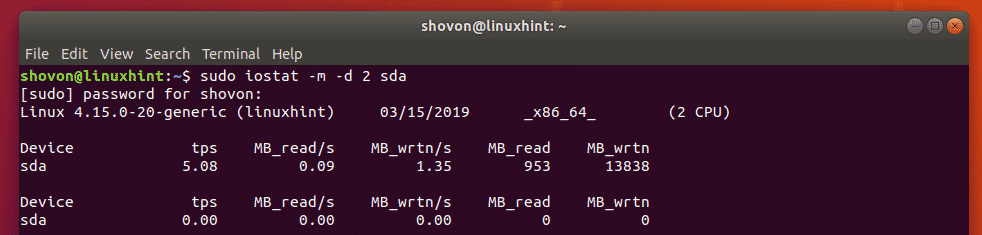
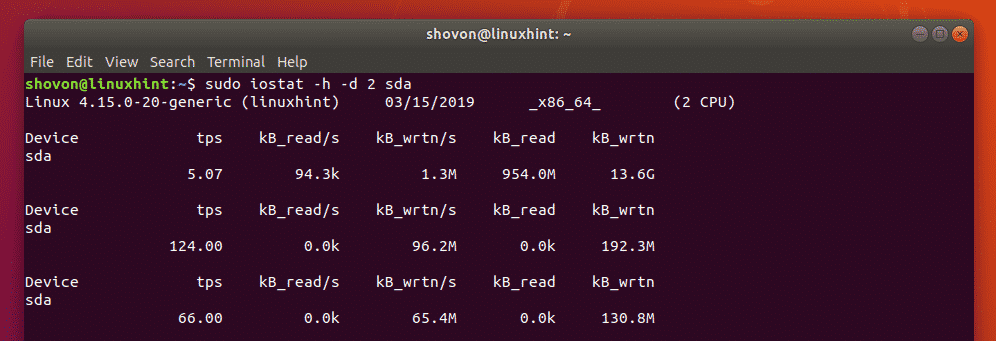
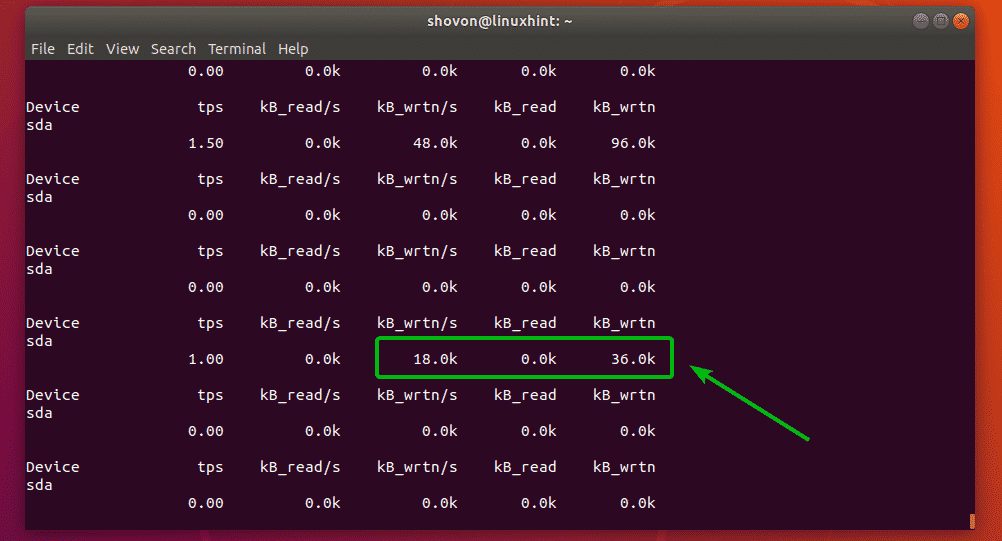
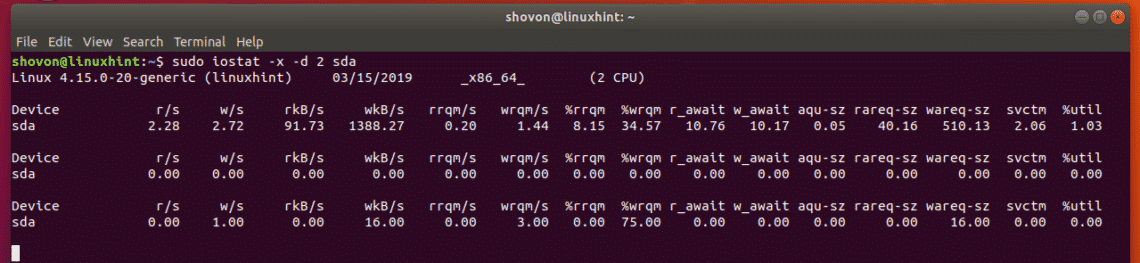
There are several large collection of Linux Tips on the Internet. Those are mixture
of obsolete and useful tips so some work need to be done selecting valuable info
from junk. Among them:
We had a client that had an OLD fileserver box, a Thecus N4100PRO. It was completely dust-ridden and the power supply had burned
out.
Since these drives were in a RAID configuration, you could not hook any one of them up to a windows box, or a linux box to see
the data. You have to hook them all up to a box and reassemble the RAID.
We took out the drives (3 of them) and then used an external SATA to USB box to connect them to a Linux server running CentOS.
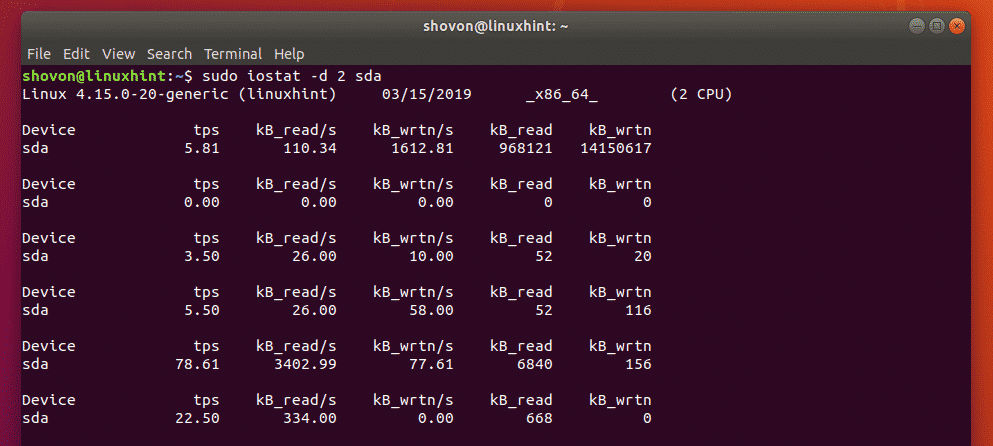
You can use parted to see what drives are now being seen by your linux system:
parted -l | grep 'raid\|sd'
Then using that output, we assembled the drives into a software array:
mdadm -A /dev/md0 /dev/sdb2 /dev/sdc2 /dev/sdd2
If we tried to only use two of those drives, it would give an error, since these were all in a linear RAID in the Thecus box.
If the last command went well, you can see the built array like so:
root% cat /proc/mdstat
Personalities : [linear]
md0 : active linear sdd2[0] sdb2[2] sdc2[1]
1459012480 blocks super 1.0 128k rounding
Note the personality shows the RAID type, in our case it was linear, which is probably the worst RAID since if any one drive fails,
your data is lost. So good thing these drives outlasted the power supply! Now we find the physical volume:
pvdisplay /dev/md0
Gives us:
-- Physical volume --
PV Name /dev/md0
VG Name vg0
PV Size 1.36 TB / not usable 704.00 KB
Allocatable yes
PE Size (KByte) 2048
Total PE 712408
Free PE 236760
Allocated PE 475648
PV UUID iqwRGX-zJ23-LX7q-hIZR-hO2y-oyZE-tD38A3
Then we find the logical volume:
lvdisplay /dev/vg0
Gives us:
-- Logical volume --
LV Name /dev/vg0/syslv
VG Name vg0
LV UUID UtrwkM-z0lw-6fb3-TlW4-IpkT-YcdN-NY1orZ
LV Write Access read/write
LV Status NOT available
LV Size 1.00 GB
Current LE 512
Segments 1
Allocation inherit
Read ahead sectors 16384
-- Logical volume --
LV Name /dev/vg0/lv0
VG Name vg0
LV UUID 0qsIdY-i2cA-SAHs-O1qt-FFSr-VuWO-xuh41q
LV Write Access read/write
LV Status NOT available
LV Size 928.00 GB
Current LE 475136
Segments 1
Allocation inherit
Read ahead sectors 16384
We want to focus on the lv0 volume. You cannot mount yet, until you are able to lvscan them.
ACTIVE '/dev/vg0/syslv' [1.00 GB] inherit
ACTIVE '/dev/vg0/lv0' [928.00 GB] inherit
Now we can mount with:
mount /dev/vg0/lv0 /mnt
And viola! We have our data up and accessable in /mnt to recover! Of course your setup is most likely going to look different
from what I have shown you above, but hopefully this gives some helpful information for you to recover your own data.
I've found a disturbing
trend in GNU/Linux, where largely unaccountable cliques of developers unilaterally decide to make fundamental changes to the way
it works, based on highly subjective and arrogant assumptions, then forge ahead with little regard to those who actually use the
software, much less the well-established principles upon which that OS was originally built. The long litany of examples includes
Ubuntu Unity ,
Gnome Shell ,
KDE 4 , the
/usr partition ,
SELinux ,
PolicyKit ,
Systemd ,
udev and
PulseAudio , to name a few.
The broken features, creeping bloat, and in particular the unhealthy tendency toward more monolithic, less modular code in certain
Free Software projects, is a very serious problem, and I have a very serous opposition to it. I abandoned Windows to get away from
that sort of nonsense, I didn't expect to have to deal with it in GNU/Linux.
Clearly this situation is untenable.
The motivation for these arbitrary changes mostly seems to be rooted in the misguided concept of "popularity", which makes no
sense at all for something that's purely academic and non-commercial in nature. More users does not equal more developers. Indeed
more developers does not even necessarily equal more or faster progress. What's needed is more of the right sort of developers,
or at least more of the existing developers to adopt the right methods.
This is the problem with distros like Ubuntu, as the most archetypal example. Shuttleworth pushed hard to attract more users,
with heavy marketing and by making Ubuntu easy at all costs, but in so doing all he did was amass a huge burden, in the form of a
large influx of users who were, by and large, purely consumers, not contributors.
As a result, many of those now using GNU/Linux are really just typical Microsoft or Apple consumers, with all the baggage that
entails. They're certainly not assets of any kind. They have expectations forged in a world of proprietary licensing and commercially-motivated,
consumer-oriented, Hollywood-style indoctrination, not academia. This is clearly evidenced by their
belligerently hostile attitudes toward the GPL, FSF,
GNU and Stallman himself, along with their utter contempt for security and other well-established UNIX paradigms, and their unhealthy
predilection for proprietary software, meaningless aesthetics and hype.
Reading the Ubuntu forums is an exercise in courting abject despair, as one witnesses an ignorant hoard demand GNU/Linux be mutated
into the bastard son of Windows and Mac OS X. And Shuttleworth, it seems, is
only too happy
to oblige , eagerly assisted by his counterparts on other distros and upstream projects, such as Lennart Poettering and Richard
Hughes, the former of whom has somehow convinced every distro to mutate the Linux startup process into a hideous
monolithic blob , and the latter of whom successfully managed
to undermine 40 years of UNIX security in a single stroke, by
obliterating the principle that unprivileged
users should not be allowed to install software system-wide.
GNU/Linux does not need such people, indeed it needs to get rid of them as a matter of extreme urgency. This is especially true
when those people are former (or even current) Windows programmers, because they not only bring with them their indoctrinated expectations,
misguided ideologies and flawed methods, but worse still they actually implement them , thus destroying GNU/Linux from within.
Perhaps the most startling example of this was the Mono and Moonlight projects, which not only burdened GNU/Linux with all sorts
of "IP" baggage, but instigated a sort of invasion of Microsoft "evangelists" and programmers, like a Trojan horse, who subsequently
set about stuffing GNU/Linux with as much bloated, patent
encumbered garbage as they could muster.
I was part of a group who campaigned relentlessly for years to oust these vermin and undermine support for Mono and Moonlight,
and we were largely successful. Some have even suggested that my
diatribes ,
articles and
debates (with Miguel
de Icaza and others) were instrumental in securing this victory, so clearly my efforts were not in vain.
Amassing a large user-base is a highly misguided aspiration for a purely academic field like Free Software. It really only makes
sense if you're a commercial enterprise trying to make as much money as possible. The concept of "market share" is meaningless for
something that's free (in the commercial sense).
Of course Canonical is also a commercial enterprise, but it has yet to break even, and all its income is derived through support
contracts and affiliate deals, none of which depends on having a large number of Ubuntu users (the Ubuntu One service is cross-platform,
for example).
You can achieve the same result by replacing the backticks with the $ parens, like in the example below:
⯠echo "There are $(ls | wc -l) files in this directory"
There are 3 files in this directory
Here's another example, still very simple but a little more realistic. I need to troubleshoot something in my network connections,
so I decide to show my total and waiting connections minute by minute.
It doesn't seem like a huge difference, right? I just had to adjust the syntax. Well, there are some implications involving
the two approaches. If you are like me, who automatically uses the backticks without even blinking, keep reading.
Deprecation and recommendations
Deprecation sounds like a bad word, and in many cases, it might really be bad.
When I was researching the explanations for the backtick operator, I found some discussions about "are the backtick operators
deprecated?"
The short answer is: Not in the sense of "on the verge of becoming unsupported and stop working." However, backticks should be
avoided and replaced by the $ parens syntax.
The main reasons for that are (in no particular order):
1. Backticks operators can become messy if the internal commands also use backticks.
You will need to escape the internal backticks, and if you have single quotes as part of the commands or part of the results,
reading and troubleshooting the script can become difficult.
If you start thinking about nesting backtick operators inside other backtick operators, things will not work as expected
or not work at all. Don't bother.
2. The $ parens operator is safer and more predictable.
What you code inside the $ parens operator is treated as a shell script. Syntactically it is the same thing as
having that code in a text file, so you can expect that everything you would code in an isolated shell script would work here.
Here are some examples of the behavioral differences between backticks and $ parens:
If you compare the two approaches, it seems logical to think that you should always/only use the $ parens approach.
And you might think that the backtick operators are only used by
sysadmins from an older era .
Well, that might be true, as sometimes I use things that I learned long ago, and in simple situations, my "muscle memory" just
codes it for me. For those ad-hoc commands that you know that do not contain any nasty characters, you might be OK using backticks.
But for anything that is more perennial or more complex/sophisticated, please go with the $ parens approach.
The ability for a Bash script to handle command line options such as -h to
display help gives you some powerful capabilities to direct the program and modify what it
does. In the case of your -h option, you want the program to print the help text
to the terminal session and then quit without running the rest of the program. The ability to
process options entered at the command line can be added to the Bash script using the
while command in conjunction with the getops and case
commands.
The getops command reads any and all options specified at the command line and
creates a list of those options. The while command loops through the list of
options by setting the variable $options for each in the code below. The case
statement is used to evaluate each option in turn and execute the statements in the
corresponding stanza. The while statement will continue to assess the list of
options until they have all been processed or an exit statement is encountered, which
terminates the program.
Be sure to delete the help function call just before the echo "Hello world!" statement so
that the main body of the program now looks like this.
############################################################
############################################################
# Main program #
############################################################
############################################################
############################################################
# Process the input options. Add options as needed. #
############################################################
# Get the options
while getopts ":h" option; do
case $option in
h) # display Help
Help
exit;;
esac
done
echo "Hello world!"
Notice the double semicolon at the end of the exit statement in the case option for
-h . This is required for each option. Add to this case statement to delineate the
end of each option.
Testing is now a little more complex. You need to test your program with several different
options -- and no options -- to see how it responds. First, check to ensure that with no
options that it prints "Hello world!" as it should.
[student@testvm1 ~]$ hello.sh
Hello world!
That works, so now test the logic that displays the help text.
[student@testvm1 ~]$ hello.sh -h
Add a description of the script functions here.
Syntax: scriptTemplate [-g|h|t|v|V]
options:
g Print the GPL license notification.
h Print this Help.
v Verbose mode.
V Print software version and exit.
That works as expected, so now try some testing to see what happens when you enter some
unexpected options.
[student@testvm1 ~]$ hello.sh -x
Hello world!
[student@testvm1 ~]$ hello.sh -q
Hello world!
[student@testvm1 ~]$ hello.sh -lkjsahdf
Add a description of the script functions here.
Syntax: scriptTemplate [-g|h|t|v|V]
options:
g Print the GPL license notification.
h Print this Help.
v Verbose mode.
V Print software version and exit.
[student@testvm1 ~]$
Handling invalid options
The program just ignores the options for which you haven't created specific responses
without generating any errors. Although in the last entry with the -lkjsahdf
options, because there is an "h" in the list, the program did recognize it and print the help
text. Testing has shown that one thing that is missing is the ability to handle incorrect input
and terminate the program if any is detected.
You can add another case stanza to the case statement that will match any option for which
there is no explicit match. This general case will match anything you haven't provided a
specific match for. The case statement now looks like this.
while getopts ":h" option; do
case $option in
h) # display Help
Help
exit;;
\?) # Invalid option
echo "Error: Invalid option"
exit;;
esac
done
This bit of code deserves an explanation about how it works. It seems complex but is fairly
easy to understand. The while – done structure defines a loop that executes once for each
option in the getopts – option structure. The ":h" string -- which requires the quotes --
lists the possible input options that will be evaluated by the case – esac structure.
Each option listed must have a corresponding stanza in the case statement. In this case, there
are two. One is the h) stanza which calls the Help procedure. After the Help procedure
completes, execution returns to the next program statement, exit;; which exits from the program
without executing any more code even if some exists. The option processing loop is also
terminated, so no additional options would be checked.
Notice the catch-all match of \? as the last stanza in the case statement. If any options
are entered that are not recognized, this stanza prints a short error message and exits from
the program.
Any additional specific cases must precede the final catch-all. I like to place the case
stanzas in alphabetical order, but there will be circumstances where you want to ensure that a
particular case is processed before certain other ones. The case statement is sequence
sensitive, so be aware of that when you construct yours.
The last statement of each stanza in the case construct must end with the double semicolon (
;; ), which is used to mark the end of each stanza explicitly. This allows those
programmers who like to use explicit semicolons for the end of each statement instead of
implicit ones to continue to do so for each statement within each case stanza.
Test the program again using the same options as before and see how this works now.
The Bash script now looks like this.
#!/bin/bash
############################################################
# Help #
############################################################
Help()
{
# Display Help
echo "Add description of the script functions here."
echo
echo "Syntax: scriptTemplate [-g|h|v|V]"
echo "options:"
echo "g Print the GPL license notification."
echo "h Print this Help."
echo "v Verbose mode."
echo "V Print software version and exit."
echo
}
############################################################
############################################################
# Main program #
############################################################
############################################################
############################################################
# Process the input options. Add options as needed. #
############################################################
# Get the options
while getopts ":h" option; do
case $option in
h) # display Help
Help
exit;;
\?) # Invalid option
echo "Error: Invalid option"
exit;;
esac
done
echo "hello world!"
Be sure to test this version of your program very thoroughly. Use random input and see what
happens. You should also try testing valid and invalid options without using the dash (
- ) in front.
Using options to enter data
First, add a variable and initialize it. Add the two lines shown in bold in the segment of
the program shown below. This initializes the $Name variable to "world" as the default.
<snip>
############################################################
############################################################
# Main program #
############################################################
############################################################
# Set variables
Name="world"
############################################################
# Process the input options. Add options as needed. #
<snip>
Change the last line of the program, the echo command, to this.
echo "hello $Name!"
Add the logic to input a name in a moment but first test the program again. The result
should be exactly the same as before.
# Get the options
while getopts ":hn:" option; do
case $option in
h) # display Help
Help
exit;;
n) # Enter a name
Name=$OPTARG;;
\?) # Invalid option
echo "Error: Invalid option"
exit;;
esac
done
$OPTARG is always the variable name used for each new option argument, no matter how many
there are. You must assign the value in $OPTARG to a variable name that will be used in the
rest of the program. This new stanza does not have an exit statement. This changes the program
flow so that after processing all valid options in the case statement, execution moves on to
the next statement after the case construct.
#!/bin/bash
############################################################
# Help #
############################################################
Help()
{
# Display Help
echo "Add description of the script functions here."
echo
echo "Syntax: scriptTemplate [-g|h|v|V]"
echo "options:"
echo "g Print the GPL license notification."
echo "h Print this Help."
echo "v Verbose mode."
echo "V Print software version and exit."
echo
}
############################################################
############################################################
# Main program #
############################################################
############################################################
# Set variables
Name="world"
############################################################
# Process the input options. Add options as needed. #
############################################################
# Get the options
while getopts ":hn:" option; do
case $option in
h) # display Help
Help
exit;;
n) # Enter a name
Name=$OPTARG;;
\?) # Invalid option
echo "Error: Invalid option"
exit;;
esac
done
echo "hello $Name!"
Be sure to test the help facility and how the program reacts to invalid input to verify that
its ability to process those has not been compromised. If that all works as it should, then you
have successfully learned how to use options and option arguments.
convert2rhel is an RPM package which contains a Python2.x script written in completely
incomprehensible over-modulazed manner. Python obscurantism in action ;-)
Looks like a "backbox" tool unless you know Python well. As such it is dangerous to rely upon.
Ensure that you have an access to RHEL packages through custom repositories configured
in the /etc/yum.repos.d/ directory and pointing, for example, to RHEL ISO , FTP, or
HTTP. Note that the OS will be converted to the version of RHEL provided by these
repositories. Make sure that the RHEL minor version is the same or later than the original
OS minor version to prevent downgrading and potential conversion failures. See
instructions on how to configure a repository .
Recommended: Update packages from the original OS to the latest version that is
available in the repositories accessible from the system, and restart the
system:
Without performing this step, the rollback feature will not work
correctly, and exiting the conversion in any phase may result in a dysfunctional
system.
IMPORTANT:
Before starting the conversion process, back up your system.
NOTE: Packages that are available only in the original distribution and do not have
corresponding counterparts in RHEL repositories, or third-party packages, which
originate neither from the original Linux distribution nor from RHEL, are left
unchanged.
Before Convert2RHEL starts replacing packages from the original
distribution with RHEL packages, the following warning message is
displayed:
The tool allows rollback of any action until this point.
By continuing all further changes on the system will need to be reverted manually by the user, if necessary.
Changes made by Convert2RHEL up to this point can be automatically
reverted. Confirm that you wish to proceed with the conversion process.
Wait until Convert2RHEL installs the RHEL packages.
NOTE: After a successful conversion, the utility prints out the
convert2rhel command with all arguments necessary for running
non-interactively. You can copy the command and use it on systems with a similar
setup.
At this point, the system still runs with the original distribution kernel loaded in
RAM. Reboot the system to boot into the newly installed RHEL kernel.
Remove third-party packages from the original OS that remained unchanged (typically
packages that do not have a RHEL counterpart). To get a list of such packages,
use:
# yum list extras --disablerepo="*" --enablerepo=<RHEL_RepoID>
If necessary, reconfigure system services after the conversion.
TroubleshootingLogs
The Convert2RHEL utility stores the convert2rhel.log file in
the /var/log/convert2rhel/ directory. Its content is identical to what is
printed to the standard output.
The output of the rpm -Va command, which is run automatically unless the
--no-rpm-va option is used, is stored in the
/var/log/convert2rhel/rpm_va.log file for debugging purposes.
The Link to "instructions on how to configure a repository." is not working (404).
Also it would be great if the tool installs the repos that are needed for the conversion
itself.
Thanks, Stefan, for pointing that out. Before we fix that, you can use this link:
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/system_administrators_guide/ch-yum#sec-Setting_repository_Options
Regarding the second point of yours - this article explains how to use convert2rhel
with custom repositories. Since Red Hat does not have the RHEL repositories public, we
leave it up to the user where they obtain the RHEL repositories. For example, when they
have a subscribed RHEL system in their company, they can create a mirror of the RHEL
repositories available on that system by following this guide:
https://access.redhat.com/solutions/23016.
However, convert2rhel is also able to connect to Red Hat Subscription Management
(RHSM), and for that you need to provide the subscription-manager package and pass the
subscription credentials to convert2rhel. Then the convert2rhel chooses the right
repository to use for the conversion. You can find the step by step guide for that in
https://www.redhat.com/en/blog/converting-centos-rhel-convert2rhel-and-satellite.
We are working on improving the user experience related to the use of RHSM.
It might surprise you to know that if you
forget to flip the network interface card (NIC) switch to the ON position (shown in the image below) during
installation, your Red Hat-based system will boot with the NIC disconnected:
Image
Setting the NIC to the ON position during installation.
More Linux resources
But, don't worry, in this article I'll
show you how to set the NIC to connect on every boot and I'll show you how to disable/enable your NIC on demand.
If your NIC isn't enabled at startup, you
have to edit the
/etc/sysconfig/network-scripts/ifcfg-NIC_name
file,
where NIC_name is your system's NIC device name. In my case, it's enp0s3. Yours might be eth0, eth1, em1, etc.
List your network devices and their IP addresses with the
ip
addr
command:
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:81:d0:2d brd ff:ff:ff:ff:ff:ff
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:4e:69:84 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:4e:69:84 brd ff:ff:ff:ff:ff:ff
Note that my primary NIC (enp0s3) has no
assigned IP address. I have virtual NICs because my Red Hat Enterprise Linux 8 system is a VirtualBox virtual
machine. After you've figured out what your physical NIC's name is, you can now edit its interface configuration
file:
$ sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
and change the
ONBOOT="no"
entry
to
ONBOOT="yes"
as
shown below:
You don't need to reboot to start the NIC,
but after you make this change, the primary NIC will be on and connected upon all subsequent boots.
To enable the NIC, use the
ifup
command:
ifup enp0s3
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/5)
Now the
ip
addr
command displays the enp0s3 device with an IP address:
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 08:00:27:81:d0:2d brd ff:ff:ff:ff:ff:ff
inet 192.168.1.64/24 brd 192.168.1.255 scope global dynamic noprefixroute enp0s3
valid_lft 86266sec preferred_lft 86266sec
inet6 2600:1702:a40:88b0:c30:ce7e:9319:9fe0/64 scope global dynamic noprefixroute
valid_lft 3467sec preferred_lft 3467sec
inet6 fe80::9b21:3498:b83c:f3d4/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:4e:69:84 brd ff:ff:ff:ff:ff:ff
inet 192.168.122.1/24 brd 192.168.122.255 scope global virbr0
valid_lft forever preferred_lft forever
4: virbr0-nic: <BROADCAST,MULTICAST> mtu 1500 qdisc fq_codel master virbr0 state DOWN group default qlen 1000
link/ether 52:54:00:4e:69:84 brd ff:ff:ff:ff:ff:ff
To disable a NIC, use the
ifdown
command.
Please note that issuing this command from a remote system will terminate your session:
ifdown enp0s3
Connection 'enp0s3' successfully deactivated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/5)
That's a wrap
It's frustrating to encounter a Linux
system that has no network connection. It's more frustrating to have to connect to a virtual KVM or to walk up to
the console to fix it. It's easy to miss the switch during installation, I've missed it myself. Now you know how
to fix the problem and have your system network-connected on every boot, so before you drive yourself crazy with
troubleshooting steps, try the
ifup
command
to see if that's your easy fix.
When you press a machine's power button, the boot process starts with a hardware-dependent
mechanism that loads a bootloader . The bootloader software finds the kernel on the disk
and boots it. Next, the kernel mounts the root filesystem and executes an init
process.
This process sounds simple, and it might be what actually happens on some Linux systems.
However, modern Linux distributions have to support a vast set of use cases for which this
procedure is not adequate.
First, the root filesystem could be on a device that requires a specific driver. Before
trying to mount the filesystem, the right kernel module must be inserted into the running
kernel. In some cases, the root filesystem is on an encrypted partition and therefore needs a
userspace helper that asks the passphrase to the user and feeds it to the kernel. Or, the root
filesystem could be shared over the network via NFS or iSCSI, and mounting it may first require
configured IP addresses and routes on a network interface.
To overcome these issues, the bootloader can pass to the kernel a small filesystem image
(the initrd) that contains scripts and tools to find and mount the real root filesystem. Once
this is done, the initrd switches to the real root, and the boot continues as usual.
The
dracut infrastructure
On Fedora and RHEL, the initrd is built through dracut . From its home page , dracut is "an event-driven initramfs
infrastructure. dracut (the tool) is used to create an initramfs image by copying tools and
files from an installed system and combining it with the dracut framework, usually found in
/usr/lib/dracut/modules.d ."
A note on terminology: Sometimes, the names initrd and initramfs are used
interchangeably. They actually refer to different ways of building the image. An initrd is an
image containing a real filesystem (for example, ext2) that gets mounted by the kernel. An
initramfs is a cpio archive containing a directory tree that gets unpacked as a tmpfs.
Nowadays, the initrd images are deprecated in favor of the initramfs scheme. However, the
initrd name is still used to indicate the boot process involving a temporary
filesystem.
Kernel command-line
Let's revisit the NFS-root scenario that was mentioned before. One possible way to boot via
NFS is to use a kernel command-line containing the root=dhcp argument.
The kernel command-line is a list of options passed to the kernel from the bootloader,
accessible to the kernel and applications. If you use GRUB, it can be changed by pressing the e
key on a boot entry and editing the line starting with linux .
The dracut code inside the initramfs parses the kernel command-line and starts DHCP on all
interfaces if the command-line contains root=dhcp . After obtaining a DHCP lease,
dracut configures the interface with the parameters received (IP address and routes); it also
extracts the value of the root-path DHCP option from the lease. The option carries an NFS
server's address and path (which could be, for example, 192.168.50.1:/nfs/client
). Dracut then mounts the NFS share at this location and proceeds with the boot.
If there is no DHCP server providing the address and the NFS root path, the values can be
configured explicitly in the command line:
The first can be used for automatic configuration (DHCP or IPv6 SLAAC), and the second for
static configuration or a combination of automatic and static. Here some examples:
Note that if you pass an ip= option, but dracut doesn't need networking to
mount the root filesystem, the option is ignored. To force network configuration without a
network root, add rd.neednet=1 to the command line.
You probably noticed that among automatic configuration methods, there is also ibft .
iBFT stands for iSCSI Boot Firmware Table and is a mechanism to pass parameters about iSCSI
devices from the firmware to the operating system. iSCSI (Internet Small Computer Systems
Interface) is a protocol to access network storage devices. Describing iBFT and iSCSI is
outside the scope of this article. What is important is that by passing ip=ibft to
the kernel, the network configuration is retrieved from the firmware.
Dracut also supports adding custom routes, specifying the machine name and DNS servers,
creating bonds, bridges, VLANs, and much more. See the dracut.cmdline man page for more
details.
Network modules
The dracut framework included in the initramfs has a modular architecture. It comprises a
series of modules, each containing scripts and binaries to provide specific functionality. You
can see which modules are available to be included in the initramfs with the command
dracut --list-modules .
At the moment, there are two modules to configure the network: network-legacy
and network-manager . You might wonder why different modules provide the same
functionality.
network-legacy is older and uses shell scripts calling utilities like
iproute2 , dhclient , and arping to configure
interfaces. After the switch to the real root, a different network configuration service runs.
This service is not aware of what the network-legacy module intended to do and the
current state of each interface. This can lead to problems maintaining the state across the
root switch boundary.
A prominent example of a state to be kept is the DHCP lease. If an interface's address
changed during the boot, the connection to an NFS share would break, causing a boot
failure.
To ensure a seamless transition, there is a need for a mechanism to pass the state between
the two environments. However, passing the state between services having different
configuration models can be a problem.
The network-manager dracut module was created to improve this situation. The
module runs NetworkManager in the initrd to configure connection profiles generated from the
kernel command-line. Once done, NetworkManager serializes its state, which is later read by the
NetworkManager instance in the real root.
Fedora 31 was the first distribution to switch to network-manager in initrd by
default. On RHEL 8.2, network-legacy is still the default, but
network-manager is available. On RHEL 8.3, dracut will use
network-manager by default.
Enabling a different network module
While the two modules should be largely compatible, there are some differences in behavior.
Some of those are documented in the nm-initrd-generator man page. In general, it
is suggested to use the network-manager module when NetworkManager is enabled.
To rebuild the initrd using a specific network module, use one of the following
commands:
The --regenerate-all option also rebuilds all the initramfs images for the
kernel versions found on the system.
The network-manager dracut module
As with all dracut modules, the network-manager module is split into stages
that are called at different times during the boot (see the dracut.modules man page for more
details).
The first stage parses the kernel command-line by calling
/usr/libexec/nm-initrd-generator to produce a list of connection profiles in
/run/NetworkManager/system-connections . The second part of the module runs after
udev has settled, i.e., after userspace has finished handling the kernel events for devices
(including network interfaces) found in the system.
When NM is started in the real root environment, it registers on D-Bus, configures the
network, and remains active to react to events or D-Bus requests. In the initrd, NetworkManager
is run in the configure-and-quit=initrd mode, which doesn't register on D-Bus
(since it's not available in the initrd, at least for now) and exits after reaching the
startup-complete event.
The startup-complete event is triggered after all devices with a matching connection profile
have tried to activate, successfully or not. Once all interfaces are configured, NM exits and
calls dracut hooks to notify other modules that the network is available.
Note that the /run/NetworkManager directory containing generated connection
profiles and other runtime state is copied over to the real root so that the new NetworkManager
process running there knows exactly what to do.
Troubleshooting
If you have network issues in dracut, this section contains some suggestions for
investigating the problem.
The first thing to do is add rd.debug to the kernel command-line, enabling debug logging in
dracut. Logs are saved to /run/initramfs/rdsosreport.txt and are also available in
the journal.
If the system doesn't boot, it is useful to get a shell inside the initrd environment to
manually check why things aren't working. For this, there is an rd.break command-line argument.
Note that the argument spawns a shell when the initrd has finished its job and is about to give
control to the init process in the real root filesystem. To stop at a different stage of dracut
(for example, after command-line parsing), use the following argument:
The initrd image contains a minimal set of binaries; if you need a specific tool at the
dracut shell, you can rebuild the image, adding what is missing. For example, to add the ping
and tcpdump binaries (including all their dependent libraries), run:
# dracut -f --install "ping tcpdump"
and then optionally verify that they were included successfully:
If you are familiar with NetworkManager configuration, you might want to know how a given
kernel command-line is translated into NetworkManager connection profiles. This can be useful
to better understand the configuration mechanism and find syntax errors in the command-line
without having to boot the machine.
