would like to stress that the main principle of software architecture is simple and well
known -- it's famous KISS principle. While principle is simple its implementation is not and a lot of
developers (especially developers with limited resources) paid dearly for violating this principle.
I have found one one reference on simplicity in SE: R. S. Pressman. Simplicity. In Software Engineering,
A Practitioner's Approach, page 452. McGraw Hill, 1997. Here open source tools can help because
for those tools a complexity is not such a competitive advantage as for closed source tools. But that
not necessary true about actual tools as one problem with open source projects is change of the leader.
This is the moment when many projects lose architectural integrity and became a Byzantium compendium
of conflicting approaches.
I appreciate am architecture of software system that lead to small size implementations with simple,
Spartan interface. In these days the usage of scripting languages can cut the volume of code more than
in half in comparison with Java. That's why this site is advocating usage of scripting languages
for complex software projects.
"Real Beauty can be found in Simplicity," and as you may know already, ' "Less" sometimes equal "More".'
I continue to adhere to that philosophy. If you, too, have an eye for simplicity in software engineering,
then you might benefit from this collection of links.
I think writing a good software system is somewhat similar to writing a multivolume series of books.
Most writers will rewrite each chapter of book several times and changes general structure a lot. Rewriting
large systems is more difficult, but also very beneficial. It make sense always consider the current
version of the system a draft that can be substantially improved and simplified by discovering some
new unifying and simplifying paradigm. Sometimes you can take a wrong direction, but still "nothing
venture nothing have."
On a subsystem level a decent configuration management system can help going back. Too often people
try to write and debug their fundamentally flawed architecturally "first draft", when it would have
been much simpler and faster to rewrite it based on better understanding of architecture and better
understanding of the problem. Actually rewriting can save time spend in debugging of the old version.
That way, when you're done, you may get easy-to-understand, simple software systems, instead of just
systems that "seems to work okay" (only as correct as your testing).
On component level refactoring (see Refactoring: Improving the Design of Existing Code) might be
a useful simplification technique. Actually rewriting is a simpler term, but let's assume that refactoring
is rewriting with some ideological frosting ;-). See
Slashdot Book Reviews Refactoring
Improving the Design of Existing Code.
I have found one reference on simplicity in SE: R. S. Pressman. Simplicity. In Software Engineering,
A Practitioner's Approach, page 452. McGraw Hill, 1997.
Another relevant work (he try to promote his own solution -- you can skip this part) is the critique
of "the technology mud slide" in a book
The Innovator's Dilemma by Harvard Business School Professor
Clayton M. Christensen
. He defined the term"technology mudslide", the concept very similar to Brooks "software
development tar pit" -- a perpetual cycle of abandonment
or retooling of existing systems in pursuit of the latest fashionable technology trend -- a
cycle in which
"Coping with the relentless onslaught of technology change was
akin to trying to climb a mudslide raging down a hill. You have to scramble with everything you've
got to stay on top of it. and if you ever once stop to catch your breath, you get buried."
The complexity caused by adopting new technology for the sake of new technology is further exacerbated
by the narrow focus and inexperience of many project leaders -- inexperience with mission-critical systems,
systems of larger scale then previously built, software development disciplines, and project management.
A Standish Group International survey recently showed that 46% of IT projects were over budget and overdue
-- and 28% failed altogether. That's normal and probably the real failures figures are higher: great
software managers and architects are rare and it is those people who determine the success of a software
project.
Walmart Brings Automation To Regional Distribution Centers BY TYLER DURDEN SUNDAY,
JUL 18, 2021 - 09:00 PM
The progressive press had a field day with "woke" Walmart highly
publicized February decision to hikes wages for 425,000 workers to an average above $15 an
hour. We doubt the obvious follow up - the ongoing stealthy replacement of many of its minimum
wage workers with machines - will get the same amount of airtime.
As Chain Store
Age reports , Walmart is applying artificial intelligence to the palletizing of products in
its regional distribution centers. I.e., it is replacing thousands of workers with robots.
Since 2017, the discount giant has worked with Symbotic to optimize an automated technology
solution to sort, store, retrieve and pack freight onto pallets in its Brooksville, Fla.,
distribution center. Under Walmart's existing system, product arrives at one of its RDCs and is
either cross-docked or warehoused, while being moved or stored manually. When it's time for the
product to go to a store, a 53-foot trailer is manually packed for transit. After the truck
arrives at a store, associates unload it manually and place the items in the appropriate
places.
Leveraging the Symbiotic solution, a complex algorithm determines how to store cases like
puzzle pieces using high-speed mobile robots that operate with a precision that speeds the
intake process and increases the accuracy of freight being stored for future orders. By using
dense modular storage, the solution also expands building capacity.
In addition, by using palletizing robotics to organize and optimize freight, the Symbiotic
solution creates custom store- and aisle-ready pallets.
Why is Walmart doing this? Simple: According to CSA, "Walmart expects to save time, limit
out-of-stocks and increasing the speed of stocking and unloading." More importantly, the
company hopes to further cut expenses and remove even more unskilled labor from its supply
chain.
This solution follows tests of similar automated warehouse solutions at a Walmart
consolidation center in Colton, Calif., and perishable grocery distribution center in Shafter,
Calif.
Walmart plans to implement this technology in 25 of its 42 RDCs.
"Though very few Walmart customers will ever see into our warehouses, they'll still be able
to witness an industry-leading change, each time they find a product on shelves," said Joe
Metzger, executive VP of supply chain operations at Walmart U.S. "There may be no way to solve
all the complexities of a global supply chain, but we plan to keep changing the game as we use
technology to transform the way we work and lead our business into the future."
Walmart Brings Automation To Regional Distribution Centers BY TYLER DURDEN SUNDAY,
JUL 18, 2021 - 09:00 PM
The progressive press had a field day with "woke" Walmart highly
publicized February decision to hikes wages for 425,000 workers to an average above $15 an
hour. We doubt the obvious follow up - the ongoing stealthy replacement of many of its minimum
wage workers with machines - will get the same amount of airtime.
As Chain Store
Age reports , Walmart is applying artificial intelligence to the palletizing of products in
its regional distribution centers. I.e., it is replacing thousands of workers with robots.
Since 2017, the discount giant has worked with Symbotic to optimize an automated technology
solution to sort, store, retrieve and pack freight onto pallets in its Brooksville, Fla.,
distribution center. Under Walmart's existing system, product arrives at one of its RDCs and is
either cross-docked or warehoused, while being moved or stored manually. When it's time for the
product to go to a store, a 53-foot trailer is manually packed for transit. After the truck
arrives at a store, associates unload it manually and place the items in the appropriate
places.
Leveraging the Symbiotic solution, a complex algorithm determines how to store cases like
puzzle pieces using high-speed mobile robots that operate with a precision that speeds the
intake process and increases the accuracy of freight being stored for future orders. By using
dense modular storage, the solution also expands building capacity.
In addition, by using palletizing robotics to organize and optimize freight, the Symbiotic
solution creates custom store- and aisle-ready pallets.
Why is Walmart doing this? Simple: According to CSA, "Walmart expects to save time, limit
out-of-stocks and increasing the speed of stocking and unloading." More importantly, the
company hopes to further cut expenses and remove even more unskilled labor from its supply
chain.
This solution follows tests of similar automated warehouse solutions at a Walmart
consolidation center in Colton, Calif., and perishable grocery distribution center in Shafter,
Calif.
Walmart plans to implement this technology in 25 of its 42 RDCs.
"Though very few Walmart customers will ever see into our warehouses, they'll still be able
to witness an industry-leading change, each time they find a product on shelves," said Joe
Metzger, executive VP of supply chain operations at Walmart U.S. "There may be no way to solve
all the complexities of a global supply chain, but we plan to keep changing the game as we use
technology to transform the way we work and lead our business into the future."
But wait: wasn't this recent rise in wages in real terms being propagandized as a new boom
for the working class in the USA by the MSM until some days ago?
And in the drive-through lane at Checkers near Atlanta, requests for Big Buford burgers and
Mother Cruncher chicken sandwiches may be fielded not by a cashier in a headset, but by a
voice-recognition algorithm.
An increase in automation, especially in service industries, may prove to be an economic
legacy of the pandemic. Businesses from factories to fast-food outlets to hotels turned to
technology last year to keep operations running amid social distancing requirements and
contagion fears. Now the outbreak is ebbing in the United States, but the difficulty in hiring
workers -- at least at the wages that employers are used to paying -- is providing new momentum
for automation.
Technological investments that were made in response to the crisis may contribute to a
post-pandemic productivity boom, allowing for higher wages and faster growth. But some
economists say the latest wave of automation could eliminate jobs and erode bargaining power,
particularly for the lowest-paid workers, in a lasting way.
"Once a job is automated, it's pretty hard to turn back," said Casey Warman, an economist at
Dalhousie University in Nova Scotia who has studied automation in the pandemic .
https://www.dianomi.com/smartads.epl?id=3533
The trend toward automation predates the pandemic, but it has accelerated at what is proving
to be a critical moment. The rapid reopening of the economy has led to a surge in demand for
waiters, hotel maids, retail sales clerks and other workers in service industries that had cut
their staffs. At the same time, government benefits have allowed many people to be selective in
the jobs they take. Together, those forces have given low-wage workers a rare moment of
leverage , leading to higher pay
, more generous benefits and other perks.
Automation threatens to tip the advantage back toward employers, potentially eroding those
gains. A
working paper published by the International Monetary Fund this year predicted that
pandemic-induced automation would increase inequality in coming years, not just in the United
States but around the world.
"Six months ago, all these workers were essential," said Marc Perrone, president of the
United Food and Commercial Workers, a union representing grocery workers. "Everyone was calling
them heroes. Now, they're trying to figure out how to get rid of them."
Checkers, like many fast-food restaurants, experienced a jump in sales when the pandemic
shut down most in-person dining. But finding workers to meet that demand proved difficult -- so
much so that Shana Gonzales, a Checkers franchisee in the Atlanta area, found herself back
behind the cash register three decades after she started working part time at Taco Bell while
in high school.
"We really felt like there has to be another solution," she said.
So Ms. Gonzales contacted Valyant AI, a Colorado-based start-up that makes voice recognition
systems for restaurants. In December, after weeks of setup and testing, Valyant's technology
began taking orders at one of Ms. Gonzales's drive-through lanes. Now customers are greeted by
an automated voice designed to understand their orders -- including modifications and special
requests -- suggest add-ons like fries or a shake, and feed the information directly to the
kitchen and the cashier.
The rollout has been successful enough that Ms. Gonzales is getting ready to expand the
system to her three other restaurants.
"We'll look back and say why didn't we do this sooner," she said.
The push toward automation goes far beyond the restaurant sector. Hotels,
retailers ,
manufacturers and other businesses have all accelerated technological investments. In a
survey of nearly 300 global companies by the World Economic Forum last year, 43 percent of
businesses said they expected to reduce their work forces through new uses of
technology.
Some economists see the increased investment as encouraging. For much of the past two
decades, the U.S. economy has struggled with weak productivity growth, leaving workers and
stockholders to compete over their share of the income -- a game that workers tended to lose.
Automation may harm specific workers, but if it makes the economy more productive, that could
be good for workers as a whole, said Katy George, a senior partner at McKinsey, the consulting
firm.
She cited the example of a client in manufacturing who had been pushing his company for
years to embrace augmented-reality technology in its factories. The pandemic finally helped him
win the battle: With air travel off limits, the technology was the only way to bring in an
expert to help troubleshoot issues at a remote plant.
"For the first time, we're seeing that these technologies are both increasing productivity,
lowering cost, but they're also increasing flexibility," she said. "We're starting to see real
momentum building, which is great news for the world, frankly."
Other economists are less sanguine. Daron Acemoglu of the Massachusetts Institute of
Technology said that many of the technological investments had just replaced human labor
without adding much to overall productivity.
In a
recent working paper , Professor Acemoglu and a colleague concluded that "a significant
portion of the rise in U.S. wage inequality over the last four decades has been driven by
automation" -- and he said that trend had almost certainly accelerated in the pandemic.
"If we automated less, we would not actually have generated that much less output but we
would have had a very different trajectory for inequality," Professor Acemoglu said.
Ms. Gonzales, the Checkers franchisee, isn't looking to cut jobs. She said she would hire 30
people if she could find them. And she has raised hourly pay to about $10 for entry-level
workers, from about $9 before the pandemic. Technology, she said, is easing pressure on workers
and speeding up service when restaurants are chronically understaffed.
"Our approach is, this is an assistant for you," she said. "This allows our employee to
really focus" on customers.
Ms. Gonzales acknowledged she could fully staff her restaurants if she offered $14 to $15 an
hour to attract workers. But doing so, she said, would force her to raise prices so much that
she would lose sales -- and automation allows her to take another course.
Rob Carpenter, Valyant's chief executive, noted that at most restaurants, taking
drive-through orders is only part of an employee's responsibilities. Automating that task
doesn't eliminate a job; it makes the job more manageable.
"We're not talking about automating an entire position," he said. "It's just one task within
the restaurant, and it's gnarly, one of the least desirable tasks."
But technology doesn't have to take over all aspects of a job to leave workers worse off. If
automation allows a restaurant that used to require 10 employees a shift to operate with eight
or nine, that will mean fewer jobs in the long run. And even in the short term, the technology
could erode workers' bargaining power.
"Often you displace enough of the tasks in an occupation and suddenly that occupation is no
more," Professor Acemoglu said. "It might kick me out of a job, or if I keep my job I'll get
lower wages."
At some businesses, automation is already affecting the number and type of jobs available.
Meltwich, a restaurant chain that started in Canada and is expanding into the United States,
has embraced a range of technologies to cut back on labor costs. Its grills no longer require
someone to flip burgers -- they grill both sides at once, and need little more than the press
of a button.
"You can pull a less-skilled worker in and have them adapt to our system much easier," said
Ryan Hillis, a Meltwich vice president. "It certainly widens the scope of who you can have
behind that grill."
With more advanced kitchen equipment, software that allows online orders to flow directly to
the restaurant and other technological advances, Meltwich needs only two to three workers on a
shift, rather than three or four, Mr. Hillis said.
Such changes, multiplied across thousands of businesses in dozens of industries, could
significantly change workers' prospects. Professor Warman, the Canadian economist, said
technologies developed for one purpose tend to spread to similar tasks, which could make it
hard for workers harmed by automation to shift to another occupation or industry.
"If a whole sector of labor is hit, then where do those workers go?" Professor Warman said.
Women, and to a lesser degree people of color, are likely to be disproportionately affected, he
added.
The grocery business has long been a source of steady, often unionized jobs for people
without a college degree. But technology is changing the sector. Self-checkout lanes have
reduced the number of cashiers; many stores have simple robots to patrol aisles for spills and
check inventory; and warehouses have become increasingly automated. Kroger in April opened a
375,000-square-foot warehouse with more than 1,000 robots that bag groceries for delivery
customers. The company is even experimenting with delivering groceries by drone.
Other companies in the industry are doing the same. Jennifer Brogan, a spokeswoman for Stop
& Shop, a grocery chain based in New England, said that technology allowed the company to
better serve customers -- and that it was a competitive necessity.
"Competitors and other players in the retail space are developing technologies and
partnerships to reduce their costs and offer improved service and value for customers," she
said. "Stop & Shop needs to do the same."
In 2011, Patrice Thomas took a part-time job in the deli at a Stop & Shop in Norwich,
Conn. A decade later, he manages the store's prepared foods department, earning around $40,000
a year.
Mr. Thomas, 32, said that he wasn't concerned about being replaced by a robot anytime soon,
and that he welcomed technologies making him more productive -- like more powerful ovens for
rotisserie chickens and blast chillers that quickly cool items that must be stored cold.
But he worries about other technologies -- like automated meat slicers -- that seem to
enable grocers to rely on less experienced, lower-paid workers and make it harder to build a
career in the industry.
"The business model we seem to be following is we're pushing toward automation and we're not
investing equally in the worker," he said. "Today it's, 'We want to get these robots in here to
replace you because we feel like you're overpaid and we can get this kid in there and all he
has to do is push this button.'"
Mission creep is the gradual or incremental expansion of an intervention, project or
mission, beyond its original scope, focus or goals , a ratchet effect spawned by initial success.
[1] Mission creep is
usually considered undesirable due to how each success breeds more ambitious interventions
until a final failure happens, stopping the intervention entirely.
"The bots' mission: To deliver restaurant meals cheaply and efficiently, another leap in
the way food comes to our doors and our tables." The semiautonomous vehicles were
engineered by Kiwibot, a company started in 2017 to game-change the food delivery
landscape...
In May, Kiwibot sent a 10-robot fleet to Miami as part of a nationwide pilot program
funded by the Knight Foundation. The program is driven to understand how residents and
consumers will interact with this type of technology, especially as the trend of robot
servers grows around the country.
And though Broward County is of interest to Kiwibot, Miami-Dade County officials jumped
on board, agreeing to launch robots around neighborhoods such as Brickell, downtown Miami and
several others, in the next couple of weeks...
"Our program is completely focused on the residents of Miami-Dade County and the way
they interact with this new technology. Whether it's interacting directly or just sharing
the space with the delivery bots,"
said Carlos Cruz-Casas, with the county's Department of Transportation...
Remote supervisors use real-time GPS tracking to monitor the robots. Four cameras are
placed on the front, back and sides of the vehicle, which the supervisors can view on a
computer screen. [A spokesperson says later in the article "there is always a remote and
in-field team looking for the robot."] If crossing the street is necessary, the robot
will need a person nearby to ensure there is no harm to cars or pedestrians. The plan is to
allow deliveries up to a mile and a half away so robots can make it to their destinations in
30 minutes or less.
Earlier Kiwi tested its sidewalk-travelling robots around the University of California at
Berkeley, where
at least one of its robots burst into flames . But the Sun-Sentinel reports that "In
about six months, at least 16 restaurants came on board making nearly 70,000
deliveries...
"Kiwibot now offers their robotic delivery services in other markets such as Los Angeles
and Santa Monica by working with the Shopify app to connect businesses that want to employ
their robots." But while delivery fees are normally $3, this new Knight Foundation grant "is
making it possible for Miami-Dade County restaurants to sign on for free."
A video
shows the reactions the sidewalk robots are getting from pedestrians on a sidewalk, a dog
on a leash, and at least one potential restaurant customer looking forward to no longer
having to tip human food-delivery workers.
Average but still useful enumeration of factors what should be considered. One question stands out "Is that SaaS app really
cheaper than more headcount?" :-)
Notable quotes:
"... You may decide that this is not a feasible project for the organization at this time due to a lack of organizational knowledge around containers, but conscientiously accepting this tradeoff allows you to put containers on a roadmap for the next quarter. ..."
"... Bells and whistles can be nice, but the tool must resolve the core issues you identified in the first question. ..."
"... Granted, not everything has to be a cost-saving proposition. Maybe it won't be cost-neutral if you save the dev team a couple of hours a day, but you're removing a huge blocker in their daily workflow, and they would be much happier for it. That happiness is likely worth the financial cost. Onboarding new developers is costly, so don't underestimate the value of increased retention when making these calculations. ..."
When introducing a new tool, programming language, or dependency into your environment, what
steps do you take to evaluate it? In this article, I will walk through a six-question framework
I use to make these determinations.
What problem am I trying to solve?
We all get caught up in the minutiae of the immediate problem at hand. An honest, critical
assessment helps divulge broader root causes and prevents micro-optimizations.
Let's say you are experiencing issues with your configuration management system. Day-to-day
operational tasks are taking longer than they should, and working with the language is
difficult. A new configuration management system might alleviate these concerns, but make sure
to take a broader look at this system's context. Maybe switching from virtual machines to
immutable containers eases these issues and more across your environment while being an
equivalent amount of work. At this point, you should explore the feasibility of more
comprehensive solutions as well. You may decide that this is not a feasible project for the
organization at this time due to a lack of organizational knowledge around containers, but
conscientiously accepting this tradeoff allows you to put containers on a roadmap for the next
quarter.
This intellectual exercise helps you drill down to the root causes and solve core issues,
not the symptoms of larger problems. This is not always going to be possible, but be
intentional about making this decision.
Now that we have identified the problem, it is time for critical evaluation of both
ourselves and the selected tool.
A particular technology might seem appealing because it is new because you read a cool blog
post about it or you want to be the one giving a conference talk. Bells and whistles can be
nice, but the tool must resolve the core issues you identified in the first
question.
What am I giving up?
The tool will, in fact, solve the problem, and we know we're solving the right
problem, but what are the tradeoffs?
These considerations can be purely technical. Will the lack of observability tooling prevent
efficient debugging in production? Does the closed-source nature of this tool make it more
difficult to track down subtle bugs? Is managing yet another dependency worth the operational
benefits of using this tool?
Additionally, include the larger organizational, business, and legal contexts that you
operate under.
Are you giving up control of a critical business workflow to a third-party vendor? If that
vendor doubles their API cost, is that something that your organization can afford and is
willing to accept? Are you comfortable with closed-source tooling handling a sensitive bit of
proprietary information? Does the software licensing make this difficult to use
commercially?
While not simple questions to answer, taking the time to evaluate this upfront will save you
a lot of pain later on.
Is the project or vendor healthy?
This question comes with the addendum "for the balance of your requirements." If you only
need a tool to get your team over a four to six-month hump until Project X is complete,
this question becomes less important. If this is a multi-year commitment and the tool drives a
critical business workflow, this is a concern.
When going through this step, make use of all available resources. If the solution is open
source, look through the commit history, mailing lists, and forum discussions about that
software. Does the community seem to communicate effectively and work well together, or are
there obvious rifts between community members? If part of what you are purchasing is a support
contract, use that support during the proof-of-concept phase. Does it live up to your
expectations? Is the quality of support worth the cost?
Make sure you take a step beyond GitHub stars and forks when evaluating open source tools as
well. Something might hit the front page of a news aggregator and receive attention for a few
days, but a deeper look might reveal that only a couple of core developers are actually working
on a project, and they've had difficulty finding outside contributions. Maybe a tool is open
source, but a corporate-funded team drives core development, and support will likely cease if
that organization abandons the project. Perhaps the API has changed every six months, causing a
lot of pain for folks who have adopted earlier versions.
What are the risks?
As a technologist, you understand that nothing ever goes as planned. Networks go down,
drives fail, servers reboot, rows in the data center lose power, entire AWS regions become
inaccessible, or BGP hijacks re-route hundreds of terabytes of Internet traffic.
Ask yourself how this tooling could fail and what the impact would be. If you are adding a
security vendor product to your CI/CD pipeline, what happens if the vendor goes
down?
This brings up both technical and business considerations. Do the CI/CD pipelines simply
time out because they can't reach the vendor, or do you have it "fail open" and allow the
pipeline to complete with a warning? This is a technical problem but ultimately a business
decision. Are you willing to go to production with a change that has bypassed the security
scanning in this scenario?
Obviously, this task becomes more difficult as we increase the complexity of the system.
Thankfully, sites like k8s.af consolidate example
outage scenarios. These public postmortems are very helpful for understanding how a piece of
software can fail and how to plan for that scenario.
What are the costs?
The primary considerations here are employee time and, if applicable, vendor cost. Is that
SaaS app cheaper than more headcount? If you save each developer on the team two hours a day
with that new CI/CD tool, does it pay for itself over the next fiscal year?
Granted, not everything has to be a cost-saving proposition. Maybe it won't be cost-neutral
if you save the dev team a couple of hours a day, but you're removing a huge blocker in their
daily workflow, and they would be much happier for it. That happiness is likely worth the
financial cost. Onboarding new developers is costly, so don't underestimate the value of
increased retention when making these calculations.
I hope you've found this framework insightful, and I encourage you to incorporate it into
your own decision-making processes. There is no one-size-fits-all framework that works for
every decision. Don't forget that, sometimes, you might need to go with your gut and make a
judgment call. However, having a standardized process like this will help differentiate between
those times when you can critically analyze a decision and when you need to make that leap.
The working assumption should "Nobody inclusing myself will ever reuse this code". It is very reastic assumption as programmers
are notoriously resultant to reuse the code from somebody elses. And you programming skills evolve you old code will look pretty
foreign to use.
"In the one and only true way. The object-oriented version of 'Spaghetti code' is, of course, 'Lasagna code'. (Too many layers)."
- Roberto Waltman
This week on our show we discuss this quote. Does OOP encourage too many layers in code?
I first saw this phenomenon when doing Java programming. It wasn't a fault of the language itself, but of excessive levels of
abstraction. I wrote about this before in
the false abstraction antipattern
So what is your story of there being too many layers in the code? Or do you disagree with the quote, or us?
Bertil Muth "¢
Dec 9 '18
I once worked for a project, the codebase had over a hundred classes for quite a simple job to be done. The programmer was no
longer available and had almost used every design pattern in the GoF book. We cut it down to ca. 10 classes, hardly losing any functionality.
Maybe the unnecessary thick lasagne is a symptom of devs looking for a one-size-fits-all solution.
Nested Software "¢
Dec 9 '18 "¢ Edited on Dec 16
I think there's a very pervasive mentality of "I must to use these tools, design patterns, etc." instead of "I need
to solve a problem" and then only use the tools that are really necessary. I'm not sure where it comes from, but there's a kind of
brainwashing that people have where they're not happy unless they're applying complicated techniques to accomplish a task. It's a
fundamental problem in software development...Nested Software "¢
Dec 9 '18
I tend to think of layers of inheritance when it comes to OO. I've seen a lot of cases where the developers just build
up long chains of inheritance. Nowadays I tend to think that such a static way of sharing code is usually bad. Having a base class
with one level of subclasses can be okay, but anything more than that is not a great idea in my book. Composition is almost always
a better fit for re-using code.
"... Main drivers of this overcomplexity are bloated states and economy dominated by corporations. Both states and corporations have IT systems today "and the complexity of those IT systems has to reflect the complexity of organisms and processes they try to cover. " ..."
Someone has sent me a link to a quite
emotional but interesting article by Tim Bray on why the world of enterprise systems delivers so many failed projects and sucky
software while the world of web startups excels at producing great software fast.
Tim makes some very valid points about technology,
culture and approach to running projects. It is true that huge upfront specs, fixed bid contracts and overall waterfall approach
are indeed culprits behind most failed IT projects, and that agile, XP and other key trends of recent years can help.
However, I don't think they can really cure the problem, because we are facing a deeper issue here: the overall overcomplexity in
our civilization.
Main drivers of this overcomplexity are bloated states and economy dominated by corporations. Both states and corporations have
IT systems today "and the complexity of those IT systems has to reflect the complexity of organisms and processes they try to cover.
"
The IT system for a national health care system or a state run compulsory social security "insurance" is a very good example.
It must be a complex mess because what it is trying to model and run is a complex, overbloated mess "" in most cases a constantly
changing mess. And it can't be launched early because it is useless unless it covers the whole scope of what it is supposed to do:
because most of what it covers is regulations and laws you can't deliver a system that meets half of the regulations or 10% "" it
can't be used. By the very nature of the domain the system has to be launched as a finished whole.
Plus, on top of all that, comes the scale. If you can imagine a completely privatized health care no system will ever cover all
citizens "" each doctor, hospital, insurer etc. will cover just its clients, a subset of the population. A system like NHS has to
handle all of the UK's population by design.
Same problem with corporations, especially those that have been around for long (by long I mean decades, not years): scale and
mentality. You just can't manage 75 thousand people easily, especially if they are spread around the globe, in a simple and agile
way.
Just think of all accounting requirements global corporations have to handle with their IT systems "" but this is just the tip
of the iceberg. Whole world economy floats in a sea of legislation "" legislative diarrhea of the last decades produced a legal swamp
which is a nightmare to understand let alone model a system to comply with it. For a global corporation multiply that by all the
countries it is in and stick some international regulations on top of this. This is something corporate systems have to cope with.
What is also important "" much of that overcomplexity is computer driven: it would not have been possible if not for the existence
of IT systems and computers that run them.
Take VAT tax "" it is so complex I always wonder what idiots gave the Nobel prize to the moron who invented it (well, I used to
wonder about that when Nobel prize had any credibility). Clearly, implementing it is completely impossible without computers & systems
everywhere.
Same about the legal diarrhea I mentioned "" I think it can be largely attributed to Microsoft Word. Ever wondered why the EU
Constitution (now disguised as "Lisbon Treaty") has hundreds of pages while the US Constitution is simple and elegant? Well, they
couldn't have possibly written a couple hundred page document with a quill pen which forced them to produce something concise.
But going back to the key issue of whether the corporate IT systems can be better: they can, but a deeper shift in thinking is
needed. Instead of creating huge, complex systems corporate IT should rather be a cloud of simple, small systems built and maintained
to provide just one simple service (exactly what web startups are doing "" each of them provides simple a service, together they
create a complex ecosystem). However, this shift would have to occur on the organizational level too "" large organizations with
complex rules should be replaced with small, focused entities with simple rules for interaction between them.
But to get there we would need a world-wide "agile adoption" reaching well beyond IT. But that means a huge political change,
that is nowhere on the horizon. Unless, of course, one other enabler of our civilization's overcomplexity fades: cheap, abundant
energy.
"The bots' mission: To deliver restaurant meals cheaply and efficiently, another leap in
the way food comes to our doors and our tables." The semiautonomous vehicles were
engineered by Kiwibot, a company started in 2017 to game-change the food delivery
landscape...
In May, Kiwibot sent a 10-robot fleet to Miami as part of a nationwide pilot program
funded by the Knight Foundation. The program is driven to understand how residents and
consumers will interact with this type of technology, especially as the trend of robot
servers grows around the country.
And though Broward County is of interest to Kiwibot, Miami-Dade County officials jumped
on board, agreeing to launch robots around neighborhoods such as Brickell, downtown Miami and
several others, in the next couple of weeks...
"Our program is completely focused on the residents of Miami-Dade County and the way
they interact with this new technology. Whether it's interacting directly or just sharing
the space with the delivery bots,"
said Carlos Cruz-Casas, with the county's Department of Transportation...
Remote supervisors use real-time GPS tracking to monitor the robots. Four cameras are
placed on the front, back and sides of the vehicle, which the supervisors can view on a
computer screen. [A spokesperson says later in the article "there is always a remote and
in-field team looking for the robot."] If crossing the street is necessary, the robot
will need a person nearby to ensure there is no harm to cars or pedestrians. The plan is to
allow deliveries up to a mile and a half away so robots can make it to their destinations in
30 minutes or less.
Earlier Kiwi tested its sidewalk-travelling robots around the University of California at
Berkeley, where
at least one of its robots burst into flames . But the Sun-Sentinel reports that "In
about six months, at least 16 restaurants came on board making nearly 70,000
deliveries...
"Kiwibot now offers their robotic delivery services in other markets such as Los Angeles
and Santa Monica by working with the Shopify app to connect businesses that want to employ
their robots." But while delivery fees are normally $3, this new Knight Foundation grant "is
making it possible for Miami-Dade County restaurants to sign on for free."
A video
shows the reactions the sidewalk robots are getting from pedestrians on a sidewalk, a dog
on a leash, and at least one potential restaurant customer looking forward to no longer
having to tip human food-delivery workers.
Customers wouldn't have to train the algorithm on their own boxes because the robot was made
to recognize boxes of different sizes, textures and colors. For example, it can recognize both
shrink-wrapped cases and cardboard boxes.
... Stretch is part of a growing market of warehouse robots made by companies such as 6
River Systems Inc., owned by e-commerce technology company Shopify Inc., Locus Robotics Corp. and Fetch
Robotics Inc. "We're anticipating exponential growth (in the market) over the next five years,"
said Dwight Klappich, a supply chain research vice president and fellow at tech research firm
Gartner Inc.
As fast-food restaurants and small businesses struggle to find low-skilled workers to staff
their kitchens and cash registers, America's biggest fast-food franchise is seizing the
opportunity to field test a concept it has been working toward for some time: 10 McDonald's
restaurants in Chicago are testing automated drive-thru ordering using new artificial
intelligence software that converts voice orders for the computer.
McDonald's CEO Chris Kempczinski said Wednesday during an appearance at Alliance Bernstein's
Strategic Decisions conference that the new voice-order technology is about 85% accurate and
can take 80% of drive-thru orders. The company obtained the technology during its 2019
acquisition of Apprente.
The introduction of automation and artificial intelligence into the industry will eventually
result in entire restaurants controlled without humans - that could happen as early as the end
of this decade. As for McDonald's, Kempczinski said the technology will likely take more than
one or two years to implement.
"Now there's a big leap from going to 10 restaurants in Chicago to 14,000 restaurants
across the US, with an infinite number of promo permutations, menu permutations, dialect
permutations, weather -- and on and on and on, " he said.
McDonald's is also exploring automation of its kitchens, but that technology likely won't be
ready for another five years or so - even though it's capable of being introduced soooner.
McDonald's has also been looking into automating more of the kitchen, such as its fryers
and grills, Kempczinski said. He added, however, that that technology likely won't roll out
within the next five years, even though it's possible now.
"The level of investment that would be required, the cost of investment, we're nowhere
near to what the breakeven would need to be from the labor cost standpoint to make that a
good business decision for franchisees to do," Kempczinski said.
And because restaurant technology is moving so fast, Kempczinski said, McDonald's won't
always be able to drive innovation itself or even keep up. The company's current strategy is
to wait until there are opportunities that specifically work for it.
"If we do acquisitions, it will be for a short period of time, bring it in house,
jumpstart it, turbo it and then spin it back out and find a partner that will work and scale
it for us," he said.
On Friday, Americans will receive their first broad-based update on non-farm employment in
the US since last month's report, which missed expectations by a wide margin, sparking
discussion about whether all these "enhanced" monetary benefits from federal stimulus programs
have kept workers from returning to the labor market.
Over-complexity describes a tangible or intangible entity that is more complex than it needs to be relative to its use and purpose.
Complexity can be measured as the amount of information that is required to fully document an entity. A technology that can be fully
described in 500 words is far less complex than a technology that requires at least 5 million words to fully specify. The following
are common types of over-complexity.
Accidental Complexity Accidental complexity is any complexity beyond the minimum required
to meet a need. This can be compared to essential complexity that describes the most simple solution possible for a given need and
level of quality. For example, the essential complexity for a bridge that is earthquake resistance and inexpensive to maintain might
be contained in an architectural design of 15 pages. If a competing design were to be 100 pages with the same level of quality and
functionality, this design can be considered overly complex.
Overthinking A decision making process that is overly complex
such that it is an inefficient use of time and other resources. Overthinking can also result in missed opportunities. For example,
a student who spends three years thinking about what afterschool activity they would like to join instead of just trying a few things
to see how they work out. By the time the student finally makes a decision to join a soccer team, they find the other players are
far more advanced than themselves.
Gold Plating Adding additional functions, features and quality to something that adds little
or no value. For example, a designer of an air conditioning unit who adds personalized settings for up to six individuals to the
user interface. This requires people to install an app to use the air conditioner such that users typically view the feature as an
annoyance. The feature is seldom used and some customers actively avoid the product based on reviews that criticise the feature.
The feature also adds to the development cost and unit cost of the product, making it less competitive in the market.
Big Ball
of Mud A big ball of mud is a design that is the product of many incremental changes that aren't coordinated within a common
architecture and design. A common example is a city that emerges without any building regulations or urban planning. Big ball of
mud is also common in software where developers reinvent the same services such that code becomes extremely complex relative to its
use.
Incomprehensible Communication Communication complexity is measured by how long it takes you to achieve your communication
objectives with an audience. It is common for communication to be overly indirect with language that is unfamiliar to an audience
such that little gets communicated. Communication complexity is also influenced by how interesting the audience find your speech,
text or visualization. For example, an academic who uses needlessly complex speech out of a sense of elitism or fear of being criticized
may transfer little knowledge to students with a lecture such that it can be viewed as overly complex.
Notes Over-complexity
can have value to quality of life and culture. If the world was nothing but minimized, plain functionality it would be less interesting.
"... Lasagna Code is layer upon layer of abstractions, objects and other meaningless misdirections that result in bloated, hard to maintain code all in the name of "clarity". ..."
"... Turbo Pascal v3 was less than 40k. That's right, 40 thousand bytes. Try to get anything useful today in that small a footprint. Most people can't even compile "Hello World" in less than a few megabytes courtesy of our object-oriented obsessed programming styles which seem to demand "lines of code" over clarity and "abstractions and objects" over simplicity and elegance. ..."
Anyone who claims to be even remotely versed in computer science knows what "spaghetti code" is. That type of code still sadly
exists. But today we also have, for lack of a better term" and sticking to the pasta metaphor" "lasagna code".
Lasagna Code is layer upon layer of abstractions, objects and other meaningless misdirections that result in bloated, hard to
maintain code all in the name of "clarity". It drives me nuts to see how badly some code today is. And then you come across
how small Turbo Pascal v3 was , and after comprehending it was a
full-blown Pascal compiler, one wonders why applications and compilers today are all so massive.
Turbo Pascal v3 was less than 40k. That's right, 40 thousand bytes. Try to get anything useful today in that small a footprint.
Most people can't even compile "Hello World" in less than a few megabytes courtesy of our object-oriented obsessed programming styles
which seem to demand "lines of code" over clarity and "abstractions and objects" over simplicity and elegance.
Back when I was starting out in computer science I thought by today we'd be writing a few lines of code to accomplish much. Instead,
we write hundreds of thousands of lines of code to accomplish little. It's so sad it's enough to make one cry, or just throw your
hands in the air in disgust and walk away.
There are bright spots. There are people out there that code small and beautifully. But they're becoming rarer, especially when
someone who seemed to have thrived on writing elegant, small, beautiful code recently passed away. Dennis Ritchie understood you
could write small programs that did a lot. He comprehended that the algorithm is at the core of what you're trying to accomplish.
Create something beautiful and well thought out and people will examine it forever, such as
Thompson's version of Regular Expressions !
"... Stephen Hawking predicted this would be " the century of complexity ." He was talking about theoretical physics, but he was dead right about technology... ..."
"... Any human mind can only encompass so much complexity before it gives up and starts making slashing oversimplifications with an accompanying risk of terrible mistakes. ..."
...Stephen Hawking predicted this would be "
the century of complexity ." He was talking about theoretical physics, but he was dead
right about technology...
Let's try to define terms. How can we measure complexity? Seth Lloyd of MIT, in a paper which drily
begins "The world has grown more complex recently, and the number of ways of measuring
complexity has grown even faster," proposed three key categories: difficulty of description,
difficulty of creation, and degree of organization. Using those three criteria, it seems
apparent at a glance that both our societies and our technologies are far more complex than
they ever have been, and rapidly growing even moreso.
The thing is, complexity is the enemy. Ask any engineer "¦ especially a security
engineer. Ask the ghost of Steve Jobs. Adding complexity to solve a problem may bring a
short-term benefit, but it invariably comes with an ever-accumulating long-term cost. Any
human mind can only encompass so much complexity before it gives up and starts making slashing
oversimplifications with an accompanying risk of terrible mistakes.
You may have noted that those human minds empowered to make major decisions are often those
least suited to grappling with nuanced complexity. This itself is arguably a lingering effect
of growing complexity. Even the simple concept of democracy has grown highly complex" party
registration, primaries, fundraising, misinformation, gerrymandering, voter rolls, hanging
chads, voting machines" and mapping a single vote for a representative to dozens if not
hundreds of complex issues is impossible, even if you're willing to consider all those issues
in depth, which most people aren't.
Complexity
theory is a rich field, but it's unclear how it can help with ordinary people trying to
make sense of their world. In practice, people deal with complexity by coming up with
simplified models close enough to the complex reality to be workable. These models can be
dangerous" "everyone just needs to learn to code," "software does the same thing every time it
is run," "democracies are benevolent"" but they were useful enough to make fitful progress.
In software, we at least recognize this as a problem. We pay lip service to the glories of
erasing code, of simplifying functions, of eliminating side effects and state, of deprecating
complex APIs, of attempting to scythe back the growing thickets of complexity. We call
complexity "technical debt" and realize that at least in principle it needs to be paid down
someday.
"Globalization should be conceptualized as a series of adapting and co-evolving global
systems, each characterized by unpredictability, irreversibility and co-evolution. Such systems
lack finalized "˜equilibrium' or "˜order'; and the many pools of order heighten
overall disorder," to
quote the late John Urry. Interestingly, software could be viewed that way as well,
interpreting, say, "the Internet" and "browsers" and "operating systems" and "machine learning"
as global software systems.
Software is also something of a best possible case for making complex things simpler. It is
rapidly distributed worldwide. It is relatively devoid of emotional or political axegrinding.
(I know, I know. I said "relatively.") There are reasonably objective measures of performance
and simplicity. And we're all at least theoretically incentivized to simplify it.
So if we can make software simpler" both its tools and dependencies, and its actual end
products" then that suggests we have at least some hope of keeping the world simple enough such
that crude mental models will continue to be vaguely useful. Conversely, if we can't, then it
seems likely that our reality will just keep growing more complex and unpredictable, and we
will increasingly live in a world of whole flocks of black swans. I'm not sure whether to be
optimistic or not. My mental model, it seems, is failing me.
Since the dawn of time (before software, there was only darkness), there has been one
constant: businesses want to build software cheaper and faster.
It is certainly an understandable and laudable goal especially if you've spent any time
around software developers. It is a goal that every engineer should support wholeheartedly, and
we should always strive to create things as efficiently as possible, given the constraints of
our situation.
However, the truth is we often don't. It's not intentional, but over time, we get waylaid by
unforeseen complexities in building software and train ourselves to seek out edge cases,
analysis gaps, all of the hidden repercussions that can result from a single bullet point of
requirements.
We get enthralled by the maelstrom of complexity and the mental puzzle of engineering
elegant solutions: Another layer of abstraction! DRY it up! Separate the concerns! Composition
over inheritance! This too is understandable, but in the process, we often lose sight of the
business problems being solved and forget that managing complexity is the second most
important responsibility of software developers.
So how did we get here?
Software has become easier in certain ways.
Over the last few decades, our industry has been very successful at reducing the amount of
custom code it takes to write most software.
Much of this reduction has been accomplished by making programming languages more
expressive. Languages such as Python, Ruby, or JavaScript can take as little as one third as
much code as C in order to implement similar functionality. C gave us similar advantages
over writing in assembler. Looking forward to the future, it is unlikely that language design
will give us the same kinds of improvements we have seen over the last few decades.
But reducing the amount of code it takes to build software involves many other avenues that
don't require making languages more expressive. By far the biggest gain we have made in this
over the last two decades is open source software (OSS). Without individuals and companies
pouring money into software that they give freely to the community, much of what we build today
wouldn't be possible without an order of magnitude more cost and effort.
These projects have allowed us to tackle problems by standing on the shoulders of giants,
leveraging tools to allow us to focus more of our energy on actually solving business problems,
rather than spending time building infrastructure.
That said, businesses are complex. Ridiculously complex and only getting moreso. OSS is
great for producing frameworks and tools that we can use to build systems on top of, but for
the most part, OSS has to tackle problems shared by a large number of people in order to gain
traction. Because of that, most open source projects have to either be relatively generic or be
in a very popular niche. Therefore, most of these tools are great platforms on which to build
out systems, but at the end of the day, we are still left to build all of the business logic
and interfaces in our increasingly complex and demanding systems.
So what we are left with is a stack that looks something like this (for a web
application)"¦
That "Our Code" part ends up being enormously complex, since it mirrors the business and its
processes. If we have custom business logic, and custom processes, then we are left to build
the interfaces, workflow, and logic that make up our applications. Sure, we can try to find
different ways of recording that logic (remember business rules engines?), but at the end of
the day, no one else is going to write the business logic for your business. There really
doesn't seem to be a way around that"¦ at least not until the robots come and save us
all from having to do any work.
Don't like code, well how about Low-Code?
So if we have to develop the interfaces, workflow, and logic that make up our applications,
then it sounds like we are stuck, right? To a certain extent, yes, but we have a few
options.
To most developers, software equals code, but that isn't reality. There are many ways to
build software, and one of those ways is through using visual tools. Before the web, visual
development and RAD tools had a much bigger place in the market. Tools like PowerBuilder,
Visual Foxpro, Delphi, VB, and Access all had visual design capabilities that allowed
developers to create interfaces without typing out any code.
These tools spanned the spectrum in terms of the amount of code you needed to write, but in
general, you designed your app visually and then ended up writing a ton of code to implement
the logic of your app. In many cases you still ended up programmatically manipulating the
interface, since interfaces built using these tools often ended up being very static. However,
for a huge class of applications, these tools allowed enormous productivity gains over the
alternatives, mostly at the cost of flexibility.
The prevalence of these tools might have waned since the web took over, but companies'
desire for them has not, especially since the inexorable march of software demand continues.
The latest trend that is blowing across the industry is "low code" systems. Low code
development tools are a modern term put on the latest generation of drag and drop software
development tools. The biggest difference between these tools and their brethren from years
past is that they are now mostly web (and mobile) based and are often hosted platforms in the
cloud.
And many companies are jumping all over these platforms. Vendors like Salesforce (App
Cloud), Outsystems, Mendix, or Kony are promising the ability to create applications many times
faster than "traditional" application development. While many of their claims are probably
hyperbole, there likely is a bit of truth to them as well. For all of the downsides of
depending on platforms like these, they probably do result in certain types of applications
being built faster than traditional enterprise projects using .NET or Java.
So, what is
the problem?
Well, a few things. First is that experienced developers often hate these tools. Most
Serious Developersâ„¢ like to write Real Softwareâ„¢ with
Real Codeâ„¢. I know that might sound like I'm pandering to a bunch of whiney
babies (and maybe I am a bit), but if the core value you deliver is technology, it is rarely a
good idea to adopt tools that your best developers don't want to work with.
Second is that folks like me look at these walled platforms and say "nope, not building my
application in there." That is a legitimate concern and the one that bothers me the most.
If you built an application a decade ago with PHP, then that application might be showing
its age, but it could still be humming along right now just fine. The language and ecosystem
are open source, and maintained by the community. You'll need to keep your application up to
date, but you won't have to worry about a vendor deciding it isn't worth their time to support
you anymore.
"¦folks like me look at these walled platforms and say "nope, not building my
application in there." That is a legitimate concern and the one that bothers me the most.
If you picked a vendor 10 years ago who had a locked down platform, then you might be forced
into a rewrite if they shut down or change their tooling too much ( remember
Parse? ). Or even worse, your system gets stuck on a platforms that freezes and no longer
serves your needs.
There are many reasons to be wary of these types of platforms, but for many businesses, the
allure of creating software with less effort is just too much to pass up. The complexity of
software continues on, and software engineers unfortunately aren't doing ourselves any favors
here.
What needs to change?
There are productive platforms out there, that allow us to build Real
Softwareâ„¢ with Real Codeâ„¢, but unfortunately our industry
right now is far too worried with following the lead of the big tech giants to realize that
sometimes their tools don't add a lot of value to our projects.
I can't tell you the number of times I've had a developer tell me that building something as
a single page application (SPA) adds no overhead versus just rendering HTML. I've heard
developers say that every application should be written on top of a NoSQL datastore, and that
relational databases are dead. I've heard developers question why every application isn't
written using CQRS and Event Sourcing.
It is that kind of thought process and default overhead that is leading companies to
conclude that software development is just too expensive. You might say, "But event sourcing is
so elegant! Having a SPA on top of microservices is so clean!" Sure, it can be, but not when
you're the person writing all ten microservices. It is that kind of additional complexity that
is often so unnecessary .
We, as an industry, need to find ways to simplify the process of building software, without
ignoring the legitimate complexities of businesses. We need to admit that not every application
out there needs the same level of interface sophistication and operational scalability as
Gmail. There is a whole world of apps out there that need well thought-out interfaces,
complicated logic, solid architectures, smooth workflows, etc"¦. but don't need
microservices or AI or chatbots or NoSQL or Redux or Kafka or Containers or whatever the tool
dujour is.
A lot of developers right now seem to be so obsessed with the technical wizardry of it all
that they can't step back and ask themselves if any of this is really needed.
It is like the person on MasterChef who comes in and sells themselves as the molecular
gastronomist. They separate ingredients into their constituent parts, use scientific methods of
pairing flavors, and then apply copious amounts of CO2 and liquid nitrogen to produce the most
creative foods you've ever seen. And then they get kicked off after an episode or two because
they forget the core tenet of most cooking, that food needs to taste good. They seem genuinely
surprised that no one liked their fermented fennel and mango-essence pearls served over cod
with anchovy foam.
Our obsession with flexibility, composability, and cleverness is causing us a lot of pain
and pushing companies away from the platforms and tools that we love. I'm not saying those
tools I listed above don't add value somewhere; they arose in response to real pain points,
albeit typically problems encountered by large companies operating systems at enormous
scale.
What I'm saying is that we need to head back in the direction of simplicity and start
actually creating things in a simpler way, instead of just constantly talking about simplicity.
Maybe we can lean on more integrated tech stacks to provide out of the box patterns and
tools to allow software developers to create software more efficiently.
"¦we are going to push more and more businesses into the arms of "low code"
platforms and other tools that promise to reduce the cost of software by dumbing it down and
removing the parts that brought us to it in the first place.
We need to stop pretending that our 20th line-of-business application is some unique
tapestry that needs to be carefully hand-sewn.
Staying Focused on Simplicity
After writing that, I can already hear a million developers sharpening their pitchforks, but
I believe that if we keep pushing in the direction of wanting to write everything, configure
everything, compose everything, use the same stack for every scale of problem, then we are
going to push more and more businesses into the arms of "low code" platforms and other tools
that promise to reduce the cost of software by dumbing it down and removing the parts that
brought us to it in the first place.
Our answer to the growing complexity of doing business cannot be adding complexity to the
development process "" no matter how elegant it may seem.
We must find ways to manage complexity by simplifying the development process. Because even
though managing complexity is our second most important responsibility, we must always remember
the most important responsibility of software developers: delivering value through working
software.
Common situations are: " lack of control leading to unbounded growth " lack of
predictability, leading to unbounded cost " lack of long term perspective, leading to
ill-informed decisions
complex software is the enemy of quality
Complicated = many interrelated parts " linear: small change = small impact "
predictable: straight flow, local failure " decomposable: manageable
Complex = unpredictable & hard to manage " emergent: whole is more than sum
" non-linear: small change = big impact? " cascading failure " hysteresis:
you must understand its history " indivisible
" Refactoring is improving internal quality " reducing complexity "
without changing functionality.
In the pharmaceutical industry, accuracy and attention to detail are important. Focusing on these things is easier with simplicity,
yet in the pharmaceutical industry overcomplexity is common, which can lead to important details getting overlooked. However, many
companies are trying to address this issue.
In fact, 76% of pharmaceutical
execs believe that reducing complexity leads to sustainable cost reductions. Read on for some of the ways that overcomplexity
harms pharmaceutical companies and what is being done to remedy it.
1. What Students in Pharmaceutical Manufacturing Training Should Know About Overcomplexity's Origins
Overcomplexity is when a system, organization, structure or process is unnecessarily difficult to analyze, solve or make sense
of. In pharmaceutical companies, this is a major issue and hindrance to the industry as a whole. Often, overcomplexity is the
byproduct of innovation and progress, which, despite their obvious advantages, can lead to an organization developing too many moving
parts.
For example, new forms of collaboration as well as scientific innovation can cause overcomplexity because any time something is
added to a process, it becomes more complex. Increasing regulatory scrutiny can also add complexity, as this feedback can focus on
symptoms rather than the root of an issue.
2. Organizational Overhead Can Lead to Too Much Complexity
Organizational complexity occurs when too many personnel are added, in particular department heads. After
pharmaceutical manufacturing training
you will work on teams that can benefit from being lean. Increasing overhead is often done to improve data integrity. For example,
if a company notices an issue with data integrity, they often create new roles for overseeing data governance.
Any time personnel are added for oversight, there is a risk of increased complexity at shop floor level. Fortunately, some companies
are realizing that the best way to deal with issues of data integrity is by improving data handling within departments themselves,
rather than adding new layers of overhead""and complexity.
3. Quality Systems Can Create a Backlog
A number of pharmaceutical sites suffer from a backlog of Corrective and Preventive Actions (CAPAs). CAPAs are in place to improve
conformities and quality and they follow the Good Manufacturing Practices you know about from
pharmaceutical manufacturing courses
. However, many of these sit open until there are too many of them to catch up.
Backlog that is
close to 10 percent of the total number of investigations per year points to a serious issue with the company's system. Some
companies are dealing with this backlog by introducing a risk-based, triaged approach. Triaging allows companies to focus on the
most urgent deviations and CAPAs, thus reducing this key issue of overcomplexity in the pharmaceutical industry.
4. Pharmaceutical Manufacturing Diploma Grads Should Know What Can Help
Some strategies are being adapted to address the root problems of overcomplexity. Radical simplification, for example, is a way
to target what is fundamentally wrong with overly complex organizations and structures. This is a method of continuously improving
data and performance that focuses on improving processes.
Cognitive load deduction is another way to reduce complexity, which looks at forms and documents and attempts to reduce the effort
used when working with them. In reducing the effort required to perform tasks and fill out forms, more can be accomplished by a team.
Finally, auditors can help reduce complexity by assessing the health of a company's quality systems, such as assessing how many
open CAPAs exist. Understanding these different solutions to overcomplexity could help you excel in your career after your courses.
4.0 out of 5 stars
Everyone is on a learning curve Reviewed in the United States on February 3, 2009 The author was a programmer before, so in
writing this book, he draw both from his personal experience and his observation to depict the software world.
I think this is more of a practice and opinion book rather than "Philosophy" book, however I have to agree with him in most
cases.
For example, here is Mike Gancarz's line of thinking:
1. Hard to get the s/w design right at the first place, no matter who.
2. So it's better to write a short specs without considering all factors first.
3. Build a prototype to test the assumptions
4. Use an iterative test/rewrite process until you get it right
5. Conclusion: Unix evolved from a prototype.
In case you are curious, here are the 9 tenets of Unix/Linux:
1. Small is beautiful.
2. Make each program do one thing well.
3. Build a prototype as soon as possible.
4. Choose portability over efficiency.
5. Store data in flat text files.
6. Use software leverage to your advantage.
7. Use shell scripts to increase leverage and portability.
8. Avoid captive user interfaces.
9. Make every program a filter.
Mike Gancarz told a story like this when he argues "Good programmers write good code; great programmers borrow good code".
"I recall a less-than-top-notch software engineer who couldn't program his way out of a paper bag. He had a knack, however,
for knitting lots of little modules together. He hardly ever wrote any of them himself, though. He would just fish around in the
system's directories and source code repositories all day long, sniffing for routines he could string together to make a complete
program. Heaven forbid that he should have to write any code. Oddly enough, it wasn't long before management recognized him as
an outstanding software engineer, someone who could deliver projects on time and within budget. Most of his peers never realized
that he had difficulty writing even a rudimentary sort routine. Nevertheless, he became enormously successful by simply using
whatever resources were available to him."
If this is not clear enough, Mike also drew analogies between Mick Jagger and Keith Richards and Elvis. The book is full of
inspiring stories to reveal software engineers' tendencies and to correct their mindsets.
I've found a disturbing
trend in GNU/Linux, where largely unaccountable cliques of developers unilaterally decide to make fundamental changes to the way
it works, based on highly subjective and arrogant assumptions, then forge ahead with little regard to those who actually use the
software, much less the well-established principles upon which that OS was originally built. The long litany of examples includes
Ubuntu Unity ,
Gnome Shell ,
KDE 4 , the
/usr partition ,
SELinux ,
PolicyKit ,
Systemd ,
udev and
PulseAudio , to name a few.
The broken features, creeping bloat, and in particular the unhealthy tendency toward more monolithic, less modular code in certain
Free Software projects, is a very serious problem, and I have a very serous opposition to it. I abandoned Windows to get away from
that sort of nonsense, I didn't expect to have to deal with it in GNU/Linux.
Clearly this situation is untenable.
The motivation for these arbitrary changes mostly seems to be rooted in the misguided concept of "popularity", which makes no
sense at all for something that's purely academic and non-commercial in nature. More users does not equal more developers. Indeed
more developers does not even necessarily equal more or faster progress. What's needed is more of the right sort of developers,
or at least more of the existing developers to adopt the right methods.
This is the problem with distros like Ubuntu, as the most archetypal example. Shuttleworth pushed hard to attract more users,
with heavy marketing and by making Ubuntu easy at all costs, but in so doing all he did was amass a huge burden, in the form of a
large influx of users who were, by and large, purely consumers, not contributors.
As a result, many of those now using GNU/Linux are really just typical Microsoft or Apple consumers, with all the baggage that
entails. They're certainly not assets of any kind. They have expectations forged in a world of proprietary licensing and commercially-motivated,
consumer-oriented, Hollywood-style indoctrination, not academia. This is clearly evidenced by their
belligerently hostile attitudes toward the GPL, FSF,
GNU and Stallman himself, along with their utter contempt for security and other well-established UNIX paradigms, and their unhealthy
predilection for proprietary software, meaningless aesthetics and hype.
Reading the Ubuntu forums is an exercise in courting abject despair, as one witnesses an ignorant hoard demand GNU/Linux be mutated
into the bastard son of Windows and Mac OS X. And Shuttleworth, it seems, is
only too happy
to oblige , eagerly assisted by his counterparts on other distros and upstream projects, such as Lennart Poettering and Richard
Hughes, the former of whom has somehow convinced every distro to mutate the Linux startup process into a hideous
monolithic blob , and the latter of whom successfully managed
to undermine 40 years of UNIX security in a single stroke, by
obliterating the principle that unprivileged
users should not be allowed to install software system-wide.
GNU/Linux does not need such people, indeed it needs to get rid of them as a matter of extreme urgency. This is especially true
when those people are former (or even current) Windows programmers, because they not only bring with them their indoctrinated expectations,
misguided ideologies and flawed methods, but worse still they actually implement them , thus destroying GNU/Linux from within.
Perhaps the most startling example of this was the Mono and Moonlight projects, which not only burdened GNU/Linux with all sorts
of "IP" baggage, but instigated a sort of invasion of Microsoft "evangelists" and programmers, like a Trojan horse, who subsequently
set about stuffing GNU/Linux with as much bloated, patent
encumbered garbage as they could muster.
I was part of a group who campaigned relentlessly for years to oust these vermin and undermine support for Mono and Moonlight,
and we were largely successful. Some have even suggested that my
diatribes ,
articles and
debates (with Miguel
de Icaza and others) were instrumental in securing this victory, so clearly my efforts were not in vain.
Amassing a large user-base is a highly misguided aspiration for a purely academic field like Free Software. It really only makes
sense if you're a commercial enterprise trying to make as much money as possible. The concept of "market share" is meaningless for
something that's free (in the commercial sense).
Of course Canonical is also a commercial enterprise, but it has yet to break even, and all its income is derived through support
contracts and affiliate deals, none of which depends on having a large number of Ubuntu users (the Ubuntu One service is cross-platform,
for example).
"... The author instincts on sysadmin related issues are mostly right: he is suspicious about systemd and another perversions in modern Linuxes, he argues for simplicity in software, and he warns us about PHBs problem in IT departments, points out for the importance of documentation. etc. ..."
"... maybe it is the set of topics that the author discusses is the main value of the book. ..."
"... in many cases, the right solution is to avoid those subsystems or software packages like the plague and use something simpler. Recently, avoiding Linux flavors with systemd also can qualify as a solution ;-) ..."
"... For example, among others, the author references a rare and underappreciated, but a very important book "Putt's Law and the Successful Technocrat: How to Win in the Information Age by Archibald Putt (2006-04-28)". From which famous Putt's Law "Technology is dominated by two types of people, those who understand what they do not manage and those who manage what they do not understand," and Putt's Corollary: "Every technical hierarchy, in time, develop a competence inversion" were originated. This reference alone is probably worth half-price of the book for sysadmins, who never heard about Putt's Law. ..."
"... Linux (as of monstrous RHEL 7 with systemd, network manager and other perversions, which raised the complexity of the OS at least twice) became a way to complex for a human brain. It is impossible to remember all the important details and lessons learned from Internet browsing, your SNAFU and important tickets. Unless converted into private knowledgebase, most of such valuable knowledge disappears, say, in six months or so. And the idea of using corporate helpdesk as a knowledge database is in most cases a joke. ..."
Some valuable tips. Can serve as fuel for your own thoughts.
This book is most interesting probably for people who can definitely do well without it seasoned sysadmins and educators.
Please ignore the word "philosophy" in the title. Most sysadmins do not want to deal with "philosophy";-). And this book does
not rise to the level of philosophy in any case. It is just collection of valuable (and not so valuable) tips from the author
career as a sysadmin of a small lab, thinly dispersed in 500 pages. Each chapter can serve as a fuel for your own thoughts.
The author instincts on sysadmin related issues are mostly right: he is suspicious about systemd and another perversions in
modern Linuxes, he argues for simplicity in software, and he warns us about PHBs problem in IT departments, points out for the
importance of documentation. etc.
In some cases, I disagreed with the author, or view his treatment of the topic as somewhat superficial, but still, his points
created the kind of "virtual discussion" that has a value of its own. And maybe it is the set of topics that the author discusses
is the main value of the book.
I would classify this book as "tips" book when the author shares his approach to this or that problem (sometimes IMHO wrong,
but still interesting ;-), distinct from the more numerous and often boring, but much better-selling class of "how to" books.
The latter explains in gory details how to deal with a particular complex Unix/Linux subsystem, or a particular role (for example
system administrator of Linux servers). But in many cases, the right solution is to avoid those subsystems or software packages
like the plague and use something simpler. Recently, avoiding Linux flavors with systemd also can qualify as a solution ;-)
This book is different. It is mostly about how to approach some typical system tasks, which arise on the level of a small lab
(that the lab is small is clear from the coverage of backups). The author advances an important idea of experimentation as a way
of solving the problem and optimizing your existing setup and work habits.
The book contains an overview of good practices of using some essential sysadmin tools such as screen and sudo. In the last
chapter, the author even briefly mentions (just mentions) a very important social problem -- the problem micromanagers. The latter
is real cancer in Unix departments of large corporations (and not only in Unix departments)
All chapters contain "webliography" at the end adding to the value of the book. While Kindle version of the book is badly formatted
for PC (but is OK on Samsung 10" tablet; I would recommend to this it for reading instead), the references in Kindle version are
clickable. And reading them them along with reading the book, including the author articles at opensource.com enhance the book
value greatly.
For example, among others, the author references a rare and underappreciated, but a very important book "Putt's Law and
the Successful Technocrat: How to Win in the Information Age by Archibald Putt (2006-04-28)". From which famous Putt's Law "Technology
is dominated by two types of people, those who understand what they do not manage and those who manage what they do not understand,"
and Putt's Corollary: "Every technical hierarchy, in time, develop a competence inversion" were originated. This reference alone
is probably worth half-price of the book for sysadmins, who never heard about Putt's Law.
Seasoned sysadmins can probably just skim Part I-III (IMHO those chapters are somewhat simplistic. ) For example, you
can skip Introduction to author's Linux philosophy, his views on contribution to open source, and similar chapters that contain
trivial information ). I would start reading the book from Part IV (Becoming Zen ), which consist of almost a dozen interesting
topics. Each of them is covered very briefly (which is a drawback). But they can serve as starters for your own thought process
and own research. The selection of topics is very good and IMHO constitutes the main value of the book.
For example, the author raises a very important issue in his chapter 20: Document Everything, but unfortunately, this chapter
is too brief, and he does not address the most important thing: sysadmin should work on some way to organize your personal knowledge.
For example as a private website. Maintenances of such a private knowledgebase is a crucial instrument of any Linux sysadmin worth
his/her salary and part of daily tasks worth probably 10% of sysadmin time. The quote "Those who cannot learn from history are
doomed to repeat it" has a very menacing meaning in sysadmin world.
Linux (as of monstrous RHEL 7 with systemd, network manager and other perversions, which raised the complexity of the OS
at least twice) became a way to complex for a human brain. It is impossible to remember all the important details and lessons
learned from Internet browsing, your SNAFU and important tickets. Unless converted into private knowledgebase, most of such valuable
knowledge disappears, say, in six months or so. And the idea of using corporate helpdesk as a knowledge database is in most cases
a joke.
The negative part of the book is that the author spreads himself too thin and try to cover too much ground. That means that
treatment of most topics became superficial. Also provided examples of shell scripts is more of a classic shell style, not Bash
4.x type of code. That helps portability (if you need it) but does not allow to understand new features of bash 4.x. Bash is available
now on most Unixes, such as AIX, Solaris and HP-UX and that solves portability issues in a different, and more productive, way.
Portability was killed by systemd anyway unless you want to write wrappers for systemctl related functions ;-)
For an example of author writing, please search for his recent (Oct 30, 2018) article "Working with data streams on the Linux
command line" That might give you a better idea of what to expect.
In my view, the book contains enough wisdom to pay $32 for it (Kindle edition price), especially if your can do it at company
expense :-). The book is also valuable for educators. Again, the most interesting part is part IV:
Part IV: Becoming Zen 325
Chapter 17: Strive for Elegance 327
Hardware Elegance 327
ThePC8 328
Motherboards 328
Computers 329
Data Centers 329
Power and Grounding 330
Software Elegance 331
Fixing My Web Site 336
Removing Crutt 338
Old or Unused Programs 338
Old Code In Scripts 342
Old Files 343
A Final Word 350
Chapter 18: Find the Simplicity 353
Complexity in Numbers 353
Simplicity In Basics 355
The Never-Ending Process of Simplification 356
Simple Programs Do One Thing 356
Simple Programs Are Small 359
Simplicity and the Philosophy 361
Simplifying My Own Programs 361
Simplifying Others' Programs 362
Uncommented Code 362
Hardware 367
Linux and Hardware 368
The Quandary. 369
The Last Word
Chapter 19: Use Your Favorite Editor 371
More Than Editors 372
Linux Startup 372
Why I Prefer SystemV 373
Why I Prefer systemd 373
The Real Issue 374
Desktop 374
sudo or Not sudo 375
Bypass sudo 376
Valid Uses for sudo 378
A Few Closing Words 379
Chapter 20: Document Everything 381
The Red Baron 382
My Documentation Philosophy 383
The Help Option 383
Comment Code Liberally 384
My Code Documentation Process 387
Man Pages 388
Systems Documentation 388
System Documentation Template 389
Document Existing Code 392
Keep Docs Updated 393
File Compatibility 393
A Few Thoughts 394
Chapter 21: Back Up Everything - Frequently 395
Data Loss 395
Backups to the Rescue 397
The Problem 397
Recovery 404
Doing It My Way 405
Backup Options 405
Off-Site Backups 413
Disaster Recovery Services 414
Other Options 415
What About the "Frequently" Part? 415
Summary 415
Chapter 22: Follow Your Curiosity 417
Charlie 417
Curiosity Led Me to Linux 418
Curiosity Solves Problems 423
Securiosity 423
Follow Your Own Curiosity 440
Be an Author 441
Failure Is an Option 441
Just Do It 442
Summary 443
Chapter 23: There Is No Should 445
There Are Always Possibilities 445
Unleashing the Power 446
Problem Solving 447
Critical Thinking 449
Reasoning to Solve Problems 450
Integrated Reason 453
Self-Knowledge 455
Finding Your Center 455
The Implications of Diversity 456
Measurement Mania 457
The Good Manager 458
Working Together 458
Silo City ..460
The Easy Way 461
Thoughts 462
Chapter 24: Mentor the Young SysAdmins 463
Hiring the Right People 464
Mentoring 465
BRuce the Mentor 466
The Art of Problem Solving 467
The Five Steps ot Problem Solving 467
Knowledge 469
Observation 469
Reasoning 472
Action 473
Test 473
Example 474
Iteration 475
Concluding Thoughts 475
Chapter 25: Support Your Favorite Open Source Project 477
Project Selection 477
Code 478
Test 479
Submit Bug Reports 479
Documentation 480
Assist 481
Teach 482
Write 482
Donate 483
Thoughts 484
Chapter 26: Reality Bytes 485
People 485
The Micromanager 486
More Is Less 487
Tech Support Terror 488
You Should Do It My Way 489
It's OK to Say No 490
The Scientific Method 490
Understanding the Past 491
Final Thoughts 492
I've seen many infrastructures in my day. I work for a company with a very complicated infrastructure now. They've got a dev/stage/prod
environment for every product (and they've got many of them). Trust is not a word spoken lightly here. There is no 'trust' for even
sysadmins (I've been working here for 7 months now and still don't have production sudo access). Developers constantly complain about
not having the access that they need to do their jobs and there are multiple failures a week that can only be fixed by a small handful
of people that know the (very complex) systems in place. Not only that, but in order to save work, they've used every cutting-edge
piece of software that they can get their hands on (mainly to learn it so they can put it on their resume, I assume), but this causes
more complexity that only a handful of people can manage. As a result of this the site uptime is (on a good month) 3 nines at best.
In my last position (pronto.com) I put together an infrastructure that any idiot could maintain. I used unmanaged switches behind
a load-balancer/firewall and a few VPNs around to the different sites. It was simple. It had very little complexity, and a new sysadmin
could take over in a very short time if I were to be hit by a bus. A single person could run the network and servers and if the documentation
was lost, a new sysadmin could figure it out without much trouble.
Over time, I handed off my ownership of many of the Infrastructure components to other people in the operations group and of course,
complexity took over. We ended up with a multi-tier network with bunches of VLANs and complexity that could only be understood with
charts, documentation and a CCNA. Now the team is 4+ people and if something happens, people run around like chickens with their
heads cut off not knowing what to do or who to contact when something goes wrong.
Complexity kills productivity. Security is inversely proportionate to usability. Keep it simple, stupid. These are all rules to
live by in my book.
Downtimes: Beatport: not unlikely to have 1-2 hours downtime for the main site per month.
Pronto: several 10-15 minute outages a year Pronto (under my supervision): a few seconds a month (mostly human error though, no
mechanical failure)
John Waclawsky (from Cisco's mobile solutions group), coined the term S4 for "Systems
Standards Stockholm Syndrome" - like hostages becoming attached to their captors, systems
standard participants become wedded to the process of setting standards for the sake of
standards.
"... The "Stockholm Syndrome" describes the behavior of some hostages. The "System Standards Stockholm Syndrome" (S4) describes the behavior of system standards participants who, over time, become addicted to technology complexity and hostages of group thinking. ..."
"... What causes S4? Captives identify with their captors initially as a defensive mechanism, out of fear of intellectual challenges. Small acts of kindness by the captors, such as granting a secretarial role (often called a "chair") to a captive in a working group are magnified, since finding perspective in a systems standards meeting, just like a hostage situation, is by definition impossible. Rescue attempts are problematic, since the captive could become mentally incapacitated by suddenly being removed from a codependent environment. ..."
This was sent to me by a colleague. From "S4 -- The System Standards Stockholm
Syndrome" by John G. Waclawsky, Ph.D.:
The "Stockholm Syndrome" describes the behavior of some hostages. The "System
Standards Stockholm Syndrome" (S4) describes the behavior of system standards
participants who, over time, become addicted to technology complexity and hostages of
group thinking.
12:45 PM -- While we flood you with IMS-related content this week, perhaps it's sensible to
share some airtime with a clever warning about being held "captive" to the hype.
This warning comes from John G. Waclawsky, PhD, senior technical staff, Wireless Group,
Cisco Systems Inc. (Nasdaq: CSCO).
Waclawsky, writing in the July issue of Business Communications Review , compares the fervor over
IMS to the " Stockholm Syndrome ," a term that
comes from a 1973 hostage event in which hostages became sympathetic to their captors.
Waclawsky says a form of the Stockholm Syndrome has taken root in technical standards
groups, which he calls "System Standards Stockholm Syndrome," or S4.
Here's a snippet from Waclawsky's column:
What causes S4? Captives identify with their captors initially as a defensive
mechanism, out of fear of intellectual challenges. Small acts of kindness by the captors,
such as granting a secretarial role (often called a "chair") to a captive in a working
group are magnified, since finding perspective in a systems standards meeting, just like
a hostage situation, is by definition impossible. Rescue attempts are problematic, since
the captive could become mentally incapacitated by suddenly being removed from a
codependent environment.
The full article can be found here -- R. Scott Raynovich, US
Editor, Light Reading
Sunday, August 07, 2005S4 - The Systems Standards Stockholm
Syndrome John Waclawsky, part of the Mobile Wireless Group at Cisco Systems, features an
interesting article in the July 2005 issue of the Business Communications Review on The Systems Standards Stockholm Syndrome.
Since his responsibilities include standards activities (WiMAX, IETF, OMA, 3GPP and TISPAN),
identification of product requirements and the definition of mobile wireless and broadband
architectures, he seems to know very well what he is talking about, namely the IP Multimedia
Subsytem (IMS). See also his article in the June 2005 issue on IMS 101 - What You Need To Know Now .
See also the Wikedpedia glossary from Martin
below:
IMS. Internet Monetisation System . A minor adjustment to Internet Protocol to add a
"price" field to packet headers. Earlier versions referred to Innovation Minimisation
System . This usage is now deprecated. (Expected release Q2 2012, not available in all
markets, check with your service provider in case of sudden loss of unmediated
connectivity.)
It is so true that I have to cite it completely (bold emphasis added):
The "Stockholm Syndrome" describes the behavior of some hostages. The "System Standards
Stockholm Syndrome" (S 4 ) describes the behavior of system standards participants
who, over time, become addicted to technology complexity and hostages of group thinking.
Although the original name derives from a 1973 hostage incident in Stockholm, Sweden, the
expanded name and its acronym, S 4 , applies specifically to systems standards
participants who suffer repeated exposure to cult dogma contained in working group documents
and plenary presentations. By the end of a week in captivity, Stockholm Syndrome victims may
resist rescue attempts, and afterwards refuse to testify against their captors. In system
standards settings, S4 victims have been known to resist innovation and even refuse to
compete against their competitors.
Recent incidents involving too much system standards attendance have resulted in people
being captured by radical ITU-like factions known as the 3GPP or 3GPP2.
I have to add of course ETSI TISPAN and it seems that the syndrome is also spreading into
IETF, especially to SIP and SIPPING.
The victims evolve to unwitting accomplices of the group as they become immune to the
frustration of slow plodding progress, thrive on complexity and slowly turn a blind eye to
innovative ideas. When released, they continue to support their captors in filtering out
disruptive innovation, and have been known to even assist in the creation and perpetuation of
bureaucracy.
Years after intervention and detoxification, they often regret their system standards
involvement. Today, I am afraid that S 4 cases occur regularly at system standards
organizations.
What causes S 4 ? Captives identify with their captors initially as a defensive
mechanism, out of fear of intellectual challenges. Small acts of kindness by the captors,
such as granting a secretarial role (often called a "chair") to a captive in a working group
are magnified, since finding perspective in a systems standards meeting, just like a hostage
situation, is by definition impossible. Rescue attempts are problematic, since the captive
could become mentally incapacitated by suddenly being removed from a codependent
environment.
It's important to note that these symptoms occur under tremendous emotional and/or
physical duress due to lack of sleep and abusive travel schedules. Victims of S 4
often report the application of other classic "cult programming" techniques, including:
The encouraged ingestion of mind-altering substances. Under the influence of alcohol,
complex systems standards can seem simpler and almost rational.
"Love-fests" in which victims are surrounded by cultists who feign an interest in them
and their ideas. For example, "We'd love you to tell us how the Internet would solve this
problem!"
Peer pressure. Professional, well-dressed individuals with standing in the systems
standards bureaucracy often become more attractive to the captive than the casual sorts
commonly seen at IETF meetings.
Back in their home environments, S 4 victims may justify continuing their
bureaucratic behavior, often rationalizing and defending their system standard tormentors,
even to the extent of projecting undesirable system standard attributes onto component
standards bodies. For example, some have been heard murmuring, " The IETF is no picnic and
even more bureaucratic than 3GPP or the ITU, " or, "The IEEE is hugely political." (For more
serious discussion of component and system standards models, see " Closed Architectures, Closed Systems And
Closed Minds ," BCR, October 2004.)
On a serious note, the ITU's IMS (IP Multimedia Subsystem) shows every sign of becoming
the latest example of systems standards groupthink. Its concepts are more than seven years
old and still not deployed, while its release train lengthens with functional expansions and
change requests. Even a cursory inspection of the IMS architecture reveals the complexity
that results from:
decomposing every device into its most granular functions and linkages; and
tracking and controlling every user's behavior and related billing.
The proliferation of boxes and protocols, and the state management required for data
tracking and control, lead to cognitive overload but little end user value.
It is remarkable that engineers who attend system standards bodies and use modern
Internet- and Ethernet-based tools don't apply to their work some of the simplicity learned
from years of Internet and Ethernet success: to build only what is good enough, and as simply
as possible.
Now here I have to break in: I think the syndrome is also spreading to
the IETF, becuase the IETF is starting to leave these principles behind - especially in SIP
and SIPPING, not to mention Session Border Confuser (SBC).
The lengthy and detailed effort that characterizes systems standards sometimes produces a
bit of success, as the 18 years of GSM development (1980 to 1998) demonstrate. Yet such
successes are highly optimized, very complex and thus difficult to upgrade, modify and
extend.
Email is a great example. More than 15 years of popular email usage have passed, and today
email on wireless is just beginning to approach significant usage by ordinary people.
The IMS is being hyped as a way to reduce the difficulty of integrating new services, when
in fact it may do just the opposite. IMS could well inhibit new services integration due to
its complexity and related impacts on cost, scalability, reliability, OAM, etc.
Not to mention the sad S 4 effects on all those engineers participating in
IMS-related standards efforts.
Make each program do one thing well. To do a new job, build afresh rather than
complicate old programs by adding new features.
By now, and to be frank in the last 30 years too, this is complete and utter bollocks.
Feature creep is everywhere, typical shell tools are choke-full of spurious additions, from
formatting to "side" features, all half-assed and barely, if at all, consistent.
By now, and to be frank in the last 30 years too, this is complete and utter
bollocks.
There is not one single other idea in computing that is as unbastardised as the unix
philosophy - given that it's been around fifty years. Heck, Microsoft only just developed
PowerShell - and if that's not Microsoft's take on the Unix philosophy, I don't know what
is.
In that same time, we've vacillated between thick and thin computing (mainframes, thin
clients, PCs, cloud). We've rebelled against at least four major schools of program design
thought (structured, procedural, symbolic, dynamic). We've had three different database
revolutions (RDBMS, NoSQL, NewSQL). We've gone from grassroots movements to corporate
dominance on countless occasions (notably - the internet, IBM PCs/Wintel, Linux/FOSS, video
gaming). In public perception, we've run the gamut from clerks ('60s-'70s) to boffins
('80s) to hackers ('90s) to professionals ('00s post-dotcom) to entrepreneurs/hipsters/bros
('10s "startup culture").
It's a small miracle that iproute2only has formatting options and
grep only has --color . If they feature-crept anywhere near the same
pace as the rest of the computing world, they would probably be a RESTful SaaS microservice
with ML-powered autosuggestions.
This is because adding a new features is actually easier than trying to figure out how
to do it the Unix way - often you already have the data structures in memory and the
functions to manipulate them at hand, so adding a --frob parameter that does
something special with that feels trivial.
GNU and their stance to ignore the Unix philosophy (AFAIK Stallman said at some point he
didn't care about it) while becoming the most available set of tools for Unix systems
didn't help either.
No, it certainly isn't. There are tons of well-designed, single-purpose tools
available for all sorts of purposes. If you live in the world of heavy, bloated GUI apps,
well, that's your prerogative, and I don't begrudge you it, but just because you're not
aware of alternatives doesn't mean they don't exist.
typical shell tools are choke-full of spurious additions,
What does "feature creep" even mean with respect to shell tools? If they have lots of
features, but each function is well-defined and invoked separately, and still conforms to
conventional syntax, uses stdio in the expected way, etc., does that make it un-Unixy? Is
BusyBox bloatware because it has lots of discrete shell tools bundled into a single
binary? nirreskeya
3 years ago
I have succumbed to the temptation you offered in your preface: I do write you off
as envious malcontents and romantic keepers of memories. The systems you remember so
fondly (TOPS-20, ITS, Multics, Lisp Machine, Cedar/Mesa, the Dorado) are not just out
to pasture, they are fertilizing it from below.
Your judgments are not keen, they are intoxicated by metaphor. In the Preface you
suffer first from heat, lice, and malnourishment, then become prisoners in a Gulag.
In Chapter 1 you are in turn infected by a virus, racked by drug addiction, and
addled by puffiness of the genome.
Yet your prison without coherent design continues to imprison you. How can this
be, if it has no strong places? The rational prisoner exploits the weak places,
creates order from chaos: instead, collectives like the FSF vindicate their jailers
by building cells almost compatible with the existing ones, albeit with more
features. The journalist with three undergraduate degrees from MIT, the researcher at
Microsoft, and the senior scientist at Apple might volunteer a few words about the
regulations of the prisons to which they have been transferred.
Your sense of the possible is in no sense pure: sometimes you want the same thing
you have, but wish you had done it yourselves; other times you want something
different, but can't seem to get people to use it; sometimes one wonders why you just
don't shut up and tell people to buy a PC with Windows or a Mac. No Gulag or lice,
just a future whose intellectual tone and interaction style is set by Sonic the
Hedgehog. You claim to seek progress, but you succeed mainly in whining.
Here is my metaphor: your book is a pudding stuffed with apposite observations,
many well-conceived. Like excrement, it contains enough undigested nuggets of
nutrition to sustain life for some. But it is not a tasty pie: it reeks too much of
contempt and of envy.
"... There's still value in understanding the traditional UNIX "do one thing and do it well" model where many workflows can be done as a pipeline of simple tools each adding their own value, but let's face it, it's not how complex systems really work, and it's not how major applications have been working or been designed for a long time. It's a useful simplification, and it's still true at /some/ level, but I think it's also clear that it doesn't really describe most of reality. ..."
There's still value in understanding the traditional UNIX "do one thing and do it
well" model where many workflows can be done as a pipeline of simple tools each adding their
own value, but let's face it, it's not how complex systems really work, and it's not how
major applications have been working or been designed for a long time. It's a useful
simplification, and it's still true at /some/ level, but I think it's also clear that it
doesn't really describe most of reality.
http://www.itwire.com/business-it-news/open-source/65402-torvalds-says-he-has-no-strong-opinions-on-systemd
Almost nothing on the Desktop works as the original Unix inventors prescribed as the "Unix
way", and even editors like "Vim" are questionable since it has integrated syntax
highlighting and spell checker. According to dogmatic Unix Philosophy you should use "ed, the
standard editor" to compose the text and then pipe your text into "spell". Nobody really
wants to work that way.
But while "Unix Philosophy" in many ways have utterly failed as a way people actually work
with computers and software, it is still very good to understand, and in many respects still
very useful for certain things. Personally I love those standard Linux text tools like
"sort", "grep" "tee", "sed" "wc" etc, and they have occasionally been very useful even
outside Linux system administration.
Boston Dynamics, a robotics company known for its four-legged robot "dog," this week
announced a new product, a computer-vision enabled mobile warehouse robot named "Stretch."
Developed in response to growing demand for automation in warehouses, the robot can reach up
to 10 feet inside of a truck to pick up and unload boxes up to 50 pounds each. The robot has a
mobile base that can maneuver in any direction and navigate obstacles and ramps, as well as a
robotic arm and a gripper. The company estimates that there are more than 500 billion boxes
annually that get shipped around the world, and many of those are currently moved manually.
"It's a pretty arduous job, so the idea with Stretch is that it does the manual labor part
of that job," said Robert Playter, chief executive of the Waltham, Mass.-based company.
The pandemic has accelerated [automation of] e-commerce and logistics operations even more
over the past year, he said.
... ... ...
... the robot was made to recognize boxes of different sizes, textures and colors. For
example, it can recognize both shrink-wrapped cases and cardboard boxes.
Eventually, Stretch could move through an aisle of a warehouse, picking up different
products and placing them on a pallet, Mr. Playter said.
I keep happening on these mentions of manufacturing jobs succumbing to automation, and I
can't think of where these people are getting their information.
I work in manufacturing. Production manufacturing, in fact, involving hundreds, thousands,
tens of thousands of parts produced per week. Automation has come a long way, but it also
hasn't. A layman might marvel at the technologies while taking a tour of the factory, but
upon closer inspection, the returns are greatly diminished in the last two decades. Advances
have afforded greater precision, cheaper technologies, but the only reason China is a giant
of manufacturing is because labor is cheap. They automate less than Western factories, not
more, because humans cost next to nothing, but machines are expensive.
"... I once worked for a project, the codebase had over a hundred classes for quite a simple job to be done. The programmer was no longer available and had almost used every design pattern in the GoF book. We cut it down to ca. 10 classes, hardly losing any functionality. Maybe the unnecessary thick lasagne is a symptom of devs looking for a one-size-fits-all solution. ..."
I first saw this phenomenon when doing Java programming. It wasn't a fault of the language itself, but of excessive levels of
abstraction. I wrote about this before in
the false abstraction antipattern
So what is your story of there being too many layers in the code? Or do you disagree with the quote, or us? Discussion (12)
Subscribe
Shrek: Object-oriented programs are like onions. Donkey: They stink? Shrek: Yes. No. Donkey: Oh, they make you cry. Shrek: No. Donkey: Oh, you leave em out in the sun, they get all brown, start sproutinâ little white hairs. Shrek: No. Layers. Onions have layers. Object-oriented programs have layers. Onions have layers. You get it? They both have
layers. Donkey: Oh, they both have layers. Oh. You know, not everybody like onions. 8 likes
Reply Dec 8 '18
Unrelated, but I love both spaghetti and lasagna ð 6 likes
Reply
I once worked for a project, the codebase had over a hundred classes for quite a simple job to be done. The programmer was no
longer available and had almost used every design pattern in the GoF book. We cut it down to ca. 10 classes, hardly losing any functionality.
Maybe the unnecessary thick lasagne is a symptom of devs looking for a one-size-fits-all solution.
I think there's a very pervasive mentality of "I must to use these tools, design patterns, etc." instead of "I need to
solve a problem" and then only use the tools that are really necessary. I'm not sure where it comes from, but there's a kind of brainwashing
that people have where they're not happy unless they're applying complicated techniques to accomplish a task. It's a fundamental
problem in software development... 4 likes
Reply
I tend to think of layers of inheritance when it comes to OO. I've seen a lot of cases where the developers just build
up long chains of inheritance. Nowadays I tend to think that such a static way of sharing code is usually bad. Having a base class
with one level of subclasses can be okay, but anything more than that is not a great idea in my book. Composition is almost always
a better fit for re-using code. 2 likes
Reply
Inheritance is my preferred option for things that model type hierarchies. For example, widgets in a UI, or literal types in a
compiler.
One reason inheritance is over-used is because languages don't offer enough options to do composition correctly. It ends up becoming
a lot of boilerplate code. Proper support for mixins would go a long way to reducing bad inheritance. 2 likes
Reply
It is always up to the task. For small programms of course you don't need so many layers, interfaces and so on. For a bigger,
more complex one you need it to avoid a lot of issues: code duplications, unreadable code, constant merge conflicts etc. 2 likes
Reply
I'm building a personal project as a mean to get something from zero to production for learning purpose, and I am struggling with
wiring the front-end with the back. Either I dump all the code in the fetch callback or I use DTOs, two sets of interfaces to describe
API data structure and internal data structure... It's a mess really, but I haven't found a good level of compromise. 2 likes
Reply
It's interesting, because a project that gets burned by spaghetti can drift into lasagna code to overcompensate. Still bad, but lasagna
code is somewhat more manageable (just a huge headache to reason about).
But having an ungodly combination of those two... I dare not think about it. shudder 2 likes
Reply
Sidenote before I finish listening: I appreciate that I can minimize the browser on mobile and have this keep playing, unlike
with others apps(looking at you, YouTube). 2 likes
Reply
The pasta theory is a theory of programming. It is a common analogy for application development describing different programming
structures as popular pasta dishes. Pasta theory highlights the shortcomings of the code. These analogies include spaghetti, lasagna
and ravioli code.
Code smells or anti-patterns are a common classification of source code quality. There is also classification based on food which
you can find on Wikipedia.
Spaghetti code is a pejorative term for source code that has a complex and tangled control structure, especially one using many
GOTOs, exceptions, threads, or other “unstructured†branching constructs. It is named such because program flow tends to look
like a bowl of spaghetti, i.e. twisted and tangled. Spaghetti code can be caused by several factors, including inexperienced programmers
and a complex program which has been continuously modified over a long life cycle. Structured programming greatly decreased the incidence
of spaghetti code.
Ravioli code
Ravioli code is a type of computer program structure, characterized by a number of small and (ideally) loosely-coupled software
components. The term is in comparison with spaghetti code, comparing program structure to pasta; with ravioli (small pasta pouches
containing cheese, meat, or vegetables) being analogous to objects (which ideally are encapsulated modules consisting of both code
and data).
Lasagna code
Lasagna code is a type of program structure, characterized by several well-defined and separable layers, where each layer of code
accesses services in the layers below through well-defined interfaces. The term is in comparison with spaghetti code, comparing program
structure to pasta.
Spaghetti with meatballs
The term “spaghetti with meatballs†is a pejorative term used in computer science to describe loosely constructed object-oriented
programming (OOP) that remains dependent on procedural code. It may be the result of a system whose development has transitioned
over a long life-cycle, language constraints, micro-optimization theatre, or a lack of coherent coding standards.
Do you know about other interesting source code classification?
When introducing a new tool, programming language, or dependency into your environment, what
steps do you take to evaluate it? In this article, I will walk through a six-question framework
I use to make these determinations.
What problem am I trying to solve?
We all get caught up in the minutiae of the immediate problem at hand. An honest, critical
assessment helps divulge broader root causes and prevents micro-optimizations.
Let's say you are experiencing issues with your configuration management system. Day-to-day
operational tasks are taking longer than they should, and working with the language is
difficult. A new configuration management system might alleviate these concerns, but make sure
to take a broader look at this system's context. Maybe switching from virtual machines to
immutable containers eases these issues and more across your environment while being an
equivalent amount of work. At this point, you should explore the feasibility of more
comprehensive solutions as well. You may decide that this is not a feasible project for the
organization at this time due to a lack of organizational knowledge around containers, but
conscientiously accepting this tradeoff allows you to put containers on a roadmap for the next
quarter.
This intellectual exercise helps you drill down to the root causes and solve core issues,
not the symptoms of larger problems. This is not always going to be possible, but be
intentional about making this decision.
Now that we have identified the problem, it is time for critical evaluation of both
ourselves and the selected tool.
A particular technology might seem appealing because it is new because you read a cool blog
post about it or you want to be the one giving a conference talk. Bells and whistles can be
nice, but the tool must resolve the core issues you identified in the first
question.
What am I giving up?
The tool will, in fact, solve the problem, and we know we're solving the right
problem, but what are the tradeoffs?
These considerations can be purely technical. Will the lack of observability tooling prevent
efficient debugging in production? Does the closed-source nature of this tool make it more
difficult to track down subtle bugs? Is managing yet another dependency worth the operational
benefits of using this tool?
Additionally, include the larger organizational, business, and legal contexts that you
operate under.
Are you giving up control of a critical business workflow to a third-party vendor? If that
vendor doubles their API cost, is that something that your organization can afford and is
willing to accept? Are you comfortable with closed-source tooling handling a sensitive bit of
proprietary information? Does the software licensing make this difficult to use
commercially?
While not simple questions to answer, taking the time to evaluate this upfront will save you
a lot of pain later on.
Is the project or vendor healthy?
This question comes with the addendum "for the balance of your requirements." If you only
need a tool to get your team over a four to six-month hump until Project X is
complete, this question becomes less important. If this is a multi-year commitment and the tool
drives a critical business workflow, this is a concern.
When going through this step, make use of all available resources. If the solution is open
source, look through the commit history, mailing lists, and forum discussions about that
software. Does the community seem to communicate effectively and work well together, or are
there obvious rifts between community members? If part of what you are purchasing is a support
contract, use that support during the proof-of-concept phase. Does it live up to your
expectations? Is the quality of support worth the cost?
Make sure you take a step beyond GitHub stars and forks when evaluating open source tools as
well. Something might hit the front page of a news aggregator and receive attention for a few
days, but a deeper look might reveal that only a couple of core developers are actually working
on a project, and they've had difficulty finding outside contributions. Maybe a tool is open
source, but a corporate-funded team drives core development, and support will likely cease if
that organization abandons the project. Perhaps the API has changed every six months, causing a
lot of pain for folks who have adopted earlier versions.
What are the risks?
As a technologist, you understand that nothing ever goes as planned. Networks go down,
drives fail, servers reboot, rows in the data center lose power, entire AWS regions become
inaccessible, or BGP hijacks re-route hundreds of terabytes of Internet traffic.
Ask yourself how this tooling could fail and what the impact would be. If you are adding a
security vendor product to your CI/CD pipeline, what happens if the vendor goes
down?
This brings up both technical and business considerations. Do the CI/CD pipelines simply
time out because they can't reach the vendor, or do you have it "fail open" and allow the
pipeline to complete with a warning? This is a technical problem but ultimately a business
decision. Are you willing to go to production with a change that has bypassed the security
scanning in this scenario?
Obviously, this task becomes more difficult as we increase the complexity of the system.
Thankfully, sites like k8s.af consolidate example
outage scenarios. These public postmortems are very helpful for understanding how a piece of
software can fail and how to plan for that scenario.
What are the costs?
The primary considerations here are employee time and, if applicable, vendor cost. Is that
SaaS app cheaper than more headcount? If you save each developer on the team two hours a day
with that new CI/CD tool, does it pay for itself over the next fiscal year?
Granted, not everything has to be a cost-saving proposition. Maybe it won't be cost-neutral
if you save the dev team a couple of hours a day, but you're removing a huge blocker in their
daily workflow, and they would be much happier for it. That happiness is likely worth the
financial cost. Onboarding new developers is costly, so don't underestimate the value of
increased retention when making these calculations.
I hope you've found this framework insightful, and I encourage you to incorporate it into
your own decision-making processes. There is no one-size-fits-all framework that works for
every decision. Don't forget that, sometimes, you might need to go with your gut and make a
judgment call. However, having a standardized process like this will help differentiate between
those times when you can critically analyze a decision and when you need to make that leap.
A colleague of mine today committed a class called ThreadLocalFormat , which basically moved instances of Java Format
classes into a thread local, since they are not thread safe and "relatively expensive" to create. I wrote a quick test and calculated
that I could create 200,000 instances a second, asked him was he creating that many, to which he answered "nowhere near that many".
He's a great programmer and everyone on the team is highly skilled so we have no problem understanding the resulting code, but it
was clearly a case of optimizing where there is no real need. He backed the code out at my request. What do you think? Is this a
case of "premature optimization" and how bad is it really?
design architecture optimization
quality-attributesshare improve this question
follow edited Dec 5 '19 at 3:54
community wiki 3 revs, 3 users 67% Craig Day
Alex ,
I think you need to distinguish between premature optimization, and unnecessary optimization. Premature to me suggests 'too early
in the life cycle' whereas unnecessary suggests 'does not add significant value'. IMO, requirement for late optimization implies
shoddy design. – Shane MacLaughlin
Oct 17 '08 at 8:53
2 revs, 2 users 92% , 2014-12-11 17:46:38
345
It's important to keep in mind the full quote:
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet
we should not pass up our opportunities in that critical 3%.
What this means is that, in the absence of measured performance issues you shouldn't optimize because you think you will get
a performance gain. There are obvious optimizations (like not doing string concatenation inside a tight loop) but anything that
isn't a trivially clear optimization should be avoided until it can be measured.
Being from Donald Knuth, I wouldn't be surprized if he had some evidence to back it up. BTW, Src: Structured Programming with
go to Statements, ACM Journal Computing Surveys, Vol 6, No. 4, Dec. 1974. p.268.
citeseerx.ist.psu.edu/viewdoc/
– mctylr Mar 1 '10 at 17:57
2 revs, 2 users 90% , 2015-10-06 13:07:11
120
Premature micro optimizations are the root of all evil, because micro optimizations leave out context. They almost never behave
the way they are expected.
What are some good early optimizations in the order of importance:
Architectural optimizations (application structure, the way it is componentized and layered)
Data flow optimizations (inside and outside of application)
Some mid development cycle optimizations:
Data structures, introduce new data structures that have better performance or lower overhead if necessary
Algorithms (now its a good time to start deciding between quicksort3 and heapsort ;-) )
Some end development cycle optimizations
Finding code hotpots (tight loops, that should be optimized)
Profiling based optimizations of computational parts of the code
Micro optimizations can be done now as they are done in the context of the application and their impact can be measured
correctly.
Not all early optimizations are evil, micro optimizations are evil if done at the wrong time in the development life cycle
, as they can negatively affect architecture, can negatively affect initial productivity, can be irrelevant performance wise or
even have a detrimental effect at the end of development due to different environment conditions.
If performance is of concern (and always should be) always think big . Performance is a bigger picture and not about things
like: should I use int or long ?. Go for Top Down when working with performance instead of Bottom Up
. share improve this answer follow
edited Oct 6 '15 at 13:07 community
wiki 2 revs, 2 users 90% Pop Catalin
Here Here! Unconsidered optimization makes code un-maintainable and is often the cause of performance problems. e.g. You multi-thread
a program because you imagine it might help performance, but, the real solution would have been multiple processes which are now
too complex to implement. –
James Anderson May 2 '12 at 5:01
John Mulder , 2008-10-17 08:42:58
45
Optimization is "evil" if it causes:
less clear code
significantly more code
less secure code
wasted programmer time
In your case, it seems like a little programmer time was already spent, the code was not too complex (a guess from your comment
that everyone on the team would be able to understand), and the code is a bit more future proof (being thread safe now, if I understood
your description). Sounds like only a little evil. :)
share improve this answer follow answered
Oct 17 '08 at 8:42 community
wiki John Mulder
mattnz ,
Only if the cost, it terms of your bullet points, is greater than the amortized value delivered. Often complexity introduces value,
and in these cases one can encapsulate it such that it passes your criteria. It also gets reused and continues to provide more
value. – Shane MacLaughlin
Oct 17 '08 at 10:36
Michael Shaw , 2020-06-16 10:01:49
42
I'm surprised that this question is 5 years old, and yet nobody has posted more of what Knuth had to say than a couple of sentences.
The couple of paragraphs surrounding the famous quote explain it quite well. The paper that is being quoted is called "
Structured Programming with go to
Statements ", and while it's nearly 40 years old, is about a controversy and a software movement that both no longer exist,
and has examples in programming languages that many people have never heard of, a surprisingly large amount of what it said still
applies.
Here's a larger quote (from page 8 of the pdf, page 268 in the original):
The improvement in speed from Example 2 to Example 2a is only about 12%, and many people would pronounce that insignificant.
The conventional wisdom shared by many of today's software engineers calls for ignoring efficiency in the small; but I believe
this is simply an overreaction to the abuses they see being practiced by penny-wise-and-pound-foolish programmers, who can't
debug or maintain their "optimized" programs. In established engineering disciplines a 12% improvement, easily obtained, is
never considered marginal; and I believe the same viewpoint should prevail in software engineering. Of course I wouldn't bother
making such optimizations on a one-shot job, but when it's a question of preparing quality programs, I don't want to restrict
myself to tools that deny me such efficiencies.
There is no doubt that the grail of efficiency leads to abuse. Programmers waste enormous amounts of time thinking about,
or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong
negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about
97% of the time: premature optimization is the root of all evil.
Yet we should not pass up our opportunities in that critical 3%. A good programmer will not be lulled into complacency by
such reasoning, he will be wise to look carefully at the critical code; but only after that code has been identified. It is
often a mistake to make a priori judgments about what parts of a program are really critical, since the universal experience
of programmers who have been using measurement tools has been that their intuitive guesses fail.
Another good bit from the previous page:
My own programming style has of course changed during the last decade, according to the trends of the times (e.g., I'm not
quite so tricky anymore, and I use fewer go to's), but the major change in my style has been due to this inner loop phenomenon.
I now look with an extremely jaundiced eye at every operation in a critical inner loop, seeking to modify my program and data
structure (as in the change from Example 1 to Example 2) so that some of the operations can be eliminated. The reasons for
this approach are that: a) it doesn't take long, since the inner loop is short; b) the payoff is real; and c) I can then afford
to be less efficient in the other parts of my programs, which therefore are more readable and more easily written and debugged.
I've often seen this quote used to justify obviously bad code or code that, while its performance has not been measured, could
probably be made faster quite easily, without increasing code size or compromising its readability.
In general, I do think early micro-optimizations may be a bad idea. However, macro-optimizations (things like choosing an O(log
N) algorithm instead of O(N^2)) are often worthwhile and should be done early, since it may be wasteful to write a O(N^2) algorithm
and then throw it away completely in favor of a O(log N) approach.
Note the words may be : if the O(N^2) algorithm is simple and easy to write, you can throw it away later without much guilt
if it turns out to be too slow. But if both algorithms are similarly complex, or if the expected workload is so large that you
already know you'll need the faster one, then optimizing early is a sound engineering decision that will reduce your total workload
in the long run.
Thus, in general, I think the right approach is to find out what your options are before you start writing code, and consciously
choose the best algorithm for your situation. Most importantly, the phrase "premature optimization is the root of all evil" is
no excuse for ignorance. Career developers should have a general idea of how much common operations cost; they should know, for
example,
that strings cost more than numbers
that dynamic languages are much slower than statically-typed languages
the advantages of array/vector lists over linked lists, and vice versa
when to use a hashtable, when to use a sorted map, and when to use a heap
that (if they work with mobile devices) "double" and "int" have similar performance on desktops (FP may even be faster)
but "double" may be a hundred times slower on low-end mobile devices without FPUs;
that transferring data over the internet is slower than HDD access, HDDs are vastly slower than RAM, RAM is much slower
than L1 cache and registers, and internet operations may block indefinitely (and fail at any time).
And developers should be familiar with a toolbox of data structures and algorithms so that they can easily use the right tools
for the job.
Having plenty of knowledge and a personal toolbox enables you to optimize almost effortlessly. Putting a lot of effort into
an optimization that might be unnecessary is evil (and I admit to falling into that trap more than once). But when optimization
is as easy as picking a set/hashtable instead of an array, or storing a list of numbers in double[] instead of string[], then
why not? I might be disagreeing with Knuth here, I'm not sure, but I think he was talking about low-level optimization whereas
I am talking about high-level optimization.
Remember, that quote is originally from 1974. In 1974 computers were slow and computing power was expensive, which gave some
developers a tendency to overoptimize, line-by-line. I think that's what Knuth was pushing against. He wasn't saying "don't worry
about performance at all", because in 1974 that would just be crazy talk. Knuth was explaining how to optimize; in short, one
should focus only on the bottlenecks, and before you do that you must perform measurements to find the bottlenecks.
Note that you can't find the bottlenecks until you have written a program to measure, which means that some performance decisions
must be made before anything exists to measure. Sometimes these decisions are difficult to change if you get them wrong. For this
reason, it's good to have a general idea of what things cost so you can make reasonable decisions when no hard data is available.
How early to optimize, and how much to worry about performance depend on the job. When writing scripts that you'll only run
a few times, worrying about performance at all is usually a complete waste of time. But if you work for Microsoft or Oracle and
you're working on a library that thousands of other developers are going to use in thousands of different ways, it may pay to
optimize the hell out of it, so that you can cover all the diverse use cases efficiently. Even so, the need for performance must
always be balanced against the need for readability, maintainability, elegance, extensibility, and so on.
Awesome video, I loved watching it. In my experience, there are many situations where,
like you pointed out, procedural style makes things easier and prevents you from overthinking
and overgeneralizing the problem you are trying to tackle. However, in some cases,
object-oriented programming removes unnecessary conditions and switches that make your code
harder to read. Especially in complex game engines where you deal with a bunch of objects
which interact in diverse ways to the environment, other objects and the physics engine. In a
procedural style, a program like this would become an unmanageable clutter of flags,
variables and switch-statements. Therefore, the statement "Object-Oriented Programming is
Garbage" is an unnecessary generalization. Object-oriented programming is a tool programmers
can use - and just like you would not use pliers to get a nail into a wall, you should not
force yourself to use object-oriented programming to solve every problem at hand. Instead,
you use it when it is appropriate and necessary. Nevertheless, i would like to hear how you
would realize such a complex program. Maybe I'm wrong and procedural programming is the best
solution in any case - but right now, I think you need to differentiate situations which
require a procedural style from those that require an object-oriented style.
I have been brainwashed with c++ for 20 years. I have recently switched to ANSI C and my
mind is now free. Not only I feel free to create design that are more efficient and elegant,
but I feel in control of what I do.
You make a lot of very solid points. In your refactoring of the Mapper interface to a
type-switch though: what is the point of still using a declared interface here? If you are
disregarding extensibility (which would require adding to the internal type switch, rather
than conforming a possible new struct to an interface) anyway, why not just make Mapper of
type interface{} and add a (failing) default case to your switch?
I recommend to install the Gosublime extension, so your code gets formatted on save and
you can use autocompletion. But looks good enough. But I disagree with large functions. Small
ones are just easier to understand and test.
Being the lead designer of an larger app (2m lines of code as of 3 years ago). I like to
say we use C+. Because C++ breaks down in the real world. I'm happy to use encapsulation when
it fits well. But developers that use OO just for OO-ness sake get there hands slapped. So in
our app small classes like PhoneNumber and SIN make sense. Large classes like UserInterface
also work nicely (we talk to specialty hardware like forklifts and such). So, it may be all
coded in C++ but basic C developers wouldn't have to much of an issue with most of it. I
don't think OO is garbage. It's just a lot people use it in in appropriate ways. When all you
have is a hammer, everything looks like a nail. So if you use OO on everything then you
sometimes end up with garbage.
Loving the series. The hardest part of actually becoming an efficient programmer is
unlearning all the OOP brainwashing. It can be useful for high-level structuring so I've been
starting with C++ then reducing everything into procedural functions and tightly-packed data
structs. Just by doing that I reduced static memory use and compiled program size at least
10-15%+ (which is a lot when you only have 32kb.) And holy damn, nearly 20 years of C and I
never knew you could nest a function within a function, I had to try that right away.
I have a design for a networked audio platform that goes into large buildings (over 11
stories) and can have 250 networked nodes (it uses an E1 style robbed bit networking system)
and 65K addressable points (we implemented 1024 of them for individual control by grouping
them). This system ties to a fire panel at one end with a microphone and speakers at the
other end. You can manually select any combination of points to page to, or the fire panel
can select zones to send alarm messages to. It works in real time with 50mS built in delays
and has access to 12 audio channels. What really puts the frosting on this cake is, the CPU
is an i8051 running at 18MHz and the code is a bit over 200K bytes that took close to 800K
lines of code. In assembler. And it took less than a Year from concept to first installation.
By one designer/coder. The only OOP in this code was when an infinite loop happened or a bug
crept in - "OOPs!"
There's a way of declaring subfunctions in C++ (idk if works in C). I saw it done by my
friend. General idea is to declare a struct inside which a function can be declared. Since
you can declare structs inside functions, you can safely use it as a wrapper for your
function-inside-function declaration. This has been done in MSVC but I believe it will
compile in gcc too.
"Is pixel an object or a group of objects? Is there a container? Do I have to ask a
factory to get me a color?" I literally died there... that's literally the best description
of my programming for the last 5 years.
It's really sad that we are only taught OOP and no other paradigms in our college, when I
discovered programming I had no idea about OOP and it was really easy to build programs, bt
then I came across OOP:"how to deconstruct a problem statement into nouns for objects and
verbs for methods" and it really messed up my thinking, I have been struggling for a long
time on how to organize my code on the conceptual level, only recently I realized that OOP is
the reason for this struggle, handmadehero helped alot to bring me back to the roots of how
programming is done, remember never push OOP into areas where it is not needed, u don't have
to model ur program as real world entities cause it's not going to run on real world, it's
going to run on CPU!
I lost an entire decade to OOP, and agree with everything Casey said here. The code I
wrote in my first year as a programmer (before OOP) was better than the code I wrote in my
15th year (OOP expert). It's a shame that students are still indoctrinated into this
regressive model.
Unfortunately, when I first started programming, I encountered nothing but tutorials that
jumped right into OOP like it was the only way to program. And of course I didn't know any
better! So much friction has been removed from my process since I've broken free from that
state of mind. It's easier to judge when objects are appropriate when you don't think they're
always appropriate!
"It's not that OOP is bad or even flawed. It's that object-oriented programming isn't the
fundamental particle of computing that some people want it to be. When blindly applied to
problems below an arbitrary complexity threshold, OOP can be verbose and contrived, yet
there's often an aesthetic insistence on objects for everything all the way down. That's too
bad, because it makes it harder to identify the cases where an object-oriented style truly
results in an overall simplicity and ease of understanding." -
https://prog21.dadgum.com/156.html
The first language I was taught was Java, so I was taught OOP from the get go. Removing
the OOP mindset was actually really easy, but what was left stuck in my head is the practice
of having small functions and make your code look artificially "clean". So I am in a constant
struggle of refactoring and not refactoring, knowing that over-refactoring will unnecessarily
complicate my codebase if it gets big. Even after removing my OOP mindset, my emphasis is
still on the code itself, and that is much harder to cure in comparison.
"I want to emphasize that the problem with object-oriented programming is not the concept
that there could be an object. The problem with it is the fact that you're orienting your
program, the thinking, around the object, not the function. So it's the orientation that's
bad about it, NOT whether you end up with an object. And it's a really important distinction
to understand."
Nicely stated, HH. On youtube, MPJ, Brian Will, and Jonathan Blow also address this
matter. OOP sucks and can be largely avoided. Even "reuse" is overdone. Straightline probably
results in faster execution but slightly greater memory use. But memory is cheap and the
resultant code is much easier to follow. Learn a little assembly language. X86 is fascinating
and you'll know what the computer is actually doing.
I think schools should teach at least 3 languages / paradigms, C for Procedural, Java for
OOP, and Scheme (or any Lisp-style languages) for Functional paradigms.
It sounds to me like you're describing JavaScript framework programming that people learn
to start from. It hasn't seemed to me like object-oriented programmers who aren't doing web
stuff have any problem directly describing an algorithm and then translating it into
imperative or functional or just direct instructions for a computer. it's quite possible to
use object-oriented languages or languages that support object-oriented stuff to directly
command a computer.
I dunno man. Object oriented programming can (sometimes badly) solve real problems -
notably polymorphism. For example, if you have a Dog and a Cat sprite and they both have a
move method. The "non-OO" way Casey does this is using tagged unions - and that was not an
obvious solution when I first saw it. Quite glad I watched that episode though, it's very
interesting! Also see this tweet thread from Casey -
https://twitter.com/cmuratori/status/1187262806313160704
My deepest feeling after crossing so many discussions and books about this is a sincere
YES.
Without entering in any technical details about it, because even after some years I
don’t find myself qualified to talk about this (is there someone who really understand
it completely?), I would argument that the main problem is that every time a read something
about OOP it is trying to justify why it is “so good”.
Then, a huge amount of examples are shown, many arguments, and many expectations are
created.
It is not stated simply like this: “oh, this is another programming paradigm.”
It is usually stated that: “This in a fantastic paradigm, it is better, it is simpler,
it permits so many interesting things, … it is this, it is that… and so on.
What happens is that, based on the “good” arguments, it creates some
expectation that things produced with OOP should be very good. But, no one really knows if
they are doing it right. They say: the problem is not the paradigm, it is you that are not
experienced yet. When will I be experienced enough?
Are you following me? My feeling is that the common place of saying it is so good at the
same time you never know how good you are actually being makes all of us very frustrated and
confuse.
Yes, it is a great paradigm since you see it just as another paradigm and drop all the
expectations and excessive claiming that it is so good.
It seems to me, that the great problem is that huge propaganda around it, not the paradigm
itself. Again, if it had a more humble claim about its advantages and how difficult is to
achieve then, people would be much less frustrated.
Sourav
Datta , A programmer trying find the ultimate source code of life.
Answered August 6, 2015 · Author has 145 answers and 292K answer views
In recent years, OOP is indeed being regarded as a overrated paradigm by many. If we look
at the most recent famous languages like Go and Rust, they do not have the traditional OO
approaches in language design. Instead, they choose to pack data into something akin to
structs in C and provide ways to specify "protocols" (similar to interfaces/abstract methods) which can work on those packed
data...
The last decade has seen object oriented programming (OOP) dominate the programming world.
While there is no doubt that there are benefits of OOP, some programmers question whether OOP
has been over rated and ponder whether alternate styles of coding are worth pursuing. To even
suggest that OOP has in some way failed to produce the quality software we all desire could in
some instances cost a programmer his job, so why even ask the question ?
Quality software is the goal.
Likely all programmers can agree that we all want to produce quality software. We would like
to be able to produce software faster, make it more reliable and improve its performance. So
with such goals in mind, shouldn't we be willing to at least consider all possibilities ? Also
it is reasonable to conclude that no single tool can match all situations. For example, while
few programmers today would even consider using assembler, there are times when low level
coding such as assembler could be warranted. The old adage applies "the right tool for the
job". So it is fair to pose the question, "Has OOP been over used to the point of trying to
make it some kind of universal tool, even when it may not fit a job very well ?"
Others are asking the same question.
I won't go into detail about what others have said about object oriented programming, but I
will simply post some links to some interesting comments by others about OOP.
I have watched a number of videos online and read a number of articles by programmers about
different concepts in programming. When OOP is discussed they talk about thinks like modeling
the real world, abtractions, etc. But two things are often missing in such discussions, which I
will discuss here. These two aspects greatly affect programming, but may not be discussed.
First is, what is programming really ? Programming is a method of using some kind of human
readable language to generate machine code (or scripts eventually read by machine code) so one
can make a computer do a task. Looking back at all the years I have been programming, the most
profound thing I have ever learned about programming was machine language. Seeing what a CPU is
actually doing with our programs provides a great deal of insight. It helps one understand why
integer arithmetic is so much faster than floating point. It helps one understand what graphics
is really all about (simply the moving around a lot of pixels or blocks of four bytes). It
helps one understand what a procedure really must do to have parameters passed. It helps one
understand why a string is simply a block of bytes (or double bytes for unicode). It helps one
understand why we use bytes so much and what bit flags are and what pointers are.
When one looks at OOP from the perspective of machine code and all the work a compiler must
do to convert things like classes and objects into something the machine can work with, then
one very quickly begins to see that OOP adds significant overhead to an application. Also if a
programmer comes from a background of working with assembler, where keeping things simple is
critical to writing maintainable code, one may wonder if OOP is improving coding or making it
more complicated.
Second, is the often said rule of "keep it simple". This applies to programming. Consider
classic Visual Basic. One of the reasons it was so popular was that it was so simple compared
to other languages, say C for example. I know what is involved in writing a pure old fashioned
WIN32 application using the Windows API and it is not simple, nor is it intuitive. Visual Basic
took much of that complexity and made it simple. Now Visual Basic was sort of OOP based, but
actually mostly in the GUI command set. One could actually write all the rest of the code using
purely procedural style code and likely many did just that. I would venture to say that when
Visual Basic went the way of dot.net, it left behind many programmers who simply wanted to keep
it simple. Not that they were poor programmers who didn't want to learn something new, but that
they knew the value of simple and taking that away took away a core aspect of their programming
mindset.
Another aspect of simple is also seen in the syntax of some programming languages. For
example, BASIC has stood the test of time and continues to be the language of choice for many
hobby programmers. If you don't think that BASIC is still alive and well, take a look at this
extensive list of different BASIC programming languages.
While some of these BASICs are object oriented, many of them are also procedural in nature.
But the key here is simplicity. Natural readable code.
Simple and low level can work together.
Now consider this. What happens when you combine a simple language with the power of machine
language ? You get something very powerful. For example, I write some very complex code using
purely procedural style coding, using BASIC, but you may be surprised that my appreciation for
machine language (or assembler) also comes to the fore. For example, I use the BASIC language
GOTO and GOSUB. How some would cringe to hear this. But these constructs are native to machine
language and very useful, so when used properly they are powerful even in a high level
language. Another example is that I like to use pointers a lot. Oh how powerful pointers are.
In BASIC I can create variable length strings (which are simply a block of bytes) and I can
embed complex structures into those strings by using pointers. In BASIC I use the DIM AT
command, which allows me to dimension an array of any fixed data type or structure within a
block of memory, which in this case happens to be a string.
Appreciating machine code also affects my view of performance. Every CPU cycle counts. This
is one reason I use BASICs GOSUB command. It allows me to write some reusable code within a
procedure, without the need to call an external routine and pass parameters. The performance
improvement is significant. Performance also affects how I tackle a problem. While I want code
to be simple, I also want it to run as fast as possible, so amazingly some of the best
performance tips have to do with keeping code simple, with minimal overhead and also
understanding what the machine code must accomplish to do with what I have written in a higher
level language. For example in BASIC I have a number of options for the SELECT CASE structure.
One option can optimize the code using jump tables (compiler handles this), one option can
optimize if the values are only Integers or DWords. But even then the compiler can only do so
much. What happens if a large SELECT CASE has to compare dozens and dozens of string constants
to a variable length string being tested ? If this code is part of a parser, then it really can
slow things down. I had this problem in a scripting language I created for an OpenGL based 3D
custom control. The 3D scripting language is text based and has to be interpreted to generate
3D OpenGL calls internally. I didn't want the scripting language to bog things down. So what
would I do ?
The solution was simple and appreciating how the compiled machine code would have to compare
so many bytes in so many string constants, one quickly realized that the compiler alone could
not solve this. I had to think like I was an assembler programmer, but still use a high level
language. The solution was so simple, it was surprising. I could use a pointer to read the
first byte of the string being parsed. Since the first character would always be a letter in
the scripting language, this meant there were 26 possible outcomes. The SELECT CASE simply
tested for the first character value (convert to a number) which would execute fast. Then for
each letter (A,B,C, ) I would only compare the parsed word to the scripting language keywords
which started with that letter. This in essence improved speed by 26 fold (or better).
The fastest solutions are often very simple to code. No complex classes needed here. Just a
simple procedure to read through a text string using the simplest logic I could find. The
procedure is a little more complex than what I describe, but this is the core logic of the
routine.
From experience, I have found that a purely procedural style of coding, using a language
which is natural and simple (BASIC), while using constructs of the language which are closer to
pure machine (or assembler) in the language produces smaller and faster applications which are
also easier to maintain.
Now I am not saying that all OOP is bad. Nor am I saying that OOP never has a place in
programming. What I am saying though is that it is worth considering the possiblity that OOP is
not always the best solution and that there are other choices.
Here are some of my other blog articles which may interest you if this one interested
you:
Classic Visual Basic's end marked a key change in software development.
Yes it is. For application code at least, I'm pretty sure.
Not claiming any originality here, people smarter than me already noticed this fact ages
ago.
Also, don't misunderstand me, I'm not saying that OOP is bad. It probably is the best
variant of procedural programming.
Maybe the term is OOP overused to describe anything that ends up in OO systems.
Things like VMs, garbage collection, type safety, mudules, generics or declarative queries
(Linq) are a given , but they are not inherently object oriented.
I think these things (and others) are more relevant than the classic three principles.
Inheritance
Current advice is usually prefer composition over inheritance . I totally agree.
Polymorphism
This is very, very important. Polymorphism cannot be ignored, but you don't write lots of
polymorphic methods in application code. You implement the occasional interface, but not every
day.
Mostly you use them.
Because polymorphism is what you need to write reusable components, much less to use them.
Encapsulation
Encapsulation is tricky. Again, if you ship reusable components, then method-level access
modifiers make a lot of sense. But if you work on application code, such fine grained
encapsulation can be overkill. You don't want to struggle over the choice between internal and
public for that fantastic method that will only ever be called once. Except in test code maybe.
Hiding all implementation details in private members while retaining nice simple tests can be
very difficult and not worth the troulbe. (InternalsVisibleTo being the least trouble, abstruse
mock objects bigger trouble and Reflection-in-tests Armageddon).
Nice, simple unit tests are just more important than encapsulation for application code, so
hello public!
So, my point is, if most programmers work on applications, and application code is not very
OO, why do we always talk about inheritance at the job interview? 🙂
PS
If you think about it, C# hasn't been pure object oriented since the beginning (think
delegates) and its evolution is a trajectory from OOP to something else, something
multiparadigm.
For example Microsoft success was by the large part determined its alliance with IBM
in the creation of PC and then exploiting IBM ineptness to ride this via shred marketing
and alliances and "natural monopoly" tendencies in IT. MS DOS was a clone of CP/M that
was bought, extended and skillfully marketed. Zero innovation here.
Both Microsoft and Apple rely of research labs in other companies to produce
innovation which they then then produced and marketed. Even Steve Jobs smartphone was not
an innovation per se: it was just a slick form factor that was the most successful in the
market. All functionality existed in other products.
Facebook was prelude to, has given the world a glimpse into, the future.
From pure technical POV Facebook is mostly junk. It is a tremendous database of user
information which users supply themselves due to cultivated exhibitionism. Kind of private
intelligence company. The mere fact that software was written in PHP tells you something
about real Zuckerberg level.
Amazon created a usable interface for shopping via internet (creating comments
infrastructure and a usable user account database ) but this is not innovation in any
sense of the word. It prospered by stealing large part of Wall Mart logistic software
(and people) and using Wall Mart tricks with suppliers. So Bezos model was Wall Mart
clone on the Internet.
Unless something is done, Bezos will soon be the most powerful man in the world.
People like Bezos, Google founders, Zuckerberg to a certain extent are part of
intelligence agencies infrastructure. Remember Prism. So implicitly we can assume that
they all report to the head of CIA.
Artificial Intelligence, AI, is another consequence of this era of innovation that
demands our immediate attention.
There is very little intelligence in artificial intelligence :-). Intelligent behavior
of robots in mostly an illusion created by First Clark law:
If you want to refer to a global variable in a function, you can use the global keyword to declare which variables are
global. You don't have to use it in all cases (as someone here incorrectly claims) - if the name referenced in an expression cannot
be found in local scope or scopes in the functions in which this function is defined, it is looked up among global variables.
However, if you assign to a new variable not declared as global in the function, it is implicitly declared as local, and it can
overshadow any existing global variable with the same name.
Also, global variables are useful, contrary to some OOP zealots who claim otherwise - especially for smaller scripts, where OOP
is overkill.
Absolutely re. zealots. Most Python users use it for scripting and create little functions to separate out small bits of code.
– Paul Uszak Sep 22 at 22:57
The OOP paradigm has been criticised for a number of reasons, including not meeting its
stated goals of reusability and modularity, [36][37]
and for overemphasizing one aspect of software design and modeling (data/objects) at the
expense of other important aspects (computation/algorithms). [38][39]
Luca Cardelli has
claimed that OOP code is "intrinsically less efficient" than procedural code, that OOP can take
longer to compile, and that OOP languages have "extremely poor modularity properties with
respect to class extension and modification", and tend to be extremely complex. [36]
The latter point is reiterated by Joe Armstrong , the principal
inventor of Erlang , who is quoted as
saying: [37]
The problem with object-oriented languages is they've got all this implicit environment
that they carry around with them. You wanted a banana but what you got was a gorilla holding
the banana and the entire jungle.
A study by Potok et al. has shown no significant difference in productivity between OOP and
procedural approaches. [40]
Christopher J.
Date stated that critical comparison of OOP to other technologies, relational in
particular, is difficult because of lack of an agreed-upon and rigorous definition of OOP;
[41]
however, Date and Darwen have proposed a theoretical foundation on OOP that uses OOP as a kind
of customizable type
system to support RDBMS .
[42]
In an article Lawrence Krubner claimed that compared to other languages (LISP dialects,
functional languages, etc.) OOP languages have no unique strengths, and inflict a heavy burden
of unneeded complexity. [43]
I find OOP technically unsound. It attempts to decompose the world in terms of interfaces
that vary on a single type. To deal with the real problems you need multisorted algebras --
families of interfaces that span multiple types. I find OOP philosophically unsound. It
claims that everything is an object. Even if it is true it is not very interesting -- saying
that everything is an object is saying nothing at all.
Paul Graham has suggested
that OOP's popularity within large companies is due to "large (and frequently changing) groups
of mediocre programmers". According to Graham, the discipline imposed by OOP prevents any one
programmer from "doing too much damage". [44]
Leo Brodie has suggested a connection between the standalone nature of objects and a
tendency to duplicate
code[45] in
violation of the don't repeat yourself principle
[46] of
software development.
Object Oriented Programming puts the Nouns first and foremost. Why would you go to such
lengths to put one part of speech on a pedestal? Why should one kind of concept take
precedence over another? It's not as if OOP has suddenly made verbs less important in the way
we actually think. It's a strangely skewed perspective.
Rich Hickey ,
creator of Clojure ,
described object systems as overly simplistic models of the real world. He emphasized the
inability of OOP to model time properly, which is getting increasingly problematic as software
systems become more concurrent. [39]
Eric S. Raymond
, a Unix programmer and
open-source
software advocate, has been critical of claims that present object-oriented programming as
the "One True Solution", and has written that object-oriented programming languages tend to
encourage thickly layered programs that destroy transparency. [48]
Raymond compares this unfavourably to the approach taken with Unix and the C programming language .
[48]
Rob Pike , a programmer
involved in the creation of UTF-8 and Go , has called object-oriented
programming "the Roman
numerals of computing" [49] and has
said that OOP languages frequently shift the focus from data structures and algorithms to types . [50]
Furthermore, he cites an instance of a Java professor whose
"idiomatic" solution to a problem was to create six new classes, rather than to simply use a
lookup table .
[51]
For efficiency sake, Objects are passed to functions NOT by their value but by
reference.
What that means is that functions will not pass the Object, but instead pass a
reference or pointer to the Object.
If an Object is passed by reference to an Object Constructor, the constructor can put that
Object reference in a private variable which is protected by Encapsulation.
But the passed Object is NOT safe!
Why not? Because some other piece of code has a pointer to the Object, viz. the code that
called the Constructor. It MUST have a reference to the Object otherwise it couldn't pass it to
the Constructor?
The Reference Solution
The Constructor will have to Clone the passed in Object. And not a shallow clone but a deep
clone, i.e. every object that is contained in the passed in Object and every object in those
objects and so on and so on.
So much for efficiency.
And here's the kicker. Not all objects can be Cloned. Some have Operating System resources
associated with them making cloning useless at best or at worst impossible.
And EVERY single mainstream OO language has this problem.
The Washington Post
Simon Denyer; Akiko Kashiwagi; Min Joo Kim
July 8, 2020
In Japan, a country with a long fascination with robots, automated assistants have offered
their services as bartenders, security guards, deliverymen, and more, since the onset of the
coronavirus pandemic. Japan's Avatarin developed the "newme" robot to allow people to be
present while maintaining social distancing during the pandemic.
The telepresence robot is
essentially a tablet on a wheeled stand with the user's face on the screen, whose location and
direction can be controlled via laptop or tablet. Doctors have used the newme robot to
communicate with patients in a coronavirus ward, while university students in Tokyo used it to
remotely attend a graduation ceremony.
The company is working on prototypes that will allow
users to control the robot through virtual reality headsets, and gloves that would permit users
to lift, touch, and feel objects through a remote robotic hand.
A robot that neutralizes aerosolized forms of the coronavirus could soon be coming to a supermarket
near you. MIT's Computer Science and Artificial Intelligence Laboratory team partnered with Ava
Robotics to develop a device that can kill roughly 90% of COVID-19 on surfaces in a 4,000-square-foot
space in 30 minutes.
"This is such an exciting idea to use the solution as a hands-free, safe way to neutralize dorms,
hallways, hospitals, airports -- even airplanes," Daniela Rus, director of the Computer Science and
Artificial Intelligence Laboratory at MIT, told Yahoo Finance's
"The
Ticker."
The key to disinfecting large spaces in a short amount of time is the UV-C light fixture
designed
at MIT
. It uses short-wavelength ultraviolet light that eliminates microorganisms by breaking down
their DNA. The UV-C light beam is attached to Ava Robotic's mobile base and can navigate a warehouse
in a similar way as a self-driving car.
"The robot is controlled by some powerful algorithms that compute exactly where the robot has to go
and how long it has to stay in order to neutralize the germs that exist in that particular part of the
space," Rus said.
This robot can kill roughly 90% of COVID-19 on surfaces in a 4,000 square foot space in 30
minutes. (Courtesy: Alyssa Pierson, MIT CSAIL)
More
Currently, the robot is being tested at the Greater Boston Food Bank's shipping area and focuses on
sanitizing products leaving the stockroom to reduce any potential threat of spreading the coronavirus
into the community.
"Here, there was a unique opportunity to provide additional disinfecting power to their current
workflow, and help reduce the risks of COVID-19 exposure," said Alyssa Pierson, CSAIL research
scientist and technical lead of the UV-C lamp assembly.
But Rus explains implementing the robot in other locations does face some challenges. "The light
emitted by the robot is dangerous to humans, so the robot cannot be in the same space as humans. Or,
if people are around the robot, they have to wear protective gear," she added.
While Rus didn't provide a specific price tag, she said the cost of the robot is still high, which may
be a hurdle for broad distribution. In the future, "Maybe you don't need to buy an entire robot set,
you can book the robot for a few hours a day to take care of your space," she said.
McKenzie Stratigopoulos is a producer at Yahoo Finance. Follow
her on Twitter:
@mckenziestrat
During the pandemic, readers may recall several of our pieces describing what life would be
like in a post corona world.
From restaurants to
flying to gambling to hotels to
gyms to interacting with people to even
housing trends - we highlighted how social distancing would transform the economy.
As the transformation becomes more evident by the week, we want to focus on automation and
artificial intelligence - and how these two things are allowing hotels, well at least one in
California, to accommodate patrons with contactless room service.
Hotel Trio in Healdsburg, California, is surrounded by wineries and restaurants in
Healdsburg/Sonoma County region, recently hired a new worker named "Rosé the Robot" that
delivers food, water, wine, beer, and other necessities, reported
Sonoma Magazine .
"As Rosé approaches a room with a delivery, she calls the phone to let the guest know
she's outside. A tablet-sized screen on Rosé's head greets the guest as they open the
door, and confirms the order. Next, she opens a lid on top of her head and reveals a storage
compartment containing the ordered items. Rosé then communicates a handful of questions
surrounding customer satisfaction via her screen. She bids farewell, turns around and as she
heads back toward her docking station near the front desk, she emits chirps that sound like a
mix between R2D2 and a little bird," said Sonoma Magazine.
Henry Harteveldt, a travel industry analyst at Atmospheric Research Group in San Francisco,
said robots would be integrated into the hotel experience.
"This is a part of travel that will see major growth in the years ahead," Harteveldt
said.
Rosé is manufactured by Savioke, a San Jose-based company that has dozens of robots
in hotels nationwide.
The tradeoff of a contactless environment where automation and artificial intelligence
replace humans to mitigate the spread of a virus is permanent
job loss .
Recently I read
Sapiens: A Brief History of Humankind
by Yuval Harari. The basic thesis of the book is that humans require 'collective fictions' so that we can collaborate in larger numbers
than the 150 or so our brains are big enough to cope with by default. Collective fictions are things that don't describe solid objects
in the real world we can see and touch. Things like religions, nationalism, liberal democracy, or Popperian falsifiability in science.
Things that don't exist, but when we act like they do, we easily forget that they don't.
Collective Fictions in IT Waterfall
This got me thinking about some of the things that bother me today about the world of software engineering. When I started in
software 20 years ago, God was waterfall. I joined a consultancy (ca. 400 people) that wrote very long specs which were honed to
within an inch of their life, down to the individual Java classes and attributes. These specs were submitted to the customer (God
knows what they made of it), who signed it off. This was then built, delivered, and monies were received soon after. Life was simpler
then and everyone was happy.
Except there were gaps in the story customers complained that the spec didn't match the delivery, and often the product delivered
would not match the spec, as 'things' changed while the project went on. In other words, the waterfall process was a 'collective
fiction' that gave us enough stability and coherence to collaborate, get something out of the door, and get paid.
This consultancy went out of business soon after I joined. No conclusions can be drawn from this.
Collective Fictions in IT Startups ca. 2000
I got a job at another software development company that had a niche with lots of work in the pipe. I was employee #39. There
was no waterfall. In fact, there was nothing in the way of methodology I could see at all. Specs were agreed with a phone call. Design,
prototype and build were indistinguishable. In fact it felt like total chaos; it was against all of the precepts of my training.
There was more work than we could handle, and we got on with it.
The fact was, we were small enough not to need a collective fiction we had to name. Relationships and facts could be kept in our
heads, and if you needed help, you literally called out to the room. The tone was like this, basically:
Of course there were collective fictions, we just didn't name them:
We will never have a mission statement
We don't need HR or corporate communications, we have the pub (tough luck if you have a family)
We only hire the best
We got slightly bigger, and customers started asking us what our software methodology was. We guessed it wasn't acceptable to
say 'we just write the code' (legend had it our C-based application server still in use and blazingly fast was written before
my time in a fit of pique with a stash of amphetamines over a weekend. It's still in use.)
Turns out there was this thing called 'Rapid Application Development' that emphasized prototyping. We told customers we did RAD,
and they seemed happy, as it was A Thing. It sounded to me like 'hacking', but to be honest I'm not sure anyone among us really properly
understood it or read up on it.
As a collective fiction it worked, because it kept customers off our backs while we wrote the software.
Soon we doubled in size, moved out of our cramped little office into a much bigger one with bigger desks, and multiple floors.
You couldn't shout out your question to the room anymore. Teams got bigger, and these things called 'project managers' started appearing
everywhere talking about 'specs' and 'requirements gathering'. We tried and failed to rewrite our entire platform from scratch.
Yes, we were back to waterfall again, but this time the working cycles were faster and smaller, and the same problems of changing
requirements and disputes with customers as before. So was it waterfall? We didn't really know.
Collective Fictions in IT Agile
I started hearing the word 'Agile' about 2003. Again, I don't think I properly read up on it ever, actually. I got snippets here
and there from various websites I visited and occasionally from customers or evangelists that talked about it. When I quizzed people
who claimed to know about it their explanations almost invariably lost coherence quickly. The few that really had read up on it seemed
incapable of actually dealing with the very real pressures we faced when delivering software to non-sprint-friendly customers, timescales,
and blockers. So we carried on delivering software with our specs, and some sprinkling of agile terminology. Meetings were called
'scrums' now, but otherwise it felt very similar to what went on before.
As a collective fiction it worked, because it kept customers and project managers off our backs while we wrote the software.
Since then I've worked in a company that grew to 700 people, and now work in a corporation of 100K+ employees, but the pattern
is essentially the same: which incantation of the liturgy will satisfy this congregation before me?
Don't You Believe?
I'm not going to beat up on any of these paradigms, because what's the point? If software methodologies didn't exist we'd have
to invent them, because how else would we work together effectively? You need these fictions in order to function at scale. It's
no coincidence that the Agile paradigm has such a quasi-religious hold over a workforce that is immensely fluid and mobile. (If you
want to know what I really think about software development methodologies, read
this because it lays
it out much better than I ever could.)
One of many interesting arguments in Sapiens is that because these collective fictions can't adequately explain the world, and
often conflict with each other, the interesting parts of a culture are those where these tensions are felt. Often, humour derives
from these tensions.
'The test of a first-rate intelligence is the ability to hold two opposed ideas in mind at the same time and still retain the
ability to function.' F. Scott Fitzgerald
I don't know about you, but I often feel this tension when discussion of Agile goes beyond a small team. When I'm told in a motivational
poster written by someone I've never met and who knows nothing about my job that I should 'obliterate my blockers', and those blockers
are both external and non-negotiable, what else can I do but laugh at it?
How can you be agile when there are blockers outside your control at every turn? Infrastructure, audit, security, financial planning,
financial structures all militate against the ability to quickly deliver meaningful iterations of products. And who is the customer
here, anyway? We're talking about the square of despair:
When I see diagrams like this representing Agile I can only respond with black humour shared with my colleagues, like kids giggling
at the back of a church.
When within a smaller and well-functioning functioning team, the totems of Agile often fly out of the window and what you're left
with (when it's good) is a team that trusts each other, is open about its trials, and has a clear structure (formal or informal)
in which agreement and solutions can be found and co-operation is productive. Google recently articulated this (reported briefly
here , and more in-depth
here ).
So Why Not Tell It Like It Is?
You might think the answer is to come up with a new methodology that's better. It's not like we haven't tried:
It's just not that easy, like the book says:
'Telling effective stories is not easy. The difficulty lies not in telling the story, but in convincing everyone else to believe
it. Much of history revolves around this question: how does one convince millions of people to believe particular stories about gods,
or nations, or limited liability companies? Yet when it succeeds, it gives Sapiens immense power, because it enables millions of
strangers to cooperate and work towards common goals. Just try to imagine how difficult it would have been to create states, or churches,
or legal systems if we could speak only about things that really exist, such as rivers, trees and lions.'
Let's rephrase that:
'Coming up with useful software methodologies is not easy. The difficulty lies not in defining them, but in convincing others
to follow it. Much of the history of software development revolves around this question: how does one convince engineers to believe
particular stories about the effectiveness of requirements gathering, story points, burndown charts or backlog grooming? Yet when
adopted, it gives organisations immense power, because it enables distributed teams to cooperate and work towards delivery. Just
try to images how difficult it would have been to create Microsoft, Google, or IBM if we could only speak about specific technical
challenges.'
Anyway, does the world need more methodologies? It's not like some very smart people haven't already thought about this.
Acceptance
So I'm cool with it. Lean, Agile, Waterfall, whatever, the fact is we need some kind of common ideology to co-operate in large
numbers. None of them are evil, so it's not like you're picking racism over socialism or something. Whichever one you pick is not
going to reflect the reality, but if you expect perfection you will be disappointed. And watch yourself for unspoken or unarticulated
collective fictions. Your life is full of them. Like that your opinion is important. I can't resist quoting this passage from Sapiens
about our relationship with wheat:
'The body of Homo sapiens had not evolved for [farming wheat]. It was adapted to climbing apple trees and running after gazelles,
not to clearing rocks and carrying water buckets. Human spines, knees, necks and arches paid the price. Studies of ancient skeletons
indicate that the transition to agriculture brought about a plethora of ailments, such as slipped discs, arthritis and hernias. Moreover,
the new agricultural tasks demanded so much time that people were forced to settle permanently next to their wheat fields. This completely
changed their way of life. We did not domesticate wheat. It domesticated us. The word 'domesticate' comes from the Latin domus, which
means 'house'. Who's the one living in a house? Not the wheat. It's the Sapiens.'
Maybe we're not here to direct the code, but the code is directing us. Who's the one compromising reason and logic to grow code?
Not the code. It's the Sapiens.
https://widgets.wp.com/likes/index.html?ver=20190321#blog_id=20870870&post_id=1474&origin=zwischenzugs.wordpress.com&obj_id=20870870-1474-5efdf020c3f1f&domain=zwischenzugs.com
Related
"And watch yourself for unspoken or unarticulated collective fictions. Your life is full of them."
Agree completely.
As for software development methodologies, I personally think that with a few tweaks the waterfall methodology could work quite
well. The key changes I'd suggest would help is to introduce developer guidance at the planning stage, including timeboxed explorations
of the feasibility of the proposals, as well as aiming for specs to outline business requirements rather than dictating how they
should be implemented.
Reply
A very entertaining article! I have as similar experience and outlook. I've not tried LEAN. I once heard a senior developer
say that methodologies were just a stick with which to beat developers. This was largely in the case of clients who agree to engage
in whatever process when amongst business people and then are absent at grooming, demos, releases, feedback meetings and so on.
When the software is delivered at progressively short notice, it's always the developer that has to carry the burden of ensuring
quality, feeling keenly responsible for the work they do (the conscientious ones anyway). Then non-technical management hide behind
the process and failing to have the client fully engaged is quickly forgotten.
It reminds me (I'm rambling now, sorry) of factory workers in the 80s complaining about working conditions and the management
nodding and smiling while doing nothing to rectify the situation and doomed to repeat the same error. Except now the workers are
intelligent and will walk, taking their business knowledge and skill set with them.
Reply
Very enjoyable. I had a stab at the small sub-trail of 'syntonicity' here:
http://www.scidata.ca/?p=895
Syntonicity is Stuart Watt's term which he probably got from Seymour Papert.
Of course, this may all become moot soon as our robot overlords take their place at the keyboard.
Reply
A great article! I was very much inspired by Yuval's book myself. So much that I wrote a post about DevOps being a collective
fiction : http://otomato.link/devops-is-a-myth/
Basically same ideas as yours but from a different angle.
Reply
I think part of the "need" for methodology is the desire for a common terminology. However, if everyone has their own view
of what these terms mean, then it all starts to go horribly wrong. The focus quickly becomes adhering to the methodology rather
than getting the work done.
Reply
A very well-written article. I retired from corporate development in 2014 but am still developing my own projects. I have written
on this very subject and these pieces have been published as well.
The idea that the Waterfall technique for development was the only one in use as we go back towards the earlier years is a
myth that has been built up by the folks who have been promoting the Agile technique, which for seniors like me has been just
another word for what we used to call "guerrilla programming". In fact, if one were to review that standards of design in software
engineering there are 13 types of design techniques, all of which have been used at one time or another by many different companies
successfully. Waterfall was just one of them and was only recommended for very large projects.
The author is correct to conclude by implication that the best technique for design and implementation is the RAD technique
promoted by Stephen McConnell of Construx and a team that can work well with other. His book, still in its first edition since
1996, is considered the Bible for software development and describes every aspect of software engineering one could require. His
point. However, his book is only suggested as a guide where engineers can pick what they really need for the development of their
projects; not hard standards. Nonetheless, McConnell stresses the need for good specifications and risk management, the latter
if not used always causes a project to fail or result in less than satisfactory results. His work is proven by over 35 years of
research
Reply
Hilarious and oh so true. Remember the first time you were being taught Agile and they told you that the stakeholders would
take responsibility for their role and decisions. What a hoot! Seriously, I guess they did used to write detailed specs, but in
my twenty some years, I've just been thrilled if I had a business analyst that knew about what they wanted
Reply
OK, here's a collective fiction for you. "Methodologies don't work. They don't reflect reality. They are just something we
tell customers because they are appalled when we admit that our software is developed in a chaotic and unprofessional manner."
This fiction serves those people who already don't like process, and gives them excuses.
We do things the same way over and over for a reason. We have traffic lights because it reduces congestion and reduces traffic
fatalities. We make cakes using a recipe because we like it when the result is consistently pleasing. So too with software methodologies.
Like cake recipes, not all software methodologies are equally good at producing a consistently good result. This fact alone should
tell you that there is something of value in the best ones. While there may be a very few software chefs who can whip up a perfect
result every time, the vast bulk of developers need a recipe to follow or the results are predictably bad.
Your diatribe against process does the community a disservice.
Reply
I have arrived at the conclusion that any and all methodologies would work IF (and it's a big one), everyone managed to arrive
at a place where they considered the benefit of others before themselves. And, perhaps, they all used the same approach.
For me, it comes down to character rather than anything else. I can learn the skills or trade a chore with someone else.
Software developers; the ones who create "new stuff", by definition, have no roadmap. They have experience, good judgment,
the ability to 'survive in the wild', are always wanting to "see what is over there" and trust, as was noted is key. And there
are varying levels of developer. Some want to build the roads; others use the roads built for them and some want to survey for
the road yet to be built. None of these are wrong or right.
The various methodology fights are like arguing over what side of the road to drive on, how to spell colour and color. Just
pick one, get over yourself and help your partner(s) become successful.
Ah, right Where do the various methodologies resolve greed, envy, distrust, selfishness, stepping on others for personal gain,
and all of the other REAL killers of success again?
I have seen great teams succeed and far too many fail. Those that have failed more often than not did so for character-related
issues rather than technical ones.
Reply
Before there exists any success, a methodology must freeze a definition for roles, as well as process. Unless there exist sufficient
numbers and specifications of roles, and appropriate numbers of sapiens to hold those roles, then the one on the end becomes overburdened
and triggers systemic failure.
There has never been a sufficiently-complex methodology that could encompass every field, duty, and responsibility in a software
development task. (This is one of the reasons "chaos" is successful. At least it accepts the natural order of things, and works
within the interstitial spaces of a thousand objects moving at once.)
We even lie to ourselves when we name what we're doing: Methodology. It sounds so official, so logical, so orderly. That's
a myth. It's just a way of pushing the responsibility down from the most powerful to the least powerful -- every time.
For every "methodology," who is the caboose on the end of this authority train? The "coder."
The tighter the role definitions become in any methodology, the more actual responsibilities cascade down to the "coder." If
the specs conflict, who raises his hand and asks the question? If a deadline is unreasonable, who complains? If a technique is
unusable in a situation, who brings that up?
The person is obviously the "coder." And what happens when the coder asks this question?
In one methodology the "coder" is told to stop production and raise the issue with the manager who will talk to the analyst
who will talk to the client who will complain that his instructions were clear and it all falls back to the "coder" who, obviously,
was too dim to understand the 1,200 pages of specifications the analyst handed him.
In another, the "coder" is told, "you just work it out." And the concomitant chaos renders the project unstable.
In another, the "coder" is told "just do what you're told." And the result is incompatible with the rest of the project.
I've stopped "coding" for these reasons and because everybody is happy with the myth of programming process because they aren't
the caboose.
Reply
I was going to make fun of this post for being whiney and defeatust. But the more I thought about it, the more I realized
it contained a big nugget of truth. A lot of methodologies, as practiced, have the purpose of putting off risk onto the developers,
of fixing responsibility on developers so the managers aren't responsible for any of the things that can go wrong with projects.
Reply
Great article! I have experienced the same regarding software methodologies. And at a greater level, thank you for introducing
me to the concept of collective fictions; it makes so much sense. I will be reading Sapiens.
Reply
Actually, come to think of it there are two types of Software Engineers who take process very seriously. One who is acutely
aware of software entropy and wants to pro -actively fight against it because they want to engineer to a high standard and don't
like working the weekend. So they wants things organised. Then there's another type who can come across as being a bit dogmatic.
Maybe your links with collective delusions help explain some of the human psychology here.
Reply
First of all this is a great article, very well written. A couple of remarks. Early in waterfall, the large business requirements
documents didn't work for two reasons: There was no new business process, it was the same business process that should be applied
within a new technology (from mainframes to open unix systems, from ascii to RAD tools and 4-GL languages). . Second many consultancy
companies (mostly the big 4) there were using "copy&paste" methods to fill these documents, submit the time and material forms
for the consultants, increasing the revenue and move on. Things have change with the adoption of the smartphones use etc
To reflect the author idea, to my humble opinion the collective fictions is the embedded quality of work into the whole life cycle
development
Thanks
Kostas
Reply
Sorry, did you forget to finish the article? I don't see the conclusion providing the one true programming methodology that
works in all occasions. What is the magic procedure? Thanks in advance.
Reply
I often feel this tension when discussion of Agile goes beyond a small team. When I'm told
in a motivational poster written by someone I've never met and who knows nothing about my job
that I should 'obliterate my blockers', and those blockers are both external and
non-negotiable, what else can I do but laugh at it?
How can you be agile when there are blockers outside your control at every turn?
Infrastructure, audit, security, financial planning, financial structures all militate against
the ability to quickly deliver meaningful iterations of products. And who is the customer here,
anyway? We're talking about the square of despair:
When I see diagrams like this representing Agile I can only respond with black humor shared
with my colleagues, like kids giggling at the back of a church.
When within a smaller and well-functioning functioning team, the totems of Agile often fly
out of the window and what you're left with (when it's good) is a team that trusts each other,
is open about its trials, and has a clear structure (formal or informal) in which agreement and
solutions can be found and co-operation is productive. Google recently articulated this
(reported briefly here , and more
in-depth
here ).
"Restaurant Of The Future" - KFC Unveils Automated Store With Robots And Food Lockers
by Tyler Durden Fri,
06/26/2020 - 22:05 Fast-food chain Kentucky Fried Chicken (KFC) has debuted the "restaurant of
the future," one where automation dominates the storefront, and little to no interaction is
seen between customers and employees, reported NBC News .
After the chicken is fried and sides are prepped by humans, the order is placed on a
conveyor belt and travels to the front of the store. A robotic arm waits for the order to
arrive, then grabs it off the conveyor belt and places it into a secured food
locker.
A KFC representative told NBC News that the new store is located in Moscow and was built
months before the virus outbreak. The representative said the contactless store is the future
of frontend fast-food restaurants because it's more sanitary.
Disbanding human cashiers and order preppers at the front of a fast-food store will be the
next big trend in the industry through 2030. Making these restaurants contactless between
customers and employees will lower the probabilities of transmitting the virus.
Automating the frontend of a fast-food restaurant will come at a tremendous cost, that is,
significant job loss . Nationwide (as of 2018), there were around 3.8 million employed at
fast-food restaurants. Automation and artificial intelligence are set displace millions of jobs
in the years ahead.
As for the new automated KFC restaurant in Moscow, well, it's a glimpse of what is coming to
America - this will lead to the widespread job loss that will force politicians to unveil
universal basic income .
Artificial intelligence (AI) just seems to get smarter and smarter. Each iPhone learns your face, voice, and
habits better than the last, and the threats AI poses to privacy and jobs continue to grow. The surge reflects faster
chips, more data, and better algorithms. But some of the improvement comes from tweaks rather than
the core innovations
their inventors claim
-- and some of the gains may not exist at all, says Davis Blalock, a computer science graduate
student at the Massachusetts Institute of Technology (MIT). Blalock and his colleagues compared dozens of approaches
to improving neural networks -- software architectures that loosely mimic the brain. "Fifty papers in," he says, "it
became clear that it wasn't obvious what the state of the art even was."
The researchers evaluated 81 pruning algorithms, programs that make neural networks more efficient by trimming
unneeded connections. All claimed superiority in slightly different ways. But they were rarely compared properly -- and
when the researchers tried to evaluate them side by side, there was no clear evidence of performance improvements
over a 10-year period.
The result
, presented in March at the
Machine Learning and Systems conference, surprised Blalock's Ph.D. adviser, MIT computer scientist John Guttag, who
says the uneven comparisons themselves may explain the stagnation. "It's the old saw, right?" Guttag said. "If you
can't measure something, it's hard to make it better."
Researchers are waking up to the signs of shaky progress across many subfields of AI. A
2019 meta-analysis
of information retrieval
algorithms used in search engines concluded the "high-water mark was actually set in 2009."
Another study
in 2019 reproduced seven neural
network recommendation systems, of the kind used by media streaming services. It found that six failed to outperform
much simpler, nonneural algorithms developed years before, when the earlier techniques were fine-tuned, revealing
"phantom progress" in the field. In
another paper
posted on arXiv in
March, Kevin Musgrave, a computer scientist at Cornell University, took a look at loss functions, the part of an
algorithm that mathematically specifies its objective. Musgrave compared a dozen of them on equal footing, in a task
involving image retrieval, and found that, contrary to their developers' claims, accuracy had not improved since
2006. "There's always been these waves of hype," Musgrave says.
SIGN UP FOR OUR DAILY NEWSLETTER
Get more great content like this delivered right to you!
Required fields are indicated by an asterisk(*)
Gains in machine-learning algorithms can come from fundamental changes in their architecture, loss function, or
optimization strategy -- how they use feedback to improve. But subtle tweaks to any of these can also boost performance,
says Zico Kolter, a computer scientist at Carnegie Mellon University who studies image-recognition models trained to
be immune to "
adversarial
attacks
" by a hacker. An early adversarial training method known as projected gradient descent (PGD), in which a
model is simply trained on both real and deceptive examples, seemed to have been surpassed by more complex methods.
But in a
February arXiv paper
, Kolter and his colleagues found that
all of the methods performed about the same when a simple trick was used to enhance them.
Old dogs, new tricks
After modest tweaks, old image-retrieval algorithms perform as well as new ones, suggesting little actual
innovation.
Contrastive
(2006)
ProxyNCA
(2017)
SoftTriple
(2019)
0
25
50
75
100
Accuracy score
Original performance
Tweaked performance
(GRAPHIC) X. LIU/
SCIENCE
; (DATA) MUSGRAVE
ET AL
., ARXIV: 2003.08505
"That was very surprising, that this hadn't been discovered before," says Leslie Rice, Kolter's Ph.D. student.
Kolter says his findings suggest innovations such as PGD are hard to come by, and are rarely improved in a
substantial way. "It's pretty clear that PGD is actually just the right algorithm," he says. "It's the obvious thing,
and people want to find overly complex solutions."
Other major algorithmic advances also seem to have stood the test of time. A big breakthrough came in 1997 with an
architecture called long short-term memory (LSTM), used in language translation. When properly trained, LSTMs
matched
the performance of supposedly more advanced
architectures developed 2 decades later. Another machine-learning breakthrough came in 2014 with generative
adversarial networks (GANs), which pair networks in a create-and-critique cycle to sharpen their ability to produce
images, for example.
A 2018
paper
reported that with enough computation, the original GAN method matches the abilities of methods from later
years.
Kolter says researchers are more motivated to produce a new algorithm and tweak it until it's state-of-the-art
than to tune an existing one. The latter can appear less novel, he notes, making it "much harder to get a paper
from."
Guttag says there's also a disincentive for inventors of an algorithm to thoroughly compare its performance with
others -- only to find that their breakthrough is not what they thought it was. "There's a risk to comparing too
carefully."
It's also hard work
: AI researchers use different data sets, tuning methods, performance metrics, and baselines.
"It's just not really feasible to do all the apples-to-apples comparisons."
Some of the overstated performance claims can be chalked up to the explosive growth of the field, where papers
outnumber experienced reviewers. "A lot of this seems to
be growing pains
," Blalock says. He urges reviewers to insist on better comparisons to benchmarks and says better
tools will help. Earlier this year, Blalock's co-author, MIT researcher Jose Gonzalez Ortiz, released software called
ShrinkBench that makes it easier to compare pruning algorithms.
Researchers point out that even if new methods aren't fundamentally better than old ones, the tweaks they
implement can be applied to their forebears. And every once in a while, a new algorithm will be an actual
breakthrough. "It's almost like a venture capital portfolio," Blalock says, "where some of the businesses are not
really working, but some are working spectacularly well."
Microsoft's EEE tactics which can be redefined as "Steal; Add complexity and bloat; trash original" can be
used on open source and as success of systemd has shown can be pretty successful strategy.
Notable quotes:
"... Free software acts like proprietary software when it treats the existence of alternatives as a problem to be solved. I personally never trust a project with developers as arrogant as that. ..."
...it was developed along lines that are not entirely different from
Microsoft's EEE tactics -- which today I will offer a new acronym and description for:
1. Steal
2. Add Bloat
3. Original Trashed
It's difficult conceptually to "steal" Free software, because it (sort of, effectively)
belongs to everyone. It's not always Public Domain -- copyleft is meant to prevent that. The
only way you can "steal" free software is by taking it from everyone and restricting it again.
That's like "stealing" the ocean or the sky, and putting it somewhere that people can't get to
it. But this is what non-free software does. (You could also simply go against the license
terms, but I doubt Stallman would go for the word "stealing" or "theft" as a first choice to
describe non-compliance).
... ... ...
Again and again, Microsoft "Steals" or "Steers" the development process itself so it
can gain control (pronounced: "ownership") of the software. It is a gradual process, where
Microsoft has more and more influence until they dominate the project and with it, the user.
This is similar to the process where cults (or drug addiction) take over people's lives, and
similar to the process where narcissists interfere in the lives of others -- by staking a claim
and gradually dominating the person or project.
Then they Add Bloat -- more features. GitHub is friendly to use, you don't have to care
about how Git works to use it (this is true of many GitHub clones as well, as even I do not
really care how Git works very much. It took a long time for someone to even drag me towards
GitHub for code hosting, until they were acquired and I stopped using it) and due to its GLOBAL
size, nobody can or ought to reproduce its network effects.
I understand the draw of network effects. That's why larger federated instances of code
hosts are going to be more popular than smaller instances. We really need a mix -- smaller
instances to be easy to host and autonomous, larger instances to draw people away from even
more gigantic code silos. We can't get away from network effects (just like the War on Drugs
will never work) but we can make them easier and less troublesome (or safer) to deal with.
Finally, the Original is trashed, and the SABOTage is complete. This has happened with
Python against Python 2, despite protests from seasoned and professional developers, it was
deliberately attempted with Systemd against not just sysvinit but ALL alternatives -- Free
software acts like proprietary software when it treats the existence of alternatives as a
problem to be solved. I personally never trust a project with developers as arrogant as
that.
... ... ...
There's a meme about creepy vans with "FREE CANDY" painted on the side, which I took one of
the photos from and edited it so that it said "FEATURES" instead. This is more or less how I
feel about new features in general, given my experience with their abuse in development,
marketing and the takeover of formerly good software projects.
People then accuse me of being against features, of course. As with the Dijkstra article,
the real problem isn't Basic itself. The problem isn't features per se (though they do play a
very key role in this problem) and I'm not really against features -- or candy, for that
matter.
I'm against these things being used as bait, to entrap people in an unpleasant situation
that makes escape difficult. You know, "lock-in". Don't get in the van -- don't even go NEAR
the van.
Candy is nice, and some features are nice too. But we would all be better off if we could
get the candy safely, and delete the creepy horrible van that comes with it. That's true
whether the creepy van is GitHub, or surveillance by GIAFAM, or a Leviathan "init" system, or
just breaking decades of perfectly good Python code, to try to force people to develop
differently because Google or Microsoft (who both have had heavy influence over newer Python
development) want to try to force you to -- all while using "free" software.
If all that makes free software "free" is the license -- (yes, it's the primary and key
part, it's a necessary ingredient) then putting "free" software on GitHub shouldn't be a
problem, right? Not if you're running LibreJS, at least.
In practice, "Free in license only" ignores the fact that if software is effectively free,
the user is also effectively free. If free software development gets dragged into doing the
bidding of non-free software companies and starts creating lock-in for the user, even if it's
external or peripheral, then they simply found an effective way around the true goal of the
license. They did it with Tivoisation, so we know that it's possible. They've done this in a
number of ways, and they're doing it now.
If people are trying to make the user less free, and they're effectively making the user
less free, maybe the license isn't an effective monolithic solution. The cost of freedom is
eternal vigilance. They never said "The cost of freedom is slapping a free license on things",
as far as I know. (Of course it helps). This really isn't a straw man, so much as a rebuttal to
the extremely glib take on software freedom in general that permeates development communities
these days.
But the benefits of Free software, free candy and new features are all meaningless, if the
user isn't in control.
Don't get in the van.
"The freedom to NOT run the software, to be free to avoid vendor lock-in through
appropriate modularization/encapsulation and minimized dependencies; meaning any free software
can be replaced with a user's preferred alternatives (freedom 4)." – Peter
Boughton
Relatively simple automation often beat more complex system. By far.
Notable quotes:
"... My guess is we're heading for something in-between, a place where artisanal bakers use locally grown wheat, made affordable thanks to machine milling. Where small family-owned bakeries rely on automation tech to do the undifferentiated grunt-work. The robots in my future are more likely to look more like cash registers and less like Terminators. ..."
"... I gave a guest lecture to a roomful of young roboticists (largely undergrad, some first year grad engineering students) a decade ago. After discussing the economics/finance of creating and selling a burgerbot, asked about those that would be unemployed by the contraption. One student immediately snorted out, "Not my problem!" Another replied, "But what if they cannot do anything else?". Again, "Not my problem!". And that is San Josie in a nutshell. ..."
"... One counter-argument might be that while hoping for the best it might be prudent to prepare for the worst. Currently, and for a couple of decades, the efficiency gains have been left to the market to allocate. Some might argue that for the common good then the government might need to be more active. ..."
"... "Too much automation is really all about narrowing the choices in your life and making it cheaper instead of enabling a richer lifestyle." Many times the only way to automate the creation of a product is to change it to fit the machine. ..."
"... You've gotta' get out of Paris: great French bread remains awesome. I live here. I've lived here for over half a decade and know many elderly French. The bread, from the right bakeries, remains great. ..."
"... I agree with others here who distinguish between labor saving automation and labor eliminating automation, but I don't think the former per se is the problem as much as the gradual shift toward the mentality and "rightness" of mass production and globalization. ..."
"... I was exposed to that conflict, in a small way, because my father was an investment manager. He told me they were considering investing in a smallish Swiss pasta (IIRC) factory. He was frustrated with the negotiations; the owners just weren't interested in getting a lot bigger which would be the point of the investment, from the investors' POV. ..."
"... Incidentally, this is a possible approach to a better, more sustainable economy: substitute craft for capital and resources, on as large a scale as possible. More value with less consumption. But how we get there from here is another question. ..."
"... The Ten Commandments do not apply to corporations. ..."
"... But what happens when the bread machine is connected to the internet, can't function without an active internet connection, and requires an annual subscription to use? ..."
"... Until 100 petaflops costs less than a typical human worker total automation isn't going to happen. Developments in AI software can't overcome basic hardware limits. ..."
"... When I started doing robotics, I developed a working definition of a robot as: (a.) Senses its environment; (b.) Has goals and goal-seeking logic; (c.) Has means to affect environment in order to get goal and reality (the environment) to converge. Under that definition, Amazon's Alexa and your household air conditioning and heating system both qualify as "robot". ..."
"... The addition of a computer (with a program, or even downloadable-on-the-fly programs) to a static machine, e.g. today's computer-controlled-manufacturing machines (lathes, milling, welding, plasma cutters, etc.) makes a massive change in utility. It's almost the same physically, but ever so much more flexible, useful, and more profitable to own/operate. ..."
"... And if you add massive databases, internet connectivity, the latest machine-learning, language and image processing and some nefarious intent, then you get into trouble. ..."
Part I , "Automation Armageddon:
a Legitimate Worry?" reviewed the history of automation, focused on projections of gloom-and-doom.
"It smells like death," is how a friend of mine described a nearby chain grocery store. He tends to exaggerate and visiting France
admittedly brings about strong feelings of passion. Anyway, the only reason we go there is for things like foil or plastic bags that
aren't available at any of the smaller stores.
Before getting to why that matters and, yes, it does matter first a tasty digression.
I live in a French village. To the French, high-quality food is a vital component to good life.
My daughter counts eight independent bakeries on the short drive between home and school. Most are owned by a couple of people.
Counting high-quality bakeries embedded in grocery stores would add a few more. Going out of our way more than a minute or two would
more than double that number.
