It is very difficult to write a good intro book for such language as Perl. Contrary to the popular opinion, the introductory O'Reilly books on Perl are no longer the best.
For some reason O'Reilly attracts complexity junkers, who use complexity for the sake
of complexity. There is actually no good introductory Perl book from O'Reilly. I really do no not
recommend buying Learning Perl as your first book, or second or even third book (unless you buy it on company
money with a half-don of others ;-).
Perl is huge language and the way to learn it for system administrator is to learn relevant
subset. Some parts of the language like OO-related parts can and should be initially omitted from study.
The same is probably true for modules. You need just to learn to use modules with CPAN, but on
introductory level I would recommend initially skip all this complex mechanics. For small to medium
scripts you can structure your program using Perl 4 libraries almost as well as with modules with
minimal additional complexity. If you want separation of namespaces just use package statements and
explicit naming (like in $html_functions::string_length )
Although the core of the language is very stable, Perl 5 is still a moving target and for non-introductory
books the age of the book still matter. In general, I recommend Perl books that are less than
five years old (the last edition of Programming Perl was printed in 2012, Intermediate Perl was
printed in 2012, Effective Perl Programming in 2010) , but every rule has its own exceptions. Please note that CGI-related books not included
in this section. They are covered elsewhere.
Books that are 5 or less years old are preferable, but there are exceptions to this
rule...
The exception are based on the fact that talented authors are very rare and the same author can
produce books of very different quality. So good books by talented authors are twice as rare ;-). As
such they have value despite their age.
In RHEL 6 version is 5.10 is used and that means that the book should cover
new constructs introduced in this version ( "state"
variables). Generally state variables is a valuable addition to the language and that makes this
version of Perl somewhat better then previous versions (the major one were 5.8, 5.6 and 5.0). At the
same time many Unixes still ship Perl 5.8 by default, so excessive hurry in switching to version
5.10 might hurt compatibility with older version of Unix/Linux.
Please note that a major revision of the language (version 6.0) is in works, but due to overcomplexity and errors
in language design chances of displacing of the version 5 are pretty slim. Recent version 5.10 incorporates
some ideas from version 6 into version 5 framework. I think that version 6 is at least another
decade from
implementation; that means that buying Perk 5.8 or Perl 5.10 book is a pretty safe bet.
You need a good development environment in order to program in Perl and first of all you need
"Perl aware" editor. See
Absence of good
development environment
Beware all second editions of Perl books from O'Reilly ;-). Paradoxically most of them are disappointing
(BTW Learning Perl is more than disappointing -- it's simply weak and only the first edition
has, mostly historical now, value). A reader can save money by getting other better books instead. There
is several books that are better as an introductory books
Beginning Perl by Curtis Poe. This is a book printed in 2012 and it
covered Perl 5.10. This is not exactly intro book as it covered "way too much language
features" which can be very confusing for beginners (the same drawback as older but also good
into book Beginning Perlby Simon Cozens suffers from).
Perl Developer's Guide This is 900+ pages book is very cheap (used) on Amazon and is a good
start. Covers Perl 5.6 only. Here are some relevant points from an Amazon Review:
...a great section on data-structures like arrays-of-arrays, and hash or hashes, etc... that
are essential if you want to do intermediate or above Perl programming.
...Some great new appendixes for Perl "grammar and structure" that weren't in the first edition.
Basically a concise reference for semantics that would benefit anybody.
...A much improved index that was practically non-existent in the first edition.
...All in all, I would say the second edition would be a good edition to learning and
even improving your Perl skills since it is a huge tome of Perl information that can be both used
as a reference and as a tutorial.
Beginning Perlby Simon Cozens. Overcomplicated, but well written
(with a lot of examples) open introductory book. Covers only Perl 5.6. It is suitable mainly for those who already know
at least one programmer language; there is also a second edition with
the primary author listed as James Lee instead of Simon Cozens and which paradoxically contains almost
a twice less pages). Consider it to be junk.
The books that have e-text freely available or at least have it on accompanying CD have a better
value and you can put with some minor shortcomings due to the advantages of having full e-text (for
example that value of index is less important -- one can search e-text instead). Old David Till's book
(see below open books ) was a good introductory book that used to be freely
available from the http://www.informit.com/ --
Macmillan online library and might still be found somewhere on the Internet...
Although the quality is very uneven and the CD lucks any good intro book, older, cheaper versions
of Perl CD Bookshelf from O'Reilly might be an interesting alternative to buying printed version of
Cookbook from O'Reilly as it is a reference. It's more convenient to have it in HTML than in a printed
edition...
There are also some underestimated books on Perl. Personally I like Perl Programming
Companion by Nigel Chapman. This is not very popular book among Amazon.com readers, but I think
that here (like in some other cases) they are wrong ;-). "Lemming effect" quite pronounced in reviews
of Learning Perl on Win32 and several other horrible
but highly praised by conformists O'Reilly books. Bias probably is present here too but with a negative sign.
Programmers with experience in any other language can definitely benefit from this nice book.
Please note that old, but still available on the Web
Camel Critiques
-- Tom Christiansen's reviews of Perl book are biased and from my point of view reviews are unfair to
non-O'Reilly authors. Please take them with a grain of salt -- even with disclaimer that he has a vested
interest in promoting O'Reilly books. Here is my (slightly skeptical ;-) opinion about on one of books
that was highly praised by Tom Christiansen in
Camel Critiques
-- Learning Perl on Win32. In short this was
junk book.
Amazon.com readers reviews can provide you with a balanced opinion if you can understand that extremes
meet, pay attention to whether people reviewed other books or this is their first review and whether
they bought the book from Amazon or not. Also some people trash books just to prove themselves -- for the same reason as other people overpraise
mediocre books. I recommend discarding way too positive ("brilliant") and way too negative
opinions unless a reviewer provides facts that substantiate his/her point of view. Also useful is checking
the reviewer other reviews. Cheap trick with asking friends of the author to write glowing reviews is
easily detected this way.
And last but not least -- please question my own reviews too. My background and priorities can be
different from yours and I learned Perl after several other languages. That means that books that are
optimal for me can be sub-optimal for you. Even i as teacher I am biased toward books that reflect
my own, Spartan preferences. For example I do I think that for Unix system administrators Perl 4
subset of Perl 5 is pretty adequate. Moreover I can confess that my opinion about books is changing
with time and with the level of success of the class when I use them in teaching Perl courses. Sometimes substantially.
P.S. Here I would like to reproduce
One Minute Perl Book Reviews
-- pretty entertaining and educating test for Perl books ;-). If a large number of elements in array
test fail that the book is really highly suspect. I am not sure about the value of positive results
(actually most of elements discussed in the test are probably absent in any introductory book). For
the actual marks of a number of book including Medinets' book see the paper.
"Its not about the acid in the paper, its about the Crack in the author."
Seems like everyone is writing a Perl book. The most disturbing part is that they're being written
by people who have nothing to do with Perl. How to decide what's crap and what's not?
Worry no more! After many mirth-filled hours of flipping through many an awful Perl book, I have
come up with a simple one-minute litmus test to determine if the book you're holding is worth the
tree its printed on.
Historical Note:This page was written back in 1999 when the flood of Perl books
hit the market.
The Perl Book Litmus Test
Remember, the point of this test is to find bad books and there can only be negative
results with this test. A book which passes all the tests put forth here CAN STILL SUCK.
The following tests check the five things books and beginning Perl programmers most commonly screw
up. Its by no means intended to be canonical, just a quick way to look for read flags. So flip to
the index. Look up the following tidbits and answer the questions.
localtime Due to localtime's ahem "vintage" interface, date generation is
usually botched in Perl. Its important that a book has a good discussion of localtime and its
caveats. Does it [explicitly] state that it returns the number of years since 1900? Does it mention
that when used in scalar context it returns a nicely formatted date? Does it avoid things like
`date`?
open || die $! "Why doesn't $line = <FILE> work?" is one of the most common newbie
questions. Its extremely important that a book drills it into the reader's head that all system
calls should be checked and proper error messages returned. This means putting some sort of error
checking on all system calls (not just open()), using and discussing $! and other good error messages.
srand Not a common problem, but something often gotten wrong. If a book does drag
out srand(), it often fails to point out that it should be called only once. (If srand is never
mentioned, that's okay.)
array size Does it clearly say that an array will return its number of elements in
scalar context, or does it use/imply $num = $#array + 1;
flock Any CGI program writing to a file is going to run into file corruption issues
pretty fast. If the book covers topics which will lead to concurrent file access, it should
talk about flock(). Does it discuss and use flock instead of lockfiles? (ie. setting some
.lock file instead of using flock()).
Portable Constants When performing flocking, socket operations or sysopens does it
use the constants defined by Perl (LOCK_SH and friends), or do they define their own unportable
constants? If the subject never comes up that's ok.
Perl Bookshelf exists in 4 editions. They do not contain identical set of books so it make sense
to buy several (they are really cheap now). See details in description below. The last one is probably
the best is you want to buy just one.
References are used frequently and extensively in Perl code. They're very important for a
Perl web developer to understand, as the syntax of element access changes depending on whether
you have a reference or direct access.
Q: In Perl, how do you initialize the
following?
an array
an array reference
A hash
A hash reference
Furthermore, how would you change an array to an array reference, a hash to a hash
reference, and vice versa? How do you access elements from within these variables?
A: The
use of hash and array references is a pretty basic concept for any experienced Perl developer,
but it may syntactically trip up some newer Perl developers or developers who never really
grasped the underlying basics.Initializing an Array:
my @arr = (0, 1, 2);
An array is initialized with an @ symbol prefixed to the variable name, which
denotes the variable type as an array; its elements are placed in
parentheses.
Initializing an Array Reference:
my $arr_ref = [0, 1, 2];
With an array reference, you use the $ symbol, which denotes 'scalar', and the
elements are placed in square brackets. The reference isn't specified as an array, just as a
scalar, so you have to be careful to handle the variable type appropriately.
Like an array reference, a hash reference variable is prefixed with a $ , but
the elements are placed in curly braces.
Referencing a Hash or an Array
Referencing an array or hash is pretty straightforward. In Perl, a backslash in front of a
variable will return the reference to it. You should expect something like the following:
my $arr_ref = \@arr;
my $hash_ref = \%hash;
Dereferencing
Dereferencing a referenced variable is as easy as reassigning it with the appropriate
variable identifier. For example, here's how you would dereference arrays and hashes:
my @arr = @$arr_ref;
my %hash = %$hash_ref;
Accessing Elements
The differences between accessing elements of these variable types and their reference
versions is another area where amateur developers may get tripped up.
# to access an element of an array
my $element = $arr[0];
Notice that for an array you are not using the @ prefix but rather the
$ to denote a scalar, which is the type returned when accessing any element of an
array. Accessing the elements of an array reference, a hash, and a hash reference follows a
similar syntax:
# to access an element of an array reference
my $element = ${$array_ref}[0];
# to access an element of a hash
my $element = $hash{0};
# to access an element of a hash reference
my $element = $hash_ref->{0};
I do not understand your train of thought. In the first example end of the
line occurred when all brackets are balanced, so it will will be interpretered as
print( "Hello World" ); if( 1 );[download]
So this is a syntactically incorrect example, as it should be. The second example will
be interpreted as
That supports another critique of the same proposal -- it might break old Perl 5 scripts
and should be implemented only as optional pragma. Useful only for programmers who
experience this problem.
Because even the fact that this error is universal and occurs to all programmers is
disputed here.
if we assume that somebody uses this formatting to suffix conditionals
I do, pretty much all the time! The ability to span a statement over multiple lines
without jumping through backslash hoops is one of the things that makes Perl so attractive.
I also think it makes code much easier to read rather than having excessively long lines
that involve either horizontal scrolling or line wrapping. As to your comment regarding excessive length
identifiers, I come from a Fortran IV background where we had a maximum of 8 characters for
identifiers (ICL 1900 Fortran compiler) so I'm all for long, descriptive and unambiguous
identifiers that aid those who come after in understanding my code.
In the following, the first line has a balance of brackets and looks syntactically
correct. Would you expect the lexer to add a semicolon?
$a = $b + $c
+ $d + $e;
Yes, and the user will get an error. This is similar to previous example with
trailing on a new line "if (1);" suffix. The first question is why he/she wants to format
the code this way if he/she suffers from this problem, wants to avoid missing semicolon
error and, supposedly enabled pragma "softsemicolons" for that?
This is the case where the user need to use #\ to inform the scanner about his choice.
But you are right in a sense that it creates a new type of errors -- "missing
continuation." And that there is no free lunch. This approach requires specific discipline
to formatting your code.
The reason I gave that code as an example is that it's a perfectly normal way of
spreading complex expressions over multiple lines: e.g. where you need to add several
variables together and the variables have non-trivial (i.e. long) names, e.g.
[download]
In this case, the automatic semicolons are unhelpful and will give rise to confusing error
messages. So you've just switched one problem for another, and raised the cognitive load - people
now need to know about your pragma and also know when its in scope.
Yes it discourages certain formatting style. So what ? If you can't live without such
formatting (many can) do not use this pragma. BTW you can always use extra parentheses,
which will be eliminated by the parser as in
* How exactly does the lexer/parser know when it should insert a soft semicolon?
* How exactly does it give a meaningful error message when it inserts one where the user
didn't intend for there to be one?
My problem with your proposal is that it seems to require the parser to apply some
complex heuristics to determine when to insert and when to complain meaningfully. It is not
obvious to me what these heuristics should be. My suspicion is that such an implementation
will just add to perl's already colourful collection of edge cases, and just confuse both
beginner and expert alike.
Bear in mind that I am one of just a handful of people who actively work on perl's lexer
and parser, so I have a good understanding of how it works, and am painfully aware of its
many complexities. (And its quite likely that I would end up being the one implementing
this.)
The lexical analyzer is Perl is quite sophisticated due to lexical complexity of the
language. So I think it already counts past lexems and thus can determine the balance of
"()", '[]' and "{}"
So you probably can initially experiment with the following scheme
If all the following conditions are true
You reached the EOL
Pragma "softsemicolon" is on
The balance is zero
The next symbol via look-ahead buffer is not one of the set "{", "}", ';', and ".",
-- no Perl statement can start with the dot. Probably this set can be extended with
"&&", '||', and "!". Also the last ',' on the current line, and some other
symbols clearly pointing toward extension of the statement on the next line should block
this insertion.
the lexical analyzer needs to insert lexem "semicolon" in the stream of lexem passed to
syntax analyzer.
The warning issued should be something like:
"Attempt to correct missing semicolon was attempted. If this is incorrect please use
extra parenthesis or disable pragma "softsemicolon" for this fragment."
From what I read, Perl syntax analyser relies on lexical analyser in some
unorthodox way, so it might be possible to use "clues" from syntax analyser for improving
this scheme. See, for example, the scheme proposed for recursive descent parsers in:
Follow set error recovery
C Stirling - Software: Practice and Experience, 1985 - Wiley Online Library
Some accounts of the recovery scheme mention and make use of non-systematic changes to
their recursive descent parsers in order to improve In the former he anticipates the possibility of
a missing semicolon whereas in the latter he does not anticipate a missing comma
All of the following satisfy your criteria, are valid and normal Perl code, and would get
a semicolon incorrectly inserted based on your criteria:
use softsemicolon;
$x = $a
+ $b;
$x = 1
if $condition;
$x = 1 unless $condition1
&& $condition2;
Yes in cases 1 and 2; it depends on depth of look-ahead in case 3. Yes if it
is one symbol. No it it is two(no Perl statement can start with && )
As for "valid and normal" your millage may vary. For people who would want to use this
pragma it is definitely not "valid and normal". Both 1 and 2 looks to me like frivolities
without any useful meaning or justification. Moreover, case 1 can be rewritten as:
$x =($a
+ $b);
[download]
The case 3 actually happens in Perl most often with regular if and here opening bracket is
obligatory:
if ( ( $tokenstr=~/a\[s\]/ || $tokenstr =~/h\[s\]/ )
&& ( $tokenstr... ) ){ .... }
[download]
Also Python-inspired fascination with eliminating all brackets does not do here any good
I was surprised that the case without brackets was accepted by the syntax analyser.
Because how would you interpret $x=1 if $a{$b}; without brackets is unclear to me.
It has dual meaning: should be a syntax error in one case
$x=1 if $a{
$b
};
[download]
and the test for an element of hash $a in another.
Both 1 and 2 looks to me like frivolities without any useful meaning or
justification
You and I have vastly differing perceptions of what constitutes normal perl
code. For example there are over 700 examples of the 'postfix if on next line' pattern in
the .pm files distributed with the perl core.
There doesn't really seem any point in discussing this further. You have failed to
convince me, and I am very unlikely to work on this myself or accept such a patch into
core.
You and I have vastly differing perceptions of what constitutes normal perl code. For
example there are over 700 examples of the 'postfix if on next line' pattern in the .pm
files distributed with the perl core.
Probably yes. I am an adherent of "defensive programming" who is against
over-complexity as well as arbitrary formatting (pretty printer is preferable to me to
manual formatting of code). Which in this audience unfortunately means that I am a
minority.
BTW your idea that this pragma (which should be optional) matters for Perl standard
library has no connection to reality.
Joe Venetos ,
history, European Union and politics, int'l relations
Answered Aug 22 2017 · Author has 485 answers and 325k answer views
Neither.
The USSR as it was was not sustainable, and the writing was all over the wall.
The reason it wasn't sustainable, however, is widely misunderstood.
The Soviet Union could have switched to a market or hybrid economy and still remained a
unified state. However, it was made up of 15 very different essentially nation-states from
Estonia to Uzbekistan, and separatist movements were tearing the Union apart.
Unlike other multi-national European empires that met their day earlier in the 20th century,
such as the British, French, Portuguese, Austro-Hungarian, or Ottoman Empires, the Russian
Empi...
The USSR as it was was not sustainable, and the writing was all over the wall.
The reason it wasn't sustainable, however, is widely misunderstood.
The Soviet Union could have switched to a market or hybrid economy and still remained a
unified state. However, it was made up of 15 very different essentially nation-states from
Estonia to Uzbekistan, and separatist movements were tearing the Union apart.
Unlike other multi-national European empires that met their day earlier in the 20th century,
such as the British, French, Portuguese, Austro-Hungarian, or Ottoman Empires, the Russian
Empire never had the chance to disband; the can was simply kicked down the road by the
Bolshevik revolution and the Soviet era. Restrictions on free speech and press, followed by a
gradual economic downturn that began in the 1970s, brewed anti-Union and separatist sentiments
among sizeable sections of society. It's important to note, however, that not everyone wanted
the disband the USSR, and not everyone in the Russian republic wanted to keep it together (the
Central Asian states were the most reluctant to secede). There was, actually, a referendum on
whether or not to keep the Union together, and a slight majority voted in favor (something
Gorbachev points out to this day), but the vote was also boycotted by quite a few people,
especially in the Baltic republics. So, we know that the citizens had mixed feelings and the
reasons for the USSR's end were far more complex than just "communism failed".
By the summer of 1991, there was nothing Gorbachev could do. The hardliners saw him as
incompetent to save the Union, but too many citizens and military personnel had defected to the
politicians of the constituent republics (rather than the Union's leadership), including Russia
itself, that were increasingly pursuing their independence since the first multiparty elections
across the Union in 1989. By December 1991, Union-level political bodies agreed to
disband. So, Gorbachev had no choice but to admit that the USSR no longer existed.
Gorbachev could have ruled with an iron fist, and he could have done so from the 1985
without ever implementing glasnost and perestroika, but that could have been a disaster.
We don't really know, actually, but in my opinion, an oligarchy -which is what the USSR
was in its later years, not an authoritarian state like it was under Stalin- still needs
some level of public consent to continue governing, like China (which is also a diverse
society, but far more homogenous than the USSR was). If you have all this economic and
separatist malaise brewing, it's not going to work out.
In the long run, Russia is much better off. They now have a state where ethnic
Russians make up 80% of the population (a good balance), from what was, I think 50% in the
USSR.
While some Russians regret that the USSR ended, others don't care or were ready to call
themselves "Russian" rather than "Soviet". It's no different to French public opinion turning
against the Algerian war in the 1960s and supporting Algerian independence, or British public
opinion starting to support the independence of India yet some people from those countries, may
look back fondly. Also, Russia went through a tough economic period in the 1990s, which
strengthened Soviet nostalgia, understandably, thinking back to a time when the state
guaranteed everyone with housing and a job. While some sentiments still exist today in
the Russian Federation that may appear pro-Soviet, it's important to point out that that
doesn't necessarily mean these folks would like to recreate the Soviet Union as it
was . Many just simply miss the heaftier influence the USSR had, versus what they perceive
to be weakness or disrespect for Russia today. The communist party today gets few votes in
Russian elections; and many Russians now were not adults prior to 1991, and thus don't quite
remember the era too well; many others may be old enough to remember the economic downturn of
the 80s, and not the economic good times of the 60s.
One final point, regarding Gorbachev being a "stooge of the West": that gives far too
much credit to America under Reagan for taking down the USSR. The "West" had nothing to do with
it. In the longer run, as we may be seeing slowly unravel since the Bush Jr administration,
America pretty much screwed itself with the massive military spending that started in the 80s
and continues upward, with supporting the mujahedeen to lure the USSR into Afghanistan in 1979
(a war that lasted until 1989), with opposing any secular regime in the Middle East
friendly to Moscow in the 70s and 80s, and so on we all know how these events started playing
out for the US much later, from 9/11 to the current Trump mess.
This code was written as a solution to the problem posed in Search for identical substrings . As best I can
tell it runs about 3 million times faster than the original code.
The code reads a series of strings and searches them for the longest substring between any
pair of strings. In the original problem there were 300 strings about 3K long each. A test set
comprising 6 strings was used to test the code with the result given below.
Someone with Perl module creation and publication experience could wrap this up and publish
it if they wish.
use strict;
use warnings;
use Time::HiRes;
use List::Util qw(min max);
my $allLCS = 1;
my $subStrSize = 8; # Determines minimum match length. Should be a power of 2
# and less than half the minimum interesting match length. The larger this value
# the faster the search runs.
if (@ARGV != 1)
{
print "Finds longest matching substring between any pair of test strings\n";
print "the given file. Pairs of lines are expected with the first of a\n";
print "pair being the string name and the second the test string.";
exit (1);
}
# Read in the strings
my @strings;
while ()
{
chomp;
my $strName = $_;
$_ = ;
chomp;
push @strings, [$strName, $_];
}
my $lastStr = @strings - 1;
my @bestMatches = [(0, 0, 0, 0, 0)]; # Best match details
my $longest = 0; # Best match length so far (unexpanded)
my $startTime = [Time::HiRes::gettimeofday ()];
# Do the search
for (0..$lastStr)
{
my $curStr = $_;
my @subStrs;
my $source = $strings[$curStr][1];
my $sourceName = $strings[$curStr][0];
for (my $i = 0; $i 0;
push @localBests, [@test] if $dm >= 0;
$offset = $test[3] + $test[4];
next if $test[4] 0;
push @bestMatches, [@test];
}
continue {++$offset;}
}
next if ! $allLCS;
if (! @localBests)
{
print "Didn't find LCS for $sourceName and $targetName\n";
next;
}
for (@localBests)
{
my @curr = @$_;
printf "%03d:%03d L[%4d] (%4d %4d)\n",
$curr[0], $curr[1], $curr[4], $curr[2], $curr[3];
}
}
}
print "Completed in " . Time::HiRes::tv_interval ($startTime) . "\n";
for (@bestMatches)
{
my @curr = @$_;
printf "Best match: %s - %s. %d characters starting at %d and %d.\n",
$strings[$curr[0]][0], $strings[$curr[1]][0], $curr[4], $curr[2], $curr[3];
}
sub expandMatch
{
my ($index1, $index2, $str1Start, $str2Start, $matchLen) = @_;
my $maxMatch = max (0, min ($str1Start, $subStrSize + 10, $str2Start));
my $matchStr1 = substr ($strings[$index1][1], $str1Start - $maxMatch, $maxMatch);
my $matchStr2 = substr ($strings[$index2][1], $str2Start - $maxMatch, $maxMatch);
($matchStr1 ^ $matchStr2) =~ /\0*$/;
my $adj = $+[0] - $-[0];
$matchLen += $adj;
$str1Start -= $adj;
$str2Start -= $adj;
return ($index1, $index2, $str1Start, $str2Start, $matchLen);
}
Joshua Day ,
Currently developing reporting and testing tools for linux
Updated Apr 26 · Author has 83 answers and 71k answer views
There are several reasons and ill try to name a few.
Perl syntax and semantics closely resembles shell languages that are part of core Unix
systems like sed, awk, and bash. Of these languages at least bash knowledge is required to
administer a Unix system anyway.
Perl was designed to replace or improve the shell languages in Unix/linux by combining
all their best features into a single language whereby an administrator can write a complex
script with a single language instead of 3 languages. It was essentially designed for
Unix/linux system administration.
Perl regular expressions (text manipulation) were modeled off of sed and then drastically
improved upon to the extent that subsequent languages like python have borrowed the syntax
because of just how powerful it is. This is infinitely powerful on a unix system because the
entire OS is controlled using textual data and files. No other language ever devised has
implemented regular expressions as gracefully as perl and that includes the beloved python.
Only in perl is regex integrated with such natural syntax.
Perl typically comes preinstalled on Unix and linux systems and is practically considered
part of the collection of softwares that define such a system.
Thousands of apps written for Unix and linux utilize the unique properties of this
language to accomplish any number of tasks. A Unix/linux sysadmin must be somewhat familiar
with perl to be effective at all. To remove the language would take considerable effort for
most systems to the extent that it's not practical.. Therefore with regard to this
environment Perl will remain for years to come.
Perl's module archive called CPAN already contains a massive quantity of modules geared
directly for unix systems. If you use Perl for your administration tasks you can capitalize
on these modules. These are not newly written and untested modules. These libraries have been
controlling Unix systems for 20 years reliably and the pinnacle of stability in Unix systems
running across the world.
Perl is particularly good at glueing other software together. It can take the output of
one application and manipulate it into a format that is easily consumable by another, mostly
due to its simplistic text manipulation syntax. This has made Perl the number 1 glue language
in the world. There are millions of softwares around the world that are talking to each other
even though they were not designed to do so. This is in large part because of Perl. This
particular niche will probably decline as standardization of interchange formats and APIs
improves but it will never go away.
I hope this helps you understand why perl is so prominent for Unix administrators. These
features may not seem so obviously valuable on windows systems and the like. However on Unix
systems this language comes alive like no other.
Daniel
Korenblum , works at Bayes Impact
Updated May 25, 2015 There are many reasons why non-OOP languages and paradigms/practices
are on the rise, contributing to the relative decline of OOP.
First off, there are a few things about OOP that many people don't like, which makes them
interested in learning and using other approaches. Below are some references from the OOP wiki
article:
One of the comments therein linked a few other good wikipedia articles which also provide
relevant discussion on increasingly-popular alternatives to OOP:
Modularity and design-by-contract are better implemented by module systems ( Standard ML
)
Personally, I sometimes think that OOP is a bit like an antique car. Sure, it has a bigger
engine and fins and lots of chrome etc., it's fun to drive around, and it does look pretty. It
is good for some applications, all kidding aside. The real question is not whether it's useful
or not, but for how many projects?
When I'm done building an OOP application, it's like a large and elaborate structure.
Changing the way objects are connected and organized can be hard, and the design choices of the
past tend to become "frozen" or locked in place for all future times. Is this the best choice
for every application? Probably not.
If you want to drive 500-5000 miles a week in a car that you can fix yourself without
special ordering any parts, it's probably better to go with a Honda or something more easily
adaptable than an antique vehicle-with-fins.
Finally, the best example is the growth of JavaScript as a language (officially called
EcmaScript now?). Although JavaScript/EcmaScript (JS/ES) is not a pure functional programming
language, it is much more "functional" than "OOP" in its design. JS/ES was the first mainstream
language to promote the use of functional programming concepts such as higher-order functions,
currying, and monads.
The recent growth of the JS/ES open-source community has not only been impressive in its
extent but also unexpected from the standpoint of many established programmers. This is partly
evidenced by the overwhelming number of active repositories on Github using
JavaScript/EcmaScript:
Because JS/ES treats both functions and objects as structs/hashes, it encourages us to blur
the line dividing them in our minds. This is a division that many other languages impose -
"there are functions and there are objects/variables, and they are different".
This seemingly minor (and often confusing) design choice enables a lot of flexibility and
power. In part this seemingly tiny detail has enabled JS/ES to achieve its meteoric growth
between 2005-2015.
This partially explains the rise of JS/ES and the corresponding relative decline of OOP. OOP
had become a "standard" or "fixed" way of doing things for a while, and there will probably
always be a time and place for OOP. But as programmers we should avoid getting too stuck in one
way of thinking / doing things, because different applications may require different
approaches.
Above and beyond the OOP-vs-non-OOP debate, one of our main goals as engineers should be
custom-tailoring our designs by skillfully choosing the most appropriate programming
paradigm(s) for each distinct type of application, in order to maximize the "bang for the buck"
that our software provides.
Although this is something most engineers can agree on, we still have a long way to go until
we reach some sort of consensus about how best to teach and hone these skills. This is not only
a challenge for us as programmers today, but also a huge opportunity for the next generation of
educators to create better guidelines and best practices than the current OOP-centric
pedagogical system.
Here are a couple of good books that elaborates on these ideas and techniques in more
detail. They are free-to-read online:
Mike MacHenry ,
software engineer, improv comedian, maker Answered
Feb 14, 2015 · Author has 286 answers and 513.7k answer views Because the phrase
itself was over hyped to an extrodinary degree. Then as is common with over hyped things many
other things took on that phrase as a name. Then people got confused and stopped calling what
they are don't OOP.
Yes I think OOP ( the phrase ) is on the decline because people are becoming more educated
about the topic.
It's like, artificial intelligence, now that I think about it. There aren't many people
these days that say they do AI to anyone but the laymen. They would say they do machine
learning or natural language processing or something else. These are fields that the vastly
over hyped and really nebulous term AI used to describe but then AI ( the term ) experienced a
sharp decline while these very concrete fields continued to flourish.
"... Per Damien Conway’s recommendations, I always unpack all the arguments from @_in the first line of a subroutine, which ends up looking just like a subroutine signature. (I almost never use shift for this purpose.) ..."
"... Perl bashing is largely hear-say. People hear something and they say it. It doesn't require a great deal of thought. ..."
"... It may not be as common as the usual gang of languages, but there's an enormous amount of work done in Perl. ..."
Perl bashing is popular sport among a particularly vocal crowd.
Perl is extremely flexible. Perl holds up TIMTOWTDI ( There Is More Than One
Way To Do It ) as a virtue. Larry Wall's Twitter handle is @TimToady, for goodness sake!
That flexibility makes it extremely powerful. It also makes it extremely easy to write
code that nobody else can understand. (Hence, Tim Toady
Bicarbonate.)
You can pack a lot of punch in a one-liner in Perl:
It is still used, but its usage is declining. People use Python today in situations when
they would have used Perl ten years ago.
The problem is that Perl is extremely pragmatic. It is designed to be “a language to
get your job done”, and it does that well; however, that led to rejection by language
formalists. However, Perl is very well designed, only it is well designed for professionals
who grab in the dark expecting that at this place there should be a button to do the desired
functionality, and indeed, there will be the button. It is much safer to use than for example
C (the sharp knife that was delivered without a handle), but it is easy to produce quite
messy code with it if you are a newbie who doesn’t understand/feel the principles of
Perl. In the 90s and 2000s, it was the goto web language, so the web was full of terrible
programs written by those newbies, and that led to the bad reputation.
Strangely enough, PHP, which is frowned upon a lot by Perl programmers, won the favour of
the noobs, but never got the general bad reputation; in fact it is missing the design
principles I mentioned, that language is just a product of adhockery.
But today, Perl went back to its status as a niche language, and you cannot mention it in
presence of a lady, so to speak. Its support is slowly waning; I’d suggest to learn
Python, but don’t force me to learn it as well.
You should learn things that make your life easier or better. I am not an excellent Perl
user, but it is usually my go-to scripting language for important projects. The syntax is
difficult, and it's very easy to forget how to use it when you take significant time away
from it.
That being said, I love how regular expressions work in Perl. I can use sed like commands
$myvar =~ s/old/new/g for string replacement when processing or filtering strings. It's much
nicer than other languages imo.
I also like Perls foreach loops and its data structures.
I tried writing a program of moderate length in Python and it just seemed to be taking up
too much space. I stopped part way though and switched to Perl. I got the whole thing
completed in much less space (lines), and seemed to have an easier time doing it.
I am not a super fanboy, but it has just always worked for me in the past, and I can't
outright discount it because of that.
Also, look up CPAN modules. The installation of those for me on GNU is a breeze.