The generator is installed in /usr/libexec/nm-initrd-generator and must be
called with the list of kernel arguments after a double dash. The --stdout option
prints the generated connections on standard output. Let's try to call the generator with a
sample command line:
$ /usr/libexec/nm-initrd-generator --stdout -- \
ip=enp1s0:dhcp:00:99:88:77:66:55 rd.peerdns=0
802-3-ethernet.cloned-mac-address: '99:88:77:66:55' is not a valid MAC
address
In this example, the generator reports an error because there is a missing field for the MTU
after enp1s0 . Once the error is corrected, the parsing succeeds and the tool prints out the
connection profile generated:
Note how the rd.peerdns=0 argument translates into the ignore-auto-dns=true property, which
makes NetworkManager ignore DNS servers received via DHCP. An explanation of NetworkManager
properties can be found on the nm-settings man page.
The NetworkManager dracut module is enabled by default in Fedora and will also soon be
enabled on RHEL. It brings better integration between networking in the initrd and
NetworkManager running in the real root filesystem.
While the current implementation is working well, there are some ideas for possible
improvements. One is to abandon the configure-and-quit=initrd mode and run
NetworkManager as a daemon started by a systemd service. In this way, NetworkManager will be
run in the same way as when it's run in the real root, reducing the code to be maintained and
tested.
To completely drop the configure-and-quit=initrd mode, NetworkManager should
also be able to register on D-Bus in the initrd. Currently, dracut doesn't have any module
providing a D-Bus daemon because the image should be minimal. However, there are already
proposals to include it as it is needed to implement some new features.
With D-Bus running in the initrd, NetworkManager's powerful API will be available to other
tools to query and change the network state, unlocking a wide range of applications. One of
those is to run nm-cloud-setup in the initrd. The service, shipped in the
NetworkManager-cloud-setup Fedora package fetches metadata from cloud providers'
infrastructure (EC2, Azure, GCP) to automatically configure the network.
... DTrace gives the operational insights that have long been missing in the data center,
such as memory consumption, CPU time or what specific function calls are being made.
Designed for use on production systems to troubleshoot performance bottlenecks
Provides a single view of the software stack - from kernel to application - leading to
rapid identification of performance bottlenecks
Dynamically instruments kernel and applications with any number of probe points,
improving the ability to service software
Enables maximum resource utilization and application performance, as well as precise
quantification of resource requirements
Fast and easy to use, even on complex systems with multiple layers of software
Developers can learn about and experiment with DTrace on Oracle Linux by installing the
appropriate RPMs:
For Unbreakable Enterprise Kernel Release 5 (UEK5) on Oracle Linux 7
dtrace-utils and dtrace-utils-devel .
For Unbreakable Enterprise Kernel Release 6 (UEK6) on Oracle Linux 7 and Oracle Linux 8
dtrace and dtrace-devel .
Stability
It's well known that Red Hat Enterprise Linux is created from the most stable and tested
Fedora innovations, but since Oracle Linux was grown from the RHEL framework yet includes
additional, built-in integrations and optimizations specifically tailored for Oracle
products, our comparison showed that Oracle Linux is actually more stable for enterprises
running Oracle systems , including Oracle databases.
Flexibility
As an industry leader, RHEL provides a wide range of integrated applications and tools that
help tailor fit the Red Hat Enterprise Linux system to highly specific business needs.
However, once again Oracle Linux was found to excel over RHEL because OL offered the Red Hat
Compatible Kernel (RHCK), option, which enables any RHEL-certified app to run on Oracle Linux
. In addition, OL offers its own network of ISVs / third-party solutions, which can help
personalize your Linux setup even more while integrating seamlessly with your on-premises or
cloud-based Oracle systems.
If you are on CentOS-7 then you will probably be okay until RedHat pulls the plug on
2024-06-30 so do don't do anything rash. If you are on CentOS-8 then your days are numbered (to
~ 365) because this OS will shift from major-minor point updates to a streaming model at the
end of 2021. Let's look at two early founders: SUSE started in Germany in 1991 whilst RedHat
started in America a year later. SUSE sells support for SLE (Suse Linux Enterprise) which means
you need a license to install-run-update-upgrade it. Likewise RedHat sells support for RHEL
(Red Hat Enterprise Linux). SUSE also offers "openSUSE Leap" (released once a year as a
major-minor point release of SLE) and "openSUSE Tumbleweed" (which is a streaming thingy). A
couple of days ago I installed "OpenSUSE Leap" onto an old HP-Compaq 6000 desktop just to try
it out (the installer actually had a few features I liked better than the CentOS-7 installer).
When I get back to the office in two weeks, I'm going to try installing "OpenSUSE Leap" onto an
HP-DL385p_gen8. I'll work with this for a few months and I am comfortable, I will migrate my
employer's solution over to "OpenSUSE Leap".
Parting thoughts:
openSUSE is run out of Germany. IMHO switching over to a European distro is similar to
those database people who preferred MariaDB to MySQL when Oracle was still hoping that
MySQL would die from neglect.
Someone cracked off to me the other day that now that IBM is pulling strings at "Red
Hat", that the company should be renamed "Blue Hat"
I downloaded and tried it last week and was actually pretty impressed. I have only ever
tested SUSE in the past. Honestly, I'll stick with Red Hat/CentOS whatever, but I was still
impressed. I'd recommend people take a look.
I have been playing with OpenSUSE a bit, too. Very solid this time around. In the past I
never had any luck with it. But Leap 15.2 is doing fine for me. Just testing it virtually. TW
also is pretty sweet and if I were to use a rolling release, it would be among the top
contenders.
One thing I don't like with OpenSUSE is that you can't really, or are not supposed to I
guess, disable the root account. You can't do it at install, if you leave the root account
blank suse, will just assign the password for the user you created to it.
Of course afterwards you can disable it with the proper commands but it becomes a pain with
YAST, as it seems YAST insists on being opened by root.
One thing I don't like with OpenSUSE is that you can't really, or are not supposed to I
guess, disable the root account. You can't do it at install, if you leave the root account
blank suse, will just assign the password for the user you created to it.
I'm running Leap 15.2 on the laptops my kids run for school. During installation, I simply
deselected the option for the account used to be an administrator; this required me to set a
different password for administrative purposes.
I think you might.
My point is/was that if I select to choose my regular user to be admin, I don't expect for
the system to create and activate a root account anyways and then just assign it my
password.
I expect the root account to be disabled.
I was surprised, too. I was bit "shocked" when I realized, after the install, that I could
login as root with my user password.
At the very least, IMHO, it should then still have you set the root password, even if you
choose to make your user admin.
It for one lets you know that OpenSUSE is not disabling root and two gives you a chance to
give it a different password.
But other than that subjective issue I found OpenSUSE Leap a very solid distro.
The big academic labs (Fermilab, CERN and DESY to only name three of many used to run
something called Scientific Linux which was also maintained by Red Hat.see: https://scientificlinux.org/ and https://en.wikipedia.org/wiki/Scientific_Linux
Shortly after Red Hat acquired CentOS in 2014, Red Hat convinced the big academic labs to begin
migrating over to CentOS (no one at that time thought that Red Hat would become Blue Hat)
11 comments 67% Upvoted Log in or sign up to leave a comment
Log In Sign Up Sort by level 1
Scientific Linux is not and was not maintained by Red Hat. Like CentOS, when it was truly
a community distribution, Scientific Linux was an independent rebuild of the RHEL source code
published by Red Hat. It is maintained primarily by people at Fermilab. (It's slightly
different from CentOS in that CentOS aimed for binary compatibility with RHEL, while that is
not a goal of Scientific Linux. In practice, SL often achieves binary compatibility, but if
you have issues with that, it's more up to you to fix them than the SL maintainers.)
I fear you are correct. I just stumbled onto this article: https://www.linux.com/training-tutorials/scientific-linux-great-distro-wrong-name/
Even the wikipedia article states "This product is derived from the free and open-source
software made available by Red Hat, but is not produced, maintained or supported by them."
But it does seem that Scientific Linux was created as a replacement for Fermilab Linux.
I've also seen references to CC7 to mean "Cern Centos 7". CERN is keeping their Linux page
up to date because what I am seeing here ( https://linux.web.cern.ch/ ) today is not what I saw
2-weeks ago.
RedHat didn't convince them to stop using Scientific Linux, Fermilab no longer needed to
have their own rebuild of RHEL sources. They switched to CentOS and modified CentOS if they
needed to (though I don't really think they needed to)
SL has always been an independent rebuild. It has never been maintained, sponsored, or
owned by Red Hat. They decided on their own to not build 8 and instead collaborate on
CentOS. They even gained representation on the CentOS board (one from Fermi, one from
CERN).
I'm not affiliated with any of those organizations, but my guess is they will switch to
some combination of CentOS Stream and RHEL (under the upcoming no/low cost program).
Is anybody considering switching to RHEL's free non-production developer
subscription? As I understand it, it is free and receives updates.
The only downside as I understand it is that you have to renew your license every year (and
that you can't use it in commercial production).
In
view of the such effective and free promotion of Oracle Linux by IBM/Red Hat brass as the top replacement for
CentOS, the script can probably be slightly enhanced.
The script works well for simple systems, but still has some sharp edges. Checks for common bottlenecks should be added. For
exmple scale in /boot should be checked if this is a separate filesystem. It was not done. See my Also, in case
it was invoked the second time after the failure of the step "Installing base packages for Oracle
Linux..." it can remove hundreds of system RPM (including sshd, cron, and several other vital
packages ;-).
And failures on this step are probably the most common type of failures in conversion.
Inexperienced sysadmins or even experienced sysadmins in a hurry often make this blunder running
the script the second time.
It probably happens due to the presence of the line 'yum remove -y "${new_releases[@]}" ' in the
function remove_repos, because in their excessive zeal to restore the system after error the
programmers did not understand that in certain situations those packages that they want to delete via YUM have dependences and a lot
of them (line 65 in the current version of the script) Yum blindly deletes over 300 packages including such vital as sshd, cron, etc. Due to this execution of the script probably
should be blocked if Oracle repositories are already present. This check is absent.
After this "mass extinction of RPM packages," event you need to be pretty well versed in yum to recover. The names of
the deleted packages are in yum log, so you can reinstall them and something it helps. In other
cases system remain unbootable and the restore from the backup is the only option.
Due sudden surge of popularity of Oracle Linux due to Red Hat CentOS8 fiasco, the script definitely can benefit from better diagnostics.
The current diagnostic is very rudimentary. It might also make sense to make steps modular in the classic /etc/init.d fashion and
make initial steps shippable so that the script can be resumed after the error. Most of the steps have few dependencies, which
can be resolved by saving variables during the first run and sourcing them if the the first step is not step 1.
Also, it makes sense to check the amount of free space in /boot filesystem if /boot is a
separate filesystem. The script requires approx 100MB of free space in this filesystem. Failure
to write a new kernel to it due to the lack of free space leads to the situation of "half-baked"
installation, which is difficult to recover without senior sysadmin skills.
Oracle Linux is free to download, distribute and use (even in production) and has been
since its release over 14 years ago
Installation media, updates and source code are all publicly available on the Oracle
Linux yum server with no login or authentication requirements
Since its first release in 2006, Oracle Linux has been 100% application binary
compatible with the equivalent RHEL version. In that time, we have never had a
compatibility bug logged.
The script can switch CentOS Linux 6, 7 or 8 to the equivalent version of Oracle Linux.
Let's take a look at just how simple the process is.
Download the centos2ol.sh
script from GitHub
The simplest way to get the script is to use curl :
$ curl -O https://raw.githubusercontent.com/oracle/centos2ol/main/centos2ol.sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 10747 100 10747 0 0 31241 0 --:--:-- --:--:-- --:--:-- 31241
If you have git installed, you could clone the git repository from GitHub
instead.
Run the centos2ol.sh script to switch to Oracle Linux
To switch to Oracle Linux, just run the script as root using sudo
:
As part of the process, the default kernel is switched to the latest release of Oracle's
Unbreakable Enterprise Kernel (UEK) to enable extensive performance and scalability
improvements to the process scheduler, memory management, file systems, and the networking
stack. We also replace the existing CentOS kernel with the equivalent Red Hat Compatible
Kernel (RHCK) which may be required by any specific hardware or application that has
imposed strict kernel version restrictions.
Switching the default kernel (optional)
Once the switch is complete, but before rebooting, the default kernel can be changed
back to the RHCK. First, use grubby to list all installed kernels:
In the output above, the first entry (index 0) is UEK R6, based on the mainline kernel
version 5.4. The second kernel is the updated RHCK (Red Hat Compatible Kernel) installed by
the switch process while the third one is the kernel that were installed by CentOS and the
final entry is the rescue kernel.
Next, use grubby to verify that UEK is currently the default boot option:
To replace the default kernel, you need to specify either the path to its
vmlinuz file or its index. Use grubby to get that information for the
replacement:
Finally, use grubby to change the default kernel, either by providing the
vmlinuz path:
[demo@c8switch ~]$ sudo grubby --set-default /boot/vmlinuz-4.18.0-240.1.1.el8_3.x86_64
The default is /boot/loader/entries/0dbb9b2f3c2744779c72a28071755366-4.18.0-240.1.1.el8_3.x86_64.conf with index 1 and kernel /boot/vmlinuz-4.18.0-240.1.1.el8_3.x86_64
Or its index:
[demo@c8switch ~]$ sudo grubby --set-default-index 1
The default is /boot/loader/entries/0dbb9b2f3c2744779c72a28071755366-4.18.0-240.1.1.el8_3.x86_64.conf with index 1 and kernel /boot/vmlinuz-4.18.0-240.1.1.el8_3.x86_64
Changing the default kernel can be done at any time, so we encourage you to take UEK for
a spin before switching back.
The last of the RHEL downstreams up for discussion today is Hewlett-Packard Enterprise's
in-house distro, ClearOS .
Hewlett-Packard makes ClearOS available as a pre-installed option on its ProLiant server line,
and the company offers a free Community version to all comers.
ClearOS is an open source software platform that leverages the open source model to
deliver a simplified, low cost hybrid IT experience for SMBs. The value of ClearOS is the
integration of free open source technologies making it easier to use. By not charging for
open source, ClearOS focuses on the value SMBs gain from the integration so SMBs only pay for
the products and services they need and value.
ClearOS is mostly notable here for its association with industry giant HPE and its
availability as an OEM distro on ProLiant servers. It seems to be a bit behind the times -- the
most recent version is ClearOS 7.x, which is in turn based on RHEL 7. In addition to being a
bit outdated compared with other options, it also appears to be a rolling release itself --
more comparable to CentOS Stream itself, than to the CentOS Linux that came before it.
ClearOS is probably most interesting to small business types who might consider buying
ProLiant servers with RHEL-compatible OEM Linux pre-installed later.
I've seen a lot of folks mistakenly recommending the deceased Scientific Linux distro as a
CentOS replacement -- that won't work, because Scientific Linux itself was deprecated in favor
of CentOS. However, Springdale
Linux is very similar -- like Scientific Linux, it's a RHEL rebuild distro made by and for
the academic scientific community. Unlike Scientific Linux, it's still actively maintained!
Springdale Linux is maintained and made available by Princeton and Rutgers universities, who
use it for their HPC projects. It has been around for quite a long time. One Springdale Linux
user from Carnegie Mellon describes their own experience with Springdale (formerly PUIAS --
Princeton University Institute for Advanced Study) as a 10-year ride.
Theresa Arzadon-Labajo, one of Springdale Linux's maintainers, gave a pretty good
seat-of-the-pants overview in a recent mailing list discussion :
The School of Mathematics at the Institute for Advanced Study has been using Springdale
(formerly PUIAS, then PU_IAS) since its inception. All of our *nix servers and workstations
(yes, workstations) are running Springdale. On the server side, everything "just works", as
is expected from a RHEL clone. On the workstation side, most of the issues we run into have
to do with NVIDIA drivers, and glibc compatibility issues (e.g Chrome, Dropbox, Skype, etc),
but most issues have been resolved or have a workaround in place.
... Springdale is a community project, and [it] mostly comes down to the hours (mostly
Josko) that we can volunteer to the project. The way people utilize Springdale varies. Some
are like us and use the whole thing. Others use a different OS and use Springdale just for
its computational repositories.
Springdale Linux should be a natural fit for universities and scientists looking for a
CentOS replacement. It will likely work for most anyone who needs it -- but its
relatively small community and firm roots in academia will probably make it the most
comfortable for those with similar needs and environments.
64 • "best idea" ... (by Otis on 2020-12-25 19:38:01 GMT from United
States) @62
dang it BSD takes care of all that anxiety about systemd and the other bloaty-with-time worries
as far as I can tell. GhostBSD and a few others are spearheading a charge into the face of The
Enemy, making BSD palatable for those of us steeped in Linux as the only alternative to we know
who.
• Centos (by David on 2020-12-22
04:29:46 GMT from United States)
I was using Centos 8.2 on an older, desktop home computer. When Centos dropped long term
support on version 8, I was a little peeved, but not a whole lot, since it is free, anyway. Out
of curiosity I installed Scientific Linux 7.9 on the same computer, and it works better that
Centos 8. Then I tried installing SL 7.9 on my old laptop -- it even worked on that!
Previously, when I had tried to install Centos 8 on the laptop, an old Dell inspiron 1501,
the graphics were garbage --the screen displayed kind of a color mosaic --and the
keyboard/everthing else was locked up. I also tried Centos 7.9 on it and installation from
minimal dvd produced a bunch of errors and then froze part way through.
I will stick with Scientific Linux 7 for now. In 2024 I will worry about which distro to
migrate to. Note: Scientific Linux websites states that they are going to reconsider (in 1st
quarter of 2021) whether they will produce a clone of rhel version 8. Previously, they stated
that they would not.
"Personal opinion only. [...] After all the years of using Linux, and experiencing
first-hand the hobby mentality that has taken over [...], I prefer to use a distribution which
has all the earmarks of [...] being developed AND MAINTAINED by a professional
organization."
Yeah, your answer is exactly what I expected it to be.
The thing with Springdale is as following: it's maintained by the very professional team of
IT specialists at the Institute for Advanced Study (Princeton University) for the own needs.
That's why there's no fancy website, RHEL Wiki, live ISOs and such.
They also maintain several other repositories for add-on packages (computing, unsupported
[with audio/video codecs] ...).
With other words, if you're a professional who needs an RHEL clone, you'll be fine with it;
if you're a hobbyist who needs a how-to on everything and anything, you can still use the
knowledge base of RHEL/CentOS/Oracle ...
If you're 'small business' who needs a professional support, you'd get RHEL - unlike CentOS,
Springdale is not a commercial distribution selling you support and schooling. Springdale is
made by professional and for the professionals.
In 2010 I had the opportunity to put my hands in the shambles of Oracle Linux during an installation and training mission carried
out on behalf of ASF (Highways of the South of France) which is now called Vinci Autoroutes. I
had just published Linux on the
onions at Eyrolles, and since the CentOS 5.3 distribution on which it was based looked 99%
like Oracle Linux 5.3 under the hood, I had been chosen by the company ASF to train their
future Linux administrators.
All these years, I knew that Oracle Linux existed, as did another series of Red Hat clones
like CentOS, Scientific Linux, White Box Enterprise Linux, Princeton University's PUIAS
project, etc. I didn't care any more, since CentOS perfectly met all my server needs.
Following the disastrous announcement of the CentOS project, I had a discussion with my
compatriot Michael Kofler, a Linux guru who
has published a series of excellent books on our favorite operating system, and who has
migrated from CentOS to Oracle Linux for the Linux ad administration courses he teaches at the
University of Graz. We were not in our first discussion on this subject, as the CentOS project
was already accumulating a series of rather worrying delays for version 8 updates. In
comparison, Oracle Linux does not suffer from these structural problems, so I kept this option
in a corner of my head.
A problematic reputation
Oracle suffers from a problematic reputation within the free software community, for a
variety of reasons. It was the company that ruined OpenOffice and Java, put the hook on MySQL
and let Solaris sink. Oracle CEO Larry Ellison has been the center of his name because of his
unhinged support for Donald Trump. As for the company's commercial policy, it has been marked
by a notorious aggressiveness in the hunt for patents.
On the other hand, we have free and free apps like VirtualBox, which run perfectly on millions of developer
workstations all over the world. And then the very discreet Oracle Linux , which works perfectly and without making any noise
since 2006, and which is also a free and free operating system.
Install Oracle Linux
For a first test, I installed Oracle Linux 7.9 and 8.3 in two virtual machines on my
workstation. Since it is a Red Hat Enterprise Linux-compliant clone, the installation procedure
is identical to that of RHEL and CentOS, with a few small details.
Normally, I never care about banner ads that scroll through graphic
installers. This time, the slogan Free to use, free to download, free to update.
Always still caught my attention.
An indestructible kernel?
Oracle Linux provides its own Linux kernel newer than the one provided by Red Hat, and named
Unbreakable Enterprise Kernel (UEK). This kernel is installed by default and replaces
older kernels provided upstream for versions 7 and 8. Here's what it looks like oracle Linux
7.9.
$ uname -a
Linux oracle-el7 5.4.17-2036.100.6.1.el7uek.x86_64 #2 SMP Thu Oct 29 17:04:48
PDT 2020 x86_64 x86_64 x86_64 GNU/Linux
Well-crafted packet deposits
At first glance, the organization of official and semi-official package filings seems much
clearer and better organized than under CentOS. For details, I refer you to the respective
explanatory pages for the 7.x and 8.x versions.
Like the organization of deposits, Oracle Linux's documentation is
worth mentioning here, because it is simply exemplary. The main index refers to the different
versions of Oracle Linux, and from there, you can access a whole series of documents in HTML
and PDF formats that explain in detail the peculiarities of the system and its day-to-day
management. As I go along with this documentation, I discover a multitude of pleasant little
details, such as the fact that Oracle packages display metadata for security updates, which is
not the case for CentOS packages.
Migrating from CentOS to Oracle Linux
The Switch your CentOS
systems to Oracle Linux web page identifies a number of reasons why Oracle Linux is a
better choice than CentOS when you want to have a company-grade free as in free beer
operating system, which provides low-risk updates for each version over a decade. This page
also features a script that transforms an existing CentOS system into a two-command Oracle
Linux system on the fly. centos2ol.sh
The script grinds about twenty minutes, we restart the machine and we end up with a clean
Oracle Linux system. To do some cleaning, just remove the deposits of saved packages.
# rm -f /etc/yum.repos.d/*.repo.deactivated
Migrating a CentOS 8.x server?
At first glance, the script only predicted the migration of CentOS 7.9 to Oracle Linux 7.9.
On a whim, I sent an email to the address at the bottom of the page, asking if support for
CentOS 8.x was expected in the near future. centos2ol.sh
A very nice exchange of emails ensued with a guy from Oracle, who patiently answered all the
questions I asked him. And just twenty-four hours later, he sent me a link to an Oracle Github repository with an
updated version of the script that supports the on-the-fly migration of CentOS 8.x to Oracle
Linux 8.x.
So I tested it with a cool installation of a CentOS 8 server at Online/Scaleway.
Again, it grinds a good twenty minutes, and at the end of the restart, we end up with a
public machine running oracle Linux 8.
Conclusion
I will probably have a lot more to say about that. For my part, I find this first experience
with Oracle Linux rather conclusive, and if I decided to share it here, it is that it will
probably solve a common problem to a lot of admins of production servers who do not support
their system becoming a moving target overnight.
Post Scriptum for the chilly purists
Finally, for all of you who want to use a free and free clone of Red Hat Enterprise Linux
without selling their soul to the devil, know that Springdale Linux is a solid alternative. It is maintained
by Princeton University in the United States according to the principle WYGIWYG (What You
Get Is What You Get ), it is provided raw de-cluttering and without any documentation, but
it works just as well.
Writing this documentation takes time and significant amounts of espresso coffee. Do you
like this blog? Give the editor a coffee by clicking on the cup.
"... If you want a free-as-in-beer RHEL clone, you have two options: Oracle Linux or Springdale/PUIAS. My company's currently moving its servers to OL, which is "CentOS done right". Here's a blog article about the subject: ..."
"... Each version of OL is supported for a 10-year cycle. Ubuntu has five years of support. And Debian's support cycle (one year after subsequent release) is unusable for production servers. ..."
"... [Red Hat looks like ]... of a cartoon character sawing off the tree branch they are sitting on." ..."
• And what about Oracle Linux? (by Microlinux on 2020-12-21 08:11:33 GMT from France)
If you want a free-as-in-beer RHEL clone, you have two options: Oracle Linux or
Springdale/PUIAS. My company's currently moving its servers to OL, which is "CentOS done
right". Here's a blog article about the subject:
Currently Rocky Linux is not much more than a README file on Github and a handful of Slack
(ew!) discussion channels.
Each version of OL is supported for a 10-year cycle. Ubuntu has five years of support. And
Debian's support cycle (one year after subsequent release) is unusable for production
servers.
9 • @Jesse on CentOS: (by dragonmouth
on 2020-12-21 13:11:04 GMT from United States)
"There is no rush and I recommend waiting a bit for the dust to settle on the situation before
leaping to an alternative. "
For private users there may be plenty of time to find an alternative. However, corporate IT
departments are not like jet skis able to turn on a dime. They are more like supertankers or
aircraft carriers that take miles to make a turn. By the time all the committees meet and come
to some decision, by the time all the upper managers who don't know what the heck they are
talking about expound their opinions and by the time the CentOS replacement is deployed, a year
will be gone. For corporations, maybe it is not a time to PANIC, yet, but it is high time to
start looking for the O/S that will replace CentOS.
Does this mean no more SIGs too? OEL 8 is about to see a giant surge in utilization!
reply link
Just a geek Dec 8, 2020 @ 23:45
Time to move to Oracle Linux. One of their partners is always talking about it, and being it is free, and tracks RHEL with
100% binary compatibly it's a good fit for use. Also looked at their support costs, and it's a fraction of RHEL pricing!
Kyle Dec 9, 2020 @ 2:13
It's an ibm money grab. It's a shame, I use centos to develop and host web applications om my linode. Obviously a small time like
that I can't afford red hat, but use it at work. Centos allowed me to come home and take skills and dev on my free time and apply
it to work.
I also use Ubuntu, but it looks like the shift will be greater to Ubuntu. Noname Dec 9, 2020 @ 4:20
As others said here, this is money grab. Me thinks IBM was the worst thing that happened to Linux since systemd... Yui
Dec 9, 2020 @ 4:49
Hello CentOS users,
I also work for a non-profit (Cancer and other research) and use CentOS for HPC. We choose CentOS over Debian due to the 10-year
support cycle and CentOS goes well with HPC cluster. We also wanted every single penny to go to research purposes and not waste our
donations and grants on software costs. What are my CentOS alternatives for HPC? Thanks in advance for any help you are able to provide.
Holmes Dec 9, 2020 @ 5:06
Folks who rely on CentOS saw this coming when Red Hat brought them 6 years ago. Last year IBM brought Red Hat. Now, IBM+Red Hat
found a way to kill the stable releases in order to get people signing up for RHEL subscriptions. Doesn't that sound exactly like
"EEE" (embrace, extend, and exterminate) model? Petr Dec 9, 2020 @ 5:08
For me it's simple.
I will keep my openSUSE Leap and expand it's footprint.
Until another RHEL compatible distro is out. If I need a RHEL compatible distro for testing, until then, I will use Oracle with the
RHEL kernel.
OpenSUSE is the closest to RHEL in terms of stability (if not better) and I am very used to it. Time to get some SLES certifications
as well. Someone Dec 9, 2020 @ 5:23
While I like Debian, and better still Devuan (systemd ), some RHEL/CentOS features like kickstart and delta RPMs don't seem to
be there (or as good). Debian preseeding is much more convoluted than kickstart for example. Vonskippy Dec 10, 2020 @ 1:24
That's ok. For us, we left RHEL (and the CentOS testing cluster) when the satan spawn known as SystemD became the standard. We're
now a happy and successful FreeBSD shop.
" People are complaining because you are suddenly killing CentOS 8 which has been released last year with the promise of binary
compatibility to RHEL 8 and security updates until 2029."
One of immanent features of GPL is that it allow clones to exist. Which means the Oracle Linix, or Rocky Linux, or Lenin Linux will
simply take CentOS place and Red hat will be in disadvantage, now unable to control the clone to the extent they managed to co-opt and
control CentOS. "Embrace and extinguish" change i now will hand on Red Hat and probably will continue to hand for years from now. That
may not be what Redhat brass wanted: reputational damage with zero of narrative effect on the revenue stream. I suppose the majority
of CentOS community will finally migrate to emerging RHEL clones. If that was the Red Hat / IBM goal - well, they will reach it.
Notable quotes:
"... availability gap ..."
"... Another long-winded post that doesn't address the single, core issue that no one will speak to directly: why can't CentOS Stream and CentOS _both_ exist? Because in absence of any official response from Red Hat, the assumption is obvious: to drive RHEL sales. If that's the reason, then say it. Stop being cowards about it. ..."
"... We might be better off if Red Hat hadn't gotten involved in CentOS in the first place and left it an independent project. THEY choose to pursue this path and THEY chose to renege on assurances made around the non-stream distro. Now they're going to choose to deal with whatever consequences come from the loss of goodwill in the community. ..."
"... If the problem was in money, all RH needed to do was to ask the community. You would have been amazed at the output. ..."
"... You've alienated a few hunderd thousand sysadmins that started upgrading to 8 this year and you've thrown the scientific Linux community under a bus. You do realize Scientific Linux was discontinued because CERN and FermiLab decided to standardize on CentOS 8? This trickled down to a load of labs and research institutions. ..."
"... Nobody forced you to buy out CentOS or offer a gratis distribution. But everybody expected you to stick to the EOL dates you committed to. You boast about being the "Enterprise" Linux distributor. Then, don't act like a freaking start-up that announces stuff today and vanishes a year later. ..."
"... They should have announced this at the START of CentOS 8.0. Instead they started CentOS 8 with the belief it was going to be like CentOS7 have a long supported life cycle. ..."
"... IBM/RH/CentOS keeps replaying the same talking points over and over and ignoring the actual issues people have ..."
"... What a piece of stinking BS. What is this "gap" you're talking about? Nobody in the CentOS community cares about this pre-RHEL gap. You're trying to fix something that isn't broken. And doing that the most horrible and bizzarre way imaginable. ..."
"... As I understand it, Fedora - RHEL - CENTOS just becomes Fedora - Centos Stream - RHEL. Why just call them RH-Alpha, RH-Beta, RH? ..."
Let's go back to 2003 where Red Hat saw the opportunity to make a fundamental change to become an enterprise software company
with an open source development methodology.
To do so Red Hat made a hard decision and in 2003
split Red Hat Linux into Red Hat
Enterprise Linux (RHEL) and Fedora Linux. RHEL was the occasional snapshot of Fedora Linux that was a product -- slowed, stabilized,
and paced for production. Fedora Linux and the Project around it were the open source community for innovating -- speedier, prone
to change, and paced for exploration. This solved the problem of trying to hold to two, incompatible core values (fast/slow) in a
single project. After that, each distribution flourished within its intended audiences.
But that split left two important gaps. On the project/community side, people still wanted an OS that strived to be slower-moving,
stable-enough, and free of cost -- an availability gap . On the product/customer side, there was an openness gap
-- RHEL users (and consequently all rebuild users) couldn't contribute easily to RHEL. The rebuilds arose and addressed the availability
gap, but they were closed to contributions to the core Linux distro itself.
In 2012, Red Hat's move toward offering products beyond the operating system resulted in a need for an easy-to-access platform
for open source development of the upstream projects -- such as Gluster, oVirt, and RDO -- that these products are derived from.
At that time, the pace of innovation in Fedora made it not an easy platform to work with; for example, the pace of kernel updates
in Fedora led to breakage in these layered projects.
We formed a team I led at Red Hat to go about solving this problem, and, after approaching and discussing it with the CentOS Project
core team, Red Hat and the CentOS Project agreed to "
join forces ." We said
joining forces because there was no company to acquire, so we hired members of the core team and began expanding CentOS beyond being
just a rebuild project. That included investing in the infrastructure and protecting the brand. The goal was to evolve into a project
that also enabled things to be built on top of it, and a project that would be exponentially more open to contribution than ever
before -- a partial solution to the openness gap.
Bringing home the CentOS Linux users, folks who were stuck in that availability gap, closer into the Red Hat family was a wonderful
side effect of this plan. My experience going from participant to active open source contributor began in 2003, after the birth of
the Fedora Project. At that time, as a highly empathetic person I found it challenging to handle the ongoing emotional waves from
the Red Hat Linux split. Many of my long time community friends themselves were affected. As a company, we didn't know if RHEL or
Fedora Linux were going to work out. We had made a hard decision and were navigating the waters from the aftershock. Since then we've
all learned a lot, including the more difficult dynamics of an open source development methodology. So to me, bringing the CentOS
and other rebuild communities into an actual relationship with Red Hat again was wonderful to see, experience, and help bring about.
Over the past six years since finally joining forces, we made good progress on those goals. We started
Special Interest Groups (SIGs) to manage the
layered project experience, such as the Storage SIG, Virt Sig, and Cloud SIG. We created a
governance structure where there hadn't been one before. We brought
RHEL source code to be housed at git.centos.org . We designed and built out
a significant public build infrastructure and
CI/CD system in a project that had previously been sealed-boxes all the way
down.
"This brings us to today and the current chapter we are living in right now. The move to shift focus of the project to
CentOS Stream is about filling that openness gap in some key ways. Essentially, Red Hat is filling the development and contribution
gap that exists between Fedora and RHEL by shifting the place of CentOS from just downstream of RHEL to just upstream of RHEL."
Another long-winded post that doesn't address the single, core issue that no one will speak to directly: why can't CentOS
Stream and CentOS _both_ exist? Because in absence of any official response from Red Hat, the assumption is obvious: to drive RHEL sales. If that's the reason, then say it. Stop being cowards about it.
Redhat has no obligation to maintain both CentOS 8 and CentOS stream. Heck, they have no obligation to maintain CentOS
either. Maintaining both will only increase the workload of CentOS maintainers. I don't suppose you are volunteering to help them
do the work? Be thankful for a distribution that you have been using so far, and move on.
We might be better off if Red Hat hadn't gotten involved in CentOS in the first place and left it an independent project.
THEY choose to pursue this path and THEY chose to renege on assurances made around the non-stream distro. Now they're going to
choose to deal with whatever consequences come from the loss of goodwill in the community.
If they were going to pull this stunt they shouldn't have gone ahead with CentOS 8 at all and fulfilled any lifecycle
expectations for CentOS 7.
Sorry, but that's a BS. CentOS Stream and CentOS Linux are not mutually replaceable. You cannot sell that BS to any people
actually knowing the intrinsics of how CentOS Linux was being developed.
If the problem was in money, all RH needed to do was to ask the community. You would have been amazed at the output.
No, it is just a primitive, direct and lame way to either force "free users" to either pay, or become your free-to-use
beta testers (CentOS Stream *is* beta, whatever you say).
I predict you will be somewhat amazed at the actual results.
Not talking about the breach of trust. Now how much would cost all your (RH's) further promises and assurances?
you can spin this to the moon and back. The fact remains you just killed CentOS Linux and your users' trust by moving
the EOL of CentOS Linux 8 from 2029 to 2021.
You've alienated a few hunderd thousand sysadmins that started upgrading to 8 this year and you've thrown the scientific
Linux community under a bus. You do realize Scientific Linux was discontinued because CERN and FermiLab decided to standardize
on CentOS 8? This trickled down to a load of labs and research institutions.