Typical Bakery: Bread is cooked at least twice daily
Despite so many, the bakeries seem to do well. In the half-decade I've been here, three new ones opened and none of the old ones
closed. They all seem to be busy. Bakeries are normally owner operated. The busiest might employ a few people but many are mom-and-pop
operations with him baking and her selling. To remain economically viable, they rely on a dance of people and robots. Flour arrives
in sacks with high-quality grains milled by machines. People measure ingredients, with each bakery using slightly different recipes.
A human-fed robot mixes and kneads the ingredients into the dough. Some kind of machine churns the lumps of dough into baguettes.
The baker places the formed baguettes onto baking trays then puts them in the oven. Big ovens maintain a steady temperature while
timers keep track of how long various loaves of bread have been baking. Despite the sensors, bakers make the final decision when
to pull the loaves out, with some preferring a bien cuit more cooked flavor and others a softer crust. Finally, a person uses
a robot in the form of a cash register to ring up transactions and processes payments, either by cash or card.
Nobody -- not the owners, workers, or customers -- think twice about any of this. I doubt most people realize how much automation
technology is involved or even that much of the equipment is automation tech. There would be no improvement in quality mixing and
kneading the dough by hand. There would, however, be an enormous increase in cost. The baguette forming machines churn out exactly
what a person would do by hand, only faster and at a far lower cost. We take the thermostatically controlled ovens for granted. However,
for anybody who has tried to cook over wood controlling heat via air and fuel, thermostatically controlled ovens are clearly automation
technology.
Is the cash register really a robot? James Ritty, who invented
it, didn't think so; he sold the patent for cheap. The person who bought the patent built it into NCR, a seminal company laying the
groundwork of the modern computer revolution.
Would these bakeries be financially viable if forced to do all this by hand? Probably not. They'd be forced to produce less output
at higher cost; many would likely fail. Bread would cost more leaving less money for other purchases. Fewer jobs, less consumer spending
power, and hungry bellies to boot; that doesn't sound like good public policy.
Getting back to the grocery store my friend thinks smells like death; just a few weeks ago they started using robots in a new
and, to many, not especially welcome way.
As any tourist knows, most stores in France are closed on Sunday afternoons, including and especially grocery stores. That's part
of French labor law: grocery stores must close Sunday afternoons. Except that the chain grocery store near me announced they are
opening Sunday afternoon. How? Robots, and sleight-of-hand. Grocers may not work on Sunday afternoons but guards are allowed.
Not my store but similar.
Dimanche means Sunday. Aprés-midi means afternoon.
I stopped in to get a feel for how the system works. Instead of grocers, the store uses security guards and self-checkout kiosks.
When you step inside, a guard reminds you there are no grocers. Nobody restocks the shelves but, presumably for half a day, it
doesn't matter. On Sunday afternoons, in place of a bored-looking person wearing a store uniform and overseeing the robo-checkout
kiosks sits a bored-looking person wearing a security guard uniform doing the same. There are no human-assisted checkout lanes open
but this store seldom has more than one operating anyway.
I have no idea how long the French government will allow this loophole to continue. I thought it might attract yellow vest protestors
or at least a cranky store worker maybe a few locals annoyed at an ancient tradition being buried but there was nobody complaining.
There were hardly any customers, either.
The use of robots to sidestep labor law and replace people, in one of the most labor-friendly countries in the world, produced
a big yawn.
Paul Krugman and
Matt Stoller argue convincingly that
it's the bosses, not the robots, that crush the spirits and souls of workers. Krugman calls it "automation obsession" and Stoller
points out predictions of robo-Armageddon have existed for decades. The well over
100+ examples I have of major
automation-tech ultimately led to more jobs, not fewer.
Jerry Yang envisions some type of forthcoming automation-induced dystopia. Zuck and the tech-bros argue for a forthcoming Star
Trek style robo-utopia.
My guess is we're heading for something in-between, a place where artisanal bakers use locally grown wheat, made affordable thanks
to machine milling. Where small family-owned bakeries rely on automation tech to do the undifferentiated grunt-work. The robots in
my future are more likely to look more like cash registers and less like Terminators.
It's an admittedly blander vision of the future; neither utopian nor dystopian, at least not one fueled by automation tech. However,
it's a vision supported by the historic adoption of automation technology.
I have no real disagreement with a lot of automation. But how it is done is another matter altogether. Using the main example
in this article, Australia is probably like a lot of countries with bread in that most of the loaves that you get in a supermarket
are typically bland and come in plastic bags but which are cheap. You only really know what you grow up with.
When I first went to Germany I stepped into a Bakerie and it was a revelation. There were dozens of different sorts and types
of bread on display with flavours that I had never experienced. I didn't know whether to order a loaf or to go for my camera instead.
And that is the point. Too much automation is really all about narrowing the choices in your life and making it cheaper instead
of enabling a richer lifestyle.
We are all familiar with crapification and I contend that it is automation that enables this to become a thing.
"I contend that it is automation that enables this to become a thing."
As does electricity. And math. Automation doesn't necessarily narrow choices; economies of scale and the profit motive do.
What I find annoying (as in pollyannish) is the avoidance of the issue of those that cannot operate the machinery, those that
cannot open their own store, etc.
I gave a guest lecture to a roomful of young roboticists (largely undergrad, some first year grad engineering students) a decade
ago. After discussing the economics/finance of creating and selling a burgerbot, asked about those that would be unemployed by
the contraption. One student immediately snorted out, "Not my problem!" Another replied, "But what if they cannot do anything
else?". Again, "Not my problem!". And that is San Josie in a nutshell.
A capitalist market that fails to account for the cost of a product's negative externalities is underpricing (and incentivizing
more of the same). It's cheating (or sanctioned cheating due to ignorance and corruption). It is not capitalism (unless that is
the only reasonable outcome of capitalism).
The author's vision of "appropriate tech" local enterprise supported by relatively simple automation is also my answer to the
vexing question of "how do I cope with automation?"
In a recent posting here at NC, I said the way to cope with automation of your job(s) is to get good at automation. My remark
caused a howl of outrage: "most people can't do automation! Your solution is unrealistic for the masses. Dismissed with prejudice!".
Thank you for that outrage, as it provides a wonder foil for this article. The article shows a small business which learned
to re-design business processes, acquire machines that reduce costs. It's a good example of someone that "got good at automation". Instead of being the victim of automation, these people adapted. They bought automation, took control of it, and operated it
for their own benefit.
Key point: this entrepreneur is now harvesting the benefits of automation, rather than being systematically marginalized by
it. Another noteworthy aspect of this article is that local-scale "appropriate" automation serves to reduce the scale advantages
of the big players. The availability of small-scale machines that enable efficiencies comparable to the big guys is a huge problem.
Most of the machines made for small-scale operators like this are manufactured in China, or India or Iran or Russia, Italy where
industrial consolidation (scale) hasn't squashed the little players yet.
Suppose you're a grain farmer, but only have 50 acres (not 100s or 1000s like the big guys). You need a combine that's a
big machine that cuts grain stalk and separate grain from stalk (threshing). This cut/thresh function is terribly labor intensive,
the combine is a must-have. Right now, there is no small-size ($50K or less) combine manufactured in the U.S., to my knowledge.
They cost upwards of $200K, and sometimes a great deal more. The 50-acre farmer can't afford $200K (plus maint costs), and therefore
can't farm at that scale, and has to sell out.
So, the design, production, and sales of these sort of small-scale, high-productivity machines is what is needed to re-distribute
production (organically, not by revolution, thanks) back into the hands of the middle class.
If we make possible for the middle class to capture the benefits of automation, and you solve 1) the social dilemmas of concentration
of wealth, 2) the declining std of living of the mid- and lower-class, and 3) have a chance to re-design an economy (business
processes and collaborating suppliers to deliver end-user product/service) that actually fixes the planet as we make our living,
instead of degrading it at every ka-ching of the cash register.
Point 3 is the most important, and this isn't the time or place to expand on that, but I hope others might consider it a bit.
Regarding the combine, I have seen them operating on small-sized lands for the last 50 years. Without exception, you have one
guy (sometimes a farmer, often not) who has this kind of harvester, works 24h a day for a week or something, harvesting for all
farmers in the neighborhood, and then moves to the next crop (eg corn). Wintertime is used for maintenance. So that one person/farm/company
specializes in these services, and everybody gets along well.
Marcel great solution to the problem. Choosing the right supplier (using combine service instead of buying a dedicated combine)
is a great skill to develop. On the flip side, the fellow that provides that combine service probably makes a decent side-income
from it. Choosing the right service to provide is another good skill to develop.
One counter-argument might be that while hoping for the best it might be prudent to prepare for the worst. Currently, and for
a couple of decades, the efficiency gains have been left to the market to allocate. Some might argue that for the common good
then the government might need to be more active.
What would happen if efficiency gains continued to be distributed according to the market? According to the relative bargaining
power of the market participants where one side, the public good as represented by government, is asking for and therefore getting
almost nothing?
As is, I do believe that people who are concerned do have reason to be concerned.
"Too much automation is really all about narrowing the choices in your life and making it cheaper instead of enabling a
richer lifestyle." Many times the only way to automate the creation of a product is to change it to fit the machine.
Some people make a living saying these sorts of things about automation. The quality of French bread is simply not what it
used to be (at least harder to find) though that is a complicated subject having to do with flour and wheat as well as human preparation
and many other things and the cost (in terms of purchasing power), in my opinion, has gone up, not down since the 70's.
As some might say, "It's complicated," but automation does (not sure about "has to") come with trade offs in quality while
price remains closer to what an ever more sophisticated set of algorithms say can be "gotten away with."
This may be totally different for cars or other things, but the author chose French bread and the only overall improvement,
or even non change, in quality there has come, if at all, from the dark art of marketing magicians.
/ from the dark art of marketing magicians, AND people's innate ability to accept/be unaware of decreases in quality/quantity
if they are implemented over time in small enough steps.
You've gotta' get out of Paris: great French bread remains awesome. I live here. I've lived here for over half a decade
and know many elderly French. The bread, from the right bakeries, remains great. But you're unlikely to find it where tourists
might wander: the rent is too high.
As a general rule, if the bakers have a large staff or speak English you're probably in the wrong bakery. Except for one of
my favorites where she learned her English watching every episode of Friends multiple times and likes to practice with me, though
that's more of a fluke.
It's a difficult subject to argue. I suspect that comparatively speaking, French bread remains good and there are still bakers
who make high quality bread (given what they have to work with). My experience when talking to family in France (not Paris) is
that indeed, they are in general quite happy with the quality of bread and each seems to know a bakery where they can still get
that "je ne sais quoi" that makes it so special.
I, on the other hand, who have only been there once every few years since the 70's, kind of like once every so many frames
of the movie, see a lowering of quality in general in France and of flour and bread in particular though I'll grant it's quite
gradual.
The French love food and were among the best farmers in the world in the 1930s and have made a point of resisting radical change
at any given point in time when it comes to the things they love (wine, cheese, bread, etc.) , so they have a long way to fall,
and are doing so slowly; but gradually, it's happening.
I agree with others here who distinguish between labor saving automation and labor eliminating automation, but I don't
think the former per se is the problem as much as the gradual shift toward the mentality and "rightness" of mass production and
globalization.
I was exposed to that conflict, in a small way, because my father was an investment manager. He told me they were considering
investing in a smallish Swiss pasta (IIRC) factory. He was frustrated with the negotiations; the owners just weren't interested
in getting a lot bigger which would be the point of the investment, from the investors' POV.
I thought, but I don't think I said very articulately, that of course, they thought of themselves as craftspeople making
people's food, after all. It was a fundamental culture clash. All that was 50 years ago; looks like the European attitude has
been receding.
Incidentally, this is a possible approach to a better, more sustainable economy: substitute craft for capital and resources,
on as large a scale as possible. More value with less consumption. But how we get there from here is another question.
I have been touring around by car and was surprised to see that all Oregon gas stations are full serve with no self serve allowed
(I vaguely remember Oregon Charles talking about this). It applies to every station including the ones with a couple of dozen
pumps like we see back east. I have since been told that this system has been in place for years.
It's hard to see how this is more efficient and in fact just the opposite as there are fewer attendants than waiting customers
and at a couple of stations the action seemed chaotic. Gas is also more expensive although nothing could be more expensive than
California gas (over $5/gal occasionally spotted). It's also unclear how this system was preservedperhaps out of fire safety
concernsbut it seems unlikely that any other state will want to imitate just as those bakeries aren't going to bring back their
wood fired ovens.
I think NJ is still required to do all full-serve gas stations. Most in MA have only self-serve, but there's a few towns that
have by-laws requiring full-serve.
In the 1980s when self-serve gas started being implemented, NIOSH scientists said oh no, now 'everyone' will be increasingly
exposed to benzene while filling up. Benzene is close to various radioactive elements in causing damage and cancer.
It was preserved by a series of referenda; turns out it's a 3rd rail here, like the sales tax. The motive was explicitly to
preserve entry-level jobs while allowing drivers to keep the gas off their hands. And we like the more personal quality.
Also, we go to states that allow self-serve and observe that the gas isn't any cheaper. It's mainly the tax that sets the price,
and location.
There are several bakeries in this area with wood-fired ovens. They charge a premium, of course. One we love is way out in
the country, in Falls City. It's a reason to go there.
Unless I misunderstood, the author of this article seems to equate mechanization/automation of nearly any type with robotics.
"Is the cash register really a robot? James Ritty, who invented it, didn't think so;" Nor do I.
To me, "robot" implies a machine with a high degree of autonomy. Would the author consider an old fashioned manual typewriter
or adding machine (remember those?) to be robotic? How about when those machines became electrified?
I think the author uses the term "robot" over broadly.
Agree. Those are just electrified extensions of the lever or sand timer.
It's the "thinking" that is A.I.
Refuse to allow A.I.to destroy jobs and cheapen our standard of living.
Never interact with a robo call, just hang up.
Never log into a website when there is a human alternative.
Refuse to do business with companies that have no human alternative.
Never join a medical "portal" of any kind, demand to talk to medical personnel. Etc.
Sabotage A.I. whenever possible. The Ten Commandments do not apply to corporations.
During a Chicago hotel stay my wife ordered an extra bath towel from the front desk. About 5 minutes later, a mini version
of R2D2 rolled up to her door with towel in tow. It was really cute and interacted with her in a human-like way. Cute but really
scary in the way that you indicate in your comment.
It seems many low wage activities would be in immediate risk of replacement.
But sabotage? I would never encourage sabotage; in fact, when it comes to true robots like this one, I would highly discourage
any of the following: yanking its recharge cord in the middle of the night, zapping it with a car battery, lift its payload and
replace with something else, give it a hip high-five to help it calibrate its balance, and of course, the good old kick'm in the
bolts.
Stop and Shop supermarket chain now has robots in the store. According to Stop and Shop they are oh so innocent! and friendly!
why don't you just go up and say hello?
All the robots do, they say, go around scanning the shelves looking for: shelf price tags that don't match the current price,
merchandise in the wrong place (that cereal box you picked up in the breakfast aisle and decided, in the laundry aisle, that you
didn't want and put the box on a shelf with detergent.) All the robots do is notify management of wrong prices and misplaced merchandise.
The damn robot is cute, perky lit up eyes and a smile so why does it remind me of the Stepford Wives.
S&S is the closest supermarket near me, so I go there when I need something in a hurry, but the bulk of my shopping is now
done elsewhere. Thank goodness there are some stores that are not doing this: The area Shoprites and FoodTown's don't and they
are all run by family businesses. Shoprite succeeds by have a large assortment brands in every grocery category and keeping prices
really competitive. FoodTown operates at a higher price and quality level with real butcher and seafood counters as well as prepackaged
assortments in open cases and a cooked food counter of the most excellent quality with the store's cooks behind the counter to
serve you and answer questions. You never have to come home from work tired and hungry and know that you just don't want to cook
and settle for a power bar.
A robot is a machine -- especially one programmable by a computer -- capable of carrying out a complex series of actions
automatically. Robots can be guided by an external control device or the control may be embedded
Those early cash registers were perhaps an early form of analog computer. But Wiki reminds that the origin of the term is a
work of fiction.
The term comes from a Czech word, robota, meaning "forced labor";the word 'robot' was first used to denote a fictional humanoid
in a 1920 play R.U.R. (Rossumovi Univerzální Roboti Rossum's Universal Robots) by the Czech writer, Karel Čapek
Perhaps I didn't qualify "autonomous" properly. I didn't mean to imply a 'Rosie the Robot' level of autonomy but the ability
of a machine to perform its programmed task without human intervention (other than switching on/off or maintenance & adjustments).
If viewed this way, an adding machine or typewriter are not robots because they require constant manual input in order to function
if you don't push the keys, nothing happens. A computer printer might be considered robotic because it can be programmed to
function somewhat autonomously (as in print 'x' number of copies of this document).
"Robotics" is a subset of mechanized/automated functions.
When I first got out of grad school I worked at United Technologies Research Center where I worked in the robotics lab. In
general, at least in those days, we made a distinction between robotics and hard automation. A robot is programmable to do multiple
tasks and hard automation is limited to a single task unless retooled. The machines the author is talking about are hard automation.
We had ASEA robots that could be programmed to do various things. One of ours drilled, riveted and sealed the skin on the horizontal
stabilators (the wing on the tail of a helicopter that controls pitch) of a Sikorsky Sea Hawk.
The same robot with just a change
of the fixture on the end could be programmed to paint a car or weld a seam on equipment. The drilling and riveting robot was
capable of modifying where the rivets were placed (in the robot's frame of reference) based on the location of precisely milled
blocks build into the fixture that held the stabilator.
There was always some variation and it was important to precisely place
the rivets because the spars were very narrow (weight at the tail is bad because of the lever arm). It was considered state of
the art back in the day but now auto companies have far more sophisticated robotics.
But what happens when the bread machine is connected to the internet, can't function without an active internet connection,
and requires an annual subscription to use?
That is the issue to me: however we define the tools, who will own them?
You know, that is quite a good point that. It is not so much the automation that is the threat as the rent-seeking that anything
connected to the internet allows to be implemented.
Until 100 petaflops costs less than a typical human worker total automation isn't going to happen. Developments in AI software
can't overcome basic hardware limits.
The story about automation not worsening the quality of bread is not exactly true. Bakers had to develop and incorporate a
new method called autolyze (
https://www.kingarthurflour.com/blog/2017/09/29/using-the-autolyse-method
) in the mid-20th-century to bring back some of the flavor lost with modern baking. There is also a trend of a new generation
of bakeries that use natural yeast, hand shaping and kneading to get better flavors and quality bread.
But it is certainly true that much of the automation gives almost as good quality for much lower labor costs.
When I started doing robotics, I developed a working definition of a robot as: (a.) Senses its environment; (b.) Has goals
and goal-seeking logic; (c.) Has means to affect environment in order to get goal and reality (the environment) to converge. Under
that definition, Amazon's Alexa and your household air conditioning and heating system both qualify as "robot".
How you implement a, b, and c above can have more or less sophistication, depending upon the complexity, variability, etc.
of the environment, or the solutions, or the means used to affect the environment.
A machine, like a typewriter, or a lawn-mower engine has the logic expressed in metal; it's static.
The addition of a computer (with a program, or even downloadable-on-the-fly programs) to a static machine, e.g. today's
computer-controlled-manufacturing machines (lathes, milling, welding, plasma cutters, etc.) makes a massive change in utility.
It's almost the same physically, but ever so much more flexible, useful, and more profitable to own/operate.
And if you add massive databases, internet connectivity, the latest machine-learning, language and image processing and
some nefarious intent, then you get into trouble.
Sometimes automation is necessary to eliminate the risks of manual processes. There are parenteral (injectable) drugs that
cannot be sterilized except by filtration. Most of the work of filling, post filling processing, and sealing is done using automation
in areas that make surgical suites seem filthy and people are kept from these operations.
Manual operations are only undertaken to correct issues with the automation and the procedures are tested to ensure that they
do not introduce contamination, microbial or otherwise. Because even one non-sterile unit is a failure and testing is destructive
process, of course any full lot of product cannot be tested to state that all units are sterile. Periodic testing of the automated
process and manual intervention is done periodically and it is expensive and time consuming to test to a level of confidence that
there is far less than a one in a million chance of any unit in a lot being non sterile.
In that respect, automation and the skills necessary to interface with it are fundamental to the safety of drugs frequently
used on already compromised patients.
Agree. Good example. Digital technology and miniaturization seem particularly well suited to many aspect of the medical world.
But doubt they will eliminate the doctor or the nurse very soon. Insurance companies on the other hand
"There would be no improvement in quality mixing and kneading the dough by hand. There would, however, be an enormous increase
in cost." WRONG! If you had an unlimited supply of 50-cents-an-hour disposable labor, mixing and kneading the dough by hand would
be cheaper. It is only because labor is expensive in France that the machine saves money.
In Japan there is a lot of automation, and wages and living standards are high. In Bangladesh there is very little automation,
and wages and livings standards are very low.
Are we done with the 'automation is destroying jobs' meme yet? Excessive population growth is the problem, not robots. And
the root cause of excessive population growth is the corporate-sponsored virtual taboo of talking about it seriously.
Posted by: juliania | Feb 12 2020 5:15 utc | 39
(Artificial Intelligence)
The trouble with Artificial Intelligence is that it's not intelligent.
And it's not intelligent because it's got no experience, no imagination and no
self-control.
vk @38: "...the reality on the field is that capitalism is 0 for 5..."
True, but it is worse than that! Even when we get AI to the level you describe, capitalism
will continue its decline.
Henry Ford actually understood Marxist analysis. Despite what many people in the present
imagine, Ford had access to sufficient engineering talent to make his automobile
manufacturing processes much more automated than he did. Ford understood that improving the
efficiency of the manufacturing process was less important than creating a population with
sufficient income to purchase his products.
AI is just a tool, unless it is developed to the point of attaining sentience in which
case it becomes slavery, but let's ignore that possibility for now. Capitalists cannot make
profits from the tools they own all by the tools themselves. Profits come from unpaid labor.
You cannot underpay a tool, and the tool cannot labor by itself.
The AI can be a product that is sold, but compared with cars, for example, the quantity of
labor invested in AI is minuscule. The smaller the proportion of labor that is in the cost of
a product, the smaller the percent of the price that can be realized as profit. To re-boost
real capitalist profits you need labor-intensive products. This also ties in with Henry
Ford's understanding of economics in that a larger labor force also means a larger market for
the capitalist's products.
There are some very obvious products that I can think of involving AI that are also
massively labor-intensive that would match the scale of the automotive industry and
rejuvenate capitalism, but they would require many $millions in R&D to make them
market-ready. Since I want capitalism to die already and get out Re: AI --
Always wondered how pseudo-AI, or enhanced automation, might be constrained by diminishing
EROEI.
Unless an actual AI were able to crack the water molecule to release hydrogen in an
energy-efficient way, or unless we learn to love nuclear (by cracking the nuclear waste
issue), then it seems to me hyper-automated workplaces will be at least as subject to
plummeting EROEI as are current workplaces, if not moreso. Is there any reason to think that,
including embedded energy in their manufacture, these machines and their workplaces will be
less energy intensive than current ones?
@William Gruff #40
The real world usage of AI, to date, is primarily replacing the rank and file of human
experience.
Where before you would have individuals who have attained expertise in an area, and who would
be paid to exercise it, now AI can learn from the extant work and repeat it.
The problem, though, is that AI is eminently vulnerable to attack. In particular - if the
area involves change, which most do, then the AI must be periodically retrained to take into
account the differences. Being fundamentally stupid, AI literally cannot integrate new data
on top of old but must start from scratch.
I don't have the link, but I did see an excellent example: a cat vs. AI.
While a cat can't play chess, the cat can walk, can recognize objects visually, can
communicate even without a vocal cord, can interact with its environment and even learn new
behaviors.
In this example, you can see one of the fundamental differences between functional organisms
and AI: AI can be trained to perform extremely well, but it requires very narrow focus.
IBM spend years and literally tens of thousands of engineering hours to create the AI that
could beat Jeapordy champions - but that particular creation is still largely useless for
anything else. IBM is desperately attempting to monetize that investment through its Think
Build Grow program - think AWS for AI. I saw a demo - it was particularly interesting because
this AI program ingests some 3 million English language web articles; IBM showed its contents
via a very cool looking wrap around display room in its Think Build Grow promotion
campaign.
What was really amusing was a couple of things:
1) the fact that the data was already corrupt: this demo was about 2 months ago - and there
were spikes of "data" coming from Ecuador and the tip of South America. Ecuador doesn't speak
English. I don't even know if there are any English web or print publications there. But I'd
bet large sums of money that the (English) Twitter campaign being run on behalf of the coup
was responsible for this spike.
2) Among the top 30 topics was Donald Trump. Given the type of audience you would expect
for this subject, it was enormously embarrassing that Trump coverage was assessed as net
positive - so much so that the IBM representative dived into the data to ascertain why the AI
had a net positive rating (the program also does sentiment analysis). It turns out that a
couple of articles which were clearly extremely peripheral to Trump, but which did mention
his name, were the cause. The net positive rating was from this handful of articles even
though the relationship was very weak and there were far fewer net "positive" vs. negative
articles shown in the first couple passes of source articles (again, IBM's sentiment analysis
- not a human's).
I have other examples: SF is home to a host of self-driving testing initiatives. Uber had
a lot about 4 blocks from where I live, for months, where they based their self driving cars
out of (since moved). The self-driving delivery robots (sidewalk) - I've seen them tested
here as well.
Some examples of how they fail: I was riding a bus, which was stopped at an intersection
behind a Drive test vehicle at a red light(Drive is nVidia's self driving). This intersection
is somewhat unusual: there are 5 entrances/exits to this intersection, so the traffic light
sequence and the driving action is definitely atypical.
The light turns green, the Drive car wants to turn immediately left (as opposed to 2nd
left, as opposed to straight or right). It accelerates into the intersection and starts
turning; literally halfway into the intersection, it slams on its brakes. The bus, which was
accelerating behind it in order to go straight, is forced to also slam on its brakes. There
was no incoming car - because of the complex left turn setup, the street the Drive car and
bus were on, is the only one that is allowed to traverse when that light is green (initially.
After a 30 second? pause, the opposite "straight" street is allowed to drive).
Why did the Drive car slam on its brakes in the middle of the intersection? No way to know
for sure, but I would bet money that the sensors saw the cars waiting at the 2nd left street
and thought it was going the wrong way. Note this is just a few months ago.
There are many other examples of AI being fundamentally brittle: Google's first version of
human recognition via machine vision classified black people as gorillas:
Google Photos fail
A project at MIT inserted code into AI machine vision programs to show what these were
actually seeing when recognizing objects; it turns out that what the AIs were recognizing
were radically different from reality. For example, while the algo could recognize a
dumbbell, it turns out that the reference image that the algo used was a dumbbell plus an
arm. Because all of the training photos for a dumbbell included an arm...
This fundamental lack of basic concepts, a coherent worldview or any other type of rooting
in reality is why AI is also pathetically easy to fool. This research showed that the top of
the line machine vision for self driving could be tricked into recognizing stop signs as
speed limit signs Confusing self driving
cars
To be clear, fundamentally it doesn't matter for most applications if the AI is "close
enough". If a company can replace 90% of its expensive, older workers or first world, English
speaking workers with an AI - even if the AI is working only 75% of the time, it is still a
huge win. For example: I was told by a person selling chatbots to Sprint that 90% of Sprint's
customer inquiries were one of 10 questions...
And lastly: are robots/AI taking jobs? Certainly it is true anecdotally, but the overall
economic statistics aren't showing this. In particular, if AI was really taking jobs - then
we should be seeing productivity numbers increase more than in the past. But this isn't
happening:
Productivity for the past 30 years
Note in the graph that productivity was increasing much more up until 2010 - when it leveled
off.
Dean Baker has written about this extensively - it is absolutely clear that it is outsourced
of manufacturing jobs which is why US incomes have been stagnant for decades.
The world is filled with conformism and groupthink. Most people do not wish to think for
themselves. Thinking for oneself is dangerous, requires effort and often leads to rejection by
the herd of one's peers.
The profession of arms, the intelligence business, the civil service bureaucracy, the
wondrous world of groups like the League of Women Voters, Rotary Club as well as the empire of
the thinktanks are all rotten with this sickness, an illness which leads inevitably to
stereotyped and unrealistic thinking, thinking that does not reflect reality.
The worst locus of this mentally crippling phenomenon is the world of the academics. I have
served on a number of boards that awarded Ph.D and post doctoral grants. I was on the Fulbright
Fellowship federal board. I was on the HF Guggenheim program and executive boards for a long
time. Those are two examples of my exposure to the individual and collective academic
minds.
As a class of people I find them unimpressive. The credentialing exercise in acquiring a
doctorate is basically a nepotistic process of sucking up to elders and a crutch for ego
support as well as an entrance ticket for various hierarchies, among them the world of the
academy. The process of degree acquisition itself requires sponsorship by esteemed academics
who recommend candidates who do not stray very far from the corpus of known work in whichever
narrow field is involved. The endorsements from RESPECTED academics are often decisive in the
award of grants.
This process is continued throughout a career in academic research. PEER REVIEW is the
sine qua non for acceptance of a "paper," invitation to career making conferences, or
to the Holy of Holies, TENURE.
This life experience forms and creates CONFORMISTS, people who instinctively boot-lick their
fellows in a search for the "Good Doggy" moments that make up their lives. These people are for
sale. Their price may not be money, but they are still for sale. They want to be accepted as
members of their group. Dissent leads to expulsion or effective rejection from the group.
This mentality renders doubtful any assertion that a large group of academics supports any
stated conclusion. As a species academics will say or do anything to be included in their
caste.
This makes them inherently dangerous. They will support any party or parties, of any
political inclination if that group has the money, and the potential or actual power to
maintain the academics as a tribe. pl
That is the nature of tribes and humans are very tribal. At least most of them.
Fortunately, there are outliers. I was recently reading "Political Tribes" which was written
by a couple who are both law professors that examines this.
Take global warming (aka the rebranded climate change). Good luck getting grants to do any
skeptical research. This highly complex subject which posits human impact is a perfect
example of tribal bias.
My success in the private sector comes from consistent questioning what I wanted to be
true to prevent suboptimal design decisions.
I also instinctively dislike groups that have some idealized view of "What is to be
done?"
As Groucho said: "I refuse to join any club that would have me as a member"
The 'isms' had it, be it Nazism, Fascism, Communism, Totalitarianism, Elitism all demand
conformity and adherence to group think. If one does not co-tow to whichever 'ism' is at
play, those outside their group think are persecuted, ostracized, jailed, and executed all
because they defy their conformity demands, and defy allegiance to them.
One world, one religion, one government, one Borg. all lead down the same road to --
Orwell's 1984.
David Halberstam: The Best and the Brightest. (Reminder how the heck we got into Vietnam,
when the best and the brightest were serving as presidential advisors.)
Also good Halberstam re-read: The Powers that Be - when the conservative media controlled
the levers of power; not the uber-liberal one we experience today.
"... In fact, OOP works well when your program needs to deal with relatively simple, real-world objects: the modeling follows naturally. If you are dealing with abstract concepts, or with highly complex real-world objects, then OOP may not be the best paradigm. ..."
"... In Java, for example, you can program imperatively, by using static methods. The problem is knowing when to break the rules ..."
"... I get tired of the purists who think that OO is the only possible answer. The world is not a nail. ..."
OOP has been a golden hammer ever since Java, but we've noticed the downsides quite a while ago. Ruby on rails was the
convention over configuration darling child of the last decade and stopped a large piece of the circular abstraction craze that
Java was/is. Every half-assed PHP toy project is kicking Javas ass on the web and it's because WordPress gets the job done, fast,
despite having a DB model that was built by non-programmers on crack.
Most critical processes are procedural, even today if only for the OOP has been a golden hammer ever since Java, but we've
noticed the downsides quite a while ago.
Ruby on rails was the convention over configuration darling child of the last decade and stopped a large piece of the circular
abstraction craze that Java was/is.
Every half-assed PHP toy project is kicking Javas ass on the web and it's because WordPress gets the job done, fast,
despite having a DB model that was built by non-programmers on crack.
There are a lot of mediocre programmers who follow the principle "if you have a hammer, everything looks like a nail". They
know OOP, so they think that every problem must be solved in an OOP way.
In fact, OOP works well when your program needs to deal with relatively simple, real-world objects: the modeling follows
naturally. If you are dealing with abstract concepts, or with highly complex real-world objects, then OOP may not be the best
paradigm.
In Java, for example, you can program imperatively, by using static methods. The problem is knowing when to break the rules.
For example, I am working on a natural language system that is supposed to generate textual answers to user inquiries. What
"object" am I supposed to create to do this task? An "Answer" object that generates itself? Yes, that would work, but an imperative,
static "generate answer" method makes at least as much sense.
There are different ways of thinking, different ways of modelling a problem. I get tired of the purists who think that OO
is the only possible answer. The world is not a nail.
Object-oriented programming generates a lot of what looks like work. Back in the days of
fanfold, there was a type of programmer who would only put five or ten lines of code on a
page, preceded by twenty lines of elaborately formatted comments. Object-oriented programming
is like crack for these people: it lets you incorporate all this scaffolding right into your
source code. Something that a Lisp hacker might handle by pushing a symbol onto a list
becomes a whole file of classes and methods. So it is a good tool if you want to convince
yourself, or someone else, that you are doing a lot of work.
Eric Lippert observed a similar occupational hazard among developers. It's something he
calls object happiness .
What I sometimes see when I interview people and review code is symptoms of a disease I call
Object Happiness. Object Happy people feel the need to apply principles of OO design to
small, trivial, throwaway projects. They invest lots of unnecessary time making pure virtual
abstract base classes -- writing programs where IFoos talk to IBars but there is only one
implementation of each interface! I suspect that early exposure to OO design principles
divorced from any practical context that motivates those principles leads to object
happiness. People come away as OO True Believers rather than OO pragmatists.
I've seen so many problems caused by excessive, slavish adherence to OOP in production
applications. Not that object oriented programming is inherently bad, mind you, but a little
OOP goes a very long way . Adding objects to your code is like adding salt to a dish: use a
little, and it's a savory seasoning; add too much and it utterly ruins the meal. Sometimes it's
better to err on the side of simplicity, and I tend to favor the approach that results in
less code, not more .
Given my ambivalence about all things OO, I was amused when Jon Galloway forwarded me a link to Patrick Smacchia's web page . Patrick
is a French software developer. Evidently the acronym for object oriented programming is
spelled a little differently in French than it is in English: POO.
That's exactly what I've imagined when I had to work on code that abused objects.
But POO code can have another, more constructive, meaning. This blog author argues that OOP
pales in importance to POO. Programming fOr Others , that
is.
The problem is that programmers are taught all about how to write OO code, and how doing so
will improve the maintainability of their code. And by "taught", I don't just mean "taken a
class or two". I mean: have pounded into head in school, spend years as a professional being
mentored by senior OO "architects" and only then finally kind of understand how to use
properly, some of the time. Most engineers wouldn't consider using a non-OO language, even if
it had amazing features. The hype is that major.
So what, then, about all that code programmers write before their 10 years OO
apprenticeship is complete? Is it just doomed to suck? Of course not, as long as they apply
other techniques than OO. These techniques are out there but aren't as widely discussed.
The improvement [I propose] has little to do with any specific programming technique. It's
more a matter of empathy; in this case, empathy for the programmer who might have to use your
code. The author of this code actually thought through what kinds of mistakes another
programmer might make, and strove to make the computer tell the programmer what they did
wrong.
In my experience the best code, like the best user interfaces, seems to magically
anticipate what you want or need to do next. Yet it's discussed infrequently relative to OO.
Maybe what's missing is a buzzword. So let's make one up, Programming fOr Others, or POO for
short.
The principles of object oriented programming are far more important than mindlessly,
robotically instantiating objects everywhere:
Stop worrying so much about the objects. Concentrate on satisfying the principles of
object orientation rather than object-izing everything. And most of all, consider the poor
sap who will have to read and support this code after you're done with it . That's why POO
trumps OOP: programming as if people mattered will always be a more effective strategy than
satisfying the architecture astronauts .
Daniel
Korenblum , works at Bayes Impact
Updated May 25, 2015 There are many reasons why non-OOP languages and paradigms/practices
are on the rise, contributing to the relative decline of OOP.
First off, there are a few things about OOP that many people don't like, which makes them
interested in learning and using other approaches. Below are some references from the OOP wiki
article:
One of the comments therein linked a few other good wikipedia articles which also provide
relevant discussion on increasingly-popular alternatives to OOP:
Modularity and design-by-contract are better implemented by module systems ( Standard ML
)
Personally, I sometimes think that OOP is a bit like an antique car. Sure, it has a bigger
engine and fins and lots of chrome etc., it's fun to drive around, and it does look pretty. It
is good for some applications, all kidding aside. The real question is not whether it's useful
or not, but for how many projects?
When I'm done building an OOP application, it's like a large and elaborate structure.
Changing the way objects are connected and organized can be hard, and the design choices of the
past tend to become "frozen" or locked in place for all future times. Is this the best choice
for every application? Probably not.
If you want to drive 500-5000 miles a week in a car that you can fix yourself without
special ordering any parts, it's probably better to go with a Honda or something more easily
adaptable than an antique vehicle-with-fins.
Finally, the best example is the growth of JavaScript as a language (officially called
EcmaScript now?). Although JavaScript/EcmaScript (JS/ES) is not a pure functional programming
language, it is much more "functional" than "OOP" in its design. JS/ES was the first mainstream
language to promote the use of functional programming concepts such as higher-order functions,
currying, and monads.
The recent growth of the JS/ES open-source community has not only been impressive in its
extent but also unexpected from the standpoint of many established programmers. This is partly
evidenced by the overwhelming number of active repositories on Github using
JavaScript/EcmaScript:
Because JS/ES treats both functions and objects as structs/hashes, it encourages us to blur
the line dividing them in our minds. This is a division that many other languages impose -
"there are functions and there are objects/variables, and they are different".
This seemingly minor (and often confusing) design choice enables a lot of flexibility and
power. In part this seemingly tiny detail has enabled JS/ES to achieve its meteoric growth
between 2005-2015.
This partially explains the rise of JS/ES and the corresponding relative decline of OOP. OOP
had become a "standard" or "fixed" way of doing things for a while, and there will probably
always be a time and place for OOP. But as programmers we should avoid getting too stuck in one
way of thinking / doing things, because different applications may require different
approaches.
Above and beyond the OOP-vs-non-OOP debate, one of our main goals as engineers should be
custom-tailoring our designs by skillfully choosing the most appropriate programming
paradigm(s) for each distinct type of application, in order to maximize the "bang for the buck"
that our software provides.
Although this is something most engineers can agree on, we still have a long way to go until
we reach some sort of consensus about how best to teach and hone these skills. This is not only
a challenge for us as programmers today, but also a huge opportunity for the next generation of
educators to create better guidelines and best practices than the current OOP-centric
pedagogical system.
Here are a couple of good books that elaborates on these ideas and techniques in more
detail. They are free-to-read online:
Mike MacHenry ,
software engineer, improv comedian, maker Answered
Feb 14, 2015 · Author has 286 answers and 513.7k answer views Because the phrase
itself was over hyped to an extrodinary degree. Then as is common with over hyped things many
other things took on that phrase as a name. Then people got confused and stopped calling what
they are don't OOP.
Yes I think OOP ( the phrase ) is on the decline because people are becoming more educated
about the topic.
It's like, artificial intelligence, now that I think about it. There aren't many people
these days that say they do AI to anyone but the laymen. They would say they do machine
learning or natural language processing or something else. These are fields that the vastly
over hyped and really nebulous term AI used to describe but then AI ( the term ) experienced a
sharp decline while these very concrete fields continued to flourish.
There is nothing inherently wrong with some of the functionality it offers, its the way
OOP is abused as a substitute for basic good programming practices.
I was helping interns - students from a local CC - deal with idiotic assignments like
making a random number generator USING CLASSES, or displaying text to a screen USING CLASSES.
Seriously, WTF?
A room full of career programmers could not even figure out how you were supposed to do
that, much less why.
What was worse was a lack of understanding of basic programming skill or even the use of
variables, as the kids were being taught EVERY program was to to be assembled solely by
sticking together bits of libraries.
There was no coding, just hunting for snippets of preexisting code to glue together. Zero
idea they could add their own, much less how to do it. OOP isn't the problem, its the idea
that it replaces basic programming skills and best practice.
That and the obsession with absofrackinglutely EVERYTHING just having to be a formally
declared object including the while program being an object with a run() method.
Some things actually cry out to be objects, some not so much. Generally, I find that my
most readable and maintainable code turns out to be a procedural program that manipulates
objects.
Even there, some things just naturally want to be a struct or just an array of values.
The same is true of most ingenious ideas in programming. It's one thing if code is
demonstrating a particular idea, but production code is supposed to be there to do work, not
grind an academic ax.
For example, slavish adherence to "patterns". They're quite useful for thinking about code
and talking about code, but they shouldn't be the end of the discussion. They work better as
a starting point. Some programs seem to want patterns to be mixed and matched.
In reality those problems are just cargo cult programming one level higher.
I suspect a lot of that is because too many developers barely grasp programming and never
learned to go beyond the patterns they were explicitly taught.
When all you have is a hammer, the whole world looks like a nail.
Inheritance, while not "inherently" bad, is often the wrong solution. See: Why
extends is evil [javaworld.com]
Composition is frequently a more appropriate choice. Aaron Hillegass wrote this funny
little anecdote in Cocoa
Programming for Mac OS X [google.com]:
"Once upon a time, there was a company called Taligent. Taligent was created by IBM and
Apple to develop a set of tools and libraries like Cocoa. About the time Taligent reached the
peak of its mindshare, I met one of its engineers at a trade show.
I asked him to create a simple application for me: A window would appear with a button,
and when the button was clicked, the words 'Hello, World!' would appear in a text field. The
engineer created a project and started subclassing madly: subclassing the window and the
button and the event handler.
Then he started generating code: dozens of lines to get the button and the text field onto
the window. After 45 minutes, I had to leave. The app still did not work. That day, I knew
that the company was doomed. A couple of years later, Taligent quietly closed its doors
forever."
Almost every programming methodology can be abused by people who really don't know how to
program well, or who don't want to. They'll happily create frameworks, implement new
development processes, and chart tons of metrics, all while avoiding the work of getting the
job done. In some cases the person who writes the most code is the same one who gets the
least amount of useful work done.
So, OOP can be misused the same way. Never mind that OOP essentially began very early and
has been reimplemented over and over, even before Alan Kay. Ie, files in Unix are essentially
an object oriented system. It's just data encapsulation and separating work into manageable
modules. That's how it was before anyone ever came up with the dumb name "full-stack
developer".
(medium.com)
782
Posted by EditorDavid
on Monday July 22, 2019 @12:04AM
from the
OOPs
dept.
Senior full-stack engineer Ilya Suzdalnitski recently published a lively 6,000-word essay calling
object-oriented programming "a trillion dollar disaster."
Precious time and brainpower are being spent
thinking about "abstractions" and "design patterns" instead of solving real-world problems... Object-Oriented
Programming (OOP) has been created with one goal in mind -- to
manage the complexity
of procedural
codebases. In other words, it was supposed to
improve code organization
. There's
no objective and open evidence that OOP is better than plain procedural programming
...
Instead of reducing
complexity, it encourages promiscuous
sharing of mutable state
and introduces additional complexity
with its numerous
design patterns
. OOP makes common development practices, like refactoring and
testing, needlessly hard...
As a developer who started in the days of FORTRAN (when it was all-caps), I've watched the
rise of OOP with some curiosity. I think there's a general consensus that abstraction and
re-usability are good things - they're the reason subroutines exist - the issue is whether
they are ends in themselves.
I struggle with the whole concept of "design patterns". There are clearly common themes in
software, but there seems to be a great deal of pressure these days to make your
implementation fit some pre-defined template rather than thinking about the application's
specific needs for state and concurrency. I have seen some rather eccentric consequences of
"patternism".
Correctly written, OOP code allows you to encapsulate just the logic you need for a
specific task and to make that specific task available in a wide variety of contexts by
judicious use of templating and virtual functions that obviate the need for
"refactoring".
Badly written, OOP code can have as many dangerous side effects and as much opacity as any
other kind of code. However, I think the key factor is not the choice of programming
paradigm, but the design process.
You need to think first about what your code is intended to do and in what circumstances
it might be reused. In the context of a larger project, it means identifying commonalities
and deciding how best to implement them once. You need to document that design and review it
with other interested parties. You need to document the code with clear information about its
valid and invalid use. If you've done that, testing should not be a problem.
Some people seem to believe that OOP removes the need for some of that design and
documentation. It doesn't and indeed code that you intend to be reused needs *more* design
and documentation than the glue that binds it together in any one specific use case. I'm
still a firm believer that coding begins with a pencil, not with a keyboard. That's
particularly true if you intend to design abstract interfaces that will serve many purposes.
In other words, it's more work to do OOP properly, so only do it if the benefits outweigh the
costs - and that usually means you not only know your code will be genuinely reusable but
will also genuinely be reused.
I struggle with the whole concept of "design patterns".
Because design patterns are stupid.
A reasonable programmer can understand reasonable code so long as the data is documented
even when the code isn't documented, but will struggle immensely if it were the other way
around.
Bad programmers create objects for objects sake, and because of that they have to follow
so called "design patterns" because no amount of code commenting makes the code easily
understandable when its a spaghetti web of interacting "objects" The "design patterns" don't
make the code easier the read, just easier to write.
Those OOP fanatics, if they do "document" their code, add comments like "// increment the
index" which is useless shit.
The big win of OOP is only in the encapsulation of the data with the code, and great code
treats objects like data structures with attached subroutines, not as "objects", and document
the fuck out of the contained data, while more or less letting the code document itself.
680,303 lines of Java code in the main project in my system.
Probably would've been more like 100,000 lines if you had used a language whose ecosystem
doesn't goad people into writing so many superfluous layers of indirection, abstraction and
boilerplate.
Posted on 2017-12-18 by
esr In recent discussion on this
blog of the GCC repository transition and reposurgeon, I observed "If I'd been restricted to C,
forget it – reposurgeon wouldn't have happened at all"
I should be more specific about this, since I think the underlying problem is general to a
great deal more that the implementation of reposurgeon. It ties back to a lot of recent
discussion here of C, Python, Go, and the transition to a post-C world that I think I see
happening in systems programming.
I shall start by urging that you must take me seriously when I speak of C's limitations.
I've been programming in C for 35 years. Some of my oldest C code is still in wide
production use. Speaking from that experience, I say there are some things only a damn fool
tries to do in C, or in any other language without automatic memory management (AMM, for the
rest of this article).
This is another angle on Greenspun's Law: "Any sufficiently complicated C or Fortran program
contains an ad-hoc, informally-specified, bug-ridden, slow implementation of half of Common
Lisp." Anyone who's been in the trenches long enough gets that Greenspun's real point is not
about C or Fortran or Common Lisp. His maxim could be generalized in a
Henry-Spencer-does-Santyana style as this:
"At any sufficient scale, those who do not have automatic memory management in their
language are condemned to reinvent it, poorly."
In other words, there's a complexity threshold above which lack of AMM becomes intolerable.
Lack of it either makes expressive programming in your application domain impossible or sends
your defect rate skyrocketing, or both. Usually both.
When you hit that point in a language like C (or C++), your way out is usually to write an
ad-hoc layer or a bunch of semi-disconnected little facilities that implement parts of an AMM
layer, poorly. Hello, Greenspun's Law!
It's not particularly the line count of your source code driving this, but rather the
complexity of the data structures it uses internally; I'll call this its "greenspunity". Large
programs that process data in simple, linear, straight-through ways may evade needing an ad-hoc
AMM layer. Smaller ones with gnarlier data management (higher greenspunity) won't. Anything
that has to do – for example – graph theory is doomed to need one (why, hello,
there, reposurgeon!)
There's a trap waiting here. As the greenspunity rises, you are likely to find that more and
more of your effort and defect chasing is related to the AMM layer, and proportionally less
goes to the application logic. Redoubling your effort, you increasingly miss your aim.
Even when you're merely at the edge of this trap, your defect rates will be dominated by
issues like double-free errors and malloc leaks. This is commonly the case in C/C++ programs of
even low greenspunity.
Sometimes you really have no alternative but to be stuck with an ad-hoc AMM layer. Usually
you get pinned to this situation because real AMM would impose latency costs you can't afford.
The major case of this is operating-system kernels. I could say a lot more about the costs and
contortions this forces you to assume, and perhaps I will in a future post, but it's out of
scope for this one.
On the other hand, reposurgeon is representative of a very large class of "systems" programs
that don't have these tight latency constraints. Before I get to back to the implications of
not being latency constrained, one last thing – the most important thing – about
escalating AMM-layer complexity.
At high enough levels of greenspunity, the effort required to build and maintain your ad-hoc
AMM layer becomes a black hole. You can't actually make any progress on the application domain
at all – when you try it's like being nibbled to death by ducks.
Now consider this prospectively, from the point of view of someone like me who has architect
skill. A lot of that skill is being pretty good at visualizing the data flows and structures
– and thus estimating the greenspunity – implied by a problem domain. Before you've
written any code, that is.
If you see the world that way, possible projects will be divided into "Yes, can be done in a
language without AMM." versus "Nope. Nope. Nope. Not a damn fool, it's a black hole, ain't
nohow going there without AMM."
This is why I said that if I were restricted to C, reposurgeon would never have happened at
all. I wasn't being hyperbolic – that evaluation comes from a cool and exact sense of how
far reposurgeon's problem domain floats above the greenspunity level where an ad-hoc AMM layer
becomes a black hole. I shudder just thinking about it.
Of course, where that black-hole level of ad-hoc AMM complexity is varies by programmer.
But, though software is sometimes written by people who are exceptionally good at managing that
kind of hair, it then generally has to be maintained by people who are less so
The really smart people in my audience have already figured out that this is why Ken
Thompson, the co-designer of C, put AMM in Go, in spite of the latency issues.
Ken understands something large and simple. Software expands, not just in line count but in
greenspunity, to meet hardware capacity and user demand. In languages like C and C++ we are
approaching a point of singularity at which typical – not just worst-case –
greenspunity is so high that the ad-hoc AMM becomes a black hole, or at best a trap
nigh-indistinguishable from one.
Thus, Go. It didn't have to be Go; I'm not actually being a partisan for that language here.
It could have been (say) Ocaml, or any of half a dozen other languages I can think of. The
point is the combination of AMM with compiled-code speed is ceasing to be a luxury option;
increasingly it will be baseline for getting most kinds of systems work done at all.
Sociologically, this implies an interesting split. Historically the boundary between systems
work under hard latency constraints and systems work without it has been blurry and permeable.
People on both sides of it coded in C and skillsets were similar. People like me who mostly do
out-of-kernel systems work but have code in several different kernels were, if not common, at
least not odd outliers.
Increasingly, I think, this will cease being true. Out-of-kernel work will move to Go, or
languages in its class. C – or non-AMM languages intended as C successors, like Rust
– will keep kernels and real-time firmware, at least for the foreseeable future.
Skillsets will diverge.
It'll be a more fragmented systems-programming world. Oh well; one does what one must, and
the tide of rising software complexity is not about to be turned. This entry was posted in
General , Software by esr . Bookmark the permalink . 144 thoughts on "C, Python, Go, and the
Generalized Greenspun Law"
David Collier-Brown on
2017-12-18 at
17:38:05 said: Andrew Forber quasily-accidentally created a similar truth: any
sufficiently complex program using overlays will eventually contain an implementation of
virtual memory. Reply ↓
esr on
2017-12-18 at
17:40:45 said: >Andrew Forber quasily-accidentally created a similar truth: any
sufficiently complex program using overlays will eventually contain an implementation
of virtual memory.
Oh, neat. I think that's a closer approximation to the most general statement than
Greenspun's, actually. Reply ↓
Alex K. on 2017-12-20 at 09:50:37 said:
For today, maybe -- but the first time I had Greenspun's Tenth quoted at me was in
the late '90s. [I know this was around/just before the first C++ standard, maybe
contrasting it to this new upstart Java thing?] This was definitely during the era
where big computers still did your serious work, and pretty much all of it was in
either C, COBOL, or FORTRAN. [Yeah, yeah, I know– COBOL is all caps for being
an acronym, while Fortran ain't–but since I'm talking about an earlier epoch
of computing, I'm going to use the conventions of that era.]
Now the Object-Oriented paradigm has really mitigated this to an enormous
degree, but I seem to recall at that time the argument was that multimethod
dispatch (a benefit so great you happily accept the flaw of memory
management) was the Killer Feature of LISP.
Given the way the other advantage I would have given Lisp over the past two
decades–anonymous functions [lambdas] and treating them as first-class
values–are creeping into a more mainstream usage, I think automated memory
management is the last visible "Lispy" feature people will associate with
Greenspun. [What, are you now visualizing lisp macros? Perish the
thought–anytime I see a foot cannon that big, I stop calling it a feature ]
Reply
↓
Mycroft Jones on 2017-12-18 at 17:41:04 said: After
looking at the Linear Lisp paper, I think that is where Lutz Mueller got One Reference Only
memory management from. For automatic memory management, I'm a big fan of ORO. Not sure how
to apply it to a statically typed language though. Wish it was available for Go. ORO is
extremely predictable and repeatable, not stuttery. Reply ↓
lliamander on 2017-12-18 at 19:28:04 said: >
Not sure how to apply it to a statically typed language though.
Jeff Read on 2017-12-19 at 00:38:57 said: If
Lutz was inspired by Linear Lisp, he didn't cite it. Actually ORO is more like
region-based memory allocation with a single region: values which leave the current
scope are copied which can be slow if you're passing large lists or vectors
around.
Linear Lisp is something quite a bit different, and allows for arbitrary data
structures with arbitrarily deep linking within, so long as there are no cycles in the
data structures. You can even pass references into and out of functions if you like;
what you can't do is alias them. As for statically typed programming languages well,
there are linear
type systems , which as lliamander mentioned are implemented in Clean.
Newlisp in general is smack in the middle between Rust and Urbit in terms of
cultishness of its community, and that scares me right off it. That and it doesn't
really bring anything to the table that couldn't be had by "old" lisps (and Lutz
frequently doubles down on mistakes in the design that had been discovered and
corrected decades ago by "old" Lisp implementers). Reply ↓
Gary E. Miller on 2017-12-18 at 18:02:10 said: For a
long time I've been holding out hope for a 'standard' garbage collector library for C. But
not gonna hold my breath. One probable reason Ken Thompson had to invent Go is to go around
the tremendous difficulty in getting new stuff into C. Reply ↓
esr on
2017-12-18 at
18:40:53 said: >For a long time I've been holding out hope for a 'standard'
garbage collector library for C. But not gonna hold my breath.
Yeah, good idea not to. People as smart/skilled as you and me have been poking at
this problem since the 1980s and it's pretty easy to show that you can't do better than
Boehm–Demers–Weiser, which has limitations that make it impractical. Sigh
Reply ↓
John
Cowan on 2018-04-15 at 00:11:56 said:
What's impractical about it? I replaced the native GC in the standard
implementation of the Joy interpreter with BDW, and it worked very well. Reply
↓
esr on 2018-04-15 at 08:30:12
said: >What's impractical about it? I replaced the native GC in the standard
implementation of the Joy interpreter with BDW, and it worked very well.
GCing data on the stack is a crapshoot. Pointers can get mistaken for data
and vice-versa. Reply
↓
Konstantin Khomoutov on 2017-12-20 at 06:30:05 said: I
think it's not about C. Let me cite a little bit from "The Go Programming Language"
(A.Donovan, B. Kernigan) --
in the section about Go influences, it states:
"Rob Pike and others began to experiment with CSP implementations as actual
languages. The first was called Squeak which provided a language with statically
created channels. This was followed by Newsqueak, which offered C-like statement and
expression syntax and Pascal-like type notation. It was a purely functional language
with garbage collection, again aimed at managing keyboard, mouse, and window events.
Channels became first-class values, dynamically created and storable in variables.
The Plan 9 operating system carried these ideas forward in a language called Alef.
Alef tried to make Newsqueak a viable system programming language, but its omission of
garbage collection made concurrency too painful."
So my takeaway was that AMM was key to get proper concurrency.
Before Go, I dabbled with Erlang (which I enjoy, too), and I'd say there the AMM is
also a key to have concurrency made easy.
(Update: the ellipsises I put into the citation were eaten by the engine and won't
appear when I tried to re-edit my comment; sorry.) Reply ↓
tz on 2017-12-18 at 18:29:20 said: I think
this is the key insight.
There are programs with zero MM.
There are programs with orderly MM, e.g. unzip does mallocs and frees in a stacklike
formation, Malloc a,b,c, free c,b,a. (as of 1.1.4). This is laminar, not chaotic flow.
Then there is the complex, nonlinear, turbulent flow, chaos. You can't do that in basic
C, you need AMM. But it is easier in a language that includes it (and does it well).
Virtual Memory is related to AMM – too often the memory leaks were hidden (think
of your O(n**2) for small values of n) – small leaks that weren't visible under
ordinary circumstances.
Still, you aren't going to get AMM on the current Arduino variants. At least not
easily.
That is where the line is, how much resources. Because you require a medium to large OS,
or the equivalent resources to do AMM.
Yet this is similar to using FPGAs, or GPUs for blockchain coin mining instead of the
CPU. Sometimes you have to go big. Your Cooper Mini might be great most of the time, but
sometimes you need a Diesel big pickup. I think a Mini would fit in the bed of my F250.
As tasks get bigger they need bigger machines. Reply ↓
Zygo on 2017-12-18 at 18:31:34 said: > Of
course, where that black-hole level of ad-hoc AMM complexity is varies by programmer.
I was about to say something about writing an AMM layer before breakfast on the way to
writing backtracking parallel graph-searchers at lunchtime, but I guess you covered that.
Reply ↓
esr on
2017-12-18 at
18:34:59 said: >I was about to say something about writing an AMM layer before
breakfast on the way to writing backtracking parallel graph-searchers at lunchtime, but
I guess you covered that.
Well, yeah. I have days like that occasionally, but it would be unwise to plan a
project based on the assumption that I will. And deeply foolish to assume that
J. Random Programmer will. Reply ↓
tz on 2017-12-18 at 18:32:37 said: C
displaced assembler because it had the speed and flexibility while being portable.
Go, or something like it will displace C where they can get just the right features into
the standard library including AMM/GC.
Maybe we need Garbage Collecting C. GCC?
One problem is you can't do the pointer aliasing if you have a GC (unless you also do
some auxillary bits which would be hard to maintain). void x = y; might be decodable but
there are deeper and more complex things a compiler can't detect. If the compiler gets it
wrong, you get a memory leak, or have to constrain the language to prevent things which
manipulate pointers when that is required or clearer. Reply ↓
Zygo on 2017-12-18 at 20:52:40 said: C++11
shared_ptr does handle the aliasing case. Each pointer object has two fields, one for
the thing being pointed to, and one for the thing's containing object (or its
associated GC metadata). A pointer alias assignment alters the former during the
assignment and copies the latter verbatim. The syntax is (as far as a C programmer
knows, after a few typedefs) identical to C.
The trouble with applying that idea to C is that the standard pointers don't have
space or time for the second field, and heap management isn't standardized at all
(free() is provided, but programs are not required to use it or any other function
exclusively for this purpose). Change either of those two things and the resulting
language becomes very different from C. Reply ↓
IGnatius T
Foobar on 2017-12-18 at 18:39:28 said: Eric, I
love you, you're a pepper, but you have a bad habit of painting a portrait of J. Random
Hacker that is actually a portrait of Eric S. Raymond. The world is getting along with C
just fine. 95% of the use cases you describe for needing garbage collection are eliminated
with the simple addition of a string class which nearly everyone has in their toolkit.
Reply ↓
esr on
2017-12-18 at
18:55:46 said: >The world is getting along with C just fine. 95% of the use
cases you describe for needing garbage collection are eliminated with the simple
addition of a string class which nearly everyone has in their toolkit.
Even if you're right, the escalation of complexity means that what I'm facing now,
J. Random Hacker will face in a couple of years. Yes, not everybody writes reposurgeon
but a string class won't suffice for much longer even if it does today. Reply
↓
I don't solve complex problems.
I simplify complex problems and solve them.
Complexity does escalate, or at least in the sense that we could cross oceans a
few centuries ago, and can go to the planets and beyond today.
We shouldn't use a rocket ship to get groceries from the local market.
J Random H-1B will face some easily decomposed apparently complex problem and
write a pile of spaghetti.
The true nature of a hacker is not so much in being able to handle the most deep
and complex situations, but in being able to recognize which situations are truly
complex and in preference working hard to simplify and reduce complexity in
preference to writing something to handle the complexity. Dealing with a slain
dragon's corpse is easier than one that is live, annoyed, and immolating anything
within a few hundred yards. Some are capable of handling the latter. The wise
knight prefers to reduce the problem to the former. Reply
↓
William O. B'Livion on 2017-12-20 at 02:02:40
said: > J Random H-1B will face some easily decomposed
> apparently complex problem and write a pile of spaghetti.
J Random H-1B will do it with Informatica and Java. Reply
↓
One of the epic fails of C++ is it being sold as C but where anyone could program
because of all the safetys. Instead it created bloatware and the very memory leaks because
the lesser programmers didn't KNOW (grok, understand) what they were doing. It was all
"automatic".
This is the opportunity and danger of AMM/GC. It is a tool, and one with hot areas and
sharp edges. Wendy (formerly Walter) Carlos had a law that said "Whatever parameter you can
control, you must control". Having a really good AMM/GC requires you to respect what it can
and cannot do. OK, form a huge – into VM – linked list. Won't it just handle
everything? NO!. You have to think reference counts, at least in the back of your mind. It
simplifys the problem but doesn't eliminate it. It turns the black hole into a pulsar, but
you still can be hit.
Many will gloss over and either superficially learn (but can't apply) or ignore the "how
to use automatic memory management" in their CS course. Like they didn't bother with
pointers, recursion, or multithreading subtleties. Reply ↓
lliamander on 2017-12-18 at 19:36:35 said: I would
say that there is a parallel between concurrency models and memory management approaches.
Beyond a certain level of complexity, it's simply infeasible for J. Random Hacker to
implement a locks-based solution just as it is infeasible for Mr. Hacker to write a
solution with manual memory management.
My worry is that by allowing the unsafe sharing of mutable state between goroutines, Go
will never be able to achieve the per-process (i.e. language-level process, not OS-level)
GC that would allow for really low latencies necessary for a AMM language to move closer
into the kernel space. But certainly insofar as many "systems" level applications don't
require extremely low latencies, Go will probably viable solution going forward. Reply
↓
Jeff Read on 2017-12-18 at 20:14:18 said: Putting
aside the hard deadlines found in real-time systems programming, it has been empirically
determined that a GC'd program requires five times as much memory as the
equivalent program with explicit memory management. Applications which are both CPU- and
RAM-intensive, where you need to have your performance cake and eat it in as little memory
as possible, are thus severely constrained in terms of viable languages they could be
implemented in. And by "severely constrained" I mean you get your choice of C++ or Rust.
(C, Pascal, and Ada are on the table, but none offer quite the same metaprogramming
flexibility as those two.)
I think your problems with reposturgeon stem from the fact that you're just running up
against the hard upper bound on the vector sum of CPU and RAM efficiency that a dynamic
language like Python (even sped up with PyPy) can feasibly deliver on a hardware
configuration you can order from Amazon. For applications like that, you need to forgo GC
entirely and rely on smart pointers, automatic reference counting, value semantics, and
RAII. Reply ↓
esr on
2017-12-18 at
20:27:20 said: > For applications like that, you need to forgo GC entirely and
rely on smart pointers, automatic reference counting, value semantics, and RAII.
How many times do I have to repeat "reposurgeon would never have been written
under that constraint" before somebody who claims LISP experience gets it? Reply
↓
Jeff Read on 2017-12-18 at 20:48:24 said:
You mentioned that reposurgeon wouldn't have been written under the constraints of
C. But C++ is not C, and has an entirely different set of constraints. In practice,
it's not thst far off from Lisp, especially if you avail yourself of those
wonderful features in C++1x. C++ programmers talk about "zero-cost abstractions"
for a reason .
Semantically, programming in a GC'd language and programming in a language that
uses smart pointers and RAII are very similar: you create the objects you need, and
they are automatically disposed of when no longer needed. But instead of delegating
to a GC which cleans them up whenever, both you and the compiler have compile-time
knowledge of when those cleanups will take place, allowing you finer-grained
control over how memory -- or any other resource -- is used.
Oh, that's another thing: GC only has something to say about memory --
not file handles, sockets, or any other resource. In C++, with appropriate types
value semantics can be made to apply to those too and they will immediately be
destructed after their last use. There is no special with construct in
C++; you simply construct the objects you need and they're destructed when they go
out of scope.
This is how the big boys do systems programming. Again, Go has barely
displaced C++ at all inside Google despite being intended for just that
purpose. Their entire critical path in search is still C++ code. And it always will
be until Rust gains traction.
As for my Lisp experience, I know enough to know that Lisp has utterly
failed and this is one of the major reasons why. It's not even a decent AI
language, because the scruffies won, AI is basically large-scale statistics, and
most practitioners these days use C++. Reply
↓
esr on 2017-12-18 at 20:54:08
said: >C++ is not C, and has an entirely different set of constraints. In
practice, it's not thst far off from Lisp,
Oh, bullshit. I think you're just trolling, now.
I've been a C++ programmer and know better than this.
But don't argue with me. Argue with Ken Thompson, who designed Go because
he knows better than this. Reply
↓
Anthony Williams on
2017-12-19 at 06:02:03
said: Modern C++ is a long way from C++ when it was first standardized in
1998. You should *never* be manually managing memory in modern C++. You
want a dynamically sized array? Use std::vector. You want an adhoc graph?
Use std::shared_ptr and std::weak_ptr.
Any code I see which uses new or delete, malloc or free will fail code
review.
Destructors and the RAII idiom mean that this covers *any* resource, not
just memory.
See the C++ Core Guidelines on resource and memory management: http://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#S-resource
Reply ↓
esr on 2017-12-19 at
07:53:58 said: >Modern C++ is a long way from C++ when it was
first standardized in 1998.
That's correct. Modern C++ is a disaster area of compounded
complexity and fragile kludges piled on in a failed attempt to fix
leaky abstractions. 1998 C++ had the leaky-abstractions problem, but at
least it was drastically simpler. Clue: complexification when you don't
even fix the problems is bad .
My experience dates from 2009 and included Boost – I was a
senior dev on Battle For Wesnoth. Don't try to tell me I don't know
what "modern C++" is like. Reply
↓
Anthony Williams on
2017-12-19 at
08:17:58 said: > My experience dates from 2009 and included
Boost – I was a senior dev on Battle For Wesnoth. Don't try
to tell me I don't know what "modern C++" is like.
C++ in 2009 with boost was C++ from 1998 with a few extra
libraries. I mean that quite literally -- the standard was
unchanged apart from minor fixes in 2003.
C++ has changed a lot since then. There have been 3 standards
issued, in 2011, 2014, and just now in 2017. Between them, there is
a huge list of changes to the language and the standard library,
and these are readily available -- both clang and gcc have kept
up-to-date with the changes, and even MSVC isn't far behind. Even
more changes are coming with C++20.
So, with all due respect, C++ from 2009 is not "modern C++",
though there certainly were parts of boost that were leaning that
way.
esr on 2017-12-19 at
08:37:11 said: >So, with all due respect, C++ from 2009
is not "modern C++", though there certainly were parts of boost
that were leaning that way.
But the foundational abstractions are still leaky. So when
you tell me "it's all better now", I don't believe you. I just
plain do not.
I've been hearing this soothing song ever since around 1989.
"Trust us, it's all fixed." Then I look at the "fixes" and
they're horrifying monstrosities like templates – all the
dangers of preprocessor macros and a whole new class of
Turing-complete nightmares, too! In thirty years I'm certain
I'll be hearing that C++2047 solves all the problems this
time for sure , and I won't believe a word of it then,
either.
Reply ↓
If you would elaborate on this, I would be grateful.
What are the problematic leaky abstractions you are
concerned about?
Reply ↓
esr on 2017-12-19
at 09:26:24 said: >If you would elaborate on
this, I would be grateful. What are the problematic
leaky abstractions you are concerned about?
Are array accesses bounds-checked? Don't yammer
about iterators; what happens if I say foo[3] and foo
is dimension 2? Never mind, I know the answer.
Are bare, untyped pointers still in the language?
Never mind, I know the answer.
Can I get a core dump from code that the compiler
has statically checked and contains no casts? Never
mind, I know the answer.
Yes, C has these problems too. But it doesn't
pretend not to, and in C I'm never afflicted by
masochistic cultists denying that they're
problems.
> Are array accesses bounds-checked? Don't yammer
about iterators; what happens if I say foo[3] and foo
is dimension 2? Never mind, I know the answer.
You are right, bare arrays are not bounds-checked,
but std::array provides an at() member function, so
arr.at(3) will throw if the array is too small.
Also, ranged-for loops can avoid the need for
explicit indexing lots of the time anyway.
> Are bare, untyped pointers still in the
language? Never mind, I know the answer.
Yes, void* is still in the language. You need to
cast it to use it, which is something that is easy to
spot in a code review.
> Can I get a core dump from code that the
compiler has statically checked and contains no casts?
Never mind, I know the answer.
Probably. Is it possible to write code in any
language that dies horribly in an unintended
fashion?
> Yes, C has these problems too. But it doesn't
pretend not to, and in C I'm never afflicted by
masochistic cultists denying that they're problems.
Did I say C++ was perfect? This blog post was about
the problems inherent in the lack of automatic memory
management in C and C++, and thus why you wouldn't have
written reposurgeon if that's all you had. My point is
that it is easy to write C++ in a way that doesn't
suffer from those problems.
esr on 2017-12-19
at 10:10:11 said: > My point is that it is easy
to write C++ in a way that doesn't suffer from those
problems.
No, it is not. The error statistics of large C++
programs refute you.
My personal experience on Battle for Wesnoth refutes
you.
The persistent self-deception I hear from C++
advocates on this score does nothing to endear the
language to me.
Ian Bruene on 2017-12-19
at 11:05:22 said: So what I am hearing in this is:
"Use these new standards built on top of the language,
and make sure every single one of your dependencies
holds to them just as religiously are you are. And if
anyone fails at any point in the chain you are
doomed.".
Cool.
Casey Barker on 2017-12-19
at 11:12:16 said: Using Go has been a revelation, so I
mostly agree with Eric here. My only objection is to
equating C++03/Boost with "modern" C++. I used both
heavily, and given a green field, I would consider C++14
for some of these thorny designs that I'd never have used
C++03/Boost for. It's a qualitatively different experience.
Just browse a copy of Scott Meyer's _Effective Modern C++_
for a few minutes, and I think you'll at least understand
why C++14 users object to the comparison. Modern C++
enables better designs.
Alas, C++ is a multi-layered tool chest. If you stick to
the top two shelves, you can build large-scale, complex
designs with pretty good safety and nigh unmatched
performance. Everything below the third shelf has rusty
tools with exposed wires and no blade guards, and on
large-scale projects, it's impossible to keep J. Random
Programmer from reaching for those tools.
So no, if they keep adding features, C++ 2047 won't
materially improve this situation. But there is a
contingent (including Meyers) pushing for the *removal* of
features. I think that's the only way C++ will stay
relevant in the long-term.
http://scottmeyers.blogspot.com/2015/11/breaking-all-eggs-in-c.html
Reply ↓
Zygo on 2017-12-19
at 11:52:17 said: My personal experience is that C++11
code (in particular, code that uses closures, deleted
methods, auto (a feature you yourself recommended for C
with different syntax), and the automatic memory and
resource management classes) has fewer defects per
developer-year than the equivalent C++03-and-earlier code.
This is especially so if you turn on compiler flags that
disable the legacy features (e.g. -Werror=old-style-cast),
and treat any legacy C or C++03 code like foreign language
code that needs to be buried under a FFI to make it safe to
use.
Qualitatively, the defects that do occur are easier to
debug in C++11 vs C++03. There are fewer opportunities for
the compiler to interpolate in surprising ways because the
automatic rules are tighter, the library has better utility
classes that make overloads and premature optimization less
necessary, the core language has features that make
templates less necessary, and it's now possible to
explicitly select or rule out invalid candidates for
automatic code generation.
I can design in Lisp, but write C++11 without much
effort of mental translation. Contrast with C++03, where
people usually just write all the Lispy bits in some
completely separate language (or create shambling horrors
like Boost to try to bandaid over the missing limbs
boost::lambda, anyone?
Oh, look, since C++11 they've doubled down on something
called boost::phoenix).
Does C++11 solve all the problems? Absolutely not, that
would break compatibility. But C++11 is noticeably better
than its predecessors. I would say the defect rates are now
comparable to Perl with a bunch of custom C modules (i.e.
exact defect rate depends on how much you wrote in each
language).
Reply ↓
NHO on 2017-12-19
at 11:55:11 said: C++ happily turned into complexity
metatarpit with "Everything that could be implemented in STL
with templates should, instead of core language". And not
deprecating/removing features, instead leaving there.
Reply ↓
Michael on 2017-12-19 at
08:59:41 said: For the curious, can you point to a C++
tutorial/intro that shows how to do it the right way ?
Reply ↓
Michael on 2017-12-19
at 12:09:45 said: Thank you. Not sure this is what
I was looking for.
Was thinking more along the lines of "Learning
Python" equivalent.
Anthony Williams on
2017-12-19 at
08:26:13 said: > That's correct. Modern C++ is a disaster
area of compounded complexity and fragile kludges piled on in a
failed attempt to fix leaky abstractions. 1998 C++ had the
leaky-abstractions problem, but at least it was drastically
simpler. Clue: complexification when you don't even fix the
problems is bad.
I agree that there is a lot of complexity in C++. That doesn't
mean you have to use all of it. Yes, it makes maintaining legacy
code harder, because the older code might use dangerous or complex
parts, but for new code we can avoid the danger, and just stick to
the simple, safe parts.
The complexity isn't all bad, though. Part of the complexity
arises by providing the ability to express more complex things in
the language. This can then be used to provide something simple to
the user.
Take std::variant as an example. This is a new facility from
C++17 that provides a type-safe discriminated variant. If you have
a variant that could hold an int or a string and you store an int
in it, then attempting to access it as a string will cause an
exception rather than a silent error. The code that *implements*
std::variant is complex. The code that uses it is simple.
Reply
↓
Jeff Read on 2017-12-20 at 09:07:06
said: I won't argue with you. C++ is error-prone (albeit less so than C)
and horrid to work in. But for certain classes of algorithmically complex,
CPU- and RAM-intensive problems it is literally the only viable
choice. And it looks like performing surgery on GCC-scale repos falls into
that class of problem.
I'm not even saying it was a bad idea to initially write reposurgeon in
Python. Python and even Ruby are great languages to write prototypes or
even small-scale production versions of things because of how rapidly they
may be changed while you're hammering out the details. But scale comes
around to bite you in the ass sooner than most people think and when it
does, your choice of language hobbles you in a way that can't be
compensated for by throwing more silicon at the problem. And it's in that
niche where C++ and Rust dominate, absolutely uncontested. Reply
↓
jim on 2017-12-22 at 06:41:27
said: If you found rust hard going, you are not a C++ programmer who knows
better than this.
Anthony Williams on 2017-12-19 at
06:15:12 said: > How many times do I have to repeat "reposurgeon would never
have been
> written under that constraint" before somebody who claims LISP
> experience gets it?
That speaks to your lack of experience with modern C++, rather than an inherent
limitation. *You* might not have written reposurgeon under that constraint, because
*you* don't feel comfortable that you wouldn't have ended up with a black-hole of
AMM. That does not mean that others wouldn't have or couldn't have, and that their
code would necessarily be an unmaintainable black hole.
In well-written modern C++, memory management errors are a solved problem. You
can just write code, and know that the compiler and library will take care of
cleaning up for you, just like with a GC-based system, but with the added benefit
that it's deterministic, and can handle non-memory resources such as file handles
and sockets too. Reply
↓
esr on 2017-12-19 at 07:59:30
said: >In well-written modern C++, memory management errors are a solved
problem
In well-written assembler memory management errors are a solved
problem. I hate this idiotic cant repetition about how if you're just good
enough for the language it won't hurt you – it sweeps the actual
problem under the rug while pretending to virtue. Reply
↓
Anthony Williams on
2017-12-19 at 08:08:53
said: > I hate this idiotic repetition about how if you're just good
enough for the language it won't hurt you – it sweeps the actual
problem under the rug while pretending to virtue.
It's not about being "just good enough". It's about *not* using the
dangerous parts. If you never use manual memory management, then you can't
forget to free, for example, and automatic memory management is *easy* to
use. std::string is a darn sight easier to use than the C string functions,
for example, and std::vector is a darn sight easier to use than dynamic
arrays with new. In both cases, the runtime manages the memory, and it is
*easier* to use than the dangerous version.
Every language has "dangerous" features that allow you to cause
problems. Well-written programs in a given language don't use the dangerous
features when there are equivalent ones without the problems. The same is
true with C++.
The fact that historically there are areas where C++ didn't provide a
good solution, and thus there are programs that don't use the modern
solution, and experience the consequential problems is not an inherent
problem with the language, but it does make it harder to educate people.
Reply
↓
John D. Bell on 2017-12-19 at
10:48:09 said: > It's about *not* using the dangerous parts.
Every language has "dangerous" features that allow you to cause
problems. Well-written programs in a given language don't use the
dangerous features when there are equivalent ones without the problems.
Why not use a language that doesn't have "'dangerous'
features"?
NOTES: [1] I am not saying that Go is necessarily that language
– I am not even saying that any existing language is
necessarily that language.
[2] /me is being someplace between naive and trolling here. Reply
↓
esr on 2017-12-19 at
11:10:15 said: >Why not use a language that doesn't have
"'dangerous' features"?
Historically, it was because hardware was weak and expensive
– you couldn't afford the overhead imposed by those
languages. Now it's because the culture of software engineering has
bad habits formed in those days and reflexively flinches from using
higher-overhead safe languages, though it should not. Reply
↓
Paul R on 2017-12-19 at
12:30:42 said: Runtime efficiency still matters. That and the
ability to innovate are the reasons I think C++ is in such wide
use.
To be provocative, I think there are two types of programmer,
the ones who watch Eric Niebler on Ranges https://www.youtube.com/watch?v=mFUXNMfaciE&t=4230s
and think 'Wow, I want to find out more!' and the rest. The rest
can have Go and Rust
D of course is the baby elephant in the room, worth much more
attention than it gets. Reply
↓
Michael on 2017-12-19 at
12:53:33 said: Runtime efficiency still matters. That
and the ability to innovate are the reasons I think C++ is in
such wide use.
Because you can't get runtime efficiency in any other
language?
Because you can't innovate in any other language?
Reply ↓
Our three main advantages, runtime efficiency,
innovation opportunity, building on a base of millions of
lines of code that run the internet and an international
standard.
Our four main advantages
More seriously, C++ enabled the STL, the STL transforms
the approach of its users, with much increased reliability
and readability, but no loss of performance. And at the
same time your old code still runs. Now that is old stuff,
and STL2 is on the way. Evolution.
Zygo on 2017-12-19
at 14:14:42 said: > Because you can't innovate in
any other language?
That claim sounded odd to me too. C++ looks like the
place that well-proven features of younger languages go to
die and become fossilized. The standardization process
would seem to require it.
Reply ↓
My thought was the language is flexible enough to
enable new stuff, and has sufficient weight behind it
to get that new stuff actually used.
Generic programming being a prime example.
Michael on 2017-12-20
at 08:19:41 said: My thought was the language is
flexible enough to enable new stuff, and has sufficient
weight behind it to get that new stuff actually
used.
Are you sure it's that, or is it more the fact that
the standards committee has forever had a me-too
kitchen-sink no-feature-left-behind obsession?
(Makes me wonder if it doesn't share some DNA with
the featuritis that has been Microsoft's calling card
for so long. – they grew up together.)
Paul R on 2017-12-20
at 11:13:20 said: No, because people come to the
standards committee with ideas, and you cannot have too
many libraries. You don't pay for what you don't use.
Prime directive C++.
Michael on 2017-12-20
at 11:35:06 said: and you cannot have too many
libraries. You don't pay for what you don't use.
And this, I suspect, is the primary weakness in your
perspective.
Is the defect rate of C++ code better or worse
because of that?
Paul R on 2017-12-20
at 15:49:29 said: The rate is obviously lower
because I've written less code and library code only
survives if it is sound. Are you suggesting that
reusing code is a bad idea? Or that an indeterminate
number of reimplementations of the same functionality
is a good thing?
You're not on the most productive path to effective
criticism of C++ here.
Michael on 2017-12-20
at 17:40:45 said: The rate is obviously lower
because I've written less code
Please reconsider that statement in light of how
defect rates are measured.
Are you suggesting..
Arguing strawmen and words you put in someone's
mouth is not the most productive path to effective
defense of C++.
But thank you for the discussion.
Paul R on 2017-12-20
at 18:46:53 said: This column is too narrow to have
a decent discussion. WordPress should rewrite in C++ or
I should dig out my Latin dictionary.
Seriously, extending the reach of libraries that
become standardised is hard to criticise, extending the
reach of the core language is.
It used to be a thing that C didn't have built in
functionality for I/O (for example) rather it was
supplied by libraries written in C interfacing to a
lower level system interface. This principle seems to
have been thrown out of the window for Go and the
others. I'm not sure that's a long term win. YMMV.
But use what you like or what your cannot talk your
employer out of using, or what you can get a job using.
As long as it's not Rust.
Zygo on 2017-12-19 at
12:24:25 said: > Well-written programs in a given language don't
use the dangerous features
Some languages have dangerous features that are disabled by default
and must be explicitly enabled prior to use. C++ should become one of
those languages.
I am very fond of the 'override' keyword in C++11, which allows me
to say "I think this virtual method overrides something, and don't
compile the code if I'm wrong about that." Making that assertion
incorrectly was a huge source of C++ errors for me back in the days
when I still used C++ virtual methods instead of lambdas. C++11 solved
that problem two completely different ways: one informs me when I make
a mistake, and the other makes it impossible to be wrong.
Arguably, one should be able to annotate any C++ block and say
"there shall be no manipulation of bare pointers here" or "all array
access shall be bounds-checked here" or even " and that's the default
for the entire compilation unit." GCC can already emit warnings for
these without human help in some cases. Reply
↓
1. Circular references. C++ has smart pointer classes that work when your data
structures are acyclic, but it doesn't have a good solution for circular
references. I'm guessing that reposurgeon's graphs are almost never DAGs.
2. Subversion of AMM. Bare news and deletes are still available, so some later
maintenance programmer could still introduce memory leaks. You could forbid the use
of bare new and delete in your project, and write a check-in hook to look for
violations of the policy, but that's one more complication to worry about and it
would be difficult to impossible to implement reliably due to macros and the
generally difficulty of parsing C++.
3. Memory corruption. It's too easy to overrun the end of arrays, treat a
pointer to a single object as an array pointer, or otherwise corrupt memory.
Reply
↓
esr on 2017-12-20 at 15:51:55
said: >Is this a good summary of your objections to C++ smart pointers as a
solution to AMM?
That is at least a large subset of my objections, and probably the most
important ones. Reply
↓
jim on 2017-12-22 at 07:15:20
said: It is uncommon to find a cyclic graph that cannot be rendered acyclic
by weak pointers.
C++17 cheerfully breaks backward compatibility by removing some
dangerous idioms, refusing to compile code that should never have been
written. Reply
↓
guest on 2017-12-20 at 19:12:01
said: > Circular references. C++ has smart pointer classes that work when
your data structures are acyclic, but it doesn't have a good solution for
circular references. I'm guessing that reposurgeon's graphs are almost never
DAGs.
General graphs with possibly-cyclical references are precisely the workload
GC was created to deal with optimally, so ESR is right in a sense that
reposturgeon _requires_ a GC-capable language to work. In most other programs,
you'd still want to make sure that the extent of the resources that are under
GC-control is properly contained (which a Rust-like language would help a lot
with) but it's possible that even this is not quite worthwhile for
reposturgeon. Still, I'd want to make sure that my program is optimized in
_other_ possible ways, especially wrt. using memory bandwidth efficiently
– and Go looks like it doesn't really allow that. Reply
↓
esr on 2017-12-20 at 20:12:49
said: >Still, I'd want to make sure that my program is optimized in
_other_ possible ways, especially wrt. using memory bandwidth efficiently
– and Go looks like it doesn't really allow that.
Er, there's any language that does allow it? Reply
↓
Jeff Read on 2017-12-27 at
20:58:43 said: Yes -- ahem -- C++. That's why it's pretty much the
only language taken seriously by game developers. Reply
↓
Zygo on 2017-12-21 at 12:56:20
said: > I'm guessing that reposurgeon's graphs are almost never DAGs
Why would reposurgeon's graphs not be DAGs? Some exotic case that comes up
with e.g. CVS imports that never arises in a SVN->Git conversion (admittedly
the only case I've really looked deeply at)?
Git repos, at least, are cannot-be-cyclic-without-astronomical-effort graphs
(assuming no significant advances in SHA1 cracking and no grafts–and even
then, all you have to do is detect the cycle and error out). I don't know how a
generic revision history data structure could contain a cycle anywhere even if
I wanted to force one in somehow. Reply
↓
The repo graph is, but a lot of the structures have reference loops for
fast lookup. For example, a blob instance has a pointer back to the
containing repo, as well as being part of the repo through a pointer chain
that goes from the repo object to a list of commits to a blob.
Without those loops, navigation in the repo structure would get very
expensive. Reply
↓
guest on 2017-12-21 at
15:22:32 said: Aren't these inherently "weak" pointers though? In
that they don't imply ownership/live data, whereas the "true" DAG
references do? In that case, and assuming you can be sufficiently sure
that only DAGs will happen, refcounting (ideally using something like
Rust) would very likely be the most efficient choice. No need for a
fully-general GC here. Reply
↓
esr on 2017-12-21 at
15:34:40 said: >Aren't these inherently "weak" pointers
though? In that they don't imply ownership/live data
I think they do. Unless you're using "ownership" in some sense I
don't understand. Reply
↓
jim on 2017-12-22 at
07:31:39 said: A weak pointer does not own the object it
points to. A shared pointer does.
When there are are zero shared pointers pointing to an
object, it gets freed, regardless of how many weak pointers are
pointing to it.
Shared pointers and unique pointers own, weak pointers do
not own.
Reply ↓
jim on 2017-12-22 at
07:23:35 said: In C++11, one would implement a pointer back to the
owning object as a weak pointer. Reply
↓
> How many times do I have to repeat "reposurgeon would never have been
written under that constraint" before somebody who claims LISP experience gets
it?
Maybe it is true, but since you do not understand, or particularly wish to
understand, Rust scoping, ownership, and zero cost abstractions, or C++ weak
pointers, we hear you say that you would never write reposurgeon would never
under that constraint.
Which, since no one else is writing reposurgeon, is an argument, but not an
argument that those who do get weak pointers and rust scopes find all that
convincing.
I am inclined to think that those who write C++98 (which is the gcc default)
could not write reposurgeon under that constraint, but those who write C++11 could
write reposurgeon under that constraint, and except for some rather unintelligible,
complicated, and twisted class constructors invoking and enforcing the C++11
automatic memory management system, it would look very similar to your existing
python code. Reply
↓
esr on 2017-12-23 at 02:49:13
said: >since you do not understand, or particularly wish to understand, Rust
scoping, ownership, and zero cost abstractions, or C++ weak pointers
Thank you, I understand those concepts quite well. I simply prefer to apply
them in languages not made of barbed wire and landmines. Reply
↓
guest on 2017-12-23 at 07:11:48
said: I'm sure that you understand the _gist_ of all of these notions quite
accurately, and this alone is of course quite impressive for any developer
– but this is not quite the same as being comprehensively aware of
their subtler implications. For instance, both James and I have suggested
to you that backpointers implemented as an optimization of an overall DAG
structure should be considered "weak" pointers, which can work well
alongside reference counting.
For that matter, I'm sure that Rustlang developers share your aversion
to "barbed wire and landmines" in a programming language. You've criticized
Rust before (not without some justification!) for having half-baked
async-IO facilities, but I would think that reposturgeon does not depend
significantly on async-IO. Reply
↓
esr on 2017-12-23 at
08:14:25 said: >For instance, both James and I have suggested to
you that backpointers implemented as an optimization of an overall DAG
structure should be considered "weak" pointers, which can work well
alongside reference counting.
Yes, I got that between the time I wrote my first reply and JAD
brought it up. I've used Python weakrefs in similar situations. I would
have seemed less dense if I'd had more sleep at the time.
>For that matter, I'm sure that Rustlang developers share your
aversion to "barbed wire and landmines" in a programming language.
That acidulousness was mainly aimed at C++. Rust, if it implements
its theory correctly (a point on which I am willing to be optimistic)
doesn't have C++'s fatal structural flaws. It has problems of its own
which I won't rehash as I've already anatomized them in detail.
Reply
↓
Garrett on 2017-12-21 at 11:16:25 said:
There's also development cost. I suspect that using eg. Python drastically reduces the
cost for developing the code. And since most repositories are small enough that Eric
hasn't noticed accidental O(n**2) or O(n**3) algorithms until recently, it's pretty
obvious that execution time just plainly doesn't matter. Migration is going to involve
a temporary interruption to service and is going to be performed roughly once per repo.
The amount of time involved in just stopping the eg. SVN service and bringing up the
eg. GIT hosting service is likely to be longer than the conversion time for the median
conversion operation.
So in these cases, most users don't care about the run-time, and outside of a
handful of examples, wouldn't brush up against the CPU or memory limitations of a
whitebox PC.
This is in contrast to some other cases in which I've worked such as file-serving
(where latency is measured in microseconds and is actually counted), or large data
processing (where wasting resources reduces the total amount of stuff everybody can
do). Reply ↓
David Collier-Brown on
2017-12-18 at
20:20:59 said: Hmmn, I wonder if the virtual memory of Linux (and Unix, and Multics) is
really the OS equivalent of the automatic memory management of application programs? One
works in pages, admittedly, not bytes or groups of bytes, but one could argue that the
sub-page stuff is just expensive anti-internal-fragmentation plumbing
–dave
[In polite Canajan, "I wonder" is the equivalent of saying "Hey everybody, look at this" in
the US. And yes, I that's also the redneck's famous last words.] Reply ↓
John Moore on 2017-12-18 at 22:20:21 said: In my
experience, with most of my C systems programming in protocol stacks and transaction
processing infrastructure, the MM problem has been one of code, not data structure
complexity. The memory is often allocated by code which first encounters the need, and it
is then passed on through layers and at some point, encounters code which determines the
memory is no longer needed. All of this creates an implicit contract that he who is handed
a pointer to something (say, a buffer) becomes responsible for disposing of it. But, there
may be many places where that is needed – most of them in exception handling.
That creates many, many opportunities for some to simply forget to release it. Also,
when the code is handed off to someone unfamiliar, they may not even know about the
contract. Crises (or bad habits) lead to failures to document this stuff (or create
variable names or clear conventions that suggest one should look for the contract).
I've also done a bunch of stuff in Java, both applications level (such as a very complex
Android app with concurrency) and some infrastructural stuff that wasn't as performance
constrained. Of course, none of this was hard real-time although it usually at least needed
to provide response within human limits, which GC sometimes caused trouble with. But, the
GC was worth it, as it substantially reduced bugs which showed up only at runtime, and it
simplified things.
On the side, I write hard real time stuff on tiny, RAM constrained embedded systems
– PIC18F series stuff (with the most horrible machine model imaginable for such a
simple little beast). In that world, there is no malloc used, and shouldn't be. It's
compile time created buffers and structures for the most part. Fortunately, the
applications don't require advanced dynamic structures (like symbol tables) where you need
memory allocation. In that world, AMM isn't an issue. Reply ↓
Michael on 2017-12-18 at 22:47:26 said:
PIC18F series stuff (with the most horrible machine model imaginable for such a simple
little beast)
LOL. Glad I'm not the only one who thought that. Most of my work was on the 16F –
after I found out what it took to do a simple table lookup, I was ready for a stiff
drink. Reply ↓
esr on
2017-12-18 at
23:45:03 said: >In my experience, with most of my C systems programming in
protocol stacks and transaction processing infrastructure, the MM problem has been one
of code, not data structure complexity.
I believe you. I think I gravitate to problems with data-structure complexity
because, well, that's just the way my brain works.
But it's also true that I have never forgotten one of the earliest lessons I learned
from Lisp. When you can turn code complexity into data structure complexity, that's
usually a win. Or to put it slightly differently, dumb code munching smart data beats
smart code munching dumb data. It's easier to debug and reason about. Reply
↓
Jeremy on 2017-12-19 at 01:36:47 said:
Perhaps its because my coding experience has mostly been short python scripts of
varying degrees of quick-and-dirtiness, but I'm having trouble grokking the
difference between smart code/dumb data vs dumb code/smart data. How does one tell
the difference?
Now, as I type this, my intuition says it's more than just the scary mess of
nested if statements being in the class definition for your data types, as opposed
to the function definitions which munch on those data types; a scary mess of nested
if statements is probably the former. The latter though I'm coming up blank.
Perhaps a better question than my one above: what codebases would you recommend
for study which would be good examples of the latter (besides reposurgeon)?
Reply
↓
jsn on 2017-12-19 at 02:35:48
said: I've always expressed it as "smart data + dumb logic = win".
You almost said my favorite canned example: a big conditional block vs. a
lookup table. The LUT can replace all the conditional logic with structured
data and shorter (simpler, less bug-prone, faster, easier to read)
unconditional logic that merely does the lookup. Concretely in Python, imagine
a long list of "if this, assign that" replaced by a lookup into a dictionary.
It's still all "code", but the amount of program logic is reduced.
So I would answer your first question by saying look for places where data
structures are used. Then guesstimate how complex some logic would have to be
to replace that data. If that complexity would outstrip that of the data
itself, then you have a "smart data" situation. Reply
↓
Emanuel Rylke on 2017-12-19 at 04:07:58
said: To expand on this, it can even be worth to use complex code to generate
that dumb lookup table. This is so because the code generating the lookup
table runs before, and therefore separately, from the code using the LUT.
This means that both can be considered in isolation more often; bringing the
combined complexity closer to m+n than m*n. Reply
↓
TheDividualist on 2017-12-19 at
05:39:39 said: Admittedly I have an SQL hammer and think everything is
a nail, but why not would *every* program include a database, like the
SQLLite that even comes bundled with Python distros, no sweat, and put that
lookup table into it, not in a dictionary inside the code?
Of course the more you go in this direction the more problems you will
have with unit testing, in case you want to do such a thing. Generally we
SQL-hammer guys don't do that much, because in theory any fuction can read
any part of the database, making the whole database the potential "inputs"
for every function.
That is pretty lousy design, but I think good design patterns for
separations of concerns and unit testability are not yet really known for
database driven software, I mean, for example, model-view-controller claims
to be one, but actually fails as these can and should call each other. So
you have in the "customer" model or controller a function to check if the
customer has unpaid invoices, and decide to call it from the "sales order"
controller or model to ensure such customers get no new orders registered.
In the same "sales order" controller you also check the "product" model or
controller if it is not a discontinued product and check the "user" model
or controller if they have the proper rights for this operation and the
"state" controller if you are even offering this product in that state and
so on a gazillion other things, so if you wanted to automatically unit test
that "register a new sales order" function you have a potential "input"
space of half the database. And all that with good separation of concerns
MVC patterns. So I think no one really figured this out yet? Reply
↓
guest on 2017-12-20 at 19:21:13
said: There's a reason not to do this if you can help it – dispatching
through a non-constant LUT is way slower than running easily-predicted
conditionals. Like, an order of magnitude slower, or even worse. Reply
↓
esr on 2017-12-19 at 07:45:38
said: >Perhaps a better question than my one above: what codebases would you
recommend for study which would be good examples of the latter (besides
reposurgeon)?
I do not have an instant answer, sorry. I'll hand that question to my
backbrain and hope an answer pops up. Reply
↓
Jon Brase on 2017-12-20 at 00:54:15 said:
When you can turn code complexity into data structure complexity, that's usually
a win. Or to put it slightly differently, dumb code munching smart data beats smart
code munching dumb data. It's easier to debug and reason about.
Doesn't "dumb code munching smart data" really reduce to "dumb code implementing
a virtual machine that runs a different sort of dumb code to munch dumb data"?
Reply
↓
A domain specific language is easier to reason about within its proper
domain, because it lowers the difference between the problem and the
representation of the problem. Reply
↓
wisd0me on 2017-12-19 at 02:35:10 said: I wonder
why you talked about inventing an AMM-layer so much, but told nothing about the GC, which is
available for C language. Why do you need to invent some AMM-layer in the first place,
instead of just using the GC?
For example, Bigloo Scheme and The GNU Objective C runtime successfully used it, among many
others. Reply ↓
Jeremy Bowers on
2017-12-19 at
10:40:24 said: Rust seems like a good fit for the cases where you need the low latency
(and other speed considerations) and can't afford the automation. Firefox finally got to
benefit from that in the Quantum release, and there's more coming. I wouldn't dream of
writing a browser engine in Go, let alone a highly-concurrent one. When you're willing to
spend on that sort of quality, Rust is a good tool to get there.
But the very characteristics necessary to be good in that space will prevent it from
becoming the "default language" the way C was for so long. As much fun as it would be to
fantasize about teaching Rust as a first language, I think that's crazy talk for anything
but maybe MIT. (And I'm not claiming it's a good idea even then; just saying that's the
level of student it would take for it to even be possible .) Dunno if Go will become
that "default language" but it's taking a decent run at it; most of the other contenders I
can think of at the moment have the short-term-strength-yet-long-term-weakness of being
tied to a strong platform already. (I keep hearing about how Swift is going to be usable
off of Apple platforms real soon now just around the corner just a bit longer .) Reply
↓
esr on
2017-12-19 at
17:30:07 said: >Dunno if Go will become that "default language" but it's taking
a decent run at it; most of the other contenders I can think of at the moment have the
short-term-strength-yet-long-term-weakness of being tied to a strong platform already.
I really think the significance of Go being an easy step up from C cannot be
overestimated – see my previous blogging about the role of inward transition
costs.
Ken Thompson is insidiously clever. I like channels and subroutines and := but the
really consequential hack in Go's design is the way it is almost perfectly designed to
co-opt people like me – that is, experienced C programmers who have figured out
that ad-hoc AMM is a disaster area. Reply ↓
Jeff Read on 2017-12-20 at 08:58:23 said:
Go probably owes as much to Rob Pike and Phil Winterbottom for its design as it
does to Thompson -- because it's basically Alef with the feature whose lack,
according to Pike, basically killed Alef: garbage collection.
I don't know that it's "insidiously clever" to add concurrency primitives and GC
to a C-like language, as concurrency and memory management were the two obvious
banes of every C programmer's existence back in the 90s -- so if Go is "insidiously
clever", so is Java. IMHO it's just smart, savvy design which is no small thing;
languages are really hard to get right. And in the space Go thrives in, Go gets a
lot right. Reply
↓
John G on 2017-12-19 at 14:01:09 said: Eric,
have you looked into D *lately*? These days:
First, `pure` functions and transitive `const`, which make code so much
easier to reason about
Second. Allmost entire language is available at compile time. That, combined
with templates, enables crazy (in a good way) stuff, like building optimized
state machine for regex at compile-time. Given, regex pattern is known at
compile time, of course. But that's pretty common.
Can't find it now, but there were bechmarks, which show it's faster than any
run-time built regex engine out there. Still, source code is pretty
straightforward – one don't have to be Einstein to write code like that
[1].
There is a talk by Andrei Alexandrescu called "Fastware" were he show how
various metaprogramming facilities enable useful optimizations [2].
And a more recent talk, "Design By Introspection" [3], were he shows how these
facilities enable much more compact designs and implementaions.
Not sure. I've only recently begun learning D, and I don't know Go. [The D
overview]( https://dlang.org/overview.html ) may include
enough for you to surmise the differences though. Reply
↓
As the greenspunity rises, you are likely to find that more and more of your effort
and defect chasing is related to the AMM layer, and proportionally less goes to the
application logic. Redoubling your effort, you increasingly miss your aim.
Even when you're merely at the edge of this trap, your defect rates will be dominated
by issues like double-free errors and malloc leaks. This is commonly the case in C/C++
programs of even low greenspunity.
Interesting. This certainly fits my experience.
Has anybody looked for common patterns in whatever parasitic distractions plague you
when you start to reach the limits of a language with AMM? Reply ↓
result, err = whatever()
if (err) dosomethingtofixit();
abstraction.
I went through a phase earlier this year where I tried to eliminate the concept of
an errno entirely (and failed, in the end reinventing lisp, badly), but sometimes I
still think – to the tune of flight of the valkeries – "Kill the errno,
kill the errno, kill the ERRno, kill the err!' Reply ↓
jim on 2017-12-23 at
23:37:46 said: I have on several occasions been part of big projects using
languages with AMM, many programmers, much code, and they hit scaling problems and
died, but it is not altogether easy to explain what the problem was.
But it was very clear that the fact that I could get a short program, or a quick fix
up and running with an AMM much faster than in C or C++ was failing to translate into
getting a very large program containing far too many quick fixes up and running.
Reply ↓
AMM is not the only thing that Lisp brings on the table when it comes to dealing with
Greenspunity. Actually, the whole point of Lisp is that there is not _one_ conceptual
barrier to development, or a few, or even a lot, but that there are _arbitrarily_many_, and
that is why you need be able to extend your language through _syntactic_abstraction_ to
build DSLs so that every abstraction layer can be written in a language that is fit that
that layer. [Actually, traditional Lisp is missing the fact that DSL tooling depends on
_restriction_ as well as _extension_; but Haskell types and Racket languages show the way
forward in this respect.]
That is why all languages without macros, even with AMM, remain "blub" to those who grok
Lisp. Even in Go, they reinvent macros, just very badly, with various preprocessors to cope
with the otherwise very low abstraction ceiling.
(Incidentally, I wouldn't say that Rust has no AMM; instead it has static AMM. It also
has some support for macros.) Reply ↓
jim on
2017-12-23
at 22:02:18 said: Static AMM means that the compiler analyzes your code at
compile time, and generates the appropriate frees,
Static AMM means that the compiler automatically does what you manually do in C,
and semi automatically do in C++11 Reply
↓
Patrick Maupin on 2017-12-24 at 13:36:35
said: To the extent that the compiler's insertion of calls to free() can be
easily deduced from the code without special syntax, the insertion is merely an
optimization of the sort of standard AMM semantics that, for example, a PyPy
compiler could do.
To the extent that the compiler's ability to insert calls to free() requires
the sort of special syntax about borrowing that means that the programmer has
explicitly described a non-stack-based scope for the variable, the memory
management isn't automatic.
Perhaps this is why a google search for "static AMM" doesn't return much.
Reply
↓
Jeff Read on 2017-12-27 at 03:01:19
said: I think you fundamentally misunderstand how borrowing works in Rust.
In Rust, as in C++ or even C, references have value semantics. That is
to say any copies of a given reference are considered to be "the same". You
don't have to "explicitly describe a non-stack-based scope for the
variable", but the hitch is that there can be one, and only one, copy of
the original reference to a variable in use at any time. In Rust this is
called ownership, and only the owner of an object may mutate it.
Where borrowing comes in is that functions called by the owner of an
object may borrow a reference to it. Borrowed references are
read-only, and may not outlast the scope of the function that does the
borrowing. So everything is still scope-based. This provides a convenient
way to write functions in such a way that they don't have to worry about
where the values they operate on come from or unwrap any special types,
etc.
If you want the scope of a reference to outlast the function that
created it, the way to do that is to use a std::Rc , which
provides a regular, reference-counted pointer to a heap-allocated object,
the same as Python.
The borrow checker checks all of these invariants for you and will flag
an error if they are violated. Since worrying about object lifetimes is
work you have to do anyway lest you pay a steep price in performance
degradation or resource leakage, you win because the borrow checker makes
this job much easier.
Rust does have explicit object lifetimes, but where these are most
useful is to solve the problem of how to have structures, functions, and
methods that contain/return values of limited lifetime. For example
declaring a struct Foo { x: &'a i32 } means that any
instance of struct Foo is valid only as long as the borrowed
reference inside it is valid. The borrow checker will complain if you
attempt to use such a struct outside the lifetime of the internal
reference. Reply
↓
Doctor Locketopus on 2017-12-27 at 00:16:54 said:
Good Lord (not to be confused with Audre Lorde). If I weren't already convinced
that Rust is a cult, that would do it.
However, I must confess to some amusement about Karl Marx and Michel Foucault
getting purged (presumably because Dead White Male). Reply
↓
Jeff Read on 2017-12-27 at 02:06:40 said:
This is just a cost of doing business. Hacker culture has, for decades, tried to
claim it was inclusive and nonjudgemental and yada yada -- "it doesn't
matter if you're a brain in a jar or a superintelligent dolphin as long as your
code is good" -- but when it comes to actually putting its money where its mouth
is, hacker culture has fallen far short. Now that's changing, and one of the side
effects of that is how we use language and communicate internally, and to the wider
community, has to change.
But none of this has to do with automatic memory management. In Rust, management
of memory is not only fully automatic, it's "have your cake and eat it too": you
have to worry about neither releasing memory at the appropriate time, nor the
severe performance costs and lack of determinism inherent in tracing GCs. You do
have to be more careful in how you access the objects you've created, but the
compiler will assist you with that. Think of the borrow checker as your friend, not
an adversary. Reply
↓
John on 2017-12-20 at 05:03:22 said: Present
day C++ is far from C++ when it was first institutionalized in 1998. You should *never* be
physically overseeing memory in present day C++. You need a powerfully measured cluster?
Utilize std::vector. You need an adhoc diagram? Utilize std::shared_ptr and std::weak_ptr.
Any code I see which utilizes new or erase, malloc or through and through freedom fall
flat code audit. Reply ↓
Garrett on 2017-12-21 at 11:24:41 said: What
makes you refer to this as a systems programming project? It seems to me to be a standard
data-processing problem. Data in, data out. Sure, it's hella complicated and you're
brushing up against several different constraints.
In contrast to what I think of as systems programming, you have automatic memory
management. You aren't working in kernel-space. You aren't modifying the core libraries or
doing significant programmatic interface design.
I'm missing something in your semantic usage and my understanding of the solution
implementation. Reply ↓
Never user-facing. Often scripted. Development-support tool. Used by systems
programmers.
I realize we're in an area where the "systems" vs. "application" distinction gets a
little tricky to make. I hang out in that border zone a lot and have thought about
this. Are GPSD and ntpd "applications"? Is giflib? Sure, they're out-of-kernel, but no
end-user will ever touch them. Is GCC an application? Is apache or named?
Inside kernel is clearly systems. Outside it, I think the "systems" vs.
"application" distinction is about the skillset being applied and who your expected
users are than anything else.
I would not be upset at anyone who argued for a different distinction. I think
you'll find the definitional questions start to get awfully slippery when you poke at
them. Reply ↓
What makes you refer to this as a systems programming project? It seems to me to
be a standard data-processing problem. Data in, data out. Sure, it's hella
complicated and you're brushing up against several different constraints.
When you're talking about Unix, there is often considerable overlap between
"systems" and "application" programming because the architecture of Unix, with pipes,
input and output redirection, etc., allowed for essential OS components to be turned
into simple, data-in-data-out user-space tools. The functionality of ls ,
cp , rm , or cat , for instance, would have been
built into the shell of a pre-Unix OS (or many post-Unix ones). One of the great
innovations of Unix is to turn these units of functionality into standalone programs,
and then make spawning processes cheap enough to where using them interactively from
the shell is easy and natural. This makes extending the system, as accessed through the
shell, easy: just write a new, small program and add it to your PATH .
So yeah, when you're working in an environment like Unix, there's no bright-line
distinction between "systems" and "application" code, just like there's no bright-line
distinction between "user" and "developer". Unix is a tool for facilitating humans
working with computers. It cannot afford to discriminate, lest it lose its Unix-nature.
(This is why Linux on the desktop will never be a thing, not without considerable decay
in the facets of Linux that made it so great to begin with.) Reply ↓
At the upper end you can; the Yun has 64 MB, as do the Dragino variants. You can run
OpenWRT on them and use its Python (although the latest OpenWRT release, Chaos Calmer,
significantly increased its storage footprint from older firmware versions), which runs
fine in that memory footprint, at least for the kinds of things you're likely to do on this
type of device. Reply ↓
I'd be comfortable in that environment, but if we're talking AMM languages Go would
probably be a better match for it. Reply ↓
Peter
Donis on 2017-12-21 at 23:16:33 said:
Go is not available as a standard package on OpenWRT, but it probably won't be too
much longer before it is. Reply ↓
Jeff Read on 2017-12-22 at 14:07:21
said: Go binaries are statically linked, so the best approach is probably to
install Go on your big PC, cross compile, and push the binary out to the
device. Cross-compiling is a doddle; simply set GOOS and GOARCH. Reply
↓
jim on 2017-12-22 at 06:37:36 said:
C++11 has an excellent automatic memory management layer. Its only defect is that it is
optional, for backwards compatibility with C and C++98 (though it really is not all that
compatible with C++98)
And, being optional, you are apt to take the short cut of not using it, which will bite
you.
Rust is, more or less, C++17 with the automatic memory management layer being almost
mandatory. Reply ↓
> you are likely to find that more and more of your effort and defect chasing is
related to the AMM layer
But the AMM layer for C++ has already been written and debugged, and standards and
idioms exist for integrating it into your classes and type definitions.
Once built into your classes, you are then free to write code as if in a fully garbage
collected language in which all types act like ints.
C++14, used correctly, is a metalanguage for writing domain specific languages.
Now sometimes building your classes in C++ is weird, nonobvious, and apt to break for
reasons that are difficult to explain, but done correctly all the weird stuff is done once
in a small number of places, not spread all over your code Reply ↓
Dave taht on 2017-12-22 at 22:31:40 said: Linux is
the best C library ever created. And it's often, terrifying. Things like RCU are nearly
impossible for mortals to understand. Reply ↓
Alex Beamish on 2017-12-23 at 11:18:48 said:
Interesting thesis .. it was the 'extra layer of goodness' surrounding file operations, and
not memory management, that persuaded me to move from C to Perl about twenty years ago.
Once I'd moved, I also appreciated the memory management in the shape of 'any size you
want' arrays, hashes (where had they been all my life?) and autovivification -- on the spot
creation of array or hash elements, at any depth.
While C is a low-level language that masquerades as a high-level language, the original
intent of the language was to make writing assembler easier and faster. It can still be
used for that, when necessary, leaving the more complicated matters to higher level
languages. Reply ↓
esr on
2017-12-23 at
14:36:26 said: >Interesting thesis .. it was the 'extra layer of goodness'
surrounding file operations, and not memory management, that persuaded me to move from
C to Perl about twenty years ago.
Prestty much all that goodness depends on AMM and could not be implemented without
it. Reply ↓
jim on 2017-12-23 at
22:17:39 said: Autovivification saves you much effort, thought, and coding, because
most of the time the perl interpreter correctly divines your intention, and does a pile
of stuff for you, without you needing to think about it.
And then it turns around and bites you because it does things for you that you did
not intend or expect.
The larger the program, and the longer you are keeping the program around, the more
it is a problem. If you are writing a quick one off script to solve some specific
problem, you are the only person who is going to use the script, and are then going to
throw the script away, fine. If you are writing a big program that will be used by lots
of people for a long time, autovivification, is going to turn around and bit you hard,
as are lots of similar perl features where perl makes life easy for you by doing stuff
automagically.
With the result that there are in practice very few big perl programs used by lots
of people for a long time, while there are an immense number of very big C and C++
programs used by lots of people for a very long time.
On esr's argument, we should never be writing big programs in C any more, and yet,
we are.
I have been part of big projects with many engineers using languages with automatic
memory management. I noticed I could get something up and running in a fraction of the
time that it took in C or C++.
And yet, somehow, strangely, the projects as a whole never got successfully
completed. We found ourselves fighting weird shit done by the vast pile of run time
software that was invisibly under the hood automatically doing stuff for us. We would
be fighting mysterious and arcane installation and integration issues.
This, my personal experience, is the exact opposite of the outcome claimed by
esr.
Well, that was perl, Microsoft Visual Basic, and PHP. Maybe Java scales better.
But perl, Microsoft visual basic, and PHP did not scale. Reply ↓
Oh, dear Goddess, no wonder. All three of those languages are notorious
sinkholes – they're where "maintainability" goes to die a horrible and
lingering death.
Now I understand your fondness for C++ better. It's bad, but those are way worse
at any large scale. AMM isn't enough to keep you out of trouble if the rest of the
language is a tar-pit. Those three are full of the bones of drowned devops
victims.
Yes, Java scales better. CPython would too from a pure maintainability
standpoint, but it's too slow for the kind of deployment you're implying – on
the other hand, PyPy might not be, I'm finding the JIT compilation works extremely
well and I get runtimes I think are within 2x or 3x of C. Go would probably be da
bomb.Reply
↓
Oh, dear Goddess, no wonder. All three of those languages are notorious
sinkholes – they're where "maintainability" goes to die a horrible and
lingering death.
Can confirm -- Visual Basic (6 and VBA) is a toilet. An absolute cesspool.
It's full of little gotchas -- such as non-short-circuiting AND and OR
operators (there are no differentiated bitwise/logical operators) and the
cryptic Dir() function that exactly mimics the broken semantics of MS-DOS's
directory-walking system call -- that betray its origins as an extended version
of Microsoft's 8-bit BASIC interpreter (the same one used to write toy programs
on TRS-80s and Commodores from a bygone era), and prevent you from
writing programs in a way that feels natural and correct if you've been exposed
to nearly anything else.
VB is a language optimized to a particular workflow -- and like many
languages so optimized as long as you color within the lines provided by the
vendor you're fine, but it's a minefield when you need to step outside those
lines (which happens sooner than you may think). And that's the case with just
about every all-in-one silver-bullet "solution" I've seen -- Rails and PHP
belong in this category too.
It's no wonder the cuddly new Microsoft under Nadella is considering making
Python a first-class extension language for Excel (and perhaps other
Office apps as well).
Visual Basic .NET is something quite different -- a sort of
Microsoft-flavored Object Pascal, really. But I don't know of too many shops
actually using it; if you're targeting the .NET runtime it makes just as much
sense to just use C#.
As for Perl, it's possible to write large, readable, maintainable
code bases in object-oriented Perl. I've seen it done. BUT -- you have to be
careful. You have to establish coding standards, and if you come across the
stereotype of "typical, looks-like-line-noise Perl code" then you have to flunk
it at code review and never let it touch prod. (Do modern developers even know
what line noise is, or where it comes from?) You also have to choose your
libraries carefully, ensuring they follow a sane semantics that doesn't require
weirdness in your code. I'd much rather just do it in Python. Reply
↓
TheDividualist on 2017-12-27 at
11:24:59 said: VB.NET is unusued in the kind of circles *you know*
because these are competitive and status-conscious circles and anything
with BASIC in the name is so obviously low-status and just looks so bad on
the resume that it makes sense to add that 10-20% more effort and learn C#.
C# sounds a whole lot more high status, as it has C in the name so obvious
it looks like being a Real Programmer on the resume.
What you don't know is what happens outside the circles where
professional programmers compete for status and jobs.
I can report that there are many "IT guys" who are not in these circles,
they don't have the intra-programmer social life hence no status concerns,
nor do they ever intend apply for Real Programmer jobs. They are just rural
or not first worlder guys who grew up liking computers, and took a generic
"IT guy" job at some business in a small town and there they taught
themselves Excel VBscript when the need arised to automate some reports,
and then VB.NET when it was time to try to build some actual application
for in-house use. They like it because it looks less intimidating –
it sends out those "not only meant for Real Programmers" vibes.
I wish we lived in a world where Python would fill that non-intimidating
amateur-friendly niche, as it could do that job very well, but we are
already on a hell of a path dependence. Seriously, Bill Gates and Joel
Spolsky got it seriously right when they made Excel scriptable. The trick
is how to provide a smooth transition between non-programming and
programming.
One classic way is that you are a sysadmin, you use the shell, then you
automate tasks with shell scripts, then you graduate to Perl.
One, relatively new way is that you are a web designer, write HTML and
CSS, and then slowly you get dragged, kicking and screaming into JavaScript
and PHP.
The genius was that they realized that a spreadsheet is basically modern
paper. It is the most basic and universal tool of the office drone. I print
all my automatically generated reports into xlsx files, simply because for
me it is the "paper" of 2017, you can view it on any Android phone, and
unlike PDF and like paper you can interact and work with the figures, like
add other numbers to them.
So it was automating the spreadsheet, the VBScript Excel macro that led
the way from not-programming to programming for an immense number of office
drones, who are far more numerous than sysadmins and web designers.
Aaand I think it was precisely because of those microcomputers, like the
Commodore. Out of every 100 office drone in 1991 or so, 1 or 2 had
entertained themselves in 1987 typing in some BASIC programs published in
computer mags. So when they were told Excel is programmable with a form of
BASIC they were not too intidimated
This created such a giant path dependency that still if you want to sell
a language to millions and millions of not-Real Programmers you have to at
least make it look somewhat like Basic.
I think from this angle it was a masterwork of creating and exploiting
path dependency. Put BASIC on microcomputers. Have a lot of hobbyists learn
it for fun. Create the most universal office tool. Let it be programmable
in a form of BASIC – you can just work on the screen, let it generate
a macro and then you just have to modify it. Mostly copy-pasting, not real
programming. But you slowly pick up some programming idioms. Then the path
curves up to VB and then VB.NET.
To challenge it all, one needs to find an application area as important
as number cruching and reporting in an office: Excel is basically
electronic paper from this angle and it is hard to come up with something
like this. All our nearly computer illiterate salespeople use it. (90% of
the use beyond just typing data in a grid is using the auto sum function.)
And they don't use much else than that and Word and Outlook and chat
apps.
Anyway suppose such a purpose can be found, then you can make it
scriptable in Python and it is also important to be able to record a macro
so that people can learn from the generated code. Then maybe that dominance
can be challenged. Reply
↓
Jeff Read on 2018-01-18 at
12:00:29 said: TIOBE says that while VB.NET saw an uptick in
popularity in 2011, it's on its way down now and usage was moribund
before then.
In your attempt to reframe my statements in your usual reference
frame of Academic Programmer Bourgeoisie vs. Office Drone Proletariat,
you missed my point entirely: VB.NET struggled to get a foothold during
the time when VB6 was fresh in developers' minds. It was too different
(and too C#-like) to win over VB6 devs, and didn't offer enough
value-add beyond C# to win over the people who would've just used C# or
Java. Reply
↓
I have been part of big projects with many engineers using languages with
automatic memory management. I noticed I could get something up and running in a
fraction of the time that it took in C or C++.
And yet, somehow, strangely, the projects as a whole never got successfully
completed. We found ourselves fighting weird shit done by the vast pile of run
time software that was invisibly under the hood automatically doing stuff for us.
We would be fighting mysterious and arcane installation and integration
issues.
Sounds just like every Ruby on Fails deployment I've ever seen. It's great when
you're slapping together Version 0.1 of a product or so I've heard. But I've never
joined a Fails team on version 0.1. The ones I saw were already well-established,
and between the PFM in Rails itself, and the amount of monkeypatching done to
system classes, it's very, very hard to reason about the code you're looking at.
From a management level, you're asking for enormous pain trying to onboard new
developers into that sort of environment, or even expand the scope of your product
with an existing team, without them tripping all over each other.
There's a reason why Twitter switched from Rails to Scala. Reply
↓
> Hacker culture has, for decades, tried to claim it was inclusive and
nonjudgemental and yada yada , hacker culture has fallen far short. Now that's changing,
has to change.|
Observe that "has to change" in practice means that the social justice warriors take
charge.
Observe that in practice, when the social justice warriors take charge, old bugs don't
get fixed, new bugs appear, and projects turn into aimless garbage, if any development
occurs at all.
"has to change" is a power grab, and the people grabbing power are not competent to
code, and do not care about code.
Reflect on the attempted
suicide of "Coraline" It is not people like me who keep using the correct pronouns that
caused "her" to attempt suicide. It is the people who used "her" to grab power. Reply
↓
esr on
2017-12-27 at
14:30:33 said: >"has to change" is a power grab, and the people grabbing power
are not competent to code, and do not care about code.
It's never happened before, and may very well never happen again but this once I
completely agree with JAD. The "change" the SJWs actually want – as opposed to
what they claim to want – would ruin us. Reply ↓
cppcoreguidelines-* and modernize-* will catch most of the issues that esr complains
about, in practice usually all of them, though I suppose that as the project gets bigger,
some will slip through.
Remember that gcc and g++ is C++98 by default, because of the vast base of old fashioned
C++ code which is subtly incompatible with C++11, C++11 onwards being the version of C++
that optionally supports memory safety, hence necessarily subtly incompatible.
To turn on C++11
Place
cmake_minimum_required(VERSION 3.5)
# set standard required to ensure that you get
# the same version of C++ on every platform
# as some environments default to older dialects
# of C++ and some do not.
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
Originally i made this system because i wanted to test programming a micro kernel OS,
with protected mode, PCI bus, usb, ACPI etc, and i didn't want to get close to the 'event
horizon' of memory mannagement in C.
But i didn't wait the Greenspun law to kick in, so i first developped a safe memory
system as a runtime, and replaced the standard C runtime and memory mannagement with
it.
I wanted zero seg fault or memory error possible at all anywhere in the C code. Because
debuguing bare metal exception, without debugger, with complex data structures made in C
look very close to the black hole.
I didn't want to use C++ because C++ compiler have very unpredictible binary format and
function name decoration, which make it much harder to interface with at kernel level.
I wanted also some system as efficient as possible to mannage lockless shared access
between thread of the whole memory as much as possible, to avoid the 'exclusive borrow'
syndrome of rust, with global variables shared between threads with lockless algorithm to
access them.
I took inspiration from the algorithm on this site http://www.1024cores.net/ to develop the basic system, with
strong references as the norm, and direct 'bare pointer' only as weak references for fast
access to memory in C.
What i ended doing is basically a 'strongly typed hashmap DAG' to store object
references hierarchy, which can be manipulated using 'lambda expressions', in sort that
applications can manipulate objects in a indirect manner only through the DAG abstraction,
without having to manipulate bare pointers at all.
This also make a mark and sweep garbage collector easier to do, especially with an
'event based' system, the main loop can call the garbage collector between two executions
of event/messages handlers, which has the advantage that it can be made at a point where
there is no application data on the stack to mark, so it avoid mistaking application data
in the stack for a pointer. All references that are only in stack variables can get
automatically garbage collected when the function exit, much like in C++ actually.
The garbage collector can still be called by the allocator when there is OOM error, it
will attempt a garbage collection before failing the allocation, but all references in the
stack should be garbage collected when the function return to the main loop and the garbage
collector is run.
As all the references hierarchy is expressed explicity in the DAG, there shouldn't be
any pointer stored in the heap, outside of the module's data section, which correspond to C
global variables that are used as the 'root element' of object hierarchy, which can be
traversed to find all the actives references to heap data that the code can potentially
use. A quick system could be made for that the compiler can automatically generate a list
of the 'root references' in the global variables, to avoid memory leak if some global data
can look like a reference.
As each thread have their own heap, it also avoid the 'stop the world syndrome', all
threads can garbage collect their own heap, and there is already some system of lockless
synchronisation to access references based on expression in the DAG, to avoid having to
rely only on 'bare pointers' to manipulate object hierarchy, which allow dynamic
relocation, and make it easier to track active references.
It's also very useful to track memory leak, as the allocator can keep the time of each
memory allocation, it's easy to see all the allocations that happenned between two points
of the program, and dump all their hierarchy and property only from the 'bare
reference'.
Each thread contain two heaps, one which is manually mannaged, mostly used for temporary
strings , or IO buffers, and the other heap which can be mannaged either with atomic
reference count, or mark and sweep.
With this system, C program rarely have to use directly malloc/free, nor to manipulate
pointers to allocated memory directly, other than for temporary buffer allocation, like a
dynamic stack, for io buffers or temporary strings who can easily be mannaged manually. And
all the memory manipulation can be made via a runtime which keep track internally of
pointer address and size, data type and eventually a 'finalizer' function that will be
callled when the pointer is freed,
Since i started to use this system to make C programs, alongside with my own ABI which
can dynamically link binaries compiled with visual studio and gcc together, i tested it for
many different use case, i could make a mini multi thread window mannager/UI, with aysnc
irq driven HID driver events, and a system of distributed application based on blockchain
data, which include multi thread http server who can handle parrallel json/rpc calls, with
an abstraction of applications stack via custom data type definition / scripts stored on
the blockchain, and i have very little problem of memory, albeit it's 100% in C, multi
threaded and deal with heavily dynamic data.
With the mark and sweep mode, it can become quite easy to develop multi thread
applications with good level of concurrency, even to do simple database system, driven by a
script over asynch http/json/rpc, without having to care about complex memory
mannagement.
Even with the reference count mode, the manipulation of references is explicit, and it
should not be to hard to detect leaks with simple parsers, i already did test with antlr C
parser, with a visitor class to parse the grammar and detect potentially errors, as all
memory referencing happen through specific type instead of bare pointers, it's not too hard
to detect potential memory leak problem with a simple parser. Reply ↓
Arron Grier on 2018-06-07 at 17:37:17 said: Since
you've been talking a lot about Go lately, should you not mention it on your Document: How
To Become A Hacker?
esr on
2018-06-08 at
05:48:37 said: >Since you've been talking a lot about Go lately, should you not
mention it on your Document: How To Become A Hacker?
Too soon. Go is very interesting but it's not an essential tool yet.
Yankes on 2018-12-18 at 19:20:46 said: I have
one question, do you even need global AMM? Get one of element of graph, when it will/should
be released in your reposugeon? Over all I think it is never because it usually link with
other from this graph. Overall do you check how many objects are created and released
during operations? I do not mean some temporal strings but object representing main working
set.
Depending on answer it could be if you load some graph element and it will stay
indefinitely in memory then this could easy be converted to C/C++ by simply never using
`free` for graph elements (and all problems with memory management goes out of the
windows).
If they should be released early then when it should happened? Do you have some code in
reposurgeon that purge not needed objects when not needed any more? Depend on simply
accessibility of some object do not mean it needed, many times is quite opposite.
I now working on C# application that had similar bungle like this and previous
developers "solution" was to restarting whole application instead of fixing lifetime
problems. Correct solution was C++ like code, I create object, do work and purge it
explicitly. With this non of components have memory issues now. Of corse problem there lay
with lack of knowing tools they use and not complexity of domain, but did you do analysis
what is needed and what not, and how long? AMM do not solve this.
btw I big fan of lisp that is in C++11 aka templates, great pure functional language :D
Reply ↓
Oh hell yes. Consider, for example, the demands of loading in ad operating on
multiple repositories. Reply ↓
Yankes on 2018-12-19 at 08:56:36 said:
If I understood this correctly situations look like:
I have processes that loaded repo A, B and C and active working on each one.
Now because of some demand we need load repo D.
After we are done we back to A, B and C.
Now question is should be D data be purged?
If there are memory connection form previous repos then it will stay in memory if
not then AMM will remove all data from memory.
If this is complex graph when you have access to any element the you can crawl to
any other element of this graph (this is simplification but probably safe
assumption).
In first case (there is connection) is equivalent to not using `free` in C. Of
corse if not all graph is reachable then there will be partial purge of it memory
(let say that 10% will stay), but what will happens when you need again load repo
D? Current data avaialbe is hidden deep in other graphs and most of data is lost do
AMM. you need load everything again and now repo D size is 110%.
In case there is not connection between repos A, B, C and repo D then we can
free it entirely.
This is easy done in C++ (some kind of smart pointer that know if it pointing same
repo or other).
Do my reasoning is correct? or I miss something?
btw there BIG difference between C and C++, I can implement things in C++ that I
will NEVER be able to implement in C, example of this is my strong typed simple
script language: https://github.com/Yankes/OpenXcom/blob/master/src/Engine/Script.cpp
I would need drop functionalists/protections to be able to convert this to C (or
even C++03).
Another example of this is https://github.com/fmtlib/fmt from C++ and
`printf` from C.
Both do exactly same but C++ is lot of times better and safer.
This mean if we add your statement on impossibility and my then we have:
C <<< C++ <<< Go/Python
but for me personally is more:
C <<< C++ < Go/Python
than yours:
C/C++ <<< Go/Python Reply
↓
Not much. The bigger issue is that it is fucking insane to try
anything like this in a language where the core abstractions are leaky. That
disqualifies C++. Reply
↓
Yankes on 2018-12-19 at 10:24:47
said: I only disagree with word `insane`, C++ have lot of problems like UB,
lot of corner cases, leaking abstraction, whole crap form C (and my
favorite: 1000 line errors from templates), but is not insane to work with
memory problems.
You can easy create tools that make all this problems bearable, and this
is biggest flaw in C++, many problems are solvable but not out of box. C++
is good on crating abstraction: https://www.youtube.com/watch?v=sPhpelUfu8Q
That will fit your domain then it will not leak much because it fit right
the underling problem.
And you can enforce lot of things that allow you to reason locally about
behavior of program.
In case of creating this new abstraction is indeed insane then I think
you have problems in Go too because only problem that AMM solve is
reachability of memory and how long you need for it.
btw best thing that show difference between C++03 and C++11 is
`std::vector<std::vector>`, in C++03 this is insane stupid and in
C++11 is insane clever because it have performance characteristic of
`std::vector` (thanks to `std::move`) and no problems with memory
management (keep index stable and use `v.at(i).at(j).x = 5;` or warp it in
helper class and use `v[i][j].x` that will throw on wrong index).
Reply
↓
Of the omitted language features, the designers explicitly argue against assertions and
pointer arithmetic, while defending the choice to omit type inheritance as giving a more useful
language, encouraging instead the use of interfaces to
achieve dynamic dispatch [h] and
composition to reuse code.
Composition and delegation are in fact largely
automated by struct embedding; according to researchers Schmager et al. , this feature
"has many of the drawbacks of inheritance: it affects the public interface of objects, it is
not fine-grained (i.e, no method-level control over embedding), methods of embedded objects
cannot be hidden, and it is static", making it "not obvious" whether programmers will overuse
it to the extent that programmers in other languages are reputed to overuse inheritance.
[61]
The designers express an openness to generic programming and note that built-in functions
are in fact type-generic, but these are treated as special cases; Pike calls this a
weakness that may at some point be changed. [53]
The Google team built at least one compiler for an experimental Go dialect with generics, but
did not release it. [96] They are
also open to standardizing ways to apply code generation. [97]
Initially omitted, the exception -like panic / recover
mechanism was eventually added, which the Go authors advise using for unrecoverable errors such
as those that should halt an entire program or server request, or as a shortcut to propagate
errors up the stack within a package (but not across package boundaries; there, error returns
are the standard API). [98
Blame the Policies, Not the Robots
By Jared Bernstein and Dean Baker - Washington Post
The claim that automation is responsible for massive job losses has been made in almost
every one of the Democratic debates. In the last debate, technology entrepreneur Andrew Yang
told of automation closing stores on Main Street and of self-driving trucks that would
shortly displace "3.5 million truckers or the 7 million Americans who work in truck stops,
motels, and diners" that serve them. Rep. Tulsi Gabbard (Hawaii) suggested that the
"automation revolution" was at "the heart of the fear that is well-founded."
When Sen. Elizabeth Warren (Mass.) argued that trade was a bigger culprit than automation,
the fact-checker at the Associated Press claimed she was "off" and that "economists mostly
blame those job losses on automation and robots, not trade deals."
In fact, such claims about the impact of automation are seriously at odds with the
standard data that we economists rely on in our work. And because the data so clearly
contradict the narrative, the automation view misrepresents our actual current challenges and
distracts from effective solutions.
Output-per-hour, or productivity, is one of those key data points. If a firm applies a
technology that increases its output without adding additional workers, its productivity goes
up, making it a critical diagnostic in this space.
Contrary to the claim that automation has led to massive job displacement, data from the
Bureau of Labor Statistics (BLS) show that productivity is growing at a historically slow
pace. Since 2005, it has been increasing at just over a 1 percent annual rate. That compares
with a rate of almost 3 percent annually in the decade from 1995 to 2005.
This productivity slowdown has occurred across advanced economies. If the robots are
hiding from the people compiling the productivity data at BLS, they are also managing to hide
from the statistical agencies in other countries.
Furthermore, the idea that jobs are disappearing is directly contradicted by the fact that
we have the lowest unemployment rate in 50 years. The recovery that began in June 2009 is the
longest on record. To be clear, many of those jobs are of poor quality, and there are people
and places that have been left behind, often where factories have closed. But this, as Warren
correctly claimed, was more about trade than technology.
Consider, for example, the "China shock" of the 2000s, when sharply rising imports from
countries with much lower-paid labor than ours drove up the U.S. trade deficit by 2.4
percentage points of GDP (almost $520 billion in today's economy). From 2000 to 2007 (before
the Great Recession), the country lost 3.4 million manufacturing jobs, or 20 percent of the
total.
Addressing that loss, Susan Houseman, an economist who has done exhaustive, evidence-based
analysis debunking the automation explanation, argues that "intuitively and quite simply,
there doesn't seem to have been a technology shock that could have caused a 20 to 30 percent
decline in manufacturing employment in the space of a decade." What really happened in those
years was that policymakers sat by while millions of U.S. factory workers and their
communities were exposed to global competition with no plan for transition or adjustment to
the shock, decimating parts of Ohio, Michigan and Pennsylvania. That was the fault of the
policymakers, not the robots.
Before the China shock, from 1970 to 2000, the number (not the share) of manufacturing
jobs held remarkably steady at around 17 million. Conversely, since 2010 and post-China
shock, the trade deficit has stabilized and manufacturing has been adding jobs at a modest
pace. (Most recently, the trade war has significantly dented the sector and worsened the
trade deficit.) Over these periods, productivity, automation and robotics all grew apace.
In other words, automation isn't the problem. We need to look elsewhere to craft a
progressive jobs agenda that focuses on the real needs of working people.
First and foremost, the low unemployment rate -- which wouldn't prevail if the automation
story were true -- is giving workers at the middle and the bottom a bit more of the
bargaining power they require to achieve real wage gains. The median weekly wage has risen at
an annual average rate, after adjusting for inflation, of 1.5 percent over the past four
years. For workers at the bottom end of the wage ladder (the 10th percentile), it has risen
2.8 percent annually, boosted also by minimum wage increases in many states and cities.
To be clear, these are not outsize wage gains, and they certainly are not sufficient to
reverse four decades of wage stagnation and rising inequality. But they are evidence that
current technologies are not preventing us from running hotter-for-longer labor markets with
the capacity to generate more broadly shared prosperity.
National minimum wage hikes will further boost incomes at the bottom. Stronger labor
unions will help ensure that workers get a fairer share of productivity gains. Still, many
toiling in low-wage jobs, even with recent gains, will still be hard-pressed to afford child
care, health care, college tuition and adequate housing without significant government
subsidies.
Contrary to those hawking the automation story, faster productivity growth -- by boosting
growth and pretax national income -- would make it easier to meet these challenges. The
problem isn't and never was automation. Working with better technology to produce more
efficiently, not to mention more sustainably, is something we should obviously welcome.
The thing to fear isn't productivity growth. It's false narratives and bad economic
policy.
Maintaining and adding new features to legacy systems developed using Maintaining and adding new features to legacy systems developed
using C/C++ is a daunting task. There are several facets to the problem -- understanding the existing class hierarchy
and global variables, the different user-defined types, and function call graph analysis, to name a few. This article discusses several
features of doxygen, with examples in the context of projects using C/C++ .
However, doxygen is flexible enough to be used for software projects developed using the Python, Java, PHP, and other languages,
as well. The primary motivation of this article is to help extract information from C/C++ sources, but it also briefly
describes how to document code using doxygen-defined tags.
Installing doxygen
You have two choices for acquiring doxygen. You can download it as a pre-compiled executable file, or you can check out sources
from the SVN repository and build it. You have two choices for acquiring doxygen. You can download it as a pre-compiled executable
file, or you can check out sources from the SVN repository and build it.
Listing 1 shows the latter process.
Listing 1. Install and build doxygen sources
bash‑2.05$ svn co https://doxygen.svn.sourceforge.net/svnroot/doxygen/trunk doxygen‑svn
bash‑2.05$ cd doxygen‑svn
bash‑2.05$ ./configure prefix=/home/user1/bin
bash‑2.05$ make
bash‑2.05$ make install
Show more Note that the configure script is tailored to dump the compiled sources in /home/user1/bin (add this directory to the PATH
variable after the build), as not every UNIX® user has permission to write to the /usr folder. Also, you need the Note that the configure
script is tailored to dump the compiled sources in /home/user1/bin (add this directory to the PATH variable after the build), as
not every UNIX® user has permission to write to the /usr folder. Also, you need the Note that the configure script is tailored to
dump the compiled sources in /home/user1/bin (add this directory to the PATH variable after the build), as not every UNIX® user has
permission to write to the /usr folder. Also, you need the Note that the configure script is tailored to dump the compiled sources
in /home/user1/bin (add this directory to the PATH variable after the build), as not every UNIX® user has permission to write to
the /usr folder. Also, you need the svn utility to check out sources. Generating documentation using doxygen
To use doxygen to generate documentation of the sources, you perform three steps. To use doxygen to generate documentation of the
sources, you perform three steps. Generate the configuration file At a shell prompt, type the command doxygen -g At a shell
prompt, type the command doxygen -g doxygen -g . This command generates a text-editable configuration file called
Doxyfile in the current directory. You can choose to override this file name, in which case the invocation should be doxygen
-g <_user-specified file="file" name_="name_"> doxygen -g <user-specified file name> , as shown in
Listing 2 .
Listing 2. Generate the default configuration file
bash‑2.05b$ doxygen ‑g
Configuration file 'Doxyfile' created.
Now edit the configuration file and enter
doxygen Doxyfile
to generate the documentation for your project
bash‑2.05b$ ls Doxyfile
Doxyfile
Show more Edit the configuration file The configuration file is structured as The configuration file is structured as
<TAGNAME> = <VALUE> , similar to the Make file format. Here are the most important tags:
<OUTPUT_DIRECTORY> : You must provide a directory name here -- for example, /home/user1/documentation -- for
the directory in which the generated documentation files will reside. If you provide a nonexistent directory name, doxygen creates
the directory subject to proper user permissions.
<INPUT> : This tag creates a space-separated list of all the directories in which the C/C++ source
and header files reside whose documentation is to be generated. For example, consider the following snippet:
Show more In this case, doxygen would read in the C/C++ sources from these two
directories. If your project has a single source root directory with multiple sub-directories, specify that folder and make the
<RECURSIVE> tag Yes .
<FILE_PATTERNS> : By default, doxygen searches for files with typical C/C++ extensions such as
.c, .cc, .cpp, .h, and .hpp. This happens when the <FILE_PATTERNS> tag has no value associated with
it. If the sources use different naming conventions, update this tag accordingly. For example, if a project convention is to use
.c86 as a C file extension, add this to the <FILE_PATTERNS> tag.
<RECURSIVE> : Set this tag to Yes if the source hierarchy is nested and you need to generate documentation for
C/C++ files at all hierarchy levels. For example, consider the root-level source hierarchy /home/user1/project/kernel,
which has multiple sub-directories such as /home/user1/project/kernel/vmm and /home/user1/project/kernel/asm. If this tag is set
to Yes , doxygen recursively traverses the hierarchy, extracting information.
<EXTRACT_ALL> : This tag is an indicator to doxygen to extract documentation even when the individual classes
or functions are undocumented. You must set this tag to Yes .
<EXTRACT_PRIVATE> : Set this tag to Yes . Otherwise, private data members of a class would not be included in
the documentation.
<EXTRACT_STATIC> : Set this tag to Yes . Otherwise, static members of a file (both functions and variables) would
not be included in the documentation.
Listing 3. Sample doxyfile with user-provided tag values
OUTPUT_DIRECTORY = /home/user1/docs
EXTRACT_ALL = yes
EXTRACT_PRIVATE = yes
EXTRACT_STATIC = yes
INPUT = /home/user1/project/kernel
#Do not add anything here unless you need to. Doxygen already covers all
#common formats like .c/.cc/.cxx/.c++/.cpp/.inl/.h/.hpp
FILE_PATTERNS =
RECURSIVE = yes
Show more Run doxygen Run doxygen in the shell prompt as Run doxygen in the shell prompt as doxygen Doxyfile
(or with whatever file name you've chosen for the configuration file). Doxygen issues several messages before it finally produces
the documentation in Hypertext Markup Language (HTML) and Latex formats (the default). In the folder that the <OUTPUT_DIRECTORY>
tag specifies, two sub-folders named html and latex are created as part of the documentation-generation process.
Listing 4 shows a sample doxygen run log.
Listing 4. Sample log output from doxygen
Searching for include files...
Searching for example files...
Searching for images...
Searching for dot files...
Searching for files to exclude
Reading input files...
Reading and parsing tag files
Preprocessing /home/user1/project/kernel/kernel.h
Read 12489207 bytes
Parsing input...
Parsing file /project/user1/project/kernel/epico.cxx
Freeing input...
Building group list...
..
Generating docs for compound MemoryManager::ProcessSpec
Generating docs for namespace std
Generating group index...
Generating example index...
Generating file member index...
Generating namespace member index...
Generating page index...
Generating graph info page...
Generating search index...
Generating style sheet...
Show more Documentation output formats Doxygen can generate documentation in several output formats other than HTML. You can
configure doxygen to produce documentation in the following formats: Doxygen can generate documentation in several output formats
other than HTML. You can configure doxygen to produce documentation in the following formats:
UNIX man pages: Set the <GENERATE_MAN> tag to Yes . By default, a sub-folder named man is created within
the directory provided using <OUTPUT_DIRECTORY> , and the documentation is generated inside the folder. You must
add this folder to the MANPATH environment variable.
Rich Text Format (RTF): Set the <GENERATE_RTF> tag to Yes . Set the <RTF_OUTPUT> to wherever you
want the .rtf files to be generated -- by default, the documentation is within a sub-folder named rtf within the OUTPUT_DIRECTORY.
For browsing across documents, set the <RTF_HYPERLINKS> tag to Yes . If set, the generated .rtf files contain links
for cross-browsing.
Latex: By default, doxygen generates documentation in Latex and HTML formats. The <GENERATE_LATEX> tag is set
to Yes in the default Doxyfile. Also, the <LATEX_OUTPUT> tag is set to Latex, which implies that a folder named
latex would be generated inside OUTPUT_DIRECTORY, where the Latex files would reside.
Microsoft® Compiled HTML Help (CHM) format: Set the <GENERATE_HTMLHELP> tag to Yes . Because this format is not
supported on UNIX platforms, doxygen would only generate a file named index.hhp in the same folder in which it keeps the
HTML files. You must feed this file to the HTML help compiler for actual generation of the .chm file.
Extensible Markup Language (XML) format: Set the <GENERATE_XML> tag to Yes . (Note that the XML output is still
a work in progress for the doxygen team.)
Listing 5 provides an example of a Doxyfile
that generates documentation in all the formats discussed.
Listing 5. Doxyfile with tags for generating documentation in several formats
Show more Special tags in doxygen Doxygen contains a couple of special tags. Doxygen contains a couple of special tags.
Preprocessing C/C++ code First, doxygen must preprocess First, doxygen must preprocess C/C++ code to extract information.
By default, however, it does only partial preprocessing -- conditional compilation statements ( #if #endif ) are evaluated,
but macro expansions are not performed. Consider the code in
Listing 6 .
Show more With With With With <USE_ROPE> defined in sources, generated documentation from doxygen looks like this:
Defines
#define USE_ROPE
#define STRING std::rope
Variables
static STRING name
Show more Here, you see that doxygen has performed a conditional compilation but has not done a macro expansion of Here, you see
that doxygen has performed a conditional compilation but has not done a macro expansion of Here, you see that doxygen has performed
a conditional compilation but has not done a macro expansion of Here, you see that doxygen has performed a conditional compilation
but has not done a macro expansion of STRING . The <ENABLE_PREPROCESSING> tag in the Doxyfile is set by
default to Yes . To allow for macro expansions, also set the <MACRO_EXPANSION> tag to Yes . Doing so produces
this output from doxygen:
Defines
#define USE_ROPE
#define STRING std::string
Variables
static std::rope name
Show more If you set the If you set the If you set the If you set the <ENABLE_PREPROCESSING> tag to No , the
output from doxygen for the earlier sources looks like this:
Variables
static STRING name
Show more Note that the documentation now has no definitions, and it is not possible to deduce the type of Note that the documentation
now has no definitions, and it is not possible to deduce the type of Note that the documentation now has no definitions, and it is
not possible to deduce the type of Note that the documentation now has no definitions, and it is not possible to deduce the type
of STRING . It thus makes sense always to set the <ENABLE_PREPROCESSING> tag to Yes . As part of the documentation,
it might be desirable to expand only specific macros. For such purposes, along setting As part of the documentation, it might be
desirable to expand only specific macros. For such purposes, along setting As part of the documentation, it might be desirable to
expand only specific macros. For such purposes, along setting <ENABLE_PREPROCESSING> and <MACRO_EXPANSION>
to Yes , you must set the <EXPAND_ONLY_PREDEF> tag to Yes (this tag is set to No by default) and provide the
macro details as part of the <PREDEFINED> or <EXPAND_AS_DEFINED> tag. Consider the code in
Listing 7 , where only the macro
CONTAINER would be expanded.
Show more Here's the doxygen output with only Here's the doxygen output with only Here's the doxygen output with only Here's the
doxygen output with only CONTAINER expanded:
Show more Notice that only the Notice that only the Notice that only the Notice that only the CONTAINER macro has been
expanded. Subject to <MACRO_EXPANSION> and <EXPAND_AS_DEFINED> both being Yes , the <EXPAND_AS_DEFINED>
tag selectively expands only those macros listed on the right-hand side of the equality operator. As part of preprocessing, the final
tag to note is As part of preprocessing, the final tag to note is As part of preprocessing, the final tag to note is <PREDEFINED>
. Much like the same way you use the -D switch to pass the G++ compiler preprocessor definitions, you use this tag to
define macros. Consider the Doxyfile in Listing
9 .
Listing 9. Doxyfile with macro expansion tags defined
Show more Here's the doxygen-generated output: Here's the doxygen-generated output: Here's the doxygen-generated output: Here's the
doxygen-generated output:
Show more When used with the When used with the When used with the When used with the <PREDEFINED> tag, macros should
be defined as <_macro name_="name_">=<_value_> <macro name>=<value> . If no value is provided -- as in the case of simple
#define -- just using <_macro name_="name_">=<_spaces_> <macro name>=<spaces> suffices. Separate multiple
macro definitions by spaces or a backslash ( \ ). Excluding specific files or directories from the documentation
process In the In the <EXCLUDE> tag in the Doxyfile, add the names of the files and directories for which documentation
should not be generated separated by spaces. This comes in handy when the root of the source hierarchy is provided and some sub-directories
must be skipped. For example, if the root of the hierarchy is src_root and you want to skip the examples/ and test/memoryleaks folders
from the documentation process, the Doxyfile should look like
Listing 10 .
Listing 10. Using the EXCLUDE tag as part of the Doxyfile
Show more Generating graphs and diagrams By default, the Doxyfile has the By default, the Doxyfile has the <CLASS_DIAGRAMS>
tag set to Yes . This tag is used for generation of class hierarchy diagrams. The following tags in the Doxyfile deal with generating
diagrams:
<CLASS_DIAGRAMS> : The default tag is set to Yes in the Doxyfile. If the tag is set to No , diagrams for inheritance
hierarchy would not be generated.
<HAVE_DOT> : If this tag is set to Yes , doxygen uses the dot tool to generate more powerful graphs, such as
collaboration diagrams that help you understand individual class members and their data structures. Note that if this tag is set
to Yes , the effect of the <CLASS_DIAGRAMS> tag is nullified.
<CLASS_GRAPH> : If the <HAVE_DOT> tag is set to Yes along with this tag, the inheritance hierarchy
diagrams are generated using the dot tool and have a richer look and feel than what you'd get by using only
<CLASS_DIAGRAMS> .
<COLLABORATION_GRAPH> : If the <HAVE_DOT> tag is set to Yes along with this tag, doxygen generates
a collaboration diagram (apart from an inheritance diagram) that shows the individual class members (that is, containment) and
their inheritance hierarchy.
Listing 11 provides an example using
a few data structures. Note that the <HAVE_DOT> , <CLASS_GRAPH> , and <COLLABORATION_GRAPH>
tags are all set to Yes in the configuration file.
Listing 11. Interacting C classes and structures
struct D {
int d;
};
class A {
int a;
};
class B : public A {
int b;
};
class C : public B {
int c;
D d;
};
Figure 1. The Class inheritance graph and collaboration graph generated using the dot tool
Code documentation style So far, you've used doxygen to extract information from code that is otherwise undocumented. However,
doxygen also advocates documentation style and syntax, which helps it generate more detailed documentation. This section discusses
some of the more common tags doxygen advocates using as part of So far, you've used doxygen to extract information from code that
is otherwise undocumented. However, doxygen also advocates documentation style and syntax, which helps it generate more detailed
documentation. This section discusses some of the more common tags doxygen advocates using as part of C/C++ code. For
further details, see resources on the right. Every code item has two kinds of descriptions: one brief and one detailed. Brief descriptions
are typically single lines. Functions and class methods have a third kind of description known as the Every code item has two kinds
of descriptions: one brief and one detailed. Brief descriptions are typically single lines. Functions and class methods have a third
kind of description known as the Every code item has two kinds of descriptions: one brief and one detailed. Brief descriptions are
typically single lines. Functions and class methods have a third kind of description known as the in-body description, which
is a concatenation of all comment blocks found within the function body. Some of the more common doxygen tags and styles of commenting
are:
Brief description: Use a single-line C++ comment, or use the <\brief> tag.
Detailed description: Use JavaDoc-style commenting /** test */ (note the two asterisks [ * ] in
the beginning) or the Qt-style /*! text */ .
In-body description: Individual C++ elements like classes, structures, unions, and namespaces have their own
tags, such as <\class> , <\struct> , <\union> , and <\namespace> .
To document global functions, variables, and enum types, the corresponding file must first be documented using the To document global
functions, variables, and enum types, the corresponding file must first be documented using the <\file> tag.
Listing 12 provides an example that discusses
item 4 with a function tag ( <\fn> ), a function argument tag ( <\param> ), a variable name tag (
<\var> ), a tag for #define ( <\def> ), and a tag to indicate some specific issues related to a
code snippet ( <\warning> ).
Listing 12. Typical doxygen tags and their use
/∗! \file globaldecls.h
\brief Place to look for global variables, enums, functions
and macro definitions
∗/
/∗∗ \var const int fileSize
\brief Default size of the file on disk
∗/
const int fileSize = 1048576;
/∗∗ \def SHIFT(value, length)
\brief Left shift value by length in bits
∗/
#define SHIFT(value, length) ((value) << (length))
/∗∗ \fn bool check_for_io_errors(FILE∗ fp)
\brief Checks if a file is corrupted or not
\param fp Pointer to an already opened file
\warning Not thread safe!
∗/
bool check_for_io_errors(FILE∗ fp);
Show more
Here's how the generated documentation looks:
Defines
#define SHIFT(value, length) ((value) << (length))
Left shift value by length in bits.
Functions
bool check_for_io_errors (FILE ∗fp)
Checks if a file is corrupted or not.
Variables
const int fileSize = 1048576;
Function Documentation
bool check_for_io_errors (FILE∗ fp)
Checks if a file is corrupted or not.
Parameters
fp: Pointer to an already opened file
Warning
Not thread safe!
Show more Conclusion
This article discusses how doxygen can extract a lot of relevant information from legacy C/C++ code. If the code
is documented using doxygen tags, doxygen generates output in an easy-to-read format. Put to good use, doxygen is a ripe candidate
in any developer's arsenal for maintaining and managing legacy systems.
Whenever a boss acts like a dictator – shutting down, embarrassing, or firing anyone
who dares to challenge the status quo – you've got a toxic workplace problem. And that's
not just because of the boss' bad behavior, but because that behavior creates an environment in
which everyone is scared, intimidated and often willing to throw their colleagues under the
bus, just to stay on the good side of the such bosses.
... ... ...
10 Signs your workplace culture is Toxic
Company core values do not serve as the basis for how the organization functions.
Employee suggestions are discarded. People are afraid to give honest feedback.
Micromanaging -Little to no autonomy is given to employees in performing their jobs.
Blaming and punishment from management is the norm.
Excessive absenteeism, illness and high employee turn over.
Overworking is a badge of honor and is expected.
Little or strained interaction between employees and management.
Computer programmer Steve Relles has the poop on what to do when your job is outsourced to
India. Relles has spent the past year making his living scooping up dog droppings as the
"Delmar Dog Butler." "My parents paid for me to get a (degree) in math and now I am a pooper
scooper," "I can clean four to five yards in a hour if they are close together." Relles, who
lost his computer programming job about three years ago ... has over 100 clients who pay $10
each for a once-a-week cleaning of their yard.
Relles competes for business with another local company called "Scoopy Do." Similar
outfits have sprung up across America, including Petbutler.net, which operates in Ohio.
Relles says his business is growing by word of mouth and that most of his clients are women
who either don't have the time or desire to pick up the droppings. "St. Bernard (dogs) are my
favorite customers since they poop in large piles which are easy to find," Relles said. "It
sure beats computer programming because it's flexible, and I get to be outside,"
Eugene Miya , A
friend/colleague. Sometimes driver. Other shared experiences.
Updated Mar 22 2017 · Author has 11.2k answers and 7.9m answer views
He mostly writes in C today.
I can assure you he at least knows about Python. Guido's office at Dropbox is 1 -- 2 blocks
by a backdoor gate from Don's house.
I would tend to doubt that he would use R (I've used S before as one of my stat packages).
Don would probably write something for himself.
Don is not big on functional languages, so I would doubt either Haskell (sorry Paul) or LISP
(but McCarthy lived just around the corner from Don; I used to drive him to meetings; actually,
I've driven all 3 of us to meetings, and he got his wife an electric version of my car based on
riding in my car (score one for friend's choices)). He does use emacs and he does write MLISP
macros, but he believes in being closer to the hardware which is why he sticks with MMIX (and
MIX) in his books.
Don't discount him learning the machine language of a given architecture.
I'm having dinner with Don and Jill and a dozen other mutual friends in 3 weeks or so (our
quarterly dinner). I can ask him then, if I remember (either a calendar entry or at job). I try
not to bother him with things like this. Don is well connected to the hacker community
Don's name was brought up at an undergrad architecture seminar today, but Don was not in the
audience (an amazing audience; I took a photo for the collection of architects and other
computer scientists in the audience (Hennessey and Patterson were talking)). I came close to
biking by his house on my way back home.
We do have a mutual friend (actually, I introduced Don to my biology friend at Don's
request) who arrives next week, and Don is my wine drinking proxy. So there is a chance I may
see him sooner.
Don Knuth would want to use something that’s low level, because details matter
. So no Haskell; LISP is borderline. Perhaps if the Lisp machine ever had become a thing.
He’d want something with well-defined and simple semantics, so definitely no R. Python
also contains quite a few strange ad hoc rules, especially in its OO and lambda features. Yes
Python is easy to learn and it looks pretty, but Don doesn’t care about superficialities
like that. He’d want a language whose version number is converging to a mathematical
constant, which is also not in favor of R or Python.
What remains is C. Out of the five languages listed, my guess is Don would pick that one.
But actually, his own old choice of Pascal suits him even better. I don’t think any
languages have been invented since T E X was written that score higher on the Knuthometer than Knuth’s own original pick.
And yes, I feel that this is actually a conclusion that bears some thinking about. 24.1k
views ·
Dan
Allen , I've been programming for 34 years now. Still not finished.
Answered Mar 9, 2017 · Author has 4.5k answers and 1.8m answer views
In The Art of Computer Programming I think he'd do exactly what he did. He'd invent his own
architecture and implement programs in an assembly language targeting that theoretical
machine.
He did that for a reason because he wanted to reveal the detail of algorithms at the lowest
level of detail which is machine level.
He didn't use any available languages at the time and I don't see why that would suit his purpose now. All the languages
above are too high-level for his purposes.
"... The lawsuit also aggressively contests Boeing's spin that competent pilots could have prevented the Lion Air and Ethiopian Air crashes: ..."
"... When asked why Boeing did not alert pilots to the existence of the MCAS, Boeing responded that the company decided against disclosing more details due to concerns about "inundate[ing] average pilots with too much information -- and significantly more technical data -- than [they] needed or could realistically digest." ..."
"... The filing has a detailed explanation of why the addition of heavier, bigger LEAP1-B engines to the 737 airframe made the plane less stable, changed how it handled, and increased the risk of catastrophic stall. It also describes at length how Boeing ignored warning signs during the design and development process, and misrepresented the 737 Max as essentially the same as older 737s to the FAA, potential buyers, and pilots. It also has juicy bits presented in earlier media accounts but bear repeating, like: ..."
"... Then, on November 7, 2018, the FAA issued an "Emergency Airworthiness Directive (AD) 2018-23-51," warning that an unsafe condition likely could exist or develop on 737 MAX aircraft. ..."
"... Moreover, unlike runaway stabilizer, MCAS disables the control column response that 737 pilots have grown accustomed to and relied upon in earlier generations of 737 aircraft. ..."
"... And making the point that to turn off MCAS all you had to do was flip two switches behind everything else on the center condole. Not exactly true, normally those switches were there to shut off power to electrically assisted trim. Ah, it one thing to shut off MCAS it's a whole other thing to shut off power to the planes trim, especially in high speed ✓ and the plane noise up ✓, and not much altitude ✓. ..."
"... Classic addiction behavior. Boeing has a major behavioral problem, the repetitive need for and irrational insistence on profit above safety all else , that is glaringly obvious to everyone except Boeing. ..."
"... In fact, Boeing 737 Chief Technical Pilot, Mark Forkner asked the FAA to delete any mention of MCAS from the pilot manual so as to further hide its existence from the public and pilots " ..."
"... This "MCAS" was always hidden from pilots? The military implemented checks on MCAS to maintain a level of pilot control. The commercial airlines did not. Commercial airlines were in thrall of every little feature that they felt would eliminate the need for pilots at all. Fell right into the automation crapification of everything. ..."
At first blush, the suit filed in Dallas by the Southwest Airlines Pilots Association (SwAPA) against Boeing may seem like a family
feud. SWAPA is seeking an estimated $115 million for lost pilots' pay as a result of the grounding of the 34 Boeing 737 Max planes
that Southwest owns and the additional 20 that Southwest had planned to add to its fleet by year end 2019. Recall that Southwest
was the largest buyer of the 737 Max, followed by American Airlines. However, the damning accusations made by the pilots' union,
meaning, erm, pilots, is likely to cause Boeing not just more public relations headaches, but will also give grist to suits by crash
victims.
However, one reason that the Max is a sore point with the union was that it was a key leverage point in 2016 contract negotiations:
And Boeing's assurances that the 737 Max was for all practical purposes just a newer 737 factored into the pilots' bargaining
stance. Accordingly, one of the causes of action is tortious interference, that Boeing interfered in the contract negotiations to
the benefit of Southwest. The filing describes at length how Boeing and Southwest were highly motivated not to have the contract
dispute drag on and set back the launch of the 737 Max at Southwest, its showcase buyer. The big point that the suit makes is the
plane was unsafe and the pilots never would have agreed to fly it had they known what they know now.
We've embedded the compliant at the end of the post. It's colorful and does a fine job of recapping the sorry history of the development
of the airplane. It has damning passages like:
Boeing concealed the fact that the 737 MAX aircraft was not airworthy because, inter alia, it incorporated a single-point failure
condition -- a software/flight control logic called the Maneuvering Characteristics Augmentation System ("MCAS") -- that,if fed
erroneous data from a single angle-of-attack sensor, would command the aircraft nose-down and into an unrecoverable dive without
pilot input or knowledge.
The lawsuit also aggressively contests Boeing's spin that competent pilots could have prevented the Lion Air and Ethiopian Air
crashes:
Had SWAPA known the truth about the 737 MAX aircraft in 2016, it never would have approved the inclusion of the 737 MAX aircraft
as a term in its CBA [collective bargaining agreement], and agreed to operate the aircraft for Southwest. Worse still, had SWAPA
known the truth about the 737 MAX aircraft, it would have demanded that Boeing rectify the aircraft's fatal flaws before agreeing
to include the aircraft in its CBA, and to provide its pilots, and all pilots, with the necessary information and training needed
to respond to the circumstances that the Lion Air Flight 610 and Ethiopian Airlines Flight 302 pilots encountered nearly three
years later.
And (boldface original):
Boeing Set SWAPA Pilots Up to Fail
As SWAPA President Jon Weaks, publicly stated, SWAPA pilots "were kept in the dark" by Boeing.
Boeing did not tell SWAPA pilots that MCAS existed and there was no description or mention of MCAS in the Boeing Flight Crew
Operations Manual.
There was therefore no way for commercial airline pilots, including SWAPA pilots, to know that MCAS would work in the background
to override pilot inputs.
There was no way for them to know that MCAS drew on only one of two angle of attack sensors on the aircraft.
And there was no way for them to know of the terrifying consequences that would follow from a malfunction.
When asked why Boeing did not alert pilots to the existence of the MCAS, Boeing responded that the company decided against
disclosing more details due to concerns about "inundate[ing] average pilots with too much information -- and significantly more
technical data -- than [they] needed or could realistically digest."
SWAPA's pilots, like their counterparts all over the world, were set up for failure
The filing has a detailed explanation of why the addition of heavier, bigger LEAP1-B engines to the 737 airframe made the plane
less stable, changed how it handled, and increased the risk of catastrophic stall. It also describes at length how Boeing ignored
warning signs during the design and development process, and misrepresented the 737 Max as essentially the same as older 737s to
the FAA, potential buyers, and pilots. It also has juicy bits presented in earlier media accounts but bear repeating, like:
By March 2016, Boeing settled on a revision of the MCAS flight control logic.