My last scripting project I did in Python and it went very well. I will probably shift to
Python more in the future, because I would like to build a stronger basis of knowledge with
the modules and basics of Python so that I can hop into it and create some powerful stuff
when needed. Ie I want to focus on 1–3 languages, and learn them to a higher level
instead of being "just ok" with 5–7.
Gary
Puckering , Fluent in C#, Python, and perl; rusty in C/C++ and too many others to count
Answered Apr 25, 2018 · Author has 1.1k answers and 2.5m answer views
Why is Perl so hated and not commonly used?
I think there are several reasons why Perl has a lot of detractors
Sigils . A lot of programmers seem to hate the $@% sigils! If you are coming
from a strongly typed language like C/C++, and also hate things like Hungarian notation,
you won’t like sigils.
One liners. As others have commented, writing dense and even obfuscated code
rose to the level of sport within the Perl community. The same thing happened, years
earlier, in the APL community. Programmers and managers saw that you could write
unmaintainable code, and that helped instill a fear that it was unavoidable and that
perhaps the language was flawed because it didn’t discourage the practice.
Auto-magic . The programming language PL/I, which attempted to combine the best
of COBOL and FORTRAN, went absolutely crazy with default behaviors. I remember reading an
article in the 1970’s where programming in PL/I was described as being like flying a
Boeing 747. The cockpit is filled with hundreds of buttons, knobs, switches and levers. The
autopilot does most of the work, but trying to figure out the interaction between it and
things you manually set can be bewildering. Perl, to some extent, suffers from the same
problem. In Perl 5, without enabling warnings and strict, variables spring into life simply
by naming them. A typo can instantiate and entirely new variable. Hashes get new keys
simply by an attempt to access a key. You can increment a scalar that contains a string and
it’ll try to generate a sequence using the string as a pattern (e.g. a, b, c …
z, aa, ab …). If you come from a language where you control everything, all this
auto-magic stuff can really bite you in the ass.
An odd object-oriented syntax. Until Moose (and now Moo and Mouse) came along,
writing classes in Perl meant using keywords like package and bless, as well as rolling all
your own accessor methods. If you come from C++, Java , Python or just about any
other language supporting OO your first question is going to be: where’s the
friggin’ class statement!
Dynamic typing . Some people like it. Some hate it. There are modules that let
you add typing I’d you wish, though it’ll only be enforced at run time.
No subroutine signatures . Although Perl 5 now supports subroutine signatures,
they are still considered “experimental”. This is a turn-off for most
programmers who are used to them. Per Damien Conway’s recommendations, I always
unpack all the arguments from @_in the first line of a subroutine, which ends up looking
just like a subroutine signature. (I almost never use shift for this purpose.)
Lots of magic symbols . Although you can use English names, and should do so for
more maintainable code, many Perl programmers stick to using special names like $_,
$’, $; etc. This makes Perl code look very cryptic, and increases your cognitive load
when working with the language. It’s a lot to remember. But if you use the English
names, you can largely avoid this issue.
Perl 6 is a discontinuous evolution . Although Perl 5 continues to evolve, and
some of the advances that have been put in Perl 6 have been added to Perl 5, the lack
of,upward compatibility between 5 and 6 creates uncertainly about its future.
And why should I learn it?
Despite the above, you can write maintainable code in Perl by following Damian
Comways’s Perl Best Practices. The utility perlcritic can be used to help train
yourself to write better Perl code.
Perl is multi-paradigm. In execution, it’s faster than Python. It has a superb
ecosystem in cpan , where you can find a module to help you solve almost every
imaginable problem. For command line utilities, file system administration, database
administration, data extraction-transformation-loading tasks, batch processes, connecting
disparate systems, and quick and dirty scripts, it’s often the best tool for the
job.
I frequently use Perl in connection with Excel. You can do a lot in Excel, and it provides
a great interactive UI. But complex formulas can be a pain to get right, and it can be
tedious to write code in VBA. Often, I find it much quicker to just copy cells to the
clipboard, switch to a command shell, run a Perl script over the data, sending the results to
the clipboard, switch back to Excel, and then paste the results in situ or in a new
location.
Perl is also deep. It does a good job of supporting imperative programming, OOP, and
functional programming. For more on the latter, see the book Higher-Order Perl .
Perl is powerful. Perl is fast. Perl is an effective tool to have in your toolkit. Those
are all good reasons to learn it.
Reed White , former
Engineer at Hewlett-Packard (1978-2000)
Answered Nov 7, 2017 · Author has 2.3k answers and 380.8k answer views
Yes, Perl takes verbal abuse; but in truth, it is an extremely powerful, reliable
language. In my opinion, one of its outstanding characteristics is that you don't need much
knowledge before you can write useful programs. As time goes by, you gradually learn the real
power of the language.
However, because Perl-bashing is popular, you might better put your efforts into learning
Python, which is also quite capable.
Richard Conto ,
Programmer in multiple languages. Debugger in even more
Answered Dec 18, 2017 · Author has 5.9k answers and 4.3m answer views
Perl bashing is largely hear-say. People hear something and they say it. It doesn't
require a great deal of thought.
As for Perl not commonly being used - that's BS. It may not be as common as the usual
gang of languages, but there's an enormous amount of work done in Perl.
As for you you should learn Perl, it's for the same reason you would learn any other
language - it helps you solve a particular problem better than another language available.
And yes, that can be a very subjective decision to make.
The truth is, that by any metric, more Perl is being done today than during the dot com
boom. It's just a somewhat smaller piece of a much bigger pie. In fact, I've heard from some
hiring managers that there's actually a shortage of Perl programmers, and not just for
maintaining projects, but for new greenfield deploys.
For web workflows check out
QuantifiedCode
. It's a data-driven code quality
platform we've built to automate code reviews. It offers you
static analysis as a service--for free.
I use pyflakes for code
checking inside Vim and find it very useful. But still, pylint is
better for pre-commit code checking. You should have two levels of
code checking: errors that cannot be commited and warnings that
are code-smells but can be commited. You can configure that and
many other things with pylint.
Sometime you might think pylint is too picky: it may complain for
something that you think is perfectly ok. Think twice about it.
Very often, I found that the warning I found overly conservative
some month ago was actually a very good advice.
So my answer is that pylint is reliable and robust, and I am not aware of a much better code analyzer.
Spending time
in the static analysis will really(really) advantage you and your
group as far as time spending on discovering bugs, as far as
disclosing the code to extend newcomers, regarding undertaking
costs and so on. On the off chance that you invest the energy
doing it forthrightly, it might appear as though you're not
chipping away at highlights but rather it will return to you later
on you will profit by this sooner or later.
There are a
couple of interesting points on our voyage for brilliant code. In
the first place, this adventure isn't one of unadulterated
objectivity. There are some solid sentiments of what top-notch
code resembles.
While everybody
can ideally concede to the identifiers referenced over, the manner
in which they get accomplished is an emotional street. The most
obstinate themes generally come up when you talk about
accomplishing intelligibility, upkeep, and extensibility.
And if you're
using Python 3.6+, you can add typing hints to your code and run
mypy
, a static typechecker over your code.
(Technically, mypy
will work with Python 2 code as well,
but given that typing hints weren't added to Python until 3.5, you
have to put the typing hints in comments which is a bit cumbersome
and hard to maintain.)
For web workflows check out
QuantifiedCode
. It's a data-driven code quality
platform we've built to automate code reviews. It offers you
static analysis as a service--for free.
I use pyflakes for code
checking inside Vim and find it very useful. But still, pylint is
better for pre-commit code checking. You should have two levels of
code checking: errors that cannot be commited and warnings that
are code-smells but can be commited. You can configure that and
many other things with pylint.
Sometime you might think pylint is too picky: it may complain for
something that you think is perfectly ok. Think twice about it.
Very often, I found that the warning I found overly conservative
some month ago was actually a very good advice.
So my answer is that pylint is reliable and robust, and I am not aware of a much better code analyzer.
Spending time
in the static analysis will really(really) advantage you and your
group as far as time spending on discovering bugs, as far as
disclosing the code to extend newcomers, regarding undertaking
costs and so on. On the off chance that you invest the energy
doing it forthrightly, it might appear as though you're not
chipping away at highlights but rather it will return to you later
on you will profit by this sooner or later.
There are a
couple of interesting points on our voyage for brilliant code. In
the first place, this adventure isn't one of unadulterated
objectivity. There are some solid sentiments of what top-notch
code resembles.
While everybody
can ideally concede to the identifiers referenced over, the manner
in which they get accomplished is an emotional street. The most
obstinate themes generally come up when you talk about
accomplishing intelligibility, upkeep, and extensibility.
And if you're
using Python 3.6+, you can add typing hints to your code and run
mypy
, a static typechecker over your code.
(Technically, mypy
will work with Python 2 code as well,
but given that typing hints weren't added to Python until 3.5, you
have to put the typing hints in comments which is a bit cumbersome
and hard to maintain.)
Hey I've been using Linux for a while and thought it was time to finally dive into shell
scripting.
The problem is I've failed to find any significant advantage of using Bash over something
like Perl or Python. Are there any performance or power differences between the two? I'd
figure Python/Perl would be more well suited as far as power and efficiency goes.
Simplicity: direct access to all wonderful linux tools wc ,
ls , cat , grep , sed ... etc. Why
constantly use python's subprocess module?
I'm increasingly fond of using gnu parallel , with which you can
execute your bash scripts in parallel. E.g. from the man page, batch create thumbs of all
jpgs in directory in parallel:
ls *.jpg | parallel convert -geometry 120 {} thumb_{}
By the way, I usually have some python calls in my bash scripts (e.g. for plotting). Use
whatever is best for the task!
bash isn't a language so much as a command interpreter that's been hacked to death to allow
for things that make it look like a scripting language. It's great for the simplest 1-5 line
one-off tasks, but things that are dead simple in Perl or Python like array manipulation are
horribly ugly in bash. I also find that bash tends not to pass two critical rules of thumb:
The 6-month rule, which says you should be able to easily discern the purpose and basic
mechanics of a script you wrote but haven't looked at in 6 months.
The 'WTF per minute' rule. Everyone has their limit, and mine is pretty small. Once I
get to 3 WTFs/min, I'm looking elsewhere.
As for 'shelling out' in scripting languages like Perl and Python, I find that I almost
never need to do this, fwiw (disclaimer: I code almost 100% in Python). The Python os and
shutil modules have most of what I need most of the time, and there are built-in modules for
handling tarfiles, gzip files, zip files, etc. There's a glob module, an fnmatch module...
there's a lot of stuff there. If you come across something you need to parallelize, then
indent your code a level, put it in a 'run()' method, put that in a class that extends either
threading.Thread or multiprocessing.Process, instantiate as many of those as you want,
calling 'start()' on each one. Less than 5 minutes to get parallel execution generally.
There are a few things you can only do in bash (for example, alter the calling environment
(when a script is sourced rather than run). Also, shell scripting is commonplace. It is
worthwhile to learn the basics and learn your way around the available docs.
Plus there are times when knowing a shell well can save your bacon (on a fork-bombed
system where you can't start any new processes, or if /usr/bin and or
/usr/local/bin fail to mount).
The advantage is that it's right there. Unless you use Python (or Perl) as your shell,
writing a script to do a simple loop is a bunch of extra work.
For short, simple scripts that call other programs, I'll use Bash. If I want to keep the
output, odds are good that I'll trade up to Python.
For example:
for file in *; do process $file ; done
where process is a program I want to run on each file, or...
while true; do program_with_a_tendency_to_fail ; done
Doing either of those in Python or Perl is overkill.
For actually writing a program that I expect to maintain and use over time, Bash is rarely
the right tool for the job. Particularly since most modern Unices come with both Perl and
Python.
The most important advantage of POSIX shell scripts over Python or Perl scripts is that a
POSIX shell is available on virtually every Unix machine. (There are also a few tasks shell
scripts happen to be slightly more convenient for, but that's not a major issue.) If the
portability is not an issue for you, I don't see much need to learn shell scripting.
If you want to execute programs installed on the machine, nothing beats bash. You can always
make a system call from Perl or Python, but I find it to be a hassle to read return values,
etc.
And since you know it will work pretty much anywhere throughout all of of time...
The advantage of shell scripting is that it's globally present on *ix boxes, and has a
relatively stable core set of features you can rely on to run everywhere. With Perl and
Python you have to worry about whether they're available and if so what version, as there
have been significant syntactical incompatibilities throughout their lifespans. (Especially
if you include Python 3 and Perl 6.)
The disadvantage of shell scripting is everything else. Shell scripting languages are
typically lacking in expressiveness, functionality and performance. And hacking command lines
together from strings in a language without strong string processing features and libraries,
to ensure the escaping is correct, invites security problems. Unless there's a compelling
compatibility reason you need to go with shell, I would personally plump for a scripting
language every time.
"... Perl has native regular expression support, ..."
"... Perl has quite a few more operators , including matching ..."
"... In PHP, new is an operator. In Perl, it's the conventional name of an object creation subroutine defined in packages, nothing special as far as the language is concerned. ..."
"... Perl logical operators return their arguments, while they return booleans in PHP. ..."
"... Perl gives access to the symbol table ..."
"... Note that "references" has a different meaning in PHP and Perl. In PHP, references are symbol table aliases. In Perl, references are smart pointers. ..."
"... Perl has different types for integer-indexed collections (arrays) and string indexed collections (hashes). In PHP, they're the same type: an associative array/ordered map ..."
"... Perl arrays aren't sparse ..."
"... Perl supports hash and array slices natively, ..."
Perl and PHP are more different than alike. Let's consider Perl 5, since Perl 6 is still under development. Some differences,
grouped roughly by subject:
Perl has native regular expression support, including regexp literals. PHP uses Perl's regexp functions as an
extension.
In PHP, new is an operator. In Perl, it's the conventional
name of an object creation
subroutine defined in packages, nothing special as far as the language is concerned.
Perl logical operators return their arguments, while they
return booleans in PHP. Try:
$foo = '' || 'bar';
in each language. In Perl, you can even do $foo ||= 'default' to set $foo to a value if it's not already set.
The shortest way of doing this in PHP is $foo = isset($foo) ? $foo : 'default'; (Update, in PHP 7.0+ you can do
$foo = $foo ?? 'default' )
Perl variable names indicate built-in
type, of which Perl has three, and the type specifier is part of the name (called a "
sigil "), so $foo is a
different variable than @foo or %foo . (related to the previous point) Perl has separate
symbol table entries
for scalars, arrays, hashes, code, file/directory handles and formats. Each has its own namespace.
Perl gives access to the symbol table
, though manipulating it isn't for the faint of heart. In PHP, symbol table manipulation is limited to creating
references and the extract function.
Note that "references" has a different meaning in PHP and Perl. In PHP,
references are symbol table aliases. In Perl,
references are smart pointers.
Perl has different types for integer-indexed collections (arrays) and string indexed collections (hashes). In PHP,
they're the same type: an associative array/ordered map.
Perl arrays aren't sparse: setting an element with index larger than the current size of the array will set all
intervening elements to undefined (see perldata
). PHP arrays are sparse; setting an element won't set intervening elements.
Perl supports hash and array slices natively,
and slices are assignable, which has all sorts of
uses . In PHP, you use array_slice to extract a slice
and array_splice to assign to a slice.
In addition, Perl has global, lexical (block), and package
scope . PHP has global, function, object,
class and namespace scope .
In Perl, variables are global by default. In PHP, variables in functions are local by default.
Perl supports explicit tail calls via the
goto function.
Perl's prototypes provide more limited type
checking for function arguments than PHP's
type hinting . As a result, prototypes are of more limited utility than type hinting.
In Perl, the last evaluated statement is returned as the value of a subroutine if the statement is an expression (i.e.
it has a value), even if a return statement isn't used. If the last statement isn't an expression (i.e. doesn't have a value),
such as a loop, the return value is unspecified (see perlsub
). In PHP, if there's no explicit return, the
return value is NULL .
Perl flattens lists (see perlsub ); for un-flattened
data structures, use references.
@foo = qw(bar baz);
@qux = ('qux', @foo, 'quux'); # @qux is an array containing 4 strings
@bam = ('bug-AWWK!', \@foo, 'fum'); # @bam contains 3 elements: two strings and a array ref
PHP doesn't flatten arrays.
Perl has special
code blocks ( BEGIN , UNITCHECK , CHECK , INIT and END
) that are executed. Unlike PHP's auto_prepend_file and
auto_append_file
, there is no limit to the number of each type of code block. Also, the code blocks are defined within the scripts, whereas
the PHP options are set in the server and per-directory config files.
In Perl, the semicolon separates statements
. In PHP, it terminates
them, excepting that a PHP close tag ("?>") can also terminate a statement.
Negative subscripts in Perl are relative to the end of the array. $bam[-1] is the final element of the array.
Negative subscripts in PHP are subscripts like any other.
In Perl 5, classes are based on packages and look nothing like classes in PHP (or most other languages). Perl 6 classes
are closer to PHP classes, but still quite different. (Perl 6 is
different from Perl 5 in many other ways, but that's
off topic.) Many of the differences between Perl 5 and PHP arise from the fact that most of the OO features are not built-in
to Perl but based on hacks. For example, $obj->method(@args) gets translated to something like (ref $obj)::method($obj,
@args) . Non-exhaustive list:
PHP automatically provides the special variable $this in methods. Perl passes a reference to the object
as the first argument to methods.
Perl requires references to be blessed to
create an object. Any reference can be blessed as an instance of a given class.
In Perl, you can dynamically change inheritance via the packages @ISA variable.
Strictly speaking, Perl doesn't have multiline comments, but the
POD system can be used for the same affect.
In Perl, // is an operator. In PHP, it's the start of a one-line comment.
Until PHP 5.3, PHP had terrible support for anonymous functions (the create_function function) and no support
for closures.
PHP had nothing like Perl's packages until version 5.3, which introduced
namespaces .
Arguably, Perl's built-in support for exceptions looks almost nothing like exceptions in other languages, so much so that
they scarcely seem like exceptions. You evaluate a block and check the value of $@ ( eval instead
of try , die instead of
throw ). The ErrorTry::Tiny module supports exceptions as you find them in other languages
(as well as some other modules listed in Error's See Also
section).
PHP was inspired by Perl the same way Phantom of the Paradise was inspired by Phantom of the Opera , or Strange
Brew was inspired by Hamlet . It's best to put the behavior specifics of PHP out of your mind when learning Perl, else
you'll get tripped up.
I've noticed that most PHP vs. Perl pages seem to be of the
PHP is better than Perl because <insert lame reason here>
ilk, and rarely make reasonable comparisons.
Syntax-wise, you will find PHP is often easier to understand than Perl, particularly when you have little experience. For example,
trimming a string of leading and trailing whitespace in PHP is simply
$string = trim($string);
In Perl it is the somewhat more cryptic
$string =~ s/^\s+//;
$string =~ s/\s+$//;
(I believe this is slightly more efficient than a single line capture and replace, and also a little more understandable.)
However, even though PHP is often more English-like, it sometimes still shows its roots as a wrapper for low level C, for example,
strpbrk and strspn are probably rarely used, because most PHP dabblers write their own equivalent functions
for anything too esoteric, rather than spending time exploring the manual. I also wonder about programmers for whom English is
a second language, as everybody is on equal footing with things such as Perl, having to learn it from scratch.
I have already mentioned the manual. PHP has a fine online manual, and unfortunately it needs it. I still refer to it from
time to time for things that should be simple, such as order of parameters or function naming convention. With Perl, you will
probably find you are referring to the manual a lot as you get started and then one day you will have an a-ha moment and
never need it again. Well, at least not until you're more advanced and realize that not only is there more than one way, there
is probably a better way, somebody else has probably already done it that better way, and perhaps you should just visit CPAN.
Perl does have a lot more options and ways to express things. This is not necessarily a good thing, although it allows code
to be more readable if used wisely and at least one of the ways you are likely to be familiar with. There are certain styles and
idioms that you will find yourself falling into, and I can heartily recommend reading
Perl Best Practices (sooner rather than
later), along with Perl Cookbook, Second Edition
to get up to speed on solving common problems.
I believe the reason Perl is used less often in shared hosting environments is that historically the perceived slowness of
CGI and hosts' unwillingness to install mod_perl due to security
and configuration issues has made PHP a more attractive option. The cycle then continued, more people learned to use PHP because
more hosts offered it, and more hosts offered it because that's what people wanted to use. The speed differences and security
issues are rendered moot by FastCGI these days, and in most
cases PHP is run out of FastCGI as well, rather than leaving it in the core of the web server.
Whether or not this is the case or there are other reasons, PHP became popular and a myriad of applications have been written
in it. For the majority of people who just want an entry-level website with a simple blog or photo gallery, PHP is all they need
so that's what the hosts promote. There should be nothing stopping you from using Perl (or anything else you choose) if you want.
At an enterprise level, I doubt you would find too much PHP in production (and please, no-one point at Facebook as a
counter-example, I said enterprise level).
Perl is used plenty for websites, no less than Python and Ruby for example. That said, PHP is used way more often than any of
those. I think the most important factors in that are PHP's ease of deployment and the ease to start with it.
The differences in syntax are too many to sum up here, but generally it is true that it has more ways to express yourself (this
is know as TIMTWOTDI, There Is More Than One Way To Do It).
My favorite thing about Perl is the way it handles arrays/lists. Here's an example of how you would make and use a Perl function
(or "subroutine"), which makes use of this for arguments:
sub multiply
{
my ($arg1, $arg2) = @_; # @_ is the array of arguments
return $arg1 * $arg2;
}
In PHP you could do a similar thing with list() , but it's not quite the same; in Perl lists and arrays are actually
treated the same (usually). You can also do things like:
And another difference that you MUST know about, is numerical/string comparison operators. In Perl, if you use <
, > , == , != , <=> , and so on, Perl converts both operands to numbers. If
you want to convert as strings instead, you have to use lt , gt , eq , ne
, cmp (the respective equivalents of the operators listed previously). Examples where this will really get you:
if ("a" == "b") { ... } # This is true.
if ("a" == 0) { ... } # This is also true, for the same reason.
Radu Grigore ,
argued rigor
Answered Apr 22 2012 I think some of the main original contributions to Computer Science
are the following:
Knuth-Bendix algorithm/orders, used in all modern theorem provers, such as Z3 and
Vampire, which in turn are used by many program analysis tools. The article is Simple Word
Problems in Universal Algebras .
Knuth-Moris-Pratt string searching (already mentioned). The article is Fast Pattern
Matching in Strings .
LR(k) grammars, which lay the foundation for parser generators (think yacc and
successors). The article is On the Translation of Languages from Left to Right .
Attribute grammars, a way to define the semantics of a (simple) programming language that
pops up in research every now and then. For example, they were used in the study of VLSI
circuits. The article is Semantics of Context-Free Languages .
I believe he was the first to profile programs. The article is An Empirical Study of
FORTRAN Programs .
He also did some work in mathematics. If I remember correctly, I saw him in a video saying
that the article he is most proud of is The Birth of the Giant Component . Mark VandeWettering , I
have a lab coat, trust me!
Answered Jan 10, 2014 · Author has 7.2k answers and 23.3m answer views Knuth won the
Turing Award in 1974 for his contributions to the analysis of algorithms I'd submit that his
"expository" work in the form of The Art of Programming go well beyond simple exposition, and
brought a rigor and precision to the analysis of algorithms which was (and probably still is)
unparalleled in term of thoroughness and scope. There is more knowledge in the margins of The
Art of Programming than there is in most programming courses. 1.2k views ·
View 7 Upvoters Eugene Miya ,
Ex-Journal Editor, parallelism DB, committees and conferences, etc.
Answered Sep 9, 2014 · Author has 11.2k answers and 7.9m answer views Everyone cites
and overcites TAOCP.
is it possible to import ( use ) a perl module within a different namespace?
Let's say I have a Module A (XS Module with no methods Exported
@EXPORT is empty) and I have no way of changing the module.
This Module has a Method A::open
currently I can use that Module in my main program (package main) by calling
A::open I would like to have that module inside my package main so
that I can directly call open
I tried to manually push every key of %A:: into %main:: however
that did not work as expected.
The only way that I know to achieve what I want is by using package A; inside
my main program, effectively changing the package of my program from main to
A . Im not satisfied with this. I would really like to keep my program inside
package main.
Is there any way to achieve this and still keep my program in package main?
Offtopic: Yes I know usually you would not want to import everything into your
namespace but this module is used by us extensively and we don't want to type A:: (well the
actual module name is way longer which isn't making the situation better)in front of hundreds
or thousands of calls
This is one of those "impossible" situations, where the clear solution -- to rework that
module -- is off limits.
But, you can alias that package's subs names, from its symbol table, to the same
names in main . Worse than being rude, this comes with a glitch: it catches all
names that that package itself imported in any way. However, since this package is a fixed
quantity it stands to reason that you can establish that list (and even hard-code it). It is
just this one time, right?
main
use warnings;
use strict;
use feature 'say';
use OffLimits;
GET_SUBS: {
# The list of names to be excluded
my $re_exclude = qr/^(?:BEGIN|import)$/; # ...
my @subs = grep { !/$re_exclude/ } sort keys %OffLimits::;
no strict 'refs';
for my $sub_name (@subs) {
*{ $sub_name } = \&{ 'OffLimits::' . $sub_name };
}
};
my $name = name('name() called from ' . __PACKAGE__);
my $id = id('id() called from ' . __PACKAGE__);
say "name() returned: $name";
say "id() returned: $id";
with OffLimits.pm
package OffLimits;
use warnings;
use strict;
sub name { return "In " . __PACKAGE__ . ": @_" }
sub id { return "In " . __PACKAGE__ . ": @_" }
1;
It prints
name() returned: In OffLimits: name() called from main
id() returned: In OffLimits: id() called from main
You may need that code in a BEGIN block, depending on other details.
Another option is of course to hard-code the subs to be "exported" (in @subs
). Given that the module is in practice immutable this option is reasonable and more
reliable.
This can also be wrapped in a module, so that you have the normal, selective,
importing.
WrapOffLimits.pm
package WrapOffLimits;
use warnings;
use strict;
use OffLimits;
use Exporter qw(import);
our @sub_names;
our @EXPORT_OK = @sub_names;
our %EXPORT_TAGS = (all => \@sub_names);
BEGIN {
# Or supply a hard-coded list of all module's subs in @sub_names
my $re_exclude = qr/^(?:BEGIN|import)$/; # ...
@sub_names = grep { !/$re_exclude/ } sort keys %OffLimits::;
no strict 'refs';
for my $sub_name (@sub_names) {
*{ $sub_name } = \&{ 'OffLimits::' . $sub_name };
}
};
1;
and now in the caller you can import either only some subs
use WrapOffLimits qw(name);
or all
use WrapOffLimits qw(:all);
with otherwise the same main as above for a test.
The module name is hard-coded, which should be OK as this is meant only for that
module.
The following is added mostly for completeness.
One can pass the module name to the wrapper by writing one's own import sub,
which is what gets used then. The import list can be passed as well, at the expense of an
awkward interface of the use statement.
It goes along the lines of
package WrapModule;
use warnings;
use strict;
use OffLimits;
use Exporter qw(); # will need our own import
our ($mod_name, @sub_names);
our @EXPORT_OK = @sub_names;
our %EXPORT_TAGS = (all => \@sub_names);
sub import {
my $mod_name = splice @_, 1, 1; # remove mod name from @_ for goto
my $re_exclude = qr/^(?:BEGIN|import)$/; # etc
no strict 'refs';
@sub_names = grep { !/$re_exclude/ } sort keys %{ $mod_name . '::'};
for my $sub_name (@sub_names) {
*{ $sub_name } = \&{ $mod_name . '::' . $sub_name };
}
push @EXPORT_OK, @sub_names;
goto &Exporter::import;
}
1;
what can be used as
use WrapModule qw(OffLimits name id); # or (OffLimits :all)
or, with the list broken-up so to remind the user of the unusual interface
use WrapModule 'OffLimits', qw(name id);
When used with the main above this prints the same output.
The use statement ends up using the import sub defined in the module, which
exports symbols by writing to the caller's symbol table. (If no import sub is
written then the Exporter 's import method is nicely used, which is
how this is normally done.)
This way we are able to unpack the arguments and have the module name supplied at
use invocation. With the import list supplied as well now we have to
push manually to @EXPORT_OK since this can't be in the
BEGIN phase. In the end the sub is replaced by Exporter::import via
the (good form of) goto , to complete the job.
You can forcibly "import" a function into main using glob assignment to alias the subroutine
(and you want to do it in BEGIN so it happens at compile time, before calls to that
subroutine are parsed later in the file):
use strict;
use warnings;
use Other::Module;
BEGIN { *open = \&Other::Module::open }
However, another problem you might have here is that open is a builtin function, which may
cause some problems . You can add
use subs 'open'; to indicate that you want to override the built-in function in
this case, since you aren't using an actual import function to do so.
Here is what I now came up with. Yes this is hacky and yes I also feel like I opened pandoras
box with this. However at least a small dummy program ran perfectly fine.
I renamed the module in my code again. In my original post I used the example
A::open actually this module does not contain any method/variable reserved by
the perl core. This is why I blindly import everything here.
BEGIN {
# using the caller to determine the parent. Usually this is main but maybe we want it somewhere else in some cases
my ($parent_package) = caller;
package A;
foreach (keys(%A::)) {
if (defined $$_) {
eval '*'.$parent_package.'::'.$_.' = \$A::'.$_;
}
elsif (%$_) {
eval '*'.$parent_package.'::'.$_.' = \%A::'.$_;
}
elsif (@$_) {
eval '*'.$parent_package.'::'.$_.' = \@A::'.$_;
}
else {
eval '*'.$parent_package.'::'.$_.' = \&A::'.$_;
}
}
}
I have a Perl module (Module.pm) that initializes a number of variables, some of which I'd
like to import ($VAR2, $VAR3) into additional submodules that it might load during execution.
The way I'm currently setting up Module.pm is as follows:
package Module;
use warnings;
use strict;
use vars qw($SUBMODULES $VAR1 $VAR2 $VAR3);
require Exporter;
our @ISA = qw(Exporter);
our @EXPORT = qw($VAR2 $VAR3);
sub new {
my ($package) = @_;
my $self = {};
bless ($self, $package);
return $self;
}
sub SubModules1 {
my $self = shift;
if($SUBMODULES->{'1'}) { return $SUBMODULES->{'1'}; }
# Load & cache submodule
require Module::SubModule1;
$SUBMODULES->{'1'} = Module::SubModule1->new(@_);
return $SUBMODULES->{'1'};
}
sub SubModules2 {
my $self = shift;
if($SUBMODULES->{'2'}) { return $SUBMODULES->{'2'}; }
# Load & cache submodule
require Module::SubModule2;
$SUBMODULES->{'2'} = Module::SubModule2->new(@_);
return $SUBMODULES->{'2'};
}
Each submodule is structured as follows:
package Module::SubModule1;
use warnings;
use strict;
use Carp;
use vars qw();
sub new {
my ($package) = @_;
my $self = {};
bless ($self, $package);
return $self;
}
I want to be able to import the $VAR2 and $VAR3 variables into each of the submodules
without having to reference them as $Module::VAR2 and $Module::VAR3. I noticed that the
calling script is able to access both the variables that I have exported in Module.pm in the
desired fashion but SubModule1.pm and SubModule2.pm still have to reference the variables as
being from Module.pm.
I tried updating each submodule as follows which unfortunately didn't work I was
hoping:
package Module::SubModule1;
use warnings;
use strict;
use Carp;
use vars qw($VAR2 $VAR3);
sub new {
my ($package) = @_;
my $self = {};
bless ($self, $package);
$VAR2 = $Module::VAR2;
$VAR3 = $Module::VAR3;
return $self;
}
Please let me know how I can successfully export $VAR2 and $VAR3 from Module.pm into each
Submodule. Thanks in advance for your help!
? Calling use Module from another package (say
Module::Submodule9 ) will try to run the Module::import method.
Since you don't have that method, it will call the Exporter::import method, and
that is where the magic that exports Module 's variables into the
Module::Submodule9 namespace will happen.
In your program there is only one Module namespace and only one instance of
the (global) variable $Module::VAR2 . Exporting creates aliases to this variable
in other namespaces, so the same variable can be accessed in different ways. Try this in a
separate script:
package Whatever;
use Module;
use strict;
use vars qw($VAR2);
$Module::VAR2 = 5;
print $Whatever::VAR2; # should be 5.
$VAR2 = 14; # same as $Whatever::VAR2 = 14
print $Module::VAR2; # should be 14
package M;
use strict;
use warnings;
#our is better than "use vars" for creating package variables
#it creates an alias to $M::foo named $foo in the current lexical scope
our $foo = 5;
sub inM { print "$foo\n" }
1;
In M/S.pm
package M;
#creates an alias to $M::foo that will last for the entire scope,
#in this case the entire file
our $foo;
package M::S;
use strict;
use warnings;
sub inMS { print "$foo\n" }
1;
In the script:
#!/usr/bin/perl
use strict;
use warnings;
use M;
use M::S;
M::inM();
M::S::inMS();
But I would advise against this. Global variables are not a good practice, and sharing
global variables between modules is even worse.