Nobody forced you to buy out CentOS or offer a gratis distribution. But everybody expected you to stick to the EOL dates
you committed to. You boast about being the "Enterprise" Linux distributor. Then, don't act like a freaking start-up that announces
stuff today and vanishes a year later.
The correct way to handle this would have been to kill the future CentOS 9, giving everybody the time to cope with the
changes.
I've earned my RHCE in 2003 (yes that's seventeen years ago). Since then, many times, I've recommended RHEL or CentOS
to the clients I do free lance work for. Just a few weeks ago I was asked to give an opinion on six CentOS 7 boxes about to be
deployed into a research system to be upgraded to 8. I gave my go. Well, that didn't last long.
What do you expect me to recommend now? Buying RHEL licenses? That may or may be not have a certain cost per year and
may or may be not supported until a given date? Once you grant yourself the freedom to retract whatever published information,
how can I trust you? What added values do I get over any of the community supported distributions (given I can support myself)?
And no, CentOS Stream cannot "cover 95% (or so) of current user workloads". Stream was introduces as "a rolling preview
of what's next in RHEL".
I'm not interested at all in a "a rolling preview of what's next in RHEL". I'm interested in a stable distribution I
can trust to get updates until the given EOL date.
I guess my biggest issue is They should have announced this at the START of CentOS 8.0. Instead they started CentOS 8
with the belief it was going to be like CentOS7 have a long supported life cycle. What they did was basically bait and switch.
Not cool. Especially not cool for those running multiple nodes on high performance computing clusters.
I have over 300,000 Centos nodes that require Long term support as it's impossible to turn them over rapidly. I also
have 154,000 RHEL nodes. I now have to migrate 454,000 nodes over to Ubuntu because Redhat just made the dumbest decision short
of letting IBM acquire them I've seen. Whitehurst how could you let this happen? Nothing like millions in lost revenue from a single customer.
Just migrated to OpenSUSE. Rather than crying for dead os it's better to act yourself. Redhat is a sinking ship it probably
want last next decade.Legendary failure like ibm never have upper hand in Linux world. It's too competitive now. Customers have
more options to choose. I think person who have take this decision probably ignorant about the current market or a top grade fool.
IBM/RH/CentOS keeps replaying the same talking points over and over and ignoring the actual issues people have. You say
you are reading them, but choose to ignore it and that is even worse!
People still don't understand why CentOS stream and CentOS can't co-exist. If your goal was not to support CentOS 8, why did you put 2029 date or why did you even release CentOS 8 in the first
place?
Hell, you could have at least had the goodwill with the community to make CentOS 8 last until end of CentOS 7! But no,
you discontinued CentOS 8 giving people only 1 year to respond, and timed it right after EOL of CentOS6.
Why didn't you even bother asking the community first and come to a compromise or something?
Again, not a single person had a problem with CentOS stream, the problem was having the rug pulled under their feet!
So stop pretending and address it properly!
Even worse, you knew this was an issue, it's like literally #1 on your issue list "Shift Board to be more transparent
in support of becoming a contributor-focused open source project"
What a piece of stinking BS. What is this "gap" you're talking about? Nobody in the CentOS community cares about this
pre-RHEL gap. You're trying to fix something that isn't broken. And doing that the most horrible and bizzarre way imaginable.
I can only comment this as disappointment, if not betrayal, to whole CentOS user base.
This decision was clearly done, without considering impact to majority of CentOS community use cases.
If you need upstream contributions channel for RHEL, create it, do not destroy the stable downstream.
Clear and simple. All other 'explanations' are cover ups for real purpose of this action.
This stinks of politics within IBM/RH meddling with CentOS.
I hope, Rocky will bring the desired stability, that community was relying on with CentOS.
We've just agreed to cancel out RHEL subscriptions and will be moving them and our Centos boxes away as well. It was
a nice run but while it will be painful, it is a chance to move far far away from the terrible decisions made here.
The intellectually easy answer to what is happening is that IBM is putting pressure on Red
Hat to hit bigger numbers in the future. Red Hat sees a captive audience in its CentOS userbase
and is looking to covert a percentage to paying customers. Everyone else can go to Ubuntu or
elsewhere if they do not want to pay...
It seemed obvious (via Occam's Razor) that CentOS had cannibalized RHEL sales for the last
time and was being put out to die. Statements like:
If you are using CentOS Linux 8 in a production environment, and are
concerned that CentOS Stream will not meet your needs, we encourage you
to contact Red Hat about options.
That line sure seemed like horrific marketing speak for "call our sales people and open your
wallet if you use CentOS in prod." ( cue evil mustache-stroking capitalist villain
).
... CentOS will no longer be downstream of RHEL as it was previously. CentOS will now
be upstream of the next RHEL minor release .
... ... ...
I'm watching Rocky Linux closely myself. While I plan to use CentOS for the vast majority of
my needs, Rocky Linux may have a place in my life as well, as an example powering my home
router. Generally speaking, I want my router to be as boring as absolute possible. That said
even that may not stay true forever, if for example CentOS gets good WireGuard support.
Lastly, but certainly not least, Red Hat has talked about upcoming low/no-cost RHEL options.
Keep an eye out for those! I have no idea the details, but if you currently use CentOS for
personal use, I am optimistic that there may be a way to get RHEL for free coming soon. Again,
this is just my speculation (I have zero knowledge of this beyond what has been shared
publicly), but I'm personally excited.
It seemed obvious (via Occam's Razor) that CentOS had cannibalized RHEL sales for the last
time and was being put out to die. Statements like:
If you are using CentOS Linux 8 in a production environment, and are
concerned that CentOS Stream will not meet your needs, we encourage you
to contact Red Hat about options.
That line sure seemed like horrific marketing speak for "call our sales people and open your
wallet if you use CentOS in prod." ( cue evil mustache-stroking capitalist villain
).
... CentOS will no longer be downstream of RHEL as it was previously. CentOS will now
be upstream of the next RHEL minor release .
... ... ...
I'm watching Rocky Linux closely myself. While I plan to use CentOS for the vast majority of
my needs, Rocky Linux may have a place in my life as well, as an example powering my home
router. Generally speaking, I want my router to be as boring as absolute possible. That said
even that may not stay true forever, if for example CentOS gets good WireGuard support.
Lastly, but certainly not least, Red Hat has talked about upcoming low/no-cost RHEL options.
Keep an eye out for those! I have no idea the details, but if you currently use CentOS for
personal use, I am optimistic that there may be a way to get RHEL for free coming soon. Again,
this is just my speculation (I have zero knowledge of this beyond what has been shared
publicly), but I'm personally excited.
Red hat always has uneasy relationship with CentOS. Red hat brass always viwed it as something that streal Red hat licences. So
"Stop thesteal" mve might be not IBM inspired but it is firmly in IBM tradition. And like many similar IBM moves it will backfire.
This hiring of CentOS developers in 2014 gave them unprecedented control over the project. Why on Earth they now want independent
projects like Rocly Linux to re-emerge to fill the vacuum. They can't avoid the side affect of using GPL -- it allows clones. .Why it
is better to have a project that are hostile to Red Hat and that "in-house" domesticated project is unclear to me. As many large enterprises
deploy mix of Red Hat and CentOS the initial reaction might in the opposite direction the Red Hat brass expected: they will get less
licesses, not more by adopting "One IBM way"
On Hacker News , the leading comment was: "Imagine if you were running
a business, and deployed CentOS 8 based on the 10-year lifespan
promise . You're totally screwed now, and Red Hat knows it. Why on earth didn't they make this switch starting with CentOS 9????
Let's not sugar coat this. They've betrayed us."
A popular tweet from The Best Linux Blog In the Unixverse, nixcraft
, an account with over 200-thousand subscribers, went: Oracle buys Sun: Solaris Unix, Sun servers/workstation, and MySQL went to
/dev/null. IBM buys Red Hat: CentOS is going to
>/dev/null . Note to self: If a big vendor such as Oracle, IBM, MS, and others buys your fav software, start the migration procedure
ASAP."
Many others joined in this choir of annoyed CentOS users that it was IBM's fault that their favorite Linux was being taken away
from them. Still, others screamed Red Hat was betraying open-source itself.
... ... ...
Still another ex-Red Hat official said. If it wasn't for CentOS, Red Hat would have been a 10-billion dollar company before
Red Hat became
a billion-dollar business .
There are companies that sell appliances based on CentOS. Websense/Forcepoint is one of
them. The Websense appliance runs the base OS of CentOS, on top of which runs their
Web-filtering application. Same with RSA. Their NetWitness SIEM runs on top of CentOS.
Likewise, there are now countless Internet servers out there that run CentOS. There's now a
huge user base of CentOS out there.
This is why the Debian project is so important. I will be converting everything that is
currently CentOS to Debian. Those who want to use the Ubuntu fork of Debian, that is also
probably a good idea.
former Red Hat executive confided, "CentOS was gutting sales. The customer perception was
'it's from Red Hat and it's a clone of RHEL, so it's good to go!' It's not. It's a second-rate
copy." From where, this person sits, "This is 100% defensive to stave off more losses to
CentOS."
Still another ex-Red Hat official said. If it wasn't for CentOS, Red Hat would have been a
10-billion dollar company before Red
Hat became a billion-dollar business .
Yet another Red Hat staffer snapped, "Look at the CentOS FAQ . It says right there:
CentOS Linux is NOT Red Hat Linux, it is NOT Fedora Linux. It is NOT Red Hat Enterprise
Linux. It is NOT RHEL. CentOS Linux does NOT contain Red Hat® Linux, Fedora, or Red
Hat® Enterprise Linux.
CentOS Linux is NOT a clone of Red Hat® Enterprise Linux.
CentOS Linux is built from publicly available source code provided by Red Hat, Inc for Red
Hat Enterprise Linux in a completely different (CentOS Project maintained) build system.
Happy to report that we've invested exactly one day in CentOS 7 to CentOS 8
migration. Thanks, IBM. Now we can turn our full attention to Debian and never look back.
Here's a hot tip for the IBM geniuses that came up with this. Rebrand CentOS as New Coke, and
you've got yourself a real winner.
"... If you need official support, Oracle support is generally cheaper than RedHat. ..."
"... You can legally run OL free and have access to patches/repositories. ..."
"... Full binary compatibility with RedHat so if anything is certified to run on RedHat, it automatically certified for Oracle Linux as well. ..."
"... Premium OL subscription includes a few nice bonuses like DTrace and Ksplice. ..."
"... Forgot to mention that converting RedHat Linux to Oracle is very straightforward - just matter of updating yum/dnf config to point it to Oracle repositories. Not sure if you can do it with CentOS (maybe possible, just never needed to convert CentOS to Oracle). ..."
My office switched the bulk of our RHEL to OL years ago, and find it a great product, and
great support, and only needing to get support for systems we actually want support on.
Oracle provided scripts to convert EL5, EL6, and EL7 systems, and was able to convert some
EL4 systems I still have running. (Its a matter of going through the list of installed
packages, use 'rpm -e --justdb' to remove the package from the rpmdb, and re-installing the
package (without dependencies) from the OL ISO.)
We have been using Oracle Linux exclusively last 5-6 years for everything - thousands of
servers both for internal use and hundred or so customers.
Not a single time regretted, had any issues or were tempted to move to RedHat let alone
CentOS.
I found Oracle Linux has several advantages over RedHat/CentOS:
If you need
official support, Oracle support is generally cheaper than RedHat.You can legally
run OL free and have access to patches/repositories.Full binary compatibility with
RedHat so if anything is certified to run on RedHat, it automatically certified for Oracle
Linux as well. It is very easy to switch between supported and free setup (say, you have
proof-of-concept setup running free OL, but then it is being promoted to production status -
just matter of registering box with Oracle, no need to reinstall/reconfigure anything). You
can easily move licensed/support from one box to another so you always run the same OS and do
not have to think and decide (RedHat for production / CentOS for Dec/test). You have a choice
to run good old RedHat kernel or use newer Oracle kernel (which is pretty much vanilla kernel
with minimal modification - just newer). We generally run Oracle kernels on all boxes unless
we have to support particularly pedantic customer who insist on using old RedHat kernel.
Premium OL subscription includes a few nice bonuses like DTrace and Ksplice.
Overall, it is pleasure to work and support OL.
Negatives:
I found RedHat knowledge base / documentation is much better than Oracle's
Oracle does not offer extensive support for "advanced" products like JBoss, Directory Server,
etc. Obviously Oracle has its own equivalent commercial offerings (Weblogic, etc) and prefers
customers to use them. Some complain about quality of Oracle's support. Can't really comment
on that. Had no much exposure to RedHat support, maybe used it couple of times and it was
good. Oracle support can be slower, but in most cases it is good/sufficient. Actually over
the last few years support quality for Linux has improved noticeably - guess Oracle pushes
their cloud very aggressively and as a result invests in Linux support (as Oracle cloud aka
OCI runs on Oracle Linux).
Forgot to mention that converting RedHat Linux to Oracle is very straightforward -
just matter of updating yum/dnf config to point it to Oracle repositories. Not sure if you
can do it with CentOS (maybe possible, just never needed to convert CentOS to
Oracle).
At the end IBM/Red Hat might even lose money as powerful organizations, such as universities, might abandon Red Hat as the
platform. Or may be not. Red Hat managed to push systemd down the throat without any major hit to the revenue. Why not to
repeat the trick with CentOS? In any case IBM owns enterprise Linux and bitter complains and threats of retribution in this forum is
just a symptom that the development now is completely driven by corporate brass, and all key decisions belong to them.
Community wise, this is plain bad news for Open Source and all Open Source communities. IBM explained to them very clearly: you
does not matter. And organized minority always beat disorganized majority. Actually most large organizations will
probably stick with Red Hat compatible OS, probably moving to Oracle Linux or Rocky Linux, is it materialize, not to Debian.
What is interesting is that most people here believe that when security patches are stopped that's the end of the life for the
particular Linux version. It is an interesting superstition and it shows how conditioned by corporations Linux folk are and
how far from BSD folk they are actually are. Security is an architectural thing first and foremost. Patched are just band aid and
they can't change general security situation in Linux no matter how hard anyone tries. But they now serve as a powerful tool
of corporate mind control over the user population. Feat is a powerful instrument of mind control.
In reality security of most systems on internal network does no change one bit with patches. And on external network only
applications that have open ports that matter (that's why ssh should be restricted to the subnets used, not to be opened to the
whole world)
Notable quotes:
"... Bad idea. The whole point of using CentOS is it's an exact binary-compatible rebuild of RHEL. With this decision RH is killing CentOS and inviting to create a new *fork* or use another distribution ..."
"... We all knew from the moment IBM bought Redhat that we were on borrowed time. IBM will do everything they can to push people to RHEL even if that includes destroying a great community project like CentOS. ..."
"... First CoreOS, now CentOS. It's about time to switch to one of the *BSDs. ..."
"... I guess that means the tens of thousands of cores of research compute I manage at a large University will be migrating to Debian. ..."
"... IBM is declining, hence they need more profit from "useless" product line. So disgusting ..."
"... An entire team worked for months on a centos8 transition at the uni I work at. I assume a small portion can be salvaged but reading this it seems most of it will simply go out the window ..."
"... Unless the community can center on a new single proper fork of RHEL, it makes the most sense (to me) to seek refuge in Debian as it is quite close to CentOS in stability terms. ..."
"... Another one bites the dust due to corporate greed, which IBM exemplifies ..."
"... More likely to drive people entirely out of the RHEL ecosystem. ..."
"... Don't trust Red Hat. 1 year ago Red Hat's CTO Chris Wright agreed in an interview: 'Old school CentOS isn't going anywhere. Stream is available in parallel with the existing CentOS builds. In other words, "nothing changes for current users of CentOS."' https://www.zdnet.com/article/red-hat-introduces-rolling-release-centos-stream/ ..."
"... 'To be exact, CentOS Stream is an upstream development platform for ecosystem developers. It will be updated several times a day. This is not a production operating system. It's purely a developer's distro.' ..."
"... Read again: CentOS Stream is not a production operating system. 'Nuff said. ..."
"... This makes my decision to go with Ansible and CentOS 8 in our enterprise simple. Nope, time to got with Puppet or Chef. ..."
"... Ironic, and it puts those of us who have recently migrated many of our development serves to CentOS8 in a really bad spot. Luckily we haven't licensed RHEL8 production servers yet -- and now that's never going to happen. ..."
"... What IBM fails to understand is that many of us who use CentOS for personal projects also work for corporations that spend millions of dollars annually on products from companies like IBM and have great influence over what vendors are chosen. This is a pure betrayal of the community. Expect nothing less from IBM. ..."
"... IBM is cashing in on its Red Hat acquisition by attempting to squeeze extra licenses from its customers.. ..."
"... Hoping that stabbing Open Source community in the back, will make it switch to commercial licenses is absolutely preposterous. This shows how disconnected they're from reality and consumed by greed and it will simply backfire on them, when we switch to Debian or any other LTS alternative. ..."
"... Centos was handy for education and training purposes and production when you couldn't afford the fees for "support", now it will just be a shadow of Fedora. ..."
"... There was always a conflict of interest associated with Redhat managing the Centos project and this is the end result of this conflict of interest. ..."
"... The reality is that someone will repackage Redhat and make it just like Centos. The only difference is that Redhat now live in the same camp as Oracle. ..."
"... Everyone predicted this when redhat bought centos. And when IBM bought RedHat it cemented everyone's notion. ..."
"... I am senior system admin in my organization which spends millions dollar a year on RH&IBM products. From tomorrow, I will do my best to convince management to minimize our spending on RH & IBM ..."
"... IBM are seeing every CentOS install as a missed RHEL subscription... ..."
"... Some years ago IBM bought Informix. We switched to PostgreSQL, when Informix was IBMized. One year ago IBM bought Red Hat and CentOS. CentOS is now IBMized. Guess what will happen with our CentOS installations. What's wrong with IBM? ..."
"... Remember when RedHat, around RH-7.x, wanted to charge for the distro, the community revolted so much that RedHat saw their mistake and released Fedora. You can fool all the people some of the time, and some of the people all the time, but you cannot fool all the people all the time. ..."
"... As I predicted, RHEL is destroying CentOS, and IBM is running Red Hat into the ground in the name of profit$. Why is anyone surprised? I give Red Hat 12-18 months of life, before they become another ordinary dept of IBM, producing IBM Linux. ..."
"... Happy to donate and be part of the revolution away the Corporate vampire Squid that is IBM ..."
"... Red Hat's word now means nothing to me. Disagreements over future plans and technical direction are one thing, but you *lied* to us about CentOS 8's support cycle, to the detriment of *everybody*. You cost us real money relying on a promise you made, we thought, in good faith. ..."
Bad idea. The whole point of using CentOS is it's an exact binary-compatible rebuild
of RHEL. With this decision RH is killing CentOS and inviting to create a new *fork* or use
another distribution. Do you realize how much market share you will be losing and how much
chaos you will be creating with this?
"If you are using CentOS Linux 8 in a production environment, and are concerned that
CentOS Stream will not meet your needs, we encourage you to contact Red Hat about options".
So this is the way RH is telling us they don't want anyone to use CentOS anymore and switch
to RHEL?
That's exactly what they're saying. We all knew from the moment IBM bought Redhat
that we were on borrowed time. IBM will do everything they can to push people to RHEL even if
that includes destroying a great community project like CentOS.
Wow. Well, I guess that means the tens of thousands of cores of research compute I
manage at a large University will be migrating to Debian. I've just started preparing to
shift from Scientific Linux 7 to CentOS due to SL being discontinued by 2024. Glad I've only
just started - not much work to throw away.
An entire team worked for months on a centos8 transition at the uni I work at. I assume a small portion can be salvaged
but reading this it seems most of it will simply go out the window. Does anyone know if this decision of dumping centos8
is final?
Unless the community can center on a new single proper fork of RHEL, it makes the
most sense (to me) to seek refuge in Debian as it is quite close to CentOS in stability
terms.
Already existing functioning distribution ecosystem, can probably do good with influx
of resources to enhance the missing bits, such as further improving SELinux support and
expanding Debian security team.
I say this without any official or unofficial involvement with the Debian project,
other than being a user.
And we have just launched hundred of Centos 8 servers.
Another one bites the dust due to corporate greed, which IBM exemplifies. This is
why I shuddered when they bought RH. There is nothing that IBM touches that gets better,
other than the bottom line of their suits!
This is a big mistake. RedHat did this with RedHat Linux 9 the market leading Linux
and created Fedora, now an also-ran to Ubuntu. I spent a lot of time during Covid to convert
from earlier versions to 8, and now will have to review that work with my
customer.
I just finished building a CentOS 8 web server, worked out all the nooks and
crannies and was very satisfied with the result. Now I have to do everything from scratch?
The reason why I chose this release was that every website and its brother were giving a 2029
EOL. Changing that is the worst betrayal of trust possible for the CentOS community. It's
unbelievable.
What a colossal blunder: a pivot from the long-standing mission of an OS providing
stability, to an unstable development platform, in a manner that betrays its current users.
They should remove the "C" from CentOS because it no longer has any connection to a community
effort. I wonder if this is a move calculated to drive people from a free near clone of RHEL
to a paid RHEL subscription? More likely to drive people entirely out of the RHEL
ecosystem.
From a RHEL perspective I understand why they'd want it this way. CentOS was
probably cutting deep into potential RedHat license sales. Though why or how RedHat would
have a say in how CentOS is being run in the first place is.. troubling.
From a CentOS perspective you may as well just take the project out back and close it now. If
people wanted to run beta-test tier RHEL they'd run Fedora. "LATER SECURITY FIXES AND
UNTESTED 'FEATURES'?! SIGN ME UP!" -nobody
I'll probably run CentOS 7 until the end and then swap over to Debian when support starts
hurting me. What a pain.
Don't trust Red Hat. 1 year ago Red Hat's CTO Chris Wright agreed in an interview:
'Old school CentOS isn't going anywhere. Stream is available in parallel with the existing
CentOS builds. In other words, "nothing changes for current users of CentOS."' https://www.zdnet.com/article/red-hat-introduces-rolling-release-centos-stream/
I'm a current user of old school CentOS, so keep your promise, Mr CTO.
That was quick: "Old school CentOS isn't going anywhere. Stream is available in parallel with the existing CentOS builds.
In other words, "nothing changes for current users of CentOS."
From the same article: 'To be exact, CentOS Stream is an upstream development platform for
ecosystem developers. It will be updated several times a day. This is
not a production operating system. It's purely a developer's distro.'
Read again: CentOS Stream is not a production operating system. 'Nuff
said.
This makes my decision to go with Ansible and CentOS 8 in our enterprise simple.
Nope, time to got with Puppet or Chef. IBM did what I thought they would screw up Red Hat. My
company is dumping IBM software everywhere - this means we need to dump CentOS now
too.
Ironic, and it puts those of us who have recently migrated many of our development
serves to CentOS8 in a really bad spot. Luckily we haven't licensed RHEL8 production servers
yet -- and now that's never going to happen.
I can't believe what IBM is actually doing. This is a direct move against all that
open source means. They want to do exactly the same thing they're doing with awx (vs. ansible
tower). You're going against everything that stands for open source. And on top of that you
choose to stop offering support for Centos 8, all of a sudden! What a horrid move on your
part. This only reliable choice that remains is probably going to be Debian/Ubuntu. What a
waste...
What IBM fails to understand is that many of us who use CentOS for personal projects
also work for corporations that spend millions of dollars annually on products from companies
like IBM and have great influence over what vendors are chosen. This is a pure betrayal of the community. Expect nothing less from IBM.
This is exactly it. IBM is cashing in on its Red Hat acquisition by attempting to squeeze extra licenses
from its customers.. while not taking into account the fact that Red Hat's strong adoption
into the enterprise is a direct consequence of engineers using the nonproprietary version to
develop things at home in their spare time.
Having an open source, non support contract version of your OS is exactly what
drives adoption towards the supported version once the business decides to put something into
production.
They are choosing to kill the golden goose in order to get the next few eggs faster.
IBM doesn't care about anything but its large enterprise customers. Very stereotypically
IBM.
So sad.
Not only breaking the support promise but so quickly (2021!)
Business wise, a lot of business software is providing CentOS packages and support.
Like hosting panels, backup software, virtualization, Management. I mean A LOT of money
worldwide is in dark waters now with this announcement. It took years for CentOS to appear in
their supported and tested distros. It will disappear now much faster.
Community wise, this is plain bad news for Open Source and all Open Source
communities. This is sad. I wonder, are open source developers nowadays happy to spend so
many hours for something that will in the end benefit IBM "subscribers" only in the end? I
don't think they are.
I don't want to give up on CentOS but this is a strong life changing decision. My
background is linux engineering with over 15+ years of hardcore experience. CentOS has always
been my go to when an organization didn't have the appetite for RHEL and the $75 a year
license fee per instance. I fought off Ubuntu take overs at 2 of the last 3 organizations
I've been with successfully. I can't, won't fight off any more and start advocating for
Ubuntu or pure Debian moving forward.
RIP CentOS. Red Hat killed a great project. I wonder if Anisble will be next?
Hoping that stabbing Open Source community in the back, will make it switch to
commercial licenses is absolutely preposterous. This shows how disconnected they're from
reality and consumed by greed and it will simply backfire on them, when we switch to Debian
or any other LTS alternative. I can't think moving everything I so caressed and loved to a
mess like Ubuntu.
Assinine. This is completely ridiculous. I have migrated several servers from CentOS
7 to 8 recently with more to go. We also have a RHEL subscription for outward facing servers,
CentOS internal. This type of change should absolutely have been announced for CentOS 9. This
is garbage saying 1 year from now when it was supposed to be till 2029. A complete betrayal.
One year to move everything??? Stupid.
Now I'm going to be looking at a couple of other options but it won't be RHEL after
this type of move. This has destroyed my trust in RHEL as I'm sure IBM pushed for this. You
will be losing my RHEL money once I chose and migrate. I get companies exist to make money
and that's fine. This though is purely a naked money grab that betrays an established
timeline and is about to force massive work on lots of people in a tiny timeframe saying "f
you customers.". You will no longer get my money for doing that to me
In hind sight it's clear to see that the only reason RHEL took over CentOS was to
kill the competition.
This is also highly frustrating as I just completed new CentOS8 and RHEL8 builds for
Non-production and Production Servers and had already begun deployments. Now I'm left in
situation of finding a new Linux distribution for our enterprise while I sweat out the last
few years of RHEL7/CentOS7. Ubuntu is probably a no go there enterprise tooling is somewhat
lacking, and I am of the opinion that they will likely be gobbled up buy Microsoft in the
next few years.
Unfortunately, the short-sighted RH/IBMer that made this decision failed to realize
that a lot of Admins that used Centos at home and in the enterprise also advocated and drove
sales towards RedHat as well. Now with this announcement I'm afraid the damage is done and
even if you were to take back your announcement, trust has been broken and the blowback will
ultimately mean the death of CentOS and reduced sales of RHEL. There is however an
opportunity for another Corporations such as SUSE which is own buy Microfocus to capitalize
on this epic blunder simply by announcing an LTS version of OpenSues Leap. This would in turn
move people/corporations to the Suse platform which in turn would drive sale for
SLES.
So the inevitable has come to pass, what was once a useful Distro will disappear
like others have. Centos was handy for education and training purposes and production when
you couldn't afford the fees for "support", now it will just be a shadow of
Fedora.
This is disgusting. Bah. As a CTO I will now - today - assemble my teams and develop a plan to migrate all DataCenters back to Debian for good. I will also instantly instruct the termination of all
mirroring of your software.
For the software (CentOS) I hope for a quick death that will not drag on for
years.
This is a bit sad. There was always a conflict of interest associated with Redhat
managing the Centos project and this is the end result of this conflict of interest.
There is
a genuine benefit associated with the existence of Centos for Redhat however it would appear
that that benefit isn't great enough and some arse clown thought that by forcing users to
migrate it will increase Redhat's revenue.
The reality is that someone will repackage Redhat
and make it just like Centos. The only difference is that Redhat now live in the same camp as
Oracle.
Thankfully we just started our migration from CentOS 7 to 8 and this surely puts a
stop to that. Even if CentOS backtracks on this decision because of community backlash, the
reality is the trust is lost. You've just given a huge leg for Ubuntu/Debian in the
enterprise. Congratulations!
I am senior system admin in my organization which spends millions dollar a year on
RH&IBM products. From tomorrow, I will do my best to convince management to minimize our
spending on RH & IBM, and start looking for alternatives to replace existing RH & IBM
products under my watch.
Some years ago IBM bought Informix. We switched to PostgreSQL, when Informix was
IBMized. One year ago IBM bought Red Hat and CentOS. CentOS is now IBMized. Guess what will
happen with our CentOS installations. What's wrong with IBM?
Remember when RedHat, around RH-7.x, wanted to charge for the distro, the community
revolted so much that RedHat saw their mistake and released Fedora. You can fool all the people some of the time, and some of the people all the time,
but you cannot fool all the people all the time.
Even though RedHat/CentOS has a very large share of the Linux server market, it will
suffer the same fate as Novell (had 85% of the matket), disappearing into darkness
!
As I predicted, RHEL is destroying CentOS, and IBM is running Red Hat into the
ground in the name of profit$. Why is anyone surprised? I give Red Hat 12-18 months of life,
before they become another ordinary dept of IBM, producing IBM Linux.
CentOS is dead. Time to
either go back to Debian and its derivatives, or just pay for RHEL, or IBMEL, and suck it
up.
I am mid-migration from Rhel/Cent6 to 8. I now have to stop a major project for
several hundred systems. My group will have to go back to rebuild every CentOS 8 system we've
spent the last 6 months deploying.
Congrats fellas, you did it. You perfected the transition to Debian from
CentOS.
I find it kind of funny, I find it kind of sad.
The dreams in which I moving 1.5K+ machines to whatever distro I yet have to find fitting for
replacement to are the..
Wait. How could one with all the seriousness consider cutting down
already published EOL a good idea?
I literally had to convince people to move from Ubuntu and
Debian installations to CentOS for sake of stability and longer support, just for become
looking like a clown now, because with single move distro deprived from both of
this.
Red Hat's word now means nothing to me. Disagreements over future plans and technical direction are one thing, but you
*lied* to us about CentOS 8's support cycle, to the detriment of *everybody*. You cost us real money relying on a promise you
made, we thought, in good faith. It is now clear Red Hat no longer knows what "good faith" means, and acts only as a
Trumpian vacuum of wealth.
I have been using CentOS for over 10 years and one of the things I loved about it was how
stable it has been. Now, instead of being a stable release, it is changing to the beta
testing ground for RHEL 8.
And instead of 10 years of a support you need to update to the latest dot release. This
has me, very concerned.
well, 10 years - have you ever contributed with anything for the CentOS community, or paid
them a wage or at least donated some decent hardware for development or maybe just being
parasite all the time and now are you surprised that someone has to buy it's your own lunches
for a change?
If you think you might have done it even better why not take RH sources and make your own
FreeRHos whatever distro, then support, maintain and patch all the subsequent versions for
free?
That's ridiculous. RHEL has benefitted from the free testing and corner case usage of
CentOS users and made money hand-over-fist on RHEL. Shed no tears for using CentOS for free.
That is the benefit of opening the core of your product.
You are missing a very important point. Goal of CentOS project was to rebuild RHEL,
nothing else. If money was the problem, they could have asked for donations and it would be
clear is there can be financial support for rebuild or not.
Putting entire community in front of done deal is disheartening and no one will trust
Red Hat that they are pro-community, not to mention Red Hat employees that sit in CentOS
board, who can trust their integrity after this fiasco?
This is a breach of trust from the already published timeline of CentOS 8 where the EOL
was May 2029. One year's notice for such a massive change is unacceptable.
This! People already started deploying CentOS 8 with the expectation of 10 years of
updates. - Even a migration to RHEL 8 would imply completely reprovisioning the systems which
is a big ask for systems deployed in the field.
I am considering creating another rebuild of RHEL and may even be able to hire some
people for this effort. If you are interested in helping, please join the HPCng slack (link
on the website hpcng.org).
This sounds like a great idea and getting control away from corporate entities like IBM
would be helpful. Have you considered reviving the Scientific Linux project?
Feel free to contact me. I'm a long time RH user (since pre-RHEL when it was RHL) in both
server and desktop environments. I've built and maintained some RPMs for some private
projects that used CentOS as foundation. I can contribute compute and storage resources. I
can program in a few different languages.
Thank you for considering starting another RHEL rebuild. If and when you do, please
consider making your new website a Brave Verified Content Creator. I earn a little bit of
money every month using the Brave browser, and I end up donating it to Wikipedia every month
because there are so few Brave Verified websites.
The verification process is free, and takes about 15 to 30 minutes. I believe that the
Brave browser now has more than 8 million users.
Wikipedia. The so called organization that get tons of money from tech oligarchs and
yet the whine about we need money and support? (If you don't believe me just check their
biggest donors) also they keen to be insanely biased and allow to write on their web whoever
pays the most... Seriously, find other organisation to donate your money
Not sure what I could do but I will keep an eye out things I could help with. This change
to CentOS really pisses me off as I have stood up 2 CentOS servers for my works production
environment in the last year.
LOL... CentOS is RH from 2014 to date. What you expected? As long as CentOS is so good
and stable, that cuts some of RHEL sales... RH and now IBM just think of profit. It was
expected, search the net for comments back in 2014.
Amazon Linux 2 is the next generation of Amazon Linux, a Linux server operating system from
Amazon Web Services (AWS). It provides a secure, stable, and high performance execution
environment to develop and run cloud and enterprise applications. With Amazon Linux 2, you get
an application environment that offers long term support with access to the latest innovations
in the Linux ecosystem. Amazon Linux 2 is provided at no additional charge.
Amazon Linux 2 is available as an Amazon Machine Image (AMI) for use on Amazon Elastic
Compute Cloud (Amazon EC2). It is also available as a Docker container image and as a virtual
machine image for use on Kernel-based Virtual Machine (KVM), Oracle VM VirtualBox, Microsoft
Hyper-V, and VMware ESXi. The virtual machine images can be used for on-premises development
and testing. Amazon Linux 2 supports the latest Amazon EC2 features and includes packages that
enable easy integration with AWS. AWS provides ongoing security and maintenance updates for
Amazon Linux 2.
"... Redhat endorsed that moral contract when you brought official support to CentOS back in 2014. ..."
"... Now that you decided to turn your back on the community, even if another RHEL fork comes out, there will be an exodus of the community. ..."
"... Also, a lot of smaller developers won't support RHEL anymore because their target weren't big companies, making less and less products available without the need of self supporting RPM builds. ..."
"... Gregory Kurtzer's fork will take time to grow, but in the meantime, people will need a clear vision of the future. ..."
"... This means that we'll now have to turn to other linux flavors, like Debian, or OpenSUSE, of which at least some have hardware vendor support too, but with a lesser lifecycle. ..."
"... I think you destroyed a large part of the RHEL / CentOS community with this move today. ..."
"... Maybe you'll get more RHEL subscriptions in the next months yielding instant profits, but the long run growth is now far more uncertain. ..."
As a lot of us here, I've been in the CentOS / RHEL community for more than 10 years.