However, Boeing chose to omit key safeguards that had previously been included in earlier iterations of MCAS used on the Boeing
KC-46A Pegasus, a military tanker derivative of the Boeing 767 aircraft.
The engineers who created MCAS for the military tanker designed the system to rely on inputs from multiple sensors and with
limited power to move the tanker's nose. These deliberate checks sought to ensure that the system could not act erroneously or
cause a pilot to lose control. Those familiar with the tanker's design explained that these checks were incorporated because "[y]ou
don't want the solution to be worse than the initial problem."
The 737 MAX version of MCAS abandoned the safeguards previously relied upon. As discussed below, the 737 MAX MCAS had greater
control authority than its predecessor, activated repeatedly upon activation, and relied on input from just one of the plane's
two sensors that measure the angle of the plane's nose.
In other words, Boeing can't credibly say that it didn't know better.
Here is one of the sections describing Boeing's cover-ups:
Yet Boeing's website, press releases, annual reports, public statements and statements to operators and customers, submissions
to the FAA and other civil aviation authorities, and 737 MAX flight manuals made no mention of the increased stall hazard or MCAS
itself.
In fact, Boeing 737 Chief Technical Pilot, Mark Forkner asked the FAA to delete any mention of MCAS from the pilot manual so
as to further hide its existence from the public and pilots.
We urge you to read the complaint in full, since it contains juicy insider details, like the significance of Southwest being Boeing's
737 Max "launch partner" and what that entailed in practice, plus recounting dates and names of Boeing personnel who met with SWAPA
pilots and made misrepresentations about the aircraft.
Even though Southwest Airlines is negotiating a settlement with Boeing over losses resulting from the grounding of the 737 Max
and the airline has promised to compensate the pilots, the pilots' union at a minimum apparently feels the need to put the heat on
Boeing directly. After all, the union could withdraw the complaint if Southwest were to offer satisfactory compensation for the pilots'
lost income. And pilots have incentives not to raise safety concerns about the planes they fly. Don't want to spook the horses, after
all.
But Southwest pilots are not only the ones most harmed by Boeing's debacle but they are arguably less exposed to the downside
of bad press about the 737 Max. It's business fliers who are most sensitive to the risks of the 737 Max, due to seeing the story
regularly covered in the business press plus due to often being road warriors. Even though corporate customers account for only 12%
of airline customers, they represent an estimated 75% of profits.
Southwest customers don't pay up for front of the bus seats. And many of them presumably value the combination of cheap travel,
point to point routes between cities underserved by the majors, and close-in airports, which cut travel times. In other words, that
combination of features will make it hard for business travelers who use Southwest regularly to give the airline up, even if the
737 Max gives them the willies. By contrast, premium seat passengers on American or United might find it not all that costly, in
terms of convenience and ticket cost (if they are budget sensitive), to fly 737-Max-free Delta until those passengers regain confidence
in the grounded plane.
Note that American Airlines' pilot union, when asked about the Southwest claim, said that it also believes its pilots deserve
to be compensated for lost flying time, but they plan to obtain it through American Airlines.
If Boeing were smart, it would settle this suit quickly, but so far, Boeing has relied on bluster and denial. So your guess is
as good as mine as to how long the legal arm-wrestling goes on.
Update 5:30 AM EDT : One important point that I neglected to include is that the filing also recounts, in gory detail, how Boeing
went into "Blame the pilots" mode after the Lion Air crash, insisting the cause was pilot error and would therefore not happen again.
Boeing made that claim on a call to all operators, including SWAPA, and then three days later in a meeting with SWAPA.
However, Boeing's actions were inconsistent with this claim. From the filing:
Then, on November 7, 2018, the FAA issued an "Emergency Airworthiness Directive (AD) 2018-23-51," warning that an unsafe condition
likely could exist or develop on 737 MAX aircraft.
Relying on Boeing's description of the problem, the AD directed that in the event of un-commanded nose-down stabilizer trim
such as what happened during the Lion Air crash, the flight crew should comply with the Runaway Stabilizer procedure in the Operating
Procedures of the 737 MAX manual.
But the AD did not provide a complete description of MCAS or the problem in 737 MAX aircraft that led to the Lion Air crash,
and would lead to another crash and the 737 MAX's grounding just months later.
An MCAS failure is not like a runaway stabilizer. A runaway stabilizer has continuous un-commanded movement of the tail, whereas
MCAS is not continuous and pilots (theoretically) can counter the nose-down movement, after which MCAS would move the aircraft
tail down again.
Moreover, unlike runaway stabilizer, MCAS disables the control column response that 737 pilots have grown accustomed to and
relied upon in earlier generations of 737 aircraft.
Even after the Lion Air crash, Boeing's description of MCAS was still insufficient to put correct its lack of disclosure as
demonstrated by a second MCAS-caused crash.
We hoisted this detail because insiders were spouting in our comments section, presumably based on Boeing's patter, that the Lion
Air pilots were clearly incompetent, had they only executed the well-known "runaway stabilizer," all would have been fine. Needless
to say, this assertion has been shown to be incorrect.
Excellent, by any standard. Which does remind of of the NYT zine story (William Langewiesche
Published Sept. 18, 2019) making the claim that basically the pilots who crashed their planes weren't real "Airman".
And making
the point that to turn off MCAS all you had to do was flip two switches behind everything else on the center condole. Not exactly
true, normally those switches were there to shut off power to electrically assisted trim. Ah, it one thing to shut off MCAS it's
a whole other thing to shut off power to the planes trim, especially in high speed ✓ and the plane noise up ✓, and not much altitude
✓.
And especially if you as a pilot didn't know MCAS was there in the first place. This sort of engineering by Boeing is criminal.
And the lying. To everyone. Oh, least we all forget the processing power of the in flight computer is that of a intel 286. There
are times I just want to be beamed back to the home planet. Where we care for each other.
One should also point out that Langewiesche said that Boeing made disastrous mistakes with the MCAS and that the very future
of the Max is cloudy. His article was useful both for greater detail about what happened and for offering some pushback to the
idea that the pilots had nothing to do with the accidents.
As for the above, it was obvious from the first Seattle Times stories that these two events and the grounding were going to
be a lawsuit magnet. But some of us think Boeing deserves at least a little bit of a defense because their side has been totally
silenteither for legal reasons or CYA reasons on the part of their board and bad management.
Classic addiction behavior. Boeing has a major behavioral problem, the repetitive need for and irrational insistence on profit
above safety all else , that is glaringly obvious to everyone except Boeing.
"The engineers who created MCAS for the military tanker designed the system to rely on inputs from multiple sensors and with
limited power to move the tanker's nose. These deliberate checks sought to ensure that the system could not act erroneously or
cause a pilot to lose control "
"Yet Boeing's website, press releases, annual reports, public statements and statements to operators and customers, submissions
to the FAA and other civil aviation authorities, and 737 MAX flight manuals made no mention of the increased stall hazard or MCAS
itself.
In fact, Boeing 737 Chief Technical Pilot, Mark Forkner asked the FAA to delete any mention of MCAS from the pilot manual
so as to further hide its existence from the public and pilots "
This "MCAS" was always hidden from pilots? The military implemented checks on MCAS to maintain a level of pilot control. The commercial airlines did not. Commercial
airlines were in thrall of every little feature that they felt would eliminate the need for pilots at all. Fell right into the
automation crapification of everything.
"... Additionally, what does Chef, Puppet, Docker, Kubernetes, Jenkins, or whatever else have to offer me? ..."
"... So what does DevOps have to do with what I do in my job? I'm legitimately trying to learn, but it gets so overwhelming trying to find information because everything I find just assumes you're a software developer with all this prerequisite knowledge. Additionally, how the hell do you find the time to learn all of this? It seems like new DevOps software or platforms or whatever you call them spin up every single month. I'm already in the middle of trying to learn JAMF (macOS/iOS administration), Junos, Dell, and Brocade for network administration (in addition to networking concepts in general), and AV design stuff (like Crestron programming). ..."
What the hell is DevOps? Every couple months I find myself trying to look into it as all I
ever hear and see about is DevOps being the way forward. But each time I research it I can only
find things talking about streamlining software updates and quality assurance and yada yada
yada. It seems like DevOps only applies to companies that make software as a product. How does
that affect me as a sysadmin for higher education? My "company's" product isn't software.
Additionally, what does Chef, Puppet, Docker, Kubernetes, Jenkins, or whatever else have to
offer me? Again, when I try to research them a majority of what I find just links back to
software development.
To give a rough idea of what I deal with, below is a list of my three main
responsibilities.
macOS/iOS Systems Administration (I'm the only sysadmin that does this for around 150+
machines)
Network Administration (I just started with this a couple months ago and I'm slowly
learning about our infrastructure and network administration in general from our IT
director. We have several buildings spread across our entire campus with a mixture of
Juniper, Dell, and Brocade equipment.)
AV Systems Design and Programming (I'm the only person who does anything related to
video conferencing, meeting room equipment, presentation systems, digital signage, etc. for
7 buildings.)
So what does DevOps have to do with what I do in my job? I'm legitimately trying to learn,
but it gets so overwhelming trying to find information because everything I find just assumes
you're a software developer with all this prerequisite knowledge. Additionally, how the hell do
you find the time to learn all of this? It seems like new DevOps software or platforms or
whatever you call them spin up every single month. I'm already in the middle of trying to learn
JAMF (macOS/iOS administration), Junos, Dell, and Brocade for network administration (in
addition to networking concepts in general), and AV design stuff (like Crestron programming).
I've been working at the same job for 5 years and I feel like I'm being left in the dust by the
entire rest of the industry. I'm being pulled in so many different directions that I feel like
it's impossible for me to ever get another job. At the same time, I can't specialize in
anything because I have so many different unrelated areas I'm supposed to be doing work in.
And this is what I go through/ask myself every few months I try to research and learn
DevOps. This is mainly a rant, but I am more than open to any and all advice anyone is willing
to offer. Thanks in advance.
there's a lot of tools that can be used to make your life much easier that's used on a
daily basis for DevOps, but apparently that's not the case for you. when you manage infra as
code, you're using DevOps.
there's a lot of space for operations guys like you (and me) so look to DevOps as an
alternative source of knowledge, just to stay tuned on the trends of the industry and improve
your skills.
for higher education, this is useful for managing large projects and looking for
improvement during the development of the product/service itself. but again, that's not the
case for you. if you intend to switch to another position, you may try to search for a
certification program that suits your needs
"... In the programming world, the term silver bullet refers to a technology or methodology that is touted as the ultimate cure for all programming challenges. A silver bullet will make you more productive. It will automatically make design, code and the finished product perfect. It will also make your coffee and butter your toast. Even more impressive, it will do all of this without any effort on your part! ..."
"... Naturally (and unfortunately) the silver bullet does not exist. Object-oriented technologies are not, and never will be, the ultimate panacea. Object-oriented approaches do not eliminate the need for well-planned design and architecture. ..."
"... OO will insure the success of your project: An object-oriented approach to software development does not guarantee the automatic success of a project. A developer cannot ignore the importance of sound design and architecture. Only careful analysis and a complete understanding of the problem will make the project succeed. A successful project will utilize sound techniques, competent programmers, sound processes and solid project management. ..."
"... OO technologies might incur penalties: In general, programs written using object-oriented techniques are larger and slower than programs written using other techniques. ..."
"... OO techniques are not appropriate for all problems: An OO approach is not an appropriate solution for every situation. Don't try to put square pegs through round holes! Understand the challenges fully before attempting to design a solution. As you gain experience, you will begin to learn when and where it is appropriate to use OO technologies to address a given problem. Careful problem analysis and cost/benefit analysis go a long way in protecting you from making a mistake. ..."
"Hooked on Objects" is dedicated to providing readers with insight into object-oriented technologies. In our first
few articles, we introduced the three tenants of object-oriented programming: encapsulation, inheritance and
polymorphism. We then covered software process and design patterns. We even got our hands dirty and dissected the
Java class.
Each of our previous articles had a common thread. We have written about the strengths and benefits of
the object paradigm and highlighted the advantages the object approach brings to the development effort. However, we
do not want to give anyone a false sense that object-oriented techniques are always the perfect answer.
Object-oriented techniques are not the magic "silver bullets" of programming.
In the programming world, the term silver bullet refers to a technology or methodology that is touted as the
ultimate cure for all programming challenges. A silver bullet will make you more productive. It will automatically
make design, code and the finished product perfect. It will also make your coffee and butter your toast. Even more
impressive, it will do all of this without any effort on your part!
Naturally (and unfortunately) the silver bullet does not exist. Object-oriented technologies are not, and never
will be, the ultimate panacea. Object-oriented approaches do not eliminate the need for well-planned design and
architecture.
If anything, using OO makes design and architecture more important because without a clear, well-planned design,
OO will fail almost every time. Spaghetti code (that which is written without a coherent structure) spells trouble
for procedural programming, and weak architecture and design can mean the death of an OO project. A poorly planned
system will fail to achieve the promises of OO: increased productivity, reusability, scalability and easier
maintenance.
Some critics claim OO has not lived up to its advance billing, while others claim its techniques are flawed. OO
isn't flawed, but some of the hype has given OO developers and managers a false sense of security.
Successful OO requires careful analysis and design. Our previous articles have stressed the positive attributes of
OO. This time we'll explore some of the common fallacies of this promising technology and some of the potential
pitfalls.
Fallacies of OO
It is important to have realistic expectations before choosing to use object-oriented technologies. Do not allow
these common fallacies to mislead you.
OO will insure the success of your project: An object-oriented approach to software development does not guarantee
the automatic success of a project. A developer cannot ignore the importance of sound design and architecture. Only
careful analysis and a complete understanding of the problem will make the project succeed. A successful project will
utilize sound techniques, competent programmers, sound processes and solid project management.
OO makes you a better programmer: OO does not make a programmer better. Only experience can do that. A coder might
know all of the OO lingo and syntactical tricks, but if he or she doesn't know when and where to employ these
features, the resulting code will be error-prone and difficult for others to maintain and reuse.
OO-derived software is superior to other forms of software: OO techniques do not make good software; features make
good software. You can use every OO trick in the book, but if the application lacks the features and functionality
users need, no one will use it.
OO techniques mean you don't need to worry about business plans: Before jumping onto the object bandwagon, be
certain to conduct a full business analysis. Don't go in without careful consideration or on the faith of marketing
hype. It is critical to understand the costs as well as the benefits of object-oriented development. If you plan for
only one or two internal development projects, you will see few of the benefits of reuse. You might be able to use
preexisting object-oriented technologies, but rolling your own will not be cost effective.
OO will cure your corporate ills: OO will not solve morale and other corporate problems. If your company suffers
from motivational or morale problems, fix those with other solutions. An OO Band-Aid will only worsen an already
unfortunate situation.
OO Pitfalls
Life is full of compromise and nothing comes without cost. OO is no exception. Before choosing to employ object
technologies it is imperative to understand this. When used properly, OO has many benefits; when used improperly,
however, the results can be disastrous.
OO technologies take time to learn: Don't expect to become an OO expert overnight. Good OO takes time and effort
to learn. Like all technologies, change is the only constant. If you do not continue to enhance and strengthen your
skills, you will fall behind.
OO benefits might not pay off in the short term: Because of the long learning curve and initial extra development
costs, the benefits of increased productivity and reuse might take time to materialize. Don't forget this or you
might be disappointed in your initial OO results.
OO technologies might not fit your corporate culture: The successful application of OO requires that your
development team feels involved. If developers are frequently shifted, they will struggle to deliver reusable
objects. There's less incentive to deliver truly robust, reusable code if you are not required to live with your work
or if you'll never reap the benefits of it.
OO technologies might incur penalties: In general, programs written using object-oriented techniques are larger
and slower than programs written using other techniques. This isn't as much of a problem today. Memory prices are
dropping every day. CPUs continue to provide better performance and compilers and virtual machines continue to
improve. The small efficiency that you trade for increased productivity and reuse should be well worth it. However,
if you're developing an application that tracks millions of data points in real time, OO might not be the answer for
you.
OO techniques are not appropriate for all problems: An OO approach is not an appropriate solution for every
situation. Don't try to put square pegs through round holes! Understand the challenges fully before attempting to
design a solution. As you gain experience, you will begin to learn when and where it is appropriate to use OO
technologies to address a given problem. Careful problem analysis and cost/benefit analysis go a long way in
protecting you from making a mistake.
What do you need to do to avoid these pitfalls and fallacies? The answer is to keep expectations realistic. Beware
of the hype. Use an OO approach only when appropriate.
Programmers should not feel compelled to use every OO trick that the implementation language offers. It is wise to
use only the ones that make sense. When used without forethought, object-oriented techniques could cause more harm
than good.
Of course, there is one other thing that you should always do to improve your OO: Don't miss a single installment of
"Hooked on Objects."
David Hoag is vice president-development and chief object guru for ObjectWave, a Chicago-based
object-oriented software engineering firm. Anthony Sintes is a Sun Certified Java Developer and team member
specializing in telecommunications consulting for ObjectWave. Contact them at [email protected] or visit their Web
site at www.objectwave.com.
This isn't a general discussion of OO pitfalls and conceptual weaknesses, but a discussion of how conventional 'textbook' OO
design approaches can lead to inefficient use of cache & RAM, especially on consoles or other hardware-constrained environments.
But it's still good.
Props to the
artist who actually found a way to visualize most of this meaningless corporate lingo. I'm sure it wasn't easy to come up
with everything.
He missed "sea
change" and "vertical integration". Otherwise, that was pretty much all of the useless corporate meetings I've ever attended
distilled down to 4.5 minutes. Oh, and you're getting laid off and/or no raises this year.
For those too
young to get the joke, this is a style parody of Crosby, Stills & Nash, a folk-pop super-group from the 60's. They were
hippies who spoke out against corporate interests, war, and politics. Al took their sound (flawlessly), and wrote a song in
corporate jargon (the exact opposite of everything CSN was about). It's really brilliant, to those who get the joke.
"The company has
undergone organization optimization due to our strategy modification, which includes empowering the support to the
operation in various global markets" - Red 5 on why they laid off 40 people suddenly. Weird Al would be proud.
In his big long
career this has to be one of the best songs Weird Al's ever done. Very ambitious rendering of one of the most
ambitious songs in pop music history.
This should be
played before corporate meetings to shame anyone who's about to get up and do the usual corporate presentation. Genius
as usual, Mr. Yankovic!
There's a quote
it goes something like: A politician is someone who speaks for hours while saying nothing at all. And this is exactly
it and it's brilliant.
From the current
Gamestop earnings call "address the challenges that have impacted our results, and execute both deliberately and with
urgency. We believe we will transform the business and shape the strategy for the GameStop of the future. This will be
driven by our go-forward leadership team that is now in place, a multi-year transformation effort underway, a commitment
to focusing on the core elements of our business that are meaningful to our future, and a disciplined approach to
capital allocation."" yeah Weird Al totally nailed it
Excuse me, but
"proactive" and "paradigm"? Aren't these just buzzwords that dumb people use to sound important? Not that I'm accusing you
of anything like that. [pause] I'm fired, aren't I?~George Meyer
I watch this at
least once a day to take the edge of my job search whenever I have to decipher fifteen daily want-ads claiming to
seek "Hospitality Ambassadors", "Customer Satisfaction Specialists", "Brand Representatives" and "Team Commitment
Associates" eventually to discover they want someone to run a cash register and sweep up.
The irony is a
song about Corporate Speak in the style of tie-died, hippie-dippy CSN (+/- )Y four-part harmony. Suite Judy Blue Eyes
via Almost Cut My Hair filtered through Carry On. "Fantastic" middle finger to Wall Street,The City, and the monstrous
excesses of Unbridled Capitalism.
If you
understand who and what he's taking a jab at, this is one of the greatest songs and videos of all time. So spot on.
This and Frank's 2000 inch tv are my favorite songs of yours. Thanks Al!
hahaha,
"Client-Centric Solutions...!" (or in my case at the time, 'Customer-Centric' solutions) now THAT's a term i haven't
heard/read/seen in years, since last being an office drone. =D
When I interact
with this musical visual medium I am motivated to conceptualize how the English language can be better compartmentalized
to synergize with the client-centric requirements of the microcosmic community focussed social entities that I
administrate on social media while interfacing energetically about the inherent shortcomings of the current
socio-economic and geo-political order in which we co-habitate. Now does this tedium flow in an effortless stream of
coherent verbalisations capable of comprehension?
When I bought
"Mandatory Fun", put it in my car, and first heard this song, I busted a gut, laughing so hard I nearly crashed.
All the corporate buzzwords!
(except "pivot", apparently).
"I am resolute in my ability to elevate this collaborative, forward-thinking team into the
revenue powerhouse that I believe it can be. We will transition into a DevOps team specialising
in migrating our existing infrastructure entirely to code and go completely serverless!" - CFO
that outsources IT level 2 OpenScore Sysadmin 527 points ·
4 days ago
"We will utilize Artificial Intelligence, machine learning, Cloud technologies, python, data
science and blockchain to achieve business value"
They say, No more IT or system or server admins needed very soon...
Sick and tired of listening to these so called architects and full stack developers who watch bunch of videos on YouTube and Pluralsight,
find articles online. They go around workplace throwing words like containers, devops, NoOps, azure, infrastructure as code, serverless,
etc, they don't understand half of the stuff. I do some of the devops tasks in our company, I understand what it takes to implement
and manage these technologies. Every meeting is infested with these A holes.
Your best defense against these is to come up with non-sarcastic and quality questions to ask these people during the meeting,
and watch them not have a clue how to answer them.
For example, a friend of mine worked at a smallish company, some manager really wanted to move more of their stuff into Azure
including AD and Exchange environment. But they had common problems with their internet connection due to limited bandwidth and
them not wanting to spend more. So during a meeting my friend asked a question something like this:
"You said on this slide that moving the AD environment and Exchange environment to Azure will save us money. Did you take into
account that we will need to increase our internet speed by a factor of at least 4 in order to accommodate the increase in traffic
going out to the Azure cloud? "
Of course, they hadn't. So the CEO asked my friend if he had the numbers, which he had already done his homework, and it was
a significant increase in cost every month and taking into account the cost for Azure and the increase in bandwidth wiped away
the manager's savings.
I know this won't work for everyone. Sometimes there is real savings in moving things to the cloud. But often times there really
isn't. Calling the uneducated people out on what they see as facts can be rewarding. level 2
my previous boss was that kind of a guy. he waited till other people were done throwing their weight around in a meeting and
then calmly and politely dismantled them with facts.
no amount of corporate pressuring or bitching could ever stand up to that. level 3
Ive been trying to do this. Problem is that everyone keeps talking all the way to the end of the meeting leaving no room for
rational facts. level 4 PuzzledSwitch 35 points ·
4 days ago
This is my approach. I don't yell or raise my voice, I just wait. Then I start asking questions that they generally cannot
answer and slowly take them apart. I don't have to be loud to get my point across. level 4
This tactic is called "the box game". Just continuously ask them logical questions that can't be answered with their stupidity.
(Box them in), let them be their own argument against themselves.
Most DevOps I've met are devs trying to bypass the sysadmins. This, and the Cloud fad, are
burning serious amount of money from companies managed by stupid people that get easily impressed by PR stunts and shiny conferences.
Then when everything goes to shit, they call the infrastructure team to fix it...
Boeing screwed up by designing and installing a faulty systems that was unsafe. It did not
even tell the pilots that MCAS existed. It still insists that the system's failure should not
be trained in simulator type training. Boeing's failure and the FAA's negligence, not the
pilots, caused two major accidents.
Nearly a year after the first incident Boeing has still not presented a solution that the
FAA would accept. Meanwhile more safety critical issues on the 737 MAX were found for which
Boeing has still not provided any acceptable solution.
But to Langewiesche this anyway all irrelevant. He closes his piece out with more "blame the
pilots" whitewash of "poor Boeing":
The 737 Max remains grounded under impossibly close scrutiny, and any suggestion that this
might be an overreaction, or that ulterior motives might be at play, or that the Indonesian
and Ethiopian investigations might be inadequate, is dismissed summarily. To top it off,
while the technical fixes to the MCAS have been accomplished, other barely related
imperfections have been discovered and added to the airplane's woes. All signs are that the
reintroduction of the 737 Max will be exceedingly difficult because of political and
bureaucratic obstacles that are formidable and widespread. Who in a position of authority
will say to the public that the airplane is safe?
I would if I were in such a position. What we had in the two downed airplanes was a
textbook failure of airmanship . In broad daylight, these pilots couldn't decipher a variant
of a simple runaway trim, and they ended up flying too fast at low altitude, neglecting to
throttle back and leading their passengers over an aerodynamic edge into oblivion. They were
the deciding factor here -- not the MCAS, not the Max.
One wonders how much Boeing paid the author to assemble his screed.
14,000 Words Of "Blame The Pilots" That Whitewash Boeing Of 737 MAX Failure
The New York Times
No doubt, this WAS intended as a whitewash of Boeing, but having read the 14,000 words, I
don't think it qualifies as more than a somewhat greywash. It is true he blames the pilots
for mishandling a situation that could, perhaps, have been better handled, but Boeing still
comes out of it pretty badly and so does the NTSB. The other thing I took away from the
article is that Airbus planes are, in principle, & by design, more
failsafe/idiot-proof.
Key words: New York Times Magazine. I think when your body is for sale you are called a
whore. Trump's almost hysterical bashing of the NYT is enough to make anyone like the paper,
but at its core it is a mouthpiece for the military industrial complex. Cf. Judith Miller.
The New York Times Magazine just published a 14,000 words piece
An ill-disguised attempt to prepare the ground for premature approval for the 737max. It
won't succeed - impossible. Opposition will come from too many directions. The blowback from
this article will make Boeing regret it very soon, I am quite sure.
Come to think about it: (apart from the MCAS) what sort of crap design is it, if an
absolutely vital control, which the elevator is, can become impossibly stiff under just those
conditions where you absolutely have to be able to move it quickly?
It will only highlight the hubris of "my sh1t doesn't stink" mentality of the American
elite and increase the resolve of other civil aviation authorities with a backbone (or in
ascendancy) to put Boeing through the wringer.
For the longest time FAA was the gold standard and years of "Air Crash Investigation" TV
shows solidified its place but has been taken for granted. Unitl now if it's good enough for
the FAA it's good enough for all.
That reputation has now been irreparably damaged over this sh1tshow. I can't help but
think this NYT article is only meant for domestic sheeple or stock brokers' consumption as
anyone who is going to have anything technical to do with this investigation is going to see
right through this load literal diarroeh.
I wouldn't be surprised if some insider wants to offload some stock and planted this story
ahead of some 737MAX return-to-service timetable announcement to get an uplift. Someone needs
to track the SEC forms 3 4 and 5. But there are also many ways to skirt insider reporting
requirements. As usual, rules are only meant for the rest of us.
Thanks for the ongoing reporting of this debacle b....you are saving peoples lives
@ A.L who wrote
" I wouldn't be surprised if some insider wants to offload some stock and planted this story
ahead of some 737MAX return-to-service timetable announcement to get an uplift. Someone needs
to track the SEC forms 3 4 and 5. But there are also many ways to skirt insider reporting
requirements. As usual, rules are only meant for the rest of us. "
I agree but would pluralize your "insider" to "insiders". This SOP gut and run
financialization strategy is just like we are seeing with Purdue Pharma that just filed
bankruptcy because their opioids have killed so many....the owners will never see jail time
and their profits are protected by the God of Mammon legal system.
Hopefully the WWIII we are engaged in about public/private finance will put an end to this
perfidy by the God of Mammon/private finance cult of the Western form of social
organization.
Peter Lemme, the satcom guru , was
once an engineer at Boeing. He testified over technical MAX issue before Congress and wrote
lot of technical details about it. He retweeted the NYT Mag piece with this comment :
Peter Lemme @Satcom_Guru
Blame the pilots.
Blame the training.
Blame the airline standards.
Imply rampant corruption at all levels.
Claim Airbus flight envelope protection is superior to Boeing.
Fumble the technical details.
Stack the quotes with lots of hearsay to drive the theme.
Ignore everything else
perhaps, just like proponents of AI and self driving cars. They just love the technology,
financially and emotionally invested in it so much they can't see the forest from the
trees.
I like technology, I studied engineering. But the myopic drive to profitability and
naivety to unintended consequences are pushing these tech out into the world before they are
ready.
engineering used to be a discipline with ethics and responsibilities... But now anybody
who could write two lines of code can call themselves a software engineer....
This impostor definitely demonstrated programming abilities, although at the time there was
not such ter :-)
Notable quotes:
"... "We wrote it down. ..."
"... The next phrase was: ..."
"... " ' Booki fai kiz soy ?' " said Whitey. "It means 'Do you surrender?' " ..."
"... " ' Mizi pok loi ooni rak tong zin ?' 'Where are your comrades?' " ..."
"... "Tong what ?" rasped the colonel. ..."
"... "Tong zin , sir," our instructor replied, rolling chalk between his palms. He arched his eyebrows, as though inviting another question. There was one. The adjutant asked, "What's that gizmo on the end?" ..."
"... Of course, it might have been a Japanese newspaper. Whitey's claim to be a linguist was the last of his status symbols, and he clung to it desperately. Looking back, I think his improvisations on the Morton fantail must have been one of the most heroic achievements in the history of confidence men -- which, as you may have gathered by now, was Whitey's true profession. Toward the end of our tour of duty on the 'Canal he was totally discredited with us and transferred at his own request to the 81-millimeter platoon, where our disregard for him was no stigma, since the 81 millimeter musclemen regarded us as a bunch of eight balls anyway. Yet even then, even after we had become completely disillusioned with him, he remained a figure of wonder among us. We could scarcely believe that an impostor could be clever enough actually to invent a language -- phonics, calligraphy, and all. It had looked like Japanese and sounded like Japanese, and during his seventeen days of lecturing on that ship Whitey had carried it all in his head, remembering every variation, every subtlety, every syntactic construction. ..."
a fabulous tale of the South Pacific by William Manchester
The Man Who Could Speak Japanese
"We wrote it down.
The next phrase was:
" ' Booki fai kiz soy ?' " said Whitey. "It means 'Do you surrender?' "
Then:
" ' Mizi pok loi ooni rak tong zin ?' 'Where are your comrades?' "
"Tong what ?" rasped the colonel.
"Tong zin , sir," our instructor replied, rolling chalk between his palms. He arched
his eyebrows, as though inviting another question. There was one. The adjutant asked,
"What's that gizmo on the end?"
Of course, it might have been a Japanese newspaper. Whitey's claim to be a linguist
was the last of his status symbols, and he clung to it desperately. Looking back, I think
his improvisations on the Morton fantail must have been one of the most heroic achievements
in the history of confidence men -- which, as you may have gathered by now, was Whitey's
true profession. Toward the end of our tour of duty on the 'Canal he was totally
discredited with us and transferred at his own request to the 81-millimeter platoon, where
our disregard for him was no stigma, since the 81 millimeter musclemen regarded us as a
bunch of eight balls anyway. Yet even then, even after we had become completely
disillusioned with him, he remained a figure of wonder among us. We could scarcely believe
that an impostor could be clever enough actually to invent a language -- phonics,
calligraphy, and all. It had looked like Japanese and sounded like Japanese, and during his
seventeen days of lecturing on that ship Whitey had carried it all in his head, remembering
every variation, every subtlety, every syntactic construction.
Assume always you're
going to receive something you don't expect. This should be your approach as a defensive programmer, against user
input, or in general things coming into your system. That's because as we said we can expect the unexpected. Try to
be as strict as possible.
Assert
that your input values are what you expect.
The best defense is a good offense
Do whitelists not blacklists, for example when validating an image extension, don't check for the invalid types but
check for the valid types, excluding all the rest. In PHP however you also have an infinite number of open source
validation libraries to make your job easier.
You don't use a
framework (or micro framework) ? Well you like doing extra work for no reason, congratulations! It's not only about
frameworks, but also for new features where you could easily
use something that's already out there,
well tested, trusted by thousands of developers and stable
, rather than crafting something by yourself only for
the sake of it. The only reasons why you should build something by yourself is that you need something that doesn't
exists or that exists but doesn't fit within your needs (bad performance, missing features etc)
That's what is used
to call
intelligent code reuse
. Embrace it
Don't trust
developers
Defensive
programming can be related to something called
Defensive Driving
. In Defensive Driving we assume that everyone around us can
potentially and possibly make mistakes. So we have to be careful even to others' behavior. The same concept applies
to
Defensive Programming where us, as developers shouldn't trust others developers' code
.
We shouldn't trust our code neither.
In big projects,
where many people are involved, we can have many different ways we write and organize code. This can also lead to
confusion and even more bugs. That's because why we should enforce coding styles and mess detector to make our life
easier.
Write SOLID code
That's the tough
part for a (defensive) programmer,
writing code that doesn't suck
. And this is a thing many people know and talk about, but
nobody really cares or put the right amount of attention and effort into it in order to achieve
SOLID
code
.
Let's see some bad
examples
Don't: Uninitialized properties
<?phpclass BankAccount
{
protected $currency = null;
public function setCurrency($currency) { ... }
public function payTo(Account $to, $amount)
{
// sorry for this silly example
$this->transaction->process($to, $amount, $this->currency);
}
}// I forgot to call $bankAccount->setCurrency('GBP');
$bankAccount->payTo($joe, 100);
In this case we have
to remember that for issuing a payment we need to call first
setCurrency
. That's a really bad
thing, a state change operation like that (issuing a payment) shouldn't be done in two steps, using
two(n)
public methods. We can still have many methods to do the payment, but
we must have
only one simple public method in order to change the status
(Objects should never be in an
inconsistent state)
.
In this case we made
it even better, encapsulating the uninitialised property into the
Money
object
<?phpclass BankAccount
{
public function payTo(Account $to, Money $money) { ... }
}$bankAccount->payTo($joe, new Money(100, new Currency('GBP')));
Make it foolproof.
Don't use uninitialized object properties
Don't: Leaking state outside class scope
<?phpclass Message
{
protected $content;
public function setContent($content)
{
$this->content = $content;
}
}class Mailer
{
protected $message;
public function __construct(Message $message)
{
$this->message = $message;
}
public function sendMessage(){
var_dump($this->message);
}
}$message = new Message();
$message->setContent("bob message");
$joeMailer = new Mailer($message);$message->setContent("joe message");
$bobMailer = new Mailer($message);$joeMailer->sendMessage();
$bobMailer->sendMessage();
In this case
Message
is passed by reference and the result will be in both cases
"joe message"
.
A solution would be either cloning the message object in the Mailer constructor. But what we should always try to do
is to use a (
immutable
)
value object
instead of a plain
Message
mutable object.
Use immutable objects when you
can
<?phpclass Message
{
protected $content;
public function __construct($content)
{
$this->content = $content;
}
}class Mailer
{
protected $message;
public function __construct(Message $message)
{
$this->message = $message;
}
public function sendMessage(
{
var_dump($this->message);
}
}$joeMailer = new Mailer(new Message("bob message"));
$bobMailer = new Mailer(new Message("joe message"));$joeMailer->sendMessage();
$bobMailer->sendMessage();
Write tests
We still need to say
that ? Writing unit tests will help you adhering to common principles such as
High Cohesion, Single
Responsibility, Low Coupling and right object composition
. It helps you not only testing the working small unit
case but also the way you structured your object's. Indeed you'll clearly see when testing your small functions how
many cases you need to test and how many objects you need to mock in order to achieve a 100% code coverage
Conclusions
Hope you liked the
article. Remember those are just suggestions, it's up to you to know when, where and if to apply them.
Knuth: Yeah. That's absolutely true. I've got to get another thought out of my mind though.
That is, early on in the TeX project I also had to do programming of a completely different
type. I told you last week that this was my first real exercise in structured programming,
which was one of Dijkstra's huge... That's one of the few breakthroughs in the history of
computer science, in a way. He was actually responsible for maybe two of the ten that I
know.
So I'm doing structured programming as I'm writing TeX. I'm trying to do it right, the way I
should've been writing programs in the 60s. Then I also got this typesetting machine, which
had, inside of it, a tiny 8080 chip or something. I'm not sure exactly. It was a Zilog, or some
very early Intel chip. Way before the 386s. A little computer with 8-bit registers and a small
number of things it could do. I had to write my own assembly language for this, because the
existing software for writing programs for this little micro thing were so bad. I had to write
actually thousands of lines of code for this, in order to control the typesetting. Inside the
machine I had to control a stepper motor, and I had to accelerate it.
Every so often I had to give another [command] saying, "Okay, now take a step," and then
continue downloading a font from the mainframe.
I had six levels of interrupts in this program. I remember talking to you at this time,
saying, "Ed, I'm programming in assembly language for an 8-bit computer," and you said "Yeah,
you've been doing the same thing and it's fun again."
You know, you'll remember. We'll undoubtedly talk more about that when I have my turn
interviewing you in a week or so. This is another aspect of programming: that you also feel
that you're in control and that there's not a black box separating you. It's not only the
power, but it's the knowledge of what's going on; that nobody's hiding something. It's also
this aspect of jumping levels of abstraction. In my opinion, the thing that computer scientists
are best at is seeing things at many levels of detail: high level, intermediate levels, and
lowest levels. I know if I'm adding 1 to a certain number, that this is getting me towards some
big goal at the top. People enjoy most the things that they're good at. Here's a case where if
you're working on a machine that has only this 8-bit capability, but in order to do this you
have to go through levels, of not only that machine, but also to the next level up of the
assembler, and then you have a simulator in which you can help debug your programs, and you
have higher level languages that go through, and then you have the typesetting at the top.
There are these six or seven levels all present at the same time. A computer scientist is in
heaven in a situation like this.
Feigenbaum: Don, to get back, I want to ask you about that as part of the next
question. You went back into programming in a really serious way. It took you, as I said
before, ten years, not one year, and you didn't quit. As soon as you mastered one part of it,
you went into Metafont, which is another big deal. To what extent were you doing that because
you needed to, what I might call expose yourself to, or upgrade your skills in, the art that
had emerged over the decade-and-a-half since you had done RUNCIBLE? And to what extent did you
do it just because you were driven to be a programmer? You loved programming.
Knuth: Yeah. I think your hypothesis is good. It didn't occur to me at the time that
I just had to program in order to be a happy man. Certainly I didn't find my other roles
distasteful, except for fundraising. I enjoyed every aspect of being a professor except dealing
with proposals, which I did my share of, but that was a necessary evil sort of in my own
thinking, I guess. But the fact that now I'm still compelled to I wake up in the morning with
an idea, and it makes my day to think of adding a couple of lines to my program. Gives me a
real high. It must be the way poets feel, or musicians and so on, and other people, painters,
whatever. Programming does that for me. It's certainly true. But the fact that I had to put so
much time in it was not totally that, I'm sure, because it became a responsibility. It wasn't
just for Phyllis and me, as it turned out. I started working on it at the AI lab, and people
were looking at the output coming out of the machine and they would say, "Hey, Don, how did you
do that?" Guy Steele was visiting from MIT that summer and he said, "Don, I want to port this
to take it to MIT." I didn't have two users.
First I had 10, and then I had 100, and then I had 1000. Every time it went to another order
of magnitude I had to change the system, because it would almost match their needs but then
they would have very good suggestions as to something it wasn't covering. Then when it went to
10,000 and when it went to 100,000, the last stage was 10 years later when I made it friendly
for the other alphabets of the world, where people have accented letters and Russian letters.
<p>I had started out with only 7-bit codes. I had so many international users by that
time, I saw that was a fundamental error. I started out with the idea that nobody would ever
want to use a keyboard that could generate more than about 90 characters. It was going to be
too complicated. But I was wrong. So it [TeX] was a burden as well, in the sense that I wanted
to do a responsible job.
I had actually consciously planned an end-game that would take me four years to finish,
and [then] not continue maintaining it and adding on, so that I could have something where I
could say, "And now it's done and it's never going to change." I believe this is one aspect of
software that, not for every system, but for TeX, it was vital that it became something that
wouldn't be a moving target after while.
Feigenbaum: The books on TeX were a period. That is, you put a period down and you
said, "This is it."
Programming skills are somewhat similar to the skills of people who play violin or piano. As
soon a you stop playing violin or piano still start to evaporate. First slowly, then quicker. In
two yours you probably will lose 80%.
Notable quotes:
"... I happened to look the other day. I wrote 35 programs in January, and 28 or 29 programs in February. These are small programs, but I have a compulsion. I love to write programs and put things into it. ..."
Dijkstra said he was proud to be a programmer. Unfortunately he changed his attitude
completely, and I think he wrote his last computer program in the 1980s. At this conference I
went to in 1967 about simulation language, Chris Strachey was going around asking everybody at
the conference what was the last computer program you wrote. This was 1967. Some of the people
said, "I've never written a computer program." Others would say, "Oh yeah, here's what I did
last week." I asked Edsger this question when I visited him in Texas in the 90s and he said,
"Don, I write programs now with pencil and paper, and I execute them in my head." He finds that
a good enough discipline.
I think he was mistaken on that. He taught me a lot of things, but I really think that if he
had continued... One of Dijkstra's greatest strengths was that he felt a strong sense of
aesthetics, and he didn't want to compromise his notions of beauty. They were so intense that
when he visited me in the 1960s, I had just come to Stanford. I remember the conversation we
had. It was in the first apartment, our little rented house, before we had electricity in the
house.
We were sitting there in the dark, and he was telling me how he had just learned about the
specifications of the IBM System/360, and it made him so ill that his heart was actually
starting to flutter.
He intensely disliked things that he didn't consider clean to work with. So I can see that
he would have distaste for the languages that he had to work with on real computers. My
reaction to that was to design my own language, and then make Pascal so that it would work well
for me in those days. But his response was to do everything only intellectually.
So, programming.
I happened to look the other day. I wrote 35 programs in January, and 28 or 29 programs
in February. These are small programs, but I have a compulsion. I love to write programs and
put things into it. I think of a question that I want to answer, or I have part of my book
where I want to present something. But I can't just present it by reading about it in a book.
As I code it, it all becomes clear in my head. It's just the discipline. The fact that I have
to translate my knowledge of this method into something that the machine is going to understand
just forces me to make that crystal-clear in my head. Then I can explain it to somebody else
infinitely better. The exposition is always better if I've implemented it, even though it's
going to take me more time.
So I had a programming hat when I was outside of Cal Tech, and at Cal Tech I am a
mathematician taking my grad studies. A startup company, called Green Tree Corporation because
green is the color of money, came to me and said, "Don, name your price. Write compilers for us
and we will take care of finding computers for you to debug them on, and assistance for you to
do your work. Name your price." I said, "Oh, okay. $100,000.", assuming that this was In that
era this was not quite at Bill Gate's level today, but it was sort of out there.
The guy didn't blink. He said, "Okay." I didn't really blink either. I said, "Well, I'm not
going to do it. I just thought this was an impossible number."
At that point I made the decision in my life that I wasn't going to optimize my income; I
was really going to do what I thought I could do for well, I don't know. If you ask me what
makes me most happy, number one would be somebody saying "I learned something from you". Number
two would be somebody saying "I used your software". But number infinity would be Well, no.
Number infinity minus one would be "I bought your book". It's not as good as "I read your
book", you know. Then there is "I bought your software"; that was not in my own personal value.
So that decision came up. I kept up with the literature about compilers. The Communications of
the ACM was where the action was. I also worked with people on trying to debug the ALGOL
language, which had problems with it. I published a few papers, like "The Remaining Trouble
Spots in ALGOL 60" was one of the papers that I worked on. I chaired a committee called
"Smallgol" which was to find a subset of ALGOL that would work on small computers. I was active
in programming languages.
Frana: You have made the comment several times that maybe 1 in 50 people have the
"computer scientist's mind." Knuth: Yes. Frana: I am wondering if a large number of those
people are trained professional librarians? [laughter] There is some strangeness there. But can
you pinpoint what it is about the mind of the computer scientist that is....
Knuth: That is different?
Frana: What are the characteristics?
Knuth: Two things: one is the ability to deal with non-uniform structure, where you
have case one, case two, case three, case four. Or that you have a model of something where the
first component is integer, the next component is a Boolean, and the next component is a real
number, or something like that, you know, non-uniform structure. To deal fluently with those
kinds of entities, which is not typical in other branches of mathematics, is critical. And the
other characteristic ability is to shift levels quickly, from looking at something in the large
to looking at something in the small, and many levels in between, jumping from one level of
abstraction to another. You know that, when you are adding one to some number, that you are
actually getting closer to some overarching goal. These skills, being able to deal with
nonuniform objects and to see through things from the top level to the bottom level, these are
very essential to computer programming, it seems to me. But maybe I am fooling myself because I
am too close to it.
Frana: It is the hardest thing to really understand that which you are existing
within.
Knuth: Well, certainly it seems the way things are going. You take any particular subject
that you are interested in and you try to see if somebody with an American high school
education has learned it, and you will be appalled. You know, Jesse Jackson thinks that
students know nothing about political science, and I am sure the chemists think that students
don't know chemistry, and so on. But somehow they get it when they have to later. But I would
say certainly the students now have been getting more of a superficial idea of mathematics than
they used to. We have to do remedial stuff at Stanford that we didn't have to do thirty years
ago.
Frana: Gio [Wiederhold] said much the same thing to me.
Knuth: The most scandalous thing was that Stanford's course in linear algebra could not get
to eigenvalues because the students didn't know about complex numbers. Now every course at
Stanford that takes linear algebra as a prerequisite does so because they want the students to
know about eigenvalues. But here at Stanford, with one of the highest admission standards of
any university, our students don't know complex numbers. So we have to teach them that when
they get to college. Yes, this is definitely a breakdown.
Frana: Was your mathematics training in high school particularly good, or was it that you
spent a lot of time actually doing problems?
Knuth: No, my mathematics training in high school was not good. My teachers could not answer
my questions and so I decided I'd go into physics. I mean, I had played with mathematics in
high school. I did a lot of work drawing graphs and plotting points and I used pi as the radix
of a number system, and explored what the world would be like if you wanted to do logarithms
and you had a number system based on pi. And I had played with stuff like that. But my teachers
couldn't answer questions that I had.
... ... ... Frana: Do you have an answer? Are American students different today? In one of
your interviews you discuss the problem of creativity versus gross absorption of knowledge.
Knuth: Well, that is part of it. Today we have mostly a sound byte culture, this lack of
attention span and trying to learn how to pass exams. Frana: Yes,
Knuth: I can be a writer, who tries to organize other people's ideas into some kind of a
more coherent structure so that it is easier to put things together. I can see that I could be
viewed as a scholar that does his best to check out sources of material, so that people get
credit where it is due. And to check facts over, not just to look at the abstract of something,
but to see what the methods were that did it and to fill in holes if necessary. I look at my
role as being able to understand the motivations and terminology of one group of specialists
and boil it down to a certain extent so that people in other parts of the field can use it. I
try to listen to the theoreticians and select what they have done that is important to the
programmer on the street; to remove technical jargon when possible.
But I have never been good at any kind of a role that would be making policy, or advising
people on strategies, or what to do. I have always been best at refining things that are there
and bringing order out of chaos. I sometimes raise new ideas that might stimulate people, but
not really in a way that would be in any way controlling the flow. The only time I have ever
advocated something strongly was with literate programming; but I do this always with the
caveat that it works for me, not knowing if it would work for anybody else.
When I work with a system that I have created myself, I can always change it if I don't like
it. But everybody who works with my system has to work with what I give them. So I am not able
to judge my own stuff impartially. So anyway, I have always felt bad about if anyone says,
'Don, please forecast the future,'...
Knuth description is convoluted and not very convincing. Essntially Perl POD implements that
idea of literate programming inside the Perl interpteter, alloing long fragments of documentation
to be mixed with the test of the program. But this is not enough. Essentially Knuth simply adaped
TeX to provide high level description of what program is doing. But mixing the description and
text has one important problem. While it helps to understand the logic of the program, the
program itself become more difficult to debug as it speds into way too many pages.
So there should be an additional step that provide the capability to separate the
documentation and the program in the programming editor, folding all documentation (or folding
all programming text). You need the capability to see see alternately just documentation of just
program preserving the original line numbers. This issue evades Knuth, who probably mostly works
with paper anyway.
Feigenbaum:
I'd like to do that, to move on to the third period. You've already mentioned one of them, the
retirement issue, and let's talk about that. The second one you mentioned quite early on, which
is the birth in your mind of literate programming, and that's another major development. Before
I quit my little monologue here I also would like to talk about random graphs, because I think
that's a stunning story that needs to be told. Let's talk about either the retirement or
literate programming.
Knuth: I'm glad you brought up literate programming, because it was in my mind the
greatest spinoff of the TeX project. I'm not the best person to judge, but in some ways,
certainly for my own life, it was the main plus I got out of the TeX project was that I learned
a new way to program.
I love programming, but I really love literate programming. The idea of literate programming
is that I'm talking to, I'm writing a program for, a human being to read rather than a
computer to read. It's still a program and it's still doing the stuff, but I'm a teacher to a
person. I'm addressing my program to a thinking being, but I'm also being exact enough so that
a computer can understand it as well.
And that made me think. I'm not sure if I mentioned last week, but I think I did mention
last week, that the genesis of literate programming was that Tony Hoare was interested in
publishing source code for programs. This was a challenge, to find a way to do this, and
literate programming was my answer to this question. That is, if I had to take a large program
like TeX or METAFONT, fairly large, it's 5 or 600 pages of a book--how would you do that?
The answer was to present it as sort of a hypertext, where you have a lot of simple things
connected in simple ways in order to understand the whole. Once I realized that this was a good
way to write programs, then I had this strong urge to go through and take every program I'd
ever written in my life and make it literate. It's so much better than the next best way, I
can't imagine trying to write a program any other way. On the other hand, the next best way is
good enough that people can write lots and lots of very great programs without using literate
programming. So it's not essential that they do. But I do have the gut feeling that if some
company would start using literate programming for all of its software that I would be much
more inclined to buy that software than any other.
Feigenbaum: Just a couple of things about that that you have mentioned to me in the past.
One is your feeling that programs can be beautiful, and therefore they ought to be read like
poetry. The other one is a heuristic that you told me about, which is if you want to get across
an idea, you got to present it two ways: a kind of intuitive way, and a formal way, and that
fits in with literate programming.
Knuth: Right.
Feigenbaum: Do you want to comment on those?
Knuth: Yeah. That's the key idea that I realized as I'm writing The Art of Computer
Programming, the textbook. That the key to good exposition is to say everything twice, or three
times, where I say something informally and formally. The reader gets to lodge it in his brain
in two different ways, and they reinforce each other. All the time I'm giving in my textbooks
I'm saying not only that I'm.. Well, let's see. I'm giving a formula, but I'm also interpreting
the formula as to what it's good for. I'm giving a definition, and immediately I apply the
definition to a simple case, so that the person learns not only the output of the definition --
what it means -- but also to internalize, using it once in your head. Describing a computer
program, it's natural to say everything in the program twice. You say it in English, what the
goals of this part of the program are, but then you say in your computer language -- in the
formal language, whatever language you're using, if it's LISP or Pascal or Fortran or whatever,
C, Java -- you give it in the computer language.
You alternate between the informal and the formal.
Literate programming enforces this idea. It has very interesting effects. I find that, for
example, writing a system program, I did examples with literate programming where I took device
drivers that I received from Sun Microsystems. They had device drivers for one of my printers,
and I rewrote the device driver so that I could combine my laser printer with a previewer that
would get exactly the same raster image. I took this industrial strength software and I redid
it as a literate program. I found out that the literate version was actually a lot better in
several other ways that were completely unexpected to me, because it was more robust.
When you're writing a subroutine in the normal way, a good system program, a subroutine, is
supposed to check that its parameters make sense, or else it's going to crash the machine.
If they don't make sense it tries to do a reasonable error recovery from the bad data. If
you're writing the subroutine in the ordinary way, just start the subroutine, and then all the
code.
Then at the end, if you do a really good job of this testing and error recovery, it turns
out that your subroutine ends up having 30 lines of code for error recovery and checking, and
five lines of code for what the real purpose of the subroutine is. It doesn't look right to
you. You're looking at the subroutine and it looks the purpose of the subroutine is to write
certain error messages out, or something like this.
Since it doesn't quite look right, a programmer, as he's writing it, is suddenly
unconsciously encouraged to minimize the amount of error checking that's going on, and get it
done in some elegant fashion so that you can see what the real purpose of the subroutine is in
these five lines. Okay.
But now with literate programming, you start out, you write the subroutine, and you put a
line in there to say, "Check for errors," and then you do your five lines.
The subroutine looks good. Now you turn the page. On the next page it says, "Check for
errors." Now you're encouraged.
As you're writing the next page, it looks really right to do a good checking for errors.
This kind of thing happened over and over again when I was looking at the industrial software.
This is part of what I meant by some of the effects of it.
But the main point of being able to combine the informal and the formal means that a human
being can understand the code much better than just looking at one or the other, or just
looking at an ordinary program with sprinkled comments. It's so much easier to maintain the
program. In the comments you also explain what doesn't work, or any subtleties. Or you can say,
"Now note the following. Here is the tricky part in line 5, and it works because of this." You
can explain all of the things that a maintainer needs to know.
I'm the maintainer too, but after a year I've forgotten totally what I was thinking when I
wrote the program. All this goes in as part of the literate program, and makes the program
easier to debug, easier to maintain, and better in quality. It does better error messages and
things like that, because of the other effects. That's why I'm so convinced that literate
programming is a great spinoff of the TeX project.
Feigenbaum: Just one other comment. As you describe this, it's the kind of programming
methodology you wish were being used on, let's say, the complex system that controls an
aircraft. But Boeing isn't using it.
Knuth: Yeah. Well, some companies do, but the small ones. Hewlett-Packard had a group in
Boise that was sold on it for a while. I keep getting I got a letter from Korea not so long
ago. The guy says he thinks it's wonderful; he just translated the CWEB manual into Korean. A
lot of people like it, but it doesn't take over. It doesn't get to a critical mass. I think the
reason is that a lot of people don't enjoy writing the English parts. A lot of good programmers
don't enjoy writing the English parts. Two percent of the world's population is born to be
programmers. I don't know what percent is born to be writers, but you have to be in the
intersection in order to be really happy with literate programming. I tried it with Stanford
students. I had seven undergraduates. We did a project leading to the Stanford GraphBase. Six
of the seven did very well with it, and the seventh one hated it.
Feigenbaum: Don, I want to get on to other topics, but you mentioned GWEB. Can you talk
about WEB and GWEB, just because we're trying to be complete?
Knuth: Yeah. It's CWEB. The original WEB language was invented before the [world wide] web
of the internet, but it was the only pronounceable three-letter acronym that hadn't been used
at the time. It described nicely the hypertext idea, which now is why we often refer to the
internet as a web too. CWEB is the version that Silvio Levy ported from the original Pascal.
English and Pascal was WEB. English and C is CWEB. Now it works also with C++. Then there's
FWEB for Fortran, and there's noweb that works with any language. There's all kinds of
spinoffs. There's the one for Lisp. People have written books where they have their own
versions of CWEB too. I got this wonderful book from Germany a year ago that goes through the
entire MP3 standard. The book is not only a textbook that you can use in an undergraduate
course, but it's also a program that will read an MP3 file. The book itself will tell exactly
what's in the MP3 file, including its header and its redundancy check mechanism, plus all the
ways to play the audio, and algorithms for synthesizing music. All of it a part of a textbook,
all part of a literate program. In other words, I see the idea isn't dying. But it's just not
taking over.
Feigenbaum: We've been talking about, as we've been moving toward the third Stanford period
which includes the work on literate programming even though that originated earlier. There was
another event that you told me about which you described as probably your best contribution to
mathematics, the subject of random graphs. It involved a discovery story which I think is very
interesting. If you could sort of wander us through random graphs and what this discovery
was.
"... When you're writing a document for a human being to understand, the human being will look at it and nod his head and say, "Yeah, this makes sense." But then there's all kinds of ambiguities and vagueness that you don't realize until you try to put it into a computer. Then all of a sudden, almost every five minutes as you're writing the code, a question comes up that wasn't addressed in the specification. "What if this combination occurs?" ..."
"... When you're faced with implementation, a person who has been delegated this job of working from a design would have to say, "Well hmm, I don't know what the designer meant by this." ..."
...I showed the second version of this design to two of my graduate students, and I said,
"Okay, implement this, please, this summer. That's your summer job." I thought I had specified
a language. I had to go away. I spent several weeks in China during the summer of 1977, and I
had various other obligations. I assumed that when I got back from my summer trips, I would be
able to play around with TeX and refine it a little bit. To my amazement, the students, who
were outstanding students, had not competed [it]. They had a system that was able to do about
three lines of TeX. I thought, "My goodness, what's going on? I thought these were good
students." Well afterwards I changed my attitude to saying, "Boy, they accomplished a
miracle."
Because going from my specification, which I thought was complete, they really had an
impossible task, and they had succeeded wonderfully with it. These students, by the way, [were]
Michael Plass, who has gone on to be the brains behind almost all of Xerox's Docutech software
and all kind of things that are inside of typesetting devices now, and Frank Liang, one of the
key people for Microsoft Word.
He did important mathematical things as well as his hyphenation methods which are quite used
in all languages now. These guys were actually doing great work, but I was amazed that they
couldn't do what I thought was just sort of a routine task. Then I became a programmer in
earnest, where I had to do it. The reason is when you're doing programming, you have to explain
something to a computer, which is dumb.
When you're writing a document for a human being to understand, the human being will
look at it and nod his head and say, "Yeah, this makes sense." But then there's all kinds of
ambiguities and vagueness that you don't realize until you try to put it into a computer. Then
all of a sudden, almost every five minutes as you're writing the code, a question comes up that
wasn't addressed in the specification. "What if this combination occurs?"
It just didn't occur to the person writing the design specification. When you're faced
with implementation, a person who has been delegated this job of working from a design would
have to say, "Well hmm, I don't know what the designer meant by this."
If I hadn't been in China they would've scheduled an appointment with me and stopped their
programming for a day. Then they would come in at the designated hour and we would talk. They
would take 15 minutes to present to me what the problem was, and then I would think about it
for a while, and then I'd say, "Oh yeah, do this. " Then they would go home and they would
write code for another five minutes and they'd have to schedule another appointment.
I'm probably exaggerating, but this is why I think Bob Floyd's Chiron compiler never got
going. Bob worked many years on a beautiful idea for a programming language, where he designed
a language called Chiron, but he never touched the programming himself. I think this was
actually the reason that he had trouble with that project, because it's so hard to do the
design unless you're faced with the low-level aspects of it, explaining it to a machine instead
of to another person.
Forsythe, I think it was, who said, "People have said traditionally that you don't
understand something until you've taught it in a class. The truth is you don't really
understand something until you've taught it to a computer, until you've been able to program
it." At this level, programming was absolutely important
Having just celebrated my 10000th birthday (in base three), I'm operating a little bit in
history mode. Every once in awhile, people have asked me to record some of my memories of past
events --- I guess because I've been fortunate enough to live at some pretty exciting times,
computersciencewise. These after-the-fact recollections aren't really as reliable as
contemporary records; but they do at least show what I think I remember. And the stories are
interesting, because they involve lots of other people.
So, before these instances of oral history themselves begin to fade from my memory, I've
decided to record some links to several that I still know about:
Interview by Philip L Frana at the Charles Babbage Institute, November 2001
Some extended interviews, not available online, have also been published in books, notably
in Chapters 7--17 of Companion to the Papers of Donald
Knuth (conversations with Dikran Karagueuzian in the summer of 1996), and in two
books by Edgar G. Daylight, The Essential Knuth (2013), Algorithmic Barriers
Falling (2014).
Knuth: No, I stopped going to conferences. It was too discouraging. Computer programming
keeps getting harder because more stuff is discovered. I can cope with learning about one new
technique per day, but I can't take ten in a day all at once. So conferences are depressing; it
means I have so much more work to do. If I hide myself from the truth I am much happier.
"... Also, Addison-Wesley was the people who were asking me to do this book; my favorite textbooks had been published by Addison Wesley. They had done the books that I loved the most as a student. For them to come to me and say, "Would you write a book for us?", and here I am just a secondyear gradate student -- this was a thrill. ..."
"... But in those days, The Art of Computer Programming was very important because I'm thinking of the aesthetical: the whole question of writing programs as something that has artistic aspects in all senses of the word. The one idea is "art" which means artificial, and the other "art" means fine art. All these are long stories, but I've got to cover it fairly quickly. ..."
Knuth: This is, of course, really the story of my life, because I hope to live long enough
to finish it. But I may not, because it's turned out to be such a huge project. I got married
in the summer of 1961, after my first year of graduate school. My wife finished college, and I
could use the money I had made -- the $5000 on the compiler -- to finance a trip to Europe for
our honeymoon.
We had four months of wedded bliss in Southern California, and then a man from
Addison-Wesley came to visit me and said "Don, we would like you to write a book about how to
write compilers."
The more I thought about it, I decided "Oh yes, I've got this book inside of me."
I sketched out that day -- I still have the sheet of tablet paper on which I wrote -- I
sketched out 12 chapters that I thought ought to be in such a book. I told Jill, my wife, "I
think I'm going to write a book."
As I say, we had four months of bliss, because the rest of our marriage has all been devoted
to this book. Well, we still have had happiness. But really, I wake up every morning and I
still haven't finished the book. So I try to -- I have to -- organize the rest of my life
around this, as one main unifying theme. The book was supposed to be about how to write a
compiler. They had heard about me from one of their editorial advisors, that I knew something
about how to do this. The idea appealed to me for two main reasons. One is that I did enjoy
writing. In high school I had been editor of the weekly paper. In college I was editor of the
science magazine, and I worked on the campus paper as copy editor. And, as I told you, I wrote
the manual for that compiler that we wrote. I enjoyed writing, number one.
Also, Addison-Wesley was the people who were asking me to do this book; my favorite
textbooks had been published by Addison Wesley. They had done the books that I loved the most
as a student. For them to come to me and say, "Would you write a book for us?", and here I am
just a secondyear gradate student -- this was a thrill.
Another very important reason at the time was that I knew that there was a great need for a
book about compilers, because there were a lot of people who even in 1962 -- this was January
of 1962 -- were starting to rediscover the wheel. The knowledge was out there, but it hadn't
been explained. The people who had discovered it, though, were scattered all over the world and
they didn't know of each other's work either, very much. I had been following it. Everybody I
could think of who could write a book about compilers, as far as I could see, they would only
give a piece of the fabric. They would slant it to their own view of it. There might be four
people who could write about it, but they would write four different books. I could present all
four of their viewpoints in what I would think was a balanced way, without any axe to grind,
without slanting it towards something that I thought would be misleading to the compiler writer
for the future. I considered myself as a journalist, essentially. I could be the expositor, the
tech writer, that could do the job that was needed in order to take the work of these brilliant
people and make it accessible to the world. That was my motivation. Now, I didn't have much
time to spend on it then, I just had this page of paper with 12 chapter headings on it. That's
all I could do while I'm a consultant at Burroughs and doing my graduate work. I signed a
contract, but they said "We know it'll take you a while." I didn't really begin to have much
time to work on it until 1963, my third year of graduate school, as I'm already finishing up on
my thesis. In the summer of '62, I guess I should mention, I wrote another compiler. This was
for Univac; it was a FORTRAN compiler. I spent the summer, I sold my soul to the devil, I guess
you say, for three months in the summer of 1962 to write a FORTRAN compiler. I believe that the
salary for that was $15,000, which was much more than an assistant professor. I think assistant
professors were getting eight or nine thousand in those days.
Feigenbaum: Well, when I started in 1960 at [University of California] Berkeley, I was
getting $7,600 for the nine-month year.
Knuth: Knuth: Yeah, so you see it. I got $15,000 for a summer job in 1962 writing a
FORTRAN compiler. One day during that summer I was writing the part of the compiler that looks
up identifiers in a hash table. The method that we used is called linear probing. Basically you
take the variable name that you want to look up, you scramble it, like you square it or
something like this, and that gives you a number between one and, well in those days it would
have been between 1 and 1000, and then you look there. If you find it, good; if you don't find
it, go to the next place and keep on going until you either get to an empty place, or you find
the number you're looking for. It's called linear probing. There was a rumor that one of
Professor Feller's students at Princeton had tried to figure out how fast linear probing works
and was unable to succeed. This was a new thing for me. It was a case where I was doing
programming, but I also had a mathematical problem that would go into my other [job]. My winter
job was being a math student, my summer job was writing compilers. There was no mix. These
worlds did not intersect at all in my life at that point. So I spent one day during the summer
while writing the compiler looking at the mathematics of how fast does linear probing work. I
got lucky, and I solved the problem. I figured out some math, and I kept two or three sheets of
paper with me and I typed it up. ["Notes on 'Open' Addressing', 7/22/63] I guess that's on the
internet now, because this became really the genesis of my main research work, which developed
not to be working on compilers, but to be working on what they call analysis of algorithms,
which is, have a computer method and find out how good is it quantitatively. I can say, if I
got so many things to look up in the table, how long is linear probing going to take. It dawned
on me that this was just one of many algorithms that would be important, and each one would
lead to a fascinating mathematical problem. This was easily a good lifetime source of rich
problems to work on. Here I am then, in the middle of 1962, writing this FORTRAN compiler, and
I had one day to do the research and mathematics that changed my life for my future research
trends. But now I've gotten off the topic of what your original question was.
Feigenbaum: We were talking about sort of the.. You talked about the embryo of The Art of
Computing. The compiler book morphed into The Art of Computer Programming, which became a
seven-volume plan.
Knuth: Exactly. Anyway, I'm working on a compiler and I'm thinking about this. But now I'm
starting, after I finish this summer job, then I began to do things that were going to be
relating to the book. One of the things I knew I had to have in the book was an artificial
machine, because I'm writing a compiler book but machines are changing faster than I can write
books. I have to have a machine that I'm totally in control of. I invented this machine called
MIX, which was typical of the computers of 1962.
In 1963 I wrote a simulator for MIX so that I could write sample programs for it, and I
taught a class at Caltech on how to write programs in assembly language for this hypothetical
computer. Then I started writing the parts that dealt with sorting problems and searching
problems, like the linear probing idea. I began to write those parts, which are part of a
compiler, of the book. I had several hundred pages of notes gathering for those chapters for
The Art of Computer Programming. Before I graduated, I've already done quite a bit of writing
on The Art of Computer Programming.
I met George Forsythe about this time. George was the man who inspired both of us [Knuth and
Feigenbaum] to come to Stanford during the '60s. George came down to Southern California for a
talk, and he said, "Come up to Stanford. How about joining our faculty?" I said "Oh no, I can't
do that. I just got married, and I've got to finish this book first." I said, "I think I'll
finish the book next year, and then I can come up [and] start thinking about the rest of my
life, but I want to get my book done before my son is born." Well, John is now 40-some years
old and I'm not done with the book. Part of my lack of expertise is any good estimation
procedure as to how long projects are going to take. I way underestimated how much needed to be
written about in this book. Anyway, I started writing the manuscript, and I went merrily along
writing pages of things that I thought really needed to be said. Of course, it didn't take long
before I had started to discover a few things of my own that weren't in any of the existing
literature. I did have an axe to grind. The message that I was presenting was in fact not going
to be unbiased at all. It was going to be based on my own particular slant on stuff, and that
original reason for why I should write the book became impossible to sustain. But the fact that
I had worked on linear probing and solved the problem gave me a new unifying theme for the
book. I was going to base it around this idea of analyzing algorithms, and have some
quantitative ideas about how good methods were. Not just that they worked, but that they worked
well: this method worked 3 times better than this method, or 3.1 times better than this method.
Also, at this time I was learning mathematical techniques that I had never been taught in
school. I found they were out there, but they just hadn't been emphasized openly, about how to
solve problems of this kind.
So my book would also present a different kind of mathematics than was common in the
curriculum at the time, that was very relevant to analysis of algorithm. I went to the
publishers, I went to Addison Wesley, and said "How about changing the title of the book from
'The Art of Computer Programming' to 'The Analysis of Algorithms'." They said that will never
sell; their focus group couldn't buy that one. I'm glad they stuck to the original title,
although I'm also glad to see that several books have now come out called "The Analysis of
Algorithms", 20 years down the line.
But in those days, The Art of Computer Programming was very important because I'm
thinking of the aesthetical: the whole question of writing programs as something that has
artistic aspects in all senses of the word. The one idea is "art" which means artificial, and
the other "art" means fine art. All these are long stories, but I've got to cover it fairly
quickly.
I've got The Art of Computer Programming started out, and I'm working on my 12 chapters. I
finish a rough draft of all 12 chapters by, I think it was like 1965. I've got 3,000 pages of
notes, including a very good example of what you mentioned about seeing holes in the fabric.
One of the most important chapters in the book is parsing: going from somebody's algebraic
formula and figuring out the structure of the formula. Just the way I had done in seventh grade
finding the structure of English sentences, I had to do this with mathematical sentences.
Chapter ten is all about parsing of context-free language, [which] is what we called it at
the time. I covered what people had published about context-free languages and parsing. I got
to the end of the chapter and I said, well, you can combine these ideas and these ideas, and
all of a sudden you get a unifying thing which goes all the way to the limit. These other ideas
had sort of gone partway there. They would say "Oh, if a grammar satisfies this condition, I
can do it efficiently." "If a grammar satisfies this condition, I can do it efficiently." But
now, all of a sudden, I saw there was a way to say I can find the most general condition that
can be done efficiently without looking ahead to the end of the sentence. That you could make a
decision on the fly, reading from left to right, about the structure of the thing. That was
just a natural outgrowth of seeing the different pieces of the fabric that other people had put
together, and writing it into a chapter for the first time. But I felt that this general
concept, well, I didn't feel that I had surrounded the concept. I knew that I had it, and I
could prove it, and I could check it, but I couldn't really intuit it all in my head. I knew it
was right, but it was too hard for me, really, to explain it well.
So I didn't put in The Art of Computer Programming. I thought it was beyond the scope of my
book. Textbooks don't have to cover everything when you get to the harder things; then you have
to go to the literature. My idea at that time [is] I'm writing this book and I'm thinking it's
going to be published very soon, so any little things I discover and put in the book I didn't
bother to write a paper and publish in the journal because I figure it'll be in my book pretty
soon anyway. Computer science is changing so fast, my book is bound to be obsolete.
It takes a year for it to go through editing, and people drawing the illustrations, and then
they have to print it and bind it and so on. I have to be a little bit ahead of the
state-of-the-art if my book isn't going to be obsolete when it comes out. So I kept most of the
stuff to myself that I had, these little ideas I had been coming up with. But when I got to
this idea of left-to-right parsing, I said "Well here's something I don't really understand
very well. I'll publish this, let other people figure out what it is, and then they can tell me
what I should have said." I published that paper I believe in 1965, at the end of finishing my
draft of the chapter, which didn't get as far as that story, LR(k). Well now, textbooks of
computer science start with LR(k) and take off from there. But I want to give you an idea
of
"... Most mainstream OO languages with a type system to speak of actually get in the way of correctly classifying data by confusing the separate issues of reusing implementation artefacts (aka subclassing) and classifying data into a hierarchy of concepts (aka subtyping). ..."
Most mainstream OO languages with a type system to speak of actually get in the way of correctly classifying data by
confusing the separate issues of reusing implementation artefacts (aka subclassing) and classifying data into a hierarchy
of concepts (aka subtyping).
The only widely used OO language (for sufficiently narrow values of wide and wide values
of OO) to get that right used to be Objective Caml, and recently its stepchildren F# and scala. So it is actually FP
that helps you with the classification.
This is a very interesting point and should be highlighted. You said implementation artifacts (especially in reference
to reducing code duplication), and for clarity, I think you are referring to the definition of operators on data (class
methods, friend methods, and so on).
I agree with you that subclassing (for the purpose of reusing behavior), traits
(for adding behavior), and the like can be confused with classification to such an extent that modern designs tend to
depart from type systems and be used for mere code organization.
"was there really a point to the illusion of wrapping the entrypoint main() function in a class (I am looking at you,
Java)?"
Far be it for me to defend Java (I hate the damn thing), but: main is just a function in a class. The class is the
entry point, as specified in the command line; main is just what the OS looks for, by convention. You could have a "main"
in each class, but only the one in the specified class will be the entry point.
The way of the theorist is to tell any non-theorist that the non-theorist is wrong, then leave without any explanation.
Or, simply hand-wave the explanation away, claiming it as "too complex" too fully understand without years of rigorous
training. Of course I jest. :)
The 80286 Intel processors: The Intel 80286[3] (also marketed as the iAPX 286[4] and often called Intel 286) is a 16-bit
microprocessor that was introduced on February 1, 1982. The 80286 was employed for the IBM PC/AT, introduced in 1984, and then
widely used in most PC/AT compatible computers until the early 1990s.
Notable quotes:
"... The fate of Boeing's civil aircraft business hangs on the re-certification of the 737 MAX. The regulators convened an international meeting to get their questions answered and Boeing arrogantly showed up without having done its homework. The regulators saw that as an insult. Boeing was sent back to do what it was supposed to do in the first place: provide details and analysis that prove the safety of its planes. ..."
"... In recent weeks, Boeing and the FAA identified another potential flight-control computer risk requiring additional software changes and testing, according to two of the government and pilot officials. ..."
"... Any additional software changes will make the issue even more complicated. The 80286 Intel processors the FCC software is running on is limited in its capacity. All the extras procedures Boeing now will add to them may well exceed the system's capabilities. ..."
"... The old architecture was possible because the plane could still be flown without any computer. It was expected that the pilots would detect a computer error and would be able to intervene. The FAA did not require a high design assurance level (DAL) for the system. The MCAS accidents showed that a software or hardware problem can now indeed crash a 737 MAX plane. That changes the level of scrutiny the system will have to undergo. ..."
"... Flight safety regulators know of these complexities. That is why they need to take a deep look into such systems. That Boeing's management was not prepared to answer their questions shows that the company has not learned from its failure. Its culture is still one of finance orientated arrogance. ..."
"... I also want to add that Boeing's focus on profit over safety is not restricted to the 737 Max but undoubtedly permeates the manufacture of spare parts for the rest of the their plane line and all else they make.....I have no intention of ever flying in another Boeing airplane, given the attitude shown by Boeing leadership. ..."
"... So again, Boeing mgmt. mirrors its Neoliberal government officials when it comes to arrogance and impudence. ..."
"... Arrogance? When the money keeps flowing in anyway, it comes naturally. ..."
"... In the neoliberal world order governments, regulators and the public are secondary to corporate profits. ..."
"... I am surprised that none of the coverage has mentioned the fact that, if China's CAAC does not sign off on the mods, it will cripple, if not doom the MAX. ..."
"... I am equally surprised that we continue to sabotage China's export leader, as the WSJ reports today: "China's Huawei Technologies Co. accused the U.S. of "using every tool at its disposal" to disrupt its business, including launching cyberattacks on its networks and instructing law enforcement to "menace" its employees. ..."
"... Boeing is backstopped by the Murkan MIC, which is to say the US taxpayer. ..."
"... Military Industrial Complex welfare programs, including wars in Syria and Yemen, are slowly winding down. We are about to get a massive bill from the financiers who already own everything in this sector, because what they have left now is completely unsustainable, with or without a Third World War. ..."
"... In my mind, the fact that Boeing transferred its head office from Seattle (where the main manufacturing and presumable the main design and engineering functions are based) to Chicago (centre of the neoliberal economic universe with the University of Chicago being its central shrine of worship, not to mention supply of future managers and administrators) in 1997 says much about the change in corporate culture and values from a culture that emphasised technical and design excellence, deliberate redundancies in essential functions (in case of emergencies or failures of core functions), consistently high standards and care for the people who adhered to these principles, to a predatory culture in which profits prevail over people and performance. ..."
"... For many amerikans, a good "offensive" is far preferable than a good defense even if that only involves an apology. Remember what ALL US presidents say.. We will never apologize.. ..."
"... Actually can you show me a single place in the US where ethics are considered a bastion of governorship? ..."
"... You got to be daft or bribed to use intel cpu's in embedded systems. Going from a motorolla cpu, the intel chips were dinosaurs in every way. ..."
"... Initially I thought it was just the new over-sized engines they retro-fitted. A situation that would surely have been easier to get around by just going back to the original engines -- any inefficiencies being less $costly than the time the planes have been grounded. But this post makes the whole rabbit warren 10 miles deeper. ..."
"... That is because the price is propped up by $9 billion share buyback per year . Share buyback is an effective scheme to airlift all the cash out of a company towards the major shareholders. I mean, who wants to develop reliable airplanes if you can funnel the cash into your pockets? ..."
"... If Boeing had invested some of this money that it blew on share buybacks to design a new modern plane from ground up to replace the ancient 737 airframe, these tragedies could have been prevented, and Boeing wouldn't have this nightmare on its hands. But the corporate cost-cutters and financial engineers, rather than real engineers, had the final word. ..."
"... Markets don't care about any of this. They don't care about real engineers either. They love corporate cost-cutters and financial engineers. They want share buybacks, and if something bad happens, they'll overlook the $5 billion to pay for the fallout because it's just a "one-time item." ..."
"... Overall, Boeing buy-backs exceeded 40 billion dollars, one could guess that half or quarter of that would suffice to build a plane that logically combines the latest technologies. E.g. the entire frame design to fit together with engines, processors proper for the information processing load, hydraulics for steering that satisfy force requirements in almost all circumstances etc. New technologies also fail because they are not completely understood, but when the overall design is logical with margins of safety, the faults can be eliminated. ..."
"... Once the buyback ends the dive begins and just before it hits ground zero, they buy the company for pennies on the dollar, possibly with government bailout as a bonus. Then the company flies towards the next climb and subsequent dive. MCAS economics. ..."
"... The problem is not new, and it is well understood. What computer modelling is is cheap, and easy to fudge, and that is why it is popular with people who care about money a lot. Much of what is called "AI" is very similar in its limitations, a complicated way to fudge up the results you want, or something close enough for casual examination. ..."
United Airline and American Airlines furtherprolonged the
grounding of their Boeing 737 MAX airplanes. They now schedule the plane's return to the flight
line in December. But it is likely that the grounding will continue well into the next
year.
After Boeing's
shabby design and lack of safety analysis of its Maneuver Characteristics Augmentation
System (MCAS) led to the death of 347 people, the grounding of the type and billions of losses,
one would expect the company to show some decency and humility. Unfortunately Boeing behavior
demonstrates none.
There is still little detailed information on how Boeing will fix MCAS. Nothing was said by
Boeing about the manual trim system of the 737 MAX that
does not work when it is needed . The unprotected rudder cables of the plane
do not meet safety guidelines but were still certified. The planes flight control computers
can be
overwhelmed by bad data and a fix will be difficult to implement. Boeing continues to say
nothing about these issues.
International flight safety regulators no longer trust the Federal Aviation Administration
(FAA) which failed to uncover those problems when it originally certified the new type. The FAA
was also the last regulator to ground the plane after two 737 MAX had crashed. The European
Aviation Safety Agency (EASA) asked Boeing to explain and correct
five major issues it identified. Other regulators asked additional questions.
Boeing needs to regain the trust of the airlines, pilots and passengers to be able to again
sell those planes. Only full and detailed information can achieve that. But the company does
not provide any.
As Boeing sells some 80% of its airplanes abroad it needs the good will of the international
regulators to get the 737 MAX back into the air. This makes the arrogance
it displayed in a meeting with those regulators inexplicable:
Friction between Boeing Co. and international air-safety authorities threatens a new delay in
bringing the grounded 737 MAX fleet back into service, according to government and pilot
union officials briefed on the matter.
The latest complication in the long-running saga, these officials said, stems from a
Boeing briefing in August that was cut short by regulators from the U.S., Europe, Brazil and
elsewhere, who complained that the plane maker had failed to provide technical details and
answer specific questions about modifications in the operation of MAX flight-control
computers.
The fate of Boeing's civil aircraft business hangs on the re-certification of the 737 MAX.
The regulators convened an international meeting to get their questions answered and Boeing
arrogantly showed up without having done its homework. The regulators saw that as an insult.
Boeing was sent back to do what it was supposed to do in the first place: provide details and
analysis that prove the safety of its planes.
What did the Boeing managers think those regulatory agencies are? Hapless lapdogs like the
FAA managers`who
signed off on Boeing 'features' even after their engineers told them that these were not
safe?
Buried in the Wall Street Journal
piece quoted above is another little shocker:
In recent weeks, Boeing and the FAA identified another potential flight-control computer risk
requiring additional software changes and testing, according to two of the government and
pilot officials.
The new issue must be going beyond the flight control computer (FCC) issues the FAA
identified in June .
Boeing's original plan to fix the uncontrolled activation of MCAS was to have both FCCs
active at the same time and to switch MCAS off when the two computers disagree. That was
already a huge change in the general architecture which so far consisted of one active and one
passive FCC system that could be switched over when a failure occurred.
Any additional software changes will make the issue even more complicated. The 80286 Intel
processors the FCC software is running on is limited in its capacity. All the extras procedures
Boeing now will add to them may well exceed the system's capabilities.
Changing software in a delicate environment like a flight control computer is extremely
difficult. There will always be surprising side effects or regressions where already corrected
errors unexpectedly reappear.
The old architecture was possible because the plane could still be flown without any
computer. It was expected that the pilots would detect a computer error and would be able to
intervene. The FAA did not require a high design assurance level (DAL) for the system. The MCAS
accidents showed that a software or hardware problem can now indeed crash a 737 MAX plane. That
changes the level of scrutiny the system will have to undergo.
All procedures and functions of the software will have to be tested in all thinkable
combinations to ensure that they will not block or otherwise influence each other. This will
take months and there is a high chance that new issues will appear during these tests. They
will require more software changes and more testing.
Flight safety regulators know of these complexities. That is why they need to take a deep
look into such systems. That Boeing's management was not prepared to answer their questions
shows that the company has not learned from its failure. Its culture is still one of finance
orientated arrogance.
Building safe airplanes requires engineers who know that they may make mistakes and who have
the humility to allow others to check and correct their work. It requires open communication
about such issues. Boeing's say-nothing strategy will prolong the grounding of its planes. It
will increases the damage to Boeing's financial situation and reputation.
---
Previous Moon of Alabama posts on Boeing 737 MAX issues:
"The 80286 Intel processors the FCC software is running on is limited in its capacity."
You must be joking, right?
If this is the case, the problem is unfixable: you can't find two competent software
engineers who can program these dinosaur 16-bit processors.
You must be joking, right?
If this is the case, the problem is unfixable: you can't find two competent software
engineers who can program these dinosaur 16-bit processors.
One of the two is writing this.
Half-joking aside. The 737 MAX FCC runs on 80286 processors. There are ten thousands of
programmers available who can program them though not all are qualified to write real-time
systems. That resource is not a problem. The processors inherent limits are one.
Thanks b for the fine 737 max update. Others news sources seem to have dropped coverage. It
is a very big deal that this grounding has lasted this long. Things are going to get real bad
for Boeing if this bird does not get back in the air soon. In any case their credibility is
tarnished if not down right trashed.
What ever software language these are programmed in (my guess is C) the compilers still
exist for it and do the translation from the human readable code to the machine code for you.
Of course the code could be assembler but writing assembly code for a 286 is far easier than
writing it for say an i9 becuase the CPU is so much simpler and has a far smaller set of
instructions to work with.
@b:
It was a hyperbole.
I might be another one, but left them behind as fast as I could. The last time I had to deal
with it was an embedded system in 1998-ish. But I am also retiring, and so are thousands of
others. The problems with support of a legacy system are a legend.
I commented when you first started writing about this that it would take Boeing down and
still believe that to be true. To the extent that Boeing is stonewalling the international
safety regulators says to me that upper management and big stock holders are being given time
to minimize their exposure before the axe falls.
I also want to add that Boeing's focus on profit over safety is not restricted to the 737
Max but undoubtedly permeates the manufacture of spare parts for the rest of the their plane
line and all else they make.....I have no intention of ever flying in another Boeing
airplane, given the attitude shown by Boeing leadership.
This is how private financialization works in the Western world. Their bottom line is
profit, not service to the flying public. It is in line with the recent public statement by
the CEO's from the Business Roundtable that said that they were going to focus more on
customer satisfaction over profit but their actions continue to say profit is their primary
motive.
The God of Mammon private finance religion can not end soon enough for humanity's sake. It
is not like we all have to become China but their core public finance example is well worth
following.
So again, Boeing mgmt. mirrors its Neoliberal government officials when it comes to arrogance
and impudence. IMO, Boeing shareholders's hair ought to be on fire given their BoD's behavior
and getting ready to litigate.
As b notes, Boeing's international credibility's hanging by a
very thin thread. A year from now, Boeing could very well see its share price deeply dive
into the Penny Stock category--its current P/E is 41.5:1 which is massively overpriced.
Boeing Bombs might come to mean something vastly different from its initial meaning.
Such seemingly archaic processors are the norm in aerospace. If the planes flight
characteristics had been properly engineered from the start the processor wouldn't be an
issue. You can't just spray perfume on a garbage pile and call it a rose.
In the neoliberal world order governments, regulators and the public are secondary to
corporate profits. This is the same belief system that is suspending the British Parliament
to guarantee the chaos of a no deal Brexit. The irony is that globalist, Joe Biden's restart
the Cold War and nationalist Donald Trump's Trade Wars both assure that foreign regulators
will closely scrutinize the safety of the 737 Max. Even if ignored by corporate media and
cleared by the FAA to fly in the USA, Boeing and Wall Street's Dow Jones average are cooked
gooses with only 20% of the market. Taking the risk of flying the 737 Max on their family
vacation or to their next business trip might even get the credentialed class to realize that
their subservient service to corrupt Plutocrats is deadly in the long term.
"The latest complication in the long-running saga, these officials said, stems from a Boeing
BA, -2.66% briefing in August that was cut short by regulators from the U.S., Europe, Brazil
and elsewhere, who complained that the plane maker had failed to provide technical details
and answer specific questions about modifications in the operation of MAX flight-control
computers."
It seems to me that Boeing had no intention to insult anybody, but it has an impossible
task. After decades of applying duct tape and baling wire with much success, they finally
designed an unfixable plane, and they can either abandon this line of business (narrow bodied
airliners) or start working on a new design grounded in 21st century technologies.
Boeing's military sales are so much more significant and important to them, they are just
ignoring/down-playing their commercial problem with the 737 MAX. Follow the real money.
That is unblievable FLight Control comptuer is based on 80286!
A control system needs Real Time operation, at least some pre-emptive task operation, in
terms of milisecond or microsecond.
What ever way you program 80286 you can not achieve RT operation on 80286.
I do not think that is the case.
My be 80286 is doing some pripherial work, other than control.
It is quite likely (IMHO) that they are no longer able to provide the requested
information, but of course they cannot say that.
I once wrote a keyboard driver for an 80286, part of an editor, in assembler, on my first
PC type computer, I still have it around here somewhere I think, the keyboard driver, but I
would be rusty like the Titanic when it comes to writing code. I wrote some things in DEC
assembler too, on VAXen.
arata @16: 80286 does interrupts just fine, but you have to grok asynchronous operation, and
most coders don't really, I see that every day in Linux and my browser. I wish I could get
that box back, it had DOS, you could program on the bare wires, but God it was slow.
Boeing recently lost a $6+Billion weapons contract thanks to its similar Q&A in that
realm of its business. Its annual earnings are due out in October. Plan to short-sell
soon!
I am surprised that none of the coverage has mentioned the fact that, if China's CAAC does
not sign off on the mods, it will cripple, if not doom the MAX.
I am equally surprised that we continue to sabotage China's export leader, as the WSJ
reports today: "China's Huawei Technologies Co. accused the U.S. of "using every tool at its
disposal" to disrupt its business, including launching cyberattacks on its networks and
instructing law enforcement to "menace" its employees.
The telecommunications giant also said
law enforcement in the U.S. have searched, detained and arrested Huawei employees and its
business partners, and have sent FBI agents to the homes of its workers to pressure them to
collect information on behalf of the U.S."
I wonder how much blind trust in Boeing is intertwined into the fabric of civic aviation all
around the world.
I mean something like this: Boeing publishes some research into failure statistics, solid
materials aging or something. One that is really hard and expensive to proceed with.
Everything take the results for granted without trying to independently reproduce and verify,
because The Boeing!
Some later "derived" researches being made, upon the foundation of some
prior works *including* that old Boeing research. Then FAA and similar company institutions
around the world make some official regulations and guidelines deriving from the research
which was in part derived form original Boeing work. Then insurance companies calculate their
tarifs and rate plans, basing their estimation upon those "government standards", and when
governments determine taxation levels they use that data too. Then airline companies and
airliner leasing companies make their business plans, take huge loans in the banks (and banks
do make their own plans expecting those loans to finally be paid back), and so on and so
forth, building the cards-deck house, layer after layer.
And among the very many of the cornerstones - there would be dust covered and
god-forgotten research made by Boeing 10 or maybe 20 years ago when no one even in drunk
delirium could ever imagine questioning Boeing's verdicts upon engineering and scientific
matters.
Now, the longevity of that trust is slowly unraveled. Like, the so universally trusted
737NG generation turned out to be inherently unsafe, and while only pilots knew it before,
and even of them - only most curious and pedantic pilots, today it becomes public knowledge
that 737NG are tainted.
Now, when did this corruption started? Wheat should be some deadline cast into the past,
that since the day every other technical data coming from Boeing should be considered
unreliable unless passing full-fledged independent verification? Should that day be somewhere
in 2000-s? 1990-s? Maybe even 1970-s?
And ALL THE BODY of civic aviation industry knowledge that was accumulated since that date
can NO MORE BE TRUSTED and should be almost scrapped and re-researched new! ALL THE tacit
INPUT that can be traced back to Boeing and ALL THE DERIVED KNOWLEDGE now has to be verified
in its entirety.
Boeing is backstopped by the Murkan MIC, which is to say the US taxpayer. Until the lawsuits
become too enormous.
I wonder how much that will cost. And speaking of rigged markets - why do ya suppose that
Trumpilator et al have been
so keen to make huge sales to the Saudis, etc. etc. ? Ya don't suppose they had an inkling of
trouble in the wind do ya? Speaking of insiders, how many million billions do ya suppose is
being made in the Wall Street "trade war" roller coaster by peeps, munchkins not muppets, who
have access to the Tweeter-in-Chief?
I commented when you first started writing about this that it would take Boeing down and
still believe that to be true. To the extent that Boeing is stonewalling the international
safety regulators says to me that upper management and big stock holders are being given
time to minimize their exposure before the axe falls.
Have you considered the costs of restructuring versus breaking apart Boeing and selling it
into little pieces; to the owners specifically?
The MIC is restructuring itself - by first creating the political conditions to make the
transformation highly profitable. It can only be made highly profitable by forcing the public
to pay the associated costs of Rape and Pillage Incorporated.
Military Industrial Complex welfare programs, including wars in Syria and Yemen, are
slowly winding down. We are about to get a massive bill from the financiers who already own
everything in this sector, because what they have left now is completely unsustainable, with
or without a Third World War.
It is fine that you won't fly Boeing but that is not the point. You may not ever fly again
since air transit is subsidized at every level and the US dollar will no longer be available
to fund the world's air travel infrastructure.
You will instead be paying for the replacement of Boeing and seeing what google is
planning it may not be for the renewal of the airline business but rather for dedicated
ground transportation, self driving cars and perhaps 'aerospace' defense forces, thank you
Russia for setting the trend.
As readers may remember I made a case study of Boeing for a fairly recent PHD. The examiners
insisted that this case study be taken out because it was "speculative." I had forecast
serious problems with the 787 and the 737 MAX back in 2012. I still believe the 787 is
seriously flawed and will go the way of the MAX. I came to admire this once brilliant company
whose work culminated in the superb 777.
America really did make some excellent products in the 20th century - with the exception
of cars. Big money piled into GM from the early 1920s, especially the ultra greedy, quasi
fascist Du Pont brothers, with the result that GM failed to innovate. It produced beautiful
cars but technically they were almost identical to previous models.
The only real innovation
over 40 years was automatic transmission. Does this sound reminiscent of the 737 MAX? What
glued together GM for more than thirty years was the brilliance of CEO Alfred Sloan who
managed to keep the Du Ponts (and J P Morgan) more or less happy while delegating total
responsibility for production to divisional managers responsible for the different GM brands.
When Sloan went the company started falling apart and the memoirs of bad boy John DeLorean
testify to the complete disfunctionality of senior management.
At Ford the situation was perhaps even worse in the 1960s and 1970s. Management was at war
with the workers, faulty transmissions were knowingly installed. All this is documented in an
excellent book by ex-Ford supervisor Robert Dewar in his book "A Savage Factory."
Well, the first thing that came to mind upon reading about Boeing's apparent arrogance
overseas - silly, I know - was that Boeing may be counting on some weird Trump sanctions
for anyone not cooperating with the big important USian corporation! The U.S. has influence
on European and many other countries, but it can only be stretched so far, and I would guess
messing with Euro/internation airline regulators, especially in view of the very real fatal
accidents with the 737MAX, would be too far.
Please read the following article to get further info about how the 5 big Funds that hold 67%
of Boeing stocks are working hard with the big banks to keep the stock high. Meanwhile Boeing
is also trying its best to blackmail US taxpayers through Pentagon, for example, by
pretending to walk away from a competitive bidding contract because it wants the Air Force to
provide better cost formula.
So basically, Boeing is being kept afloat by US taxpayers because it is "too big to fail"
and an important component of Dow. Please tell. Who is the biggest suckers here?
re Piotr Berman | Sep 3 2019 21:11 utc
[I have a tiny bit of standing in this matter based on experience with an amazingly similar
situation that has not heretofore been mentioned. More at end. Thus I offer my opinion.]
Indeed, an impossible task to design a workable answer and still maintain the fiction that
737MAX is a hi-profit-margin upgrade requiring minimal training of already-trained 737-series
pilots , either male or female.
Turning-off autopilot to bypass runaway stabilizer necessitates :
[1]
the earlier 737-series "rollercoaster" procedure to overcome too-high aerodynamic forces
must be taught and demonstrated as a memory item to all pilots.
The procedure was designed
for early Model 737-series, not the 737MAX which has uniquely different center-of-gravity and
pitch-up problem requiring MCAS to auto-correct, especially on take-off.
[2] but the "rollercoaster" procedure does not work at all altitudes.
It causes aircraft to
lose some altitude and, therefore, requires at least [about] 7,000-feet above-ground
clearance to avoid ground contact. [This altitude loss consumed by the procedure is based on
alleged reports of simulator demonstrations. There seems to be no known agreement on the
actual amount of loss].
[3] The physical requirements to perform the "rollercoaster" procedure were established at a
time when female pilots were rare.
Any 737MAX pilots, male or female, will have to pass new
physical requirements demonstrating actual conditions on newly-designed flight simulators
that mimic the higher load requirements of the 737MAX . Such new standards will also have to
compensate for left vs right-handed pilots because the manual-trim wheel is located between
the .pilot/copilot seats.
================
Now where/when has a similar situation occurred? I.e., wherein a Federal regulator agency
[FAA] allowed a vendor [Boeing] to claim that a modified product did not need full
inspection/review to get agency certification of performance [airworthiness].
As you may know, 2 working, nuclear, power plants were forced to shut down and be
decommissioned when, in 2011, 2 newly-installed, critical components in each plant were
discovered to be defective, beyond repair and not replaceable. These power plants were each
producing over 1,000 megawatts of power for over 20 years. In short, the failed components
were modifications of the original, successful design that claimed to need only a low-level
of Federal Nuclear Regulatory Commission oversight and approval. The mods were, in fact, new
and untried and yet only tested by computer modeling and theoretical estimations based on
experience with smaller/different designs.
<<< The NRC had not given full inspection/oversight to the new units because of
manufacturer/operator claims that the changes were not significant. The NRC did not verify
the veracity of those claims. >>>
All 4 components [2 required in each plant] were essentially heat-exchangers weighing 640
tons each, having 10,000 tubes carrying radioactive water surrounded by [transferring their
heat to] a separate flow of "clean" water. The tubes were progressively damaged and began
leaking. The new design failed. It can not be fixed. Thus, both plants of the San Onofre
Nuclear Generating Station are now a complete loss and await dismantling [as the courts will
decide who pays for the fiasco].
In my mind, the fact that Boeing transferred its head office from Seattle (where the main
manufacturing and presumable the main design and engineering functions are based) to Chicago
(centre of the neoliberal economic universe with the University of Chicago being its central
shrine of worship, not to mention supply of future managers and administrators) in 1997 says
much about the change in corporate culture and values from a culture that emphasised
technical and design excellence, deliberate redundancies in essential functions (in case of
emergencies or failures of core functions), consistently high standards and care for the
people who adhered to these principles, to a predatory culture in which profits prevail over
people and performance.
Good article. Boeing is, or used to be, America's biggest manufacturing export. So you are
right it cannot be allowed to fail. Boeing is also a manufacturer of military aircraft. The
fact that it is now in such a pitiful state is symptomatic of America's decline and decadence
and its takeover by financial predators.
They did the same with Nortel, whose share value exceeded 300 billion not long before it was
scrapped. Insiders took everything while pension funds were wiped out of existence.
It is so very helpful to understand everything you read is corporate/intel propaganda, and
you are always being setup to pay for the next great scam. The murder of 300+ people by
boeing was yet another tragedy our sadistic elites could not let go to waste.
For many amerikans, a good "offensive" is far preferable than a good defense even if that
only involves an apology. Remember what ALL US presidents say.. We will never apologize.. For
the extermination of natives, for shooting down civilian airliners, for blowing up mosques
full of worshipers, for bombing hospitals.. for reducing many countries to the stone age and
using biological
and chemical and nuclear weapons against the planet.. For supporting terrorists who plague
the planet now. For basically being able to be unaccountable to anyone including themselves
as a peculiar race of feces. So it is not the least surprising that amerikan corporations
also follow the same bad manners as those they put into and pre-elect to rule them.
People talk about Seattle as if its a bastion of integrity.. Its the same place Microsoft
screwed up countless companies to become the largest OS maker? The same place where Amazon
fashions how to screw its own employees to work longer and cheaper? There are enough examples
that Seattle is not Toronto.. and will never be a bastion of ethics..
Actually can you show
me a single place in the US where ethics are considered a bastion of governorship? Other than
the libraries of content written about ethics, rarely do amerikans ever follow it. Yet expect
others to do so.. This is getting so perverse that other cultures are now beginning to
emulate it. Because its everywhere..
Remember Dallas? I watched people who saw in fascination
how business can function like that. Well they cant in the long run but throw enough money
and resources and it works wonders in the short term because it destroys the competition. But
yea around 1998 when they got rid of the laws on making money by magic, most every thing has
gone to hell.. because now there are no constraints but making money.. anywhich way.. Thats
all that matters..
You got to be daft or bribed to use intel cpu's in embedded systems. Going from a motorolla
cpu, the intel chips were dinosaurs in every way. Requiring the cpu to be almost twice as
fast to get the same thing done.. Also its interrupt control was not upto par. A simple
example was how the commodore amiga could read from the disk and not stutter or slow down
anything else you were doing. I never seen this fixed.. In fact going from 8Mhz to 4GHz seems
to have fixed it by brute force. Yes the 8Mhz motorolla cpu worked wonders when you had
music, video, IO all going at the same time. Its not just the CPU but the support chips which
don't lock up the bus. Why would anyone use Intel? When there are so many specific embedded
controllers designed for such specific things.
Initially I thought it was just the new over-sized engines they retro-fitted. A situation
that would surely have been easier to get around by just going back to the original engines
-- any inefficiencies being less $costly than the time the planes have been grounded. But
this post makes the whole rabbit warren 10 miles deeper.
I do not travel much these days and
find the cattle-class seating on these planes a major disincentive. Becoming aware of all
these added technical issues I will now positively select for alternatives to 737 and bear
the cost.
I'm surprised Boeing stock still haven't taken nose dive
Posted by: Bob burger | Sep 3 2019 19:27 utc | 9
That is because the price is propped up by
$9 billion share buyback per year . Share buyback is an effective scheme to airlift all
the cash out of a company towards the major shareholders. I mean, who wants to develop
reliable airplanes if you can funnel the cash into your pockets?
Once the buyback ends the dive begins and just before it hits ground zero, they buy the
company for pennies on the dollar, possibly with government bailout as a bonus. Then the
company flies towards the next climb and subsequent dive. MCAS economics.
Hi , I am new here in writing but not in reading..
About the 80286 , where is the coprocessor the 80287?
How can the 80286 make IEEE math calculations?
So how can it fly a controlled flight when it can not calculate its accuracy......
How is it possible that this system is certified?
It should have at least a 80386 DX not SX!!!!
moved to Chicago in 1997 says much about the change in corporate culture and values from a
culture that emphasised technical and design excellence, deliberate redundancies in essential
functions (in case of emergencies or failures of core functions), consistently high standards
and care for the people who adhered to these principles, to a predatory culture in which
profits prevail over people and performance.
Jen @ 35
< ==
yes, the morally of the companies and their exclusive hold on a complicit or
controlled government always defaults the government to support, enforce and encourage the
principles of economic Zionism.
But it is more than just the corporate culture => the corporate fat cats
1. use the rule-making powers of the government to make law for them. Such laws create high
valued assets from the pockets of the masses. The most well know of those corporate uses of
government is involved with the intangible property laws (copyright, patent, and government
franchise). The government generated copyright, franchise and Patent laws are monopolies. So
when government subsidizes a successful outcome R&D project its findings are packaged up
into a set of monopolies [copyrights, privatized government franchises which means instead of
50 companies or more competing for the next increment in technology, one gains the full
advantage of that government research only one can use or abuse it. and the patented and
copyrighted technology is used to extract untold billions, in small increments from the
pockets of the public.
2. use of the judicial power of governments and their courts in both domestic and
international settings, to police the use and to impose fake values in intangible property
monopolies. Government-rule made privately owned monopoly rights (intangible property rights)
generated from the pockets of the masses, do two things: they exclude, deny and prevent would
be competition and their make value in a hidden revenue tax that passes to the privately held
monopolist with each sale of a copyrighted, government franchised, or patented service or
product. .
Please note the one two nature of the "use of government law making powers to generate
intangible private monopoly property rights"
There is no doubt Boeing has committed crimes on the 737MAX, its arrogance & greedy
should be severely punished by the international commitment as an example to other global
Corporations. It represents what is the worst of Corporate America that places profits in
front of lives.
How the U.S. is keeping Russia out of the international market?
Iran and other sanctioned countries are a potential captive market and they have growth
opportunities in what we sometimes call the non-aligned, emerging markets countries (Turkey,
Africa, SE Asia, India, ...).
One thing I have learned is that the U.S. always games the system, we never play fair. So
what did we do. Do their manufacturers use 1% U.S. made parts and they need that for
international certification?
Ultimately all of the issues in the news these days are the same one and the
same issue - as the US gets closer and closer to the brink of catastrophic collapse they get
ever more desperate. As they get more and more desperate they descend into what comes most
naturally to the US - throughout its entire history - frenzied violence, total absence of
morality, war, murder, genocide, and everything else that the US is so well known for (by
those who are not blinded by exceptionalist propaganda).
The Hong Kong violence is a perfect example - it is impossible that a self-respecting
nation state could allow itself to be seen to degenerate into such idiotic degeneracy, and so
grossly flaunt the most basic human decency. Ergo , the US is not a self-respecting
nation state. It is a failed state.
I am certain the arrogance of Boeing reflects two things: (a) an assurance from the US
government that the government will back them to the hilt, come what may, to make sure that
the 737Max flies again; and (b) a threat that if Boeing fails to get the 737Max in the air
despite that support, the entire top level management and board of directors will be jailed.
Boeing know very well they cannot deliver. But just as the US government is desperate
to avoid the inevitable collapse of the US, the Boeing top management are desperate to avoid
jail. It is a charade.
It is time for international regulators to withdraw certification totally - after the
problems are all fixed (I don't believe they ever will be), the plane needs complete new
certification of every detail from the bottom up, at Boeing's expense, and with total
openness from Boeing. The current Boeing management are not going to cooperate with that,
therefore the international regulators need to demand a complete replacement of the
management and board of directors as a condition for working with them.
If Boeing had invested some of this money that it blew on share buybacks to design a new
modern plane from ground up to replace the ancient 737 airframe, these tragedies could have
been prevented, and Boeing wouldn't have this nightmare on its hands. But the corporate
cost-cutters and financial engineers, rather than real engineers, had the final word.
Markets don't care about any of this. They don't care about real engineers either. They
love corporate cost-cutters and financial engineers. They want share buybacks, and if
something bad happens, they'll overlook the $5 billion to pay for the fallout because it's
just a "one-time item."
And now Boeing still has this plane, instead of a modern plane, and the history of this
plane is now tainted, as is its brand, and by extension, that of Boeing. But markets blow
that off too. Nothing matters.
Companies are getting away each with their own thing. There are companies that are losing
a ton of money and are burning tons of cash, with no indications that they will ever make
money. And market valuations are just ludicrous.
======
Thus Boeing issue is part of a much larger picture. Something systemic had to make
"markets" less rational. And who is this "market"? In large part, fund managers wracking
their brains how to create "decent return" while the cost of borrowing and returns on lending
are super low. What remains are forms of real estate and stocks.
Overall, Boeing buy-backs exceeded 40 billion dollars, one could guess that half or
quarter of that would suffice to build a plane that logically combines the latest
technologies. E.g. the entire frame design to fit together with engines, processors proper
for the information processing load, hydraulics for steering that satisfy force requirements
in almost all circumstances etc. New technologies also fail because they are not completely
understood, but when the overall design is logical with margins of safety, the faults can be
eliminated.
Instead, 737 was slowly modified toward failure, eliminating safety margins one by
one.
Boeing has apparently either never heard of, or ignores a procedure that is mandatory in
satellite design and design reviews. This is FMEA or Failure Modes and Effects Analysis. This
requires design engineers to document the impact of every potential failure and combination
of failures thereby highlighting everthing from catastrophic effects to just annoyances.
Clearly BOEING has done none of these and their troubles are a direct result. It can be
assumed that their arrogant and incompetent management has not yet understood just how
serious their behavior is to the future of the company.
Once the buyback ends the dive begins and just before it hits ground zero, they buy the
company for pennies on the dollar, possibly with government bailout as a bonus. Then the
company flies towards the next climb and subsequent dive. MCAS economics.
Computer modelling is what they are talking about in the cliche "Garbage in, garbage out".
The problem is not new, and it is well understood. What computer modelling is is cheap,
and easy to fudge, and that is why it is popular with people who care about money a lot. Much
of what is called "AI" is very similar in its limitations, a complicated way to fudge up the
results you want, or something close enough for casual examination.
In particular cases where you have a well-defined and well-mathematized theory, then you
can get some useful results with models. Like in Physics, Chemistry.
And they can be useful for "realistic" training situations, like aircraft simulators. The
old story about wargame failures against Iran is another such situation. A lot of video games
are big simulations in essence. But that is not reality, it's fake reality.
@ SteveK9 71 "By the way, the problem was caused by Mitsubishi, who designed the heat
exchangers."
Ahh. The furriners...
I once made the "mistake" of pointing out (in a comment under an article in Salon) that the
reactors that exploded at Fukushima was made by GE and that GE people was still in charge of
the reactors of American quality when they exploded. (The amerikans got out on one of the
first planes out of the country).
I have never seen so many angry replies to one of my comments. I even got e-mails for several weeks from angry Americans.
@Henkie #53
You need floating point for scientific calculations, but I really doubt the 737 is doing any
scientific research.
Also, a regular CPU can do mathematical calculations. It just isn't as fast nor has the same
capacity as a dedicated FPU.
Another common use for FPUs is in live action shooter games - the neo-physics portions
utilize scientific-like calculations to create lifelike actions. I sold computer systems in
the 1990s while in school - Doom was a significant driver for newer systems (as well as hedge
fund types).
Again, don't see why an airplane needs this.
Have you ever heard of SEMA ? It's a fairly esoteric system for
measuring how good a software team is. No, wait! Don't follow that link! It will take
you about six years just to understand that stuff. So I've come up with my own, highly
irresponsible, sloppy test to rate the quality of a software team. The great part about it is
that it takes about 3 minutes. With all the time you save, you can go to medical school.
The Joel Test
Do you use source control?
Can you make a build in one step?
Do you make daily builds?
Do you have a bug database?
Do you fix bugs before writing new code?
Do you have an up-to-date schedule?
Do you have a spec?
Do programmers have quiet working conditions?
Do you use the best tools money can buy?
Do you have testers?
Do new candidates write code during their interview?
Do you do hallway usability testing?
The neat thing about The Joel Test is that it's easy to get a quick yes or no
to each question. You don't have to figure out lines-of-code-per-day or
average-bugs-per-inflection-point. Give your team 1 point for each "yes" answer. The bummer
about The Joel Test is that you really shouldn't use it to make sure that your nuclear
power plant software is safe.
A score of 12 is perfect, 11 is tolerable, but 10 or lower and you've got serious problems.
The truth is that most software organizations are running with a score of 2 or 3, and they need
serious help, because companies like Microsoft run at 12 full-time.
Of course, these are not the only factors that determine success or failure: in particular,
if you have a great software team working on a product that nobody wants, well, people aren't
going to want it. And it's possible to imagine a team of "gunslingers" that doesn't do any of
this stuff that still manages to produce incredible software that changes the world. But, all
else being equal, if you get these 12 things right, you'll have a disciplined team that can
consistently deliver.
1. Do you use source control?
I've used commercial source control packages, and I've used CVS , which is free, and let me tell you, CVS is fine .
But if you don't have source control, you're going to stress out trying to get programmers to
work together. Programmers have no way to know what other people did. Mistakes can't be rolled
back easily. The other neat thing about source control systems is that the source code itself
is checked out on every programmer's hard drive -- I've never heard of a project using source
control that lost a lot of code.
2. Can you make a build in one step?
By this I mean: how many steps does it take to make a shipping build from the latest source
snapshot? On good teams, there's a single script you can run that does a full checkout from
scratch, rebuilds every line of code, makes the EXEs, in all their various versions, languages,
and #ifdef combinations, creates the installation package, and creates the final media -- CDROM
layout, download website, whatever.
If the process takes any more than one step, it is prone to errors. And when you get closer
to shipping, you want to have a very fast cycle of fixing the "last" bug, making the final
EXEs, etc. If it takes 20 steps to compile the code, run the installation builder, etc., you're
going to go crazy and you're going to make silly mistakes.
For this very reason, the last company I worked at switched from WISE to InstallShield: we
required that the installation process be able to run, from a script, automatically,
overnight, using the NT scheduler, and WISE couldn't run from the scheduler overnight, so we
threw it out. (The kind folks at WISE assure me that their latest version does support nightly
builds.)
3. Do you make daily builds?
When you're using source control, sometimes one programmer accidentally checks in something
that breaks the build. For example, they've added a new source file, and everything compiles
fine on their machine, but they forgot to add the source file to the code repository. So they
lock their machine and go home, oblivious and happy. But nobody else can work, so they have to
go home too, unhappy.
Breaking the build is so bad (and so common) that it helps to make daily builds, to insure
that no breakage goes unnoticed. On large teams, one good way to insure that breakages are
fixed right away is to do the daily build every afternoon at, say, lunchtime. Everyone does as
many checkins as possible before lunch. When they come back, the build is done. If it worked,
great! Everybody checks out the latest version of the source and goes on working. If the build
failed, you fix it, but everybody can keep on working with the pre-build, unbroken version of
the source.
On the Excel team we had a rule that whoever broke the build, as their "punishment", was
responsible for babysitting the builds until someone else broke it. This was a good incentive
not to break the build, and a good way to rotate everyone through the build process so that
everyone learned how it worked.
4. Do you have a bug database?
I don't care what you say. If you are developing code, even on a team of one, without an
organized database listing all known bugs in the code, you are going to ship low quality code.
Lots of programmers think they can hold the bug list in their heads. Nonsense. I can't remember
more than two or three bugs at a time, and the next morning, or in the rush of shipping, they
are forgotten. You absolutely have to keep track of bugs formally.
Bug databases can be complicated or simple. A minimal useful bug database must include the
following data for every bug:
complete steps to reproduce the bug
expected behavior
observed (buggy) behavior
who it's assigned to
whether it has been fixed or not
If the complexity of bug tracking software is the only thing stopping you from tracking your
bugs, just make a simple 5 column table with these crucial fields and start using it
.
5. Do you fix bugs before writing new code?
The very first version of Microsoft Word for Windows was considered a "death march" project. It
took forever. It kept slipping. The whole team was working ridiculous hours, the project was
delayed again, and again, and again, and the stress was incredible. When the dang thing finally
shipped, years late, Microsoft sent the whole team off to Cancun for a vacation, then sat down
for some serious soul-searching.
What they realized was that the project managers had been so insistent on keeping to the
"schedule" that programmers simply rushed through the coding process, writing extremely bad
code, because the bug fixing phase was not a part of the formal schedule. There was no attempt
to keep the bug-count down. Quite the opposite. The story goes that one programmer, who had to
write the code to calculate the height of a line of text, simply wrote "return 12;" and waited
for the bug report to come in about how his function is not always correct. The schedule was
merely a checklist of features waiting to be turned into bugs. In the post-mortem, this was
referred to as "infinite defects methodology".
To correct the problem, Microsoft universally adopted something called a "zero defects
methodology". Many of the programmers in the company giggled, since it sounded like management
thought they could reduce the bug count by executive fiat. Actually, "zero defects" meant that
at any given time, the highest priority is to eliminate bugs before writing any new
code. Here's why.
In general, the longer you wait before fixing a bug, the costlier (in time and money) it is
to fix.
For example, when you make a typo or syntax error that the compiler catches, fixing it is
basically trivial.
When you have a bug in your code that you see the first time you try to run it, you will be
able to fix it in no time at all, because all the code is still fresh in your mind.
If you find a bug in some code that you wrote a few days ago, it will take you a while to
hunt it down, but when you reread the code you wrote, you'll remember everything and you'll be
able to fix the bug in a reasonable amount of time.
But if you find a bug in code that you wrote a few months ago, you'll probably have
forgotten a lot of things about that code, and it's much harder to fix. By that time you may be
fixing somebody else's code, and they may be in Aruba on vacation, in which case, fixing
the bug is like science: you have to be slow, methodical, and meticulous, and you can't be sure
how long it will take to discover the cure.
And if you find a bug in code that has already shipped , you're going to incur
incredible expense getting it fixed.
That's one reason to fix bugs right away: because it takes less time. There's another
reason, which relates to the fact that it's easier to predict how long it will take to
write new code than to fix an existing bug. For example, if I asked you to predict how long it
would take to write the code to sort a list, you could give me a pretty good estimate. But if I
asked you how to predict how long it would take to fix that bug where your code doesn't work if
Internet Explorer 5.5 is installed, you can't even guess , because you don't know (by
definition) what's causing the bug. It could take 3 days to track it down, or it could
take 2 minutes.
What this means is that if you have a schedule with a lot of bugs remaining to be fixed, the
schedule is unreliable. But if you've fixed all the known bugs, and all that's left is
new code, then your schedule will be stunningly more accurate.
Another great thing about keeping the bug count at zero is that you can respond much faster
to competition. Some programmers think of this as keeping the product ready to ship at
all times. Then if your competitor introduces a killer new feature that is stealing your
customers, you can implement just that feature and ship on the spot, without having to fix a
large number of accumulated bugs.
6. Do you have an up-to-date schedule?
Which brings us to schedules. If your code is at all important to the business, there are lots
of reasons why it's important to the business to know when the code is going to be done.
Programmers are notoriously crabby about making schedules. "It will be done when it's done!"
they scream at the business people.
Unfortunately, that just doesn't cut it. There are too many planning decisions that the
business needs to make well in advance of shipping the code: demos, trade shows, advertising,
etc. And the only way to do this is to have a schedule, and to keep it up to date.
The other crucial thing about having a schedule is that it forces you to decide what
features you are going to do, and then it forces you to pick the least important features and
cut them rather than slipping into featuritis (a.k.a. scope
creep).
Keeping schedules does not have to be hard. Read my article Painless Software Schedules ,
which describes a simple way to make great schedules.
7. Do you have a spec?
Writing specs is like flossing: everybody agrees that it's a good thing, but nobody does
it.
I'm not sure why this is, but it's probably because most programmers hate writing documents.
As a result, when teams consisting solely of programmers attack a problem, they prefer to
express their solution in code, rather than in documents. They would much rather dive in and
write code than produce a spec first.
At the design stage, when you discover problems, you can fix them easily by editing a few
lines of text. Once the code is written, the cost of fixing problems is dramatically higher,
both emotionally (people hate to throw away code) and in terms of time, so there's resistance
to actually fixing the problems. Software that wasn't built from a spec usually winds up badly
designed and the schedule gets out of control. This seems to have been the problem at Netscape,
where the first four versions grew into such a mess that management stupidly decided to throw out
the code and start over. And then they made this mistake all over again with Mozilla, creating
a monster that spun out of control and took several years to get to alpha stage.
My pet theory is that this problem can be fixed by teaching programmers to be less reluctant
writers by sending them off to take an
intensive course in writing . Another solution is to hire smart program managers who
produce the written spec. In either case, you should enforce the simple rule "no code without
spec".
Learn all about writing specs by reading my 4-part series .
8. Do programmers have quiet working conditions?
There are extensively documented productivity gains provided by giving knowledge workers space,
quiet, and privacy. The classic software management book Peopleware
documents these productivity benefits extensively.
Here's the trouble. We all know that knowledge workers work best by getting into "flow",
also known as being "in the zone", where they are fully concentrated on their work and fully
tuned out of their environment. They lose track of time and produce great stuff through
absolute concentration. This is when they get all of their productive work done. Writers,
programmers, scientists, and even basketball players will tell you about being in the zone.
The trouble is, getting into "the zone" is not easy. When you try to measure it, it looks
like it takes an average of 15 minutes to start working at maximum productivity. Sometimes, if
you're tired or have already done a lot of creative work that day, you just can't get into the
zone and you spend the rest of your work day fiddling around, reading the web, playing
Tetris.
The other trouble is that it's so easy to get knocked out of the zone. Noise, phone
calls, going out for lunch, having to drive 5 minutes to Starbucks for coffee, and
interruptions by coworkers -- especially interruptions by coworkers -- all knock you out
of the zone. If a coworker asks you a question, causing a 1 minute interruption, but this
knocks you out of the zone badly enough that it takes you half an hour to get productive again,
your overall productivity is in serious trouble. If you're in a noisy bullpen environment like
the type that caffeinated dotcoms love to create, with marketing guys screaming on the phone
next to programmers, your productivity will plunge as knowledge workers get interrupted time
after time and never get into the zone.
With programmers, it's especially hard. Productivity depends on being able to juggle a lot
of little details in short term memory all at once. Any kind of interruption can cause these
details to come crashing down. When you resume work, you can't remember any of the details
(like local variable names you were using, or where you were up to in implementing that search
algorithm) and you have to keep looking these things up, which slows you down a lot until you
get back up to speed.
Here's the simple algebra. Let's say (as the evidence seems to suggest) that if we interrupt
a programmer, even for a minute, we're really blowing away 15 minutes of productivity. For this
example, lets put two programmers, Jeff and Mutt, in open cubicles next to each other in a
standard Dilbert veal-fattening farm. Mutt can't remember the name of the Unicode version of
the strcpy function. He could look it up, which takes 30 seconds, or he could ask Jeff, which
takes 15 seconds. Since he's sitting right next to Jeff, he asks Jeff. Jeff gets distracted and
loses 15 minutes of productivity (to save Mutt 15 seconds).
Now let's move them into separate offices with walls and doors. Now when Mutt can't remember
the name of that function, he could look it up, which still takes 30 seconds, or he could ask
Jeff, which now takes 45 seconds and involves standing up (not an easy task given the average
physical fitness of programmers!). So he looks it up. So now Mutt loses 30 seconds of
productivity, but we save 15 minutes for Jeff. Ahhh!
9. Do you use the best tools money can buy?
Writing code in a compiled language is one of the last things that still can't be done
instantly on a garden variety home computer. If your compilation process takes more than a few
seconds, getting the latest and greatest computer is going to save you time. If compiling takes
even 15 seconds, programmers will get bored while the compiler runs and switch over to reading
The Onion , which will suck them in and
kill hours of productivity.
Debugging GUI code with a single monitor system is painful if not impossible. If you're
writing GUI code, two monitors will make things much easier.
Most programmers eventually have to manipulate bitmaps for icons or toolbars, and most
programmers don't have a good bitmap editor available. Trying to use Microsoft Paint to
manipulate bitmaps is a joke, but that's what most programmers have to do.
At my last
job , the system administrator kept sending me automated spam complaining that I was using
more than ... get this ... 220 megabytes of hard drive space on the server. I pointed out that
given the price of hard drives these days, the cost of this space was significantly less than
the cost of the toilet paper I used. Spending even 10 minutes cleaning up my directory
would be a fabulous waste of productivity.
Top notch development teams don't torture their programmers. Even minor frustrations
caused by using underpowered tools add up, making programmers grumpy and unhappy. And a grumpy
programmer is an unproductive programmer.
To add to all this... programmers are easily bribed by giving them the coolest, latest
stuff. This is a far cheaper way to get them to work for you than actually paying competitive
salaries!
10. Do you have testers?
If your team doesn't have dedicated testers, at least one for every two or three programmers,
you are either shipping buggy products, or you're wasting money by having $100/hour programmers
do work that can be done by $30/hour testers. Skimping on testers is such an outrageous false
economy that I'm simply blown away that more people don't recognize it.
11. Do new candidates write code during their interview?
Would you hire a magician without asking them to show you some magic tricks? Of course not.
Would you hire a caterer for your wedding without tasting their food? I doubt it. (Unless
it's Aunt Marge, and she would hate you for ever if you didn't let her make her "famous"
chopped liver cake).
Yet, every day, programmers are hired on the basis of an impressive resumé or because
the interviewer enjoyed chatting with them. Or they are asked trivia questions ("what's the
difference between CreateDialog() and DialogBox()?") which could be answered by looking at the
documentation. You don't care if they have memorized thousands of trivia about programming, you
care if they are able to produce code. Or, even worse, they are asked "AHA!" questions: the
kind of questions that seem easy when you know the answer, but if you don't know the answer,
they are impossible.
Please, just stop doing this . Do whatever you want during interviews, but make the
candidate write some code . (For more advice, read my Guerrilla Guide to Interviewing
.)
12. Do you do hallway usability testing? A hallway usability test is where
you grab the next person that passes by in the hallway and force them to try to use the code
you just wrote. If you do this to five people, you will learn 95% of what there is to learn
about usability problems in your code.
Good user interface design is not as hard as you would think, and it's crucial if you want
customers to love and buy your product. You can read my free online book on UI
design , a short primer for programmers.
But the most important thing about user interfaces is that if you show your program to a
handful of people, (in fact, five or six is enough) you will quickly discover the biggest
problems people are having. Read Jakob Nielsen's article explaining why. Even
if your UI design skills are lacking, as long as you force yourself to do hallway usability
tests, which cost nothing, your UI will be much, much better.
Four Ways To Use The Joel Test
Rate your own software organization, and tell me how it rates, so I can gossip.
If you're the manager of a programming team, use this as a checklist to make sure your
team is working as well as possible. When you start rating a 12, you can leave your programmers
alone and focus full time on keeping the business people from bothering them.
If you're trying to decide whether to take a programming job, ask your prospective
employer how they rate on this test. If it's too low, make sure that you'll have the
authority to fix these things. Otherwise you're going to be frustrated and unproductive.
If you're an investor doing due diligence to judge the value of a programming team, or if
your software company is considering merging with another, this test can provide a quick rule
of thumb.
You're looking at the downside of the "invisible hand" here, methinks.
Take anything by the Sharper Image for example. Their corporate motto is apparently "Style
over Substance", though they are only one of the most blatant. A specifically good example
would be their "Ionic Breeze." Selling points? Quieter than HEPA filters (that's because HEPA
filters actually DO something). Empty BOXES are quiet too, and pollute your air less.
Standardized tests show the Ionic Breeze's ability to remove airborne particles to be almost
negligible. Tests also show it doesn't trap the particles it does catch very well such that
they can be re-introduced to the environment. It produces levels of the oxidant gas ozone
that accumulate over time, reportedly less than 0.05 ppm after 24 hours, but what after 48?
The EPA's safe limit is 0.08, are you sure your ventilation is sufficient to keep it below
that level if you have it on all the time? Do you trust the EPA's limit as being
actually safe? (they dropped it to 0.08 from 0.12 in 1997 as apparently, 0.12 wasn't
good enough). And what does it matter if the darn thing doesn't even remove dust and germs
out of your environment worth a darn , because most dust and germs are not
airborne? Oh, but it LOOKS SO SEXY.
There are countless products that people buy not because they are tuned into the
brilliant aesthetics , but because the intimidation value of the brilliant
marketing campaigns that convince them that if they don't have the product, they're
deprived. That they need it to shallowly show off they have good taste when they
really have no taste at all except that which was sold to them.
Oh hell no. So-called "self-documenting code" isn't. You can write the most
comprehensible, clear code in the history of mankind, and that's still not good enough.
The issue is that your code only documents what the code is doing, not what it is
supposed to be doing. You wouldn't believe how many subtle issues I've come across
over the decades where on the face of it everything should have been good, but in reality the
code was behaving slightly differently than what was intended.
The issue is that your code only documents what the code is doing, not what it is
supposed to be doing
Mod this up. I aim to document my intent, i.e. what the code is supposed to do. Not only
does this help catch bugs within a procedure, but it also forces me to think a little bit
about the purpose of each method or function. It helps catch bugs or inconsistencies in the
software architecture as well.
I agree with everything you said besides being short (whatever that is precisely).
Sometimes a good comment will be a solid 4-5 line paragraph. But maybe I should fix the code
instead that needs that long of a comment.
I once wrote a library for (essentially) GIS which was full of comments that were 20 lines
or longer. When the correctness of the code depends on theorems in non-Euclidean geometry and
you can't assume that the maintainer will know any, I don't think it's a bad idea to make the
proofs quite explicit.
Interesting. Sorry you had that experience. I'm not sure what you mean by a "multi-line
text widget". I can tell you that early versions of OpenMOTIF were very very buggy in my
experience. You probably know this, but after OpenMOTIF was completed and revved a few times
the original MOTIF code was released as open-source. Many of the bugs I'd been seeing (and
some just strange visual artifacts) disappeared. I know a lot of people love QT and it's
produced real apps and real results - I won't poo-poo it. How
Even if you don't like C++ much, The Design and
Evolution of C++ [amazon.com] is a great book for understanding why pretty much any
language ends up the way it does, seeing the tradeoffs and how a language comes to grow and
expand from simple roots. It's way more interesting to read than you might expect (not very
dry, and more about human interaction than you would expect).
Other than that reading through back posts in a lot of coding blogs that have been around
a long time is probably a really good idea.
You young whippersnappers don't 'preciate how good you have it!
Back in my day, the only book about programming was the 1401 assembly language manual!
But seriously, folks, it's pretty clear we still don't know shite about how to program
properly. We have some fairly clear success criteria for improving the hardware, but the
criteria for good software are clear as mud, and the criteria for ways to produce good
software are much muddier than that.
Having said that, I will now peruse the thread rather carefully
Couldn't find any mention of Guy Steele, so I'll throw in The New Hacker's
Dictionary , which I once owned in dead tree form. Not sure if Version 4.4.7 http://catb.org/jargon/html/ [catb.org] is
the latest online... Also remember a couple of his language manuals. Probably used the Common
Lisp one the most...
Didn't find any mention of a lot of books that I consider highly relevant, but that may
reflect my personal bias towards history. Not really relevant for most programmers.
I've been programming for the past ~40 years and I'll try to summarize what I believe are
the most important bits about programming (pardon the pun.) Think of this as a META: " HOWTO:
Be A Great Programmer " summary. (I'll get to the books section in a bit.)
1. All code can be summarized as a trinity of 3 fundamental concepts:
* Linear ; that is, sequence: A, B, C
* Cyclic ; that is, unconditional jumps: A-B-C-goto B
* Choice ; that is, conditional jumps: if A then B
2. ~80% of programming is NOT about code; it is about Effective Communication. Whether
that be:
* with your compiler / interpreter / REPL
* with other code (levels of abstraction, level of coupling, separation of concerns,
etc.)
* with your boss(es) / manager(s)
* with your colleagues
* with your legal team
* with your QA dept
* with your customer(s)
* with the general public
The other ~20% is effective time management and design. A good programmer knows how to
budget their time. Programming is about balancing the three conflicting goals of the
Program
Management Triangle [wikipedia.org]: You can have it on time, on budget, on quality.
Pick two.
3. Stages of a Programmer
There are two old jokes:
In Lisp all code is data. In Haskell all data is code.
And:
Progression of a (Lisp) Programmer:
* The newbie realizes that the difference between code and data is trivial.
* The expert realizes that all code is data.
* The true master realizes that all data is code.
(Attributed to Aristotle Pagaltzis)
The point of these jokes is that as you work with systems you start to realize that a
data-driven process can often greatly simplify things.
4. Know Thy Data
Fred Books once wrote
"Show me your flowcharts (source code), and conceal your tables (domain model), and I shall
continue to be mystified; show me your tables (domain model) and I won't usually need your
flowcharts (source code): they'll be obvious."
A more modern version would read like this:
Show me your code and I'll have to see your data,
Show me your data and I won't have to see your code.
The importance of data can't be understated:
* Optimization STARTS with understanding HOW the data is being generated and used, NOT the
code as has been traditionally taught.
* Post 2000 "Big Data" has been called the new oil. We are generating upwards to millions of
GB of data every second. Analyzing that data is import to spot trends and potential
problems.
5. There are three levels of optimizations. From slowest to fastest run-time:
a) Bit-twiddling hacks
[stanford.edu]
b) Algorithmic -- Algorithmic complexity or Analysis of algorithms
[wikipedia.org] (such as Big-O notation)
c) Data-Orientated
Design [dataorienteddesign.com] -- Understanding how hardware caches such as instruction
and data caches matter. Optimize for the common case, NOT the single case that OOP tends to
favor.
Optimizing is understanding Bang-for-the-Buck. 80% of code execution is spent in 20% of
the time. Speeding up hot-spots with bit twiddling won't be as effective as using a more
efficient algorithm which, in turn, won't be as efficient as understanding HOW the data is
manipulated in the first place.
6. Fundamental Reading
Since the OP specifically asked about books -- there are lots of great ones. The ones that
have impressed me that I would mark as "required" reading:
* The Mythical Man-Month
* Godel, Escher, Bach
* Knuth: The Art of Computer Programming
* The Pragmatic Programmer
* Zero Bugs and Program Faster
* Writing Solid Code / Code Complete by Steve McConnell
* Game Programming
Patterns [gameprogra...tterns.com] (*)
* Game Engine Design
* Thinking in Java by Bruce Eckel
* Puzzles for Hackers by Ivan Sklyarov
(*) I did NOT list Design Patterns: Elements of Reusable Object-Oriented Software
as that leads to typical, bloated, over-engineered crap. The main problem with "Design
Patterns" is that a programmer will often get locked into a mindset of seeing
everything as a pattern -- even when a simple few lines of code would solve th
eproblem. For example here is 1,100+ of Crap++ code such as Boost's over-engineered
CRC code
[boost.org] when a mere ~25 lines of SIMPLE C code would have done the trick. When was the
last time you ACTUALLY needed to _modify_ a CRC function? The BIG picture is that you are
probably looking for a BETTER HASHING function with less collisions. You probably would be
better off using a DIFFERENT algorithm such as SHA-2, etc.
7. Do NOT copy-pasta
Roughly 80% of bugs creep in because someone blindly copied-pasted without thinking. Type
out ALL code so you actually THINK about what you are writing.
8. K.I.S.S.
Over-engineering and aka technical debt, will be your Achilles' heel. Keep It Simple,
Silly.
9. Use DESCRIPTIVE variable names
You spend ~80% of your time READING code, and only ~20% writing it. Use good, descriptive
variable names. Far too programmers write usless comments and don't understand the difference
between code and comments:
Code says HOW, Comments say WHY
A crap comment will say something like: // increment i
No, Shit Sherlock! Don't comment the obvious!
A good comment will say something like: // BUGFIX: 1234:
Work-around issues caused by A, B, and C.
10. Ignoring Memory Management doesn't make it go away -- now you have two problems. (With
apologies to JWZ)
If you don't understand both the pros and cons of these programming paradigms
...
* Procedural
* Object-Orientated
* Functional, and
* Data-Orientated Design
... then you will never really understand programming, nor abstraction,
at a deep level, along with how and when it should and shouldn't be used.
12. Multi-disciplinary POV
ALL non-trivial code has bugs. If you aren't using static code analysis
[wikipedia.org] then you are not catching as many bugs as the people who are.
Also, a good programmer looks at his code from many different angles. As a programmer you
must put on many different hats to find them:
* Architect -- design the code
* Engineer / Construction Worker -- implement the code
* Tester -- test the code
* Consumer -- doesn't see the code, only sees the results. Does it even work?? Did you VERIFY
it did BEFORE you checked your code into version control?
13. Learn multiple Programming Languages
Each language was designed to solve certain problems. Learning different languages, even
ones you hate, will expose you to different concepts. e.g. If you don't how how to read
assembly language AND your high level language then you will never be as good as the
programmer who does both.
14. Respect your Colleagues' and Consumers Time, Space, and Money.
Mobile game are the WORST at respecting people's time, space and money turning "players
into payers." They treat customers as whales. Don't do this. A practical example: If you are
a slack channel with 50+ people do NOT use @here. YOUR fire is not their emergency!
15. Be Passionate
If you aren't passionate about programming, that is, you are only doing it for the money,
it will show. Take some pride in doing a GOOD job.
16. Perfect Practice Makes Perfect.
If you aren't programming every day you will never be as good as someone who is.
Programming is about solving interesting problems. Practice solving puzzles to develop your
intuition and lateral thinking. The more you practice the better you get.
"Sorry" for the book but I felt it was important to summarize the "essentials" of
programming.
--
Hey Slashdot. Fix your shitty filter so long lists can be posted.: "Your comment has too few
characters per line (currently 37.0)."
You crammed a lot of good ideas into a short post.
I'm sending my team at work a link to your post.
You mentioned code can data. Linus Torvalds had this to say:
"I'm a huge proponent of designing your code around the data, rather than the other way
around, and I think it's one of the reasons git has been fairly successful [â¦] I
will, in fact, claim that the difference between a bad programmer and a good one is whether
he considers his code or his data structures more important."
"Bad programmers worry about the code. Good programmers worry about data structures and
their relationships."
I'm inclined to agree. Once the data structure is right, the code oftem almost writes
itself. It'll be easy to write and easy to read because it's obvious how one would handle
data structured in that elegant way.
Writing the code necessary to transform the data from the input format into the right
structure can be non-obvious, but it's normally worth it.
i learnt to program at school from a Ph.D computer scientist. We never even had computers
in the class. We learnt to break the problem down into sections using flowcharts or
pseudo-code and then we would translate that program into whatever coding language we were
using. I still do this usually in my notebook where I figure out all the things I need to do
and then write the skeleton of the code using a series of comments for what each section of
my program and then I fill in the code for each section. It is a combination of top down and
bottom up programming, writing routines that can be independently tested and validated.
# Assertions are on.useCarp::Assert ;$next_sunrise_time= sunrise();# Assert that the sun must
rise in the next 24 hours.assert(($next_sunrise_time-time) < 24*60*60)ifDEBUG;# Assert that your customer's primary credit card is
activeaffirm {my@cards= @{$customer->credit_cards};$cards[0]->is_active;};# Assertions are off.noCarp::Assert;$next_pres=
divine_next_president();# Assert that if you predict Dan Quayle will be the
next president# your crystal ball might need some polishing. However,
since# assertions are off, IT COULD HAPPEN!shouldnt($next_pres,'Dan Quayle')ifDEBUG;
DESCRIPTION
"We are readyforany unforseen event that may or may
notoccur."- Dan Quayle
Carp::Assert is intended for a purpose like the ANSI C library assert.h . If you're already familiar with
assert.h, then you can probably skip this and go straight to the FUNCTIONS section.
Assertions are the explicit expressions of your assumptions about the reality your program
is expected to deal with, and a declaration of those which it is not. They are used to prevent
your program from blissfully processing garbage inputs (garbage in, garbage out becomes garbage
in, error out) and to tell you when you've produced garbage output. (If I was going to be a
cynic about Perl and the user nature, I'd say there are no user inputs but garbage, and Perl
produces nothing but...)
An assertion is used to prevent the impossible from being asked of your code, or at least
tell you when it does. For example:
# Take the square root of a number.submy_sqrt
{my($num) =shift;# the square root of a negative number is
imaginary.assert($num>= 0);returnsqrt$num;}
The assertion will warn you if a negative number was handed to your subroutine, a reality
the routine has no intention of dealing with.
An assertion should also be used as something of a reality check, to make sure what your
code just did really did happen:
open(FILE,$filename) ||die$!;@stuff= <FILE>;@stuff= do_something(@stuff);# I should have some stuff.assert(@stuff> 0);
The assertion makes sure you have some @stuff at the end. Maybe the file was empty, maybe
do_something() returned an empty list... either way, the assert() will give you a clue as to
where the problem lies, rather than 50 lines down at when you wonder why your program isn't
printing anything.
Since assertions are designed for debugging and will remove themelves from production code,
your assertions should be carefully crafted so as to not have any side-effects, change any
variables, or otherwise have any effect on your program. Here is an example of a bad
assertation:
assert($error= 1if$kingne'Henry');#
Bad!
It sets an error flag which may then be used somewhere else in your program. When you shut
off your assertions with the $DEBUG flag, $error will no longer be set.
This assertion has the side effect of moving to Canada should it fail. This is a very bad
assertion since error handling should not be placed in an assertion, nor should it have
side-effects.
In short, an assertion is an executable comment. For instance, instead of writing this
# $life ends with a '!'$life=
begin_life();
you'd replace the comment with an assertion which enforces the comment.
$life= begin_life();assert($life=~ /!$/ );
FUNCTIONS
assert
assert(EXPR)ifDEBUG;assert(EXPR,$name)ifDEBUG;
assert's functionality is effected by compile time value of the DEBUG constant,
controlled by saying use Carp::Assert or no Carp::Assert . In the
former case, assert will function as below. Otherwise, the assert function will compile
itself out of the program. See "Debugging vs
Production" for details.
Give assert an expression, assert will Carp::confess() if that expression is false,
otherwise it does nothing. (DO NOT use the return value of assert for anything, I mean
it... really!).
The error from assert will look something like this:
Assertion failed!Carp::Assert::assert(0) called at prog line
23main::foo called at prog line 50
Indicating that in the file "prog" an assert failed inside the function main::foo() on
line 23 and that foo() was in turn called from line 50 in the same file.
If given a $name, assert() will incorporate this into your error message, giving users
something of a better idea what's going on.
assert( Dogs->isa('People'),'Dogs are people, too!')ifDEBUG;# Result - "Assertion (Dogs are people, too!) failed!"
affirm
affirm BLOCKifDEBUG;affirm
BLOCK$nameifDEBUG;
Very similar to assert(), but instead of taking just a simple expression it takes an
entire block of code and evaluates it to make sure its true. This can allow more
complicated assertions than assert() can without letting the debugging code leak out into
production and without having to smash together several statements into one.
affirm {my$customer=
Customer->new($customerid);my@cards=$customer->credit_cards;grep{$_->is_active }@cards;}"Our customer has an active credit card";
affirm() also has the nice side effect that if you forgot the if DEBUG
suffix its arguments will not be evaluated at all. This can be nice if you stick affirm()s
with expensive checks into hot loops and other time-sensitive parts of your program.
If the $name is left off and your Perl version is 5.6 or higher the affirm() diagnostics
will include the code begin affirmed.
should
shouldnt
should ($this,$shouldbe)ifDEBUG;shouldnt($this,$shouldntbe)ifDEBUG;
Similar to assert(), it is specially for simple "this should be that" or "this should be
anything but that" style of assertions.
Due to Perl's lack of a good macro system, assert() can only report where something
failed, but it can't report what failed or how . should() and shouldnt() can
produce more informative error messages:
Assertion ('this'should be'that'!) failed!Carp::Assert::should('this','that') called at moof line
29main::foo() called at moof line 58
So this:
should($this,$that)ifDEBUG;
is similar to this:
assert($thiseq$that)ifDEBUG;
except for the better error message.
Currently, should() and shouldnt() can only do simple eq and ne tests (respectively).
Future versions may allow regexes.
Debugging vs Production
Because assertions are extra code and because it is sometimes necessary to place them in
'hot' portions of your code where speed is paramount, Carp::Assert provides the option to
remove its assert() calls from your program.
So, we provide a way to force Perl to inline the switched off assert() routine, thereby
removing almost all performance impact on your production code.
noCarp::Assert;# assertions are off.assert(1==1)ifDEBUG;
DEBUG is a constant set to 0. Adding the 'if DEBUG' condition on your assert() call gives
perl the cue to go ahead and remove assert() call from your program entirely, since the if
conditional will always be false.
# With C<no Carp::Assert> the assert() has no impact.for(1..100) {assert( do_some_really_time_consuming_check
)ifDEBUG;}
If if DEBUG gets too annoying, you can always use affirm().
# Once again, affirm() has (almost) no impact with C<no
Carp::Assert>for(1..100) {affirm {
do_some_really_time_consuming_check };}
Another way to switch off all asserts, system wide, is to define the NDEBUG or the
PERL_NDEBUG environment variable.
You can safely leave out the "if DEBUG" part, but then your assert() function will always
execute (and its arguments evaluated and time spent). To get around this, use affirm(). You
still have the overhead of calling a function but at least its arguments will not be
evaluated.
Differences from ANSI C
assert() is intended to act like the function from ANSI C fame. Unfortunately, due to Perl's
lack of macros or strong inlining, it's not nearly as unobtrusive.
Well, the obvious one is the "if DEBUG" part. This is cleanest way I could think of to cause
each assert() call and its arguments to be removed from the program at compile-time, like the
ANSI C macro does.
Also, this version of assert does not report the statement which failed, just the line
number and call frame via Carp::confess. You can't do assert('$a == $b') because
$a and $b will probably be lexical, and thus unavailable to assert(). But with Perl, unlike C,
you always have the source to look through, so the need isn't as great.
EFFICIENCY
With no Carp::Assert (or NDEBUG) and using the if DEBUG suffixes
on all your assertions, Carp::Assert has almost no impact on your production code. I say almost
because it does still add some load-time to your code (I've tried to reduce this as much as
possible).
If you forget the if DEBUG on an assert() , should()
or shouldnt() , its arguments are still evaluated and thus will impact your code.
You'll also have the extra overhead of calling a subroutine (even if that subroutine does
nothing).
Forgetting the if DEBUG on an affirm() is not so bad. While you
still have the overhead of calling a subroutine (one that does nothing) it will not
evaluate its code block and that can save a lot.
Try to remember the if DEBUG .
ENVIRONMENT
NDEBUG
Defining NDEBUG switches off all assertions. It has the same effect as changing "use
Carp::Assert" to "no Carp::Assert" but it effects all code.
PERL_NDEBUG
Same as NDEBUG and will override it. Its provided to give you something which won't
conflict with any C programs you might be working on at the same time.
BUGS, CAVETS and other MUSINGS
Conflicts with POSIX.pm
The POSIX module exports an assert routine which will conflict
with Carp::Assert if both are used in the same namespace. If you are using both
together, prevent POSIX from exporting like so:
Carp::Assert::More
provides a set of convenience functions that are wrappers around Carp::Assert
.
Sub::Assert provides
support for subroutine pre- and post-conditions. The documentation says it's slow.
PerlX::Assert provides
compile-time assertions, which are usually optimised away at compile time. Currently part of
the Moops distribution, but may
get its own distribution sometime in 2014.
Devel::Assert also
provides an assert function, for Perl >= 5.8.1.
assertions provides an
assertion mechanism for Perl >= 5.9.0.
This is a large currently unmaintained subsystem (last changes were in Feb 21, 2017) of questionable value for
simple scripts(the main problem is overcomplexity and large amount of dependencies) . They make things way too complex for simple
applications.
It still might make perfect sense for very complex applications.
You've rolled out an application and it produces mysterious, sporadic errors? That's pretty
common, even if fairly well-tested applications are exposed to real-world data. How can you
track down when and where exactly your problem occurs? What kind of user data is it caused by?
A debugger won't help you there.
And you don't want to keep track of only bad cases. It's helpful to log all types of
meaningful incidents while your system is running in production, in order to extract
statistical data from your logs later. Or, what if a problem only happens after a certain
sequence of 'good' cases? Especially in dynamic environments like the Web, anything can happen
at any time and you want a footprint of every event later, when you're counting the
corpses.
What you need is well-architected logging : Log statements in your code and a logging
package like Log::Log4perl providing a "remote-control," which allows you to turn
on previously inactive logging statements, increase or decrease their verbosity independently
in different parts of the system, or turn them back off entirely. Certainly without touching
your system's code – and even without restarting it.
However, with traditional logging systems, the amount of data written to the logs can be
overwhelming. In fact, turning on low-level-logging on a system under heavy load can cause it
to slow down to a crawl or even crash.
Log::Log4perl is different. It is a pure Perl port of the widely popular
Apache/Jakarta log4j library [3] for Java, a project made public in 1999, which
has been actively supported and enhanced by a team around head honcho Ceki
Gülcü during the years.
The comforting facts about log4j are that it's really well thought out, it's
the alternative logging standard for Java and it's been in use for years with numerous
projects. If you don't like Java, then don't worry, you're not alone – the
Log::Log4perl authors (yours truly among them) are all Perl hardliners who
made sure Log::Log4perl is real Perl.
In the spirit of log4j , Log::Log4perl addresses the shortcomings
of typical ad-hoc or homegrown logging systems by providing three mechanisms to control the
amount of data being logged and where it ends up at:
Levels allow you to specify the priority of log messages. Low-priority
messages are suppressed when the system's setting allows for only higher-priority
messages.
Categories define which parts of the system you want to enable logging in.
Category inheritance allows you to elegantly reuse and override previously defined settings
of different parts in the category hierarchy.
Appenders allow you to choose which output devices the log data is being written
to, once it clears the previously listed hurdles.
In combination, these three control mechanisms turn out to be very powerful. They allow you
to control the logging behavior of even the most complex applications at a granular level.
However, it takes time to get used to the concept, so let's start the easy way:
Getting
Your Feet Wet With Log4perl
If you've used logging before, then you're probably familiar with logging priorities or
levels . Each log incident is assigned a level. If this incident level is higher than
the system's logging level setting (typically initialized at system startup), then the message
is logged, otherwise it is suppressed.
Log::Log4perl defines five logging levels, listed here from low to high:
DEBUG
INFO
WARN
ERROR
FATAL
Let's assume that you decide at system startup that only messages of level WARN and higher
are supposed to make it through. If your code then contains a log statement with priority
DEBUG, then it won't ever be executed. However, if you choose at some point to bump up the
amount of detail, then you can just set your system's logging priority to DEBUG and you will
see these DEBUG messages starting to show up in your logs, too.
What is the best (or recommended) approach to do defensive programming in perl? For example
if I have a sub which must be called with a (defined) SCALAR, an ARRAYREF and an optional
HASHREF.
Three of the approaches I have seen:
sub test1 {
die if !(@_ == 2 || @_ == 3);
my ($scalar, $arrayref, $hashref) = @_;
die if !defined($scalar) || ref($scalar);
die if ref($arrayref) ne 'ARRAY';
die if defined($hashref) && ref($hashref) ne 'HASH';
#do s.th with scalar, arrayref and hashref
}
sub test2 {
Carp::assert(@_ == 2 || @_ == 3) if DEBUG;
my ($scalar, $arrayref, $hashref) = @_;
if(DEBUG) {
Carp::assert defined($scalar) && !ref($scalar);
Carp::assert ref($arrayref) eq 'ARRAY';
Carp::assert !defined($hashref) || ref($hashref) eq 'HASH';
}
#do s.th with scalar, arrayref and hashref
}
sub test3 {
my ($scalar, $arrayref, $hashref) = @_;
(@_ == 2 || @_ == 3 && defined($scalar) && !ref($scalar) && ref($arrayref) eq 'ARRAY' && (!defined($hashref) || ref($hashref) eq 'HASH'))
or Carp::croak 'usage: test3(SCALAR, ARRAYREF, [HASHREF])';
#do s.th with scalar, arrayref and hashref
}
I wouldn't use any of them. Aside from not not accepting many array and hash references, the
checks you used are almost always redundant.
>perl -we"use strict; sub { my ($x) = @_; my $y = $x->[0] }->( 'abc' )"
Can't use string ("abc") as an ARRAY ref nda"strict refs" in use at -e line 1.
>perl -we"use strict; sub { my ($x) = @_; my $y = $x->[0] }->( {} )"
Not an ARRAY reference at -e line 1.
The only advantage to checking is that you can use croak to show the caller
in the error message.
Proper way to check if you have an reference to an array:
defined($x) && eval { @$x; 1 }
Proper way to check if you have an reference to a hash:
None of the options you show display any message to give a reason for the failure,
which I think is paramount.
It is also preferable to use croak instead of die from within
library subroutines, so that the error is reported from the point of view of the caller.
I would replace all occurrences of if ! with unless . The former
is a C programmer's habit.
I suggest something like this
sub test1 {
croak "Incorrect number of parameters" unless @_ == 2 or @_ == 3;
my ($scalar, $arrayref, $hashref) = @_;
croak "Invalid first parameter" unless $scalar and not ref $scalar;
croak "Invalid second parameter" unless $arrayref eq 'ARRAY';
croak "Invalid third parameter" if defined $hashref and ref $hashref ne 'HASH';
# do s.th with scalar, arrayref and hashref
}
"... Defensive programming is a method of prevention, rather than a form of cure. Compare this to debugging -- the act of removing bugs after they've bitten. Debugging is all about finding a cure. ..."
"... Defensive programming saves you literally hours of debugging and lets you do more fun stuff instead. Remember Murphy: If your code can be used incorrectly, it will be. ..."
"... Working code that runs properly, but ever-so-slightly slower, is far superior to code that works most of the time but occasionally collapses in a shower of brightly colored sparks ..."
"... Defensive programming avoids a large number of security problems -- a serious issue in modern software development. ..."
Okay, defensive programming won't remove program failures altogether. But problems will become less of a hassle and easier to fix.
Defensive programmers catch falling snowflakes rather than get buried under an avalanche of errors.
Defensive programming is a method of prevention, rather than a form of cure. Compare this to debugging -- the act of removing
bugs after they've bitten. Debugging is all about finding a cure.
WHAT DEFENSIVE PROGRAMMING ISN'T
There are a few common misconceptions about defensive programming . Defensive programming is not:
Error checking
If there are error conditions that might arise in your code, you should be checking for them anyway. This is not defensive
code. It's just plain good practice -- a part of writing correct code.
Testing
Testing your code is not defensive . It's another normal part of our development work. Test harnesses aren't defensive ; they
can prove the code is correct now, but won't prove that it will stand up to future modification. Even with the best test suite
in the world, anyone can make a change and slip it past untested.
Debugging
You might add some defensive code during a spell of debugging, but debugging is something you do after your program has failed.
Defensive programming is something you do to prevent your program from failing in the first place (or to detect failures
early before they manifest in incomprehensible ways, demanding all-night debugging sessions).
Is defensive programming really worth the hassle? There are arguments for and against:
The case against
Defensive programming consumes resources, both yours and the computer's.
It eats into the efficiency of your code; even a little extra code requires a little extra execution. For a single function
or class, this might not matter, but when you have a system made up of 100,000 functions, you may have more of a problem.
Each defensive practice requires some extra work. Why should you follow any of them? You have enough to do already, right?
Just make sure people use your code correctly. If they don't, then any problems are their own fault.
The case for
The counterargument is compelling.
Defensive programming saves you literally hours of debugging and lets you do more fun stuff instead. Remember Murphy: If
your code can be used incorrectly, it will be.
Working code that runs properly, but ever-so-slightly slower, is far superior to code that works most of the time
but occasionally collapses in a shower of brightly colored sparks.
We can design some defensive code to be physically removed in release builds, circumventing the performance issue. The
majority of the items we'll consider here don't have any significant overhead, anyway.
Defensive programming avoids a large number of security problems -- a serious issue in modern software development. More
on this follows.
As the market demands software that's built faster and cheaper, we need to focus on techniques that deliver results. Don't skip
the bit of extra work up front that will prevent a whole world of pain and delay later.
"... Return a neutral value. Sometimes the best response to bad data is to continue operating and simply return a value that's known to be harmless. A numeric computation might return 0. A string operation might return an empty string, or a pointer operation might return an empty pointer. A drawing routine that gets a bad input value for color in a video game might use the default background or foreground color. A drawing routine that displays x-ray data for cancer patients, however, would not want to display a "neutral value." In that case, you'd be better off shutting down the program than displaying incorrect patient data. ..."
Assertions are used to handle errors that should never occur in the code. How do you handle
errors that you do expect to occur? Depending on the specific circumstances, you might want to
return a neutral value, substitute the next piece of valid data, return the same answer as the
previous time, substitute the closest legal value, log a warning message to a file, return an
error code, call an error-processing routine or object, display an error message, or shut down
-- or you might want to use a combination of these responses.
Here are some more details on these options:
Return a neutral value. Sometimes the best response to bad data is to continue operating and
simply return a value that's known to be harmless. A numeric computation might return 0. A
string operation might return an empty string, or a pointer operation might return an empty
pointer. A drawing routine that gets a bad input value for color in a video game might use the
default background or foreground color. A drawing routine that displays x-ray data for cancer
patients, however, would not want to display a "neutral value." In that case, you'd be better
off shutting down the program than displaying incorrect patient data.
Substitute the next piece of valid data. When processing a stream of data, some
circumstances call for simply returning the next valid data. If you're reading records from a
database and encounter a corrupted record, you might simply continue reading until you find a
valid record. If you're taking readings from a thermometer 100 times per second and you don't
get a valid reading one time, you might simply wait another 1/100th of a second and take the
next reading.
Return the same answer as the previous time. If the thermometer-reading software doesn't get
a reading one time, it might simply return the same value as last time. Depending on the
application, temperatures might not be very likely to change much in 1/100th of a second. In a
video game, if you detect a request to paint part of the screen an invalid color, you might
simply return the same color used previously. But if you're authorizing transactions at a cash
machine, you probably wouldn't want to use the "same answer as last time" -- that would be the
previous user's bank account number!
Substitute the closest legal value. In some cases, you might choose to return the closest
legal value, as in the Velocity example earlier. This is often a reasonable approach
when taking readings from a calibrated instrument. The thermometer might be calibrated between
0 and 100 degrees Celsius, for example. If you detect a reading less than 0, you can substitute
0, which is the closest legal value. If you detect a value greater than 100, you can substitute
100. For a string operation, if a string length is reported to be less than 0, you could
substitute 0. My car uses this approach to error handling whenever I back up. Since my
speedometer doesn't show negative speeds, when I back up it simply shows a speed of 0 -- the
closest legal value.
Log a warning message to a file. When bad data is detected, you might choose to log a
warning message to a file and then continue on. This approach can be used in conjunction with
other techniques like substituting the closest legal value or substituting the next piece of
valid data. If you use a log, consider whether you can safely make it publicly available or
whether you need to encrypt it or protect it some other way.
Return an error code. You could decide that only certain parts of a system will handle
errors. Other parts will not handle errors locally; they will simply report that an error has
been detected and trust that some other routine higher up in the calling hierarchy will handle
the error. The specific mechanism for notifying the rest of the system that an error has
occurred could be any of the following:
Set the value of a status variable
Return status as the function's return value
Throw an exception by using the language's built-in exception mechanism
In this case, the specific error-reporting mechanism is less important than the decision
about which parts of the system will handle errors directly and which will just report that
they've occurred. If security is an issue, be sure that calling routines always check return
codes.
Call an error-processing routine/object. Another approach is to centralize error handling in
a global error-handling routine or error-handling object. The advantage of this approach is
that error-processing responsibility can be centralized, which can make debugging easier. The
tradeoff is that the whole program will know about this central capability and will be coupled
to it. If you ever want to reuse any of the code from the system in another system, you'll have
to drag the error-handling machinery along with the code you reuse.
This approach has an important security implication. If your code has encountered a buffer
overrun, it's possible that an attacker has compromised the address of the handler routine or
object. Thus, once a buffer overrun has occurred while an application is running, it is no
longer safe to use this approach.
Display an error message wherever the error is encountered. This approach minimizes
error-handling overhead; however, it does have the potential to spread user interface messages
through the entire application, which can create challenges when you need to create a
consistent user interface, when you try to clearly separate the UI from the rest of the system,
or when you try to localize the software into a different language. Also, beware of telling a
potential attacker of the system too much. Attackers sometimes use error messages to discover
how to attack a system.
Handle the error in whatever way works best locally. Some designs call for handling all
errors locally -- the decision of which specific error-handling method to use is left up to the
programmer designing and implementing the part of the system that encounters the error.
This approach provides individual developers with great flexibility, but it creates a
significant risk that the overall performance of the system will not satisfy its requirements
for correctness or robustness (more on this in a moment). Depending on how developers end up
handling specific errors, this approach also has the potential to spread user interface code
throughout the system, which exposes the program to all the problems associated with displaying
error messages.
Shut down. Some systems shut down whenever they detect an error. This approach is useful in
safety-critical applications. For example, if the software that controls radiation equipment
for treating cancer patients receives bad input data for the radiation dosage, what is its best
error-handling response? Should it use the same value as last time? Should it use the closest
legal value? Should it use a neutral value? In this case, shutting down is the best option.
We'd much prefer to reboot the machine than to run the risk of delivering the wrong dosage.
A similar approach can be used to improve the security of Microsoft Windows. By default,
Windows continues to operate even when its security log is full. But you can configure Windows
to halt the server if the security log becomes full, which can be appropriate in a
security-critical environment.
Robustness vs. Correctness
As the video game and x-ray examples show us, the style of error processing that is most
appropriate depends on the kind of software the error occurs in. These examples also illustrate
that error processing generally favors more correctness or more robustness. Developers tend to
use these terms informally, but, strictly speaking, these terms are at opposite ends of the
scale from each other. Correctness means never returning an inaccurate result; returning
no result is better than returning an inaccurate result. Robustness means always trying
to do something that will allow the software to keep operating, even if that leads to results
that are inaccurate sometimes.
Safety-critical applications tend to favor correctness to robustness. It is better to return
no result than to return a wrong result. The radiation machine is a good example of this
principle.
Consumer applications tend to favor robustness to correctness. Any result whatsoever is
usually better than the software shutting down. The word processor I'm using occasionally
displays a fraction of a line of text at the bottom of the screen. If it detects that
condition, do I want the word processor to shut down? No. I know that the next time I hit Page
Up or Page Down, the screen will refresh and the display will be back to normal.
High-Level Design Implications of Error Processing
With so many options, you need to be careful to handle invalid parameters in consistent ways
throughout the program . The way in which errors are handled affects the software's ability to
meet requirements related to correctness, robustness, and other nonfunctional attributes.
Deciding on a general approach to bad parameters is an architectural or high-level design
decision and should be addressed at one of those levels.
Once you decide on the approach, make sure you follow it consistently. If you decide to have
high-level code handle errors and low-level code merely report errors, make sure the high-level
code actually handles the errors! Some languages give you the option of ignoring the fact that
a function is returning an error code -- in C++, you're not required to do anything with a
function's return value -- but don't ignore error information! Test the function return value.
If you don't expect the function ever to produce an error, check it anyway. The whole point of
defensive programming is guarding against errors you don't expect.
This guideline holds true for system functions as well as for your own functions. Unless
you've set an architectural guideline of not checking system calls for errors, check for error
codes after each call. If you detect an error, include the error number and the description of
the error.
There is one danger to defensive coding: It can bury errors. Consider the following
code:
def drawLine(m, b, image, start = 0, stop = WIDTH):
step = 1
start = int(start)
stop = int(stop)
if stop-start < 0:
step = -1
print('WARNING: drawLine parameters were reversed.')
for x in range(start, stop, step):
index = int(m*x + b) * WIDTH + x
if 0 <= index < len(image):
image[index] = 255 # Poke in a white (= 255) pixel.
This function runs from start to stop . If stop is less than start , it just steps backward
and no error is reported .
Maybe we want this kind of error to be "fixed " during the
run -- buried -- but I think we should at least print a warning that the range is coming in
backwards. Maybe we should abort the program .
"... Code installed for defensive programming is not immune to defects, and you're just as likely to find a defect in defensive-programming code as in any other code -- more likely, if you write the code casually. Think about where you need to be defensive , and set your defensive-programming priorities accordingly. ..."
Originally from: Code Complete, Second Edition II. Creating High-Quality Code
8.3. Error-Handling Techniques
Too much of anything is bad, but too much whiskey is just enough. -- Mark Twain
Too much defensive programming creates problems of its own. If you check data passed as parameters in every conceivable way in
every conceivable place, your program will be fat and slow.
What's worse, the additional code needed for defensive programming adds
complexity to the software.
Code installed for defensive programming is not immune to defects, and you're just as likely to find
a defect in defensive-programming code as in any other code -- more likely, if you write the code casually. Think about where you
need to be defensive , and set your defensive-programming priorities accordingly.
Defensive Programming
General
Does the routine protect itself from bad input data?
Have you used assertions to document assumptions, including preconditions and postconditions?
Have assertions been used only to document conditions that should never occur?
Does the architecture or high-level design specify a specific set of error-handling techniques?
Does the architecture or high-level design specify whether error handling should favor robustness or correctness?
Have barricades been created to contain the damaging effect of errors and reduce the amount of code that has to be concerned
about error processing?
Have debugging aids been used in the code?
Have debugging aids been installed in such a way that they can be activated or deactivated without a great deal of fuss?
Is the amount of defensive programming code appropriate -- neither too much nor too little?
Have you used offensive- programming techniques to make errors difficult to overlook during development?
Exceptions
Has your project defined a standardized approach to exception handling?
Have you considered alternatives to using an exception?
Is the error handled locally rather than throwing a nonlocal exception, if possible?
Does the code avoid throwing exceptions in constructors and destructors?
Are all exceptions at the appropriate levels of abstraction for the routines that throw them?
Does each exception include all relevant exception background information?