These are the oldest type of variables in Perl. They are still used in some cases, even
though in most cases you should just use lexical variables.
In old times, if we started to use a variable without declaring it with the my or state
keywords, we automatically got a variable in the current namespace. Thus we could write:
$x = 42 ;
print "$x\n" ; # 42
Please note, we don't use strict; in these examples. Even though you should always use strict . We'll fix this in a
bit.
The default namespace in every perl script is called "main" and you can always access
variables using their full name including the namespace:
$x = 42 ;
print "$x\n" ; # 42
print "$main::x\n" ; # 42
The package keyword is used to switch namespaces:
$x = 42 ;
print "$x\n" ; # 42
print "$main::x\n" ; # 42
package Foo ;
print "Foo: $x\n" ; # Foo:
Please note, once we switched to the "Foo" namespace, the $x name refers to the variable in
the Foo namespace. It does not have any value yet.
$x = 42 ;
print "$x\n" ; # 42
print "$main::x\n" ; # 42
package Foo ;
print "Foo: $x\n" ; # Foo:
$x = 23 ;
print "Foo: $x\n" ; # Foo 23;
Do we really have two $x-es? Can we reach the $x in the main namespace while we are in the
Foo namespace?
$x = 42 ;
print "$x\n" ; # 42
print "$main::x\n" ; # 42
package Foo ;
print "Foo: $x\n" ; # Foo:
$x = 23 ;
print "Foo: $x\n" ; # Foo 23
print "main: $main::x\n" ; # main: 42
print "Foo: $Foo::x\n" ; # Foo: 23
package main ;
print "main: $main::x\n" ; # main: 42
print "Foo: $Foo::x\n" ; # Foo: 23
print "$x\n" ; # 42
We even switched back to the main namespace (using package main; ) and if you look closely,
you can see that while we were already in the main package we could reach to the $x of the Foo
package using $Foo::x but if we accessed $x without the full package name, we reach the one in
the main namespace.
Every package (or namespace) can hold variables with the same name.
In the Beginning, some time around 1960, every part of your program had access to all the
variables in every other part of the program. That turned out to be a problem, so language
designers invented local variables, which were visible in only a small part of the program.
That way, programmers who used a variable x could be sure that nobody was able to
tamper with the contents of x behind their back. They could also be sure that by using
x they weren't tampering with someone else's variable by mistake.
Every programming language has a philosophy, and these days most of these philosophies have
to do with the way the names of variables are managed. Details of which variables are visible
to which parts of the program, and what names mean what, and when, are of prime importance. The
details vary from somewhat baroque, in languages like Lisp, to extremely baroque, in languages
like C++. Perl unfortunately, falls somewhere towards the rococo end of this scale.
The problem with Perl isn't that it has no clearly-defined system of name management, but
rather that it two systems, both working at once. Here's the Big Secret about Perl variables
that most people learn too late: Perl has two completely separate, independent sets of
variables. One is left over from Perl 4, and the other is new. The two sets of variables are
called `package variables' and `lexical variables', and they have nothing to do with each
other.
Package variables came first, so we'll talk about them first. Then we'll see some problems
with package variables, and how lexical variables were introduced in Perl 5 to avoid these
problems. Finally, we'll see how to get Perl to automatically diagnose places where you might
not be getting the variable you meant to get, which can find mistakes before they turn into
bugs.
Here, $x is a package
variable . There are two important things to know about package variables:
Package variables are what you get if you don't say otherwise.
Package variables are always global.
Global means that package variables are
always visible everywhere in every program. After you do $x = 1 , any other part of
the program, even some other subroutine defined in some other file, can inspect and modify the
value of $x . There's no exception to this; package variables are always global.
Package variables are divided into families, called packages . Every package variable has a name with two parts. The two
parts are analogous to the variable's given name and family name. You can call the
Vice-President of the United States `Al', if you want, but that's really short for his full
name, which is `Al Gore'. Similarly, $x has a full name, which is something like
$main::x . The main part is the package qualifier , analogous to the `Gore' part of `Al
Gore'. Al Gore and Al Capone are different people even though they're both named `Al'. In the
same way, $Gore::Al and $Capone::Al are different variables, and
$main::x and $DBI::x are different variables.
You're always allowed to include the package part of the variable's name, and if you do,
Perl will know exactly which variable you mean. But for brevity, you usually like to leave the
package qualifier off. What happens if you do?
If you just say $x , perl assumes that you mean the variable $x in the
current package. What's the current package? It's normally main , but you can change
the current package by writing
package Mypackage;
in your program; from that point on, the current package is Mypackage . The only
thing the current package does is affect the interpretation of package variables that you wrote
without package names. If the current package is Mypackage , then $x really
means $Mypackage::x . If the current package is main , then $x
really means $main::x.
If you were writing a module, let's say the MyModule module, you would probably put
a line like this at the top of the module file:
package MyModule;
From there on, all the package variables you used in the module file would be in package
MyModule , and you could be pretty sure that those variables wouldn't conflict with
the variables in the rest of the program. It wouldn't matter if both you and the author of
DBI were to use a variable named $x , because one of those $x es
would be $MyModule::x and the other would be $DBI::x .
Remember that package variables are always global. Even if you're not in package DBI, even
if you've never heard of package DBI, nothing can stop you from reading from or writing
to $DBI::errstr . You don't have to do anything special. $DBI::errstr , like
all package variables, is a global variable, and it's available globally; all you have to do is
mention its full name to get it. You could even say
There are only three other things to know about package variables, and you might want to
skip them on the first reading:
The package with the empty name is the same as main . So $::x is the
same as $main::x for any x .
Some variables are always forced to be in package main. For example, if you mention
%ENV , Perl assumes that you mean %main::ENV , even if the current package
isn't main . If you want %Fred::ENV , you have to say so explicitly, even
if the current package is Fred . Other names that are special this way include
INC , all the one-punctuation-character names like $_ and $$ ,
@ARGV , and STDIN , STDOUT , and STDERR .
Package names, but not variable names, can contain :: . You can have a variable
named $DBD::Oracle::x. This means the variable x in the package
DBD::Oracle ; it has nothing at all to do with the package DBD which is
unrelated. Isaac Newton is not related to Olivia Newton-John, and Newton::Isaac is
not related to Newton::John::Olivia . Even though it appears that they both begin
with Newton , the appearance is deceptive. Newton::John::Olivia is in
package Newton::John , not package Newton.
That's all there is to know about package variables.
Package variables are global, which is dangerous, because you can never be sure that someone
else isn't tampering with them behind your back. Up through Perl 4, all variables were package
variables, which was worrisome. So Perl 5 added new variables that aren't
global.
Perl's other set of variables are called lexical variables (we'll see why later) or private
variables because they're private. They're also sometimes called my variables
because they're always declared with my . It's tempting to call them `local
variables', because their effect is confined to a small part of the program, but don't do that,
because people might think you're talking about Perl's local operator, which we'll see
later. When you want a `local variable', think my , not local .
The declaration
my $x;
creates a new variable, named x , which is totally inaccessible to most parts of
the program---anything outside the block where the variable was declared. This block is called
the scope of the variable. If the variable
wasn't declared in any block, its scope is from the place it was declared to the end of the
file.
You can also declare and initialize a my variable by writing something like
my $x = 119;
You can declare and initialize several at once:
my ($x, $y, $z, @args) = (5, 23, @_);
Let's see an example of where some private variables will be useful. Consider this
subroutine:
If lookup_salary happens to also use a variable named $employee , that's
going to be the same variable as the one used in print_report , and the works might
get gummed up. The two programmers responsible for print_report and
lookup_salary will have to coordinate to make sure they don't use the same variables.
That's a pain. In fact, in even a medium-sized project, it's an intolerable pain.
The solution: Use my variables:
sub print_report {
my @employee_list = @_;
foreach my $employee (@employee_list) {
my $salary = lookup_salary($employee);
print_partial_report($employee, $salary);
}
}
my @employee_list creates a new array variable which is totally inaccessible
outside the print_report function. for my $employee creates a new scalar
variable which is totally inaccessible outside the foreach loop, as does my
$salary . You don't have to worry that the other functions in the program are tampering
with these variables, because they can't; they don't know where to find them, because the names
have different meanings outside the scope of the my declarations. These `my variables'
are sometimes called `lexical' because their scope depends only on the program text itself, and
not on details of execution, such as what gets executed in what order. You can determine the
scope by inspecting the source code without knowing what it does. Whenever you see a variable,
look for a my declaration higher up in the same block. If you find one, you can be
sure that the variable is inaccessible outside that block. If you don't find a declaration in
the smallest block, look at the next larger block that contains it, and so on, until you do
find one. If there is no my declaration anywhere, then the variable is a package
variable.
my variables are not package variables. They're not part of a package, and they
don't have package qualifiers. The current package has no effect on the way they're
interpreted. Here's an example:
my $x = 17;
package A;
$x = 12;
package B;
$x = 20;
# $x is now 20.
# $A::x and $B::x are still undefined
The declaration my $x = 17 at the top creates a new lexical variable named x whose
scope continues to the end of the file. This new meaning of $x overrides the default
meaning, which was that $x meant the package variable $x in the current
package.
package A changes the current package, but because $x refers to the
lexical variable, not to the package variable, $x=12 doesn't have any effect on
$A::x . Similarly, after package B , $x=20 modifies the lexical
variable, and not any of the package variables.
At the end of the file, the lexical variable $x holds 20, and the package variables
$main::x , $A::x , and $B::x are still undefined. If you had wanted
them, you could still have accessed them by using their full names.
The maxim you must remember is:
Package variables are global variables.
For private variables, you must use my .
Almost everyone already knows that there's a local function that has something to
do with local variables. What is it, and how does it related to my ? The answer is
simple, but bizarre:
my creates a local variable. local doesn't.
First, here's what local $x really does: It saves the current value of the
package variable $x in a safe place, and replaces it with a new value, or with
undef if no new value was specified. It also arranges for the old value to be restored
when control leaves the current block. The variables that it affects are package variables,
which get local values. But package variables are always global, and a local
package variable is no exception. To see the difference, try this:
$lo = 'global';
$m = 'global';
A();
sub A {
local $lo = 'AAA';
my $m = 'AAA';
B();
}
sub B {
print "B ", ($lo eq 'AAA' ? 'can' : 'cannot') ,
" see the value of lo set by A.\n";
print "B ", ($m eq 'AAA' ? 'can' : 'cannot') ,
" see the value of m set by A.\n";
}
This prints
B can see the value of lo set by A.
B cannot see the value of m set by A.
What happened here? The local declaration in A saved a new temporary
value, AAA , in the package variable $lo . The old value, global ,
will be restored when A returns, but before that happens, A calls B
. B has no problem accessing the contents of $lo , because $lo is a
package variable and package variables are always available everywhere, and so it sees the
value AAA set by A .
In contrast, the my declaration created a new, lexically scoped variable named
$m , which is only visible inside of function A . Outside of A ,
$m retains its old meaning: It refers the the package variable $m ; which is
still set to global . This is the variable that B sees. It doesn't see the
AAA because the variable with that value is a lexical variable, and only exists inside
of A .
Because local does not actually create local variables, it is not very much use.
If, in the example above, B happened to modify the value of $lo , then the
value set by A would be overwritten. That is exactly what we don't want to happen. We want each
function to have its own variables that are untouchable by the others. This is what my
does.
Why have local at all? The answer is 90% history. Early versions of Perl only had
global variables. local was very easy to implement, and was added to Perl 4 as a
partial solution to the local variable problem. Later, in Perl 5, more work was done, and real
local variables were put into the language. But the name local was already taken, so
the new feature was invoked with the word my . my was chosen because it
suggests privacy, and also because it's very short; the shortness is supposed to encourage you
to use it instead of local . my is also faster than local
.
Every time control reaches a my declaration, Perl creates a new, fresh variable.
For example, this code prints x=1 fifty times:
for (1 .. 50) {
my $x;
$x++;
print "x=$x\n";
}
You get a new $x , initialized to undef , every time through the loop.
If the declaration were outside the loop, control would only pass by it once, so there would
only be one variable:
{ my $x;
for (1 .. 50) {
$x++;
print "x=$x\n";
}
}
This prints x=1 , x=2 , x=3 , ... x=50 .
You can use this to play a useful trick. Suppose you have a function that needs to remember
a value from one call to the next. For example, consider a random number generator. A typical
random number generator (like Perl's rand function) has a seed in it. The seed
is just a number. When you ask the random number generator for a random number, the function
performs some arithmetic operation that scrambles the seed, and it returns the result. It also
saves the result and uses it as the seed for the next time it is called.
Here's typical code: (I stole it from the ANSI C standard, but it behaves poorly, so don't
use it for anything important.)
There's a problem here, which is that $seed is a global variable, and that means we
have to worry that someone might inadvertently tamper with it. Or they might tamper with it on
purpose, which could affect the rest of the program. What if the function were used in a
gambling program, and someone tampered with the random number generator?
But we can't declare $seed as a my variable in the function:
sub my_rand {
my $seed;
$seed = int(($seed * 1103515245 + 12345) / 65536) % 32768;
return $seed;
}
If we did, it would be initialized to undef every time we called my_rand .
We need it to retain its value between calls to my_rand .
The declaration is outside the function, so it only happens once, at the time the program is
compiled, not every time the function is called. But it's a my variable, and it's in a
block, so it's only accessible to code inside the block. my_rand is the only other
thing in the block, so the $seed variable is only accessible to the my_rand
function.
$seed here is sometimes called a `static' variable, because it stays the same in
between calls to the function. (And because there's a similar feature in the C language that is
activated by the static keyword.)
You can't declare a variable my if its name is a punctuation character, like
$_ , @_ , or $$ . You can't declare the backreference variables
$1 , $2 , ... as my . The authors of my thought that that
would be too confusing.
Obviously, you can't say my $DBI::errstr , because that's contradictory---it
says that the package variable $DBI::errstr is now a lexical variable. But you
can say local $DBI::errstr ; it saves the current value of
$DBI::errstr and arranges for it to be restored at the end of the block.
New in Perl 5.004, you can write
foreach my $i (@list) {
instead, to confine the $i to the scope of the loop instead. Similarly,
If you're writing a function, and you want it to have private variables, you need to declare
the variables with my . What happens if you forget?
sub function {
$x = 42; # Oops, should have been my $x = 42.
}
In this case, your function modifies the global package variable $x . If you were
using that variable for something else, it could be a disaster for your program.
Recent versions of Perl have an optional protection against this that you can enable if you
want. If you put
use strict 'vars';
at the top of your program, Perl will require that package variables have an explicit
package qualifier. The $x in $x=42 has no such qualifier, so the program
won't even compile; instead, the compiler will abort and deliver this error message:
Global symbol "$x" requires explicit package name at ...
If you wanted $x to be a private my variable, you can go back and add the
my . If you really wanted to use the global package variable, you could go back and
change it to
$main::x = 42;
or whatever would be appropriate.
Just saying use strict turns on strict vars , and several other checks
besides. See perldoc strict for more details.
Now suppose you're writing the Algorithms::KnuthBendix modules, and you want the
protections of strict vars But you're afraid that you won't be able to finish the
module because your fingers are starting to fall off from typing
$Algorithms::KnuthBendix::Error all the time.
Package variables are always global. They have a name and a package qualifier. You can omit
the package qualifier, in which case Perl uses a default, which you can set with the
package declaration. For private variables, use my . Don't use local
; it's obsolete.
You should avoid using global variables because it can be hard to be sure that no two parts
of the program are using one another's variables by mistake.
To avoid using global variables by accident, add use strict 'vars' to your program.
It checks to make sure that all variables are either declared private, are explicitly qualified
with package qualifiers, or are explicitly declared with use vars .
The tech editors complained about my maxim `Never use local .' But 97% of the
time, the maxim is exactly right. local has a few uses, but only a few, and they
don't come up too often, so I left them out, because the whole point of a tutorial article is
to present 97% of the utility in 50% of the space.
I was still afraid I'd get a lot of tiresome email from people saying ``You forgot to
mention that local can be used for such-and-so, you know.'' So in the colophon at
the end of the article, I threatened to deliver Seven Useful Uses for local
in three months. I mostly said it to get people off my back about local . But it
turned out that I did write it, and it was published some time later.
Here's another potentially interesting matter that I left out for space and clarity. I
got email from Robert Watkins with a program he was writing that didn't work. The essence of
the bug looked like this:
my $x;
for $x (1..5) {
s();
}
sub s { print "$x, " }
Robert wanted this to print 1, 2, 3, 4, 5, but it did not. Instead, it printed
, , , , , . Where did the values of $x go?
The deal here is that normally, when you write something like this:
for $x (...) { }
Perl wants to confine the value of the index variable to inside the loop. If $x
is a package variable, it pretends that you wrote this instead:
{ local $x; for $x (...) { } }
But if $x is a lexical variable, it pretends you wrote this instead, instead:
{ my $x; for $x (...) { } }
This means that the loop index variable won't get propagated to subroutines, even if
they're in the scope of the original declaration.
I probably shouldn't have gone on at such length, because the perlsyn manual page
describes it pretty well:
...the variable is implicitly local to the loop and regains its former value upon exiting
the loop. If the variable was previously declared with my , it uses that
variable instead of the global one, but it's still localized to the loop. (Note that a
lexically scoped variable can cause problems if you have subroutine or format
declarations within the loop which refer to it.)
In my opinion, lexically scoping the index variable was probably a mistake. If you had
wanted that, you would have written for my $x ... in the first place. What I would
have liked it to do was to localize the lexical variable: It could save the value of the
lexical variable before the loop, and restore it again afterwards. But there may be
technical reasons why that couldn't be done, because this doesn't work either:
my $m;
{ local $m = 12;
...
}
The local fails with this error message:
Can't localize lexical variable $m...
There's been talk on P5P about making this work, but I gather it's not trivial.
Added 2000-01-05: Perl 5.6.0 introduced a new our(...) declaration. Its syntax
is the same as for my() , and it is a replacement for use vars .
Without getting into the details, our() is just like use vars ; its
only effect is to declare variables so that they are exempt from the strict 'vars'
checking. It has two possible advantages over use vars , however: Its syntax is
less weird, and its effect is lexical. That is, the exception that it creates to the
strict checking continues only to the end of the current block:
use strict 'vars';
{
our($x);
$x = 1; # Use of global variable $x here is OK
}
$x = 2; # Use of $x here is a compile-time error as usual
So whereas use vars '$x' declares that it is OK to use the global variable
$x everywhere, our($x) allows you to say that global $x should
be permitted only in certain parts of your program, and should still be flagged as an error
if you accidentally use it elsewhere.
Added 2000-01-05: Here's a little wart that takes people by surprise. Consider the
following program:
use strict 'vars';
my @lines = <>;
my @sorted = sort backwards @lines;
print @sorted;
sub backwards { $b cmp $a }
Here we have not declared $a or $b , so they are global variables. In
fact, they have to be global, because the sort operator must to be able to set
them up for the backwards function. Why doesn't strict produce a
failure?
The variables $a and $b are exempted from strict vars
checking, for exactly this reason.
You can see that Larry Wall bought OO paradigm "hook, line and sinker" , and that was very bad, IMHO disastrous decision. There
were several areas were Perl 5 could be more profitably be extended such as exceptions, coroutines and, especially, introducing types
of variables. He also did not realize that Javascript prototypes based OO model has much better implementation of OO then Simula-67
model. And that Perl 5 modules do 80% of what is useful in classes (namely provide a separate namespace and the ability to share variables
in this namespace between several subroutines)
Notable quotes:
"... Perl 5 had this problem with "do" loops because they weren't real loops - they were a "do" block followed by a statement modifier, and people kept wanting to use loop control it them. Well, we can fix that. "loop" now is a real loop. And it allows a modifier on it but still behaves as a real loop. And so, do goes off to have other duties, and you can write a loop that tests at the end and it is a real loop. And this is just one of many many many things that confused new Perl 5 programmers. ..."
"... We have properties which you can put on variables and onto values. These are generalizations of things that were special code in Perl 5, but now we have general mechanisms to do the same things, they're actually done using a mix-in mechanism like Ruby. ..."
"... Smart match operators is, like Damian say, equal-tilda ("=~") on steroids. Instead of just allowing a regular expression on the right side it allows basically anything, and it figures out that this wants to do a numeric comparison, this wants to do a string comparison, this wants to compare two arrays, this wants to do a lookup in the hash; this wants to call the closure on the right passing in the left argument, and it will tell if you if $x can quack. Now that looks a little strange because you can just say "$x.can('quack')". Why would you do it this way? Well, you'll see. ..."
"If I wanted it fast, I'd write it in C" - That's almost a direct quote from the original awk page.
"I thought of a way to do it so it must be right" - That's obviously PHP. ( laughter and applause )
"You can build anything with NAND gates" - Any language designed by an electrical engineer. ( laughter )
"This is a very high level language, who cares about bits?" - The entire scope of fourth generation languages fell into this...
problem.
"Users care about elegance" - A lot of languages from Europe tend to fall into this. You know, Eiffel.
"The specification is good enough" - Ada.
"Abstraction equals usability" - Scheme. Things like that.
"The common kernel should be as small as possible" - Forth.
"Let's make this easy for the computer" - Lisp. ( laughter )
"Most programs are designed top-down" - Pascal. ( laughter )
"Everything is a vector" - APL.
"Everything is an object" - Smalltalk and its children. (whispered:) Ruby. ( laughter )
"Everything is a hypothesis" - Prolog. ( laughter )
"Everything is a function" - Haskell. ( laughter )
"Programmers should never have been given free will" - Obviously, Python. ( laughter )
So my psychological conjecture is that normal people, if they perceive that a computer language is forcing them to learn theory,
they won't like it. In other words, hide the fancy stuff. It can be there, just hide it. Fan Mail (14:42)
Q: "Dear Larry, I love Perl. It has saved my company, my crew, my sanity and my marriage. After Perl I can't imagine going
back to any other language. I dream in Perl, I tell everyone else about Perl. How can you improve on perfection? Signed, Happy
in Haifa."
A: "Dear Happy,
You need to recognize that Perl can be good in some dimensions and not so good in other dimensions. You also need to recognize
that there will be some pain in climbing over or tunneling through the barrier to the true minimum."
Now Perl 5 has a few false minima. Syntax, semantics, pragmatics, ( laughter ), discourse structure, implementation, documentation,
culture... Other than that Perl 5 is not too bad.
Q: "Dear Larry,
You have often talked about the waterbed theory of linguistic complexity, and beauty times brains equals a constant. Isn't
it true that improving Perl in some areas will automatically make it worse in other areas? Signed, Terrified in Tel-Aviv."
A: "Dear Terrified,
...
No." ( laughter )
You see, you can make some things so they aren't any worse. For instance, we changed all the sigils to be more consistent, and
they're just the same length, they're just different. And you can make some things much better. Instead of having to write all this
gobbledygook to dereference references in Perl 5 you can just do it straight left to right in Perl 6. Or there's even more shortcuts,
so multidimensional arrays and constant hash subscripts get their own notation, so it's even clearer, at least once you've learned
it. Again, we're optimizing for expressiveness, not necessarily learnability.
Q: "Dear Larry,
I've heard a disturbing rumor that Perl 6 is turning into Java, or Python, or (whispered:) Ruby, or something. What's the
point of using Perl if it's just another object-oriented language? Why are we changing the arrow operator to the dot operator?
Signed, Nervous in Netanya."
A: "Dear Nervous,
First of all, we can do object orientation better without making other things worse. As I said. Now, we're changing from
arrow to dot, because ... because ... Well, just 'cuz I said so!"
You know, actually, we do have some good reasons - it's shorter, it's the industry standard, I wanted the arrow for something
else, and I wanted the dot as a secondary sigil. Now we can have it for attributes that have accessors. I also wanted the unary dot
for topical type calls, with an assumed object on the left and finally, because I said so. Darn it.
... ... ...
No arbitrary limits round two : Perl started off with the idea that strings should grow infinitely, if you have memory.
Just let's get rid of those arbitrary limits that plagued Unix utilities in the early years. Perl 6 is taking this in a number of
different dimensions than just how long your strings are. No arbitrary limits - you ought to be able to program very abstractly,
you ought to be able to program very concretely - that's just one dimension.
... .. ...
Perl 5 is just all full of these strange gobbledygooky variables which we all know and love - and hate. So the error variables
are now unified into a single error variable. These variables have been deprecated forever, they're gone! These weird things that
just drive syntax highlighters nuts ( laughter ) now actually have more regular names. The star there, $*GID, that's what
we call a secondary sigil, what that just says is this is in the global namespace. So we know that that's a global variable for the
entire process. Similarly for uids.
... ... ...
Perl 5 had this problem with "do" loops because they weren't real loops - they were a "do" block followed by a statement modifier,
and people kept wanting to use loop control it them. Well, we can fix that. "loop" now is a real loop. And it allows a modifier on
it but still behaves as a real loop. And so, do goes off to have other duties, and you can write a loop that tests at the end and
it is a real loop. And this is just one of many many many things that confused new Perl 5 programmers.
... ... ...
Perl 5, another place where it was too orthogonal - we defined parameter passing to just come in as an array. You know arrays,
subroutines - they're just orthogonal. You just happen to have one called @_, which your parameters come in, and it was wonderfully
orthogonal, and people built all sorts of stuff on top of it, and it's another place where we are changing.
... .. ...
Likewise, if you turn them inside out - the french quotes - you can use the regular angle brackets, and yes, we did change here-docs
so it does not conflict, then that's the equivalent of "qw". This qw interpolates, with single-angles it does not interpolate - that
is the exact "qw".
We have properties which you can put on variables and onto values. These are generalizations of things that were special code
in Perl 5, but now we have general mechanisms to do the same things, they're actually done using a mix-in mechanism like Ruby.
Smart match operators is, like Damian say, equal-tilda ("=~") on steroids. Instead of just allowing a regular expression on the
right side it allows basically anything, and it figures out that this wants to do a numeric comparison, this wants to do a string
comparison, this wants to compare two arrays, this wants to do a lookup in the hash; this wants to call the closure on the right
passing in the left argument, and it will tell if you if $x can quack. Now that looks a little strange because you can just say "$x.can('quack')".
Why would you do it this way? Well, you'll see.
... ... ..
There's a lot of cruft that we inherited from the UNIX culture and we added more cruft, and we're cleaning it up. So in Perl 5
we made the mistake of interpreting regular expressions as strings, which means we had to do weird things like back-references are
\1 on the left, but they're $1 on the right, even though it means the same thing. In Perl 6, because it's just a language, (an embedded
language) $1 is the back-reference. It does not automatically interpolate this $1 from what it was before. You can also get it translated
to Euros I guess.
die " Reports of my death are greatly exaggerated . \n "
Perl is alive and well, but it has steadily been losing promise over the past 20
years.
It's still heavily used for the tasks it was used for when I learnt it, in 1994–1995,
but at that time, it looked set for an even brighter future: it was developing into one of the
top-5 languages, a universal scripting language, a language you expect to find wherever
scripting or dynamically typed languages are appropriate.
You can still find evidence of that today: some software has an extension API in Perl, some
web applications are written in Perl, some larger system administration software is written in
Perl, etcetera. But these systems are typically 20 years old. If you do this today, be prepared
to justify yourself.
This is not because Perl has become any less suitable for doing these things. On the
contrary, it has continued to improve. Yet, people have turned away from Perl, towards newer
scripting languages such as Python, PHP, Ruby, and Lua, for tasks that in 1995 they would
probably have used Perl for.
Why?
I believe the reason is simple: Perl is very free, syntactically and semantically. This
makes it very good at what it was designed to do (scripting) but less suited for larger-scale
programming.
Perl's syntactic freedom mostly originates from its mimicking idioms from other languages.
It was designed to be a suitable replacement for other scripting languages, most notably the
Bourne shell (
/bin/ sh ) and awk , so it adopts some of their idioms. This is
perfect if you like these idioms for their compactness.
For instance, in the Bourne shell, we can write
if mkdir $directory
then
echo successfully created directory : $directory
elif test - d $directory
then
echo pre - existing directory : $directory
else
echo cannot create directory : $directory
fi
In the Bourne shell, every statement is a Unix command invocation; in this case,
test and mkdir . (Some commands, such as test , were
built into the shell later.) Every command will succeed or fail, so we can use it in the
condition of an if statement.
Now what if we only want to print a warning when something went wrong? We can write
this:
if mkdir $directory
then
: # nothing
elif test - d $directory
then
: # nothing
else
echo cannot create directory : $directory
fi
or we can combine the two conditions:
if mkdir $directory || test - d $directory
then
: # nothing
else
echo cannot create directory : $directory
fi
or we can combine them even further:
mkdir $directory ||
test - d $directory ||
echo cannot create directory : $directory
These all do the same exact thing; clearly, the last version is the most compact. In a shell
script with a lot of tests like this, writing things this way can save a considerable amount of
space. Especially in throwaway scripts of a few lines, it's a lot easier to use more compact
syntax.
Most programmers are familiar with seeing some special syntax for conditions in
if statements. For this reason, Unix has the [ command, which scans
its arguments for a matching ], and then invokes test with the arguments up to
that point. So we can always replace
test - d $directory
with
[ - d $directory ]
in the pieces of code above. It means the same thing.
Now, Perl comes onto the scene. It is designed to be easy to replace Bourne shell scripts
with. This is a very frequent use case for Perl, even today: I regularly find myself rewriting
my Bourne shell scripts into Perl by going through them line by line.
So what do the Perl replacements of the above look like?
Here we go:
if ( mkdir $directory )
{
# nothing
} elsif (- d $directory )
{
# nothing
} else {
say "cannot create directory: $directory"
}
or we can combine the two conditions:
if ( mkdir $directory || - d $directory )
{
# nothing
} else {
say "cannot create directory: $directory"
}
or we can combine them even further:
mkdir $directory or
- d $directory or
say "cannot create directory: $directory"
As you can see, these are literal transliterations of the corresponding Bourne shell
fragments.
In a language such as Java, you can use the first two forms, but not the third one. In such
languages, there is a syntactic separation between expressions , which yield a value,
and must be used in a context that demands such a value, and statements , which do not
yield a value, and must be used in contexts that do not demand one. The third form is
syntactically an expression, used in a context that demands a statement, which is invalid in
such a language.
No such distinction is made in Perl, a trait it inherited from the Bourne shell, which in
turn took it from Algol 68.
So here we have an example of syntactic freedom in Perl that many other languages lack, and
in this case, Perl took it from the Bourne shell.
Allowing more compactness isn't the only reason for this freedom. The direct reason the
Bourne shell doesn't make the distinction is that it relies on Unix commands, which do not make
the distinction, either. Every Unix command can return a value (a return code) to indicate
whether it failed and how. Therefore, it acts both as a statement and as a condition. There is
a deeper reason behind this: concurrency.
For instance, when we want to create a directory, we can't separate doing it from testing
whether it can/could be done. We could try and write something like
if ( some test to see if we can mkdir $directory )
then
mkdir directory
fi
if ( some test to see if we managed to mkdir directory )
then
[...]
fi
but that logic isn't correct. Unix is a multiprogramming environment, so anything could
happen between our first test and our mkdir command, and before our mkdir command
and the second test. Someone else might create that directory or remove it, or do something
else that causes problems. Therefore, the only correct way to write code that tries to create a
directory and determines whether it succeeds is to actually issue the mkdir command and
check the value it returned. Which is what the constructs above do.
A shortcut like
mkdir $directory or
- d $directory or
say "cannot create directory: $directory"
is just a consequence. Of course, you can still object to using it for stylistic reasons,
but at least the construct makes sense once you know its origins.
Programmers who are unfamiliar with the paradigm of mixing statements and expressions, who
have never seen any but the simplest of Bourne shell scripts, who have only been given
programming tasks in which their program calls all the shots and nothing else can interfere,
have never encountered a reason to treat statements and expressions as the same thing. They
will be taken aback by a construct like this. I can't read this , they will mutter,
it's incomprehensible gibberish . And if Perl is the first language they've seen that
allows it, they will blame Perl. Only because they were never subjected to a large amount of
Bourne shell scripting. Once you can read that, you can read anything ; Perl will look
pretty tame in comparison.
Similar reasons can be given for most of the other syntactical freedom in Perl. I must say,
Perl sometimes seems to make a point of being quirky, and I find some of the resulting oddities
hard to justify, but they do make sense in context. The overall motivation is compactness. In
scripting, where you type a lot and throw away a lot, the ability to write compact code is a
great virtue.
Due to these syntactic quirks, Perl got a reputation for being a write-only language -
meaning that when programmer A is faced with programmer B 's code, B may
have used all kinds of idioms that A is unfamiliar with, causing delays for A .