Reasons of that choice were stability, long term support and good hardware vendor support.
Like many others, I've built much of my skills upon this linux flavor for years, and have been implicated into the community
for numerous bug reports, bug fixes, and howto writeups.
Using CentOS was the good alternative to RHEL on a lot of non critical systems, and for smaller companies like the one I work
for.
The moral contract has always been a rock solid "Community Enterprise OS" in exchange of community support, bug reports & fixes,
and growing interest from developers.
Redhat endorsed that moral contract when you brought official support to CentOS back in 2014.
Now that you decided to turn your back on the community, even if another RHEL fork comes out, there will be an exodus of the
community.
Also, a lot of smaller developers won't support RHEL anymore because their target weren't big companies, making less and less
products available without the need of self supporting RPM builds.
This will make RHEL less and less widely used by startups, enthusiasts and others.
CentOS Stream being the upstream of RHEL, I highly doubt system architects and developers are willing to be beta testers for RHEL.
Providing a free RHEL subscription for Open Source projects just sounds like your next step to keep a bit of the exodus from happening,
but I'd bet that "free" subscription will get more and more restrictions later on, pushing to a full RHEL support contract.
As a lot of people here, I won't go the Oracle way, they already did a very good job destroying other company's legacy.
Gregory Kurtzer's fork will take time to grow, but in the meantime, people will need a clear vision of the future.
This means that we'll now have to turn to other linux flavors, like Debian, or OpenSUSE, of which at least some have hardware
vendor support too, but with a lesser lifecycle.
I think you destroyed a large part of the RHEL / CentOS community with this move today.
Maybe you'll get more RHEL subscriptions in the next months yielding instant profits, but the long run growth is now far more
uncertain.
IBM have a history of taking over companies and turning them into junk, so I am not that
surprised. I am surprised that it took IBM brass so long to kill CentOS after Red Hat
acquisition.
Notable quotes:
"... By W3Tech 's count, while Ubuntu is the most popular Linux server operating system with 47.5%, CentOS is number two with 18.8% and Debian is third, 17.5%. RHEL? It's a distant fourth with 1.8%. ..."
"... Red Hat will continue to support CentOS 7 and produce it through the remainder of the RHEL 7 life cycle . That means if you're using CentOS 7, you'll see support through June 30, 2024 ..."
I'm far from alone. By W3Tech 's count,
while Ubuntu is the most popular Linux server operating system with 47.5%, CentOS is number two
with 18.8% and Debian is third, 17.5%. RHEL? It's a distant fourth with 1.8%.
If you think you just realized why Red Hat might want to remove CentOS from the server
playing field, you're far from the first to think that.
Red Hat will continue to support CentOS 7 and produce it through the remainder of the
RHEL 7 life
cycle . That means if you're using CentOS 7, you'll see support through June 30, 2024
I wonder what Red Hat's plan is WRT companies like Blackmagic Design that ship CentOS as part of their studio equipment.
The cost of a RHEL license isn't the issue when the overall cost of the equipment is in the tens of thousands but unless I
missed a change in Red Hat's trademark policy, Blackmagic cannot distribute a modified version of RHEL and without removing all
trademarks first.
I don't think a rolling release distribution is what BMD wants.
My gut feeling is that something like Scientific Linux will make a return and current CentOS users will just use that.
We firmly believe that Oracle Linux is the best Linux distribution on the market today. It's reliable, it's affordable, it's 100%
compatible with your existing applications, and it gives you access to some of the most cutting-edge innovations in Linux like Ksplice
and DTrace.
But if you're here, you're a CentOS user. Which means that you don't pay for a distribution at all, for at least some of your
systems. So even if we made the best paid distribution in the world (and we think we do), we can't actually get it to you... or
can we?
We're putting Oracle Linux in your hands by doing two things:
We've made the Oracle Linux software available free of charge
We've created a simple script to switch your CentOS systems to Oracle Linux
We think you'll like what you find, and we'd love for you to give it a try.
FAQ
Wait, doesn't Oracle Linux cost money?
Oracle Linux support costs money. If you just want the software, it's 100% free. And it's all in our yum repo at
yum.oracle.com . Major releases, errata, the whole shebang. Free source
code, free binaries, free updates, freely redistributable, free for production use. Yes, we know that this is Oracle, but it's
actually free. Seriously.
Is this just another CentOS?
Inasmuch as they're both 100% binary-compatible with Red Hat Enterprise Linux, yes, this is just like CentOS. Your applications
will continue to work without any modification whatsoever. However, there are several important differences that make Oracle Linux
far superior to CentOS.
How is this better than CentOS?
Well, for one, you're getting the exact same bits our paying enterprise customers are getting . So that means a few
things. Importantly, it means virtually no delay between when Red Hat releases a kernel and when Oracle Linux does:
So if you don't want to risk another CentOS delay, Oracle Linux is a better alternative for you. It turns out that our enterprise
customers don't like to wait for updates -- and neither should you.
What about the code quality?
Again, you're running the exact same code that our enterprise customers are, so it has to be rock-solid. Unlike CentOS, we
have a large paid team of developers, QA, and support engineers that work to make sure this is reliable.
What if I want support?
If you're running Oracle Linux and want support, you can purchase a support contract from us (and it's significantly cheaper
than support from Red Hat). No reinstallation, no nothing -- remember, you're running the same code as our customers.
Contrast that with the CentOS/RHEL story. If you find yourself needing to buy support, have fun reinstalling your system with
RHEL before anyone will talk to you.
Why are you doing this?
This is not some gimmick to get you running Oracle Linux so that you buy support from us. If you're perfectly happy running
without a support contract, so are we. We're delighted that you're running Oracle Linux instead of something else.
At the end of the day, we're proud of the work we put into Oracle Linux. We think we have the most compelling Linux offering
out there, and we want more people to experience it.
centos2ol.sh can convert your CentOS 6 and 7 systems to Oracle Linux.
What does the script do?
The script has two main functions: it switches your yum configuration to use the Oracle Linux yum server to update some core
packages and installs the latest Oracle Unbreakable Enterprise Kernel. That's it! You won't even need to restart after switching,
but we recommend you do to take advantage of UEK.
Is it safe?
The centos2ol.sh script takes precautions to back up and restore any repository files it changes, so if it does not work on
your system it will leave it in working order. If you encounter any issues, please get in touch with us by emailing
[email protected] .
IBM is messing up RedHat after the take over last year. This is the most unfortunate news
to the Free Open-Source community. Companies have been using CentOS as a testing bed before
committing to purchase RHEL subscription licenses.
We need to rethink before rolling out RedHat/CentOS 8 training in our Centre.
You can use Oracle Linux in exactly the same way as you did CentOS except that you have
the option of buying support without reinstalling a "commercial" variant.
Everything's in the public repos except a few addons like ksplice. You don't even have to
go through the e-delivery to download the ISOs any more, they're all linked from
yum.oracle.com
Not likely. Oracle Linux has extensive use by paying Oracle customers as a host OS for
their database software and in general purposes for Oracle Cloud Infrastructure.
Oracle customers would be even less thrilled about Streams than CentOS users. I hate to
admit it, but Oracle has the opportunity to take a significant chunk of the CentOS user base
if they don't do anything Oracle-ish, myself included.
I'll be pretty surprised if they don't completely destroy their own windfall opportunity,
though.
IBM has discontinued CentOS. Oracle is producing a working replacement for CentOS. If, at
some point, Oracle attacks their product's users in the way IBM has here, then one can move
to Debian, but for now, it's a working solution, as CentOS no longer is.
You can use Oracle Linux exactly like CentOS, only better
Ang says: December 9, 2020 at 5:04 pm "I never thought we'd see the day Oracle is more
trustworthy than RedHat/IBM. But I guess such things do happen with time..."
Notable quotes:
"... The link says that you don't have to pay for Oracle Linux . So switching to it from CentOS 8 could be a very easy option. ..."
"... this quick n'dirty hack worked fine to convert centos 8 to oracle linux 8, ymmv: ..."
Oracle Linux is free. The only thing that costs money is support for it. I quote
"Yes, we know that this is Oracle, but it's actually free.
Seriously."
In the first command, as an example, we used ' single quotes. This resulted in
our subshell command, inside the single quotes, to be interpreted as literal text instead of a
command. This is standard Bash: ' indicates literal, " indicates that
the string will be parsed for subshells and variables.
In the second command we swap the ' to " and thus the string is
parsed for actual commands and variables. The result is that a subshell is being started,
thanks to our subshell syntax ( $() ), and the command inside the subshell (
echo 'a' ) is being executed literally, and thus an a is produced,
which is then inserted in the overarching / top level echo . The command at that
stage can be read as echo "a" and thus the output is a .
In the third command, we further expand this to make it clearer how subshells work
in-context. We echo the letter b inside the subshell, and this is joined on the
left and the right by the letters a and c yielding the overall output
to be abc in a similar fashion to the second command.
In the fourth and last command, we exemplify the alternative Bash subshell syntax of using
back-ticks instead of $() . It is important to know that $() is the
preferred syntax, and that in some remote cases the back-tick based syntax may yield some
parsing errors where the $() does not. I would thus strongly encourage you to
always use the $() syntax for subshells, and this is also what we will be using in
the following examples.
Example 2: A little more complex
$ touch a
$ echo "-$(ls [a-z])"
-a
$ echo "-=-||$(ls [a-z] | xargs ls -l)||-=-"
-=-||-rw-rw-r-- 1 roel roel 0 Sep 5 09:26 a||-=-
Here, we first create an empty file by using the touch a command. Subsequently,
we use echo to output something which our subshell $(ls [a-z]) will
generate. Sure, we can execute the ls directly and yield more or less the same
result, but note how we are adding - to the output as a prefix.
In the final command, we insert some characters at the front and end of the
echo command which makes the output look a bit nicer. We use a subshell to first
find the a file we created earlier ( ls [a-z] ) and then - still
inside the subshell - pass the results of this command (which would be only a
literally - i.e. the file we created in the first command) to the ls -l using the
pipe ( | ) and the xargs command. For more information on xargs,
please see our articles xargs for beginners with
examples and multi threaded xargs with
examples .
Example 3: Double quotes inside subshells and sub-subshells!
echo "$(echo "$(echo "it works")" | sed 's|it|it surely|')"
it surely works
Cool, no? Here we see that double quotes can be used inside the subshell without generating
any parsing errors. We also see how a subshell can be nested inside another subshell. Are you
able to parse the syntax? The easiest way is to start "in the middle or core of all subshells"
which is in this case would be the simple echo "it works" .
This command will output it works as a result of the subshell call $(echo
"it works") . Picture it works in place of the subshell, i.e.
echo "$(echo "it works" | sed 's|it|it surely|')"
it surely works
This looks simpler already. Next it is helpful to know that the sed command
will do a substitute (thanks to the s command just before the |
command separator) of the text it to it surely . You can read the
sed command as replace __it__ with __it surely__. The output of the subshell
will thus be it surely works`, i.e.
echo "it surely works"
it surely works
Conclusion
In this article, we have seen that subshells surely work (pun intended), and that they can
be used in wide variety of circumstances, due to their ability to be inserted inline and within
the context of the overarching command. Subshells are very powerful and once you start using
them, well, there will likely be no stopping. Very soon you will be writing something like:
$ VAR="goodbye"; echo "thank $(echo "${VAR}" | sed 's|^| and |')" | sed 's|k |k you|'
This one is for you to try and play around with! Thank you and goodbye
Is Oracle A Real Alternative To CentOS? Home "
CentOS " Is Oracle A Real Alternative To CentOS? December 8,
2020 Frank Cox CentOS 33 Comments
Is Oracle a real alternative to
CentOS ? I'm asking because genuinely don't know; I've never paid any attention to Oracle's Linux offering before now.
But today I've seen a couple of the folks here mention Oracle Linux and I see that Oracle even offers a script to convert
CentOS 7 to Oracle. Nothing about
CentOS 8 in that script, though.
That page seems to say that Oracle Linux is everything that
CentOS was prior to today's announcement.
But someone else here just said that the first thing Oracle Linux does is to sign you up for an Oracle account.
So, for people who know a lot more about these things than I do, what's the downside of using Oracle Linux versus CentOS? I assume
that things like epel/rpmfusion/etc will work just as they do under CentOS since it's supposed to be bit-for-bit compatible like
CentOS was. What does the "sign up with Oracle" stuff actually do, and can you cancel, avoid, or strip it out if you don't want it?
Based on my extremely limited knowledge around Oracle Linux, it sounds like that might be a go-to solution for CentOS refugees.
$ cat /etc/redhat-release Red Hat Enterprise Linux Server release 7.7 (Maipo)
$ cat /etc/oracle-release Oracle Linux Server release 7.7
This is generally done so that sw pieces officially certified only on upstream enterprise vendor and that test contents of
the redhat-release file are satisfied. Using the lsb_release command on an Oracle Linux 7.6 machine:
# lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: OracleServer Description: Oracle Linux Server release 7.6
Release: 7.6
Codename: n/a
#
KVM is a subscription feature. They want you to run Oracle VM Server for x86 (which is based on Xen) so they can try to upsell
you to use the Oracle Cloud. There's other things, but that stood out immediately.
That's it. I know Oracle's history, but I think for Oracle Linux, they may be much better than their reputation. I'm currently
fiddling around with it, and I like it very much. Plus there's a nice script to turn an existing CentOS installation into an Oracle
Linux system.
Am Dienstag, den 15.12.2020, 10:14 +0100 schrieb Ruslanas Gžibovskis:
According to the Oracle license terms and official statements, it is "free to download, use and share. There is no license
cost, no need for a contract, and no usage audits."
Recommendation only: "For business-critical infrastructure, consider Oracle Linux Support." Only optional, not a mandatory
requirement. see: https://www.oracle.com/linux
No need for such a construct. Oracle Linux can be used on any production system without the legal requirement to obtain a extra
commercial license. Same as in CentOS.
So Oracle Linux can be used free as in "free-beer" currently for any system, even for commercial purposes. Nevertheless, Oracle
can change that license terms in the future, but this applies as well to all other company-backed linux distributions.
--
Peter Huebner
1 - Catchall for general errors. The exit code is 1 as the operation was not
successful.
2 - Misuse of shell builtins (according to Bash documentation)
126 - Command invoked cannot execute.
127 - "command not found".
128 - Invalid argument to exit.
128+n - Fatal error signal "n".
130 - Script terminated by Control-C.
255\* - Exit status out of range.
There is no "recipe" to get the meanings of an exit status of a given terminal command.
My first attempt would be the manpage:
user@host:~# man ls
Exit status:
0 if OK,
1 if minor problems (e.g., cannot access subdirectory),
2 if serious trouble (e.g., cannot access command-line argument).
Third : The exit statuses of the shell, for example bash. Bash and it's builtins may use
values above 125 specially. 127 for command not found, 126 for command not executable. For more
information see the bash
exit codes .
Some list of sysexits on both Linux and BSD/OS X with preferable exit codes for programs
(64-78) can be found in /usr/include/sysexits.h (or: man sysexits on
BSD):
0 /* successful termination */
64 /* base value for error messages */
64 /* command line usage error */
65 /* data format error */
66 /* cannot open input */
67 /* addressee unknown */
68 /* host name unknown */
69 /* service unavailable */
70 /* internal software error */
71 /* system error (e.g., can't fork) */
72 /* critical OS file missing */
73 /* can't create (user) output file */
74 /* input/output error */
75 /* temp failure; user is invited to retry */
76 /* remote error in protocol */
77 /* permission denied */
78 /* configuration error */
/* maximum listed value */
The above list allocates previously unused exit codes from 64-78. The range of unallotted
exit codes will be further restricted in the future.
However above values are mainly used in sendmail and used by pretty much nobody else, so
they aren't anything remotely close to a standard (as pointed by
@Gilles ).
In shell the exit status are as follow (based on Bash):
1 - 125 - Command did not complete successfully. Check the
command's man page for the meaning of the status, few examples below:
1 - Catchall for general errors
Miscellaneous errors, such as "divide by zero" and other impermissible operations.
Example:
$ let "var1 = 1/0"; echo $?
-bash: let: var1 = 1/0: division by 0 (error token is "0")
1
2 - Misuse of shell builtins (according to Bash documentation)
Missing keyword or command, or permission problem (and diff return code on a failed
binary file comparison).
Example:
empty_function() {}
6 - No such device or address
Example:
$ curl foo; echo $?
curl: (6) Could not resolve host: foo
6
128 - 254 - fatal error signal "n" - command died due to
receiving a signal. The signal code is added to 128 (128 + SIGNAL) to get the status
(Linux: man 7 signal , BSD: man signal ), few examples below:
130 - command terminated due to Ctrl-C being pressed, 130-128=2
(SIGINT)
Example:
$ cat
^C
$ echo $?
130
137 - if command is sent the KILL(9) signal (128+9), the exit
status of command otherwise
exit takes only integer args in the range 0 - 255.
Example:
$ sh -c 'exit 3.14159'; echo $?
sh: line 0: exit: 3.14159: numeric argument required
255
According to the above table, exit codes 1 - 2, 126 - 165, and 255 have special meanings,
and should therefore be avoided for user-specified exit parameters.
Please note that out of range exit values can result in unexpected exit codes (e.g. exit
3809 gives an exit code of 225, 3809 % 256 = 225).
You will have to look into the code/documentation. However the thing that comes closest to a
"standardization" is errno.h share improve this answer
follow answered Jan 22 '14 at 7:35 Thorsten Staerk 2,885 1 1 gold
badge 17 17 silver badges 25 25 bronze badges
PSkocik ,
thanks for pointing the header file.. tried looking into the documentation of a few utils..
hard time finding the exit codes, seems most will be the stderrs... – precise Jan 22 '14 at
9:13
The first thing that you want to do anytime that you need to make changes to your disk is to
find out what partitions you already have. Displaying existing partitions allows you to make
informed decisions moving forward and helps you nail down the partition names will need for
future commands. Run the parted command to start parted in
interactive mode and list partitions. It will default to your first listed drive. You will then
use the print command to display disk information.
[root@rhel ~]# parted /dev/sdc
GNU Parted 3.2
Using /dev/sdc
Welcome to GNU Parted! Type 'help' to view a list of commands.
(parted) print
Error: /dev/sdc: unrecognised disk label
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: unknown
Disk Flags:
(parted)
Creating new partitions with parted
Now that you can see what partitions are active on the system, you are going to add a new
partition to /dev/sdc . You can see in the output above that there is no partition
table for this partition, so add one by using the mklabel command. Then use
mkpart to add the new partition. You are creating a new primary partition using
the ext4 architecture. For demonstration purposes, I chose to create a 50 MB partition.
(parted) mklabel msdos
(parted) mkpart
Partition type? primary/extended? primary
File system type? [ext2]? ext4
Start? 1
End? 50
(parted)
(parted) print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 50.3MB 49.3MB primary ext4 lba
Modifying existing partitions with parted
Now that you have created the new partition at 50 MB, you can resize it to 100 MB, and then
shrink it back to the original 50 MB. First, note the partition number. You can find this
information by using the print command. You are then going to use the
resizepart command to make the modifications.
(parted) resizepart
Partition number? 1
End? [50.3MB]? 100
(parted) print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 100MB 99.0MB primary
You can see in the above output that I resized partition number one from 50 MB to 100 MB.
You can then verify the changes with the print command. You can now resize it back
down to 50 MB. Keep in mind that shrinking a partition can cause data loss.
(parted) resizepart
Partition number? 1
End? [100MB]? 50
Warning: Shrinking a partition can cause data loss, are you sure you want to
continue?
Yes/No? yes
(parted) print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
1 1049kB 50.0MB 49.0MB primary
Removing partitions with parted
Now, let's look at how to remove the partition you created at /dev/sdc1 by
using the rm command inside of the parted suite. Again, you will need
the partition number, which is found in the print output.
NOTE: Be sure that you have all of the information correct here, there are no safeguards or
are you sure? questions asked. When you run the rm command, it will
delete the partition number you give it.
(parted) rm 1
(parted) print
Model: ATA VBOX HARDDISK (scsi)
Disk /dev/sdc: 1074MB
Sector size (logical/physical): 512B/512B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system Flags
For security reasons, it defaults to "" , which disables explainshell integration. When set, this extension will
send requests to the endpoint and displays documentation for flags.
Once https://github.com/idank/explainshell/pull/125
is merged, it would be possible to set this to "https://explainshell.com" , however doing this is not recommended as
it will leak all your shell scripts to a third party -- do this at your own risk, or better always use a locally running
Docker image.
I can't figure out how to disable the startup graphic in centos 7 64bit.
In centos 6 I always did it by removing "rhgb quiet" from /boot/grub/grub.conf but there is no
grub.conf in centos 7. I also tried yum remove rhgb but that wasn't present either.
<moan> I've never understood why the devs include this startup graphic, I see loads of
users like me who want a text scroll instead.</moan>
Thanks for any help.
I can't figure out how to disable the startup graphic in centos 7 64bit.
In centos 6 I always did it by removing "rhgb quiet" from /boot/grub/grub.conf but there is no
grub.conf in centos 7. I also tried yum remove rhgb but that wasn't present either.
<moan> I've never understood why the devs include this startup graphic, I see loads of
users like me who want a text scroll instead.</moan>
Thanks for any help. Top
The file to amend now is /boot/grub2/grub.cfg and also
/etc/default/grub. If you only amend the defaults file then you need to run grub2-mkconfig -o
/boot/grub2/grub.cfg afterwards to get a new file generated but you can also edit the grub.cfg
file directly though your changes will be wiped out next kernel install if you don't also edit
the 'default' file. CentOS 6 will die in November 2020 - migrate sooner rather than later!
CentOS 5 has been EOL for nearly 3 years and should no longer be used for anything!
Full time Geek, part time moderator. Use the FAQ Luke Top
The preferred method to do this is using the command plymouth-set-default-theme.
If you enter this command, without parameters, as user root you'll see something like
>plymouth-set-default-theme
charge
details
text
This lists the themes installed on your computer. The default is 'charge'. If you want to
see the boot up details you used to see in version 6, try
>plymouth-set-default-theme details
Followed by the command
>dracut -f
Then reboot.
This process modifies the boot loader so you won't have to update your grub.conf file
manually everytime for each new kernel update.
There are numerous themes available you can download from CentOS or in general. Just google
'plymouth themes' to see other possibilities, if you're looking for graphics type screens.
Top
Editing /etc/default/grub to remove rhgb quiet makes it permanent too.
CentOS 6 will die in November 2020 - migrate sooner rather than later!
CentOS 5 has been EOL for nearly 3 years and should no longer be used for anything!
Full time Geek, part time moderator. Use the FAQ Luke Top
I tried both TrevorH's and LarryG's methods, and LarryG wins.
Editing /etc/default/grub to remove "rhgb quiet" gave me the scrolling boot messages I want,
but it reduced maxmum display resolution (nouveau driver) from 1920x1080 to 1024x768! I put
"rhgb quiet" back in and got my 1920x1080 back.
Then I tried "plymouth-set-default-theme details; dracut -f", and got verbose booting
without loss of display resolution. Thanks LarryG! Top
I have used this mod to get back the details for grub boot, thanks to
all for that info.
However when I am watching it fills the page and then rather than scrolling up as it did in
V5 it blanks and starts again at the top. Of course there is FAIL message right before it
blanks that I want to see and I can't slam the Scroll Lock fast
enough to catch it. Anyone know how to get the details to scroll up rather than the blank and
re-write?
Yeah the scroll lock/ctrl+q/ctrl+s will not work with systemd you can't pause the
screen like you used to be able to (it was a design choice, due to parallel daemon launching,
apparently).
If you do boot, you can always use journalctrl to view the logs.
In Fedora you can use journalctl --list-boots to list boots (not 100% sure about CentOS 7.x -
perhaps in 7.1 or 7.2?). You can also use things like journalctl --boot=-1 (the last boot), and
parse the log at you leisure. Top
aks wrote: Yeah the scroll lock/ctrl+q/ctrl+s will not work with systemd you
can't pause the screen like you used to be able to (it was a design choice, due to parallel
daemon launching, apparently).
If you do boot, you can always use journalctrl to view the logs.
In Fedora you can use journalctl --list-boots to list boots (not 100% sure about CentOS 7.x -
perhaps in 7.1 or 7.2?). You can also use things like journalctl --boot=-1 (the last boot),
and parse the log at you leisure.
Thanks for the followup aks. Actually I have found that the Scroll Lock
does pause (Ctrl-S/Q not) but it all goes by so fast that I'm not fast enough to stop it
before the screen blanks and then starts writing again. What I am really wondering is how to
get the screen to scroll up when it gets to the bottom of the screen rather than blanking and
starting to write again at the top. That is annoying!
Lately, booting Ubuntu on my desktop has become seriously slow. We're talking two minutes. It
used to take 10-20 seconds. Because of plymouth, I can't see what's going on. I would like to
deactivate it, but not really uninstall it. What's the quickest way to do that? I'm using
Precise, but I suspect a solution for 11.10 would work just as well.
Easiest quick fix is to edit the grub line as you boot.
Hold down the shift key so you see the menu. Hit the e key to edit
Edit the 'linux' line, remove the 'quiet' and 'splash'
To disable it in the long run
Edit /etc/default/grub
Change the line – GRUB_CMDLINE_LINUX_DEFAULT="quiet splash" to
GRUB_CMDLINE_LINUX_DEFAULT=""
And then update grub
sudo update-grub
Panther , 2016-10-27 15:43:04
Removing quiet and splash removes the splash, but I still only have a purple screen with no
text. What I want to do, is to see the actual boot messages. – Jo-Erlend Schinstad Jan 25 '12 at
22:25
Tuminoid ,
How about pressing CTRL+ALT+F2 for console allowing you to see whats going on..
You can go back to GUI/Plymouth by CTRL+ALT+F7 .
Don't have my laptop here right now, but IIRC Plymouth has upstart job in
/etc/init , named plymouth???.conf, renaming that probably achieves what you
want too more permanent manner.
Mirroring a running system into a ramdiskGreg Marsden
In this blog post, Oracle Linux kernel developer William Roche presents a method to
mirror a running system into a ramdisk.
A RAM mirrored System ?
There are cases where a system can boot correctly but after some time, can lose its system
disk access - for example an iSCSI system disk configuration that has network issues, or any
other disk driver problem. Once the system disk is no longer accessible, we rapidly face a hang
situation followed by I/O failures, without the possibility of local investigation on this
machine. I/O errors can be reported on the console:
XFS (dm-0): Log I/O Error Detected....
Or losing access to basic commands like:
# ls
-bash: /bin/ls: Input/output error
The approach presented here allows a small system disk space to be mirrored in memory to
avoid the above I/O failures situation, which provides the ability to investigate the reasons
for the disk loss. The system disk loss will be noticed as an I/O hang, at which point there
will be a transition to use only the ram-disk.
To enable this, the Oracle Linux developer Philip "Bryce" Copeland created the following
method (more details will follow):
Create a "small enough" system disk image using LVM (a minimized Oracle Linux
installation does that)
After the system is started, create a ramdisk and use it as a mirror for the system
volume
when/if the (primary) system disk access is lost, the ramdisk continues to provide all
necessary system functions.
Disk and memory sizes:
As we are going to mirror the entire system installation to the memory, this system
installation image has to fit in a fraction of the memory - giving enough memory room to hold
the mirror image and necessary running space.
Of course this is a trade-off between the memory available to the server and the minimal
disk size needed to run the system. For example a 12GB disk space can be used for a minimal
system installation on a 16GB memory machine.
A standard Oracle Linux installation uses XFS as root fs, which (currently) can't be shrunk.
In order to generate a usable "small enough" system, it is recommended to proceed to the OS
installation on a correctly sized disk space. Of course, a correctly sized installation
location can be created using partitions of large physical disk. Then, the needed application
filesystems can be mounted from their current installation disk(s). Some system adjustments may
also be required (services added, configuration changes, etc...).
This configuration phase should not be underestimated as it can be difficult to separate the
system from the needed applications, and keeping both on the same space could be too large for
a RAM disk mirroring.
The idea is not to keep an entire system load active when losing disks access, but to be
able to have enough system to avoid system commands access failure and analyze the
situation.
We are also going to avoid the use of swap. When the system disk access is lost, we don't
want to require it for swap data. Also, we don't want to use more memory space to hold a swap
space mirror. The memory is better used directly by the system itself.
The system installation can have a swap space (for example a 1.2GB space on our 12GB disk
example) but we are neither going to mirror it nor use it.
Our 12GB disk example could be used with: 1GB /boot space, 11GB LVM Space (1.2GB swap
volume, 9.8 GB root volume).
Ramdisk
memory footprint:
The ramdisk size has to be a little larger (8M) than the root volume size that we are going
to mirror, making room for metadata. But we can deal with 2 types of ramdisk:
A classical Block Ram Disk (brd) device
A memory compressed Ram Block Device (zram)
We can expect roughly 30% to 50% memory space gain from zram compared to brd, but zram must
use 4k I/O blocks only. This means that the filesystem used for root has to only deal with a
multiple of 4k I/Os.
Basic commands:
Here is a simple list of commands to manually create and use a ramdisk and mirror the root
filesystem space. We create a temporary configuration that needs to be undone or the subsequent
reboot will not work. But we also provide below a way of automating at startup and
shutdown.
Note the root volume size (considered to be ol/root in this example):
# lvconvert -y -m 0 ol/root /dev/ram0Logical volume ol/rootsuccessfully converted.# vgreduce ol /dev/ram0Removed"/dev/ram0"from volume group"ol"# mount /boot# mount /boot/efi# swapon
-a
What about in-memory compression ?
As indicated above, zRAM devices can compress data in-memory, but 2 main problems need to be
fixed:
LVM does take into account zRAM devices by default
zRAM only works with 4K I/Os
Make lvm work with zram:
The lvm configuration file has to be changed to take into account the "zram" type of
devices. Including the following "types" entry to the /etc/lvm/lvm.conf file in its "devices"
section:
We can notice here that the sector size (sectsz) used on this root fs is a standard 512
bytes. This fs type cannot be mirrored with a zRAM device, and needs to be recreated with 4k
sector sizes.
Transforming the root file system to 4k sector size:
This is simply a backup (to a zram disk) and restore procedure after recreating the root FS.
To do so, the system has to be booted from another system image. Booting from an installation
DVD image can be a good possibility.
Boot from an OL installation DVD [Choose "Troubleshooting", "Rescue a Oracle Linux
system", "3) Skip to shell"]
A service Unit file can also be created: /etc/systemd/system/raid1-ramdisk.service
[https://github.com/oracle/linux-blog-sample-code/blob/ramdisk-system-image/raid1-ramdisk.service]
[Unit]Description=Enable RAMdisk RAID 1 on LVMAfter=local-fs.targetBefore=shutdown.target reboot.target halt.target[Service]ExecStart=/usr/sbin/start-raid1-ramdiskExecStop=/usr/sbin/stop-raid1-ramdiskType=oneshotRemainAfterExit=yesTimeoutSec=0[Install]WantedBy=multi-user.target
Conclusion:
When the system disk access problem manifests itself, the ramdisk mirror branch will provide
the possibility to investigate the situation. This procedure goal is not to keep the system
running on this memory mirror configuration, but help investigate a bad situation.
When the problem is identified and fixed, I really recommend to come back to a standard
configuration -- enjoying the entire memory of the system, a standard system disk, a possible
swap space etc.
Hoping the method described here can help. I also want to thank for their reviews Philip
"Bryce" Copeland who also created the first prototype of the above scripts, and Mark Kanda who
also helped testing many aspects of this work.
In Figure 1, two complete physical hard drives and one partition from a third hard drive
have been combined into a single volume group. Two logical volumes have been created from the
space in the volume group, and a filesystem, such as an EXT3 or EXT4 filesystem has been
created on each of the two logical volumes.
Figure 1: LVM allows combining partitions and entire hard drives into Volume
Groups.
Adding disk space to a host is fairly straightforward but, in my experience, is done
relatively infrequently. The basic steps needed are listed below. You can either create an
entirely new volume group or you can add the new space to an existing volume group and either
expand an existing logical volume or create a new one.
Adding a new logical volume
There are times when it is necessary to add a new logical volume to a host. For example,
after noticing that the directory containing virtual disks for my VirtualBox virtual machines
was filling up the /home filesystem, I decided to create a new logical volume in which to store
the virtual machine data, including the virtual disks. This would free up a great deal of space
in my /home filesystem and also allow me to manage the disk space for the VMs
independently.
The basic steps for adding a new logical volume are as follows.
If necessary, install a new hard drive.
Optional: Create a partition on the hard drive.
Create a physical volume (PV) of the complete hard drive or a partition on the hard
drive.
Assign the new physical volume to an existing volume group (VG) or create a new volume
group.
Create a new logical volumes (LV) from the space in the volume group.
Create a filesystem on the new logical volume.
Add appropriate entries to /etc/fstab for mounting the filesystem.
Mount the filesystem.
Now for the details. The following sequence is taken from an example I used as a lab project
when teaching about Linux filesystems.
Example
This example shows how to use the CLI to extend an existing volume group to add more space
to it, create a new logical volume in that space, and create a filesystem on the logical
volume. This procedure can be performed on a running, mounted filesystem.
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted
filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
Install
hard drive
If there is not enough space in the volume group on the existing hard drive(s) in the system
to add the desired amount of space it may be necessary to add a new hard drive and create the
space to add to the Logical Volume. First, install the physical hard drive, and then perform
the following steps.
Create Physical Volume from hard drive
It is first necessary to create a new Physical Volume (PV). Use the command below, which
assumes that the new hard drive is assigned as /dev/hdd.
pvcreate /dev/hdd
It is not necessary to create a partition of any kind on the new hard drive. This creation
of the Physical Volume which will be recognized by the Logical Volume Manager can be performed
on a newly installed raw disk or on a Linux partition of type 83. If you are going to use the
entire hard drive, creating a partition first does not offer any particular advantages and uses
disk space for metadata that could otherwise be used as part of the PV.
Extend the
existing Volume Group
In this example we will extend an existing volume group rather than creating a new one; you
can choose to do it either way. After the Physical Volume has been created, extend the existing
Volume Group (VG) to include the space on the new PV. In this example the existing Volume Group
is named MyVG01.
vgextend /dev/MyVG01 /dev/hdd
Create the Logical Volume
First create the Logical Volume (LV) from existing free space within the Volume Group. The
command below creates a LV with a size of 50GB. The Volume Group name is MyVG01 and the Logical
Volume Name is Stuff.
lvcreate -L +50G --name Stuff MyVG01
Create the filesystem
Creating the Logical Volume does not create the filesystem. That task must be performed
separately. The command below creates an EXT4 filesystem that fits the newly created Logical
Volume.
mkfs -t ext4 /dev/MyVG01/Stuff
Add a filesystem label
Adding a filesystem label makes it easy to identify the filesystem later in case of a crash
or other disk related problems.
e2label /dev/MyVG01/Stuff Stuff
Mount the filesystem
At this point you can create a mount point, add an appropriate entry to the /etc/fstab file,
and mount the filesystem.
You should also check to verify the volume has been created correctly. You can use the
df , lvs, and vgs commands to do this.