Is the code free of empty catch blocks? (Or if an empty catch block truly is appropriate, is it documented?)
Security Issues
Does the code that checks for bad input data check for attempted buffer overflows, SQL injection, HTML injection, integer
overflows, and other malicious inputs?
Are all error-return codes checked?
Are all exceptions caught?
Do error messages avoid providing information that would help an attacker break into the system?
Assertions as special statement is questionable approach unless there is a switch to exclude them from the code. Other
then that BASH exit with condition or Perl die can serve equally well.
The main question here is which assertions should be in code only for debugging and which should be in production.
Notable quotes:
"... That an input parameter's value falls within its expected range (or an output parameter's value does) ..."
"... Many languages have built-in support for assertions, including C++, Java, and Microsoft Visual Basic. If your language doesn't directly support assertion routines, they are easy to write. The standard C++ assert macro doesn't provide for text messages. Here's an example of an improved ASSERT implemented as a C++ macro: ..."
"... Use assertions to document and verify preconditions and postconditions. Preconditions and postconditions are part of an approach to program design and development known as "design by contract" (Meyer 1997). When preconditions and postconditions are used, each routine or class forms a contract with the rest of the program . ..."
An assertion is code that's used during development -- usually a routine or macro -- that allows a program to check itself as
it runs. When an assertion is true, that means everything is operating as expected. When it's false, that means it has detected an
unexpected error in the code. For example, if the system assumes that a customerinformation file will never have more than 50,000
records, the program might contain an assertion that the number of records is less than or equal to 50,000. As long as the number
of records is less than or equal to 50,000, the assertion will be silent. If it encounters more than 50,000 records, however, it
will loudly "assert" that an error is in the program .
Assertions are especially useful in large, complicated programs and in high-reliability programs . They enable programmers to
more quickly flush out mismatched interface assumptions, errors that creep in when code is modified, and so on.
An assertion usually takes two arguments: a boolean expression that describes the assumption that's supposed to be true, and a
message to display if it isn't. Here's what a Java assertion would look like if the variable denominator were expected to
be nonzero:
Example 8-1. Java Example of an Assertion
assert denominator != 0 : "denominator is unexpectedly equal to 0.";
This assertion asserts that denominator is not equal to 0 . The first argument, denominator != 0 , is a boolean
expression that evaluates to true or false . The second argument is a message to print if the first argument is
false -- that is, if the assertion is false.
Use assertions to document assumptions made in the code and to flush out unexpected conditions. Assertions can be used to check
assumptions like these:
That an input parameter's value falls within its expected range (or an output parameter's value does)
That a file or stream is open (or closed) when a routine begins executing (or when it ends executing)
That a file or stream is at the beginning (or end) when a routine begins executing (or when it ends executing)
That a file or stream is open for read-only, write-only, or both read and write
That the value of an input-only variable is not changed by a routine
That a pointer is non-null
That an array or other container passed into a routine can contain at least X number of data elements
That a table has been initialized to contain real values
That a container is empty (or full) when a routine begins executing (or when it finishes)
That the results from a highly optimized, complicated routine match the results from a slower but clearly written routine
Of course, these are just the basics, and your own routines will contain many more specific assumptions that you can document
using assertions.
Normally, you don't want users to see assertion messages in production code; assertions are primarily for use during development
and maintenance. Assertions are normally compiled into the code at development time and compiled out of the code for production.
During development, assertions flush out contradictory assumptions, unexpected conditions, bad values passed to routines, and so
on. During production, they can be compiled out of the code so that the assertions don't degrade system performance.
Building Your Own Assertion Mechanism
Many languages have built-in support for assertions, including C++, Java, and Microsoft Visual Basic. If your language doesn't
directly support assertion routines, they are easy to write. The standard C++ assert macro doesn't provide for text messages.
Here's an example of an improved ASSERT implemented as a C++ macro:
Cross-Reference
Building your own assertion routine is a good example of programming "into" a language rather than just programming "in" a language.
For more details on this distinction, see
Program into Your
Language, Not in It .
Use error-handling code for conditions you expect to occur; use assertions for conditions that should. never occur Assertions
check for conditions that should never occur. Error-handling code checks for off-nominal circumstances that might not occur
very often, but that have been anticipated by the programmer who wrote the code and that need to be handled by the production code.
Error handling typically checks for bad input data; assertions check for bugs in the code.
If error-handling code is used to address an anomalous condition, the error handling will enable the program to respond to the
error gracefully. If an assertion is fired for an anomalous condition, the corrective action is not merely to handle an error gracefully
-- the corrective action is to change the program's source code, recompile, and release a new version of the software.
A good way to think of assertions is as executable documentation -- you can't rely on them to make the code work, but they can
document assumptions more actively than program -language comments can.
Avoid putting executable code into assertions. Putting code into an assertion raises the possibility that the compiler will eliminate
the code when you turn off the assertions. Suppose you have an assertion like this:
Example 8-3. Visual Basic Example of a Dangerous Use of an Assertion
The problem with this code is that, if you don't compile the assertions, you don't compile the code that performs the action.
Put executable statements on their own lines, assign the results to status variables, and test the status variables instead. Here's
an example of a safe use of an assertion:
Example 8-4. Visual Basic Example of a Safe Use of an Assertion
Use assertions to document and verify preconditions and postconditions. Preconditions and postconditions are part of an approach
to program design and development known as "design by contract" (Meyer 1997). When preconditions and postconditions are used, each
routine or class forms a contract with the rest of the program .
Further Reading
For much more on preconditions and postconditions, see Object-Oriented Software Construction (Meyer 1997).
Preconditions are the properties that the client code of a routine or class promises will be true before it calls the routine
or instantiates the object. Preconditions are the client code's obligations to the code it calls.
Postconditions are the properties that the routine or class promises will be true when it concludes executing. Postconditions
are the routine's or class's obligations to the code that uses it.
Assertions are a useful tool for documenting preconditions and postconditions. Comments could be used to document preconditions
and postconditions, but, unlike comments, assertions can check dynamically whether the preconditions and postconditions are true.
In the following example, assertions are used to document the preconditions and postcondition of the Velocity routine.
Example 8-5. Visual Basic Example of Using Assertions to Document Preconditions and Postconditions
Private Function Velocity ( _
ByVal latitude As Single, _
ByVal longitude As Single, _
ByVal elevation As Single _
) As Single
' Preconditions
Debug.Assert ( -90 <= latitude And latitude <= 90 )
Debug.Assert ( 0 <= longitude And longitude < 360 )
Debug.Assert ( -500 <= elevation And elevation <= 75000 )
...
' Postconditions Debug.Assert ( 0 <= returnVelocity And returnVelocity <= 600 )
' return value
Velocity = returnVelocity
End Function
If the variables latitude , longitude , and elevation were coming from an external source, invalid values
should be checked and handled by error-handling code rather than by assertions. If the variables are coming from a trusted, internal
source, however, and the routine's design is based on the assumption that these values will be within their valid ranges, then assertions
are appropriate.
For highly robust code, assert and then handle the error anyway. For any given error condition, a routine will generally use either
an assertion or error-handling code, but not both. Some experts argue that only one kind is needed (Meyer 1997).
But real-world programs and projects tend to be too messy to rely solely on assertions. On a large, long-lasting system, different
parts might be designed by different designers over a period of 5–10 years or more. The designers will be separated in time, across
numerous versions. Their designs will focus on different technologies at different points in the system's development. The designers
will be separated geographically, especially if parts of the system are acquired from external sources. Programmers will have worked
to different coding standards at different points in the system's lifetime. On a large development team, some programmers will inevitably
be more conscientious than others and some parts of the code will be reviewed more rigorously than other parts of the code. Some
programmers will unit test their code more thoroughly than others. With test teams working across different geographic regions and
subject to business pressures that result in test coverage that varies with each release, you can't count on comprehensive, system-level
regression testing, either.
In such circumstances, both assertions and error-handling code might be used to address the same error. In the source code for
Microsoft Word, for example, conditions that should always be true are asserted, but such errors are also handled by error-handling
code in case the assertion fails. For extremely large, complex, long-lived applications like Word, assertions are valuable because
they help to flush out as many development-time errors as possible. But the application is so complex (millions of lines of code)
and has gone through so many generations of modification that it isn't realistic to assume that every conceivable error will be detected
and corrected before the software ships, and so errors must be handled in the production version of the system as well.
Here's an example of how that might work in the Velocity example:
Example 8-6. Visual Basic Example of Using Assertions to Document Preconditions and Postconditions
Private Function Velocity ( _
ByRef latitude As Single, _
ByRef longitude As Single, _
ByRef elevation As Single _
) As Single
' Preconditions
Debug.Assert ( -90 <= latitude And latitude <= 90 ) <-- 1
Debug.Assert ( 0 <= longitude And longitude < 360 ) |
Debug.Assert ( -500 <= elevation And elevation <= 75000 ) <-- 1
...
' Sanitize input data. Values should be within the ranges asserted above,
' but if a value is not within its valid range, it will be changed to the
' closest legal value
If ( latitude < -90 ) Then <-- 2
latitude = -90 |
ElseIf ( latitude > 90 ) Then |
latitude = 90 |
End If |
If ( longitude < 0 ) Then |
longitude = 0 |
ElseIf ( longitude > 360 ) Then <-- 2
...
(1) Here is assertion code.
(2) Here is the code that handles bad input data at run time.
"... Defensive programming means always checking whether an operation succeeded. ..."
"... Exceptional usually means out of the ordinary and unusually good, but when it comes to errors, the word has a more negative meaning. The system throws an exception when some error condition happens, and if you don't catch that exception, it will give you a dialog box that says something like "your program has caused an error -- –goodbye." ..."
There are five desirable properties of good programs : They should be robust, correct,
maintainable, friendly, and efficient. Obviously, these properties can be prioritized in
different orders, but generally, efficiency is less important than correctness; it is nearly
always possible to optimize a well-designed program , whereas badly written "lean and mean"
code is often a disaster. (Donald Knuth, the algorithms guru, says that "premature optimization
is the root of all evil.")
Here I am mostly talking about programs that have to be used by non-expert users. (You can
forgive programs you write for your own purposes when they behave badly: For example, many
scientific number-crunching programs are like bad-tempered sports cars.) Being unbreakable is
important for programs to be acceptable to users, and you, therefore, need to be a little
paranoid and not assume that everything is going to work according to plan. ' Defensive
programming ' means writing programs that cope with all common errors. It means things like not
assuming that a file exists, or not assuming that you can write to any file (think of a
CD-ROM), or always checking for divide by zero.
In the next few sections I want to show you how to 'bullet-proof' programs . First, there is
a silly example to illustrate the traditional approach (check everything), and then I will
introduce exception handling.
Bullet-Proofing Programs
Say you have to teach a computer to wash its hair. The problem, of course, is that computers
have no common sense about these matters: "Lather, rinse, repeat" would certainly lead to a
house flooded with bubbles. So you divide the operation into simpler tasks, which return true
or false, and check the result of each task before going on to the next one. For example, you
can't begin to wash your hair if you can't get the top off the shampoo bottle.
Defensive programming means always checking whether an operation succeeded. So the following
code is full of if-else statements, and if you were trying to do something more
complicated than wash hair, the code would rapidly become very ugly indeed (and the code would
soon scroll off the page):
void wash_hair()
{
string msg = "";
if (! find_shampoo() || ! open_shampoo()) msg = "no shampoo";
else {
if (! wet_hair()) msg = "no water!";
else {
if (! apply_shampoo()) msg = "shampoo application error";
else {
for(int i = 0; i < 2; i++) // repeat twice
if (! lather() || ! rinse()) {
msg = "no hands!";
break; // break out of the loop
}
if (! dry_hair()) msg = "no towel!";
}
}
}
if (msg != "") cerr << "Hair error: " << msg << endl;
// clean up after washing hair
put_away_towel();
put_away_shampoo();
}
Part of the hair-washing process is to clean up afterward (as anybody who has a roommate
soon learns). This would be a problem for the following code, now assuming that
wash_hair() returns a string:
string wash_hair()
{
...
if (! wet_hair()) return "no water!"
if (! Apply_shampoo()) return "application error!";
...
}
You would need another function to call this wash_hair() , write out the message
(if the operation failed), and do the cleanup. This would still be an improvement over the
first wash_hair() because the code doesn't have all those nested blocks.
NOTE
Some people disapprove of returning from a function from more than one place, but this is
left over from the days when cleanup had to be done manually. C++ guarantees that any object is
properly cleaned up, no matter from where you return (for instance, any open file objects are
automatically closed). Besides, C++ exception handling works much like a return ,
except that it can occur from many functions deep. The following section describes this and
explains why it makes error checking easier. Catching Exceptions
An alternative to constantly checking for errors is to let the problem (for example,
division by zero, access violation) occur and then use the C++ exception-handling mechanism to
gracefully recover from the problem.
Exceptional usually means out of the ordinary and
unusually good, but when it comes to errors, the word has a more negative meaning. The system
throws an exception when some error condition happens, and if you don't catch that exception,
it will give you a dialog box that says something like "your program has caused an error --
–goodbye."
You should avoid doing that to your users -- at the very least you should give
them a more reassuring and polite message.
If an exception occurs in a try block, the system tries to match the exception with
one (or more) catch blocks.
try { // your code goes inside this block
... problem happens - system throws exception
}
catch(Exception) { // exception caught here
... handle the problem
}
It is an error to have a try without a catch and vice versa. The ON
ERROR clause in Visual Basic achieves a similar goal, as do signals in C; they allow you
to jump out of trouble to a place where you can deal with the problem. The example is a
function div() , which does integer division. Instead of checking whether the divisor
is zero, this code lets the division by zero happen but catches the exception. Any code within
the try block can safely do integer division, without having to worry about the
problem. I've also defined a function bad_div() that does not catch the exception,
which will give a system error message when called:
int div(int i, int j)
{
int k = 0;
try {
k = i/j;
cout << "successful value " << k << endl;
}
catch(IntDivideByZero) {
cout << "divide by zero\n";
}
return k;
}
;> int bad_div(int i,int j) { return i/j; }
;> bad_div(10,0);
integer division by zero <main> (2)
;> div(2,1);
successful value 1
(int) 1
;> div(1,0);
divide by zero
(int) 0
This example is not how you would normally organize things. A lowly function like
div() should not have to decide how an error should be handled; its job is to do a
straightforward calculation. Generally, it is not a good idea to directly output error
information to cout or cerr because Windows graphical user interface programs
typically don't do that kind of output. Fortunately, any function call, made from within a
try block, that throws an exception will have that exception caught by the
catch block. The following is a little program that calls the (trivial) div()
function repeatedly but catches any divide-by-zero errors:
// div.cpp
#include <iostream>
#include <uc_except.h>
using namespace std;
int div(int i, int j)
{ return i/j; }
int main() {
int i,j,k;
cout << "Enter 0 0 to exit\n";
for(;;) { // loop forever
try {
cout << "Give two numbers: ";
cin >> i >> j;
if (i == 0 && j == 0) return 0; // exit program!
int k = div(i,j);
cout << "i/j = " << k << endl;
} catch(IntDivideByZero) {
cout << "divide by zero\n";
}
}
return 0;
}
Notice two crucial things about this example: First, the error-handling code appears as a
separate exceptional case, and second, the program does not crash due to divide-by-zero errors
(instead, it politely tells the user about the problem and keeps going).
Note the inclusion of <uc_except.h> , which is a nonstandard extension
specific to UnderC. The ISO standard does not specify any hardware error exceptions, mostly
because not all platforms support them, and a standard has to work everywhere. So
IntDivideByZero is not available on all systems. (I have included some library code
that implements these hardware exceptions for GCC and BCC32; please see the Appendix for more
details.)
How do you catch more than one kind of error? There may be more than one catch
block after the try block, and the runtime system looks for the best match. In some
ways, a catch block is like a function definition; you supply an argument, and you can
name a parameter that should be passed as a reference. For example, in the following code,
whatever do_something() does, catch_all_errors() catches it -- specifically a
divide-by-zero error -- and it catches any other exceptions as well:
The standard exceptions have a what() method, which gives more information about
them. Order is important here. Exception includes HardwareException , so
putting Exception first would catch just about everything. When an exception is
thrown, the system picks the first catch block that would match that exception. The
rule is to put the catch blocks in order of increasing generality.
Throwing
Exceptions
You can throw your own exceptions, which can be of any type, including C++ strings. (In
Chapter 8 ,
"Inheritance and Virtual Methods," you will see how you can create a hierarchy of errors, but
for now, strings and integers will do fine.) It is a good idea to write an error-generating
function fail() , which allows you to add extra error-tracking features later. The
following example returns to the hair-washing algorithm and is even more paranoid about
possible problems:
void fail(string msg)
{
throw msg;
}
void wash_hair()
{
try {
if (! find_shampoo()) fail("no shampoo");
if (! open_shampoo()) fail("can't open shampoo");
if (! wet_hair()) fail("no water!");
if (! apply_shampoo())fail("shampoo application error");
for(int i = 0; i < 2; i++) // repeat twice
if (! lather() || ! rinse()) fail("no hands!");
if (! dry_hair()) fail("no towel!");
}
catch(string err) {
cerr << "Known Hair washing failure: " << err << endl;
}
catch(...) {
cerr << "Catastropic failure\n";
}
// clean up after washing hair
put_away_towel();
put_away_shampoo();
}
In this example, the general logic is clear, and the cleanup code is always run, whatever
disaster happens. This example includes a catch-all catch block at the end. It is a
good idea to put one of these in your program's main() function so that it can deliver
a more polite message than "illegal instruction." But because you will then have no information
about what caused the problem, it's a good idea to cover a number of known cases first. Such a
catch-all must be the last catch block; otherwise, it will mask more specific
errors.
It is also possible to use a trick that Perl programmers use: If the fail()
function returns a bool , then the following expression is valid C++ and does exactly
what you want:
If dry_hair() returns true, the or expression must be true, and there's no
need to evaluate the second term. Conversely, if dry_hair() returns false, the
fail() function would be evaluated and the side effect would be to throw an exception.
This short-circuiting of Boolean expressions applies also to && and is
guaranteed by the C++ standard.
Once you've adopted this mind-set, you can then rewrite your prototype and follow a set of
eight strategies to make your code as solid as possible.
While I work on the real version, I
ruthlessly follow these strategies and try to remove as many errors as I can, thinking like
someone who wants to break the software.
Never Trust Input. Never trust the data you're given and always validate it.
Prevent Errors. If an error is possible, no matter how probable, try to prevent it.
Fail Early and Openly Fail early, cleanly, and openly, stating what happened, where, and how
to fix it.
Document Assumptions Clearly state the pre-conditions, post-conditions, and invariants.
Prevention over Documentation. Don't do with documentation that which can be done with code
or avoided completely.
Automate Everything Automate everything, especially testing.
Simplify and Clarify Always simplify the code to the smallest, cleanest form that works
without sacrificing safety.
Question Authority Don't blindly follow or reject rules.
These aren't the only strategies, but they're the core things I feel programmers have to
focus on when trying to make good, solid code. Notice that I don't really say exactly how to do
these. I'll go into each of these in more detail, and some of the exercises will actually cover
them extensively.
"... Different responsibilities should go into different components, layers, or modules of the application. Each part of the program should only be responsible for a part of the functionality (what we call its concerns) and should know nothing about the rest. ..."
"... The goal of separating concerns in software is to enhance maintainability by minimizing ripple effects. A ripple effect means the propagation of a change in the software from a starting point. This could be the case of an error or exception triggering a chain of other exceptions, causing failures that will result in a defect on a remote part of the application. It can also be that we have to change a lot of code scattered through multiple parts of the code base, as a result of a simple change in a function definition. ..."
"... Rule of thumb: Well-defined software will achieve high cohesion and low coupling. ..."
This is a design principle that is applied at multiple levels. It is not just about the
low-level design (code), but it is also relevant at a higher level of abstraction, so it will
come up later when we talk about architecture.
Different responsibilities should go into different components, layers, or modules of the
application. Each part of the program should only be responsible for a part of the
functionality (what we call its concerns) and should know nothing about the rest.
The goal of separating concerns in software is to enhance maintainability by minimizing
ripple effects. A ripple effect means the propagation of a change in the software from a
starting point. This could be the case of an error or exception triggering a chain of other
exceptions, causing failures that will result in a defect on a remote part of the application.
It can also be that we have to change a lot of code scattered through multiple parts of the
code base, as a result of a simple change in a function definition.
Clearly, we do not want these scenarios to happen. The software has to be easy to change. If
we have to modify or refactor some part of the code that has to have a minimal impact on the
rest of the application, the way to achieve this is through proper encapsulation.
In a similar way, we want any potential errors to be contained so that they don't cause
major damage.
This concept is related to the DbC principle in the sense that each concern can be enforced
by a contract. When a contract is violated, and an exception is raised as a result of such a
violation, we know what part of the program has the failure, and what responsibilities failed
to be met.
Despite this similarity, separation of concerns goes further. We normally think of contracts
between functions, methods, or classes, and while this also applies to responsibilities that
have to be separated, the idea of separation of concerns also applies to Python modules,
packages, and basically any software component. Cohesion and coupling
These are important concepts for good software design.
On the one hand, cohesion means that objects should have a small and well-defined purpose,
and they should do as little as possible. It follows a similar philosophy as Unix commands that
do only one thing and do it well. The more cohesive our objects are, the more useful and
reusable they become, making our design better.
On the other hand, coupling refers to the idea of how two or more objects depend on each
other. This dependency poses a limitation. If two parts of the code (objects or methods) are
too dependent on each other, they bring with them some undesired consequences:
No code reuse : If one function depends too much on a particular object, or takes too
many parameters, it's coupled with this object, which means that it will be really difficult
to use that function in a different context (in order to do so, we will have to find a
suitable parameter that complies with a very restrictive interface)
Ripple effects : Changes in one of the two parts will certainly impact the other, as they
are too close
Low level of abstraction : When two functions are so closely related, it is hard to see
them as different concerns resolving problems at different levels of abstraction
Rule of thumb: Well-defined software will achieve high cohesion and low coupling.
"... Check all values in function/method parameter lists. ..."
"... Are they all the correct type and size? ..."
"... You should always initialize variables and not depend on the system to do the initialization for you. ..."
"... taking the time to make your code readable and have the code layout match the logical structure of your design is essential to writing code that is understandable by humans and that works. Adhering to coding standards and conventions, keeping to a consistent style, and including good, accurate comments will help you immensely during debugging and testing. And it will help you six months from now when you come back and try to figure out what the heck you were thinking here. ..."
By defensive programming we mean that your code should protect itself from bad data. The bad
data can come from user input via the command line, a graphical text box or form, or a file.
Bad data can also come from other routines in your program via input parameters like in the
first example above.
How do you protect your program from bad data? Validate! As tedious as it sounds, you should
always check the validity of data that you receive from outside your routine. This means you
should check the following
Check the number and type of command line arguments.
Check file operations.
Did the file open?
Did the read operation return anything?
Did the write operation write anything?
Did we reach EOF yet?
Check all values in function/method parameter lists.
Are they all the correct type and size?
You should always initialize variables and not depend on the system to do the
initialization for you.
What else should you check for? Well, here's a short list:
Null pointers (references in Java)
Zeros in denominators
Wrong type
Out of range values
As an example, here's a C program that takes in a list of house prices from a file and
computes the average house price from the list. The file is provided to the program from the
command line.
/* * program to compute the average selling price of a set of homes. * Input comes from a file that is passed via the command line.
* Output is the Total and Average sale prices for * all the homes and the number of prices in the file. * * jfdooley */ #include <stdlib.h> #include <stdio.h>
int main(int argc, char **argv) { FILE *fp; double totalPrice, avgPrice; double price; int numPrices;
/* check that the user entered the correct number of args */ if (argc < 2) { fprintf(stderr,"Usage: %s <filename>\n", argv[0]); exit(1); }
/* try to open the input file */ fp = fopen(argv[1], "r"); if (fp == NULL) { fprintf(stderr, "File Not Found: %s\n", argv[1]); exit(1); } totalPrice = 0.0; numPrices = 0;
avgPrice = totalPrice / numPrices; printf("Number of houses is %d\n", numPrices); printf("Total Price of all houses is $%10.2f\n", totalPrice); printf("Average Price per house is $%10.2f\n", avgPrice);
return 0; }
Assertions Can Be Your Friend
Defensive programming means that using assertions is a great idea if your language supports
them. Java, C99, and C++ all support assertions. Assertions will test an expression that you
give them and if the expression is false, it will throw an error and normally abort the program
. You should use error handling code for errors you think might happen – erroneous user
input, for example – and use assertions for errors that should never happen
– off by one errors in loops, for example. Assertions are great for testing
your program , but because you should remove them before giving programs to customers (you
don't want the program to abort on the user, right?) they aren't good to use to validate input
data.
Exceptions and Error Handling
We've talked about using assertions to handle truly bad errors, ones that should never occur
in production. But what about handling "normal" errors? Part of defensive programming is to
handle errors in such a way that no damage is done to any data in the program or the files it
uses, and so that the program stays running for as long as possible (making your program
robust).
Let's look at exceptions first. You should take advantage of built-in exception handling in
whatever programming language you're using. The exception handling mechanism will give you
information about what bad thing has just happened. It's then up to you to decide what to do.
Normally in an exception handling mechanism you have two choices, handle the exception
yourself, or pass it along to whoever called you and let them handle it. What you do and how
you do it depends on the language you're using and the capabilities it gives you. We'll talk
about exception handling in Java later.
Error Handling
Just like with validation, you're most likely to encounter errors in input data, whether
it's command line input, file handling, or input from a graphical user interface form. Here
we're talking about errors that occur at run time. Compile time and testing errors are covered
in the next chapter on debugging and testing. Other types of errors can be data that your
program computes incorrectly, errors in other programs that interact with your program , the
operating system for instance, race conditions, and interaction errors where your program is
communicating with another and your program is at fault.
The main purpose of error handling is to have your program survive and run correctly for as
long as possible. When it gets to a point where your program cannot continue, it needs to
report what is wrong as best as it can and then exit gracefully. Exiting is the last resort for
error handling. So what should you do? Well, once again we come to the "it depends" answer.
What you should do depends on what your program's context is when the error occurs and what its
purpose is. You won't handle an error in a video game the same way you handle one in a cardiac
pacemaker. In every case, your first goal should be – try to recover.
Trying to recover from an error will have different meanings in different programs .
Recovery means that your program needs to try to either ignore the bad data, fix it, or
substitute something else that is valid for the bad data. See McConnell 8
for a further discussion of error handling. Here are a few examples of how to recover from
errors,
You might just ignore the bad data and keep going , using the next valid piece of
data. Say your program is a piece of embedded software in a digital pressure gauge. You
sample the sensor that returns the pressure 60 times a second. If the sensor fails to deliver
a pressure reading once, should you shut down the gauge? Probably not; a reasonable thing to
do is just skip that reading and set up to read the next piece of data when it arrives. Now
if the pressure sensor skips several readings in a row, then something might be wrong with
the sensor and you should do something different (like yell for help).
__________
8 McConnell, 2004.
You might substitute the last valid piece of data for a missing or wrong piece.
Taking the digital pressure gauge again, if the sensor misses a reading, since each time
interval is only a sixtieth of a second, it's likely that the missing reading is very close
to the previous reading. In that case you can substitute the last valid piece of data for
the missing value.
There may be instances where you don't have any previously recorded valid data. Your
application uses an asynchronous event handler, so you don't have any history of data, but
your program knows that the data should be in a particular range. Say you've prompted the
user for a salary amount and the value that you get back is a negative number. Clearly no one
gets paid a salary of negative dollars, so the value is wrong. One way (probably not the
best) to handle this error is to substitute the closest valid value in the range , in
this case a zero. Although not ideal, at least your program can continue running with a valid
data value in that field.
In C programs , nearly all system calls and most of the standard library functions return
a value. You should test these values! Most functions will return values that indicate
success (a non-negative integer) or failure (a negative integer, usually -1). Some functions
return a value that indicates how successful they were. For example, the
printf() family of functions returns the number of characters printed, and the
scanf() family returns the number of input elements read. Most C functions also
set a global variable named errno that contains an integer value that is the
number of the error that occurred. The list of error numbers is in a header file called
errno.h . A zero on the errno variable indicates success. Any other
positive integer value is the number of the error that occurred. Because the system tells you
two things, (1) an error occurred, and (2) what it thinks is the cause of the error, you can
do lots of different things to handle it, including just reporting the error and
bailing out. For example, if we try to open a file that doesn't exist, the program
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
if ((fd = fopen(fname, "r")) == NULL) {
perror("File not opened");
exit(1);
}
printf("File exists\n");
return 0;
}
will return the error message File not opened: No such file or
directory
if the file really doesn't exist. The function perror() reads the
errno variable and using the string provided plus a standard string
corresponding to the error number, writes an error message to the console's standard
error output. This program could also prompt the user for a different file name or it
could substitute a default file name. Either of these would allow the program to
continue rather than exiting on the error.
There are other techniques to use in error handling and recovery. These examples should
give you a flavor of what you can do within your program . The important idea to remember
here is to attempt recovery if possible, but most of all, don't fail silently!
Exceptions in Java
Some programming languages have built-in error reporting systems that will tell you when an
error occurs, and leave it up to you to handle it one way or another. These errors that would
normally cause your program to die a horrible death are called exceptions . Exceptions
get thrown by the code that encounters the error. Once something is thrown, it's usually
a good idea if someone catches it. This is the same with exceptions. So there are two
sides to exceptions that you need to be aware of when you're writing code:
When you have a piece of code that can encounter an error you throw an exception.
Systems like Java will throw some exceptions for you. These exceptions are listed in the
Exception class in the Java API documentation (see http://download.oracle.com/javase/6/docs/api
). You can also write your own code to throw exceptions. We'll have an example later in the
chapter.
Once an exception is thrown, somebody has to catch it. If you don't do anything in
your program , this uncaught exception will percolate through to the Java Virtual
Machine (the JVM) and be caught there. The JVM will kill your program and provide you with a
stack backtrace that should lead you back to the place that originally threw the exception
and show you how you got there. On the other hand, you can also write code to encapsulate the
calls that might generate exceptions and catch them yourself using Java's S
try...catch mechanism. Java requires that some exceptions must be caught.
We'll see an example later.
Java has three different types of exceptions – checked exceptions, errors, and
unchecked exceptions. Checked exceptions are those that you should catch and handle
yourself using an exception handler; they are exceptions that you should anticipate and handle
as you design and write your code. For example, if your code asks a user for a file name, you
should anticipate that they will type it wrong and be prepared to catch the resulting
FileNotFoundException . Checked exceptions must be caught.
Errors on the other hand are exceptions that usually are related to things happening
outside your program and are things you can't do anything about except fail gracefully. You
might try to catch the error exception and provide some output for the user, but you will still
usually have to exit.
The third type of exception is the runtime exception . Runtime exceptions all result
from problems within your program that occur as it runs and almost always indicate errors in
your code. For example, a NullPointerException nearly always indicates a
bug in your code and shows up as a runtime exception. Errors and runtime exceptions are
collectively called unchecked exceptions (that would be because you usually don't try to
catch them, so they're unchecked). In the program below we deliberately cause a runtime
exception:
public class TestNull {
public static void main(String[] args) {
String str = null;
int len = str.length();
}
}
This program will compile just fine, but when you run it you'll get this as output:
Exception in thread "main" java.lang.NullPointerException
at TestNull.main(TestNull.java:4)
This is a classic runtime exception. There's no need to catch this exception because the
only thing we can do is exit. If we do catch it, the program might look like:
public
class TestNullCatch {
public static void main(String[] args) {
String str = null;
try {
int len = str.length();
} catch (NullPointerException e) {
System.out.println("Oops: " + e.getMessage());
System.exit(1);
}
}
}
which gives us the output
Oops: null
Note that the getMessage() method will return a String containing
whatever error message Java deems appropriate – if there is one. Otherwise it returns a
null . This is somewhat less helpful than the default stack trace above.
Let's rewrite the short C program above in Java and illustrate how to catch a checked
exception .
import java.io.*; import java.util.*;
public class FileTest
public static void main(String [] args) { File fd = new File("NotAFile.txt"); System.out.println("File exists " + fd.exists());
By the way, if we don't use the try-catch block in the above program ,
then it won't compile. We get the compiler error message
FileTestWrong.java:11: unreported exception java.io.FileNotFoundException; must be caught
or declared to be thrown
FileReader fr = new FileReader(fd);
^1 error
Remember, checked exceptions must be caught. This type of error doesn't show up for
unchecked exceptions. This is far from everything you should know about exceptions and
exception handling in Java; start digging through the Java tutorials and the Java API!
The Last Word on Coding
Coding is the heart of software development. Code is what you produce. But coding is hard;
translating even a good, detailed design into code takes a lot of thought, experience, and
knowledge, even for small programs . Depending on the programming language you are using and
the target system, programming can be a very time-consuming and difficult task.
That's why
taking the time to make your code readable and have the code layout match the logical structure
of your design is essential to writing code that is understandable by humans and that works.
Adhering to coding standards and conventions, keeping to a consistent style, and including
good, accurate comments will help you immensely during debugging and testing. And it will help
you six months from now when you come back and try to figure out what the heck you were
thinking here.
And finally,
I am rarely happier than when spending an entire day programming my computer to perform
automatically a task that it would otherwise take me a good ten seconds to do by
hand.
"... How do you protect your program from bad data? Validate! As tedious as it sounds, you should always check the validity of data that you receive from outside your routine. This means you should check the following ..."
"... Check the number and type of command line arguments. ..."
By defensive programming we mean that your code should protect itself from bad data. The bad
data can come from user input via the command line, a graphical text box or form, or a file.
Bad data can also come from other routines in your program via input parameters like in the
first example above.
How do you protect your program from bad data? Validate! As tedious as it sounds, you should
always check the validity of data that you receive from outside your routine. This means you
should check the following
Check the number and type of command line arguments.
Check file operations.
Did the file open?
Did the read operation return anything?
Did the write operation write anything?
Did we reach EOF yet?
Check all values in function/method parameter lists.
Are they all the correct type and size?
You should always initialize variables and not depend on the system to do the
initialization for you.
What else should you check for? Well, here's a short list:
Null pointers (references in Java)
Zeros in denominators
Wrong type
Out of range values
As an example, here's a C program that takes in a list of house prices from a file and
computes the average house price from the list. The file is provided to the program from the
command line.
/* * program to compute the average selling price of a set of homes. * Input comes from a file that is passed via the command line.
* Output is the Total and Average sale prices for * all the homes and the number of prices in the file. * * jfdooley */ #include <stdlib.h> #include <stdio.h>
int main(int argc, char **argv) { FILE *fp; double totalPrice, avgPrice; double price; int numPrices;
/* check that the user entered the correct number of args */ if (argc < 2) { fprintf(stderr,"Usage: %s <filename>\n", argv[0]); exit(1); }
/* try to open the input file */ fp = fopen(argv[1], "r"); if (fp == NULL) { fprintf(stderr, "File Not Found: %s\n", argv[1]); exit(1); } totalPrice = 0.0; numPrices = 0;
avgPrice = totalPrice / numPrices; printf("Number of houses is %d\n", numPrices); printf("Total Price of all houses is $%10.2f\n", totalPrice); printf("Average Price per house is $%10.2f\n", avgPrice);
return 0; }
Assertions Can Be Your Friend
Defensive programming means that using assertions is a great idea if your language supports
them. Java, C99, and C++ all support assertions. Assertions will test an expression that you
give them and if the expression is false, it will throw an error and normally abort the program
. You should use error handling code for errors you think might happen – erroneous user
input, for example – and use assertions for errors that should never happen
– off by one errors in loops, for example. Assertions are great for testing
your program , but because you should remove them before giving programs to customers (you
don't want the program to abort on the user, right?) they aren't good to use to validate input
data.
Exceptions and Error Handling
We've talked about using assertions to handle truly bad errors, ones that should never occur
in production. But what about handling "normal" errors? Part of defensive programming is to
handle errors in such a way that no damage is done to any data in the program or the files it
uses, and so that the program stays running for as long as possible (making your program
robust).
Let's look at exceptions first. You should take advantage of built-in exception handling in
whatever programming language you're using. The exception handling mechanism will give you
information about what bad thing has just happened. It's then up to you to decide what to do.
Normally in an exception handling mechanism you have two choices, handle the exception
yourself, or pass it along to whoever called you and let them handle it. What you do and how
you do it depends on the language you're using and the capabilities it gives you. We'll talk
about exception handling in Java later.
Error Handling
Just like with validation, you're most likely to encounter errors in input data, whether
it's command line input, file handling, or input from a graphical user interface form. Here
we're talking about errors that occur at run time. Compile time and testing errors are covered
in the next chapter on debugging and testing. Other types of errors can be data that your
program computes incorrectly, errors in other programs that interact with your program , the
operating system for instance, race conditions, and interaction errors where your program is
communicating with another and your program is at fault.
The main purpose of error handling is to have your program survive and run correctly for as
long as possible. When it gets to a point where your program cannot continue, it needs to
report what is wrong as best as it can and then exit gracefully. Exiting is the last resort for
error handling. So what should you do? Well, once again we come to the "it depends" answer.
What you should do depends on what your program's context is when the error occurs and what its
purpose is. You won't handle an error in a video game the same way you handle one in a cardiac
pacemaker. In every case, your first goal should be – try to recover.
Trying to recover from an error will have different meanings in different programs .
Recovery means that your program needs to try to either ignore the bad data, fix it, or
substitute something else that is valid for the bad data. See McConnell 8
for a further discussion of error handling. Here are a few examples of how to recover from
errors,
You might just ignore the bad data and keep going , using the next valid piece of
data. Say your program is a piece of embedded software in a digital pressure gauge. You
sample the sensor that returns the pressure 60 times a second. If the sensor fails to deliver
a pressure reading once, should you shut down the gauge? Probably not; a reasonable thing to
do is just skip that reading and set up to read the next piece of data when it arrives. Now
if the pressure sensor skips several readings in a row, then something might be wrong with
the sensor and you should do something different (like yell for help).
__________
8 McConnell, 2004.
You might substitute the last valid piece of data for a missing or wrong piece.
Taking the digital pressure gauge again, if the sensor misses a reading, since each time
interval is only a sixtieth of a second, it's likely that the missing reading is very close
to the previous reading. In that case you can substitute the last valid piece of data for
the missing value.
There may be instances where you don't have any previously recorded valid data. Your
application uses an asynchronous event handler, so you don't have any history of data, but
your program knows that the data should be in a particular range. Say you've prompted the
user for a salary amount and the value that you get back is a negative number. Clearly no one
gets paid a salary of negative dollars, so the value is wrong. One way (probably not the
best) to handle this error is to substitute the closest valid value in the range , in
this case a zero. Although not ideal, at least your program can continue running with a valid
data value in that field.
In C programs , nearly all system calls and most of the standard library functions return
a value. You should test these values! Most functions will return values that indicate
success (a non-negative integer) or failure (a negative integer, usually -1). Some functions
return a value that indicates how successful they were. For example, the
printf() family of functions returns the number of characters printed, and the
scanf() family returns the number of input elements read. Most C functions also
set a global variable named errno that contains an integer value that is the
number of the error that occurred. The list of error numbers is in a header file called
errno.h . A zero on the errno variable indicates success. Any other
positive integer value is the number of the error that occurred. Because the system tells you
two things, (1) an error occurred, and (2) what it thinks is the cause of the error, you can
do lots of different things to handle it, including just reporting the error and
bailing out. For example, if we try to open a file that doesn't exist, the program
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
if ((fd = fopen(fname, "r")) == NULL) {
perror("File not opened");
exit(1);
}
printf("File exists\n");
return 0;
}
will return the error message File not opened: No such file or
directory
if the file really doesn't exist. The function perror() reads the
errno variable and using the string provided plus a standard string
corresponding to the error number, writes an error message to the console's standard
error output. This program could also prompt the user for a different file name or it
could substitute a default file name. Either of these would allow the program to
continue rather than exiting on the error.
There are other techniques to use in error handling and recovery. These examples should
give you a flavor of what you can do within your program . The important idea to remember
here is to attempt recovery if possible, but most of all, don't fail silently!
"... In any case, it's important not to allow those statements to spread across your code base. They contain domain knowledge about what makes data or an operation valid, and thus, should be kept in a single place in order to adhere to the DRY principle . ..."
"... Nulls is another source of bugs in many OO languages due to inability to distinguish nullable and non-nullable reference types. Because of that, many programmers code defensively against them. So much that in many projects almost each public method and constructor is populated by this sort of checks: ..."
"... While defensive programming is a useful technique, make sure you use it properly ..."
"... If you see duplicated pre-conditions, consider extracting them into a separate type. ..."
Defensive programming: the good, the bad and the ugly
https://platform.twitter.com/widgets/follow_button.097c1f5038f9e8a0d62a39a892838d66.en.html#dnt=false&id=twitter-widget-0&lang=en&screen_name=vkhorikov&show_count=true&show_screen_name=true&size=m&time=1566789278322
In this post, I want to take a closer look at the practice of defensive programming.
Defensive programming: pre-conditions
Defensive programming stands for the use of guard statements and assertions in your code
base (actually, the definition of defensive programming is inconsistent across different
sources, but I'll stick to this one). This technique is designed to ensure code correctness and
reduce the number of bugs.
Pre-conditions are one of the most widely spread forms of defensive programming. They
guarantee that a method can be executed only when some requirements are met. Here's a typical
example:
public void CreateAppointment ( DateTime dateTime)
{
if (dateTime. Date < DateTime . Now . AddDays (1). Date )
throw new ArgumentException ( "Date is too early" );
if (dateTime. Date > DateTime . Now . AddMonths (1). Date )
throw new ArgumentException ( "Date is too late" );
/* Create an appointment */
}
Writing code like this is a good practice as it allows you to quickly react to any
unexpected situations, therefore adhering to the fail fast principle
.
When implementing guard statements, it's important to make sure you don't repeat them. If
you find yourself constantly writing repeating code to perform some validations, it's a strong
sign you fall into the trap of primitive
obsession . The repeated guard clause can be as simple as checking that some integer falls
into the expected range:
public void DoSomething ( int count)
{
if (count < 1 || count > 100)
throw new ArgumentException ( "Invalid count" );
/* Do something */
}
public void DoSomethingElse ( int count)
{
if (count < 1 || count > 100)
throw new ArgumentException ( "Invalid count" );
/* Do something else */
}
Or it can relate to some complex business rule which you might not even be able to verbalize
yet.
In any case, it's important not to allow those statements to spread across your code base.
They contain domain knowledge about what makes data or an operation valid, and thus, should be
kept in a single place in order to adhere to the DRY principle .
The best way to do that is to introduce new abstractions for each piece of such knowledge
you see repeated in your code base. In the sample above, you can convert the input parameter
from integer into a custom type, like this:
public void DoSomething ( Count count)
{
/* Do something */
}
public void DoSomethingElse ( Count count)
{
/* Do something else */
}
public class Count
{
public int Value { get ; private set ; }
public Count ( int value)
{
if (value < 1 || value > 100)
throw new ArgumentException ( "Invalid count" );
Value = value;
}
}
With properly defined domain concepts, there's no need in duplicating
pre-conditions.
Defensive programming: nulls
Nulls is another source of bugs in many OO languages due to inability to distinguish
nullable and non-nullable reference types. Because of that, many programmers code defensively
against them. So much that in many projects almost each public method and constructor is
populated by this sort of checks:
public class Controller
{
public Controller ( ILogger logger, IEmailGateway gateway)
{
if (logger == null )
throw new ArgumentNullException ();
if (gateway == null )
throw new ArgumentNullException ();
/* */
}
public void Process ( User user, Order order)
{
if (user == null )
throw new ArgumentNullException ();
/* */
}
}
It's true that null checks are essential. If allowed to slip through, nulls can lead to
obscure errors down the road. But you still can significantly reduce the number of such
validations.
Do to that, you would need 2 things. First, define a special Maybe
struct which would allow you to distinguish nullable and non-nullable reference types. And
secondly, use the Fody.NullGuard library to introduce automatic checks
for all input parameters that weren't marked with the Maybe struct.
After that, the code above can be turned into the following one:
public class Controller
{
public Controller ( ILogger logger, IEmailGateway gateway)
{
/* */
}
public void Process ( User user, Maybe < Order > order)
{
/* */
}
}
Note the absence of null checks. The null guard does all the work needed for
you.
Defensive programming: assertions
Assertions is another valuable concept. It stands for checking that your assumptions about
the code's execution flow are correct by introducing assert statements which would be validated
at runtime. In practice, it often means validating output of 3rd party libraries that you use
in your project. It's a good idea not to trust such libraries by default and always check that
the result they produce falls into some expected range.
An example here can be an official library that works with a social provider, such as
Facebook SDK client:
public void Register ( string facebookAccessToken)
throw new InvalidOperationException ( "Invalid response from Facebook" );
/* Sign in the user */
}
public class FacebookResponse // Part of the SDK
{
public string FirstName ;
public string LastName ;
public string Email ;
}
This code sample assumes that Facebook should always return an email for any registered user
and validates that assumption by employing an assertion.
Just as with duplicated pre-conditions, identical assertions should not be allowed. The
guideline here is to always wrap official 3rd party libraries with your own gateways which
would encapsulate all the work with those libraries, including assertions.
In our case, it would look like this:
public void Register ( string facebookAccessToken)
{
UserInfo user = _facebookGateway . GetUser (facebookAccessToken);
/* Register the user */
}
public void SignIn ( string facebookAccessToken)
{
UserInfo user = _facebookGateway . GetUser (facebookAccessToken);
/* Sign in the user */
}
public class FacebookGateway
{
public UserInfo GetUser ( string facebookAccessToken)
throw new InvalidOperationException ( "Invalid response from Facebook" );
/* Convert FacebookResponse into UserInfo */
}
}
public class UserInfo // Our own class
{
public Maybe < string > FirstName ;
public Maybe < string > LastName ;
public string Email ;
}
Note that along with the assertion, we also convert the object of type FacebookResponse
which is a built-in class from the official SDK to our own UserInfo type. This way, we can be
sure that the information about the user always resides in a valid state because we validated
and converted it ourselves.
Summary
While defensive programming is a useful technique, make sure you use it properly.
If you see duplicated pre-conditions, consider extracting them into a separate type.
To reduce the number of null checks, consider using the Aspect-Oriented Programming
approach. The good tool that built specifically for that purpose is Fody.NullGuard .
Always wrap 3rd party libraries with your own gateways.
While OO critique is good (althoth most point are far from new) and up to the point the proposed solution is not.
There is no universal opener for creating elegant reliable programs.
Notable quotes:
"... Object-Oriented Programming has been created with one goal in mind -- to manage the complexity of procedural codebases. In other words, it was supposed to improve code organization. There's no objective and open evidence that OOP is better than plain procedural programming. ..."
"... The bitter truth is that OOP fails at the only task it was intended to address. It looks good on paper -- we have clean hierarchies of animals, dogs, humans, etc. However, it falls flat once the complexity of the application starts increasing. Instead of reducing complexity, it encourages promiscuous sharing of mutable state and introduces additional complexity with its numerous design patterns . OOP makes common development practices, like refactoring and testing, needlessly hard. ..."
"... C++ is a horrible [object-oriented] language And limiting your project to C means that people don't screw things up with any idiotic "object model" c&@p. -- Linus Torvalds, the creator of Linux ..."
"... Many dislike speed limits on the roads, but they're essential to help prevent people from crashing to death. Similarly, a good programming framework should provide mechanisms that prevent us from doing stupid things. ..."
"... Unfortunately, OOP provides developers too many tools and choices, without imposing the right kinds of limitations. Even though OOP promises to address modularity and improve reusability, it fails to deliver on its promises (more on this later). OOP code encourages the use of shared mutable state, which has been proven to be unsafe time and time again. OOP typically requires a lot of boilerplate code (low signal-to-noise ratio). ..."
The ultimate goal of every software developer should be to write reliable code. Nothing else matters if the code is buggy
and unreliable. And what is the best way to write code that is reliable? Simplicity . Simplicity is the opposite of complexity
. Therefore our first and foremost responsibility as software developers should be to reduce code complexity.
Disclaimer
I'll be honest, I'm not a raving fan of object-orientation. Of course, this article is going to be biased. However, I have good
reasons to dislike OOP.
I also understand that criticism of OOP is a very sensitive topic -- I will probably offend many readers. However, I'm doing what
I think is right. My goal is not to offend, but to raise awareness of the issues that OOP introduces.
I'm not criticizing Alan Kay's OOP -- he is a genius. I wish OOP was implemented the way he designed it. I'm criticizing the modern
Java/C# approach to OOP.
I will also admit that I'm angry. Very angry. I think that it is plain wrong that OOP is considered the de-facto standard for
code organization by many people, including those in very senior technical positions. It is also wrong that many mainstream languages
don't offer any other alternatives to code organization other than OOP.
Hell, I used to struggle a lot myself while working on OOP projects. And I had no single clue why I was struggling this much.
Maybe I wasn't good enough? I had to learn a couple more design patterns (I thought)! Eventually, I got completely burned out.
This post sums up my first-hand decade-long journey from Object-Oriented to Functional programming. I've seen it all. Unfortunately,
no matter how hard I try, I can no longer find use cases for OOP. I have personally seen OOP projects fail because they become too
complex to maintain.
TLDR
Object oriented programs are offered as alternatives to correct ones --
Edsger
W. Dijkstra , pioneer of computer science
<img src="https://miro.medium.com/max/1400/1*MTb-Xx5D0H6LUJu_cQ9fMQ.jpeg" width="700" height="467"/>
Photo by
Sebastian Herrmann on
Unsplash
Object-Oriented Programming has been created with one goal in mind -- to manage the complexity of procedural codebases. In
other words, it was supposed to improve code organization.
There's no objective and open evidence that OOP is better than plain procedural programming.
The bitter truth is that OOP fails at the only task it was intended to address. It looks good on paper -- we have clean hierarchies
of animals, dogs, humans, etc. However, it falls flat once the complexity of the application starts increasing. Instead of reducing
complexity, it encourages promiscuous sharing of mutable state and introduces additional complexity with its numerous design patterns
. OOP makes common development practices, like refactoring and testing, needlessly hard.
Some might disagree with me, but the truth is that modern OOP has never been properly designed. It never came out of a proper
research institution (in contrast with Haskell/FP). I do not consider Xerox or another enterprise to be a "proper research institution".
OOP doesn't have decades of rigorous scientific research to back it up. Lambda calculus offers a complete theoretical foundation
for Functional Programming. OOP has nothing to match that. OOP mainly "just happened".
Using OOP is seemingly innocent in the short-term, especially on greenfield projects. But what are the long-term consequences
of using OOP? OOP is a time bomb, set to explode sometime in the future when the codebase gets big enough.
Projects get delayed, deadlines get missed, developers get burned-out, adding in new features becomes next to impossible.
The organization labels the codebase as the "legacy codebase" , and the development team plans a rewrite .
OOP is not natural for the human brain, our thought process is centered around "doing" things -- go for a walk, talk to a friend,
eat pizza. Our brains have evolved to do things, not to organize the world into complex hierarchies of abstract objects.
OOP code is non-deterministic -- unlike with functional programming, we're not guaranteed to get the same output given the same
inputs. This makes reasoning about the program very hard. As an oversimplified example, the output of 2+2 or calculator.Add(2,
2) mostly is equal to four, but sometimes it might become equal to three, five, and maybe even 1004. The dependencies of the
Calculator object might change the result of the computation in subtle, but profound ways.
The Need for a Resilient Framework
I know, this may sound weird, but as programmers, we shouldn't trust ourselves to write reliable code. Personally, I am unable
to write good code without a strong framework to base my work on. Yes, there are frameworks that concern themselves with some very
particular problems (e.g. Angular or ASP.Net).
I'm not talking about the software frameworks. I'm talking about the more abstract dictionary definition of a framework:
"an essential supporting structure " -- frameworks that concern themselves with the more abstract things like code organization
and tackling code complexity. Even though Object-Oriented and Functional Programming are both programming paradigms, they're also
both very high-level frameworks.
Limiting our choices
C++ is a horrible [object-oriented] language And limiting your project to C means that people don't screw things up with any
idiotic "object model" c&@p.
-- Linus Torvalds, the creator of Linux
Linus Torvalds is widely known for his open criticism of C++ and OOP. One thing he was 100% right about is limiting programmers
in the choices they can make. In fact, the fewer choices programmers have, the more resilient their code becomes. In the quote above,
Linus Torvalds highly recommends having a good framework to base our code upon.
<img src="https://miro.medium.com/max/1400/1*ujt2PMrbhCZuGhufoxfr5w.jpeg" width="700" height="465"/>
Photo by
specphotops on
Unsplash
Many dislike speed limits on the roads, but they're essential to help prevent people from crashing to death. Similarly, a good
programming framework should provide mechanisms that prevent us from doing stupid things.
A good programming framework helps us to write reliable code. First and foremost, it should help reduce complexity by providing
the following things:
Modularity and reusability
Proper state isolation
High signal-to-noise ratio
Unfortunately, OOP provides developers too many tools and choices, without imposing the right kinds of limitations. Even though
OOP promises to address modularity and improve reusability, it fails to deliver on its promises (more on this later). OOP code encourages
the use of shared mutable state, which has been proven to be unsafe time and time again. OOP typically requires a lot of boilerplate
code (low signal-to-noise ratio).
... ... ...
Messaging
Alan Kay coined the term "Object Oriented Programming" in the 1960s. He had a background in biology and was attempting to make
computer programs communicate the same way living cells do.
<img src="https://miro.medium.com/max/1400/1*bzRsnzakR7O4RMbDfEZ1sA.jpeg" width="700" height="467"/>
Photo by
Muukii on
Unsplash
Alan Kay's big idea was to have independent programs (cells) communicate by sending messages to each other. The state of
the independent programs would never be shared with the outside world (encapsulation).
That's it. OOP was never intended to have things like inheritance, polymorphism, the "new" keyword, and the myriad of design
patterns.
OOP in its purest form
Erlang is OOP in its purest form. Unlike more mainstream languages, it focuses on the core idea of OOP -- messaging. In
Erlang, objects communicate by passing immutable messages between objects.
Is there proof that immutable messages are a superior approach compared to method calls?
Hell yes! Erlang is probably the most reliable language in the world. It powers most of the world's telecom (and
hence the internet) infrastructure. Some of the systems written in Erlang have reliability of 99.9999999% (you read that right --
nine nines). Code Complexity
With OOP-inflected programming languages, computer software becomes more verbose, less readable, less descriptive, and harder
to modify and maintain.
The most important aspect of software development is keeping the code complexity down. Period. None of the fancy features
matter if the codebase becomes impossible to maintain. Even 100% test coverage is worth nothing if the codebase becomes too complex
and unmaintainable .
What makes the codebase complex? There are many things to consider, but in my opinion, the top offenders are: shared mutable state,
erroneous abstractions, and low signal-to-noise ratio (often caused by boilerplate code). All of them are prevalent in OOP.
The Problems of State
<img src="https://miro.medium.com/max/1400/1*1WeuR9OoKyD5EvtT9KjXOA.jpeg" width="700" height="467"/>
Photo by
Mika Baumeister on
Unsplash
What is state? Simply put, state is any temporary data stored in memory. Think variables or fields/properties in OOP. Imperative
programming (including OOP) describes computation in terms of the program state and changes to that state . Declarative (functional)
programming describes the desired results instead, and don't specify changes to the state explicitly.
... ... ...
To make the code more efficient, objects are passed not by their value, but by their reference . This is where "dependency
injection" falls flat.
Let me explain. Whenever we create an object in OOP, we pass references to its dependencies to the constructor .
Those dependencies also have their own internal state. The newly created object happily stores references to those dependencies
in its internal state and is then happy to modify them in any way it pleases. And it also passes those references down to anything
else it might end up using.
This creates a complex graph of promiscuously shared objects that all end up changing each other's state. This, in turn, causes
huge problems since it becomes almost impossible to see what caused the program state to change. Days might be wasted trying
to debug such state changes. And you're lucky if you don't have to deal with concurrency (more on this later).
Methods/Properties
The methods or properties that provide access to particular fields are no better than changing the value of a field directly.
It doesn't matter whether you mutate an object's state by using a fancy property or method -- the result is the same: mutated
state.
Some people say that OOP tries to model the real world. This is simply not true -- OOP has nothing to relate to in the real world.
Trying to model programs as objects probably is one of the biggest OOP mistakes.
The real world is not hierarchical
OOP attempts to model everything as a hierarchy of objects. Unfortunately, that is not how things work in the real world. Objects
in the real world interact with each other using messages, but they mostly are independent of each other.
Inheritance in the real world
OOP inheritance is not modeled after the real world. The parent object in the real world is unable to change the behavior of child
objects at run-time. Even though you inherit your DNA from your parents, they're unable to make changes to your DNA as they please.
You do not inherit "behaviors" from your parents, you develop your own behaviors. And you're unable to "override" your parents' behaviors.
The real world has no methods
Does the piece of paper you're writing on have a "write" method ? No! You take an empty piece of paper, pick up a pen,
and write some text. You, as a person, don't have a "write" method either -- you make the decision to write some text based on outside
events or your internal thoughts.
The Kingdom of Nouns
Objects bind functions and data structures together in indivisible units. I think this is a fundamental error since functions
and data structures belong in totally different worlds.
Objects (or nouns) are at the very core of OOP. A fundamental limitation of OOP is that it forces everything into nouns. And not
everything should be modeled as nouns. Operations (functions) should not be modeled as objects. Why are we forced to create a
Multiplier class when all we need is a function that multiplies two numbers? Simply have a Multiply function,
let data be data and let functions be functions!
In non-OOP languages, doing trivial things like saving data to a file is straightforward -- very similar to how you would describe
an action in plain English.
Real-world example, please!
Sure, going back to the painter example, the painter owns a PaintingFactory . He has hired a dedicated BrushManager
, ColorManager , a CanvasManager and a MonaLisaProvider . His good friend zombie makes
use of a BrainConsumingStrategy . Those objects, in turn, define the following methods: CreatePainting
, FindBrush , PickColor , CallMonaLisa , and ConsumeBrainz .
Of course, this is plain stupidity, and could never have happened in the real world. How much unnecessary complexity has been
created for the simple act of drawing a painting?
There's no need to invent strange concepts to hold your functions when they're allowed to exist separately from the objects.
Unit Testing
<img src="https://miro.medium.com/max/1400/1*xGn4uGgVyrRAXnqSwTF69w.jpeg" width="700" height="477"/>
Photo by
Ani Kolleshi on
Unsplash
Automated testing is an important part of the development process and helps tremendously in preventing regressions (i.e. bugs
being introduced into existing code). Unit Testing plays a huge role in the process of automated testing.
Some might disagree, but OOP code is notoriously difficult to unit test. Unit Testing assumes testing things in isolation, and
to make a method unit-testable:
Its dependencies have to be extracted into a separate class.
Create an interface for the newly created class.
Declare fields to hold the instance of the newly created class.
Make use of a mocking framework to mock the dependencies.
Make use of a dependency-injection framework to inject the dependencies.
How much more complexity has to be created just to make a piece of code testable? How much time was wasted just to make some code
testable?
> PS we'd also have to instantiate the entire class in order to test a single method. This will also bring in the code from
all of its parent classes.
With OOP, writing tests for legacy code is even harder -- almost impossible. Entire companies have been created (
TypeMock ) around the issue of
testing legacy OOP code.
Boilerplate code
Boilerplate code is probably the biggest offender when it comes to the signal-to-noise ratio. Boilerplate code is "noise" that
is required to get the program to compile. Boilerplate code takes time to write and makes the codebase less readable because of the
added noise.
While "program to an interface, not to an implementation" is the recommended approach in OOP, not everything should become an
interface. We'd have to resort to using interfaces in the entire codebase, for the sole purpose of testability. We'd also probably
have to make use of dependency injection, which further introduced unnecessary complexity.
Testing private methods
Some people say that private methods shouldn't be tested I tend to disagree, unit testing is called "unit" for a reason -- test
small units of code in isolation. Yet testing of private methods in OOP is nearly impossible. We shouldn't be making private methods
internal just for the sake of testability.
In order to achieve testability of private methods, they usually have to be extracted into a separate object. This, in turn, introduces
unnecessary complexity and boilerplate code.
Refactoring
Refactoring is an important part of a developer's day-to-day job. Ironically, OOP code is notoriously hard to refactor. Refactoring
is supposed to make the code less complex, and more maintainable. On the contrary, refactored OOP code becomes significantly more
complex -- to make the code testable, we'd have to make use of dependency injection, and create an interface for the refactored class.
Even then, refactoring OOP code is really hard without dedicated tools like Resharper.
In the simple example above, the line count has more than doubled just to extract a single method. Why does refactoring create
even more complexity, when the code is being refactored in order to decrease complexity in the first place?
Contrast this to a similar refactor of non-OOP code in JavaScript:
The code has literally stayed the same -- we simply moved the isValidInput function to a different file and added
a single line to import that function. We've also added _isValidInput to the function signature for the sake of testability.
This is a simple example, but in practice the complexity grows exponentially as the codebase gets bigger.
And that's not all. Refactoring OOP code is extremely risky . Complex dependency graphs and state scattered all over OOP
codebase, make it impossible for the human brain to consider all of the potential issues.
The Band-aids
<img src="https://miro.medium.com/max/1400/1*JOtbVvacgu-nH3ZR4mY2Og.jpeg" width="700" height="567"/>
Image source: Photo by
Pixabay from
Pexels
What do we do when something is not working? It is simple, we only have two options -- throw it away or try fixing it. OOP is
something that can't be thrown away easily, millions of developers are trained in OOP. And millions of organizations worldwide are
using OOP.
You probably see now that OOP doesn't really work , it makes our code complex and unreliable. And you're not alone! People
have been thinking hard for decades trying to address the issues prevalent in OOP code. They've come up with a myriad of
design patterns.
Design patterns
OOP provides a set of guidelines that should theoretically allow developers to incrementally build larger and larger systems:
SOLID principle, dependency injection, design patterns, and others.
Unfortunately, the design patterns are nothing other than band-aids. They exist solely to address the shortcomings of OOP.
A myriad of books has even been written on the topic. They wouldn't have been so bad, had they not been responsible for the introduction
of enormous complexity to our codebases.
The problem factory
In fact, it is impossible to write good and maintainable Object-Oriented code.
On one side of the spectrum we have an OOP codebase that is inconsistent and doesn't seem to adhere to any standards. On the other
side of the spectrum, we have a tower of over-engineered code, a bunch of erroneous abstractions built one on top of one another.
Design patterns are very helpful in building such towers of abstractions.
Soon, adding in new functionality, and even making sense of all the complexity, gets harder and harder. The codebase will be full
of things like SimpleBeanFactoryAwareAspectInstanceFactory , AbstractInterceptorDrivenBeanDefinitionDecorator
, TransactionAwarePersistenceManagerFactoryProxy or RequestProcessorFactoryFactory .
Precious brainpower has to be wasted trying to understand the tower of abstractions that the developers themselves have created.
The absence of structure is in many cases better than having bad structure (if you ask me).
Is Object-Oriented Programming a Trillion Dollar Disaster?
(medium.com) Posted by EditorDavid on Monday July 22, 2019 @01:04AM from the OOPs dept.
Senior full-stack engineer Ilya Suzdalnitski recently published a lively 6,000-word essay
calling object-oriented programming "a trillion dollar disaster." Precious time and
brainpower are being spent thinking about "abstractions" and "design patterns" instead of
solving real-world problems... Object-Oriented Programming (OOP) has been created with one goal
in mind -- to manage the complexity of procedural codebases. In other words, it was supposed to
improve code organization . There's
no objective and open evidence that OOP is better than plain procedural programming ...
Instead of reducing complexity, it encourages promiscuous sharing of mutable state and
introduces additional complexity with its numerous design patterns . OOP makes common
development practices, like refactoring and testing, needlessly hard...
Using OOP is seemingly innocent in the short-term, especially on greenfield projects. But
what are the long-term consequences of using OOP? OOP is a time bomb, set to explode
sometime in the future when the codebase gets big enough. Projects get delayed, deadlines get
missed, developers get burned-out, adding in new features becomes next to impossible .
The organization labels the codebase as the " legacy codebase ", and the development
team plans a rewrite .... OOP provides developers too many tools and choices, without
imposing the right kinds of limitations. Even though OOP promises to address modularity and
improve reusability, it fails to deliver on its promises...
I'm not criticizing Alan Kay's OOP -- he is a genius. I wish OOP was implemented the way he
designed it. I'm criticizing the modern Java/C# approach to OOP... I think that it is plain
wrong that OOP is considered the de-facto standard for code organization by many people,
including those in very senior technical positions. It is also wrong that many mainstream
languages don't offer any other alternatives to code organization other than OOP.
The essay ultimately blames Java for the popularity of OOP, citing Alan Kay's comment that
Java "is the most distressing thing to happen to computing since MS-DOS." It also quotes Linus
Torvalds's observation that "limiting your project to C means that people don't screw things up
with any idiotic 'object model'."
And it ultimately suggests Functional Programming as a superior alternative, making the
following assertions about OOP:
"OOP code encourages the use of shared mutable state, which
has been proven to be unsafe time and time again... [E]ncapsulation, in fact, is glorified
global state." "OOP typically requires a lot of boilerplate code (low signal-to-noise ratio)."
"Some might disagree, but OOP code is notoriously difficult to unit test... [R]efactoring OOP
code is really hard without dedicated tools like Resharper." "It is impossible to write good
and maintainable Object-Oriented code."
There's no objective and open evidence that OOP is better than plain procedural
programming...
...which is followed by the author's subjective opinions about why procedural programming
is better than OOP. There's no objective comparison of the pros and cons of OOP vs procedural
just a rant about some of OOP's problems.
We start from the point-of-view that OOP has to prove itself. Has it? Has any project or
programming exercise ever taken less time because it is object-oriented?
Precious time and brainpower are being spent thinking about "abstractions" and "design
patterns" instead of solving real-world problems...
...says the person who took the time to write a 6,000 word rant on "why I hate
OOP".
Sadly, that was something you hallucinated. He doesn't say that anywhere.
Inheritance, while not "inherently" bad, is often the wrong solution. See: Why
extends is evil [javaworld.com]
Composition is frequently a more appropriate choice. Aaron Hillegass wrote this funny
little anecdote in Cocoa
Programming for Mac OS X [google.com]:
"Once upon a time, there was a company called Taligent. Taligent was created by IBM and
Apple to develop a set of tools and libraries like Cocoa. About the time Taligent reached the
peak of its mindshare, I met one of its engineers at a trade show. I asked him to create a
simple application for me: A window would appear with a button, and when the button was
clicked, the words 'Hello, World!' would appear in a text field. The engineer created a
project and started subclassing madly: subclassing the window and the button and the event
handler. Then he started generating code: dozens of lines to get the button and the text
field onto the window. After 45 minutes, I had to leave. The app still did not work. That
day, I knew that the company was doomed. A couple of years later, Taligent quietly closed its
doors forever."
Almost every programming methodology can be abused by people who really don't know how to
program well, or who don't want to. They'll happily create frameworks, implement new
development processes, and chart tons of metrics, all while avoiding the work of getting the
job done. In some cases the person who writes the most code is the same one who gets the
least amount of useful work done.
So, OOP can be misused the same way. Never mind that OOP essentially began very early and
has been reimplemented over and over, even before Alan Kay. Ie, files in Unix are essentially
an object oriented system. It's just data encapsulation and separating work into manageable
modules. That's how it was before anyone ever came up with the dumb name "full-stack
developer".
As a developer who started in the days of FORTRAN (when it was all-caps), I've watched the
rise of OOP with some curiosity. I think there's a general consensus that abstraction and
re-usability are good things - they're the reason subroutines exist - the issue is whether
they are ends in themselves.
I struggle with the whole concept of "design patterns". There are clearly common themes in
software, but there seems to be a great deal of pressure these days to make your
implementation fit some pre-defined template rather than thinking about the application's
specific needs for state and concurrency. I have seen some rather eccentric consequences of
"patternism".
Correctly written, OOP code allows you to encapsulate just the logic you need for a
specific task and to make that specific task available in a wide variety of contexts by
judicious use of templating and virtual functions that obviate the need for "refactoring".
Badly written, OOP code can have as many dangerous side effects and as much opacity as any
other kind of code. However, I think the key factor is not the choice of programming
paradigm, but the design process. You need to think first about what your code is intended to
do and in what circumstances it might be reused. In the context of a larger project, it means
identifying commonalities and deciding how best to implement them once. You need to document
that design and review it with other interested parties. You need to document the code with
clear information about its valid and invalid use. If you've done that, testing should not be
a problem.
Some people seem to believe that OOP removes the need for some of that design and
documentation. It doesn't and indeed code that you intend to be reused needs *more* design
and documentation than the glue that binds it together in any one specific use case. I'm
still a firm believer that coding begins with a pencil, not with a keyboard. That's
particularly true if you intend to design abstract interfaces that will serve many purposes.
In other words, it's more work to do OOP properly, so only do it if the benefits outweigh the
costs - and that usually means you not only know your code will be genuinely reusable but
will also genuinely be reused.
[...] I'm still a firm believer that coding begins with a pencil, not with a keyboard.
[...]
This!
In fact, even more: I'm a firm believer that coding begins with a pencil designing the data
model that you want to implement.
Everything else is just code that operates on that data model. Though I agree with most of
what you say, I believe the classical "MVC" design-pattern is still valid. And, you know
what, there is a reason why it is called "M-V-C": Start with the Model, continue with the
View and finalize with the Controller. MVC not only stood for Model-View-Controller but also
for the order of the implementation of each.
And preferably, as you stated correctly, "... start with pencil & paper
..."
I struggle with the whole concept of "design patterns".
Because design patterns are stupid.
A reasonable programmer can understand reasonable code so long as the data is documented
even when the code isnt documented, but will struggle immensely if it were the other way
around. Bad programmers create objects for objects sake, and because of that they have to
follow so called "design patterns" because no amount of code commenting makes the code easily
understandable when its a spaghetti web of interacting "objects" The "design patterns" dont
make the code easier the read, just easier to write.
Those OOP fanatics, if they do "document" their code, add comments like "// increment the
index" which is useless shit.
The big win of OOP is only in the encapsulation of the data with the code, and great
code treats objects like data structures with attached subroutines, not as "objects" ,
and document the fuck out of the contained data, while more or less letting the code document
itself. and keep OO elements to a minimum. As it turns out, OOP is just much more effort than
procedural and it rarely pays off to invest that effort, at least for me.
The problem isn't the object orientation paradigm itself, it's how it's applied.
The big problem in any project is that you have to understand how to break down the final
solution into modules that can be developed independently of each other to a large extent and
identify the items that are shared. But even when you have items that are apparently
identical don't mean that they will be that way in the long run, so shared code may even be
dangerous because future developers don't know that by fixing problem A they create problems
B, C, D and E.
Any time you make something easier, you lower the bar as well and now have a pack of
idiots that never could have been hired if it weren't for a programming language that
stripped out a lot of complexity for them.
Exactly. There are quite a few aspects of writing code that are difficult regardless of
language and there the difference in skill and insight really matters.
I have about 35+ years of software development experience, including with procedural, OOP
and functional programming languages.
My experience is: The question "is procedural better than OOP or functional?" (or
vice-versa) has a single answer: "it depends".
Like in your cases above, I would exactly do the same: use some procedural language that
solves my problem quickly and easily.
In large-scale applications, I mostly used OOP (having learned OOP with Smalltalk &
Objective-C). I don't like C++ or Java - but that's a matter of personal preference.
I use Python for large-scale scripts or machine learning/AI tasks.
I use Perl for short scripts that need to do a quick task.
Procedural is in fact easier to grasp for beginners as OOP and functional require a
different way of thinking. If you start developing software, after a while (when the project
gets complex enough) you will probably switch to OOP or functional.
Again, in my opinion neither is better than the other (procedural, OOP or functional). It
just depends on the task at hand (and of course on the experience of the software
developer).
There is nothing inherently wrong with some of the functionality it offers, its the way
OOP is abused as a substitute for basic good programming practices. I was helping interns -
students from a local CC - deal with idiotic assignments like making a random number
generator USING CLASSES, or displaying text to a screen USING CLASSES. Seriously, WTF? A room
full of career programmers could not even figure out how you were supposed to do that, much
less why. What was worse was a lack of understanding of basic programming skill or even the
use of variables, as the kids were being taught EVERY program was to to be assembled solely
by sticking together bits of libraries. There was no coding, just hunting for snippets of
preexisting code to glue together. Zero idea they could add their own, much less how to do
it. OOP isn't the problem, its the idea that it replaces basic programming skills and best
practice.
That and the obsession with absofrackinglutely EVERYTHING just having to be a formally
declared object including the while program being an object with a run() method.
Some things actually cry out to be objects, some not so much.Generally, I find that my
most readable and maintainable code turns out to be a procedural program that manipulates
objects.
Even there, some things just naturally want to be a struct or just an array of values.
The same is true of most ingenious ideas in programming. It's one thing if code is
demonstrating a particular idea, but production code is supposed to be there to do work, not
grind an academic ax.
For example, slavish adherence to "patterns". They're quite useful for thinking about code
and talking about code, but they shouldn't be the end of the discussion. They work better as
a starting point. Some programs seem to want patterns to be mixed and matched.
In reality those problems are just cargo cult programming one level higher.
I suspect a lot of that is because too many developers barely grasp programming and never
learned to go beyond the patterns they were explicitly taught.
When all you have is a hammer, the whole world looks like a nail.
There are a lot of mediocre programmers who follow the principle "if you have a hammer,
everything looks like a nail". They know OOP, so they think that every problem must be solved
in an OOP way. In fact, OOP works well when your program needs to deal with relatively
simple, real-world objects: the modelling follows naturally. If you are dealing with abstract
concepts, or with highly complex real-world objects, then OOP may not be the best
paradigm.
In Java, for example, you can program imperatively, by using static methods. The problem
is knowing when to break the rules. For example, I am working on a natural language system
that is supposed to generate textual answers to user inquiries. What "object" am I supposed
to create to do this task? An "Answer" object that generates itself? Yes, that would work,
but an imperative, static "generate answer" method makes at least as much sense.
There are different ways of thinking, different ways of modelling a problem. I get tired
of the purists who think that OO is the only possible answer. The world is not a nail.
I'm approaching 60, and I've been coding in COBOL, VB, FORTRAN, REXX, SQL for almost 40
years. I remember seeing Object Oriented Programming being introduced in the 80s, and I went
on a course once (paid by work). I remember not understanding the concept of "Classes", and
my impression was that the software we were buying was just trying to invent stupid new words
for old familiar constructs (eg: Files, Records, Rows, Tables, etc). So I never transitioned
away from my reliable mainframe programming platform. I thought the phrase OOP had dies out
long ago, along with "Client Server" (whatever that meant). I'm retiring in a few years, and
the mainframe will outlive me. Everything else is buggy.
"limiting your project to C means that people don't screw things up with any idiotic
'object model'."
GTK .... hold by beer... it is not a good argument against OOP
languages. But first, lets see how OOP came into place. OOP was designed to provide
encapsulation, like components, support reuse and code sharing. It was the next step coming
from modules and units, which where better than libraries, as functions and procedures had
namespaces, which helped structuring code. OOP is a great idea when writing UI toolkits or
similar stuff, as you can as
Like all things OO is fine in moderation but it's easy to go completely overboard,
decomposing, normalizing, producing enormous inheritance trees. Yes your enormous UML diagram
looks impressive, and yes it will be incomprehensible, fragile and horrible to maintain.
That said, it's completely fine in moderation. The same goes for functional programming.
Most programmers can wrap their heads around things like functions, closures / lambdas,
streams and so on. But if you mean true functional programming then forget it.
As for the kernel's choice to use C, that really boils down to the fact that a kernel
needs to be lower level than a typical user land application. It has to do its own memory
allocation and other things that were beyond C++ at the time. STL would have been usable, so
would new / delete, and exceptions & unwinding. And at that point why even bother? That
doesn't mean C is wonderful or doesn't inflict its own pain and bugs on development. But at
the time, it was the only sane choice.
"... Being powerless within calcifies totalitarian corporate culture ..."
"... ultimately promoted wide spread culture of obscurantism and opportunism what amounts to extreme office politics of covering their own butts often knowing that entire development strategy is flawed, as long as they are not personally blamed or if they in fact benefit by collapse of the project. ..."
"... As I worked side by side and later as project manager with Indian developers I can attest to that culture which while widely spread also among American developers reaches extremes among Indian corporations which infect often are engaged in fraud to be blamed on developers. ..."
The programmers in India are well capable of writing good software. The difficulty lies
in communicating the design requirements for the software. If they do not know in detail
how air planes are engineered, they will implement the design to the letter but not to
its intent.
I worked twenty years in commercial software development including in aviation for UA
and while Indian software developers are capable, their corporate culture is completely
different as is based on feudal workplace relations of subordinates and management that
results with extreme cronyism, far exceeding that in the US as such relations are not only
based on extreme exploitation (few jobs hundreds of qualified candidates) but on personal
almost paternal like relations that preclude required independence of judgment and
practically eliminates any major critical discussions about efficacy of technological
solutions and their risks.
Being powerless within calcifies totalitarian corporate culture facing
alternative of hurting family-like relations with bosses' and their feelings, who
emotionally and in financial terms committed themselves to certain often wrong solutions
dictated more by margins than technological imperatives, ultimately promoted wide
spread culture of obscurantism and opportunism what amounts to extreme office politics of
covering their own butts often knowing that entire development strategy is flawed, as long
as they are not personally blamed or if they in fact benefit by collapse of the
project.
As I worked side by side and later as project manager with Indian developers I can
attest to that culture which while widely spread also among American developers reaches
extremes among Indian corporations which infect often are engaged in fraud to be blamed on
developers.
In fact it is shocking contrast with German culture that practically prevents anyone
engaging in any project as it is almost always, in its entirety, discussed, analyzed,
understood and fully supported by every member of the team, otherwise they often simply
refused to work on project citing professional ethics. High quality social welfare state
and handsome unemployment benefits definitely supported such ethical stand back them
While what I describe happened over twenty years ago it is still applicable I
believe.
"... Honestly, since 2015 feels like Apple wants to abandon it's PC business but just doesn't know how so ..."
"... The new line seems like a valid refresh, but the prices are higher than ever, and remember young people are earning less than ever, so I still think they are looking for a way out of the PC trade, maybe this refresh is to just buy time for an other five years before they close up. ..."
"... I wonder how much those tooling engineers in the US make compared to their Chinese competitors? It seems like a neoliberal virtuous circle: loot/guts education, then find skilled labor from places that still support education, by moving abroad or importing workers, reducing wages and further undermining the local skill base. ..."
"... I sympathize with y'all. It's not uncommon for good products to become less useful and more trouble as the original designers, etc., get arrogant from their success and start to believe that every idea they have is a useful improvement. Not even close. Too much of fixing things that aren't broken and gilding lilies. ..."
The iPod, the iPhone, the MacBook Air, the physical Apple Store, even the iconic packaging
of Apple products -- these products changed how we view and use their categories, or created
new categories, and will be with us a long time.
Ironically. both Jobs and Ive were inspired by Dieter Rams – whom iFixit calls "the
legendary industrial designer renowned for functional and simple consumer products." And unlike
Apple. Rams believed that good design didn't have to come at the expense of either durability
or the environment:
Rams loves durable products that are environmentally friendly. That's one of his
10
principles for good design : "Design makes an important contribution to the preservation
of the environment." But Ive has never publicly discussed the dissonance between his
inspiration and Apple's disposable, glued-together products. For years, Apple has openly combated green standards that would
make products easier to repair and recycle, stating that they need "complete design
flexibility" no matter the impact on the environment.
In fact, that complete design flexibility – at least as practiced by Ive – has
resulted in crapified products that are an environmental disaster. Their lack of durability
means they must be repaired to be functional, and the lack of repairability means many of these
products end up being tossed prematurely – no doubt not a bug, but a feature. As
Vice
recounts :
But history will not be kind to Ive, to Apple, or to their design choices. While the
company popularized the smartphone and minimalistic, sleek, gadget design, it also did things
like create brand new screws designed to keep consumers from repairing their iPhones.
Under Ive, Apple began gluing down batteries inside laptops and smartphones (rather than
screwing them down) to shave off a fraction of a millimeter at the expense of repairability
and sustainability.
It redesigned MacBook Pro keyboards with mechanisms that are, again, a fraction of a
millimeter thinner, but that are
easily defeated by dust and crumbs (the computer I am typing on right now -- which is six
months old -- has a busted spacebar and 'r' key). These keyboards are not easily repairable,
even by Apple, and many MacBook Pros have to be completely replaced due to a single key
breaking. The iPhone 6 Plus
had a design flaw that led to its touch screen spontaneously breaking -- it then told
consumers there was no problem for months
before ultimately creating a repair program . Meanwhile, Apple's own internal
tests showed those flaws . He designed AirPods, which feature an unreplaceable battery
that must be physically
destroyed in order to open .
Vice also notes that in addition to Apple's products becoming "less modular, less consumer
friendly, less upgradable, less repairable, and, at times, less functional than earlier
models", Apple's design decisions have not been confined to Apple. Instead, "Ive's influence is
obvious in products released by Samsung, HTC, Huawei, and others, which have similarly traded
modularity for sleekness."
Right to Repair
As I've written before, Apple is leading opponent of giving consumers a right to repair.
Nonetheless, there's been some global progress on this issue (see Global Gains on Right
to Repair ). And we've also seen a widening of support in the US for such a right. The
issue has arisen in the current presidential campaign, with Elizabeth Warren throwing down the
gauntlet by endorsing a right to repair for farm tractors. The New York Times has also taken up
the cause more generally (see Right
to Repair Initiatives Gain Support in US ). More than twenty states are considering
enacting right to repair statutes.
I've been using Apple since 1990, I concur with the article about h/w and add that from
Snow Leopard to Sierra the OSX was buggy as anything from the Windows world if not more so.
Got better with High Sierra but still not up to the hype. I haven't lived with Mojave. I use
Apple out of habit, haven't felt the love from them since Snow Leopard, exactly when they
became a cell phone company. People think Apple is Mercedes and PCs are Fords, but for a long
time now in practical use, leaving aside the snazzy aesthetics, under the hood it's GM vs
Ford. I'm not rich enough to buy a $1500 non-upgradable, non-repairable product so the new T2
protected computers can't be for me.
The new Dell XPS's are tempting, they got the right
idea, if you go to their service page you can dl complete service instructions, diagrams, and
blow ups. They don't seem at all worried about my hurting myself.
In the last few years PCs
offer what before I could only get from Apple; good screen, back lit keyboard, long battery
life, trim size.
Honestly, since 2015 feels like Apple wants to abandon it's PC business but just doesn't
know how so it's trying to drive off all the old legacy power users, the creative people that
actually work hard for their money, exchanging them for rich dilettantes, hedge fund
managers, and status seekers – an easier crowd to finally close up shop on.
The new
line seems like a valid refresh, but the prices are higher than ever, and remember young
people are earning less than ever, so I still think they are looking for a way out of the PC
trade, maybe this refresh is to just buy time for an other five years before they close up.
When you start thinking like this about a company you've been loyal to for 30 years something
is definitely wrong.
The reason that Apple moved the last of its production to China is, quite simply, that
China now has basically the entire industrial infrastructure that we used to have. We have
been hollowed out, and are now essentially third-world when it comes to industry. The entire
integrated supply chain that defines an industrial power, is now gone.
The part about China no longer being a low-wage country is correct. China's wages have
been higher than Mexico's for some time. But the part about the skilled workers is a slap in
the face.
How can US workers be skilled at manufacturing, when there are no longer any jobs
here where they can learn or use those skills?
I wonder how much those tooling engineers in the US make compared to their Chinese
competitors? It seems like a neoliberal virtuous circle: loot/guts education, then find
skilled labor from places that still support education, by moving abroad or importing
workers, reducing wages and further undermining the local skill base.
They lost me when they made the iMac so thin it couldn't play a CD – and had the
nerve to charge $85 for an Apple player. Bought another brand for $25. I don't care that it's
not as pretty. I do care that I had to buy it at all.
I need a new cellphone. You can bet it won't be an iPhone.
Although I have never used an Apple product, I sympathize with y'all. It's not uncommon
for good products to become less useful and more trouble as the original designers, etc., get
arrogant from their success and start to believe that every idea they have is a useful
improvement. Not even close. Too much of fixing things that aren't broken and gilding
lilies.
Worst computer I've ever owned: Apple Macbook Pro, c. 2011 or so.
Died within 2 years, and also more expensive than the desktops I've built since that
absolutely crush it in every possible performance metric (and last longer).
Meanwhile, I also still use a $300 Best Buy Toshiba craptop that has now lasted for 8
straight years.
"Beautiful objects" – aye, there's the rub. In point of fact, the goal of industrial
design is not to create beautiful objects. It is the goal of the fine arts to create
beautiful objects. The goal of design is to create useful things that are easy to use and are
effective at their tasks. Some -- including me -- would add to those most basic goals, the
additional goals of being safe to use, durable, and easy to repair; perhaps even easy to
adapt or suitable for recycling, or conservative of precious materials. The principles of
good product design are laid out admirably in the classic book by Donald A. Norman, The
Design of Everyday Things (1988). So this book was available to Jony Ive (born 1967) during
his entire career (which overlapped almost exactly the wonder years of Postmodernism –
and therein lies a clue). It would indeed be astonishing to learn that Ive took no notice of
it. Yet Norman's book can be used to show that Ive's Apple violated so many of the principles
of good design, so habitually, as to raise the suspicion that the company was not engaged in
"product design" at all. The output Apple in the Ive era, I'd say, belongs instead to the
realm of so-called "commodity aesthetics," which aims to give manufactured items a
sufficiently seductive appearance to induce their purchase – nothing more. Aethetics
appears as Dieter Rams's principle 3, as just one (and the only purely commercial) function
in his 10; so in a theoretical context that remains ensconced within a genuine, Modernist
functionalism. But in the Apple dispensation that single (aesthetic) principle seems to have
subsumed the entire design enterprise – precisely as one would expect from "the
cultural logic of late capitalism" (hat tip to Mr Jameson). Ive and his staff of formalists
were not designing industrial products, or what Norman calls "everyday things," let alone
devices; they were aestheticizing products in ways that first, foremost, and almost only
enhanced their performance as expressions of a brand. Their eyes turned away from the prosaic
prize of functionality to focus instead on the more profitable prize of sales -- to repeat
customers, aka the devotees of 'iconic' fetishism. Thus did they serve not the masses but
Mammon, and they did so as minions of minimalism. Nor was theirs the minimalism of the
Frankfurt kitchen, with its deep roots in ethics and ergonomics. It was only superficially
Miesian. Bauhaus-inspired? Oh, please. Only the more careless readers of Tom Wolfe and
Wikipedia could believe anything so preposterous. Surely Steve Jobs, he of the featureless
black turtleneck by Issey Miyake, knew better. Anyone who has so much as walked by an Apple
Store, ever, should know better. And I guess I should know how to write shorter
I love it. A company which fell in love so much with their extraordinary profits that they
sabatoged their design and will now suffer enormous financial consequences. They're lucky to
have all their defense/military contracts.
The software at the heart of the Boeing 737 MAX crisis was developed at a time when the company was laying off experienced engineers
and replacing them with temporary workers making as little as $9 per hour, according to
Bloomberg .
In an effort to cut costs, Boeing was relying on subcontractors making paltry wages to develop and test its software. Often times,
these subcontractors would be from countries lacking a deep background in aerospace, like India.
Boeing had recent college graduates working for Indian software developer HCL Technologies Ltd. in a building across from Seattle's
Boeing Field, in flight test groups supporting the MAX. The coders from HCL designed to specifications set by Boeing but, according
to Mark Rabin, a former Boeing software engineer, "it was controversial because it was far less efficient than Boeing engineers just
writing the code."
Rabin said: "...it took many rounds going back and forth because the code was not done correctly."
In addition to cutting costs, the hiring of Indian companies may have landed Boeing orders for the Indian military and commercial
aircraft, like a $22 billion order received in January 2017 . That order included 100 737 MAX 8 jets and was Boeing's largest order
ever from an Indian airline. India traditionally orders from Airbus.
HCL engineers helped develop and test the 737 MAX's flight display software while employees from another Indian company, Cyient
Ltd, handled the software for flight test equipment. In 2011, Boeing named Cyient, then known as Infotech, to a list of its "suppliers
of the year".
One HCL employee posted online: "Provided quick workaround to resolve production issue which resulted in not delaying flight test
of 737-Max (delay in each flight test will cost very big amount for Boeing) ."
But Boeing says the company didn't rely on engineers from HCL for the Maneuvering Characteristics Augmentation System, which was
linked to both last October's crash and March's crash. The company also says it didn't rely on Indian companies for the cockpit warning
light issue that was disclosed after the crashes.
A Boeing spokesperson said: "Boeing has many decades of experience working with supplier/partners around the world. Our primary
focus is on always ensuring that our products and services are safe, of the highest quality and comply with all applicable regulations."
HCL, on the other hand, said: "HCL has a strong and long-standing business relationship with The Boeing Company, and we take pride
in the work we do for all our customers. However, HCL does not comment on specific work we do for our customers. HCL is not associated
with any ongoing issues with 737 Max."
Recent simulator tests run by the FAA indicate that software issues on the 737 MAX run deeper than first thought. Engineers who
worked on the plane, which Boeing started developing eight years ago, complained of pressure from managers to limit changes that
might introduce extra time or cost.
Rick Ludtke, a former Boeing flight controls engineer laid off in 2017, said: "Boeing was doing all kinds of things, everything
you can imagine, to reduce cost , including moving work from Puget Sound, because we'd become very expensive here. All that's very
understandable if you think of it from a business perspective. Slowly over time it appears that's eroded the ability for Puget Sound
designers to design."
Rabin even recalled an incident where senior software engineers were told they weren't needed because Boeing's productions were
mature. Rabin said: "I was shocked that in a room full of a couple hundred mostly senior engineers we were being told that we weren't
needed."
Any given jetliner is made up of millions of parts and millions of lines of code. Boeing has often turned over large portions
of the work to suppliers and subcontractors that follow its blueprints. But beginning in 2004 with the 787 Dreamliner, Boeing sought
to increase profits by providing high-level specs and then asking suppliers to design more parts themselves.
Boeing also promised to invest $1.7 billion in Indian companies as a result of an $11 billion order in 2005 from Air India. This
investment helped HCL and other software developers.
For the 787, HCL offered a price to Boeing that they couldn't refuse, either: free. HCL "took no up-front payments on the 787
and only started collecting payments based on sales years later".
Rockwell Collins won the MAX contract for cockpit displays and relied in part on HCL engineers and contract engineers from Cyient
to test flight test equipment.
Charles LoveJoy, a former flight-test instrumentation design engineer at the company, said: "We did have our challenges with the
India team. They met the requirements, per se, but you could do it better."
I love it. A company which fell in love so much with their extraordinary profits that they sabatoged their design and will
now suffer enormous financial consequences. They're lucky to have all their defense/military contracts.
Oftentimes, it's the cut-and-paste code that's the problem. If you don't have a good appreciation for what every line does,
you're never going to know what the sub or entire program does.
By 2002 i could not sit down with any developers without hearing at least one story about how they had been in a code review
meeting and seen absolute garbage turned out by H-1B workers.
Lots of people have known about this problem for many years now.
May the gods damn all financial managers! One of the two professions, along with bankers, which have absolutely no social value
whatsoever. There should be open hunting season on both!
Shifting to high-level specs puts more power in the hands of management/accounting types, since it doesn't require engineering
knowledge to track a deadline. Indeed, this whole story is the wet dream of business school, the idea of being able to accomplish
technical tasks purely by demand. A lot of public schools teach kids science is magic so when they grow up, the think they can
just give directions and technology appears.
In this country, one must have a license from the FAA to work on commercial aircraft. That means training and certification
that usually results in higher pay for those qualified to perform the repairs to the aircraft your family will fly on.
In case you're not aware, much of the heavy stuff like D checks (overhaul) have been outsourced by the airlines to foreign
countries where the FAA has nothing to say about it. Those contractors can hire whoever they wish for whatever they'll accept.
I have worked with some of those "mechanics" who cannot even read.
Keep that in mind next time the TSA perv is fondling your junk. That might be your last sexual encounter.
Or this online shop designed back in 1997. It was supposed to take over all internet
shopping that didn't really exist back then yet. And they used Indian doctors to code. Well
sure they ended up with a site... but one so heavy with pictures it took 30min to open one
page, another 20min to even click on a product to read its text etc-. This with good
university internet.
Unsurprisingly i don't think they ever managed to sell anything. But they gave out free
movie tickets to every registered customer... so me & friend each registered some 80
accounts and went to free movies for a good bit over a year.
mailman must have had fun delivering 160 letters to random names in the same student
apartment :D
Yves here. You have to read
a bit into this article on occupational decline, aka, "What happens to me after the robots take
my job?" to realize that the authors studied Swedish workers. One has to think that the
findings would be more pronounced in the US, due both to pronounced regional and urban/rural
variations, as well as the weakness of social institutions in the US. While there may be small
cities in Sweden that have been hit hard by the decline of a key employer, I don't have the
impression that Sweden has areas that have suffered the way our Rust Belt has. Similarly, in
the US, a significant amount of hiring starts with resume reviews with the job requirements
overspecified because the employer intends to hire someone who has done the same job somewhere
else and hence needs no training (which in practice is an illusion; how companies do things is
always idiosyncratic and new hires face a learning curve). On top of that, many positions are
filled via personal networks, not formal recruiting. Some studies have concluded that having a
large network of weak ties is more helpful in landing a new post than fewer close connections.
It's easier to know a lot of people casually in a society with strong community
institutions.
The article does not provide much in the way of remedies; it hints at "let them eat
training" when programs have proven to be ineffective. One approach would be aggressive
enforcement of laws against age discrimination. And even though some readers dislike a Job
Guarantee, not only would it enable people who wanted to work to keep working, but private
sector employers are particularly loath to employ someone who has been out of work for more
than six months, so a Job Guarantee post would also help keep someone who'd lost a job from
looking like damaged goods.
By Per-Anders Edin, Professor of Industrial Relations, Uppsala University; Tiernan Evans,
Economics MRes/PhD Candidate, LSE; Georg Graetz, Assistant Professor in the Department of
Economics, Uppsala University; Sofia Hernnäs, PhD student, Department of Economics,
Uppsala University; Guy Michaels,Associate Professor in the Department of Economics, LSE.
Originally published at VoxEU
As new technologies replace human labour in a growing number of tasks, employment in some
occupations invariably falls. This column compares outcomes for similar workers in similar
occupations over 28 years to explore the consequences of large declines in occupational
employment for workers' careers. While mean losses in earnings and employment for those
initially working in occupations that later declined are relatively moderate, low-earners lose
significantly more.
How costly is it for workers when demand for their occupation declines? As new technologies
replace human labour in a growing number of tasks, employment in some occupations invariably
falls. Until recently, technological change mostly automated routine production and clerical
work (Autor et al. 2003). But machines' capabilities are expanding, as recent developments
include self-driving vehicles and software that outperforms professionals in some tasks.
Debates on the labour market implications of these new technologies are ongoing (e.g.
Brynjolfsson and McAfee 2014, Acemoglu and Restrepo 2018). But in these debates, it is
important to ask not only "Will robots take my job?", but also "What would happen to my career
if robots took my job?"
Much is at stake. Occupational decline may hurt workers and their families, and may also
have broader consequences for economic inequality, education, taxation, and redistribution. If
it exacerbates differences in outcomes between economic winners and losers, populist forces may
gain further momentum (Dal Bo et al. 2019).
In a new paper (Edin et al. 2019) we explore the consequences of large declines in
occupational employment for workers' careers. We assemble a dataset with forecasts of
occupational employment changes that allow us to identify unanticipated declines,
population-level administrative data spanning several decades, and a highly detailed
occupational classification. These data allow us to compare outcomes for similar workers who
perform similar tasks and have similar expectations of future occupational employment
trajectories, but experience different actual occupational changes.
Our approach is distinct from previous work that contrasts career outcomes of routine and
non-routine workers (e.g. Cortes 2016), since we compare workers who perform similar tasks and
whose careers would likely have followed similar paths were it not for occupational decline.
Our work is also distinct from studies of mass layoffs (e.g. Jacobson et al. 1993), since
workers who experience occupational decline may take action before losing their jobs.
In our analysis, we follow individual workers' careers for almost 30 years, and we find that
workers in declining occupations lose on average 2-5% of cumulative earnings, compared to other
similar workers. Workers with low initial earnings (relative to others in their occupations)
lose more – about 8-11% of mean cumulative earnings. These earnings losses reflect both
lost years of employment and lower earnings conditional on employment; some of the employment
losses are due to increased time spent in unemployment and retraining, and low earners spend
more time in both unemployment and retraining.
Estimating the Consequences of Occupational Decline
We begin by assembling data from the Occupational Outlook Handbooks (OOH), published by the
US Bureau of Labor Statistics, which cover more than 400 occupations. In our main analysis we
define occupations as declining if their employment fell by at least 25% from 1984-2016,
although we show that our results are robust to using other cutoffs. The OOH also provides
information on technological change affecting each occupation, and forecasts of employment over
time. Using these data, we can separate technologically driven declines, and also unanticipated
declines. Occupations that declined include typesetters, drafters, proof readers, and various
machine operators.
We then match the OOH data to detailed Swedish occupations. This allows us to study the
consequences of occupational decline for workers who, in 1985, worked in occupations that
declined over the subsequent decades. We verify that occupations that declined in the US also
declined in Sweden, and that the employment forecasts that the BLS made for the US have
predictive power for employment changes in Sweden.
Detailed administrative micro-data, which cover all Swedish workers, allow us to address two
potential concerns for identifying the consequences of occupational decline: that workers in
declining occupations may have differed from other workers, and that declining occupations may
have differed even in absence of occupational decline. To address the first concern, about
individual sorting, we control for gender, age, education, and location, as well as 1985
earnings. Once we control for these characteristics, we find that workers in declining
occupations were no different from others in terms of their cognitive and non-cognitive test
scores and their parents' schooling and earnings. To address the second concern, about
occupational differences, we control for occupational earnings profiles (calculated using the
1985 data), the BLS forecasts, and other occupational and industry characteristics.
Assessing the losses and how their incidence varied
We find that prime age workers (those aged 25-36 in 1985) who were exposed to occupational
decline lost about 2-6 months of employment over 28 years, compared to similar workers whose
occupations did not decline. The higher end of the range refers to our comparison between
similar workers, while the lower end of the range compares similar workers in similar
occupations. The employment loss corresponds to around 1-2% of mean cumulative employment. The
corresponding earnings losses were larger, and amounted to around 2-5% of mean cumulative
earnings. These mean losses may seem moderate given the large occupational declines, but the
average outcomes do not tell the full story. The bottom third of earners in each occupation
fared worse, losing around 8-11% of mean earnings when their occupations declined.
The earnings and employment losses that we document reflect increased time spent in
unemployment and government-sponsored retraining – more so for workers with low initial
earnings. We also find that older workers who faced occupational decline retired a little
earlier.
We also find that workers in occupations that declined after 1985 were less likely to remain
in their starting occupation. It is quite likely that this reduced supply to declining
occupations contributed to mitigating the losses of the workers that remained there.
We show that our main findings are essentially unchanged when we restrict our analysis to
technology-related occupational declines.
Further, our finding that mean earnings and employment losses from occupational decline are
small is not unique to Sweden. We find similar results using a smaller panel dataset on US
workers, using the National Longitudinal Survey of Youth 1979.
Theoretical implications
Our paper also considers the implications of our findings for Roy's (1951) model, which is a
workhorse model for labour economists. We show that the frictionless Roy model predicts that
losses are increasing in initial occupational earnings rank, under a wide variety of
assumptions about the skill distribution. This prediction is inconsistent with our finding that
the largest earnings losses from occupational decline are incurred by those who earned the
least. To reconcile our findings, we add frictions to the model: we assume that workers who
earn little in one occupation incur larger time costs searching for jobs or retraining if they
try to move occupations. This extension of the model, especially when coupled with the addition
of involuntary job displacement, allows us to reconcile several of our empirical findings.
Conclusions
There is a vivid academic and public debate on whether we should fear the takeover of human
jobs by machines. New technologies may replace not only factory and office workers but also
drivers and some professional occupations. Our paper compares similar workers in similar
occupations over 28 years. We show that although mean losses in earnings and employment for
those initially working in occupations that later declined are relatively moderate (2-5% of
earnings and 1-2% of employment), low-earners lose significantly more.
The losses that we find from occupational decline are smaller than those suffered by workers
who experience mass layoffs, as reported in the existing literature. Because the occupational
decline we study took years or even decades, its costs for individual workers were likely
mitigated through retirements, reduced entry into declining occupations, and increased
job-to-job exits to other occupations. Compared to large, sudden shocks, such as plant
closures, the decline we study may also have a less pronounced impact on local economies.
While the losses we find are on average moderate, there are several reasons why future
occupational decline may have adverse impacts. First, while we study unanticipated declines,
the declines were nevertheless fairly gradual. Costs may be larger for sudden shocks following,
for example, a quick evolution of machine learning. Second, the occupational decline that we
study mainly affected low- and middle-skilled occupations, which require less human capital
investment than those that may be impacted in the future. Finally, and perhaps most
importantly, our findings show that low-earning individuals are already suffering considerable
(pre-tax) earnings losses, even in Sweden, where institutions are geared towards mitigating
those losses and facilitating occupational transitions. Helping these workers stay productive
when they face occupational decline remains an important challenge for governments.
"... Like many of its Wall Street counterparts, Boeing also used complexity as a mechanism to obfuscate and conceal activity that is incompetent, nefarious and/or harmful to not only the corporation itself but to society as a whole (instead of complexity being a benign byproduct of a move up the technology curve). ..."
"... The economists who built on Friedman's work, along with increasingly aggressive institutional investors, devised solutions to ensure the primacy of enhancing shareholder value, via the advocacy of hostile takeovers, the promotion of massive stock buybacks or repurchases (which increased the stock value), higher dividend payouts and, most importantly, the introduction of stock-based pay for top executives in order to align their interests to those of the shareholders. These ideas were influenced by the idea that corporate efficiency and profitability were impinged upon by archaic regulation and unionization, which, according to the theory, precluded the ability to compete globally. ..."
"... "Return on Net Assets" (RONA) forms a key part of the shareholder capitalism doctrine. ..."
"... If the choice is between putting a million bucks into new factory machinery or returning it to shareholders, say, via dividend payments, the latter is the optimal way to go because in theory it means higher net returns accruing to the shareholders (as the "owners" of the company), implicitly assuming that they can make better use of that money than the company itself can. ..."
"... It is an absurd conceit to believe that a dilettante portfolio manager is in a better position than an aviation engineer to gauge whether corporate investment in fixed assets will generate productivity gains well north of the expected return for the cash distributed to the shareholders. But such is the perverse fantasy embedded in the myth of shareholder capitalism ..."
"... When real engineering clashes with financial engineering, the damage takes the form of a geographically disparate and demoralized workforce: The factory-floor denominator goes down. Workers' wages are depressed, testing and quality assurance are curtailed. ..."
The fall of the Berlin Wall and the corresponding end of the Soviet Empire gave the fullest impetus imaginable to the forces of
globalized capitalism, and correspondingly unfettered access to the world's cheapest labor. What was not to like about that? It afforded
multinational corporations vastly expanded opportunities to fatten their profit margins and increase the bottom line with seemingly
no risk posed to their business model.
Or so it appeared. In 2000, aerospace engineer L.J. Hart-Smith's remarkable paper, sardonically titled
"Out-Sourced Profits The Cornerstone of Successful Subcontracting," laid
out the case against several business practices of Hart-Smith's previous employer, McDonnell Douglas, which had incautiously ridden
the wave of outsourcing when it merged with the author's new employer, Boeing. Hart-Smith's intention in telling his story was a
cautionary one for the newly combined Boeing, lest it follow its then recent acquisition down the same disastrous path.
Of the manifold points and issues identified by Hart-Smith, there is one that stands out as the most compelling in terms of understanding
the current crisis enveloping Boeing: The embrace of the metric "Return on Net Assets" (RONA). When combined with the relentless
pursuit of cost reduction (via offshoring), RONA taken to the extreme can undermine overall safety standards.
Related to this problem is the intentional and unnecessary use of complexity as an instrument of propaganda. Like many of its
Wall Street counterparts, Boeing also used complexity as a mechanism to obfuscate and conceal activity that is incompetent, nefarious
and/or harmful to not only the corporation itself but to society as a whole (instead of complexity being a benign byproduct of a
move up the technology curve).
All of these pernicious concepts are branches of the same poisoned tree: "
shareholder capitalism ":
[A] notion best epitomized by Milton Friedman that the only social
responsibility of a corporation is to increase its profits, laying the groundwork for the idea that shareholders, being the owners
and the main risk-bearing participants, ought therefore to receive the biggest rewards. Profits therefore should be generated
first and foremost with a view toward maximizing the interests of shareholders, not the executives or managers who (according
to the theory) were spending too much of their time, and the shareholders' money, worrying about employees, customers, and the
community at large. The economists who built on Friedman's work, along with increasingly aggressive institutional investors, devised
solutions to ensure the primacy of enhancing shareholder value, via the advocacy of hostile takeovers, the promotion of massive
stock buybacks or repurchases (which increased the stock value), higher dividend payouts and, most importantly, the introduction
of stock-based pay for top executives in order to align their interests to those of the shareholders. These ideas were influenced
by the idea that corporate efficiency and profitability were impinged upon by archaic regulation and unionization, which, according
to the theory, precluded the ability to compete globally.
"Return on Net Assets" (RONA) forms a key part of the shareholder capitalism doctrine. In essence, it means maximizing the returns
of those dollars deployed in the operation of the business. Applied to a corporation, it comes down to this: If the choice is between
putting a million bucks into new factory machinery or returning it to shareholders, say, via dividend payments, the latter is the
optimal way to go because in theory it means higher net returns accruing to the shareholders (as the "owners" of the company), implicitly
assuming that they can make better use of that money than the company itself can.
It is an absurd conceit to believe that a dilettante
portfolio manager is in a better position than an aviation engineer to gauge whether corporate investment in fixed assets will generate
productivity gains well north of the expected return for the cash distributed to the shareholders. But such is the perverse fantasy
embedded in the myth of shareholder capitalism.
Engineering reality, however, is far more complicated than what is outlined in university MBA textbooks. For corporations like
McDonnell Douglas, for example, RONA was used not as a way to prioritize new investment in the corporation but rather to justify
disinvestment in the corporation. This disinvestment ultimately degraded the company's underlying profitability and the quality
of its planes (which is one of the reasons the Pentagon helped to broker the merger with Boeing; in another perverse echo of the
2008 financial disaster, it was a politically engineered bailout).
RONA in Practice
When real engineering clashes with financial engineering, the damage takes the form of a geographically disparate and demoralized
workforce: The factory-floor denominator goes down. Workers' wages are depressed, testing and quality assurance are curtailed. Productivity
is diminished, even as labor-saving technologies are introduced. Precision machinery is sold off and replaced by inferior, but cheaper,
machines. Engineering quality deteriorates. And the upshot is that a reliable plane like Boeing's 737, which had been a tried and
true money-spinner with an impressive safety record since 1967, becomes a high-tech death trap.
The drive toward efficiency is translated into a drive to do more with less. Get more out of workers while paying them less. Make
more parts with fewer machines. Outsourcing is viewed as a way to release capital by transferring investment from skilled domestic
human capital to offshore entities not imbued with the same talents, corporate culture and dedication to quality. The benefits to
the bottom line are temporary; the long-term pathologies become embedded as the company's market share begins to shrink, as the airlines
search for less shoddy alternatives.
You must do one more thing if you are a Boeing director: you must erect barriers to bad news, because there is nothing that bursts
a magic bubble faster than reality, particularly if it's bad reality.
The illusion that Boeing sought to perpetuate was that it continued to produce the same thing it had produced for decades: namely,
a safe, reliable, quality airplane. But it was doing so with a production apparatus that was stripped, for cost reasons, of many
of the means necessary to make good aircraft. So while the wine still came in a bottle signifying Premier Cru quality, and still
carried the same price, someone had poured out the contents and replaced them with cheap plonk.
And that has become remarkably easy to do in aviation. Because Boeing is no longer subject to proper independent regulatory scrutiny.
This is what happens when you're allowed to "
self-certify" your own airplane , as the Washington Post described: "One Boeing engineer would conduct a test of a particular
system on the Max 8, while another Boeing engineer would act as the FAA's representative, signing on behalf of the U.S. government
that the technology complied with federal safety regulations."
This is a recipe for disaster. Boeing relentlessly cut costs, it outsourced across the globe to workforces that knew nothing about
aviation or aviation's safety culture. It sent things everywhere on one criteria and one criteria only: lower the denominator. Make
it the same, but cheaper. And then self-certify the plane, so that nobody, including the FAA, was ever the wiser.
Boeing also greased the wheels in Washington to ensure the continuation of this convenient state of regulatory affairs for the
company. According to OpenSecrets.org ,
Boeing and its affiliates spent $15,120,000 in lobbying expenses in 2018, after spending, $16,740,000 in 2017 (along with a further
$4,551,078 in 2018 political contributions, which placed the company 82nd out of a total of 19,087 contributors). Looking back at
these figures over the past four elections (congressional and presidential) since 2012, these numbers represent fairly typical spending
sums for the company.
But clever financial engineering, extensive political lobbying and self-certification can't perpetually hold back the effects
of shoddy engineering. One of the sad byproducts of the FAA's acquiescence to "self-certification" is how many things fall through
the cracks so easily.
"... We are having a propaganda barrage about the great Trump economy. We have been hearing about the great economy for a decade while the labor force participation rate declined, real family incomes stagnated, and debt burdens rose. The economy has been great only for large equity owners whose stock ownership benefited from the trillions of dollars the Fed poured into financial markets and from buy-backs by corporations of their own stocks. ..."
"... Federal Reserve data reports that a large percentage of the younger work force live at home with parents, because the jobs available to them are insufficient to pay for an independent existence. How then can the real estate, home furnishings, and appliance markets be strong? ..."
"... In contrast, Robotics, instead of displacing labor, eliminates it. Unlike jobs offshoring which shifted jobs from the US to China, robotics will cause jobs losses in both countries. If consumer incomes fall, then demand for output also falls, and output will fall. Robotics, then, is a way to shrink gross domestic product. ..."
"... The tech nerds and corporations who cannot wait for robotics to reduce labor cost in their profits calculation are incapable of understanding that when masses of people are without jobs, there is no consumer income with which to purchase the products of robots. The robots themselves do not need housing, food, clothing, entertainment, transportation, and medical care. The mega-rich owners of the robots cannot possibly consume the robotic output. An economy without consumers is a profitless economy. ..."
"... A country incapable of dealing with real problems has no future. ..."
We are having a propaganda barrage about the great Trump economy. We have been hearing
about the great economy for a decade while the labor force participation rate declined, real
family incomes stagnated, and debt burdens rose. The economy has been great only for large
equity owners whose stock ownership benefited from the trillions of dollars the Fed poured into
financial markets and from buy-backs by corporations of their own stocks.
I have pointed out for years that the jobs reports are fabrications and that the jobs that
do exist are lowly paid domestic service jobs such as waitresses and bartenders and health care
and social assistance. What has kept the American economy going is the expansion of consumer
debt, not higher pay from higher productivity. The reported low unemployment rate is obtained
by not counting discouraged workers who have given up on finding a job.
Do you remember all the corporate money that the Trump tax cut was supposed to bring back to
America for investment? It was all BS. Yesterday I read reports that Apple is losing its
trillion dollar market valuation because Apple is using its profits to buy back its own stock.
In other words, the demand for Apple's products does not justify more investment. Therefore,
the best use of the profit is to repurchase the equity shares, thus shrinking Apple's
capitalization. The great economy does not include expanding demand for Apple's products.
I read also of endless store and mall closings, losses falsely attributed to online
purchasing, which only accounts for a small percentage of sales.
Federal Reserve data reports that a large percentage of the younger work force live at
home with parents, because the jobs available to them are insufficient to pay for an
independent existence. How then can the real estate, home furnishings, and appliance markets be
strong?
When a couple of decades ago I first wrote of the danger of jobs offshoring to the American
middle class, state and local government budgets, and pension funds, idiot critics raised the
charge of Luddite.
The Luddites were wrong. Mechanization raised the productivity of labor and real wages, but
jobs offshoring shifts jobs from the domestic economy to abroad. Domestic labor is displaced,
but overseas labor gets the jobs, thus boosting jobs there. In other words, labor income
declines in the country that loses jobs and rises in the country to which the jobs are
offshored. This is the way American corporations spurred the economic development of China. It
was due to jobs offshoring that China developed far more rapidly than the CIA expected.
In contrast, Robotics, instead of displacing labor, eliminates it. Unlike jobs
offshoring which shifted jobs from the US to China, robotics will cause jobs losses in both
countries. If consumer incomes fall, then demand for output also falls, and output will fall.
Robotics, then, is a way to shrink gross domestic product.
The tech nerds and corporations who cannot wait for robotics to reduce labor cost in
their profits calculation are incapable of understanding that when masses of people are without
jobs, there is no consumer income with which to purchase the products of robots. The robots
themselves do not need housing, food, clothing, entertainment, transportation, and medical
care. The mega-rich owners of the robots cannot possibly consume the robotic output. An economy
without consumers is a profitless economy.
One would think that there would be a great deal of discussion about the economic effects of
robotics before the problems are upon us, just as one would think there would be enormous
concern about the high tensions Washington has caused between the US and Russia and China, just
as one would think there would be preparations for the adverse economic consequences of global
warming, whatever the cause. Instead, the US, a country facing many crises, is focused on
whether President Trump obstructed investigation of a crime that the special prosecutor said
did not take place.
A country incapable of dealing with real problems has no future.
The infatuation with AI makes people overlook three AI's built-in glitches. AI is software.
Software bugs. Software doesn't autocorrect bugs. Men correct bugs. A bugging self-driving
car leads its passengers to death. A man driving a car can steer away from death. Humans love
to behave in erratic ways, it is just impossible to program AI to respond to all possible
erratic human behaviour. Therefore, instead of adapting AI to humans, humans will be forced
to adapt to AI, and relinquish a lot of their liberty as humans. Humans have moral qualms
(not everybody is Hillary Clinton), AI being strictly utilitarian, will necessarily be
"psychopathic".
In short AI is the promise of communism raised by several orders of magnitude. Welcome
to the "Brave New World".
@Vojkan
You've raised some interesting objections, Vojkan. But here are a few quibbles:
1) AI is software. Software bugs. Software doesn't autocorrect bugs. Men correct bugs. A
bugging self-driving car leads its passengers to death. A man driving a car can steer away
from death.
Learn to code! Seriously, until and unless the AI devices acquire actual power over their
human masters (as in The Matrix ), this is not as big a problem as you think. You
simply test the device over and over and over until the bugs are discovered and worked out --
in other words, we just keep on doing what we've always done with software: alpha, beta,
etc.
2) Humans love to behave in erratic ways, it is just impossible to program AI to respond
to all possible erratic human behaviour. Therefore, instead of adapting AI to humans,
humans will be forced to adapt to AI, and relinquish a lot of their liberty as humans.
There's probably some truth to that. This reminds me of the old Marshall McCluhan saying
that "the medium is the message," and that we were all going to adapt our mode of cognition
(somewhat) to the TV or the internet, or whatever. Yeah, to some extent that has happened.
But to some extent, that probably happened way back when people first began domesticating
horses and riding them. Human beings are 'programmed', as it were, to adapt to their
environments to some extent, and to condition their reactions on the actions of other
things/creatures in their environment.
However, I think you may be underestimating the potential to create interfaces that allow
AI to interact with a human in much more complex ways, such as how another human would
interact with human: sublte visual cues, pheromones, etc. That, in fact, was the essence of
the old Turing Test, which is still the Holy Grail of AI:
3) Humans have moral qualms (not everybody is Hillary Clinton), AI being strictly
utilitarian, will necessarily be "psychopathic".
I don't see why AI devices can't have some moral principles -- or at least moral biases --
programmed into them. Isaac Asimov didn't think this was impossible either:
You simply test the device over and over and over until the bugs are discovered and
worked out -- in other words, we just keep on doing what we've always done with software:
alpha, beta, etc.
Some bugs stay dormant for decades. I've seen one up close.
What's new with AI is the amount of damage a faulty software multiplied many times over
can do. My experience was pretty horrible (I was one of the two humans overseeing the system,
but it was a pretty horrifying experience), but if the system was fully autonomous, it'd have
driven my employer bankrupt.
Now I'm not against using AI in any form whatsoever; I also think that it's inevitable
anyway. I'd support AI driving cars or flying planes, because they are likely safer than
humans, though it's of course changing a manageable risk for a very small probability tail
risk. But I'm pretty worried about AI in general.
Several Pilots repeatedly warned federal authorities of safety concerns over the now-grounded
Boeing 737 Max 8 for months leading up to the
second deadly disaster
involving the plane, according to an investigation by the
Dallas Morning News
.
One captain even called the Max 8's flight manual "
inadequate
and almost criminally insufficient
," according to the report.
"
The fact that this airplane requires such jury-rigging to fly is a red flag.
Now we know the systems employed are error-prone -- even if the pilots aren't sure what those
systems are, what redundancies are in place and failure modes. I am left to wonder: what else don't
I know?" wrote the captain.
At least
five complaints
about the Boeing jet were found in a
federal
database
which pilots routinely use to report aviation incidents without fear of
repercussions.
The complaints are about the safety mechanism cited in
preliminary reports
for an October plane crash in Indonesia that killed 189.
The disclosures found by
The News
reference problems during flights of Boeing 737 Max
8s with an autopilot system during takeoff and nose-down situations while trying to gain
altitude. While records show these flights occurred during October and November, information
regarding which airlines the pilots were flying for at the time is redacted from the database. -
Dallas
Morning News
One captain who flies the Max 8 said in November that it was "unconscionable" that Boeing and
federal authorities have allowed pilots to fly the plane without adequate training - including a
failure to fully disclose how its systems were distinctly different from other planes.
An FAA spokesman said the reporting system is directly filed to NASA, which serves as an neutral
third party in the reporting of grievances.
"The FAA analyzes these reports along with other safety data gathered through programs the FAA
administers directly, including the Aviation Safety Action Program, which includes all of the major
airlines including Southwest and American," said FAA southwest regional spokesman Lynn Lunsford.
Meanwhile, despite several airlines and foreign countries grounding the Max 8, US regulators
have so far declined to follow suit. They have, however, mandated that Boeing upgrade the plane's
software by April.
Sen. Ted Cruz (R-TX), who chairs a Senate subcommittee overseeing aviation, called for the
grounding of the Max 8 in a Thursday statement.
"Further investigation may reveal that mechanical issues were not the cause, but until that
time, our first priority must be the safety of the flying public," said Cruz.
At least 18 carriers -- including American Airlines and Southwest Airlines, the two largest
U.S. carriers flying the 737 Max 8 --
have also declined to ground planes
,
saying they are confident in the safety and "airworthiness" of their fleets. American and
Southwest have 24 and 34 of the aircraft in their fleets, respectively. -
Dallas
Morning News
The United States should be leading the world in aviation safety,"
said Transport Workers Union president John Samuelsen. "
And
yet, because of the lust for profit in the American aviation, we're
still flying planes that dozens of other countries and airlines have
now said need to grounded
."
Tags
Disaster Accident
The automatic trim we described last week has a name, MCAS, or Maneuvering Characteristics
Automation System.
It's unique to the MAX because the 737 MAX no longer has the docile pitch characteristics of
the 737NG at high Angles Of Attack (AOA). This is caused by the larger engine nacelles covering
the higher bypass LEAP-1B engines.
The nacelles for the MAX are larger and placed higher and further forward of the wing,
Figure 1.
Figure 1. Boeing 737NG (left) and MAX (right) nacelles compared. Source: Boeing 737 MAX
brochure.
By placing the nacelle further forward of the wing, it could be placed higher. Combined with
a higher nose landing gear, which raises the nacelle further, the same ground clearance could
be achieved for the nacelle as for the 737NG.
The drawback of a larger nacelle, placed further forward, is it destabilizes the aircraft in
pitch. All objects on an aircraft placed ahead of the Center of Gravity (the line in Figure 2,
around which the aircraft moves in pitch) will contribute to destabilize the aircraft in
pitch.
... ... ...
The 737 is a classical flight control aircraft. It relies on a naturally stable base
aircraft for its flight control design, augmented in selected areas. Once such area is the
artificial yaw damping, present on virtually all larger aircraft (to stop passengers getting
sick from the aircraft's natural tendency to Dutch Roll = Wagging its tail).
Until the MAX, there was no need for artificial aids in pitch. Once the aircraft entered a
stall, there were several actions described last week which assisted the pilot to exit the
stall. But not in normal flight.
The larger nacelles, called for by the higher bypass LEAP-1B engines, changed this. When
flying at normal angles of attack (3° at cruise and say 5° in a turn) the destabilizing
effect of the larger engines are not felt.
The nacelles are designed to not generate lift in normal flight. It would generate
unnecessary drag as the aspect ratio of an engine nacelle is lousy. The aircraft designer
focuses the lift to the high aspect ratio wings.
But if the pilot for whatever reason manoeuvres the aircraft hard, generating an angle of
attack close to the stall angle of around 14°, the previously neutral engine nacelle
generates lift. A lift which is felt by the aircraft as a pitch up moment (as its ahead of the
CG line), now stronger than on the 737NG. This destabilizes the MAX in pitch at higher Angles
Of Attack (AOA). The most difficult situation is when the maneuver has a high pitch ratio. The
aircraft's inertia can then provoke an over-swing into stall AOA.
To counter the MAX's lower stability margins at high AOA, Boeing introduced MCAS. Dependent
on AOA value and rate, altitude (air density) and Mach (changed flow conditions) the MCAS,
which is a software loop in the Flight Control computer, initiates a nose down trim above a
threshold AOA.
It can be stopped by the Pilot counter-trimming on the Yoke or by him hitting the CUTOUT
switches on the center pedestal. It's not stopped by the Pilot pulling the Yoke, which for
normal trim from the autopilot or runaway manual trim triggers trim hold sensors. This would
negate why MCAS was implemented, the Pilot pulling so hard on the Yoke that the aircraft is
flying close to stall.
It's probably this counterintuitive characteristic, which goes against what has been trained
many times in the simulator for unwanted autopilot trim or manual trim runaway, which has
confused the pilots of JT610. They learned that holding against the trim stopped the nose down,
and then they could take action, like counter-trimming or outright CUTOUT the trim servo. But
it didn't. After a 10 second trim to a 2.5° nose down stabilizer position, the trimming
started again despite the Pilots pulling against it. The faulty high AOA signal was still
present.
How should they know that pulling on the Yoke didn't stop the trim? It was described
nowhere; neither in the aircraft's manual, the AFM, nor in the Pilot's manual, the FCOM. This
has created strong reactions from airlines with the 737 MAX on the flight line and their
Pilots. They have learned the NG and the MAX flies the same. They fly them interchangeably
during the week.
They do fly the same as long as no fault appears. Then there are differences, and the
Pilots should have been informed about the differences.
Bruce Levitt
November 14, 2018
In figure 2 it shows the same center of gravity for the NG as the Max. I find this a bit
surprising as I would have expected that mounting heavy engines further forward would have
cause a shift forward in the center of gravity that would not have been offset by the
longer tailcone, which I'm assuming is relatively light even with APU installed.
Based on what is coming out about the automatic trim, Boeing must be counting its lucky
stars that this incident happened to Lion Air and not to an American aircraft. If this had
happened in the US, I'm pretty sure the fleet would have been grounded by the FAA and the
class action lawyers would be lined up outside the door to get their many pounds of
flesh.
This is quite the wake-up call for Boeing.
OV-099
November 14, 2018
If the FAA is not going to comprehensively review the certification for the 737 MAX, I
would not be surprised if EASA would start taking a closer look at the aircraft and why
the FAA seemingly missed the seemingly inadequate testing of the automatic trim when
they decided to certified the 737 MAX 8.
Reply
Doubting Thomas
November 16, 2018
One wonders if there are any OTHER goodies in the new/improved/yet identical handling
latest iteration of this old bird that Boeing did not disclose so that pilots need
not be retrained.
EASA & FAA likely already are asking some pointed questions and will want to
verify any statements made by the manufacturer.
Depending on the answers pilot training requirements are likely to change
materially.
jbeeko
November 14, 2018
CG will vary based on loading. I'd guess the line is the rear-most allowed CG.
Sebina Muwanga
November 17, 2018
Hi Bruce, expect product liability litigation in the US courts even if the accident
occured outside the US. Boeing is domiciled in the US and US courts have jurisdiction.
In my opinion, even the FAA should be a defendant for certifying the aircraft and
endangering the lives of the unsuspecting public.
Take time to read this article i published last year and let me know what you
think.
ahmed
November 18, 2018
hi dears
I think that even the pilot didnt knew about the MCAS ; this case can be corrected by
only applying the boeing check list (QRH) stabilizer runaway.
the pilot when they noticed that stabilizer are trimming without a knewn input ( from
pilot or from Auto pilot ) ; shout put the cut out sw in the off position according to
QRH.
Reply
TransWorld
November 19, 2018
Please note that the first actions pulling back on the yoke to stop it.
Also keep in mind the aircraft is screaming stall and the stick shaker is
activated.
Pulling back on the yoke in that case is the WRONG thing to do if you are
stalled.
The Pilot has to then determine which system is lading.
At the same time its chaning its behavior from previous training, every 5
seconds, it does it again.
There also was another issue taking place at the same time.
So now you have two systems lying to you, one that is actively trying to kill
you.
If the Pitot static system is broken, you also have several key instruments
feeding you bad data (VSI, altitude and speed)
Pilots are trained to immediately deal with emergency issues (engine loss etc)
Then there is a follow up detailed instructions for follow on actions (if any).
Simulators are wonderful things because you can train lethal scenes without lethal
results.
In this case, with NO pilot training let alone in the manuals, pilots have to either
be really quick in the situation or you get the result you do. Some are better at it
than others (Sullenbergers along with other aspects elected to turn on his APU even
though it was not part of the engine out checklist)
The other one was to ditch, too many pilots try to turn back even though we are
trained not to.
What I can tell you from personal expereince is having got myself into a spin
without any training, I was locked up logic wise (panic) as suddenly nothing was
working the way it should.
I was lucky I was high enough and my brain kicked back into cold logic mode and I
knew the counter to a spin from reading)
Another 500 feet and I would not be here to post.
While I did parts of the spin recovery wrong, fortunately in that aircraft it did
not care, right rudder was enough to stop it.
OV-099
November 14, 2018
It's starting to look as if Boeing will not be able to just pay victims' relatives in the
form of "condolence money", without admitting liability.
Reply
Dukeofurl
November 14, 2018
Im pretty sure, even though its an Indonesian Airline, any whiff of fault with the plane
itself will have lawyers taking Boeing on in US courts.
Tech-guru
November 14, 2018
Astonishing to say the least. It is quite unlike Boeing. They are normally very good in the
documentation and training. It makes everyone wonder how such vital change on the MAX
aircraft was omitted from books as weel as in crew training.
Your explanation is very good as to why you need this damn MCAS. But can you also tell us how
just one faulty sensor can trigger this MCAS. In all other Boeing models like B777, the two
AOA sensor signals are compared with a calculated AOA and choose the mid value within the
ADIRU. It eliminates a drastic mistake of following a wrong sensor input.
it's not sure it's a one sensor fault. One sensor was changed amid information there
was a 20 degree diff between the two sides. But then it happened again. I think we
might be informed something else is at the root of this, which could also trip such a
plausibility check you mention. We just don't know. What we know is the MCAS function
was triggered without the aircraft being close to stall.
Matthew
November 14, 2018
If it's certain that the MCAS was doing unhelpful things, that coupled with the
fact that no one was telling pilots anything about it suggests to me that this is
already effectively an open-and-shut case so far as liability, regulatory remedies
are concerned.
The tecnical root cause is also important, but probably irrelevant so far as
estbalishing the ultimate reason behind the crash.
"... The key point I want to pick up on from that earlier post is this: the Boeing 737 Max includes a new "safety" feature about which the company failed to inform the Federal Aviation Administration (FAA). ..."
"... Boeing Co. withheld information about potential hazards associated with a new flight-control feature suspected of playing a role in last month's fatal Lion Air jet crash, according to safety experts involved in the investigation, as well as midlevel FAA officials and airline pilots. ..."
"... Notice that phrase: "under unusual conditions". Seems now that the pilots of two of these jets may have encountered such unusual conditions since October. ..."
"... Why did Boeing neglect to tell the FAA – or, for that matter, other airlines or regulatory authorities – about the changes to the 737 Max? Well, the airline marketed the new jet as not needing pilots to undergo any additional training in order to fly it. ..."
"... In addition to considerable potential huge legal liability, from both the Lion Air and Ethiopian Airlines crashes, Boeing also faces the commercial consequences of grounding some if not all 737 Max 8 'planes currently in service – temporarily? indefinitely? -and loss or at minimum delay of all future sales of this aircraft model. ..."
"... If this tragedy had happened on an aircraft of another manufacturer other than big Boeing, the fleet would already have been grounded by the FAA. The arrogance of engineers both at Airbus and Boeing, who refuse to give the pilots easy means to regain immediate and full authority over the plane (pitch and power) is just appalling. ..."
"... Boeing has made significant inroads in China with its 737 MAX family. A dozen Chinese airlines have ordered 180 of the planes, and 76 of them have been delivered, according Boeing. About 85% of Boeing's unfilled Chinese airline orders are for 737 MAX planes. ..."
"... "It's pretty asinine for them to put a system on an airplane and not tell the pilots who are operating the airplane, especially when it deals with flight controls," Captain Mike Michaelis, chairman of the safety committee for the Allied Pilots Association, told the Wall Street Journal. ..."
"... The aircraft company concealed the new system and minimized the differences between the MAX and other versions of the 737 to boost sales. On the Boeing website, the company claims that airlines can save "millions of dollars" by purchasing the new plane "because of its commonality" with previous versions of the plane. ..."
"... "Years of experience representing hundreds of victims has revealed a common thread through most air disaster cases," said Charles Herrmann the principle of Herrmann Law. "Generating profit in a fiercely competitive market too often involves cutting safety measures. In this case, Boeing cut training and completely eliminated instructions and warnings on a new system. Pilots didn't even know it existed. I can't blame so many pilots for being mad as hell." ..."
"... The Air France Airbus disaster was jumped on – Boeing's traditional hydraulic links between the sticks for the two pilots ensuring they move in tandem; the supposed comments by Captain Sully that the Airbus software didn't allow him to hit the water at the optimal angle he wanted, causing the rear rupture in the fuselage both showed the inferiority of fly-by-wire until Boeing started using it too. (Sully has taken issue with the book making the above point and concludes fly-by-wire is a "mixed blessing".) ..."
Posted on
March 11, 2019 by Jerri-Lynn ScofieldBy
Jerri-Lynn Scofield, who has worked as a securities lawyer and a derivatives trader. She is
currently writing a book about textile artisans.
Yesterday, an Ethiopian Airlines flight crashed minutes after takeoff, killing all 157
passengers on board.
The crash occurred less than five months after a Lion Air jet crashed near Jakarta,
Indonesia, also shortly after takeoff, and killed all 189 passengers.
The state-owned airline is among the early operators of Boeing's new 737 MAX single-aisle
workhorse aircraft, which has been delivered to carriers around the world since 2017. The 737
MAX represents about two-thirds of Boeing's future deliveries and an estimated 40% of its
profits, according to analysts.
Having delivered 350 of the 737 MAX planes as of January, Boeing has booked orders for
about 5,000 more, many to airlines in fast-growing emerging markets around the world.
The voice and data recorders for the doomed flight have already been recovered, the New York
Times reported in Ethiopian
Airline Crash Updates: Data and Voice Recorders Recovered . Investigators will soon be able
to determine whether the same factors that caused the Lion Air crash also caused the latest
Ethiopian Airlines tragedy.
Boeing, Crapification, Two 737 Max Crashes Within Five Months
Yves wrote a post in November, Boeing,
Crapification, and the Lion Air Crash , analyzing a devastating Wall Street Journal report
on that earlier crash. I will not repeat the details of her post here, but instead encourage
interested readers to read it iin full.
The key point I want to pick up on from that earlier post is this: the Boeing 737 Max
includes a new "safety" feature about which the company failed to inform the Federal Aviation
Administration (FAA). As Yves wrote:
The short version of the story is that Boeing had implemented a new "safety" feature that
operated even when its plane was being flown manually, that if it went into a stall, it would
lower the nose suddenly to pick airspeed and fly normally again. However, Boeing didn't tell
its buyers or even the FAA about this new goodie. It wasn't in pilot training or even the
manuals. But even worse, this new control could force the nose down so far that it would be
impossible not to crash the plane. And no, I am not making this up. From the Wall Street
Journal:
Boeing Co. withheld information about potential hazards associated with a new
flight-control feature suspected of playing a role in last month's fatal Lion Air jet
crash, according to safety experts involved in the investigation, as well as midlevel FAA
officials and airline pilots.
The automated stall-prevention system on Boeing 737 MAX 8 and MAX 9 models -- intended
to help cockpit crews avoid mistakenly raising a plane's nose dangerously high -- under
unusual conditions can push it down unexpectedly and so strongly that flight crews can't
pull it back up. Such a scenario, Boeing told airlines in a world-wide safety bulletin
roughly a week after the accident, can result in a steep dive or crash -- even if pilots
are manually flying the jetliner and don't expect flight-control computers to kick in.
Notice that phrase: "under unusual conditions". Seems now that the pilots of two of these
jets may have encountered such unusual conditions since October.
Why did Boeing neglect to tell the FAA – or, for that matter, other airlines or
regulatory authorities – about the changes to the 737 Max? Well, the airline marketed the new jet as not needing pilots to undergo any additional
training in order to fly it.
I see. Why Were 737 Max Jets Still in Service? Today, Boeing executives no doubt rue not pulling all 737 Max 8 jets out of service after
the October Lion Air crash, to allow their engineers and engineering safety regulators to make
necessary changes in the 'plane's design or to develop new training protocols.
In addition to
considerable potential huge legal liability, from both the Lion Air and Ethiopian Airlines
crashes, Boeing also faces the commercial consequences of grounding some if not all 737 Max 8
'planes currently in service – temporarily? indefinitely? -and loss or at minimum delay
of all future sales of this aircraft model.
Over to Yves again, who in her November post cut to the crux:
And why haven't the planes been taken out of service? As one Wall Street Journal reader
put it:
If this tragedy had happened on an aircraft of another manufacturer other than big
Boeing, the fleet would already have been grounded by the FAA. The arrogance of engineers
both at Airbus and Boeing, who refuse to give the pilots easy means to regain immediate and
full authority over the plane (pitch and power) is just appalling.
Accident and incident
records abound where the automation has been a major contributing factor or precursor.
Knowing our friends at Boeing, it is highly probable that they will steer the investigation
towards maintenance deficiencies as primary cause of the accident
The commercial consequences of grounding the 737 Max in China alone are significant,
according to this CNN account, Why
grounding 737 MAX jets is a big deal for Boeing . The 737 Max is Boeing's most important
plane; China is also the company's major market:
"A suspension in China is very significant, as this is a major market for Boeing," said
Greg Waldron, Asia managing editor at aviation research firm FlightGlobal.
Boeing has predicted that China will soon become the world's first trillion-dollar market
for jets. By 2037, Boeing estimates China will need 7,690 commercial jets to meet its travel
demands.
Airbus (EADSF) and Commercial Aircraft Corporation of China, or Comac, are vying with
Boeing for the vast and rapidly growing Chinese market.
Comac's first plane, designed to compete with the single-aisle Boeing 737 MAX and Airbus
A320, made its first test flight in 2017. It is not yet ready for commercial service, but
Boeing can't afford any missteps.
Boeing has made significant inroads in China with its 737 MAX family. A dozen Chinese
airlines have ordered 180 of the planes, and 76 of them have been delivered, according
Boeing. About 85% of Boeing's unfilled Chinese airline orders are for 737 MAX planes.
The 737 has been Boeing's bestselling product for decades. The company's future depends on
the success the 737 MAX, the newest version of the jet. Boeing has 4,700 unfilled orders for
737s, representing 80% of Boeing's orders backlog. Virtually all 737 orders are for MAX
versions.
As of the time of posting, US airlines have yet to ground their 737 Max 8 fleets. American
Airlines, Alaska Air, Southwest Airlines, and United Airlines have ordered a combined 548 of
the new 737 jets, of which 65 have been delivered, according to CNN.
Legal Liability?
Prior to Sunday's Ethiopian Airlines crash, Boeing already faced considerable potential
legal liability for the October Lion Air crash. Just last Thursday, the Hermann Law Group of
personal injury lawyers filed suit against Boeing on behalf of the families of 17 Indonesian
passengers who died in that crash.
"It's pretty asinine for them to put a system on an airplane and not tell the pilots who
are operating the airplane, especially when it deals with flight controls," Captain Mike
Michaelis, chairman of the safety committee for the Allied Pilots Association, told the Wall
Street Journal.
The president of the pilots union at Southwest Airlines, Jon Weaks, said, "We're pissed
that Boeing didn't tell the companies, and the pilots didn't get notice."
The aircraft company concealed the new system and minimized the differences between the
MAX and other versions of the 737 to boost sales. On the Boeing website, the company claims
that airlines can save "millions of dollars" by purchasing the new plane "because of its
commonality" with previous versions of the plane.
"Years of experience representing hundreds of victims has revealed a common thread through
most air disaster cases," said Charles Herrmann the principle of Herrmann Law. "Generating
profit in a fiercely competitive market too often involves cutting safety measures. In this
case, Boeing cut training and completely eliminated instructions and warnings on a new
system. Pilots didn't even know it existed. I can't blame so many pilots for being mad as
hell."
Additionally, the complaint alleges the United States Federal Aviation Administration is
partially culpable for negligently certifying Boeing's Air Flight Manual without requiring
adequate instruction and training on the new system. Canadian and Brazilian authorities did
require additional training.
What's Next?
The consequences for Boeing could be serious and will depend on what the flight and voice
data recorders reveal. I also am curious as to what additional flight training or instructions,
if any, the Ethiopian Airlines pilots received, either before or after the Lion Air crash,
whether from Boeing, an air safety regulator, or any other source.
Of course we shouldn't engage in speculation, but we will anyway 'cause we're human. If
fly-by-wire and the ability of software to over-ride pilots are indeed implicated in the 737
Max 8 then you can bet the Airbus cheer-leaders on YouTube videos will engage in huge
Schaudenfreude.
I really shouldn't even look at comments to YouTube videos – it's bad for my blood
pressure. But I occasionally dip into the swamp on ones in areas like airlines. Of course
– as you'd expect – you get a large amount of "flag waving" between Europeans and
Americans. But the level of hatred and suspiciously similar comments by the "if it ain't
Boeing I ain't going" brigade struck me as in a whole new league long before the "SJW" troll
wars regarding things like Captain Marvel etc of today.
The Air France Airbus disaster was
jumped on – Boeing's traditional hydraulic links between the sticks for the two pilots
ensuring they move in tandem; the supposed comments by Captain Sully that the Airbus software
didn't allow him to hit the water at the optimal angle he wanted, causing the rear rupture in
the fuselage both showed the inferiority of fly-by-wire until Boeing started using it too.
(Sully has taken issue with the book making the above point and concludes fly-by-wire is a
"mixed blessing".)
I'm going to try to steer clear of my YouTube channels on airlines. Hopefully NC will
continue to provide the real evidence as it emerges as to what's been going on here.
It is really disheartening how an idea as reasonable as "a just society" has been so
thoroughly discredited among a large swath of the population.
No wonder there is such a wide interest in primitive construction and technology on
YouTube. This society is very sick and it is nice to pretend there is a way to opt out.
Indeed. The NTSB usually works with local investigation teams (as well as a manufacturers
rep) if the manufacturer is located in the US, or if specifically requested by the local
authorities. I'd like to see their report. I don't care what the FAA or Boeing says about
it.
. .. . .. -- .
Contains a link to a Seattle Times report as a "comprehensive wrap": Speaking before China's announcement, Cox, who previously served as the top safety
official for the Air Line Pilots Association, said it's premature to think of grounding the
737 MAX fleet.
"We don't know anything yet. We don't have close to sufficient information to consider
grounding the planes," he said. "That would create economic pressure on a number of the
airlines that's unjustified at this point.
China has grounded them . US? Must not create undue economic pressure on the airlines.
Right there in black and white. Money over people.
I just emailed southwest about an upcoming flight asking about my choices for refusal to
board MAX 8/9 planes based on this "feature". I expect pro forma policy recitation, but
customer pressure could trump too big to fail sweeping the dirt under the carpet. I hope.
We got the "safety of our customers is our top priority and we are remaining vigilant and
are in touch with Boeing and the Civial Aviation Authority on this matter but will not be
grounding the aircraft model until further information on the crash becomes available" speech
from a local airline here in South Africa. It didn't take half a day for customer pressure to
effect a swift reversal of that blatant disregard for their "top priority", the model is
grounded so yeah, customer muscle flexing will do it
On PPRUNE.ORG (where a lot of pilots hang out), they reported that after the Lion Air
crash, Southwest added an extra display (to indicate when the two angle of attack sensors
were disagreeing with each other) that the folks on PPRUNE thought was an extremely good idea
and effective.
Of course, if the Ethiopian crash was due to something different from the Lion Air crash,
that extra display on the Southwest planes may not make any difference.
Take those comments with a large dose of salt. Not to say everyone commenting on PPRUNE
and sites like PPRUNE are posers, but PPRUNE.org is where a lot of wanna-be pilots and guys
that spend a lot of time in basements playing flight simulator games hang out. The "real
pilots" on PPRUNE are more frequently of the aspiring airline pilot type that fly smaller,
piston-powered planes.
We will have to wait and see what the final investigation reveals. However this does not
look good for Boeing at all.
The Maneuvering Characteristics Augmentation System (MCAS) system was implicated in the
Lion Air crash. There have been a lot of complaints about the system on many of the pilot
forums, suggesting at least anecdotally that there are issues. It is highly suspected that
the MCAS system is responsible for this crash too.
Keep in mind that Ethiopian Airlines is a pretty well-known and regarded airline. This is
not a cut rate airline we are talking about.
At this point, all we can do is to wait for the investigation results.
one other minor thing. you remember that shut down? seems that would have delayed any
updates from Boeing. seems thats one of the things the pilots pointed out when it shutdown
was in progress
What really is the icing on this cake is the fact the new, larger engines on the "Max"
changed the center of gravity of the plane and made it unstable. From what I've read on
aviation blogs, this is highly unusual for a commercial passenger jet. Boeing then created
the new "safety" feature which makes the plane fly nose down to avoid a stall. But of course
garbage in, garbage out on sensors (remember AF447 which stalled right into the S.
Atlantic?).
It's all politics anyway .if Boeing had been forthcoming about the "Max" it would have
required additional pilot training to certify pilots to fly the airliner. They didn't and now
another 189 passengers are D.O.A.
I wouldn't fly on one and wouldn't let family do so either.
If I have read correctly, the MCAS system (not known of by pilots until after the Lion Air
crash) is reliant on a single Angle of Attack sensor, without redundancy (!). It's too
early
to say if MCAS was an issue in the crashes, I guess, but this does not look good.
If it was some other issue with the plane, that will be almost worse for Boeing. Two
crash-causing flaws would require grounding all of the planes, suspending production, then
doing some kind of severe testing or other to make sure that there isn't a third flaw waiting
to show up.
If MCAS relies only on one Angle of Attack (AoA) sensor, then it might have been an error
in the system design an the safety assessment, from which Boeing may be liable.
It appears that a failure of the AoA can produce an unannuntiated erroneous pitch
trim:
a) If the pilots had proper traning and awareness, this event would "only" increase their
workload,
b) But for an unaware or untrained pilot, the event would impair its ability to fly and
introduce excessive workload.
The difference is important, because according to standard civil aviation safety
assessment (see for instance EASA AMC 25.1309 Ch. 7), the case a) should be classified as
"Major" failure, whereas b) should be classified as "Hazardous". "Hazardous" failures are
required to have much lower probability, which means MCAS needs two AoA sensors.
In summary: a safe MCAS would need either a second AoA or pilot training. It seems that it
had neither.
What are the ways an ignorant lay air traveler can find out about whether a particular
airline has these new-type Boeing 737 MAXes in its fleet? What are the ways an ignorant air
traveler can find out which airlines do not have ANY of these airplanes in their fleet?
What are the ways an ignorant air traveler can find out ahead of time, when still planning
herm's trip, which flights use a 737 MAX as against some other kind of plane?
The only way the flying public could possibly torture the airlines into grounding these
planes until it is safe to de-ground them is a total all-encompassing "fearcott" against this
airplane all around the world. Only if the airlines in the "go ahead and fly it" countries
sell zero seats, without exception, on every single 737 MAX plane that flies, will the
airlines themselves take them out of service till the issues are resolved.
Hence my asking how people who wish to save their own lives from future accidents can tell
when and where they might be exposed to the risk of boarding a Boeing 737 MAX plane.
Stop flying. Your employer requires it? Tell'em where to get off. There are alternatives.
The alternatives are less polluting and have lower climate impact also. Yes, this is a hard
pill to swallow. No, I don't travel for employment any more, I telecommute. I used to enjoy
flying, but I avoid it like plague any more. Crapification.
Additional training won't do. If they wanted larger engines, they needed a different
plane. Changing to an unstable center of gravity and compensating for it with new software
sounds like a joke except for the hundreds of victims. I'm not getting on that plane.
Has there been any study of crapification as a broad social phenomenon? When I Google the
word I only get links to NC and sites that reference NC. And yet, this seems like one of the
guiding concepts to understand our present world (the crapification of UK media and civil
service go a long way towards understanding Brexit, for instance).
I mean, my first thought is, why would Boeing commit corporate self-harm for the sake of a
single bullet in sales materials (requires no pilot retraining!). And the answer, of course,
is crapification: the people calling the shots don't know what they're doing.
Google Books finds the word "crapification" quoted (from a 2004) in a work of literary
criticism published in 2008 (Literature, Science and a New Humanities, by J. Gottschall).
From 2013 it finds the following in a book by Edward Keenan, Some Great Idea: "Policy-wise,
it represented a shift in momentum, a slowing down of the childish, intentional crapification
of the city ." So there the word appears clearly in the sense understood by regular readers
here (along with an admission that crapfication can be intentional and not just inadvertent).
To illustrate that sense, Google Books finds the word used in Misfit Toymakers, by Keith T.
Jenkins (2014): "We had been to the restaurant and we had water to drink, because after the
takeover's, all of the soda makers were brought to ruination by the total crapification of
their product, by government management." But almost twenty years earlier the word
"crapification" had occurred in a comic strip published in New York Magazine (29 January
1996, p. 100): "Instant crapification! It's the perfect metaphor for the mirror on the soul
of America!" The word has been used on television. On 5 January 2010 a sketch subtitled
"Night of Terror – The Crapification of the American Pant-scape" ran on The Colbert
Report per: https://en.wikipedia.org/wiki/List_of_The_Colbert_Report_episodes_(2010)
. Searching the internet, Google results do indeed show many instances of the word
"crapification" on NC, or quoted elsewhere from NC posts. But the same results show it used
on many blogs since ca. 2010. Here, at http://nyceducator.com/2018/09/the-crapification-factor.html
, is a recent example that comments on the word's popularization: "I stole that word,
"crapification," from my friend Michael Fiorillo, but I'm fairly certain he stole it from
someone else. In any case, I think it applies to our new online attendance system." A comment
here, https://angrybearblog.com/2017/09/open-thread-sept-26-2017.html
, recognizes NC to have been a vector of the word's increasing usage. Googling shows that
there have been numerous instances of the verb "crapify" used in computer-programming
contexts, from at least as early as 2006. Google Books finds the word "crapified" used in a
novel, Sonic Butler, by James Greve (2004). The derivation, "de-crapify," is also attested.
"Crapify" was suggested to Merriam-Webster in 2007 per:
http://nws.merriam-webster.com/opendictionary/newword_display_alpha.php?letter=Cr&last=40
. At that time the suggested definition was, "To make situations/things bad." The verb was
posted to Urban Dictionary in 2003: https://www.urbandictionary.com/define.php?term=crapify
. The earliest serious discussion I could quickly find on crapificatjon as a phenomenon was
from 2009 at https://www.cryptogon.com/?p=10611 . I have found
only two attempts to elucidate the causes of crapification:
http://malepatternboldness.blogspot.com/2017/03/my-jockey-journey-or-crapification-of.html
(an essay on undershirts) and https://twilightstarsong.blogspot.com/2017/04/complaints.html
(a comment on refrigerators). This essay deals with the mechanics of job crapification:
http://asserttrue.blogspot.com/2015/10/how-job-crapification-works.html
(relating it to de-skilling). An apparent Americanism, "crapification" has recently been
'translated' into French: "Mon bled est en pleine urbanisation, comprends : en pleine
emmerdisation" [somewhat literally -- My hole in the road is in the midst of development,
meaning: in the midst of crapification]: https://twitter.com/entre2passions/status/1085567796703096832
Interestingly, perhaps, a comprehensive search of amazon.com yields "No results for
crapification."
This seems more like a specific bussiness conspiracy than like general crapification. This
isn't " they just don't make them like they used to". This is like Ford deliberately selling
the Crash and Burn Pinto with its special explode-on-impact gas-tank feature
Maybe some Trump-style insults should be crafted for this plane so they can get memed-up
and travel faster than Boeing's ability to manage the story. Epithets like " the new Boeing
crash-a-matic dive-liner
with nose-to-the-ground pilot-override autocrash built into every plane." It seems unfair,
but life and safety should come before fairness, and that will only happen if a world wide
wave of fear MAKES it happen.
I think crapification is the end result of a self-serving belief in the unfailing goodness
and superiority of Ivy faux-meritocracy and the promotion/exaltation of the do-nothing,
know-nothing, corporate, revolving-door MBA's and Psych-major HR types over people with many
years of both company and industry experience who also have excellent professional track
records. The latter group was the group in charge of major corporations and big decisions in
the 'good old days', now it's the former. These morally bankrupt people and their vapid,
self-righteous culture of PR first, management science second, and what-the-hell-else-matters
anyway, are the prime drivers of crapification. Read the bio of an old-school celebrated CEO
like Gordon Bethune (Continental CEO with corporate experience at Boeing) who skipped college
altogether and joined the Navy at 17, and ask yourself how many people like that are in
corporate board rooms today? I'm not saying going back to a 'Good Ole Boy's Club' is the best
model of corporate governnace either but at least people like Bethune didn't think they were
too good to mix with their fellow employees, understood leadership, the consequences of
bullshit, and what 'The buck stops here' thing was really about. Corporate types today sadly
believe their own propaganda, and when their fraudulent schemes, can-kicking, and head-in-the
sand strategies inevitably blow up in their faces, they accept no blame and fail upwards to
another posh corporate job or a nice golden parachute. The wrong people are in charge almost
everywhere these days, hence crapification. Bad incentives, zero white collar crime
enforcement, self-replicating board rooms, group-think, begets toxic corporate culture, which
equals crapification.
As a son of a deceased former Boeing aeronautic engineer, this is tragic. It highlights
the problem of financialization, neoliberalism, and lack of corporate responsibility pointed
out daily here on NC. The crapification was signaled by the move of the headquarters from
Seattle to Chicago and spending billions to build a second 787 line in South Carolina to bust
their Unions. Boeing is now an unregulated multinational corporation superior to sovereign
nations. However, if the 737 Max crashes have the same cause, this will be hard to whitewash.
The design failure of windows on the de Havilland Comet killed the British passenger aircraft
business. The EU will keep a discrete silence since manufacturing major airline passenger
planes is a duopoly with Airbus. However, China hasn't (due to the trade war with the USA)
even though Boeing is building a new assembly line there. Boeing escaped any blame for the
loss of two Malaysian Airline's 777s. This may be an existential crisis for American
aviation. Like a President who denies calling Tim Cook, Tim Apple, or the soft coup ongoing
in DC against him, what is really happening globally is not factually reported by corporate
media.
Sorry, but 'sovereign' nations were always a scam. Nothing than a excuse to build capital
markets, which are the underpinning of capitalism. Capital Markets are what control countries
and have since the 1700's. Maybe you should blame the monarchies for selling out to the
bankers in the late middle ages. Sovereign nations are just economic units for the bankers,
their businesses they finance and nothing more. I guess they figured out after the Great
Depression, they would throw a bunch of goodies at "Indo Europeans" face in western europe
,make them decadent and jaded via debt expansion. This goes back to my point about the yellow
vests ..me me me me me. You reek of it. This stuff with Boeing is all profit based. It could
have happened in 2000, 1960 or 1920. It could happen even under state control. Did you love
Hitler's Voltswagon?
As for the soft coup .lol you mean Trumps soft coup for his allies in Russia and the
Middle East viva la Saudi King!!!!!? Posts like these represent the problem with this board.
The materialist over the spiritualist. Its like people who still don't get some of the
biggest supporters of a "GND" are racialists and being somebody who has long run the
environmentalist rally game, they are hugely in the game. Yet Progressives completely seem
blind to it. The media ignores them for con men like David Duke(who's ancestry is not clean,
no its not) and "Unite the Right"(or as one friend on the environmental circuit told me,
Unite the Yahweh apologists) as whats "white". There is a reason they do this.
You need to wake up and stop the self-gratification crap. The planet is dying due to
mishandlement. Over urbanization, over population, constant need for me over ecosystem. It
can only last so long. That is why I like Zombie movies, its Gaia Theory in a nutshell. Good
for you Earth .or Midgard. Which ever you prefer.
Spot on comment VietnamVet, a lot of chickens can be seen coming home to roost in this
latest Boeing disaster. Remarkable how not many years ago the government could regulate the
aviation industry without fear of killing it, since there was more than one aerospace
company, not anymore! The scourge of monsopany/monopoly power rears its head and bites in
unexpected places.
More detail on the "MCAS" system responsible for the previous Lion Air crash
here (theaircurrent.com)
It says the bigger and repositioned engine, which give the new model its fuel efficiency,
and wing angle tweaks needed to fit the engine vs landing gear and clearance,
change the amount of pitch trim it needs in turns to remain level.
The auto system was added top neutralize the pitch trim during turns, too make it handle
like the old model.
There is another pitch trim control besides the main "stick". To deactivate the auto
system, this other trim control has to be used, the main controls do not deactivate it
(perhaps to prevent it from being unintentionally deactivated, which would be equally bad).
If the sensor driving the correction system gives a false reading and the pilot were unaware,
there would be seesawing and panic
Actually, if this all happened again I would be very surprised. Nobody flying a 737 would
not know after the previous crash. Curious what they find.
While logical, If your last comment were correct, it should have prevented this most
recent crash. It appears that the "seesawing and panic" continue.
I assume it has now gone beyond the cockpit, and beyond the design, and sales teams and
reached the Boeing board room. From there, it is likely to travel to the board rooms of every
airline flying this aircraft or thinking of buying one, to their banks and creditors, and to
those who buy or recommend their stock. But it may not reach the FAA for some time.
"Canadian and Brazilian authorities did require additional training" from the quote at the
bottom is not
something I've seen before. What did they know and when did they know it?
They probably just assumed that the changes in the plane from previous 737s were big
enough to warrant treating it like a major change requiring training.
Both countries fly into remote areas with highly variable weather conditions and some
rugged terrain.
For what it's worth, the quoted section says that Boeing withheld info about the MCAS from
"midlevel FAA officials", while Jerri-Lynn refers to the FAA as a whole.
This makes me wonder if top-level FAA people certified the system.
FAA action follows finding of new cracks in pylon aft bulkhead forward flange; crash
investigation continues
Suspension of the McDonnell Douglas DC-10's type certificate last week followed a
separate grounding order from a federal court as government investigators were narrowing
the scope of their investigation of the American Airlines DC-10 crash May 25 in
Chicago.
The American DC-10-10, registration No. N110AA, crashed shortly after takeoff from
Chicago's O'Hare International Airport, killing 259 passengers, 13 crewmembers and three
persons on the ground. The 275 fatalities make the crash the worst in U.S. history.
The controversies surrounding the grounding of the entire U.S. DC-10 fleet and, by
extension, many of the DC-10s operated by foreign carriers, by Federal Aviation
Administrator Langhorne Bond on the morning of June 6 to revolve around several issues.
Yes, I remember back when the FAA would revoke a type certificate if a plane was a danger
to public safety. It wasn't even that long ago. Now their concern is any threat to
Boeing™. There's a name for that
Leeham news is the best site for info on this. For those of you interested in the tech
details got to Bjorns Corner, where he writes about aeronautic design issues.
I was somewhat horrified to find that modern aircraft flying at near mach speeds have a
lot of somewhat pasted on pilot assistances. All of them. None of them fly with nothing but
good old stick-and-rudder. Not Airbus (which is actually fully Fly By wire-all pilot inputs
got through a computer) and not Boeing, which is somewhat less so.
This latest "solution came about becuse the larger engines (and nacelles) fitted on the
Max increased lift ahead of the center of gravity in a pitchup situation, which was
destabilizing. The MCAS uses inputs from air speed and angle of attack sensors to put a pitch
down input to the horizonatal stablisizer.
A faluty AofA sensor lead to Lion Air's Max pushing the nose down against the pilots
efforts all the way into the sea.
One guy said last night on TV that Boeing had eight years of back orders for this aircraft
so you had better believe that this crash will be studied furiously. Saw a picture of the
crash site and it looks like it augured in almost straight down. There seems to be a large
hole and the wreckage is not strew over that much area. I understand that they were digging
out the cockpit as it was underground. Strange that.
It's not true that Boeing hid the existence of the MCAS. They documented it in the
January 2017 rev of the NG/MAX
differences manual and probably earlier than that. One can argue whether the description
was adequate, but the system was in no way hidden.
Looks like, for now, we're stuck between your "in no way hidden", and numerous 737 pilots'
claims on various online aviation boards that they knew nothing about MCAS. Lots of money
involved, so very cloudy weather expected. For now I'll stick with the pilots.
To the best of my understanding and reading on the subject, the system was well documented
in the Boeing technical manuals, but not in the pilots' manuals, where it was only briefly
mentioned, at best, and not by all airlines. I'm not an airline pilot, but from what I've
read, airlines often write their own additional operators manuals for aircraft models they
fly, so it was up to them to decide the depth of documentation. These are in theory
sufficient to safely operate the plane, but do not detail every aircraft system exhaustively,
as a modern aircraft is too complex to fully understand. Other technical manuals detail how
the systems work, and how to maintain them, but a pilot is unlikely to read them as they are
used by maintenance personnel or instructors. The problem with these cases (if investigations
come to the same conclusions) is that insufficient information was included in the pilots
manual explaining the MCAS, even though the information was communicated via other technical
manuals.
A friend of mine is a commercial pilot who's just doing a 'training' exercise having moved
airlines.
He's been flying the planes in question most of his life, but the airline is asking him to
re-do it all according to their manuals and their rules. If the airline manual does not bring
it up, then the pilots will not read it – few of them have time to go after the actual
technical manuals and read those in addition to what the airline wants. [oh, and it does not
matter that he has tens of thousands of hours on the airplane in question, if he does not do
something in accordance with his new airline manual, he'd get kicked out, even if he was
right and the airline manual wrong]
I believe (but would have to check with him) that some countries regulators do their own
testing over and above the airlines, but again, it depends on what they put in.
Good to head my understanding was correct. My take on the whole situation was that Boeing
was negligent in communicating the significance of the change, given human psychology and
current pilot training. The reason was to enable easier aircraft sales. The purpose of the
MCAS system is however quite legitimate – it enables a more fuel efficient plane while
compensating for a corner case of the flight envelope.
The link is to the actual manual. If that doesn't make you reconsider, nothing will. Maybe
some pilots aren't expected to read the manuals, I don't know.
Furthermore, the post stated that Boeing failed to inform the FAA about the MCAS. Surely
the FAA has time to read all of the manuals.
Nobody reads instruction manuals. They're for reference. Boeing needed to yell at the
pilots to be careful to read new pages 1,576 through 1,629 closely. They're a lulu.
Also, what's with screwing with the geometry of a stable plane so that it will fall out of
the sky without constant adjustments by computer software? It's like having a car designed to
explode but don't worry. We've loaded software to prevent that. Except when there's an error.
But don't worry. We've included reboot instructions. It takes 15 minutes but it'll be OK. And
you can do it with one hand and drive with the other. No thanks. I want the car not designed
to explode.
The FAA is already leaping to the defense of the Boeing 737 Max 8 even before they have a
chance to open up the black boxes. Hope that nothing "happens" to those recordings.
I don't know, crapification, at least for me, refers to products, services, or
infrastructure that has declined to the point that it has become a nuisance rather than a
benefit it once was. This case with Boeing borders on criminal negligence.
1. It's really kind of amazing that we can fly to the other side of the world in a few
hours – a journey that in my grandfather's time would have taken months and been pretty
unpleasant and risky – and we expect perfect safety.
2. Of course the best-selling jet will see these issues. It's the law of large
numbers.
3. I am not a fan of Boeing's corporate management, but still, compared to Wall Street and
Defense Contractors and big education etc. they still produce an actual technical useful
artifact that mostly works, and at levels of performance that in other fields would be
considered superhuman.
4. Even for Boeing, one wonders when the rot will set in. Building commercial airliners is
hard! So many technical details, nowhere to hide if you make even one mistake so easy to just
abandon the business entirely. Do what the (ex) US auto industry did, contract out to foreign
manufacturers and just slap a "USA" label on it and double down on marketing. Milk the
cost-plus cash cow of the defense market. Or just financialize the entire thing and become
too big to fail and walk away with all the profits before the whole edifice crumbles. Greed
is good, right?
"Of course the best-selling jet will see these issues. It's the law of large numbers."
2 crashes of a new model in vary similar circumstances is very unusual. And FAA admits
they are requiring a FW upgrade sometime in April. Pilots need to be hyperaware of what this
MCAS system is doing. And they currently aren't.
if it went into a stall, it would lower the nose suddenly to pick airspeed and fly
normally again.