There is some truth to this, but the problem is exaggerated: syntax is the first thing you
notice about a program, which is why it sticks out, but it's pretty superficial: new syntax
really isn't so hard to learn.
So I'm not really convinced Perl's syntactic freedom is such a bad thing, except that people
tend to blow it out of proportion.
However, Perl is also very free semantically : it is a truly dynamic language,
allowing programmers to do all kinds of things that stricter languages forbid. For instance, I
can monkey-patch
functions and methods in arbitrary code that I'm using. This can make it very hard for
programmers to understand how a piece of code is working, or whether it is working as
intended.
This becomes more important when a software system grows larger or when others than the
original author start to rely on it. The code doesn't just need to work, but it must be
understandable to others. Consequently, in large, stable code bases, compactness and freedom of
expression are less important than consistency, a smooth learning curve for beginners, and
protection against routine errors. Therefore, many software development teams prefer languages
such as Java, with its very limited syntactic freedom and strict compile-time type checking.
Perl is at the opposite end of the spectrum, with its extreme syntactic and semantic
freedom.
This wouldn't be a problem if there were ways to straitjacket Perl if you wanted to; if
there was a way to say: for this project, be as rigid as Java syntactically or semantically; I
want as few surprises as possible in code that I didn't write. Sure enough, Perl has support
for compile-time checking ( use strict ; use warnings , and the
perlcritic utility) and consistent code formatting (the perltidy
utility), but they were added as afterthoughts and cannot come anywhere near the level of
strictness a Java programmer would expect.
To support that, the language needed to be redesigned from scratch, and the result would be
incompatible with the original. This effort has been made, producing Perl 6, but in the
meantime, many other languages sprung up and became popular for the cases Perl programmers
wanted to use Perl for, and if you're going to switch to an incompatible language anyway, why
not use one of those instead?
A module is a container which holds a group of variables and subroutines which can be used in a program. Every module has a public
interface, a set of functions and variables.
To use a module into your program, require or use statement can be used, although their semantics are slightly different.
The 'require' statement loads module at runtime to avoid redundant loading of module. The 'use' statement is like require with
two added properties, compile time loading and automatic importing.
Namespace is a container of a distinct set of identifiers (variables, functions). A namespace would be like name::variable .
Every piece of Perl code is in a namespace.
In the following code,
use strict;
use warnings;
my $x = "Hello" ;
$main ::x = "Bye" ;
print "$main::x\n" ; # Bye
print "$x\n" ; # Hello
Here are two different variables defined as x . the $main::x is a package variable and $x is a lexical variable. Mostly we use
lexical variable declared with my keyword and use namespace to separate functions.
In the above code, if we won't use use strict , we'll get a warning message as
Name "main::x" used only once: possible typo at line..
The main is the namespace of the current script and of current variable. We have not written anything and yet we are already in
the 'main' namespace.
By adding 'use strict', now we got the following error,
Global symbol "$x" requires explicit package name
In this error, we got a new word 'package'. It indicates that we forgot to use 'my' keyword before declaring variable but actually
it indicates that we should provide name of the package the variable resides in.
Perl Switching namespace using package keyword
Look at the following code,
use strict;
use warnings;
use 5.010;
sub hii {
return "main" ;
}
package two;
sub hii {
return "two" ;
}
say main::hii(); # main
say two::hii(); # two
say hii(); # two
package main;
say main::hii(); # main
say two::hii(); # two
say hii(); # main
Here we are using package keyword to switch from 'main' namespace to 'two' namespace.
Calling hii() with namespaces returns respective namespaces. Like , say main::hii(); returns 'main' and say two::hii(); returns
'two'.
Calling hii() without namespace prefix, returns the function that was local to the current namespace. In first time, we were in
'two' namespace. Hence it returned 'two'. In second time, we switched the namespace using package main. Hence it returns 'main'.
This title was published in hardcover in March 2005 by Apress, a relatively new member of
the technical publishing world. The publisher has a
Web page for the book that includes links to all of the source code in a Zip file, the
table of contents in PDF format, and a form for submitting errata. The book comprises 269
pages, the majority of which are organized into 16 chapters:
Introduction (not to be confused with the true Introduction immediately preceding
it),
Inspecting Variables and Getting Help, Controlling Program Execution, Debugging a
Simple Command Line Program, Tracing Execution, Debugging Modules, Debugging Object-Oriented
Perl, Using the Debugger As a Shell, Debugging a CGI Program, Perl Threads and Forked
Processes, Debugging Regular Expressions, Debugger Customization, Optimization and Performance
Hints and Tips, Command Line and GUI Debuggers, Comprehensive Command Reference, Book
References and URLs.
When debugging I emphasize the use of "warn" over "print". It's the same syntax, but the
warn statements don't get spooled and therefore their timing is quicker.
This is vital when you code just plain blows up. Using "print" means that a statement
which got executed before the disaster may not make it to console, thus leading you to
believe that it never got executed. "warn" avoids this problem and thus leads you to the
problem more accurately. It also makes it easy to globally comment out the warn statements
before going releasing the code.
[That's one freelance Perl programmer I'll have to remember never to hire.]
Seriously, I'm one of those people who use a debugger every day. Actually, when I write new
code in Perl, often the first thing I do is step through it in the debugger to make sure it
does what I think it should. Especially in Perl, it is very easy to accidentally do something
that's a little off. With the "wait until something goes wrong before I investigate" attitude
demonstrated here, you'll never know anything is amiss until some nasty bug crops up as a
result. Using the debugger to sanity check my code means that I catch most bugs before they
ever cause problems.
I'm sure I'm going to get some snide remarks about this approach, but really, I've been a
serious Perl programmer for about eight years now, and often write moderately complex Perl
programs that work perfectly the first time--run through the debugger or not. I can't say that
about any other language, and it's something most people can't say about any language, let
alone Perl ;)
Matt Egan , former
US Intelligence Officer (1967-2006)
Answered Sep 8, 2017 · Author has 4.8k answers and 2.3m answer views
It does appear he said something very much along those lines, though I doubt it meant what
it appears to mean absent the context. He made the statement not long after he became the
Director of Central Intelligence, during a discussion of the fact that, to his amazement, about
80 percent of the contents of typical CIA intelligence publications was based on information
from open, unclassified sources, such as newspapers and magazines.
Apparently, and reasonably,
he judged that about the same proportion of Soviet intelligence products was probably based on
open sources, as well. That meant that CIA disinformation programs directed at the USSR
wouldn't work unless what was being disseminated by US magazines and newspapers on the same
subjects comported with what the CIA was trying to sell the Soviets.
Given that the CIA could
not possibly control the access to open sources of all US publications, the subjects of CIA
disinformation operations had to be limited to topics not being covered by US public media. To
be sure, some items of disinformation planted by the CIA in foreign publications might
subsequently be discovered and republished by US media. I'm guessing the CIA would not leap to
correct those items.
But that is a far cry from concluding that the CIA would (or even could) arrange that
"everything the American public believes is false."
"... You've heard of the "Manchurian Candidate"? We are the "Manchurian Populace". They spout the aforementioned mantra, and we all turn into mindless followers ..."
"... Assume that CIA launched disinformation in a hostile country to impact them. Then international news agencies picked it up and it got published by media in the US. If the disinformation were harmless to the US, then our Federal Government would not comment and would let the disinformation stand. To repudiate it might have bad effects on national security. Would this be a case of the CIA lying to the American people? No. ..."
"... The CIA once had influence in a number of English language publications abroad, some of which stories were reprinted in the US media. This was known as "blowback", and unintended in most cases. ..."
"... The CIA fabricated a story that the Russians in Afghanistan made plastic bombs in the shape of toys, to blow up children. Casey repeated this story, knowing it to be disinformation, as fact to US journalists and politicians. ..."
"... He doesn't need to have said it. CIA has run many disinformation campaigns against American public. Operation Mockingbird ..."
Not that it matters. No conservative I know retains the ability to
think off script, let alone rise above his indoctrination, and
neither the script or their indoctrination allows this to be real.
So as far as they're concerned, it simply isn't possible.
Neither was David Stockman's admission that the idea of 'trickle
down' was to bankrupt the federal government so they could finally do
away with social security, while making themselves filthy rich...
Or Reagan being a traitor for negotiating with the Iranians BEFORE he
was elected....
The fact that our
"leaders" continue to put our brave young men and women in harm's
way, as we also kill millions of "others", and the American people
stand idly by, is proof enough for me. "So and so is evil and he
oppresses his people, so we need to remove him and bring democracy to
such and such country!" This has been the game plan for decades. In
the info age we know all this.
A convicted war criminal like Eliot
Abrams is hired by a president the media and the Democrats hate and
call a liar, and we suddenly suspend our disbelief, and follow
blindly into another regime change war while we are buddies with many
dictators around the world.
You've heard of the "Manchurian
Candidate"? We are the "Manchurian Populace". They spout the
aforementioned mantra, and we all turn into mindless followers of
these MONSTERS!
806 views
� View 3 Upvoters
About two years
ago, one Barbara Honneger said in Quora that she was there. But I can
find no credible news source that affirms this.
It is possible
that Director Casey said it without any negative significance for the
American people.
How?
Assume that CIA launched disinformation in a hostile country to impact them. Then international news agencies picked it up
and it got published by media in the US. If the disinformation were harmless to the US, then our Federal Government would not
comment and would let the disinformation stand. To repudiate it might have bad effects on national security. Would this be a case
of the CIA lying to the American people? No.
The CIA once had influence in a number of English language
publications abroad, some of which stories were reprinted in the US
media. This was known as "blowback", and unintended in most cases.
The CIA fabricated a story that the Russians in Afghanistan made plastic bombs in the shape of toys, to blow up children.
Casey repeated this story, knowing it to be disinformation, as fact to US journalists and politicians.
"... There is a photo of someone who looks like him standing in front of the School Book Depository. Bush is one of the few people in America who can't remember where he was that day. ..."
There is some flimsy photo evidence of someone who looked like him in Dealey Plaza, so my
answer would be, "not sure." But anecdotally, there sure seems to be a large number of
"coincidences" around a guy who could apparently walk across a snow covered field without
leaving foot prints , so maybe.
Since the beginning, the rumored driving motive for JFK's assassination, (from both sides
really) was the cluster-fuck known as "The Bay of Pigs invasion," so we'll start there. At the
end of Mark Lane's book "Plausible Denial," (the account of E. Howard Hunt's ill-fated lawsuit
against The Liberty Lobby) some interesting facts about the Bay of Pigs invasion were tossed
out that leaves one scratching his or her head and wondering if 41 had anything to do with it.
The operation was ostensibly to deliver small arms and ordnance to a (turns out to be
fictional) 25,000 man rebel army that was in the Cuban hills waiting for help to depose Castro.
The US Navy supplied a couple of ships, but they were decommissioned, had their numbers scraped
off, and were renamed the "Houston" and the "Barbara," (or the Spanish spelling of Barbara.)
This is while 41 was living in Houston with his wife Barbara. Also, the CIA code name for the
invasion was "Operation Zapata."
This while the name of 41's business was "Zapata Offshore."
(Or something like that. 41 had business' using Zapata's name since his days as an oilman in
Midland Texas.) The day after Kennedy's killing, a George Bush met with Army Intel. What went
on in that meeting is a mystery, and the CIA unconvincingly claims that they had another guy
working for them named George Bush, only he wasn't hired until 1964 and his expertise was
meteorology so it's difficult to understand why they wanted to talk with him on that day. Then
there's the fact that Oswald's CIA handler, a guy name Georges DeMorinshilt (sp?) had the name
George (Poppy) Bush in his address book along with 41's Houston address and phone number.
Of course this is all coincidental, but consider: 41 was a failed two-term congressman who
couldn't hold his seat, (in Houston Texas of all places) and yet was made by Nixon the
ambassador to the UN, then Ford named him ambassador to China and the Director of the CIA. Wow!
What a lucky guy.
So was he involved with the Kennedy assassination and photographed in Dealey Plaza? Don't
know. I was 13 at the time, but in the intervening years, the politics in this country,
especially relating to the Republican Party, have become shall we say, "Kalfkaesque."
There is a photo of someone who looks like him standing in front of the School Book
Depository. Bush is one of the few people in America who can't remember where he was that day.
There is also a memo by J.Edgar Hoover referencing a "George Bush of the CIA" reporting on
"misguided Cubans" in Dallas that day. The CIA had a safe house stuffed with Cuban agents in
the Oak Cliff neighborhood, and Lee Harvey Oswald rented a room nearby shortly before the
assassination took place.
Astoundingly, Bush, the elder, claims that he does not remember where he was when Kennedy
was assassinated. I do. I'll bet a dollar that you do (if old enough). Everyone above the age
of fifty-five does except George H. W. Bush. He does however, remember that he was not at
Dealey Plaza at the time.
It is interesting to note that photographs and videos exist showing a man who looks very
much like Bush, at the site, at the time. It was not difficult to find them on line in the
past. Now, they seem to have been expunged somehow, though a few blurry photos can still be
found.
Christopher Story
Lives in Hawai'i
25.3k answer views
788
this month
Christopher Story
Answered
Sep
1 2015
�
Author has
64
answers and
25.3k
answer views
One could say that an
ideology is a religion if and only if it is theocratic, but I find
Yuval Harari's understanding of religion less arbitrary and more
compelling.
"Religion is any system of human norms and values that is
founded on a belief in superhuman laws. Religion tells us that we
must obey certain laws that were not invented by humans, and that
humans cannot change at will. Some religions, such as Islam,
Christianity and Hinduism, believe that these super-human laws
were created by the gods. Other religions, such as Buddhism,
Communism and Nazism, believe that these super-human laws are
natural laws. Thus Buddhists believe in the natural laws of karma,
Nazis argued that their ideology reflected the laws of natural
selection, and Communists believe that they follow the natural
laws of economics. No matter whether they believe in divine laws
or in natural laws, all religions have exactly the same function:
to give legitimacy to human norms and values, and to give
stability to human institutions such as states and corporations.
Without some kind of religion, it is simply impossible to maintain
social order. During the modern era religions that believe in
divine laws went into eclipse. But religions that believe in
natural laws became ever more powerful. In the future, they are
likely to become more powerful yet. Silicon Valley, for example,
is today a hot-house of new techno-religions, that promise
humankind paradise here on earth with the help of new technology."
"... No. Possibly Boeing & the FAA will solve the immediate issue, but they have destroyed Trust. ..."
"... It has emerged on the 737MAX that larger LEAP-1B engines were unsuited to the airframe and there is no way now to alter the airframe to balance the aircraft. ..."
"... Boeing failed to provide training or training material to pilots or even advise them the existence of MCAS. There was a complex two step process required of pilots in ET302 and JT610 crashes and their QRH handbook did not explain this: ..."
No. Possibly
Boeing & the FAA will solve the immediate issue, but they have
destroyed Trust.
Other brands of
aircraft like Airbus with AF447 established trust after their A330
aircraft plunged into the Atlantic in a mysterious accident.
With Airbus
everyone saw transparency & integrity in how their accidents were
investigated. How Boeing & FAA approached accident investigation
destroyed public Trust.
By direct
contrast in the mysterious disappearance of MH370, Boeing
contributed nothing to the search effort and tried to blame the
pilot or hijackers.
With the 737MAX
in Lion Air and Ethiopian crashes Boeing again tried to blame
pilots, poor training, poor maintenance and then when mechanical
defect was proven, Boeing tried to downplay how serious the issue
was and gave false assurances after Lion Air that the plane was
still safe. ET302 proved otherwise.
It is no longer
possible to trust the aircraft's certification. It is no longer
possible to trust that safety was the overriding principle in
design of the Boeing 737 MAX nor several other Boeing designs for
that matter.
The Public have
yet to realize that the Boeing 777 is an all electric design where
in certain scenarios like electrical fire in the avionics bay, an
MEC override vent opens allowing cabin air pressure to push out
smoke. This silences the cabin depressurization alarms.
As an
electrical failure worsens, in that scenario another system called
ELMS turns off electrical power to the Air Cycle Machine which
pumps pressurized air into the cabin. The result of ELMS cutting
power means the override vent fails to close again and no new
pressurized air maintains pressure in the cabin. Pilots get no
warning.
An incident in
2007 is cited as AD 2007�07�05 by the FAA in which part but not
all of this scenario played out in a B777 at altitude.
MH370 may have
been the incident in which the full scenario played out, but of
course Boeing is not keen for MH370 to be found and unlike Airbus
which funded the search for AF447, Boeing contributed nothing to
finding MH370.
It has emerged
on the 737MAX that larger LEAP-1B engines were unsuited to the
airframe and there is no way now to alter the airframe to balance
the aircraft.
It also emerged
that the choice to fit engines to this airframe have origins in a
commercial decision to please Southwest Airlines and cancel the
Boeing 757.
Boeing failed
to provide training or training material to pilots or even advise
them the existence of MCAS. There was a complex two step process
required of pilots in ET302 and JT610 crashes and their QRH
handbook did not explain this:
The MAX is
an aerodynamically unbalanced aircraft vulnerable to any sort of
disruption, ranging from electrical failure, out of phase
generator, faulty AOA sensor, faulty PCU failure alert, digital
encoding error in the DFDAU.
Jason Eaton
Former Service Manager
Studied at University of
Life
Lives in Sydney,
Australia
564k answer views
50.7k
this month
Answered Mar 24, 2019
�
No I wouldn't.
I'm not a pilot or an aerospace technician but I am a mechanical
engineer, so I know a little bit about physics and stuff.
The 737�8
is carrying engines it was never designed for, that cause it to
become inherently unstable. So unstable in fact, that it can't be
controlled by humans and instead relies on computer aided control
to maintain the correct attitude, particularly during ascent and
descent.
The MCAS system
is, effectively, a band aid to fix a problem brought about by poor
design philosophy. Boeing should have designed a new airframe that
complements the new engines, instead of ruining a perfectly good
aircraft by bolting on power units it's not designed to carry, and
then trying to solve the resulting instability with software. And
if that isn't bad enough, the system relies on data from just the
one sensor which if it doesn't agree with, it'll force the
aircraft nose down regardless of the pilots' better judgement.
That might be
ok for the Eurofighter Typhoon but it's definitely not ok for fare
paying passengers on a commercial jetliner.
So, no. I won't
be flying on a 737�8 until it's been redesigned to fly safely. You
know, like a properly designed aeroplane should.
4.8k
Views
�
View 36 Upvoters
He and the rest of his family are all crooks as are most politicians. Deals are made
between thieves. Wealth serves as a mask.
I wonder how much he will make! Am so sick at
the lack of morals among officials all over the world. Do good because it is the right
thing to do not because of the accolades. Let thereby real judge!
No! Of course not. Why does anyone believe this nonsense!
First off, I think by "bring peace to the Middle East" you must be referring to "solve the
Israeli-Palestinian dilemma". There are numerous conflicts in the broader Middle East that make
broader peace impossible.
Jared Kushner has no diplomatic experience. He doesn't seem to have any special knowledge
about the conflict between Israel and the Palestinians. Being raised an Orthodox Jew, I think
it will be impossible for the Palestinians to see him as a neutral party.
Here's something that people should have learned before the election: p...
(more)
The main benefit of Docker is that it automatically solves the problems with versioning and
cross-platform deployment, as the images can be easily recombined to form any version and can
run in any environment where Docker is installed. "Run anywhere" meme...
James Lee ,
former Software Engineer at Google (2013-2016) Answered Jul
12 · Author has 106 answers and 258.1k answer views
There are many beneifits of Docker. Firstly, I would mention the beneifits of Docker and
then let you know about the future of Docker. The content mentioned here is from my recent
article on Docker.
Docker Beneifits:
Docker is an open-source project based on Linux containers. It uses the features based on
the Linux Kernel. For example, namespaces and control groups create containers. But are
containers new? No, Google has been using it for years! They have their own container
technology. There are some other Linux container technologies like Solaris Zones, LXC, etc.
These container technologies are already there before Docker came into existence. Then why
Docker? What difference did it make? Why is it on the rise? Ok, I will tell you why!
Number 1: Docker offers ease of use
Taking advantage of containers wasn't an easy task with earlier technologies. Docker has
made it easy for everyone like developers, system admins, architects, and more. Test portable
applications are easy to build. Anyone can package an application from their laptop. He/She can
then run it unmodified on any public/private cloud or bare metal. The slogan is, "build once,
run anywhere"!
Number 2: Docker offers speed
Being lightweight, the containers are fast. They also consume fewer resources. One can
easily run a Docker container in seconds. On the other side, virtual machines usually take
longer as they go through the whole process of booting up the complete virtual operating
system, every time!
Number 3: The Docker Hub
Docker offers an ecosystem known as the Docker Hub. You can consider it as an app store for
Docker images. It contains many public images created by the community. These images are ready
to use. You can easily search the images as per your requirements.
Number 4: Docker gives modularity and scalability
It is possible to break down the application functionality into individual containers.
Docker gives this freedom! It is easy to link containers together and create your application
with Docker. One can easily scale and update components independently in the future.
The Future
A lot of people come and ask me that "Will Docker eat up virtual machines?" I don't think
so! Docker is gaining a lot of momentum but this won't affect virtual machines. This reason is
that virtual machines are better under certain circumstances as compared to Docker. For
example, if there is a requirement of running multiple applications on multiple servers, then
virtual machines is a better choice. On the contrary, if there is a requirement to run multiple
copies of a single application, Docker is a better choice.
Docker containers could create a problem when it comes to security because containers share
the same kernel. The barriers between containers are quite thin. But I do believe that security
and management improve with experience and exposure. Docker certainly has a great future! I
hope that this Docker tutorial has helped you understand the basics of Containers, VM's, and
Dockers. But Docker in itself is an ocean. It isn't possible to study Docker in just one
article. For an in-depth study of Docker, I recommend this Docker course.
Please feel free to Like/Subscribe/Comment on my YouTube Videos/Channel mentioned below
:
"Docker is both a daemon (a process running in the background) and a client command. It's
like a virtual machine but it's different in important ways. First, there's less duplication.
With each extra VM you run, you duplicate the virtualization of CPU and memory and quickly run
out resources when running locally. Docker is great at setting up a local development
environment because it easily adds the running process without duplicating the virtualized
resource. Second, it's more modular. Docker makes it easy to run multiple versions or instances
of the same program without configuration headaches and port collisions. Try that in a VM!
With Docker, developers can focus on writing code without worrying about the system on which
their code will run. Applications become truly portable. You can repeatably run your
application on any other machine running Docker with confidence. For operations staff, Docker
is lightweight, easily allowing the running and management of applications with different
requirements side by side in isolated containers. This flexibility can increase resource use
per server and may reduce the number of systems needed because of its lower overhead, which in
turn reduces cost.
Docker has made Linux containerization technology easy to use.
There are a dozen reasons to use Docker. I'll focus here on three: consistency, speed and
isolation. By consistency , I mean that Docker provides a consistent environment for
your application from development all the way through production – you run from the same
starting point every time. By speed , I mean you can rapidly run a new process on a
server. Because the image is preconfigured and installed with the process you want to run, it
takes the challenge of running a process out of the equation. By isolation , I mean that
by default each Docker container that's running is isolated from the network, the file system
and other running processes.
A fourth reason is Docker's layered file system. Starting from a base image, every change
you make to a container or image becomes a new layer in the file system. As a result, file
system layers are cached, reducing the number of repetitive steps during the Docker build
process AND reducing the time it takes to upload and download similar images. It also allows
you to save the container state if, for example, you need troubleshoot why a container is
failing. The file system layers are like Git, but at the file system level. Each Docker image
is a particular combination of layers in the same way that each Git branch is a particular
combination of commits."
Docker is the most popular file format for Linux-based container development and
deployments. If you're using containers, you're most likely familiar with the
container-specific toolset of Docker tools that enable you to create and deploy container
images to a cloud-based container hosting environment.
This can work great for brand-new environments, but it can be a challenge to mix container
tooling with the systems and tools you need to manage your traditional IT environments. And, if
you're deploying your containers locally, you still need to manage the underlying
infrastructure and environment.
Portability: let's suppose in the case of Linux you have your own customized Nginx
container. You can run that Nginx container anywhere, no matter it's a cloud or data center on
even your own laptop as long as you have a docker engine running Linux OS.
Rollback: you can just run your previous build image and all charges will
automatically roll back.
Image Simplicity: Every image has a tree hierarchy and all the child images depend
upon its parent image. For example, let's suppose there is a vulnerability in docker container,
you can easily identify and patch that parent image and when you will rebuild child,
variability will automatically remove from the child images also.
Container Registry: You can store all images at a central location, you can apply
ACLs, you can do vulnerability scanning and image signing.
Runtime: No matter you want to run thousand of container you can start all within
five seconds.
Isolation: We can run hundred of the process in one Os and all will be isolated to
each other.
Ethen , Web Designer
(2015-present) Answered
Aug 30, 2018 · Author has 154 answers and 56.2k answer views
Docker is an open platform for every one of the developers bringing them a large number of
open source venture including the arrangement open source Docker
tools , and the management framework with in excess of 85,000 Dockerized applications.
Docker is even today accepted to be something more than only an application stage. What's more,
the compartment eco framework is proceeding to develop so quick that with such a large number
of Docker devices being made accessible on the web, it starts to feel like an overwhelming
undertaking when you are simply attempting to comprehend the accessible alternatives kept
directly before you.
From my personal experience, I think people just want to containerize everything without
looking at how the architectural considerations change which basically ruins the
technology.
e.g. How will someone benefit from creating FAT container images of a size of a VM when the
basic advantage of docker is to ship lightweight images.
Google
schedules their performance reviews twice a year -- one major one at the end of the year and a
smaller one mid-year. This answer is based on my experience as a Google engineer, and the
performance review process may differ slightly for other positions.
Each review consists of a self-assessment, a set of peer reviews, and if you're applying for
a promotion, reasons for why should be promoted to the next level. Each review component is
submitted via an online tool. Around performance review time, it's not uncommon to see many
engineers taking a day or more just to write the reviews through the tool.
In the self-assessment, you summarize your major accomplishments and contributions since the
last review. You're also asked to describe your strengths and areas for improvement; typically
you'd frame them with respect to the job expectations described by your career ladder. For
example, if you're a senior engineer, you might write about your strengths being the tech lead
of your current project.
For peer reviews, employees are expected to choose around 3-8 peers (fellow engineers,
product managers, or others that can comment on their work) to write their peer reviews.
Oftentimes, managers will also assign additional individuals to write peer reviews for one of
their reports, particularly newer or younger reports who may be less familiar with the
process.
Peers comment on your projects and contributions, on your strengths, and on areas for
improvement. The peer reviews serve three purposes:
They allow your peers to give you direct feedback on your code quality, your teamwork,
etc., and to give direct feedback to your manager that you don't feel comfortable directly
sharing with the employee.
Along with the self-assessment, they feed into your manager's decision regarding your
performance rating, which determines your yearly bonus multiplier.
If you apply for a promotion, the peer reviews also become part of your promotion
application packet.
An additional part of the peer review is indicating a list of engineers that are working
below the level of the peer and a list of engineers that are working above the level of the
peer. These factor into a total ordering of engineers within a team and are used to determine
cutoffs for bonuses and promotions.
If you're applying for a promotion during a performance review cycle, you're given an
additional opportunity to explain why you should be promoted. A key part to a strong
application is explaining with specific details and examples how you're achieving and
contributing based on the expectations of the next level in the job ladder.
"... Reviews should never (ever ever ever) be a surprise to either party (ever). If there is something in your review that was never brought up before, ask why your manager waited until now to bring it up instead of addressing it in the moment. ..."
"... Does the company as a whole actually give a crap about reviews? Are reviews used to make decisions on what departments to trim/cut and who is at the bottom? Are they used for financial decisions? (none of those uses is good by the way). ..."
Reviews should never (ever ever ever) be a surprise to either party (ever). If there is
something in your review that was never brought up before, ask why your manager waited until
now to bring it up instead of addressing it in the moment. Have an uncomfortable
discussion (yikes! YES. have an uncomfortable dialogue about it). Uncomfortable doesn't mean
ugly or yelling or fist pounding. We don't like conflict, so we don't like asking people to
explain why they chose to act in a certain way when we feel wronged. Get over that discomfort
(respectfully). You have every right to ask why something was put in your review if it was a
surprise.
Does the company as a whole actually give a crap about reviews? Are reviews used to make
decisions on what departments to trim/cut and who is at the bottom? Are they used for financial
decisions? (none of those uses is good by the way). Or do they sit in a file gathering
dust? Has anyone ever actually pulled out someone's performance review from 2 years ago and
taken action on it? If none of these things are true, while the bad review is still crappy,
perhaps it's less of an issue overall.
... ... ...
If the comments are more behavioral or personal, this will be tougher. "Johnny rarely
demonstrates a positive attitude" or "Johnny is difficult to work with" or "Johnny doesn't seem
to be a team player" - for statements like this, you must ask for a detailed explanation. Not
to defend yourself (at first anyway) but to understand. What did they mean exactly by the
attitude or difficulty or team player? Ask for specific examples. "Please tell me when I
demonstrated a bad attitude because I really want to understand how it comes across that way".
BUT you MUST listen for the answer. If you are not willing to hear the answer and then work on
it, then the entire exercise is a waste of time. You have a right to ask for these specifics.
If your boss hesitates on giving examples, your response is then "How can I correct this issue
if I don't know what the issue is?"
... ... ...
Lastly, if all of this fails and you're not given a chance to discuss the review and you
truly believe it is wrong, ask for a meeting with HR to start that discussion. But be sure that
you come across with the desire to come to an understanding by considering all the issues
together professionally. And don't grumble and complain about it to colleagues unless everyone
else is getting the same bad review treatment. This situation is between you and your manager
and you should treat it as such or it can backfire.
If traditional performance reviews aren't officially dead, they certainly should be.
The arbitrary task of assigning some meaningless ranking number which is not connected to
anything actionable is a painful waste of everyone's time. "You look like a 3.2 today, Joe looks
like a 2.7, but Mary looks like a 4.1." In today's environment filled with knowledge workers,
such rankings are silly at best and demotivating at worst. There is no proven correlation that
such a system yields high-performance productivity results.
David Spearman ,
I operate by Crocker's Rules. Answered
Feb 26, 2015 Yes if and only if you have documentation that some factual information in the
review is false. Even then, you need to be careful to be as polite as possible. Anything else
is unlikely to get you anywhere and may make your situation much worse.
It's not MCQ type exam where u will be given options to select right one ..Rather u have to
configure everything practically. LDAP, autofs,user management,LVM . 20 questions to be
configured in exam setup
The example included some tricky details, so you can fail the first time even if you are
experience Linux sysadmin, but did not use particular daemons or functions. You should have
working knowledge about LVM, IPtables and SELinux as well as some rounting. You should practice
it over and over again until you are confident that you can take the exam.
My answer is slightly dated, I did my RHCE on RHEL4 so it is now expired. At the time, the
exam was offered as a combination RHCSA and RHCE exam, where if you received less than 80% you
received RHCSA designation and over 80%, RHCE. I took the 4 day bootcamp before the exam as my
prep. There were a range of people in the course, from yearlings like you to people with 10+
years of sysadmin work under their belt. Only 2 of us out of 7 got RHCE, although one of the
people at the exam didn't take the course (he was disappointed, as he was quite experienced and
thought he'd get the advanced cert), but everyone passed and got RHCSA at least.
The main difference between the RHCEs and the RHCSAs was speed. The test required a lot of
work to be done fast and without error. I still supervise and work with hands-on admins, and I
think if you've been working on it and do some studying you'll have no trouble with RHCSA.
They actually put us under NDA for the exam so I can't talk about what was that old one, but
it's pretty well documented what the required skills are, so just make sure you're fresh and
are ready to troubleshoot and build cleanly and quickly.
If you have any kind of background in Linux, it is not too difficult. There are a number of
books withexample test scenarios, and if you go through those and practice them for a few
evenings you will be fine.
The RHCSA questions are not terribly hard, and the exam is "performance-based," meaning you
are given tasks to accomplish on an actual RHEL system, and you are graded by the end state of
the system. If you accomplish the task, you get credit for that question. It is not a
multiple-choice exam.
Gautam K , Red Hat
Certified Engineer (RHCE)
Updated Jun 22 2016 · Author has 281 answers and 902.3k answer views
RHCSA is not so hard, but You need to know the Exam Environment.
According to my experience, You will get 20-22 questions along of these:
You need to prepare:-
File Systems User Administration Archiving (Compression) Finding & Processing Job Scheduling LVM Swap LDAP ACL Permission
Suraj Lulla , Certified RHCSA Red Hat 7,
Co-founder Websiters.in
Answered Aug 10, 2016 · Author has 65 answers and 94.3k answer views
RHCSA certification is not at all tough if you're good at handling linux. If you're good at
the following, you're ready to rock.
Resetting password of the virtual machine's user.
Changing SELinux's status (enforcing).
Creating a new kernel.
Creation of cron jobs.