Resizing a logical volume in
an LVM filesystem
The need to resize a filesystem has been around since the beginning of the first versions of
Unix and has not gone away with Linux. It has gotten easier, however, with Logical Volume
Management.
If necessary, install a new hard drive.
Optional: Create a partition on the hard drive.
Create a physical volume (PV) of the complete hard drive or a partition on the hard
drive.
Assign the new physical volume to an existing volume group (VG) or create a new volume
group.
Create one or more logical volumes (LV) from the space in the volume group, or expand an
existing logical volume with some or all of the new space in the volume group.
If you created a new logical volume, create a filesystem on it. If adding space to an
existing logical volume, use the resize2fs command to enlarge the filesystem to fill the
space in the logical volume.
Add appropriate entries to /etc/fstab for mounting the filesystem.
Mount the filesystem.
Example
This example describes how to resize an existing Logical Volume in an LVM environment using
the CLI. It adds about 50GB of space to the /Stuff filesystem. This procedure can be used on a
mounted, live filesystem only with the Linux 2.6 Kernel (and higher) and EXT3 and EXT4
filesystems. I do not recommend that you do so on any critical system, but it can be done and I
have done so many times; even on the root (/) filesystem. Use your judgment.
WARNING: Only the EXT3 and EXT4 filesystems can be resized on the fly on a running, mounted
filesystem. Many other filesystems including BTRFS and ZFS cannot be resized.
Install the
hard drive
If there is not enough space on the existing hard drive(s) in the system to add the desired
amount of space it may be necessary to add a new hard drive and create the space to add to the
Logical Volume. First, install the physical hard drive and then perform the following
steps.
Create a Physical Volume from the hard drive
It is first necessary to create a new Physical Volume (PV). Use the command below, which
assumes that the new hard drive is assigned as /dev/hdd.
pvcreate /dev/hdd
It is not necessary to create a partition of any kind on the new hard drive. This creation
of the Physical Volume which will be recognized by the Logical Volume Manager can be performed
on a newly installed raw disk or on a Linux partition of type 83. If you are going to use the
entire hard drive, creating a partition first does not offer any particular advantages and uses
disk space for metadata that could otherwise be used as part of the PV.
Add PV to
existing Volume Group
For this example, we will use the new PV to extend an existing Volume Group. After the
Physical Volume has been created, extend the existing Volume Group (VG) to include the space on
the new PV. In this example, the existing Volume Group is named MyVG01.
vgextend /dev/MyVG01 /dev/hdd
Extend the Logical Volume
Extend the Logical Volume (LV) from existing free space within the Volume Group. The command
below expands the LV by 50GB. The Volume Group name is MyVG01 and the Logical Volume Name is
Stuff.
lvextend -L +50G /dev/MyVG01/Stuff
Expand the filesystem
Extending the Logical Volume will also expand the filesystem if you use the -r option. If
you do not use the -r option, that task must be performed separately. The command below resizes
the filesystem to fit the newly resized Logical Volume.
resize2fs /dev/MyVG01/Stuff
You should check to verify the resizing has been performed correctly. You can use the
df , lvs, and vgs commands to do this.
Tips
Over the years I have learned a few things that can make logical volume management even
easier than it already is. Hopefully these tips can prove of some value to you.
Use the Extended file systems unless you have a clear reason to use another filesystem.
Not all filesystems support resizing but EXT2, 3, and 4 do. The EXT filesystems are also very
fast and efficient. In any event, they can be tuned by a knowledgeable sysadmin to meet the
needs of most environments if the defaults tuning parameters do not.
Use meaningful volume and volume group names.
Use EXT filesystem labels.
I know that, like me, many sysadmins have resisted the change to Logical Volume Management.
I hope that this article will encourage you to at least try LVM. I am really glad that I did;
my disk management tasks are much easier since I made the switch. TopicsBusiness Linux How-tos and tutorials
SysadminAbout the author David Both - David Both is an Open Source Software and
GNU/Linux advocate, trainer, writer, and speaker who lives in Raleigh North Carolina. He is a
strong proponent of and evangelist for the "Linux Philosophy." David has been in the IT
industry for nearly 50 years. He has taught RHCE classes for Red Hat and has worked at MCI
Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open
Source Software for over 20 years. David prefers to purchase the components and build
his...
"... If you lose a drive in a volume group, you can force the volume group online with the missing physical volume, but you will be unable to open the LV's that were contained on the dead PV, whether they be in whole or in part. ..."
"... So, if you had for instance 10 LV's, 3 total on the first drive, #4 partially on first drive and second drive, then 5-7 on drive #2 wholly, then 8-10 on drive 3, you would be potentially able to force the VG online and recover LV's 1,2,3,8,9,10.. #4,5,6,7 would be completely lost. ..."
"... LVM doesn't really have the concept of a partition it uses PVs (Physical Volumes), which can be a partition. These PVs are broken up into extents and then these are mapped to the LVs (Logical Volumes). When you create the LVs you can specify if the data is striped or mirrored but the default is linear allocation. So it would use the extents in the first PV then the 2nd then the 3rd. ..."
"... As Peter has said the blocks appear as 0's if a PV goes missing. So you can potentially do data recovery on files that are on the other PVs. But I wouldn't rely on it. You normally see LVM used in conjunction with RAIDs for this reason. ..."
"... it's effectively as if a huge chunk of your disk suddenly turned to badblocks. You can patch things back together with a new, empty drive to which you give the same UUID, and then run an fsck on any filesystems on logical volumes that went across the bad drive to hope you can salvage something. ..."
1) How does the system determine what partition to use first?
2) Can I find what disk a file or folder is physically on?
3) If I lose a drive in the LVM, do I lose all data, or just data physically on that disk?
storage lvm
share
HopelessN00b 49k 25 25 gold badges
121 121 silver badges 194 194 bronze badges asked Dec 2 '10 at 2:28 Luke has no
name Luke has no name 989 10 10 silver badges 13 13 bronze badges
The system fills from the first disk in the volume group to the last, unless you
configure striping with extents.
I don't think this is possible, but where I'd start to look is in the lvs/vgs commands
man pages.
If you lose a drive in a volume group, you can force the volume group online with the
missing physical volume, but you will be unable to open the LV's that were contained on the
dead PV, whether they be in whole or in part.
So, if you had for instance 10 LV's, 3 total on
the first drive, #4 partially on first drive and second drive, then 5-7 on drive #2 wholly,
then 8-10 on drive 3, you would be potentially able to force the VG online and recover LV's
1,2,3,8,9,10.. #4,5,6,7 would be completely lost.
Peter Grace Peter Grace 2,676 2 2 gold
badges 22 22 silver badges 38 38 bronze badges
1) How does the system determine what partition to use first?
LVM doesn't really have the concept of a partition it uses PVs (Physical Volumes), which can
be a partition. These PVs are broken up into extents and then these are mapped to the LVs
(Logical Volumes). When you create the LVs you can specify if the data is striped or mirrored
but the default is linear allocation. So it would use the extents in the first PV then the 2nd
then the 3rd.
2) Can I find what disk a file or folder is physically on?
You can determine what PVs a LV has allocation extents on. But I don't know of a way to get
that information for an individual file.
3) If I lose a drive in the LVM, do I lose all data, or just data physically on that
disk?
As Peter has said the blocks appear as 0's if a PV goes missing. So you can potentially do
data recovery on files that are on the other PVs. But I wouldn't rely on it. You normally see
LVM used in conjunction with RAIDs for this reason.
So here's a derivative of my question: I have 3x1 TB drives and I want to use 3TB of that
space. What's the best way to configure the drives so I am not splitting my data over
folders/mountpoints? or is there a way at all, other than what I've implied above? –
Luke has no
name Dec 2 '10 at 5:12
If you want to use 3TB and aren't willing to split data over folders/mount points I don't
see any other way. There may be some virtual filesystem solution to this problem like unionfs
although I'm not sure if it would solve your particular problem. But LVM is certainly the
most straight forward and simple solution as such it's the one I'd go with. –
3dinfluence Dec 2
'10 at 14:51
add a comment | 2 I don't know the answer to #2, so I'll leave that
to someone else. I suspect "no", but I'm willing to be happily surprised.
1 is: you tell it, when you combine the physical volumes into a volume group.
3 is: it's effectively as if a huge chunk of your disk suddenly turned to badblocks. You can
patch things back together with a new, empty drive to which you give the same UUID, and then
run an fsck on any filesystems on logical volumes that went across the bad drive to hope you can
salvage something.
And to the overall, unasked question: yeah, you probably don't really want to do that.
"... RAID5 can survive a single drive failure. However, once you replace that drive, it has to be initialized. Depending on the controller and other things, this can take anywhere from 5-18 hours. During this time, all drives will be in constant use to re-create the failed drive. It is during this time that people worry that the rebuild would cause another drive near death to die, causing a complete array failure. ..."
"... If during a rebuild one of the remaining disks experiences BER, your rebuild stops and you may have headaches recovering from such a situation, depending on controller design and user interaction. ..."
"... RAID5 + a GOOD backup is something to consider, though. ..."
"... Raid-5 is obsolete if you use large drives , such as 2TB or 3TB disks. You should instead use raid-6 ..."
"... RAID 6 offers more redundancy than RAID 5 (which is absolutely essential, RAID 5 is a walking disaster) at the cost of multiple parity writes per data write. This means the performance will be typically worse (although it's not theoretically much worse, since the parity operations are in parallel). ..."
RAID5 can survive a single drive failure. However, once you replace that drive, it has to be initialized. Depending on the
controller and other things, this can take anywhere from 5-18 hours. During this time, all drives will be in constant use to re-create
the failed drive. It is during this time that people worry that the rebuild would cause another drive near death to die, causing
a complete array failure.
This isn't the only danger. The problem with 2TB disks, especially if they are not 4K sector disks, is that they have relative
high BER rate for their capacity, so the likelihood of BER actually occurring and translating into an unreadable sector is something
to worry about.
If during a rebuild one of the remaining disks experiences BER, your rebuild stops and you may have headaches recovering from
such a situation, depending on controller design and user interaction.
So i would say with modern high-BER drives you should say:
RAID5: 0 complete disk failures, BER covered
RAID6: 1 complete disk failure, BER covered
So essentially you'll lose one parity disk alone for the BER issue. Not everyone will agree with my analysis, but considering
RAID5 with today's high-capacity drives 'safe' is open for debate.
RAID5 + a GOOD backup is something to consider, though.
So you're saying BER is the error count that 'escapes' the ECC correction? I do not believe that is correct, but i'm open
to good arguments or links.
As i understand, the BER is what prompt bad sectors, where the number of errors exceed that of the ECC error correcting
ability; and you will have an unrecoverable sector (Current Pending Sector in SMART output).
The short story first: Your consumer level 1TB SATA drive has a 44% chance that it can be completely read without any error.
If you run a RAID setup, this is really bad news because it may prevent rebuilding an array in the case of disk failure,
making your RAID not so Redundant. Click to expand...
Not sure on the numbers the article comes up with, though.
BER simply means that while reading your data from the disk drive you will get an average of one non-recoverable error in
so many bits read, as specified by the manufacturer. Click to expand...
Rebuilding the data on a replacement drive with most RAID algorithms requires that all the other data on the other drives
be pristine and error free. If there is a single error in a single sector, then the data for the corresponding sector on
the replacement drive cannot be reconstructed, and therefore the RAID rebuild fails and data is lost. The frequency of this
disastrous occurrence is derived from the BER. Simple calculations will show that the chance of data loss due to BER is
much greater than all other reasons combined. Click to expand...
These links do suggest that BER works to produce un-recoverable sectors, and not 'escape' them as 'undetected' bad sectors,
if i understood you correctly.
That's guy's a bit of a scaremonger to be honest. He may have a point with consumer drives, but the article is sensationalised
to a certain degree. However, there are still a few outfits that won't go past 500GB/drive in an array (even with enterprise
drives), simply to reduce the failure window during a rebuild. Click to expand...
Why is he a scaremonger? He is correct. Have you read his article? In fact, he has copied his argument from Adam Leventhal(?)
that was one of the ZFS developers I believe.
Adam's argument goes likes this:
Disks are getting larger all the time, in fact, the storage increases exponentially. At the same time, the bandwidth is increasing
not that fast - we are still at 100MB/sek even after decades. So, bandwidth has increased maybe 20x after decades. While storage
has increased from 10MB to 3TB = 300.000 times.
The trend is clear. In the future when we have 10TB drives, they will not be much faster than today. This means, to repair
an raid with 3TB disks today, will take several days, maybe even one week. With 10TB drives, it will take several weeks, maybe
a month.
Repairing a raid stresses the other disks much, which means they can break too. Experienced sysadmins reports that this
happens quite often during a repair. Maybe because those disks come from the same batch, they have the same weakness. Some
sysadmins therefore mix disks from different vendors and batches.
Hence, I would not want to run a raid with 3TB disks and only use raid-5. During those days, if only another disk crashes
you have lost all your data.
Hence, that article is correct, and he is not a scaremonger. Raid-5 is obsolete if you use large drives, such as 2TB or
3TB disks. You should instead use raid-6 (two disks can fail). That is the conclusion of the article: use raid-6 with large
disks, forget raid-5. This is true, and not scaremongery.
In fact, ZFS has therefore something called raidz3 - which means that three disks can fail without problems. To the OT:
no raid-5 is not safe. Neither is raid-6, because neither of them can not always repair nor detect corrupted data. There are
cases when they dont even notice that you got corrupted bits. See my other thread for more information about this. That is
the reason people are switching to ZFS - which always CAN detect and repair those corrupted bits. I suggest, sell your hardware
raid card, and use ZFS which requires no hardware. ZFS just uses JBOD.
The trend is clear. In the future when we have 10TB drives, they will not be much faster than today. This means, to repair
an raid with 3TB disks today, will take several days, maybe even one week. With 10TB drives, it will take several weeks,
maybe a month. Click to expand...
While I agree with the general claim that the larger HDDs (1.5, 2, 3TBs) are best used in RAID 6, your claim about rebuild
times is way off.
I think it is not unreasonable to assume that the 10TB drives will be able to read and write at 200 MB/s or more. We already
have 2TB drives with 150MB/s sequential speeds, so 200 MB/s is actually a conservative estimate.
10e12/200e6 = 50000 secs = 13.9 hours. Even if there is 100% overhead (half the throughput), that is less than 28 hours
to do the rebuild. It is a long time, but it is no where near a month! Try to back your claims in reality.
And you have again made the false claim that "ZFS - which always CAN detect and repair those corrupted bits". ZFS can usually
detect corrupted bits, and can usually correct them if you have duplication or parity, but nothing can always detect and repair.
ZFS is safer than many alternatives, but nothing is perfectly safe. Corruption can and has happened with ZFS, and it will happen
again.
Hence, that article is correct, and he is not a scaremonger. Raid-5 is obsolete if you use large drives , such as 2TB or
3TB disks. You should instead use raid-6 ( two disks can fail). That is the conclusion of the article: use raid-6 with large
disks, forget raid-5 . This is true, and not scaremongery.
RAID 6 offers more redundancy than RAID 5 (which is absolutely essential, RAID 5 is a walking disaster) at
the cost of multiple parity writes per data write. This means the performance will be typically worse (although it's not theoretically
much worse, since the parity operations are in parallel).
Can I recover a RAID 5 array if two drives have failed?Ask Question Asked 9 years ago Active
2 years, 3 months ago Viewed 58k times I have a Dell 2600 with 6 drives configured in a
RAID 5 on a PERC 4 controller. 2 drives failed at the same time, and according to what I know a
RAID 5 is recoverable if 1 drive fails. I'm not sure if the fact I had six drives in the array
might save my skin.
I bought 2 new drives and plugged them in but no rebuild happened as I expected. Can anyone
shed some light? raid
raid5 dell-poweredge share Share a link to this question
11 Regardless of how many drives are in use, a RAID 5 array only allows
for recovery in the event that just one disk at a time fails.
What 3molo says is a fair point but even so, not quite correct I think - if two disks in a
RAID5 array fail at the exact same time then a hot spare won't help, because a hot spare
replaces one of the failed disks and rebuilds the array without any intervention, and a rebuild
isn't possible if more than one disk fails.
For now, I am sorry to say that your options for recovering this data are going to involve
restoring a backup.
For the future you may want to consider one of the more robust forms of RAID (not sure what
options a PERC4 supports) such as RAID 6 or a nested RAID array . Once you get above a
certain amount of disks in an array you reach the point where the chance that more than one of
them can fail before a replacement is installed and rebuilt becomes unacceptably high.
share Share a link to this
answer Copy link | improve this answer edited Jun 8 '12 at 13:37
longneck 21.1k 3 3 gold badges 43 43 silver
badges 76 76 bronze badges answered Sep 21 '10 at 14:43 Rob Moir Rob Moir 30k 4 4 gold badges 53 53
silver badges 84 84 bronze badges
1 thanks robert I will take this advise into consideration when I rebuild the server,
lucky for me I full have backups that are less than 6 hours old. regards – bonga86 Sep 21 '10 at
15:00
If this is (somehow) likely to occur again in the future, you may consider RAID6. Same
idea as RAID5 but with two Parity disks, so the array can survive any two disks failing.
– gWaldo Sep 21
'10 at 15:04
g man(mmm...), i have recreated the entire system from scratch with a RAID 10. So
hopefully if 2 drives go out at the same time again the system will still function? Otherwise
everything has been restored and working thanks for ideas and input – bonga86 Sep 23 '10 at
11:34
Depends which two drives go... RAID 10 means, for example, 4 drives in two mirrored pairs
(2 RAID 1 mirrors) striped together (RAID 0) yes? If you lose both disks in 1 of the mirrors
then you've still got an outage. – Rob Moir Sep 23 '10 at 11:43
add a comment | 2 You can try to force one or both of the failed
disks to be online from the BIOS interface of the controller. Then check that the data and the
file system are consistent. share Share a link to this answer Copy link | improve this answer answered Sep 21 '10 at
15:35 Mircea
Vutcovici Mircea Vutcovici 13.6k 3 3 gold badges 42 42 silver badges 69 69 bronze badges
2 Dell systems, especially, in my experience, built on PERC3 or PERC4 cards had a nasty
tendency to simply have a hiccup on the SCSI bus which would know two or more drives
off-line. A drive being offline does NOT mean it failed. I've never had a two drives fail at
the same time, but probably a half dozen times, I've had two or more drives go off-line. I
suggest you try Mircea's suggestion first... could save you a LOT of time. – Multiverse IT Sep 21 '10 at
16:32
Hey guys, i tried the force option many times. Both "failed" drives would than come back
online, but when I do a restart it says logical drive :degraded and obviously because of that
they system still could not boot. – bonga86 Sep 23 '10 at 11:27
add a comment | 2 Direct answer is "No". In-direct -- "It depends".
Mainly it depends on whether disks are partially out of order, or completely. In case there're
partially broken, you can give it a try -- I would copy (using tool like ddrescue) both failed
disks. Then I'd try to run the bunch of disks using Linux SoftRAID -- re-trying with proper
order of disks and stripe-size in read-only mode and counting CRC mismatches. It's quite
doable, I should say -- this text in Russian mentions 12 disk RAID50's
recovery using LSR , for example. share Share a link to this answer Copy link | improve this answer edited Jun 8 '12 at 15:12
Skyhawk 13.5k 3 3 gold badges 45 45 silver
badges 91 91 bronze badges answered Jun 8 '12 at 14:11 poige poige 7,370 2 2 gold badges
16 16 silver badges 38 38 bronze badges add a comment | 0 It is possible if raid was with one spare drive ,
and one of your failed disks died before the second one. So, you just need need to try
reconstruct array virtually with 3d party software . Found small article about this process on
this page: http://www.angeldatarecovery.com/raid5-data-recovery/
And, if you realy need one of died drives you can send it to recovery shops. With of this
images you can reconstruct raid properly with good channces.
In this article we will talk about foremost , a very useful open source
forensic utility which is able to recover deleted files using the technique called data
carving . The utility was originally developed by the United States Air Force Office of
Special Investigations, and is able to recover several file types (support for specific file
types can be added by the user, via the configuration file). The program can also work on
partition images produced by dd or similar tools.
Software Requirements and Linux Command Line Conventions
Category
Requirements, Conventions or Software Version Used
System
Distribution-independent
Software
The "foremost" program
Other
Familiarity with the command line interface
Conventions
# - requires given linux commands to be executed with root
privileges either directly as a root user or by use of sudo command $ - requires given linux commands to be executed as a regular
non-privileged user
Installation
Since foremost is already present in all the major Linux distributions
repositories, installing it is a very easy task. All we have to do is to use our favorite
distribution package manager. On Debian and Ubuntu, we can use apt :
$ sudo apt install foremost
In recent versions of Fedora, we use the dnf package manager to install
packages , the dnf is a successor of yum . The name of the
package is the same:
$ sudo dnf install foremost
If we are using ArchLinux, we can use pacman to install foremost .
The program can be found in the distribution "community" repository:
$ sudo pacman -S foremost
SUBSCRIBE TO NEWSLETTER
Subscribe to Linux Career NEWSLETTER and
receive latest Linux news, jobs, career advice and tutorials.
WARNING
No matter which file recovery tool or process your are going to use to recover your files,
before you begin it is recommended to perform a low level hard drive or partition backup,
hence avoiding an accidental data overwrite !!! In this case you may re-try to recover your
files even after unsuccessful recovery attempt. Check the following dd command guide on
how to perform hard drive or partition low level backup.
The foremost utility tries to recover and reconstruct files on the base of
their headers, footers and data structures, without relying on filesystem metadata
. This forensic technique is known as file carving . The program supports various
types of files, as for example:
jpg
gif
png
bmp
avi
exe
mpg
wav
riff
wmv
mov
pdf
ole
doc
zip
rar
htm
cpp
The most basic way to use foremost is by providing a source to scan for deleted
files (it can be either a partition or an image file, as those generated with dd
). Let's see an example. Imagine we want to scan the /dev/sdb1 partition: before
we begin, a very important thing to remember is to never store retrieved data on the same
partition we are retrieving the data from, to avoid overwriting delete files still present on
the block device. The command we would run is:
$ sudo foremost -i /dev/sdb1
By default, the program creates a directory called output inside the directory
we launched it from and uses it as destination. Inside this directory, a subdirectory for each
supported file type we are attempting to retrieve is created. Each directory will hold the
corresponding file type obtained from the data carving process:
When foremost completes its job, empty directories are removed. Only the ones
containing files are left on the filesystem: this let us immediately know what type of files
were successfully retrieved. By default the program tries to retrieve all the supported file
types; to restrict our search, we can, however, use the -t option and provide a
list of the file types we want to retrieve, separated by a comma. In the example below, we
restrict the search only to gif and pdf files:
$ sudo foremost -t gif,pdf -i /dev/sdb1
https://www.youtube.com/embed/58S2wlsJNvo
In this video we will test the forensic data recovery program Foremost to
recover a single png file from /dev/sdb1 partition formatted with the
EXT4 filesystem.
As we already said, if a destination is not explicitly declared, foremost creates an
output directory inside our cwd . What if we want to specify an
alternative path? All we have to do is to use the -o option and provide said path
as argument. If the specified directory doesn't exist, it is created; if it exists but it's not
empty, the program throws a complain:
ERROR: /home/egdoc/data is not empty
Please specify another directory or run with -T.
To solve the problem, as suggested by the program itself, we can either use another
directory or re-launch the command with the -T option. If we use the
-T option, the output directory specified with the -o option is
timestamped. This makes possible to run the program multiple times with the same destination.
In our case the directory that would be used to store the retrieved files would be:
/home/egdoc/data_Thu_Sep_12_16_32_38_2019
The configuration file
The foremost configuration file can be used to specify file formats not
natively supported by the program. Inside the file we can find several commented examples
showing the syntax that should be used to accomplish the task. Here is an example involving the
png type (the lines are commented since the file type is supported by
default):
# PNG (used in web pages)
# (NOTE THIS FORMAT HAS A BUILTIN EXTRACTION FUNCTION)
# png y 200000 \x50\x4e\x47? \xff\xfc\xfd\xfe
The information to provide in order to add support for a file type, are, from left to right,
separated by a tab character: the file extension ( png in this case), whether the
header and footer are case sensitive ( y ), the maximum file size in Bytes (
200000 ), the header ( \x50\x4e\x47? ) and and the footer (
\xff\xfc\xfd\xfe ). Only the latter is optional and can be omitted.
If the path of the configuration file it's not explicitly provided with the -c
option, a file named foremost.conf is searched and used, if present, in the
current working directory. If it is not found the default configuration file,
/etc/foremost.conf is used instead.
Adding the support for a file type
By reading the examples provided in the configuration file, we can easily add support for a
new file type. In this example we will add support for flac audio files.
Flac (Free Lossless Audio Coded) is a non-proprietary lossless audio format which
is able to provide compressed audio without quality loss. First of all, we know that the header
of this file type in hexadecimal form is 66 4C 61 43 00 00 00 22 (
fLaC in ASCII), and we can verify it by using a program like hexdump
on a flac file:
As you can see the file signature is indeed what we expected. Here we will assume a maximum
file size of 30 MB, or 30000000 Bytes. Let's add the entry to the file:
flac y 30000000 \x66\x4c\x61\x43\x00\x00\x00\x22
The footer signature is optional so here we didn't provide it. The program
should now be able to recover deleted flac files. Let's verify it. To test that
everything works as expected I previously placed, and then removed, a flac file from the
/dev/sdb1 partition, and then proceeded to run the command:
As expected, the program was able to retrieve the deleted flac file (it was the only file on
the device, on purpose), although it renamed it with a random string. The original filename
cannot be retrieved because, as we know, files metadata is contained in the filesystem, and not
in the file itself:
The audit.txt file contains information about the actions performed by the program, in this
case:
Foremost version 1.5.7 by Jesse Kornblum, Kris
Kendall, and Nick Mikus
Audit File
Foremost started at Thu Sep 12 23:47:04 2019
Invocation: foremost -i /dev/sdb1 -o /home/egdoc/Documents/output
Output directory: /home/egdoc/Documents/output
Configuration file: /etc/foremost.conf
------------------------------------------------------------------
File: /dev/sdb1
Start: Thu Sep 12 23:47:04 2019
Length: 200 MB (209715200 bytes)
Num Name (bs=512) Size File Offset Comment
0: 00020482.flac 28 MB 10486784
Finish: Thu Sep 12 23:47:04 2019
1 FILES EXTRACTED
flac:= 1
------------------------------------------------------------------
Foremost finished at Thu Sep 12 23:47:04 2019
Conclusion
In this article we learned how to use foremost, a forensic program able to retrieve deleted
files of various types. We learned that the program works by using a technique called
data carving , and relies on files signatures to achieve its goal. We saw an
example of the program usage and we also learned how to add the support for a specific file
type using the syntax illustrated in the configuration file. For more information about the
program usage, please consult its manual page.
Before EFI, the standard boot process
for virtually all PC systems was called "MBR", for Master Boot Record; today you are likely to
hear it referred to as "Legacy Boot". This process depended on using the first physical block
on a disk to hold some information needed to boot the computer (thus the name Master Boot
Record); specifically, it held the disk address at which the actual bootloader could be found,
and the partition table that defined the layout of the disk. Using this information, the PC
firmware could find and execute the bootloader, which would then bring up the computer and run
the operating system.
This system had a number of rather obvious weaknesses and shortcomings. One of the biggest
was that you could only have one bootable object on each physical disk drive (at least as far
as the firmware boot was concerned). Another was that if that first sector on the disk became
corrupted somehow, you were in deep trouble.
Over time, as part of the Extensible Firmware Interface, a new approach to boot
configuration was developed. Rather than storing critical boot configuration information in a
single "magic" location, EFI uses a dedicated "EFI boot partition" on the desk. This is a
completely normal, standard disk partition, the same as which may be used to hold the operating
system or system recovery data.
The only requirement is that it be FAT formatted, and it should have the boot and
esp partition flags set (esp stands for EFI System Partition). The specific data and
programs necessary for booting is then kept in directories on this partition, typically in
directories named to indicate what they are for. So if you have a Windows system, you would
typically find directories called 'Boot' and 'Microsoft' , and perhaps one named for the
manufacturer of the hardware, such as HP. If you have a Linux system, you would find
directories called opensuse, debian, ubuntu, or any number of others depending on what
particular Linux distribution you are using.
It should be obvious from the description so far that it is perfectly possible with the EFI
boot configuration to have multiple boot objects on a single disk drive.
Before going any further, I should make it clear that if you install Linux as the only
operating system on a PC, it is not necessary to know all of this configuration information in
detail. The installer should take care of setting all of this up, including creating the EFI
boot partition (or using an existing EFI boot partition), and further configuring the system
boot list so that whatever system you install becomes the default boot target.
If you were to take a brand new computer with UEFI firmware, and load it from scratch with
any of the current major Linux distributions, it would all be set up, configured, and working
just as it is when you purchase a new computer preloaded with Windows (or when you load a
computer from scratch with Windows). It is only when you want to have more than one bootable
operating system – especially when you want to have both Linux and Windows on the same
computer – that things may become more complicated.
The problems that arise with such "multiboot" systems are generally related to getting the
boot priority list defined correctly.
When you buy a new computer with Windows, this list typically includes the Windows
bootloader on the primary disk, and then perhaps some other peripheral devices such as USB,
network interfaces and such. When you install Linux alongside Windows on such a computer, the
installer will add the necessary information to the EFI boot partition, but if the boot
priority list is not changed, then when the system is rebooted after installation it will
simply boot Windows again, and you are likely to think that the installation didn't work.
There are several ways to modify this boot priority list, but exactly which ones are
available and whether or how they work depends on the firmware of the system you are using, and
this is where things can get really messy. There are just about as many different UEFI firmware
implementations as there are PC manufacturers, and the manufacturers have shown a great deal of
creativity in the details of this firmware.
First, in the simplest case, there is a software utility included with Linux called
efibootmgr that can be used to modify, add or delete the boot priority list. If this
utility works properly, and the changes it makes are permanent on the system, then you would
have no other problems to deal with, and after installing it would boot Linux and you would be
happy. Unfortunately, while this is sometimes the case it is frequently not. The most common
reason for this is that changes made by software utilities are not actually permanently stored
by the system BIOS, so when the computer is rebooted the boot priority list is restored to
whatever it was before, which generally means that Windows gets booted again.
The other common way of modifying the boot priority list is via the computer BIOS
configuration program. The details of how to do this are different for every manufacturer, but
the general procedure is approximately the same. First you have to press the BIOS configuration
key (usually F2, but not always, unfortunately) during system power-on (POST). Then choose the
Boot item from the BIOS configuration menu, which should get you to a list of boot targets
presented in priority order. Then you need to modify that list; sometimes this can be done
directly in that screen, via the usual F5/F6 up/down key process, and sometimes you need to
proceed one level deeper to be able to do that. I wish I could give more specific and detailed
information about this, but it really is different on every system (sometimes even on different
systems produced by the same manufacturer), so you just need to proceed carefully and figure
out the steps as you go.
I have seen a few rare cases of systems where neither of these methods works, or at least
they don't seem to be permanent, and the system keeps reverting to booting Windows. Again,
there are two ways to proceed in this case. The first is by simply pressing the "boot
selection" key during POST (power-on). Exactly which key this is varies, I have seen it be F12,
F9, Esc, and probably one or two others. Whichever key it turns out to be, when you hit it
during POST you should get a list of bootable objects defined in the EFI boot priority list, so
assuming your Linux installation worked you should see it listed there. I have known of people
who were satisfied with this solution, and would just use the computer this way and have to
press boot select each time they wanted to boot Linux.
The alternative is to actually modify the files in the EFI boot partition, so that the
(unchangeable) Windows boot procedure would actually boot Linux. This involves overwriting the
Windows file bootmgfw.efi with the Linux file grubx64.efi. I have done this, especially in the
early days of EFI boot, and it works, but I strongly advise you to be extremely careful if you
try it, and make sure that you keep a copy of the original bootmgfw.efi file. Finally, just as
a final (depressing) warning, I have also seen systems where this seemed to work, at least for
a while, but then at some unpredictable point the boot process seemed to notice that something
had changed and it restored bootmgfw.efi to its original state – thus losing the Linux
boot configuration again. Sigh.
So, that's the basics of EFI boot, and how it can be configured. But there are some
important variations possible, and some caveats to be aware of.
There are several different applications available for free use which will allow you to flash ISO images to USB drives. In this
example, we will use Etcher. It is a free and open-source utility for flashing images to SD cards & USB drives and supports Windows,
macOS, and Linux.
Head over to the Etcher downloads page , and download the
most recent Etcher version for your operating system. Once the file is downloaded, double-click on it and follow the installation
wizard.
Creating Bootable Linux USB Drive using Etcher is a relatively straightforward process, just follow the steps outlined below:
Connect the USB flash drive to your system and Launch Etcher.
Click on the Select image button and locate the distribution .iso file.
If only one USB drive is attached to your machine, Etcher will automatically select it. Otherwise, if more than one SD cards
or USB drives are connected make sure you have selected the correct USB drive before flashing the image.
Monitoring Specific Storage Devices or Partitions with iostat:
By default, iostat monitors all the storage devices of your computer. But, you can monitor
specific storage devices (such as sda, sdb etc) or specific partitions (such as sda1, sda2,
sdb4 etc) with iostat as well.
For example, to monitor the storage device sda only, run iostat as follows:
$ sudo iostat
sda
Or
$ sudo iostat -d 2 sda
As you can see, only the storage device sda is monitored.
You can also monitor multiple storage devices with iostat.
For example, to monitor the storage devices sda and sdb , run iostat as follows:
$ sudo
iostat sda sdb
Or
$ sudo iostat -d 2 sda sdb
If you want to monitor specific partitions, then you can do so as well.
For example, let's say, you want to monitor the partitions sda1 and sda2 , then run iostat
as follows:
$ sudo iostat sda1 sda2
Or
$ sudo iostat -d 2 sda1 sda2
As you can see, only the partitions sda1 and sda2 are monitored.
Monitoring
LVM Devices with iostat:
You can monitor the LVM devices of your computer with the -N option of iostat.
To monitor the LVM devices of your Linux machine as well, run iostat as follows:
$ sudo
iostat -N -d 2
You can also monitor specific LVM logical volume as well.
For example, to monitor the LVM logical volume centos-root (let's say), run iostat as
follows:
$ sudo iostat -N -d 2 centos-root
Changing
the Units of iostat:
By default, iostat generates reports in kilobytes (kB) unit. But there are options that you
can use to change the unit.
For example, to change the unit to megabytes (MB), use the -m option of iostat.
You can also change the unit to human readable with the -h option of iostat. Human readable
format will automatically pick the right unit depending on the available data.
To change the unit to megabytes, run iostat as follows:
$ sudo iostat -m -d 2 sda
To change the unit to human readable format, run iostat as follows:
$ sudo iostat -h -d 2
sda
I copied as file and as you can see, the unit is now in megabytes (MB).
It changed to kilobytes (kB) as soon as the file copy is over.
Extended
Display of iostat:
If you want, you can display a lot more information about disk i/o with iostat. To do that,
use the -x option of iostat.