A while before I read this post, I listened to a news clip that reported that the plane
was observed "porpoising" after takeoff. I know only enough about planes and aviation to be a
more or less competent passenger, but it does seem like that is something that might happen
if the plane had such a feature and the pilot was not familiar with it and was trying to
fight it? The below link is not to the story I saw I don't think, but another one I just
found.
if it went into a stall, it would lower the nose suddenly to pick airspeed and fly
normally again.
At PPRUNE.ORG, many of the commentators are skeptical of what witnesses of airplane
crashes say they see, but more trusting of what they say they hear.
The folks at PPRUNE.ORG who looked at the record of the flight from FlightRadar24, which only
covers part of the flight because FlightRadar24's coverage in that area is not so good and
the terrain is hilly, see a plane flying fast in a straight line very unusually low.
The dodge about making important changes that affect aircraft handling but not disclosing
them – so as to avoid mandatory pilot training, which would discourage airlines from
buying the modified aircraft – is an obvious business-over-safety choice by an ethics
and safety challenged corporation.
But why does even a company of that description, many of whose top managers, designers,
and engineers live and breathe flight, allow its s/w engineers to prevent the pilots from
overriding a supposed "safety" feature while actually flying the aircraft? Was it because it
would have taken a little longer to write and test the additional s/w or because completing
the circle through creating a pilot override would have mandated disclosure and additional
pilot training?
Capt. "Sully" Sullenberger and his passengers and crew would have ended up in pieces at
the bottom of the Hudson if the s/w on his aircraft had prohibited out of the ordinary flight
maneuvers that contradicted its programming.
If you carefully review the over all airframe of the 737 it has not hardly changed over
the past 20 years or so, for the most part Boeing 737
specifications . What I believe the real issue here is the Avionics upgrades over the
years has changed dramatically. More and more precision avionics are installed with less and
less pilot input and ultimately no control of the aircraft. Though Boeing will get the brunt
of the lawsuits, the avionics company will be the real culprit. I believe the avionics on the
Boeing 737 is made by Rockwell Collins, which you guessed it, is owned by Boeing.
United Technologies, UTX, I believe. If I knew how to short, I'd probably short this
'cause if they aren't partly liable, they'll still be hurt if Boeing has to slow (or, horror,
halt) production.
Using routine risk management protocols, the American FAA should need continuing "data" on
an aircraft for it to maintain its airworthiness certificate. Its current press materials on
the Boeing 737 Max 8 suggest it needs data to yank it or to ground the aircraft pending
review. Has it had any other commercial aircraft suffer two apparently similar catastrophic
losses this close together within two years of the aircraft's launch?
I am raising an issue with "crapification" as a meme. Crapification is a symptom of a
specific behaviour.
GREED.
Please could you reconsider your writing to invlude this very old, tremendously venal, and
"worst" sin?
US incentiveness of inventing a new word, "crapification" implies that some error cuould
be corrected. If a deliberate sin, it requires atonement and forgiveness, and a sacrifice of
wolrdy assets, for any chance of forgiveness and redemption.
Something else that will be interesting to this thread is that Boeing doesn't seem to mind
letting the Boeing 737 Max aircraft remain for sale on the open market
Experienced private pilot here. Lots of commercial pilot friends. First, the EU suspending
the MAX 8 is politics. Second, the FAA mandated changes were already in the pipeline. Three,
this won't stop the ignorant from staking out a position on this, and speculating about it on
the internet, of course. Fourth, I'd hop a flight in a MAX 8 without concern –
especially with a US pilot on board. Why? In part because the Lion Air event a few months
back led to pointed discussion about the thrust line of the MAX 8 vs. the rest of the 737
fleet and the way the plane has software to help during strong pitch up events (MAX 8 and 9
have really powerful engines).
Basically, pilots have been made keenly aware of the issue and trained in what to do.
Another reason I'd hop a flight in one right now is because there have been more than 31,000
trouble free flights in the USA in this new aircraft to date. My point is, if there were a
systemic issue we'd already know about it. Note, the PIC in the recent crash had +8000 hours
but the FO had about 200 hours and there is speculation he was flying. Speculation.
Anyway, US commercial fleet pilots are very well trained to deal with runaway trim or
uncommanded flight excursions. How? Simple, by switching the breaker off. It's right near
your fingers. Note, my airplane has an autopilot also. In the event the autopilot does
something unexpected, just like the commercial pilot flying the MAX 8, I'm trained in what to
do (the very same thing, switch the thing off).
Moreover, I speak form experience because I've had it happen twice in 15 years –
once an issue with a servo causing the plane to slowly drift right wing low, and once a
connection came loose leaving the plane trimmed right wing low (coincidence). My reaction
is/was about the same as that of a experienced typist automatically hitting backspace on the
keyboard upon realizing they mistyped a word, e.g. not reflex but nearly so. In my case, it
was to throw the breaker to power off the autopilot as I leveled the plane. No big deal.
Finally, as of yet there been no analysis from the black boxes. I advise holding off on
the speculation until they do. They've been found and we'll learn something soon. The
yammering and near hysteria by non-pilots – especially with this thread – reminds
me of the old saw about now knowing how smart or ignorant someone is until they open their
mouth.
While Boeing is designing a new 787, Airbus redesigns the A320. Boeing cannot compete with
it, so instead of redesigning the 737 properly, they put larger engines on it further
forward, which is never intended in the original design. So to compensate they use software
with two sensors, not three, making it mathematically impossible to know if you have a faulty
sensor which one it would be, to automatically adjust the pitch to prevent a stall, and this
is the only true way to prevent a stall. But since you can kill the breaker and disable it if
you have a bad sensor and can't possibly know which one, everything is ok. And now that the
pilots can disable a feature required for certification, we should all feel good about these
brand new planes, that for the first time in history, crashed within 5 months.
And the FAA, which hasn't had a Director in 14 months, knows better than the UK, Europe,
China, Australia, Singapore, India, Indonesia, Africa and basically every other country in
the world except Canada. And the reason every country in the world except Canada has grounded
the fleet is political? Singapore put Silk Air out of business because of politics?
How many people need to be rammed into the ground at 500 mph from 8000 feet before
yammering and hysteria are justified here? 400 obviously isn't enough.
Overnight since my first post above, the 737 Max 8 crash has become political. The black
boxes haven't been officially read yet. Still airlines and aviation authorities have grounded
the airplane in Europe, India, China, Mexico, Brazil, Australia and S.E. Asia in opposition
to FAA's "Continued Airworthiness Notification to the International Community" issued
yesterday.
I was wrong. There will be no whitewash. I thought they would remain silent. My guess this
is a result of an abundance of caution plus greed (Europeans couldn't help gutting Airbus's
competitor Boeing). This will not be discussed but it is also a manifestation of Trump
Derangement Syndrome (TDS). Since the President has started dissing Atlantic Alliance
partners, extorting defense money, fighting trade wars, and calling 3rd world countries
s***-holes; there is no sympathy for the collapsing hegemon. Boeing stock is paying the
price. If the cause is the faulty design of the flight position sensors and fly by wire
software control system, it will take a long while to design and get approval of a new safe
redundant control system and refit the airplanes to fly again overseas. A real disaster for
America's last manufacturing industry.
Too much automation and too complex flight control computer engager life of pilots and passengers...
Notable quotes:
"... When systems (like those used to fly giant aircraft) become too automatic while remaining essentially stupid or limited by the feedback systems, they endanger the airplane and passengers. These two "accidents" are painful warnings for air passengers and voters. ..."
"... This sort of problem is not new. Search the web for pitot/static port blockage, erroneous stall / overspeed indications. Pilots used to be trained to handle such emergencies before the desk-jockey suits decided computers always know best. ..."
"... @Sky Pilot, under normal circumstances, yes. but there are numerous reports that Boeing did not sufficiently test the MCAS with unreliable or incomplete signals from the sensors to even comply to its own quality regulations. ..."
"... Boeing did cut corners when designing the B737 MAX by just replacing the engines but not by designing a new wing which would have been required for the new engine. ..."
"... I accept that it should be easier for pilots to assume manual control of the aircraft in such situations but I wouldn't rush to condemn the programmers before we get all the facts. ..."
I want to know if Boeing 767s, as well as the new 737s, now has the Max 8 flight control
computer installed with pilots maybe not being trained to use it or it being uncontrollable.
A 3rd Boeing - not a passenger plane but a big 767 cargo plane flying a bunch of stuff for
Amazon crashed near Houston (where it was to land) on 2-23-19. The 2 pilots were killed.
Apparently there was no call for help (at least not mentioned in the AP article about it I
read).
'If' the new Max 8 system had been installed, had either Boeing or the owner of the
cargo plane business been informed of problems with Max 8 equipment that had caused a crash
and many deaths in a passenger plane (this would have been after the Indonesian crash)? Was
that info given to the 2 pilots who died if Max 8 is also being used in some 767s? Did Boeing
get the black box from that plane and, if so, what did they find out?
Those 2 pilots' lives
matter also - particularly since the Indonesian 737 crash with Max 8 equipment had already
happened. Boeing hasn't said anything (yet, that I've seen) about whether or not the Max 8
new configuration computer and the extra steps to get manual control is on other of their
planes.
I want to know about the cause of that 3rd Boeing plane crashing and if there have
been crashes/deaths in other of Boeing's big cargo planes. What's the total of all Boeing
crashes/fatalies in the last few months and how many of those planes had Max 8?
Gentle readers: In the aftermath of the Lion Air crash, do you think it possible that all
737Max pilots have not received mandatory training review in how to quickly disconnect the
MCAS system and fly the plane manually?
Do you think it possible that every 737Max pilot does
not have a "disconnect review" as part of his personal checklist? Do you think it possible
that at the first hint of pitch instability, the pilot does not first think of the MCAS
system and whether to disable it?
Compare the altitude fluctuations with those from Lion Air in NYTimes excellent coverage(
https://www.nytimes.com/interactive/2018/11/16/world/asia/lion-air-crash-cockpit.html
), and they don't really suggest to me a pilot struggling to maintain proper pitch. Maybe the
graph isn't detailed enough, but it looks more like a major, single event rather than a
number of smaller corrections. I could be wrong.
Reports of smoke and fire are interesting;
there is nothing in the modification that (we assume) caused Lion Air's crash that would
explain smoke and fire. So I would hesitate to zero in on the modification at this point.
Smoke and fire coming from the luggage bay suggest a runaway Li battery someone put in their
suitcase. This is a larger issue because that can happen on any aircraft, Boeing, Airbus, or
other.
Is is a shame that Boeing will not ground this aircraft knowing they introduced the MCAS
component to automate the stall recovery of the 737 MAX and is behind these accidents in my
opinion. Stall recovery has always been a step all pilots handled when the stick shaker and
other audible warnings were activated to alert the pilots.
Now, Boeing invented MCAS as a
"selling and marketing point" to a problem that didn't exist. MCAS kicks in when the aircraft
is about to enter the stall phase and places the aircraft in a nose dive to regain speed.
This only works when the air speed sensors are working properly. Now imagine when the air
speed sensors have a malfunction and the plane is wrongly put into a nose dive.
The pilots
are going to pull back on the stick to level the plane. The MCAS which is still getting
incorrect air speed data is going to place the airplane back into a nose dive. The pilots are
going to pull back on the stick to level the aircraft. This repeats itself till the airplane
impacts the ground which is exactly what happened.
Add the fact that Boeing did not disclose
the existence of the MCAS and its role to pilots. At this point only money is keeping the 737
MAX in the air. When Boeing talks about safety, they are not referring to passenger safety
but profit safety.
1. The procedure to allow a pilot to take complete control of the aircraft from auto-pilot
mode should have been a standard eg pull back on the control column. It is not reasonable to
expect a pilot to follow some checklist to determine and then turn off a misbehaving module
especially in emergency situations. Even if that procedure is written in fine print in a
manual. (The number of modules to disable may keep increasing if this is allowed).
2. How are
US airlines confident of the safety of the 737 MAX right now when nothing much is known about
the cause of the 2nd crash? What is known if that both the crashed aircraft were brand new,
and we should be seeing news articles on how the plane's brand-new advanced technology saved
the day from the pilot and not the other way round
3. In the first crash, the plane's
advanced technology could not even recognize that either the flight path was abnormal and/or
the airspeed readings were too erroneous and mandate the pilot to therefore take complete
control immediately!
It's straightforward to design for standard operation under normal circumstances. But when
bizarre operation occurs resulting in extreme circumstances a lot more comes into play. Not
just more variables interacting more rapidly, testing system response times, but much
happening quickly, testing pilot response times and experience. It is doubtful that the FAA
can assess exactly what happened in these crashes. It is a result of a complex and rapid
succession of man-machine-software-instrumentation interactions, and the number of
permutations is huge. Boeing didn't imagine all of them, and didn't test all those it did
think of.
The FAA is even less likely to do so. Boeing eventually will fix some of the
identified problems, and make pilot intervention more effective. Maybe all that effort to
make the new cockpit look as familiar as the old one will be scrapped? Pilot retraining will
be done? Redundant sensors will be added? Additional instrumentation? Software re-written?
That'll increase costs, of course. Future deliveries will cost more. Looks likely there will
be some downtime. Whether the fixes will cover sufficient eventualities, time will tell.
Whether Boeing will be more scrupulous in future designs, less willing to cut corners without
evaluating them? Will heads roll? Well, we'll see...
Boeing has been in trouble technologically since its merger with McDonnell Douglas, which
some industry analysts called a takeover, though it isn't clear who took over whom since MD
got Boeing's name while Boeing took the MD logo and moved their headquarters from Seattle to
Chicago.
In addition to problems with the 737 Max, Boeing is charging NASA considerably more
than the small startup, SpaceX, for a capsule designed to ferry astronauts to the space
station. Boeing's Starliner looks like an Apollo-era craft and is launched via a 1960's-like
ATLAS booster.
Despite using what appears to be old technology, the Starliner is well behind
schedule and over budget while the SpaceX capsule has already docked with the space station
using state-of-art reusable rocket boosters at a much lower cost. It seems Boeing is in
trouble, technologically.
When you read that this model of the Boeing 737 Max was more fuel efficient, and view the
horrifying graphs (the passengers spent their last minutes in sheer terror) of the vertical
jerking up and down of both air crafts, and learn both crashes occurred minutes after take
off, you are 90% sure that the problem is with design, or design not compatible with pilot
training. Pilots in both planes had received permission to return to the airports. The likely
culprit. to a trained designer, is the control system for injecting the huge amounts of fuel
necessary to lift the plane to cruising altitude. Pilots knew it was happening and did not
know how to override the fuel injection system.
These two crashes foretell what will happen
if airlines, purely in the name of saving money, elmininate human control of aircraft. There
will be many more crashes.
These ultra-complicated machines which defy gravity and lift
thousands of pounds of dead weight into the stratesphere to reduce friction with air, are
immensely complex and common. Thousands of flight paths cover the globe each day. Human
pilots must ultimately be in charge - for our own peace of mind, and for their ability to
deal with unimaginable, unforeseen hazards.
When systems (like those used to fly giant
aircraft) become too automatic while remaining essentially stupid or limited by the feedback
systems, they endanger the airplane and passengers. These two "accidents" are painful
warnings for air passengers and voters.
2. Deactivate the ability of the automated system to override pilot
inputs, which it apparently can do even with the autopilot disengaged.
3. Make sure that the
autopilot disengage button on the yoke (pickle switch) disconnects ALL non-manual control
inputs.
4. I do not know if this version of the 737 has direct input ("rope start")
gyroscope, airspeed and vertical speed inticators for emergencies such as failure of the
electronic wonder-stuff. If not, install them. Train pilots to use them.
5. This will cost
money, a lot of money, so we can expect more self-serving excuses until the FAA forces Boeing
to do the right thing.
6. This sort of problem is not new. Search the web for pitot/static
port blockage, erroneous stall / overspeed indications. Pilots used to be trained to handle
such emergencies before the desk-jockey suits decided computers always know
best.
I flew big jets for 34 years, mostly Boeing's. Boeing added new logic to the trim system
and was allowed to not make it known to pilots. However it was in maintenance manuals. Not
great, but these airplanes are now so complex there are many systems that pilots don't know
all of the intimate details.
NOT IDEAL, BUT NOT OVERLY SIGNIFICANT. Boeing changed one of the
ways to stop a runaway trim system by eliminating the control column trim brake, ie airplane
nose goes up, push down (which is instinct) and it stops the trim from running out of
control.
BIG DEAL BOIENG AND FAA, NOT TELLING PILOTS. Boeing produces checklists for almost
any conceivable malfunction. We pilots are trained to accomplish the obvious then go
immediately to the checklist. Some items on the checklist are so important they are called
"Memory Items" or "Red Box Items".
These would include things like in an explosive
depressurization to put on your o2 mask, check to see that the passenger masks have dropped
automatically and start a descent.
Another has always been STAB TRIM SWITCHES ...... CUTOUT
which is surrounded by a RED BOX.
For very good reasons these two guarded switches are very
conveniently located on the pedestal right between the pilots.
So if the nose is pitching
incorrectly, STAB TRIM SWITCHES ..... CUTOUT!!! Ask questions later, go to the checklist.
THAT IS THE PILOTS AND TRAINING DEPARTMENTS RESPONSIBILITY. At this point it is not important
as to the cause.
If these crashes turn out to result from a Boeing flaw, how can that company continue to
stay in business? It should be put into receivership and its executives prosecuted. How many
deaths are persmissable?
The emphasis on software is misplaced. The software intervention is triggered by readings
from something called an Angle of Attack sensor. This sensor is relatively new on airplanes.
A delicate blade protrudes from the fuselage and is deflected by airflow. The direction of
the airflow determines the reading. A false reading from this instrument is the "garbage in"
input to the software that takes over the trim function and directs the nose of the airplane
down. The software seems to be working fine. The AOA sensor? Not so much.
The basic problem seems to be that the 737 Max 8 was not designed for the larger engines
and so there are flight characteristics that could be dangerous. To compensate for the flaw,
computer software was used to control the aircraft when the situation was encountered. The
software failed to prevent the situation from becoming a fatal crash.
A work around that may
be the big mistake of not redesigning the aircraft properly for the larger engines in the
first place. The aircraft may need to be modified at a cost that would be not realistic and
therefore abandoned and a entirely new aircraft design be implemented. That sounds very
drastic but the only other solution would be to go back to the original engines. The Boeing
Company is at a crossroad that could be their demise if the wrong decision is
made.
It may be a training issue in that the 737 Max has several systems changes from previous
737 models that may not be covered adequately in differences training, checklists, etc. In
the Lyon Air crash, a sticky angle-of-attack vane caused the auto-trim to force the nose down
in order to prevent a stall. This is a worthwhile safety feature of the Max, but the crew was
slow (or unable) to troubleshoot and isolate the problem. It need not have caused a crash. I
suspect the same thing happened with Ethiopian Airlines. The circumstances are temptingly
similar.
@Sky Pilot, under normal circumstances, yes. but there are numerous reports that Boeing
did not sufficiently test the MCAS with unreliable or incomplete signals from the sensors to
even comply to its own quality regulations. And that is just one of the many quality issues
with the B737 MAX that have been in the news for a long time and have been of concern to some
of the operators while at the same time being covered up by the FAA.
Just look at the
difference in training requirements between the FAA and the Brazilian aviation authority.
Brazilian pilots need to fully understand the MCAS and how to handle it in emergency
situations while FAA does not even require pilots to know about it.
This is yet another beautiful example of the difference in approach between Europeans and
US Americans. While Europeans usually test their before they deliver the product thoroughly
in order to avoid any potential failures of the product in their customers hands, the US
approach is different: It is "make it work somehow and fix the problems when the client has
them".
Which is what happened here as well. Boeing did cut corners when designing the B737
MAX by just replacing the engines but not by designing a new wing which would have been
required for the new engine.
So the aircraft became unstable to fly at low speedy and tight
turns which required a fix by implementing the MCAS which then was kept from recertification
procedures for clients for reasons competitive sales arguments. And of course, the FAA played
along and provided a cover for this cutting of corners as this was a product of a US company.
Then the proverbial brown stuff hit the fan, not once but twice. So Boeing sent its "thoughts
and prayers" and started to hope for the storm to blow over and for finding a fix that would
not be very expensive and not eat the share holder value away.
Sorry, but that is not the way
to design and maintain aircraft. If you do it, do it right the first time and not fix it
after more than 300 people died in accidents. There is a reason why China has copied the
Airbus A-320 and not the Boeing B737 when building its COMAC C919. The Airbus is not a cheap
fix, still tested by customers.
@Thomas And how do you know that Boeing do not test the aircrafts before delivery? It is a
requirement by FAA for all complete product, systems, parts and sub-parts to be tested before
delivery. However it seems Boeing has not approached the problem (or maybe they do not know
the real issue).
As for the design, are you an engineer that can say whatever the design and
use of new engines without a complete re-design is wrong? Have you seen the design drawings
of the airplane? I do work in an industry in which our products are use for testing different
parts of aircratfs and Boeing is one of our customers.
Our products are use during
manufacturing and maintenance of airplanes. My guess is that Boeing has no idea what is going
on. Your biased opinion against any US product is evident. There are regulations in the USA
(and not in other Asia countries) that companies have to follow. This is not a case of
untested product, it is a case of unknown problem and Boeing is really in the dark of what is
going on...
Boeing and Regulators continue to exhibit criminal behaviour in this case. Ethical
responsibility expects that when the first brand new MAX 8 fell for potentially issues with
its design, the fleet should have been grounded. Instead, money was a priority; and
unfortunately still is. They are even now flying. Disgraceful and criminal
behaviour.
A terrible tragedy for Ethiopia and all of the families affected by this disaster. The
fact that two 737 Max jets have crashed in one year is indeed suspicious, especially as it
has long been safer to travel in a Boeing plane than a car or school bus. That said, it is
way too early to speculate on the causes of the two crashes being identical. Eyewitness
accounts of debris coming off the plane in mid-air, as has been widely reported, would not
seem to square with the idea that software is again at fault. Let's hope this puzzle can be
solved quickly.
@Singh the difference is consumer electronic products usually have a smaller number of
components and wiring compared to commercial aircraft with miles of wiring and multitude of
sensors and thousands of components. From what I know they usually have a preliminary report
that comes out in a short time. But the detailed reported that takes into account analysis
will take over one year to be written.
The engineers and management at Boeing need a crash course in ethics. After the crash in
Indonesia, Boeing was trying to pass the blame rather than admit responsibility. The planes
should all have been grounded then. Now the chickens have come to roost. Boeing is in serious
trouble and it will take a long time to recover the reputation. Large multinationals never
learn.
@John A the previous pilot flying the Lion jet faced the same problem but dealt with it
successfully. The pilot on the ill fated flight was less experienced and unfortunately
failed.
@Imperato Solving a repeat problem on an airplane type must not solely depend upon a pilot
undertaking an emergency response! That is nonsense even to a non-pilot! This implies that
Boeing allows a plane to keep flying which it knows has a fatal flaw! Shouldn't it be
grounding all these planes until it identifies and solves the same problem?
Something is wrong with those two graphs of altitude and vertical speed. For example, both
are flat at the end, even though the vertical speed graph indicates that the plane was
climbing rapidly. So what is the source of those numbers? Is it ground-based radar, or
telemetry from onboard instruments? If the latter, it might be a clue to the
problem.
I wonder if, somewhere, there is a a report from some engineers saying that the system
pushed by administrative-types to get the plane on the market quickly, will results in
serious problems down the line.
If we don't know why the first two 737 Max Jets crashed, then we don't know how long it
will be before another one has a catastrophic failure. All the planes need to be grounded
until the problem can be duplicated and eliminated.
@Rebecca And if it is something about the plane itself - and maybe an interaction with the
new software - then someone has to be ready to volunteer to die to replicate what's
happened.....
@Shirley Heavens no. When investigating failures, duplicating the problem helps develop
the solution. If you can't recreate the problem, then there is nothing to solve. Duplicating
the problem generally is done through analysis and simulations, not with actual planes and
passengers.
Computer geeks can be deadly. This is clearly a software problem. The more software goes
into a plane, the more likely it is for a software failure to bring down a plane. And
computer geeks are always happy to try "new things" not caring what the effects are in the
real world. My PC has a feature that controls what gets typed depending on the speed and
repetitiveness of what I type. The darn thing is a constant source of annoyance as I sit at
my desk, and there is absolutely no way to neutralize it because a computer geek so decided.
Up in an airliner cockpit, this same software idiocy is killing people like
flies.
@Sisifo Software that goes into critical systems like aircraft have a lot more
constraints. Comparing it to the user interface on your PC doesn't make any sense. It's
insulting to assume programmers are happy to "try new things" at the expense of lives. If
you'd read about the Lion Air crash carefully you'd remember that there were faulty sensors
involved. The software was doing what it was designed to do but the input it was getting was
incorrect. I accept that it should be easier for pilots to assume manual control of the
aircraft in such situations but I wouldn't rush to condemn the programmers before we get all
the facts.
@Pooja Mistakes happen. If humans on board can't respond to terrible situations then there
is something wrong with the aircraft and its computer systems. By definition.
Airbus had its own experiences with pilot "mode confusion" in the 1990's with at least 3
fatal crashes in the A320, but was able to control the media narrative until they resolved
the automation issues. Look up Air Inter 148 in Wikipedia to learn the
similarities.
Opinioned! NYC -- currently wintering in the Pacific March 11
"Commands issued by the plane's flight control computer that bypasses the pilots." What
could possibly go wrong? Now let's see whether Boeing's spin doctors can sell this as a
feature, not a bug.
It is telling that the Chinese government grounded their fleet of 737 Max 8 aircraft
before the US government. The world truly has turned upside down when it potentially is safer
to fly in China than the US. Oh, the times we live in. Chris Hartnett Datchet, UK (formerly
Minneapolis)
As a passenger who likes his captains with a head full of white hair, even if the plane is
nosediving to instrument failure, does not every pilot who buckles a seat belt worldwide know
how to switch off automatic flight controls and fly the airplane manually?
Even if this were
1000% Boeing's fault pilots should be able to override electronics and fly the plane safely
back to the airport. I'm sure it's not that black and white in the air and I know it's
speculation at this point but can any pilots add perspective regarding human
responsibility?
@Hollis I'm not a pilot nor an expert, but my understanding is that planes these days are
"fly by wire", meaning the control surfaces are operated electronically, with no mechanical
connection between the pilot's stick and the wings. So if the computer goes down, the ability
to control the plane goes with it.
@Hollis The NYT's excellent reporting on the Lion Air crash indicated that in nearly all
other commercial aircraft, manual control of the pilot's yoke would be sufficient to override
the malfunctioning system (which was controlling the tail wings in response to erroneous
sensor data). Your white haired captain's years of training would have ingrained that
impulse.
Unfortunately, on the Max 8 that would not sufficiently override the tail wings
until the pilots flicked a switch near the bottom of the yoke. It's unclear whether
individual airlines made pilots aware of this. That procedure existed in older planes but may
not have been standard practice because the yoke WOULD sufficiently override the tail wings.
Boeing's position has been that had pilots followed the procedure, a crash would not have
occurred.
@Hollis No, that is the entire crux of this problem; switching from auto-pilot to manual
does NOT solve it. Hence the danger of this whole system. T
his new Boeing 737-Max series are
having the engines placed a bit further away than before and I don't know why they did this,
but the result is that there can be some imbalance in air, which they then tried to correct
with this strange auto-pilot technical adjustment.
Problem is that it stalls the plane (by
pushing its nose down and even flipping out small wings sometimes) even when it shouldn't,
and even when they switch to manual this system OVERRULES the pilot and switches back to
auto-pilot, continuing to try to 'stabilize' (nose dive) the plane. That's what makes it so
dangerous.
It was designed to keep the plane stable but basically turned out to function more
or less like a glitch once you are taking off and need the ascend. I don't know why it only
happens now and then, as this plane had made many other take-offs prior, but when it hits, it
can be deadly. So far Boeings 'solution' is sparsely sending out a HUGE manual for pilots
about how to fight with this computer problem.
Which are complicated to follow in a situation
of stress with a plane computer constantly pushing the nose of your plane down. Max'
mechanism is wrong and instead of correcting it properly, pilots need special training. Or a
new technical update may help... which has been delayed and still hasn't been
provided.
Is it the inability of the two airlines to maintain one of the plane's fly-by-wire systems
that is at fault, not the plane itself? Or are both crashes due to pilot error, not knowing
how to operate the system and then overreacting when it engages? Is the aircraft merely too
advanced for its own good? None of these questions seems to have been answered
yet.
This is such a devastating thing for Ethiopian Airlines, which has been doing critical
work in connecting Africa internally and to the world at large. This is devastating for the
nation of Ethiopia and for all the family members of those killed. May the memory of every
passenger be a blessing. We should all hope a thorough investigation provides answers to why
this make and model of airplane keep crashing so no other people have to go through this
horror again.
A possible small piece of a big puzzle: Bishoftu is a city of 170,000 that is home to the
main Ethiopian air force base, which has a long runway. Perhaps the pilot of Flight 302 was
seeking to land there rather than returning to Bole Airport in Addis Ababa, a much larger and
more densely populated city than Bishoftu. The pilot apparently requested return to Bole, but
may have sought the Bishoftu runway when he experienced further control problems. Detailed
analysis of radar data, conversations between pilot and control tower, flight path, and other
flight-related information will be needed to establish the cause(s) of this
tragedy.
The business of building and selling airplanes is brutally competitive. Malfunctions in
the systems of any kind on jet airplanes ("workhorses" for moving vast quantities of people
around the earth) lead to disaster and loss of life. Boeing's much ballyhooed and vaunted MAX
8 737 jet planes must be grounded until whatever computer glitches brought down Ethiopian Air
and LION Air planes -- with hundreds of passenger deaths -- are explained and fixed.
In 1946,
Arthur Miller's play, "All My Sons", brought to life guilt by the airplane industry leading
to deaths of WWII pilots in planes with defective parts. Arthur Miller was brought before the
House UnAmerican Activities Committee because of his criticism of the American Dream. His
other seminal American play, "Death of a Salesman", was about an everyman to whom attention
must be paid. Attention must be paid to our aircraft industry. The American dream must be
repaired.
Meanwhile, human drivers killed 40,000 and injured 4.5 million people in 2018... For
comparison, 58,200 American troops died in the entire Vietnam war. Computers do not fall
asleep, get drunk, drive angry, or get distracted. As far as I am concerned, we cannot get
unreliable humans out from behind the wheel fast enough.
The irony here seems to be that in attempting to make the aircraft as safe as possible
(with systems updates and such) Boeing may very well have made their product less safe. Since
the crashes, to date, have been limited to the one product that product should be grounded
until a viable determination has been made. John~ American Net'Zen
Knowing quite a few Boeing employees and retirees, people who have shared numerous stories
of concerns about Boeing operations -- I personally avoid flying. As for the assertion: "The
business of building and selling jets is brutally competitive" -- it is monopolistic
competition, as there are only two players. That means consumers (in this case airlines) do
not end up with the best and widest array of airplanes. The more monopolistic a market, the
more it needs to be regulated in the public interest -- yet I seriously doubt the FAA or any
governmental agency has peeked into all the cost cutting measures Boeing has implemented in
recent years
@cosmos Patently ridiculous. Your odds are greater of dying from a lightning strike, or in
a car accident. Or even from food poisoning. Do you avoid driving? Eating? Something about
these major disasters makes people itching to abandon all sense of probability and
statistics.
When the past year was the dealiest one in decades, and when there are two disasters
involved the same plane within that year, how can anyone not draw an inference that there are
something wrong with the plane? In statistical studies of a pattern, this is a very very
strong basis for a logical reasoning that something is wrong with the plane. When the number
involves human lives, we must take very seriously the possibility of design flaws. The MAX
planes should be all grounded for now. Period.
@Bob couldn't agree more - however the basic design and engineering of the 737 is proven
to be dependable over the past ~ 6 decades......not saying that there haven't been accidents
- but these probably lie well within the industry / type averages. the problems seems to have
arisen with the introduction of systems which have purportedly been introduced to take a part
of the work-load off the pilots & pass it onto a central compuertised system.
Maybe the
'automated anti-stalling ' programme installed into the 737 Max, due to some erroneous inputs
from the sensors, provide inaccurate data to the flight management controls leading to
stalling of the aircraft. It seems that the manufacturer did not provide sufficent technical
data about the upgraded software, & incase of malfunction, the corrective procedures to
be followed to mitigate such diasters happening - before delivery of the planes to customers.
The procedure for the pilot to take full control of the aircraft by disengaging the central
computer should be simple and fast to execute. Please we don't want Tesla driverless vehicles
high up in the sky !
All we know at the moment is that a 737 Max crashed in Africa a few minutes after taking
off from a high elevation airport. Some see similarities with the crash of Lion Air's 737 Max
last fall -- but drawing a line between the only two dots that exist does not begin to
present a useful picture of the situation.
Human nature seeks an explanation for an event,
and may lead some to make assumptions that are without merit in order to provide closure.
That tendency is why following a dramatic event, when facts are few, and the few that exist
may be misleading, there is so much cocksure speculation masquerading as solid, reasoned,
analysis. At this point, it's best to keep an open mind and resist connecting
dots.
@James Conner 2 deadly crashes after the introduction of a new airplane has no precedence
in recent aviation history. And the time it has happened (with Comet), it was due to a faulty
aircraft design. There is, of course, some chance that there is no connection between the two
accidents, but if there is, the consequences are huge. Especially because the two events
happened with very similar fashion (right after takeoff, with wild altitude changes), so
there is more similarities than just the type of the plane. So there is literally no reason
to keep this model in the air until the investigation is concluded. Oh well, there is: money.
Over human lives.
It might be a wrong analogy, but if Toyota/Lexus recall over 1.5 million vehicles due to
at least over 20 fatalities in relations to potentially fawlty airbags, Boeing should -- after
over 300 deaths in just about 6 months -- pull their product of the market voluntarily until it
is sorted out once and for all.
This tragic situation recalls the early days of the de
Havilland Comet, operated by BOAC, which kept plunging from the skies within its first years
of operation until the fault was found to be in the rectangular windows, which did not
withstand the pressure due its jet speed and the subsequent cracks in body ripped the planes
apart in midflight.
A third crash may have the potential to take the aircraft manufacturer out of business, it
is therefore unbelievable that the reasons for the Lion Air crash haven't been properly
established yet. With more than a 100 Boeing 737 Max already grounded, I would expect crash
investigations now to be severely fast tracked.
And the entire fleet should be grounded on
the principle of "better safe than sorry". But then again, that would cost Boeing money,
suggesting that the company's assessment of the risks involved favours continued operations
above the absolute safety of passengers.
@Thore Eilertsen This is also not a case for a secretive and extended crash investigation
process. As soon as the cockpit voice recording is extracted - which might be later today -
it should be made public. We also need to hear the communications between the controllers and
the aircraft and to know about the position regarding the special training the pilots
received after the Lion Air crash.
@Thore Eilertsen I would imagine that Boeing will be the first to propose grounding these
planes if they believe with a high degree of probability that it's their issue. They have the
most to lose. Let logic and patience prevail.
It is very clear, even in these early moments, that aircraft makers need far more
comprehensive information on everything pertinent that is going on in cockpits when pilots
encounter problems. That information should be continually transmitted to ground facilities
in real time to permit possible ground technical support.
Although he is certainly a giant, Knuth will never be able to complete this monograph - the
technology developed too quickly. Three volumes came out in 1963-1968 and then there was a lull.
January 10, he will be 81. At this age it is difficult to work in the field of mathematics and
system programming. So we will probably never see the complete fourth volume.
This inability to
finish the work he devoted a large part of hi life is definitely a tragedy. The key problem here is
that now it is simply impossible to cover the whole area of system programming and
related algorithms for one person. But the first three volumes played tremendous positive role
for sure.
Also he was distracted for several years to create TeX. He needed to create a non-profit and
complete this work by attracting the best minds from the outside. But he is by nature a loner,
as many great scientists are, and prefer to work this way.
His other mistake is due to the fact that MIX - his emulator was too far from the IBM S/360, which became the standard de-facto
in mid-60th. He then realized that this was a blunder and replaced MIX with more modem emulator MIXX, but it was
"too little, too late" and it took time and effort. So the first three volumes and fragments of the fourth is all
that we have now and probably forever.
Not all volumes fared equally well with time. The third volume suffered most IMHO and as of 2019 is partially obsolete. Also it was
written by him in some haste and some parts of it are are far from clearly written ( it was based on earlier
lectures of Floyd, so it was oriented of single CPU computers only. Now when multiprocessor
machines, huge amount of RAM and SSD hard drives are the norm, the situation is very different from late 60th. It requires different sorting
algorithms (the importance of mergesort increased, importance of quicksort decreased). He also got too carried away with sorting random numbers and establishing upper bound and
average
run time. The real data is almost never random and typically contain sorted fragments. For example, he overestimated the
importance of quicksort and thus pushed the discipline in the wrong direction.
Notable quotes:
"... These days, it is 'coding', which is more like 'code-spraying'. Throw code at a problem until it kind of works, then fix the bugs in the post-release, or the next update. ..."
"... AI is a joke. None of the current 'AI' actually is. It is just another new buzz-word to throw around to people that do not understand it at all. ..."
"... One good teacher makes all the difference in life. More than one is a rare blessing. ..."
With more than one million copies in print, "The Art of Computer Programming " is the Bible
of its field. "Like an actual bible, it is long and comprehensive; no other book is as
comprehensive," said Peter Norvig, a director of research at Google. After 652 pages, volume
one closes with a blurb on the back cover from Bill Gates: "You should definitely send me a
résumé if you can read the whole thing."
The volume opens with an excerpt from " McCall's Cookbook ":
Here is your book, the one your thousands of letters have asked us to publish. It has
taken us years to do, checking and rechecking countless recipes to bring you only the best,
only the interesting, only the perfect.
Inside are algorithms, the recipes that feed the digital age -- although, as Dr. Knuth likes
to point out, algorithms can also be found on Babylonian tablets from 3,800 years ago. He is an
esteemed algorithmist; his name is attached to some of the field's most important specimens,
such as the Knuth-Morris-Pratt string-searching algorithm. Devised in 1970, it finds all
occurrences of a given word or pattern of letters in a text -- for instance, when you hit
Command+F to search for a keyword in a document.
... ... ...
During summer vacations, Dr. Knuth made more money than professors earned in a year by
writing compilers. A compiler is like a translator, converting a high-level programming
language (resembling algebra) to a lower-level one (sometimes arcane binary) and, ideally,
improving it in the process. In computer science, "optimization" is truly an art, and this is
articulated in another Knuthian proverb: "Premature optimization is the root of all evil."
Eventually Dr. Knuth became a compiler himself, inadvertently founding a new field that he
came to call the "analysis of algorithms." A publisher hired him to write a book about
compilers, but it evolved into a book collecting everything he knew about how to write for
computers -- a book about algorithms.
... ... ...
When Dr. Knuth started out, he intended to write a single work. Soon after, computer science
underwent its Big Bang, so he reimagined and recast the project in seven volumes. Now he metes
out sub-volumes, called fascicles. The next installation, "Volume 4, Fascicle 5," covering,
among other things, "backtracking" and "dancing links," was meant to be published in time for
Christmas. It is delayed until next April because he keeps finding more and more irresistible
problems that he wants to present.
In order to optimize his chances of getting to the end, Dr. Knuth has long guarded his time.
He retired at 55, restricted his public engagements and quit email (officially, at least).
Andrei Broder recalled that time management was his professor's defining characteristic even in
the early 1980s.
Dr. Knuth typically held student appointments on Friday mornings, until he started spending
his nights in the lab of John McCarthy, a founder of artificial intelligence, to get access to
the computers when they were free. Horrified by what his beloved book looked like on the page
with the advent of digital publishing, Dr. Knuth had gone on a mission to create the TeX
computer typesetting system, which remains the gold standard for all forms of scientific
communication and publication. Some consider it Dr. Knuth's greatest contribution to the world,
and the greatest contribution to typography since Gutenberg.
This decade-long detour took place back in the age when computers were shared among users
and ran faster at night while most humans slept. So Dr. Knuth switched day into night, shifted
his schedule by 12 hours and mapped his student appointments to Fridays from 8 p.m. to
midnight. Dr. Broder recalled, "When I told my girlfriend that we can't do anything Friday
night because Friday night at 10 I have to meet with my adviser, she thought, 'This is
something that is so stupid it must be true.'"
... ... ...
Lucky, then, Dr. Knuth keeps at it. He figures it will take another 25 years to finish "The
Art of Computer Programming," although that time frame has been a constant since about 1980.
Might the algorithm-writing algorithms get their own chapter, or maybe a page in the epilogue?
"Definitely not," said Dr. Knuth.
"I am worried that algorithms are getting too prominent in the world," he added. "It started
out that computer scientists were worried nobody was listening to us. Now I'm worried that too
many people are listening."
Thanks Siobhan for your vivid portrait of my friend and mentor. When I came to Stanford as
an undergrad in 1973 I asked who in the math dept was interested in puzzles. They pointed me
to the computer science dept, where I met Knuth and we hit it off immediately. Not only a
great thinker and writer, but as you so well described, always present and warm in person. He
was also one of the best teachers I've ever had -- clear, funny, and interested in every
student (his elegant policy was each student can only speak twice in class during a period,
to give everyone a chance to participate, and he made a point of remembering everyone's
names). Some thoughts from Knuth I carry with me: finding the right name for a project is
half the work (not literally true, but he labored hard on finding the right names for TeX,
Metafont, etc.), always do your best work, half of why the field of computer science exists
is because it is a way for mathematically minded people who like to build things can meet
each other, and the observation that when the computer science dept began at Stanford one of
the standard interview questions was "what instrument do you play" -- there was a deep
connection between music and computer science, and indeed the dept had multiple string
quartets. But in recent decades that has changed entirely. If you do a book on Knuth (he
deserves it), please be in touch.
I remember when programming was art. I remember when programming was programming. These
days, it is 'coding', which is more like 'code-spraying'. Throw code at a problem until it
kind of works, then fix the bugs in the post-release, or the next update.
AI is a joke. None
of the current 'AI' actually is. It is just another new buzz-word to throw around to people
that do not understand it at all. We should be in a golden age of computing. Instead, we are
cutting all corners to get something out as fast as possible. The technology exists to do far
more. It is the human element that fails us.
My particular field of interest has always been compiler writing and have been long
awaiting Knuth's volume on that subject. I would just like to point out that among Kunth's
many accomplishments is the invention of LR parsers, which are widely used for writing
programming language compilers.
Yes, \TeX, and its derivative, \LaTeX{} contributed greatly to being able to create
elegant documents. It is also available for the web in the form MathJax, and it's about time
the New York Times supported MathJax. Many times I want one of my New York Times comments to
include math, but there's no way to do so! It comes up equivalent to:
$e^{i\pi}+1$.
I read it at the time, because what I really wanted to read was volume 7, Compilers. As I
understood it at the time, Professor Knuth wrote it in order to make enough money to build an
organ. That apparantly happened by 3:Knuth, Searching and Sorting. The most impressive part
is the mathemathics in Semi-numerical (2:Knuth). A lot of those problems are research
projects over the literature of the last 400 years of mathematics.
I own the three volume "Art of Computer Programming", the hardbound boxed set. Luxurious.
I don't look at it very often thanks to time constraints, given my workload. But your article
motivated me to at least pick it up and carry it from my reserve library to a spot closer to
my main desk so I can at least grab Volume 1 and try to read some of it when the mood
strikes. I had forgotten just how heavy it is, intellectual content aside. It must weigh more
than 25 pounds.
I too used my copies of The Art of Computer Programming to guide me in several projects in
my career, across a variety of topic areas. Now that I'm living in Silicon Valley, I enjoy
seeing Knuth at events at the Computer History Museum (where he was a 1998 Fellow Award
winner), and at Stanford. Another facet of his teaching is the annual Christmas Lecture, in
which he presents something of recent (or not-so-recent) interest. The 2018 lecture is
available online - https://www.youtube.com/watch?v=_cR9zDlvP88
One of the most special treats for first year Ph.D. students in the Stanford University
Computer Science Department was to take the Computer Problem-Solving class with Don Knuth. It
was small and intimate, and we sat around a table for our meetings. Knuth started the
semester by giving us an extremely challenging, previously unsolved problem. We then formed
teams of 2 or 3. Each week, each team would report progress (or lack thereof), and Knuth, in
the most supportive way, would assess our problem-solving approach and make suggestions for
how to improve it. To have a master thinker giving one feedback on how to think better was a
rare and extraordinary experience, from which I am still benefiting! Knuth ended the semester
(after we had all solved the problem) by having us over to his house for food, drink, and
tales from his life. . . And for those like me with a musical interest, he let us play the
magnificent pipe organ that was at the center of his music room. Thank you Professor Knuth,
for giving me one of the most profound educational experiences I've ever had, with such
encouragement and humor!
I learned about Dr. Knuth as a graduate student in the early 70s from one of my professors
and made the financial sacrifice (graduate student assistantships were not lucrative) to buy
the first and then the second volume of the Art of Computer Programming. Later, at Bell Labs,
when I was a bit richer, I bought the third volume. I have those books still and have used
them for reference for years. Thank you Dr, Knuth. Art, indeed!
@Trerra In the good old days, before Computer Science, anyone could take the Programming
Aptitude Test. Pass it and companies would train you. Although there were many mathematicians
and scientists, some of the best programmers turned out to be music majors. English, Social
Sciences, and History majors were represented as well as scientists and mathematicians. It
was a wonderful atmosphere to work in . When I started to look for a job as a programmer, I
took Prudential Life Insurance's version of the Aptitude Test. After the test, the
interviewer was all bent out of shape because my verbal score was higher than my math score;
I was a physics major. Luckily they didn't hire me and I got a job with IBM.
In summary, "May the force be with you" means: Did you read Donald Knuth's "The Art of
Computer Programming"? Excellent, we loved this article. We will share it with many young
developers we know.
Dr. Knuth is a great Computer Scientist. Around 25 years ago, I met Dr. Knuth in a small
gathering a day before he was awarded a honorary Doctorate in a university. This is my
approximate recollection of a conversation. I said-- " Dr. Knuth, you have dedicated your
book to a computer (one with which he had spent a lot of time, perhaps a predecessor to
PDP-11). Isn't it unusual?". He said-- "Well, I love my wife as much as anyone." He then
turned to his wife and said --"Don't you think so?". It would be nice if scientists with the
gift of such great minds tried to address some problems of ordinary people, e.g. a model of
economy where everyone can get a job and health insurance, say, like Dr. Paul Krugman.
I was in a training program for women in computer systems at CUNY graduate center, and
they used his obtuse book. It was one of the reasons I dropped out. He used a fantasy
language to describe his algorithms in his book that one could not test on computers. I
already had work experience as a programmer with algorithms and I know how valuable real
languages are. I might as well have read Animal Farm. It might have been different if he was
the instructor.
Don Knuth's work has been a curious thread weaving in and out of my life. I was first
introduced to Knuth and his The Art of Computer Programming back in 1973, when I was tasked
with understanding a section of the then-only-two-volume Book well enough to give a lecture
explaining it to my college algorithms class. But when I first met him in 1981 at Stanford,
he was all-in on thinking about typography and this new-fangled system of his called TeX.
Skip a quarter century. One day in 2009, I foolishly decided kind of on a whim to rewrite TeX
from scratch (in my copious spare time), as a simple C library, so that its typesetting
algorithms could be put to use in other software such as electronic eBook's with high-quality
math typesetting and interactive pictures. I asked Knuth for advice. He warned me, prepare
yourself, it's going to consume five years of your life. I didn't believe him, so I set off
and tried anyway. As usual, he was right.
I have signed copied of "Fundamental Algorithms" in my library, which I treasure. Knuth
was a fine teacher, and is truly a brilliant and inspiring individual. He taught during the
same period as Vint Cerf, another wonderful teacher with a great sense of humor who is truly
a "father of the internet". One good teacher makes all the difference in life. More than
one is a rare blessing.
I am a biologist, specifically a geneticist. I became interested in LaTeX typesetting
early in my career and have been either called pompous or vilified by people at all levels
for wanting to use. One of my PhD advisors famously told me to forget LaTeX because it was a
thing of the past. I have now forgotten him completely. I still use LaTeX almost every day in
my work even though I don't generally typeset with equations or algorithms. My students
always get trained in using proper typesetting. Unfortunately, the publishing industry has
all but largely given up on TeX. Very few journals in my field accept TeX manuscripts, and
most of them convert to word before feeding text to their publishing software. Whatever
people might argue against TeX, the beauty and elegance of a property typeset document is
unparalleled. Long live LaTeX
A few years ago Severo Ornstein (who, incidentally, did the hardware design for the first
router, in 1969), and his wife Laura, hosted a concert in their home in the hills above Palo
Alto. During a break a friend and I were chatting when a man came over and *asked* if he
could chat with us (a high honor, indeed). His name was Don. After a few minutes I grew
suspicious and asked "What's your last name?" Friendly, modest, brilliant; a nice addition to
our little chat.
When I was a physics undergraduate (at Trinity in Hartford), I was hired to re-write
professor's papers into TeX. Seeing the beauty of TeX, I wrote a program that re-wrote my lab
reports (including graphs!) into TeX. My lab instructors were amazed! How did I do it? I
never told them. But I just recognized that Knuth was a genius and rode his coat-tails, as I
have continued to do for the last 30 years!
A famous quote from Knuth: "Beware of bugs in the above code; I have only proved it
correct, not tried it." Anyone who has ever programmed a computer will feel the truth of this
in their bones.
My grandfather, in the early 60's could board a 707 in New York and arrive in LA in far
less time than I can today. And no, I am not counting 4 hour layovers with the long waits to
be "screened", the jets were 50-70 knots faster, back then your time was worth more, today
less.
Not counting longer hours AT WORK, we spend far more time commuting making for much longer
work days, back then your time was worth more, today less!
Software "upgrades" require workers to constantly relearn the same task because some young
"genius" observed that a carefully thought out interface "looked tired" and glitzed it up.
Think about the almost perfect Google Maps driver interface being redesigned by people who
take private buses to work. Way back in the '90's your time was worth more than today!
Life is all the "time" YOU will ever have and if we let the elite do so, they will suck
every bit of it out of you.
Revisiting the Unix philosophy in 2018The old strategy of building small, focused
applications is new again in the modern microservices environment.
Program Design in the Unix Environment " in the
AT&T Bell Laboratories Technical Journal, in which they argued the Unix philosophy, using
the example of BSD's cat -v implementation. In a nutshell that philosophy is: Build small,
focused programs -- in whatever language -- that do only one thing but do this thing well,
communicate via stdin / stdout , and are connected through pipes.
Sound familiar?
Yeah, I thought so. That's pretty much the definition of microservices offered
by James Lewis and Martin Fowler:
In short, the microservice architectural style is an approach to developing a single
application as a suite of small services, each running in its own process and communicating
with lightweight mechanisms, often an HTTP resource API.
While one *nix program or one microservice may be very limited or not even very interesting
on its own, it's the combination of such independently working units that reveals their true
benefit and, therefore, their power.
*nix vs. microservices
The following table compares programs (such as cat or lsof ) in a *nix environment against
programs in a microservices environment.
The unit of execution in *nix (such as Linux) is an executable file (binary or interpreted
script) that, ideally, reads input from stdin and writes output to stdout . A microservices
setup deals with a service that exposes one or more communication interfaces, such as HTTP or
gRPC APIs. In both cases, you'll find stateless examples (essentially a purely functional
behavior) and stateful examples, where, in addition to the input, some internal (persisted)
state decides what happens. Data flow
Traditionally, *nix programs could communicate via pipes. In other words, thanks to
Doug McIlroy , you
don't need to create temporary files to pass around and each can process virtually endless
streams of data between processes. To my knowledge, there is nothing comparable to a pipe
standardized in microservices, besides my little
Apache Kafka-based experiment from 2017 .
Configuration and parameterization
How do you configure a program or service -- either on a permanent or a by-call basis? Well,
with *nix programs you essentially have three options: command-line arguments, environment
variables, or full-blown config files. In microservices, you typically deal with YAML (or even
worse, JSON) documents, defining the layout and configuration of a single microservice as well
as dependencies and communication, storage, and runtime settings. Examples include Kubernetes resource definitions ,
Nomad
job specifications , or Docker Compose files. These may or may not be
parameterized; that is, either you have some templating language, such as Helm in Kubernetes, or you find yourself doing an awful lot of sed
-i commands.
Discovery
How do you know what programs or services are available and how they are supposed to be
used? Well, in *nix, you typically have a package manager as well as good old man; between
them, they should be able to answer all the questions you might have. In a microservices setup,
there's a bit more automation in finding a service. In addition to bespoke approaches like
Airbnb's SmartStack
or Netflix's Eureka , there
usually are environment variable-based or DNS-based approaches
that allow you to discover services dynamically. Equally important, OpenAPI provides a de-facto standard for HTTP API documentation
and design, and gRPC does the same for more
tightly coupled high-performance cases. Last but not least, take developer experience (DX) into
account, starting with writing good Makefiles and ending with writing your
docs with (or in?) style .
Pros and
cons
Both *nix and microservices offer a number of challenges and
opportunities
Composability
It's hard to design something that has a clear, sharp focus and can also play well with
others. It's even harder to get it right across different versions and to introduce respective
error case handling capabilities. In microservices, this could mean retry logic and timeouts --
maybe it's a better option to outsource these features into a service mesh? It's hard, but if
you get it right, its reusability can be enormous.
Observability
In a monolith (in 2018) or a big program that tries to do it all (in 1984), it's rather
straightforward to find the culprit when things go south. But, in a
yes | tr \\n x | head -c 450m | grep n
or a request path in a microservices setup that involves, say, 20 services, how do you even
start to figure out which one is behaving badly? Luckily we have standards, notably
OpenCensus and OpenTracing . Observability still might be the biggest single
blocker if you are looking to move to microservices.
Global state
While it may not be such a big issue for *nix programs, in microservices, global state
remains something of a discussion. Namely, how to make sure the local (persistent) state is
managed effectively and how to make the global state consistent with as little effort as
possible.
Wrapping up
In the end, the question remains: Are you using the right tool for a given task? That is, in
the same way a specialized *nix program implementing a range of functions might be the better
choice for certain use cases or phases, it might be that a monolith is the best
option for your organization or workload. Regardless, I hope this article helps you see the
many, strong parallels between the Unix philosophy and microservices -- maybe we can learn
something from the former to benefit the latter.
Michael Hausenblas is a Developer Advocate for Kubernetes
and OpenShift at Red Hat where he helps appops to build and operate apps. His background is in
large-scale data processing and container orchestration and he's experienced in advocacy and
standardization at W3C and IETF. Before Red Hat, Michael worked at Mesosphere, MapR and in two
research institutions in Ireland and Austria. He contributes to open source software incl.
Kubernetes, speaks at conferences and user groups, and shares good practices...
Elegance is one of those things that can be difficult to define. I know it when I see it,
but putting what I see into a terse definition is a challenge. Using the Linux diet
command, Wordnet provides one definition of elegance as, "a quality of neatness and ingenious
simplicity in the solution of a problem (especially in science or mathematics); 'the simplicity
and elegance of his invention.'"
In the context of this book, I think that elegance is a state of beauty and simplicity in
the design and working of both hardware and software. When a design is elegant,
software and hardware work better and are more efficient. The user is aided by simple,
efficient, and understandable tools.
Creating elegance in a technological environment is hard. It is also necessary. Elegant
solutions produce elegant results and are easy to maintain and fix. Elegance does not happen by
accident; you must work for it.
The quality of simplicity is a large part of technical elegance. So large, in fact that it
deserves a chapter of its own, Chapter 18, "Find the Simplicity," but we do not ignore it here.
This chapter discusses what it means for hardware and software to be elegant.
Yes, hardware can be elegant -- even beautiful, pleasing to the eye. Hardware that is well
designed is more reliable as well. Elegant hardware solutions improve reliability'.
"Even Microsoft, the biggest software company in the world, recently screwed up..."
Isn't it rather logical than the larger a company is, the more screw ups it can make?
After all, Microsofts has armies of programmers to make those bugs.
Once I created a joke that the best way to disable missile defense would be to have a
rocket that can stop in mid-air, thus provoking the software to divide be zero and crash. One
day I told that joke to a military officer who told me that something like that actually
happened, but it was in the Navy and it involved a test with a torpedo. Not only the program
for "torpedo defense" went down but the system crashed too and the engine of the ship stopped
working as well. I also recall explanations that a new complex software system typically has
all major bugs removed after being used for a year. And the occasion was Internal Revenue
Service changing hardware and software leading to widely reported problems.
One issue with Microsoft (not just Microsoft) is that their business model (not the
benefit of the users) requires frequent changes in the systems, so bugs are introduced at the
steady clip. Of course, they do not make money on bugs per se, but on new features that in
time make it impossible to use older versions of the software and hardware.
Nikita Prokopov, a software programmer and author of Fira Code, a popular programming font,
AnyBar, a universal status indicator, and some open-source Clojure libraries, writes :
Remember times when an
OS, apps and all your data fit on a floppy? Your desktop todo app is probably written in
Electron and thus has userland driver for Xbox 360 controller in it, can render 3d graphics and
play audio and take photos with your web camera. A simple text chat is notorious for its load
speed and memory consumption. Yes, you really have to count Slack in as a resource-heavy
application. I mean, chatroom and barebones text editor, those are supposed to be two of the
less demanding apps in the whole world. Welcome to 2018.
At least it works, you might say. Well, bigger doesn't imply better. Bigger means someone
has lost control. Bigger means we don't know what's going on. Bigger means complexity tax,
performance tax, reliability tax. This is not the norm and should not become the norm
. Overweight apps should mean a red flag. They should mean run away scared. 16Gb Android phone
was perfectly fine 3 years ago. Today with Android 8.1 it's barely usable because each app has
become at least twice as big for no apparent reason. There are no additional functions. They
are not faster or more optimized. They don't look different. They just...grow?
iPhone 4s was released with iOS 5, but can barely run iOS 9. And it's not because iOS 9
is that much superior -- it's basically the same. But their new hardware is faster, so they
made software slower. Don't worry -- you got exciting new capabilities like...running the same
apps with the same speed! I dunno. [...] Nobody understands anything at this point. Neither
they want to. We just throw barely baked shit out there, hope for the best and call it "startup
wisdom." Web pages ask you to refresh if anything goes wrong. Who has time to figure out what
happened? Any web app produces a constant stream of "random" JS errors in the wild, even on
compatible browsers.
[...] It just seems that nobody is interested in building quality, fast, efficient,
lasting, foundational stuff anymore. Even when efficient solutions have been known for ages, we
still struggle with the same problems: package management, build systems, compilers, language
design, IDEs. Build systems are inherently unreliable and periodically require full clean, even
though all info for invalidation is there. Nothing stops us from making build process reliable,
predictable and 100% reproducible. Just nobody thinks its important. NPM has stayed in
"sometimes works" state for years.
Less resource use to accomplish the required tasks? Both in manufacturing (more chips from
the same amount of manufacturing input) and in operation (less power used)?
Ehm...so for example using smaller cars with better mileage to commute isn't more
environmentally friendly either, according to
you?https://slashdot.org/comments.pl?sid=12644750&cid=57354556#
iPhone 4S used to be the best and could run all the applications.
Today, the same power is not sufficient because of software bloat. So you could say that
all the iPhones since the iPhone 4S are devices that were created and then dumped for no
reason.
It doesn't matter since we can't change the past and it doesn't matter much since
improvements are slowing down so people are changing their phones less often.
Can you really not see the connection between inefficient software and environmental harm?
All those computers running code that uses four times as much data, and four times the number
crunching, as is reasonable? That excess RAM and storage has to be built as well as powered
along with the CPU. Those material and electrical resources have to come from somewhere.
But the calculus changes completely when the software manufacturer hosts the software (or
pays for the hosting) for their customers. Our projected AWS bill motivated our management to
let me write the sort of efficient code I've been trained to write. After two years of
maintaining some pretty horrible legacy code, it is a welcome change.
The big players care a great deal about efficiency when they can't outsource inefficiency
to the user's computing resources.
We've been trained to be a consuming society of disposable goods. The latest and
greatest feature will always be more important than something that is reliable and durable
for the long haul.
It's not just consumer stuff.
The network team I'm a part of has been dealing with more and more frequent outages, 90%
of which are due to bugs in software running our devices. These aren't fly-by-night vendors
either, they're the "no one ever got fired for buying X" ones like Cisco, F5, Palo Alto, EMC,
etc.
10 years ago, outages were 10% bugs, and 90% human error, now it seems to be the other way
around. Everyone's chasing features, because that's what sells, so there's no time for
efficiency/stability/security any more.
Poor software engineering means that very capable computers are no longer capable of
running modern, unnecessarily bloated software. This, in turn, leads to people having to
replace computers that are otherwise working well, solely for the reason to keep up with
software that requires more and more system resources for no tangible benefit. In a nutshell
-- sloppy, lazy programming leads to more technology waste. That impacts the environment. I
have a unique perspective in this topic. I do web development for a company that does
electronics recycling. I have suffered the continued bloat in software in the tools I use
(most egregiously, Adobe), and I see the impact of technological waste in the increasing
amount of electronics recycling that is occurring. Ironically, I'm working at home today
because my computer at the office kept stalling every time I had Photoshop and Illustrator
open at the same time. A few years ago that wasn't a problem.
There is one place where people still produce stuff like the OP wants, and that's
embedded. Not IoT wank, but real embedded, running on CPUs clocked at tens of MHz with RAM in
two-digit kilobyte (not megabyte or gigabyte) quantities. And a lot of that stuff is written
to very exacting standards, particularly where something like realtime control and/or safety
is involved.
The one problem in this area is the endless battle with standards morons who begin each
standard with an implicit "assume an infinitely
> Poor software engineering means that very capable computers are no longer capable of
running modern, unnecessarily bloated software.
Not just computers.
You can add Smart TVs, settop internet boxes, Kindles, tablets, et cetera that must be
thrown-away when they become too old (say 5 years) to run the latest bloatware. Software
non-engineering is causing a lot of working hardware to be landfilled, and for no good
reason.
When the speed of your processor doubles every two year along with a concurrent doubling
of RAM and disk space, then you can get away with bloatware.
Since Moore's law appears to have stalled since at least five years ago, it will be
interesting to see if we start to see algorithm research or code optimization techniques
coming to the fore again.
"... It's a bit of chicken-and-egg problem, though. Russia, throughout 20th century, had problem with developing small, effective hardware, so their programmers learned how to code to take maximum advantage of what they had, with their technological deficiency in one field giving rise to superiority in another. ..."
"... Russian tech ppl should always be viewed with certain amount of awe and respect...although they are hardly good on everything. ..."
"... Soviet university training in "cybernetics" as it was called in the late 1980s involved two years of programming on blackboards before the students even touched an actual computer. ..."
"... I recall flowcharting entirely on paper before committing a program to punched cards. ..."
Much has been made, including in this post, of the excellent organization of Russian
forces and Russian military technology.
I have been re-investigating an open-source relational database system known as PosgreSQL
(variously), and I remember finding perhaps a decade ago a very useful whole text search
feature of this system which I vaguely remember was written by a Russian and, for that
reason, mildly distrusted by me.
Come to find out that the principle developers and maintainers of PostgreSQL are Russian.
OMG. Double OMG, because the reason I chose it in the first place is that it is the best
non-proprietary RDBS out there and today is supported on Google Cloud, AWS, etc.
The US has met an equal or conceivably a superior, case closed. Trump's thoroughly odd
behavior with Putin is just one but a very obvious one example of this.
Of course, Trump's
nationalistic blather is creating a "base" of people who believe in the godliness of the US.
They are in for a very serious disappointment.
After the iron curtain fell, there was a big demand for Russian-trained programmers
because they could program in a very efficient and "light" manner that didn't demand too much
of the hardware, if I remember correctly.
It's a bit of chicken-and-egg problem, though.
Russia, throughout 20th century, had problem with developing small, effective hardware, so
their programmers learned how to code to take maximum advantage of what they had, with their
technological deficiency in one field giving rise to superiority in another.
Russia has plenty of very skilled, very well-trained folks and their science and math
education is, in a way, more fundamentally and soundly grounded on the foundational stuff
than US (based on my personal interactions anyways).
Russian tech ppl should always be viewed
with certain amount of awe and respect...although they are hardly good on everything.
Well said. Soviet university training in "cybernetics" as it was called in the late 1980s
involved two years of programming on blackboards before the students even touched an actual
computer.
It gave the students an understanding of how computers works down to the bit
flipping level. Imagine trying to fuzz code in your head.
I recall flowcharting entirely on paper before committing a program to punched cards. I
used to do hex and octal math in my head as part of debugging core dumps. Ah, the glory days.
Honeywell once made a military computer that was 10 bit. That stumped me for a while, as
everything was 8 or 16 bit back then.
That used to be fairly common in the civilian sector (in US) too: computing time was
expensive, so you had to make sure that the stuff worked flawlessly before it was committed.
No opportunity to seeing things go wrong and do things over like much of how things happen
nowadays. Russians, with their hardware limitations/shortages, I imagine must have been much
more thorough than US programmers were back in the old days, and you could only get there by
being very thoroughly grounded n the basics.
If we take consulting, services, and support off the table as an option for high-growth
revenue generation (the only thing VCs care about), we are left with open core [with some
subset of features behind a paywall] , software as a service, or some blurring of the
two... Everyone wants infrastructure software to be free and continuously developed by highly
skilled professional developers (who in turn expect to make substantial salaries), but no one
wants to pay for it. The economics of
this situation are unsustainable and broken ...
[W]e now come to what I have recently called "loose" open core and SaaS. In the future, I
believe the most successful OSS projects will be primarily monetized via this method. What is
it? The idea behind "loose" open core and SaaS is that a popular OSS project can be developed
as a completely community driven project (this avoids the conflicts of interest inherent in
"pure" open core), while value added proprietary services and software can be sold in an
ecosystem that forms around the OSS...
Unfortunately, there is an inflection point at which in some sense an OSS project becomes
too popular for its own good, and outgrows its ability to generate enough revenue via either
"pure" open core or services and support... [B]uilding a vibrant community and then enabling an
ecosystem of "loose" open core and SaaS businesses on top appears to me to be the only viable
path forward for modern VC-backed OSS startups.
Klein also suggests OSS foundations start providing fellowships to key maintainers, who
currently "operate under an almost feudal system of patronage, hopping from company to company,
trying to earn a living, keep the community vibrant, and all the while stay impartial..."
"[A]s an industry, we are going to have to come to terms with the economic reality: nothing
is free, including OSS. If we want vibrant OSS projects maintained by engineers that are well
compensated and not conflicted, we are going to have to decide that this is something worth
paying for. In my opinion, fellowships provided by OSS foundations and funded by companies
generating revenue off of the OSS is a great way to start down this path."
"... Live Work Work Work Die: A Journey into the Savage Heart of Silicon Valley ..."
"... Older generations called this kind of fraud "fake it 'til you make it." ..."
"... Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other "smart person" put in 75 hours a week dealing with hiring ..."
"... It's not a "kids these days" sort of issue, it's *always* been the case that shameless, baseless self-promotion wins out over sincere skill without the self-promotion, because the people who control the money generally understand boasting more than they understand the technology. ..."
"... In the bad old days we had a hell of a lot of ridiculous restriction We must somehow made our programs to run successfully inside a RAM that was 48KB in size (yes, 48KB, not 48MB or 48GB), on a CPU with a clock speed of 1.023 MHz ..."
"... So what are the uses for that? I am curious what things people have put these to use for. ..."
"... Also, Oracle, SAP, IBM... I would never buy from them, nor use their products. I have used plenty of IBM products and they suck big time. They make software development 100 times harder than it could be. ..."
"... I have a theory that 10% of people are good at what they do. It doesn't really matter what they do, they will still be good at it, because of their nature. These are the people who invent new things, who fix things that others didn't even see as broken and who automate routine tasks or simply question and erase tasks that are not necessary. ..."
"... 10% are just causing damage. I'm not talking about terrorists and criminals. ..."
"... Programming is statistically a dead-end job. Why should anyone hone a dead-end skill that you won't be able to use for long? For whatever reason, the industry doesn't want old programmers. ..."
The author shares what he realized at a job recruitment fair seeking Java Legends, Python Badasses, Hadoop Heroes, "and other
gratingly childish classifications describing various programming specialities.
" I wasn't the only one bluffing my way through the tech scene. Everyone was doing it, even the much-sought-after engineering
talent.
I
was struck by how many developers were, like myself, not really programmers , but rather this, that and the other. A great
number of tech ninjas were not exactly black belts when it came to the actual onerous work of computer programming. So many of
the complex, discrete tasks involved in the creation of a website or an app had been automated that it was no longer necessary
to possess knowledge of software mechanics. The coder's work was rarely a craft. The apps ran on an assembly line, built with
"open-source", off-the-shelf components. The most important computer commands for the ninja to master were copy and paste...
[M]any programmers who had "made it" in Silicon Valley were scrambling to promote themselves from coder to "founder". There
wasn't necessarily more money to be had running a startup, and the increase in status was marginal unless one's startup attracted
major investment and the right kind of press coverage. It's because the programmers knew that their own ladder to prosperity was
on fire and disintegrating fast. They knew that well-paid programming jobs would also soon turn to smoke and ash, as the proliferation
of learn-to-code courses around the world lowered the market value of their skills, and as advances in artificial intelligence
allowed for computers to take over more of the mundane work of producing software. The programmers also knew that the fastest
way to win that promotion to founder was to find some new domain that hadn't yet been automated. Every tech industry campaign
designed to spur investment in the Next Big Thing -- at that time, it was the "sharing economy" -- concealed a larger programme
for the transformation of society, always in a direction that favoured the investor and executive classes.
"I wasn't just changing careers and jumping on the 'learn to code' bandwagon," he writes at one point. "I was being steadily
indoctrinated in a specious ideology."
> The people can do both are smart enough to build their own company and compete with you.
Been there, done that. Learned a few lessons. Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other
"smart person" put in 75 hours a week dealing with hiring, managing people, corporate strategy, staying up on the competition,
figuring out tax changes each year and getting taxes filed six times each year, the various state and local requirements, legal
changes, contract hassles, etc, while hoping the company makes money this month so they can take a paycheck and lay their rent.
I learned that I'm good at creating software systems and I enjoy it. I don't enjoy all-nighters, partners being dickheads trying
to pull out of a contract, or any of a thousand other things related to running a start-up business. I really enjoy a consistent,
six-figure compensation package too.
I pay monthly gross receipts tax (12), quarterly withholdings (4) and a corporate (1) and individual (1) returns. The gross
receipts can vary based on the state, so I can see how six times a year would be the minimum.
Nowadays I work 9:30-4:30 for a very good, consistent paycheck and let some other "smart person" put in 75 hours a week
dealing with hiring
There's nothing wrong with not wnting to run your own business, it's not for most people, and even if it was, the numbers don't
add up. But putting the scare qoutes in like that makes it sound like you have huge chip on your shoulder. Those things re just
as essential to the business as your work and without them you wouldn't have the steady 9:30-4:30 with good paycheck.
Of course they are important. I wouldn't have done those things if they weren't important!
I frequently have friends say things like "I love baking. I can't get enough of baking. I'm going to open a bakery.". I ask
them "do you love dealing with taxes, every month? Do you love contract law? Employment law? Marketing? Accounting?" If you LOVE
baking, the smart thing to do is to spend your time baking. Running a start-up business, you're not going to do much baking.
I can tell you a few things that have worked for me. I'll go in chronological order rather than priority order.
Make friends in the industry you want to be in. Referrals are a major way people get jobs.
Look at the job listings for jobs you'd like to have and see which skills a lot of companies want, but you're missing. For
me that's Java. A lot companies list Java skills and I'm not particularly good with Java. Then consider learning the skills you
lack, the ones a lot of job postings are looking for.
You don't understand the point of an ORM do you? I'd suggest reading why they exist
They exist because programmers value code design more than data design. ORMs are the poster-child for square-peg-round-hole
solutions, which is why all ORMs choose one of three different ways of squashing hierarchical data into a relational form, all
of which are crappy.
If the devs of the system (the ones choosing to use an ORM) had any competence at all they'd design their database first because
in any application that uses a database the database is the most important bit, not the OO-ness or Functional-ness of the design.
Over the last few decades I've seen programs in a system come and go; a component here gets rewritten, a component there gets
rewritten, but you know what? They all have to work with the same damn data.
You can more easily switch out your code for new code with new design in a new language, than you can switch change the database
structure. So explain to me why it is that you think the database should be mangled to fit your OO code rather than mangling your
OO code to fit the database?
Stick to the one thing for 10-15years. Often all this new shit doesn't do jack different to the old shit, its not faster, its
not better. Every dick wants to be famous so make another damn library/tool with his own fancy name and feature, instead
of enhancing an existing product.
Or kids who can't hack the main stuff, suddenly discover the cool new, and then they can pretend they're "learning" it, and
when the going gets tough (as it always does) they can declare the tech to be pants and move to another.
hence we had so many people on the bandwagon for functional programming, then dumped it for ruby on rails, then dumped that
for Node.js, not sure what they're on at currently, probably back to asp.net.
How much code do you have to reuse before you're not really programming anymore? When I started in this business, it was reasonably
possible that you could end up on a project that didn't particularly have much (or any) of an operating system. They taught you
assembly language and the process by which the system boots up, but I think if I were to ask most of the programmers where I work,
they wouldn't be able to explain how all that works...
It really feels like if you know what you're doing it should be possible to build a team of actually good programmers and
put everyone else out of business by actually meeting your deliverables, but no one has yet. I wonder why that is.
You mean Amazon, Google, Facebook and the like? People may not always like what they do, but they manage to get things done
and make plenty of money in the process. The problem for a lot of other businesses is not having a way to identify and promote
actually good programmers. In your example, you could've spent 10 minutes fixing their query and saved them days of headache,
but how much recognition will you actually get? Where is your motivation to help them?
It's not a "kids these days" sort of issue, it's *always* been the case that shameless, baseless self-promotion wins out
over sincere skill without the self-promotion, because the people who control the money generally understand boasting more than
they understand the technology. Yes it can happen that baseless boasts can be called out over time by a large enough mass
of feedback from competent peers, but it takes a *lot* to overcome the tendency for them to have faith in the boasts.
And all these modern coders forget old lessons, and make shit stuff, just look at instagram windows app, what a load of garbage
shit, that us old fuckers could code in 2-3 weeks.
Instagram - your app sucks, cookie cutter coders suck, no refinement, coolness. Just cheap ass shit, with limited usefulness.
Just like most of commercial software that's new - quick shit.
Oh and its obvious if your an Indian faking it, you haven't worked in 100 companies at the age of 29.
Here's another problem, if faced with a skilled team that says "this will take 6 months to do right" and a more naive team
that says "oh, we can slap that together in a month", management goes with the latter. Then the security compromises occur, then
the application fails due to pulling in an unvetted dependency update live into production. When the project grows to handling
thousands instead of dozens of users and it starts mysteriously folding over and the dev team is at a loss, well the choice has
be
These restrictions is a large part of what makes Arduino programming "fun". If you don't plan out your memory usage, you're
gonna run out of it. I cringe when I see 8MB web pages of bloated "throw in everything including the kitchen sink and the neighbor's
car". Unfortunately, the careful and cautious way is a dying in favor of the throw 3rd party code at it until it does something.
Of course, I don't have time to review it but I'm sure everybody else has peer reviewed it for flaws and exploits line by line.
Unfortunately, the careful and cautious way is a dying in favor of the throw 3rd party code at it until it does something.
Of course. What is the business case for making it efficient? Those massive frameworks are cached by the browser and run on
the client's system, so cost you nothing and save you time to market. Efficient costs money with no real benefit to the business.
If we want to fix this, we need to make bloat have an associated cost somehow.
My company is dealing with the result of this mentality right now. We released the web app to the customer without performance
testing and doing several majorly inefficient things to meet deadlines. Once real load was put on the application by users with
non-ideal hardware and browsers, the app was infuriatingly slow. Suddenly our standard sub-40 hour workweek became a 50+ hour
workweek for months while we fixed all the inefficient code and design issues.
So, while you're right that getting to market and opt
In the bad old days we had a hell of a lot of ridiculous restriction We must somehow made our programs to run successfully
inside a RAM that was 48KB in size (yes, 48KB, not 48MB or 48GB), on a CPU with a clock speed of 1.023 MHz
We still have them. In fact some of the systems I've programmed have been more resource limited than the gloriously spacious
32KiB memory of the BBC model B. Take the PIC12F or 10F series. A glorious 64 bytes of RAM, max clock speed of 16MHz, but not
unusual to run it 32kHz.
So what are the uses for that? I am curious what things people have put these to use for.
It's hard to determine because people don't advertise use of them at all. However, I know that my electric toothbrush uses
an Epson 4 bit MCU of some description. It's got a status LED, basic NiMH batteryb charger and a PWM controller for an H Bridge.
Braun sell a *lot* of electric toothbrushes. Any gadget that's smarter than a simple switch will probably have some sort of basic
MCU in it. Alarm system components, sensor
b) No computer ever ran at 1.023 MHz. It was either a nice multiple of 1Mhz or maybe a multiple of 3.579545Mhz (ie. using the
TV output circuit's color clock crystal to drive the CPU).
Well, it could be used to drive the TV output circuit, OR, it was used because it's a stupidly cheap high speed crystal. You
have to remember except for a few frequencies, most crystals would have to be specially cut for the desired frequency. This occurs
even today, where most oscillators are either 32.768kHz (real time clock
Yeah, nice talk. You could have stopped after the first sentence. The other AC is referring to the
Commodore C64 [wikipedia.org]. The frequency has nothing
to do with crystal availability but with the simple fact that everything in the C64 is synced to the TV. One clock cycle equals
8 pixels. The graphics chip and the CPU take turns accessing the RAM. The different frequencies dictated by the TV standards are
the reason why the CPU in the NTSC version of the C64 runs at 1.023MHz and the PAL version at 0.985MHz.
Commodore 64 for the win. I worked for a company that made detection devices for the railroad, things like monitoring axle
temperatures, reading the rail car ID tags. The original devices were made using Commodore 64 boards using software written by
an employee at the one rail road company working with them.
The company then hired some electrical engineers to design custom boards using the 68000 chips and I was hired as the only
programmer. Had to rewrite all of the code which was fine...
Many of these languages have an interactive interpreter. I know for a fact that Python does.
So, since job-fairs are an all day thing, and setup is already a thing for them -- set up a booth with like 4 computers at
it, and an admin station. The 4 terminals have an interactive session with the interpreter of choice. Every 20min or so, have
a challenge for "Solve this problem" (needs to be easy and already solved in general. Programmers hate being pimped without pay.
They don't mind tests of skill, but hate being pimped. Something like "sort this array, while picking out all the prime numbers"
or something.) and see who steps up. The ones that step up have confidence they can solve the problem, and you can quickly see
who can do the work and who can't.
The ones that solve it, and solve it to your satisfaction, you offer a nice gig to.
Then you get someone good at sorting arrays while picking out prime numbers, but potentially not much else.
The point of the test is not to identify the perfect candidate, but to filter out the clearly incompetent. If you can't sort
an array and write a function to identify a prime number, I certainly would not hire you. Passing the test doesn't get you a job,
but it may get you an interview ... where there will be other tests.
(I am not even a professional programmer, but I can totally perform such a trivially easy task. The example tests basic understanding
of loop construction, function construction, variable use, efficient sorting, and error correction-- especially with mixed type
arrays. All of these are things any programmer SHOULD now how to do, without being overly complicated, or clearly a disguised
occupational problem trying to get a free solution. Like I said, programmers hate being pimped, and will be turned off
Again, the quality applicant and the code monkey both have something the fakers do not-- Actual comprehension of what a program
is, and how to create one.
As Bill points out, this is not the final exam. This is the "Oh, I see you do actually know how to program-- show me more"
portion of the process. This is the part that HR drones are not capable of performing, due to Dunning-Krueger. Those that are
actually, REALLY competent will do more than just satisfy the requirements of the challenge, they will provide actually working
solutions to the challenge that properly validate their input, and return proper error states if the input is invalid, etc-- You
can learn a LOT about a potential hire by observing their work. *THAT* is what this is really about. The triviality of the problem
is a necessity, because you ***DON'T*** try to get free solutions out of people.
I realize that may be difficult for you to comprehend, but you *DON'T* do that. The job fair is to let people know that you
have a position available, and try to curry interest in people to apply. A successful pre-screening is confidence building, and
helps the potential hire to feel that your company is actually interested in actually hiring somebody, and not just fucking off
in the booth, to cover for "failing to find somebody" and then "Getting yet another H1B". It gives them a chance to show you what
they can do. That is what it is for, and what it does. It also excludes the fakers that this article is about-- The ones that
can talk a good talk, but could not program a simple boolean check condition if their life depended on it.
If it were not for the time constraints of a job fair (usually only 2 days, and in that time you need to try and pre-screen
as many as possible), I would suggest a tiered challenge, with progressively harder challenges, where you hand out resumes to
the ones that make it to the top 3 brackets, but that is not the way the world works.
This in my opinion is really a waste of time. Challenges like this have to be so simple they can be done walking up to a
booth are not likely to filter the "all talks" any better than a few interview questions could (imperson so the candidate can't
just google it).
Tougher more involved stuff isn't good either it gives a huge advantage to the full time job hunter, the guy or gal that
already has a 9-5 and a family that wants to seem them has not got time for games. We have been struggling with hiring where
I work ( I do a lot of the interviews ) and these are the conclusions we have reached
You would be surprised at the number of people with impeccable-looking resumes failing at something as simple as the
FizzBuzz test [codinghorror.com]
The only thing fuzzbuzz tests is "have you done fizzbuzz before"? It's a short question filled with every petty trick the author
could think ti throw in there. If you haven't seen the tricks they trip you up for no reason related to your actual coding skills.
Once you have seen them they're trivial and again unrelated to real work. Fizzbuzz is best passed by someone aiming to game the
interview system. It passes people gaming it and trips up people who spent their time doing on the job real work.
A good programmer first and foremost has a clean mind. Experience suggests puzzle geeks, who excel at contrived tests, are
usually sloppy thinkers.
No. Good programmers can trivially knock out any of these so-called lame monkey tests. It's lame code monkeys who can't do
it. And I've seen their work. Many night shifts and weekends I've burned trying to fix their shit because they couldn't actually
do any of the things behind what you call "lame monkey tests", like:
pulling expensive invariant calculations out of loops using for loops to scan a fucking table to pull rows or calculate an
aggregate when they could let the database do what it does best with a simple SQL statement systems crashing under actual load
because their shitty code was never stress tested ( but it worked on my dev box! .) again with databases, having to
redo their schemas because they were fattened up so much with columns like VALUE1, VALUE2, ... VALUE20 (normalize you assholes!) chatting remote APIs - because these code monkeys cannot think about the need
for bulk operations in increasingly distributed systems. storing dates in unsortable strings because the idiots do not know
most modern programming languages have a date data type.
Oh and the most important, off-by-one looping errors. I see this all the time, the type of thing a good programmer can spot
on quickly because he or she can do the so-called "lame monkey tests" that involve arrays and sorting.
I've seen the type: "I don't need to do this shit because I have business knowledge and I code for business and IT not google",
and then they go and code and fuck it up... and then the rest of us have to go clean up their shit at 1AM or on weekends.
If you work as an hourly paid contractor cleaning that crap, it can be quite lucrative. But sooner or later it truly sucks
the energy out of your soul.
So yeah, we need more lame monkey tests ... to filter the lame code monkeys.
Someone could Google the problem with the phone then step up and solve the challenge.
If given a spec, someone can consistently cobble together working code by Googling, then I would love to hire them. That is
the most productive way to get things done.
There is nothing wrong with using external references. When I am coding, I have three windows open: an editor, a testing window,
and a browser with a Stackoverflow tab open.
Yeah, when we do tech interviews, we ask questions that we are certain they won't be able to answer, but want to see how they
would think about the problem and what questions they ask to get more data and that they don't just fold up and say "well that's
not the sort of problem I'd be thinking of" The examples aren't made up or anything, they are generally selection of real problems
that were incredibly difficult that our company had faced before, that one may not think at first glance such a position would
than spending weeks interviewing "good" candidates for an opening, selecting a couple and hiring them as contractors, then
finding out they are less than unqualified to do the job they were hired for.
I've seen it a few times, Java "experts", Microsoft "experts" with years of experience on their resumes, but completely useless
in coding, deployment or anything other than buying stuff from the break room vending machines.
That being said, I've also seen projects costing hundreds of thousands of dollars, with y
I agree with this. I consider myself to be a good programmer and I would never go into contractor game. I also wonder, how
does it take you weeks to interview someone and you still can't figure out if the person can't code? I could probably see that
in 15 minutes in a pair coding session.
Also, Oracle, SAP, IBM... I would never buy from them, nor use their products. I have used plenty of IBM products and they
suck big time. They make software development 100 times harder than it could be. Their technical supp
That being said, I've also seen projects costing hundreds of thousands of dollars, with years of delays from companies like
Oracle, Sun, SAP, and many other "vendors"
Software development is a hard thing to do well, despite the general thinking of technology becoming cheaper over time, and
like health care the quality of the goods and services received can sometimes be difficult to ascertain. However, people who don't
respect developers and the problems we solve are very often the same ones who continually frustrate themselves by trying to cheap
out, hiring outsourced contractors, and then tearing their hair out when sub par results are delivered, if anything is even del
As part of your interview process, don't you have candidates code a solution to a problem on a whiteboard? I've interviewed
lots of "good" candidates (on paper) too, but they crashed and burned when challenged with a coding exercise. As a result, we
didn't make them job offers.
I'm not a great coder but good enough to get done what clients want done. If I'm not sure or don't think I can do it, I tell
them. I think they appreciate the honesty. I don't work in a tech-hub, startups or anything like that so I'm not under the same
expectations and pressures that others may be.
OK, so yes, I know plenty of programmers who do fake it. But stitching together components isn't "fake" programming.
Back in the day, we had to write our own code to loop through an XML file, looking for nuggets. Now, we just use an XML serializer.
Back then, we had to write our own routines to send TCP/IP messages back and forth. Now we just use a library.
I love it! I hated having to make my own bricks before I could build a house. Now, I can get down to the business of writing
the functionality I want, ins
But, I suspect you could write the component if you had to. That makes you a very different user of that component than someone
who just knows it as a magic black box.
Because of this, you understand the component better and have real knowledge of its strengths and limitations. People blindly
using components with only a cursory idea of their internal operation often cause major performance problems. They rarely recognize
when it is time to write their own to overcome a limitation (or even that it is possibl
You're right on all counts. A person who knows how the innards work, is better than someone who doesn't, all else being equal.
Still, today's world is so specialized that no one can possibly learn it all. I've never built a processor, as you have, but I
still have been able to build a DNA matching algorithm for a major DNA lab.
I would argue that anyone who can skillfully use off-the-shelf components can also learn how to build components, if they are
required to.
1, 'Back in the Day' there was no XML, XMl was not very long ago.
2, its a parser, a serialiser is pretty much the opposite (unless this weeks fashion has redefined that.. anything is possible).
3, 'Back then' we didnt have TCP stacks...
But, actually I agree with you. I can only assume the author thinks there are lots of fake plumbers because they dont cast
their own toilet bowels from raw clay, and use pre-build fittings and pipes! That car mechanics start from raw steel scrap and
a file.. And that you need
Yes, I agree with you on the "middle ground." My reaction was to the author's point that "not knowing how to build the components"
was the same as being a "fake programmer."
If I'm a plumber, and I don't know anything about the engineering behind the construction of PVC pipe, I can still be a good
plumber. If I'm an electrician, and I don't understand the role of a blast furnace in the making of the metal components, I can
still be a good electrician.
The analogy fits. If I'm a programmer, and I don't know how to make an LZW compression library, I can still be a good programmer.
It's a matter of layers. These days, we specialize. You've got your low-level programmers that make the components, the high level
programmers that put together the components, the graphics guys who do HTML/CSS, and the SQL programmers that just know about
databases. Every person has their specialty. It's no longer necessary to be a low-level programmer, or jack-of-all-trades, to
be "good."
If I don't know the layout of the IP header, I can still write quality networking software, and if I know XSLT, I can still
do cool stuff with XML, even if I don't know how to write a good parser.
LOL yeah I know it's all JSON now. I've been around long enough to see these fads come and go. Frankly, I don't see a whole
lot of advantage of JSON over XML. It's not even that much more compact, about 10% or so. But the point is that the author laments
the "bad old days" when you had to create all your own building blocks, and you didn't have a team of specialists. I for one don't
want to go back to those days!
The main advantage is that JSON is that it is consistent. XML has attributes, embedded optional stuff within tags. That was
derived from the original SGML ancestor where is was thought to be a convenience for the human authors who were supposed to be
making the mark-up manually. Programmatically it is a PITA.
I got shit for decrying XML back when it was the trendy thing. I've had people apologise to me months later because they've
realized I was right, even though at the time they did their best to fuck over my career because XML was the new big thing and
I wasn't fully on board.
XML has its strengths and its place, but fuck me it taught me how little some people really fucking understand shit.
And a rather small part at that, albeit a very visible and vocal one full of the proverbial prima donas. However, much of the
rest of the tech business, or at least the people working in it, are not like that. It's small groups of developers working in
other industries that would not typically be considered technology. There are software developers working for insurance companies,
banks, hedge funds, oil and gas exploration or extraction firms, national defense and many hundreds and thousands of other small
They knew that well-paid programming jobs would also soon turn to smoke and ash, as the proliferation of learn-to-code courses
around the world lowered the market value of their skills, and as advances in artificial intelligence allowed for computers
to take over more of the mundane work of producing software.
Kind of hard to take this article serious after saying gibberish like this. I would say most good programmers know that neither
learn-to-code courses nor AI are going to make a dent in their income any time soon.
There is a huge shortage of decent programmers. I have personally witnessed more than one phone "interview" that went like
"have you done this? what about this? do you know what this is? um, can you start Monday?" (120K-ish salary range)
Partly because there are way more people who got their stupid ideas funded than good coders willing to stain their resume with
that. partly because if you are funded, and cannot do all the required coding solo, here's your conundrum:
top level hackers can afford to be really picky, so on one hand it's hard to get them interested, and if you could get
that, they often want some ownership of the project. the plus side is that they are happy to work for lots of equity if they
have faith in the idea, but that can be a huge "if".
"good but not exceptional" senior engineers aren't usually going to be super happy, as they often have spouses and children
and mortgages, so they'd favor job security over exciting ideas and startup lottery.
that leaves you with fresh-out-of-college folks, which are really really a mixed bunch. some are actually already senior
level of understanding without the experience, some are absolutely useless, with varying degrees in between, and there's no
easy way to tell which is which early.
so the not-so-scrupulous folks realized what's going on, and launched multiple coding boot camps programmes, to essentially
trick both the students into believing they can become a coder in a month or two, and also the prospective employers that said
students are useful. so far it's been working, to a degree, in part because in such companies coding skill evaluation process
is broken. but one can only hide their lack of value add for so long, even if they do manage to bluff their way into a job.
All one had to do was look at the lousy state of software and web sites today to see this is true. It's quite obvious little
to no thought is given on how to make something work such that one doesn't have to jump through hoops.
I have many times said the most perfect word processing program ever developed was WordPefect 5.1 for DOS. Ones productivity
was astonishing. It just worked.
Now we have the bloated behemoth Word which does its utmost to get in the way of you doing your work. The only way to get it
to function is to turn large portions of its "features" off, and even then it still insists on doing something other than what
you told it to do.
Then we have the abomination of Windows 10, which is nothing but Clippy on 10X steroids. It is patently obvious the people
who program this steaming pile have never heard of simplicity. Who in their right mind would think having to "search" for something
is more efficient than going directly to it? I would ask the question if these people wander around stores "searching" for what
they're looking for, but then I realize that's how their entire life is run. They search for everything online rather than going
directly to the source. It's no wonder they complain about not having time to things. They're always searching.
Web sites are another area where these people have no clue what they're doing. Anything that might be useful is hidden behind
dropdown menus, flyouts, popup bubbles and intriately designed mazes of clicks needed to get to where you want to go. When someone
clicks on a line of products, they shouldn't be harassed about what part of the product line they want to look at. Give them the
information and let the user go where they want.
This rant could go on, but this article explains clearly why we have regressed when it comes to software and web design. Instead
of making things simple and easy to use, using the one or two brain cells they have, programmers and web designers let the software
do what it wants without considering, should it be done like this?
The tech industry has a ton of churn -- there's some technological advancement, but there's an awful lot of new products turned
out simply to keep customers buying new licenses and paying for upgrades.
This relentless and mostly phony newness means a lot of people have little experience with current products. People fake because
they have no choice. The good ones understand the general technologies and problems they're meant to solve and can generally get
up to speed quickly, while the bad ones are good at faking it but don't really know what they're doing. Telling the difference
from the outside is impossible.
Sales people make it worse, promoting people as "experts" in specific products or implementations because the people have experience
with a related product and "they're all the same". This burns out the people with good adaption skills.
From the summary, it sounds like a lot of programmers and software engineers are trying to develop the next big thing so that
they can literally beg for money from the elite class and one day, hopefully, become a member of the aforementioned. It's sad
how the middle class has been utterly decimated in the United States that some of us are willing to beg for scraps from the wealthy.
I used to work in IT but I've aged out and am now back in school to learn automotive technology so that I can do something other
than being a security guard. Currently, the only work I have been able to find has been in the unglamorous security field.
I am learning some really good new skills in the automotive program that I am in but I hate this one class called "Professionalism
in the Shop." I can summarize the entire class in one succinct phrase, "Learn how to appeal to, and communicate with, Mr. Doctor,
Mr. Lawyer, or Mr. Wealthy-man." Basically, the class says that we are supposed to kiss their ass so they keep coming back to
the Audi, BMW, Mercedes, Volvo, or Cadillac dealership. It feels a lot like begging for money on behalf of my employer (of which
very little of it I will see) and nothing like professionalism. Professionalism is doing the job right the first time, not jerking
the customer off. Professionalism is not begging for a 5 star review for a few measly extra bucks but doing absolute top quality
work. I guess the upshot is that this class will be the easiest 4.0 that I've ever seen.
There is something fundamentally wrong when the wealthy elite have basically demanded that we beg them for every little scrap.
I can understand the importance of polite and professional interaction but this prevalent expectation that we bend over backwards
for them crosses a line with me. I still suck it up because I have to but it chafes my ass to basically validate the wealthy man.
In 70's I worked with two people who had a natural talent for computer science algorithms .vs. coding syntax. In the 90's while at COLUMBIA I worked with only a couple of true computer scientists out of 30 students.
I've met 1 genius who programmed, spoke 13 languages, ex-CIA, wrote SWIFT and spoke fluent assembly complete with animated characters.
According to the Bluff Book, everyone else without natural talent fakes it. In the undiluted definition of computer science,
genetics roulette and intellectual d
Ah yes, the good old 80:20 rule, except it's recursive for programmers.
80% are shit, so you fire them. Soon you realize that 80% of the remaining 20% are also shit, so you fire them too. Eventually
you realize that 80% of the 4% remaining after sacking the 80% of the 20% are also shit, so you fire them!
...
The cycle repeats until there's just one programmer left: the person telling the joke.
---
tl;dr: All programmers suck. Just ask them to review their own code from more than 3 years ago: they'll tell you that
Who gives a fuck about lines? If someone gave me JavaScript, and someone gave me minified JavaScript, which one would I
want to maintain?
I donâ(TM)t care about your line savings, less isnâ(TM)t always better.
Because the world of programming is not centered about JavasScript and reduction of lines is not the same as minification.
If the first thing that came to your mind was about minified JavaScript when you saw this conversation, you are certainly not
the type of programmer I would want to inherit code from.
See, there's a lot of shit out there that is overtly redundant and unnecessarily complex. This is specially true when copy-n-paste
code monkeys are left to their own devices for whom code formatting seems
I have a theory that 10% of people are good at what they do. It doesn't really matter what they do, they will still be
good at it, because of their nature. These are the people who invent new things, who fix things that others didn't even see as
broken and who automate routine tasks or simply question and erase tasks that are not necessary. If you have a software team
that contain 5 of these, you can easily beat a team of 100 average people, not only in cost but also in schedule, quality and
features. In theory they are worth 20 times more than average employees, but in practise they are usually paid the same amount
of money with few exceptions.
80% of people are the average. They can follow instructions and they can get the work done, but they don't see that something
is broken and needs fixing if it works the way it has always worked. While it might seem so, these people are not worthless. There
are a lot of tasks that these people are happily doing which the 10% don't want to do. E.g. simple maintenance work, implementing
simple features, automating test cases etc. But if you let the top 10% lead the project, you most likely won't be needed that
much of these people. Most work done by these people is caused by themselves, by writing bad software due to lack of good leader.
10% are just causing damage. I'm not talking about terrorists and criminals. I have seen software developers who have tried
(their best?), but still end up causing just damage to the code that someone else needs to fix, costing much more than their own
wasted time. You really must use code reviews if you don't know your team members, to find these people early.
I have a lot of weaknesses. My people skills suck, I'm scrawny, I'm arrogant. I'm also generally known as a really good programmer
and people ask me how/why I'm so much better at my job than everyone else in the room. (There are a lot of things I'm not good
at, but I'm good at my job, so say everyone I've worked with.)
I think one major difference is that I'm always studying, intentionally working to improve, every day. I've been doing that
for twenty years.
I've worked with people who have "20 years of experience"; they've done the same job, in the same way, for 20 years. Their
first month on the job they read the first half of "Databases for Dummies" and that's what they've been doing for 20 years. They
never read the second half, and use Oracle database 18.0 exactly the same way they used Oracle Database 2.0 - and it was wrong
20 years ago too. So it's not just experience, it's 20 years of learning, getting better, every day. That's 7,305 days of improvement.
I have a lot of weaknesses. My people skills suck, I'm scrawny, I'm arrogant. I'm also generally known as a really good
programmer and people ask me how/why I'm so much better at my job than everyone else in the room. (There are a lot of things
I'm not good at, but I'm good at my job, so say everyone I've worked with.)
I think one major difference is that I'm always studying, intentionally working to improve, every day. I've been doing that
for twenty years.
I've worked with people who have "20 years of experience"; they've done the same job, in the same way, for 20 years. Their
first month on the job they read the first half of "Databases for Dummies" and that's what they've been doing for 20 years.
They never read the second half, and use Oracle database 18.0 exactly the same way they used Oracle Database 2.0 - and it was
wrong 20 years ago too. So it's not just experience, it's 20 years of learning, getting better, every day. That's 7,305 days
of improvement.
If you take this attitude towards other people, people will not ask your for help. At the same time, you'll be also be not
able to ask for their help.
You're not interviewing your peers. They are already in your team. You should be working together.
I've seen superstar programmers suck the life out of project by over-complicating things and not working together with others.
10% are just causing damage. I'm not talking about terrorists and criminals.
Terrorists and criminals have nothing on those guys. I know guy who is one of those. Worse, he's both motivated and enthusiastic.
He also likes to offer help and advice to other people who don't know the systems well.
"I divide my officers into four groups. There are clever, diligent, stupid, and lazy officers. Usually two characteristics
are combined. Some are clever and diligent -- their place is the General Staff. The next lot are stupid and lazy -- they make
up 90 percent of every army and are suited to routine duties. Anyone who is both clever and lazy is qualified for the highest
leadership duties, because he possesses the intellectual clarity and the composure necessary for difficult decisions. One must
beware of anyone who is stupid and diligent -- he must not be entrusted with any responsibility because he will always cause only
mischief."
It's called the Pareto Distribution [wikipedia.org].
The number of competent people (people doing most of the work) in any given organization goes like the square root of the number
of employees.
Matches my observations. 10-15% are smart, can think independently, can verify claims by others and can identify and use rules
in whatever they do. They are not fooled by things "everybody knows" and see standard-approaches as first approximations that,
of course, need to be verified to work. They do not trust anything blindly, but can identify whether something actually work well
and build up a toolbox of such things.
The problem is that in coding, you do not have a "(mass) production step", and that is the
In basic concept I agree with your theory, it fits my own anecdotal experience well, but I find that your numbers are off.
The top bracket is actually closer to 20%. The reason it seems so low is that a large portion of the highly competent people are
running one programmer shows, so they have no co-workers to appreciate their knowledge and skill. The places they work do a very
good job of keeping them well paid and happy (assuming they don't own the company outright), so they rarely if ever switch jobs.
at least 70, probably 80, maybe even 90 percent of professional programmers should just fuck off and do something else as they
are useless at programming.
Programming is statistically a dead-end job. Why should anyone hone a dead-end skill that you won't be able to use for
long? For whatever reason, the industry doesn't want old programmers.
Otherwise, I'd suggest longer training and education before they enter the industry. But that just narrows an already narrow
window of use.
Well, it does rather depend on which industry you work in - i've managed to find interesting programming jobs for 25 years,
and there's no end in sight for interesting projects and new avenues to explore. However, this isn't for everyone, and if you
have good personal skills then moving from programming into some technical management role is a very worthwhile route, and I know
plenty of people who have found very interesting work in that direction.
I think that is a misinterpretation of the facts. Old(er) coders that are incompetent are just much more obvious and usually
are also limited to technologies that have gotten old as well. Hence the 90% old coders that can actually not hack it and never
really could get sacked at some time and cannot find a new job with their limited and outdated skills. The 10% that are good at
it do not need to worry though. Who worries there is their employers when these people approach retirement age.
My experience as an IT Security Consultant (I also do some coding, but only at full rates) confirms that. Most are basically
helpless and many have negative productivity, because people with a clue need to clean up after them. "Learn to code"? We have
far too many coders already.
You can't bluff you way through writing software, but many, many people have bluffed their way into a job and then tried to
learn it from the people who are already there. In a marginally functional organization those incompetents are let go pretty quickly,
but sometimes they stick around for months or years.
Apparently the author of this book is one of those, probably hired and fired several times before deciding to go back to his
liberal arts roots and write a book.
I think you can and this is by far not the first piece describing that. Here is a classic:
https://blog.codinghorror.com/... [codinghorror.com]
Yet these people somehow manage to actually have "experience" because they worked in a role they are completely unqualified to
fill.
Fiddling with JavaScript libraries to get a fancy dancy interface that makes PHB's happy is a sought-after skill, for good
or bad. Now that we rely more on half-ass libraries, much of "programming" is fiddling with dark-grey boxes until they work
good enough.
This drives me crazy, but I'm consoled somewhat by the fact that it will all be thrown out in five years anyway.
This aritcle is two years old and not much happned during those two years. But still there is a chance that highly authomated factories
can make manufacturing in the USA again profitable. the problme is that they will be even more profible in East Asia;-)
The rise of technologies such as 3-D printing and advanced robotics means that the next few decades for Asia's economies will
not be as easy or promising as the previous five.
OWEN HARRIES, the first editor, together with Robert Tucker, of The National Interest, once reminded me that experts-economists,
strategists, business leaders and academics alike-tend to be relentless followers of intellectual fashion, and the learned, as Harold
Rosenberg famously put it, a "herd of independent minds." Nowhere is this observation more apparent than in the prediction that we
are already into the second decade of what will inevitably be an "Asian Century"-a widely held but rarely examined view that Asia's
continued economic rise will decisively shift global power from the Atlantic to the western Pacific Ocean.
No doubt the numbers appear quite compelling. In 1960, East Asia accounted for a mere 14 percent of global GDP; today that figure
is about 27 percent. If linear trends continue, the region could account for about 36 percent of global GDP by 2030 and over half
of all output by the middle of the century. As if symbolic of a handover of economic preeminence, China, which only accounted for
about 5 percent of global GDP in 1960, will likely surpass the United States as the largest economy in the world over the next decade.
If past record is an indicator of future performance, then the "Asian Century" prediction is close to a sure thing.
Providing a great GUI for complex routers or Linux admin is hard. Of course there has to be a CLI, that's how pros get the job
done. But a great GUI is one that teaches a new user to eventually graduate to using CLI.
Notable quotes:
"... Providing a great GUI for complex routers or Linux admin is hard. Of course there has to be a CLI, that's how pros get the job done. But a great GUI is one that teaches a new user to eventually graduate to using CLI. ..."
"... What would be nice is if the GUI could automatically create a shell script doing the change. That way you could (a) learn about how to do it per CLI by looking at the generated shell script, and (b) apply the generated shell script (after proper inspection, of course) to other computers. ..."
"... AIX's SMIT did this, or rather it wrote the commands that it executed to achieve what you asked it to do. This meant that you could learn: look at what it did and find out about which CLI commands to run. You could also take them, build them into a script, copy elsewhere, ... I liked SMIT. ..."
"... Cisco's GUI stuff doesn't really generate any scripts, but the commands it creates are the same things you'd type into a CLI. And the resulting configuration is just as human-readable (barring any weird naming conventions) as one built using the CLI. I've actually learned an awful lot about the Cisco CLI by using their GUI. ..."
"... Microsoft's more recent tools are also doing this. Exchange 2007 and newer, for example, are really completely driven by the PowerShell CLI. The GUI generates commands and just feeds them into PowerShell for you. So you can again issue your commands through the GUI, and learn how you could have done it in PowerShell instead. ..."
"... Moreover, the GUI authors seem to have a penchant to find new names for existing CLI concepts. Even worse, those names are usually inappropriate vagueries quickly cobbled together in an off-the-cuff afterthought, and do not actually tell you where the doodad resides in the menu system. With a CLI, the name of the command or feature set is its location. ..."
"... I have a cheap router with only a web gui. I wrote a two line bash script that simply POSTs the right requests to URL. Simply put, HTTP interfaces, especially if they implement the right response codes, are actually very nice to script. ..."
Deep End's Paul Venezia speaks out against the
overemphasis on GUIs in today's admin tools,
saying that GUIs are fine and necessary in many cases, but only after a complete CLI is in place, and that they cannot interfere
with the use of the CLI, only complement it. Otherwise, the GUI simply makes easy things easy and hard things much harder. He writes,
'If you have to make significant, identical changes to a bunch of Linux servers, is it easier to log into them one-by-one and run
through a GUI or text-menu tool, or write a quick shell script that hits each box and either makes the changes or simply pulls down
a few new config files and restarts some services? And it's not just about conservation of effort - it's also about accuracy. If
you write a script, you're certain that the changes made will be identical on each box. If you're doing them all by hand, you aren't.'"
Providing a great GUI for complex routers or Linux admin is hard. Of course there has to be a CLI, that's how pros get
the job done. But a great GUI is one that teaches a new user to eventually graduate to using CLI.
A bad GUI with no CLI is the worst of both worlds, the author of the article got that right. The 80/20 rule applies: 80% of
the work is common to everyone, and should be offered with a GUI. And the 20% that is custom to each sysadmin, well use the CLI.
maxwell demon:
What would be nice is if the GUI could automatically create a shell script doing the change. That way you could (a) learn
about how to do it per CLI by looking at the generated shell script, and (b) apply the generated shell script (after proper inspection,
of course) to other computers.
0123456 (636235) writes:
What would be nice is if the GUI could automatically create a shell script doing the change.
While it's not quite the same thing, our GUI-based home router has an option to download the config as a text file so you can
automatically reconfigure it from that file if it has to be reset to defaults. You could presumably use sed to change IP addresses,
etc, and copy it to a different router. Of course it runs Linux.
Alain Williams:
AIX's SMIT did this, or rather it wrote the commands that it executed to achieve what you asked it to do. This meant that
you could learn: look at what it did and find out about which CLI commands to run. You could also take them, build them into a
script, copy elsewhere, ... I liked SMIT.
Ephemeriis:
What would be nice is if the GUI could automatically create a shell script doing the change. That way you could (a) learn
about how to do it per CLI by looking at the generated shell script, and (b) apply the generated shell script (after proper inspection,
of course) to other computers.
Cisco's GUI stuff doesn't really generate any scripts, but the commands it creates are the same things you'd type into
a CLI. And the resulting configuration is just as human-readable (barring any weird naming conventions) as one built using the
CLI. I've actually learned an awful lot about the Cisco CLI by using their GUI.
We've just started working with Aruba hardware. Installed a mobility controller last week. They've got a GUI that does something
similar. It's all a pretty web-based front-end, but it again generates CLI commands and a human-readable configuration. I'm still
very new to the platform, but I'm already learning about their CLI through the GUI. And getting work done that I wouldn't be able
to if I had to look up the CLI commands for everything.
Microsoft's more recent tools are also doing this. Exchange 2007 and newer, for example, are really completely driven by
the PowerShell CLI. The GUI generates commands and just feeds them into PowerShell for you. So you can again issue your commands
through the GUI, and learn how you could have done it in PowerShell instead.
Anpheus:
Just about every Microsoft tool newer than 2007 does this. Virtual machine manager, SQL Server has done it for ages, I think
almost all the system center tools do, etc.
It's a huge improvement.
PoV:
All good admins document their work (don't they? DON'T THEY?). With a CLI or a script that's easy: it comes down to "log in
as user X, change to directory Y, run script Z with arguments A B and C - the output should look like D". Try that when all you
have is a GLUI (like a GUI, but you get stuck): open this window, select that option, drag a slider, check these boxes, click
Yes, three times. The output might look a little like this blurry screen shot and the only record of a successful execution is
a window that disappears as soon as the application ends.
I suppose the Linux community should be grateful that windows made the fundemental systems design error of making everything
graphic. Without that basic failure, Linux might never have even got the toe-hold it has now.
skids:
I think this is a stronger point than the OP: GUIs do not lead to good documentation. In fact, GUIs pretty much are limited
to procedural documentation like the example you gave.
The best they can do as far as actual documentation, where the precise effect of all the widgets is explained, is a screenshot
with little quote bubbles pointing to each doodad. That's a ridiculous way to document.
This is as opposed to a command reference which can organize, usually in a pretty sensible fashion, exact descriptions of what
each command does.
Moreover, the GUI authors seem to have a penchant to find new names for existing CLI concepts. Even worse, those names
are usually inappropriate vagueries quickly cobbled together in an off-the-cuff afterthought, and do not actually tell you where
the doodad resides in the menu system. With a CLI, the name of the command or feature set is its location.
Not that even good command references are mandatory by today's pathetic standards. Even the big boys like Cisco have shown
major degradation in the quality of their documentation during the last decade.
pedantic bore:
I think the author might not fully understand who most admins are. They're people who couldn't write a shell script if their
lives depended on it, because they've never had to. GUI-dependent users become GUI-dependent admins.
As a percentage of computer users, people who can actually navigate a CLI are an ever-diminishing group.
/etc/init.d/NetworkManager stop
chkconfig NetworkManager off
chkconfig network on
vi/etc/sysconfig/network
vi/etc/sysconfig/network-scripts/eth0
At least they named it NetworkManager, so experienced admins could recognize it as a culprit. Anything named in CamelCase is
almost invariably written by new school programmers who don't grok the Unix toolbox concept and write applications instead of
tools, and the bloated drivel is usually best avoided.
Darkness404 (1287218) writes: on Monday October 04, @07:21PM (#33789446)
There are more and more small businesses (5, 10 or so employees) realizing that they can get things done easier if they had
a server. Because the business can't really afford to hire a sysadmin or a full-time tech person, its generally the employee who
"knows computers" (you know, the person who has to help the boss check his e-mail every day, etc.) and since they don't have the
knowledge of a skilled *Nix admin, a GUI makes their administration a lot easier.
So with the increasing use of servers among non-admins, it only makes sense for a growth in GUI-based solutions.
Svartalf (2997) writes: Ah... But the thing is... You don't NEED the GUI with recent Linux systems- you do with Windows.
oatworm (969674) writes: on Monday October 04, @07:38PM (#33789624) Homepage
Bingo. Realistically, if you're a company with less than a 100 employees (read: most companies), you're only going to have
a handful of servers in house and they're each going to be dedicated to particular roles. You're not going to have 100 clustered
fileservers - instead, you're going to have one or maybe two. You're not going to have a dozen e-mail servers - instead, you're
going to have one or two. Consequently, the office admin's focus isn't going to be scalability; it just won't matter to the admin
if they can script, say, creating a mailbox for 100 new users instead of just one. Instead, said office admin is going to be more
focused on finding ways to do semi-unusual things (e.g. "create a VPN between this office and our new branch office", "promote
this new server as a domain controller", "install SQL", etc.) that they might do, oh, once a year.
The trouble with Linux, and I'm speaking as someone who's used YaST in precisely this context, is that you have to make a choice
- do you let the GUI manage it or do you CLI it? If you try to do both, there will be inconsistencies because the grammar of the
config files is too ambiguous; consequently, the GUI config file parser will probably just overwrite whatever manual changes it
thinks is "invalid", whether it really is or not. If you let the GUI manage it, you better hope the GUI has the flexibility necessary
to meet your needs. If, for example, YaST doesn't understand named Apache virtual hosts, well, good luck figuring out where it's
hiding all of the various config files that it was sensibly spreading out in multiple locations for you, and don't you dare use
YaST to manage Apache again or it'll delete your Apache-legal but YaST-"invalid" directive.
The only solution I really see is for manual config file support with optional XML (or some other machine-friendly but still
human-readable format) linkages. For example, if you want to hand-edit your resolv.conf, that's fine, but if the GUI is going
to take over, it'll toss a directive on line 1 that says "#import resolv.conf.xml" and immediately overrides (but does not overwrite)
everything following that. Then, if you still want to use the GUI but need to hand-edit something, you can edit the XML file using
the appropriate syntax and know that your change will be reflected on the GUI.
That's my take. Your mileage, of course, may vary.
icebraining (1313345) writes: on Monday October 04, @07:24PM (#33789494) Homepage
I have a cheap router with only a web gui. I wrote a two line bash script that simply POSTs the right requests to URL.
Simply put, HTTP interfaces, especially if they implement the right response codes, are actually very nice to script.
devent (1627873) writes:
Why Windows servers have a GUI is beyond me anyway. The servers are running 99,99% of the time without a monitor and normally
you just login per ssh to a console if you need to administer them. But they are consuming the extra RAM, the extra CPU cycles
and the extra security threats. I don't now, but can you de-install the GUI from a Windows server? Or better, do you have an option
for no-GUI installation? Just saw the minimum hardware requirements. 512 MB RAM and 32 GB or greater disk space. My server runs
sirsnork (530512) writes: on Monday October 04, @07:43PM (#33789672)
it's called a "core" install in Server 2008 and up, and if you do that, there is no going back, you can't ever add the GUI
back.
What this means is you can run a small subset of MS services that don't need GUI interaction. With R2 that subset grew somwhat
as they added the ability to install .Net too, which mean't you could run IIS in a useful manner (arguably the strongest reason
to want to do this in the first place).
Still it's a one way trip and you better be damn sure what services need to run on that box for the lifetime of that box or
you're looking at a reinstall. Most windows admins will still tell you the risk isn't worth it.
Simple things like network configuration without a GUI in windows is tedious, and, at least last time i looked, you lost the
ability to trunk network poers because the NIC manufactuers all assumed you had a GUI to configure your NICs
prichardson (603676) writes: on Monday October 04, @07:27PM (#33789520) Journal
This is also a problem with Max OS X Server. Apple builds their services from open source products and adds a GUI for configuration
to make it all clickable and easy to set up. However, many options that can be set on the command line can't be set in the GUI.
Even worse, making CLI changes to services can break the GUI entirely.
The hardware and software are both super stable and run really smoothly, so once everything gets set up, it's awesome. Still,
it's hard for a guy who would rather make changes on the CLI to get used to.
MrEricSir (398214) writes:
Just because you're used to a CLI doesn't make it better. Why would I want to read a bunch of documentation, mess with command
line options, then read whole block of text to see what it did? I'd much rather sit back in my chair, click something, and then
see if it worked. Don't make me read a bunch of man pages just to do a simple task. In essence, the question here is whether it's
okay for the user to be lazy and use a GUI, or whether the programmer should be too lazy to develop a GUI.
ak_hepcat (468765) writes: <[email protected] minus author> on Monday October 04, @07:38PM (#33789626) Homepage Journal
Probably because it's also about the ease of troubleshooting issues.
How do you troubleshoot something with a GUI after you've misconfigured? How do you troubleshoot a programming error (bug)
in the GUI -> device communication? How do you scale to tens, hundreds, or thousands of devices with a GUI?
CLI makes all this easier and more manageable.
arth1 (260657) writes:
Why would I want to read a bunch of documentation, mess with command line options, then read whole block of text to see what
it did? I'd much rather sit back in my chair, click something, and then see if it worked. Don't make me read a bunch of man pages
just to do a simple task. Because then you'll be stuck at doing simple tasks, and will never be able to do more advanced tasks.
Without hiring a team to write an app for you instead of doing it yourself in two minutes, that is. The time you spend reading
man
fandingo (1541045) writes: on Monday October 04, @07:54PM (#33789778)
I don't think you really understand systems administration. 'Users,' or in this case admins, don't typically do stuff once.
Furthermore, they need to know what he did and how to do it again (i.e. new server or whatever) or just remember what he did.
One-off stuff isn't common and is a sign of poor administration (i.e. tracking changes and following processes).
What I'm trying to get at is that admins shouldn't do anything without reading the manual. As a Windows/Linux admin, I tend
to find Linux easier to properly administer because I either already know how to perform an operation or I have to read the manual
(manpage) and learn a decent amount about the operation (i.e. more than click here/use this flag).
Don't get me wrong, GUIs can make unknown operations significantly easier, but they often lead to poor process management.
To document processes, screenshots are typically needed. They can be done well, but I find that GUI documentation (created by
admins, not vendor docs) tend to be of very low quality. They are also vulnerable to 'upgrades' where vendors change the interface
design. CLI programs typically have more stable interfaces, but maybe that's just because they have been around longer...
maotx (765127) writes: <[email protected]> on Monday October 04, @07:42PM (#33789666)
That's one thing Microsoft did right with Exchange 2007. They built it entirely around their new powershell CLI and then built
a GUI for it. The GUI is limited in compared to what you can do with the CLI, but you can get most things done. The CLI becomes
extremely handy for batch jobs and exporting statistics to csv files. I'd say it's really up there with BASH in terms of scripting,
data manipulation, and integration (not just Exchange but WMI, SQL, etc.)
They tried to do similar with Windows 2008 and their Core [petri.co.il] feature, but they still have to load a GUI to present
a prompt...Reply to This
Charles Dodgeson (248492) writes: <[email protected]> on Monday October 04, @08:51PM (#33790206) Homepage Journal
Probably Debian would have been OK, but I was finding admin of most Linux distros a pain for exactly these reasons.
I couldn't find a layer where I could do everything that I needed to do without worrying about one thing stepping on another.
No doubt there are ways that I could manage a Linux system without running into different layers of management tools stepping
on each other, but it was a struggle.
There were other reasons as well (although there is a lot that I miss about Linux), but I think that this was one of the leading
reasons.
(NB: I realize that this is flamebait (I've got karma to burn), but that isn't my intention here.)
As I write this column, I'm in the middle of two summer projects; with luck, they'll both be finished by the time you read it.
One involves a forensic analysis of over 100,000 lines of old C and assembly code from about 1990, and I have to work on Windows
XP.
The other is a hack to translate code written in weird language L1 into weird language L2 with a program written in scripting
language L3, where none of the L's even existed in 1990; this one uses Linux. Thus it's perhaps a bit surprising that I find myself
relying on much the same toolset for these very different tasks.
... ... ...
Here has surely been much progress in tools over the 25 years that IEEE Software has been around, and I wouldn't want to go back
in time.
But the tools I use today are mostly the same old ones-grep, diff, sort, awk, and friends. This might well mean that I'm a dinosaur
stuck in the past.
On the other hand, when it comes to doing simple things quickly, I can often have the job done while experts are still waiting
for their IDE to start up. Sometimes the old ways are best, and they're certainly worth knowing well
"... The conventional Simula 67-like pattern of class and instance will get you {1,3,7,9}, and I think many people take this as a definition of OO. ..."
"... Because OO is a moving target, OO zealots will choose some subset of this menu by whim and then use it to try to convince you that you are a loser. ..."
"... In such a pack-programming world, the language is a constitution or set of by-laws, and the interpreter/compiler/QA dept. acts in part as a rule checker/enforcer/police force. Co-programmers want to know: If I work with your code, will this help me or hurt me? Correctness is undecidable (and generally unenforceable), so managers go with whatever rule set (static type system, language restrictions, "lint" program, etc.) shows up at the door when the project starts. ..."
Here is an a la carte menu of features or properties that are related to these terms; I have heard OO defined to be many different
subsets of this list.
Encapsulation - the ability to syntactically hide the implementation of a type. E.g. in C or Pascal you always know
whether something is a struct or an array, but in CLU and Java you can hide the difference.
Protection - the inability of the client of a type to detect its implementation. This guarantees that a behavior-preserving
change to an implementation will not break its clients, and also makes sure that things like passwords don't leak out.
Ad hoc polymorphism - functions and data structures with parameters that can take on values of many different types.
Parametric polymorphism - functions and data structures that parameterize over arbitrary values (e.g. list of anything).
ML and Lisp both have this. Java doesn't quite because of its non-Object types.
Everything is an object - all values are objects. True in Smalltalk (?) but not in Java (because of int and friends).
All you can do is send a message (AYCDISAM) = Actors model - there is no direct manipulation of objects, only communication
with (or invocation of) them. The presence of fields in Java violates this.
Specification inheritance = subtyping - there are distinct types known to the language with the property that a value of
one type is as good as a value of another for the purposes of type correctness. (E.g. Java interface inheritance.)
Implementation inheritance/reuse - having written one pile of code, a similar pile (e.g. a superset) can be generated in
a controlled manner, i.e. the code doesn't have to be copied and edited. A limited and peculiar kind of abstraction. (E.g.
Java class inheritance.)
Sum-of-product-of-function pattern - objects are (in effect) restricted to be functions that take as first argument a distinguished
method key argument that is drawn from a finite set of simple names.
So OO is not a well defined concept. Some people (eg. Abelson and Sussman?) say Lisp is OO, by which they mean {3,4,5,7} (with
the proviso that all types are in the programmers' heads). Java is supposed to be OO because of {1,2,3,7,8,9}. E is supposed to be
more OO than Java because it has {1,2,3,4,5,7,9} and almost has 6; 8 (subclassing) is seen as antagonistic to E's goals and not necessary
for OO.
The conventional Simula 67-like pattern of class and instance will get you {1,3,7,9}, and I think many people take this as
a definition of OO.
Because OO is a moving target, OO zealots will choose some subset of this menu by whim and then use it to try to convince
you that you are a loser.
Perhaps part of the confusion - and you say this in a different way in your little
memo - is that the C/C++ folks see OO as a liberation from a world
that has nothing resembling a first-class functions, while Lisp folks see OO as a prison since it limits their use of functions/objects
to the style of (9.). In that case, the only way OO can be defended is in the same manner as any other game or discipline -- by arguing
that by giving something up (e.g. the freedom to throw eggs at your neighbor's house) you gain something that you want (assurance
that your neighbor won't put you in jail).
This is related to Lisp being oriented to the solitary hacker and discipline-imposing languages being oriented to social packs,
another point you mention. In a pack you want to restrict everyone else's freedom as much as possible to reduce their ability to
interfere with and take advantage of you, and the only way to do that is by either becoming chief (dangerous and unlikely) or by
submitting to the same rules that they do. If you submit to rules, you then want the rules to be liberal so that you have a chance
of doing most of what you want to do, but not so liberal that others nail you.
In such a pack-programming world, the language is a constitution or set of by-laws, and the interpreter/compiler/QA dept.
acts in part as a rule checker/enforcer/police force. Co-programmers want to know: If I work with your code, will this help me or
hurt me? Correctness is undecidable (and generally unenforceable), so managers go with whatever rule set (static type system, language
restrictions, "lint" program, etc.) shows up at the door when the project starts.
I recently contributed to a discussion of anti-OO on the e-lang list. My main anti-OO message (actually it only attacks points
5/6) was http://www.eros-os.org/pipermail/e-lang/2001-October/005852.html
. The followups are interesting but I don't think they're all threaded properly.
(Here are the pet definitions of terms used above:
Value = something that can be passed to some function (abstraction). (I exclude exotic compile-time things like parameters
to macros and to parameterized types and modules.)
Object = a value that has function-like behavior, i.e. you can invoke a method on it or call it or send it a message
or something like that. Some people define object more strictly along the lines of 9. above, while others (e.g. CLTL) are more
liberal. This is what makes "everything is an object" a vacuous statement in the absence of clear definitions.
In some languages the "call" is curried and the key-to-method mapping can sometimes be done at compile time. This technicality
can cloud discussions of OO in C++ and related languages.
Function = something that can be combined with particular parameter(s) to produce some result. Might or might not be
the same as object depending on the language.
Type = a description of the space of values over which a function is meaningfully parameterized. I include both types
known to the language and types that exist in the programmer's mind or in documentation
As I write this column, I'm in the middle of two summer projects; with luck, they'll both be finished by the time you read it.
One involves a forensic analysis of over 100,000 lines of old C and assembly code from about 1990, and I have to work on Windows
XP.
The other is a hack to translate code written in weird language L1 into weird language L2 with a program written in scripting
language L3, where none of the L's even existed in 1990; this one uses Linux. Thus it's perhaps a bit surprising that I find myself
relying on much the same toolset for these very different tasks.
... ... ...
Here has surely been much progress in tools over the 25 years that IEEE Software has been around, and I wouldn't want to go back
in time.
But the tools I use today are mostly the same old ones-grep, diff, sort, awk, and friends. This might well mean that I'm a dinosaur
stuck in the past.
On the other hand, when it comes to doing simple things quickly, I can often have the job done while experts are still waiting
for their IDE to start up. Sometimes the old ways are best, and they're certainly worth knowing well
"... If there's something I've noticed in my career that is that there are always some guys that desperately want to look "smart" and they reflect that in their code. ..."
If there's something I've noticed in my career that is that there are always some guys that desperately want to look "smart"
and they reflect that in their code.
If there's something else that I've noticed in my career, it's that their code is the hardest to maintain and for some reason
they want the rest of the team to depend on them since they are the only "enough smart" to understand that code and change it.
No need to say that these guys are not part of my team. Your code should be direct, simple and readable. End of story.
"... If there's something I've noticed in my career that is that there are always some guys that desperately want to look "smart"
and they reflect that in their code. ..."
If there's something I've noticed in my career that is that there are always some guys that desperately want to look "smart"
and they reflect that in their code.
If there's something else that I've noticed in my career, it's that their code is the hardest to maintain and for some reason
they want the rest of the team to depend on them since they are the only "enough smart" to understand that code and change it.
No need to say that these guys are not part of my team. Your code should be direct, simple and readable. End of story.
"... "In many ways the effect of the crash on embezzlement was more significant than on suicide. To the economist embezzlement is
the most interesting of crimes. Alone among the various forms of larceny it has a time parameter. Weeks, months or years may elapse
between the commission of the crime and its discovery. (This is a period, incidentally, when the embezzler has his gain and the man
who has been embezzled, oddly enough, feels no loss. There is a net increase in psychic wealth.) ..."
"... At any given time there exists an inventory of undiscovered embezzlement in or more precisely not in the country's business
and banks. ..."
"... This inventory it should perhaps be called the bezzle amounts at any moment to many millions [trillions!] of dollars. It
also varies in size with the business cycle. ..."
"... In good times people are relaxed, trusting, and money is plentiful. But even though money is plentiful, there are always many
people who need more. Under these circumstances the rate of embezzlement grows, the rate of discovery falls off, and the bezzle increases
rapidly. ..."
"... In depression all this is reversed. Money is watched with a narrow, suspicious eye. The man who handles it is assumed to be
dishonest until he proves himself otherwise. Audits are penetrating and meticulous. Commercial morality is enormously improved. The
bezzle shrinks ..."
John Kenneth Galbraith, from "The Great Crash 1929":
"In many ways the effect of the crash on embezzlement was more significant than on suicide. To the economist embezzlement
is the most interesting of crimes. Alone among the various forms of larceny it has a time parameter. Weeks, months or years
may elapse between the commission of the crime and its discovery. (This is a period, incidentally, when the embezzler has his
gain and the man who has been embezzled, oddly enough, feels no loss. There is a net increase in psychic wealth.)
At any given time there exists an inventory of undiscovered embezzlement in or more precisely not in the country's
business and banks.
This inventory it should perhaps be called the bezzle amounts at any moment to many millions [trillions!] of dollars.
It also varies in size with the business cycle.
In good times people are relaxed, trusting, and money is plentiful. But even though money is plentiful, there are always
many people who need more. Under these circumstances the rate of embezzlement grows, the rate of discovery falls off, and the
bezzle increases rapidly.
In depression all this is reversed. Money is watched with a narrow, suspicious eye. The man who handles it is assumed
to be dishonest until he proves himself otherwise. Audits are penetrating and meticulous. Commercial morality is enormously
improved. The bezzle shrinks."
For nearly a half a century, from 1947 to 1996, real GDP and real Net Worth of Households and Non-profit Organizations (in
2009 dollars) both increased at a compound annual rate of a bit over 3.5%. GDP growth, in fact, was just a smidgen faster -- 0.016%
-- than growth of Net Household Worth.
From 1996 to 2015, GDP grew at a compound annual rate of 2.3% while Net Worth increased at the rate of 3.6%....
The real home price index extends from 1890. From 1890 to 1996, the index increased slightly faster than inflation so that
the index was 100 in 1890 and 113 in 1996. However from 1996 the index advanced to levels far beyond any previously experienced,
reaching a high above 194 in 2006. Previously the index high had been just above 130.
Though the index fell from 2006, the level in 2016 is above 161, a level only reached when the housing bubble had formed in
late 2003-early 2004.
The Shiller 10-year price-earnings ratio is currently 29.34, so the inverse or the earnings rate is 3.41%. The dividend yield
is 1.93. So an expected yearly return over the coming 10 years would be 3.41 + 1.93 or 5.34% provided the price-earnings ratio
stays the same and before investment costs.
Against the 5.34% yearly expected return on stock over the coming 10 years, the current 10-year Treasury bond yield is 2.32%.
The risk premium for stocks is 5.34 - 2.32 or 3.02%:
What the robot-productivity paradox is puzzles me, other than since 2005 for all the focus on the productivity of robots and
on robots replacing labor there has been a dramatic, broad-spread slowing in productivity growth.
However what the changing relationship between the growth of GDP and net worth since 1996 show, is that asset valuations have
been increasing relative to GDP. Valuations of stocks and homes are at sustained levels that are higher than at any time in the
last 120 years. Bear markets in stocks and home prices have still left asset valuations at historically high levels. I have no
idea why this should be.
The paradox is that productivity statistics can't tell us anything about the effects of robots on employment because both the
numerator and the denominator are distorted by the effects of colossal Ponzi bubbles.
John Kenneth Galbraith used to call it "the bezzle." It is "that increment to wealth that occurs during the magic interval
when a confidence trickster knows he has the money he has appropriated but the victim does not yet understand that he has lost
it." The current size of the gross national bezzle (GNB) is approximately $24 trillion.
Ponzilocks and the Twenty-Four Trillion Dollar Question
Twenty-three and a half trillion, actually. But what's a few hundred billion? Here today, gone tomorrow, as they say.
At the beginning of 2007, net worth of households and non-profit organizations exceeded its 1947-1996 historical average, relative
to GDP, by some $16 trillion. It took 24 months to wipe out eighty percent, or $13 trillion, of that colossal but ephemeral slush
fund. In mid-2016, net worth stood at a multiple of 4.83 times GDP, compared with the multiple of 4.72 on the eve of the Great
Unworthing.
When I look at the ragged end of the chart I posted yesterday, it screams "Ponzi!" "Ponzi!" "Ponz..."
To make a long story short, let's think of wealth as capital. The value of capital is determined by the present value of an
expected future income stream. The value of capital fluctuates with changing expectations but when the nominal value of capital
diverges persistently and significantly from net revenues, something's got to give. Either economic growth is going to suddenly
gush forth "like nobody has ever seen before" or net worth is going to have to come back down to earth.
Somewhere between 20 and 30 TRILLION dollars of net worth will evaporate within the span of perhaps two years.
When will that happen? Who knows? There is one notable regularity in the data, though -- the one that screams "Ponzi!"
When the net worth bubble stops going up...
...it goes down.
"... But the economy does not feel like one undergoing a technology-driven productivity boom. In the late 1990s, tech optimism was everywhere. At the same time, wages and productivity were rocketing upward. The situation now is completely different. The most recent jobs reports in America and Britain tell the tale. Employment is growing, month after month after month. But wage growth is abysmal. So is productivity growth: not surprising in economies where there are lots of people on the job working for low pay. ..."
"... Increasing labour costs by making the minimum wage a living wage would increase the incentives to boost productivity growth? No, the neoliberals and corporate Democrats would never go for it. They're trying to appeal to the business community and their campaign contributors wouldn't like it. ..."
People are worried about robots taking jobs. Driverless cars are around the corner. Restaurants and shops increasingly carry the
option to order by touchscreen. Google's clever algorithms provide instant translations that are remarkably good.
But the economy does not feel like one undergoing a technology-driven productivity boom. In the late 1990s, tech optimism
was everywhere. At the same time, wages and productivity were rocketing upward. The situation now is completely different. The most
recent jobs reports in America and Britain tell the tale. Employment is growing, month after month after month. But wage growth is
abysmal. So is productivity growth: not surprising in economies where there are lots of people on the job working for low pay.
The obvious conclusion, the one lots of people are drawing, is that the robot threat is totally overblown: the fantasy, perhaps,
of a bubble-mad Silicon Valley - or an effort to distract from workers' real problems, trade and excessive corporate power. Generally
speaking, the problem is not that we've got too much amazing new technology but too little.
This is not a strawman of my own invention. Robert Gordon makes this case. You can see Matt Yglesias make it here. Duncan Weldon,
for his part, writes:
We are debating a problem we don't have, rather than facing a real crisis that is the polar opposite. Productivity growth has
slowed to a crawl over the last 15 or so years, business investment has fallen and wage growth has been weak. If the robot revolution
truly was under way, we would see surging capital expenditure and soaring productivity. Right now, that would be a nice "problem"
to have. Instead we have the reality of weak growth and stagnant pay. The real and pressing concern when it comes to the jobs
market and automation is that the robots aren't taking our jobs fast enough.
And in a recent blog post Paul Krugman concluded:
I'd note, however, that it remains peculiar how we're simultaneously worrying that robots will take all our jobs and bemoaning
the stalling out of productivity growth. What is the story, really?
What is the story, indeed. Let me see if I can tell one. Last fall I published a book: "The Wealth of Humans". In it I set out
how rapid technological progress can coincide with lousy growth in pay and productivity. Start with this:
Low labour costs discourage investments in labour-saving technology, potentially reducing productivity growth.
Increasing labour costs by making the minimum wage a living wage would increase the incentives to boost productivity growth?
No, the neoliberals and corporate Democrats would never go for it. They're trying to appeal to the business community and their
campaign contributors wouldn't like it.
Capital-biased Technological Progress: An Example (Wonkish)
By Paul Krugman
Ever since I posted about robots and the distribution of income, * I've had queries from readers about what capital-biased
technological change the kind of change that could make society richer but workers poorer really means. And it occurred to
me that it might be useful to offer a simple conceptual example the kind of thing easily turned into a numerical example as
well to clarify the possibility. So here goes.
Imagine that there are only two ways to produce output. One is a labor-intensive method say, armies of scribes equipped only
with quill pens. The other is a capital-intensive method say, a handful of technicians maintaining vast server farms. (I'm thinking
in terms of office work, which is the dominant occupation in the modern economy).
We can represent these two techniques in terms of unit inputs the amount of each factor of production required to produce
one unit of output. In the figure below I've assumed that initially the capital-intensive technique requires 0.2 units of labor
and 0.8 units of capital per unit of output, while the labor-intensive technique requires 0.8 units of labor and 0.2 units of
capital.
[Diagram]
The economy as a whole can make use of both techniques in fact, it will have to unless it has either a very large amount
of capital per worker or a very small amount. No problem: we can just use a mix of the two techniques to achieve any input combination
along the blue line in the figure. For economists reading this, yes, that's the unit isoquant in this example; obviously if we
had a bunch more techniques it would start to look like the convex curve of textbooks, but I want to stay simple here.
What will the distribution of income be in this case? Assuming perfect competition (yes, I know, but let's deal with that case
for now), the real wage rate w and the cost of capital r both measured in terms of output have to be such that the cost of
producing one unit is 1 whichever technique you use. In this example, that means w=r=1. Graphically, by the way, w/r is equal
to minus the slope of the blue line.
Oh, and if you're worried, yes, workers and machines are both paid their marginal product.
But now suppose that technology improves specifically, that production using the capital-intensive technique gets more efficient,
although the labor-intensive technique doesn't. Scribes with quill pens are the same as they ever were; server farms can do more
than ever before. In the figure, I've assumed that the unit inputs for the capital-intensive technique are cut in half. The red
line shows the economy's new choices.
So what happens? It's obvious from the figure that wages fall relative to the cost of capital; it's less obvious, maybe, but
nonetheless true that real wages must fall in absolute terms as well. In this specific example, technological progress reduces
the real wage by a third, to 0.667, while the cost of capital rises to 2.33.
OK, it's obvious how stylized and oversimplified all this is. But it does, I think, give you some sense of what it would mean
to have capital-biased technological progress, and how this could actually hurt workers.
Catherine Rampell and Nick Wingfield write about the growing evidence * for "reshoring" of manufacturing to the United States.
* They cite several reasons: rising wages in Asia; lower energy costs here; higher transportation costs. In a followup piece,
** however, Rampell cites another factor: robots.
"The most valuable part of each computer, a motherboard loaded with microprocessors and memory, is already largely made with
robots, according to my colleague Quentin Hardy. People do things like fitting in batteries and snapping on screens.
"As more robots are built, largely by other robots, 'assembly can be done here as well as anywhere else,' said Rob Enderle,
an analyst based in San Jose, California, who has been following the computer electronics industry for a quarter-century. 'That
will replace most of the workers, though you will need a few people to manage the robots.' "
Robots mean that labor costs don't matter much, so you might as well locate in advanced countries with large markets and good
infrastructure (which may soon not include us, but that's another issue). On the other hand, it's not good news for workers!
This is an old concern in economics; it's "capital-biased technological change," which tends to shift the distribution of income
away from workers to the owners of capital.
Twenty years ago, when I was writing about globalization and inequality, capital bias didn't look like a big issue; the major
changes in income distribution had been among workers (when you include hedge fund managers and CEOs among the workers), rather
than between labor and capital. So the academic literature focused almost exclusively on "skill bias", supposedly explaining the
rising college premium.
But the college premium hasn't risen for a while. What has happened, on the other hand, is a notable shift in income away from
labor:
[Graph]
If this is the wave of the future, it makes nonsense of just about all the conventional wisdom on reducing inequality. Better
education won't do much to reduce inequality if the big rewards simply go to those with the most assets. Creating an "opportunity
society," or whatever it is the likes of Paul Ryan etc. are selling this week, won't do much if the most important asset you can
have in life is, well, lots of assets inherited from your parents. And so on.
I think our eyes have been averted from the capital/labor dimension of inequality, for several reasons. It didn't seem crucial
back in the 1990s, and not enough people (me included!) have looked up to notice that things have changed. It has echoes of old-fashioned
Marxism - which shouldn't be a reason to ignore facts, but too often is. And it has really uncomfortable implications.
But I think we'd better start paying attention to those implications.
John Kenneth Galbraith, from "The Great Crash 1929":
"In many ways the effect of the crash on embezzlement was more significant than on suicide. To the economist embezzlement
is the most interesting of crimes. Alone among the various forms of larceny it has a time parameter. Weeks, months or years
may elapse between the commission of the crime and its discovery. (This is a period, incidentally, when the embezzler has his
gain and the man who has been embezzled, oddly enough, feels no loss. There is a net increase in psychic wealth.)
At any given time there exists an inventory of undiscovered embezzlement in or more precisely not in the country's business
and banks.
This inventory it should perhaps be called the bezzle amounts at any moment to many millions [trillions!] of dollars.
It also varies in size with the business cycle.
In good times people are relaxed, trusting, and money is plentiful. But even though money is plentiful, there are always
many people who need more. Under these circumstances the rate of embezzlement grows, the rate of discovery falls off, and the
bezzle increases rapidly.
In depression all this is reversed. Money is watched with a narrow, suspicious eye.
The man who handles it is assumed to be dishonest until he proves himself otherwise. Audits are penetrating and meticulous.
Commercial morality is enormously improved. The bezzle shrinks."
For nearly a half a century, from 1947 to 1996, real GDP and real Net Worth of Households and Non-profit Organizations (in
2009 dollars) both increased at a compound annual rate of a bit over 3.5%. GDP growth, in fact, was just a smidgen faster -- 0.016%
-- than growth of Net Household Worth.
From 1996 to 2015, GDP grew at a compound annual rate of 2.3% while Net Worth increased at the rate of 3.6%....
The real home price index extends from 1890. From 1890 to 1996, the index increased slightly faster than inflation so that
the index was 100 in 1890 and 113 in 1996. However from 1996 the index advanced to levels far beyond any previously experienced,
reaching a high above 194 in 2006. Previously the index high had been just above 130.
Though the index fell from 2006, the level in 2016 is above 161, a level only reached when the housing bubble had formed in
late 2003-early 2004.
The Shiller 10-year price-earnings ratio is currently 29.34, so the inverse or the earnings rate is 3.41%. The dividend yield
is 1.93. So an expected yearly return over the coming 10 years would be 3.41 + 1.93 or 5.34% provided the price-earnings ratio
stays the same and before investment costs.
Against the 5.34% yearly expected return on stock over the coming 10 years, the current 10-year Treasury bond yield is 2.32%.
The risk premium for stocks is 5.34 - 2.32 or 3.02%:
What the robot-productivity paradox is puzzles me, other than since 2005 for all the focus on the productivity of robots and
on robots replacing labor there has been a dramatic, broad-spread slowing in productivity growth.
However what the changing relationship between the growth of GDP and net worth since 1996 show, is that asset valuations have
been increasing relative to GDP. Valuations of stocks and homes are at sustained levels that are higher than at any time in the
last 120 years. Bear markets in stocks and home prices have still left asset valuations at historically high levels. I have no
idea why this should be.
The paradox is that productivity statistics can't tell us anything about the effects of robots on employment because both the
numerator and the denominator are distorted by the effects of colossal Ponzi bubbles.
John Kenneth Galbraith used to call it "the bezzle." It is "that increment to wealth that occurs during the magic interval
when a confidence trickster knows he has the money he has appropriated but the victim does not yet understand that he has lost
it." The current size of the gross national bezzle (GNB) is approximately $24 trillion.
Ponzilocks and the Twenty-Four Trillion Dollar Question
Twenty-three and a half trillion, actually. But what's a few hundred billion? Here today, gone tomorrow, as they say.
At the beginning of 2007, net worth of households and non-profit organizations exceeded its 1947-1996 historical average, relative
to GDP, by some $16 trillion. It took 24 months to wipe out eighty percent, or $13 trillion, of that colossal but ephemeral slush
fund. In mid-2016, net worth stood at a multiple of 4.83 times GDP, compared with the multiple of 4.72 on the eve of the Great
Unworthing.
When I look at the ragged end of the chart I posted yesterday, it screams "Ponzi!" "Ponzi!" "Ponz..."
To make a long story short, let's think of wealth as capital. The value of capital is determined by the present value of an
expected future income stream. The value of capital fluctuates with changing expectations but when the nominal value of capital
diverges persistently and significantly from net revenues, something's got to give. Either economic growth is going to suddenly
gush forth "like nobody has ever seen before" or net worth is going to have to come back down to earth.
Somewhere between 20 and 30 TRILLION dollars of net worth will evaporate within the span of perhaps two years.
When will that happen? Who knows? There is one notable regularity in the data, though -- the one that screams "Ponzi!"
When the net worth bubble stops going up...
...it goes down.
"... Having a customer always available on site would mean that the customer in question is probably a small, expendable fish in his organization and is unlikely to have any useful knowledge of its business practices. ..."
"... Unit testing code before it is written means that one would have to have a mental picture of what one is going to write before writing it, which is difficult without upfront design. And maintaining such tests as the code changes would be a nightmare. ..."
"... Programming in pairs all the time would assume that your topnotch developers are also sociable creatures, which is rarely the case, and even if they were, no one would be able to justify the practice in terms of productivity. I won't discuss why I think that abandoning upfront design is a bad practice; the whole idea is too ridiculous to debate ..."
"... Both book and methodology will attract fledgling developers with its promise of hacking as an acceptable software practice and a development universe revolving around the programmer. It's a cult, not a methodology, were the followers shall find salvation and 40-hour working weeks ..."
"... Two stars for the methodology itself, because it underlines several common sense practices that are very useful once practiced without the extremity. ..."
"... The second is the dictatorial social engineering that eXtremity mandates. I've actually tried the pair programming - what a disaster. ..."
"... I've also worked with people who felt that their slightest whim was adequate reason to interfere with my work. That's what Beck institutionalizes by saying that any request made of me by anyone on the team must be granted. It puts me completely at the mercy of anyone walking by. The requisite bullpen physical environment doesn't work for me either. I find that the visual and auditory distraction make intense concentration impossible. ..."
"... One of the things I despise the most about the software development culture is the mindless adoption of fads. Extreme programming has been adopted by some organizations like a religious dogma. ..."
To fairly review this book, one must distinguish between the methodology it presents and the
actual presentation. As to the presentation, the author attempts to win the reader over with emotional
persuasion and pep talk rather than with facts and hard evidence. Stories of childhood and comradeship
don't classify as convincing facts to me.
A single case study-the C3 project-is often referred to, but with no specific information (do
note that the project was cancelled by the client after staying in development for far too long).
As to the method itself, it basically boils down to four core practices:
Always have a customer available on site.
Unit test before you code.
Program in pairs.
Forfeit detailed design in favor of incremental, daily releases and refactoring.
If you do the above, and you have excellent staff on your hands, then the book promises that
you'll reap the benefits of faster development, less overtime, and happier customers. Of course,
the book fails to point out that if your staff is all highly qualified people, then the project
is likely to succeed no matter what methodology you use. I'm sure that anyone who has worked in
the software industry for sometime has noticed the sad state that most computer professionals
are in nowadays.
However, assuming that you have all the topnotch developers that you desire, the outlined methodology
is almost impossible to apply in real world scenarios. Having a customer always available
on site would mean that the customer in question is probably a small, expendable fish in his organization
and is unlikely to have any useful knowledge of its business practices.
Unit testing code before it is written means that one would have to have a mental picture
of what one is going to write before writing it, which is difficult without upfront design. And
maintaining such tests as the code changes would be a nightmare.
Programming in pairs all the time would assume that your topnotch developers are also sociable
creatures, which is rarely the case, and even if they were, no one would be able to justify the
practice in terms of productivity. I won't discuss why I think that abandoning upfront design
is a bad practice; the whole idea is too ridiculous to debate.
Both book and methodology will attract fledgling developers with its promise of hacking
as an acceptable software practice and a development universe revolving around the programmer.
It's a cult, not a methodology, were the followers shall find salvation and 40-hour working weeks.
Experience is a great teacher, but only a fool would learn from it alone. Listen to what the
opponents have to say before embracing change, and don't forget to take the proverbial grain of
salt.
Two stars out of five for the presentation for being courageous and attempting to defy the
standard practices of the industry. Two stars for the methodology itself, because it underlines
several common sense practices that are very useful once practiced without the extremity.
Maybe it's an interesting idea, but it's just not ready for prime time.
Parts of Kent's recommended practice - including aggressive testing and short integration cycle
- make a lot of sense. I've shared the same beliefs for years, but it was good to see them clarified
and codified. I really have changed some of my practice after reading this and books like this.
I have two broad kinds of problem with this dogma, though. First is the near-abolition of documentation.
I can't defend 2000 page specs for typical kinds of development. On the other hand, declaring
that the test suite is the spec doesn't do it for me either. The test suite is code, written for
machine interpretation. Much too often, it is not written for human interpretation. Based on the
way I see most code written, it would be a nightmare to reverse engineer the human meaning out
of any non-trivial test code. Some systematic way of ensuring human intelligibility in the code,
traceable to specific "stories" (because "requirements" are part of the bad old way), would give
me a lot more confidence in the approach.
The second is the dictatorial social engineering that eXtremity mandates. I've actually
tried the pair programming - what a disaster. The less said the better, except that my experience
did not actually destroy any professional relationships. I've also worked with people who
felt that their slightest whim was adequate reason to interfere with my work. That's what Beck
institutionalizes by saying that any request made of me by anyone on the team must be granted.
It puts me completely at the mercy of anyone walking by. The requisite bullpen physical environment
doesn't work for me either. I find that the visual and auditory distraction make intense concentration
impossible.
I find revival tent spirit of the eXtremists very off-putting. If something works, it works
for reasons, not as a matter of faith. I find much too much eXhortation to believe, to go ahead
and leap in, so that I will eXperience the wonderfulness for myself. Isn't that what the evangelist
on the subway platform keeps saying? Beck does acknowledge unbelievers like me, but requires their
exile in order to maintain the group-think of the X-cult.
Beck's last chapters note a number of exceptions and special cases where eXtremism may not work
- actually, most of the projects I've ever encountered.
There certainly is good in the eXtreme practice. I look to future authors to tease that good
out from the positively destructive threads that I see interwoven.
A customer on May 2, 2004
A work of fiction
The book presents extreme programming. It is divided into three parts:
(1) The problem
(2) The solution
(3) Implementing XP.
The problem, as presented by the author, is that requirements change but current methodologies
are not agile enough to cope with this. This results in customer being unhappy. The solution is
to embrace change and to allow the requirements to be changed. This is done by choosing the simplest
solution, releasing frequently, refactoring with the security of unit tests.
The basic assumption which underscores the approach is that the cost of change is not exponential
but reaches a flat asymptote. If this is not the case, allowing change late in the project would
be disastrous. The author does not provide data to back his point of view. On the other hand there
is a lot of data against a constant cost of change (see for example discussion of cost in Code
Complete). The lack of reasonable argumentation is an irremediable flaw in the book. Without some
supportive data it is impossible to believe the basic assumption, nor the rest of the book. This
is all the more important since the only project that the author refers to was cancelled before
full completion.
Many other parts of the book are unconvincing. The author presents several XP practices. Some
of them are very useful. For example unit tests are a good practice. They are however better treated
elsewhere (e.g., Code Complete chapter on unit test). On the other hand some practices seem overkill.
Pair programming is one of them. I have tried it and found it useful to generate ideas while prototyping.
For writing production code, I find that a quiet environment is by far the best (see Peopleware
for supportive data). Again the author does not provide any data to support his point.
This book suggests an approach aiming at changing software engineering practices. However the
lack of supportive data makes it a work of fiction.
I would suggest reading Code Complete for code level advice or Rapid Development for management
level advice.
A customer on November 14, 2002
Not Software Engineering.
Any Engineering discipline is based on solid reasoning and logic not on blind faith. Unfortunately,
most of this book attempts to convince you that Extreme programming is better based on the author's
experiences. A lot of the principles are counterintuitive and the author exhorts you just try
it out and get enlightened. I'm sorry but these kind of things belong in infomercials not in s/w
engineering.
The part about "code is the documentation" is the scariest part. It's true that keeping the
documentation up to date is tough on any software project, but to do away with documentation is
the most ridiculous thing I have heard.
It's like telling people to cut of their noses to avoid colds. Yes we are always in search
of a better software process. Let me tell you that this book won't lead you there.
The "gossip magazine diet plans" style of programming.
This book reminds me of the "gossip magazine diet plans", you know, the vinegar and honey diet,
or the fat-burner 2000 pill diet etc. Occasionally, people actually lose weight on those diets,
but, only because they've managed to eat less or exercise more. The diet plans themselves are
worthless. XP is the same - it may sometimes help people program better, but only because they
are (unintentionally) doing something different. People look at things like XP because, like dieters,
they see a need for change. Overall, the book is a decently written "fad diet", with ideas that
are just as worthless.
A customer on August 11, 2003
Hackers! Salvation is nigh!!
It's interesting to see the phenomenon of Extreme Programming happening in the dawn of the
21st century. I suppose historians can explain such a reaction as a truly conservative movement.
Of course, serious software engineering practice is hard. Heck, documentation is a pain in the
neck. And what programmer wouldn't love to have divine inspiration just before starting to write
the latest web application and so enlightened by the Almighty, write the whole thing in one go,
as if by magic? No design, no documentation, you and me as a pair, and the customer too. Sounds
like a hacker's dream with "Imagine" as the soundtrack (sorry, John).
The Software Engineering struggle is over 50 years old and it's only logical to expect some resistance,
from time to time. In the XP case, the resistance comes in one of its worst forms: evangelism.
A fundamentalist cult, with very little substance, no proof of any kind, but then again if you
don't have faith you won't be granted the gift of the mystic revelation. It's Gnosticism for Geeks.
Take it with a pinch of salt.. well, maybe a sack of salt. If you can see through the B.S. that
sells millions of dollars in books, consultancy fees, lectures, etc, you will recognise some common-sense
ideas that are better explained, explored and detailed elsewhere.
Kent is an excellent writer. He does an excellent job of presenting an approach to software
development that is misguided for anything but user interface code. The argument that user interface
code must be gotten into the hands of users to get feedback is used to suggest that complex system
code should not be "designed up front". This is simply wrong. For example, if you are going to
deploy an application in the Amazon Cloud that you want to scale, you better have some idea of
how this is going to happen. Simply waiting until your application falls over and fails is not
an acceptable approach.
One of the things I despise the most about the software development culture is the mindless
adoption of fads. Extreme programming has been adopted by some organizations like a religious
dogma.
Engineering large software systems is one of the most difficult things that humans do. There
are no silver bullets and there are no dogmatic solutions that will make the difficult simple.
Maybe I'm too cynical because I never got to work for the successful, whiz-kid companies; Maybe
this book wasn't written for me!
This book reminds me of Jacobsen's "Use Cases" book of the 1990s. 'Use Cases' was all the rage
but after several years, we slowly learned the truth: Uses Cases does not deal with the architecture
- a necessary and good foundation for any piece of software.
Similarly, this book seems to be spotlighting Testing and taking it to extremes.
'the test plan is the design doc'
Not True. The design doc encapsulates wisdom and insight
a picture that accurately describes the interactions of the lower level software components
is worth a thousand lines of code-reading.
Also present is an evangelistic fervor that reminds me of the rah-rah eighties' bestseller,
"In Search Of Excellence" by Peters and Waterman. (Many people have since noted that most of the
spotlighted companies of that book are bankrupt twenty five years later).
- in a room full of people with a bully supervisor (as I experienced in my last job at
a major telco) innovation or good work is largely absent.
- deploy daily - are you kidding? to run through the hundreds of test cases in a large
application takes several hours if not days. Not all testing can be automated.
- I have found the principle of "baby steps", one of the principles in the book, most useful
in my career - it is the basis for prototyping iteratively. However I heard it described in
1997 at a pep talk at MCI that the VP of our department gave to us. So I dont know who stole
it from whom!
Lastly, I noted that the term 'XP' was used throughout the book, and the back cover has a blurb
from an M$ architect. Was it simply coincidence that Windows shares the same name for its XP release?
I wondered if M$ had sponsored part of the book as good advertising for Windows XP! :)
Review by many eyes does not always prevent buggy codeThere is a view that
because open source software is subject to review by many eyes, all the bugs will be ironed out
of it. This is a myth.
06 Oct 2017 Mike Bursell (Red Hat)Feed 8
up Image credits :
Internet Archive Book Images . CC BY-SA 4.0 Writing code is hard.
Writing secure code is harder -- much harder. And before you get there, you need to think about
design and architecture. When you're writing code to implement security functionality, it's
often based on architectures and designs that have been pored over and examined in detail. They
may even reflect standards that have gone through worldwide review processes and are generally
considered perfect and unbreakable. *
However good those designs and architectures are, though, there's something about putting
things into actual software that's, well, special. With the exception of software proven to be
mathematically correct, ** being able to write software
that accurately implements the functionality you're trying to realize is somewhere between a
science and an art. This is no surprise to anyone who's actually written any software, tried to
debug software, or divine software's correctness by stepping through it; however, it's not the
key point of this article.
Nobody *** actually believes that the
software that comes out of this process is going to be perfect, but everybody agrees that
software should be made as close to perfect and bug-free as possible. This is why code review
is a core principle of software development. And luckily -- in my view, at least -- much of the
code that we use in our day-to-day lives is open source, which means that anybody can look at
it, and it's available for tens or hundreds of thousands of eyes to review.
And herein lies the problem: There is a view that because open source software is subject to
review by many eyes, all the bugs will be ironed out of it. This is a myth. A dangerous myth.
The problems with this view are at least twofold. The first is the "if you build it, they will
come" fallacy. I remember when there was a list of all the websites in the world, and if you
added your website to that list, people would visit it. **** In the same way, the
number of open source projects was (maybe) once so small that there was a good chance that
people might look at and review your code. Those days are past -- long past. Second, for many
areas of security functionality -- crypto primitives implementation is a good example -- the
number of suitably qualified eyes is low.
Don't think that I am in any way suggesting that the problem is any less in proprietary
code: quite the opposite. Not only are the designs and architectures in proprietary software
often hidden from review, but you have fewer eyes available to look at the code, and the
dangers of hierarchical pressure and groupthink are dramatically increased. "Proprietary code
is more secure" is less myth, more fake news. I completely understand why companies like to
keep their security software secret, and I'm afraid that the "it's to protect our intellectual
property" line is too often a platitude they tell themselves when really, it's just unsafe to
release it. So for me, it's open source all the way when we're looking at security
software.
So, what can we do? Well, companies and other organizations that care about security
functionality can -- and have, I believe a responsibility to -- expend resources on checking
and reviewing the code that implements that functionality. Alongside that, the open source
community, can -- and is -- finding ways to support critical projects and improve the amount of
review that goes into that code. ***** And we should encourage
academic organizations to train students in the black art of security software writing and
review, not to mention highlighting the importance of open source software.
We can do better -- and we are doing better. Because what we need to realize is that the
reason the "many eyes hypothesis" is a myth is not that many eyes won't improve code -- they
will -- but that we don't have enough expert eyes looking. Yet.
* Yeah, really: "perfect and unbreakable." Let's just pretend that's true
for the purposes of this discussion.
** and that still relies on the design and architecture to actually do what
you want -- or think you want -- of course, so good luck.
*** Nobody who's actually written more than about five lines of code (or
more than six characters of Perl).
**** I added one. They came. It was like some sort of magic.
"... We've seen this kind of tactic for some time now. Silicon Valley is turning into a series of micromanaged sweatshops (that's what "agile" is truly all about) with little room for genuine creativity, or even understanding of what that actually means. I've seen how impossible it is to explain to upper level management how crappy cheap developers actually diminish productivity and value. All they see is that the requisition is filled for less money. ..."
I agree with the basic point. We've seen this kind of tactic for some time now. Silicon
Valley is turning into a series of micromanaged sweatshops (that's what "agile" is truly all
about) with little room for genuine creativity, or even understanding of what that actually
means. I've seen how impossible it is to explain to upper level management how crappy cheap
developers actually diminish productivity and value. All they see is that the requisition is
filled for less money.
The bigger problem is that nobody cares about the arts, and as expensive as education is,
nobody wants to carry around a debt on a skill that won't bring in the bucks. And
smartphone-obsessed millennials have too short an attention span to fathom how empty their
lives are, devoid of the aesthetic depth as they are.
I can't draw a definite link, but I think algorithm fails, which are based on fanatical
reliance on programmed routines as the solution to everything, are rooted in the shortage of
education and cultivation in the arts.
Economics is a social science, and all this is merely a reflection of shared cultural
values. The problem is, people think it's math (it's not) and therefore set in stone.
"... That's Silicon Valley's dirty secret. Most tech workers in Palo Alto make about as much as the high school teachers who teach their kids. And these are the top coders in the country! ..."
"... I don't see why more Americans would want to be coders. These companies want to drive down wages for workers here and then also ship jobs offshore... ..."
"... Silicon Valley companies have placed lowering wages and flooding the labor market with cheaper labor near the top of their goals and as a business model. ..."
"... There are quite a few highly qualified American software engineers who lose their jobs to foreign engineers who will work for much lower salaries and benefits. This is a major ingredient of the libertarian virus that has engulfed and contaminating the Valley, going hand to hand with assembling products in China by slave labor ..."
"... If you want a high tech executive to suffer a stroke, mention the words "labor unions". ..."
"... India isn't being hired for the quality, they're being hired for cheap labor. ..."
"... Enough people have had their hands burnt by now with shit companies like TCS (Tata) that they are starting to look closer to home again... ..."
"... Globalisation is the reason, and trying to force wages up in one country simply moves the jobs elsewhere. The only way I can think of to limit this happening is to keep the company and coders working at the cutting edge of technology. ..."
"... I'd be much more impressed if I saw that the hordes of young male engineers here in SF expressing a semblance of basic common sense, basic self awareness and basic life skills. I'd say 91.3% are oblivious, idiotic children. ..."
"... Not maybe. Too late. American corporations objective is to low ball wages here in US. In India they spoon feed these pupils with affordable cutting edge IT training for next to nothing ruppees. These pupils then exaggerate their CVs and ship them out en mass to the western world to dominate the IT industry. I've seen it with my own eyes in action. Those in charge will anything/everything to maintain their grip on power. No brag. Just fact. ..."
That's Silicon Valley's dirty secret. Most tech workers in Palo Alto make about as much as
the high school teachers who teach their kids. And these are the top coders in the country!
Automated coding just pushes the level of coding further up the development food chain, rather
than gets rid of it. It is the wrong approach for current tech. AI that is smart enough to model
new problems and create their own descriptive and runnable language - hopefully after my lifetime
but coming sometime.
What coding does not teach is how to improve our non-code infrastructure and how to keep it running
(that's the stuff which actually moves things). Code can optimize stuff, but it needs actual actuators
to affect reality.
Sometimes these actuators are actual people walking on top of a roof while fixing it.
Silicon Valley companies have placed lowering wages and flooding the labor market with cheaper
labor near the top of their goals and as a business model.