Accessing directories, adding users + groups and giving them permissions via
Terminal.
NTP - your timezone.
Using yum install and vi editor.
Creating different types of compressed archives via terminal.
Time consuming ones:
LDAP
Logical volumes
Once you're fast enough on the above mentioned simple stuff, you can surely give it a
try.
I left the United States
because I married a Danish woman. We tried living in
New York, but we struggled a lot. She was not used to
being without the normal help she gets from the Danish
system. We...
(more)
Loading
I left the United States
because I married a Danish woman. We tried living in
New York, but we struggled a lot. She was not used to
being without the normal help she gets from the Danish
system. We made the move a few years ago, and right
away our lives started to improve dramatically.
Now I am working in IT,
making a great money, with private health insurance.
Yes I pay high taxes, but the benefits outweigh the
costs. The other things is that the Danish people
trust in the government and trust in each other. There
is no need for #metoo or blacklivesmatter, because the
people already treat each other with respect.
While I now enjoy an easier
life in Denmark, I sit back and watch the country I
fiercely love continue to fall to pieces because of
divisive rhetoric and the corporate greed buying out
our government.
Trump is just a symptom of
the problem. If people could live in the US as they
did 50 years ago, when a single person could take care
of their entire family, and an education didn't cost
so much, there would be no need for this revolution.
But wages have been stagnant since the 70's and the
wealth has shifted upwards from the middle class to
the top .001 percent. This has been decades in the
making. You can't blame Obama or Trump for this.
Meanwhile, I sit in Denmark
watching conservatives blame liberalism, immigrants,
poor people, and socialism, while Democrats blame
rednecks, crony capitalism, and republican greed.
Everything is now "fake news". Whether it be CNN or
FOX, no one knows who to trust anymore. Everything has
become a conspiracy. Our own president doesn't even
trust his own FBI or CIA. And he pushes conspiracy
theories to mobilize his base. I am glad to be away
from all that, and living in a much healthier
environment, where people aren't constantly attacking
one another.
Maybe if the US can get it's
healthcare and education systems together, I would
consider moving back one day. But it would also be
nice if people learned to trust one another, and trust
in the system again. Until then, I prefer to be around
emotionally intelligent people, who are objective, and
don't fall for every piece of propaganda. Not much of
that happening in America these days. The left has
gone off the deep end playing identity politics and
focusing way too much on implementing government
mandated Social Justice. Meanwhile the conservatives
are using any propaganda and lying necessary to push
their corporate backed agenda. This is all at the cost
of our environment, our free trade agreements, peace
treaties, and our European allies. Despite how much I
love my country, I breaks my heart to say, I don't see
myself returning any time soon I'm afraid.
jpk1292000
has asked for the wisdom of the Perl Monks
concerning the following question:
Hi monks, I'm new to the board and I've been struggling with this problem for some time now.
Hope someone can give me some suggestions... I am trying to read a binary file with the following format: The 4-byte
integer and (4 byte float) are in the native format of the machine.
*** First record (4 byte integer) - byte size of record (4*N) (f77 header) (4 byte float) ..
value 1 (4 byte float) .. value 2 ... (4 byte float) .. value N N = number of grid points in the field (4 byte
integer) .. byte size of record (4*N) (f77 trailer) **** Second record (4 byte integer) - byte size of record (4*N)
(f77 header) (4 byte float) .. value 1 (4 byte float) .. value 2 ... (4 byte float) .. value N N = number of grid
points in the field (4 byte integer) .. byte size of record (4*N) (f77 trailer)
[download]
The data is meteorological data (temperature in degrees K) on a 614 x 428 grid. I tried coding up a reader for this,
but am getting nonsensical results. Here is the code:
my $out_file = "/dicast2-papp/DICAST/smg_data/" . $gfn . ".bin"; #path
+
to binary file my $template = "if262792i"; #binary layout (integer 262792 floats
in
+
teger) as described in the format documentation
above (not sure if th
+
is is correct) my $record_length
= 4; #not sure what record_length is supposed to rep
+
resent
(number of values in 1st record, or should it be length of var
+
iable
[4 bytes]) my (@fields,$record); open (FH, $out_files ) || die "couldn't open $out_files\n"; until (eof(FH)) { my $val_of_read
= read (FH, $record, $record_length) == $record_
+
length
or die "short read\n"; @fields = unpack ($template, $record); print "field = $fields[0]\n"; }
[download]
The results I get when I print out the first field are non-sensical (negative numbers, etc). I think the issue is
that I'm not properly setting up my template and record length. Also, how do I find out what is "the native format of
the machine"?
You can find out more about how "read" works by reading
its documentation
.
From there, you'll find out that the third parameter (your $record_length) is the number of bytes to read
from the filehandle[1]. As your template is set up to handle all of the data for one record in one go, you'll
need to read one record's worth of data. That's 4 * (1 + 262792 + 1) bytes of data. Currently you're reading
four bytes, and the template is looking for a lot more.
If there are more pack codes or if the repeat count of a field or a group is larger than what the
remainder of the input string allows, the result is not well defined: in some cases, the repeat count is
decreased, or unpack() will produce null strings or zeroes, or terminate with an error. If the input string
is longer than one described by the TEMPLATE, the rest is ignored.
[1] Actually, the number of _characters_ but let's assume single byte characters for the time being.
Depending on your OS, another problem is the lack of
binmode
. Add
binmode(FH)
after the
open
so that Perl doesn't mess
with the data. Not all OSes require
binmode
, but it's safe to use
binmode
on all OSes.
Oh and I'd use
l
instead of
i
.
i
is not guaranteed to be 4 bytes.
jpk1292000
(Initiate)
on Nov 16, 2006 at 19:09 UTC
by
jpk1292000
(Initiate)
on Nov 16, 2006 at 19:09 UTC
Got it working. Thanks for help. My problem was two-fold. I wasn't using the correct record length, and I
wasn't using bin mode. Once I fixed these two issues, it worked.
Something like this should do it. See the docs and/or ask for anything you do not understand.
#! perl -slw use strict; my @grid; open my $fh, '<:raw', 'the file' or die $!; while( 1
) { my( $recSize, $dummy, $record ); sysread( $fh, $recSize, 4 ) or last; $recSize = unpack 'N', $recSize;
##(*) sysread( $fh, $record, $recSize ) == $recSize or die "truncated record"; sysread( $fh, $dummy, 4 ) == 4
and unpack( 'N', $dummy ) == $recSize ##(*) or die "missing or invalid trailer"; ## (*) You may need V
depending upon which platform your file was
+
created
on push @grid, [ unpack 'N*', $record ]; } close $fh; ## @grid should now contain your data ## Addressable in
the usual $grid[ X ][ Y ] manner. ## Though it might be $array[ Y ][ X ] ## I forget which order FORTRAN
writes arrays in?
[download]
Examine what is said, not who speaks -- Silence betokens consent -- Love the truth but pardon error.
Lingua non convalesco, consenesco et abolesco. -- Rule 1 has a caveat! -- Who broke the cabal?
"Science is about questioning the status quo. Questioning authority".
In the absence of evidence, opinion is indistinguishable from prejudice.
Why sysread over read? The only difference is that read is buffered, which is a good thing. I'd
replace sysread with read.
Partially habit. On my system, at least at some point in the past, the interaction between Perl
buffering and the OS caching was less productive that using the systems caching alone.
It bypasses buffered IO, so mixing this with other kinds of reads, print, write, seek, tell, or eof can
cause confusion because the perlio or stdio layers usually buffers data.
And since I used
'<:raw'
, which (as I understand it, bypasses PerlIO
layers), it seems prudent to avoid buffered IO calls.
N* for floats?
Mea culpa. The code is untested as I don't have a relevant data file, and could not mock one up because
I do not know what system it was written on.
Basically, the code I posted was intended as an example of how to proceed, not production ready
copy&paste.
I don't think a smaller than expected return value is an error. It simply means you need to call the read
function again.
I think that's true when reading from a stream device--terminal, socket or pipe--but for a disk file, if
you do not get the requested number of bytes, (I believe) it means end of file.
I'm open to correction on that, but I do not see the circumstances in which a disk read would fail to
return the requested number of bytes if they are available?
Examine what is said, not who speaks -- Silence betokens consent -- Love the truth but pardon error.
Lingua non convalesco, consenesco et abolesco. -- Rule 1 has a caveat! -- Who broke the cabal?
"Science is about questioning the status quo. Questioning authority".
In the absence of evidence, opinion is indistinguishable from prejudice.
#!/usr/bin/perl -w use strict; open FILE, 'file.bin' or die "Couldn't open file: $!\n";
binmode FILE; my $record = 1; my $buffer = ''; while ( read( FILE, $buffer, 4 ) ) { my $record_length =
unpack 'N', $buffer; my $num_fields = $record_length / 4; printf "Record %d. Number of fields = %d\n",
$record, $num_fie
+
lds; for (1 .. $num_fields ) {
read( FILE, $buffer, 4 ); my $temperature = unpack 'f', $buffer; # Or if the above gives the wrong result try
this: #my $temperature = unpack 'f', reverse $buffer; print "\t", $temperature, "\n"; } # Read but ignore
record trailer. read( FILE, $buffer, 4 ); print "\n"; $record++; } __END__
[download]
If the number of fields is wrong subtitute
unpack 'V'
for
unpack 'N'
. If the float is wrong
try the
reverse
ed value that is commented out.
Modern Perl is one way to describe the way the world's most effective Perl 5
programmers work. They use language idioms. They take advantage of the CPAN. They show good
taste and craft to write powerful, maintainable, scalable, concise, and effective code. You can
learn these skills too!
Perl first appeared in 1987 as a simple tool for system administration. Though it began by
declaring and occupying a comfortable niche between shell scripting and C programming, it has
become a powerful, general-purpose language family. Perl 5 has a solid history of pragmatism
and a bright future of polish and enhancement Perl 6 is a reinvention of programming based on
the solid principles of Perl, but it's a subject of another book.
Over Perl's long history -- especially the 17 years of Perl 5 -- our understanding of what
makes great Perl programs has changed. While you can write productive programs which never take
advantage of all the language has to offer, the global Perl community has invented, borrowed,
enhanced, and polished ideas and made them available to anyone willing to learn them.
"... temporarily changes the value of the variable ..."
"... within the scope ..."
"... Unlike dynamic variables created by the local operator, lexical variables declared with my are totally hidden from the outside world, including any called subroutines. ..."
Dynamic Scoping. It is a neat concept. Many people don't use it, or understand it.
Basically think of my as creating and anchoring a variable to one block of
{}, A.K.A. scope.
my $foo if (true); # $foo lives and dies within the if statement.
So a my variable is what you are used to. whereas with dynamic scoping $var
can be declared anywhere and used anywhere. So with local you basically suspend
the use of that global variable, and use a "local value" to work with it. So
local creates a temporary scope for a temporary variable.
The short answer is that my marks a variable as private in a lexical scope, and
local marks a variable as private in a dynamic scope.
It's easier to understand my , since that creates a local variable in the
usual sense. There is a new variable created and it's accessible only within the enclosing
lexical block, which is usually marked by curly braces. There are some exceptions to the
curly-brace rule, such as:
foreach my $x (@foo) { print "$x\n"; }
But that's just Perl doing what you mean. Normally you have something like this:
sub Foo {
my $x = shift;
print "$x\n";
}
In that case, $x is private to the subroutine and it's scope is enclosed by
the curly braces. The thing to note, and this is the contrast to local , is that
the scope of a my variable is defined with respect to your code as it is written
in the file. It's a compile-time phenomenon.
To understand local , you need to think in terms of the calling stack of your
program as it is running. When a variable is local , it is redefined from the
point at which the local statement executes for everything below that on the
stack, until you return back up the stack to the caller of the block containing the
local .
This can be confusing at first, so consider the following example.
sub foo { print "$x\n"; }
sub bar { local $x; $x = 2; foo(); }
$x = 1;
foo(); # prints '1'
bar(); # prints '2' because $x was localed in bar
foo(); # prints '1' again because local from foo is no longer in effect
When foo is called the first time, it sees the global value of
$x which is 1. When bar is called and local $x runs,
that redefines the global $x on the stack. Now when foo is called
from bar , it sees the new value of 2 for $x . So far that isn't
very special, because the same thing would have happened without the call to
local . The magic is that when bar returns we exit the dynamic
scope created by local $x and the previous global $x comes back
into scope. So for the final call of foo , $x is 1.
You will almost always want to use my , since that gives you the local
variable you're looking for. Once in a blue moon, local is really handy to do
cool things.
But local is misnamed, or at least misleadingly named. Our friend Chip Salzenberg says
that if he ever gets a chance to go back in a time machine to 1986 and give Larry one piece
of advice, he'd tell Larry to call local by the name "save" instead.[14] That's because
local actually will save the given global variable's value away, so it will later
automatically be restored to the global variable. (That's right: these so-called "local"
variables are actually globals!) This save-and-restore mechanism is the same one we've
already seen twice now, in the control variable of a foreach loop, and in the @_ array of
subroutine parameters.
So, local saves a global variable's current value and then set it to some
form of empty value. You'll often see it used to slurp an entire file, rather than leading
just a line:
my $file_content;
{
local $/;
open IN, "foo.txt";
$file_content = <IN>;
}
Calling local $/ sets the input record separator (the value that Perl stops
reading a "line" at) to an empty value, causing the spaceship operator to read the entire
file, so it never hits the input record separator.
Word of warning: both of these articles are quite old, and the second one (by the author's
own warning) is obsolete. It demonstrates techniques for localization of file handles that
have been superseded by lexical file handles in modern versions of Perl. – dan1111
Jan 28 '13 at 11:21
Unlike dynamic variables created by the local operator, lexical variables declared with
my are totally hidden from the outside world, including any called subroutines. This is
true if it's the same subroutine called from itself or elsewhere--every call gets its own
copy.
A local modifies its listed variables to be "local" to the enclosing block, eval, or do
FILE --and to any subroutine called from within that block. A local just gives temporary
values to global (meaning package) variables. It does not create a local variable. This is
known as dynamic scoping. Lexical scoping is done with my, which works more like C's auto
declarations.
I don't think this is at all unclear, other than to say that by "local to the enclosing
block", what it means is that the original value is restored when the block is exited.
While this may be true, it's basically a side effect of the fact that "local"s are intended
to be visible down the callstack, while "my"s are not. And while overriding the value of a
global may be the main reason for using "local", there's no reason you can't use "local" to
define a new variable. – Kevin Crumley
Sep 24 '08 at 20:27
local does not actually define a new variable. For example, try using local to define a
variable when option explicit is enabled. You need to use "our" or "my" to define a new
global or local variable. "local" is correctly used to give a variable a new value –
1800
INFORMATION
Jan 21 '09 at 10:02
Jesus did I really say option explicit to refer to the Perl feature. I meant obviously "use
strict". I've obviously not coded in Perl in a while – 1800 INFORMATION
Jan 29 '09 at 10:45
Unlike dynamic variables created by the local operator, lexical variables declared
with my are totally hidden from the outside world, including any called subroutines.
So, oversimplifying, my makes your variable visible only where it's declared.
local makes it visible down the call stack too. You will usually want to use
my instead of local .
Your confusion is understandable. Lexical scoping is fairly easy to understand but dynamic
scoping is an unusual concept. The situation is made worse by the names my and
local being somewhat inaccurate (or at least unintuitive) for historical
reasons.
my declares a lexical variable -- one that is visible from the point of
declaration until the end of the enclosing block (or file). It is completely independent from
any other variables with the same name in the rest of the program. It is private to that
block.
local , on the other hand, declares a temporary change to the value of a
global variable. The change ends at the end of the enclosing scope, but the variable -- being
global -- is visible anywhere in the program.
As a rule of thumb, use my to declare your own variables and
local to control the impact of changes to Perl's built-in variables.
For a more thorough description see Mark Jason Dominus' article Coping with Scoping .
local is an older method of localization, from the times when Perl had only dynamic scoping.
Lexical scoping is much more natural for the programmer and much safer in many situations. my
variables belong to the scope (block, package, or file) in which they are declared.
local variables instead actually belong to a global namespace. If you refer to a variable
$x with local, you are actually referring to $main::x, which is a global variable. Contrary
to what it's name implies, all local does is push a new value onto a stack of values for
$main::x until the end of this block, at which time the old value will be restored. That's a
useful feature in and of itself, but it's not a good way to have local variables for a host
of reasons (think what happens when you have threads! and think what happens when you call a
routine that genuinely wants to use a global that you have localized!). However, it was the
only way to have variables that looked like local variables back in the bad old days before
Perl 5. We're still stuck with it.
"my" variables are visible in the current code block only. "local" variables are also visible
where ever they were visible before. For example, if you say "my $x;" and call a
sub-function, it cannot see that variable $x. But if you say "local $/;" (to null out the
value of the record separator) then you change the way reading from files works in any
functions you call.
In practice, you almost always want "my", not "local".
dinomite's example of using local to redefine the record delimiter is the only time I have
ran across in a lot of perl programming. I live in a niche perl environment [security
programming], but it really is a rarely used scope in my experience.
I have a variable $x which currently has a local scope in A.pm and I want to use the output
of $x (which is usually PASSED/FAILED) in an if else statement in B.pm
Something like below
A.pm:
if (condition1) { $x = 'PASSED'; }
if (condition2) { $x = 'FAILED'; }
B.pm:
if ($x=='PASSED') { $y=1; } else { $y=0; }
I tried using require ("A.pm"); in B.pm but it gives me an error global
symbol requires an explicit package name which means it is not able to read the
variable from require. Any inputs would help
This sounds like a very strange configuration. Your A.pm has executable code as
well as values that you want to access externally. Is that code in subroutines? Are you
aware that any code outside a subroutine will be executed the first time the external
code requires the file? You need to show us the contents of A.pm or
we can't help you much. – Borodin
Apr 3 '14 at 17:27
Normally, you'd return $x from a function defined in A and called in B; this is
a much cleaner, less pathological way of getting at the information. – Jonathan Leffler
Apr 3 '14 at 17:29
Yes the above if conditions in A.pm are in a subroutine. Is there a way I could read that
subroutine outside to extract the value of $x? – Rancho
Apr 3 '14 at 17:41
I have a variable $x which currently has a local scope in A.pm and I want to use the
output of $x (which is usually PASSED/FAILED) in an if else statement in B.pm
We could show you how to do this, but this is a really bad, awful idea.
There's a reason why variables are scoped, and even global variables declared
with our and not my are still scoped to a particular package.
Imagine someone modifying one of your packages, and not realizing there's a direct
connection to a variable name $x . They could end up making a big mess without
even knowing why.
What I would HIGHLY recommend is that you use functions (subroutines) to pass
around the value you need:
Local/A.pm
package Local::A;
use strict;
use warnings;
use lib qw($ENV{HOME});
use Exporter qw(import);
our @EXPORT_OK = qw(set_condition);
sub set_condition {
if ( condition1 ) {
return "PASSED";
elsif ( condition2 ) {
return "FALSED";
else {
return "Huh?";
}
1;
Here's what I did:
I can't use B as a module name because that's an actual module. Therefore,
I used Local::B and Local::A instead. The Local
module namespace is undefined in CPAN and never used. You can always declare your own
modules under this module namespace.
The use lib allows me to specify where to find my modules.
The package command gives this module a completely separate namespace.
This way, variables in A.pm don't affect B.pm .
use Exporter allows me to export subroutines from one module to
another. @EXPORT_OK are the names of the subroutines I want to export.
Finally, there's a subroutine that runs my test for me. Instead of setting a variable
in A.pm , I return the value from this subroutine.
Check your logic. Your logic is set that $x isn't set if neither condition
is true. You probably don't want that.
Your module can't return a zero as the last value. Thus, it's common to always put
1; as the last line of a module.
Local/B.pm
package Local::B;
use lib qw($ENV{HOME});
use Local::A qw(set_condition);
my $condition = set_contition();
my $y;
if ( $condition eq 'PASSED' ) { # Note: Use `eq` and not `==` because THIS IS A STRING!
$y = 1;
else {
$y = 0;
}
1;
Again, I define a separate module namespace with package .
I use Local::A qw(set_condition); to export my set_condition
subroutine into B.pm . Now, I can call this subroutine without prefixing it
with Local::A all of the time.
I set a locally scoped variable called $condition to the status of my
condition.
Now, I can set $y from the results of the subroutine
set_condition . No messy need to export variables from one package to
another.
If all of this looks like mysterious magic, you need to read about Perl modules . This isn't light summer
reading. It can be a bit impenetrable, but it's definitely worth the struggle. Or, get
Learning Perl
and read up on Chapter 11.
print "$Robert has canned $name's sorry butt\n"; I tried running this in PERL and it yelled
at me saying that it didn't like $name::s. I changed this line of code to: print "$Robert has
canned $name sorry butt\n"; And it worked fine 0_o An error in the tutorial perhaps?
Aristotle (Chancellor)
on Dec 24, 2004 at 01:50 UTC
by Aristotle (Chancellor) on
Dec 24, 2004 at 01:50 UTC
Try
print "$Robert has canned ${name}'s sorry butt\n";[download]
The apostrophe is the old-style package separator, still supported, so $name's
is indeed equivalent to $name::s . By putting the curlies in there, you tell Perl
exactly which part of the string to consider part of the variable name, and which part to
consider a literal value.
#!/usr/local/bin/perl use strict;
foreach my $name ('A', 'B') { my $res = 'Init' if (0); if (defined ($res)) { print "$name: res
= $res\n"; } else { print "$name: res is undef\n" } $res = 'Post'; }[download]
Result:
A: res is undef
B: res = Post
As $res is under lexical variable scope, shouldn't it disappear at the bottom of the
block
and be recreated by the second pass, producing an identical result?
Bug? Feature? Saving CPU?
perl -v
This is perl, v5.10.1 (*) built for x86_64-linux-thread-multi
NOTE: The behaviour of a my , state , or our modified
with a statement modifier conditional or loop construct (for example, my $x if ...
) is undefined . The value of the my variable may be undef , any
previously assigned value, or possibly anything else. Don't rely on it. Future versions of
perl might do something different from the version of perl you try it out on. Here be
dragons.
Update: Heh, Eily and
I posted within 4 seconds of another ;-)
BEGIN { my $static_val = 0; sub gimme_another { return
++$static_val; } } # - OR - in Perl >=5.10: use feature 'state'; sub gimme_another { state
$static_val = 0; return ++$static_val; }[download]
$ perl -e 'my $x if
0' Deprecated use of my() in false conditional. This will be a fatal erro r in Perl 5.30 at
-e line 1.[download]
Update 3: Apparently, the warning " Deprecated use of my() in false
conditional " first showed up in Perl 5.10 and became a default warning in 5.12. Note
that your Perl 5.10.1 is now more than eight years old, and you should upgrade. Also, you
should generally use warnings; ( Use strict and warnings ).
NOTE: The behaviour of a my, state, or our modified with a statement modifier conditional
or loop construct (for example, my $x if ... ) is undefined. The value of the my variable
may be undef, any previously assigned value, or possibly anything else. Don't rely on it.
Future versions of perl might do something different from the version of perl you try it
out on. Here be dragons.
So neither bug nor feature, third option.
AnomalousMonk
(Chancellor) on Nov 10, 2017 at 17:07 UTC
I'm new to Perl programming. I've noticed that every time I want to declare a new variable, I
should use the my keyword before that variable if strict and
warnings are on (which I was told to do, for reasons also I do not know.)
So how to declare a variable in perl without using my and without getting
warnings?
My question is: Is it possible to declare a variable without using my and
without omitting the use strict; and use warnings; and without
getting warnings at all?
checklist
of tips and techniques to get you started.
This list is meant for debugging some of the most common Perl programming problems; it
assumes no prior working experience with the Perl debugger ( perldebtut ). Think of it as a First Aid kit,
rather than a fully-staffed state-of-the-art operating room.
These tips are meant to act as a guide to help you answer the following questions:
Are you sure your data is what you think it is?
Are you sure your code is what you think it is?
Are you inadvertently ignoring error and warning messages?
Display the contents of variables using print or warnwarn "$var\n"; print "@things\n";
# array with spaces between elements[download]
Check for unexpected whitespace
chomp , then print with
delimiters of your choice, such as colons or balanced brackets, for visibility chomp
$var; print ">>>$var<<<\n";[download]
Check for unprintable characters by converting them into their ASCII hex codes using
ordmy $copy = $str; $copy =~ s/([^\x20-\x7E])/sprintf '\x{%02x}', ord $1/eg; print
":$copy:\n";[download]
Dump arrays,
hashes and arbitrarily complex data structures. You can get started using the core module
Data::Dumper . Should
the output prove to be unsuitable to you, other alternatives can be downloaded from CPAN,
such as Data::Dump , YAML , or JSON . See also How can I visualize my complex data structure?use Data::Dumper; print Dumper(\%hash); print Dumper($ref);[download]
If you were expecting a ref erence, make sure it is the
right kind (ARRAY, HASH, etc.) print ref $ref, "\n";[download]
Check to see if your code is what you thought it was: B::Deparse$ perl -MO=Deparse -p
program.pl[download]
Check the return ( error ) status of your commands
open with $!open my $fh,
'<', 'foo.txt' or die "can not open foo.txt: $!";[download]
system and backticks (
qx )
with $?if (system $cmd) {
print "Error: $? for command $cmd" } else { print "Command $cmd is OK" } $out = `$cmd`;
print $? if $?;[download]
Demystify regular expressions by installing and using the CPAN module YAPE::Regex::Explain# what the heck does /^\s+$/ mean? use YAPE::Regex::Explain; print
YAPE::Regex::Explain->new('/^\s+$/')->explain();[download]
Neaten up your code by installing and using the CPAN script perltidy . Poor indentation can often obscure
problems.
Checklist for debugging when using CPAN modules:
Check the Bug List by following the module's "View Bugs" link.
Is your installed version the latest version? If not, check the change log by
following the "Changes" link. Also follow the "Other Tools" link to "Diff" and "Grep" the
release.
If a module provides status methods, check them in your code as you would check
return status of built-in functions: use WWW::Mechanize; if ($mech->success()) {
... }[download]
What's next? If you are not already doing so, use an editor that understands Perl syntax
(such as vim or emacs), a GUI debugger (such as Devel::ptkdb ) or use a full-blown IDE.
Lastly, use a version control system so that you can fearlessly make these temporary hacks to
your code without trashing the real thing.
Damned decent posting :D ... just a couple of suggestions tho'...
Step 5 - Use a stringified ref. to provide straightforward visual comparison of 2, or
more, ref.s - I've recently been using this to verify that a ref. in 2 different places is
actually the same object.
Step 7 - add use autodie; to provide default exception throwing on
failure
Step 7 & 8 - add use CGI::Carp; for CGI/WWW scripts
Your final observation WRT IDEs etc. could, IMHO, suggest that the use of Eclipse, for
perl dev't, isn't for the fainthearted...
When debugging warnings from the perl core like Use of uninitialized value ... let
the debugger pause right there. Then have a good look at the context that led to this
situation and investigate variables and the callstack.
To let the debugger do this automatically I use a debugger customization script:
sub afterinit
{
$::SIG{'__WARN__'} = sub {
my $warning = shift;
if ( $warning =~ m{\s at \s \S+ \s line \s \d+ \. $}xms ) {
$DB::single = 1; # debugger stops here automatically
}
warn $warning;
};
print "sigwarn handler installed!\n";
return;
}
Save the content to file .perldb (or perldb.ini on Windows) and place it in
the current or in your HOME directory.
The subroutine will be called initially by the debugger and installs a signal handler for
all warnings. If the format matches one from the perl core, execution in the debugger is
paused by setting $DB::single = 1 .
If you don't quite understand what you're looking at (output of deparse, perl syntax),
then ppi_dumper can help
you look at the right part of the manual, an example
The package directive sets the namespace. As such, the namespace is also called
the package.
Perl doesn't have a formal definition of module. There's a lot of variance, but the
following holds for a huge majority of modules:
A file with a .pm extension.
The file contains a single package declaration that covers the entirety of
the code. (But see below.)
The file is named based on the namespace named by that package .
The file is expected to return a true value when executed.
The file is expected to be executed no more than once per interpreter.
It's not uncommon to encounter .pm files with multiple packages. Whether
that's a single module, multiple modules or both is up for debate.
Namespace is a general computing term meaning a container for a distinct set of
identifiers. The same identifier can appear independently in different namespaces and refer
to different objects, and a fully-qualified identifier which unambiguously identifies an
object consists of the namespace plus the identifier.
Perl implements namespaces using the package keyword.
A Perl module is a different thing altogether. It is a piece of Perl code that
can be incorporated into any program with the use keyword. The filename should
end with .pm - for erl odule - and the code it contains should have a
package statement using a package name that is equivalent to the file's name,
including its path. For instance, a module written in a file called
My/Useful/Module.pm should have a package statement like
package My::Useful::Module .
What you may have been thinking of is a class which, again, is a general
computing term, this time meaning a type of object-oriented data. Perl uses its packages as
class names, and an object-oriented module will have a constructor subroutine -
usually called new - that will return a reference to data that has been
blessed to make it behave in
an object-oriented fashion. By no means all Perl modules are object-oriented ones: some can
be simple libraries of subroutines.
1 does not matter. It can be 2 , it can be "foo" , it
can be ["a", "list"] . What matters is it's not 0 , or anything
else that evaluates as false, or use would fail. – Amadan
Aug 4 '10 at 5:32
.pl is actually a perl library - perl scripts, like C programs or programs written in other
languages, do not have an ending, except on operating systems that need one to functiopn,
such as windows. – Marc Lehmann
Oct 16 '15 at 22:08
At the very core, the file extension you use makes no difference as to how perl
interprets those files.
However, putting modules in .pm files following a certain directory structure
that follows the package name provides a convenience. So, if you have a module
Example::Plot::FourD and you put it in a directory
Example/Plot/FourD.pm in a path in your @INC , then use and require will do the
right thing when given the package name as in use Example::Plot::FourD .
The file must return true as the last statement to indicate successful execution of any
initialization code, so it's customary to end such a file with 1; unless
you're sure it'll return true otherwise. But it's better just to put the 1; ,
in case you add more statements.
If EXPR is a bareword, the require assumes a ".pm" extension
and replaces "::" with "/" in the filename for you, to make it easy to load standard
modules. This form of loading of modules does not risk altering your namespace.
All use does is to figure out the filename from the package name provided,
require it in a BEGIN block and invoke import on the
package. There is nothing preventing you from not using use but taking those
steps manually.
For example, below I put the Example::Plot::FourD package in a file called
t.pl , loaded it in a script in file s.pl .
C:\Temp> cat t.pl
package Example::Plot::FourD;
use strict; use warnings;
sub new { bless {} => shift }
sub something { print "something\n" }
"Example::Plot::FourD"
C:\Temp> cat s.pl
#!/usr/bin/perl
use strict; use warnings;
BEGIN {
require 't.pl';
}
my $p = Example::Plot::FourD->new;
$p->something;
C:\Temp> s
something
This example shows that module files do not have to end in 1 , any true value
will do.
In .pm ( Perl Module ) you have
functions that you can use from other Perl scripts:
A Perl module is a self-contained piece of Perl code that can be used by a Perl program
or by other Perl modules. It is conceptually similar to a C link library, or a C++
class.
"A .pl is a single script." Not true. It's only on broken operating systems that you need to
identify Perl programs with a .pl extension. And originally .pl indicated a "Perl library" -
external subroutines that you loaded with a "require" or "do" command. – Dave Cross
Sep 17 '10 at 9:37
Great question: How does our differ from my and what
does our do?
In Summary:
Available since Perl 5, my is a way to declare:
non-package variables, that are
private,
new ,
non-global variables,
separate from any package. So that the variable cannot be accessed in the form
of $package_name::variable .
On the other hand, our variables are:
package variables, and thus automatically
global variables,
definitely not private ,
nor are they necessarily new; and they
can be accessed outside the package (or lexical scope) with the qualified namespace,
as $package_name::variable .
Declaring a variable with our allows you to predeclare variables in order
to use them under use strict without getting typo warnings or compile-time
errors. Since Perl 5.6, it has replaced the obsolete use vars , which was
only file-scoped, and not lexically scoped as is our
For example, the formal, qualified name for variable $x inside package main
is $main::x . Declaring our $x allows you to use the bare
$x variable without penalty (i.e., without a resulting error), in the scope of the
declaration, when the script uses use strict or use strict "vars"
. The scope might be one, or two, or more packages, or one small block.