For example, to display extended information about disk i/o, run iostat as follows:
$
sudo iostat -x -d 2 sda
You can find what each of these fields (rrqm/s, %wrqm etc) means in the man page of
iostat.
Getting
Help:
If you need more information on each of the supported options of iostat and what each of the
fields of iostat means, I recommend you take a look at the man page of iostat.
You can access the man page of iostat with the following command:
$ man iostat
So, that's how you use iostat in Linux. Thanks for reading this article.
I use Tilda (drop-down terminal) on Ubuntu as my "command central" - pretty much the way
others might use GNOME Do, Quicksilver or Launchy.
However, I'm struggling with how to completely detach a process (e.g. Firefox) from the
terminal it's been launched from - i.e. prevent that such a (non-)child process
is terminated when closing the originating terminal
"pollutes" the originating terminal via STDOUT/STDERR
For example, in order to start Vim in a "proper" terminal window, I have tried a simple
script like the following:
exec gnome-terminal -e "vim $@" &> /dev/null &
However, that still causes pollution (also, passing a file name doesn't seem to work).
First of all; once you've started a process, you can background it by first stopping it (hit
Ctrl - Z ) and then typing bg to let it resume in the
background. It's now a "job", and its stdout / stderr /
stdin are still connected to your terminal.
You can start a process as backgrounded immediately by appending a "&" to the end of
it:
firefox &
To run it in the background silenced, use this:
firefox </dev/null &>/dev/null &
Some additional info:
nohup is a program you can use to run your application with such that its
stdout/stderr can be sent to a file instead and such that closing the parent script won't
SIGHUP the child. However, you need to have had the foresight to have used it before you
started the application. Because of the way nohup works, you can't just apply
it to a running process .
disown is a bash builtin that removes a shell job from the shell's job list.
What this basically means is that you can't use fg , bg on it
anymore, but more importantly, when you close your shell it won't hang or send a
SIGHUP to that child anymore. Unlike nohup , disown is
used after the process has been launched and backgrounded.
What you can't do, is change the stdout/stderr/stdin of a process after having
launched it. At least not from the shell. If you launch your process and tell it that its
stdout is your terminal (which is what you do by default), then that process is configured to
output to your terminal. Your shell has no business with the processes' FD setup, that's
purely something the process itself manages. The process itself can decide whether to close
its stdout/stderr/stdin or not, but you can't use your shell to force it to do so.
To manage a background process' output, you have plenty of options from scripts, "nohup"
probably being the first to come to mind. But for interactive processes you start but forgot
to silence ( firefox < /dev/null &>/dev/null & ) you can't do
much, really.
I recommend you get GNU screen . With screen you can just close your running
shell when the process' output becomes a bother and open a new one ( ^Ac ).
Oh, and by the way, don't use " $@ " where you're using it.
$@ means, $1 , $2 , $3 ..., which
would turn your command into:
gnome-terminal -e "vim $1" "$2" "$3" ...
That's probably not what you want because -e only takes one argument. Use $1
to show that your script can only handle one argument.
It's really difficult to get multiple arguments working properly in the scenario that you
gave (with the gnome-terminal -e ) because -e takes only one
argument, which is a shell command string. You'd have to encode your arguments into one. The
best and most robust, but rather cludgy, way is like so:
Reading these answers, I was under the initial impression that issuing nohup
<command> & would be sufficient. Running zsh in gnome-terminal, I found that
nohup <command> & did not prevent my shell from killing child
processes on exit. Although nohup is useful, especially with non-interactive
shells, it only guarantees this behavior if the child process does not reset its handler for
the SIGHUP signal.
In my case, nohup should have prevented hangup signals from reaching the
application, but the child application (VMWare Player in this case) was resetting its
SIGHUP handler. As a result when the terminal emulator exits, it could still
kill your subprocesses. This can only be resolved, to my knowledge, by ensuring that the
process is removed from the shell's jobs table. If nohup is overridden with a
shell builtin, as is sometimes the case, this may be sufficient, however, in the event that
it is not...
disown is a shell builtin in bash , zsh , and
ksh93 ,
<command> &
disown
or
<command> &; disown
if you prefer one-liners. This has the generally desirable effect of removing the
subprocess from the jobs table. This allows you to exit the terminal emulator without
accidentally signaling the child process at all. No matter what the SIGHUP
handler looks like, this should not kill your child process.
After the disown, the process is still a child of your terminal emulator (play with
pstree if you want to watch this in action), but after the terminal emulator
exits, you should see it attached to the init process. In other words, everything is as it
should be, and as you presumably want it to be.
What to do if your shell does not support disown ? I'd strongly advocate
switching to one that does, but in the absence of that option, you have a few choices.
screen and tmux can solve this problem, but they are much
heavier weight solutions, and I dislike having to run them for such a simple task. They are
much more suitable for situations in which you want to maintain a tty, typically on a
remote machine.
For many users, it may be desirable to see if your shell supports a capability like
zsh's setopt nohup . This can be used to specify that SIGHUP
should not be sent to the jobs in the jobs table when the shell exits. You can either apply
this just before exiting the shell, or add it to shell configuration like
~/.zshrc if you always want it on.
Find a way to edit the jobs table. I couldn't find a way to do this in
tcsh or csh , which is somewhat disturbing.
Write a small C program to fork off and exec() . This is a very poor
solution, but the source should only consist of a couple dozen lines. You can then pass
commands as commandline arguments to the C program, and thus avoid a process specific entry
in the jobs table.
I've been using number 2 for a very long time, but number 3 works just as well. Also,
disown has a 'nohup' flag of '-h', can disown all processes with '-a', and can disown all
running processes with '-ar'.
Silencing is accomplished by '$COMMAND &>/dev/null'.
in tcsh (and maybe in other shells as well), you can use parentheses to detach the process.
Compare this:
> jobs # shows nothing
> firefox &
> jobs
[1] + Running firefox
To this:
> jobs # shows nothing
> (firefox &)
> jobs # still shows nothing
>
This removes firefox from the jobs listing, but it is still tied to the terminal; if you
logged in to this node via 'ssh', trying to log out will still hang the ssh process.
,
To disassociate tty shell run command through sub-shell for e.g.
(command)&
When exit used terminal closed but process is still alive.
Have a look at reptyr ,
which does exactly that. The github page has all the information.
reptyr - A tool for "re-ptying" programs.
reptyr is a utility for taking an existing running program and attaching it to a new
terminal. Started a long-running process over ssh, but have to leave and don't want to
interrupt it? Just start a screen, use reptyr to grab it, and then kill the ssh session
and head on home.
USAGE
reptyr PID
"reptyr PID" will grab the process with id PID and attach it to your current
terminal.
After attaching, the process will take input from and write output to the new
terminal, including ^C and ^Z. (Unfortunately, if you background it, you will still have
to run "bg" or "fg" in the old terminal. This is likely impossible to fix in a reasonable
way without patching your shell.)
EDIT : As Stephane Gimenez said, it's not that simple. It's only allowing you to print to a
different terminal.
You can try to write to this process using /proc . It should be located in
/proc/ pid /fd/0 , so a simple :
echo "hello" > /proc/PID/fd/0
should do it. I have not tried it, but it should work, as long as this process still has a
valid stdin file descriptor. You can check it with ls -l on /proc/ pid
/fd/ .
if it's a link to /dev/null => it's closed
if it's a link to /dev/pts/X or a socket => it's open
See nohup for more
details about how to keep processes running.
Just ending the command line with & will not completely detach the process,
it will just run it in the background. (With zsh you can use &!
to actually detach it, otherwise you have do disown it later).
When a process runs in the background, it won't receive input from its controlling
terminal anymore. But you can send it back into the foreground with fg and then
it will read input again.
Otherwise, it's not possible to externally change its filedescriptors (including stdin) or
to reattach a lost controlling terminal unless you use debugging tools (see Ansgar's answer , or have a
look at the retty command).
Since a few days I'm successfully running the new Minecraft Bedrock Edition dedicated
server on my Ubuntu 18.04 LTS home server. Because it should be available 24/7 and
automatically startup after boot I created a systemd service for a detached tmux session:
Everything works as expected but there's one tiny thing that keeps bugging me:
How can I prevent tmux from terminating it's whole session when I press
Ctrl+C ? I just want to terminate the Minecraft server process itself instead of
the whole tmux session. When starting the server from the command line in a manually
created tmux session this does work (session stays alive) but not when the session was
brought up by systemd .
When starting the server from the command line in a manually created tmux session this
does work (session stays alive) but not when the session was brought up by systemd
.
The difference between these situations is actually unrelated to systemd. In one case,
you're starting the server from a shell within the tmux session, and when the server
terminates, control returns to the shell. In the other case, you're starting the server
directly within the tmux session, and when it terminates there's no shell to return to, so
the tmux session also dies.
tmux has an option to keep the session alive after the process inside it dies (look for
remain-on-exit in the manpage), but that's probably not what you want: you want
to be able to return to an interactive shell, to restart the server, investigate why it died,
or perform maintenance tasks, for example. So it's probably better to change your command to
this:
That is, first run the server, and then, after it terminates, replace the process (the
shell which tmux implicitly spawns to run the command, but which will then exit) with
another, interactive shell. (For some other ways to get an interactive shell after the
command exits, see e. g. this question – but note that the
<(echo commands) syntax suggested in the top answer is not available in
systemd unit files.)
Or in other words, a simple, reliable and clear solution (which has some faults due to its age) was replaced with a gigantic KISS
violation. No engineer worth the name will ever do that. And if it needs doing, any good engineer will make damned sure to achieve maximum
compatibility and a clean way back. The systemd people seem to be hell-bent on making it as hard as possible to not use their monster.
That alone is a good reason to stay away from it.
Notable quotes:
"... We are systemd. Lower your memory locks and surrender your processes. We will add your calls and code distinctiveness to our own. Your functions will adapt to service us. Resistance is futile. ..."
"... I think we should call systemd the Master Control Program since it seems to like making other programs functions its own. ..."
"... RHEL7 is a fine OS, the only thing it's missing is a really good init system. ..."
Systemd is nothing but a thinly-veiled plot by Vladimir Putin and Beyonce to import illegal German Nazi immigrants over the
border from Mexico who will then corner the market in kimchi and implement Sharia law!!!
We are systemd. Lower your memory locks and surrender your processes. We will add your calls and code distinctiveness to
our own. Your functions will adapt to service us. Resistance is futile.
Recently I wanted to deepen my understanding of bash by researching as much of it as
possible. Because I felt bash is an often-used (and under-understood) technology, I ended up
writing a book on it
.
You don't have to look hard on the internet to find plenty of useful one-liners in bash, or
scripts. And there are guides to bash that seem somewhat intimidating through either their
thoroughness or their focus on esoteric detail.
Here I've focussed on the things that either confused me or increased my power and
productivity in bash significantly, and tried to communicate them (as in my book) in a way that
emphasises getting the understanding right.
Enjoy!
1)
`` vs $()
These two operators do the same thing. Compare these two lines:
$ echo `ls`
$ echo $(ls)
Why these two forms existed confused me for a long time.
If you don't know, both forms substitute the output of the command contained within it into
the command.
The principal difference is that nesting is simpler.
Which of these is easier to read (and write)?
$ echo `echo \`echo \\\`echo inside\\\`\``
or:
$ echo $(echo $(echo $(echo inside)))
If you're interested in going deeper, see here or
here .
2) globbing vs regexps
Another one that can confuse if never thought about or researched.
While globs and regexps can look similar, they are not the same.
Consider this command:
$ rename -n 's/(.*)/new$1/' *
The two asterisks are interpreted in different ways.
The first is ignored by the shell (because it is in quotes), and is interpreted as '0 or
more characters' by the rename application. So it's interpreted as a regular expression.
The second is interpreted by the shell (because it is not in quotes), and gets replaced by a
list of all the files in the current working folder. It is interpreted as a glob.
So by looking at man bash can you figure out why these two commands produce
different output?
$ ls *
$ ls .*
The second looks even more like a regular expression. But it isn't!
3) Exit Codes
Not everyone knows that every time you run a shell command in bash, an 'exit code' is
returned to bash.
Generally, if a command 'succeeds' you get an error code of 0 . If it doesn't
succeed, you get a non-zero code. 1 is a 'general error', and others can give you
more information (eg which signal killed it, for example).
But these rules don't always hold:
$ grep not_there /dev/null
$ echo $?
$? is a special bash variable that's set to the exit code of each command after
it runs.
Grep uses exit codes to indicate whether it matched or not. I have to look up every time
which way round it goes: does finding a match or not return 0 ?
Grok this and a lot will click into place in what follows.
4) if
statements, [ and [[
Here's another 'spot the difference' similar to the backticks one above.
What will this output?
if grep not_there /dev/null
then
echo hi
else
echo lo
fi
grep's return code makes code like this work more intuitively as a side effect of its use of
exit codes.
Now what will this output?
a) hihi
b) lolo
c) something else
if [ $(grep not_there /dev/null) = '' ]
then
echo -n hi
else
echo -n lo
fi
if [[ $(grep not_there /dev/null) = '' ]]
then
echo -n hi
else
echo -n lo
fi
The difference between [ and [[ was another thing I never really
understood. [ is the original form for tests, and then [[ was
introduced, which is more flexible and intuitive. In the first if block above, the
if statement barfs because the $(grep not_there /dev/null) is evaluated to
nothing, resulting in this comparison:
[ = '' ]
which makes no sense. The double bracket form handles this for you.
This is why you occasionally see comparisons like this in bash scripts:
if [ x$(grep not_there /dev/null) = 'x' ]
so that if the command returns nothing it still runs. There's no need for it, but that's why
it exists.
5) set s
Bash has configurable options which can be set on the fly. I use two of these all the
time:
set -e
exits from a script if any command returned a non-zero exit code (see above).
This outputs the commands that get run as they run:
set -x
So a script might start like this:
#!/bin/bash
set -e
set -x
grep not_there /dev/null
echo $?
What would that script output?
6) <()
This is my favourite. It's so under-used, perhaps because it can be initially baffling, but
I use it all the time.
It's similar to $() in that the output of the command inside is re-used.
In this case, though, the output is treated as a file. This file can be used as an argument
to commands that take files as an argument.
Quoting's a knotty subject in bash, as it is in many software contexts.
Firstly, variables in quotes:
A='123'
echo "$A"
echo '$A'
Pretty simple – double quotes dereference variables, while single quotes go
literal.
So what will this output?
mkdir -p tmp
cd tmp
touch a
echo "*"
echo '*'
Surprised? I was.
8) Top three shortcuts
There are plenty of shortcuts listed in man bash , and it's not hard to find
comprehensive lists. This list consists of the ones I use most often, in order of how often I
use them.
Rather than trying to memorize them all, I recommend picking one, and trying to remember to
use it until it becomes unconscious. Then take the next one. I'll skip over the most obvious
ones (eg !! – repeat last command, and ~ – your home
directory).
!$
I use this dozens of times a day. It repeats the last argument of the last command. If
you're working on a file, and can't be bothered to re-type it command after command it can save
a lot of work:
grep somestring /long/path/to/some/file/or/other.txt
vi !$
!:1-$
This bit of magic takes this further. It takes all the arguments to the previous command and
drops them in. So:
The ! means 'look at the previous command', the : is a separator,
and the 1 means 'take the first word', the - means 'until' and the
$ means 'the last word'.
Note: you can achieve the same thing with !* . Knowing the above gives you the
control to limit to a specific contiguous subset of arguments, eg with !:2-3 .
:h
I use this one a lot too. If you put it after a filename, it will change that filename to
remove everything up to the folder. Like this:
grep isthere /long/path/to/some/file/or/other.txt
cd !$:h
which can save a lot of work in the course of the day.
9) startup order
The order in which bash runs startup scripts can cause a lot of head-scratching. I keep this
diagram handy (from this great page):
It shows which scripts bash decides to run from the top, based on decisions made about the
context bash is running in (which decides the colour to follow).
So if you are in a local (non-remote), non-login, interactive shell (eg when you run bash
itself from the command line), you are on the 'green' line, and these are the order of files
read:
/etc/bash.bashrc
~/.bashrc
[bash runs, then terminates]
~/.bash_logout
This can save you a hell of a lot of time debugging.
10) getopts (cheapci)
If you go deep with bash, you might end up writing chunky utilities in it. If you do, then
getting to grips with getopts can pay large dividends.
For fun, I once wrote a script called
cheapci which I used to work like a Jenkins job.
The code here implements the
reading of the two required, and 14
non-required arguments . Better to learn this than to build up a bunch of bespoke code that
can get very messy pretty quickly as your utility grows.
"... The book talks about how checklists reduce major errors in surgery. Hospitals that use checklists are drastically less likely to amputate the wrong leg . ..."
"... any checklist should start off verifying that what you "know" to be true is true ..."
"... Before starting, ask the "Is it plugged in?" question first. What happened today was an example of when asking "Is it plugged in?" would have helped. ..."
"... moral of the story: Make sure that your understanding of the current state is correct. If you're a developer trying to fix a problem, make sure that you are actually able to understand the problem first. ..."
The book talks about how checklists reduce major errors in surgery. Hospitals that use
checklists are drastically less likely to
amputate the wrong leg .
So, the takeaway for me is this: any checklist should start off verifying that what you
"know" to be true is true . (Thankfully, my errors can be backed out with very little long
term consequences, but I shouldn't use this as an excuse to forego checklists.)
Before starting, ask the "Is it plugged in?" question first. What happened today was an
example of when asking "Is it plugged in?" would have helped.
Today I was testing the thumbnailing of some MediaWiki code and trying to understand the
$wgLocalFileRepo variable.
I copied part of an /images/ directory over from another wiki to my test wiki. I
verified that it thumbnailed correctly.
So far so good.
Then I changed the directory parameter and tested. No thumbnail. Later, I realized this is
to be expected because I didn't copy over the original images. So that is one issue.
I erased (what I thought was) the thumbnail image and tried again on the main repo. It
worked again–I got a thumbnail.
I tried copying over the images directory to the new directory, but it the new thumbnailing
directory structure didn't produce a thumbnail.
I tried over and over with the same thumbnail and was confused because it kept telling me
the same thing.
I added debugging statements and still got no where.
Finally, I just did an ls on the directory to verify it was there. It
was. And it had files in it.
But not the file I was trying to produce a thumbnail of.
The system that "worked" had the thumbnail, but not the original file.
So, moral of the story: Make sure that your understanding of the current state is
correct. If you're a developer trying to fix a problem, make sure that you are actually able to
understand the problem first.
Maybe your perception of reality is wrong. Mine was. I was sure that the thumbnails
were being generated each time until I discovered that I hadn't deleted the thumbnails, I had
deleted the original.
How do I find out running processes were associated with each open port? How do I find out what process has open tcp port 111
or udp port 7000 under Linux?
You can the following programs to find out about port numbers and its associated process:
netstat – a command-line tool that displays network connections, routing tables, and a number of network interface statistics.
fuser – a command line tool to identify processes using files or sockets.
lsof – a command line tool to list open files under Linux / UNIX to report a list of all open files and the processes that
opened them.
/proc/$pid/ file system – Under Linux /proc includes a directory for each running process (including kernel processes) at
/proc/PID, containing information about that process, notably including the processes name that opened port.
You must run above command(s) as the root user.
netstat example
Type the following command: # netstat -tulpn
Sample outputs:
OR try the following ps command: # ps -eo pid,user,group,args,etime,lstart | grep '[3]813'
Sample outputs:
3813 vivek vivek transmission 02:44:05 Fri Oct 29 10:58:40 2010
Another option is /proc/$PID/environ, enter: # cat /proc/3813/environ
OR # grep --color -w -a USER /proc/3813/environ
Sample outputs (note –colour option): Fig.01: grep output
Now, you get more information about pid # 1607 or 1616 and so on: # ps aux | grep '[1]616'
Sample outputs: www-data 1616 0.0 0.0 35816 3880 ? S 10:20 0:00 /usr/sbin/apache2 -k start
I recommend the following command to grab info about pid # 1616: # ps -eo pid,user,group,args,etime,lstart | grep '[1]616'
Sample outputs:
/usr/sbin/apache2 -k start : The command name and its args
03:16:22 : Elapsed time since the process was started, in the form [[dd-]hh:]mm:ss.
Fri Oct 29 10:20:17 2010 : Time the command started.
Help: I Discover an Open Port Which I Don't Recognize At All
The file /etc/services is used to map port numbers and protocols to service names. Try matching port numbers: $ grep port /etc/services
$ grep 443 /etc/services
Sample outputs:
https 443/tcp # http protocol over TLS/SSL
https 443/udp
Check For rootkit
I strongly recommend that you find out which processes are really running, especially servers connected to the high speed Internet
access. You can look for rootkit which is a program designed to take fundamental control (in Linux / UNIX terms "root" access, in
Windows terms "Administrator" access) of a computer system, without authorization by the system's owners and legitimate managers.
See how to detecting
/ checking rootkits under Linux .
Keep an Eye On Your Bandwidth Graphs
Usually, rooted servers are used to send a large number of spam or malware or DoS style attacks on other computers.
See also:
See the following man pages for more information: $ man ps
$ man grep
$ man lsof
$ man netstat
$ man fuser
How can I find which process is constantly writing to disk?
I like my workstation to be close to silent and I just build a new system (P8B75-M + Core i5 3450s -- the 's' because it has
a lower max TDP) with quiet fans etc. and installed Debian Wheezy 64-bit on it.
And something is getting on my nerve: I can hear some kind of pattern like if the hard disk was writing or seeking someting
( tick...tick...tick...trrrrrr rinse and repeat every second or so).
In the past I had a similar issue in the past (many, many years ago) and it turned out it was some CUPS log or something and
I simply redirected that one (not important) logging to a (real) RAM disk.
But here I'm not sure.
I tried the following:
ls -lR /var/log > /tmp/a.tmp && sleep 5 && ls -lR /var/log > /tmp/b.tmp && diff /tmp/?.tmp
but nothing is changing there.
Now the strange thing is that I also hear the pattern when the prompt asking me to enter my LVM decryption passphrase is showing.
Could it be something in the kernel/system I just installed or do I have a faulty harddisk?
hdparm -tT /dev/sda report a correct HD speed (130 GB/s non-cached, sata 6GB) and I've already installed and compiled
from big sources (Emacs) without issue so I don't think the system is bad.
Are you sure it's a hard drive making that noise, and not something else? (Check the fans, including PSU fan. Had very strange
clicking noises once when a very thin cable was too close to a fan and would sometimes very slightly touch the blades and bounce
for a few "clicks"...) – Mat
Jul 27 '12 at 6:03
@Mat: I'll take the hard drive outside of the case (the connectors should be long enough) to be sure and I'll report back ; )
– Cedric Martin
Jul 27 '12 at 7:02
Make sure your disk filesystems are mounted relatime or noatime. File reads can be causing writes to inodes to record the access
time. – camh
Jul 27 '12 at 9:48
thanks for that tip. I didn't know about iotop . On Debian I did an apt-cache search iotop to find out that I had
to apt-get iotop . Very cool command! –
Cedric Martin
Aug 2 '12 at 15:56
I use iotop -o -b -d 10 which every 10secs prints a list of processes that read/wrote to disk and the amount of IO
bandwidth used. – ndemou
Jun 20 '16 at 15:32
You can enable IO debugging via echo 1 > /proc/sys/vm/block_dump and then watch the debugging messages in /var/log/syslog
. This has the advantage of obtaining some type of log file with past activities whereas iotop only shows the current
activity.
It is absolutely crazy to leave sysloging enabled when block_dump is active. Logging causes disk activity, which causes logging,
which causes disk activity etc. Better stop syslog before enabling this (and use dmesg to read the messages) –
dan3
Jul 15 '13 at 8:32
You are absolutely right, although the effect isn't as dramatic as you describe it. If you just want to have a short peek at the
disk activity there is no need to stop the syslog daemon. –
scai
Jul 16 '13 at 6:32
I've tried it about 2 years ago and it brought my machine to a halt. One of these days when I have nothing important running I'll
try it again :) – dan3
Jul 16 '13 at 7:22
I tried it, nothing really happened. Especially because of file system buffering. A write to syslog doesn't immediately trigger
a write to disk. – scai
Jul 16 '13 at 10:50
auditctl -S sync -S fsync -S fdatasync -a exit,always
Watch the logs in /var/log/audit/audit.log . Be careful not to do this if the audit logs themselves are flushed!
Check in /etc/auditd.conf that the flush option is set to none .
If files are being flushed often, a likely culprit is the system logs. For example, if you log failed incoming connection attempts
and someone is probing your machine, that will generate a lot of entries; this can cause a disk to emit machine gun-style noises.
With the basic log daemon sysklogd, check /etc/syslog.conf : if a log file name is not be preceded by -
, then that log is flushed to disk after each write.
It might be your drives automatically spinning down, lots of consumer-grade drives do that these days. Unfortunately on even a
lightly loaded system, this results in the drives constantly spinning down and then spinning up again, especially if you're running
hddtemp or similar to monitor the drive temperature (most drives stupidly don't let you query the SMART temperature value without
spinning up the drive - cretinous!).
I disable idle-spindown on all my drives with the following bit of shell code. you could put it in an /etc/rc.boot script,
or in /etc/rc.local or similar.
for disk in /dev/sd? ; do
/sbin/hdparm -q -S 0 "/dev/$disk"
done
that you can't query SMART readings without spinning up the drive leaves me speechless :-/ Now obviously the "spinning down" issue
can become quite complicated. Regarding disabling the spinning down: wouldn't that in itself cause the HD to wear out faster?
I mean: it's never ever "resting" as long as the system is on then? –
Cedric Martin
Aug 2 '12 at 16:03
IIRC you can query some SMART values without causing the drive to spin up, but temperature isn't one of them on any of the drives
i've tested (incl models from WD, Seagate, Samsung, Hitachi). Which is, of course, crazy because concern over temperature is one
of the reasons for idling a drive. re: wear: AIUI 1. constant velocity is less wearing than changing speed. 2. the drives have
to park the heads in a safe area and a drive is only rated to do that so many times (IIRC up to a few hundred thousand - easily
exceeded if the drive is idling and spinning up every few seconds) –
cas
Aug 2 '12 at 21:42
It's a long debate regarding whether it's better to leave drives running or to spin them down. Personally I believe it's best
to leave them running - I turn my computer off at night and when I go out but other than that I never spin my drives down. Some
people prefer to spin them down, say, at night if they're leaving the computer on or if the computer's idle for a long time, and
in such cases the advantage of spinning them down for a few hours versus leaving them running is debatable. What's never good
though is when the hard drive repeatedly spins down and up again in a short period of time. –
Micheal Johnson
Mar 12 '16 at 20:48
Note also that spinning the drive down after it's been idle for a few hours is a bit silly, because if it's been idle for
a few hours then it's likely to be used again within an hour. In that case, it would seem better to spin the drive down promptly
if it's idle (like, within 10 minutes), but it's also possible for the drive to be idle for a few minutes when someone is using
the computer and is likely to need the drive again soon. –
Micheal Johnson
Mar 12 '16 at 20:51
,
I just found that s.m.a.r.t was causing an external USB disk to spin up again and again on my raspberry pi. Although SMART is
generally a good thing, I decided to disable it again and since then it seems that unwanted disk activity has stopped
(or some variant of parameters with lsof) I can determine which process is bound to a particular port. This is useful say if
I'm trying to start something that wants to bind to 8080 and some else is already using that port, but I don't know what.
Is there an easy way to do this without using lsof? I spend time working on many systems and lsof is often not installed.
netstat -lnp will list the pid and process name next to each listening port. This will work under Linux, but not
all others (like AIX.) Add -t if you want TCP only.
# netstat -lntp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:24800 0.0.0.0:* LISTEN 27899/synergys
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN 3361/python
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN 2264/mysqld
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 22964/apache2
tcp 0 0 192.168.99.1:53 0.0.0.0:* LISTEN 3389/named
tcp 0 0 192.168.88.1:53 0.0.0.0:* LISTEN 3389/named
etc.
xxx , Mar 14, 2011 at 21:01
Cool, thanks. Looks like that that works under RHEL, but not under Solaris (as you indicated). Anybody know if there's something
similar for Solaris? – user5721
Mar 14 '11 at 21:01
Thanks for this! Is there a way, however, to just display what process listen on the socket (instead of using rmsock which attempt
to remove it) ? – Olivier Dulac
Sep 18 '13 at 4:05
@vitor-braga: Ah thx! I thought it was trying but just said which process holds in when it couldn't remove it. Apparently it doesn't
even try to remove it when a process holds it. That's cool! Thx! –
Olivier Dulac
Sep 26 '13 at 16:00
Another tool available on Linux is ss . From the ss man page on Fedora:
NAME
ss - another utility to investigate sockets
SYNOPSIS
ss [options] [ FILTER ]
DESCRIPTION
ss is used to dump socket statistics. It allows showing information
similar to netstat. It can display more TCP and state informations
than other tools.
Example output below - the final column shows the process binding:
I was once faced with trying to determine what process was behind a particular port (this time it was 8000). I tried a variety
of lsof and netstat, but then took a chance and tried hitting the port via a browser (i.e.
http://hostname:8000/ ). Lo and behold, a splash screen greeted me, and it
became obvious what the process was (for the record, it was Splunk ).
One more thought: "ps -e -o pid,args" (YMMV) may sometimes show the port number in the arguments list. Grep is your friend!
In the same vein, you could telnet hostname 8000 and see if the server prints a banner. However, that's mostly useful
when the server is running on a machine where you don't have shell access, and then finding the process ID isn't relevant. –
Gilles
May 8 '11 at 14:45
How can I find which process is constantly writing to disk?
I like my workstation to be close to silent and I just build a new system (P8B75-M + Core i5 3450s -- the 's' because it has
a lower max TDP) with quiet fans etc. and installed Debian Wheezy 64-bit on it.
And something is getting on my nerve: I can hear some kind of pattern like if the hard disk was writing or seeking someting
( tick...tick...tick...trrrrrr rinse and repeat every second or so).
In the past I had a similar issue in the past (many, many years ago) and it turned out it was some CUPS log or something and
I simply redirected that one (not important) logging to a (real) RAM disk.
But here I'm not sure.
I tried the following:
ls -lR /var/log > /tmp/a.tmp && sleep 5 && ls -lR /var/log > /tmp/b.tmp && diff /tmp/?.tmp
but nothing is changing there.
Now the strange thing is that I also hear the pattern when the prompt asking me to enter my LVM decryption passphrase is showing.
Could it be something in the kernel/system I just installed or do I have a faulty harddisk?
hdparm -tT /dev/sda report a correct HD speed (130 GB/s non-cached, sata 6GB) and I've already installed and compiled
from big sources (Emacs) without issue so I don't think the system is bad.
Are you sure it's a hard drive making that noise, and not something else? (Check the fans, including PSU fan. Had very strange
clicking noises once when a very thin cable was too close to a fan and would sometimes very slightly touch the blades and bounce
for a few "clicks"...) – Mat
Jul 27 '12 at 6:03
@Mat: I'll take the hard drive outside of the case (the connectors should be long enough) to be sure and I'll report back ; )
– Cedric Martin
Jul 27 '12 at 7:02
Make sure your disk filesystems are mounted relatime or noatime. File reads can be causing writes to inodes to record the access
time. – camh
Jul 27 '12 at 9:48
thanks for that tip. I didn't know about iotop . On Debian I did an apt-cache search iotop to find out that I had
to apt-get iotop . Very cool command! –
Cedric Martin
Aug 2 '12 at 15:56
I use iotop -o -b -d 10 which every 10secs prints a list of processes that read/wrote to disk and the amount of IO
bandwidth used. – ndemou
Jun 20 '16 at 15:32
You can enable IO debugging via echo 1 > /proc/sys/vm/block_dump and then watch the debugging messages in /var/log/syslog
. This has the advantage of obtaining some type of log file with past activities whereas iotop only shows the current
activity.
It is absolutely crazy to leave sysloging enabled when block_dump is active. Logging causes disk activity, which causes logging,
which causes disk activity etc. Better stop syslog before enabling this (and use dmesg to read the messages) –
dan3
Jul 15 '13 at 8:32
You are absolutely right, although the effect isn't as dramatic as you describe it. If you just want to have a short peek at the
disk activity there is no need to stop the syslog daemon. –
scai
Jul 16 '13 at 6:32
I've tried it about 2 years ago and it brought my machine to a halt. One of these days when I have nothing important running I'll
try it again :) – dan3
Jul 16 '13 at 7:22
I tried it, nothing really happened. Especially because of file system buffering. A write to syslog doesn't immediately trigger
a write to disk. – scai
Jul 16 '13 at 10:50
auditctl -S sync -S fsync -S fdatasync -a exit,always
Watch the logs in /var/log/audit/audit.log . Be careful not to do this if the audit logs themselves are flushed!
Check in /etc/auditd.conf that the flush option is set to none .
If files are being flushed often, a likely culprit is the system logs. For example, if you log failed incoming connection attempts
and someone is probing your machine, that will generate a lot of entries; this can cause a disk to emit machine gun-style noises.
With the basic log daemon sysklogd, check /etc/syslog.conf : if a log file name is not be preceded by -
, then that log is flushed to disk after each write.
It might be your drives automatically spinning down, lots of consumer-grade drives do that these days. Unfortunately on even a
lightly loaded system, this results in the drives constantly spinning down and then spinning up again, especially if you're running
hddtemp or similar to monitor the drive temperature (most drives stupidly don't let you query the SMART temperature value without
spinning up the drive - cretinous!).
I disable idle-spindown on all my drives with the following bit of shell code. you could put it in an /etc/rc.boot script,
or in /etc/rc.local or similar.
for disk in /dev/sd? ; do
/sbin/hdparm -q -S 0 "/dev/$disk"
done
that you can't query SMART readings without spinning up the drive leaves me speechless :-/ Now obviously the "spinning down" issue
can become quite complicated. Regarding disabling the spinning down: wouldn't that in itself cause the HD to wear out faster?
I mean: it's never ever "resting" as long as the system is on then? –
Cedric Martin
Aug 2 '12 at 16:03
IIRC you can query some SMART values without causing the drive to spin up, but temperature isn't one of them on any of the drives
i've tested (incl models from WD, Seagate, Samsung, Hitachi). Which is, of course, crazy because concern over temperature is one
of the reasons for idling a drive. re: wear: AIUI 1. constant velocity is less wearing than changing speed. 2. the drives have
to park the heads in a safe area and a drive is only rated to do that so many times (IIRC up to a few hundred thousand - easily
exceeded if the drive is idling and spinning up every few seconds) –
cas
Aug 2 '12 at 21:42
It's a long debate regarding whether it's better to leave drives running or to spin them down. Personally I believe it's best
to leave them running - I turn my computer off at night and when I go out but other than that I never spin my drives down. Some
people prefer to spin them down, say, at night if they're leaving the computer on or if the computer's idle for a long time, and
in such cases the advantage of spinning them down for a few hours versus leaving them running is debatable. What's never good
though is when the hard drive repeatedly spins down and up again in a short period of time. –
Micheal Johnson
Mar 12 '16 at 20:48
Note also that spinning the drive down after it's been idle for a few hours is a bit silly, because if it's been idle for
a few hours then it's likely to be used again within an hour. In that case, it would seem better to spin the drive down promptly
if it's idle (like, within 10 minutes), but it's also possible for the drive to be idle for a few minutes when someone is using
the computer and is likely to need the drive again soon. –
Micheal Johnson
Mar 12 '16 at 20:51
,
I just found that s.m.a.r.t was causing an external USB disk to spin up again and again on my raspberry pi. Although SMART is
generally a good thing, I decided to disable it again and since then it seems that unwanted disk activity has stopped
It's a important topic for Linux admin (such a wonderful topic) so, everyone must be aware of this and practice how to use this in
the efficient way.