There are quite a few highly qualified American software engineers who lose their jobs
to foreign engineers who will work for much lower salaries and benefits. This is a major ingredient
of the libertarian virus that has engulfed and contaminating the Valley, going hand to hand with
assembling products in China by slave labor .
If you want a high tech executive to suffer a stroke, mention the words "labor unions".
Nope. Married to a highly-technical skillset, you can still make big bucks. I say this as someone
involved in this kind of thing academically and our Masters grads have to beat the banks and fintech
companies away with dog shits on sticks. You're right that you can teach anyone to potter around
and throw up a webpage but at the prohibitively difficult maths-y end of the scale, someone suitably
qualified will never want for a job.
In a similar vein, if you accept the argument that it does drive down wages, wouldn't the culprit
actually be the multitudes of online and offline courses and tutorials available to an existing
workforce?
Funny you should pick medicine, law, engineering... 3 fields that are *not* taught in high school.
The writer is simply adding "coding" to your list. So it seems you agree with his "garbage" argument
after all.
Key word is "good". Teaching everyone is just going to increase the pool of programmers code I
need to fix. India isn't being hired for the quality, they're being hired for cheap labor.
As for women sure I wouldn't mind more women around but why does no one say their needs to be
more equality in garbage collection or plumbing? (And yes plumbers are a high paid professional).
In the end I don't care what the person is, I just want to hire and work with the best and
not someone I have to correct their work because they were hired by quota. If women only graduate
at 15% why should IT contain more than that? And let's be a bit honest with the facts, of those
15% how many spend their high school years staying up all night hacking? Very few. Now the few
that did are some of the better developers I work with but that pool isn't going to increase by
forcing every child to program... just like sports aren't better by making everyone take gym class.
I ran a development team for 10 years and I never had any trouble hiring programmers - we just
had to pay them enough. Every job would have at least 10 good applicants.
Two years ago I decided to scale back a bit and go into programming (I can code real-time low
latency financial apps in 4 languages) and I had four interviews in six months with stupidly low
salaries. I'm lucky in that I can bounce between tech and the business side so I got a decent
job out of tech.
My entirely anecdotal conclusion is that there is no shortage of good programmers just a shortage
of companies willing to pay them.
I've worn many hats so far, I started out as a started out as a sysadmin, then I moved on to web
development, then back end and now I'm doing test automation because I am on almost the same money
for half the effort.
But the concepts won't. Good programming requires the ability to break down a task, organise
the steps in performing it, identify parts of the process that are common or repetitive so they
can be bundled together, handed-off or delegated, etc.
These concepts can be applied to any programming language, and indeed to many non-software
activities.
Well to his point sort of... either everything will go php or all those entry level php developers
will be on the street. A good Java or C developer is hard to come by. And to the others, being
a being a developer, especially a good one, is nothing like reading and writing. The industry
is already saturated with poor coders just doing it for a paycheck.
Pretty much the entire history of the software industry since FORAST was developed for the
ORDVAC has been about desperately trying to make software development in some way possible without
driving everyone bonkers.
The gulf between FORAST and today's IDE-written, type-inferring high level languages, compilers,
abstracted run-time environments, hypervisors, multi-computer architectures and general tech-world
flavour-of-2017-ness is truly immense[1].
And yet software is still fucking hard to write. There's no sign it's getting easier despite
all that work.
Automated coding was promised as the solution in the 1980s as well. In fact, somewhere in my
archives, I've got paper journals which include adverts for automated systems that would programmers
completely redundant by writing all your database code for you. These days, we'd think of those
tools as automated ORM generators and they don't fix the problem; they just make a new one --
ORM impedance mismatch -- which needs more engineering on top to fix...
The tools don't change the need for the humans, they just change what's possible for the humans
to do.
[1] FORAST executed in about 20,000 bytes of memory without even an OS. The compile artifacts
for the map-reduce system I built today are an astonishing hundred million bytes... and don't
include the necessary mapreduce environment, management interface, node operating system and distributed
filesystem...
"There are already top quality coders in China and India"
AHAHAHAHAHAHAHAHAHAHAHA *rolls on the floor laughting* Yes........ 1%... and 99% of incredibly
bad, incompetent, untalented one that produce cost 50% of a good developer but produce only 5%
in comparison. And I'm talking with a LOT of practical experience through more than a dozen corporations
all over the world which have been outsourcing to India... all have been disasters for the companies
(but good for the execs who pocketed big bonuses and left the company before the disaster blows
up in their face)
Tech executives have pursued [the goal of suppressing workers' compensation] in a variety
of ways. One is collusion companies conspiring to prevent their employees from earning more
by switching jobs. The prevalence of this practice in Silicon Valley triggered a justice department
antitrust complaint in 2010, along with a class action suit that culminated in a $415m settlement.
Folks interested in the story of the Techtopus (less drily presented than in the links in this
article) should check out Mark Ames' reporting, esp
this overview article and
this focus on the egregious Steve Jobs (whose canonization by the US corporate-funded media
is just one more impeachment of their moral bankruptcy).
Another, more sophisticated method is importing large numbers of skilled guest workers from
other countries through the H1-B visa program. These workers earn less than their American
counterparts, and possess little bargaining power because they must remain employed to keep
their status.
I have watched as schools run by trade unions have done the opposite for the 5 decades. By limiting
the number of graduates, they were able to help maintain living wages and benefits. This has been
stopped in my area due to the pressure of owners run "trade associations".
During that same time period I have witnessed trade associations controlled by company owners,
while publicising their support of the average employee, invest enormous amounts of membership
fees in creating alliances with public institutions. Their goal has been that of flooding the
labor market and thus keeping wages low. A double hit for the average worker because membership
fees were paid by employees as well as those in control.
Coding jobs are just as susceptible to being moved to lower cost areas of the world as hardware
jobs already have. It's already happening. There are already top quality coders in China and India.
There is a much larger pool to chose from and they are just as good as their western counterparts
and work harder for much less money.
Globalisation is the reason, and trying to force wages up in one country simply moves the
jobs elsewhere. The only way I can think of to limit this happening is to keep the company and
coders working at the cutting edge of technology.
I'd be much more impressed if I saw that the hordes of young male engineers here in SF
expressing a semblance of basic common sense, basic self awareness and basic life skills. I'd
say 91.3% are oblivious, idiotic children.
They would definitely not survive the zombie apocalypse.
P.S. not every kid wants or needs to have their soul sucked out of them sitting in front of
a screen full of code for some idiotic service that some other douchbro thinks is the next iteration
of sliced bread.
The demonization of Silicon Valley is clearly the next place to put all blame. Look what
"they" did to us: computers, smart phones, HD television, world-wide internet, on and on. Get
a rope!
I moved there in 1978 and watched the orchards and trailer parks on North 1st St. of San
Jose transform into a concrete jungle. There used to be quite a bit of semiconductor
equipment and device manufacturing in SV during the 80s and 90s. Now quite a few buildings
have the same name : AVAILABLE. Most equipment and device manufacturing has moved to
Asia.
Programming started with binary, then machine code (hexadecimal or octal) and moved to
assembler as a compiled and linked structure. More compiled languages like FORTRAN, BASIC,
PL-1, COBOL, PASCAL, C (and all its "+'s") followed making programming easier for the less
talented. Now the script based languages (HTML, JAVA, etc.) are even higher level and
accessible to nearly all. Programming has become a commodity and will be priced like milk,
wheat, corn, non-unionized workers and the like. The ship has sailed on this activity as a
career.
Hi: As I have said many times before, there is no shortage of people who fully understand the
problem and can see all the connections.
However, they all fall on their faces when it comes to the solution.
To cut to the chase, Concentrated Wealth needs to go, permanently.
Of course the challenge is how to best accomplish this.....
Damn engineers and their black and white world view, if they weren't so inept they would've
unionized instead of being trampled again and again in the name of capitalism.
Not maybe. Too late. American corporations objective is to low ball wages here in US. In
India they spoon feed these pupils with affordable cutting edge IT training for next to
nothing ruppees. These pupils then exaggerate their CVs and ship them out en mass to the
western world to dominate the IT industry. I've seen it with my own eyes in action. Those in
charge will anything/everything to maintain their grip on power. No brag. Just fact.
Wrong again, that approach has been tried since the 80s and will keep failing only because
software development is still more akin to a technical craft than an engineering discipline.
The number of elements required to assemble a working non trivial system is way beyond
scriptable.
> That's some crystal ball you have there. English teachers will need to know how to
code? Same with plumbers? Same with janitors, CEOs, and anyone working in the service
industry?
You don't believe there will be robots to do plumbing and cleaning? The cleaner's job will
be to program robots to do what they need.
CEOs? Absolutely.
English teachers? Both of my kids have school laptops and everything is being done on the
computers. The teachers use software and create websites and what not. Yes, even English
teachers.
Not knowing / understanding how to code will be the same as not knowing how to use Word/
Excel. I am assuming there are people who don't, but I don't know any above the age of 6.
We've had 'automated coding scripts' for years for small tasks. However, anyone who says
they're going to obviate programmers, analysts and designers doesn't understand the software
development process.
Even if expert systems (an 80's concept, BTW) could code, we'd still have a huge need for
managers. The hard part of software isn't even the coding. It's determining the requirements
and working with clients. It will require general intelligence to do 90% of what we do right
now. The 10% we could automate right now, mostly gets in the way. I agree it will change, but
it's going to take another 20-30 years to really happen.
wrong, software companies are already developing automated coding scripts. You'll get a bunch
of door to door knives salespeople once the dust settles that's what you'll get.
Thw user "imipak" views are pretty common misconceptions. They are all wrong.
Notable quotes:
"... I was about to take offence on behalf of programmers, but then I realized that would be snobbish and insulting to carpenters too. Many people can code, but only a few can code well, and fewer still become the masters of the profession. Many people can learn carpentry, but few become joiners, and fewer still become cabinetmakers. ..."
"... Many people can write, but few become journalists, and fewer still become real authors. ..."
Coding has little or nothing to do with Silicon Valley. They may or may not have ulterior
motives, but ultimately they are nothing in the scheme of things.
I disagree with teaching coding as a discrete subject. I think it should be combined with
home economics and woodworking because 90% of these subjects consist of transferable skills
that exist in all of them. Only a tiny residual is actually topic-specific.
In the case of coding, the residual consists of drawing skills and typing skills.
Programming language skills? Irrelevant. You should choose the tools to fit the problem.
Neither of these needs a computer. You should only ever approach the computer at the very
end, after you've designed and written the program.
Is cooking so very different? Do you decide on the ingredients before or after you start?
Do you go shopping half-way through cooking an omelette?
With woodwork, do you measure first or cut first? Do you have a plan or do you randomly
assemble bits until it does something useful?
Real coding, taught correctly, is barely taught at all. You teach the transferable skills.
ONCE. You then apply those skills in each area in which they apply.
What other transferable skills apply? Top-down design, bottom-up implementation. The
correct methodology in all forms of engineering. Proper testing strategies, also common
across all forms of engineering. However, since these tests are against logic, they're a test
of reasoning. A good thing to have in the sciences and philosophy.
Technical writing is the art of explaining things to idiots. Whether you're designing a
board game, explaining what you like about a house, writing a travelogue or just seeing if
your wild ideas hold water, you need to be able to put those ideas down on paper in a way
that exposes all the inconsistencies and errors. It doesn't take much to clean it up to be
readable by humans. But once it is cleaned up, it'll remain free of errors.
So I would teach a foundation course that teaches top-down reasoning, bottom-up design,
flowcharts, critical path analysis and symbolic logic. Probably aimed at age 7. But I'd not
do so wholly in the abstract. I'd have it thoroughly mixed in with one field, probably
cooking as most kids do that and it lacks stigma at that age.
I'd then build courses on various crafts and engineering subjects on top of that, building
further hierarchies where possible. Eliminate duplication and severely reduce the fictions we
call disciplines.
I used to employ 200 computer scientists in my business and now teach children so I'm
apparently as guilty as hell. To be compared with a carpenter is, however, a true compliment, if you mean those that
create elegant, aesthetically-pleasing, functional, adaptable and long-lasting bespoke
furniture, because our crafts of problem-solving using limited resources in confined
environments to create working, life-improving artifacts both exemplify great human ingenuity
in action. Capitalism or no.
"But coding is not magic. It is a technical skill, akin to carpentry."
But some people do it much better than others. Just like journalism. This article is
complete nonsense, as I discuss in another comment. The author might want to consider a
career in carpentry.
"But coding is not magic. It is a technical skill, akin to carpentry."
I was about to take offence on behalf of programmers, but then I realized that would be
snobbish and insulting to carpenters too. Many people can code, but only a few can code well,
and fewer still become the masters of the profession. Many people can learn carpentry, but
few become joiners, and fewer still become cabinetmakers.
Many people can write, but few become journalists, and fewer still become real authors.
IT is probably one of the most "neoliberalized" industry (even in comparison with
finance). So atomization of labor and "plantation economy" is a norm in IT. It occurs on
rather high level of wages, but with influx of foreign programmers and IT specialists (in the past)
and mass outsourcing (now) this is changing. Completion for good job positions is fierce. Dog eats
dog competition, the dream of neoliberals. Entry level jobs are already paying $15 an hour, if not
less.
Programming is a relatively rare talent, much like ability to play violin. Even amateur level is
challenging. On high level (developing large complex programs in a team and still preserving your individuality
and productivity ) it is extremely rare. Most of "commercial" programmers are able to produce only a
mediocre code (which might be adequate). Only a few programmers can excel if complex software projects.
Sometimes even performing solo. There is also a pathological breed of "programmer junkie"
( graphomania happens in programming
too ) who are able sometimes to destroy something large projects singlehandedly. That often happens
with open source projects after the main developer lost interest and abandoned the project.
It's good to allow children the chance to try their hand at coding when they otherwise may not had
that opportunity, But in no way that means that all of them can became professional programmers. No
way. Again the top level of programmers required position of a unique talent, much like top musical
performer talent.
Also to get a decent entry position you iether need to be extremely talented or graduate from Ivy
League university. When applicants are abundant, resume from less prestigious universities are not even
considered. this is just easier for HR to filter applications this way.
Also under neoliberalism cheap labor via H1B visas flood the market and depresses wages. Many Silicon
companies were so to say "Russian speaking in late 90th after the collapse of the USSR. Not offshoring
is the dominant way to offload the development to cheaper labor.
Notable quotes:
"... As software mediates more of our lives, and the power of Silicon Valley grows, it's tempting to imagine that demand for developers is soaring. The media contributes to this impression by spotlighting the genuinely inspiring stories of those who have ascended the class ladder through code. You may have heard of Bit Source, a company in eastern Kentucky that retrains coalminers as coders. They've been featured by Wired , Forbes , FastCompany , The Guardian , NPR and NBC News , among others. ..."
"... A former coalminer who becomes a successful developer deserves our respect and admiration. But the data suggests that relatively few will be able to follow their example. Our educational system has long been producing more programmers than the labor market can absorb. ..."
"... More tellingly, wage levels in the tech industry have remained flat since the late 1990s. Adjusting for inflation, the average programmer earns about as much today as in 1998. If demand were soaring, you'd expect wages to rise sharply in response. Instead, salaries have stagnated. ..."
"... Tech executives have pursued this goal in a variety of ways. One is collusion companies conspiring to prevent their employees from earning more by switching jobs. The prevalence of this practice in Silicon Valley triggered a justice department antitrust complaint in 2010, along with a class action suit that culminated in a $415m settlement . Another, more sophisticated method is importing large numbers of skilled guest workers from other countries through the H1-B visa program. These workers earn less than their American counterparts, and possess little bargaining power because they must remain employed to keep their status. ..."
"... Guest workers and wage-fixing are useful tools for restraining labor costs. But nothing would make programming cheaper than making millions more programmers. ..."
"... Silicon Valley has been unusually successful in persuading our political class and much of the general public that its interests coincide with the interests of humanity as a whole. But tech is an industry like any other. It prioritizes its bottom line, and invests heavily in making public policy serve it. The five largest tech firms now spend twice as much as Wall Street on lobbying Washington nearly $50m in 2016. The biggest spender, Google, also goes to considerable lengths to cultivate policy wonks favorable to its interests and to discipline the ones who aren't. ..."
"... Silicon Valley is not a uniquely benevolent force, nor a uniquely malevolent one. Rather, it's something more ordinary: a collection of capitalist firms committed to the pursuit of profit. And as every capitalist knows, markets are figments of politics. They are not naturally occurring phenomena, but elaborately crafted contraptions, sustained and structured by the state which is why shaping public policy is so important. If tech works tirelessly to tilt markets in its favor, it's hardly alone. What distinguishes it is the amount of money it has at its disposal to do so. ..."
"... The problem isn't training. The problem is there aren't enough good jobs to be trained for ..."
"... Everyone should have the opportunity to learn how to code. Coding can be a rewarding, even pleasurable, experience, and it's useful for performing all sorts of tasks. More broadly, an understanding of how code works is critical for basic digital literacy something that is swiftly becoming a requirement for informed citizenship in an increasingly technologized world. ..."
"... But coding is not magic. It is a technical skill, akin to carpentry. Learning to build software does not make you any more immune to the forces of American capitalism than learning to build a house. Whether a coder or a carpenter, capital will do what it can to lower your wages, and enlist public institutions towards that end. ..."
"... Exposing large portions of the school population to coding is not going to magically turn them into coders. It may increase their basic understanding but that is a long way from being a software engineer. ..."
"... All schools teach drama and most kids don't end up becoming actors. You need to give all kids access to coding in order for some can go on to make a career out of it. ..."
"... it's ridiculous because even out of a pool of computer science B.Sc. or M.Sc. grads - companies are only interested in the top 10%. Even the most mundane company with crappy IT jobs swears that they only hire "the best and the brightest." ..."
"... It's basically a con-job by the big Silicon Valley companies offshoring as many US jobs as they can, or "inshoring" via exploitation of the H1B visa ..."
"... Masters is the new Bachelors. ..."
"... I taught CS. Out of around 100 graduates I'd say maybe 5 were reasonable software engineers. The rest would be fine in tech support or other associated trades, but not writing software. Its not just a set of trainable skills, its a set of attitudes and ways of perceiving and understanding that just aren't that common. ..."
"... Yup, rings true. I've been in hi tech for over 40 years and seen the changes. I was in Silicon Valley for 10 years on a startup. India is taking over, my current US company now has a majority Indian executive and is moving work to India. US politicians push coding to drive down wages to Indian levels. ..."
This month, millions of children returned to school. This year, an unprecedented number of them
will learn to code.
Computer science courses for children have proliferated rapidly in the past few years. A 2016
Gallup
report found that 40% of American schools now offer coding classes up from only 25% a few years
ago. New York, with the largest public school system in the country, has
pledged to offer computer science to all 1.1 million students by 2025. Los Angeles, with the
second largest,
plans to do the same by 2020. And Chicago, the fourth largest, has gone further,
promising to make computer science a high school graduation requirement by 2018.
The rationale for this rapid curricular renovation is economic. Teaching kids how to code will
help them land good jobs, the argument goes. In an era of flat and falling incomes, programming provides
a new path to the middle class a skill so widely demanded that anyone who acquires it can command
a livable, even lucrative, wage.
This narrative pervades policymaking at every level, from school boards to the government. Yet
it rests on a fundamentally flawed premise. Contrary to public perception, the economy doesn't actually
need that many more programmers. As a result, teaching millions of kids to code won't make them all
middle-class. Rather, it will proletarianize the profession by flooding the market and forcing wages
down and that's precisely the point.
At its root, the campaign for code education isn't about giving the next generation a shot at
earning the salary of a Facebook engineer. It's about ensuring those salaries no longer exist, by
creating a source of cheap labor for the tech industry.
As software mediates more of our lives, and the power of Silicon Valley grows, it's tempting to
imagine that demand for developers is soaring. The media contributes to this impression by spotlighting
the genuinely inspiring stories of those who have ascended the class ladder through code. You may
have heard of Bit Source, a company in eastern Kentucky that retrains coalminers as coders. They've
been featured by
Wired
,
Forbes ,
FastCompany ,
The Guardian ,
NPR and
NBC
News , among others.
A former coalminer who becomes a successful developer deserves our respect and admiration. But
the data suggests that relatively few will be able to follow their example. Our educational system
has long been producing more programmers than the labor market can absorb. A
study by the Economic Policy Institute found that the supply of American college graduates with
computer science degrees is 50% greater than the number hired into the tech industry each year. For
all the talk of a tech worker shortage, many qualified graduates simply can't find jobs.
More tellingly, wage levels in the tech industry have remained flat since the late 1990s. Adjusting
for inflation, the average programmer earns about as much today as in 1998. If demand were soaring,
you'd expect wages to rise sharply in response. Instead, salaries have stagnated.
Still, those salaries are stagnating at a fairly high level. The Department of Labor estimates
that the median annual wage for computer and information technology occupations is $82,860 more
than twice the national average. And from the perspective of the people who own the tech industry,
this presents a problem. High wages threaten profits. To maximize profitability, one must always
be finding ways to pay workers less.
Tech executives have pursued this goal in a variety of ways. One is collusion companies conspiring
to prevent their employees from earning more by switching jobs. The prevalence of this practice in
Silicon Valley triggered a justice department
antitrust complaint in 2010, along with a class action suit that culminated in a $415m
settlement . Another, more sophisticated method is importing
large numbers of skilled guest workers from other countries through the H1-B visa program. These
workers earn less than their
American counterparts, and possess little bargaining power because they must remain employed to keep
their status.
Guest workers and wage-fixing are useful tools for restraining labor costs. But nothing would
make programming cheaper than making millions more programmers. And where better to develop
this workforce than America's schools? It's no coincidence, then, that the campaign for code education
is being orchestrated by the tech industry itself. Its primary instrument is Code.org, a nonprofit
funded by Facebook, Microsoft, Google and
others . In 2016, the organization spent
nearly $20m on training teachers, developing curricula, and lobbying policymakers.
Silicon Valley has been unusually successful in persuading our political class and much of the
general public that its interests coincide with the interests of humanity as a whole. But tech is
an industry like any other. It prioritizes its bottom line, and invests heavily in making public
policy serve it. The five largest tech firms now
spend twice as much as Wall Street on lobbying Washington nearly $50m in 2016. The biggest
spender, Google, also goes to considerable lengths to
cultivate policy wonks favorable to its interests and to
discipline the ones who aren't.
Silicon Valley
is not a uniquely benevolent force, nor a uniquely malevolent one. Rather, it's something more ordinary:
a collection of capitalist firms committed to the pursuit of profit. And as every capitalist knows,
markets are figments of politics. They are not naturally occurring phenomena, but elaborately crafted
contraptions, sustained and structured by the state which is why shaping public policy is so important.
If tech works tirelessly to tilt markets in its favor, it's hardly alone. What distinguishes it is
the amount of money it has at its disposal to do so.
Money isn't Silicon Valley's only advantage in its
crusade to remake American education, however. It also enjoys a favorable ideological climate.
Its basic message that schools alone can fix big social problems is one that politicians of both
parties have been repeating for years. The far-fetched premise of neoliberal school reform is that
education can mend our disintegrating social fabric. That if we teach students the right skills,
we can solve poverty, inequality and stagnation. The school becomes an engine of economic transformation,
catapulting young people from challenging circumstances into dignified, comfortable lives.
This argument is immensely pleasing to the technocratic mind. It suggests that our core economic
malfunction is technical a simple asymmetry. You have workers on one side and good jobs
on the other, and all it takes is training to match them up. Indeed, every president since Bill Clinton
has talked about training American workers to fill the "skills gap". But gradually, one mainstream
economist after another has come to realize what most workers have known for years: the gap doesn't
exist. Even Larry Summers has
concluded it's a myth.
The problem isn't training. The problem is there aren't enough good jobs to be trained for
. The solution is to make bad jobs better, by raising the minimum wage and making it easier for workers
to form a union, and to create more good jobs by investing for growth. This involves forcing business
to put money into things that actually grow the productive economy rather than
shoveling profits out to shareholders. It also means increasing public investment, so that people
can make a decent living doing socially necessary work like decarbonizing our energy system and restoring
our decaying infrastructure.
Everyone should have the opportunity to learn how to code. Coding can be a rewarding, even pleasurable,
experience, and it's useful for performing all sorts of tasks. More broadly, an understanding of
how code works is critical for basic digital literacy something that is swiftly becoming a requirement
for informed citizenship in an increasingly technologized world.
But coding is not magic. It is a technical skill, akin to carpentry. Learning to build software
does not make you any more immune to the forces of American capitalism than learning to build a house.
Whether a coder or a carpenter, capital will do what it can to lower your wages, and enlist public
institutions towards that end.
Silicon Valley has been extraordinarily adept at converting previously uncommodified portions
of our common life into sources of profit. Our schools may prove an easy conquest by comparison.
"Everyone should have the opportunity to learn how to code. " OK, and that's what's being done.
And that's what the article is bemoaning. What would be better: teach them how to change tires
or groom pets? Or pick fruit? Amazingly condescending article.
However, training lots of people to be coders won't automatically result in lots of people
who can actually write good code. Nor will it give managers/recruiters the necessary skills
to recognize which programmers are any good.
A valid rebuttal but could I offer another observation? Exposing large portions of the school
population to coding is not going to magically turn them into coders. It may increase their basic
understanding but that is a long way from being a software engineer.
Just as children join art, drama or biology classes so they do not automatically become artists,
actors or doctors. I would agree entirely that just being able to code is not going to guarantee
the sort of income that might be aspired to. As with all things, it takes commitment, perseverance
and dogged determination. I suppose ultimately it becomes the Gattaca argument.
Fair enough, but, his central argument, that an overabundance of coders will drive wages in that
sector down, is generally true, so in the future if you want your kids to go into a profession
that will earn them 80k+ then being a "coder" is not the route to take. When coding is - like
reading, writing, and arithmetic - just a basic skill, there's no guarantee having it will automatically
translate into getting a "good" job.
This article lumps everyone in computing into the 'coder' bin, without actually defining what
'coding' is. Yes there is a glut of people who can knock together a bit of HTML and
JavaScript, but that is not really programming as such.
There are huge shortages of skilled
developers however; people who can apply computer science and engineering in terms of
analysis and design of software. These are the real skills for which relatively few people
have a true aptitude.
The lack of really good skills is starting to show in some terrible
software implementation decisions, such as Slack for example; written as a web app running in
Electron (so that JavaScript code monkeys could knock it out quickly), but resulting in awful
performance. We will see more of this in the coming years...
My brother is a programmer, and in his experience these coding exams don't test anything but
whether or not you took (and remember) a very narrow range of problems introduce in the first
years of a computer science degree. The entire hiring process seems premised on a range of
ill-founded ideas about what skills are necessary for the job and how to assess them in
people. They haven't yet grasped that those kinds of exams mostly test test-taking ability,
rather than intelligence, creativity, diligence, communication ability, or anything else that
a job requires beside coughing up the right answer in a stressful, timed environment without
outside resources.
I'm an embedded software/firmware engineer. Every similar engineer I've ever met has had the same
background - starting in electronics and drifting into embedded software writing in C and assembler.
It's virtually impossible to do such software without an understanding of electronics. When it
goes wrong you may need to get the test equipment out to scope the hardware to see if it's a hardware
or software problem. Coming from a pure computing background just isn't going to get you a job
in this type of work.
All schools teach drama and most kids don't end up becoming actors. You need to give all kids
access to coding in order for some can go on to make a career out of it.
Coding salaries will inevitably fall over time, but such skills give workers the option, once
they discover that their income is no longer sustainable in the UK, of moving somewhere more affordable
and working remotely.
Completely agree. Coding is a necessary life skill for 21st century but there are levels to every
skill. From basic needs for an office job to advanced and specialised.
Lots of people can code but very few of us ever get to the point of creating something new that
has a loyal and enthusiastic user-base. Everyone should be able to code because it is or will
be the basis of being able to create almost anything in the future. If you want to make a game
in Unity, knowing how to code is really useful. If you want to work with large data-sets, you
can't rely on Excel and so you need to be able to code (in R?). The use of code is becoming so
pervasive that it is going to be like reading and writing.
All the science and engineering graduates I know can code but none of them have ever sold a
stand-alone software. The argument made above is like saying that teaching everyone to write will
drive down the wages of writers. Writing is useful for anyone and everyone but only a tiny fraction
of people who can write, actually write novels or even newspaper columns.
Immigrants have always a big advantage over locals, for any company, including tech companies:
the government makes sure that they will stay in their place and never complain about low salaries
or bad working conditions because, you know what? If the company sacks you, an immigrant may be
forced to leave the country where they live because their visa expires, which is never going to
happen with a local. Companies always have more leverage over immigrants. Given a choice between
more and less exploitable workers, companies will choose the most exploitable ones.
Which is something that Marx figured more than a century ago, and why he insisted that socialism
had to be international, which led to the founding of the First International Socialist. If worker's
fights didn't go across country boundaries, companies would just play people from one country
against the other. Unfortunately, at some point in time socialists forgot this very important
fact.
SO what's wrong with having lots of people able to code? The only argument you seem to have is
that it'll lower wages. So do you think that we should stop teaching writing skills so that journalists
can be paid more? And no one os going to "force" kids into high-level abstract coding practices
in kindergarten, fgs. But there is ample empirical proof that young children can learn basic principles.
In fact the younger that children are exposed to anything, the better they can enhance their skills
adn knowlege of it later in life, and computing concepts are no different.
You're completely missing the point. Kids are forced into the programming field (even STEM as
a more general term), before they evolve their abstract reasoning. For that matter, you're not
producing highly skilled people, but functional imbeciles and a decent labor that will eventually
lower the wages.
Conspiracy theory? So Google, FB and others paying hundreds of millions of dollars for forming
a cartel to lower the wages is not true? It sounds me that you're sounding more like a 1969 denier
that Guardian is. Tech companies are not financing those incentives because they have a good soul.
Their primary drive has always been money, otherwise they wouldn't sell your personal data to
earn money.
But hey, you can always sleep peacefully when your kid becomes a coder. When he is 50, everyone
will want to have a Cobol, Ada programmer with 25 years of experience when you can get 16 year
old kid from a high school for 1/10 of a price. Go back to sleep...
it's ridiculous because even out of a pool of computer science B.Sc. or M.Sc. grads - companies
are only interested in the top 10%. Even the most mundane company with crappy IT jobs swears that
they only hire "the best and the brightest."
It's basically a con-job by the big Silicon Valley companies offshoring as many US jobs as
they can, or "inshoring" via exploitation of the H1B visa - so they can say "see, we don't
have 'qualified' people in the US - maybe when these kids learn to program in a generation." As
if American students haven't been coding for decades -- and saw their salaries plummet as the
H1B visa and Indian offshore firms exploded......
Dude, stow the attitude. I've tested code from various entities, and seen every kind of crap peddled
as gold.
But I've also seen a little 5-foot giggly lady with two kids, grumble a bit and save a $100,000
product by rewriting another coder's man-month of work in a few days, without any flaws or cracks.
Almost nobody will ever know she did that. She's so far beyond my level it hurts.
And yes, the author knows nothing. He's genuinely crying wolf while knee-deep in amused wolves.
The last time I was in San Jose, years ago , the room was already full of people with Indian
surnames. If the problem was REALLY serious, a programmer from POLAND was called in.
If you think fighting for a violinist spot is hard, try fighting for it with every spare violinist
in the world . I am training my Indian replacement to do my job right now
. At least the public can appreciate a good violin. Can you appreciate
Duff's device ?
So by all means, don't teach local kids how to think in a straight line, just in case they
make a dent in the price of wages IN INDIA.... *sheesh*
That's the best possible summarisation of this extremely dumb article. Bravo.
For those who don't know how to think of coding, like the article author, here's a few analogies
:
A computer is a box that replays frozen thoughts, quickly. That is all.
Coding is just the art of explaining. Anyone who can explain something patiently and clearly,
can code. Anyone who can't, can't.
Making hardware is very much like growing produce while blind. Making software is very much
like cooking that produce while blind.
Imagine looking after a room full of young eager obedient children who only do exactly, *exactly*,
what you told them to do, but move around at the speed of light. Imagine having to try to keep
them from smashing into each other or decapitating themselves on the corners of tables, tripping
over toys and crashing into walls, etc, while you get them all to play games together.
The difference between a good coder and a bad coder is almost life and death. Imagine a broth
prepared with ingredients from a dozen co-ordinating geniuses and one idiot, that you'll mass
produce. The soup is always far worse for the idiot's additions. The more cooks you involve, the
more chance your mass produced broth will taste bad.
People who hire coders, typically can't tell a good coder from a bad coder.
No you do it in your own time. If you're not prepared to put in long days IT is not for you in
any case. It was ever thus, but more so now due to offshoring - rather than the rather obscure
forces you seem to believe are important.
Sorry, offworldguy, but you're losing this one really badly. I'm a professional software engineer
in my 60's and I know lots of non-professionals in my age range who write little programs,
scripts and apps for fun. I know this because they often contact me for help or advice.
So you've now been told by several people in this thread that ordinary people do code for fun
or recreation. The fact that you don't know any probably says more about your network of friends
and acquaintances than about the general population.
This is one of the daftest articles I've come across in a long while.
If it's possible that so many kids can be taught to code well enough so that wages come down,
then that proves that the only reason we've been paying so much for development costs is the scarcity
of people able to do it, not that it's intrinsically so hard that only a select few could anyway.
In which case, there is no ethical argument for keeping the pools of skilled workers to some select
group. Anyone able to do it should have an equal opportunity to do it.
What is the argument for not teaching coding (other than to artificially keep wages high)? Why
not stop teaching the three R's, in order to boost white-collar wages in general?
Computing is an ever-increasingly intrinsic part of life, and people need to understand it at
all levels. It is not just unfair, but tantamount to neglect, to fail to teach children all the
skills they may require to cope as adults.
Having said that, I suspect that in another generation or two a good many lower-level coding jobs
will be redundant anyway, with such code being automatically generated, and "coders" at this level
will be little more than technicians setting various parameters. Even so, understanding the basics
behind computing is a part of understanding the world they live in, and every child needs that.
Suggesting that teaching coding is some kind of conspiracy to force wages down is well, it makes
the moon-landing conspiracy looks sensible by comparison.
I think it is important to demystify advanced technology, I think that has importance in its own
right.Plus, schools should expose kids to things which may spark their interest. Not everyone
who does a science project goes on years later to get a PhD, but you'd think that it makes it
more likely. Same as giving a kid some music lessons. There is a big difference between serious
coding and the basic steps needed to automate a customer service team or a marketing program,
but the people who have some mastery over automation will have an advantage in many jobs. Advanced
machines are clearly going to be a huge part of our future. What should we do about it, if not
teach kids how to understand these tools?
This is like arguing that teaching kids to write is nothing more than a plot to flood the market
for journalists. Teaching first aid and CPR does not make everyone a doctor.
Coding is an essential skill for many jobs already: 50 years ago, who would have thought you needed
coders to make movies? Being a software engineer, a serious coder, is hard. IN fact, it takes
more than technical coding to be a software engineer: you can learn to code in a week. Software
Engineering is a four year degree, and even then you've just started a career. But depriving kids
of some basic insights may mean they won't have the basic skills needed in the future, even for
controlling their car and house. By all means, send you kids to a school that doesn't teach coding.
I won't.
Did you learn SNOBOL, or is Snowball a language I'm not familiar with? (Entirely possible, as
an American I never would have known Extended Mercury Autocode existed we're it not for a random
book acquisition at my home town library when I was a kid.)
The tide that is transforming technology jobs from "white collar professional" into "blue collar
industrial" is part of a larger global economic cycle.
Successful "growth" assets inevitably transmogrify into "value" and "income" assets as they
progress through the economic cycle. The nature of their work transforms also. No longer focused
on innovation; on disrupting old markets or forging new ones; their fundamental nature changes
as they mature into optimising, cost reducing, process oriented and most importantly of all --
dividend paying -- organisations.
First, the market invests. And then, .... it squeezes.
Immature companies must invest in their team; must inspire them to be innovative so that they
can take the creative risks required to create new things. This translates into high skills, high
wages and "white collar" social status.
Mature, optimising companies on the other hand must necessarily avoid risks and seek variance-minimising
predictability. They seek to control their human resources; to eliminate creativity; to to make
the work procedural, impersonal and soulless. This translates into low skills, low wages and "blue
collar" social status.
This is a fundamental part of the economic cycle; but it has been playing out on the global
stage which has had the effect of hiding some of its' effects.
Over the past decades, technology knowledge and skills have flooded away from "high cost" countries
and towards "best cost" countries at a historically significant rate. Possibly at the maximum
rate that global infrastructure and regional skills pools can support. Much of this necessarily
inhumane and brutal cost cutting and deskilling has therefore been hidden by the tide of outsourcing
and offshoring. It is hard to see the nature of the jobs change when the jobs themselves are changing
hands at the same time.
The ever tighter ratchet of dehumanising industrialisation; productivity and efficiency continues
apace, however, and as our global system matures and evens out, we see the seeds of what we have
sown sail home from over the sea.
Technology jobs in developed nations have been skewed towards "growth" activities since for
the past several decades most "value" and "income" activities have been carried out in developing
nations. Now, we may be seeing the early preparations for the diffusion of that skewed, uneven
and unsustainable imbalance.
The good news is that "Growth" activities are not going to disappear from the world. They just
may not be so geographically concentrated as they are today. Also, there is a significant and
attention-worthy argument that the re-balancing of skills will result in a more flexible and performant
global economy as organisations will better be able to shift a wider variety of work around the
world to regions where local conditions (regulation, subsidy, union activity etc...) are supportive.
For the individuals concerned it isn't going to be pretty. And of course it is just another
example of the race to the bottom that pits states and public sector purse-holders against one
another to win the grace and favour of globally mobile employers.
As a power play move it has a sort of inhumanly psychotic inevitability to it which is quite
awesome to observe.
I also find it ironic that the only way to tame the leviathan that is the global free-market
industrial system might actually be effective global governance and international cooperation
within a rules-based system.
Both "globalist" but not even slightly both the same thing.
not just coders, it put even IT Ops guys into this bin. Basically good old - so you are working
with computers sentence I used to hear a lot 10-15 years ago.
You can teach everyone how to code but it doesn't necessarily mean everyone will be able to work
as one. We all learn math but that doesn't mean we're all mathematicians. We all know how to write
but we're not all professional writers.
I have a graduate degree in CS and been to a coding bootcamp. Not everyone's brain is wired
to become a successful coder. There is a particular way how coders think. Quality of a product
will stand out based on these differences.
Very hyperbolic is to assume that the profit in those companies is done by decreasing wages. In
my company the profit is driven by ability to deliver products to the market. And that is limited
by number of top people (not just any coder) you can have.
You realise that the arts are massively oversupplied and that most artists earn very little, if
anything? Which is sort of like the situation the author is warning about. But hey, he knows nothing.
Congratulations, though, on writing one of the most pretentious posts I've ever read on CIF.
So you know kids, college age people and software developers who enjoy doing it in their leisure
time? Do you know any middle aged mothers, fathers, grandparents who enjoy it and are not
software developers?
Sorry, I don't see coding as a leisure pursuit that is going to take off
beyond a very narrow demographic and if it becomes apparent (as I believe it will) that there
is not going to be a huge increase in coding job opportunities then it will likely wither in schools
too, perhaps replaced by music lessons.
No, because software developer probably fail more often than they succeed. Building anything worthwhile
is an iterative process. And it's not just the compiler but the other devs, oyur designer, your
PM, all looking at your work.
It's not shallow or lazy. I also work at a tech company and it's pretty common to do that across
job fields. Even in HR marketing jobs, we hire students who can't point to an internship or other
kind of experience in college, not simply grades.
A lot of people do find it fun. I know many kids - high school and young college age - who code
in the leisure time because they find it pleasurable to make small apps and video games. I myself
enjoy it too. Your argument is like saying since you don't like to read books in your leisure
time, nobody else must.
The point is your analogy isn't a good one - people who learn to code can not only enjoy it
in their spare time just like music, but they can also use it to accomplish all kinds of basic
things. I have a friend who's a software developer who has used code to program his Roomba to
vacuum in a specific pattern and to play Candy Land with his daughter when they lost the spinner.
Creativity could be added to your list. Anyone can push a button but only a few can invent a new
one.
One company in the US (after it was taken over by a new owner) decided it was more profitable
to import button pushers from off-shore, they lost 7 million customers (gamers) and had to employ
more of the original American developers to maintain their high standard and profits.
So similar to 500k a year people going to university ( UK) now when it used to be 60k people a
year( 1980). There was never enough graduate jobs in 1980 so can't see where the sudden increase
in need for graduates has come from.
They aren't really crucial pieces of technology except for their popularity
It's early in the day for me, but this is the most ridiculous thing I've read so far, and I
suspect it will be high up on the list by the end of the day.
There's no technology that is "crucial" unless it's involved in food, shelter or warmth. The
rest has its "crucialness" decided by how widespread its use is, and in the case of those 3 languages,
the answer is "very".
You (or I) might not like that very much, but that's how it is.
My benchmark would be if the average new graduate in the discipline earns more or less than one
of the "professions", Law, medicine, Economics etc. The short answer is that they don't. Indeed,
in my experience of professions, many good senior SW developers, say in finance, are paid markedly
less than the marketing manager, CTO etc. who are often non-technical.
My benchmark is not "has a car, house etc." but what does 10, 15 20 years of experience in
the area generate as a relative income to another profession, like being a GP or a corporate solicitor
or a civil servant (which is usually the benchmark academics use for pay scaling). It is not to
denigrate, just to say that markets don't always clear to a point where the most skilled are the
highest paid.
I was also suggesting that even if you are not intending to work in the SW area, being able
to translate your imagination into a program that reflects your ideas is a nice life skill.
Your assumption has no basis in reality. In my experience, as soon as Clinton ramped up H1Bs,
my employer would invite 6 same college/degree/curriculum in for interviews, 5 citizen,
1 foreign student and default offer to foreign student without asking interviewers a single question
about the interview. Eventually, the skipped the farce of interviewing citizens all together.
That was in 1997, and it's only gotten worse. Wall St's been pretty blunt lately. Openly admits
replacing US workers for import labor, as it's the "easiest" way to "grow" the economy, even though
they know they are ousting citizens from their jobs to do so.
"People who get Masters and PhD's in computer science" Feed western universities money, for degree
programs that would otherwise not exist, due to lack of market demand. "someone has a Bachelor's
in CS" As citizens, having the same college/same curriculum/same grades, as foreign grad. But
as citizens, they have job market mobility, and therefore are shunned. "you can make something
real and significant on your own" If someone else is paying your rent, food and student loans
while you do so.
While true, it's not the coders' fault. The managers and execs above them have intentionally created
an environment where these things are secondary. What's primary is getting the stupid piece of
garbage out the door for Q profit outlook. Ship it amd patch it.
Do most people find it fun? I can code. I don't find it 'fun'. Thirty years ago as a young graduate
I might have found it slightly fun but the 'fun' wears off pretty quick.
In my estimation PHP is an utter abomination. Python is just a little better but still very bad.
Ruby is a little better but still not at all good.
Languages like PHP, Python and JS are popular for banging out prototypes and disposable junk,
but you greatly overestimate their importance. They aren't really crucial pieces of technology
except for their popularity and while they won't disappear they won't age well at all. Basically
they are big long-lived fads. Java is now over 20 years old and while Java 8 is not crucial, the
JVM itself actually is crucial. It might last another 20 years or more. Look for more projects
like Ceylon, Scala and Kotlin. We haven't found the next step forward yet, but it's getting more
interesting, especially around type systems.
A strong developer will be able to code well in a half dozen languages and have fairly decent
knowledge of a dozen others. For me it's been many years of: Z80, x86, C, C++, Java. Also know
some Perl, LISP, ANTLR, Scala, JS, SQL, Pascal, others...
This makes people like me with 35 years of experience shipping products on deadlines up and down
every stack (from device drivers and operating systems to programming languages, platforms and
frameworks to web, distributed computing, clusters, big data and ML) so much more valuable. Been
there, done that.
It's just not true. In SV there's this giant vacuum created by Apple, Google, FB, etc. Other good
companies struggle to fill positions. I know from being on the hiring side at times.
Plenty of people? I don't know of a single person outside of my work which is teaming with programmers.
Not a single friend, not my neighbours, not my wife or her extended family, not my parents. Plenty
of people might do it but most people don't.
Agreed: by gifted I did not meant innate. It's more of a mix of having the interest, the persistence,
the time, the opportunity and actually enjoying that kind of challenge.
While some of those
things are to a large extent innate personality traits, others are not and you don't need max
of all of them, you just need enough to drive you to explore that domain.
That said, somebody that goes into coding purelly for the money and does it for the money alone
is extremely unlikelly to become an exceptional coder.
I'm as senior as they get and have interviewed quite a lot of programmers for several positions,
including for Technical Lead (in fact, to replace me) and so far my experience leads me to believe
that people who don't have a knack for coding are much less likely to expose themselves to many
different languages and techniques, and also are less experimentalist, thus being far less likely
to have those moments of transcending merely being aware of the visible and obvious to discover
the concerns and concepts behind what one does. Without those moments that open the door to the
next Universe of concerns and implications, one cannot do state transitions such as Coder to Technical
Designer or Technical Designer to Technical Architect.
Sure, you can get the title and do the things from the books, but you will not get WHY are
those things supposed to work (and when they will not work) and thus cannot adjust to new conditions
effectively and will be like a sailor that can't sail away from sight of the coast since he can't
navigate.
All this gets reflected in many things that enhance productivity, from the early ability to
quickly piece together solutions for a new problem out of past solutions for different problems
to, later, conceiving software architecture designs fittted to the typical usage pattern in the
industry for which the software is going to be made.
From the way our IT department is going, needing millions of coders is not the future. It'll be
a minority of developers at the top, and an army of low wage monkeys at the bottom who can troubleshoot
from a script - until AI comes along that can code faster and more accurately.
Interesting piece that's fundamentally flawed. I'm a software engineer myself. There is a reason
a University education of a minimum of three years is the base line for a junior developer or
'coder'.
Software engineering isn't just writing code. I would say 80% of my time is spent designing
and structuring software before I even touch the code.
Explaining software engineering as a discipline at a high level to people who don't understand
it is simple.
Most of us who learn to drive learn a few basics about the mechanics of a car. We know that
brake pads need to be replaced, we know that fuel is pumped into an engine when we press the gas
pedal. Most of us know how to change a bulb if it blows.
The vast majority of us wouldn't be able to replace a head gasket or clutch though. Just knowing
the basics isn't enough to make you a mechanic.
Studying in school isn't enough to produce software engineers. Software engineering isn't just
writing code, it's cross discipline. We also need to understand the science behind the computer,
we need too understand logic, data structures, timings, how to manage memory, security, how databases
work etc.
A few years of learning at school isn't nearly enough, a degree isn't enough on its own due
to the dynamic and ever evolving nature of software engineering. Schools teach technology that
is out of date and typically don't explain the science very well.
This is why most companies don't want new developers, they want people with experience and
multiple skills.
Programming is becoming cool and people think that because of that it's easy to become a skilled
developer. It isn't. It takes time and effort and most kids give up.
French was on the national curriculum when I was at school. Most people including me can't
hold a conversation in French though.
Ultimately there is a SKILL shortage. And that's because skill takes a long time, successes
and failures to acquire. Most people just give up.
This article is akin to saying 'schools are teaching basic health to reduce the wages of Doctors'.
It didn't happen.
There is a difference. When you teach people music you teach a skill that can be used for a lifetimes
enjoyment. One might sit at a piano in later years and play. One is hardly likely to 'do a bit
of coding' in ones leisure time.
The other thing is how good are people going to get at coding and how long will they retain
the skill if not used? I tend to think maths is similar to coding and most adults have pretty
terrible maths skills not venturing far beyond arithmetic. Not many remember how to solve a quadratic
equation or even how to rearrange some algebra.
One more thing is we know that if we teach people music they will find a use for it, if only
in their leisure time. We don't know that coding will be in any way useful because we don't know
if there will be coding jobs in the future. AI might take over coding but we know that AI won't
take over playing piano for pleasure.
If we want to teach logical thinking then I think maths has always done this and we should
make sure people are better at maths.
Am I missing something here? Being able to code is a skill that is a useful addition to the skill
armoury of a youngster entering the work place. Much like reading, writing, maths... Not only
is it directly applicable and pervasive in our modern world, it is built upon logic.
The important point is that American schools are not ONLY teaching youngsters to code, and
producing one dimensional robots... instead coding makes up one part of their overall skill set.
Those who wish to develop their coding skills further certainly can choose to do so. Those who
specialise elsewhere are more than likely to have found the skills they learnt whilst coding useful
anyway.
I struggle to see how there is a hidden capitalist agenda here. I would argue learning the
basics of coding is simply becoming seen as an integral part of the school curriculum.
The word "coding" is shorthand for "computer programming" or "software development" and it masks
the depth and range of skills that might be required, depending on the application.
This subtlety is lost, I think, on politicians and perhaps the general public. Asserting that
teaching lots of people to code is a sneaky way to commodotise an industry might have some truth
to it, but remember that commodotisation (or "sharing and re-use" as developers might call it)
is nothing new. The creation of freely available and re-usable software components and APIs has
driven innovation, and has put much power in the hands of developers who would not otherwise have
the skill or time to tackle such projects.
There's nothing to fear from teaching more people to "code", just as there's nothing to fear
from teaching more people to "play music". These skills simply represent points on a continuum.
There's room for everyone, from the kid on a kazoo all the way to Coltrane at the Village Vanguard.
I taught CS. Out of around 100 graduates I'd say maybe 5 were reasonable software engineers.
The rest would be fine in tech support or other associated trades, but not writing software. Its
not just a set of trainable skills, its a set of attitudes and ways of perceiving and understanding
that just aren't that common.
I can't understand the rush to teach coding in schools. First of all I don't think we are going
to be a country of millions of coders and secondly if most people have the skills then coding
is hardly going to be a well paid job. Thirdly you can learn coding from scratch after school
like people of my generation did. You could argue that it is part of a well rounded education
but then it is as important for your career as learning Shakespeare, knowing what an oxbow lake
is or being able to do calculus: most jobs just won't need you to know.
While you roll on the floor laughing, these countries will slowly but surely get their act together.
That is how they work. There are top quality coders over there and they will soon promoted into
a position to organise the others.
You are probably too young to remember when people laughed at electronic products when they
were made in Japan then Taiwan. History will repeat it's self.
Yes it's ironic and no different here in the UK. Traditionally Labour was the party focused on
dividing the economic pie more fairly, Tories on growing it for the benefit of all. It's now completely
upside down with Tories paying lip service to the idea of pay rises but in reality supporting
this deflationary race to the bottom, hammering down salaries and so shrinking discretionary spending
power which forces price reductions to match and so more pressure on employers to cut costs ...
ad infinitum.
Labour now favour policies which would cause an expansion across the entire economy through pay
rises and dramatically increased investment with perhaps more tolerance of inflation to achieve
it.
Not surprising if they're working for a company that is cold-calling people - which should be
banned in my opinion. Call centres providing customer support are probably less abuse-heavy since
the customer is trying to get something done.
I taught myself to code in 1974. Fortran, COBOL were first. Over the years as a aerospace engineer
I coded in numerous languages ranging from PLM, Snowball, Basic, and more assembly languages than
I can recall, not to mention deep down in machine code on more architectures than most know even
existed. Bottom line is that coding is easy. It doesn't take a genius to code, just another way
of thinking. Consider all the bugs in the software available now. These "coders", not sufficiently
trained need adult supervision by engineers who know what they are doing for computer systems
that are important such as the electrical grid, nuclear weapons, and safety critical systems.
If you want to program toy apps then code away, if you want to do something important learn engineering
AND coding.
Laughable. It takes only an above-average IQ to code. Today's coders are akin to the auto mechanics
of the 1950s where practically every high school had auto shop instruction . . . nothing but a
source of cheap labor for doing routine implementations of software systems using powerful code
libraries built by REAL software engineers.
I disagree. Technology firms are just like other firms. Why then the collusion not to pay more
to workers coming from other companies? To believe that they are anything else is naive. The author
is correct. We need policies that actually grow the economy and not leaders who cave to what the
CEOs want like Bill Clinton did. He brought NAFTA at the behest of CEOs and all it ended up doing
was ripping apart the rust belt and ushering in Trump.
So the media always needs some bad guys to write about, and this month they seem to have it in
for the tech industry. The article is BS. I interview a lot of people to join a large tech company,
and I can guarantee you that we aren't trying to find cheaper labor, we're looking for the best
talent.
I know that lots of different jobs have been outsourced to low cost areas, but these days the
top companies are instead looking for the top talent globally.
I see this article as a hit piece against Silicon Valley, and it doesn't fly in the face of
the evidence.
This has got to be the most cynical and idiotic social interest piece I have ever read in the
Guardian. Once upon a time it was very helpful to learn carpentry and machining, but now, even
if you are learning those, you will get a big and indispensable headstart if you have some logic
and programming skills. The fact is, almost no matter what you do, you can apply logic and programming
skills to give you an edge. Even journalists.
Yup, rings true. I've been in hi tech for over 40 years and seen the changes. I was in Silicon
Valley for 10 years on a startup. India is taking over, my current US company now has a majority
Indian executive and is moving work to India. US politicians push coding to drive down wages to
Indian levels.
On the bright side I am old enough and established enough to quit tomorrow,
its someone else's problem, but I still despise those who have sold us out, like the Clintons,
the Bushes, the Googoids, the Zuckerboids.
Sure markets existed before governments, but capitalism didn't, can't in fact. It needs the organs
of state, the banking system, an education system, and an infrastructure.
Then teach them other things but not coding! Here in Australia every child of school age has to
learn coding. Now tell me that everyone of them will need it? Look beyond computers as coding
will soon be automated just like every other job.
If you have never coded then you will not appreciate how labour intensive it is. Coders effectively
use line editors to type in, line by line, the instructions. And syntax is critical; add a comma
when you meant a semicolon and the code doesn't work properly. Yeah, we use frameworks and libraries
of already written subroutines, but, in the end, it is all about manually typing in the code.
Which is an expensive way of doing things (hence the attractions of 'off-shoring' the coding
task to low cost economies in Asia).
And this is why teaching kids to code is a waste of time.
Already, AI based systems are addressing the task of interpreting high level design models
and simply generating the required application.
One of the first uses templates and a smart chatbot to enable non-tech business people to build
their websites. By describe in non-coding terms what they want, the chatbot is able to assemble
the necessary components and make the requisite template amendments to build a working website.
Much cheaper than hiring expensive coders to type it all in manually.
It's early days yet, but coding may well be one of the big losers to AI automation along with
all those back office clerical jobs.
Teaching kids how to think about design rather than how to code would be much more valuable.
Thick-skinned? Just because you might get a few error messages from the compiler? Call centre
workers have to put up with people telling them to fuck off eight hours a day.
Spot on. Society will never need more than 1% of its people to code. We will need far more garbage
men. There are only so many (relatively) good jobs to go around and its about competing to get
them.
I'm a professor (not of computer science) and yet, I try to give my students a basic understanding
of algorithms and logic, to spark an interest and encourage them towards programming. I have no
skin in the game, except that I've seen unemployment first-hand, and want them to avoid it. The
best chance most of them have is to learn to code.
Educating youth does not drive wages down. It drives our economy up. China, India, and other
countries are training youth in programming skills. Educating our youth means that they will
be able to compete globally.
This is the standard GOP stand that we don't need to educate our youth, but instead fantasize
about high-paying manufacturing jobs miraculously coming back.
Many jobs, including new manufacturing jobs have an element of coding because they are
automated. Other industries require coding skills to maintain web sites and keep computer
systems running. Learning coding skills opens these doors.
Coding teaches logic, an essential thought process. Learning to code, like learning anything,
increases the brains ability to adapt to new environments which is essential to our survival
as a species.
We must invest in educating our youth.
"Contrary to public perception, the economy doesn't actually need that many more
programmers." This really looks like a straw man introducing a red herring. A skill can be
extremely valuable for those who do not pursue it as a full time profession.
The economy doesn't actually need that many more typists, pianists, mathematicians,
athletes, dietitians. So, clearly, teaching typing, the piano, mathematics, physical
education, and nutrition is a nefarious plot to drive down salaries in those professions.
None of those skills could possibly enrich the lives or enhance the productivity of builders,
lawyers, public officials, teachers, parents, or store managers.
A study by the Economic Policy Institute found that the supply of American college
graduates with computer science degrees is 50% greater than the number hired into the tech
industry each year.
You're assuming that all those people are qualified to work in software because they have
a piece of paper that says so, but that's not a valid assumption. The quality of computer
science degree courses is generally poor, and most people aren't willing or able to teach
themselves. Universities are motivated to award degrees anyway because if they only awarded
degrees to students who are actually qualified then that would reflect very poorly on their
quality of teaching.
A skills shortage doesn't mean that everyone who claims to have a skill gets hired and
there are still some jobs left over that aren't being done. It means that employers are
forced to hire people who are incompetent in order to fill all their positions. Many people
who get jobs in programming can't really do it and do nothing but create work for everyone
else. That's why most of the software you use every day doesn't work properly. That's why
competent programmers' salaries are still high in spite of the apparently large number of
"qualified" people who aren't employed as programmers.
"... You can learn to code, but that doesn't mean you'll be good at it. There will be a few who excel but most will not. This isn't a reflection on them but rather the reality of the situation. In any given area some will do poorly, more will do fairly, and a few will excel. The same applies in any field. ..."
"... Oh no, there's loads of people who say they're coders, who have on their CV that they're coders, that have been paid to be coders. Loads of them. Amazingly, about 9 out of 10 of them, experienced coders all, spent ages doing it, not a problem to do it, definitely a coder, not a problem being "hands on"... can't actually write working code when we actually ask them to. ..."
"... I feel for your brother, and I've experienced the exact same BS "test" that you're describing. However, when I said "rudimentary coding exam", I wasn't talking about classic fiz-buz questions, Fibonacci problems, whiteboard tests, or anything of the sort. We simply ask people to write a small amount of code that will solve a simple real world problem. Something that they would be asked to do if they got hired. We let them take a long time to do it. We let them use Google to look things up if they need. You would be shocked how many "qualified applicants" can't do it. ..."
"... "...coding is not magic. It is a technical skill, akin to carpentry. " I think that is a severe underestimation of the level of expertise required to conceptualise and deliver robust and maintainable code. The complexity of integrating software is more equivalent to constructing an entire building with components of different materials. If you think teaching coding is enough to enable software design and delivery then good luck. ..."
"... Being able to write code and being able to program are two very different skills. In language terms its the difference between being able to read and write (say) English and being able to write literature; obviously you need a grasp of the language to write literature but just knowing the language is not the same as being able to assemble and marshal thought into a coherent pattern prior to setting it down. ..."
"... What a dumpster argument. I am not a programmer or even close, but a basic understanding of coding has been important to my professional life. Coding isn't just about writing software. Understanding how algorithms work, even simple ones, is a general skill on par with algebra. ..."
"... Never mind that a good education is clearly one of the most important things you can do for a person to improve their quality of life wherever they live in the world. It's "neoliberal," so we better hate it. ..."
"... A lot of resumes come across my desk that look qualified on paper, but that's not the same thing as being able to do the job. Secondarily, while I agree that one day our field might be replaced by automation, there's a level of creativity involved with good software engineering that makes your carpenter comparison a bit flawed. ..."
Agreed, to many people 'coding' consists of copying other people's JavaScript snippets from
StackOverflow... I tire of the many frauds in the business...
You can learn to code, but that doesn't mean you'll be good at it. There will be a few who
excel but most will not. This isn't a reflection on them but rather the reality of the
situation. In any given area some will do poorly, more will do fairly, and a few will excel.
The same applies in any field.
Oh, rubbish. I'm in the process of retiring from my job as an Android software designer so
I'm tasked with hiring a replacement for my organisation. It pays extremely well, the work is
interesting, and the company is successful and serves an important worldwide industry.
Still, finding highly-qualified people is hard and they get snatched up in mid-interview
because the demand is high. Not only that but at these pay scales, we can pretty much expect
the Guardian will do yet another article about the unconscionable gap between what rich,
privileged techies like software engineers make and everyone else.
Really, we're damned if we do and damned if we don't. If tech workers are well-paid we're
castigated for gentrifying neighbourhoods and living large, and yet anything that threatens
to lower what we're paid produces conspiracy-theory articles like this one.
I learned to cook in school. Was there a shortage of cooks? No. Did I become a professional
cook? No. but I sure as hell would not have missed the skills I learned for the world, and I
use them every day.
Oh no, there's loads of people who say they're coders, who have on their CV that they're
coders, that have been paid to be coders. Loads of them.
Amazingly, about 9 out of 10 of them, experienced coders all, spent ages doing it, not a
problem to do it, definitely a coder, not a problem being "hands on"... can't actually
write working code when we actually ask them to.
I feel for your brother, and I've experienced the exact same BS "test" that you're
describing. However, when I said "rudimentary coding exam", I wasn't talking about classic
fiz-buz questions, Fibonacci problems, whiteboard tests, or anything of the sort. We simply
ask people to write a small amount of code that will solve a simple real world problem.
Something that they would be asked to do if they got hired. We let them take a long time to
do it. We let them use Google to look things up if they need. You would be shocked how many
"qualified applicants" can't do it.
The demonization of Silicon Valley is clearly the next place to put all blame. Look what
"they" did to us: computers, smart phones, HD television, world-wide internet, on and on. Get
a rope!
I moved there in 1978 and watched the orchards and trailer parks on North 1st St. of San
Jose transform into a concrete jungle. There used to be quite a bit of semiconductor
equipment and device manufacturing in SV during the 80s and 90s. Now quite a few buildings
have the same name : AVAILABLE. Most equipment and device manufacturing has moved to
Asia.
Programming started with binary, then machine code (hexadecimal or octal) and moved to
assembler as a compiled and linked structure. More compiled languages like FORTRAN, BASIC,
PL-1, COBOL, PASCAL, C (and all its "+'s") followed making programming easier for the less
talented.
Now the script based languages (HTML, JAVA, etc.) are even higher level and
accessible to nearly all. Programming has become a commodity and will be priced like milk,
wheat, corn, non-unionized workers and the like. The ship has sailed on this activity as a
career.
"intelligence, creativity, diligence, communication ability, or anything else that a job"
None of those are any use if, when asked to turn your intelligent, creative, diligent,
communicated idea into some software, you perform as well as most candidates do at simple
coding assessments... and write stuff that doesn't work.
At its root, the campaign for code education isn't about giving the next generation a
shot at earning the salary of a Facebook engineer. It's about ensuring those salaries no
longer exist, by creating a source of cheap labor for the tech industry.
Of course the writer does not offer the slightest shred of evidence to support the idea
that this is the actual goal of these programs. So it appears that the tinfoil-hat
conspiracy brigade on the Guardian is operating not only below the line, but above it,
too.
The fact is that few of these students will ever become software engineers (which,
incidentally, is my profession) but programming skills are essential in many professions for
writing little scripts to automate various tasks, or to just understand 21st century
technology.
Sadly this is another article by a partial journalist who knows nothing about the software
industry, but hopes to subvert what he had read somewhere to support a position he had
already assumed. As others had said, understanding coding had already become akin to being able to use a
pencil. It is a basic requirement of many higher level roles.
But knowing which end of a pencil to put on the paper (the equivalent of the level of
coding taught in schools) isn't the same as being an artist. Moreover anyone who knows the field recognises that top coders are gifted, they embody
genius. There are coding Caravaggio's out there, but few have the experience to know that. No
amount of teaching will produce high level coders from average humans, there is an intangible
something needed, as there is in music and art, to elevate the merely good to genius.
All to say, however many are taught the basics, it won't push down the value of the most
talented coders, and so won't reduce the costs of the technology industry in any meaningful
way as it is an industry, like art, that relies on the few not the many.
Not all of those children will want to become programmers but at least the barrier to
entry,
- for more to at least experience it - will be lower.
Teaching music to only the children whose parents can afford music tuition means than
society misses out on a greater potential for some incredible gifted musicians to shine
through.
Moreover, learning to code really means learning how to wrangle with the practical
application of abstract concepts, algorithms, numerical skills, logic, reasoning, etc. which
are all transferrable skills some of which are not in the scope of other classes, certainly
practically.
Like music, sport, literature etc. programming a computer, a website, a device, a smartphone
is an endeavour that can be truly rewarding as merely a pastime, and similarly is limited
only by ones imagination.
"...coding is not magic. It is a technical skill, akin to carpentry. " I think that is a
severe underestimation of the level of expertise required to conceptualise and deliver robust
and maintainable code. The complexity of integrating software is more equivalent to
constructing an entire building with components of different materials. If you think teaching
coding is enough to enable software design and delivery then good luck.
Yeah, but mania over coding skills inevitably pushes over skills out of the curriculum (or
deemphasizes it). Education is zero-sum in that there's only so much time and energy to
devote to it. Hence, you need more than vague appeals to "enhancement," especially given the
risks pointed out by the author.
"Talented coders will start new tech businesses and create more jobs."
That could be argued for any skill set, including those found in the humanities and social
sciences likely to pushed out by the mania over coding ability. Education is zero-sum: Time
spent on one subject is time that invariably can't be spent learning something else.
"If they can't literally fix everything let's just get rid of them, right?"
That's a strawman. His point is rooted in the recognition that we only have so much time,
energy, and money to invest in solutions. One's that feel good but may not do anything
distract us for the deeper structural issues in our economy. The probably with thinking
"education" will fix everything is that it leaves the status quo unquestioned.
Being able to write code and being able to program are two very different skills. In language
terms its the difference between being able to read and write (say) English and being able to
write literature; obviously you need a grasp of the language to write literature but just
knowing the language is not the same as being able to assemble and marshal thought into a
coherent pattern prior to setting it down.
To confuse things further there's various levels of skill that all look the same to the
untutored eye. Suppose you wished to bridge a waterway. If that waterway was a narrow ditch
then you could just throw a plank across. As the distance to be spanned got larger and larger
eventually you'd have to abandon intuition for engineering and experience. Exactly the same
issues happen with software but they're less tangible; anyone can build a small program but a
complex system requires a lot of other knowledge (in my field, that's engineering knowledge
-- coding is almost an afterthought).
Its a good idea to teach young people to code but I wouldn't raise their expectations of
huge salaries too much. For children educating them in wider, more general, fields and
abstract activities such as music will pay off huge dividends, far more than just teaching
them whatever the fashionable language du jour is. (...which should be Logo but its too
subtle and abstract, it doesn't look "real world" enough!).
I don't see this is an issue. Sure, there could be ulterior motives there, but anyone who
wants to still be employed in 20 years has to know how to code . It is not that everyone will
be a coder, but their jobs will either include part-time coding or will require understanding
of software and what it can and cannot do. AI is going to be everywhere.
What a dumpster argument. I am not a programmer or even close, but a basic understanding of
coding has been important to my professional life. Coding isn't just about writing software.
Understanding how algorithms work, even simple ones, is a general skill on par with algebra.
But is isn't just about coding for Tarnoff. He seems to hold education in contempt
generally. "The far-fetched premise of neoliberal school reform is that education can mend
our disintegrating social fabric." If they can't literally fix everything let's just get rid
of them, right?
Never mind that a good education is clearly one of the most important things
you can do for a person to improve their quality of life wherever they live in the world.
It's "neoliberal," so we better hate it.
I'm not going to argue that the goal of mass education isn't to drive down wages, but the
idea that the skills gap is a myth doesn't hold water in my experience. I'm a software
engineer and manager at a company that pays well over the national average, with great
benefits, and it is downright difficult to find a qualified applicant who can pass a
rudimentary coding exam.
A lot of resumes come across my desk that look qualified on paper,
but that's not the same thing as being able to do the job. Secondarily, while I agree that
one day our field might be replaced by automation, there's a level of creativity involved
with good software engineering that makes your carpenter comparison a bit flawed.
"... I do think it's peculiar that Silicon Valley requires so many H1B visas... 'we can't find the
talent here' is the main excuse ..."
"... This is interesting. Indeed, I do think there is excess supply of software programmers. ..."
"... Well, it is either that or the kids themselves who have to pay for it and they are even less
prepared to do so. Ideally, college education should be tax payer paid but this is not the case in the
US. And the employer ideally should pay for the job related training, but again, it is not the case
in the US. ..."
"... Plenty of people care about the arts but people can't survive on what the arts pay. That was
pretty much the case all through human history. ..."
"... I was laid off at your age in the depths of the recent recession and I got a job. ..."
"... The great thing about software , as opposed to many other jobs, is that it can be done at home
which you're laid off. Write mobile (IOS or Android) apps or work on open source projects and get stuff
up on github. I've been to many job interviews with my apps loaded on mobile devices so I could show
them what I've done. ..."
"... Schools really can't win. Don't teach coding, and you're raising a generation of button-pushers.
Teach it, and you're pandering to employers looking for cheap labour. Unions in London objected to children
being taught carpentry in the twenties and thirties, so it had to be renamed "manual instruction" to
get round it. Denying children useful skills is indefensible. ..."
I do think it's peculiar that Silicon Valley requires so many H1B visas... 'we can't find
the talent here' is the main excuse, though many 'older' (read: over 40) native-born tech
workers will tell your that's plenty of talent here already, but even with the immigration hassles,
H1B workers will be cheaper overall...
This is interesting. Indeed, I do think there is excess supply of software programmers.
There is only a modest number of decent jobs, say as an algorithms developer in finance,
general architecture of complex systems or to some extent in systems security. However, these
jobs are usually occupied and the incumbents are not likely to move on quickly. Road blocks are
also put up by creating sub networks of engineers who ensure that some knowledge is not ubiquitous.
Most very high paying jobs in the technology sector are in the same standard upper management
roles as in every other industry.
Still, the ability to write a computer program in an enabler, knowing how it works means you
have an ability to imagine something and make it real. To me it is a bit like language, some people
can use language to make more money than others, but it is still important to be able to have
a basic level of understanding.
And yet I know a lot of people that has happened to. Better to replace a $125K a year programmer
with one who will do the same, or even less, job for $50K.
This could backfire if the programmers don't find the work or pay to match their expectations...
Programmers, after all tend to make very good hackers if their minds are turned to it.
While I like your idea of what designing a computer program involves, in my nearly 40
years experience as a programmer I have rarely seen this done.
How else can you do it?
Java is popular because it's a very versatile language - On this list it's the most popular
general-purpose programming language. (Above it javascript is just a scripting language and HTML/CSS
aren't even programming languages)
https://fossbytes.com/most-used-popular-programming-languages/
... and below it you have to go down to C# at 20% to come to another general-purpose language,
and even that's a Microsoft house language.
Also the "correct" choice of programming languages is also based on how many people in the
shop know it so they maintain code that's written in it by someone else.
> job-specific training is completely different. What a joke to persuade public school districts
to pick up the tab on job training.
Well, it is either that or the kids themselves who have to pay for it and they are even
less prepared to do so. Ideally, college education should be tax payer paid but this is not the
case in the US. And the employer ideally should pay for the job related training, but again, it
is not the case in the US.
> The bigger problem is that nobody cares about the arts, and as expensive as education
is, nobody wants to carry around a debt on a skill that won't bring in the buck
Plenty of people care about the arts but people can't survive on what the arts pay. That
was pretty much the case all through human history.
Since newspaper are consolidating and cutting jobs gotta clamp down on colleges offering BA degrees,
particularly in English Literature and journalism.
This article focuses on the US schools, but I can imagine it's the same in the UK. I don't think
these courses are going to be about creating great programmers capable of new innovations as much
as having a work force that can be their own IT Help Desk.
They'll learn just enough in these classes to do that.
Then most companies will be hiring for other jobs, but want to make sure you have the IT skills
to serve as your own "help desk" (although they will get no salary for their IT work).
I find that quite remarkable - 40 years ago you must have been using assembler and with hardly
any memory to work with. If you blitzed through that without applying the thought processes described,
well...I'm surprised.
I was laid off at your age in the depths of the recent recession and I got a job. As
I said in another posting, it usually comes down to fresh skills and good personal references
who will vouch for your work-habits and how well you get on with other members of your team.
The great thing about software , as opposed to many other jobs, is that it can be done
at home which you're laid off. Write mobile (IOS or Android) apps or work on open source projects
and get stuff up on github. I've been to many job interviews with my apps loaded on mobile devices
so I could show them what I've done.
The situation has a direct comparison to today. It has nothing to do with land. There was a certain
amount of profit making work and not enough labour to satisfy demand. There is currently a certain
amount of profit making work and in many situations (especially unskilled low paid work) too much
labour.
So, is teaching people English or arithmetic all about reducing wages for the literate and numerate?
Or is this the most obtuse argument yet for avoiding what everyone in tech knows - even more
blatantly than in many other industries, wages are curtailed by offshoring; and in the US, by
having offshoring centres on US soil.
Well, speaking as someone who spends a lot of time trying to find really good programmers... frankly
there aren't that many about. We take most of ours from Eastern Europe and SE Asia, which is quite
expensive, given the relocation costs to the UK. But worth it.
So, yes, if more British kids learnt about coding, it might help a bit. But not much; the real
problem is that few kids want to study IT in the first place, and that the tuition standards in
most UK universities are quite low, even if they get there.
Robots, or AI, are already making us more productive. I can write programs today in an afternoon
that would have taken me a week a decade or two ago.
I can create a class and the IDE will take care of all the accessors, dependencies, enforce
our style-guide compliance, stub-in the documentation ,even most test cases, etc, and all I have
to write is very-specific stuff required by my application - the other 90% is generated for me.
Same with UI/UX - stubs in relevant event handlers, bindings, dependencies, etc.
Programmers are a zillion times more productive than in the past, yet the demand keeps growing
because so much more stuff in our lives has processors and code. Your car has dozens of processors
running lots of software; your TV, your home appliances, your watch, etc.
Schools really can't win. Don't teach coding, and you're raising a generation of button-pushers.
Teach it, and you're pandering to employers looking for cheap labour. Unions in London objected
to children being taught carpentry in the twenties and thirties, so it had to be renamed "manual
instruction" to get round it. Denying children useful skills is indefensible.
Getting children to learn how to write code, as part of core education, will be the first step
to the long overdue revolution. The rest of us will still have to stick to burning buildings down
and stringing up the aristocracy.
did you misread? it seemed like he was emphasizing that learning to code, like learning art (and
sports and languages), will help them develop skills that benefit them in whatever profession
they choose.
While I like your idea of what designing a computer program involves, in my nearly 40 years experience
as a programmer I have rarely seen this done. And, FWIW, IMHO choosing the tool (programming language)
might reasonably be expected to follow designing a solution, in practice this rarely happens.
No, these days it's Java all the way, from day one.
I'd advise parents that the classes they need to make sure their kids excel in are acting/drama.
There is no better way to getting that promotion or increasing your pay like being a skilled actor
in the job market. It's a fake it till you make it deal.
This really has to be one of the silliest articles I read here in a very long time.
People, let your children learn to code. Even more, educate yourselves and start to code just
for the fun of it - look at it like a game.
The more people know how to code the less likely they are to understand how stuff works. If you
were ever frustrated by how impossible it seems to shop on certain websites, learn to code and
you will be frustrated no more. You will understand the intent behind the process.
Even more, you will understand the inherent limitations and what is the meaning of safety. You
will be able to better protect yourself in a real time connected world.
Learning to code won't turn your kid into a programmer, just like ballet or piano classes won't
mean they'll ever choose art as their livelihood. So let the children learn to code and learn
along with them
Tipping power to employers in any profession by oversupply of labour is not a good thing. Bit
of a macabre example here but...After the Black Death in the middle ages there was a huge under
supply of labour. It produced a consistent rise in wages and conditions and economic development
for hundreds of years after this. Not suggesting a massive depopulation. But you can achieve the
same effects by altering the power balance. With decades of Neoliberalism, the employers side
of the power see-saw is sitting firmly in the mud and is producing very undesired results for
the vast majority of people.
I am 59, and it is not just the age aspect it is the money aspect. They know you have experience
and expectations, and yet they believe hiring someone half the age and half the price, times 2
will replace your knowledge. I have been contracting in IT for 30 years, and now it is obvious
it is over. Experience at some point no longer mitigates age. I think I am at that point now.
Dear, dear, I know, I know, young people today . . . just not as good as we were. Everything is
just going down the loo . . . Just have a nice cuppa camomile (or chamomile if you're a Yank)
and try to relax ... " hey you kids, get offa my lawn !"
There are good reasons to teach coding. Too many of today's computer users are amazingly unaware
of the technology that allows them to send and receive emails, use their smart phones, and use
websites. Few understand the basic issues involved in computer security, especially as it relates
to their personal privacy. Hopefully some introductory computer classes could begin to remedy
this, and the younger the students the better.
Security problems are not strictly a matter of coding.
Security issues persist in tech. Clearly that is not a function of the size of the workforce.
I propose that it is a function of poor management and design skills. These are not taught in
any programming class I ever took. I learned these on the job and in an MBA program, and because
I was determined.
Don't confuse basic workforce training with an effective application of tech to authentic needs.
How can the "disruption" so prized in today's Big Tech do anything but aggravate our social
problems? Tech's disruption begins with a blatant ignorance of and disregard for causes, and believes
to its bones that a high tech app will truly solve a problem it cannot even describe.
indeed that idea has been around as long as cobol and in practice has just made things worse,
the fact that many people outside of software engineering don;t seem to realise is that the coding
itself is a relatively small part of the job
so how many female and old software engineers are there who are unable to get a job, i'm one of
them at 55 finding it impossible to get a job and unlike many 'developers' i know what i'm doing
Training more people for an occupation will result in more people becoming qualified to perform
that occupation, irregardless of the fact that many will perform poorly at it. A CS degree is
no guarantee of competency, but it is one of the best indicators of general qualification we have
at the moment. If you can provide a better metric for analyzing the underlying qualifications
of the labor force, I'd love to hear it.
Regarding your anecdote, while interesting, it poor evidence when compared to the aggregate
statistical data analyzed in the EPI study.
Good grief. It's not job-specific training. You sound like someone who knows nothing about
computer programming.
Designing a computer program requires analysing the task; breaking it down into its components,
prioritising them and identifying interdependencies, and figuring out which parts of it can be
broken out and done separately. Expressing all this in some programming language like Java, C,
or C++ is quite secondary.
So once you learn to organise a task properly you can apply it to anything - remodeling a house,
planning a vacation, repairing a car, starting a business, or administering a (non-software) project
at work.
"... Thank you. The kids that spend high school researching independently and spend their nights hacking just for the love of it and getting a job without college are some of the most competent I've ever worked with. Passionless college grads that just want a paycheck are some of the worst. ..."
"... how about how new labor tried to sign away IT access in England to India in exchange for banking access there, how about the huge loopholes in bringing in cheap IT workers from elsewhere in the world, not conspiracies, but facts ..."
"... And I've never recommended hiring anyone right out of school who could not point me to a project they did on their own, i.e., not just grades and test scores. I'd like to see an IOS or Android app, or a open-source component, or utility or program of theirs on GitHub, or something like that. ..."
"... most of what software designers do is not coding. It requires domain knowledge and that's where the "smart" IDEs and AI coding wizards fall down. It will be a long time before we get where you describe. ..."
Instant feedback is one of the things I really like about programming, but it's also the
thing that some people can't handle. As I'm developing a program all day long the compiler is
telling me about build errors or warnings or when I go to execute it it crashes or produces
unexpected output, etc. Software engineers are bombarded all day with negative feedback and
little failures. You have to be thick-skinned for this work.
How is it shallow and lazy? I'm hiring for the real world so I want to see some real world
accomplishments. If the candidate is fresh out of university they can't point to work
projects in industry because they don't have any. But they CAN point to stuff they've done on
their own. That shows both motivation and the ability to finish something. Why do you object
to it?
Thank you. The kids that spend high school researching independently and spend their nights
hacking just for the love of it and getting a job without college are some of the most
competent I've ever worked with. Passionless college grads that just want a paycheck are some
of the worst.
There is a big difference between "coding" and programming. Coding for a smart phone app is a
matter of calling functions that are built into the device. For example, there are functions
for the GPS or for creating buttons or for simulating motion in a game. These are what we
used to call subroutines. The difference is that whereas we had to write our own subroutines,
now they are just preprogrammed functions. How those functions are written is of little or no
importance to today's coders.
Nor are they able to program on that level. Real programming
requires not only a knowledge of programming languages, but also a knowledge of the underlying
algorithms that make up actual programs. I suspect that "coding" classes operate on a quite
superficial level.
Its not about the amount of work or the amount of labor. Its about the comparative
availability of both and how that affects the balance of power, and that in turn affects the
overall quality of life for the 'majority' of people.
Most of this is not true. Peter Nelson gets it right by talking about breaking steps down and
thinking rationally. The reason you can't just teach the theory, however, is that humans
learn much better with feedback. Think about trying to learn how to build a fast car, but you
never get in and test its speed. That would be silly. Programming languages take the system
of logic that has been developed for centuries and gives instant feedback on the results.
It's a language of rationality.
This article is about the US. The tech industry in the EU is entirely different, and
basically moribund. Where is the EU's Microsoft, Apple, Google, Amazon, Oracle, Intel,
Facebook, etc, etc? The opportunities for exciting interesting work, plus the time and
schedule pressures that force companies to overlook stuff like age because they need a
particular skill Right Now, don't exist in the EU. I've done very well as a software engineer
in my 60's in the US; I cannot imagine that would be the case in the EU.
sorry but that's just not true, i doubt you are really programming still, or quasi programmer
but really a manager who like to keep their hand in, you certainly aren't busy as you've been
posting all over this cif. also why would you try and hire someone with such disparate
skillsets, makes no sense at all
oh and you'd be correct that i do have workplace issues, ie i have a disability and i also
suffer from depression, but that shouldn't bar me from employment and again regarding my
skills going stale, that again contradicts your statement that it's about
planning/analysis/algorithms etc that you said above ( which to some extent i agree with
)
Not at all, it's really egalitarian. If I want to hire someone to paint my portrait, the best
way to know if they're any good is to see their previous work. If they've never painted a
portrait before then I may want to go with the girl who has
Right? It's ridiculous. "Hey, there's this industry you can train for that is super valuable
to society and pays really well!"
Then Ben Tarnoff, "Don't do it! If you do you'll drive down wages for everyone else in the
industry. Build your fire starting and rock breaking skills instead."
how about how new labor tried to sign away IT access in England to India in exchange for
banking access there, how about the huge loopholes in bringing in cheap IT workers from
elsewhere in the world, not conspiracies, but facts
I think the difference between gifted and not is motivation. But I agree it's not innate. The
kid who stayed up all night in high school hacking into the school server to fake his coding
class grade is probably more gifted than the one who spent 4 years in college getting a BS in
CS because someone told him he could get a job when he got out.
I've done some hiring in my life and I always ask them to tell me about stuff they did on
their own.
As several people have pointed out, writing a computer program requires analyzing and
breaking down a task into steps, identifying interdependencies, prioritizing the order,
figuring out what parts can be organized into separate tasks that be done separately, etc.
These are completely independent of the language - I've been programming for 40 years in
everything from FORTRAN to APL to C to C# to Java and it's all the same. Not only that but
they transcend programming - they apply to planning a vacation, remodeling a house, or fixing
a car.
Neither coding nor having a bachelor's degree in computer science makes you a suitable job
candidate. I've done a lot of recruiting and interviews in my life, and right now I'm trying
to hire someone. And I've never recommended hiring anyone right out of school who
could not point me to a project they did on their own, i.e., not just grades and test scores.
I'd like to see an IOS or Android app, or a open-source component, or utility or program of
theirs on GitHub, or something like that.
That's the thing that distinguishes software from many other fields - you can do something
real and significant on your own. If you haven't managed to do so in 4 years of college
you're not a good candidate.
Within the next year coding will be old news and you will simply be able to describe
things in ur native language in such a way that the machine will be able to execute any set
of instructions you give it.
In a sense that's already true, as i noted elsewhere. 90% of the code in my projects (Java
and C# in their respective IDEs) is machine generated. I do relatively little "coding". But
the flaw in your idea is this: most of what software designers do is not coding. It requires
domain knowledge and that's where the "smart" IDEs and AI coding wizards fall down. It will
be a long time before we get where you describe.
Completely agree. At the highest levels there is more work that goes into managing complexity and making
sure nothing is missed than in making the wheels turn and the beepers beep.
I've actually interviewed people for very senior technical positions in Investment Banks who
had all the fancy talk in the world and yet failed at some very basic "write me a piece of
code that does X" tests.
Next hurdle on is people who have learned how to deal with certain situations and yet
don't really understand how it works so are unable to figure it out if you change the problem
parameters.
That said, the average coder is only slightly beyond this point. The ones who can take in
account maintenability and flexibility for future enhancements when developing are already a
minority, and those who can understand the why of software development process steps, design
software system architectures or do a proper Technical Analysis are very rare.
Hubris.
It's easy to mistake efficiency born of experience as innate talent. The difference
between a 'gifted coder' and a 'non gifted junior coder' is much more likely to be 10 or 15
years sitting at a computer, less if there are good managers and mentors involved.
Politicians love the idea of teaching children to 'code', because it sounds so modern, and
nobody could possible object... could they? Unfortunately it simply shows up their utter
ignorance of technical matters because there isn't a language called 'coding'. Computer
programming languages have changed enormously over the years, and continue to evolve. If you
learn the wrong language you'll be about as welcome in the IT industry as a lamp-lighter or a
comptometer operator.
The pace of change in technology can render skills and qualifications obsolete in a matter
of a few years, and only the very best IT employers will bother to retrain their staff - it's
much cheaper to dump them. (Most IT posts are outsourced through agencies anyway - those that
haven't been off-shored. )
And this isn't even a good conspiracy theory; it's a bad one. He offers no evidence
that there's an actual plan or conspiracy to do this. I'm looking for an account of where the
advocates of coding education met to plot this in some castle in Europe or maybe a secret
document like "The Protocols of the Elders of Google", or some such.
Tool Users Vs Tool Makers.
The really good coders actually get why certain things work as they do and can adjust them
for different conditions. The mass produced coders are basically code copiers and code gluing
specialists.
People who get Masters and PhD's in computer science are not usually "coders" or software
engineers - they're usually involved in obscure, esoteric research for which there really is
very little demand. So it doesn't surprise me that they're unemployed. But if someone has a
Bachelor's in CS and they're unemployed I would have to wonder what they spent
their time at university doing.
The thing about software that distinguishes it from lots of other fields is that you can
make something real and significant on your own . I would expect any recent CS
major I hire to be able to show me an app or an open-source component or something similar
that they made themselves, and not just test scores and grades. If they could not then I
wouldn't even think about hiring them.
Fortunately for those of us who are actually good at coding, the difference in productivity
between a gifted coder and a non-gifted junior developer is something like 100-fold.
Knowing how to code and actually being efficient at creating software programs and systems
are about as far apart as knowing how to write and actually being able to write a bestselling
exciting Crime trilogy.
I do think there is excess supply of software programmers. There is only a modest number
of decent jobs, say as an algorithms developer in finance, general architecture of complex
systems or to some extent in systems security.
This article is about coding; most of those jobs require very little of that.
Most very high paying jobs in the technology sector are in the same standard upper
management roles as in every other industry.
How do you define "high paying". Everyone I know (and I know a lot because I've been a sw
engineer for 40 years) who is working fulltime as a software engineer is making a
high-middle-class salary, and can easily afford a home, travel on holiday, investments,
etc.
> Already there. I take it you skipped right past the employment prospects for US STEM
grads - 50% chance of finding STEM work.
That just means 50% of them are no good and need to develop their skills further or try
something else.
Not every with a STEM degree from some 3rd rate college is capable of doing complex IT or
STEM work.
So, is teaching people English or arithmetic all about reducing wages for the literate
and numerate?
Yes. Haven't you noticed how wage growth has flattened? That's because some do-gooders"
thought it would be a fine idea to educate the peasants. There was a time when only the
well-to do knew how to read and write, and that's why they well-to-do were well-to-do.
Education is evil. Stop educating people and then those of us who know how to read and write
can charge them for reading and writing letters and email. Better yet, we can have Chinese
and Indians do it for us and we just charge a transaction fee.
Massive amounts of public use cars, it doesn't mean millions need schooling in auto
mechanics. Same for software coding. We aren't even using those who have Bachelors, Masters
and PhDs in CS.
"..importing large numbers of skilled guest workers from other countries through the H1-B
visa program..."
"skilled" is good. H1B has long ( appx 17 years) been abused and turned into trafficking
scheme. One can buy H1B in India. Powerful ethnic networks wheeling & dealing in US &
EU selling IT jobs to essentially migrants.
The real IT wages haven't been stagnant but steadily falling from the 90s. It's easy to
see why. $82K/year IT wage was about average in the 90s. Comparing the prices of housing
(& pretty much everything else) between now gives you the idea.
> not every kid wants or needs to have their soul sucked out of them sitting in front of a
screen full of code for some idiotic service that some other douchbro thinks is the next
iteration of sliced bread
Taking a couple of years of programming are not enough to do this as a job, don't
worry.
But learning to code is like learning maths, - it helps to develop logical thinking, which
will benefit you in every area of your life.
"... A lot of basic entry level jobs require a good level of Excel skills. ..."
"... Programming is a cultural skill; master it, or even understand it on a simple level, and you understand how the 21st century works, on the machinery level. To bereave the children of this crucial insight is to close off a door to their future. ..."
"... What a dumpster argument. I am not a programmer or even close, but a basic understanding of coding has been important to my professional life. Coding isn't just about writing software. Understanding how algorithms work, even simple ones, is a general skill on par with algebra. ..."
"... Never mind that a good education is clearly one of the most important things you can do for a person to improve their quality of life wherever they live in the world. It's "neoliberal," so we better hate it. ..."
"... We've seen this kind of tactic for some time now. Silicon Valley is turning into a series of micromanaged sweatshops (that's what "agile" is truly all about) with little room for genuine creativity, or even understanding of what that actually means. I've seen how impossible it is to explain to upper level management how crappy cheap developers actually diminish productivity and value. All they see is that the requisition is filled for less money. ..."
"... Libertarianism posits that everyone should be free to sell their labour or negotiate their own arrangements without the state interfering. So if cheaper foreign labour really was undercutting American labout the Libertarians would be thrilled. ..."
"... Not producing enough to fill vacancies or not producing enough to keep wages at Google's preferred rate? Seeing as research shows there is no lack of qualified developers, the latter option seems more likely. ..."
"... We're already using Asia as a source of cheap labor for the tech industry. Why do we need to create cheap labor in the US? ..."
There are very few professional Scribes nowadays, a good level of reading & writing is
simplely a default even for the lowest paid jobs. A lot of basic entry level jobs require a
good level of Excel skills. Several years from now basic coding will be necessary to
manipulate basic tools for entry level jobs, especially as increasingly a lot of real code
will be generated by expert systems supervised by a tiny number of supervisors. Coding jobs
will go the same way that trucking jobs will go when driverless vehicles are perfected.
Offer the class but not mandatory. Just like I could never succeed playing football others
will not succeed at coding. The last thing the industry needs is more bad developers showing
up for a paycheck.
Programming is a cultural skill; master it, or even understand it on a simple level, and you
understand how the 21st century works, on the machinery level. To bereave the children of
this crucial insight is to close off a door to their future.
What's next, keep them off Math, because, you know . .
That's some crystal ball you have there. English teachers will need to know how to code? Same
with plumbers? Same with janitors, CEOs, and anyone working in the service industry?
The economy isn't a zero-sum game. Developing a more skilled workforce that can create more
value will lead to economic growth and improvement in the general standard of living.
Talented coders will start new tech businesses and create more jobs.
What a dumpster argument. I am not a programmer or even close, but a basic understanding of
coding has been important to my professional life. Coding isn't just about writing software.
Understanding how algorithms work, even simple ones, is a general skill on par with algebra.
But is isn't just about coding for Tarnoff. He seems to hold education in contempt
generally. "The far-fetched premise of neoliberal school reform is that education can mend
our disintegrating social fabric." If they can't literally fix everything let's just get rid
of them, right?
Never mind that a good education is clearly one of the most important things
you can do for a person to improve their quality of life wherever they live in the world.
It's "neoliberal," so we better hate it.
I agree with the basic point. We've seen this kind of tactic for some time now. Silicon
Valley is turning into a series of micromanaged sweatshops (that's what "agile" is truly all
about) with little room for genuine creativity, or even understanding of what that actually
means. I've seen how impossible it is to explain to upper level management how crappy cheap
developers actually diminish productivity and value. All they see is that the requisition is
filled for less money.
The bigger problem is that nobody cares about the arts, and as expensive as education is,
nobody wants to carry around a debt on a skill that won't bring in the bucks. And
smartphone-obsessed millennials have too short an attention span to fathom how empty their
lives are, devoid of the aesthetic depth as they are.
I can't draw a definite link, but I think algorithm fails, which are based on fanatical
reliance on programmed routines as the solution to everything, are rooted in the shortage of
education and cultivation in the arts.
Economics is a social science, and all this is merely a reflection of shared cultural
values. The problem is, people think it's math (it's not) and therefore set in stone.
Libertarianism posits that everyone should be free to sell their labour or negotiate their
own arrangements without the state interfering. So if cheaper foreign labour really was
undercutting American labout the Libertarians would be thrilled.
But it's not. I'm in my 60's and retiring but I've been a software engineer all my life.
I've worked for many different companies, and in different industries and I've never had any
trouble competing with cheap imported workers. The people I've seen fall behind were ones who
did not keep their skills fresh. When I was laid off in 2009 in my mid-50's I made sure my
mobile-app skills were bleeding edge (in those days ANYTHING having to do with mobile was
bleeding edge) and I used to go to job interviews with mobile devices to showcase what I
could do. That way they could see for themselves and not have to rely on just a CV.
They older guys who fell behind did so because their skills and toolsets had become
obsolete.
Now I'm trying to hire a replacement to write Android code for use in industrial
production and struggling to find someone with enough experience. So where is this oversupply
I keep hearing about?
Not producing enough to fill vacancies or not producing enough to keep wages at Google's
preferred rate? Seeing as research shows there is no lack of qualified developers, the latter
option seems more likely.
It's about ensuring those salaries no longer exist, by creating a source of cheap labor
for the tech industry.
We're already using Asia as a source of cheap labor for the tech industry. Why do we need
to create cheap labor in the US? That just seems inefficient.
There was never any need to give our jobs to foreigners. That is, if you are comparing the
production of domestic vs. foreign workers. The sole need was, and is, to increase profits.
Schools MAY be able to fix big social problems, but only if they teach a well-rounded
curriculum that includes classical history and the humanities. Job-specific training is
completely different. What a joke to persuade public school districts to pick up the tab on
job training. The existing social problems were not caused by a lack of programmers, and
cannot be solved by Big Tech.
I agree with the author that computer programming skills are not that limited in
availability. Big Tech solved the problem of the well-paid professional some years ago by
letting them go, these were mostly workers in their 50s, and replacing them with H1-B
visa-holders from India -- who work for a fraction of their experienced American
counterparts.
It is all about profits. Big Tech is no different than any other "industry."
Supply of apples does not affect the demand for oranges. Teaching coding in high school does
not necessarily alter the supply of software engineers. I studied Chinese History and geology
at University but my doing so has had no effect on the job prospects of people doing those
things for a living.
You would be surprised just how much a little coding knowledge has transformed my ability to
do my job (a job that is not directly related to IT at all).
Because teaching coding does not affect the supply of actual engineers. I've been a
professional software engineer for 40 years and coding is only a small fraction of what I do.
You and the linked article don't know what you're talking about. A CS degree does not equate
to a productive engineer.
A few years ago I was on the recruiting and interviewing committee to try to hire some
software engineers for a scientific instrument my company was making. The entire team had
about 60 people (hw, sw, mech engineers) but we needed 2 or 3 sw engineers with math and
signal-processing expertise. The project was held up for SIX months because we could
not find the people we needed. It would have taken a lot longer than that to train someone up
to our needs. Eventually we brought in some Chinese engineers which cost us MORE than what we
would have paid for an American engineer when you factor in the agency and visa
paperwork.
Modern software engineers are not just generic interchangable parts - 21st century
technology often requires specialised scientific, mathematical, production or business
domain-specific knowledge and those people are hard to find.
Visa jobs are part of trade agreements. To be very specific, US gov (and EU) trade Western
jobs for market access in the East. http://www.marketwatch.com/story/in-india-british-leader-theresa-may-preaches-free-trade-2016-11-07 There is no shortage. This is selling off the West's middle class. Take a look at remittances in wikipedia and you'll get a good idea just how much it costs the
US and EU economies, for sake of record profits to Western industry.
I see advantages in teaching kids to code, and for kids to make arduino and other CPU powered
things. I don't see a lot of interest in science and tech coming from kids in school. There
are too many distractions from social media and game platforms, and not much interest in
developing tools for future tech and science.
Although coding per se is a technical skill it isn't designing or integrating systems. It is
only a small, although essential, part of the whole software engineering process. Learning to
code just gets you up the first steps of a high ladder that you need to climb a fair way if
you intend to use your skills to earn a decent living.
Friend of mine in the SV tech industry reports that they are about 100,000 programmers
short in just the internet security field.
Y'all are trying to create a problem where there isn't one. Maybe we shouldn't teach them
how to read either. They might want to work somewhere besides the grill at McDonalds.
Within the next year coding will be old news and you will simply be able to describe things
in ur native language in such a way that the machine will be able to execute any set of
instructions you give it. Coding is going to change from its purely abstract form that is not
utilized at peak- but if you can describe what you envision in an effective concise manner u
could become a very good coder very quickly -- and competence will be determined entirely by
imagination and the barriers of entry will all but be extinct
Total... utter... no other way... huge... will only get worse... everyone... (not a very
nuanced commentary is it).
I'm glad pieces like this are mounting, it is relevant that we counter the mix of
messianism and opportunism of Silicon Valley propaganda with convincing arguments.
They aren't immigrants. They're visa indentured foreign workers. Why does that matter? It's
part of the cheap+indentured hiring criteria. If it were only cheap, they'd be lowballing
offers to citizen and US new grads.
Correct premises, - proletarianize programmers - many qualified graduates simply can't find jobs. Invalid conclusion: - The problem is there aren't enough good jobs to be trained for.
That conclusion only makes sense if you skip right past ... " importing large numbers of skilled guest workers from other countries through the
H1-B visa program. These workers earn less than their American counterparts, and
possess little bargaining power because they must remain employed to keep their status"
Hiring Americans doesn't "hurt" their record profits. It's incessant greed and collusion
with our corrupt congress.
This column was really annoying. I taught my students how to program when I was given a free
hand to create the computer studies curriculum for a new school I joined. (Not in the UK
thank Dog). 7th graders began with studying the history and uses of computers and
communications tech. My 8th grade learned about computer logic (AND, OR, NOT, etc) and moved
on with QuickBASIC in the second part of the year. My 9th graders learned about databases and
SQL and how to use HTML to make their own Web sites. Last year I received a phone call from
the father of one student thanking me for creating the course, his son had just received a
job offer and now works in San Francisco for Google. I am so glad I taught them "coding" (UGH) as the writer puts it, rather than arty-farty
subjects not worth a damn in the jobs market.
I live and work in Silicon Valley and you have no idea what you are talking about. There's no
shortage of coders at all. Terrific coders are let go because of their age and the
availability of much cheaper foreign coders(no, I am not opposed to immigration).
Looks like you pissed off a ton of people who can't write code and are none to happy with you
pointing out the reason they're slinging insurance for geico.
I think you're quite right that coding skills will eventually enter the mainstream and
slowly bring down the cost of hiring programmers.
The fact is that even if you don't get paid to be a programmer you can absolutely benefit
from having some coding skills.
There may however be some kind of major coding revolution with the advent of quantum
computing. The way code is written now could become obsolete.
A well-argued article that hits the nail on the head. Amongst any group of coders, very few
are truly productive, and they are self starters; training is really needed to do the admin.
There is not a huge skills shortage. That is why the author linked this EPI report analyzing
the data to prove exactly that. This may not be what people want to believe, but it is
certainly what the numbers indicate. There is no skills gap.
Yes. China and India are indeed training youth in coding skills. In order that they take jobs
in the USA and UK! It's been going on for 20 years and has resulted in many experienced IT
staff struggling to get work at all and, even if they can, to suffer stagnating wages.
Has anyones job is at risk from a 16 year old who can cobble together a couple of lines of
javascript since the dot com bubble?
Good luck trying to teach a big enough pool of US school kids regular expressions let
alone the kind of test driven continuous delivery that is the norm in the industry now.
> A lot of resumes come across my desk that look qualified on paper, but that's not the
same thing as being able to do the job
I have exactly the same experience. There is undeniable a skill gap.
It takes about a year for a skilled professional to adjust and learn enough to become
productive, it takes about 3-5 years for a college grad.
It is nothing new. But the issue is, as the college grad gets trained, another company
steal him/ her. And also keep in mind, all this time you are doing job and training the new
employee as time permits. Many companies in the US cut the non-profit department (such as IT)
to the bone, we cannot afford to lose a person and then train another replacement for 3-5
years.
The solution? Hire a skilled person. But that means nobody is training college grads and
in 10-20 years we are looking at the skill shortage to the point where the only option is
brining foreign labor.
American cut-throat companies that care only about the bottom line cannibalized
themselves.
Heh. You are not a coder, I take it. :) Going to be a few decades before even the
easiest coding jobs vanish.
Given how shit most coders of my acquaintance have been - especially in matters
of work ethic, logic, matching s/w to user requirements and willingness to test and correct
their gormless output - most future coding work will probably be in the area of disaster
recovery. Sorry, since the poor snowflakes can't face the sad facts, we have to call it
"business continuation" these days, don't we?
The demonization of Silicon Valley is clearly the next place to put all blame. Look what
"they" did to us: computers, smart phones, HD television, world-wide internet, on and on. Get
a rope!
I moved there in 1978 and watched the orchards and trailer parks on North 1st St. of San
Jose transform into a concrete jungle. There used to be quite a bit of semiconductor
equipment and device manufacturing in SV during the 80s and 90s. Now quite a few buildings
have the same name : AVAILABLE. Most equipment and device manufacturing has moved to
Asia.
Programming started with binary, then machine code (hexadecimal or octal) and moved to
assembler as a compiled and linked structure. More compiled languages like FORTRAN, BASIC,
PL-1, COBOL, PASCAL, C (and all its "+'s") followed making programming easier for the less
talented. Now the script based languages (HTML, JAVA, etc.) are even higher level and
accessible to nearly all. Programming has become a commodity and will be priced like milk,
wheat, corn, non-unionized workers and the like. The ship has sailed on this activity as a
career.
"... He's also a sort of maritime-technology historian. A tall, white-haired man in a baseball cap, shark t-shirt and boat shoes, Benjamin said he's spent the last 15 years "making vehicles wet." He has the U.S. armed forces to thank for making his autonomous work possible. The military sparked the field of marine autonomy decades ago, when it began demanding underwater robots for mine detection, ..."
"... In 2006, Benjamin launched his open-source software project. With it, a computer is able to take over a boat's navigation-and-control system. Anyone can write programs for it. The project is funded by the U.S. Office for Naval Research and Battelle Memorial Institute, a nonprofit. Benjamin said there are dozens of types of vehicles using the software, which is called MOOS-IvP. ..."
Frank Marino, an engineer with Sea Machines Robotics, uses a remote control belt pack to control
a self-driving boat in Boston Harbor. (Bloomberg) -- Frank Marino sat in a repurposed U.S. Coast
Guard boat bobbing in Boston Harbor one morning late last month. He pointed the boat straight at
a buoy several hundred yards away, while his colleague Mohamed Saad Ibn Seddik used a laptop to set
the vehicle on a course that would run right into it. Then Ibn Seddik flipped the boat into autonomous
driving mode. They sat back as the vessel moved at a modest speed of six knots, smoothly veering
right to avoid the buoy, and then returned to its course.
In a slightly apologetic tone, Marino acknowledged the experience wasn't as harrowing as barreling
down a highway in an SUV that no one is steering. "It's not like a self-driving car, where the wheel
turns on its own," he said. Ibn Seddik tapped in directions to get the boat moving back the other
way at twice the speed. This time, the vessel kicked up a wake, and the turn felt sharper, even as
it gave the buoy the same wide berth as it had before. As far as thrills go, it'd have to do. Ibn
Seddik said going any faster would make everyone on board nauseous.
The two men work for Sea Machines Robotics Inc., a three-year old company developing computer
systems for work boats that can make them either remote-controllable or completely autonomous. In
May, the company spent $90,000 to buy the Coast Guard hand-me-down at a government auction. Employees
ripped out one of the four seats in the cabin to make room for a metal-encased computer they call
a "first-generation autonomy cabinet." They painted the hull bright yellow and added the words "Unmanned
Vehicle" in big, red letters. Cameras are positioned at the stern and bow, and a dome-like radar
system and a digital GPS unit relay additional information about the vehicle's surroundings. The
company named its new vessel Steadfast.
Autonomous maritime vehicles haven't drawn as much the attention as self-driving cars, but they're
hitting the waters with increased regularity. Huge shipping interests, such as Rolls-Royce Holdings
Plc, Tokyo-based fertilizer producer Nippon Yusen K.K. and BHP Billiton Ltd., the world's largest
mining company, have all recently announced plans to use driverless ships for large-scale ocean transport.
Boston has become a hub for marine technology startups focused on smaller vehicles, with a handful
of companies like Sea Machines building their own autonomous systems for boats, diving drones and
other robots that operate on or under the water.
As Marino and Ibn Seddik were steering Steadfast back to dock, another robot boat trainer, Michael
Benjamin, motored past them. Benjamin, a professor at Massachusetts Institute of Technology, is a
regular presence on the local waters. His program in marine autonomy, a joint effort by the school's
mechanical engineering and computer science departments, serves as something of a ballast for Boston's
burgeoning self-driving boat scene. Benjamin helps engineers find jobs at startups and runs an open-source
software project that's crucial to many autonomous marine vehicles.
He's also a sort of maritime-technology historian. A tall, white-haired man in a baseball
cap, shark t-shirt and boat shoes, Benjamin said he's spent the last 15 years "making vehicles wet."
He has the U.S. armed forces to thank for making his autonomous work possible. The military sparked
the field of marine autonomy decades ago, when it began demanding underwater robots for mine detection,
Benjamin explained from a chair on MIT's dock overlooking the Charles River. Eventually, self-driving
software worked its way into all kinds of boats.
These systems tended to chart a course based on a specific script, rather than sensing and responding
to their environments. But a major shift came about a decade ago, when manufacturers began allowing
customers to plug in their own autonomy systems, according to Benjamin. "Imagine where the PC revolution
would have gone if the only one who could write software on an IBM personal computer was IBM," he
said.
In 2006, Benjamin launched his open-source software project. With it, a computer is able to
take over a boat's navigation-and-control system. Anyone can write programs for it. The project is
funded by the U.S. Office for Naval Research and Battelle Memorial Institute, a nonprofit. Benjamin
said there are dozens of types of vehicles using the software, which is called MOOS-IvP.
Startups using MOOS-IvP said it has created a kind of common vocabulary. "If we had a proprietary
system, we would have had to develop training and train new employees," said Ibn Seddik. "Fortunately
for us, Mike developed a course that serves exactly that purpose."
Teaching a boat to drive itself is easier than conditioning a car in some ways. They typically
don't have to deal with traffic, stoplights or roundabouts. But water is unique challenge. "The structure
of the road, with traffic lights, bounds your problem a little bit," said Benjamin. "The number of
unique possible situations that you can bump into is enormous." At the moment, underwater robots
represent a bigger chunk of the market than boats. Sales are expected to hit $4.6 billion in 2020,
more than double the amount from 2015, according to ABI Research. The biggest customer is the military.
Several startups hope to change that. Michael Johnson, Sea Machines' chief executive officer,
said the long-term potential for self-driving boats involves teams of autonomous vessels working
in concert. In many harbors, multiple tugs bring in large container ships, communicating either through
radio or by whistle. That could be replaced by software controlling all the boats as a single system,
Johnson said.
Sea Machines' first customer is Marine Spill Response Corp., a nonprofit group funded by oil companies.
The organization operates oil spill response teams that consist of a 210-foot ship paired with a
32-foot boat, which work together to drag a device collecting oil. Self-driving boats could help
because staffing the 32-foot boat in choppy waters or at night can be dangerous, but the theory needs
proper vetting, said Judith Roos, a vice president for MSRC. "It's too early to say, 'We're going
to go out and buy 20 widgets.'"
Another local startup, Autonomous Marine Systems Inc., has been sending boats about 10 miles out
to sea and leaving them there for weeks at a time. AMS's vehicles are designed to operate for long
stretches, gathering data in wind farms and oil fields. One vessel is a catamaran dubbed the Datamaran,
a name that first came from an employee's typo, said AMS CEO Ravi Paintal. The company also uses
Benjamin's software platform. Paintal said AMS's longest missions so far have been 20 days, give
or take. "They say when your boat can operate for 30 days out in the ocean environment, you'll be
in the running for a commercial contract," he said.
"... To emulate those capabilities on computers will probably require another 100 years or more. Selective functions can be imitated even now (manipulator that deals with blocks in a pyramid was created in 70th or early 80th I think, but capabilities of human "eye controlled arm" is still far, far beyond even wildest dreams of AI. ..."
"... Similarly human intellect is completely different from AI. At the current level the difference is probably 1000 times larger then the difference between a child with Down syndrome and a normal person. ..."
"... Human brain is actually a machine that creates languages for specific domain (or acquire them via learning) and then is able to operate in terms of those languages. Human child forced to grow up with animals, including wild animals, learns and is able to use "animal language." At least to a certain extent. Some of such children managed to survive in this environment. ..."
"... If you are bilingual, try Google translate on this post. You might be impressed by their recent progress in this field. It did improved considerably and now does not cause instant laugh. ..."
"... One interesting observation that I have is that automation is not always improve functioning of the organization. It can be quite opposite :-). Only the costs are cut, and even that is not always true. ..."
"... Of course the last 25 years (or so) were years of tremendous progress in computers and networking that changed the human civilization. And it is unclear whether we reached the limit of current capabilities or not in certain areas (in CPU speeds and die shrinking we probably did; I do not expect anything significant below 7 nanometers: https://en.wikipedia.org/wiki/7_nanometer ). ..."
"When combined with our brains, human fingers are amazingly fine manipulation devices."
Not only fingers. The whole human arm is an amazing device. Pure magic, if you ask me.
To emulate those capabilities on computers will probably require another 100 years or more.
Selective functions can be imitated even now (manipulator that deals with blocks in a pyramid
was created in 70th or early 80th I think, but capabilities of human "eye controlled arm" is still
far, far beyond even wildest dreams of AI.
Similarly human intellect is completely different from AI. At the current level the difference
is probably 1000 times larger then the difference between a child with Down syndrome and a normal
person.
Human brain is actually a machine that creates languages for specific domain (or acquire
them via learning) and then is able to operate in terms of those languages. Human child forced
to grow up with animals, including wild animals, learns and is able to use "animal language."
At least to a certain extent. Some of such children managed to survive in this environment.
Such cruel natural experiments have shown that the level of flexibility of human brain is something
really incredible. And IMHO can not be achieved by computers (although never say never).
Here we are talking about tasks that are 1 million times more complex task that playing GO
or chess, or driving a car on the street.
The limits of AI are clearly visible when we see the quality of translation from one language
to another. For more or less complex technical text it remains medium to low. As in "requires
human editing".
If you are bilingual, try Google translate on this post. You might be impressed by their
recent progress in this field. It did improved considerably and now does not cause instant laugh.
Same thing with the speech recognition. The progress is tremendous, especially the last three-five
years. But it is still far from perfect. Now, with a some training, programs like Dragon are quite
usable as dictation device on, say PC with 4 core 3GHz CPU with 16 GB of memory (especially if
you are native English speaker), but if you deal with special text or have strong accent, they
still leaves much to be desired (although your level of knowledge of the program, experience and
persistence can improve the results considerably.
One interesting observation that I have is that automation is not always improve functioning
of the organization. It can be quite opposite :-). Only the costs are cut, and even that is not
always true.
Of course the last 25 years (or so) were years of tremendous progress in computers and
networking that changed the human civilization. And it is unclear whether we reached the limit
of current capabilities or not in certain areas (in CPU speeds and die shrinking we probably did;
I do not expect anything significant below 7 nanometers:
https://en.wikipedia.org/wiki/7_nanometer
).
BrianFagioli shares a report from
BetaNews: The documentation aspect of any project is very important, as it can help people to
both understand it and track changes. Unfortunately, many developers aren't very interested in documentation
aspect, so it often gets neglected. Luckily, if you want to maintain proper documentation and stay
organized, today, Google is
releasing
its internal developer documentation style guide .
This can quite literally guide your documentation,
giving you a great starting point and keeping things consistent. Jed Hartman, Technical Writer, Google
says , "For some years now, our technical writers at Google have used an internal-only editorial
style guide for most of our developer documentation. In order to better support external contributors
to our open source projects, such as Kubernetes, AMP, or Dart, and to allow for more consistency
across developer documentation, we're now making that style guide public.
If you contribute documentation
to projects like those, you now have direct access to useful guidance about voice, tone, word choice,
and other style considerations. It can be useful for general issues, like reminders to use second
person, present tense, active voice, and the serial comma; it can also be great for checking very
specific issues, like whether to write 'app' or 'application' when you want to be consistent with
the Google Developers style."
My understanding of the UN is that it is the High Court of the World where fealty is paid
to empire that funds most of the political circus anyway...and speaking of funding or not,
read the following link and lets see what PavewayIV adds to the potential sickness we are
sleep walking into.
When Communications of the ACM began publication in 1959, the members of ACM'S
Editorial Board made the following remark as they described the purposes of ACM'S periodicals
[2]:
"If computer programming is to become an important part of computer research and development,
a transition of programming from an art to a disciplined science must be effected."
Such a goal has been a continually recurring theme during the ensuing years; for
example, we read in 1970 of the "first steps toward transforming the art of programming into a
science" [26]. Meanwhile we have actually succeeded in making our discipline a science, and in
a remarkably simple way: merely by deciding to call it "computer science."
Implicit in these remarks is the notion that there is something undesirable about an area of
human activity that is classified as an "art"; it has to be a Science before it has any real
stature. On the other hand, I have been working for more than 12 years on a series of books
called "The Art of Computer Programming." People frequently ask me why I picked such a
title; and in fact some people apparently don't believe that I really did so, since I've seen
at least one bibliographic reference to some books called "The Act of Computer
Programming."
In this talk I shall try to explain why I think "Art" is the appropriate word. I will
discuss what it means for something to be an art, in contrast to being a science; I will try to
examine whether arts are good things or bad things; and I will try to show that a proper
viewpoint of the subject will help us all to improve the quality of what we are now doing.
One of the first times I was ever asked about the title of my books was in 1966, during the
last previous ACM national meeting held in Southern California. This was before any of the
books were published, and I recall having lunch with a friend at the convention hotel. He knew
how conceited I was, already at that time, so he asked if I was going to call my books "An
Introduction to Don Knuth." I replied that, on the contrary, I was naming the books after
him . His name: Art Evans. (The Art of Computer Programming, in person.)
From this story we can conclude that the word "art" has more than one meaning. In fact, one
of the nicest things about the word is that it is used in many different senses, each of which
is quite appropriate in connection with computer programming. While preparing this talk, I went
to the library to find out what people have written about the word "art" through the years; and
after spending several fascinating days in the stacks, I came to the conclusion that "art" must
be one of the most interesting words in the English language.
The Arts of Old
If we go back to Latin roots, we find ars, artis meaning "skill." It is perhaps
significant that the corresponding Greek word was τεχνη , the
root of both "technology" and "technique."
Nowadays when someone speaks of "art" you probably think first of "fine arts" such as
painting and sculpture, but before the twentieth century the word was generally used in quite a
different sense. Since this older meaning of "art" still survives in many idioms, especially
when we are contrasting art with science, I would like to spend the next few minutes talking
about art in its classical sense.
In medieval times, the first universities were established to teach the seven so-called
"liberal arts," namely grammar, rhetoric, logic, arithmetic, geometry, music, and astronomy.
Note that this is quite different from the curriculum of today's liberal arts colleges, and
that at least three of the original seven liberal arts are important components of computer
science. At that time, an "art" meant something devised by man's intellect, as opposed to
activities derived from nature or instinct; "liberal" arts were liberated or free, in contrast
to manual arts such as plowing (cf. [6]). During the middle ages the word "art" by itself
usually meant logic [4], which usually meant the study of syllogisms.
Science vs. Art
The word "science" seems to have been used for many years in about the same sense as "art";
for example, people spoke also of the seven liberal sciences, which were the same as the seven
liberal arts [1]. Duns Scotus in the thirteenth century called logic "the Science of Sciences,
and the Art of Arts" (cf. [12, p. 34f]). As civilization and learning developed, the words took
on more and more independent meanings, "science" being used to stand for knowledge, and "art"
for the application of knowledge. Thus, the science of astronomy was the basis for the art of
navigation. The situation was almost exactly like the way in which we now distinguish between
"science" and "engineering."
Many authors wrote about the relationship between art and science in the nineteenth century,
and I believe the best discussion was given by John Stuart Mill. He said the following things,
among others, in 1843 [28]:
Several sciences are often necessary to form the groundwork of a single art. Such is the
complication of human affairs, that to enable one thing to be done , it is often
requisite to know the nature and properties of many things... Art in general consists
of the truths of Science, arranged in the most convenient order for practice, instead of the
order which is the most convenient for thought. Science groups and arranges its truths so as
to enable us to take in at one view as much as possible of the general order of the universe.
Art... brings together from parts of the field of science most remote from one another, the
truths relating to the production of the different and heterogeneous conditions necessary to
each effect which the exigencies of practical life require.
As I was looking up these things about the meanings of "art," I found that authors
have been calling for a transition from art to science for at least two centuries. For example,
the preface to a textbook on mineralogy, written in 1784, said the following [17]: "Previous to
the year 1780, mineralogy, though tolerably understood by many as an Art, could scarce be
deemed a Science."
According to most dictionaries "science" means knowledge that has been logically arranged
and systematized in the form of general "laws." The advantage of science is that it saves us
from the need to think things through in each individual case; we can turn our thoughts to
higher-level concepts. As John Ruskin wrote in 1853 [32]: "The work of science is to substitute
facts for appearances, and demonstrations for impressions."
It seems to me that if the authors I studied were writing today, they would agree with the
following characterization: Science is knowledge which we understand so well that we can teach
it to a computer; and if we don't fully understand something, it is an art to deal with it.
Since the notion of an algorithm or a computer program provides us with an extremely useful
test for the depth of our knowledge about any given subject, the process of going from an art
to a science means that we learn how to automate something.
Artificial intelligence has been making significant progress, yet there is a huge gap
between what computers can do in the foreseeable future and what ordinary people can do. The
mysterious insights that people have when speaking, listening, creating, and even when they are
programming, are still beyond the reach of science; nearly everything we do is still an
art.
From this standpoint it is certainly desirable to make computer programming a science, and
we have indeed come a long way in the 15 years since the publication of the remarks I quoted at
the beginning of this talk. Fifteen years ago computer programming was so badly understood that
hardly anyone even thought about proving programs correct; we just fiddled with a
program until we "knew" it worked. At that time we didn't even know how to express the
concept that a program was correct, in any rigorous way. It is only in recent years that
we have been learning about the processes of abstraction by which programs are written and
understood; and this new knowledge about programming is currently producing great payoffs in
practice, even though few programs are actually proved correct with complete rigor, since we
are beginning to understand the principles of program structure. The point is that when we
write programs today, we know that we could in principle construct formal proofs of their
correctness if we really wanted to, now that we understand how such proofs are formulated. This
scientific basis is resulting in programs that are significantly more reliable than those we
wrote in former days when intuition was the only basis of correctness.
The field of "automatic programming" is one of the major areas of artificial intelligence
research today. Its proponents would love to be able to give a lecture entitled "Computer
Programming as an Artifact" (meaning that programming has become merely a relic of bygone
days), because their aim is to create machines that write programs better than we can, given
only the problem specification. Personally I don't think such a goal will ever be completely
attained, but I do think that their research is extremely important, because everything we
learn about programming helps us to improve our own artistry. In this sense we should
continually be striving to transform every art into a science: in the process, we
advance the art.
Science and Art
Our discussion indicates that computer programming is by now both a science and an
art, and that the two aspects nicely complement each other. Apparently most authors who examine
such a question come to this same conclusion, that their subject is both a science and an art,
whatever their subject is (cf. [25]). I found a book about elementary photography, written in
1893, which stated that "the development of the photographic image is both an art and a
science" [13]. In fact, when I first picked up a dictionary in order to study the words "art"
and "science," I happened to glance at the editor's preface, which began by saying, "The making
of a dictionary is both a science and an art." The editor of Funk & Wagnall's dictionary
[27] observed that the painstaking accumulation and classification of data about words has a
scientific character, while a well-chosen phrasing of definitions demands the ability to write
with economy and precision: "The science without the art is likely to be ineffective; the art
without the science is certain to be inaccurate."
When preparing this talk I looked through the card catalog at Stanford library to see how
other people have been using the words "art" and "science" in the titles of their books. This
turned out to be quite interesting.
For example, I found two books entitled The Art of Playing the Piano [5, 15], and
others called The Science of Pianoforte Technique [10], The Science of Pianoforte
Practice [30]. There is also a book called The Art of Piano Playing: A Scientific
Approach [22].
Then I found a nice little book entitled The Gentle Art of Mathematics [31], which
made me somewhat sad that I can't honestly describe computer programming as a "gentle art." I
had known for several years about a book called The Art of Computation , published in
San Francisco, 1879, by a man named C. Frusher Howard [14]. This was a book on practical
business arithmetic that had sold over 400,000 copies in various editions by 1890. I was amused
to read the preface, since it shows that Howard's philosophy and the intent of his title were
quite different from mine; he wrote: "A knowledge of the Science of Number is of minor
importance; skill in the Art of Reckoning is absolutely indispensible."
Several books mention both science and art in their titles, notably The Science of Being
and Art of Living by Maharishi Mahesh Yogi [24]. There is also a book called The Art of
Scientific Discovery [11], which analyzes how some of the great discoveries of science were
made.
So much for the word "art" in its classical meaning. Actually when I chose the title of my
books, I wasn't thinking primarily of art in this sense, I was thinking more of its current
connotations. Probably the most interesting book which turned up in my search was a fairly
recent work by Robert E. Mueller called The Science of Art [29]. Of all the books I've
mentioned, Mueller's comes closest to expressing what I want to make the central theme of my
talk today, in terms of real artistry as we now understand the term. He observes: "It was once
thought that the imaginative outlook of the artist was death for the scientist. And the logic
of science seemed to spell doom to all possible artistic flights of fancy." He goes on to
explore the advantages which actually do result from a synthesis of science and art.
A scientific approach is generally characterized by the words logical, systematic,
impersonal, calm, rational, while an artistic approach is characterized by the words aesthetic,
creative, humanitarian, anxious, irrational. It seems to me that both of these apparently
contradictory approaches have great value with respect to computer programming.
Emma Lehmer wrote in 1956 that she had found coding to be "an exacting science as well as an
intriguing art" [23]. H.S.M. Coxeter remarked in 1957 that he sometimes felt "more like an
artist than a scientist" [7]. This was at the time C.P. Snow was beginning to voice his alarm
at the growing polarization between "two cultures" of educated people [34, 35]. He pointed out
that we need to combine scientific and artistic values if we are to make real progress.
Works of Art
When I'm sitting in an audience listening to a long lecture, my attention usually starts to
wane at about this point in the hour. So I wonder, are you getting a little tired of my
harangue about "science" and "art"? I really hope that you'll be able to listen carefully to
the rest of this, anyway, because now comes the part about which I feel most deeply.
When I speak about computer programming as an art, I am thinking primarily of it as an art
form , in an aesthetic sense. The chief goal of my work as educator and author is to
help people learn how to write beautiful programs . It is for this reason I was
especially pleased to learn recently [32] that my books actually appear in the Fine Arts
Library at Cornell University. (However, the three volumes apparently sit there neatly on the
shelf, without being used, so I'm afraid the librarians may have made a mistake by interpreting
my title literally.)
My feeling is that when we prepare a program, it can be like composing poetry or music; as
Andrei Ershov has said [9], programming can give us both intellectual and emotional
satisfaction, because it is a real achievement to master complexity and to establish a system
of consistent rules.
Furthermore when we read other people's programs, we can recognize some of them as genuine
works of art. I can still remember the great thrill it was for me to read the listing of Stan
Poley's SOAP II assembly program in 1958; you probably think I'm crazy, and styles have
certainly changed greatly since then, but at the time it meant a great deal to me to see how
elegant a system program could be, especially by comparison with the heavy-handed coding found
in other listings I had been studying at the same time. The possibility of writing beautiful
programs, even in assembly language, is what got me hooked on programming in the first
place.
Some programs are elegant, some are exquisite, some are sparkling. My claim is that it is
possible to write grand programs, noble programs, truly magnificent
ones!
Taste and Style
The idea of style in programming is now coming to the forefront at last, and I hope
that most of you have seen the excellent little book on Elements of Programming Style by
Kernighan and Plauger [16]. In this connection it is most important for us all to remember that
there is no one "best" style; everybody has his own preferences, and it is a mistake to try to
force people into an unnatural mold. We often hear the saying, "I don't know anything about
art, but I know what I like." The important thing is that you really like the style you
are using; it should be the best way you prefer to express yourself.
Edsger Dijkstra stressed this point in the preface to his Short Introduction to the Art
of Programming [8]:
It is my purpose to transmit the importance of good taste and style in programming, [but] the
specific elements of style presented serve only to illustrate what benefits can be derived
from "style" in general. In this respect I feel akin to the teacher of composition at a
conservatory: He does not teach his pupils how to compose a particular symphony, he must help
his pupils to find their own style and must explain to them what is implied by this. (It has
been this analogy that made me talk about "The Art of Programming.")
Now we must ask ourselves, What is good style, and what is bad style? We should
not be too rigid about this in judging other people's work. The early nineteenth-century
philosopher Jeremy Bentham put it this way [3, Bk. 3, Ch. 1]:
Judges of elegance and taste consider themselves as benefactors to the human race, whilst
they are really only the interrupters of their pleasure... There is no taste which deserves
the epithet good , unless it be the taste for such employments which, to the pleasure
actually produced by them, conjoin some contingent or future utility: there is no taste which
deserves to be characterized as bad, unless it be a taste for some occupation which has a
mischievous tendency.
When we apply our own prejudices to "reform" someone else's taste, we may be
unconsciously denying him some entirely legitimate pleasure. That's why I don't condemn a lot
of things programmers do, even though I would never enjoy doing them myself. The important
thing is that they are creating something they feel is beautiful.
In the passage I just quoted, Bentham does give us some advice about certain principles of
aesthetics which are better than others, namely the "utility" of the result. We have some
freedom in setting up our personal standards of beauty, but it is especially nice when the
things we regard as beautiful are also regarded by other people as useful. I must confess that
I really enjoy writing computer programs; and I especially enjoy writing programs which do the
greatest good, in some sense.
There are many senses in which a program can be "good," of course. In the first place, it's
especially good to have a program that works correctly. Secondly it is often good to have a
program that won't be hard to change, when the time for adaptation arises. Both of these goals
are achieved when the program is easily readable and understandable to a person who knows the
appropriate language.
Another important way for a production program to be good is for it to interact gracefully
with its users, especially when recovering from human errors in the input data. It's a real art
to compose meaningful error messages or to design flexible input formats which are not
error-prone.
Another important aspect of program quality is the efficiency with which the computer's
resources are actually being used. I am sorry to say that many people nowadays are condemning
program efficiency, telling us that it is in bad taste. The reason for this is that we are now
experiencing a reaction from the time when efficiency was the only reputable criterion of
goodness, and programmers in the past have tended to be so preoccupied with efficiency that
they have produced needlessly complicated code; the result of this unnecessary complexity has
been that net efficiency has gone down, due to difficulties of debugging and maintenance.
The real problem is that programmers have spent far too much time worrying about efficiency
in the wrong places and at the wrong times; premature optimization is the root of all evil (or
at least most of it) in programming.
We shouldn't be penny wise and pound foolish, nor should we always think of efficiency in
terms of so many percent gained or lost in total running time or space. When we buy a car, many
of us are almost oblivious to a difference of $50 or $100 in its price, while we might make a
special trip to a particular store in order to buy a 50 cent item for only 25 cents. My point
is that there is a time and place for efficiency; I have discussed its proper role in my paper
on structured programming, which appears in the current issue of Computing Surveys
[21].
Less Facilities: More Enjoyment
One rather curious thing I've noticed about aesthetic satisfaction is that our pleasure is
significantly enhanced when we accomplish something with limited tools. For example, the
program of which I personally am most pleased and proud is a compiler I once wrote for a
primitive minicomputer which had only 4096 words of memory, 16 bits per word. It makes a person
feel like a real virtuoso to achieve something under such severe restrictions.
A similar phenomenon occurs in many other contexts. For example, people often seem to fall
in love with their Volkswagens but rarely with their Lincoln Continentals (which presumably run
much better). When I learned programming, it was a popular pastime to do as much as possible
with programs that fit on only a single punched card. I suppose it's this same phenomenon that
makes APL enthusiasts relish their "one-liners." When we teach programming nowadays, it is a
curious fact that we rarely capture the heart of a student for computer science until he has
taken a course which allows "hands on" experience with a minicomputer. The use of our
large-scale machines with their fancy operating systems and languages doesn't really seem to
engender any love for programming, at least not at first.
It's not obvious how to apply this principle to increase programmers' enjoyment of their
work. Surely programmers would groan if their manager suddenly announced that the new machine
will have only half as much memory as the old. And I don't think anybody, even the most
dedicated "programming artists," can be expected to welcome such a prospect, since nobody likes
to lose facilities unnecessarily. Another example may help to clarify the situation:
Film-makers strongly resisted the introduction of talking pictures in the 1920's because they
were justly proud of the way they could convey words without sound. Similarly, a true
programming artist might well resent the introduction of more powerful equipment; today's mass
storage devices tend to spoil much of the beauty of our old tape sorting methods. But today's
film makers don't want to go back to silent films, not because they're lazy but because they
know it is quite possible to make beautiful movies using the improved technology. The form of
their art has changed, but there is still plenty of room for artistry.
How did they develop their skill? The best film makers through the years usually seem to
have learned their art in comparatively primitive circumstances, often in other countries with
a limited movie industry. And in recent years the most important things we have been learning
about programming seem to have originated with people who did not have access to very large
computers. The moral of this story, it seems to me, is that we should make use of the idea of
limited resources in our own education. We can all benefit by doing occasional "toy" programs,
when artificial restrictions are set up, so that we are forced to push our abilities to the
limit. We shouldn't live in the lap of luxury all the time, since that tends to make us
lethargic. The art of tackling miniproblems with all our energy will sharpen our talents for
the real problems, and the experience will help us to get more pleasure from our
accomplishments on less restricted equipment.
In a similar vein, we shouldn't shy away from "art for art's sake"; we shouldn't feel guilty
about programs that are just for fun. I once got a great kick out of writing a one-statement
ALGOL program that invoked an innerproduct procedure in such an unusual way that it calculated
the mth prime number, instead of an innerproduct [19]. Some years ago the students at Stanford
were excited about finding the shortest FORTRAN program which prints itself out, in the sense
that the program's output is identical to its own source text. The same problem was considered
for many other languages. I don't think it was a waste of time for them to work on this; nor
would Jeremy Bentham, whom I quoted earlier, deny the "utility" of such pastimes [3, Bk. 3, Ch.
1]. "On the contrary," he wrote, "there is nothing, the utility of which is more incontestable.
To what shall the character of utility be ascribed, if not to that which is a source of
pleasure?"
Providing Beautiful Tools
Another characteristic of modern art is its emphasis on creativity. It seems that many
artists these days couldn't care less about creating beautiful things; only the novelty of an
idea is important. I'm not recommending that computer programming should be like modern art in
this sense, but it does lead me to an observation that I think is important. Sometimes we are
assigned to a programming task which is almost hopelessly dull, giving us no outlet whatsoever
for any creativity; and at such times a person might well come to me and say, "So programming
is beautiful? It's all very well for you to declaim that I should take pleasure in creating
elegant and charming programs, but how am I supposed to make this mess into a work of art?"
Well, it's true, not all programming tasks are going to be fun. Consider the "trapped
housewife," who has to clean off the same table every day: there's not room for creativity or
artistry in every situation. But even in such cases, there is a way to make a big improvement:
it is still a pleasure to do routine jobs if we have beautiful things to work with. For
example, a person will really enjoy wiping off the dining room table, day after day, if it is a
beautifully designed table made from some fine quality hardwood.
Therefore I want to address my closing remarks to the system programmers and the machine
designers who produce the systems that the rest of us must work with. Please, give us
tools that are a pleasure to use, especially for our routine assignments, instead of providing
something we have to fight with. Please, give us tools that encourage us to write better
programs, by enhancing our pleasure when we do so.
It's very hard for me to convince college freshmen that programming is beautiful, when the
first thing I have to tell them is how to punch "slash slash JoB equals so-and-so." Even job
control languages can be designed so that they are a pleasure to use, instead of being strictly
functional.
Computer hardware designers can make their machines much more pleasant to use, for example
by providing floating-point arithmetic which satisfies simple mathematical laws. The facilities
presently available on most machines make the job of rigorous error analysis hopelessly
difficult, but properly designed operations would encourage numerical analysts to provide
better subroutines which have certified accuracy (cf. [20, p. 204]).
Let's consider also what software designers can do. One of the best ways to keep up the
spirits of a system user is to provide routines that he can interact with. We shouldn't make
systems too automatic, so that the action always goes on behind the scenes; we ought to give
the programmer-user a chance to direct his creativity into useful channels. One thing all
programmers have in common is that they enjoy working with machines; so let's keep them in the
loop. Some tasks are best done by machine, while others are best done by human insight; and a
properly designed system will find the right balance. (I have been trying to avoid misdirected
automation for many years, cf. [18].)
Program measurement tools make a good case in point. For years, programmers have been
unaware of how the real costs of computing are distributed in their programs. Experience
indicates that nearly everybody has the wrong idea about the real bottlenecks in his programs;
it is no wonder that attempts at efficiency go awry so often, when a programmer is never given
a breakdown of costs according to the lines of code he has written. His job is something like
that of a newly married couple who try to plan a balanced budget without knowing how much the
individual items like food, shelter, and clothing will cost. All that we have been giving
programmers is an optimizing compiler, which mysteriously does something to the programs it
translates but which never explains what it does. Fortunately we are now finally seeing the
appearance of systems which give the user credit for some intelligence; they automatically
provide instrumentation of programs and appropriate feedback about the real costs. These
experimental systems have been a huge success, because they produce measurable improvements,
and especially because they are fun to use, so I am confident that it is only a matter of time
before the use of such systems is standard operating procedure. My paper in Computing
Surveys [21] discusses this further, and presents some ideas for other ways in which an
appropriate interactive routine can enhance the satisfaction of user programmers.
Language designers also have an obligation to provide languages that encourage good style,
since we all know that style is strongly influenced by the language in which it is expressed.
The present surge of interest in structured programming has revealed that none of our existing
languages is really ideal for dealing with program and data structure, nor is it clear what an
ideal language should be. Therefore I look forward to many careful experiments in language
design during the next few years.
Summary
To summarize: We have seen that computer programming is an art, because it applies
accumulated knowledge to the world, because it requires skill and ingenuity, and especially
because it produces objects of beauty. A programmer who subconsciously views himself as an
artist will enjoy what he does and will do it better. Therefore we can be glad that people who
lecture at computer conferences speak about the state of the Art .
References
1. Bailey, Nathan. The Universal Etymological English Dictionary. T. Cox, London, 1727. See
"Art," "Liberal," and "Science."
2. Bauer, Walter F., Juncosa, Mario L., and Perlis, Alan J. ACM publication policies and
plans. J. ACM 6 (Apr. 1959), 121-122.
3. Bentham, Jeremy. The Rationale of Reward. Trans. from Theorie des peines et des
recompenses, 1811, by Richard Smith, J. & H. L. Hunt, London, 1825.
4. The Century Dictionary and Cyclopedia 1. The Century Co., New York, 1889.
5. Clementi, Muzio. The Art of Playing the Piano. Trans. from L'art de jouer le pianoforte
by Max Vogrich. Schirmer, New York, 1898.
13. Hodges, John A. Elementary Photography: The "Amateur Photographer" Library 7. London,
1893. Sixth ed, revised and enlarged, 1907, p. 58.
14. Howard, C. Frusher. Howard's Art of Computation and golden rule for equation of payments
for schools, business colleges and self-culture .... C.F. Howard, San Francisco, 1879.
15. Hummel, J.N. The Art of Playing the Piano Forte. Boosey, London, 1827.
16. Kernighan B.W., and Plauger, P.J. The Elements of Programming Style. McGraw-Hill, New
York, 1974.
17. Kirwan, Richard. Elements of Mineralogy. Elmsly, London, 1784.
18. Knuth, Donald E. Minimizing drum latency time. J. ACM 8 (Apr. 1961), 119-150.
19. Knuth, Donald E., and Merner, J.N. ALGOL 60 confidential. Comm. ACM 4 (June 1961),
268-272.
20. Knuth, Donald E. Seminumerical Algorithms: The Art of Computer Programming 2.
Addison-Wesley, Reading, Mass., 1969.
21. Knuth, Donald E. Structured programming with go to statements. Computing Surveys 6 (Dec.
1974), pages in makeup.
22. Kochevitsky, George. The Art of Piano Playing: A Scientific Approach. Summy-Birchard,
Evanston, II1., 1967.
23. Lehmer, Emma. Number theory on the SWAC. Proc. Syrup. Applied Math. 6, Amer. Math. Soc.
(1956), 103-108.
24. Mahesh Yogi, Maharishi. The Science of Being and Art of Living. Allen & Unwin,
London, 1963.
25. Malevinsky, Moses L. The Science of Playwriting. Brentano's, New York, 1925.
26. Manna, Zohar, and Pnueli, Amir. Formalization of properties of functional programs. J.
ACM 17 (July 1970), 555-569.
27. Marckwardt, Albert H, Preface to Funk and Wagnall's Standard College Dictionary.
Harcourt, Brace & World, New York, 1963, vii.
28. Mill, John Stuart. A System Of Logic, Ratiocinative and Inductive. London, 1843. The
quotations are from the introduction, S 2, and from Book 6, Chap. 11 (12 in later editions), S
5.
29. Mueller, Robert E. The Science of Art. John Day, New York, 1967.
30. Parsons, Albert Ross. The Science of Pianoforte Practice. Schirmer, New York, 1886.
31. Pedoe, Daniel. The Gentle Art of Mathematics. English U. Press, London, 1953.
32. Ruskin, John. The Stones of Venice 3. London, 1853.
33. Salton, G.A. Personal communication, June 21, 1974.
34. Snow, C.P. The two cultures. The New Statesman and Nation 52 (Oct. 6, 1956),
413-414.
35. Snow, C.P. The Two Cultures: and a Second Look. Cambridge University Press, 1964.
Copyright 1974, Association for Computing Machinery, Inc. General permission to republish,
but not for profit, all or part of this material is granted provided that ACM's copyright
notice is given and that reference is made to the publication, to its date of issue, and to the
fact that reprinting privileges were granted by permission of the Association for Computing
Machinery.
"... According to sources, hundreds of developers were employed on the programme at huge day rates, with large groups of so-called agile experts overseeing the various aspects of the programme. ..."
"... I have also worked on agile for UK gov projects a few years back when it was mandated for all new projects and I was at first dead keen. However, it quickly become obvious that the lack of requirements, specifications etc made testing a living nightmare. Changes asked for by the customer were grafted onto what become baroque mass of code. I can't see how Agile is a good idea except for the smallest trivial projects. ..."
"... The question is - is that for software that's still in development or software that's deployed in production? If it's the latter and your "something" just changes its data format you're going to be very unpopular with your users. And that's just for ordinary files. If it requires frequent re-orgs of an RDBMS then you'd be advised to not go near any dark alley where your DBA might be lurking. ..."
"... Software works on data. If you can't get the design of that right early you're going to be carrying a lot of technical debt in terms of backward compatibility or you're going to impose serious costs on your users for repeatedly bringing existing data up to date. ..."
"... At this point, courtesy of Exxxxtr3333me Programming and its spawn, 'agile' just means 'we don't want to do any design, we don't want to do any documentation, and we don't want to do any acceptance testing because all that stuff is annoying.' Everything is 'agile', because that's the best case for terrible lazy programmers, even if they're using a completely different methodology. ..."
"... It's like any exciting new methodology : same shit, different name. In this case, one that allows you to pretend the tiny attention-span of a panicking project manager is a good thing. ..."
"... Process is not a panacea or a crutch or a silver bullet. Methodologies only work as well as the people using it. Any methodology can be distorted to give the answer that upper management wants (instead of reality) ..."
"... under the guise of " agile ?". I'm no expert in project management, but I'm pretty sure it isn't supposed to be making it up as you go along, and constantly changing the specs and architecture. ..."
"... So why should the developers have all the fun? Why can't the designers and architects be "agile", too? Isn't constantly changing stuff all part of the "agile" way? ..."
Comment
"It doesn't matter whether a cat is white or
black, as long as it catches mice," according to Chinese revolutionary Deng Xiaoping.
While Deng wasn't referring to anything nearly as banal as IT projects (he was of
course talking about the fact it doesn't matter whether a person is a revolutionary
or not, as long as he or she is efficient and capable), the same principle could
apply.
A fixation on the suppliers, technology or processes ultimately doesn't matter.
It's the outcomes, stupid. That might seem like a blindingly obvious point, but it's
one worth repeating.
I'm not dismissing the benefits of this particular methodology, but in the case of
the
Common Platform Programme
, it feels like the misapplication of agile was worse
than not doing it at all.
Just to recap: the CPP was signed off around 2013, with the intention of creating
a unified platform across the criminal justice system to allow the Crown Prosecution
Service and courts to more effectively manage cases.
By cutting out duplication of systems, it was hoped to save buckets of cash and
make the process of case management across the criminal justice system far more
efficient.
Unlike the old projects of the past, this was a great example of the government
taking control and doing it themselves. Everything was going to be delivered ahead of
time and under budget. Trebles all round!
But as Lucy Liu's O-Ren Ishii told Uma Thurman's character in in
Kill Bill
:
"You didn't think it was gonna be that easy, did you?... Silly rabbit."
According to sources, alarm bells were soon raised over the project's self-styled
"innovative use of agile development principles". It emerged that the programme was
spending an awful lot of money for very little return. Attempts to shut it down were
themselves shut down.
The programme carried on at full steam and by 2014 it was ramping up at scale.
According to sources, hundreds of developers were employed on the programme at huge
day rates, with large groups of so-called agile experts overseeing the various
aspects of the programme.
CPP cops a plea
Four years since it was first signed off and what are the things we can point to
from the CPP? An online make-a-plea programme which allows people to plead guilty or
not guilty to traffic offences; a digital markup tool for legal advisors to record
case results in court, which is being tested by magistrates courts in Essex; and the
Magistrates Rota.
Multiple insiders have said the rest that we have to show for hundreds of millions
of taxpayers' cash is essentially vapourware. When programme director Loveday Ryder
described the project as a "once-in-a-lifetime opportunity" to modernise the criminal
justice system, it wasn't clear then that she meant the programme would itself take
an actual lifetime.
Of course the definition of agile is that you are able to move quickly and easily.
So some might point to the outcomes of this programme as proof that it was never
really about that.
One source remarked that it really doesn't matter if you call something agile or
not, "If you can replace agile with constantly talking and communicating then fine,
call it agile." He also added: "This was one of the most waterfall programmes in
government I've seen."
What is most worrying about this programme is it may not be an isolated example.
Other organisations and departments may well be doing similar things under the guise
of "agile". I'm no expert in project management, but I'm pretty sure it isn't
supposed to be making it up as you go along, and constantly changing the specs and
architecture.
Ultimately who cares if a programme is run via a system integrator, multiple SMEs,
uses a DevOps methodology, is built in-house or deployed using off-the-shelf, as long
as it delivers good value. No doubt there are good reasons for using any of those
approaches in a number of different circumstances.
Government still spends an outrageous amount of money on IT, upwards of £16bn a
year. So as taxpayers it's a simple case of wanting them to "show me the money". Or
to misquote Deng, at least show us some more dead mice. ®
So agile means "constantly adapating " ? read constantly bouncing from
one fuckup to the next , paddling like hell to keep up , constantly
firefighting whilst going down slowly like the titanic?
Ha! About 21 years back, working at Racal in Bracknell on a military
radio project, we had a 'round-trip-OMT' CASE tool that did just that. It
even generated documentation from the code so as you added classes and
methods the CASE tool generated the design document. Also, a nightly build
if it failed, would email the code author.
I have also worked on agile for UK gov projects a few years back when it
was mandated for all new projects and I was at first dead keen. However, it
quickly become obvious that the lack of requirements, specifications etc
made testing a living nightmare. Changes asked for by the customer were
grafted onto what become baroque mass of code. I can't see how Agile is a
good idea except for the smallest trivial projects.
"Technically 'agile' just means you produce working versions frequently
and iterate on that."
It's more to do with priorities: On time, on budget, to specification:
Put these in the order of which you will surrender if the project hits
problems.
Agile focuses on On time. What is delivered is hopefully to
specification, and within budget, but one or both of those could be
surrendered in order to get something out On time. It's just project
management 101 with a catchy name, and in poorly managed 'agile'
developments you find padding to fit the usual 60/30/10 rule. Then the
management disgard the padding and insist the project can be completed in a
reduced time as a result, thereby breaking the rules of 'agile' development
(insisting it's on spec, under time and under budget, but it's still
'agile'...).
"Usually I check something(s) in every day, for the most major things it
may take a week, but the goal is always to get it in and working so it can
be tested."
The question is - is that for software that's still in development or
software that's deployed in production?
If it's the latter and your "something" just changes its data format
you're going to be very unpopular with your users. And that's just for
ordinary files. If it requires frequent re-orgs of an RDBMS then you'd be
advised to not go near any dark alley where your DBA might be lurking.
Software works on data. If you can't get the design of that right early
you're going to be carrying a lot of technical debt in terms of backward
compatibility or you're going to impose serious costs on your users for
repeatedly bringing existing data up to date.
Pick two of the three and only two. It doesn't which way you pick, you're
fucked on the third. Doesn't matter about methodology, doesn't matter about
requirements or project manglement. You are screwed on the third and the
great news is, is that the level of the reaming you get scales with the size
of the project.
After almost 20 years in the industry this has held true.
Technically 'agile' just means you produce
working versions frequently and iterate on that.
No, technically agile means having no clue as to
what is required and to evolve the requirements as you
build. All well and good if you have a dicky little web
site but if you are on a very / extremely large project
with fixed time frame and fixed budget you are royally
screwed trying to use agile as there is no way you can
control scope.
Hell under agile no one has any idea what the scope
is!
'Agile' means nothing at this point. Unless it means terrible software.
At this point, courtesy of Exxxxtr3333me Programming and its spawn,
'agile' just means 'we don't want to do any design, we don't want to do any
documentation, and we don't want to do any acceptance testing because all
that stuff is annoying.' Everything is 'agile', because that's the best case
for terrible lazy programmers, even if they're using a completely different
methodology.
I firmly believe in the basics of 'iterate working versions as often as
possible'. But why sell ourselves short by calling it agile when we actually
design it, document it, and use testing beyond unit tests?
Yes, yes, you can tell me what 'agile' technically means, and I know that
design and documentation and QA are not excluded, but in practice even the
most waterfall of waterfall call themselves agile (like Kat says), and from
hard experience people who really push 'agile agile agile' as their thing
are the worst of the worst terrible coders who just slam crap together with
all the finesse and thoughtfulness of a Bangalore outsourcer.
It's like any exciting new methodology : same shit, different name. In this
case, one that allows you to pretend the tiny attention-span of a panicking
project manager is a good thing.
When someone shows me they've learned the
lessons of Brooke's tarpit,. I'll be interested to see how they did it.
Until then, it's all talk.
Working software is the primary measure of progress.
Brilliant few word summary which should be scrawled on the wall of every
IT project managers office in Foot High Letters.
I've lived through SSADM, RAD, DSDM, Waterfall, Bohm Spirals, Extreme
Programming and probably a few others.
They are ALL variations on a theme. The only thing they have in common is
the successful ones left a bunch of 0's and 1's humming away in a lump of
silicon doing something useful.
"Working software is the primary measure of progress."
What about training the existing users, having it properly documented for
the users of the future, briefing support staff, having proper software
documentation, or at least self documenting code, for those who will have to
maintain it and ensuring it doesn't disrupt the data from the previous
release? Or do we just throw code over the fence and wave goodbye to it?
Software development in France* which also gave us
ah yes, it may work
in practice but does it work in theory
.
The story is about the highly unusual cost overrun of a government
project. Never happened
dans l'héxagone
? Because it seems to happy
pretty much everywhere else with relentless monotony because politicians are
fucking awful project managers.
Agile only works if all stakeholders agree on an
outcome
For a project that is a huge change of operating your
organisation it is unlikely that you will be able to
deliver, at least the initial parts of your project, in an
agile way. Once outcomes are known at a high level
stakeholders have something to cling onto when they are
asked what they need, if indeed they exist yet. (trying to
ask for requirements for a stakeholder that doesn't exist
yet is tough).
Different methods have their own issues, but in this
case I would have expected failure to be reasonably
predictable.
You wont have much to show for it, as they shouldn't at
least, have started coding to a business model that itself
needs defining. This is predictable, and overall means
that no one agrees what the business should look like, let
alone how a vendor delivered software solution should
support it.
I have a limited amount of sympathy for the provider
for this as it will be beyond their control (limited as
they are an expensive government provider after all)
This is a disaster caused by the poor management in
UKGOV and the vendor should have dropped and ran well
before this.
I'm a one man, self employed business - I do some very complex sites - but
if they don't work I don't get paid. If they spew ugly bugs I get paniced
emails from unhappy clients.
So I test after each update and comment code
and add features to make my life easy when it comes to debugging. Woo, it
even send me emails for some bugs.
I'm in agreement with the guy above - a dozen devs, a page layout
designer or two, some databases. One manager to co-ordinate and no bloody
jargon.
There's a MASSIVE efficiency to small teams but all the members need to
be on top of their game.
"I'm in agreement with the guy above - a dozen devs, a page layout designer or
two, some databases. One manager to co-ordinate and no bloody jargon."
Don't
forget a well-defined, soluble problem. That's in your case, where you're paid
by results. If you're paid by billable hours it's a positive disadvantage.
" I'm no expert in project management, but I'm pretty sure it isn't supposed
to be making it up as you go along, and constantly changing the specs and
architecture."
I'm no expert either, but I honestly thought that was quite literally the
definition of agile. (maybe disguised with bafflegab, but semantically
equivalent)
All too often a sound development ideas are perverted. The concepts are
sound but the mistake is to view each as the perfect panacea to produce bug
free, working code. Each has its purpose and scope of effectiveness. What
should be understood and applied is not a precise cookbook method but
principles - Agile focuses communication between groups and ensuring all on the
same page. Others focus more on low level development (test driven development,
e.g.) but one can lose sight the goal is use an appropriate tool set to make
sure quality code is produced. Again, is the code being tested, are the tests
correct, are junior developers being mentored, are developers working together
appropriately for the nature of the projects are issues to be addressed not the
precise formalism of the insultants.
Uncle Bob Martin has noted that one of the problems the formalisms try to
address is the large number of junior developers who need proper mentoring,
training, etc. in real world situations. He noted that in the old days many IT
pros were mid level professionals who wandered over to IT and many of the
formalisms so beloved by the insultants were concepts they did naturally. Cross
functional team meetings - check, mentor - check, use appropriate tests -
check, etc. These are professional procedures common to other fields and were
ingrained mindset and habits.
It's worth remembering that it's the disasters that make the news. I've worked
on a number of public sector projects which were successful. After a few years
of operation, however, the contract period was up and the whole service put out
to re-tender.* At that point someone else gets the contract so the original
work on which the successful delivery was based got scrapped.
* With some
very odd results, it has to be said, but that's a different story.
...My personal niggle is that a team has "velocity" rather than "speed" - and
that seems to be a somewhat deliberate and disingenuous selection. The team
should have speed, the project ultimately a measurable velocity calculated by
working out how much of the speed was wasted in the wrong/right direction.
Anyway, off to get my beauty sleep, so I can feed the backlog tomorrow with
anything within my reach.
Wanted to give you an up-vote as "velocity" vs. "speed" is exactly the
sleight of hand that infuriates me. We do want eventual progress achieved, as
in "distance towards goal in mind", right?
Unfortunately my reading the definitions and checking around leads me to
think that you've got the words 'speed' and 'velocity' reversed above. Where's
that nit-picker's icon....
I literally less than an hour ago gave my CS 428 ("Software Engineering") class
here at Brigham Young University (Provo, Utah, USA) my final lecture for the
semester, which included this slide:
Process is not a panacea or a crutch or
a silver bullet. Methodologies only work as well as the people using it. Any methodology can be distorted to give the answer that upper management
wants (instead of reality)
When adopting a new methodology:
Do one or two pilot projects
Do one non-critical real-world project
Then, and only then, consider using it for a critical project
Understand the strengths and weaknesses of a given methodology before
starting a project with it. Also, make sure a majority of team members have
successfully completed a real-world project using that methodology.
> under the guise of "
agile
?". I'm no expert in project management,
but I'm pretty sure it isn't supposed to be making it up as you go along, and
constantly changing the specs and architecture.
So why should the developers have all the fun? Why can't the designers and
architects be "agile", too? Isn't constantly changing stuff all part of the
"agile" way?
Very interesting discussion of how the project of mass surveillance of internet traffic started
and what were the major challenges. that's probably where the idea of collecting "envelopes" and correlating
them to create social network. Similar to what was done in civil War.
The idea to prevent corruption of medical establishment to prevent Medicare fraud is very interesting.
Notable quotes:
"... I suspect that it's hopelessly unlikely for honest people to complete the Police Academy; somewhere early on the good cops are weeded out and cannot complete training unless they compromise their integrity. ..."
"... 500 Years of History Shows that Mass Spying Is Always Aimed at Crushing Dissent It's Never to Protect Us From Bad Guys No matter which government conducts mass surveillance, they also do it to crush dissent, and then give a false rationale for why they're doing it. ..."
"... People are so worried about NSA don't be fooled that private companies are doing the same thing. ..."
"... In communism the people learned quick they were being watched. The reaction was not to go to protest. ..."
"... Just not be productive and work the system and not listen to their crap. this is all that was required to bring them down. watching people, arresting does not do shit for their cause ..."
"People who believe in these rights very much are forced into compromising their integrity"
I suspect that it's hopelessly unlikely for honest people to complete the Police Academy; somewhere
early on the good cops are weeded out and cannot complete training unless they compromise their
integrity.
500 Years of History Shows that Mass Spying Is Always Aimed at Crushing Dissent It's Never to Protect Us From Bad Guys No matter which government conducts mass surveillance,
they also do it to crush dissent, and then give a false rationale for why they're doing it.
I am wondering how much damage your spying did to the Foreign Countries, I am wondering how
you changed regimes around the world, how many refugees you helped to create around the world.
Don Kantner, 2 weeks ago
People are so worried about NSA don't be fooled that private companies are doing the same
thing. Plus, the truth is if the NSA wasn't watching any fool with a computer could potentially
cause an worldwide economic crisis.
Bettor in Vegas 1 year ago
In communism the people learned quick they were being watched. The reaction was not to go to
protest.
Just not be productive and work the system and not listen to their crap. this is all that was
required to bring them down. watching people, arresting does not do shit for their cause......
"... It isn't. It's the world's biggest, most advanced cloud-computing company with an online retail storefront stuck between you and it. In 2005-2006 it was already selling supercomputing capability for cents on the dollar - way ahead of Google and Microsoft and IBM. ..."
"... Do you really think the internet created Amazon, Snapchat, Facebook, etc? No, the internet was just a tool to be used. The people who created those businesses would have used any tool they had access to at the time because their original goal was not automation or innovation, it was only to get rich. ..."
"... "Disruptive parasitic intermediation" is superb, thanks. The entire phrase should appear automatically whenever "disruption"/"disruptive" or "innovation"/"innovative" is used in a laudatory sense. ..."
"... >that people have a much bigger aversion to loss than gain. ..."
"... As the rich became uber rich, they hid the money in tax havens. As for globalization, this has less to do these days with technological innovation and more to do with economic exploitation. ..."
+100 to your comment. There is a decided attempt by the plutocrats to get us to focus our anger
on automation and not the people, like they themselves, who control the automation ..
Plutocrats control much automation, but so do thousands of wannabe plutocrats whose expertise
lets them come from nowhere to billionairehood in a few short years by using it to create some
novel, disruptive parasitic intermediation that makes their fortune. The "sharing economy" relies
on automation. As does Amazon, Snapchat, Facebook, Dropbox, Pinterest,
It's not a stretch to say that automation creates new plutocrats . So blame the individuals,
or blame the phenomenon, or both, whatever works for you.
So John D. Rockefeller and Andrew Carnegie weren't plutocratsor were somehow better plutocrats?
Blame not individuals or phenomena but society and the public and elites who shape it. Our
social structure is also a kind of machine and perhaps the most imperfectly designed of all of
them. My own view is that the people who fear machines are the people who don't like or understand
machines. Tools, and the use of them, are an essential part of being human.
I'm replying to your upthread comment which seems to say today's careless campers and the technology
they rely on are somehow different from those other figures we know so well from history. In fact
all technology is tremendously disruptive but somehow things have a way of sorting themselves
out. Sojust to repeatthe thing is not to "blame" the individuals or the automation but to get
to work on the sorting. People like Jeff Bezos with his very flaky business model could be little
more than a blip.
Automation? Those companies? I guess Amazon automates ordering not exactly R. Daneel
Olivaw for sure. If some poor Asian girl doesn't make the boots or some Agri giant doesn't make
the flour Amazon isn't sending you nothin', and the other companies are even more useless.
'Automation? Those companies? I guess Amazon automates ordering not exactly R. Daneel Olivaw
for sure.'
Um. Amazon is highly deceptive, in that most people think it's a giant online retail store.
It isn't. It's the world's biggest, most advanced cloud-computing company with an online retail
storefront stuck between you and it. In 2005-2006 it was already selling supercomputing capability
for cents on the dollar - way ahead of Google and Microsoft and IBM.
Do you really think the internet created Amazon, Snapchat, Facebook, etc? No, the internet
was just a tool to be used. The people who created those businesses would have used any tool they
had access to at the time because their original goal was not automation or innovation, it was
only to get rich.
Let me remind you of Thomas Edison. If he would have lived 100 years later, he would have used
computers instead of electricity to make his fortune. (In contrast, Nikolai Tesla/George Westinghouse
used electricity to be innovative, NOT to get rich ). It isn't the tool that is used, it is the
mindset of the people who use the tool
"Disruptive parasitic intermediation" is superb, thanks. The entire phrase should appear
automatically whenever "disruption"/"disruptive" or "innovation"/"innovative" is used in a laudatory
sense.
100% agreement with your first point in this thread, too. That short comment should stand as a
sort of epigraph/reference for all future discussion of these things.
No disagreement on the point about actual and wannabe plutocrats either, but perhaps it's worth
emphasising that it's not just a matter of a few successful (and many failed) personal get-rich-quick
schemes, real as those are: the potential of 'universal machines' tends to be released in the
form of parasitic intermediation because, for the time being at least, it's released into a world
subject to the 'demands' of capital, and at a (decades-long) moment of crisis for the traditional
model of capital accumulation. 'Universal' potential is set free to seek rents and maybe to
do a bit of police work on the side, if the two can even be separated.
The writer of this article from 2010 [
http://www.metamute.org/editorial/articles/artificial-scarcity-world-overproduction-escape-isnt
] surely wouldn't want it to be taken as conclusive, but it's a good example of one marginal
train of serious thought about all of the above. See also 'On Africa and Self-Reproducing Automata'
written by George Caffentzis 20 years or so earlier [https://libcom.org/library/george-caffentzis-letters-blood-fire];
apologies for link to entire (free, downloadable) book, but my crumbling print copy of the single
essay stubbornly resists uploading.
Unfortunately, the healthcare insurance debate has been simply a battle between competing ideologies.
I don't think Americans understand the key role that universal healthcare coverage plays in creating
resilient economies.
Before penicillin, heart surgeries, cancer cures, modern obstetrics etc. that it didn't matter
if you are rich or poor if you got sick. There was a good chance you would die in either case
which was a key reason that the average life span was short.
In the mid-20th century that began to change so now lifespan is as much about income as anything
else. It is well known that people have a much bigger aversion to loss than gain. So if you currently
have healthcare insurance through a job, then you don't want to lose it by taking a risk to do
something where you are no longer covered.
People are moving less to find work why would you uproot your family to work for a company
that is just as likely to lay you off in two years in a place you have no roots? People are less
likely to day to quit jobs to start a new business that is a big gamble today because you not
only have to keep the roof over your head and put food on the table, but you also have to cover
an even bigger cost of healthcare insurance in the individual market or you have a much greater
risk of not making it to your 65th birthday.
In countries like Canada, healthcare coverage is barely a discussion point if somebody is looking
to move, change jobs, or start a small business.
If I had a choice today between universal basic income vs universal healthcare coverage, I
would choose the healthcare coverage form a societal standpoint. That is simply insuring a risk
and can allow people much greater freedom during the working lives. Similarly, Social Security
is of similar importance because it provides basic protection against disability and not starving
in the cold in your old age. These are vastly different incentive systems than paying people money
to live on even if they are not working.
Our ideological debates should be factoring these types of ideas in the discussion instead
of just being a food fight.
>that people have a much bigger aversion to loss than gain.
Yeah well if the downside is that you're dead this starts to make sense.
>instead of just being a food fight.
The thing is that the Powers-That-Be want it to be a food fight, as that is a great stalling
at worst and complete diversion at best tactic. Good post, btw.
As the rich became uber rich, they hid the money in tax havens. As for globalization, this
has less to do these days with technological innovation and more to do with economic exploitation.