@Nathan Fellman, local doesn't create variables. It doesn't relate to my
and our at all. local temporarily backs up the value of variable and
clears its current value. �
ikegami
Sep 21 '11 at 16:57
our variables are not package variables. They aren't globally-scoped, but lexically-scoped
variables just like my variables. You can see that in the following program:
package Foo; our $x = 123; package Bar; say $x; . If you want to "declare" a package
variable, you need to use use vars qw( $x ); . our $x; declares a lexically-scoped
variable that is aliased to the same-named variable in the package in which the our
was compiled. � ikegami
Nov 20 '16 at 1:15
The PerlMonks and PerlDoc links from cartman and Olafur are a great reference - below is my crack
at a summary:
my variables are lexically scoped within a single block defined by {}
or within the same file if not in {} s. They are not accessible from packages/subroutines
defined outside of the same lexical scope / block.
our variables are scoped within a package/file and accessible from any code that
use or require that package/file - name conflicts are resolved between
packages by prepending the appropriate namespace.
Just to round it out, local variables are "dynamically" scoped, differing from
my variables in that they are also accessible from subroutines called within the
same block.
use strict;
for (1 .. 2){
# Both variables are lexically scoped to the block.
our ($o); # Belongs to 'main' package.
my ($m); # Does not belong to a package.
# The variables differ with respect to newness.
$o ++;
$m ++;
print __PACKAGE__, " >> o=$o m=$m\n"; # $m is always 1.
# The package has changed, but we still have direct,
# unqualified access to both variables, because the
# lexical scope has not changed.
package Fubb;
print __PACKAGE__, " >> o=$o m=$m\n";
}
# The our() and my() variables differ with respect to privacy.
# We can still access the variable declared with our(), provided
# that we fully qualify its name, but the variable declared
# with my() is unavailable.
print __PACKAGE__, " >> main::o=$main::o\n"; # 2
print __PACKAGE__, " >> main::m=$main::m\n"; # Undefined.
# Attempts to access the variables directly won't compile.
# print __PACKAGE__, " >> o=$o\n";
# print __PACKAGE__, " >> m=$m\n";
# Variables declared with use vars() are like those declared
# with our(): belong to a package; not private; and not new.
# However, their scoping is package-based rather than lexical.
for (1 .. 9){
use vars qw($uv);
$uv ++;
}
# Even though we are outside the lexical scope where the
# use vars() variable was declared, we have direct access
# because the package has not changed.
print __PACKAGE__, " >> uv=$uv\n";
# And we can access it from another package.
package Bubb;
print __PACKAGE__, " >> main::uv=$main::uv\n";
Coping with Scoping
is a good overview of Perl scoping rules. It's old enough that our is not discussed
in the body of the text. It is addressed in the Notes section at the end.
The article talks about package variables and dynamic scope and how that differs from lexical
variables and lexical scope.
Be careful tossing around the words local and global. The proper terms are lexical and package.
You can't create true global variables in Perl, but some already exist like $_, and local refers
to package variables with localized values (created by local), not to lexical variables (created
with my). � Chas. Owens
May 11 '09 at 0:16
It's an old question, but I ever met some pitfalls about lexical declarations in Perl that messed
me up, which are also related to this question, so I just add my summary here:
1. definition or declaration?
local $var = 42;
print "var: $var\n";
The output is var: 42 . However we couldn't tell if local $var = 42;
is a definition or declaration. But how about this:
use strict;
use warnings;
local $var = 42;
print "var: $var\n";
The second program will throw an error:
Global symbol "$var" requires explicit package name.
$var is not defined, which means local $var; is just a declaration!
Before using local to declare a variable, make sure that it is defined as a global
variable previously.
But why this won't fail?
use strict;
use warnings;
local $a = 42;
print "var: $a\n";
The output is: var: 42 .
That's because $a , as well as $b , is a global variable pre-defined
in Perl. Remember the sort
function?
2. lexical or global?
I was a C programmer before starting using Perl, so the concept of lexical and global variables
seems straightforward to me: just corresponds to auto and external variables in C. But there're
small differences:
In C, an external variable is a variable defined outside any function block. On the other hand,
an automatic variable is a variable defined inside a function block. Like this:
int global;
int main(void) {
int local;
}
While in Perl, things are subtle:
sub main {
$var = 42;
}
&main;
print "var: $var\n";
The output is var: 42 , $var is a global variable even it's defined
in a function block! Actually in Perl, any variable is declared as global by default.
The lesson is to always add use strict; use warnings; at the beginning of a Perl
program, which will force the programmer to declare the lexical variable explicitly, so that we
don't get messed up by some mistakes taken for granted.
Unlike my, which both allocates storage for a variable and associates a simple name with
that storage for use within the current scope, our associates a simple name with a package
variable in the current package, for use within the current scope. In other words, our has
the same scoping rules as my, but does not necessarily create a variable.
This is only somewhat related to the question, but I've just discovered a (to me) obscure bit
of perl syntax that you can use with "our" (package) variables that you can't use with "my" (local)
variables.
Not so. $foo ${foo} ${'foo'} ${"foo"} all work the same for variable assignment or dereferencing.
Swapping the our in the above example for my does work. What you probably experienced
was trying to dereference $foo as a package variable, such as $main::foo or $::foo which will
only work for package globals, such as those defined with our . �
Cosmicnet
Oct 21 '14 at 14:08
My test (on windows): perl -e "my $foo = 'bar'; print $foo; ${foo} = 'baz'; pr int $foo"
output: barbazperl -e "my $foo = 'bar'; print $foo; ${"foo"} = 'baz'; print
$foo" output: barbazperl -e "my $foo = 'bar'; print $foo; ${\"foo\"}
= 'baz'; print $foo" output: barbar So in my testing I'd fallen into the same
trap. ${foo} is the same as $foo, the brackets are useful when interpolating. ${"foo"} is actually
a look up to $main::{} which is the main symbol table, as such only contains package scoped variables.
� Cosmicnet
Nov 22 '14 at 13:44
${"main::foo"}, ${"::foo"}, and $main::foo are the same as ${"foo"}. The shorthand is package
sensitive perl -e "package test; our $foo = 'bar'; print $foo; ${\"foo\"} = 'baz'; print
$foo" works, as in this context ${"foo"} is now equal to ${"test::foo"}.
Of Symbol Tables and Globs
has some information on it, as does the Advanced Perl programming book. Sorry for my previous
mistake. � Cosmicnet
Nov 22 '14 at 13:57
print "package is: " . __PACKAGE__ . "\n";
our $test = 1;
print "trying to print global var from main package: $test\n";
package Changed;
{
my $test = 10;
my $test1 = 11;
print "trying to print local vars from a closed block: $test, $test1\n";
}
&Check_global;
sub Check_global {
print "trying to print global var from a function: $test\n";
}
print "package is: " . __PACKAGE__ . "\n";
print "trying to print global var outside the func and from \"Changed\" package: $test\n";
print "trying to print local var outside the block $test1\n";
Will Output this:
package is: main
trying to print global var from main package: 1
trying to print local vars from a closed block: 10, 11
trying to print global var from a function: 1
package is: Changed
trying to print global var outside the func and from "Changed" package: 1
trying to print local var outside the block
In case using "use strict" will get this failure while attempting to run the script:
Global symbol "$test1" requires explicit package name at ./check_global.pl line 24.
Execution of ./check_global.pl aborted due to compilation errors.
in simple words: Our (as the name sais) is a variable decliration to use that variable from any
place in the script (function, block etc ...), every variable by default (in case not declared)
belong to "main" package, our variable still can be used even after decliration of another package
in the script. "my" variable in case declared in a block or function, can be used in that block/function
only. in case "my" variable was declared not closed in a block, it can be used any where in the
scriot, in a closed block as well or in a function as "our" variable, but can't used in case package
changed � Lavi
Buchnik
Sep 6 '14 at 20:08
My script above shows that by default we are in the "main" package, then the script print an "our"
variable from "main" package (not closed in a block), then we declare two "my" variables in a
function and print them from that function. then we print an "our" variable from another function
to show it can be used in a function. then we changing the package to "changed" (not "main" no
more), and we print again the "our" variable successfully. then trying to print a "my" variable
outside of the function and failed. the script just showing the difference between "our" and "my"
usage. � Lavi Buchnik
Sep 6 '14 at 20:13
#!/usr/local/bin/perl
use feature ':5.10';
#use warnings;
package a;
{
my $b = 100;
our $a = 10;
print "$a \n";
print "$b \n";
}
package b;
#my $b = 200;
#our $a = 20 ;
print "in package b value of my b $a::b \n";
print "in package b value of our a $a::a \n";
This explains the difference between my and our. The my variable goes out of scope outside the
curly braces and is garbage collected but the our variable still lives. �
Yugdev
Nov 5 '15 at 14:03
#!/usr/bin/perl -l
use strict;
# if string below commented out, prints 'lol' , if the string enabled, prints 'eeeeeeeee'
#my $lol = 'eeeeeeeeeee' ;
# no errors or warnings at any case, despite of 'strict'
our $lol = eval {$lol} || 'lol' ;
print $lol;
Can you explain what this code is meant to demonstrate? Why are our and my
different? How does this example show it? �
Nathan Fellman
May 16 '13 at 11:07
Let us think what an interpreter actually is: it's a piece of code that stores values in memory
and lets the instructions in a program that it interprets access those values by their names,
which are specified inside these instructions. So, the big job of an interpreter is to shape the
rules of how we should use the names in those instructions to access the values that the interpreter
stores.
On encountering "my", the interpreter creates a lexical variable: a named value that the interpreter
can access only while it executes a block, and only from within that syntactic block. On encountering
"our", the interpreter makes a lexical alias of a package variable: it binds a name, which the
interpreter is supposed from then on to process as a lexical variable's name, until the block
is finished, to the value of the package variable with the same name.
The effect is that you can then pretend that you're using a lexical variable and bypass the
rules of 'use strict' on full qualification of package variables. Since the interpreter automatically
creates package variables when they are first used, the side effect of using "our" may also be
that the interpreter creates a package variable as well. In this case, two things are created:
a package variable, which the interpreter can access from everywhere, provided it's properly designated
as requested by 'use strict' (prepended with the name of its package and two colons), and
its lexical alias.
"... Perl version 5.10 of Perl was released on the 20th anniversary of Perl 1.0: December 18, 2007. Version 5.10 marks the start of the "Modern Perl" movement. ..."
Larry Wall released Perl 1.0 to the comp.sources.misc Usenet newsgroup on December 18, 1987. In
the nearly 30 years since then, both the language and the community of enthusiasts that sprung up
around it have grown and thrived -- and they continue to do so, despite suggestions to the contrary!
Wall's fundamental assertion -- there is more than one way to do it -- continues to resonate
with developers. Perl allows programmers to embody the three chief virtues of a programmer: laziness,
impatience, and hubris. Perl was originally designed for utility, not beauty. Perl is a programming
language for fixing things, for quick hacks, and for making complicated things possible partly through
the power of community. This was a conscious decision on Larry Wall's part: In an interview in 1999,
he posed the question, "When's the last time you used duct tape on a duct?"
A history lesson
Perl 1.0 - Perl 4.036 Perl allows programmers to embody the three chief virtues of
a programmer: laziness, impatience, and hubris. Larry Wall developed the first Perl interpreter
and language while working for System Development Corporation, later a part of Unisys. Early releases
focused on the tools needed for the system engineering problems that he was trying to solve. Perl
2's release in 1988 made improvements on the regular expression engine. Perl 3, in 1989, added
support for binary data streams. In March of 1991, Perl 4 was released, along with the first edition
of Programming
Perl , by Larry Wall and Randal L. Schwartz. Prior to Perl 4, the documentation for Perl
had been maintained in a single document, but the O'Reilly-published "Camel Book," as it is called,
continues to be the canonical reference for the Perl language. As Perl has changed over the years,
Programming Perl has been updated, and it is now in its fourth edition.
Early Perl 5 Perl 5.000, released on October 17, 1994, was a nearly complete rewrite
of the interpreter. New features included objects, references, lexical variables, and the use
of external, reusable modules. This new modularity provides a tool for growing the language without
modifying the underlying interpreter. Perl 5.004 introduced CGI.pm, which contributed to its use
as an early scripting language for the internet. Many Perl-driven internet applications and sites
still in use today emerged about this time, including IMDB, Craigslist, Bugzilla, and cPanel.
Modern Perl 5Perl version 5.10 of Perl was released on the 20th anniversary of
Perl 1.0: December 18, 2007. Version 5.10 marks the start of the "Modern Perl" movement.
Modern Perl is a style of development that takes advantage of the newest language features, places
a high importance on readable code, encourages testing, and relies heavily on the use of the CPAN
ecosystem of contributed code. Development of Perl 5 continues along more modern lines, with attention
in recent years to Unicode compatibility, JSON support, and other useful features for object-oriented
coders.
... ... ...
The Perl community
... ... ...
Perl Mongers In 1997, a group of Perl enthusiasts from the New York City area met at
the first O'Reilly Perl Conference (which later became OSCON), and formed the New York Perl Mongers,
or NY.pm
. The ".pm" suffix for Perl Mongers groups is a play on the fact that shared-code Perl files are
suffixed .pm, for "Perl module." The Perl Mongers
organization has, for the past 20 years, provided a framework for the foundation and nurturing
of local user groups all over the world and currently boasts of 250 Perl monger groups. Individual
groups, or groups working as a team, sponsor and host conferences, hackathons, and workshops from
time to time, as well as local meetings for technical and social discussions.
PerlMonks Have a question? Want to read the wisdom of some of the gurus of Perl? Check
out PerlMonks . You'll find numerous tutorials,
a venue to ask questions and get answers from the community, along with lighthearted bits about
Perl and the Perl community. The software that drives PerlMonks is getting a little long in the
tooth, but the community continues to thrive, with new posts daily and a humorous take on the
religious fervor that developers express about their favorite languages. As you participate, you
gain points and levels
. The Meditations contains
discussions about Perl, hacker culture, or other related things; some include suggestions and
ideas for new features.
... ... ...
As Perl turns 30, the community that emerged around Larry Wall's solution to sticky system administration
problems continues to grow and thrive. New developers enter the community all the time, and substantial
new work is being done to modernize the language and keep it useful for solving a new generation
of problems. Interested? Find your local Perl Mongers group, or join us online, or attend a Perl
Conference near you!
Ruth Holloway - Ruth Holloway has been a system administrator and software developer for
a long, long time, getting her professional start on a VAX 11/780, way back when. She spent a lot
of her career (so far) serving the technology needs of libraries, and has been a contributor since
2008 to the Koha open source library automation suite.Ruth is currently a Perl Developer at cPanel
in Houston, and also serves as chief of staff for an obnoxious cat. In her copious free time, she
occasionally reviews old romance... "
The author pays outsize attention to superficial things like popularity with particular
groups of users. For sysadmin this matter less then the the level of integration with the underling
OS and the quality of the debugger.
The real story is that Python has less steep initial learning curve and that helped to entrenched
it in universities. Students brought it to large companies like Red Hat. The rest is history. Google support also was a positive factor.
Python also basked in OO hype. So this is more widespread language now much like Microsoft
Basic. That does not automatically makes it a better language in sysadmin domain.
The phase " Perl's quirky stylistic conventions, such as using $ in front to declare
variables, are in contrast for the other declarative symbol $ for practical programmers today�the
money that goes into the continued development and feature set of Perl's frenemies such as Python
and Ruby." smells with "syntax junkie" mentality. What wrong with dereferencing using $ symbol?
yes it creates problem if you are using simultaneously other languages like C or Python, but for
experienced programmer this is a minor thing. Yes Perl has some questionable syntax choices so so
are any other language in existence. While painful, it is the semantic and "programming
environment" that mater most.
My impression is that Perl returned to its roots -- migrated back to being an
excellent sysadmin tool -- as there is strong synergy between Perl and Unix shells. The fact
that Perl 5 is reasonably stable is a huge plus in this area.
Notable quotes:
"... By the late 2000s Python was not only the dominant alternative to Perl for many text parsing tasks typically associated with Perl (i.e. regular expressions in the field of bioinformatics ) but it was also the most proclaimed popular language , talked about with elegance and eloquence among my circle of campus friends, who liked being part of an up-and-coming movement. ..."
"... Others point out that Perl is left out of the languages to learn first �in an era where Python and Java had grown enormously, and a new entrant from the mid-2000s, Ruby, continues to gain ground by attracting new users in the web application arena (via Rails ), followed by the Django framework in Python (PHP has remained stable as the simplest option as well). ..."
"... In bioinformatics, where Perl's position as the most popular scripting language powered many 1990s breakthroughs like genetic sequencing, Perl has been supplanted by Python and the statistical language R (a variant of S-plus and descendent of S , also developed in the 1980s). ..."
"... By 2013, Python was the language of choice in academia, where I was to return for a year, and whatever it lacked in OOP classes, it made up for in college classes. Python was like Google, who helped spread Python and employed van Rossum for many years. Meanwhile, its adversary Yahoo (largely developed in Perl ) did well, but comparatively fell further behind in defining the future of programming. Python was the favorite and the incumbent; roles had been reversed. ..."
"... from my experience? Perl's eventual problem is that if the Perl community cannot attract beginner users like Python successfully has ..."
"... The fact that you have to import a library, or put up with some extra syntax, is significantly easier than the transactional cost of learning a new language and switching to it. ..."
"... MIT Python replaced Scheme as the first language of instruction for all incoming freshman, in the mid-2000s ..."
I first heard of Perl when I was in middle school in the early
2000s. It was one of the world's most versatile programming languages, dubbed the
Swiss army knife of the Internet.
But compared to its rival Python, Perl has faded from popularity. What happened to the web's most
promising language? Perl's low entry barrier compared to compiled, lower level language alternatives
(namely, C) meant that Perl attracted users without a formal CS background (read: script kiddies
and beginners who wrote poor code). It also boasted a small group of power users ("hardcore hackers")
who could quickly and flexibly write powerful, dense programs that fueled Perl's popularity to a
new generation of programmers.
A central repository (the Comprehensive Perl Archive Network, or
CPAN ) meant that for every person who wrote code,
many more in the Perl community (the
Programming Republic of Perl
) could employ it. This, along with the witty evangelism by eclectic
creator Larry Wall , whose interest in
language ensured that Perl led in text parsing, was a formula for success during a time in which
lots of text information was spreading over the Internet.
As the 21st century approached, many pearls of wisdom were wrought to move and analyze information
on the web. Perl did have a learning curve�often meaning that it was the third or fourth language
learned by adopters�but it sat at the top of the stack.
"In the race to the millennium, it looks like C++ will win, Java will place, and Perl will show,"
Wall said in the third State of Perl address in 1999. "Some of you no doubt will wish we could erase
those top two lines, but I don't think you should be unduly concerned. Note that both C++ and Java
are systems programming languages. They're the two sports cars out in front of the race. Meanwhile,
Perl is the fastest SUV, coming up in front of all the other SUVs. It's the best in its class. Of
course, we all know Perl is in a class of its own."
Then Python came along. Compared to Perl's straight-jacketed scripting, Python was a lopsided
affair. It even took after its namesake, Monty Python's Flying Circus. Fittingly, most of Wall's
early references to Python were lighthearted jokes at its expense. Well, the millennium passed, computers
survived Y2K , and
my teenage years came and went. I studied math, science, and humanities but kept myself an arm's
distance away from typing computer code. My knowledge of Perl remained like the start of a new text
file: cursory , followed by a lot of blank space to fill up.
In college, CS friends at Princeton raved about Python as their favorite language (in spite of
popular professor
Brian
Kernighan on campus, who helped popularize C). I thought Python was new, but I later learned
it was around when I grew up as well,
just not visible on the
charts.
By the late 2000s Python was not only the dominant alternative to Perl for many text parsing tasks
typically associated with Perl (i.e.
regular expressions
in the field of
bioinformatics
) but it was also the
most proclaimed popular language
, talked about with elegance and eloquence among my circle of
campus friends, who liked being part of an up-and-coming movement.
Despite Python and Perl's
well documented rivalry
and design decision differences�which persist to this day�they occupy a similar niche in the
programming ecosystem. Both are frequently referred to as "scripting languages," even though later
versions are retro-fitted with object oriented programming (OOP) capabilities.
Stylistically, Perl and Python have different philosophies. Perl's best known mottos is "
There's
More Than One Way to Do It ". Python is designed to have one obvious way to do it. Python's construction
gave an advantage to beginners: A syntax with more rules and stylistic conventions (for example,
requiring whitespace indentations for functions) ensured newcomers would see a more consistent set
of programming practices; code that accomplished the same task would look more or less the same.
Perl's construction favors experienced programmers: a more compact, less verbose language with built-in
shortcuts which made programming for the expert a breeze.
During the dotcom era and the tech recovery of the mid to late 2000s, high-profile websites and
companies such as
Dropbox
(Python) and Amazon and
Craigslist
(Perl), in addition to some of the world's largest news organizations (
BBC ,
Perl ) used
the languages to accomplish tasks integral to the functioning of doing business on the Internet.
But over the course of the last
15 years , not only how companies do business has changed and grown, but so have the tools they
use to have grown as well,
unequally to the
detriment of Perl. (A growing trend that was identified in the last comparison of the languages,
" A Perl
Hacker in the Land of Python ," as well as from the Python side
a Pythonista's evangelism aggregator
, also done in the year 2000.)
Today, Perl's growth has stagnated. At the Orlando Perl Workshop in 2013, one of the talks was
titled "
Perl is not Dead, It is a Dead End
," and claimed that Perl now existed on an island. Once Perl
programmers checked out, they always left for good, never to return.
Others
point out that Perl is
left out of the languages to learn first
�in an era where Python and Java had grown enormously,
and a new entrant from the mid-2000s, Ruby, continues to gain ground by attracting new users in the
web application arena (via Rails ), followed
by the Django framework in Python (PHP
has remained stable as the simplest option as well).
In bioinformatics, where Perl's position as the most popular scripting language powered many 1990s
breakthroughs like genetic sequencing, Perl has been supplanted by Python and the statistical language
R (a variant of S-plus and descendent of
S , also
developed in the 1980s).
In scientific computing, my present field, Python, not Perl, is the open source overlord, even
expanding at Matlab's expense (also a
child of the 1980s
, and similarly retrofitted with
OOP abilities
). And upstart PHP grew in size
to the point where it is now arguably the most common language for web development (although its
position is dynamic, as Ruby
and Python have quelled PHP's dominance and are now entrenched as legitimate alternatives.)
While Perl is not in danger of disappearing altogether, it
is in danger of
losing cultural relevance , an ironic fate given Wall's love of language. How has Perl become
the underdog, and can this trend be reversed? (And, perhaps more importantly, will
Perl 6 be released!?)
Why Python , and not Perl?
Perhaps an illustrative example of what happened to Perl is my own experience with the language.
In college, I still stuck to the contained environments of Matlab and Mathematica, but my programming
perspective changed dramatically in 2012. I realized lacking knowledge of structured computer code
outside the "walled garden" of a desktop application prevented me from fully simulating hypotheses
about the natural world, let alone analyzing data sets using the web, which was also becoming an
increasingly intellectual and financially lucrative skill set.
One year after college, I resolved to learn a "real" programming language in a serious manner:
An all-in immersion taking me over the hump of knowledge so that, even if I took a break, I would
still retain enough to pick up where I left off. An older alum from my college who shared similar
interests�and an experienced programmer since the late 1990s�convinced me of his favorite language
to sift and sort through text in just a few lines of code, and "get things done": Perl. Python, he
dismissed, was what "what academics used to think." I was about to be acquainted formally.
Before making a definitive decision on which language to learn, I took stock of online resources,
lurked on PerlMonks , and acquired several used
O'Reilly books, the Camel
Book and the Llama Book
, in addition to other beginner books. Yet once again,
Python reared its head , and
even Perl forums and sites
dedicated to the language were lamenting
the
digital siege their language was succumbing to . What happened to Perl? I wondered. Ultimately
undeterred, I found enough to get started (quality over quantity, I figured!), and began studying
the syntax and working through examples.
But it was not to be. In trying to overcome the engineered flexibility of Perl's syntax choices,
I hit a wall. I had adopted Perl for text analysis, but upon accepting an engineering graduate program
offer, switched to Python to prepare.
By this point, CPAN's enormous
advantage had been whittled away by ad hoc, hodgepodge efforts from uncoordinated but overwhelming
groups of Pythonistas that now assemble in
Meetups , at startups, and on
college and
corporate campuses
to evangelize the Zen of Python . This has created a lot of issues with importing (
pointed out by Wall
), and package download synchronizations to get scientific computing libraries (as I found),
but has also resulted in distributions of Python such as
Anaconda that incorporate
the most important libraries besides the standard library to ease the time tariff on imports.
As if to capitalize on the zeitgiest, technical book publisher O'Reilly
ran this ad , inflaming
Perl devotees.
By 2013, Python was the language of choice in academia, where I was to return for a year, and
whatever it lacked in OOP classes, it made up for in college classes. Python was like Google, who
helped spread Python and
employed van Rossum
for many years. Meanwhile, its adversary Yahoo (largely developed in
Perl
) did well, but comparatively fell further behind in defining the future of programming.
Python was the favorite and the incumbent; roles had been reversed.
So after six months of Perl-making effort, this straw of reality broke the Perl camel's back and
caused a coup that overthrew the programming Republic which had established itself on my laptop.
I sheepishly abandoned the llama
. Several weeks later, the tantalizing promise of a
new MIT edX course
teaching general CS principles in Python, in addition to
numerous n00b examples , made Perl's
syntax all too easy to forget instead of regret.
Measurements of the popularity of programming languages, in addition to friends and fellow programming
enthusiasts I have met in the development community in the past year and a half, have confirmed this
trend, along with the rise of Ruby in the mid-2000s, which has also eaten away at Perl's ubiquity
in stitching together programs written in different languages.
While historically many arguments could explain away any one of these studies�perhaps Perl programmers
do not cheerlead their language as much, since they are too busy productively programming. Job listings
or search engine hits could mean that a programming language has many errors and issues with it,
or that there is simply a large temporary gap between supply and demand.
The concomitant picture, and one that many in the Perl community now acknowledge, is that Perl
is now essentially a second-tier language, one that has its place but will not be the first several
languages known outside of the Computer Science domain such as Java, C, or now Python.
I believe
Perl has a future
, but it could be one for a limited audience. Present-day Perl is more suitable
to users who have
worked with the language from its early days
, already
dressed to impress
. Perl's quirky stylistic conventions, such as using $ in front to declare
variables, are in contrast for the other declarative symbol $ for practical programmers today�the
money that goes into the continued development and feature set of Perl's frenemies such as Python
and Ruby. And the high activation cost of learning Perl, instead of implementing a Python solution.
Ironically, much in the same way that Perl jested at other languages, Perl now
finds
itself at the receiving
end .
What's wrong
with Perl , from my experience? Perl's eventual problem is that if the Perl community cannot
attract beginner users like Python successfully has, it runs the risk of become like Children of Men
, dwindling away to a standstill; vast repositories of hieroglyphic code looming in sections
of the Internet and in data center partitions like the halls of the Mines of
Moria . (Awe-inspiring
and historical? Yes. Lively? No.)
Perl 6 has been an ongoing
development since 2000. Yet after 14 years it is not officially done
, making it the equivalent of Chinese Democracyfor Guns N'
Roses. In Larry Wall's words
: "We're not trying to make Perl a better language than C++, or Python, or Java, or JavaScript.
We're trying to make Perl a better language than Perl. That's all." Perl may be on the same self-inflicted
path to perfection as Axl Rose, underestimating not others but itself. "All" might still be too much.
Absent a game-changing Perl release (which still could be "too little, too late") people who learn
to program in Python have no need to switch if Python can fulfill their needs, even if it is widely
regarded as second or third best in some areas. The fact that you have to import a library, or put
up with some extra syntax, is significantly easier than the transactional cost of learning a new
language and switching to it. So over time, Python's audience stays young through its gateway strategy
that van Rossum himself pioneered,
Computer Programming for Everybody
. (This effort has been a complete success. For example, at MIT
Python replaced Scheme as
the first language of instruction for all incoming freshman, in the mid-2000s.)
Python continues to gain footholds one by one in areas of interest, such as visualization (where
Python still lags behind other language graphics, like Matlab, Mathematica, or
the recent d3.js
), website creation (the Django framework is now a mainstream choice), scientific
computing (including NumPy/SciPy), parallel programming (mpi4py with CUDA), machine learning, and
natural language processing (scikit-learn and NLTK) and the list continues.
While none of these efforts are centrally coordinated by van Rossum himself, a continually expanding
user base, and getting to CS students first before other languages (such as even Java or C), increases
the odds that collaborations in disciplines will emerge to build a Python library for themselves,
in the same open source spirit that made Perl a success in the 1990s.
As for me? I'm open to returning to Perl if it can offer me a significantly different experience
from Python (but "being frustrating" doesn't count!). Perhaps Perl 6 will be that release. However,
in the interim, I have heeded the advice of many others with a similar dilemma on the web. I'll just
wait and C .
**** the author tried to cover way too much for the introductory book. If
you skip some chapters this might be book introductory book. Otherwise it is tilted toward intermediate.
Most material is well written and it is clear that the author is knowledgabe in the subject he is trying
to cover.
Utterly inadequate editing. e.g. In the references chapter, where a backslash is essential
to the description at hand, the backslashes don't show. There are numerous other less critical
editing failures.
The result makes the book useless as a training aid.
Preface
I have been dabbling in Perl on and off since about 1993. For a decade or so, it was mostly "off",
and then I took a position programming Perl full time about a year ago. We currently use perl
5.8.9, and I spend part of my time teaching Perl to old school mainframe COBOL programmers. Dare
I say, I am the target market for this book?
Chapter 1
The author takes the time, to explain that you should ever use `PERL', since it's not an acronym.
I find it funny that the section headings utilize an "all caps" font, so the author does end up
using `PERL'. That's not even a quibble, I just chuckle at such things.
The author covers the perlbrew utility. Fantastic! What about all of us schmucks that are stuck
with Windows at work, or elsewhere? Throw us a bone!! Ok, I don't think there is a bone to throw
us, but the author does a great job of covering the options for Windows.
He covers the community! Amazing! Wonderful! Of all things a beginner should know, this is
one of them, and it's great that the author has taken some time to describe what's out there.
One other note are the...notes. I love the fact that the author has left little breadcrumbs
in the book (each starts with "NOTE" in a grey box), warning you about things that could ultimately
hurt you. Case in point, the warning on page 13 regarding the old OO docs that came with 5.8 and
5.10. Wonderful.
Chapter 2
An entire chapter on CPAN? Yes!!! CPAN is a great resource, and part of what makes Perl so great.
The author even has some advice regarding how to evaluate a module. Odd, though, there is no mention
of the wonderful http://metacpan.org site. That is quickly becoming the favorite of a lot of people.
It is great that the author covers the various cpan clients. However, if you end up in a shop
like mine, that ends up being useless as you have to beg some sysadmin for every module you want
installed.
Chapter 3
The basics of Perl are covered here in a very thorough way. The author takes you from "What is
programming?" to package variables and some of the Perl built-in variables in short order.
Chapter 4
Much more useful stuff is contained in this chapter. I mean I wish pack() and unpack() were made
known to me when I first saw Perl, but hey, Perl is huge and I can understand leaving such things
out, but I'm happy the author left a lot of them in.
Herein lies another one of those wonderful grey boxes. On page 106 you'll find the box labeled
`What is "TRUTH"?' So many seem to stumble over this, so it is great that it's in the book and
your attention is drawn to it.
Chapter 5
Here you'll find the usual assortment of control-flow discussion including the experimental given/when,
which most will know as a "switch" or "case" statement. The author even has a section to warn
you against your temptation to use the "Switch" module. That's good stuff.
Chapter 6
Wow references so early in the book!?!? Upon reflecting a bit, I think this is a good move. They
allow so much flexibility with Perl, that I'm happy the author has explored them so early.
Chapter 7
I do find it odd that a chapter on subroutines comes after a chapter on references, though. It
seems like subroutines are the obvious choice to get a beginning programmer to start organizing
their code. Hence, it should have come earlier.
Having said that, I love the authors technique of "Named Arguments" and calling the hash passed
in "%arg_for". It reads so well! I'm a fan and now tend to use this. Of course, it is obvious
now that references needed to be discussed first, or this technique would just be "black magic"
to a new Perl person.
There are so many other good things in this chapter: Carp, Try::Tiny, wantarray, Closures,
recursion, etc. This is definitely a good chapter to read a couple of times and experiment with
the code.
Chapter 8
As the author points out, an entire book has been written on the topic of regular expressions
(perhaps even more than one book). The author does a good job of pulling out the stuff you're
most likely to use and run across in code.
Chapter 9
Here's one that sort of depends on what you do. It's good to know, but if you spend your days
writing web apps that never interact with the file system, you'll never use this stuff. Of course
thinking that will mean that you'll use it tomorrow, so read the chapter today anyway. :)
Chapter 10
A chapter on just sort, map, and grep? Yes, yes there is, and it is well worth reading. This kind
of stuff is usually left for some sort of "intermediate" level book, but it's good to read about
it now and try to use them to see how they can help.