In Linux, whenever we install any packages which has services or daemons. By default all the services "init & systemd" scripts
will be added into it but it wont enabled.
Hence, we need to enable or disable the service manually if it's required. There are three major init systems are available in
Linux which are very famous and still in use.
What is init System?
In Linux/Unix based operating systems, init (short for initialization) is the first process that started during the system boot
up by the kernel.
It's holding a process id (PID) of 1. It will be running in the background continuously until the system is shut down.
Init looks at the /etc/inittab file to decide the Linux run level then it starts all other processes & applications
in the background as per the run level.
BIOS, MBR, GRUB and Kernel processes were kicked up before hitting init process as part of Linux booting process.
Below are the available run levels for Linux (There are seven runlevels exist, from zero to six).
0: halt
1: Single user mode
2: Multiuser, without NFS
3: Full multiuser mode
4: Unused
5: X11 (GUI – Graphical User Interface)
: reboot
Below three init systems are widely used in Linux.
System V (Sys V)
Upstart
systemd
What is System V (Sys V)?
System V (Sys V) is one of the first and traditional init system for Unix like operating system. init is the first process that
started during the system boot up by the kernel and it's a parent process for everything.
Most of the Linux distributions started using traditional init system called System V (Sys V) first. Over the years, several replacement
init systems were released to address design limitations in the standard versions such as launchd, the Service Management Facility,
systemd and Upstart.
But systemd has been adopted by several major Linux distributions over the traditional SysV init systems.
What is Upstart?
Upstart is an event-based replacement for the /sbin/init daemon which handles starting of tasks and services during boot, stopping
them during shutdown and supervising them while the system is running.
It was originally developed for the Ubuntu distribution, but is intended to be suitable for deployment in all Linux distributions
as a replacement for the venerable System-V init.
It was used in Ubuntu from 9.10 to Ubuntu 14.10 & RHEL 6 based systems after that they are replaced with systemd.
What is systemd?
Systemd is a new init system and system manager which was implemented/adapted into all the major Linux distributions over the
traditional SysV init systems.
systemd is compatible with SysV and LSB init scripts. It can work as a drop-in replacement for sysvinit system. systemd is the
first process get started by kernel and holding PID 1.
It's a parant process for everything and Fedora 15 is the first distribution which was adapted systemd instead of upstart. systemctl
is command line utility and primary tool to manage the systemd daemons/services such as (start, restart, stop, enable, disable, reload
& status).
systemd uses .service files Instead of bash scripts (SysVinit uses). systemd sorts all daemons into their own Linux cgroups and
you can see the system hierarchy by exploring /cgroup/systemd file.
How to Enable or Disable Services on Boot Using chkconfig Commmand?
The chkconfig utility is a command-line tool that allows you to specify in which
runlevel to start a selected service, as well as to list all available services along with their current setting.
Also, it will allows us to enable or disable a services from the boot. Make sure you must have superuser privileges (either root
or sudo) to use this command.
All the services script are located on /etc/rd.d/init.d .
How to list All Services in run-level
The -–list parameter displays all the services along with their current status (What run-level the services are enabled
or disabled).
British software company Micro Focus International has agreed to sell SUSE Linux and its
associated software business to Swedish private equity group EQT Partners for $2.535 billion.
Read the details. rm 3 months ago
This comment is awaiting moderation
Novell acquired SUSE in 2003 for $210 million
asoc 4 months ago
This comment is awaiting moderation
"It has over 1400 employees all over the globe "
They should be updating their CVs.
Objective Our goal is to build rpm packages with custom content, unifying scripts
across any number of systems, including versioning, deployment and undeployment. Operating
System and Software Versions
Operating system: Red Hat Enterprise Linux 7.5
Software: rpm-build 4.11.3+
Requirements Privileged access to the system for install, normal access for build.
Difficulty MEDIUM Conventions
# - requires given linux commands to be executed with root
privileges either directly as a root user or by use of sudo command
$ - given linux
commands to be executed as a regular non-privileged user
Introduction One of the core feature of any Linux system is that they are built for
automation. If a task may need to be executed more than one time - even with some part of it
changing on next run - a sysadmin is provided with countless tools to automate it, from simple
shell scripts run by hand on demand (thus eliminating typo errors, or only save
some keyboard hits) to complex scripted systems where tasks run from cron at a
specified time, interacting with each other, working with the result of another script, maybe
controlled by a central management system etc.
While this freedom and rich toolset indeed adds to productivity, there is a catch: as a
sysadmin, you write a useful script on a system, which proves to be useful on another, so you
copy the script over. On a third system the script is useful too, but with minor modification -
maybe a new feature useful only that system, reachable with a new parameter. Generalization in
mind, you extend the script to provide the new feature, and complete the task it was written
for as well. Now you have two versions of the script, the first is on the first two system, the
second in on the third system.
You have 1024 computers running in the datacenter, and 256 of them will need some of the
functionality provided by that script. In time you will have 64 versions of the script all
over, every version doing its job. On the next system deployment you need a feature you recall
you coded at some version, but which? And on which systems are they?
On RPM based systems, such as Red Hat flavors, a sysadmin can take advantage of the package
manager to create order in the custom content, including simple shell scripts that may not
provide else but the tools the admin wrote for convenience.
In this tutorial we will build a custom rpm for Red Hat Enterprise Linux 7.5 containing two
bash scripts, parselogs.sh and pullnews.sh to provide a
way that all systems have the latest version of these scripts in the
/usr/local/sbin directory, and thus on the path of any user who logs in to the
system.
Distributions, major and minor versions In general, the minor and major version of the
build machine should be the same as the systems the package is to be deployed, as well as the
distribution to ensure compatibility. If there are various versions of a given distribution, or
even different distributions with many versions in your environment (oh, joy!), you should set
up build machines for each. To cut the work short, you can just set up build environment for
each distribution and each major version, and have them on the lowest minor version existing in
your environment for the given major version. Of cause they don't need to be physical machines,
and only need to be running at build time, so you can use virtual machines or containers.
In this tutorial our work is much easier, we only deploy two scripts that have no
dependencies at all (except bash ), so we will build noarch packages
which stand for "not architecture dependent", we'll also not specify the distribution the
package is built for. This way we can install and upgrade them on any distribution that uses
rpm , and to any version - we only need to ensure that the build machine's
rpm-build package is on the oldest version in the environment. Setting up
building environment To build custom rpm packages, we need to install the
rpm-build package:
# yum install rpm-build
From now on, we do not useroot user, and for a good reason. Building
packages does not require root privilege, and you don't want to break your building
machine.
Building the first version of the package Let's create the directory structure needed
for building:
$ mkdir -p rpmbuild/SPECS
Our package is called admin-scripts, version 1.0. We create a specfile that
specifies the metadata, contents and tasks performed by the package. This is a simple text file we
can create with our favorite text editor, such as vi . The previously installed
rpmbuild package will fill your empty specfile with template data if you use
vi to create an empty one, but for this tutorial consider the specification below
called admin-scripts-1.0.spec :
Name: admin-scripts
Version: 1
Release: 0
Summary: FooBar Inc. IT dept. admin scripts
Packager: John Doe
Group: Application/Other
License: GPL
URL: www.foobar.com/admin-scripts
Source0: %{name}-%{version}.tar.gz
BuildArch: noarch
%description
Package installing latest version the admin scripts used by the IT dept.
%prep
%setup -q
%build
%install
rm -rf $RPM_BUILD_ROOT
mkdir -p $RPM_BUILD_ROOT/usr/local/sbin
cp scripts/* $RPM_BUILD_ROOT/usr/local/sbin/
%clean
rm -rf $RPM_BUILD_ROOT
%files
%defattr(-,root,root,-)
%dir /usr/local/sbin
/usr/local/sbin/parselogs.sh
/usr/local/sbin/pullnews.sh
%doc
%changelog
* Wed Aug 1 2018 John Doe
- release 1.0 - initial release
Place the specfile in the rpmbuild/SPEC directory we created earlier.
We need the sources referenced in the specfile - in this case the two shell
scripts. Let's create the directory for the sources (called as the package name appended with
the main version):
As this tutorial is not about shell scripting, the contents of these scripts are irrelevant. As
we will create a new version of the package, and the pullnews.sh is the script we
will demonstrate with, it's source in the first version is as below:
#!/bin/bash
echo "news pulled"
exit 0
Do not forget to add the appropriate rights to the files in the source - in our case,
execution right:
We'll get some output about the build, and if anything goes wrong, errors will be shown (for
example, missing file or path). If all goes well, our new package will appear in the RPMS directory
generated by default under the rpmbuild directory (sorted into subdirectories by
architecture):
$ ls rpmbuild/RPMS/noarch/
admin-scripts-1-0.noarch.rpm
We have created a simple yet fully functional rpm package. We can query it for all the
metadata we supplied earlier:
$ rpm -qpi rpmbuild/RPMS/noarch/admin-scripts-1-0.noarch.rpm
Name : admin-scripts
Version : 1
Release : 0
Architecture: noarch
Install Date: (not installed)
Group : Application/Other
Size : 78
License : GPL
Signature : (none)
Source RPM : admin-scripts-1-0.src.rpm
Build Date : 2018. aug. 1., Wed, 13.27.34 CEST
Build Host : build01.foobar.com
Relocations : (not relocatable)
Packager : John Doe
URL : www.foobar.com/admin-scripts
Summary : FooBar Inc. IT dept. admin scripts
Description :
Package installing latest version the admin scripts used by the IT dept.
And of cause we can install it (with root privileges): Installing custom scripts with rpm
As we installed the scripts into a directory that is on every user's $PATH , you
can run them as any user in the system, from any directory:
$ pullnews.sh
news pulled
The package can be distributed as it is, and can be pushed into repositories available to any
number of systems. To do so is out of the scope of this tutorial - however, building another
version of the package is certainly not. Building another version of the package Our package
and the extremely useful scripts in it become popular in no time, considering they are reachable
anywhere with a simple yum install admin-scripts within the environment. There will be
soon many requests for some improvements - in this example, many votes come from happy users that
the pullnews.sh should print another line on execution, this feature would save the
whole company. We need to build another version of the package, as we don't want to install another
script, but a new version of it with the same name and path, as the sysadmins in our organization
already rely on it heavily.
First we change the source of the pullnews.sh in the SOURCES to something even
more complex:
#!/bin/bash
echo "news pulled"
echo "another line printed"
exit 0
We need to recreate the tar.gz with the new source content - we can use the same filename as
the first time, as we don't change version, only release (and so the Source0 reference
will be still valid). Note that we delete the previous archive first:
cd rpmbuild/SOURCES/ && rm -f admin-scripts-1.tar.gz && tar -czf admin-scripts-1.tar.gz admin-scripts-1
Now we create another specfile with a higher release number:
We don't change much on the package itself, so we simply administrate the new version as
shown below:
Name: admin-scripts
Version: 1
Release: 1
Summary: FooBar Inc. IT dept. admin scripts
Packager: John Doe
Group: Application/Other
License: GPL
URL: www.foobar.com/admin-scripts
Source0: %{name}-%{version}.tar.gz
BuildArch: noarch
%description
Package installing latest version the admin scripts used by the IT dept.
%prep
%setup -q
%build
%install
rm -rf $RPM_BUILD_ROOT
mkdir -p $RPM_BUILD_ROOT/usr/local/sbin
cp scripts/* $RPM_BUILD_ROOT/usr/local/sbin/
%clean
rm -rf $RPM_BUILD_ROOT
%files
%defattr(-,root,root,-)
%dir /usr/local/sbin
/usr/local/sbin/parselogs.sh
/usr/local/sbin/pullnews.sh
%doc
%changelog
* Wed Aug 22 2018 John Doe
- release 1.1 - pullnews.sh v1.1 prints another line
* Wed Aug 1 2018 John Doe
- release 1.0 - initial release
All done, we can build another version of our package containing the updated script. Note that
we reference the specfile with the higher version as the source of the build:
If the build is successful, we now have two versions of the package under our RPMS directory:
ls rpmbuild/RPMS/noarch/
admin-scripts-1-0.noarch.rpm admin-scripts-1-1.noarch.rpm
And now we can install the "advanced" script, or upgrade if it is already installed.
Upgrading custom scripts with rpm
And our sysadmins can see that the feature request is landed in this version:
rpm -q --changelog admin-scripts
* sze aug 22 2018 John Doe
- release 1.1 - pullnews.sh v1.1 prints another line
* sze aug 01 2018 John Doe
- release 1.0 - initial release
Conclusion
We wrapped our custom content into versioned rpm packages. This means no
older versions left scattered across systems, everything is in it's place, on the version we
installed or upgraded to. RPM gives the ability to replace old stuff needed only in previous
versions, can add custom dependencies or
provide some tools or services our other packages rely on. With effort, we can pack nearly any of
our custom content into rpm packages, and distribute it across our environment, not only with ease,
but with consistency.
Most of the time on newly created file systems of NFS filesystems we see error
like below :
1 2 3 4
root @ kerneltalks # touch file1 touch : cannot touch ' file1 ' : Read - only file
system
This is because file system is mounted as read only. In such scenario you have to mount it
in read-write mode. Before that we will see how to check if file system is mounted in read only
mode and then we will get to how to re mount it as a read write filesystem.
How to check if file system is read only
To confirm file system is mounted in read only mode use below command –
Grep your mount point in cat /proc/mounts and observer third column which shows
all options which are used in mounted file system. Here ro denotes file system is
mounted read-only.
You can also get these details using mount -v command
1 2 3 4
root @ kerneltalks # mount -v |grep datastore / dev / xvdf on / datastore type ext3 (
ro , relatime , seclabel , data = ordered )
In this output. file system options are listed in braces at last column.
Re-mount file system in read-write mode
To remount file system in read-write mode use below command –
1 2 3 4 5 6
root @ kerneltalks # mount -o remount,rw /datastore root @ kerneltalks # mount -v |grep
datastore / dev / xvdf on / datastore type ext3 ( rw , relatime , seclabel , data = ordered
)
Observe after re-mounting option ro changed to rw . Now, file
system is mounted as read write and now you can write files in it.
Note : It is recommended to fsck file system before re mounting it.
You can check file system by running fsck on its volume.
1 2 3 4 5 6 7 8 9 10
root @ kerneltalks # df -h /datastore Filesystem Size Used Avail Use % Mounted on / dev
/ xvda2 10G 881M 9.2G 9 % / root @ kerneltalks # fsck /dev/xvdf fsck from util - linux
2.23.2 e2fsck 1.42.9 ( 28 - Dec - 2013 ) / dev / xvdf : clean , 12 / 655360 files , 79696 /
2621440 blocks
Sometimes there are some corrections needs to be made on file system which needs reboot to
make sure there are no processes are accessing file system.
You can see that user has to type 'y' for each query. It's in situation like these where yes
can help. For the above scenario specifically, you can use yes in the following way:
yes | rm -ri test Q3. Is there any use of yes when it's used alone?
Yes, there's at-least one use: to tell how well a computer system handles high amount of
loads. Reason being, the tool utilizes 100% processor for systems that have a single processor.
In case you want to apply this test on a system with multiple processors, you need to run a yes
process for each processor.
To open multiple files, command would be same as is for a single file; we just add the file
name for second file as well.
$ vi file1 file2 file 3
Now to browse to next file, we can use
$ :n
or we can also use
$ :e filename
Run external commands inside the editor
We can run external Linux/Unix commands from inside the vi editor, i.e. without exiting the
editor. To issue a command from editor, go back to Command Mode if in Insert mode & we use
the BANG i.e. '!' followed by the command that needs to be used. Syntax for running a command
is,
$ :! command
An example for this would be
$ :! df -H
Searching for a pattern
To search for a word or pattern in the text file, we use following two commands in command
mode,
command '/' searches the pattern in forward direction
command '?' searched the pattern in backward direction
Both of these commands are used for same purpose, only difference being the direction they
search in. An example would be,
$ :/ search pattern (If at beginning of the file)
$ :/ search pattern (If at the end of the file)
Searching & replacing a
pattern
We might be required to search & replace a word or a pattern from our text files. So
rather than finding the occurrence of word from whole text file & replace it, we can issue
a command from the command mode to replace the word automatically. Syntax for using search
& replacement is,
$ :s/pattern_to_be_found/New_pattern/g
Suppose we want to find word "alpha" & replace it with word "beta", the command would
be
$ :s/alpha/beta/g
If we want to only replace the first occurrence of word "alpha", then the command would
be
$ :s/alpha/beta/
Using Set commands
We can also customize the behaviour, the and feel of the vi/vim editor by using the set
command. Here is a list of some options that can be use set command to modify the behaviour of
vi/vim editor,
$ :set ic ignores cases while searching
$ :set smartcase enforce case sensitive search
$ :set nu display line number at the begining of the line
$ :set hlsearch highlights the matching words
$ : set ro change the file type to read only
$ : set term prints the terminal type
$ : set ai sets auto-indent
$ :set noai unsets the auto-indent
Some other commands to modify vi editors are,
$ :colorscheme its used to change the color scheme for the editor. (for VIM editor only)
$ :syntax on will turn on the color syntax for .xml, .html files etc. (for VIM editor
only)
This complete our tutorial, do mention your queries/questions or suggestions in the comment
box below.
"... Note that we unset the config variable after we're done, otherwise it'll be in the namespace of our shell where we don't need it. You may also wish to check for the existence of the ~/.bashrc.d directory, check there's at least one matching file inside it, or check that the file is readable before attempting to source it, depending on your preference. ..."
"... Thanks to commenter oylenshpeegul for correcting the syntax of the loops. ..."
Large shell startup scripts ( .bashrc , .profile ) over about fifty
lines or so with a lot of options, aliases, custom functions, and similar tweaks can get cumbersome
to manage over time, and if you keep your dotfiles under version control it's not terribly helpful
to see large sets of commits just editing the one file when it could be more instructive if broken
up into files by section.
Given that shell configuration is just shell code, we can apply the source builtin
(or the . builtin for POSIX sh ) to load several files at the end of a
.bashrc , for example:
This is a better approach, but it still binds us into using those filenames; we still have to
edit the ~/.bashrc file if we want to rename them, or remove them, or add new ones.
Fortunately, UNIX-like systems have a common convention for this, the .d directory
suffix, in which sections of configuration can be stored to be read by a main configuration file
dynamically. In our case, we can create a new directory ~/.bashrc.d :
$ ls ~/.bashrc.d
options.bash
aliases.bash
functions.bash
With a slightly more advanced snippet at the end of ~/.bashrc , we can then load
every file with the suffix .bash in this directory:
# Load any supplementary scripts
for config in "$HOME"/.bashrc.d/*.bash ; do
source "$config"
done
unset -v config
Note that we unset the config variable after we're done, otherwise it'll be in the
namespace of our shell where we don't need it. You may also wish to check for the existence of the
~/.bashrc.d directory, check there's at least one matching file inside it, or check
that the file is readable before attempting to source it, depending on your preference.
The same method can be applied with .profile to load all scripts with the suffix
.sh in ~/.profile.d , if we want to write in POSIX sh , with
some slightly different syntax:
# Load any supplementary scripts
for config in "$HOME"/.profile.d/*.sh ; do
. "$config"
done
unset -v config
Another advantage of this method is that if you have your dotfiles under version control, you
can arrange to add extra snippets on a per-machine basis unversioned, without having to update your
.bashrc file.
Here's my implementation of the above method, for both .bashrc and .profile
:
If you pass -1 as the process ID argument to either the
kill shell command or the
kill C function , then the signal is sent to all the processes it can reach, which
in practice means all the processes of the user running the kill command or syscall.
pkill - ... signal processes based on name and other attributes
-u, --euid euid,...
Only match processes whose effective user ID is listed.
Either the numerical or symbolical value may be used.
-U, --uid uid,...
Only match processes whose real user ID is listed. Either the
numerical or symbolical value may be used.
-u, --user
Kill only processes the specified user owns. Command names
are optional.
I think, any utility used to find process in Linux/Solaris style /proc (procfs) will use
full list of processes (doing some readdir of /proc ). I think, they will
iterate over /proc digital subfolders and check every found process for
match.
To get list of users, use getpwent
(it will get one user per call).
skill (procps & procps-ng)
and killall (psmisc)
tools both uses getpwnam library call
to parse argument of -u option, and only username will be parsed.
pkill (procps & procps-ng)
uses both atol and getpwnam to parse -u / -U argument and allow
both numeric and textual user specifier.
; ,Aug 4, 2011 at 10:11
pkill is not obsolete. It may be unportable outside Linux, but the question was about Linux
specifically. – Lars Wirzenius
Aug 4 '11 at 10:11
Opens another terminal window at the current location.
Use Case
I often cd into a directory and decide it would be useful to open another terminal in
the same folder, maybe for an editor or something. Previously, I would open the terminal
and repeat the CD command.
I have aliased this command to open so I just type open and I get a new
terminal already in my desired folder.
The & disown part of the command stops the new terminal from being
dependant on the first meaning that you can still use the first and if you close the
first, the second will remain open. Limitations
It relied on you having the $TERMINAL global variable set. If you don't have this set
you could easily change it to something like the following:
While the original one-liner is indeed IMHO the canonical way to loop over numbers,
the brace expansion syntax of Bash 4.x has some kick-ass features such as correct padding
of the number with leading zeros. Limitations
This is similar to seq , but portable. seq does not
exist in all systems and is not recommended today anymore. Other variations to
emulate various uses with seq :
# seq 1 2 10
for ((i=1; i<=10; i+=2)); do echo $i; done
# seq -w 5 10
for ((i=5; i<=10; ++i)); do printf '%02d\n' $i; done
The -i parameter is to edit the file in-place. Limitations
This works as posted in GNU sed . In BSD sed , the
-i flag requires a parameter to use as the suffix of a backup file. You can
set it to empty to not use a backup file:
The here-document is great, but it's messing up your shell script's formatting. You want to
be able to indent for readability. Solution
Use <<- and then you can use tab characters (only!) at the beginning of lines to
indent this portion of your shell script.
$ cat myscript.sh
...
grep $1 <<-'EOF'
lots of data
can go here
it's indented with tabs
to match the script's indenting
but the leading tabs are
discarded when read
EOF
ls
...
$
Discussion
The hyphen just after the << is enough to tell bash to ignore the leading tab
characters. This is for tab characters only and not arbitrary white space. This is
especially important with the EOF or any other marker designation. If you have
spaces there, it will not recognize the EOF as your ending marker, and the "here"
data will continue through to the end of the file (swallowing the rest of your script).
Therefore, you may want to always left-justify the EOF (or other marker) just to
be safe, and let the formatting go on this one line.
The Bourne shell provides here documents to allow block of data to be passed to a process
through STDIN. The typical format for a here document is something similar to this:
command <<ARBITRARY_TAG
data to pass 1
data to pass 2
ARBITRARY_TAG
This will send the data between the ARBITRARY_TAG statements to the standard input of the
process. In order for this to work, you need to make sure that the data is not indented. If you
indent it for readability, you will get a syntax error similar to the following:
./test: line 12: syntax error: unexpected end of file
To allow your here documents to be indented, you can append a "-" to the end of the
redirection strings like so:
if [ "${STRING}" = "SOMETHING" ]
then
somecommand <<-EOF
this is a string1
this is a string2
this is a string3
EOF
fi
You will need to use tabs to indent the data, but that is a small price to pay for added
readability. Nice!
To enable automatic user logout, we will be using the TMOUT shell variable,
which terminates a user's login shell in case there is no activity for a given number of
seconds that you can specify.
To enable this globally (system-wide for all users), set the above variable in the
/etc/profile shell initialization file.
"... ', the pattern removal operation is applied to each positional parameter in turn, and the expansion is the resultant list. If parameter is an array variable subscripted with '@' or ' ..."
Following some issues with scp (it did not like the presence of the bash bind command in my
.bashrc
file, apparently), I followed the advice of a clever guy on the Internet
(I just cannot find that post right now) that put at the top of its
.bashrc
file
this:
[[ ${-#*} != ${-} ]] || return
in order to make sure that the bash initialization is NOT executed unless in interactive
session.
Now, that works. However, I am not able to figure how it works. Could you enlighten
me?
According to
this
answer
, the
$-
is the current options set for the shell and I know that the
${}
is the so-called "substring" syntax for expanding variables.
However, I do not understand the
${-#*i}
part. And why
$-#*i
is
not the same as
${-#*i}
.
The word is expanded to produce a pattern just as in filename expansion. If the pattern
matches the beginning of the expanded value of parameter, then the result of the expansion
is the expanded value of parameter with the shortest matching pattern (the '#' case) or the
longest matching pattern (the '##' case) deleted.
If parameter is '@' or '
', the
pattern removal operation is applied to each positional parameter in turn, and the
expansion is the resultant list. If parameter is an array variable subscripted with '@' or
'
', the pattern removal operation is applied to each member of the array in turn, and
the expansion is the resultant list.
So basically what happens in
${-#*i}
is that
*i
is expanded, and
if it matches the beginning of the value of
$-
, then the result of the whole
expansion is
$-
with the shortest matching pattern between
*i
and
$-
deleted.
Example
VAR "baioasd"
echo ${VAR#*i};
outputs
oasd
.
In your case
If shell is interactive,
$-
will contain the letter 'i', so when you strip
the variable
$-
of the pattern
*i
you will get a string that is
different from the original
$-
(
[[ ${-#*i} != ${-} ]]
yelds true).
If shell is not interactive,
$-
does not contain the letter 'i' so the pattern
*i
does not match anything in
$-
and
[[ ${-#*i} != $-
]]
yelds false, and the
return
statement is executed.
To determine within a startup script whether or not Bash is running interactively, test
the value of the '-' special parameter. It contains i when the shell is interactive
Your substitution removes the string up to, and including the
i
and tests if
the substituted version is equal to the original string. They will be different if there is
i
in the
${-}
.
Using
declare
(which will
detect
when it was called from within a
function and make the variable(s) local).
myfunc
()
local
var
=VALUE
# alternative, only when used INSIDE a function
declare
var
=VALUE
...
The
local
keyword (or declaring a variable using the
declare
command)
tags a variable to be treated
completely local and separate
inside the function where
it was declared:
foo
=external
printvalue
()
local
foo
=internal
echo
$foo
# this will print "external"
echo
$foo
# this will print "internal"
printvalue
# this will print - again - "external"
echo
$foo
The environment space is not directly related to the topic about scope, but it's worth
mentioning.
Every UNIX® process has a so-called
environment
. Other items, in addition to
variables, are saved there, the so-called
environment variables
. When a child process
is created (in Bash e.g. by simply executing another program, say
ls
to list
files), the whole environment
including the environment variables
is copied to the new
process. Reading that from the other side means: Only variables that are part of the
environment are available in the child process.
A variable can be tagged to be part of the environment using the
export
command:
# create a new variable and set it:
# -> This is a normal shell variable, not an environment variable!
myvariable
"Hello world."
# make the variable visible to all child processes:
# -> Make it an environment variable: "export" it
export
myvariable
Remember that the
exported
variable is a copy . There is no provision to "copy it
back to the parent." See the article about
Bash in the process tree
!
1)
under specific
circumstances, also by the shell itself
:
(colon) and input redirection. The
:
does nothing, it's a pseudo
command, so it does not care about standard input. In the following code example, you want to
test mail and logging, but not dump the database, or execute a shutdown:
#!/bin/bash
# Write info mails, do some tasks and bring down the system in a safe way
echo
"System halt requested"
mail
-s
"System halt"
netadmin
example.com
logger
-t
SYSHALT
"System halt requested"
##### The following "code block" is effectively ignored
:
<<
"SOMEWORD"
etc
init.d
mydatabase clean_stop
mydatabase_dump
var
db
db1
mnt
fsrv0
backups
db1
logger
-t
SYSHALT
"System halt: pre-shutdown actions done, now shutting down the system"
shutdown
-h
NOW
SOMEWORD
##### The ignored codeblock ends here
What happened? The
:
pseudo command was given some input by redirection (a
here-document) - the pseudo command didn't care about it, effectively, the entire block was
ignored.
The here-document-tag was quoted here to avoid substitutions in the "commented" text! Check
redirection with
here-documents
for more
# MS-DOS / XP cmd like stuff
alias edit = $VISUAL
alias copy = 'cp'
alias cls = 'clear'
alias del = 'rm'
alias dir = 'ls'
alias md = 'mkdir'
alias move = 'mv'
alias rd = 'rmdir'
alias ren = 'mv'
alias ipconfig = 'ifconfig'
The variable CDPATH defines the search path for the directory containing directories. So it served much like "directories
home". The dangers are in creating too complex CDPATH. Often a single directory works best. For example export CDPATH = /srv/www/public_html
. Now, instead of typing cd /srv/www/public_html/CSS I can simply type: cd CSS
Use CDPATH to access frequent directories in bash
Mar 21, '05 10:01:00AM • Contributed by:
jonbauman
I often find myself wanting to cd to the various directories beneath my home directory (i.e. ~/Library, ~/Music, etc.),
but being lazy, I find it painful to have to type the ~/ if I'm not in my home directory already. Enter CDPATH
, as desribed in man bash ):
The search path for the cd command. This is a colon-separated list of directories in which the shell looks for destination
directories specified by the cd command. A sample value is ".:~:/usr".
Personally, I use the following command (either on the command line for use in just that session, or in .bash_profile
for permanent use):
CDPATH=".:~:~/Library"
This way, no matter where I am in the directory tree, I can just cd dirname , and it will take me to the directory that
is a subdirectory of any of the ones in the list. For example:
$ cd
$ cd Documents
/Users/baumanj/Documents
$ cd Pictures
/Users/username/Pictures
$ cd Preferences
/Users/username/Library/Preferences
etc...
[ robg adds: No, this isn't some deeply buried treasure of OS X, but I'd never heard of the CDPATH variable, so
I'm assuming it will be of interest to some other readers as well.]
cdable_vars is also nice
Authored by: clh on Mar 21, '05 08:16:26PM
Check out the bash command shopt -s cdable_vars
From the man bash page:
cdable_vars
If set, an argument to the cd builtin command that is not a directory is assumed to be the name of a variable whose value
is the directory to change to.
With this set, if I give the following bash command:
export d="/Users/chap/Desktop"
I can then simply type
cd d
to change to my Desktop directory.
I put the shopt command and the various export commands in my .bashrc file.
For privacy of my data I wanted to lock down /downloads on my file server. So I
ran:
chmod
0000
/
downloads
chmod 0000 /downloads
The root user can still has access and ls and cd commands will not work. To go
back:
chmod
0755
/
downloads
chmod 0755 /downloads
Clear gibberish all over the screen
Just type:
reset
reset
Becoming human
Pass the
-h
or
-H
(and other options) command line option
to GNU or BSD utilities to get output of command commands like ls, df, du, in
human-understandable formats:
ls
-lh
# print sizes in human readable format (e.g., 1K 234M 2G)
df
-h
df
-k
# show output in bytes, KB, MB, or GB
free
-b
free
-k
free
-m
free
-g
# print sizes in human readable format (e.g., 1K 234M 2G)
du
-h
# get file system perms in human readable format
stat
-c
%
A
/
boot
# compare human readable numbers
sort
-h
-a
file
# display the CPU information in human readable format on a Linux
lscpu
lscpu
-e
lscpu
-e
=cpu,node
# Show the size of each file but in a more human readable way
tree
-h
tree
-h
/
boot
ls -lh # print sizes in human readable
format (e.g., 1K 234M 2G) df -h df -k # show output in bytes, KB, MB, or GB
free -b free -k free -m free -g # print sizes in human readable format (e.g.,
1K 234M 2G) du -h # get file system perms in human readable format stat -c %A
/boot # compare human readable numbers sort -h -a file # display the CPU
information in human readable format on a Linux lscpu lscpu -e lscpu -e=cpu,node
# Show the size of each file but in a more human readable way tree -h tree -h
/boot
Show information about known users in the Linux based system
Just type:
## linux version ##
lslogins
## BSD version ##
logins
## linux version ## lslogins## BSD
version ## logins
Sample outputs:
UID USER PWD-LOCK PWD-DENY LAST-LOGIN GECOS
0 root 0 0 22:37:59 root
1 bin 0 1 bin
2 daemon 0 1 daemon
3 adm 0 1 adm
4 lp 0 1 lp
5 sync 0 1 sync
6 shutdown 0 1 2014-Dec17 shutdown
7 halt 0 1 halt
8 mail 0 1 mail
10 uucp 0 1 uucp
11 operator 0 1 operator
12 games 0 1 games
13 gopher 0 1 gopher
14 ftp 0 1 FTP User
27 mysql 0 1 MySQL Server
38 ntp 0 1
48 apache 0 1 Apache
68 haldaemon 0 1 HAL daemon
69 vcsa 0 1 virtual console memory owner
72 tcpdump 0 1
74 sshd 0 1 Privilege-separated SSH
81 dbus 0 1 System message bus
89 postfix 0 1
99 nobody 0 1 Nobody
173 abrt 0 1
497 vnstat 0 1 vnStat user
498 nginx 0 1 nginx user
499 saslauth 0 1 "Saslauthd user"
Confused on a top command output?
Seriously, you need to try out htop instead of top:
sudo
htop
sudo htop
Want to run the same command again?
Just type
!!
. For example:
/
myhome
/
dir
/
script
/
name arg1 arg2
# To run the same command again
!!
## To run the last command again as root user
sudo
!!
/myhome/dir/script/name arg1 arg2# To
run the same command again !!## To run the last command again as root user sudo
!!
The
!!
repeats the most recent command. To run the most recent
command beginning with "foo":
!
foo
# Run the most recent command beginning with "service" as root
sudo
!
service
!foo # Run the most recent command
beginning with "service" as root sudo !service
The
!$
use to run command with the last argument of the most recent
command:
# Edit nginx.conf
sudo
vi
/
etc
/
nginx
/
nginx.conf
# Test nginx.conf for errors
/
sbin
/
nginx
-t
-c
/
etc
/
nginx
/
nginx.conf
# After testing a file with "/sbin/nginx -t -c /etc/nginx/nginx.conf", you
# can edit file again with vi
sudo
vi
!
$
# Edit nginx.conf sudo vi
/etc/nginx/nginx.conf# Test nginx.conf for errors /sbin/nginx -t -c
/etc/nginx/nginx.conf# After testing a file with "/sbin/nginx -t -c
/etc/nginx/nginx.conf", you # can edit file again with vi sudo vi !$
Get a reminder you when you have to leave
If you need a reminder to leave your terminal, type the following command:
leave +hhmm
leave +hhmm
Where,
hhmm
– The time of day is in the form hhmm where hh is a time in
hours (on a 12 or 24 hour clock), and mm are minutes. All times are converted
to a 12 hour clock, and assumed to be in the next 12 hours.