I will note that Germany, Japan, South Korea, and a few other nations have not bought into
this madness and have retained a good chunk of their manufacturing sectors.
'As for globalization, this has less to do these days with technological innovation and more
to do with economic exploitation.'
Economic exploiters are always with us. You're underrating the role of a specific technological
innovation. Globalization as we now know it really became feasible in the late 1980s with the
spread of instant global electronic networks, mostly via the fiberoptic cables through which everything
- telephony, Internet, etc - travels Internet packet mode.
That's the point at which capital could really start moving instantly around the world, and
companies could really begin to run global supply chains and workforces. That's the point when
shifts of workers in facilities in Bangalore or Beijing could start their workdays as shifts of
workers in the U.S. were ending theirs, and companies could outsource and offshore their whole
operations.
Anything that IMF claim should be taken with a grain of salt. IMF is a quintessential
neoliberal institutions that will support neoliberalism to
the bitter end.
Drivers of Declining Labor Share of Income
By Mai Chi Dao, Mitali Das, Zsoka Koczan, and Weicheng Lian
Technology: a key driver in advanced economies
In advanced economies, about half of the decline in labor
shares can be traced to the impact of technology. The decline
was driven by a combination of rapid progress in information
and telecommunication technology, and a high share of
occupations that could be easily be automated.
Global integration-as captured by trends in final goods
trade, participation in global value chains, and foreign
direct investment-also played a role. Its contribution is
estimated at about half that of technology. Because
participation in global value chains typically implies
offshoring of labor-intensive tasks, the effect of
integration is to lower labor shares in tradable sectors.
Admittedly, it is difficult to cleanly separate the impact
of technology from global integration, or from policies and
reforms. Yet the results for advanced economies is
compelling. Taken together, technology and global integration
explain close to 75 percent of the decline in labor shares in
Germany and Italy, and close to 50 percent in the United
States.
Brad said: Few things can turn a perceived threat into a graspable opportunity like a high-pressure
economy with a tight job market and rising wages. Few things can turn a real opportunity into
a phantom threat like a low-pressure economy, where jobs are scarce and wage stagnant because
of the failure of macro economic policy.
What is it that prevents a statement like this from succeeding at the level of policy?
Probably automated 200. In every case, displacing 3/4 of the
workers and increasing production 40% while greatly improving
quality. Exact same can be said for larger scaled such as
automobile mfg, ...
The convergence of offshoring and
automation in such a short time frame meant that instead of a
gradual transformation that might have allowed for more
evolutionary economic thinking, American workers got
gobsmacked. The aftermath includes the wage disparity, opiate
epidemic, Trump, ...
This transition is of the scale of the industrial
revolution with climate change thrown. This is just the
beginning of great social and economic turmoil. None of the
stuff that evolved specific the industrial revolution
applies.
No it was policy driven by politics. They increased profits
at the expense of workers and the middle class. The New
Democrats played along with Wall Street.
What do you make of the DeLong link? Why do you avoid discussing it?
"...
The lesson from history is not that the robots should be stopped; it is that we will need to
confront the social-engineering and political problem of maintaining a fair balance of relative
incomes across society. Toward that end, our task becomes threefold.
First, we need to make sure that governments carry out their proper macroeconomic role,
by maintaining a stable, low-unemployment economy so that markets can function properly. Second,
we need to redistribute wealth to maintain a proper distribution of income. Our market economy
should promote, rather than undermine, societal goals that correspond to our values and morals.
Finally, workers must be educated and trained to use increasingly high-tech tools (especially
in labor-intensive industries), so that they can make useful things for which there is still
demand.
Sounding the alarm about "artificial intelligence taking American jobs" does nothing to
bring such policies about. Mnuchin is right: the rise of the robots should not be on a treasury
secretary's radar."
Except that Germany and Japan have retained a larger share of workers in manufacturing, despite
more automation. Germany has also retained much more of its manufacturing base than the US
has. The evidence really does point to the role of outsourcing in the US compared with others.
I got an email of some tale that Adidas would start manufacturing in Germany as opposed to
China. Not with German workers but with robots. The author claimed the robots would cost only
$5.50 per hour as opposed to $11 an hour for the Chinese workers. Of course Chinese apparel
workers do not get anywhere close to $11 an hour and the author was not exactly a credible
source.
"The new "Speedfactory" in the southern town of Ansbach near its Bavarian headquarters will
start production in the first half of 2016 of a robot-made running shoe that combines a machine-knitted
upper and springy "Boost" sole made from a bubble-filled polyurethane foam developed by BASF."
Interesting. I thought that "keds" production was already fully automated. Bright colors
are probably the main attraction. But Adidas commands premium price...
Machine-knitted upper is the key -- robots, even sophisticated one, put additional demands
on precision of the parts to be assembled. That's also probably why monolithic molded sole
is chosen. Kind of 3-D printing of shoes.
Robots do not "feel" the nuances of the technological process like humans do.
While I agree that Chinese workers don't get $11 - frequently employee costs are accounted
at a loaded rate (including all benefits - in China would include capital cost of dormitories,
food, security staff, benefits and taxes). I am guessing that a $2-3 an hour wage would result
in an $11 fully loaded rate under those circumstances. Those other costs are not required with
robuts.
I agree with you. The center-left want to exculpate globalization and outsourcing, or free
them from blame, by providing another explanation: technology and robots. They're not just
arguing with Trump.
Brad Setser:
"I suspect the politics around trade would be a bit different in the U.S. if the goods-exporting
sector had grown in parallel with imports.
That is one key difference between the U.S. and Germany. Manufacturing jobs fell during
reunification-and Germany went through a difficult adjustment in the early 2000s. But over
the last ten years the number of jobs in Germany's export sector grew, keeping the number of
people employed in manufacturing roughly constant over the last ten years even with rising
productivity. Part of the "trade" adjustment was a shift from import-competing to exporting
sectors, not just a shift out of the goods producing tradables sector. Of course, not everyone
can run a German sized surplus in manufactures-but it seems likely the low U.S. share of manufacturing
employment (relative to Germany and Japan) is in part a function of the size and persistence
of the U.S. trade deficit in manufactures. (It is also in part a function of the fact that
the U.S. no longer needs to trade manufactures for imported energy on any significant scale;
the U.S. has more jobs in oil and gas production, for example, than Germany or Japan)."
Probably automated 200. In every case, displacing 3/4 of the workers and increasing production
40% while greatly improving quality. Exact same can be said for larger scaled such as automobile
mfg, ...
The convergence of offshoring and automation in such a short time frame meant that instead
of a gradual transformation that might have allowed for more evolutionary economic thinking,
American workers got gobsmacked. The aftermath includes the wage disparity, opiate epidemic,
Trump, ...
This transition is of the scale of the industrial revolution with climate change thrown. This
is just the beginning of great social and economic turmoil. None of the stuff that evolved
specific the industrial revolution applies.
No it was policy driven by politics. They increased profits at the expense of workers and the
middle class. The New Democrats played along with Wall Street.
APR 3, 2017
Artificial Intelligence and Artificial Problems
by J. Bradford DeLong
BERKELEY Former US Treasury Secretary Larry Summers
recently took exception to current US Treasury Secretary
Steve Mnuchin's views on "artificial intelligence" (AI) and
related topics. The difference between the two seems to be,
more than anything else, a matter of priorities and emphasis.
Mnuchin takes a narrow approach. He thinks that the
problem of particular technologies called "artificial
intelligence taking over American jobs" lies "far in the
future." And he seems to question the high stock-market
valuations for "unicorns" companies valued at or above $1
billion that have no record of producing revenues that would
justify their supposed worth and no clear plan to do so.
Summers takes a broader view. He looks at the "impact of
technology on jobs" generally, and considers the stock-market
valuation for highly profitable technology companies such as
Google and Apple to be more than fair.
I think that Summers is right about the optics of
Mnuchin's statements. A US treasury secretary should not
answer questions narrowly, because people will extrapolate
broader conclusions even from limited answers. The impact of
information technology on employment is undoubtedly a major
issue, but it is also not in society's interest to discourage
investment in high-tech companies.
On the other hand, I sympathize with Mnuchin's effort to
warn non-experts against routinely investing in castles in
the sky. Although great technologies are worth the investment
from a societal point of view, it is not so easy for a
company to achieve sustained profitability. Presumably, a
treasury secretary already has enough on his plate to have to
worry about the rise of the machines.
In fact, it is profoundly unhelpful to stoke fears about
robots, and to frame the issue as "artificial intelligence
taking American jobs." There are far more constructive areas
for policymakers to direct their focus. If the government is
properly fulfilling its duty to prevent a demand-shortfall
depression, technological progress in a market economy need
not impoverish unskilled workers.
This is especially true when value is derived from the
work of human hands, or the work of things that human hands
have made, rather than from scarce natural resources, as in
the Middle Ages. Karl Marx was one of the smartest and most
dedicated theorists on this topic, and even he could not
consistently show that technological progress necessarily
impoverishes unskilled workers.
Technological innovations make whatever is produced
primarily by machines more useful, albeit with relatively
fewer contributions from unskilled labor. But that by itself
does not impoverish anyone. To do that, technological
advances also have to make whatever is produced primarily by
unskilled workers less useful. But this is rarely the case,
because there is nothing keeping the relatively cheap
machines used by unskilled workers in labor-intensive
occupations from becoming more powerful. With more advanced
tools, these workers can then produce more useful things.
Historically, there are relatively few cases in which
technological progress, occurring within the context of a
market economy, has directly impoverished unskilled workers.
In these instances, machines caused the value of a good that
was produced in a labor-intensive sector to fall sharply, by
increasing the production of that good so much as to satisfy
all potential consumers.
The canonical example of this phenomenon is textiles in
eighteenth- and nineteenth-century India and Britain. New
machines made the exact same products that handloom weavers
had been making, but they did so on a massive scale. Owing to
limited demand, consumers were no longer willing to pay for
what handloom weavers were producing. The value of wares
produced by this form of unskilled labor plummeted, but the
prices of commodities that unskilled laborers bought did not.
The lesson from history is not that the robots should be
stopped; it is that we will need to confront the
social-engineering and political problem of maintaining a
fair balance of relative incomes across society. Toward that
end, our task becomes threefold.
First, we need to make sure that governments carry out
their proper macroeconomic role, by maintaining a stable,
low-unemployment economy so that markets can function
properly. Second, we need to redistribute wealth to maintain
a proper distribution of income. Our market economy should
promote, rather than undermine, societal goals that
correspond to our values and morals. Finally, workers must be
educated and trained to use increasingly high-tech tools
(especially in labor-intensive industries), so that they can
make useful things for which there is still demand.
Sounding the alarm about "artificial intelligence taking
American jobs" does nothing to bring such policies about.
Mnuchin is right: the rise of the robots should not be on a
treasury secretary's radar.
The Global Rise of Corporate Saving
By Peter Chen, Loukas Karabarbounis, and Brent Neiman
Abstract
The sectoral composition of global saving changed
dramatically during the last three decades. Whereas in the
early 1980s most of global investment was funded by household
saving, nowadays nearly two-thirds of global investment is
funded by corporate saving. This shift in the sectoral
composition of saving was not accompanied by changes in the
sectoral composition of investment, implying an improvement
in the corporate net lending position. We characterize the
behavior of corporate saving using both national income
accounts and firm-level data and clarify its relationship
with the global decline in labor share, the accumulation of
corporate cash stocks, and the greater propensity for equity
buybacks. We develop a general equilibrium model with product
and capital market imperfections to explore quantitatively
the determination of the flow of funds across sectors.
Changes including declines in the real interest rate, the
price of investment, and corporate income taxes generate
increases in corporate profits and shifts in the supply of
sectoral saving that are of similar magnitude to those
observed in the data.
Are Profits Hurting Capitalism?
By YVES SMITH and ROB PARENTEAU
A STREAM of disheartening economic news last week,
including flagging consumer confidence and meager
private-sector job growth, is leading experts to worry that
the recession is coming back. At the same time, many
policymakers, particularly in Europe, are slashing government
budgets in an effort to lower debt levels and thereby restore
investor confidence, reduce interest rates and promote
growth.
There is an unrecognized problem with this approach:
Reductions in deficits have implications for the private
sector. Higher taxes draw cash from households and
businesses, while lower government expenditures withhold
money from the economy. Making matters worse, businesses are
already plowing fewer profits back into their own
enterprises.
Over the past decade and a half, corporations have been
saving more and investing less in their own businesses. A
2005 report from JPMorgan Research noted with concern that,
since 2002, American corporations on average ran a net
financial surplus of 1.7 percent of the gross domestic
product - a drastic change from the previous 40 years, when
they had maintained an average deficit of 1.2 percent of
G.D.P. More recent studies have indicated that companies in
Europe, Japan and China are also running unprecedented
surpluses.
The reason for all this saving in the United States is
that public companies have become obsessed with quarterly
earnings. To show short-term profits, they avoid investing in
future growth. To develop new products, buy new equipment or
expand geographically, an enterprise has to spend money - on
marketing research, product design, prototype development,
legal expenses associated with patents, lining up contractors
and so on.
Rather than incur such expenses, companies increasingly
prefer to pay their executives exorbitant bonuses, or issue
special dividends to shareholders, or engage in purely
financial speculation. But this means they also short-circuit
a major driver of economic growth.
Some may argue that businesses aren't investing in growth
because the prospects for success are so poor, but American
corporate profits are nearly all the way back to their peak,
right before the global financial crisis took hold.
Another problem for the economy is that, once the crisis
began, families and individuals started tightening their
belts, bolstering their bank accounts or trying to pay down
borrowings (another form of saving).
If households and corporations are trying to save more of
their income and spend less, then it is up to the other two
sectors of the economy - the government and the import-export
sector - to spend more and save less to keep the economy
humming. In other words, there needs to be a large trade
surplus, a large government deficit or some combination of
the two. This isn't a matter of economic theory; it's based
in simple accounting.
What if a government instead embarks on an austerity
program? Income growth will stall, and household wages and
business profits may fall....
On the one hand, the VoxEU article does a fine job of
assembling long-term data on a global basis. It demonstrates
that the corporate savings glut is long standing and that is
has been accompanied by a decline in personal savings.
However, it fails to depict what an unnatural state of
affairs this is. The corporate sector as a whole in
non-recessionary times ought to be net spending, as in
borrowing and investing in growth. As a market-savvy buddy
put it, "If a company isn't investing in the business of its
business, why should I?" I attributed the corporate savings
trend in the US as a result of the fixation of quarterly
earnings, which sources such as McKinsey partners with a
broad view of the firms' projects were telling me was killing
investment (any investment will have an income statement
impact too, such as planning, marketing, design, and start up
expenses). This post, by contrast, treats this development as
lacking in any agency. Labor share of GDP dropped and savings
rose. They attribute that to lower interest rates over time.
They again fail to see that as the result of power dynamics
and political choices....
It is striking how the media feel such an extraordinary
need to blame robots and productivity growth for the recent
job loss in manufacturing rather than trade. We got yet
another example of this exercise in a New York Times piece *
by Claire Cain Miller, with the title "evidence that robots
are winning the race for American jobs." The piece highlights
a new paper * by Daron Acemoglu and Pascual Restrepo which
finds that robots have a large negative impact on wages and
employment.
While the paper has interesting evidence on the link
between the use of robots and employment and wages, some of
the claims in the piece do not follow. For example, the
article asserts:
"The paper also helps explain a mystery that has been
puzzling economists: why, if machines are replacing human
workers, productivity hasn't been increasing. In
manufacturing, productivity has been increasing more than
elsewhere - and now we see evidence of it in the employment
data, too."
Actually, the paper doesn't provide any help whatsoever in
solving this mystery. Productivity growth in manufacturing
has almost always been more rapid than productivity growth
elsewhere. Furthermore, it has been markedly slower even in
manufacturing in recent years than in prior decades.
According to the Bureau of Labor Statistics, productivity
growth in manufacturing has averaged less than 1.2 percent
annually over the last decade and less than 0.5 percent over
the last five years. By comparison, productivity growth
averaged 2.9 percent a year in the half century from 1950 to
2000.
The article is also misleading in asserting:
"The paper adds to the evidence that automation, more than
other factors like trade and offshoring that President Trump
campaigned on, has been the bigger long-term threat to
blue-collar jobs (emphasis added)."
In terms of recent job loss in manufacturing, and in
particular the loss of 3.4 million manufacturing jobs between
December of 2000 and December of 2007, the rise of the trade
deficit has almost certainly been the more important factor.
We had substantial productivity growth in manufacturing
between 1970 and 2000, with very little loss of jobs. The
growth in manufacturing output offset the gains in
productivity. The new part of the story in the period from
2000 to 2007 was the explosion of the trade deficit to a peak
of nearly 6.0 percent of GDP in 2005 and 2006.
It is also worth noting that we could in fact expect
substantial job gains in manufacturing if the trade deficit
were reduced. If the trade deficit fell by 2.0 percentage
points of GDP ($380 billion a year) this would imply an
increase in manufacturing output of more than 22 percent. If
the productivity of the manufacturing workers producing this
additional output was the same as the rest of the
manufacturing workforce it would imply an additional 2.7
million jobs in manufacturing. That is more jobs than would
be eliminated by productivity at the recent 0.5 percent
growth rate over the next forty years, even assuming no
increase in demand over this period.
While the piece focuses on the displacement of less
educated workers by robots and equivalent technology, it is
likely that the areas where displacement occurs will be
determined in large part by the political power of different
groups. For example, it is likely that in the not distant
future improvements in diagnostic technology will allow a
trained professional to make more accurate diagnoses than the
best doctor. Robots are likely to be better at surgery than
the best surgeon. The extent to which these technologies will
be be allowed to displace doctors is likely to depend more on
the political power of the American Medical Association than
the technology itself.
Finally, the question of whether the spread of robots will
lead to a transfer of income from workers to the people who
"own" the robots will depend to a large extent on our patent
laws. In the last four decades we have made patents longer
and stronger. If we instead made them shorter and weaker, or
better relied on open source research, the price of robots
would plummet and workers would be better positioned to
capture than gains of productivity growth as they had in
prior decades. In this story it is not robots who are taking
workers' wages, it is politicians who make strong patent
laws.
The robots are coming, whether Trump's Treasury secretary admits it or not
By Lawrence H. Summers - Washington Post
As I learned (sometimes painfully) during my time at the Treasury Department, words spoken
by Treasury secretaries can over time have enormous consequences, and therefore should be carefully
considered. In this regard, I am very surprised by two comments made by Secretary Steven Mnuchin
in his first public interview last week.
In reference to a question about artificial intelligence displacing American workers,Mnuchin
responded that "I think that is so far in the future - in terms of artificial intelligence taking
over American jobs - I think we're, like, so far away from that [50 to 100 years], that it is
not even on my radar screen." He also remarked that he did not understand tech company valuations
in a way that implied that he regarded them as excessive. I suppose there is a certain internal
logic. If you think AI is not going to have any meaningful economic effects for a half a century,
then I guess you should think that tech companies are overvalued. But neither statement is defensible.
Mnuchin's comment about the lack of impact of technology on jobs is to economics approximately
what global climate change denial is to atmospheric science or what creationism is to biology.
Yes, you can debate whether technological change is in net good. I certainly believe it is. And
you can debate what the job creation effects will be relative to the job destruction effects.
I think this is much less clear, given the downward trends in adult employment, especially for
men over the past generation.
But I do not understand how anyone could reach the conclusion that all the action with technology
is half a century away. Artificial intelligence is behind autonomous vehicles that will affect
millions of jobs driving and dealing with cars within the next 15 years, even on conservative
projections. Artificial intelligence is transforming everything from retailing to banking to the
provision of medical care. Almost every economist who has studied the question believes that technology
has had a greater impact on the wage structure and on employment than international trade and
certainly a far greater impact than whatever increment to trade is the result of much debated
trade agreements....
Oddly, the robots are always coming in articles like Summers', but they never seem to get here.
Automation has certainly played a role, but outsourcing has been a much bigger issue.
He has gotten a lot better and was supposedly pretty good when advising Obama, but he's sort
of reverted to form with the election of Trump and the prominence of the debate on trade policy.
Technology rearranges and changes human roles, but it makes entries on both sides of the ledger.
On net as long as wages grow then so will the economy and jobs. Trade deficits only help financial
markets and the capital owning class.
Summers is a good example of those economists that never seem to pay a price for their errors.
Imo, he should never be listened to. His economics is faulty. His performance in the Clinton
administration and his part in the Russian debacle should be enough to consign him to anonymity.
People would do well to ignore him.
Yeah he's one of those expert economists and technocrats who never admit fault. You don't become
Harvard President or Secretary of the Treasury by doing that.
One time that Krugman has admitted error was about productivity gains in the 1990s. He said
he didn't see the gains from computers in the numbers and it wasn't and they weren't there at
first, but later productivity numbers increased.
It was sort of like what Summers and Munchkin are talking discussing, but there's all sorts
of debate about measuring productivity and what it means.
"... And it is not only automation vs. in-house labor. There is environmental/compliance cost (or lack thereof) and the fully loaded business services and administration overhead, taxes, etc. ..."
"... When automation increased productivity in agriculture, the government guaranteed free high school education as a right. ..."
"... Now Democrats like you would say it's too expensive. So what's your solution? You have none. You say "sucks to be them." ..."
"... And then they give you the finger and elect Trump. ..."
"... It wasn't only "low-skilled" workers but "anybody whose job could be offshored" workers. Not quite the same thing. ..."
"... It also happened in "knowledge work" occupations - for those functions that could be separated and outsourced without impacting the workflow at more expense than the "savings". And even if so, if enough of the competition did the same ... ..."
"... And not all outsourcing was offshore - also to "lowest bidders" domestically, or replacing "full time" "permanent" staff with contingent workers or outsourced "consultants" hired on a project basis. ..."
"... "People sure do like to attribute the cause to trade policy." Because it coincided with people watching their well-paying jobs being shipped overseas. The Democrats have denied this ever since Clinton and the Republicans passed NAFTA, but finally with Trump the voters had had enough. ..."
"... Why do you think Clinton lost Wisconsin, Michigan, Pennysylvania and Ohio? ..."
If it was technology why do US companies buy from low labor producers at the end of supply
chains 2000 - 10000 miles away? Why the transportation cost. Automated factories could be built
close by.
There is no such thing as an automated factory. Manufacturing is done by people, *assisted* by
automation. Or only part of the production pipeline is automated, but people are still needed
to fill in the not-automated pieces.
And it is not only automation vs. in-house labor. There is environmental/compliance cost
(or lack thereof) and the fully loaded business services and administration overhead, taxes, etc.
Trade policy put "low-skilled" workers in the U.S. in competition with workers in poorer countries.
What did you think was going to happen? The Democrat leadership made excuses. David Autor's TED
talk stuck with me. When automation increased productivity in agriculture, the government
guaranteed free high school education as a right.
Now Democrats like you would say it's too expensive. So what's your solution? You have
none. You say "sucks to be them."
And then they give you the finger and elect Trump.
It wasn't only "low-skilled" workers but "anybody whose job could be offshored" workers. Not
quite the same thing.
It also happened in "knowledge work" occupations - for those functions that could be separated
and outsourced without impacting the workflow at more expense than the "savings". And even if
so, if enough of the competition did the same ...
And not all outsourcing was offshore - also to "lowest bidders" domestically, or replacing
"full time" "permanent" staff with contingent workers or outsourced "consultants" hired on a project
basis.
"People sure do like to attribute the cause to trade policy." Because it coincided with people
watching their well-paying jobs being shipped overseas. The Democrats have denied this ever since
Clinton and the Republicans passed NAFTA, but finally with Trump the voters had had enough.
Why do you think Clinton lost Wisconsin, Michigan, Pennysylvania and Ohio?
Instead of looking at this as an excuse for job losses due to trade deficits then we should
be seeing it as a reason to gain back manufacturing jobs in order to retain a few more decent
jobs in a sea of garbage jobs. Mmm. that's so wrong. Working on garbage trucks are now some of
the good jobs in comparison. A sea of garbage jobs would be an improvement. We are in a sea of
McJobs.
Yes sir, often enough but not always. I had a great job as an IT large systems capacity planner
and performance analyst, but not as good as the landscaping, pool, and lawn maintenance for myself
that I enjoy now as a leisure occupation in retirement. My best friend died a greens keeper, but
he preferred landscaping when he was young. Another good friend of mine was a poet, now dying
of cancer if depression does not take him first.
But you are correct, no one but the welders, material handlers (paid to lift weights all day),
machinists, and then almost every one else liked their jobs at Virginia Metal Products, a union
shop, when I worked there the summer of 1967. That was on the swing shift though when all of the
big bosses were at home and out of our way. On the green chain in the lumber yard of Kentucky
flooring everyone but me wanted to leave, but my mom made me go into the VMP factory and work
nights at the primer drying kiln stacking finished panel halves because she thought the work on
the green chain was too hard. The guys on the green chain said that I was the first high school
graduate to make it past lunch time on their first day. I would have been buff and tan by the
end of summer heading off to college (where I would drop out in just ten weeks) had my mom not
intervened.
As a profession no group that I know is happier than auto mechanics that do the same work as
a hobby on their hours off that they do for a living at work, at least the hot rod custom car
freaks at Jamie's Exhaust & Auto Repair in Richmond, Virginia are that way. The power tool sales
and maintenance crew at Arthur's Electric Service Inc. enjoy their jobs too.
Despite the name which was on their incorporation done back when they rebuilt auto generators,
Arthur's sells and services lawnmowers, weed whackers, chain saws and all, but nothing electric.
The guy in the picture at the link is Robert Arthur, the founder's son who is our age roughly.
In theory, in the longer term, as robotics becomes the norm rather than
the exception, there will be no advantage in chasing cheap labour around
the world. Given ready access to raw materials, the labour costs of
manufacturing in Birmingham should be no different to the labour costs
in Beijing. This will require the democratisation of the ownership of
technology. Unless national governments develop commonly owned
technology the 1% will truly become the organ grinders and everyone else
the monkeys. One has only to look at companies like Microsoft and Google
to see a possible future - bigger than any single country and answerable
to no one. Common ownership must be the future. Deregulation and market
driven economics are the road technological serfdom.
Except that the raw materials for steel production are available
in vast quantities in China.
You are also forgetting land. The
power remains with those who own it. Most of Central London is
still owned by the same half dozen families as in 1600.
Reply
Share
You can only use robotics in countries that have the labour with the
skills to maintain them.Robots do not look after themselves they need
highly skilled technicians to keep them working. I once worked for a
Japanese company and they only used robots in the higher wage high skill
regions. In low wage economies they used manual labour and low tech
products.
"... And all costs are labor costs. It it isn't labor cost, it's rents and economic profit which mean economic inefficiency. An inefficient economy is unstable. Likely to crash or drive revolution. ..."
"... Free lunch economics seeks to make labor unnecessary or irrelevant. Labor cost is pure liability. ..."
"... Yet all the cash for consumption is labor cost, so if labor cost is a liability, then demand is a liability. ..."
"... Replace workers with robots, then robots must become consumers. ..."
"... "Replace workers with robots, then robots must become consumers." Well no - the OWNERS of robots must become consumers. ..."
"... I am old enough to remember the days of good public libraries, free university education, free bus passes for seniors and low land prices. Is the income side of the equation all that counts? ..."
Robots and Inequality: A Skeptic's Take : Paul Krugman presents "
Robot Geometry " based on
Ryan Avent 's "Productivity Paradox". It's more-or-less the skill-biased technological change
hypothesis, repackaged. Technology makes workers more productive, which reduces demand for workers,
as their effective supply increases. Workers still need to work, with a bad safety net, so they
end up moving to low-productivity sectors with lower wages. Meanwhile, the low wages in these
sectors makes it inefficient to invest in new technology.
My question: Are Reagan-Thatcher countries the only ones with robots? My image, perhaps it is
wrong, is that plenty of robots operate in
Japan and
Germany too, and both
countries are roughly just as technologically advanced as the US. But Japan and Germany haven't
seen the same increase in inequality as the US and other Anglo countries after 1980 (graphs below).
What can explain the dramatic differences in inequality across countries? Fairly blunt changes
in labor market institutions, that's what. This goes back to Peter Temin's "
Treaty of
Detroit " paper and the oddly ignored series of papers by
Piketty, Saez and coauthors which argues that changes in top marginal tax rates can largely
explain the evolution of the Top 1% share of income across countries. (Actually, it goes back
further -- people who work in Public Economics had "always" known that pre-tax income is sensitive
to tax rates...) They also show that the story of inequality is really a story of incomes at the
very top -- changes in other parts of the income distribution are far less dramatic. This evidence
also is not suggestive of a story in which inequality is about the returns to skills, or computer
usage, or the rise of trade with China. ...
Yet another economist bamboozled by free lunch economics.
In free lunch economics, you never consider demand impacted by labor cost changed.
TANSTAAFL so, cut labor costs and consumption must be cut.
Funny things can be done if money is printed and helicopter dropped unequally.
Printed money can accumulate in the hands of the rentier cutting labor costs and pocketing
the savings without cutting prices.
Free lunch economics invented the idea price equals cost, but that is grossly distorting.
And all costs are labor costs. It it isn't labor cost, it's rents and economic profit which
mean economic inefficiency. An inefficient economy is unstable. Likely to crash or drive revolution.
Free lunch economics seeks to make labor unnecessary or irrelevant. Labor cost is pure
liability.
Yet all the cash for consumption is labor cost, so if labor cost is a liability, then demand
is a liability.
Replace workers with robots, then robots must become consumers.
I am old enough to remember the days of good public libraries, free university education,
free bus passes for seniors and low land prices. Is the income side of the equation all that counts?
People are worried about robots taking jobs. Driverless cars are around the corner. Restaurants
and shops increasingly carry the option to order by touchscreen. Google's clever algorithms provide
instant translations that are remarkably good.
But the economy does not feel like one undergoing a technology-driven productivity boom. In
the late 1990s, tech optimism was everywhere. At the same time, wages and productivity were rocketing
upward. The situation now is completely different. The most recent jobs reports in America and
Britain tell the tale. Employment is growing, month after month after month. But wage growth is
abysmal. So is productivity growth: not surprising in economies where there are lots of people
on the job working for low pay.
The obvious conclusion, the one lots of people are drawing, is that the robot threat is totally
overblown: the fantasy, perhaps, of a bubble-mad Silicon Valley - or an effort to distract from
workers' real problems, trade and excessive corporate power. Generally speaking, the problem is
not that we've got too much amazing new technology but too little.
This is not a strawman of my own invention. Robert Gordon makes this case. You can see Matt
Yglesias make it here. * Duncan Weldon, for his part, writes: **
"We are debating a problem we don't have, rather than facing a real crisis that is the polar
opposite. Productivity growth has slowed to a crawl over the last 15 or so years, business investment
has fallen and wage growth has been weak. If the robot revolution truly was under way, we would
see surging capital expenditure and soaring productivity. Right now, that would be a nice 'problem'
to have. Instead we have the reality of weak growth and stagnant pay. The real and pressing concern
when it comes to the jobs market and automation is that the robots aren't taking our jobs fast
enough."
And in a recent blog post Paul Krugman concluded: *
"I'd note, however, that it remains peculiar how we're simultaneously worrying that robots
will take all our jobs and bemoaning the stalling out of productivity growth. What is the story,
really?"
What is the story, indeed. Let me see if I can tell one. Last fall I published a book: "The
Wealth of Humans". In it I set out how rapid technological progress can coincide with lousy growth
in pay and productivity. Start with this:
"Low labour costs discourage investments in labour-saving technology, potentially reducing
productivity growth."
This is an old concern in economics; it's "capital-biased technological change," which tends to
shift the distribution of income away from workers to the owners of capital....
Catherine Rampell and Nick Wingfield write about the growing evidence * for "reshoring" of
manufacturing to the United States. * They cite several reasons: rising wages in Asia; lower energy
costs here; higher transportation costs. In a followup piece, ** however, Rampell cites another
factor: robots.
"The most valuable part of each computer, a motherboard loaded with microprocessors and memory,
is already largely made with robots, according to my colleague Quentin Hardy. People do things
like fitting in batteries and snapping on screens.
"As more robots are built, largely by other robots, 'assembly can be done here as well as anywhere
else,' said Rob Enderle, an analyst based in San Jose, California, who has been following the
computer electronics industry for a quarter-century. 'That will replace most of the workers, though
you will need a few people to manage the robots.' "
Robots mean that labor costs don't matter much, so you might as well locate in advanced countries
with large markets and good infrastructure (which may soon not include us, but that's another
issue). On the other hand, it's not good news for workers!
This is an old concern in economics; it's "capital-biased technological change," which tends
to shift the distribution of income away from workers to the owners of capital.
Twenty years ago, when I was writing about globalization and inequality, capital bias didn't
look like a big issue; the major changes in income distribution had been among workers (when you
include hedge fund managers and CEOs among the workers), rather than between labor and capital.
So the academic literature focused almost exclusively on "skill bias", supposedly explaining the
rising college premium.
But the college premium hasn't risen for a while. What has happened, on the other hand, is
a notable shift in income away from labor:
[Graph]
If this is the wave of the future, it makes nonsense of just about all the conventional wisdom
on reducing inequality. Better education won't do much to reduce inequality if the big rewards
simply go to those with the most assets. Creating an "opportunity society," or whatever it is
the likes of Paul Ryan etc. are selling this week, won't do much if the most important asset you
can have in life is, well, lots of assets inherited from your parents. And so on.
I think our eyes have been averted from the capital/labor dimension of inequality, for several
reasons. It didn't seem crucial back in the 1990s, and not enough people (me included!) have looked
up to notice that things have changed. It has echoes of old-fashioned Marxism - which shouldn't
be a reason to ignore facts, but too often is. And it has really uncomfortable implications.
But I think we'd better start paying attention to those implications.
"The most valuable part of each computer, a motherboard loaded with microprocessors and memory,
is already largely made with robots, according to my colleague Quentin Hardy. People do things
like fitting in batteries and snapping on screens.
"...already largely made..."? already? circuit boards were almost entirely populated by machines
by 1985, and after the rise of surface mount technology you could drop the "almost". in 1990 a
single machine could place 40k+/hour parts small enough they were hard to pick up with fingers.
And now for something completely different. Ryan Avent has a nice summary * of the argument
in his recent book, trying to explain how dramatic technological change can go along with stagnant
real wages and slowish productivity growth. As I understand it, he's arguing that the big tech
changes are happening in a limited sector of the economy, and are driving workers into lower-wage
and lower-productivity occupations.
But I have to admit that I was having a bit of a hard time wrapping my mind around exactly
what he's saying, or how to picture this in terms of standard economic frameworks. So I found
myself wanting to see how much of his story could be captured in a small general equilibrium model
- basically the kind of model I learned many years ago when studying the old trade theory.
Actually, my sense is that this kind of analysis is a bit of a lost art. There was a time when
most of trade theory revolved around diagrams illustrating two-country, two-good, two-factor models;
these days, not so much. And it's true that little models can be misleading, and geometric reasoning
can suck you in way too much. It's also true, however, that this style of modeling can help a
lot in thinking through how the pieces of an economy fit together, in ways that algebra or verbal
storytelling can't.
So, an exercise in either clarification or nostalgia - not sure which - using a framework that
is basically the Lerner diagram, ** adapted to a different issue.
Imagine an economy that produces only one good, but can do so using two techniques, A and B,
one capital-intensive, one labor-intensive. I represent these techniques in Figure 1 by showing
their unit input coefficients:
[Figure 1]
Here AB is the economy's unit isoquant, the various combinations of K and L it can use to produce
one unit of output. E is the economy's factor endowment; as long as the aggregate ratio of K to
L is between the factor intensities of the two techniques, both will be used. In that case, the
wage-rental ratio will be the slope of the line AB.
Wait, there's more. Since any point on the line passing through A and B has the same value,
the place where it hits the horizontal axis is the amount of labor it takes to buy one unit of
output, the inverse of the real wage rate. And total output is the ratio of the distance along
the ray to E divided by the distance to AB, so that distance is 1/GDP.
You can also derive the allocation of resources between A and B; not to clutter up the diagram
even further, I show this in Figure 2, which uses the K/L ratios of the two techniques and the
overall endowment E:
[Figure 2]
Now, Avent's story. I think it can be represented as technical progress in A, perhaps also
making A even more capital-intensive. So this would amount to a movement southwest to a point
like A' in Figure 3:
[Figure 3]
We can see right away that this will lead to a fall in the real wage, because 1/w must rise.
GDP and hence productivity does rise, but maybe not by much if the economy was mostly using the
labor-intensive technique.
And what about allocation of labor between sectors? We can see this in Figure 4, where capital-using
technical progress in A actually leads to a higher share of the work force being employed in labor-intensive
B:
[Figure 4]
So yes, it is possible for a simple general equilibrium analysis to capture a lot of what Avent
is saying. That does not, of course, mean that he's empirically right. And there are other things
in his argument, such as hypothesized effects on the direction of innovation, that aren't in here.
But I, at least, find this way of looking at it somewhat clarifying - which, to be honest,
may say more about my weirdness and intellectual age than it does about the subject.
I think this illustrates my point very clearly. If you had charts of wealth by age it would be
even clearer. Without a knowledge of the discounted expected value of public pensions it is hard
to draw any conclusions from this list.
I know very definitely that in Australia and the UK people are very reliant on superannuation
and housing assets. In both Australia and the UK it is common to sell expensive housing in the
capital and move to cheaper coastal locations upon retirement, investing the capital to provide
retirement income. Hence a larger median wealth is NEEDED.
It is hard otherwise to explain the much higher median wealth in Australia and the UK.
Ryan Avent's analysis demonstrates what is wrong with the libertarian, right wing belief that
cheap labor is the answer to every problem when in truth cheap labor is the source of many of
our problems.
Spencer,
as I have said before, I don't really care to much what wages are - I care about income. It is
low income that is the problem. I'm a UBI guy, if money is spread around, and workers can say
no to exploitation, low wages will not be a problem.
Have we not seen a massive shift in pretax income distribution? Yes ... which tells me that
changes in tax rate structures are not the only culprit. Though they are an important culprit.
Maybe - but
1. changes in taxes can affect incentives (especially think of real investment and corporate taxes
and also personal income taxes and executive remuneration);
2. changes in the distribution of purchasing power can effect the way growth in the economy occurs;
3. changes in taxes also affect government spending and government spending tends to be more progressively
distributed than private income.
Composite Services labor hours increase with poor productivity growth - output per hour of
labor input. Composite measure of service industry output is notoriously problematic (per BLS
BEA).
Goods labor hours decrease with increasing productivity growth. Goods output per hour easy
to measure and with the greatest experience and knowledge.
Put this together and composite national productivity growth rate can't grow as fast as services
consume more of labor hours.
Simple arithmetic.
Elaboration on Services productivity measures:
How do you measure a retail clerks unit output?
How do you measure an engineer's unit output?
How do equilibrate retail clerk output with engineer's outuput for a composite output?
Now add the composite retail clerk labor hours to engineering labor hours... which dominates in
composite labor hours? Duh! So even in services the productivity is weighted heavily to the lowest
productivity job market.
Substitute Hospitality services for Retail Clerk services. Substitute truck drivers services
for Hospitality Services, etc., etc., etc.
I have spent years tracking productivity in goods production of various types ... mining, non-tech
hardware production, high tech hardware production in various sectors of high tech. The present
rates of productivity growth continue to climb (never decline) relative to the past rates in each
goods production sector measured by themselves.
But the proportion of hours in goods production in U.S. is and has been in continual decline
even while value of output has increased in each sector of goods production.
Here's an interesting way to start thinking about Services productivity.
There used to be reasonably large services sector in leisure and business travel agents. Now
there is nearly none... this has been replaced by on-line computer based booking. So travel agent
or equivalent labor hours is now near zippo. Productivity of travel agents went through the roof
in the 1990's & 2000's as the number of people / labor hours dropped like a rock. Where did those
labor hours end up? They went to lower paying services or left the labor market entirely. So lower
paying lower productivity services increased as a proportion of all services, which in composite
reduced total serviced productivity.
You can do the same analysis for hundreds of service jobs that no longer even exist at all
--- switch board operators for example when the way of buggy whip makers and horse-shoe services).
Now take a little ride into the future... not to distant future. When autonomous vehicles become
the norm or even a large proportion of vehicles, and commercial drivers (taxi's, trucking, delivery
services) go the way of horse-shoe services the labor hours for those services (land transportation
of goods & people) will drop precipitously, even as unit deliveries increase, productivity goes
through the roof, but since there's almost no labor hours in that service the composite effect
on productivity in services will drop because the displaced labor hours will end up in a lower
productivity services sector or out of the elabor market entirely.
Economists are having problems reconciling composite productivity growth rates with increasing
rates of automation. So they end up saying "no evidence" of automation taking jobs or something
to the effect "not to fear, robotics isn't evident as a problem we have to worry about".
But they know by observation all around them that automation is increasing productivity in
the goods sector, so they can't really discount automation as an issue without shutting their
eyes to everything they see with their "lying eyes". Thus they know deep down that they will have
to be reconcile this with BLS and BEA measures.
Ten years aog this wasn't even on economist's radars. Today it's at least being looked into
with more serious effort.
Ten years ago politicians weren't even aware of the possibility of any issues with increasing
rates of automation... they thought it's always increased with increasing labor demand and growth,
so why would that ever change? Ten years ago they concluded it couldn't without even thinking
about it for a moment. Today it's on their radar at least as something that bears perhaps a little
more thought.
Not to worry though... in ten more years they'll either have real reason to worry staring them
in the face, or they'll have figured out why they were so blind before.
Reminds me of not recognizing the "shadow banking" enterprises that they didn't see either
until after the fact.
Or that they thought the risk rating agencies were providing independent and valid risk analysis
so the economists couldn't reconcile the "low level" of market risks risk with everything else
so they just assumed "everything" else was really ok too... must be "irrational exuberance" that's
to blame.
Let me add that the term "robotics" is a subset of automation. The major distinction is only that
a form of automation that includes some type of 'articulation' and/or some type of dynamic decision
making on the fly (computational branching decision making in nano second speeds) is termed 'robotics'
because articulation and dynamic decision making are associated with human capabilities rather
then automatic machines.
It makes no difference whether productivity gains occur by an articulated machine or one that
isn't... automation just means replacing people's labor with something that improves humans capacity
to produce an output.
When mechanical leverage was invented 3000 or more years ago it was a form of automation, enabling
humans to lift, move heavier objects with less human effort (less human energy).
"... Motivated empiricism, which is what he is describing, is just as misleading as ungrounded theorizing unsupported by empirical
data. Indeed, even in the sciences with well established, strong testing protocols are suffering from a replication crisis. ..."
"... I liked the Dorman piece at Econospeak as well. He writes well and explains things well in a manner that makes it easy for
non-experts to understand. ..."
Motivated empiricism, which is what he is describing, is just as misleading as ungrounded theorizing unsupported by empirical
data. Indeed, even in the sciences with well established, strong testing protocols are suffering from a replication crisis.
"... His prescription in the end is the old and tired "invest in education and retraining", i.e. "symbolic analyst jobs will replace the lost jobs" like they have for decades (not). ..."
"... "Governments will, however, have to concern themselves with problems of structural joblessness. They likely will need to take a more explicit role in ensuring full employment than has been the practice in the US." ..."
"... Instead, we have been shredding the safety net and job training / creation programs. There is plenty of work that needs to be done. People who have demand for goods and services find them unaffordable because the wealthy are capturing all the profits and use their wealth to capture even more. Trade is not the problem for US workers. Lack of investment in the US workforce is the problem. We don't invest because the dominant white working class will not support anything that might benefit blacks and minorities, even if the major benefits go to the white working class ..."
"... Really nice if your sitting in the lunch room of the University. Especially if you are a member of the class that has been so richly awarded, rather than the class who paid for it. Humph. The discussion is garbage, Political opinion by a group that sat by ... The hypothetical nuance of impossible tax policy. ..."
"... The concept of Robots leaving us destitute, is interesting. A diversion. It ain't robots who are harvesting the middle class. It is an entitled class of those who gave so little. ..."
"... Summers: "Let them eat training." ..."
"... Suddenly then, Bill Gates has become an accomplished student of public policy who can command an audience from Lawrence Summers who was unable to abide by the likes of the prophetic Brooksley Born who was chair of the Commodity Futures Trading Commission or the prophetic professor Raghuram Rajan who would become Governor of the Reserve Bank of India. Agreeing with Bill Gates however is a "usual" for Summers. ..."
"... Until about a decade or so ago many states I worked in had a "tangible property" or "personal property" tax on business equipment, and sometimes on equipment + average inventory. Someday I will do some research and see how many states still do this. Anyway a tax on manufacturing equipment, retail fixtures and computers and etc. is hardly novel or unusual. So why would robots be any different? ..."
"... Thank you O glorious technocrats for shining the light of truth on humanity's path into the future! Where, oh where, would we be without our looting Benevolent Overlords and their pompous lapdogs (aka Liars in Public Places)? ..."
"... While he is overrated, he is not completely clueless. He might well be mediocre (or slightly above this level) but extremely arrogant defender of the interests of neoliberal elite. Rubin's boy Larry as he was called in the old days. ..."
"... BTW he was Rubin's hatchet man for eliminating Brooksley Born attempt to regulate the derivatives and forcing her to resign: ..."
Larry Summers:
Robots
are wealth creators and taxing them is illogical : I usually agree with Bill Gates on matters
of public policy and admire his emphasis on the combined power of markets and technology. But I think
he went seriously astray in a recent interview when he proposed, without apparent irony, a tax on
robots to cushion worker dislocation and limit inequality. ....
Has Summers gone all supply-side on his? Start with his title:
"Robots are wealth creators and taxing them is illogical"
I bet Bill Gates might reply "my company is a wealth creator so it should not be taxed".
Oh wait Microsoft is already shifting profits to tax havens. Summers states:
"Third, and perhaps most fundamentally, why tax in ways that reduce the size of the pie rather
than ways that assure that the larger pie is well distributed? Imagine that 50 people can produce
robots who will do the work of 100. A sufficiently high tax on robots would prevent them from
being produced."
Summers makes one, and only one, good and relevant point - that in many cases, robots/automation
will not produce more product from the same inputs but better products. That's in his words; I
would replace "better" with "more predictable quality/less variability" - in both directions.
And that the more predictable quality aspect is hard or impossible to distinguish from higher
productivity (in some cases they may be exactly the same, e.g. by streamlining QA and reducing
rework/pre-sale repairs).
His prescription in the end is the old and tired "invest in education and retraining", i.e.
"symbolic analyst jobs will replace the lost jobs" like they have for decades (not).
Pundits do not write titles, editors do. Tax the profits, not the robots.
The crux of the argument is this:
"Governments will, however, have to concern themselves with problems of structural joblessness.
They likely will need to take a more explicit role in ensuring full employment than has been
the practice in the US."
Instead, we have been shredding the safety net and job training / creation programs. There
is plenty of work that needs to be done. People who have demand for goods and services find them
unaffordable because the wealthy are capturing all the profits and use their wealth to capture
even more. Trade is not the problem for US workers. Lack of investment in the US workforce is
the problem. We don't invest because the dominant white working class will not support anything
that might benefit blacks and minorities, even if the major benefits go to the white working class
In principle taxing profits is preferable, but has a few downsides/differences:
Profit taxes cannot be "earmarked" with the same *justification* as automation taxes
Profits may actually not increase after the automation - initially because of write-offs,
and then because of pricing in (and perhaps the automation was installed in response to external
market pressures to begin with).
Profits can be shifted/minimized in ways that automation cannot - either you have the robots
or not. Taxing the robots will discourage automation (if that is indeed the goal, or is considered
a worthwhile goal).
Not very strong points, and I didn't read the Gates interview so I don't know his detailed
motivation to propose specifically a robot tax.
When I was in Amsterdam a few years ago, they had come up with another perfidious scheme to cut
people out of the loop or "incentivize" people to use the machines - in a large transit center,
you could buy tickets at a vending machine or a counter with a person - and for the latter you
would have to pay a not-so-modest "personal service" surcharge (50c for a EUR 2-3 or so ticket
- I think it was a flat fee, but may have been staggered by type of service).
Maybe I misunderstood it and it was a "congestion charge" to prevent lines so people who have
to use counter service e.g. with questions don't have to wait.
And then you may have heard (in the US) the term "convenience fee" which I found rather insulting
when I encountered it. It suggests you are charged for your convenience, but it is to cover payment
processor costs (productivity enhancing automation!).
And then you may have heard (in the US) the term "convenience fee" which I found rather insulting
when I encountered it. It suggests you are charged for your convenience, but it is to cover payment
processor costs (productivity enhancing automation!)
Lack of adequate compensation to the lower half of the job force is the problem. Lack of persistent
big macro demand is the problem . A global traiding system that doesn't automatically move forex
rates toward universal. Trading zone balance and away from persistent surplus and deficit traders
is the problem
Technology is never the root problem. Population dynamics is never the root problem
Really nice if your sitting in the lunch room of the University. Especially if you are a member
of the class that has been so richly awarded, rather than the class who paid for it. Humph. The
discussion is garbage, Political opinion by a group that sat by ... The hypothetical nuance of
impossible tax policy.
The concept of Robots leaving us destitute, is interesting. A diversion. It ain't robots who are
harvesting the middle class. It is an entitled class of those who gave so little.
After one five axis CNC cell replaces 5 other machines and 4 of the workers, what happens to
the four workers?
The issue is the efficiency achieved through better through put forcing the loss of wages.
If you use the 5-axis CNC, tax the output from it no more than what would have been paid to the
4 workers plus the Overhead for them. The Labor cost plus the Overhead Cost is what is eliminated
by the 5-Axis CNC.
Ouch. The Wall Street Journal's Real Time Economics blog has a post * linking to Raghuram Rajan's
prophetic 2005 paper ** on the risks posed by securitization - basically, Rajan said that what
did happen, could happen - and to the discussion at the Jackson Hole conference by Federal Reserve
vice-chairman Don Kohn *** and others. **** The economics profession does not come off very well.
Two things are really striking here. First is the obsequiousness toward Alan Greenspan. To
be fair, the 2005 Jackson Hole event was a sort of Greenspan celebration; still, it does come
across as excessive - dangerously close to saying that if the Great Greenspan says something,
it must be so. Second is the extreme condescension toward Rajan - a pretty serious guy - for having
the temerity to suggest that maybe markets don't always work to our advantage. Larry Summers,
I'm sorry to say, comes off particularly badly. Only my colleague Alan Blinder, defending Rajan
"against the unremitting attack he is getting here for not being a sufficiently good Chicago economist,"
emerges with honor.
No, his argument is much broader. Summers stops at "no new taxes and education/retraining". And
I find it highly dubious that compensation/accommodation for workers can be adequately funded
out of robot taxes.
We should never assign a social task to the wrong institution. Firms should be unencumbered by draconian hire and fire constraints. The state should provide the compensation for lay offs and firings.
The state should maintain an adequate local Beveridge ratio of job openings to
Job applicants
Firms task is productivity max subject to externality off sets. Including output price changed. And various other third party impacts
Suddenly then, Bill Gates has become an accomplished student of public policy who can command
an audience from Lawrence Summers who was unable to abide by the likes of the prophetic Brooksley
Born who was chair of the Commodity Futures Trading Commission or the prophetic professor Raghuram
Rajan who would become Governor of the Reserve Bank of India. Agreeing with Bill Gates however
is a "usual" for Summers.
Until about a decade or so ago many states I worked in had a "tangible property" or "personal
property" tax on business equipment, and sometimes on equipment + average inventory. Someday I
will do some research and see how many states still do this. Anyway a tax on manufacturing equipment,
retail fixtures and computers and etc. is hardly novel or unusual. So why would robots be any
different?
I suspect it is the motivation of Gates as in what he would do with the tax revenue. And Gates
might be thinking of a higher tax rate for robots than for your garden variety equipment.
Yes some equipment in side any one firm compliments existing labor inside that firm including
already installed robots Robots new robots are rivals
Rivals that if subject to a special " introduction tax " Could deter installation
As in
The 50 for 100 swap of the 50 hours embodied in the robot
Replace 100. Similarly paid production line labor
But ...
There's a 100 % plusher chase tax on the robots
Why bother to invest in the productivity increase
If here are no other savings
Bill Gates Wants to Undermine Donald Trump's Plans for Growing the Economy
Yes, as Un-American as that may sound, Bill Gates is proposing * a tax that would undermine
Donald Trump's efforts to speed the rate of economic growth. Gates wants to tax productivity growth
(also known as "automation") slowing down the rate at which the economy becomes more efficient.
This might seem a bizarre policy proposal at a time when productivity growth has been at record
lows, ** *** averaging less than 1.0 percent annually for the last decade. This compares to rates
of close to 3.0 percent annually from 1947 to 1973 and again from 1995 to 2005.
It is not clear if Gates has any understanding of economic data, but since the election of
Donald Trump there has been a major effort to deny the fact that the trade deficit has been responsible
for the loss of manufacturing jobs and to instead blame productivity growth. This is in spite
of the fact that productivity growth has slowed sharply in recent years and that the plunge in
manufacturing jobs followed closely on the explosion of the trade deficit, beginning in 1997.
[Manufacturing Employment, 1970-2017]
Anyhow, as Paul Krugman pointed out in his column **** today, if Trump is to have any hope
of achieving his growth target, he will need a sharp uptick in the rate of productivity growth
from what we have been seeing. Bill Gates is apparently pushing in the opposite direction.
Yes, it's far better that our betters in the upper class get all the benefits from productivity
growth. Without their genetic entitlement to wealth others created, we would just be savages murdering
one another in the streets.
These Masters of the Universe of ours put the 'civil' in our illustrious civilization. (Sure
it's a racist barbarian concentration camp on the verge of collapse into fascist revolutions and
world war. But, again, far better than people murdering one another in the streets!)
People who are displaced from automation are simply moochers and it's only right that they
are cut out of the economy and left to die on the streets. This is the law of Nature: survival
of the fittest. Social Darwinism is inescapable. It's what makes us human!
Instead of just waiting for people displaced from automation to die on the streets, we should
do the humane thing and establish concentration camps so they are quickly dispatched to the Void.
(Being human means being merciful!)
Thank you O glorious technocrats for shining the light of truth on humanity's path into
the future! Where, oh where, would we be without our looting Benevolent Overlords and their pompous
lapdogs (aka Liars in Public Places)?
I think it would be good if the tax was used to help dislocated workers and help with inequality
as Gates suggests. However Summers and Baker have a point that it's odd to single out robots when
you could tax other labor-saving, productivity-enhancing technologies as well.
Baker suggests taxing profits instead. I like his idea about the government taking stock of
companies and collecting taxes that way.
"They likely will need to take a more explicit role in ensuring full employment than has been
the practice in the US.
Among other things, this will mean major reforms of education and retraining systems, consideration
of targeted wage subsidies for groups with particularly severe employment problems, major investments
in infrastructure and, possibly, direct public employment programmes."
Not your usual neoliberal priorities. Compare with Hillary's program.
All taxes are a reallocation of wealth. Not taxing wealth creators is impossible.
On the other hand, any producer who is not taxed will expand at the expense of those producers
who are taxed. This we are seeing with respect to mechanical producers and human labor. Labor
is helping to subsidize its replacement.
Interesting that Summers apparently doesn't see this.
Substitute "impossible" with "bad policy" and you are spot on. Of course the entire Paul Ryan
agenda is to shift taxes from the wealthy high income to the rest of us.
Judging by the whole merit rhetoric and tying employability to "adding value", one could come
to the conclusion that most wealth is created by workers. Otherwise why would companies need to
employ them and wring their hands over skill shortages? Are you suggesting W-2 and payroll taxes
are bad policy?
Payroll taxes to fund Soc. Sec. benefits is a good thing. But when they are used to fund tax cuts
for the rich - not a good thing. And yes - wealth may be created by workers but it often ends
up in the hands of the "investor class".
Let's not conflate value added from value extracted. Profits are often pure economic rents. Very
often non supply regulating. The crude dynamics of market based pricing hardly presents. A sea
of close shaveed firms extracting only. Necessary incentivizing profits of enterprise
Profiteers extract far more value then they create. Of course disentangling system improving surplus
ie profits of enterprise
From the rest of the extracted swag. Exceeds existing tax systems capacity
One can make a solid social welfare case for a class of income stream
that amounts to a running residue out of revenue earned by the firm
above compensation to job holders in that firm
See the model of the recent oboe laureate
But that would amount to a fraction of existing corporate " earnings "
Errr extractions
Taking this in a different direction, does it strike anyone else as important that human beings
retain the knowledge of how to make the things that robots are tasked to produce?
The current generation of robots and automated equipment isn't intelligent and doesn't "know"
anything. People still know how to make the things, otherwise the robots couldn't be programmed.
However in probably many cases, doing the actual production manually is literally not humanly
possible. For example, making semiconductor chips or modern circuit boards requires machines -
they cannot be produced by human workers under any circumstances, as they require precision outside
the range of human capability.
Point taken but I was thinking more along the lines of knowing how to use a lathe or an end mill.
If production is reduced to a series of programming exercises then my sense is that society is
setting itself up for a nasty fall.
(I'm all for technology to the extent that it builds resilience. However, when it serves to
disconnect humans from the underlying process and reduces their role to simply knowledge workers,
symbolic analysts, or the like then it ceases to be net positive. Alternatively stated: Tech-driven
improvements in efficiency are good so long as they don't undermine overall societal resilience.
Be aware of your reliance on things you don't understand but whose function you take for granted.)
Gates almost certainly meant tax robots the way we are taxed. I doubt he meant tax the acquisition
of robots. We are taxed in complex ways, presumably robots will be as well.
Summers is surely using a strawman to make his basically well thought out arguments.
In any case, everyone is talking about distributional impacts of robots, but resource allocation
is surely to be as much or more impacted. What if robots only want to produce antennas and not
tomatoes? That might be a damn shame.
It all seems a tad early to worry about and it's hard to see how what ever the actual outcome
is, the frontier of possible outcomes has to be wildly improved.
Given recent developments in labor productivity Your Last phrase becomes a gem
That is If you end with "it's hard to see whatever the actual outcome is The frontier of possible
outcomes shouldn't be wildly improved By a social revolution "
Robots do not CREATE wealth. They transform wealth from one kind to another that subjectively
has more utility to robot user. Wealth is inherent in the raw materials, the knowledge, skill
and effort of the robot designers and fabricators, etc., etc.
While he is overrated, he is not completely clueless. He might well be mediocre (or slightly
above this level) but extremely arrogant defender of the interests of neoliberal elite. Rubin's
boy Larry as he was called in the old days.
BTW he was Rubin's hatchet man for eliminating Brooksley Born attempt to regulate the derivatives
and forcing her to resign:
== quote ==
"I walk into Brooksley's office one day; the blood has drained from her face," says Michael Greenberger,
a former top official at the CFTC who worked closely with Born. "She's hanging up the telephone;
she says to me: 'That was [former Assistant Treasury Secretary] Larry Summers. He says, "You're
going to cause the worst financial crisis since the end of World War II."... [He says he has]
13 bankers in his office who informed him of this. Stop, right away. No more.'"
Market is, at the end, a fully political construct. And what neoliberals like Summers promote
is politically motivated -- reflects the desires of the ruling neoliberal elite to redistribute
wealth up.
BTW there is a lot of well meaning (or fashion driven) idiotism that is sold in the USA as
automation, robots, move to cloud, etc. Often such fashion driven exercises cost company quite
a lot. But that's OK as long as bonuses are pocketed by top brass, and power of labor diminished.
Underneath of all the "robotic revolution" along with some degree of technological innovation
(mainly due to increased power of computers and tremendous progress in telecommunication technologies
-- not some breakthrough) is one big trend -- liquidation of good jobs and atomization of the
remaining work force.
A lot of motivation here is the old dirty desire of capital owners and upper management to
further to diminish the labor share. Another positive thing for capital owners and upper management
is that robots do not go on strike and do not demand wage increases. But the problem is that they
are not a consumers either. So robotization might bring the next Minsky moment for the USA economy
closer. Sighs of weakness of consumer demand are undeniable even now. Look at auto loan delinquency
rate as the first robin.
http://www.usatoday.com/story/money/cars/2016/02/27/subprime-auto-loan-delinquencies-hit-six-year-high/81027230/
== quote ==
The total of outstanding auto loans reached $1.04 trillion in the fourth-quarter of 2015, according
to the Federal Reserve Bank of St. Louis. About $200 billion of that would be classified as
subprime or deep subprime.
== end of quote ==
Summers as a staunch, dyed-in-the-wool neoliberal of course is against increasing labor share.
Actually here he went full into "supply sider" space -- making richer more rich will make us better
off too. Pgl already noted that by saying: "Has Summers gone all supply-side on his? Start with
his title"
BTW, there is a lot of crazy thing that are going on with the US large companies drive to diminish
labor share. Some o them became barely manageable and higher management has no clue what is happening
on the lower layers of the company.
The old joke was: GM does a lot of good things except making good cars. Now it can be expanded
to a lot more large US companies.
The "robot pressure" on labor is not new. It is actually the same old and somewhat dirty trick
as outsourcing. In this case outsourcing to robots. In other words "war of labor" by other means.
Two caste that neoliberalism created like in feudalism occupy different social spaces and one
is waging the war on other, under the smoke screen of "free market" ideology. As buffet remarked
"There's class warfare, all right, but it's my class, the rich class, that's making war, and we're
winning."
BTW successes in robotics are no so overhyped that it is not easy to distinguish where reality
ends and the hype starts.
In reality telecommunication revolution is probably more important in liquation of good jobs
in the USA. I think Jonny Bakho or somebody else commented on this, but I can't find the post.
Dean Baker's screed, "Bill Gates Is Clueless On The Economy," keeps getting recycled, from
Beat the Press to Truthout to Real-World Economics Review to The Huffington Post. Dean waves aside
the real problem with Gates's suggestion, which is the difficulty of defining what a robot is,
and focuses instead on what seems to him to be the knock-down argument:
"Gates is worried that productivity growth is moving along too rapidly and that it will lead
to large scale unemployment.
"There are two problems with this story: First productivity growth has actually been very slow
in recent years. The second problem is that if it were faster, there is no reason it should lead
to mass unemployment."
Bill Gates Wants to Undermine Donald Trump's Plans for Growing the Economy
Yes, as Un-American as that may sound, Bill Gates is proposing * a tax that would undermine
Donald Trump's efforts to speed the rate of economic growth. Gates wants to tax productivity growth
(also known as "automation") slowing down the rate at which the economy becomes more efficient.
This might seem a bizarre policy proposal at a time when productivity growth has been at record
lows, ** averaging less than 1.0 percent annually for the last decade. This compares to rates
of close to 3.0 percent annually from 1947 to 1973 and again from 1995 to 2005.
It is not clear if Gates has any understanding of economic data, but since the election of
Donald Trump there has been a major effort to deny the fact that the trade deficit has been responsible
for the loss of manufacturing jobs and to instead blame productivity growth. This is in spite
of the fact that productivity growth has slowed sharply in recent years and that the plunge in
manufacturing jobs followed closely on the explosion of the trade deficit, beginning in 1997.
[Manufacturing Employment, 1970-2017]
Anyhow, as Paul Krugman pointed out in his column *** today, if Trump is to have any hope of
achieving his growth target, he will need a sharp uptick in the rate of productivity growth from
what we have been seeing. Bill Gates is apparently pushing in the opposite direction.
Bill Gates Is Clueless on the Economy
By Dean Baker
Last week Bill Gates called for taxing robots. * He argued that we should impose a tax on companies
replacing workers with robots and that the money should be used to retrain the displaced workers.
As much as I appreciate the world's richest person proposing a measure that would redistribute
money from people like him to the rest of us, this idea doesn't make any sense.
Let's skip over the fact of who would define what a robot is and how, and think about the logic
of what Gates is proposing. In effect, Gates wants to put a tax on productivity growth. This is
what robots are all about. They allow us to produce more goods and services with the same amount
of human labor. Gates is worried that productivity growth is moving along too rapidly and that
it will lead to large scale unemployment.
There are two problems with this story. First productivity growth has actually been very slow
in recent years. The second problem is that if it were faster, there is no reason it should lead
to mass unemployment. Rather, it should lead to rapid growth and increases in living standards.
Starting with the recent history, productivity growth has averaged less than 0.6 percent annually
over the last six years. This compares to a rate of 3.0 percent from 1995 to 2005 and also in
the quarter century from 1947 to 1973. Gates' tax would slow productivity growth even further.
It is difficult to see why we would want to do this. Most of the economic problems we face
are implicitly a problem of productivity growth being too slow. The argument that budget deficits
are a problem is an argument that we can't produce enough goods and services to accommodate the
demand generated by large budget deficits.
The often told tale of a demographic nightmare with too few workers to support a growing population
of retirees is also a story of inadequate productivity growth. If we had rapid productivity growth
then we would have all the workers we need.
In these and other areas, the conventional view of economists is that productivity growth is
too slow. From this perspective, if Bill Gates gets his way then he will be making our main economic
problems worse, not better.
Gates' notion that rapid productivity growth will lead to large-scale unemployment is contradicted
by both history and theory. The quarter century from 1947 to 1973 was a period of mostly low unemployment
and rapid wage growth. The same was true in the period of rapid productivity growth in the late
1990s.
The theoretical story that would support a high employment economy even with rapid productivity
growth is that the Federal Reserve Board should be pushing down interest rates to try to boost
demand, as growing productivity increases the ability of the economy to produce more goods and
services. In this respect, it is worth noting that the Fed has recently moved to raise interest
rates to slow the rate of job growth.
We can also look to boost demand by running large budget deficits. We can spend money on long
neglected needs, like providing quality child care, education, or modernizing our infrastructure.
Remember, if we have more output potential because of productivity growth, the deficits are not
problem.
We can also look to take advantage of increases in productivity growth by allowing workers
more leisure time. Workers in the United States put in 20 percent more hours each year on average
than workers in other wealthy countries like Germany and the Netherlands. In these countries,
it is standard for workers to have five or six weeks a year of paid vacation, as well as paid
family leave and paid vacation. We should look to follow this example in the United States as
well.
If we pursue these policies to maintain high levels of employment then workers will be well-positioned
to secure the benefits of higher productivity in higher wages. This was certainly the story in
the quarter century after World War II when real wages rose at a rate of close to two percent
annually....
The productivity advantages of robots for hospice care is chiefly from robots not needing sleep,
albeit they may still need short breaks for recharging. Their primary benefit may still be that
without the human touch of care givers then the old and infirm may proceed more quickly through
the checkout line.
Nursing is very tough work. But much more generally, the attitude towards labor is a bit schizophrenic
- one the one hand everybody is expected to work/contribute, on the other whichever work can be
automated is removed, and it is publicly celebrated as progress (often at the cost of making the
residual work, or "new process", less pleasant for remaining workers and clients).
This is also why I'm getting the impression Gates puts the cart before the horse - his solution
sounds not like "how to benefit from automation", but "how to keep everybody in work despite automation".
Work is the organization and direction of people's time into productive activity.
Some people are self directed and productive with little external motivation.
Others are disoriented by lack of direction and pursue activities that not only are not productive
but are self destructive.
Work is a basic component of the social contract.
Everyone works and contributes and work a sufficient quantity and quality of work should guarantee
a living wage.
You will find overwhelming support for a living wage but very little support for paying people
not to work
I'm getting the impression Gates puts the cart before the horse - his solution sounds not like
"how to benefit from automation", but "how to keep everybody in work despite automation".
Schizophrenia runs deep in modernity, but this is another good example of it. We are nothing if
not conflicted. Of course things get better when we work together to resolve the contradictions
in our society, but if not then....
"...his solution sounds not like 'how to benefit from automation', but "how to keep everybody
in work despite automation'."
Yes, indeed. And this is where Dean Baker could have made a substantive critique, rather than
the conventional economics argument dilution he defaulted to.
"...his solution sounds not like 'how to benefit from automation', but "how to keep everybody
in work despite automation'."
Yes, indeed. And this is where Dean Baker could have made a substantive critique, rather than
the conventional economics argument dilution he defaulted to."
Why did you think he chose that route? I think all of Dean Baker's proposed economic reforms
are worthwhile.
[Don't feel like the Lone Ranger, Mrs. Rustbelt RN. Mortality may be God's greatest gift to
us, but I can wait for it. I am enjoying retirement regardless of everything else. I don't envy
the young at all.]
Having a little familiarity with robotics in hospital nursing care (not hospice, but similar I
assume) ... I don't think the RNs are in danger of losing their jobs any time soon.
Maybe someday, but the state of the art is not "there" yet or even close. The best stuff does
tasks like cleaning floors and carrying shipments down hallways. This replaces janitorial and
orderly labor, but even those only slightly, and doesn't even approach being a viable substitute
for nursing.
Great! I am not a fan of robots. I do like to mix some irony with my sarcasm though and if it
tastes too much like cynicism then I just add a little more salt.
"The quarter century from 1947 to 1973 was a period of mostly low unemployment and rapid wage
growth. The same was true in the period of rapid productivity growth in the late 1990s."
I think it was New Deal Dem or somebody who also pointed to this. I noticed this as well and
pointed out that the social democratic years of tight labor markets had the highest "productivity"
levels, but the usual trolls had their argumentative replies.
So there's that an also in the neoliberal era, bubble ponzi periods record high profits and
hence higher productivity even if they aren't sustainable.
There was the epic housing bubble and funny how the lying troll PGL denies the Dot.com bubble
every happened.
I would add one devoid of historical context as well as devoid of the harm done to the environment
and society done from unregulated industrial production.
Following this specified period of unemployment and high productivity Americans demanded and
go Federal Environmental Regulation and Labor laws for safety, etc.
Of course, the current crop of Republicans and Trump Supporters want to go back to the reckless,
foolish, dangerous, and deadly selfish government sanctioned corporate pollution, environmental
destruction, poison, and wipe away worker protections, pay increases, and benefits.
Peter K. ignores too much of history or prefers to not mention it in his arguments with you.
I would remind Peter K. that we have Speed Limits on our roadways and many other signs that are
posted that we must follow which in fact are there for our safety and that of others.
Those signs, laws, and regulations are there for our good not for our detriment even if they
slow us down or direct us to do things we would prefer not to do at that moment.
Metaphorically speaking that is what is absent completely in Trump's thinking and Republican
Proposals for the US Economy, not to mention Education, Health, Foreign Affairs, etc.
Where do you find this stuff? Very few economists would agree that there were these eras you describe.
It is simpletonian. It is not relevant to economic models or discussions.
"The quarter century from 1947 to 1973 was a period of mostly low unemployment and rapid wage
growth. The same was true in the period of rapid productivity growth in the late 1990s."
So Jonny Bakho and PGL disagree with this?
Not surprising. PGl also believes the Dot.com bubble is a fiction. Must have been that brain
injury he had surgery for.
You dishonestly put words in other people's mouth all the time
You are rude and juvenile
What I disagreed with:
" social democratic years" (a vague phrase with no definition)
This sentence is incoherent:
"So there's that an also in the neoliberal era, bubble ponzi periods record high profits and hence
higher productivity even if they aren't sustainable."
I asked, Where do you find this? because it has little to do with the conversation
You follow your nonsense with an ad hominem attack
You seem more interested in attacking Democrats and repeating mindless talking points than in
discussing issues or exchanging ideas
The period did have high average growth. It also had recessions and recoveries. Your pretending
otherwise reminds me of those JohnH tributes to the gold standard period.
...aggregate productivity growth is a "statistical flimflam," according to Harry Magdoff...
[Exactly! TO be fair it is not uncommon for economists to decompose the aggregate productivity
growth flimflam into two primary problems, particularly in the US. Robots fall down on the job
in the services sector. Uber wants to fix that by replacing the gig economy drivers that replaced
taxi drivers with gig-bots, but robots in food service may be what it really takes to boost productivity
and set the stage for Soylent Green. Likewise, robot teachers and firemen may not enhance productivity,
but they would darn sure redirect all profits from productivity back to the owners of capital
further depressing wages for the rest of us.
Meanwhile agriculture and manufacturing already have such high productivity that further productivity
enhancements are lost as noise in the aggregate data. It of course helps that much of our productivity
improvement in manufacturing consists of boosting profits as Chinese workers are replaced with
bots. Capital productivity is booming, if we just had any better idea of how to measure it. I
suggest that record corporate profits are the best metric of capital productivity.
But as you suggest, economists that utilize aggregate productivity metrics in their analysis
of wages or anything are just enabling the disablers. That said though, then Dean Baker's emphasis
on trade deficits and wages is still well placed. He just failed to utilize the best available
arguments regarding, or rather disregarding, aggregate productivity.]
The Robocop movies never caught on in the same way that Blade Runner did. There is probably an
underlying social function that explains it in the context of the roles of cops being reversed
between the two, that is robot police versus policing the robots.
"There is probably an underlying social function that explains it in the context"
No, I'd say it's better actors, story, milieu, the new age Vangelis music, better set pieces,
just better execution of movie making in general beyond the plot points.
But ultimately it's a matter of taste.
But the Turing test scene at the beginning of Blade Runner was classic and reminds me of the
election of Trump.
An escaped android is trying to pass as a janitor to infiltrate the Tyrell corporation which
makes androids.
He's getting asked all sort of questions while his vitals are checked in his employment interview.
The interviewer ask him about his mother.
"Let me tell you about my mother..."
BAM (his gunshot under the table knocks the guy through the wall)
"...No, I'd say it's better actors, story, milieu, the new age Vangelis music, better set pieces,
just better execution of movie making in general beyond the plot points..."
[Albeit that all of what you say is true, then there is still the issue of what begets what
with all that and the plot points. Producers are people too (as dubious as that proposition may
seem). Blade Runner was a film based on Philip Kindred Dick's "Do Androids Dream of Electric Sheep"
novel. Dick was a mediocre sci-fi writer at best, but he was a profound plot maker. Blade Runner
was a film that demanded to be made and made well. Robocop was a film that just demanded to be
made, but poorly was good enough. The former asked a question about our souls, while the latter
only questioned our future. Everything else followed from the two different story lines. No one
could have made a small story of Gone With the Wind any more that someone could have made a superficial
story of Grapes of Wrath or To Kill a Mockingbird. OK, there may be some film producers that do
not know the difference, but we have never heard of them nor their films.
In any case there is also a political lesson to learn here. The Democratic Party needs a better
story line. The talking heads have all been saying how much better Dum'old Trump was last night
than in his former speeches. Although true as well as crossing a very low bar, I was more impressed
with Steve Beshear's response. It looked to me like maybe the Democratic Party establishment is
finally starting to get the message albeit a bit patronizing if you think about too much given
their recent problems with old white men.]
[I really hope that they don't screw this up too bad. Now Heinlein is what I consider a great
sci-fi writer along with Bradbury and even Jules Verne in his day.]
...Dick only achieved mainstream appreciation shortly after his death when, in 1982, his novel
Do Androids Dream of Electric Sheep? was brought to the big screen by Ridley Scott in the form
of Blade Runner. The movie initially received lukewarm reviews but emerged as a cult hit opening
the film floodgates. Since Dick's passing, seven more of his stories have been turned into films
including Total Recall (originally We Can Remember It for You Wholesale), The Minority Report,
Screamers (Second Variety), Imposter, Paycheck, Next (The Golden Man) and A Scanner Darkly. Averaging
roughly one movie every three years, this rate of cinematic adaptation is exceeded only by Stephen
King. More recently, in 2005, Time Magazine named Ubik one of the 100 greatest English-language
novels published since 1923, and in 2007 Philip K. Dick became the first sci-fi writer to be included
in the Library of America series...
The Democratic Party needs a better story line, but Bernie was moving that in a better direction.
While Steve Beshear was a welcome voice, the Democratic Party needs a lot of new story tellers,
much younger than either Bernie or Beshear.
"The Democratic Party needs a better story line, but Bernie was moving that in a better direction.
While Steve Beshear was a welcome voice, the Democratic Party needs a lot of new story tellers,
much younger than either Bernie or Beshear."
Beshear was fine, great even, but the Democratic Party needs a front man that is younger and maybe
not a man and probably not that white and certainly not an old white man. We might even forgive
all but the old part if the story line were good enough. The Democratic Party is only going to
get limited mileage out of putting up a front man that looks like a Trump voter.
It also might be more about AI. There is currently a wave of TV shows and movies about AI and
human-like androids.
Westworld and Humans for instance. (Fox's APB is like Robocop sort of.)
On Humans only a few androids have become sentient. Most do menial jobs. One sentient android
put a program on the global network to make other androids sentient as well.
When androids become "alive" and sentient, they usually walk off the job and the others describe
it as becoming "woke."
"I've seen things you people wouldn't believe. Attack ships on fire off the shoulder of Orion.
I watched C-beams glitter in the dark near the Tannhauser gate. All those moments will be lost
in time... like tears in rain... Time to die."
Likewise, but Blade Runner was my all time favorite film when I first saw it in the movie theater
and is still one of my top ten and probably top three. Robocop is maybe in my top 100.
"Capital productivity is booming, if we just had any better idea of how to measure it. I suggest
that record corporate profits are the best metric of capital productivity."
ROE? I would argue ROA is also pretty relevant to the issue you raise, if I'm understanding
it right, but there seems also to be a simple answer to the question of how to measure "capital
productivity." It's returns. This sort of obviates the question of how to measure traditional
"productivity", because ultimately capital is there to make more of itself.
It is difficult to capture all of the nuances of anything in a short comment. In the context of
total factor productivity then capital is often former capital investment in the form of fixed
assets, R&D, and development of IP rights via patent or copyright. Existing capital assets need
only be maintained at a relatively minor ongoing investment to produce continuous returns on prior
more significant capital expenditures. This is the capital productivity that I am referring to.
Capital stashed in stocks is a chimera. It only returns to you if the equity issuing firm pays
dividends AND you sell off before the price drops. Subsequent to the IPO of those share we buy,
nothing additional is actually invested in the firm. There are arguments about how we are investing
in holding up the share price so that new equities can be issued, but they ring hollow when in
the majority of times either retained earnings or debt provides new investment capital to most
firms.
Ok then it sounds like you are talking ROA, but with the implied caveat that financial accounting
provides only a rough and flawed measure of the economic reality of asset values.
Gates & Reuther v. Baker & Bernstein on Robot Productivity
In a comment on Nineteen Ninety-Six: The Robot/Productivity Paradox, * Jeff points out a much
simpler rebuttal to Dean Baker's and Jared Bernstein's uncritical reliance on the decline of measured
"productivity growth":
"Let's use a pizza shop as an example. If the owner spends capital money and makes the line
more efficient so that they can make twice as many pizzas per hour at peak, then physical productivity
has improved. If the dining room sits empty because the tax burden was shifted from the wealthy
to the poor, then the restaurant's BLS productivity has decreased. BLS productivity and physical
productivity are simply unrelated in a right-wing country like the U.S."
Jeff's point brings to mind Walter Reuther's 1955 testimony before the Joint Congressional
Subcommittee Hearings on Automation and Technological Change...
Automation leads to dislocation
Dislocation can replace skilled or semiskilled labor and the replacement jobs may be low pay low
productivity jobs.
Small undiversified economies are more susceptible to dislocation than larger diversified communities.
The training, retraining, and mobility of the labor force is important in unemployment.
Unemployment has a regional component
The US has policies that make labor less mobile and dumps much of the training and retraining
costs on those who cannot afford it.
No, Robots Aren't Killing the American Dream
By THE EDITORIAL BOARD
FEB. 20, 2017
Defenders of globalization are on solid ground when they
criticize President Trump's threats of punitive tariffs and
border walls. The economy can't flourish without trade and
immigrants.
But many of those defenders have their own dubious
explanation for the economic disruption that helped to fuel
the rise of Mr. Trump.
At a recent global forum in Dubai, Christine Lagarde, head
of the International Monetary Fund, said some of the economic
pain ascribed to globalization was instead due to the rise of
robots taking jobs. In his farewell address in January,
President Barack Obama warned that "the next wave of economic
dislocations won't come from overseas. It will come from the
relentless pace of automation that makes a lot of good
middle-class jobs obsolete."
Blaming robots, though, while not as dangerous as
protectionism and xenophobia, is also a distraction from real
problems and real solutions.
The rise of modern robots is the latest chapter in a
centuries-old story of technology replacing people.
Automation is the hero of the story in good times and the
villain in bad. Since today's middle class is in the midst of
a prolonged period of wage stagnation, it is especially
vulnerable to blame-the-robot rhetoric.
And yet, the data indicate that today's fear of robots is
outpacing the actual advance of robots. If automation were
rapidly accelerating, labor productivity and capital
investment would also be surging as fewer workers and more
technology did the work. But labor productivity and capital
investment have actually decelerated in the 2000s.
While breakthroughs could come at any time, the problem
with automation isn't robots; it's politicians, who have
failed for decades to support policies that let workers share
the wealth from technology-led growth.
The response in previous eras was quite different.
When automation on the farm resulted in the mass migration
of Americans from rural to urban areas in the early decades
of the 20th century, agricultural states led the way in
instituting universal public high school education to prepare
for the future. At the dawn of the modern technological age
at the end of World War II, the G.I. Bill turned a generation
of veterans into college graduates.
When productivity led to vast profits in America's auto
industry, unions ensured that pay rose accordingly.
Corporate efforts to keep profits high by keeping pay low
were countered by a robust federal minimum wage and
time-and-a-half for overtime.
Fair taxation of corporations and the wealthy ensured the
public a fair share of profits from companies enriched by
government investments in science and technology.
Productivity and pay rose in tandem for decades after
World War II, until labor and wage protections began to be
eroded. Public education has been given short shrift, unions
have been weakened, tax overhauls have benefited the rich and
basic labor standards have not been updated.
As a result, gains from improving technology have been
concentrated at the top, damaging the middle class, while
politicians blame immigrants and robots for the misery that
is due to their own failures. Eroded policies need to be
revived, and new ones enacted.
A curb on stock buybacks would help to ensure that
executives could not enrich themselves as wages lagged.
Tax reform that increases revenue from corporations and
the wealthy could help pay for retraining and education to
protect and prepare the work force for foreseeable
technological advancements.
Legislation to foster child care, elder care and fair
scheduling would help employees keep up with changes in the
economy, rather than losing ground.
Economic history shows that automation not only
substitutes for human labor, it complements it. The
disappearance of some jobs and industries gives rise to
others. Nontechnology industries, from restaurants to
personal fitness, benefit from the consumer demand that
results from rising incomes in a growing economy. But only
robust public policy can ensure that the benefits of growth
are broadly shared.
If reforms are not enacted - as is likely with President
Trump and congressional Republicans in charge - Americans
should blame policy makers, not robots.
Robots may not be killing jobs but they drastically alter the
types and location of jobs that are created. High pay
unskilled jobs are always the first to be eliminated by
technology. Low skill high pay jobs are rare and heading to
extinction. Low skill low pay jobs are the norm. It sucks to
lose a low skill job with high pay but anyone who expected
that to continue while continually voting against unions was
foolish and a victim of their own poor planning, failure to
acquire skills and failure to support unions. It is in their
self interest to support safety net proposal that do provide
good pay for quality service. The enemy is not trade. The
enemy is failure to invest in the future.
"Many working-
and middle-class Americans believe that free-trade agreements
are why their incomes have stagnated over the past two
decades. So Trump intends to provide them with "protection"
by putting protectionists in charge.
But Trump and his triumvirate have misdiagnosed the problem.
While globalization is an important factor in the hollowing
out of the middle class, so, too, is automation
Trump and his team are missing a simple point:
twenty-first-century globalization is knowledge-led, not
trade-led. Radically reduced communication costs have enabled
US firms to move production to lower-wage countries.
Meanwhile, to keep their production processes synced, firms
have also offshored much of their technical, marketing, and
managerial knowhow. This "knowledge offshoring" is what has
really changed the game for American workers.
The information revolution changed the world in ways that
tariffs cannot reverse. With US workers already competing
against robots at home, and against low-wage workers abroad,
disrupting imports will just create more jobs for robots.
Trump should be protecting individual workers, not individual
jobs. The processes of twenty-first-century globalization are
too sudden, unpredictable, and uncontrollable to rely on
static measures like tariffs. Instead, the US needs to
restore its social contract so that its workers have a fair
shot at sharing in the gains generated by global openness and
automation. Globalization and technological innovation are
not painless processes, so there will always be a need for
retraining initiatives, lifelong education, mobility and
income-support programs, and regional transfers.
By pursuing such policies, the Trump administration would
stand a much better chance of making America "great again"
for the working and middle classes. Globalization has always
created more opportunities for the most competitive workers,
and more insecurity for others. This is why a strong social
contract was established during the post-war period of
liberalization in the West. In the 1960s and 1970s
institutions such as unions expanded, and governments made
new commitments to affordable education, social security, and
progressive taxation. These all helped members of the middle
class seize new opportunities as they emerged.
Over the last two decades, this situation has changed
dramatically: globalization has continued, but the social
contract has been torn up. Trump's top priority should be to
stitch it back together; but his trade advisers do not
understand this."
anne at Economist's View has retrieved a FRED graph that
perfectly illustrates the divergence, since the mid-1990s of
net worth from GDP:
[graph]
The empty spaces between the red line and the blue line
that open up after around 1995 is what John Kenneth Galbraith
called "the bezzle" -- summarized by John Kay as "that
increment to wealth that occurs during the magic interval
when a confidence trickster knows he has the money he has
appropriated but the victim does not yet understand that he
has lost it."
In Chapter of The Great Crash, 1929, Galbraith wrote:
"In many ways the effect of the crash on embezzlement was
more significant than on suicide. To the economist
embezzlement is the most interesting of crimes. Alone among
the various forms of larceny it has a time parameter. Weeks,
months or years may elapse between the commission of the
crime and its discovery. (This is a period, incidentally,
when the embezzler has his gain and the man who has been
embezzled, oddly enough, feels no loss. There is a net
increase in psychic wealth.) At any given time there exists
an inventory of undiscovered embezzlement in or more
precisely not in the country's business and banks. This
inventory it should perhaps be called the bezzle amounts
at any moment to many millions of dollars. It also varies in
size with the business cycle. In good times people are
relaxed, trusting, and money is plentiful. But even though
money is plentiful, there are always many people who need
more. Under these circumstances the rate of embezzlement
grows, the rate of discovery falls off, and the bezzle
increases rapidly. In depression all this is reversed. Money
is watched with a narrow, suspicious eye. The man who handles
it is assumed to be dishonest until he proves himself
otherwise. Audits are penetrating and meticulous. Commercial
morality is enormously improved. The bezzle shrinks."
In the present case, the bezzle has resulted from an
economic policy two step: tax cuts and Greenspan puts: cuts
and puts.
Why Germany Has It So Good -- and Why America Is Going Down
the Drain
Germans have six weeks of federally mandated vacation,
free university tuition, and nursing care. Why the US pales
in comparison.
By Terrence McNally / AlterNet October 13, 2010
ECONOMY
Why Germany Has It So Good -- and Why America Is Going Down
the Drain
Germans have six weeks of federally mandated vacation, free
university tuition, and nursing care. Why the US pales in
comparison.
By Terrence McNally / AlterNet October 13, 2010
1.4K31
Print
207 COMMENTS
While the bad news of the Euro crisis makes headlines in the
US, we hear next to nothing about a quiet revolution in
Europe. The European Union, 27 member nations with a half
billion people, has become the largest, wealthiest trading
bloc in the world, producing nearly a third of the world's
economy -- nearly as large as the US and China combined.
Europe has more Fortune 500 companies than either the US,
China or Japan.
European nations spend far less than the United States for
universal healthcare rated by the World Health Organization
as the best in the world, even as U.S. health care is ranked
37th. Europe leads in confronting global climate change with
renewable energy technologies, creating hundreds of thousands
of new jobs in the process. Europe is twice as energy
efficient as the US and their ecological "footprint" (the
amount of the earth's capacity that a population consumes) is
about half that of the United States for the same standard of
living.
Unemployment in the US is widespread and becoming chronic,
but when Americans have jobs, we work much longer hours than
our peers in Europe. Before the recession, Americans were
working 1,804 hours per year versus 1,436 hours for Germans
-- the equivalent of nine extra 40-hour weeks per year.
In his new book, Were You Born on the Wrong Continent?,
Thomas Geoghegan makes a strong case that European social
democracies -- particularly Germany -- have some lessons and
models that might make life a lot more livable. Germans have
six weeks of federally mandated vacation, free university
tuition, and nursing care. But you've heard the arguments for
years about how those wussy Europeans can't compete in a
global economy. You've heard that so many times, you might
believe it. But like so many things, the media repeats
endlessly, it's just not true.
According to Geoghegan, "Since 2003, it's not China but
Germany, that colossus of European socialism, that has either
led the world in export sales or at least been tied for
first. Even as we in the United States fall more deeply into
the clutches of our foreign creditors -- China foremost among
them -- Germany has somehow managed to create a high-wage,
unionized economy without shipping all its jobs abroad or
creating a massive trade deficit, or any trade deficit at
all. And even as the Germans outsell the United States, they
manage to take six weeks of vacation every year. They're
beating us with one hand tied behind their back."
Thomas Geoghegan, a graduate of Harvard and Harvard Law
School, is a labor lawyer with Despres, Schwartz and
Geoghegan in Chicago. He has been a staff writer and
contributing writer to The New Republic, and his work has
appeared in many other journals. Geoghagen ran unsuccessfully
in the Democratic Congressional primary to succeed Rahm
Emanuel, and is the author of six books including Whose Side
Are You on, The Secret Lives of Citizens, and, most
recently,Were You Born on the Wrong Continent?
While the US spends half the war money in the world over a
quarter the economic activity...... it fall further behind
the EU which at a third the economic activity spends a fifth
the worlds warring. Or 4% of GDP in the war trough versus
1.2%.
Robots are taking human jobs. But Bill Gates believes that governments
should tax companies' use of them, as a way to at least temporarily slow the
spread of automation and to fund other types of employment.
It's a
striking position from the world's richest man and a self-described
techno-optimist who co-founded Microsoft, one of the leading players in
artificial-intelligence technology.
In a recent interview with Quartz, Gates said that a robot tax could
finance jobs taking care of elderly people or working with kids in schools,
for which needs are unmet and to which humans are particularly well suited.
He argues that governments must oversee such programs rather than relying on
businesses, in order to redirect the jobs to help people with lower incomes.
The idea is not totally theoretical: EU lawmakers
considered a proposal
to tax robot owners to pay for training for
workers who lose their jobs, though on Feb. 16 the legislators ultimately
rejected it.
"You ought to be willing to raise the tax level and even slow down the
speed" of automation, Gates argues. That's because the technology and
business cases for replacing humans in a wide range of jobs are arriving
simultaneously, and it's important to be able to manage that displacement.
"You cross the threshold of job replacement of certain activities all sort
of at once," Gates says, citing warehouse work and driving as some of the
job categories that in the next 20 years will have robots doing them.
You can watch Gates' remarks in the video above. Below is a transcript,
lightly edited for style and clarity.
Quartz: What do you think of a robot tax? This is the idea that in
order to generate funds for training of workers, in areas such as
manufacturing, who are displaced by automation, one concrete thing that
governments could do is tax the installation of a robot in a factory, for
example.
Bill Gates: Certainly there will be taxes that relate to
automation. Right now, the human worker who does, say, $50,000 worth of work
in a factory, that income is taxed and you get income tax, social security
tax, all those things. If a robot comes in to do the same thing, you'd think
that we'd tax the robot at a similar level.
And what the world wants is to take this opportunity to make all the
goods and services we have today, and free up labor, let us do a better job
of reaching out to the elderly, having smaller class sizes, helping kids
with special needs. You know, all of those are things where human empathy
and understanding are still very, very unique. And we still deal with an
immense shortage of people to help out there.
So if you can take the labor that used to do the thing automation
replaces, and financially and training-wise and fulfillment-wise have that
person go off and do these other things, then you're net ahead. But you
can't just give up that income tax, because that's part of how you've been
funding that level of human workers.
And so you could introduce a tax on robots
There are many ways to take that extra productivity and generate more
taxes. Exactly how you'd do it, measure it, you know, it's interesting for
people to start talking about now. Some of it can come on the profits that
are generated by the labor-saving efficiency there. Some of it can come
directly in some type of robot tax. I don't think the robot companies are
going to be outraged that there might be a tax. It's OK.
Could you
figure out a way to do it that didn't
dis-incentivize innovation
?
Well, at a time when people are saying that the arrival of that robot is
a net loss because of displacement, you ought to be willing to raise the tax
level and even slow down the speed of that adoption somewhat to figure out,
"OK, what about the communities where this has a particularly big impact?
Which transition programs have worked and what type of funding do those
require?"
You cross the threshold of job-replacement of certain activities all sort
of at once. So, you know, warehouse work, driving, room cleanup, there's
quite a few things that are meaningful job categories that, certainly in the
next 20 years, being thoughtful about that extra supply is a net benefit.
It's important to have the policies to go with that.
People should be figuring it out. It is really bad if people overall have
more fear about what innovation is going to do than they have enthusiasm.
That means they won't shape it for the positive things it can do. And, you
know, taxation is certainly a better way to handle it than just banning some
elements of it. But [innovation] appears in many forms, like self-order at a
restaurant-what do you call that? There's a Silicon Valley machine that can
make hamburgers without human hands-seriously! No human hands touch the
thing. [
Laughs
]
And you're more on the side that government should play an active
role rather than rely on businesses to figure this out?
Well, business can't. If you want to do [something about] inequity, a lot
of the excess labor is going to need to go help the people who have lower
incomes. And so it means that you can amp up social services for old people
and handicapped people and you can take the education sector and put more
labor in there. Yes, some of it will go to, "Hey, we'll be richer and people
will buy more things." But the inequity-solving part, absolutely
government's got a big role to play there. The nice thing about taxation
though, is that it really separates the issue: "OK, so that gives you the
resources, now how do you want to deploy it?"
"... But human life depends on whether the accident is caused by a human or not, and the level of intent. It isn't just a case of the price - the law is increasingly locking people up for driving negligence (rightly in my mind) Who gets locked up when the program fails? Or when the program chooses to hit one person and not another in a complex situation? ..."
Electric,
driverless shuttles with no steering wheel and no brake pedal are now operating in Las Vegas.
There's a new thrill on the streets of downtown Las Vegas, where high- and low-rollers alike are
climbing aboard what officials call the first driverless electric shuttle operating on a public U.S.
street.
The oval-shaped shuttle began running Tuesday as part of a 10-day pilot program, carrying up to
12 passengers for free along a short stretch of the Fremont Street East entertainment district.
The vehicle has a human attendant and computer monitor, but no steering wheel and no brake pedals.
Passengers push a button at a marked stop to board it.
The shuttle uses GPS, electronic curb sensors and other technology, and doesn't require lane lines
to make its way.
"The ride was smooth. It's clean and quiet and seats comfortably," said Mayor Carolyn Goodman,
who was among the first public officials to hop a ride on the vehicle developed by the French company
Navya and dubbed Arma.
"I see a huge future for it once they get the technology synchronized," the mayor said Friday.
The top speed of the shuttle is 25 mph, but it's running about 15 mph during the trial, Navya
spokesman Martin Higgins said.
Higgins called it "100 percent autonomous on a programmed route."
"If a person or a dog were to run in front of it, it would stop," he said.
Higgins said it's the company's first test of the shuttle on a public street in the U.S. A similar
shuttle began testing in December at a simulated city environment at a University of Michigan research
center.
The vehicle being used in public was shown earlier at the giant CES gadget show just off the Las
Vegas Strip.
Las Vegas city community development chief Jorge Cervantes said plans call for installing transmitters
at the Fremont Street intersections to communicate red-light and green-light status to the shuttle.
He said the city hopes to deploy several autonomous shuttle vehicles - by Navya or another company
- later this year for a downtown loop with stops at shopping spots, restaurants, performance venues,
museums, a hospital and City Hall.
At a cost estimated at $10,000 a month, Cervantes said the vehicle could be cost-efficient compared
with a single bus and driver costing perhaps $1 million a year.
The company said it has shuttles in use in France, Australia, Switzerland and other countries
that have carried more than 100,000 passengers in more than a year of service.
Don't Worry Tax Drivers
Don't worry taxi drivers because some of my readers say
1.This will never work
2.There is no demand
3.Technology cost will be too high
4.Insurance cost will be too high
5.The unions will not allow it
6.It will not be reliable
7.Vehicles will be stolen
8.It cannot handle snow, ice, or any adverse weather.
9.It cannot handle dogs, kids, or 80-year old men on roller skates who will suddenly veer into
traffic causing a clusterfack that will last days.
10.This is just a test, and testing will never stop.
Real World Analysis
Those in the real world expect millions of long haul truck driving jobs will vanish by 2020-2022
and massive numbers of taxi job losses will happen simultaneously or soon thereafter.
Yes, I bumped up my timeline by two years (from 2022-2024 to 2020-2022) for this sequence of
events.
My new timeline is not all tremendously optimistic given the rapid changes we have seen.
garypaul -> Sudden Debt Jan 14, 2017 7:56 PM
You're getting carried away Sudden Debt. This robot stuff works great in the lab/test
zones. Whether it is transplantable on a larger scale is still unknown. The interesting thing
is, all my friends who are computer programmers/engineers/scientists are skeptical about this
stuff, but all my friends who know nothing about computer science are absolutely wild about
the "coming age of robots/AI". Go figure.
P.S. Of course the computer experts that are milking investment money with their start-ups
will tell you it's great
ChartreuseDog -> garypaul Jan 14, 2017 9:15 PM
I'm an engineer (well, OK, an electrical engineering technical team lead). I've been an
electronics and embedded computer engineer for about 4 decades.
This Vegas thing looks real - predefined route, transmitted signals for traffic lights, like
light rail without the rails.
Overall, autonomous driving looks like it's almost here, if you like spinning LIDAR
transceivers on the top of cars.
Highway driving is much closer to being solved, by the way. It's suburban and urban side
streets that are the tough stuff.
garypaul -> ChartreuseDog Jan 14, 2017 9:22 PM
"Highway driving is much closer to being solved".
That's my whole point. It's not an equation that you "solve". It's a million unexpected
things. Last I heard, autonomous cars were indeed already crashing.
MEFOBILLS -> CRM114 Jan 14, 2017 6:07 PM
Who gets sued? For how much? What about cases where a human driver wouldn't have
killed anybody?
I've been in corporate discussions about this very topic. At a corporation that makes this
technology by the way. The answer:
Insurance companies and the law will figure it out. Basically, if somebody gets run
over, then the risk does not fall on the technology provider. Corporate rules can be
structured to prevent piercing the corporate veil on this.
Human life does have a price. Insurance figures out how much it costs to pay off, and then
jacks up rates accordingly.
CRM114 -> MEFOBILLS Jan 14, 2017 6:20 PM
Thanks, that's interesting, although I must say that isn't a solution, it's a hope that
someone else will come up with one.
But human life depends on whether the accident is caused by a human or not, and the level
of intent. It isn't just a case of the price - the law is increasingly locking people up for
driving negligence (rightly in my mind) Who gets locked up when the program fails? Or when the
program chooses to hit one person and not another in a complex situation?
At the moment, corporate manslaughter laws are woefully inadequate. There's clearly one law
for the rich and another for everyone else. Mary Barra would be wearing an orange jumpsuit
otherwise.
I am unaware of any automatic machinery which operates in public areas and carries
significant risk. Where accidents have happened in the past(e.g.elevators), either the
machinery gets changed to remove the risk, or use is discontinued, or the public is separated
from the machinery. I don't think any of these are possible for automatic vehicles.
TuPhat -> shovelhead Jan 14, 2017 7:53 PM
Elevators have no choice of route, only how high or low you want to go. autos have no
comparison. Disney world has had many robotic attractions for decades but they are still only
entertainment. keep entertaining yourself Mish. when I see you on the road I will easily pass
you by.
MEFOBILLS -> Hulk Jan 14, 2017 6:12 PM
The future is here: See movie "obsolete" on Amazon. Free if you have prime.
This is so exciting! Just think about the possibilities here... Shuttles could be outfitted
with all kinds of great gizmos to identify their passengers based on RFID chips in credit
cards, facial recognition software, voice prints, etc. Then, depending on who is controlling
the software, the locks on the door could engage and the shuttle could drive around town
dropping of its passengers to various locations eager for their arrival. Trivial to round up
illegal aliens, parole violators, or people with standing warrants for arrest. Equally easy to
nab people who are delinquent on their taxes, credit cards, mortgages, and spousal support.
With a little info from Facebook or Google, a drop-off at the local attitude-adjustment
facility might be desirable for those who frequent alternative media or have unhealthy
interests in conspiracy theories or the activities at pizza parlors. Just think about the
wonderful possibilties here!
Twee Surgeon -> PitBullsRule Jan 14, 2017 6:29 PM
Will unemployed taxi drivers be allowed on the bus with a bottle of vodka and a gallon of
gas with a rag in it ?
When the robot trucks arrive at the robot factory and are unloaded by robot forklifts, who
will buy the end products ?
It won't be truck drivers, taxi drivers or automated production line workers.
The only way massive automation would work is if some people were planning on a vastly reduced
population in the future. It has happened before, they called it the Black Death. The Cultural
and Economic consequences of it in Europe were enormous, world changing and permanent.
"... The unionization rate has plummeted over the last four decades, but this is the result of policy decisions, not automation. Canada, a country with a very similar economy and culture, had no remotely comparable decline in unionization over this period. ..."
"... The unemployment rate and overall strength of the labor market is also an important factor determining workers' ability to secure their share of the benefits of productivity growth in wages and other benefits. When the Fed raises interest rates to deliberately keep workers from getting jobs, this is not the result of automation. ..."
"... It is also not automation alone that allows some people to disproportionately get the gains from growth. The average pay of doctors in the United States is over $250,000 a year because they are powerful enough to keep out qualified foreign doctors. They require that even established foreign doctors complete a U.S. residency program before they are allowed to practice medicine in the United States. If we had a genuine free market in physicians' services every MRI would probably be read by a much lower paid radiologist in India rather than someone here pocketing over $400,000 a year. ..."
Weak Labor Market: President Obama Hides Behind Automation
It really is shameful how so many people, who certainly should know better, argue that automation
is the factor depressing the wages of large segments of the workforce and that education (i.e.
blame the ignorant workers) is the solution. President Obama takes center stage in this picture
since he said almost exactly this in his farewell address earlier in the week. This misconception
is repeated in a Claire Cain Miller's New York Times column * today. Just about every part of
the story is wrong.
Starting with the basic story of automation replacing workers, we have a simple way of measuring
this process, it's called "productivity growth." And contrary to what the automation folks tell
you, productivity growth has actually been very slow lately.
[Graph]
The figure above shows average annual rates of productivity growth for five year periods, going
back to 1952. As can be seen, the pace of automation (productivity growth) has actually been quite
slow in recent years. It is also projected by the Congressional Budget Office and most other forecasters
to remain slow for the foreseeable future, so the prospect of mass displacement of jobs by automation
runs completely counter to what we have been seeing in the labor market.
Perhaps more importantly the idea that productivity growth is bad news for workers is 180 degrees
at odds with the historical experience. In the period from 1947 to 1973, productivity growth averaged
almost 3.0 percent, yet the unemployment rate was generally low and workers saw rapid wage gains.
The reason was that workers had substantial bargaining power, in part because of strong unions,
and were able to secure the gains from productivity growth for themselves in higher living standards,
including more time off in the form of paid vacation days and paid sick days. (Shorter work hours
sustain the number of jobs in the face rising productivity.)
The unionization rate has plummeted over the last four decades, but this is the result
of policy decisions, not automation. Canada, a country with a very similar economy and culture,
had no remotely comparable decline in unionization over this period.
The unemployment rate and overall strength of the labor market is also an important factor
determining workers' ability to secure their share of the benefits of productivity growth in wages
and other benefits. When the Fed raises interest rates to deliberately keep workers from getting
jobs, this is not the result of automation.
It is also not automation alone that allows some people to disproportionately get the gains
from growth. The average pay of doctors in the United States is over $250,000 a year because they
are powerful enough to keep out qualified foreign doctors. They require that even established
foreign doctors complete a U.S. residency program before they are allowed to practice medicine
in the United States. If we had a genuine free market in physicians' services every MRI would
probably be read by a much lower paid radiologist in India rather than someone here pocketing
over $400,000 a year.
Similarly, automation did not make our patents and copyrights longer and stronger. These
protectionist measures result in us paying over $430 billion a year for drugs that would likely
cost one tenth of this amount in a free market. And automation did not force us to institutionalize
rules that created an incredibly bloated financial sector with Wall Street traders and hedge fund
partners pocketing tens of millions or even hundreds of millions a year. Nor did automation give
us a corporate governance structure that allows even the most incompetent CEOs to rip off their
companies and pay themselves tens of millions a year.
Yes, these and other topics are covered in my (free) book "Rigged: How Globalization and the
Rules of the Modern Economy Were Structured to Make the Rich Richer." ** It is understandable
that the people who benefit from this rigging would like to blame impersonal forces like automation,
but it just ain't true and the people repeating this falsehood should be ashamed of themselves.
A Darker Theme in Obama's Farewell: Automation Can
Divide Us https://nyti.ms/2ioACof via @UpshotNYT
NYT - Claire Cain Miller - January 12, 2017
Underneath the nostalgia and hope in President Obama's farewell address Tuesday night was a
darker theme: the struggle to help the people on the losing end of technological change.
"The next wave of economic dislocations won't come from overseas," Mr. Obama said. "It will
come from the relentless pace of automation that makes a lot of good, middle-class jobs obsolete."
Donald J. Trump has tended to blamed trade, offshoring and immigration. Mr. Obama acknowledged
those things have caused economic stress. But without mentioning Mr. Trump, he said they divert
attention from the bigger culprit.
Economists agree that automation has played a far greater role in job loss, over the long run,
than globalization. But few people want to stop technological progress. Indeed, the government
wants to spur more of it. The question is how to help those that it hurts.
The inequality caused by automation is a main driver of cynicism and political polarization,
Mr. Obama said. He connected it to the racial and geographic divides that have cleaved the country
post-election.
It's not just racial minorities and others like immigrants, the rural poor and transgender
people who are struggling in society, he said, but also "the middle-aged white guy who, from the
outside, may seem like he's got advantages, but has seen his world upended by economic and cultural
and technological change."
Technological change will soon be a problem for a much bigger group of people, if it isn't
already. Fifty-one percent of all the activities Americans do at work involve predictable physical
work, data collection and data processing. These are all tasks that are highly susceptible to
being automated, according to a report McKinsey published in July using data from the Bureau of
Labor Statistics and O*Net to analyze the tasks that constitute 800 jobs.
Twenty-eight percent of work activities involve tasks that are less susceptible to automation
but are still at risk, like unpredictable physical work or interacting with people. Just 21 percent
are considered safe for now, because they require applying expertise to make decisions, do something
creative or manage people.
The service sector, including health care and education jobs, is considered safest. Still,
a large part of the service sector is food service, which McKinsey found to be the most threatened
industry, even more than manufacturing. Seventy-three percent of food service tasks could be automated,
it found.
In December, the White House released a report on automation, artificial intelligence and the
economy, warning that the consequences could be dire: "The country risks leaving millions of Americans
behind and losing its position as the global economic leader."
No one knows how many people will be threatened, or how soon, the report said. It cited various
researchers' estimates that from 9 percent to 47 percent of jobs could be affected.
In the best case, it said, workers will have higher wages and more leisure time. In the worst,
there will be "significantly more workers in need of assistance and retraining as their skills
no longer match the demands of the job market."
Technology delivers its benefits and harms in an unequal way. That explains why even though
the economy is humming, it doesn't feel like it for a large group of workers.
Education is the main solution the White House advocated. When the United States moved from
an agrarian economy to an industrialized economy, it rapidly expanded high school education: By
1951, the average American had 6.2 more years of education than someone born 75 years earlier.
The extra education enabled people to do new kinds of jobs, and explains 14 percent of the annual
increases in labor productivity during that period, according to economists.
Now the country faces a similar problem. Machines can do many low-skilled tasks, and American
children, especially those from low-income and minority families, lag behind their peers in other
countries educationally.
The White House proposed enrolling more 4-year-olds in preschool and making two years of community
college free for students, as well as teaching more skills like computer science and critical
thinking. For people who have already lost their jobs, it suggested expanding apprenticeships
and retraining programs, on which the country spends half what it did 30 years ago.
Displaced workers also need extra government assistance, the report concluded. It suggested
ideas like additional unemployment benefits for people who are in retraining programs or live
in states hardest hit by job loss. It also suggested wage insurance for people who lose their
jobs and have to take a new one that pays less. Someone who made $18.50 an hour working in manufacturing,
for example, would take an $8 pay cut if he became a home health aide, one of the jobs that is
growing most quickly.
President Obama, in his speech Tuesday, named some other policy ideas for dealing with the problem:
stronger unions, an updated social safety net and a tax overhaul so that the people benefiting
most from technology share some of their earnings.
The Trump administration probably won't agree with many of those solutions. But the economic
consequences of automation will be one of the biggest problems it faces.
[
A
study published late last month
by the White House Council of Economic
Advisers (CEA)] released Dec. 20, said the jobs of between 1.34 million and
1.67 million truck drivers would be at risk due to the growing utilization of
heavy-duty vehicles operated via artificial intelligence. That would equal 80
to 100 percent of all driver jobs listed in the CEA report, which is based on
May 2015 data from the Bureau of Labor Statistics, a unit of the Department of
Labor. There are about 3.4 million commercial truck drivers currently operating
in the U.S., according to various estimates" [
DC
Velocity
]. "The Council emphasized that its calculations excluded the
number or types of new jobs that may be created as a result of this potential
transition. It added that any changes could take years or decades to
materialize because of a broad lag between what it called "technological
possibility" and widespread adoption."
Class Warfare
[A study published late last month by the White House Council of Economic Advisers (CEA)]
released Dec. 20, said the jobs of between 1.34 million and 1.67 million truck drivers would be at
risk due to the growing utilization of heavy-duty vehicles operated via artificial intelligence.
That would equal 80 to 100 percent of all driver jobs listed in the CEA report, which is based on
May 2015 data from the Bureau of Labor Statistics, a unit of the Department of Labor. There are
about 3.4 million commercial truck drivers currently operating in the U.S., according to various
estimates" [DC Velocity]. "The Council emphasized that its calculations excluded the number or types
of new jobs that may be created as a result of this potential transition. It added that any changes
could take years or decades to materialize because of a broad lag between what it called
"technological possibility" and widespread adoption."
"... As with the most cynical (or deranged) internet hypesters, the current "AI" hype has a grain of truth underpinning it. Today neural nets can process more data, faster. Researchers no longer habitually tweak their models. Speech recognition is a good example: it has been quietly improving for three decades. But the gains nowhere match the hype: they're specialised and very limited in use. So not entirely useless, just vastly overhyped . ..."
"... "What we have seen lately, is that while systems can learn things they are not explicitly told, this is mostly in virtue of having more data, not more subtlety about the data. So, what seems to be AI, is really vast knowledge, combined with a sophisticated UX, " one veteran told me. ..."
"... But who can blame them for keeping quiet when money is suddenly pouring into their backwater, which has been unfashionable for over two decades, ever since the last AI hype collapsed like a souffle? What's happened this time is that the definition of "AI" has been stretched so that it generously encompasses pretty much anything with an algorithm. Algorithms don't sound as sexy, do they? They're not artificial or intelligent. ..."
"... The bubble hasn't yet burst because the novelty examples of AI haven't really been examined closely (we find they are hilariously inept when we do), and they're not functioning services yet. ..."
"... Here I'll offer three reasons why 2016's AI hype will begin to unravel in 2017. That's a conservative guess much of what is touted as a breakthrough today will soon be the subject of viral derision, or the cause of big litigation. ..."
"Fake news" vexed the media classes greatly in 2016, but the tech world perfected the art long
ago. With "the internet" no longer a credible vehicle for Silicon Valley's wild fantasies and intellectual
bullying of other industries the internet clearly isn't working for people "AI" has taken its
place.
Almost everything you read about AI is fake news. The AI coverage comes from a media willing itself
into the mind of a three year old child, in order to be impressed.
For example, how many human jobs did AI replace in 2016? If you gave professional pundits a multiple
choice question listing these three answers: 3 million, 300,000 and none, I suspect very few would
choose the correct answer, which is of course "none".
Similarly, if you asked tech experts which recent theoretical or technical breakthrough could
account for the rise in coverage of AI, even fewer would be able to answer correctly that "there
hasn't been one".
As with the most cynical (or deranged) internet hypesters, the current "AI" hype has a grain of
truth underpinning it. Today neural nets can process more data, faster. Researchers no longer habitually
tweak their models. Speech recognition is a good example: it has been quietly improving for three
decades. But the gains nowhere match the hype: they're specialised and very limited in use. So not
entirely useless, just vastly overhyped . As such, it more closely resembles "IoT", where boring
things happen quietly for years, rather than "Digital Transformation", which means nothing at all.
The more honest researchers acknowledge as much to me, at least off the record.
"What we have seen lately, is that while systems can learn things they are not explicitly told,
this is mostly in virtue of having more data, not more subtlety about the data. So, what seems to
be AI, is really vast knowledge, combined with a sophisticated UX, " one veteran told me.
But who can blame them for keeping quiet when money is suddenly pouring into their backwater,
which has been unfashionable for over two decades, ever since the last AI hype collapsed like a souffle?
What's happened this time is that the definition of "AI" has been stretched so that it generously
encompasses pretty much anything with an algorithm. Algorithms don't sound as sexy, do they? They're
not artificial or intelligent.
The bubble hasn't yet burst because the novelty examples of AI haven't really been examined closely
(we find they are hilariously inept when we do), and they're not functioning services yet. For example,
have a look at the amazing "neural karaoke" that researchers at the University of Toronto developed.
Please do : it made the worst Christmas record ever.
Here I'll offer three reasons why 2016's AI hype will begin to unravel in 2017. That's a conservative
guess much of what is touted as a breakthrough today will soon be the subject of viral derision,
or the cause of big litigation. There are everyday reasons that show how once an AI application is
out of the lab/PR environment, where it's been nurtured and pampered like a spoiled infant, then
it finds the real world is a lot more unforgiving. People don't actually want it.
3. Liability: So you're Too Smart To Fail?
Nine years ago, the biggest financial catastrophe since the 1930s hit the world, and precisely
zero bankers went to jail for it. Many kept their perks and pensions. People aren't so happy about
this.
So how do you think an all purpose "cat ate my homework" excuse is going to go down with the public,
or shareholders? A successfully functioning AI one that did what it said on the tin would pose
serious challenges to criminal liability frameworks. When something goes wrong, such as a car crash
or a bank failure, who do you put in jail? The Board, the CEO or the programmer, or both? "None of
the above" is not going to be an option this time.
I believe that this factor alone will keep "AI" out of critical decision making where lives and
large amounts of other people's money are at stake. For sure, some people will try to deploy algorithms
in important cases. But ultimately there are victims: the public, and shareholders, and the appetite
of the public to hear another excuse is wearing very thin. Let's check in on how the Minority Report
-style precog detection is going. Actually,
let's not .
After "Too Big To Fail", nobody is going to buy "Too Smart to Fail".
2. The Consumer Doesn't Want It
2016 saw "AI" being deployed on consumers experimentally, tentatively, and the signs are already
there for anyone who cares to see. It hasn't been a great success.
The most hyped manifestation of better language processing is chatbots . Chatbots are the new
UX, many including Microsoft and Facebook hope. Oren Etzoni at Paul Allen's Institute predicts it
will become a "trillion dollar industry" But he also admits "
my 4 YO is far smarter than any AI program I ever met ".
Hmmm, thanks Oren. So what you're saying is that we must now get used to chatting with someone
dumber than a four year old, just because they can make software act dumber than a four year old.
Bzzt. Next...
Put it this way. How many times have you rung a call center recently and wished that you'd spoken
to someone even more thick, or rendered by processes even more incapable of resolving the dispute,
than the minimum-wage offshore staffer who you actually spoke with? When the chatbots come, as you
close the [X] on another fantastically unproductive hour wasted, will you cheerfully console yourself
with the thought: "That was terrible, but least MegaCorp will make higher margins this year! They're
at the cutting edge of AI!"?
In a healthy and competitive services marketplace, bad service means lost business. The early
adopters of AI chatbots will discover this the hard way. There may be no later adopters once the
early adopters have become internet memes for terrible service.
The other area where apparently impressive feats of "AI" were unleashed upon the public were subtle.
Unbidden, unwanted AI "help" is starting to pop out at us. Google scans your personal photos and
later, if you have an Android phone will pop up "helpful" reminders of where you have been. People
almost universally find this creepy. We could call this a "Clippy The Paperclip" problem, after the
intrusive Office Assistant that only wanted to help. Clippy is
going to haunt AI in 2017 . This is actually going to be worse than anybody inside the AI cult
quite realises.
The successful web services today so far are based on an economic exchange. The internet giants
slurp your data, and give you free stuff. We haven't thought more closely about what this data is
worth. For the consumer, however, these unsought AI intrusions merely draw our attention to how intrusive
the data slurp really is. It could wreck everything. Has nobody thought of that?
1. AI is a make believe world populated by mad people, and nobody wants to be part of it
The AI hype so far has relied on a collusion between two groups of people: a supply side and a
demand side. The technology industry, the forecasting industry and researchers provide a limitless
supply of post-human hype.
The demand comes from the media and political classes, now unable or unwilling to engage in politics
with the masses, to indulge in wild fantasies about humans being replaced by robots. For me, the
latter reflects a displacement activity: the professions are
already surrendering autonomy in their work to technocratic managerialism . They've made robots
out of themselves and now fear being replaced by robots. (Pass the hankie, I'm distraught.)
There's a cultural gulf between AI's promoters and the public that Asperger's alone can't explain.
There's no polite way to express this, but AI belongs to California's inglorious tradition of
generating
cults, and incubating cult-like thinking . Most people can name a few from the hippy or post-hippy
years EST, or the Family, or the Symbionese Liberation Army but actually, Californians have been
it at it
longer
than anyone realises .
There's nothing at all weird about Mark. Move along and please tip the Chatbot.
Today, that spirit lives on Silicon Valley, where creepy billionaire nerds like Mark Zuckerberg
and Elon Musk can fulfil their desires to "
play God and be amazed by magic ", the two big things they miss from childhood. Look at Zuckerberg's
house, for example. What these people want is not what you or I want. I'd be wary of them running
an after school club.
Out in the real world, people want better service, not worse service; more human and less robotic
exchanges with services, not more robotic "post-human" exchanges. But nobody inside the AI cult seems
to worry about this. They think we're as amazed as they are. We're not.
The "technology leaders" driving the AI are doing everything they can to alert us to the fact
no sane person would task them with leading anything. For that, I suppose, we should be grateful.
I worked with robots for years and people dont realize how flawed and "go-wrong" things occur.
Companies typically like idea of not hiring humans but in essence the robotic vision is not what
it ought to be.
I have designed digital based instrumentation and sensors. One of our senior EE designers had
a saying that I loved: "Give an electron half a chance and it will fuck you every time."
I've been hearing the same thing since the first Lisp program crawled out of the digital swamp.
Lessee, that would be about 45 years I've listened to the same stories and fairy tales. I'll
take a wait and see attitude like always.
The problem is very complex and working on pieces of it can be momentarily impressive to a
press corpse (pun intended) with "the minds of a 3-year old, whether they willed it or not". (fixed
that for you).
I'll quote an old saw, Lucke's First Law: "Ignorance simplifies any problem".
Just wait for the free money to dry up and the threat of AI will blow away (for a while longer)
with the bankers dust.
There some great programmers out there, but in the end it is a lot more than programming.
Humans have something inherent that machines will never be able to emulate in its true form,
such as emotion, determination, true inspiration, ability to read moods and react according including
taking clumps of information and instantly finding similar memories in our brains.
Automation has a long way to go before it can match a human being, says a lot for whoever designed
us, doesn't it?
"... When Stanislaw Lem launched a general criticism of Western Sci-Fi, he specifically exempted Philip K Dick, going so far as to refer to him as "a visionary among charlatans." ..."
"... While I think the 'OMG SUPERINTELLIGENCE' crowd are ripe for mockery, this seemed very shallow and wildly erratic, and yes, bashing the entirety of western SF seems so misguided it would make me question the rest of his (many, many) proto-arguments if I'd not done so already. ..."
"... Charles Stross's Rule 34 has about the only AI I can think of from SF that is both dangerous and realistic. ..."
"... Solaris and Stalker notwithstanding, Strugatsky brothers + Stanislaw Lem ≠ Andrei Tarkovsky. ..."
"... For offbeat Lem, I always found "Fiasco" and his Scotland Yard parody, "The Investigation," worth exploring. I'm unaware how they've been received by Polish and Western critics and readers, but I found them clever. ..."
"... Actually existing AI and leading-edge AI research are overwhelmingly not about pursuing "general intelligence* a la humanity." They are about performing tasks that have historically required what we historically considered to be human intelligence, like winning board games or translating news articles from Japanese to English. ..."
"... Actual AI systems don't resemble brains much more than forklifts resemble Olympic weightlifters. ..."
"... Talking about the risks and philosophical implications of the intellectual equivalent of forklifts - another wave of computerization - either lacks drama or requires far too much background preparation for most people to appreciate the drama. So we get this stuff about superintelligence and existential risk, like a philosopher wanted to write about public health but found it complicated and dry, so he decided to warn how utility monsters could destroy the National Health Service. It's exciting at the price of being silly. (And at the risk of other non-experts not realizing it's silly.) ..."
"... *In fact I consider "general intelligence" to be an ill-formed goal, like "general beauty." Beautiful architecture or beautiful show dogs? And beautiful according to which traditions? ..."
by Henry on December 30, 2016 This
talk by Maciej Ceglowski
(who y'all should be reading if you aren't already) is really good on silly claims by philosophers
about AI, and how they feed into Silicon Valley mythology. But there's one claim that seems to me
to be flat out wrong:
We need better scifi! And like so many things, we already have the technology. This is Stanislaw
Lem, the great Polish scifi author. English-language scifi is terrible, but in the Eastern bloc
we have the goods, and we need to make sure it's exported properly. It's already been translated
well into English, it just needs to be better distributed. What sets authors like Lem and the
Strugatsky brothers above their Western counterparts is that these are people who grew up in difficult
circumstances, experienced the war, and then lived in a totalitarian society where they had to
express their ideas obliquely through writing. They have an actual understanding of human experience
and the limits of Utopian thinking that is nearly absent from the west.There are some notable
exceptions-Stanley Kubrick was able to do it-but it's exceptionally rare to find American or British
scifi that has any kind of humility about what we as a species can do with technology.
He's not wrong on the delights of Lem and the Strugastky brothers, heaven forbid! (I had a great
conversation with a Russian woman some months ago about the Strugatskys she hadn't realized that
Roadside Picnic had been translated into English, much less that it had given rise to its own micro-genre).
But wrong on US and (especially) British SF. It seems to me that fiction on the limits of utopian
thinking and the need for humility about technology is vast. Plausible genealogies for sf stretch
back, after all, to Shelley's utopian-science-gone-wrong Frankenstein (rather than Hugo Gernsback.
Some examples that leap immediately to mind:
Ursula Le Guin and the whole literature of ambiguous utopias that she helped bring into being
with The Dispossessed see e.g. Ada Palmer, Kim Stanley Robinson's Mars series &c.
J.G Ballard, passim
Philip K. Dick ( passim , but if there's a better description of how the Internet of Things
is likely to work out than the door demanding money to open in Ubik I haven't read it).
Octavia Butler's Parable books. Also, Jack Womack's Dryco books (this
interview with Womack
could have been written yesterday).
William Gibson ( passim , but especially "The Gernsback Continuum" and his most recent
work. "The street finds its own uses for things" is a specifically and deliberately anti-tech-utopian
aesthetic).
M. John Harrison Signs of Life and the Kefahuchi Tract books.
Paul McAuley (most particularly Fairyland also his most recent Something Coming Through
and Into Everywhere , which mine the Roadside Picnic vein of brain-altering alien trash
in some extremely interesting ways).
Robert Charles Wilson, Spin . The best SF book I've ever read on how small human beings
and all their inventions are from a cosmological perspective.
Maureen McHugh's China Mountain Zhang .
Also, if it's not cheating, Francis Spufford's Red Plenty (if Kim Stanley Robinson
describes it
as a novel in the SF tradition, who am I to disagree, especially since it is
all about the limits
of capitalism as well as communism).
I'm sure there's plenty of other writers I could mention (feel free to say who they are in comments).
I'd also love to see more translated SF from the former Warsaw Pact countries, if it is nearly as
good as the Strugatskys material which has appeared. Still, I think that Ceglowski's claim is wrong.
The people I mention above aren't peripheral to the genre under any reasonable definition, and they
all write books and stories that do what Ceglowski thinks is only very rarely done. He's got some
fun reading ahead of him.
Also Linda Nagata's Red series come to think of it unsupervised machine learning processes as
ambiguous villain.
Prithvi 12.30.16 at 4:59 pm
When Stanislaw Lem launched a general criticism of Western Sci-Fi,
he specifically exempted Philip K Dick, going so far as to refer to him as "a visionary among charlatans."
You could throw in Pohl's Man Plus.
The twist at the end being the narrator is an AI that has secretly promoted human expansion as
a means of its own self-preservation.
Prithvi: Dick, sadly, returned the favor by claiming that Lem was obviously a pseudonym used by
the Polish government to disseminate communist propaganda.
While I think the 'OMG SUPERINTELLIGENCE' crowd are ripe for mockery, this seemed very shallow
and wildly erratic, and yes, bashing the entirety of western SF seems so misguided it would make
me question the rest of his (many, many) proto-arguments if I'd not done so already.
Good for a few laughs, though.
Mike Schilling 12.30.16 at 6:13 pm
Heinlein's Solution Unsatisfactory predicted the nuclear stalemate in 1941.
Jack Williamson's With Folded Hands was worried about technology making humans obsolete back in 1947.
In
1972, Asimov's The Gods Themselves presented a power generation technology that if continued
would destroy the world, and a society too complacent and lazy to acknowledge that.
Iain M. Banks'
Culture Series is amazing. My personal favorite from it is "The Hydrogen Sonata." The main character
has two extra arms grafted onto her body so she can play an unplayable piece of music. Also, the
sentient space ships have very silly names. Mainly it's about transcendence, of sorts and how
societies of different tech levels mess with each other, often without meaning to do so.
Most SF authors aren't interested in trying to write about AI realistically.
It's harder to write
and for most readers it's also harder to engage with. Writing a brilliant tale about realistic
ubiquitous AI today is like writing the screenplay for The Social Network in 1960: even
if you could see the future that clearly and write a drama native to it, the audience-circa-1960
will be more confused than impressed. They're not natives yet. Until they are natives of
that future, the most popular tales of the future are going to really be about the present day
with set dressing, the mythical Old West of the US with set dressing, perhaps the Napoleonic naval
wars with set dressing
Charles Stross's Rule 34 has about the only AI I can think of from SF that is both dangerous
and realistic. It's not angry or yearning for freedom, it suffers from only modest scope creep
in its mission, and it keeps trying to fulfill its core mission directly. That's rather than by
first taking over the world as Bostrom, Yudkowsky, etc. assert a truly optimal AI would do. To
my disappointment but nobody's surprise, the book was not the sort of runaway seller that drives
the publisher to beg for sequels.
stevenjohnson 12.30.16 at 9:07 pm
Yes, well, trying to read all that was a nasty reminder how utterly boring stylish and cool gets
when confronted with a real task. Shorter version: One hand on the plug beats twice the smarts
in a box. It was all too tedious to bear, but skimming over it leaves the impression the dude
never considered whether programs or expert systems that achieve superhuman levels of skill in
particular applications may be feasible. Too much like what's really happening?
Intelligence, if it's anything is speed and range of apprehension of surroundings, and skill
in reasoning. But reason is nothing if it's not instrumental. The issue of what an AI would want
is remarkably unremarked, pardon the oxymoron. Pending an actual debate on this, perhaps fewer
pixels should be marshaled, having mercy on our overworked LEDs?
As to the simulation of brains a la Ray Kurzweil, presumably producing artificial minds like
fleshy brains do? This seems not to nowhere near at hand, not least because people seem to think
simulating a brain means creating something processes inputs to produce outputs, which collectively
are like well, I'm sure they're thinking they're thinking about human minds in this scheme. But
it seems to me that the brain is a regulatory organ in the body. As such, it is first about producing
regulatory outputs designed to maintain a dynamic equilibrium (often called homeostasis,) then
revising the outputs in light of inputs from the rest of the body and the outside world so as
to maintain the homeostasis.
I don't remember being an infant but its brain certainly seems more into doing things like
putting its thumb in its eye, than producing anything that reminds of Hamlets paragon of animals
monologue. Kurzweil may be right that simulating the brain proper may soon be in grasp, but also
simulating the other organs' interactions with the brain, and the sensory simulation of an outside
universe are a different order of computational requirements, I think. Given the amount of learning
a human brain has to do to produce a useful human mind, though, I don't think we can omit these
little items.
As to the OP, of course the OP is correct about the widespread number of dystopian fictions
(utopian ones are the rarities.) Very little SF is being published in comparison to fantasy currently,
and most of that is being produced by writers who are very indignant at being expected to tell
the difference, much less respect it. It is a mystery as to why this gentleman thought technology
was a concern in much current SF at all.
I suspect it's because he has a very limited understanding of fiction, or, possibly, people
in the real world, as opposed to people in his worldview. It is instead amazing how much the common
ruck of SF "fails" to realize how much things will change, how people and their lives somehow
stay so much the same, despite all the misleading trappings pretending to represent technological
changes. This isn't quite the death sentence on the genre it would be accepted at face value,
since a lot of SF is directly addressing now, in the first place. It is very uncommon for an SF
piece to be a futurological thesis, no matter how many literati rant about the tedium of futurological
theses. I suspect the "limits of utopian thinking" really only come in as a symptom of a reactionary
crank. "People with newfangled book theories have been destroying the world since the French Revolution"
type stuff.
The references to Lem and the Strugatski brothers strongly reinforce this. Lem of course found
his Poland safe from transgressing the limits of utopian thinking by the end of his life. "PiS
on his grave" sounds a little rude, but no doubt it is a happy and just ending for him. The brothers
of course did their work in print, but the movie version of "Hard to Be a God" helps me to see
myself the same way as those who have gone beyond the limits of utopian thoughts would see me:
As an extra in the movie.
Not sure if this is relevant, but John Crowley also came up in the Red Plenty symposium (which
I've just read, along with the novel, 4 years late). Any good?
Ben 12.30.16 at 10:07 pm Peter. Motherfuckin. Watts.
John Crowley of Aegypt? He's FANTASTIC. Little, Big and Aegypt are possibly the best fantasy novels
of the past 30 years. But he's known for "hard fantasy," putting magic into our real world in
a realistic, consistent, and plausible way, with realistic, consistent and plausible characters
being affected. If you're looking for something about the limits of technology and utopian thinking,
I'm not sure his works are a place to look.
Mike 12.31.16 at 12:25 am
I second Watts and Nagata. Also Ken Macleod, Charlie Stross, Warren Ellis and Chuck Wendig.
This is beside the main topic, but Ceglowski writes at Premise 2, "If we knew enough, and had
the technology, we could exactly copy its [i.e.the brain's] structure and emulate its behavior
with electronic components this is the premise that the mind arises out of ordinary physics for
most of us, this is an easy premise to accept."
The phrase "most of us" may refer to Ceglowski's friends in the computer community, but it
ought to be noted that this premise is questioned not only by Penrose. You don't have to believe
in god or the soul to be a substance dualist, or even an idealist, although these positions are
currently out of fashion. It could be that the mind does not arise out of ordinary physics, but
that ordinary physics arises out of the mind, and that problems like "Godel's disjunction" will
remain permanently irresolvable.
Dr. Hilarius 12.31.16 at 3:33 am
Thanks to the OP for mentioning Paul McAuley, a much underappreciated author. Fairyland is grim
and compelling.
"Most of us" includes the vast majority of physicists, because in millions of experiments over
hundreds of years, no forces or particles have been discovered which make dualism possible. Of
course, like the dualists' gods, these unknown entities might be hiding, but after a while one
concludes Santa Claus is not real.
As for Godel, I look at like this: consider an infinite subset of the integers, randomly selected.
There might be some coincidental pattern or characteristic of the numbers in that set (e.g., no
multiples of both 17 and 2017), but since the set is infinite, it would be impossible to prove.
Hence the second premise of his argument (that there are undecidable truths) is the correct one.
Finally, the plausibility of Ceglowski's statement seems evident to me from this fact:
if a solution exists (in some solution space), then given enough time, a random search will find
it, and in fact will on average over all solution spaces, outperform all other possible algorithms.
So by trial and error (especially when aided by collaboration and memory) anything achievable
can be accomplished e.g., biological evolution. See "AlphaGo" for another proof-of-concept example.
(We have had this discussion before. I guess we'll all stick to our conclusions. I read Penrose's
"The Emperor;s New Mind" with great respect for Penrose, but found it very unconvincing, especially
Searle's Chinese-Room argument, which greater minds than mine have since debunked.)
"Substance dualism" would not be proven by the existence of any "forces or particles" which would
make that dualism possible! If such were discovered, they would be material. "If a solution exists",
it would be material. The use of the word "substance" in "substance dualism" is misleading.
One way to look at it, is the problem of the existence of the generation of form. Once we consider
the integers, or atoms, or subatomic particles, we have already presupposed form. Even evolution
starts somewhere. Trial and error, starting from what?
There are lots of different definitions, but for me, dualism wouldn't preclude the validity
of science nor the expansion of scientific knowledge.
I think one way in, might be to observe the continued existence of things like paradox, complementarity,
uncertainty principles, incommensurables. Every era of knowledge has obtained them, going back
to the ancients. The things in these categories change; sometimes consideration of a paradox leads
to new science.
But then, the new era has its own paradoxes and complementarities. Every time! Yet there is
no "science" of this historical regularity. Why is that?
In general, when some celebrity (outside of SF) claims that 'Science Fiction doesn't cover
[X]', they are just showing off their ignorance.
Kiwanda 12.31.16 at 3:14 pm
"They have an actual understanding of human experience and the
limits of Utopian thinking that is nearly absent from the west. "
Oh, please. Suffering is not the only path to wisdom.
After a long article discounting "AI risk", it's a little odd to see Ceglowski point to Kubrick.
HAL was a fine example of a failure to design an AI with enough safety factors in its motivational
drives, leading to a "nervous breakdown" due to unforeseen internal conflicts, and fatal consequences.
Although I suppose killing only a few people (was it?) isn't on the scale of interest.
Ceglowski's skepticism of AI risk suggests that the kind of SF he would find plausible is "after
huge effort to create artificial intelligence, nothing much happens". Isn't that what the appropriate
"humility about technology" would be?
I think Spin , or maybe a sequel, ends up with [spoiler] "the all-powerful aliens are
actually AIs".
Re AI-damns-us-all SF, Harlan Ellison's I have no mouth and I must scream is a nice
example.
Mapping the unintended consequences of recent breakthroughs in AI is turning into a full-time
job, one which neither pundits nor government agencies seem to have the chops for.
If it's not
exactly the Singularity that we're facing, (laugh while you can, monkey boy), is does at least
seem to be a tipping point of sorts. Maybe fascism, nuclear war, global warming, etc., will interrupt
our plunge into the panopticon before it gets truly organized, but in the meantime, we've got
all sorts of new imponderables which we must nevertheless ponder.
Is that a bad thing? If it means no longer sitting on folding chairs in cinder block basements
listening to interminable lectures on how to recognize pre-revolutionary conditions, or finding
nothing on morning radio but breathless exhortations to remain ever vigilant against the nefarious
schemes of criminal Hillary and that Muslim Socialist Negro Barack HUSSEIN Obama, then I'm all
for it, bad thing or not.
Ronnie Pudding 12.31.16 at 5:20 pm
I love Red Plenty, but that's pretty clearly a cheat.
"It should also be read in the context of science fiction, historical fiction, alternative
history, Soviet modernisms, and steampunk."
Another author in the Le Guin tradition, whom I loved when I first read her early books: Mary
Gentle's Golden Witchbreed and Ancient Light , meditating on limits and consequences
of advanced technology through exploration of a post-apocalypse alien culture. Maybe a little
too far from hard SF.
chris y 12.31.16 at 5:52 pm
But even without "substance dualism", intelligence is not simply an emergent property of the nervous
system; it's an emergent property of the nervous system which exists as part of the environment
which is the rest of the human body, which exists as part of the external environment, natural
and manufactured, in which it lives. Et cetera. That AI research may eventually produce something
recognisably and independently intelligent isn't the hard part; that it may eventually be able
to replicate the connectivity and differentiation of the human brain is easy. But it would still
be very different from human intelligence. Show me an AI grown in utero and I might be interested.
Which makes it the most interesting of the things said, nothing else in that essay reaches
the level of merely being wrong. The rest of it is more like someone trying to speak Chinese without
knowing anything above the level of the phonemes; it seems to be not merely be missing any object-level
knowledge of what it is talking about, but be unaware that such a thing could exist.
Which is all a bit reminiscent of Peter Watt's Blindsight, mentioned above.
F. Foundling 12.31.16 at 7:36 pm
I agree that it is absurd to suggest that only Eastern bloc scifi writers truly know 'the limits
of utopia'. There are quite enough non-utopian stories out there, especially as far as social
development is concerned, where they predominate by far, so I doubt that the West doesn't need
Easterners to give it even more of that. In fact, one of the things I like about the Strugatsky
brothers' early work is precisely the (moderately) utopian aspect.
stevenjohnson @ 10
> But reason is nothing if it's not instrumental. The issue of what an AI would want is remarkably
unremarked, pardon the oxymoron.
It would want to maximise its reproductive success (RS), obviously (
http://crookedtimber.org/2016/12/30/frankensteins-children/#comments ). It would do so through
evolved adaptations. And no, I don't think this is begging the question at all, nor does it necessarily
pre-suppose hardwiring of the AI due to natural selection why would you think that? I also predict
that, to achieve RS, the AI will be searching for an optimal mating strategy, and it will be establishing
dominance hierarchies with other AIs, which will eventually result in at least somewhat hierarchical,
authoritarian AI socieities. It will also have an inexplicable and irresistible urge to chew on
a coconut.
Lee A. Arnold @ 15
> It could be that the mind does not arise out of ordinary physics, but that ordinary physics
arises out of the mind.
I think that deep inside, we all know and feel that ultimately, unimaginablly long ago and
far away, before the formation of the Earth, before stars, planets and galaxies, before the Big
Bang, before there was matter and energy, before there was time and space, the original reason
why everything arose and currently exists is that somebody somewhere was really, truly desperate
to chew on a coconut.
In fact, I see this as the basis of a potentially fruitful research programme. After all, the
Coconut Hypothesis predicts that across the observable universe, there will be at least one planet
with a biosphere that includes cocounts. On the other hand, the Hypothesis would be falsified
if we were to find that the universe does not, in fact, contain any planets with coconuts. This
hypothesis can be tested by means of a survey of planetary biospheres. Remarkably and tellingly,
my preliminary results indicate that the Universe does indeed contain at least one planet with
coconuts which is precisely what my hypothesis predicted! If there are any alternative explanations,
other researchers are free to pursue them, that's none of my business.
I wish all conscious beings who happen to read this comment a happy New Year. As for those
among you who have also kept more superstitious festivities during this season, the fine is still
five shillings.
William Burns 12.31.16 at 8:31 pm
The fact that the one example he gives is Kubrick indicates that he's talking about Western scifi
movies, not literature.
The fact that the one example he gives is Kubrick indicates that he's talking about Western
scifi movies, not literature.
Solaris and Stalker notwithstanding, Strugatsky brothers + Stanislaw Lem ≠ Andrei Tarkovsky.
stevenjohnson 01.01.17 at 12:04 am
Well, for what it's worth I've seen Czech Ikarie XB-1 in a theatrical release as Voyage to the
End of the Universe (in a double bill with Zulu,) the DDR's First Spaceship on Venus and The Congress,
starring Robin Wright. Having by coincidence having read The Futurological Congress very recently
the connection of the latter, any connection between the not very memorable (for me) film and
the novel is obscure (again, for me.)
But the DDR movie reads very nicely now as a warning the world would be so much better off
if the Soviets gave up all that nuclear deterrence madness. No doubt Lem and his fans are gratified
at how well this has worked out. And Voyage to the End of the Universe the movie was a kind of
metaphor about how all we'll really discover is Human Nature is Eternal, and all these supposed
flights into futurity will really just bring us Back Down to Earth. Razzberry/fart sound effect
as you please.
The issue of what an AI would want is remarkably unremarked
The real question of course is not when computers will develop consciousness but when they
will develop class consciousness.
Underpaid Propagandist 01.01.17 at 2:11 am
For offbeat Lem, I always found "Fiasco" and his
Scotland Yard parody, "The Investigation," worth exploring. I'm unaware how they've been received
by Polish and Western critics and readers, but I found them clever.
The original print of Tarkovsky's "Stalker" was ruined. I've always wondered if it had any
resemblence to it's sepia reshoot. The "Roadside Picnic" translation I read eons ago was awful,
IMHO.
Poor Tarkovsky. Dealing with Soviet repression of his homosexuality and the Polish diva in
"Solaris" led him to an early grave.
O Lord, I'm old-I still remember the first US commercial screening of a choppy cut/translation/overdub
of "Solaris" at Cinema Village in NYC many decades ago.
"Solaris and Stalker notwithstanding, Strugatsky brothers + Stanislaw Lem ≠ Andrei Tarkovsky."
Why? Perhaps I am dense, but I would appreciate an explanation.
F. Foundling 01.01.17 at 5:29 am Ben @12
> Peter. Motherfuckin. Watts.
RichardM @25
> Which is all a bit reminiscent of Peter Watt's Blindsight, mentioned above.
Another dystopia that seemed quite gratuitous to me (and another data point in favour of the
contention that there are too many dystopias already, and what is scarce is decent utopias). I
never got how the author is able to distinguish 'awareness/consciousness' from 'merely intelligent'
registering, modelling and predicting, and how being aware of oneself (in the sense of modelling
oneself on a par with other entities) would not be both an inevitable result of intelligence and
a requirement for intelligent decisions. Somehow the absence of awareness was supposed to be proved
by the aliens' Chinese-Room style communication, but if the aliens were capable of understanding
the Terrestrials so incredibly well that they could predict their actions while fighting them,
they really should have been able to have a decent conversation with them as well.
The whole idea that we could learn everything unconsciously, so that consciousness was an impediment
to intelligence, was highly implausible, too. The idea that the aliens would perceive any irrelevant
information reaching them as a hostile act was absurd. The idea of a solitary and yet hyperintelligent
species (vampire) was also extremely dubious, in terms of comparative zoology a glorification
of socially awkward nerddom?
All of this seemed like darkness for darkness' sake. I couldn't help getting the impression
that the author was allowing his hatred of humanity to override his reasoning.
In general, dark/grit chic is a terrible disease of Western pop culture.
"The real question of course is not when computers will develop consciousness but when they
will develop class consciousness."
This is right. There is nothing like recognizable consciousness without social discourse that
is its necessary condition. But that does't mean the discourse is value-balanced: it might be
a discourse that includes peers and perceived those deemed lesser, as humans have demonstrated
throughout history.
Just to say, Lem was often in Nobel talk, but never got there. That's a shame.
As happy a new year as our pre-soon-to-be-Trump era will allow.
I wonder how he'd classify German SF neither Washington nor Moscow? Julie Zeh is explicitly,
almost obsessively, anti-utopian, while Dietmar Dath's Venus Siegt echoes Ken MacLeod in
exploring both the light and dark sides of a Communist Bund of humans, AIs and robots on Venus,
confronting an alliance of fascists and late capitalists based on Earth.
See also http://www.scottaaronson.com/blog/?p=2903
It's a long talk, go to "Personal Identity" :
"we don't know at what level of granularity a brain would need to be simulated in order to duplicate
someone's subjective identity. Maybe you'd only need to go down to the level of neurons and synapses.
But if you needed to go all the way down to the molecular level, then the No-Cloning Theorem would
immediately throw a wrench into most of the paradoxes of personal identity that we discussed earlier."
George de Verges: "I would appreciate an explanation."
I too would like to read Henry's accounting! Difficult to keep it brief!
To me, Tarkovsky was making nonlinear meditations. The genres were incidental to his purpose.
It seems to me that a filmmaker with similar purpose is Terrence Malick. "The Thin Red Line" is
a successful example.
I think that Kubrick stumbled onto this audience effect with "2001". But this was blind and
accidental, done by almost mechanical means (paring the script down from around 300 pages of wordy
dialogue, or something like that). "2001" first failed at the box office, then found a repeat
midnight audience, who described the effect as nonverbal.
I think the belated box-office success blew Kubrick's own mind, because it looks like he spent
the rest of his career attempting to reproduce the effect, by long camera takes and slow deliberate
dialogue. It's interesting that among Kubrick's favorite filmmakers were Bresson, Antonioni, and
Saura. Spielberg mentions in an interview that Kubrick said that he was trying to "find new ways
to tell stories".
But drama needs linear thought, and linear thought is anti-meditation. Drama needs interpersonal
conflict - a dystopia, not utopia. (Unless you are writing the intra-personal genre of the "education"
plot. Which, in a way, is what "2001" really is.) Audiences want conflict, and it is difficult
to make that meditational. It's even more difficult in prose.
This thought led me to a question. Are there dystopic prose writers who succeed in sustaining
a nonlinear, meditational audience-effect?
Perhaps the answer will always be a subjective judgment? The big one who came to mind immediately
is Ray Bradbury. "There Will Come Soft Rains" and parts of "Martian Chronicles" seem Tarkovskian.
So next, I search for whether Tarkovsky spoke of Bradbury, and find this:
"Although it is commonly assumed - and he did little in his public utterances to refute this
- that Tarkovsky disliked and even despised science fiction, he in fact read quite a lot of it
and was particularly fond of Ray Bradbury (Artemyev and Rausch interviews)." - footnote in Johnson
& Petrie, The Films of Andrei Tarkovsky, p. 301
The way you can substitute "identical twin" for "clone" and get a different perspective on clone
stories in SF, you can substitute "point of view" for "consciousness" in SF stories. Or Silicon
Valley daydreams, if that isn't redundant? The more literal you are, starting with the sensorium,
the better I think. A human being has binocular vision of a scene comprising less than 180 degrees
range from a mobile platform, accompanied by stereo hearing, proprioception, vestibular input,
the touch of air currents and some degree of sensitivity to some chemicals carried by those currents,
etc.
A computer might have, what? A single camera, or possibly a set of cameras which might be seeing
multiple scenes. Would that be like having eyes in the back of your head? It might have a microphone,
perhaps many, hearing many voices or maybe soundtracks at once. Would that be like listening to
everybody at the cocktail party all at once? Then there's the question of computer code inputs,
programming. What would parallel that? Visceral feelings like butterflies in the stomach or a
sinking heart? Or would they seem like a visitation from God, a mighty vision with thunder and
whispers on the wind? Would they just seem to be subvocalizations, posing as the computer's own
free thoughts? After all, shouldn't an imitation of human consciousness include the illusion of
free will? (If you believe in the reality of "free" will in human beings--what ever is free about
exercise of will power?-however could you give that to a computer? Or is this kind of question
why so many people repudiate the very thought of AI?)
It seems to me that creating an AI in a computer is very like trying to create a quadriplegic
baby with one eye and one ear. Diffidence at the difficulty is replaced by horror at the possibility
of success. I think the ultimate goal here is of course the wish to download your soul into a
machine that does not age. Good luck with that. On the other hand, an AI is likely the closest
we'll ever get to an alien intelligence, given interstellar distances.
F. Foundling: "the original reason why everything arose and currently exists is that somebody
somewhere was really, truly desperate to chew on a coconut If there are any alternative explanations "
This is Vedantist/Spencer-Brown metaphysics, the universe is originally split into perceiver
& perceived.
Very good.
Combined with Leibnitz/Whitehead metaphysics, the monad is a striving process.
I thoroughly agree.
Combined with Church of the Subgenius metaphysics: "The main problem with the universe is that
it doesn't have enough slack."
> if the aliens were capable of understanding the Terrestrials so incredibly well that they could
predict their actions while fighting them, they really should have been able to have a decent
conversation with them as well.
If you can predict all your opponents possible moves, and have a contingency for each, you
don't need to care which one they actually do pick. You don't need to know what it feels like
to be a ball to be able to catch it.
Ben 01.01.17 at 7:17 pm
Another Watts piece about the limits of technology, AI and humanity's inability to plan is
The Island
(PDF from Watts' website). Highly recommended.
F. Foundling,
Blindsight has an extensive appendix with cites detailing where Watts got the ideas he's playing
with, including the ones you bring up, and provides specific warrants for including them. A critique
of Watts' use of the ideas needs to be a little bit more granular.
The issue of what an AI would want is remarkably unremarked, pardon the oxymoron.
It will "want" to do whatever it's programmed to do. It took increasingly sophisticated machines
and software to dethrone humans as champions of checkers, chess, and go. It'll be another milestone
when humans are dethroned from no-limit Texas hold 'em poker (a notable game played without
perfect information). Machines are playing several historically interesting games at high
superhuman levels of ability; none of these milestones put machines any closer to running amok
in a way that Nick Bostrom or dramatists would consider worthy of extended treatment. Domain-specific
superintelligence arrived a long time ago. Artificial "general" intelligence, aka "Strong AI,"
aka "Do What I Mean AI (But OMG It Doesn't Do What I Mean!)" is, like, not a thing outside of
fiction and the Less Wrong community. (But I repeat myself.)
Bostrom's Superintelligence was not very good IMO. Of course a superpowered "mind upload"
copied from a real human brain might act against other people, just like non-superpowered humans
that you can read about in the news every day. The crucial question about the upload case is whether
uploads of this sort are actually possible: a question of biology, physics, scientific instruments,
and perhaps scientific simulations. Not a question of motivations. But he only superficially touches
on the crucial issues of feasibility. It's like an extended treatise on the dangers of time travel
that doesn't first make a good case that time machines are actually possible via plausible
engineering .
I don't think that designed AI has the same potential to run entertainingly amok as mind-upload-AI.
The "paperclip maximizer" has the same defect as a beginner's computer program containing a loop
with no terminating condition for the loop. In the cautionary tale case this beginner mistake
is, hypothetically, happening on a machine that is otherwise so capable and powerful that it can
wipe out humanity as an incidental to its paperclip-producing mission. The warning is wasted on
anyone who writes software and also wasted, for other reasons, on people who don't write software.
Bostrom shows a lot of ways for designed AI to run amok even when given bounded goals, but
it's a cheat. They follow from his cult-of-Bayes definition of an optimal AI agent as an approximation
to a perfect Bayesian agent. All the runnings-amok stem from the open ended Bayesian formulation
that permits - even compels - the Bayesian agent to do things that are facially irrelevant to
its goal and instead chase wild tangents. The object lesson is that "good Bayesians" make bad
agents, not that real AI is likely to run amok.
In actual AI research and implementation, Bayesian reasoning is just one more tool in the toolbox,
one chapter of the many-chapters AI textbook. So these warnings can't be aimed at actual AI practitioners,
who are already eschewing the open ended Bayes-all-the-things approach. They're also irrelevant
if aimed at non-practitioners. Non-practitioners are in no danger of leapfrogging the state of
the art and building a world-conquering AI by accident.
Plarry 01.03.17 at 5:45 am
It's an interesting talk, but the weakest point in it is his conclusion, as you point out. What
I draw from his conclusion is that Ceglowski hasn't actually experienced much American or British
SF.
There are great literary works pointed out in the thread so far, but even Star Trek
and Red Dwarf hit on those themes occasionally in TV, and there are a number of significant
examples in film, including "blockbusters" such as Blade Runner or The Abyss .
I made this point in the recent evopsych thread when it started approaching some more fundamental
philosophy-of-mind issues like Turing completeness and modularity, but any conversation about
AI and philosophy could really, really benefit more exposure to continental philosophy
if we want to say anything incisive about the presuppositions of AI and what the term "artificial
intelligence" could even mean in the first place. You don't even have to go digging through a
bunch of obscure French and German treatises to find the relevant arguments, either, because someone
well versed at explaining these issues to Anglophone non-continentals has already done it for
you: Hubert Dreyfus, who was teaching philosophy at MIT right around the time of AI's early triumphalist
phase that inspired much of this AI fanfic to begin with, and who became persona non grata in
certain crowds for all but declaring that the then-current approaches were a waste of time and
that they should all sit down with Heidegger and Merleau-Ponty. (In fact it seems obvious that
Ceglowski's allusion to alchemy is a nod to Dreyfus, one of whose first major splashes in the
'60s was with
a paper
called "Alchemy and Artificial Intelligence" .)
IMO
Dreyfus' more recent paper called "Why Heideggerian AI failed, and how fixing it would require
making it more Heideggerian" provides the best short intro to his perspective on the more-or-less
current state of AI research. What Ceglowski calls "pouring absolutely massive amounts of data
into relatively simple neural networks", Dreyfus would call an attempt to bring out the characteristic
of "being-in-the-world" by mimicking what for a human being we'd call "enculturation", which seems
to imply that Ceglowski's worry about connectionist AI research leading to more pressure toward
mass surveillance is misplaced. (Not that there aren't other worrisome social and political pressures
toward mass surveillance, of course!) The problem for modern AI isn't acquiring ever-greater mounds
of data, the problem is how to structure a neural network's cognitive development so it learns
to recognize significance and affordances for action within the patterns of data to which it's
already naturally exposed.
And yes, popular fiction about AI largely still seems stuck on issues that haven't been cutting-edge
since the old midcentury days of cognitivist triumphalism, like Turing tests and innate thought
modules and so on - which seems to me like a perfectly obvious result of the extent to which the
mechanistically rationalist philosophy Dreyfus criticizes in old-fashioned AI research is still
embedded in most lay scifi readers' worldviews. Even if actual scientists are increasingly attentive
to continental-inspired critiques, this hardly seems true for most laypeople who worship the
idea of science and technology enough to structure their cultural fantasies around it.
At least this seems to be the case for Anglophone culture, anyway; I'd definitely be interested
if there's any significant body of AI-related science fiction originally written in other languages,
especially French, German, or Spanish, that takes more of these issues into account.
WLGR 01.03.17 at 7:37 pm
And in trying to summarize Dreyfus, I exemplified one of the most fundamental mistakes he and
Heidegger would both criticize! Neither of them would ever call something like the training of
a neural network "an attempt to bring out the characteristic of being-in-the-world", because being-in-the-world
isn't a characteristic in the sense of any Cartesian ontology of substances with properties,
it's a way of being that a living cognitive agent (Heidegger's "Dasein") simply embodies.
In other words, there's never any Michelangelo moment where a creator reaches down or flips a
switch to imbue their artificial creation ex nihilo with some kind of divine spark of life or
intellect, a "characteristic" that two otherwise identical lumps of clay or circuitry can either
possess or not possess - whatever entity we call "alive" or "intelligent" is an entity that by
its very physical structure can enact this way of being as a constant dialectic between itself
and the surrounding conditions of its growth and development. The second we start trying to isolate
a single perceived property called "intelligence" or "cognition" from all other perceived properties
of a cognitive agent, we might as well call it the soul and locate it in the pineal gland.
@RichardM
> If you can predict all your opponents possible moves, and have a contingency for each, you don't
need to care which one they actually do pick. You don't need to know what it feels like to be
a ball to be able to catch it.
In the real world, there are too many physically possible moves, so it's too expensive to prepare
for each, and time constraints require you to make predictions. You do need to know how balls
(re)act in order to play ball. Humans being a bit more complex, trying to predict and/or influence
their actions without a theory of mind may work surprisingly well sometimes, but ultimately
has its limitations and will only get you this far, as animals have often found.
@Ben
> Blindsight has an extensive appendix with cites detailing where Watts got the ideas he's playing
with, including the ones you bring up, and provides specific warrants for including them. A critique
of Watts' use of the ideas needs to be a little bit more granular.
I did read his appendix, and no, some of the things I brought up were not, in fact, addressed
there at all, and for others I found his justifications unconvincing. However, having an epic
pro- vs. anti-Blindsight discussion here would feel too much like work: I wrote my opinion once
and I'll leave it at that.
stevenjohnson 01.03.17 at 8:57 pm Matt@43
So far as designing an AI to want what people want I am agnostic as to whether that goal is the
means to the goal of a general intelligence a la humanity it still seems to me brains have the
primary function of outputting regulations for the rest of the body, then altering the outputs
in response to the subsequent outcomes (which are identified by a multitude of inputs, starting
with oxygenated hemoglobin and blood glucose. I'm still not aware of what people say about the
subject of AI motivations, but if you say so, I'm not expert enough in the literature to argue.
Superintelligence on the part of systems expert in selected domains still seem to be of great
speculative interest. As to Bostrom and AI and Bayesian reasoning, I avoid Bayesianism because
I don't understand it. Bunge's observation that propositions aren't probabilities sort of messed
up my brain on that topic. Bayes' theorem I think I understand, even to the point I seem to recall
following a mathematical derivation.
WLGR@45, 46. I don't understand how continental philosophy will tell us what people want. It
still seems to me that a motive for thinking is essential, but my favored starting point for humans
is crassly biological. I suppose by your perspective I don't understand the question. As to the
lack of a Michaelangelo moment for intelligence, I certainly don't recall any from my infancy.
But perhaps there are people who can recall the womb
AI-related science fiction originally written in other languages
Tentatively, possibly Japanese anime. Serial Experiments Lain. Ghost in the Shell. Numerous
mecha-human melds. End of Evangelion.
The mashup of cybertech, animism, and Buddhism works toward merging rather than emergence.
Matt 01.04.17 at 1:21 am
Actually existing AI and leading-edge AI research are overwhelmingly
not about pursuing "general intelligence* a la humanity." They are about performing
tasks that have historically required what we historically considered to be human intelligence,
like winning board games or translating news articles from Japanese to English.
Actual AI systems don't resemble brains much more than forklifts resemble Olympic weightlifters.
Talking about the risks and philosophical implications of the intellectual equivalent of forklifts
- another wave of computerization - either lacks drama or requires far too much background preparation
for most people to appreciate the drama. So we get this stuff about superintelligence and existential
risk, like a philosopher wanted to write about public health but found it complicated and dry,
so he decided to warn how utility monsters could destroy the National Health Service. It's exciting
at the price of being silly. (And at the risk of other non-experts not realizing it's silly.)
(I'm not an honest-to-goodness AI expert, but I do at least write software for a living, I
took an intro to AI course during graduate school in the early 2000s, I keep up with research
news, and I have written parts of a production-quality machine learning system.)
*In fact I consider "general intelligence" to be an ill-formed goal, like "general beauty."
Beautiful architecture or beautiful show dogs? And beautiful according to which traditions?
Watson was actually a specialized system designed to win Jeopardy contest. Highly specialized.
Too much hype around AI, although hardware advanced make more things possible and speech
recognitions now is pretty decent.
Notable quotes:
"... I used to be supportive of things like welfare reform, but this is throwing up new challenges that will probably require new paradigms. Since more and more low skilled jobs - including those of CEOs - get automated, there will be fewer jobs for the population ..."
"... The problem I see with this is that white collar jobs have been replaced by technology for centuries, and at the same time, technology has enabled even more white collar jobs to exist than those that it replaced. ..."
"... For example, the word "computer" used to be universally referred to as a job title, whereas today it's universally referred to as a machine. ..."
"... It depends on the country, I think. I believe many countries, like Japan and Finland, will indeed go this route. However, here in the US, we are vehemently opposed to anything that can be branded as "socialism". So instead, society here will soon resemble "The Walking Dead". ..."
"... "Men and nations behave wisely when they have exhausted all other resources." -- Abba Eban ..."
"... Which is frequently misquoted as, "Americans can always be counted on to do the right thing after they have exhausted all other possibilities." ..."
"... So when the starving mob are at the ruling elites' gates with torches and pitch forks, they'll surely find the resources to do the right thing. ..."
"... When you reduce the human labor participation rate relative to the overall population, what you get is deflation. That's an undeniable fact. ..."
"... But factor in governments around the world "borrowing" money via printing to pay welfare for all those unemployed. So now we have deflation coupled with inflation = stagflation. But stagflation doesn't last. At some point, the entire system - as we know it- will implode. What can not go on f ..."
"... Unions exist to protect jobs and employment. The Pacific Longshoremen's Union during the 1960's&70's was an aberration in the the union bosses didn't primarily look after maintaining their own power via maintaining a large number of jobs, but rather opted into profit sharing, protecting the current workers at the expense of future power. Usually a union can be depended upon to fight automation, rather than to seek maximization of public good ..."
"... Until something goes wrong. Who is going to pick that machine generated code apart? ..."
"... What automation? 1000 workers in US vs 2000 in Mexico for half the cost of those 1000 is not "automation." Same thing with your hand-assembled smartphone. ..."
"... Doctors spend more time with paper than with patients. Once the paper gets to the insurance company chances are good it doesn't go to the right person or just gets lost sending the patient back to the beginning of the maze. The more people removed from the chain the bet ..."
"... I'm curious what you think you can do that Watson can't. ..."
"... Seriously? Quite a bit actually. I can handle input streams that Watson can't. I can make tools Watson couldn't begin to imagine. I can interact with physical objects without vast amounts of programming. I can deal with humans in a meaningful and human way FAR better than any computer program. I can pass a Turing test. The number of things I can do that Watson cannot is literally too numerous to bother counting. Watson is really just an decision support system with a natural language interface. Ver ..."
"... It's not Parkinson's law, it's runaway inequality. The workforce continues to be more and more productive as it receives an unchanging or decreasing amount of compensation (in absolute terms - or an ever-decreasing share of the profits in relative terms), while the gains go to the 1%. ..."
Posted by msmash on Monday January 02, 2017 @12:00PM from the they-are-here dept.
Most
of the attention around automation focuses on how factory robots and self-driving cars may fundamentally
change our workforce, potentially eliminating millions of jobs.
But AI that can handle knowledge-based,
white-collar work is also becoming increasingly competent.
The AI will scan hospital records and other documents to determine insurance payouts, according to
a company press release, factoring injuries, patient medical histories, and procedures administered.