Chapter 11
Ah, yes, a good chapter for when you've gotten past a single file with 100 subroutines and want
to organize that in a more manageable way. I find it a bit odd that POD comes up in this chapter,
rather than somewhere else. I guess it makes sense here, but would you really not document until
you got to this point? Perhaps, but hey, at least you're documenting now. :)
Chapter 12 and 13
I like the author's presentation of OO. I think you get a good feel for the "old school" version
that you are likely to see in old code bases with a good comparison of how that can be easier
by using Moose. These two chapters are worth reading a few times and playing with some code.
Chapter 14
Unit testing for the win! I loved seeing this chapter. I walked into a shop with zero unit tests
and have started the effort. Testing has been part of the Perl culture since the beginning. Embrace
it. We can't live in a world without unit tests. I've been doing that and it hurts, don't do that
to yourself.
Chapter 15
"The Interwebs", really? I don't know what I would have called this chapter, but I'm happy it
exists. Plack is covered, yay!!! Actually, this is a good overview of "web programming", and just
"how the web works". Good stuff.
Chapter 16
A chapter on DBI? Yes! This is useful. If you work in almost any shop, data will be in a database
and you'll need to get to it.
Chapter 17
"Plays well with others"...hmmm....another odd title, yet I can't think of a more appropriate
one. How about "The chapter about STDIN, STDOUT, and STDERR". That's pretty catchy, right?
Chapter 18
A chapter on common tasks, yet I've only had to do one of those things ( parsing and manipulating
dates). I think my shop is weird, or I just haven't gotten involved with projects that required
any of the other activities, such as reading/writing XML.
Including the debugger and a profiler is good. However, how do you use the debugger with a
web app? I don't know. Perhaps one day I'll figure it out. That's a section I wish was in the
book. The author doesn't mention modulinos, but I think that's the way to use the debugger for
stepping through module. I could be wrong. In any case, a little more on debugger scenarios would
have been helpful. A lot of those comments also apply to profiling. I hope I just missed that
stuff in this chapter. :)
Chapter 19
Wow, the sort of "leftover" chapter, yet still useful. It is good to know about ORMs for instance,
even if you are like me and can't use them at work (yet).
Quick coverage of templates and web frameworks? Yes, and Yes! I love a book that doesn't mention
CGI.pm, since it is defunct now. Having said that, there are probably tons of shops that use it
(like mine) until their employees demand that it be deleted from systems without remorse. So,
it probably should have been given at least some lip service.
I am an admitted "fanboy" of Ovid. Given that, I can see how you might think I got paid for
this or something. I didn't. I just think that he did a great job covering Perl with this book.
He gives you stuff here that other authors have separated into multiple books. So much, in fact,
that you won't even miss the discussion of what was improved with Perl's past v5.10.
All in all, if you buy this book, I think you'll be quite happy with it.
Here maintainers went in wrong direction. Those guys are playing dangerous games and keeping
users hostage. I wonder why this warning is installed but in any case it is implemented
incorrectly. It raised the warning in $zone
=~/^(\d{4})\/(\d{1,2})\/(\d{1,2})$/ which breaks compatibility with huge mass of Perl scripts
and Perl books. Is not this stupid? I think this is a death sentence for version 5.22.
Reading Perl delta it looks like developers do not have any clear ideas how version 5 of the
language should develop, do not write any documents about it that could be discussed.
Notable quotes:
"... A literal { should now be escaped in a pattern ..."
in reply to "Unescaped left brace in regex is deprecated"
From the perldelta for Perl v5.22.0:
A literal { should now be escaped in a pattern
If you want a literal left curly bracket (also called a left brace) in a regular expression
pattern, you should now escape it by either preceding it with a backslash (\{) or enclosing it
within square brackets [{], or by using \Q; otherwise a deprecation warning will be raised.
This was first announced as forthcoming in the v5.16 release; it will allow future extensions
to the language to happen.
The LWP (Library for WWW in Perl) suite of modules lets your programs download and extract information
from the Web. Perl & LWP shows how to make web requests, submit forms, and even provide authentication
information, and it demonstrates using regular expressions, tokens, and trees to parse HTML. This
book is a must have for Perl programmers who want to automate and mine the Web.
Gavin
Excellent coverage of LWP, packed full of useful examples, on July 16, 2002
I was definitely interested when I first heard that O'Reilly were publishing a book on LWP.
LWP is a definitive collection of perl modules covering everything you could think of doing with
URIs, HTML, and HTTP. While 'web services' are the buzzword friendly technology of the day, sometimes
you need to roll your sleeves up and get a bit dirty scraping screens and hacking at HTML. For
such a deep subject, this book weighs in at a slim 242 pages. This is a very good thing. I'm far
too busy to read these massive shelf-destroying tomes that seem to be churned out recently.
It covers everything you need to know with concise examples, which is what makes this book
really shine. You start with the basics using LWP::Simple through to more advanced topics using
LWP::UserAgent, HTTP::Cookies, and WWW::RobotRules. Sean shows finger saving tips and shortcuts
that take you more than a couple notches above what you can learn from the lwpcook manpage, with
enough depth to satisfy somebody who is an experienced LWP hacker.
This book is a great reference, just flick through and you'll find a relevant chapter with
an example to save the day. Chapters include filling in forms and extracting data from HTML using
regular expressions, then more advanced topics using HTML::TokeParser, and then my preferred tool,
the author's own HTML::TreeBuilder. The book ends with a chapter on spidering, with excellent
coverage of design and warnings to get your started on your web trawling.
This book is the much needed update to the first book by Ed and Michelle, published in 1998 that
went by a different name, "Perl 5, Complete". The first book came out way too early with too many
errors. Ed acknowledges this in his preface to the second edition. I enjoyed his first book, because
catching errors made me learn the material better, but the second edition is soo much better.
High points for this second edition include:
a good tutorial for object-oriented programming starting with creating modules up to full object-oriented
programming with perl/tk.
a great section on data-structures like arrays-of-arrars, and hash or hashes, etc... that are
essential if you want to do intermediate or above Perl programming.
A great chapter on real-world examples using perl/tk and OLE programing with Perl for Microsoft
Windows plus other code samples.
Some great new appendixes for Perl "grammer and structure" that weren't in the first edition.
Basically a concise reference for symantics that would benefit anybody.
A much improved index that was practically non-existent in the first edition.
All in all, I would say the second edition would be a good edition to learning and even
improving your Perl skills since it is a huge tome of Perl information that can be both used as a
reference and as a tutorial.
I have only the first edition that was called
Perl 5 Complete. I even wrote the first review about the first edition of the book on Amazon.com.
I also used it in one introductory e-commerce class. As usuall, you love a textbook much less
after you use it a class -- errors and omissions became more evident :-(.
Still, most my students were able to grasp details of the language from the book, but now the
book looks a little bit watery -- each chapter can be compressed into half without losing any useful
content. So the number of pages can probably reduced in half. Also examples in the first edition
are not that great and somewhat buggy.
All-in-all this is a good intro Perl 5 book with some well thought examples and multi-OS coverage.
Chapter 9 on regular expressions is not bad and many readers on Amazon like it. I was not impressed,
but still I agree that it's OK, especially for novices.
Last seven chapters actually constitute a good intermediate book. They contain detailed treatment
(with good examples) of interesting topics like PerlTk, interfacing Perl to Win32 applications, databases
and more.
Attention: CGI coverage is very weak. File operations are much better covered in other
books.
Even with problems mentioned above it is probably one of the best introductory Perl book. It is
more suitable for those who have some programming experience in other language.
For people without programming experience no book can probably help ;-), but Jon Orwant's book
might to be an alternative. The main problem with it is that it overstresses regular expression (at
least more than I like in the beginner-oriented book). If you have some experience with other high
level languages this book is a reasonable choice, although nothing is perfect in this world ;-)
***+ The first two chapters of this book is not a usual junk OO book it cut thou OO hype and reveal
how to make components ;-). After that it is regular OO junk.
1.0 out of 5 stars Surprisingly Disappointing, August 13, 2003
After reading so many positive reviews of Damian Conway's "Object Oriented (OO) Perl," I
decided to buy a copy and increase my understanding of said subject. Unfortunately, after about
two months of thoroughly dissecting each chapter in the book, I must admit that I was surprisingly
disappointed.
I consider the first two chapters ("What you need to know first" and "What you need to know
second") to be well written and quite useful. These chapters effectively and succinctly expressed
the non-OO aspect of Perl programming. When I delved excitedly into chapter three, however,
it seemed to me that Damian Conway lost his interest in teaching Perl, in lieu of underlining
his own mastery of the language. Too many times I recall his overly complicated one-liners
getting in the way of a clear explanation of the point he was trying to convey. I bought Damian
Conway's OO Perl because I wanted to learn more about object orientation in Perl-not to view
obfuscated code. A *lot* more clarity would have the made the book much more useful.
A second frustrating point about the book is how Damian writes a given class, and then fails
to provide even a simple example of how to use said class. As a programmer reading the book,
I found it quite annoying that I had to so often write my own "class calling" scripts. Of the
many classes contained in the contents of the book, I recall only one or two working examples
of how to use said classes! This baffled me throughout the book. I kept wondering, "Are examples
of how to use these classes available on a website or something?" Even as I write this review
now, I'm shaking my head at the lack of examples provided in the book.
In my opinion, the most appropriate title for Damian Conway's book is "Obfuscated Object
Oriented Perl." The solid first two chapters aren't worth the ...cost of the book, and
the OO chapters (3-14) are practically worthless-both as a reference, and as a means of instruction.
The freely available OO Perl tutorials are of much more value than Damian's book. Said tutorials
will not only save you money, but they will also bolster your understanding of OO Perl, which
is something I so greatly wanted, but so widely failed to receive, from Damian Conway's OO
Perl.
**** (HTML text of this book id available on Perl CD)
Generally this is a good book. But the author is too preoccupied with finding shortcuts and Perl idioms
and that negatively influence the book in some places. Recommended as a useful reference or second book
on Perl. E-text is available from Perl CD only (not with the book). In some ways demonstrate the flaws
of Perl -- after reading 100 recipes one can think whether it is necessary to spend time on mustering
all this complex and arcane things and whether there is a better way to do this in TCL ;-)
This book is more a reference that a textbook. When you start reading this book as a textbook the
first dozen recipes is really exiting, after than it became boring and then annoying ;-).
Again this is a reference. It's difficult to read it as a book: just too much recipes and one can
start thinking that Perl has some inherent flaws that can probably be solved by better design of the
language...
After dog-earring (sic) the pages of the first edition of Programming Perl (the Camel book), I
quickly glommed on to the second edition, thinking that they'll have even more informed narrative
and great examples. The enhanced narrative WAS worth purchase of the second edition, but, as mentioned
in the Amazon.com review, the "Command Tasks with Perl" and "Real Perl Programs" chapters had
been dropped... it's been the closest I've ever come to letter-bombing a book publisher. Little
did we know that there was a cunning plan by the Perl wizards and O'Reilly to produce The Perl
Cookbook.
While in this world of instant communication some say that two years was a long time
to wait for the Cookbook, the wait was definitely worth it. The Cookbook is a treasure trove of
examples, and should be considered a mandatory companion to Programming Perl AND Advanced Perl
Programming on the bookshelf of intermediate and advanced perl programmers.
The Cookbook is also a great place for the novice to feed after cutting their teeth on Learning
Perl. Each section is a mini-tutorial with nice examples to enter and ponder. Combined with the
Camel book as general background and reference, you'll go a long way in finding quick solutions
to common problems.
I'm not sure what was the problem of one reviewer regarding typographical errors. I've been
using the first edition of the Cookbook, and have not encountered any serious difficulties. It
seems that any typographical errors (and I haven't seen any, but then I haven't been looking)
would have at worst lost one star in rating the Cookbook. Benefits of the Cookbook seem to far
outweigh the nits on which this reviewer has focused. I do agree with the reviewer's final note:
buy copies from the second and third printings, as I'm sure the first edition has already sold
out! (... and some perl book geek will view this as an opportunity to collect a "first edition.")
It's not often I'm moved to write an online review. The Perl Cookbook is a superb reference
for any serious perl programmer and especially for the novice and intermediate wanting to improve
their skills. Buy this book! Bon appetit!
The day I got this book, I turned to page 1 and started reading. Two hours later, I had made
it only to page 80. Why? Because this book is DENSE and FULL of tips and tricks that will expand
the horizons of the intermediate programmer. I spent a lot of time studying the numerous examples
in order to soak up all the information that was being presented.
I've been programming with Perl since 1992 and teach it at a community college. And yet with every
turn of the page, I learned something new. Examples:
Making regular expressions more efficient
Using map() and grep()
How to call a subroutine from inside a string
Great stuff! The techniques I've learned from this book have been incorporated into my new
Perl scripts and they are shorter and faster than ever before.
I can't lavish enough praise on this book. Authors Joseph Hall and Randal Schwartz should be commended.
If you have been using Perl for some time and want to hone your skills, get this book now.
****(also included in HTML form included in Perl CD bookshelf, first edition). A very old but still
valuable book on advanced topics. One chapter is even devoted to the programming Tetris in Perl ;-).
Examples and corrections (this is the first edition) are available from O'Reilly web site. Should not
be your first or only book on Perl and probably one should first read
Effective
Perl Programming. But I do recommend you to read or at least browse this book. In my opinion this
is one of the best book that explains the namescapes in Perl more or less well. That also means that
you can understand what modules in Perl are really about and do no need rely of superficial hype of
some other books ;-) I Also like the author style. He really understands a lot about software engineering
not only about Perl and that colors the book.
A real outdated masterpiece that may not appeal to everyone, June 7, 2000
This is, as the title implies, a book for advanced programmers. You are not supposed to be reading
it until "Learning Perl" seems really basic to you and when you are ready to make the progression
from browsing "Programming Perl" (the Camel book) -a reference guide to ALL of Perl- to writing
a real & complex application. This book serves then as an introduction to several complex topics
(DBI, data structures, Tk, OO, & Perl C internals) and gives a better explanation in some areas
where the Camel book falls short or becomes too complex (here the explanations are better, but
don't expect full tutorials from A to Z). I warn you.
It is the perfect companion to introduce you to a new subject while reading the online docs
or other. You also might want to browse thru it if you are an experienced programmer with other
scripting languages like TCL, Java or Python, since the comparisons at the end of each chapter
is really excellent. As anything that was once considered advanced (and therefore, cutting edge),
the book has aged.
Things like the persistent data manipulation module presented in the book have since been improved
upon by newer ones. Some of the TCL comparisons are not entirely fair anymore (although mostly
still correct). Tom Christiansen's perltoot for OO included with Perl is a much better and thorough
introduction than the one offered here.
Also, if you are the type of programmer that reads every single little piece of documentation
that comes with Perl, then well, you won't find anything new here --but some concepts that could
have been unclear might be clarified here (the ideas presented are still correct, even if some
of the code is not anymore).
Steve Wainsteadon July 17, 2000
But one of the great things about this book is its overall passion for programming and
computer science
Compared to "Programming Perl" the explanations of references and complex data structures
are worth the price alone. They are clear and concise.
The OOP chapters are a little thick, but if you are new to OOP they are a decent introduction.
But one of the great things about this book is its overall passion for programming and
computer science; you can tell the author loves his work. It really shows. I bought "Programming
Pearls" (not "Perls") as a result of this, and there's a neat chapter on dynamic code generation,
an essential tool for the web developer's toolbox. All Perl hackers need this one.
Jack D. Herringtonon, December 13, 2003
Best way to learn references
This is one of the four critical books you need to learn Perl; Programming Perl, Learning Perl,
Perl Cookbook and Advanced Perl Programming.
This book provides a deep understanding of how references (pointers) can be used to increase
performance. In addition the book gives you a deeper understanding about how to make better use
of hash tables as data structures.
The section on code generation using templates is great as well.
Reilly Perl bookshelf contains several Perl books in HTMl format.
I would like to name this type of publishing "parallel publishing" and it has several very important
advantages over pure electronic e-text or pure paper publishing. First it's much more than "try before
you buy" although the best introductory book depends on your background and it's worth to shop about
for the best match. Still the availability of a regular "paper" book is much for convenient for studying
as you cannot compare the resolution and quality of text on the paper with that on the screen. Actually
the cost of printing it a sizable book on the laser printer exceeds the cost of buying a pri in contrast
to the vague, theory ridden texts IT is plagued with.
We cover dynamic programming, lambda abstraction, and other techniques
with the same approach.
Moderate through advanced experience level. Similar to "Design Pattern" books
for Java, C++, influenced heavily by "A Pattern Language", Christopher
Alexander.
At the time of this writing, approximately 100 pages worth of content exist, entirely covering the traditional,
expected patterns. A snapshot can be fetched from
http://wiki.slowass.net/assemble.cgi?PerlDesignPatterns.
Browsing the Wiki directly at
http://wiki.slowass.net/?PerlDesignPatterns directly has the advantage of allowing you submit questions,
corrections,
ideas, and amendments directly, as well as browse non-linearly. CVS access is
available as well, in some cases.
Mason is a tool for embedding the Perl programming language into text, in order to create text
dynamically, most often in HTML. But Mason does not simply stop at HTML. It can just as easily create
XML, WML, POD, configuration files, or the complete works of Shakespeare.
This is an old hat now, but you bac buy it really cheap. Six O'Reilly books on one CD-ROM in HTML
format. Only one book is really good (cookbook). Advanced Perl can be useful too. CD includes:
Perl in a Nutshell; Programming Perl, 2nd Edition; Perl Cookbook(very good);
Advanced Perl Programming(good); Learning Perl(outdated and weak); and Learning
Perl on Win32 Systems(this is just a bad joke). As a bonus, the almost useless printed version
of Perl in a Nutshell is also included.
***
This tutorial assumes no prior programming knowledge or experience. It starts with basic concepts, and
then builds upon them. Each chapter contains a Q&A section, summary, quiz, and a series of exercises
which allow the reader to practice using the language features which were just learned.
Teach Yourself Perl 5 in 21 Days, Second Edition is the ideal book for beginning - and intermediate
- level users who want to gain a solid understanding of this programming language. Using step-by-step
tutorials and the easy-to-follow approach, you can Teach yourself Perl 5 in 21 Days! Through various
teaching elements, you'll learn everything you need to know about this popular programming language.
You'll discover how to manipulate text, generate reports, and perform system tasks. Through practical,
hands-on instructions, logically organized lessons, and helpful Q & A sections, you'll master Perl functions
and concepts and be developing robust programs in no time. Plus, Do/Don't boxes show you how to avoid
potential programming pitfalls, illustrations explain constructs such as associative arrays, and tables
serve as handy references.
This well-structured book is actually both a good introductory text and a reference. For more obscure
example one can use some examples form the David Medinets' book. It assumes that you are familiar with
the basics of using the UNIX operating system. It is good for Linux users but will be extremely useful
for Windows users too. Contains exercises after each chapter, "Do and Don't" boxes and unlike other
books it does contain a chapter on Perl debugger !
Paperback, 870 pages,/ Published by Sams 16-May-1996 (second edition)
ISBN: 0672308940 ;
Avg. Customer Review: ***+ Number of Reviews: 38
From Amazon readers reviews:
A reader from San Diego, CA , January 28, 1999 ***** The Best PERL Book Available!
This is both an excellent way to learn Perl and a great reference book. The book is easy to read,
really teaches the essentials of the language, and has a great index for reference (although not
as good as the previous Perl 4 version of the book)...
David Medinets./ Que's October 1996/658 pages/CD-ROM/ISBN: 0789708663 Paperback - 658 pages Bk&Cd-Rom
edition (October 1996)
Que Corp; ISBN: 0789708663 ; Dimensions (in inches): 1.74 x 9.04 x 7.37
Currently it's probably the secondary choice among the open introductory books on Perl. I do not
recommend it as an introductory book. Simon cozens and David Till's books are a better introductory
books and I realized it hard way -- by teaching a class using Perl5 by Example. My experience suggests
that it should not be used in the university environment but probably can be OK for self-study, especially
if one have some experience with other languages. As an introductory book it's pretty weak -- the
author uses too much obscure Perl idioms and many examples are weak and poorly thought out. In case
you decided to use it, the book probably should be used only as a reference with
Teach Yourself Perl 5 in 21 Days as a primary text.
The main advantage of the book is that the full text is available both on the CD-ROM and online
from the Web(for example here Perl 5 by Example
-- try to search Yahoo! for the mirror nearest to you; ).
David Medinets "... has been programming since 1980, when he starting with a Radio Shack Model 1.".
He has written also Visual Basic Script Quick Reference, and HTML Quick Reference, 2nd Edition for
Que and also co-authored books on such topics as Lotus Notes, C++, Visual Basic, and Microsoft Office.
In past he used REXX that probably is an advantage for any Perl programmer/writer as REXX (although
a weaker scripting language) has some features that are difficult to program in Perl. This seems
to be his first scripting language book. He is also a co-author of
Using
Lotus Notes 4 (1996). The book is conveniently structured into four parts:
Part I: Basic Perl
Part II: Intermediate Perl
Part III: Advanced Perl
Part IV: Perl and the Internet
There are also 5 appendixes:
A - Review Questions
B - Glossary
C - Function List
D - The Windows Registry
E - What's On the CD?
Strangely enough most of readers reviews in the Amazon.com website are quite positive. Here is one
example:[email protected] from Utah , January 30, 1999 ******
The Best Perl
Book I've studied
Perl 5 by example is the best Perl book I've studied. I use the Perl 5 book along with the 'CGI For
Windows' book to teach an internet/multimedia class, at an University level. 'Perl 5 by example'
has an excellent teaching format: Definition, explanation, and hundreds of sample code fragments,
to illustrate the point. 'Perl 5 by example' combines beginning concepts, intermediate, and advance
Perl programming practices. One of the most valuable sections in 'Perl 5 by example' is the creating
reports section. The second most valuable section is the regular expression explanation. I keep the
'Perl 5 by example' book close as a valuable language reference. Database is also a key interest
for me. Combining Perl with Sybase and using the reporting capability helps students start learning
how to create enterprise wide solutions. Write to me for details on some of the Perl projects that
were created using the book. Upon studying this book and reader should have the knowledge to write
numerous cgi scripts, create Perl modules, and understand at an intermediate level the Perl language.
Finding a decent introductory Perl books is not that difficult as there are several excellent books
on the subject. Selecting between them is a little bit more tricky ;-). At the same time probably does
not make much sense to buy two introductory books. I recommend
Effective
Perl Programming as your second book. In no way Learning Perl should
be your first Perl book.
Perl 5 Interactive Course : Certified Editionhas e-text and support site but does not
cover Perl 5.6.
Paperback - 700 pages 1st edition (May 25, 2000)
Wrox Press Inc; ISBN: 1861003145
Avg. Customer Review:
[Note this is an open book. PDF in available from
http://learn.perl.org/library/beginning_perl
TOC
Introduction
Chapter 1: First Steps In Perl
Chapter 2: Working with Simple Values
Chapter 3: Lists and Hashes
Chapter 4: Loops and Decisions
Chapter 5: Regular Expressions
Chapter 6: Files and Data
Chapter 7: References
Chapter 8: Subroutines
Chapter 9: Running and Debugging Perl
Chapter 10: Modules
Chapter 11: Object-Oriented Perl
Chapter 12: Introduction to CGI
Chapter 13: Perl and Databases
Chapter 14: The World of Perl
Appendix A: Regular Expressions
Appendix B: Special Variables
Appendix C: Function Reference
Appendix D: The Perl Standard Modules
Appendix E: Command Line Reference
Appendix F: The ASCII Character Set
Appendix G: Licenses
Appendix H: Solutions to Exercises
Appendix J: Support, Errata and P2P.Wrox.Com
Index
Great for Teaching Perl, February 14, 2007 F. L. Fabrizio
I use this book to teach Perl in a university course. I feel it does a very good job at exposing
just enough of Perl to make it useful without confusing beginning students. I chose this over O'Reilly's
Learning Perl (also a good book) because this book goes into References, Modules and a bit of OO
Perl, and also has what I feel is slightly better treatment of shortcuts like $_ as well as lexically-scoped
variables with 'my'. O'Reilly has broken these topics across two books (Learning Perl and Intermediate
Perl), both fine books but I only want the students to have to buy one book. I feel that Perl is
not very useful without references, so that was the major reason for switching to this book for a
beginning Perl course. I highly recommend it.
Beginning Perl, 2nd Edition, October 6, By T. Barr (Mt. Prospect, IL United States)
Beginning Perl, 2nd edition, by James Lee, et al., is a splendid
introduction to the Perl programming language, version 5.8.3. The flow
of the book is logical, straightforward, and highly readable. Text is
heavily sprinkled with program examples that the reader can easily try
out along the way, as well as exercises at the end of most chapters,
with solutions in the appendix. Chapters are short, clear, and
engaging.
After a brief discussion of the history of Perl and a listing of
numerous helpful online resources, the book quickly moves on to the
logistics of running a Perl program, followed by descriptions of basic
program elements and control flow. Then it's ahead to more
sophisticated data elements - lists, arrays, and hashes - and finally
functions and subroutines.
After a solid and seemingly effortless explanation of these "basics,"
the book moves to one of the most powerful features in Perl - regular
expressions - and how these can be used to access files and data. From
there, the discussion expands to string processing and references. The
book concludes with discussions of more "advanced" Perl features,
including object-orientation, modules, and use with webservers and
databases.
Regardless of topic, the writing style stays crisp, clear, and
example-filled, making this book a highly effective and enjoyable way to
get a jump-start into Perl programming for the novice or a quick
refresher for the expert wanting a Perl 5 update.
***+ Nikolai Bezroukov's review: A very good introductory book with exercises and quizzes.
Slightly outdated (not Perl 5.6).
Jon Orwant used to publish Linux Journal. This is second or third edition.
Probably should be your first book on Perl, especially if you try to study it by yourself.
I like the illustrations. The book contains very useful quizzes and exercises after each lesson
-- the best of any introductory book I read. Web site
www.waite.com/ezone (or
http://www.mcp.com/distance_learning/frame_ezone.html
)contains e-text, additional materials, quizes that can be graded automatically and the reader can ask
questions about the book. Good typographic quality, far superior in comparison with O'Reilly books.
e-text and on-line quizzes are available from the support site. This is just great !
Negative points -- the author too much emphasize regular expressions at the expense of more procedural
operations on string (substr, index, pack, etc.) and that might be a problem for beginners. Some tests
are pretty obscure and actually teach wrong practice (see tests for control structures and subroutines
as an example). The book does not provide enough warning about problems with Perl and how to avoid them.
Jon Orwant / Paperback, 2-d edition / Published 1997
Paperback - 860 pages Bk&Cd-Rom edition (November 1, 1997)
Waite Group Pr; ISBN: 1571691138 ; Avg. Customer Review: *****
Number of Reviews: 11
Here are some reviews from amazon.com that probably worth reading:
[email protected] from New York, USA , July 15, 1999 ***** It is a great book!
When I read other people's reviews, I always wonder what kind of background these people have in
programming. Well, here is my background: I know HTML, JavaScript, C++, a little bit of Java, DHTML,
and databases. When I found out that I had to learn Perl, I was scared because, after 4 years of
college, that is the first language that I had to learn completely on my own. However, this book
made my learning experience as easy as possible. The book provides very good explanations, a lot
of examples, and an EXCELLENT reference section. I think this is one of the best programming books
I have read so far.
A reader from New Jersey , January 30, 1999 ***** A Strong Learning Tool for the Perl Language
As far as books that claim they will teach you Perl in any number of days / lessons, this book is
by far the best. The lessons, exercises and on-line quizzes are structured very well to make sure
you understand the material in the lesson. The lessons are short and sweet and cover only a few topics
at a time, which makes it easy to master a lesson at a time.
The examples in the book are effective and can be used immediately to help you solve those simple
real world problems. The book does fall short in helping you easily conquer more complex issues quickly.
However, the online resources are great for helping you address these problems.
Steven Holzner / Paperback / Published 1999
Amazon price: $39.99 ~ You Save: $10.00 (20%)
Average Customer Review:
A good quick-reference as well as having sufficient depth , April 3, 2000 Reviewer:
gooberboy (see more about me)from Australia
As an electrical engineer with a reasonable programming background, I needed a book that would allow
me to come up to speed in Perl quickly without having to first plough through endless tutorials or
mindless banter that those 'Dummies' books (or similar) offer. The Black Book meets this need using
a unique format -- 'quick solutions' to common programming problems, like data storage, flow control,
formatting, etc, ordered in a well indexed and logically laid out volume. I found this format facilitated
the learning of the language rapidly while I was developing my first Perl applications. The Black
Book's only negative aspect is the author's annoying little 'stories' at the beginning of each section
involving the reader and fictional characters like the 'Big Boss' and the 'Novice Programmer'. These
stories don't suit the otherwise excellent format of the book and only distract. Ignore the first
paragraph of each section that contains them and the Perl Black Book is a handy reference you'll
certainly keep near your computer.
Ideal Reference Material , July 26, 2000
Reviewer: A reader from Mt. Pleasant, USA
Perl Black Book is probably the best technical book I have ever read. This book will save you time
through its organization, concise explanatory style, and content. The "Black Book" enables a programmer
to quickly access information, especially keyword syntax. Each chapter begins with an overview of
what will be covered including page numbers for "immediate solutions" to those problems you need
a quick answer to. I don't know how many times I have spent more time than I would like sifting through
pages of text looking for the correct syntax for the 'if' construct, or playing back-and-forth with
the glossary trying to locate a specific function to manipulate a string. This book will help you
find answers quickly. The book covers nearly every major aspect of beginning/intermediate level Perl
programming in a consistent, fluent, and well-organized manner. Regular expressions, cgi programming
w/ Perl, OO, and Perl/Tk are all covered. If you have an understanding of the basic elements of programming,
this book serves as a valuable reference, and helps to further explain and clarify some of the more
difficult aspects of the language without being too verbose. This book does not provide very many
references to additional information, however.
Although my bookshelves are already full of 700-page Perl books of the "Teach Yourself" variety,
I was unable to find any good explanations of the LWP module. When I found a chapter devoted to LWP
in Perl Power, I was thrilled and immediately bought the book.
What I didn't expect was the bonus of someone finally providing a good explanation of Perl 5 and
object-oriented Perl. That section ALSO would have been worth the price of the book.
Even the first chapter had all sorts of insights and explanations I found invaluable. I've been
using Perl off and on for about 3 years, mostly writing quick utilities, and I'll credit this book
with wanting to make me use Perl more.
*****Perl power December 30, 1999 Reviewer: Dennis Krystowiak from Detroit, Michigan
Excellent book that gets you started with lots of areas of Perl. Most of the code I have tried
works fine with Activestates's 523 build and with the Perl development kit 1.2.4. Having code that
work is rare with these books especially with Windows. I use 98 and NT and unix. This book is not
a definitive guide to Perl but it gives you a good summary in most of the important area's and enough
code to get started quickly. It gave me lots of ideas on things I could use Perl for. I also like
"Perl 5 complete" for theory, but the code for that book is very buggy and hard to get to work. I
like its detailed explanation of how things are suppose to work. "Perl Cookbook" is also excellent
for how to solve problems various kinds of problems. These are the best of the Perl books I have.
Bill Frischling ([email protected]) from Arlington, VA , July 20, 1999 *****
A Must-Have Perl Reference
This book is a must have, and an excellent addition to the shelf of any Perl programmer, beginner
or otherwise. You should be comfortable with general programming concepts to get the best use out
of it. Great use of examples in here, and a very, *very* good read in comparison to other, denser
volumes that cover this topic. Writing style does make it far easier to get the gist in this book,
and Mr. Schilli does not bore you to tears with geek prose, thank heavens. You get the info you need
with a snappy style to boot.
[email protected] from Memphis, TN , February 13, 1999 *****
A "Perl of great worth"!
Somehow the phrase "jump start" seems a little feeble when Schilli's energetic style catapults you
into Perl. I didn't expect to be impressed by a "jump start guide" to a language with which I'm already
familiar, but a brief thumb-through quickly changed my mind.
The first hundred pages or so provide a lightening-strike introduction to the basics of Perl.
Best-suited for a reader with prior programming experience, the first chapter illustrates the most
important Perl concepts efficiently, but also includes enough subtleties and effective examples that
it's worth a look by a non-beginner.
After equally vigorous introductions to Perl objects and modules, Schilli focuses on two exciting
areas where Perl's unique strengths are well-suited, Tk-based graphical user interface development
and internet programming. Although Perl has many important uses beyond these two, they make an effective
introduction to the breadth and power of the language.
Even the appendices contain a surprising variety of useful information, from the instructions
for installing Perl from the included CD, to the quick references to HTML and POD, to the links to
a variety of resources available through the 'Net.
Clearly, a "jump start guide" can't cover every detail of a language as eclectic as Perl; nevertheless,
Schilli has done a very good job of selecting topics that will get the reader up and running quickly,
while leaving them prepared to learn even more. I also consider this book nearly ideal for the reader
who is already familiar with Perl as a rapid-development text-processing and scripting language,
and who is now ready to move into full-blown application development in Perl.