Home sweet home
Want to go the directory you were just in? Run:
cd -
Need to quickly return to your home directory? Enter:
cd
The variable
CDPATH
defines the search path for the directory
containing directories:
export
CDPATH
=
/
var
/
www:
/
nas10
export CDPATH=/var/www:/nas10
Now, instead of typing
cd /var/www/html/
I can simply type the
following to cd into /var/www/html path:
cd
html
cd html
Editing a file being viewed with less pager
To edit a file being viewed with less pager, press
v
. You will have
the file for edit under $EDITOR:
less
*
.c
less
foo.html
## Press v to edit file ##
## Quit from editor and you would return to the less pager again ##
less *.c less foo.html ## Press v to
edit file ## ## Quit from editor and you would return to the less pager again
##
List all files or directories on your system
To see all of the directories on your system, run:
find
/
-type
d
|
less
# List all directories in your $HOME
find
$HOME
-type
d
-ls
|
less
find / -type d | less# List all
directories in your $HOME find $HOME -type d -ls | less
To see all of the files, run:
find
/
-type
f
|
less
# List all files in your $HOME
find
$HOME
-type
f
-ls
|
less
find / -type f | less# List all files
in your $HOME find $HOME -type f -ls | less
Build directory trees in a single command
You can create directory trees one at a time using mkdir command by passing the
-p
option:
To see all of the directories on your system, run:
find
/
-type
d
|
less
# List all directories in your $HOME
find
$HOME
-type
d
-ls
|
less
find / -type d | less# List all directories in your $HOME find $HOME -type d -ls | less
To see all of the files, run:
find
/
-type
f
|
less
# List all files in your $HOME
find
$HOME
-type
f
-ls
|
less
[Jan 26, 2012] A last-resort trick to recover your machine from the brink of
death
Have you heard of the magic SysRq key?
No?
Well, it's magic. It's directly shunted to the Linux
kernel. You press ALT, press the PrintScreen (SysRq) key, and while
holding them both down, press one of the letters (each letter has a
different function assigned to it).
It's not normally enabled, but you can enable it by putting
kernel.sysrq = 1
in your machine's /etc/sysctl.conf file. Oh, and
then rebooting.
Here's why it's useful.
So, what does SysRq do, really?
Hit Alt+SysRq+K - the windowing system will restart. More
effective than Ctrl+Alt+Backspace.
Suppose a GUI application you just opened is starting to swallow
massive amounts of RAM. Like, one gigabyte, perhaps? Your machine is
locking up, and you feel the mouse start to stutter at first, then
freeze completely - while the hard disk light in your computer's
front panel is lighting up frantically, gasping for
air (aka memory) .
You now have three choices:
Sit it out and let the Linux kernel detect this situation
and kill the abusive application. This can take way more than 15
minutes.
Press the computer's power off button for 5 seconds. This
shuts your machine down uncleanly and leads to data loss.
Hit the magic SysRq combo: Alt+SysRq+K.
Should you choose option 3, the graphical subsystem dies
immediately. That's because Alt+SysRq+K kills any application that
holds the keyboard open - and, you guessed it, the graphical
subsystem is holding it open. This premature death of the GUI causes
all GUI applications to die in a cascade, including the abusive
application.
Two to ten seconds later, you will be presented with a login
prompt.
Sure, you lost changes to all files you haven't saved, and all
the tabs in your Web browser… but at least you didn't have to reboot
uncleanly, did you?
But, Ctrl+Alt+Backspace?
Once the machine is in a critically heavy memory crunch,
Ctrl+Alt+Backspace will take too much time to work, because the
windowing system will be pressed for memory to even execute. The
magic SysRq key has the luxury of not having that problem
- if Ctrl+Alt+Backspace were an IV drip, SysRq would be like a
central line.
Why this key combination exists
The reason this key combo exists is simple. Alt+SysRq+K is called
SAK (System Attention Key). It was designed back in the days of, um,
yore, to kill all applications snooping on the keyboard - so
administrators wishing to log in could safely do so without anyone
sniffing their passwords.
As a preventative security measure, it sure works against
keyloggers and other malware that may be snooping on your keyboard,
may I say. And it most definitely works against your run-of-the-mill
temporary memory shortage ;-).
Advantages/disadvantages
Well, the major disadvantages are:
Anyone with keyboard access can reboot or hang your machine
using a SysRq key combination.
Once you hit it, since the GUI dies, all of your open
[In GUI environment]
applications close, forcibly.
But, on a memory crunch, this beats rebooting hands-down. And
that's the biggest advantage.
Sometimes, buggy memory hogs can choke your machine. Here, two
tricks: one to recover from a memory choke, another to prevent
memory chokes forever.
Misbehaving application frozen?
Has an application stopped responding on your machine? Well, as
long as your machine is still responsive, you can use these tricks
to nuke it safely.
On KDE
Hit Ctrl+Alt+Esc. Your mouse cursor will change - from an arrow
to a small skull/crossbones combo. Hit the stubborn application with
the skull.
It'll die.
On GNOME
Add a new launcher to your panel and set it so it executes the
xkill application. Now, when an application starts
stupidifying itself, just hit the launcher you created (the cursor
will change to a square-type "target"), then hit the application
with your mouse cursor.
It'll die.
Application choking your machine?
Of course, if your machine is already too slow to use these
tricks, they won't help you much. Here's why, sometimes, your
machine ditches itself into a molasses pit, and how to rescue it
from certain death.
Memory and pathologies
…almost all applications have this pathological idea (encouraged
by the operating system) that memory is a limitless resource…
You see, almost all applications have this pathological idea
(encouraged by the operating system) that memory is a limitless
resource - and when they go overboard, the operating system just
dips into the hard disk to simulate memory.
Sometimes,
bugs in an application do cause them to go haywire, requesting
memory like there's no end. Once your machine goes down that lane,
there isn't a simple way to recover it, short of powering it off
forcibly.
A fortress-like operating system like Linux isn't supposed to
die, and yet it does. However, the fortress I'm so proud of can, and
does, provide you with effective measures against premature deaths
of these sort.
A last-resort trick to recover your machine from the brink of
death
Have you heard of the magic SysRq key?
No?
Well, it's magic. It's directly shunted to the Linux
kernel. You press ALT, press the PrintScreen (SysRq) key, and while
holding them both down, press one of the letters (each letter has a
different function assigned to it).
It's not normally enabled, but you can enable it by putting
kernel.sysrq = 1
in your machine's /etc/sysctl.conf file. Oh, and
then rebooting.
Here's why it's useful.
So, what does SysRq do, really?
Hit Alt+SysRq+K - the windowing system will restart. More
effective than Ctrl+Alt+Backspace.
Suppose a GUI application you just opened is starting to swallow
massive amounts of RAM. Like, one gigabyte, perhaps? Your machine is
locking up, and you feel the mouse start to stutter at first, then
freeze completely - while the hard disk light in your computer's
front panel is lighting up frantically, gasping for
airmemory.
You now have three choices:
Sit it out and let the Linux kernel detect this situation
and kill the abusive application. This can take way more than 15
minutes.
Press the computer's power off button for 5 seconds. This
shuts your machine down uncleanly and leads to data loss.
Hit the magic SysRq combo: Alt+SysRq+K.
Should you choose option 3, the graphical subsystem dies
immediately. That's because Alt+SysRq+K kills any application that
holds the keyboard open - and, you guessed it, the graphical
subsystem is holding it open. This premature death of the GUI causes
all GUI applications to die in a cascade, including the abusive
application.
Two to ten seconds later, you will be presented with a login
prompt.
Sure, you lost changes to all files you haven't saved, and all
the tabs in your Web browser… but at least you didn't have to reboot
uncleanly, did you?
But, Ctrl+Alt+Backspace?
Once the machine is in a critically heavy memory crunch,
Ctrl+Alt+Backspace will take too much time to work, because the
windowing system will be pressed for memory to even execute. The
magic SysRq key has the luxury of not having that problem
- if Ctrl+Alt+Backspace were an IV drip, SysRq would be like a
central line.
Why this key combination exists
The reason this key combo exists is simple. Alt+SysRq+K is called
SAK (System Attention Key). It was designed back in the days of, um,
yore, to kill all applications snooping on the keyboard - so
administrators wishing to log in could safely do so without anyone
sniffing their passwords.
As a preventative security measure, it sure works against
keyloggers and other malware that may be snooping on your keyboard,
may I say. And it most definitely works against your run-of-the-mill
temporary memory shortage ;-).
Advantages/disadvantages
Well, the major disadvantages are:
Anyone with keyboard access can reboot or hang your machine
using a SysRq key combination.
Once you hit it, since the GUI dies, all of your open
applications close, forcibly.
But, on a memory crunch, this beats rebooting hands-down. And
that's the biggest advantage.
A definitive cure to runaway applications
Become an administrator (root) and use your favorite text editor
to open the file /etc/security/limits.conf:
# /etc/security/limits.conf
#
#Each line describes a limit for a user in the form:
#
#<domain> <type> <item> <value>
#
#Where:
#<domain> can be:
# - an user name
# - a group name, with @group syntax
# - the wildcard *, for default entry
# - the wildcard %, can be also used with %group syntax,
# for maxlogin limit
#
#<type> can have the two values:
# - "soft" for enforcing the soft limits
# - "hard" for enforcing hard limits
#
#<item> can be one of the following:
# - core - limits the core file size (KB)
# - data - max data size (KB)
# - fsize - maximum filesize (KB)
# - memlock - max locked-in-memory address space (KB)
# - nofile - max number of open files
# - rss - max resident set size (KB)
# - stack - max stack size (KB)
# - cpu - max CPU time (MIN)
# - nproc - max number of processes
# - as - address space limit
Add the following line anywhere on the file:
* soft as 512000
limits.conf is a little-known godsend, and a
definite requirement to keep large computing farms or terminal
servers under control.
You will need to restart any sessions (graphical/terminal) for
this change to take effect. Additionally, you will need to restart
the graphical session manager (GDM or KDM).
Of course, 512000 is just my favorite setting - but that's
because I have the privilege of using multi-gigabyte memory sticks
on my machine. If you have much less memory than me, you will want
to tune this, while keeping in mind that modern applications can and
do take more than 300 MB under exceptional circumstances.
Like, for example, Firefox with 50 tabs/windows open. Or
Evolution managing 2 GB of e-mail. Hey, both circumstances happen to
me, but I guess I'm an oddball.
What this "magic incantation" in limits.conf does
limits.conf is the file that lets you set
per-user/process/system resource limits. There are several limits to
choose from.
One of them is the address space (as). The address
space refers to the maximum amount of RAM (in kilobytes) that a
process may request from the operating system. Any requests above
the configured limit are simply refused.
Advantages/disadvantages
The fortunate side effect of this recipe is that the majority of
applications will disappear and die a horrible death if they request
memory indiscriminately. Which beats having to turn the machine off.
The unfortunate side effect of refused requests for more memory
is that the majority of applications will disappear and die a
horrible death if they request memory indiscriminately. That's
because they don't know how to cope with more memory. Until software
developers actually implement error handling for lack of memory,
this will be a small nuisance - hey, save often and you'll be safe
;-).
Temporarily disabling memory limits for picky applications
Another disadvantage: certain applications don't run when a limit
is set. WINE is among those applications. However, you can use a
terminal window to disable this limit temporarily (within any
applications started from the terminal):
So, the infrequent dead application, SAKing your computer, or
powering it off… what do you prefer? Me… well, once I upgraded my
new "desktop" machine (1U Dell PowerEdge SC1425) to 2 GB, I haven't
looked back.
But my old machine did thank me a lot for keeping it off memory
crunches :-). It's now safe in PVR heaven,
piratingtime-shifting
TV shows for my pleasure.
While performing some testing a few weeks ago, I needed to create a ramdisk
on one of my redhat AS 4.0 servers. I knew Solaris supported tmpfs, and after
a bit of googling was surprised to find that Linux supported the tmpfs pseudo-file
system as well. To create a ramdisk on a Linux host, you first need to find
a suitable place to mount the tmpfs file system. For my tests, I used mkdir
to create a directory valled /var/ramdisk:
$ mkdir /var/ramdisk
Once the mount point is identified, you can use the mount command to mount
a tmpfs file system on top of that mount point:
$ mount -t tmpfs none /var/ramdisk -o size=28m
Now each time you access /var/ramdisk, your reads and writes will be coming
directly from memory. Nice!
I use this one alot when I am either coding or writing a
research paper for school. More often than not I find I have copied something
new only to discover I need to paste a link or block of code again from
two copies back. Having a tray icon where I can recall the last ten copies
or so is mighty useful.
Gnome-Do
Most anyone who uses the computer in their everyday work will tell you
that less mouse clicks means faster speed and thus (typically) more productivity.
Gnome-Do is a program that allows you to cut down on mouse clicks (so long
as you know what program you are looking to load). The jist of what it does
is this: you assign a series of hot keys to call up the search bar (personally
I use control+alt+space) and then you start typing in the name of an application
or folder you want to open and it will start searching for it - once the
correct thing is displayed all you need to do is tap enter to load it up.
The best part is that it remembers which programs you use most often. Meaning
that most times you only need to type the first letter or two of a commonly
used application for it to find the one you are looking for.
[Aug 7, 2009] atd daemon is not running on Suse 10 SP2
by default, so at commands fail.
It needs to be manually enabled via
chkconfig
and started with service
command to ensure consistency in behavior with the Solaris. AIX and HP-UX.
Linux has become so idiot proof nowadays that there is less and less need
to use the command line. However, the commands and shell scripts have remained
powerful for advanced users to utilize to help them do complicated tasks quickly
and efficiently.
To those of you who are aspiring to become a UNIX/Linux guru, you have to
know loads of commands and learn how to effectively use them. But there
is really no need to memorize everything since there are plenty of cheat
sheets available on the web and on books. To spare you from the hassles
of searching, I have here a collection of 10 essential UNIX/Linux cheat
sheets that can greatly help you on your quest for mastery...
I've been using this grep invocation for years to trim comments out of config
files. Comments are great but can get in your way if you just want to see the
currently running configuration. I've found files hundreds of lines long which
had fewer than ten active configuration lines, it's really hard to get an overview
of what's going on when you have to wade through hundreds of lines of comments.
$ grep ^[^#] /etc/ntp.conf
The regex ^[^#] matches the first character of any line, as long as that
character that is not a #. Because blank lines don't have a first character
they're not matched either, resulting in a nice compact output of just the active
configuration lines.
My last
blog entry explains how to use xmodmap to remap the Caps Lock key to the
Escape key in X. That takes care of the keyboard mapping when you are in X.
What about when you are in a virtual console window? You need to follow the
steps below. Make sure that you sudo root before you execute the following commands.
Find out the keycode of the key that you want remapped.
Execute the showkey command as root in a virtual consolde:
$ showkey
kb mode was UNICODE
press any key (program terminates after 10s of last keypress)...
0x9c
Hit the Caps Lock key, wait 10 seconds (default timeout), and the showkey
command will exit on its own.
$ showkey
kb mode was UNICODE
press any key (program terminates after 10s of last keypress)...
0x9c
0x3a
0xba
The keycode for the Caps Lock key is 0x3a in hex, or 58 in decimal.
Find out the symbolic name (key symbol) of the key that you want to
map to.
You can list all the supported symbolic names by dumpkeys -l and grep for
esc:
Thanks to cjwatson who pointed me to prepending the keymaps statement from
dumpkeys. The keymaps statement is a shorthand notation defining what key
modifiers you are defining with the key. See man keymaps(5) for more info.
To make the new key mapping permanent, you need to put the
loadkeys command in a bootup script.
For my Debian Etch system, I put the
(echo `dumpkeys |grep -i keymaps`; echo keycode 58 = Escape) |loadkeys -
command in /etc/rc.local.
# Make the Caps Lock key be a Control key:
xmodmap -e "remove lock = Caps_Lock"
xmodmap -e "add control = Caps_Lock"
# Make the Left Control key be a Caps Lock key:
xmodmap -e "remove control = Control_L"
xmodmap -e "add lock = Control_L"
Questions Answered Below
How do you remap your keyboard to, say, turn the caps lock key into
a control key?
How about remapping other keys?
What are the underlying concepts that man xmodmap fails
to explain?
The instructions in this page apply only to Linux in an X environment (like
KDE).
Terminology
Keycode
A keycode represents a key. Each key on the keyboard
has a unique keycode.
Keysym
A keysym represents an action (I use the terms "action"
and "keysym" synonymously below). Examples include "print the letter
c" and "start behaving like the left shift key
has been pressed".
Modifiers
The modifiers include shift, control, (caps) lock,
and others (mod1 through mod5). Modifiers add another level of indirection
and are managed with their own set of commands in xmodmap.
How These Relate To One Another
Keycodes, keysyms, and modifiers relate in the following way:
keycode → keysym → modifier (optional)
So for example, on my keyboard:
keycode 38 (the 'a' key) → keysym 0x61 (the symbol 'a')
keycode 50 (the left 'shift' key) → keysym 0xffe1 (the action
'the left shift key is down') → the shift modifier
Note that technically, each keycode can be mapped to more than one keysym.
The first mapping applies when no modifier is pressed; the second applies when
the shift key is pressed. (I haven't figured out how to use the third and fourth
yet.) So for example, the second mapping on my 'a' key is:
keycode 38 (the 'a' key) → keysym 0x61 (the symbol 'A')
In other words, when modifier 'shift' is active, my 'a' key generates an
'A' instead of an 'a'.
Viewing Your Settings
xmodmap -pke displays the mapping between and keysyms.
For example (key on the left, action on the right):
This tells me that keycode 37 (which happens to be my left control key)
is mapped to the Control_L action. Keycode 38 (my 'a') key is mapped to
the action 'a' (with no modifieres pressed), the action 'A' (with shift
pressed) or a variety of other actions when I'm pressing other modifiers.
The last line says that keycode 66 (which happens to be my Caps Lock key)
is mapped to the Caps_Lock action.
xmodmap -pm displays the mapping between modifiers and
keysyms. For example (modifiers on the left, keysyms on the right):
The first line says that the "left shift" action and the "right shift"
action both invoke the "shift". The second line says that no keysym invokes
the "caps lock" modifier. The third says that the Caps_Lock action and the
two Control actions invoke the control modifier.
xev
Allows you to view keycodes and keysyms by pressing the key. For example,
when I press the left 'shift' key:
KeyPress event, serial 25, synthetic NO, window 0x3200001,
root 0xc8, subw 0x0, time 126222719, (-659,738), root:(1087,758),
state 0x0, keycode 50 (keysym 0xffe1, Shift_L), same_screen YES,
XLookupString gives 0 bytes: ""
Line 3 tells me that the left shift key has keycode 50, and that it's
currently mapped to keysym 0xffe1 (Shift_L).
Changing Your Settings
Say you want to map the caps lock key to be the control modifier. You have
two sensible choices for how to do this:
Caps Lock Key → Caps Lock action → Control Modifier
Caps Lock Key → Control_L action → Control Modifier
To do the first, you need to change the action → modifier mapping. Do this
as follows:
To do the second, you need to change the keycode → action mapping, so you'll
need to know the keycode of your caps lock key. To find the keycode for your
caps lock key use xev, as described above. Mine is 66. So:
xmodmap -e "keycode 66 = Control_L"
Help!
If you mess things up, the simplest way to fix things is to log out of the
window manager and log back in.
For More Information
/usr/include/X11/keysymdef.h
This file will show you what keysyms exist. Note that you need to omit
the XK_ prefix when specifying the keysym.
Notes
This is all determined from experimenting, so it may be wrong. But I
think it's right!
I did this on an x86 under (Red Hat) Linux in KDE, with a basic-looking
HP keyboard -- your results may vary.
The Caps Lock key on most PC keyboards is in the position where the Control
key is on many other keyboards, and vice versa. This can make it difficult
for programmers to use the "wrong" kind of keyboard.
One really stupid thing about PeeCee
keyboards is that manufacturers even realized that putting caps-lock on
home row was a bad idea because people kept hitting it with the 'a' key.
Did they move it? No, that would be too sensible. They carved a little piece
of it off to leave a bigger gap. So now if I re-map a standard PC-10* keyboard
so that left-control is in a sensible place, it is still harder to use than
it should be. :(
Many people (the majority, clearly) feel that the placement of CTRL below
the SHIFT key is a better location for it. However, the backspace key is
way out of the way -- it would be better if the CAPSLOCK and backspace keys
were swapped.
Unix, Console
If you have loadkeys (as you would under Linux), this should do the trick:
To reset to the defaults (you may have to switch to another tty and back
to undo ctrl-lock):
loadkeys -d
Unix, X
Under Redhat 8.0, just enable the following line in /etc/X11/XF86Config
Option "XkbOptions" "ctrl:swapcaps"
Replace "swapcaps" with "nocaps" to turn both keys into "Control."
With X, there are at least 2 different ways to remap the keys. One is
using xmodmap. For example, man xmodmap shows how to swap
the left control key and the CapsLock
key:
! Swap Caps_Lock and Control_L
!
remove Lock = Caps_Lock
remove Control = Control_L
keysym Control_L = Caps_Lock
keysym Caps_Lock = Control_L
add Lock = Caps_Lock
add Control = Control_L
Many people don't want a CapsLock
key at all. They can change the
CapsLock key to a ControlKey?
by using the following lines in xmodmap:
clear Lock
keycode 0x7e = Control_R
add Control = Control_R
Maybe you have to change the keycode 0x7e. You can find the keycodes
with xev. I Furthermore, this only works if you don't have a right
control key. I hope somebody has a solution which does not have this restriction.
This solution might be the easiest one. If you do not have a problem owning
a dead key in your keyboard you might disable
CapsLock at all:
"remove lock = Caps_Lock" (or just: "clear lock")
A better solution might be this sequence, which is keycode independent and
does not remove existing control keys:
remove Lock = Caps_Lock
remove Control = Control_L
keysym Caps_Lock = Control_L
add Lock = Caps_Lock
add Control = Control_L
Now, you can use another solution which uses xkb. For that, you
will have to find the sybols directory on your unix system. There, you add
a file which might be called 'ctrl' containing the following:
// eliminate the caps lock key completely (replace with control)
partial modifier_keys
xkb_symbols "nocaps" {
key <CAPS> { symbols[Group1]= [ Control_L ] };
modifier_map Control { <CAPS>, <LCTL> };
};
This eliminates the caps lock key if included in a keymap. We can do this
by changing the file en_US:
The dmidecode command can be used
to display information from the systems' BIOS that includes the maximum memory
that the BIOS will support. This information is displayed by
dmidecode as type 16 (Physical Memory
Array) which can be filtered with the command
dmidecode -t 16.
For instance, the following output shows a system that can support a maximum
of 16GB of RAM.
Handle 0x0032, DMI type 16, 15 bytes
Physical Memory Array
Location: System Board Or Motherboard
Use: System Memory
Error Correction Type: None
Maximum Capacity: 16 GB
Error Information Handle: Not Provided
Number Of Devices: 4
One of the major benefits to using Red Hat Enterprise Linux is that once the
operating system is up and running, it tends to stay that way. This also holds
true when it comes to reconfiguring a system; mostly. One Achilles heel for
Linux, until the past couple of years, has been the fact that the Linux kernel
only reads partition table information at system initialization, necessitating
a reboot any time you wish to add new disk partitions to a running system.
The good news, however, is that disk re-partitioning can now also be handled
'on-the-fly' thanks to the 'partprobe' command, which is part of the 'parted'
package.
Using 'partprobe' couldn't be more simple. Any time you use 'fdisk', 'parted'
or any other favorite partitioning utility you may have to modify the partition
table for a drive, run 'partprobe' after you exit the partitioning utility and
'partprobe' will let the kernel know about the modified partition table information.
If you have several disk drives and want to specify a specific drive for 'partprobe'
to scan, you can run 'partprobe <device_node>'
Of course, given a particular hardware configuration, shutting down your
system to add hardware may be unavoidable, it's still nice to be given the option
of not having to do so and 'partprobe' fills that niche quite nicely.
partprobe [-d] [-s] [devices...]
DESCRIPTION
This manual page documents briefly the partprobe command.
partprobe is a program that informs the operating system kernel of
partition table changes, by requesting that the operating system re-read the
partition table.
Yum & Repositories
I noticed this issue with both CentOS 4 and 5 - Yum will often choose bad mirrors
from the mirrorlist file - for example, choosing overseas servers, when an official
NZ server exists. And in some cases, the servers it has chosen are horribly
slow.
You will probably find that you get better download speeds by editing /etc/yum.repos.d/CentOS-Base.repo
and commenting out the mirrorlist lines and setting the baseurl line to point
to your preferred local mirror.
Yum-updatesd
CentOS 5 has a new daemon called yum-updatesd, which replaces the old cron job
yum update scripts. This script will check frequently for updates, and can be
configured to download and/or install them.
However, this daemon is bad for a server, since it doesn't run at a fixed time
- I really don't want my server downloading and updating software during the
busiest time of day thank-you-very-much!
So, it's bad for a server. Let's disable it with:
service yum-updatesd stop
chkconfig --level 2345 yum-updatesd off
Plus I don't like the idea of having a full blown daemon where a simple cronjob
will do the trick perfectly fine - seems like overkill. (although it appears
yum-updatesd has some useful features like dbus integration for desktop users)
So, I replace it with my favorite cronjob script approach, by running the following
(as root of course):
(please excuse the leading space infront of the comments ( #) - it is to
work around a limitation in my site, which I will fix shortly. Just copy the
lines into a text editor and remove the space, before pasting into the terminal)
This will install 2 scripts that get run around 4:00am (as set in /etc/crontab)
which will check for updates and download and install any automatically. If
there were any updates, it will send out an email, if there were none, it doesn't
send anything.
(of course, you need sendmail/whatever_fucking_email_server_you_like configured
correctly to get the alerts!)
You can change yum to just download and not install the updates (just RTFM),
but I've never had a update break anything - update compatibility and quality
is always very high - so I use automatic updates.
CentOS 4 had something very similar to this, with the addition of a bootscript
to turn the cronjobs on and off.
* Please check out the update at the bottom of this page for futher information
on this.
Apache Quirks
If you are using indexing in apache (indexing is when you can browse folders/files),
you may find that the browsing page looks small and nasty.
The fix is to edit /etc/httpd/conf/httpd.conf and change the following line:
This should make the index full screen again. I'm not sure if this is an apache
bug, a distro bug or some other weird issue, because I'm sure HTMLTable isn't
supposed to be all small like that.
(FYI: CentOS 4 did not have the HTMLTable option active)
SSL Certificates
Redhat have moved things around with SSL certificates a lot. What it seems like
happened (I have only had a quick look into this), is that they were going to
provide a new tool to generate SSL certificates called "genkey" but pulled it
out before release.
To make things more fun, they also removed the good old Makefile that was in
/etc/httpd/conf/ that allowed you to generate SSL certificates & keys.
However, I found the same Makefile again in /etc/pki/tls/certs/
That's all the issues that I've come across for now - if I find any more things
to note, I'll update this page with the information and put a note on my blog.
Note the NETMASK should be defined in /etc/sysconfig/network-scripts/ifcfg-eth0
/etc/sysconfig/network
The /etc/sysconfig/network file is used to specify
information about the desired network configuration. The following values may
be used:
NETWORKING=<value>,
where <value>
is one of the following boolean values:
yes - Networking should be configured.
no - Networking should not be configured.
HOSTNAME=<value>,
where <value>
should be the Fully Qualified Domain Name (FQDN),
such as hostname.expample.com, but can be whatever
hostname is necessary.
Note
For compatibility with older software that some users may need to
install, such as trn, the
/etc/HOSTNAME file should contain the same
value as set here.
GATEWAY=<value>,
where <value>
is the IP address of the network's gateway.
GATEWAYDEV=<value>,
where <value>
is the gateway device, such as eth0.
NISDOMAIN=<value>,
where <value>
is the NIS domain name.
How to see parameter of ext3 filesystem
# tune2fs -l /dev/mapper/vg00-lv06
tune2fs 1.38 (30-Jun-2005)
Filesystem volume name: <none>
Last mounted on: <not available>
Filesystem UUID: c0615eba-5bb6-443d-81c7-7f3c1eb829b2
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic) Filesystem features: has_journal filetype needs_recovery
sparse_super
Default mount options: (none)
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 1310720
Block count: 2621440
Reserved block count: 131072
Free blocks: 2365370
Free inodes: 1309130
First block: 0
Block size: 4096
Fragment size: 4096
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 16384
Inode blocks per group: 512
Filesystem created: Mon May 21 11:16:17 2007
Last mount time: Tue May 6 17:40:40 2008
Last write time: Tue May 6 17:40:40 2008
Mount count: 3
Maximum mount count: 500
Last checked: Thu Apr 3 11:51:39 2008
Check interval: 5184000 (2 months)
Next check after: Mon Jun 2 11:51:39 2008
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 128
Journal inode: 8
Default directory hash: tea
Directory Hash Seed: 36a54cdf-3f8e-482b-9e2c-a48b6ac1d27e
Journal backup: inode blocks
About:
Expect-lite is a wrapper for expect, created to make expect programming even
easier. The wrapper permits the creation of expect script command files by using
special character(s) at the beginning of each line to indicate the expect-lite
action. Basic expect-lite scripts can be created by simply cutting and pasting
text from a terminal window into a script, and adding '>' '
Release focus: Major feature enhancements
Changes:
The entire command script read subsystem has changed. The previous system read
directly from the script file. The new system reads the script file into a buffer,
which can be randomly accessed. This permits looping (realistically only repeat
loops). Infinite loop protection has been added. Variable increment and decrement
have been added to support looping.
Nowadays, many machines are running with 2-4 gigabytes of RAM, and their owners are discovering a problem: When they run 32-bit GNU/Linux distributions, their extra RAM is not being used. Fortunately, correcting the problem is only a matter of installing or building a kernel with a few specific parameters enabled or disabled.
The problem exists because 32-bit Linux kernels are designed to access only 1GB of RAM by default. The
workaround for this limitation is vaguely reminiscent of the virtual memory solution once used by DOS, with a high memory area of virtual memory being constantly mapped to physical addresses. This high memory can be enabled for up to 4GB by one kernel parameter, or up to 64GB on a Pentium Pro or higher processor with another parameter. However, since these parameters have not been needed on most machines until recently, the standard kernels in many distributions have not enabled them.
Increasingly, many distributions are enabling high memory for 4GB. Ubuntu default kernels have been enabling this process at least since version 6.10, and so have Fedora 7's. By contrast, Debian's default 486 kernels do not. Few distros, if any, enable 64GB by default.
To check whether your kernel is configured to use all your RAM, enter the command
free -m. This command gives you the total amount of unused RAM on your system, as well as the size of your swap file, in megabytes. If the total memory is 885, then no high memory is enabled on your system (the rest of the first gigabyte is reserved by the kernel for its own purposes). Similarly, if the result shows over 1 gigabyte but less than 4GB when you know you have more, then the 4GB parameter is enabled, but not the 64GB one. In either case, you will need to add a new kernel to take full advantage of your RAM.
[Nov 20, 2007] Games with discolors
eval `dircolors ~/.dir_colors`
alias ls="ls --color=auto"
The command 'dircolors' takes its data from the file ~/.dir_colors and
creates an environment variable LS_COLORS. The command 'ls --color' takes
its colors from the environmental variable LS_COLORS.
So, write a suitable ~/.dir_colors file, and execute the command
'dircolors'. To get a starting file for editing, do this:
dircolors -p > ~/.dir_colors
The ~/.dir_colors file so created includes directions on coding the colors
for different kinds of files.
See man dircolors.
[Nov 1, 2007] Changing Gnome behavior to standard UNIX CDE style (application
displayed on a particular desktop are visible only this desktop toolbar.
Well, it's magic. It's directly shunted to the Linux kernel. You
press ALT, press the PrintScreen (SysRq) key, and while holding them both down,
press one of the letters (each letter has a different function assigned to it).
It's not normally enabled, but you can enable it by putting
kernel.sysrq = 1
in your machine's /etc/sysctl.conf file. Oh, and then rebooting.
Here's why it's useful.
So, what does SysRq do, really?
Hit Alt+SysRq+K - the windowing system will restart. More effective than
Ctrl+Alt+Backspace.
Suppose a GUI application you just opened is starting to swallow massive
amounts of RAM. Like, one gigabyte, perhaps? Your machine is locking up, and
you feel the mouse start to stutter at first, then freeze completely - while
the hard disk light in your computer's front panel is lighting up frantically,
gasping for airmemory.
You now have three choices:
Sit it out and let the Linux kernel detect this situation and kill the
abusive application. This can take way more than 15 minutes.
Press the computer's power off button for 5 seconds. This shuts your
machine down uncleanly and leads to data loss.
Hit the magic SysRq combo: Alt+SysRq+K.
Should you choose option 3, the graphical subsystem dies immediately. That's
because Alt+SysRq+K kills any application that holds the keyboard open - and,
you guessed it, the graphical subsystem is holding it open. This premature death
of the GUI causes all GUI applications to die in a cascade, including the abusive
application.
Two to ten seconds later, you will be presented with a login prompt.
Sure, you lost changes to all files you haven't saved, and all the tabs in
your Web browser… but at least you didn't have to reboot uncleanly, did you?
But, Ctrl+Alt+Backspace?
Once the machine is in a critically heavy memory crunch, Ctrl+Alt+Backspace
will take too much time to work, because the windowing system will be pressed
for memory to even execute. The magic SysRq key has the luxury of not having
that problem
- if Ctrl+Alt+Backspace were an IV drip, SysRq would be like a central line.
Why this key combination exists
The reason this key combo exists is simple. Alt+SysRq+K is called SAK (System
Attention Key). It was designed back in the days of, um, yore, to kill all applications
snooping on the keyboard - so administrators wishing to log in could safely
do so without anyone sniffing their passwords.
As a preventative security measure, it sure works against keyloggers and
other malware that may be snooping on your keyboard, may I say. And it most
definitely works against your run-of-the-mill temporary memory shortage ;-).
Advantages/disadvantages
Well, the major disadvantages are:
Anyone with keyboard access can reboot or hang your machine using a
SysRq key combination.
Once you hit it, since the GUI dies, all of your open applications close,
forcibly.
But, on a memory crunch, this beats rebooting hands-down. And that's the
biggest advantage.
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.
level 1
Normally, I never care about banner ads that scroll through graphic installers. This time, the slogan Free to use, free to download, free to update. Always still caught my attention.

TrevorH
that I want to see and I can't slam the Scroll Lock fast enough to catch it. Anyone know how to get the details to scroll up rather than the blank and re-write?

Rob Moir Rob Moir 30k 4 4 gold badges 53 53 silver badges 84 84 bronze badges
<img src=https://linuxconfig.org/images/foremost_manual.png alt=foremost-manual width=1200 height=675 /> Foremost is a forensic data recovery program for Linux used to recover files using their headers, footers, and data structures through a process known as file carving. Software Requirements and Conventions Used

Installing custom scripts with rpm
Upgrading custom scripts with rpm
- if Ctrl+Alt+Backspace were an IV drip, SysRq would be like a central line.