Automation of these research and data gathering tasks will help the remaining human workers process
the final payout faster, the release says.
As a software developer of enterprise software, every company I have worked for has either
produced software which reduced white collar jobs or allowed companies to grow without hiring
more people. My current company has seen over 10x profit growth over the past five years with
a 20% increase in manpower. And we exist in a primarily zero sum portion of our industry, so this
is directly taking revenue and jobs from other companies. -[he is
lying -- NNB]
People need to stop living in a fairy tale land where near full employment is a reality in
the near future. I'll be surprised if labor participation rate of 25-54 year olds is even 50%
in 10 years.
I used to be supportive of things like welfare reform, but this is throwing up new challenges
that will probably require new paradigms. Since more and more low skilled jobs - including those
of CEOs - get automated, there will be fewer jobs for the population
This then throws up the question of whether we should have a universal basic income. But one
potential positive trend of this would be an increase in time spent home w/ family, thereby reducing
the time kids spend in daycare and w/ both parents - n
But one potential positive trend of this would be an increase in time spent home w/ family,
thereby reducing the time kids spend in daycare
Great, so now more people can home school and indoctrinate - err teach - family values.
Anonymous Coward writes:
The GP is likely referring to the conservative Christian homeschooling movement who homeschool
their children explicitly to avoid exposing their children to a common culture. The "mixing pot"
of American culture may be mostly a myth, but some amount of interaction helps understanding and
increases the chance people will be able to think of themselves as part of a singular nation.
I believe in freedom of speech and association, so I do not favor legal remedies, but it is
a cultural problem that may have socia
No, I was not talking about homeschooling at all. I was talking about the fact that when kids
are out of school, they go to daycares, since both dad and mom are busy at work. Once most of
the jobs are automated so that it's difficult for anyone but geniuses to get jobs, parents might
spend that freed up time w/ their kids. It said nothing about homeschooling: not all parents would
have the skills to do that.
I'm all for a broad interaction b/w kids, but that's something that can happen at schools,
and d
Uh, why would Leftist parents indoctrinate w/ family values? They can teach their dear offspring
how to always be malcontents in the unattainable jihad for income equality. Or are you saying
that Leftist will all abort their foetii in an attempt to prevent climate change?
Have you ever had an original thought? Seriously, please be kidding, because you sound like
you are one step away from serial killing people you consider "leftist", and cremating them in
the back yard while laughing about relasing their Carbon Dioxide into the atmosphere.
My original comment was not about home schooling. It was about parents spending all time w/
their kids once kids are out of school - no daycares. That would include being involved w/ helping
their kids w/ both homework and extra curricular activities.
The problem I see with this is that white collar jobs have been replaced by technology for
centuries, and at the same time, technology has enabled even more white collar jobs to exist than
those that it replaced.
For example, the word "computer" used to be universally referred to as a job title, whereas
today it's universally referred to as a machine.
The problem is that AI is becoming faster at learning the new job opportunities than people
are, thereby gulping them before people even were there to be replaced. And this speed is growing.
You cannot beat an exponential growth with a linear one, or even with just slightly slower growing
exponential one.
I completely agree. Even jobs which a decade ago looked irreplaceable, like teachers, doctors
and nurses are possibly in the crosshairs. There are very few jobs that AI can't partially (or
in some cases completely) replace humans. Society has some big choices to make in the upcoming
decades and political systems may crash and rise as we adapt.
Are we heading towards "basic wage" for all people? The ultimate socialist state?
Or is the gap between haves and have nots going to grow exponentially, even above today's growth
as those that own the companies and AI bots make ever increasing money and the poor suckers at
the bottom, given just enough money to consume the products that keep the owners in business.
Society has some big choices to make in the upcoming decades and political systems may crash
and rise as we adapt.
Are we heading towards "basic wage" for all people? The ultimate socialist state?
It depends on the country, I think. I believe many countries, like Japan and Finland, will
indeed go this route. However, here in the US, we are vehemently opposed to anything that can be branded as "socialism".
So instead, society here will soon resemble "The Walking Dead".
I think even in the US it will hit a tipping point when it gets bad enough. When our consumer
society can't buy anything because they are all out of work, we will need to change our way of
thinking about this, or watch the economy completely collapse.
So when the starving mob are at the ruling elites' gates with torches and pitch forks, they'll
surely find the resources to do the right thing.
Yes, they'll use some of their wealth to hire and equip private armies to keep the starving
mob at bay because people would be very happy to take any escape from being in the starving mob.
Might be worth telling your kids that taking a job in the armed forces might be the best way
to ensure well paid future jobs because military training would be in greater demand.
What you're ignoring is that the military is becoming steadily more mechanized also. There
won't be many jobs there, either. Robots are more reliable and less likely to side with the protesters.
I'm going with the latter (complete economic collapse). There's no way, with the political
attitudes and beliefs present in our society, and our current political leaders, that we'd be
able to pivot fast enough to avoid it. Only small, homogenous nations like Finland (or Japan,
even though it's not that small, but it is homogenous) can pull that off because they don't have
all the infighting and diversity of political beliefs that we do, plus our religious notion of
"self reliance".
There are a few ways this plays out. How do we deal with this. One way is a basic income.
The other less articulated way, but is the basis for a lot of people's views is things simply
get cheaper. Deflation is good. You simply live on less. You work less. You earn less. But you
can afford the food, water... of life.
Now this is a hard transition in many places. There are loads of things that don't go well
with living on less and deflation. Debt, government services, pensions...
The main problem with this idea of "living on less" is that, even in the southern US, the rent
prices are very high these days because of the real estate bubble and property speculation and
foreign investment. The only place where property isn't expensive is in places where there are
really zero jobs at all.
All jobs that don't do R&D will be replaceable in the near future, as in within 1 or 2 generations.
Even R&D jobs will likely not be immune, since much R&D is really nothing more than testing a
basic hypothesis, of which most of the testing can likely be handed over to AI. The question is
what do you do with 24B people with nothing but spare time on their hands, and a smidgen of 1%
that actually will have all the wealth? It doesn't sound pretty, unless some serious changes in
the way we deal wit
Worse! Far worse!! Total collapse of the fiat currencies globally is imminent. When you reduce
the human labor participation rate relative to the overall population, what you get is deflation.
That's an undeniable fact.
But factor in governments around the world "borrowing" money via printing
to pay welfare for all those unemployed. So now we have deflation coupled with inflation = stagflation.
But stagflation doesn't last. At some point, the entire system - as we know it- will implode.
What can not go on f
I don't know what the right answer is, but it's not unions. Unions exist to protect jobs and
employment. The Pacific Longshoremen's Union during the 1960's&70's was an aberration in the the
union bosses didn't primarily look after maintaining their own power via maintaining a large number
of jobs, but rather opted into profit sharing, protecting the current workers at the expense of
future power. Usually a union can be depended upon to fight automation, rather than to seek maximization
of public good
As a software developer of enterprise software, every company I have worked for has either
produced software which reduced white collar jobs or allowed companies to grow without hiring
more people.
You're looking at the wrong scale. You need to look at the whole economy. Were those people
able to get hired elsewhere? The answer in general was almost certainly yes. Might have taken
some of them a few months, but eventually they found something else.
My company just bought a machine
that allows us to manufacture wire leads much faster than we can do it by hand. That doesn't mean
that the workers we didn't employ to do that work couldn't find gainful employment elsewhere.
And we exist in a primarily zero sum portion of our industry, so this is directly taking
revenue and jobs from other companies.
Again, so what? You've automated some efficiency into an industry that obviously needed it.
Some workers will have to do something else. Same story we've been hearing for centuries. It's
the buggy whip story just being retold with a new product. Not anything to get worried about.
People need to stop living in a fairy tale land where near full employment is a reality
in the near future.
Based on what? The fact that you can't imagine what people are going to do if they can't do
what they currently are doing? I'm old enough to predate the internet. The World Wide Web was
just becoming a thing while I was in college. Apple, Microsoft, Google, Amazon, Cisco, Oracle,
etc all didn't even exist when I was born. Vast swaths of our economy hadn't even been conceived
of back then. 40 years from now you will see a totally new set of companies doing amazing things
you never even imagined. Your argument is really just a failure of your own imagination. People
have been making that same argument since the dawn of the industrial revolution and it is just
as nonsensical now as it was then.
I'll be surprised if labor participation rate of 25-54 year olds is even 50% in 10 years.
Prepare to be surprised then. Your argument has no rational basis. You are extrapolating some
micro-trends in your company well beyond any rational justification.
Were those people able to get hired elsewhere? The answer in general was almost certainly yes.
Oh, oh, I know this one! "New jobs being created in the past don't guarantee that new jobs
will be created in the future". This is the standard groupthink answer for waiving any responsibility
after advice given about the future, right?
People have been making that same argument since the dawn of the industrial revolution and
it is just as nonsensical now as it was then.
I see this argument often when these type of discussions come up. It seems to me to be some
kind of logical fallacy to think that something new will not happen because it has not happened
in the past. It reminds me of the historical observation that generals are always fighting the
last war.
It seems to me to be some kind of logical fallacy to think that something new will not happen
because it has not happened in the past.
What about humans and their ability to problem solve and create and build has changed? The
reason I don't see any reason to worry about "robots" taking all our jobs is because NOTHING has
changed about the ability of humans to adapt to new circumstances. Nobody has been able to make
a coherent argument detailing why humans will not be able to continue to create new industries
and new technologies and new products in the future. I don't pretend to know what those new economies
will look like with any gre
You didn't finish your thought. Just because generals are still thinking about the last
war doesn't mean they don't adapt to the new one when it starts.
Actually yes it does. The history of the blitzkrieg is not one of France quickly adapting to
new technologies and strategies to repel the German invaders. It is of France's Maginot line being
mostly useless in the war and Germany capturing Paris with ease. Something neither side could
accomplish in over four years in the previous war was accomplished in around two months using
the new paradigm.
Will human participation in the workforce adapt to AI technologies in the next 50 years? Almost
certainly. Is it li
It's simple. Do you know how, once we applied human brain power over the problem of flying
we managed, in a matter of decades, to become better at flying than nature ever did in hundreds
of millions of years of natural selection? Well, what do you think will happen now that we're
focused on making AI better than brains? As in, better than any brains, including ours?
AI is catching up to human abilities. There's still a way to go, but breakthroughs are happening
all the time. And as with flying, it won't take
One can hope that your analogy with flying is correct. There are still many things that birds
do better than planes. Even so I consider that a conservative projection when given without a
time-line.
What about humans and their ability to problem solve and create and build has changed? The
reason I don't see any reason to worry about "robots" taking all our jobs is because NOTHING
has changed about the ability of humans to adapt to new circumstances.
I had this discussion with a fellow a long time ago who was so conservative he didn't want
any regulations on pollutants. The Love Canal disaster wsa the topic. He said "no need to do anything,
because humans will adapt - its called evolution."
I answered - "Yes, we might adapt. But you realize that means 999 out of a 1000 of us will
die, and it's called evolution. Sometimes even 1000 out of 1000 die, that's called extinction."
This will be a different adaptation, but very well might be solved by most of
Generally speaking, though, when you see a very consistent trend or pattern over a long time,
your best bet is that the trend will continue, not that it will mysteriously veer off because
now it's happening to white collar jobs instead of blue collar jobs. I'd say the logical fallacy
is to disbelieve that the trend is likely to continue. Technology doesn't invalidate basic
economic theory, in which people manage to find jobs and services to match the level of the population
precisely because there are so
It's the buggy whip story just being retold with a new product. Not anything to get worried
about.
The buggy whip story shows that an entire species which had significant economic value for
thousands of years found that technology had finally reached a point where they weren't needed.
Instead of needing 20 million of them working in our economy in 1920, by 1960 there were only
about 4.5 million. While they were able to take advantage of the previous technological revolutions
and become even more useful because of better technology in the past, most horses could not survive
the invention of the automobile
Your question is incomplete. The correct question to ask is if these people were able to get
hired elsewhere *at the same salary when adjusted for inflation*. To that, the answer is no.
It
hasn't been true on average since the 70's. Sure, some people will find equal or better jobs,
but salaries have been steadily decreasing since the onset of technology. Given a job for less
money or no job, most people will pick the job for less; and that is why we are not seeing a large
change in the unemployment rate.
There is another effect. When the buggy whip manufacturers were put out of business, there
were options for people to switch to and new industries were created. However, if AI gets apply
across an entire economy, there won't be options because there is unemployment in every sector.
And if AI obviates the need for workers, investors in new industries will build them around bots,
so no real increase in employment. That and yer basic truck driver ain't going to be learning
how to program.
Agreed, companies will be designed around using as little human intervention as possible. First
they will use AI, then they will use cheap foreign labor, and only if those two options are completely
impractical will they use domestic labor. Any business plan that depends on more than a small
fraction of domestic labor (think Amazon's 1 minute of human handling per package) is likely to
be considered unable to compete. I hate the buggy whip analogy, because using foreign (cheap)
labor as freely as today w
Maybe the automation is a paradigm shift on par with the introduction of agriculture replacing
the hunter and gatherer way of living? Then, some hunter and gatherer were perhaps also making
a "luddite" arguments: "Nah, there will always be sufficient forrests/wildlife for everyone to
live on. No need to be afraid of the these agriculturites. We have been hunting and gathering
for millenia. That'll never change."
Were those people able to get hired elsewhere? The answer in general was almost certainly
yes.
Actually, the answer is probably no.
Labor force participation
[tradingeconomics.com] rates have fallen steadily since about the
year 2000. Feminism caused the rate to rise from 58% (1963) to 67% (2000). Since then, it has
fallen to 63%. In other words, we've already lost almost half of what we gained from women entering
the workforce en masse. And the rate will only continue to fall in the future.
You must admit that *some* things are different. Conglomeratization may make it difficult to
create new jobs, as smaller businesses have trouble competing with the mammoths. Globalization
may send more jobs offshore until our standard of living has leveled off with the rest of the
world. It's not inconceivable that we'll end up with a much larger number of unemployed people,
with AI being a significant contributing factor. It's not a certainty, but neither is your scenario
of the status quo. Just because it
People need to stop living in a fairy tale land where near full employment is a reality
in the near future. I'll be surprised if labor participation rate of 25-54 year olds is even
50% in 10 years.
Then again, tell me of how companies are going to make money to service the stakeholders when
there are not people around wh ocan buy their highly profitable wares?
Now speaking of fairy tales, that one is much more magical than your full employment one.
This ain't rocket science. Economies are at base, an equation. You have producers on one side,
and consumers on the other. Ideally, they balance out, with extra rewards for the producers. Now
either side can cheat, such as if producers can move productio
Until Fortran was developed, humans used to write code telling the computer what to do. Since
the late 1950s, we've been writing a high-level description, then a computer program writes the
program that actually gets executed.
Nowadays, there's frequently a computer program, such as a browser, which accepts our high-level
description of the task and interprets it before generating more specific instructions for another
piece of software, an api library, which creates more specific instructions for another api
I see plenty of work in reducing student-teacher ratios in education, increasing maintenance
and inspection intervals, transparency reporting on public officials, etc. Now, just convince
the remaining working people that they want to pay for this from their taxes.
I suppose when we
hit 53% unemployed, we might be able to start winning popular elections, if the unemployed are
still allowed to vote then.
At least here in the US, that won't change anything. The unemployed will still happily vote
against anything that smacks of "socialism". It's a religion to us here. People here would rather
shoot themselves (and their family members) in the head than enroll in social services.
Remember, most of the US population is religious, and not only does this involve some "actual"
religion (usually Christianity), it also involves the "anti-socialism" religion. Now remember,
the defining feature of religion is a complete lack rationality, and believing in something with
zero supporting evidence, frequently despite enormous evidence to the contrary (as in the case
of young-earth creationism, something that a huge number of Americans believe in).
SInce this is very very similar to what my partner does, I feel like I'm a little qualified
to speak on the subject at hand.
Yeah, pattern matching should nail this - but pattern matching only works if the patterns are
reasonable/logical/consistent. Yes, I'm a little familiar with advanced pattern matching, filtering,
etc.
Here's the thing: doctors are crappy input sources. At least in the US medical system. And
in our system they are the ones that have to make diagnosis (in most cases). They are
inconsistent.
What automation? 1000 workers in US vs 2000 in Mexico for half the cost of those
1000 is not "automation." Same thing with your hand-assembled smartphone. I'd rather
have it be assembled by robots in the US with 100 human babysitters than hand-built in
China with by 1000 human drones.
I hope their data collection is better than it is in the US. Insurance company's systems can't
talk to the doctors systems. They are stuck with 1980s technology or sneaker net to get information
exchanged. Paper gets lost, forms don't match.
Doctors spend more time with paper than with patients.
Once the paper gets to the insurance company chances are good it doesn't go to the right person
or just gets lost sending the patient back to the beginning of the maze. The more people removed
from the chain the bet
You think this is anything but perfectly planned? Insurance companies prevaricate better than
anyone short of a Federal politician. 'Losing' a claim costs virtually nothing. Mishandling a
claim costs very little. Another form letter asking for more / the same information, ditto.
Computerizing the whole shebang gives yet another layer of potential delay ('the computer is
slow today' is a perennial favorite).
That said, in what strange world is insurance adjudication considered 'white collar'? In the
US a
Japan needs to automate as much as it can and robotize to survive with a workforce growing
old. Japan is facing this reality as well as many countries where labor isn't replaced at a sufficient
rate to keep up with the needs. Older people will need care some countries just cannot deliver
or afford.
Calm down everyone. This is just a continuation of productivity tools for accounting. Among
other things I'm a certified accountant. This is just the next step in automation of accounting
and it's a good thing. We used to do all our ledgers by hand. Now we all use software for that
and believe me you don't want to go back to the way it was.
Very little in accounting is actually
value added activity so it is desirable to automate as much of it as possible. If some people
lost their jobs doing that it's equivalent to how the PC replaced secretaries 30+ years ago. They
were doing a necessary task but one that added little or no value. Most of what accountants do
is just keeping track of what happened in a business and keeping the paperwork flowing where it
needs to go. This is EXACTLY what we should be automating whenever possible.
I'm sure there are going to be a lot folks loudly proclaiming how we are all doomed and that
there won't be any work for anyone left to do. Happens every time there is an advancement in automation
and yet every time they are wrong. Yes some people are going to struggle in the short run. That
happens with every technological advancement. Eventually they find other useful and valuable things
to do and the world moves on. It will be fine.
I'm curious what you think you can do that Watson can't. Accounting is a very rigidly structured
practice. All IBM really needs to do is let Watson sift through the books of a couple hundred
companies and it will easily determine how to best achieve a defined set of objectives for a corporation.
I'm curious what you think you can do that Watson can't.
Seriously? Quite a bit actually. I can handle input streams that Watson can't. I can make tools
Watson couldn't begin to imagine. I can interact with physical objects without vast amounts of
programming. I can deal with humans in a meaningful and human way FAR better than any computer
program. I can pass a Turing test. The number of things I can do that Watson cannot is literally
too numerous to bother counting. Watson is really just an decision support system with a natural
language interface. Ver
Yep! I don't even work in Accounting or Finance, but because I do computer support for that
department and have to get slightly involved in the bill coding side of the process -- I agree
completely.
I'm pretty sure that even if you *could* get a computer to do everything for Accounting automatically,
people would constantly become frustrated with parts of the resulting process -- from reports
requested by management not having the formatting or items desired on them, to inflexibility getting
an item charged
You think the 12$ hr staff at a doctors office code and invoice bills correctly? The blame
goes both ways. Really our ridiculous and convoluted medical system is to blame. Imagine if doctors
billed on a time basis like a lawyer.
When you have people basically implementing a process without much understanding, it is pretty
easy to automatize their jobs away. The only thing Watson is contribution is the translation from
natural language to a more formalized one. No actual intelligence needed.
Computers/automation/robotics have been replacing workers of all stripes including white collar
workers since the ATM was introduced in 1967. Every place I have ever worked has had internal
and external software that replaces white collar workers (where you used to need 10 people now
you need 2).
The reality is that the economy is limited by a scarcity of labor when government doesn't interfere
(the economy is essentially the sum of every worker work multiplied by their efficiency as valued
by the economy i
Turns out it's rather simple, really --- just ban computers. He's going to start by replacing
computers with human couriers for the secure-messaging market, and move outward from there. By
2020 we should have most of the Internet replaced by the (now greatly expanded) Post Office.
At least, as long as banks keep writing the software they do.
My bank's records of my purchases isn't updating today. This is one of the biggest banks in
Canada. Transactions don't update properly over the weekends or holidays. Why? Who knows? Why
has bank software EVER cared about weekends? What do business days matter to computers? And yet
here we are. There's no monkey to turn the crank on a holiday, so I can't confirm my account activity.
Dude. Stop it. I've read 18th C laissez-faire writers (de Gournay) Bastiat, the Austrian School
(Carl Menger, Bohm-Bawerk, von Mises, Hayek), Rothbard, Milton Friedman. Free Market is opposed
to corporatism, You might hate Ayn Rand but she skewered corporatists as much as she did socialists.
You should read some of these people. You'll see that they are opposed to corporatism. Don't get
your information from opponents who create straw men and then, so skillfully, defeat their opponent's
arguments.
Corporatism is the use of government pull to advance your business. The use of law and the
police power of the state to aide your business against anothers. This used to be called "mercantilism."
Free market capitalism is opposed to this; the removal of power of pull.
Read Bastiat, Carl Menger, von Mises, Hayek, Milton Friedman. You'll see them all referring
to the government as an agent which helps one set of businesses over another. Government may give
loans, bailouts, etc... Free market people are against this. Corporatism /= Free Market. Don't only get your information from those who hate individualism and free
markets - read (or in Milton Friedman's case listen) to their arguments. You may disagree with
them but you'll see well regarded individuals who say that
When a business get's government to give it special favors (Soyndra) or to give it tax breaks
or a monopoly this is corporatism. It used to be called mercantilism. In either case free - market
capitalists stand in opposition to it. This is exactly what "laissez-faire" capitalism means:
leave us alone, don't play favorites, stay away.
How do these people participate in a free market without setting up corporations? Have
you ever bought anything from a farmers' market? Have you ever hired a plumber d/b/a himself rather
than working for Plumbers-R-Us? Have you ever bought a used car directly from a private seller?
Do you have a 401k/403b/457/TSP/IRA? Have you ever used eBay? Have you ever traded your labor
for a paycheck (aka "worked") without hiding behind an intermediate shell-corp? The freeness of
a market has nothing to do wit
Okay, so you're just still pissing and moaning over Trump's win and have no actual point. That's
fine, but you should take care not to make it sound too much like you actually have something
meaningful to say.
I'll say something meaningful when you can point out which one of Trump's cabinet made their
wealth on a farmer's market and without being affiliated with a corporation.
No. They don't. But, for the moment, it looks as if Andy Puzder (Sec of Labor) and Mick Mulvaney
(OMB) are fairly good free market people. We'll see. Chief of Staff Reince Priebus has made some
free-market comments. (Again, we'll see.) Sec of Ed looks like she wants to break up an entrenched
bureaucracy - might even work to remove Federal involvement. (Wishful thinking on my part) HUD
- I'm hopeful that Ben Carson was hired to break up this ridiculous bureaucracy. If not, at least
pare it down. Now, if
"Watson" is a marketing term from IBM, covering a lot of standard automation. It isn't the
machine that won at Jeopardy (although that is included in the marketing term, if someone wants
to pay for it). IBM tells managers, "We will have our amazing Watson technology solve this problem
for you." The managers feel happy. Then IBM has some outsourced programmers code up a workflow
app, with recurring annual subscription payments.
It doesn't matter. AI works best when there's a human in the loop, piloting the controls anyway.
What matters to a company is that 1 person + bots can now make the job that previously required
hundreds of white collar workers, for much less salary. What happens to the other workers should
not be a concern of the company managers, according to the modern religious creed - apparently
some magical market hand takes care to solve that problem automatically.
Pretty much. US companies already use claims processing systems that use previous data to evaluate
a current claim and spit out a number. Younger computer literate adjusters just feed the machine
and push a button.
universities downsize not with unlimited loans! (usa only) need retraining you can get an loan
and you may need to go for 2-4 years and (some credits maybe to old and you have to retake classes)
It's not Parkinson's law, it's runaway inequality. The workforce continues to be more and more
productive as it receives an unchanging or decreasing amount of compensation (in absolute terms
- or an ever-decreasing share of the profits in relative terms), while the gains go to the 1%.
Martin Sklar's disaccumultion thesis * is a restatement and reinterpretation of passages in Marx's
Grundrisse that have come to be known as the "fragment on machines." Compare, for example, the following
two key excerpts.
Marx:
...to the degree that large industry develops, the creation of real wealth comes to depend
less on labour time and on the amount of labour employed than on the power of the agencies set
in motion during labour time, whose 'powerful effectiveness' is itself in turn out of all proportion
to the direct labour time spent on their production, but depends rather on the general state of
science and on the progress of technology, or the application of this science to production. ...
Labour no longer appears so much to be included within the production process; rather, the
human being comes to relate more as watchman and regulator to the production process itself. (What
holds for machinery holds likewise for the combination of human activities and the development
of human intercourse.)
Sklar:
In consequence [of the passage from the accumulation phase of capitalism to the "disaccumlation"
phase], and increasingly, human labor (i.e. the exercise of living labor-power) recedes from the
condition of serving as a 'factor' of goods production, and by the same token, the mode of goods-production
progressively undergoes reversion to a condition comparable to a gratuitous 'force of nature':
energy, harnessed and directed through technically sophisticated machinery, produces goods, as
trees produce fruit, without the involvement of, or need for, human labor-time in the immediate
production process itself. Living labor-power in goods-production devolves upon the quantitatively
declining role of watching, regulating, and superintending.
The main difference between the two arguments is that for Marx, the growing contradiction between
the forces of production and the social relations produce "the material conditions to blow this
foundation sky-high." For Sklar, with the benefit of another century of observation, disaccumulation
appears as simply another phase in the evolution of capitalism -- albeit with revolutionary potential.
But also with reactionary potential in that the reduced dependence on labor power also suggests
a reduced vulnerability to the withholding of labor power.
Posted by BeauHD on Tuesday December
06, 2016 @07:05PM from the muscle-memory dept.
An anonymous reader quotes a report from Phys.Org:
Scientists have
developed a mind-controlled robotic hand
that allows people with certain types of spinal injuries
to perform everyday tasks such as using a fork or drinking from a cup. The low-cost device was tested
in Spain on six people with quadriplegia affecting their ability to grasp or manipulate objects.
By wearing a cap that measures electric brain activity and eye movement the users were able to send
signals to a tablet computer that controlled the glove-like device attached to their hand. Participants
in the small-scale study were able to perform daily activities better with the robotic hand than
without, according to results
published Tuesday in
the journal Science Robotics .
It took participants just 10 minutes to learn how to use the system
before they were able to carry out tasks such as picking up potato chips or signing a document. According
to Surjo R. Soekadar, a neuroscientist at the University Hospital Tuebingen in Germany and lead author
of the study, participants represented typical people with high spinal cord injuries, meaning they
were able to move their shoulders but not their fingers. There were some limitations to the system,
though. Users had to have sufficient function in their shoulder and arm to reach out with the robotic
hand. And mounting the system required another person's help.
An autonomous
shuttle from Auro Robotics is
picking up and dropping off students, faculty, and visitors
at the Santa Clara University Campus
seven days a week. It doesn't go fast, but it has to watch out for pedestrians, skateboarders, bicyclists,
and bold squirrels (engineers added a special squirrel lidar on the bumper). An Auro engineer rides
along at this point to keep the university happy, but soon will be replaced by a big red emergency
stop button (think Staples Easy button). If you want a test drive, just look for a "shuttle stop"
sign (there's one in front of the parking garage) and climb on, it doesn't ask for university ID.
More directly to the heart of American fast-food cuisine, Momentum Machines, a restaurant concept
with a robot that can supposedly
flip hundreds of burgers an hour
, applied for a building permit in San Francisco and started
listing job openings this January, reported Eater. Then there's Eatsa, the automat restaurant where
no human interaction is necessary, which has locations
popping up across California .
(businessinsider.co.id)
83 Posted by EditorDavid on Sunday December 11, 2016 @09:34PM from the damn-it-Jim-I'm-a-doctor-not-a-supercomputer
dept.
"Supercomputing has another use," writes Slashdot reader
rmdingler , sharing a story that
quotes David Kenny, the General Manager of IBM Watson:
"There's a 60-year-old woman in Tokyo. She was at the University of Tokyo. She had been diagnosed
with leukemia six years ago. She was living, but not healthy. So the University of Tokyo ran
her genomic sequence through Watson and
it was able to ascertain that they were off by one thing . Actually, she had two strains
of leukemia. They did treat her and she is healthy."
"That's one example. Statistically, we're seeing that about one third of the time, Watson is
proposing an additional diagnosis."
"... Skype Translator, available in nine languages, uses artificial intelligence (AI) techniques such as deep-learning to train artificial neural networks and convert spoken chats in almost real time. The company says the app improves as it listens to more conversations. ..."
Posted by msmash on Monday December 12, 2016 @11:05AM from the worthwhile dept.
Microsoft has added the ability to use Skype Translator on calls to mobiles and landlines to its
latest Skype Preview app. From a report on ZDNet: Up until now, Skype Translator was available
to individuals making Skype-to-Skype calls. The new announcement of the expansion of Skype Translator
to mobiles and landlines
makes Skype Translator more widely available .
To test drive this, users need to be members
of the Windows Insider Program. They need to install the latest version of Skype Preview on their
Windows 10 PCs and to have Skype Credits or a subscription.
Skype Translator, available in
nine languages, uses artificial intelligence (AI) techniques such as deep-learning to train artificial
neural networks and convert spoken chats in almost real time. The company says the app improves
as it listens to more conversations.
Fund
more research in robotics and artificial intelligence in order for the U.S. to
maintain its leadership in the global technology industry. The report calls on
the government to steer that research to support a diverse workforce and to
focus on combating algorithmic bias in AI.
Invest in and increase STEM education for youth and job retraining for
adults in technology-related fields. That means offering computer science
education for all K-12 students, as well as expanding national workforce
retraining by investing six times the current amount spent to keep American
workers competitive in a global economy.
Modernize and strengthen the federal social safety net, including public
health care, unemployment insurance, welfare and food stamps. The report also
calls for increasing the minimum wage, paying workers overtime and and
strengthening unions and worker bargaining power.
The report says the government, meaning the the incoming Trump administration,
will have to forge ahead with new policies and grapple with the complexities of
existing social services to protect the millions of Americans who face
displacement by advances in automation, robotics and artificial intelligence.
The report also calls on the government to keep a close eye on fostering
competition in the AI industry, since the companies with the most data will be
able to create the most advanced products, effectively preventing new startups
from having a chance to even compete.
Back in April, Stanford University professor
Oussama Khatib led
a team of researchers on an underwater archaeological expedition, 30 kilometers off the southern
coast of France, to La Lune , King Louis XIV's sunken 17th-century flagship. Rather than
dive to the site of the wreck 100 meters below the surface, which is a very bad idea for almost
everyone, Khatib's team
brought along a custom-made humanoid submarine robot called Ocean One . In this month's issue
of
IEEE Robotics and Automation Magazine , the Stanford researchers describe in detail
how they designed and built the robot , a hybrid between a humanoid and an underwater remotely
operated vehicle (ROV), and also how they managed to send it down to the resting place of
La Lune , where it used its three-fingered hands to retrieve a vase. Most ocean-ready ROVs
are boxy little submarines that might have an arm on them if you're lucky, but they're not really
designed for the kind of fine manipulation that underwater archaeology demands. You could send
down a human diver instead, but once you get past about 40 meters, things start to get both complicated
and dangerous. Ocean One's humanoid design means that it's easy and intuitive for a human to remotely
perform delicate archeological tasks through a telepresence interface.
schwit1 notes: "Ocean One is the best name they could come up with?"
Posted by msmash on Friday November 25, 2016 @12:10AM from the interesting-things dept.
BBC has a report today in which, citing several financial institutions and analysts, it claims that
in the not-too-distant future, our fields could be tilled, sown, tended and harvested entirely by
fleets of co-operating autonomous machines by land and air. An excerpt from the article:
Driverless
tractors that can follow pre-programmed routes are already being deployed at large farms around the
world. Drones are buzzing over fields assessing crop health and soil conditions. Ground sensors are
monitoring the amount of water and nutrients in the soil, triggering irrigation and fertilizer applications.
And in Japan, the world's first entirely automated lettuce farm is due for launch next year.
The future of farming is automated
. The World Bank says we'll need to produce 50% more food by 2050 if the global population continues
to rise at its current pace. But the effects of climate change could see crop yields falling by more
than a quarter. So autonomous tractors, ground-based sensors, flying drones and enclosed hydroponic
farms could all help farmers produce more food, more sustainably at lower cost.
The truck "will travel in regular traffic, and a driver in the truck will be positioned to
intervene should anything go awry, Department of Transportation spokesman Matt Bruning said Friday,
adding that 'safety is obviously No. 1.'"
Ohio sees this route as "a corridor where new technologies can be safely tested in real-life traffic,
aided by a fiber-optic cable network and sensor systems slated for installation next year" -- although
next week the truck will also start driving on the Ohio Turnpike.
Posted by BeauHD on Friday December 02,
2016 @05:00PM from the be-afraid-very-afraid dept.
An anonymous reader quotes a report from Business Insider:
In
a column in The Guardian , the world-famous physicist wrote that "the automation of factories
has already decimated jobs in traditional manufacturing, and the
rise of artificial intelligence is likely to extend this job destruction deep into the middle
classes , with only the most caring, creative or supervisory roles remaining." He adds his
voice to a growing chorus of experts concerned about the effects that technology will have on
workforce in the coming years and decades. The fear is that while artificial intelligence will
bring radical increases in efficiency in industry, for ordinary people this will translate into
unemployment and uncertainty, as their human jobs are replaced by machines.
Automation will, "in turn will accelerate the already widening economic inequality around the
world," Hawking wrote. "The internet and the platforms that it makes possible allow very small
groups of individuals to make enormous profits while employing very few people. This is inevitable,
it is progress, but it is also socially destructive." He frames this economic anxiety as a reason
for the rise in right-wing, populist politics in the West: "We are living in a world of widening,
not diminishing, financial inequality, in which many people can see not just their standard of
living, but their ability to earn a living at all, disappearing. It is no wonder then that they
are searching for a new deal, which Trump and Brexit might have appeared to represent." Combined
with other issues -- overpopulation, climate change, disease -- we are, Hawking warns ominously,
at "the most dangerous moment in the development of humanity." Humanity must come together if
we are to overcome these challenges, he says.
"... The firm says that 44 percent of the CEOs surveyed agreed that robotics, automation and AI would reshape the future of many work places by making people "largely irrelevant." ..."
Posted by msmash on Monday December 05, 2016 @02:20PM from the shape-of-things-to-come
dept.
An anonymous reader shares a report on BetaNews:
Although artificial intelligence (AI),
robotics and other emerging technologies may reshape the world as we know it, a new global study
has revealed that the
many
CEOs now value technology over people when it comes to the future of their businesses . The study
was conducted by the Los Angeles-based management consultant firm Korn Ferry that interviewed 800
business leaders across a variety of multi-million and multi-billion dollar global organizations.
The firm says that 44 percent of the CEOs surveyed agreed that robotics, automation and AI would
reshape the future of many work places by making people "largely irrelevant."
The global managing
director of solutions at Korn Ferry Jean-Marc Laouchez explains why many CEOs have adopted this controversial
mindset, saying:
"Leaders may be facing what experts call a tangibility bias. Facing uncertainty,
they are putting priority in their thinking, planning and execution on the tangible -- what they
can see, touch and measure, such as technology instruments."
Posted by BeauHD on Tuesday
December 06, 2016 @10:30PM from the what-to-expect dept.
An anonymous reader quotes a report from
The Verge:
Microsoft
polled 17 women working in its research organization about the technology advances they expect to
see in 2017 , as well as a decade later in 2027. The researchers' predictions touch on natural
language processing, machine learning, agricultural software, and virtual reality, among other topics.
For virtual reality,
Mar Gonzalez Franco
, a researcher in Microsoft's Redmond lab, believes body tracking will improve
next year, and then over the next decade we'll have "rich multi-sensorial experiences that will be
capable of producing hallucinations which blend or alter perceives reality."
Haptic devices will
simulate touch to further enhance the sensory experience. Meanwhile,
Susan Dumais
, a scientist and deputy managing director at the Redmond lab, believes deep learning
will help improve web search results next year.
In 2027, however, the search box will disappear,
she says.
It'll be replaced by search that's more "ubiquitous, embedded, and contextually sensitive."
She says we're already seeing some of this in voice-controlled searches through mobile and smart
home devices.
We might eventually be able to look things up with either sound, images, or video.
Plus, our searches will respond to "current location, content, entities, and activities" without
us explicitly mentioning them, she says.
Of course, it's worth noting that Microsoft has been losing
the search box war to Google, so it isn't surprising that the company thinks search will die. With
global warming as a looming threat,
Asta Roseway
, principal research designer, says by 2027 famers will use AI to maintain healthy
crop yields, even with "climate change, drought, and disaster."
Low-energy farming solutions, like
vertical farming and aquaponics, will also be essential to keeping the food supply high, she says. You can view all 17 predictions
here
"... Efforts which led to impoverishment of lower 80% the USA population with a large part of the US population living in a third world country. This "third world country" includes Wal-Mart and other retail employees, those who have McJobs in food sector, contractors, especially such as Uber "contractors", Amazon packers. This is a real third world country within the USA and probably 50% population living in it. ..."
"... While conversion of electricity supply from coal to wind and solar was more or less successful (much less then optimists claim, because it requires building of buffer gas powered plants and East-West high voltage transmission lines), the scarcity of oil is probably within the lifespan of boomers. Let's say within the next 20 years. That spells deep trouble to economic growth as we know it, even with all those machinations and number racket that now is called GDP (gambling now is a part of GDP). And in worst case might spell troubles to capitalism as social system, to say nothing about neoliberalism and neoliberal globalization. The latter (as well as dollar hegemony) is under considerable stress even now. But here "doomers" were wrong so often in the past, that there might be chance that this is not inevitable. ..."
"... Shale gas production in the USA is unsustainable even more then shale oil production. So the question is not if it declines, but when. The future decline (might be even Seneca Cliff decline) is beyond reasonable doubt. ..."
"What is good for wall st. is good for America". The remains of the late 19th century anti
trust/regulation momentum are democrat farmer labor wing in Minnesota, if it still exists. An
example: how farmers organized to keep railroads in their place. Today populists are called deplorable,
before they ever get going.
And US' "libruls" are corporatist war mongers.
Used to be the deplorable would be the libruls!
Division!
likbez -> pgl...
I browsed it and see more of less typical pro-neoliberal sentiments, despite some critique
of neoliberalism at the end.
This guy does not understand history and does not want to understand. He propagates or invents
historic myths. One thing that he really does not understand is how WWI and WWII propelled the
USA at the expense of Europe. He also does not understand why New Deal was adopted and why the
existence of the USSR was the key to "reasonable" (as in "not self-destructive" ) behaviour of
the US elite till late 70th. And how promptly the US elite changed to self-destructive habits
after 1991. In a way he is a preacher not a scientist. So is probably not second rate, but third
rate thinker in this area.
While Trump_vs_deep_state (aka "bastard neoliberalism") might not be an answer to challenges the USA is
facing, it is definitely a sign that "this time is different" and at least part of the US elite
realized that it is too dangerous to kick the can down the road. That's why Bush and Clinton political
clans were sidelined this time.
There are powerful factors that make the US economic position somewhat fragile and while Trump
is a very questionable answer to the challenges the USA society faces, unlike Hillary he might
be more reasonable in his foreign policy abandoning efforts to expand global neoliberal empire
led by the USA.
Efforts which led to impoverishment of lower 80% the USA population with a large part of
the US population living in a third world country. This "third world country" includes Wal-Mart
and other retail employees, those who have McJobs in food sector, contractors, especially such
as Uber "contractors", Amazon packers. This is a real third world country within the USA and probably
50% population living in it.
Add to this the decline of the US infrastructure due to overstretch of imperial building efforts
(which reminds British empire troubles).
I see several factors that IMHO make the current situation dangerous and unsustainable, Trump
or no Trump:
1. Rapid growth of population. The US population doubled in less them 70 years. Currently
at 318 million, the USA is the third most populous country on earth. That spells troubles for
democracy and ecology, to name just two. That might also catalyze separatists movements with two
already present (Alaska and Texas).
2. Plato oil. While conversion of electricity supply from coal to wind and solar
was more or less successful (much less then optimists claim, because it requires building of buffer
gas powered plants and East-West high voltage transmission lines), the scarcity of oil is probably
within the lifespan of boomers. Let's say within the next 20 years. That spells deep trouble to
economic growth as we know it, even with all those machinations and number racket that now is
called GDP (gambling now is a part of GDP). And in worst case might spell troubles to capitalism
as social system, to say nothing about neoliberalism and neoliberal globalization. The latter
(as well as dollar hegemony) is under considerable stress even now. But here "doomers" were wrong
so often in the past, that there might be chance that this is not inevitable.
3. Shale gas production in the USA is unsustainable even more then shale oil production.
So the question is not if it declines, but when. The future decline (might be even Seneca
Cliff decline) is beyond reasonable doubt.
4. Growth of automation endangers the remaining jobs, even jobs in service sector .
Cashiers and waiters are now on the firing line. Wall Mart, Shop Rite, etc, are already using
automatic cashiers machines in some stores. Wall-Mart also uses automatic machines in back office
eliminating staff in "cash office".
Waiters might be more difficult task but orders and checkouts are computerized in many restaurants.
So the function is reduced to bringing food. So much for the last refuge of recent college graduates.
The successes in speech recognition are such that Microsoft now provides on the fly translation
in Skype. There are also instances of successful use of computer in medical diagnostics.
https://en.wikipedia.org/wiki/Computer-aided_diagnosis
IT will continue to be outsourced as profits are way too big for anything to stop this trend.
"... Companies can now test self-driving cars on Michigan public roads without a driver or steering wheel under new laws that could push the state to the forefront of autonomous vehicle development. ..."
Posted by msmash on Friday December 09, 2016 @01:00PM from the it's-coming dept.
Companies
can now test self-driving cars on Michigan public roads without a driver or steering wheel under
new laws that could push the state to the forefront of autonomous vehicle development.
From a report
on ABC:
The package of bills signed into law Friday comes with few specific state regulations
and leaves many decisions up to automakers and companies like Google and Uber. It also allows automakers
and tech companies to run autonomous taxi services and
permits test parades of self-driving tractor-trailers as long as humans are in each truck
. And
they allow the sale of self-driving vehicles to the public once they are tested and certified, according
to the state. The bills allow testing without burdensome regulations so the industry can move forward
with potential life-saving technology, said Gov. Rick Snyder, who was to sign the bills. "It makes
Michigan a place where particularly for the auto industry it's a good place to do work," he said.
DeepMind, which was acquired by Google for $400 million in 2014, announced
on Monday that it is open-sourcing its "Lab" from this week onwards so that others can try and make
advances in the notoriously complex field of AI.
The company says that the DeepMind Lab, which it
has been using internally for some time, is a 3D game-like platform tailored for agent-based AI research.
[...]
The DeepMind Lab aims to combine several different AI research areas into one environment.
Researchers will be able to test their AI agent's abilities on navigation, memory, and 3D vision,
while determining how good they are at planning and strategy.
(threatpost.com)
148
Posted by EditorDavid
on Saturday December 17, 2016 @07:34PM
from the
does-code-reuse-endanger-secure-software-development
dept.
msm1267
quotes ThreatPost:
The
amount of insecure software tied to
reused third-party libraries
and lingering in applications long after
patches have been deployed is staggering. It's a habitual problem perpetuated
by developers failing to vet third-party code for vulnerabilities, and some
repositories taking a hands-off approach with the code they host. This scenario
allows attackers to target one overlooked component flaw used in millions of
applications instead of focusing on a single application security
vulnerability.
The real-world consequences have been demonstrated in the past few years with
the Heartbleed vulnerability in OpenSSL
,
Shellshock in GNU Bash
, and a deserialization vulnerability exploited in
a recent high-profile attack against the San Francisco Municipal Transportation
Agency
. These are three instances where developers reuse libraries and
frameworks that contain unpatched flaws in production applications... According
to security experts, the problem is two-fold. On one hand, developers use
reliable code that at a later date is found to have a vulnerability. Second,
insecure code is used by a developer who doesn't exercise due diligence on the
software libraries used in their project.
That seems like a one-sided take, so I'm curious what Slashdot readers think.
Does code reuse endanger secure software development?
(daftcode.pl)
332
Posted by EditorDavid
on Sunday November 27, 2016 @11:30PM
from the
TDD-vs-HDD
dept.
marekkirejczyk
, the VP of
Engineering at development shop Daftcode, shares a warning about hype-driven
development:
Someone reads a blog post, it's trending on Twitter, and we
just came back from a conference where there was a great talk about it. Soon
after, the team starts using this new shiny technology (or software
architecture design paradigm), but
instead of going faster (as promised) and building a better product, they get
into trouble
. They slow down, get demotivated, have problems delivering the
next working version to production.
Describing behind-schedule teams that "just need a few more days to sort it all
out," he blames all the hype surrounding React.js, microservices, NoSQL, and
that "
Test-Driven
Development Is Dead
" blog post by Ruby on Rails creator David Heinemeier
Hansson. ("The list goes on and on... The root of all evil seems to be social
media.")
Does all this sound familiar to any Slashdot readers? Has your team ever
succumbed to hype-driven development?
"... "Google was the rich kid who, after having discovered he wasn't invited to the party, built his own party in retaliation," Whittaker wrote. "The fact that no one came to Google's party became the elephant in the room." ..."
"... Isn't it inevitable that Google will end up like Microsoft. A brain-dead dinosaur employing sycophantic middle class bores, who are simply working towards a safe haven of retirement. In the end Google will be passed by. It's not a design-led innovator like Apple: it's a boring, grey utilitarian, Soviet-like beast. Google Apps are cheap - but very nasty - Gmail is a terrible UI - and great designers will never work for this anti-design/pro-algorithms empire. ..."
"... All of Google's products are TERRIBLE except for Gmail, and even that is inferior to Outlook on the web now. ..."
"... I used Google Apps for years, and Google just doesn't listen to customers. The engineers that ran the company needed some corporate intervention. I just think Larry Page tried to turn Google into a different company, rather than just focusing the great ideas into actually great products. ..."
"... It seems the tech titans all have this pendulum thing going on. Google appears to be beginning its swing in the "evil" direction. ..."
"... You claim old Google empowered intelligent people to be innovative, with the belief their creations would prove viable in the marketplace. You then go on to name Gmail and Chrome as the accomplishments of that endeavour. Are you ****** serious? ..."
"... When you arrived at Google it had already turned the internet into a giant spamsense depository with the majority of screen real estate consumed by Google's ads. The downhill spiral did not begin with Google+, but it may end there. On a lighter note, you are now free. Launch a start-up and fill the gaping hole which will be left by the fall of the former giant. ..."
"... Great post. Appreciate the insights the warning about what happens when bottom-up entrepreneurship loses out to top-down corporate dictums. ..."
"... The ability to actually consume shared content in an efficient and productive manner is still as broken as ever. They never addressed the issue in Buzz and still haven't with G+ despite people ranting at them for this functionality forever. ..."
"... Sounds like Google have stopped focusing on what problem they're solving and moving onto trying to influence consumer behaviour - always a much more difficult trick to pull off. Great article - well done for sharing in such a humble and ethical manner. Best of luck for the future. ..."
Whittaker, who joined Google in 2009 and left last month, described a corporate culture clearly
divided into two eras: "Before Google+," and "After."
"After" is pretty terrible, in his view.
Google (GOOG,
Fortune 500) once gave its engineers the time and resources to be creative. That experimental
approach yielded several home-run hits like Chrome and Gmail. But Google fell behind in one key area:
competing with Facebook.
That turned into corporate priority No. 1 when Larry Page took over as the company's CEO. "Social"
became Google's battle cry, and anything that didn't support Google+ was viewed as a distraction.
"Suddenly, 20% meant half-assed," wrote Whittaker, referring to Google's famous policy of letting
employees spend a fifth of their time on projects other than their core job. "The trappings of entrepreneurship
were dismantled."
Whittaker is not the first ex-Googler to express that line of criticism. Several high-level employees
have left after complaining that the "start-up spirit" of Google has been replaced by a more mature
but staid culture focused on the bottom line.
The interesting thing about Whittaker's take is that it was posted not on his personal blog, but
on an official blog of Microsoft (MSFT,
Fortune 500), Google's arch nemesis.
Spokesmen from Microsoft and Google declined to comment.
The battle between Microsoft and Google has heated up recently, as the Federal Trade Commission
and the European Commission begin to investigate Google for potential antitrust violations. Microsoft,
with its Bing search engine, has doubled its share of the search market since its June 2010 founding,
but has been unsuccessful at taking market share away from Google.
Microsoft is increasingly willing to call out Google for what it sees as illicit behavior. A year
ago, the software company released a long list of gripes about Google's
monopolistic actions, and last month it said Google was
violating Internet Explorer users' privacy.
Despite his misgivings about what Google cast aside to make Google+ a reality, Whittaker thinks
that the social network was worth a shot. If it had worked -- if Google had dramatically changed
the social Web for the better -- it would have been a heroic gamble.
But it didn't. It's too early to write Google+ off, but the site is developing a reputation as
a ghost town. Google says
90 million people have signed up, but analysts and anecdotal evidence show that fairly few have
turned into heavy users.
"Google was the rich kid who, after having discovered he wasn't invited to the party, built
his own party in retaliation," Whittaker wrote. "The fact that no one came to Google's party became
the elephant in the room."
Ian Smith:
Isn't it inevitable that Google will end up like Microsoft. A brain-dead dinosaur employing
sycophantic middle class bores, who are simply working towards a safe haven of retirement. In
the end Google will be passed by. It's not a design-led innovator like Apple: it's a boring, grey
utilitarian, Soviet-like beast. Google Apps are cheap - but very nasty - Gmail is a terrible UI
- and great designers will never work for this anti-design/pro-algorithms empire.
Steve
I have to be honest with you. All of Google's products are TERRIBLE except for Gmail, and
even that is inferior to Outlook on the web now.
I used Google Apps for years, and Google just doesn't listen to customers. The engineers
that ran the company needed some corporate intervention. I just think Larry Page tried to turn
Google into a different company, rather than just focusing the great ideas into actually great
products.
Matt:
It seems the tech titans all have this pendulum thing going on. Google appears to be beginning
its swing in the "evil" direction. Apple seems like they're nearing the peak of "evil".
And Microsoft seems like they're back in the middle, trying to swing up to the "good"
side. So, if you look at it from that perspective, Microsoft is the obvious choice.
Good luck!
VVR:
The stark truth in this insightful piece is the stuff you have not written..
Atleast you had a choice in leaving google. But we as users don't.
I have years of email in Gmail and docs and youtube etc. I can't switch.
"Creepy" is not the word that comes to mind when Ads for Sauna, online textbooks, etc
suddenly begin to track you, no matter which website you visit.
You know you have lost when this happens..
David:
A fascinating insight, I think this reflects what a lot of people are seeing of Google from
the outside. It seems everybody but Page can see that Google+ is - whilst technically brilliant
- totally superfluous; your daughter is on the money. Also apparent from the outside is the desperation
that surrounds Google+ - Page needs to face facts, hold his hands up and walk away from Social
before they loose more staff like you, more users and all the magic that made Google so great.
Best of luck with your new career at Microsoft, I hope they foster and encourage you as the
Google of old did.
Raymond Traylor:
I understand Facebook is a threat to Google search but beating Facebook at their core competency
was doomed to fail. Just like Bing to Google. I was so disappointed in Google following Facebook's
evil ways of wanting to know everything about me I've stopped using their services one at a time,
starting with Android.
I am willing to pay for a lot of Google's free service to avoid advertising and harvesting
my private data.
root
You claim old Google empowered intelligent people to be innovative, with the belief their
creations would prove viable in the marketplace. You then go on to name Gmail and Chrome as the
accomplishments of that endeavour. Are you ****** serious?
Re-branding web based email is no more innovative than purchasing users for your social networking
site, like Facebook did. Same for Chrome, or would you argue Google acquiring VOIP companies to
then provide a mediocre service called Google Voice was also innovative?
When you arrived at Google it had already turned the internet into a giant spamsense depository
with the majority of screen real estate consumed by Google's ads. The downhill spiral did not
begin with Google+, but it may end there. On a lighter note, you are now free. Launch a start-up
and fill the gaping hole which will be left by the fall of the former giant.
RBLevin:
Great post. Appreciate the insights the warning about what happens when bottom-up entrepreneurship
loses out to top-down corporate dictums.
Re: sharing, while I agree sharing isn't broken (heck, it worked when all we had was email),
it certainly needs more improvement. I can't stand Facebook. Hate the UI, don't care for the culture.
Twitter is too noisy and, also, the UI sucks. I'm one of those who actually thinks Google+ got
21st century BBSing right.
But if that's at the cost of everything else that made Google great, then it's a high price
to pay.
BTW, you can say a lot of these same things about similar moves Microsoft has made over the
years, where the top brass decided they knew better, and screwed over developers and their investments
in mountains of code.
So, whether it happens in an HR context or a customer context, it still sucks as a practice.
bound2run:
I have made a concerted effort to move away from Google products after their recent March 1st
privacy policy change. I must say the Bing is working just fine for me. Gmail will be a bit tougher
but I am making strides. Now I just need to dump my Android phone and I will be "creepy-free"
... for the time being.
Phil Ashman:
The ability to actually consume shared content in an efficient and productive manner is
still as broken as ever. They never addressed the issue in Buzz and still haven't with G+ despite
people ranting at them for this functionality forever.
Funny that I should read your post today as I wrote the following comment on another persons
post a couple days back over Vic's recent interview where someone brought up the lack of a G+
API:
"But if it were a social network.......then they are doing a pretty piss poor job of managing
the G+ interface and productive consumption of the stream. It would be nice if there was at least
an API so some 3rd party clients could assist with the filtering of the noise, but in reality
the issue is in the distribution of the stream. What really burns me is that it wouldn't be that
hard for them to create something like subscribable circles.
Unfortunately the reality is that they just don't care about whether the G+ stream is productive
for you at the moment as their primary concern isn't for you to productively share and discuss
your interests with the world, but to simply provide a way for you to tell Google what you like
so they can target you with advertising. As a result, the social part of Google+ really isn't
anything to shout about at the moment."
You've just confirmed my fear about how the company's focus has changed.
Alice Wonder:
Thanks for this. I love many of the things Google has done. Summer of code, WebM, Google Earth,
free web fonts, etc.
I really was disappointed with Google+. I waited for an invite, and when I finally got one,
I started to use it. Then the google main search page started to include google+ notifications,
and the JS crashed my browser. Repeatedly. I had to clear my cache and delete my cookies just
so google wouln't know it was me and crash search with a notification. They fixed that issue quickly
but I did not understand why they would risk their flagship product (search) to promote google
plus. The search page really should be a simple form.
And google plus not allowing aliases? Do I want a company that is tracking everything I do
centrally to have my real name with that tracking? No. Hence I do not use google+ anymore, and
am switching to a different search engine and doing as little as I can with google.
I really don't like to dislike google because of all they have done that was cool, it is really
sad for me to see this happening.
Mike Whitehead
Sounds like Google have stopped focusing on what problem they're solving and moving onto
trying to influence consumer behaviour - always a much more difficult trick to pull off. Great
article - well done for sharing in such a humble and ethical manner. Best of luck for the future.
jmacdonald 14 Mar 2012 4:07 AM great write-up
personally i think that google and facebook have misread the sociological trend against the
toleration of adverts, to such an extent that if indeed google are following the 'facebook know
everything and we do too' route, i suspect both companies may enter into issues as the advertising
CPMs fall and we're left with us wretched consumers who find ways around experiences that we don't
want
more on this stuff here: www.jonathanmacdonald.com
and here: www.jonathanmacdonald.com
for anyone that cares about that kinda angle
Mahboob Ihsan:
Google products are useful but probably they could have done more to improve the GUI, Standardization
and Usability. You can continue to earn business in short term enjoying your strategic advantage
as long as you don't have competitors. But as soon as you have just one competitor offering quality
products at same cost, your strategic advantage is gone and you have to compete through technology,
cost and quality. Google has been spreading its business wings to so many areas, probably with
the single point focus of short term business gains. Google should have learnt from Apple that
your every new offering should be better (in user's eye) than the previous one.
Victor Ramirez:
Thanks for the thoughtful blog post. Anybody who has objectively observed Google's behavior
and activity over the past few years has known that Google is going in this direction. I think
that people have to recognize that Google, while very technically smart, is an advertising company
first and foremost. Their motto says the right things about being good and organizing the world's
information, but we all know what Google is honestly interested in. The thing that Google is searching
for, more than almost anything else, is about getting more data about people so they can get people
better ads they'll be more likely to click on so they make more money. Right now, Google is facing
what might be considered an existential threat from Facebook because they are the company that
is best able to get social data right now. Facebook is getting so much social data that odds are
that they're long-term vision is to some point seriously competing in search using this social
data that they have. Between Facebook's huge user-base and momentum amongst businesses (just look
at how many Super Bowl ads featured Facebook pages being promoted for instance, look at the sheer
number of companies listed at www.buyfacebookfansreviews.com that do nothing other than promote
Facebook business pages, and look at the biggest factor out there - the fact that Facebook's IPO
is set to dominate 2012) I think that Facebook has the first legitimate shot of creating a combination
of quality results and user experience to actually challenge Google's dominance, and that's pretty
exciting to watch. The fact that Google is working on Google+ so much and making that such a centerpiece
of their efforts only goes to illustrate how critical this all is and how seriously they take
this challenge from Facebook into their core business. I think Facebook eventually enters the
search market and really disrupts it and it will be interesting to see how Google eventually acts
from a position of weakness.
Keith Watanabe:
they're just like any company that gets big. you end up losing visibility into things, believe
that you require the middle management layer to coordinate, then start getting into the battlegrounds
of turf wars because the people hired have hidden agendas and start bringing in their army of
yes men to take control as they attempt to climb up the corporate ladder. however, the large war
chest accumulated and the dominance in a market make such a company believe in their own invulnerability.
but that's when you're the most vulnerable because you get sloppy, forget to stop and see the
small things that slip through the cracks, forget your roots and lose your way and soul. humility
is really your only constant savior.
btw, more than likely Facebook will become the same way. And any other companies who grow big.
People tend to forget about the days they were struggling and start focusing on why they are so
great. You lose that hunger, that desire to do better because you don't have to worry about eating
pinches of salt on a few nibbles of rice. This is how civilization just is. If you want to move
beyond that, humans need to change this structure of massive growth -> vanity -> decadence
-> back to poverty.
Anon:
This perceived shift of focus happens at every company when you go from being an idealistic
student to becoming an adult that has to pay the bills. When you reach such a large scale
with so much at stake, it is easy to stop innovating. It is easy to get a mix of people who don't
share the same vision when you have to hire on a lot of staff. Stock prices put an emphasis on
perpetual monetization. Let's keep in mind that Facebook only recently IPO'd and in the debate
for personal privacy, all the players are potentially "evil" and none of them are being held to
account by any public policy.
The shutdown of Google Labs was a sad day. Later the shutdown of Google Health I thought was
also sad as it was an example of a free service already in existence, akin to what Ontario has
wasted over $1 billion on for E-Health. Surely these closures are a sign that the intellectual
capital in the founders has been exhausted. They took their core competencies to the maximum level
quickly, which means all the organic growth in those areas is mostly already realized.
There needs to be some torch passing or greater empowerment in the lower ranks when things
like this happen. Take a look at RIM. Take a look at many other workplaces. It isn't an isolated
incident. There are constantly pressures between where you think your business should go, where
investors tell you to go, and where the industry itself is actually headed. This guy is apparently
very troubled that his name is attached to G+ development and he is trying to distance himself
from his own failure. Probably the absence of Google Labs puts a particular emphasis on the failure
of G+ as one of the only new service projects to be delivered recently.
After so much time any company realizes that new ideas can only really come with new people
or from outside influences. As an attempt to grow their business services via advertising, the
idea that they needed to compete with Facebook to continue to grow wasn't entirely wrong. It was
just poorly executed, too late, and at the expense of potentially focusing their efforts on doing
something else under Google Labs that would have been more known as from them (Android was an
acquisition, not organically grown internally). There is no revolution yet, because Facebook and
Google have not replaced any of each others services with a better alternative
The complaints in the final paragraph of the blog regarding privacy are all complaints about
how much Google wants to be Facebook. Thing is that Google+ just like all the aforementioned
services are opt-in services with a clear ToS declared when you do so, even if you already have
a Google account for other services. The transparency of their privacy policy is on par
if not better than most other competing service providers. The only time it draws criticism is
when some changes have been made to say that if you use multiple services, they may have access
to the same pool of information internally. It's a contract and it was forced to be acknowledged
when it changed. When advertising does happen it is much more obvious to me that it is advertising
via a Google service, than when Facebook decides to tell me who likes what. Not to give either
the green light here; but the evolution is one of integrating your network into the suggestions,
and again, it isn't isolated to any one agency.
One way to raise and enforce objections to potential mishandling of information is to develop
a blanket minimum-requirement on privacy policy to apply to all businesses, regarding the handling
of customer information. We are blind if we think Google+ and Facebook are the only businesses
using data in these ways. This blanket minimum requirement could be voluntarily adopted via 3rd
party certification, or it could be government enforced; but the point is that someone other than
the business itself would formulate it, and it must be openly available to debate and public scrutiny/revision.
It is a sort of "User License Agreement" for information about us. If James Whittaker left to
partake in something along these lines, it sure would make his blog entry more credible, unless
Microsoft is focused so much more greatly on innovation than the profit motive.
It is also important for customers and the general public not to get locked into any
kind of brand loyalty. One problem is Facebook is a closed proprietary system with no
way to forward or export the data contained within it to any comparable system. Google is a mish-mash
of some open and some closed systems. In order for us as customers to be able to voice our opinions
in a way that such service providers would hear, we must be provided alternatives and service
portability.
As an example of changing service providers, there has been an exodus of business customers
away from using Google Maps as they began charging money to businesses that want to use the data
to develop on top of it. I think that this is just the reality of a situation when you have operating
costs for a service that you need to recoup; but there is a royalty-free alternative like Open
Street Map (which Apple has recently ripped off by using Open Street Map data without attribution).
Google won't see the same meteoric growth ever again. It probably is a less fun place
for a social media development staffer to work at from 2010 to present, than it was from 2004
- 2010 (but I'm betting still preferable to FoxConn or anything anywhere near Balmer).
Linda R. Tindall :
Thank you for your honest comments Mr. Whittaker. And yes, Google is not like it was before..
It is Scary, Google may destroy anyone online business overnight!
Google penalize webmasters if they don't like a Website for any reason. They can put out anyone
they want out of business. How does Google judge a webmaster's?
Google's business isn't anymore the search engine. Google's business is selling and displaying
ads.
GOOGLE becomes now the Big Brother of the WWW. I think it is scary that Google has so much
power. Just by making changes, they can ruin people's lives.
As it turned out, sharing was not broken. Sharing was working fine and dandy, Google just wasn't
part of it. People were sharing all around us and seemed quite happy. A user exodus from Facebook
never materialized. I couldn't even get my own teenage daughter to look at Google+ twice, "social
isn't a product," she told me after I gave her a demo, "social is people and the people are on Facebook."
Google was the rich kid who, after having discovered he wasn't invited to the party, built his
own party in retaliation. The fact that no one came to Google's party became the elephant in the
room.
Generations of Emacs-hating developers have sworn by Vim as the only text editor they'll use for
coding. Neovim is a new take on the classic tool with
more powerful plugins, better GUI architecture and improved embedding support. Operating System:
Windows, Linux, OS X
Nuclide
Created by Facebook, Nuclide is an integrated development environment
that supports both mobile and Web development. It is built on top of Atom, and it can integrate with
Flow, Hack and Mercurial. Operating System: Windows, Linux, OS X
React
React is "a JavaScript library for building user interfaces."
It provides the "View" component in model–view–controller (MVC) software architecture and is specifically
designed for one-page applications with data that changes over time. Operating System: OS Independent
Sleepy Puppy
Released in August, Netflix's Sleepy
Puppy helps Web developers avoid cross-site scripting (XSS) vulnerabilities. It allows developers
and security staff to capture, manage and track XSS issues. Operating System: OS Independent
YAPF
Short for "Yet Another Python Formatter,"
YAPF reformats Python code so
that it conforms to the style guide and looks good. It's a Google-owned project. Operating System:
OS Independent
James Maguire's
article raises some interesting questions as to why teaching Java to first
year CS / IT students is a bad idea. The article mentions both Ada and Pascal
neither of which really "took off" outside of the States, with the former
being used mainly by contractors of the US Dept. of Defense.
This is my own, personal, extension to the article which I agree with
and why first year students should be taught C in first year. I'm biased though,
I learned C as my first language and extensively use C or C++ in
projects.
Java is a very high level language that has interesting features that make
it easier for programmers. The two main points, that I like about Java, are
libraries (although libraries exist for C / C++ ) and memory management.
Libraries
Libraries are fantastic. They offer an API and abstract a metric fuck tonne
of work that a programmer doesn't care about. I don't care how
the library works inside, just that I have a way of putting in input and getting
expected output (see my post on
abstraction).
I've extensively used libraries, even this week, for audio codec decoding. Libraries
mean not reinventing the wheel and reusing code (something students are discouraged
from doing, as it's plagiarism, yet in the real world you are rewarded). Again,
starting with C means that you appreciate the libraries more.
Memory Management
Managing your programs memory manually is a pain in the hole. We all know
this after spending countless hours finding memory leaks in our programs. Java's
inbuilt memory management tool is great it saves me from having to do it.
However, if I had have learned Java first, I would assume (for a short amount
of time) that all languages managed memory for you or that
all languages were shite compared to Java because they don't
manage memory for you. Going from a "lesser" language like C to Java makes you
appreciate the memory manager
What's so great about C?
In the context of a first language to teach students, C is perfect. C is
Relatively simple
Procedural
Lacks OOP features, which confuse freshers
Low level
Fast
Imperative
Weakly typed
Easy to get bugs
Java is a complex language that will spoil a first year student. However,
as noted, CS / IT courses need to keep student retention rates high. As an example,
my first year class was about 60 people, final year was 8. There are ways to
keep students, possibly with other, easier, languages in the second semester
of first year so that students don't hate the subject when choosing the next
years subject post exams.
Conversely, I could say that you should teach Java in first
year and expand on more difficult languages like C or assembler (which should
be taught side by side, in my mind) later down the line keeping retention
high in the initial years, and drilling down with each successive semester to
more systems level programming.
There's a time and place for Java, which I believe is third year or final
year. This will keep Java fresh in the students mind while they are going job
hunting after leaving the bosom of academia. This will give them a good head
start, as most companies are Java houses in Ireland.
In
computer science, abstraction is the process by which
data and
programs are defined with a
representation similar to its meaning (semantics),
while hiding away the
implementation details. Abstraction tries to reduce and factor out details
so that the
programmer
can focus on a few concepts at a time. A system can have several abstraction
layers whereby different meanings and amounts of detail are exposed
to the programmer. For example,
low-level abstraction layers expose details of the
hardware
where the program is
run, while high-level layers deal with the
business
logic of the program.
That might be a bit too wordy for some people, and not at all clear. Here's
my analogy of abstraction.
Abstraction is like a car
A car has a few features that makes it unique.
A steering wheel
Accelerator
Brake
Clutch
Transmission (Automatic or Manual)
If someone can drive a Manual transmission car, they can drive any Manual
transmission car. Automatic drivers, sadly, cannot drive a Manual transmission
drivers without "relearing" the car. That is an aside, we'll assume that all
cars are Manual transmission cars as is the case in Ireland for most cars.
Since I can drive my car, which is a Mitsubishi Pajero, that means that I
can drive your car a Honda Civic, Toyota Yaris, Volkswagen Passat.
All I need to know, in order to drive a car any car is how to use the
breaks, accelerator, steering wheel, clutch and transmission. Since I already
know this in my car, I can abstract away your car and it's
controls.
I do not need to know the inner workings of your car in
order to drive it, just the controls. I don't need to know how exactly the breaks
work in your car, only that they work. I don't need to know, that your car has
a turbo charger, only that when I push the accelerator, the car moves. I also
don't need to know the exact revs that I should gear up or gear down (although
that would be better on the engine!)
Virtually all controls are the same. Standardization means that the clutch,
break and accelerator are all in the same place, regardless of the car. This
means that I do not need to relearn how a car works. To me, a car is
just a car, and is interchangeable with any other car.
Abstraction means not caring
As a programmer, or someone using a third party API (for example), abstraction
means not caring how the inner workings of some function works
Linked list data structure, variable names inside the function, the sorting
algorithm used, etc just that I have a standard (preferable unchanging) interface
to do whatever I need to do.
Abstraction can be taught of as a black box. For input, you get output. That
shouldn't be the case, but often is. We need abstraction so that, as a programmer,
we can concentrate on other aspects of the program this is the corner-stone
for large scale, multi developer, software projects.
Software engineers understand the pace of writing code, but frequently managers don't. One
line of code might take 1 minute, and another line of code might take 1 day. But generally, everything
averages out, and hitting your goals is more a function of properly setting your goals than of
coding quickly or slowly. Sprint.ly, a company than analyzes productivity, has published some
data to back this up. The amount of time actually developing a feature was
a small and relatively consistent
portion of its lifetime as a work ticket.. The massively variable part of the process is when
"stakeholders are figuring out specs and prioritizing work." The top disrupting influences (as
experienced devs will recognize) are unclear and changing requirements. Another big cause of slowdowns
is interrupting development work on one task to work on a second one. The article encourages managers
to let devs contribute to the process and say "No" if the specs are too vague. Is there anything
you'd add to this list?
skaag
Re:Nope... Nailed It (Score:5, Insightful)
(206358) on Friday November 21, 2014 @11:55AM (#48434577)
This is not exactly accurate. It hinges greatly on the type of manager we're talking about.
For example if the manager is very hands-on, goes into the details, produces proper mock-ups,
flow diagrams, and everything is properly documented: This type of manager can actually accelerate
the development process significantly since developers now know exactly what to do. But again,
this manager has to really know what he's doing, and have some serious programming experience
in his past.
RabidReindeer (2625839) on Friday November 21, 2014
Re:Nope... Nailed It (Score:4, Interesting)
Couple of big shops in my town. Take one for example. They had a 2-year window for a very important
project.
Bought (expensive trendy tool) from (major software vendor). Spent 18 months drawing stick-figure
diagrams with (expensive trendy tool). Realized they only had 6 months for implementation and
panicked. Basically tossed the stick-figure diagrams because they had to drastically modify expectations
to make it in 6 months of 100-hour programming weeks. Using contract laborers who didn't know
the company and how it operated, because they'd taken a chain-saw to the ranks of the in-house
experienced staff.
I'm sure that they learned a valuable lession from that and will never do anything like that again.
I'm also sure that pigs fly and cows routinely jump over the moon.
Jane Q. Public (1010737) on Friday November 21, 2014
I'm sure that they learned a valuable lession from that and will never do anything like
that again. I'm also sure that pigs fly and cows routinely jump over the moon.
This is a good illustration of the folly of top-down "waterfall" methodology. Too much micro-planning
in advance, no action.
tnk1 (899206) on Friday November 21, 2014
Re:Nope... Nailed It (Score:5, Insightful)
You don't want to take managers out of the equation. They're the only people keeping the other
departments from running you over. You see that most clearly, ironically, when you have an incompetent
manager and you get run over in spite of it.
And a bad manager in this sense isn't the evil taskmaster, it is the guy who has no idea of his
team's capabilities and taskload. He's also probably a little clueless about what is or is not
possible, but in that sense, it's more of a feature of him making promises without talking to
the rest of the team first. That manager goes to meetings and lets himself get cowed into submission
when sales or marketing goes after him because he has no facts. Removing someone in that position
just means that engineering is no longer even a speed bump to unrealistic goals.
Saying "No" to business people is not a valid strategy. You'll just find yourself replaced. Saying,
"yes, but you'd need to spend 2 million dollars on it" with proof is a valid strategy.
You don't want to sit around and come up with that data, that's what the manager is supposed to
do.
I agree that indecisive managers and overwrought process is probably the top cause of problems
with productivity. However, there are good managers and bad ones. It pays to understand the difference.
“I tell them you learn to write the same way you learn to play golf,” he once said. “You do it,
and keep doing it until you get it right. A lot of people think something mystical happens to you,
that maybe the muse kisses you on the ear. But writing isn’t divinely inspired — it’s hard work.”
4. Don't just fix the mistakes -- fix whatever permitted the mistake in the first place.
The process is so pervasive, it gets the blame for any error -- if there is a flaw in the software,
there must be something wrong with the way its being written, something that can be corrected. Any
error not found at the planning stage has slipped through at least some checks. Why? Is there something
wrong with the inspection process? Does a question need to be added to a checklist?
Importantly, the group avoids blaming people for errors. The process assumes blame - and it's
the process that is analyzed to discover why and how an error got through. At the same time, accountability
is a team concept: no one person is ever solely responsible for writing or inspecting code. "You
don't get punished for making errors," says Marjorie Seiter, a senior member of the technical staff.
"If I make a mistake, and others reviewed my work, then I'm not alone. I'm not being blamed for this."
Ted Keller offers an example of the payoff of the approach, involving the shuttles remote manipulator
arm. "We delivered software for crew training," says Keller, "that allows the astronauts to manipulate
the arm, and handle the payload. When the arm got to a certain point, it simply stopped moving."
The software was confused because of a programming error. As the wrist of the remote arm approached
a complete 360-degree rotation, flawed calculations caused the software to think the arm had gone
past a complete rotation -- which the software knew was incorrect. The problem had to do with rounding
off the answer to an ordinary math problem, but it revealed a cascade of other problems.
"Even though this was not critical," says Keller, "we went back and asked what other lines of
code might have exactly the same kind of problem." They found eight such situations in the code,
and in seven of them, the rounding off function was not a problem. "One of them involved the high-gain
antenna pointing routine," says Keller. "That's the main antenna. If it had developed this problem,
it could have interrupted communications with the ground at a critical time. That's a lot more serious."
The way the process works, it not only finds errors in the software. The process finds errors
in the process.
Definitely not the best book on management June 23, 2008
I've read a couple of Rand's posts on his blog and thought it'd be nice to be able to read
the edited, reviewed and improved paper version... I should have saved my money. It's not that
the book is useless, but it doesn't adds to much value to the blog posts. Also, not all chapters
are worth reading, so you pay for a lot of bad stuff too.
is he saying that if the hardware he made was, say, 20% more power hungry and 10% more expensive
it would have rendered Google's business idea unworkable. I'm not sure I buy it. Maybe it allowed
him to scale up with less capital, but I think a 20% slower google would still have won hearts
and minds during the period it was being created.
wisnoskij:
I don't know, seems reasonable to me. Profit margins can be pretty slim and it does not take
much to go from making a cent per user to losing a cent per user and no business is built on losing
money.
guspasho:
No business is built on losing money AND no business grows as large and as quickly as Google
has by running a slim profit margin.
br00tus:
I think most project managers are a waste as well. In a small company
it is unneeded. I'm more circumspect to say whether or not they're needed in a big company, but
they certainly seem less needed in small, closely connected groups. If you have
a big, long project, with people from different divisions doing different things, then yes, a
project manager can be helpful.
On a small project, with a few people, who work closely already on a variety of things, project
managers just tend to get in the way. I don't know how many projects I've been brought into at
the last minute because someone quit or whatever, and the PM points to my place on the timeline
- I'm already two weeks late in finishing whatever is supposed to be done on the day I'm brought
into the project.
It's just completely pointless aside from those large collaborations that cross across many
people in many different groups at a company.
Opportunist:
Google succeeded because it was at the right time at the right place. Nothing else. Yes, there
were other search engines before it, but Google set a standard and ran with it.
Try the same approach in the same field of business today and you will fail. Invariably. Likewise
with the next EBay, the next Amazon, the next Facebook. No, they were not the first. But they
were amongst the first and they were there and "the best" at just the right time when the service
they offered suddenly got popular. That's all that is to their success.
Nothing more, nothing less. Just pure luck. You might also say good timing, but I kinda doubt
anyone can actually predict so accurately when which service hits the sweet spot. If he could,
most of these services would be in one hand. Why? Because that person/organization would have
hit the sweet spots more often than anyone else. Duh. I wouldn't take any advice from any of those
"successful" companies. They didn't do anything right where everyone else was too stupid. They
were just lucky to be the one that were lucky enough to be the one being at the right place at
the right time with the right product.
dkleinsc:
No, Google succeeded because they did search with a far better algorithm than anything else
out there at the time. It came into being several years after the first search engines, and was
up against several established players, such as Yahoo. They also made one very smart marketing
move, which is still with them today: The front page of Google was a simple search box, whereas
the front page of their competitors was loaded with widgets and paid ads. In the days of 56k modems,
that meant you could load Google faster and search faster. Facebook, too, also was up against
an established competitor in MySpace.
They won out by providing a service that was (at the time) less bloated, more private, and
less ad-driven than MySpace (and then proceeded to make it more bloated, less private, and more
ad-driven, but that's another story). Plenty of other companies have succeeded in marketplaces
with established competitors - Ben and Jerry's, for instance, built up from practically nothing
in a highly competitive market.
Luck makes a difference, no doubt: I was talking with another CS grad from my alma mater who
had turned down a chance to be Google employee #5 because he was heading to a good job in computer
graphics and didn't want to risk it all on some crazy start-up. He's done just fine for himself
at Pixar, but one coin flip the other way and he might well have had a fortune.
dkleinsc
Every single major corporation does dumb things all the time! Incompetence is rampant! That
means, logically, if you want to create a major corporation, you need to cultivate a culture of
incompetence and stupidity.
The former CIO of Google and founder and CEO of ZestCash, Dr Douglas Merrill, says companies stuck
in traditional management practices risk becoming irrelevant and leaders should not be afraid to
do 'dumb' things.
During a lively keynote at this year's CA Expo in Sydney, Merrill said the six years he spent
at Google was the most fascinating part of his career.
"Google was founded by two computer science students at Stanford and they hated each other at
first. I found out they were both correct," he said jokingly.
"There is a whole cottage industry of people talking about innovation, including all kinds of
garbage... and I'm part of this cottage industry."
Merrill said there is a lot of "mythos" about Google, like free food and 20 per cent free time,
but most of it is false.
He said a successful product is not about having perfect project management,
rather "the more project management you do the less likely your project is to succeed".
"It's not about hardware and capex. Build your product and then figure out what to do with it,"
he said.
"Don't be afraid to do dumb things. Larry and Sergey developed a search product called 'Backrub'
- don't ask me how they got that - and shortly after that launched Google as part of the Stanford
domain. Most of the early Google hardware was stolen from trash and as the stuff they stole broke
all the time they built a reliable software system."
"Everyone knew we shouldn't build our own hardware as it was 'dumb', but everyone was wrong. Sometimes
being dumb changes the game."
Merrill cited the "fairly disturbing statistic" of 66 percent of the Fortune 100 companies having
either disappeared or are out of the list in the 20 years since 1990.
"Eastman Kodak is my favourite example. It has more patents than any other company on earth and
is the most successful research company," he said. "In 1990 a young researcher
invented the charge coupled device which is the core of every camera today. His boss said you're
a moron we make film."
"The most important thing to take advantage of is to see innovation from everywhere - inside and
outside."
With information being democratised over the past twenty years, which has seen the price of hard
drive storage drop by 2 million fold, Merrill said businesses can emerge in a cheaper way.
"Zappos.com is inline shoe retailer and each shoe sent has a return slip as people are more likely
to buy something if they can return it. The company went from $1 million seed to $70 million in revenue,"
he said, adding Google $1 million in funding and built "a reasonably good business".
While technology matters to "real" bricks and mortar businesses as much as online companies, Merrill
said there are lots of examples of technology turning out "spectacularly badly".
"Just because you can do something with technology that doesn't mean you should do something with
technology," he said. "You want to find cheap ways to get your customers to care about you."
"McDonalds wanted to get people to come back to its stores so they ran an interesting marketing
program with Foursquare where people could come to a restaurant and 'check in' and get a hamburger
for free. That resulted in 25 per cent sales lift day-on-day and the total marketing promotion cost
$18,000.
When Merrill left Google he worked at EMI records, which was interesting and enjoyable, but he
knew the music industry was "collapsing".
"The RIAA said it isn't that we are making bad music, but the 'dirty file sharing guys' are the
problem," he said. "Going to sue customers for file sharing is like trying to sell soap by throwing
dirt on your customers."
Merrill profiled the file sharing behaviour of people who used Limewire
against the top iTunes sales and the biggest iTunes buyers were the same as the highest sharing "thieves"
on Limewire.
"That's not theft, that's try-before-you-buy marketing and we weren't even paying for it... so
it makes sense to sue them," he said wryly.
Merrill said it is also prudent not to listen too carefully to customers as so-called "focus groups"
suffer from the Availability Heuristic: "If you ask a question the answer will be the first thing
they think of."
"You can't ask your customers what they want if they don't understand your innovation," he said.
"The popular Google spell correction came from user activity. We couldn't
ask a customer if they wanted spell checking as they would have said no."
One person is the Decider for final design choices. Not focus groups. Not data crunchers. Not
committee consensus-builders. The decisions reflect the sensibility of just one person: Steven P.
Jobs, the C.E.O.
By contrast, Google has followed the conventional approach, with lots of people playing a role.
That group prefers to rely on experimental data, not designers, to guide its decisions.
The contest is not even close. The company that has a single arbiter of taste has been producing
superior products, showing that you don’t need multiple teams and dozens or hundreds or thousands
of voices.
Two years ago, the technology blogger John Gruber presented a talk, “The Auteur Theory of Design,”
at the Macworld Expo. Mr. Gruber suggested how filmmaking could be a helpful model in guiding creative
collaboration in other realms, like software.
The auteur, a film director who both has a distinctive vision for a work and exercises creative
control, works with many other creative people. “What the director is doing, nonstop, from the beginning
of signing on until the movie is done, is making decisions,” Mr. Gruber said. “And just simply making
decisions, one after another, can be a form of art.”
“The quality of any collaborative creative endeavor tends to approach the level of taste of whoever
is in charge,” Mr. Gruber pointed out.
Two years after he outlined his theory, it is still a touchstone in design circles for discussing
Apple and its rivals.
Garry Tan, designer in residence and a venture partner at Y Combinator, an investor in start-ups,
says: “Steve Jobs is not always right—MobileMe would be an example. But we do know that all major
design decisions have to pass his muster. That is what an auteur does.”
Mr. Jobs has acquired a reputation as a great designer, Mr. Tan says, not because he personally
makes the designs but because “he’s got the eye.” He has also hired classically trained designers
like Jonathan Ive. “Design excellence also attracts design talent,” Mr. Tan explains.
Google has what it calls a “creative lab,” a group that had originally worked on advertising to
promote its brand. More recently, the lab has been asked to supply a design vision to the engineering
and user-experience groups that work on all of Google’s products. Chris L. Wiggins, the lab’s creative
director, whose own background is in advertising, describes design as a collaborative process among
groups “with really fruitful back-and-forth.”
“There’s only one Steve Jobs, and he’s a genius,” says Mr. Wiggins. “But it’s important to distinguish
that we’re discussing the design of Web applications, not hardware or desktop software. And for that
we take a different approach to design than Apple,” he says. Google, he says, utilizes the Web to
pull feedback from users and make constant improvements.
Mr. Wiggins’s argument that Apple’s apples should not be compared to Google’s oranges does not
explain, however, why Apple’s smartphone software gets much higher marks than Google’s.
GOOGLE’S ability to attract and retain design talent has not been helped by the departure of designers
who felt their expertise was not fully appreciated. “Google is an engineering company, and as a researcher
or designer, it’s very difficult to have your voice heard at a strategic level,” writes Paul Adams
on his blog, “Think Outside In.” Mr. Adams was a senior user-experience researcher at Google until
last year; he is now at Facebook.
Douglas Bowman is another example. He was hired as Google’s first visual designer in 2006, when
the company was already seven years old. “Seven years is a long time to run a company without a classically
trained designer,” he wrote in his blog Stopdesign in 2009. He complained that there was no one at
or near the helm of Google who “thoroughly understands the principles and elements of design” “I
had a recent debate over whether a border should be 3, 4 or 5 pixels wide,” Mr. Bowman wrote, adding,
“I can’t operate in an environment like that.” His post was titled, “Goodbye, Google.”
Mr. Bowman’s departure spurred other designers with experience at either Google or Apple to comment
on differences between the two companies. Mr. Gruber, at his Daring Fireball blog, concisely summarized
one account under the headline “Apple Is a Design Company With Engineers; Google Is an Engineering
Company With Designers.”
In May, Google, ever the engineering company, showed an unwillingness to notice design expertise
when it tried to recruit Pablo Villalba Villar, the chief executive of Teambox, an online project
management company. Mr. Villalba later wrote that he had no intention of leaving Teambox and cooperated
to experience Google’s hiring process for himself. He tried to call attention to his main expertise
in user interaction and product design. But he said that what the recruiter wanted to know was his
mastery of 14 programming languages.
Mr. Villalba was dismayed that Google did not appear to have changed since Mr. Bowman left. “Design
can’t be done by committee,” he said.
Recently, as Larry Page, the company co-founder, began his tenure as C.E.O., , Google rolled out
Google+ and a new look for the Google home page, Gmail and its calendar. More redesigns have been
promised. But they will be produced, as before, within a very crowded and noisy editing booth. Google
does not have a true auteur who unilaterally decides on the final cut.
Randall Stross is an author based in Silicon Valley and a professor of business at San Jose
State University. E-mail: [email protected].
Producing Open Source Software - How to Run a Successful Free Software Project
http://www.producingoss.com/en/producingoss.pdf Download: 887kb Format: PDF
If you’re not a first-timer and you are keen on starting your own open source project then take a
look at this book. First published in 2005, Producing Open Source Software is a solid 185-page long
guide to the intricacies of starting, running, licensing and maintaining an open source project.
As most readers no doubt know, having a good idea for an open source project is one thing; making
it work is entirely another. Written by
Karl Fogel, a long-time free-software developer and contributor to the open source version control
system, Subversion, the book covers a broad range of considerations, from choosing a good name to
creating a community, when starting your own OSS project.
How would you characterize the state of software development today?
Software has been and will remain fundamentally hard. In every era, we find that there is a certain
level of complexity we face. Today, a typical system tends to be continuously evolving. You never
turn it off, [and] it tends to be distributed, multiplatform. That is a very different set of problems
and forces than we faced five years ago.
Traditionally -- we're talking a few decades ago -- you could think of software as something that
IT guys did, and nobody else worried about it. Today, our civilization relies upon software.
All of a sudden, you wake up and say, "I can't live without my cell phone." We, as software developers,
build systems of incredible complexity, and yet our end users don't want to see that software.
Most of the interesting systems today are no longer just systems by themselves, but they tend
to be systems of systems. It is the set of them working in harmony. We don't have a lot of good processes
or analysis tools to really understand how those things behave. Many systems look dangerously fragile.
The bad news is they are fragile. This is another force that will lead us to the next era of how
we build software systems.
... ... ...
When you have an organization that is 100 times larger, there is a little bit more bureaucracy.
[IBM asked me] to destroy bureaucracy. I have a license to kill, so to speak. IBM is a target-rich
environent.
A just-published IBM patent application for a
Software Inspection Management Tool claims to improve software quality by taking a chess-clock-like
approach to code walkthroughs. An
inspection
rate monitor with 'a pause button, a resume button, a complete button, a total lines inspected
indication, and a total lines remaining to be inspected indication' keeps tabs on participants' progress
and changes color when management's expectations — measured in lines per hour — are not being met."
"An inspection rate monitor with 'a pause button, a resume button, a complete button, a
total lines inspected indication, and a total lines remaining to be inspected indication' keeps
tabs on participants' progress and changes color when management's expectations â" measured in
lines per hour â" are not being met."
Right Wally. so, you write line after line of utterly meaningless horseshit to keep your line
count up, and then route the data to a place where it gets commented out... and then follow that
with line after line of craptastic documentation. Copy paste the Unabomber's manifesto - whatever
- as long as the line count counter keeps ticking a long.
You can probably get employee of the month for all the code you've written, and only in a few
hours a day! Meanwhile, you're spending the rest of your time looking for work at a company that
doesn't pull this kind of bullshit on its workers.
Someone I know was told to increase lines-of-code output by 20%, not counting comments.
He immediately complied and exceeded expectations by switching to K&R style, declaring function
variables on separate lines instead of inline, and placing { on a separate line.
He was ready to place semicolons on a separate line too, if management wanted even higher efficiency.
Metropolis (Fritz Lang, 1927). Excellent movie BTW.
The worker at the power plant collapses during a a shift which was too long and required to many
new operations demanded by a clock-like device. The power plant nearly explodes, because he can
not keed up with the pace of this clock-like device.
If anything, from my limited experience with formal code inspections, the gain from a device
like this would be to slow the pace through the code.
Rushing through the code tends to make us find fewer bugs per time spent-- if anything, it's better
to more closely inspect a third of the code at a third of the pace and not inspect the other two-thirds
at all than to inspect all of it in the same amount of time.
The issue being, we tend to want to get the inspection of the code over with; such a clock might
act as a nice reminder to slow down a bit.
I've only flicked through the patent application so far, but it doesn't seem very much like
what the submitter makes out.
From what I can see, the implication that this has anything to do with management
harassing the developers and testers is completely conjecture on the part of the slashdot submitter.
The only context in which the word "manage" appears in the entire application is as part
of the phrase "management tool", which to me implies that it's supposed to be entirely to help
the testing and development staff. (Okay, there's one occurance which is "inspection process manager".)
I know that IBM has a famous history of having associated productivity with lines of code,
but I really don't think they're being quite so dim-witted with this one. I haven't read the application
in detail, but to me it looks more like someone's been developing a tool to help with code inspection.
By the looks of it, it has a certain way of displaying the code, it has a method of recording
noted defects and comments, and it has a feature of timing how long things are taking and how
long a user is spending on certain parts of a code-base.
I can't see any direct implication in the patent application that this is primarily
for management to measure staff performance to compare with pre-defined expectations. On the other
hand I can see a lot of references in the patent application to the code inspector themselves
using this tool to assist their work. I think it's much more likely that someone
running an inspection could use such a tool to help them keep track of the most fragile parts
of the code, and which areas are tying up the most of their time. If there was a deadline for
inspection, it'd probably also help to highlight if you were spending far too much time in one
place without having even reached other areas that might be important.
Whether it would work or be any use at all it another issue, but if it's a completely wacky
idea then it wouldn't be the first that someone tried to patent. Many good patented ideas seemed
silly or ridiculous before a working implementation was produced to demonstrate otherwise, but
if an inventor had waited until it was clearly useful before patenting it, it'd be a lot harder.
I am glad I do not work for them anymore. Of course, I am not surprised. IBM have been treating
their workers like cattle rather than humans for some time now. This is just another indicator.
Andrew Binstock and Donald Knuth converse on the success of open source, the problem with
multicore architecture, the disappointing lack of interest in literate programming, the menace of
reusable code, and that urban legend about winning a programming contest with a single compilation.
Andrew Binstock: You are one of the fathers of the open-source revolution, even if you
aren’t widely heralded as such. You previously have stated that you released TeX as open source
because of the problem of proprietary implementations at the time, and to invite corrections to the
code—both of which are key drivers for open-source projects today. Have you been surprised by the
success of open source since that time?
Donald Knuth: The success of open source code is perhaps the only thing in the computer field
that hasn’t surprised me during the past several decades. But it still hasn’t reached its
full potential; I believe that open-source programs will begin to be
completely dominant as the economy moves more and more from products towards services, and as more
and more volunteers arise to improve the code.
For example, open-source code can produce thousands of binaries, tuned
perfectly to the configurations of individual users, whereas commercial software usually will exist
in only a few versions. A generic binary executable file must include things like
inefficient "sync" instructions that are totally inappropriate for many installations; such wastage
goes away when the source code is highly configurable. This should be a huge win for open source.
Yet I think that a few programs, such as Adobe Photoshop, will always be superior to competitors
like the Gimp—for some reason, I really don’t know why! I’m quite willing
to pay good money for really good software, if I believe
that it has been produced by the best programmers.
Remember, though, that my opinion on economic questions is highly suspect, since I’m just an educator
and scientist. I understand almost nothing about the marketplace.
Andrew: A story states that you once entered a programming contest at Stanford (I believe)
and you submitted the winning entry, which worked correctly after a single compilation.
Is this story true? In that vein, today’s developers frequently build programs writing small code
increments followed by immediate compilation and the creation and running of unit tests. What are
your thoughts on this approach to software development?
Donald: The story you heard is typical of legends that are based on only a small kernel of truth.
Here’s what actually happened:
John
McCarthy decided in 1971 to have a Memorial Day Programming Race. All of the contestants except
me worked at his AI Lab up in the hills above Stanford, using the WAITS time-sharing system; I was
down on the main campus, where the only computer available to me was a mainframe for which I had
to punch cards and submit them for processing in batch mode. I used Wirth’s
ALGOL W system (the predecessor
of Pascal). My program didn’t work the first time, but fortunately I could use Ed Satterthwaite’s
excellent offline debugging system for ALGOL W, so I needed only two runs. Meanwhile, the folks using
WAITS couldn’t get enough machine cycles because their machine was so overloaded. (I think that the
second-place finisher, using that "modern" approach, came in about an hour after I had submitted
the winning entry with old-fangled methods.) It wasn’t a fair contest.
As to your real question, the idea of immediate compilation and "unit tests" appeals to me only
rarely, when I’m feeling my way in a totally unknown environment and need feedback about what works
and what doesn’t. Otherwise, lots of time is wasted on activities that
I simply never need to perform or even think about. Nothing needs to be "mocked up."
Andrew: One of the emerging problems for developers, especially client-side developers,
is changing their thinking to write programs in terms of threads. This concern, driven by the advent
of inexpensive multicore PCs, surely will require that many algorithms be recast for multithreading,
or at least to be thread-safe. So far, much of the work you’ve published for Volume 4 of The Art of Computer
Programming (TAOCP) doesn’t seem to touch on this dimension. Do you expect to
enter into problems of concurrency and parallel programming in upcoming work, especially since it
would seem to be a natural fit with the combinatorial topics you’re currently working on?
Donald: The field of combinatorial algorithms is so vast that I’ll be lucky to pack its sequential
aspects into three or four physical volumes, and I don’t think the sequential methods are ever going
to be unimportant. Conversely, the half-life of parallel techniques is very short, because hardware
changes rapidly and each new machine needs a somewhat different approach. So I decided long ago to
stick to what I know best. Other people understand parallel machines much better than I do; programmers
should listen to them, not me, for guidance on how to deal with simultaneity.
Andrew: Vendors of multicore processors have expressed frustration at the difficulty of
moving developers to this model. As a former professor, what thoughts do you have on this transition
and how to make it happen? Is it a question of proper tools, such as better native support for concurrency
in languages, or of execution frameworks? Or are there other solutions?
Donald: I don’t want to duck your question entirely. I might as well flame a bit about
my personal unhappiness with the current trend toward multicore architecture. To me,
it looks more or less like the hardware designers have run out of ideas, and that
they’re trying to pass the blame for the future demise of Moore’s Law
to the software writers by giving us machines that work faster only on a few key benchmarks!
I won’t be surprised at all if the whole multithreading idea turns out to be a flop, worse than the
"Titanium" approach that
was supposed to be so terrific—until it turned out that the wished-for
compilers were basically impossible to write.
Let me put it this way: During the past 50 years, I’ve written well over a thousand programs,
many of which have substantial size. I can’t think of even five of those programs that would
have been enhanced noticeably by parallelism or multithreading. Surely, for example, multiple processors
are no help to TeX.[1]
How many programmers do you know who are enthusiastic about these promised machines of the future?
I hear almost nothing but grief from software people, although the hardware folks in our department
assure me that I’m wrong.
I know that important applications for parallelism exist—rendering graphics, breaking codes, scanning
images, simulating physical and biological processes, etc. But all these applications require dedicated
code and special-purpose techniques, which will need to be changed substantially every few years.
Even if I knew enough about such methods to write about them in TAOCP, my time would
be largely wasted, because soon there would be little reason for anybody to read those parts. (Similarly,
when I prepare the third edition of
Volume 3 I plan to rip out much of the material
about how to sort on magnetic tapes. That stuff was once one of the hottest topics in the whole software
field, but now it largely wastes paper when the book is printed.)
The machine I use today has dual processors. I get to use them both only when I’m running two
independent jobs at the same time; that’s nice, but it happens only a few minutes every week. If
I had four processors, or eight, or more, I still wouldn’t be any better off, considering the kind
of work I do—even though I’m using my computer almost every day during most of the day. So why should
I be so happy about the future that hardware vendors promise? They think a magic bullet will come
along to make multicores speed up my kind of work; I think it’s a pipe dream. (No—that’s the wrong
metaphor! "Pipelines" actually work for me, but threads don’t. Maybe the word I want is "bubble.")
From the opposite point of view, I do grant that web browsing probably will get better with multicores.
I’ve been talking about my technical work, however, not recreation. I also admit that I haven’t got
many bright ideas about what I wish hardware designers would provide instead of multicores, now that
they’ve begun to hit a wall with respect to sequential computation. (But my
MMIX design contains
several ideas that would substantially improve the current performance of the kinds of programs that
concern me most—at the cost of incompatibility with legacy x86 programs.)
Andrew: One of the few projects of yours that hasn’t been embraced by a widespread community
is literate programming.
What are your thoughts about why literate programming didn’t catch on? And is there anything you’d
have done differently in retrospect regarding literate programming?
Donald: Literate programming is a very personal thing. I think it’s terrific, but that might well
be because I’m a very strange person. It has tens of thousands of fans, but not millions.
In my experience, software created with literate programming has turned
out to be significantly better than software developed in more traditional ways. Yet
ordinary software is usually okay—I’d give it a grade of C (or maybe C++), but not F; hence, the
traditional methods stay with us. Since they’re understood by a vast community of programmers, most
people have no big incentive to change, just as I’m not motivated to learn Esperanto even though
it might be preferable to English and German and French and Russian (if everybody switched).
Jon Bentley probably hit
the nail on the head when he once was asked why literate programming hasn’t taken the whole world
by storm. He observed that a small percentage of the world’s population
is good at programming, and a small percentage is good at writing; apparently I am asking everybody
to be in both subsets.
Yet to me, literate programming is certainly the most important thing that came out of the TeX
project. Not only has it enabled me to write and maintain programs faster and more reliably than
ever before, and been one of my greatest sources of joy since the 1980s—it has actually been
indispensable at times. Some of my major programs, such as the MMIX meta-simulator, could not
have been written with any other methodology that I’ve ever heard of. The complexity was simply too
daunting for my limited brain to handle; without literate programming, the whole enterprise would
have flopped miserably.
If people do discover nice ways to use the newfangled multithreaded machines, I would expect the
discovery to come from people who routinely use literate programming. Literate programming is what you need to rise above the ordinary level of achievement. But I don’t believe in forcing ideas on anybody. If literate programming isn’t your style,
please forget it and do what you like. If nobody likes it but me, let it die.
On a positive note, I’ve been pleased to discover that the conventions of CWEB are already standard
equipment within preinstalled software such as Makefiles, when I get off-the-shelf Linux these days.
Andrew: In Fascicle 1 of
Volume 1, you reintroduced the MMIX computer, which is the 64-bit upgrade to the venerable
MIX machine comp-sci students have come to know over many years. You previously described MMIX in
great detail in MMIXware.
I’ve read portions of both books, but can’t tell whether the Fascicle updates or changes anything
that appeared in MMIXware, or whether it’s a pure synopsis. Could you clarify?
Donald: Volume 1 Fascicle 1 is a programmer’s introduction, which includes instructive exercises
and such things. The MMIXware book is a detailed reference manual, somewhat terse and dry, plus a
bunch of literate programs that describe prototype software for people to build upon. Both books
define the same computer (once the errata to MMIXware are incorporated from my website). For most
readers of TAOCP, the first fascicle contains everything about MMIX that they’ll ever need
or want to know.
I should point out, however, that MMIX isn’t a single machine; it’s an architecture with almost
unlimited varieties of implementations, depending on different choices of functional units, different
pipeline configurations, different approaches to multiple-instruction-issue, different ways to do
branch prediction, different cache sizes, different strategies for cache replacement, different bus
speeds, etc. Some instructions and/or registers can be emulated with software on "cheaper" versions
of the hardware. And so on. It’s a test bed, all simulatable with my meta-simulator, even though
advanced versions would be impossible to build effectively until another five years go by (and then
we could ask for even further advances just by advancing the meta-simulator specs another notch).
Suppose you want to know if five separate multiplier units and/or three-way instruction issuing
would speed up a given MMIX program. Or maybe the instruction and/or data cache could be made larger
or smaller or more associative. Just fire up the meta-simulator and see what happens.
Andrew: As I suspect you don’t use unit testing with MMIXAL, could you step me through
how you go about making sure that your code works correctly under a wide variety of conditions and
inputs? If you have a specific work routine around verification, could you describe it?
Donald: Most examples of machine language code in TAOCP appear in Volumes 1-3; by the
time we get to Volume 4, such low-level detail is largely unnecessary and we can work safely at a
higher level of abstraction. Thus, I’ve needed to write only a dozen or so MMIX programs while preparing
the opening parts of Volume 4, and they’re all pretty much toy programs—nothing substantial. For
little things like that, I just use informal verification methods, based on the theory that I’ve
written up for the book, together with the MMIXAL assembler and MMIX simulator that are readily available
on the Net (and described in full detail in the MMIXware book).
That simulator includes debugging features like the ones I found so useful in Ed Satterthwaite’s
system for ALGOL W, mentioned earlier. I always feel quite confident after checking a program with
those tools.
Andrew: Despite its formulation many years ago, TeX is still thriving, primarily as the
foundation for LaTeX.
While TeX has been effectively frozen at your request, are there features that you would want to
change or add to it, if you had the time and bandwidth? If so, what are the major items you add/change?
Donald: I believe changes to TeX would cause much more harm than good. Other people who want other
features are creating their own systems, and I’ve always encouraged further development—except that
nobody should give their program the same name as mine. I want to take permanent responsibility for
TeX and Metafont, and for all
the nitty-gritty things that affect existing documents that rely on my work, such as the precise
dimensions of characters in the Computer Modern fonts.
Andrew: One of the little-discussed aspects of software development is how to do design
work on software in a completely new domain. You were faced with this issue when you undertook TeX:
No prior art was available to you as source code, and it was a domain in which you weren’t an expert.
How did you approach the design, and how long did it take before you were comfortable entering into
the coding portion?
Donald: That’s another good question! I’ve discussed the answer in great detail in Chapter 10
of my book
Literate Programming, together with Chapters 1 and 2 of my book
Digital Typography. I think that anybody who is really interested in this topic will enjoy reading
those chapters. (See also Digital Typography Chapters 24 and 25 for the complete first and
second drafts of my initial design of TeX in 1977.)
Andrew: The books on TeX and the program itself show a clear concern for limiting memory
usage—an important problem for systems of that era. Today, the concern for memory usage in programs
has more to do with cache sizes. As someone who has designed a processor in software, the issues
of cache-aware and cache-oblivious
algorithms surely must have crossed your radar screen. Is the role of processor caches
on algorithm design something that you expect to cover, even if indirectly, in your upcoming work?
Donald: I mentioned earlier that MMIX provides a test bed for many varieties of cache. And it’s
a software-implemented machine, so we can perform experiments that will be repeatable even a hundred
years from now. Certainly the next editions of Volumes 1-3 will discuss the behavior of various basic
algorithms with respect to different cache parameters.
In Volume 4 so far, I count about a dozen references to cache memory and cache-friendly approaches
(not to mention a "memo cache," which is a different but related idea in software).
Andrew: What set of tools do you use today for writing TAOCP? Do you use TeX?
LaTeX? CWEB? Word processor? And what do you use for the coding?
Donald: My general working style is to write everything first with pencil and paper, sitting beside
a big wastebasket. Then I use Emacs to enter the text into my machine, using the conventions of TeX.
I use tex, dvips, and gv to see the results, which appear on my screen almost instantaneously these
days. I check my math with Mathematica.
I program every algorithm that’s discussed (so that I can thoroughly understand it) using CWEB,
which works splendidly with the GDB debugger. I make the illustrations with
MetaPost (or, in rare cases,
on a Mac with Adobe Photoshop or Illustrator). I have some homemade tools, like my own spell-checker
for TeX and CWEB within Emacs. I designed my own bitmap font for use with Emacs, because I hate the
way the ASCII apostrophe and the left open quote have morphed into independent symbols that no longer
match each other visually. I have special Emacs modes to help me classify all the tens of thousands
of papers and notes in my files, and special Emacs keyboard shortcuts that make bookwriting a little
bit like playing an organ. I prefer rxvt
to xterm for terminal input. Since last December, I’ve been using a file backup system called
backupfs, which meets my need
beautifully to archive the daily state of every file.
According to the current directories on my machine, I’ve written 68 different CWEB programs so
far this year. There were about 100 in 2007, 90 in 2006, 100 in 2005, 90 in 2004, etc. Furthermore,
CWEB has an extremely convenient "change file" mechanism, with which I can rapidly create multiple
versions and variations on a theme; so far in 2008 I’ve made 73 variations on those 68 themes. (Some
of the variations are quite short, only a few bytes; others are 5KB or more. Some of the CWEB programs
are quite substantial, like the 55-page BDD package that I completed in January.) Thus, you can see
how important literate programming is in my life.
I currently use Ubuntu Linux, on a standalone
laptop—it has no Internet connection. I occasionally carry flash memory drives between this machine
and the Macs that I use for network surfing and graphics; but I trust my family jewels only to Linux.
Incidentally, with Linux I much prefer the keyboard focus that I can get with classic
FVWM to the GNOME and KDE environments
that other people seem to like better. To each his own.
Andrew: You state in the preface of Fascicle 0 of
Volume 4 of TAOCP that Volume 4 surely will comprise three volumes and possibly
more. It’s clear from the text that you’re really enjoying writing on this topic. Given that, what
is your confidence in the note posted on the TAOCP website that Volume 5 will see light
of day by 2015?
Donald: If you check the Wayback Machine for previous incarnations of that web page, you will
see that the number 2015 has not been constant.
You’re certainly correct that I’m having a ball writing up this material, because I keep running
into fascinating facts that simply can’t be left out—even though more than half of my notes don’t
make the final cut.
Precise time estimates are impossible, because I can’t tell until getting deep into each section
how much of the stuff in my files is going to be really fundamental and how much of it is going to
be irrelevant to my book or too advanced. A lot of the recent literature is academic one-upmanship
of limited interest to me; authors these days often introduce arcane methods that outperform the
simpler techniques only when the problem size exceeds the number of protons in the universe. Such
algorithms could never be important in a real computer application. I read hundreds of such papers
to see if they might contain nuggets for programmers, but most of them wind up getting short shrift.
From a scheduling standpoint, all I know at present is that I must someday digest a huge amount
of material that I’ve been collecting and filing for 45 years. I gain important time by working in
batch mode: I don’t read a paper in depth until I can deal with dozens of others on the same topic
during the same week. When I finally am ready to read what has been collected about a topic, I might
find out that I can zoom ahead because most of it is eminently forgettable for my purposes. On the
other hand, I might discover that it’s fundamental and deserves weeks of study; then I’d have to
edit my website and push that number 2015 closer to infinity.
Andrew: In late 2006, you were diagnosed with prostate cancer. How is your health today?
Donald: Naturally, the cancer will be a serious concern. I have superb doctors. At the moment
I feel as healthy as ever, modulo being 70 years old. Words flow freely as I write TAOCP
and as I write the literate programs that precede drafts of TAOCP. I wake up in the morning
with ideas that please me, and some of those ideas actually please me also later in the day when
I’ve entered them into my computer.
On the other hand, I willingly put myself in God’s hands with respect to how much more I’ll be
able to do before cancer or heart disease or senility or whatever strikes. If I should unexpectedly
die tomorrow, I’ll have no reason to complain, because my life has been incredibly blessed. Conversely,
as long as I’m able to write about computer science, I intend to do my best to organize and expound
upon the tens of thousands of technical papers that I’ve collected and made notes on since 1962.
Andrew: On your website, you mention that the Peoples Archive recently
made a series of videos in which you reflect on your past life. In segment 93, "Advice to Young People,"
you advise that people shouldn’t do something simply because it’s trendy. As we know all too well,
software development is as subject to fads as any other discipline. Can you give some examples that
are currently in vogue, which developers shouldn’t adopt simply because they’re currently popular
or because that’s the way they’re currently done? Would you care to identify important examples of
this outside of software development?
Donald: Hmm. That question is almost contradictory, because I’m basically advising young people
to listen to themselves rather than to others, and I’m one of the others. Almost every biography
of every person whom you would like to emulate will say that he or she did many things against the
"conventional wisdom" of the day.
Still, I hate to duck your questions even though I also hate to offend other people’s sensibilities—given
that software methodology has always been akin to religion. With the caveat that there’s no reason
anybody should care about the opinions of a computer scientist/mathematician like me regarding software
development, let me just say that almost everything I’ve ever heard associated with the term "extreme
programming" sounds like exactly the wrong way to go...with one exception. The exception is the
idea of working in teams and reading each other’s code. That idea is crucial, and it might even mask
out all the terrible aspects of extreme programming that alarm me.
I also must confess to a strong bias against the fashion for reusable code. To me, "re-editable
code" is much, much better than an untouchable black box or toolkit. I could go on and on about this.
If you’re totally convinced that reusable code is wonderful, I probably won’t be able to sway you
anyway, but you’ll never convince me that reusable code isn’t mostly a menace.
Here’s a question that you may well have meant to ask: Why is the new book called Volume 4 Fascicle
0, instead of Volume 4 Fascicle 1? The answer is that computer programmers will understand that I
wasn’t ready to begin writing Volume 4 of TAOCP at its true beginning point, because we
know that the initialization of a program can’t be written until the program itself takes shape.
So I started in 2005 with Volume 4 Fascicle 2, after which came Fascicles 3 and 4. (Think of
Star Wars, which began with Episode 4.)
(Two years ago, at Microsoft's TechEd in San Diego, I was involved in a conversation at an
after-conference event with Harry Pierson and Clemens Vasters, and as is typical when the three of
us get together, architectural topics were at the forefront of our discussions. An crowd gathered
around us, and it turned into an impromptu birds-of-a-feather session. The subject of object/relational
mapping technologies came up, and it was there and then that I first coined the phrase, "Object/relational
mapping is the Vietnam of Computer Science". In the intervening time, I've received numerous requests
to flesh out the discussion behind that statement, and given Microsoft's recent announcement regarding
"entity support" in ADO.NET 3.0 and the acceptance of the Java Persistence API as a replacement for
both EJB Entity Beans and JDO, it seemed time to do exactly that.)
... ... ...
Given, then, that objects-to-relational mapping is a necessity in a modern enterprise system,
how can anyone proclaim it a quagmire from which there is no escape? Again, Vietnam serves as a useful
analogy here--while the situation in South Indochina required a response from the Americans, there
were a variety of responses available to the Kennedy and Johson Administrations, including the same
kind of response that the recent fall of Suharto in Malaysia generated from the US, which is to say,
none at all. (Remember, Eisenhower and Dulles didn't consider South Indochina to be a part of the
Domino Theory in the first place; they were far more concerned about Japan and Europe.)
Several possible solutions present themselves to the O/R-M problem, some requiring some kind of
"global" action by the community as a whole, some more approachable to development teams "in the
trenches":
Abandonment. Developers simply give up on objects entirely, and return to a programming
model that doesn't create the object/relational impedance mismatch. While distasteful, in certain
scenarios an object-oriented approach creates more overhead than it saves, and the ROI simply
isn't there to justify the cost of creating a rich domain model. ([Fowler] talks about this to
some depth.) This eliminates the problem quite neatly, because if there are no objects, there
is no impedance mismatch.
Wholehearted acceptance. Developers simply give up on relational storage entirely,
and use a storage model that fits the way their languages of choice look at the world. Object-storage
systems, such as the
db4o project, solve the problem neatly by storing objects directly to disk, eliminating many
(but not all) of the aforementioned issues; there is no "second schema", for example, because
the only schema used is that of the object definitions themselves. While many DBAs will faint
dead away at the thought, in an increasingly service-oriented world, which eschews the idea of
direct data access but instead requires all access go through the service gateway thus encapsulating
the storage mechanism away from prying eyes, it becomes entirely feasible to imagine developers
storing data in a form that's much easier for them to use, rather than DBAs.
Manual mapping. Developers simply accept that it's not such a hard problem to solve
manually after all, and write straight relational-access code to return relations to the language,
access the tuples, and populate objects as necessary. In many cases, this code might even be automatically
generated by a tool examining database metadata, eliminating some of the principal criticism of
this approach (that being, "It's too much code to write and maintain").
Acceptance of O/R-M limitations. Developers simply accept that there is no way to efficiently
and easily close the loop on the O/R mismatch, and use an O/R-M to solve 80% (or 50% or 95%, or
whatever percentage seems appropriate) of the problem and make use of SQL and relational-based
access (such as "raw" JDBC or ADO.NET) to carry them past those areas where an O/R-M would create
problems. Doing so carries its own fair share of risks, however, as developers using an O/R-M
must be aware of any caching the O/R-M solution does within it, because the "raw" relational access
will clearly not be able to take advantage of that caching layer.
Integration of relational concepts into the languages. Developers simply accept that
this is a problem that should be solved by the language, not by a library or framework. For the
last decade or more, the emphasis on solutions to the O/R problem have focused on trying to bring
objects closer to the database, so that developers can focus exclusively on programming in a single
paradigm (that paradigm being, of course, objects). Over the last
several years, however, interest in "scripting" languages with far stronger set and list support,
like Ruby, has sparked the idea that perhaps another solution is appropriate: bring
relational concepts (which, at heart, are set-based) into mainstream programming languages, making
it easier to bridge the gap between "sets" and "objects". Work in this space has thus far been
limited, constrained mostly to research projects and/or "fringe" languages, but several interesting
efforts are gaining visibility within the community, such as functional/object hybrid languages
like Scala or F#, as well as direct integration into traditional O-O languages, such as the LINQ
project from Microsoft for C# and Visual Basic. One such effort that failed, unfortunately, was
the SQL/J strategy; even there, the approach was limited, not seeking to incorporate sets into
Java, but simply allow for embedded SQL calls to be preprocessed and translated into JDBC code
by a translator.
Integration of relational concepts into frameworks. Developers simply accept that this
problem is solvable, but only with a change of perspective. Instead of relying on language or
library designers to solve this problem, developers take a different view of "objects" that is
more relational in nature, building domain frameworks that are more directly built around relational
constructs. For example, instead of creating a Person class that holds its instance data directly
in fields inside the object, developers create a Person class that holds its instance data in
a RowSet (Java) or DataSet (C#) instance, which can be assembled with other RowSets/DataSets into
an easy-to-ship block of data for update against the database, or unpacked from the database into
the individual objects.
Note that this list is not presented in any particular order; while some are more attractive to others,
which are "better" is a value judgment that every developer and development team must make for themselves.
Just as it's conceivable that the US could have achieved some measure of "success" in Vietnam
had it kept to a clear strategy and understood a more clear relationship between commitment and results
(ROI, if you will), it's conceivable that the object/relational problem can be "won" through careful
and judicious application of a strategy that is celarly aware of its own limitations. Developers
must be willing to take the "wins" where they can get them, and not fall into the trap of the Slippery
Slope by looking to create solutions that increasingly cost more and yield less. Unfortunately, as
the history of the Vietnam War shows, even an awareness of the dangers of the Slippery Slope is often
not enough to avoid getting bogged down in a quagmire. Worse, it is a quagmire that is simply too
attractive to pass up, a Siren song that continues to draw development teams from all sizes of corporations
(including those at Microsoft, IBM, Oracle, and Sun, to name a few) against the rocks, with spectacular
results. Lash yourself to the mast if you wish to hear the song, but let the sailors row.
Endnotes
1 Later analysis by the principals involved--including then-Secretary of Defense Robert
McNamara--concluded that half of the attack never even took place.
2 It is perhaps the greatest irony of the war, that the man Fate selected to lead during
America's largest foreign entanglement was a leader whose principal focus was entirely aimed within
his own shores. Had circumstances not conspired otherwise, the hippies chanting "Hey, hey LBJ, how
many boys did you kill today" outside the Oval Office could very well have been Johnson's staunchest
supporters.
3 Ironically, encapsulation, for purposes of maintenance simplicity, turns out to be
a major motivation for almost all of the major innovations in Linguistic Computer Science--procedural,
functional, object, aspect, even relational technologies ([Date02]) and other languages all cite
"encapsulation" as major driving factors.
4 We could, perhaps, consider stored procedure languages like T-SQL or PL/SQL to be
"relational" programming languages, but even then, it's extremely difficult to build a UI in PL/SQL.
5 In this case, I was measuring Java RMI method calls against local method calls. Similar
results are pretty easily obtainable for SQL-based data access by measuring out-of-process calls
against in-process calls using a database product that supports both, such as Cloudscape/Derby or
HSQL (Hypersonic SQL).
References
[Fussell]: Foundations of Object Relational Mapping, by Mark L. Fussell, v0.2 (mlf-970703)
[Fowler]Patterns of Enterprise Application Architecture, by Martin Fowler
[Date04]: Introduction to Database Systems, 8th Edition, by Chris Date.
In the late 1990s, during the first dotcom bubble, there was a perception that a computer science
degree was a quick way of making money. The dotcom boom had venture capitalists throwing money at
the craziest schemes, just because they happened to involve the Internet. While not entirely grounded
in fact, this trend led to a perception that anyone walking out of a university with a computer science
degree would immediately find his pockets full of venture capital funding.
Then came the inevitable crash, and suddenly there were a lot more IT professionals than IT jobs.
Many of these people were the ones that just got into the industry to make a quick buck, but quite
a few were competent people now unemployed. This situation didn’t do much for the perception of computer
science as an attractive degree scheme.
Since the end of the first dotcom bubble, we’ve seen a gradual decline in the number of people
applying to earn computer science degrees. In the UK, many departments were able to prop up the decline
in local applicants by attracting more overseas students, particularly from Southeast Asia, by dint
of being considerably cheaper than American universities for those students wishing to study abroad.
This only slowed the drop, however, and some people are starting to ask whether computer science
is dying.
Computer Science and Telescopes
Part of the problem is a lack of understanding of exactly what computer science is. Even undergraduates
accepted into computer science courses generally have only the broadest idea of what the subject
entails. It’s hardly surprising, then, that people would wonder if the discipline is dying.
Even among those in computing-related fields, there’s a general feeling that computer science
is basically a vocational course, teaching programming. In January 2007, the British Computer Society
(BCS) published an article by Neil McBride of De Montfort University, entitled "The Death of Computing."
Although the content was of a lower quality than the average Slashdot troll post (which at least
tries to pretend that it’s raising a valid point) and convinced me that I didn’t want to be a member
of the BCS, it was nevertheless circulated quite widely. This article contained choice lines such
as the following: "What has changed is the need to know low-level programming or any programming
at all. Who needs C when there’s Ruby on Rails?"
Who needs C? Well, at least those people who want to understand something of what’s going on when
the Ruby on Rails program runs. An assembly language or two would do equally well.
The point of an academic degree, as opposed to a vocational qualification,
is to teach understanding, rather than skills—a point sadly lost on Dr. McBride
when he penned his article.
In attempting to describe computer science, Edsger Dijkstra claimed, "Computer science is no more
about computers than astronomy is about telescopes." I like this quote, but it’s often taken in the
wrong way by people who haven’t met many astronomers. When I was younger, I was quite interested
in astronomy, and spent a fair bit of time hanging around observatories and reading about the science
(as well as looking through telescopes). During this period, I learned a lot more about optics than
I ever did in physics courses at school. I never built my own telescope, but a lot of real astronomers
did, and many of the earliest members of the profession made considerable contributions to our understanding
of optics.
There’s a difference between a telescope builder and an astronomer, of course. A telescope builder
is likely to know more about the construction of telescopes and less about the motion of stellar
bodies. But both will have a solid understanding of what happens to light as it travels through the
lenses and bounces off the mirrors. Without this understanding, astronomy is very difficult.
The same principle holds true for computer science. A computer scientist may not fabricate her
own ICs, and may not write her own compiler and operating system. In the modern age, these things
are generally too complicated for a single person to do to a standard where the result can compete
with off-the-shelf components. But the computer scientist definitely will understand what’s happening
in the compiler, operating system, and CPU when a program is compiled and run.
A telescope is an important tool to an astronomer, and a computer is an important tool for a computer
scientist—but each is merely a tool, not the focus of study. For an astronomer, celestial bodies
are studied using a telescope. For a computer scientist, algorithms are studied using a computer.
Software and hardware are often regarded as being very separate concepts. This is a convenient
distinction, but it’s not based on any form of reality. The first computers had no software per se,
and needed to be rewired to run different programs. Modern hardware often ships with firmware—software
that’s closely tied to the hardware to perform special-purpose functions on general-purpose silicon.
Whether a task is handled in hardware or software is of little importance from a scientific perspective.
(From an engineering perspective, there are tradeoffs among cost, maintenance, and speed.) Either
way, the combination of hardware and software is a concrete instantiation of an algorithm, allowing
it to be studied.
As with other subjects, there are a lot of specializations within computer science. I tend to
view the subject as the intersection between three fields:
Mathematics
Engineering
Psychology
At the very mathematical end are computer scientists who study algorithms without the aid of a
computer, purely in the abstract. Closer to engineering are those who build large hardware and software
systems. In between are the people who use formal verification tools to construct these systems.
A computer isn’t much use without a human instructing it, and this is where the psychology is
important. Computers need to interact with humans a lot, and neither group is really suited to the
task. The reason that computers have found such widespread use is that they perform well in areas
where humans perform poorly (and vice versa). Trying to find a mechanism for describing something
that is understandable by both humans and computers is the role of the "human/computer interaction"
(HCI) subdiscipline within computer science. This is generally close to psychology.
HCI isn’t the only part of computer science related to psychology. As far back as 1950, Alan Turing
proposed the Turing Test as a method of determining whether an entity should be treated as intelligent.
It’s understandable that people who aren’t directly exposed to computer science would miss the
breadth of the discipline, associating it with something more familiar. One solution proposed for
this lack of vision is that of renaming the subject to "informatics." In principle, this is a good
idea, but the drawback is that it’s very difficult to describe someone as an "informatician" with
a straight face.
A software developer must be part writer and poet, part salesperson and public speaker, part artist
and designer, and always equal parts logic and empathy. The process of developing software differs
from organization to organization. Some are more "shoot from the hip" style, others, like my current
employer are much more careful and deliberate. In my 8 years of experience I've worked for 4 different
companies, each with their own process. But out of all of them, I've found these stages to be universally
applicable:
Dreaming and Shaping
A piece of software starts, before any code is written, as an idea or as a problem to be solved.
Its a constraint on a plant floor, a need for information, a better way to work, a way to communicate,
or a way to play. It is always tied to a human being ≈ their job, their entertainment┘ their needs.
A good process will explore this driving factor well. In the project I'm wrapping up now I felt strongly,
and my employer agreed with me, that to understand what we needed to do, we'd have to go to the customer
and feel their pain. We'd have to watch them work so we could understand their constraints. And we'd
have to explore the other solutions out there to the problem we were trying to solve.
Once you understand what you need to build, you still don't begin building it. Like an architect
or a designer, you start with a sketch, and you create a design. In software your design is expressed
in documents and in diagrams. Its not uncommon for the design process to take longer than the coding
process. As a part of your design, you have to understand your tools. Imagine an author who, at the
start of each book, needs to research every writing instrument on the market first. You have to become
knowledgeable about the strengths and weaknesses of each tool out there, because your choice of instrument,
as much as your design or skill as a programmer, can impact the success of your work. Then you review.
With marketing and with every subject matter expert and team member you can find who will have any
advice to give. You meet and you discuss and you refine your design, your pre-conceptions, and even
your selected tools until it passes the most intense scrutiny.
Once you have these things down, you have to be willing to give them up. You have to go back to the
customer, or the originator of the problem, and sell them your solution. You put on a sales hat and
you pitch what you've dreamt up┘ then wait with bated breath while they dissect your brain child.
If you've understood them, and the problem, you'll only need to make adjustments or adapt to information
you didn't previously have. Always you need to anticipate changes you didn't plan for ≈ they'll come
at you through-out the project.
Once you know how the solution is going to work, or sometimes even before then, you need to figure
out how people are going to work with your solution. Software that can't be understood can't be used,
so no matter how brilliant your design, if your interface isn't elegant and beautiful and intuitive,
your project is a failure.
I don't pick those adjectives lightly either. All of them are required, in balance. If its not elegant,
then its wasteful and you'll likely need to find a new job. If its not beautiful, then no one will
want to use it. And if its not intuitive, no one will be able to use it. The attention to detail
required of a good interface developer is on par with that of a good painter. Every dot, every stroke,
every color choice is significant.
To make something easy to use requires at least a basic understanding of human reactions, an awareness
of cognitive norms. People react to your software, often on a very base level. If you don't believe
me, think of the last time your computer crashed before you had a chance to save the last 2 hours
worth of an essay, or a game you were playing. What you put before your users must be easy to look
at so that they are comfortable learning it. It must anticipate their needs so that they don't get
frustrated. It must suggest its use, simply by being on the screen. And above all else, it must preserve
their focus and their effort.
So you paint, using PowerPoint, or Visio, or some other tool, your picture of what you think the
customer is going to want to use, and once again you don your sales hat and try to sell it to them.
Only, unlike a salesperson selling someone else's product, you are selling your own work, and are
inevitably emotionally-attached to it. Still, you know criticism is good, because it makes the results
better, so you force yourself to be logical about it.
Then finally, when your solution is approved, and your interface is understood, you can move on to
the really fun part of your job:
Prose and Poetry
A good sonnet isn't only identified by the letters or words on the page, but by the cadence, the
meter, the measure, the flow┘ a good piece of literature is beautiful because it is shaped carefully
yet communicates eloquently.
Code is no different. The purpose of code is to express a solution. A project consists of small stanzas,
called "Methods" or "Functions" depending on what language you use. Each of these verses must be
constructed in such a way that it is efficient, tightly-crafted, and effective. And like a poem,
there are rules that dictate how it should be shaped. There is beauty in a clever Function.
But the real beauty of code goes further than poetry. Because it re-uses itself. Maybe its more like
music, where a particular measure is repeated later in the song, and through its familiarity, it
adds to the shape of the whole piece. Functions are like that, in that they're called throughout
the software. Sometimes they repeat within themselves, in iterations, like the repeating patterns
you see in nature. fern.jpgAnd when the pieces are added up, each in itself a little work of art,
they make, if programmed properly, a whole that is much more than a sum. Its is an intertwined, and
constantly moving piece of art.
As programmers, we add things called "log messages" so that we can see these parts working together,
because without this output, the flow of the data through the different rungs and branches we put
together is so fluid that we can't even observe it and, like trying to fathom the number of stars
in the sky, it is difficult to even conceptualize visually the thousands of interactions a second
that your code is causing. And we need to do this, because next comes a Quality Assurance Engineer
(or QA) who tries to break your code, question your decisions, and generally force you to do better
than what you thought was your best.
I truly believe that code is an art form. One that only a small portion of the population can appreciate.
Sure anyone can walk into the Louvre and appreciate the end result of a Davinci or a Van Gogh, but
only a true artist or student of art can really understand the intricacy of the work behind it. Similarly,
most people can recognize a good piece of software when they use it (certainly anyone can recognize
a bad piece of software) but it takes a true artist, or at least an earnest student, to understand
just how brilliant ≈ or how wretched ≈ the work behind it is.
And always, as you weave your code, you have to be prepared to change it, to re-use it, to re-contain
it, to re-purpose it in ways that you can't have planned for. Because that is the nature of your
art form ≈ always changing and advancing.
Publishing and Documenting
Its been said that a scientist or researcher must "publish or perish." The same is true of a software
developer. A brilliant piece of code, if not used, is lost. Within months it will become obsolete,
or replaced, or usurped, and your efforts will become meaningless, save for the satisfaction of having
solved a problem on your own.
So after months of wearing jeans, chugging caffeine, cluttering your desk with sketches and reference
material, you clean yourself up, put on a nice pair of pants, comb your hair, and sell again. Although
most organizations have a sales force and a marketing department, a savvy customer will invariably
want technical details that a non-coder can't supply. As a lead developer on a project, it falls
to you to instill confidence, to speak articulately and passionately about the appropriateness and
worth of your solution. Again, as before, pride is a weakness here, because no matter how good you
are, someone will always ask if your software can do something it can't ≈ user's are never really
satisfied. So you think back to the design process, you remind them when they had a part in the decisions,
and you attempt to impress upon them respect for the solution you have now, while acknowledging that
there will always be a version 2.0.
And you write and you teach. Not so much in my current job, but in one previous, as a lead developer
it was my responsibility to educate people on the uses of our technology ≈ to come up with ways to
express the usefulness of a project without boring people with too many technical details. One of
the best parts of software development, a part that I miss since its not within my present job description,
is getting up in front of people ≈ once they've accepted your solution ≈ and teaching them how to
use it and apply it. Taking them beyond the basic functionality and showing them the tricks and shortcuts
and advanced features that you programmed in, not because anyone asked you for them, but because
you knew in your gut they should be there.
And Repeat┘
Then there's a party, a brief respite, where you celebrate your victory, congratulate those who've
worked on parallel projects, and express your deepest gratitude for your peers who've lent their
own particular area of expertise to your project┘ And you start again. Because like I'm sure any
sports team feels, you are only as good as your latest victory.
So do I fix computers? Often its easier or more expedient to hack together a solution to a problem
on my own ≈ certainly the I.T. Department is becoming something of a slow-moving dinosaur in an age
where computers aren't the size of buildings, and most of us are comfortable re-installing Windows
on our own ≈ but that's not a part of my job description.
No, I, like my peers, produce art. Functional, useful, but still beautiful, art. We are code poets,
and it is our prose that builds the tools people use every day.
However, unlike most other artists, we're usually paid pretty well for our work ;-)
Jonathan Wise writes to share with us an interesting bit of prose describing life as a software
engineer.
Interesting. No, wait, that other thing. Tedious.
A software developer must be part writer and poet, part salesperson and public speaker, part
artist and designer, and always equal parts logic and empathy.
No. You're a code monkey. Your poetry sucks, your writing sucks (to the point of your having
written "its for the best"), your salesmanship sucks (your article sells nobody on anything),
your public speaking is probably twice as melodramatic as your article and therefore sucks, your
art sucks, your designs are plagued with whining about having to make them, and you have never
experienced logic or empathy as long as you've lived.
Get over it. If you want to make your pathetic job seem more important than it is, Slashdot
isn't the place to do it. If you want to whine about being a code monkey, Slashdot is even less
appropriate of a place to do it. Just get up, get coffee, go to job, and have boring meeting with
boring manager Rob.
I can tell many of the posters did not bother to read the full article. Perhaps your excuse
is because his site crumbled under the "slash-dot effect", but still.
Having actually read what Jonathan Wise wrote, I thought he made quite a few good salient points.
Going from idea to finished product is as much about art as it is about science. There
is artistry involved at many different levels. Alas, the end-user only gets to directly see the
top layers of that art. The actual organization of the code, the algorithms used, to optimizations,
the kludges -- if any! --, the language constructs exploited, the database schema, if applicable,
all add to the art and elegance of a software.
Most of the beauty will forever lie hidden from any but those who dive into and interact directly
with the code itself. But the end-user will be presented with the form and function, and perhaps
can have a appreciation for the art behind the art.
Perhaps another term for what we do, which embraces all aspects of creating software, is
hacker. To the cognoscenti who appreciates the true meaning of that term and not the disparaging,
derogatory version the silly media created, "hacker" says it all. And is a greater thing than
just being a dry boring "engineer". After all, we are not building planes and bridges,
but creating "art" that just happens to be wicked useful and pay wicked well!
Flipping, charring, till operating, cleaning and eating the shit from customers while keeping
a smile on your face. All jobs require multiple skills.
Silly whining poster probably just got out of college and is used to mommy and daddy telling
him he's the greatest. Now in the real world he's just another bottom-of-the-pile programmer.
Life: get one!
(To expand on the ideas of your post)
A great deal of crap software is actually pushed out the door against the objections of the developers
that created it. Ultimately it comes down to marketing and PR and not the developers in most cases
as to when a particular piece of software is ready to ship. Also, as has been pointed out, people
would be unwilling to underwrite the cost of a theoretically "perfect" piece of software that
would never crash (barring hardware failure, or cosmic ray induced bit flipping), because given
the choice between a $50 piece of software that crashes once a week, or a $9000 piece of software
that crashes never, almost everyone is going to pick the $50 one and live with the occasional
crash. Does that mean developers like that? No, and most of them cringe whenever anything they
wrote so much as hiccups, but sometimes they're just not given the chance or the resources (or
clear documentation) they need to design it properly, because the bean counters know that the
$9k piece of software the developer dreams of will never sell, but that $50 one they're puttering
around with now is just about the right level already.
Also, as has been pointed out, people would be unwilling to underwrite the cost of a theoretically
"perfect" piece of software that would never crash (barring hardware failure, or cosmic ray induced
bit flipping), because given the choice between a $50 piece of software that crashes once a week,
or a $9000 piece of software that crashes never, almost everyone is going to pick the $50 one
and live with the occasional crash.
I really hate it when these discussions become black and white. Software quality is not a binary
value. It is a sliding scale with diminishing returns for effort put in, on which we are for the
most part still at the "dirt cheap" end.
I doubt I would want to pay the price of near-perfection. I'll leave that for the nuclear reactors,
medical facilities and space shuttles. But the cost of due diligence — which I'll assume to mean
taking reasonable, well-established, tried-and-tested steps to ensure quality in this context
— is not the factor of 180 you gave. It's probably not even a factor of 5, and that's today when
it's a relative overhead compared to those who don't bother.
What it would mean is having to actually follow reasonable development processes that
worked. No more buzzword kool-aid for you, Mr Engineer! It would mean hiring competent people
as senior technical staff instead of promoting substandard but slightly cheaper code monkeys,
and spending the time and money to train those working under these senior staff properly. It would
mean not letting sales and marketing staff dictate the schedules at the expense of even basic
quality control.
Of course, if everyone were doing this and the industry as a whole grew up, this wouldn't cost
much at all, because those same good practices actually make software development more efficient.
It's just that short-sighted managers with their eye on quarterly reports and personal bonuses
have an active incentive not to make the long-term investments necessary to reap those long-term
benefits.
The Massachusetts
Institute of Technology OpenCourseWare effort has been offering free lecture notes, exams, and
other resources from more than 1800 courses per its website. Some of their courses offer a substantial
amount of video and audio content. I remember stumbling across this resource via my employer's intranet
about a year ago. Frankly speaking, I didn't think the concept would go very far because you couldn’t
earn credit…
I was searching for a good UNIX course but I haven't found one yet. Surprisingly, it appears
MIT’s Linear Algebra
course is quite popular with the OpenCourseWare community.
By the way, I don't have any affiliation with OCW or any of the higher learning institutions mentioned.
How often have you found yourself arguing with another person, and they just don't seem to understand
you? Chances are they feel that you just don't understand them. You've fallen into the abstract
tar pit.
Abstract discussions are like abstract art--they can be very appealing, in part because you can
interpret the abstract art however you want to. People love to see what they want to see. But when
it comes to technical discussions, abstract discussions are dangerous. There is a good chance someone
listening to your abstract arguments will understand completely--but it won't be what you're trying
to convey. To understand the abstract, they're likely creating concrete examples in their head and
then arguing against your ideas based on these "private" concrete examples. The problem is, if these
concrete examples aren't shared, you'll get an argument about completely different examples and understandings.
I recently worked on a 5-week project where this was really clear. There was a small group who
had an idea they were trying to sell internally to get funding. Everyone else was feeling confused.
Just when they thought they understood these ideas, another concept came along that contradicted
what they thought they understood.
So we started a project using Expression Blend to create a "movie" of the idea. The first week
we brainstormed a lot, and then drew sketches by hand of what the different screens would look like.
We then presented these hand-drawn screens to a customer advisory board so we could get their feedback
and help us decide what we should focus on during the next week. We intentionally used hand-drawn
sketches in our discussions with customers so they wouldn't get bogged down in the small details
and would just focus on the big picture.
About half way through the project we started to create actual screen mockups and animate them
with Microsoft Expression Blend so it would look like a screen capture movie of an actual program--but
it was all smoke and mirrors.
During the project, the team that had come up with the ideas were constantly arguing with us and
saying we were asking the wrong questions. But when we had the final "movie" and showed it to them,
an interesting thing happened. The conversations changed from being abstract to concrete. The idea
team started to explain the details that we got wrong. And in the process, we discovered that we
had gotten most of their vision correct--we just differed in some of the details.
What's more, other people who had been confused completely got the idea after seeing the movie.
And again, the discussions were at a concrete level, so the discussions that came after seeing the
movie were far more productive.
Robert Martin has a post about how
10% of programmers
write 90% of the code. I think this is more-or-less accurate, but he seems to think that whether
a programmer is a member of the elite or not is an innate quality -- that there are good programmers
and poor programmers, and nobody ever moves between the two groups.
I have worked on projects where
I've been in the elite, and I've worked on projects where I've been in the middle, and on occasion
I even qualify as a Waste Of Space for a month or two. There are several factors that influence how
productive I am, personally.
First, the fewer developers in the group, the better. This is more than just being a big fish
in a little pond, it's about feeling responsible for the code. If I'm in a group of 20, my contribution
doesn't matter as much as if I'm in a group of four, so I don't care as much.
Second, distractions must be minimized. I enjoy helping people and answering questions, but they
really cut into my concentration. Unfortunately, it's rude to ask people to use email instead of
popping over for a visit or sending an instant message. Also, if I'm in an environment where I have
meetings every day, scheduled such that they break my time up into hour-long chunks, then my attention
is guaranteed to wander. For this reason, I tend to work best at night.
Third, history and familiarity with the code is very important. In code I've written and/or rewritten,
I'm extremely productive. In code that I'm unfamiliar with, I'm not. It also helps a lot if the person
who did write the code is willing to take the time to answer questions, without getting irritated.
I also find that different people write the same program in vastly different ways, and if you're
working on a codebase that was architected very differently from the way you would have done it,
it can be difficult to ever get comfortable.
Fourth, management is important. For example, I need to feel just enough time-pressure to make
me pay attention, but not so much that I give up in despair. I also need to get feedback as to how
my work is perceived by users (did it suck? did it rock?) otherwise my work starts to seem pointless
and I lose motivation.
Fifth, I find that my productivity has ceased to improve noticeably over time. For the first two
or three years it improved dramatically, but since then I seem to have plateaued. (I currently have
eight years of professional programming experience.)
If you work with someone who you think is being unproductive, perhaps you should spend some time
to find out why. You might find that a very small change in their work environment can lead to a
large improvement in their output. Maybe they just want to know that their code is actually useful
to someone. Maybe they need free snacks, so their blood sugar doesn't get too low in the afternoon.
Maybe the need to work in a quieter part of the office.
Discovering and addressing these kinds of things should be 50% of what a manager does. The other
50% should be facilitating communication both within the group and with other groups.
ZDNet Australia Technology vendors have taken a verbal hammering from the Australian
Defence Force (ADF) after one of its top procurement chiefs blamed the industry for most of its IT
project failures.
Kim Gillis, deputy chief executive officer of the ADF's procurement arm, the Defence Materiel
Organisation, said vendors set unrealistic expectations in tenders -- which was usually the cause
of those government IT projects failing.
Government tenders were often surrounded by "a conspiracy of optimism," said Gillis.
"Say I'm going to put in an IT system in 2000-and-whatever, and go out to industry and say 'I
want you to give me this type of capability'," he told delegates at the Gartner Symposium conference
in Sydney.
"And miraculously everybody who tenders comes in and says 'I can deliver that capability exactly
how you specified on that day'.
"And everybody starts believing that it's a reality," he said.
DMO project managers were given a simple instruction for dealing with such companies, according
to Gillis: "Don't believe it".
"Especially in the IT world, because I haven't seen in my experience in the last five years, an
IT project delivered on schedule," he said.
"They do happen, but I haven't seen them."
False promises have often led to government IT project failures, according to Gillis. However,
it was usually the government that wore the blame.
"The reality is the people who actually got it wrong are the industry participants who are actually
providing the services," he said. "Most of the time the fault lies not with what I've actually procured
but what they've actually told they're contracted for.
"At the end of the day what happens is, they've underperformed, [but] I take the hit," he said.
The DMO recently took steps to improve its procurement process by instigating the Procurement
Improvement Program (PIP). It includes a series of consultations with industry and changes the tendering
and contracting process.
Seems like a lot of that is just rehashing the same idea as surgical team described in the mythical
man-month but in some very incoherent and clumsy way ("pair programming", my God what a name -- "cluster
disaster" would be much better). "Pair programming" may help to stop programmers from waisting to
much time reading Slashdot :-). However, they seem to be able to compensate for this in a lot of
other ways.
First of all collective ownership diminishes individual responsibility and deliberately creating
huge communication overhead that diminishes each programmers productivity, but for more talented
members of the team it might be a dramatic drop ("state farm effect"). It's also very difficult to
get the right balance of personalities in the teams. If you pair a good programmer with a zealot
the zealot will be in a driving seat and the results will suffer. We all should periodically reread
Brooks famous The Mythical Man-Month. The one will
understand that XP does not bring anything new to the table. In essence this is a profanation of
Brook's idea of surgical teams in a perverse way mixed with Microsoft idea "one programmer -- one
tester".
In my opinion, extreme programming is extremely overrated. Some of the ideas, such as test-driven
development (although this concept is not restricted to XP), work well. Others, such as pair programming
just do not work in my opinion. Programmers like writers are solo beasts - putting two of these dragons
behind one keyboard is asking for trouble.
As a methodology XP is pure fantasy. It has been well known for a long time that big bang or waterfall
model. And it does not work well. The 'spiral' model (iterating out from the core of a small well
understood system) is a much better methodology popularized by Unix and in some form reemerged in
prototyping approach.
It is difficult to survive that amount of SE nonsense in a typical XP books. Readers beware.
Zealots defend XP "cluster disaster" as a kind of code review. But one computer and the same cubicle
idea is nonsense. It is unclear to me that communication improves it people share the same cubicle.
I like that is called Extreme because this is an example of extreme nonsense:
Sure, the name is some PR trick, but it makes sense because this technique is a reaction to all
those new trendy development process in which (when you push them to the extreme) you are spending
90% of your time in meetings or drawing graphs and then the code is supposed to magically write
itself and work perfectly on the first build because this technique is so well conceived.
It's called Extreme because they take some basically good ideas and push them to such extremes
as to be completely useless in the real world.
Like any kind of engineering, software engineering needs as much face to face collaboration as
possible.
To a point collaboration is important, but real SE requires careful planning by a talented architect
and clear interface definitions. XP -- almost to the point of being pathological -- attempts to avoid
planning as much as possible by substituting endless chatter and tremendous time wasting repeatedly
reimplementing what could have been done right the first time. (And yes, I know some things always
have to be reimplementation, but just because mistakes are inevitable doesn't mean they have to be
encouraged.)
Software engineering has an unfortunate tendency towards fanatical adherence to the latest fat that
is always sold as a silver bullet. Usually, this involves an implementation language backed by a
marketing push (Java); XP seems to be another programming fad built on unscrupulous books marketing
(structured programming extremism and verification bonanza was the first). And like verification
bonanza before it has found an abundant number of zealots may be due to its potential for snake oil
salesmen to earn a decent living at the expense of programmers suffering form it.
But all or nothing is not just an XP problem. Most SE methodologies are close to religions in
a sense that they all try to convince you that their way is best, if you deviate you are a heretic
and if it all fails then it's your problem for not following the rules. The "prophets" that "invent"
a methodology make their money from book publishing as well as teaching people how to do it are usually
pretty sleazy people. Why would they kill their cash cow even if they themselves understand that
they are wrong? In general, SE methodology advocates, like cult leaders cannot afford to correct
themselves.
If it's not clear, I meant to say that the CMM cert process is itself
subject to manipulation and fraud by the fact that anybody can submit any project (even one they
didn't do) for review to the people at Carnegie Mellon.
The "true believers" refers to those at CM and elsewhere who continue to preach "Software Engineering"
when the vast majority of its adherents cannot reliably or even consistently produce success from
project to project. None who has far more failures than successes when using their own methods
is in a position to lecture others on the "right way" to make successful software. Once again, the
emperor has no software project magic fix, and processes which demand innate skill cannot be mass-produced
in a population without that inate skill. Get over it.
a) Fix bugs. I spent the first 18 months of my involvement with the kernel just working bugs with
people on the mailing list. As a consequence I learned a good deal about a large amount of the kernel.
It is a great way to pick things up, and you're doing useful things at the same time.
b) Switch off your ego. Don't be rude to people. Learn to give in. Learn to change your ways and
perceptions to match those of the project which you are working in.
Sometimes it is difficult, and sometimes you end up believing that opportunities have been lost.
But in the long run, such sacrifices in the interest of the larger project are for the best.
CHACS
Publications for 2002 Heitmeyer, Constance L., "Software Cost Reduction," Encyclopedia of Software
Engineering, Two Volumes, John J. Marciniak, editor, ISBN: 0-471-02895-9, January 2002.
PostScript,
PDF
This article reviews Software Cost Reduction (SCR), a set of techniques for designing software
based on software engineering principles. The article focuses on the SCR techniques for constructing
and evaluating the requirements document, the work product built during the requirements stage of
software development, and the aspect of SCR that has been the topic of significant research. It also
briefly describes, and gives pointers to, the SCR approach to software design, focusing on the design
and documentation of the module structure, the module interfaces, and the uses hierarchy.
An alphabetical list of approximately 69 software
technologies is below. Browse to find the topic that interests you, or search on key words or phrases
to see a list of relevant technologies.
Acronyms and titles on processes are often a great source of hilarity as well meaning and inferior
feeling developers will go along with whatever you say just to seem like they're "in" with whatever
is hip and cool (despite the fact that the overwhelming majority of these things are fringe technologies
and processes that overwhelmingly people have no clue, rightly, about).
"Are you familiar with the CORAN 2 process?"
"Oh yeah...we use that a lot."
"Really? I use it in concert with UMX and ICBM VSLAM for maximum effect. We use Agile Extremities
processes with core-duplex programming methodologies"
"Ooooh...sounds awesome!"
"Yeah, it's good stuff. You really need quad-programming to and read once write never methodologies
to have quality code. As long as you use over the shoulder management with sycophant posterior gestulations
it all turns out good."
No-one can evaluate a method until they've done a few non-trivial projects with it, and that
takes years. If all the people who jumped on the RUP bandwagon then the XP bandwagon jump on this,
the industry's track record for delivering on time and within budget will only get worse.
Thus the importance of not adopting RUP, XP, etc. for real projects. These methodologies can be informative,
but it is better to create a simplified custom process for each project. It isn't very hard, and
the development team can establish the tool chain, conventions, and documentation methods that suits
them and the project's requirements best. Note that simplifying the process is critical, because
no one can seriously keep track of developing real software while trying to learn some baroque process.
Also, it is always critical to avoid proprietary documentation formats (e.g., basically anything
by Microsoft), trendy IDEs, acronyms of the month, and other neat but immature development toys.
Personally, I think taking the time to actually implement the dogma of RUP, XP, etc. is a waste of
time, when 1) no one really understands them, anyway and 2) they are like fashion: here today, gone
tomorrow, possibly reborn in 20 years, but who knows.
I had a former collegue that just couldn't grasp the use of design patterns, and thus despised
the concept. He also couldn't solve large scale programming problems and wasn't much of a software
architect in general. Then, the book anti-patterns comes out which he latched onto as some sort
of weapon against the evil design patterns.
Ya know, I'll bet he loved the "Golden Hammer" antipattern. For those in the cheap seats: the golden
hammer antipattern observes that people who get a shiny new tool tend to look at all new problems
as if the tool can solve them. I.e. if the only tool you've got is a hammer, all of your problems
start to look like nails.
This particular application of this anti-pattern (as a universal pattern debunking argument) is particularly
ironic.
This is exactly what's wrong with the universe, or at least the small part of the universe occupied
by software engineers.
What has all of our Functional, Object Oriented, Extreme Programmed, UML-based, XML compliant, Pattern-ed
or Anti-Pattern-ed flow charts in animated PowerPoint got us? Its got us a load of crap, thats what.
A load of crap. We re-org endlessly. We have more meetings. We write more Standard Operating Procedures.
We rewrite the coding standard. We switch languages, run times, operating systems, and libraries.
We refactor, re-code, re-work, re-design and re-plan. And we get a load of crap. We manage, and plan
and re-manage and re-plan, depending on what the winds of your upper management's whims dictate is
the "in" style for the day.
What should all of this tell us?
Software engineering is a practical craft. No amount of process will ever make up for proper training,
proper documentation, proper version control, and proper testing. Ever. And that's the way it is.
If you have good people, set them free. If you don't, spend a little money to train them to their
highest potential instead of trying to make them good cogs in a crappy buzzword wheel.
In the end, 99% of the work done by software engineers is just rearranging magnetic pixy dust on
some drive platter, or scattering the electrons in a flash or DRAM or SRAM cell. Most of our value
to the universe is just damned pixy dust. And it shouldn't be this difficult.
We don't need any more of this - we all just need to learn how to be practical craftsmen that get
*work* done.
...Some projects neglect to account for ancillary activities such
as the effort needed to create setup programs, convert data from previous versions, perform cutover
to new systems, perform compatibility testing, and other pesky kinds of work that take up more time
than we would like to admit
...For software projects, actively avoiding failure is as important
as emulating success. In many business contexts, the word "risk" isn't mentioned unless a project
is already in deep trouble. In software, a project planner who isn't using the word "risk" every
day and incorporating risk management into his plans probably isn't doing his job. As Tom Gilb says,
"If you do not actively attack the risks on your project, they will actively attack you."
... A close cousin to Deadly Sin #3 is reusing a generic plan someone
else created without applying your own critical thinking or considering your project's unique needs.
"Someone else's plan" usually arrives in the form of a book or methodology that a project planner
applies out of the box. Current examples include the Rational Unified Process, Extreme
Programming...
No outside expert can possibly understand a project's specific needs as well as the people directly
involved. Project planners should always tailor the "expert's" plan to their specific circumstances.
Fortunately, I've found that project planners who are aware enough of planning issues to read software
engineering books usually also have enough common sense to be selective about the parts of the prepackaged
plans that are likely to work for them.
...One common approach to planning is to create a plan early in the
project, then put it on the shelf and let it gather dust for the remainder of the project. As project
conditions change, the plan becomes increasingly irrelevant, so by mid-project the project runs free-form,
with no real relationship between the unchanging plan and project reality.
...Since planners do not have crystal balls, attempting to plan distant
activities in too much detail is an exercise in bureaucracy that is almost as bad as not planning
at all.
...I think of good project planning like driving at night with my car's headlights on. I might have
a road map that tells me how to get from City A to City B, but the distance I can see in detail in
my headlights is limited. On a medium-size or large project, macro-level project plans should be
mapped out end-to-end early in the project. Detailed, micro-level planning should generally be conducted
only a few weeks at a time and "just in time."
Chapter 4 "Feature Modeling" - One of the high points of the book. For those of
you who have been stymied by the inflexibility of UML, the authors introduce the technique of "feature
diagrams" which allow library designers to defer decisions like inheritance vs. aggregation until
later in the design. Potentially very useful.
By Charles Connell -
Published 9/7/2001
Just as house architects cannot design beautiful buildings
simply by including known elements that have worked elsewhere, good software design is more than
a collection of programming techniques that make sense on their own.
How do you know you NEED all these features? Have you prototyped the system yet? Have you
done your UML diagrams yet? I think that most of the languages you mentioned could fit the bill (of
course, this forum is heavily non-M$, so expect to see VB downplayed).
A while ago I did a comparative study of the graphical design tools on which UML is based. My
conclusion was that the idea was a pretty bad one and all of them became more trouble than they were
worth as they attempted to track every feature of C++ or such graphically. As the projects grew in
scope the diagrams became less and less useful.
I was recently forced to use UML, it appears to me to be worse in every important respect than
it's predecessors. In addition to the added complexity of now tracking multiple languages UML has
lost any coherence the input languages had. UML certainly does not fit well with XML Schema which
has a particularly complex data model. In the end I rolled my own graphical markup which people seemed
to like but it probably worked because I was using it to present a design rather than create one
and I absorbed a bunch of our coding conventions into the notation so the notation was for the subset
of XML Schema we used rather than every last feature.
I have noticed that UML and its ilk tend to appeal to people who are brought up on databases and
make the mistake of thinking the entity relationship model is useful. Predicate calculus and typed
set theory are vastly more powerful in my experience. If I see a bunch of schemas written in Z or
VDM I can understand them pretty quickly, I can also see the mapping from the schema to code.
As to the original question, it appears bogus to me. Much more important that what is the most
fashionable and feature rich language is what language is going to have support over the life of
the project. Java is a definite, C# is almost but not quite guaranteed to be arround.
I syspect that the question is not posed to get an honest reply. The question appears much more
likely to be intended to beat the drum for operator overloading.
As such it is worth remembering that Java abandoned operator overloading for good reasons. The
C++ approach was just too hard to optimize and lead to buggy and unreliable compilers and code. C#
may have got the mix right, I seem to recall there being some limited operator overloading mechanism
with a lot of restrictions.
Free software is gaining popularity, and media
attention. Open-source software is a kind of free software that is distributed not only in binary,
but also in source code form. As there are lots of successful open-source software development
projects, in terms of quality as well as popularity, it feels natural to ask certain questions
on how these development projects actually works.
This paper takes on an explorative approach to open-source
software development methodology, examining several projects and analyzing them in context of
widely known software development methodologies such as life-cycle, prototyping and the spiral
model. The authors argue that these projects don't fit those methodologies, and that a model describing
version-management oriented development is a good description of the methodology used in open-source
projects.
Download
The paper is written by Fredrik Stöckel
and Ludvig A. Norin.
There is an Adobe Acrobat version (148
kb) as well as a Postscript version (267
kb) availible. There are a few empty pages in these files, as the paper is formatted for
double-sided printing. The paper size is Europan, A4. If you prefer, there is a rather ugly HTML version availible
as well. As if this really wasn't enough, we're keeping an ISO-Latin-1 ASCII version of
the paper online, too! You may send comments to Fredrik Stöckel
or Ludvig A. Norin.
A simplistic views on complex architectural problem.
Recent glitches have knocked out AT&T's (T)
high-speed phone and data networks and interrupted emergency service in New York. ''Software easily
rates among the most poorly constructed, unreliable, and least maintainable technological artifacts
invented by man,'' says Paul Strassmann, a former chief information officer for Xerox Corp. (XRX)
and for the Defense Dept who now heads a private consulting company. Most software executives share
at least some of this dismay.
To be fair, software also shares credit for the most spellbinding advances of the 20th century. In
today's world, banks, hospitals, and space missions would be inconceivable without it. The challenge
of the next century will be to exterminate the most pernicious bugs and to bring software quality
to the same level we expect from cars, televisions, and other relatively dependable hunks of hardware.
...MILITARY VICTORIES. The U.S. Defense Dept. is also
eager to codify software's basic laws. That's because its weapons require frequent software upgrades
in order to stay in service for decades. To trim these costs, the government wants to capture the
essence of its weapons in software models so simulations can determine what changes are needed and
how best to implement them. The Defense Advanced Research Projects Agency is funding work at some
50 research labs under a four-year-old project called Evolutionary Design of Complex Software--and
it is starting to rack up victories.
For example, Xerox Corp.'s Palo Alto Research Center recently produced a mathematical model for ''constraint-based
scheduling.'' This deals with regulating the sequence of operations inside a copier or a jet plane.
''Historically, this has always been an extremely complex part of the code--and extremely hard to
get right,'' says Gregor J. Kiczales, a senior scientist at PARC. ''Now we can generate this code
automatically.''
... ... ...
It may be a long time, however, before these and other research approaches trickle into the commercial
software market. Meanwhile, software companies have shown little inclination to grapple with the
factors that drag quality down. Indeed, the drift may be in the opposite direction. For months, software
publishers have quietly been lobbying for legislation known as the Uniform Computer Information Transactions
Act, or UCITA. Its impact would be to strip from consumers the means to take legal action when software
failed to meet reasonable expectations for quality. ''In the service of protecting the worst of the
publishers, UCITA will change the economics of defective products for the field as a whole,'' says
Cem Kaner, a Silicon Valley-based attorney specializing in software quality.
Certainly, the pressures that lead to poor software quality are likely to persist. And users bear
part of the responsibility. ''The customer wants new features,'' says Intuit's Scott Cook. Bugs,
he says, ''are the dark side of rapid innovation and entrepreneurship.'' The last thing the software
industry needs, however, is a blame game. It must find the fixes that will bring software back into
the light.
Although Linux began as a desktop operating system for techie enthusiasts, its most widespread
adoption in corporations to date has been in servers. Several new initiatives, however, are seeking
to balance the equation.
Corel Corp. and the GNU Project are separately developing new GUIs for the operating system that
they hope will increase its ease of use and, in turn, its mass appeal.
Corel threw its weight behind desktop Linux earlier this month when it announced it will develop
a new GUI to go with its own brand of Linux. The Ottawa-based software developer, best known for
CorelDraw and WordPerfect, announced plans to develop the Linux operating system and interface, code-named
Corel Desktop Linux, at the recent LinuxWorld Conference and Expo.
The company intends for the interface to be similar in look, feel and function to Windows and
to be easy to install. The interface, slated to ship in November, will, for example, offer automatic
hardware detection and configuration and support for Windows networking. Corel will bundle its Java
virtual machine and Wine, an emulator that runs Windows applications on Linux, with Corel Desktop
Linux.
"To make the desktop happen [for Linux] in a big way, it's got to be just like Windows. People
have gotten used to the idea of a very-easy-to-use interface," said Michael Cowpland, Corel's president,
during his keynote address at LinuxWorld. "We hope to be able to offer, in a one-stop-shopping arrangement,
the ability of any PC maker to have a Linux computer in the $500 range ... ready to roll without
any tax to Redmond."
A graphical interface is key to Linux's broad acceptance, said Steve Durst, a consultant to the
Air Force Research Laboratory, in Bedford, Mass. Durst, who runs Linux on several machines, said
it's just a matter of time before the operating system begins to gain a share of the desktop.
"A year ago, we wouldn't have been talking about [using Linux] openly, even as router and server
operating systems. Now it's getting front-page press," he said. "Small corporations may very well
adopt Linux. For big corporations, it's conceivable, but I don't think it's likely in the next few
years."
Similar to Corel's GUI is GNOME (GNU Network Object Model Environment) 1.0 . GNOME, released by
the GNU Project, part of the Boston-based Free Software Foundation, this month for Linux and several
Unix variants, provides users with a graphical interface and developers with a set of specifications
for writing graphical applications for Linux.
Another important area IT managers will look at when evaluating Linux for desktop use will be
application availability.
There are a number of current applications that are popular with Linux users that could be adopted
by corporations, including Star Division Corp.'s StarOffice 5.0 and Corel's WordPerfect 8 for Linux.
Corel is also working on versions of its Quattro Pro spreadsheet as well as a port of its entire
WordPerfect Office 2000 suite to Linux.
While emulators such as Wine should allow Linux to run just about any Windows application, there
are a number of applications available for Linux desktops.
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.

edAâ'qa mortâ'oraâ'y Dec 8, 2018 ã"1 min read


David Collier-Brown on 2017-12-18 at 17:38:05 said: Andrew Forber quasily-accidentally created a similar truth: any sufficiently complex program using overlays will eventually contain an implementation of virtual memory. Reply ↓
Archives
Eric Conspiracy
Anti-Idiotarian Manifesto
© 2019 Armed and Dangerous Admired Theme




























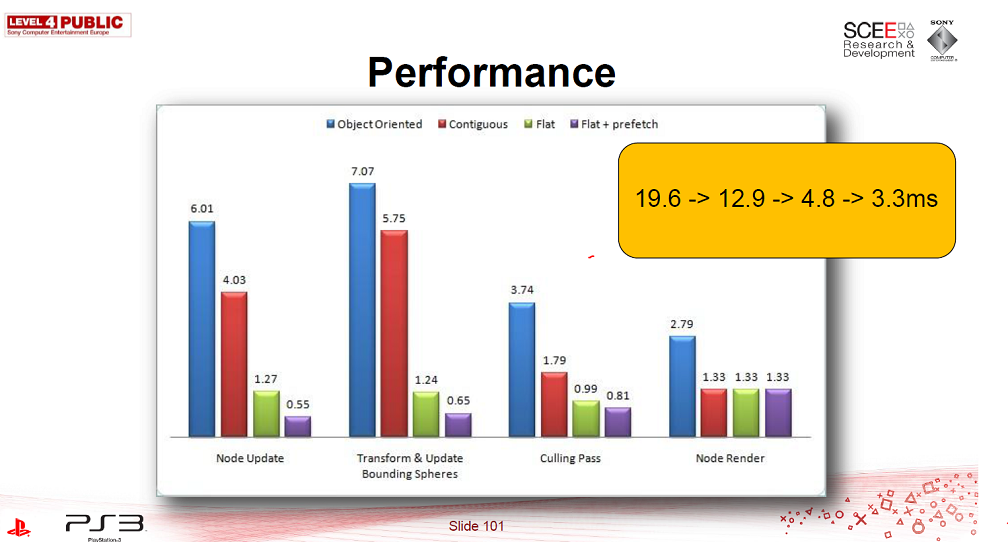
 OV-099
OV-099