***+ A good book. It's more about programming in Perl that elements of Perl ;-) In total
number pages it's close to Learning Perl, but quality is higher. This is Perl 5 book, not Perl 4 book
like Learning Perl I think that it's an excellent
replacement for the outdated Learning Perl.
The author manage to produce very solid introductory programming text that covers a lot of ground
but still is accessible for novices. Some points are very realistic like the fact that comments often
obscure the text of the program more than they help to comprehend it. The book covers a lot of introductory
material and is less watery than Perl Complete.
In general this is a solid introduction to the programming in a pretty difficult and large language.
I would like to stress the word "programming". Language constructs are not the primary focus of the
book and probably one needs an additional reference of tutorial book that focuses on that topic. What
is especially good is that the author pays proper attention to the debugging issues.
No book is without its flaws, and my biggest complain would be chapter 2 content and the absence
of the introduction of Perl features (the latter can be compensated by using WEB books). The usual "level
zero" Perl tutorial section is missing and the author starts to discuss programming issues in Chapter
2 and use complex language constructs like regular expressions without any warning. This chapter dives
in too fast for beginners without explaining little, but very important bits that would aid greatly
in achieving a solid foundation. Such an approach might put some people off the book. I recommend to
use an additional online book to compensate for this. One may try my
Introduction to Perl for Unix System Administrators
Anyway I would have expected a better introduction, given that Perl isn't as well known as C.
My other complaint is that the book is too small for such a huge language. Just 350 pages in comparison
with 1K pages in Perl 5 Complete and 860 pages in
Perl 5 Interactive Course.
Well, no -- it's just right actually if you want the book that competes with Learning Perl, but the
book try to cover so many topics that readers might feel lost and feel that the author should have used
a bit more in-depth treatment, or more extended examples. The author might have felt the same way, since
at the end of most chapters, there are pointers to further information, which are usually pretty useful.
Paperback - 350 pages (October 1999)
Manning Publications Company; ISBN: 1884777805 ; Dimensions (in inches): 0.78 x 9.23 x 7.39
**** Too much spread out too thin
Reviewer:
Andy Lester from McHenry, IL April 5, 2000 This book doesn't feel like a Perl book. It feels like Johnson is a C programmer at heart, trying
to write a book about Perl.
Worse, it's such a wide survey of Perl as to be incongruous. He's got pages devoted to the
thought process behind how to structure a program, which is fine for an introductory text; but then
he gets into anonymous hashes and different sorting algorithms. Is this an introductory book or not?
The chart on page 184 of all the regex elements is completely useless. It shows all the elements,
but doesn't explain at all what they do.
It sure LOOKS great. I love the visual internal style of all the Manning books.
I haven't seen anything that's incorrect, and he writes clearly enough. It's just poorly organized
and feels like it was thrown together.
***** Emphasis on Programming
Reviewer: A reader from Syracuse, NY April
4, 2000
I came to this book with some experience in Javascript and Lingo,
but no foundation in programming concepts and a desire to learn Perl. This book was perfect
for me.
It focuses on programming practices from the beginning, using Perl code for examples of
major concepts. By the time it deals directly with the language, you're already familiar with
the way Perl looks and works.
For me, some of the early material wasn't necessary, but the author's style is transparent
enough not to become obsequious. It's refreshingly free of "now let's do ____; but first let's
do ____" idioms that insult and baffle simultaneously.
Anyone who wants to learn programming, but doesn't plan to actually use Visual Basic in
the future, should consider this book. It makes a primer on programming concepts unnecessary,
and it give a solid introduction to a widely useful language.
**** Excellent reading
Reviewer: PHO January 26, 2000
I am pleased to recommend this book. As another reviewer wrote,
I have also read Learning Perl and looked through Programming Perl, but while I was able to
learn a fair amount from them, I kept feeling a bit lost when it came to things like how exactly
do I use regexes and the types of data structures etc. I took a programming course in Pascal
and Fortran too long ago (21 years), I think. At any rate, this book helped me feel a lot more
confident with Perl - how to use CPAN, the abundant Perl documentation etc. I don't think that
it would be the best book for a first-time programmer without an instructor, but if you have
the stamina and perserverance to learn on your own, then this book is a must. Further, the
book reads well. In addition, all errata in the first edition can be found at the publishers
website, and are generally minor corrections.
I owned the first edition. The first edition was pretty decent and contained some examples that
you can use in your own development, especially related to Perl/Tk.
Parts of Perl like regular expressions are treated superficially.
See also a review by Donald Bryson in
UnixWorld Online.
The book does not have a e-text online (or at least beta as
Perl
5 Complete).
Amazon Price: $31.99
Paperback - 500 pages 2nd Bk&cdr edition (September 2000)
IDG Books Worldwide; ISBN: 0764547291
See also his book Perl Modules The book has a web site at
http://www.pconline.com/~erc/perlbook.htm,
but it's not very useful for Perl (but contains a good links for Linux).
I owned the first edition. The first edition was pretty decent and contained some examples that
you can use in your own development, especially related to Perl/Tk.
Parts of Perl like regular expressions are treated superficially.
See also a review by Donald Bryson in
UnixWorld
Online. The book does not have a e-text online (or at least beta as
Perl 5 Complete).
Eric F. Johnson is a prolific writer and authored several books including:
**+ (Junk) The main advantage of the book is that it is short. It covers only Perl 4. The second
edition is not much different from the first one and if you like to buy the book you can save some money
buying the first edition -- it still can be found 50%-75% off.
Again -- buyer beware it's just an introduction to Perl 4 not to Perl 5. Perl 4 is a reasonable subset
of Perl to master at the beginning level, but the the problem is that some Perl 5 features simplify
programming of typical algorithms and you learn the wrong language.
The first edition was one of the first books on Perl published and this it has definite historical value.
The second edition is simply disappointing. It's kind of Randall L. Schwartz fiasko. The "Just Another
Perl Hacker" as any hacker should be lazy, but probably not to such an extent: the only one new chapter
(brief overview of CGI) and one new appendix (listing of standard Perl modules) were added (probably
by Tom Christiansen, as the team now includes him). The examples and exercises are identical to the
the first edition. You may try Perl Complete instead, if this is your first book. Skip this book if
you already have at least one introductory book on Perl.
If you like Randal Schwartz convoluted "hacker" style with excessive emphasis on Perl idioms, Effective
Perl Programming might be a better deal...
Randall L. Schwartz, Tom Christiansen / Paperback, 302 pages / O'Reilly,
July 1997/ 2-nd edition
*** Poorly organized and difficult to use April 8, 1999 Reviewer: A reader from Illinois
As an experienced systems administrator and script writer I was extremely offput by this book.
Of course it's an ORA book and thus the quality is there, but I swear I have no idea how the authors
got this poorly organized, confusing amalgamation past the editors unless they were simply too baffled
to reject it and gave up. For starters, the footnotes often contradict the text which references
them. The writing is thick and assumes too much. The authors' sense of humor apparently dictates
the presense of smart-alecky and totally irrelevant commentary at random spots, just to make sure
that the reader is absolutely lost. And the index! The index references such important aspects of
Perl as "Astro [from "the Jetsons"], pronouncing 'Windex'" and "Max Headroom," yet if you look up
the keyword "hash" -- which has an entire chapter devoted to it -- there is no listing at all in
the entire index. You can look up associative arrays (a deprecated term) though. I found this book
to be hostile to the learning process. In fact, I picked it up no fewer than three times trying to
learn basic perl from it, only to toss it down in frustration after pulling my hair out. Compare
the ORA Korn shell book, which is beautifully instructive, concise and clear, and with a wonderful
index with nearly every important function listed. This was the first ORA book I wished I hadn't
bothered to purchase. One could argue that perl5 is simply too complex to be gently introduced, yet
I learned more about perl from reading Webmonkey's quickie six page tutorial than I did from "Learning
Perl." I was quite disappointed with this book. Buy a copy if you must, but plan to use it as a (poor)
reference because its teaching abilities are limited.
* (junk) I bought it and had found that it completely
missed the target. Words "W32 Systems" in the
title is a joke. Content is essentially the same as in
Learning Perl so this book is a self-plagiarism. Do not buy this book unless it is discounted
50% or more.
Paperback / Published 1997
*** Generic perl topic are OK, Win32 and NT specifics are poor, March 30, 1999
I bought this book as starter to learn more about Perl in general (and for Win32 systems). I found
the very first chapters to be of good service, though I spotted these elementary Perl programming
techniques in other O'Reilly books too. The Win32 part is in my opinion very poor, it doesn't explain
things very well like OLE, reading/writing the Event log and other rudimentary system administration
tasks. If you have a lot of free time on your hands like I sometimes tend to have, take some time
to search for example scripts for Win32, and together with this book you will be able to understand.
Though I think a new edition would be a good idea, covering specifically Win32 platform (people should
buy other books to learn Perl in general, I do not like to see the same 3 chapters in every book
over again).
by Larry Wall, Tom Christiansen, Jon Orwant
Amazon Price: $39.96
Paperback - 1067 pages 3rd edition (July 2000)
O'Reilly & Associates; ISBN: 0596000278 ; Dimensions (in inches): 1.70 x 9.21 x 7.04
Avg. Customer Review:
Number of Reviews: 3
Pretty average book and I'm a little bit surprised by the generosity of the reader reviews. Perl
is something of a cult, so I think in a lot of cases a positive review means "I like Perl" more than
it means "I like 'Programming Perl.' book ". There is something like "Lemmings effects" here. People
hesitate (understandably, I think) to insult a book that's closely associated with a great open-source
language.
This is not a textbook, this is a reference pretty close to Perl man pages. Should not be your first
or only book on Perl. IMHO neither Perl nor REXX became much better with introduction of OOP features,
so you could probably benefit from getting the first edition of the book if you can find it. Anyway
it make sense to learn procedural style before trying to master OOP stuff. You also can try to get the
first edition if you can as it contains some chapters that were moved to the Cookbook in the second
and third editions.
See some reviews of the second edition:
A "don't have to" read, May 30, 2000
Reviewer:
Joseph N. Hall (see more about me)from Chandler, AZ
The official reference for the Perl language did not improve in its second generation. The original
"purple Camel" is, in my opinion, a true classic where books about programming and programming languages
are concerned--I rank it right there with The C Programming Language, Anatomy of Lisp, Algorithms +
Data Structures = Programs, and so forth. It was a classic because it was filled with lucid expressions
of the thoughts of Perl's quintessentially pragmatic creator, Larry Wall. It was a classic because it
provided a literate and thoroughly reasoned counterpoint to arguments in favor of more formally based
languages and programming styles.
But ... somewhere in the extensive revisions, additions, extensions, and deletions that transformed
the first Camel book into this, the second Camel book, the magic went away. And some very suspicious
stuff went in. The book lost its digressive, essayic feel and became more of a perfunctory reference
work. Additionally, some of the completely new material turned out to be just a little ... strange.
The discussion of object-oriented programming based around the term "thingy" just doesn't do it for
me. (Ignore all that and read Damian Conway's book instead.)
Preferences of style and tone aside, an unavoidable flaw of an infrequently-updated book like this
one is that it inevitably refers to an obsolescent version of Perl. If you want current Perl documentation,
you need to read the man(ual) pages that came with that version of Perl. What's in this book is generally
but not completely accurate for newer versions of Perl. And because it's intended to be a more or less
complete reference covering even small details, it can't help but be dead wrong on some points as the
language continues to evolve. Bear in mind, also, that much of the material in this book comes STRAIGHT
from the man pages. (Just not the up-to-date versions.)
A third edition is in the works, which will no doubt be at least a temporary improvement. If the
newer version restores the insight and charm of the original, it will certainly deserve a place on your
programming bookshelf. But as a reference work intended to cover a constantly-evolving language, Programming
Perl will always suffer by being out of date.
If you are the type who dislikes reading electronic documentation, by all means, buy a copy of this
book. But you'll find that you have to use the online documentation anyway.
Badly Organized, but a Great Reference, February 3, 2000
Reviewer:
Dan Budowski (see more about me)from Israel
The book itself, used as a Reference and for mastering Perl, is a five star book. But there are a quite
a few disadvantages:
1. The book is not intended to the ones who have no programming experience at all. The read should
be at least an intermediate programmer, because the basic programming concepts of the language (Variables,
Subs and etc..) are badly explained.
2. Because of Perl's C Like Syntax, it is recommended that the reader will know C, Awk, or Grep and
Some experience in the Unix Environment.
3. The Book itself is badly organized, certain complicated things are shown in examples and explanations,
and those things are taught many pages afterwards. For Example: An Example of a perl program is shown
on page 10, and that example contains subs and pattern matching, which are taught 100 Pages later!
These are the 3 Main Disadvantages. For Conclusion, if you're new to programming, or want to learn
Perl easliy, buy "Learning Perl", but if you're a somewhat experienced programmer, and want to master
Perl, this book is the best one you'll find for that purpose.
Steven Holzner / Paperback / Published 1999
Amazon price: $39.99 ~ You Save: $10.00 (20%)
Average Customer Review:
A good quick-reference as well as having sufficient depth , April 3, 2000 Reviewer:
gooberboy (see more about me)from Australia
As an electrical engineer with a reasonable programming background, I needed a book that would allow
me to come up to speed in Perl quickly without having to first plough through endless tutorials or mindless
banter that those 'Dummies' books (or similar) offer. The Black Book meets this need using a unique
format -- 'quick solutions' to common programming problems, like data storage, flow control, formatting,
etc, ordered in a well indexed and logically laid out volume. I found this format facilitated the learning
of the language rapidly while I was developing my first Perl applications. The Black Book's only negative
aspect is the author's annoying little 'stories' at the beginning of each section involving the reader
and fictional characters like the 'Big Boss' and the 'Novice Programmer'. These stories don't suit the
otherwise excellent format of the book and only distract. Ignore the first paragraph of each section
that contains them and the Perl Black Book is a handy reference you'll certainly keep near your computer. Ideal
Reference Material , July 26, 2000
Reviewer: A reader from Mt. Pleasant, USA
Perl Black Book is probably the best technical book I have ever read. This book will save you time through
its organization, concise explanatory style, and content. The "Black Book" enables a programmer to quickly
access information, especially keyword syntax. Each chapter begins with an overview of what will be
covered including page numbers for "immediate solutions" to those problems you need a quick answer to.
I don't know how many times I have spent more time than I would like sifting through pages of text looking
for the correct syntax for the 'if' construct, or playing back-and-forth with the glossary trying to
locate a specific function to manipulate a string. This book will help you find answers quickly. The
book covers nearly every major aspect of beginning/intermediate level Perl programming in a consistent,
fluent, and well-organized manner. Regular expressions, cgi programming w/ Perl, OO, and Perl/Tk are
all covered. If you have an understanding of the basic elements of programming, this book serves as
a valuable reference, and helps to further explain and clarify some of the more difficult aspects of
the language without being too verbose. This book does not provide very many references to additional
information, however.
David Till / Paperback, 870 pages / Published by Sams 16-May-1996 (second edition)/ ISBN: 0672308940
;
This well-structured book is actually a reference and as such it might complement David Medinets'
book, which is also an open book.
It assumes that you are familiar with the basics of using the UNIX operating system. So it is good
for Linux users. Books contain exercises after each chapter, "Do and Don't" boxes and unlike other books
it does contain a chapter on Perl debugger.
Avg. Customer Review: ***+ Number of Reviews: 38
From readers reviews:
This is both an excellent first book on Perl. The book is easy to read, really teaches the essentials
of the language, and has a great index for reference (although not as good as the previous Perl 4
version of the book).
Stephen Asbury(Editor), et al / Paperback / Published 1997
Amazon price: $39.99 ~ You Save: $10.00 (20%)
Actually this book is a competitor to Cookbook. It also contain implementation of several algorithms
in Perl
Here is one review from Amazon.com:
Great book premise/very helpful
I just bought this book today after much Perl book researching. This book is well organized/layed out
and every example shows how to accomplish a real world task. Normally I go for the O'Reilly books, but
this book illustrates how to do so much (dynamic HTML, sockets, forking processes, etc.) in one volume.
I do wish that the book did touch more on SQL database access modules. Very happy I found this book.
Steven Holzner / Paperback / Published 1999
Amazon price: $19.99 ~ You Save: $5.00 (20%)
Steven Holzner is a professional who have wrote a several dozens of books. So he definitely know
the ropes of a language textbook writing. Here are some reviews from Amazon.com
A reader from Texas, USA , August 18, 1999 ***** Will Wonders Never Cease?
The first Perl book I've seen that is truely great for beginners, great for people who are already
Perl programmers, has a lot of example code, is a great reference, has a good reference section,
and also seems to not leave any important details/sections out. The fact that it is very well organized/divided
is definately a plus! Any person who wishes to learn Perl or have a great reference, MUST have this
on their bookshelf.
A reader from usa , April 15, 1999 ****
Good Book for Perl. Lots of Example Code
I think this is a great reference book for perl. It covers all the major topics with examples on
each of the minor details. Chapters are divided by topics such as hashs,arrays,cgi. Excellent reference.
Biggest draw back is sometimes the examples are too short so that it becomes difficult to figure
out how it would operate in a large program.
Sriram Srinivasan / Paperback / Published 1997 -- a very good book on advanced topics. One chapter
is even devoted to the programming Tetris in Perl ;-). Examples and corrections (this is the first
edition) are available from O'Reilly web site. Should not be your first or only book on Perl and
probably one should first read
Effective Perl Programming. But I do recommend you to read or at least browse this book. In my
opinion this is one of the best book that explains the namespaces in Perl more or less well. That
also means that you can understand what modules in Perl are really about and do no need rely of superficial
hype of some other books ;-) I Also like the author style. He really understands a lot about software
engineering not only about Perl and that colors the book.
Damian Conway, Randal L. Schwartz (Foreword) / Paperback / Published
1999
Amazon price: $25.77 ~ You Save: $17.18 (40%)
Average Customer Review: ***** This book not a usual junk OO book ;-). It really worth reading.
Paperback - 292 pages (September 1997)
John Wiley & Sons; ISBN: 047197563X ; Dimensions (in inches): 0.73 x 9.08 x 7.44 Amazon.com Sales Rank: 26,637 Avg. Customer Review: ****+
Number of Reviews: 10
This is the only book on Perl that I know that was written by the author of a C++ book. IMHO
this book is most useful, if you already know Perl a little bit, so it should not be your first book.
The text is not available electronically, but to have some idea about the book you can read an introduction
online (see Introduction)
The book suffers from Pascal style syntax diagrams ;-), but I really like the author's style -- a very
intelligent style indeed.
The book greatly benefited from the author background and understanding of C++ and thus it provides
some insights into Perl that other books on Perl do not offer. Chapman explains how to use Perl effectively,
along with the language's nuances. He also devotes some effort in describing good Perl programming style.
This is the only book on Perl that discuss trade offs made by Larry Wall in designing the language.
The style is more European that in other Perl books. This is not surprising as the author is British.
The British generally seem to be more articulate than Americans, so the language reflects that difference.
Malcolm Beattie, release manager for 5.005 and the author of the Perl code-generator is listed a reviewer
of the final draft.
On the negative side I would like to note that Pascal-style diagrams are not very useful. The layout
and typography could be better.
Joseph N. Hall, Randal L. Schwartz / Paperback / Published 1998
Paperback - 288 pages 1st edition (January 1998)
Addison-Wesley Pub Co; ISBN: 0201419750 ; Dimensions (in inches): 0.63 x 9.17 x 7.34 Amazon.com Sales Rank: 3,991 Avg. Customer Review: *****
Number of Reviews: 10
A useful intermediate to advanced level book on Perl. Explains a lot of idioms and pitfalls of the language.
Not all recommendations should be taken for granted. Highly recommended as a second book on Perl. I
prefer it to the Cookbook, but you is involved with the language on daily basis you probably should
think about buying both. Like Tom Christiansen this guy is obsessed with finding shortcuts in Perl,
but if you ignore this perversion the book is pretty much OK.
The author cares about his book. The Joseph Hall's website
http://www.effectiveperl.com/ contains some
chapters in PDF format. I also like his growing
Perl Recipes area. In general the
quality of the web site distinguish this book from others even more.
Like Scott Meyers' Effective C++, on which it is modeled, Joseph Hall's Effective Perl Programming
is not for the novices. In some way it demonstrates Perl design flaws. Text contain 60 topics (called
items), grouped into 10 sections, that illuminate difficult parts of the language. For example assigning
undef to an array creates an array with one element -- uninitialized arrays in Perl have value (), the
empty list. Sometimes show useful idioms like ($i, $j)=($j, $i) for exchanging two elements. It also
includes several tips on using the debugger effectively and submitting modules to the Comprehensive
Perl Archive Network (http://www.perl.org/CPAN/).
Here is one amazon.com review:
A reader from Seattle, WA , June 30, 1999 ***** code with style . . .
One beauty of perl is that there are so many ways to do any given task. This can also make life hell
when you have to maintain other people's code, or even your own code several months later. While
this book doesn't tell you 'one right way' to do things, it does show you how to do things with style.
Not only will you feel cool for writing pretty code, you'll be much happier with it in the long run.
The book is not limited to Perl. Perl just over-rely on them in parsing the text. Regexs are also
used in such languages as Python, TCL, Expect, AWK, Lex, in utilities like Grep Egrep, and most editors
including Emacs, vi, and sed. See also WEB site
Mastering Regular Expressions
that contains links to the additional material from the book.
Regular expressions are a mixed blessing. Like other functional languages using regular expressions
is not that difficult after you have (a lot of) experience, but at the beginning learning is usually
very frustrating. People just do not understand that regex evolved in a very complex language.
To make things worse you just cannot accomplish simple things without learning a lot of stuff. Semantic
of some characters in regular expressions is different from Perl and is dependent upon context (for
example the meaning of "^" in /^a/ and /[^a]/ ).
To make things worse documentation about regular expressions is usually bad and uncompleted. There
is no regular expression debugger. So the best way to go is to create a list of typical regular expressions
that you may need and debug them beforehand (cookbook approach). Generally the best way out is to avoid
complex regular expressions (KISS principle) and use non-greedy matching whenever possible. And here
the book can help a lot as it contains many useful examples, although there should be more. Among them:
[0-9]+(\.[0-9])+ -- regular expression for matching IP addresses
Paperback, 282 pages/Published by Prentice Hall: May 1995/ISBN: 013016965X
An interesting approach to Perl. See the contents of the book
for more details. This book uses Perl as a sample language to explore the practical aspects of Toolsmithing,
prototyping, and reuse. Topics like metrics, configuration management and portability are also discussed.
But the book does not have a Web site (there is a page
http://www.primenet.com/~peasem/ but
it contains nothing interesting).
Paperback - 429 pages (March 1998)
IDG Books Worldwide; ISBN: 1558515704 ; Dimensions (in inches): 1.20 x 9.28 x 7.45
Availability: This title usually ships within 4-6 weeks. Please note that titles occasionally go out
of print or publishers run out of stock. We will notify you within 2-3 weeks if we have trouble obtaining
this title. Avg. Customer Review: Number of Reviews: 1 Good
book, but the print is too big, June 24, 1999
Reviewer: A reader from Sacramento, CA
The book has some quite useful code and good examples of how OO works in Perl. I think they could have
shrunk the font size down alot and saved a tree when they published it, though. It does have some real
good source code that came with it, as well.
Actually I do not know what to recommend to the reader who wants to master Perl in Win32 environment
other than Scott McMahan book. I have more or less positive experience with Perl Complete that is a
really good introductory book, but it's not Win32 specific.
Scott McMahan / Paperback / Published 1999
Amazon price: $27.96 ~ You Save: $6.99 (20%)
R & D Books; ISBN: 0879305894 ; Dimensions (in inches): 0.70 x 9.25 x 7.40 Amazon.com Sales Rank: 6,094 Avg. Customer Review: *****
Number of Reviews: 2
Probably the first book completely devoted to the using Perl in Win32 environment Paperback
- 350 pages Bk&Cd Rom edition (September 1999)
The author has an impressive site:
The Cyber Reviews. See his
Resume. Two reviews about the books
(I usually am suspect about the first one, but once I manage to write the first review myself (for Perl
Complete), so not all of them are written by the author friends ;-) are positive. Here is the second
review:
[email protected] from Seattle, WA , September 28,
1999 ***** How To Use Perl With Windows To Get A Big Fat Raise
This book should be titled "How To Use Perl With Windows To Get A Big Fat Raise Raise".
Imagine the following on your annual review form:
"Automated my daily build to occur off-hours, thereby saving a hour per day for more productive activities.
Provided free software and training to my colleages to automate each team member's daily build, providing
a net increase of useful development team time of 12-1/2 percent."
Don't you think ought to be worth an easy 10-15% raise? (If not, then you really need to find a new
employer.)
If that is not enough, try this:
"Implemented Automation interfaces in developed code to facilitate automated testing of code off-hours.
Automated test procedures provided email report of nightly test results to all concerned parties."
I can not recall any book packed with more useful, relevant, and exciting information. As the title
states, it shows how to use Perl to automate mundane tasks such as daily builds and nightly back-ups.
In addition, it shows how to use COM/OLE Automation to advantage in your Perl scripts. Need a quick
UI element and you don't want to use Perl/Tk? This book shows how to use Visual C++ to create an Automation
DLL for the purpose of executing dialogs from your script, with, of course, native look-and-feel. Need
to do some heavy lifting in C++? Need to drive the Automation interface of MS applications? This books
shows how to use COM Automation to do the heavy lifting, drive DevStudio, and drive some of the Office
applications.
The content of this book drips with pragmatism. It seems to emphasize using the right tool for the
job, and avoids unnecessary heroics. There are some very thoughtful sections concerning anti-Microsoft
sentiment, as well as what is good and bad about both Windows and Unix. This book manages to avoid both
bashing or cheerleading, it just informs. It shows you how to use the strengths of the combination of
the Windows platform and Perl, and highlights some weaknesses in the Windows platform that a developer
needs to be aware of. (In particular, read the section on distributing a VC++ 6.0 Automation Server
on page 125. This section illuminates a problem that would be truly dreadful to debug.)
The Perl used in this book is at a level that anybody who read the O'Reilly Gecko or Llama books
should understand. The author seems to forego the geeky Perl power one-liners common in other Perl books
in the interest of clarity.
Quit wasting any more time reading this review. Buy the book and get back to work!
Dave Roth / Paperback / Published 1999
Amazon price: $40.00
Paperback - 614 pages 1 edition (January 1999)
Macmillan Technical Publishing; ISBN: 1578700671 ; Dimensions (in inches): 1.59 x 8.96 x 5.99
Amazon.com Sales Rank: 15,655
Avg. Customer Review: ****
Number of Reviews: 12.
Pretty expensive. But there is not much competition in this area to keep prices down. Also you can
usually buy it with 30% or better discount. Here is one review that I like:
The creator of most of the Win32 extensions of Perl provides numerous proven examples and practical
uses of Perl to solve everyday Win32 problems.
Mixed feelings about this book. Some chapters are fine - others leave a lot to be desired. Overall
it is worth having as it does clear up some issues and the chapters on writing your own extensions,
file management, data access and processes are very good. There are some errors and typos that
would stump a novice Win32 perl programmer however.
I got the impression that the author concentrated on the extensions he developed very well but only
gave the other (more useful?) extensions a decent explanation if he was interested in them.
The book starts off well detailing error handling and system administration for Perl on the Win32
platform. It started to dissapoint here as, in places, much more detail is included on the authors own
web pages. There is a lot of detail on the more esetoric details of Win32 Perl such as Com & OLE, consoles
and sound. This stuff is interesting but not as important as the more common and useful extensions dealing
in, say, system administration.
The author (not surprisingly!) treats the extensions he has written himself in most detail - ODBC
in particular. This is fine but glaring omissions are even here. For example the chapter on communication
mentions the win32::pipe and win32::message extensions but nowhere does it explain that these are additional
extensions that need to be downloaded and installed first (in most cases at least). I know from first
hand experience that this would fox a newcomer to Win32 Perl builds.
Shawn P. Wallace, Richard Koman (Editor) / Paperback / Published 1999
Amazon price: $23.96 ~ You Save: $5.99 (20%) Great advanced book in a very interesting area
It does contain implementation of several algorithms in Perl (sorting, trees, etc.)
Here is one review from Amazon.com:
Great book premise/very helpful
I just bought this book today after much Perl book researching. This book is well organized/layed out
and every example shows how to accomplish a real world task. Normally I go for the O'Reilly books, but
this book illustrates how to do so much (dynamic HTML, sockets, forking processes, etc.) in one volume.
I do wish that the book did touch more on SQL database access modules. Very happy I found this book.
The Last but not LeastTechnology is dominated by
two types of people: those who understand what they do not manage and those who manage what they do not understand ~Archibald Putt.
Ph.D
Copyright � 1996-2021 by Softpanorama Society. www.softpanorama.org
was initially created as a service to the (now defunct) UN Sustainable Development Networking Programme (SDNP)
without any remuneration. This document is an industrial compilation designed and created exclusively
for educational use and is distributed under the Softpanorama Content License.
Original materials copyright belong
to respective owners. Quotes are made for educational purposes only
in compliance with the fair use doctrine.
FAIR USE NOTICEThis site contains
copyrighted material the use of which has not always been specifically
authorized by the copyright owner. We are making such material available
to advance understanding of computer science, IT technology, economic, scientific, and social
issues. We believe this constitutes a 'fair use' of any such
copyrighted material as provided by section 107 of the US Copyright Law according to which
such material can be distributed without profit exclusively for research and educational purposes.
This is a Spartan WHYFF (We Help You For Free)
site written by people for whom English is not a native language. Grammar and spelling errors should
be expected. The site contain some broken links as it develops like a living tree...
You can use PayPal to to buy a cup of coffee for authors
of this site
Disclaimer:
The statements, views and opinions presented on this web page are those of the author (or
referenced source) and are
not endorsed by, nor do they necessarily reflect, the opinions of the Softpanorama society.We do not warrant the correctness
of the information provided or its fitness for any purpose. The site uses AdSense so you need to be aware of Google privacy policy. You you do not want to be
tracked by Google please disable Javascript for this site. This site is perfectly usable without
Javascript.
Eugene Miya , Ex-Journal Editor, parallelism DB, committees and conferences, etc. Answered Sep 9, 2014 · Author has 11.2k answers and 7.9m answer views Everyone cites and overcites TAOCP.

Christopher Story Answered Sep 1 2015 � Author has 64 answers and 25.3k answer views One could say that an ideology is a religion if and only if it is theocratic, but I find Yuval Harari's understanding of religion less arbitrary and more compelling.


Bill William , M.C.A Software and Applications & Java, SRM University, Kattankulathur (2006) Answered Jan 5, 2018
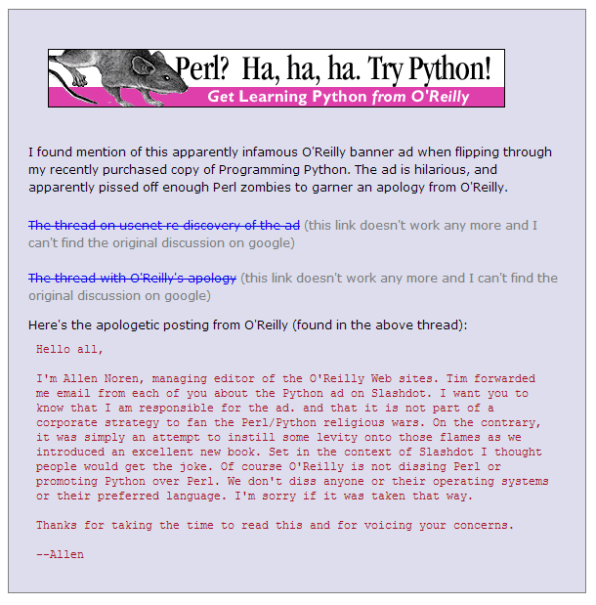
A much better second edition , July 20, 2000
[Note this is an open book. PDF in available from http://learn.perl.org/library/beginning_perl
TOC Introduction Chapter 1: First Steps In Perl Chapter 2: Working with Simple Values Chapter 3: Lists and Hashes Chapter 4: Loops and Decisions Chapter 5: Regular Expressions Chapter 6: Files and Data Chapter 7: References Chapter 8: Subroutines Chapter 9: Running and Debugging Perl Chapter 10: Modules Chapter 11: Object-Oriented Perl Chapter 12: Introduction to CGI Chapter 13: Perl and Databases Chapter 14: The World of Perl Appendix A: Regular Expressions Appendix B: Special Variables Appendix C: Function Reference Appendix D: The Perl Standard Modules Appendix E: Command Line Reference Appendix F: The ASCII Character Set Appendix G: Licenses Appendix H: Solutions to Exercises Appendix J: Support, Errata and P2P.Wrox.Com Index
